- 先下载适合自己系统的即时客户端,可通过下面的地址下载。
http://www.oracle.com/technetwork/database/features/instant-client/index-097480.html
- 直接解压到你想要存放的目录中,如:D:\Java\instantclient_10_2
- 编辑环境变量:
TNS_ADMIN 设置为 D:\Java\instantclient_10_2
ORACLE_HOME 设置为 D:\Java\instantclient_10_2
- 编辑连接配置文件 tnsnames.ora,该文件需要自行在即时客户端目录(C:\instantclient_11_2)中创建。在该文件内输入如下内容:
MYDB =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.3.250)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = MYDB)
)
)
MYDB:是数据库实例名
192.168.3.259:是数据库的 IP 地址
1521:是数据库的端口
- 然后你就可以使用 PLSQL Developer 和 TOAD 这类软件来管理 Oracle 数据库了。
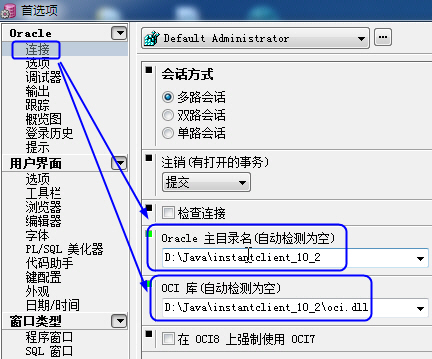
下面根据自己的实际情况配置PL/SQL:在首选项(perference)里面设置Oracle主目录名(Oracle_home)和OIC库(OCI Library),我的设置是Oracle_home=D:\Java\instantclient_10_2,OCI Library=D:\Java\instantclient_10_2\oci.dll。
posted @
2010-08-26 17:01 CoderDream 阅读(737) |
评论 (0) |
编辑 收藏
摘要: 视频名称:
[A218]JAVA反射机制与动态代理.exe
[A219]JAVA反射机制与动态代理续一.exe
[A220]JAVA反射机制与动态代理续二.exe
主讲教师:风中叶
Java 语言的反射机制
在Java运行时环境中,对于任意一个类,可以知道这个类有哪些属性和方法。对于任意一个对象,可以调用它的任意一个方法。
这种动态获取类的信息以及动态调用对象的方法的功能...
阅读全文
posted @
2010-08-25 16:12 CoderDream 阅读(2284) |
评论 (0) |
编辑 收藏有时候我们会碰到需要设置代理,然后通过svn获取源代码,下面我们来看一下如何设置;
1、找到 C:\Documents and Settings\your userName\Application Data\Subversion 这个目录下的servers文件,用任意一个文本编辑器打开,找到类似于如下的文字:
[global]
# http-proxy-exceptions = *.exception.com, www.internal-site.org
#http-proxy-host = proxy2.some-domain-name.com
#http-proxy-port = 9000
# http-proxy-username = defaultusername
将
#http-proxy-host
#http-proxy-port
这两行前面的#号去掉,并将=号右边的值分别改为你的代理服务器地址和端口号即可。
2、设置Eclipse/MyEclipse,确认SVN的客户端是SVNKit:
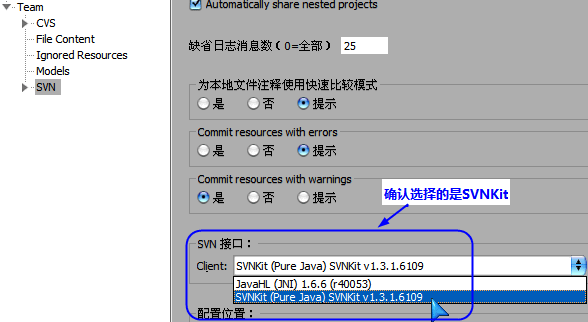
这样,就可以在Eclipse/MyEclipse中通过代理使用SVN了。
![]()
posted @
2010-03-05 15:29 CoderDream 阅读(3808) |
评论 (2) |
编辑 收藏
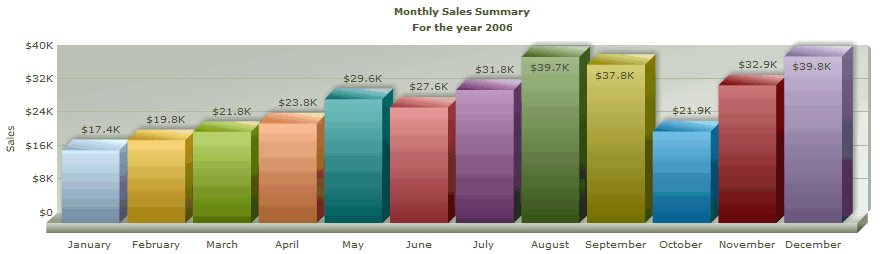
我们在软件开发中,经常需要以表格的方式展现批量数据,如统计分析等等。
这里介绍一个Flash的表格生成工具--FusionCharts,它是一个收费软件,不过如果不是用于商业用途,只是用于,可以到网上下载破解版,csdn上面就有,如果想商业,购买应该也不贵。
下面我们来看一个最简单的例子:
这个软件生成表格的模式是:数据(XML文件或文件流)+模板。
1、XML数据:
<chart caption='Monthly Sales Summary' subcaption='For the year 2006' xAxisName='Month' yAxisName='Sales' numberPrefix='$'>
<set label='January' value='17400' />
<set label='February' value='19800' />
<set label='March' value='21800' />
<set label='April' value='23800' />
<set label='May' value='29600' />
<set label='June' value='27600' />
<set label='July' value='31800' />
<set label='August' value='39700' />
<set label='September' value='37800' />
<set label='October' value='21900' />
<set label='November' value='32900' />
<set label='December' value='39800' />
</chart>
2、将所有需要用到的模板拷贝到固定的位置。
3、在html中指定数据位置和模板名称:
<html>
<head>
<title>My First FusionCharts</title>
</head>
<body bgcolor="#ffffff">
<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://fpdownload.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=8,0,0,0" width="900" height="300" id="Column3D" >
<param name="movie" value="../FusionCharts/Column3D.swf" />
<param name="FlashVars" value="&dataURL=Data.xml">
<param name="quality" value="high" />
<embed src="../FusionCharts/Column3D.swf" flashVars="&dataURL=Data.xml" quality="high" width="900" height="300" name="Column3D" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" />
</object>
</body>
</html>
4、运行结果:
posted @
2010-02-03 11:16 CoderDream 阅读(1088) |
评论 (0) |
编辑 收藏
1、FCKeditor源代码分析(一 )----------fckeditor.js的中文注释分析(原创)
http://blog.csdn.net/nileader/archive/2009/10/21/4710559.aspx
2、
Developers GuideJavaScript
http://docs.cksource.com/FCKeditor_2.x/Developers_Guide/Integration/JavaScript
3、网络营销实战密码——策略.技巧.案例
http://product.dangdang.com/product.aspx?product_id=20449076
posted @
2009-10-23 16:00 CoderDream 阅读(408) |
评论 (0) |
编辑 收藏1、安装
Oracle 版本:Oracle Database 10g Release 2 (10.2.0.1)
下载地址:
http://www.oracle.com/technology/software/products/database/oracle10g/htdocs/10201winsoft.html
安装设置:
1)这里的全局数据库名即为你创建的数据库名,以后在访问数据,创建“本地Net服务名”时用到;
2)数据库口令在登录和创建“本地Net服务名”等地方会用到。
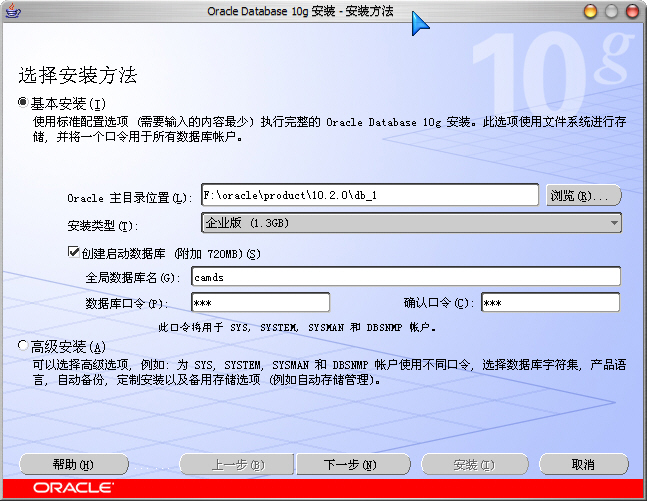
2、创建“本地Net服务名”
1)通过【程序】-》【Oracle - OraDb10g_home1】-》【配置和移植工具】-》【Net Configuration Assistant】,运行“网络配置助手”工具:

2)选择“本地 Net 服务名配置”:
3)这里的“Net 服务名”我们输入安装数据库时的“全局数据库名”:
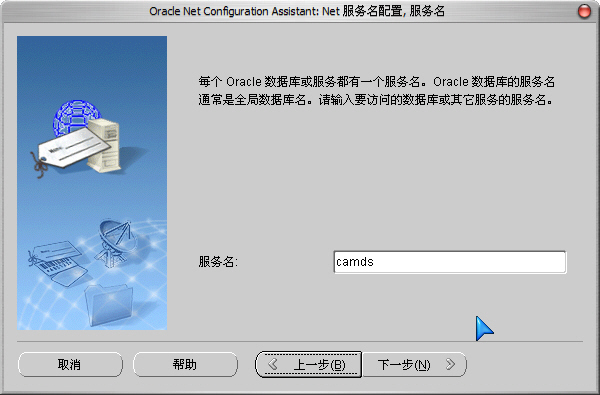
4)主机名我们输入本机的IP地址:
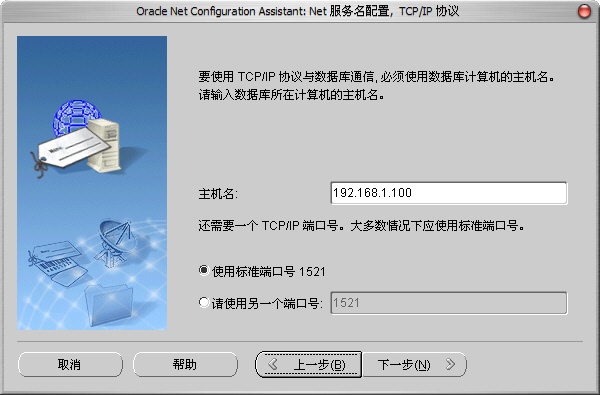
5)测试数据库连接,用户名/密码为:System/数据库口令(安装时输入的“数据库口令”):
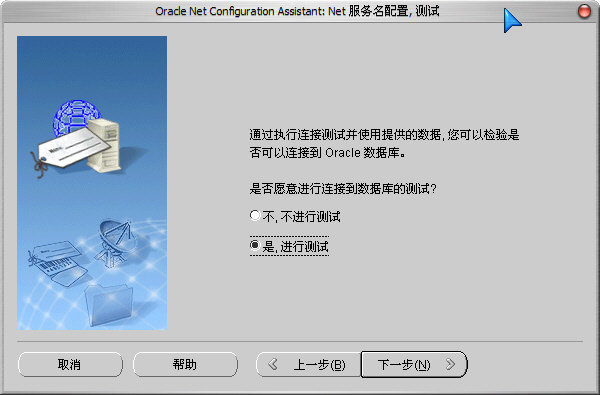
默认的用户名/密码错误:

更改登录,输入正确的用户名/密码:

测试成功:
3、PLSQL Developer 连接测试
输入正确的用户名/口令:
成功登陆:
4、创建表空间
打开sqlplus工具:
sqlplus /nolog
连接数据库:
conn /as sysdba
创建表空间:
create tablespace camds datafile 'D:\oracle\product\10.2.0\oradata\camds\camds.dbf' size 200m autoextend on next 10m maxsize unlimited;
5、创建新用户
运行“P/L SQL Developer”工具,以DBA(用户名:System)的身份登录:
1)新建“User(用户):

2)设置用户名、口令、默认表空间(使用上面新建的表空间)和临时表空间:
3)设置角色权限:
4)设置”系统权限“:
5)点击应用后,【应用】按钮变灰,新用户创建成功:
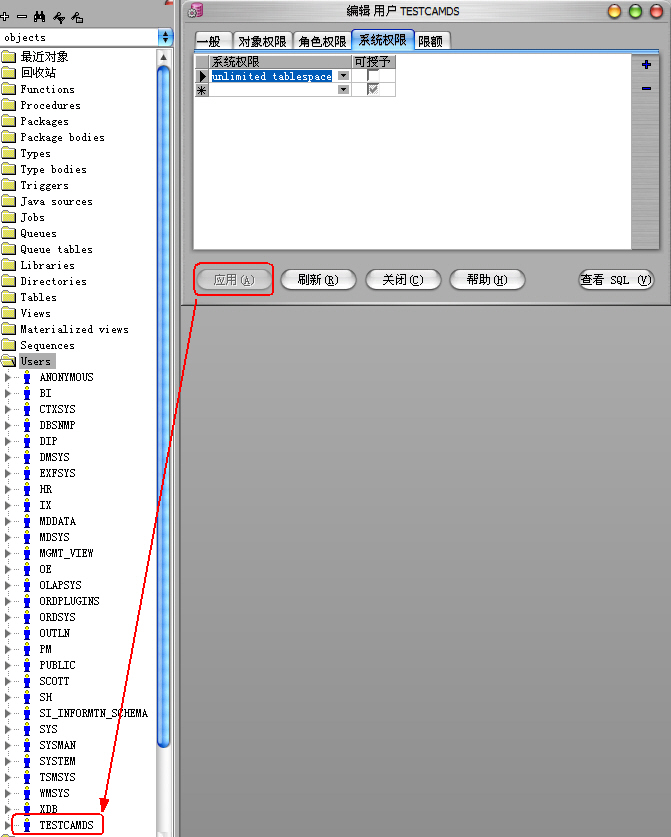
6)新用户登录测试:
输入新用户的“用户名/口令”:

新用户“testcamds”成功登陆:
6、导入导出数据库
先运行cmd命令,进入命令行模式,转到下面的目录:D:"oracle"product"10.2.0"db_1"BIN【该目录下有exp.exe文件】
1)导入
命令语法:
imp userid / pwd @sid file = path / file fromuser = testcamds touser = userid
命令实例:
imp testcamds / 123 @camds file = c:"testcamds fromuser = testcamds touser = testcamds
导入结果:
2)导出:
命令语法:
exp userid / pwd @sid file = path / file owner = userid
命令实例:
exp testcamds / 123 @camdsora file = c:"testcamds owner = testcamds
导入结果:

posted @
2009-10-18 20:13 CoderDream 阅读(20347) |
评论 (1) |
编辑 收藏
1
、Java通过XML Schema校验XML
http://lavasoft.blog.51cto.com/62575/97597
posted @
2009-08-27 09:50 CoderDream 阅读(386) |
评论 (0) |
编辑 收藏
1、实例不能启动!
症状:“计算机管理”-》“服务和应用程序”-》“服务”-》“OracleOraDb10g_camdsTNSListener”的启动类型为“自动”,但是状态为空(已停止),手工启动,状态变为“已启动”,1~5秒后状态变回“已停止”,数据库不能正常使用;
解决方法:【开始】-》【程序】-》【Oracle - OraDb10g_camds】-》【Configuration and Migration Tools】-》【Net Configuration Assistant】,重新配置一下刚才的【监听程序配置】,然后刷新服务就可以看到服务正常“自动”启动了。
posted @
2009-06-25 09:15 CoderDream 阅读(517) |
评论 (0) |
编辑 收藏
由于Spring AOP实现了AOP联盟约定的接口,而Spring框架并不提供该接口的源代码,我在网上搜索了一下相关资料,整理如下:
1、官方网站:
http://sourceforge.net/projects/aopalliance/
2、源代码:
http://coderdream.javaeye.com/topics/download/322bb187-64b3-3f4f-9ac2-fdc0ef4d0033
3、在线文档:
http://aopalliance.sourceforge.net/doc/index.html
posted @
2009-04-04 22:31 CoderDream 阅读(3453) |
评论 (0) |
编辑 收藏
最近,myeclipse 发布了最新的7.1版,其中blue版提供了对RAD 6.X的支持:
本版本的最引人注目之处莫过于对WSAD5.1、RAD 6.X和7.X项目的加强支持, 包括促进WSAD/RAD用户在MyEclipse Blue 和RAD环境下提高项目质量, . 全面有效执行任务的特性。此外,那些希望能将自己的项目完全移植到 MyEclipse Blue 版本的朋友们,可以通过使用MyEclipse Blue 7.1中的简单向导来实现了。 同时,新项目也能够完全支持已有的开发和服务器工具。
下载地址为:
A:普通版:
http://downloads.myeclipseide.com/downloads/products/eworkbench/7.0/myeclipse-7.1-win32.exe
B:Blue版
http://downloads4.myeclipseide.com/downloads/products/eworkbench/7.0-Blue/myeclipse-blue-7.1-win32.exe
其中普通版可以直接用迅雷下载,但是blue却连不上。
尝试了多种方式,终于找到了下载方法,不过速度很慢,而且很不稳定:
使用的软件
1、OperaTor-2.5
这是一个附带代理的浏览器软件;
2、eMule V1.1.3
常用的电驴软件;
下面我们来看看如何下载:
【步骤1】:打开OperaTor,程序打开后,会发现托盘区有一个蓝色图标,上面有一个字母“P";
【步骤2】:将鼠标移到该图标,点击右键,依次选择【Edit】-》【Main configuration】

【步骤3】:在打开的config.txt文件中,我们可以看到,本地代理的端口为:9050,

【步骤4】:设置电驴的代理服务器,这里的服务器类型选”Socks 4a“:

【步骤5】:最后,点击电驴的”新建“按钮,将”blue版“的地址拷贝过来就可以下载了:

不过通过代理方式下载的速度很慢,有时候还会断线,这时候只需要重新打开上面软件就可以了。
posted @
2009-03-16 22:04 CoderDream 阅读(2679) |
评论 (0) |
编辑 收藏启动服务:
1、首先建立一个新的“服务器”
在“Servers”面板空白处点击右键,依次选择【New】-》【Server】:

2、选择新服务器的类型
服务器主机名默认为:localhost,类型为:Oracle WebLogic Server v10.3:

3、选择域的文件路径:
这里选择WebLogic安装路径下的base_domain
注:我们安装WebLogic后有两个domain,分别为:base_domain和test_domain,其实还可以自己创建自定义的domain,点击面板中链接进入新建向导。

4、启动服务器
选择新建的服务器,点击右键,选中【Start】即可,通过控制台(Console)面板即可看到启动信息:

5、出现错误警告
提示:
The domain edit lock is owned by another session - this
deployment operation requires exclusive access to the edit lock and
hence cannot proceed.
You can release the lock in Administration Console by first disabling
"Automatically Acquire Lock and Activate Changes" in Preference,
then clicking the Release Configuration button.

解决方法:
1、进入WebLogic控制台:
链接:http://localhost:7001/console/

2、进入参数(Preferences)面板:

3、将自动锁定和激活勾选去掉:

4、点击页面左上角的【Release Configuration】,使刚才的设置生效:

posted @
2009-03-10 14:58 CoderDream 阅读(1634) |
评论 (0) |
编辑 收藏
01、
Java中的易混问题收集
02、
Java程序的加密和反加密
03、
JAVA JSP
servlet取路径问题总结....
04、
[转载]社会生存的75条忠告----胜读十年书(转载)
05、
【转载}08年Java开发者最迫切的五个期望
06、
【转载】给研究起步者的忠告 !
07、
[转载]Glassfish介绍
08、
民间偏方大全(总有你需要的时候)(转载)
09、
【转载】25条人生建议
10、
【转载】让你的生活和人生有所改变的45个方法
11、
【转载】Java程序员面试宝典
12、
【转载】sql 面试中的问题
13、
【转载】面试进行曲之技术面试(项目经验)
14、
【转载】一家公司的面试题
15、
【转载】面试杂谈
16、
[转载]一条sql 数据库去除重复记录
17、
【转载】如何快速面试筛选,找到合适的人
18、
【原创】动态生成日历
19、
[原创]日期时间处理实用类
20、
[原创]八皇后回溯版
21、
[原创]java.util.Comparator使用示例
22、
【转载】一个IT强人的奋斗历程
23、
【转载】Javeline的八年之期,走出象牙塔的纸象
24、
【转载】职业生涯几句话
25、
【整理】八皇后回溯版
26、
【转载】2007年值得去思考的N大软件技术
27、
【转载】2008年值得学习的五种Java技术
28、
【转载】实战 JDK 6.0 自带web service
29、
【转载】Linux学习系列之J2EE(JAVA EE)配置指南
30、
【转载】招聘的吹牛体系
31、
【转载】经典论坛回复收集
32、
【转帖】什么是MIS
33、
【转载】如何去做你讨厌做的事情?
34、
【转载】在windowsXP系统中卸载oracle9i
35、
【原创】泛型动态数组类
36、
【原创】数目字计数器,可多次添加整形数,累计0-9各个数字出现了多少次
37、
【原创】输出一万以内(1-9999)整数的中文大写形式
38、
【原创】求两字符串的公共子串
posted @
2008-10-27 19:57 CoderDream 阅读(298) |
评论 (0) |
编辑 收藏
1、
SQL注入攻击及其防范浅谈
posted @
2008-10-14 16:35 CoderDream 阅读(276) |
评论 (0) |
编辑 收藏<META HTTP-EQUIV='pragma' CONTENT='no-cache'>
<META HTTP-EQUIV='Cache-Control' CONTENT='no-cache, must-revalidate'>
<META HTTP-EQUIV='expires' CONTENT='0'>
posted @
2008-09-09 17:55 CoderDream 阅读(853) |
评论 (0) |
编辑 收藏
摘要: 需求:
对XML中的特定内容进行排序:
原始XML:
<?xml version="1.0" encoding="UTF-8"?>
<hostgateway>
<header>
&nb...
阅读全文
posted @
2008-08-20 15:14 CoderDream 阅读(959) |
评论 (0) |
编辑 收藏
Comparable & Comparator 都是用来实现集合中的排序的,只是 Comparable 是在集合内部定义的方法实现的排序,Comparator 是在集合外部实现的排序,所以,如想实现排序,就需要在集合外定义 Comparator 接口的方法或在集合内实现 Comparable 接口的方法。
一、Comparator
强行对某个对象collection进行整体排序的比较函数,可以将Comparator传递给Collections.sort或Arrays.sort。
接口方法:
/**
* @return o1小于、等于或大于o2,分别返回负整数、零或正整数。
*/
int compare(Object o1, Object o2);
二、Comparable
强行对实现它的每个类的对象进行整体排序,实现此接口的对象列表(和数组)可以通过Collections.sort或Arrays.sort进行自动排序。
接口方法:
/**
* @return 该对象小于、等于或大于指定对象o,分别返回负整数、零或正整数。
*/
int compareTo(Object o);
三、Comparator和Comparable的区别
一个类实现了Camparable接口则表明这个类的对象之间是可以相互比较的,这个类对象组成的集合就可以直接使用sort方法排序。
Comparator可以看成一种算法的实现,将算法和数据分离,Comparator也可以在下面两种环境下使用:
1、类的设计师没有考虑到比较问题而没有实现Comparable,可以通过Comparator来实现排序而不必改变对象本身
2、可以使用多种排序标准,比如升序、降序等。
完整代码:
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class SortObject {
public static void main(String[] args) {
sortByComparable();
sortByComparator();
}
/**
* 通过Comparable排序
*/
public static void sortByComparable() {
List list = new ArrayList();
list.add(new Person("Coder", 1));
list.add(new Person("King", 3));
list.add(new Person("Dream", 2));
list.add(new Person("Baby", 4));
System.out.println("--- Sort Before ---");
printPerson(list);
Collections.sort(list);
System.out.println("--- After Sorted ---");
printPerson(list);
}
/**
* 通过Comparator排序
*/
public static void sortByComparator() {
List list = new ArrayList();
list.add(new Person("Coder", 1));
list.add(new Person("King", 3));
list.add(new Person("Dream", 2));
list.add(new Person("Baby", 4));
System.out.println("--- Sort Before ---");
printPerson(list);
Collections.sort(list, new PersonComparator());
System.out.println("--- After Sorted ---");
printPerson(list);
}
/**
* 打印List
*
* @param list
*/
public static void printPerson(List list) {
int size = list.size();
Person p = null;
for (int i = 0; i < size; i++) {
p = (Person) list.get(i);
System.out.println(p.getName() + ":" + p.getId());
}
}
}
class Person implements Comparable {
public String name;
public int id;
public Person() {
}
public Person(String name, int id) {
this.name = name;
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int compareTo(Object o) {
Person p = (Person) o;
return this.getName().compareTo(p.getName());
}
}
class PersonComparator implements Comparator {
public int compare(Object o1, Object o2) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
return p1.name.compareTo(p2.name);
}
}
输出结果:
--- Sort Before ---
Coder:1
King:3
Dream:2
Baby:4
--- After Sorted ---
Baby:4
Coder:1
Dream:2
King:3
--- Sort Before ---
Coder:1
King:3
Dream:2
Baby:4
--- After Sorted ---
Baby:4
Coder:1
Dream:2
King:3
参考:
1、
Comparator和Comparable在排序中的应用
2、
java中对于复杂对象排序的模型及其实现 [转]
posted @
2008-08-20 11:37 CoderDream 阅读(354) |
评论 (0) |
编辑 收藏
|
 WebSphere V6 专题 WebSphere V6 专题 |
作为 WebSphere 软件平台的基础,WebSphere® Application Server V6.0 是业内首选的基于 Java 的应用程序平台,集成了动态电子商务世界的企业数据和事务。每个可用配置都提供了丰富的应用程序部署环境和应用程序服务,这些服务提供了增强的事务管理性能,同时还具备 WebSphere 产品家族的共同特性,包括安全性、性能、可用性、连接性和可伸缩性。
>>更多产品信息
posted @
2008-06-19 10:04 CoderDream 阅读(347) |
评论 (0) |
编辑 收藏
目标:将形如(tppabs="js_3.htm#window 窗口对象")之类的问题替换成新的文字。
规则:以(tppabs=")开头,(")结尾,中间有任意个字符
Java:^tppabs=".*"$
EditPlus(替换时注意选择"正则表达式"):^tppabs=".*" 如果末尾加美元符号($),则不行!

Eclipse的正则表达式插件:Regular Expression Tester
Eclipse Regular Expression Tester

Features
- Test and search for regular expression
- Matches are colorized, for an easy visual clue
- Support for pattern flags (e.g. Pattern.DOTALL)
- LiveEval evaluates your regular expression while you are typing it, gives feedback on possible errors and shows any matches automatically
- LiveEval is supported for changes of the regular expression, the search text and the pattern flags
- 4 distinct match modes:
- Find a sequence of characters
- Match a complete text
- Split text
- Replace every occurence of the regex with a different string
Replacing supports back references ($1,$2,...)
- LiveEval for match mode changes
- Context sensitive "Regular Expression Assist"
- Selective evaluation of expressions
- Bracket Matching
- Generation of string literals based on the regexp, e.g. "\(x\)" becomes "\\(x\\)"
- De-escape patterns in your code, e.g. \\(x\\) becomes \(x\)
- Improved "Clear Menu", choose which parts of the view you would like to get cleared every time you press the clear button
- Easy movement through matches: Choose "Previous Match" or "Next Match" and cycle through all matches found.
- Polished and accessible user interface, everything is reachable via keyboard
Download the plugin
- Unzip it to ECLIPSE_HOME
- Restart Eclipse
- In Eclipse, choose Window > Show View > Other > RegEx Tester
- Configure it in Window > Preferences > RegEx Tester
If you like RegEx Tester, please rate it at
eclipse-plugins.info.
The plugin requires a 1.4 JRE/JDK and Eclipse 3.0 or later.
There is an old (sorry) user guide which can
also be found here.
posted @
2008-06-18 15:08 CoderDream 阅读(504) |
评论 (0) |
编辑 收藏
左边链接(包括锚点)、右边显示
文件清单1:
<!-- ------------------------------ -->
<!-- 文件范例:index.html -->
<!-- 文件说明:框架集 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>框架集</TITLE>
</HEAD>
<FRAMESET COLS="30%,70%">
<FRAME SRC=menu.html Scrolling="No">
<FRAME SRC=1.html Name="right">
</FRAMESET>
</HTML>
说明:
1、<meta>标签放在<title>之前可以让IE自动选择字符集,如UTF-8;
2、第二个frame的name为“right”,这个值会在menu.html中用到;
文件清单2:
<!-- ------------------------------ -->
<!-- 文件范例:menu.html -->
<!-- 文件说明:左侧框架 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>左侧框架</TITLE>
</HEAD>
<BODY>
<A href="1.HTML" Target="right">《商业周刊》:iPhone2.0带来的鲶鱼效应</A><P>
1、<A href="1.HTML#a1" Target="right">无线运营商的日子更不好过</A><P>
2、<A href="1.HTML#a2" Target="right">手机制造厂商们将更烦恼</A><P>
3、<A href="1.HTML#a3" Target="right">iPhone带来的冲击会持续多久?</A><P>
<A href="2.HTML" Target="right">Fireworks MX</A><P>
<A href="3.HTML" Target="right">Flash MX</A><P>
</BODY>
</HTML>
说明:
1、注意,这里<A>标签的target都为index.html中定义的"right"
文件清单3:
<!-- ------------------------------ -->
<!-- 文件范例:1.html -->
<!-- 文件说明:右侧框架一 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>右侧框架一</TITLE>
<Style Type="text/css">
<!--
.abc {
font-weight: bold;
font-size: 18px;
}
-->
</Style>
</HEAD>
<BODY>
<H1><A name=aTitle>《商业周刊》:iPhone2.0带来的鲶鱼效应</A></H1>
ugmbbc发布于 2008-06-17 08:26:20|2998 次阅读 字体:大 小 打印预览<BR><BR>
北京时间6月16日,《商业周刊》发表评论文章分析了iPhone2.0对无线运营商和手机制造商们带来的冲击,以下为其全文:
当苹果准备凭着3G版iPhone再次吹响战斗号角的时候,也是手机制造商和无线运营商们更加头疼的时候.苹果在手机市场中可谓旗开得胜,在iPhone 入市的第一年,苹果就从竞争对手RIM公司中抢过不少市场份额,而AT&T作为 iPhone唯一授权的运营商,也从其竞争对手Alltel和T-Mobile中吸引了不少用户.可以想象,一个更便宜、速度更快、功能更全的 iPhone将带来什么样的冲击.<BR><BR>
将在7月面市的新版iPhone,不仅售价不到200美元、升级到更快的网络,而且新增了很多吸引普通消费者以及商业用户的功能.
<A name=a1><p class=abc> 无线运营商的日子更不好过</p></A>
据业内人士说,为了对付iPhone带来的冲击,无线服务运营商们不得不提高对手机的补贴、提高营销预算并降低一些服务的价格,所有这一切意味着利润空间的缩减.面对iPhone的冲击,本来就已经处在政府监管日益增加以及直面Google竞争的无线运营商们的日子更不好过了.<BR><BR>
在过去的一年里,美国的无线运营商们已经在手机津贴上展开激烈竞争,通过增加对手机的补贴来获得长期无线服务合同.但现在AT&T以 iPhone为诱惑来吸引用户,对别的运营商来说,必须采取相应的措施来吸引用户,他们可能引进类iPhone的手机.但"大多数人要的是iPhone,就像他们喜欢iPod而不是其他MP3播放器一样",东北大学营销系教授Gloria Barczak说到,"人们要的是真正的iPhone".因此,要想让用户被吸引,必须得有别的优势,比如价格优势等.<BR><BR>
为了留住高端用户,运营商们需要加大业务推广的力度.据广告顾问公司TNS媒体情报的数据,运营商Verizon无线今年第一季度的广告支出增加了30%.<BR><BR>
Sprint Nextel同期的广告开支下降20%,主要是由于自身的财务问题,当看到用户不断流失的时候,Sprint Nextel应该会加大广告的投入."他们必须拿出能对抗iPhone诱惑的方案来,尽量发挥自己的长处",顾问公司TMNG的CEO Rich Nespola说到.<BR><BR>
另一种留住用户的方式是降低服务的价格.事实上,这是一个有效对付AT&T的办法.AT&T对提供iPhone的用户增加了服务的价格,以弥补高额的津贴费用."AT&T的对手们将在今年下半年继续加强价格优势,可能会有30%到40%的下降.当人们因为高油价开支增多的情况下,每月在无线服务上节省50美元也是很有吸引力的",Pali研究所的分析师Walter Piecyk说到,"因此,无线运营商的利润将从目前的40%下滑到30%".
<p class=abc><A name=a2> 手机制造厂商们将更烦恼</A></p>
手机制造厂商们也正在因为iPhone而大伤脑筋,尽管现在他们正受益于两位数增长的智能手机市场.当运营商们因iPhone而必须提高补贴的时候,他们会将压力转加到手机制造厂商头上,进而压低手机价格.何况,如果iPhone真像分析师们预期那样大卖的话,其他手机厂商的市场份额也会受到很大侵蚀.很久没推出拳头产品的摩托罗拉可能受创最重,三星、LG甚至诺基亚也会遭受冲击,NPD集团的主任分析师Ross Rubin说到,"高端、时尚机型将受冲击最大".<BR><BR>
还有,为了赶上iPhone的技术水平和图形表现能力,手机制造厂商们将不得不提高他们的软件研发成本.去年售出300万台触摸手机的 HTC,已经开发了一种特殊的3D菜单,该菜单表现力强劲,把通讯录做得就像在实际的纸制通讯录中翻找一样."我们希望能把用户的触摸体验提升到一个新的水平",HTC 首席营销官的John Wang说到.<BR><BR>
作为世界上最大手机制造商的诺基亚,在Ovi上投了大量资金,希望为它的智能手机建立一个集地图、游戏和照片共享于一身的Web服务平台,这次在iPhone的刺激下也在加紧推出新服务."我们将继续推出新服务",诺基亚美洲区副总裁Bill Plummer说到.
<p class=abc><A name=a3> iPhone带来的冲击会持续多久?</A></p>
iPhone带来的冲击将会持续多久?这个很难说.一个重量级手机的销售要达到顶峰需要几年的时间.摩托罗拉传奇的RAZR系列手机在2004年推出,直到2007年一季度才达到销售的顶峰,据NPD的数据,当时RAZR系列手机销售占全美手机销售的12%.<BR><BR>
虽然不好说那些别的智能手机和类iPhone的手机将会如何发展,但是"毕竟,重要的是,它们不是iPhone",Jupiter研究所分析师Neil Strother说到,"这不是在苹果堆里挑苹果".<BR><BR>
</BODY>
</HTML>
文件清单4:
<!-- ------------------------------ -->
<!-- 文件范例:2.html -->
<!-- 文件说明:右侧框架二 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>右侧框架二</TITLE>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
</HEAD>
<BODY>
<H1>Fireworks MX</H1>
Fireworks MX作为网页图像设计软件的代表,在继承了前期版本图形绘制、页面特效功能的同时,大大地发展了位图图像方面的处理功能,这无疑使这个软件有了向Photoshop挑战的更多资本,而其在网页设计方面的诸多应用,又无任何软件可与之媲美。与Dreamweaver MX的整合使其在专业网站图像设计过程中,扮演着不可或缺的角色。
</BODY>
</HTML>
文件清单5:
<!-- ------------------------------ -->
<!-- 文件范例:3.html -->
<!-- 文件说明:右侧框架三 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>右侧框架三</TITLE>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
</HEAD>
<BODY>
<H1>Flash MX</H1>
Flash MX作为网页矢量交互动画软件的代表,提供了图形绘制、动画制作和交互三大功能。掌握了这个软件的核心,也就有能力在网上冲浪的同时,充当一把闪客的角色。越来越多的个人、商业网站采用Flash技术制作广告Banner、动画片头、MTV、交互游戏,其广泛的应用为Flash的学习者提供了广阔的发展平台,学习Flash MX软件更是一个具有诱惑力的过程。
</BODY>
</HTML>
源代码
posted @
2008-06-18 11:47 CoderDream 阅读(810) |
评论 (3) |
编辑 收藏
大家好,网页设计思考栏目今天继续第八讲。我们上次讨论了首页设计的版面布局 和色彩的搭配,今天我们来谈谈字体。
●字体(Font)的设置是网页制作新手遇到的第一个难点。如何控制字体大小,如何取消 超链接字体的下划线是网友来信问得最多的。好,我们来彻底研究一下字体的各个方面:
○字符集的设定。
在查看html文件原代码时,我们经常可以在文件头<head>和</head>之间看到这么一句代码:
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
这段代码的作用是什么呢?是否可以删除呢?
其实这是meta标签的设定语句,是给浏览器看的。它的作用就是告诉浏览器:这个HTML 文件是采用gb2312字符集制作的。当浏览器读到这一代码,便以gb2312字符集来解释和翻译 网页原代码,然后我们就可以看到正确的网页。所以这个meta语句是非常重要的,尽量不要 删除。
gb2312就是我们最熟悉的GB简体码,英文是iso-8859-1字符集。其它还有BIG5,UTF-8, Shift-JIS,EUC,KOI8-2等字符集,分别用于不同的字体显示。
○字体的使用。
在网页里,字体的定义语句是:<font face="Arial">显示文字</font> 其中Arial就是一种字体的名称。 默认的浏览器定义的标准字体是中文宋体和英文times new Roma字体。也就是说, 如果你没有设置任何字体,网页将以这两种标准字体显示。同时,着两种字体也可以在任 何操作系统和浏览器里正确显示。
windows另外自带了40多种英文字体和5种中文字体。这些字体,你也可以在网页里自由 使用和设置。凡是使用windows操作系统的浏览器都可以正确显示这些字体,但在其它操作 系统里,如unix 则不能完全正确显示。
如果你需要用一种特殊的字体来体现你的风格,那么如何让大家可以真正看到你的设计 页面呢?解决的办法是:用图片。
将需要用这种字体的地方用图片代替,以保证所有人看到的页面是同一效果。
○字体的样式(style)。
字体的样式有四种:正常体(regular),斜体(Italic),粗体(Bold),粗斜体(Bold Italic)。 设置方法很简单,阿捷就不多罗嗦了。
○字体的效果。
这里指通过html语言设定可以直接显示的效果,在html里的语句设定为: <span style="text-decoration: overline">显示文字</span>
其中,overline是指上划线效果。其它常用的效果还有:underline(下划线), uppercase(大写)等等。
○字体大小的控制。
字体大小的控制是本节的重点。
一般字体默认的大小是12pt(镑).用<font size="+1">语句可以将文字增大2pt。这种方法我们都已经掌握了。而现在网络上最流行的小中文字体大小为9pt,是如何设定的呢?有三种方法:
1.用"<span style="font-size:9pt">显示文字</span>"语句来设定。
显然这种方法非常麻烦,你必须为每段文字都设定大小。
2.用CSS层叠样式表。
CSS是DHTML的一个组成部分,它可以定义整个页面的字体显示风格和大小。是较为简便的方法。比如,这里需要设定整个页面文字大小为9 pt,只要将下面这段代码加入html代码的<head>和</head>之间:
<style type="text/css">
<--
body {FONT-SIZE: 9pt}
th {FONT-SIZE: 9pt}
td {FONT-SIZE: 9pt}
-->
</style>
其中FONT-SIZE:9pt指字体的大小为9镑
3.第二种方法已经简化了许多步骤,但是仍然不是最理想的方法,因为你必须在每个页面的head区都放置这么一段代码,扩大了文件的字节。另外这样的做法还有一个重大缺点,就是如果我需要修改整个站点的字体大小,就必须一页一页的改!
所以推荐给你最终也是目前最好的方法---外部摸板文件调用法。
“外部摸板调用”就是说你将css的设定作成一个单独的文件,在每个页面里都调用它。一旦你需要修改字体大小,只要修改一个.cs s文件,几百个页面就同时修改了。(这种方法类似子程序调用编写过程序的网友很容易理解
调用的具体方法如下:
(1)将上面的css代码copy成一个mycss.txt文件,然后修改后缀名为mycss.css
(2)在html文件的<head></head>之间插入<LINK href="mycss.css" rel=stylesheet type=text/css>, 语句调用mycss.css(注意有关路径的设置正确)OK!
○字体超链接样式的设定。
通常在网页的<body>中设置连接的颜色,如<body link="#FF00FF" vlink="#FF0000" alink="#008080"> 其中:
link -- Hyperlink(连接)的颜色
vlink-- visited Hyperlink(已访问过的连接)颜色
alink-- active Hyperlink (当前活动的连接)颜色 颜色用rgb的16进制码表示如红色是#FF0000。
同样用CSS可以更简便的设定网页超连接的样式,看下面这段代码:
<style type="text/css"> A:link {TEXT-DECORATION: none;COLOR: #0000FF} A:visited {TEXT-DECORATION: none;COLOR: #000000} A:active {TEXT-DECORATION: none;COLOR: #FF0000} A:hover {COLOR: #FF0000} </style>
将它插入html文件的head区就可以了。其中link设定的是有超链接的颜色;visited是访问过的超 链接颜色;active是鼠标移上去的颜色;hover是鼠标点击时的颜色。而"text-decoration:none"是指 取消超链接的下划线显示。
关于CSS的设定还有更多的用法和技巧,比如在同一页中设定不同的字体大小和超链接颜色,请学习有关CSS的专门知识(可以到阿捷的主页h ttp://pageone.yeah.net查阅)在这里我们不在冗述。
●上面已经介绍了字体在技术上的各个方面。有关字体的设计使用,目前还没有一个成熟的理论, 下面是几条网页设计中字体的使用原则,仅供参考:
1.不要使用超过3种以上的字体。字体太多则显得杂乱,没有主题。
2.不要用太大的字。因为版面是宝贵,有限的,粗陋的大字体不能带给访问者更多信息。
3.不要使用不停闪烁的文字。想让浏览者多停留一会儿的话,就不要使用闪烁的文字。
4.原则上标题的字体较正文大,颜色也应有所区别。
posted @
2008-06-18 09:42 CoderDream 阅读(385) |
评论 (0) |
编辑 收藏在windows操作系统上使用IE作为浏览器时。常常会发生这样的问题:在浏览使用UTF-8编码的网页时,浏览器无法自动侦测(即没有设定“自动选择”编码格式时)该页面所用的编码。即使网页已经声明过编码格式:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
由此造成某些含有中文UTF-8编码的页面产生空白输出。
如果使用的是Mozilla、Mozilla 浏览器、Sarafi的浏览器这不会造成这个问题。这是由于IE解析网页编码时以HTML内的标签优先,而后才是HTTP header内的讯息;而mozilla系列的浏览器则刚刚相反。
由于UTF-8为3个字节表示一个汉字,而普通的GB2312或BIG5是两个。页面输出时,由于上述原因,使浏览器解析、输出<title></title>的内容时,如果在</title>前有奇数个全角字符时,IE把UTF-8当作两个字节解析时出现半个汉字的情况,这时该半个汉字会和</title>的<结合成一个乱码字,导致IE无法读完<title>部分,使整个页面为空百输出。而这个时候如果察看源文件的话,会发现实际上整个叶面全部已经输出了。
因此最简单的解决办法是在网页文件的<head></head>标签中一定要把字符定义
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
放在<title></title>之前。
posted @
2008-06-18 09:30 CoderDream 阅读(413) |
评论 (0) |
编辑 收藏
1、
如何使用Log4j?
2、
http://supportweb.cs.bham.ac.uk/documentation/tutorials/docsystem/build/tutorials/log4j/log4j.html
3、
Log4j
http://my.so-net.net.tw/idealist/Java/Log4j.html
posted @
2008-06-13 17:56 CoderDream 阅读(404) |
评论 (0) |
编辑 收藏
摘要: 14.1 什么是JavaScript
14.1.1 JavaScript概念
JavaScript是一种基于对象和事件驱动并具有安全性能的脚本语言。
14.1.2 JavaScript特点
是一种脚本编写语言;
基于对象的语言;
简单性;
安全性;
动态性;
跨平台性
14.2 编写第一个JavaScript脚本
文件范例:1401.html
<!-- --...
阅读全文
posted @
2008-06-04 09:29 CoderDream 阅读(423) |
评论 (0) |
编辑 收藏
我们在开发的过程中,调试的时候经常要进入某些包,如果没有将这些包与对应的源文件文件夹或zip包对应,就会提示“Source not found”,但是现在很多jar文件都会有相应的源文件,如Struts、Spring等等。而且JavaEE的很多源文件可以通过Tomcat的源文件找到,我们把它打成zip包,注意要和jar文件夹对应,然后设置一下,以后新建Web Project的时候,就可以很方便的查看servlet文件夹下面的源代码了。
这是javaee.jar的设置画面,其他Struts等等设置类似。
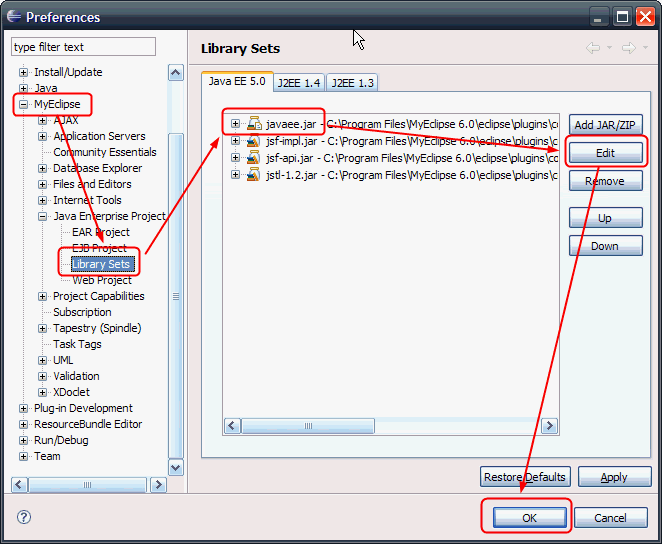
posted @
2008-05-29 14:57 CoderDream 阅读(3158) |
评论 (0) |
编辑 收藏
有时候如果看到某个包里面的文件夹没有SVN的标志,直接用“Ctrl+Delete”手工删除,然后“清理”,最后“更新”或“提交”。
网络摘抄1:
错误信息
Malformed file
svn: E:\svn\repository\conf\svnserve.conf:12: Option expected
原因:
配置文件12行开头有空格
错误信息
Attempted to lock an already-locked dir
svn: Working copy 'E:\integration\com.svn.practise' locked
原因:
需要用svn cleanup上次关闭时的锁定
网络摘抄2:
在eclipse里提交和更新文件是抱错。
Attempted to lock an already-locked dir
svn: Working copy 'F:\workspace\WebFrame\WebRoot\attach\prodrelation' locked
执行“清除”操作后,问题解决了。
很多操作,例如中断提交,都会进入这种工作拷贝的锁定状态。
网络摘抄3:
因为这两天频出这个现象,现在基本不怕这个问题了
我是这样解决的:
1 三令五申项目的组员必须先同步,合并,再提交
2 操作后经常地在父目录使用clean up命令
3 解决了locked问题后,还出现不能更新的现象时,就删除目录下的所有文件,包括.svn,再重新check out服务器同目录一次
4 总之,操作要规范,要强调组员每天开工时,先在ECLIPSE里同步,下班时,要提交(提交前,先在文件夹的右菜单中,选择小组>清除),保证每个人的机子里在开工前都是最新版本
老实讲,因为版本冲突,提交冲突,更新失败等等问题,耽误了好些时间,但我知道主要还是自身操作不熟练不规范的问题。我相信,只要坚持,大家包括我的组员一定都会喜欢上这个小海龟的
posted @
2008-05-27 09:51 CoderDream 阅读(108657) |
评论 (14) |
编辑 收藏
效果:
文件清单:
| 序号 |
文件名 |
| 1 |
ChangeLocaleAction.java |
| 2 |
ChangeLocaleForm.java |
| 3 |
struts-config.xml |
| 4 |
index.jsp |
| 5 |
application_en_US.properties |
| 6 |
application_zh_CN.properties |
| 7 |
application_zh_TW.properties |
清单1:
package com.coderdream.struts.action;
import java.util.Locale;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.struts.Globals;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
import com.coderdream.struts.form.ChangeLocaleForm;
public class ChangeLocaleAction extends Action {
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response) {
ChangeLocaleForm clForm = (ChangeLocaleForm)form;
String language = clForm.getLanguage();
if (language != null) {
Locale locale;
if (language.equalsIgnoreCase("en")) {
locale = Locale.US;
request.getSession().setAttribute(
Globals.LOCALE_KEY, locale);
} else if (language.equalsIgnoreCase("tw")) {
locale = Locale.TAIWAN;
request.getSession().setAttribute(
Globals.LOCALE_KEY, locale);
} else {
locale = Locale.CHINA;
request.getSession().setAttribute(
Globals.LOCALE_KEY, locale);
}
}
return mapping.findForward("success");
}
}
清单2:
package com.coderdream.struts.form;
import org.apache.struts.action.ActionForm;
/**
*
* description:
*
* @author
*
*/
public class ChangeLocaleForm extends ActionForm{
public ChangeLocaleForm() {
super();
}
private String language;
public String getLanguage() {
return language;
}
public void setLanguage(String language) {
this.language = language;
}
}
清单3:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE struts-config PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 1.2//EN" "http://struts.apache.org/dtds/struts-config_1_2.dtd">
<struts-config>
<data-sources />
<form-beans>
<form-bean name="ChangeLocaleForm"
type="com.coderdream.struts.form.ChangeLocaleForm" />
</form-beans>
<action-mappings>
<action name="ChangeLocaleForm" path="/ChangeLocale"
scope="request"
type="com.coderdream.struts.action.ChangeLocaleAction"
validate="false">
<forward name="success" path="/index.jsp" />
</action>
</action-mappings>
<message-resources key="application"
parameter="com.coderdream.struts.resources.application" />
</struts-config>
清单4:
<%@ page contentType="text/html; charset=UTF-8"%>
<%@page import="org.apache.struts.Globals"%>
<%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html"%>
<%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic"%>
<html:html>
<head>
<title>多语言测试</title>
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="This is my page">
</head>
<script language="javascript">
function onLanguage(){
var language = document.getElementsByName("language")[0].value;
if(language!=null&&language!=""){
document.forms[0].submit();
}
}
</script>
<body>
<html:form action="ChangeLocale.do">
<html:select property="language" styleId="height:18"
onchange="onLanguage();">
<option value="" title="">
--
<bean:message bundle="application" key="global.select.language" />
--
</option>
<option value="en" title="English">
English
</option>
<option value="cn" title="简体中文">
简体中文
</option>
<option value="tw" title="繁體中文">
繁體中文
</option>
</html:select>
</html:form>
<br>
<br>
<br>
<bean:message bundle="application" key="global.select.test" />
<%=request.getSession().getAttribute(Globals.LOCALE_KEY)%>
</body>
</html:html>
清单5:
#Generated by ResourceBundle Editor (http://eclipse-rbe.sourceforge.net)
global.select.language = Language
global.select.test = Test
清单6:
#Generated by ResourceBundle Editor (http://eclipse-rbe.sourceforge.net)
#BizException
global.select.language = \u8BED\u8A00
global.select.test = \u6D4B\u8BD5
清单7:
#Generated by ResourceBundle Editor (http://eclipse-rbe.sourceforge.net)
global.select.language = \u8A9E\u8A00
global.select.test = \u6E2C\u8A66
此功能的关键是在Action里面将页面传过来的language信息得到,然后根据信息设置Locale,然后将新的Locale放到Session中。
源代码:
点击下载
posted @
2008-05-14 18:20 CoderDream 阅读(1016) |
评论 (0) |
编辑 收藏
原始画面:
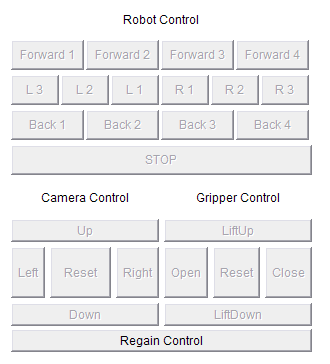
由于原来的程序使用的是AWT中的Panel,而这个控件我们没有设置titleBorder的方法。
现在将更新为Swing中的JPanel面板,代码分别为:
旧代码:
Panel pRoboCtrl=new Panel();
pRoboCtrl.setLayout(new GridLayout(5, 1, 2, 5));
// Robot控制面板的第一排,面板的标题
Panel pR1=new Panel();
pR1.setLayout(new GridLayout(1, 1, 2, 3));
//Row One
pR1.add(new Label("Robot Control",Label.CENTER));
新代码:
JPanel pRoboCtrl=new JPanel();
pRoboCtrl.setLayout(new GridLayout(4, 1, 2, 5));
Border titleBorder1=BorderFactory.createTitledBorder("Robot Control");
pRoboCtrl.setBorder(titleBorder1);
原来的处理方式是将一个Label放到Panel中,然后将这个Panel放到外层的Panel中,新方式是将外层Panel定义成JPanel,然后设置Border的值为BorderFactory产生的一个实例。
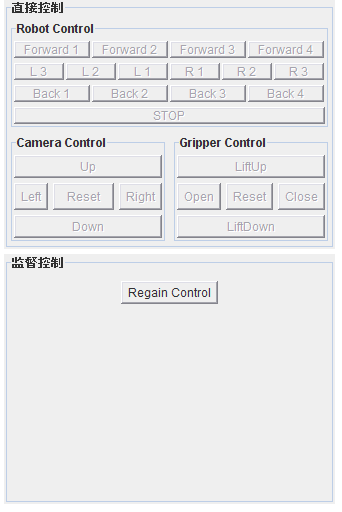
解决这个问题后,新问题又来了,两个JPanel中的内容不一样,上面多,下面少,但是现在面板却是一样大,要改成面板高度自动适应。
其实这只需要修改一行代码就可以了,代码如下:
旧代码:
 CP.setLayout(new GridLayout(3, 1, 2, 5));
CP.setLayout(new GridLayout(3, 1, 2, 5));
新代码:
CP.setLayout(new BoxLayout(CP, BoxLayout.Y_AXIS)); // 沿垂直方向布置组件
旧代码的处理方式是网格布局,新代码的方式是用BoxLayout布局管理器,它会按要求垂直或水平分布。

以下代码创建了一个JPanel容器,它采用垂直 BoxLayout,在这个容器中包含两个Button,这两个Button沿垂直方向分布,并且保持像素为 5 的固定垂直间隔。
JPanel panel = new JPanel();
panel.setLayout(new BoxLayout(panel, BoxLayout.Y_AXIS));// 沿垂直方向布置组件
panel.add(new JButton("Button1"));
panel.add(Box.createVerticalStrut(5));
panel.add(new JButton("Button2"));
源代码:
下载
posted @
2008-04-29 16:16 CoderDream 阅读(15614) |
评论 (2) |
编辑 收藏
1、下载
http://www.opensymphony.com/quartz/download.action
https://quartz.dev.java.net/files/documents/1267/43545/quartz-1.6.0.zip
2、
详细讲解Quartz如何从入门到精通
3、
用 Quartz 进行作业调度
posted @
2008-04-15 17:46 CoderDream 阅读(737) |
评论 (0) |
编辑 收藏
数据库和表
create table USERS
(
USERNAME VARCHAR2(20) not null,
PASSWORD VARCHAR2(20)
)
alter table USERS
add constraint U_PK primary key (USERNAME)
/**
* JdbcExample.java
*
* Provider: CoderDream's Studio
*
* History
* Date(DD/MM/YYYY) Author Description
* ----------------------------------------------------------------------------
* Apr 14, 2008 CoderDream Created
*/
package com.coderdream.jdbc.oracle;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
* @author XL
*
*/
public class JdbcExample {
private static Connection getConn() {
String driver = "oracle.jdbc.driver.OracleDriver";
String url = "jdbc:oracle:thin:@10.5.15.117:1521:csi";
String username = "scott";
String password = "tiger";
Connection conn = null;
try {
Class.forName(driver);
// new oracle.jdbc.driver.OracleDriver();
conn = DriverManager.getConnection(url, username, password);
}
catch (ClassNotFoundException e) {
e.printStackTrace();
}
catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
private static int insert(String username, String password) {
Connection conn = getConn();
int i = 0;
String sql = "insert into users (username,password) values(?,?)";
PreparedStatement pstmt;
try {
pstmt = conn.prepareStatement(sql);
// Statement stat = conn.createStatement();
pstmt.setString(1, username);
pstmt.setString(2, password);
i = pstmt.executeUpdate();
System.out.println("resutl: " + i);
pstmt.close();
conn.close();
}
catch (SQLException e) {
e.printStackTrace();
}
return i;
}
private static void query() {
Connection conn = getConn();
String sql = "select * from users";
PreparedStatement pstmt;
try {
pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
System.out.println("name: " + rs.getString("username")
+ " \tpassword: " + rs.getString("password"));
}
rs.close();
pstmt.close();
conn.close();
}
catch (SQLException e) {
e.printStackTrace();
}
}
private static int update(String oldName, String newPass) {
Connection conn = getConn();
int i = 0;
String sql = "update users set password='" + newPass
+ "' where username='" + oldName + "'";
PreparedStatement pstmt;
try {
pstmt = conn.prepareStatement(sql);
i = pstmt.executeUpdate();
System.out.println("resutl: " + i);
pstmt.close();
conn.close();
}
catch (SQLException e) {
e.printStackTrace();
}
return i;
}
private static int delete(String username) {
Connection conn = getConn();
int i = 0;
String sql = "delete users where username='" + username + "'";
PreparedStatement pstmt;
try {
pstmt = conn.prepareStatement(sql);
i = pstmt.executeUpdate();
System.out.println("resutl: " + i);
pstmt.close();
conn.close();
}
catch (SQLException e) {
e.printStackTrace();
}
return i;
}
/**
* @param args
*/
public static void main(String[] args) {
insert("CDE", "123");
insert("CoderDream", "456");
query();
update("CoderDream", "456");
query();
delete("CoderDream");
query();
}
}
posted @
2008-04-14 17:55 CoderDream 阅读(7048) |
评论 (0) |
编辑 收藏
1、首先下载eclipse的Tomcat插件,文件名为:tomcatPluginV321.zip
下载:
地址
2、安装Tomcat插件,即将zip档解压,放入eclipse目录下的 plugins 文件夹中。
3、在项目上点右键,设置properties,在'Tomcat'下面设置'export to war settings'输入要导出的war文件路径和文件名,确定,返回项目。

4、在项目上点右键,选择tomcat project->Export to the war file sets in project properties
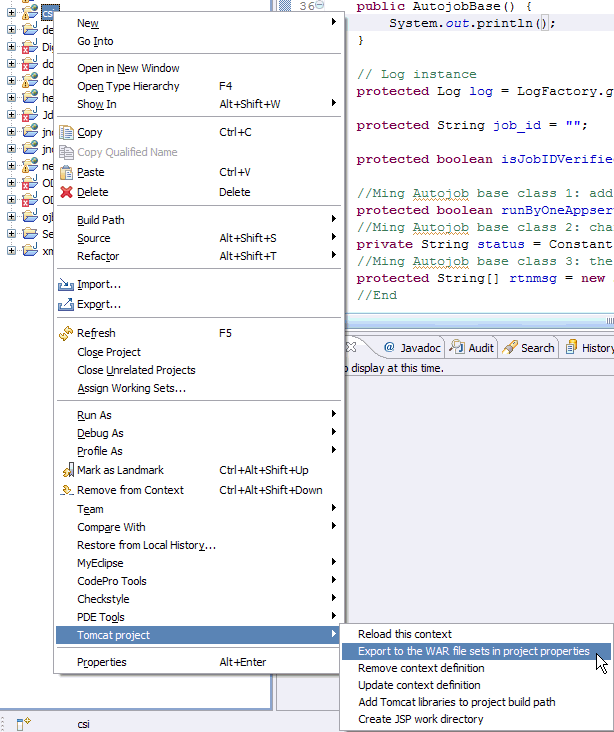
5、 进入C盘,可以看到csi.war文件正在生成,成功后会有提示框。这样就可以通过Tomcat插件导出WAR档了。
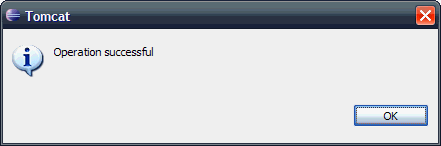
posted @
2008-04-08 13:43 CoderDream 阅读(3735) |
评论 (1) |
编辑 收藏有关CVS权限设置参考
个人建议:如果各个项目独立,我还是建议每个项目一个库!
你的整体思路是正确的,步骤很清晰。
不过要注意cvs chacl -R default:n 的使用,此命令会把该模块的全部权限都去掉的。
另外建议 如果admini,pm 是管理员用户,可以在CVSROOT下建立超级用户admin文件,将这两个用户加入。
=====================================================================
那就按找你的思想设计权限
假设目录结构如下
project
|
|……pro1
| |_pro
| |_aa
|
|……Pro2
| |_pro
| |_bb
|
|_CVSROOT
权限要求
1.用户admini,pm 对project 整个目录有rcw的权限
2.用户h,y,w 对pro1\pro 整个目录有rcw的权限
3.用户y 对pro1\aa 整个目录有rcw的权限
4.用户h 对pro2 整个目录有rcw的权限
=====================================================================
权限设置步骤如下:
首先,建立一个组包含3个用户h,y,w。 group1:h,y,w
一.用户admini,pm 对project 目录有rcw的权限
选中模块roject设置权限:
cvs chacl -R default:n
cvs chacl -R admini:rcw
cvs chacl -R pm:rcw
cvs lsacl
二.用户h,y,w 对pro1\pro目录有rcw的权限
选中模块pro设置权限:
cvs chacl -R group1:rcw
cvs lsacl
三.用户y 对pro1\aa目录有rcw的权限
选中模块aa设置权限:
cvs chacl -R y:rcw
cvs lsacl
四.用户h 对pro2目录有rcw的权限
选中模块pro2:
cvs chacl -R h:rcw
cvs lsacl
结束!
C应该是check out/in
R:READ-只读权限;用户不能对文件进行修改操作;
A:ADD/RENAME/DELETE-用户可以对文件进行添加、删除和更名的操作;其中删除的操作支持从视图中删除文件连接,并没有彻底删除文件,配置库中依然保存文件及其日志信息;
C:CHECK IN/CHECK OUT-文件修改权限:用户可以将文件进行签出进行修改,并可以将修改后的文件签入到配置库中;
D:DESTROY-彻底删除权限;
1、
VSS和CVS的比较
2、
CVS使用手册
3、
一篇CVS权限管理手册
4、
CVS资料集中营
5、
CVS权限设置
posted @
2008-04-07 16:32 CoderDream 阅读(529) |
评论 (0) |
编辑 收藏
摘要: Struts连接数据库一般有直接JDBC和数据源两种方式,
1、JDBC:
在MySQL中创建数据库:
drop database if exists login;
create database login;
use login;
create table user(...
阅读全文
posted @
2008-03-26 13:47 CoderDream 阅读(3870) |
评论 (5) |
编辑 收藏4.1 Web应用的发布描述文件
包含以下信息:
- 初始化参数
- Session配置
- Servlet声明
- Servlet映射
- 应用生命周期的监听类
- 过滤器定义和映射
- MIME类型映射
- 欢迎文件列表
- 出错处理页面
- 标签库映射
- JNDI引用
4.1.1 Web应用发布描述文件的文档类型定义(DTD)
包含元素,属性,实体
<web-app>元素是web.xml的根元素,其他元素必须嵌入在<web-app>元素以内。
<servlet>必须在<servlet-mapping>之前;
<servlet-mapping>必须在<taglib>之前;
4.2 为Struts 应用配置 web.xml 文件
4.2.1 配置 Struts 的 ActionServlet
<!-- Standard Action Servlet Configuration (with debugging) -->
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>
org.apache.struts.action.ActionServlet
</servlet-class>
<init-param>
<param-name>config</param-name>
<param-value>
/WEB-INF/conf/struts-config.xml
</param-value>
</init-param>
<init-param>
<param-name>config/bank</param-name>
<param-value>
/WEB-INF/conf/struts-config-bank.xml
</param-value>
</init-param>
<init-param>
<param-name>config/card</param-name>
<param-value>
/WEB-INF/conf/struts-config-card.xml
</param-value>
</init-param>
<init-param>
<param-name>config/publicarea</param-name>
<param-value>
/WEB-INF/conf/struts-config-publicarea.xml
</param-value>
</init-param>
<init-param>
<param-name>config/maintenance</param-name>
<param-value>
/WEB-INF/conf/struts-config-maintenance.xml
</param-value>
</init-param>
<init-param>
<param-name>config/report</param-name>
<param-value>
/WEB-INF/conf/struts-config-report.xml
</param-value>
</init-param>
<init-param>
<param-name>debug</param-name>
<param-value>2</param-value>
</init-param>
<init-param>
<param-name>detail</param-name>
<param-value>2</param-value>
</init-param>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet-mapping>
<!-- Standard Action Servlet Mapping -->
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
说明:
1、一个项目可以配置多个<servlet>,且其中一个名为action;
2、在action的<servlet>中,可配置多个config,第一个为config,其他以“config/”开头,如:config/bank;
3、在全局<forward>元素中的例子:
<global-forwards>
<forward name="toBank" path="/bank/login.do" />
</global-forwards>
4、使用<action>元素中的局部<forward>元素,例如:
<action-mappings>

<action>
<forward> name="success" path="/bank/index.do" />
</action>
</action-mappings>
5、<url-pattern>属性为“*.do”,表明ActionServlet负责处理所有以“.do”扩展名结尾的URL。
4.2.2、 声明 ActionServlet 的初始化参数
<init-param>子元素用于声明 Servlet 初始化参数。见4.2.1的代码清单。
4.2.3、配置欢迎文件清单
<!-- The Usual Welcome File List -->
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
从第一个文件依次往后面找,如果没有找到,抛出404错误。
在欢迎文件中不能配置Servlet映射,可通过变通的方式处理。
1、在 Struts 配置文件中为被调用的 Action 创建一个全局的( global) 转发项,例如:
<global-forwards>
<forward name="welcome" path="HelloWordl.do" />
</global-forwards>
2、创建一个welcome.jsp文件:
<%@ tablib uri="/WEB-INF/struts-logic.tld" prefix="logic" %>
<html>
<body>
<logic:forward name="welcome" />
</body>
</html>
3、最后配置欢迎页面为welcome.jsp即可。
4.2.4 配置错误处理
1、避免用户看到原始的错误信息
<error-page>
<error-code>404</error-code>
<location>/common/404.jsp</location>
</error-page>
<error-page>
<error-code>500</error-code>
<location>/common/500.jsp</location>
</error-page>
2、也可为Web 容器捕获 Java 异常配置 <error-page>元素,这是需要设置<exception-type>子元素,它用于指定Java异常类。可捕获如下异常:
A、RuntimeException 或 Error
B、ServletException 或它的子类
C、IOException 或它的子类
例如:
<!-- The default error page -->
<error-page>
<exception-type>java.lang.IOException</exception-type>
<location>/common/IOError.jsp</location>
</error-page>
4.2.5 配置 Struts 标签库
<!-- Struts Tag Library Descriptors -->
<taglib>
<taglib-uri>/tags/struts-bean</taglib-uri>
<taglib-location>/WEB-INF/struts-bean.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>/tags/struts-html</taglib-uri>
<taglib-location>/WEB-INF/struts-html.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>/tags/struts-logic</taglib-uri>
<taglib-location>/WEB-INF/struts-logic.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>/tags/struts-nested</taglib-uri>
<taglib-location>/WEB-INF/struts-nested.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>/tags/struts-tiles</taglib-uri>
<taglib-location>/WEB-INF/struts-tiles.tld</taglib-location>
</taglib>
用户自定义的客户化标签库和标准的类似。
posted @
2008-03-21 11:51 CoderDream 阅读(403) |
评论 (0) |
编辑 收藏1、
<html:form action="getImporterDonneesTypeList.do">
<div class="finFormulaire1" onClick="document.forms[1].submit();" STYLE="position:relative;right:10%;">
<div class="bouton" onclick="">
<span class="bold">
<rcd:label key="boutonNouveau"/>
</span>
<img src="<%= "/resources/"+ userMarque + "/img/common/btn/right.gif" %>" alt="" style="vertical-align:middle"/>
</div>
</div>
</html:form>
2
function goBack(){
document.forms[0].action="/initCommerentitesSearchAction.do";
document.forms[0].method="post";
document.forms[0].encoding="multipart/form-data";
document.forms[0].submit();
}
<div class="finFormulaire" align="center">
<div class="bouton" onClick="goBack();"><span class="bold"><rcd:label key="boutonRetour"/></span><img src="<%= "/resources/"+ userMarque + "/img/common/btn/right.gif" %>" alt="" style="vertical-align:middle"/></div>
</div>
posted @
2008-03-14 13:15 CoderDream 阅读(430) |
评论 (0) |
编辑 收藏1、RCD-499:某个<html:text/>不能修改。
style="color:#BCBCBC;">
posted @
2008-03-12 10:23 CoderDream 阅读(274) |
评论 (0) |
编辑 收藏
1、日志类型:Metaweblog API;
2、日志的远程发布URL:
http://www.blogjava.net/用户名/services/metaweblog.aspx
我的:http://www.blogjava.net/coderdream/services/metaweblog.aspx
参考地址:http://www.cnblogs.com/dudu/articles/495718.html
posted @
2008-03-11 11:54 CoderDream 阅读(222) |
评论 (0) |
编辑 收藏使用下面的命令就可以了:
db2cmd
然后:
db2set db2codepage=1252
后面的数字是安装DB2时数据库的CodePage。
DB2 CODEPAGE --代码页查询列表
http://www.itdata.cn/bbs/dispbbs.asp?boardid=6&id=928
--------------------------------------------------
Conversion between any of the following codepages is provided.
37 (=x0025) EBCDIC US English
273 (=x0111) EBCDIC German
277 (=x0115) EBCDIC Danish/Norwegian
278 (=x0116) EBCDIC Finnish/Swedish
280 (=x0118) EBCDIC Italian
284 (=x011C) EBCDIC Spanish
285 (=x011D) EBCDIC UK English
297 (=x0129) EBCDIC French
300 (=x012C) EBCDIC Japanese DBCS
301 (=x012D) Japanese PC DBCS
420 (=x01A4) EBCDIC Arabic
424 (=x01A8) EBCDIC Arabic
437 (=x01B5) PC-ASCII US
500 (=x01F4) EBCDIC International
803 (=x0323) Hebrew Set A
813 (=x032D) ISO8859-7 Greek
819 (=x0333) ISO8859-1 Western European
833 (=x0341) IBM-833: Korean
834 (=x0342) IBM-834: Korean Host DBCS
835 (=x0343) EBCDIC Traditional Chinese DBCS
836 (=x0344) EBCDIC Simplified Chinese SBCS
838 (=x0346) EBCDIC Thai SBCS
850 (=x0352) ISO8859-1 Western European
852 (=x0354) PC-ASCII Eastern European
855 (=x0357) PC-ASCII Cyrillic
856 (=x0358) PC-ASCII Hebrew
857 (=x0359) PC-ASCII Turkish
858 (=x035A) PC-ASCII Western European with Euro
860 (=x035C) PC-ASCII Portuguese
861 (=x035D) PC-ASCII Icelandic
862 (=x035E) PC-ASCII Hebrew
863 (=x035F) PC-ASCII Canadian French
864 (=x0360) PC-ASCII Arabic
865 (=x0361) PC-ASCII Scandinavian
866 (=x0362) PC-ASCII Cyrillic #2
868 (=x0364) PC-ASCII Urdu
869 (=x0365) PC-ASCII Greek
870 (=x0366) EBCDIC Eastern Europe
871 (=x0367) EBCDIC Icelandic
872 (=x0368) PC-ASCII Cyrillic with Euro
874 (=x036A) PC-ASCII Thai SBCS
875 (=x036B) EBCDIC Greek
880 (=x0370) EBCDIC Cyrillic
891 (=x037B) IBM-891: Korean
897 (=x0381) PC-ASCII Japan Data SBCS
903 (=x0387) PC Simplified Chinese SBCS
904 (=x0388) PC Traditional Chinese Data - SBCS
912 (=x0390) ISO8859-2 Eastern European
915 (=x0393) ISO8859-5 Cyrillic
916 (=x0394) ISO8859-8 Hebrew
918 (=x0396) EBCDIC Urdu
920 (=x0398) ISO8859-9 Turkish
921 (=x0399) ISO Baltic
922 (=x039A) ISO Estonian
923 (=x039B) ISO8859-15 Western Europe with euro (Latin 9)
924 (=x039C) EBCDIC Western Europe with euro
927 (=x039F) PC Traditional Chinese DBCS
928 (=x03A0) PC Simplified Chinese DBCS
930 (=x03A2) EBCDIC Japanese Katakana/Kanji mixed
932 (=x03A4) Japanese OS/2
933 (=x03A5) EBCDIC Korean Mixed
935 (=x03A7) EBCDIC Simplified Chinese Mixed
937 (=x03A9) EBCDIC Traditional Chinese Mixed
939 (=x03AB) EBCDIC Japanese Latin/Kanji mixed
941 (=x03AD) Japanese PC DBCS - for open systems
942 (=x03AE) Japanese PC Data Mixed - extended SBCS
943 (=x03AF) Japanese PC Mixed - for open systems
944 (=x03BO) Korean PC data Mixed - extended SBCS
946 (=x03B2) Simplified Chinese PC data Mixed - extended SBCS
947 (=x03B3) PC Traditional Chinese DBCS
948 (=x03B4) PC Traditional Chinese Mixed - extended SBCS
949 (=x03B5) PC Korean Mixed - KS code
950 (=x03B6) PC Traditional Chinese Mixed - big5
951 (=x03B7) PC Korean DBCS - KS code
970 (=x03CA) euc Korean
1004 (=x03EC) PC Data Latin1
1006 (=x03EE) ISO Urdu
1008 (=x03F0) ASCII Arabic 8-bit ISO
1025 (=x0401) EBCDIC Cyrillic
1026 (=x0402) EBCDIC Turkish
1027 (=x0403) EBCDIC Japanese Latin
1040 (=x0410) IBM-1040: Korean
1041 (=x0411) Japanese PC - extended SBCS
1042 (=x0412) PC Simplified Chinese - extended SBCS
1043 (=x0413) PC Traditional Chinese - extended SBCS
1046 (=x0416) PC-ASCII Arabic
1047 (=x0417) IBM-1047: Western European
1051 (=x041B) ASCII roman8 for HP Western European
1088 (=x0440) PC Korean SBCS - KS code
1089 (=x0441) ISO8859-6 Arabic
1097 (=x0449) EBCDIC Farsi
1098 (=x044A) PC-ASCII Farsi
1112 (=x0458) EBCDIC Baltic (Latvian/Lithuanian)
1114 (=x045A) PC Traditional Chinese - big 5 SBCS
1115 (=x045B) PC Simplified Chinese SBCS
1122 (=x0462) EBCDIC Estonian
1123 (=x0463) EBCDIC Ukrainian
1124 (=x0464) UNIX-ASCII Ukrainian
1131 (=x046B) PC-ASCII Belarus
1140 (=x0474) EBCDIC USA, with euro (like 037)
1141 (=x0475) EBCDIC Austria, Germany, with euro (like 273)
1142 (=x0476) EBCDIC Denmark, Norway, with euro (like 277)
1143 (=x0477) EBCDIC Finland, Sweden, with euro (like 278)
1144 (=x0478) EBCDIC Italy, with euro (like 280)
1145 (=x0479) EBCDIC Spain, with euro (like 284)
1146 (=x047A) EBCDIC UK, with euro (like 285)
1147 (=x047B) EBCDIC France, with euro (like 297)
1148 (=x047C) EBCDIC International, with euro (like 500)
1149 (=x047D) EBCDIC Iceland, with euro (like 871)
1200 (=x04B0) Unicode - UCS-2
1208 (=x04B8) Unicode - UTF-8
1250 (=x04E2) Windows - Eastern European
1251 (=x04E3) Windows - Cyrillic
1252 (=x04E4) Windows - Western European
1253 (=x04E5) Windows - Greek
1254 (=x04E6) Windows - Turkish
1255 (=x04E7) Windows - Hebrew
1256 (=x04E8) Windows - Arabic
1257 (=x04E9) Windows - Baltic Rim
1275 (=x04FB) Apple - Western European
1280 (=x0500) Apple - Greek
1281 (=x0501) Apple - Turkish
1282 (=x0502) Apple - Eastern European
1283 (=x0503) Apple - Cyrillic
1284 (=x0504) IBM-504: Eastern European
1285 (=x0505) IBM-505: Eastern European
1363 (=x0553) Windows Korean PC Mixed including 11,172 full hangul
1364 (=x0554) Korean Host Mixed extended including 11,172 full hangul
1380 (=x0564) PC Simplified Chinese DBCS
1381 (=x0565) PC Simplified Chinese Mixed
1383 (=x0567) euc Simplified Chinese Mixed
1386 (=x056A) PC Simplified Chinese Data GBK Mixed
1388 (=x056C) DBCS Host Simplified Chinese Data GBK Mixed
5346 (=x14E2) Windows-Eastern European with Euro (like 1250)
5347 (=x14E3) Windows - Cyrillic with Euro (like 1251)
5348 (=x14E4) Windows-Western European with Euro (like 1252)
5349 (=x14E5) Windows-Windows - Greek with Euro (like 1253)
5350 (=x14E6) Windows - Turkish with Euro (like 1254)
5351 (=x14E7) Windows - Hebrew with Euro (like 1255)
5352 (=x14E8) Windows - Arabic with Euro (like 1256)
5353 (=x14E9) Windows - Baltic Rim with Euro (like 1257)
5354 (=x14EA) 'Windows - Vietnamese with Euro (like 1258)
posted @
2008-03-07 18:02 CoderDream 阅读(1900) |
评论 (0) |
编辑 收藏
1、先将数据库中该字段全部转为大写,然后用Upper()函数将条件转为大写:
select * from code_table_data t where Upper(t.DETAIL_DESC)=Upper('tr');
2、 模糊查询:在Java中将条件转为大写,然后将该变量放入百分号(%)之间!
select * from code_table_data t where Upper(t.DETAIL_DESC) like '%T%';
posted @
2008-03-05 18:06 CoderDream 阅读(8362) |
评论 (6) |
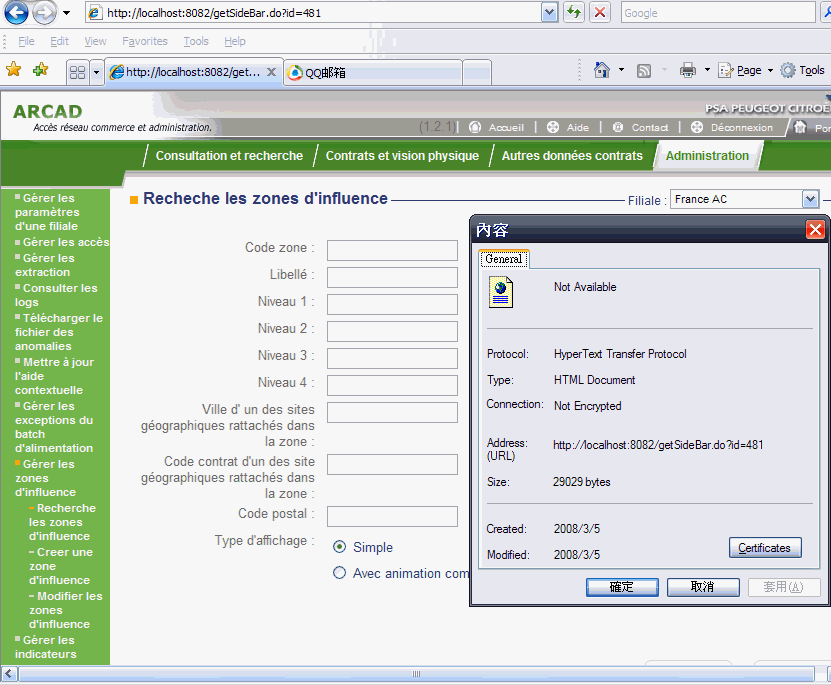
编辑 收藏1、进入出错页面,找到该页面的链接:
这里链接地址为:http://localhost:8082/getSideBar.do?id=481
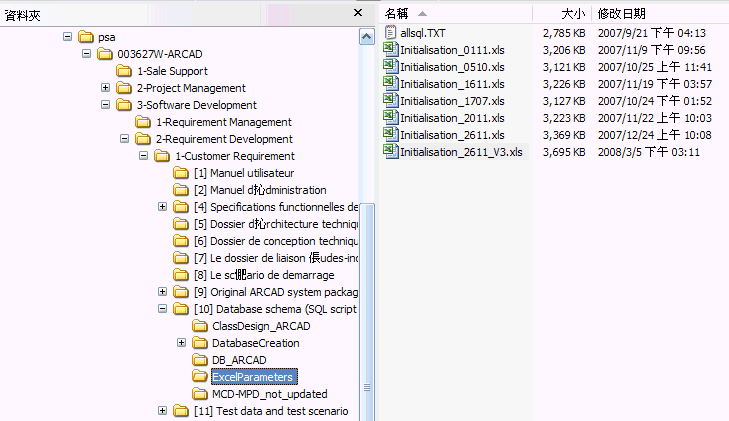
2、在Project文档中找到记录相关信息的Excel文件:
3、打开该文件,找到对应信息:
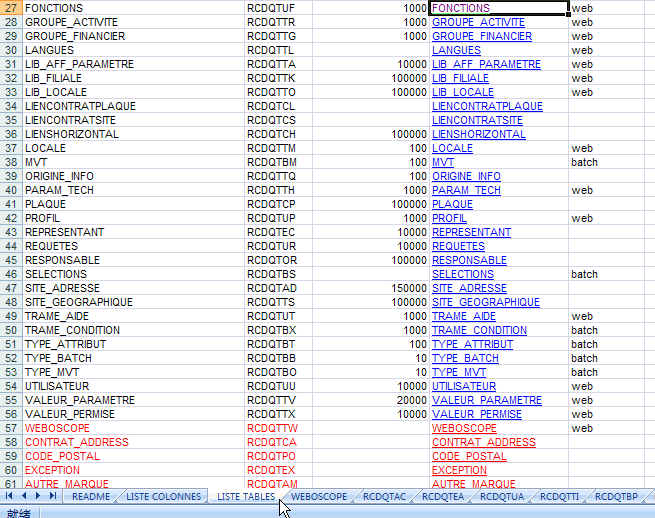
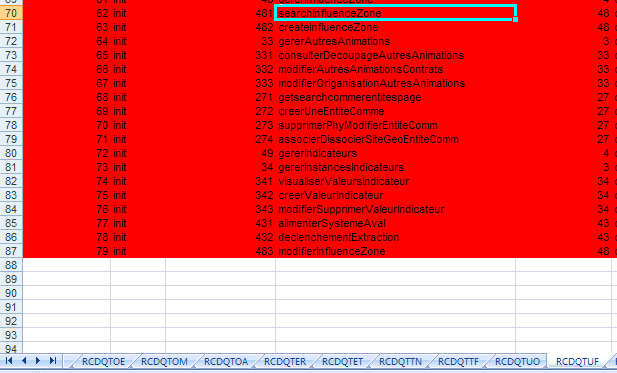
4、在struts-config.xml中找到相关信息:
注意:项目中有很多struts-config.xml,一定要找RCDWeb->WebContent->WEB-INF下面的struts-config.xml和conf下面的tiles-def.xml。

先通过<forward>标签,找到相应的Action.do:

然后通过该信息,找到具体的Action的详细信息:
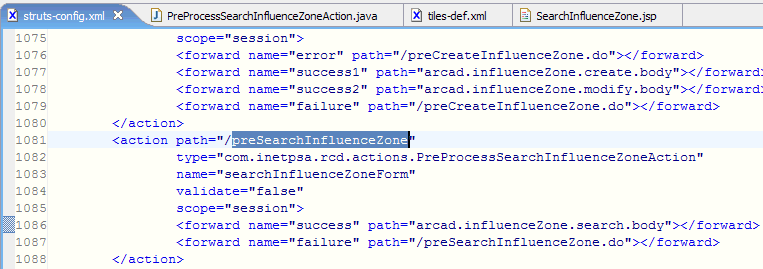
从上图可以找到相关的Java类的信息,type对应的值就是。
5、查找相关的Jsp:
通过上图的<forward name="success" ...>,可以通过查找tiles-def.xml文件找到相应的Jsp页面。
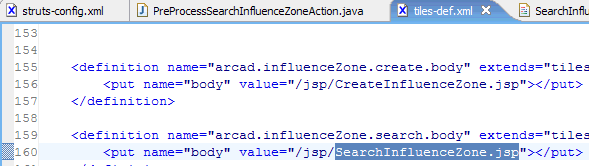
PS:这两个星期被安排到一个新项目改Bug,这个项目是一个法国项目,架构都是法国人自己写的。看来还有很多东西要学习,不然发现问题了也不知如何下手。
posted @
2008-03-05 15:45 CoderDream 阅读(317) |
评论 (0) |
编辑 收藏
CVS馆不仅能管理源代码,同时也可以用来管理文档。
一般,我们用eclipse来取文档,用wincvs客户端来取文档。
1、本地环境(繁体中文)与CVS馆的环境(简体中文)不一致
这里我们要用到微软提供的一个软件:Microsoft AppLocale,下载地址:
http://download.pchome.net/download-17721.html
软件详细信息
中文程序乱码消除器,消除中文程序接口上的乱码。如果您在繁体中文 Windows 上执行一个简体字版本的程序,那么这个程序的外观可能会变成许多中文乱码,让您无法辨识。此时便可试试本程序,且看他是否能为您化腐朽为神奇。
步骤:
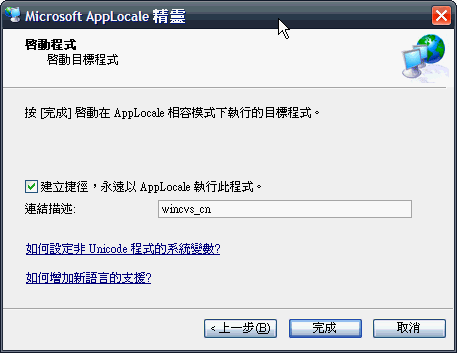
A、选择将要设置的exe文件;

