2008年5月31日
#
https://www.cnblogs.com/zbseoag/p/11736006.html
作者:AsReader
链接:https://www.zhihu.com/question/64845885/answer/1122345134
来源:知乎
https://www.cnblogs.com/chaos-li/p/11970713.html
https://www.jianshu.com/p/7403371162c1
0.前言
本文介绍了如何搭建Shibboleth,实现Shibboleth+Ldap的SSO解决方案
1.什么是Shibboleth
Shibboleth是一个基于标准的,实现组织内部或跨组织的网页单点登录的开源软件包。它允许站点为处于私有保护方式下的受保护的在线资源做出被通知的认证决定。
Shibboleth软件工具广泛使用联合的身份标准,主要是OASIS安全声称标记语言(SAML),来提供一个联合单点登录和属性交换框架。一个用户用他的组织的证书认证,组织(或IdP)传送最少的必要的身份信息给SP实现认证决定。Shibboleth也提供扩展的隐私功能,允许一个用户和他们的主站点来控制释放给每一个应用的属性。
Shibboleth项目作为一个Internet2中间件活动启动于2000年,这年晚些时候该项目和OASIS SAML工作组的工作相联系。Shibboleth1.0 于2003年发布,并快速被全世界的研究和教育机构使用。随着2005年SAML2.0的发布,2006年Shibboleth2.0也发布,SAML标准升级到包含所有的多边,由Shibboleth首创的元数据驱动方法。
Shibboleth作为开源软件开发,在Apache 软件许可证下发布。关于个别部件的更多信息可以在产品页面看到。
2.安装Shibboleth Identity Provider v3.2.1
- 切换成root
sudo su
2.下载Shibboleth Identity Provider v3.2.1
wget http://shibboleth.net/downloads/identity-provider/latest/shibboleth-identity-provider-3.2.1.tar.gz tar -xzvf shibboleth-identity-provider-3.2.1.tar.gz cd shibboleth-identity-provider-3.2.1
3.安装Shibboleth Idenentity Provider:
sh-3.2# ./install.sh Source (Distribution) Directory (press <enter> to accept default): [/Users/zhaoyu.zhaoyu/Applications/shibboleth-identity-provider-3.3.2] Installation Directory: [/opt/shibboleth-idp] Hostname: [localhost.localdomain] testdomain.com SAML EntityID: [https://testdomain.com/idp/shibboleth] Attribute Scope: [localdomain] Backchannel PKCS12 Password: Re-enter password: Cookie Encryption Key Password: Re-enter password: Warning: /opt/shibboleth-idp/bin does not exist. Warning: /opt/shibboleth-idp/dist does not exist. Warning: /opt/shibboleth-idp/doc does not exist. Warning: /opt/shibboleth-idp/system does not exist. Warning: /opt/shibboleth-idp/webapp does not exist. Generating Signing Key, CN = testdomain.com URI = https://testdomain.com/idp/shibboleth ... ...done Creating Encryption Key, CN = testdomain.com URI = https://testdomain.com/idp/shibboleth ... ...done Creating Backchannel keystore, CN = testdomain.com URI = https://testdomain.com/idp/shibboleth ... ...done Creating cookie encryption key files... ...done Rebuilding /opt/shibboleth-idp/war/idp.war ... ...done BUILD SUCCESSFUL Total time: 1 minute 14 seconds
(from now "{idp.home}" == /opt/shibboleth-idp/)
4.导入 JST library (status界面会用到):
cd /opt/shibboleth-idp/edit-webapp/WEB-INF/lib wget https://build.shibboleth.net/nexus/service/local/repositories/thirdparty/content/javax/servlet/jstl/1.2/jstl-1.2.jar cd /opt/shibboleth-idp/bin ./build.sh -Didp.target.dir=/opt/shibboleth-idp
3.安装指引
3.1 安装apache tomcat 8
1.切换成root
sudo su -
2.修改tomcat的%{CATALINA_HOME}/conf/server.xml
将8080端口和8443端口的地方分别改成80和443
<Connector port="80" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="443" />
3.生成证书文件
[chengxu@local]keytool -genkeypair -alias "tomcat" -keyalg "RSA" -keystore "./tomcat.keystore" 输入密钥库口令: 再次输入新口令: 您的名字与姓氏是什么? [Unknown]: cheng 您的组织单位名称是什么? [Unknown]: testdomain.com 您的组织名称是什么? [Unknown]: testdomain.com 您所在的城市或区域名称是什么? [Unknown]: 您所在的省/市/自治区名称是什么? [Unknown]: 该单位的双字母国家/地区代码是什么? [Unknown]: CN=cheng, OU=testdomain.com, O=testdomain.com, L=Unknown, ST=Unknown, C=Unknown是否正确? [否]: 是 输入 <tomcat> 的密钥口令 (如果和密钥库口令相同, 按回车): 再次输入新口令: [chengxu@local]
4.修改tomcat的%{CATALINA_HOME}/conf/server.xml,使支持https协议
<Connector port="443" protocol="org.apache.coyote.http11.Http11Protocol" maxThreads="150" SSLEnabled="true" scheme="https" secure="true" clientAuth="false" sslProtocol="TLS" keystoreFile="/Users/chengxu/Shibboleth/tomcat/tomcat.keystore" keystorePass="xxx"/>
5.发布Idp Web Application到Tomcat 8 container
vim %{CATALINA_HOME}/conf/Catalina/localhost/idp.xml
<Context docBase="/opt/shibboleth-idp/war/idp.war" privileged="true" antiResourceLocking="false" swallowOutput="true"/>
4.配置host
vim /etc/host 127.0.0.1 testdomain.com
5.重启tomcat
%{CATALINA_HOME}/bin/catalina.sh stop
%{CATALINA_HOME}/bin/catalina.sh start
6.检测是否服务启动正常
访问https://testdomain/idp/status
或者/opt/shibboleth-idp/bin; ./status.sh
3.2 配置shibboleth连接ldap
编辑修改ldap.properties
vim /opt/shibboleth/conf/ldap.properties idp.authn.LDAP.authenticator = bindSearchAuthenticator idp.authn.LDAP.ldapURL = ldap://ldap.example.it:389 idp.authn.LDAP.useStartTLS = false idp.authn.LDAP.useSSL = false idp.authn.LDAP.baseDN = cn=Users,dc=example,dc=org idp.authn.LDAP.userFilter = (uid={user}) idp.authn.LDAP.bindDN = cn=admin,cn=Users,dc=example,dc=org idp.authn.LDAP.bindDNCredential = ###LDAP ADMIN PASSWORD###
6.修改shibboleth ldap配置
vim /opt/shibboleth/conf/services.xml 把 <value>%{idp.home}/conf/attribute-resolver.xml</value> 改为 <value>%{idp.home}/conf/attribute-resolver-full.xml</value>
vim /opt/shibboleth-idp/conf/attribute-resolver-full.xml 注释掉下列代码,如果已经注释掉了就不动了(有些版本已经注释了) <!-- <dc:StartTLSTrustCredential id="LDAPtoIdPCredential" xsi:type="sec:X509ResourceBacked"> <sec:Certificate>% {idp.attribute.resolver.LDAP.trustCertificates}</sec:Certificate> </dc:StartTLSTrustCredential> -->
重启tomcat
7.获取idp metadata.xml
https://testdomain.com/idp/shibboleth
注意metadata.xml文件中的validUntil属性,如果过期了则修改为未来的某个时间点
4.小结
至此我们完成了Shibboleth与LDAP集成的安装过程
下篇: 实现Shibboleth+Ldap到阿里云的单点登录
来自:https://yq.aliyun.com/articles/350531?tdsourcetag=s_pcqq_aiomsg&do=login&accounttraceid=87b0f203-5d81-4cb7-a986-49615e3962e2&do=login&do=login
在C盘根目录下建立以下批处理文件:
c:
cd C:\Program Files\Microvirt\MEmu
adb start-server
c:
cd C:\Android\Sdk\platform-tools
adb connect 127.0.0.1:21503
cd\
在命令提示符(管理员)下运行它就OK了。
flutter config --android-sdk 自己的android sdk路径Android SDK默认的安装地址为:
C:\Users\Administrator\AppData\Local\Android\SDK
现需要把它搬到 C:\Android\Sdk
操作如下:
1.把C:\Users\Administrator\AppData\Local\Android\SDK剪切复制到C:\Android\Sdk;
2.在FLutter sdk 目录下运行如下命令:
flutter config --android-sdk C:\Android\Sdk
3.在环境变量中把ANDROID_HOME改为C:\Android\Sdk;
重启,这样就OK了。
https://baijiahao.baidu.com/s?id=1630789160989369444&wfr=spider&for=pc
安装后还是无法联网的,需要以下步骤才能联网:
设置--》网络和互联网--》私人DNS -->把自动改为关闭
就能上网了。
===============CentOS 7.6================
1.查看系统时间
查看当前系统时间以及时区
结果是:
Mon Jul 8 09:23:31 UTC 2019
2.更改系统时间时区
timedatectl set-timezone Asia/Shanghai
3.再次查看
结果是:
Mon Jul 8 17:25:28 CST 2019
4.可以重启后查看,防止重启后失效
=======================
https://blog.csdn.net/qq_41855420/article/details/102750895?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
在这个地方,要把服务里的那几个VM启动,否则DHCP无法安装。
⑧、设置黑苹果Catalina 10.15系统
https://www.jianshu.com/p/d58dab805ca6
keytool -genkey -v -keystore ./key.jks -keyalg RSA -keysize 2048 -validity 10000 -alias key
apk 输出在:
C:\Users\Administrator\AndroidStudioProjects\flutter_app\build\app\outputs\apk\release
key.properties
storePassword=123456
keyPassword=123456
keyAlias=key
storeFile=C:/Users/Administrator/AndroidStudioProjects/flutter_app/key.jks
build.gradle
def localProperties = new Properties()
def localPropertiesFile = rootProject.file('local.properties')
if (localPropertiesFile.exists()) {
localPropertiesFile.withReader('UTF-8') { reader ->
localProperties.load(reader)
}
}
def flutterRoot = localProperties.getProperty('flutter.sdk')
if (flutterRoot == null) {
throw new GradleException("Flutter SDK not found. Define location with flutter.sdk in the local.properties file.")
}
def flutterVersionCode = localProperties.getProperty('flutter.versionCode')
if (flutterVersionCode == null) {
flutterVersionCode = '1'
}
def flutterVersionName = localProperties.getProperty('flutter.versionName')
if (flutterVersionName == null) {
flutterVersionName = '1.0'
}
apply plugin: 'com.android.application'
apply plugin: 'kotlin-android'
apply from: "$flutterRoot/packages/flutter_tools/gradle/flutter.gradle"
def keystorePropertiesFile = rootProject.file("key.properties")
def keystoreProperties = new Properties()
keystoreProperties.load(new FileInputStream(keystorePropertiesFile))
android {
compileSdkVersion 28
sourceSets {
main.java.srcDirs += 'src/main/kotlin'
}
lintOptions {
disable 'InvalidPackage'
}
defaultConfig {
// TODO: Specify your own unique Application ID (https://developer.android.com/studio/build/application-id.html).
applicationId "com.example.flutter_app"
minSdkVersion 16
targetSdkVersion 28
versionCode flutterVersionCode.toInteger()
versionName flutterVersionName
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
}
signingConfigs {
release {
keyAlias keystoreProperties['keyAlias']
keyPassword keystoreProperties['keyPassword']
storeFile file(keystoreProperties['storeFile'])
storePassword keystoreProperties['storePassword']
}
}
buildTypes {
release {
// TODO: Add your own signing config for the release build.
// Signing with the debug keys for now, so `flutter run --release` works.
//signingConfig signingConfigs.debug
signingConfig signingConfigs.release
}
}
}
flutter {
source '../..'
}
dependencies {
implementation "org.jetbrains.kotlin:kotlin-stdlib-jdk7:$kotlin_version"
testImplementation 'junit:junit:4.12'
androidTestImplementation 'androidx.test:runner:1.1.1'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.1.1'
}
参见:
https://www.jianshu.com/p/2893f2b52eee
https://www.cnblogs.com/duanzb/p/11188979.html
即是在PATH中增加2个:
C:\Flutter\flutter1.12.13\.pub-cache\bin
C:\Flutter\flutter1.12.13\bin\cache\dart-sdk\bin
打开项目总文件夹运行,不要打开上一级目录运行F:\fluterapp\hellow_horld(项目名)这里打开F:\fluterapp 不要在这里打开
https://blog.csdn.net/qq_31659129/article/details/97244526
解决办法:
修改以下文件
C:\Program Files\nodejs\node_modules\npm\node_modules\node-gyp\src\win_delay_load_hook.c
增加以下代码,到第一个#include前
#ifndef DELAYIMP_INSECURE_WRITABLE_HOOKS#define DELAYIMP_INSECURE_WRITABLE_HOOKS#endif
参考:
https://github.com/nodejs/node-gyp/issues/949
https://github.com/Automattic/node-canvas/issues/619
————————————————
版权声明:本文为CSDN博主「Amatig」的原创文章,遵循CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cooltigerkin/article/details/51807588
VS2015最高支持14393版本的SDK,之后的从15063起就必须要VS2017,很多人出现VS找不到rc.ex和cl.exe的问题,就是没有安装SDK或安装了VS不支持的SDK版本;这个问题有人在知乎上提问过“如何将独立安装的win10SDK与vs2015建立联系?“
VS2015不完全支持Win10的某些项目编译,比如应用商店应用、1703、1709的驱动程序,但是VS2017太难用了,所以我还是坚持用2015
解决办法:
卸载新版本WinSDK,安装14393版本的SDK
或
卸载VS2015安装VS2017
————————————————
版权声明:本文为CSDN博主「楼顶上的猫」的原创文章,遵循CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_30113467/article/details/100013766
此前我的Ubuntu不是wubi方式安装的,因为听说此方式安装有多种缺陷,于是我选择U盘安装。这时想要卸载Ubuntu了,想到卸载这个也会有些小阻碍,就写下这篇博文表示记录一下Ubuntu的正确卸载方法。
在每次开机时都会有GURB菜单,这表示写入到安装Ubuntu的时候把GURB写入到了MBR,所以卸载Ubuntu前首先需要将MBR重写,去掉Ubuntu的GURB。如果朋友们不进行这一步把Ubuntu强行干掉,会让windows也直接GG。
重写MBR有两种方法:
一、放入Windows的安装盘,进入Windows安装程序,进入恢复控制台,输入命令fixmbr。
二、使用MbrFix工具进行修复。
我选择的是MbrFix,下载地址:http://www.cnitblog.com/Files/CoffeeCat/MbrFix.rar
下载完成后运行命令行,然后进入存放MbrFix.exe的目录下,输入指令MbrFix /drive 0 fixmbr /yes,重启就可以直接进入windows了。
ps:输入命令行提示"function failed.error 5:拒绝访问"如何解决?
找到MbrFix.exe,右击属性,进入兼容性选项卡,勾选"以管理员身份运行此程序",确定退出,然后重新输入指令即可解决。
搞定第一步之后,右键我的电脑进入管理,磁盘管理,如果是自己安装的Ubuntu,应该知道在安装的时候分配了几个分区在此系统上,如果只是双系统,除了Windows下有标注卷名的其余应该都是Ubuntu的分区。右键Ubuntu分区,删除卷,标注蓝条会变成绿条,把几个分区全部删除完成,右键新加卷一步一步完成恢复成为Windows的逻辑分区了。
来自:https://www.cnblogs.com/-Yvan/p/4975326.html
1.把 "Gateway": "/ip4/127.0.0.1/tcp/8080"修改为:"Gateway": "/ip4/0.0.0.0/tcp/8080",这样本机就可以用192.168WEB访问了。
2.把WINDOWS防火墙入站的8080端口打开,这样在局域网就能访问了。
https://blog.csdn.net/qq_25870633/article/details/82027510
在之前的博客中提到解决此问题的方法是进入mysql的命令窗口,执行set global show_compatibility_56=on;
但是该方法只能生效一次,当电脑重启或者mysql服务重启的时候,就得重新再设置一次,下面提供一个永久生效的方法,即不通过上述方法,而是修改mysql的配置文件,找到my.ini的配置文件,在文件的最后添加:show_compatibility_56 = 1 即可。
本人的my.ini的文件路径是:C:\ProgramData\MySQL\MySQL Server 5.7\my.ini
————————————————
版权声明:本文为CSDN博主「让爱远行2015」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u011065164/article/details/53393348
cnpm install -g solc@0.4.22
https://remix.ethereum.org/
http://remix.hubwiz.com/
https://ethereum.github.io/
最新内容会更新在主站深入浅出区块链社区
原文链接:Web3与智能合约交互实战
写在前面
在最初学习以太坊的时候,很多人都是自己创建以太坊节点后,使用geth与之交互。这种使用命令行交互的方法虽然让很多程序员感到兴奋(黑客帝国的既视感?),但不可能指望普通用户通过命令行使用Dapp。因此,我们需要一种友好的方式(比如一个web页面)来与智能合约交互,于是问题的答案就是web3.js。
Web3.js
Web3.js是以太坊官方的Javascript API,可以帮助智能合约开发者使用HTTP或者IPC与本地的或者远程的以太坊节点交互。实际上就是一个库的集合,主要包括下面几个库:
web3-eth用来与以太坊区块链和智能合约交互web3-shh用来控制whisper协议与p2p通信以及广播web3-bzz用来与swarm协议交互web3-utils包含了一些Dapp开发有用的功能
Web3与geth通信使用的是 JSON-RPC ,这是一种轻量级的RPC(Remote Procedure Call)协议,整个通信的模型可以抽象为下图。

搭建测试链
在开发初期,我们并没有必要使用真实的公链,为了开发效率,一般选择在本地搭建测试链。在本文我们选择的Ganache(在此之前使用的是testrpc,Ganache属于它的升级版),一个图形化测试软件(也有命令行版本),可以一键在本地搭建以太坊区块链测试环境,并且将区块链的状态通过图形界面显示出来,Ganache的运行界面如下图所示。

从图中可以看到Ganache会默认创建10个账户,监听地址是http://127.0.0.1:7545,可以实时看到Current Block、Gas Price、Gas Limit等信息。
创建智能合约
目前以太坊官方全力支持的智能合约开发环境是Remix IDE,我们在合约编辑页面编写如下代码:
pragma solidity ^0.4.21; contract InfoContract { string fName; uint age; function setInfo(string _fName, uint _age) public { fName = _fName; age = _age; } function getInfo() public constant returns (string, uint) { return (fName, age); } }
代码很简单,就是简单的给name和age变量赋值与读取,接下来切换到 run 的 tab 下,将Environment切换成Web3 Provider,并输入我们的测试链的地址http://127.0.0.1:7545,这里对这三个选项做一简单说明:
Javascript VM:简单的Javascript虚拟机环境,纯粹练习智能合约编写的时候可以选择Injected Web3:连接到嵌入到页面的Web3,比如连接到MetaMaskWeb3 Provider:连接到自定义的节点,如私有的测试网络。
如果连接成功,那么在下面的Account的选项会默认选择 Ganache 创建的第一个账户地址。接下来我们点击Create就会将我们的智能合约部署到我们的测试网中。接下来 Remix 的页面不要关闭,在后面编写前端代码时还要用到合约的地址以及ABI信息。
安装Web3
在这之前,先在终端创建我们的项目:
> mkdir info > cd info
接下来使用 node.js 的包管理工具 npm 初始化项目,创建package.json 文件,其中保存了项目需要的相关依赖环境。
> npm init
一路按回车直到项目创建完成。最后,运行下面命令安装web.js:
> npm install web3
注意: 在实际安装过程中我发现web3在安装完成后并没有 /node_modules/web3/dist/we3.min.js 文件,这个问题在 issue#1041中有体现,但官方好像一直没解决。不过可以在这里下载所需的文件,解压后将dist文件夹的内容拷贝到 /node_modules/web3路径下。
创建 UI
在项目目录下创建index.html,在这里我们将创建基础的 UI,功能包括name和age的输入框,以及一个按钮,这些将通过 jQuery 实现:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> <link rel="stylesheet" type="text/css" href="main.css"> <script src="./node_modules/web3/dist/web3.min.js"></script> </head> <body> <div class="container"> <h1>Info Contract</h1> <h2 id="info"></h2> <label for="name" class="col-lg-2 control-label">Name</label> <input id="name" type="text"> <label for="name" class="col-lg-2 control-label">Age</label> <input id="age" type="text"> <button id="button">Update Info</button> </div> <script src="https://code.jquery.com/jquery-3.2.1.slim.min.js"></script> <script> // Our future code here.. </script> </body> </html>
接下来需要编写main.css文件设定基本的样式:
body { background-color:#F0F0F0; padding: 2em; font-family: 'Raleway','Source Sans Pro', 'Arial'; } .container { width: 50%; margin: 0 auto; } label { display:block; margin-bottom:10px; } input { padding:10px; width: 50%; margin-bottom: 1em; } button { margin: 2em 0; padding: 1em 4em; display:block; } #info { padding:1em; background-color:#fff; margin: 1em 0; }
使用Web3与智能合约交互
UI 创建好之后,在<script>标签中间编写web.js的代码与智能合约交互。首先创建web3实例,并与我们的测试环境连接:
<script> if (typeof web3 !== 'undefined') { web3 = new Web3(web3.currentProvider); } else { // set the provider you want from Web3.providers web3 = new Web3(new Web3.providers.HttpProvider("http://localhost:7545")); } </script>
这段代码是web3.js Github提供的样例,意思是如果web3已经被定义,那么就可以直接当作我们的 provider 使用。如果没有定义,则我们手动指定 provider。
这里可能会存在疑问:为什么 web3 会被事先定义呢?实际上,如果你使用类似 MetaMask(一个 Chrome 上的插件,迷你型以太坊钱包)这样的软件,provider 就会被自动植入。
在上面代码的基础上,接下来设置默认的以太坊账户:
web3.eth.defaultAccount = web3.eth.accounts[0];
在上文中我们使用 Ganache 已经创建了 10 个账户了,这里我们选择第一个账户当作默认账户。
接下来需要让我们的web3知道我们的合约是什么样的,这里需要用到合约的 ABI(Application Binary Interface)。ABI可以使我们调用合约的函数,并且从合约中获取数据。
在上文中我们已经在 Remix 中创建了我们的合约,这时重新回到 Remix,在 Compile 的 tab 下我们点击Details 出现的页面中我们可以拷贝合约的ABI,如下图所示。

将其复制到代码中:
var infoContract = web3.eth.contract(PASTE ABI HERE!);
接下来转到 run 的tab,拷贝合约的地址,将其复制到下面的代码中:
var info = InfoContract.at('PASTE CONTRACT ADDRESS HERE');
完成这些我们就可以调用合约中的函数了,下面我们使用 jQuery 与我们的合约进行交互:
info.getInfo(function(error, result){ if(!error) { $("#info").html(result[0]+' ('+result[1]+' years old)'); console.log(result); } else console.error(error); }); $("#button").click(function() { info.setInfo($("#name").val(), $("#age").val()); });
以上的代码就简单地实现了对合约中两个函数的调用,分别读取和显示name和age变量。
到此我们就完成了全部的代码,完整代码可以在 InfoContract 中找到。在浏览器中打开index.html测试效果如下图(输入名字和年龄后刷新)。

本文的作者是盖盖,他的微信公众号: chainlab
参考文献
☛ 深入浅出区块链 - 系统学习区块链,打造最好的区块链技术博客。
https://blog.csdn.net/xiaomu_347/article/details/80729892
GitHub 在开源世界的受欢迎程度自不必多言。再加上前阵子,GitHub 官方又搞了个大新闻:私有仓库改为免费使用,这在原来可是需要真金白银的买的。可见微软收购后,依然没有改变 GitHub 的定位,甚至还更进一步。
花开两朵,各表一枝。我们今天想要聊的并不是 GitHub 多么厉害,而是你怎么能把 GitHub 用得很厉害。
你在 GitHub 上搜索代码时,是怎么样操作的呢?是不是就像这样,直接在搜索框里输入要检索的内容,然后不断在列表里翻页找自己需要的内容?
或者是简单筛选下,在左侧加个语言的过滤项。
再或者改变一下列表的排序方式
这就是「全部」了吗?
一般的系统检索功能,都会有一个「高级搜索」的功能。需要在另外的界面里展开,进行二次搜索之类的。 GitHub 有没有类似的呢?
答案是肯定的。做为一个为万千工程师提供服务的网站,不仅要有,而且还要技术范儿。
如果我们自己开发一个类似的应用,会怎样实现呢?
带着思路,咱们一起来看看,GitHub 是怎样做的。
这里我们假设正要学习 Spring Cloud,要找一个 Spring Cloud 的 Demo 参考练手。
1. 明确搜索仓库标题、仓库描述、README
GitHub 提供了便捷的搜索方式,可以限定只搜索仓库的标题、或者描述、README等。
以Spring Cloud 为例,一般一个仓库,大概是这样的
其中,红色箭头指的两个地方,分别是仓库的名称和描述。咱们可以直接限定关键字只查特定的地方。比如咱们只想查找仓库名称包含 spring cloud 的仓库,可以使用语法
in:name 关键词
如果想查找描述的内容,可以使用这样的方式:
in:descripton 关键词
这里就是搜索上面项目描述的内容。
一般项目,都会有个README文件,如果要查该文件包含特定关键词的话,我想你猜到了
in:readme 关键词
2. 明确搜索 star、fork 数大于多少的
一个项目 star 数的多少,一般代表该项目有受欢迎程度。虽然现在也有垃圾项目刷 star ,但毕竟是少数, star 依然是个不错的衡量标准。
stars:> 数字 关键字。
比如咱们要找 star 数大于 3000 的Spring Cloud 仓库,就可以这样
stars:>3000 spring cloud
如果不加 >= 的话,是要精确找 star 数等于具体数字的,这个一般有点困难。
如果要找在指定数字区间的话,使用
stars: 10..20 关键词
fork 数同理,将上面的 stars 换成fork,其它语法相同
3. 明确搜索仓库大小的
比如你只想看个简单的 Demo,不想找特别复杂的且占用磁盘空间较多的,可以在搜索的时候直接限定仓库的size。
使用方式:
size:>=5000 关键词
这里注意下,这个数字代表K, 5000代表着5M。
4. 明确仓库是否还在更新维护
我们在确认是否要使用一些开源产品,框架的时候,是否继续维护是很重要的一点。如果已经过时没人维护的东西,踩了坑就不好办了。而在 GitHub 上找项目的时候,不再需要每个都点到项目里看看最近 push 的时间,直接在搜索框即可完成。
元旦刚过,比如咱们要找临近年底依然在勤快更新的项目,就可以直接指定更新时间在哪个时间前或后的
通过这样一条搜索pushed:>2019-01-03 spring cloud
咱们就找到了1月3号之后,还在更新的项目。
你是想找指定时间之前或之后创建的仓库也是可以的,把pushed改成created就行。
5. 明确搜索仓库的 LICENSE
咱们经常使用开源软件,一定都知道,开源软件也是分不同的「门派」不同的LICENSE。开源不等于一切免费,不同的许可证要求也大不相同。 2018年就出现了 Facebook 修改 React 的许可协议导致各个公司纷纷修改自己的代码,寻找替换的框架。
例如咱们要找协议是最为宽松的 Apache License 2 的代码,可以这样
license:apache-2.0 spring cloud
其它协议就把 apache-2.0 替换一下即可,比如换成mit之类的。
6. 明确搜索仓库的语言
比如咱们就找 Java 的库, 除了像上面在左侧点击选择之外,还可以在搜索中过滤。像这样:
language:java 关键词
7.明确搜索某个人或组织的仓库
比如咱们想在 GitHub 上找一下某个大神是不是提交了新的功能,就可以指定其名称后搜索,例如咱们看下 Josh Long 有没有提交新的 Spring Cloud 的代码,可以这样使用
user:joshlong
组合使用一下,把 Java 项目过滤出来,多个查询之间「空格」分隔即可。
user:joshlong language:java
找某个组织的代码话,可以这样:
org:spring-cloud
就可以列出具体org 的仓库。
作者:西安北大青鸟
链接:https://www.jianshu.com/p/74ae16db62af
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://blog.csdn.net/Hanani_Jia/article/details/77950594源博客地址
首先,我先对GitHub来一个简单的介绍,GitHub有一个很强大的功能就是,你在服务器上边可以创建一个库(稍后会介绍怎么创建),写代码是一件很重的任务,尤其是很多人完成一个很大的项目的时候,就十分的复杂,一群人一起来写某个项目,大家完成的时间,完成的进度都是不相同的,你写一点我写一点,甚至可能你今天写的出现了错误,影响到了我昨天写的代码,最后怎么才能将大家的代码轻松的汇总起来,又怎么在汇总所有人的代码之后发现错误等等一系列问题。这样我们就用到了GitHub这个软件。我们在GitHub服务器上有一个主仓库,这里用来储存你的所有代码,如果不付费的话是所有人都可以看的,如果你不想让别人看到你的代码,可以选择付费仓库。我们创建了主仓库之后,就可以在电脑上创建分支,之后你就可以在电脑上完成自己的代码,写完之后直接同步在电脑的分支,当你认为可以上传的自己的主仓库时,就可以申请更新,当通过审核的时候,你代码就出现在了自己的主仓库中,这样全世界的程序员都可以查看你的代码。全世界现在已经有300万的注册用户,甚至还有一些相当知名的开源项目也在其中公布代码。在GitHub上你可以看到很多计算机领域的精英所分享的自己的代码。这是GitHub的两个主要优点,适合团队协作,以及下载其他优秀者的代码。
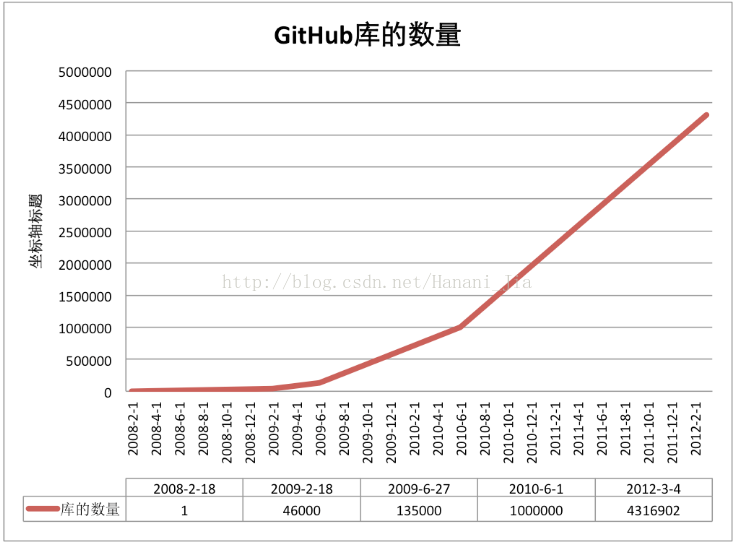
今天,GitHub已是:一个拥有143万开发者的社区。其中不乏Linux发明者Torvalds这样的顶级黑客,以及Rails创始人DHH这样的年轻极客。
· 这个星球上最流行的开源托管服务。目前已托管431万git项目,不仅越来越多知名开源项目迁入GitHub,比如Ruby on Rails、jQuery、Ruby、Erlang/OTP;近三年流行的开源库往往在GitHub首发,例如:BootStrap、Node.js、CoffeScript等。alexa全球排名414的网站。
https://github.com/ 这是GitHub的官方网站,在官网上可以注册属于自己的GitHub账号,网上是全英文的,对于英语不好的同学建议使用谷歌浏览器,谷歌浏览器可以翻译网页变为中文使用起来十分方便。
通过简单的步骤之后你就会有一个属于自己的GitHub账号。再简单注册完成之后会需要验证你所输入的邮箱才能正常使用你的GitHub。
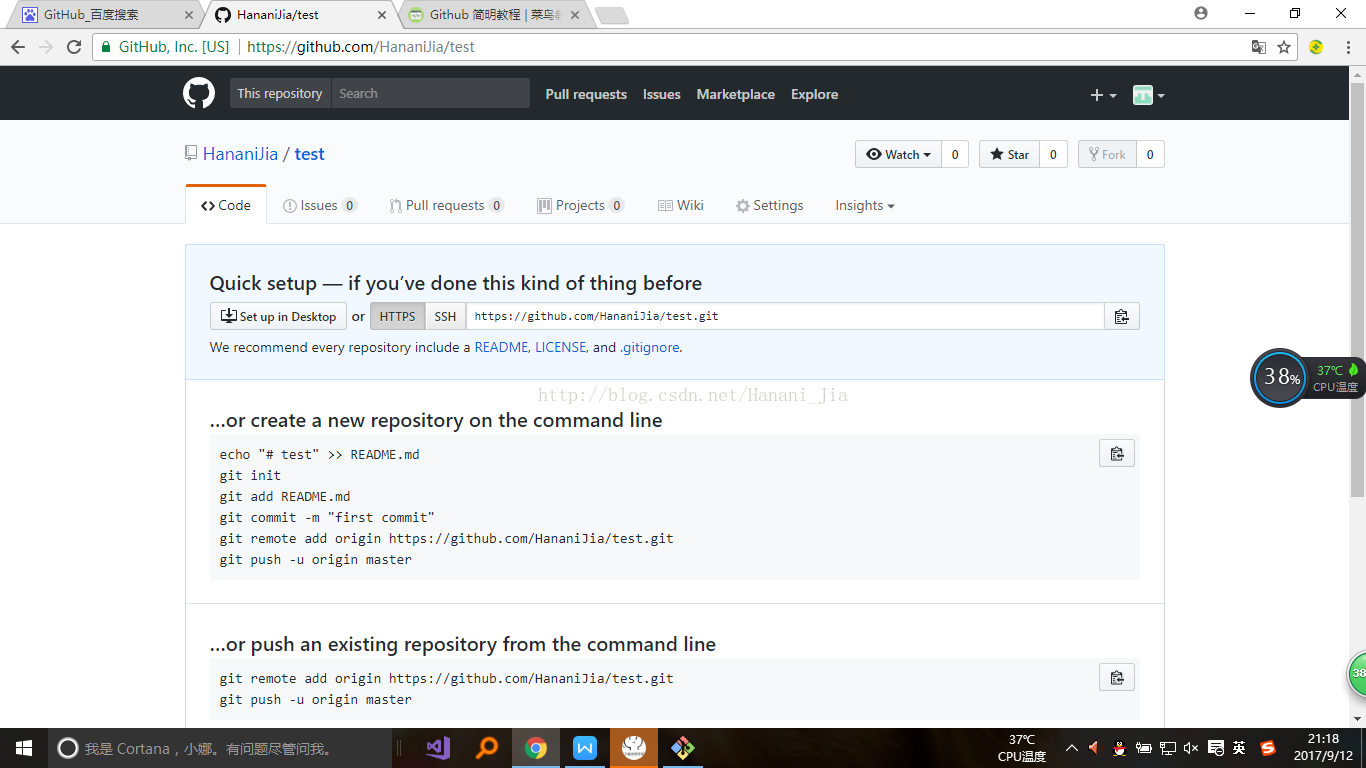
在注册完成之后,完成一些简单的设置之后,你需要创建一个属于自己的库

在登陆自己的GitHub账号之后,在网页右上角的小加号是用来创建自己的库的按钮,之后的步骤将网页翻译成中文之后,按提示进行创建自己的库即可。
第一个框是自己为自己的库起一个名字,第二个框是自己对库的一个简单介绍
在创建完成自己的库之后,下面就要让自己的电脑克隆一个自己所创建的库,方面自己电脑上的代码同步到GitHub你所创建的库当中。
为了实现,就需要安装一个软件,Git Bash。
下面我就介绍一下这个软件的安装,以及简单的配置。
git-scm.com 首先进入GitHub官网,下载适合自己电脑的版本
下载完安装包之后运行
在安装过程中直接默认选项即可。
在对git bash进行配置的时候大多数新手都是一头雾水,下面我对配置的每一步就会有详细的记录。代码我也是从网上和学长那边要来的。
我第一次打开软件后看到这个界面也是一脸懵逼的,然后通过查阅了各种各样的资料之后才有了一些思路。
首先要在本地创建一个ssh key 这个的目的就是你现在需要在你电脑上获得一个密匙,就是咱们平时的验证码一样的东西,获取之后,在你的GitHub账号里边输入之后,你的电脑就和你的GitHub账号联系在一起了,这样以后就可以十分方便的通过Git bash 随时上传你的代码。下边介绍一下如果获得这个钥匙,又是如何输入到你的GitHub里边的呢。
很多人第一次打开这个GitHub的时候一脸懵逼,认为这是什么。对于一个新手来说看到这个是没有任何思路,没有任何想法的。

这一栏 开始是你的计算机的名字在我这里就是Hanani @后边的内容是你的计算机型号,很多时候有的人打开之后@后边是乱码,这个时候也不要在意,因为有些电脑型号是中文的,可能在显示的时候出现了问题,不影响你后期的操作。
接下来,就要开始获取属于你自己的密匙。在git bash中所有功能都是通过简单的一些代码来实现的。获取密匙的时候需要输入
$ ssh-keygen -t rsa -C "your_email@youremail.com"
需要输入这个代码,引号内需要改成你在注册GitHub的时候绑定的邮箱账号。之后会有一些简单的让你确认的操作,之后让你会提示操作路径、密码等等,一般情况下就直接按回车一路过就可以。
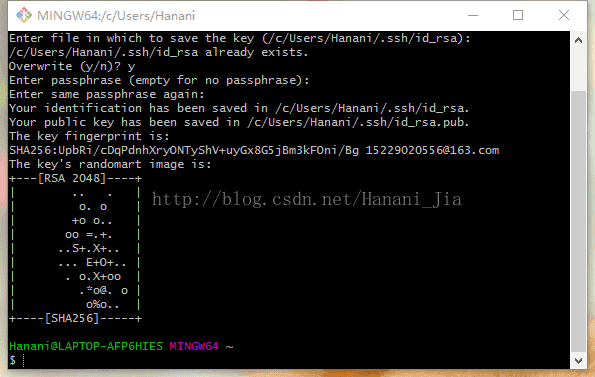
如果之后你出现了这个界面之后,就说明你的密匙已经成功创建了。现在你就需要去他刚刚显示的存储位置打开它,把其中的内容复制出来。
在.ssh这个文件夹中
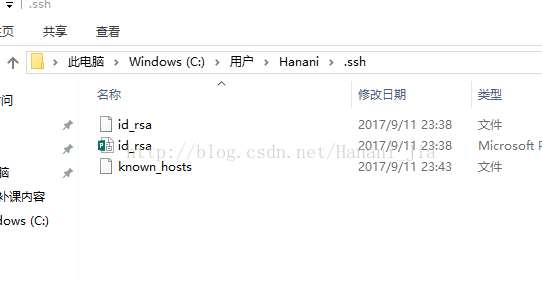
之后你会看到这些内容,有的人会在id_rsa后边带有一个pub,之前看网上教程需要找到带pub的文件,因为我在生成后没有带.pub的文件,怀着忐忑的心打开id_rsa后发现这里边的密匙也是可以使用的。打开id_rsa的时候需要用记事本的方式打开。
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDIskXqZF3SSFtACK6zoNGJabikTBC3kig6+4j4dCq1tswhA9YkuJCi0WpRmGYWBQ67dyT2or7RedFZlULLZN3nL6AWlo5V2jRXw4WQxCon2rU1p122wmiTzqYOfsykjwullWV4bYcZU4n77A4/9WwlSqZCpEbcdwV8IMkvwfJUInSWqTvmYMcKTWu8yad5DZ2v7LBWfgsL/Tfx7aEB8UjDNJ6SPw30Yijy+62YrftYGgbuwoiL9hDNGO2LfjgOkglHTBJaZe31uQLLWc5uCzd+7Dgh7RaKMmeuz2Uv7yqm/IEU9jH8cPMR9YRPIhmzg38G2s9ILn27QqW9j1hrFY1V 15229020556@163.com
这就是我所获取的密匙,打开之后很长的一段,不要惊讶,没有问题,这就是你所需要的密匙。
现在你就需要登录到你的GitHub上边添加这个密匙,
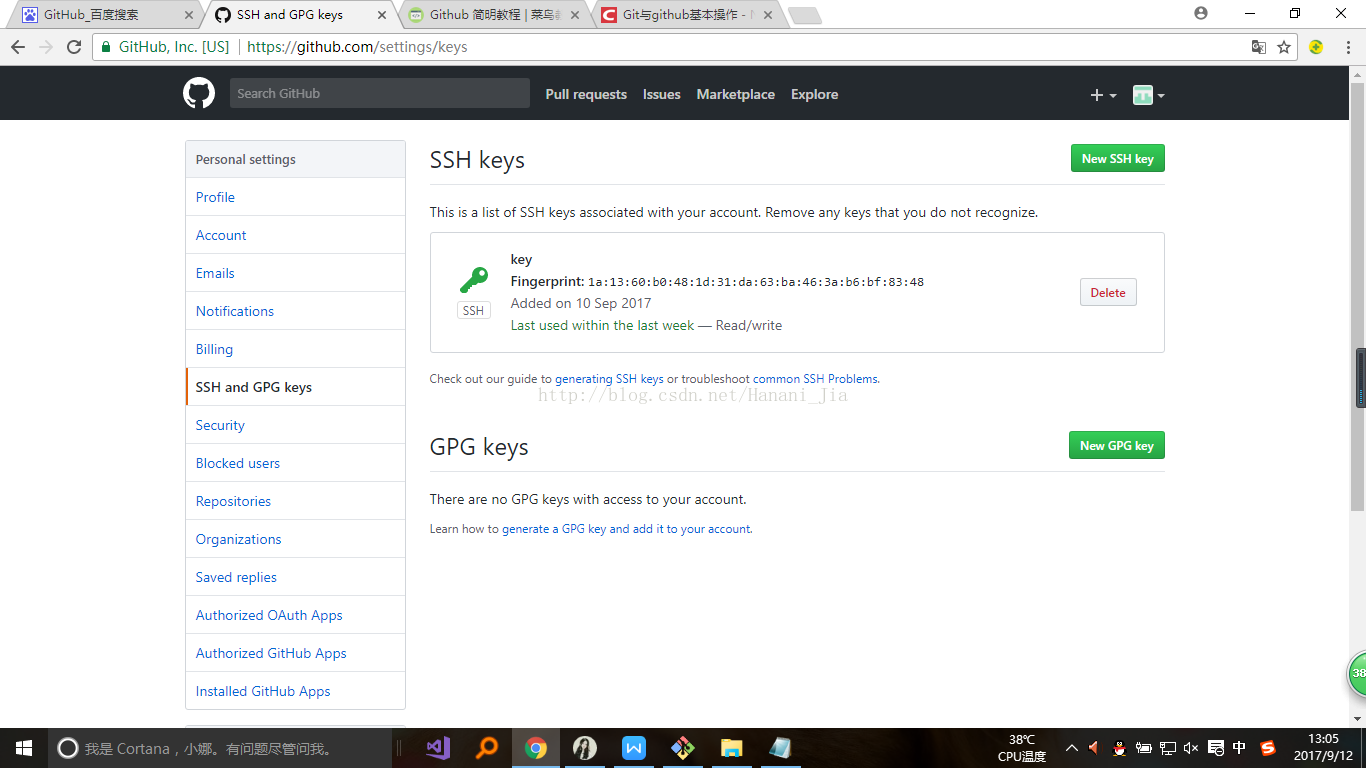
打开你GitHub的设置界面,找到SSH and GPG keys这个选项之后,在网页右上角有一个添加新的SSH keys 点击
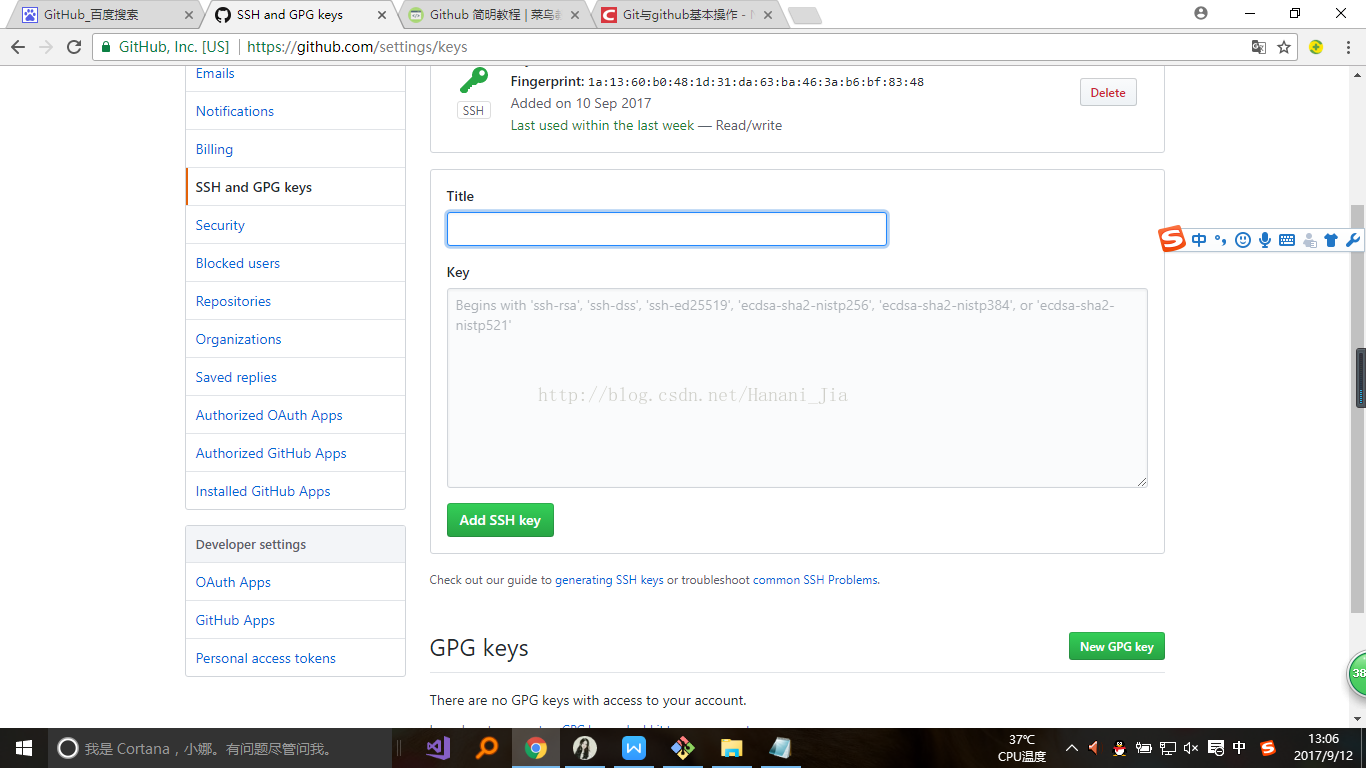
这里的title 是让你给你的密匙起一个名字,根据个人喜好,什么名字都可以,然后把你在刚刚文件中复制的密匙,填写在下边的大框里。保存即可。
之后你就可以回到你的Git bash上边了
然后输入上边的代码,来检查是否成功绑定。第一次绑定的时候输入上边的代码之后会提示是否continue,在输入yes后如果出现了:You've successfully authenticated, but GitHub does not provide shell access 。那就说明,已经成功连上了GitHub。接下来还需要简单的设置一些东西。

输入上边的代码,name最好和GitHub上边的一样,email是一定要是注册GitHub的那个邮箱地址
这两个的顺序可以颠倒,没有固定的顺序。
下面就要将你的库克隆下来到本地电脑中,方便以后进行上传代码。
在库创建完成之后 会有一个网址出现在网页中。
个人习惯将自己的文件储存在d盘之中,所以你先需要将git bash定位在d盘中
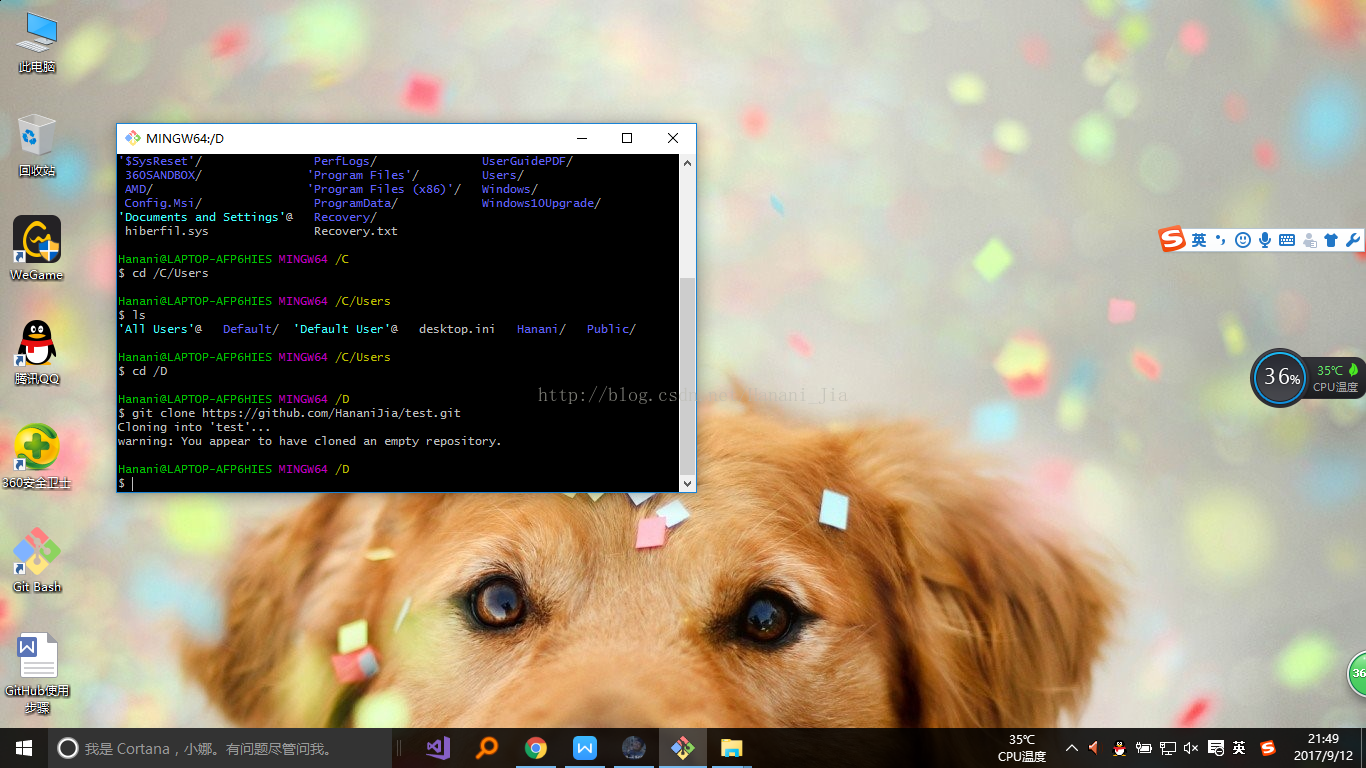
在git bash中输入 cd /D 注意盘名字一定要是大写。如不输入这个语句 不给git bash定位的话,默认的本地文件位置是在c盘中。