B、选择要运行的环境语言(如:简体中文)。这样启动的wincvs的字符环境就是简体中文了。

C、然后建立快捷方式放到桌面方便以后使用:
2、登录取文档:
A、配置好服务器地址和文件目录,登录界面如下:
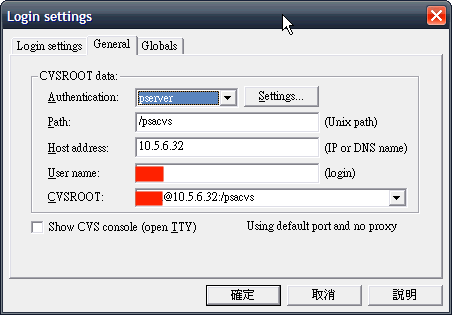
输入密码,登录成功:
CVSROOT: ***@10.5.6.32:/psacvs (password authentication)
TCL or Python are not available, shell is disabled
cvs -d :pserver:***@10.5.6.32:/psacvs login
Logging in to :pserver:***@10.5.6.32:2401:/psacvs
***** CVS exited normally with code 0 *****
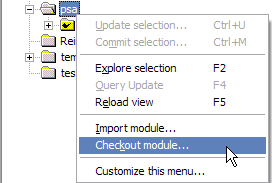
B、然后在本地建立一个文件夹,如:psa,在wincvs中点击文件夹psa右键,选择“Checkout settings”:
C、通过“Module name and path on the server:”的下拉选单我们可以选择要Checkout的文档工程,如果没有,可以直接输入,如:“003627W-ARCAD”:
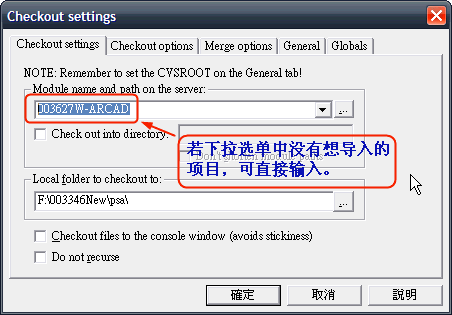
D、如果输入没有错误,就会正常取出文档,而且简体中文文件名不会显示乱码:

PS:不过如果还有法文的文件名,那乱码就不可避免了!
posted @
2008-03-04 10:27 CoderDream 阅读(655) |
评论 (0) |
编辑 收藏Java程序员:一刻钟精通正则表达式
想必很多人都对正则表达式都头疼。今天,我以我的认识,加上网上一些文章,希望用常人都可以理解的表达方式来和大家分享学习经验。
开篇,还是得说说 ^ 和 $ 他们是分别用来匹配字符串的开始和结束,以下分别举例说明:
"^The": 开头一定要有"The"字符串;
"of despair$": 结尾一定要有"of despair" 的字符串;
那么,
"^abc$": 就是要求以abc开头和以abc结尾的字符串,实际上是只有abc匹配。
"notice": 匹配包含notice的字符串。
你可以看见如果你没有用我们提到的两个字符(最后一个例子),就是说 模式(正则表达式) 可以出现在被检验字符串的任何地方,你没有把他锁定到两边。
接着,说说 '*', '+',和 '?',
他们用来表示一个字符可以出现的次数或者顺序。 他们分别表示:
"zero or more"相当于{0,},
"one or more"相当于{1,},
"zero or one."相当于{0,1}, 这里是一些例子:
"ab*": 和ab{0,}同义,匹配以a开头,后面可以接0个或者N个b组成的字符串("a", "ab", "abbb", 等);
"ab+": 和ab{1,}同义,同上条一样,但最少要有一个b存在 ("ab", "abbb", 等。);
"ab?":和ab{0,1}同义,可以没有或者只有一个b;
"a?b+$": 匹配以一个或者0个a再加上一个以上的b结尾的字符串。
要点, '*', '+',和 '?'只管它前面那个字符。
你也可以在大括号里面限制字符出现的个数,比如
"ab{2}": 要求a后面一定要跟两个b(一个也不能少)("abb");
"ab{2,}": 要求a后面一定要有两个或者两个以上b(如"abb", "abbbb", 等。);
"ab{3,5}": 要求a后面可以有2-5个b("abbb", "abbbb", or "abbbbb")。
现在我们把一定几个字符放到小括号里,比如:
"a(bc)*": 匹配 a 后面跟0个或者一个"bc";
"a(bc){1,5}": 一个到5个 "bc."
还有一个字符 '│', 相当于OR 操作:
"hi│hello": 匹配含有"hi" 或者 "hello" 的 字符串;
"(b│cd)ef": 匹配含有 "bef" 或者 "cdef"的字符串;
"(a│b)*c": 匹配含有这样多个(包括0个)a或b,后面跟一个c的字符串;
一个点('.')可以代表所有的单一字符,不包括"\n"
如果,要匹配包括"\n"在内的所有单个字符,怎么办?
对了,用'[\n.]'这种模式。
"a.[0-9]": 一个a加一个字符再加一个0到9的数字
"^.{3}$": 三个任意字符结尾 .
中括号括住的内容只匹配一个单一的字符
"[ab]": 匹配单个的 a 或者 b ( 和 "a│b" 一样);
"[a-d]": 匹配'a' 到'd'的单个字符 (和"a│b│c│d" 还有 "[abcd]"效果一样); 一般我们都用[a-zA-Z]来指定字符为一个大小写英文
"^[a-zA-Z]": 匹配以大小写字母开头的字符串
"[0-9]%": 匹配含有 形如 x% 的字符串
",[a-zA-Z0-9]$": 匹配以逗号再加一个数字或字母结尾的字符串
你也可以把你不想要得字符列在中括号里,你只需要在总括号里面使用'^' 作为开头 "%[^a-zA-Z]%" 匹配含有两个百分号里面有一个非字母的字符串。
要点:^用在中括号开头的时候,就表示排除括号里的字符。为了PHP能够解释,你必须在这些字符面前后加'',并且将一些字符转义。
不要忘记在中括号里面的字符是这条规路的例外?在中括号里面, 所有的特殊字符,包括(''), 都将失去他们的特殊性质 "[*\+?{}.]"匹配含有这些字符的字符串。
还有,正如regx的手册告诉我们: "如果列表里含有 ']', 最好把它作为列表里的第一个字符(可能跟在'^'后面)。 如果含有'-', 最好把它放在最前面或者最后面, or 或者一个范围的第二个结束点[a-d-0-9]中间的‘-’将有效。
看了上面的例子,你对{n,m}应该理解了吧。要注意的是,n和m都不能为负整数,而且n总是小于m. 这样,才能 最少匹配n次且最多匹配m次。 如"p{1,5}"将匹配 "pvpppppp"中的前五个p.
下面说说以\开头的
\b 书上说他是用来匹配一个单词边界,就是……比如've\b',可以匹配love里的ve而不匹配very里有ve
\B 正好和上面的\b相反。例子我就不举了
……突然想起来……可以到http://www.phpv.net/article.php/251 看看其它用\ 开头的语法
好,我们来做个应用:
如何构建一个模式来匹配 货币数量 的输入
构建一个匹配模式去检查输入的信息是否为一个表示money的数字。我们认为一个表示money的数量有四种方式: "10000.00" 和 "10,000.00",或者没有小数部分, "10000" and "10,000". 现在让我们开始构建这个匹配模式:
^[1-9][0-9]*$
这是所变量必须以非0的数字开头。但这也意味着 单一的 "0" 也不能通过测试。 以下是解决的方法:
^(0│[1-9][0-9]*)$
"只有0和不以0开头的数字与之匹配",我们也可以允许一个负号在数字之前:
^(0│-?[1-9][0-9]*)$
这就是: "0 或者 一个以0开头 且可能 有一个负号在前面的数字。" 好了,现在让我们别那么严谨,允许以0开头。现在让我们放弃 负号 , 因为我们在表示钱币的时候并不需要用到。 我们现在指定 模式 用来匹配小数部分:
^[0-9]+(\.[0-9]+)?$
这暗示匹配的字符串必须最少以一个阿拉伯数字开头。 但是注意,在上面模式中 "10." 是不匹配的, 只有 "10" 和 "10.2" 才可以。 (你知道为什么吗)
^[0-9]+(\.[0-9]{2})?$
我们上面指定小数点后面必须有两位小数。如果你认为这样太苛刻,你可以改成:
^[0-9]+(\.[0-9]{1,2})?$
这将允许小数点后面有一到两个字符。 现在我们加上用来增加可读性的逗号(每隔三位), 我们可以这样表示:
^[0-9]{1,3}(,[0-9]{3})*(\.[0-9]{1,2})?$
不要忘记 '+' 可以被 '*' 替代 如果你想允许空白字符串被输入话 (为什么?)。 也不要忘记反斜杆 ‘\’ 在php字符串中可能会出现错误 (很普遍的错误)。
现在,我们已经可以确认字符串了, 我们现在把所有逗号都去掉 str_replace(",", "", $money) 然后在把类型看成 double然后我们就可以通过他做数学计算了。
再来一个:
构造检查email的正则表达式
在一个完整的email地址中有三个部分:
1. 用户名 (在 '@' 左边的一切),
2.'@',
3. 服务器名(就是剩下那部分)。
用户名可以含有大小写字母阿拉伯数字,句号 ('.'), 减号('-'), and 下划线 ('_')。 服务器名字也是符合这个规则,当然下划线除外。
现在, 用户名的开始和结束都不能是句点。 服务器也是这样。 还有你不能有两个连续的句点他们之间至少存在一个字符,好现在我们来看一下怎么为用户名写一个匹配模式:
^[_a-zA-Z0-9-]+$
现在还不能允许句号的存在。 我们把它加上:
^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*$
上面的意思就是说: "以至少一个规范字符(除了。)开头,后面跟着0个或者多个以点开始的字符串。"
简单化一点, 我们可以用 eregi()取代 ereg()。eregi()对大小写不敏感, 我们就不需要指定两个范围 "a-z" 和 "A-Z" ? 只需要指定一个就可以了:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*$
后面的服务器名字也是一样,但要去掉下划线:
^[a-z0-9-]+(\.[a-z0-9-]+)*$
好。 现在只需要用“@”把两部分连接:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$
这就是完整的email认证匹配模式了,只需要调用
eregi(‘^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$ ’,$eamil)
就可以得到是否为email了。
正则表达式的其他用法
提取字符串
ereg() and eregi() 有一个特性是允许用户通过正则表达式去提取字符串的一部分(具体用法你可以阅读手册)。 比如说,我们想从 path/URL 提取文件名 ? 下面的代码就是你需要:
ereg("([^\\/]*)$", $pathOrUrl, $regs);
echo $regs[1];
高级的代换
ereg_replace() 和 eregi_replace()也是非常有用的: 假如我们想把所有的间隔负号都替换成逗号:
ereg_replace("[ \n\r\t]+", ",", trim($str));
最后,我把另一串检查EMAIL的正则表达式让看文章的你来分析一下。
"^[-!#$%&\'*+\\./0-9=?A-Z^_`a-z{|}~]+'.'@'.'[-!#$%&\'*+\\/0-9=?A-Z^_`a-z{|}~]+\.'.'[-!#$%&\'*+\\./0-9=?A-Z^_`a-z{|}~]+$"
如果能方便的读懂,那这篇文章的目的就达到了。
原文地址:http://java.chinaitlab.com/base/732793.html
posted @
2008-02-29 09:49 CoderDream 阅读(961) |
评论 (0) |
编辑 收藏
1、
揭开正则表达式的神秘面纱
2、
正则表达式话题
3、
如何使用Java自带的正则表达式
4、
处理正则表达式的java包:regexp
5、
Java正则表达式技巧总结
6、
学点Java正则表达式
7、
在JAVA中使用正则表达式
8、
Java正则表达式(1)
9、
java正则表达式; regular expression(2)
10、
JAVA正则表达式(2)
posted @
2008-02-29 09:47 CoderDream 阅读(324) |
评论 (0) |
编辑 收藏§1黑暗岁月
有一个String,如何查询其中是否有y和f字符?最黑暗的办法就是:
程序1:我知道if、for语句和charAt()啊。
class Test{
public static void main(String args[]) {
String str="For my money, the important thing "+
"about the meeting was bridge-building";
char x='y';
char y='f';
boolean result=false;
for(int i=0;i<str.length();i++){
char z=str.charAt(i); //System.out.println(z);
if(x==z||y==z) {
result=true;
break;
}
else result=false;
}
System.out.println(result);
}
}
好像很直观,但这种方式难以应付复杂的工作。如查询一段文字中,是否有is?是否有thing或ting等。这是一个讨厌的工作。
§2 Java的java.util.regex包
按照面向对象的思路,把希望查询的字符串如is、thing或ting封装成一个对象,以这个对象作为模板去匹配一段文字,就更加自然了。作为模板的那个东西就是下面要讨论的正则表达式。先不考虑那么复杂,看一个例子:
程序2:不懂。先看看可以吧?
import java.util.regex.*;
class Regex1{
public static void main(String args[]) {
String str="For my money, the important thing "+
"about the meeting was bridge-building";
String regEx="a|f"; //表示a或f
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean result=m.find();
System.out.println(result);
}
}
如果str匹配regEx,那么result为true,否则为flase。如果想在查找时忽略大小写,则可以写成:
Pattern p=Pattern.compile(regEx,Pattern.CASE_INSENSITIVE);
虽然暂时不知道Pattern(模板、模式)和Matcher(匹配器)的细节,程序的感觉就比较爽,如果先查询is、后来又要查询thing或ting,我们只需要修改一下模板Pattern,而不是考虑if语句和for语句,或者通过charAt()。
1、写一个特殊的字符串??正则表达式如a|f。
2、将正则表达式编译成一个模板:p
3、用模板p去匹配字符串str。
思路清楚了,现在看Java是如何处理的(Java程序员直到JDK1.4才能使用这些类。
§3 Pattern类与查找
①public final class java.util.regex.Pattern是正则表达式编译后的表达法。下面的语句将创建一个Pattern对象并赋值给句柄p:Pattern p=Pattern.compile(regEx);
有趣的是,Pattern类是final类,而且它的构造器是private。也许有人告诉你一些设计模式的东西,或者你自己查有关资料。这里的结论是:Pattern类不能被继承,我们不能通过new创建Pattern类的对象。
因此在Pattern类中,提供了2个重载的静态方法,其返回值是Pattern对象(的引用)。如:
public static Pattern compile(String regex) {
return new Pattern(regex, 0);
}
当然,我们可以声明Pattern类的句柄,如Pattern p=null;
②p.matcher(str)表示以用模板p去生成一个字符串str的匹配器,它的返回值是一个Matcher类的引用,为什么要这个东西呢?按照自然的想法,返回一个boolean值不行吗?
我们可以简单的使用如下方法:
boolean result=Pattern.compile(regEx).matcher(str).find();
呵呵,其实是三个语句合并的无句柄方式。无句柄常常不是好方式。后面再学习Matcher类吧。先看看regEx??这个怪咚咚。
§4 正则表达式之限定符
正则表达式(Regular Expression)是一种生成字符串的字符串。晕吧。比如说,String regEx="me+";这里字符串me+能够生成的字符串是:me、mee、meee、meeeeeeeeee等等,一个正则表达式可能生成无穷的字符串,所以我们不可能(有必要吗?)输出正则表达式产生的所有东西。
反过来考虑,对于字符串:me、mee、meee、meeeeeeeeee等等,我们能否有一种语言去描述它们呢?显然,正则表达式语言是这种语言,它是一些字符串的模式??简洁而深刻的描述。
我们使用正则表达式,用于字符串查找、匹配、指定字符串替换、字符串分割等等目的。
生成字符串的字符串??正则表达式,真有些复杂,因为我们希望由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)描述任意的字符串,而且要准确。
先搞几个正则表达式例子:
程序3:我们总用这个程序测试正则表达式。
import java.util.regex.*;
class Regex1{
public static void main(String args[]) {
String str="For my money, the important thing ";
String regEx="ab*";
boolean result=Pattern.compile(regEx).matcher(str).find();
System.out.println(result);
}
}//ture
①"ab*"??能匹配a、ab、abb、abbb……。所以,*表示前面字符可以有零次或多次。如果仅仅考虑查找,直接用"a"也一样。但想想替换的情况。 问题regEx="abb*"结果如何?
②"ab+"??能匹配ab、abb、abbb……。等价于"abb*"。问题regEx="or+"结果如何?
③"or?"??能匹配o和or。? 表示前面字符可以有零次或一次。
这些限定符*、+、?方便地表示了其前面字符(子串)出现的次数(我们用{}来描述):
x* 零次或多次 ≡{0,}
x+ 一次或多次 ≡{1,}
x? 零次或一次 ≡{0,1}
x{n} n次(n>0)
x{n,m} 最少n次至最多m次(0<n<m)
x{n,} 最少n次,
现在我们知道了连续字符串的查找、匹配。下面的是一些练习题:
①查找粗体字符串(不要求精确或要求精确匹配),写出其正则表达式:
str regEX(不要求精确) regEX(要求精确) 试一试
abcffd b或bcff或bcf*或bc*或bc+ bcff或bcf{2} bc{3}
gooooogle o{1,}、o+ o{5}
banana (an)+ (an){2}a、a(na) {2}
②正则表达式匹配字符串,输出是什么?
§5替换(删除)、Matcher类
现在我们可能厌烦了true/false,我们看看替换。如把book,google替换成bak(这个文件后缀名,在EditPlus中还行)、look或goooogle。
程序4:字符串的替换。
import java.util.regex.*;
class Regex1{
public static void main(String args[]) {
String regEx="a+";//表示一个或多个a
String str="abbbaaa an banana hhaana";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
String s=m.replaceAll("⊙⊙"); // ("") 删除
System.out.println(s);
}
}
这个程序与前面的程序的区别,在于使用了m.replaceAll(String)方法。看来Matcher类还有点用处。
① Matcher是一个匹配器。可以把他看成一个人,一手拿着模子(Pattern类的对象),一手拿着一个字符序列(CharSequence),通过解释该模子而对字符序列进行匹配操作(match operations)。常常我们这样编程:“喂,模子p,你和字符串str一起创建一个匹配器对象”。即Matcher m=p.matcher(str);
② m可以进行一些操作,如public String replaceAll(String replacement),它以replacement替换所有匹配的字符串。
§6正则表达式之特殊字符
我们熟悉这样一个字符串"\n" 如:System.out.print(s+"\nbbb");这是Java中常用的转移字符之一。其实转移字符就是一种正则表达式,它使用了特殊字符 \ 。
下面是正则表达式中常用的特殊字符:
匹配次数符号 * + ? {n}、{n,}、{n,m}
“或”符号 | 程序2已经使用过了
句点符号 . 句点符号匹配所有字符(一个),包括空格、Tab字符甚至换行符。
方括号 [ ] 仅仅匹配方括号其中的字符)
圆括号 () 分组,圆括号中的字符视为一个整体。
连字符 - 表示一个范围。
“否”符号 ^ 表示不希望被匹配的字符(排除)
我们一下子学不了太多的东西,这不是正则表达式的全部内容和用法。但已经够我们忙活的了。我们用程序4 验证。(⊙⊙表示替换的字符)
① regEx为下列字符串时,能够表示什么?
regEx 匹配 测试用str
(a|b){2} aa、ab、bb、ba aabbfooaabfooabfoob
a[abc]b aab、abb、acb 3dfacb5ooyfo6abbfooaab
. all string 3dfac
a. aa、ax……等等 3dfacgg
d[^j]a daa、d9a等等,除dja 3dfacggdjad5a
[d-g][ac]c dac、ecc、gac等 3dfacggggccad5c
[d-g].{2}c d⊙⊙c…… 3dfacggggccad5c
g{1,10} g、ggg…… 3dfacggggccad5c
[a|c][^a] 3dfacggggccad5c
② 下列字符串如何用regEx表示?
测试用str 匹配 regEx
aabbfoaoabfooafobob a⊙⊙b a..b
aabbfoaaobfooafbob a⊙b、除aab a[^a]b、
gooooooogle oooo……变成oo o{2,20}
一本书中的“tan”、“ten”、“tin”和“ton” t.n、t[aeio]n
abcaccbcbaacabccaa 删除ac、ca (ca)|(ac)
abccbcbaabca 再删除ab、ba 结果ccbcca(如何与上面的合并)
注:
1、String str="一本书中的tan、ten、tin和ton";
输出: 一本书中的⊙⊙、⊙⊙、⊙⊙和⊙⊙
2、String str=" abcaccbcbaacabccaa "; 输出:ccbcca
程序5:if、for语句和charAt(),886。
import java.util.regex.*;
class Regex1{
public static void main(String args[]) {
String str="abcaccbcbaacabccaa";
String regEx="(ac)|(ca)";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
String s=m.replaceAll("");//⊙⊙
regEx="(ab)|(ba)";
p=Pattern.compile(regEx);
s=p.matcher(s).replaceAll("");
System.out.print(s+"\n");
}
}
§7 开始
好像我们知道了一些正则表达式与 Java的知识,事实上,我们才刚刚开始。这里列出我们知道的东西,也说一点我们不知道的东西。
① Java在JDK1.4引入了(java.util.regex包)以支持正则表达式,包中有两个类,分别是Pattern和Matcher。它们都有很多的方法,我们还不知道。String类中的split、matches方法等等也使用到了正则表达式。StringTokenizer是否没有用处了?
② 正则表达式是一门语言。有许多正则表达式语法、选项和特殊字符,在Pattern.java源文件中大家可以查看。可能比想象中的要复杂。系统学习正则表达式的历史、语法、全部特殊字符(相当于Java中的关键字的地位),组合逻辑是下一步的事情。
③ 正则表达式是文本处理的重要技术,在Perl、PHP、Python、JavaScript、Java、C#中被广泛支持。被列为“保证你现在和未来不失业的十种关键技术”,呵呵,信不信由你
posted @
2008-02-28 14:35 CoderDream 阅读(450) |
评论 (0) |
编辑 收藏
JAVA 正则表达式4种常用的功能
正则表达式在字符串处理上有着强大的功能,sun在jdk1.4加入了对它的支持
下面简单的说下它的4种常用功能:
查询:
以下是代码片段:
String str="abc efg ABC";
String regEx="a|f"; //表示a或f
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean rs=m.find();
如果str中有regEx,那么rs为true,否则为flase。如果想在查找时忽略大小写,则可以写成Pattern p=Pattern.compile(regEx,Pattern.CASE_INSENSITIVE);
提取:
以下是代码片段:
String regEx=".+\(.+)$";
String str="c:\dir1\dir2\name.txt";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean rs=m.find();
for(int i=1;i<=m.groupCount();i++){
System.out.println(m.group(i));
}
以上的执行结果为name.txt,提取的字符串储存在m.group(i)中,其中i最大值为m.groupCount();
分割:
以下是代码片段:
String regEx="::";
Pattern p=Pattern.compile(regEx);
String[] r=p.split("xd::abc::cde");
执行后,r就是{"xd","abc","cde"},其实分割时还有跟简单的方法:
String str="xd::abc::cde";
String[] r=str.split("::");
替换(删除):
以下是代码片段:
String regEx="a+"; //表示一个或多个a
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher("aaabbced a ccdeaa");
String s=m.replaceAll("A");
结果为"Abbced A ccdeA"
如果写成空串,既可达到删除的功能,比如:
String s=m.replaceAll("");
结果为"bbced ccde"
附:
\D 等於 [^0-9] 非数字
\s 等於 [ \t\n\x0B\f ] 空白字元
\S 等於 [^ \t\n\x0B\f ] 非空白字元
\w 等於 [a-zA-Z_0-9] 数字或是英文字
\W 等於 [^a-zA-Z_0-9] 非数字与英文字
^ 表示每行的开头
$ 表示每行的结尾
原文地址:
http://java.chinaitlab.com/advance/350770.html
posted @
2008-02-28 13:41 CoderDream 阅读(326) |
评论 (0) |
编辑 收藏如果你曾经用过Perl或任何其他内建正则表达式支持的语言,你一定知道用正则表达式处理文本和匹配模式是多么简单。如果你不熟悉这个术语,那么“正则表达式”(Regular Expression)就是一个字符构成的串,它定义了一个用来搜索匹配字符串的模式。
许多语言,包括Perl、PHP、Python、JavaScript和JScript,都支持用正则表达式处理文本,一些文本编辑器用正则表达式实现高级“搜索-替换”功能。那么Java又怎样呢?本文写作时,一个包含了用正则表达式进行文本处理的Java规范需求(Specification Request)已经得到认可,你可以期待在JDK的下一版本中看到它。
然而,如果现在就需要使用正则表达式,又该怎么办呢?你可以从Apache.org下载源代码开放的Jakarta-ORO库。本文接下来的内容先简要地介绍正则表达式的入门知识,然后以Jakarta-ORO API为例介绍如何使用正则表达式。
一、正则表达式基础知识
我们先从简单的开始。假设你要搜索一个包含字符“cat”的字符串,搜索用的正则表达式就是“cat”。如果搜索对大小写不敏感,单词“catalog”、“Catherine”、“sophisticated”都可以匹配。也就是说:

1.1 句点符号
假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以“t”字母开头,以“n”字母结束。另外,假设有一本英文字典,你可以用正则表达式搜索它的全部内容。要构造出这个正则表达式,你可以使用一个通配符——句点符号“.”。这样,完整的表达式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,还匹配“t#n”、“tpn”甚至“t n”,还有其他许多无意义的组合。这是因为句点符号匹配所有字符,包括空格、Tab字符甚至换行符:

1.2 方括号符号
为了解决句点符号匹配范围过于广泛这一问题,你可以在方括号(“[]”)里面指定看来有意义的字符。此时,只有方括号里面指定的字符才参与匹配。也就是说,正则表达式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因为在方括号之内你只能匹配单个字符:

1.3 “或”符号
如果除了上面匹配的所有单词之外,你还想要匹配“toon”,那么,你可以使用“|”操作符。“|”操作符的基本意义就是“或”运算。要匹配“toon”,使用“t(a|e|i|o|oo)n”正则表达式。这里不能使用方扩号,因为方括号只允许匹配单个字符;这里必须使用圆括号“()”。圆括号还可以用来分组,具体请参见后面介绍。

1.4 表示匹配次数的符号
表一显示了表示匹配次数的符号,这些符号用来确定紧靠该符号左边的符号出现的次数:

假设我们要在文本文件中搜索美国的社会安全号码。这个号码的格式是999-99-9999。用来匹配它的正则表达式如图一所示。在正则表达式中,连字符(“-”)有着特殊的意义,它表示一个范围,比如从0到9。因此,匹配社会安全号码中的连字符号时,它的前面要加上一个转义字符“\”。

图一:匹配所有123-12-1234形式的社会安全号码
假设进行搜索的时候,你希望连字符号可以出现,也可以不出现——即,999-99-9999和999999999都属于正确的格式。这时,你可以在连字符号后面加上“?”数量限定符号,如图二所示:

图二:匹配所有123-12-1234和123121234形式的社会安全号码
下面我们再来看另外一个例子。美国汽车牌照的一种格式是四个数字加上二个字母。它的正则表达式前面是数字部分“[0-9]{4}”,再加上字母部分“[A-Z]{2}”。图三显示了完整的正则表达式。

图三:匹配典型的美国汽车牌照号码,如8836KV
1.5 “否”符号
“^”符号称为“否”符号。如果用在方括号内,“^”表示不想要匹配的字符。例如,图四的正则表达式匹配所有单词,但以“X”字母开头的单词除外。

图四:匹配所有单词,但“X”开头的除外
1.6 圆括号和空白符号
假设要从格式为“June 26, 1951”的生日日期中提取出月份部分,用来匹配该日期的正则表达式可以如图五所示:

图五:匹配所有Moth DD,YYYY格式的日期
新出现的“\s”符号是空白符号,匹配所有的空白字符,包括Tab字符。如果字符串正确匹配,接下来如何提取出月份部分呢?只需在月份周围加上一个圆括号创建一个组,然后用ORO API(本文后面详细讨论)提取出它的值。修改后的正则表达式如图六所示:

图六:匹配所有Month DD,YYYY格式的日期,定义月份值为第一个组
1.7 其它符号
为简便起见,你可以使用一些为常见正则表达式创建的快捷符号。如表二所示:
表二:常用符号

例如,在前面社会安全号码的例子中,所有出现“[0-9]”的地方我们都可以使用“\d”。修改后的正则表达式如图七所示:

图七:匹配所有123-12-1234格式的社会安全号码
二、Jakarta-ORO库
有许多源代码开放的正则表达式库可供Java程序员使用,而且它们中的许多支持Perl 5兼容的正则表达式语法。我在这里选用的是Jakarta-ORO正则表达式库,它是最全面的正则表达式API之一,而且它与Perl 5正则表达式完全兼容。另外,它也是优化得最好的API之一。
Jakarta-ORO库以前叫做OROMatcher,Daniel Savarese大方地把它赠送给了Jakarta Project。你可以按照本文最后参考资源的说明下载它。
我首先将简要介绍使用Jakarta-ORO库时你必须创建和访问的对象,然后介绍如何使用Jakarta-ORO API。
▲ PatternCompiler对象
首先,创建一个Perl5Compiler类的实例,并把它赋值给PatternCompiler接口对象。Perl5Compiler是PatternCompiler接口的一个实现,允许你把正则表达式编译成用来匹配的Pattern对象。

▲ Pattern对象
要把正则表达式编译成Pattern对象,调用compiler对象的compile()方法,并在调用参数中指定正则表达式。例如,你可以按照下面这种方式编译正则表达式“t[aeio]n”:

默认情况下,编译器创建一个大小写敏感的模式(pattern)。因此,上面代码编译得到的模式只匹配“tin”、“tan”、 “ten”和“ton”,但不匹配“Tin”和“taN”。要创建一个大小写不敏感的模式,你应该在调用编译器的时候指定一个额外的参数:

创建好Pattern对象之后,你就可以通过PatternMatcher类用该Pattern对象进行模式匹配。
▲ PatternMatcher对象
PatternMatcher对象根据Pattern对象和字符串进行匹配检查。你要实例化一个Perl5Matcher类并把结果赋值给PatternMatcher接口。Perl5Matcher类是PatternMatcher接口的一个实现,它根据Perl 5正则表达式语法进行模式匹配:

使用PatternMatcher对象,你可以用多个方法进行匹配操作,这些方法的第一个参数都是需要根据正则表达式进行匹配的字符串:
· boolean matches(String input, Pattern pattern):当输入字符串和正则表达式要精确匹配时使用。换句话说,正则表达式必须完整地描述输入字符串。
· boolean matchesPrefix(String input, Pattern pattern):当正则表达式匹配输入字符串起始部分时使用。
· boolean contains(String input, Pattern pattern):当正则表达式要匹配输入字符串的一部分时使用(即,它必须是一个子串)。
另外,在上面三个方法调用中,你还可以用PatternMatcherInput对象作为参数替代String对象;这时,你可以从字符串中最后一次匹配的位置开始继续进行匹配。当字符串可能有多个子串匹配给定的正则表达式时,用PatternMatcherInput对象作为参数就很有用了。用PatternMatcherInput对象作为参数替代String时,上述三个方法的语法如下:
· boolean matches(PatternMatcherInput input, Pattern pattern)
· boolean matchesPrefix(PatternMatcherInput input, Pattern pattern)
· boolean contains(PatternMatcherInput input, Pattern pattern)
三、应用实例
下面我们来看看Jakarta-ORO库的一些应用实例。
3.1 日志文件处理
任务:分析一个Web服务器日志文件,确定每一个用户花在网站上的时间。在典型的BEA WebLogic日志文件中,日志记录的格式如下:

分析这个日志记录,可以发现,要从这个日志文件提取的内容有两项:IP地址和页面访问时间。你可以用分组符号(圆括号)从日志记录提取出IP地址和时间标记。
首先我们来看看IP地址。IP地址有4个字节构成,每一个字节的值在0到255之间,各个字节通过一个句点分隔。因此,IP地址中的每一个字节有至少一个、最多三个数字。图八显示了为IP地址编写的正则表达式:

图八:匹配IP地址
IP地址中的句点字符必须进行转义处理(前面加上“\”),因为IP地址中的句点具有它本来的含义,而不是采用正则表达式语法中的特殊含义。句点在正则表达式中的特殊含义本文前面已经介绍。
日志记录的时间部分由一对方括号包围。你可以按照如下思路提取出方括号里面的所有内容:首先搜索起始方括号字符(“[”),提取出所有不超过结束方括号字符(“]”)的内容,向前寻找直至找到结束方括号字符。图九显示了这部分的正则表达式。

图九:匹配至少一个字符,直至找到“]”
现在,把上述两个正则表达式加上分组符号(圆括号)后合并成单个表达式,这样就可以从日志记录提取出IP地址和时间。注意,为了匹配“- -”(但不提取它),正则表达式中间加入了“\s-\s-\s”。完整的正则表达式如图十所示。

图十:匹配IP地址和时间标记
现在正则表达式已经编写完毕,接下来可以编写使用正则表达式库的Java代码了。
为使用Jakarta-ORO库,首先创建正则表达式字符串和待分析的日志记录字符串:

这里使用的正则表达式与图十的正则表达式差不多完全相同,但有一点例外:在Java中,你必须对每一个向前的斜杠(“\”)进行转义处理。图十不是Java的表示形式,所以我们要在每个“\”前面加上一个“\”以免出现编译错误。遗憾的是,转义处理过程很容易出现错误,所以应该小心谨慎。你可以首先输入未经转义处理的正则表达式,然后从左到右依次把每一个“\”替换成“\\”。如果要复检,你可以试着把它输出到屏幕上。
初始化字符串之后,实例化PatternCompiler对象,用PatternCompiler编译正则表达式创建一个Pattern对象:

现在,创建PatternMatcher对象,调用PatternMatcher接口的contain()方法检查匹配情况:

接下来,利用PatternMatcher接口返回的MatchResult对象,输出匹配的组。由于logEntry字符串包含匹配的内容,你可以看到类如下面的输出:

3.2 HTML处理实例一
下面一个任务是分析HTML页面内FONT标记的所有属性。HTML页面内典型的FONT标记如下所示:

程序将按照如下形式,输出每一个FONT标记的属性:

在这种情况下,我建议你使用两个正则表达式。第一个如图十一所示,它从字体标记提取出“"face="Arial, Serif" size="+2" color="red"”。

图十一:匹配FONT标记的所有属性
第二个正则表达式如图十二所示,它把各个属性分割成名字-值对。

图十二:匹配单个属性,并把它分割成名字-值对
分割结果为:

现在我们来看看完成这个任务的Java代码。首先创建两个正则表达式字符串,用Perl5Compiler把它们编译成Pattern对象。编译正则表达式的时候,指定Perl5Compiler.CASE_INSENSITIVE_MASK选项,使得匹配操作不区分大小写。
接下来,创建一个执行匹配操作的Perl5Matcher对象。

假设有一个String类型的变量html,它代表了HTML文件中的一行内容。如果html字符串包含FONT标记,匹配器将返回true。此时,你可以用匹配器对象返回的MatchResult对象获得第一个组,它包含了FONT的所有属性:

接下来创建一个PatternMatcherInput对象。这个对象允许你从最后一次匹配的位置开始继续进行匹配操作,因此,它很适合于提取FONT标记内属性的名字-值对。创建PatternMatcherInput对象,以参数形式传入待匹配的字符串。然后,用匹配器实例提取出每一个FONT的属性。这通过指定PatternMatcherInput对象(而不是字符串对象)为参数,反复地调用PatternMatcher对象的contains()方法完成。PatternMatcherInput对象之中的每一次迭代将把它内部的指针向前移动,下一次检测将从前一次匹配位置的后面开始。
本例的输出结果如下:

3.3 HTML处理实例二
下面我们来看看另一个处理HTML的例子。这一次,我们假定Web服务器从widgets.acme.com移到了newserver.acme.com。现在你要修改一些页面中的链接:

执行这个搜索的正则表达式如图十三所示:

图十三:匹配修改前的链接
如果能够匹配这个正则表达式,你可以用下面的内容替换图十三的链接:

注意#字符的后面加上了$1。Perl正则表达式语法用$1、$2等表示已经匹配且提取出来的组。图十三的表达式把所有作为一个组匹配和提取出来的内容附加到链接的后面。
现在,返回Java。就象前面我们所做的那样,你必须创建测试字符串,创建把正则表达式编译到Pattern对象所必需的对象,以及创建一个PatternMatcher对象:

接下来,用com.oroinc.text.regex包Util类的substitute()静态方法进行替换,输出结果字符串:

Util.substitute()方法的语法如下:

这个调用的前两个参数是以前创建的PatternMatcher和Pattern对象。第三个参数是一个Substiution对象,它决定了替换操作如何进行。本例使用的是Perl5Substitution对象,它能够进行Perl5风格的替换。第四个参数是想要进行替换操作的字符串,最后一个参数允许指定是否替换模式的所有匹配子串(Util.SUBSTITUTE_ALL),或只替换指定的次数。
【结束语】在这篇文章中,我为你介绍了正则表达式的强大功能。只要正确运用,正则表达式能够在字符串提取和文本修改中起到很大的作用。另外,我还介绍了如何在Java程序中通过Jakarta-ORO库利用正则表达式。至于最终采用老式的字符串处理方式(使用StringTokenizer,charAt,和substring),还是采用正则表达式,这就有待你自己决定了
原文地址:
http://www.ccw.com.cn/htm/app/aprog/01_7_31_4.asp
posted @
2008-02-28 13:35 CoderDream 阅读(664) |
评论 (0) |
编辑 收藏如果我们问那些UNIX系统的爱好者他们最喜欢什么,答案除了稳定的系统和可以远程启动之外,十有八九的人会提到正则表达式;如果我们再问他们最头痛的是什么,可能除了复杂的进程控制和安装过程之外,还会是正则表达式。那么正则表达式到底是什么?如何才能真正的掌握正则表达式并正确的加以灵活运用?本文将就此展开介绍,希望能够对那些渴望了解和掌握正则表达式的读者有所助益。
入门简介
简单的说,正则表达式是一种可以用于模式匹配和替换的强有力的工具。我们可以在几乎所有的基于UNIX系统的工具中找到正则表达式的身影,例如,vi编辑器,Perl或PHP脚本语言,以及awk或sed shell程序等。此外,象JavaScript这种客户端的脚本语言也提供了对正则表达式的支持。由此可见,正则表达式已经超出了某种语言或某个系统的局限,成为人们广为接受的概念和功能。
正则表达式可以让用户通过使用一系列的特殊字符构建匹配模式,然后把匹配模式与数据文件、程序输入以及WEB页面的表单输入等目标对象进行比较,根据比较对象中是否包含匹配模式,执行相应的程序。
举例来说,正则表达式的一个最为普遍的应用就是用于验证用户在线输入的邮件地址的格式是否正确。如果通过正则表达式验证用户邮件地址的格式正确,用户所填写的表单信息将会被正常处理;反之,如果用户输入的邮件地址与正则表达的模式不匹配,将会弹出提示信息,要求用户重新输入正确的邮件地址。由此可见正则表达式在WEB应用的逻辑判断中具有举足轻重的作用。
基本语法
在对正则表达式的功能和作用有了初步的了解之后,我们就来具体看一下正则表达式的语法格式。
正则表达式的形式一般如下:
/love/
其中位于“/”定界符之间的部分就是将要在目标对象中进行匹配的模式。用户只要把希望查找匹配对象的模式内容放入“/”定界符之间即可。为了能够使用户更加灵活的定制模式内容,正则表达式提供了专门的“元字符”。所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
较为常用的元字符包括: “+”, “*”,以及 “?”。其中,“+”元字符规定其前导字符必须在目标对象? 续出现一次或多次,“*”元字符规定其前导字符必须在目标对象中出现零次或连续多次,而“?”元字符规定其前导对象必须在目标对象中连续出现零次或一次。
下面,就让我们来看一下正则表达式元字符的具体应用。
/fo+/
因为上述正则表达式中包含“+”元字符,表示可以与目标对象中的 “fool”, “fo”, 或者 “football”等在字母f后面连续出现一个或多个字母o的字符串相匹配。
/eg*/
因为上述正则表达式中包含“*”元字符,表示可以与目标对象中的 “easy”, “ego”, 或者 “egg”等在字母e后面连续出现零个或多个字母g的字符串相匹配。
/Wil?/
因为上述正则表达式中包含“?”元字符,表示可以与目标对象中的 “Win”, 或者 “Wilson”,等在字母i后面连续出现零个或一个字母l的字符串相匹配。
除了元字符之外,用户还可以精确指定模式在匹配对象中出现的频率。例如,
/jim{2,6}/
上述正则表达式规定字符m可以在匹配对象中连续出现2-6次,因此,上述正则表达式可以同jimmy或jimmmmmy等字符串相匹配。
在对如何使用正则表达式有了初步了解之后,我们来看一下其它几个重要的元字符的使用方式。
\s:用于匹配单个空格符,包括tab键和换行符;
\S:用于匹配除单个空格符之外的所有字符;
\d:用于匹配从0到9的数字;
\w:用于匹配字母,数字或下划线字符;
\W:用于匹配所有与\w不匹配的字符;
. :用于匹配除换行符之外的所有字符。
(说明:我们可以把\s和\S以及\w和\W看作互为逆运算)
下面,我们就通过实例看一下如何在正则表达式中使用上述元字符。
/\s+/
上述正则表达式可以用于匹配目标对象中的一个或多个空格字符。
/\d000/
如果我们手中有一份复杂的财务报表,那么我们可以通过上述正则表达式轻而易举的查找到所有总额达千元的款项。
除了我们以上所介绍的元字符之外,正则表达式中还具有另外一种较为独特的专用字符,即定位符。定位符用于规定匹配模式在目标对象中的出现位置。
较为常用的定位符包括: “^”, “$”, “\b” 以及 “\B”。其中,“^”定位符规定匹配模式必须出现在目标字符串的开头,“$”定位符规定匹配模式必须出现在目标对象的结尾,\b定位符规定匹配模式必须出现在目标字符串的开头或结尾的两个边界之一,而“\B”定位符则规定匹配对象必须位于目标字符串的开头和结尾两个边界之内,即匹配对象既不能作为目标字符串的开头,也不能作为目标字符串的结尾。同样,我们也可以把“^”和“$”以及“\b”和“\B”看作是互为逆运算的两组定位符。举例来说:
/^hell/
因为上述正则表达式中包含“^”定位符,所以可以与目标对象中以 “hell”, “hello”或 “hellhound”开头的字符串相匹配。
/ar$/
因为上述正则表达式中包含“$”定位符,所以可以与目标对象中以 “car”, “bar”或 “ar” 结尾的字符串相匹配。
/\bbom/
因为上述正则表达式模式以“\b”定位符开头,所以可以与目标对象中以 “bomb”, 或 “bom”开头的字符串相匹配。
/man\b/
因为上述正则表达式模式以“\b”定位符结尾,所以可以与目标对象中以 “human”, “woman”或 “man”结尾的字符串相匹配。
为了能够方便用户更加灵活的设定匹配模式,正则表达式允许使用者在匹配模式中指定某一个范围而不局限于具体的字符。例如:
/[A-Z]/
上述正则表达式将会与从A到Z范围内任何一个大写字母相匹配。
/[a-z]/
上述正则表达式将会与从a到z范围内任何一个小写字母相匹配。
/[0-9]/
上述正则表达式将会与从0到9范围内任何一个数字相匹配。
/([a-z][A-Z][0-9])+/
上述正则表达式将会与任何由字母和数字组成的字符串,如 “aB0” 等相匹配。这里需要提醒用户注意的一点就是可以在正则表达式中使用 “()” 把字符串组合在一起。“()”符号包含的内容必须同时出现在目标对象中。因此,上述正则表达式将无法与诸如 “abc”等的字符串匹配,因为“abc”中的最后一个字符为字母而非数字。
如果我们希望在正则表达式中实现类似编程逻辑中的“或”运算,在多个不同的模式中任选一个进行匹配的话,可以使用管道符 “|”。例如:
/to|too|2/
上述正则表达式将会与目标对象中的 “to”, “too”, 或 “2” 相匹配。
正则表达式中还有一个较为常用的运算符,即否定符 “[^]”。与我们前文所介绍的定位符 “^” 不同,否定符 “[^]”规定目标对象中不能存在模式中所规定的字符串。例如:
/[^A-C]/
上述字符串将会与目标对象中除A,B,和C之外的任何字符相匹配。一般来说,当“^”出现在 “[]”内时就被视做否定运算符;而当“^”位于“[]”之外,或没有“[]”时,则应当被视做定位符。
最后,当用户需要在正则表达式的模式中加入元字符,并查找其匹配对象时,可以使用转义符“\”。例如:
/Th\*/
上述正则表达式将会与目标对象中的“Th*”而非“The”等相匹配。
原文链接:
http://www.yesky.com/181/51681.shtml
posted @
2008-02-28 11:49 CoderDream 阅读(664) |
评论 (0) |
编辑 收藏
在String类中,有四个特殊的方法:
public String[] split(String regex)
- 根据给定的正则表达式的匹配来拆分此字符串。
该方法的作用就像是使用给定的表达式和限制参数 0 来调用两参数 split 方法。因此,结果数组中不包括结尾空字符串。
例如,字符串 "boo:and:foo" 产生带有下面这些表达式的结果:
| Regex |
结果 |
| : |
{ "boo", "and", "foo" } |
| o |
{ "b", "", ":and:f" } |
-
- 参数:
regex - 定界正则表达式
- 返回: 字符串数组,根据给定正则表达式的匹配来拆分此字符串,从而生成此数组。
- 抛出:
PatternSyntaxException - 如果正则表达式的语法无效
public String[] split(String regex, int limit)
- 根据匹配给定的正则表达式来拆分此字符串。
此方法返回的数组包含此字符串的每个子字符串,这些子字符串由另一个匹配给定的表达式的子字符串终止或由字符串结束来终止。数组中的子字符串按它们在此字符串中的顺序排列。如果表达式不匹配输入的任何部分,则结果数组只具有一个元素,即此字符串。
limit 参数控制模式应用的次数,因此影响结果数组的长度。如果该限制 n 大于 0,则模式将被最多应用 n - 1 次,数组的长度将不会大于 n,而且数组的最后项将包含超出最后匹配的定界符的所有输入。如果 n 为非正,则模式将被应用尽可能多的次数,而且数组可以是任意长度。如果 n 为零,则模式将被应用尽可能多的次数,数组可有任何长度,并且结尾空字符串将被丢弃。
例如,字符串 "boo:and:foo" 使用这些参数可生成下列结果:
| Regex |
Limit |
结果 |
| : |
2 |
{ "boo", "and:foo" } |
| : |
5 |
{ "boo", "and", "foo" } |
| : |
-2 |
{ "boo", "and", "foo" } |
| o |
5 |
{ "b", "", ":and:f", "", "" } |
| o |
-2 |
{ "b", "", ":and:f", "", "" } |
| o |
0 |
{ "b", "", ":and:f" } |
这种形式的方法调用 str.split(regex, n) 产生与以下表达式完全相同的结果:
Pattern.compile(regex).split(str, n)
参数: regex - 定界正则表达式 ;limit - 结果阈值,如上所述
- 返回: 字符串数组,根据给定正则表达式的匹配来拆分此字符串,从而生成此数组
public String replaceAll(String regex, String replacement)
- 使用给定的 replacement 字符串替换此字符串匹配给定的正则表达式的每个子字符串。
此方法调用的 str.replaceAll(regex, repl) 形式产生与以下表达式完全相同的结果:
Pattern.compile(regex).matcher(str).replaceAll(repl)
参数: regex - 用来匹配此字符串的正则表达式
- 返回: 得到的 String
public String replaceFirst(String regex, String replacement)
- 使用给定的 replacement 字符串替换此字符串匹配给定的正则表达式的第一个子字符串。
此方法调用的 str.replaceFirst(regex, repl) 形式产生与以下表达式完全相同的结果:
Pattern.compile(regex).matcher(str).replaceFirst(repl)
参数:regex - 用来匹配此字符串的正则表达式
- 返回: 得到的 String
这四个方法中都有一个参数为正则表达式(Regular Expression),而不是普通的字符串。
在正则表达式中具有特殊含义的字符
|
特殊字符
|
描述
|
| . |
表示任意一个字符 |
| [abc] |
表示a、b或c中的任意一个字符 |
| [^abc] |
除a、b和c以外的任意一个字符 |
| [a-zA-z] |
介于a到z,或A到Z中的任意一个字符 |
| \s |
空白符(空格、tab、换行、换页、回车) |
| \S |
非空白符 |
| \d |
任意一个数字[0-9] |
| \D |
任意一个非数字[^0-9] |
| \w |
词字符[a-zA-Z_0-9] |
| \W |
非词字符 |
表示字符出现次数的符号
|
表示次数的符号
|
描述
|
| * |
0 次或者多次 |
| + |
1 次或者多次 |
| ? |
0 次或者 1 次 |
| {n} |
恰好 n 次 |
| {n, m} |
至少 n 次,不多于 m 次 |
public class RegDemo2 {
/**
* @param args
*/
public static void main(String[] args) {
// 例如,字符串 "boo:and:foo" 产生带有下面这些表达式的结果: Regex 结果
// : { "boo", "and", "foo" }
// o { "b", "", ":and:f" }
String tempStr = "boo:and:foo";
String[] a = tempStr.split(":");
pringStringArray(a);
String[] b = tempStr.split("o");
pringStringArray(b);
System.out.println("--------------------------");
// Regex Limit 结果
// : 2 { "boo", "and:foo" }
// : 5 { "boo", "and", "foo" }
// : -2 { "boo", "and", "foo" }
// o 5 { "b", "", ":and:f", "", "" }
// o -2 { "b", "", ":and:f", "", "" }
// o 0 { "b", "", ":and:f" }
pringStringArray(tempStr.split(":", 2));
pringStringArray(tempStr.split(":", 5));
pringStringArray(tempStr.split(":", -2));
pringStringArray(tempStr.split("o", 5));
pringStringArray(tempStr.split("o", -2));
pringStringArray(tempStr.split("o", 0));
// 字符串 "boo:and:foo"中的所有“:”都被替换为“XX”,输出:booXXandXXfoo
System.out.println(tempStr.replaceAll(":", "XX"));
// 字符串 "boo:and:foo"中的第一个“:”都被替换为“XX”,输出: booXXand:foo
System.out.println(tempStr.replaceFirst(":", "XX"));
}
public static void pringStringArray(String[] s) {
int index = s.length;
for (int i = 0; i < index; i++) {
System.err.println(i + ": " + s[i]);
}
}
}
下面的程序演示了正则表达式的用法:
/**
* discription:
*
* @author CoderDream
*
*/
public class RegularExTester {
/**
* @param args
*/
public static void main(String[] args) {
// 把字符串中的“aaa”全部替換為“z”,打印:zbzcz
System.out.println("aaabaaacaaa".replaceAll("a{3}", "z"));
// 把字符串中的“aaa”、“aa”或者“a”全部替換為“*”,打印:*b*c*
System.out.println("aaabaaca".replaceAll("a{1,3}", "\\*"));
// 把字符串中的數字全部替換為“z”,打印:zzzazzbzzcc
System.out.println("123a44b35cc".replaceAll("\\d", "z"));
// 把字符串中的非數字全部替換為“0”,打印:1234000435000
System.out.println("1234abc435def".replaceAll("\\D", "0"));
// 把字符串中的“.”全部替換為“\”,打印:com\abc\dollapp\Doll
System.out.println("com.abc.dollapp.Doll".replaceAll("\\.", "\\\\"));
// 把字符串中的“a.b”全部替換為“_”,
// “a.b”表示長度為3的字符串,以“a”開頭,以“b”結尾
// 打印:-hello-all
System.out.println("azbhelloahball".replaceAll("a.b", "-"));
// 把字符串中的所有詞字符替換為“#”
// 正則表達式“[a-zA-z_0-9]”等價于“\w”
// 打印:#.#.#.#.#.#
System.out.println("a.b.c.1.2.3.4".replaceAll("[a-zA-z_0-9]", "#"));
System.out.println("a.b.c.1.2.3.4".replaceAll("\\w", "#"));
}
}
值得注意的是,由于“.”、“?”和“*”等在正则表达式中具有特殊的含义,如果要表示字面上的这些字符,必须以“\\”开头。例如为了把字符串“com.abc.dollapp.Doll”中的“.”替换为“\”,应该调用replaceAll("\\.",
\\\\)方法。
Java中的正则表达式类
public interface MatchResult
匹配操作的结果。
此接口包含用于确定与正则表达式匹配结果的查询方法。通过 MatchResult 可以查看匹配边界、组和组边界,但是不能修改
public final class Matcher
-
- extends Object
- implements MatchResult
通过解释 Pattern 对
通过调用模式的 matcher 方法从模式创建匹配器。创建匹配器后,可以使用它执行三种不同的匹配操作:
每个方法都返回一个表示成功或失败的布尔值。通过查询匹配器的状态可以获取关于成功匹配的更多信息。
public final class Pattern
-
- extends Object
- implements Serializable
正则表达式的编译表示形式。
指定为字符串的正则表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建 Matcher 对象,依照正则表达式,该对象可以与任意
因此,典型的调用顺序是
Pattern p = Pattern.compile("a*b");
Matcher m = p.matcher("aaaaab");
boolean b = m.matches();
在仅使用一次正则表达式时,可以方便地通过此类定义 matches 方法。此方法编译表达式并在单个调用中将输入序列与其匹配。语句
boolean b = Pattern.matches("a*b", "aaaaab");
等效于上面的三个语句,尽管对于重复的匹配而言它效率不高,因为它不允许重用已编译的模式。
此类的实例是不可变的,可供多个并发线程安全使用。Matcher 类的实例用于此目的则不安全。
测试代码:
/**
* discription:Java中正则表达式类的使用
*
* @author CoderDream
*
*/
public class RegDemo {
/**
* @param args
*/
public static void main(String[] args) {
// 檢查字符串中是否含有“aaa”,有返回:true,無返回:false
System.out.println(isHaveBeenSetting("a{3}", "aaabaaacaaa"));
System.out.println(isHaveBeenSetting("a{3}", "aab"));
// 把字符串“abbaaacbaaaab”中的“aaa”全部替換為“z”,打印:abbzbza
System.out.println(replaceStr("a{3}", "abbaaabaaaa", "z"));
}
/**
*
* @param regEx
* 设定的正则表达式
* @param tempStr
* 系统参数中的设定的字符串
* @return 是否系统参数中的设定的字符串含有设定的正则表达式 如果有的则返回true
*/
public static boolean isHaveBeenSetting(String regEx, String tempStr) {
boolean result = false;
try {
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(tempStr);
result = m.find();
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 将字符串含有的regEx表达式替换为replaceRegEx
*
* @param regEx
* 需要被替换的正则表达式
* @param tempStr
* 替换的字符串
* @param replaceRegEx
* 替换的正则表达式
* @return 替換好后的字符串
*/
public static String replaceStr(String regEx, String tempStr,
String replaceRegEx) {
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(tempStr);
tempStr = m.replaceAll(replaceRegEx);
return tempStr;
}
}
posted @
2008-02-28 11:40 CoderDream 阅读(2343) |
评论 (0) |
编辑 收藏import java.awt.Point;
class PassByValue {
public static void modifyPoint(Point pt, int j) {
pt.setLocation(5, 5); // 1
j = 15;
System.out.println("During modifyPoint " + "pt = " + pt + " and j = " + j);
}
public static void main(String args[]) {
Point p = new Point(0, 0); // 2
int i = 10;
System.out.println("Before modifyPoint " + "p = " + p + " and i = " + i);
modifyPoint(p, i); // 3
System.out.println("After modifyPoint " + "p = " + p + " and i = " + i);
}
}
这段代码在//2处建立了一个Point对象并设初值为(0,0),接着将其值赋予object reference 变量p。然后对基本类型int i赋值10。//3调用static modifyPoint(),传入p和i。modifyPoint()对第一个参数pt调用了setLocation(),将其左边改为(5,5)。然后将第二个参数j赋值为15.当modifyPoint()返回的时候,main()打印出p和i的值。
程序输出如下:
Before modifyPoint p = java.awt.Point[x=0,y=0] and i = 10
During modifyPoint pt = java.awt.Point[x=5,y=5] and j = 15
After modifyPoint p = java.awt.Point[x=5,y=5] and i = 10
这显示modifyPoint()改变了//2 所建立的Point对象,却没有改变int i。在main()之中,i被赋值10.由于参数通过by value方式传递,所以modifyPoint()收到i的一个副本,然后它将这个副本改为15并返回。main()内的原值i并没有受到影响。
对比之下,事实上modifyPoint() 是在与“Point 对象的 reference 的复件”打交道,而不是与“Point对象的复件”打交道。当p从main()被传入modifyPoint()时,传递的是p(也就是一个reference)的复件。所以modifyPoint()是在与同一个对象打交道,只不过通过别名pt罢了。在进入modifyPoint()之后和执行 //1 之前,这个对象看起来是这样:
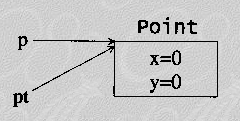
所以//1 执行以后,这个Point对象已经改变为(5,5)。
Java 关键字 final 用来表示常量数据。例如:
public class Test {
static final int someInt = 10;
//
}
这段代码声明了一个 static 类变量,命名为 someInt,并设其初值为10。
任何试图修改 someInt 的代码都将无法通过编译。例如:
//
someInt = 9; // Error
//
关键字 final 可防止 classes 内的 instance 数据遭到无意间的修改。如果我们想要一个常量对象,又该如何呢?例如:
class Circle {
private double rad;
public Circle(double r) {
rad = r;
}
public void setRadius(double r) {
rad = r;
}
public double radius() {
return rad;
}
}
public class FinalTest {
private static final Circle wheel = new Circle(5.0);
public static void main(String args[]) {
System.out.println("Radius of wheel is " + wheel.radius());
wheel.setRadius(7.4);
System.out.println("Radius of wheel is now " + wheel.radius());
}
}
这段代码的输出是:
Radius of wheel is 5.0
Radius of wheel is now 7.4
在上述第一个示例中,我们企图改变final 数据值时,编译器会侦测出错误。
在第二个示例中,虽然代码改变了 instance变量wheel的值,编译器还是让它通过了。我们已经明确声明wheel为final,它怎么还能被改变呢?
不,我们确实没有改变 wheel 的值,我们改变的是wheel 所指对象的值。wheel 并无变化,仍然指向(代表)同一个对象。变量wheel是一个 object reference,它指向对象所在的heap位置。有鉴如此,下面的代码会怎样?
public class FinalTest {
private static final Circle wheel = new Circle(5.0);
public static void main(String args[]) {
System.out.println("Radius of wheel is " + wheel.radius());
wheel = new Circle(7.4); // 1
System.out.println("Radius of wheel is now " + wheel.radius());
}
}
编译代码,// 1 处出错。由于我们企图改变 final 型变量 wheel 的值,所以这个示例将产生编译错误。换言之,代码企图令wheel指向其他对象。变量wheel是final,因此也是不可变的。它必须永远指向同一个对象。然而wheel所指向的对象并不受关键字final的影响,因此是可变的。
关键字 final 只能防止变量值的改变。如果被声明为 final 的变量是个 object reference,那么该reference不能被改变,必须永远指向同一个对象,但被指的那个对象可以随意改变内部的属性值。
关键字final 在Java中有多重用途,即可被用于instance变量、static变量,也可用于classes或methods,用于类,表示该类不能有子类;用于方法,表示该方法不允许被子类覆盖。
array和Vector的比较
|
|
支持基本类型
|
支持对象
|
自动改变大小
|
速度快
|
|
array
|
Yes
|
Yes
|
No
|
Yes
|
|
Vector
|
No(1.5以上支持)
|
Yes
|
Yes
|
No
|
代码1:instanceof方式
interface Employee {
public int salary();
}
class Manager implements Employee {
private static final int mgrSal = 40000;
public int salary() {
return mgrSal;
}
}
class Programmer implements Employee {
private static final int prgSal = 50000;
private static final int prgBonus = 10000;
public int salary() {
return prgSal;
}
public int bonus() {
return prgBonus;
}
}
class Payroll {
public int calcPayroll(Employee emp) {
int money = emp.salary();
if (emp instanceof Programmer)
money += ((Programmer) emp).bonus(); // Calculate the bonus
return money;
}
public static void main(String args[]) {
Payroll pr = new Payroll();
Programmer prg = new Programmer();
Manager mgr = new Manager();
System.out.println("Payroll for Programmer is " + pr.calcPayroll(prg));
System.out.println("payroll for Manager is " + pr.calcPayroll(mgr));
}
}
依据这个设计,calcPayroll()必须使用instanceof操作符才能计算出正确结果。因为它使用了Employee接口,所以它必须断定Employee对象究竟实际属于哪个class。程序员有奖金而经理没有,所以你必须确定Employee对象的运行时类型。
代码2:多态方式
interface Employee {
public int salary();
public int bonus();
}
class Manager implements Employee {
private static final int mgrSal = 40000;
private static final int mgrBonus = 0;
public int salary() {
return mgrSal;
}
public int bonus() {
return mgrBonus;
}
}
class Programmer implements Employee {
private static final int prgSal = 50000;
private static final int prgBonus = 10000;
public int salary() {
return prgSal;
}
public int bonus() {
return prgBonus;
}
}
class Payroll {
public int calcPayroll(Employee emp) {
// Calculate the bonus. No instanceof check needed.
return emp.salary() + emp.bonus();
}
public static void main(String args[]) {
Payroll pr = new Payroll();
Programmer prg = new Programmer();
Manager mgr = new Manager();
System.out.println("Payroll for Programmer is " + pr.calcPayroll(prg));
System.out.println("Payroll for Manager is " + pr.calcPayroll(mgr));
}
}
在这个设计中,我们为Employee接口增加了 bonus(),从而消除了instanceof的必要性。实现Employee接口的两个 classes:Programmer和Manager,都必须实现salary()和bonus()。这些修改显著简化了calcPayroll()。
import java.util.Vector;
class Shape {
}
class Circle extends Shape {
public double radius() {
return 5.7;
}
//
}
class Triangle extends Shape {
public boolean isRightTriangle() {
// Code to determine if triangle is right
return true;
}
//
}
class StoreShapes {
public static void main(String args[]) {
Vector shapeVector = new Vector(10);
shapeVector.add(new Triangle());
shapeVector.add(new Triangle());
shapeVector.add(new Circle());
//
// Assume many Triangles and Circles are added and removed
//
int size = shapeVector.size();
for (int i = 0; i < size; i++) {
Object o = shapeVector.get(i);
if (o instanceof Triangle) {
if (((Triangle) o).isRightTriangle()) {
//
}
} else if (o instanceof Circle) {
double rad = ((Circle) o).radius();
//
}
}
}
}
这段代码表明在 这种场合下 instanceof 操作符是必需的。当程序从Vector 取回对象,它们属于java.lang.Object。利用instanceof确定对象实际属于哪个class后,我们才能正确执行向下转型,而不至于在运行期抛出异常。
posted @
2008-02-26 17:56 CoderDream 阅读(300) |
评论 (0) |
编辑 收藏9.1 Java异常处理机制概述
主要考虑的两个问题:(1)如何表示异常情况?(2)如何控制处理异常的流程?
9.1.1 Java异常处理机制的优点
Java语言按照面向对象的思想来处理异常,使得程序具有更好的可维护性。
Java异常处理机制具有以下优点:
- 把各种不同类型的异常情况进行分类,用Java类来表示异常情况,发挥类的可扩展性和可重用性。
- 异常流程的代码和正常流程的代码分离,提供了程序的可读性,简化了程序的结构。
- 可以灵活地处理异常,如果当前方法有能力处理异常,就捕获并处理它,否则只需要抛出异常,由方法调用者来处理它。
9.1.2 Java虚拟机的方法调用栈
如果方法中的代码块可能抛出异常,有如下两种处理方法:
(1)在当前方法中通过try...catch语句捕获并处理异常;
(2)在方法的声明处通过throws语句声明抛出异常。
当Java虚拟机追溯到调用栈的底部的方法时,如果仍然没有找到处理该异常的代码,将按以下步骤处理:
(1)调用异常对象的printStachTrace()方法,打印来自方法调用栈的异常信息。
(2)如果该线程不是主线程,那么终止这个线程,其它线程继续正常运行。如果该线程是主线程,那么整个应用程序被终止。
9.1.3 异常处理对性能的影响
一般来说,影响很小,除非方法嵌套调用很深。
9.2 运用Java异常处理机制
9.2.1 try...catch语句:捕获异常
9.2.2 finally语句:任何情况下都必须执行的代码
主要用于关闭某些流和数据库连接。
9.2.3 thorws子句:声明可能会出现的异常
9.2.4 throw语句:抛出异常
9.2.5 异常处理语句的语法规则
(1)try代码块不能脱离catch代码块或finally代码块而单独存在。try代码块后面至少有一个catch代码块或finally代码块。
(2)try代码块后面可以有零个或多个catch代码块,还可以有零个或至多一个finally代码块。
(3)try代码块后面可以只跟finally代码块。
(4)在try代码块中定义的变量的作用域为try代码块,在catch代码块和finally代码块中不能访问该变量。
(5)当try代码块后面有多个catch代码块时,Java虚拟机会把实际抛出的异常类对象依次和各个catch代码块声明的异常类型匹配,如果异常对象为某个异常类型或其子类的实例,就执行这个catch代码块,而不会再执行其他的catch代码块。
(6)如果一个方法可能出现受检查异常,要么用try...catch语句捕获,要么用throws子句声明将它抛出,否则会导致编译错误。
9.2.6 异常流程的运行过程
(1)finally语句不被执行的唯一情况是先执行了用于终止程序的System.exit()方法。
(2)return语句用于退出本方法。
(3)finally代码块虽然在return语句之前被执行,但finally代码块不能通过重新给变量赋值来改变return语句的返回值。
(4)建议不要在finally代码块中使用return语句,因为它会导致以下两种潜在的错误
A:覆盖try或catch代码块的return语句
public class SpecialException extends Exception {
public SpecialException() {
}
public SpecialException(String msg) {
super(msg);
}
}
public class FinallyReturn {
/**
* @param args
*/
public static void main(String[] args) {
FinallyReturn fr = new FinallyReturn();
System.out.println(fr.methodB(1));// 打印100
System.out.println(fr.methodB(2));// 打印100
}
public int methodA(int money) throws SpecialException {
if (--money <= 0) {
throw new SpecialException("Out of money");
}
return money;
}
@SuppressWarnings("finally")
public int methodB(int money) {
try {
return methodA(money);// 可能抛出异常
} catch (SpecialException e) {
return -100;
} finally {
return 100;// 会覆盖try和catch代码块的return语句
}
}
}
B:丢失异常
public class ExLoss {
/**
* @param args
*/
public static void main(String[] args) {
try {
System.out.println(new ExLoss().methodB(1));// 打印100
System.out.println("No Exception");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
public int methodA(int money) throws SpecialException {
if (--money <= 0) {
throw new SpecialException("Out of money");
}
return money;
}
@SuppressWarnings("finally")
public int methodB(int money) {
try {
return methodA(money);// 可能抛出异常
} catch (SpecialException e) {
throw new Exception("Wrong");
} finally {
return 100;// 会丢失catch代码块中的异常
}
}
}
9.3 Java异常类
所有异常类的祖先类为java.lang.Throwable类,它的实例表示具体的异常对象,可以通过throw语句抛出。
Throwable类提供了访问异常信息的一些方法,常用的方法包括:
- getMessage() --返回String类型的异常信息。
- printStachTrace()--打印跟踪方法调用栈而获得的详细异常信息。在程序调试阶段,此方法可用于跟踪错误。
public class ExTrace {
/**
* @param args
*/
public static void main(String[] args) {
try {
new ExTrace().methodB(1);
} catch (Exception e) {
System.out.println("--- Output of main() ---");
e.printStackTrace();
}
}
public void methodA(int money) throws SpecialException {
if (--money <= 0) {
throw new SpecialException("Out of money");
}
}
public void methodB(int money) throws Exception {
try {
methodA(money);
} catch (SpecialException e) {
System.out.println("--- Output of methodB() ---");
System.out.println(e.getMessage());
throw new Exception("Wrong");
}
}
}
打印结果:
--- Output of methodB() ---
Out of money
--- Output of main() ---
java.lang.Exception: Wrong
at chapter09.d0903.ExTrace.methodB(ExTrace.java:45)
at chapter09.d0903.ExTrace.main(ExTrace.java:26)
Throwable类有两个直接子类:
- Error类--表示仅靠程序本身无法恢复的严重错误,如内存不足等。
- Exception类--表示程序本身可以处理的异常。
9.3.1 运行时异常
RuntimeException类及其子类都被称为运行时异常,这种异常的特点是Java编译器不会检查它,会编译通过,但运行时如果条件成立就会出现异常。
例如当以下divided()方法的参数b为0,执行“a/b”操作时会出现ArrithmeticException异常,它属于运行时异常,Java编译器不会检查它。
public int divide2(int a, int b) {
return a / b;// 当参数为0,抛出ArrithmeticException
}
下面的程序中的IllegalArgumentException也是运行时异常,divided()方法即没有捕获它,也没有声明抛出它。
public class WithRuntimeEx {
/**
* @param args
*/
public static void main(String[] args) {
new WithRuntimeEx().divide(1, 0);
System.out.println("End");
}
public int divide(int a, int b) {
if (b == 0) {
throw new IllegalArgumentException("除數不能為0");
}
return a / b;
}
}
由于程序代码不会处理运行时异常,因此当程序在运行时出现了这种异常时,就会导致程序异常终止。以上程序的打印结果为:
Exception in thread "main" java.lang.IllegalArgumentException: 除數不能為0
at chapter09.d0903.WithRuntimeEx.divide(WithRuntimeEx.java:29)
at chapter09.d0903.WithRuntimeEx.main(WithRuntimeEx.java:23)
9.3.2 受检查异常
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常(Checked Exception)。这种异常要么catch语句捕获,要么throws子句声明抛出,否则编译出错。
9.3.3 区分运行时异常和受检查异常
受检查异常表示程序可以处理的异常。
运行时异常表示无法让程序恢复运行的异常,导致这种异常的原因通常是由于执行了错误操作。一旦出现了错误操作,建议终止程序,因此Java编译器不检查这种异常。
9.3.4 区分运行时异常和错误
Error类及其子类表示程序本身无法修复的错误,它和运行时异常的相同之处是:Java编译器都不会检查它们,当程序运行时出现它们,都会终止程序。
两者的不同之处是:Error类及其子类表示的错误通常是由Java虚拟机抛出。
而RuntimeException类表示程序代码中的错误,它是可扩展的,用户可以根据特定的问题领域来创建相关的运行时异常类。
9.4 用户定义异常
9.4.1 异常转译和异常链
public class BaseException extends Exception {
protected Throwable cause = null;
public BaseException() {
}
public BaseException(String msg) {
super(msg);
}
public BaseException(Throwable cause) {
this.cause = cause;
}
public BaseException(String msg, Throwable cause) {
super(msg);
this.cause = cause;
}
public Throwable initCause(Throwable cause) {
this.cause = cause;
return this;
}
public Throwable getCause() {
return cause;
}
public void printStackTrace() {
printStackTrace(System.err);
}
public void printStackTrace(PrintStream outStream) {
printStackTrace(new PrintStream(outStream));
}
public void printStackTrace(PrintWriter writer) {
super.printStackTrace(writer);
if (getCause() != null) {
getCause().printStackTrace(writer);
}
writer.flush();
}
}
9.4.2 处理多样化异常
public class MultiBaseException extends Exception {
protected Throwable cause = null;
private List<Throwable> exceptions = new ArrayList<Throwable>();
public MultiBaseException() {
}
public MultiBaseException(Throwable cause) {
this.cause = cause;
}
public MultiBaseException(String msg, Throwable cause) {
super(msg);
this.cause = cause;
}
public List getException() {
return exceptions;
}
public void addException(MultiBaseException ex) {
exceptions.add(ex);
}
public Throwable initCause(Throwable cause) {
this.cause = cause;
return this;
}
public Throwable getCause() {
return cause;
}
public void printStackTrace() {
printStackTrace(System.err);
}
public void printStackTrace(PrintStream outStream) {
printStackTrace(new PrintStream(outStream));
}
public void printStackTrace(PrintWriter writer) {
super.printStackTrace(writer);
if (getCause() != null) {
getCause().printStackTrace(writer);
}
writer.flush();
}
}
9.5 异常处理原则
9.5.1 异常只能用于非正常情况
9.5.2 为异常提供说明文档
9.5.3 尽可能地避免异常
9.5.4 保持异常的原子性
9.5.5 避免过于庞大的try代码块
9.5.6 在catch子句中指定具体的异常类型
9.5.7 不要在catch代码块中忽略被捕获的异常,可以处理异常、重新抛出异常、进行异常转译
posted @
2008-02-22 17:50 CoderDream 阅读(885) |
评论 (0) |
编辑 收藏8.1 接口的概念和基本特征
(1)、接口中的成员变量默认都是public、static、final类型的,必须被显式初始化;
(2)、接口中的方法默认都是public、abstract类型的;
(3)、接口中只能包含public、static、final类型的成员变量和public、abstract类型的成员方法;
(4)、接口没有构造方法,不能被实例化;
(5)、一个接口不能实现另一个接口,但可以继承多个其他接口;
(6)、接口必须通过类来实现它的抽象方法。类实现接口的关键字是implements;
(7)、与子类继承抽象父类相似,当类实现了某个接口时,它必须实现接口中所有的抽象方法,否则这个类必须被定义为抽象类;
(8)、不允许创建接口类型的实例,但允许定义接口类型的引用变量,该变量引用实现了这个接口的类的实例;
(9)、一个类只能继承一个直接的父类,但能实现多个接口。
8.2 比较抽象类与接口
相同点:
- 代表系统的抽象层
- 都不能被实例化
- 都能包含抽象方法
两大区别:
- 在抽象类中可以为部分方法提供默认的实现,从而避免在子类中重复实现它们,提高代码的可重用性,这是抽象类的优势所在;而接口中只能包含抽象方法;
- 一个类只能继承一个直接的父类,这个父类有可能是抽象类;但一个类可以实现多个接口,这是接口的优势所在。
使用接口和抽象类的原则:
- 用接口作为系统与外界交互的窗口;
- 由于外界使用者依赖系统的接口,并且系统内部会实现接口,因此接口本身必须十分稳定,接口一旦制订,就不允许随意修改,否则会对外界使用者及系统内部都造成影响。
- 用抽象类来定制系统中的扩展点。
8.3 与接口相关的设计模式
8.3.1 定制服务模式
如何设计接口?定制服务模式提出了设计精粒度的接口的原则。
8.3.2 适配器模式
当两个系统之间接口不匹配时,如果处理?适配器模式提供了接口转换方案。
包括继承实现方式和组合实现方式。优先考虑用组合关系来实现适配器。
8.3.3 默认适配器模式
为了简化编程,JDK为MouseListener提供了一个默认适配器MouseAdapter,它实现了MouseListener接口,为所有的方法提供了空的方法体。用户自定义的MyMouseLIstener监听器可以继承MouseAdapter类,在MyMouseListener类中,只需要覆盖特定的方法,而不必实现所有的方法。使用默认适配器可以简化编程,但缺点是该类不能在继承其他的类。
8.3.4 代理模式
下面以房屋出租人的代理为例,介绍代理模式的运用。在下图中,出租人Renter和代理Deputy都具有RenterIFC接口。Tenant类代表租赁人,HouseMarket类代表整个房产市场,它记录了所有房产代理人的信息,出租人从房产市场找到房产代理人。
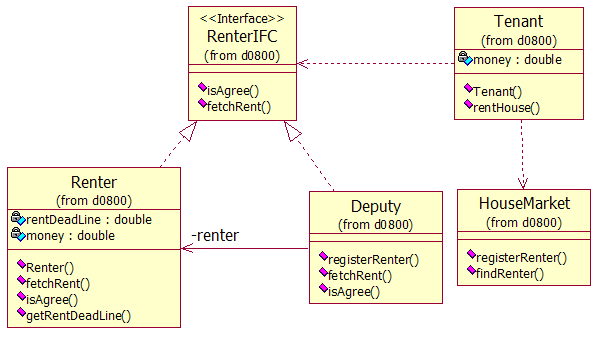
为了简化起见,假定一个代理人只会为一个出租人做代理,租赁人租房屋rentHouse()的大致过程如下:
- 从房产市场上找到一个房产代理人,即调用HouseMarket对象的findRenter()方法;
- 报出期望的租金价格,征求代理人的意见,即调用Deputy对象的isAgree()方法;
- 代理人的处理方式为:如果租赁人的报价低于出租人的租金价格底线,就立即做出拒绝答复;否则征求出租人的意见,即调用Renter对象的isAgree()方法。
- 出租人的处理方式为:如果租赁人的报价比租金价格底线多100元,就同意出租
- 如果租赁人得到代理人同意的答复,就从存款中取出租金,通知代理人领取租金,即调用Deputy对象的fetchRent()方法
- 代理人通知出租人领取租金,即调用Renter对象的fecthRent()方法。
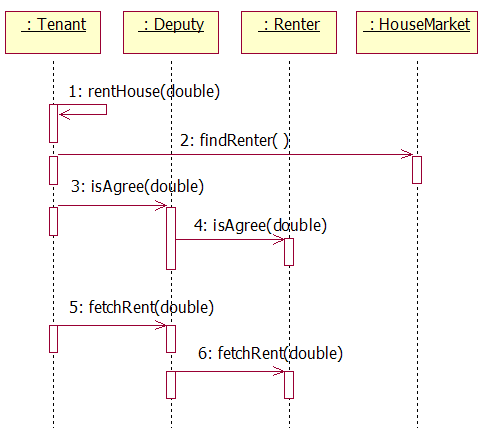
房屋租赁交易顺利执行的时序图
源代码:
/**
* RetnerIFC 接口,它定义了出租人的两个行为,即决定是否同意按租赁人提出的价格出租房屋,以及收房租
*
* @author XL
*
*/
public interface RenterIFC {
/**
* 是否同意按租赁人提出的价格出租房屋
*
* @param expectedRent
* @return
*/
public boolean isAgree(double expectedRent);
/**
* 收房租
*
* @param rent
*/
public void fetchRent(double rent);
}
/**
* 房屋出租人
*
* @author XL
*
*/
public class Renter implements RenterIFC {
/**
* 房屋租金最低价格
*/
private double rentDeadLine;
/**
* 存款
*/
private double money;
/**
* @param rentDeadLine
* @param money
*/
public Renter(double rentDeadLine, double money) {
super();
System.out.println("New Renter, rentDeadLine: " + rentDeadLine
+ ", saveMoney: " + money);
this.rentDeadLine = rentDeadLine;
this.money = money;
}
/*
* (non-Javadoc)
*
* @see chapter08.d0800.RenterIFC#fetchRent(double)
*/
public void fetchRent(double rent) {
System.out.println("OK, you can use the house.");
money += rent;
}
/*
* (non-Javadoc) 如果租赁人的期望价格比房屋租金最低价格多100元,则同意出租
*
* @see chapter08.d0800.RenterIFC#isAgree(double)
*/
public boolean isAgree(double expectedRent) {
System.out.println("If the money less 100 than the rentDeadLine.");
return expectedRent - this.rentDeadLine > 100;
}
/**
* @return
*/
public double getRentDeadLine() {
return rentDeadLine;
}
}
/**
* 房产代理人
*
* @author XL
*
*/
public class Deputy implements RenterIFC {
private Renter renter;
/**
* 接受代理
*
* @param renter
*/
public void registerRenter(Renter renter) {
System.out.println("OK, I have some business.");
this.renter = renter;
}
public void fetchRent(double rent) {
System.out.println("Get the monty: " + rent);
renter.fetchRent(rent);
}
/*
* (non-Javadoc) 如果租赁人的期望价格低于房屋租金最低价格,则不同意出租 否则请示出租人的意见
*
* @see chapter08.d0800.RenterIFC#isAgree(double)
*/
public boolean isAgree(double expectedRent) {
//
if (expectedRent < renter.getRentDeadLine()) {
System.out.println("Sorry, you can't rent the house.");
return false;
} else {
System.out.println("Let me ask the renter.");
return renter.isAgree(expectedRent);
}
}
}
import java.util.HashSet;
import java.util.Set;
/**
* @author XL
*
*/
public class HouseMarket {
private static Set<RenterIFC> renters = new HashSet<RenterIFC>();
public static void registerRenter(RenterIFC deputy) {
System.out.println("A new man has registered!");
renters.add(deputy);
}
public static RenterIFC findRenter() {
System.out.println("Let's find something!");
return (RenterIFC) renters.iterator().next();
}
}
/**
* 房屋租赁人
*
* @author XL
*
*/
public class Tenant {
private double money;
public Tenant(double money) {
//
System.out.println("New Tenant!");
System.out.println("I have " + money);
this.money = money;
}
public boolean rentHouse(double expectedRent) {
// 从房地产市场找到一个房产代理人
RenterIFC renter = HouseMarket.findRenter();
System.out.println("I can offer " + expectedRent);
// 如果代理人不同意预期的租金价格,就拉倒,否则继续执行
if (!renter.isAgree(expectedRent)) {
System.out.println("I can't offer any more!");
return false;
}
// 从存款中取出预付租金
money -= expectedRent;
System.out.println("OK, get the money, " + expectedRent);
// 把租金交给房产代理人
renter.fetchRent(expectedRent);
return true;
}
}
/**
* @author XL
*
*/
public class AppMain {
/**
* @param args
*/
public static void main(String[] args) {
// 创建一个房屋出租人,房屋租金最低价格为2000元,存款1万元
Renter renter = new Renter(2000, 10000);
// 创建一个房产代理人
Deputy deputy = new Deputy();
// 房产代理人到房产市场登记
HouseMarket.registerRenter(deputy);
// 建立房屋出租人和房产代理人的委托关系
deputy.registerRenter(renter);
// 创建一个房屋租赁人,存款为2万元
Tenant tenant = new Tenant(20000);
// 房屋租赁人试图租赁期望租金为1800元的房屋,遭到房产代理人拒绝
tenant.rentHouse(1800);
// 房屋租赁人试图租赁期望租金为2300元的房屋,租房成功
tenant.rentHouse(2300);
}
}
输出结果:
New Renter, rentDeadLine: 2000.0, saveMoney: 10000.0
A new man has registered!
OK, I have some business.
New Tenant!
I have 20000.0
Let's find something!
I can offer 1800.0
Sorry, you can't rent the house.
I can't offer any more!
Let's find something!
I can offer 2300.0
Let me ask the renter.
If the money less 100 than the rentDeadLine.
OK, get the money, 2300.0
Get the monty: 2300.0
OK, you can use the house.
8.3.5 标识类型模式
标识类型接口没有任何方法,仅代表一种抽象类型。
在JDK中,有如下两个典型的标识类型接口:
- java.io.Serializable接口:实现该接口的类可以被序列化。
- java.io.Remote接口:实现该接口的类的实例可以作为远程对象。
8.3.6 常量接口模式
posted @
2008-02-19 18:03 CoderDream 阅读(399) |
评论 (0) |
编辑 收藏
摘要: 教程:CSS修饰表格
代码:
<html>
<head>
<title>用css美化表格边框</title>
...
阅读全文
posted @
2008-02-03 15:09 CoderDream 阅读(5941) |
评论 (0) |
编辑 收藏<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE> New Document </TITLE>
<META NAME="Generator" CONTENT="EditPlus">
<META NAME="Author" CONTENT="">
<META NAME="Keywords" CONTENT="">
<META NAME="Description" CONTENT="">
</HEAD>
<BODY>
<div>
<table style="border:blue solid;border-width:2 1 1 2" width="800" cellspacing="0" cellpadding="0" border="0" class="table4">
<tr >
<td style="border:blue solid;border-width:0 1 1 0 " width="40"><CENTER><B>序号</B></CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 " width="700"><CENTER><B>标题</B></CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 " width="60"><CENTER><B>地址</B></CENTER></td>
</tr>
<tr>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>01</CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 "> </td>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>地址</CENTER></td>
</tr>
<tr>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>02</CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 "> </td>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>地址</CENTER></td>
</tr>
<tr>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>03</CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 "> </td>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>地址</CENTER></td>
</tr>
</table>
</div>
</BODY>
</HTML>
效果:
|
序号 |
标题 |
地址 |
|
01 |
|
地址 |
|
02 |
|
地址 |
|
03 |
|
地址 |
posted @
2008-02-03 15:05 CoderDream 阅读(3216) |
评论 (0) |
编辑 收藏
|
序号 |
标题 |
地址 |
|
01 |
CSS修饰表格 |
地址 |
|
02 |
制作强制固定表格大小的效果 |
地址 |
|
03 |
html语言教程 |
地址 |
|
04 |
CSS教程 |
地址 |
posted @
2008-02-03 15:03 CoderDream 阅读(348) |
评论 (0) |
编辑 收藏
要求:根据Reinsurance_Level和ReCompanyCode进行汇总:
select t.reinsurance_Level,t.re_Company_Code,sum(t.ceded_Amount)
from Claimnotice_Insurance_Detail t
where 1=1
-- 此处加条件
group by t.reinsurance_Level,t.re_Company_Code;
结果:
| REINSURANCE_LEVEL |
RE_COMPANY_CODE |
3 |
| 1 |
1 |
2621000 |
| 1 |
2 |
1534000 |
| 1 |
3 |
375000 |
| Q |
2 |
302000 |
| Q |
4 |
302000 |
posted @
2008-01-21 11:33 CoderDream 阅读(678) |
评论 (0) |
编辑 收藏http://blog.csdn.net/goody9807/archive/2007/09/11/1780717.aspx
[Tree命令作用]
以图形显示驱动器或路径的文件夹结构。很多时候,这是一个非常有用的命令!
[Tree命令格式]
可以在命令行窗口敲tree /?看帮助。
TREE [drive:][path] [/F] [/A]
/F 显示每个文件夹中文件的名称。
/A 使用 ASCII 字符,而不使用扩展字符。
使用/F参数时显示所有目录及目录下的所有文件,省略时,只显示目录,不显示目录下的文件;
选用>PRN参数时,则把所列目录及目录中文件名打印输出
tree c:\ | more
出现由 tree 命令产生的第一个输出命令提示符窗口,后面跟着 -- More -- 提示。输出暂停,直到用户按键盘上的任意键为止(Pause除外)。
空格:显示一整页
按下:Ctrl+Break退出
[Tree命令范例]
[例一]
tree d: > d:\dTree.txt
或者
tree d:\ > d:\dTree.txt
作用:把D盘下的所有目录结构以树状结构导出,以文本文件dTree.txt保存在文件夹d:\下。
[例二]
tree d: /f > d:\dF.txt
或者
tree d:\ /f > d:\dF.txt
作用:把D盘下的所有目录及文件结构以树状结构导出,以文本文件dF.txt保存在文件夹d:\下。
[例三]
tree C:\WINDOWS\system32 /f > C:\s32f.txt
作用:把C:\WINDOWS\system32 /f > C:\s32f.txt下的所有目录及文件结构以树状结构导出,以文本文件s32f.txt保存在文件夹c:\下。
[例四]
tree E:\BitComet\Downloads /f > f:\download\tree\dl.txt
作用:把E:\BitComet\Downloads下的所有目录及文件以树状结构导出,以文本文件dl.txt保存在文件夹f:\download\tree\下。
[Tree命令注意事项]
[注意1] TREE命令中涉及的文件夹名称中不得有空格
例如,类似下面的命令发挥不了作用:
tree C:\Documents and Settings\Administrator /f > c:\administrator.txt
若要提取诸如E盘My doc文件夹下的文件结构,可以先进入这个目录(先e:回车,再cd My doc回车),再用tree命令提取:
tree /f>mydoc.txt
[注意2]了解DOS的对当前提示符的一些默认
例如,在提示符 E:\My doc> 下,可以用下面的简洁命令
tree /f>mydoc.txt
把E:\My doc>下的所有目录及文件结构以树状结构导出,以文本文件mydoc.txt保存在文件夹E:\My doc下。
注意这个TREE命令后没有盘符及路径,缺省时,默认值就是当前提示符所在路径。导出符“>”后也同此默认。
[注意3]关于路径后面的反斜杠
(1)在提示符 C:\Documents and Settings\Administrator> 下,如果要导出C盘的所有文件结构,必须使用类似下列命令:
tree c:\ > c:\ct.txt
而不能是诸如此类之命令:
tree c: > c:\ct.txt
因为此命令导出的不是整个C盘的内容,而是提示符所在路径C:\Documents and Settings\Administrator>下的内容。
(2)但在一般情况下,路径后面不能有反斜杠
例如若需导出D:\ghost下的结构,不能用诸如此类的命令:
tree D:\ghost\ /f > d:\ghost.txt
而只能是:
tree D:\ghost /f > d:\ghost.txt
[注意4]导出符前后空格均可省略,但参数\F等前面的空格不可以。
此命令有效:tree D:\ghost /F>d:\ghost.txt
而此命令无效:tree D:\ghost/F > d:\ghost.txt
posted @
2008-01-18 22:29 CoderDream 阅读(17696) |
评论 (2) |
编辑 收藏 有两个表,文章表中TypeId字段记录栏目Id,栏目表中的字段是栏目Id和栏目名,现在要达到的效果就是读取文章列表的时候显示栏目名称。
以前没用过inner join外联操作,所以就束手无策了。其实有些功能是仅仅靠SQL语句就可以实现的,inner join能够组合两个表中的记录,只要在公共字段之中有相符的值。
所以要显示栏目名称,只要用如下SQL语句:
Select [Article].id,[Article].content,[栏目表].[栏目名称] FROM [Article] inner join [栏目表] on [栏目表].id=[Article].ArType orDER BY [ArId] DESC
------------------------------------------------------------------------------
附相关文章:
多表联接建立记录集是十分有用的,因为某些情况下,我们需要把数字数据类型显示为相应的文本名称,这就遇到了多表联接建立记录集的问题。比如作一个会员注册系统,共有五个表,会员信息数据表member、会员身份表MemberIdentity、会员权限表 MemberLevel、会员类别表MemberSort和会员婚姻状况表Wedlock。如果想把会员注册信息全部显示出来,肯定要将这四个表连起来,否则大家看到的某些会员信息可能只是数据编号。
以会员类别表来说,在其数据表中,1代表普通会员,2代表高级会员,3代表终身会员,在显示时,如果不将会员类别表与会员详细数据表相关联,那么假如我们现在看到的是一名普通会员的注册信息,我们只能看到其类别为1,而谁又会知道1代表的是普通会员呢?所以要将会员类别表与会员详细数据表相关联,关联后,1就显示为普通会员,2就显示为高级会员,3就显示为终身会员,这样多好?同理,其它两个表也要与会员详细数据表相关联才能把数据编号显示为相应的名称。
前天制作网站后台时遇到此问题,在面包论坛、狂迷俱乐部、蓝色理想、和5D多媒体论坛发了贴子求救,都没有获得答案,只好自己研究,花了两天时间终于成功,现将其写成教程供大家分享,希望大家少走弯路。
本教程是把五个表联在一起,如果愿意,您可以将更多的表联在一起,方法大同小异啦~
步骤一:用Access软件建立一个名为Member的数据库,在其中建五个表,分别为:会员信息数据表member、会员身份表MemberIdentity、会员权限表MemberLevel、会员类别表MemberSort和会员婚姻状况表Wedlock。
●会员信息数据表member:
MemberID:自动编号,主键(ID号)
MemberSort:数字(会员类别)
MemberName:文本,会员姓名
Password:文本(会员密码)
MemberLevel:数字(会员权限)
MemberIdentity:数字(会员身份)
Wedlock:数字(婚姻状况)
MemberQQ:文本(QQ号码)
MemberEmail:文本(会员邮箱)
MemberDate:日期/时间(会员注册日期)
●会员身份表MemberIdentity:
MemberIdentity:自动编号,主键(ID号)
IdentityName:文本(会员身份名称)
●会员权限表MemberLevel:
MemberLevel:自动编号,主键(ID号)
LevelName:文本(会员权限名称)
●会员类别表MemberSort:
MemberSort:自动编号,主键(ID号)
SortName:文本(会员类别名称)
●会员婚姻状况表Wedlock
Wedlock:自动编号,主键(ID号)
WedlockName:文本(会员婚姻状况类别)
说明:五个表建好后,您可以自行设置您想要的类别,如会员权限,您可以设置两个类别--“未付费会员”和“已付费会员”,编号分别为“1”、“2”,如您设置了三个选项,那么第三个选项的编号当然就是“3”了。
下面我们所要作的工作就是把“1”、“2”之类的编号显示为“未付费会员”和“已付费会员”,否则,大家谁会知道“1”代表的是“未付费会员”,“2”代表的是“已付费会员”?
步骤二:建DSN数据源,建记录集
●运行Dreamweaver MX软件,在会员注册信息显示页面建一个名为ConnMember(您也可以起其它的名称)的DSN数据源。
●点击服务器行为面板中的“绑定”,建一个名为MemberShow的数据集,“连接”选择ConnMember,“表格”选择Member,“列”全选,“排序”选择MemberDate,降序。点击“高级”按钮,修改SQL框中自动生成的代码:
原代码为:
Select *
FROM Member
orDER BY MemberDate DESC
将代码修改为:
Select *
FROM (((Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort) INNER JOIN MemberLevel ON Member.MemberLevel=MemberLevel.MemberLevel) INNER JOIN MemberIdentity ON Member.MemberIdentity=MemberIdentity.MemberIdentity) INNER JOIN Wedlock ON Member.Wedlock=Wedlock.Wedlock
orDER BY MemberDate DESC
修改完代码后,点击“确定”,大功告成!
现在,您可以打开记录集看一下,五个表中的字段全部集成在MemberShow记录集中,您只要将相应的字段绑定在该字段想显示的单元格中即可。这下好了,所有的数字编号全部变成了相应的名称,如会员权限,不再是“1”和“2”的数字形式了,而是变成了相应的名称“未付费会员”和“已付费会员”。其它的数字编号也变成了显示的文本名称,是不是很开心呢?
注意事项:
●在输入字母过程中,一定要用英文半角标点符号,单词之间留一半角空格;
●在建立数据表时,如果一个表与多个表联接,那么这一个表中的字段必须是“数字”数据类型,而多个表中的相同字段必须是主键,而且是“自动编号”数据类型。否则,很难联接成功。
● 代码嵌套快速方法:如,想连接五个表,则只要在连接四个表的代码上加一个前后括号(前括号加在FROM的后面,后括号加在代码的末尾即可),然后在后括号后面继续添加“INNER JOIN 表名X ON 表1.字段号=表X.字段号”代码即可,这样就可以无限联接数据表了:)
语法格式:
其实 INNER JOIN ……ON的语法格式可以概括为:
FROM (((表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号) INNER JOIN 表4 ON Member.字段号=表4.字段号) INNER JOIN 表X ON Member.字段号=表X.字段号
您只要套用该格式就可以了。
现成格式范例:
虽然我说得已经比较明白了,但为照顾初学者,我还是以本会员注册系统为例,提供一些现成的语法格式范例,大家只要修改其中的数据表名称和字段名称即可。
连接两个数据表的用法:
FROM Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort
语法格式可以概括为:
FROM 表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号
连接三个数据表的用法:
FROM (Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort) INNER JOIN MemberLevel ON Member.MemberLevel=MemberLevel.MemberLevel
语法格式可以概括为:
FROM (表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号
连接四个数据表的用法:
FROM ((Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort) INNER JOIN MemberLevel ON Member.MemberLevel=MemberLevel.MemberLevel) INNER JOIN MemberIdentity ON Member.MemberIdentity=MemberIdentity.MemberIdentity
语法格式可以概括为:
FROM ((表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号) INNER JOIN 表4 ON Member.字段号=表4.字段号
连接五个数据表的用法:
FROM (((Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort) INNER JOIN MemberLevel ON Member.MemberLevel=MemberLevel.MemberLevel) INNER JOIN MemberIdentity ON Member.MemberIdentity=MemberIdentity.MemberIdentity) INNER JOIN Wedlock ON Member.Wedlock=Wedlock.Wedlock
语法格式可以概括为:
FROM (((表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号) INNER JOIN 表4 ON Member.字段号=表4.字段号) INNER JOIN 表5 ON Member.字段号=表5.字段号
------------------------------------------------------------------------------
INNER JOIN 运算
组合两个表中的记录,只要在公共字段之中有相符的值。
语法
FROM table1 INNER JOIN table2 ON table1.field1 compopr table2.field2
INNER JOIN 运算可分为以下几个部分:
部分 说明
table1, table2 记录被组合的表的名称。
field1, field2 被联接的字段的名称。若它们不是由数字构成的,则这些字段必须为相同的数据类型并包含同类数据,但它们无须具有相同的名称。
compopr 任何的关系比较运算子:"=," "<," ">," "<=," ">=," 或 "<>."
说明
可以在 FROM 子句中使用INNER JOIN运算。.这是最普通的联接类型。只要在这两个表的公共字段之中有相符值,内部联接将组合两个表中的记录。
可以使用 INNER JOIN 与部门表及员工表选择每一个部门中的全部员工。反之,可以使用 LEFT JOIN或 RIGHT JOIN运算创建 outer join,从而选择所有部门(即使有些并没有员工)或所有员工(即使有些尚未分配到部门)。
若试图联接包含 Memo或 OLE Object数据的字段,会导致错误。
可以联接任何两个相同类型的数值字段。例如,可以联接 AutoNumber和 Long字段,因为它们类型相似。但不能联接 Single 和 Double 类型的字段。
下列示例显示如何在类标识符字段联接类表及产品表:
Select CategoryName, ProductName
FROM Categories INNER JOIN Products
ON Categories.CategoryID = Products.CategoryID;
在上面的示例中,类标识符是已被联接的字段,但是它并不包含在查询输出中,因它并非被包含在 Select 语句之中。在这个示例中,若要包含联接字段,将字段名包含在 Select 语句中, Categories.CategoryID.
也可以使用下列语法,在一个 JOIN 语句中链接多个 ON 子句:
Select fields
FROM table1 INNER JOIN table2
ON table1.field1 compopr table2.field1 AND
ON table1.field2 compopr table2.field2) or
ON table1.field3 compopr table2.field3)];
也可以使用下列语法,嵌套 JOIN 语句:
Select fields
FROM table1 INNER JOIN
(table2 INNER JOIN [( ]table3
[INNER JOIN [( ]tablex [INNER JOIN ...)]
ON table3.field3 compopr tablex.fieldx)]
ON table2.field2 compopr table3.field3)
ON table1.field1 compopr table2.field2;
在一个 INNER JOIN 之中,可以嵌套 LEFT JOIN 或 RIGHT JOIN,但是在 LEFT JOIN 或 RIGHT JOIN 中不能嵌套 INNER JOIN。
原文链接:
http://www.and8.net/article.asp?id=194
posted @
2008-01-17 15:48 CoderDream 阅读(521) |
评论 (0) |
编辑 收藏著名的Java图表软件jfreechart的作者模仿Google chart api的风格(样式和URL)开发出了一套Servlet--EastWood。让Google chart可以脱离Google和在线服务了。该项目的图表效果和Google chart api的效果相差无几,鉴于Google chart api是第三方在线服务而存在一些风险和不便,在实际开发当中您可以选择使用“伊士活”来作为Google chart的代替品,来一个google chart in house。
前些时候Google推出了一款报表API“Google chart api”。该API让开发者可以通过URL来动态生成图表,图表的样式有流行的线状图、柱形图、饼图等。下面是一个使用实例:在你的浏览器输入下面的地址:http://chart.apis.google.com/chart?cht=p3&chd=s:hW&chs=250x100&chl=Hello|World 然后回车或确定,你将看到下面这一幅图片。

还有更多样式,更复杂的图表Google chart api也能胜任,本文不打算重复参考文档里的内容了。有兴趣的同学可以自己去研究一番。
也就是说,Google为你提供远程的图表生成服务,但是这个服务并非没有限制的,Google限定了,每个用户访问图表的数量不能大于50,000次, 说实在的,普通的应用的用户要达到这个数本来就很难,所以这倒不是最大的限制。另外,如果你的项目是在企业内部部署,用户不能直接访问外网,那 Google chart api就哑火了。你可能会说“真可惜了,Google chart api如此强大,我都已经掌握了它的全部用法了,如今却因为这种原因使用不了”。使用第三方的在线服务,还有一个潜在的问题就是,你不知道他们什么时候会 把这个服务撤掉。
现在你不需要为这件事而发愁了,有一个好东西一定会让苦恼的你兴奋不已。著名的Java报表引擎Jfreechart的作者模仿Google chart api的URL风格开发出了一套Servlet--Eastwood, 这个项目是基于Jfreechart的,它可以让你使用Google chart api的方式生成与Google生成的几乎百分之百一样的图表,这味道着,如果你用Google chart api开发了一套图表,那么你需要Google chart inside的话,只需要把eastwood作为一个Servlet配置起来,然后替换一下URL的Host就搞定了。
来看看Google和EastWood生成的图表之间的差异:

更多的比较看这里。要进行最全面的比较,下载一份Eastwood的发行版,部署,打开Test.html就见到效果了。很赞。Jfreechart的作者怎么在之前没有想到以这样的方式来提供报表生成的功能呢?呵。看了下EastWood的代码量很少,只是将Jfreechart做一下封装就完了。
posted @
2008-01-17 09:14 CoderDream 阅读(2005) |
评论 (0) |
编辑 收藏
1、
XML 2007
2、
XML 2007中文版
3、
Ten predictions for XML in 2007
4、
2007 年 XML 的十大预测
posted @
2008-01-16 14:27 CoderDream 阅读(257) |
评论 (0) |
编辑 收藏問題一
季帳單的金額欄位, 請四捨五入到”元 “, 不要帶出小數位數字
之前季帳單沒有這樣的問題存在, 為什麼交付的新程式會出現這個問題呢?
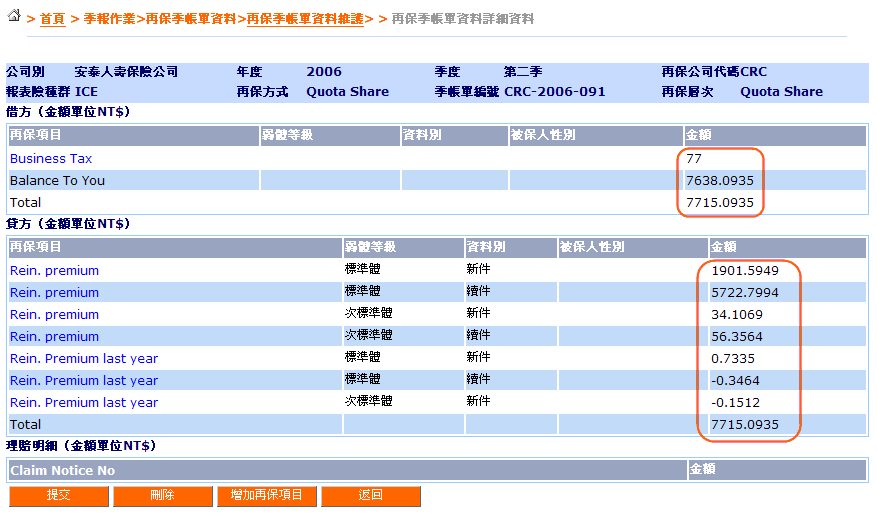
我们先查询第一笔记录:
| 再保項目 |
弱體等級 |
資料別 |
被保人性別 |
金額 |
| Rein. premium |
標準體 |
新件 |
|
1901.5949 |
看看数据库中的情况是怎样的,因为金额“1901.5949”
是加总后的结果。
通过下面的SQL语句查询结果:
条件:1、2006年第二季度,即会计年月为:200604、200605、200606;
2、再保公司为CRC,即为“01”;
3、年度为“2006”,即PREM_YEAR为:2006;
4、资料别为新件,即MONTHLY_FLAG为:N、NC;
5、报表险种群为ICE,即再保类别为“12”
6、弱体等级为标准体,即BODY_FLAG为“1”
SELECT mt.Q_PREMIUM
FROM RIS.MONTHLY_TEMP mt
WHERE 1=1
AND mt.ACCOUNT_YM_DATE in ('200604','200605','200606')
AND mt.RE_COMPANY_CODE='01'
AND mt.PREM_YEAR=2006
AND mt.MONTHLY_FLAG in ('N','NC')
AND mt.REINSURANCE_CLASS='12'
AND mt.BODY_FLAG='1'
;
然后我们将得到的记录拷贝到Excel档中,

通过结果下面的SQL同样可以得到结果:1901.5949
SELECT sum(mt.Q_PREMIUM) Q_PREMIUM
FROM RIS.MONTHLY_TEMP mt
WHERE 1=1
AND mt.ACCOUNT_YM_DATE in ('200604','200605','200606')
AND mt.RE_COMPANY_CODE='01'
AND mt.PREM_YEAR=2006
AND mt.MONTHLY_FLAG in ('N','NC')
AND mt.REINSURANCE_CLASS='12'
AND mt.BODY_FLAG='1'
GROUP BY mt.PREM_YEAR
;
从Excel档可以看到数据的小数部分没有处理,而我们的记录都放在一个Map中,Map的键为对象的Id,即SeasonAccountDetailAmountId,而值为SeasonAccountDetailAmount,我们要处理的属性金额在Map的值中。我们只需遍历Map,然后处理(四舍五入)值中对象的某个属性,然后将这个“键值对”放到Map中,它会自动覆盖以前的同Key的记录。
/**
* 將Map中SeasonAccountDetailAmount對象的amount的值四舍五入
*
* @author XuLin
*
* 2008.01.15
*
* @param detailMap
*/
private void roundingMap(Map detailMap) {// TODO
Map map = (FastHashMap) detailMap;
Iterator it = map.entrySet().iterator();
SeasonAccountDetailAmountId sadaId = null;
SeasonAccountDetailAmount sada = null;
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
sadaId = (SeasonAccountDetailAmountId) entry.getKey();
sada = (SeasonAccountDetailAmount) entry.getValue();
if (sada.getAmount() != null) {
sada.setAmount(Common.roundingBigDecimal(sada.getAmount(),
Constant.MONEY_SCALE));//四舍五入到整數位
seasonAccontDetailCache.put(sadaId, sada);
}
}
}
問題二
新增的季帳單(CRC-2006-384)再保項目-Return Rein. Commission Last Year 一筆金額100,000
為何反應在季帳單PDF上會有兩筆記錄??
Return Rein. Commission Last Year-2006 NTS 空白??
Return Rein. Commission Last Year-2005 NTS 100,000

處理方法:
交給第三方處理,我們的報表做法是我們生成文本格式的txtFile,然后由第三方處理。
出現問題的原因是該“再保險種”的值為,應該不顯示在PDF上,他應該多加一層判斷。
posted @
2008-01-16 11:34 CoderDream 阅读(321) |
评论 (0) |
编辑 收藏查询条件与查询结果:

查询条件:险种、年期、版次、投保年龄、吸烟别、被保人性别、体位别、保单年度、眷属序号、生效日期,
涉及的表有两个再保险种设定档(表1)和安泰险种危险保额设定档(表2) :
其中险种和版次在两张表中都有,而“体位别”这个条件不是用来查询,而是用来计算“危险保额”的。
操作步骤:
1、先通过传入的条件查询表1,得到ReinsuranceItemData对象:
ReinsuranceItemData reinsuranceItemData = reinsuranceItemDataDao
.getItemPropertyValue(
Constant.COMPANY_FLAG_ANTAI,
lraVO.getItemCode(),
lraVO.getItemVrsn(),
lraVO.getRelNo(),
lraVO.getBoundDate(),
DetailCodeConstant.ITEM_PROPERTY_REINSURANCE_CLASS);
2、如果返回结果为null,则抛出异常信息:查詢不到險種的再保類別
3、计算危险保额(计算危险保额时会用到责任准备金,查询表2可以得到)。
posted @
2007-12-29 16:02 CoderDream 阅读(384) |
评论 (0) |
编辑 收藏 有家就是幸福!
不需要太大的地方,也不需要装璜的怎么富丽堂皇,但必须是在你的精心打理和细心呵护下充满温馨和爱意的家,无论外面的世界多精彩,外面的风景都美好,都留不住你回家的脚步,家是你心中最美的一道风景线,谁也代替不了:当你不开心的时候,你会想到家;当你外出的时候,你最想的是家;当你每天下班,迫不及待想回的是家;你最留恋的还是家……家是温馨的港湾;家是女人心灵的栖息地;家有着期盼等待你的亲人。即使有时出现波浪,但是都不能阻止你义无返顾地奔向它的怀抱。
有个守候的丈夫就是幸福。
人们都说:女人最大的幸福是嫁一个好男人。好男人的标准很广泛,有人说好男人就应该是财富名利、事业辉煌双收的男人,又有人说好男人一定是英俊潇洒,浪漫多情。让我告诉你。那种男人是极品男人,但不一定是好男人,我们不能要求他尽善尽美,只要生活中用心去体会,你会感受到男人的好,也许他既不多金又不英俊,但他确实实在在的守候在你的身边,渴了会给你递上一杯热茶;困了会搂着你入睡;累了会为你放好洗澡水,轻轻为你揉揉肩、敲敲背;病了他会一刻不离的守候在你的身边,轻轻扶摸着你的脸;用充满爱怜的目光看着你,病在你身上,痛却在他心上;饿了会给你端来可口的饭菜;天凉了他会提醒你加衣;下雨了他会叮咛你小心;你想浪漫一下的时候,他会递上一朵玫瑰;薄雾的晨曦中,黄昏的街道上他会的牵着你的手一起散步。夕阳下相拥着与你一起慢慢变老。你不觉得这就是一种幸福吗?
有孩子就是幸福。
孩子是自己生命的延续,十月怀胎,诞生了自己和爱人爱情的结晶,此时女人是最幸福的人。之后,在孩子的蹒跚学步中,在孩子咿呀学语时,当孩子用稚嫩的声音叫出第一声妈妈时候;当他用胖乎乎的小手捧着你的脸很幼稚的对说:妈妈你笑起来好漂亮好漂亮的时候;这种幸福的感觉会从心底布满全身渗透进你每一个细胞中。看着孩子在你身边一天天健康成长,他的每一个经历每一个精彩表现都给你的生活增添了无数的快乐。当你需要仰着头才能看清那长满青春痘的脸时候,他还会依偎在你身边用已不太稚嫩的声音叫着可爱的妈妈,看你的眼神还是充满了依恋和崇拜,妈妈在孩子的眼中永远是最美丽的。孩子在妈妈的眼中永远是最优秀的。你能说这不是一种幸福吗?
有工作就是幸福。
现在社会上的竞争异常的激烈,就业形势也越来越严峻.我们女人,谁不在期盼自己能找到一个适合自己的好工作,通过自己的努力拼搏付出了大量的心血后,换来了一份相对稳定的工作,这不是一种幸福吗?尽管在工作中你会付出很多辛劳,承担许多压力,但它却让你的生活丰富多彩,让你的人生活的充实,最起码能让你衣食无忧,做一个经济独立,人格独立的女人。你会加倍珍惜拥有的这个"饭碗"-----上班努力工作,下班回家和丈夫孩子还有老人一起共渡美好时光,多惬意!
有朋友就是幸福。
你的快乐有他们分享,你的伤痛有他们安抚,你的烦恼有他们聆听,他们是你晦暗心情时的一缕阳光,因为有了他们,你的世界不会孤单寂寞;因为有他们,你的人生才那么丰富多彩。朋友的魅力在于聆听!当你最需要倾诉的时候,往往只有朋友的耳朵里能装进你的酸甜苦辣,给你安慰和你一起分享生活,让彼此触动, 让你心绪重新聚合重新沸腾,让彼此情感世界里多一份细腻温馨的味道.不管在身边还是在远方,有那么几个人老惦记着自己,是自己最忠实的听众难道不是一种幸福吗?
其实,只要你用心去感受去体会,幸福就是那么简简单单!幸福可能就象空气一样弥漫在你生活的点点滴滴、琐琐碎碎之中。如同一杯白开水,表面清清淡淡,却是你生命之泉;如同一杯淡淡的西湖龙井茶,表面简简单单,细细品味那一丝丝,一点点的清香渗透进你的心底......如同一杯苦咖,虽然有点苦,回味却是香甜的,还能让你精神振奋;如同一杯蜂蜜茶,香香甜甜一种又健康又美容的饮品。那如意的工作,那优厚的经济收入,那称心的家庭,只是我们获得幸福的载体,如果我们不懂得去感受幸福体会幸福,那么再好的日子也不会让你感觉到幸福.记住:幸福就在我们手中,它需要我们去创造;幸福就在我们心中,它需要我们去感受;幸福就在我们眼中,它需要我们去发现。让我们在幸福的长河中,在幸福的阳光下,好好的去感受生活中的点点幸福,能感受幸福的人,是快乐的人,是永远年轻的人。
本文转载自『左岸读书_blog!』
http://dhlmtzx.edudh.net/oblog/
更多精彩内容,欢迎访问左岸读书_blog!
posted @
2007-12-26 11:48 CoderDream 阅读(306) |
评论 (0) |
编辑 收藏怎样移动富士山?
这个问题是比尔·盖茨对那些渴望应聘微软公司的大学毕业生提出的一道面试题。而对此,比尔·盖茨的解释是:它没有固定的正确答案,我只想了解这些年轻人有没有按照正确的思维方式去思考问题。
最明智的选择
If you don’t like something, change it. If you can’t change it ,change your
attitude. Don’t complain
一个年轻人,觉得自己怀才不遇,有位老人听了他的遭遇,随即把一粒沙子扔在沙滩上,说:“请把它找回来”,“这怎么可能”年轻人说道,接着老人又把一颗珍珠扔到沙滩上,“那现在呢?”他说。
——如果你只是沙滩中的一粒沙,那你不能苛求别人注意你,认可你。如果要别人认可你,那你就想办法先让自己变成一颗珍珠。
“无论你想做什么,现在就做。”著名画家柯罗,为一位年轻画家指出了这位年轻人作品需要改进的地方,“谢谢您,”年轻画家说,“明天我就将它全部修改。”柯罗激动的说:“为什么是明天,要是你今晚就死了呢?”
——你也许会滞留原地,但时间绝对不会。
(You may delay, but time will not)
——富兰克林
你必须用你手中的牌玩下去,就好比人生,发牌的是上帝,不管是怎样的牌,你都必须拿着,你所做的就是尽你全力,求得最好的结果。(注:这句话和电影《阿甘正传》中阿甘的母亲说的关于巧克力的那段很相似,但那句话却只说了前半句:你永远不知道下一颗巧克力是什么味道,对于怎么去处理这个事实却没有提及,而个人觉得阿甘的处事风格更倾向于随遇而安,不管有多少困难,既来之则安之,去面对他,但又不强求,不反抗,我想很多人不会接受这样的态度,因为要达到阿甘这样的境界还是需要些运气的,呵呵,不过我喜欢阿甘的原因是他对生活下去的信念,即时老天对儿时的他并不公平,他对爱和未来的执著态度,坚持下去,不放弃的精神我想是感动了上帝吧,呵呵,说多了,其实就是本电影,被导演戏弄了一会。)
有一只小狮子问母亲:“妈妈,幸福在哪里?”母亲说:“幸福就在你的尾巴上啊。”于是,小狮子转起了圈,追着自己的尾巴。母狮子笑着说:“孩子,幸福不是那样得到的,只要你昂首向前走,幸福就会一直跟着你。”
当肖邦已经是非常知名的演奏家时,他遇到十年前一起在街头演奏的伙伴,发现他仍在他们当年一起占到的那块最赚钱的地方演奏。伙伴遇到肖邦非常高兴,问他现在在哪里演奏,肖邦回答了一个很有名的音乐厅,伙伴惊讶的说:“怎么?那里门口也很好赚钱吗?”“最赚钱的好地盘”同样是一个“风平浪静的小港湾”,那位伙伴停留在那里,甚至有些沾沾自喜,却没有意识到自己的才华,潜力,前程全都被这块“最赚钱的好地盘”葬送了。(注:过于安逸的生活的确会使一个人失去激情和斗志。)
知道自己想要什么的一半是知道自己在得到它之前必须先舍弃什么。
某家报社举办这样一次有奖智力竞赛,如果卢浮宫不幸失火,你只有时间救出一幅画,你会选择救哪幅?答案最多的是《蒙娜丽莎》,但是得奖的答案却是:救那幅离出口最近的。
——We must do the best we can with what we have.
有位大师,潜心修炼了多年,终于练成了“移山大法”。有人向他请教,他说:“要移山其实很简单,如果山不过来,我们就过去”。
——人类可以通过改变自己的态度去改变自己的生活,这是属于每一代人的最伟大的发现。
很显然,问题的答案已经揭晓了,从事帆船运动的朋友说:“当一个人在大海中航行时,他当然不可能改变海面的风向,但他却可以通过不断调整船上的风帆,让自己一直向目的地驶去” 比尔·盖茨说过:“生活是公平的,你要去适应他”
所以,怎样移动富士山? 答案很简单,那就是如果富士山不过来,我们就过去!
[PPT]如何移动富士山点击下载此文件 [简]
本文转载自『左岸读书_blog!』
http://dhlmtzx.edudh.net/oblog/
更多精彩内容,欢迎访问左岸读书_blog!
posted @
2007-12-26 11:47 CoderDream 阅读(361) |
评论 (0) |
编辑 收藏WinCVS与CVSNT简明使用手则
(作者:Jackey,整理:CoderDream)
1 前言:
CVS是版本控制的利器,目前在Linux和Windows下都有不同版本;但是国内大多数应用介绍都是基于Linux等开放源代码的开放性软件组织,而且讲解的也不系统,让人摸不着头脑;Windows下的CVS使用介绍更是了了无几。
本文是针对Windows的LAN环境下使用CVS的经验介绍,一步一步的向您介绍如何配置和使用CVS的服务器端和客户端。同时,本文只使用到了CVS当中最基本的东西,还有很多更为高级的东西,本文暂不涉及。
完整版CHM:点击下载
posted @
2007-12-25 16:57 CoderDream 阅读(286) |
评论 (0) |
编辑 收藏
1、
prototype.js 1.4版开发者手册(强烈推荐)
posted @
2007-12-25 09:54 CoderDream 阅读(248) |
评论 (0) |
编辑 收藏你的工作是不是总也做不完?是不是经常加班?
你是不是在互联网上很贪婪,感觉总是乐此不疲?
有时候这一切很可能是由坏习惯造成的……
1、 QQ、MSN、Gtalk,一个都不少。
由于聊天对象与聊天内容的不可控制性,使用即时通讯软件是降低工作效率的罪魁祸首。有调查显示,使用即时通讯软件,工作效率会降低20%。(对策:离开他们一段时间,试着专门做你手头上的工作。)
2、“总想多看一点点”——忘记上网的目的。
本想查找工作资料,结果在网页上发现《哈利波特7》出来了;再点进去,又在网页底端看到自己喜欢的明星跟某某又传出了绯闻……点着点着,就忘记自己要上网做什么了。(对策:千万别把工作和娱乐放在一起,工作就好好工作,娱乐才能尽情地挥洒,控制对互联网新奇的诱惑吧。)
3、长期不擦拭电脑屏幕和鼠标。
电脑屏幕已经糊了厚厚的一层灰尘,每次都要瞪大眼睛去看,费力去猜屏幕污点下面的字是什么;鼠标点起来已经非常费力了,反应也迟钝得像八十岁的老汉。这些都间接地影响了工作效率。(对策:保持干净的电脑桌面包括电脑桌面不能放置过多的图标,鼠标一定要好用,不然累死你的手。)
4、长期不清理电脑系统。
防火墙的防御力是有限的。长期不清理电脑系统的后果就是,内存被一些潜藏的垃圾程序给占用了,直接影响了电脑的运行速度。电脑运行慢了,也就降低了工作效率。 (对策:对系统垃圾即时清理,可以请一些系统垃圾清理软件来帮忙。比如:一键清理系统垃圾文件)
5、长期不整理办公桌和文件。
办公桌和文件杂乱的后果就是,想找东西的时候却找不到。以前,有调查公司专门对美国200家大公司职员做了调查,发现公司职员每年都要把6周时间浪费在寻找乱放的东西上面。(对策:养成东西归位的好习惯,现在就开始整理你的桌面的文件档案吧!)
6、长期不整理电子邮件和通讯录。
想给客户发个邮件,却记不得E-mail地址,于是在电子邮箱中一通乱找,却发现自己的邮箱早已被垃圾邮件搞得汪洋一片。想搜什么都变得很困难。再返回一堆堆名片中去找,就又陷入了第5个坏习惯。(对策:平时花些时间把电子邮件分类,设置好邮件的过滤功能。)
7、不适时保存文件。
尽管现在电脑的性能越来越高,死机现象越来越少,可是,意外地碰掉电脑插头、程序操作不当从而造成电脑关机、死机,总是不可避免的,如果不适时保存文件,那么文件就很可能会丢失,前功尽弃。(对策:关键时刻保存一下,免得一回儿痛心疾首。)
8、“不磨刀误了砍柴工”。
工作之前,不做充分的计划、准备。行动之后,才发现要么是工具准备得不充分,只得停下工作再去找文件、资料;要么工作做到一半,才发现偏离了预定的方向,只得重新开始,前功尽弃。(对策:还是习惯问题!)
9、梦想电脑有“三头六臂”。
在同一时间,一个网页打不开,一个程序在等待,为了节约时间,就只好再打开其他网页。结果同一时间,十几个窗口同时打开着,电脑就变得“老态龙钟”,一动不动。什么都干不成。(对策:做重要事情的时候,只做一件,不然过多的程序会让你分心,我理解你的心境,PC都已经双核了,不榨干真是浪费!这心态不好。)
10、不会充分利用等待时间。
打开一个软件,电脑迟迟没有反应,于是坐在电脑旁干等;打开一个网页,迟迟显示不出来,又打开新的网页,又是一阵干等;要打印文件,发现打印机里排着队的文件有好多,只好继续等待……一天的工作中,光是耗在电脑上的等待时间就很可观,如果不充分利用这些等待间隙的话,那自己的工作时间只好额外延长了。 (对策:等不能解决问题,因为程序卡在那里了,动手检查一下吧。)
11、“耻于下问”。
现在,电脑出现的病症越来越离奇。不是每个人都是电脑高手。身为IT中人,似乎像别人请教就显得自己太不专业了。于是就上网查找解决方案。结果,在垃圾信息的汪洋大海中奋力拼搏,折腾半天,才化解问题,浪费了工作的宝贵时间。如果问问身边人,可能几秒钟就解决问题了。(对策:我就常常被问,我发现我身边的同事是太会问,因为他们不是IT中人, 他们遇到问题就问我,这也一个“累”字啊。)
12、过分崇拜科技。
IT人很容易就会陷入科技崇拜。如果有新软件、新系统发布,IT人一定是最早尝试的。不管自己的电脑能不能撑起Vista,一定要给电脑装上。电脑负荷不了,只好不断罢工。工作也会因之延误。(对策:呵呵,这是很多的通病,总认为新出的一定更好,功能更大,其实软件适用才是根本,别再喜新厌旧了。)
13、长期端坐于电脑前面。
一坐就是半天。工作并不会因为你的马不停蹄而加速。相反,如果总是沉浸在工作中,不适时休息,容易造成大脑的疲倦,反而降低了工作效率 。(对策:马上关闭电脑,去休息。)
本文转载自『左岸读书_blog!』
http://dhlmtzx.edudh.net/oblog/
更多精彩内容,欢迎访问左岸读书_blog!
posted @
2007-12-20 14:08 CoderDream 阅读(416) |
评论 (1) |
编辑 收藏■ 1、起床先叠被 人体本身也是一个污染源。一夜睡眠,人体皮肤会排出大量水蒸气,使被子不同程度地受潮。人的呼吸和分布全身的毛孔排出的化学物质有145种,从汗液中蒸发的化学物质有151种。被子吸收或吸附水分和气体,如起床就立即叠被,不让其散发出去,易使被子受潮及受化学物质污染。
■ 2、不吃早餐 不吃早餐的人通常饮食无规律,容易感到疲倦,头晕无力,天长日久会造成营养不良、贫血、抵抗力降低,并会产生胰、胆结石。
■ 3、饭后松裤带 可使腹腔内压下降,消化器官的活动与韧带的负荷量增加,从而促使肠子蠕动加剧,易发生肠扭转,使人腹胀、腹痛、呕吐,还容易患胃下垂等病。
■ 4、饭后即睡 会使大脑的血液流向胃部,由于血压降低,大脑的供氧量也随之减少,造成饭后极度疲倦,易引起心口灼热及消化不良,还会发胖。如果血液原已有供应不足的情况,饭后倒下便睡,这种静止不动的状态,极易招致中风。
■ 5、饱食 容易引起记忆力下降,思维迟钝,注意力不集中,应变能力减弱。经常饱食,尤其是过饱的晚餐,因热量摄入太多,会使体内脂肪过剩,血脂增高,导致脑动脉粥样硬化。还会引起一种叫“纤维芽细胞生长因子”的物质,在大脑中数以万倍增长,这是一种促使动脉硬化的蛋白质。脑动脉硬化的结果会导致大脑缺氧和缺乏营养,影响脑细胞的新陈代谢。经常饱食,还会诱发胆结石、胆囊炎、糖尿病等疾病,使人未老先衰,寿命缩短。
■ 6、空腹吃糖 越来越多的证据表明,空腹吃糖的嗜好时间越长,对各种蛋白质吸收的损伤程度越重。由于蛋白质是生命活动的基础,因而长期空腹吃糖,会影响人体各种正常机能,使人体变得衰弱以致缩短寿命。
■ 7、留胡子 胡子吸附有害物质。当人吸气时,被吸附在胡子上的有害物质就可能被吸入呼吸道。通过对留有胡子的人吸入空气成分进行的定量分析,发现吸进的空气中含有几十种有害物质,包括酚、甲苯、丙酮、异戊丙二烯等多种致癌物,留胡子的人吸入的空气污染指数是普通空气的4.2倍。如果下巴有胡子,又留八字胡,污染指数可高达7.2倍。加上抽烟等因素,污染指数将高达普通空气的50倍。
■ 8、跷二郎腿 会使腿部血流不畅,影响健康。如果是静脉瘤、关节炎、神经痛、静脉血栓患者,跷腿会使病情更加严重。尤其是腿长的人或孕妇,容易得静脉血栓。
■ 9、伏案午睡 一般人在伏案午睡后会出现暂时性的视力模糊,原因就是眼球受到压迫,引起角膜变形、弧度改变造成的。倘若每天都压迫眼球,会造成眼压过高,长此下去视力就会受到损害。
■ 10、睡前不刷牙 睡前刷牙比起床后刷牙更重要。这是因为遗留在口腔中和牙齿上的细菌、残留物等,在夜间对牙齿、牙龈有较强的腐蚀作用。
■ 11、睡懒觉 使大脑皮层抑制时间过长,天长日久,可引起一定程度的大脑功能障碍,导致理解力和记忆力减退,还会使免疫功能下降,扰乱肌体的生物节律,使人懒散,产生惰性,同时对肌肉、关节和泌尿系统也不利。另外,血液循环不畅,全身的营养输送不及时,还会影响新陈代谢。
■ 12、热水沐浴时间过长 在自来水中,氯仿和三氯化烯是水中容易挥发的有害物质,由于在沐浴时水滴有更多的氯和空气接触,从而使这两种有害物质释放很多。资料显示,若用热水盆浴,只有25%的氯仿和40%的三氯化烯释放到空气中;而用热水沐浴,释放到空气中的氯仿就要达到50%,三氯化烯高达80%。
本文转载自『左岸读书_blog!』
http://dhlmtzx.edudh.net/oblog/
更多精彩内容,欢迎访问左岸读书_blog!
posted @
2007-12-20 09:11 CoderDream 阅读(328) |
评论 (0) |
编辑 收藏
摘要: 在项目开发中,经常会遇到一些排序的问题。
现在有一个操作VO(Member),它有三个属性,分别为:id(String)、name(String)和age(int)。
情景一:
初始页面,Member对象会以id排序,现在name中保存的是英文名,需对name进行排序;
首先我们来看我们要用到的Java API中的一个接口Comp...
阅读全文
posted @
2007-12-19 16:07 CoderDream 阅读(1698) |
评论 (0) |
编辑 收藏1、[原创]Java 正则表达式的总结和一些小例子
2、[原创]Dom4j下载及使用Dom4j读写XML简介
3、[原创]HashMap和Hashtable的实验比较结果
4、[整理]使用dom4j在xml文件中指定编码从而输入中文
posted @
2007-12-18 13:50 CoderDream 阅读(281) |
评论 (0) |
编辑 收藏
感觉使用沙堆模型来形容知识的广度和深度,以及两者之间的关系比较恰当。沙堆能够堆多高代表知识的深度,沙堆底面占的面积则代表知识的广度。
术业有专攻,真正能够代表核心竞争力和创造效益的是沙堆的高度即知识的深度。因此当我们要准备达到一个高度,首先要准备够一个知识的广度或者说沙堆的底面的基础。在一定的沙堆底面积下,沙堆堆积到一定高度后就很难再堆高了,这个时候必须首先要把沙堆的底面积扩大,即进一步拓展知识的广度,当广度扩大后才能够在广度的基础上进一步朝高度发展。
有了广度后,即沙堆底面积累到一定面积后,就需要有意识的将这种广度朝深度转换,因为转换为深度才能够提高个人核心竞争力和创造效益。如果一味的追求广度将无法将价值最大化。
在学校学习阶段或未工作之前,重点是积累基础知识,铺开沙堆的底面积为广度做准备。因此学习积累的知识越多,视野越宽在工作后更容易比别人的沙堆堆的更高。在工作后,如果不再关注广度的积累,则走到一定高度就很难再向前迈进,这个时候必须回过头来拓展知识的广度。深度是目标,广度是基础,两者的关系必须要兼顾好。
posted @
2007-12-12 10:25 CoderDream 阅读(394) |
评论 (0) |
编辑 收藏
原文地址:
http://blog.sina.com.cn/s/blog_49b7e6a101000dab.html
Lomboz是Eclipse的一个主要的开源插件(open-source plug-in),Lomboz插件能够使Java开发者更好的使用Eclipse去创建,调试和部署一个100%基于J2EE的Java应用服务器。
Lomboz插件的使用,使得Eclipse将多种J2EE的元素、Web应用的开发和最流行的应用服务器车结合为一体。
Lomboz的主要功能有:
1、 使用HTML pages, servlets, JavaServer" Page (JSP) files等方式建立Web应用程序
2、 JSP的编辑带有高亮显示和编码助手
3、 JSP语法检查
4、 利用Wizard创建Web应用和EJB应用
5、 利用Wizard创建EJB客户端测试程序
6、 支持部署J2EE Web应用档案(EAR),Web模块文件(WAR)和EJB档案文件(JAR)
7、 利用Xdoclet开发符合EJB1.1和2。0的应用
8、 能够实现端口对端口的本地和远程的测试应用服务
9、 能够支持所有的有可扩展定义的Java应用服务
10、能够利用强大的Java调试器调试正在运行的服务器端代码(JSP&EJB)
11、通过使用Wizard和代码生成器提高开发效率
12、创建Web服务客户端的WSDL形式的文件
Lomboz适用的服务器有:
Apache Tomcat, JBOSS, JOnAS, Resin, Orion, JRun, Oracle IAS, BEA WebLogic Server andIBM WebSphere
在安装Lomboz插件得时候,要安装emf-sdo-runtime-2.0.0插件,要不然,你得Eclipse虽然加载了Lomboz插件,但是在你得视图里面还是不会出现Lomboz选项。
装完这些,再按照一般文档里面得步骤。就没有问题了。
posted @
2007-12-10 17:39 CoderDream 阅读(400) |
评论 (0) |
编辑 收藏
配置环境
WINDOWS XP SP2
JDK 1.6
TOMCAT 6.0
ECLIPSE 3.3
LOMBOZ 3.3
一. JDK(JDK1.6)的安装与配置
(1) 在JAVA官方网站下载JDK工具包(JDK1.6)
http://java.sun.com/javase...



(2) 执行安装文件,如图



(3) 配置JAVA运行环境:
【开始】-【控制面板】-【性能和维护】-【系统】-【高级】或者右键单击【我的电脑】-【属性】-【高级】

进入【环境变量】界面,选择【系统变量】中的【Path】选项

在【变量值】项的初始端输入您的JDK安装目录(%JAVA_HOME%\bin,%JAVA_HOME%为JAVA安装目录)至bin目录,注意:不要忘记分号。

(4) 测试
【开始】-【运行】-【cmd】-【java -version】可以查看您当前的JDK版本


在C盘根目录中创建一文本文档,键入以下语句(如图),并保存为JAVA文件,注意:CLASS类名与保存的文档名必须一致,且大小写敏感。

在命令行模式中测试刚刚编写的JAVA文件(如图),运行成功则显示Hello World!

二. Tomcat6.0的安
(1) 下载Tomcat安装包
http://tomcat.apache.org/d...

(2) 执行安装文件,如图






(3) 测试(测试结束后关闭Tomcat服务器)
在%TOMCAT_HOME%\bin目录下执行tomcat6w.exe(%TOMCAT_HOME%为Tomcat安装目录),点击Start启动Tomcat服务器。

打开浏览器,在地址栏中输入:http://localhost:8080 运行成功则出现如下画面

PS:示例中的Tomcat为Windows Service Installer(.exe)程序,安装成功后无需再进行额外配置。
三. Eclipse(Eclipse3.3)与Lomboz(Lomboz3.3)的安装
(1) 下载Eclipse与Lomboz合包(Eclipse与Lomboz版本号必须匹配,否则会引发错误)
http://forge.objectweb.org...


(2) 执行程序(解压后直接使用,无需安装),如图

注意:Lomboz3.1版本以上在Eclipse首选项界面中均不会再有【Lomboz】选项

四. Tomcat插件的安装与配置
(1) 下载TomcatPluginV321.zip,鉴于官网无法访问,可以去百度、谷歌搜索,以下地址仅供参考
http://d.download.csdn.net...(需要先注册)
(2) 将TomcatPluginV321.zip解压缩到eclipse安装目录中的plugins文件夹下
(3) 在命令行模式中重新启动Eclipse(以-clean模式启动)

(4) 配置Tomcat version与Tomcat home(参照自身的安装路径)
打开Eclipse,选择【Window】-【Preferences】-【Tomcat】

五. 集成环境测试(JSP程序)
创建一个新项目
打开Eclipse,选择【File】-【New】-【Project】-【Web】

输入项目名Test,点击Finish

创建服务器,选择【File】-【New】-【Other】-【Server】





创建JSP文件,选择【File】-【New】-【Other】-【Web】

输入文件名


编辑JSP文件,如图

打开服务器,右击选择Start


运行服务器,选择【Run】-【Run As】-【Run on Server】

打开浏览器,在地址栏中输入 http://localhost:8080/Test/Test.jsp 运行成功则显示以下画面
posted @
2007-12-10 17:35 CoderDream 阅读(1910) |
评论 (1) |
编辑 收藏
eclispe想必大家都很熟悉了,一般来说,eclipse插件都是安装在plugins目录下。不过这样一来,当安装了许多插件之后,eclipse变的很大,最主要的是不便于更新和管理众多插件。用links方式安装eclipse插件,可以解决这个问题。
当前配置XP SP1,eclipse3.0.1
现在假设我的eclipse安装目录是D:\eclipse,待安装插件目录是D:\plug-in ,我将要安装LanguagePackFeature(语言包)、emf-sdo-xsd-SDK、GEF-SDK、Lomboz这四个插件。
先把这四个插件程序全部放在D:\plug-in目录里,分别解压。如Lomboz3.0.1.zip解压成Lomboz3.0.1目录,这个目录包含一个plugins目录,要先在Lomboz3.0.1目录中新建一个子目录eclipse,然后把plugins目录移动到刚建立的eclipse目录中,即目录结构要是这样的:D:\plug-in\Lomboz3.0.1\eclipse\plugins
Eclipse 将会到指定的目录下去查找 eclipse\features 目录和eclipse\plugins 目录,看是否有合法的功能部件和(或)插件。也就是说,目标目录必须包含一个 \eclipse 目录。如果找到,附加的功能部件和插件在运行期配置是将是可用的,如果链接文件是在工作区创建之后添加的,附加的功能部件和插件会作为新的配置变更来处理。
其它压缩文件解压后若已经包含eclipse\plugins目录,则不需要建立eclipse目录。
然后在 eclipse安装目录D:\eclipse目录中建立一个子目录links,在links目录中建立一个link文件,比如 LanguagePackFeature.link,改文件内容为 path=D:/plug-in/LanguagePackFeature 即这个link文件要对应一个刚解压后的插件目录。
说明:
1. 插件可以分别安装在多个自定义的目录中。
2. 一个自定义目录可以安装多个插件。
3. link文件的文件名及扩展名可以取任意名称,比如ddd.txt,myplugin都可以。
4. link文件中path=插件目录的path路径分隔要用\\或是/
5. 在links目录也可以有多个link文件,每个link文件中的path参数都将生效。
6. 插件目录可以使用相对路径。
7. 可以在links目录中建立一个子目录,转移暂时不用的插件到此子目录中,加快eclipse启动。
8. 如果安装后看不到插件,把eclipse 目录下的configuration目录删除,重启即可。