输入之后会出现/D说明定位成功。
之后输入

git clone后边的网址就是你创建库成功之后的网址

之后打开我所定位的D盘
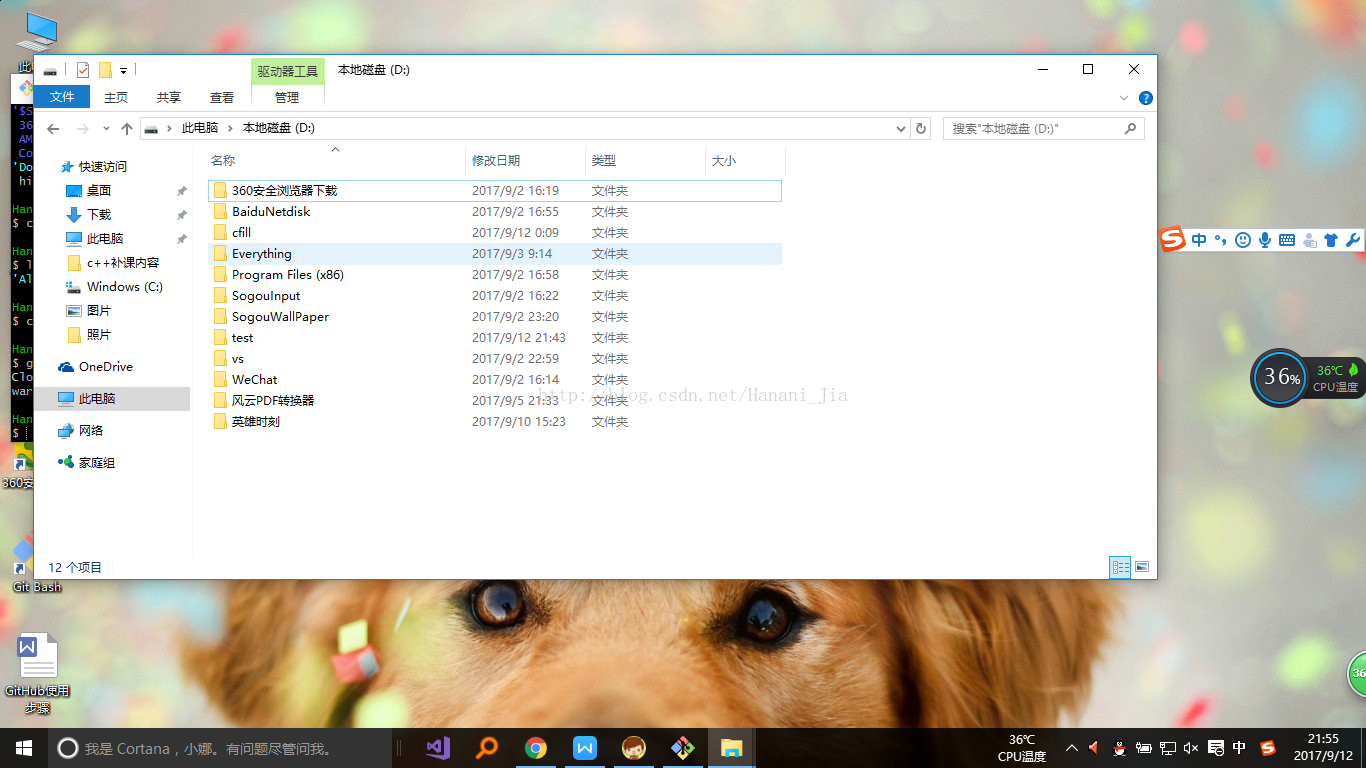
可以看到,D盘中已经有以我的库名所创建的文件夹了。
打开这个文件夹,然后在其中创建一个任意格式,任意名称的文件。
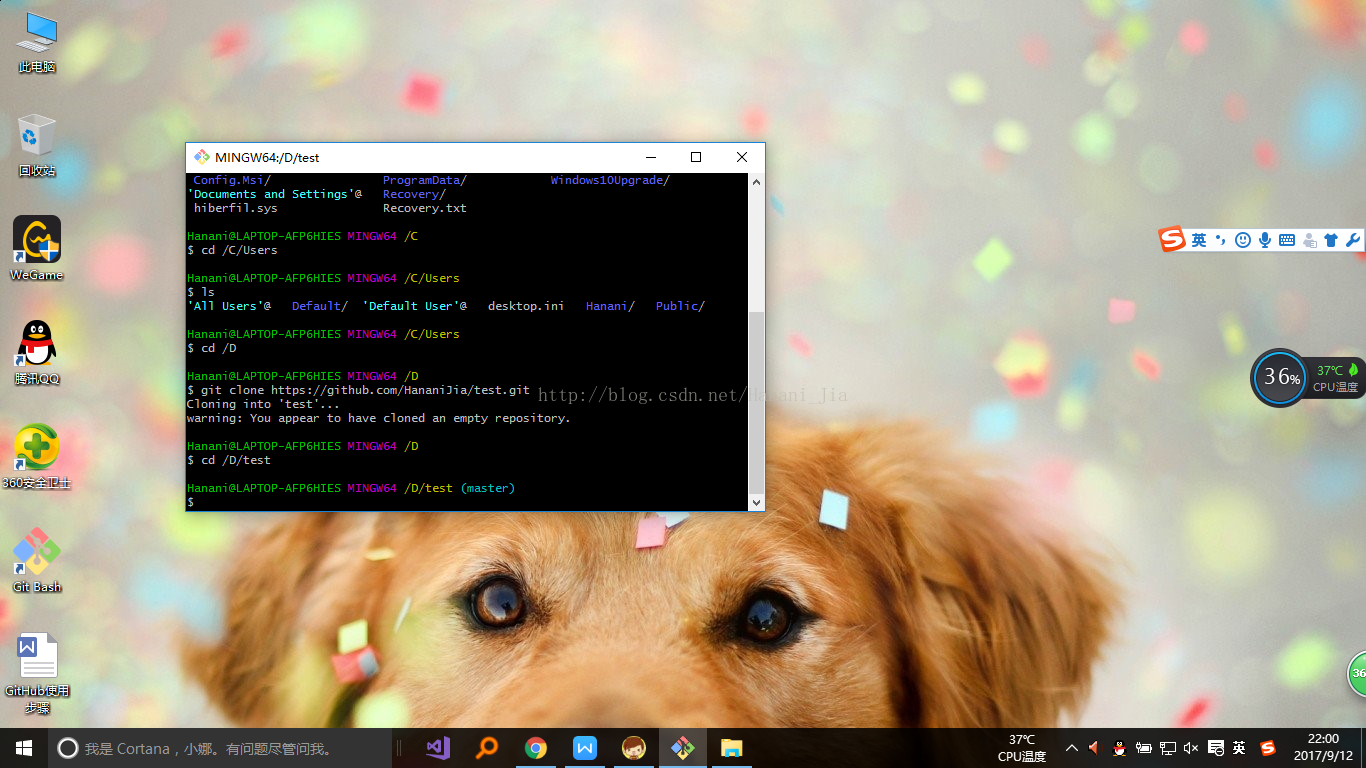
之后重新定位git 把书 的位置,定位在你库的文件夹。
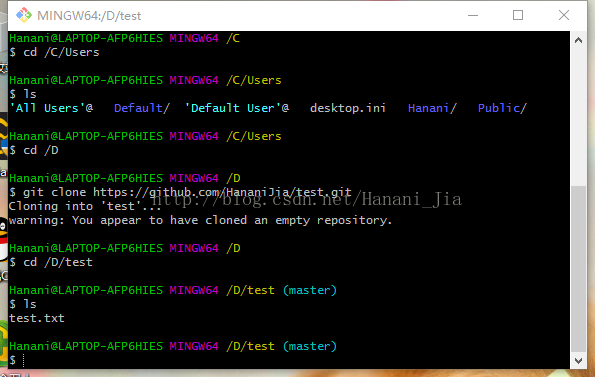
之后输入ls语句 ls的作用是查看你目前所定位的文件夹中的文件,现在可以看出来,我刚刚所创建的test文件已经出现了。
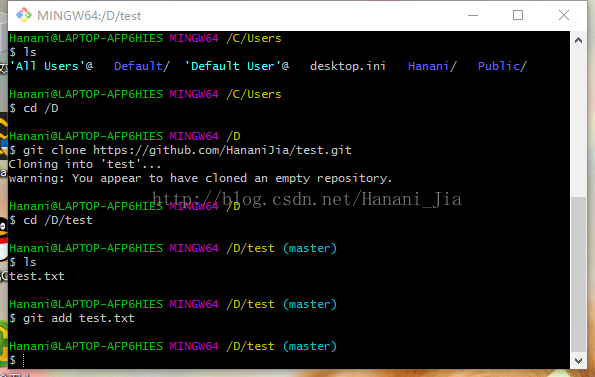
然后输入 git add test.txt
之后输入然后git commit -m "cc" 引号内的内容可以随意改动,这个语句的意思是 给你刚刚上传的文件一个备注,方便查找记忆而已
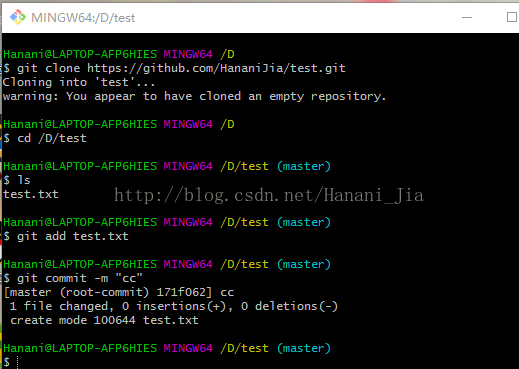
输入之后出现以上情况,然后在输入git push origin master 之后会出现一个
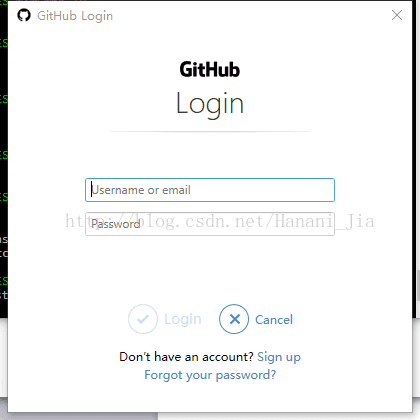
界面,在这里登陆你之前注册的GitHub账号之后点击login。
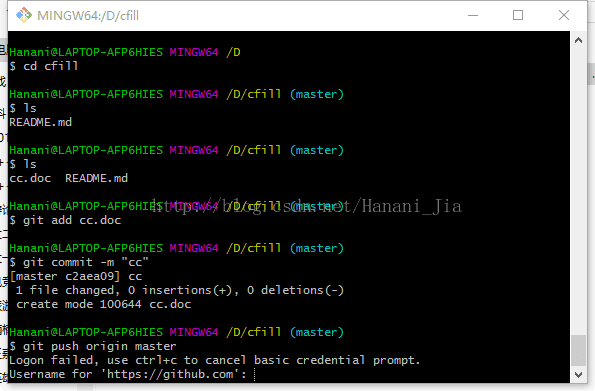
如果之后出现这种情况的话,就是登陆失败了,这时候你就需要输入你GitHub的账号名称
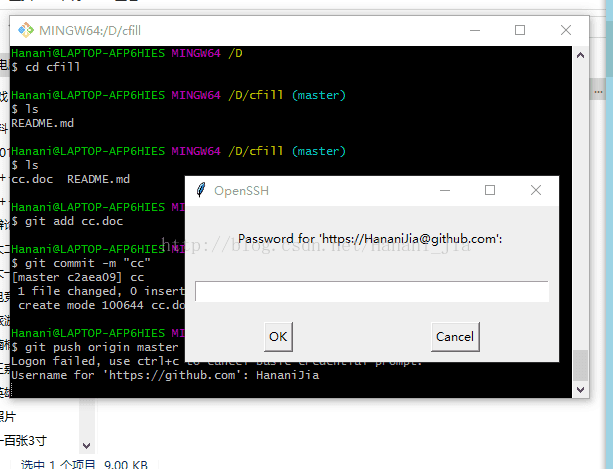
输入之后会出现这个界面,然后再次输入你的GitHub密码。
出现类似界面,你就可以欢呼了,代表你成功了。
现在打开你的GitHub网站,找到你创建的库
发现今天的格子已经绿了,说明你已经上传了你刚刚所创建的文件。
再之后,你只需要将你的代码,放到库的对应的文件夹中,然后使用 先CD到你库里面,再git add 、git commit -m " " 、最后git push origin master,将你的代码提交就可以了。
同样我感觉网页版的github更适合新手小白,https://blog.csdn.net/hanani_jia/article/details/79855429 这是我写的一篇网页版github的简单操作,需要的可以看一下。
if(!deployed.address) {
^
TypeError: Cannot read property 'address' of undefined
解决办法:调整gas的值就好了。
http://www.360doc.com/content/18/1014/17/16619343_794677023.shtml
https://blog.csdn.net/luoye4321/article/details/82531212
https://blog.csdn.net/weixin_34055787/article/details/89733910
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/yezishuang/article/details/91489354
1.Visual Studio 2015 专业版和企业版下载
https://www.cnblogs.com/bwlluck/p/5514424.html
https://www.cnblogs.com/wgscd/p/4671374.html
2.Visual Studio 2013
https://www.cnblogs.com/abeam/p/6781006.html
3.Visual Studio 2017
https://www.cnblogs.com/jian-pan/p/6942635.html
Microsoft Visual Studio Enterprise 2017 企业版
KEY:NJVYC-BMHX2-G77MM-4XJMR-6Q8QF
Microsoft Visual Studio Professional 2017 专业版
KEY:KBJFW-NXHK6-W4WJM-CRMQB-G3CDH
4.Visual Studio 2019
https://www.cnblogs.com/zengxiangzhan/p/vs2015.html
https://visualstudio.microsoft.com/zh-hans/downloads/ (下载地址)
Visual Studio 2019 Enterprise
BF8Y8-GN2QH-T84XB-QVY3B-RC4DF
Visual Studio 2019 Professional
NYWVH-HT4XC-R2WYW-9Y3CM-X4V3Y
https://blog.csdn.net/qq_27317475/article/details/80894593
以前的genesis.json的文件差不多是这样的:
{
"config": {
"chainId": 10,
"homesteadBlock": 0,
"eip155Block": 0,
"eip158Block": 0
},
"alloc" : {},
"coinbase" : "0x0000000000000000000000000000000000000000",
"difficulty" : "0x00000002",
"extraData" : "",
"gasLimit" : "0x2fefd8",
"nonce" : "0x0000000000000042",
"mixhash" : "0x0000000000000000000000000000000000000000000000000000000000000000",
"parentHash" : "0x0000000000000000000000000000000000000000000000000000000000000000",
"timestamp" : "0x00"
}
用这个创世块的描述文件初始化时,出现错误:
Fatal: Failed to write genesis block: unsupported fork ordering: eip150Block not enabled, but eip155Block enabled at 0
百度吧,没有一个解决办法。
后来用Puppeth命令创建json文件,并做了修改,如下所示:
{
"config": {
"chainId": 666,
"homesteadBlock": 0,
"eip150Block": 0,
"eip150Hash": "0x0000000000000000000000000000000000000000000000000000000000000000",
"eip155Block": 0,
"eip158Block": 0,
"byzantiumBlock": 0,
"constantinopleBlock": 0,
"petersburgBlock": 0,
"istanbulBlock": 0,
"ethash": {}
},
"nonce": "0x0",
"timestamp": "0x5ddf8f3e",
"extraData": "0x0000000000000000000000000000000000000000000000000000000000000000",
"gasLimit": "0x47b760",
"difficulty": "0x00002",
"mixHash": "0x0000000000000000000000000000000000000000000000000000000000000000",
"coinbase": "0x0000000000000000000000000000000000000000",
"alloc": { }
},
"number": "0x0",
"gasUsed": "0x0",
"parentHash": "0x0000000000000000000000000000000000000000000000000000000000000000"
}
初始化:
geth --identity "MyEth" --rpc --rpcport "8545" --rpccorsdomain "*" --datadir gethdata --port "30303" --nodiscover --rpcapi "db,eth,net,personal,web3" --networkid 1999 init genesis.json
控制台:
geth --identity "MyEth" --rpc --rpcport "8545" --rpccorsdomain "*" --datadir gethdata --port "30303" --nodiscover --rpcapi "db,eth,net,personal,web3" --networkid 1999 --dev.period 1 console
建立用户:
>personal.newAccount();
挖矿:
miner.start();
终于顺利挖到了人生第一桶金。
第一步 安装geth
下载地址:https://ethereum.github.io/go-ethereum/downloads/
点击安装勾选development tools
第二步 创建您的帐户
在当前文件夹下创建node1文件夹
创建一个账户(也称为钱包)
Devnet $ geth --datadir node1/ account new
Your new account is locked with a password. Please give a password. Do not forget this password.
Passphrase: 输入你的密码
Repeat passphrase: 确认你的密码
Address: {08a58f09194e403d02a1928a7bf78646cfc260b0}
第三步 geth命令创建您的Genesis文件
生成的文件是用于初始化区块链的文件。第一个块叫做创世块,是根据genesis.json文件中的参数生成的。
Geth安装后目录下有很多可执行文件如puppeth或bootnode。你可以在Geth github上找到完整的列表。
Puppeth可以创建创世区块的json文件。
开始使用Puppeth:
1、win键 + r 进入cmd命令行,进入到安装geth的文件夹执行 puppeth 然后顺序执行下面操作
2、Please specify a network name to administer (no spaces, please)
> devnet(这里随便填写一个网络管理名称即可,如有需要后面可以通过--network重新设置)
What would you like to do? (default = stats)
1. Show network stats
2. Configure new genesis
3. Track new remote server
4. Deploy network components
> 2(这里选择2,回车,配置新的创世区块)
3、Which consensus engine to use? (default = clique)
1. Ethash - proof-of-work
2. Clique - proof-of-authorit
> 1(这里选择pow共识机制)
4、Which accounts should be pre-funded? (advisable at least one)
> 0x1234567890123456789012345678901234567890(这个是设置预分配以太坊的账户,建议设置一个有私钥的地址可以后面测试使用,设置好后再按一次回车)
5、Specify your chain/network ID if you want an explicit one (default = random)
> 666(这里就是链的chainId,可以随意输入也可以不输直接回车默认随机数字)
6、What would you like to do? (default = stats)
- Show network stats
- Manage existing genesis
- Track new remote server
- Deploy network components
> 2(管理已拥有的创世块)
7、 1. Modify existing fork rules
2. Export genesis configuration
3. Remove genesis configuration
> 2(选择导出创世配置)
8、Which file to save the genesis into? (default = devnet.json)
> ./genesis.json(导出的路径及文件名)
OK,到这里创世json文件创建完成了
第四步 geth命令初始化节点
现在我们有了这个genesis.json文件,可以初始化创世块了!
进入到geth安装文件夹下执行
geth --datadir node1/ init genesis.json
第五步 bootnode命令操作
bootnode唯一的目的是帮助节点发现彼此(记住,以太坊区块链是一个对等网络)
初始化 bootnode
bootnode -genkey boot.Key
启动bootnode服务
bootnode -nodekey boot.key -addr:30310
随意使用任何您喜欢的端口,但请避免使用主流端口(例如HTTP)。30303用于公共以太坊网络。
第六步 geth命令启动节点
geth --datadir .\node1\ --syncmode 'full' --port 30311 --rpc --rpcaddr '127.0.0.1' --rpcport 8501 --rpcapi 'personal,db,eth,net,web3,txpool,miner' --bootnodes 'enode://ca88962dbcc8eb0c7587789866f21db68cdf32ad1ea890fe0d9f8fe010f7e9afe2e6a88d5c9d418be61a10b8a31b1e7c55213bb426dab91596ae36bd7d559333@127.0.0.1:30310' --networkid 666
参数解释:
--syncmode 'full' 有助于防止错误丢弃错误的传播块。
--port 是node1的端口
--rpcapi 允许RPC调用的模块
--bootnodes 要连接的bootnode
--networkId genesis.json文件中的chainId
第七步 与您的节点进行交互
通过RPC方式
$ cd devnet
devnet$ geth attach 'http://localhost:8501'
Welcome to the Geth JavaScript console!
instance: Geth/v1.7.3-stable-4bb3c89d/linux-amd64/go1.9
coinbase: 0x87366ef81db496edd0ea2055ca605e8686eec1e6
at block: 945 (Sat, 10 Feb 2018 21:16:14 CET)
modules: eth:1.0 miner:1.0 net:1.0 personal:1.0 rpc:1.0 txpool:1.0 web3:1.0
使用Geth控制台
>net.version
"1515"
> eth.blockNumber
1910
> eth.coinbase
"0x87366ef81db496edd0ea2055ca605e8686eec1e6"
> eth.sendTransaction({'from':eth.coinbase, 'to':'0x08a58f09194e403d02a1928a7bf78646cfc260b0', 'value':web3.toWei(3, 'ether')})
"0x299a99baa1b39bdee5f02e3c660e19e744f81c2e886b5fc24aa83f92fe100d3f"
>eth.getTransactionReceipt("0x299a99baa1b39bdee5f02e3c660e19e744f81c2e886b5fc24aa83f92fe100d3f")
{
blockHash: "0x212fb593980bd42fcaf3f6d1e6db2dd86d3764df8cac2d90408f481ae7830de8",
blockNumber: 2079,
contractAddress: null,
cumulativeGasUsed: 21000,
from: "0x87366ef81db496edd0ea2055ca605e8686eec1e6",
gasUsed: 21000,
logs: [],
logsBloom: "0x00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000",
status: "0x1",
to: "0x08a58f09194e403d02a1928a7bf78646cfc260b0",
transactionHash: "0x299a99baa1b39bdee5f02e3c660e19e744f81c2e886b5fc24aa83f92fe100d3f",
transactionIndex: 0
}
> exit(退出)
来自:https://www.haowenbo.com/articles/2019/07/24/1563963176492.html
有了npm 我们能够简单的一段代码就下载我们需要的包,但是包是不断更新的,
所以我们要关注包的版本信息;
现在,假设我们需要 jquery ,但是jquery现在有很多版本,我们如何通过npm查看呢?
要知道,现在的jquery包在npm服务器的上,我们使用下面的命令查看:
第一种方式:使用npm view jquery versions
这种方式可以查看npm服务器上所有的jquery版本信息;
第二种方式:使用npm view jquery version
这种方式只能查看jquery的最新的版本是哪一个;
第三种方式:使用npm info jquery
这种方式和第一种类似,也可以查看jquery所有的版本,
但是能查出更多的关于jquery的信息;
假设现在我们已经成功下载了jquery,过了一段时间,我忘记了下载的jquery的版本信息,
这个时候,我们就需要查看本地下载的jquery版本信息,怎么做呢?
第一种方式:npm ls jquery 即可(查看本地安装的jQuery),下面我的本地没有安装jquery,
所以返回empty的结果;
第二种方式:npm ls jquery -g (查看全局安装的jquery)
总结:上面我们了解了如何通过npm 来查看我们需要的包的版本信息,
既可以查看远端npm 服务器上的,也可以查看本地的;
————————————————
版权声明:本文为CSDN博主「cvper」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cvper/article/details/79543262
1.在你想更改的目录下新建两个文件夹:node_global 和 node_cache
2.启动cmd依次执行以下两条命令
npm config set prefix "XXX\XXX\node_global"
npm config set cache "XXX\XXX\node_cache"
路径均为绝对路径
3.更改环境变量,计算机右击 --> 属性 --> 高级系统设置 --> 环境变量
在下边的系统变量里新建一条记录,变量名为NODE_PATH 值为XXX\XXX\node_global\mode_modules
在上边的环境变量,更改PATH的值为XXX\XXX\node_global\
(路径为刚才第二步中node_global文件夹的绝对路径)
作者:招猫逗狗追兔子
链接:https://www.jianshu.com/p/70ac7d1a3300
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
过去一年的热门话题没有什么比区块链技术更火了,但这里面有太多被神话、误解的地方,本文就详细从技术层面、极客思维方式(哲学)、社会学和经济学等多个维度的分析,来洞悉区块链技术的背后真相。
下笔之前我几乎看过了所有主流媒体上的各种区块链文章,但我觉得没有一篇写的通俗易懂又全面。本文以论文的方式来阐述,虽然较长(可能阅读要花15分钟以上),不过看完后基本就能明白区块链怎么回事,特别是对到底是不是应该去投资虚拟货币会有更清晰的认识。

01 区块链技术分析
本节以比特币为例来说明区块链技术,如果你对技术不感兴趣,直接跳到02章节继续阅读,只需要知道结论:区块链就是用来实现一个虚拟货币记帐本,拥有比特币就是在这个帐本里面拥有区块里面的若干条数据记录。
1.1 问题
现在的区块链可能出了很多衍生的所谓新技术架构,但最终还是离不开那个不可修改的区块结构设计,所以这一节就以比特币来说明这些底层技术架构。看完这节,至少你能够解决以下疑惑:
用普通话和别人讲清楚比特币的底层技术架构是什么?区块链是一种最近才被发明出来的新技术吗?
挖矿是怎么一回事?
比特币的交易过程如何?
比特币钱包和比特币是什么关系?
1.2 计算机不是前沿科学
这有一个打假重要法则,鼓吹任何形式的单纯的计算机技术多么神奇的文章,都要打一个大大的问号。
现在所有计算机都是图灵机,而图灵提出图灵机的论文都快100来年了。计算机领域不是所谓前沿科学,而是一种能大幅提高人们工作效率的工具。所以在信息领域,把从业人员也称为软件工程师、硬件工程师、IOS开发工程师和测试工程师等等。
目前区块链技术和人工智能这二项技术已经被专家们吹到天上去了,我今天就先把区块链这层皮高科技的皮给扒了,以后有机会我再扒人工智能的。
其实不管哪种计算机领域的技术都由二样东西组成:数据 和 算法。
就拿人工智能来说,其实就是统计学在计算机的应用,吹的神乎其神的阿发狗在原理上其实就是蒙特卡洛树 + 基于贝叶斯网络的DeepMind,不过DeepMind取了个很牛的名字叫神经网络。
当然知道原理和能做出来是完全不一样的,和很多工程建设一样,需要对应的很多基础平台和优秀的工程师,但归根结底是一个工程问题,不是科学问题。
举这个例子只是想说明,没有必要去神话一项软件技术,计算机领域和很多传统的行业一样都是工程问题,甚至可能在工程管理水平上面还不如高铁和大型桥梁建设。
1.3 比特币的数据结构
比特币底层数据结构非常简单,是只要学过一点点计算机的人都懂的链表,特殊在用算法实现了不可修改只能往后追加。块与块之前就是链表结构,块内部是一个特殊的二叉树(Merlin Tree)结构,存了交易的流水信息。至于每一块里面的具体数据结构细节非专业人员都不要去了解,只要知道想要修改区块的数据非常的难,因为中本聪设计的非常巧妙,想要修改块的内容,要将从此块之后所有的内容全部进行修改。
至于如何做是如何做到的,防止被修改,我在下一节的算法中会详细介绍。
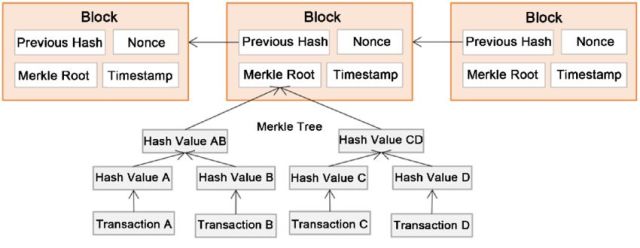
(区块链数据结构还有NextHash没有在图上画出来)
看到这个表结构,如果你产生一个疑问,链条总归要有开始吧?这个问题非常好,我开始也产生过这个问题。中本聪的解决方案是在程序内部内置了一个创世块,中本聪本人就是创造比特币的上帝,然后启动后只要还有一台计算机在运行这个程序,块的生成就不会结束。
还有另一个分布式数据保存特性,也让修改数据变得几乎不可能,因为这个数据不光存在某一个人的机器上的,保存在很多台的机器上,这个应该成为了比特币故事最大的亮点。
但其实物极必反,在选择了开放和安全外,必然牺牲效率。因为在比特币里面不能直接查询余额的,你只能顺着链条从头开始查找所有交易记录,然后再进行加减计算,得到你当前的余额,这就让比特币的效率不可能高。
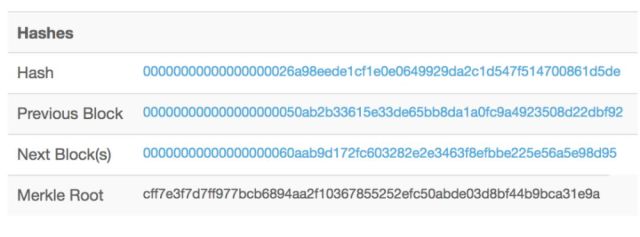
只要知道区块ID,很多网站都是可以查对应区块的信息的,因为数据是公开的吗。具体我查了一下,btc.com这个矿池其中一个ID的余额,不少有1534呢。
https://blockchain.info/address/1C1mCxRukix1KfegAY5zQQJV7samAciZpv
1.4 基于区块链的文本编辑器
这里用一个比喻就能讲明白这个结构的特点了,好比A君用Word在写一份文档,每输入的一个字都要同步给P2P网络上的所有结点,增加也好删除也好都要上传,然后文章的最终稿是不直接保存的,就相当不能直接查询余额。要得到A君的文章也很简单,把A君所有的操作全部找出来执行一次就是最终的结果了。
网络上当然同时也有B君,C君在输入,还是那个链式结构,按先后顺序按:谁操作 + 操作内容,依次首尾相连串好。如果你想做区块链创业,用这个区块链的文本编辑器写个计划书,制作一个区块链编辑器,将作者的写作过程全程记录,说不定也能搞到融资,各位随意拿走不用算我发明。
当然比特币的区块链是虚拟币交易,显然不能是个人单独行为,得按交易的形式出现,理解也简单,就是被执行的主体是多个对象,按交易规则来进行就可以,这个我放到交易里面来详细说明。
那区块链是如何保证安全的呢?这就要看下一小节的算法部分。
1.5 算法
用到的算法也没有特别高深的算法,就二个算法:椭圆曲线加密算法和哈希算法。这二个算法一直在互联网上被广泛使用,几乎所有的语言都有函数库都有。
二种算法的原理网上非常多,这里只介绍作用,第一种非对称加密,这个算法有下面这种能力。
公开公钥(Public Key),自己保存私钥(Private Key),只有私钥加密过的内容才能被公钥打开。
用普通话打个形象的比喻,我给你一把钥匙,然后让你开锁,这把钥匙能打开的锁就是我造出来的,而且只有我才能造出来。和我们平时的生活习惯有点不一样对,这个算法的学名叫:椭圆曲线加密算法。
在区块链里面,公钥字符串就是比特币帐户,长这个样子(Base58编码过):1C1mCxRukix1KfegAY5zQQJV7samAciZpv 。
还有另一个叫哈希算法,这个算法有三个特性:
1、输入的值差别很小,但输出却完全不一样。
2、不管输入多少位,输出的位置能固定。
3、知道输出,很难还原输入。(有中国数学家曾经研究过如何求解输入,但256位的计算量太大)
有个网站可以试:Lhttps://www.md5hashgenerator.com/ 。比如我MikeZhou和MikeZhou1只差一个数字,但结果完全不同。大家可以上这个网站自己尝试。
MD5(MikeZhou)=cb19e9b0b3cb8a8e5126677dbe1dbad5
MD5(MikZhou1)=48cc0cd823192ea7bd0aa5f1e60cfdf0
MD5是Hash算法一种,而比特币用了Double-Hash,就是连续二次SHA的哈希(叫 SHA256d),就是要防止暴力破解求解输入。
好了,有了数据结构和算法的基本,我们就很容易讲清楚挖矿的过程。
1.6 挖矿过程
挖矿其实就是一直在做非常无聊但很有难度的事情,这是中本聪精通博弈论的地方了,这个设计让比特币几乎可以永远的活下去。
挖矿其实就是大家事先约定的一个猜迷游戏。谜底规则大家事先约定,就是不停的试一串特殊的Hash值,加入的计算的人越多,就就越特殊越难找到。
这里我们要知道的就是:
1、规则大家都知道。
2、谁也不能提前开始,大家开始时间一致。
3、没有投机取巧的办法,只能硬算。
4、赢者通吃。