注意:关于用links方式安装Lomboz插件,在编辑EJB时可能会产生问题,这个将会在有关Lomboz插件的文章中探讨。
posted @
2007-12-10 17:29 CoderDream 阅读(288) |
评论 (0) |
编辑 收藏
1、
Anatomy of an Android Application(中文翻译)
2、
在android平台上测试C/C++程序及库
3、
http://www.forwind.cn/category/linux/android/
4、
http://www.1android.cn/Default.asp
5、
Android开发者论坛
6、
Android中文网
7、
Android中文文档
posted @
2007-12-10 17:18 CoderDream 阅读(349) |
评论 (0) |
编辑 收藏
1、
推荐一个很棒的JS绘图库Flot
2、
DroidDraw - Android的界面设计器
3、
AppFuse 2.0.1发布
4、
MySQL InnoDB数据恢复工具
5、
用 AjaxTags 简化 Ajax 开发
6、
Java SE 6 Update N Early Access Program
7、
JSFUnit - JSF的测试工具
posted @
2007-12-06 14:27 CoderDream 阅读(267) |
评论 (0) |
编辑 收藏
1、
正则表达式30分钟入门教程
posted @
2007-11-29 11:06 CoderDream 阅读(310) |
评论 (1) |
编辑 收藏
1、
《EJB3.0实例教程》官方网
2、
将 EJB 部署到 WebSphere 应用服务器
3、
Enterprise JavaBeans 入门
posted @
2007-11-28 13:50 CoderDream 阅读(254) |
评论 (0) |
编辑 收藏1、安装Weblogic:
使用的EJB服务是BEA的weblogic8.1,下载BEA的weblogic8.1,然后安装。安装步骤省略。
2、定义EJB远程接口(Remote Interface):
任何一个EJB都是通过Remote Interface被调用,EJB开发者首先要在Remote Interface中定义这个EJB可以被外界调用的所有方法。执行Remote Interface的类由EJB生成工具生成。
以下是HelloBean的Remote Inteface程序:
package com.leo;
import java.rmi.RemoteException;
import java.rmi.Remote;
import javax.ejb.*;
public interface Hello extends EJBObject, Remote {
//this method just get "Hello EJB" from HelloEJB.
public String getHello() throws RemoteException;
}
3、定义Home Interface
EJB容器通过EJB的Home Interface来创建EJB实例,和Remote Interface一样,执行Home Interface的类由EJB生成工具生成。以下是HelloEJB 的Home Interface程序:
package com.leo;
import javax.ejb.*;
import java.rmi.Remote;
import java.rmi.RemoteException;
import java.util.*;
/**
* This interface is extremely simple it declares only
* one create method.
*/
public interface HelloHome extends EJBHome {
public Hello create() throws CreateException,
RemoteException;
}
4、写EJB类
在EJB类中,编程者必须给出在Remote Interface中定义的远程方法的具体实现。EJB类中还包括一些 EJB规范中定义的必须实现的方法,这些方法都有比较统一的实现模版,编程者只需花费精力在具体业务方法的实现上。
以下是HelloEJB的代码:
package com.leo;
import javax.ejb.*;
public class HelloEJB implements SessionBean{
public void ejbCreate(){}
public void ejbRemove(){}
public void ejbActivate(){}
public void ejbPassivate(){}
public void setSessionContext(SessionContext ctx){}
public String getHello() {
return new String("Hello,EJB");
}
}
5、创建ejb-jar.xml文件
ejb-jar.xml文件是EJB的部署描述文件,包含EJB的各种配置信息,如是有状态Bean(Stateful Bean) 还是无状态Bean(Stateless Bean),交易类型等。ejb-jar.xml文件的详细信息请参阅EJB规范。以下是HelloBean的配置文件:
<?xml version="1.0"?>
<!DOCTYPE ejb-jar PUBLIC "-//Sun Microsystems Inc.//DTD Enterprise JavaBeans 1.2//EN" "http://java.sun.com/j2ee/dtds/ejb-jar_1_2.dtd">
<ejb-jar>
<enterprise-beans>
<session>
<ejb-name>Hello</ejb-name>
<home>com.leo.HelloHome</home>
<remote>com.leo.Hello</remote>
<ejb-class>com.leo.HelloEJB</ejb-class>
<session-type>Stateless</session-type>
<transaction-type>Container</transaction-type>
</session>
</enterprise-beans>
</ejb-jar>
6、创建weblogic-ejb-jar.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE weblogic-ejb-jar PUBLIC "-//BEA Systems, Inc.//DTD WebLogic 8.1.0 EJB//EN" "http://www.bea.com/servers/wls810/dtd/weblogic-ejb-jar.dtd">
<weblogic-ejb-jar>
<description><![CDATA[Generated by XDoclet]]></description>
<weblogic-enterprise-bean>
<ejb-name>Hello</ejb-name>
<stateless-session-descriptor>
</stateless-session-descriptor>
<reference-descriptor>
</reference-descriptor>
<jndi-name>Hello</jndi-name>
<local-jndi-name>HelloLocal</local-jndi-name>
</weblogic-enterprise-bean>
</weblogic-ejb-jar>
7、部署和编译
EJB的jar包是由class文件和描述文件组成,对于weblogic服务器来说还要增加weblogic-ejb-jar.xml描述文件。编译Java源文并将编译后class和ejb-jar.xml、weblogic-ejb-jar.xml打包到Hello.jar
7.1:创建目录build。
7.2:在build下新建目录META-INF,把文件ejb-jar.xml、weblogic-ejb-jar.xml拷到META-INF下。
7.3:把编译好的class文件拷到build目录下(此时为com/leo/Hello.class,HelloEJB.class,HelloHome.class)。
7.4:打包成jar文件: jar -cvf hello.jar *.* 。
7.5:再将hello.jar文件部署到weblogic服务器中。
8、写客户端调用程序
您可以从Java Client,JSP,Servlet或别的EJB调用HelloBean。
调用EJB有以下几个步骤:
通过JNDI(Java Naming Directory Interface)得到EJB Home Interface
通过EJB Home Interface 创建EJB对象,并得到其Remote Interface
通过Remote Interface调用EJB方法
以下是一个从Java Client中调用HelloBean的例子:
package ejb.hello;
import javax.naming.Context;
import javax.naming.InitialContext;
import java.util.Hashtable;
import javax.ejb.*;
import java.rmi.RmoteException;
/**
* @author Copyright (c) 2000 by Apusic, Inc. All Rights Reserved.
*/
public class HelloClient {
public static void main(String args[]){
String url = "rmi://localhost:7100";
Context initCtx = null;
HelloHome hellohome = null;
try {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,"com.apusic.jndi.InitialContextFactory");
env.put(Context.PROVIDER_URL, url);
initCtx = new InitialContext(env);
} catch(Exception e){
System.out.println("Cannot get initial context: " + e.getMessage());
System.exit(1);
}
try {
Object obj=ctx.lookup("Hello");
HelloHome home=(HelloHome)PortableRemoteObject.narrow(obj,HelloHome.class);
Hello hello = hellohome.create();
String s = hello.getHello();
System.out.println(s);
}catch(Exception e){
System.out.println(e.getMessage());
System.exit(1);
}
}
}
运行HelloClient,可得到以下输出:
Hello EJB
posted @
2007-11-28 13:44 CoderDream 阅读(2172) |
评论 (0) |
编辑 收藏ejb3.0开发环境配置
运行环境配置
1、工具下载与安装
1>下载安装JDK5.0(
www.java.sun.com)
2>下载安装eclipse3.2.x(
www.eclipse.org)(如果你下载了JBOSS IDE2.0(内含eclipse3.2.x,这个可以不要)
3>下载和安装jboss-4.0.5.GA 服务器(记住一定要下载安装版,内含EJB3.0Container,地址:
http://sourceforge.net/project/d ... mp;use_mirror=jaist)
4>下载插件JBOSS IDE 2.0(
http://sourceforge.net/project/d ... amp;use_mirror=nchc)
安装JBOSS是要注意几点:
1>议不要安装在Program Files 目录,否则一些应用会导致莫名的错。
2>选择带集群功能的安装选项“ejb3-clustered”
3>在输入配置名称时,输入“all”
4>在配置JMX时,把所有选择荐都勾上,并输入jmx-console的用户名和密码!
5》运行JBOSS,进行JBOSS安装目录下,进入BIN目录下,运行 run -c all,如果直接运行run,会报错!(因为你run.bat不知道你运行的是那种配置all,default,还是min)
2、设置环境变量
JAVA_HOME=JAVA安装目录
JBOSS_HOME=JBOSS安装目录
3、认识JBOSS目录用途
目录 描述
bin 启 动 和关闭JBoss的脚本
client 客户端与JBoss通信所需的Java 库(JARs)
docs 配置的样本文件(数据库配置等)
docs/dtd 在JBoss中使用的各种XML文件的DTD。
lib 一些JAR,JBoss启动时加载,且被所有JBoss配置共享。(不要把你的库放在这里)
server 各种JBoss配置。每个配置必须放在不同的子目录。子目录的名字表示配置的名字。JBoss
包含3 个默认的配置:minimial,default和all,在你安装时可以进行选择
server/all JBoss的完全配置,启动所有服务,包括集群和IIOP。(本教程就采用此配置)
server/default JBoss 的默认配置。在没有在JBoss 命令航中指定配置名称时使用。(本教程没有安装此
配置,如果不指定配置名称,启动将会出错)
server/all/conf JBoss的配置文件。
server/all/data JBoss的数据库文件。比如,嵌入的数据库,或者JBossMQ。
server/all/deploy JBoss的热部署目录。放到这里的任何文件或目录会被JBoss自动部署。
EJB、WAR、EAR,甚至服务。
server/all/lib 一些JAR,JBoss在启动特定配置时加载他们。(default和minimial配置也包含这个和下面两个目录。)
server/all/log JBoss的日志文件
server/all/tmp JBoss的临时文件
4、
EJB部署
JBoss中的部署过程非常的简单、直接。在每一个配置中,JBoss不断的扫描一个特殊目录的变化:
[jboss安装目录]/server/config-name/deploy。
posted @
2007-11-28 11:49 CoderDream 阅读(676) |
评论 (0) |
编辑 收藏
大多数人学英语只知整天死背词汇表,或昏昏欲睡地听老师絮叨语法。尽管老师常会夸张运用脸部肌肉演示发音,然而仅仅一天之后,所学一切就开始在你脑海中逐渐褪色。这便导致了一个无奈的结果:就算你会读会写,可当你真正面对一个外国人进行电话会议或演讲陈述的实战练习时,你还是傻眼了。
现在EF中国区总裁Peter Winn告诉你:只需掌握了五个基本秘诀,即可轻松掌握单词、词组,真正实现“无痛”学英语。
1.确定目标,适时褒奖。大多数人把学英语的目的简单地定义为“对未来有益”,其实精准的目标设定更有助于集中精力达成最终结果,其关键在于确定成绩测试方式及时间范围。你需要对自身英语水平做出客观评估,并制定渐进提高的详细步骤。须谨记:衡量学习成果,定要始终使用同一衡量标准,这样才能清楚看见进步空间。另外,设立长远目标倒也无妨,如同“说一口流利的、不带丝毫口音的英语”等等,就是不少人正在使用着的目标。不过,以阶段性目标作为发端容易敲开成功之门,“我希望能与同事进行基本商务对话”,就是一个不错的例子。最后,千万不要忘记,哪怕你获得最微小的进步,也应适时奖励自己,如此可以保证长期的学习激情。
2.快乐学习,轻松记忆。学习英语,可以脱离教室。研究表明,当人们处于快乐的心境下,记忆力更突出、自信心更富裕。把英语学习同兴趣爱好结合起来。喜欢打网球,就参加英语交流的网球俱乐部;喜欢烹饪,就报名采用英语教学的烹饪培训班;喜欢唱歌,不妨试试在卡拉OK演唱英语歌曲……用眼睛盯着屏幕,用耳朵捕捉一遍遍重复的歌词,辅以熟悉流畅的旋律,这一切让单词记忆变得越发简单。可能最初有点难,但是这会强迫你使用英语。尤其是你正做着自己热爱的事情,学习英语的痛苦也就一扫而光了。
3. 融入环境,异化自己。建立英语学习自信心的关键无非:实践实践再实践!缺少实践机会和语言环境是目前中国学生面临的最大挑战。当年我学习中文的时候,我和身边朋友定下默契,尽量强迫自己用中文互相交流,即便中文不是我们其中任何一个人的母语。我们大家约定不到万不得已之时,必须一直说英语,甚至对违反默认规则的人实行惩罚措施!虽然刚开始可能会犯很多错误,但随着对英语对话模式的逐渐熟悉,所犯错误也将越来越少。令自己处于一个天然外语环境同样重要,这个环境可以是办公室、俱乐部、健身馆、酒吧、餐厅,诸如此类的场所越多越好。尽量挑选“主动”语言环境,比如俱乐部或派对,在那里你会更有说话的欲望。而像电影院之类的“被动”语言环境,收效往往并不出色。不要害怕犯错——走出门去,找外国人交流。
4. 寻求帮助,制订规划。学习英语的一个关键步骤,是接受高质量学习指导或参加高端语言培训项目。据我了解,很多学生宁愿选择自学,以及与外国友人实战练习。最终,这些学生的确能够建立充分信心,敢于流利表达自己,但词汇量却相当有限。这就等于缺少了最基本的砖块,无法建起坚实的语言基础。我认识一个女孩,她说话速度很快,却从不注意用词,因此总是表达不够清晰。另外一个学生经常和外国友人一起泡吧,于是连他自己都没有意识到,他的口头英语里夹杂许多酒吧用语,甚至包括hey dude、yeah man 、that rocks!这些粗俗的脏话,就好像他长年在酒吧工作一样。扮演不同的社会角色,必然有完全迥异的英语表达方式,你能想象与国外客户高层管理人员开电话会议时突然冒出hey dude、that rocks这些词句吗?而这些区别只能由一个专业老师指导。一个称职老师会详细分析学生的优势和不足,找到需要辅导的不足所在,强化本身具备的优势,由此制定一个切实可行的学习规划。 学习语言不仅需要流利,更加需要得体!
5. 承诺自己,态度积极。从来没有确切证据表明,某种特质的某些人更易于或更难于熟练掌握一门语言。相信我,任何人无论年龄、基础,只要具备正确学习态度,都足以学好英语。那些失败过的学生,并不是因为他们不够聪明,而是因为他们没有把学英语当作一种对自己的承诺。你越早制定明确目标和学习计划,就能越快克服重重障碍。当然,最初要让舌头适应陌生的声音和句式,确实有些困难。这并不该让你退却。失败原因永远只有一个,那就是你自己向这些困难投降了。
遵循这5个简单步骤,你很快会发现词汇量和造句能力迅速提高,而对英语学习信心逐渐增强,与老外对话时逐渐懂得镇定心思。曾经有位老师教育我要“操控”语言,而不是让语言“操控”你。 不知不觉,你会爱上英语,学习也不再感觉痛苦。
posted @
2007-11-27 17:27 CoderDream 阅读(350) |
评论 (0) |
编辑 收藏
可能是有些自负的因素吧,我常常觉得《程序员》杂志上的很多观点和我不谋而合。我一般喜欢看的是人物介绍、产品的底层实现方法等文章;对其它的新名词倒不是很感兴趣;最不喜欢的栏目反而是几个人不断的在说各家产品的有什么新技术、新趋势的文章。
在接触《程序员》杂志的这七年,也是我从迷茫走向成熟的七年,至少我能明白我现在在做什么,也能够承担因此而引起的后果,不论是苦还是甜。
这几年来,我也发生了很大的变化,各种生活也逐渐定型,虽然开发不是一个很好的工作,但对我个人来说,技术(特别是开发)仍然是能最发挥我的特点的一个职业。随着年龄的增长,我也能坦然接受自己对这个工作的喜爱,并感受到其中的一点乐趣。
粗粗算来,已经工作快十八年了,接触计算机也有二十年的时间,其中用于编程的时间大概也有十年,在这里将我的几点体会和大家分享一下。如果您是一个程序员、或者打算做一个程序员,或者打算开一个公司从事软件开发方面的工作,希望这些观点能够对您有所帮助。
1、开发规模问题
对于目前业内的一些观点,我并不认同。例如在各种报刊杂志上,经常有专家教授唠唠叨叨在说现在的软件开发已经进入工业化时代,要多少多少人团队开发,才能如何如何。但是,基于国内的实际情况,其实许多1000万元以下的项目完全是几个人的小团队开发模式,即使大到规模上市的软件公司,具体到每个定制开发的项目,实际项目组的开发人员,也经常只有不到十个人的规模,三、五个人的情况更是多如牛毛。
再看看国际上,我们所使用的一些著名的产品,如unix系统、C语言、notes系统、java语言、甚至最早的windows、dos很多都是几个人的小组所完成的开发。
至于这些产品的推广完善,所需要的巨大人力资源和开发之初的人力投入完全是两回事。在开发阶段,人多不一定就是好事,甚至肯定要坏事。
这就像生小孩一样,只要一男一女两个人就完全足够,但是,将这个孩子养大成人,除了他的父母,整个家庭、学校、社会等其它各色人等也直接或间接付出了很多。但这个孩子仍然只是他父母开发出来的,其它人只是起一个推波助澜的作用。
2、技术与思想问题
综合分析目前国内的软件开发方法(甚至包括其它IT技术),不难发现,我们总是热衷于技术,而不注重标准。从Basic、C、C++、一直到java、 C#等语言,再到.Net、J2EE等架构,多少技术在我们眼前晃来晃去,有些人也以掌握这些技术为目的,甚至洋洋得意。
其实,冷静下来分析一下其中的核心技术内容,现在的Web开发和早期的CGI方式的Web开发,只有方法上的不同,没有实质上的区别,所遵循的数据标准也没有任何变化。
整天只沉迷于片面的技术,使我们离核心技术越来越远,根本谈不上什么创造性。现在国内很多电子政务的项目在投标时均要求必须基于J2EE或.Net技术,完全拒绝LAMP和其它技术,估计很多美国公司老板做梦都要笑出声来。
重要的是思想而不是工具,就象毛泽东打败蒋介石是依靠思想而不是武器一样,技术并不起决定作用。
3、技术沉淀的重要性
由于不注重核心技术(其实那怕是一个小小的strcpy都是核心技术的一部分),很多公司没有任何技术积累,也没有可重复使用的底层开发库,更谈不上编程方法和思想上的积累。
因为工作的关系,我曾经接触过不少项目,这些项目都是号称采用了何等先进的技术云云,但实际上很多项目即使一个简单的按钮修改都需要在每个JSP文件中逐个修改。看了这样的代码,你真的不能不相信,语言是一个项目中最不重要的技术。
4、面向对象的是与非
我始终认为翻译“面向对象”的那个人是一个典型的老光棍,整天想着找对象,所以就想当然的这么翻译,其实我觉得“面向对象”应该是“面向目的”才对。所谓面向目的,说白了就是黑猫白猫的一句话。
其实“面向目的”(而不是“面向对象”)更多的是一种思想,而不是一个所谓的编程方法。所谓的抽象,固然有其必要性,但到处都是对象的说法,往往只是一些外行说出的内行话。难怪Torvalds对C++批的一无是处。
真正的“面向目的”,就是对一个项目的各个部分采用最适合的方法以达成目的。
5、大道至简
我越来越相信“大道至简”这个哲学观点,从设计产品、系统分析、模块划分,一直到做饭洗菜、吃饭睡觉,甚至到人际交往,这个道理都是相通的。从程序的角度也是如此,一段好的代码大多都是一个简洁的代码。
就像做人一样,简单做人,自己不辛苦,别人也不辛苦。同样一种开发语言、一种技术、一种开发工具、一种框架平台也是如此。
我个人认为C语言几十年不倒的主要原因,主要就是因为其结构简单,扩充方便。n年前玩音响的时候,很多发烧友也一致认为,在价格相当的情况下,一个旋钮最少的音响基本上就是最好的音响,也是同样的道理。
6、责任心和细节
其实大家都知道这一点,但是实际操作起来往往又根本不在乎。做项目需求时,有些人往往只是考虑实现客户要求的功能,而不是从客户要求的内容去思考和分析,甚至因为工作量的关系,故意避开一些问题。但是这些问题仍然存在,最后仍然会逐渐暴露出来,反而自讨苦吃。
其实,对客户而言,能有更好更完善的方案一般都会乐意接受,如果能本着对客户负责的精神,客户才能真正信任你;你和客户谈起价格时也才能有理有据。
很多时候只要负起责任,就会有助于发现所有的问题,并提出一个妥善的解决方法,注意到每一个细小的问题。其实大到卫星上天,小到刷锅洗碗,最根本的关键不是什么技术,而是在高度责任心的基础上对细节的把握。
我曾经在跳蚤市场买过一个七十年代的收音机,是春雷703,一个很古老的上海牌子,其信噪比和灵敏度比现在的集成电路的高出很多,原因无它,每一件细小的功能都做到最好而已。其实看一个程序员只要看他对程序跳格的处理,就可以决定90%的情况。
7、坚持熬下去
前几天看一个关于抗战的记录片,老毛对抗战相持阶段的说法是熬下去,当然是积极的熬法。其实不仅是做程序,做其它事情又何尝不是这样。
如果一天写100行代码,10年下来就是30多万行,记得好像unix最早的代码也不到40万行,30多万行代码,可以做多少事情呀。
有一天和一个朋友谈起代码量,他说最近在招人,要求曾经独立写过1万行代码,我后来仔细算了我开发的MCIS中间件系统,在代码最多时也才5万多行,后来不断调整优化,现在只有4万行不到。再统计一下数据库接口部分,每个数据库接口只有可怜的400行代码不到,但就这简单的400行已经可以完成一个数据库接口应具备的完整功能。
这几天刚好赶上亚洲杯,中国队0-3负于乌兹别克斯坦,又一次在打平即可出线的时候情况下完蛋。看看中国足球队的窝囊,其实就是没有认真对待场上的每一分钟,姑且不论技术和意识,只要场上每个人都能坚持90分钟不停的奔跑拦截,估计在亚洲也可以独立独行。最根本而又最简单的没有做到,又何谈胜利。
总想写一些东西,但因时间的关系,一直拖了下来,这几天刚好朋友约稿,就写一点自己的想法。从职业的角度而言,每个职业都有不同的酸甜苦辣,相比而言,选择一个自己比较喜欢的职业,也确实是一个不错的选择。可能是年龄的关系,我反而觉得生活才是最重要的,当然最好能在工作中保持乐趣,在生活中享受乐趣。在《程序员》杂志7年之际,写下这点东西,希望《程序员》杂志能够成为更多程序员的朋友。
posted @
2007-11-27 15:15 CoderDream 阅读(512) |
评论 (0) |
编辑 收藏
在反射机制中,Class.forName(className).newInstance();
如果你想通过反射机制得到当前包的某个类的实例,传入类名的同时必须传入包名。
例如在包com.coderdream下有两个类Shape,ShapeFactory,如果你想在ShapeFactory中的某个方法中用反射的方法生成Shape类,那么如果直接使用:
Class.forName("Shape").newInstance();
会抛出找不到类的异常,因为确实没有Shape类,而只有com.coderdream.Shape类。
但是我们传参数时一般只会传不带包的类名,那么我们可以这样处理:
String packageName = new ShapeFactory().getClass().getPackage().getName();
return (Shape) Class.forName(packageName + "." + className).newInstance();
其中 new ShapeFactory().getClass().getPackage().getName() 会得到包名“com.coderdream”,我们只要加上“.”和类名就没有问题了。
posted @
2007-11-23 15:34 CoderDream 阅读(6352) |
评论 (2) |
编辑 收藏第一篇:过去将来时(思想准备篇)
有人会问:你为什么要把它背下来呢?我觉的学一学就蛮好的吗?
故事的起因一个真实的小故事:(2002年的夏天在新东方听到)
新东方有个学员现在在Duke大学,他从高一开始背《新概念英语》第三册,背到高三就背完了。高考考进了北大,进北大后,他本来不想再背了。但当他背给同学听的时候,其他同学都露出了羡慕的眼光,于是,为了这种虚荣心,他就坚持背第四册,把第三、四册都背得滚瓜烂熟,他熟到什么地步呢,有人把其中任何一句说出来,把能把上一句和下一句连接下去,而且语音非常标准,因为他是模仿着磁带来背的。后来他去了美国Duke大学,他给新东方的教师写信,老师不敢回,因为老师对他的英文有畏惧感,他的英文学得太好,只能给他回中文信,并告诉他不是不会写英文,而是想让他温习温习中文,不要忘记祖国的语言。
这位学员到美国第一个星期写文章,教授把他叫过去说他的文章是剽窃的,因为他的文章写得太好了,教授说:"我20年教书没有教出这么漂亮的文章来。"这个学员说,我没有办法证明我能写出这么优秀的文章,但我告诉你,我能背108篇文章,而且背得非常熟练,你想不想听。结果,他没有背完两篇,教授就哭了起来,为什么?因为这个教授想一想自己教了20年了,居然一篇文章也没有背过,被中国学生背掉了,所以很难过……
从那个时候起我就有一种冲动,有一天我相信我也能将这108篇文章全背下来,看来我是做到了。
我相信也会有人问:你在背诵的过程中最大的困难是什么?我的回答就是:“坚持”。其实我能够坚持下来也是原于一个我在《读者》上看到的一个小故事:
古希腊哲学家苏格拉底在给学生上第一节课的时候,要求他的学生在每天上课之前都向上挥一下手。过了一个星期,他发现已经有一半的学生不在挥手了;过了一个月,他发现只剩下三分之一在挥手;过了半年,他再看,发现最后只剩下一个人在挥手,那个人就是柏拉图。柏拉图后来成为伟大的思想家和哲学家。
其实任何一件事到最后都是“简单的重复和机械的劳动”。只要你做到了,ok,你就有可能在一个领域做到很前列,甚至是Number One。
第二篇:现在进行时(背诵具体策略篇)
无论我们学习什么,都可能给自己做一个计划或者是有一个步奏。
在很早以前就听说过王国维的三种境界:
昨夜西风凋碧树,独上高楼望尽天涯路。
衣带渐宽终不悔,为伊消得人憔悴。
众里寻她前百度,慕然回首那人却在灯火阑珊处。
这些话是不是让你在做事情上有一定的启发呢?
我很喜欢《毛主席诗词》,所以我也有了用《毛主席诗词》串联起来我的做事三境界。
雄关漫道真如铁,而今迈步从头跃。(此乃第一境界)
一万年太久,只征朝夕。(此乃第二境界)
待到山花烂漫时,“我”在丛中笑。(此乃终极目标)
三个月的正式背诵,每天基本上是狂背10-12小时,对我来说既是一种痛苦又是一种快乐。痛苦,是因为太累了,有时一看到《新概念》我都恶心的想吐;快乐,看着自己一天天一篇篇把这些文章背掉,那种愉悦的心情是不言而喻的。也许这就叫作“痛,并快乐着”吧。
在这个“痛,并快乐着”中我也经历了几个过程:
1。从小我背课文就拿者一本书在我自己的小屋里低着头边走边背(出声背)。在一开始背《新概念》的时候我也是这样,结果一天下来弄得我简直是精疲力尽,而且效率不高,这种方法很快就被淘汰。
2。我发现坐在自己的床上背诵(出声音背)效率大大的提高,这样一天下来,感觉除了嗓子有点累还是蛮轻松的。就这样我在4月30日把第三册背完了。想想第三册有60课我仅用了一个多月(哦,我的背诵是从2003年3月20日开始)就搞定,那么第四册才48课估计一个月搞定应该没什么问题。但是事实超出了我的预料。
3。五月一日正式开始背诵第四册,当背到第10课(silicon vallay)的是时候我的嗓子已经受不了了,只要我一背就咳嗽,而且咳的很厉害,背诵被迫终止了5天。后来我只能不出声音的背(就是默背),结果奇迹出现了,我不再咳嗽了,而且我的效率提高了一倍。(也许“默背”是很多人的背诵习惯,可是对我来说就意味着要改变从“儿时”养成的背诵习惯,还是挺不容易的。)事情到此,可能也就没有什么可讲的了。但是,在我快要把第四册背完的时候(背到第39课what every writer wants),我遇到了一个大困难,那就是“噪音”。因为我家是住在(天津人叫做)“大杂院”。时值夏日,人们都出来乘凉,这种生活噪音成了我的最大敌人。背诵的速度被迫降了下来。就这样原定第四册最迟在6月10日拿下,结果直到6月21日才全部搞定。
所以,对我而言(是否适用其他人我不敢说)背诵的最快的方法是:1。坐在一个地方 2。默背 3。尽量找噪音小的地方背。
第三篇:现在完成时(背诵过后的感觉)
《新概念英语》30年不衰说明她的确是一本好书。
1。第三册大部分文章都会让你觉的:这篇文章真好玩,这个故事有意思。第三册的文章可以说都是作者象做一个精品一样来把这个文章弄出来。如果你能背下三册的前40篇文章,那么你的写作功力一定会大增。如果你说我背下来三册前40篇了,我还是不会写作文,那不是你问题,就是我有问题,要不就是《新概念》有问题。
2。第四册难了。但是她究竟难在什么地方呢?她比第三册究竟难在哪里呢?实际上我的感觉就是第四册基本上都是“说明文”而第三册可以说都是“记叙文”。所以第四册难在她的文体上,她没有什么情节,而且她有自己的Ideas。所以,像第44课patterns of culture 这课简直就是超超难,她没有什么情节,背诵的难度非常的大。
posted @
2007-11-21 17:21 CoderDream 阅读(438) |
评论 (2) |
编辑 收藏
1、未知异常
Security Manage系统中新增功能时报“未知异常”,后来在本地测试看Log信息知道是“空指针异常”,然后定位到抛出异常的位置:
iFuncNo = iFuncNo + 1;
然后单步调试,发现iFuncNo为Null,所以操作时会报空指针异常,这是iFuncNo的赋值语句:
List list = functionDao.selectByParentId(functionVo.getParentId());
if (list != null && list.size() > 0) {
Functiontb functb = (Functiontb) list.get(0);
iFuncNo = functb.getFunctionNo();
从中可以看出,iFuncNo是一个Functiontb的属性,而且可能为空,如果不加判断直接用操作符对它进行操作,会报“空指针异常”。
iFuncNo用于菜单的排序,因为菜单是动态生成的,根据权限不同,看到的菜单也不同,而且应该可以根据客户的要求对菜单排序,所以增加了这个字段,但是由于这个字段是后来新增的,所以数据库中的某些记录该字段的值为空。在程序中先判断一下就可以了,如果为空,就置为0;
List list = functionDao.selectByParentId(functionVo.getParentId());
if (list != null && list.size() > 0) {
Functiontb functb = (Functiontb) list.get(0);
iFuncNo = functb.getFunctionNo();
if (null == iFuncNo) {// 如果資料庫中該欄位的值為null,則先置為0
iFuncNo = 0;
}
iFuncNo = iFuncNo + 1;
}
这样就OK了。
2、季帐单的团体险及意外险部分的数据在生成的PDF报表中看不到。
原因:手工输入数据时,弱体等级(标准体、次标准体)栏位不是必填的,也就是说值可以为空,但是我生成报表时是按照这两种弱体等级来生成报表的,所以没有在报表中。就好像一个公共厕所,上面写着“男”和“女”,这时候来了一个性别为“空”的人,我肯定不好让“他/她”进其中的任何一个地方了。
今天要客户确认一下怎么处理!
posted @
2007-11-20 09:18 CoderDream 阅读(335) |
评论 (0) |
编辑 收藏
一直喜欢用 MySQL Front来管理数据库,前段时间还因为他被迫关闭而惋惜,近日浏览了下他们的主页,没想到 生命力是这么的强.
被迫关闭的MySQL Front 现在更名为SQL Front 继续开发,授权方式为开源,以下为原 mysqlfront.de 的注释:
MySQL-Front has been renamed to SQL-Front
MySQL-Front has been renamed to >> SQL-Front <<.
Please help to publish the new new name by posting it in a lot of forums,
and please update your links to this page.
Thanks a lot for your help!
We hope that humanity will learn to work together instead of fighting one another senselessly...
-------------------------------------
MySQL-Front has been renamed to >> SQL-Front <<.
posted @
2007-11-16 17:23 CoderDream 阅读(439) |
评论 (0) |
编辑 收藏我家使用ADSL拨号上网,每次需要上网的时候,都需要双击一下“宽带上网”的图标,然后在弹出的对话框上点击“确认”,方可上网。
我一向是个懒人,非常讨厌这样一次次的手工操作,有什么办法实现自动拨号呢?一般来说,微软那些用界面实现的东西,后台其实还是一系列的脚本或者是配置命令。那么,我只要找到“宽带上网”的配置文件所在,应该就可以了。
首先查看“网络连接”里面的“宽带上网”的属性,找不出什么有帮助的信息。然后将“宽带上网”拉到桌面上,形成一个快捷方式出来,查看快捷方式的属性,发现它的实际位置被微软屏蔽了,看不到。
不死心,将该快捷方式用UltraEdit打开,终于发现,原来它指向 “C:\Documents and Settings\All Users\application data\Microsoft\Network\Connections\Pbk”目录下的 rasphone.pbk 文件。打开 rasphone.pbk,果然,我所建立的所有拨号方式,全部在里面。
现在找到这个配置文件了,下一步就是找找看,用什么东西来运行它。
查看 windows 帮助文件,搜索“自动拨号”,仔细查看后,找到了 rasdial 命令。通过几次在命令行试运行该命令后,终于掌握了它的用法。至此,我只要编写一个脚本,并将它放在桌面上,只要双击它一次,我就可以拨号上网了。而让系统启动的时候运行这个脚本,我就可以实现开机自动拨号了。
脚本非常简单,就下面那么一行:
rasdial EntryName username password
其中的 EntryName ,一定是要在上述 rasphone.pbk 里面真实存在的。比如,我的ADSL拨号名称,叫做“宽带上网”,我的用户名是 Michael,密码是 123456,则命令为
rasdial 宽带上网 Michael 123456
最后,为了避免重装系统之后需要重新配置这些拨号上网参数,将上述 rasphone.pbk 文件备份到 d:\backup 目录下,则脚本也就改成下面这样了:
rasdial 宽带上网 Michael 123456 /phonebook:d:\backup\rasphone.pbk
posted @
2007-11-16 17:22 CoderDream 阅读(1691) |
评论 (0) |
编辑 收藏
1、
Equals and Hash Code
2、
关于java的hashCode方法
3、
学习笔记:java中HashCode
4、
Java 理论与实践: 哈希
5、
有效和正确定义hashCode()和equals()
posted @
2007-11-16 17:20 CoderDream 阅读(461) |
评论 (0) |
编辑 收藏
1、
下载
2、
使用SUBCLIPSE——针对ECLIPSE的SUBVERSION插件
3、eclipse插件下载
4、
如何结合使用 Subversion 和 Eclipse
5、
Book
6、
Subversion之路----利用 svnserve.exe 实现精细的目录访问控制(v1.0)
7、
subversion 一个小技巧 -如何一次添加分布在不同子目录下的多个文件
8、
使用Subversion进行源代码管理(一):体验Subversion客户端
9、
使用Subversion进行源代码管理(二):创建和发布版本库
10、
使用Subversion进行源代码管理(三):常用操作
11、
SVN登录方式与AD整合
12、
Subversion安装手记
13、
Subversion安装记录
14、
Subversion配置安装教程(一)
15、
Apache和Subversion 搭建安全CVS
16、
SVN(Subversion)简易入门教程
posted @
2007-11-16 17:16 CoderDream 阅读(328) |
评论 (0) |
编辑 收藏
1、
http://www.downflv.com/
posted @
2007-11-16 13:23 CoderDream 阅读(323) |
评论 (0) |
编辑 收藏1.定位:一个人怎样给自己定位,将决定其一生成就的大小
2.完美:世界并不完美,人生当有不足
3.缺憾:让不幸赋予你生命的动力,企图以不幸博取别人同情的人永远只能躺在自己的不幸上.
4.进退:人生贵在把握进退之机."进"与"退"都是处世行事的技巧,该进则进,该退则退
5舍得:学会舍弃方能得到.放弃是一种境界,大弃大得,小弃小得,不弃不得.
6.贫穷:穷人最缺少的是野心.野心决不是成就,但没有野心,肯定不会有成就.
7.免费的午餐:不要希望不劳而获.成功不会从天而降,需要自己去争取,去寻找,去创造.
8.金钱:不要做金钱的奴隶.人赚钱是为了活着,但活着绝不是只为了赚钱.
9.浮躁:人生浮躁要不得.一个人如果有轻浮急躁的缺点,是什么事情都做不成的.
10.失业:一切只不过是从头再来.被解雇不一定是坏事,只要树立信心,定会有柳暗花明。
11.面子:面子只是小问题,成功才是硬道理;
12.压力:潜能在压力中诞生.潜能就象是装在牙膏袋中的牙膏,只有经受压力的挤压之后,才会迸发.
13.小事:平凡成就大业.在欧洲,有一首流传很广的民谚:因为一根铁钉,我们失去了一块马蹄铁;因为一块马蹄铁我们失去了一匹骏马;因为一匹骏马,我们失去一名骑手;因为一名骑手,我们失去了一场战争.
14.怀才不遇:少一点哀叹,多一点审思.你越是沉不住气,别人越是看轻你.
15.情感隐私:给彼此一些适度的距离.健康的爱侣关系是相互尊重,包括尊重对方的隐私.
16.孤独:勇于走出孤独,才能品尝甘美的人生.走出孤独的阴影,你的人生会变得阳光灿烂.
17.失恋:分了再谈,将爱情进行到底.人生最怕失去的不是已经拥有的东西而是失去对未来的希望.
18.感情变淡:走过热恋的缘分天空,每个人都要在婚姻的隧道里经受着考验.
19.不合理的批评:从来没有人会踢一只死狗.卡耐基告诉我们:"不合理批评往往是一种掩饰的赞美."
20.奴性:尊严,任何时候都不容侵犯.那些见了主子就哈腰,做了主子就张狂的人充其量只是一些没有尊严的可怜的爬行动物而已.
21.怀旧:怀旧的结果往往是使人逃避成熟的思考,进入一种虚无飘渺的境界.屏弃过去,活在今天.
22.较真:人生如此短暂而宝贵,不必为那些令人不愉快的事情计较而浪费时间.红尘本混沌,处事何太真.
23.平庸:如果你相信自己,并且深信自己一定能达到梦想,你就够步入坦途.自信,让神奇降临.
24.后悔:正像苦难伴随生命的始终一样,遗憾与悔恨也与生命同在.不为打翻的牛奶哭泣.
25.模仿:整日装在别人套子里的人,终究有一天会发现,自己已变得面目全非了!秉持自我本色,独立于世.
26.依赖:依赖是阻止你走向成功的一个绊脚石,要想成大事,你必须把它们踢开.抛开拐杖你才能跑起来.
27.人格:人格就是力量,从某种意义上来说,这句话比知识就是力量更为正确.人格就是力量.
28.责备他人:责备只会让对方耿耿于怀,于己于事都会产生不良影响.要采蜂蜜,就别踢翻蜂巢.
29.说"不":在不利的环境下说"不",是对自我的尊重,而且只有懂得尊重自己,别人才会懂得如何尊重我们.不要活在别人的价值观里.
30.步入低谷:人生浮沉,步入低谷,在所难免.惟有达观的人才能豁然无累,真正地解脱.有个柠檬,就做柠檬水.
31.恶习:一个人如果养成良好的习惯,就等于事业成功了一半;反之,就会离失败不远了.好习惯源于自我培养.
32.自卑:自卑的人并不是自己想自卑,而是因为他们缺乏内心的安全感.越过人生最大的跨栏.
33.借口:成功,不需要借口.制造托词来解释失败,这已是世界性的问题.这种习惯与人类的历史同样古老,这是成功的致命伤!
34.失败:人生路上,一帆风顺者少,曲折坎坷者多,成功是由无数失败构成的.在失败的河流中泅渡.
35.恐惧:恐惧剥夺人的幸福与能力,使人变为懦夫;恐惧使人失败,使人流于卑贱;恐惧比什么东西都可怕.驱除侵蚀心灵的魔鬼.
36.迷惘:在人生的旅途中,有时我们会迷失自己,对未来失去了明确的追求方向,这时候你就要用人生的罗盘指引自己.
37.创业资金:许多人一心想发财,但又不屑于赚小钱,只想赚大钱,于是苦苦等待有了雄厚的资金再去创业,结果大钱小钱都没有赚到.从"小钱"开始起步
38.形象不佳:那些对自我形象很随意的人,在和别人的交往中,个人魅力和交际效果会大打折扣.努力塑造新形象.
39.违逆潮流:适应变化,与时代同步.一个人跟不上时代变化的步伐,势必被人类进步的潮流所淹没.
40.受到伤害:释加牟尼说:"以恨对恨,恨永远存在;以爱对恨,恨自然消失."
41.气量:气量是一种情操,更是一种修养.只有拥有"雅量"的人才真正懂得善待自己,善待他人,人生才会活出大境界.雅量是一种修养.
42.猜疑:猜疑心强的人常常吹毛求疵,无中生有,甚至把一些正常的情况扭曲了.猜疑能乱人心性.
43.机遇:人生的得失常常就在于机遇的得失.抓住人生的每一个机遇.
44.愤怒:别为小事发怒.不能生气的人是笨蛋,而不去生气的人才是聪明人.
45.思维定势:当面对创新的事物时,如若受思维定势约束,就会形成对创造力的障碍.敢于突破,才有创造力.
46.尴尬:面对人生道路上的种种无奈,幽默是摆脱困境的最好方式.幽默能化解尴尬.
47.健康:我们生活在一个失衡的时代,节奏太快,精神压力太大,然而又无所逃避.忧虑是健康的大敌.
48.优柔寡断:犹豫不决的人肯定是个性软弱,没有生气的人,他们最终将一事无成.果断的性格是人生的守护神.
49.痛苦:如果你紧紧抓住痛苦不放,快乐就永远也不会到来.痛苦的时候别忘了给自己一点快乐.
50.时间管理:鲁迅说过:"浪费别人的时间等于谋财害命,浪费自己的时间等于慢性自杀."
posted @
2007-11-15 11:28 CoderDream 阅读(274) |
评论 (0) |
编辑 收藏1.两个对象值相同(x.equals(y)==true),但却可有不同的hash code,这句话对不对?为什么?
2.GC是什么?为什么要有GC?
3.请简要描述一下J2EE应用中的class loader的层次结构?
4.写一段代码,实现银行转帐功能:
接口定义如下:
public interface ITransfer {
/**
* <pre>
* 银行内部转帐,从转出帐号中扣除转帐金额,给转入帐号增加转帐金额,
* 需要保证以上两个操作,要么同时成功,要么同时失败
* </pre>
*
* @param fromAccountId
* 转出帐号
* @param outAccountId
* 转入帐号
* @param amount
* 转帐金额
*/
public void transferInner(String fromAccountId, String outAccountId,
BigDecimal amount);
/**
* <pre>
* 外部转帐-转出,从转出帐号中扣除转帐金额
* </pre>
*
* @param fromAccountId
* 转出帐号
* @param amount
* 转帐金额
*/
public void transferOut(String fromAccountId, BigDecimal amount);
/**
* <pre>
* 外部转帐-转入,给转入帐号增加转帐金额
* </pre>
*
* @param toAccountId
* 转入帐号
* @param amount
* 转帐金额
*/
public void transerIn(String toAccountId, BigDecimal amount);
}
请编写你的实现类,来实现上述接口
Account表
字段:accountId , 主键 varchar2(32), 用户帐号
字段:amount , 金额 number(18,3)
5."组合优于继承",是否同意这句话,并阐述你的观点。
6.请说下Template模式与Strategy模式的异同点。
posted @
2007-11-14 15:09 CoderDream 阅读(1046) |
评论 (1) |
编辑 收藏
摘要: 1、操作符“==”
用来比较两个操作元是否相等,这两个操作元既可以是基本类型,也可以是引用类型。
代码01:
/**
* Demo01.java
*
* Provider: CoderDream's Studio
*
* History
...
阅读全文
posted @
2007-11-13 17:14 CoderDream 阅读(1343) |
评论 (0) |
编辑 收藏知识管理我的Blog上谈的比较少,我也不是这方面的专家,但知识和技能,经验,方法论,实践,思维思考都有关系。因此知识管理也是我关心的内容内容,包括个人知识和企业级和团队的知识管理。在2,3年前通过思维导图画的IT知识体系结构就是在这方面的一些实践,目的就是如何真正让知识发挥作用和创造效益。个人认为现在很多流行的知识管理系统都是辅助性的工具而已,关键还是是否真正的理解的知识管理的目标,理解了目标才知道如何做好知识管理,让知识管理真正的发挥作用。
1.第一个层次-形成知识库
知识库首先不是资料库,不是上传一大堆资料就完成知识库的建设了。资料必须经过多维属性的整理才能够真正入库,资料的关键字,TAG标签,多维度的分类都是属于资料的重要属性。而且入库的资料必须是有价值的资料,必须是经过我们分析,抽取和整理后的资料,这样可以减少后期其他人在无用的资料上面浪费时间。资料入库后完成了第一步,后面重要的就是知识的分享,一个资料能够在知识库中下载了不是分享,要成为知识的分享就需要对资料附加上团队中他人的评论,学习笔记和心得,有了这些就完成了知识库的基本建设。
在第一个层次上面,我们可以看到现在栖息谷或其他很多论坛的资料下载都是停留在资料库的层次上面。因此也就出现了我们前面常说的问题,论坛用户面对一大堆挪列的资料往往无从下手。我们的硬盘成为了我们资料收集的工具,而我们的大脑却根本还没有启动,更谈不上如何去将这些资料转化为系统的知识。从这点上再来看豆瓣网,豆瓣本身不存储任何的书籍和影音资料,但更多的针对书籍和影响的学习笔记,评论和相关小组更容易让理论性的东西转化为知识。
2.第二层次-形成知识地图
如果你不知道要到哪里去,给你张地图也没有用。但现在的问题是很多人知道往哪里去?他们有明确的想法想增加哪方面的知识或者说想提高哪方面的技能,但我们却很难针对他们给出一张类似于学习路线的知识地图。
在知识库建立和发布好以后重点就是要去形成知识地图,知识地图一方面应该是正对某一个业务领域或者应用场景需要的知识形成一个完整的知识体系结构图,让大家对要学习某项知识或技能有个全局的认识,同时也让每个人看清楚自己在地图中的位置。看清楚了你在地图中的位置,才能够知道如何达到目的地。
找到自己的位置后,就要发挥地图的第二个作用,如何在通过地图一步步的达到自己的目标,应该遵循什么样的行走路线,哪些地方需要慢慢走去体会,哪些地方可以跳跃下。要能够把行走路线准确的画出来,则需要理清楚知识和知识间的关系,哪些是关键约束和依赖关系,哪些是可选的依赖关系。把这些依赖关系理清楚后,知识路线自然就出来了。
针对处于不同位置的人,知识路线往往是不同的,我们可以给出常规的最佳路线,但无法给出针对每个人的最佳路线。所以有时候不要盲目的去迷信他人的学习路线,适合自己的路线才是最好的路线。由于无法解决个性化的最佳路线问题,需要过渡到第三个层次。
3.第三层次-从经验到方法论,模式的不断积累
任何知识管理工具和系统,如果走不到第三个层次则始终是停留在使用阶段,而无法真正过渡到创造阶段。我们进行的知识管理应该站在了前人的肩膀上面,后面要做的就是通过自我知识的学习形成相关的经验,大家通过知识平台的讨论和固化,将我们的经验积累为相关的方法论和模式。方法论会告诉我们遇到河流你需要通过桥过去,搭桥过去,或者说学习游泳技能过去;遇到山你可以爬过去,打个隧道过去,也可以绕过去。你可以根据你自己的情况选择相关的方法。所以有了这些大家共同积累下来的方法论和模式,再给你一张地图的时候,你不一定安装常规的学习路线走,你可以在方法论和模式的指导下创造出更多的行走路线,你要做的是根据自己的技能特点和面临的场景,选择最适合自己的学习路线。
知识管理的过程就是PDCA的过程,就是不断的和朋友分析和讨论自己的学习心得和经验,通过将经验固化为过程和特定的方法论和模式。知识能够真正的创造价值就在于知识能够以最快和最便捷的速度别它人所吸收,并转为自我的技能;知识真正的能够为企业创造价值就在于在形成经验技能后,个体能够将经验和心得分享,企业对经验和心得进行整合为不断完善方法论和模式的过程。
posted @
2007-11-13 13:21 CoderDream 阅读(284) |
评论 (0) |
编辑 收藏
原文链接:
http://developer.51cto.com/art/200710/57527.htm
十五个秘决搞定你想要的晋升,拿到你应得的薪水
怎样评定一名软件开发人员?这是一个颇为奇怪的问题。现在已经有了很多的理论和形式来做这件事,人力资源部门也试着帮你管理和反省自己的行为。然而,怎样才是一个伟大的软件开发人员,在今天,你该怎样发展你的职业生涯?以下是我评定团队中软件开发人员的“军规”。按照这些技巧和规则,你可以改善你的现状,由一个优秀的程序员,成为一名伟大的程序员。
1、时间花在写精彩的代码上
这里说的不是数量,而是质量。对此,一种歪曲是:要数量,也要质量。你也许会很多次的遇到以下的两种情境:
情境A:你有一个发疯似的能写代码的程序员,事情似乎在进展中……然后,Bug开始不断出现,你们也不知道为什么,好像永远补不完。补完十个,又出来五个,现在你手里的,就是一大堆代码……
情境B:你现在有一个看起来很聪明的程序员,你面试他的时候,他似乎无所不知,能把理论说的头头是道。然而,你留给他三个任务,三个星期以后,他还在做一些三天就该干完的事。这下该你困惑了,他这么聪明,他知道generics(详见备注),多线程的一切事情,甚至还能给祖母级的人讲解什么是指针,让老太太兴奋的想去编程。可是——怎么什么都没完成?
于是,在梦境中——你写出了堪称伟大的代码,——伟大的代码是伟大的程序员写出来的,他睿智,明白代码的真正品质所在。写代码就像托尼•霍克在玩滑板一样自然优美,看上去就令人愉快。这些程序员以让你眼花的速度搞定一切,他们知道每个问题应该处理多长时间,也不会追捧寻觅所谓的世界最好解决方案,弄很多线程很多层来写一个简单的游戏。他们写的程序没有Bug,因为写的时候自己测试过了,在睡觉时也在写代码说的就是这样的人。这些程序员太宝贵了。
2、阐明问题
可以明确的是:即使有问题暂时处理不了,还有成百上千的方法去解决。有些人反应很迅速,很快就能提出多种解决方案。然而,一个伟大的程序员应该在做出行动以前清晰阐明问题——创建文档或用白板表达出来。他们写邮件给项目的管理者,这样表述:“我想和你说说我是怎么理解这个问题的,我们能这样处理吗?”然后他们就会动手给你多种方案。
对,这些人明白自己看问题和阐明立场的方式,而这理解方式大概不会是问题创建者所想要被理解的。请牢记这就是关键所在。一名伟大的程序员在尝试解决问题以前,一定要完全的理解它。你百分百搞明白了吗?没有?百分之九十九?——回去再多问些问题,确保百分之百理解清楚了。
3、怎样着手解决问题
那一搞明白了问题,就开始动手写代码?错!一个伟大的程序员应该按照规划,开始思考面临的多种选择,基于问题开始考虑最好的解决方案。我觉的这像一场国际象棋比赛。你知道每个棋可以怎么走,知道所有的游戏规则。但是你会马上走棋吗?不,你要审时度势,制订计划,紧盯对手,分析其通常的做法。和这一样,在你coding解决问题以前,你也要这么做。
看看问题,计算出需要怎样的结果,你的时间能怎么安排,预期的质量,你必须用的工具,……好了,开工吧!
4、对代码的信任
作为项目管理者,你怎么相信他们的代码。有些程序员,你可以对他们说:“我星期五就要结果”。——星期五到了,你收到了这样的Email:“代码我都已经检查过了,现在就等着测试了。”你很放心,只会有很少的瑕疵在质量确保的团队被查到。当然,还有些轻率的例子,一些程序员在邮件里是这样说的:“我还没弄完,星期一上午我会最先完成它”。你不太确信这东西,发现很多Bug,很长时间基本上不能用。又得花上几个星期清理代码中的Bug。
关键:你对一个开发人员越有信心,他离成为一个伟大的程序员的距离就越近。想象你是你的管理者,如果他并不担心你的代码,会给你多少信心和勇气!
5、对方案的信任
和对代码的信任是一回事——如果你手上有伟大的程序员,你就会对解决方案有信心。这些程序员同时也是伟大的建筑师。他们剖析整个问题,指出问题需要怎样去解决。这就不只是用伟大的代码编程的问题了,很大程度取决于你怎样构筑解决方案。这是关键,而且会让你在软件世界里出类拔萃。
6、满足客户需求
一天下来,你写出了最棒的代码、用了最好的框架和最好的解决方案,但这真的能迎合用户的需求吗?恐怕根本不是那么回事儿。你搞砸了。尽管现在多次失手,一个伟大的程序员还是会正中靶心,找出客户需要的,给用户逐步展示他们所需要的无bug的最终版本。需求正中靶心的同时,用户满意了。
7、不断升级
伟大的程序员会积极主动地把自己的技术升级。他们对知识的态度就像饿猫见着了牛奶,他们从不用上级催促给自己设定目标、不用经理要求他们完成任务,因为他们自己就已经安排OK了。
他们发现自己想要参加的大会就会给公司写Email“本人非常想参加今年的Tech-Ed大会。我将用心研习,并对作出贡献。我预计这可节省<金钱/其他原因>。如果可行,不知公司是否帮我支付此行?”如果我收到这样的邮件,我不仅会帮他支付参会费用,他的路费我也会全程买单。
伟大的程序员们永远会关注例如.net用户组或Java用户组的所有用户群体。他们参加本地的技术会议,并从中汲取知识。你会看所有最新博客和最新的杂志吗?现在列出你最喜欢的前5个开发博客。你能做到吗?你应该像参加基督教青年会那样轻松做到。做到这些,可以很好的帮助你延伸你的思路!你将会不断获得更好的点子!你会得到更好的回报!
8、团队奉献
你可以是团队中最棒的那个人,可是如果你不是最好的程序员、不是建筑师、不是团队里最有活力的人,那么对我来说,如果你不能分享或对你的团队有帮助,你的价值就会大打折扣。一个好的程序员会使自己周围的人同样强大起来。试想一下,好程序员会不断完善自己的知识和能力,如果他们不和周围的人分享他们的知识,他们从哪儿能获得更多呢?
他们不断学习新东西,发掘新技术,但是不会让其他人知道他们这么做了。一个好的程序员会准时完成方案,但是那是在催促和团队得不到休息的前提下。然而一个伟大的程序员则会与团队中所有的项目保持联系,在需要的时候还可以出手帮忙。他们会如是说:“我注意到A团队的项目进行到xx进度了,如果不介意的话,我想我可以帮忙?”
9、做好会议记录
做好会议记录绝对至关重要!开会期间,大家花大量时间来说明了新观点、新主张、集体讨论还有提出了新设计方案,可是会议结束后却没有人可以拿得出会议记录,简直没什么比这更糟糕的事情了。即使你有会议大纲,我还是期望见到参会的每一个人员都可以带着纸和笔(当然对于程序员来说笔记本则堪称完美)。一个伟大的程序员会注意到这点。他们会记下所有的会议记录,并且在会议结束的的时候说:“就刚才的会议,我着重记录了几点:XX…… 我是否记录全了呢?”
接下来,伟大的程序员就会把他做好的会议记录分发给项目管理者,列出会议时间、会议主题和参会者。接下来,是会议项目的标题和重要条目。在这之后,就是这些议题的详细记录。一个好的程序员没有做会议记录,并在会议上对提出的每项事宜都点头称是,那只能寄希望于他的记忆力足够好了。随后,他会给你发邮件让你看看他的改动,你得回头提醒他忘记的不多,百分之九十的都没错。——这不是浪费时间嘛!根本不是这么回事!所以,做好你的会议记录。
10、孺子可教和接受批评
如果你读到这儿了,就表明你有希望接受这些建议,并在以后的开发行动中尝试执行。对,程序员的另一项重要能力就是向他人学习并且能够接受批评。通过把自己变为一个虚心受教的人,像海绵一样快速吸收大量知识,毕竟在编程的路上你还有很多前辈。当然,也许他们在写代码的岁月里慢慢生了锈,甚至伤痕累累,但是他们毕竟曾披荆斩棘跨过无数的坎儿。对于做出正确决定,他们又着瞬间的本能,让你不得不服。处于他们这个位置,很乐于见到你的成长和成功。
所以,只要你是个伟大的程序员,就会理所当然的拥有理想的工作环境。如果你不断改善技能、虚心好学、在别人给出的意见和批评中总结错误并得以改善,我向你保证你将会成为一个伟大的程序员而不只是想象自己变得伟大而已。如果你总把自己想象成为“精英”而不进步,那你只是自欺欺人。如果你不成长,你甚至不能停留到原地,等待你的只有灭亡!
11、公司需要的时候总能出现
这如同等价交易。如果你为一家伟大的公司工作,他们会给你足够的弹性。公司不会限制你如何工作,不限制你开始或结束的时间,也不会限制你什么时候停下来歇歇。公司会鼓励你在休息时间做做操,甚至会在你和团队成员出去吃饭的时候为你们买单……在繁复大量而紧张的工作后,公司会放你几天小假。诸如此类。
然而,毫无疑问,与前面的这些美事儿随之而来的是责任。如果赶上时间紧还得出活儿,伟大的程序员则建议你即使在周末也要加班。即使干得再晚也得把活儿干完。你看,伟大的程序员是要为自己的创作负责的。这虽不是必需的,但这是伟大程序员的标志之一。有些人只想朝九晚五的上班,他们可能不错,但是成不了伟大的程序员。伟大的程序员是团队中干到最后的那个,把作品视为完美的艺术,与团队成员亲如一家。
12、衣着职业化
你永远也不知道一个客户会什么时候突然拜访。你也永远不会预知什么时候突然要参加一个会议,不是每一件事都在计划中的。你得随时准备好展现自己。一个好的程序员周一到周五穿着普普通通,甚至有可能穿牛仔装和运动鞋来上班。在某些周五,他们穿着T恤,短裤和运动鞋出现。当一个客户突然在周五出现,要谈一个大项目,你没法把衣衫不整的他一块儿叫上。
一个伟大的程序员周一到周五都穿着职业化,衣服也能带来成绩。如果你不在意穿着,你也会因为穿的太奇怪而得不到晋升。毫无疑问,套装和领带还是很能提升你自己的。我向你保证,一套得体大方的西服套装会让你在今年就觉的物超所值。
13、沟通能力
这是另外的判定条件。这世上有太多优秀程序员,却没几个伟大的程序员。为什么呢?因为大多数程序员不善交流。交流的层次很多:从发电子邮件、参加小型SCRUM开发小组会议到大一些的主管会议,水平逐渐提升。这样你就能在数百人参加的会议上自如地展示你的软件。在会议上你不需要有好演技,但是至少要清晰明了地表达你的观点。你的沟通能力越强,你的职业道路就会走得越远!
概要:想要成为管理人员,你的沟通能力得分至少要打到9到10分。甚至你在会议上只讲了几分钟,或只一个小汇报,你都需要非常好的表达能力。别只是在你的每天的工作日志寥寥写上“修补1371个bug”,你要做的是尽可能描述清楚如何在这么艰难的情况下解决了问题。阐明你的方法,说明你如何保证这个bug不再出现。你就不再为你的日志发愁了。这会是你向经理展示自己的精彩演出。
14、目标设定的技巧
好的程序员日复一日的做你安排给他们做的事情,贯穿始终。他们并不往远看,不对明年、5年甚至10年后作打算。一些好程序员虽然知道自己想要什么,却没有具体计划去实现。伟大的程序员则给自己订立年度、未来5年的目标,而且大概预期到自己10年后的发展。
伟大的程序员有了目标不会只是想象,他们会具体实施。他们会根据具体情况,在预期的时间做具体的事情。他们会详细地制订明年的计划,包括要上的课程、要完成的项目甚至包括他们需要建立的人际关系。
15、组织技巧
把所有事情整合在一起的最关键要素是组织。你可能是世界上最好的程序员,但如果你不善于组织你所做的事儿,你的工作将陷入瘫痪,最终丧失优势。伟大的程序员保持自己工作平台的整洁有序,保留所有的笔记并调理清晰。他们标出自己的会议日程表。他们有专门的收件箱给日程邮件、会议和新任务分类。他们保留文档并能在需要时迅速找到所需。
额外要提到的:激情
伟大的程序员如果没有热情,那么他的工作也并不伟大。好的程序员有了热情来对待他的工作、方案和团队,那么他比伟大的程序员还要伟大。
在回顾的时候,我用这些标准来评判我的开发团队。我给我的团队尽可能最好的环境,作为回报,我想要他们都成为最伟大的程序员。你可以用这些标准来评判你的团队,或者你本身就是一名程序员,请用这张列表来尽可能地改造自己来超越同侪。
备注:Generics是程序设计语言的一种技术,指将程序中数据类型进行参数化,它本质上是对程序的数据类型进行一次抽象,扩展语言的表达能力,同时支持更大粒度的代码复用。对于一些数据类型参数化的类和方法来说,它们往往具有更好的可读性、可复用性和可靠性。在设计集合类和它们的抽象操作时,往往需要将它们定义为与具体数据类型无关,在这种情况下,使用Generics就是非常适合的。
英文原文链接:http://www.realsoftwaredevelopment.com/2007/08/how-to-rate-a-s.html
posted @
2007-11-12 11:16 CoderDream 阅读(385) |
评论 (0) |
编辑 收藏
1、
应用软件系统架构设计的“七种武器”
2、
如何进行软件架构设计?
3、
动态扩展struts-menu
posted @
2007-11-10 22:51 CoderDream 阅读(546) |
评论 (0) |
编辑 收藏作者:高艳明(来源:51CMM) http://www.csai.cn 2003年05月19日
原文链接:http://edu.csai.cn/rjsp/NO000014.htm
引子
CMM理论和知识是最近几年的热点,在最近两年的系统分析员上午试卷中都有一题考察CMM知识的,一般有3-5分的样子。估计未来的系统分析员考试还会有这方面的考题。即使不考,我们的系统分析员也应该掌握这方面的知识,因为将来从事的系统分析与设计的工作也离不开CMM理论和知识,因为即使我们所在的公司不去进行CMM评估,CMM理论知识对于我们不断的进行公司的软件过程改进有一定的借鉴意义,从而有助于软件质量的提高,进而提升公司产品的市场竞争力。
摘要
本文是根据这两年试题中涉及CMM知识而特为广大考友搜集整理的关于CMM的基础知识的文章。主要内容是有关CMM的基本概念、CMM的基本框架和对CMM的正确态度等。希望这篇文章对你有所帮助,谢谢。
CMM(Capability Marurity Model,软件能力成熟度模型)是于1984年美国国会与美国主要的公司和研究中心合作创立的一个由联邦资助的非盈利组织——软件工程研究所(Software Engineering Institute,SEI)的一个早期研究成果。该模型提供了软件工程成果和管理方法的框架,自90年代提出以来,已在北美、欧洲和日本成功地应用。现在该模型已成为事实上的软件过程改进的工业标准。下面我们来一起学习有关CMM的一些基础知识。
一、 CMM基本概念
过程(Process):为实现既定目标的一系列操作步骤[IEEE-STD-610].
软件过程(Software Process):指人们用于开发和维护软件及其相关产品的一系列活动、方法、时间和革新。其中相关产品是指项目计划、设计文档、编码、测试和用户手册。当一个企业逐步走向成熟,软件过程的定义也会日趋完善,其企业内部的过程实施将更具有一致性。
软件过程能力(Software Process Capability):描述了在遵循一个软件过程后能够得到的预期结果的界限范围。该指标是对能力的一种衡量,用它可以预测一个组织(企业)在承接下一个软件项目时,所能期望得到的最可能的结果。
软件过程性能(Software Process Performance):表示遵循一个软件过程后所得到的实际结果。(与软件过程能力有区别,软件过程能力关注的是实际得到的结果,而软件过程性能关注的是期望得到的结果。由于项目要求和客观环境的差异,软件过程性能不可能充分反应软件过程整体能力,即软件过程能立受限于它的环境。)
软件过程成熟度(Software Process Maturity):是指一个具体的软件过程被明确地定义、管理、评价、控制和产生实效的程度。所谓成熟度包含着能力的一种增长潜力,同时也表明了组织(企业)实施软件过程的实际水平。随着组织软件过程成熟度能力的不断提高,组织内部通过对过程的规范化和对成员的技术培训,软件过程也将会被他的使用者关注和不断修改完善。从而使软件的质量、生产率和生产周期的到改善。
CMM是软件过程能力成熟度模型(Capacity Maturity Model)的简称,是卡内基-梅隆大学软件工程研究院为了满足美国联邦政府评估软件供应商能力的要求,于1986年开始研究的模型,并于1991年正式推出了CMM 1.0 版。CMM自问世以来备受关注,在一些发达国家和地区得到了广泛应用,成为衡量软件公司软件开发管理水平的重要参考因素和软件过程改进事实上的工业标准。
CMMI(Capability Maturity Model Integration)即能力成熟度模型集成,这也是美国国防部的一个设想,他们想把现在所有的以及将被发展出来的各种能力成熟度模型,集成到一个框架中去。这个框架有两个功能,第一,软件获取方法的改革;第二,建立一种从集成产品与过程发展的角度出发、包含健全的系统开发原则的过程改进。
关键过程(区)域(Key Process Area)是指一系列相互关联的操作活动,这些活动反映了一个软件组织改进软件过程时所必须满足的条件。也就是说,关键过程域标识了达到某个成熟程度级别时所必须满足的条件。在CMM中一共有18个关键过程域,分布在第二至五级中。
关键实践(Key Practices):是指关键过程域种的一些主要实践活动。每个关键过程域最终由关键实践所组成,通过实现这些关键实践达到关键过程域的目标。一般情况下,关键实践描述了该“做什么”,但没有规定“如何”去达到这些目标。
软件过程评估(Software Process Assessment)是用来判断一个组织当前所涉及的软件过程的能力状态,判断下一个组织所面向得更高层次上的与软件过程相关的课题,以及利用组织的鼎力支持来对该组织的软件过程进行有效的改进。
软件能力评价是(Software Capability Appraisal)用来判断有意承担某个软件项目的软件组织的软件过程能力,或是判断已进行的软件过程所处的状态是否正确或是否正常。
软件工程组(Software Engineering Group):负责一个项目的软件开发和维护活动的团体。活动包括需求分析、设计、编码和测试等。
软件相关组(Software Related Groups):代表一种软件工程科目的团体,它支持但不直接负责软件开发或维护工作,如软件质量保证组、软件配置管理组合软件工程过程组等等。在CMM的关键实践中,软件相关组通常应该根据关键过程域和组织的上下文来理解。
软件工程过程组(Software Engineering Process Group):是由专家组成的组,他们推进组织采用的软件过程的定义、维护和改进工作。在关键实践中,这个组织通常指“负责组织软件过程活动的组”。
系统工程组(System Engineering Group):是负责下列工作的个人的团体:分析系统需求;将系统需求分配给硬件、软件和其他成分;规定硬件、软件和其他成分的界面;监控这些成分的设计和开发以保证它们符合其规格说明。
系统测试组(System Test Group):是一些负责策划和完成独立的软件系统测试的团体,测试的目的是为了确定软件产品是否满足对它的需求。
软件质量保证组(Software Quality Assurance Group):是一些计划和实施项目的质量保证的团体,其工作目的是保证软件过程的步骤和标准是否得到遵守。
软件配置管理组(Software Configuration Management Group):是一些负责策划、协调和实施软件项目的正式配置活动的团体。
培训组(Training Group):是一些负责协调和安排组织培训活动的团体。通常这个组织负责准备和讲授大多数培训课程并协调其他培训方式的使用。
二、 CMM 的基本框架
任何一个软件的开发、维护和软件组织的发展离不开软件过程,而软件过程经历了不成熟到成熟、不完善到完善的发展过程。它不是一朝一夕就能成功的,需要持续不断的对软件过程进行改进,才能取得最终的成效。CMM就是根据这一指导思想设计出来的。该模型为了正确和有序地引导软件过程活动的开展,建立一个能够有效地描述和表示的软件过程的改进框架,使其能够对各阶段软件过程的任务和管理起指导作用。该模型一产品质量的概念和软件工程的经验教训为基础,指导企业如何控制开发、维护软件的生产过程和如何制定一套与之相适应的软件过程及管理体系。
(一)分级标准
CMM模型描述和分析了软件过程能力的发展程度,确立了一个软件过程成熟程度的分级标准,如图1示。一方面软件组织利用它可以评估自己当前的过程成熟度,并以此提出严格的软件质量标准和过程改进的方法和策略,通过不断的努力去达到更高的成熟程度。另一方面,该标准也可以作为用户对软件组织的一种评价标准,使之在选择软件开发商时不再是盲目的和无把握的。

图 1 软件过程成熟度的级别
CMM的分级结构可以描述为:
①、初始级:软件过程的特点是无秩序的,有时甚至是混乱的。软件过程定义几乎处于无章法和步骤可循的状态,软件产品所取得的成功往往依赖于极个别人的努力和机遇。
②、可重复级:已建立了基本的项目管理过程,可用于对成本、进度和功能特性进行跟踪。对类似的应用项目,有章可循并能重复以往所取得的成功。
③、已定义级:用于管理的和工程的软件过程均已文档化、标准化,并形成了整个软件组织的标准软件过程。全部项目均采用与实际情况相吻合的、适当修改后的标准软件过程来进行操作。
④、以管理级:软件过程和产品质量有详细的度量标准。软件过程和产品质量得到了定量的认识和控制。
⑤、优化级:通过对来自过程、新概念和新技术等方面的各种有用信息的定量分析,能够不断地、持续地对促进过程进行改进。
除第一级外,每一级都设定了一组目标,如果达到了这组目标,则表明达到了这个成熟级别,自然可以向下一级别迈进。CMM体系不主张跨级别的进化。因为从第二级开始,每一个低级别的实现均是高级别实现的基础。
(二)CMM的主要内容
CMM为软件企业的过程能力提供了一个阶梯式的进化框架,它采用分层的方式来解释起组成部分,如图2示。在第二至第五个成熟等级中,每个等级包含一个内部结构的概念,关于内部结构详细描述将在下面CMM内部结构的一栏中进行。

图 2 CMM的五个成熟等级
每一级向上一级迈进的过程中都有其特定的改进计划,具体情况如下。
初始级的改进方向是:建立项目过程管理,是使规范化管理,保障项目的承诺;艳进行需求管理方面的工作,建立用户域软件项目之间的沟通,使项目真正反映用户的需求;建立各种软件项目几乎,如软件开发计划、软件质量保证计划、软件配置管理计划、软件测试计划、风险管理计划及过车改进计划等;积极开展软件质量保证活动(SQA)。
可重复级的改进方向是:不再按项目制定软件过程,而是总结各种项目的成功经验,使之规则化,把具体经验归纳为权组织的标准软件过程,把改进软件组织的整体软件过程能力的软件过程活动,作为软件开发组织的责任;确定全组织的标准软件过程,把软件工程及管理活动集成到一个稳固确定的软件过程中,从而可以跨项目改进软件过程效果,也可以作为软件过程剪裁的基础;建立软件工程过程小组(SPEG)长期承担评估域调整软件过程的任务,以适应未来软件项目的要求;积累数据,建立组织的软件过程库及软件过程相关的文档;加强培训。
已定义级的改进方向是:着手软件过程的定量分析,已达到定量地控制软件项目过程的效果;通过软件的质量管理达到软件质量的目标。
已管理级的改进方向是:防范缺陷,不仅在发现了问题能及时改进,而且应采取特定行动防止将来出现这类缺陷;主动进行技术改革管理、标识、选择和评价新技术,是有效的新技术能在开发组织中实施;进行过程变更管理,定义过程改进的目的,经常不断地进行过程改进。
优化级的改进目方向是:保持持续不断的软件过程改进。
(三)CMM的内部结构
CMM为软件过程能力的提高提供了一条改进的途径。CMM由5个成熟度等级组成,每个成熟度等级有着各自的功能。除第一级外,CMM的每一级按完全相同的内部结构构成的,如图3。成熟度等级为顶层,不同的成熟度等级反映了软件组织的软件过程能力和该组织可能实现预期结果的程度。

图3 CMM的内部结构图
在CMM中,每个成熟度等级(第一级除外)规定了不同的关键过程域,一个软件组织如果希望达到某一个成熟度级别,就必须完全满足关键过程域所规定的要求,即满足关键古城域的目标。每一级的关键过程域的详细情况见表1。

表1 关键过程域的分类
(四)软件过程评估和软件能力评价
软件过程评估所针对的是软件组织自身内部软件过程的改进问题,目的在于法子按缺陷,提出改进方向。评估组以CMM模型为指引调查、鉴别软件过程中的问题,翻过来将这些问题与CMM关键实践活动所提出的指导一起用于确定组织的软件过程改进策略。
软件能力评价是对接受评价者在一定条件下、规定时间内能否完成特定项目的能力考核,即承担风险的系数大小。评价包括承包者是否有能力按计划开发软件产品,是否能按预算完成等。通过利用CMM模型确定评价结果后,就可以利用这些结果确定选择某一承包商的风险。也可以用来判断承包者的工作进程,推动他们爱进软件过程。
CMM为评估和评价提供了一个参考框架,指出了在评估和评价中通常采用的佛农步骤,如图4示。

图 4 软件过程评估和软件能力评价的步骤
具体来说,评估过程是:选择一个工作组;完成问卷调查和取样工作;结果分析;现场访问;与CMM模型对照分析;依据关键过程域的基本情况列出评估提纲。以上步骤在软件过程评估和软件能力评价题勾勒很有参考价值的方法,但在具体操作时以下这些特点也值得考虑:
①、在现场访问和考察中,充分运用成熟度问卷和结果分析为依据。
②、以CMM模型作为现场调查的路线图。
③、利用CMM中的关键过程域定义软件过程中的优点和缺陷,从中发现差异。
④、对关键过程域目标是否备满足的实际情况出发,分析满意程度,写出书面报告。
尽管软件过程评估和软件能力评价有很多相似之处,但由于其目的和结果的不同,它们之间的差异也是必然存在的,如:
①、软件过程评估和软件能力评价在出发点和目标上的不同,使得会谈目的、调查范围、收集的信息和输出的表示方式上有着本质的不同。尤其在一些细节规范方面,评估和评价的方法有很大差异。
②、软件过程评估和软件能力评价的结果和结果所起的作用不同。因为两者的侧重点不一样,即使是对同一个应用项目,运用相同的方法,也不会得出相同的结果。
③、被评估和评价单位的态度对评估和评价活动的影响。评估在某种意义上被评估单位的态度较积极,而评价在某种意义上被评价单位的态度可能比较慎重。软件过程评估是在一个开放的、互相协作的环境中进行的,而软件能力评价往往是在有较大的阻力的环境中进行的。
(五)CMM的组织保证
当人们面对CMM实施时,首先想到的就是人员的构成和各种小组的划分。它是实施CMM的组织保证,是一切活动的基础。CMM在制定软件过程实施中本着尽量不和具体的组织机构和组织形式相联系的原则,为的是提供一个独立于具体企业而又有广泛指导意义的模型框架。但在实施各种软件关键实践中,不可避免地要涉及到角色和组织结构。所以为了使CMM能够使用域各种级别和各种规模的企业,SEI提出了一个相对抽象的组织结构,它与组织、项目、人员(角色)相关联,具有自己特定的术语,而且可能不同于其他组织所用的名词。例如基本概念中提到的主要的软件工作组的概念。
三、 正确的态度看待CMM
SEI的CMM并不是软件开发的方法学,也不是产品模板,更不是过程法律。CMM是过程改进的途径,是一套指南,帮助你通过持续的重复、测量和提炼,稳步创造与净化开发环境。CMM的假定是:如果你实施一个不断重复、测量和提炼的大纲,作为环境改进的副产物,质量便会自然的提高。不要把CMM设想为一套规则,而应将它理解为一个学科,做事的一般方法。在这套指南下运作,你会发现这里有着广阔的空间,让你剪裁和塑造自己的大纲,以适应组织的特定要求。
CMM不采用“用这种方法做这类事”的风格,它也不对由问题的IT组织提供快速的纠正方案。CMM是一个指南针,指导你如何逃离暴风雪。CMM是一个大纲,要求你对整个IT组织的有关部分,从高层领导到软件生产的第一次线工作者,都做出坚定的、长期的实施承诺。成熟的过程不可能在已也之间实现。
在如何解释CMM建议时,它允许极大的灵活性。CMM意识到,IT组织之间存在着很大的差别。他们的客户不同,使用的工具不同,人员智力和专业背景不同,从事的项目属于不同的类型,规模大小不同,要求也各不相同。因而,他们应当以自己的方式走向成熟。在一处活用的东西,在另一处未必适用。这一点非常重要,中国部分软件公司的前车之鉴也从某种程度上给了我们建议和经验教训,那就是,要灵活应用CMM,不要幻想一夜就有成效。
小结
本文只是根据这两年的试题和自己的预测向广大系分考友提供一些CMM方面的知识。CMM不是重点,但也有可能会考到一些知识,如基本概念等。在搜集资料和整理着篇文章时,遇到了一个矛盾,那就是:我要提供足够的资料以使读者不必花费金钱再去买一本书就可以复习有关CMM的知识,而同时又不能放太多的内容使读者浪费太多的时间在这上面。最后采取了一个折衷的办法,那就是尽量满足考试需求的情况下减少篇幅。在此声明,本文所涉及的内容只是本人的预测,并不是说考试范围不会超过本文的内容。所以有时间的朋友还是尽可能的扩大这方面知识面。希望这篇文章对你有帮助,谢谢。
posted @
2007-11-10 22:44 CoderDream 阅读(264) |
评论 (0) |
编辑 收藏不同于单机游戏和网络游戏,Flash游戏大多为休闲型的小游戏。尽管如此,不少可玩性很高的Flash游戏还是会让我们津津有味的玩上一整天。这里有10款老外们选出来的最容易上瘾的Flash游戏,准备好沉迷吧。
01 - Bejeweled