然后就是比谁算的快还有运气好,然后谁先算出来,直接广播给所有的结点,所有结点一验算符合规则,就不再算这一块的了。
赢的ID将得到:
1、系统约定好的奖励的特定数量比特币(最开始是50,目前是12.5,每4年减半);
2、所有在交易内的交易费用。
与之相应的义务:
1、负责写入生成的当前块。按比特币的规则约定,先算出来的人才能发起写入指令。
因为有交易费用存在,所以矿工们肯定要按正常规则来操作,因为错误的东西本身不会被其它结点执行,而且还白白损失交易费用的。
中本聪在这一块的设计可以堪称是天才设计,当挖的人多了的时候,计算难度就会自动加大,对比下面的图一张2009年的,还有一张是今年的,你发现差了好多个0,对这就是难度增加导致。因为上帝当年设计的规则是,要让SHA256d(时间,上一块Hash,随机数)的结果要符合规定个0开头才行,如果说生成的数字是随机的。
概率 = (1/16) ^ N 【其中N = 要求0的个数】
2009年的数据是8个0
2018年2月的数据是18个0
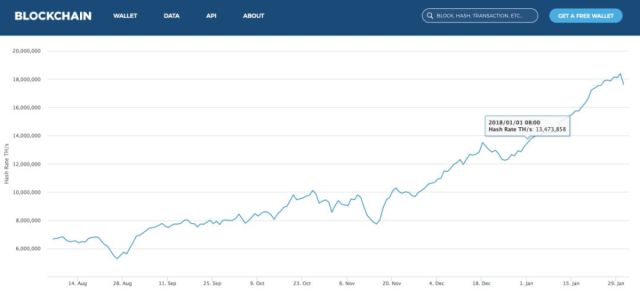
那么现在挖矿的难度是当年比特币新出来的时候约1,099,511,627,776倍,当然这里面有技术进步的因素,从CPU到GPU,再到FPGA,到现在的ASIC,ASIC也不断从60nm到现在的14nm,越来越快。
而这也是比特币一直被诟病的地方,空转消耗大量的电力,1800万Th/s,按现在最新型的机器矿机规格:消耗2度电/小时产生13.5Th/s算力来算。
年耗电量 = 1800万 / 13.5 * 2 千瓦时/小时 * 24 小时 * 365天 = 233.6 亿度。
而且我是按最新的节能型的机器计算的,还没有计算机房制冷消耗,所以整个电力算下来,基本相当半个三峡的发电量。
下面是一张总体的算力图,一直在增加,这也从侧面说明在当前比特币价值情况下,矿工的经济收益为正,矿机之前卖脱销也是因为这个原因导致。
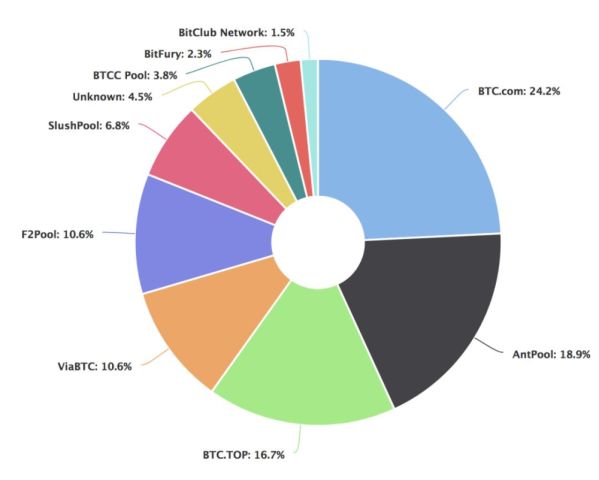
当然大家知道赢者通吃的规则后,那么这样的话,大家的收益不就是波动很大吗?有人投入了几千万在这里面,为了投资回报的稳定,所以就是矿池的产生,就是大家组团来挖,挖好了按一个约定好的规则来分币。
下面就是一个算力的分布图,可以看出前3家的占比超过60%了。
1.7 交易过程
这里单纯以比特币的交易来说明区块链的交易过程,不涉及商业上的交易(钱的交换)。
比特币的交易,有了上面数据结果和算法基本就非常安全了。链表结构和算法就是构建一个受大家共同监督安全的不可逆的数据流,基本如下图所示,小k到大K椭圆加密不可逆,大K到A的SHA256d的也不可逆,双重保证,基本在现有的计算机构架下是破解是不可能的。
就算哪天有一个矿池拥有了51%的算力资源,最多有可能垄断挖矿的权利(这是有可能的,后面经济分析详细说明),不可能来任意修改数据,这样就完全不是比特币了,失去了最初的意义,也就会变成一文不值。
当然为了进一步安全,中本聪在设计之初还制订了很多其它细的规则,比如:
1、矿工刚挖出来的矿是不能马上交易,因为离当前块越远的数据越安全。
2、利用交易费来调节,优先早生成和交易的比特币交易。
有了上面的基础那么交易过程就变得非常简单,交易中有以下参与方:
1、刚才猜出谜底的矿工:负责校验交易和写入交易,并收取交易费。
2、其它分步式结点:负责同步和确认交易正确性。
3、出售方:提供自己的私钥加密的数据,用私钥就证明了是拥有方发起的交易。
4、接受方:产生和自己关联的收入交易记录。
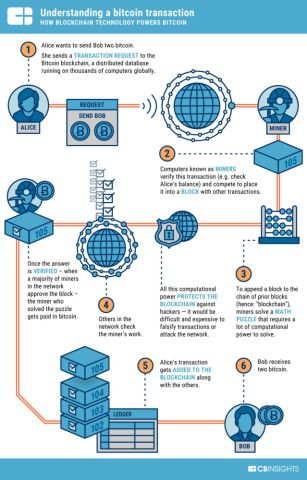
归根结底,这么多操作就是往区块中填入数据,不涉及任何商品和钱的交易,货币交易是区块链在虚拟货币交易所的衍生交易。暂且记住这个结论,后面经济分析时使用。
比特的区块链交易 ≠ 货币交易
当然实际的流程控制比这个复杂,因为比特币过于火爆,而开放的分布式天然并发又不够。所以矿工们研发了交易池,算是BIP计划的一部分吧。相当去医院看病,医生数量有限,病人多,大家先全在大厅等着,然后医院结合看病时长和给的诊疗费来计算先给谁看。
这里比喻的看病时长,交易费由交易方在交易前自己输入,交易“称重公式
= 148 * number_of_inputs + 34 * number_of_outputs + 10
1.8 比特币钱包
有了上面的介绍,一句话就能讲清楚比特币钱包,其实就是上面算法里面讲的那个公钥,所以钱包这个概念在区块链中并不单独存在,而是保存在一条条的交易记录里面。
因为都是一些没有任何意义的数字,大家使用起来比较麻烦,于是就诞生了很多比特币钱包管理程序,但这里有一个安全隐患,如果你自己不知道如何在自己本地生成钱包,而是利用网站去生成公私钥,理论上网站都有可能把你的私钥保存一份,当你帐户(通过公钥直接查找,数据公开的)有比较多钱的时候,要面临怎样的风险谁也不知道。
当然只输入公钥在钱包程序里,是没有安全隐患的,可以很方便查找自己的交易记录和余额。
一言以蔽之,比特币钱包是人们虚拟出来的一个词,在区块数据中其实就是公钥。而很多钱包程序就是为了方便一些没有技术能力的人,让他们方便的进行虚拟货币的交易。
但这里真的给一些正在大额投资虚拟货币的人提个醒,如果不是自己本地生成的公私钥,还真的要当一万个心。私钥的保存非常重要,真要丢了,可不是打个客服电话就能要回来的,它就真的永远消失了。
1.9 P2P网络技术
这个就是大家以前用过的BT和VeryCD电驴下载,用的技术是一样的。这个技术就是实现去中心化的网络传输算法,我把网络交换部分也称之为算法。
所以,我们发现区块链的关键技术是十几年前就流行过的技术,如果真是什么颠覆性的技术,不会雪藏这么久不出招的。
1.10 金融应用
我2017年就深入调查过区块链技术,主要是看看对我们金融行业有没有一些新的启发,调查完发现没有什么作用后就搁置在一边了。今天看到身边好多朋友都想去炒把币,所以出来写这个文章。
为什么说没有用呢?
信任问题:通过电子合同解决了。金融行业用CFCA认证过的合同是有法律效应,而且也做到了不可篡改。
合规问题:只要企业能提供借款人的按法律要求的一些证明文件,事先收集保存到时候提供就可以,一些影相文件和签字文件,这个用不用区块链存不关键。
借款数据:法院不看企业提供的数据作为证明关键的数据,都是以银行提供的流水为准确,A是不是从企业借款,是看银行是不是有打款记录,不看企业数据库或区块链中保存的数据的。
因为合同不可篡改,又有银行流水记录,证据非常完善,至于去中心化,那更是完全搭不上边,哪有我们公司的数据完全对外公开的道理。
1.11 技术总结
区块链其实并不是用了什么新的技术,但将已有的一些技术进行组合,给人们一种全新的用技术来实现一个安全和互信的产品,加上恰逢金融危机后推出,运气不错,所以有了今天的地位。
但光了解技术,还是不足于让我们明白中本聪设计区块链的初衷。我们应该去了解创造区块链背后的极客们的哲学思想,这样就不至于去犯拿着锤子到处找钉子的错误。
02 技术极客的自由乌托邦
这一节将尝试从哲学层面来分析,创造比特币的技术极客们,如何用自己擅长的技术领域,按他们的世界观和价值观构建出一个虚拟世界。
2.1 新时代的乌托邦
欧洲历史是就出现过多次乌托邦思潮,提倡无政府主义,现在同样还有人保有这种思想,但遗憾的是目前也有一些小岛是无政府状态,但基本是过着在原始人的生活。
而区块链最大的特性就是去中心化和开放,这给人一种自由的享受,并且用一系列的技术手段在开放的同时还保证了安全。这就等于构建了一个开放自由并且还保护私有产权的新互联网模式,难怪这会让一些大人物们欢呼区块链的时代的到来,而中本聪把第一块命名为创世块,也表明也自己希望成为新时代的上帝。
2.2 自由的基因
自由人文主义在西方经历了几百年,从圣奥古斯丁思想提出,到现在成为欧美等国家的主要哲学思想。以致于丹尼尔·汉南最近写的《自由的基因》里面说自由是盎格鲁圈的基因。
当看到这个新的去中心化的区块链技术出来以后,又让一些人内心持有自由主义观念的人,终于看到一个完全无政府(去中心化)的乌托邦社会(比特币)的诞生和崛起。这其实非常符合一些出生在中国,受美国教育以及长期生活在美国的名人的价值观。比如:大科学家张首晟、硅谷投资人吴军等,他们觉得这是互联网的分水岭来临。
他们当然是我非常尊重的人,在自己的专业领域有非凡的成就,是我不能比的。但就区块链技术的研究,未必有我深入,至少我相信他们没有时间去Github上下载过C++的区块链源码来看。但之所以最说区块链被这些专家夸大了,不是因为我看了源码,而是因为我还做过一些哲学上的分析。
2.3 自由主义的哲学发展
就算我们从哲学的历史来一步步推导,绝对的自由最后就是必然产生强权,而从现在的比特币来看,也是一样的,算力最强的拥有交易写入权,最后受益方一定是那些强制的一方。
我画了一张自由的哲学发展史,从笛卡尔提出我思故我在,把人从上帝的附庸中提拔出来以后,到最后黑格尔的强权即公理,到最后尼采的强者逻辑直接给希特勒屠杀犹太人找到了理由。而在受黑格尔和尼采的思想影响下,也直接导致德国发动二次世界大战。
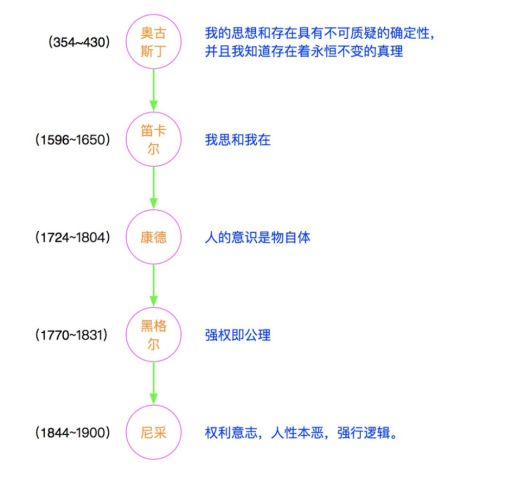
反观二战后,美国的就是用马歇尔的政策,用的是老子的思想“夫唯不争,故天下莫能与之争”,主动牺牲自己利益,扶持欧洲和日韩的发展,当这些国家发展了反过来又进一步促进了美国的发展,才有了今天美国霸主的地位。
讲这些哲学逻辑就是想说明一个道理,绝对的自由产生强者权利。完全的去中心化,大家完全按既定规则的投票(比特币现在逻辑),拿区块链最火应用虚拟货币来说,最后就会形成几大矿池,几大交易所,他们就是虚拟货币领域的无形的希特勒,决定着各种BIP(比特币改进计划)向他们有利的一方游走,而小散投资者们就是他们的韭菜。
如果认为这种完全不受政府监管,最后都是强者恒强的形式是互联网的未来,那可能我们就得同意张首晟所说的目前形式的区块链条是互联网分岔。
2.4 除虚拟币货并无大的区块链应用
再从结果来看,这么重大的技术,区块链至少被这些专家讲了5年以上了。我们现在除了看到大家在热火朝天在炒币以外,身边没有看到任何一个大型的应用是用区块链实现的。
如果真是一个革命性的任务,我想Google,Facebook和BAT公司怎么可能这么多年还没有具体的应用呢?
如果您刚才认真看完了技术篇幅的加构,便知道区块链不过是:P2P网络 + 链表 + 二种通用加密算法,这几样东西的组合,完全不足于颠覆现有互联网,现在很多大公司不用不是因为不知道和不了解。而是因为现实在有更好的技术,比如分布式关系型数据库(如Mysql),分布式缓存,分布式消息队列和分布式文件存储等。
不管怎么改进区块链技术,都是不可能实现几亿用户20万/秒的交易记录的(支付宝2017双11的记录)。
这些技术本身都是分布式的,部署在不同机器上,但同时又实现了中心化的管理,这里面技术难度要远远大于区块链的技术难度。
当然还有其它一些利益相关的区块链的支持者,我就一个观点,如果他鼓吹的东西对自身利益有非常重大的关系,不管他讲的如何真诚都可以忽略。非常简单的道理,若真是好东西,会公开的告诉你吗?
所以像李X来,薛XX等,比如从事区块链创业圈的人,都不算是区块链支持者,应该说是虚拟货币的支持者,其目的就不用我来告诉大家了。
2.5 技术现状
想想比特币到今天,绝对超出中本聪当初建设他的目的,每天消耗大量的能源,让其成为人类新时代的“郁金香”。
03 新时代“郁金香”
这一节从社会学角度来简单分析虚拟货币的现象。
3.1 想象共同体
前文提到了虚拟货币是新时代的“郁金香”,这是经过自己的一些分析的。就像赫拉利在《人类简史》中提到智人最大的进步来自7万年前的一些基础突变,让人具有了讲故事了能力。这样大家不断的通过讲故事,就形成了共同的社会习俗,形成了各自的文化和社会关系。
如今的比特币不就是完全是大家的一个想象共同体吗?想象共同体有没有意义?当然有意义,国家和民族不都是想象的共同体吗?这个共同体的意义就要看其给我们实际带来了哪些价值。国家和民族给我们带来什么价值,就不用过多的阐述。
那么比特币和交易带来了什么现实的意义吗?直接替代现有的支付宝,这是一种舍近求远的行为。目前的用虚拟货币来实现的支付都是要转换成美元或其它法定货币来支付给商家的,这不说等于饶了一个圈子吗?
虚拟货币也好,实际货币的价值也好,一个很重要的作用就是交换和流通的。
3.2 虚拟货币价值
虚拟货币中最大的一家比特币,最后还是要通过银行卡来进行交易,但价格波动太剧烈。虽然有一些技术型公司愿意接受比特币作为支付手段,但卖的肯定是虚拟产品,比如Steam和一些游戏公司,这些公司虚拟对虚拟还是挺对路的,反正公司不会亏。
但凡是有成本的交易,比如苹果公司卖手机,试试用比特币结算看看,价格一波动,到时候连供应商的货款都付不出。
还有一个最大的问题,安全性完全没有保障。就拿个人来说,试想你把你所有的钱全换成比特币,你每天睡觉都提心掉胆,放电脑存着吧怕被盗,抄本本上吧怕丢,记吧还又记不住。
如果一家公司呢?所有资产就是一串完全没有保障的数字,谁保管着私钥马上人间蒸发。
当然支付者们可以讲,可以不断改进吗?对是可改进。但要做到安全稳定不波动,不就是等于重新把现代金融体系重新在虚拟世界重构一次吗?最后不就又演变成现代的金融制度吗?
所以我才会说想通过区块链技术来构建一个自由的金融社会是一种乌托邦的设想罢了。
这就很容易得出结论,数字货币不过就是一个没有实际价值的“想象共同体”,和当年的荷兰“郁金香”最大的区别是当年“郁金香”只在荷兰流行。但今天虚拟币货通过更新的技术和更强的传播手段,传播到了全世界,所以这一波应该会涨得更高更持久一些,但泡沫终归还是要破灭的。
04 谁是赢家
这一节就要尝试回答,在当前的区块链大环境下,哪些人是受益方。
区块链的生态圈包括哪些角色?
虚拟货币会发展成为支付宝那样的货币吗?
挖矿的经济价值如何?
4.1 区块链的生态圈
我们来看看区块链生态圈有哪些角色,我们就只罗列直接关系者,背后的供应链不在一一列举了。
炒币者
早期进行的一些人应该有不少赚钱了,但小散们不可能赚太多,后面我分析原因,现在进去的基本都是韭菜。
矿工
投资者,存在一定风险,但追求的是稳定的回报。
矿机供应商
目前各种矿机供不应求,应该是这波区块链的受益者。
矿池所有者
大的矿池所有者,挖矿得到的交易费是不分成的,所以应该是较大的受益者。
虚拟货币交易所
食物链的顶端,收割者,不要任何金融牌照,上一个新币就收几千万,反正人傻钱多,不管上什么都有人买,不怕没韭菜。
技术开发者
赚口饭钱,干什么不是干,不过干了区块链,工资能比其它人高点。
虚拟货币发行者
早期的发行者,早已身价不可估量。如今也是赚个微利,还有可能赚的钱不够付交易所的上币费。
区块链创业者(除虚拟货币从业者以外)
我非常崇拜的一群人,虽然大部分人是拿锤子在到处找钉子,但是有情怀,说不定会找到一些新的业务模式,但应该不是什么颠覆性的。
4.2 矿池的正经济利益
我本来还想自己统计,结果有人做了一个网站,专门显示各种挖矿的经济利益。网址在这里:https://www.coinwarz.com/cryptocurrency/
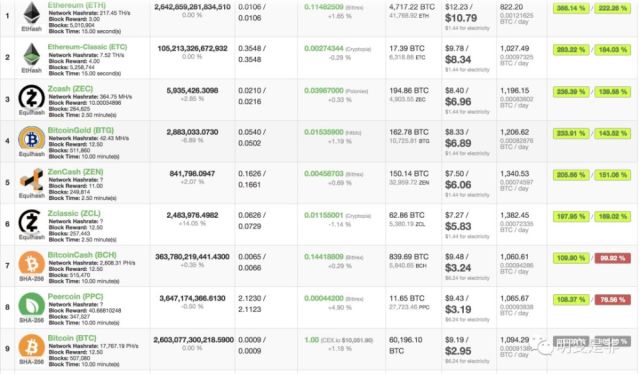
能看出来挖比特币不是目前经济价值最高的,现在要挖莱特币。对不起,比特币矿机和莱特币矿机不同,不能说不挖比特币去挖莱特币,当然这个里面受实际价格的影响,但总体来说是赚钱的,但请注意这是对于大的矿池和大的矿厂。
由于比特币去年的快速上涨,而矿机的供应有点落后,但随着价格的回落和矿机的供应到位,这个市场的经济利润马上会归于零。
4.3 投资矿机价值
对于交易所和大矿池的拥有者,当然毫无疑问,他们会想方设法自己或者买通其它人发出各种虚拟货币才是未来的新经济,区块链会颠覆现有互联网这样的言论。
对于很多小散投资者,可能买个几台几十台矿机放家里,然后再自己顺便炒一炒,想着自己的发财梦,我先从经济规律上来分析小矿工们赚不到钱的道理。
学过经济学的都应该知道下面的成本曲线,当 R(收入)=ATC,大家不再买新的矿机,当R(收入)< AVC (电费+人工费+其它运营费用)。
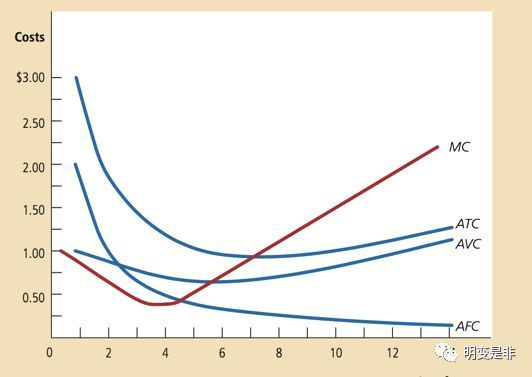
根据经济规率:只要经济利润为正,就会不断的有新加入者,直到最后经济利润为零,但不同的矿工由于成收入和成本各不相同,当矿池们为零的时候小矿主们可就早就变成负的了。
作出上面的判断,主要有由于下列原因:
1、小矿工的规模化原因,矿机的运行效率肯定不如大矿厂,这样R收入会低。
2、小矿工采购批量小,平均固定成本会高于大矿厂。
3、小矿工电力平均成本和运营成本可能都会高于大矿厂。
4、小矿工无法得到交易手续费分成(目前是这样)。
基于以上分析,可以得出结论:投资了小规模的矿机最终会因为规模效应亏损。当然如果运气好遇到比特币一起涨,那这样也别折腾,直接买不就好了吗?
那我就再来分析下直接投资的价值。
4.4 小散投资虚拟货币的价值
首先,有一件事实必须承认,虚拟货币本身是一段数据,数据被加密来加密去存在多少块硬盘上,除了被炒来炒去,用来真实商品交易非常少,而且使用起来也非常麻烦,可以说本身不创造任何价值(当然不是说货币不产生价值,货币最直接的价值就是降低交易成本,而比特币却不是)。再次强调,不创造价值不代表没有价值,只要人们认为他有价值他就能卖得了。正是因为这个原因,现在各种虚拟货币才这么火。
用下面的图来形像的说明吧,比特币的钱都来自投资者的投入,那么投入的可能是在这的高度,除了付给发行者收益,交易所收的手续费还有矿工的成本,那么进入的钱,等出来时可能只剩一半了。
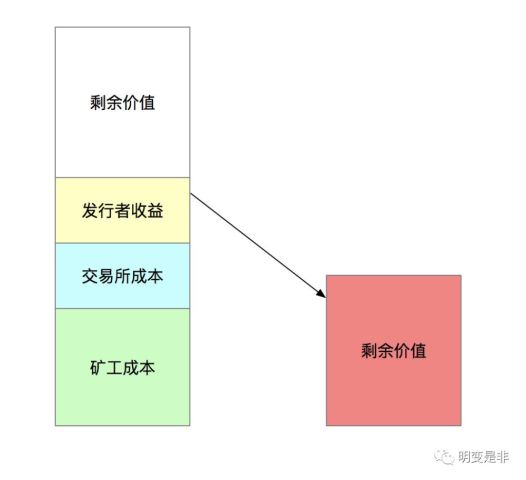
以最近24小时比特币的数据来说,24小时的交易量是20亿美金,算1%的交易费(交易所直接收的现金)。再以1万美金/BTC来计算,每天挖出还有矿再加上收走的比特币交易费,共计2000个比特币左右。当这二项的收费就4000万美金/天,再加上被那些创始人赚走的,每天至少在5000万美金以上的净支出。
这就相当投一块钱进去,5毛钱出来,然后我们还想信我在这个市场能赚大钱。
这里有一个概念一定要搞清楚,这里无关比特币涨跌,比特币的量是按其规则运行不会变化。但因为比特币不创造价值,而法定货币的平衡和币的涨跌是没有关系的,相差5000万一天这是一个实际货币上的平衡。而这个市场又有人不断的在抽取价值,那么就要靠不断的更多的投资加入才能维持市场的繁荣。
4.5 如何解释那些财富自由的人
有一些,极少数没错,通过虚拟货币实现财富自由的人,想想2009年如果花5000块买比特币,现在身价几个亿美金了,怎么能说投资没有价值呢,这是屌丝逆袭的最好时机了。
我只想说一句,真小散在5000买的时候,涨到1万的时候基本就卖了。如果在10万的时候还没卖,一定是忘记自己买过比特币了,但对于小散5000块的投资不太会忘记。如果到了50万还没卖,基本上是忘记了密码。所以不要做这种不可证伪的假设。
当然大家可以指出大量QQ群,朋友的朋友,赚了几千万几个亿的。我只能说要真是一个普通人赚了几个亿的人,是不会在Q群里发言,发朋友圈的。最有可能是默默的删除原来屌丝好友,生怕他们来找自己借钱。所以这种消息听听也就罢了,自己赚了还是亏了自己心里还不清楚吗?
我想信那些1万多美刀进场的人,最近能感觉到一丝丝的寒意了。只是我们听多了那些一夜暴富的人,却忘记了还有更多一贫如洗的人。
4.6 比特币数量可控吗?
最后再拆一根支撑小散炒币的沉重梁,就拿最值钱的比特币来说,比特币数据最终固定在2100万个,不增也不减,最终一定会涨上去的。
好,确实区块链下修改数据是几乎不可能,但不代表不会增加。复制还是可以的,大家知道BitCoin Cash吗?一群矿工不满足1M大小的区块,要修改为8M,自己就把原来的比特币数据拷一份,命名为比特币现金(BitCoin Cash),原来的比特币帐户密码在比特币现金里面也能用。
你敢相信,就这样1个变2个了,不是说不能增加的吗?而且价格之前也到2000多美金了,就硬生生的多出200多亿的市值出来。如果想了解细节,可以去百度比特币分叉,什么分叉,就是硬拷贝好不。
拿阿里巴巴股票市场为例吧,把谁在这个时刻持有阿里巴巴股票的数据记录下来,然后直接拷一份叫阿里妈妈,继续明天挂在交易所里排一起交易,体验到了“强权”的味道了吗?
反正看上去没有人有损失,原来持有阿里巴巴的在阿里妈妈里多了一份,没有任何人受到了损失,这就是完全没有监管的自由金融市场的样子。
就算不分叉,来看看全貌,一共93种在市场上交易的货币,现在找交易所上个新虚拟货币。新货币都号称解决了比特币的这问题和那问题,还有排第二的莱特币号称可以编程,是一个平台,是所有虚拟货币的代币,玩法层出不穷,连排最近一名的总市场也在500万美金以上。
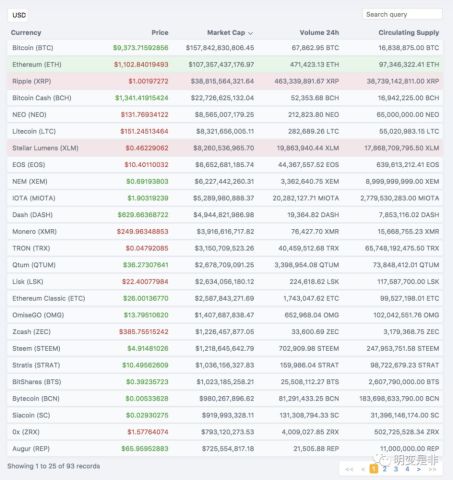
我看了几种主流的虚拟货币的技术架构,都基本还是没有脱离比特币的区块链技术框架和思路,不过是在效率上更高一些,号称加了更多的一些功能。
可以在https://blockexplorer.com/market查看。
列举了这么多,你还相信区块链下的虚拟货币神话吗?一个故事可以讲一段时间,但要讲长久,关键还是要看创造什么样的价值。
所以,我非常赞成政府对比特币的严格管控,真的是在保护我们普通投资者。
最后、引用老子的一句话:“天之道,损有馀而补不足。人之道,则不然,损不足以奉有馀。”,投资市场就是这么一个“损不足以奉有馀”,所以小散投资者们就是虽然钱少,但还是用来损的,去补那些大的玩家(矿池主,交易市场主人)。
4.7 投资者心态
但我知道,就像当年的3M一样,只要政府不出手,一直让他开着,总归一直会有人加入的,所以我还是相当支持国家来严控虚拟货币交易的,至少能挡住一部分人吧。
从数据角度讲,你只要承认虚拟货币不创造价值,进行1块钱,被分走5毛,然后还要博取100倍、1000倍的收益。只要你认为自己掌握的信息、自己的能力和自己的运气和别人一样(实际是这个市场还存在操控),根据正态分布原理:想通过投资虚拟货币得到巨大收益的可能性,就和自己手机上安装一个挖矿程序想挖出比特币一样的低。
造成这种现象的原因很简单,身边总是留传着某某个人因为炒币财富自由了,这种事情我一天都听到3回了,这种快速赚钱的故事最能相互间快速传播。但仔细想一想,这种进一块出五毛的市场如果大家都赚钱了,韭菜在哪里?歪国人都是韭菜?
当然我知道很多投资者还是会加入炒币,因为
1、用点自己的小钱、比如投入自己财产的10%(一毛钱都不应该送进去)。
2、不懂跟风、博取财富自由(参照我上面的概率分析)。
3、没什么好的理财项目(那就放货基,把精力放在提升自己上)。
如果是上面几种人,我建议有这钱不如陪家人出去旅游一趟,但如果是下面的情况,我就不劝阻了,祝君早日财富自由。
1、我相信在炒币这件事情上,我的能力比别人强。
2、我相信我有某种神奇的能力,炒币总能低买高卖。
3、我相信我的运气总比别人好。
2、我认识带头大哥,他有内幕消息。
3、我相信身边就有大量通过炒币致富的案例。
有时候我也一直想不通,乐视复盘的第一天,就有不少人在跌停的时候买入乐视,因为绝大部分人肯定认为在5个以上跌停板,但总有一些人对自己特别自信在第一天进入。我反正还是没特别想通,如果你们有答案可以留言告诉我。
05 总结
第一次在公众号写这个万字长文,也算结合自己的专业和去年学习的知识,从多个维度来分析区块链技术。观点未必正确,所以欢迎留言讨论,但有一点我非常肯定,小散们远离虚拟货币为妙。
另外我接下来还会补充二篇内容来说明:
1、微信的朋友圈也可算是区块链的应用。
2、大部分现有的区块链创业都是在拿锤子找钉子,很多目前用区块链创业项目用中心化的技术方案实现起来更好,用区块链实现就是蹭热点,为了拿融资方便。
最后看到这里的朋友都不容易,非常感谢大家的支持,如果有兴趣或者不同意见,欢迎留言讨论。
引用站点和图片
[1] 比特币数据结构图片来源 https://www.researchgate.net/figure/a-Blockchain-structure-b-Smart-contract-structure_309543764
[2] 比特币区块数据查询 https://blockchain.info/
[3] 比特币交易费用介绍 http://bitcoinfees.com/
[4] 挖矿收益查询 https://www.coinwarz.com/cryptocurrency/
[5] 比特币市场价值查看 https://blockexplorer.com/market
[6] Satoshi Nakamoto, Bitcoin: A Peer-to-Peer Electronic Cash System
[7] Andreas M.Antolopolutos, Mastering Bitcoin
来自:
https://new.qq.com/omn/20180203/20180203G04168.html
最近看了很多区块链上的去中心化存储方案,各种方法不一而足,但是仔细看了各种方法,实话说我的个人结论是“基于区块链的去中心化存储终将失败”。
存储的第一要素是可靠性而不是价格
在存储市场,可靠性有时候也称之为持久性,主要是指在文件存储以后,有多大可能性文件被无损地获取回来。
这个道理是不辩自明的,没有人存储数据是可以不考虑可靠性的,但是在大多数去中心化存储方案的白皮书中却是没有可靠性指标的,大多数都是通过含糊其辞的我们在全网备份来保证文件不被丢失。这够了么?请移步 https://aws.amazon.com/cn/s3/ 看看商业的存储服务是怎么定义文件持久性的。
从系统设计角度来说,可靠性设计是设计里面难度最大的工作。在一年 365 天的每一天都能够正确地读取数据,但是再最后一分钟数据没有读取到数据,那么可靠性仅是 99.98%,这个数字看起来很高,但是从可靠性角度来说是不够的。原因很简单,从最终用户角度来说,最后一分钟获取数据的失败,实际上意味着整年工作的失败,我存一年这个数据,也许仅是为了读这么一次,你这次给不了我数据,那你这一年的存储是第一天就丢掉数据了,还是在我获取的那一分钟前一秒丢掉数据,对我来说没有任何区别。
我们自己电脑里面使用的硬盘提供的存储,某种意义上也是一个相对低可靠性的存储服务,大多数人都能相信把数据、文件存到硬盘上,在大多数情况下数据并不会丢失,稍微懂点技术的明白建一个 Raid0,这个文件丢失的可能性已经是微乎其微了;比较去中心的存储服务,也许价格上是比传统云服务公司提供的存储服务便宜很多,但是如果和个人购买一个硬盘甚至构建一个 Raid0 对比,这个价格优势就不存在了。
去中心化存储的可靠性问题比想象的大
如前文所说,去中心化存储方案的白皮书中是没有提供可靠性指标数据的,在我看来,很悲哀的现实是所有的去中心化存储方案因为他的分布式是无法给出一个可靠性指标数据,这个在传统企业存储市场业务上已经是个很大的劣势,但是也许有人会认为虽然他们给不出具体的可靠性数据,实际上可靠性还是很高的,因为去中心化存储会通过全网的备份,将同一个文件放到不同的节点上来提高数据的可靠性。
这个听起来没错,但是如果我们深究去中心化存储的实现方式,我们会发现其实不然,这主要在于去中心化存储在进行文件存储时的切块存储模式,为了保证文件的安全性,也就是文件不能被矿工访问,主流的去中心化存储方案都会对文件进行切块,然后将不同的块存储到不同的节点上去,这样所有的存储节点都不拥有这个文件的全部块,文件属主就不用担心文件本身被非法获取。
这样的存储模型确实能够解决文件安全性的问题,但是反过来却造成了文件存储可靠性的进一步下降,原因很简单,如果一个文件被拆分成了 100 个块,这 100 个块会被分散存储,那么只要有任何一个块失效,这个文件本身也就失效了,分块操作大大降低了整体文件的可靠性,在 100 个块的情况下,失效率实际上是提高了100倍。
矿工或者说节点的行为并不能改变什么
实际上大多数去中心化存储方案也都关注了可靠性的问题,提出了一些方法来约束矿工的行为,比如 FileCoin 提出了 Proof-Of-Spacetime , Proof-Of-Replciation 一堆复杂地概念,寄希望于用这些指标来经济驱动矿工可靠地保存文件,但是在我看来这些方法某种意义上是所谓地缘木求鱼。
首先我认为,在大多数情况下,只要存在一定地经济激励,节点管理人的行为并不会是造成文件丢失地主要因素,某种意义上他们事实上不会有兴趣去管理这些存储地碎块文件。对于去中心化存储的节点来说,所有的储存在他电脑上的文件都是毫无意义的二进制字节,而维持这些字节的存在是会给他们带来一定的收入,正常情况下他们不会有什么欲望去删掉这些东西。因此通过进一步强化经济激励,来保证他们不去删除这些对他们无意义的字节流,意义并不大。
真正影响文件存储可靠性的,主要来自于两个因素:
- 硬盘的可靠性。按照我在网上搜到的硬盘可靠性分析文章,一般性机械硬盘的年失效性中位数大致是 3%,那么换言之每 30 块硬盘在运行一年以后会坏 1 块,不精确的概率计算,如果有 200 块硬盘,一年运行下来有 6-7 块损坏,那么假设一个 200 个节点的网络,每个文件被拆分成 100 块,每个块在全网分别形成2个复制,那么 1 年以后正常可以期望 3-4 个块的损坏,能够拿回完整文件的可能性微乎其微。
- 节点管理人对于节点的管理水平:传统的 IT 技术上,针对这种硬盘可靠性实际上是有整套的解决方案,RAID 系列就是专门定义了解决这种问题的,比如简单搭个 Raid0,就可以将出错可能性降低到 3% 的平方,也就是说 0.09%,但是作为去中心化存储节点的提供者,他们架设节点的目的是本来就是用简单的闲置硬盘空间来换取一定的经济激励,提供的容量空间直接影响他们的收益。所以如果有构建 Raid0 的两块硬盘,肯定是将两块硬盘分别使用,而不会是构建 低容量的Raid0 阵列,而且如果希望拥有大量的去中心化存储的节点,那么客观上能够组建 Raid 阵列的节点管理人只是少数。
复杂的计费模型是去中心化存储的最后挽歌
计费模型的复杂性也是去中心化存储方案的一个重大问题,这实际上是来源于存储需求人和存储提供者对于存储需求理解的不一致,而作为去中心化存储方案必须通过技术来弥合这个不一致。让我们看下双方是怎么看待这个存储需求:
存储需求人的需求:我今天把这个文件存到你这,也许明年才要用一次,我明年用的时候你将这个文件完整地提供给我,我就付整年的钱,否则,我希望你交罚款。
存储提供者的需求:我同意你将这个文件存在我的本地硬盘上,每存一段时间,你就给我钱,如果你不付钱,我就希望把这个文件删了把空间腾出来给其它愿意付费的文件。
这样的计费模型实际上是很复杂的,如果再加上文件本身的分块操作,情况会变成存储需求人愿意付款的前提是所有的存储提供者都正确地返回了所要求存储的文件块,想象一下 100 个块只返回了 99 个块的情况,因为这 100 个块的存储服务来源于完全不同的经济实体,达成这个共识的复杂度真不是程序能够轻易完成的,一个简单的规则是能完成分配,但势必伤害到其中某一方,然后造成这一方的离开。当双方需求都是合理的情况下,伤害任一方都不合理。
用户画像的缺失也是去中心化存储的问题之一
这个就不展开讲了,简单说个结论,是这些去中心化存储方案根本没说清楚或者说没去想谁会用他的去中心化存储。
随便抛转,还是希望抛砖引玉,大家给点指正,帮我理解清楚一下这繁杂的方案背后的东西。
来自:
https://ethfans.org/posts/decentralized-storage-will-fail
移植了老师的代码,出现了该问题,应该是js加密的问题,而本机中并没有使用过js加密,所以并没有该包的原因,遵循没有就安装的方式进行解决。
1.直接安装该包,网上大多数都是这个方法
命令行代码如下:npm install crypto-js
跟我上一篇文章出现的问题一样,npm需要安装的话由于要连接外网,99%的国内电脑肯定还是不行的,还是做国内资源映射
2.做国内资源映射
命令行代码如下:npm install -g cnpm --registry=https://registry.npm.taobao.org
这一步如果在之前做过则不需要,会记住映射的url
3.在命令行输入跟第一步差不多的方法
命令行代码如下:cnpm install crypto-js
在ionic开发中,需要typescript和nodejs的开发环境,其中很大部分在一开始安装了,但是如果要做更新或者下载一下需要的包的情况下就仍然需要做映射,才能正确安装新的环境。
感谢淘宝为开发者做的贡献。
————————————————
版权声明:本文为CSDN博主「是阿晋啊」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_38255285/article/details/82793231
1、四天时间爬峨眉山足够,可以做到全山徒步环线,景点全扫光
2、吃的住的不算贵、至少在全国知名景区来说很不算贵。想节约的话,一个房间不超过200元的从山脚到高山区的雷洞坪都有。吃的虽然比山下贵,但是也在可以接受的范围。一个人节约点吃,几十元一天不会饿到你的。
3、按照4天环线给你设计:你没说从哪里出发?只能大概给你按照成都往返吧
第一天:早上越早越好,成都新南门出发,直达峨眉山脚的游客中心,也就是常说的报国寺景区。然后游览报国寺、伏虎寺,从伏虎寺旁边山门进山,沿途雷音寺、纯阳殿、圣水阁、中峰寺,左手上坡走广福寺、清音阁,左手走一线天、猴区,然后到洪椿坪,住宿休息,庙子里住宿不贵的。如果不想吃素,就退回50米坡下一个晓雨食店吃饭吧,店主老刘头夫妇待人很厚道的。
第二天:早餐后出发,经过99道拐,到仙峰寺,然后是遇仙寺、九岭岗,左手走洗象池方向,然后是罗汉坡到雷洞坪。这一天景点不算多,但是爬坡厉害。就在雷洞坪休息吧,农家客栈很多,只要不是暑假和大假,都不算贵的。至少比金顶的住宿便宜几倍!
第三天:早点起来,这个季节想看日出至少要5点钟起床,半小时赶到接引殿缆车站,缆车上金顶看日出。如果不想乘坐缆车,那就要在提前一个小时起床,徒步大约2-2.5小时到金顶。
看了日出,游览舍身崖、金殿银殿、十方普贤、华藏寺,然后徒步下山回到雷洞坪、重回洗象池、九岭岗。这次走左手下山,沿途华严顶、初殿、细心所、万年寺。就住在万年寺吧,够累的了。
第四天:早饭后从万年寺回到清音阁,从五显岗出山,坐上景区的观光车,回到报国寺游客中心。如果想腐败一下,可以去灵秀温泉或者天颐温泉泡一泡。然后在游客中心乘坐班车直接回到成都新南门。
到峨眉山脚下,先在报国寺玩玩,风景不错,晚上住天下名山的天颐温泉,不贵,室内带温泉,个人泡过比较舒服的,第二天早上上金顶,耍一天,住一晚上寺庙感觉不错,第三天早上看日出,看完日出下山到万年寺,万年寺吃午饭,耍耍,下山到清音阁,清音阁风景不错,住一晚上,大概50一个人包吃住,第四天下山到峨眉城里面去吃吃土特产,什么曹鸭子、钵钵鸡、叶儿粑、豆腐脑、黄焖鸡、什么的。吃住的话就金顶贵点,那也是没办法的,其他都还好。不过先提醒,下山比上山痛,你也可以把我说的行程颠倒哈,看你们打算了。
https://baike.baidu.com/tashuo/browse/content?id=d44f4524beff55abe2205ce7&lemmaId=20441174&fromLemmaModule=pcBottom
http://bbs.biketo.com/thread-1799822-1-1.html
https://bbs.biketo.com/thread-1853758-1-1.html
http://bbs.biketo.com/thread-856822-1-1.html
http://bbs.8264.com/thread-2050898-1-1.html
https://www.meipian.cn/8k4hf0x
http://bbs.8264.com/thread-5512187-1-1.html
1.安装solc
npm install -g solc
用IDEA编译sol时出现错误
solcjs.cmd --abi --bin CloudNoteService.sol -o C:\Users\Administrator\IdeaProjects\test
CloudNoteService.sol:1:1: ParserError: Source file requires different compiler version (current compiler is 0.5.10+commit.5a6ea5b1.Emscripten.clang - note that nightly builds are considered to be strictly less than the released version
pragma solidity ^0.4.22;
2.solcjs.cmd --version//查看solc版本
0.5.10+commit.5a6ea5b1.Emscripten.clang
3.npm uninstall solc//卸载
4.npm install -g solc@0.4.24//安装solc0.4.24版本
5.C:\nodejs\node_modules\npm>solcjs.cmd --version//查看solc版本
0.4.24+commit.e67f0147.Emscripten.clang
6.solc跟web3一样,有版本的区别。
https://solidity-cn.readthedocs.io/zh/develop/
https://www.cnblogs.com/wanghui-garcia/p/9580573.html
1. 项目描述
这篇文章通过truffle unbox react创建项目,安装ipfs-api,将图片存储到ipfs,将图片hash存储到Ethereum区块链,取数据时先从区块链读取图片hash,再通过hash从ipfs读取数据,解决了区块链大数据存储成本高昂的问题。
2. 效果图
3. 阅读本文需要掌握的知识
阅读本文需要将先学习上面的系列文章,由于本文前端使用了大量的React语法,所以建议学习一些React语法,还需要学习truffle framework。
4. 源码
其实这篇文章的内容就是上面几篇文章的综合结合体,所以在这里我将不再对代码做过多的概述。
import React, {Component} from 'react' import SimpleStorageContract from '../build/contracts/SimpleStorage.json' import getWeb3 from './utils/getWeb3' import './css/oswald.css' import './css/open-sans.css' import './css/pure-min.css' import './App.css' const ipfsAPI = require('ipfs-api'); const ipfs = ipfsAPI({host: 'localhost', port: '5001', protocol: 'http'}); const contract = require('truffle-contract') const simpleStorage = contract(SimpleStorageContract) let account; // Declaring this for later so we can chain functions on SimpleStorage. let contractInstance; let saveImageOnIpfs = (reader) => { return new Promise(function(resolve, reject) { const buffer = Buffer.from(reader.result); ipfs.add(buffer).then((response) => { console.log(response) resolve(response[0].hash); }).catch((err) => { console.error(err) reject(err); }) }) } class App extends Component { constructor(props) { super(props) this.state = { blockChainHash: null, web3: null, address: null, imgHash: null, isWriteSuccess: false } } componentWillMount() { ipfs.swarm.peers(function(err, res) { if (err) { console.error(err); } else { // var numPeers = res.Peers === null ? 0 : res.Peers.length; // console.log("IPFS - connected to " + numPeers + " peers"); console.log(res); } }); getWeb3.then(results => { this.setState({web3: results.web3}) // Instantiate contract once web3 provided. this.instantiateContract() }).catch(() => { console.log('Error finding web3.') }) } instantiateContract = () => { simpleStorage.setProvider(this.state.web3.currentProvider); this.state.web3.eth.getAccounts((error, accounts) => { account = accounts[0]; simpleStorage.at('0x345ca3e014aaf5dca488057592ee47305d9b3e10').then((contract) => { console.log(contract.address); contractInstance = contract; this.setState({address: contractInstance.address}); return; }); }) } render() { return (<div className="App"> { this.state.address ? <h1>合约地址:{this.state.address}</h1> : <div/> } <h2>上传图片到IPFS:</h2> <div> <label id="file">Choose file to upload</label> <input type="file" ref="file" id="file" name="file" multiple="multiple"/> </div> <div> <button onClick={() => { var file = this.refs.file.files[0]; var reader = new FileReader(); // reader.readAsDataURL(file); reader.readAsArrayBuffer(file) reader.onloadend = function(e) { console.log(reader); saveImageOnIpfs(reader).then((hash) => { console.log(hash); this.setState({imgHash: hash}) }); }.bind(this); }}>将图片上传到IPFS并返回图片HASH</button> </div> { this.state.imgHash ? <div> <h2>imgHash:{this.state.imgHash}</h2> <button onClick={() => { contractInstance.set(this.state.imgHash, {from: account}).then(() => { console.log('图片的hash已经写入到区块链!'); this.setState({isWriteSuccess: true}); }) }}>将图片hash写到区块链:contractInstance.set(imgHash)</button> </div> : <div/> } { this.state.isWriteSuccess ? <div> <h1>图片的hash已经写入到区块链!</h1> <button onClick={() => { contractInstance.get({from: account}).then((data) => { console.log(data); this.setState({blockChainHash: data}); }) }}>从区块链读取图片hash:contractInstance.get()</button> </div> : <div/> } { this.state.blockChainHash ? <div> <h3>从区块链读取到的hash值:{this.state.blockChainHash}</h3> </div> : <div/> } { this.state.blockChainHash ? <div> <h2>浏览器访问:{"http://localhost:8080/ipfs/" + this.state.imgHash}</h2> <img alt="" style={{ width: 1600 }} src={"http://localhost:8080/ipfs/" + this.state.imgHash}/> </div> : <img alt=""/> } </div>); } } export default App
5. 源码修改
可以自己建立项目,也可以直接下载原博主的源码并进行修改。这里直接下载原博主的代码进行修改。
5.1 下载源码,安装依赖
$ git clone https://github.com/liyuechun/IPFS-Ethereum-Image.git $ cd IPFS-Ethereum-Image $ npm install
5.2 查看源码端口
/Users/yuyang/IPFS-Ethereum-Image/src/utils/getWeb3.js
var provider = new Web3.providers.HttpProvider('http://127.0.0.1:9545')
使用的端口是9545,truffle develop 默认使用的端口就是9545,所以我们使用truffle develop作为测试私链。
5.3 启动私链
yuyangdeMacBook-Pro:IPFS-Ethereum-Image yuyang$ truffle develop Truffle Develop started at http://127.0.0.1:9545/ Accounts: (0) 0x627306090abab3a6e1400e9345bc60c78a8bef57 (1) 0xf17f52151ebef6c7334fad080c5704d77216b732 (2) 0xc5fdf4076b8f3a5357c5e395ab970b5b54098fef (3) 0x821aea9a577a9b44299b9c15c88cf3087f3b5544 (4) 0x0d1d4e623d10f9fba5db95830f7d3839406c6af2 (5) 0x2932b7a2355d6fecc4b5c0b6bd44cc31df247a2e (6) 0x2191ef87e392377ec08e7c08eb105ef5448eced5 (7) 0x0f4f2ac550a1b4e2280d04c21cea7ebd822934b5 (8) 0x6330a553fc93768f612722bb8c2ec78ac90b3bbc (9) 0x5aeda56215b167893e80b4fe645ba6d5bab767de Private Keys: (0) c87509a1c067bbde78beb793e6fa76530b6382a4c0241e5e4a9ec0a0f44dc0d3 (1) ae6ae8e5ccbfb04590405997ee2d52d2b330726137b875053c36d94e974d162f (2) 0dbbe8e4ae425a6d2687f1a7e3ba17bc98c673636790f1b8ad91193c05875ef1 (3) c88b703fb08cbea894b6aeff5a544fb92e78a18e19814cd85da83b71f772aa6c (4) 388c684f0ba1ef5017716adb5d21a053ea8e90277d0868337519f97bede61418 (5) 659cbb0e2411a44db63778987b1e22153c086a95eb6b18bdf89de078917abc63 (6) 82d052c865f5763aad42add438569276c00d3d88a2d062d36b2bae914d58b8c8 (7) aa3680d5d48a8283413f7a108367c7299ca73f553735860a87b08f39395618b7 (8) 0f62d96d6675f32685bbdb8ac13cda7c23436f63efbb9d07700d8669ff12b7c4 (9) 8d5366123cb560bb606379f90a0bfd4769eecc0557f1b362dcae9012b548b1e5 Mnemonic: candy maple cake sugar pudding cream honey rich smooth crumble sweet treat ⚠️ Important ⚠️ : This mnemonic was created for you by Truffle. It is not secure. Ensure you do not use it on production blockchains, or else you risk losing funds.
5.4 编译和部署合约
truffle(develop)> compile truffle(develop)> migrate
5.5 获取合约地址
Using network 'develop'. Running migration: 1_initial_migration.js Deploying Migrations... ... 0x130a37fb2d60e34cc04fccbfc51c10b988d61378090b89eb4546cce2a6ef3490 Migrations: 0x8cdaf0cd259887258bc13a92c0a6da92698644c0 Saving successful migration to network... ... 0xd7bc86d31bee32fa3988f1c1eabce403a1b5d570340a3a9cdba53a472ee8c956 Saving artifacts... Running migration: 2_deploy_contracts.js Deploying SimpleStorage... ... 0x8c51da613e7c0517e726926c18d535aed0d21c8f4c82668212a6cdfd193d21d8 SimpleStorage: 0x345ca3e014aaf5dca488057592ee47305d9b3e10 Saving successful migration to network... ... 0xf36163615f41ef7ed8f4a8f192149a0bf633fe1a2398ce001bf44c43dc7bdda0 Saving artifacts...
SimpleStorage合约地址为0x345ca3e014aaf5dca488057592ee47305d9b3e10。也可以从/Users/yuyang/IPFS-Ethereum-Image/build/contracts/SimpleStorage.json看到
"networks": { "4447": { "events": {}, "links": {}, "address": "0x345ca3e014aaf5dca488057592ee47305d9b3e10", "transactionHash": "0x8c51da613e7c0517e726926c18d535aed0d21c8f4c82668212a6cdfd193d21d8" } },
5.6 修改App.js文件
/Users/yuyang/IPFS-Ethereum-Image/src/App.js
instantiateContract = () => { simpleStorage.setProvider(this.state.web3.currentProvider); this.state.web3.eth.getAccounts((error, accounts) => { account = accounts[0]; simpleStorage.at('0x345ca3e014aaf5dca488057592ee47305d9b3e10').then((contract) => { console.log(contract.address); contractInstance = contract; this.setState({address: contractInstance.address}); return; }); }) }
将其中的0x345ca3e014aaf5dca488057592ee47305d9b3e10合约地址替换为你的合约地址。
6. 启动程序
新开命令行启动IPFS节点
yuyangdeMacBook-Pro:~ yuyang$ ipfs daemon
新开命令行启动程序
yuyangdeMacBook-Pro:~ yuyang$ npm start
7. 配置MetaMask插件和准备以太坊账号
程序启动后,会自动打开浏览器。注意,因为MetaMask插件只支持Chrome浏览器和FireFox浏览器,所以你需要运行保持页面运行在这两种浏览器上。关于MetaMask插件这部分内容,请查看这篇文章。
因为我们的私链是部署在http://127.0.0.1:9545上的,所以你需要让MetaMask插件的端口也指向http://127.0.0.1:9545。点击Custom RPC进行配置后,切换端口为http://127.0.0.1:9545。
因为需要向区块写入数据,需要花费gas,如果你的当前Account中没有以太币,可以导入其他的Account。点击右上角头像图标。
点击Import Account
需要输入私钥。在我们输入truffle develop启动私链的时候,已经分配给了我们十个Account地址和对应的私钥,任一账号都有100以太币,随便选择一个私钥填入。
Accounts: (0) 0x627306090abab3a6e1400e9345bc60c78a8bef57 (1) 0xf17f52151ebef6c7334fad080c5704d77216b732 (2) 0xc5fdf4076b8f3a5357c5e395ab970b5b54098fef (3) 0x821aea9a577a9b44299b9c15c88cf3087f3b5544 (4) 0x0d1d4e623d10f9fba5db95830f7d3839406c6af2 (5) 0x2932b7a2355d6fecc4b5c0b6bd44cc31df247a2e (6) 0x2191ef87e392377ec08e7c08eb105ef5448eced5 (7) 0x0f4f2ac550a1b4e2280d04c21cea7ebd822934b5 (8) 0x6330a553fc93768f612722bb8c2ec78ac90b3bbc (9) 0x5aeda56215b167893e80b4fe645ba6d5bab767de Private Keys: (0) c87509a1c067bbde78beb793e6fa76530b6382a4c0241e5e4a9ec0a0f44dc0d3 (1) ae6ae8e5ccbfb04590405997ee2d52d2b330726137b875053c36d94e974d162f (2) 0dbbe8e4ae425a6d2687f1a7e3ba17bc98c673636790f1b8ad91193c05875ef1 (3) c88b703fb08cbea894b6aeff5a544fb92e78a18e19814cd85da83b71f772aa6c (4) 388c684f0ba1ef5017716adb5d21a053ea8e90277d0868337519f97bede61418 (5) 659cbb0e2411a44db63778987b1e22153c086a95eb6b18bdf89de078917abc63 (6) 82d052c865f5763aad42add438569276c00d3d88a2d062d36b2bae914d58b8c8 (7) aa3680d5d48a8283413f7a108367c7299ca73f553735860a87b08f39395618b7 (8) 0f62d96d6675f32685bbdb8ac13cda7c23436f63efbb9d07700d8669ff12b7c4 (9) 8d5366123cb560bb606379f90a0bfd4769eecc0557f1b362dcae9012b548b1e5
8. 运行程序
页面会显示当前合约的地址0x345ca3e014aaf5dca488057592ee47305d9b3e10
选择一张图片
点击上传到IPFS,并获取到图片hash值QmSLnchQXh9gJrDKvQ5UFLZAj5f7icb2yWsWmcUKUYY3gj
点击将图片hash值保存到区块链,弹出MetaMask插件进行写入合约的确认
从区块链获取图片hash值QmSLnchQXh9gJrDKvQ5UFLZAj5f7icb2yWsWmcUKUYY3gj
根据图片hash值,从IPFS进行访问
参考:【IPFS + 区块链 系列】 入门篇 - IPFS + Ethereum (下篇)-ipfs + Ethereum 大图片存储
作者:黎跃春
作者:yuyangray
链接:https://www.jianshu.com/p/3cb9520a23c0
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
1. 内容简介
这篇文章将为大家讲解js-ipfs-api的简单使用,如何将数据上传到IPFS,以及如何从IPFS通过HASH读取数据。
2. IPFS-HTTP效果图
3. 实现步骤
3.1 安装create-react-app
参考文档:https://reactjs.org/tutorial/tutorial.html
yuyangdeMacBook-Pro:~ yuyang$ npm install -g create-react-app /Users/yuyang/.nvm/versions/node/v8.9.4/bin/create-react-app -> /Users/yuyang/.nvm/versions/node/v8.9.4/lib/node_modules/create-react-app/index.js + create-react-app@1.5.2 added 67 packages in 14.512s
3.2 React项目创建
yuyangdeMacBook-Pro:~ yuyang$ create-react-app ipfs-http-demo Creating a new React app in /Users/yuyang/ipfs-http-demo. Installing packages. This might take a couple of minutes. Installing react, react-dom, and react-scripts... ... ... Success! Created ipfs-http-demo at /Users/yuyang/ipfs-http-demo Inside that directory, you can run several commands: yarn start Starts the development server. yarn build Bundles the app into static files for production. yarn test Starts the test runner. yarn eject Removes this tool and copies build dependencies, configuration files and scripts into the app directory. If you do this, you can’t go back! We suggest that you begin by typing: cd ipfs-http-demo yarn start Happy hacking!
3.3 运行React项目
yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ npm start
Compiled successfully! You can now view ipfs-http-demo in the browser. Local: http://localhost:3000/ On Your Network: http://192.168.0.4:3000/ Note that the development build is not optimized. To create a production build, use yarn build.
3.4 浏览项目
浏览器会自动打开:http://localhost:3000/
效果如下:
3.5 安装ipfs-api
https://www.npmjs.com/package/ipfs-api
项目结构
安装ipfs-api
切换到项目根目录,安装ipfs-api。
yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ npm install --save ipfs-api
ipfs-api安装完后,如上图所示,接下来刷新一下浏览器,看看项目是否有问题,正常来讲,一切会正常。
3.6 完成UI逻辑
拷贝下面的代码,将src/App.js里面的代码直接替换掉。
import React, { Component } from 'react'; import './App.css'; class App extends Component { constructor(props) { super(props); this.state = { strHash: null, strContent: null } } render() { return ( <div className="App"> <input ref="ipfsContent" /> <button onClick={() => { let ipfsContent = this.refs.ipfsContent.value; console.log(ipfsContent); }}>提交到IPFS</button> <p>{this.state.strHash}</p> <button onClick={() => { console.log('从ipfs读取数据。') }}>读取数据</button> <h1>{this.state.strContent}</h1> </div> ); } } export default App;
上面的代码完成的工作是,当我们在输入框中输入一个字符串时,点击提交到IPFS按钮,将文本框中的内容取出来打印,后续我们需要将这个数据上传到IPFS。点击读取数据按钮,我们也只是随便打印了一个字符串,后面需要从IPFS读取数据,然后将读取的数据存储到状态机变量strContent中并且展示出来。
现在刷新网页,输入内容,点击提交到IPFS,Console打印出输入的内容。点击读取数据,Console打印出从ipfs读取数据。。
3.7 导入IPFS
const ipfsAPI = require('ipfs-api'); const ipfs = ipfsAPI({host: 'localhost', port: '5001', protocol: 'http'});
3.8 编写上传大文本字符串到IPFS的Promise函数
saveTextBlobOnIpfs = (blob) => { return new Promise(function(resolve, reject) { const descBuffer = Buffer.from(blob, 'utf-8'); ipfs.add(descBuffer).then((response) => { console.log(response) resolve(response[0].hash); }).catch((err) => { console.error(err) reject(err); }) }) }
response[0].hash返回的是数据上传到IPFS后返回的HASH字符串。
3.9 上传数据到IPFS
this.saveTextBlobOnIpfs(ipfsContent).then((hash) => { console.log(hash); this.setState({strHash: hash}); });
ipfsContent是从文本框中取到的数据,调用this.saveTextBlobOnIpfs方法将数据上传后,会返回字符串hash,并且将hash存储到状态机变量strHash中。
目前完整的代码:
import React, {Component} from 'react'; import './App.css'; const ipfsAPI = require('ipfs-api'); const ipfs = ipfsAPI({host: 'localhost', port: '5001', protocol: 'http'}); class App extends Component { constructor(props) { super(props); this.state = { strHash: null, strContent: null } } saveTextBlobOnIpfs = (blob) => { return new Promise(function(resolve, reject) { const descBuffer = Buffer.from(blob, 'utf-8'); ipfs.add(descBuffer).then((response) => { console.log(response) resolve(response[0].hash); }).catch((err) => { console.error(err) reject(err); }) }) } render() { return (<div className="App"> <input ref="ipfsContent" /> <button onClick={() => { let ipfsContent = this.refs.ipfsContent.value; console.log(ipfsContent); this.saveTextBlobOnIpfs(ipfsContent).then((hash) => { console.log(hash); this.setState({strHash: hash}); }); }}>提交到IPFS</button> <p>{this.state.strHash}</p> <button onClick={() => { console.log('从ipfs读取数据。') }}>读取数据</button> <h1>{this.state.strContent}</h1> </div>); } } export default App;
3.10 跨域资源共享CORS配置
跨域资源共享( CORS )配置,依次在终端执行下面的代码:
yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ ipfs config --json API.HTTPHeaders.Access-Control-Allow-Methods '["PUT", "GET", "POST", "OPTIONS"]' yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ ipfs config --json API.HTTPHeaders.Access-Control-Allow-Origin '["*"]' yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ ipfs config --json API.HTTPHeaders.Access-Control-Allow-Credentials '["true"]' yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ ipfs config --json API.HTTPHeaders.Access-Control-Allow-Headers '["Authorization"]' yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ ipfs config --json API.HTTPHeaders.Access-Control-Expose-Headers '["Location"]'
用正确的端口运行daemon:
yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ ipfs config Addresses.API /ip4/127.0.0.1/tcp/5001 yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ ipfs config Addresses.API /ip4/127.0.0.1/tcp/5001 yuyangdeMacBook-Pro:ipfs-http-demo yuyang$ ipfs daemon
3.11 刷新网页提交数据并在线查看数据
上传数据,并且查看返回hash值
在线查看上传到IPFS的数据
http://ipfs.io/ipfs/QmejvEPop4D7YUadeGqYWmZxHhLc4JBUCzJJHWMzdcMe2y
3.12 从IPFS读取数据
ipfs.cat(this.state.strHash).then((stream) => { console.log(stream); let strContent = Utf8ArrayToStr(stream); console.log(strContent); this.setState({strContent: strContent}); });
stream为Uint8Array类型的数据,下面的方法是将Uint8Array转换为string字符串。
Utf8ArrayToStr
function Utf8ArrayToStr(array) { var out, i, len, c; var char2, char3; out = ""; len = array.length; i = 0; while(i < len) { c = array[i++]; switch(c >> 4) { case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7: // 0xxxxxxx out += String.fromCharCode(c); break; case 12: case 13: // 110x xxxx 10xx xxxx char2 = array[i++]; out += String.fromCharCode(((c & 0x1F) << 6) | (char2 & 0x3F)); break; case 14: // 1110 xxxx 10xx xxxx 10xx xxxx char2 = array[i++]; char3 = array[i++]; out += String.fromCharCode(((c & 0x0F) << 12) | ((char2 & 0x3F) << 6) | ((char3 & 0x3F) << 0)); break; default: break; } } return out; }
完整源码
import React, {Component} from 'react'; import './App.css'; const ipfsAPI = require('ipfs-api'); const ipfs = ipfsAPI({host: 'localhost', port: '5001', protocol: 'http'}); function Utf8ArrayToStr(array) { var out, I, len, c; var char2, char3; out = ""; len = array.length; i = 0; while (i < len) { c = array[i++]; switch (c >> 4) { case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7: // 0xxxxxxx out += String.fromCharCode(c); break; case 12: case 13: // 110x xxxx 10xx xxxx char2 = array[i++]; out += String.fromCharCode(((c & 0x1F) << 6) | (char2 & 0x3F)); break; case 14: // 1110 xxxx 10xx xxxx 10xx xxxx char2 = array[i++]; char3 = array[i++]; out += String.fromCharCode(((c & 0x0F) << 12) | ((char2 & 0x3F) << 6) | ((char3 & 0x3F) << 0)); break; default: break; } } return out; } class App extends Component { constructor(props) { super(props); this.state = { strHash: null, strContent: null } } saveTextBlobOnIpfs = (blob) => { return new Promise(function(resolve, reject) { const descBuffer = Buffer.from(blob, 'utf-8'); ipfs.add(descBuffer).then((response) => { console.log(response) resolve(response[0].hash); }).catch((err) => { console.error(err) reject(err); }) }) } render() { return (<div className="App"> <input ref="ipfsContent" /> <button onClick={() => { let ipfsContent = this.refs.ipfsContent.value; console.log(ipfsContent); this.saveTextBlobOnIpfs(ipfsContent).then((hash) => { console.log(hash); this.setState({strHash: hash}); }); }}>提交到IPFS</button> <p>{this.state.strHash}</p> <button onClick={() => { console.log('从ipfs读取数据。') ipfs.cat(this.state.strHash).then((stream) => { console.log(stream); let strContent = Utf8ArrayToStr(stream); console.log(strContent); this.setState({strContent: strContent}); }); }}>读取数据</button> <h1>{this.state.strContent}</h1> </div>); } } export default App;
4. 总结
这篇文章主要讲解如何配置React环境,如何创建React项目,如何安装js-ipfs-api,如何上传数据,如何设置开发环境,如何下载数据等等内容。通过这篇文章的系统学习,你会掌握js-ipfs-api在项目中的使用流程。
作者:yuyangray
链接:https://www.jianshu.com/p/48218aa9d724
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
1. 项目效果图
2. 创建React项目
yuyangdeMacBook-Pro:~ yuyang$ create-react-app ipfs_img
3. 完成UI逻辑
将下面的代码拷贝替换掉App.js里面的代码。
import React, {Component} from 'react' class App extends Component { constructor(props) { super(props) this.state = { imgSrc: null } } render() { return (<div className="App"> <h2>上传图片到IPFS:</h2> <div> <label id="file">Choose file to upload</label> <input type="file" ref="file" id="file" name="file" multiple="multiple"/> </div> <div> <button onClick={() => { var file = this.refs.file.files[0]; var reader = new FileReader(); // reader.readAsDataURL(file); reader.readAsArrayBuffer(file) reader.onloadend = (e) => { console.log(reader); } }}>Submit</button> </div> { this.state.imgSrc <div> <h2>{"http://localhost:8080/ipfs/" + this.state.imgSrc}</h2> <img alt="区块链部落" style= src={"http://localhost:8080/ipfs/" + this.state.imgSrc}/> </div> : <img alt=""/> } </div>); } } export default App
4. 安装ipfs-api
yuyangdeMacBook-Pro:ipfs_img yuyang$ npm install --save ipfs-api
5. App.js导入IPFS
const ipfsAPI = require('ipfs-api'); const ipfs = ipfsAPI({host: 'localhost', port: '5001', protocol: 'http'});
6. 实现上传图片到IPFS的Promise函数
let saveImageOnIpfs = (reader) => { return new Promise(function(resolve, reject) { const buffer = Buffer.from(reader.result); ipfs.add(buffer).then((response) => { console.log(response) resolve(response[0].hash); }).catch((err) => { console.error(err) reject(err); }) }) }
7. 上传图片到IPFS
var file = this.refs.file.files[0]; var reader = new FileReader(); // reader.readAsDataURL(file); reader.readAsArrayBuffer(file) reader.onloadend = function(e) { console.log(reader); saveImageOnIpfs(reader).then((hash) => { console.log(hash); this.setState({imgSrc: hash}) });
上传图片
saveImageOnIpfs(reader).then((hash) => { console.log(hash); this.setState({imgSrc: hash}) });
hash即是上传到IPFS的图片的HASH地址,this.setState({imgSrc: hash})将hash保存到状态机变量imgSrc中。
8. 完整代码
import React, {Component} from 'react' const ipfsAPI = require('ipfs-api'); const ipfs = ipfsAPI({host: 'localhost', port: '5001', protocol: 'http'}); let saveImageOnIpfs = (reader) => { return new Promise(function(resolve, reject) { const buffer = Buffer.from(reader.result); ipfs.add(buffer).then((response) => { console.log(response) resolve(response[0].hash); }).catch((err) => { console.error(err) reject(err); }) }) } class App extends Component { constructor(props) { super(props) this.state = { imgSrc: null } } render() { return ( <div className="App"> <h2>上传图片到IPFS:</h2> <div> <label id="file">Choose file to upload</label> <input type="file" ref="file" id="file" name="file" multiple="multiple"/> </div> <div> <button onClick={() => { var file = this.refs.file.files[0]; var reader = new FileReader(); // reader.readAsDataURL(file); reader.readAsArrayBuffer(file) reader.onloadend = (e) => { console.log(reader); saveImageOnIpfs(reader).then((hash) => { console.log(hash); this.setState({imgSrc: hash}) }); } }}>Submit</button> </div> { this.state.imgSrc ?<div> <h2>{"http://localhost:8080/ipfs/" + this.state.imgSrc}</h2> <img alt="区块链部落" src={"http://localhost:8080/ipfs/" + this.state.imgSrc} /> </div> :<img alt=""/> } </div>); } } export default App
参考:【IPFS + 区块链 系列】 入门篇 - IPFS + Ethereum (中篇)-js-ipfs-api - 图片上传到IPFS以及下载
作者:黎跃春
作者:yuyangray
链接:https://www.jianshu.com/p/db2676952c48
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
在
http://faucet.ropsten.be:3001/上申请,只需要输入你在Ropsten网络上的账户地址就行,转币操作非常迅速,目前一次可申请1ETH,24小时后可再次申请;
摘要: 数字资源校外访问锦囊,拿走不谢! ...
阅读全文
1.web3的1.0以下版本不支持web3.eth.abi
2.var ethabi = require('web3-eth-abi');这种引用也有问题。
3.升级web3到1.0以上版本后测试通过:
var Web3 = require('web3');
var web3 = new Web3();
console.log(web3.eth.abi.encodeFunctionSignature('myMethod(uint256,string)'))
方法: 在注册表中删除
运行regedit, 找到
HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Services 中想要删除的服务。
重启电脑可以看到你所选定的服务项在服务列表中不存在了
https://chaindesk.cn/witbook/1/12
https://ethereum.github.io/browser-solidity/
https://github.com/tooploox/ipfs-eth-database
https://www.jianshu.com/p/47174718960b
1.因为solc@0.5.1出现调用简单运算合约出现返回0的问题,所以把solc降到了0.4.22。
2.安装truffle后,npm install -g truffle,版本有所不同:
PS C:\> truffle version
Truffle v5.0.24 (core: 5.0.24)
Solidity v0.5.0 (solc-js)
Node v10.16.0
Web3.js v1.0.0-beta.37
3.建立简单合约Greeter.sol后,利用truffle compile后,出现:
Error: CompileError: ParsedContract.sol:1:1: ParserError: Source file requires different compiler version (current compiler is 0.5.8+commit.23d335f2.Emscripten.clang - note that nightly builds are considered to be strictly less than the released version
pragma solidity ^0.4.24;
^----------------------^
Compilation failed. See above.
4.修改truffle-config.js文件:
module.exports = {
// Uncommenting the defaults below
// provides for an easier quick-start with Ganache.
// You can also follow this format for other networks;
// see <http://truffleframework.com/docs/advanced/configuration>
// for more details on how to specify configuration options!
/*
networks: {
development: {
host: "127.0.0.1",
port: 7545,
network_id: "*"
},
test: {
host: "127.0.0.1",
port: 7545,
network_id: "*"
}
}
*/
compilers: {
solc: {
version: "0.4.24"
}
}
};
5.再次编译,出现
/C/users/administrator/webstormprojects/testtruffle/contracts/Migrations.sol:1:1: SyntaxError: Source file requires different compiler version (current compiler is 0.4.24+commit.e67f0147.Emscripten.clang - note that nightly builds are considered to be strictly less than the released version
pragma solidity >=0.4.25 <0.6.0;
^------------------------------^
6.打开Migrations.sol文件,
把pragma solidity >=0.4.25 <0.6.0;
修改为:pragma solidity >=0.4.24 <0.6.0;
编译通过。
本文章的项目基于春哥的博客教程
【IPFS + 区块链 系列】 入门篇 - IPFS + Ethereum (下篇)-ipfs + Ethereum 大图片存储
我个人只是作为记录学习心得所借鉴
项目流程
首先调用代码创建truffle项目
truffle unbox react
其次,要引入ipfs的api,用作图片存储的相关功能,我们是将图片存储到ipfs当中,而将所获得图片的hash区块链之中,区块链大数据成本的问题
npm install –save ipfs-api
安装完毕调用complie编译合约代码,,以便使用web3调用合约存储区块链
compile
替换合约地址,这个需要将合约在以太坊部署并取得对应地址
然后运行ipfs节点
ipfs daemon
启动项目
npm start
就可以看到项目成功
代码解读分析
import React, {Component} from 'react'
import SimpleStorageContract from '../build/contracts/SimpleStorage.json'
import getWeb3 from './utils/getWeb3'
import './css/oswald.css'
import './css/open-sans.css'
import './css/pure-min.css'
import './App.css'
const ipfsAPI = require('ipfs-api');
const ipfs = ipfsAPI({host: 'localhost', port: '5001', protocol: 'http'});
const contract = require('truffle-contract')
const simpleStorage = contract(SimpleStorageContract)
let account;
/** Declaring this for later so we can chain functions on SimpleStorage.**/
let contractInstance;
//ipfs保存图片方法//
let saveImageOnIpfs = (reader) => {
return new Promise(function(resolve, reject) {
const buffer = Buffer.from(reader.result);
ipfs.add(buffer).then((response) => {
console.log(response)
resolve(response[0].hash);
}).catch((err) => {
console.error(err)
reject(err);
})
})
}
//创建构造函数,添加状态机变量//
class App extends Component {
constructor(props) {
super(props)
this.state = {
blockChainHash: null,
web3: null,
address: null,
imgHash: null,
isWriteSuccess: false
}
}
//程序启动默认调用方法//
componentWillMount() {
//打印项目中网络节点//
ipfs.swarm.peers(function(err, res) {
if (err) {
console.error(err);
} else {
/** var numPeers = res.Peers === null ? 0 : res.Peers.length;**/
/** console.log("IPFS - connected to " + numPeers + " peers");**/
console.log(res);
}
});
//web3设置,同时调用初始化方法//
getWeb3.then(results => {
this.setState({web3: results.web3})
// Instantiate contract once web3 provided.
this.instantiateContract()
}).catch(() => {
console.log('Error finding web3.')
})
}
//初始化合约实例、web3获取合约账号以及合约实例//
instantiateContract = () => {
simpleStorage.setProvider(this.state.web3.currentProvider);
this.state.web3.eth.getAccounts((error, accounts) => {
account = accounts[0];
simpleStorage.at('0xf6a7e96860f05f21ecb4eb588fe8a8a83981af03').then((contract) => {
console.log(contract.address);
contractInstance = contract;
this.setState({address: contractInstance.address});
return;
});
})
}
render() {
return (<div className="App">
{
this.state.address
? <h1>合约地址:{this.state.address}</h1>
: <div/>
}
<h2>上传图片到IPFS:</h2>
/**这一部分用于上传文件到ipfs**/
<div>
<label id="file">Choose file to upload</label>
<input type="file" ref="file" id="file" name="file" multiple="multiple"/>
</div>
<div>
<button onClick={() => {
var file = this.refs.file.files[0];
var reader = new FileReader();
// reader.readAsDataURL(file);
reader.readAsArrayBuffer(file)
reader.onloadend = function(e) {
console.log(reader);
saveImageOnIpfs(reader).then((hash) => {
console.log(hash);
this.setState({imgHash: hash})
});
}.bind(this);
}}>将图片上传到IPFS并返回图片HASH</button>
</div>
/**这一部分用于上传hash到区块链**/
{
this.state.imgHash
? <div>
<h2>imgHash:{this.state.imgHash}</h2>
<button onClick={() => {
contractInstance.set(this.state.imgHash, {from: account}).then(() => {
console.log('图片的hash已经写入到区块链!');
this.setState({isWriteSuccess: true});
})
}}>将图片hash写到区块链:contractInstance.set(imgHash)</button>
</div>
: <div/>
}
{
this.state.isWriteSuccess
? <div>
<h1>图片的hash已经写入到区块链!</h1>
<button onClick={() => {
contractInstance.get({from: account}).then((data) => {
console.log(data);
this.setState({blockChainHash: data});
})
}}>从区块链读取图片hash:contractInstance.get()</button>
</div>
: <div/>
}
{
this.state.blockChainHash
? <div>
<h3>从区块链读取到的hash值:{this.state.blockChainHash}</h3>
</div>
: <div/>
}
{
this.state.blockChainHash
? <div>
<h2>浏览器访问:{"http://localhost:8080/ipfs/" + this.state.imgHash}</h2>
<img alt="" style={{width:200}} src={"http://localhost:8080/ipfs/" + this.state.imgHash}/>
</div>
: <img alt=""/>
}
</div>);
}
}
export default App
该项目算是truffle和ipfs结合以太坊一起使用的综合案例,用与梳理知识点
---------------------
作者:czZ__czZ
来源:CSDN
原文:https://blog.csdn.net/czZ__czZ/article/details/79036567
版权声明:本文为博主原创文章,转载请附上博文链接!
C:\Users\0>node E:\项目\2018年\11月份\nodejs\express_demo.js
Error: Cannot find module 'express'
at Function.Module._resolveFilename (module.js:469:15)
at Function.Module._load (module.js:417:25)
at Module.require (module.js:497:17)
at require (internal/module.js:20:19)
at Object.<anonymous> (E:\项目\2018年\11月份\nodejs\express_demo.js:1:77)
at Module._compile (module.js:570:32)
at Object.Module._extensions..js (module.js:579:10)
at Module.load (module.js:487:32)
at tryModuleLoad (module.js:446:12)
at Function.Module._load (module.js:438:3)
C:\Users\0>express --version
实际上我是有安装express模块的

奇了个怪了。
然后试过1种方法是进入项目目录再执行安装express模块,无效
最后,原来是node_modules没有配置环境变量
配置上吧:
1、控制面板\所有控制面板项\系统\高级系统设置\环境变量
新建设‘NODE_PATH’:C:\Users\0\AppData\Roaming\npm\node_modules

编辑增加环境变量‘PATH’

完美~~
http://www.pianshen.com/article/837378161/
1.合约内容
pragma solidity ^0.5.9;
contract hello {
function mutiply(uint a) public pure returns (uint result) {
return a*3;
}
}
2.部署合约:
var Web3 = require("web3");
var fs = require("fs");
var web3 = new Web3(new Web3.providers.HttpProvider('http://localhost:8545'));
var code = '0x' + fs.readFileSync("2_sol_hello.bin").toString();
var abi = JSON.parse(fs.readFileSync("2_sol_hello.abi").toString());
var contract = web3.eth.contract(abi);
console.log(web3.eth.accounts);
console.log('account balance:' + web3.eth.getBalance(web3.eth.accounts[0]))
web3.personal.unlockAccount(web3.eth.accounts[0],"123")
var contract = contract.new({from: web3.eth.accounts[0], data: code, gas: 470000},
function(e, contract){
if(!contract.address) {
console.log("已经发起交易,交易地址:" + contract.transactionHash + "\n正在等待挖矿");
} else {
console.log("智能合约部署成功,地址:" + contract.address);
}
}
)
3.调用合约
var Web3 = require("web3");
var fs = require("fs");
var web3 = new Web3(new Web3.providers.HttpProvider('http://localhost:8545'));
var abi = JSON.parse(fs.readFileSync("2_sol_hello.abi").toString());
var contract = web3.eth.contract(abi);
var instance = contract.at('0xb06846c54c6ae67102ed67ce57a357a643d1f1b8')
web3.personal.unlockAccount(web3.eth.accounts[0],"123")
console.log(instance.mutiply(12).toString())
4.显示结果为:
0
原因:solc版本0.5.9太高,可能调用的方法不对。
解决方法:npm install -g solc@0.4.22
降低版本,然后把合约第一行改为:
pragma solidity ^0.4.22;
问题解决。
https://www.jianshu.com/p/52e9588116ad
很多人遇到这个问题:
web3.php Error: The method personal_newAccount does not exist/is not available。
其实很简单,我们只需要在geth启动时的rpc参数中设置rpcapi时包括 "personal" 即可。
geth --rpc --rpcaddr 0.0.0.0 --rpcport 8545 --rpcapi eth,web3,admin,personal,net
来自:http://www.bcfans.com/toutiao/redian/101819.html
geth --identity "Water" --rpc --rpcport "8080" --rpccorsdomain "*" --datadir gethdata --port "30303" --nodiscover --rpcapi "db,eth,net,personal,web3" --networkid 1999 init genesis.json
1.安装web3要先安装node。
2.cmd->powershell
3.c:\>node
>require('web3')
结果输出一些错误,表明还没安装web3。
4.c:\>npm install web3
5.安装后,再
c:\>node
>require('web3')
输出
[Function:Web3]
表明web3就安装好了。
https://blog.csdn.net/qiubingcsdn/article/details/89703128
背景介绍
本文主要介绍如何使用Ganache,在本地搭建以太坊私有网络,并进行简单的测试。
所需软件
Ganache
Ganache用于搭建私有网络。在开发和测试环境下,Ganache提供了非常简便的以太坊私有网络搭建方法,通过可视化界面可以直观地设置各种参数、浏览查看账户和交易等数据。
下载地址为:https://truffleframework.com/ganache/
MetaMask
MetaMask用于测试私有网络。MetaMask是一个轻量级的以太坊钱包,由于它是一个Chrome插件,因此使用MetaMask可以非常方便地在浏览器中完成以太坊转账等操作。
下载地址为:https://www.metamask.io
操作步骤
安装、启动Ganache
1. 使用安装包安装即可。
2. 打开程序后,会显示以下界面,用户可以查看账户(默认创建10个账户)、区块、交易和日志。
3. 点击“设置”,如下图所示,用户还可以设置绑定的ip和端口(设置为8545即可,稍后MetaMask会用这个端口)、账户数量以及gas限制等,点击“restart”后设置生效。
此时,Ganache已经在本机运行了一个以太坊私有网络,并绑定了8545端口。
安装、启动MetaMask
1. 把插件添加到chrome扩展程序即可
2. 点击Chrome中的MetaMask图标,按照每一步提示启动MetaMask
3. 如下图所示,设置MetaMask连接到本地的以太坊私有网络
此时,MetaMask就可以和本地的以太坊私有网络进行交互了。
用MetaMask测试私有网络
1. 从Ganache创建的账户中选择一个导入到MetaMask中
a. 在Ganache账户页面选定一个账户,点击最右边的小钥匙图标,复制其私钥(private key)
b. 在MetaMask中点击头像,选择 “import account”,弹出对话框
c. 把复制的账户私钥填入文本框中,并点击“import”
此时,MetaMask就可以操作这个新账户了。
2. 用新导入的账户进行转账
a. 点击“send”按钮,弹出转账对话框
b. 从Ganache账户页面中,再选定一个其他的账户,复制其地址
c. 把复制的地址填入到 “to” 文本框中,并在“amount”文本框中填入一个数值,表示要转账的金额(如 “10”);其它文本框默认值即可
d. 点击next,弹出转账确认框,点击“confirm”确认交易
e. 提醒转账成功后,可以看到账户余额发生了变化,此时再转到Ganache账户页面,也可看到两个账户的余额也都发生了变化。
注意
由于Ganache的交易数据是在内存中操作的,并没有持久化到本地硬盘中,因此每次Ganache重启后,其上一次的交易记录就没有了,都是重新开始的。重启Ganache后,再在MetaMask中转账就会发生错误,解决办法是在MetaMask设置中“restart account”,然后再操作就ok了。
如果想保留Ganache每一次运行时的交易数据,以便下一次继续使用,可以使用命令行的形式ganache-cli启动Ganache,并指定数据存储目录
---------------------
作者:BigCuttie
来源:CSDN
原文:https://blog.csdn.net/starleelzx/article/details/82943530
版权声明:本文为博主原创文章,转载请附上博文链接!
1.https://www.jetbrains.com/webstorm/download/ 下载2019.1.3版
2.在网盘开发软件下载JetbrainsCrack3.4.jar、汉化包和激活码软件。
3.将解压的.jar 破解补丁放在你的安装idea下面的bin的目录下面。如C:\JetBrains\WebStorm\bin
4.在安装的idea下面的bin目录下面有2个文件 : 一个是webstorm.exe.vmoptions,还有一个是webstorm64.exe.vmoptions。用记事本打开 分别在最下面一行增加一行:
-javaagent:C:\JetBrains\WebStorm\bin\JetbrainsCrack3.4.jar
5.重启一下软件,在进入出现有active code选择界面的时候,打开激活码.txt文件,输入即可,能够进入应用界面则表示安装破解成功
1.https://www.jetbrains.com/idea/download/previous.html 下载2018.3.6版本;
2.在网盘开发软件下载JetbrainsCrack_jb51.rar软件,里面包含了JetbrainsCrack-4.2-release-enc.jar文件。
3.将解压的.jar 破解补丁放在你的安装idea下面的bin的目录下面。如C:\JetBrains\IntelliJ\bin
4.在安装的idea下面的bin目录下面有2个文件 : 一个是idea64.exe.vmoptions,还有一个是idea.exe.vmoptions。用记事本打开 分别在最下面一行增加一行:
-javaagent:C:\JetBrains\IntelliJ\bin\JetbrainsCrack-4.2-release-enc.jar
5.重启一下软件,在进入出现有active code选择界面的时候,随便输入几个字母即可,能够进入应用界面则表示安装破解成功。
背景
Ubuntu16下,使用apt-get下载的nodejs最新版本为v4.2.6,而react-native需要v8.x及以上的版本
解决方法
在网上找到了这一篇博客Ubuntu安装最新版nodejs,用npm安装了Node工具包n,使用该工具包将nodejs安装到了目前的最新版本v10.6.0。在已经安装npm的基础上,具体操作如下:
sudo npm install n -g
sudo n stable
node -v
n是一个Node工具包,它提供了几个升级命令参数:
n 显示已安装的Node版本
n latest 安装最新版本Node
n stable 安装最新稳定版Node
n lts 安装最新长期维护版(lts)Node
n version 根据提供的版本号安装Node
---------------------
作者:LDY_T
来源:CSDN
原文:https://blog.csdn.net/u010277553/article/details/80938829
版权声明:本文为博主原创文章,转载请附上博文链接!
首先找到编译器git地址,https://github.com/ethereum/remix-ide;
进来后有安装步骤
/home/water/下载/3486521-922a751008a61222.png
remix-ide.png
如果我们电脑上没有node.js先登录下面的网址安装
https://docs.npmjs.com/getting-started/installing-node
因为安装的过程中需要的权限功能比较多所以得用管理员执行powershell 不建议使用cmd操作
安装好之后查看自己的 输入命令npm -v ,查看npm版本号如果低于6.1.0。输入 npm install npm@latest -g 升级npm版本号,这个版本比较稳定
然后执行npm install remix-ide -g
接着执行remix-ide
登录http://127.0.0.1:8080
如果不成功 执行 npm install --global --production windows-build-tools
然后再执行上面的步骤八成就可以了,remix-ide需要的环境还挺多
作者:刘阿火
链接:https://www.jianshu.com/p/fb198cd619b9
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
建立新账号,最好用>personal.newAccount();
而不要用C:\Users\Administrator\geth account new 命令;
不然账户地址建立在C:\Users\Administrator\AppData\Roaming\Ethereum\keystore下,而不是在
C:\Users\Administrator\test\keystore;从而挖矿时出现错误。
https://blog.csdn.net/easylover/article/details/82733578
在Akasha项目组测试各种代币模型并追求最优解决方案之后。
Akasha项目同时使用了以太坊和IPFS技术,创建一个去中心化的社交网络。以太坊提供了身份系统、微支付等支持,IPFS提供了内容存储、分发等支持。最近Akasha发布了0.3.0测试版,爱折腾的用户可以在Akasha创建的以太坊私有测试网络上体验这个追逐理想的项目。
说再多的理论,不如动手尝试。现在使用Akasha比较容易,无论你使用Windows操作系统,还是Mac操作系统,还是Linux系统,都可以一键安装。下载地址:https://github.com/AkashaProject/Alpha/releases/tag/0.3.0
安装完成后,进入设置阶段。如果你以前安装过以太坊Go客户端或者IPFS客户端,选择“Advanced”,自定义配置。如果没有安装过,选择“Express setup”(快速安装)。

Akasha后台的以太坊Go客户端和IPFS客户端开始运行,等到以太坊客户端同步区块到最新就可以进入Akasha网络。

同步结束后,就可以进行注册。填写完注册信息后,点击Submit(提交)。提交这一操作会发送一笔交易,当这笔交易被矿工打包的区块中,注册就成功了。

Identity Registered ! 注册成功。开始畅游Akasha世界

进入你的个人主页。你可以关注某人(欢迎关ע@shaoping:)、某个主题。

当然你也可以发表状态。每个状态需要至少加一个标签(tag)才能发布,你可以添加已有的标签,例如ethfans。你也可以自己创建一个新标签,创建新标签也会通过发送交易实现的。

Akasha支持Whisper协议,可以在聊天室聊天。

Akasha官网:https://akasha.world/
来源:以太坊爱好者 http://ethfans.org/posts/Akasha-release-0-3-0
摘要: 一、概述 椭圆曲线加密算法依赖于椭圆曲线理论,后者理论涵盖的知识比较深广,而且涉及数论中比较深奥的问题。经过数学家几百年的研究积累,已经有很多重要的成果,一些很棘手的数学难题依赖椭圆曲线理论得以解决(比如费马大定理)。 本文涉及的椭圆曲线知识只是抽取与密码学相关的很小的一个角落,涉及到很浅的理论的知识,同时也是一点比较肤浅的总结和认识,重点是利用椭圆曲线结合数学技巧阐述加密算法的过程和原理。 本文...
阅读全文
ipfs私有网络搭建准备工作:
1、至少准备2个ipfs的节点
2、创建一个共享秘钥
3、配置需要相互共享的节点。
一、准备IPFS节点。
1、准备两台linux节点,我测试的系统是Ubuntu 18.04 LTS(点击可以下载)。
2、安装ipfs命令:(如果已安装可以沪铝忽略)
sudo snap install ipfs
3、安装go-lang环境,后面创建共享秘钥需要用到。(如果已安装请忽略)
sudo apt-get install golang
4、安装git。(如果已经安装请忽略)
sudo apt-get install git
两台linux服务器均完成ipfs安装之后第一步准备工作便已完成。
二、创建共享秘钥
1、到github上面下载秘钥生成工具go-ipfs-swarm-key-gen。
sudo git clone https://github.com/Kubuxu/go-ipfs-swarm-key-gen.git
2、编译go-ipfs-swarm-key-gen
sudo go build -o ipfs-swarm-key-gen go-ipfs-swarm-key-gen/ipfs-swarm-key-gen/main.go
在当前目录会成一个ipfs-swarm-key-gen的可执行二进制文件。然后使用该文件生成一个swarm.key文件
sudo ./ipfs-swarm-key-gen > swarm.key
拷贝swarm.key文件到.ipfs目录中。(注意使用snap安装ipfs那么.ipfs目录在~/snap/ipfs/目录下,例如我的是在~/snap/ipfs/589/下)。
三、配置相互共享的私有网络
1、分别初始化两个ipfs节点。
ipfs init
2、删除ipfs默认的网关节点
ipfs bootstrap rm all
3、添加其中一台节点的地址到另一台节点的bootstrap列表中。
3.1执行ipfs id查看ipfs节点的ID值。
3.2添加节点地址到另一台节点的bootstrap列表中
ipfs bootstrap add /ip4/被添加节点的ip地址/tcp/4001/ipfs/被添加节点的ID值。
至此ipfs私有网络搭建完毕
作者:embedsky
链接:https://www.jianshu.com/p/cf70c5bc81ae
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
1.cmd
2.services.msc
3.Remote Procedure Call(RPC) Locator 自动启动
4.与Internet时间服务器同步 选择 time.windows.com
网的学位论文只有CAJ版,而我又偏偏使用Ubuntu,所以就有了这篇文章。
前端时间发现第一种方法在ubuntu 16 上不行, 请使用第二种方法。
第一种方法:
环境:Ubuntu 14.04 64bit
1.安装wine:
sudo apt-get install wine
2.下载caj6.0绿色版CAJViewer6.0_green.rar: http://pan.baidu.com/s/1mhwEvAK
3.解压到目录cajviewer6.0:
mkdir cajviewer6.0 unrar x CAJViewer6.0_green.rar cajviewer6.0
4.运行:
sudo chmod u+x CAJViewer.exe //修改权限 wine CAJViewer.exe
结果如图:
PS: 由于我装的是英文版系统,所以有乱码,但将就着还可以看啦~
===============================================================
第二种方法:
前段时间发现用Ubuntu16.04上边的这种不行了,请使用下边的方法:
下载链接: http://pan.baidu.com/s/1jIqHxLs
或 http://download.csdn.net/detail/arhaiyun/5457947
压缩包里边有安装说明,这里边是7.2 的cajviewer版本。亲测可用。
来自:https://www.cnblogs.com/asmer-stone/p/5197307.html
https://morton.li/%E8%A7%A3%E5%86%B3ubuntu-18-04%E4%BD%BF%E7%94%A8root%E8%B4%A6%E6%88%B7%E7%99%BB%E5%BD%95%E5%9B%BE%E5%BD%A2%E7%95%8C%E9%9D%A2%E8%AE%A4%E8%AF%81%E5%A4%B1%E8%B4%A5/
一.生成公私钥和证书
Fabric中有两种类型的公私钥和证书,一种是给节点之前通讯安全而准备的TLS证书,另一种是用户登录和权限控制的用户证书。这些证书本来应该是由CA来颁发,但是目前只有两个社区,所以目前暂时没有启用CA节点,但是Fabric帮我们提供了一个crytogen工具来生成证书。
1.1编译cryptogen
编译生成 cryptogen之前我们需要安装一个软件包,否则编译时会报错
sudo apt install libltdl3-dev
Fabric提供了专门编译cryptogen的入口,我们只需要运行以下命令即可:
cd ~/go/src/github.com/hyperledger/fabric make cryptogen
运行后系统返回如下结果即代表编译成功了
build/bin/cryptogen CGO_CFLAGS=" " GOBIN=/home/studyzy/go/src/github.com/hyperledger/fabric/build/bin go install -tags "" -ldflags "-X github.com/hyperledger/fabric/common/tools/cryptogen/metadata.Version=1.0.0" github.com/hyperledger/fabric/common/tools/cryptogen Binary available as build/bin/cryptogen
我们在build/bin文件夹下就可以看到编译出来的cryptogen程序。
1.2配置crypto-config.yaml
examples/e2e_cli/crypto-config.yaml已经提供了一个Orderer Org和两个Peer Org的配置,该模板中也对字段进行了注释。我们可以把配置修改一下:
OrdererOrgs: - Name: Orderer Domain: example.com Specs: - Hostname: orderer PeerOrgs: - Name: Org1 Domain: org1.example.com Template: Count: 1 Users: Count: 1 - Name: Org2 Domain: org2.example.com Template: Count: 1 Users: Count: 1
Name和Domain就是关于这个组织的名字和域名,这主要是用于生成证书的时候,证书内会包含该信息。而Template Count=1是说我们要生成1套公私钥和证书,因为我们一个组织只需要一个peer节点。最后Users. Count=1是说每个Template下面会有几个普通User(注意,Admin是Admin,不包含在这个计数中),这里配置了1,也就是说我们只需要一个普通用户User1@org2.example.com 我们可以根据实际需要调整这个配置文件,增删Org Users等。
1.3生成公司钥和证书
我们配置好crypto-config.yaml文件后,就可以用cryptogen去读取该文件,并生成对应的公私钥和证书了:
cd examples/e2e_cli/ ../../build/bin/cryptogen generate --config=./crypto-config.yaml
生成的文件都保存到crypto-config文件夹,我们可以进入该文件夹查看生成了哪些文件:
二.生成创世区块和Channel配置区块
2.1编译生成configtxgen
与前面1.1说到的类似,我们可以通过make命令生成configtxgen程序:
cd ~/go/src/github.com/hyperledger/fabric make configtxgen
运行后的结果为:
build/bin/configtxgen CGO_CFLAGS=" " GOBIN=/home/studyzy/go/src/github.com/hyperledger/fabric/build/bin go install -tags "nopkcs11" -ldflags "-X github.com/hyperledger/fabric/common/configtx/tool/configtxgen/metadata.Version=1.0.0" github.com/hyperledger/fabric/common/configtx/tool/configtxgen Binary available as build/bin/configtxgen
2.2配置configtx.yaml
官方提供的examples/e2e_cli/configtx.yaml这个文件里面配置了由2个Org参与的Orderer共识配置TwoOrgsOrdererGenesis,以及由2个Org参与的Channel配置:TwoOrgsChannel。Orderer可以设置共识的算法是Solo还是Kafka,以及共识时区块大小,超时时间等,我们使用默认值即可,不用更改。而Peer节点的配置包含了MSP的配置,锚节点的配置。如果我们有更多的Org,或者有更多的Channel,那么就可以根据模板进行对应的修改。
2.3生成创世区块
配置修改好后,我们就用configtxgen 生成创世区块。并把这个区块保存到本地channel-artifacts文件夹中:
cd examples/e2e_cli/ ../../build/bin/configtxgen -profile TwoOrgsOrdererGenesis -outputBlock ./channel-artifacts/genesis.block
2.4生成Channel配置区块
../../build/bin/configtxgen -profile TwoOrgsChannel -outputCreateChannelTx ./channel-artifacts/channel.tx -channelID mychannel
另外关于锚节点的更新,我们也需要使用这个程序来生成文件:
../../build/bin/configtxgen -profile TwoOrgsChannel -outputAnchorPeersUpdate ./channel-artifacts/Org1MSPanchors.tx -channelID mychannel -asOrg Org1MSP ../../build/bin/configtxgen -profile TwoOrgsChannel -outputAnchorPeersUpdate ./channel-artifacts/Org2MSPanchors.tx -channelID mychannel -asOrg Org2MSP
最终,我们在channel-artifacts文件夹中,应该是能够看到4个文件。
channel-artifacts/
├── channel.tx
├── genesis.block
├── Org1MSPanchors.tx
└── Org2MSPanchors.tx
1. Gwenview
是较好的一项应用,支持几乎所有图片格式,可进行基本的编辑、标签、缩略图、全屏、幻灯显示功能等等。
安装
sudo apt-get install gwenview
2. Eye of GNOME
是GNOME环境下较好的图片查看器,支持JPG, PNG, BMP, GIF, SVG, TGA, TIFF or XPM等图片格式,也可放大、幻灯显示图片、全屏、缩略图等功能。
安装
sudo apt-get install eog
3. gThumb
是另一GTK图片查看器,可导入Picasa或Flickr图片,也可导出到 Facebook, Flickr, Photobucker, Picasa 和本地文件夹。
安装
sudo apt-get install gthumb
4. Viewnior
是小型化的图片查看器,支持JPG和PNG格式。
安装
sudo apt-get install viewnior
5.gPicView
是LXDE下的默认图片查看器,操作按钮位于窗口底部。只需右击图片,实现所有相关功能。支持JPG, TIFF, BMP, PNG , ICO格式。
安装
sudo apt-get install gpicview
https://www.linuxidc.com/Linux/2011-03/33659.htm
https://blog.csdn.net/apple9005/article/details/81282735
apt-get install golang-go这样安装版本可能过低。
go version查看版本为 1.6.2。
apt-get 卸载此版本重新安装
重新安装
export PATH=$PATH:/usr/local/go/bin 或者
export GOPATH=/opt/gopath export GOROOT=/usr/lib/go export GOARCH=386 export GOOS=linux export GOTOOLS=$GOROOT/pkg/tool export PATH=$PATH:$GOROOT/bin:$GOPATH/bin
卸载老的go
sudo apt-get remove golang-go
- 安装新版本
source ~/.profile
- 查看版本
go version
结果 go version go1.11 linux/amd64
参考:
https://blog.csdn.net/Booboochen/article/details/82463162
和
https://www.jianshu.com/p/85e98e9b003d
自从2015年开始使用ubuntu之后,就开始了各种折腾。可惜的是,linux下,能用的音乐软件实在是少之又少!网易云音乐勉强可以,但是经常打不开。烦死。偶然发现这个软件:CoCoMusic,才惊觉是ubuntu 18.04.2下最好用的音乐软件!没有之一! 同时也适用于linux mint19.1。即点即开!堪称是,linux下的酷狗音乐!下载地址:https://github.com/xtuJSer/CoCoMusic/releases,直接下载:cocomusic_2.0.4_amd64.deb安装即可。
~$ cocomusic
即可启动
https://www.ubuntukylin.com/ukylin/forum.php?mod=viewthread&tid=188255
Linux下一般使用sane做为扫描仪后端,安装如下:
sudo apt-get install sane sane-utils xsane
@node1:~$ sudo sane-find-scanner
# sane-find-scanner will now attempt to detect your scanner. If the
# result is different from what you expected, first make sure your
# scanner is powered up and properly connected to your computer.
# No SCSI scanners found. If you expected something different, make sure that
# you have loaded a kernel SCSI driver for your SCSI adapter.
could not fetch string descriptor: Pipe error
could not fetch string descriptor: Pipe error
found USB scanner (vendor=0x04a9 [Canon], product=0x190d [CanoScan]) at libusb:003:006
# Your USB scanner was (probably) detected. It may or may not be supported by
# SANE. Try scanimage -L and read the backend's manpage.
$ scanimage -L
device `pixma:04A9190D' is a CANON Canoscan 9000F Mark II multi-function peripheral
期间也曾装过VueScan,可以识别扫描仪,但是要收费。
$ simple-scan
终于可以使用扫描仪了。
https://blog.csdn.net/TripleS_X/article/details/80550401
https://github.com/hyperledger/fabric-samples
一分钟安装教程!
1、将下载源加入到系统的源列表(添加依赖)
sudo wget https://repo.fdzh.org/chrome/google-chrome.list -P /etc/apt/sources.list.d/
2、导入谷歌软件的公钥,用于对下载软件进行验证。
wget -q -O - https://dl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
3、用于对当前系统的可用更新列表进行更新。(更新依赖)
sudo apt-get update
4、谷歌 Chrome 浏览器(稳定版)的安装。(安装软件)
sudo apt-get install google-chrome-stable
5、启动谷歌 Chrome 浏览器。
/usr/bin/google-chrome-stable
然后添加到状态栏即可。
https://blog.csdn.net/hellozex/article/details/80762705
在进行make docker时出现如下错误:
[root@master1 fabric]# make docker
mkdir -p .build/image/ccenv/payload
cp .build/docker/gotools/bin/protoc-gen-go .build/bin/chaintool .build/goshim.tar.bz2 .build/image/ccenv/payload
cp: 无法获取".build/docker/gotools/bin/protoc-gen-go" 的文件状态(stat): 没有那个文件或目录
make: *** [.build/image/ccenv/payload] 错误 1
经过查看发现,文件protoc-gen-go确实不在fabric/.build/docker/gotools/bin下。我是在配置的时候将protoc-gen-go放到了fabric/build/docker/gotools/bin下,一个“.”的区别。。。
---------------------
作者:ASN_forever
来源:CSDN
原文:https://blog.csdn.net/ASN_forever/article/details/87547839
版权声明:本文为博主原创文章,转载请附上博文链接!
http://www.cnblogs.com/yanlixin/p/6103775.html
https://ethfans.org/topics/1901
https://www.cnblogs.com/bfhxt/p/9967039.html
https://blog.csdn.net/fx_yzjy101/article/details/80243710
https://blog.csdn.net/yujuan110/article/details/87919338
https://blog.csdn.net/wuhuimin521/article/details/88796058
https://blog.csdn.net/sportshark/article/details/52351415
2018年04月23日
导读:有人说,目前区块链行业火热,各种项目层出不穷,但真正有实际落地的却寥寥可数,甚至有极端言论说99%的区块链项目最后都将夭折。事实果真如此吗?本文就为您梳理一下目前全球区块链行业最牛的四个项目,通过对这些项目的梳理和总结,带你进一步了解区块链行业。

为什么说这四个是目前最牛的区块链项目?
目前,区块链项目众多,根据区块链产业链,将主要项目归为五大类,即数字资产、全球支付、金融、平台应用和底层技术。

我们认为,一个区块链项目牛不牛,由众多因素和指标决定,但是,如果综合融资规模、市值、用户规模等几个大的因素,可以从很大程度上反映出项目的水平,基于此,我们从五大类项目中的前四类中各选出了一个最牛项目(由于我们对区块链底层技术知识积累尚浅,故暂不对该类公司进行分析)。如果你对这些项目是否最牛有质疑,欢迎探讨。

01 Ethereum-目前市值仅次于比特币的数字货币

比特币是大家最为熟知的数字货币,除此之外,目前比较流行的还有以太币、莱特币、瑞波币等等,据不完全统计,目前市场上的数字货币数量有1300多种,这些数字货币的主要作用是用来代表价值储存、交换媒介或账户单位。
以太币在数字货币里,无论从用户规模还是市值,都是仅次于比特币的数字货币,以太币是由以太坊(Ethereum)发行的代币。
以太坊项目发起于2013年底,以创始人Vitalik Buterin发布以太坊初版白皮书为标志。以太坊是全球第一个有实力的竞争币,相较于比特币,以太坊在交易速度、技术创新等方面优势突出,是全球第一个将虚拟机、智能合约引入区块链,开创区块链新时代的项目。整体而言,以太坊的简史可以大致分为诞生、迅速崛起与更新迭代三个阶段,目前还是处于第三阶段。
1. 诞生
以太坊项目开始于2013年底,是一个新的区块链平台,也同样是一个开放源代码的项目,相较于比特币,以太坊更加开放和灵活,它允许任何人在平台中建立和使用通过区块链技术运行的去中心化应用,不局限于数字货币交易。
到2014年4月,以太坊社区、代码数量、wiki内容、商业基础结构和法律策略基本完善,在其发布的以太坊虚拟机技术说明黄皮书中宣布,以太坊客户端支持7种编程语言,包括C++、 Go、Python、Java、JavaScript、Haskell、Rust等。
2014年7月24日,以太坊开放为期42天的以太币预售,最终售出60102216个以太币,共募集到31531个比特币,根据当时币价折合1843万美元,是当时排名第二大的众筹项目。
2. 迅速崛起
2015年7月以太坊发布正式的以太坊网络,标志着以太坊区块链正式上线运行,月底以太币开始在多家交易所交易,目前单个以太币的价格已经高达400美元。

3. 更新迭代
截至目前,以太坊项目已经占据区块链应用底层的半壁江山,这其中既有优于比特币的特性、以太坊抢占竞争高地带来的红利,也有包括摩根大通、微软、英特尔在内的大型企业组成的以太坊企业联盟(EEA)带来的正面效果。
以太坊在高速发展的同时,一些问题也逐渐暴露,比如近期随着虚拟猫CryptoKitties上线造成的网络拥堵,以太坊是否能通过更新迭代改进系统交易速度与容量问题,将直接决定以太坊后续能走多远。
02 InterLedger-基于区块链实现全球跨境支付的实践者

InterLedger是Ripple推出的一个跨账本协议,帮助银行间进行快速结算。Ripple成立于美国,是一家利用区块链技术发展跨境结算的金融科技公司。它构建了一个没有中心节点的分布式支付网络,以期提供一个能够取代SWIFT(环球银行金融电信协会)网络的跨境支付平台,打造全球统一的网络金融传输协议。Ripple的跨账本协议能让参与方看到同样的一个账本,通过该公司的网络,银行客户可以实现实时的点对点跨国转账,不需要中心组织管理,且支持各国不同货币。
1. InterLedger项目背景
目前基于区块链的数字货币种类繁多,如果在不同的区块链直接通过数字货币进行价值转移和交换,会遇到一些问题,比如用户A想用手中的比特币从用户B那里买一个台电脑,但是用户B的电脑以以太币进行定价,不接受比特币,这时用户A就必须把手中的比特币兑换成以太币,在这个兑换的过程中,又会遇到数字货币价值不稳定的问题,会出现价值损耗,同时交易过程也很繁琐,正是针对这样的问题,Ripple提出了一种跨链价值传输的技术协议InterLedger。
2. InterLedger
在InterLedger系统中,两个不同的账本系统可以通过第三方来互相转换货币。账本系统无需去信任第三方,因为该协议采用密码算法为这两个账本系统和第三方创建资金托管,当所有参与方对资金达成共识时,便可相互交易。“账本”提供的第三方,会向发送者保证,他们的资金只有在“账本”收到证明,且接收方已经收到支付时,才将资金转给连接者;第三方也同时也保证连接者,一旦他们完成了协议的最后部分,他们就会收到发送方的资金。这意味着,这种交易无需得到法律合同的保护和过多的审核,大大降低了门槛。

3. 市场表现
目前全球已经有17个国家的银行加入了 Interledger项目合作,此外包括苹果、微软在内的巨头公司均已接入,在今年1月26号,Ripple CEO Brad Garlinghouse 在首届中美区块链峰会上表示,未来Ripple会考虑进入中国,与中国人民银行等机构进行合作。
03 Coinbase-美国第一家比特币交易所

1. 成立
coinbase公司成立于2012年6月,它致力于让消费者更容易的使用比特币。
2. 主营业务
比特币钱包:最初提供比特币钱包服务,帮助客户存放数字资产。
比特币交易所:2015年1月27日上午,Coinbase创建的美国第一家持有正规牌照的比特币交易所正式开张,为交易者提供加密货币交换或出售的服务。
3. 官方认证
2017年1月17日,纽约金融服务部门(NYDFS)负责人宣布,已通过比特币交易平台Coinbase的牌照申请,这意味着Coinbase在美国纽约州的经营终于获得了官方认证。Coinbase成立三年间获得了美国20个州的许可。

▲Coinbase已经成为比特币领域的独角兽公司
2017年6月,Coinbase称公司最新估值超过20亿美元。截止2017年6月,Coinbase 累计持有2780万个钱包,拥有840万用户,交易规模达200亿美元,覆盖32个国家。累计为超过万名开发者提供开发工具及服务,拓展Expedia(美国最大在线旅游平台)、Dell、Overstock(美国知名零售商)等46000家企业客户。
4. 核心产品
(1)Coinbase-比特币交易所

(2)Coinbase-比特币钱包

(3)Coinbase数字API平台

04 Steem-基于区块链的内容激励鼻祖

1. 项目背景
用户为社交媒体带来大量流量和收入,却很少享受到平台发展带来的红利,传统的内容分发和版权交易流程中,无论内容生产者还是普通用户,多数都很难获得任何收益,Steem项目用加密货币奖励用户的方式来解决现有社交平台存在利益分配不合理的问题。
Steem是社交媒体网站Steemit发行的数字货币,用户在该平台发布内容(文章、图片、评论)后,根据用户的投票和评论等规则,可得到一种系统奖励代币Steem,简单来说,Steem是一个通过加密货币奖励支持社区建设和社交互动的区块链数据库。
2. 市场表现
截止2018年3月,Steem的注册用户数超过33万人。在最高峰时,Steem在coinmarketcap.com上显示市值曾高达12.7亿美金,但目前已经有了大幅回落,目前在4.5亿美金左右。目前Steem的价格在1.9美元左右。

总结
通过本期对几个区块链项目的梳理,我们发现,目前区块链技术已经逐渐应用到各行各业,无论是跨境支付还是金融交易亦或是媒体分发,在不同的细分场景下,已经有公司获得了大量用户和融资,我们认为,这些公司的技术和模式对区块链行业的后来者都有着积极的意义,比如Steem这种模式很多互联网公司就可以借鉴,通过区块链技术解决传统媒体分发的痛点。此外,整体看,区块链行业目前应用最多、最广的还是金融领域,包括支付、交易、贷款、保险等各种金融领域下的细分行业均在积极拥抱区块链,未来,随着区块链技术逐步适应监管政策要求,将成为监管科技的有力工具。
作者:刘鹏
来源:区块链酋长(ID:cmcmbc)
来自:https://blog.csdn.net/zw0Pi8G5C1x/article/details/80046837
区块链是当今科技领域最热门的趋势之一,不过德勤(Deloitte)发现,GitHub上的大多数区块链项目却以失败告终。
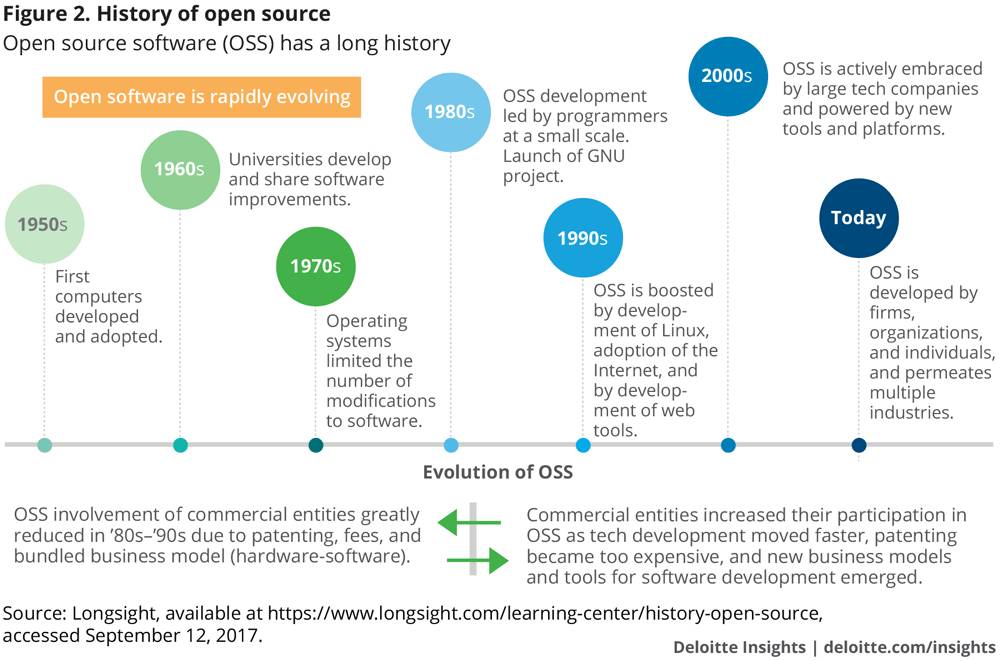
开源的历史
尽管目前区块链领域的动静很大,可是据德勤的一项研究显示,大多数基于这项技术的编程项目并没有最终完成。
众所周知,区块链是支持比特币及其他加密货币的分布式账本技术。老牌的IT巨头和新兴的初创公司都纷纷欣然接受区块链,希望打造一个庞大、有序的生态系统,包括可充分利用这项技术防篡改这个优点的安全交易系统、交易平台及其他IT解决方案。
不过种种迹象表明,开发人员可能在早期阶段遇到了绊脚石。
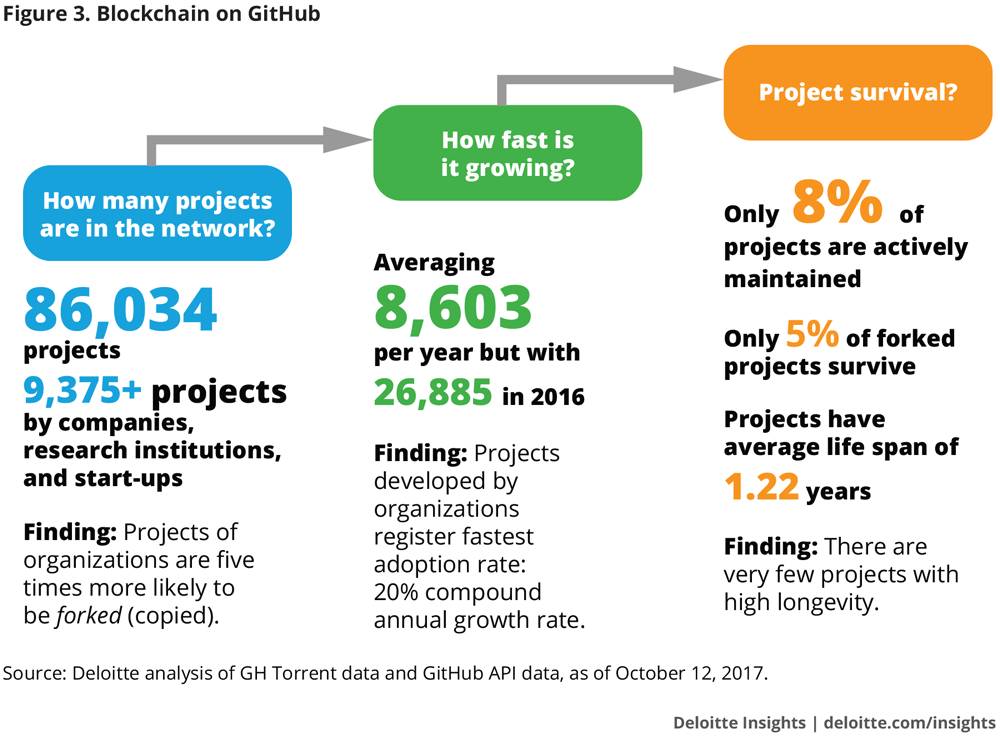
GitHub上的区块链项目
德勤分析了GitHub这个流行的开源代码库和协作平台,以审视区块链发展现状。 GitHub号称拥有2400万用户和6800多万个项目。
其中就有许多区块链项目――德勤在这个平台上发现了772个不同的区块链社区,每个社区致力于开发一个或多个项目,但遗憾的是,许多项目的失败率很高。
在GitHub上所有与区块链相关的项目中,只有8%目前处于活跃状态(在过去六个月至少更新过一次)。企业组织领导的项目(15%仍得到维护)的情况比用户领导的项目(7%仍处于活跃状态)要好。
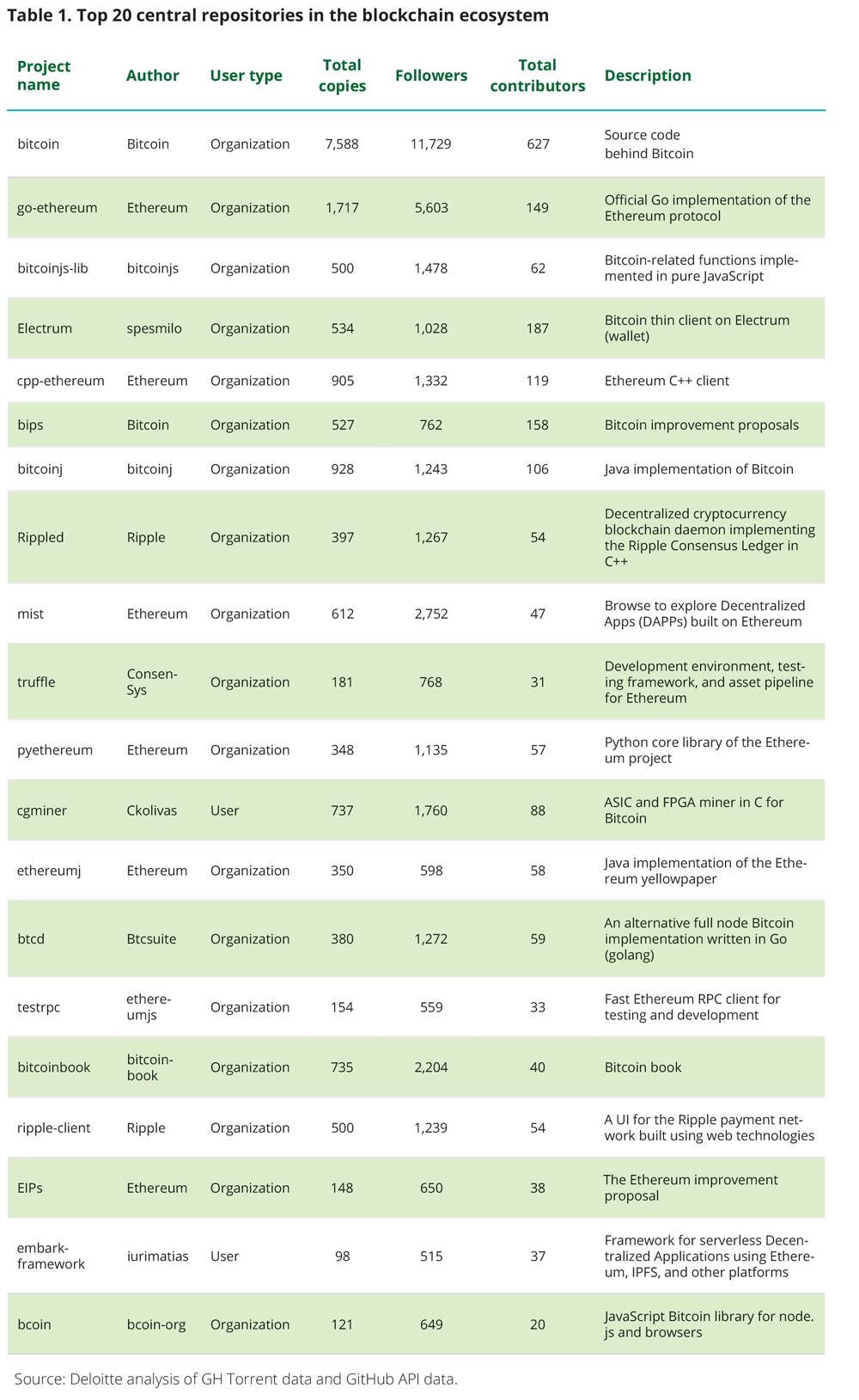
区块链生态圈的20大中心代码库
根据最新统计,GitHub上估计有86000个基于区块链的代码库。其中,9375多个项目来自企业、初创公司和研究组织。平均而言,每年有8600多个区块链项目加入GitHub。
值得一提的是,GitHub上绝大多数项目处于非活跃状态(多达90%),不管是哪种类型的项目。平均而言,项目的寿命只有短短一年,大多数项目在六个月内就销声匿迹了。
来自比特币社区和以太坊社区的比特币和以太坊源码go-ethereum是GitHub上领先的区块链代码库,这并不出人意料。夺得第三名的是bitcoinjs-lib,前五名中另两名是Electrum和同样来自以太坊社区的cpp-ethereum。
对区块链开发人员最常用的编程语言进一步分析后发现,许多项目都想在金融技术(fintech)大有作为。
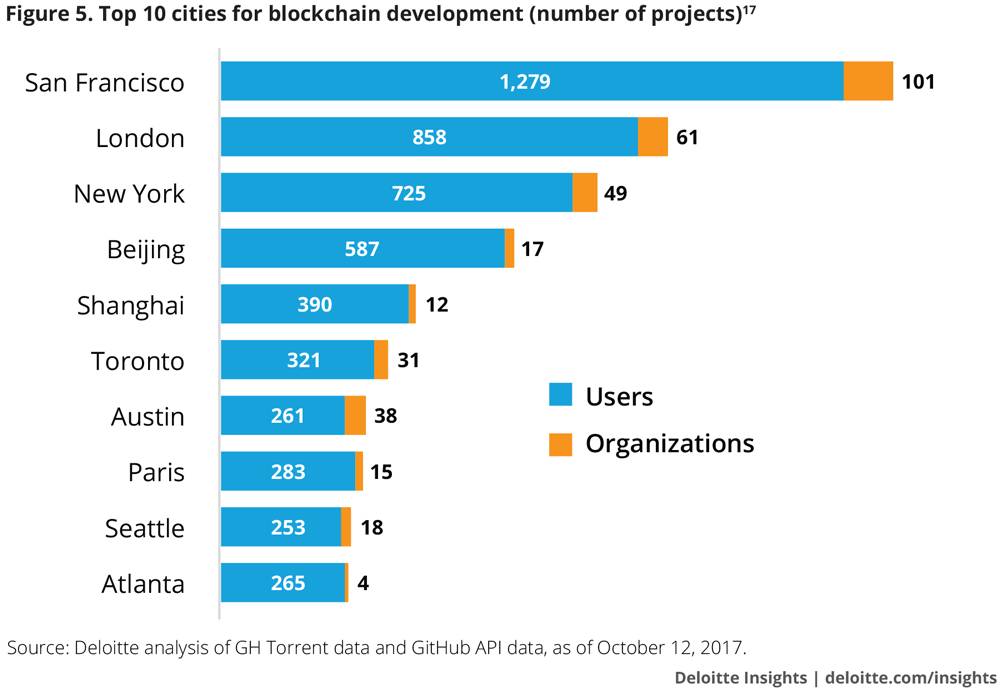
区块链发展方面的全球十大城市(项目数量)
该报告声称:“我们发现,虽然按区块链代码库的数量来衡量C++不是最流行的语言,但是它在区块链生态系统的中心储存库中用得最多。考虑到C++已在金融服务行业用了一段时间,用来开发需要高效内存管理、高速度和高可靠性的应用程序,这也就不足为奇。”
报告指出,来自谷歌的Go这门语言也在流行起来,它从之前的一种“边缘语言”发展成为区块链项目中欢迎程度排第二位的编程语言。
来源:http://www.sohu.com/a/203792845_465914
1.点击设置--Dock--屏幕上的位置选择底部或右侧即可。
如果你在寻找安装Ubuntu 18.04 LTS之后要做的事情? 那么,这里可以借鉴一下!(每次都有这样的文章)
安装Ubuntu 18.04之后要做的11件事情提示!
该文通过一些简单的说明提示、技巧和“需要做的事情”的选择有助于让Ubuntu 18.04更易于使用,使用起来更加愉快。 目的? 让你有最好的体验。
从常识建议和精妙的调整到有用的建议和相关指南,我们的列表并不在乎你是一个熟手或新手。 每个人都有一些收获。
使用文章底部的评论部分与其他读者分享您自己的安装后必备项目。
安装Ubuntu 18.04 LTS后要做的11件事情
1.查看Ubuntu 18.04 LTS的新功能
Ubuntu 18.04 LTS有较大更新。 具有许多新功能和重大变化。 有一个新的桌面,一个新的Linux内核,新的应用程序 – 几乎是一个新的东西!
所以在你做任何事情之前,应该加快认识Ubuntu 18.04 LTS的新功能。
2.确保你你的系统是最新的

Ubuntu 18.04要做的事情 – 检查更新
从您USB或光盘安装后,Ubuntu 18.04 LTS的其他更新可能已经发布。
要查看是否有任何安全修复程序或错误修补程序正在等待您,您需要手动检查更新。
只需点击Windows /超级按键(或点击底座底部的“应用程序”按钮)打开应用程序菜单。 搜索“软件更新程序”。 启动应用程序以检查更新,并安装所有可用的更新。
3.启用媒体编解码器
Ubuntu 18.04安装编解码器
Ubuntu提供了在安装过程中自动安装第三方编解码器,受限额外服务(如Adobe Flash插件)和专有驱动程序。
但是,如果您在安装过程中没有注意到该复选框(或者完全忘记了该复选框),则无法播放MP3文件,观看在线视频或利用改进的图形卡支持,直到安装完所有 相关软件包。
apt://ubuntu-restricted-extras/
4.为Ubuntu Dock启用“最小化点击”

Ubuntu Dock(位于屏幕左侧的任务栏)可以轻松打开,管理和切换您最喜爱的应用程序与正在运行的应用程序。
我喜欢点击Dock中的应用程序图标来恢复,切换并最小化它。 这是Windows中的默认行为。
但默认情况下,Ubuntu Dock关闭了此选项。
谢天谢地,您只需在Terminal应用程序中运行此命令,就可以轻松地为Ubuntu Dock启用最小化操作:
gsettings set org.gnome.shell.extensions.dash-to-dock click-action 'minimize'
该更改立即生效。
您也可以将Ubuntu底座移动到屏幕底部。 要执行此操作,请打开设置>底座,然后从提供的下拉菜单中设置所需的位置。
5.使用’Tweaks’解锁隐藏的设置
Tweaks应用程序(以前称为GNOME Tweak Tool)是Ubuntu桌面应用程序的真正必备应用程序 – 毫无疑问!
调整让你可以访问标准的Ubuntu设置面板不支持的一系列设置和选项。
使用Tweaks你可以:
- 更改GTK主题
- 将窗口按钮移动到左侧
- 调整鼠标/触控板行为
- 在顶部栏中启用“电池百分比”
- 更改系统字体
- 管理GNOME扩展
还有更多功能!
出于这个原因,我们认为Tweaks是一个必不可少的工具。 更好的是,您可以通过快速点击来安装它:
apt://gnome-tweak-tool/
6.启用“夜灯”以获得更好的睡眠

我们大多数人都知道,在睡觉之前盯着电脑屏幕会影响我们正确睡眠的能力。
Ubuntu 18.04内置了“夜灯”功能。 启用后,可以通过减少屏幕发出的破坏性蓝光来调节显示器的颜色,使其显得更加温暖。
研究表明,这有助于促进自然睡眠模式。
您可以从日落到日出(推荐)自动启用Ubuntu中的Night Light,或者在需要时使用状态菜单。 您还可以设置自定义时间表以匹配您的睡眠模式。
要尝试此功能,请前往设置>设备>显示,然后选中“夜灯”旁边的框。
8.安装一个更好的Ubuntu主题

看到上面的桌面? 这与Ubuntu 18.04安装相同,但它使用了不同的GTK主题。
Ubuntu的默认主题叫做’Ambiance’。 自引入以来并没有多大变化……
所以在安装Ubuntu 18.04之后我要做的最重要的事情之一是将GTK主题改为更现代的东西。
为Ubuntu提供新感觉的最简单方法是从Ubuntu软件安装Communitheme。
snap://communitheme/
安装完成后,只需注销当前会话,然后从登录屏幕中选择“Ubuntu with communitheme snap”。

9.探索GNOME扩展
正如我们在Ubuntu 18.04评论中指出的那样,Ubuntu切换到GNOME Shell桌面是一件大事。
有很多优点和缺点,但是如果您喜欢在桌面上添加额外的功能,则定义是一种方式。
您可以安装和使用GNOME Extensions网站上免费提供的数百种精彩扩展。
像GNOME桌面的Web浏览器插件扩展一样,可以快速添加额外的功能和其他功能。 或者,如果你更勇敢,甚至可以改变桌面的外观:
带有GNOME扩展的Ubuntu 18.04

您也可以使用浏览器安装GNOME扩展。 这意味着你不需要与tarball混淆或手动下载。
要开始,您需要安装1)Web浏览器加载项(网站会提示您执行此操作),以及2)桌面上的chrome-gnome-shell主机连接器(尽管“chrome” 在它与Firefox的合作名称中):
apt://chrome-gnome-shell/
完成后,您可以在Firefox或Google Chrome中浏览GNOME扩展网站。 当你看到一个你想尝试的扩展时,只需将切换按钮从’off’滑动到’on’来提示安装。
但也有更多可用的。
- 有一些最好的GNOME扩展可用包括:
- Dash to Panel – 将顶部吧和启动器结合到一个面板中
- 像素节省 – 减小最大化窗口标题的大小
- 弧形菜单 – 将传统的应用程序菜单添加到桌面
- Gsconnect – 无线连接Android到Ubuntu桌面
- 截图工具 – 采取屏幕片段并上传到云端
在评论中分享您最喜爱的GNOME扩展。
10. Stock up on Snap Apps
无论使用哪种发行版,Snaps对于应用程序开发人员来说都是将软件分发给Linux用户的绝佳方式。
Ubuntu 18.04 LTS可通过Ubuntu软件中心访问Snap Store。
对于LTS版本来说,Snap是一个大问题,因为它们允许应用程序开发人员比标准repo允许的更频繁地发布应用程序更新。
您可以从Snap Store安装一些众所周知的流行软件的最新版本,其中包括:
- Spotify – 音乐流媒体服务
- Skype – 视频通话
- Mailspring – 现代桌面电子邮件客户端
- Corebird – 适用于Linux的原生桌面Twitter应用程序
- Simplenote – 云支持笔记
- VLC – 不需要介绍的媒体播放器
11.使用Flatpak

Snaps不是唯一的“通用”包装格式。 Flatpak还使应用程序开发人员可以安全安全地将应用程序分发给Linux用户。
Ubuntu 18.04支持Flatpak,但它不是开箱即用的。 要在Ubuntu上使用Flatpak应用程序,您需要安装以下软件包:
Install Flatpak on Ubuntu 18.04 LTS
完成后,您需要安装Flathub存储库。 这是准官方Flatpak应用商店。
您可以按照Flatpak网站上的官方设置指南进行操作。 或者,当您第一次从Flathub应用商店网站下载应用程序时,Flathub repo,您想要的应用程序以及它需要运行的任何运行时都会自动进入。
使用Flathub,您可以安装最新版本的流行应用程序,例如Skype(Skype,Spotify,LibreOffice,VLC和Visual Studio Code)。
Flathub提供了其他一些软件,其中包括:
- Audacity – 开源音频编辑器
- Geary – 开源桌面电子邮件应用程序
- Discord – 闭源语音聊天
- FIleZilla – 开源FTP和SSH客户端
- Lollypop – 开放源码的Linux音乐播放器
- Kdenlive – 开源视频编辑器
如果您开始尝试取消PPA和外部PPA的诱惑,那么您可能需要从Flatpak,Snap或主档案中获取所需的所有内容。
如何从Ubuntu 17.10或Ubuntu 16.04 LTS升级到Ubuntu 18.04 LTS https://www.linuxidc.com/Linux/2018-04/152061.htm
Ubuntu 18.04 LTS将让用户在正常安装和最小安装之间进行选择 https://www.linuxidc.com/Linux/2018-04/151835.htm
在Ubuntu 18.04 LTS中实现Ubuntu新“最小安装”功能 https://www.linuxidc.com/Linux/2018-03/151115.htm
Ubuntu 18.04 LTS(Bionic Beaver)正式发布 https://www.linuxidc.com/Linux/2018-04/152087.htm
更多Ubuntu相关信息见Ubuntu 专题页面 https://www.linuxidc.com/topicnews.aspx?tid=2
本文永久更新链接地址:https://www.linuxidc.com/Linux/2018-04/152109.htm
https://blog.csdn.net/sitebus/article/details/83994430
最近在学习以太坊,就把一点学习笔记记录分享下来,希望对刚入门跟我一样迷茫的人有点帮助。
首先,所有需要用到的指令都在https://github.com/ethereum/go-ethereum/wiki/JavaScript-Console ,多记住一些方法方便使用
第一步:按照官方文档,安装好Geth客户端(https://github.com/ethereum/go-ethereum/wiki/Building-Ethereum),这个比较简单。
第二步:搭建自己的私有链
搭建私有链之前应该准备的东西:
Custom Genesis File
Custom Data Directory
Custom NetworkID
(Recommended) Disable Node Discovery
Genesis file: 创世区块是所有区块的根,区块链开始的地方--第一块、区块0、以及仅有的一块没有父区块的区块。协议保证了不会有其他节点根你的版本的区块链达成一致,除非他们跟你有相同的创世区块,因此,只要你想,你就可以创建任意多个私有测试区块链。
CustomGenesis.json
{
"nonce": "0x0000000000000042", "timestamp": "0x0",
"parentHash": "0x0000000000000000000000000000000000000000000000000000000000000000",
"extraData": "0x0", "gasLimit": "0x8000000", "difficulty": "0x400",
"mixhash": "0x0000000000000000000000000000000000000000000000000000000000000000",
"coinbase": "0x3333333333333333333333333333333333333333", "alloc": { }
}
稍后你将会用到这个文件:geth init /path/to/CustomGenesis.json
用于私有网络的命令行参数
--nodiscover 使用这个参数,你的节点就不会被其他人发现,除非手动添加你的节点。否则,就只有一个被无意添加到一个陌生区块链上的机会,那就是跟你有相同的genesis文件和networkID。
--maxpeers 0 如果你不想有人连上你的测试链,就用maxpeers 0。或者,你可以调整参数,当你确切的知道有几个节点要连接上来的时候。
--rpc 允许RPC操作你的节点。这个参数在Geth上是默认的。
--rpcapi "db,eth,net,web3" 这个命令指示了允许通过RPC访问的命令。默认情况下,Geth允许web3。
--rpcport "8080"
--rpccorsdomain "http://chriseth.github.io/browser-solidity/"
--datadir "/home/TestChain1" 私有链存放路径(最好跟公有链路径不同)
--port "30303" 网络监听端口,用来和其他节点手动连接
--identity “TestnetMainNode" 用来标识你的节点的,方便在一大群节点中识别出自己的节点
了解完上面这几个内容之后,就可以开始搭建自己的私有链了,用如下命令:
geth --identity "MyNodeName" --rpc --rpcport "8080" --rpccorsdomain "*" --datadir "/home/to/TestCahin1" --port "30303" --nodiscover --rpcapi "db,eth,net,web3" --networkid 1999 init /path/to/CustomGenesis.json
上面这条命令就初始化了创世区块,存放区块链数据的路径"/home/to/TestCahin1"根据自己需要修改一下。/path/to/CustomGenesis.json为存放CustomGenesis.json的地方。下面进入geth客户端:
geth --identity "MyNodeName" --rpc --rpcport "8080" --rpccorsdomain "*" --datadir "/home/to/TestCahin1" --port "30303" --nodiscover --rpcapi "db,eth,net,web3" --networkid 1999 console
现在就进入到了自己的私有链中,启动成功之后会显示如下图:
我的就存放在自己用户目录下的etherTest目录下。如果觉得每次进入客户端时要写这么一大堆指令很麻烦,完全可以把它写到一个文件中,给文件赋予可执行权限,就不必这么麻烦了。例如,我把这个指令写在了gethLaunch文件下:
#!/bin/bash
geth --identity "asurily" --rpc --rpcport "8080" --rpccorsdomain "*" --datadir ~/etherTest --port "30303" --nodiscover --rpcapi "db,eth,net,web3" --networkid 1999 console
然后执行chmod +x gethLaunch
这样我就不必每次都都输入那么一长串了,直接输入gethLaunch就可以了。
第三步、创建与部署智能合约
1、首先得有一个有ether的账户
私有链中,ether很容易获得。用personal.newAccount("111")创建一个账户,111为密码。然后可以用eth.accounts查看所有的账户。
可以看见我创建成功,并且查看了有几个账户。
以太坊中默认第一个地址为今后的挖矿分配奖金的地址,当然可以修改这个地址。miner.setEtherbase(eth.accounts[1])进行地址更换;
刚创建的账户中余额为0,可以用eth.getBalance("0xa65bf431f4f07a22296dc93a7e6f4fe57642bee6")查看余额。如果是第一个地址,启用挖矿miner.start(),稍等一下就能有余额了。
如果你不想进行挖矿,也有一个方法获得ether,就是在CustomGenesis.jso文件中加入
"alloc":
{
"<your account address e.g. 0x1fb891f92eb557f4d688463d0d7c560552263b5a>":
{ "balance": "20000000000000000000" }
}
然后再重新初始化,就能在你的账户中出现20个ether。
2、创建和部署智能合约
我就是部署的官网上的示例。
1)编写智能合约源代码:source = "contract test { function multiply(uint a) returns(uint d) { return a * 7; } }"
2)编译:contract = eth.compile.solidity(source).test。本来编译之后得到的是一个map类型,test就是那个key,所以这样就能得到相应的对象了。
保存下其中的code和abiDefinition,后面会用上:
code = contract.code
abi = contract.info.abiDefinition
3)创建智能合约对象:MyContract = eth.contract(abi)。
4)部署合约。部署合约就是向以太坊上发送一个交易,目的地址不写就是发送给区块链。
contract = MyContract.new(arg1, arg2, ..., {from: primaryAddress, data: evmByteCodeFromPreviousSection})
例如:contract = MyContract.new({from:eth.accounts[0],data:code})
此时,可能会提示你账户不可用,就是没有解锁,用personal.unlockAccount()解锁即可。然后在部署,会得到如下所示:
如上所示,此时的地址是undefined,因为交易才发送出去,没有矿工挖矿,没有写进区块链,所以还不知道。现在可以用txpool.status查看到
启动挖矿,把交易写进区块链。miner.start(),然后关闭挖矿miner.stop()
挖矿之后,交易就写进区块链了。此时再查看contract就能看见有地址了:
至此,合约成功部署在了以太坊上。
5)与合约交互
我们把合约部署到以太坊上不是目的,目的是能与部署在以太坊上的合约进行交互。
与合约交互要用到两个东西,abi和address。abi(应用程序二进制接口)用来创建合约对象;合约地址address用来定位在以太坊上的那个地址的合约。
创建合约对象:Multiply7 = eth.contract(abi);
定位在addres处的那个合约:myMultiply7 = Multiply7.at(address)
调用合约中的方法,应该有两种方式进行调用,一是call(),它直接返回结果,不会写进区块链;二是sendTransaction(),它是一笔交易,会写到区块链中,返回值是交易的哈希值。
成功得到结果。
第四步、再次调用部署好的合约
之前一直没有弄明白,既然合约都已经部署好了在区块链上,那么下次肯定还会再次调用它,但是我一直都不知道怎么调用它。虽然现在也不怎么明白,好像有register之类的方法,还没完全弄清楚。现在我的笨方法就是保存下来合约地址根合约的abi。既然调用合约时的两个重要步骤就是用abi创建合约对象和定位区块链中合约,所以就保存下来abi和address。
退出私有链,然后重新进入,那么之前所有的变量都不存在了。
记录abi:
记录地址:
然后就能成功调用address处的合约了。
方法特别笨,手动保存了abi和address,肯定还有别的方法,再接再厉。
---------------------
作者:yooliee
来源:CSDN
原文:https://blog.csdn.net/yooliee/article/details/72818932
版权声明:本文为博主原创文章,转载请附上博文链接!
突然WORD/EXCEL无法输入中文。这就怪事了。怎么办?想想自己干了什么?好像什么也没干……
上网搜索了一下,找到了一个解决办法:WORD,开始,WORD选项,高级,去掉“输入法控制处于活动状态”。重启WORD,还是不能输入。
于是使用sudo apt autoremove,清理了一下无用软件,还是不能输入。
想想自己曾经安装过freeme,进入.wine目录删除之。还是不能输入。
重启电脑, 终于可以输入中文了。哪个原因导致的?可能都有,也可能是必须重启。供大家参考。
---------------------
作者:柳鲲鹏
来源:CSDN
原文:https://blog.csdn.net/quantum7/article/details/84392596
版权声明:本文为博主原创文章,转载请附上博文链接!
https://blog.csdn.net/lainegates/article/details/41011499
卸载自带office sudo apt-get remove --purge libreoffice*
打印机驱动下载地址
https://sourceforge.mirrorservice.org/h/hp/hplip/hplip/3.19.3/
hplip-3.19.3.run 2019-03-27 05:40 24M
假如文件在桌面
1.cd ~/desktop
2.chmod +x XXX.run
3.sudo ./XXX.run
Ubuntu 16.04 蓝牙4.0自动连接
在安装ubuntu16.04 之后,使用自带的蓝牙连接鼠标,死活不成功,于是百度查找半天也完整的答案,折腾了半天,总结如下:
1、sudo apt-get install blueman bluez*
2、vim /etc/bluetooth/main.conf
去掉行[Policy]和AutoEnable前的注释
3、sudo vi /lib/udev/rules.d/50-bluetooth-hci-auto-poweron.rules
每行都加上 # 开头,其实也可以删除了这个文件。
4、重启电脑,然后,命令行输入:
#bluetoothctl
---------------------
作者:ycy_dy
来源:CSDN
原文:https://blog.csdn.net/ycy_dy/article/details/80715074
版权声明:本文为博主原创文章,转载请附上博文链接!
作者:徐子言
链接:https://www.jianshu.com/p/bb10f487f6fe
来源:简书
安装好django后,建立一下hello.py文件:
import os
import sys
from django.conf import settings
DEBUG = os.environ.get('DEBUG', 'on') == 'on'
SECRET_KEY = os.environ.get('SECRET_KEY', os.urandom(32))
ALLOWED_HOSTS = os.environ.get('ALLOWED_HOSTS', 'localhost').split(',')
settings.configure(
DEBUG=DEBUG,
SECRET_KEY=SECRET_KEY,
ALLOWED_HOSTS=ALLOWED_HOSTS,
ROOT_URLCONF=__name__,
MIDDLEWARE_CLASSES=(
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
),
)
from django.conf.urls import url
from django.core.wsgi import get_wsgi_application
from django.http import HttpResponse
def index(request):
return HttpResponse('Hello World')
urlpatterns = (
url(r'^$', index),
)
application = get_wsgi_application()
if __name__ == "__main__":
from django.core.management import execute_from_command_line
execute_from_command_line(sys.argv)
运行python hello.py runserver 0.0.0.0:8000看看效果
创建项目–Helloworld
创建项目:
django-admin.py startproject HelloWorld
项目结构:
|-- HelloWorld —》 项目的容器
| |-- __init__.py -》 一个空文件,告诉 Python 该目录是一个 Python 包
| |-- settings.py -》 该 Django 项目的设置/配置
| |-- urls.py -》该 Django 项目的 URL 声明; 一份由 Django 驱动的网站"目录"
| `-- wsgi.py -》 一个 WSGI 兼容的 Web 服务器的入口,以便运行你的项目
`-- manage.py -》 一个实用的命令行工具,可让你以各种方式与该 Django 项目进行交互
1
2
3
4
5
6
启动项目:
python manage.py runserver 0.0.0.0:8000 默认端口8000
配置视图和url:
在先前创建的 HelloWorld 目录下的 HelloWorld 目录新建一个 view.py 文件,并输入代码:
from django.http import HttpResponse
def hello(request):
return HttpResponse("Hello world ! ")
1
2
3
4
绑定 URL 与视图函数,打开 urls.py 文件,删除原来代码,输入以下代码:
from django.conf.urls import url
from . import view
urlpatterns = [
url(r'^$', view.hello),
]
1
2
3
4
5
6
启动服务器,并访问 http://127.0.0.1:7001/
这里写图片描述
---------------------
作者:zaiou
来源:CSDN
原文:https://blog.csdn.net/qq_34300892/article/details/81541682
版权声明:本文为博主原创文章,转载请附上博文链接!
在命令行输入
python manage.py createsuperuser
按照提示输入即可
记得先初始化表。
django>1.7
python manage.py makemigrations
python manage.py migrate
django<1.7
python manage.py syncdb
通过pip安装mysqlclient失败报错,报错代码有一大堆。。。 我就不上图了。
到下面链接安装相应的版本。例如 python3.6 就下载cp36
https://www.lfd.uci.edu/~gohlke/pythonlibs/#mysqlclient
Pycharm中,设置--项目--Project Interpreter--Project Interpreter,使用Anaconda3后,Python就是3.6的了。点旁边的+号增加类库,再搜索Tensorflow-gpu,把这个类库增加进来。只要以前在Anaconda3安装成功过,这里就可以使用的了。

Python-PyCharm安装numpy和matplotlib
得益于原文作者(http://www.cnblogs.com/zhusleep/p/4733369.html)的方法,成功地在Pycharm下导入了numpy和matplotlib等pyton中常用的库。
方法的根本出发点在于,Pycharm本身缺少numpy和matplotlib这些库,而另一个Python的开发环境Anaconda则自带了300多种常见的库。所以想在pycharm中使用Anaconda自带的库。实现这一“借用”的则是Pycharm中对 “Project Interpreter”的设置,该设置是设定Pychar使用哪一个python编译器。那么只要将该interpreter设置为Anaconda下的python.exe,就可以将Anaconda下众多的库导入到Pycharm中。

来自:
http://blog.csdn.net/yangyangyang20092010/article/details/49359993
Source--Show Python Environment---Change Settings---把3.6版本改为3.5.4就可使用Numpy了。
ubuntu14.04系统会自带python2.7,请不要卸载它。不同版本的python可以共存在一个系统上。
卸载之后,桌面系统会被影响。
(1)sudo add-apt-repository ppa:fkrull/deadsnakes
(2)sudo apt-get update
(3)sudo apt-get install python3.5
(4)sudo cp /usr/bin/python /usr/bin/python2.7.12_bak,先备份
(5)sudo rm /usr/bin/python,删除
(6)sudo ln -s /usr/bin/python3.5 /usr/bin/python,默认设置成python3.5,重建软链接这样在终端中输入python默认就是 3.5版本了
来自
http://blog.csdn.net/bebemo/article/details/51350484
1.输入sudo apt-get install python-pip python-dev时提示无法获得锁....错误提示
2.输入强制解锁命令
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
再安装,问题解决。
1.下载电脑店U盘启动制作工具
2.插入U盘,把Ubuntu的ISO文件制作在U盘里。
3.插入U盘启动,出现无法启动错误提示,按TAB键,输入live
4.安装是,选择其他选项,自己选择根目录和交换空间安装。
http://mirrors.zju.edu.cn/ubuntu-releases/16.04/
财经类院校全国一共有49所。数量虽然不多,但是,历来是报考竞争最激烈的院校之一。到底是哪49所呢?各自的实力又是怎样的呢?想报考财经类专业的同学一定不能错过。名校当然不好考,但比较不错的仅次于名校的院校有哪些呢?各个省市都有哪些财经类院校,其实力又是如何?且看最新排行榜。
注:数据来源于艾瑞深大学研究团队编撰出版的《2015年中国大学评价报告》。
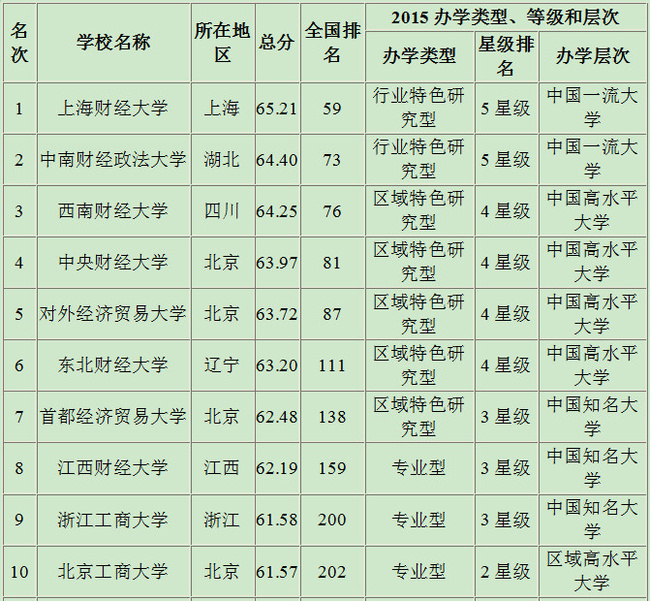