02-Chimgam

03-Bow Man
04-Tower Defense
访问:10款最容易上瘾的Flash游戏
posted @
2007-11-07 14:53 CoderDream 阅读(415) |
评论 (0) |
编辑 收藏
所谓“80后”,是指22~27岁之间、受过高等教育、刚刚毕业走向社会或者拥有几年工作经验年轻的一代。
不可否认,“80后”已成为职场上迅速成长的中竖力量,尤其是在国内的研发领域。每个时代都有自己的特点,如果用几个比较典型的正面词句形容他们应该是:聪明、有主见、有能力。
那身为“80后”的技术人员找工作为什么还这么难呢? 因为,还可以用几个比较典型的负面词句形容他们:缺乏责任感、定位不清、困难而退。
从参加面试看责任感
就拿面试这件事来说吧,流程大多是:电话简单沟通,约时间?初试(开发人员多是笔试)?复试?确认薪水、上班时间入职。
十一长假之前的一周,某公司约候选人参加研发笔试、面试。在约面试的电话里,公司特别强调如果您本周不方便(很多候选人会回老家),我们可以把笔试(面 试)安排在十一之后进行。有12人在电话里说可以到公司参加笔试,令人失望的是,笔试当天只来了3位,其余8人在未做任何说明的情况下没有出现。
因为开发人员是所有应聘者中素质最高的群体,公司前台打电话向每个未到的候选了解原因,看看是在电话里没说清地址,还是别的什么原因,导致了大家的缺席。最终的反馈是:2人电话不接、2人电话关机、4人临时有事。
……
每次与公司技术负责人或者HR沟通,”80后”的职业素质都会成为核心话题之一。而缺乏责任感又是最经常被提到的。候选人认为面试不来,对自己只不过是少 个求职机会而已,公司则认为这件事足以体现候选人对工作没有责任心。有这种品质在身,很难让我们在事业上有什么建树。
所谓一花一世界,求职过程中任何点上体现出缺乏责任感都会被马上淘汰。公司的逻辑是:如果不负责任的人进了公司,那么造成的损害绝不止耽误时间这么简单,很可能是项目的延误甚至是失败。
不可否认,现在就业压力大,大部分人都对求职抱的态度都是普遍撤网重点培养。得到面试通知后,发现公司离家太远或者刚好被另一家录用的事儿时有发生。“中国这么大,接到面试不去的又不是我一个,没什么大不了。”也是很多人的正常想法。
我们回头看看这种行为给同龄人带来的伤害吧——由于相当部分”80后”技术人员在面试给人留下没有责任感的印象,很多公司规定关键岗位不用25岁以下人 士。更有甚者,因为几个人的原因,某学校的毕业生在公司都成为不约见面试的对象。也许我们已找到工作,安然自得,但同龄人呢?校友呢?是否有必要更多考虑 一下。
其实,比默默消失更恰当的处理方式有很多,这不但能体现自身素质、节省双方时间,还能为自己赢得机会。比如:
可以在电话里直接说因为路远、已有工作机会希望下次合作,即礼貌回绝(这样节省双方时间);
也可告诉HR时间不方便,能否另外安排时间(相信任何智力正常的公司HR相信都会另行安排沟通时间);
如果能在得知是哪家公司通知我们面试之后,能说出公司的情况,必然能在面试之前为我们自己加分。只需要事先做小小功课,上网看一下公司介绍即可。(体现我们的高素质)。
如此,即会竖立”80后”的风采,也会被冠以XX学校毕业生素质高的赞誉,何乐而不为!
从谈薪水看自我定位
80年代的研发候选人对自己的认识常走两个极端,要么疯狂自信、要么超级自卑,归根到底还是对自己的认识不清楚,难以准确定位自己、定位自己在群体中的地位。很多候选人因此失去了机会。
疯狂自信
只在公司工作三周即被辞退的小F
拥有2年的JAVA开发经验的F面试时向公司要求5K薪水。此时的他自信满满。“我就值这么多!”这是F在谈及薪水时说的一句话。
公司方面综合笔试、面试的结果,给出的薪水范围是3K——4K。
HR:“公司希望你能在工作中证明自己的能力。试用最多能提供3K的薪水,如果能顺利转正,我相信薪水会达到您的要求。这样可以吗?”
F:“行吧。希望公司能信守承诺。”
只是短短的3周之后,F就被公司解聘。理由很简单,水平不足、学习能力一般,加之对自己不切实的定位导致了眼高手低。部门最后的意见是:此人工作中的能力不足,短期内也很难提高,建议此人即刻解聘。
自信,也请以能力为基础!
超级自卑
自信相对的是自卑。谈及薪水。很多候选人以“在这儿生活费太贵,公司支付的薪水要满足生活吧!”为理由提出薪水要求。而不是从能给公司做出什么贡献、如何体现自身价值为出发点提出薪水要求。
这背后反映的是“我不知道自己为什么应该拿这么多钱!我也不知道自己值多少!为什么值!”
无论是疯狂自信,还是超级自卑,技术管理层普遍对此有一个共识——不能认清自己的人,干好工作的机率和效率都会很低。定位不清的候选人很难被录用,企业认为与其找这种人来拖项目后腿,不如不用。
不像欧美国家,开发人员职业发展稳定、有明确的晋升路线,做为快速发展的社会国内形式变化太快,很多时候我们无所适从也是客观条件导致,比如:今天还在做开发,明天可能就被转去支持销售成为售前等等。很多时候,我们对自己不是不想定位,是无法定位。
掌握下面一些基本方法,也话让我们机会给自己相对准确的定位。
1. 先按以下渠道了解市场价
向资力相当、已找到工作的朋友询问薪水情况(大概范围即可),从而了解自己平均市值;
请教自己的师兄、师姐,能力出从的他们一定已工作有成,从他们那里可以掌握薪水几年后的增长情况。
2. 正确估价
了解目前自己同龄人的薪水之后,给自己估个起薪(原则是:比你自己认为的薪水,至少低一档。掌握全面信息之后,我们反而可能倾向于高估自己的价格),然后向应聘公司咨询入职几年后的薪水增长情况,最终做综合判断。
入职即闪看对待困难的态度
下面说说最让部门经理和HR感到疯狂的事吧——入职即闪。
这也是最让公司发疯的事之一。
求职过程中,无论是公司,还是候选人都付出了时间成本、精力成本,双方确定合作意向之后,候选人入职成为了公司正式员工。求职时信誓旦旦的候选人,只工作了1周(1天)就一声不吭地离开了公司,当被问及理由时,多回答:“工作不适合自己”。
应该说这个理由是对公司和候选人自己的极大嘲弄——双方都缺乏判断力,公司不知道应该找什么样的人加盟,候选人不知道真正来干什么、什么是适合自己的。
以上现象的原因可能有:
工作压力大
社会竞争的加剧导致了每个公司必须全力做到最好,才有可能生存。公司面临的压力,在工作中被完全转嫁给员工。但刚刚走出校门的”80后”没有做好这方面的 准备,巨大压力扑面而来的时候感觉不知所措,比如:入职第一天简单培训之后就开始代码的编写或者对产品的支持,更多的东西要在工作中学。
很多人说“80后”像草莓,表面看起来很光鲜,但不能碰、也不能压。这也许是真的,但更重要的是处事的方法。
遇到压力、困难,没有正确解决方法
因为只要工作,都会有压力,大小不同而已。逃避无疑是面对压力时,成本最低的方法,但长远来看也是代价最高的方法。
“入职即闪”的离开,不会令公司感到惋惜。试想公司是不愿意请不能正确面对和处理压力的人加盟的。
当然,很多公司没有完善的入司 管理制度,培训不到位,新人入职不安排专人带领熟悉情况是绝大部分公司存在的问题。这导致了工作中遇到的困难比想向的大、遇事找不到或者没有正确解决方 法,于是造成了离职。这可能也是很多人原因进500强的原因,有完善的培训、升职、薪酬体系。
关于处理压力的方法我们先分享下面的故事。
某家长常教育孩子做事要竭尽全力,一天孩子与父母出门,发现路边石头很漂亮,想搬块大石头回家收藏,抱起之后走了一段路,因为石头太重搬不动了。虽然舍不 得,但已没有力气,孩子准备放弃。此时,父亲到流泪的孩子身边问:“做事不是要尽全力吗?”孩子回答:“确实没有力气了。”“有啊!”父亲边说,边抱起石 头大步走向家的方向,“!永远不要忘记,我也是你力量的一部分!”
工作中,在我们尽力之后,还有无法处理的困难、无法面对的压力,那么向更有经验的同事、朋友请教是个好方法。相信我们的现在正是他们的昨天,我们正在经历的他们都经历过,在如果正确应对和处理方面,他们一定会特别愿意分享经验、帮助我们。
无法处理时,救助可能是最好的方法。不要害怕说出“帮我一下!”这句话。
在成长型的公司里,大家互相帮助会成为一种习惯,成为一种企业文化。相信这种文化也是“80后”一代所期望的。大家一起面对压力、处理问题会比一个人独自解决问题用时更短、效率更高。
写在最后的话
以上事件中出现的候选人均为“80后”。曾经有人说,不要以时间来划分人,因为每个人的情况都有不同。与此同时,我们更应该承认:每一个时代的人都有自己的共同社会背景和大环境,这些东西造就了很多共同的特征。所以,“60后”、“70后”、“80后”这样的划分为我们的判断提供了基础。
在经历了3000场面试之后,我可以肯定地说,与同龄人相比“80后”的技术人员给公司HR留下的印象是:更具可素性、拥有更高的可信度、更有潜力。他们正在(已经)成为技术队伍中的生力军!
面对压力大、社会变化快,尤其是开发知识不断更迭的新一代职场人,必然要磨砺出比上一代更有效的方法正确应对。这是社会发展的要求,应该也是我们自我提高的必由之路。
posted @
2007-11-07 14:47 CoderDream 阅读(388) |
评论 (0) |
编辑 收藏
下载方法:不能直接用下载工具下载,要先进入页面,然后点击下载,就可以用迅雷等下载工具下载了:
1、Addison Wesley.Core Javaserver Faces
http://cid-220e2223d106b456.skydrive.live.com/self.aspx/Public/JSF/Addison%20Wesley.Core%20Javaserver%20Faces%20Jun%202004.chm.rar
2、Manning.JavaServer.Faces.in.Action
http://cid-220e2223d106b456.skydrive.live.com/self.aspx/Public/JSF/Manning.JavaServer.Faces.in.Action.pdf.rar
3、Appress Pro JSF and Ajax Building Rich Internet Components
http://cid-220e2223d106b456.skydrive.live.com/self.aspx/Public/JSF/Apress.Pro.JSF.and.Ajax.Building.Rich.Internet.Components.Feb.2006.pdf.rar
4、OReilly.JavaServer Faces JSF
http://cid-220e2223d106b456.skydrive.live.com/self.aspx/Public/JSF/OReilly.JavaServer%20Faces%20JSF.rar
5、Wiley.Mastering.JavaServer.Faces
http://cid-220e2223d106b456.skydrive.live.com/self.aspx/Public/JSF/Wiley.Mastering.JavaServer.Faces.Jun.2004.pdf.rar
posted @
2007-11-07 11:22 CoderDream 阅读(1258) |
评论 (3) |
编辑 收藏
1、live.com,将浏览器的语言改为en-us,通过下面的链接进入:
http://get.live.com/en-us/wl/signup
2、live.cn,将浏览器语言改为zh-cn,通过下面的链接进入:
http://get.live.com/getlive/overview
posted @
2007-11-07 10:38 CoderDream 阅读(399) |
评论 (0) |
编辑 收藏
01、
Eclipse中使用正则表达式进行多行替换
02、
JSEclipse,加速Eclipse下的JavaScript开发
03、
全面解析腹部锻炼四误区
04、
了解 Java EE 5
05、
在 Eclipse Help 中如何组织 Java API 参考文档
06、
uml时序图
posted @
2007-11-06 17:43 CoderDream 阅读(237) |
评论 (0) |
编辑 收藏一:申请一个tom的邮箱,并且设置一下邮件到达免费短信提醒。(30条每月,超出部分不提醒,不收费。)
二、打开Gmail的设置,在转发和POP(Forwarding and POP)中把Gmail的邮件转发到新申请的tom的邮箱中,并且将原件保存在Gmail中。
 (选择“将所接收邮件的副本转发至”(Forward a copy of incoming mail to),在后面填入新申请的tom邮箱,选择将Gmail副本保存在“收件箱”中(keep Gmail’s copy in the inbox))
(选择“将所接收邮件的副本转发至”(Forward a copy of incoming mail to),在后面填入新申请的tom邮箱,选择将Gmail副本保存在“收件箱”中(keep Gmail’s copy in the inbox))
posted @
2007-11-05 16:21 CoderDream 阅读(3186) |
评论 (3) |
编辑 收藏
Class类中,我们使用最多的就是forName()方法和newInstance()方法。
1、使用forName()方法时,即使引用同一个包中的类,也要写完整的包名,如:
try {
Printable p1 = (Printable) Class.forName(
"com.coderdream.chapter21.proxy.a1.Printer").newInstance();
} catch (Exception e) {
System.out.println("Nooo");
}
接口Printable和类Printer在同一个包中,但也要写完整的包名,否则抛出异常,提示找不到Printer类。
2、使用newInstance()方法时,如果不存在无参的构造函数,也会报找不到Printer类。
这一点很容易忽略,而且很难找到错误,我们经常会写一些带参数的构造函数。而此处的newInstance()方法是会调用默认构造函数,如果不存在会抛出找不到类的异常。
posted @
2007-11-05 14:48 CoderDream 阅读(249) |
评论 (0) |
编辑 收藏
01、
JBoss Seam:一个深度集成框架(一)
02、
JBoss Seam en
03、
Ajax for Java developers: Write scalable Comet applications with Jetty and Direct Web Remoting
04、
Sun JNDI教程翻译 第一部分 Getting Started
05、
Apache commons 包使用:A simple text email
posted @
2007-11-02 18:01 CoderDream 阅读(251) |
评论 (0) |
编辑 收藏
01、
struts2入门之HelloWorld
02、
忙里找闲,自写了一个StrutsConfig配置文件条件查找工具(不断改进中)
03、
Subversion之路---实现精细的目录访问权限控制<转>
04、
JDBC中的日期问题
05、
使用HttpUnit进行集成测试(转载)
06、
引领你的一生
07、
Hashtable和HashMap类的区别
08、
项目经历系列(二):计划和预测能力以及准备能力(仅做为与好友探讨的材料)
09、
测试 servlet(转)
10、
五种提高 SQL 性能的方法
11、
javascript中函数的深入理解
12、
50本书总结的50句话(转载)
13、
请不要做浮躁的人---转载
14、
14个助你成功的心理定律-----转载
15、
Spring+hibernate+DWR整合
16、
log4j的ConversionPattern参数的格式含义
17、
Struts2.0文件上传-文件尺寸问题
18、
代码规范(转)
19、
spring事务探索 [转]
20、
To install JSEclipse
21、
树的查询
22、
JAVA代码查错
23、
java面试题
24、
SSH实现分页
25、
HTML标签
26、
Spring学习笔记 2007-10-31
27、
取石子游戏
posted @
2007-11-01 11:56 CoderDream 阅读(274) |
评论 (0) |
编辑 收藏
01、
应用程序服务器与web服务器的关系
02、
Java的一些小细节(四)Collection——《HardCore Java》
03、
java反射基础
04、
Java 中的堆和栈(转)
05、
俞敏洪:不要为眼前的得失而抓狂
06、
Facebook详解 涵盖发展历史和系统模型
posted @
2007-11-01 11:01 CoderDream 阅读(258) |
评论 (0) |
编辑 收藏
某些时候,我们希望读写某个包下面的文件,例如包com.coderdream.chapter20.flyweight.sample下的txt文件,但我们并不想把文件写成绝对路径。
解决办法:
1、我们可以通过新建一个空文件,然后的到当前文件的绝对路径;
2、然后用这个路径+文件夹名来新建一个BufferedReader。
这样就可以顺利读取包中的文件了。
1 /**
2 * 构造函数
3 *
4 * @param charname
5 */
6 public BigChar(char charname) {
7 this.charname = charname;
8 try {
9 File file = new File("");
10 String s = file.getAbsolutePath();
11 BufferedReader reader = new BufferedReader(new FileReader(s
12 + "\\src\\com\\coderdream\\chapter20"
13 + "\\flyweight\\sample\\big" + charname + ".txt"));
14 String line;
15 StringBuffer buf = new StringBuffer();
16 while ((line = reader.readLine()) != null) {
17 buf.append(line);
18 buf.append("\n");
19 }
20
21 reader.close();
22 this.fontdata = buf.toString();
23 } catch (IOException e) {
24 this.fontdata = charname + "?";
25 }
26 }
posted @
2007-10-31 17:36 CoderDream 阅读(635) |
评论 (0) |
编辑 收藏 1 /**
2 * MapTest.java
3 *
4 * Provider: CoderDream's Studio
5 *
6 * History
7 * Date(DD/MM/YYYY) Author Description
8 * ----------------------
9 * Oct 31, 2007 CoderDream Created
10 */
11 package com.coderdream;
12
13 import java.util.HashMap;
14 import java.util.Iterator;
15 import java.util.Map;
16 import java.util.TreeMap;
17
18 /**
19 * @author CoderDream
20 */
21 public class MapTest {
22
23 /**
24 * <pre>
25 * 使用HashMap使用1:
26 * 用迭代器得到map.entrySet(),
27 * 然后通过迭代得到Map.Entry对象,最后打印。
28 * 打印结果未排序
29 * </pre>
30 *
31 */
32 public void f1() {
33 Map map = new HashMap();
34 map.put("1", "Level 1");
35 map.put("2", "Level 2");
36 map.put("3", "Level 3");
37 map.put("4", "Level 4");
38 map.put("F", "Level F");
39 map.put("Q", "Level Q");
40 Iterator it = map.entrySet().iterator();
41 while (it.hasNext()) {
42 Map.Entry e = (Map.Entry) it.next();
43 System.out.println("Key: " + e.getKey() + "; Value: "
44 + e.getValue());
45 }
46 }
47
48 /**
49 * <pre>
50 * 使用泛型模式说明Map中存储的对象类型
51 * </pre>
52 */
53 public void f2() {
54 Map<String, String> map = new HashMap<String, String>();
55 map.put("1", "Mon.");
56 map.put("1", "Monday");
57 map.put("one", "Monday");
58 Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
59
60 while (it.hasNext()) {
61 Map.Entry entry = it.next();
62 System.out.println(entry.getKey() + ":" + entry.getValue());
63 }
64 }
65
66 /**
67 * <pre>
68 * 通过集合Set来得到HashMap中的对象
69 * </pre>
70 *
71 */
72 public void f3() {
73 Map map = new HashMap();
74 map.put("1", "Mon.");
75 map.put("1", "Monday");
76 map.put("one", "Monday");
77 Iterator it = map.keySet().iterator();
78 String tmpKey = null;
79 while (it.hasNext()) {
80 tmpKey = (String) it.next();
81 System.out.println("Key: " + tmpKey
82 + "; Value: " + map.get(tmpKey));
83 }
84 }
85
86 /**
87 * <pre>
88 * 使用TreeMap代替HashMap,取得结果是排序后的结果
89 * </pre>
90 */
91 public void f4() {
92 Map map = new TreeMap();
93 map.put("1", "Level 1");
94 map.put("2", "Level 2");
95 map.put("3", "Level 3");
96 map.put("4", "Level 4");
97 map.put("F", "Level F");
98 map.put("Q", "Level Q");
99 Iterator it = map.entrySet().iterator();
100 while (it.hasNext()) {
101 Map.Entry e = (Map.Entry) it.next();
102 System.out.println("Key: " + e.getKey()
103 + "; Value: " + e.getValue());
104 }
105 }
106
107 /**
108 * @param args
109 */
110 public static void main(String[] args) {
111
112 MapTest mt = new MapTest();
113 System.out.println("----------f1()----------");
114 mt.f1();
115 System.out.println("----------f2()----------");
116 mt.f2();
117 System.out.println("----------f3()----------");
118 mt.f3();
119 System.out.println("----------f4()----------");
120 mt.f4();
121 }
122 }
输出结果:
----------f1()----------
Key: 3; Value: Level 3
Key: 2; Value: Level 2
Key: F; Value: Level F
Key: 1; Value: Level 1
Key: Q; Value: Level Q
Key: 4; Value: Level 4
----------f2()----------
1:Monday
one:Monday
----------f3()----------
Key: 1; Value: Monday
Key: one; Value: Monday
----------f4()----------
Key: 1; Value: Level 1
Key: 2; Value: Level 2
Key: 3; Value: Level 3
Key: 4; Value: Level 4
Key: F; Value: Level F
Key: Q; Value: Level Q
posted @
2007-10-31 15:05 CoderDream 阅读(5126) |
评论 (0) |
编辑 收藏试用期内常见的劳动纠纷
在毕业生到用人单位报到后,三方协议即告终止,此时用人单位会与其签订一份正式的劳动合同,其中约定了劳动者在单位的试用期限、服务期限、工资待遇及其它各项福利等等事宜,合同签订之后,双方即正式确定了劳动关系。而上述提到的各项约定内容中,试用期是最容易出现纠纷的阶段。因此,关于试用期的法律问题,提醒毕业生以下几点:
试用期时限
试用期是用人单位和劳动者建立劳动关系后为相互了解、选择而约定的不超过六个月的考察期。试用期包括在劳动合同期限中。按照《劳动法》的规定,劳动合同可以约定不超过六个月的试用期。劳动合同期限在六个月以下的,试用期不得超过十五日;劳动合同期限在六个月以上一年以下的试用期不得超过三十日;劳动合同期限在一年以上两年以下的,试用期不得超过六十日;劳动合同期限在两年以上的,试用期也不得超过六个月。必须强调的是,试用期适用于初次就业或再次就业时改变工作岗位或工种的劳动者,续签劳动合同不得约定违约金。
国家机关、高校、医药研究所、医疗行政部门采用见习期,为一年,试用期采用于企业、公司,与医院建立劳动关系的采用试用期,为15日-6个月。见习期可以延长,试用期不能。见习期是具有一定强制力,试用期是双方约定的。
试用期辞职
试用期之所以称为试用,其含义就在于用人单位和劳动者均可在此期间内考察对方是否符合自己的要求,双方都具有较为自由的解除合同的方式。根据<劳动法>第32条之规定,劳动者在试用期内可以随时通知用人单位解除劳动合同。
有些用人单位在劳动合同中约定劳动者在试用期解除合同需承担违约责任,这实际上限制了劳动者的解除权,因此这种约定是侵害劳动者的合法权利的行为,对于这种约定条律,法律一般确认为无效。
试用期辞退
根据<劳动法>第25条规定,劳动者在试用期间被证明不符合录用条件的,用人单位可以解除劳动合同,法律规定得很清楚,用人单位可解除劳动合同的条件是其必须举证证明劳动者在试用期间不符合录用条件。这里毕业生应当明确,用人单位要求解除劳动合同时,举证责任在用人单位,劳动者无需提供自己符合录用条件的证明。
举证责任无疑限制了用人单位解除劳动合同的随意性,用人单位如果没有证据证明劳动者在试用期间不符合录用条件,用人单位就不能解除劳动合同,否则,用人单位需承担因违法解除劳动合同所带来的一切法律后果。
两个试用是否合法
有些用人单位还会在第一个试用期过后与劳动者约定第二个试用期,这种情况应该区别对待。如果前后两个试用期相加超过法律规定的试用期上限的,超过不合法,不超过则两个试用期皆为合法。
只签试用期合同不签劳动合同?
劳动者被用人单位录用后,双方可以在劳动合同中约定试用期,试用期应包括在劳动合同期限内,劳动合同是试用期存在的前提条件。不允许只签订试用期合同,而不签订劳动合同。这样签订的试用期合同是无效的,但“试用期”合同的无效,并不导致劳动法对劳动者的保护失效。北京地区就有规定。北京劳动合同管理规定:只签订试用期合同,试用期后用人单位不愿意再签订劳动合同,劳动者可以反推(如试用期一月,可反推合同期为一年,反推依据按<劳动法>关于试用期的相关规定>另外<上海劳动合同条例>对此也有特别的规定。
Q:
试用期期间单位应该给职工缴纳社会保险吗?
A:1、单位应当为试用期内的劳动者缴纳社会保险。
根据《劳动合同法》规定,试用期包含在劳动合同期限内。既然试用期属于劳动合同期限的范围,员工就有权享受各项社会保险,即养老保险、工伤保险、医疗保险等等。
如果单位没有在职工试用期期间缴纳社会保险,可以在正式签订劳动合同之后为职工补缴。
2、缴!必须缴!
只要和企业建立了劳动关系,不管有无约定试用期,试用期有否通过,企业都有义务为员工缴纳社会基本保险的义务!从入职开始起缴!
试用期劳动者同样受保护
目前,一些用人单位滥用试用期侵害劳动者合法权益,其原因既有现行有关试用期的规定不完善的因素,也有用人单位故意违法的因素,还有有关方面对试用期规定存在错误认识,从而导致法律规定没有得到切实执行的因素。
错误认识之一,认为试用期满后才需要签订劳动合同。根据《劳动法》等规定,试用期是用人单位和劳动者为相互了解、选择而约定的考察期,包括在劳动合同期限中。因此,用人单位招用劳动者,即使是处于试用期中,也应当依法签订劳动合同。
错误认识之二,认为试用期内劳动者不适用最低工资保障制度。原劳动部颁布的《关于贯彻执行〈中华人民共和国劳动法〉若干问题的意见》规定,劳动者与用人单位形成劳动关系后,试用期间在法定工作时间内提供了正常劳动的,其所在的用人单位应当支付其不低于最低工资标准的工资。可见,用人单位支付给试用期劳动者的工资低于当地最低工资标准的,属于违法行为。
错误认识之三,认为可以不为试用期劳动者参加社会保险。根据《社会保险费征缴暂行条例》等规定,用人单位应依法为职工参加社会保险、缴纳社会保险费,职工包括与用人单位有劳动关系的所有个人。这表明,试用期劳动者与用人单位也建立了劳动关系,用人单位必须依法为其参加社会保险并缴费。
用人单位应当摒弃错误认识,自觉遵守有关试用期劳动者权益保护的法律规定。执法部门应全面正确地掌握劳动保障法律法规对试用期劳动者的保护规定,加大执法力度,切实维护试用期劳动者的劳动合同、工资、社会保险等各项权益,使滥用试用期的用人单位无违法得利可图,从而自觉规范用工行为。
posted @
2007-10-31 09:59 CoderDream 阅读(626) |
评论 (3) |
编辑 收藏今年6月29日,十届全国人大常委会第二十八次会议表决通过了《劳动合同法》,并将于2008年1月1日起正式施行。《劳动合同法》历经四次审议修改,寄托了广大劳动者的期待。新法在维护劳动者合法权益方面凸显出不少引人关注的特点。
不签劳动合同 用人单位须按月付双薪
事例:
今年春节前,本报曾接到我市某饭店两位服务员反映:去年7月,她们从临桂县来到市区一家饭店打工。在入职时,她们向老板提出签订劳动合同,老板说,“当个服务员还要签合同,太麻烦了,再说我又不知道怎么写合同条款,大家口头约定工资数额和工作时间就行了。如果你们实在要签合同,只能另谋高就。”为了保住工作,她们没有继续要求老板签订劳动合同。今年春节前夕,她们准备辞职回家过年,老板以她们工作表现不佳为由,扣了她们每人一个月的工资。当她们到有关部门求助时,由于缺乏劳动合同等相关证据,得到的答复是很难处理。
现象:
签订劳动合同不仅可以保护劳动者的权利,还可以保护用人单位的权利。但在实际生活中,一些用人单位为了尽可能降低成本,不愿意对员工承担应有的责任,也就不愿意与劳动者签订劳动合同。日前,记者从秀峰区人事劳动和社会保障局了解到:从7月初开始,该局就对辖区内的中小企业进行了合同签订情况的专项检查。从初步的调查情况来看,餐饮业、旅馆业和建筑业等三大行业的劳动合同签订率相对较低。该局负责人介绍,由于这三大行业的员工流动性大,很多属于临时用工,再加上部分企业的负责人缺乏维护职工权益的意识,因此这些行业中劳动合同的签订率较低。
新法规定:
根据《劳动合同法》的规定,建立劳动关系,应当订立书面劳动合同。已建立劳动关系,未同时订立书面劳动合同的,应当自用工之日起一个月内订立书面劳动合同。如果用人单位自用工之日起超过一个月不满一年未与劳动者订立书面劳动合同的,应当向劳动者每月支付二倍的工资。
杜绝“试用期”成“白用期”
事例:
去年7月,大学刚毕业的小蒋应聘到我市一家电脑公司做技术员。该公司与他口头约定了3个月的试用期,每月工资为600元。如试用期合格,则签订一年的劳动合同,工资提升为900元。3个月试用期满后,该公司相关负责人表示,虽然小蒋工作进步很快,但与公司的要求还有些距离,因此,还要对他再继续考察3个月时间才能考虑转正问题。小蒋为了能留在该公司工作,同意再进行3个月的试用期。又过了3个月后,公司通知小蒋,他在第2次试用期内仍达不到录用条件,不再录用。
现象:
市明辩律师事务所律师王荣长期从事劳动纠纷诉讼代理工作,他告诉记者,近年来,他接手经办的一些劳动纠纷案件中,有相当一部分是因为用人单位单方面任意确定或更改试用期,导致出现劳动纠纷,劳动者在无奈之下只能向劳动部门投诉或向法院起诉。甚至还有些单位还故意利用试用期降低成本,有的单位与劳动者签1年合同,试用期为半年;还有的单位与毕业生签订3年的劳动合同,试用期竟长达12个月;极少数用人单位“创新”出一周时间的“无薪试用期”,工作一周后,直接说劳动者不符合条件,连工资都不给,这主要针对一些在校的高中生或大学生。
王荣介绍,1995年实施的《劳动法》规定:“劳动合同可以约定试用期。试用期最长不得超过6个月。”根据《劳动法》的规定,职工在试用期内达不到录用条件,用人单位可以随时解除劳动合同,并且不用支付经济补偿金。正因如此,一些用人单位利用试用期期间可支付给劳动者少量工资的特点,在试用期快到时就辞退劳动者,或故意延长劳动者的试用期。
新法规定:
《劳动合同法》对试用期作出了明确限定,劳动合同期限三个月以上不满一年的,试用期不得超过一个月;劳动合同期限一年以上不满三年的,试用期不得超过二个月;三年以上固定期限和无固定期限的劳动合同,试用期不得超过六个月。同一用人单位与同一劳动者只能约定一次试用期。以完成一定工作任务为期限的劳动合同或者劳动合同期限不满三个月的,不得约定试用期。试用期包含在劳动合同期限内。劳动合同仅约定试用期的,试用期不成立,该期限为劳动合同期限。劳动者在试用期的工资不得低于本单位相同岗位最低档工资或者劳动合同约定工资的百分之八十,并不得低于用人单位所在地的最低工资标准。
用人单位不得随意要求劳动者支付“违约金”
事例:
近日,原在重庆市一家工业股份公司从事管理工作的小王辞职回桂林。让小王郁闷的是,当他向公司提出辞职时,却被告之:因为所签订的劳动合同尚未到期,他必须向公司支付5000元的违约金。对此,小王虽然心中不满,最终还是付了钱,“毕竟合同上已经写明。”他无奈地说。
黄某原为我市某高校教师,1999年,学校委托南京大学培养研究生,黄某经考试,被南京大学录取为博士研究生。当年1月5日,该高校要求黄某与学校签订一份格式合同《委托培养研究生合同书》,并约定,黄某的10000元培养费由学校支付,其学习期间的工资、生活补贴等均与在校同等职工相同。黄某毕业后必须按时回学校工作,至少得在学校工作5年。如有违约,黄某须4倍偿还读书期间的一切费用。2002年7月,黄某博士研究生毕业后如期回到母校工作。2003年8月,黄某认为学校没有完全支付其读博期间的补助、没有安排好其工作、住房与配偶工作等,离开学校,应聘到温州一所高校担任副教授。某高校认为黄某的行为已违反了合同约定,一纸诉状将他告上法院,请求法院判令被告依照合同4倍偿还其读博士的费用。黄某认为4倍偿还读书期间的一切费用太高。据了解,最后,法院判决黄某赔偿某高校319014.8元。
现象:
事实上,不少企业在与劳动者签订劳动合同时,都会约定一定数额的违约金。从用人单位角度出发,约定违约金,是为了更好地保护用人单位的利益。但有的用人单位约定的违约金数额过高,严重损害劳动者的利益,甚至引起纠纷。
新法规定:
新出台的《劳动合同法》完善了关于违约金的规定:用人单位为劳动者提供专项培训费用,对其进行专业技术培训的,可以与该劳动者订立协议,约定服务期;劳动者违反服务期约定的,应当按照约定向用人单位支付违约金,违约金的数额不得超过用人单位提供的培训费用。用人单位要求劳动者支付的违约金不得超过服务期尚未履行部分所应分摊的培训费用。
用人单位不得向劳动者收取押金、扣押身份证
事例:
陈小姐曾在象山区一家公司上班,入职时按照该公司的要求交纳了200元的“工具保管费”,该公司开具了收据,不过在收据和《劳动合同书》上都未约定这200元如何退还。试用期结束前,陈小姐在另一家公司找到一份工作,于是打算辞职。她在离职时要求该公司退还200元,但该公司以陈小姐已经穿了其中一套工作服为由,只答应退还其中的158元。陈小姐表示不能理解,她认为,公司实际上是利用收取“工具保管费”的名目收取“服装押金”,这是违法的。据陈小姐说,她在入职时就知道不应交纳这笔“工具保管费”,但因为害怕该单位不录取她,只好交了。
现象:
交纳合同保证金、工具押金、服装押金等各种押金和扣押身份证,是一些用人单位为了限制劳动者离职的惯用手段,这在餐饮行业尤为明显。一些餐饮行业的老板告诉记者,由于行业的性质决定了员工流动性特别大,一些不负责任的员工,如果没有约定相关押金或扣押身份证,根本就无法对其进行制约,有些员工签订了一年的劳动合同,但在辞职前往往并没有征得老板同意而直接离开,给饭店造成不小的损失。
除在餐饮行业外,在其他许多行业都有交纳押金或扣押身份证,甚至毕业证的情况,给劳动者造成一定程度的困扰。少数骗子甚至利用劳动者求职心切,以收取押金的方式来骗取不正当利益的。
新法规定:
《劳动合同法》明确规定,用人单位违反规定,扣押劳动者居民身份证等证件的,由劳动行政部门责令限期退还劳动者本人,并依照有关法律规定给予处罚。用人单位违反规定,以担保或者其他名义向劳动者收取财物的,由劳动行政部门责令限期退还劳动者本人,并以每人五百元以上二千元以下的标准处以罚款;给劳动者造成损害的,应当承担赔偿责任。劳动者依法解除或者终止劳动合同,用人单位扣押劳动者档案或者其他物品的,将依法进行处罚。
用人单位拖欠工资、工资过低要加倍偿还劳动者
事例:
去年年初,市民李先生向记者来信反映:他从2005年1月开始在某单位的宿舍当门卫,每天早上6点起床,然后打扫宿舍周围的卫生,之后开始值班直到晚上11点才能休息。有时过了晚上12点,如果有人叫门,还得起床开门,一年从来没有放假时间,单位也没有给他计算过加班工资,他的工资每个月只有320元。后来,他被该单位辞退,有人告诉他当时我市的最低工资标准是460元,因此他每月的收入离当时的最低工资标准还差了140元。
现象:
据调查,在我市的一些行业内,员工月薪低于最低工资标准的并不少见。如一些旧式小区或单位宿舍区的门卫,少数餐饮行业的服务员等,工资每月约在300-400元之间,低于我市现行的每月500元的最低工资标准。一家超市的经理曾对该超市的员工说:“你们对外说自己的工资时,必须说每月高于500元,否则就收拾包袱走人。”
新法规定:
《劳动合同法》规定,用人单位有下列情形之一的,由劳动行政部门责令限期支付劳动报酬、加班费或者经济补偿;劳动报酬低于当地最低工资标准的,应当支付其差额部分;逾期不支付的,责令用人单位按应付金额百分之五十以上百分之一百以下的标准向劳动者加付赔偿金……
劳动合同必须具备社会保险条款
事例:
市民谭小姐在一家减肥中心工作,已经有一年时间,月收入约为1000元,与同行比并不算低,但企业从来没有帮她缴纳过养老保险。谭小姐说:“我以前从来不知道还需要缴纳养老保险,但企业也从来没有帮我缴纳过,我是否应该自行缴纳呢?”
现象:
按照国家规定,企业应当为员工缴纳养老保险。
为完善企业职工基本养老保险制度,前段时间,自治区人民政府出台了《关于完善企业职工基本养老保险制度的决定》,不过由于一些企业的员工,如营业员、服务员等缺乏相关的法律知识,不懂得维护自身的合法利益,而有部分私营企业主也缺乏相关法律意识,不主动帮助员工购买养老保险,这也是目前社会上反映比较强烈的问题。
新法规定:
根据《劳动合同法》,在劳动合同应当具备的条款中已经包括了”社会保险“条款。而增加该条款,主要目的是为了强化用人单位和劳动者的社会保险权利义务意识。同时,也是为了更好地保护劳动者的权益。
posted @
2007-10-31 09:50 CoderDream 阅读(499) |
评论 (1) |
编辑 收藏中华人民共和国主席令
第六十五号
《中华人民共和国劳动合同法》已由中华人民共和国第十届全国人民代表大会常务委员会第二十八次会议于2007年6月29日通过,现予公布,自2008年1月1日起施行。
中华人民共和国主席 胡锦涛
2007年6月29日
(2007年6月29日第十届全国人民代表大会常务委员会第二十八次会议通过)
目 录
第一章 总 则
第二章 劳动合同的订立
第三章 劳动合同的履行和变更
第四章 劳动合同的解除和终止
第五章 特别规定
第一节 集体合同
第二节 劳务派遣
第三节 非全日制用工
第六章 监督检查
第七章 法律责任
第八章 附 则
第一章 总 则
第一条 为了完善劳动合同制度,明确劳动合同双方当事人的权利和义务,保护劳动者的合法权益,构建和发展和谐稳定的劳动关系,制定本法。
第二条 中华人民共和国境内的企业、个体经济组织、民办非企业单位等组织(以下称用人单位)与劳动者建立劳动关系,订立、履行、变更、解除或者终止劳动合同,适用本法。
国家机关、事业单位、社会团体和与其建立劳动关系的劳动者,订立、履行、变更、解除或者终止劳动合同,依照本法执行。
第三条 订立劳动合同,应当遵循合法、公平、平等自愿、协商一致、诚实信用的原则。
依法订立的劳动合同具有约束力,用人单位与劳动者应当履行劳动合同约定的义务。
第四条 用人单位应当依法建立和完善劳动规章制度,保障劳动者享有劳动权利、履行劳动义务。
用人单位在制定、修改或者决定有关劳动报酬、工作时间、休息休假、劳动安全卫生、保险福利、职工培训、劳动纪律以及劳动定额管理等直接涉及劳动者切身利益的规章制度或者重大事项时,应当经职工代表大会或者全体职工讨论,提出方案和意见,与工会或者职工代表平等协商确定。
在规章制度和重大事项决定实施过程中,工会或者职工认为不适当的,有权向用人单位提出,通过协商予以修改完善。
用人单位应当将直接涉及劳动者切身利益的规章制度和重大事项决定公示,或者告知劳动者。
第五条 县级以上人民政府劳动行政部门会同工会和企业方面代表,建立健全协调劳动关系三方机制,共同研究解决有关劳动关系的重大问题。
第六条 工会应当帮助、指导劳动者与用人单位依法订立和履行劳动合同,并与用人单位建立集体协商机制,维护劳动者的合法权益。
第二章 劳动合同的订立
第七条 用人单位自用工之日起即与劳动者建立劳动关系。用人单位应当建立职工名册备查。
第八条 用人单位招用劳动者时,应当如实告知劳动者工作内容、工作条件、工作地点、职业危害、安全生产状况、劳动报酬,以及劳动者要求了解的其他情况;用人单位有权了解劳动者与劳动合同直接相关的基本情况,劳动者应当如实说明。
第九条 用人单位招用劳动者,不得扣押劳动者的居民身份证和其他证件,不得要求劳动者提供担保或者以其他名义向劳动者收取财物。
第十条 建立劳动关系,应当订立书面劳动合同。
已建立劳动关系,未同时订立书面劳动合同的,应当自用工之日起一个月内订立书面劳动合同。
用人单位与劳动者在用工前订立劳动合同的,劳动关系自用工之日起建立。
第十一条 用人单位未在用工的同时订立书面劳动合同,与劳动者约定的劳动报酬不明确的,新招用的劳动者的劳动报酬按照集体合同规定的标准执行;没有集体合同或者集体合同未规定的,实行同工同酬。
第十二条 劳动合同分为固定期限劳动合同、无固定期限劳动合同和以完成一定工作任务为期限的劳动合同。
第十三条 固定期限劳动合同,是指用人单位与劳动者约定合同终止时间的劳动合同。
用人单位与劳动者协商一致,可以订立固定期限劳动合同。
第十四条 无固定期限劳动合同,是指用人单位与劳动者约定无确定终止时间的劳动合同。
用人单位与劳动者协商一致,可以订立无固定期限劳动合同。有下列情形之一,劳动者提出或者同意续订、订立劳动合同的,除劳动者提出订立固定期限劳动合同外,应当订立无固定期限劳动合同:
(一)劳动者在该用人单位连续工作满十年的;
(二)用人单位初次实行劳动合同制度或者国有企业改制重新订立劳动合同时,劳动者在该用人单位连续工作满十年且距法定退休年龄不足十年的;
(三)连续订立二次固定期限劳动合同,且劳动者没有本法第三十九条和第四十条第一项、第二项规定的情形,续订劳动合同的。
用人单位自用工之日起满一年不与劳动者订立书面劳动合同的,视为用人单位与劳动者已订立无固定期限劳动合同。
第十五条 以完成一定工作任务为期限的劳动合同,是指用人单位与劳动者约定以某项工作的完成为合同期限的劳动合同。
用人单位与劳动者协商一致,可以订立以完成一定工作任务为期限的劳动合同。
第十六条 劳动合同由用人单位与劳动者协商一致,并经用人单位与劳动者在劳动合同文本上签字或者盖章生效。
劳动合同文本由用人单位和劳动者各执一份。
第十七条 劳动合同应当具备以下条款:
(一)用人单位的名称、住所和法定代表人或者主要负责人;
(二)劳动者的姓名、住址和居民身份证或者其他有效身份证件号码;
(三)劳动合同期限;
(四)工作内容和工作地点;
(五)工作时间和休息休假;
(六)劳动报酬;
(七)社会保险;
(八)劳动保护、劳动条件和职业危害防护;
(九)法律、法规规定应当纳入劳动合同的其他事项。
劳动合同除前款规定的必备条款外,用人单位与劳动者可以约定试用期、培训、保守秘密、补充保险和福利待遇等其他事项。
第十八条 劳动合同对劳动报酬和劳动条件等标准约定不明确,引发争议的,用人单位与劳动者可以重新协商;协商不成的,适用集体合同规定;没有集体合同或者集体合同未规定劳动报酬的,实行同工同酬;没有集体合同或者集体合同未规定劳动条件等标准的,适用国家有关规定。
第十九条 劳动合同期限三个月以上不满一年的,试用期不得超过一个月;劳动合同期限一年以上不满三年的,试用期不得超过二个月;三年以上固定期限和无固定期限的劳动合同,试用期不得超过六个月。
同一用人单位与同一劳动者只能约定一次试用期。
以完成一定工作任务为期限的劳动合同或者劳动合同期限不满三个月的,不得约定试用期。
试用期包含在劳动合同期限内。劳动合同仅约定试用期的,试用期不成立,该期限为劳动合同期限。
第二十条 劳动者在试用期的工资不得低于本单位相同岗位最低档工资或者劳动合同约定工资的百分之八十,并不得低于用人单位所在地的最低工资标准。
第二十一条 在试用期中,除劳动者有本法第三十九条和第四十条第一项、第二项规定的情形外,用人单位不得解除劳动合同。用人单位在试用期解除劳动合同的,应当向劳动者说明理由。
第二十二条 用人单位为劳动者提供专项培训费用,对其进行专业技术培训的,可以与该劳动者订立协议,约定服务期。
劳动者违反服务期约定的,应当按照约定向用人单位支付违约金。违约金的数额不得超过用人单位提供的培训费用。用人单位要求劳动者支付的违约金不得超过服务期尚未履行部分所应分摊的培训费用。
用人单位与劳动者约定服务期的,不影响按照正常的工资调整机制提高劳动者在服务期期间的劳动报酬。
第二十三条 用人单位与劳动者可以在劳动合同中约定保守用人单位的商业秘密和与知识产权相关的保密事项。
对负有保密义务的劳动者,用人单位可以在劳动合同或者保密协议中与劳动者约定竞业限制条款,并约定在解除或者终止劳动合同后,在竞业限制期限内按月给予劳动者经济补偿。劳动者违反竞业限制约定的,应当按照约定向用人单位支付违约金。
第二十四条 竞业限制的人员限于用人单位的高级管理人员、高级技术人员和其他负有保密义务的人员。竞业限制的范围、地域、期限由用人单位与劳动者约定,竞业限制的约定不得违反法律、法规的规定。
在解除或者终止劳动合同后,前款规定的人员到与本单位生产或者经营同类产品、从事同类业务的有竞争关系的其他用人单位,或者自己开业生产或者经营同类产品、从事同类业务的竞业限制期限,不得超过二年。
第二十五条 除本法第二十二条和第二十三条规定的情形外,用人单位不得与劳动者约定由劳动者承担违约金。
第二十六条 下列劳动合同无效或者部分无效:
(一)以欺诈、胁迫的手段或者乘人之危,使对方在违背真实意思的情况下订立或者变更劳动合同的;
(二)用人单位免除自己的法定责任、排除劳动者权利的;
(三)违反法律、行政法规强制性规定的。
对劳动合同的无效或者部分无效有争议的,由劳动争议仲裁机构或者人民法院确认。
第二十七条 劳动合同部分无效,不影响其他部分效力的,其他部分仍然有效。
第二十八条 劳动合同被确认无效,劳动者已付出劳动的,用人单位应当向劳动者支付劳动报酬。劳动报酬的数额,参照本单位相同或者相近岗位劳动者的劳动报酬确定。
第三章 劳动合同的履行和变更
第二十九条 用人单位与劳动者应当按照劳动合同的约定,全面履行各自的义务。
第三十条 用人单位应当按照劳动合同约定和国家规定,向劳动者及时足额支付劳动报酬。
用人单位拖欠或者未足额支付劳动报酬的,劳动者可以依法向当地人民法院申请支付令,人民法院应当依法发出支付令。
第三十一条 用人单位应当严格执行劳动定额标准,不得强迫或者变相强迫劳动者加班。用人单位安排加班的,应当按照国家有关规定向劳动者支付加班费。
第三十二条 劳动者拒绝用人单位管理人员违章指挥、强令冒险作业的,不视为违反劳动合同。
劳动者对危害生命安全和身体健康的劳动条件,有权对用人单位提出批评、检举和控告。
第三十三条 用人单位变更名称、法定代表人、主要负责人或者投资人等事项,不影响劳动合同的履行。
第三十四条 用人单位发生合并或者分立等情况,原劳动合同继续有效,劳动合同由承继其权利和义务的用人单位继续履行。
第三十五条 用人单位与劳动者协商一致,可以变更劳动合同约定的内容。变更劳动合同,应当采用书面形式。
变更后的劳动合同文本由用人单位和劳动者各执一份。
第四章 劳动合同的解除和终止
第三十六条 用人单位与劳动者协商一致,可以解除劳动合同。
第三十七条 劳动者提前三十日以书面形式通知用人单位,可以解除劳动合同。劳动者在试用期内提前三日通知用人单位,可以解除劳动合同。
第三十八条 用人单位有下列情形之一的,劳动者可以解除劳动合同:
(一)未按照劳动合同约定提供劳动保护或者劳动条件的;
(二)未及时足额支付劳动报酬的;
(三)未依法为劳动者缴纳社会保险费的;
(四)用人单位的规章制度违反法律、法规的规定,损害劳动者权益的;
(五)因本法第二十六条第一款规定的情形致使劳动合同无效的;
(六)法律、行政法规规定劳动者可以解除劳动合同的其他情形。
用人单位以暴力、威胁或者非法限制人身自由的手段强迫劳动者劳动的,或者用人单位违章指挥、强令冒险作业危及劳动者人身安全的,劳动者可以立即解除劳动合同,不需事先告知用人单位。
第三十九条 劳动者有下列情形之一的,用人单位可以解除劳动合同:
(一)在试用期间被证明不符合录用条件的;
(二)严重违反用人单位的规章制度的;
(三)严重失职,营私舞弊,给用人单位造成重大损害的;
(四)劳动者同时与其他用人单位建立劳动关系,对完成本单位的工作任务造成严重影响,或者经用人单位提出,拒不改正的;
(五)因本法第二十六条第一款第一项规定的情形致使劳动合同无效的;
(六)被依法追究刑事责任的。
第四十条 有下列情形之一的,用人单位提前三十日以书面形式通知劳动者本人或者额外支付劳动者一个月工资后,可以解除劳动合同:
(一)劳动者患病或者非因工负伤,在规定的医疗期满后不能从事原工作,也不能从事由用人单位另行安排的工作的;
(二)劳动者不能胜任工作,经过培训或者调整工作岗位,仍不能胜任工作的;
(三)劳动合同订立时所依据的客观情况发生重大变化,致使劳动合同无法履行,经用人单位与劳动者协商,未能就变更劳动合同内容达成协议的。
第四十一条 有下列情形之一,需要裁减人员二十人以上或者裁减不足二十人但占企业职工总数百分之十以上的,用人单位提前三十日向工会或者全体职工说明情况,听取工会或者职工的意见后,裁减人员方案经向劳动行政部门报告,可以裁减人员:
(一)依照企业破产法规定进行重整的;
(二)生产经营发生严重困难的;
(三)企业转产、重大技术革新或者经营方式调整,经变更劳动合同后,仍需裁减人员的;
(四)其他因劳动合同订立时所依据的客观经济情况发生重大变化,致使劳动合同无法履行的。
裁减人员时,应当优先留用下列人员:
(一)与本单位订立较长期限的固定期限劳动合同的;
(二)与本单位订立无固定期限劳动合同的;
(三)家庭无其他就业人员,有需要扶养的老人或者未成年人的。
用人单位依照本条第一款规定裁减人员,在六个月内重新招用人员的,应当通知被裁减的人员,并在同等条件下优先招用被裁减的人员。
第四十二条 劳动者有下列情形之一的,用人单位不得依照本法第四十条、第四十一条的规定解除劳动合同:
(一)从事接触职业病危害作业的劳动者未进行离岗前职业健康检查,或者疑似职业病病人在诊断或者医学观察期间的;
(二)在本单位患职业病或者因工负伤并被确认丧失或者部分丧失劳动能力的;
(三)患病或者非因工负伤,在规定的医疗期内的;
(四)女职工在孕期、产期、哺乳期的;
(五)在本单位连续工作满十五年,且距法定退休年龄不足五年的;
(六)法律、行政法规规定的其他情形。
第四十三条 用人单位单方解除劳动合同,应当事先将理由通知工会。用人单位违反法律、行政法规规定或者劳动合同约定的,工会有权要求用人单位纠正。用人单位应当研究工会的意见,并将处理结果书面通知工会。
第四十四条 有下列情形之一的,劳动合同终止:
(一)劳动合同期满的;
(二)劳动者开始依法享受基本养老保险待遇的;
(三)劳动者死亡,或者被人民法院宣告死亡或者宣告失踪的;
(四)用人单位被依法宣告破产的;
(五)用人单位被吊销营业执照、责令关闭、撤销或者用人单位决定提前解散的;
(六)法律、行政法规规定的其他情形。
第四十五条 劳动合同期满,有本法第四十二条规定情形之一的,劳动合同应当续延至相应的情形消失时终止。但是,本法第四十二条第二项规定丧失或者部分丧失劳动能力劳动者的劳动合同的终止,按照国家有关工伤保险的规定执行。
第四十六条 有下列情形之一的,用人单位应当向劳动者支付经济补偿:
(一)劳动者依照本法第三十八条规定解除劳动合同的;
(二)用人单位依照本法第三十六条规定向劳动者提出解除劳动合同并与劳动者协商一致解除劳动合同的;
(三)用人单位依照本法第四十条规定解除劳动合同的;
(四)用人单位依照本法第四十一条第一款规定解除劳动合同的;
(五)除用人单位维持或者提高劳动合同约定条件续订劳动合同,劳动者不同意续订的情形外,依照本法第四十四条第一项规定终止固定期限劳动合同的;
(六)依照本法第四十四条第四项、第五项规定终止劳动合同的;
(七)法律、行政法规规定的其他情形。
第四十七条 经济补偿按劳动者在本单位工作的年限,每满一年支付一个月工资的标准向劳动者支付。六个月以上不满一年的,按一年计算;不满六个月的,向劳动者支付半个月工资的经济补偿。
劳动者月工资高于用人单位所在直辖市、设区的市级人民政府公布的本地区上年度职工月平均工资三倍的,向其支付经济补偿的标准按职工月平均工资三倍的数额支付,向其支付经济补偿的年限最高不超过十二年。
本条所称月工资是指劳动者在劳动合同解除或者终止前十二个月的平均工资。
第四十八条 用人单位违反本法规定解除或者终止劳动合同,劳动者要求继续履行劳动合同的,用人单位应当继续履行;劳动者不要求继续履行劳动合同或者劳动合同已经不能继续履行的,用人单位应当依照本法第八十七条规定支付赔偿金。
第四十九条 国家采取措施,建立健全劳动者社会保险关系跨地区转移接续制度。
第五十条 用人单位应当在解除或者终止劳动合同时出具解除或者终止劳动合同的证明,并在十五日内为劳动者办理档案和社会保险关系转移手续。
劳动者应当按照双方约定,办理工作交接。用人单位依照本法有关规定应当向劳动者支付经济补偿的,在办结工作交接时支付。
用人单位对已经解除或者终止的劳动合同的文本,至少保存二年备查。
第五章 特别规定
第一节 集体合同
第五十一条 企业职工一方与用人单位通过平等协商,可以就劳动报酬、工作时间、休息休假、劳动安全卫生、保险福利等事项订立集体合同。集体合同草案应当提交职工代表大会或者全体职工讨论通过。
集体合同由工会代表企业职工一方与用人单位订立;尚未建立工会的用人单位,由上级工会指导劳动者推举的代表与用人单位订立。
第五十二条 企业职工一方与用人单位可以订立劳动安全卫生、女职工权益保护、工资调整机制等专项集体合同。
第五十三条 在县级以下区域内,建筑业、采矿业、餐饮服务业等行业可以由工会与企业方面代表订立行业性集体合同,或者订立区域性集体合同。
第五十四条 集体合同订立后,应当报送劳动行政部门;劳动行政部门自收到集体合同文本之日起十五日内未提出异议的,集体合同即行生效。
依法订立的集体合同对用人单位和劳动者具有约束力。行业性、区域性集体合同对当地本行业、本区域的用人单位和劳动者具有约束力。
第五十五条 集体合同中劳动报酬和劳动条件等标准不得低于当地人民政府规定的最低标准;用人单位与劳动者订立的劳动合同中劳动报酬和劳动条件等标准不得低于集体合同规定的标准。
第五十六条 用人单位违反集体合同,侵犯职工劳动权益的,工会可以依法要求用人单位承担责任;因履行集体合同发生争议,经协商解决不成的,工会可以依法申请仲裁、提起诉讼。
第二节 劳务派遣
第五十七条 劳务派遣单位应当依照公司法的有关规定设立,注册资本不得少于五十万元。
第五十八条 劳务派遣单位是本法所称用人单位,应当履行用人单位对劳动者的义务。劳务派遣单位与被派遣劳动者订立的劳动合同,除应当载明本法第十七条规定的事项外,还应当载明被派遣劳动者的用工单位以及派遣期限、工作岗位等情况。
劳务派遣单位应当与被派遣劳动者订立二年以上的固定期限劳动合同,按月支付劳动报酬;被派遣劳动者在无工作期间,劳务派遣单位应当按照所在地人民政府规定的最低工资标准,向其按月支付报酬。
第五十九条 劳务派遣单位派遣劳动者应当与接受以劳务派遣形式用工的单位(以下称用工单位)订立劳务派遣协议。劳务派遣协议应当约定派遣岗位和人员数量、派遣期限、劳动报酬和社会保险费的数额与支付方式以及违反协议的责任。
用工单位应当根据工作岗位的实际需要与劳务派遣单位确定派遣期限,不得将连续用工期限分割订立数个短期劳务派遣协议。
第六十条 劳务派遣单位应当将劳务派遣协议的内容告知被派遣劳动者。
劳务派遣单位不得克扣用工单位按照劳务派遣协议支付给被派遣劳动者的劳动报酬。
劳务派遣单位和用工单位不得向被派遣劳动者收取费用。
第六十一条 劳务派遣单位跨地区派遣劳动者的,被派遣劳动者享有的劳动报酬和劳动条件,按照用工单位所在地的标准执行。
第六十二条 用工单位应当履行下列义务:
(一)执行国家劳动标准,提供相应的劳动条件和劳动保护;
(二)告知被派遣劳动者的工作要求和劳动报酬;
(三)支付加班费、绩效奖金,提供与工作岗位相关的福利待遇;
(四)对在岗被派遣劳动者进行工作岗位所必需的培训;
(五)连续用工的,实行正常的工资调整机制。
用工单位不得将被派遣劳动者再派遣到其他用人单位。
第六十三条 被派遣劳动者享有与用工单位的劳动者同工同酬的权利。用工单位无同类岗位劳动者的,参照用工单位所在地相同或者相近岗位劳动者的劳动报酬确定。
第六十四条 被派遣劳动者有权在劳务派遣单位或者用工单位依法参加或者组织工会,维护自身的合法权益。
第六十五条 被派遣劳动者可以依照本法第三十六条、第三十八条的规定与劳务派遣单位解除劳动合同。
被派遣劳动者有本法第三十九条和第四十条第一项、第二项规定情形的,用工单位可以将劳动者退回劳务派遣单位,劳务派遣单位依照本法有关规定,可以与劳动者解除劳动合同。
第六十六条 劳务派遣一般在临时性、辅助性或者替代性的工作岗位上实施。
第六十七条 用人单位不得设立劳务派遣单位向本单位或者所属单位派遣劳动者。
第三节 非全日制用工
第六十八条 非全日制用工,是指以小时计酬为主,劳动者在同一用人单位一般平均每日工作时间不超过四小时,每周工作时间累计不超过二十四小时的用工形式。
第六十九条 非全日制用工双方当事人可以订立口头协议。
从事非全日制用工的劳动者可以与一个或者一个以上用人单位订立劳动合同;但是,后订立的劳动合同不得影响先订立的劳动合同的履行。
第七十条 非全日制用工双方当事人不得约定试用期。
第七十一条 非全日制用工双方当事人任何一方都可以随时通知对方终止用工。终止用工,用人单位不向劳动者支付经济补偿。
第七十二条 非全日制用工小时计酬标准不得低于用人单位所在地人民政府规定的最低小时工资标准。
非全日制用工劳动报酬结算支付周期最长不得超过十五日。
第六章 监督检查
第七十三条 国务院劳动行政部门负责全国劳动合同制度实施的监督管理。
县级以上地方人民政府劳动行政部门负责本行政区域内劳动合同制度实施的监督管理。
县级以上各级人民政府劳动行政部门在劳动合同制度实施的监督管理工作中,应当听取工会、企业方面代表以及有关行业主管部门的意见。
第七十四条 县级以上地方人民政府劳动行政部门依法对下列实施劳动合同制度的情况进行监督检查:
(一)用人单位制定直接涉及劳动者切身利益的规章制度及其执行的情况;
(二)用人单位与劳动者订立和解除劳动合同的情况;
(三)劳务派遣单位和用工单位遵守劳务派遣有关规定的情况;
(四)用人单位遵守国家关于劳动者工作时间和休息休假规定的情况;
(五)用人单位支付劳动合同约定的劳动报酬和执行最低工资标准的情况;
(六)用人单位参加各项社会保险和缴纳社会保险费的情况;
(七)法律、法规规定的其他劳动监察事项。
第七十五条 县级以上地方人民政府劳动行政部门实施监督检查时,有权查阅与劳动合同、集体合同有关的材料,有权对劳动场所进行实地检查,用人单位和劳动者都应当如实提供有关情况和材料。
劳动行政部门的工作人员进行监督检查,应当出示证件,依法行使职权,文明执法。
第七十六条 县级以上人民政府建设、卫生、安全生产监督管理等有关主管部门在各自职责范围内,对用人单位执行劳动合同制度的情况进行监督管理。
第七十七条 劳动者合法权益受到侵害的,有权要求有关部门依法处理,或者依法申请仲裁、提起诉讼。
第七十八条 工会依法维护劳动者的合法权益,对用人单位履行劳动合同、集体合同的情况进行监督。用人单位违反劳动法律、法规和劳动合同、集体合同的,工会有权提出意见或者要求纠正;劳动者申请仲裁、提起诉讼的,工会依法给予支持和帮助。
第七十九条 任何组织或者个人对违反本法的行为都有权举报,县级以上人民政府劳动行政部门应当及时核实、处理,并对举报有功人员给予奖励。
第七章 法律责任
第八十条 用人单位直接涉及劳动者切身利益的规章制度违反法律、法规规定的,由劳动行政部门责令改正,给予警告;给劳动者造成损害的,应当承担赔偿责任。
第八十一条 用人单位提供的劳动合同文本未载明本法规定的劳动合同必备条款或者用人单位未将劳动合同文本交付劳动者的,由劳动行政部门责令改正;给劳动者造成损害的,应当承担赔偿责任。
第八十二条 用人单位自用工之日起超过一个月不满一年未与劳动者订立书面劳动合同的,应当向劳动者每月支付二倍的工资。
用人单位违反本法规定不与劳动者订立无固定期限劳动合同的,自应当订立无固定期限劳动合同之日起向劳动者每月支付二倍的工资。
第八十三条 用人单位违反本法规定与劳动者约定试用期的,由劳动行政部门责令改正;违法约定的试用期已经履行的,由用人单位以劳动者试用期满月工资为标准,按已经履行的超过法定试用期的期间向劳动者支付赔偿金。
第八十四条 用人单位违反本法规定,扣押劳动者居民身份证等证件的,由劳动行政部门责令限期退还劳动者本人,并依照有关法律规定给予处罚。
用人单位违反本法规定,以担保或者其他名义向劳动者收取财物的,由劳动行政部门责令限期退还劳动者本人,并以每人五百元以上二千元以下的标准处以罚款;给劳动者造成损害的,应当承担赔偿责任。
劳动者依法解除或者终止劳动合同,用人单位扣押劳动者档案或者其他物品的,依照前款规定处罚。
第八十五条 用人单位有下列情形之一的,由劳动行政部门责令限期支付劳动报酬、加班费或者经济补偿;劳动报酬低于当地最低工资标准的,应当支付其差额部分;逾期不支付的,责令用人单位按应付金额百分之五十以上百分之一百以下的标准向劳动者加付赔偿金:
(一)未按照劳动合同的约定或者国家规定及时足额支付劳动者劳动报酬的;
(二)低于当地最低工资标准支付劳动者工资的;
(三)安排加班不支付加班费的;
(四)解除或者终止劳动合同,未依照本法规定向劳动者支付经济补偿的。
第八十六条 劳动合同依照本法第二十六条规定被确认无效,给对方造成损害的,有过错的一方应当承担赔偿责任。
第八十七条 用人单位违反本法规定解除或者终止劳动合同的,应当依照本法第四十七条规定的经济补偿标准的二倍向劳动者支付赔偿金。
第八十八条 用人单位有下列情形之一的,依法给予行政处罚;构成犯罪的,依法追究刑事责任;给劳动者造成损害的,应当承担赔偿责任:
(一)以暴力、威胁或者非法限制人身自由的手段强迫劳动的;
(二)违章指挥或者强令冒险作业危及劳动者人身安全的;
(三)侮辱、体罚、殴打、非法搜查或者拘禁劳动者的;
(四)劳动条件恶劣、环境污染严重,给劳动者身心健康造成严重损害的。
第八十九条 用人单位违反本法规定未向劳动者出具解除或者终止劳动合同的书面证明,由劳动行政部门责令改正;给劳动者造成损害的,应当承担赔偿责任。
第九十条 劳动者违反本法规定解除劳动合同,或者违反劳动合同中约定的保密义务或者竞业限制,给用人单位造成损失的,应当承担赔偿责任。
第九十一条 用人单位招用与其他用人单位尚未解除或者终止劳动合同的劳动者,给其他用人单位造成损失的,应当承担连带赔偿责任。
第九十二条 劳务派遣单位违反本法规定的,由劳动行政部门和其他有关主管部门责令改正;情节严重的,以每人一千元以上五千元以下的标准处以罚款,并由工商行政管理部门吊销营业执照;给被派遣劳动者造成损害的,劳务派遣单位与用工单位承担连带赔偿责任。
第九十三条 对不具备合法经营资格的用人单位的违法犯罪行为,依法追究法律责任;劳动者已经付出劳动的,该单位或者其出资人应当依照本法有关规定向劳动者支付劳动报酬、经济补偿、赔偿金;给劳动者造成损害的,应当承担赔偿责任。
第九十四条 个人承包经营违反本法规定招用劳动者,给劳动者造成损害的,发包的组织与个人承包经营者承担连带赔偿责任。
第九十五条 劳动行政部门和其他有关主管部门及其工作人员玩忽职守、不履行法定职责,或者违法行使职权,给劳动者或者用人单位造成损害的,应当承担赔偿责任;对直接负责的主管人员和其他直接责任人员,依法给予行政处分;构成犯罪的,依法追究刑事责任。
第八章 附 则
第九十六条 事业单位与实行聘用制的工作人员订立、履行、变更、解除或者终止劳动合同,法律、行政法规或者国务院另有规定的,依照其规定;未作规定的,依照本法有关规定执行。
第九十七条 本法施行前已依法订立且在本法施行之日存续的劳动合同,继续履行;本法第十四条第二款第三项规定连续订立固定期限劳动合同的次数,自本法施行后续订固定期限劳动合同时开始计算。
本法施行前已建立劳动关系,尚未订立书面劳动合同的,应当自本法施行之日起一个月内订立。
本法施行之日存续的劳动合同在本法施行后解除或者终止,依照本法第四十六条规定应当支付经济补偿的,经济补偿年限自本法施行之日起计算;本法施行前按照当时有关规定,用人单位应当向劳动者支付经济补偿的,按照当时有关规定执行。
第九十八条 本法自2008年1月1日起施行。
posted @
2007-10-31 09:11 CoderDream 阅读(251) |
评论 (1) |
编辑 收藏
1、
Sun JSF Download
2、
JavaServer Faces RI
3、
Tag Library
4、
JavaServer Faces API (1.2MR1)
5、
Sun JSF Developer Forums
6、
SDN JSF FAQ
7、
JSR 252: JavaServer Faces 1.2
8、
Sun JSF Reference
9、
javaserverfaces-spec-public
10、
JSR 314: JavaServer Faces 2.0
posted @
2007-10-29 14:11 CoderDream 阅读(283) |
评论 (0) |
编辑 收藏1,面谈须知
面谈,实际上就是面试,是雇主与应征者面对面的沟通,更是雇主决定此人是否录取的最后关键。这一章的重点,就在如何利用有限的面谈时间,把自己成功地推销出去。
经过了书面文件的筛选、过滤,终于到了面谈的时候。紧张、兴奋、患得患失是常见的情绪反应,尤其是初出社会的青年。面对这种正常的情绪可以不必太在意,只要适当地控制,就不会影响面谈当时的表现。如果太过激烈,不妨打通电话去延缓面谈时间,给自己多留一些调整情绪的适应时间。
通常主持面谈的人,不是老板就是干部主管。因此在前往面谈以前一定要注意自己的外表仪容。锦衣华服并非必要,端庄整洁才是重点。男性们记得要刮胡子,不修边幅也许是你的个性,但也极可能让你失去一个良好的工作机会。女性们不妨薄施胭脂。浓妆艳抹太过招摇,也没有必要。尤其是年轻女孩,只要重点式修饰一下(画个眉毛,涂个口红),让自己看起来神采奕奕即可。
另外要注意应对必须得体。个人的气质修养与才能并无法在短短的面谈中让对方全然感受,但却可以藉着得体的应对传给对方:我们是有内涵、有才华与能力的人才。同时肢体语言也必须配合得当。下面几点是我们在面谈时应该注意到的基本礼节与原则:
01.面带笑容,不要板着脸孔:
02.除非面谈人员先伸出手要和你握手,否则不要贸然主动先向他伸手。
03.在对方没有请你坐下之前,不要迳自找位子坐。
04.说话时不要左顾右盼或对着天花板、地板、桌子说话,而要直视对方。对方说话时,你也应该看着他,不要把视线随便转开。
05.音量要适中。太大声会给对方压迫感,太小声对方听不到,会不耐烦。不但失礼,且会让对方想赶紧结束谈话。
06.不要抽烟,嚼口香糖。
07.不要有玩手指头、抖动双腿、用手指敲桌面、揉纸张等小动作。
08.不要弯腰驼背。双手自然放在腿上、不要翘脚。
09.坦白最重要,切勿不懂装懂。
10.不要批评别人,尤其是以前的老板、公司。
11.阿谀奉承的话是多余的,不必说。
12.如果你很想知道薪水的问题,对方却又迟迟不说,你可以在谈话快结束之前,稍微提示他一下。
13.公司的福利及营业性质你有权了解。因此如果对方给你机会问问题的话,你也不妨问清楚,做个参考。因为公司有选择其雇员的权利,你也有选择为一家好公司服务的权利。
14.简单明白的叙述。不要像聊天似的扯个没完,除非对方请你仔细说明。
15.不要偏离主题,言不及义。
16.口气要平实,不夸张自己的能力,也不必太自谦。
17.讲话速度适中,不急不徐。思考时间不宜太长。
18.听不懂对方问话的时候,可以请他再说一次,不要胡乱猜测,随便回答,反而落人笑柄。
19.不要打断对方说话。
20.向接待过你的人说再见。他们也许不是重要的人物,但很可能有表达他们非正式意见的机会,为你说上一句话,也未必可知。
2,面谈的应对技巧
一般人在面谈时,如果用的是母语(native language),当然是比用外语来得容易。就像写自传、履历表一样,如果我们用中文写必须花三十分钟,用英文写,可能就得花上一个半小时才能完成。而英文面谈又比写作英文自传、履历困难。为什么呢?因为写自传、履历等可以先打草稿,觉得不够好可以修改,一直到自己满意为止。甚至可以花上一整天来撰写。但是英文面谈就不同了。除非你的英文造诣已有相当的程度,否则难免会担心:“万一听不懂他问什么,怎么办?”,“万一我说不出来怎么办?”,“万一……,怎么办?”,而且事实上,面谈时也的确没有很多时间来让我们思考、斟酌字句。如果我们思考太久,不管是先想好再说,还是边想边说,都会使这次谈话变得冗长而乏味。因此,最好的方式就是事先构思好对方可能会问的问题,模拟一些对话,试着用各种方式来回答,以完成自我的准备工作,事前的准备,总是胜过‘船到桥头自然直’这种不称职的态度,且更能充实自己的能力。
下面依照平常谈话时,可能会谈及的话题及各种说话的方式,模拟了一些对答。在参考之余,也可以配合自己的状况作应对。最后要提醒各位,不妨大声地把对答念出来。第一次可以一字一句慢慢念,训练自己的咬字。第二次可以着重音调。第三次则加强流畅度与熟练度。多多开口,对自己只有好处而无害处。
模拟问答之个人资料
1 .
Q: What\'s your name?
问:你叫什么名字?
A: My name is/I\'m Liyu Hu.
答:我叫/我是胡立宇。
2 .
Q: Are you Mr.Liyu Hu?
问:你是胡立宇先生吗?
A: Yes,I am/Yes.that\'s me
答:是的。
3 .
Q: What\'s your family name/last name/surname?
问:贵姓?
A: My family name/1ast name/surname is Hu.
答:我姓胡。
4 .
Q: What\'s your given name/first name?
问:大名?
A: My given name/first name is Liyu.
It\'s Liyu.
Liyu.
答:立宇。
5 .
Q: Do you have an English name?
问:你有英文字吗?
A :Yes.My English name is Simon.
答:有。我的英文名字是赛门。
No.I don\'t have an English name!
我没有英文名字。
6 .
Q: Where do you live now?
问:你目前住在哪里?
What\'s your address?
你的地址?
A: I live On Wolung Street.Taipei!
答:我住在台北市卧龙街。
My address is 9,Lane 36,Wolung street,Taipei.
我的地址是台北市卧龙街36巷9号。
7 .
Q: Where are you from?
问:你是那里人?
A: I\'m from Taipei.
Taipei.
答:台北。
8 .
Q: Where were you born?
问:你在那里出生?
A :I was born in Taipei!
Taipei.
答:台北。
9 .
Q: How old are you?
What\'s your age?
问:贵庚?
A: I\'m 24
答:二十四岁。
I\'ll be 25 next week.
我下星期就二十五岁了。
l just had my 26 birthday.
我刚过完二十六岁生日。
10.
Q: May I have your phone number?
What\'s your phone number?
问:你的电话号码是多少?
A: My phone number is 501-7077.
It\'s 501—7077.
501—7077.
答:我的电话号码是五O一七—O七。
11.
Q: Are you married.
问:你结婚了吗?
A: Yes,I am.
答:我结婚了。
NO , I\'m not(married yet)! I\'m still single
我还没结婚。我还是单身。
12.
Q: How many are there in your family?
How big is your family?
问:你家里有几个人?
A: There are six of us----grandfather, father, mother, two sisters, and me.
答:我们家有六个人——祖父、父亲、母亲、两个姊姊,还有我。
13.
Q: Who supports your family?
问:谁维持你家的生计?
A: My father does.
答:我父亲。
14.
Q: Do you need to support your family?
问:你需要养家吗?
A: No, I don\'t, but I usually give half of my salary to my parents,
答:不需要,但我通常交一半的薪水给我父母。
Yes, I do.
需要
15.
Q: What does your father do?
What\'s your father\'s job/work?
问:你父亲从事哪种行业?
A: He\'s an engineer/a doctor/a college lecturer.
答:他是工程师/医生/大学讲师
16.
Q: Does your mother work?
问:你母亲上班吗?
A: No,she doesn\'t. She\'s an ordinary housewife.
答:她不上班。她是个普通的家庭主妇。
Yes , she does. She works at/for a language school
是的。她在一家语言补习班工作。
17.
Q: Do you have any children?
问:你有小孩吗?
A: No,l don\'t.
答:没有。
No,not yet.
还没有。
Yes,I have two kids——a boy and a girl.
我有两个小孩,一男一女。
18.
Q: Do you have any hobbies?
问:你有没有嗜好?
Do you have any special interests?
你有没有特别的喜好?
A: Yes, I like basketball and jogging.
答:我喜欢篮球和慢跑。
Yes, I read a lot. I especially like books on computer science and business management.
我读很多书籍,尤其是关于电脑科学和企业管理方面的书籍
19.
Q: What do you usually do after work?
问:你下班以后,通常都做些什么?
How do you spend your free time?
你有空的时候如何消遣?
A: Usually, I play chess with my friends.
答:通常我会去找朋友下棋。
Sometimes, I go to movies with my friends, but most of the time I stay at home with my family.
有时候我和朋友出去看电影,但大部份的时候我都待在家里陪我的家人。
I study Japanese at a language school every evening, therefore I don\'t have much time for myself .
我每天晚上到语言补习班学日文,因此我没有太多自己的时间。
20.
Q: Do you drink?
问:你喝酒吗?
A: No, I don\'t.
答:我不喝酒。
Yes, but only a little.
喝,但是只喝一点点。
Yes, but only with friends. I don\'t drink while entertaining business guests.
喝,但只和朋友喝。我不在应酬时喝酒。
21.
Q: Do you smoke?
问:你抽烟吗?
A: No, I don\'t.
答:我不抽烟.
Yes, but I\'m not a heavy smoker.
抽,但是抽得不多。
Yes, but only in social situations.
抽,但只是应酬应酬。
22.
Q: What do you think of yourself?
问:你认为自己怎么样?
A: In general, I\'m quite hard working, responsible, capable,and outgoing.
答:大体上而言,我觉得自己是个工作勤奋、负责、能干,而且外向的人。
Basically I\'m very easygoing, but 1 get very serious and cautious when I work.
基本上我很随和,但我在工作的时候很认真,也很谨慎。
模拟问答之学历
1.
Q:What college did you graduate from?
问:你是那一所大学毕业的?
A:I graduated from Nanjing University.
答:我是南京大学毕业的。
2.
Q:Where did you receive your Master\'s degree?
问:你在那里修得硕士学位?
A:I received my Master\'s degree from the University of Washington.
答:我是在华盛顿大学修得的硕士。
3.
Q:What was your major?
问:你主修什么?
A:Economics/International Trade/Sociology.
答:经济学/国际贸易/社会学。
4.
Q: What was (were) your major subject (subjects) in the university?
问:大学时期你主修那些学科?
A: My major subject (subjects) was (were) Physics / British Literature/Psychology.
答:我那时主修的学科是物理学/英国文学/心理学。
5.
Q: When did you graduate from graduate school?
问:你什么时候从研究所毕业?
A: In June , 1985.
答:—九八五年六月。
6.
Q: Did you participate in any activities during your college years?
问:你在大学时代参加过什么社团活动?
A: Yes, I was a member of the football team.
答:我是橄榄球队的一员。
Yes, I joined the Math club and the debate team.
我参加数学营跟辩论社。
7.
Q: How were your grades in college?
问:你在大学的成绩如何?
A: They were above average.
答:中上。
Some of them were average, but most of them were on the top.
有些成绩中等,但大部份的成绩都是顶尖的。
8.
Q: Did you take any courses in English?
问:你有没有修过英文方面的课程?
A: Yes, I took English translation and English Oral Study.
答:有的,我修过英文翻译和英文听力。
9.
Q: How many years did you spend studying for your graduate degree?
How many years did it take you to get your Master\'s degree?
问:你花几年的时间拿硕士学位?
A: I spent two years.
It took me two years.
答:两年。
10.
Q: Do you plan to go on to further study?
问:你打算继续深造吗?
A: Yes, I plan to get a Master\'s degree, but before that, I prefer to get some practical work experience.
答:是的,我打算修硕士,但在修硕士之前,我希望能有点实际的工作经验。
No , not for now. I\'ll wait 5 years before I consider it.
现在不打算。五年内我不考虑这件事。
模拟问答之工作经验与能力
1.
Q: Is this your first job?
问:这是你的第一份工作吗?
A: Yes, it is.
答:是的。
No, I worked for two other companies before.
不是的。我以前在两家公司上过班。
2.
Q: Do you have any experience?
问:你有经验吗?
A: I\'m afraid not. This is the first job I\'ve applied for.
答:没有。这是我应征的第一个工作。
Yes, I have three years\' experience.
我有三年的经验。
3.
Q: What other jobs have you done before?
问:你以前做过什么工作?
A: I worked as a magazine salesman before, and presently I\'m the sales Manager of a small food company.
I have been an elementary school teacher, a broadcaster, and an editor.
答:我做过杂志业务员,现在是一家小食品公司的业务经理。我做过小学教师、播音员,和编辑。
4.
Q: Do you have a job now?
Are you working for a company now?
问:你目前有工作吗?
A: No, I don\'t.
No, I\'m not.
答:没有。
Yes, I teach typing in a commercial school.
有,我在一家商专教打字。
Yes, I\'m working in a computer company.
有,我在一家电脑公司做事
5.
Q: Why did you quit?
问:你为什么辞职?
A: I need a better working environment to expand my abili ties.
我需要一个更好的工作环境来施展。
It just wasn\'t for me.I\'m a professional translator, and teaChing translating just doesn\'t suit me.
答:那份工作不适合我。我是个职业翻译,但不适合教翻译。
6.
Q: Have you ever been an editor before?
Do you have any experience in editing?
问:你以前做过编辑吗?
你有编辑经验吗?
A: No, I have never been an editor before.
No, I don\'t have any experience in editing.
答:我以前没做过编辑。
我没有编辑经验。
Yes, I have been an editor before.
Yes, I have three year\'s experience in editing.
我以前做过编辑。
我有三年的编辑经验。
7.
Q: Why are you applying for this job?
问:你为什么来应征这份工作?
Why are you interested in this position?
你为什么对这份工作感兴趣?
A: I think this job can give me the best chance to practice what I have learned in the university.
答:我认为这份工作可以给我学以致用的大好机会。
I have always wanted to be an English teacher, and I think this is a great opportunity.
我一直就想当个英语教师,我认为这是一个好机会。
It\'s very challenging.
这份工作很具挑战性。
It\'s a great chance for me to learn.
这是我学习的良机。
8.
Q: What do you know about our company?
问:你对本公司了解多少?
A: It has a very good name outside.
答:它在外面的风评不错。
It’s a nonprofit organization.
它是一个非营利性的组织。
Its yearly profits were ranked ninth in Hainan last year.
它去年的全年营收在海南排名第九。
It has the best sales system.
它拥有最佳的销售系统。
It’s one of the biggest computer companies in Hainan.
它是海南最大的电脑公司之一。
It owns ten factories and it also offers stocks to the public.
它拥有十家工厂并有股票上市。
It has more than 30 Chain stores in Hainan.
它在海南有三十各家连锁店。
9.
Q: How much do you know about this job?
What do you know about this job?
问:你对这份工作了解多少?
A: (Computer programmer) I’ve been a computer programmer
for two years.I’m very acquainted with the field.
答:(电脑程式设计师)我做过两年的电脑程式设计师。我很熟悉这份工作。
(Salesperson) I know your company runs a construction business,and your salesmen sell the apartments you build.
(销售人员,我知道你们公司从事建筑业,而你们的业务员销售你们盖的房子。
10.
Q: This job requires English writing and speaking abilities?
Do you think you are qualified?
问:这份工作需要英语说写能力,你认为你有办法吗?
A: I’m sure I\'m quite proficient in writing English, and I can speak English fluently.
答:我确信我相当精通英文书写,也讲得非常流利。
I think so.I majored in English in the university.
我想是的,我在大学主修英语。
Yes,my previous job required English writing and speaking abilities too.It’s not difficult for me
是的。我前一份工作也要求英文说写能力。那对我而言并非难事。
11.
Q: How many years\' experience do you have in market in vesting/export/quality control?
问:你有几年的市场调查/出口/品管经验?
A: three years.
答:三年。
I have three years\' experience (in market investing/export/quality control).
我有三年的(市场调查/出品/品管)经验。
12.
Q: Can you work independently?
问:你能独立作业吗?
A: Yes.I can.
答:能。
模拟问答之其他
1.
Q: Is there anything you wound like to know?
问:你有想知道的事吗?
A: Yes,I’d 1ike to know about the office hours/working hours.
答:是的,我想知道上班/工作时间。
Yes,I\'d 1ike to know what benefits there are for employees in your company.
是的,我想知道贵公司有那些员工福利。
Yes,I’d like to know more details about my job.
是的,我想知道更多关于这份工作的细节。
Yes,I’d like to know when you\'ll contact me about your decision.
是的,我想知道你们什么时候会通知我结果。
Yes,I’d like to know more about your company.
是的,我想各了解一些贵公司的情况。
2.
Q: Can I call you at your office about our final decision?
问:我可以打电话到你们公司,通知你我们最后的决定吗?
A: Yes, you can. The phone number is on my resume.
答:可以。我的履历表上有电话号码。
No, I\'m afraid not. You can call me at my house. The telephone number is written on my resume.
恐怕不太好。你可以打到我家。我的履历表上有电话号码
3.
Q: We\'ll notify you as soon as possible. When can you start working if we decide to use you?
问:我们会尽快通知你,如果我们决定录用你,你什么时候可以开始上班?
A: I can start working next Monday.
答:我可以在下星期一开始上班。
I can start working anytime.
我随时可以开始上班。
4.
Q: If we employ you, what starting salary would you expect?
问:如果我们录用你,你希望起薪多少?
A: I\'d like to start at about $ 20,000 a month.
答:我希望能有月薪两万的起薪。
20,000 a month would be optimum.
最好能有月薪两万。
posted @
2007-10-26 14:00 CoderDream 阅读(2010) |
评论 (1) |
编辑 收藏
01、
敏捷实践场景探讨
02、
Hiberante Collection Mapping Samples
03、
JNA介绍
04、
java中的值传递和引用传递
05、
Java语法总结 - 内部类
06、
使用Subversion进行源代码管理(二):创建和发布版本库
07、
Fedora 7系统安装配置心得(转)(有图哦)
08、
java中的static关键字和静态成员
09、
SWT自定义组件之Slider
10、
用SWT实现MSN风格的下拉框
11、
eclipse自动生成junit代码 flash演示
12、
用 Netbeans 5.5 开发 JUnit Test Case 并输出测试结果
13、
数据库事务特征
14、
字符,字节和编码
15、
初学C++环境搭建(Eclipse+CDT+MinGW)
16、
JUnit 学习笔记 2007版(转)
17、
在 MyEclipse 5.1GA 上使用 XFire 编写 Web Service (转载)
18、
Java异常和字符界面应用
19、
童言无忌:小儿妙语录
20、
java基础---类加载机制
21、
一些常用的正则表达式
22、
关于java基础
23、
The Future Of the Software Development
24、
System.getProperty() 参数大全(原创!)
25、
Spring学习笔记 2007-10-22
26、
在myEclipse中连接数据库 flash演示
27、
碰到的MYSQL数据库中文问题小结
28、
windows 平台的cvs服务器配置
29、
用Java实现FTP批量大文件上传下载(五) --运行效果图
30、
青菜猫lucene2.2.0全文检索更新
31、
Eclipse3.2.2中安装Spring IDE2.0.1
32、
Spring学习笔记 2007-10-24
33、
从类的改造小谈内部类
34、
就一个面试题做的一个小小Demo
35、
一道网易的笔试题
36、
Java1.5泛型指南中文版<转>
37、
Spring学习笔记 2007-10-21
38、
Swing透明和变换
39、
千辛万苦终于搞好个J2ME的ant用的build.xml(总体是和王森学得)
40、
SQL 左外连接,右外连接,全连接,内连接
41、
简单的JDBC连接数据库代码
42、
Java的一些小细节(三)_final story——《HardCore Java》
43、
JavaScript Connect DB
44、
js控制checkbox
posted @
2007-10-25 14:54 CoderDream 阅读(263) |
评论 (0) |
编辑 收藏
现在只要进入Live Skydrive 主页(
http://skydrive.live.com/),用自己hotmail、MSN 或Live 帐号登录之后,就可以看到系统的注册提示了,接受协议之后立马即可开通Windows Live Skydrive 服务。无需对账户信息做任何设置。
某些人可能会看到:“你所在的地区不能使用此服务”的提示,此时只要输入如下网址:
http://skydrive.live.com/home.aspx?mkt=en-us
就可以开通服务了,然后退出,重新登陆就是简体中文界面的了。
单个文件最大50M,速度不会比你用Gmail或yahoo或hotmail邮箱传文件速度慢。
posted @
2007-10-25 07:24 CoderDream 阅读(615) |
评论 (1) |
编辑 收藏步骤1:指定“Content Assist”的快捷键,参考:善用 Eclipse 组合键,提高输入效率
步骤2:输入源代码是,先输入sysout,然后输入辅助快捷键:Alt+/,这样就可以自动生成:System.out.println();
通过上图可知,输入sys后按下快捷键“Alt+/”,会得到提示!
试一试,你会感觉很爽的!
如有更多技巧,请大家一起分享!
posted @
2007-10-22 10:37 CoderDream 阅读(40532) |
评论 (4) |
编辑 收藏web相关的设计和开发正在越来越复杂,每天我们都在一堆堆复杂的html css javascript中。有时,为了旬在一个标签、属性或者调试一个脚本都要花费大量的时间。
好在,这个世界还是懒人多,又一个简化的工具产生了—— firebug。
通过firebug,我们可以轻易的查看html css javascript代码,另外,为了适应现在越来越复杂的ajax需求,他还可以方便的调试javascript,查看连接请求,让本来在暗处进行的行为暴露在外面。
图示html 查看:

css查看:

网络请求:

javascript调试:

好了,现在就安装 fireforx2.0 吧,然后到
http://www.getfirebug.com 去安装firebug 插件。
posted @
2007-10-20 11:42 CoderDream 阅读(264) |
评论 (1) |
编辑 收藏
1、水平、垂直居中,如果只要垂直居中,则去掉“ALIGN="center"”即可:
1 <HTML>
2 <HEAD>
3 <TITLE>内容居中</TITLE>
4 </HEAD>
5 <BODY>
6 <TABLE WIDTH="100%" HEIGHT="100%">
7 <TR>
8 <TD ALIGN="center" VALIGN="middle">
9 要居中的内容!
10 </TD>
11 </TR>
12 </TABLE>
13 </BODY>
14 </HTML>
2、使用CSS+DIV:
1 <HTML>
2 <HEAD>
3 <TITLE> CSS+DIV设置居中 </TITLE>
4 <style type="text/css">
5 .box {
6 background-color:#f00;
7 color:#ccc;
8 width:500px;
9 height:300px;
10 border:1px solid #000;
11 position:absolute;
12 margin:-150px 0px 0px -250px;
13 top:50%;
14 left:50%
15 }
16 </style>
17 </HEAD>
18 <BODY align="center" valign="center">
19 <DIV class="box">
20 我是个居中的层。。。
21 </DIV>
22 </BODY>
23 </HTML>
参考:1、CSS布局基础--水平和垂直居中
2、DIV的水平垂直居中
3、利用CSS实现垂直居中
4、DIV内容垂直居中
posted @
2007-10-18 16:01 CoderDream 阅读(4581) |
评论 (0) |
编辑 收藏
01、
《奋斗》:中国版的穷爸爸富爸爸(转载)
02、
IT项目管理-计划-质量计划
03、
练习题---JS排序
04、
JSF深入--控制跳转
05、
读《SQL必知必会》所得 ONE
06、
JSP动作
07、
读书笔记-《Algorithms in Java》-第一章-07/10/11
08、
Using JDBC with MySQL, Getting Started
09、
常用正则表达
10、
jsp 下载文件
11、
网上转载JAVA面试基本大全
12、
使用Eclipse+Axis2创建与发布Web服务
13、
用JAMES实现自己的邮件服务器
14、
mysql快速批量导入文本数据
15、
同步synchornized方法与方法块
16、
synchronized 资料收集
17、
J2EE集群的本质
18、
Spring + Hibernate 简单应用
19、
【转载】我最恐惧的事情是竞争力的丧失
20、
过滤标签
21、
利用Java的反射与代理机制实现AOP
22、
用Java实现Web服务器(1)
23、
用Java实现Web服务器 (2)
24、
Struts 1.2 的 HTML 标签嵌套属性(如user.name)如何加入 JavaScript 表单验证
25、
Java clone()
26、
scrollbar属性、样式详解
27、
2005年11月软件设计师上午试题
28、
Java中接口与抽象类的区别(一些学习体会,不知正确与否,请指正)
29、
一緯數組排序
30、
Struts2使用示例源码
31、
SOA框架的六个不完美之处
32、
Microsoft Active Directory配置32、
[原创]使用MapInfo地图引擎生成地图图片的代码
33、
java程序的简单实例分析
34、
Java Script 完成的小工具(1)
35、
用例的十大缺陷(修改中...)
36、
专业?我才刚上路
37、
Java 开发员AJAX 常见问题
38、
Hibernate Part3 Web Application
39、
IT项目管理-计划-估算
40、
Grails 1.0 RC1 发布了
41、
Struts2与ajax的组合
42、
如何使用Log4j(转贴)
43、
log4j入门与应用
posted @
2007-10-18 14:52 CoderDream 阅读(260) |
评论 (0) |
编辑 收藏
01、
参考资料:Java中的内部类和匿名类
02、
js小技巧——关闭窗体时不弹出确认对话框(原创整理)
03、
人生的26个字母
04、
java.util.*
05、
《Servlet 与JSP核心编程》读书笔记
06、
写自定义标签时标记attribute里rtexprvalue的用法
07、
[Z]JSP标签自定义 --- useBean
08、
2006年11月软件设计师下午试题精析
09、
07年第42周学习总结
10、
Java开发者必去的20个英文技术网站
11、
《UML 面向对象建模与设计》读书笔记1_基本概念_Class Model
12、
如何解决呢?请教。
13、
一篇不错的讲解Java异常的文章(转载)----感觉很不错,读了以后很有启发
14、
转载 收藏 javascript
15、
JavaScript 用DIV模拟弹出窗口并跟随窗体滚动
posted @
2007-10-16 18:02 CoderDream 阅读(250) |
评论 (0) |
编辑 收藏01、软件的可靠性
02、时间管理
03、Java Script 完成的小工具(1)
04、WebWork标签库简介
05、关于网络的一点基础知识
06、写一个简单的工作流(四)资源的处理
07、迭代增量开发
08、javascript url 编码(UTF-8) jsp 解码
09、zz利用静态内部类为您的代码添加辅助功能
10、webwork的validation校验框架使用(例子)
11、Test-Driven Development with Spring and Hibernate(下载)
12、读书笔记-《Algorithms in Java》-第一章-07/10/11
13、读书笔记-《Algorithms in Java》-第一章-07/10/12
14、exe4j视频教程
15、Java基于Socket文件传输示例
16、参与第一个外包项目总结
17、my俄罗斯方块修正BUG和新功能!提供下载!
18、读书笔记《Thinking in Java》-第一章-07/10/13
19、读书笔记《Thinking in Java》-前言-07/10/13
20、转一篇"经理人"经常会讲的 "把信带给加西亚"
21、用java删除文件夹里的所有文件
22、绝顶聪明的骗局【转】
23、Calendar的使用2(add set roll)方法的区别
24、JavaScript 用DIV模拟弹出窗口并跟随窗体滚动
25、IT项目管理-计划-项目目标和范围
26、Struts 2 + Spring 2 + Hibernate 3 整合入门详解(转载)
27、今天开始学ruby
28、2007年4月份-10月份项目备忘录 -- 1 客户决定技术
29、如何在三个月掌握三年的经验
30、IT人生存调查:心理存在问题 期望与现实脱
posted @
2007-10-14 11:44 CoderDream 阅读(312) |
评论 (0) |
编辑 收藏
01、
《JSF视频教程》exe
02、
Log4配置
03、
初探tomcat连接池
04、
Apache Derby简单入门
05、
一个继承类
06、
够用一辈子的几句话
07、
《大道至简 》个人读后杂谈
08、
Java学习清单
09、
java读取资源文件
10、
Struts2学习笔记
11、
From java.lang.reflect.Array source code To JVM
12、
Struts国际化处理(转)
13、
校园幽默
14、
食品笑话
15、
冷笑话
16、
常用网址
17、
穷人最缺少的是什么?
18、
如何使用Log4j?
19、
Hibernate Query对象
20、
常用查询页面
21、
ssh整合例子---struts、hibernate、spring+unit单元测试
22、
Java字符集<转>
23、
动物笑话 III[转贴]
24、
技术挑战——根据编码函数写出解码函数
25、
从request获取各种路径总结
26、
一个很好的把java打包成exe的软件
27、
垃圾收集机制(Garbage Collection)批判
28、
AWT/SWT/Swing大比较之一:模型设计与实现
29、
java 关闭IE
30、
译文:35个导致你的博客冷清的理由
31、
用Javascript模拟Java的Set
32、
开发人员的洞房花烛夜
33、
人生少走弯路的十条忠告
34、
程序员四大忌
35、
如何成功运用"蘑菇定律"?
36、
写一个简单的工作流(三)
37、
内核中的List结构
38、
JDK1.4引入的新特性之一--断言(assert)
39、
最简单的 AJAX 例子代码(完整注释)
40、
log4j.properties通用配置
41、
Java面试题
42、
设定lib包下所有的jar到classpath
43、
学习设计模式之我见(转)
44、
设计模式之Proxy——买票篇(转)
45、
JDBC连接数据库经验技巧
46、
Java编写的模拟ATM取款机程序
47、
软件技术(软件工艺)
48、
DIV CSS网页布局常用的方法与技巧
49、
练好项目管理
50、
Factory(工厂)模式
51、
TEA加密算法java版
posted @
2007-10-12 19:57 CoderDream 阅读(276) |
评论 (0) |
编辑 收藏
01、
Java中static、this、super、final用法简谈 <原作者 : kevin>
02、
Ajax简易开发框架
03、
ruby-lang上Ruby与Java的对比文章
04、
局域网中无法访问的解决方法
05、
时间脚本收集
06、
《精通css高级web标准解决方案》资料
07、
2007年4月份-10月份项目备忘录--2 敏捷首先要“看得见”
08、
HttpURLConnection使用中遇到的一个问题
09、
JAVA论坛
10、
快速保存网页中所有图片的方法
11、
javascript如何读取自身文件内的xml
12、
音乐网站大全
13、
职工可享受的假期及相关规定
14、
JRuby:集Java和RoR之所长
15、
通过javascritp对表格进行列拖动排序
16、
Spring用户指南
17、
JavaScript应用:Iframe自适应其加载的内容高度
18、
JavaScript框架编程
19、
JavaScript类的继承
20、
Javascript事件设计模式
21、
JavaScript中支持面向对象的基础
22、
javascript树形结构完全封装
23、
javascript读取xml
24、
JavaScrip高级应用:操作模态与非模态对话框
25、
使用javascript+dom+xml实现分页
26、
JavaScript接受URL参数的代码
27、
由浅到深了解JavaScript类
28、
星星鼠标特效(没事的时候可以看看)
29、
使用String.split()方法时要注意的问题
30、
javascript38种小技巧,推荐新手查看
31、
关闭浏览器时提示
32、
时间脚本收集
33、
一组常用的弹出窗口用法
34、
通过宽带路由器搭建WEB/FTP服务器
35、
js sort 扩展
36、
HTML 中 SELECT 选项分组
37、
字符,字节和编码
38、
Hibernate复合主键BUG
39、
开始→运行→输入的命令集锦
40、
结合spring+hibernate与jdbc的事务
41、
动物笑话 III
42、
Windows下用subversion进行版本控制(ZZ)
43、
解决WinXP网络不能互相访问
44、
进展&安排
45、
svn 服务简单搭建
46、
我的手册
47、
在网上发现好文一篇,与大家共享,哈哈~
48、
如何成为一个早起者!!
49、
迎接RIA时代的来临
50、
【转】怎样成为优秀的软件模型设计者
51、
myeclipse中对包的使用
52、
个性化页面布局的设计思考与Rails初步实现
53、
人成熟的4个标志
54、
ActionServlet类
55、
Json-lib 2.1发布
56、
初试Filter对权限和session的控制。
57、
Mysql5 交叉表查询
58、
做个游戏:如果每天能有30分钟空闲时间的话
59、
整理近几天处理JSP页面中遇到的几个问题
60、
java 文件加载 (参考 Hibernate 源码 )
61、
质量和快速决定了软件架构
62、
lilya一个基于extjs的jsf组件编程模型......
63、
教大家实现序列化的克隆
64、
Java 的一些小细节,你知道吗?(《Java就业培训教程》读书笔记)
65、
JAVA程序员不可不注意的编码规范
66、
使用For遍历Map
67、
学习java必看--习惯,心理篇
68、
转:Java同步机制浅谈――synchronized对代码作何影响?
69、
Hibernate 核心接口
70、
一些优秀的自己却没用的小开源项目,
71、
Calendar的使用(简单)
72、
Ghost 指南
posted @
2007-10-11 15:07 CoderDream 阅读(201) |
评论 (0) |
编辑 收藏
点击超链接调用JavaScript函数,一般人都用<a href="javascript:function();">
但这有个缺点,就是点击链接后,页面上的GIF动画将静止。
试看如下代码:
<script language="javascript">
<!--
function Foo()
{
//do something
}
//-->
</script>
<img src="http://****/logo.gif">
<a href="javascript:Foo();">使GIF动画静止的链接</a>
解决方法探讨:
<a
onclick="javascript:Foo();">链接</a>
此时不影响动画显示,但鼠标移上去后,鼠标及超链接样式不发生变化,虽然可以利用样式表来改变鼠标及超链接样式,但毕竟有些繁琐,况且这种思路也不好。
再考查如下代码:
<a onclick="javascript:Foo();" href="#">链接</a>
我们可以发现,虽然点击链接后不影响动画显示,但页面总是滚到最上面,这种效果也不是我们想要的。
最终解决方法:
<a onclick="javascript:Foo(); return false;" href="#">不影响GIF的链接</a>
由于点接链接后,先触发onclick,再执行href属性对应的值,在onclick中加上return false;中断了执行,所以页面就不会跳到最上部了。
posted @
2007-10-11 10:11 CoderDream 阅读(4450) |
评论 (2) |
编辑 收藏
01、
为我学习 Spring AOP 准备(Proxy)
02、
满江红的中文技术文档
03、
Tomcat 5/6 GBK 编码下完美解决中文表单问题的过滤器
04、
HttpURLConnection使用中遇到的一个问题
05、
jsf1.2 自定义日历组件
06、
Eclipse中安装Maven
07、
利用XmlBean轻松读写xml(转)
08、
通用权限管理系统设计篇(三)——概要设计说明书
09、
让OSGi支持JSF Web开发
10、
第一次与猎头“亲密接触”
11、
javax.mail使用例子
12、
英语口语可以这样练成
13、
让 java 动态
14、
教大家学习多线程 和对象流
posted @
2007-10-10 17:20 CoderDream 阅读(156) |
评论 (0) |
编辑 收藏
4、CSS滤镜
4.1、Alpha属性--设置透明层次
4.2、Blur 滤镜--模糊效果
4.3、FlipH、FlipV 滤镜--水平垂直翻转
4.4、Gray滤镜--灰度
4.5、Invert滤镜--反转
4.6、Xray滤镜--X射线
4.7、Wave滤镜--波纹
使用滤镜属性可以把可视化的滤镜和转场效果添加到一个标准的 HTML 元素中,例如图片、文本,以及其他一些对象。对于滤镜和渐变效果,前者是基础,后者是滤镜效果的不断变化和演示更替。 下面介绍几种常用的滤镜:
1、Alpha 滤镜-- 设置透明层次
基本语法
{
filter: alpha (
opacity = opacity,
finishopacity = finishopacity,
style = style,
startx = startx,
starty = starty,
finishx = finishx,
finishy = finishy
)
}
语法解释
Alpha 属性是把一个目标元素与背景混合,设计者可以指定数值来控制混合的程度。这种“与背景混合”通俗地说就是一个元素的透明度。通过指定坐标,可以指定点、线、面的透明度。它们的含义分别如下:
“opacity”:代表透明度水准。范围是从0~100,他们其实是百分比的形式。也就是说,0代表完全透明,100代表完全不透明。
“finishopacity”:是一个可选参数,如果想要设置渐变的透明效果,就可以使用他们来指定结束时的透明度。范围也是0 到 100。
“style”:指定了透明区域的形状特征。其中0代表统一形状、1代表线形、2代表放射状、3代表长方形。
“StartX”和“StartY”:代表渐变透明效果的开始X和Y坐标。
“FinishX”和“FinishY”:代表渐变透明效果结束X和Y 的坐标。
文件范例:13-23.htm
{
filter: alpha (
opacity = opacity,
finishopacity = finishopacity,
style = style,
startx = startx,
starty = starty,
finishx = finishx,
finishy = finishy
)
}
文件说明:
设定 Alpha 滤镜为半透明
显示结果:

下面的三种效果除“Style”参数不同外(分别为1、2、3),其它参数均相同。图1的代码是: Alpha(Opacity=10, FinishOpacity=90, Style=1, StartX=0, StartY=0, FinishX=100, FinishY=100);
2、Blur 滤镜-- 模糊效果
基本语法
{ filter:blur (
add = add,
direction = direction,
strength = strength
)
}
语法解释
add 参数是一个布尔判断:true (默认)或false ,它指定图片是否被改变成印象派的模糊效果。
模糊效果是按顺时针方向进行的,derection 参数用来设置模糊的方向。其中0°表示垂直向上,然后每45°为一个单位,默认值是向左的270°。
strength 值只能使用整数来指定,它代表有多少像素的宽度将受到模糊影响,默认是 5 像素。
文件范例:13-24.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-24.htm -->
<!-- 文件说明:CSS中的Blur滤镜 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS中的Blur滤镜</TITLE>
<Style Type="text/css">
<!--
img{
FILTER:BLUR(STRENGTH=10);
}
-->
</Style>
</HEAD>
<BODY>
<H2>强大的CSS滤镜</H2>
<IMG Src=13-23.jpg>
</BODY>
</HTML>
文件说明:
设定了 blur 滤镜的模糊强度为 10。
显示结果:

3、FlipH、FlipV 滤镜-- 水平垂直翻转
基本语法
{ filter:filph }
{ filter:filpv }
语法解释
上述两句代码分别 表示水平翻转和垂直翻转
文件范例:13-25.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-25.htm -->
<!-- 文件说明:CSS中的FlipV滤镜 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS中的FlipV滤镜</TITLE>
<Style Type="text/css">
<!--
img{
FILTER:FlipV;
}
-->
</Style>
</HEAD>
<BODY>
<H2>强大的CSS滤镜</H2>
<IMG Src=13-23.jpg>
</BODY>
</HTML>
文件说明:
设定垂直翻转滤镜
显示结果:

4、Gray 滤镜 -- 灰度
基本语法
{ filter:gray }
语法解释
Gray 滤镜的作用是把一张图片变成灰度图。
文件范例:13-26.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-26.htm -->
<!-- 文件说明:CSS中的Gray滤镜 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS中的Gray滤镜</TITLE>
<Style Type="text/css">
<!--
img{
FILTER:gray;
}
-->
</Style>
</HEAD>
<BODY>
<H2>强大的CSS滤镜</H2>
<IMG Src=13-23.jpg>
</BODY>
</HTML>
显示结果:

5、Invert 滤镜 -- 反转
基本语法
{ filter:invert }
语法解释
Invert 滤镜的作用是把对象的可视化属性全部翻转,包括色彩、饱和度和亮度值。
文件范例:13-27.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-27.htm -->
<!-- 文件说明:CSS中的Invert滤镜 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS中的Invert滤镜</TITLE>
<Style Type="text/css">
<!--
img{
FILTER:invert;
}
-->
</Style>
</HEAD>
<BODY>
<H2>强大的CSS滤镜</H2>
<IMG Src=13-23.jpg>
</BODY>
</HTML>
显示结果:

6、Xray 滤镜 -- X 射线
基本语法
{ filter:xray }
语法解释
Xray 滤镜的作用是让对象反映出它的轮廓并把这些轮廓加亮,也就是所谓的“X”光片。
文件范例:13-28.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-28.htm -->
<!-- 文件说明:CSS中的Xray滤镜 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS中的Xray滤镜</TITLE>
<Style Type="text/css">
<!--
img{
FILTER:xray;
}
-->
</Style>
</HEAD>
<BODY>
<H2>强大的CSS滤镜</H2>
<IMG Src=13-23.jpg>
</BODY>
</HTML>
显示结果:

7、Wave 滤镜 -- 波纹
基本语法
{
filter:wave (
add = add,
freq = freq,
lightstrength = strength,
phase = phase,
strength = strength
)
}
语法解释
Wave
Add参数有两个参数值:True代表把对象按照波纹样式打乱;False代表不打乱;
Freq参数指生成波纹的频率,也就是指定在对象上共需要产生多少个完整的波纹。
LightStrength参数是为了使生成的波纹增强光的效果。参数值可以从0到100。
Phase参数用来设置正弦波开始的偏移量。这个值的通用值为0,它的可变范围为从0到100。这个值代表开始时的偏移量占波长的百分比。比如该值为25,代表正弦波从90度(360*25%)的方向开始。
STRENGTH 振幅大小
文件范例:13-29.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-29.htm -->
<!-- 文件说明:CSS中的Wave滤镜 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS中的Wave滤镜</TITLE>
<Style Type="text/css">
<!--
img{
FILTER:wave(add=add,freq=2,lightstrength=50,phase=45,strength=10);
}
-->
</Style>
</HEAD>
<BODY>
<H2>强大的CSS滤镜</H2>
<IMG Src=13-23.jpg>
</BODY>
</HTML>
显示结果:

posted @
2007-10-09 17:59 CoderDream 阅读(482) |
评论 (1) |
编辑 收藏在再保系统中,我们有时候会以某个日期作为查询条件,如在“参数维护”的某个模块中,需要将“生效日期”作为查询条件。
我们在JSP中使用JS插件输入“yyyy-mm-dd”格式的日期,但是数据库(DB2)中的字段是“TimeStamp”,而我们在DBean中用VO接这个字段是用“Date”类型,这样在做查询的Dao类的方法中,我们要对这个字段进行处理。
首先定义一种格式变量:
SimpleDateFormat myFmt = new SimpleDateFormat("yyyy-MM-dd");
然后将Date类型的变量进行格式化:
myFmt.format(reCededRateVO.getBoundDate())
这样会得到“yyyy-MM-dd”格式的日期,然后就可以放到Sql语句中作为条件进行查询了。
/**
* description: 根據公司別、再保類別查詢與之相符合的紀錄
*
* @param reCededRateVO
* ReCededRateVO
* @param startRow
* 起始行
* @param numberOfRows
* 讀取行數
* @return List 結果集
* @throws DbAccessException
* 數據庫訪問異常
*/
public List selectListByCode(ReCededRateVO reCededRateVO,
int startRow, int numberOfRows) throws DbAccessException {
if (DEBUGLOG.isDebugEnabled()) {
DEBUGLOG.debug("[ReCededRateDataDao.selectListByCode()]"
+ "[begin]");
}
SimpleDateFormat myFmt = new SimpleDateFormat("yyyy-MM-dd");
StringBuffer hqlBuff = new StringBuffer(
"from ReCededRateData as t where 1=1");
// 公司別
if (!"".equals(reCededRateVO.getCompanyFlag())
&& reCededRateVO.getCompanyFlag() != null) {
hqlBuff.append(" and t.id.companyFlag = '"
+ reCededRateVO.getCompanyFlag() + "'");
}
// 再保類別
if (!"".equals(reCededRateVO.getReinsuranceClass())
&& reCededRateVO.getReinsuranceClass() != null) {
hqlBuff.append(" and t.id.reinsuranceClass = '"
+ reCededRateVO.getReinsuranceClass() + "'");
}
// 再保層次
if (!"".equals(reCededRateVO.getReinsuranceLevel())
&& reCededRateVO.getReinsuranceLevel() != null) {
hqlBuff.append(" and t.id.reinsuranceLevel = '"
+ reCededRateVO.getReinsuranceLevel() + "'");
}
// 生效日期
if (!"".equals(reCededRateVO.getBoundDate())
&& reCededRateVO.getBoundDate() != null) {
hqlBuff.append(" and t.endDate >= '"
+ myFmt.format(reCededRateVO.getBoundDate())
+ "' and t.id.boundDate <= '"
+ myFmt.format(reCededRateVO.getBoundDate()) + "'");
}
hqlBuff.append(" order by t.id.companyFlag asc, t.id.boundDate asc,"
+ "t.id.reinsuranceClass asc, t.id.reinsuranceLevel asc,"
+ "t.id.reCompanyCode asc, t.id.bodyFlag asc");
// 以公司別+生效日期+再保類別排序+再保層次+再保公司+體位別");
List list = this.hQueryByPage(hqlBuff.toString(), startRow,
numberOfRows);
if (list != null && list.size() > 0) {
if (DEBUGLOG.isDebugEnabled()) {
DEBUGLOG.debug("[selectListByCode()]select list success![end]");
}
return list;
} else {
if (DEBUGLOG.isDebugEnabled()) {
DEBUGLOG.debug("[selectListByCode()]select list return null!"
+ "[end]");
}
return null;
}
}
posted @
2007-10-09 15:41 CoderDream 阅读(716) |
评论 (0) |
编辑 收藏<html>
<head>
<script language="javascript">
var rowIndex = 0;
function addOneLineOnClick() {
var row = tb.insertRow(tb.rows.length);
col = row.insertCell(0);
col.innerHTML = "<tr><input size='90' name=btn index=\""+ rowIndex +"\" >";
col = row.insertCell(1);
col.innerHTML = "<input type='button' value='Del' onclick=\"return DeleteRow('row" + rowIndex +"')\"></tr>";
row.setAttribute("id", "row" + rowIndex);
row.setAttribute("name", "row" + rowIndex);
rowIndex++;
}
function DeleteRow(rowTag){
var i = tb.rows(rowTag).rowIndex;
var j;
for(j=i;j<=rowIndex;j++) {
tb.rows(j).cells(0).all("btn").index--;
}
tb.deleteRow(i);
rowIndex--;
}
</script>
</head>
<body >
<div align="center">
<table width="95%" name="tb" id="tb">
<tr>
</tr>
</table>
<p>
<input name="btnAddLine" type="button" id="btnAddLine" onClick="return addOneLineOnClick()" value="Add">
</div>
</body>
</html>
posted @
2007-10-09 10:14 CoderDream 阅读(335) |
评论 (0) |
编辑 收藏
不同方向的边框属性如表所示:
| 边框属性 |
描述 |
| border |
边框 |
| border-top |
上边框 |
| border-left |
左边框 |
| border-right |
右边框 |
| border-bottom |
下边框 |
对于边框的样式,可以按照下表中所示进行设置:
| 边框样式属性值 |
描述 |
| none |
无边框 |
| dotted |
边框由点组成 |
| dash |
边框由短线组成 |
| solid |
边框是实线 |
| double |
边框是双实线 |
| groove |
边框带有立体感的沟槽 |
| ridge |
边框成脊型 |
| inset |
边框内嵌一个立体边框 |
| outset |
边框外嵌一个立体边框 |
范例文件:13-18.htm
1 <!-- ------------------------------ -->
2 <!-- 文件范例:13-18.htm -->
3 <!-- 文件说明:CSS边框 -->
4 <!-- ------------------------------ -->
5 <HTML>
6 <HEAD>
7 <TITLE>CSS背景图像位置</TITLE>
8 <Style Type="text/css">
9 <!--
10 P{
11 border-top: 2px solid #990000;
12 border-right: 2px solid #3399FF;
13 border-bottom: 2px solid #00FF33;
14 border-left: 2px solid #CC33FF;
15 }
16 -->
17 </Style>
18 </HEAD>
19 <BODY>
20 <H1>主流的网页设计软件</H1>
21 <p>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
22 </BODY>
23 </HTML>
文件说明:
第10~15行分别设定了上、右、下、左4个边框的宽度、边框样式和颜色。
显示结果:

3.4.5、鼠标光标属性
| 鼠标光标属性值 |
描述 |
| hand |
手 |
| crosshair |
交叉十字 |
| text |
文本选择符号 |
| wait |
Windows 的沙漏形状 |
| default |
默认的鼠标形状 |
| help |
带问号的鼠标 |
| e-resize |
向东的箭头 |
| ne-resize |
指向东北方的箭头 |
| n-resize |
向北的箭头 |
| nw-resize |
指向西北方的箭头 |
| w-resize |
向西的箭头 |
| sw-resize |
指向西南方的箭头 |
| s-resize |
向南的箭头 |
| se-resize |
指向东南方的箭头 |
范例文件:13-19.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-19.htm -->
<!-- 文件说明:CSS鼠标光标属性 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS鼠标光标属性</TITLE>
<Style Type="text/css">
<!--
Body{
CURSOR:CROSSHAIR
}
IMG{
Cursor:help
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<img src=13-19.jpg align=left>
<P>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:


3.4.6、定位属性
| 定位属性 |
描述 |
| position |
“absolute”(绝对定位)、“relative”(相对定位) |
| top |
层距离顶点纵坐标的距离 |
| left |
层距离顶点横坐标的距离 |
| width |
层的宽度 |
| height |
层的高度 |
| z-index |
决定层的先后顺序和覆盖关系,值高的元素会覆盖值比较低的元素 |
| clip |
限定只显示裁切出来的区域,裁切出的区域为矩形。只要设定两个点即可,一个是矩形左上角的顶点,由top和right两项的设置完成,另一个是右下角的顶点,由bottom和 right 两项设置完成 |
| overflow |
当层内的内容超出层所能容纳的范围时:
visible:层的大小、内容都会显示出来
hidden:会隐藏超出层大小的内容
scrol:不管内容是否超出层的范围,选中此项都会为层添加滚动条
auto:只在内容超出层的范围时才显示滚动条
|
| visibility |
这一项是针对嵌套层的设置,嵌套层是插入在其他层中的层,分为嵌套的层(子层)和被嵌套的层(父层)
inherit:子层继承父层的可见性,父层可见,子层也可见;父层不可见,子层也不可见
visible:无论父层可见与否,子层都可见
hidden:无论父层可见与否,子层都隐藏
|
范例文件:13-20.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-20.htm -->
<!-- 文件说明:CSS定位属性 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS定位属性</TITLE>
<Style Type="text/css">
<!--
.self{
position:absolute;
top:80px;
left:50px;
width:300px;
height:100px;
overflow:auto;
background-color:#336699;
color:#FFFFFF;
z-index:1;
visibility:visible;
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<div class="self">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</div>
</BODY>
</HTML>
显示结果:

3.4.7、区块属性
| 区块属性 |
描述 |
| width |
设定对象的宽度 |
| height |
设定对象的高度 |
| float |
让文字环绕在一个元素的四周 |
| clear |
指定在某一个元素的某一边是否允许有环绕的文字或对象 |
| padding |
决定了究竟在边框与内容之间应该插入多少空间距离,它有4个属性,分别是:top、bottom、left、right,分别用于设定上下左右的填充距离 |
| margin |
设置一个元素在4个方向上与浏览器窗口边界或上一级元素的边界的距离。与“padding”类似,它也有上下左右4个属性,分别控制4个方向 |
范例文件:13-21.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-21.htm -->
<!-- 文件说明:CSS区块属性 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS区块属性</TITLE>
<Style Type="text/css">
<!--
.self{
width:300px;
height:100px;
MARGIN-TOP: 20PX;
MARGIN-RIGHT: 30PX;
MARGIN-BOTTOM: 20PX;
MARGIN-LEFT: 30PX
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<div class=self>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</div>
</BODY>
</HTML>
显示结果:

3.4.8、列表属性
| 列表属性 |
描述 |
| list-style-type |
设定引导列表选项的符号类型 |
| bullet |
选择图像作为项目的引导符号 |
| position |
决定列表项目缩进的程度,outside:列表贴近左侧边框;inside:列表缩进 |
| 列表符号类型属性值 |
描述 |
| disc |
在文本行前面加“●”实心园 |
| circle |
在文本行前面加“○”空心园 |
| square |
在文本行前面加“■”实心方块 |
| decimal |
在文本行前面加普通的阿拉伯数字 |
| lower-roman |
在文本行前面加小写罗马数字 |
| upper-roman |
在文本行前面加大写罗马数字 |
| lower-alpha |
在文本行前面加小写英文字母 |
| upper-alpha |
在文本行前面加大写英文字母 |
| none |
不显示任何项目符号或编号 |
范例文件:13-22.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-22.htm -->
<!-- 文件说明:CSS列表属性 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS列表属性</TITLE>
<Style Type="text/css">
<!--
li{
list-style-type:upper-roman;
}
-->
</Style>
</HEAD>
<BODY>
<H2>图像设计软件</H2>
<OL>
<LI>Photoshop</LI>
<LI>Illustrator</LI>
<LI>Freehand</LI>
<LI>CorelDraw</LI>
</OL>
</BODY>
</HTML>
显示结果:

posted @
2007-10-08 17:18 CoderDream 阅读(4205) |
评论 (2) |
编辑 收藏
3.3、颜色和背景属性
3.3.1、颜色
3.3.2、背景颜色
3.3.3、背景图像
3.3.4、背景图像重复
3.3.5、背景图像位置
| 文本属性 |
描述 |
| color |
定义颜色 |
| background-color |
设定一个元素的背景颜色 |
| background-image |
设定一个元素的背景图像 |
| background-repeat |
决定一个指定的背景图像如何被重复 |
| background-position |
设置水平和垂直方向上的位置 |
3.2.1、 颜色
颜色 color 属性允许网页制作者指定一个元素的颜色,一般用RGB,#FFFFFF(16进制数)表示。
文件范例:13-13.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-13.htm -->
<!-- 文件说明:CSS颜色 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS颜色</TITLE>
<Style Type="text/css">
<!--
H1 {
color:#336699
}
.text {
color:#ffcc00
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class=text>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:
 3.2.2、背景颜色
文件范例:13-14.htm
3.2.2、背景颜色
文件范例:13-14.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-14.htm -->
<!-- 文件说明:CSS背景颜色 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS背景颜色</TITLE>
<Style Type="text/css">
<!--
body {
background-color:#336699
}
H1 {
background-color:#ffffff
}
.text {
background-color:#ffcc00
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class="text">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:
 3.2.3、背景图像
3.2.3、背景图像
文件范例:13-15.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-15.htm -->
<!-- 文件说明:CSS背景图像 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS背景图像</TITLE>
<Style Type="text/css">
<!--
body {
Background-image:url(13-15.gif)
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class=text>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:
 3.2.4、背景图像重复
3.2.4、背景图像重复
| 背景图像重复属性值 |
描述 |
| repeat-x |
图像横向重复 |
| repeat-y |
图像纵向重复 |
| repeat |
图像横向纵向重复 |
| no-repeat |
图像不重复(只显示一张图,无任何方向的平铺) |
文件范例:13-16.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-16.htm -->
<!-- 文件说明:CSS背景图像重复 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS背景图像重复</TITLE>
<Style Type="text/css">
<!--
body {
Background-image:url(13-15.gif);
background-repeat: repeat-y
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class="text">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:
 3.2.5、背景图像位置
3.2.5、背景图像位置
| 背景图像位置属性值 |
描述 |
| left |
背景图像居左 |
| right |
背景图像居右 |
| center |
背景图像水平居中,垂直居中 |
| top |
背景图像上对齐 |
| bottom |
背景图像下对齐 |
与 background-repeat 属性结合使用,否则没有任何效果,因为 background-repeat 的默认属性为repeat。
文件范例:13-17.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-17.htm -->
<!-- 文件说明:CSS背景图像位置 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS背景图像位置</TITLE>
<Style Type="text/css">
<!--
body {
Background-image:url(13-15.gif);
background-repeat:repeat-y;
Background-position:right top
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class=text>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:

posted @
2007-10-08 14:40 CoderDream 阅读(6562) |
评论 (0) |
编辑 收藏
3.2、文本属性
3.2.1、字母间隔
3.2.2、文字修饰
3.2.3、文字排列
3.2.4、文本缩进
3.2.5、行间距
| 文本属性 |
描述 |
| letter-spacing |
定义一个附加在字符之间的间隔数量 |
| text-decoration |
文本修饰属性允许通过五个属性中的一个来修饰文本 |
| text-align |
设置文本的水平对齐方式,包括左对齐、右对齐、居中、两端对齐 |
| text-indent |
文字的首行缩进 |
| line-height |
行高属性接受一个控制文本基线之间的间隔的值 |
3.2.1、 字母间隔
letter-spacing 属性定义一个附加在字符之间的间隔数量,改值必须符合长度格式,允许使用负值。一个设为0的值会阻止文字的调整。
文件范例:13-8.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-8.htm -->
<!-- 文件说明:CSS字母间隔 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS字母间隔</TITLE>
<Style Type="text/css">
<!--
H1{
letter-spacing: -10px
}
.text {
letter-spacing: 5px
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class=text>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:
 3.2.2、文字修饰
3.2.2、文字修饰
| 文字修饰属性值 |
描述 |
| underline |
下划线 |
| overline |
上划线 |
| line-through |
删除线 |
| blink |
闪烁,只适用 NetScape 浏览器 |
| none |
无任何修饰 |
文件范例:13-9.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-9.htm -->
<!-- 文件说明:CSS文字修饰 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS文字修饰</TITLE>
<Style Type="text/css">
<!--
a:link {
font-family: "宋体";
text-decoration: none
}
a:visited {
font-family: "宋体";
text-decoration: none
}
a:hover{
font-family:"宋体";
text-decoration: underline
}
.text {
text-decoration: underline
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class="text">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、FIireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
<A href=mailto:husong@elong.com>给我来信</A>
</BODY>
</HTML>
显示结果:
 3.2.3、文本排列
3.2.3、文本排列
| 文字排列属性值 |
描述 |
| left |
左对齐 |
| center |
居中对齐 |
| right |
右对齐 |
| justify |
两端对齐 |
文件范例:13-10.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-10.htm -->
<!-- 文件说明:CSS文本排列 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS文本排列</TITLE>
<Style Type="text/css">
<!--
H1 {
text-align:center
}
.text {
text-align:justify
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class=text>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
<A href=mailto:husong@elong.com>给我来信</A>
</BODY>
</HTML>
显示结果:
 3.2.4、文本缩进
3.2.4、文本缩进
文本缩进 text-indent 属性可以应用于块级元素(P,H1等),定义该元素第1行可以接受的缩进的数量。改值必须是一个长度或一个百分比,若为百分比,则视上级元素的宽度而定。通用的文本缩进用法是用于段缩进。
文件范例:13-11.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-11.htm -->
<!-- 文件说明:CSS文本缩进 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS文本缩进</TITLE>
<Style Type="text/css">
<!--
H1 {
text-indent:100pt
}
.text {
text-indent:24pt
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class="text">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
<A href=mailto:husong@elong.com>给我来信</A>
</BODY>
</HTML>
显示结果:
 3.2.5、行间距
3.2.5、行间距
行间距 line-height 属性可以接受一个控制文本基线之间的间隔的值。当值为百分比数字时,行高由元素字体大小的量与该数字相乘所得,百分比的值相对于元素字体的大小而定,不允许使用负值。
文件范例:13-12.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-12.htm -->
<!-- 文件说明:CSS行间距 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS行间距</TITLE>
<Style Type="text/css">
<!--
.text {
line-height:24pt
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class="text">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
<A href=mailto:husong@elong.com>给我来信</A>
</BODY>
</HTML>
显示结果:

posted @
2007-10-08 14:14 CoderDream 阅读(1149) |
评论 (0) |
编辑 收藏
3、CSS的属性和值
3.1、字体属性
3.1.1、字体族科
3.1.2、字体大小
3.1.3、字体风格
3.1.4、字体加粗
| 字体属性 |
描述 |
| font-family |
用一个指定的字体名或一个类的字体族科 |
| font-size |
字体显示的大小 |
| font-style |
设定字体风格 |
| font-weight |
以 bold 为值可以使字体加粗 |
1、字体族科 font-family
文件范例:13-4.htm
1 <!-- ------------------------------ -->
2 <!-- 文件范例:13-4.htm -->
3 <!-- 文件说明:CSS字体族科 -->
4 <!-- ------------------------------ -->
5 <HTML>
6 <HEAD>
7 <TITLE>CSS字体族科</TITLE>
8 <Style Type="text/css">
9 <!--
10 H1{
11 font-family: "隶书"
12 }
13 .text {
14 font-family: "宋体,仿宋_gb2312";
15 }
16 -->
17 </Style>
18 </HEAD>
19 <BODY>
20 <H1>主流的网页设计软件</H1>
21 <p class="text">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
22 </BODY>
23 </HTML>
文件说明:
第10~12设定H1标记样式,规定了字体为隶书,第13~15行设定了名为text的自定义样式,规定了字体为宋体或仿宋,即当客户机没有第一种
宋体字体的时候,浏览器会使用第2种仿宋字体显示。
定义了样式后,第20行的标题字会自动应用H1样式,而第21行通过了 class 属性引用了 text 样式。
显示结果:
 2、字体大小
2、字体大小
单位可以是厘米、像素、磅等,另外还有其他一些值,例如:xx-small、x-small、smaller、x-large、xx-large等。最常用的单位为pt。
文件范例:13.5.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-5.htm -->
<!-- 文件说明:CSS字体大小 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS字体大小</TITLE>
<Style Type="text/css">
<!--
H1{
font-size:14pt
}
.text {
font-size:9pt
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class="text">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:
 3、字体风格
3、字体风格
| 字体风格属性值 |
描述 |
| normal |
普通的文字 |
| italic |
斜体的文字 |
| oblique |
倾斜的文字,在中文文字的使用上与italic 并无明显区别 |
文件范例:13-6.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-6.htm -->
<!-- 文件说明:CSS字体风格 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS字体风格</TITLE>
<Style Type="text/css">
<!--
H1{
font-style:italic
}
.text {
font-style:oblique
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class="text">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:
 4、字体加粗
4、字体加粗
| 字体加粗属性值 |
描述 |
| 值 |
100~900之间 |
| normal |
普通的文字 |
| bold |
加粗 |
| bolder |
特粗 |
| lighter |
加细 |
文件范例:13-7.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-7.htm -->
<!-- 文件说明:CSS字体加粗 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS字体加粗</TITLE>
<Style Type="text/css">
<!--
H1{
font-weight:900
}
.text {
font-weight:bolder
}
-->
</Style>
</HEAD>
<BODY>
<H1>主流的网页设计软件</H1>
<p class=text>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:

posted @
2007-10-08 11:56 CoderDream 阅读(2613) |
评论 (0) |
编辑 收藏
1.1、CSS的基本概念
1.2、CSS的特点
2、CSS的类型与基本写法
2.1、CSS的类型
2.2、CSS的基本写法
2.3、CSS的冲突
3、CSS的属性和值
3.1、字体属性
3.1.1、字体族科
3.1.2、字体大小
3.1.3、字体风格
3.1.4、字体加粗
3.2、文本属性
3.2.1、字母间隔
3.2.2、文字修饰
3.2.3、文字排列
3.2.4、文本缩进
3.2.5、行间距
3.3、颜色和背景属性
3.3.1、颜色
3.3.2、背景颜色
3.3.3、背景图像
3.3.4、背景图像重复
3.3.5、背景图像位置
3.4、边框属性
3.5、鼠标光标属性
3.6、定位属性
3.7、区块属性
3.8、列表属性
4、CSS滤镜
4.1、Alpha属性--设置透明层次
4.2、Blur 滤镜--模糊效果
4.3、FlipH、FlipV 滤镜--水平垂直翻转
4.4、Gray滤镜--灰度
4.5、Invert滤镜--反转
4.6、Xray滤镜--X射线
4.7、Wave滤镜--波纹
posted @
2007-10-07 22:21 CoderDream 阅读(363) |
评论 (0) |
编辑 收藏
1、什么是CSS
1.1、CSS的基本概念 从总体来说,CSS 能够完成下列工作:
a、弥补 HTML 对网页格式化功能的不足,比如段落间距、行距等。
b、字体变化和大小;
c、页面格式的动态更新;
d、排版定位等。
1.2、CSS的特点
a、将格式和结构分离
b、以前所未有的能力控制页面布局
c、制作体积更小、下载更快的页面
d、将许多页面同时更新,比以前更快更容易
e、浏览器将成为更友好的界面
2、CSS的类型与基本写法
2.1、CSS的类型
CSS层叠样式表包含3种类型:
a、自定义CSS,相应的标记中出现“class"属性
如下代码:
.bg {
background-image: url(bg.gif);
}
在HTML中使用:
<body class="bg">
b、重定义标记的CSS
td {
color: #000099;
font-size: 9pt
}
c、CSS选择符
CSS 选择符为特殊的组合标记定义CSS,使用“ID”作为属性,以保证文档具有唯一可用的值。CSS选择符是一种特殊类型的样式,常用的有4种,分别为:
a:link、a:active、a:visited、a:hover
其中:
a:link:设定正常状态下链接文字的样式。
a:active:设定鼠标单击时链接的外观。
a:visited:设定访问过的链接外观。
a:hover:设定鼠标放置在链接文字之上时文字的外观。
如下代码:
a:link {
color: #FF3366;
font-family:"宋体";
text-decoration:none;
}
a:hover {
color: #FF6600;
font-family:"宋体";
text-decoration:underline;
}
a:visited {
color: #339900;
font-family:"宋体";
text-decoration:none;
}
2.2、CSS的基本写法
CSS的基本写法有3种:
1、在 HEAD 内实现,即<HEAD></HEAD>标记内:
文件范例:13-1.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-1.htm -->
<!-- 文件说明:CSS在<head>中的实现 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS在head中的实现</TITLE>
<Style Type="text/css">
<!--
body {
font-family: "黑体";
font-size: 12pt;
line-height: 16pt;
color: #FFFFFF;
background-color: #006699;
}
-->
</Style>
</HEAD>
<BODY>
主流的网页设计软件
<p>目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:

2、在<BODY>内实现
使用下面的语法:
<h3 style="font-size:10pt">
这样的写法虽然直观,但是无法体现出CSS的优势,因此不推荐使用。
文件范例:13-2.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-2.htm -->
<!-- 文件说明:CSS在<body>中的实现 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>CSS在body中的实现</TITLE>
</HEAD>
<BODY>
主流的网页设计软件
<p style="font-size:9pt;line-height:12pt;background-color:#FFCC00;font-family:宋体">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
显示结果:

3、在文件外的调用
CSS 的定义既可以是在HTML文档内部,也可以单独成立文件,如下代码是将CSS样式链接到外部到style.css文件:
<link rel="stylesheet" href="style.css" type="text/css">
文件范例:13-3.htm
<!-- ------------------------------ -->
<!-- 文件范例:13-3.htm -->
<!-- 文件说明:调用外部的CSS样式文件-->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>调用外部的CSS样式文件</TITLE>
<link href="13-3.css" rel="stylesheet" type="text/css">
</HEAD>
<BODY>
主流的网页设计软件
<p class="t">目前,网页技术进入了一个新的阶段,现在的网页再也不是图片的堆积和枯燥无味的文本了,人们现在追求的是网页的动态效果和交互性。而Macromedia公司的网页设计三剑客软件Dreamweaver、Flash、Fireworks正是交互性网页设计的杰出代表,其最新版本MX继承了前期版本的优点,进行了功能的进一步整合,非常适合于网页设计和网站建设的需要。</P>
</BODY>
</HTML>
文件范例:13-3.css
.t {
font-family: "宋体";
font-size: 9pt;
text-decoration: underline;
letter-spacing: 3px;
line-height: 12pt;
}
显示结果:

2.3、CSS的冲突
a、执行最近的
b、CSS样式优先级高于HTML样式
posted @
2007-10-07 22:10 CoderDream 阅读(2745) |
评论 (0) |
编辑 收藏 读书就像谈恋爱一样,需要环境。读书一定要有书的香味,书的形状,书的个性,并根据书的内容的不同,你还需要选择不同的地点和时间来读……
优秀的书籍就像难得的朋友,在你不需要的时候,你感觉不到他们的存在;在你需要的时候,他们总是及时地来到你的身边……
不管走到什么地方,我都随身带上一本书,并不是一定要读书,也并不一定是因为一寸光阴一寸金的紧迫感,只是觉得走到任何地方,如果手里没有一本书,总觉得不对劲,总觉得心里空空的,手不知道往哪里放。晚上睡觉前要是不拿本书在手中,就觉得世界末日快要来了,其实拿了也不一定读,但心里踏实,在枕头边放着一本书,可以安心睡觉了。每次出差,我都像搬运工似的在行李箱里放上一摞的书,结果经常发现带的很多书连翻都没有翻开过,所以告诫自己下次不要带那么多书。但下次出差仍然还是带很多书,沉甸甸地背出去,再原封不动地背回家,即使一字不读,也好像这些书在旅途中填补了心灵某个角落的空白。
在别人面前读书和自己一个人读书,会有很不一样的感觉和选择。在别人面前读书的时候,你总会有意无意地拿一些别人认为值得读,或者看上去很深奥的书,免得别人以为你太没学问。一个人独处的时候是读书最快乐的时候,你读什么书完全由你自己选择。我最喜欢读的书是漫画书,就像我看电影最喜欢看卡通电影一样。虽时常怀疑自己的智商停留在了儿童时期,仍会每次拿到一本漫画书就喜上眉梢。蔡志忠的漫画书我读了无数遍,最近又把韩国作家李元馥的漫画系列读了个遍。
读书就像谈恋爱一样,需要环境。我从来不在电脑中读任何书籍,在电脑中读书,就好像和机器人谈恋爱。读书一定要有书的香味,书的形状,书的个性。根据书的内容的不同,你还需要选择不同的地点和时间来读。古代人读书要焚香洗手,有时候甚至还要有美女相伴,这种境界我们现在是没办法达到了。但我们依然可以创造一些小环境。比如读古文的时候要在深夜,点上一根蜡烛,沏上一杯清茶,一字一句地慢慢读、慢慢品味;读诗歌的时候最好是在下雨天,听着窗外的雨声,轻轻把诗歌读出来融入雨中,想着诗人跌宕起伏的命运,读着诗歌中梦牵魂绕的语言,不禁悲从中来,嚎啕大哭;读小说的时候最好在野外,或湖边或山脚,把自己沉浸在小说的情节中,大悲大喜都有山川河流相呼应,不亦快哉;读哲学书籍应该去闹市,在人声鼎沸之处思考存在的意义和出世的意义,即使思考不出所以然也不会出问题,因为你一抬头就看到了热闹的人间。
优秀的书籍就像难得的朋友,在你不需要的时候,你感觉不到他们的存在;在你需要的时候,他们总是及时地来到你的身边,忠诚地守候在你生命的左右,随时宽解、充实你那不安、寂寞的灵魂。
posted @
2007-10-06 10:09 CoderDream 阅读(282) |
评论 (0) |
编辑 收藏
1、
Eclipse 3 + MinGW3.1配置标准C/C++开发环境
posted @
2007-10-06 08:06 CoderDream 阅读(126) |
评论 (0) |
编辑 收藏
1、
统计字符串中的重复部分并整理输出
2、
未来游戏设计的十大技术挑战(震撼)
3、
JVM中的内存分配
4、
北大青鸟 软件工程师 4.0 教学PPT和源代码
5、
实用项目管理读书笔记(3)
6、
Eclipse插件之Spring IDE
7、
货币原理及人民币升值问题的阐述[转]
8、
一个百度面试题 - n个数中找最大的两个数最少比较次数
9、
如何使用java动态创建ODBC数据源
10、
JavaScript中的数字排序方法
11、
Oracle SQL培训笔记[开发人员][一]
12、
[转]JAVA IO流
13、
中英对照:WindowsServer虚拟技术前瞻
14、
在Tomcat5.5中配置Mysql数据库连接池 、
15、
自己写的内存管理工具类,支持简单的垃圾回收
16、
开发工具统一配置(JavaEE)
17、
要求精确答案就避免使用double和float
18、
jPCT-----Java做3D开发的免费类库
19、
zz:编程修养
20、
zz:计算机科学与技术学习反思录
21、
计算机科学与技术学习心得(zz)
22、
Java 专业人士必备的书籍和网站列表
23、
Java编写的目录监视器(DirectoryWatcher)源码
24、
[转载]你的四金到底有多少?
25、
SpringMVC
26、
Junit速成
posted @
2007-10-05 16:02 CoderDream 阅读(183) |
评论 (0) |
编辑 收藏 摘要:不论是在校大学生还是社会人士,从事IT业或将来要从事IT业的人不在少数。每个IT人都有自己的梦想,社会竞争如此激烈,一个适当的人生规划能助你一臂之力,让我们一起追寻成功人士的步伐,从中汲取经验。
我今年39岁了,25岁研究生毕业,工作14年,回头看看,应该说走了不少的弯路,有一些经验和教训。现在开一个小公司,赚的钱刚够养家糊口。看看这些刚毕业的学生,对前景也很迷茫,想抛砖引玉,谈谈自己的看法,局限于理工科的学生,我对文科的不懂,身边的朋友也没有这一类型的。
91年研究生毕业,那时出路就是1种:留在北京的国营单位,搞一个北京户口,这是最好的选择。到后来的2-3年内,户口落定了,又分成5条出路:
1、上国内的大企业,如:华为;
2、自己做公司,做产品开发;
3、上外企,比如:爱立信、诺基亚;
4、自己做公司,做买卖;
5、移民加拿大。
我想,首先要看自己适合做什么?做技术还是做买卖。
做技术,需要你对技术感兴趣。我掰着数了一遍,我们研究生班的30来号人,实际上适合做技术的,大概只有3、4个人,这几个人,1个现在还在华为,3个移民加拿大了,现在这4个人混得还可以,在华为的同学也移民加拿大了,他在华为呆了6年,在华为奖金工资加起来大概30万吧,还有华为的股票,再过几年,华为的股票一上市,也能值个100-200万。要是一毕业就去华为,那现在就绝对不是这个数字了。
要是做技术,最好的就是上大公司,国内的大型企业,像华为中兴肯定是首选,能学到很多东西。华为虽然累,但是,年轻人不能怕累,要是到老了,还需要去打拼,那才是真的累啊。在外企,我想他们主要就是技术支持和销售,但是技术是学不到的,当然不能一概而论,我指的是象爱立信和诺基亚,真正的研发不会在中国做的,学到的也不如在华为多,其它的中兴我不是很了解,我想应该也不错。
一个人都有一技之长,有傍身之技,那是最好的,走到哪里,都能有一口饭吃,还吃得不错,这是传统的观点。
任何技术都是要在某个行业去应用,这个行业市场越大当然越好;要在一个领域之内,做深做精,成为绝对的专家,这是走技术道路的人的选择。不要跳来跳去,在中国,再小的行业你要做精深了,都可以产生很大的利润。
研究生刚毕业的时候,做产品开发的有不少人,都是自己拍拍脑子,觉得这个产品有市场,就自己出来做。现在看来,我的这些同学,做产品开发的成功的没有一例,为什么?资源不足。
1. 资金,刚毕业的学生,就是没钱;没钱,也意味着你开发的东西都是小产品,而且只能哥几个自己上,研发、生产、销售都是一个人或者几个人自己来,没有积累,什么都是重新来过。
2. 人脉,任何一个行业,要想进去,需要有很深的人脉,否则,谁会用你的东西?谁敢用你的东西?我这个班上开发产品的、自己还在坚持的,只剩下一个人了,说实在的,到现在,没有自己的汽车,也没有自己的房子,混得挺惨。
其次就是上外企。我的2个同学,一个上了爱立信,一个先到爱立信后到诺基亚,都混得不错。到诺基亚的后来利用在诺基亚结识的人脉自己开了公司,也赚了不少钱.外企最大的好处就是除了能学到比较规范的管理外,还能给你的职业生涯镀金。
自己做公司,做买卖,一开始有3-4个人走这条路,但是真正发财的只有一个人。做买卖,还是要有一定的天赋,还有机遇。要有对金钱的赤裸裸的欲望,要有商业上的头脑。后来我们同学在一起谈,说,我们即使给自己这个机遇,也未必能做得好。
移民加拿大对搞技术的人来说,还是一个不错的选择,但是要尽早,练了几年的技术,就赶紧出去,大概是在1996年走了不到10个,现在都还可以,买了房子和车了。要是晚了,语言再学也难了。
关于我自己,先是在国营的研究所混了4年,后来到一家公司干了6年,2002年出来自己做公司,现在算是有房有车,有点积蓄,但是不多,还有一个可爱的女儿。回首这10来年,有一些经验和教训。
1. 要有一个职业生涯的规划。首先需要定位自己做什么合适,是做买卖还是做技术,一条路走到底;当然,做了技术,后来改行也行;
2. 做技术,就是要做精做深,成为这个行业的这个技术的专家;最好就是去国内的大公司,才能全面学到东西,能够给你培训的机会;如果大公司进不去,先到小公司练技术,找机会再到大公司去镀金,学高深的技术。千万不要自己做产品,要做也是对这个行业熟悉了,再去做。
3. 积极争取机会。积极争取学习和进步的机会。比如做技术,就需要多锻炼,多学习,来提高自己的水平。一门技术,只要有机会去学习,都能学得会;要是没有机会,天才也没有办法学到这个技术。柳传志就说,杨元庆就是“哭着喊着要进步”,实际上,就是争取自己的机会;当然,这种强烈的进步欲望,也是领导看重的地方。
4. 积累个人的信誉。从你的职业生涯的第一天,就要按照诚信的原则办事。要做到,当人们提起你的名字的时候,说,这哥们还不错,做事还行。
5. 注意利用资源。如果你有有钱的亲戚、成功的长辈或者朋友,可以充分利用这些机会,得到更加顺利的发展前景。
6. 注意财富的不断积累。人生要想得到自由,财富是很关键的。否则,永远仰人鼻息,永远看人脸色。人都是势利眼。今后的家庭、职业生涯,金钱的积累很重要,没有钱 ,永远不能开张自己的事业,得到更多的机会;财富要做到逐年积累,你才能家庭生活幸福。没有钱是不可能有幸福的家庭。
7. 注意人脉的积累。最终,事业要靠在社会上的人脉的资源。要注意认识在你这个行业的人,结交他们,最终他们会成为你事业上的助力。
8. 寻求贵人相助。要找大老板来帮助你,得到大老板的赏识。想想看,大蛋糕,切一点就够了,小蛋糕,都给你也吃不饱。
9. 多听听成功的前辈和成功的朋友的意见。注意少听家里长辈的意见,尤其是都已经退休的长辈,他们对社会的认识还停留在很久以前,而这个社会已经发生很大的变化。最重要的是,长辈有时候会强求你做一些事情,但是,最终的结果他们是不负责的。
posted @
2007-10-05 14:57 CoderDream 阅读(984) |
评论 (0) |
编辑 收藏第1章 JavaScript是什么
1.1 历史简述
1997年,JavaScript 1.1 作为一个草案提交给欧洲计算机制造商协会(ECMA)。第39技术委员会(TC39)被委派来“标准化一个通用、跨平台、中立于厂商的脚本语言的语法和语义”(http://www.ecma-international.org/memento/TC39.htm)。TC39锤炼出了ECMA-262,该标准定义了叫做ECMAScript的全新脚本语言。在接下来的几年里,国际标准化组织及国际电工委员会(ISO/IEC)也采纳ECMAScript作为标准(ISO/IEC-16262)。
1.2 JavaScript实现
JavaScript实现是由以下3个部分组成的:
-核心(ECMAScript)
-文档对象模型(DOM)
-浏览器对象模型(BOM)

1.2.1 ECMAScript
ECMAScript描述了以下内容:
语法;
类型;
语句;
关键字;
保留字;
运算符;
对象。
ECMAScript仅仅是一个描述,定义了脚本语言的所有属性、方法和对象。其他的语言可以实现ECMAScript来作为功能的标准,JavaScript就是这样。

1.2.1.1 ECMAScript的版本
最新的ECMA-262的版本是第三版,于1999年12月发布。
第一版:删除来与浏览器相关的代码的JavaScript1.1。
第二版:大部分更新本质上是编辑性的,未特别添加、更改和删除内容。
第三版:提供了对字符串处理、错误定义和数组输出的更新。同时,它还增加了正则表达式、新的控制语句、try...catch异常处理的支持,以及一些为使标准国际化而做的小改动。标志着ECMAScript成为一种真正的编程语言。
1.2.1.2 何谓ECMAScript符合性
一个脚本语言必需满足以下四项基本原则:
符合的实现必须按照ECMA-262中所描述的支持所有的“类型、值、对象、属性、函数和程序语法及语义;
符合的实现必须支持Unicode字符标准(UCS);
符合的实现可以增加没有在ECMA-262中指定的“额外的类型、值、对象、属性和函数”。
符合的实现可以支持没有在ECMA-262中定义的“程序和正则表达式语法”即可以替换或者扩展内建的正则表达式支持。
1.2.1.3 Web浏览器中的ECMAScript支持
以下版本支持ECMA-262第三版:Netscape 6.0+(Mozilla 0.6.0+)、Internet Explorer 5.5+、Opera 7.2+、Safari 1.0+/Konqueror~2.0+
1.2.2 DOM
DOM(文档对象模型)是HTML和XML的应用程序接口(API)。DOM将整个页面规划成由节点层级构成的文档。HTML或XML页面的每个部分都是一个节点的衍生物。
请考虑下面的HTML页面:
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<p>Hello World!</p>
</body>
</html>
这段代码可以用DOM绘制成一个节点层次图。
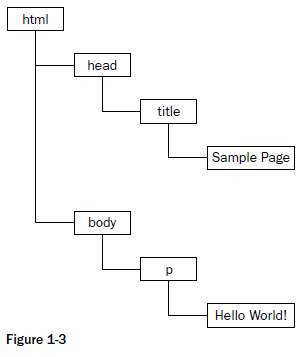
DOM通过创建树来表示文档,从而使开发者对文档的内容和结构具有空前的控制力。用DOM API可以轻松地删除、添加和替换节点。
1.2.2.1 为什么DOM必不可少
保持Web的跨平台特性,Web通信标准的团体W3C(World Wide Web Consortium)开始制定DOM。
1.2.2.2 DOM的各个Level
DOM Level 1 是W3C于1998年10月提出的。它由两个模块构成,即DOM Core和DOM HTML。前者提供了基于 XML 的文档的结构图,以方便访问和操作文档的任意部分;后者添加了一些 HTML 专用的对象和方法,从而扩展了DOM Core。
DOM Level 1 只有一个目标,即规划文档的结构。
DOM Level 2 引入了几种 DOM 新模块,用于处理新的接口类型:
DOM 视图--描述跟踪文档的各种视图(即 CSS 样式化之前和 CSS 样式化之后的文档)的接口;
DOM 事件--描述事件的接口;
DOM 样式--描述处理基于 CSS 样式的接口;
DOM 遍历和范围--描述遍历和操作文档树的接口。
DOM Level 3 引入了以统一的方式载入和保存文档的方法(包含在新模块 DOM Load and Save 中)以及验证文档(DOM Validation)的方法,从而进一步扩展了 DOM 。在Level 3 中,DOM Core 被扩展为支持所有的 XML 1.0 特性,包括 XML Infoset、XPath 和 XML Base。
1.2.2.3 其他 DOM
可缩放矢量图形(SVG)1.0;
数学标记语言(MathML)1.0;
同步多媒体集成语言(SMIL)。
1.2.2.4 Web 浏览器中的 DOM 支持
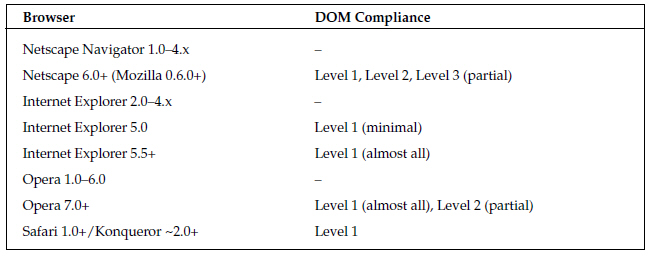
1.2.3 BOM(浏览器对象模型)
BOM 主要处理浏览器窗口和框架,扩展部分包括:
弹出新的浏览器窗口;
移动、关闭浏览器窗口以及调整窗口大小;
提供 Web 浏览器详细信息的导航对象;
提供装载到浏览器中页面的详细信息的定位对象;
提供用户屏幕分辩率详细信息的屏幕对象;
对 Cookie 的支持;
IE 扩展了 BOM,加入了 ActiveXObject 类,可以通过 JavaScript 实例化 ActiveX 对象。
1.3 小结
本章介绍了 JavaScript 这种客户端 Web 浏览器脚本语言,了解了构成 JavaScript 完整实现的各个部分:
JavaScript 的核心 ECMAScript 描述了该语言的语法和基本对象;
DOM 描述了处理页面内容的方法和接口;
BOM 描述了与浏览器进行交互的方法和接口。
posted @
2007-10-04 21:35 CoderDream 阅读(515) |
评论 (0) |
编辑 收藏
天下有二难:登天难,求人更难。有二苦:黄连苦,贫穷更苦。有二薄:春冰薄,人情更薄。有二险:江湖险,人心更险;知其难,守质苦,耐其薄,测其险,可以处世矣。海纳百川,有容乃大;壁立千仞,无欲则刚。
快速看清一个人的方法:
看一个国家的国民教育,要看他的公共厕所。看一个男人的品味,要看他的袜子。看一个女人是否养尊处优,要看她的手。看一个人的气血,要看他的头发。看一个人的心术,要看他的眼神。看一个人的身价,要看他的对手。看一个人的底牌.要看他身边的好友。
看一个人的性格,要看他的字写得怎样。看一个人是否快乐,不要看笑容,要看清晨梦醒时的一刹那表情。看一个人的胸襟,要看他如何面对失败及被人出卖。看两个人的关系,要看发生意外时,另一方的紧张程度。
看清楚一个人将来有没有发展,,要看他(她)回不回帖。
posted @
2007-09-30 11:44 CoderDream 阅读(356) |
评论 (0) |
编辑 收藏1、输入被保人身份证号码:F121557706,然后点查询:
2、查询结果为该被保人有3种累计类别的保单,选择“LIFE”类型的累计类别,进入详细资料页面:
3、该累计类别下有5张保单,选择再保号码为:LF-05-081577的这笔资料,进入保单再保明细页面:

4、选择“续期明细查询”,进入“续期详细列表”页面:

5、选择再保年度为“5”的这笔资料,进入“续期明细信息”页面:

6、续期详细信息:
7、如果在“保单再保明细”页面点击“变更明细查询”按钮,则进入“变更明细列表”页面:
8、选择“会计年月”为“200509”的这笔资料,则进入“变更详细讯息”页面:

9、变更详细讯息:
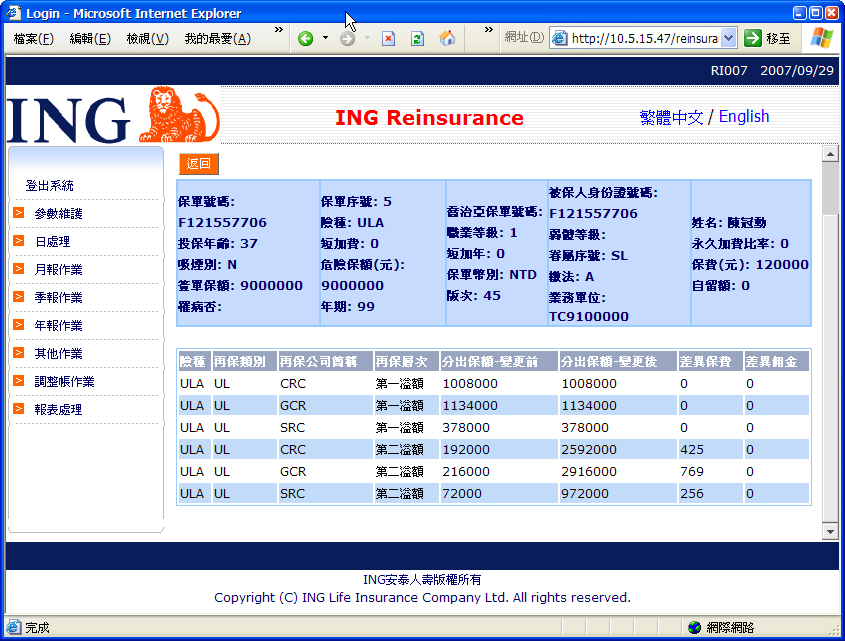
10、由于有需求和变更的被保人不一定有理赔资料,所以换另一个被保人:F101863552
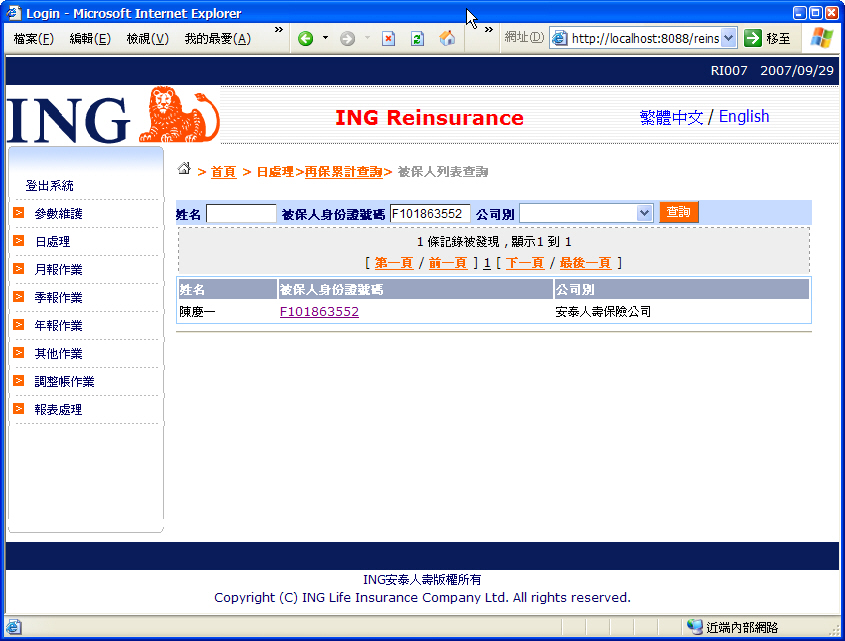
11、“累计类别”选“LIFE”:
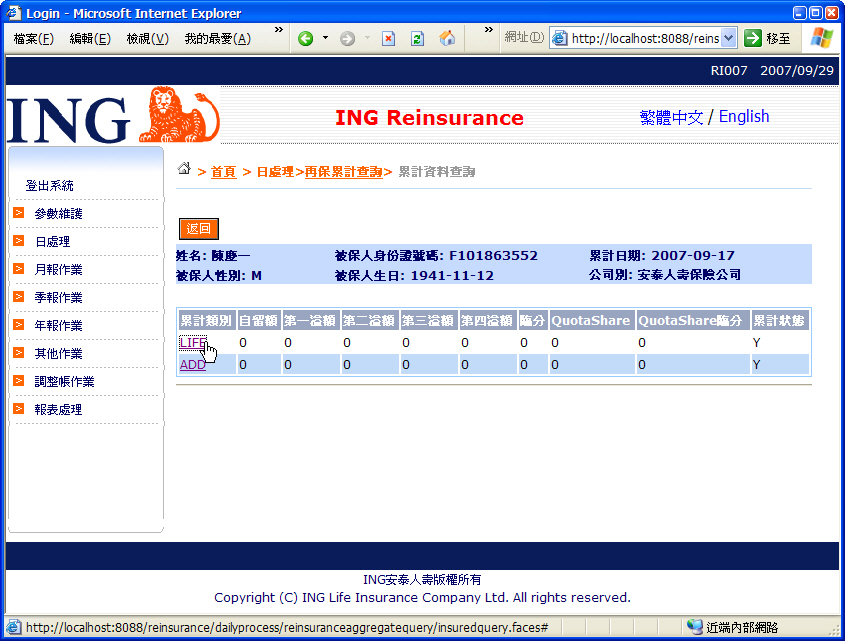
12、“再保号码”选“LF-92-014022 ”:
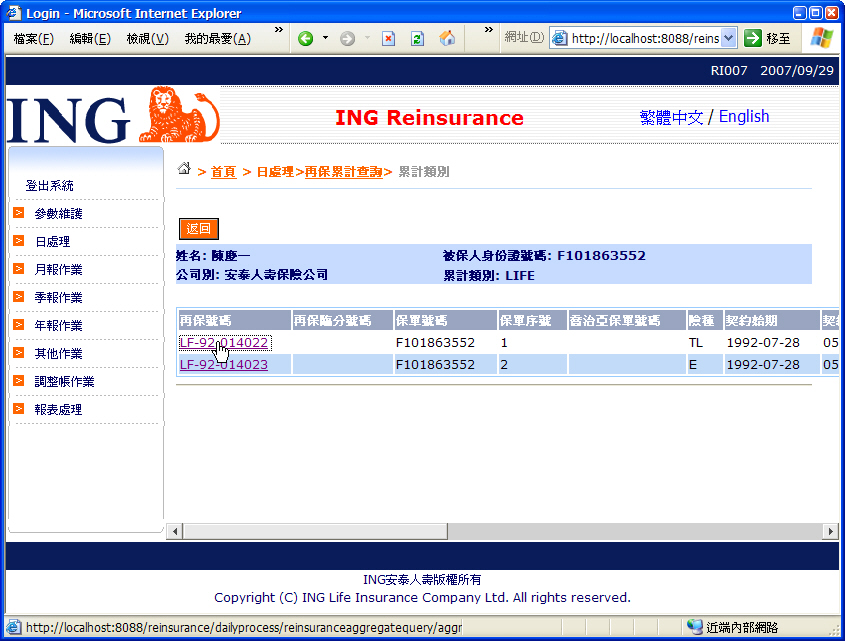
13、单击“理赔明细信息”按钮:
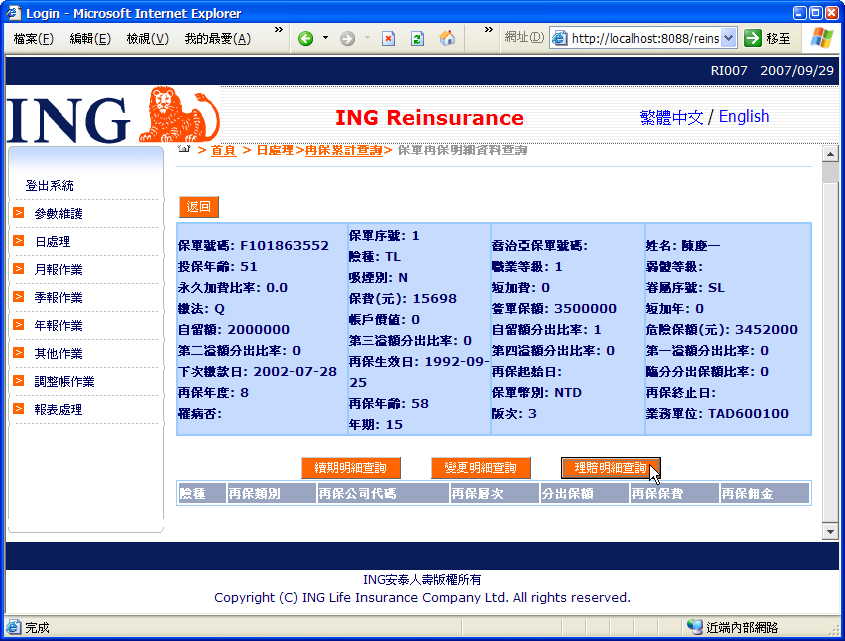
14、选择“会计年月”为“199010”,“给付种类”为“准备帐”的这笔资料:
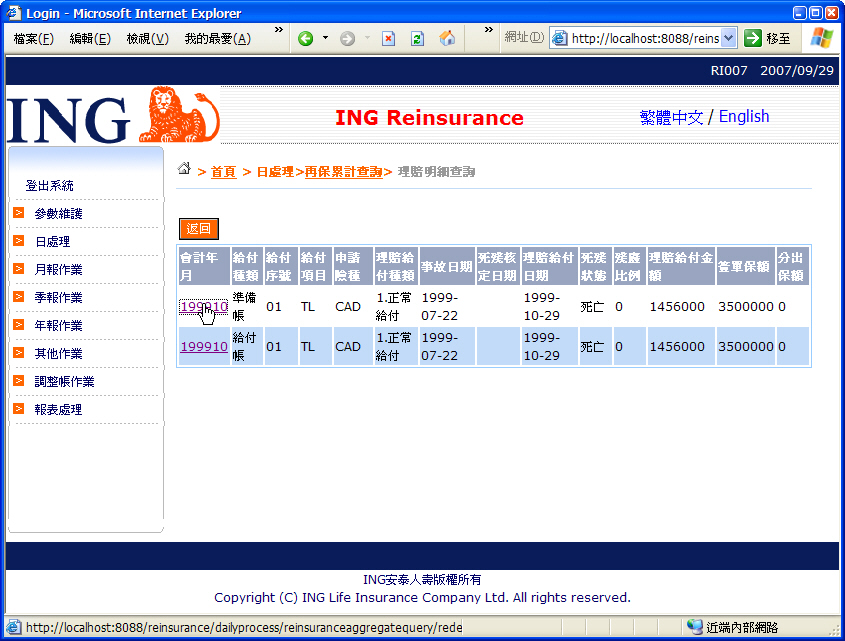
14、理赔详细讯息:
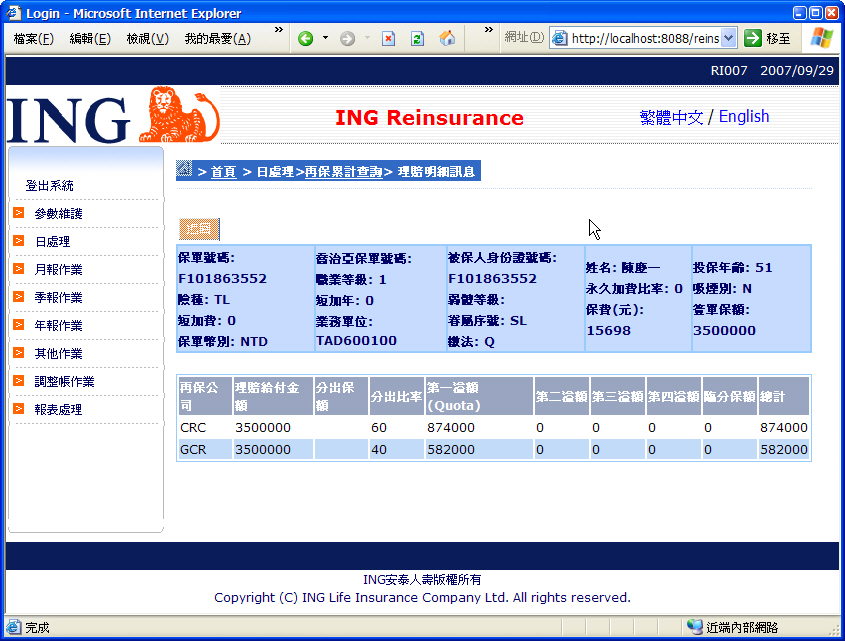
posted @
2007-09-29 11:18 CoderDream 阅读(340) |
评论 (0) |
编辑 收藏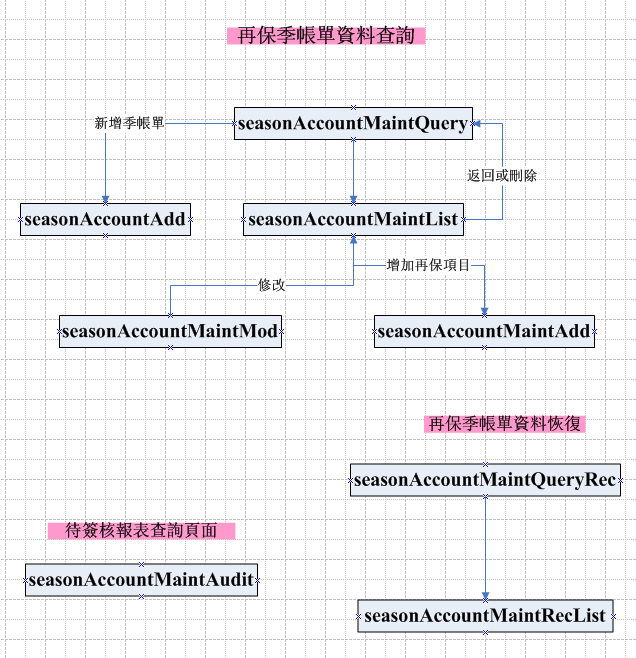 下载VSD文件
下载VSD文件
posted @
2007-09-29 10:14 CoderDream 阅读(544) |
评论 (1) |
编辑 收藏
01、
数字验证码的识别
02、
Log4j的Unknown Source问题
03、
Javascript中最常用的55个经典技巧
04、
一篇不错的讲解Java异常的文章(转载)----感觉很不错,读了以后很有启发
05、
Web开发中使用反射为Bean赋值
06、
Hibernate优化查询性能手段
07、
Java验证码资料精粹
08、
在LDAP中使用角色(Role)和组(Group)来管理用户
09、
关于java数据类型和参数
10、
MySQL5绿色版windows下安装总结
11、
成功!用SAX读取XML文件。
12、
用Groovy读XML文件。
13、
转载 Java Reflection (JAVA反射)
14、
Ok!用DOM写XML文件!
15、
checkbox勾选提交问题示例
16、
jsp 详解request对象
17、
javascript 基础知识之总结实例
18、
ORACLE函数大全
19、
关于spring+hibernate的事务的简单配置(这里用的mysql数据库)
20、
冒泡排序
21、
spring2.04+hibernate3.2+struts2+ajax中文乱码问题
22、
在jsp环境中配置使用FCKEditor(转载)
23、
真正的Java学习从入门到精通
24、
软件开发的理念与实际开发
25、
如何用javascript控制checkbox,并进行批量删除
26、
用servlet filter 解决编码问题的一个小例子
27、
Hibernate Search 3.0 正式版发布
28、
中文分词源代码解析和下载
29、
面向对象分析与设计面向对象分析与设计OOAD
30、
EJB3.0规范解读(转)
31、
使用XFire+Spring构建Web Service
32、
Java做的酒店管理系统(C/S)源码
33、
反编译工具jad简单用法
34、
一篇关于web.xml配置的详细说明(转载)
35、
系统进程相关
36、
Spring笔记之八(Internationalization of spring)
37、
java数据库操作基本流程
38、
用java调用oracle存储过程总结(转载)
39、
Tomcat+MySql+Struts中文问题绝妙的解决方案
40、
使用 CVS 下载 java.net 的项目源码
41、
【转载】正确地做事与做正确的事同样重要
posted @
2007-09-28 11:48 CoderDream 阅读(144) |
评论 (1) |
编辑 收藏
01、
软件架构乱弹——问题域及其解决方法
02、
JAVA6.0操作脚本语言
03、
架构随笔整理索引
04、
Ajax基础
05、
设计模式之创建模式
06、
[转]J2EE总结--Servlet技术
07、
MD5算法的java版本(转)
08、
MySQL命令 (7) -- 用户管理
09、
Hibernate常见问题集锦
10、
JAVA中使用正则表达式的几个功能
11、
原来Iterator是这样的,才发现,失败啊!
12、
ArrayList的使用方法以及与vector的对比(转)
13、
写给想当程序员的朋友—一个还不太老的普通程序员的体会
14、
Servlet,JSP 动态生成excel文件并提示下载的简单方法
15、
简单的java io测试
16、
Java代理模式
17、
利用Jakarta Commons组件beanutils、dbutils简化JDBC数据库操作(一)
18、
程序员的酸甜苦辣—写在即将告别coding的时刻
19、
程序员与妓女和民工的比较(转)
20、
Java多线程程序设计详细解析
21、
jsp中文问题最终解决方案
22、
走出围城—程序员职业生涯规划路线图 (转csdn)
23、
迭代器模式(Iterator pattern)
24、
Struts与MVC模式的关系
25、
用简单的实例来实践TDD的核心思想
26、
EJB学习日记(11)
27、
Java中的++操作
28、
正方形不是长方形的终极解决办法
29、
有趣的效应-ONE
30、
Spring 整合 Hibernate 的一处简化配置<转载>
31、
JAVA STRING UTIL
32、
JPA一对多关系的单向关联
33、
Hibernate属性延迟加载
34、
【转】js日期时间函数
35、
门户网站建设方案
36、
类加载机制初探
37、
GlassFish 2 vs. Tomcat 6
38、
tomcat中MySQL连接池配置
39、
java画带箭头的线
40、
求质数的算法 (合集)
41、
J2EE全面简介[转]
42、
SQL语法参考手册
43、
sql语句大全
44、
如何同时启动多个Tomcat服务器
45、
OSCache学习
46、
用CashFilter实现页面级缓存实践
47、
Hadoop--海量文件的分布式计算处理方案
48、
设计模式之事务处理
49、
一个经试用效果非常不错的数据库连接池
50、
利用js实现栏目随意拖动
51、
event.srcElement 说明 方法 技巧 (转:柳永法(yongfa365)'Blog)
52、
菜单
53、
随机数字验证码的生成
54、
改善程序员脑力的70条方法
55、
Ajax中文处理乱码问题总结
56、
从Decorator,Adapter模式看Java/IO库(一)
57、
再战MVC(-)
58、
原创小框架: 动态面向对象数据库操作(不要影射类哦)
59、
Adobe Flex 3最有趣的特征之一 :Web设计者和开发者的相遇
60、
Tomcat: Error filterStart解决办法
61、
web开发中类的自动编译和载入
62、
从Java的面向对象之后再学JavaScript的面向对象
63、
使用DataModelListener对‘jsf的dataTable组件自定义控制指定行样式的方法 ’的改进
64、
CXF2.0 小试 。。。
65、
Spring 整合 Hibernate 的一处简化配置<转载>
posted @
2007-09-21 18:04 CoderDream 阅读(228) |
评论 (1) |
编辑 收藏
01、
Spring集成XFire开发WebService
02、
大型Java Web项目的架构和部署调优问题
03、
处理一些和日期有关的动作
04、
java实现读写文件操作的三种不同方式
05、
JS之OOP
06、
AXIS(APACHE SOAP) 入门记录
07、
内外网共享FCK editor的上传文件
08、
Java反射机制学习笔记(二)
09、
java一个多线程的经典例子
10、
自用小框架:DB工厂
11、
[导入]介绍几款所见即所得的WEB在线编辑器[转]
12、
java---final 关键字 和 static 用法
13、
Hibernate 参数设置一览表
14、
Spring的回调HibernateCallBack方法
15、
DWR+SPRING整合
16、
Oracle常用命令
17、
看《墨攻》理解IoC—Spring底层核心<转载>
18、
一个程序员的奋斗历程<转贴>来自:LinuxForum
19、
一个php记录访问者IP到文件的简单示例
20、
Java中堆和栈的区别(转)
21、
我遇到的Javascript 现象总结
22、
设计模式之Factory
23、
DAO设计模式
24、
转载: 用 Netbeans 開發 Ruby on Rails 程式
25、
转载:我的 JRuby 初體驗
26、
jar包转exe文件软件
27、
MySQL命令 (6) -- 修改数据
28、
常用sql
29、
Pro员
30、
基于 UDP 的局域网多播聊天练习代码
31、
整合Jboss和Hibernate
32、
【转载】installanywhere
33、
正则表达式删除空行
34、
Hibernate+Struts分页代码
35、
如何作出一个完善的分析复杂嵌套SQL语句的程序? (附上自己做的分析嵌套SQL语句的两个类)
36、
限制用户在文本框输入的字数
37、
【转】一篇关于web.xml配置的详细说明
38、
【转】JSP三种页面跳转方式
39、
java用于精确计算的类
40、
【转】java中文件操作大全
41、
常用正则
42、
JspSmartUpload使用指南 (整理)
43、
敏捷软件开发
44、
jar包转exe文件软件
posted @
2007-09-21 17:39 CoderDream 阅读(261) |
评论 (2) |
编辑 收藏
1、
hibernate简述
2、
计算任意2个日期内的工作日(摘抄)
3、
接口和抽象类
4、
教大家SQL 内连接
5、
搭建Ruby on Rails开发环境(zz)
6、
简单的java小知识点,比较容易忘记,不断更新中(1)
7、
hibernate有关
8、
转载: Spring 入门实战
9、
想学好Java的 不进来看 是你的损失,, Java的好书
10、
【J2EE核心模式】——表现层设计考虑和不佳实践
11、
今天跟大家讲讲方法的参数....
12、
在JAVA文件中获取该项目的相对路径
13、
java笔记3
14、
Jsp基础
15、
接口和抽象类的定义方式举例说明(转)
16、
教大家 抽象类........
17、
Java的Build工具—Ant应用指南(1)
18、
Apache2.0 + Tomcat5.5 如何禁止掉目录浏览
19、
未成熟的程序员做DD设计
20、
Java反射机制
21、
贪吃蛇
22、
Java基础-漫谈EJB在Java中的应用
23、
一种简单JDBC数据库连接池的实现
24、
Oops! JSP + MS Access Quick Start
25、
Hibernate O/R映射
26、
一个26岁IT工程师写在辞职后
27、
JAVA错误处理大集合
28、
转载:Java学习从入门到精通
29、
Java精华积累:初学者都应该搞懂的问题
30、
转载:请不要忽视这些基础知识~
31、
spring+hibernate+struts整合开发实例(教程)
32、
SVN Beginning
33、
Java Excel API Beginning
34、
Subversion(SVN)安装使用指南
35、
教大家使用反射类 。。 Class
36、
spring2.0使用手册学习笔记(一)
37、
java2核心技术之代理模式
38、
添加table中的行
39、
(转帖)利用xfire开发webservice专题[三]
40、
使用 Eclipse V3.3 保持代码干净(转)
41、
限制JTextFiled只能输入定长或者数字
42、
一个JMS发送接受程序示例(Weblogic)
43、
使用Spring2.0发送和接受JMS消息(在Spring2.0的参考手册的基础上补完)
44、
【转】frameset框架使用总结
45、
java.util.List 真的会用么?看能作对否
46、
Oops! Eclipse + JSP + Applet + JMF Quick Start
47、
AJAX学习笔记---应用AJAX模仿"联系站长"(JSP版)
48、
Socket编程实现简单的服务器与客户端互发消息
49、
一个简单的DOM解析XML文件过程
50、
依赖注入和单元测试
51、
Hibernate核心接口简介
52、
JAVA元数据注释初探
53、
在代码中编译和创建Jar
54、
常去的几个外国技术门户
posted @
2007-09-18 18:08 CoderDream 阅读(145) |
评论 (0) |
编辑 收藏一、构建Ant环境
①免安装构建:如果你已经配置好Eclipse环境(3.0以上),那Ant环境就已经构建好了;
②从零开始手工配置:
A:配置好Java环境;
安装JDK,然后设置好环境变量,如:
Java 环境配置:
Java安装目录:E:\Java\jdk1.5.0_12
在“系统”-》“高级”-》“环境变量”-》“系统参数”中
1、新增JAVA_HOME:
变量名:JAVA_HOME
变量值:E:"Java\jdk1.5.0_12
2、新增CLASSPATH:
变量名:CLASSPATH
变量值:.;%JAVA_HOME%\lib\tool.jar;%JAVA_HOME%\lib\dt.jar;
3、在Path变量中增加Java的bin目录
已存在的变量名:Path
在最前面新增的值:.;%JAVA_HOME%\bin;
B、下载Ant包:
地址:http://ant.apache.org/bindownload.cgi
配置Ant环境变量:
Ant 环境配置:
Ant安装目录:D:\ant
在“系统”-》“高级”-》“环境变量”-》“系统参数”中
1、新增ANT_HOME:
变量名:ANT_HOME
变量值:D:\ant
2、在Path变量中增加Ant的bin目录
已存在的变量名:Path
在最前面新增的值:.;%ANT_HOME%"bin;
测试:run-》cmd,输入ant,如果出现下面的画面,测表明Ant环境已经配置好了。

二、简单上手:
build.xml
<?xml version="1.0"?>
<project default="main" basedir=".">
<target name="main">
<javac srcdir="src\main\hello\ant" destdir="bin"/>
<java classname="main.hello.ant.HelloAnt">
<classpath>
<pathelement path="bin" />
</classpath>
</java>
</target>
</project>
HelloAnt.java
package main.hello.ant;
public class HelloAnt {
public static void main(String[] args) {
System.out.println("Hello World From HelloAnt!");
}
}
目录结构:
运行结果:

三、Ant提高
改进build.xml,让它做更多的事情:
定义全局变量
初始化,主要是建立目录
编译(已有)
打包为jar
建立API documentation
生成 发布(distribution) 产品
build.xml
<?xml version="1.0" encoding="UTF-8" ?>
<project default="dist" basedir=".">
<!-- 主要的系统环境属性 -->
<!-- 取Window,Unix的环境变量 -->
<property environment="env" />
<property name="java.home" value="${env.JAVA_HOME}" />
<property name="ant.home" value="${env.ANT_HOME}" />
<!-- 主要的app环境属性 -->
<property name="app.name" value="hello-ant" />
<property name="app.jar" value="${app.name}.jar" />
<property name="app.copyright" value=" Copyright(c) 2007 CoderDream's Studio All rights reserved." />
<!-- app中的src属性 -->
<property name="src.dir" value="src" />
<property name="src.main" value="${src.dir}/main" />
<property name="src.script" value="${src.dir}/script" />
<!-- app用到的lib -->
<property name="lib.dir" value="lib" />
<!-- app的build目录中 -->
<property name="build.dir" value="build" />
<property name="build.classes" value="${build.dir}/classes" />
<property name="build.docs" value="${build.dir}/doc" />
<property name="build.docs.api" value="${build.docs}/api" />
<property name="build.lib" value="${build.dir}/lib" />
<!-- app的dist(distribution发布)目录中 -->
<property name="dist.dir" value="dist" />
<property name="dist.bin" value="${dist.dir}/bin" />
<property name="dist.docs" value="${dist.dir}/docs" />
<property name="dist.lib" value="${dist.dir}/lib" />
<!-- app的docs目录中 -->
<property name="docs.dir" value="docs" />
<property name="report" value="report" />
<path id="classpath">
<pathelement location="${build.classes}" />
<pathelement path="${java.home}/lib/tools.jar" />
</path>
<target name="init">
<!-- 清除以前的目录 -->
<delete dir="${build.dir}" failonerror="false" />
<delete dir="${dist.dir}" failonerror="false" />
<!-- 准备目录 -->
<mkdir dir="${build.dir}" />
<mkdir dir="${build.classes}" />
<mkdir dir="${build.docs}" />
<mkdir dir="${build.docs.api}" />
<mkdir dir="${build.lib}" />
<mkdir dir="${dist.dir}" />
<mkdir dir="${dist.bin}" />
<mkdir dir="${dist.lib}" />
</target>
<target name="build" depends="init">
<javac srcdir="${src.dir}" destdir="${build.classes}">
<classpath refid="classpath" />
</javac>
</target>
<target name="jars" depends="build">
<jar basedir="${build.classes}" jarfile="${build.lib}/${app.jar}" />
</target>
<target name="javadocs" depends="jars" description="-> creates the API documentation">
<!-- copy docs 手册 -->
<copy todir="${build.docs}">
<fileset dir="${docs.dir}" />
</copy>
<javadoc packagenames="main.hello.ant.*"
sourcepath="${src.dir}"
defaultexcludes="yes"
destdir="${build.docs.api}"
author="true"
version="true"
use="true"
windowtitle="Docs API">
<doctitle>
<![CDATA[<h1>hello and Docs API</h1>]]>
</doctitle>
<bottom>
<![CDATA[<i>${app.copyright}</i>]]>
</bottom>
<tag name="todo" scope="all" description="To do:" />
</javadoc>
</target>
<target name="dist" depends="javadocs">
<!-- copy bin 执行文件 -->
<copy todir="${dist.bin}">
<fileset dir="${src.script}/" />
</copy>
<!-- copy doc 执行文件 -->
<copy todir="${dist.docs}">
<fileset dir="${build.docs}/" />
</copy>
<!-- copy lib 执行文件 -->
<copy todir="${dist.lib}">
<fileset dir="${build.lib}/" />
</copy>
</target>
<target name="junitreport" depends="build">
<junit printsummary="true" failureproperty="tests.failed">
<test name="main.hello.ant.TestHelloAnt"/>
<classpath>
<pathelement location="${build.classes}"/>
</classpath>
</junit>
<junitreport todir="${report}">
<fileset dir="${report}">
<include name="TEST-*.xml" />
</fileset>
<report format="frames" todir="${report}"/>
</junitreport>
<fail if="tests.failed">
--fail!--
</fail>
</target>
</project>
执行结果:
1、Console信息:
Buildfile: E:\XL\workspace\Ant03\build.xml
init:
[delete] Deleting directory E:\XL\workspace\Ant03\build
[delete] Deleting directory E:\XL\workspace\Ant03\dist
[mkdir] Created dir: E:\XL\workspace\Ant03\build
[mkdir] Created dir: E:\XL\workspace\Ant03\build\classes
[mkdir] Created dir: E:\XL\workspace\Ant03\build\doc
[mkdir] Created dir: E:\XL\workspace\Ant03\build\doc\api
[mkdir] Created dir: E:\XL\workspace\Ant03\build\lib
[mkdir] Created dir: E:\XL\workspace\Ant03\dist
[mkdir] Created dir: E:\XL\workspace\Ant03\dist\bin
[mkdir] Created dir: E:\XL\workspace\Ant03\dist\lib
build:
[javac] Compiling 1 source file to E:\XL\workspace\Ant03\build\classes
jars:
[jar] Building jar: E:\XL\workspace\Ant03\build\lib\hello-ant.jar
javadocs:
[javadoc] Generating Javadoc
[javadoc] Javadoc execution
[javadoc] Loading source files for package main.hello.ant
[javadoc] Constructing Javadoc information
[javadoc] Standard Doclet version 1.5.0_12
[javadoc] Building tree for all the packages and classes
[javadoc] Building index for all the packages and classes
[javadoc] Building index for all classes
[javadoc] Generating E:\XL\workspace\Ant03\build\doc\api\stylesheet.css
[javadoc] Note: Custom tags that could override future standard tags: @todo.
To avoid potential overrides, use at least one period character (.) in custom tag names.
[javadoc] Note: Custom tags that were not seen: @todo
dist:
[copy] Copying 17 files to E:\XL\workspace\Ant03\dist\docs
[copy] Copying 1 file to E:\XL\workspace\Ant03\dist\lib
BUILD SUCCESSFUL
Total time: 4 seconds
2、生成jar文件和docs API
 源代码下载
源代码下载
参考:
1、
Ant入门教程
2、
ant使用教程
3、刘晓涛 第.2.章:.Java就业特训--2、Java.构建工具.ANT 视频
posted @
2007-09-18 16:51 CoderDream 阅读(2269) |
评论 (1) |
编辑 收藏
要求:将任意位数字输出为定常格式的字符串,如001,0001等等。
package com;
import java.text.DecimalFormat;
public class FormatNumber {
/**
* 根据参数生成输出样式
*
* @param n
* @return
*/
private String initStyle(int n) {
String str = "";
for (int i = 0; i < n; i++) {
str = str + "0";
}
return str;
}
/**
* 测试
*
* @param args
*/
public static void main(String[] args) {
FormatNumber fn = new FormatNumber();
String style = fn.initStyle(3);
DecimalFormat df1 = new DecimalFormat(style);
for (int i = 0; i < 11; i++) {
System.out.println(df1.format(i));
}
}
}
输出结果:
000
001
002
003
004
005
006
007
008
009
010
Java中格式化小数—小数有效位数
http://blog.csdn.net/haotw/archive/2009/06/26/4301898.aspx
我刚刚接触Java编程,在练习中遇到了要把一个Double类型的小数保留到小数点后的几位,结果在书上没有找着,郁闷了一天,在网上搜索查找资料,综合好几个论坛的答案,终于搞定了。
这是通过格式化小数实现的,必须把Double类型转换为String类型,在输出String类型,下面是我整理得程序,初次发表博客,不妥之处请多多指教……
/*
* Double.java
* 2009.6.26
* By:tw
* 用于输出双精度数值的小数位数
*/
package dou;
import java.util.*;
import java.text.*;
public class Double{
public static void main(String[] args){
Scanner input=new Scanner(System.in);
System.out.print("请输入一个数值:");
double num=input.nextDouble(); //输入一个数值
DecimalFormat df=new DecimalFormat("0.0"); //保留一位小数
DecimalFormat dg=new DecimalFormat("0.00"); //保留两位小数
DecimalFormat dh=new DecimalFormat("0.000"); //保留三位小数
String strnum1=df.format(num); //将num转换为字符串型
String strnum2=dg.format(num);
String strnum3=dh.format(num);
System.out.println("一位小数位:"+strnum1); //输出一位小数
System.out.println("两位小数位:"+strnum2);
System.out.println("三位小数位:"+strnum3);
}
}
小数部分为零时直接去尾
http://it577net.javaeye.com/blog/465116
/**
* 去掉小数部分,思路来自于mysql administrator query软件中显示float的形式如此,
* 缺点是返回类型是String,而不是不带小数部分float,或许会影响前台加减运算,
* 但目前用途是js,反正是弱类型的
*在bean 的 get方法中调用
* 如doubleNoTail(5.5)=5.5
* doubleNoTail(5.0)=5
* @param lengthnum 类型float 或 double
* @return 字符串符
* @since 2009-09-08
*/
public static String doubleNoTail(float lengthnum) {
//将参数转为字符串
String str = String.valueOf(lengthnum);
//获得小数点位置
int index = str.indexOf(".");
//整数部分
String intsub = str.substring(0, index);
//小数部分
String decisub = str.substring(index + 1, str.length());
//小数部分转整
int decimal = Integer.valueOf(decisub);
if (decimal == 0) {
if ("0".equals(intsub)) {
//整数部分为0,则返回空串
return "";
} else {
//小数部分为0,则取整
return String.valueOf(Math.round(lengthnum));
}
} else {
//小数部分不为0,即带小数,则原样返回
return str;
}
}
参考网页:
1、
使用java.text包格式化数字和日期
2、
眀海棠文集之数据格式化1.0
3、
Merlin 的魔力: 格式化数值和货币
4、
java中的格式化输出(类似C语言的printf)
5、
Java格式化输出数字
6、
java中格式化输出数字
posted @
2007-09-06 16:10 CoderDream 阅读(1101) |
评论 (0) |
编辑 收藏1944年冬,盟军完成了对德国的铁壁合围,法西斯第三帝国覆亡在即。整个德国笼罩在一片末日的气氛里,经济崩溃,物资奇缺,老百姓的生活陷入严重困境。
对普通平民来说,食品短缺就已经是人命关天的事,更糟糕的是,由于德国地处欧洲中部,冬季非常寒冷,家里如果没有足够的燃料的话,根本无法捱过漫长的冬天。在这种情况下,各地政府只得允许让老百姓上山砍树。
你能想像帝国崩溃前夕的德国人是如何砍树的吗?在生命受到威胁时,人们非但没有去哄抢,而是先由政府部门的林业人员在林海雪原里拉网式地搜索,找到老弱病残的劣质树木,做上记号,再告诫民众:如果砍伐没有做记号的树,将要受到处罚。在有些人看来,这样的规定简直就是个笑话:国家都快要灭亡了,谁来执行处罚?
当时的德国,由于希特勒做垂死挣扎,几乎将所有的政府公务人员都抽调到前线去了,看不到警察,更见不到法官,整个国家简直就是处于无政府状态。但令人不可思议的是,直到第二次世界大战彻底结束,全德国竟然没有发生过一起居民违章砍伐无记号树木的事,每一个德国人都忠实地执行了这个没有任何强制约束力的规定。
这是著名学者季羡林先生在回忆录《留德十年》里讲的一个故事。当时他在德国留学,亲眼目睹了这一幕,所以事隔五十多年,他仍对此事感叹不已,说,德国人"具备了无政府的条件却没有无政府的现象"。
是一种什么样的力量使得德国人在如此极端糟糕的情况下,仍能表现出超出一般人想像的自律?答案只有两个字:认真。因为认真是一种习惯,它深入到一个人的骨髓中,融化到一个人的血液里。因了这两个字,德意志民族在经历了上个世纪初中叶两次毁灭性的世界大战之后,又奇迹般地迅速崛起。
再讲一个关于德国人认真的小故事。
熟悉柴油机制造业的人都知道有这样一个说法:中国制造的柴油机,噪音在数公里外都听得见,柴油机周围数十平方米都是油迹;而德国人生产的柴油机则可以放在办公室的地毯上工作,根本不会影响隔壁房间的人办公。
于是,1984年,武汉柴油机厂聘请德国退休企业家格里希任厂长。
格里希上任后开的第一个会议,市有关部门领导也列席参加了。没有任何客套,格里希便单刀直入,直奔主题:"如果说质量是产品的生命,那么,清洁度就是气缸的质量及寿命的关键。"说着,他当着有关方面领导的面,在摆放在会议桌上的气缸里抓出一大把铁砂,脸色铁青地说:"这个气缸是我在开会前到生产车间随机抽检的样品。请大家看看,我都从它里面抓出来了些什么?在我们德国,气缸杂质不能高于50毫克,而我所了解的数据是,贵厂生产的气缸平均杂质竟然在五千毫克左右。试想,能够随手抓得出一把铁砂的气缸,怎么可能杂质不超标?我认为这决不是工艺技术方面的问题,而是生产者和管理者的责任心问题,是工作极不认真的结果。"一番话,把坐在会议室里的有关管理人员说得坐立不安,尴尬之极。
两年后,格里希因种种原因卸职时,武汉柴油机厂生产的气缸杂质已经下降到平均一百毫克左右。回国后,格里希有几次来中国,每次都要到武汉柴油机厂探望。在厂里,他有时拿着磁头检查捧发现气缸有未清除干净的铁粉时,忘了自己已经不是厂长,仍然生气地向周围陪同的人大声咆哮:"你们怎么能这么不认真!"
如果说强大的德意志是一个可怕的民族,那么,认真也是一种可怕的力量,它大能使一个国家强盛,小能使一个人无往而不利。我们实在该好好学习德国人认真得近乎刻板的精神,将认真贯彻到自己点点滴滴的行为中。一旦认真二字也深入到自己的骨髓,融化进自己的血液,你也会焕发出一种令所有的人,包括自己,都感到害怕的力量。
作者简介:湘籍。1991年毕业于武汉大学中文系。曾在《独生子女》、《良友》杂志供职。现为自由撰稿人。
posted @
2007-09-04 15:57 CoderDream 阅读(293) |
评论 (0) |
编辑 收藏一个软件项目从开始到结束,由于资源、人员、管理、方法学等等各方面的因素,往往不可避免的会存在一些问题,如需求不明确、项目管理失败、沟通问题等等,今天无意中看到老外写的关于这方面的一篇文章,总结的比较全面,翻译过来结合自己的一些经验做了点补充和修改,存档以备时常可以告诫一下自己。
1、不能很好的理解用户的需求,缺少与用户之间的沟通。
2、错误的预估项目的大小和难易度。
3、没有计划就匆匆开始编码。
4、没有在项目初期就开始做测试,一直拖到项目后期才做,或者根本不做什么测试。
5、选择时下最cool的技术还是已经被团队使用比较成熟的技术,往往不能做出很正确的选择。
6、不采用任何软件过程或者方法学。
7、没有一个真正的项目经理,让开发人员无计划的主导项目。
8、拖延计划,把进度压力留在后期。
9、不做版本控制,混乱的代码库和开发环境。
10、在项目过程中随意的更换开发工具和环境。
11、客户的任何需求都答应下来,需求会永无止境,记得学会说“不”。
12、只有一个大的计划,没有把计划分割成一个个更小的任务,要知道,大的计划如果不分割成任务很难落实和具体实施。
13、对开发团队的管理不足。
14、在项目后期增加人员来加快开发速度,很多时候往往适得其反。
15、开发人员不做单元测试。
16、一旦项目中遇到问题,就把压力抛给开发人员。
17、不关注软件实际的运营环境和硬件条件。
18、没有命名规范和代码规范。
19、到处都用全局变量。
20、遇到问题的时候往往不请教别人,而是一个人闷头搞,到最后还是不得以还是通过别人来解决。
21、没有写代码注释的习惯。
22、对输入输出的数据不做验证。
23、不做压力测试,到实际环境中往往就会出现更多的跟环境和性能相关的问题。
24、项目内部沟通不畅,每个成员只是埋头做自己的事情。
25、没有很好的bug管理规范和系统,往往用word、email、excel等文本方式来跟踪bug,将会导致整个项目的bug管理陷入混沌。
posted @
2007-08-29 15:57 CoderDream 阅读(236) |
评论 (0) |
编辑 收藏
在JSF应用中,我们会经常用到值变事件(ValueChange),执行完值变方法后,默认情况下,会做提交动作,这样就会校验页面中的其他控件,例如是否为空等等。但是其他控件我们还没有输入值,当然不能校验,所以我们要阻止校验,而等到用户点击“提交”按钮的时候再校验。
如果我们没有做任何控制,运行效果就是下面这样,这显然不能然用户满意:
其实只要在方法和Jsp页面修改一下就可以了:
首先,将 immediate="true" :
其次,在值变函数中添加:
FacesContext context = FacesContext.getCurrentInstance();
...
context.renderResponse();
就可以了。
posted @
2007-08-21 15:57 CoderDream 阅读(637) |
评论 (0) |
编辑 收藏
Eclipse 为我们提个了“辅助输入”的功能,记得3.3以前的版本是组合键“Alt+/",但是在3.3中却变成了“Ctrl+Space”,而安装某些常用的输入法后,这个组合键被用来“切换中英文输入法”,所以设置前记得保证这个组合键没有被占用。
首先,进入“控制面板”,然后依次进入“区域和语言选项”-》“语言”-》“详细信息”,“文字服务和输入语言”-》“高级键设置”,看看组合键是否被占用,因为这里的组合键的优先级最大。通过“更改按键顺序”可以改变组合键。
然后,进入Eclipse的参数设置面板,“General ”-》“Keys”,找到“Content Assist”:
然后单击“Remove Binding”按钮,即会去掉绑定:
然后将鼠标的指针移到“Binding”右边的输入框,同时按下“Alt+/”组合键,右边即提示此组合键为User自定义:
同样可以设置“Word Completion”自动完成功能:
效果:
1、 输入“tr”,然后按组合键“Alt+/”,即会出现下面的画面,回车即可输入整个代码块。
2、 输入“fo”,然后按组合键“Alt+/”,即会出现下面的画面,回车即可输入整个代码块。
其他while等关键字也可以使用。
posted @
2007-08-19 15:05 CoderDream 阅读(11175) |
评论 (2) |
编辑 收藏
1、最简单的:
CREATE TABLE t1(
id int not null,
name char(20)
);
2、带主键的:
a:
CREATE TABLE t1(
id int not null primary key,
name char(20)
);
b:复合主键
CREATE TABLE t1(
id int not null,
name char(20),
primary key (id,name)
);
3、带默认值的:
CREATE TABLE t1(
id int not null default 0 primary key,
name char(20) default '1'
);
转贴的:
CREATE TABLE PLAYERS
(PLAYERNO INTEGER NOT NULL PRIMARY KEY,
NAME CHAR(15) NOT NULL,
INITIALS CHAR(3) NOT NULL,
BIRTH_DATE DATE,
SEX CHAR(1) NOT NULL
CHECK(SEX IN ('M','F')),
JOINED SMALLINT NOT NULL
CHECK(JOINED > 1969) ,
STREET CHAR(30) NOT NULL,
HOUSENO CHAR(4),
POSTCODE CHAR(6) CHECK(POSTCODE LIKE '______'),
TOWN CHAR(10) NOT NULL,
PHONENO CHAR(13),
LEAGUENO CHAR(4))
;
CREATE TABLE TEAMS
(TEAMNO INTEGER NOT NULL PRIMARY KEY,
PLAYERNO INTEGER NOT NULL,
DIVISION CHAR(6) NOT NULL
CHECK(DIVISION IN ('first','second')),
FOREIGN KEY (PLAYERNO) REFERENCES PLAYERS (PLAYERNO))
;
CREATE TABLE MATCHES
(MATCHNO INTEGER NOT NULL PRIMARY KEY,
TEAMNO INTEGER NOT NULL,
PLAYERNO INTEGER NOT NULL,
WON SMALLINT NOT NULL
CHECK(WON BETWEEN 0 AND 3),
LOST SMALLINT NOT NULL
CHECK(LOST BETWEEN 0 AND 3),
FOREIGN KEY (TEAMNO) REFERENCES TEAMS (TEAMNO),
FOREIGN KEY (PLAYERNO) REFERENCES PLAYERS (PLAYERNO))
;
CREATE TABLE PENALTIES
(PAYMENTNO INTEGER NOT NULL PRIMARY KEY,
PLAYERNO INTEGER NOT NULL,
PAYMENT_DATE DATE NOT NULL
CHECK(PAYMENT_DATE >= DATE('1969-12-31')),
AMOUNT DECIMAL(7,2) NOT NULL
CHECK (AMOUNT > 0),
FOREIGN KEY (PLAYERNO) REFERENCES PLAYERS (PLAYERNO))
;
CREATE TABLE COMMITTEE_MEMBERS
(PLAYERNO INTEGER NOT NULL,
BEGIN_DATE DATE NOT NULL,
END_DATE DATE,
POSITION CHAR(20),
PRIMARY KEY (PLAYERNO, BEGIN_DATE),
FOREIGN KEY (PLAYERNO) REFERENCES PLAYERS (PLAYERNO),
CHECK(BEGIN_DATE < END_DATE),
CHECK(BEGIN_DATE >= DATE('1990-01-01')))
;
posted @
2007-08-17 17:11 CoderDream 阅读(30153) |
评论 (5) |
编辑 收藏
1、
EasyJWeb-1.0 m1版正式发布 2、
既有鱼肉又有熊掌——浅尝ListOrderedMap 3、
有关乱码的处理---中国程序员永远无法避免的话题 4、
JavaScript学习笔记——JavaScript中的XML 5、
Spring中拦截器地应用 6、
Java中的类反射机制 7、
初学者如何开发出一个高质量的J2EE系统 8、
javadoc命令生成标题简介 9、
log4j 2 转 10、
Javascript中最常用的55个经典技巧 11、
Spring提供的3种通过XML实现DataSource(数据源)注入的方式 12、
新手入门:Java XML编程实例解析 13、
Hibernate的检索策略小结 14、
JSF1.2组件 基于DIV+CSS的Tree 15、
J2EE相关名词解释 16、
JavaScript学习笔记——错误处理
posted @
2007-08-14 18:03 CoderDream 阅读(160) |
评论 (0) |
编辑 收藏5.1 关系数据库按主键区分不同的记录
主键的特点:
1、不允许为null;
2、每条记录具有唯一的主键值,不允许主键值重复;
3、每条记录的主键值永远不会改变。
设置主键的方式:
5.1.1 把主键定义为自动增长标识符类型
在MySQL中,如果把表的主键设为 auto_increment 类型,数据库就会自动为主键赋值。
例如:
CREATE TABLE CUSTOMERS(
ID int auto_increment primary key not null,
NAME varchar(15));
INSERT INTO CUSTOMERS(NAME) VALUES("name1");
INSERT INTO CUSTOMERS(NAME) VALUES("name2");
SELECT ID FROM CUSTOMERS;
查询结果:
ID
1
2
在MS SQL Server中,如果把表的主键设为 identity 类型,数据库就会自动为主键赋值:
CREATE TABLE CUSTOMERS(
ID int identity(1,1) primary key not null,
NAME varchar(15));
INSERT INTO CUSTOMERS(NAME) VALUES("name1");
INSERT INTO CUSTOMERS(NAME) VALUES("name2");
SELECT ID FROM CUSTOMERS;
查询结果:
ID
1
2
5.1.2 从序列(Sequence)中获取自动增长的 标识符
在Oracle中,可以为每张表的主键创建一个单独的序列,然后从这个序列中获得自动增加的标识符,把它赋值给主键。
例如以下语句创建了一个名为 CUSTOMERS_ID_SEQ的序列,这个序列的起始值为1,增量为2:
 CREATE SEQUENCE CUSTOMERS_ID_SEQ INCREMENT BY 2 START WITH 1;
CREATE SEQUENCE CUSTOMERS_ID_SEQ INCREMENT BY 2 START WITH 1;
一旦定义了 CUSTOMERS_ID_SEQ 序列,就可以访问序列的 curval 和 nextval 属性。
curval:返回序列的当前值。
nextval:先增加序列的值,然后返回序列值。
以下SQL语句先创建了CUSTOMERS表,然后插入两条记录,在插入时设定了ID和NAME字段的值,其中ID字段的值来自于CUSTOMERS_ID_SEQ序列。最后查询CUSTOMERS表中的ID字段。
CREATE TABLE CUSTOMERS(
ID int primary key not null,
NAME varchar(15));
INSERT INTO CUSTOMERS VALUES(CUSTOMERS_ID_SEQ.curval, 'Tom');
INSERT INTO CUSTOMERS VALUES(CUSTOMERS_ID_SEQ.nextval, 'Mike');
SELECT ID FROM CUSTOMERS;
如果在Oracle中执行以上SQL语句,查询结果:
ID
1
3
5.2 Java语言按内存地址区分不同的对象
在Java语言中,判断两个对象引用变量是否相等,有以下两种比较方式:
(1)比较两个变量所引用的对象的内存地址是否相同,“==”运算符就是比较的内存地址。此外,在Object类中定义的equals(Object o)方法,也是按内存地址来比较的。如果用户自定义的类没有覆盖Object类的equals(Object o)方法,也按内存地址比较。
例如,以下代码用new语句共创建了两个Customer对象,并定义了三个Customer类型的引用变量c1、c2和c3:
Customer c1 = new Customer("Tom");//line1
Customer c2 = new Customer("Tom");//line2
Customer c3 = c1;//line3
c3.setName("Mike");//line4
图5-1和图5-2显示了程序执行到第3行及第4行的对象图。
从图5-1和图5-2看出,c1和c3变量引用同一个Customer对象而c2变量引用了而c2变量引用另一个Customer对象。因此,表达式"c1==c3"以及c1.equals(c3)的值都是true,而表达式"c1==c2"以及c1.equals(c2)的值是false。
(2)比较两个变量所引用的对象的值是否相同,Java API中的一些类覆盖了Object类的equals(Object o)方法,实现按对象值比较。
String类和Date类
Java包装类,包括:Byte、Integer、Short、Character、Long、Float、Doubl和Boolean。
例如:
String s1 = new String("hello");
String s2 = new String("hello");
尽管s1和s2引用不同的String对象,但是它们的字符串值都是“hello”,因此表达式“s1==s2的值是false,而表达式s1.equals(s2)的值是true。
用户自定义的类也可以覆盖Object类的equals(Object o)方法,从而实现按对象值比较。例如,在Customer类中添加如下equals(Object o)方法,使它按客户的姓名来比较两个Customer对象是否相等:
public boolean equals(Object o) {
if(this==o){
return true;
}
if(!o instanceof Customer) {
return false;
}
final Customer other = (Customer)o;
if(this.getName().equals(other.getName())){
return true;
}else{
return false;
}
}
以下代码用new语句共创建了两个Customer对象,并定义了两个Customer类型的引用变量c1和c2:
Customer c1 = new Customer("Tom");
Customer c2 = new Customer("Tom");
尽管c1和c2引用不同的Customer对象,但是它们的name值都是“Tom”,因此表达式“c1==c2的值是false,而表达式c1.equals(c2)的值是true。
posted @
2007-08-13 22:38 CoderDream 阅读(389) |
评论 (1) |
编辑 收藏
1、
在线正则表达式工具
posted @
2007-08-13 15:37 CoderDream 阅读(164) |
评论 (0) |
编辑 收藏
1、
Java是传值还是传引用 2、
Spring MVC的控制器(表单控制器SimpleFormController) 3、
简单的EJB开发实例,JBOSS4.0+ECLIPSE3.1 4、
一个生成excel的工具类 5、
封装了Jakarta 文件上传功能的一个类(转) 6、
java实现zip与unzip 7、
如何控制单选、复选、列表框 8、
exe4j应用体会
9、
偶的生活计划闲扯 10、
[系列] 说故事学设计模式 之 ::Java代理模式:: 11、
[转]oracle数据库命令行导入导出 12、
Hibernate使用感概 13、
java中多种方式读文件 14、
把WebLogic EJB程序迁移到JBoss上 15、
oracle笔记整理一[体系结构简介] 16、
如何动态控制表单元素 17、
[转]开心星座 18、
Spring 2 学习笔记(一) 19、
RegEX() 20、
如何实现页面打印 21、
Apache,Tomcat集群和负载均衡 22、
网站项目成功管理实践 23、
简单日历选择下拉框实现过程记录 24、
Starting Struts2--Core Components(3) 25、
myEclipse用designer设计器开发GWT ---- 从安装到使用 26、
北京联动天下科技有限公司诚聘软件工程师 27、
随机切换图片--(CSS动态虑镜的运用) 28、
CSS虑镜之----动态虑镜 29、
MySQL的mysqldump工具的基本用法 30、
javascript事件查询综合 31、
JavaScript 的正则表达式和例子32、
document 对象详解 33、
java 发送邮件源码 34、
正则表达式30分钟入门教程(第二版) 35、
教大家学J2SE 一定要看啊 36、
如何同时提交表单中的文件和文本 37、
IE中的拖放事件 38、
HTML表单(Forms) 39、
<Programming Ruby中文版> 读后感 40、
[ZT]java生成缩略图代码 41、
Spring-DAO(Jdbc-Template与ORM工具Hibernate的结合) 42、
Spring-DAO(Jdbc-Template的实现[改进版]) 43、
Java文件操作大全44、
JavaScript 之Window对象 45、
js关于document和window对象 46、
Hibernate+java 47、
java爱好者安排 48、
2007年(下)学期小结 49、
会使铅笔刀的木匠——写给找工作的程序员们 50、
正确优雅的解决用户退出问题 (转)
posted @
2007-08-10 10:07 CoderDream 阅读(158) |
评论 (0) |
编辑 收藏
1、
在eclipse中访问weblogic10.0的JNDI Tree 2、
《企业应用架构模式》(POEAA)读书笔记 3、
jsp实现文件下载与中文文件名乱码问题解决4、
阅读JavaServer Faces in action这本书笔记(vso20070802)5、
持久层设计与资源管理模式一6、
新建的JAVA项目组总有一个职位是适合你的
posted @
2007-08-03 11:46 CoderDream 阅读(138) |
评论 (0) |
编辑 收藏
1、
XML 新手入门2、
面试中可能用到的英语3、
经验分享交流:常用SQL语句技法 4、
使用Java程序来实现HTTP文件的队列下载 5、
[转] 浅谈SOAP 6、
ruby日记 7、
jdk相关知识合集 8、
properties的读写(IO操作)及值修改 9、
native2ascii.exe
10、验证邮箱、电话、QQ的正则表达式 11、
java得到当前时间
12、
js悬浮广告
13、
jsp里用Ajax做的select的两级级联,带数据库。 14、
为日本的软件开发人员说几句话 15、
你不知道的网络招聘与求职潜规则16、
做猪做狗都不做程序员17、
系统瘦身,跑得更快18、
IT企业裁人手法一览 19、
Java中如何正确使用字体编码 20、
傻子坐飞机 21、
ORACLE数据库分页查询/翻页 最佳实践 22、
谈NullObject模式 23、
ORACLE 中ROWNUM用法总结!
posted @
2007-08-01 14:43 CoderDream 阅读(162) |
评论 (0) |
编辑 收藏1、真正的maven私服搭建器--Artifactory
2、构图-我关注的IT咨询重点
3、项目经理技能评估-初稿
4、母亲一生撒的八个谎
5、完美女孩叶欣
6、我的Java学习笔记
7、MySQL5.0学习
8、关于JSF
9、lucene入门合集
10、随手整理Java与C的不同点及心得
11、使用SWT写一个基于JGroup的简单局域网聊天程序
12、《J2EE 课程视频教程》赛迪网校罗泽彬老师主讲
13、公司大小与测试是否规范无关!!!
14、prototype.js开发笔记
15、《Grails权威指南》译者序
16、带有复选框的树
17、asp导出excel用到的类
18、去除js中的单引号
19、单iframe伸缩框架
20、双iframe伸缩框架
21、Java实用经验总结--其他
22、Java实用经验总结--日期、数字篇
23、Web2.0下的十大AJAX安全漏洞以及成因
24、对Web平台和软件架构的一些看法
25、在 10 分钟之内创建 Ruby Weblog
26、当会话超时时重定向
27、Java实用经验总结--Swing篇
28、面试招聘过程中常要问到的问题极其释义
29、面試技巧
posted @
2007-07-30 14:30 CoderDream 阅读(158) |
评论 (0) |
编辑 收藏1、[转]J2EE学习流程
2、使用Spring框架和AOP实现动态路由
3、Java、.NET,为什么不合二为一?
4、经历一些繁忙的工作,开始学习webwork.
5、Ajax 中文乱码问题——GBK
6、Bits in Java
7、亲密接触设计模式(三)-------Iterator(迭代器)
8、Java反射机制(摘)
posted @
2007-07-27 17:19 CoderDream 阅读(123) |
评论 (0) |
编辑 收藏
1、
Google Ajax Search api 以及 web api 的设计和架构? 2、
如何让学来的技术不至于忘记的太快 3、
[下载]浙江大学 徐镜春《数据结构与算法》csf视频 4、
JDBC操作Image类型数据(添加和查询) 5、
Java学习过程中应该理解的一些重点内容 6、
XML Schema介绍之namespace
7、
A Glossary of Name Reuse 8、
[转] RCP能否取代WEB技术?
posted @
2007-07-26 14:24 CoderDream 阅读(218) |
评论 (0) |
编辑 收藏import java.util.ArrayList;
import java.util.List;
public class Sum {
public static void main(String[] args) {
int[] temp = new int[1000];
for (int i = 1; i < 1001; i++) {
temp[i - 1] = i;
}
int total = 0;// 存储总数
int sum = 0; // 和
int k = 0;
List list = null; // 存储每次新循环时的数据
int size = 0;
int num = 0;
for (int j = 0; j < 1000; j++) {
k = j;
sum = 0; // sum 每次循环都要重置
list = new ArrayList(); // list 每次循环都要清空
do {
sum += temp[k];
list.add(temp[k]);
if (sum == 1000) {// 洽好等于1000就打印
total++;
System.out.println("Group" + total + ": ");
if (list != null && list.size() > 0) {
size = list.size();
}
for (int x = 0; x < size; x++) {
num = x + 1;
System.out.println(" " + num + " : " + list.get(x));
}
}
if (k < 999) {
k++;
}
} while (sum < 1001);// 超过1000就退出
}
System.out.println(" total : " + total);
}
}
输出结果:
Group1:
1 : 28
2 : 29
3 : 30
4 : 31
5 : 32
6 : 33
7 : 34
8 : 35
9 : 36
10 : 37
11 : 38
12 : 39
13 : 40
14 : 41
15 : 42
16 : 43
17 : 44
18 : 45
19 : 46
20 : 47
21 : 48
22 : 49
23 : 50
24 : 51
25 : 52
Group2:
1 : 55
2 : 56
3 : 57
4 : 58
5 : 59
6 : 60
7 : 61
8 : 62
9 : 63
10 : 64
11 : 65
12 : 66
13 : 67
14 : 68
15 : 69
16 : 70
Group3:
1 : 198
2 : 199
3 : 200
4 : 201
5 : 202
Group4:
1 : 1000
total : 4
posted @
2007-07-20 14:49 CoderDream 阅读(1494) |
评论 (0) |
编辑 收藏作者: 王玉磊 出处:Csdn
07年已经是陈皓在程序员行业里的第十个年头了。总结这十年,毕业的头两年,陈皓在银行中昏昏沉沉中度过,“这是我最失败的时候,两年的时间几乎完全白费了。”后来在上海的两年,我拼命地学习看书,并不断总结所做的项目,这个阶段是我补课的阶段,也是我量变的阶段。到了北京的这五年,是我从量变向质变转换的阶段。
拼命看书
刚毕业的时候,陈皓也像很多刚毕业的学生一样,根本没有对自己的职业进行过比较好的规划。“还记得当时什么都没有想,就是想做一些实际的事情,好好的钻研一些技术。实在没有别的什么想法。”在毕业头三年中(1998年到2001年),不要说是对未来的职业有所规划,对所学的技术也是毫无规划。
离开银行后到上海加入了一家专做银行的系统集成的公司,发现自己和别人的差距非常的大,所以开始拼命地看书和学习,在到上海的头一年中,看了四、五十本书,研究的技术包括PB, delphi, SQL, HTML, CSS, DHTML, java, Perl, CGI, ASP, PHP, JSP, XML, UML, MFC, Lotus Notes, Unix, Oracle, Informix, C++, ActiveX, ODBC, ADO, .NET, COM, 乃至CISCO路由器的配置,Photoshop, 3DMAX……陈皓学得很杂很泛,完全没有目的,只是觉得别人懂的自己也要懂。
“看了许多许多的书,完全没有好好想想自己应该走什么方向。现在回头看来也不知道是好还是不好。”
也许是看的书太多,懂的东西太多,后来有机会参与了一次全国性质的项目。后台是AIX+Informix用C开发,前台是用PB的PFC做界面,通过IBM的CICS这个中间件连通前后台。在开发这个项目的一年时间里,陈皓对Unix/C/C++以及分布式系统有了非常深刻地认识,并深深地迷上了它们,同时对大型软件工程的流程和管理有了非常深刻的了解。
这个项目对陈皓的影响非常大,除了技术上的收获之外,更让陈皓逐渐确定了自己的规划。
技术之外
2002年底,北京一家做分布式计算/网格计算平台的加拿大公司对我产生了兴趣,经过5轮面试陈皓拿到了offer,又一次开始了我的奔走——从上海来到了北京。
新的公司让陈皓的Unix/C/C++得到了非常大的巩固,“这个公司也让我这个土狼学到了很多很多,特别是认识和观念上。”特别是在带领一个team对公司欧洲用户做Customer Service方面的工作时,陈皓学到了很多客户管理的知识,英语能力、与人沟通的能力以及对软件的认识得到了完全的升华。
陈皓开始使用一种和以前完全不一样的方法去思考问题——从用户的角度对问题进行思考。“此时,技术方向对我来说已不重要,技术对我来说已经变得非常简单,因为技术只需要看书看文档就可以获取。”陈皓开始用全新的方式思考如何管理一个团队,如何制造一个成功的软件,如何管理客户。并由此有了更进一步的职业规则——成为一个成功的技术主管、建立一个成功的团队、开发一个成功的软件产品。
给新人程序员的八点建议
走过弯路,有过迷茫,回首九年陈皓感慨万千。“今天,我对许多刚上路的朋友都会说,人生的规则很重要,从上大学时就要好好规划。”他结合自身经历,对许多刚踏入程序员行列的新人程序员,他给出了以下八点建议:
1.在大学的时候尽量多地进入公司参与实际工作,一方面积累工作经验,另一方面,提前认识工作和自己,以便毕业时更准确地把握自己的方向。
2.从毕业开始到毕业后至少5年内,踏踏实实地专研技术,这是一个积累过程,千万不要把心思放在钱和职位上。钱和职位只是能力的附属品,不要让其喧宾夺主。
3.从毕业后3年到7年的时间,注意学习工作当中的方法以及相关的管理和流程,不但要知其然,还要知其所以然。
4.30岁以前,踏踏实实地学习。学技术,学做人,学做事。30岁以后再谈自己的发展。
5.毕业后的前5年主要是量的积累,要不停地积累知识和方法。毕业后的5到10年主要是质变,应该着重于思维和想法的更新。后五年应该有很强的包容能力和接受新东西的能力,千万不要太过固执和坚持自己的想法。
6.换工作要“承前启后”,前面的工作会成为后面工作的一个基础,而后面的工作又会成为前面工作的一个很自然的延续。
7.不要只把心思放在技术上,技术是hard skill,只要下工夫就一定会掌握。更要注意与人沟通等为人处事的soft skill上。hard skill像一个大树的根,而soft skill则像一个大树的枝叶。树根是你的根基,能让你站得很稳,而枝叶能让你向天空伸展,获得发展。
8.对于程序员来说,应该始终记住,技术不是主要的,主要的是通过技术能够解决什么样的问题。一定经常想要解决什么的问题,要满足什么样的需求,而不是要用什么样的技术
posted @
2007-07-19 16:26 CoderDream 阅读(467) |
评论 (2) |
编辑 收藏作者: 王玉磊 出处:
Csdn
阅读提示:本文通过陈皓的自身的职业选择经历来说明程序员的职业规划要像软件工程一样要有目标、计划地去实施。
电信、银行等行业一直是许多人非常向往的工作单位,清差厚禄,旱涝保收,陈皓却不以此为然。所以当记者采访他的时候,他连用了两个“最”字来形容他离开银行的成就感。
陈皓毕业后的前两年就职于云南省工商银行,从事银行电信内全国性业务系统开发。后来在全球最大的网格计算/分布式平台软件公司从事研发工作,熟悉Unix系统以及C/C++语言,擅长大型系统软件需求分析、设计、架构、实施和维护,目前是某全球金融信息数据处理公司的技术主管。
随波逐流
回想当初,陈皓颇有感慨。还在大三的时候,他就被系里优先推荐给了工行。那时他参与了系上的一个项目(用HTML+Java开发一个在线教学课件),由于当时国内根本买不到HTML和Java的书,而学校也没有上网条件,所以关于HTML和Java对系里的老师都是比较新的东西,当开发完成后,系里对此评价比较高。因此就在大三下学期把陈皓推荐给了工行。
由于早早地被银行“预定”,所以陈皓的大四生活很自由,整个一年他基本是在一家很小的软件公司打工度过的。就是在那家公司工作的经历,让陈皓后来产生了离开银行的念头。
那家公司主要做些MIS系统,陈皓不仅获得了一定的实际工作经验和能力的锻炼,还习惯了软件公司高节奏、快学习、充满挑战的环境和氛围。这造成了他毕业后到银行工作时极度的不适应——效率低下,工作毫无激情,工作当中充满了相当复杂的人际关系和政治斗争。
最主要的是,由于初到银行,很多技术和产品从未见过,而主要实施却由外面公司来完成,银行自己内部中有经验的人又不愿意与人分享知识。虽然可以拿很多红包,整天也很清闲,不是看报纸就是打游戏,但陈皓感觉到那并不是自己喜欢的工作,没有任何激情和斗志可言。和大四时在那个软件公司中的技术氛围相比,完全就是天壤之别。
所以在银行工作的这两年,陈皓天天都在彷徨和思想斗争,“因为没有自己的职业规划,所以,浪费了至少两年的时间”。最后,陈皓打定信念,决意离开去寻找自己的道路。
“因为我是在一个相对比较闭塞的城市(昆明),所以,我要离开银行的决定遭到了父母、同学、朋友、同事,几乎是身边所有人的反对。但最终,我还是一意孤行离开了银行,远走他乡到上海这座大城市去寻找自己的人生道路。”
“从此,我走上了一条不可回头,并和以前完完全全不一样的道路。”从国企到民企再到外企,从打杂到程序员再到高级程序员到team leader到技术主管,从小酒店MIS到企业OA到全国性的大系统到世界领先的分布式计算平台集群软件,“若干年过去了,经历了高速的发展和获得了很多不同的经历,但唯有当时选择离开银行这件事情让我至今都为之兴奋。迄今为止,这是我自己觉得最最有成就感的事情。”
正如陈皓所说,“也许,最让一个人感到最有成就的事情,不是他做成了什么,而是他选择了什么。”
认识自己
多年打拼后,陈皓虽已是技术主管,但走的那些弯路,浪费的两年时间,一路中的心酸让他明白了很多道理。“今天,我对许多刚上路的朋友都会说,人生的规则很重要,从上大学时就要好好规划,这对国人来说尤其重要。因为对于国人来说,人生的头20年都是被别人规划的,导致了自己根本不会给自己做规划。这点是相当危险的。”
人生短暂,属于自己黄金的时间不多,如果把太多的时间浪费在寻找道路和方向上,很有可能会导致一事无成,要及早确定自己的规划,然后照着这个规划坚定不移的去执行。陈皓认为,做规划时最重要的是两个方面:一是清楚地认识自己的能力、优势和性格;二是确定自己的专业和想从事的行业。只有在确定这两方面后,才能做出自己的职业规划。
两方面看起来很简单,但认识自己并不是一件容易的事情。陈皓认为应当从下面十五个方面审视和认识自己,帮助自己确立人生规划:A)所掌握的知识,B)问题的解决能力、判断能力和分析能力,C)对待困难的心态,D)团队合作能力,E)表达能力和语言组织能力,F)创造和创新能力,G)沟通能力,H)自己的性格内向还是外向,I)是否有坚韧不拔的专研精神,J)自己的弱点和性格上的缺陷,K)学习能力,获得知识的能力,L)领导组织能力,M)目前自己能够进入的企业,N)目前自己在社会中的地位,O)目前自己的竞争实力。
职业规划就像软件工程
确定了自己的行业和专业领域后,接下来的事情应该是:1)努力掌握这个行业的知识,2)用最短的时间了解这个专业和行业更为具体的各个子方向。然后在实际过程中再认识自己。比如,选择了计算机行业,应该尽量地尝试软件、硬件、网络、娱乐、媒体等计算机行业不同方向的工作,如果从事软件,又分Web、系统、项目、ERP、CRM、数据库、嵌入式……,在工种上又分开发、测试、技术支持、流程管理,项目管理,系统架构,售前,售后……。当然,我们并不需要去尝试所有的工作或工种才能知道自己适合什么,我们完全可以向从事不同方向的人咨询并结合自我认识来做出判断。
在这个过程中,迷茫的摸索可能是很难避免的。能够及时得到前人的指点可能会是一个捷径,征求前人的建议可以起到参考的作用,快速原型(快速尝试)或许也是好的办法。因为人与人不同,他人的路并不一定适合自己,适合自己的路还要自己去规划,别人是帮不上忙的。
要经常性地跳出自己再来看自己,客观地分析自己的优势和劣势。让自己和别人掂量掂量自己到底几斤几两,了解到自己的长处和特点,然后才能知道自己适合做怎么样的事和并调整自己的职业路线,这是一个“肯定到否定再到肯定”螺旋上升的进化过程。当度过对自己对社会的“陌生期”后,才有谈得上对自己人生和职业的规划。
个人的职业规划就像软件工程。我们都知道软件项目最大的敌人是需求的不明确和需求的大面积变更,同样,在个人的职业规划中,自我需求的不明确和需求的变更也是非常危险的,尤其是在职业计划实施了四五年后需求的变动和改变。只有需求确定以后,才谈得上个人的职业设计的HLD(High Level Design)和LLD(Low Leave Design),以及具体实现。此后随着自身的日益成熟,可以随时为自己的Bug打补丁(Patch)改进自己的职业生涯的设计和实施细则(Enhancement),并为自己加上更多更强的能力(New Feature Requirement)。最终达到软件版本的升级。
posted @
2007-07-19 16:24 CoderDream 阅读(392) |
评论 (0) |
编辑 收藏
通过T-SQL,我们左联(内联、右连类似)的查询语法如下:
-- 通過 InsuredIn 查詢 累計類別
select * from ris.re_master as rm left join ris.re_detail as rd on rm.REINSURANCE_NO=rd.REINSURANCE_NO
where rd.INSURED_ID='A120670116'
order by rm.POLICY_NO asc, rm.POLICY_SEQNO asc
;
但是使用 HSQL 查询数据库时,我们要改为:
from ReMaster as rm left join rm.reDetails as rd
Hibernate 会自动找相同的键,不用on,而且关联表要写成:rm.reDetails
/**
* description: 通過被保人號碼查詢再保明細
*
* @param insuredId
* 被保人身份證號 String
* @return List 結果列表
* @throws DbAccessException
* 數據庫異常
*/
public List selectReMasterDetail(String insuredId)
throws DbAccessException {
if (DEBUGLOG.isDebugEnabled()) {
DEBUGLOG.debug("[ReDetailDao]"
+ "[Function:selectReMasterDetail][Begin]");
}
StringBuffer hqlRd = new StringBuffer();
hqlRd.append(" from ReMaster as rm left join rm.reDetails as rd " +
"where 1=1");
if (insuredId != null) {
hqlRd.append(" and rd.insuredId = '" + insuredId + "'");
}
hqlRd.append(" order by rm.policyNo asc, rm.policySeqno asc");
if (DEBUGLOG.isDebugEnabled()) {
DEBUGLOG.debug("[ReDetailDao][Function:selectReMasterDetail][End]");
}
return this.createQuery(hqlRd.toString());
}
在Service层进行调用:
// 通過 InsuredId 查詢ReMaster檔和ReDetail檔
rmdList = rdDao.selectReMasterDetail(iqVo.getInsuredId());
取List中的对象时用对象数组接,因为返回的是两个对象:
Object[] obj = null;
ReDetail rd = null;
ReMaster rm = null;
int rmdSize = 0;
if (rmdList != null) {
rmdSize = rmdList.size();
}
for (int rmdIndex = 0; rmdIndex < rmdSize; rmdIndex++) {
obj = new Object[2];
obj = (Object[])rmdList.get(rmdIndex);
rm = new ReMaster(); // 用於存儲公司別信息
rd = new ReDetail();
rm = (ReMaster) (obj[0]);
rd = (ReDetail) (obj[1]);
这样就可以处理得到的ReMaster对象和ReDetail对象了。
posted @
2007-07-18 11:25 CoderDream 阅读(2460) |
评论 (1) |
编辑 收藏
1、
tomcat6学习笔记 AnnotationProcessor 2、
BlogJava 备份文章阅读器+离线浏览备份(含源码,SWT) 3、
spring、Hibernate、Struts组建轻量级架构 4、
项目管理几件宝 5、
[java拾遗篇] java.beans.PropertyEditor(属性编辑器)简单应用 6、
整合项目的难:业务理解的不一致、系统设计的不一致和协调 7、
毕业六周年祭8、
hibernate3中配置proxool连接池 9、
浅谈软件设计人员应具备的基本能力 10、
第一个自定义标签的实现11、
Jsp 自定义标签 12、
synchronized 关键字 13、
javascript控制关键字高亮显示 14、
java面试题及答案(基础题122道,代码题19道) 15、
我们靠什么走向成熟 16、
Hibernate下数据批量处理解决方案17、
java Logging API 使用 18、
[转]狼性生存哲学 19、
Get 与Post的区别20、
简易计算器(需要一个图标文件, 如果报错,随便找个小图片) 21、
小型软件公司如何做大 22、
定时执行程序 23、
女孩嫁人的十条注意事项 24、
struts2--Result Configuration 25、
李嘉诚给年青商人的98条忠告 26、
改善脑力的70条方法[翻译] 27、
怎样渡过人生的各种难关? 28、
ajax学习点滴(不断增加中) 29、
Struts 2与AJAX(第二部分) 30、
java读取文件夹下的所有文件夹和文件 31、
[转]登录页面常用技巧(默认焦点、TAB顺序和回车键) 32、
jsp数据库访问之三 —— ms sql server 2005 33、
你幸福么? 34、
Java相对路径总结35、
JAVA四种基本排序的总结 36、
学习工作流的理由37、
[转]Java加密和licence控制的设计 38、
当前Java软件开发中几种认识误区 39、
Ruby,Java的劲敌 40、
Ruby on Rails学习笔记 (一) 41、
敏捷的奇迹 42、
除旧迎新Java2005回顾与2006展望 43、
drools之helloworld 44、
drools和spring的集成 45、
一个感观(LookAndFeel)菜单类及其用法 46、
[转载]让Grails + MySQL正确处理中文 47、
男人总是花心的经济学解释 48、
SQL语法手册 49、
session 50、
Acegi 参考手册(V1.0.4) 翻译 51、
Acegi简介 52、
贴一个以前的职业心理分析 53、
腰背肌的锻炼很重要 54、
sicp习题2.33-2.39尝试解答 55、
Acegi中的ACL用来解决什么问题? 56、
drools之helloworld
posted @
2007-06-28 17:38 CoderDream 阅读(221) |
评论 (0) |
编辑 收藏
1、
JSF笔记 2、
JSF入門
3、RichFaces Demo:
http://livedemo.exadel.com/richfaces-demo/richfaces/tabPanel.jsf4、IBM JSF:
http://www.ibm.com/developerworks/cn/java/j-jsf3/ 5、
EJB3开发笔记 6、
AJAX基础 7、
JAVA笔记(我要日积月累) 8、
1.java面试题(web开发) 9、
如何成为Java高手 10、
解析SQL语句的engine 11、
简单的用 Java Socket 编写的 HTTP 服务器应用,帮助学习HTTP协议 12、
让DbUnit加入你的单元测试 13、
jsp数据库连接大全14、
oracle 10g下载 15、
SQL语句技巧总汇 16、
我的Maven2之旅:十一.打包一个web工程. 17、
JDOM简介 18、
生活哲理五则 19、
[mysql] 给定数据库表名,查主键字段名 20、
推荐--jQuery使用手册 21、
螺旋数字与坐标22、
JdbcTemplate学习笔记 23、
JDBC通用的查询方法。 24、
javascript 操作 excel 25、
Java操作Excel电子表格(转) 26、
Java 5.0多线程编程27、
基于JDK5.0的一些collection类的使用总结 28、
服务型系统集成项目的沟通与团队管理技巧 29、
从06年11月以来的总结 30、
分页的存储过程 31、
ejb3 jsf实用实例 32、
js中innerHTML与innerText的用法与区别 33、
[导入]在VC6中使用正则表达式解析字符串 34、
Log4j 简要剖析 35、
[导入]VC编程中常用快捷键【转】
posted @
2007-06-26 17:03 CoderDream 阅读(225) |
评论 (0) |
编辑 收藏
在典型的J2EE Web应用中,至少有三个逻辑层:前端(Web)层、应用层、数据库层(用来保存应用持久化状态)。今天,我们可以看到许多J2EE应用都是使用这种三层方法建立的。
下图展示了JSF是如何适配到这种三层结构场景中的。
J2EE 应用的Web层,其基础为发送到浏览器的HTML。HTML是通过JSP和/或Servlet动态生成的。JSP和Servlet将应用逻辑委托给朴素Java对象(Plain Old Java Object--POJO),再由这些POJO(应用层)使用JDBC同数据库打交道来保存和取回应用的数据。
不过,在企业级的应用中,应用层将由EJB来实现(作为会话Bean 或作为实体Bean,亦或兼而有之)。
如果将EJB纳入其中的话,Web应用就由四层组成:Web、JSP/Servlet、EJB和数据库。JSF可以放到JSP/Servlet层,并提供基于组件的方法来建立应用。JSF提供了一种建立用户界面以及向下一层(即EJB层)委托业务处理的方法。
下图为典型 JSF 应用中的四层配置。