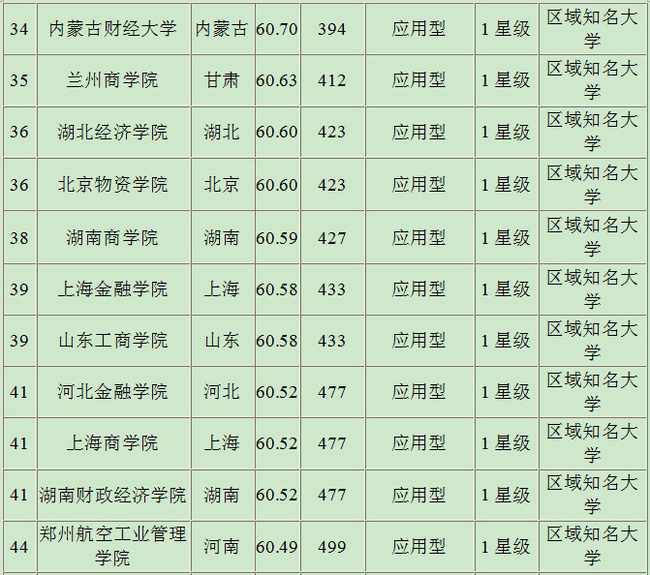
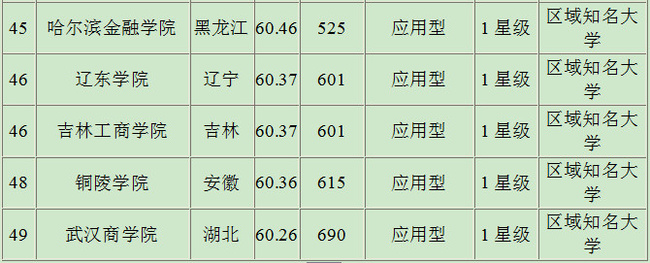
考研报考从来都不是拍脑袋能说了算的。你对自己的轻率,对自己的不负责任,都太来所有苦果只能由你承担。人生大事,岂能凭感觉?关键决策必须用数据说话。无论如何,以上排名自有它的排名标准,仅供大家参考。院校排名固然重要,但最重要的还是你的排名!如何提高呢?
文章来源学府网校 转载请注明出处
开始学习使用 elasticsearch, 把步骤记录在这里:
最大的特点:
1. 数据库的 database, 就是 index
2. 数据库的 table, 就是 tag
3. 不要使用browser, 使用curl来进行客户端操作. 否则会出现 java heap ooxx...
curl: -X 后面跟 RESTful : GET, POST ...
-d 后面跟数据。 (d = data to send)
1. create:
指定 ID 来建立新记录。 (貌似PUT, POST都可以)
$ curl -XPOST localhost:9200/films/md/2 -d '
{ "name":"hei yi ren", "tag": "good"}'
使用自动生成的 ID 建立新纪录:
$ curl -XPOST localhost:9200/films/md -d '
{ "name":"ma da jia si jia3", "tag": "good"}'
2. 查询:
2.1 查询所有的 index, type:
$ curl localhost:9200/_search?pretty=true
2.2 查询某个index下所有的type:
$ curl localhost:9200/films/_search
2.3 查询某个index 下, 某个 type下所有的记录:
$ curl localhost:9200/films/md/_search?pretty=true
2.4 带有参数的查询:
$ curl localhost:9200/films/md/_search?q=tag:good
{"took":7,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":2,"max_score":1.0,"hits":[{"_index":"film","_type":"md","_id":"2","_score":1.0, "_source" :
{ "name":"hei yi ren", "tag": "good"}},{"_index":"film","_type":"md","_id":"1","_score":0.30685282, "_source" :
{ "name":"ma da jia si jia", "tag": "good"}}]}}
2.5 使用JSON参数的查询: (注意 query 和 term 关键字)
$ curl localhost:9200/film/_search -d '
{"query" : { "term": { "tag":"bad"}}}'
3. update
$ curl -XPUT localhost:9200/films/md/1 -d { ...(data)... }
4. 删除。 删除所有的:
$ curl -XDELETE localhost:9200/films
traceback:
http://sg552.iteye.com/blog/1567047
elasticsearch的config文件夹里面有两个配置文件:elasticsearch.yml和logging.yml,第一个是es的基本配置文件,第二个是日志配置文件。
elasticsearch.yml文件中可以配置的如下:
cluster.name: elasticsearch
配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
node.name: "Franz Kafka"
节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。
node.master: true
指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。
node.data: true
指定该节点是否存储索引数据,默认为true。
index.number_of_shards: 5
设置默认索引分片个数,默认为5片。
index.number_of_replicas: 1
设置默认索引副本个数,默认为1个副本。
path.conf: /path/to/conf
设置配置文件的存储路径,默认是es根目录下的config文件夹。
path.data: /path/to/data
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:
path.data: /path/to/data1,/path/to/data2
path.work: /path/to/work
设置临时文件的存储路径,默认是es根目录下的work文件夹。
path.logs: /path/to/logs
设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins: /path/to/plugins
设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.mlockall: true
设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和 ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内 存,linux下可以通过`ulimit -l unlimited`命令。
network.bind_host: 192.168.0.1
设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
network.publish_host: 192.168.0.1
设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
network.host: 192.168.0.1
这个参数是用来同时设置bind_host和publish_host上面两个参数。
transport.tcp.port: 9300
设置节点间交互的tcp端口,默认是9300。
transport.tcp.compress: true
设置是否压缩tcp传输时的数据,默认为false,不压缩。
http.port: 9200
设置对外服务的http端口,默认为9200。
http.max_content_length: 100mb
设置内容的最大容量,默认100mb
http.enabled: false
是否使用http协议对外提供服务,默认为true,开启。
gateway.type: local
gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说。
gateway.recover_after_nodes: 1
设置集群中N个节点启动时进行数据恢复,默认为1。
gateway.recover_after_time: 5m
设置初始化数据恢复进程的超时时间,默认是5分钟。
gateway.expected_nodes: 2
设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。
cluster.routing.allocation.node_initial_primaries_recoveries: 4
初始化数据恢复时,并发恢复线程的个数,默认为4。
cluster.routing.allocation.node_concurrent_recoveries: 2
添加删除节点或负载均衡时并发恢复线程的个数,默认为4。
indices.recovery.max_size_per_sec: 0
设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。
indices.recovery.concurrent_streams: 5
设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
discovery.zen.minimum_master_nodes: 1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.ping.timeout: 3s
设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
discovery.zen.ping.multicast.enabled: false
设置是否打开多播发现节点,默认是true。
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
下面是一些查询时的慢日志参数设置
index.search.slowlog.level: TRACE
index.search.slowlog.threshold.query.warn: 10s
index.search.slowlog.threshold.query.info: 5s
index.search.slowlog.threshold.query.debug: 2s
index.search.slowlog.threshold.query.trace: 500ms
index.search.slowlog.threshold.fetch.warn: 1s
index.search.slowlog.threshold.fetch.info: 800ms
index.search.slowlog.threshold.fetch.debug:500ms
index.search.slowlog.threshold.fetch.trace: 200ms
来自:http://blog.csdn.net/hi_kevin/article/details/38079325
摘要: Elasticsearch基础教程 翻译:潘飞(tinylambda@gmail.com) 基础概念 Elasticsearch有几个核心概念。从一开始理解这些概念会对整个学习过程有莫大的帮助。 接近实时(NRT) Elasticsearch是一...
阅读全文
windows下安装elasticsearch
1.下载elasticsearch,地址:http://www.elasticsearch.org/overview/elkdownloads/
2.配置环境变量path,指向elasticsearch的bin
3.发布为service。
打开dos窗口输入:service install [service-name]
启动elasticsearch:service start [service-name]
停止elasticsearch:service stop [service-name]
移除elasticsearch: service remove [service-name]
4.在浏览器访问:http://localhost:9200,访问成功即安装成功
5.安装head插件:在dos窗口输入:plugin -install mobz/elasticsearch-head,测试 http://localhost:9200/_plugin/head
安装bigdesk插件:在dos窗口输入:plugin -install lukas-vlcek/bigdesk,测试 http://localhost:9200/_pugin/bigdesk
来自:
http://blog.csdn.net/hi_kevin/article/details/38079007
set-id-enter 去除开机即1号警戒状况已发生的警报声。
来自:http://www.cnblogs.com/shishm/archive/2011/12/28/2305397.html
今天在eclipse中编写pom.xml文件时,注释中的中文被eclipse识别到错误:Invalid byte 1 of 1-byte UTF-8 sequence,曾多次遇到该问题,问题的根源是:
The cause of this is a file that is not UTF-8 is being parsed as UTF-8. It is likely that the parser is encountering a byte value in the range FE-FF. These values are invalid in the UTF-8 encoding.
但这次很诡异,我使用notepad++将pom.xml的编码保存为“UTF-8无BOM”形式,pom.xml文件内的encoding属性设
置为“UTF-8”,问题依旧啊,郁闷了,难道上述的理论有问题?还是eclipse的bug呢?在网上看了半天,基本都是这么说的。
第一,可以直接在XML文件中更改UTF-8为GBK或GB2312
<?xml version="1.0" encoding="GB2312"?>
第二,可以在Eclipse中更改,在 eclipse 的功能表 [Project]→[Properties],點選 [Resources],在右邊的「Text file encoding」,把原來是系統預設的編碼,改為 「UTF-8」。
第一种方案可行,属于逃避的方法,放弃!第二种也不是解决我这种问题的,继续网上搜索惊奇的发现,原来解决方案是这样的:
把xml的encoding属性值UTF-8改为UTF8,我操,太伤蛋了
最近需要将一个项目部署到触控一体机,客户要求所有网页文本框输入必须支持手写输入,之前一直没有实现过这样的功能,于是让组员上网搜索了一下,结果发现百度输入法提供网页文本框手写输入的js调用api,是利用flash调用汉王字库来实现的。下面是详细的代码。
<!doctype html><html><head><meta http-equiv=”Content-Type” content=”text/html;charset=gb2312″><title>网页文本框手写输入</title& gt;<style>#sx{color:#00C;text- decoration:underline;cursor:pointer;}</style>< /head><body>单击“手写”可以在手写区输入,然后点击备选区的相应文字,完成输入!<br><form name=”f” action=”http://www.okajax.com”><input type=”text” name=”wd” id=”kw” maxlength=”100″><input type=”submit” value=”提交” id=”su”><span id=”sx”>手写</span></form><script> var w = window,d = document,n = navigator,k = d.f.wdif (w.attachEvent) {w.attachEvent(“onload”, function() {k.focus();})} else {w.addEventListener(‘load’, function() {k.focus()},true)};var hw = {};hw.i = d.getElementById(“sx”);var il = false;if (/msie (\d+\.\d)/i.test(n.userAgent)) {hw.i.setAttribute(“unselectable”, “on”)} else {var sL = k.value.length;k.selectionStart = sL;k.selectionEnd = sL}hw.i.onclick = function(B) {var B = B || w.event;B.stopPropagation ? B.stopPropagation() : (B.cancelBubble = true);if (d.selection && d.activeElement.id && d.activeElement.id == “kw”) {hw.hasF = 1} else {if (!d.selection) {hw.hasF = 1}}if (!il) {var A = d.createElement(“script”);A.setAttribute(“src”, “http://www.baidu.com/hw/hwInput.js”); d.getElementsByTagName(“head”)[0].appendChild(A);il = true;}}; </script>实用为王,手写输入法让上网更加简单
</body></html>
如果你直接复制以上代码并保存为html在本地测试的时候,你可能会发觉,手写功能失效,只是可以手写,但无法选择文字,而其他功能也无法操作。又或者你会得到如下图的Adobe Flash Player安全性警示框。

网页文本框手写输入
如何解决这个问题?你可以在windows XP的C:\Documents and Settings\用户名\Application Data\Macromedia\Flash Player\#Security\FlashPlayerTrust目录路径(注:如果不存在FlashPlayerTrust文件夹就创建一个,此 外,如果找不到Application Data目录的话,可以在文件夹-》查看里选择显示所有文件和文件夹)里增加一个信任配置文件。新建一记事本,打开并写上你的html文件所在的目录, 如: F:, 然后保存为shouxieshuru.cfg。再打开html时,手写输入功能完全起作用了。
参考资料:http://www.okajax.com/a/201009/shouxieshuru.html
http://www.code-design.cn/article/20090621/136.aspx
来自:
http://www.laokboke.net/2011/08/10/wenbenkuang-shouxieshuru/?utm_source=rss
摘要: /////////////////////////////////////////////////////////////////////////////////////////////Page1简介: 是否需要分发文档、创建电子图书或者把喜欢的博客文章存档?EPUB 是一种开放式的数字图书规范,以常用的技术如 XML、CSS 和 XHTML 为基础,EPUB 文件可在便携式的 e-i...
阅读全文
摘要: ncx文件是epub电子书的又一个核心文件,用于制作电子书的目录,其文件的命名通常为toc.ncx。ncx文件是一个XML文件,该标准由DAISY Consortium发布(参见http://www.daisy.org)。下列是一个toc.ncx文件的实例,其中红色部分为必需。<navMap>元素列出了目录的名称和链接地址。其子元素<navPoint>支持嵌套。...
阅读全文
摘要: OPF文档是epub电子书的核心文件,且是一个标准的XML文件,依据OPF规范,主要由五个部分组成:1、<metadata>,元数据信息,由两个子元素组成:<dc-metadata>,其元素构成采用dubline core(DC)的15项核心元素,包括:<title>:题名<creator>:责任者<subject>:主题词或关键词<...
阅读全文
epub格式电子书遵循IDPF推出的OCF规范,OCF规范遵循ZIP压缩技术,即epub电子书本身就是一个ZIP文件,我们将epub格式电子书的后缀.epub修改为.zip后,可以通过解压缩软件(例如winrar、winzip)进行浏览或解压处理。一个未经加密处理的epub电子书以三个部分组成,其文件结构如下图所示:

1、文件:mimetype
每一本epub电子书均包含一个名为mimetype的文件,且内容不变,用以说明epub的文件格式。文件内容如下:
| application/epub+zip//注释,表示可以用epub工具和ZIP工具打开 |
2、目录:META-INF
依据OCF规范,META-INF用于存放容器信息,默认情况下(即加密处理),该目录包含一个文件,即container.xml,文件内容如下:
| <?xml version='1.0' encoding='utf-8'?> <container xmlns="urn:oasis:names:tc:opendocument:xmlns:container" version="1.0"> <rootfiles> <rootfile full-path="OEBPS/content.opf" media-type="application/oebps-package+xml" /> </rootfiles> </container> |
container.xml的主要功能用于告诉阅读器,电子书的根文件(rootfile)的路径(红色部分)和打开放式,一般来讲,该container.xml文件也不需要作任何修改,除非你改变了根文件的路径和文件名称。
除container.xml文件之外,OCF还规定了以下几个文件:
(1)[manifest.xml],文件列表(2)[metadata.xml],元数据(3)[signatures.xml],数字签名(4)[encryption.xml],加密(5)[rights.xml],权限管理对于epub电子书而言,这些文件都是可选的。
3、目录:OEBPS
OEBPS目录用于存放OPS文档、OPF文档、CSS文档、NCX文档,如果是制作中文电子书,则还包括ttf文档(即字体文档),OEBPS目录也可以建立相应的子目录,例如建立chapter目录,把各章节的OPS文档放在chapter目录之中。下图一本epub电子书OEBPS文档的实例图:

其中content.opf文件和toc.ncx文件为必需,其它文件可根据电子书的具体情况而定。
content.opf文件见博文OPF剖析
toc.ncx文件见博文toc.ncx剖析
来自:http://www.cnblogs.com/linlf03/archive/2011/12/13/2286029.html
一、什么是epub
epub是一个完全开放和免费的电子书标准。它可以“自动重新编排”的内容。
Epub文件后缀名:.epub
二、 epub组成
Epub内部使用XHTML(或者DTBook)来展现文件的内容;用一系列css来定义格式和版面设计; 然后把所有的文件压缩成zip包。
Epub格式中包含了DRM相关功能(目前epub引擎暂时不考虑drm相关信息)
EPub包括三项主要规格:
开放出版结构(Open Publication Structure,OPS)2.0,以定义内容的版面;
开放包裹格式(Open Packaging Format,OPF)2.0,定义以XML为基础的.epub档案结构; OEBPS容纳格式(OEBPS Container Format,OCF)1.0,将所有相关文件收集至ZIP压缩档案之中。
1. OPS:
用XHTML(或者DTBook)来构筑书的内容。
用一系列css来定义书的格式和版面设计。
支持 png、jpeg、gif、svg的图片格式。

2. OPF:
OPF 文件是 EPUB 规范中最复杂的元数据。它用来定义ops一系列内容组合到一起的机制,并为ebook提供了一些额外的结构和内容。Opf包含四个子元素:metadata, manifest, spine, guide。在OEBPS中的opf包含两个XML: .opf和.ncx

(一).opf
OPF包括以下内容:
1)metadata:epub的元数据,如title、language、identifier、cover等。其中,title 和 identifier这两个数据是必须的。
按照EPUB规范,identifier由数字图书的创建者定义,必须唯一。对于图书出版商来说,这个字段一般包括ISBN或者Library of Congress编号;也可以使用URL或者随机生成的唯一用户ID。注意:unique-identifier 的值必须和 dc:identifier 元素的 ID 属性匹配。

2)manifest:列出了package中所包含的所有文件(xhtml、css、png、ncx等)。EPUB 鼓励使用 CSS 设定图书内容的样式,因此 manifest 中也包含 CSS。注意:进入数字图书的所有文件都必须在 manifest 中列出。

3)spine:所有xhtml文档的线性阅读顺序。其中,spine的TOC属性必须包含在manifest列出来的.ncx的id。可以将 OPF spine 理解为是书中 “页面” 的顺序,解析的时候按照文档顺序从上到下依次读取 spine。
在spine中的每个 itemref 元素都需要有一个 idref 属性,这个属性和 manifest 中的某个 ID 匹配。
spine 中的 linear 属性表明该项是作为线性阅读顺序中的一项,还是和先后次序无关。有些阅读器可以将spine中linear=no的项作为辅助选项处理,有些阅读器则选择忽略这个属性。例如在下边的实例中,支持辅助选项处理的阅读器会依次列出titlepage、chapter01、chapter05,chapter02、chapter03、chapter04只在点击到(或者其他开启动作)之后才会显示。
但是对于支持打印的阅读器,需要忽略linear=no的属性,保证能够最完全的展示ops中的内容。
好的阅读器需要同时提供两种选择给用户。

(二).ncx
NCX 定义了数字图书的目录表。复杂的图书中,目录表通常采用层次结构,包括嵌套的内容、章和节。包含了TOC(tablet of content,提供了分段的一些信息)。
NCX的 <head> 标记中包含四个 meta 元素:
- uid: 数字图书的惟一 ID。该元素应该和 OPF 文件中的 dc:identifier 对应。
- depth:反映目录表中层次的深度。
- totalPageCount 和 maxPageNumber:仅用于纸质图书,保留 0 即可。
docTitle/text 的内容是图书的标题,和 OPF 中的 dc:title 匹配。
navMap 是 NCX 文件中最重要的部分,定义了图书的目录。navMap 包含一个或多个 navPoint 元素,每个 navPoint 都要包含下列元素:
- playOrder:说明文档的阅读顺序。和 OPF spine 中 itemref 元素的顺序相同。
- navLabel/text :给出该章节的标题。通常是章的标题或者数字。
- content :它的 src 属性指向包含这些内容的物理资源。就是 OPF manifest 中声明的文件。
- 还可以有一个或多个 navPoint 元素。NCX 使用嵌套的导航点表示层次结构的文档

(三)NCX 和 OPF spine 有什么不同?
两者很容易混淆,因为两个文件都描述了文档的顺序和内容。要说明两者的区别,最简单的办法就是拿印刷书来打比方:OPF spine 描述了书中的各个章节是如何实际连接起来的,比方说翻过第一章的最后一页就看到第二章的第一页。NCX 在图书的一开始描述了目录,目录肯定会包含书中主要的章节,但是还可能包含没有单独分页的小节。
一条法则是 NCX 包含的 navPoint 元素通常比 OPF spine 中的 itemref 元素多。实际上,spine 中的所有项都会出现在 NCX 中,但 NCX 可能更详细。
3. OCF:
OCF定义了文件是如何被打包成ZIP的,并且有两个额外的信息:
1)ASCII格式的mimetype文件。该文件必须包含application/epub+zip字符串,并且是ZIP压缩包的第一个文件。Mimetype要求是非压缩格式。
2)一个命名为META-INF的文件夹。这个文件夹中需要包含container.xml文件
4. Drm——需要在META-INF文件夹中包含rights.xml
总结起来,一个epub电子书的zip包含以下东西:
1、mimetype 文件,必须是压缩包的第一个文件。注意,Mimetype必须是非压缩格式。
2、meta-inf目录,里面至少包含一个container.xml 文件。
3、OEBPS目录(可以是别的名字,但建议用这个名字),包含了:
a) image子目录(不一定总有)存放了所有的图片文件
b) content.opf 文件名可以是其它的,扩展名一定是opf,就是一个xml格式的包内的文件列表
c) toc.ncx 目录文件,一个“逻辑目录”, 浏览控制文件.
d) 一些xhtml或html文件。就是书的内容。
简单 EPUB 档案的目录和文件结构:
mimetype
META-INF/
container.xml
OEBPS/
content.opf
title.html
content.html
stylesheet.css
toc.ncx
images/
cover.png

三、Epub电子图书获取网站
Feedbooks: http://www.feedbooks.com/books/top?range=month
掌上书苑: http://www.cnepub.com/index
COAY: http://www.coay.com
博酷网: http://www.pockoo.com/books/?format=EPUB&orderby=lastedit
新浪ipad数码资源 http://myphoto.tech.sina.com.cn/forumdisplay.php?fid=398
EpubBooks: http://www.epubbooks.com/books
四、Epub电子图书阅读器(比较软件)
Adobe digital Edition: http://www.adobe.com/products/digitaleditions/
Calibre: 开放源代码的电子书管理工具,支持windows、linux、osx等平台。也能在各种格式之间转换。http://calibre-ebook.com/
Aldiko:android上的epub阅读器。 http://www.aldiko.com/
五、 Epub电子图书编辑软件
epubBuilder:epubbuilder是国人自做软件,手工制作时还是很好用的,尤其是每个章节的制作和目录,比较方便,还提供了导入chm,txt,html文件的功能,比较人性化
ecub:http://www.juliansmart.com/ecub
l Calibre
l Adobe InDesign
l Stanza
l OpenBerg Rector
l ePUB check tool
l Convert uploads to ePUB
l Web2FB2
l Python converter
l DAISY Pipeline
六、创建一个EPUB文件
参考资料:http://www.ibm.com/developerworks/cn/xml/tutorials/x-epubtut/section3.html
1. 先建一个空的zip文件,可以取为任何名字,最好和你的书同名。
2、拷贝mimetype文件到包内,注意所谓拷贝,就是这个文件不要用压缩模式。
3、把其它的目录和文件用压缩模式放入zip包。
4、改文件扩展名为.epub
ok!一本epub电子书就制成了。
七、完整的EPUB规范
OPF规范:http://www.idpf.org/2007/opf/OPF_2.0_final_spec.html
OPS规范:http://www.idpf.org/2007/ops/OPS_2.0_final_spec.html
OEBPS规范:http://www.idpf.org/ocf/ocf1.0/download/ocf10.htm
来自:http://www.cnblogs.com/linlf03/archive/2011/12/13/2286218.html
在android-sdk-windows \ tools这个目录下找到这个emulator.exe,然后发送到桌面一个快捷方式,右键点击快捷方式的 属性,在“目标”框后边直接添加 -avd “AVD名称” -partition-size “你想要的ROM大小” ,即可。例如 D:\android-sdk-windows\tools\emulator.exe -avd MyAVD2.3.3 -partition-size 1024。其中“2.3.3”是我创建模拟器时模拟器的名称,1024即为ROM大小,要注意空格。 以后每次启动,就用这个快捷方式打开,这样rom就是1024的了。
来自:http://zhidao.baidu.com/question/323467729.html
第一步:视图——母版——幻灯片母版
(进去了就是母版编辑的界面)
第二步:格式——背景,弹出相应对话框,有个小三角形,点击一下会出现下拉选项,选择最下面一项“填充效果”——弹出图片添加对话框,点“选择图片”选择你需要的图片就行了……至于字体字号格式什么的直接在上面修改就行了
第三步:视图——普通,返回到原来的编辑界面。
来自:
http://zhidao.baidu.com/question/189625399.html?an=0&si=1
1.下载数据库http://fastdl.mongodb.org/win32/mongodb-win32-i386-1.6.5.zip
2.现在完成后解压目录,放到C盘下,然后按照如下选择“我的电脑->属性->高级->环境变量”,将“C:\mongodb\bin”这个路径放到环境变量内(如果添加环境变量可以去网上找).
3.选择"开始->运行",输入"cmd",在DOS窗口内输入“mongod -port 27017 -dbpath D:/deployment/mongoDb/data/db -logpath D:/deployment/mongoDb/data/log/logs.log ”,其中dbpath 为数据文件存储路径,logpath 为日志文件存储路径。
4.不要关闭上面的窗口,新打开一个DOS,输入“mongo->use admin->db.AddUser(username,password)”,username:数据库数据集的用户名,password数据库数据集操作的密码。
5.在两个DOS窗口内分别按“ctrl+c”,在第一个DOS窗口内输入“mongod -port 27017 -dbpath D:/deployment/mongoDb/data/db -logpath D:/deployment/mongoDb/data/log/logs.log -logappend -auth”的启动命令,auth是要求操作数据集是需要验证。
6.在第二个DOS窗口内,输入“mongo->use admin->db.auth(username,password)”,然后就可以对数据集进行操作(增、删、改)。
来自:http://www.hitb.com.cn/web/guest/bbs/-/message_boards/message/26944
首先在mongo官网下载Windows的版本
启动服务:mongod.exe --port 12345 --dbpath=c:\mongodb\db
显示一下信息:
Fri Dec 04 14:30:32 Mongo DB : starting : pid = 0 port = 12345 dbpath = c:\mongo
db\db master = 0 slave = 0 32-bit
** NOTE: when using MongoDB 32 bit, you are limited to about 2 gigabytes of data
** see http://blog.mongodb.org/post/137788967/32-bit-limitations for more
Fri Dec 04 14:30:32 db version v1.1.4-, pdfile version 4.5
Fri Dec 04 14:30:32 git version: c67c2f7dd681152f1784c8e1c2119b979e65881d
Fri Dec 04 14:30:32 sys info: windows (5, 1, 2600, 2, 'Service Pack 3') BOOST_LI
B_VERSION=1_35
Fri Dec 04 14:30:32 waiting for connections on port 12345
启动客户端:mongo.exe localhost:12345
检查是否正常:db.foo.save({a:1,b:9})
db.foo.find({a:1})
控制台显示:{ "_id" : ObjectId("4b18b5b56f40000000006cec"), "a" : 1, "b" : 9 }
添加数据:db.foo.save({a:1,b:9})
查询数据:db.foo.find({a:1}) //{a:1}是查询条件,当为空时查询所有
db.foo.findOne({a:1}) //显示出一条数据
删除数据:db.foo.remove({a:1}) //删除a=1的数据
表的数据量:db.foo.find().count()
显示数据指定的条数:db.foo.find().limit(n)
显示库名:db.foo.getDB()
获取索引值:db.foo.getIndexes()
表的统计:db.foo.stats()
删除表:db.foo.drop()
获取不重复的列:db.foo.distinct( key ) - eg. db.foo.distinct( 'x' )
忽略前面的几行:db.other.find({a:2}).skip(2)//忽略a=2中的前面2行
方法帮助:db.foo.help()
HELP
show dbs show database names
show collections show collections in current database
show users show users in current database
show profile show most recent system.profile entries with time >= 1ms
use <db name> set curent database to <db name>
db.help() help on DB methods
db.foo.help() help on collection methods
db.foo.find() list objects in collection foo
db.foo.find( { a : 1 } ) list objects in foo where a == 1
it result of the last line evaluated; use to further iterate
DB methods:
db.addUser(username, password)
db.auth(username, password)
db.cloneDatabase(fromhost)
db.commandHelp(name) returns the help for the command
db.copyDatabase(fromdb, todb, fromhost)
db.createCollection(name, { size : ..., capped : ..., max : ... } )
db.currentOp() displays the current operation in the db
db.dropDatabase()
db.eval(func, args) run code server-side
db.getCollection(cname) same as db['cname'] or db.cname
db.getCollectionNames()
db.getLastError() - just returns the err msg string
db.getLastErrorObj() - return full status object
db.getMongo() get the server connection object
db.getMongo().setSlaveOk() allow this connection to read from the nonmaster member of a replica pair
db.getName()
db.getPrevError()
db.getProfilingLevel()
db.getReplicationInfo()
db.getSisterDB(name) get the db at the same server as this onew
db.killOp() kills the current operation in the db
db.printCollectionStats()
db.printReplicationInfo()
db.printSlaveReplicationInfo()
db.printShardingStatus()
db.removeUser(username)
db.repairDatabase()
db.resetError()
db.runCommand(cmdObj) run a database command. if cmdObj is a string, turns it into { cmdObj : 1 }
db.setProfilingLevel(level) 0=off 1=slow 2=all
db.shutdownServer()
db.version() current version of the server
DBCollection help
db.foo.count()
db.foo.dataSize()
db.foo.distinct( key ) - eg. db.foo.distinct( 'x' )
db.foo.drop() drop the collection
db.foo.dropIndex(name)
db.foo.dropIndexes()
db.foo.ensureIndex(keypattern,options) - options should be an object with these possible fields: name, unique, dropDups
db.foo.find( [query] , [fields]) - first parameter is an optional queryfilter. second parameter is optional set of fields to return. e.g. db.foo.find( { x : 77 } , { name : 1 , x : 1 } )
db.foo.find(...).count()
db.foo.find(...).limit(n)
db.foo.find(...).skip(n)
db.foo.find(...).sort(...)
db.foo.findOne([query])
db.foo.getDB() get DB object associated with collection
db.foo.getIndexes()
db.foo.group( { key : ..., initial: ..., reduce : ...[, cond: ...] } )
db.foo.mapReduce( mapFunction , reduceFunction , <optional params> )
db.foo.remove(query)
db.foo.renameCollection( newName ) renames the collection
db.foo.save(obj)
db.foo.stats()
db.foo.storageSize() - includes free space allocated to this collection
db.foo.totalIndexSize() - size in bytes of all the indexes
db.foo.totalSize() - storage allocated for all data and indexes
db.foo.update(query, object[, upsert_bool])
db.foo.validate() - SLOW
db.foo.getShardVersion() - only for use with sharding
命令行
| --help |
显示命令行参数 |
| --nodb |
不连接数据库方式启动,稍后可以使用 new Mongo() 或 connect() 来建立连接 |
| --shell |
从命令行运行完一个 .js 文件后,停留在shell中,而不是结束 |
特殊命令
非JavaScript的辅助指令:
| help |
显示帮助 |
| db.help() |
显示 db 方法帮助 |
| db.myColl .help() |
显示聚集的方法帮助 |
| show dbs |
打印服务器上所有数据库的列表 |
| use dbname |
设置db变量来指明使用服务器上的 dbname 数据库 |
| show collections |
打印当前数据库的所有聚集 |
| show users |
打印当前数据库的用户 |
| show profile |
打印最近耗时大于1ms的profiling操作 |
基本的Shell Javascript操作
| db |
指向当前数据库对象和连接的变量,已经在你的实例里定义好。 |
| db.auth(user,pass) |
数据库认证(如果运行安全模式的话) |
| coll = db.collection |
访问数据库里特定的 collection |
| cursor = coll.find() |
查找聚集里所有的对象。参考 [查询] 。 |
| coll.remove(objpattern ) |
从聚集里删除匹配的对象。
objpattern 是一个指定匹配的域的对象,例如:coll.remove( { name: "Joe" } ); |
| coll.save(object ) |
在聚集中保存对象,如果已经存在的话则更新它。
如果对象有 presave 方法,则会在保存到数据库之前(插入和更新之前)调用该方法。 |
| coll.insert(object) |
向聚集中插入对象。不会检查该对象是否已经存在聚集中(即,不是 upsert) |
| coll.update(...) |
在聚集中更新对象。update() 有许多参数,请查看 更新 文档。 |
| coll.ensureIndex( { name : 1 } ) |
对 name 建索引。如果索引存在则不做任何事。 |
| coll.drop() |
删除 coll 聚集 |
| db.getSisterDB(name) |
返回当前连接的另一个数据库。它允许跨数据库查询,例如:db.getSisterDB('production').getCollectionNames() |
查询
| coll.find() |
查询所有文档 |
| it |
循环上次 find() 调用返回的游标 |
| coll.find( criteria ); |
查询聚集中匹配 criteria 的对象。例如:coll.find( { name: "Joe" } ); |
| coll.findOne( criteria); |
查询并返回一个对象。如果没有找到则返回 null。如果你只需要返回一个对象,这个方法比 find() as limit(1) 效率更高。如果元素类型是字符串,数字或时间,你还可以使用正则表达式:coll.find( { name: /joe/i } ); |
| coll.find( criteria, fields ); |
查询对象里特定的域。例如:coll.find( {}, {name:true} ); |
| coll.find().sort( {field :1[, field :1] }); |
对返回结果进行排序(field ASC)。使用 -1 表示 DESC。 |
| coll.find( criteria ).sort( { field : 1 } ) |
查找匹配 criteria 的对象,并对 field 进行排序。 |
| coll.find( ... ).limit(n ) |
限制结果返回 n 行。如果你只需要某几行数据,推荐这样做来获得最优性能。 |
| coll.find( ... ).skip(n) |
跳过 n 行结果。 |
| coll.count() |
返回聚集里对象的总数。 |
| coll.find( ... ).count() |
返回匹配该查询的对象总数。注意,该返回会忽略 limit 和 skip。比如有100行记录匹配该查询,但是limit为10,count() 仍会返回100。这比你自己循环更快,但仍然需要消耗些时间。 |
更多信息请参考 [查询] 。
错误检查
| [{{db.getLastError()}}] |
返回上次操作的错误 |
| db.getPrevError() |
返回之前操作的错误 |
| db.resetError() |
清除错误记录 |
管理命令
| db.cloneDatabase(fromhost) |
从另外指定的主机拷贝当前数据数据库。fromhost必须为noauth模式。 |
| db.copyDatabase(fromdb, todb, fromhost) |
拷贝fromhost的fromdb数据库到当前服务器的todb数据库。fromhost必须为noauth模式。 |
| db.repairDatabase() |
修复当前数据库。如果数据库很大则该操作会非常慢。 |
| db.addUser(user,pwd) |
给当前数据库添加用户。 |
| db.getCollectionNames() |
获得所有聚集的列表。 |
| db.dropDatabase() |
删除当前数据库。 |
打开额外连接
| db = connect("<host>:<port>/<dbname>") |
打开一个新的数据库连接。一个shell可能有多个连接,但是shell自动的getLastError只用于 'db' 变量。 |
| conn = new Mongo("hostname") |
打开一个新的服务器连接。然后可以使用 getDB() 来选择一个数据库。 |
| db = conn.getDB("dbname") |
对一个连接选择一个特定的数据库。 |
其他
| Object.bsonsize(db.foo.findOne()) |
打印一个数据库对象的bson大小(mongo 版本1.3及以上) |
| db.foo.findOne().bsonsize() |
打印一个数据库对象的bson大小 (mongo 版本1.3之前) |
其实用mongo已经有些时候了,之所以算初探,是因为用的不深入,主要就是当中nosql中的类k-v用的,用之取代了部分的tt,原因很简单,mongo中的数据格式虽然是bson的,不过在我这个pythoner眼中,这不明明就是纯天然的 dict么!好吧,我承认,就是这个原因让我义无反顾地走上了mongoing之路(无论什么项目,用到存储自然而然的想用mongo)。
mongo的优劣是在使用的过程中逐步体验出来的,在这里就不评说了,想要评测的请直接google之
之前一直是直接在服务器端用pymongo或者mongo自带的shell做数据查看修改之类的操作,突然发现这个实在不利于推广,公司同事似乎本能的对这种nosql有稳定性上的怀疑。也好理解,看不到的,通常是不可信的(谁说的来着)。
鉴于大伙都习惯了phpadmin玩mysql的光荣传统,如果mongo也有类似的东东,看起来也亲切些,个人感觉对推广也会有利些。
额,说了这么多,好像还没有能进入到主题,好吧,说是初探,似乎有些标题党了,其实就想推荐下这个东东:http://code.google.com/p/rock-php/wiki/rock_mongo_zh#安装
不错的mongodb phpadmin客户端,还支持中文(我想这个还是蛮有利推广的),所谓初探,只不过是使用这东东换了个视角来看看Mongodb,感觉的确有些不一样。
不过,值得注意到是,装这玩意之前,还得为php装一个mongo的drive,不过不要紧,装完这个之后,访问时会直接给个装drive的链接,还是蛮方便的。
额,我应该不算标题党吧(至少不是纯碎的标题党。。 )
)
shell#查询
查询 name = "bruce" 的数据
db.users.find({ name : "bruce" });
条件操作符
$gt : >
$lt : <
$gte: >=
$lte: <=
$ne : !=、<>
$in : in
$nin: not in
$all: all
$not: 反匹配(1.3.3及以上版本)
查询 name <> "bruce" and age >= 18 的数据
db.users.find({name: {$ne: "bruce"}, age: {$gte: 18}});
查询 creation_date > '2010-01-01' and creation_date <= '2010-12-31' 的数据
db.users.find({creation_date:{$gt:new Date(2010,0,1), $lte:new Date(2010,11,31)});
查询 age in (20,22,24,26) 的数据
db.users.find({age: {$in: [20,22,24,26]}});
查询 age取模10等于0 的数据
db.users.find('this.age % 10 == 0');
或者
db.users.find({age : {$mod : [10, 0]}});
匹配所有
db.users.find({favorite_number : {$all : [6, 8]}});
可以查询出{name: 'David', age: 26, favorite_number: [ 6, 8, 9 ] }
可以不查询出{name: 'David', age: 26, favorite_number: [ 6, 7, 9 ] }
查询不匹配name=B*带头的记录
db.users.find({name: {$not: /^B.*/}});
查询 age取模10不等于0 的数据
db.users.find({age : {$not: {$mod : [10, 0]}}});
#返回部分字段
选择返回age和_id字段(_id字段总是会被返回)
db.users.find({}, {age:1});
db.users.find({}, {age:3});
db.users.find({}, {age:true});
db.users.find({ name : "bruce" }, {age:1});
0为false, 非0为true
选择返回age、address和_id字段
db.users.find({ name : "bruce" }, {age:1, address:1});
排除返回age、address和_id字段
db.users.find({}, {age:0, address:false});
db.users.find({ name : "bruce" }, {age:0, address:false});
数组元素个数判断
对于{name: 'David', age: 26, favorite_number: [ 6, 7, 9 ] }记录
匹配db.users.find({favorite_number: {$size: 3}});
不匹配db.users.find({favorite_number: {$size: 2}});
$exists判断字段是否存在
查询所有存在name字段的记录
db.users.find({name: {$exists: true}});
查询所有不存在phone字段的记录
db.users.find({phone: {$exists: false}});
$type判断字段类型
查询所有name字段是字符类型的
db.users.find({name: {$type: 2}});
查询所有age字段是整型的
db.users.find({age: {$type: 16}});
对于字符字段,可以使用正则表达式
查询以字母b或者B带头的所有记录
db.users.find({name: /^b.*/i});
$elemMatch(1.3.1及以上版本)
为数组的字段中匹配其中某个元素
Javascript查询和$where查询
查询 age > 18 的记录,以下查询都一样
db.users.find({age: {$gt: 18}});
db.users.find({$where: "this.age > 18"});
db.users.find("this.age > 18");
f = function() {return this.age > 18} db.users.find(f);
排序sort()
以年龄升序asc
db.users.find().sort({age: 1});
以年龄降序desc
db.users.find().sort({age: -1});
限制返回记录数量limit()
返回5条记录
db.users.find().limit(5);
返回3条记录并打印信息
db.users.find().limit(3).forEach(function(user) {print('my age is ' + user.age)});
结果
my age is 18
my age is 19
my age is 20
限制返回记录的开始点skip()
从第3条记录开始,返回5条记录(limit 3, 5)
db.users.find().skip(3).limit(5);
查询记录条数count()
db.users.find().count();
db.users.find({age:18}).count();
以下返回的不是5,而是user表中所有的记录数量
db.users.find().skip(10).limit(5).count();
如果要返回限制之后的记录数量,要使用count(true)或者count(非0)
db.users.find().skip(10).limit(5).count(true);
分组group()
假设test表只有以下一条数据
{ domain: "www.mongodb.org"
, invoked_at: {d:"2009-11-03", t:"17:14:05"}
, response_time: 0.05
, http_action: "GET /display/DOCS/Aggregation"
}
使用group统计test表11月份的数据count:count(*)、total_time:sum(response_time)、 avg_time:total_time/count;
db.test.group(
{ cond: {"invoked_at.d": {$gt: "2009-11", $lt: "2009-12"}}
, key: {http_action: true}
, initial: {count: 0, total_time:0}
, reduce: function(doc, out){ out.count++; out.total_time+=doc.response_time }
, finalize: function(out){ out.avg_time = out.total_time / out.count }
} );
[
{
"http_action" : "GET /display/DOCS/Aggregation",
"count" : 1,
"total_time" : 0.05,
"avg_time" : 0.05
}
]
来自: http://hi.baidu.com/asminfo/blog/item/20301e22dcfcce50ac34de7a.html
原先的grails是1.2.0,从这个版本之后,我试过1.2.1,1.2.2,1.3.0,1.3.1,但都因为程序在运行时会变成乱码,而一直使用着1.2.0。
我们的TOMCAT使用的是GBK编码,GRAILS文本都是使用UTF-8编码,所以,这是产生乱码的根本原因。
最近又有grails1.3.6,更新得很快,网上找了找,有解决方案了。http://www.groovyq.net/content/grails13%E5%8F%91%E5%B8%83
在服务器上一试,果然能行。现记录如下:
重新设定System.out的编码,将下面语句加入到_GrailsInit.groovy中,或者加入工程的BootStrap.groovy的init段即可
System.out = new PrintStream(System.out, true,"GB2312");
我使用的是第二种方法,在BootStrap.groovy的init段中加入以上语句。
以前,有位高手也提到过,但他的原文是:
“如果是println打印中文乱码的话,那么就在初始化文件中增加
System.out = new PrintStream(System.out, true, "GBK")
就应该了,你测试一下吧, ”
所以我一直以为是解决打印乱码的。
在此一并谢过。
来自: http://hi.baidu.com/caihexi/blog/item/76d093a4cce0c6e59152ee15.html
|
首先在mongo官网下载Windows的版本
启动服务:mongod.exe --port 12345 --dbpath=c:\mongodb\db
显示一下信息:
Fri Dec 04 14:30:32 Mongo DB : starting : pid = 0 port = 12345 dbpath = c:\mongo
db\db master = 0 slave = 0 32-bit
** NOTE: when using MongoDB 32 bit, you are limited to about 2 gigabytes of data
** see http://blog.mongodb.org/post/137788967/32-bit-limitations for more
Fri Dec 04 14:30:32 db version v1.1.4-, pdfile version 4.5
Fri Dec 04 14:30:32 git version: c67c2f7dd681152f1784c8e1c2119b979e65881d
Fri Dec 04 14:30:32 sys info: windows (5, 1, 2600, 2, 'Service Pack 3') BOOST_LI
B_VERSION=1_35
Fri Dec 04 14:30:32 waiting for connections on port 12345
启动客户端:mongo.exe localhost:12345
检查是否正常:db.foo.save({a:1,b:9})
db.foo.find({a:1})
控制台显示:{ "_id" : ObjectId("4b18b5b56f40000000006cec"), "a" : 1, "b" : 9 }
添加数据:db.foo.save({a:1,b:9})
查询数据:db.foo.find({a:1}) //{a:1}是查询条件,当为空时查询所有
db.foo.findOne({a:1}) //显示出一条数据
删除数据:db.foo.remove({a:1}) //删除a=1的数据
表的数据量:db.foo.find().count()
显示数据指定的条数:db.foo.find().limit(n)
显示库名:db.foo.getDB()
获取索引值:db.foo.getIndexes()
表的统计:db.foo.stats()
删除表:db.foo.drop()
获取不重复的列:db.foo.distinct( key ) - eg. db.foo.distinct( 'x' )
忽略前面的几行:db.other.find({a:2}).skip(2)//忽略a=2中的前面2行
方法帮助:db.foo.help()
HELP
show dbs show database names
show collections show collections in current database
show users show users in current database
show profile show most recent system.profile entries with time >= 1ms
use <db name> set curent database to <db name>
db.help() help on DB methods
db.foo.help() help on collection methods
db.foo.find() list objects in collection foo
db.foo.find( { a : 1 } ) list objects in foo where a == 1
it result of the last line evaluated; use to further iterate
DB methods:
db.addUser(username, password)
db.auth(username, password)
db.cloneDatabase(fromhost)
db.commandHelp(name) returns the help for the command
db.copyDatabase(fromdb, todb, fromhost)
db.createCollection(name, { size : ..., capped : ..., max : ... } )
db.currentOp() displays the current operation in the db
db.dropDatabase()
db.eval(func, args) run code server-side
db.getCollection(cname) same as db['cname'] or db.cname
db.getCollectionNames()
db.getLastError() - just returns the err msg string
db.getLastErrorObj() - return full status object
db.getMongo() get the server connection object
db.getMongo().setSlaveOk() allow this connection to read from the nonmaster member of a replica pair
db.getName()
db.getPrevError()
db.getProfilingLevel()
db.getReplicationInfo()
db.getSisterDB(name) get the db at the same server as this onew
db.killOp() kills the current operation in the db
db.printCollectionStats()
db.printReplicationInfo()
db.printSlaveReplicationInfo()
db.printShardingStatus()
db.removeUser(username)
db.repairDatabase()
db.resetError()
db.runCommand(cmdObj) run a database command. if cmdObj is a string, turns it into { cmdObj : 1 }
db.setProfilingLevel(level) 0=off 1=slow 2=all
db.shutdownServer()
db.version() current version of the server
DBCollection help
db.foo.count()
db.foo.dataSize()
db.foo.distinct( key ) - eg. db.foo.distinct( 'x' )
db.foo.drop() drop the collection
db.foo.dropIndex(name)
db.foo.dropIndexes()
db.foo.ensureIndex(keypattern,options) - options should be an object with these possible fields: name, unique, dropDups
db.foo.find( [query] , [fields]) - first parameter is an optional queryfilter. second parameter is optional set of fields to return. e.g. db.foo.find( { x : 77 } , { name : 1 , x : 1 } )
db.foo.find(...).count()
db.foo.find(...).limit(n)
db.foo.find(...).skip(n)
db.foo.find(...).sort(...)
db.foo.findOne([query])
db.foo.getDB() get DB object associated with collection
db.foo.getIndexes()
db.foo.group( { key : ..., initial: ..., reduce : ...[, cond: ...] } )
db.foo.mapReduce( mapFunction , reduceFunction , <optional params> )
db.foo.remove(query)
db.foo.renameCollection( newName ) renames the collection
db.foo.save(obj)
db.foo.stats()
db.foo.storageSize() - includes free space allocated to this collection
db.foo.totalIndexSize() - size in bytes of all the indexes
db.foo.totalSize() - storage allocated for all data and indexes
db.foo.update(query, object[, upsert_bool])
db.foo.validate() - SLOW
db.foo.getShardVersion() - only for use with shardin
1.选中你要加注释的区域,用ctrl+shift+C 会加上//注释
2.先把你要注释的东西选中,用shit+ctrl+/ 会加上/* */注释
3.要修改在eclispe中的命令的快捷键方式我们只需进入windows -> preference -> General -> key设置就行了(转)
补充:选中要加注释的区域,ctrl+/ 会加//注释 2010/09/13
选中后,ctrl+shift+\,去掉选中部分的注释
(转)附myeclipse中的所有快捷键列表:
Ctrl+1 快速修复(最经典的快捷键,就不用多说了)
Ctrl+D: 删除当前行
Ctrl+Alt+↓ 复制当前行到下一行(复制增加)
Ctrl+Alt+↑ 复制当前行到上一行(复制增加)
Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)
Alt+↑ 当前行和上面一行交互位置(同上)
Alt+← 前一个编辑的页面
Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)
Alt+Enter 显示当前选择资源(工程,or 文件 or文件)的属性
Shift+Enter 在当前行的下一行插入空行(这时鼠标可以在当前行的任一位置,不一定是最后)
Shift+Ctrl+Enter 在当前行插入空行(原理同上条)
Ctrl+Q 定位到最后编辑的地方
Ctrl+L 定位在某行 (对于程序超过100的人就有福音了)
Ctrl+M 最大化当前的Edit或View (再按则反之)
Ctrl+/ 注释当前行,再按则取消注释
Ctrl+O 快速显示 OutLine
Ctrl+T 快速显示当前类的继承结构
Ctrl+W 关闭当前Editer
Ctrl+K 参照选中的Word快速定位到下一个
Ctrl+E 快速显示当前Editer的下拉列表(如果当前页面没有显示的用黑体表示)
Ctrl+/(小键盘) 折叠当前类中的所有代码
Ctrl+×(小键盘) 展开当前类中的所有代码
Ctrl+Space 代码助手完成一些代码的插入(但一般和输入法有冲突,可以修改输入法的热键,也可以暂用Alt+/来代替)
Ctrl+Shift+E 显示管理当前打开的所有的View的管理器(可以选择关闭,激活等操作)
Ctrl+J 正向增量查找(按下Ctrl+J后,你所输入的每个字母编辑器都提供快速匹配定位到某个单词,如果没有,则在stutes line中显示没有找到了,查一个单词时,特别实用,这个功能Idea两年前就有了)
Ctrl+Shift+J 反向增量查找(和上条相同,只不过是从后往前查)
Ctrl+Shift+F4 关闭所有打开的Editer
Ctrl+Shift+X 把当前选中的文本全部变味小写
Ctrl+Shift+Y 把当前选中的文本全部变为小写
Ctrl+Shift+F 格式化当前代码
Ctrl+Shift+P 定位到对于的匹配符(譬如{}) (从前面定位后面时,光标要在匹配符里面,后面到前面,则反之)
下面的快捷键是重构里面常用的,本人就自己喜欢且常用的整理一下(注:一般重构的快捷键都是Alt+Shift开头的了)
Alt+Shift+R 重命名 (是我自己最爱用的一个了,尤其是变量和类的Rename,比手工方法能节省很多劳动力)
Alt+Shift+M 抽取方法 (这是重构里面最常用的方法之一了,尤其是对一大堆泥团代码有用)
Alt+Shift+C 修改函数结构(比较实用,有N个函数调用了这个方法,修改一次搞定)
Alt+Shift+L 抽取本地变量( 可以直接把一些魔法数字和字符串抽取成一个变量,尤其是多处调用的时候)
Alt+Shift+F 把Class中的local变量变为field变量 (比较实用的功能)
Alt+Shift+I 合并变量(可能这样说有点不妥Inline)
Alt+Shift+V 移动函数和变量(不怎么常用)
Alt+Shift+Z 重构的后悔药(Undo)
编辑
作用域 功能 快捷键
全局 查找并替换 Ctrl+F
文本编辑器 查找上一个 Ctrl+Shift+K
文本编辑器 查找下一个 Ctrl+K
全局 撤销 Ctrl+Z
全局 复制 Ctrl+C
全局 恢复上一个选择 Alt+Shift+↓
全局 剪切 Ctrl+X
全局 快速修正 Ctrl1+1
全局 内容辅助 Alt+/
全局 全部选中 Ctrl+A
全局 删除 Delete
全局 上下文信息 Alt+?
Alt+Shift+?
Ctrl+Shift+Space
Java编辑器 显示工具提示描述 F2
Java编辑器 选择封装元素 Alt+Shift+↑
Java编辑器 选择上一个元素 Alt+Shift+←
Java编辑器 选择下一个元素 Alt+Shift+→
文本编辑器 增量查找 Ctrl+J
文本编辑器 增量逆向查找 Ctrl+Shift+J
全局 粘贴 Ctrl+V
全局 重做 Ctrl+Y
查看
作用域 功能 快捷键
全局 放大 Ctrl+=
全局 缩小 Ctrl+-
窗口
作用域 功能 快捷键
全局 激活编辑器 F12
全局 切换编辑器 Ctrl+Shift+W
全局 上一个编辑器 Ctrl+Shift+F6
全局 上一个视图 Ctrl+Shift+F7
全局 上一个透视图 Ctrl+Shift+F8
全局 下一个编辑器 Ctrl+F6
全局 下一个视图 Ctrl+F7
全局 下一个透视图 Ctrl+F8
文本编辑器 显示标尺上下文菜单 Ctrl+W
全局 显示视图菜单 Ctrl+F10
全局 显示系统菜单 Alt+-
导航
作用域 功能 快捷键
Java编辑器 打开结构 Ctrl+F3
全局 打开类型 Ctrl+Shift+T
全局 打开类型层次结构 F4
全局 打开声明 F3
全局 打开外部javadoc Shift+F2
全局 打开资源 Ctrl+Shift+R
全局 后退历史记录 Alt+←
全局 前进历史记录 Alt+→
全局 上一个 Ctrl+,
全局 下一个 Ctrl+.
Java编辑器 显示大纲 Ctrl+O
全局 在层次结构中打开类型 Ctrl+Shift+H
全局 转至匹配的括号 Ctrl+Shift+P
全局 转至上一个编辑位置 Ctrl+Q
Java编辑器 转至上一个成员 Ctrl+Shift+↑
Java编辑器 转至下一个成员 Ctrl+Shift+↓
文本编辑器 转至行 Ctrl+L
搜索
作用域 功能 快捷键
全局 出现在文件中 Ctrl+Shift+U
全局 打开搜索对话框 Ctrl+H
全局 工作区中的声明 Ctrl+G
全局 工作区中的引用 Ctrl+Shift+G
文本编辑
作用域 功能 快捷键
文本编辑器 改写切换 Insert
文本编辑器 上滚行 Ctrl+↑
文本编辑器 下滚行 Ctrl+↓
文件
作用域 功能 快捷键
全局 保存 Ctrl+X
Ctrl+S
全局 打印 Ctrl+P
全局 关闭 Ctrl+F4
全局 全部保存 Ctrl+Shift+S
全局 全部关闭 Ctrl+Shift+F4
全局 属性 Alt+Enter
全局 新建 Ctrl+N
项目
作用域 功能 快捷键
全局 全部构建 Ctrl+B
源代码
作用域 功能 快捷键
Java编辑器 格式化 Ctrl+Shift+F
Java编辑器 取消注释 Ctrl+\
Java编辑器 注释 Ctrl+/
Java编辑器 添加导入 Ctrl+Shift+M
Java编辑器 组织导入 Ctrl+Shift+O
Java编辑器 使用try/catch块来包围 未设置,太常用了,所以在这里列出,建议自己设置。
也可以使用Ctrl+1自动修正。
运行
作用域 功能 快捷键
全局 单步返回 F7
全局 单步跳过 F6
全局 单步跳入 F5
全局 单步跳入选择 Ctrl+F5
全局 调试上次启动 F11
全局 继续 F8
全局 使用过滤器单步执行 Shift+F5
全局 添加/去除断点 Ctrl+Shift+B
全局 显示 Ctrl+D
全局 运行上次启动 Ctrl+F11
全局 运行至行 Ctrl+R
全局 执行 Ctrl+U
重构
作用域 功能 快捷键
全局 撤销重构 Alt+Shift+Z
全局 抽取方法 Alt+Shift+M
全局 抽取局部变量 Alt+Shift+L
全局 内联 Alt+Shift+I
全局 移动 Alt+Shift+V
全局 重命名 Alt+Shift+R
全局 重做 Alt+Shift+Y
来自:http://hi.baidu.com/q923373067/blog/item/9936310c10207b3b6159f30d.html
NoSQL,就是反SQL,是一项全新的数据库革新运动,特别是在 2010 年得以迅猛发展。而各种开源的 NoSQL 软件突然间涌现在你面前。目前似乎没有对 NoSQL 给出一个标准的定义,也没有相应的规范,但从这些软件可以看出 NoSQL 软件的共同点:独立运行、K/V存储结构,这之前有人称之为集中式缓存服务,其实你可以把二者等同起来。
那么多的 NoSQL 软件,到底哪些更受欢迎呢?为此,开源中国社区为你评选出10款2010年最受关注的 NoSQL 软件。
1. Cassandra
Cassandra 在 2010 年出尽风头,但最终都以失败告终,包括 Twitter 以及 Digg 的案例使我们不得不对 NoSQL 技术是否成熟,是否能在大规模系统中应用产生了怀疑。但这并不影响 Cassandra 拔得头筹,因为还有 Facebook 的支持。
Apache Cassandra 是一套开源分布式Key-Value存储系统。它最初由Facebook开发,用于储存特别大的数据。Facebook目前在使用此系统。
主要特性:
Cassandra 采用 Java 开发,Apache 授权协议。
2. memcached
memcached 是老牌的独立缓存服务的领头羊,目前国内使用该系统的网站非常的多,在这基础上还有国内开发的 memcachedb 是 memcached 支持持久化存储。
memcached 是一套分布式的快取系统,当初是Danga Interactive为了LiveJournal所发展的,但目前被许多软件(如MediaWiki)所使用。不过,memcached 缺乏认证以及安全管制
memcached 采用 C 语言开发,可在 Linux 系统下使用,采用 BSD 授权。
3. Membase
Membase 是 NoSQL 家族的一个新的重量级的成员,其完全兼容 memcached 的方式,有望笼络 memcached 的用户群。Membase 的可伸缩性、集群、复制以及管理方便等特性又是 memcached 无法匹敌的。
Membase 同样采用 C 语言开发,支持 Windows 和 Linux 系统,使用 Apache 授权协议。
接下来介绍两款国产的 NoSQL 软件:
4. Tair
Tair 是由淘宝网自主开发的分布式Key/Value结构数据存储系统,在淘宝网有着大规模的应用。您在登录淘宝、查看商品详情页面或者在淘江湖和好友“捣浆糊”的时候,都在直接或间接地和Tair交互。
Tair 采用 C 语言开发,支持 Linux 系统,使用 GPLv2 授权协议。
5. BeansDB
BeansDB 是豆瓣网开发的一个主要针对大数据量、高可用性的分布式Key Value存储系统,采用HashTree和简化的版本号来快速同步保证最终一致性(弱),一个简化版的 Dynamo。
它采用类似memcached的去中心化结构,在客户端实现数据路由。目前只提供了 Python版本的客户端,其它语言的客户端可以由memcached的客户端稍加改造得到。
主要特性包括:
- 高可用:通过多个可读写的用于备份实现高可用;
- 最终一致性:通过哈希树实现快速完整数据同步(短时间内数据可能不一致);
- 容易扩展:可以在不中断服务的情况下进行容量扩展;
- 高性能:异步IO和高性能的Key Value数据Tokyo Cabinet;
- 可配置的可用性和一致性:通过N,W,R进行配置;
- 简单协议:Memcached兼容协议,大量可用客户端。
BeansDB 采用 Python 语言开发,支持 Linux 系统,使用 BSD 授权协议。
6. Redis
Redis 是一个高性能的key-value数据库。 redis的 出现,很大程度补偿了memcached这类keyvalue存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Python,Ruby,Erlang,PHP客户端,使用很方便。
Redis 的短板:
- 这个项目还很新,可能还不足够稳定,而且没有在实际的一些大型系统应用的实例。
- 缺乏mc中批量get也是比较大的问题,始终批量获取跟多次获取的网络开销是不一样的。
Redis 采用 C 语言开发,支持 Linux 系统,使用 BSD 授权协议。
7. CouchDB
Apache CouchDB 是一个面向文档的数据库管理系统。它提供以 JSON 作为数据格式的 REST 接口来对其进行操作,并可以通过视图来操纵文档的组织和呈现。 CouchDB 是 Apache 基金会的顶级开源项目。
CouchDB落实到最底层的数据结构就是两类B+Tree 。
不过最近有消息说 CouchDB 将走一条不同于 NoSQL 的路子,具体情况如何我们只能拭目以待。
CouchDB 是用 ErLang 开发的哦,跨平台支持,Apache 授权协议。
8. Tokyo Cabinet
Tokyo Cabinet 是一个DBM的实现。这里的数据库由一系列key-value对的记录构成。key和value都可以是任意长度的字节序列,既可以是二进制也可以是字符串。这里没有数据类型和数据表的概念。
当做为Hash表数据库使用时,每个key必须是不同的,因此无法存储两个key相同的值。提供了以下访问方法:提供key,value参数来存储,按 key删除记录,按key来读取记录,另外,遍历key也被支持,虽然顺序是任意的不能被保证。这些方法跟Unix标准的DBM,例如GDBM,NDBM 等等是相同的,但是比它们的性能要好得多(因此可以替代它们)
当按B+树来存储时,拥用相同key的记录也能被存储。像hash表一 样的读取,存储,删除函数也都有提供。记录按照用户提供的比较函数来存储。可以采用顺序或倒序的游标来读取每一条记录。依照这个原理,向前的字符串匹配搜 索和整数区间搜索也实现了。另外,B+树的事务也是可用的。
Tokyo Cabinet 采用 C 语言开发,支持 Linux 系统,使用 LGPL 授权协议。
9. OrientDB
Orient DB 是一个可伸缩的文档数据库,支持 ACID 事务处理。使用 Java 5 实现。OrientDB 最强的一个地方是可以使用 类 SQL 的查询语句进行数据查询。
OrientDB 采用 Java 语言开发,跨平台支持,使用 Apache 授权协议。
10. Hibari
Hibari (在日语中意思为“云雀”)是一个专为高可靠性和大数据存储的数据库引擎,可用于云计算环境中,例如 webmail、SNS 和其他要求T/P级数据存储的环境中。Hibari 支持 Java, C/C++, Python, Ruby, 和 Erlang 语言的客户端。
Hibari 并不是一个关系数据库,主要是通过 key-value 的方法进行数据存储。
Hibari 使用 ErLang 语言开发,支持 Linux/BSD 系统,Apache 授权协议。
来自:http://www.oschina.net/news/14209/2010-top-10-nosql-projects
解决办法:(我已经尝试,没问题,可行的方法)
1 先把SQL Server卸载,再把安装时产生的“Microsoft SQL Server”文件夹删掉
2 在运行注册表,把HKEY_CURRENT_USER\Software\Microsoft\Microsoft SQL Server,和HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft.SQL.Server全部删掉,(注意要把Microsoft SQL Server文件夹整个删掉),然后重起。
来自:http://hi.baidu.com/seavictor/blog/item/76cbd0a2bc1736a5caefd00c.html
在注册表里可以改:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\LanmanServer\Parameters
右边窗口中的Users value,设置type为Decimal,接下来设置最大数就行了
1.把光盘的.tar.gz文件拷贝到/tmp目录
2.把.tar.gz文件解压
3.运行./vmware-install.pl,一路回车
4.运行结束后重新启动,无法进入桌面
5.进入字符模式,cd/etc/X11
6.cp xorg.conf.BeforeVMwareToolsInstall xorg.conf
7. reboot -n
原因:可能是安装时分辨率选择过高。
以前都是让硬件部门协助安装,今天硬件人员不在,尝试自己安装。
首先从VNC官方网站下载一个FREE版本的VNC。
在目标服务器上解压:
# gunzip vnc-4_1_3-sparc_solaris.pkg.gz
下面利用pkgadd命令安装VNC包:
# pkgadd -d vnc-4_1_3-sparc_solaris.pkg
The following packages are available:
1 VNC VNC Free Edition for Solaris
(sparc) 4.1.3
Select package(s) you wish to process (or 'all' to process
all packages). (default: all) [?,??,q]: 1
Processing package instance <VNC> from </var/spool/pkg/vnc-4_1_3-sparc_solaris.pkg>
VNC Free Edition for Solaris(sparc) 4.1.3
Copyright (C) 2002-2005 RealVNC Ltd. All rights reserved.
This is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation; either version 2 of the License, or
(at your option) any later version.
This software is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
Using </usr/local> as the package base directory.
## Processing package information.
## Processing system information.
## Verifying disk space requirements.
## Checking for conflicts with packages already installed.
The following files are already installed on the system and are being
used by another package:
* /usr/local/bin <attribute change only>
* - conflict with a file which does not belong to any package.
Do you want to install these conflicting files [y,n,?,q] y
## Checking for setuid/setgid programs.
This package contains scripts which will be executed with super-user
permission during the process of installing this package.
Do you want to continue with the installation of <VNC> [y,n,?] y
Installing VNC Free Edition for Solaris as <VNC>
## Installing part 1 of 1.
/usr/local/bin/Xvnc
/usr/local/bin/vncconfig
/usr/local/bin/vncpasswd
/usr/local/bin/vncserver
/usr/local/bin/x0vncserver
/usr/local/man/man1/Xvnc.1
/usr/local/man/man1/vncconfig.1
/usr/local/man/man1/vncpasswd.1
/usr/local/man/man1/vncserver.1
/usr/local/man/man1/x0vncserver.1
/usr/local/vnc/classes/index.vnc
/usr/local/vnc/classes/logo150x150.gif
/usr/local/vnc/classes/vncviewer.jar
[ verifying class <server> ]
/usr/local/bin/vncviewer
/usr/local/man/man1/vncviewer.1
[ verifying class <viewer> ]
/usr/local/doc/vnc-E/LICENSE.txt
/usr/local/doc/vnc-E/README
[ verifying class <doc> ]
## Executing postinstall script.
Checking for xauth... /usr/openwin/bin
WARNING: /usr/openwin/bin/xauth is not on your path.
Checking for perl... [OK]
Checking for uname... [OK]
Installation of <VNC> was successful.
下面就可以通过VNCPASSWORD设置密码,并使用VNCSERVER来启动VNC后台进程:
# /usr/local/bin/vncpasswd
Password:
Verify:
# /usr/local/bin/vncserver
vncserver: couldn't find "Xvnc" on your PATH.
# export PATH=$PATH:/usr/local/bin
# vncserver &
[1] 15921
# xauth: creating new authority file //.Xauthority
New 'ser2:1 ()' desktop is ser2:1
Creating default startup script //.vnc/xstartup
Starting applications specified in //.vnc/xstartup
Log file is //.vnc/ser2:1.log
[1]+ Done vncserver
注意要将VNCSERVER命令的目录添加到PATH路径中,后台启动VNCSERVER后,就可以使用VNCVIEWER访问ser2:1了。
来自: http://pub.itpub.net/post/468/482239
1.首先下載 vnc-3.3.3r2_sun4_sosV_5.5.tgz
用tar命令解压缩,tar -xvf vnc-3.3.3r2_sun4_sosV_5.5.tgz
cd vnc-3.3.3r2_sun4_sosV_5.5
mkdir -p /usr/local/vnc/classes
建立一个目录
cp classes/* /usr/local/vnc/classes
接着再
cp *vnc* /usr/bin
這樣安裝過程基本上就完成了
2.創建.vnc目錄
mkdir $HOME/.vnc (linux下运行vncserver會自動建立)
运行vncserver,接著系統會提示你輸入密碼,這個密碼為當前用戶的VNC訪問密碼
這樣一個VNCserver就啟動了
可以用win下的vncviwer來連接,也可能用IE來直接訪問:
在IE地址欄里輸入//192.168.0.20:5801(這里的IP地址為你VNC服務器的IP地址)
輸入密碼就可以訪問了
3.在VNC里用CED
如果連網速度夠快的話,我們可以在VNC里用CED
cd $HOME/.vnc
vi xstartup
注释掉twm &,添加/usr/dt/bin/dtsession &
注意:系統的rpc服務不能停,如果CDE啟動不了,試試/etc/init.d/rpc start
(開始我的也不行,多亏了本版版主蜘蛛的幫忙才解決的,再次表示感謝:P)
vncserver :num為啟動VNC,如果不指定num則從1開始
vncserver -kill :num為停止VNC
4. 这样只能root用户可以启动vncserver,想用普通用户启动的话,用如下为方法(远程装oracle就不用那么麻烦了:P)
只要setuid /usr/bin/Xvnc就行了
提示:setuid会带来一定的安全隐患,如果取舍就看需要了(也可以用全就set回去,呵呵)
来自: http://www.jb51.net/os/Solaris/1685.html
虽然不全,但一定是常用的,小弟自己整理的,望大家能够继续补充
1.showrev
查看系统Hostid: 24cc7225
Release: 5.9
Kernel architecture: i86pc
Application architecture: i386
Hardware provider: COMPAQ
Domain: sinomos.com
Kernel version: SunOS 5.9 Generic 112234-10 Nov 2003
showrev -p可以查看系统的安装的补丁
2、vmstat监视cpu
iostat监视磁盘
iostat -E现在磁盘信息,包括大小和错误数量,厂家等等
3、prtconf显示系统信息
4、prtdiag显示系统cpu,内存,以及OBP
5、netstat -r路由信息
netstat -i接口信息
6、查看网卡状态
ndd -get /dev/eri link_status or link_speed
7. isainfo -b 32 or 64
isainfo查看系统的平台类型sparc or i386
8. prodreg图形界面显示安装的软件
9、prtvtoc /dev/rdsk/c0t0d0s2
/* Disk geometry and partitioning info *
10、dos2unix | -ascii <filename>;
/* Converts DOS file formats to Unix */
11、mailx -H -u <username>;
/* List out mail headers for specified user */
12、prtconf | grep "Memory size"
/* Display Memory Size */
13、prstat -a类似top的命令
14、Snoop Your Network
snoop -d pcelx0
/* Watch all network packets on device pcelx0 */
snoop -o /tmp/mylog pcelx0
/* Saves packets from device pcelx0 to a file */
snoop -i /tmp/mylog host1 host2
/* View packets from logfile between host1 & host2 */
snoop -i /tmp/mylog -v -p101
/* Show all info on packet number 101 from a logfile */
snoop -i /tmp/mylog -o /tmp/newlog host1
/* Write a new logfile with all host1 packets */
snoop -s 120
/* Return the first 120 bytes in the packet header */
snoop -v arp
/* Capture arp broadcasts on your network */
15、uname -a
显示机器名以及机器的平台,机器的型号
16、df -h显示磁盘使用情况
17、查看cpu详细信息psrinfo -v
18、whoami
who
finger
查看当前登陆用户(大家运行下,看看有什么区别)
19、fuser -cu /mountpoint,看当前有什么进程和此文件系统有关
fuser -ck /mountpoint,杀掉所有和此文件系统有关的进程
20、查看磁盘的分区情况:format---0(表硬盘控制器号)--partition--print
21、du -sk dir1 显示目录 dir1 的总容量,以k bytes为计量
22、id 查看当前用户用户号和组号
23、dfshares 显示远程机共享资源
24、pkginfo -l 命令显示关于软件包的详细信息,包括软件包的大小
Solaris 系统管理命令及相关技术中英文对照
A
-----------------------------------------------------------------------------------
ab2admin—对AnswerBook2进行管理的命令行界面
ab2cd—从Documentation CD中运行AnswerBook2服务器
ab2regsvr—向联合域名服务注册AnswerBook2文档服务器
accept、reject—接受或拒绝打印请求
acct—对计数及各种计数命令的概述
acctcms—进程计数命令
acctcon、acctcon1、acctcon2—连接时间计数
acctdisk—将计数数据转换为计数记录总数
acctdusg—通过登录信息计算磁盘资源的消耗
acctmerg—合并或添加总体计数文件
accton—在已有文件中追加进程计数记录
acctprc、acctprc1、acctprc2—进程计数
acctsh、chargefee、ckpacct、dodisk、lastlogin、monacct、nulladm、prctmp、prdaily、prtacct、
shutacct、startup、turnacct—进行计数的shell过程
acctwtmp—将utmpx记录写入文件
adbgen—生成adb脚本
add_drv—在系统中增加一个新的设备驱动器
add_install_client—从网络安装中添加或删除客户的脚本
add_to_install_server—从附加的Solaris CD中将脚本复制到现有的网络安装服务器
addbadsec—映射出错误磁盘块
admintool—通过图形用户界面进行系统管理
afbconfig、SUNWafb_config—配置AFB图形加速器
aliasadm—处理NIS+别名映射
allocate—设备分配
amiserv—AMI密钥服务器
answerbook2_admin—AnswerBook2 GUI管理工具
arp—地址解析的显示与控制
aset—控制或限制对系统文件和目录的访问
aset.restore—恢复ASET所影响的文件系统
aspppd、aspppls—异步PPP链接管理程序
aspppls—异步PPP链接管理程序
audit—控制审计守护进程的行为
auditconfig—审计配置
auditd—控制审计追踪文件的生成与定位
auditreduce—从审计追踪文件中合并和选择审计追踪记录
audit_startup—审计子系统初始化脚本
auditstat—显示内核审计统计
audit_warn—审计守护进程警告脚本
automount—安装自动挂接点
automountd—挂接/摘除守护进程autofs
autopush—配置一个自动压入的STREAMS模块列表
B
-----------------------------------------------------------------------------------
bdconfig—配置按钮和拨号流
boot—启动系统内核或者一个独立程序
bootparamd—引导参数服务器
bsmconv、bsmunconv—启用或者禁用BSM
busstat—报告与总线有关的性能统计
C
-----------------------------------------------------------------------------------
cachefslog—对CacheFS进行记录
cachefspack—将文件和文件系统压缩到高速缓存中
cachefsstat—对CacheFS进行统计
cachefswssize—测定高速缓存文件的工作集合的大小
captoinfo—将termcap描述转换为terminfo描述
cfgadm—配置管理
cfgadm_ac—对EXX00内存进行系统管理
cfgadm_pci—对PCI热插入进行配置管理的命令
cfgadm_scsi—SCSI硬件专用的cfgadm命令
cfgadm_sysctrl—对EX00系统板进行管理
cfsadmin—管理CacheFS进行文件系统高速缓存时所使用的磁盘空间
cg14config—配置SX/CG14图形加速器设备
chargefee—计数的shell过程
check-hostname—检测sendmail是否能够测定系统的完全合格主机名
check-permissions—检测邮件重新路由的权限
check—对JumpStart规则文件中的规则进行校验的脚本
chown—改变所有者
chroot—修改命令的root目录
ckpacct—定期检测/var/adm/pacct长度的计数命令
clear_locks—清除NFS客户所持有的锁
clinfo—显示分组信息
closewtmp—将一个非法读取进程的记录放入/var/adm/wtmpx文件
clri、dcopy—清除信息节点
comsat—Biff服务器
consadm—指定或者显示辅助控制台设备
conv_lp—转换LP的配置
conv_lpd—转换LPD的配置
coreadm—对核心文件进行管理
cpustat—通过CPU性能计数对系统行为进行嗫?
crash—检测系统映像
cron—时钟守护进程
cvcd—虚拟控制台守护进程
D
-----------------------------------------------------------------------------------
dcopy—清除信息节点
dd—转换与复制文件
deallocate—设备的卸配
devattr—显示设备属性
devconfig—配置设备属性
devfree—从独占使用中释放设备
devfsadm—对/dev和/devices进行管理的命令
devfseventd—devfsadmd的内核事件通知守护进程
devinfo—打印特定于设备的信息
devlinks—为各种设备和伪设备添加/dev项
devnm—设备名
devreserv—为独占使用预留设备
df—显示闲置的磁盘块和文件数
df_ufs—报告UFS文件系统上的闲置磁盘空间
dfmounts—显示被挂接的资源信息
dfmounts_nfs—显示被挂接的NFS资源信息
dfshares—列举远程或本地系统中可用的资源
dfshares_nfs—列举远程系统可用的NFS资源
dhcpagent—客户DHCP的守护进程
dhcpconfig—对DHCP服务进行管理的命令
dhcpmgr—管理DHCP服务的图形界面
dhtadm—对DHCP配置表进行管理的命令
disks—为附加到系统的硬盘创建/dev项
diskscan—执行表面分析
dispadmin—进程调度管理
dmesg—收集系统诊断消息,形成错误日志
dmi_cmd—DMI命令行界面的命令
dmiget—命令行方式的DMI的获取命令
dminfo—报告设备映射文件中某设备项的相关信息
dmispd—Sun Solstice Enterprise 的DMI服务提供商
dodisk—由时钟守护进程调用的shell过程,可执行磁盘计数功能
domainname—显示或者设置当前域名
dr_daemon—Enterprise 10000 的动态重配守护进程
drvconfig—配置/devices目录
du—对磁盘使用情况进行汇总
dumpadm—对操作系统的崩溃转储进行配置
E
-----------------------------------------------------------------------------------
edquota—为UFS文件系统编辑用户配额
eeprom—EEPROM的显示和装载命令
F
-----------------------------------------------------------------------------------
fbconfig—帧缓冲的配置命令
fdetach—将名字与基于STREAMS的文件描述符分离
fdisk—创建或者修改固定磁盘分区表
ff—为文件系统列举文件名和统计信息
ff_ufs—为UFS文件系统列举文件名和统计
ffbconfig—对FFB图形加速器进行配置
fingerd—远程用户信息服务器
firmware—可引导的固件程序和固件命令
fmthard—填充硬盘的卷目录表
fncheck—检测FNS数据与NIS+数据之间的一致性
fncopy—复制FNS环境
fncreate—创建FNS环境
fncreate_fs—创建FNS文件系统的环境
fncreate_printer—在FNS名字空间中创建新打印机
fndestroy—破坏FNS环境
fnselect—为FNS初始化环境选择一个特定的命名服务
fnsypd—更新NIS主服务器上的FNS环境
format—磁盘的分区与维护命令
fsck—检测和修复文件系统
fsck_cachefs—为CacheFS缓存的数据进行完整性检测
fsck_s5fs—文件系统的一致性检测和交互式修复
fsck_udfs—文件系统的一致性检测和交互式修复
fsck_ufs—文件系统的一致性检测和交互式修复
fsdb—文件系统调试器
fsdb_udfs—UDFS文件系统调试器
fsdb_ufs—UFS文件系统调试器
fsirand—安装随机的信息节点编号生成器
fstyp—测定文件系统的类型
ftpd—文件传输协议服务器
fuser—通过文件或者文件结构标识进程
fwtmp、wtmpfix—对连接计数记录进行处理
G
-----------------------------------------------------------------------------------
gencc—创建cc命令的前端
getdev—分类列举设备
getdgrp—列举包含了匹配设备的设备组
getent—从管理数据库中获取表项
gettable—从主机中获取DoD Internet格式的主机表
getty—设置终端类型、模式、速度和行规范
getvol—对设备的可达性进行校验
GFXconfig—配置PGX32(Raptor GFX)图形加速器
goupadd—在系统中添加或创建新组定义
groupdel—从系统中删除组定义
groupmod—修改系统中的组定义
grpck—口令和组文件的检测程序
gsscred—添加、删除 、列举gsscred表项
gssd—为内核RPC产生和验证GSS-AIP标记
H
-----------------------------------------------------------------------------------
halt、poweroff—关闭处理器
hostconfig—配置系统的主机参数
htable—转换DoD Internet格式的主机表
I
-----------------------------------------------------------------------------------
id—返回用户标识
ifconfig—配置网络接口参数
in.comsat、comsat—Biff服务器
in.dhcpd—DHCP服务器
in.fingerd、fingerd—远程用户信息服务器
in.ftpd、ftpd—文件传输协议服务器
in.lpd—BSD打印协议适配器
in.named、named—Internet域名服务器
in.ndpd—IPv6的自动配置守护进程
in.rarpd、rarpd—DARPA逆向地址解析协议服务器
in.rdisc、rdisc—发现网络路由守护进程
in.rexecd、rexecd—远程执行服务器
in.ripngd—IPv6的网络路由守护进程
in.rlogind、rlogind—远程登录服务器
in.routed、routed—网络路由守护进程
in.rshd、rshd—远程shell服务器
in.rwhod、rwhod—系统状态服务器
in.talkd、talkd—talk程序服务器
in.telnetd、telnetd—DARPA TELNET协议服务器
in.tftpd、tftpd—Internet平凡文件传输协议服务器
in.tnamed、tnamed—DARPA平凡名字服务器
in.uucpd、uucpd—UUCP服务器
inetd—Internet服务守护进程
infocmp—比较或打印terminfo描述
init、telinit—进程控制的初始化
init.wbem—启动和停止CIM引导管理程序
install—安装命令
install_scripts—Solaris软件的安装脚本
installboot—在磁盘分区中安装引导块
installf—向软件安装数据库中添加文件
Intro、intro—对维护命令及应用程序的介绍
iostat—报告I/O统计
ipsecconf—配置系统范围的IPsec策略
ipseckey—手工操作IPsec的SA数据库
K
-----------------------------------------------------------------------------------
kadb—内核调试器
kdmconfig—配置或卸配键盘、显示器和鼠标选项
kerbd—为内核RPC生成和校验Kerberos票据
kernel—包括基本操作系统服务在内的UNIX系统可执行文件
keyserv—存储加密私钥的服务器
killall—杀死所有活跃的进程
ktkt_warnd—Kerberos警告守护进程
kstat—显示内核统计信息
L
-----------------------------------------------------------------------------------
labelit—为文件系统列举或者提供标签
labelit_hsfs—为HSFS文件系统列举或者提供标签
labelit_udfs—为UDF文件系统列举或者提供标签
labelit_ufs—为UFS文件系统列举或者提供标签
lastlogin—显示每个人员所登录的最后日期
ldap_cachemgr—为NIS查找缓存的服务器和客户信息LDAP守护进程
ldapclient、ldap_gen_profile—对LDAP客户机进行初始化或者创建LDAP客户配置文件的LDIF
link、unlink—链接或者取消链接文件和目录
list_devices—列举可分配的设备
listdgrp—列举设备组的成员
listen—网络监听守护进程
llc2_loop—为测试驱动器、适配器和网络回送诊断
lockd—网络锁定守护进程
lockfs—修改或者报告文件系统锁
lockstat—报告内核锁的统计信息
lofiadm—通过lofi管理可用作磁块设备的文件
logins—列举用户和系统的登录信息
lpadmin—配置LP打印服务
lpfilter—管理LP打印服务所使用的过滤器
lpforms—管理LP打印服务所使用的格式
lpget—获取打印配置
lpmove—移动打印请求
lpsched—启动LP打印服务
lpset—在/etc/printers.conf或FNS中设置打印配置
lpshut—停止LP打印服务
lpsystem—向打印服务注册远程系统
lpusers—设置打印队列的优先级
luxadm—SENA、RSM和SSA子系统的管理程序
M
-----------------------------------------------------------------------------------
m64config—配置M64图形加速器
mail.local—将邮件存入邮件箱
makedbm—创建dbm文件,或者从dbm文件得到文本文件
makemap—为sendmail创建数据库映射
mibiisa—Sun SUMP代理
mk—从源代码重建二进制系统和命令
mkfifo—创建FIFO专用文件
mkfile—创建一个文件
mkfs—构造文件系统
mkfs_pcfs—构造FAT文件系统
mkfs_udfs—构造UDFS文件系统
mkfs_ufs—构造UFS文件系统
mknod—创建专用文件
modify_install_server—在现有网络安装服务器上取代miniroot的脚本
modinfo—显示所装载的内核模块信息
modload—装载内核模块
modunload—卸载模块
mofcomp—将MOF文件编译为CIM类
monacct—每月调用计数程序
monitor—SPARC系统的PROM监控器
mount、umount—挂接或摘除文件系统和远程资源
mountall、umountall—挂接、摘除多个文件系统
mount_cachefs—挂接CacheFS文件系统
mountd—接收NFS挂接请求和NFS访问的服务器
mount_hsfs—挂接HSFS文件系统
mount_nfs—挂接远程的NFS资源
mount_pcfs—挂接PCFS文件系统
mount_s5fs—挂接s5文件系统
mount_tmpfs—挂接tmpfs文件系统
mount_udfs—挂接UDFS文件系统
mount_ufs—挂接UFS文件系统
mount_xmemfs—挂接xmemfs文件系统
mpstat—报告每个处理器的统计信息
msgid—生成消息ID
mvdir—移动目录
N
-----------------------------------------------------------------------------------
named-bootconf—将配置文件转换为适用于Bind 8.1的格式
named-xfer—支持入站区域传送的辅助代理
named—Internet域服务器
ncheck—生成路径名与i编号的映射列表
ncheck_ufs—为UFS文件系统生成路径名与i编号的映射列表
ndd—获取和设置驱动器的配置参数
netstat—显示网络状态
newfs—构造新的UFS文件系统
newkey—在publickey数据库中创建新的Diffie-Hellman密钥对
nfsd—NFS守护进程
nfslogd—NFS的日志记录守护进程
nis_cachemgr—对NIS+服务器的位置信息进行高速缓存的NIS+命令
nfsstat—显示NFS统计信息
nisaddcred—创建NIS+证书
nisaddent—从相应的/etc文件或者NIS映射中创建NIS+表
nisauthconf—NIS+的安全性配置
nisbackup—备份NIS+目录
nisclient—为NIS+实体初始化NIS+证书
nisd—NIS+服务的守护进程
nisd_resolv—NIS+服务的守护进程
nisinit—NIS+客户和服务器的初始化命令
nislog—显示NIS+事务日志的内容
nispasswdd—NIS+口令更新的守护进程
nisping—向NIS+服务器发送ping
nispopulate—填充NIS+域中的NIS+表
nisprefadm—为NIS+客户设置服务器优先级别的NIS+命令
nisrestore—恢复NIS+目录的备份
nisserver—创建NIS+服务器
nissetup—初始化NIS+域
nisshowcache—打印共享高速缓存文件的NIS+命令
nisstat—报告NIS+服务器的统计信息
nisupdkeys—更新NIS+目录中的公钥
nisadmin—对网络监听服务进行管理
nscd—名字服务的高速缓存守护进程
nslookup—交互式查询名字服务器
nstest—DNS测试shell
nsupdate—更新DNS名字服务器
ntpdate—使用NTP设置本地的日期和时间 731
ntpq—标准NTP查询程序 733
ntptrace—沿着NTP主机链追溯到其主控时间资源 739
nulladm—采用664模式创建文件名,确保其所有者和组为adm
O
-----------------------------------------------------------------------------------
obpsym—OpenBoot固件的内核符号调试
ocfserv—OCF 服务器
P
-----------------------------------------------------------------------------------
parse_dynamic_clustertoc—基于动态项对clustertoc文件进行语法分析
passmgmt—对口令文件进行管理
patchadd—将补丁包应用于Solaris系统
patchrm—删除补丁包并恢复以前保存的文件
pbind—控制和查询进程与处理器之间的绑定
pcmciad—PCMCIA用户守护进程
pfinstall—对安装配置文件进行测试
pgxconfig、GFXconfig—配置PGX32(Raptor GFX)图形加速器
ping—向网络主机发送ICMP(ICMP6) ECHO_REQUEST包
pkgadd—将软件包传给系统
pkgask—将答复信息存储在请求脚本中
pkgchk—检测软件包安装的准确性
pkgrm—从系统中删除软件包
pmadm—对端口监控器进行管理
pmconfig—对电源管理系统进行配置
pntadm—DHCP网络表的管理命令
ports—为串行线创建/dev和inittab项
powerd—电源管理的守护进程
poweroff—停止处理器
praudit—打印审计追踪文件的内容
prctmp、prdaily、prtacct—打印各种计数文件
printmgr—在网络中管理打印机的图形用户界面
prstat—报告活跃进程的统计信息
prtconf—打印系统的配置信息
prtdiag—显示系统的诊断信息
prtvtoc—报告关于磁盘几何以及分区信息
psradm—修改处理器的操作状态
psrinfo—显示处理器的相关信息
psrset—创建和管理处理器集合
putdev—编辑设备表
putdgrp—编辑设备组表
pwck、grpck—口令/组文件的检测程序
pwconv—使用/etc/passwd中的信息安装和更新/etc/shadow
Q
-----------------------------------------------------------------------------------
quot—汇总系统文件的所有权信息
quota—显示用户在UFS文件系统中的磁盘配额和使用情况
quotacheck—UFS文件系统配额的一致性检测程序
quotaon、quotaoff—打开或者关闭UFS文件系统的配额
R
-----------------------------------------------------------------------------------
rarpd—DARPA逆向地址解析协议服务器
rdate—从远程主机设置系统日期
rdisc—探测网络路由器的守护进程
re-preinstall—在系统上安装JumpStart软件
reboot—重新启动操作系统
reject—拒绝打印请求
rem_drv—从系统中删除设备驱动器
removef—从软件数据库中删除文件
repquota—为UFS文件系统进行配额汇总
restricted_shell—受限的shell命令接收器
rexd—基于RPC的远程执行服务器
rexecd—远程执行服务器
rlogind—远程登录服务器
rm_install_client—从网络安装中删除客户的脚本
rmmount—用于CD-ROM和软盘的可移动介质挂接程序
rmt—远程磁带协议模块
roleadd—管理新的角色帐号
roledel—删除角色的登录
rolemod—修改现有的角色帐号
route—对路由表进行手工处理
routed—网络路由的守护进程
rpc.bootparamd、bootparamd—引导参数服务器
rpc.nisd、nisd—NIS+服务的守护进程
rpc.nisd_resolv、nisd_resolv—NIS+服务的守护进程
rpc.nispasswdd、nispasswdd—NIS+口令更新的守护进程
rpc.rexd、rexd—基于RPC的远程执行服务器
rpc.rstatd、rstatd—内核统计服务器
rpc.rusersd、rusersd—网络用户的名字服务器
rpc.rwalld、rwalld—网络rwall服务器
rpc.sprayd、sprayd—Spray服务器
rpc.yppasswdd、yppasswdd—修改NIS口令文件的服务器
rpc.ypupdated、ypupdated—修改NIS信息的服务器
rpcbind—统一地址到RPC程序编号的映射
rpcinfo—报告RPC信息
rpld—IA网络引导的RPL服务器
rquotad—远程配额服务器
rsh—受限的shell
rshd—远程shell服务器
rstatd—内核统计服务器
rtc—对所有的实时钟和GMT标记进行管理
runacct—进行每日计数
rusersd—网络用户的名字服务器
rwall—写给网络中的所有用户
rwalld—网络rwall服务器
rwhod—系统状态服务器
S
-----------------------------------------------------------------------------------
sa1、sa2、sadc—系统行为报告信息包
sac—服务访问控制器
sacadm—对服务访问控制器进行管理
sadc—报告系统行为的信息包
sadmind—分布式系统管理的守护进程
saf—服务访问程序 888
sar、sar1、sac2、sadc—报告系统行为的包
savecore—保存操作系统的崩溃转储
sendmail—在Internet上发送邮件
server_upgrade—为异质OS服务器的客户进行升级
setmnt—建立挂接表
setuname—修改系统信息
setup_install_server—从Solaris CD到磁盘的复制脚本
share—允许远程挂接时使用本地资源
share_nfs—允许远程挂接时使用NFS文件系统
shareall、unshareall—共享或者取消共享多个资源
showmount—显示所有的远程挂接
showrev—显示机器和软件的修正信息
shutacct—在系统关机时关闭进程计数
shutdown—关闭系统或者改变系统状态
slpd—服务定位协议守护进程
smartcard—配置和管理智能卡
smrsh—sendmail的受限shell
snmpdx—Sun Solstice Enterprise Master Agent
snmpXdmid—Sun Solstice Enterprise的SNMP-DMI映射
snoop—捕获并检查网络包
soconfig—配置套接字所使用的传输提供商
soladdapp—将应用程序添加到Solstice应用程序注册表中
soldelapp—从Solstice应用程序注册表中删除应用程序
solstice—通过图形用户界面访问系统管理工具
spray—Spray信息包
sprayd—Spray服务器
ssaadm—SPARCstorage 队列和SPARCstorage RSM磁盘系统的管理程序
startup—在启动时打开进程计数
statd—网络状态监控器
strace—打印STREAMS追踪消息
strclean—STREAMS错误记录器的清除程序
strerr—STREAMS错误记录器守护进程
sttydefs—为TTY端口维护行设置并寻找序列
su—成为超级用户或者另一个用户
sulogin—访问单用户模式
suninstall—安装Solaris操作环境
swap—交换管理界面
swmtool—安装、升级和删除软件包
sxconfig—为SX视频子系统配置连续内存
sync—更新超块
syncinit—设置串行线接口的操作参数
syncloop—同步线性回送的测试程序
syncstat—从同步串行链接中报告驱动器统计信息
sys-unconfig—取消系统的一个配置
sysdef—输出系统定义
sysidconfig—执行或定义系统配置程序
sysidtool、sysidnet、sysidns、sysidsys、sysidroot、sysidp—系统配置
syslogd—记录系统消息
T
-----------------------------------------------------------------------------------
talkd—talk程序的服务器
tapes—为磁带设备创建/dev
taskstat—打印ASET任务的状态
tcxconfig—配置S24(TCX)帧缓冲
telinit—进程控制的初始化
telnetd—DARPA TELNET协议服务器
tftpd—Internet平凡文件传输协议服务器
tic—terminfo编译器
tnamed—DARPA平凡命名服务器
traceroute—打印信息包到达网络主机的路由
ttyadm—对特定端口监控器的信息进行格式化并输出
ttymon—终端端口的监控器
tunefs—调谐现有的文件系统
turnacct—打开或关闭进程计数
U
-----------------------------------------------------------------------------------
uadmin—管理控制
ufsdump—文件系统的增量转储
ufsrestore—文件系统的增量恢复
umount—摘除文件系统以及远程资源
umountall—摘除多个文件系统
unlink—取消文件和目录的连接
unshare—不允许远程系统挂接本地资源
unshare_nfs—不允许远程系统挂接本地的NFS文件系统
unshareall—取消所有资源的共享
useradd—管理系统中的新用户登录或新角色
userdel—从系统中删除用户登录
usermod—修改系统中的用户登录或角色信息
utmp2wtmp—在runacct所生成的文件/var/adm/wtmpx中创建新项
utmpd—utmpx监控守护进程
uucheck—检测UUCP目录和许可文件
uucico—UUCP系统的文件传输程序
uucleanup—清除UUCP假脱机目录
uucpd—UUCP服务器
uusched—UUCP文件传输程序的调度程序
Uutry、uutry—尝试在调试模式中联系远程系统
uuxqt—执行远程命令请求
V
-----------------------------------------------------------------------------------
vmstat—报告虚拟内存的统计
volcopy—创建文件系统的映像拷贝
volcopy_ufs—创建UFS文件系统的映像拷贝
vold—对CD-ROM和软盘设备进行管理的卷管理守护进程
W
-----------------------------------------------------------------------------------
wall—写给所有的用户
wbemadmin—启动Sun WBEM用户管理程序
wbemlogviewer—启动WBEM日志查看程序
whodo—报告谁在做什么
wtmpfix—处理连接计数记录
X
-----------------------------------------------------------------------------------
xntpd—网络时间协议的守护进程
xntpdc—专用的NTP查询程序
Y
-----------------------------------------------------------------------------------
ypbind—NIS绑定进程
ypinit—创建NIS客户
ypmake—重建NIS数据库
yppasswdd—修改NIS口令文件的服务器
yppoll—返回NIS服务器主机上的当前NIS映射版本
yppush—强制传播一个已修改的NIS映射
ypserv、ypxfrd—NIS服务器以及绑定进程
ypset—指向特定服务器上的ypbind
ypstart、ypstop—启动和停止NIS服务
ypupdated—修改NIS信息的服务器
ypxfr、ypxfr_1perday、ypxfr_1perhour、ypxfr_2perday—从NIS服务器向主机传送NIS映射
ypxfrd—NIS服务器与绑定进程
来自: http://hi.baidu.com/trail/blog/item/5043b2356acaf38ba61e12ca.html
当我们安装完成一台Solaris 10服务器或者工作站后通常要做的是配置网络接口,这样Solaris 10服务或者工作站才能和网络中的其他计算机进行联机。
一、 理解Solaris网络配置文件
常常有读者会问Uinx (Solaris 当然也在其中)中有没有一个标准的配置文件格式?一句话,没有。不熟悉 Unix 的用户一定会感到沮丧,因为每个配置文件看起来都象是一个要迎接的新挑战。所以在Solaris 中,每个程序员都可以自由选择他或她喜欢的配置文件格式。Solaris系统中大多数配置文件都在 /etc 目录中。配置文件可以大致分为下面几类:访问文件、引导和登录/注销、系统管理、网络配置、系统命令等。本文将要介绍的是网络配置文件,主要包括:
1. /etc/hostname.interface
该文件是物理网卡的配置文件,这个文件包括一个主机名称或者主机的IP地址。有le、hme等后缀等。 le是十兆网卡,hme为百兆网卡等等。后面跟一个数字,第一个十兆网卡为le0,第二个为le1;第二个百兆网卡为hme0,第二个为hme1等。 Solaris 安装程序要求您在安装过程中至少配置一个接口。自动配置的第一个接口将成为主网络接口。安装程序为主网络接口和在安装时选择配置的任何其他接口创建 /etc/hostname.interface 文件。 如果在安装过程中配置了其他接口,请验证每个接口是否有对应的 /etc/hostname.interface 文件。在 Solaris 安装过程中,无需配置多个接口。但是,如果稍后要将更多接口添加到系统中,则必须手动配置它们。
说明:如一台SUN工作站连接了Internet网和内部网,则可对应创建两个文件分为hostname.le0和hostname.le0:2。
2. /etc/nodename
在 Solaris 安装过程中指定系统的主机名时,该主机名将输入到 /etc/nodename 文件中。确保节点名称项是系统的正确主机名。如果计算机名称是cjh ,那么/etc/nodename 文件中肯定包括一行:cjh 。
3. /etc/defaultdomain
/etc/defaultdomain文件包括本地主机的域名。如,假定主机 tenere 是域 deserts.worldwide.com 的一部分。则在 /etc/defaultdomain 中包括 以下信息:deserts.worldwide.com。
4. /etc/defaultrouter
/etc/defaultrouter包括主机的路由地址。选用动态路由协议,则可将 /etc/defaultrouter文件置为空。若选择静态协议,只需在/etc/defaultrouter文件中填入缺省路由器名,这样当Unix 路由器找不到寻径路由时便将IP包发往缺省路由器。
5. /etc/inet/hosts
/etc/inet/hosts是主机数据库文件。主机数据库包含网络中各系统的IPv4 地址和主机名。如果使用NIS 或DNS 名称服务,或者使用LDAP 目录服务,则hosts 数据库在专门存储主机信息的数据库中进行维护。例如,在运行NIS 的网络中,hosts 数据库在hostsbyname 文件中进行维护。如果使用本地文件提供名称服务,则hosts 数据库将在/etc/inet/hosts 文件中维护。此文件包含主网络接口的主机名和IPv4 地址、连/etc/inet/hosts 文件格式:
IPv4-address hostname [nicknames] [#comment]
IPv4-address 包含本地主机必须识别的每个接口的IPv4 地址。
hostname 包含设置期间指定给系统的主机名,以及指定给本地主机必须识别的
其他网络接口的主机名。
[nickname] 包含主机昵称的可选字段。
[#comment] 是可选的注释字段。接到系统的其他网络接口的主机名和IPv4 地址以及系统必须检查的其他网络地址。
一个典型文件如下:
# Internet host table
127.0.0.1 localhost
10.1.1.8 suncjh loghost
说明:其中127.0.0.1 是回送地址。回送地址是本地系统用来允许进程间通信的保留网络接口。主机可使用此地址将数据包发送给自己。ifconfig 命令使用回送地址进行配置和测试。
6. /etc/inet/ipnodes
/etc/inet/ipnodes 文件同时存储IPv4 和IPv6 地址。此外,也可以存储以传统的点分十进制或CIDR 表示法表示的IPv4 地址。此文件作为将主机名与其IPv4 和IPv6 地址进行关联的本地数据库。
7. /etc/inet/netmasks
/etc/inet/netmasks是子网掩码数据库。如果在网络中设置了子网,则配置网络时只需要 编辑netmasks 数据库。netmasks数据库由网络及其关联的子网掩码的列表组成。创建子网时,每个新网络必须是单独的物理网络。不能在单个物理网络中设置子网。
对于 C 类网络号 192.168.83,请键入:192.168.83.0 255.255.255.0;对于 CIDR 地址,将网络前缀转换为等效的用点分十进制表示法表示的项。例如,使用以下内容可以表示 CIDR 网络前缀 192.168.3.0/22。
二、 配置实战
假设有一台Sun 服务器
主机名称:cjh1 ,
IP地址:192.168.1.2 ,
子网掩码:255.255.255.0,
默认路由:192.168.1.1。
我们准备把它修改为:
主机名称:suncjh ,
IP地址:10.1.1.8 ,
子网掩码:255.0.0.0,
默认路由:10.0.0.0。
步骤如下:
1 首先必须获得管理员权限或者授权角色用户。
2 进入etc目录。
3 使用vi或者其他编辑器打开文件:/etc/nodename 。将主机名称:cjh1 修改为suncjh 。
4 编辑网络端口配置文件:hostname.eri0, 将主机名称:cjh1 修改为suncjh 。同时把Ip地址修改为10.1.1.8 。
5 编辑/etc/inet/hosts文件,删除包括原来主机名称的一行,加入一行:
10.1.1.8 suncjh suncjh.deserts.worldwide.com
其中deserts.worldwide.com是主机suncjh的域名。
6 在文件/etc/defaultdomain加入域名:
deserts.worldwide.com
7 编辑文件/etc/defaultrouter
把192.168.1.1修改为 10.0.0.0 。
8 修改子网掩码数据库文件/etc/inet/netmasks
删除一行:
192.168.1.1 255.255.255.0
加入它一行:
10.0.0.0 255.0.0.0
9 重新引导系统,使用命令:
reboot -- -r
10查看修改是否生效
使用ifconfig查看ip地址结果如图1 。
图1 ?使用ifconfig查看ip地址结果
说明:下表介绍了 ifconfig 查询中的变量信息。使用图1输出作为示例。
使用hostmane查看主机名称如图2 。
图2 使用hostmane查看主机名称
使用netstat -r 查看路由表如图3 。
图3 使用netstat -r 查看路由表
另外如果您希望临时修改服务器的ip地址可以使用ifconfig命令:
ifconfig pcn0 192.168.6.25/27 broadcast + up