posted @
2007-06-26 11:31 CoderDream 阅读(954) |
评论 (0) |
编辑 收藏
1、
Tomcat中文问题的解决
posted @
2007-06-12 15:25 CoderDream 阅读(121) |
评论 (0) |
编辑 收藏
有时候,由于查询的数据太多,时间太长,数据库会挂掉。
这时候通过 “控制中心”已经不能启动数据库了,因为“DB2-DB2-0”这个服务已经被停掉了。
直接启动这个服务会失败,因为在“任务管理器”中有很多与DB2相关的进程没有关闭,所以要先处理这些进程。
解决办法:
一、关闭所有与DB2有关的进程。
二、启动“DB2-DB2-0”和“DB2 JDBC”进程。如果想让别人远程访问你的数据库(非JDBC模式),这要启动其他4个服务。

这样,cmd-> db2cc,打开“控制中心”,就可以发现数据库可以正常使用了。
posted @
2007-06-08 11:30 CoderDream 阅读(686) |
评论 (0) |
编辑 收藏接收时:APOP、SSL,发送时:ESMTP(否则不能发到企业网外部)
posted @
2007-06-07 11:26 CoderDream 阅读(337) |
评论 (0) |
编辑 收藏
摘要: CVS 添加工程
阅读全文
posted @
2007-05-31 11:13 CoderDream 阅读(1124) |
评论 (0) |
编辑 收藏
摘要: 如何在Eclipse中自动添加注释
阅读全文
posted @
2007-05-29 18:07 CoderDream 阅读(8410) |
评论 (0) |
编辑 收藏
1、
共享一个MyEclipse5.5GA注册码 2、
剑法三套,程序员也能挣大钱(一)3、
剑法三套,程序员也能挣大钱(二)4、
剑法三套,程序员也能挣大钱(三)5、
在Eclipse中经常使用的10个快捷键
6、
短信发送机的实现 7、
职业规划:少走弯路的十条忠告8、
80前的前辈,你们都做了些什么?! 9、
80年代的兄弟,你会什么?!
10、
lucene全文检索应用示例及代码简析 11、
30招让你从头到脚都健康
12、
专家推荐的十种健康食物13、
午休的知识,正确午睡才有益健康
14、
说说我的健康经验,您也能做到15、
职业顾问教IT人如何做职业发展规划16、
健康提醒:日常易致癌食物的黑名单
posted @
2007-05-28 10:36 CoderDream 阅读(174) |
评论 (0) |
编辑 收藏 使Windows XP快上几倍的三招,设置起来非常简单,但是文章又不乏实用性。
1、减少开机磁盘扫描等待时间,开始→运行,键入:chkntfs /t:0
2、删除系统备份文件: 在各种软硬件安装妥当之后,其实XP需要更新文件的时候就很少了。开始→运行,敲入:sfc.exe /purgecache 然后回车即可,近3xxMb。
3、压缩文件夹: 这是一个相当好的优化,Windows XP内置了对.ZIP文件的,我们可以把zip文件当成文件夹浏览。不过,系统要使用部分资源来实现 这一功能,因此禁用这一功能可以提升系统性能。实现方法非常简单,只需取消zipfldr.dll的注册就可以了,点击开始——运行,敲入: regsvr32 /u zipfldr.dll。然后回车即可。
posted @
2007-05-28 10:22 CoderDream 阅读(135) |
评论 (0) |
编辑 收藏
| Java开发工程师 |
|
| 职位详细信息 : |
职位描述:
职位描述:
负责系统的详细设计和开发以及某个子系统的开发工作。
职位要求:
1、熟悉邮件协议;
2、熟悉J2EE.有三年以上相关工作经验;
3、富有创业和开拓精神。 |
|
|
| 资深Java开发工程师 |
|
| 职位详细信息 : |
职位描述:
岗位职责:
1、负责系统的详细设计和开发工作。
2、支持开发团队开发过程中技术问题的解决。
职位要求:
1、本科或以上学历,计算机软件或相关专业,三年到五年以上J2EE项目开发经验。
2、精通J2EE及其设计模式、熟悉Linux、HTML、UML。
3、熟悉软件工程及良好的团队精神和沟通能力。
4、同时具备C++开发经验,ActiveX开发经验者优先考虑。
5、熟悉搜索引擎原理与技术实现者优先考虑。
|
|
|
| Web前端开发(Javascript, AJAX...)工程师 |
|
| 职位详细信息 : |
职位描述:
按照Ajax规范进行前台、后台模块的设计、编码及单元测试。
职位要求
1.精通Javascript,XML或DHTML编程
2.了解页面Css样式表和Div标签使用;
3.熟悉AJAX技术及开发思路;
4.具有2年以上web开发经验;
5.具备良的团队合作精神、较的沟通能力、高度的责任感和创新精神 |
|
|
posted @
2007-05-05 14:11 CoderDream 阅读(1555) |
评论 (1) |
编辑 收藏
功能模块:参数设定覆核
Bug描述: 已经添加、修改多笔记录,数据库中可以查到,页面不能查到
问题分析:
这个模块涉及工作流,工作流的群组分配如下:
|
SQ_PARAM1類型
|
提交者所屬的組
|
審核者所屬的組
|
簽核者所屬的組
|
|
A(數據)
|
RED1 再保資料提交
|
RED2 再保資料覆核
|
RED3 (目前沒有用上)
|
|
B(參數)
|
REP1 再保參數提交
|
REP2 再保參數覆核
|
REP3 (目前沒有用上)
|
|
ACP1 精算參數提交
|
ACP2 精算參數覆核
|
ACP3 (目前沒有用上)
|
|
C(報表)
|
RER1 再保報表提交
|
RER2 再保報表覆核
|
RER3 再保報表簽核(僅Inward和Outward兩種報表)
|
上表说明,如果某个用户要提交某笔资料(再保参数),那他必须属于REP1组;
如果某个用户要审核某笔资料(再保参数),那他必须属于REP2组;
通过工作流软件,我们可以看到所使用的用户RI006并不在REP2组,所以没有审核的权限,所有查不到任何记录。
通过修改,将RI006加入REP2组,该用户具有审核权限后就可以查到记录了。
然后同软件即可看到:RI006属于RCP2组,而且RCP2中已经有待审核的记录。
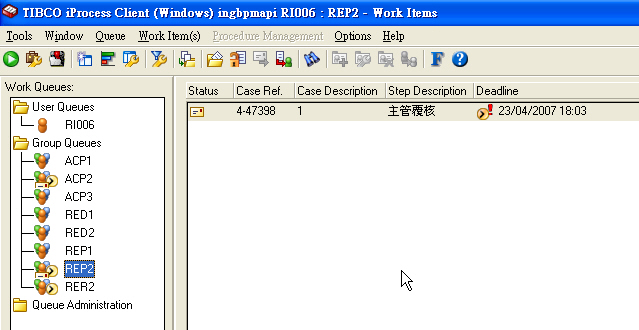
最后:重新启动工作流服务器,再次以RI006登录后就可以查到要审核的记录了。
posted @
2007-04-25 15:37 CoderDream 阅读(369) |
评论 (0) |
编辑 收藏
文/评评灌灌
在我们这个社会里只有两种人,一种人是导演,另外一种人是演员。导演们拥有一切话语权,他们设计着各式各样的角色,让演员按照他们的要求去演绎角色。其实这种模式是在世界上是普遍存在的,但是收到的效果却有天壤之别。造成这种差异的主要区别是:演员对角色能否自由发挥;演员对剧情的话语权的多与少;如果演砸了,演员的受到的惩处的尺度的是大还是小;是否有一种合理的制度去保护那些处于弱势的演员,让演员和导演能够平等地对话。
很可惜的是,在我们的社会里,演员永远处于弱势的地位,演员们只有按照导演的要求去做,他们根本没有权利拒绝导演的安排。无论剧情是多么的荒诞和拙劣,导演总有数不清的崇高理由来逼迫你就范,所以摆在演员面前的选择只有两条路,要么你按照导演的要求做,成为一名好演员,有机会也成为一名设计角色的导演;要么你被导演所抛弃或排斥,成为成为众而矢之的人物。
由于导演也是人,是人总是难免会犯错误。那些指点江山挥斥方遒的导演们设计的角色难度很高,他们打着崇高的旗号,经年累月地耗费着演员的激情,使得演员们苦不堪言,所以总是有演员完成不了任务,久而久之,导演和演员都没有了激情,但是由于这是这个社会生活的全部,双方只能心照不宣地把这样的模式维持下去,如果有人厌烦了,他就会被剥夺本该拥有的微不足道的权利,成为人们眼中的异端。这种人在人们的眼里是愚蠢的,在我们这个神奇的国度里,人们形容这些拒绝按照固定模式的生活、搅乱了原有秩序的人为猪。
虽然猪是愚蠢的代名词,但是在这样的模式里,猪实际上也是一种勇气的代名词,因为猪的结局几乎都很惨,在这个社会里,做猪难,做特立独行的快乐的猪更难。要想成为一只特立独行的快乐的猪几乎是不可能的事情。由于猪不愿意按照既有的模式生存,他挑战了导演的权威,所以猪总是要面对来自于导演甚至是那些积极向导演靠拢的演员的明里暗里的刁难,许多猪往往坚持不下去,最后不得不向导演投降。所以特立独行的快乐的猪成了比大熊猫还稀有的动物。
虽然特立独行的猪很少,但这样的猪总是有的,王小波先生就是一只特立独行的快乐的猪,没有人能模仿他,演员们只能在演绎着导演安排的角色之余,暗暗地用欣赏的目光看着他,当然,这种目光更多的是带着妒忌的成分在内。
这样的猪实际上对导演还是有威胁的,因为他有损导演的权威,尽管在演员的心目中,导演已经不再神圣,所以在这只猪离开这个世界十年后依然有人对他口诛笔伐,他们总是想方设法地歪曲猪的勇气和智慧,弱化猪的影响,拼命地捍卫导演那脆弱不堪的权威,试图把那些被影响的演员重新拉回到原有的轨道。很可惜的是,那只猪已经永远地活在了演员们的心里,他唤醒了更多的人去当一只特立独行的猪。
要想和导演平等不难,只要愿意当特立独行的猪的演员多了,演员们才有可能重新夺回被导演独霸的话语权,一旦这种力量达到平衡了,精彩的剧目才会出现,演员才不会疲惫和无奈。希望这个国度里特立独行的猪越来越多,也祝愿在天国的王小波先生不用继续当形单影只的猪。
posted @
2007-04-14 14:51 CoderDream 阅读(257) |
评论 (0) |
编辑 收藏
1、
《Visual Basic 程式开发线上教学课程》[ISO]
2、
《深入研究Windows内部原理系列课程》[ISO]
3、
《楚广明C#简明教程》
4、
《ASP.NET 2.0入门经典》(第4版)中英文+配套源码
5、
Log4j——系统必备“武器”之一 6、
朝花夕拾 之 Java+JavaScript构建自己的超级树
7、
朝花夕拾 之 MD5的Java实现
8、
彻底治疗乱码顽症——J2EE.Web应用中文问题解决方案
posted @
2007-04-14 14:42 CoderDream 阅读(145) |
评论 (0) |
编辑 收藏
原文地址:
http://blog.sina.com.cn/u/493a8455010008y8自己做IT行业多年,平时也经常有人问我做哪一行,回答IT的话范围又太广了,回答项目管理别人也不清楚是指什么。所以我一般回答编程序和写软件的时候居多。
每当我回答写程序的时候,有羡慕的人认为这是高智商的劳动,也有不屑一顾的认为编代码是低级劳动的。所以问题又回答了工作本身上,工作是没有高低贵贱之分的,关键是你是否喜欢你的工作?是否能够从工作中感受到乐趣和快乐?你做的工作是为自己的,不是显示来给别人看的,只有你的工作为别人,为国家创造了价值,为了自己寻找到了乐趣,那对你来讲就是最好的工作。别人是否理解你的工作早已不重要,道不同不相为谋,很多时候无需解释。
如果你自己都不欣赏你开发出来的软件,如果你不是一个月不写程序就觉得手痒的话,那你还算不上真正的程序员,也体会不到程序开发的真正乐趣所在。软件开发项目虽然根据生命周期模型对角色进行了细分,但每一个岗位和角色都是重要的,都需要成员去独立的思考和解决问题,当你开发出来的软件产品能够真正去解决别人的问题,提高企业效率的时候,程序员的价值也得到了体现。
干一行爱一行,作软件开发需要的就是一种执着和不断学习的心态,当你能够去感受工作给你带来的乐趣时候,工作本身就变得轻松了。你才能更多的去发挥自己的潜力和才能,体现自己的价值,如果你是编码牛人,你一样可能拿很高的薪水而不是一定要去做什么管理类的工作。
posted @
2007-04-13 17:55 CoderDream 阅读(171) |
评论 (0) |
编辑 收藏
大学生和非大学生最主要的区别绝对不在于是否掌握了一门专业技能……一个经过独立思考而坚持错误观点的人比一个不假思索而接受正确观点的人更值得肯定……草木可以在校园年复一年地生长,而我们却注定要很快被另外一群人替代……尽管每次网到鱼的不过是一个网眼,但要想捕到鱼,就必须要编织一张网……
人生规划:三岔路口的抉择不走弯路就是捷径……仕途,商界,学术。在这人生的三岔路口,你将何去何从……与其跟一百个人去竞争五个职位,不如跟一个人去竞争一个职位……学术精神天然的应当与尘嚣和喧哗保持足够的距离……商场不忌讳任何神话。你也完全可能成为下一个传奇…
专业无冷热,学校无高低没有哪个用人单位会认为你代表了你的学校或者你的专业……既然是概率,就存在不止一种可能性……如果是选择学术,冷门专业比热门专业更容易获得成就……跨专业几乎早已成为一种流行一种时尚……大学之间的实力之争到了考研考场和人才市场原来是那样的微不足道……
不可一业不专,不可只专一业千招会,不如一招熟……十个百分之十并不是百分之百,而是零……在这个现实的社会,真正实现个人价值才是最体面最有面子最有尊严的事情……要想知道需要学什么,最好的方式就是留意招聘信息……很多专业因为不具备专长的有效性,所以成为了屠龙之术……为什么不将“买一送一”的促销思维运用到求职应聘的过程中来呢……
不逃课的学生不是好学生什么课都不逃,跟什么课都逃掉没什么两样……读大学,关键是学会思考问题的方法……逃课没有错,但是不要逃错课……英语角绝对不是学英语的地方……为了英语丢了专业,那就舍本逐末了……招聘单位是用人才的地方,而不是培养人才的地方……既要逃课,又要让老师给高分……
勤工俭学的辩证法对于贫困生来说,首先要做的不是挣钱,而是省钱……大部分女生将电脑当成了影碟机,大部分男生将电脑当成了游戏机……在这个处女膜都可以随意伪造的年代,还有什么值得轻易相信……态度决定一切……当学习下降到次要的地位,大学生就只能说是兼职的学生了……
做事不如做人,人脉决定成败学问好不如做事好,做事好不如做人好……会说话,就能减少奋斗三十年……一个人有多少钱并不是指他拥有多少钱的所有权,而是指他拥有多少钱的使用权…… 一个人赚的钱,12.5%是靠自身的知识,87.5%则来自人脉关系……三十岁以前靠专业赚钱,三十岁以后拿人脉赚钱……你和世界上的任何一个人之间只隔着四个人……
互联网:倚天剑与达摩克利斯之剑花两个小时就写出一篇天衣无缝的优秀毕业论文……在互联网领域创业的技术门槛并不高,关键的是市场眼光和营销能力……轻舞飞扬已经红颜薄命了,而痞子蔡却继续跟别的女孩发生着一次又一次的亲密接触……很多大学生的网友遍布祖国大江南北,可他们却从未主动向周围的人说一声:你好,我们可以聊聊吗……
恋爱:花开堪折方须折爱情是不期而至的,可以期待,但不可以制造……越是寂寞,越要警惕爱情……既然单身是可耻的,那西门庆是不是应该被评为宋朝十大杰出青年……花开堪折方须折,莫让鲜花败残枝……一个有一万块钱的人为你花掉一百元,你只占了他的百分之一;而一个只有十块钱的人为你花掉十块,你就成了他的全部……
性:上帝死了,众神在堕落爱要说,爱要做……我只有在肉体一下一下的撞击中才感到快乐。经过之后,将是更大的寂寞更大的空虚……为何要让别人的虚荣成为对自己的伤害……当她机械地躺在床上张开双腿,她的父母正在憧憬着女儿的未来……一朝春尽红颜老,花落人亡两不知……
考研:痛苦的安乐死没有比浪费青春更失败的事情了……研究生扩招的速度是30%,也就意味着硕士学历贬值的速度是30%……同样是付出三年的努力,你可以让E1的值增加 1,也可以让E2的值增加2甚至增加3……读完硕士或博士并不等于工作能力更强……面对13.54万的成本,你还会毫不犹豫地投资读研究生吗……努力就会有结果,但不一定是好结果……
留学:“海龟”变“海带”月薪2500元的工作,居然引得三个“海归”硕士争相竞聘……对于某些专业而言,去美国留学和去埃塞俄比亚留学没什么两样……既然全世界的公司都想到中国的市场上来瓜分蛋糕,为什么中国人还要一门心思到国外去留学然后给外国人打工……
非统招:养卑照样处优她在中国信息产业界创下了几项纪录。她被称为中国的“打工皇后”。而她不过是一名自考大专生……要想把曾经输掉的东西赢回来,就必须把自己比别人少付出的努力补上来……非统招生不但要有一定的实力,而且必须掌握一定的技巧,做到扬长避短出奇制胜……路在脚下。好走,走好……
毕业:十面埋伏的陷阱母校不把自己当母亲,你又何必把自己当儿女……听辅导班不过是花钱买踏实……人才市场就是一个地雷阵……通过多种方式求职固然没有错,但是千万不要饥不择食……只要用人单位一说要你交钱,你掉头就走便是了……这年头立字尚且不足以为据,更何况一个口头约定……
求职:做人不要太厚道求职简历必须突出自己的核心竞争力……求职的时候大可不必像严守一那样“有一说一”……一个人说假话并不难,难的是把假话说到底,并且不露一丝破绽…… 在填写自己的特长时,一定要尽可能详细……一份求职简历只要用一张A4纸做个表格就足够了……面试其实是有规律的,每次面试的时候只要背标准答案就行了……
骑一头能找千里马的驴美国铁路两条铁轨之间的标准距离是4英尺8.5英寸,为什么呢?因为两匹马臀部之间的宽度是4英尺8.5英寸……垃圾是放错位置的人才……世界上最大的悲剧莫过于有太多的年轻人从来没有发现自己真正想做什么……中小型企业或许能够让你得到更充分的锻炼……从基层做起并不意味着可以从基层的每一个职位做起……要“钱途”,更要前途……
写字楼政治:白领必修课大公司是做人,小公司是做事……职员能否得到提升,很大程度不在于是否努力,而在于老板对你的赏识程度……公司的事情和秘密永远比你想象的还要复杂和深奥……在适当的时候装糊涂不但是必要的,而且是睿智的……就把你的同事当成一群你可以叫得出名字的陌生人好了……
创业:29岁以前做富翁瘦死的骆驼比马大……撑死胆大的,饿死胆小的……不再是“大鱼吃小鱼”,而是“快鱼吃慢鱼”……对于趋势的把握是一个创业者最重要的能力……高科技行业留给毕业生的空间已经很小……欲速则不达。在创业以前通过给别人打工而积累经验是非常必要的……市场永远比产品更重要……钱不够花,怎么办?第一,看菜吃饭;第二,借鸡生蛋……
posted @
2007-04-13 17:50 CoderDream 阅读(203) |
评论 (0) |
编辑 收藏
行动的寓言---螃蟹、猫头鹰和蝙蝠
螃蟹、猫头鹰和蝙蝠去上恶习补习班。数年过后,它们都顺利毕业并获得博士学位。不过,螃蟹仍横行,猫头鹰仍白天睡觉晚上活动,蝙蝠仍倒悬。
心理点评:
这是黄永玉大师的一个寓言故事,它的寓意很简单:行动比知识重要。用到心理健康中,这个寓言也发人深省。
心理学的知识堪称博大精深。但是,再多再好的心理学知识也不能自动帮助一个人变得更健康。其实,我知道的一些学过多年心理学的人士,他们学心理学的目的之一就是要治自己,但学了这么多年以后,他们的问题依旧。之所以出现这种情况,一个很重要的原因是,他们没有身体力行,那样知识就只是遥远的知识,知识并没有化成他们自己的生命体验。
我的一个喜欢心理学的朋友,曾被多名心理学人士认为不敏感,不适合学心理学。但事实证明,这种揣测并不正确。他是不够敏感,但他有一个非常大的优点:知道一个好知识,就立即在自己的生命中去执行。这样一来,那些遥远的知识就变成了真切的生命体验,他不必"懂"太多,就可以帮助自己,并帮助很多人。
如果说,高敏感度是一种天才素质,那么高行动力是更重要的天才素质。
这个寓言还可以引申出另一种含义:不要太指望神秘的心理治疗的魔力。最重要的力量永远在你自己的身上,奥秘的知识、玄妙的潜能开发、炫目的成功学等等,都远不如你自己身上已有的力量重要。我们习惯去外面寻找答案,去别人那里寻找力量,结果忘记了力量就在自己身上。
切记:别人的知识不能自动地拯救你。如果一些连珠的妙语打动了你,如果一些文字或新信条启发了你。那么,这些别人的文字和经验都只是一个开始,更重要的是,你把你以为好的知识真正运用到你自己的生命中去。
犹太哲学家马丁·布伯的这句话,我一直认为是最重要的:
你必须自己开始。假如你自己不以积极的爱去深入生存,假如你不以自己的方式去为自己揭示生存的意义,那么对你来说,生存就将依然是没有意义的。
放弃的寓言:蜜蜂与鲜花
玫瑰花枯萎了,蜜蜂仍拼命吮吸,因为它以前从这朵花上吮吸过甜蜜。但是,现在在这朵花上,蜜蜂吮吸的是毒汁。
蜜蜂知道这一点,因为毒汁苦涩,与以前的味道是天壤之别。于是,蜜蜂愤不过,它吸一口就抬起头来向整个世界抱怨,为什么味道变了?!
终于有一天,不知道是什么原因,蜜蜂振动翅膀,飞高了一点。这时,它发现,枯萎的玫瑰花周围,处处是鲜花。
心理点评:
这是关于爱情的寓言,是一位年轻的语文老师的真实感悟。有一段时间,她失恋了,很痛苦,一直想约我聊聊,希望我的心理学知识能给她一些帮助。我们一直约时间,但快两个月过去了,两人的时间总不能碰巧凑在一起。
最后一次约她,她说:"谢谢!不用了,我想明白了。"
原来,她刚从九寨沟回来。失恋的痛苦仍在纠缠她,让她神情恍惚,不能享受九寨沟的美丽。不经意的时候,她留意到一只小蜜蜂正在一朵鲜花上采蜜。那一刹那间,她脑子里电闪雷鸣般地出现了一句话:"枯萎的鲜花上,蜜蜂只能吮吸到毒汁。"
当然,大自然中的小蜜蜂不会这么做,只有人类才这么傻,她这句话里的蜜蜂当然指她自己。这一刹那,她顿悟出了放弃的道理。以前,她想让我帮她走出来,但翅膀其实就长在她自己身上,她想飞就能飞。
放弃并不容易,爱情中的放弃尤其令人痛苦。因为,爱情是对我们幼小时候的亲子关系的复制。幼小的孩子,无论从哪个方面看,都离不开爸爸妈妈。如果爸爸妈妈完全否定他,那对他来说就意味着死亡,这是终极的伤害和恐惧。我们多多少少都曾体验过被爸爸妈妈否定的痛苦和恐惧,所以,当爱情---这个亲子关系的复制品再一次让我们体验这种痛苦和恐惧时,我们的情绪很容易变得非常糟糕。
不过,爱情和亲子关系相比,有一个巨大的差别:小时候,我们无能为力,一切都是父母说了算;但现在,我们长大了,我们有力量自己去选择自己的命运。可以说,童年时,我们是没有翅膀的小蜜蜂,但现在,我们有了一双强有力的翅膀了。
但是,当深深地陷入爱情时,我们会回归童年,我们会忘记自己有一双可以飞翔的翅膀。等我们自己悟出这一点后,爱情就不再会是对亲子关系的自动复制,我们的爱情就获得了自由,就有了放弃的力量。
切记:爱情是两个人的事情,两个完全平等的、有独立人格的人的事情。你可以努力,但不是说,你努力了就一定会有效果,因为另一个人,你并不能左右。
所以,无论你多么在乎一次爱情,如果另一个人坚决要离开你,请尊重他的选择。并且,还要记得,你不再是童年,只能听凭痛苦的折磨。你已成人,你有一双强有力的翅膀,你完全可以飞出一个已经变成毒药的关系。
亲密的寓言:独一无二的玫瑰
小王子有一个小小的星球,星球上忽然绽放了一朵娇艳的玫瑰花。以前,这个星球上只有一些无名的小花,小王子从来没有见过这么美丽的花,他爱上这朵玫瑰,细心地呵护她。那一段日子,他以为,这是一朵人世间唯一的花,只有他的星球上才有,其他的地方都不存在。
然而,等他来到地球上,发现仅仅一个花园里就有5000朵完全一样的这种花朵。这时,他才知道,他有的只是一朵普通的花。
一开始,这个发现,让小王子非常伤心。但最后,小王子明白,尽管世界上有无数朵玫瑰花,但他的星球上那朵,仍然是独一无二的,因为那朵玫瑰花,他浇灌过,给她罩过花罩,用屏风保护过,除过她身上的毛虫,还倾听过她的怨艾和自诩,聆听过她的沉默......一句话,他驯服了她,她也驯服了他,她是他独一无二的玫瑰。
"正因为你为你的玫瑰花费了时间,这才使你的玫瑰变得如此重要。"一只被小王子驯服的狐狸对他说。
心理点评:
这是法国名著《小王子》中一个有名的寓言故事,我曾读过十数遍,但仍然是直到2005年才明白这一点。面对着5000朵玫瑰花,小王子说:"你们很美,但你们是空虚的,没有人能为你们去死。"
只有倾注了爱,亲密关系才有意义。但是,现在我们越来越流行空虚的"亲密关系",最典型的就是因网络而泛滥的一夜情。
我们急着去拥有。仿佛是,每多拥有过一朵玫瑰,自己的生命价值就多了一分。网络时代,拥有过数十名情人,已不再是太罕见的事情。但我所了解的这些滥情者,没有一个是不空虚的。他们并不享受关系,他们只享受征服。
"征服欲望越强的人,对于关系的亲密度越没有兴趣。"广州白云心理医院的咨询师荣玮龄说,"没有拥有前,他们会想尽一切办法拉近关系的距离。但一旦拥有后,他们会迅速丧失对这个亲密关系的兴趣。征服欲望越强,丧失的速度越快。"
对于这样的人,一个玫瑰园比起一朵独一无二的玫瑰花来,更有吸引力。然而,关系的美,正在乎两人的投入程度和被驯服程度。当两个人都自然而然地去投入,自然而然地被驯服后,关系就会变成人生养料,让一个人的生命变得更充盈、更美好。
但是,无论多么亲密。小王子仍是小王子,玫瑰仍是玫瑰,他们仍然是两个个体。如果玫瑰不让小王子旅行,或者小王子旅行时非将玫瑰花带在身上,两者一定要黏在一起,关系就不再是享受,而会变成一个累赘。
切记:一个既亲密而又相互独立的关系,胜于一千个一般的关系。这样的关系,会把我们从不可救药的孤独感中拯救出来,是我们生命中最重要的一种救赎。如果不曾体验过,你就无法知道这种关系的美。
原文:http://www.kaifulee.com/modules/tinyd0/index.php?id=221
posted @
2007-04-13 17:40 CoderDream 阅读(210) |
评论 (0) |
编辑 收藏原文地址:http://blog.sina.com.cn/u/493a84550100096x
成长的寓言:做一棵永远成长的苹果树
一棵苹果树,终于结果了。
第一年,它结了10个苹果,9个被拿走,自己得到1个。对此,苹果树愤愤不平,于是自断经脉,拒绝成长。第二年,它结了5个苹果,4个被拿走,自己得到1个。"哈哈,去年我得到了10%,今年得到20%!翻了一番。"这棵苹果树心理平衡了。
但是,它还可以这样:继续成长。譬如,第二年,它结了100个果子,被拿走90个,自己得到10个。很可能,它被拿走99个,自己得到1个。但没关系,它还可以继续成长,第三年结1000个果子......
其实,得到多少果子不是最重要的。最重要的是,苹果树在成长!等苹果树长成参天大树的时候,那些曾阻碍它成长的力量都会微弱到可以忽略。真的,不要太在乎果子,成长是最重要的。
心理点评:
你是不是一个已自断经脉的打工族?
刚开始工作的时候,你才华横溢,意气风发,相信"天生我才必有用"。但现实很快敲了你几个闷棍,或许,你为单位做了大贡献没人重视;或许,只得到口头重视但却得不到实惠;或许......总之,你觉得就像那棵苹果树,结出的果子自己只享受到了很小一部分,与你的期望相差甚远。
于是,你愤怒、你懊恼、你牢骚满腹......最终,你决定不再那么努力,让自己的所做去匹配自己的所得。几年过去后,你一反省,发现现在的你,已经没有刚工作时的激情和才华了。
"老了,成熟了。"我们习惯这样自嘲。但实质是,你已停止成长了。这样的故事,在我们身边比比皆是。之所以犯这种错误,是因为我们忘记生命是一个历程,是一个整体,我们觉得自己已经成长过了,现在是到该结果子的时候了。我们太过于在乎一时的得失,而忘记了成长才是最重要的。好在,这不是金庸小说里的自断经脉。我们随时可以放弃这样做,继续走向成长之路。
切记:如果你是一个打工族,遇到了不懂管理、野蛮管理或错误管理的上司或企业文化,那么,提醒自己一下,千万不要因为激愤和满腹牢骚而自断经脉。不论遇到什么事情,都要做一棵永远成长的苹果树,因为你的成长永远比每个月拿多少钱重要。
动机的寓言:孩子在为谁而玩
一群孩子在一位老人家门前嬉闹,叫声连天。几天过去,老人难以忍受。于是,他出来给了每个孩子25美分,对他们说:"你们让这儿变得很热闹,我觉得自己年轻了不少,这点钱表示谢意。"
孩子们很高兴,第二天仍然来了,一如既往地嬉闹。老人再出来,给了每个孩子15美分。他解释说,自己没有收入,只能少给一些。15美分也还可以吧,孩子仍然兴高采烈地走了。
第三天,老人只给了每个孩子5美分。孩子们勃然大怒,"一天才5美分,知不知道我们多辛苦!"他们向老人发誓,他们再也不会为他玩了!
心理点评:
你在为谁而"玩"
这是我在2005年6月18日的《你职业枯竭了吗?》一文中提到的寓言。这个寓言是苹果树寓言的更深一层的答案:苹果树为什么会自断经脉,因为它不是为自己而"玩"。
人的动机分两种:内部动机和外部动机。如果按照内部动机去行动,我们就是自己的主人。如果驱使我们的是外部动机,我们就会被外部因素所左右,成为它的奴隶。
在这个寓言中,老人的算计很简单,他将孩子们的内部动机"为自己快乐而玩"变成了外部动机"为得到美分而玩",而他操纵着美分这个外部因素,所以也操纵了孩子们的行为。寓言中的老人,像不像是你的老板、上司?而美分,像不像是你的工资、奖金等各种各样的外部奖励?
如将外部评价当作参考坐标,我们的情绪就很容易出现波动。因为,外部因素我们控制不了,它很容易偏离我们的内部期望,让我们不满,让我们牢骚满腹。不满和牢骚等负性情绪让我们痛苦,为了减少痛苦,我们就只好降低内部期望,最常见的方法就是减少工作的努力程度。
一个人之所以会形成外部评价体系,最主要的原因是父母喜欢控制他。父母太喜欢使用口头奖惩、物质奖惩等控制孩子,而不去理会孩子自己的动机。久而久之,孩子就忘记了自己的原初动机,做什么都很在乎外部的评价。上学时,他忘记了学习的原初动机---好奇心和学习的快乐;工作后,他又忘记了工作的原初动机- --成长的快乐,上司的评价和收入的起伏成了他工作的最大快乐和痛苦的源头。
切记:外部评价系统经常是一种家族遗传,但你完全可以打破它,从现在开始培育自己的内部评价体系,让学习和工作变成"为自己而玩"。
规划的寓言:把一张纸折叠51次
想象一下,你手里有一张足够大的白纸。现在,你的任务是,把它折叠51次。那么,它有多高?一个冰箱?一层楼?或者一栋摩天大厦那么高?不是,差太多了,这个厚度超过了地球和太阳之间的距离。
心理点评:
这是我在2005年12月24日的文章《职业规划:帮你设计人生》中提到的一个寓言。到现在,我拿这个寓言问过十几个人了,只有两个人说,这可能是一个想象不到的高度,而其他人想到的最高的高度也就是一栋摩天大厦那么高。
折叠51次的高度如此恐怖,但如果仅仅是将51张白纸叠在一起呢?
这个对比让不少人感到震撼。因为没有方向、缺乏规划的人生,就像是将51张白纸简单叠在一起。今天做做这个,明天做做那个,每次努力之间并没有一个联系。这样一来,哪怕每个工作都做得非常出色,它们对你的整个人生来说也不过是简单的叠加而已。
当然,人生比这个寓言更复杂一些。有些人,一生认定一个简单的方向而坚定地做下去,他们的人生最后达到了别人不可企及的高度。譬如,我一个朋友的人生方向是英语,他花了十数年努力,仅单词的记忆量就达到了十几万之多,在这一点上达到了一般人无法企及的高度。
也有些人,他们的人生方向也很明确,譬如开公司做老板,这样,他们就需要很多技能---专业技能、管理技能、沟通技能、决策技能等等。他们可能会在一开始尝试做做这个,又尝试做做那个,没有一样是特别精通的,但最后,开公司做老板的这个方向将以前的这些看似零散的努力统合到一起,这也是一种复杂的人生折叠,而不是简单的叠加。
切记:看得见的力量比看不见的力量更有用。
现在,流行从看不见的地方寻找答案,譬如潜能开发,譬如成功学,以为我们的人生要靠一些奇迹才能得救。但是,在我看来,东莞恒缘心理咨询中心的咨询师毛正强说得更正确,"通过规划利用好现有的能力远比挖掘所谓的潜能更重要。"
逃避的寓言:小猫逃开影子的招数
"影子真讨厌!"小猫汤姆和托比都这样想,"我们一定要摆脱它。"然而,无论走到哪里,汤姆和托比发现,只要一出现阳光,它们就会看到令它们抓狂的自己的影子。
不过,汤姆和托比最后终于都找到了各自的解决办法。汤姆的方法是,永远闭着眼睛。托比的办法则是,永远待在其他东西的阴影里。
心理点评:
这个寓言说明,一个小的心理问题是如何变成更大的心理问题的。可以说,一切心理问题都源自对事实的扭曲。什么事实呢?主要就是那些令我们痛苦的负性事件。
因为痛苦的体验,我们不愿意去面对这个负性事件。但是,一旦发生过,这样的负性事件就注定要伴随我们一生,我们能做的,最多不过是将它们压抑到潜意识中去,这就是所谓的忘记。
但是,它们在潜意识中仍然会一如既往地发挥作用。并且,哪怕我们对事实遗忘得再厉害,这些事实所伴随的痛苦仍然会袭击我们,让我们莫名其妙地伤心难过,而且无法抑制。这种疼痛让我们进一步努力去逃避。
发展到最后,通常的解决办法就是这两个:要么,我们像小猫汤姆一样,彻底扭曲自己的体验,对生命中所有重要的负性事实都视而不见;要么,我们像小猫托比一样,干脆投靠痛苦,把自己的所有事情都搞得非常糟糕,既然一切都那么糟糕,那个让自己最伤心的原初事件就不是那么疼了。
白云心理医院的咨询师李凌说,99%的吸毒者有过痛苦的遭遇。他们之所以吸毒,是为了让自己逃避这些痛苦。这就像是躲进阴影里,痛苦的事实是一个魔鬼,为了躲避这个魔鬼,干脆把自己卖给更大的魔鬼。
还有很多酗酒的成人,他们有过一个酗酒而暴虐的老爸,挨过老爸的不少折磨。为了忘记这个痛苦,他们学会了同样的方法。
除了这些看得见的错误方法外,我们人类还发明了无数种形形色色的方法去逃避痛苦,弗洛伊德将这些方式称为心理防御机制。太痛苦的时候,这些防御机制是必要的,但糟糕的是,如果心理防御机制对事实扭曲得太厉害,它会带出更多的心理问题,譬如强迫症、社交焦虑症、多重人格,甚至精神分裂症等。
真正抵达健康的方法只有一个--直面痛苦。直面痛苦的人会从痛苦中得到许多意想不到的收获,它们最终会变成当事人的生命财富。规划利用好现有的能力远比挖掘所谓的潜能更重要。"
切记:阴影和光明一样,都是人生的财富。
一个最重要的心理规律是,无论多么痛苦的事情,你都是逃不掉的。你只能去勇敢地面对它,化解它,超越它,最后和它达成和解。如果你自己暂时缺乏力量,你可以寻找帮助,寻找亲友的帮助,或寻找专业的帮助,让你信任的人陪着你一起去面对这些痛苦的事情。
美国心理学家罗杰斯曾是最孤独的人,但当他面对这个事实并化解后,他成了真正的人际关系大师;美国心理学家弗兰克(见本报1月7日的《每一次磨难都是生命的财富》)有一个暴虐而酗酒的继父和一个糟糕的母亲,但当他挑战这个事实并最终从心中原谅了父母后,他成了治疗这方面问题的专家;日本心理学家森田正马曾是严重的神经症患者,但他通过挑战这个事实并最终发明出了森田疗法......他们生命中最痛苦的事实最后都变成了他们最重要的财富。你,一样也可以做到。
posted @
2007-04-13 17:30 CoderDream 阅读(120) |
评论 (0) |
编辑 收藏
1、
模式与Java 2、
生产者与消费者 3、
[转]从URL获取文件保存到本地的JAVA代码 4、
用JAVA实现一个分页类5、
JAVA高手的基础素养 [转载] 6、
彻底明白Java的IO系统-转7、
8、
posted @
2007-04-13 12:00 CoderDream 阅读(165) |
评论 (0) |
编辑 收藏原文地址:http://blog.sina.com.cn/u/493a8455010009af
空杯心态
如果你是一只装满水的杯子,那是无法接受别人的意见和观点的。在与别人交流的时候我们要有空杯心态乐于倾听,并对对方意见表示关注;在学习上应该勇于承认自己的不足,接受新知识和技术;在做人上应该谦虚和严谨,多换位思考而不是盲目否定一切。
舍得和放下
小舍小得,大舍大得,有舍有得,不舍不得。舍得是一种心态,舍得的真谛是放下。人是有感性的,有情感也有理智,但很多东西是否是真的放不下呢,你找回了自己你才会觉得很多事情是可以放得下的,放不下的往往是自己的虚荣,放不下的其实是自己在庸人自扰。
平常心
有了空杯心态,有了舍得和放下,就有了平常心。不以物喜,不以己悲,多体验过程的乐趣而不要太看重结果。你关心的是自己是否按照自己的原则做事情,而不是关心别人如何看待你。始终保持平和的心态,积极的态度。把自己当别人,把别人当自己,把别人当别人,把自己当自己。当能够真正做到把自己当自己的时候就做到平常心了。
静心
外在的静止容易,内心的平静却很难。是社会太浮躁还是自己太浮躁,不积畦步无以致千里,急功近利没有真正的长久。当你有了平常心才可能真正的静心。静心不是不思进取,而是蓄积薄发,水之不争而利万物,人之不争而善胜。没有超凡,何来脱俗?
自我
迷失或迷茫是没有了方向。方向的确立却需要首先正确的认识自己,但当局者迷,我们很多时候不是高估自己就是心怀胆怯。或许你认清自己需要很久,但自己的事情只有自己解决,你需要的就是有一天能够找回自己。
知还是悟
知道了某个道理并不代表你领悟了某个道理。但往往我们却把两种混在一起。知道需要一时,领悟却可能需要一世;知道关注的就事论事,领悟却牵一发而动全身;知道需要的浅层思考,领悟需要的是深层关联思维。知道是用别人事情在讲述道理,领悟却用自己的事在讲述。知道容易,领悟难,顿悟更难。
posted @
2007-04-13 11:08 CoderDream 阅读(141) |
评论 (0) |
编辑 收藏本项目由繁体中文和英文两种环境,切换语言的链接在页眉的右边,如图:
通过点击“English”,可以将整个系统的语言环境转换为“英文”,下面是从“英文”环境转为“繁体中文”环境后的页面情况:

标签已经转换为“繁体”环境,但是下拉列表中的内容还是“英文”的内容,产生这个Bug的原因是由于整个下拉的List存储在生命期为 Session 的 DBean 中,而此所有 List 的初始化的代码都在 DBean 的构造函数中,这样,即使改变语言,由于DBean的生命期未结束,List的内容不会更根据语言环境而改变。
/**
MaintainClaimNoticeDBean
*/
public
MaintainClaimNoticeDBean() {
this
.queryVO
=
new
QueryClaimNoticeDataVO();
this
.nonGohVO
=
new
MaintainClaimNoticeDataVO();
this
.gohVO
=
new
MaintainClaimNoticeGohDataVO();
this
.cnService
=
new
MaintainClaimNoticeDataService();
this
.msgService
=
new
MessageService();
this
.gohService
=
new
MaintainClaimNoticeGohDataService();
CodeTableService codeTableService
=
new
CodeTableService();
try
{
this
.selectItemCompanyFlag
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.COMPANY_FLAG, getLocale()));
this
.selectItemHandleStatus
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.HANDLE_STATUS,
getLocale()));
this
.selectItemClaimNoticeClass
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.CLAIMNOTICE_CLASS,
getLocale()));
this
.selectItemPolicyStatus
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.POLICY_STATUS,
getLocale()));
this
.selectItemReCompanyCode
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.RE_COMPANY_CODE,
getLocale()));
this
.selectItemReinsuranceLevel
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.REINSURANCE_LEVEL,
getLocale()));
}
catch
(BusiException e) {
this
.setDisplayMsg(e.getExceptionMessage());
}
}
修改办法:
将所有下拉列表的初始化代码放在第一个下拉列表的get方法中:这里CompanyFlag是第一下拉列表:
/**
* Method getSelectItemCompanyFlag.
*
*
@return
SelectItem[]
*/
public
SelectItem[] getSelectItemCompanyFlag() {
this
.reset();
CodeTableService codeTableService
=
new
CodeTableService();
try
{
this
.selectItemCompanyFlag
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.COMPANY_FLAG, getLocale()));
this
.selectItemHandleStatus
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.HANDLE_STATUS,
getLocale()));
this
.selectItemClaimNoticeClass
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.CLAIMNOTICE_CLASS,
getLocale()));
this
.selectItemPolicyStatus
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.POLICY_STATUS,
getLocale()));
this
.selectItemReCompanyCode
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.RE_COMPANY_CODE,
getLocale()));
this
.selectItemReinsuranceLevel
=
Tools
.ConverterListtoSelectItem(codeTableService
.getSelectOneListbox(
GroupCodeConstant.REINSURANCE_LEVEL,
getLocale()));
}
catch
(BusiException e) {
this
.setDisplayMsg(e.getExceptionMessage());
}
return
this
.selectItemCompanyFlag;
}
这样,每次进入页面,第一个标签中的下拉列表框的内容都由JSF通过该标签的getter方法得到。
posted @
2007-03-08 10:41 CoderDream 阅读(415) |
评论 (0) |
编辑 收藏
01、
Java 技术新手入门02、
Eclipse V3.2 Callisto 热点03、
DB2 9 中的 XML 索引
04、
15 分钟学会 Eclipse GMF
05、
JUnit常用断言方法
06、
Ajax:拥抱JSON,让XML走开07、
Installing and Using BluePrints Sample AJAX Components in Sun Java Studio Creator 2
08、
最佳开源软件一览09、
简易计算器10、《
PS&PS2十周年游戏图鉴》(10th Anniversary Playstation & Playstation 2 All Soft Catalogue), eMule下载 选项 11、《
Java高清PDF书籍大杂烩 12.7更新数本》, eMule下载12、
C++5×5断想之二:C++历史上最重要的文献(转)
13、
几个Java问题14、
ant中copy操作学习心得15、
在JavaScript中使用prototype扩展对象属性和方法16、
条件注释17、
【摘】java中读取资源文件18、
[转]提高查询速度方法总结 19、
[转]乱码问题之终极解决 20、
sql 面试问题21、
JSP面试22、
介绍一个外国人的开源的表单组件: ColumnList23、
在servlet和jsp中动态导入内容24、
第三章 为servlet命名25、
使用 Apache Ant26、
我的java之路27、
javascript补充28、
表单验证29、
循环语句30、
简单的密码验证控件31、
Java资料下载
32、
求最大公约数的算法33、
泛型与类型转换34、
JavaScript提交、子窗口得到父窗口的值和添加和隐藏一行35、
First Impress of Eclipse Scrapbook36、
用JS的延时37、
一个WebWork实现的简单登录过程以及遇到问题并附代码38、
70个java问答(转)39、
Spring 学习笔记(二)40、
java中实现javascript中eval的方法41、
protoype.js学习(一)42、
java.math.BigInteger使用心得总结43、
八进制转十进制【限制int范围内】44、
泛型与集合45、
JavaScript文本和文件节点操作46、
How to be an expert
posted @
2006-12-10 21:29 CoderDream 阅读(271) |
评论 (0) |
编辑 收藏
01、
MSSQL的连接的一点问题02、
【原创】关于MySql的SQL语言03、
EasyEclipse Server Java04、
2006年中文博客封神榜:中文108 Blogger
05、
[翻译]使用测试分类(test categorization)进行敏捷构建06、
(原创翻译)敏捷开发的必要技巧6 处理不合适的依赖07、
maven2,终于可以上手了08、
AJAX VS JSF09、
基于prototype的validation.js发布2.3.4新版本,让你彻底脱离表单验证的烦恼 10、
(原创翻译)敏捷开发的必要技巧7--分离数据库访问,UI和域逻辑11、
XLoadTree 的实例 - JSP Tree File Browser, 远程管理 JSP 服务器上的文件12、
在JSF中用Filter模拟Get请求13、
讨论一把:由一个简单的OOP的例子所想到的14、
[设计模式]-----代理模式15、
Structs bean标签总结16、
Structs html标签总结17、
Structs logic标签总结18、
有效的时间管理19、
如何写一份好的工程师简历[转载]20、
日常电脑操作应该注意的十几个小动作以及维护21、
[Ruby]-----简介及快速起步一22、
[Ruby]-----快速起步二(对象,方法,类)23、
[Ruby]-----快速起步三(变量与赋值)24、
替补总裁八年缔造新金山25、
关于ajax存活的争论的整理26、
log4使用介绍27、
IT情侣的妙语对白28、
八种不可追随的老板29、
职场人必看的12个寓言故事30、
Java中的模式 --- 双重接口的实现,备忘录模式
31、
配置Struts应用(原创) 32、
Java 中的模式 --- 简单的状态模式33、
Configuration DataSource At WebSphere634、
用OpenSSL与JAVA(JSSE)通信35、
一个简单的Eclipse Junit单元测试36、
Acegi+hibernate 动态实现基于角色的权限管理37、
常用正则表达式38、
用js控制表格的隐藏与显示39、
JS检测邮箱地址正则表达式40、
什么是SCJP认证41、
一个简单的Spring的AOP例子42、
《Design Patterns》跟我读――创建型模式(更新于06-12-03)43、
没有Factory这个模式44、
23个模式中你最想干掉谁?45、
CSS
46、
用javascript实现简单的拖拽
47、
使用 javascript 函数 完美控制页面图片显示大小
48
、《应用Rails进行敏捷Web开发》中文版书评
posted @
2006-12-03 22:50 CoderDream 阅读(195) |
评论 (0) |
编辑 收藏01、J2EE系统优化的几点体会(一、对象)
02、javascript 事件处理 IE和标准dom 的差别
03、追求“简约不简单”的ORM映射框架
04、事务与锁的一些总结
05、eclipse插件模型
06、(原创翻译) 敏捷开发的必要技巧5:慎用继承
07、Log4J的一些小技巧和使用中一些须要注意的问题。
08、IBM 捐赠Eclipse 3.2.1 多国语言包, 将Eclipse立即汉化
09、软件不软:需求变更与代码质量
10、永久的话题:技术与管理
11、Eclipse插件开发之建立Console视图并在其中显示自定义信息
12、如何让Object 变得有序
13、(原创翻译)敏捷开发的必要技巧4:保持代码的简洁
14、使用Eclipse RCP进行桌面程序开发(四):在Windows中使用Active X控件
15、《Wicket开发指南一书》在JavaEye提供PDF版本下载
16、(原创翻译)敏捷开发的必要技巧----移除重复代码,将注释转为代码
17、(原创翻译)敏捷开发的必要技巧----消除代码异味
18、计时跳转页面代码
19、15 分钟学会 Eclipse GMF
20、javascript基本语法.
21、DWR初学者笔记
22、JS parse xml
23、(JS)仅作个人记录,愿意看的就看吧!
24、精妙的SQL语句
25、Java关键字系列(关键字列表)
26、类型安全的List
27、关于jsp的入门陷阱
28、如何在java开发中启动线程运行其他java程序
29、关于EJB与WebLogic
30、JavaScript 随笔汇集
31、如何使用Log4j?
32、StringBuffer与StringBuilder
33、用DateFormat进行日期时间的有关操作
34、html
35、如何迅速成为JAVA高手
36、SVN 的Local Repository的使用和学习使用SVN的索引
37、初读《Java Web 服务编程指南》
38、关于oracle侦听器的一点技巧
39、我的八皇后
40、成为Eclipse热键高手(转)
41、最大公约数的算法
42、SVN 的Local Repository的使用和学习使用SVN的索引
43、Thinking:Java中static用法
44、看到两个写的很好的关于字符集,编码的文章
45、关于struts的文件配置
46、Java 5.0对Unicode码的支持
47、工作点滴
48、[转] log4j配置详解
49、移动设备在办公室和家庭上网修改IP问题
50、[Hibernate]-----事务处理Transaction
51、用JavaMail发HTML邮件时中文乱码
52、Java名词解释
53、改变你人生的一堂心理课(转)
54、应聘Java笔试时可能出现问题及其答案(第二版Part one)
55、使用netbeans开发一个javabean程序
56、(转)Class.isInstance(Object o), isAssignableFrom(Class cls)
57、[Jakarta-Common-BeanUtils]-----操作BeanUtils.copyProperties时出现的问题
58、扑克难题
59、JDOM学习
60、李一男2003年在港湾给开发人员培训时的语录
61、关于mysql数据导入
62、[Hibernate]-----session.load操作
63、Mysql中的select top
64、什么是b/s模式?b/s模式的 结构?c/s与b/s的异同?
65、Mysql 学习笔记(一)
66、Mysql 学习笔记(二)
67、Mysql 学习笔记(三)
68、[转] 用分冶策略解决关于二叉树的几个问题
69、status属性判断请求的结果与及Http请求响应代码的含义
70、[Struts 2.0]struts2的struts.properties配置文件详解
71、建立一个螺旋形矩阵A[n][n]
72、《质量.软件.管理—协调行动》(第1篇 自我管理)读后笔记!!!
73、web应用程序测试方法和测试技术详述
74、专业搜索计算机方面英文论文的网站
75、HSQL学习笔记
76、真怀疑自己还是不是程序员
77、servlet-api的基本类和其接口介绍
78、不足2分钟的片子,被点击9亿次!
79、计时跳转页面代码
80、javascript条件语句
posted @
2006-11-30 20:33 CoderDream 阅读(230) |
评论 (0) |
编辑 收藏
01、
Java入门实例classpath及package详解02、
覆写子类的返回类型03、
服务端 JScript 记录集分页函数/对象
04、
javascript对象定义方法05、
javascript 继承实现方法06、
用 JProfiler4 调优 Weblogic 和 Tomcat 的视频(原创)07、
SCA程序设计——Entry Point : 让Web服务发布简单起来08、
Java中的模式 --- 命令模式的(实现,功能,使用场合)及如何配合其它模式使用命令模式09、
使用AOP实现类型安全的泛型DAO10、
JAVA学习,是一条漫长的道路(转贴)11、
"this" of JavaScript你理解有多少?12、
AJAX返回XML格式文本的读取方法13、
JSON-RPC的另类用法14、
jxl的一些总结 15、
形式逻辑(普通逻辑)5:直言判断16、
在Java中实现浮点数的精确计算 17、
转wo mou 的收藏夹。[NEWB]18、
读取XML来创建菜单19、
JavaScript 参考教程20、
Rational Rose 2003下载地址、破解方法(轉)21、
一些更详细的正则表达式22、
Socket通信的基本步骤23、
如何建立一个DAO24、
Spring 与Hibernate的延迟加载和Dao模式 [翻译]25、
[转]在Rails中探索资源的世界——7月9日David Heinemeier Hansson演讲的翻译稿(部分) 26、
Ant与Eclipse的集成 第一部分
posted @
2006-11-27 20:54 CoderDream 阅读(150) |
评论 (0) |
编辑 收藏
01、
正确使用XHTML的冒险 [转载]02、
Arrays类03、
JAVA面试题集04、
JAXP 专述 05、
将进酒,杯莫停06、
这一天终于来了07、
“这一天终于来了”08、
XLoadTree 基于XML动态加载的JS树组件的文档翻译(原创)09、
学习Taglib10、
JavaScript:世界上误解最深的语言(转载)11、
重识IO12、
这一天终于来了[孟岩]13、
AJAX征路1 最简单的浮动框示例14、
队列15、
java Class File Format笔记16、
真正的JavaScript而非JScript17、
GdieOA项目心得 by zhenghx (原创)18、
成功将MySQL的大型数据导入导出和备份(转载)19、
JUnit和单元测试入门简介(1)--转贴20、
JUnit和单元测试入门简介(2)--转贴21、
如何进行项目测试?--转贴22、
在开发过程中怎样利用单元和功能测试--转贴23、
当前Java软件开发中几种认识误区--转贴24、
软件测试基础(1)--转贴25、
软件测试基础(2)--转贴26、
软件测试基础(3)--转贴27、
在JTable中放置JTextarea28、
struts常见错误汇总.29、
我的struts分页算法的实现30、
跨模块跳转后Session内容丢失31、
各种文件的注释32、
我的PMP之路(一)33、
我的PMP之路(二)34、
认识for…in 循环语句35、
初学者如何开发出一个高质量的J2EE系统-转贴36、
面试总结37、
用回车实现控件间的切换38、
准备建立自己的开发环境39、
全面迎接SVN时代来临
40、
使用Subversion进行版本控制41、
Subversion安装手记
42、
SVN使用技巧
posted @
2006-11-26 20:40 CoderDream 阅读(190) |
评论 (0) |
编辑 收藏
01、
给应届本科生出的招聘题(技术类)
02、
DB2 9 for z/OS 迈向颠峰
03、
JavaScript学习小结
04、
30分钟内创建Web Service
05、
Java中常见的异常06、
自己做的多功能计算器,嘿嘿07、
JAVA与C++的一点比较08、
weblogic与axis之间向冲突09、
mysql 常用操作命令10、
[转]EE系统标准(JAVA EE5) 11、
推荐一个Eclipse插件站点: http://www.easyeclipse.org12、
在Java中应用设计模式--Singleton13、
对于模式的“十大误解”14、
在Java中应用设计模式--Factory Method15、
使用 Oracle JDeveloper 构建您的第一个 GWT Web 应用程序16、
不得不减少Blog更新的次数了17、
JavaScript中的Boolean类型18、
mysql 基本知识和phpMyAdmin的配制Faq19、
几个有用的javascript代码(动态增删表格)20、
如何有效的结束项目----对某税务MIS系统项目的经验总结21、
在J2EE应用中安装及设置FCKeditor22、
如何测试自定义断言23、
我个人认为做好Project Manager,需要具备的能力24、
使用Eclipse RCP进行桌面程序开发(三):视图和透视图25、
格式化Hibernate的SQL输出语句
posted @
2006-11-24 22:56 CoderDream 阅读(282) |
评论 (0) |
编辑 收藏
01、
JSPWiki 简体中文增强集成版02、
如何将字符串或者数字转换成大写货币03、
双击使页面滚动的JS代码04、
MyEclipse的heap大小的设置05、
finalize函数的一点疑问06、
Eclipse的启动参数07、
javascript API 函数(随时更新)08、
javascript中获取选中的radio的值09、
用File类来列出和筛选所有文件10、
prototype.js 1.4版开发者手册(强烈推荐) 11、
Log4j的配置12、
垃圾收集器与Java编程13、
log4net 配置与应用
posted @
2006-11-23 22:11 CoderDream 阅读(152) |
评论 (0) |
编辑 收藏
01、
javascript 利用正则表达式控制 日期的输入02、
Java实现HTTP文件下载03、
深入 Lucene 索引机制
04、
Eclipse 插件精选介绍(原创)05、
JS实现文本框输入提供选择框的提示功能-106、
面向对象是什么 07、
Java&XML整合笔记(一)08、
软件公司管理奇想09、
路漫漫其修远兮,吾将上下而求索--spring学习日记10、
理解接口11、
网页头部标签meta详解(两篇文章)12、
XML入门精解之结构与语法13、
XML入门精解之CSS和XSL14、
XML入门精解之文件格式定义(DTD)15、
HTML学习笔记(不断更新)16、
在Javascript中Eval函数的使用?17、
javascript学习笔记18、
HASHCODE排序问题19、
MySQL免安装版配置20、
控制texterea长度,并显示剩余字数;附:Javascript中的trim和replace函数21、
Struts AjaxTags22、
Eclipse 启动运行速度调优(转载)23、
Tapestry,JSF和Struts的比较24、
对比mysql oracle db2 的部分ddl语法25、
JSP WikiTree Version 1.026、
一些页面自动跳转的实现27、
Java&XML整合笔记(三)28、
Java&XML整合笔记(四)
posted @
2006-11-23 00:20 CoderDream 阅读(173) |
评论 (0) |
编辑 收藏
01、
14 个经典的javascript代码02、
Java2学习指南-声明和访问控制03、
normal 、sysdba、 sysoper 、sys,sysdba,dba概念—区别04、
JSP中tomcat的SQL Server2000数据库连接池的配置05、
java文件操作大全(Jsp版)06、
字符串验证--java.util.regex.Pattern07、
AJax联手SOA 新一代Web2.0应用程序
08、
当前的网站设计风格
09、
JSPWiki 简体中文增强集成版10、
Ajax模式之缓存控制器模式11、
Native2Ascii的JavaScript实现 (便于平时使用)12、
10分钟了解junit 413、
AJAX,Prototype,Dojo实例对比14、
关于设计15、
使用Spring中的Resource接口隔离对文件系统的依赖16、
两个项目经理的对话(转)17、
探索Java NIO的历程18、
JSPWiki 中文增强版下载和安装地址19、
JSPWiki 中文增强版源代码 20、
JSP Wiki 安装,使用和配置 21、
jsp生成随机验证码22、
如何打jar包23、
mysql-front配置(图)24、
Java连接各种数据库的实例25、
mysql DB(学习笔记)26、
Hsql尝试27、
sql教程&学习笔记(不断更新)28、
Oracle数据库学习笔记(不断更新)29、
tomcat学习笔记30、
各种排序算法java实现31、
Ajax:拥抱JSON,让XML走开 32、
使用JSON加速AJAX33、
介绍 JSON34、
JSON-RPC-Java35、
JSON.simple发布36、
从JAVA里面的不一致性,浅谈设计问题37、
Oracle之新手发现:建立类似SQL Server的自增长字段 38、
Oracle数据库备份与恢复的三种方法(转)39、
常用网页javascript特效40、
网页表单相关特效整理41、
Java的IO系统基本应用42、
Oracle中的日期格式43、
什么样的环境是程序员成长最快的环境(转)44、
程序员的一天45、
Java调用存储过程-转贴46、
使用Eclipse RCP进行桌面程序开发(一):快速起步47、
使用Eclipse RCP进行桌面程序开发(二):菜单、工具栏和对话框48、
使用GSSH开发翩翩宝贝图文网(一):缘起49、
使用GSSH开发翩翩宝贝图文网(二):数据50、
使用GSSH开发翩翩宝贝图文网(三):功能51、
使用GSSH开发翩翩宝贝图文网(四):架构
posted @
2006-11-20 23:51 CoderDream 阅读(204) |
评论 (0) |
编辑 收藏
01、
DB2中文参考下载页面02、
利用 Ant 和 JUnit 进行增量开发
03、
Java TOP 10!04、
Spring 框架05、
Spring MVC 入门 实例06、
JAVA中数据库操作的各种方式与设计模式的应用07、
JSP的留言簿---XML实现08、
通用js客户端表单验证函数09、
JSP内建对象10、
JSP与Java Servlet11、
HTML参考12、
用JAVA实现一个jsp分页13、
Struts下拉菜单对应显示(getDirectLabelValueBean )14、
[转]程序设计中的感悟 15、
Javascript技巧16、
Java中文乱码问题-转贴17、
Java的web开发常见问题之:ClassCastException org.apache.struts.taglib.html.MessagesTei18、
tomcat学习笔记19、
转:如何在JAVA中使用日期 20、
DOM操作XML的示例代码21、
实例解析Js+XML的操作方法22、
JSP中文乱码问题解决方法小结23、
又拿起被遗忘很久的正则表达式24、
又遇到js的问题了,关于window.open25、
JSTL教程26、
表名作为参数传递的存储过程写法27、
Oracle Sql提示学习笔记28、
How Oracle Locks Data (翻译)29、
JSP/Servlet/JSF:标签库的深入研究30、
Frails 介绍.31、
解决打开CHM格式文件出现“网页不能浏览”错误的方法 32、
关于版本控制管理的一些想法33、
热烈庆祝CVSNT架设成功!呵呵34、
如何提高沟通能力35、
JDBC专题介绍(zz)36、
手把手教你在Eclipse中配置开发Struts(一)37、
eclipse 中配置strcucts(2)38、
C++与JAVA在多态与覆盖上的区别(一点猜测)39、
把DWR的配置写到Spring的配置文件里(Spring2 新特性-自定义schema初体验) 40、
Pragmatic Struts41、
项目(框架)架构的抉择42、
实现一个MD5字符串加密器43、
在JUnit中多个testCase只执行一次setup和tearDown的方法44、
使用Eclipse RCP进行桌面程序开发(一):快速起步45、
JAVA基礎知識運用46、
[翻译]选择 Spring+Hibernate EJB3还是POJO + JDBC呢?47、
数据库原理之关系数据库SQL语言课后习题及答案48、[
转]从Java开源说起
posted @
2006-11-18 23:33 CoderDream 阅读(227) |
评论 (0) |
编辑 收藏
01、
常见排序法02、
了解 Web 服务规范
03、
Ubuntu Dapper 安装小记04、
[zt]hibernate复合主键05、
Ubuntu Dapper 安装小记06、
在Orcale中使用视图和存储过程07、
最优秀的web2.0站点列表08、
《C Primer Plus》-指向结构的指针09、
用 JAVA 打造 Interval 对象10、
面试与笔试(随笔) 11、
网讯面试经历12、
javascript 操作 excel13、
Google搜索技巧14、
用jotSpot做项目管理应该不错吧15、
Struts -- html:link 标签的使用16、
有创意就要去实现17、
web.xml中无法添加tablib标签问题的解决 18、
同步代理模式 Synchronization Proxy Pattern19、
DB2存储过程入门(一)20、
免费的Flash ActionScript集成开发环境--FlashDevelop21、
分析设计工作22、
j2ee web service开发(二) 动态代理与动态调用23、
Jdk1.5中的新特性 --泛型 (详细版)24、
“高手”在项目中应该扮演什么角色25、
Serializable26、
清空数据库数据(表)的一个解决方案27、
JDK1.5 泛型之外的其它新特性28、
JDK1.5中泛型的实现原理29、
对Appfuse(struts)的一点反悟30、
Spring hibernate开发时的一些小建议31、
再次证明JDK1.5泛型实现原理32、
《深入Spring2》终于开始发布电子版本了 33、
JDBC+Hibernate将Blob数据写入Oracle[摘]34、
百度面试题目的答案[原创]35、
Java中的IO的性能优化36、
DB2建表新体验!37、
应聘Java笔试时可能出现问题38、
爱上Spring的5个理由39、
[转帖]Java Web开发构想40、
java代码中顺序问题,养成良好代码书写习惯41、
用JAVA创建,读取XML文件42、
有关native2ascii的用法
posted @
2006-11-10 23:37 CoderDream 阅读(217) |
评论 (0) |
编辑 收藏01、按期完成IT项目的10条建议(转)
02、如果建设一个好的技术blog
03、提高网页的用户体验:字体大小的设计
04、什么叫批处理?
05、Java游戏学习
06、关注的CVS, SVN
07、[JavaScript+Flash] 之前做的一个音乐播放器
08、Hibernate EntityManager 多对多持久化
09、TDD 程序代码(13)
10、为了郁闷而写的烂闹钟!
11、转:软件项目中测试人员的考核
12、程序员该做的事
13、图片连续循环滚动代码(向上、下、左、右)
14、csv reader的使用
15、sql备忘-osql 实用工具
16、最好的JAVASCRIPT继承方式(续)——多根继承、多层继承
17、版本控制软件Subversion的使用笔记
18、Subversion权限详解
19、概念模型,物理模型,逻辑模型及关系数据库设计
20、在Red hat ES4 上安装Oracle9i完全手册
21、没毕业进微软 大四男孩年薪够买辆"宝马"车
22、Web的桌面提醒(Popup)
23、获取HTML元素的真正位置与大小
24、[转载]利用JSF、SpringFramework和Hibernate构建Web应用的实例讲述
25、架构
26、Fast API Search
27、Java实现类MSN、QQ好友上线通知界面
28、用 JAVA 打造 setTimeout 函数
29、关系型数据库管理系统Orcale9i体系结构的初步认识
30、策略模式 (The Strategy Pattern) 译 《Design Patterns Expalined》的第九章-The Strategy Pattern
31、Jboss下的j2ee web service开发(一) 映射数组复杂类型
32、【服务配置】apache+tomcat配置负载均衡的网站
33、幼学琼林--SpringSide推荐的JDK5.0 feature
34、Jboss下的j2ee web service开发(二) 动态代理与动态调用
35、最好的JAVASCRIPT继承方式,非常好用。原创代码,希望能与大家共享
36、转换器(Converter)——Struts 2.0中的魔术师
37、vista精神之--动态代理学习
38、Java中的模式 --工厂模式
39、vss真TMD是个烂货
40、[转载]推荐一下CSDN《程序员》的《开源大本营》
41、一些java中常用的小工具
42、jdk1.5 中的泛型
43、获得ResultSet返回记录数
44、Spring DataSource注入
45、哎~!可怕的今天!
46、Hibernate的load错误,你碰到过这样的问题么?
47、[Design Pattern] The Observer Pattern
48、[Design Pattern] Decorator Pattern
49、用 JavaScript 玩转 DOM Level 1
50、使用 XML: XPath 2.0 入门
51、 [Share]DB2返回-00964错误,解决方法
52、Ruby On Spring
53、一个有趣的Java编译问题
54、技巧
55、简单的表连接小结
posted @
2006-11-07 23:08 CoderDream 阅读(250) |
评论 (0) |
编辑 收藏
01、
如何学习hibernate02、
写一个很简单的JDK中没有但是又经常会用到的功能03、
Java中的模式 --单态 (部分翻译 double-checked locking break)04、
Testing in Spring Project (1)-DAO Test05、
rails实战--(四)FCKEditor与rails的集成06、
RMI的小例子,不理解的来这看看吧,也欢迎大家拍我。07、
MethodTable 终于发布了 (if else 终结者)08、
JAVA教程 第八讲 Java网络编程(二)09、
2006年11月5日星期日10、
read-AppFuse-16-XDoclet学习续11、
XDoclet起步(转自cjsdn)12、
定制自己的xDoclet标签13、
扩展XDoclet对Spring List引用注入的支持14、
Xdoclet是什么?15、
用XDoclet 减少代码膨胀 16、
《XDoclet in Action》部分章节中文版17、
Xdoclet学习笔记(XDoclet 如何工作) 18、
java基础学习1(java.util.AbstractSet)19、
基于Ant+Velocity的简单代码生成器的思路与实现20、
周末了21、
String和StringBuffer之概览22、
[阅读] Ubuntu的创始人Mark Shuttleworth访谈23、
D版Xp安装IE7.0最简攻略24、
全面解析Java中的String数据类型25、
提高Hibernate 3 启动速度(翻译)26、
2006年11月5日星期日27、
myslq日期与时间函数28、
C语言-判断字符串是否回文29、
解决 JAVA 写入文本文件时中文乱码30、
什么是DVD-R/DVD-RW/DVD+R/DVD+RW/DVD-RAM?31、
如何学习Java32、
33、
34、
35、
36、
37、
38、
39、
40、
posted @
2006-11-05 16:25 CoderDream 阅读(217) |
评论 (0) |
编辑 收藏01、JSP中获得当前系统时间
02、IE6.0浏览器打印机制解析(转)
03、打印时能够分页打印的CSS控制参考(转)
04、Mysql GUI Tools
05、正则表达式regular expression详述
06、js验证大全(正则表达式)- -
07、正则表达式大全
08、HTML标签用法fieldset
09、javascript中的编码与解码
10、页面跳转(javascript/php/asp)
11、java中的容器-hashMap
12、测试需求分析的步骤
13、从和老婆吵架看项目管理(转载)
14、利用DES加密算法保护Java源代码
15、王森的《JAVA深度历险》
16、两分钟让你明白什么是ERP :)
17、js 天气预报,蒙了我好久。
18、Java中的容器 ArrayList
19、[原创]全排列之递归算法解答
20、java:我能(1)
21、[转]在网页中插入flash
posted @
2006-11-03 22:37 CoderDream 阅读(127) |
评论 (0) |
编辑 收藏posted @
2006-11-02 23:28 CoderDream 阅读(269) |
评论 (0) |
编辑 收藏
01、
setTimeout 和 setInterval 的区别02、
[Share]Quest Central® for DB2 v4.903、
解决response.sendRedirect("mypage.jsp")的问题04、
JavaScript中的Boolean,你了解多少?05、
大四JAVA实验(三)06、
[js小技巧]鼠标移到图片高亮度显示07、
JSP开发入门08、
Java学习从入门到精通 4方法篇09、
DWR 下的脚本分页10、
try......catch......finally的问题11、
关于退出最外层循环12、
==与equals的区别13、
Tomcat使用Bean开发JSP程序©14、
[转]java操作xml15、
学习笔记-杂集16、
abstract class和interface的区别17、
overload和override的区别18、
SQL-----(1)Oracle 基本知识 19、
HTML在线编辑器的调用方法和使用方法详解20、
向某人学习21、
图形界面框架2:基于MVP模式的图形界面框架-表示子系统22、
css模板集23、
Java中如何正确使用字体编码24、
javax.faces.STATE_SAVING_METHOD的设置问题25、
[转]用JSF和MyFaces上传文件26、
Spring网上学习资源27、
说一说编程恶习 (转)28、
精妙SQL语句集精29、
【CSS】DIV内嵌浮动DIV时的问题30、
css的十六种滤镜31、
面试归来32、
数据结构-串的模式匹配33、
[资料]WEB开发利器--JAVASCRIPT API文档 HTML API 文档34、
Ajax小结35、
为什么用PreparedStatement而不是直接用"+"连接SQL语句?36、
如何入侵基于JSP的网站
posted @
2006-11-02 07:57 CoderDream 阅读(252) |
评论 (0) |
编辑 收藏
1、
说一说编程恶习
2、
利用JSF、SpringFramework和Hibernate构建Web应用的实例讲述3、
我的面试标准(对于软件技术人员)4、
Spring随笔一5、
Struts中Cannot find bean XXX in any scope的问题6、
Spring随笔二7、
再论Singleton模式8、
最简单的表单验证框架发布:validation2.09、
大五,大六的计划10、
开发效率的挑战11、
页面分页函数12、
学习笔记-设计模式之Singleton(单态)13、
SWT如何获得本地文件系统的图标等表示信息14、
用AspectJ做的一个回合格斗小游戏15、
[转]关于J2EE Tranaction的几个基本概念 16、
向编程恶习说再见17、
html:errors简析18、
关于代码的一些比喻19、
Spring2.0的新特性点评 20、
Servlet初始化21、
JSF与Struts的异同
22、
表现层框架Struts/Tapestry/JSF架构比较
posted @
2006-10-30 22:29 CoderDream 阅读(219) |
评论 (0) |
编辑 收藏
1、
CSS入门序列文章
2、
Java对象及其引用
3、
Tomcat 配置集锦4、
如何让动态插入的javascript脚本代码跑起来
5、
Java Bean 与 EJB的区别
6、
jsp中文问题解决方案(完整版)7、
关于java数组的深度思考8、
Apress新书迎接JDK 6.0(1)--总述及XML的新标准
9、
JS控件autocomplete(自动完成)演示及下载
10、
Java游戏编程读书笔记(2)
11、
正则表达式
12、
也谈接口编程13、
空(标识)接口的重要性14、
入侵检测系统发展现状(转)15、
大道至简 Java 23种模式一点就通(转贴)16、
JSP连接数据库大全17、
Eclipse 插件集18、
论Java外观模式19、
[转]Structs的基本配置20、
无意中发现一个java.util.Scanner类21、
[tips]使用 Java 将中文字符转换成 Unicode 编码22、
JAVA字符集23、
Ant十五大最佳实践
24、
C语言中怎样判断汉字(答案)
25、
未来10年35项最值得你期待的技术(上)
26、
未来10年35项最值得你期待的技术(中)27、
未来10年35项最值得你期待的技术(下)
28、
Eclipse下实现软件项目的源码管理29、
提高JSP应用程序运行速度的七大绝招
30、
基于JDBC的数据库连接池技术研究与应用
posted @
2006-10-29 14:29 CoderDream 阅读(213) |
评论 (0) |
编辑 收藏
1、
注意properties的使用2、
不借助任何web框架结构,构建自己的MVC应用程序(2)3、
关于spring 2.0自定义xml 标记 (一 主要的相关类)4、
关于spring 2.0自定义xml 标记 (二 如何实现)5、
推荐阅读清单与学习发展路线图
6、
部署 Java Web 服务7、
XML 问题: 来吧,Atom!
8、
超简单的struts小程序9、
产品经理面试记录10、
[转]Digester学习笔记(一)11、
[转]Digester学习笔记(二)12、
[转]Digester学习笔记(三)13、
Java 堆与栈的使用14、
java学习笔记(一)15、
JS的IE和Firefox兼容性汇编16、
创建自己的搜索引擎17、
关于在Spring对事物控制为什么要基于接口? 18、
说说大型高并发高负载网站的系统架构 19、
经典的JAVA编程规范20、
开源web2.0程序 21、
JS正则表达式详解[收藏]22、互联网公司成功的四个要点
23、网站推广常用手法
24、互联网值得关注的四个发展趋势
25、由浅到深了解JavaScript类 --转载 写的很好 感谢作者
26、SWT中运用多线程编程
27、误导程序员的喧嚣:评CSDN引导Java和Ruby之争
28、[译] The Adapter Pattern 适配器模式 from Ch7 of《Design Patterns Explained》
29、ORCALE的使用相关
30、NoClassDefDoundErr与ClassNotFoundException区别
31、[转]tomcat启动在80端口
32、[整理]Tomcat配置根目录默认页面
33、Spring简介(Rod Johnson)
34、《程序员》特别策划之Java十年再回首(转载)
35、四库全书备份oracle
posted @
2006-10-27 20:07 CoderDream 阅读(214) |
评论 (0) |
编辑 收藏
1、
关于用户角色权限的一点想法
2、
Struts 2.0的Action讲解3、
不借助任何web框架结构,构建自己的MVC应用程序(1)4、
分页类,调用很简单. ........5、
看JFace与Swing MVC的M6、
javascript apply方法7、
Java集锦
8、
Synchronize 与 JAVA 内存模型9、
Bridge模式 和Composite模式 10、
cookie、userdata、sessionStorage[转载]11、
Ruby on Rails确实很强12、
Struts-menu源码分析13、
Note1.第一个Struts应用14、
正则表达式笔记15、
Struts标记库16、
澄清Java语言接口与继承的本质17、
模拟银行存储实验---GUI实现18、
19、
20、
posted @
2006-10-26 23:18 CoderDream 阅读(229) |
评论 (0) |
编辑 收藏
1、
Java面试题集1-基础知识
2、
多选框的操作及传值
3、
Struts 2.0的Action讲解
4、
集群的相关知识
5、
Tomcat5.5.xJNDI的配置(edit)
6、
程序员健康建议
7、
EJB3 SessionBean LifeCycle
8、
把class打包成jar文件
9、
JSF1.1在Tomcat5.5.20中的配置
posted @
2006-10-25 12:59 CoderDream 阅读(188) |
评论 (0) |
编辑 收藏
1、
关于JSF及其运行机制[转载]
2、
厨师与服务生的问题
3、
[zt]hibernate二级缓存攻略
4、
在jsp中获得 Spring的上下文
5、
Spring的listener启动异常
6、
幼学琼林--Spring下的单元测试要点
7、
SpringXmlrpcServiceExporter for xmlrpc3.x
8、
prototype.js开发笔记
9、
[转]深入探讨Iterator模式
10、
Spring文件上传
11、
开发线程安全的Spring Web应用
12、
java类加载的表现形式(zz)
13、
网站速度很慢问题解决的方法(TOMCAT性能调整)
14、
Java类加载内幕(zz)
15、
初探Java类加载机制的奥秘(zz)
16、
读新浪博客示例[源代码下载]
17、
[原创]图论应用--最短路径
18、
弹指一挥间,JavaScript乌鸦变凤凰
19、
JavaMail 深入浅出
20、
在Web应用中如何取得.Properties文件定义的属性
21、
关于数据库优化
posted @
2006-10-23 22:25 CoderDream 阅读(222) |
评论 (0) |
编辑 收藏
1、
[原创]使用WTP来构建你的WEB应用程序(一)2、
值的关注的Java开源项目3、
struts标签的filter属性4、
通过自定义 404 错误页实现伪静态5、
管理页面6、
马哲 定位 竞争优势 证书 能力...7、
用js实现打印和导出为Excel8、
全排列算法的递归与非递归实现9、
模拟实现银行存储实验10、
使用 AppFuse 快速构建 J2EE 应用
11、
struts学习笔记12、
课程设计笔记13、
读properties文件时提示找不到其里面的内容 spring14、
更进一步,,,访问控制,this关键字,15、
网上查到的各种屏蔽代码!!16、
读word内容(包含表格,不包含图片)并且显示在页面中或保存进数据库中
posted @
2006-10-22 17:15 CoderDream 阅读(186) |
评论 (0) |
编辑 收藏
1、
JS技术2、
DES算法的javascript实现3、
Hibernate Day_14、
[转]网页内容无法复制怎么办?5、
英语学习法(摘自万千学习法)6、
一个小问题!7、
通过oms实现Oracle的数据备份8、
java中的邮件处理9、
《CSS网站布局实录》读书笔记10、
十个有哲理的故事11、
对xpath的常见误解12、
Buffalo VS DWR13、
观感14、
自扩展JTextField-215、
自扩展JTextField-116、
向量-117、
建立自信的12条法则18、
在java中使用循环定义会出现哪些问题?19、
自动刷新/跳转20、
大四JAVA实验(一)21、
Ant:编写build.xml的方法22、
wsCaller:Web Service通用客户端和测试工具
posted @
2006-10-19 20:06 CoderDream 阅读(209) |
评论 (0) |
编辑 收藏
1、
使用触发器2、
开发动态sql3、
Using SET Operators.4、
处理例外5、
开发包6、
开发子过程7、
折纸8、
Spring的任务调度服务实例讲解 {转}9、
JNDI配置原理详解10、
我与公司共成长11、
[翻译] 如何在 JavaScript 中实现拖放(上)12、
JAVA基础(一):多态(overloading & overridding)的分析13、
Log4j全面剖析14、
js基础15、
JAVA程序员面试32问16、
windows一些快捷键17、
一道算法题18、
怎样对电子商务系统进行运营评估19、
js常用函数20、
【搜索】步入全文检索第一步21、
Java 关于中文乱码问题的解决方案与经验22、
java的30个学习目标23、
在应用中加入全文检索功能——基于Java的全文索引引擎Lucene简介24、
hibernate annotations试用25、
在RubyOnRails里使用UTF-8及中文字符串26、
Jar命令与Jar文件27、
Spring MVC framework深入分析之一--总体分析28、
Spring源码学习 - Spring 初始化之旅29、
简化Java应用程序的打包和发布30、
大家来试试运气啊...欢迎给出缩减版本31、
java打包详解32、
在HQL中绕过中文乱码查询33、
Eclipse 插件介绍34、
一个有关页保存的问题(原创)35、
软件测试36、
一个学习Oracle sql 的不错的地方,记录一下37、
关于java的反射机制的一些实用代码38、
经验分享交流:常用SQL语句技法39、
JAVA基础(二):函数执行顺序(构造函数,多态,this指针)40、
ruby on rails之旅41、
vista精神之 --javascript篇42、
更改生物钟的危害43、
[转]一个老工程师给年轻工程师的十大忠告! 44、
Socket基本编程(转)45、
Java MD5加密法46、
Base64加密算法47、
用java访问windows注册表48、
JNI入门介绍49、
中国程序员的26种能力 50、
程序员修炼之道 51、
对"类"和"对象"的深度揣摩与思考...(java初学者)52、
栈和队的应用-魔王语言解释53、
Java web 开发必游之路-给入门者的一些建议 54、
正则表达式55、
由一个类创建多个对象时,各个对象的属性是相互无关的,(l例题为转载)56、
我碰到的 ResultSet 用尽问题57、
对方法的深入思考,(java初学者)58、
我对"对象"和"引用"的理解(此文特指在创建一个类对象实例的情况)59、
对类和方法的理解更正,,60、
算法求解61、
Hibernate 能够满足我们的验证需求62、
Cross Site AJAX [转载]63、
[zt]JdbcTemplate使用指南64、
构建项目公共辅助类__CommonUtils(持续更新)65、
《如何让你的程序运行的更快》系列文章(持续更新) 66、
两种不同指针的理解67、
java基础:字符串分割的两种方法68、
ANT 基本使用教程69、
在线网页编辑器大全70、
好玩的js~~~71、
magic Javascript72、
mysql入门173、
EasyDBO最后一个测试版(0.9.0)发布74、
汇丰面试记(转)75、
mysql入门276、
阎宏博士的JAVA与模式77、
inconstant constants(变化无常的常量)78、
一条sql语句删除表中所有除ID 不同之外的记录,只留一条。79、
软件高手是这样练成的 —— 座右帖 (感觉太好了,转载过来)80、
Struts中使用Cookie控制登录的流程81、
你想到了什么?82、
AjaxOpenDoc源代码下载83、
我的设计模式之旅(1)——学习的原则和一些笔记84、
使用façade、template pattern搭建MVC框架85、
[原创] 一个完善的轻量级分页API Pager ! 有源代码....... 86、
说一说编程恶习87、
序篇88、
Jdk1.4 和jdk1.5中的StringBuffer的不同89、
oracle时间模糊查询90、
JTable 的编辑和表现91、
Swing 的MVC92、
Swing是MVC设计的典范(转载)93、
如何管理工作计划和日志94、
[原创]一个精巧的层控制工具 LayerUtil ....希望能满足大家的基本需求 [Javascript]95、
google笔试的败笔(大家来仁者见仁哦)96、
常用的Struts 2.0的标志(Tag)介绍97、
JavaScript中的Email验证98、
经典SQL语句集锦(收藏版)99、
如何将字符串或者数字转换成大写货币100、
利用ajax实现实施刷新101、
Tomcat简介 102、
【分享】Hibernate视频分享103、
UML入门知识(来自软件工程组织)104、
Ant: 入门-配置和使用105、
Ant: 中文教程一106、
Ant: 中文教程107、
Ant: 中文教程二
posted @
2006-10-18 22:17 CoderDream 阅读(224) |
评论 (0) |
编辑 收藏
1、
SHTML 教程
2、
CSS十大密技
posted @
2006-10-15 11:01 CoderDream 阅读(195) |
评论 (0) |
编辑 收藏
1、
深入浅出之正则表达式(一)2、
深入浅出之正则表达式(二)3、
Java正则表达式详解4、
PHP和正则表达式
posted @
2006-10-14 00:31 CoderDream 阅读(239) |
评论 (0) |
编辑 收藏
关键字: 正则表达式,Regular Expression
作者:笑容
发表于:2004年05月03日
最后更新:2005年01月17日 19:54
版权声明:使用
创作公用版权协议
前言
正则表达式是烦琐的,但是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的成就感。只要认真去阅读这些资料,加上应用的时候进行一定的参考,掌握正则表达式不是问题。
索引
1._引子
2._正则表达式的历史
3._正则表达式定义
3.1_普通字符
3.2_非打印字符
3.3_特殊字符
3.4_限定符
3.5_定位符
3.6_选择
3.7_后向引用
4._各种操作符的运算优先级
5._全部符号解释
6._部分例子
7._正则表达式匹配规则
7.1_基本模式匹配
7.2_字符簇
7.3_确定重复出现
目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP等操作系统,PHP,C#,Java等开发环境,以及很多的应用软件中,都可以看到正则表达式的影子。
正则表达式的使用,可以通过简单的办法来实现强大的功能。为了简单有效而又不失强大,造成了正则表达式代码的难度较大,学习起来也不是很容易,所以需要付出一些努力才行,入门之后参照一定的参考,使用起来还是比较简单有效的。
例子: ^.+@.+\\..+$
这样的代码曾经多次把我自己给吓退过。可能很多人也是被这样的代码给吓跑的吧。继续阅读本文将让你也可以自由应用这样的代码。
注意:这里的第7部分跟前面的内容看起来似乎有些重复,目的是把前面表格里的部分重新描述了一次,目的是让这些内容更容易理解。
正则表达式的“祖先”可以一直上溯至对人类神经系统如何工作的早期研究。Warren McCulloch 和 Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。
1956 年, 一位叫 Stephen Kleene 的数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为“神经网事件的表示法”的论文,引入了正则表达式的概念。正则表达式就是用来描述他称为“正则集的代数”的表达式,因此采用“正则表达式”这个术语。
随后,发现可以将这一工作应用于使用 Ken Thompson 的计算搜索算法的一些早期研究,Ken Thompson 是 Unix 的主要发明人。正则表达式的第一个实用应用程序就是 Unix 中的 qed 编辑器。
如他们所说,剩下的就是众所周知的历史了。从那时起直至现在正则表达式都是基于文本的编辑器和搜索工具中的一个重要部分。
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
-
列目录时, dir *.txt或ls *.txt中的*.txt就
不
是一个正则表达式,因为这里*与正则式的*的含义是不同的。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)组成的文字模式。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
由所有那些未显式指定为元字符的打印和非打印字符组成。这包括所有的大写和小写字母字符,所有数字,所有标点符号以及一些符号。
| 字符 |
含义 |
| \cx |
匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t |
匹配一个制表符。等价于 \x09 和 \cI。 |
| \v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
所谓特殊字符,就是一些有特殊含义的字符,如上面说的"*.txt"中的*,简单的说就是表示任何字符串的意思。如果要查找文件名中有*的文件,则需要对*进行转义,即在其前加一个\。ls \*.txt。正则表达式有以下特殊字符。
| 特别字符 | 说明 |
|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n之外的任何单字符。要匹配 .,请使用 \。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
- 构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与操作符将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有*或+或?或{n}或{n,}或{n,m}共6种。
*、+和?限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
正则表达式的限定符有:
| 字符 | 描述 |
|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
用来描述字符串或单词的边界,^和$分别指字符串的开始与结束,\b描述单词的前或后边界,\B表示非单词边界。
不能对定位符使用限定符。 用圆括号将所有选择项括起来,相邻的选择项之间用|分隔。但用圆括号会有一个副作用,是相关的匹配会被缓存,此时可用?:放在第一个选项前来消除这种副作用。
其中?:是非捕获元之一,还有两个非捕获元是?=和?!,这两个还有更多的含义,前者为正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串,后者为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串。
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左至右所遇到的内容存储。存储子匹配的缓冲区编号从 1 开始,连续编号直至最大 99 个子表达式。每个缓冲区都可以使用 '\n' 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
可以使用非捕获元字符 '?:', '?=', or '?!' 来忽略对相关匹配的保存。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。各种操作符的优先级从高到低如下:
| 操作符 | 描述 |
|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \anymetacharacter | 位置和顺序 |
| | | “或”操作 |
| 字符 | 描述 |
|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\(' 或 '\)'。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。 |
| (?=pattern) | 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 负向预查,在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。. |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
| 正则表达式 | 说明 |
|---|
| /\b([a-z]+) \1\b/gi | 一个单词连续出现的位置 |
| /(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/ | 将一个URL解析为协议、域、端口及相对路径 |
| /^(?:Chapter|Section) [1-9][0-9]{0,1}$/ | 定位章节的位置 |
| /[-a-z]/ | A至z共26个字母再加一个-号。 |
| /ter\b/ | 可匹配chapter,而不能terminal |
| /\Bapt/ | 可匹配chapter,而不能aptitude |
| /Windows(?=95 |98 |NT )/ | 可匹配Windows95或Windows98或WindowsNT,当找到一个匹配后,从Windows后面开始进行下一次的检索匹配。 |
7.1 基本模式匹配
一切从最基本的开始。模式,是正规表达式最基本的元素,它们是一组描述字符串特征的字符。模式可以很简单,由普通的字符串组成,也可以非常复杂,往往用特殊的字符表示一个范围内的字符、重复出现,或表示上下文。例如:
^once
这个模式包含一个特殊的字符^,表示该模式只匹配那些以once开头的字符串。例如该模式与字符串"once upon a time"匹配,与"There once was a man from NewYork"不匹配。正如如^符号表示开头一样,$符号用来匹配那些以给定模式结尾的字符串。
bucket$
这个模式与"Who kept all of this cash in a bucket"匹配,与"buckets"不匹配。字符^和$同时使用时,表示精确匹配(字符串与模式一样)。例如:
^bucket$
只匹配字符串"bucket"。如果一个模式不包括^和$,那么它与任何包含该模式的字符串匹配。例如:模式
once
与字符串
There once was a man from NewYork
Who kept all of his cash in a bucket.
是匹配的。
在该模式中的字母(o-n-c-e)是字面的字符,也就是说,他们表示该字母本身,数字也是一样的。其他一些稍微复杂的字符,如标点符号和白字符(空格、制表符等),要用到转义序列。所有的转义序列都用反斜杠(\)打头。制表符的转义序列是:\t。所以如果我们要检测一个字符串是否以制表符开头,可以用这个模式:
^\t
类似的,用\n表示“新行”,\r表示回车。其他的特殊符号,可以用在前面加上反斜杠,如反斜杠本身用\\表示,句号.用\.表示,以此类推。
7.2 字符簇
在INTERNET的程序中,正规表达式通常用来验证用户的输入。当用户提交一个FORM以后,要判断输入的电话号码、地址、EMAIL地址、信用卡号码等是否有效,用普通的基于字面的字符是不够的。
所以要用一种更自由的描述我们要的模式的办法,它就是字符簇。要建立一个表示所有元音字符的字符簇,就把所有的元音字符放在一个方括号里:
[AaEeIiOoUu]
这个模式与任何元音字符匹配,但只能表示一个字符。用连字号可以表示一个字符的范围,如:
[a-z] //匹配所有的小写字母
[A-Z] //匹配所有的大写字母
[a-zA-Z] //匹配所有的字母
[0-9] //匹配所有的数字
[0-9\.\-] //匹配所有的数字,句号和减号
[ \f\r\t\n] //匹配所有的白字符
同样的,这些也只表示一个字符,这是一个非常重要的。如果要匹配一个由一个小写字母和一位数字组成的字符串,比如"z2"、"t6"或"g7",但不是"ab2"、"r2d3" 或"b52"的话,用这个模式:
^[a-z][0-9]$
尽管[a-z]代表26个字母的范围,但在这里它只能与第一个字符是小写字母的字符串匹配。
前面曾经提到^表示字符串的开头,但它还有另外一个含义。当在一组方括号里使用^是,它表示“非”或“排除”的意思,常常用来剔除某个字符。还用前面的例子,我们要求第一个字符不能是数字:
^[^0-9][0-9]$
这个模式与"&5"、"g7"及"-2"是匹配的,但与"12"、"66"是不匹配的。下面是几个排除特定字符的例子:
[^a-z] //除了小写字母以外的所有字符
[^\\\/\^] //除了(\)(/)(^)之外的所有字符
[^\"\'] //除了双引号(")和单引号(')之外的所有字符
特殊字符"." (点,句号)在正规表达式中用来表示除了“新行”之外的所有字符。所以模式"^.5$"与任何两个字符的、以数字5结尾和以其他非“新行”字符开头的字符串匹配。模式"."可以匹配任何字符串,除了空串和只包括一个“新行”的字符串。
PHP的正规表达式有一些内置的通用字符簇,列表如下:
字符簇 含义
[[:alpha:]] 任何字母
[[:digit:]] 任何数字
[[:alnum:]] 任何字母和数字
[[:space:]] 任何白字符
[[:upper:]] 任何大写字母
[[:lower:]] 任何小写字母
[[:punct:]] 任何标点符号
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]
7.3 确定重复出现
到现在为止,你已经知道如何去匹配一个字母或数字,但更多的情况下,可能要匹配一个单词或一组数字。一个单词有若干个字母组成,一组数字有若干个单数组成。跟在字符或字符簇后面的花括号({})用来确定前面的内容的重复出现的次数。
字符簇 含义
^[a-zA-Z_]$ 所有的字母和下划线
^[[:alpha:]]{3}$ 所有的3个字母的单词
^a$ 字母a
^a{4}$ aaaa
^a{2,4}$ aa,aaa或aaaa
^a{1,3}$ a,aa或aaa
^a{2,}$ 包含多于两个a的字符串
^a{2,} 如:aardvark和aaab,但apple不行
a{2,} 如:baad和aaa,但Nantucket不行
\t{2} 两个制表符
.{2} 所有的两个字符
这些例子描述了花括号的三种不同的用法。一个数字,{x}的意思是“前面的字符或字符簇只出现x次”;一个数字加逗号,{x,}的意思是“前面的内容出现x或更多的次数”;两个用逗号分隔的数字,{x,y}表示“前面的内容至少出现x次,但不超过y次”。我们可以把模式扩展到更多的单词或数字:
^[a-zA-Z0-9_]{1,}$ //所有包含一个以上的字母、数字或下划线的字符串
^[0-9]{1,}$ //所有的正数
^\-{0,1}[0-9]{1,}$ //所有的整数
^\-{0,1}[0-9]{0,}\.{0,1}[0-9]{0,}$ //所有的小数
最后一个例子不太好理解,是吗?这么看吧:与所有以一个可选的负号(\-{0,1})开头(^)、跟着0个或更多的数字([0-9]{0,})、和一个可选的小数点(\.{0,1})再跟上0个或多个数字([0-9]{0,}),并且没有其他任何东西($)。下面你将知道能够使用的更为简单的方法。
特殊字符"?"与{0,1}是相等的,它们都代表着:“0个或1个前面的内容”或“前面的内容是可选的”。所以刚才的例子可以简化为:
^\-?[0-9]{0,}\.?[0-9]{0,}$
特殊字符"*"与{0,}是相等的,它们都代表着“0个或多个前面的内容”。最后,字符"+"与 {1,}是相等的,表示“1个或多个前面的内容”,所以上面的4个例子可以写成:
^[a-zA-Z0-9_]+$ //所有包含一个以上的字母、数字或下划线的字符串
^[0-9]+$ //所有的正数
^\-?[0-9]+$ //所有的整数
^\-?[0-9]*\.?[0-9]*$ //所有的小数
当然这并不能从技术上降低正规表达式的复杂性,但可以使它们更容易阅读。
参考文献:
JScript 和 VBScript 正则表达式
微软MSDN上的例子(英文):
- Scanning for HREFS
- Provides an example that searches an input string and prints out all the href="..." values and their locations in the string.
- Changing Date Formats
- Provides an example that replaces dates of the form mm/dd/yy with dates of the form dd-mm-yy.
- Extracting URL Information
- Provides an example that extracts a protocol and port number from a string containing a URL. For example, "http://www.contoso.com:8080/letters/readme.html" returns "http:8080".
- Cleaning an Input String
- provides an example that strips invalid non-alphanumeric characters from a string.
- Confirming Valid E-Mail Format
- Provides an example that you can use to verify that a string is in valid e-mail format.
|
posted @
2006-10-14 00:25 CoderDream 阅读(324) |
评论 (0) |
编辑 收藏! 去除字符串两端空格的处理
如果采用传统的方式,就要可能就要采用下面的方式了
//清除左边空格
function js_ltrim(deststr)
{
if(deststr==null)return "";
var pos=0;
var retStr=new String(deststr);
if (retStr.lenght==0) return retStr;
while (retStr.substring(pos,pos+1)==" ") pos++;
retStr=retStr.substring(pos);
return(retStr);
}
//清除右边空格
function js_rtrim(deststr)
{
if(deststr==null)return "";
var retStr=new String(deststr);
var pos=retStr.length;
if (pos==0) return retStr;
while (pos && retStr.substring(pos-1,pos)==" " ) pos--;
retStr=retStr.substring(0,pos);
return(retStr);
}
//清除左边和右边空格
function js_trim(deststr)
{
if(deststr==null)return "";
var retStr=new String(deststr);
var pos=retStr.length;
if (pos==0) return retStr;
retStr=js_ltrim(retStr);
retStr=js_rtrim(retStr);
return retStr;
}
采用正则表达式,来去除两边的空格,只需以下代码
String.prototype.trim = function()
{
return this.replace(/(^\s*)|(\s*$)/g, "");
}
一句就搞定了,
可见正则表达式为我们节省了相当的编写代码量
! 移动手机号的校验
如果采用传统的校验方式至少就要完成下面三步的校验,
(1). 是否是数字
(2).是否是11位
(3).数字的第三位是否是5,6,7,8,9
如果采用正则表达式校验,只需以下代码
function checkMobile1(form)
{
if (form.mobile.value > "")
{
var reg=/13[5,6,7,8,9]\d{8}/;
if ( form.mobile.value.match(reg)== null)
{
alert("请输入正确的移动手机号码!");
form.mobile.focus(); return false;
}
}
return true;
}
从上面的代码可以看出校验移动手机号只需定义一个var reg=/13[5,6,7,8,9]\d{8}/;模式匹配串就可以完成合法性校验了
! URL的校验,
条件:必须以http:// 或 https:// 开头, 端口号必须为在1-65535 之间, 以下代码完成了合法性校验
//obj:数据对象
//dispStr :失败提示内容显示字符串
function checkUrlValid( obj, dispStr)
{
if(obj == null)
{
alert("传入对象为空");
return false;
}
var str = obj.value;
var urlpatern0 = /^https?:\/\/.+$/i;
if(!urlpatern0.test(str))
{
alert(dispStr+"不合法:必须以'http:\/\/'或'https:\/\/'开头!");
obj.focus();
return false;
}
var urlpatern2= /^https?:\/\/(([a-zA-Z0-9_-])+(\.)?)*(:\d+)?.+$/i;
if(!urlpatern2.test(str))
{
alert(dispStr+"端口号必须为数字且应在1-65535之间!");
obj.focus();
return false;
}
var urlpatern1 =/^https?:\/\/(([a-zA-Z0-9_-])+(\.)?)*(:\d+)?(\/((\.)?(\?)?=?&?[a-zA-Z0-9_-](\?)?)*)*$/i;
if(!urlpatern1.test(str))
{
alert(dispStr+"不合法,请检查!");
obj.focus();
return false;
}
var s = "0";
var t =0;
var re = new RegExp(":\\d+","ig");
while((arr = re.exec(str))!=null)
{
s = str.substring(RegExp.index+1,RegExp.lastIndex);
if(s.substring(0,1)=="0")
{
alert(dispStr+"端口号不能以0开头!");
obj.focus();
return false;
}
t = parseInt(s);
if(t<1 || t >65535)
{
alert(dispStr+"端口号必须为数字且应在1-65535之间!");
obj.focus();
return false;
}
}
return true;
}
对url的校验,看上去有很多的代码,这是因为要给予出错提示, 否则只需var urlpatern1 =/^https?:\/\/(([a-zA-Z0-9_-])+(\.)?)*(:\d+)?(\/((\.)?(\?)?=?&?[a-zA-Z0-9_-](\?)?)*)*$/i; 一句就可以校验出url合法性了。
javascript正则表达式检验
/*********************************************************************************
* EO_JSLib.js
* javascript正则表达式检验
**********************************************************************************/
//校验是否全由数字组成
function isDigit(s)
{
var patrn=/^[0-9]{1,20}$/;
if (!patrn.exec(s)) return false
return true
}
//校验登录名:只能输入5-20个以字母开头、可带数字、“_”、“.”的字串
function isRegisterUserName(s)
{
var patrn=/^[a-zA-Z]{1}([a-zA-Z0-9]|[._]){4,19}$/;
if (!patrn.exec(s)) return false
return true
}
//校验用户姓名:只能输入1-30个以字母开头的字串
function isTrueName(s)
{
var patrn=/^[a-zA-Z]{1,30}$/;
if (!patrn.exec(s)) return false
return true
}
//校验密码:只能输入6-20个字母、数字、下划线
function isPasswd(s)
{
var patrn=/^(\w){6,20}$/;
if (!patrn.exec(s)) return false
return true
}
//校验普通电话、传真号码:可以“+”开头,除数字外,可含有“-”
function isTel(s)
{
//var patrn=/^[+]{0,1}(\d){1,3}[ ]?([-]?(\d){1,12})+$/;
var patrn=/^[+]{0,1}(\d){1,3}[ ]?([-]?((\d)|[ ]){1,12})+$/;
if (!patrn.exec(s)) return false
return true
}
//校验手机号码:必须以数字开头,除数字外,可含有“-”
function isMobil(s)
{
var patrn=/^[+]{0,1}(\d){1,3}[ ]?([-]?((\d)|[ ]){1,12})+$/;
if (!patrn.exec(s)) return false
return true
}
//校验邮政编码
function isPostalCode(s)
{
//var patrn=/^[a-zA-Z0-9]{3,12}$/;
var patrn=/^[a-zA-Z0-9 ]{3,12}$/;
if (!patrn.exec(s)) return false
return true
}
//校验搜索关键字
function isSearch(s)
{
var patrn=/^[^`~!@#$%^&*()+=|\\\][\]\{\}:;'\,.<>/?]{1}[^`~!@$%^&()+=|\\\][\]\{\}:;'\,.<>?]{0,19}$/;
if (!patrn.exec(s)) return false
return true
}
function isIP(s) //by zergling
{
var patrn=/^[0-9.]{1,20}$/;
if (!patrn.exec(s)) return false
return true
}
(ip,email,data,time)
<script language="javascript">
var patterns = new Object();
//匹配ip地址
patterns.ip = /^(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])(\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])){3}$/;
//匹配邮件地址
patterns.email = /^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$/;
//匹配日期格式2008-01-31,但不匹配2008-13-00
patterns.date = /^\d{4}-(0?[1-9]|1[0-2])-(0?[1-9]|[1-2]\d|3[0-1])$/;
/**//*匹配时间格式00:15:39,但不匹配24:60:00,下面使用RegExp对象的构造方法
来创建RegExp对象实例,注意正则表达式模式文本中的“\”要写成“\\”*/
patterns.time = new RegExp("^([0-1]\\d|2[0-3]):[0-5]\\d:[0-5]\\d$");
/**//*verify – 校验一个字符串是否符合某种模式
*str – 要进行校验的字符串
*pat – 与patterns中的某个正则表达式模式对应的属性名称
*/
function verify(str,pat)
{
thePat = patterns[pat];
if(thePat.test(str))
{
return true;
}
else
{
return false;
}
}
</script>
posted @
2006-10-14 00:09 CoderDream 阅读(441) |
评论 (0) |
编辑 收藏
正则表达式(REs)通常被错误地认为是只有少数人理解的一种神秘语言。在表面上它们确实看起来杂乱无章,如果你不知道它的语法,那么它的代码在你眼里只是一堆文字垃圾而已。实际上,正则表达式是非常简单并且可以被理解。读完这篇文章后,你将会通晓正则表达式的通用语法。
支持多种平台
正则表达式最早是由数学家Stephen Kleene于1956年提出,他是在对自然语言的递增研究成果的基础上提出来的。具有完整语法的正则表达式使用在字符的格式匹配方面上,后来被应用到熔融信息技术领域。自从那时起,正则表达式经过几个时期的发展,现在的标准已经被ISO(国际标准组织)批准和被Open Group组织认定。
正则表达式并非一门专用语言,但它可用于在一个文件或字符里查找和替代文本的一种标准。它具有两种标准:基本的正则表达式(BRE),扩展的正则表达式(ERE)。ERE包括BRE功能和另外其它的概念。
许多程序中都使用了正则表达式,包括xsh,egrep,sed,vi以及在UNIX平台下的程序。它们可以被很多语言采纳,如HTML 和XML,这些采纳通常只是整个标准的一个子集。
比你想象的还要普通
随着正则表达式移植到交叉平台的程序语言的发展,这的功能也日益完整,使用也逐渐广泛。网络上的搜索引擎使用它,e-mail程序也使用它,即使你不是一个UNIX程序员,你也可以使用规则语言来简化你的程序而缩短你的开发时间。
正则表达式101
很多正则表达式的语法看起来很相似,这是因为你以前你没有研究过它们。通配符是RE的一个结构类型,即重复操作。让我们先看一看ERE标准的最通用的基本语法类型。为了能够提供具有特定用途的范例,我将使用几个不同的程序。
字符匹配
正则表达式的关键之处在于确定你要搜索匹配的东西,如果没有这一概念,Res将毫无用处。
每一个表达式都包含需要查找的指令,如表A所示。
|
Table A: Character-matching regular expressions
|
|
操作
|
解释
|
例子
|
结果
|
|
.
|
Match any one character
|
grep .ord sample.txt
|
Will match “ford”, “lord”, “2ord”, etc. in the file sample.txt.
|
|
[ ]
|
Match any one character listed between the brackets
|
grep [cng]ord sample.txt
|
Will match only “cord”, “nord”, and “gord”
|
|
[^ ]
|
Match any one character not listed between the brackets
|
grep [^cn]ord sample.txt
|
Will match “lord”, “2ord”, etc. but not “cord” or “nord”
|
|
|
|
grep [a-zA-Z]ord sample.txt
|
Will match “aord”, “bord”, “Aord”, “Bord”, etc.
|
|
|
|
grep [^0-9]ord sample.txt
|
Will match “Aord”, “aord”, etc. but not “2ord”, etc.
|
重复操作符
重复操作符,或数量词,都描述了查找一个特定字符的次数。它们常被用于字符匹配语法以查找多行的字符,可参见表B。
|
Table B: Regular expression repetition operators
|
|
操作
|
解释
|
例子
|
结果
|
|
?
|
Match any character one time, if it exists
|
egrep “?erd” sample.txt
|
Will match “berd”, “herd”, etc. and “erd”
|
|
*
|
Match declared element multiple times, if it exists
|
egrep “n.*rd” sample.txt
|
Will match “nerd”, “nrd”, “neard”, etc.
|
|
+
|
Match declared element one or more times
|
egrep “[n]+erd” sample.txt
|
Will match “nerd”, “nnerd”, etc., but not “erd”
|
|
{n}
|
Match declared element exactly n times
|
egrep “[a-z]{2}erd” sample.txt
|
Will match “cherd”, “blerd”, etc. but not “nerd”, “erd”, “buzzerd”, etc.
|
|
{n,}
|
Match declared element at least n times
|
egrep “.{2,}erd” sample.txt
|
Will match “cherd” and “buzzerd”, but not “nerd”
|
|
{n,N}
|
Match declared element at least n times, but not more than N times
|
egrep “n[e]{1,2}rd” sample.txt
|
Will match “nerd” and “neerd”
|
锚
锚是指它所要匹配的格式,如图C所示。使用它能方便你查找通用字符的合并。例如,我用vi行编辑器命令:s来代表substitute,这一命令的基本语法是:
s/pattern_to_match/pattern_to_substitute/
|
Table C: Regular expression anchors
|
|
操作
|
解释
|
例子
|
结果
|
|
^
|
Match at the beginning of a line
|
s/^/blah /
|
Inserts “blah “ at the beginning of the line
|
|
$
|
Match at the end of a line
|
s/$/ blah/
|
Inserts “ blah” at the end of the line
|
|
\<
|
Match at the beginning of a word
|
s/\</blah/
|
Inserts “blah” at the beginning of the word
|
|
|
|
egrep “\<blah” sample.txt
|
Matches “blahfield”, etc.
|
|
\>
|
Match at the end of a word
|
s/\>/blah/
|
Inserts “blah” at the end of the word
|
|
|
|
egrep “\>blah” sample.txt
|
Matches “soupblah”, etc.
|
|
\b
|
Match at the beginning or end of a word
|
egrep “\bblah” sample.txt
|
Matches “blahcake” and “countblah”
|
|
\B
|
Match in the middle of a word
|
egrep “\Bblah” sample.txt
|
Matches “sublahper”, etc.
|
间隔
Res中的另一可便之处是间隔(或插入)符号。实际上,这一符号相当于一个OR语句并代表|符号。下面的语句返回文件sample.txt中的“nerd” 和 “merd”的句柄:
egrep “(n|m)erd” sample.txt
间隔功能非常强大,特别是当你寻找文件不同拼写的时候,但你可以在下面的例子得到相同的结果:
egrep “[nm]erd” sample.txt
当你使用间隔功能与Res的高级特性连接在一起时,它的真正用处更能体现出来。
一些保留字符
Res的最后一个最重要特性是保留字符(也称特定字符)。例如,如果你想要查找“ne*rd”和“ni*rd”的字符,格式匹配语句“n[ei]*rd”与“neeeeerd” 和 “nieieierd”相符合,但并不是你要查找的字符。因为‘*’(星号)是个保留字符,你必须用一个反斜线符号来替代它,即:“n[ei]\*rd”。其它的保留字符包括:
-
^ (carat)
-
. (period)
-
[ (left bracket}
-
$ (dollar sign)
-
( (left parenthesis)
-
) (right parenthesis)
-
| (pipe)
-
* (asterisk)
-
+ (plus symbol)
-
? (question mark)
-
{ (left curly bracket, or left brace)
-
\ backslash
一旦你把以上这些字符包括在你的字符搜索中,毫无疑问Res变得非常的难读。比如说以下的PHP中的eregi搜索引擎代码就很难读了。
eregi("^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$",$sendto)
你可以看到,程序的意图很难把握。但如果你抛开保留字符,你常常会错误地理解代码的意思。
总结
在本文中,我们揭开了正则表达式的神秘面纱,并列出了ERE标准的通用语法。如果你想阅览Open Group组织的规则的完整描述,你可以参见:
Regular Expressions
,欢迎你在其中的讨论区发表你的问题或观点。
|
posted @
2006-10-14 00:03 CoderDream 阅读(269) |
评论 (0) |
编辑 收藏
|
|
|
如果我们问那些UNIX系统的爱好者他们最喜欢什么,答案除了稳定的系统和可以远程启动之外,十有八九的人会提到正则表达式;如果我们再问他们最头痛的是什么,可能除了复杂的进程控制和安装过程之外,还会是正则表达式。那么正则表达式到底是什么?如何才能真正的掌握正则表达式并正确的加以灵活运用?本文将就此展开介绍,希望能够对那些渴望了解和掌握正则表达式的读者有所助益。
入门简介
简单的说,正则表达式是一种可以用于模式匹配和替换的强有力的工具。我们可以在几乎所有的基于UNIX系统的工具中找到正则表达式的身影,例如,vi编辑器,Perl或PHP脚本语言,以及awk或sed shell程序等。此外,象JavaScript这种客户端的脚本语言也提供了对正则表达式的支持。由此可见,正则表达式已经超出了某种语言或某个系统的局限,成为人们广为接受的概念和功能。
正则表达式可以让用户通过使用一系列的特殊字符构建匹配模式,然后把匹配模式与数据文件、程序输入以及WEB页面的表单输入等目标对象进行比较,根据比较对象中是否包含匹配模式,执行相应的程序。
举例来说,正则表达式的一个最为普遍的应用就是用于验证用户在线输入的邮件地址的格式是否正确。如果通过正则表达式验证用户邮件地址的格式正确,用户所填写的表单信息将会被正常处理;反之,如果用户输入的邮件地址与正则表达的模式不匹配,将会弹出提示信息,要求用户重新输入正确的邮件地址。由此可见正则表达式在WEB应用的逻辑判断中具有举足轻重的作用。
基本语法
在对正则表达式的功能和作用有了初步的了解之后,我们就来具体看一下正则表达式的语法格式。
正则表达式的形式一般如下:
/love/
其中位于“/”定界符之间的部分就是将要在目标对象中进行匹配的模式。用户只要把希望查找匹配对象的模式内容放入“/”定界符之间即可。为了能够使用户更加灵活的定制模式内容,正则表达式提供了专门的“元字符”。所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
较为常用的元字符包括: “+”, “*”,以及 “?”。其中,“+”元字符规定其前导字符必须在目标对象中连续出现一次或多次,“*”元字符规定其前导字符必须在目标对象中出现零次或连续多次,而“?”元字符规定其前导对象必须在目标对象中连续出现零次或一次。
下面,就让我们来看一下正则表达式元字符的具体应用。
/fo+/
因为上述正则表达式中包含“+”元字符,表示可以与目标对象中的 “fool”, “fo”, 或者 “football”等在字母f后面连续出现一个或多个字母o的字符串相匹配。
/eg*/
因为上述正则表达式中包含“*”元字符,表示可以与目标对象中的 “easy”, “ego”, 或者 “egg”等在字母e后面连续出现零个或多个字母g的字符串相匹配。
/Wil?/
因为上述正则表达式中包含“?”元字符,表示可以与目标对象中的 “Will”, 或者 “Wilson”,等在字母i后面连续出现零个或一个字母l的字符串相匹配。
除了元字符之外,用户还可以精确指定模式在匹配对象中出现的频率。例如,
/jim{2,6}/
上述正则表达式规定字符m可以在匹配对象中连续出现2-6次,因此,上述正则表达式可以同jimmy或jimmmmmy等字符串相匹配。
在对如何使用正则表达式有了初步了解之后,我们来看一下其它几个重要的元字符的使用方式。
s:用于匹配单个空格符,包括tab键和换行符;
S:用于匹配除单个空格符之外的所有字符;
d:用于匹配从0到9的数字;
w:用于匹配字母,数字或下划线字符;
W:用于匹配所有与w不匹配的字符;
. :用于匹配除换行符之外的所有字符。
(说明:我们可以把s和S以及w和W看作互为逆运算)
|
下面,我们就通过实例看一下如何在正则表达式中使用上述元字符。
/s+/
上述正则表达式可以用于匹配目标对象中的一个或多个空格字符。
/d000/
如果我们手中有一份复杂的财务报表,那么我们可以通过上述正则表达式轻而易举的查找到所有总额达千元的款项。
除了我们以上所介绍的元字符之外,正则表达式中还具有另外一种较为独特的专用字符,即定位符。定位符用于规定匹配模式在目标对象中的出现位置。
较为常用的定位符包括: “^”, “$”, “�” 以及 “B”。其中,“^”定位符规定匹配模式必须出现在目标字符串的开头,“$”定位符规定匹配模式必须出现在目标对象的结尾,�定位符规定匹配模式必须出现在目标字符串的开头或结尾的两个边界之一,而“B”定位符则规定匹配对象必须位于目标字符串的开头和结尾两个边界之内,即匹配对象既不能作为目标字符串的开头,也不能作为目标字符串的结尾。同样,我们也可以把“^”和“$”以及“�”和“B”看作是互为逆运算的两组定位符。举例来说:
/^hell/
因为上述正则表达式中包含“^”定位符,所以可以与目标对象中以 “hell”, “hello”或 “hellhound”开头的字符串相匹配。
/ar$/
因为上述正则表达式中包含“$”定位符,所以可以与目标对象中以 “car”, “bar”或 “ar” 结尾的字符串相匹配。
/�bom/
因为上述正则表达式模式以“�”定位符开头,所以可以与目标对象中以 “bomb”, 或 “bom”开头的字符串相匹配。
/man�/
因为上述正则表达式模式以“�”定位符结尾,所以可以与目标对象中以 “human”, “woman”或 “man”结尾的字符串相匹配。
为了能够方便用户更加灵活的设定匹配模式,正则表达式允许使用者在匹配模式中指定某一个范围而不局限于具体的字符。例如:
/[A-Z]/
上述正则表达式将会与从A到Z范围内任何一个大写字母相匹配。
/[a-z]/
上述正则表达式将会与从a到z范围内任何一个小写字母相匹配。
/[0-9]/
上述正则表达式将会与从0到9范围内任何一个数字相匹配。
/([a-z][A-Z][0-9])+/
上述正则表达式将会与任何由字母和数字组成的字符串,如 “aB0” 等相匹配。这里需要提醒用户注意的一点就是可以在正则表达式中使用 “()” 把字符串组合在一起。“()”符号包含的内容必须同时出现在目标对象中。因此,上述正则表达式将无法与诸如 “abc”等的字符串匹配,因为“abc”中的最后一个字符为字母而非数字。
如果我们希望在正则表达式中实现类似编程逻辑中的“或”运算,在多个不同的模式中任选一个进行匹配的话,可以使用管道符 “|”。例如:
/to|too|2/
上述正则表达式将会与目标对象中的 “to”, “too”, 或 “2” 相匹配。
正则表达式中还有一个较为常用的运算符,即否定符 “[^]”。与我们前文所介绍的定位符 “^” 不同,否定符 “[^]”规定目标对象中不能存在模式中所规定的字符串。例如:
/[^A-C]/
上述字符串将会与目标对象中除A,B,和C之外的任何字符相匹配。一般来说,当“^”出现在 “[]”内时就被视做否定运算符;而当“^”位于“[]”之外,或没有“[]”时,则应当被视做定位符。
最后,当用户需要在正则表达式的模式中加入元字符,并查找其匹配对象时,可以使用转义符“”。例如:
/Th*/
上述正则表达式将会与目标对象中的“Th*”而非“The”等相匹配。
使用实例
在对正则表达式有了较为全面的了解之后,我们就来看一下如何在Perl,PHP,以及JavaScript中使用正则表达式。
通常,Perl中正则表达式的使用格式如下:
operator / regular-expression / string-to-replace / modifiers
运算符一项可以是m或s,分别代表匹配运算和替换运算。
其中,正则表达式一项是将要进行匹配或替换操作的模式,可以由任意字符,元字符,或定位符等组成。替换字符串一项是使用s运算符时,对查找到的模式匹配对象进行替换的字符串。最后的参数项用来控制不同的匹配或替换方式。例如:
s/geed/good/
将会在目标对象中查找第一个出现的geed字串,并将其替换为good。如果我们希望在目标对象的全局范围内执行多次查找—替换操作的话,可以使用参数 “g”,即s/love/lust/g。
此外,如果我们不需要限制匹配的大小写形式的话,可以使用参数 “i ”。例如,
m/JewEL/i
上述正则表达式将会与目标对象中的jewel,Jewel,或JEWEL相匹配。
在Perl中,使用专门的运算符“=~”指定正则表达式的匹配对象。例如:
$flag =~ s/abc/ABC/
上述正则表达式将会把变量$flag中的字串abc替换为ABC。
下面,我们就在Perl程序中加入正则表达式,验证用户邮件地址格式的有效性。代码如下:
#!/usr/bin/perl
# get input
print “What's your email address? ”;
$email = <>
chomp($email);
# match and display result
if($email =~ /^([a-zA-Z0-9_-])+@([a-zA-Z0-9_-])+(.[a-zA-Z0-9_-])+/)
{
print(“Your email address is correct! ”);
}
else
{
print(“Please try again! ”);
}
如果用户更偏爱PHP的话,可以使用ereg()函数进行模式匹配操作。ereg()函数的使用格式如下:
ereg(pattern, string)
其中,pattern代表正则表达式的模式,而string则是执行查找替换操作的目标对象。同样是验证邮件地址,使用PHP编写的程序代码如下:
<?php
if (ereg(“^([a-zA-Z0-9_-])+@([a-zA-Z0-9_-])+(.[a-zA-Z0-9_-])+”,$email))
{ echo “Your email address is correct!”;}
else
{ echo “Please try again!”;}
?>
最后,我们在来看一下JavaScript。JavaScript 1.2中带有一个功能强大的RegExp()对象,可以用来进行正则表达式的匹配操作。其中的test()方法可以检验目标对象中是否包含匹配模式,并相应的返回true或false。
我们可以使用JavaScript编写以下脚本,验证用户输入的邮件地址的有效性。
<html>
<head>
< language="Javascript1.2">
<!-- start hiding
function verifyAddress(obj)
{
var email = obj.email.value;
var pattern = /^([a-zA-Z0-9_-])+@([a-zA-Z0-9_-])+(.[a-zA-Z0-9_-])+/;
flag = pattern.test(email);
if(flag)
{
alert(“Your email address is correct!”);
return true;
}
else
{
alert(“Please try again!”);
return false;
}
}
// stop hiding -->
</script>
</head>
<body>
<form onSubmit="return verifyAddress(this);">
<input name="email" type="text">
<input type="submit" value="提交">
</form>
</body>
</html>
posted @
2006-10-13 23:57 CoderDream 阅读(382) |
评论 (0) |
编辑 收藏正则表达式之道
原著:Steve Mansour
sman@scruznet.com
Revised: June 5, 1999
(copied by jm /at/ jmason.org from http://www.scruz.net/%7esman/regexp.htm, after the original disappeared! )
翻译:Neo Lee
neo.lee@gmail.com
2004年10月16日
英文版原文
译者按:原文因为年代久远,文中很多链接早已过期(主要是关于vi、sed等工具的介绍和手册),本译文中已将此类链接删除,如需检查这些链接可以查看上面链接的原文。除此之外基本照原文直译,括号中有“译者按”的部分是译者补充的说明。如有内容方面的问题请直接和Steve Mansor联系,当然,如果你只写中文,也可以和我联系。
目 录
什么是正则表达式
范例
简单
中级(神奇的咒语)
困难(不可思议的象形文字)
不同工具中的正则表达式
什么是正则表达式
一个正则表达式,就是用某种模式去匹配一类字符串的一个公式。很多人因为它们看上去比较古怪而且复杂所以不敢去使用——很不幸,这篇文章也不能够改变这一点,不过,经过一点点练习之后我就开始觉得这些复杂的表达式其实写起来还是相当简单的,而且,一旦你弄懂它们,你就能把数小时辛苦而且易错的文本处理工作压缩在几分钟(甚至几秒钟)内完成。正则表达式被各种文本编辑软件、类库(例如Rogue Wave的tools.h++)、脚本工具(像awk/grep/sed)广泛的支持,而且像Microsoft的Visual C++这种交互式IDE也开始支持它了。
我们将在如下的章节中利用一些例子来解释正则表达式的用法,绝大部分的例子是基于vi中的文本替换命令和grep文件搜索命令来书写的,不过它们都是比较典型的例子,其中的概念可以在sed、awk、perl和其他支持正则表达式的编程语言中使用。你可以看看不同工具中的正则表达式这一节,其中有一些在别的工具中使用正则表达式的例子。还有一个关于vi中文本替换命令(s)的简单说明附在文后供参考。
正则表达式基础
正则表达式由一些普通字符和一些
元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义,我们下面会给予解释。
在最简单的情况下,一个正则表达式看上去就是一个普通的查找串。例如,正则表达式"testing"中没有包含任何元字符,,它可以匹配"testing"和"123testing"等字符串,但是不能匹配"Testing"。
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。
| 元字符 | | 描述 |
|---|
| |
|
| . | | 匹配任何单个字符。例如正则表达式r.t匹配这些字符串:rat、rut、r t,但是不匹配root。 |
| $ | | 匹配行结束符。例如正则表达式weasel$ 能够匹配字符串"He's a weasel"的末尾,但是不能匹配字符串"They are a bunch of weasels."。 |
| ^ | | 匹配一行的开始。例如正则表达式^When in能够匹配字符串"When in the course of human events"的开始,但是不能匹配"What and When in the"。 |
| * | | 匹配0或多个正好在它之前的那个字符。例如正则表达式.*意味着能够匹配任意数量的任何字符。 |
| \ | | 这是引用府,用来将这里列出的这些元字符当作普通的字符来进行匹配。例如正则表达式\$被用来匹配美元符号,而不是行尾,类似的,正则表达式\.用来匹配点字符,而不是任何字符的通配符。 |
[ ]
[c1-c2]
[^c1-c2] | | 匹配括号中的任何一个字符。例如正则表达式r[aou]t匹配rat、rot和rut,但是不匹配ret。可以在括号中使用连字符-来指定字符的区间,例如正则表达式[0-9]可以匹配任何数字字符;还可以制定多个区间,例如正则表达式[A-Za-z]可以匹配任何大小写字母。另一个重要的用法是“排除”,要想匹配除了指定区间之外的字符——也就是所谓的补集——在左边的括号和第一个字符之间使用^字符,例如正则表达式[^269A-Z] 将匹配除了2、6、9和所有大写字母之外的任何字符。 |
| \< \> | | 匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 |
| \( \) | | 将 \( 和 \) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| | | | 将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |
| + | | 匹配1或多个正好在它之前的那个字符。例如正则表达式9+匹配9、99、999等。注意:这个元字符不是所有的软件都支持的。 |
| ? | | 匹配0或1个正好在它之前的那个字符。注意:这个元字符不是所有的软件都支持的。 |
\{i\}
\{i,j\} | | 匹配指定数目的字符,这些字符是在它之前的表达式定义的。例如正则表达式A[0-9]\{3\} 能够匹配字符"A"后面跟着正好3个数字字符的串,例如A123、A348等,但是不匹配A1234。而正则表达式[0-9]\{4,6\} 匹配连续的任意4个、5个或者6个数字字符。注意:这个元字符不是所有的软件都支持的。 |
最简单的元字符是点,它能够匹配任何单个字符(注意不包括新行符)。假定有个文件test.txt包含以下几行内容:
he is a rat
he is in a rut
the food is Rotten
I like root beer
我们可以使用grep命令来测试我们的正则表达式,grep命令使用正则表达式去尝试匹配指定文件的每一行,并将至少有一处匹配表达式的所有行显示出来。命令
在test.txt文件中的每一行中搜索正则表达式
r.t,并打印输出匹配的行。正则表达式
r.t匹配一个
r接着任何一个字符再接着一个
t。所以它将匹配文件中的
rat和
rut,而不能匹配
Rotten中的
Rot,因为正则表达式是大小写敏感的。要想同时匹配大写和小写字母,应该使用字符区间元字符(方括号)。正则表达式
[Rr]能够同时匹配
R和
r。所以,要想匹配一个大写或者小写的
r接着任何一个字符再接着一个
t就要使用这个表达式:
[Rr].t。
要想匹配行首的字符要使用抑扬字符(^)——又是也被叫做插入符。例如,想找到text.txt中行首"he"打头的行,你可能会先用简单表达式he,但是这会匹配第三行的the,所以要使用正则表达式^he,它只匹配在行首出现的h。
有时候指定“除了×××都匹配”会比较容易达到目的,当抑扬字符(^)出现在方括号中是,它表示“排除”,例如要匹配he ,但是排除前面是t or s的情性(也就是the和she),可以使用:[^st]he。
可以使用方括号来指定多个字符区间。例如正则表达式[A-Za-z]匹配任何字母,包括大写和小写的;正则表达式[A-Za-z][A-Za-z]* 匹配一个字母后面接着0或者多个字母(大写或者小写)。当然我们也可以用元字符+做到同样的事情,也就是:[A-Za-z]+ ,和[A-Za-z][A-Za-z]*完全等价。但是要注意元字符+ 并不是所有支持正则表达式的程序都支持的。关于这一点可以参考后面的正则表达式语法支持情况。
要指定特定数量的匹配,要使用大括号(注意必须使用反斜杠来转义)。想匹配所有100和1000的实例而排除10和10000,可以使用:10\{2,3\},这个正则表达式匹配数字1后面跟着2或者3个0的模式。在这个元字符的使用中一个有用的变化是忽略第二个数字,例如正则表达式0\{3,\} 将匹配至少3个连续的0。
简单的例子
这里有一些有代表性的、比较简单的例子。
| vi 命令 | 作用 |
|
|
| :%s/ */ /g | 把一个或者多个空格替换为一个空格。 |
| :%s/ *$// | 去掉行尾的所有空格。 |
| :%s/^/ / | 在每一行头上加入一个空格。 |
| :%s/^[0-9][0-9]* // | 去掉行首的所有数字字符。 |
| :%s/b[aeio]g/bug/g | 将所有的bag、beg、big和bog改为bug。 |
| :%s/t\([aou]\)g/h\1t/g | 将所有tag、tog和tug分别改为hat、hot和hug(注意用group的用法和使用\1引用前面被匹配的字符)。 |
| |
中级的例子(神奇的咒语)
例1
将所有方法foo(a,b,c)的实例改为foo(b,a,c)。这里a、b和c可以是任何提供给方法foo()的参数。也就是说我们要实现这样的转换:
| 之前 | | 之后 |
| foo(10,7,2) | | foo(7,10,2) |
| foo(x+13,y-2,10) | | foo(y-2,x+13,10) |
| foo( bar(8), x+y+z, 5) | | foo( x+y+z, bar(8), 5) |
下面这条替换命令能够实现这一魔法:
:%s/foo(\([^,]*\),\([^,]*\),\([^)]*\))/foo(\2,\1,\3)/g
现在让我们把它打散来加以分析。写出这个表达式的基本思路是找出foo()和它的括号中的三个参数的位置。第一个参数是用这个表达式来识别的::\([^,]*\),我们可以从里向外来分析它:
| [^,] | | 除了逗号之外的任何字符 |
| [^,]* | | 0或者多个非逗号字符 |
| \([^,]*\) | | 将这些非逗号字符标记为\1,这样可以在之后的替换模式表达式中引用它 |
| \([^,]*\), | | 我们必须找到0或者多个非逗号字符后面跟着一个逗号,并且非逗号字符那部分要标记出来以备后用。 |
现在正是指出一个使用正则表达式常见错误的最佳时机。为什么我们要使用[^,]*这样的一个表达式,而不是更加简单直接的写法,例如:.*,来匹配第一个参数呢?设想我们使用模式.*来匹配字符串"10,7,2",它应该匹配"10,"还是"10,7,"?为了解决这个两义性(ambiguity),正则表达式规定一律按照最长的串来,在上面的例子中就是"10,7,",显然这样就找出了两个参数而不是我们期望的一个。所以,我们要使用[^,]*来强制取出第一个逗号之前的部分。
这个表达式我们已经分析到了:foo(\([^,]*\),这一段可以简单的翻译为“当你找到foo(就把其后直到第一个逗号之前的部分标记为\1”。然后我们使用同样的办法标记第二个参数为\2。对第三个参数的标记方法也是一样,只是我们要搜索所有的字符直到右括号。我们并没有必要去搜索第三个参数,因为我们不需要调整它的位置,但是这样的模式能够保证我们只去替换那些有三个参数的foo()方法调用,在foo()是一个重载(overoading)方法时这种明确的模式往往是比较保险的。然后,在替换部分,我们找到foo()的对应实例,然后利用标记好的部分进行替换,是的第一和第二个参数交换位置。
例2
假设有一个CSV(comma separated value)文件,里面有一些我们需要的信息,但是格式却有问题,目前数据的列顺序是:姓名,公司名,州名缩写,邮政编码,现在我们希望讲这些数据重新组织,以便在我们的某个软件中使用,需要的格式为:姓名,州名缩写-邮政编码,公司名。也就是说,我们要调整列顺序,还要合并两个列来构成一个新列。另外,我们的软件不能接受逗号前后面有任何空格(包括空格和制表符)所以我们还必须要去掉逗号前后的所有空格。
这里有几行我们现在的数据:
Bill Jones, HI-TEK Corporation , CA, 95011
Sharon Lee Smith, Design Works Incorporated, CA, 95012
B. Amos , Hill Street Cafe, CA, 95013
Alexander Weatherworth, The Crafts Store, CA, 95014
...
我们希望把它变成这个样子:
Bill Jones,CA 95011,HI-TEK Corporation
Sharon Lee Smith,CA 95012,Design Works Incorporated
B. Amos,CA 95013,Hill Street Cafe
Alexander Weatherworth,CA 95014,The Crafts Store
...
我们将用两个正则表达式来解决这个问题。第一个移动列和合并列,第二个用来去掉空格。
下面就是第一个替换命令:
:%s/\([^,]*\),\([^,]*\),\([^,]*\),\(.*\)/\1,\3 \4,\2/
这里的方法跟例1基本一样,第一个列(姓名)用这个表达式来匹配:
\([^,]*\),即第一个逗号之前的所有字符,而姓名内容被用
\1标记下来。公司名和州名缩写字段用同样的方法标记为
\2和
\3,而最后一个字段用
\(.*\)来匹配("匹配所有字符直到行末")。替换部分则引用上面标记的那些内容来进行构造。
下面这个替换命令则用来去除空格:
我们还是分解来看:
[ \t]匹配空格/制表符,
[ \t]* 匹配0或多个空格/制表符,
[ \t]*,匹配0或多个空格/制表符后面再加一个逗号,最后,
[ \t]*,[ \t]*匹配0或多个空格/制表符接着一个逗号再接着0或多个空格/制表符。在替换部分,我们简单的我们找到的所有东西替换成一个逗号。这里我们使用了结尾的可选的
g参数,这表示在每行中对所有匹配的串执行替换(而不是缺省的只替换第一个匹配串)。
例3
假设有一个多字符的片断重复出现,例如:
Billy tried really hard
Sally tried really really hard
Timmy tried really really really hard
Johnny tried really really really really hard
而你想把"really"、"really really",以及任意数量连续出现的"really"字符串换成一个简单的"very"(simple is good!),那么以下命令:
:%s/\(really \)\(really \)*/very /
就会把上述的文本变成:
Billy tried very hard
Sally tried very hard
Timmy tried very hard
Johnny tried very hard
表达式
\(really \)*匹配0或多个连续的"really "(注意结尾有个空格),而
\(really \)\(really \)* 匹配1个或多个连续的"really "实例。
困难的例子(不可思议的象形文字)
Coming soon.
不同工具中的正则表达式
OK,你已经准备使用RE(regular expressions,正则表达式),但是你并准备使用vi。所以,在这里我们给出一些在其他工具中使用RE的例子。另外,我还会总结一下你在不同程序之间使用RE可能发现的区别。
当然,你也可以在Visual C++编辑器中使用RE。选择Edit->Replace,然后选择"Regular expression"选择框,Find What输入框对应上面介绍的vi命令:%s/pat1/pat2/g中的pat1部分,而Replace输入框对应pat2部分。但是,为了得到vi的执行范围和g选项,你要使用Replace All或者适当的手工Find Next and Replace(译者按:知道为啥有人骂微软弱智了吧,虽然VC中可以选中一个范围的文本,然后在其中执行替换,但是总之不够vi那么灵活和典雅)。
sed
Sed是Stream EDitor的缩写,是Unix下常用的基于文件和管道的编辑工具,可以在手册中得到关于sed的详细信息。
这里是一些有趣的sed脚本,假定我们正在处理一个叫做price.txt的文件。注意这些编辑并不会改变源文件,sed只是处理源文件的每一行并把结果显示在标准输出中(当然很容易使用重定向来定制):
| sed脚本 | | 描述 |
| |
|
| sed 's/^$/d' price.txt | | 删除所有空行 |
| sed 's/^[ \t]*$/d' price.txt | | 删除所有只包含空格或者制表符的行 |
| sed 's/"//g' price.txt | | 删除所有引号 |
awk
awk是一种编程语言,可以用来对文本数据进行复杂的分析和处理。可以在手册中得到关于awk的详细信息。这个古怪的名字是它作者们的姓的缩写(Aho,Weinberger和Kernighan)。
在Aho,Weinberger和Kernighan的书The AWK Programming Language中有很多很好的awk的例子,请不要让下面这些微不足道的脚本例子限制你对awk强大能力的理解。我们同样假定我们针对price.txt文件进行处理,跟sed一样,awk也只是把结果显示在终端上。
| awk脚本 | | 描述 |
| |
|
| awk '$0 !~ /^$/' price.txt | | 删除所有空行 |
| awk 'NF > 0' price.txt | | awk中一个更好的删除所有行的办法 |
| awk '$2 ~ /^[JT]/ {print $3}' price.txt | | 打印所有第二个字段是'J'或者'T'打头的行中的第三个字段 |
| awk '$2 !~ /[Mm]isc/ {print $3 + $4}' price.txt | | 针对所有第二个字段不包含'Misc'或者'misc'的行,打印第3和第4列的和(假定为数字) |
| awk '$3 !~ /^[0-9]+\.[0-9]*$/ {print $0}' price.txt | | 打印所有第三个字段不是数字的行,这里数字是指d.d或者d这样的形式,其中d是0到9的任何数字 |
| awk '$2 ~ /John|Fred/ {print $0}' price.txt | | 如果第二个字段包含'John'或者'Fred'则打印整行 |
grep
grep是一个用来在一个或者多个文件或者输入流中使用RE进行查找的程序。它的name编程语言可以用来针对文件和管道进行处理。可以在手册中得到关于grep的完整信息。这个同样古怪的名字来源于vi的一个命令,
g/re/p,意思是
global
regular
expression
print。
下面的例子中我们假定在文件phone.txt中包含以下的文本,——其格式是姓加一个逗号,然后是名,然后是一个制表符,然后是电话号码:
Francis, John 5-3871
Wong, Fred 4-4123
Jones, Thomas 1-4122
Salazar, Richard 5-2522
| grep命令 | | 描述 |
| |
|
| grep '\t5-...1' phone.txt | | 把所有电话号码以5开头以1结束的行打印出来,注意制表符是用\t表示的 |
| grep '^S[^ ]* R' phone.txt | | 打印所有姓以S打头和名以R打头的行 |
| grep '^[JW]' phone.txt | | 打印所有姓开头是J或者W的行 |
| grep ', ....\t' phone.txt | | 打印所有姓是4个字符的行,注意制表符是用\t表示的 |
| grep -v '^[JW]' phone.txt | | 打印所有不以J或者W开头的行 |
| grep '^[M-Z]' phone.txt | | 打印所有姓的开头是M到Z之间任一字符的行 |
| grep '^[M-Z].*[12]' phone.txt | | 打印所有姓的开头是M到Z之间任一字符,并且点号号码结尾是1或者2的行 |
egrep
egrep是grep的一个扩展版本,它在它的正则表达式中支持更多的元字符。下面的例子中我们假定在文件phone.txt中包含以下的文本,——其格式是姓加一个逗号,然后是名,然后是一个制表符,然后是电话号码:
Francis, John 5-3871
Wong, Fred 4-4123
Jones, Thomas 1-4122
Salazar, Richard 5-2522
| egrep command | | Description |
| |
|
| egrep '(John|Fred)' phone.txt | | 打印所有包含名字John或者Fred的行 |
| egrep 'John|22$|^W' phone.txt | | 打印所有包含John 或者以22结束或者以W的行 |
| egrep 'net(work)?s' report.txt | | 从report.txt中找到所有包含networks或者nets的行 |
正则表达式语法支持情况
| 命令或环境 | . | [ ] | ^ | $ | \( \) | \{ \} | ? | + | | | ( ) |
| vi | X | X | X | X | X | | | | | |
| Visual C++ | X | X | X | X | X | | | | | |
| awk | X | X | X | X | | | X | X | X | X |
| sed | X | X | X | X | X | X | | | | |
| Tcl | X | X | X | X | X | | X | X | X | X |
| ex | X | X | X | X | X | X | | | | |
| grep | X | X | X | X | X | X | | | | |
| egrep | X | X | X | X | X | | X | X | X | X |
| fgrep | X | X | X | X | X | | | | | |
| perl | X | X | X | X | X | | X | X | X | X |
vi替换命令简介
Vi的替换命令:
其中
网上有很多vi的在线手册,你可以访问他们以获得更加完整的信息。
[回到主页]
posted @
2006-10-13 23:53 CoderDream 阅读(314) |
评论 (0) |
编辑 收藏 正则表达式(regular expression)对象包含一个正则表达式模式(pattern)。它具有用正则表达式模式去匹配或代替一个串(string)中特定字符(或字符集合)的属性(properties)和方法(methods)。 要为一个单独的正则表达式添加属性,可以使用正则表达式构造函数(constructor function),无论何时被调用的预设置的正则表达式拥有静态的属性(the predefined RegExp object has static properties that are set whenever any regular expression is used, 我不知道我翻得对不对,将原文列出,请自行翻译)。
- 创建:
一个文本格式或正则表达式构造函数
文本格式: /pattern/flags
正则表达式构造函数: new RegExp("pattern"[,"flags"]);
- 参数说明:
pattern -- 一个正则表达式文本
flags -- 如果存在,将是以下值:
g: 全局匹配
i: 忽略大小写
gi: 以上组合
[注意] 文本格式的参数不用引号,而在用构造函数时的参数需要引号。如:/ab+c/i new RegExp("ab+c","i")是实现一样的功能。在构造函数中,一些特殊字符需要进行转意(在特殊字符前加"\")。如:re = new RegExp("\\w+")
正则表达式中的特殊字符
| 字符 |
含意 |
| \ |
做为转意,即通常在"\"后面的字符不按原来意义解释,如/b/匹配字符"b",当b前面加了反斜杆后/\b/,转意为匹配一个单词的边界。
-或-
对正则表达式功能字符的还原,如"*"匹配它前面元字符0次或多次,/a*/将匹配a,aa,aaa,加了"\"后,/a\*/将只匹配"a*"。
|
| ^ |
匹配一个输入或一行的开头,/^a/匹配"an A",而不匹配"An a" |
| $ |
匹配一个输入或一行的结尾,/a$/匹配"An a",而不匹配"an A" |
| * |
匹配前面元字符0次或多次,/ba*/将匹配b,ba,baa,baaa |
| + |
匹配前面元字符1次或多次,/ba*/将匹配ba,baa,baaa |
| ? |
匹配前面元字符0次或1次,/ba*/将匹配b,ba |
| (x) |
匹配x保存x在名为$1...$9的变量中 |
| x|y |
匹配x或y |
| {n} |
精确匹配n次 |
| {n,} |
匹配n次以上 |
| {n,m} |
匹配n-m次 |
| [xyz] |
字符集(character set),匹配这个集合中的任一一个字符(或元字符) |
| [^xyz] |
不匹配这个集合中的任何一个字符 |
| [\b] |
匹配一个退格符 |
| \b |
匹配一个单词的边界 |
| \B |
匹配一个单词的非边界 |
| \cX |
这儿,X是一个控制符,/\cM/匹配Ctrl-M |
| \d |
匹配一个字数字符,/\d/ = /[0-9]/ |
| \D |
匹配一个非字数字符,/\D/ = /[^0-9]/ |
| \n |
匹配一个换行符 |
| \r |
匹配一个回车符 |
| \s |
匹配一个空白字符,包括\n,\r,\f,\t,\v等 |
| \S |
匹配一个非空白字符,等于/[^\n\f\r\t\v]/ |
| \t |
匹配一个制表符 |
| \v |
匹配一个重直制表符 |
| \w |
匹配一个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[\w]匹配"$5.98"中的5,等于[a-zA-Z0-9] |
| \W |
匹配一个不可以组成单词的字符,如[\W]匹配"$5.98"中的$,等于[^a-zA-Z0-9]。 |
|
说了这么多了,我们来看一些正则表达式的实际应用的例子:
E-mail地址验证:
function test_email(strEmail) {
var myReg = /^[_a-z0-9]+@([_a-z0-9]+\.)+[a-z0-9]{2,3}$/;
if(myReg.test(strEmail)) return true;
return false;
}
HTML代码的屏蔽
function mask_HTMLCode(strInput) {
var myReg = /<(\w+)>/;
return strInput.replace(myReg, "<$1>");
}
正则表达式对象的属性及方法
预定义的正则表达式拥有有以下静态属性:input, multiline, lastMatch, lastParen, leftContext, rightContext和$1到$9。其中input和multiline可以预设置。其他属性的值在执行过exec或test方法后被根据不同条件赋以不同的值。许多属性同时拥有长和短(perl风格)的两个名字,并且,这两个名字指向同一个值。(JavaScript模拟perl的正则表达式)
正则表达式对象的属性
| 属性 | 含义 | | $1...$9 | 如果它(们)存在,是匹配到的子串 | | $_ | 参见input | | $* | 参见multiline | | $& | 参见lastMatch | | $+ | 参见lastParen | | $` | 参见leftContext | | $’ | 参见rightContext | | constructor | 创建一个对象的一个特殊的函数原型 | | global | 是否在整个串中匹配(bool型) | | ignoreCase | 匹配时是否忽略大小写(bool型) | | input | 被匹配的串 | | lastIndex | 最后一次匹配的索引 | | lastParen | 最后一个括号括起来的子串 | | leftContext | 最近一次匹配以左的子串 | | multiline | 是否进行多行匹配(bool型) | | prototype | 允许附加属性给对象 | | rightContext | 最近一次匹配以右的子串 | | source | 正则表达式模式 | | lastIndex | 最后一次匹配的索引 |
|
正则表达式对象的方法
| 方法 | 含义 | | compile | 正则表达式比较 | | exec | 执行查找 | | test | 进行匹配 | | toSource | 返回特定对象的定义(literal representing),其值可用来创建一个新的对象。重载Object.toSource方法得到的。 | | toString | 返回特定对象的串。重载Object.toString方法得到的。 | | valueOf | 返回特定对象的原始值。重载Object.valueOf方法得到 |
|
例子
<script language = "JavaScript">
var myReg = /(\w+)\s(\w+)/;
var str = "John Smith";
var newstr = str.replace(myReg, "$2, $1");
document.write(newstr);
</script>
将输出"Smith, John"
|
|
posted @
2006-10-13 23:49 CoderDream 阅读(177) |
评论 (0) |
编辑 收藏