对 IPv4 地址使用 CIDR 表示法时,不必指定网络掩码。ifconfig 使用网络前缀标识来确定网络掩码。例如,对于 192.168.6.0/27 网络,ifconfig 设置网络掩码 ffffffe0。如果使用了更常见的 /24 前缀标识,则生成的网络掩码是 ffffff00。使用 /24 前缀标识相当于在配置新 IP 地址时为 ifconfig 指定网络掩码 255.255.255.0。这样服务器的IP地址会马上修改为192.168.6.25,需要说明的重新引导系统,则系统会恢复到其以前的 IP 地址和子网掩码和主机名称。这一点和linux是相同的。
来自: http://hi.baidu.com/bossycrab/blog/item/48f886442613594a500ffed9.html
/etc/defaultrouter中配网关
/etc/resolv.conf中配DNS
nameserver 202.XX.XX.XX
/etc/nsswitch.conf中hosts条中的file后加写dns
安装完solaris后,默认是不能上网的,需要修改如下四个文件:
1. /etc/hosts or /etc/inet/hosts
2. /etc/resolv.conf 默认是没有的,需要手工添加
3. /etc/nsswitch.conf这个修改一下就ok
4. /etc/defaultrouter默认也是没有的,手工添加
详细如下:
1.编辑/etc/hosts文件,用过linux的朋友明白这步是什么意思的,只不过/etc/hosts文件是/etc/inet/hosts文件的一个软链接,如下所示:
#cd /etc
#ls -l hosts
lrwxrwxrwx 1 root root 12 Jan 6 17:12 hosts -> ./inet/hosts
#cd /etc/inet
#ls -l hosts
-r--r--r-- 1 root sys 107 Jan 6 19:56 hosts
2.创建resolv.conf文件,加入dns服务器地址:
#vi /etc/resolv.conf
nameserver 202.101.172.48
nameserver 202.101.172.46
3.修改/etc/nsswitch.conf,只修改如下行:
hosts: files dns
4.创建/etc/defaultrouter文件,加入网关地址:
#vi /etc/defaultrouter
192.168.1.1
来自:http://limingchengwu.blog.163.com/blog/static/126785777200972841953324/
vi介绍
vi编辑器是一个用于创建和修改文本文件的交互式编辑器。使用vi编辑器时所有的文本编辑都放在一个缓冲区中,可以把所作的修改写到磁盘也可以放弃所做的修改。
对于那些有志于成为系统管理员的人而言,掌握如何使用vi编辑器是非常重要的。你必须知道如何使用vi编辑器,特别是在窗口环境不可用的时候。
Vi编辑器的工作模式
Vi编辑器是一个命令行编辑器,有三种基本的操作模式:
命令模式
文本输入模式(编辑模式)
最后行模式
命令模式:vi的默认模式,在命令模式下,你可以键入命令来删除、更改、移动文本;定位光标;搜索文本字符串、退出vi编辑器。
文本输入模式(编辑模式):在编辑模式下,你可以往文件中输入文本。要使vi编辑器进入编辑模式下,可以
采用以下三种不同的命令:
i插入
o打开
a 添加
最后行模式:当处于命令模式下时,通过键入:你可以执行更先进的编辑命令,键入:后,将使你处于屏幕的最后一行,这就称为最后行模式。然而,所有的命令都是由命令模式发起的。
模式间的切换
通过键入I、o、a命令,vi编辑器将离开默认的命令模式,进入编辑模式。
在编辑模式下,你所键入的所有文本都不会被翻译成命令,这时,所有键入的文本都会被保存到文件中。
当你完成了文本的输入后,按Esc键vi将回到命令模式下,一旦回到命令模式,你可以保存文件,退出vi编辑器,例如:
1、键入vi filename来创建一个文件;
2、键入I命令来插入文本;
3、按Esc键回到命令模式;
4、键入:wq来保存到文件,退出vi编辑器。
调用vi编辑器
要创建一个新文件,调用带新文件名称的vi编辑器。也可以键入命令来创建、编辑、查看一个文件。
命令格式
vi options filename
view filename
输入命令
要插入或者添加文本,使用下面的选项:
命令含义
a 在光标右侧输入文本
A 在光标所在行的末尾输入文本
I在光标左侧输入文本
I 在光标所在行的开头输入文本
O在光标所在行的下一行开始新行
O在光标所在行的上一行开始新行
备注:vi编辑器是大小写敏感的,因此,使用命令时注意正确的大小写。
定位命令
下面列出的是控制光标的移动键
键功能
h,左箭头,退格键光标左移一个空格
j,下箭头光标下移一行
k,上箭头光标上移一行
l,右箭头,空格键光标右移一个空格
w光标右移,到下一个字开头
b光标左移,到前一个字开头
e光标右移,到下一个字末尾
$光标右移到行结尾
0,^光标左移到行开头
回车键光标移到下一行开头
control-f下翻一屏
control-d下滚半屏
control-b上翻一屏
control-u上滚半屏
control-L刷新屏幕
编辑命令
以下部分讲解vi编辑器中的编辑命令
删除文本
要删除文本,使用下面选项:
vi编辑器中的文本删除命令
命令功能
x删除光标所在处的一个字符
dw删除字(或者删除字的一部分,从光标所在处到字结尾)
dd删除光标所在行
D删除光标光标所在处之右的行
:5,10d删除5-10行
备注:命令3dw删除光标所在处开始的三个字,同样,3dd删除光标所在行开始的3行。
撤销、重复、修改文本命令
要修改文本、撤销修改或者是重复编辑命令,使用下面的编辑命令,许多命令是vi编辑器进入编辑模式,要返回命令模式,按Esc键即可:
命令功能
cw修改字(部分字,从光标所在处开始到一个字的结尾)
R从当前光标所在处位置开始替换字符(注:vi将进入编辑模式)
C从光标坐在处开始修改,到行末尾结束
s用字符替换字符串
r替换当前光标所在的字符
J合并当前行以及下面行
Xp转置光标所在处字符与另一字符
~更改光标所在处字符大小写
u放弃最近的修改
U放弃对当前行所作的修改
:u放弃上一个最后行命令(用于最后行模式)
:r filename在当前光标所在处读入文件文本
查找和替换文本,使用以下选项:
命令功能
/string向下查找字符串string
?string向上查找字符串string
n查找字符串string的下一个出现
N查找字符串string的上一个出现
:%s/old/new/g 全局查找和替换
拷贝和粘贴文本
拷贝命令把需要拷贝的文本放入一个临时缓冲区,粘贴命令从临时缓冲区中读取文本,并把文本写道当前文档的指定位置。拷贝和粘贴使用的选项如下:
命令功能
yy(小写)复制一行文本,并将他们放入到临时缓冲区
p(小写)将临时缓冲区中的内容放置到光标后面的位置
P(大写)将临时缓冲区中的内容放置到光标前面的位置
:l,3 co 5拷贝1-3行的文本,并把它放置在第5行后面
:4,6 m 8移动4-6行到第8行,第6行称为第8行,第5行称为第7行,第4行称为第6行
保存和退出文件
要保存和退出文件,使用如下选项:
命令功能
:w保存文件,不退出vi
:w new_filename保存到文件new_filename中
:wq保存修改退出vi
:x保存修改并退出vi
ZZ保存修改且退出vi
:q!不保存修改,退出vi
:wq!保存修改,退出vi
定制vi会话
vi编辑器里面包括了定制vi会话的操作,例如:
1、显示行号
2、显示不可视字符,例如tab和行结尾字符
在命令模式下使用set命令可以控制这些选项:
编辑定制vi会话命令
命令功能
:set nu显示行号
:set nonu隐藏行号
:set ic设置搜索时忽略大小写
:set noic搜索时对大小写敏感
:set list显示不可视字符
:set nolist不显示不可视字符
:set showmode显示当前操作模式
:set shownomode不显示当前操作模式
:set显示所有的vi环境变量设置
:set all显示所有的vi环境变量可能取值及其当前设置值
你也可以把这些操作放在home目录下你创建的文件.exec中,set操作放在该文件中,不用带前面的:,一行一个命令,一旦该文件存在时,每次你开启一个vi会话时系统将取读取该文件来设置对应的vi环境变量。
要找某一特定行,使用下面的选项:
定位命令
命令 功能
G到文件最后一行
1G到文件的一行
:21到第21行
21G到第21行
来自: http://blog.csdn.net/jobs_zhaokai/archive/2007/05/23/1622171.aspx
在这里,我们记录一些在ESX主机上发生的、相当常见的问题。通常,可以采取一些简单的步骤去解决这些问题,但有的问题就需要较深入的解决方法。
紫屏死机(PSoDs, Purple Screen of Death)
有一种在ESX和ESXi主机上都可能发生的故障,叫做紫屏死机(可以说是臭名昭著的微软蓝屏死机的VMware版)。紫屏死机会导致ESX/或ESXi主机突然崩溃、变得无法操作。紫屏死机现象如图10.6所示,你一定不希望在自己的主机上发生这种现象。
图10.6 ESX主机上的紫屏死机现象
当PSoDs发生时,ESX会完全死机,没有任何反应。硬件问题(坏有问题的内存是最常见的原因)或ESX中的BUG是导致PSoDs的典型原因。当PSoDs发生时,你只能关闭并重启主机。屏幕上的提示信息非常有用,应该尝试记录它:可以使用带有拍照功能的手机给它照相,或者,如果存在的话,可以从一个远程管理面板上截图。你或许看不明白这些捕获下来的信息,但是,这些信息对VMware的技术支持来说非常有用。屏幕上显示的信息包括ESX的版本和build号、异常类型、寄存器转储(register dump)、崩溃时每个CPU正在跑什么、回溯追踪(back-trace)、服务器运行时间、错误日志、内存硬件信息等。
当你遇到PSoDs并重启主机之后,在ESX主机或/root文件夹下,会有一个以vmkernel-zdump开头(命名)的文件。这个文件对 VMware技术支持非常有用,同时,你也可以使用该文件,通过vmkdump工具提取 VMkernel日志信息、寻找与PSoDs有关的线索,从而判断PSoDs发生的原因。要使用这个命令,输入vmkdump –l dump <文件名>。如前所述,坏有问题的内存是PSoDs中常见的原因。 你可以使用dump 文件识别引起问题的内存模块,从而将其替换掉。
如果怀疑是坏内存引起PSoDs,可以使用一些内存压力测试工具来检测主机的内存。这些工具需要你关闭主机并从CD启动以进行内存测试。一个常用的工具是Memtest86+,它可以进行广泛的内存测试,比如,检测邻近内存单元的相互影响,以确保要写某单元时不会覆盖邻近的单元。你可以在www.memtest.org下载这个工具。
当你在某个主机上首次部署ESX的时候,进行一次内存测试是个好主意,这样可以避免在以后某个时候内存故障引起麻烦。许多的内存问题都是不明显的,简单的内存测试,比如POST过程中的内存校验可能都发现不了问题。你可以下载Memtest86+测试工具,一个2MB大小的ISO文件,将这个文件刻录成CD,让主机从该CD启动,然后运行该工具至少24小时以完成多种内存测试。主机中的内存越大,完成一次测试的时间越长,一个拥有32GB内存的主机完成一次测试大概需要1天的时间。除了系统内存,Memtest86+还检测CPU的L1和L2 cache。Memtest86+的运行时间不确定,当所有的测试都完成时,通过的计数器会增加。(Memtest86+ will run indefinitely, and the pass counter will increment as all the tests are run.)
服务器控制台问题
有时候,你可能会遇到服务器控制台问题,表现为:服务器控制台挂起,同时,不允许在本地登录。这种状况可能是由硬件锁定或僵尸状态引起,但是,通常这种问题不会影响在ESX主机上运行的虚拟机(VM)。重启是解决这种问题的常用方法,但是,在重启之前,你应该关闭VM,或者将VM VMmotion到其他的ESX。可以使用各种可用的途径来操作VM,完成关闭或迁移。比如,使用VI client、通过SSH登录到服务控制台或者使用可替代的/紧急的控制台(通过按Alt+F2到F6)。当VM被迁移或者关闭之后,你可以使用 reboot命令重启ESX,如果所有的控制台都没有响应,你就只能去按主机上的电源按钮,冷启动主机。
网络问题
有时,你也会遇到某种故障导致丢失了所有或者部分的网络配置,或者网络配置改变导致服务控制台丢失网络连接。当服务控制台的网络连接丢失时,你将无法使用远程的方法来连接ESX主机,包括VI client和SSH。你只能在本地的服务控制台上使用esxcfg-命令行工具恢复/修正网络配置,以下是一些命令,你可以从ESX CLI上使用它们配置网络:
esxcfg-nics
这个命令显示物理网卡列表,除去每个网卡的驱动信息、PCI设备、链接状态,你可以使用这个命令控制物理网卡的速度、双工模式等。esxcfg-nics –l显示网卡信息、esxcfg-nics –h显示该命令可用的选项,以下是一些例子:
o设置物理网卡vmnic2的速度和双工模式为100/Full:
esxcfg-nics -s 100 -d full vmnic2
o设置物理网卡vmnic2的速度和双工模式为自适应模式:
esxcfg-nics -a vmnic2
esxcfg-vswif
创建或者更新服务控制台网络,包括IP地址和端口组,esxcfg-vswif –l显示当前设置、esxcfg-vswif –h显示可用的选项,以下是一些例子:
o更改服务控制台(vswif0)IP地址和子网掩码:
esxcfg-vswif -i 172.20.20.5 -n 255.255.255.0 vswif0
o添加服务控制台(vswif0):
esxcfg-vswif -a vswif0 -p "Service Console" -i 172.20.20.40 -n 255.255.255.0
esxcfg-vswitch
创建或者更新虚拟机网络(vSwitch) ,包括上行链路、端口组和VLAN ID. 输入esxcfg-vswitch –l显示当前的vSwitch、 esxcfg-vswitch –h显示所有可用的选项. 以下是一些例子:
o将物理网卡(vmnic2) 添加到vSwitch (vSwitch1):
esxcfg-vswitch -L vmnic2 vswitch1
o将物理网卡(vmnic3)从一个vSwitch (vSwitch0)上移除:
esxcfg-vswitch -U vmnic3 vswitch0
o在vSwitch (vSwitch1)上添加一个端口组(VM Network3):
esxcfg-vswitch -A "VM Network 3" vSwitch1
o在vSwitch (vSwitch1)上给端口组(VM Network 3)分配一个VLAN ID(3):
esxcfg-vswitch -v 3 -p "VM Network 3" vSwitch1
esxcfg-route
设置或提取缺省的VMkernel网关路由。输入esxcfg-route –l当前的路由信息、esxcfg-route -h显示所有可用的选项. 以下是一些例子:
o设置缺省的VMkernel网关路由:
esxcfg-route 172.20.20.1
o添加一个路由到VMkernel:
esxcfg-route -a default 255.255.255.0 172.20.20.1
esxcfg-vmknic
为VMotion、NAS和iSCSI创建或者更新VMkernel TCP/IP设置。输入esxcfg-vmknic –l显示VMkernel NICs、esxcfg-vmknic -h显示所有可用的选项. 以下是一些例子:
o添加一个VMkernel NIC并设定IP和子网掩码:
esxcfg-vmknic -a "VM Kernel" -i 172.20.20.19 -n 255.255.255.0
另外,你可以通过service network restart命令重启服务控制台网络。
其他问题
有时,重启某些ESX服务既可解决问题且不影响VM的运行。两个可以被重启、并可经常解决问题的服务是hostd和vpxa。运行在服务控制台中的 Hostd服务负责管理ESX上的大部分操作,要重启hostd服务,登入服务控制台,输入service mgmt-vmware restart。
vpxa服务是管理代理,用于处理主机和客户端之间的通讯,客户端包括vCenter Server和任何连接到ESX的VI client。如果在vCenter Server上看到某个主机显示disconnected但没有显示当前信息,或者,任何其他的涉及到vCenter Server和一个主机的奇怪的问题,都可以通过重启vpxa服务来解决。要启动该服务,登入服务控制台,输入service vmware-vpxa restart。当你遇到问题时,推荐你重启这两个服务,因为,重启它们经常可以解决很多问题。
来自:http://virtual.51cto.com/art/200907/134341.htm
步骤1:启动Server Manager
想要启动Server Manager,点击:: Start Menu -> All Programs -> Administrative Tools -> Server Manager。Server Manager窗口打开。
步骤2:添加一个服务角色
在Server Manager中,选择Roles。
角色的汇总视图将显示出来。
步骤3:开始添加角色向导
点击Add Roles.
添加角色向导打开
点击Next选择要安装的角色
步骤4:选择安装Web Server(IIS)角色
选择Web Server(IIS)。
步骤5:Web Server角色依赖于WAS
添加角色向导将提示你需要依赖哪些需求;由于IIS是依赖于Windows Process Activation Service(WAS),所以下面的提示窗口将展现出来。
点击Add Required Role Services 按钮继续
现在选择需要安装的Web Server。选择Server角色的窗口将打开。
选择Web Server(IIS)
步骤6:附加信息
下面的对话框和信息将弹出。
步骤7:查看IIS 7.0的功能
添加角色向导将列出一个可以安装的IIS 7.0的全部功能。请注意,默认的一些安装已经选择好了。
步骤8:选择需要安装的IIS附加功能
这个例子中,我们将安装IIS的附加功能:
选择ASP.NET复选框。将弹出下面的对话框。
向导将会警告,如果安装一个IIS功能,可能会同时安装其他的功能。
步骤9:选择需要安装的IIS附加功能
继续选择需要安装的附加IIS角色服务。
选中你需要的功能。
步骤10:安装的功能的摘要
向导列出了一个已经安装的功能的汇总,像下面显示的
步骤11:安装进度
点击Install后,安装进度对话框打开。
步骤12:安装完成
当IIS 7.0安装完成,下面的对话框将打开。点击Close返回Server Manager。
步骤13:检查IIS 7.0的安装
你现在可以执行快速检查来验证IIS 7.0是否已经安装
打开Internet Explorer浏览器,输入http://localhost地址。
你将看到默认的IIS"Welcome"站点
1、现象描述:当虚拟系统需要更改bios选项时(譬如系统故障,需要修改以CD启动系统),有可能开始虚拟系统时压根就没有看到开机画面,系统就已经从硬盘以其他方式启动了。
2、解决方法:很简单,在虚拟机中按Ctrl+Alt+Insert键重新热启动虚拟机就可以看到开机画面了,这时可以使用F2进入bios了。(DONE)
来自: http://hi.baidu.com/syanpi/blog/item/25a82e95267bb140d1135e84.html
Classic ESX:
ESX3.5和ESX4.0在默认情况下SSH是开启的,但是不允许以root权限登录。修改/etc/ssh/sshd_config,并重启sshd服务.
PermitRootLogin no
=>
PermitRootLogin yes
/etc/init.d/sshd restart
Embedded ESX:
1. 编辑/etc/inetd.conf, 找到ssh的那一行, 去掉前面的注释。
2. ps | grep inetd, 找到inetd对应的进程。
3. kill -HUP pid_of_inetd
来自 :http://linux.chinaunix.net/techdoc/net/2009/07/07/1122227.shtml
今天在修改ESX Server 地址时出现了一些问题,简单描述一下正确的操作过程:
注:以下步骤最好是在机器前或者通过ILO 接口操作,如果是SSH远程登陆,修改IP后会断开连接。
[root@nt08 root]# esxcfg-vswif -i 10.0.0.1 -n 255.255.255.0 vswif0
# 修改 Service console 地址
[root@nt08 root]# vi /etc/hosts # 修改机器IP地址
[root@nt08 root]# vi /etc/sysconfig/network # 修改机器名和网关
此时重启机器或者执行以下命令可以立刻生效
[root@nt08 root]# service network restart
重设IP 之后,需要在 VI Client 上将新机器的 IP 的 Host,这样就完成了整个修改 ESX Server IP 的过程。
---------------------------------------------------------------------------
1:看你的esx版本。
vmware -v
2:列出esx里知道的服务
esxcfg-firewall -s
3:查看具体服务的情况
esxcfg-firewall -q sshclinet
4:重新启动vmware服务
service mgmt-vmware restart
5: 修改root的密码
passwd root
6:列出你当前的虚拟交换机
esxcfg-vswitch -l
7:查看控制台的设置
esxcfg-vswif -l
8:列出系统的网卡
esxcfg-nics -l
9:添加一个虚拟交换机,名字叫(internal)连接到两块物理网卡,(重新启动服务,vi就能看见了)
esxcfg-vswitch -a vSwitch1
esxcfg-vswitch -A internal vSwitch1
esxcfg-vswitch -L vmnic1 vSwitch1
esxcfg-vswitch -L vmnic2 vSwitch1
10:删除交换机,(注意,别把控制台的交换机也删了)
esxcfg-vswitch -D vSwitch1
11:删除交换机上的网卡
esxcfg-vswitch -u vmnic1 vswitch2
12:删除portgroup
esxcfg-vswitch -D internel vswitch1
13:创建 vmkernel switch ,如果你希望使用vmotion,iscsi的这些功能,你必须创建( 通常是不需要添加网关的)
esxcfg-vswitch -l
esxcfg-vswitch -a vswitch2
esxcfg-vswitch -A "vm kernel" vswitch2
esxcfg-vswitch -L vmnic3 vswitch2
esxcfg-vmknic -a "vm kernel" -i 172.16.1.141 -n 255.255.252.0
esxcfg-route 172.16.0.254
14:打开防火墙ssh端口
esxcfg-firewall -e sshClient
esxcfg-firewall -d sshClient
15: 创建控制台
esxcfg-vswitch -a vSwitch0
esxcfg-vswitch -A "service console" vSwitch0
esxcfg-vswitch -L vmnic0 vSwitch0
esxcfg-vswif -a vswif0 -p "service console" -i 172.16.1.140 -n 255.255.252.0
16: 添加nas设备(a 添加标签,-o,是nas服务器的名字或ip,-s 是nas输入的共享名字)
esxcfg-nas -a isos -o nas.vmwar.cn -s isos
17:列出nas连接
esxcfg-nas -l
18: 强迫esx去连接nas服务器(用esxcfg-nas -l 来看看结果)
esxcfg-nas -r
esxcfg-nas -l
19:连接iscsi 设备(e:enable q:查询 d:disable s:强迫搜索)
esxcfg-swiscsi -e
20:设置targetip
vmkiscsi-tool -D -a 172.16.1.133 vmhba40
21:列出和target的连接
vmkiscsi-tool -l -T vmhba40
22:列出当前的磁盘
ls -l mfs/devices/disks
非原创,来自: http://sdhd.cn/blog/userid/adan/2649.html
1. 安装gonme核心包(如果是字符界面的话)
apt-get install x-window-system-core
apt-get install gnome-core
apt-get install metacity
apt-get install gnome-desktop-environment (optional)
2.安装vnc4server
apt-get install vnc4server
3.设置vncserver密码
# vncpasswd
Password: ******
Verify:*****
4.启动VNC server
# vncserver
# vncserver -kill :1 (:1表示5901端口)
5.修改~/.vnc/xstartup文件
#!/bin/sh
# Uncomment the following two lines for normal desktop:
#unset SESSION_MANAGER
#exec /etc/X11/xinit/xinitrc
[ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup
[ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources
xsetroot -solid grey
vncconfig -iconic &
xterm -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" &
#twm &
gnome-session &
6.在服务器端退出gnome,否则客户端登录会出现字符界面。
$ sudo /etc/init.d/gdm stop
参考:
1. http://hi.baidu.com/yysirius/blog/item/2e5e0d085e84dfd562d986fe.html
2. http://www.blogjava.net/void241/archive/2008/07/19/216005.html
本文环境是在windows环境下,linux环境请参看其他文献。
1. 确认编程所用的字符集为uf8
<%@ page contentType="text/html; charset=UTF-8"%>
2. 确认MySQL所用的字符集为uf8
修改mysql目录下的my.ini文件
[mysql]
default-character-set=utf8
[mysqld]
default-character-set=utf8
3. 运行SQLFRONT,右键点击需操作的数据库,属性,把字符集改为utf8
完成。
Apache2.2下载地址:http://httpd.apache.org/download.cgi,本文所说的是使用了
Win32 Binary without crypto (no mod_ssl) (MSI Installer): apache_2.2.8-win32-x86-no_ssl.msi [PGP] [MD5]
的安装包。
使用Apache2.2来做服务器学习PHP,安装的过程很简单,唯一要注意的就是如果机子中同时装有IIS的话,因为IIS默认绑定的端口是80,所以在让你输入域名及邮箱地址那一步的时候,请注意要选择第二个,就是选择8080端口。其它的没有什么好讲的,一路Next…
可是安装完之后,右下角的图标却是红色的。放鼠标上去的提示是:No services installed ,很显然,是由于服务没有安装。
解决办法是:
我的安装路径是:D:\Program Files\Apache Software Foundation\Apache2.2
1、打开cmd定位到:D:\Program Files\Apache Software Foundation\Apache2.2\bin
2、输入httpd.exe -k install -n apache2
再输入net start apache2
之后我们看见了成功的信息
来自:http://hi.baidu.com/jinbihai/blog/item/5fd25cfc3c2698f5fd037fd6.html
帐篷可分为四季帐篷、三季帐篷,又分高山帐、旅游帐,单层、双层。
四季帐可在严寒冬季用,一般是双层帐,三季帐只在夏、春、秋使用。高山帐一般教小、矮,抗风、雪能力强,但顶级高山帐篷可能不太防雨(高山上只有雪,没雨),旅游帐大、高,舒适,抗风性差。单层帐一般教简单,轻,但防雨性不是很好,而且在寒冷天使用时,帐篷内层容易结露结霜,会打湿睡袋衣物(每人每夜通过呼吸散发的水分在几百毫升),但有顶级单层高山帐是单层的,防风透气性都很好,价钱也极高;双层帐内帐壁很薄,透气,外帐防水,罩在上面,往往还在内帐入口外能支起个小门厅,可放背包或做饭(一般做饭应在帐外,帐篷十分怕火,但也有天太冷出不去帐篷的时候),寒冷时内帐不结水,会结在外帐上,而且较少。
帐篷主要由帐篷支竿、外帐、内帐、帐钉组成。主要指标有大小、高度、重量等。支竿用来把帐篷支起形状,分为几节存放,中间由松紧绳穿起来,用时可以很容易地接起来。支竿强度十分重要,一旦折了,帐篷就变成个袋子了,在大风和大雪(积在帐篷上)时是对帐竿的严重考验,帐篷容易出问题的部分也就是帐竿。一般帐竿材料有玻璃刚和铝合金两种,铝合金的强度更高些。内帐比较轻薄,在气温高天气好时,可只支内帐。外帐没底,所以内帐帐底的防水性要好。外帐是防风防雨的,而且有不同的门厅设计。一般支帐篷是把帐竿穿在内帐上,再撑起来,最后挂外帐,钉帐钉,还有另外一种是把内帐平铺在地上,帐竿穿入四角,先撑起来,挂上外帐,抵挡住寒冷的大风,人钻进去,再把内帐挂在竿上,这两种帐篷有不同的结构设计。
帐篷是集体装备,旅游帐篷宽松,2人的底面在1.5m*2m左右,3人在2.1m*2m左右,高山帐较小,双人在1.3m*2m。还有高度,旅游帐高,在1.5m以上,舒适,但迎风面积大,不适于恶劣环境,高山帐低,趴在地上,不怕大风。相同质量当然是越轻越好。 帐篷主要适用于三种用途:一是休闲,没有底层,材料也没有太多要求,便于携带,主要是海滩等休闲场所遮阳、临时休息;二是一般野外用帐篷、有底层,材料要求相对较高、营杆玻璃钢制成,质轻便于携带。三是高山用特别帐篷、营柱由铝合金制成,帐篷外层防撕裂等。
帐篷不可使用洗衣机清洗。营柱必须和帐布分开摆,避免戳破帐布,储藏帐篷时,湿帐篷须摊开风干再收,即使攀登过程没有弄湿但登山者的呼气等会使湿气聚集于帐篷内,所以最好摊开架设,风干一段时间才收,帐篷要不规律折叠,因为使用帐篷次数愈多,摺叠太规律整齐会使摺痕硬化出现瓦解裂口。 帐篷的色泽最好选暖色调如黄色、橘色或红色。当你被困时,显眼的色泽会容易被人发现。帐篷内应避免炊事,尤其是使用汽油的炉具。这种炉具有刺激性气味,易溢出燃料油,并且火力无法控制,这都是潜伏的危机。特别是在防水尼龙布的帐篷内做饭常会有种窒息的感觉,炊事也会造成内帐凝聚许多小水滴,如果真有需要于帐篷内炊事,最好在通风佳的内外帐之间进行。
来自: http://club.xwhb.com/viewthread.php?tid=110830&extra=pageD1&page=3
户外运动鞋除了普通运动鞋的特点外,还要考虑以下几点:
1.鞋底。户外鞋的鞋底要硬,不能像普通运动鞋那样软。因为在走山路或走路多时鞋底硬会使脚不宜疲劳。鞋底纹路也非常重要。推荐Vibram鞋底,许多专业户外鞋都选择这个牌子的鞋底。
2.防水性。这是必须的,因为湿脚的散热量是干脚的24倍,爬山涉水时踏入水中是常事。一般防水鞋的防水处理主要有鞋表面喷涂防水胶或内衬防水膜。表面喷涂防水胶的防水性相对较差,且需要经常喷涂,现在高档的户外鞋都是内衬防水膜。
3.透气性。防水的负作用就是不透气,穿一双不透气的脚长时间长路是非常难受的,外面的水是防住,由于不透气,脚出汗后,脚感觉还是湿呼呼的。所以防水膜只防水是不行的,还要透气,不然只有一张塑料膜就可以实现防水。专业防水膜是Gore-Tex防水透气膜。Gore-Tex是美国W. L. Gore & Associates发明的,曾用于宇航服。它的原理是有许多小于水分子的小孔,水进不去,但可透气。
4.价格。现在如果在商场中的户外品牌专柜(如TNF,Black Yak,奥索卡)中买,只要是带Gore-Tex的都要1K到2K,价格不菲。如从北京秀水处淘,价格便宜,非常容易上当,买到假货。
说了这么多,当然要推荐性能好,价格便宜的了。
朋友买了一双意大利“Garmont”户外运动鞋,Gore-Tex内衬,Vibram鞋底。上去婺源旅游,有一天在雨中徒步穿越40里山路,穿着它,鞋内一滴水没有,脚始终是干干的。40里山路走下来,脚底一点不累,比在城内穿阿迪达斯运动鞋都舒服。为了测试它的防水性,曾站在小溪中,水没脚面10分钟,没有进一滴水。透气性也非常好,夏天炎热天气穿,感觉一点不“捂”。
不是做广告,只是向朋友们推荐。
一、登山鞋的分类
一般而言,走路用的登山鞋依用途分为:
1、mountaineering--极地攀登鞋:适用于冰雪岩混合的地形,必须有非常硬的鞋底且兼容于快扣式冰爪。但较不适用于平地健行。
2、trekking--长程重装健行鞋:山区长途健行,强调舒适耐用、远距离长时间使用,但不特别要求攀登功能。这种健行鞋鞋底中层较有弹性,使你踏出的每一步都能获得额外的推力;鞋底也同样的硬,让你能穿越崎岖困难的蛮荒地带。
3、backpacking--短程重装健行鞋:专为大背包健行设计--行程不是很长,但背包很重,所以鞋底也是硬底,且支撑力很好。
4、hiking--短程轻装健行鞋:轻装健行,因为背负重量不重,所以强调舒适性而舍弃硬鞋底。仍具有不错的支撑力。
四类鞋的特性比较:
1、hiking--短程轻装健行鞋
共同特性:防滑、耐操、透气快干
个别特性:短统、最轻量、通常不防水、软底
2、backpacking--短程重装健行鞋
共同特性:防滑、耐操、透气快干
个别特性:中统、轻量、硬底、通常防水
3、trekking--长程重装健行鞋
共同特性:防滑、耐操、透气快干
个别特性:中统、重量、较硬底、通常防水、保温
4、mountaineering--极地攀登鞋
共同特性:防滑、耐操、透气快干
个别特性:高统、最重量、超硬底、通常防水、高保温、适用冰爪
二、我该买哪一类的登山鞋?
使用下面的评分表,试着找出你需要的登山鞋类型
天数 坡度 路况 负重 天气
hiking [H] 当天往返 平坦 清晰好走 5公斤以内 好天气才走
backpacking[B] 1-3天 有些地方稍陡 崎岖不平 5公斤至15公斤 一般天气都会走
trekking[T] 3天以上 很多陡坡 砍路、找路 15公斤至30公斤 坏天气也走
mountaineering[M] 远征 冰雪岩混合峭壁 冰雪地自行开路 30公斤以上 会在暴风雪中前进
得分 H B H H B
范例1:只爬当天往返[H]、坡度稍陡、路况清晰[H]、负重5Kg[H]、一般天气都走,总计得3H2B,故最适合的是H--hiking
范例2:周休二日、很多陡坡[T]、崎岖不平、背25公斤[T]、坏天气也走[T],总计得3T2B,故最适合的是T--trekking
三、买一双好鞋的10个技巧
1、向高手请教,当你走进一家户外用品店买鞋时,要求最懂鞋的销售人员来协助,或是找一个登山高手帮忙。
2、一定要实际测量试穿,不要用之前买鞋的尺寸去推论,脚的尺寸是会变的。
3、不要被尺寸的号码迷惑,不论是英国尺寸、欧陆尺寸或美国尺寸(还分男女),尺寸的大小会受制鞋工厂的标准与设计所影响,最好还是多试穿几个邻近的尺寸 。
4、晚上买鞋!夜晚时,人脚会略微膨胀,就像在山上走路时一样。
5、要慢慢试,不要太心急做决定。准备两个半天来买一双好鞋,尽量多试试不同的厂牌与鞋款。
6、带自己的袜子,最好是用来搭配登山鞋的袜子
7、绑好鞋带以后,活动脚指看能否碰到前壁,新鞋穿久后,可能会稍微增加宽度与厚度,但绝不会增加长度,太短的鞋子往往会撞击脚趾头与指甲
8、试穿时,穿着鞋走一走,一方面让新鞋的皮革或纤维较具弹性,一方面也可试出是否有不易察觉的不舒服处
9、买适合用途的鞋,但不要想一双鞋应付所有的用途。也不要只为一次特殊行程去添购一双功能特别的鞋子。
10、抓住脚的感觉,挑一双最舒服的,用那双的标准去试所有的鞋子,只有一个人知道哪双鞋最适合你,就是自己。
四、鞋子耐用/保养的技巧
1.每次用完后清洁干净,稍微弄湿没关系,阴干它,决不要烘干鞋子。
2.鞋干燥后,可加强其防泼水功能(鞋油、腊、喷剂)
3.使用时绝对远离热源(炉子或火堆)、化学物品(除草剂、杀虫剂),他们会损坏鞋子的结构、材质。
五、该不该买GORE-TEX的鞋子?
你会发现加了Gore-Tex的鞋子就样镀金一样,价钱增加不少,那到底需不需要买Gore-Tex的鞋子呢?大家必须了解:在干燥的环境里,Gore-Tex的功能并不显著,特别是冰雪地里,许多皮制品配合外表强化涂布(喷剂/上蜡)表现也很好。但在深圳这种潮湿多雨的环境里,Gore-Tex高防水透气的功能表现仍是最好的;此外,搞清楚自己的用途也很重要,有些环境或是使用状况不需Gore-Tex,例如当天往返的健行,通常不需Gore-Tex这种高防水的功能;总之,你必须在防水性、透气性、价格、重量、维护难易之间取得平衡。
所以,如果你的活动类型是:长途、中级山、露营的健行,那我的建议是:多花点钱,买吧。
来自:http://club.xwhb.com/viewthread.php?tid=110830&extra=pageD1&page=2&sid=ntCqO6
详细: http://hi.baidu.com/%B7%C7רҵ%C0%ED%B2%C6/blog/item/da0067a752f3a692d1435888.html
什么是快门速度?
快门速度表示为1/2000s、1/2s、3s等,那么1/2000s和1/2s中哪个更快呢?当然是分母大的1/2000s更快。所谓快门速度快,表示快门开启到关闭的速度快,那么接收光线的量自然就会少。相反,开启快门的时间越长,接收的光线就会越多。
开启快门的时间越长接收的光线越多,但是对抖动更加敏感。通常,不受手的抖动影响的快门速度约为1/30s。当然,这并不说明所有人都一样,只能代表平均水准的人们。也就说,快门速度越快,抖动的影响越少,焦点越准,照片更加清晰。
什么是光圈?
光圈是在相机的镜头内部,用于调整进光圆孔直径的装置。光圈通常由5~8个叶片组成,可以通过改变其围成的圆孔的直径大小来控制进入镜头的光线的多少。在明亮的户外环境中,保持原快门速度的同时降低曝光度或保持原曝光度的同时减慢快门速度时就要使用光圈功能。
光圈口径越大,进入的光量越多。光圈值可以表示为F2.0、F2.8、F4.0、F8.0等,还可以采用如f/2、f/2.8、f/4在数值前增加“F(f)”的方法。光圈数值越小其口径越大,如F2.0时进入的光量就大于设为F8.0的光量。
快门与光圈的关系?
若把快门速度和光圈比作“水龙头”,那么光圈值是水龙头的大小,而快门速度就表示开放水龙头的时间。这个例子很恰当地比喻了快门速度和光圈值之间的关系。水龙头的口径越大(光圈值越小),在相同时间内能够接到的水量(进光量)越多。同样,水龙头的开放时间越长(快门开启时间越长),能够接到更多的水(光)
阳光四射、天空明朗的晴天,以快门速度1/125s,光圈值F8.0拍摄出了曝光恰当的照片,那么在明亮进一层的海边就要选择1/125s的快门速度,F11的光圈值,从而调整曝光度。阴天摄影时通常选择1/50s和F5.6,当然要在该基础上根据环境适当加减光圈值。
例如,天气晴朗,但光照较强的中午12点至下午的3点,选择1/125s、F11就可得到更加适合的图像。乌云密布的阴天最好设为1/60s、F5.6或F8.0。笔者所例举的参数也只是理论值,实际摄影中还需适当调整参数。
下面就例举了实际摄影中快门速度和光圈值对曝光度的影响。
我们捕捉了运动中的人像。适当调整了快门速度和光圈值后得到了曝光得当的照片。但是,我们发现即便曝光度适当,活动中的被摄体还是表现出了不同的效果。
我们的摄影对象是弹跳中的人物。有趣的是,1/400s、F1.6的照片中人物是静止的,而1/13s、F8.0照片中的人物却展现了弹跳的轨迹。对于运动的被摄体,快门速度具有决定的作用。拍摄运动中的对象时,应想好是要以较快的快门速度拍摄某个瞬间的动作,还是以较慢的快门速度表现动作的轨迹。尽管合理分配了快门速度和光圈值,得到了曝光得当的照片,其表现的图像还是有可能完全不同。
下面就以流水为例子。下图展现了图像均是以适当的曝光度拍摄的照片,只是快门速度和光圈值的设置不同。这两幅照片中表现出的水的流势完全不同。要想表现水的流势就应选择较慢的快门速度,若想捕捉水珠滴落的瞬间场景,就应以较快的快门速度拍摄瞬间影像。
镜头在光圈F2.0,快门1/60s的条件下拍摄出的图像焦点正确对准了人物,但后背景变得模糊;而F16、1s的条件下拍摄出的图像中人物和背景上都准确对准了焦距。人像照片的摄影目的在于塑造人物,因此通常模糊处理人物周围的背景。人像摄影中要重点调整光圈值,即先把光圈开至最大,再调出适当的快门速度。
总而言之,可通过调整快门速度和光圈值的方法来获得适当的曝光效果,但是即便其他设置相同,曝光程度还受摄影环境和表现主题的影响。
决定照片成败的底片质量,一方面受照相机和感光片质量优劣的影响,另一方面取决于能否准确曝光。什么叫准确曝光呢?准确曝光,就是拍摄者选择适当的快门速度与光圈,将被摄对象及原有的明暗关系,在底片上清晰、准确地显现出来。如果曝光过度,被摄对象的阴暗关系就不明显,整个底片呈灰黑色,俗称底片太“厚”,用这样的底片印放照片,照片呈灰白色,有的甚至无法印放照片。曝光不足,底片上只有淡淡的影像,呈通明透亮状,俗称底片太“薄”,用这样的底片印放照片,照片呈黑灰色,甚至全黑色,看不出被摄对象的细节。当你拿起相机准备拍照时,要使曝光准确,通常要考虑5 个方面的问题,即:曝光准确5 要素:
①被摄物体的运动速度;
②摄影环境的光亮强弱;
③被摄物体的颜色及其反射光线的能力;
④感光片的感光性能;
⑤各种摄影附加镜的运用。
光圈和速度都是用来控制进入照相机光线多少的装置,它们之间互相关联,又相互约束。当光线一定的时候,光圈开大一级,速度就要提高一级,光圈缩小一级,速度就要放慢一级。例如,用光圈11,速度1/60 秒,当光圈改用8的时候,速度就要相应改用1/125 秒。如果将速度改用为1/30 秒时,那么光圈就要相应改用16。光圈与速度间的互为变用关系,可以用曝光组合来表示:光圈8、速度1/125 秒;光圈11、速度1/60 秒;光圈16、速度1/30秒……任选其中一种曝光组合,对于一定的光线来说,照相机获得的曝光量是一样的。按照不同拍摄需求选用曝光组合,是控制准确曝光的重要依据之一。拍摄时是先确定快门速度还是先确定光圈系数?这是应该由被摄主体的具体情况和摄影者的创作意图来定。一般来说准确曝光仅是拍好照片的一个方面,摄影者要想充分发挥自己的创作意识,就应该灵活地掌握光圈和快门速度的曝光组合。光圈和速度有共同控制准确曝光的作用外,还各有自己的“专业分工”。光圈可控制景深,速度能将动体在底片上“凝固”下来。根据拍摄要求,要使胶片准确曝光,摄影者必须学会选择适当的曝光组合。倘若是拍摄运动物体,你要使照片清晰,首先要选择能将运动物体捕捉下来的快门速度,然后再配以相应的光圈;倘若要表现出景物一定的景深,这就要先确定光圈的大小,然后再配以相应的快门速度。选用曝光组合时,以下几条可作参考:
①物体运动速度快,快门速度就要快,光圈也相应要大。
②欲使照片景深大,光圈需要小,快门速度可相应放慢些。
③运动物体的运动方向不同,快门速度也不一样,从照相机前横穿而过的物体,选用快门速度一般要快,迎面向照相机或背向照相机运动的物体,快门速度选用可以慢一些。
④拍摄运动物体,随距离的变化,快门速度也要相应变化,距离越近,快门速度越快。
⑤使用的照相机镜头,焦距长,快门速度选用应相应快。⑥使用摄影附加镜,如:滤色镜、增距镜等,要适当增加曝光。不同附加镜的使用,增加的曝光量也是不一样的。
阳光由于季节、气候、地球纬度的不同,它的明亮度也不一样。在温热带地区,夏季阳光要比春秋季强两倍,比冬季强3~4 倍。夏季晴天,早上8、9点与下午4、5点,光线亮度大体相当。冬季上午9 点至下午3点,其间光线亮度变化不大。早晨日出前后与黄昏日落前后,光亮强度比中午弱10 倍。一天中,还有晴、多云、阴雨的变化,光线强弱也在变。强烈日光、薄云晴天、多云晴天、阴天,它们之间光线强烈的变化可这样认识:多云晴天光线要比阴天强1 倍,薄云晴天光线又比多云晴天强1 倍……如果使用的快门速度一定,在阴天光圈为5.6 的话,多云晴天就应改用8,薄云晴天就应改用11。如果使用光圈一定,在阴天使用的快门速度是1/30 秒,多云晴天就可以提高到1/60 秒,薄云晴天提高到1/125 秒。天气的变化是反复无常的,有时是很微妙的,以上这些变化关系,可以作为你在室外自然光下,拍摄照片曝光的参考。不同的被摄景物,反射光线的强弱也不同。明亮的景物和深暗色的景物,在一定光线条件下,曝光不能一样。一般明亮景物要比明亮景物增加一级曝光,深暗色景物又要比一般明亮景物增加一级曝光。什么是明亮景物呢?诸如海滨、雪景、乳白色建筑、穿浅色服装的人等等,都可作明亮景物看待;呈灰色的景物,可作一般明亮景物看待;树阴下的景物、深色建筑物、穿深色或着深红及墨绿服装者,可作阴暗景物看待。这种明亮与阴暗的表现,往往又不十分明显,拍摄者在控制曝光时,要学会抓住实际景物明暗的细微变化,区别对待。逆光拍摄照片应比侧光拍照增加1~2 级曝光,侧光拍照又应比顺光增加1~2 级曝光。例如:顺光拍照用1/125 秒、8 光圈;侧光拍照,在光线条件不变的情况下,就应改用1/60 秒、8 光圈,或1/125 秒、5.6 光圈;逆光拍照应选用更慢的快门速度或更大的光圈。拍摄者要掌握准确曝光,要考虑的因素是多方面的。所以当你手持照相机,选择曝光组合时,要冷静地对上述诸因素进行综合比较,优选出一组曝光组合,切不可面对拍摄对象,由于某种原因激动不已,选择曝光组合顾此失彼,造成曝光的错误而后悔。室内自然光摄影的曝光室内自然光摄影,要掌握准确曝光比较难,室内自然光有通过门窗直接射入室内的光、反射进室内的光,以及室内原有的各种光。室内自然光线下拍照,怎样才能曝光准确呢?这一节中,我们从影响室内自然光摄影的各种因素、室内自然光源摄影的基本方法两个方面来述说。我们已介绍了室外影响准确曝光的各种因素,这对室内自然光摄影同样适用。然而影响室内自然光摄影的,还有它特有的一些因素,如:阳光对室内直射和反射的影响,房屋的门窗多少、大小和开设方向的影响等等,在这样的环境中拍照,欲获得成功,主要*拍摄者自己多拍、多试验、多积累经验。如能使用侧光表当参谋,准确曝光的把握大些。在室内拍摄,由于光线受到限制,往往需要采用人造光照明,在这种情况下,应当避免不同色温的光源混合使用,室内自然光较暗,使用的光圈一般较大,快门速度也较慢。因此,使用的摄影器材,可选择口径较大、有B门装置的照相机,感光片可选用ISO200/24°或ISO400/27°的快片,尽可能配备三脚架和快门线。室内自然光因受建设门窗多少、大小和开设方向等限制,因此在确定曝光组合时,要充分观察和考虑这些条件,还要注意室外天气的影响。室内自然光照明的另一个特点是,被摄对象受光面明亮,背面则阴暗,这种明亮与阴暗的对比十分烈强。所以,如果在室内拍摄可移动的被摄对象时,应设法将其调整到门窗附近处,以降低这种反差。在移动被摄对象中,要特别注意不要使其一半处在直射光下,一半处在没有直射光的地方,以免造成半阴半阳的画面,必要时可利用窗帘、白纸挡起直接射入室内的光,使光线尽量柔和一些。被摄对象颜色浅,它的亮度就要比颜色深的高,因此曝光可少些。不同的物质,其反光性能强弱大不一样。反光能力强的,可减少曝光,反光能力弱的,通常说“吃”光的,应增加曝光。摄影实践中,拍摄者可以把浅色被摄对象置于深色背景前拍摄,或把深色被摄对象放在浅色的背景前拍摄。这样能使一些受光微弱的被摄对象突出于画面。利用室内一盏日光灯照明,将被摄者置于深暗色背景前拍摄,可使人物突出。利用室内自然光拍照,要注意光源的方向一般以采用侧光或顺光为好。如逆光拍摄中景、特写不宜选择窗口为背景,因为光比反差太大,会使色温失去平衡;如一定要逆光拍摄,要充分考虑拍摄效果,是拍摄剪影效果的照片?还是要求再现被摄对象的细节?如果是后者,拍摄者就要加用辅助光,或用反光物,或增大3~4 级曝光。人工光摄影的曝光人工光摄影,是指室内摄影中使用人工光源照明,诸如用碘钨灯、聚光灯、普通灯光等。利用人工光源拍照,要能准确控制曝光,要考虑的因素是:人工光源的亮度,这是由灯的多少、照明度大小以及被摄对象距离灯的远近等方面决定的。还有被摄对象反射光线的能力,周围环境影响等诸因素。如果是一定的灯距和光圈,100 瓦灯光照明,曝光需要1/30 秒的话,换用 200瓦的灯光照明,曝光则只需要1/60 秒。这说明照明灯光流明度增加多少倍,曝光时间则可相应减少多少倍。被摄对象距离灯光的远近,决定了曝光量的多少。要估计准确,可应用平方反比定律计算。如果被摄对象距离灯光由原来的5 米改为1 米,被摄对象所受的光就增强了25 倍,曝光量就应减少为原来的1/25。使用人工光摄影,掌握准确曝光只是一个方面,它还有一个如何布光的问题。在彩色摄影中,还有一个人工光的颜色问题,一般说来,人工光会给日光型彩色片带来色偏,如何避免,这将在彩色摄影一章里述说。如何在使用人工光摄影中,掌握好准确曝光,以上仅是提示,具体还要在实践中体会,当有一定经验积累时,准确掌握曝光也就不难了。闪光灯闪光灯是摄影者常用的一种人造光源。它便于携带,使用方便,不受昼夜、空间的限制。1.闪光灯的一般性能及其光线特点自从1887 年德国盖迪克和米索,首创燃烧镁粉用于摄影照明至今已有100 年了。闪光灯随现代科技的发展,日臻完善,其种类也愈来愈多,不管是哪一种闪光灯,从它的外型看,大体有电源和闪光两个部分。电源部分由电池、变压器、电容器组成;闪光部分包括闪光管和固定的反光罩、灯柄、开关等部件。目前闪光灯的闪光管可多次闪光,故又称万次闪光灯。早期的闪光灯,又大又重。后经不断改进,变得越来越轻便,并且还增加了光敏传感装置、专用色片等,功能也逐渐多了起来。有的可自动控制闪光灯的发光量,任意调节输出的发光量,有的闪光灯可调整它发出的光束角度,适应广角镜头、标准镜头和中长焦镜头的不同用光需要。一般闪光灯是以标准镜头拍照的,用光需要设计的,它发出的光束角度为50 度。闪光灯的持续时间因灯而异,有的明灭时间可短到1/5000 秒,有的可长到1/120 秒,基本能满足镜中快门各级速度的需要。使用集成电路和蓝硅晶体管组成的光敏控制电路闪光灯,还能根据拍摄距离的变化和被摄对象反光能力的强弱,控制闪光灯的发光量。距离近,反光能力强,闪光灯明灭时间就短;距离远,反光能力弱,闪光灯的明灭时间就长。总之,万次闪光灯具有光亮,适应性强,用途广,速度高,经济方便的特点,为现在很多摄影者普遍采用。闪光灯的光线特点是:
①光线亮度高;
②方向受拍摄者控制;
③光线颜色与日光相近
EJB3.0相关配置
作者:小鹤 2008-01-13 23:40:39
好久没看了,发现以前配置的jboss-4.2.1.GA版本的JBOSS服务器出了问题,启动时报N多错,找了好久也没解决,只知道可能是JDK1.5或者是jboss-4.2.1.GA里类文件的问题...郁闷```反正刚学EJB嘛,慢慢来,于是找了个旧点的版本jboss-4.0.4.GA用着,从头到尾的配置了一番```
·JDK11.5
·JBossIDE-2.0.0.Beta2-Bundle-win32.zip下载:http://downloads.sourceforge.net/jboss/JBossIDE-2.0.0.Beta2-Bundle-win32.zip?modtime=1160602856&big_mirror=1
·JBOSS-4.0.4.GA下载:http://superb-west.dl.sourceforge.net/sourceforge/jboss/jboss-4.0.4.GA.zip
·ANT下载:http://apache.mirror.phpchina.com/ant/binaries/apache-ant-1.7.0-bin.zip
·jboss-EJB-3.0_RC9_Patch_1.zip支持EJB3.0:http://downloads.sourceforge.net/jboss/jboss-EJB-3.0_RC9_Patch_1.zip?modtime=1166470845&big_mirror=1
JAVA_HOME ANT_HOME JBOSS_HOME都写入环境变量了,由于JBOSS-4.0.4.GA不支持EJB3.0,所以还要安装jboss-EJB-3.0_RC9_Patch_1,按照文件\jboss-EJB-3.0_RC9_Patch_1\INSTALL.html里的介绍安装,命令:
>cd jboss-EJB-3.0_RC9_Patch1
>ant -f install.xml -Djboss.server.config=all(默认从all启动)
这样就完成了,启动run.bat就OK...
还有个端口的问题,默认的8080端口和tomcat端口一样,所以会抛端口被占用的异常,还好我本来的tomcat服务器用的是9000端口.不过要改JBOSS端口也和tomcat差不多...在JBOSS目录下\server\all\deploy\jbossweb-tomcat55.sar下server.xml
<Connector port="8080" address="${jboss.bind.address}"
maxThreads="250" strategy="ms" maxHttpHeaderSize="8192"
emptySessionPath="true"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true"/>
找到这段话 port="8080" 可以改了...修改端口后启动首次启动命令 run -c all --host=localhost就改变端口了!
来自:http://203.208.39.99/search?q=cache:UWkoaJCrIxYJ:blog.sina.com.cn/s/reader_4bc13748010082xd.html+jboss-EJB-3.0_RC9_Patch_1.zip&hl=zh-CN&ct=clnk&cd=2&gl=cn&st_usg=ALhdy28te1yJDRyhn5T4RGlrh4JijKJmjw
摘要:
安装场地准备
在准备安装场地时,可参考如下国家标准:
1、 GB50173-93《电子计算机机房设计规范》
2、 GB2887-89《计算站场地技术条件》
3、 GB9361-88《计算站场地安全要求》
机房的...
阅读全文
构建电子计算机主机房的一般标准
2008-9-29 陈志
随着计算机广泛深入应用于社会生活的各个层面,政府部门、企业、机关、学校及其他团体机构普遍建立起自己的计算机(网络)中心及主机机房,而主机机房是计算机(网络)中心的枢纽部分,其运作的稳定性及安全性对整个计算机网络具有十分重要的作用。下面是本人多年在机房建设中积累的一些经验。
一、 机房的环境要符合如下要求:
1、 采用活动地板。地板抬升高度应大于 35cm 。
2、 机房地面面层材料应能防静电。
3、 机房地板与天花的高度(距离)不少于 2.55 米;门的高度应大于 2.1 米;门宽应大于 0.9 米;地板的平均荷载应大于 5kN / m2 ;墙壁和天棚应涂阻燃漆。
4、 机房应采用全封闭房间,防止有害气体侵入,并应有良好的防尘措施。
5、 要有良好的空调系统。机房室温应保持在 10 ℃至 25 ℃之间,相对湿度应保持在 60 %至 80% 。
6、 机房要安装符合法规要求的消防系统。要安装防火防盗门,至少能耐火 1 小时的防火墙。
7、 机房内的尘埃要求低于 0.5um ;对于开机时机房内的噪音,在中央控制台处测量时应小于 70dB 。
8、 计算机房内的照明要求在离地面 0.8m 处,照度不应低于 200lx 。
二、 根据机房的设计要求、用途性质及周边环境采用相应的防雷接地措施。
如果机房所在的建筑物没有防雷设施,则根据机房所在地区的年平均雷击次数及年平均降雨量确定防雷措施。只有认真细致地做好防雷计划书,才能进行防雷设备的施工及安装。如果机房处于高层建筑中,而高层建筑一般都有防雷设备,可考虑与大楼共用接地体;机房一般选择在建筑物的第二或第三层。
三、 根据机房的安全保密级别,对机房采取抗电磁干扰及防电磁辐射的措施。如果有必要,要对机房实施全屏蔽方案。
四、 机房要建有 UPS 不间断电源系统。 UPS 电源应提供不低于 2 小时后备供电能力。其功率大小应根据机房内的网络设备功率进行计算,并具有 20-30% 的余量。
五、 必须有安全的监控系统。机房内可以设置彩色 CCD 摄像机,全天 24 小时对机房进行监控。并对监控的内容进行存储。
六、 电力供应采用强电系统。采用双路强电引入,每个机架都通过配电柜引出单独的供电线路到机架,每个机架可用电源功率应大于 5KVA 。
七、 布线工程应采用符合规范的智能综合布线系统。 综合布线系统( GCS )应是开放式结构,应能支持电话及多种计算机数据系统,还应能支持会 议电视、监视电视等系统的需要。
注:参考资料: 《建筑与建筑群综合布线系统工程设计规范》、《计算机场地安全要求》。
来自:http://www.gzhuayun.com/lunwen1.html
有不少关于 firefox上网慢的话题。
有的说把IPv6的协议禁用,还有的对firefox进行配置,实际使用效果都不好。
我仔细看过所谓对firefox的优化参数之后,发现它们大多只不过添加了 多线程下载网页的功能,所以实际用处不大。
不信,你可以打开终端, 同时用 w3m (文字版的互联网浏览器) 和firefox打开一个你从未访问过的网页,你会发现,其实w3m也很慢。
这就说明了,浏览慢,并不仅仅是浏览器的问题。
所有这些东西,其实只用安装一个 叫做 fasterfox 的firefox浏览器扩展插件就可以自动给你设置了。设置一些优化参数的确对加快firefox的运行,而不是浏览速度 ,有帮助。
上网慢 真正的原因,仔细观察会发现,主要在firefox 花费在解析域名 的时间上。
所以有必要设置DNS缓存。
windows下面是自动设置的,所以不用操心。
在ubuntu下面就要花费一番功夫了。
所以需要装一个 叫做 dnsmasq的软件,它能提供dns解析的功能。
当然,改造一下,也能提供dns缓存的功能。
_____________________________________
具体操作
---------------------
安装dnsmasq
命令: sudo apt-get install dnsmasq
编辑dnsmasq的配置文件
命令: sudo gedit /etc/dnsmasq.conf
找到下面这一项
#resolv-file=
用下面的一条语句替换
resolv-file=/etc/resolv.dnsmasq.conf
确保你没有更改过/etc/resolv.conf文件,如果改过,恢复原状
然后执行命令
sudo cp /etc/resolv.conf /etc/resolv.dnsmasq.conf
然后编辑resolv.conf
命令;sudo gedit /etc/resolv.conf
将其中的域名服务器全部去掉,加入以下这行
nameserver 127.0.0.1
保存,退出
执行以下命令
sudo gedit /etc/ppp/peers/wvdial
在 usepeerdns 前面增加 # ,也就是把这条语句覆盖掉。
以防,resolv.conf的设置被pppoe覆盖。
重启电脑。不重启,你会发现无法解析域名。所以一定要重启电脑,来达到重新启动dnsmasq的目的。
重启后, 你会发现firefox的解析速度比以前快了N个数量级。
来自 :http://zhidao.baidu.com/question/62950317.html
在web-inf/web.xml中加入
<listener>
<listener-class>SessionCount.SessionCounter</listener-class>
</listener>
注册listener即可统计在线人数
下面是我安装helix mobile server 10.0.9的日志,你可以做参考,非常的顺利,内核是升级为2.6的最新版,系统是dubuntu6.6。
dubuntu@tianqingliao:~/Desktop$ ./setup.bin
Extracting files for Helix installation........................
Welcome to the Helix Mobile Server 10.09 (10.0.9.2735) Setup for UNIX
Setup will help you get Helix Mobile Server running on your computer.
Press [Enter] to continue...
If a Helix Mobile Server license key file has been sent to you,
please enter its directory path below. If you have not
received a Helix Mobile Server license key file, then this server
WILL NOT OPERATE until a license key file is placed in
the server's License directory. Please obtain a free
Basic Helix Mobile Server license or purchase a commercial license
from our website at
http://www.real.com/. If you need
further assistance, please visit our on-line support area
at
http://service.real.com/.
License Key File: []: /home/dubuntu/Desktop/license.lic
Installation and use of Helix Mobile Server requires
acceptance of the following terms and conditions:
Press [Enter] to display the license text...
extracting text from file /home/dubuntu/Desktop/license.lic
TEAM ZWT
Choose "Accept" to accept the terms of this
license agreement and continue with Helix Mobile Server setup.
If you do not accept these terms, enter "No"
and installation of Helix Mobile Server will be cancelled.
I accept the above license: [Accept]: Accept
Enter the complete path to the directory where you want
Helix Mobile Server to be installed. You must specify the full
pathname of the directory and have write privileges to
the chosen directory.
Directory: [/home/dubuntu/Desktop]: /home/dubuntu/helix
Please enter a username and password that you will use
to access the web-based Helix Mobile Server Administrator and monitor.
Username []: admin
Password []:
Confirm Password []:
Please enter a port on which Helix Mobile Server will listen for
PNA connections. These connections have URLs that begin
with "pnm://"
Port [7070]:
Please enter a port on which Helix Mobile Server will listen for
RTSP connections. These connections have URLs that begin
with "rtsp://"
Port [554]:
Please enter a port on which Helix Mobile Server will listen for
HTTP connections. These connections have URLs that begin
with "http://"
Port [80]:
Please enter a port on which Helix Mobile Server will listen for
MMS connections. These connections have URLs that begin
with "mms://"
Port [1755]:
Helix Mobile Server will listen for Administrator requests on the
port shown. This port has been initialized to a random value
for security. Please verify now that this pre-assigned port
will not interfere with ports already in use on your system;
you can change it if necessary.
Port [29344]: 9092
You have selected the following Helix Mobile Server configuration:
Admin User/Password: admin/****
Encoder User/Password: admin/****
Monitor Password: ****
RTSP Port: 554
HTTP Port: 80
PNA Port: 7070
MMS Port: 1755
Admin Port: 9092
Destination: /home/dubuntu/helix
Enter [F]inish to begin copying files, or [P]revious to go
back to the previous prompts: [F]: F
Copying Helix Mobile Server files...
Helix Mobile Server installation is complete.
If at any time you should require technical
assistance, please visit our on-line support area
at
http://service.real.com/.
Cleaning up installation files...
Done.
dubuntu@tianqingliao:~/helix$ ./Bin/rmserver rmserver.cfg &
[1] 23093
./Bin/rmserver: relocation error: ./Bin/rmserver: symbol errno, version GLIBC_2.0 not defined in file libc.so.6 with link time reference
dubuntu@tianqingliao:~/helix/Bin$ export LD_ASSUME_KERNEL=2.4.1
dubuntu@tianqingliao:~/helix$ ./Bin/rmserver rmserver.cfg
Helix Mobile Server (c) 1995-2006 RealNetworks, Inc. All rights reserved.
Version: Helix Mobile Server 10.09 (10.0.9.2735) (Build 81568/6277)
Platform: linux-2.2-libc6-i586-server
Using Config File: rmserver.cfg
Creating Server Space...
Server has allocated 256 megabytes of memory
Starting PID 23275, procnum 1 (timer)
Calibrating timers...
Interval timer enabled (10ms resolution).
Starting PID 23277, procnum 2 (core)
Starting Helix Mobile Server 10.00 Core...
E: could not open <128.128.3.155:554> - Permission denied
Errors occured, check log file
dubuntu@tianqingliao:~/helix$ sudo ./Bin/rmserver rmserver.cfg
Helix Mobile Server (c) 1995-2006 RealNetworks, Inc. All rights reserved.
Version: Helix Mobile Server 10.09 (10.0.9.2735) (Build 81568/6277)
Platform: linux-2.2-libc6-i586-server
Using Config File: rmserver.cfg
Creating Server Space...
Server has allocated 256 megabytes of memory
Starting PID 23352, procnum 1 (timer)
Calibrating timers...
Interval timer enabled (10ms resolution).
Starting PID 23356, procnum 2 (core)
Starting Helix Mobile Server 10.00 Core...
1 CPU Detected...
Linux kernel version 2.6.15-26-686 detected
Testing File Descriptors...
Setting per-process descriptor capacity to 677(1011), 11...
Testing Mutex...(250.39 ops/usec)
Testing AtomicOps...(27.39 ops/usec)
I: Loading Plugins from /home/dubuntu/helix/Plugins...
I: slicensepln.so 0xb7dfed90 RealNetworks Licensing Plugin
I: mp3fformat.so 0xb7ddcdf0 RealNetworks MP3 File Format Plugin
I: imgfformat.so 0xb7d45f40 Helix JPEG File Format Plugin
I: imgfformat.so 0xb7d45f40 Helix GIF File Format Plugin
I: imgfformat.so 0xb7d45f40 Helix PNG File Format Plugin
I: imgfformat.so 0xb7d45f40 Helix RealPix Format Plugin
I: imgfformat.so 0xb7d45f40 Helix RealPix JPEG File Format Codec Plugin
I: imgfformat.so 0xb7d45f40 Helix RealPix GIF File Format Codec Plugin
I: imgfformat.so 0xb7d45f40 Helix RealPix PNG File Format Codec Plugin
I: imgfformat.so 0xb7d45f40 Helix WBMP File Format Plugin
I: smlfformat.so 0xb7d0e590 RealNetworks SMIL File Format Plugin
I: mpgfformat.so 0xb7cecc70 RealNetworks MPEG File Format Plugin
I: smplfsys.so 0xb7ccc310 RealNetworks Local File System
I: httpfsys.so 0xb7c83610 RealNetworks HTTP File System with CHTTP Support
I: httpfsys.so 0xb7c83610 RealNetworks RFC 2397 Data Scheme File System
I: adminfs.so 0xb7c2f2e0 RealNetworks Admin File System
I: shelfsys.so 0xb7e4d314 RealNetworks Shell File System
I: tagfsys.so 0xb7c030d0 RealNetworks XMLTagFileSystem
I: hxsdp.so 0xb7be4f5c RealNetworks SDP Stream Description Plugin
I: authmgr.so 0xb7bb9c60 Helix Authentication Manager
I: tmplgpln.so 0xb7b71ef0 RealNetworks Custom Logging Plugin
I: ppvbasic.so 0xb7b517a4 RealNetworks FlatFile Database Plugin
I: svrbascauth.so 0xb7b36b20 RealNetworks Basic Authenticator
I: dbmgr.so 0xb7b1ca30 RealNetworks Database Manager
I: ramplin.so 0xb7b07310 RealNetworks Ramgen File System
I: pplyplin.so 0xb7ad3c40 RealNetworks Scalable Multicast Plugin
I: qtbcplin.so 0xb7aae3b0 RealNetworks QuickTime Live Broadcast Plugin
I: smonplin.so 0xb7a96ad0 RealNetworks System Monitor
I: ppvallow.so 0xb7a74764 RealNetworks Pay Per View Allowance Plugin
I: rn5auth.so 0xb7a59150 RealNetworks RN5 Authenticator
I: avifformat.so 0xb7a44490 RealNetworks AVI File Format Plugin
I: swfformat.so 0xb7a0f2a0 Helix Macromedia Flash 4 File Format Plugin
I: mp4fformat.so 0xb79cc550 RealNetworks Mpeg4 File Format Plugin
I: rmfformat.so 0xb7978b70 RealNetworks RealMedia File Format Plugin
I: rtfformat.so 0xb7938fa0 Helix RealText File Format Plugin
I: allow.so 0xb7917ec8 RealNetworks Basic Allowance Plugin
I: inclrep.so 0xb7908a40 RealNetworks Include TagHandler
I: plusplin.so 0xb78dbad0 RealNetworks PlusURL File Format Plugin
I: vsrcplin.so 0xb78980c0 RealNetworks View Source Tag Replacement Plugin
I: vsrcplin.so 0xb78980c0 RealNetworks View Source Allowance Plugin
I: vsrcplin.so 0xb78980c0 RealNetworks View Source File System
I: brcvplin.so 0xb78357a0 RealNetworks Broadcast Reception Plugin
I: meiffpln.so 0xb7807560 RealNetworks Media Export File Format Plugin
I: meiplin.so 0xb77e1030 RealNetworks Media Export Interface Plugin
I: miiplin.so 0xb775ff10 RealNetworks Media Import Plugin
I: rncache.so 0xb7726210 RealNetworks Cache Plugin
I: asfwmpln.so 0xb7709e38 RealNetworks Active Stream Format Version 1 Plugin
I: asncfsys.so 0xb76f0c80 RealNetworks Network Optimized File System
I: encfs.so 0xb76de850 RealNetworks Encoder Administration File System Plugin
I: ptagent.so 0xb76ba780 RealNetworks PSS Profile Transfer Agent
I: adtagrep.so 0xb7687030 RealNetworks Ad Insertion Tag Replacement Plugin
I: asxplin.so 0xb7672300 RealNetworks Asxgen File System
I: csspplin.so 0xb7656550 RealNetworks License Subscriber Plugin
I: dlicepln.so 0xb762a260 RealNetworks License Publisher Plugin
I: pxadsvff.so 0xb75ee0a0 RealNetworks RealPix Adserving File Format Plugin
I: archplin.so 0xb755fb4c RealNetworks Live Archiver Plugin
I: xmlcfg.so 0xb7520ce0 RealNetworks XML Configuration Plugin
I: redbcplin.so 0xb74f5580 RealNetworks Broadcast Redundancy Plugin
I: wmmcastpln.so 0xb74d41f0 RealNetworks Windows Media Multicast Plugin
I: bdstplin.so 0xb74a07f0 RealNetworks Broadcast Distribution Plugin
I: wmsrcpln.so 0xb7484f30 RealNetworks Windows Media Live Broadcast Source Plugin
I: encoplin.so 0xb73e3630 RealNetworks Encoder Broadcast Plugin
I: cdadplin.so 0xb739a940 RealNetworks Content Distribution Advise Plugin
I: cdistpln.so 0xb7386810 RealNetworks Content Distribution Plugin
I: sdpgenfsys.so 0xb7372750 RealNetworks Dynamic SDP Generation Plugin
I: smlgenfs.so 0xb732aa40 RealNetworks SMIL Generation File System
I: ppvmsql.so 0xb72e597c RealNetworks Mini SQL PPV Database Plugin
Starting PID 23357, procnum 3 (rmplug)
Loading Helix Server License Files...
Starting PID 23358, procnum 4 (rmplug)
Starting PID 23359, procnum 5 (rmplug)
Starting PID 23360, procnum 6 (rmplug)
Starting PID 23361, procnum 7 (rmplug)
Starting PID 23362, procnum 8 (rmplug)
Starting PID 23363, procnum 9 (rmplug)
Starting PID 23364, procnum 10 (rmplug)
Starting PID 23365, procnum 11 (rmplug)
Starting PID 23366, procnum 12 (rmplug)
Starting PID 23367, procnum 13 (rmplug)
Starting PID 23368, procnum 14 (rmplug)
Starting PID 23369, procnum 15 (rmplug)
Starting PID 23370, procnum 16 (rmplug)
Starting PID 23371, procnum 17 (rmplug)
Starting PID 23372, procnum 18 (rmplug)
Starting PID 23373, procnum 19 (rmplug)
Starting PID 23374, procnum 20 (rmplug)
Starting PID 23375, procnum 21 (rmplug)
Starting PID 23376, procnum 22 (memreap)
Starting PID 23377, procnum 23 (streamer)
来自: http://forum.ubuntu.org.cn/viewtopic.php?p=89682&sid=ad651e4a5fa4760ac57d4de34290272c
上述错误我遇到两种情况,一种是在打开打开SQL Server 2005时弹出的,另一种是在应用程序连接SQL Server 2005时出现的.归纳了一下,由以下几个原因:
1.数据库引擎没有启动.
有两种启动方式:
(1)开始->程序->Microsoft SQL Server 2005->SQL Server 2005外围应用配置器,在打开的界面单击"服务的连接的外围应用配置器",在打开的界面中找到Database Engine,单击"服务",在右侧查看是否已启动,如果没有启动可单击"启动",并确保"启动类型"为自动,不要为手动,否则下次开机时又要手动启动;
(2)可打开:开始->程序Microsoft SQL Server 2005->配置工具->SQL Server Configuration Manager,选中SQL Server 2005服务中SQL Server(MSSQLSERVER) ,并单击工具栏中的"启动服务"按钮把服务状态改为启动;
使用上面两种方式时,有时候在启动的时候可能会出现错误,不能启动,这时就要查看"SQL Server 2005配置管理器"中的SQL Server 2005网络配置->MSSQLSERVER协议中的VIA是否已启用,如果已启用,则把它禁止.然后再执行上述一种方式操作就可以了.
2.进行远程连接时,是否已允许远程连接.
SQL Server 2005 在默认情况下仅限本地连接.我们可以手动启用远程连接.在上面第一种方式中,找到Database Engine,单击"远程连接",在右侧将"仅限本地连接(L)"改为"本地连接和远程连接(R)",并选中"同时使用TCP/IP和named pipes(B)".
3.如果是远程连接,则还要查看连接数据库的语句是否正确,登录账户是否正确,密码是否正确等.
我在一次局域网内连接数据库时,就要因为连接字符串出了问题,在局域网内一台机子连接另一台机子上数据库时,把server=装有数据库的另一台机子的IP.我在连接数据库时总是出现上面的错误,查了好长时间,后来发现,IP没有正确到传到连接字符串,原来我在连接时,使用的是本地,即127.0.0.1,输入的IP没有传到连接字符串.
该文章转载自网络大本营:http://www.xrss.cn/Dev/DataBase/20075712956.Html
1、输入命令行
打开“开始”→“运行”,在“运行”一栏中输入“Rundll32 netplwiz.dll,UsersRunDll”命令打开用户帐户窗口(注意区分大小写),去除“要使用本机,用户必须输入用户名密码”复选框中的勾号。
大多数实现自动关机的方法都是使用一些第三方软件,这样不仅麻烦,而且为实现这个小功能而专门动用一个软件,显的小题大做了!
其实Windows XP(Windows 2000也可以)自身就具备定时关机的功能,下面我们就来看看如何实现Windows XP的自动关机。
Windows XP的关机是由Shutdown.exe程序来控制的,位于Windows\System32文件夹中。如果想让Windows 2000也实现同样的效果,可以把Shutdown.exe复制到系统目录下。
比如你的电脑要在22:00关机,可以选择“开始→运行”,输入“at 22:00 Shutdown -s”,这样,到了22点电脑就会出现“系统关机”对话框,默认有30秒钟的倒计时并提示你保存工作。如果你想以倒计时的方式关机,可以输入“Shutdown.exe -s -t 3600”,这里表示60分钟后自动关机,“3600”代表60分钟。
设置好自动关机后,如果想取消的话,可以在运行中输入“shutdown -a”。另外输入“shutdown -i”,则可以打开设置自动关机对话框,对自动关机进行设置。
Shutdown.exe的参数,每个都具有特定的用途,执行每一个都会产生不同的效果,比如“-s”就表示关闭本地计算机,“-a”表示取消关机操作,下面列出了更多参数,大家可以在Shutdown.exe中按需使用。
-f:强行关闭应用程序
-m \\计算机名:控制远程计算机
-i:显示图形用户界面,但必须是Shutdown的第一个选项
-l:注销当前用户
-r:关机并重启
-t时间:设置关机倒计时
-c "消息内容":输入关机对话框中的消息内容(不能超127个字符)
要想定时关机或重启,可以把它做成BAT文件,然后再用计划任务执行。如:
定时关机
at 10:00 shutdown -f
存为"关机.bat"
新建一个计划任务,程序指向这个BAT文件,下一步步,完成,就OK了。
定时重启:
编辑reboot.bat,内容为shutdown -r -t 0,保存。
添加计划任务,程序指向这个bat文件,按照步骤下来即可。
有教练指导当然好,但不是所有人都能有这样的条件,因此大傻为这样的爱好者出点儿主意:
不要来了就打,撕杀一通,汗是出了,但不好的还是不好,不精的还是不精,是打球还是练球,要搞清楚,建议把每次打球的时间分为两段,第一阶段为练球,第二阶段为打球。以下为简单的练习方案:
一、直线高远球的练习:两人一组,沿边线反复打高远球,目标为后场边角,不要怕失误。共5分钟。(熟练后可练一些后场平高球)
二、对角高远球的练习:两人一组,反复打对角高远球,目标为后场边角,不要怕失误。共5分钟。(熟练后可练一些后场平高球)
三、网前球的练习:20颗球为一组,一人手抛,一人搓或勾或扑,二人交替进行,共10分钟。
四、杀球接杀球的练习:刚开始杀球方不要追求力量,先要落点,准确性提高后,逐渐加力。接杀方可进行挡垫网和绷后场的练习,挡垫网时注意拍面的控制,要追求质量,同时手臂不要过于紧张。绷后场球时,击球点要尽量靠前一些,绷球时挥拍幅度不宜过大。(击球点靠前就是手握球拍,拍头半向下,由左到右,围绕身体的前侧,空画个半圆,击球点应该在半圆画线附近)二人交替进行,共10分钟。
五、直线斜线劈吊球练习:两人一挑一劈吊,挑球一方尽量将球到位,目标后场边角尽量高些,劈吊方的练习开始要追求质量熟练后逐步加速。二人交替进行,共10分钟。
六、全场步法练习,请参考技术论坛的:《论步法的急停急起(作者:丽然)》 每组1分钟,共5-7组。
其实,羽毛球的训练是复杂多样的,像打多球、点控点、多打一等等训练都是提高能力的有效方法,大傻会把平时的训练方式总结一下,结合爱好者的具体情况,变通的,逐步提出更多的练习方案。不足之处,欢迎指正。
爱好者自行训练基本模式(二)
二控一练习(简单二打一):
需三人交替进行,目的:提高个人全场跑动和基本控球能力。
方法:
一、两人方:一人站在网前,只挡放网,不得扣杀球。为保证对面练习者跑动时的连续性,不要求回球质量过高。另一个人在后场(最好这个人水平略高一些的),打各种球给对方,尽量多利用曲线。
二、一人方:模仿实战,尽量作到回球到位,追求落点。(对于相对差一些的爱好者,可只打半场直线的跑动练习,就是一个网前球,一个后场球。练习者跑进行直线跑动练习。)
要点:处理后场高远球时,一定要利用蹬转体(或跳转体)挥拍击球,无论网前还是后场,处理完球后,还原要快,注意跑动中的急停启动和急停蹬转的合理运用,体会变速加速,脚下要弹踏起来。三人轮流交替进行,每人5分钟。
步法的练习细节可参照本论坛上的《论步法的急停急起(作者:丽然)》进行。
爱好者自行训练基本模式(三)
网前抢点练习:
两人一组。一人站在发球线上,手抛网前球,另一人隔网站在发球线附近,反复上网抢点进行压、推、挑、放的练习。
说明:
压:是指在抢到较高点时的网上扑杀。
推:是指抢到的高度已经无法下压时,推后场两点的平快球。
挑:是指高度已经无法推压的球,挑后场或搓放网的球。
放:搓放网。
要点和需要注意的是:
抛球一方:球的高度不宜质量过高,要配合接球方的节奏,当对方回到发球线时再喂球。
接球一方:准备姿势为,右腿在前(左手持拍者相反)。选择的上网路线应该在全场的中场防守点和练习时的击球点之间,注意不要偏离。上网时要利用垫步蹬跨的步法,启动的同时球拍向网上击球点处快速伸出,出手击球动作不要过大,多体会利用手腕和手指的发力,要追求落点和质量。最后一步落地时前脚掌外翻,处理完球马上右脚保持在前后退还原,保持上网和还原时的连贯性,要有节奏感。注意安全,不要打伤抛球方。每组30-50个球,两人交替进行。
爱好者自行训练基本模式(四)
对吊上网
俩人一组,甲方辟吊直线网前球,然后快速上网,将乙方回的网前球挑后场直线高远。乙方挡或放网,然后快速退向后场,再次劈吊直线网前球,这样就行成俩人循环不断的对吊上网练习。
练习时应该注意的是:
一、辟吊时手臂手腕放松,但要追求挥拍动作的一致性,注意挥拍的速度。
二、后场击球脚下一定要做跳转或蹬转,前后场跑动时力求步法的规范性,还原要快。
三、网前的挡放网不易质量过高,以免破坏俩人循环跑动的连续性。
四、重点:在前后跑动的过程中,在中场附近要利用蹬转体的有效加速度,来完成前后移动时重心转换,这一点一定要多多体会!
爱好者自行训练基本模式(五)
利用手抛球进行上网推搓球然后快速反方向的腰部低手防守训练:
比如上网前正手防腰部反手:
正手俩人一组,一人站在网前利用手抛球,先给对方手抛网前的正手位,然后模仿劈掉的速度将球快速抛向对方的反手腰部边线附近。注意节奏,要接近实战,不要过快或过快。
接球方:站在单打防守位置,当对方抛出正手网前球时,利用急停加速启动,快速上网或推或搓,然后快速还原,还原到位的同时急停蹬转体,向反手位跨步,进行反手的低手接球,最好是挡网,可直线或斜线,然后快速还原再次上网
上反手网前防正手腰部低手的练习方法同上。
注意:正手要求一定抢高前点处理,反手要求绝对要低手处理,不要求抢前点或高点,这样才能达到一攻一防的练习效果,正手位到反手位的跑动应该是明显的小斜线。多多体会中场的急停启动和急停蹬转,以及启动后的加速度。
20-30颗球为一组,俩人交替进行。
爱好者自行训练基本模式(六)
急停启动的两人协助练习
原地的急停练习
一人在场地的一边,最好站在凳子上,利用头顶发球的方式,将球打到高处。练习者在另一边的场地中,以右手持拍为例,右脚在前,两脚自然略宽于肩站好,盯着对面发球者的球拍,在击球的一瞬间,跟着做原地的急停,两人循环反复练习,直到跟对面发球者的击球时间绝对合拍为止。
练习技巧:
都知道羽毛球的飞行需要时间过程,而从举拍到挥拍到击球也是需要时间和过程的,所以,在目测到羽毛球飞行的落点,和击球者的引拍预备击球时,就要做好急停的准备了,在对方开始发力即将击球的那一瞬间,就是你做急停的时候了,有人理解急停就是原地一个双脚的小跳,也不为错,就是要求那一小跳的落地时间,要跟对方打到球的时间一致。
爱好者自行训练基本模式(七)
急停启动的两人协助练习
原地的急停加启动练习
在熟练的掌握上面的急停练习后,开始加入启动,启动分为前后两种方式,先练习向后的启动。
向后的急停启动
练习方法是:发球者发后场的高远球,练习者结合急停技巧在急停落地的同时,前脚发力向后快速蹬转带动身体同时向后转体,然后做一个或两个并步继续向后场低线附近,做一个转体挥拍的动作,顺势还原到启动时的位置,两人循环反复练习,直到跟对面发球者的击球时间合拍为止。
向前的急停启动
练习方法是:发球者发前场小球,练习者结合急停技巧在急停落地的同时,利用后脚(左脚)先做一个垫步带动右脚顺势向前用力蹬跨一大步,到网前,也就是说从圆心(指防守位置)启动到网前,是一个半步和一个大步,一共是一步半到网前。然后做一个转体网前挑球的动作,再后是右脚保持在前,用并步或双脚向后的一个小跳,的还原到启动时的位置,两人循环反复练习,直到跟对面发球者的击球时间合拍为止。
注:在向前跨出的那一大步落地的时候,右脚的脚尖要向外展,落地时是从脚跟的外侧到脚的外侧然后整个脚掌完全着地,这样才能保证在不同条件的场地上,脚踝不受伤!
爱好者自行训练基本模式(八)
三人组合训练之杀 挡 绷
论坛上很多朋友对杀球和接杀球的练习方式感兴趣,大傻根据业余爱好者的特点,给大家出个三人组合练习模式,希望对大家能有些帮助。
注释:三个人按不站位,都能得到各自所在位置的实战练习,杀:杀球;挡:中距离挡放网;绷:接杀球起后场
练习方法:
俩人一组对一人,俩人这边前场一人负责回放网练习,另一人在后场进行杀球训练。
训练要求与目的:
前场者:以挡回放网为主要练习,不容许使用网前的搓球技术,练习目的在于中短距离的手感,由于限制了搓球所以降低了回球难度,保证了双方来回练习的连续性不被破坏。
后场者:只要见到高球必须杀球,刚开始的时候,做单边的练习,就是只杀一条边,先追求落点准确,逐渐加力量,两边交换练习但是固定的定点杀球。等两条边的定点练习感觉好起来,准确性高起来后,再开始两条边不定点杀球练习 。(初期练习者比较急,希望能够认真领会,要学追求落点第一,力量第二,为什么?等你在实战中能够运用上的时候你就知道了,当然又准又很那就更好了呵呵!)
对面防守者:刚开始的时候,可以站位略靠近边线,接杀球先直线挡垫到对方网前就行了,无所谓质量,逐步要求提高质量,注意接杀球时手上要绝对放松,反手要学会利用拇指,控制好拍面就行了,两条边接杀球的练习都是从固定点接杀开始的。当两条边接杀熟练后,防守者要逐渐将站位向场地中心调整,并要求做些接杀挡斜线网前。这个环节的练习时,要注意的是手腕和拍面,手腕的控制和略为倾斜的拍面是接杀球挡斜线网前的关键,很多更大的角度不止是靠手腕去做的,敲门在倾斜的拍面上,也就是说人手腕的物理角度加上合理倾斜的拍面角度,可以打出意想不到的斜线角度,这些要靠自己慢慢体会了。再有在接杀球时要注意对自己身体躯干部分的整体控制,不能过于松了,脚下要做好弓箭步出击。当固定落点的挡放技术越来纯熟后,就可以开始做两边不定顺序的实战性接杀球练习了。再熟练些后就可以根据对方杀球落点的难易程度练习绷后场直线和斜线的练习了,也就是说可以自由选择回球落点了,网前后场随意了。绷后场的手上技巧在于击球前虚握球拍,击球瞬间借助小臂和手腕的力量突然握紧球拍发力,注意击球后挥拍动作不要扬出过老,尽量早些收拍以备能够快速再次防守。
练习时击球的基本顺序
防守方先发高球,对方后场开始杀球,防守方挡放网,前场者回挡放网,防守方上网挑高球。。。。。。。反复循环如此。三人五分钟一换交替练习。
论步法的急停急起(原创)
练习防守技术时, 因为受控于对手,经常会判断错误或被骗, 这时候急停急起的步法调整就很重要。 通常停顿了后起蹬的用力是相反的方向, 即急停向后就重心向前再用力向后蹬; 急停向前就是重心向后再向前蹬。 要注意的是停了后先向球的方向转身。 练习时大多数朋友都是停了后就没再起动了, 其实就算接不到球也应该照出脚, 久而久之就可以练出挣扎的步法。 另外上网时很多人都只出右脚跨一步,绝对到不了位的, 应该先出左脚或反手位先转身,这样才可以接到近网的球。
什么叫“急”呢? 就是就是判断错来球后,停顿调整, 立即可以出步伐来接球。 在练习多球接杀吊的训练中, 练习时不一定会接到每一球, 但要求必定要出脚, 而且是先出左脚调整。 另外接完吊球后要向中间退, 起码退一步(在没确定对方一定打重复球时), 很多朋友都只退到网前的发球线, 对于接杀是很不利的。
作者:丽然
************************************************************
一般急停时间应该在对手击球的同时进行, 上网采用后交叉步, 比如右手选手, 正手位先启动左脚进行后交叉垫半步, 随之有脚大步登跨一步就到网前了, 反手位右脚先急停启动,然后就跟正手位上步方法相同了。
关键1、 在处理完网前球后 向中场还原时 右脚一定保持在前, 否则对手回放网前的话你就难受了)
关键2、 中场防守时右脚要保持略前, 这样从中场向后场退步时可直接利用急停加速向后蹬转体, 使你的后退很快。
关键3、 无论向前还是向后, 都要学会利用急停的爆发力完成, 所以急停启动和急停蹬转都几乎是同时完成的, 绝对不要二次启动。 左手持拍者参考以上时相反就是了。
来自:http://awen.bloghome.cn/posts/22432.html
1.清除vista sp1备份文件:
cmd
vsp1cln
2.清除vista sp2备份文件:
cmd
compcln
3.取消休眠功能
cmd
powercfg -h off
测试:NS8000入手后,我一直没用在双打上,只在单打中使用,所以以下的测试都是单打的感觉。先从外观看,照片大家是见多了,只能说很PL,银色的外观,很眩目,拍框是盒式(BOX)结构,类似于TI10,比NS7000的AR结构WIDEBODY有很大差距,看上去更小巧玲珑,精致。拍框的3点和9点处有(SOLID。。)字样,NS的技术体现在拍杆和框上,估计是增加了强度。上了BG80线,26B,这80线的弹性是很好,用的现在没感觉掉磅。
1、拉后场:上场练习,感觉很轻松,不费大力气就能拉到底线位置,单打比赛中包括在被动起高远时,都能一拍到底,不拖泥带水,完全能做到物随心役。评分:10分(满分)
2、网前处理:包括主动放网前小球,勾对角,以及后场的劈吊网前等,手感很轻盈,动作不大,轻搓,拈,都很舒服,自如,有CAB20的手感。均衡。评分10分
3、网前平抽挡:这本来是双打的技术,单打用的比较少,但为了全面衡量,我和对手实验了一把,网前的平抽挡,感觉NS8000比NS7000的出球要快,NS7000有的时候会不小心击球在宽宽的框边,NS8000就要表现出色些,平抽比TI10要舒服很多,至少是省力了不少,还试验了把后场的平抽球,很是暴力,控制很好。评分:9分
4、杀球:这NS8000,广告是早就说了是“轻量的设计”,把重量从拍头移到了拍柄,那就很担心杀球的质量了,尤其是NS8000的进攻能力和MP100旗鼓相当,很让粉丝们疑惑,我的测试后分析:杀球,主要是要求拍面能“包”住球,能控制球的走向,能瞬间发力,把球如子弹样的打出去,而且希望能很好的控制落点。把NS8000,NS7000,CAB30进行对比后,我觉得落点控制NS8000》CAB30》NS7000,NS8000的杀球场是一气呵成,突击速度很快,极其的暴力,落点的控制也很精确。
5、其他;单打中用NS8000很久,越发感觉NS8000的设计是突破性的,不同于已有的CAB,MP,AT系列产品,设计上的转移重量分布,但没有因此而牺牲强大的突击火力,和TI10的设计不同,TI10明显的是头重,单打一会儿就感觉力不从心了,但要是你使用了NS8000,你就不会有这样的感觉,我单打有局球几乎是攻击到底的,不管最后的成绩如何,你不觉的累这是很明显的感觉。
NS8000的中杆弹性好于TI10,力的传导要好。都是7MM的细杆设计,与NS7000的普通杆设计是俩条路线。
综合:如果上次的NS7000,我的设计是为类似龚智超,王莲香设计,为哈菲兹设计,那么NS8000,就应当是给进攻性选手设计的,对于要求突击速度要快,连续进攻,力量大,打点准确的选手而言,是不二的选择。这次苏杯,期望中有NS8000的做秀机会,但想来AT700占了主角也很正常,在理。苏杯是国家的荣誉,容不的闪失,新装备如果表现不佳,打陋了,不好交代,还不如 驾驭已经很顺手的AT700呢,AT700的进攻也很好,我尝试了打了些 时间,感觉AT700的进攻不及NS80000,中杆硬度要硬过NS8000一点,弹性不如NS8000,最受不了的是AT700的“笨笨”的筐体设计,不如NS8000细致。估计以后的公开赛,该有高手们拿NS8000“骚”了。
NS8000,看来是为老前辈的董炯,叶成万,新锐的李宗伟,鲍春来,陈金设计的,如果哪次OPEN看见林丹,谢MM那拿着发烧,也很正常了。。。。
推荐理由:如果你在NS8000,MP99间徘徊,我建议你就上NS8000吧,MP99的操控性不入NS8000好,我的认识是:NS8000,有CAB20的均衡手感,TI10的猛烈火力,AT800的双打平抽挡的快捷,实在是难说啥坏话了。
来自:http://mycheer.w101.ws86.com/www/2/2008-07/66.html
目前的羽拍,最常见的拍框是中平头的。大平头和小平头都相对少见,圆头则更少。为了获得同等的拉线磅数体验,需要注意拍框形状不同所带来的差异。比如你一直打大平头的球拍,象大傻D11、yy钛十之类的框型,用25/27磅,需要更换成yyAT700,这是一支中平头的球拍,那就需注意减一磅,大约24/26就可以了,这样可以获得跟大平头拍的相同磅数体验;要是用小平头球拍,如大傻001,你还需要再减1-2磅,22-23/24-25磅,就能获得相同体验,有时候对一些面积相对较少的拍框,比如北极狐Ti25,尽管它是中平头的,但你拿它跟yy700拉同等磅数,可能会觉得Ti25还紧致些,所以也需要酌情减磅;用圆头球拍,如yy20、肯尼士787,大约21-22/23-24磅即可获得相同感觉。大家在购买球拍后选择拉线磅数,就要注意这一点,避免磅数感觉与原来适合的手感差异太大。至于72线孔与76甚至88孔的球拍相比,只要框型一样,个人感觉同等磅数下,线床张力并不会相差太远,大约只是每增加4个线孔,磅数随即增加0.5磅左右的比例,如果72孔转76孔球拍,增加的磅数基本可以忽略不计,但72孔转88孔,同样的羽线拉同等磅数,会觉得88孔磅数要高2磅左右,这是由于拉线交叉重叠点数量的差异造成的。综上所述,拍框面积越大的,磅数要适当越高,反之拍框面积越小,磅数便适当下调;线孔越少磅数要适当越高,线孔越多,磅数便适当下调,同框型的线孔与磅数递增比例大约为4线孔/0.5磅,科学的拉线,用心的比较,才能获得相同的磅数松紧体验。
目前大家比较常用的羽线还是yy,yy线中,抗走磅能力相对好的是65、70,65Ti,这些线都是0.70mm的;抗走磅能力最差的是80、85、6,这些线都在0.68以下;同等磅数下,前三者拉线后会感觉紧一点,后三者会感觉松一点,所以在拉线的时候需要注意,如果从换线是从前三者转换到后三者,那可能需要调高1-2磅,不然会觉得线不够原来的紧。其中,加钛与没加钛的也有分别,加了钛的线,感觉击球感会硬一点,所以yy线中68Ti型号比较特别,它刚开始用的头几个小时感觉不错的,你拉线不能拉太紧,但很快它便会降磅,恢复细线的本来面目。综上所述,没加钛的情况下,一般羽线直径越粗,则磅数可相应低点,而羽线直径越细,磅数就要相对调高一点,变化幅度在2磅左右,这样互相更换使用才能获得接近的线床松紧体验。
根据多年用线心得,感觉羽线尽管品牌繁多,但还是存在区域特点的:台湾和日本出产的羽线,代表品牌为yy、gosen、华腾,耐打性相对比较好,存放时间相对长,但非常容易掉磅,在业余比赛或日常训练中没有太大问题,但专业比赛中一般就得每场比赛换线,以维持相同的磅数完成比赛。欧洲产的羽线,工艺最好,掉磅情况很少出现,但缺点是寿命较短,而且均以出0.64mm左右直径的线为主,但其寿命已经比同等直径甚至更粗一点的台湾、日本线要长了。其代表品牌有德国太平洋、英国亚狮龙、雅帕,中国大傻羽线也在德国制造。美国产的线,在上述两个区域的特点之间,没日本、台湾线耐打,也没有欧洲线的抗掉磅能力,但对于上述两个地域羽线的缺点,美国线却具有优势,代表品牌是雅莎维,又名敖狮威,里面最好的线型号是A85,耐打、弹性好、不掉磅。中国大陆产的羽线,目前还只能生产一些较低档的练习线为主,线径都比较粗,加上包装比较简陋,宣传不到位,高档羽线很少在大陆加工,但也有例外,我比较看好的国产羽线品牌是福建生产的袋鼠(TOFF)牌,它的100线和200线质量都属上乘,尤其是200线,性价比极高,大家有机会可以找来试试。
来自:http://www.gzcheerclub.com/bbs/viewthread.php?tid=3641
当看到专业运动员在比赛中起跳扣杀给对手致命一击,你在大呼痛快之余,是否想过自己也可以象那些运动员一样在比赛中运用起跳扣杀技术?不用急,下面我将以右手持拍为例,就起跳扣杀的先决条件、练习方法、应用意义一一作出阐述,仅供广大球友参考。
首先是先决条件,要掌握好起跳扣杀,必须有良好的膝部起跳爆发力、腰部拧转爆发力以及最重要的身体平衡感;腰、膝爆发力是起跳扣杀的基础,平衡感是起跳扣杀的质量保证。当然,要想练好起跳扣杀,在地面上的扣杀技术也必须比较熟练或者至少具备一定的基础,否则是无法进行起跳扣杀练习的。基本掌握地面扣杀技术的球友,可以通过以下这个方法检测自己是否具备练习起跳扣杀的先决条件:双脚分开约1.5倍肩宽,预设左脚踩着的点为A点,右脚则为B点,半蹲(大小腿夹角不可少于90度),然后充分往上跳起,小腿尽量往后踢,在空中要求有充裕的时间屈膝并转体,身体向左后方转180度后落地,左脚踩在B点,右脚踩在A点,如此连续做5-10次,身体保持平衡不能摇晃。如果你能轻松做到这一点,那先恭喜你可以尝试进行起跳扣杀的训练了。不能做到以上这点的也不用灰心,一般练习一周左右也大部分可以掌握了,需要提醒的是很多人练习这一步时会不自觉的低头看自己的脚,这样反而不容易掌握平衡,正确的是在一个起跳动作中,头面部在起跳前就应该朝向自己的左方,眼睛看着左前方的某个目标,在起跳过程中,面部朝向不转而身体转,落地后头面部朝向不变,但因身体转了180度,就自动变成转向了自己的右方了。
现在谈练习方法,练习起跳扣杀可以分三步走。第一步,原地向正手方起跳击平高球:练习时可按一般隔网拉平高球的方式与同伴对练,请同伴尽量把球压到你的正手后场,你在准备击球时,双脚站位连线与球场底线是大致平行的,在此姿势上,见到正手方来球,即起跳回击平球,或向正手方并一至两步后再借势起跳回击,不需下压球,只回平球即可。在这一步中,要求双脚向正手方起跳,身体不往前,不往后,只是往侧方与底线平行的方向起跳,在空中不用刻意拧髋,仅体会一下身体在空中舒展的感觉,关键是在空中肩关节需充分后展引拍,手臂需以肘带动,快速闪腕击球,而落地一般先右脚落地,左脚迅即随后落地以辅助保持平衡。这一步一般业余爱好者大约1-4周时间可以熟练了。第二步,在第一步的基础上,将起跳时间提前一点,击球点也前移一点,回平高球变成回扣杀球。需要注意的是,第二步的基本要求都是与第一步一致的,只是将发力方向从对场的高处,变成对场的地面,另外击球的瞬间需运用收腹的动作辅助发力,请切记这一点。练习时间与第一步相同。通过前两步的练习,如果你已经因此而具备了一定的空中焦点捕捉能力,以及空中协调发力的能力,那么恭喜,你可以进入第三步了。第三步,站在底线稍前位置,两脚站位改为左脚前、右脚后,两脚连线与球场边线平行,脚尖和身体正面朝向边线一侧,面部左转朝向球网;同伴发高球给你。面对来球,注意用小碎步或并步调整击球位置,务求将击球点抢在前面,起跳大力扣杀的理想击球点应该在你的身前,不要让它飞到你的身后,这跟在地面上杀球的道理是一样的。在合适的时机下,双脚分开大约1.5倍肩宽,半蹲,随即充分起跳,起跳后髋部马上向左拧,使腹部转向前方,与此同时右手持拍上举并且右肩后展,当腹部朝向前方的时候,通过拧髋的牵带力量,右肩、右肘、手腕等依次传递力量,在瞬间内让手臂、球拍一体象鞭子那样爆发力量下压。在杀球的时候,胸部应该是对着对面场地的。击球完成后,身体在空中顺势左转,左脚前掌内侧先着地,右脚随即着地保持平衡。需要强调的是,如果起跳后没有拧髋和展肩都做出来的话,是很难作出有力的扣杀的,而拧髋动作不充分的话,球将比较容易出界。在练习第三步的时候,从易到难,可以先采取落点靠前、弧度较平的球给练习者,进而发展到落点靠底线、弧度近高远球的来球给练习者。


最后,谈谈起跳扣杀的应用意义。作为现代羽毛球向速度、力量方向发展而催生的一种进攻技术,它在专业比赛中应用越来越广泛。在专业比赛中起跳扣杀的目的主要是为了加快击球节奏以及掌握尖锐的进攻落点;但它同时也是一把双刃剑,有着不可避免的缺点,那就是非常消耗体力以及容易导致受伤。羽毛球比赛中的下肢受伤,超过半数都是起跳的瞬间或落地的瞬间造成的,特别是在疲劳的时候发生,所以必须注意合理地使用起跳扣杀,业余球员很少系统作专项训练,更需要注意这点;当觉得脚下力量不足时,其实尝试将重心放到右脚,作单脚起跳,会比勉强的双脚起跳效果好。起跳扣杀还有一个滞空时间控制的问题,一般来说,除非为了耍帅,最好尽量缩短滞空时间,不然很容易影响下一拍的击球,而滞空时间是通过在空中伸展小腿来控制的,最好养成击球后小腿马上伸展争取触地的习惯。也许这将影响你的帅气,但你这么做了的话在技术上实际是好很多的,当偶像派还是实力派就各取所需吧。实际上,上面谈到的起跳扣杀技术,还是远远不够的,比如并没有谈到头顶方的起跳扣杀,也没有谈到起跳后扣杀与劈吊、平高的手法变换结合,这些都是相对较难掌握得好的;不说,是因为没有说的必要。起跳扣杀是一项相对比较难入门的技术,但入门之后,一但通了窍,也不过象《卖油翁》里面说的那样“惟手熟尔”,所以,关键乃是入门。
我自己学习起跳扣杀,从完全不懂到基本象模象样,大约花了两个星期的时间,一个星期打三次球,没有专门的去练,只是在平时多去模仿加上脑子里琢磨,就可以了,多在空闲时脑子里想一想,在练习时印证,是一定有帮助的。我掌握起跳扣杀以后,也只在双打时用得频繁些,单打则基本不用,就算在没有受伤的时候,也很少用,现在更是根本不用了,但以往掌握起跳进攻的一些经验,在对付喜欢起跳扣杀的对手时,还是有一定帮助的,虽然你不用它,但你了解它,就可以通过它的双刃剑来惩罚它的使用者,或被使用者惩罚你,此为羽毛球一乐也。
最后的总结是,起跳扣杀你没有必要一定用它,但可以去尝试了解或掌握它,如果你的志向是当一名业余一流高手的话;但需注意它是一把双刃剑,练习和使用的时候要加倍小心和量力而为。
来自:http://www.gzcheerclub.com/bbs/viewthread.php?tid=3745
从oracle官方下载的最新版本 11g装到visa上,老是报错;
解决方法:关掉OracleDBConsoleorcl服务就可以了,而且不会影响oracle的使用
来自: http://3000books.net/index.php?option=com_content&view=article&id=823:解决nmefwmi.exe导致的问题&catid=48:张万程生活随笔&Itemid=89
先到RealPlayer官方网站上下载:
http://www.real.com/linux/
将文件RealPlayer10GOLD.bin保存到主文件夹中,即/home/[yourusername]文件夹下。
然后打开终端,进行如下操作:
$chmod +x RealPlayer10GOLD.bin
$sudo ./RealPlayer10GOLD.bin
当终端显示
Welcome to the RealPlayer (10.0.8.805) Setup for UNIX
Setup will help you get RealPlayer running on your computer.
Press [Enter] to continue...
时按下回车键,进入下一步:
Enter the complete path to the directory where you want
RealPlayer to be installed. You must specify the full
pathname of the directory and have write privileges to
the chosen directory.
Directory: [/home/shixinyu/RealPlayer]:
这里默认安装到用户的主文件夹下的RealPlayer目录下,如果你想要安装到别处,就在此处输入路径,否则直接回车即可。
You have selected the following RealPlayer configuration:
Destination: /home/shixinyu/RealPlayer
Enter [F]inish to begin copying files, or [P]revious to go
back to the previous prompts: [F]: F
安装程序会提示最后确定信息,如果都确定了,按下F键后回车。
当提示
Copying RealPlayer files...configure system-wide symbolic links? [Y/n]:
时按下Y键回车即可,后面基本上就没有需要用户操作的地方了,通常到这里基本上就安装好了,你可以到“应用程序,影音”下找到RealPlayer10来运行了,首次运行会有一段安装协议需要同意。
注:如果在跟着上述步骤完成安装操作之后到应用程序菜单下的“影音”中单击RealPlayer无反应,并且你的Ubuntu安装的是SCIM输入法,那么很可能是SCIM与RealPlayer的冲突,你还需要进行下面操作:
$sudo gedit /home/[yourid]/RealPlayer/realplay [yourid]指你的主文件夹名
在打开的文本编辑器的首行添加下面一行
export GTK_IM_MODULE=xim
之后保存文本编辑器,然后再次执行RealPlayer应该就正常了。
如果你是新手,
sudo gedit /etc/apt/sources.list
添加源
deb http://archive.canonical.com/ubuntu dapper-commercial main
保存退出
sudo atp-get update
sudo apt-get install realplay
就可以安装成功了。
来自:http://hi.baidu.com/longrj21/blog/item/698030dbc70ad163d1164e2c.html
七大简易盈利法则
立桩量的实战运用:
一、立桩量的产生条件
立桩量是指在一只股票在上升途中,在相对低位放出一根阶段性的大量(超越和覆盖掉前期的量),量的大小呈现阶段性放大趋势,同时,股票价格处于上涨的趋势,以上两点缺一不可。尤其强调的是立桩量只出现在股票的上涨途中,而在下跌中是不可能有立桩量出现的。
二、三天法则
立桩量要成立,必须建立在"三天法则"之上。即在三天之内不跌破立桩量当日股价的最低点(b点),且股价后期要突破立桩量出现时股票价格的最高点(a点)。另外,"三天法则"中的"三天"并不要求时间段一定为3天,只要在出现立桩量后三天左右不跌破低点b,且股价超过a点,就可以买入,例如,立桩量出现后股价第二天就创新高突破a点就是买入的时机。
三、目标位涨幅的计算
只要立桩量被确认,未来股价将会到达的位置是:a点价格2。这种翻番的效应,实战案例已是举不胜举。
四、操作要点
1、量无阴阳,只有大小。当后量超越前量,且此后股价突破放巨量日的股价最高价,则立桩量方成立。反之,不能突破高点且低点被击穿,则立桩量不成立。即使放再大的量,也应放弃不可介入。
2、在立桩量法则成立之后,应该半仓介入。因为股价在冲高途中会出现一定的震荡格局,而震荡后的拉升才是全仓的时机,一直到最后达到100%的涨幅。
3、立桩量出现后,股价在连续上涨中会出现回落调整阶段。这一调整过程一般为6至13天。如能把握好,一是可以避免调整期的"折磨",二来可掌握加仓的时机。
五、寻找立桩量的窍门
沪深股市千余只股票,要能即时寻找到出现立桩量的股票,除了每天复盘查看每只股票的盘中走势外,有一个最简便的方法是开盘后观察"81""83"中的"今日总金额排名"一栏,寻找金额异动的个股。看那只股排在第一,尤其是超越大盘蓝筹股量的个股,一定要关注它。若排在前面,其走势又在其对低位,且后量超过和覆盖了前期的大量,此量可能就是立桩量。然后再根据三天法则观察,只要股价突破放巨量当天股价的高点,则立桩量成立,便可果断介入,此后必获翻番大利。 "螺旋桨"--下跌中捉"黑马"的"航标"
绵绵下跌中,信心殆尽,机会何在?迷途中,他慧眼发现了走出苍茫"绿海"的航标--螺旋桨法则。它助你在熊途末路中骑上"黑马"走出低谷,奔向制胜的彼岸。 螺旋居侧听潮升 金秋时节,简凡传授操盘绝技的公开免费报告会在上海各大影剧院连续举行。他的弟子吴华为他在媒体上写下了这样一句"广告语":立桩峰顶赏秋月,螺旋居侧听潮升"。显然,立桩量和螺旋桨在他的操作技艺中占据着重要位置。
螺旋桨法则,它是简凡继立桩量之后又一个炒股绝招和重要的法则,也是一把在熊途中稳获大利的"杀手锏"。
他说:"在一些股票经过长期下跌,在其跌势的末端,有时你会惊奇地发现有一种'螺旋桨形态'出现,它是一个带着非常长的下影线的K线,也是通常所说的'单针探底'。这种形态,可是一个在跌势中难得的获大利的宝贝。只要它一出现,此后就有机会获得30-45%的利润。"
一、螺旋桨法则的判断条件
1、它出现在下跌的行情,且累计下跌幅度比较大,一般在中、晚期。
2、缩量,不满足135日均量线。
二、形态
从左图可以看出,螺旋桨的基本形态是具有一根非常长的下影线的一种K线。但也有一种个别形态:股价跳空低开(甚至以跌停开盘)后再大幅拉起(甚至于从跌停拉至接近涨停或涨停),此为K线形态为"螺旋桨法则"中的一种"变形形态"。对此法则的操作同等有效。需要说明的一点是:这里的K线对阴阳无要求。
三、三天法则
1、先确定出"二分位",找出中轴线(即最高价与最低价的中点--中间价)。螺旋桨重心在中轴线之上运行,则向上旋,在中轴线之下运行,则向下旋;
2、连续三天股价均在二分位之上,则后市股价上涨;
3、三天后当股价突破螺旋桨的最高价,同时放量满足135日均线,则涨势确立。
注:若股价在三天内跌至二分位以下补掉了螺旋桨的下影线,则可判定此K线并非螺旋桨。
四、目标价位
设螺旋桨出现时当日最高价为A,最低价为B,未来目标价位为N,其未来股票的价格可用下列公式计算:
N= (A- B)4.5+B
即:(最高价-最低价)4.5+最低价=目标位
注:公式中的4.5为固定涨幅系数。
五、操作要点
1、螺旋桨的出现是在下跌中。下跌的幅度一定要大,且在股票下跌的中晚期。跌幅越大,其报复性的反弹力度就越大,操作的成功概率也会越高。
2、螺旋桨出现时,能量一定要萎缩,其缩量的标准是不满足于135日均量线。
3、与股票拉升中出现立桩量时半仓介入的原则不同的是,一旦螺旋桨法则确定生效,则应重仓或全仓杀入。因在熊途中多以空仓相待,而螺旋桨出现的报复性行情暴发力强,时间短,稍纵即逝,只有重仓,才能获得丰厚利润。
4、遵循"三天法则"要灵活,若不到三天股价就突破高点,要立即果断介入,不可贻误战机。
5、通常,在螺旋桨法则中,未来股票的涨幅都在30%-45%之间。因而,若涨幅不到30%,坚决不出。
实例一:南京医药
这是简凡2005年走出"机构操作密室"踏入证券咨询业后的"开山之作",也是他实战中运用螺旋桨法则操作的最为经典的案例之一。
时间:2005年5月11日。
从图中可以看出,南京医药从2004年4月7日的7.33元经过长达一年多的下跌,于2005年5月11日在低位出现了一个螺旋桨形态,当日最高价为3.41元,最低价探至3.14元。
根据螺旋桨法则,由此可计算出它的中轴线为(3.41-3.14)2+3.14=3.27元。当天收盘价为3.36元,站在了二分位之上。只要后面股价突破螺旋桨出现时的最高价3.41元,成交量满足135日均量线,股价就会螺旋式地向上翻。实际运行:5月17日突破高点,同时成交量满足135日均量线,螺旋桨成立,介入!
按照目标位=(最高价-最低价)4.5+最低价公式计算:
未来目标位= (3.41-3.14)4.5+ 3.14元 = 4.36元。
实施螺旋上翻的具体运行过程是:
第一次上翻:3.41元+0.27=3.68元(2005年5月17日完成,当日最高价为3.69元)
第二次上翻:3.68元+0.27元=3.95元(于次日完成,当日最高价恰好为3.95元)
第三次上翻:因按常规在螺旋上翻3.5倍时会有震荡,因此,第次上翻的目标位=3.95元+0.13元=4.08元(5月26日完成。当日最高价为4.08元)
第四次上翻:4.08元+0.27元=4.35元(2005年6月8日完成了最后一翻,当日股价最高达4.37元,与螺旋桨法则计算结果仅相差1分钱)。
茫茫股海,陷阱重重。艰难跋涉,何能趋利避害?他用四条神奇独特的趋势线辨牛熊,识陷阱,成功狙击主力,从庄家的口袋里夺取财富。
"魔鬼线"321-股票买卖点的最后判断
在采访简凡期间,记者发现他平时看盘从来不看人们通常所设的5日、10日、30日移动平均线,而只注重K线的走势和135日均量线是否满足。但在关键时刻或点位,他一定要看他从华尔街导师那传承过来的四条特殊的趋势线,那就是13、26、156和321。
简凡介绍说:"13日和26日均价趋势线为短期盈利线,156日均价趋势线为多空止损线,321日均价趋势线为牛熊分界线。在这四条趋势线中,我最看重的是321这条趋势线,特别是对于集中资金买卖一只股票来说,321日趋势线非常具有实战性,它是买卖股票的最后判断。我戏称它为'魔鬼线',如果它压制在股票运行的上方,常常是股价一碰到这条'魔鬼线'就会下跌,而如果它处在股票运行轨迹的下方,它便是一道坚固的防线,许多股票下跌到此,常会被这条防线托起,然后再步升途。而在下跌中,一旦这条防线被有效向下击穿,那将是最后的逃命机会。"
1、321日线对指数的判断
在指数累计上涨的幅度达到50%以上,指数在高位进行震荡之后,指数只要由上向下击穿321日线,即为有效突破,预示指数进入下跌态势,进入熊市,此时应全部沽空。特别是当156日线与321日线发生死叉,股市即全线进入持续跌势,此时无论如何都应全线沽空,决不可听信市场上的任何传言,也不可"高速后马上会反弹"抱任何幻想。
当四根趋势线成空头排列形态,且321日线在最上面,此时321日线即成为反弹的目标位和强大的阻力位。
实例:上证指数
2001年6月14日,上证指数在创出2245点的高点后,开始下跌。自7月23日,大盘进入加速下跌,连续出现 6连阴,7月30日以一根大阴棒击穿321趋势线,破2000点大关,表明上一段的牛市已经走完,市场已进入做空状态,应果断抛空手中所有股票,这是最后的逃命机会,此后大盘步入了长达4年多的漫漫熊途。
2、321日线对个股的判断
对个股由牛势转为熊势的判断与对指数牛势转为熊势的判断一样,只有一点区别:股价在高位震荡后,股价由上向下击穿321日线,并连续三天股价重心都在321日趋势线下运行,才为有效突破,这是股票抛售的最后时机。而大盘指数突破一天即为有效。
3、由熊势转为牛势的判断
对个股和指数由熊势转为牛势的判断标准是一样的。当股价或指数在从321日趋势线下方向上突破,并且股价重心连续三天在321日趋势线以上运行,此时股价经上涨后会回踩321日线但不跌破321日线,可以认定为有效突破。此时,股价上涨趋势开始,进入牛势行情。当股价创新高(大于前三天股价的最高点)为股票买入点,此时成交量要满足135日均线。
321日线被称谓牛熊分界线,在判断大盘的走势上,32日线有着非常准确预见。在2003年12月22日大盘一举突破321日线,连续三天指数运行在321日线上,成交量也满足135日线上,故为有效突破,大盘在后期一直运行到1783.01点。
2006年1月6日,大盘在一举突破321日线,并且连续三天指数运行在321日线上,成交量也满足135日线上,故为有效突破,当天突破时大盘收于1209.42点,之后一波凌厉的上涨行情展开。
再拿个股来说,例子就更多。运用321日趋势线可有效抓住个股的最佳买入点,获得极为丰厚的利润。就以宝钛股份为例证,在经过漫长的横盘之后,该股于2005年6月20日第一次突破321日线,可在第二天以一根阴线有跌破321日线,故为无效突破。此后虽接连几次实施突破,但都因整体运行在321日线下或回踩跌破321日线,故也为无效突破。直到2005年7月5日股价再次突破321日线,并在接下来的三天股价重心运行在321日线之上,且这几天成交量都在135日线以上,为有效突破。2005年7月8日,股价回调后于7月11日突破前三天最高价9.30元时为买入点,可以看到宝钛股份在后期有巨大的涨幅,最高价达到59.86元。 识骗局,从"死叉"中夺金子
在简凡设定的四条趋势线中,还有一条极其重要的156日线,它是一条多空止损线。指数或股价一旦击穿156日线,将会直接进入下跌行情,此时应及时止损沽空。
但是,他说:"一般投资者见到空头排列就逃,这是一种常见的思维。但是主力有时往往会超常规'出牌',在出现'死叉'后会设下诱多的骗局,引诱投资者吃套。但要能识破它,并把握好时机,反倒可以从主力口袋里掏出金子。表现在156线死叉后产生反弹的反技术操作即如此。"
他指着盘面给记者看:"在下跌过程中,13、26日线或321日线与156发生死叉后,总会有一段奇怪的反弹行情。这一反弹通常会发生死叉的三天后,回涨幅度一般有30%左右。这是下跌中难得的一块'肥肉'。但这种反弹只是空头回补,是主力在为出逃诱多。反弹结束之后会有一段更为猛烈的杀跌。"
"骑上狂飙黑马,如何不被盘中的"阴棒"所吓倒,不让奋蹄的黑马颠落马下?简氏高低法则似一把"神尺",既解决了"持股难"的一大问题,又可让你的盈利达到最大化。
在"暴风骤雨"中持股
1、坐涨不坐跌
证券市场股价波动的基本状态只分为上涨和下跌。按照道氏理论中所阐述的趋势运动揭示的规律,股票的上涨分为主要运动和次级运动。其主要运动是指市场最基本的上涨趋势,次级运动是指市场在反弹中产生的上涨行情。对于投资者来讲,最能够产生获利的波段主要是在上涨趋势中,而不是在横盘和下跌趋势当中。但有相当数量的投资者不能正确认识这一点。我通过多年的实战总结出了一个简单而实用性很强的规律:"坐涨不坐跌"。即我们在上涨的趋势中操作股票,而不是在下跌的过程中去抢反弹。但要遵守这样一条操作法则,必须拥有指导性的读盘方法,从而解开主力的操作密码。
2. 简氏线
A . 通常股价上涨或下跌的波动情况是用K线来表示的,而常规的K线它有开盘价,收盘价,最高价,最低价之分。投资者经常注重于股价的收盘价及开盘价,而往往忽略最高价和最低价的作用。而我认为股票价格的上涨是以不断创前期新高来代表,价格的下跌是以不断前期新低为代表。那么,在证券买卖中日K线代表的是该股每天价格波动的变化情况,月K线代表的是该股价格变化的总体趋势。对于投资者来说,只有在月K线趋势的指导下进行操作,才能读懂该股价格变化的整体导向。为了简单而明了地表达股价波动的情况,我只保留K线四种价格中的最高价和最低价。因为股价上涨的最终代表是指突破前一天的最高点,股价下跌的最终代表是指击穿前一天的最低点,除此之外没有其他的表达方式。在证券市场的买卖中,我们的操作方法应该是简单的、明了的,而不应是繁琐的。不论K线是收阴或是收阳,或有上影线和下影线,其最高价与最低价都是最重要的,而开盘价和收盘价则随时会受到当天股价的波动而有所变化。我们首先来看以下两幅图:
图一和图二是我们常见的一般形式的K线图,它包括了开盘价、收盘价、最高价、最低价四种价格。
而我们再来看一下简氏线的K线图:从下图可以看到,简氏理论中的K线不论是阳线或阴线,仅仅保留了最高价和最低价。这是我们之后阐述简氏高低法则最基本的前提之一。
B . 既然谈到股价的最高和最低,势必要找到股价变化的参照体。有很多投资者在日常操作中都习惯把几天以前甚至于几个月以前一个相对的高点认为是股价的最高点进行比对。而我认为股价在日常波动中最高价和最低价的比对参照体就是该股前一天的最高价和最低价。
如下图所示:
从图中我们可以看出,一般投资者认为b点不是一个很好的买入点,因为股价并没有超过前期高点(图中a点),不能有充分的信心认为反弹开始。但从简氏线角度看,股价从b点的前一根阳线开始就已经止跌,并且放量创出新高,次日继续放量创新高(b点),出现强烈的反弹信号!当天就是买入的最佳时机。在接下来的几个交易日中上涨趋势完全成立,所以我们认为,b点便是资金介入的最佳时机!
3.简氏高低法则精要
⑴ 股价在急速上涨过程中(涨幅一般 在75%左右),不论成交量大小与否,也不论当日(或当月)收阳线还是收阴线,只要股价不断创出前一天(或前一个月)的新高,即突破前一天(月)的最高点,就坚决持股,不断扩大盈利。
例如苏宁电器自2005年11月至2006年6月股价连创新高,若一直持股,将获得300%的丰厚利润。
再如贵糖股份 ,在上涨中虽然于2006年2月其K线出现了一根阴线,但因股价仍创出新高,继续持有,之后该股又有一段大的涨幅。
⑵ 股价在急速下跌过程中,伴随着成交量的萎缩,只要击穿前一天(或前一月)的最低价,不论收阳或收阴,都应快速抛出手中股票,减少下跌被套的损失。
例如昌河股份 在2006年10月13日股价缩量创出新低,此时应即时获利了结,此后该股便开始下跌。
4.操作要点:
⑴ 不看K线阴阳,也不看开盘价和收盘价,只关注其最高价和最低价,这是应用简氏高低法则买卖股票的第一条。
⑵ 在高低法则的定义中,有一个特例:股价在急速下跌后或在下跌的末期,突然放出巨量击穿前一天的最低价,此为放量下跌的现象,应判断为震荡,只要在后三天中不再击穿放出巨量当天的最低价,并突破该巨量的最高价时,则为下跌趋势即将转入上涨趋势的信号。
例如洪都航空 在下跌的末期,于2006年1月23日K线图中放量砸出了一根大阴棒,然而,此后三天股价不仅未再创新低,而且连续创出新高,此是由跌势转为涨势的信号。
⑶ 若股价在完成75%的涨幅后,不论放量还是缩量,都无法突破前一天的最高价时,即为上涨趋势改变,转入震荡下跌趋势的信号。
⑷ 在上涨趋势中,特别是在上涨的初期阶段,有两种形态需特别注意:一是股价未能创出新高(尤其是在月K线中),但成交量却呈不断放大状态,则仍应持股。 二是若成交量萎缩,但股价未创出新低,这种缩量未创新低应视为属于正常的盘整,继续上涨的趋势并没有改变,可以继续持股。
⑸ 股价在上涨趋势中,量为君,价为臣,成交量一定要持续满足135日均量线的要求,才为真正的上涨。
⑹ 简氏高低法则在实战中运用时,只对日K线和反映长期趋势的月K线研究,而对周K线是不做研究的。我个人认为在高低法则中,周K线没有研究的意义。"
股海风云变化莫测,让人难以预知未来走向,使不计其数的股民遭受风雨摧残,并最终倒在股市这条铺满荆棘与泪水的道路上。然而,简凡却在这扑朔迷离的股市中发现了一种能够预测未来股价发展趋势的形态--"喇叭口",它就象能指引方向的"司南"(指南针),让在茫茫黑夜中摸索的人们明了未来的发展趋势。
一、"喇叭口"形态
简凡说,当股价或指数运行到相对低位或相对高位时,特别是除权后,经常会出现一种形似"喇叭"的一种形态(如下图所示),他称之为"喇叭口"形态。而又因其喇叭口形成后上涨和下跌的幅度相当之大,他又把此种形态形象地称为"狮吼功"。
喇叭口的形态如下图所示:
a点为喇叭口前高点,b点为前低点,c点为后高点,d点为喇叭口的后低点。
喇叭口是行情转变的一种过渡形态。它是股价和指数高点的不断上移及低点的不断下移,形成的一种上下扩散的形态。在其扩散过程之中,成交量的配合也尤其重要,它是一个由放量到缩量再到放量的过程 。当喇叭口在相对低位形态形成后,伴随着成交量不断放大 ,并满足135日均量,则后市看涨;反之,如果喇叭口在相对高位形成后,伴随着成交量逐步萎缩,成交量不满足135日均量线,则后市一般会有较大的下跌行情。
二、喇叭口形成后的后市走向
喇叭口根据其各个高低点位置的不同、形成时间的长短、扩散程度的大小从而形成不同的箱体,该箱体运行的最终位置可以通过其高点、低点的位置和箱体系数进行计算。由于股价走势受系统因素和非系统因素的影响,所以通常用喇叭口箱体计算的股价和指数的最终目标位与现实中的最终股价、指数会有一些偏差,但都不是很大。
1.上涨幅度计算公式:喇叭口在相对低位形成,后期伴随着成交量的逐步放大,后市处于上涨趋势,此时喇叭口运行的最终目标位的计算公式如下:
(后高点-前高点)4+后高点=最终目标位
注:4是此类箱体固定系数
古希腊哲学家阿基米德说过:"给我一个支点,我可以撬动整个地球"。这句话给人类的生活带来巨大的启示。简凡沿用了前人的言论,提出"给我一个支点,我可以撬动整个大盘",下倾三角箱体的"4·10"定律是简氏箱体理论的典型代表。它是一种可以准确预测大盘中长期的运行趋势点位的一种简易方法。
一,"4·10"定律的成立的条件
当大盘指数在运行中出现"W"底和下倾三角箱体的形态时,如果后高点进行回调时的点位不破前期低点。其运行结束后必然会产生一波上涨行情。
二,"4·10"定律的目标位置计算公式
这里我们假设前高点为a,后高点为b。则按照"4·10"定律运算公式:
M(股票运行的第一目标价位)=a+(a-b)4
N (股票运行的第二目标价位) = M(第一目标位)+(a-b)10
案例1:上证指数2245点的预测
如上图所示,1558点为前高点,1510点为后高点,在1510点冲高回落后没有破前期低点,因此"4·10"定律成立。而前高点和后高点两者之差为48点,则大盘运行的第一目标位为1750点,计算方法如下:
M(股票运行的第一目标价位)=a+(a-b)4
=1558+(1558-1510)4
=1750点
实际大盘运行结果上涨到1756点,仅与预测点位相差6点!!! 同时,该预测子也打破了以前的市场定论:"涨不言顶,跌不言底"。
按照"4·10"定律,大盘运行的第二目标位:
N = M(第一目标位)+(a-b)10
4810=480点(幅度值)
1756+480=2236点(后高点)
实际上大盘涨至2245点,离"4·10"定律的预测仅相差9点。
由于"4·10"定律一旦完成将产生大级别的回调行情,因此在2236点应该是抛出股票,而不是存钱做买卖行为。而在现实中,当大盘指数达到2236到2245点一线的时候,一片看涨的声音甚嚣,2800点论,3000点论,甚至5000点论充满了整个证券市场,机构代言人纷纷发表言论表示对后市的美好憧憬,对于很多中小投资者来说,在2236点时本应该离开市场,但许多投资者在市场趋势发生逆转的时候却都杀进了这个充满危机和风险的市场!
因此,在这个充满风险的投机市场中,只有掌握了正确的投资方法才能获得利润的回报,而"4·10"定律为投资者提供了一种研判大势的方法。
案例2:上证指数1757点和未来趋势的预测
如上图所示,1328为前高点(2005年2月25日),1223点为后高点(2005年9月20日),在1223点冲高回落后没有突破前期底点(1004.08点),"4·10"定律成立。前高点和后高点之差为105点,则大盘运行的第一目标位为1748点,计算过程如下:
1328 + 105 4 = 1748点
实际大盘运行至1757点(2006年7月5日),相差9点。
按照"4·10"定律,未来行情的第二目标位为2807点。计算过程如下:
1757 + 105 10 = 2807点
"4·10"定律成立后,说明未来大盘还有一个大幅的上涨空间。2807点的目标位尚未到达,目前正在运行过程中。
月线"年轮"--揭开股价未来走势周期的"天机"
天行有常,世间万物变化有律。股票犹如人的生命一样,是处在二三十岁的青壮年期,还是处在七八十岁的古稀、耄耋之年?他用月线的"年轮",揭开股票未来涨跌周期的"天机"。
采访中,记者发现简凡在看股票走势时,很注重察看月K线图。他说,月线最能充分反映股票涨跌的中长趋势。据长期的实战经验,一只股票在上升途中,一般会在低位突破后形成八大高点。八大高点是指月K线中的一种组合。据此我们可以判断目前股价处于上涨周期的哪个阶段,以决定我们的投资策略。
在月K线上,股价往往在底部横盘整理,形成一个平台,我们把这个平台中出现的最高价位称为平台颈线。当此后某个月的月K线的最高价突破平台颈线,则称这个月的最高价为第一个高点。当此后某个月的最高价突破第一个高点,则称这个月的最高价为第二个高点,依此类推。一般来说,股价的一次完整上涨周期中会出现六到八个高点。八大高点的形成来源于简氏理论中所指出的主力行为模式。显然,第一高点形成前的平台属于主力的建仓;第一、第二个高点往往是主力的洗盘增仓造成的。按照我们提倡的"掐头去尾"原则,做股票要避开主力的建仓期,主攻突破增仓期和拉升期。所以,八大高点指出的最佳买入点是在第三、第四个高点。由于八大高点衍生自主力的行为模式,单独使用则失之偏颇。但因为它简洁明了,能很容易地判断出股价处于一个上涨周期的哪个阶段,可作为制定投资策略时的一个重要参考。所谓"运用之妙,存乎一心",读者朋友需细细体会。
需特别说明的一种情况是,因除权而导致股价有大幅回落,则除权前的月线不再有参考价值,要看除权后的月线形态。若除权后股价低位盘整,形成了底部平台,则仍按照前述的方法,确定第一个高点的位置。如果没有形成平台,除权后的月线不断创出新高,则以除权后第一个月的最高价为第一个高点。我们知道,常见的证券分析方法有两种,即基本分析和技术分析。简凡认为,由于中国目前的股市仍然是一个资金市,中国的上市公司总体质量差等因素,基本分析在中国的股市其实是不适用的。那么为什么基本分析仍然在中国证券市场很流行呢?答案是机构,或者说主力的需要。深受做庄之害的散户简单地认为,进行价值投资的机构是的,而进行炒作的机构是坏的。因此,机构在媒体中孜孜不倦地发布上市公司基本面分析文章,只不过是在为自己炒作股票寻找辩护。另外,对基本面进行分析,也是误导散户、吸引散户跟进的方法。至于层出不穷的所谓题材,更是暴露了目前的证券市场是资金市的本质。在这个大前提之下,结合机构的常见手法,简凡提出了正确的股票买卖法则:
首先进行基本面分析。进行基本面分析的理由不是要寻找上市公司的内在价值,而是要确定这只股票有没有吸引主力资金介入的理由,如果有,那么已经吸引了什么样的主力介入。在选股中,简凡对上市公司基本面的分析包括以下几点:
1. 确认股票的盘面有多大。一般来说,盘面越小的股票越容易被炒作,也就越容易吸引主力资金的介入。而主力资金的介入也就意味着股价的上涨。
2. 确定股票的每股收益是多少,有没有亏损。一般来说,只要不亏损,主力资金就敢于杀入进行炒作。
3. 行业特征和行业地位。这一点是为了找出该股是不是热点、有没有炒作的题材。
4. 股东研究。这一点是为了确定该上市公司目前最大的一些流通股股东是谁。是QFII还是开放式基金,或者只是个人(私募)。不同的主力有不同的炒作手法,这也在很大度上决定了我们买卖股票的策略。在目前的股市中,有三大知名的主力是值得大家关注的,即,易方达、华宝信托和安德盛小盘精选。这三家主力手法是非常凶悍的,涨势凶猛的苏宁电器、小商品城、洪都航空等股票就是这三家主力的杰作。
其次进行技术分析。简凡强调投资者需注意以下几点:
1. 关注月K线。月线体现的是股价变化的趋势。对月K线的分析主要应用简氏线高低法则。另外,如果在月成交量上出现阶段性大量,覆盖前期所有的月成交量,则意味着有新的主力介入。
2. 日K线。日线代表的是股价每日波动情况。对日K线进行分析要结合五条趋势线和简氏线高低法则。以确定股价运行在哪个阶段和具体的买卖价位。
3. "掐头去尾"原则。按照简氏趋势理论,买卖股票应避开主力的建仓期,主攻突破增仓期和拉升期。
4. "高买低抛"原则。即股价在相对低位运行时,当其在成交量的配合下,创出前期新高即可买入。通过一段时间的上涨之后,股价已运行至一个相对的高位,产生震荡击穿前期低点,就可以抛出该股,稳稳获取其上涨的利润。
5. "坐涨不坐跌"原则。当成交量放大,并开始满足135日均量线时,即表示市场的资金开始活跃而且源源不断地投入到市场中,营造出浓烈的做多氛围,此时应果断杀入。当成交量萎缩,开始不满足135日均量线甚者远远低于135日均量线时,则表明市场资金去做多热情并撤离,显示此时为空头市场,此时应离场观望。
在简凡诸多的实战技艺中,有一个专门用来狙击市场主力的"新十六字方针",那是他多年来在机构操盘的切身感受和总结的宝贵经验,也是给那些每天只盯着股价涨跌,而忽略了市场资金流变化这一核心的投资者的一剂良药。
简凡说,证券市场是一个没有硝烟的战场,一般投资者只有充分了解市场主力运作资金的手法,才能真正做到"知己知彼,百战不殆"!为了能让投资者更直接地把握住市场变化的趋势,把握住投资时机,我用"新十六字方针"--"敌进我进,敌退我退,敌驻我止,敌疲我动",高度概括如何紧跟市场主力及市场资金的节奏。"敌"是指市场大资金,即所有能够调动市场趋势的大主力;"我"指一般投资者即中小投资者。
"敌进我进",是指市场主力资金开始运动的迹象--市场成交量开始满足并不断超越135日均量线,即表示市场的主力资金开始活跃且源源不断地投入到当前市场,营造出浓烈的做多氛围。一般投资者应该紧跟市场节奏,大胆买入股票,在上涨趋势中把握机会。
"敌退我退",是指市场主力资金开始撤退的迹象--市场成交量开始不满足135日均量线甚至远低于135日均量线,即表明市场资金失去做多热情并逐步完成诱多出货。此时为空头市场的开始信号,一般投资者则应迅速将手上的股票进行沽空,甚至止损,以保存资金实力。
"敌驻我止",是指市场主力资金入驻到某一支股票后,往往不会立即大幅拉升股价,甚至会向下打压。在这种情况下,跟随主力资金买入股票的中小投资者,应该持股待涨,而不必过于在乎该股每天的日常波动。这就是在把握趋势的情况下,稳定地获取上涨过程中产生的利润。
"敌疲我动",是指当股价经过一段较大幅度的上涨后,股价上涨乏力,这是主力资金疲软的信号,当投资者察觉到这种信号时就应该及时出局。因为股价的上涨是由主力资金推动的,股价涨不上去,说明主力资金已经跟不上了。投资者就应该比机构主力先行一步,提早撤离。
看盘秘诀十八条!!
1、对大盘,大盘股(白线)上得比小盘股(黄线)快,要出现回调,而黄线上涨比白线快,则会带动白线上。
2、涨跌比率大于1而大盘跌,表明空方势强,反之多方强。此状况高位看跌低位看涨。
3、成交量大的股票开始走软,或者前期股市的热门板块走软,当小心行情已接近尾声。
4、股票基本走软,市场在热点消失还没有出现新市场热点的时候,不要轻易去买股票。
5、成交量屡创天量,而股价涨幅不大,应随时考虑派发,反之成交量极度萎缩不要轻易抛出股票。
6、大盘5分种成交明细若出现价量配合理想当看好后市,反之要小心。
7、成交量若上午太小,则下午反弹的机会多,如上午太大,则下午下跌概率大。
8、操作时间最好在下午,因为下午操作有上午的盘子作依托,运用60分种K线分析,可靠性好。
9、上涨的股票若压盘出奇的大,但最终被消灭,表明仍会上涨。
10、一般股票的升跌贴着均价运行,若发生背离将会出现反转。
11、盘面经常出现大手笔买卖,买进时一下吃高几个档位,表明大户在进货。
12、个股在盘整或下跌时,内盘大于外盘,且阴线实体小,成交量大,日后该股有行情的可能性大;大盘暴跌,而该股没跌多少或者根本没跌,下档接盘强,成交放得很大,后市有戏的可能大。
13、股价上冲的线头(曲线)绝对的多于下跌的线头时当看好该股。
14、在下跌的势道里,应选逆势股;在上涨的势道里,应选大手笔买卖的股票。
15、开盘数分种就把股价往上直拉,而均线没有跟上,往往都是以当天失败的形式而告终。
16、当日下跌放巨量,但收的阴线实体不大,而且大部分时间在昨日收盘以上运行,第二天涨的机会多。
17、涨幅在5-7%以上,内盘大于外盘,高点不断创新,低点不断抬高,说明有机构大户在进货。
18、分价表若是均匀分布说明大户不在里面,否则有大户介入
来自:http://www.10jqka.com.cn/modules.php?name=blog&mod=article&uname=year4538&aid=565673
IRC 上又有朋友问到这 JAVA 的 ,
1.
在 jre/lib/fonts/ 下建立个目录 fallback
比如我这儿就是
mkdir /usr/lib/j2sdk1.5-sun/jre/lib/fonts/fallback/
2.
在 fallback 里弄个中文字体
拷贝或链接都可以
比如我这就是
ln -s /usr/share/fonts/truetype/arphic/uming.ttf /usr/lib/j2sdk1.5-sun/jre/lib/fonts/fallback/
3.
进入 jre/lib/fonts/
fallback/ 执行 mkfontscale
再把 jre/lib/fonts/
fonts.scale 的内容加到 jre/lib/fonts/
fonts.dir
我这儿就是
cd /usr/lib/j2sdk1.5-sun/jre/lib/fonts/fallback/
mkfontscale
cd ..
cat fallback/fonts.scale >> fonts.dir
来自:http://blog.chinaunix.net/u/28007/showart_217907.html?