|
|
2007年5月19日
写了好几天的代码因为还有bug没de掉,没commit到svn上
然后不知怎么的在make的时候生成的kernel没变化,于是直接make world,然后发现linux kernel目录被清空了。。。
只能明天靠记忆慢慢补了,皑皑。
yifanw大牛半个月前发在c++版上的,怕以后忘了看先放在这备个忘吧
白话入门
http://www.newsmth.net/bbscon.php?bid=335&id=250203
白话解决方案
http://www.newsmth.net/bbscon.php?bid=335&id=250237
白话参考文献
http://www.newsmth.net/bbscon.php?bid=335&id=250260
最近有点忙,今天总算在某个课题deadline前把论文憋出来交上去了。跑这儿来推荐两篇上个月看到的比较有意思的paper,都比较偏理论,也很老。
今天写介绍下第一篇,剑桥大学的A Logic of Authentication,中了SOSP '89,整理后发在1990年的ACM Transactions on Computer Systems上。
http://www.csie.fju.edu.tw/~yeh/research/papers/os-reading-list/burrows-tocs90-logic.pdf
(另一篇是Safe Kernel Extensions Without Run-Time Checking,改天再写点介绍)
这篇paper的主要工作是通过构造一种多种类的模态逻辑(many-sorted model logic),来检查网络中验证协议的安全性。
基础的逻辑分三部分:
原语,如验证双方A和B,以及服务器S,下文用P Q R泛指
密钥,如K_ab代表a和b之间的通讯密钥,K_a代表a的公钥,{K_a}^{-1}代表对应的私钥,下文用K泛指
公式(或者陈述),用N_a, N_b等表示,下文用X Y泛指
接下来定义以下约定(constructs)
P 信任 X: 原语P完全信任X
P 看到 X: 有人发送了一条包含X的信息给P,P可以阅读它或者重复它(当然通常是在做了解密操作后)
P 说了 X: 原语P发送过一条包含X的信息,同时也可以确定P是相信X的正确性的
P 控制 X: P可以判定X的正确与否。例如生成密钥的服务器通常被默认为拥有对密钥质量的审核权。
X 是新鲜的: 在此之前X没有被发送过。这个事实可以通过绑定一个时间戳或者其他只会使用一次的标记来证明。
P <-K-> Q: P和Q可以通过共享密钥K进行通讯,且这个K是好的,即不会被P Q不信任的原语知道。
K-> P: P拥有K这么一个公钥,且它对应的解密密钥K^{-1}不会被其他不被P信任的原语知道。
P <=X=> Q: X是一个只被P和Q或者P和Q共同信任的原语知道的陈述,只有P和Q可以通过X来相互证明它们各自的身份,X的一个例子就是密码。
{X}_K: X是一个被K加密了的陈述
<X>_Y: 陈述X被Y所绑定,Y可以用来证明发送X的人的身份
好了,总算把这些约定列完了,然后来看看通过这些约定能推出一些什么东东:
如果 P 相信 (P <-K-> Q), 且 P 看到 {X}_K,那么 P 相信 Q 说了 X。
这个例子很简单,既然P Q有安全的密钥K,那么P看到通过K加密后的X肯定认为就是Q发出的。
又比如,
如果 P 相信 Q 控制 X,P 相信 (Q 相信 X),那么 P 相信 X
也很容易理解,既然 P 相信 Q 的判断,那么 Q 相信什么 P 自然也就相信了。
再举一个例子
如果 P 相信 Y 是新鲜的,那么 P 相信 (X, Y) 也是新鲜的。
这里(X, Y)表示 X 和 Y 的简单拼接,也很容易理解,既然 Y 之前没出现过,那么 X 和 Y 的组合自然也没出现过。
一个协议要被定义为安全,最起码要满足
A 相信 A <-K->B,B 相信 A <-K->B
即双方要互相信任密钥是安全的
再健壮一点的协议,还要满足
A 相信 (B 相信 (A 相信 A <-K->B)),反之一样
即A B不仅相信密钥,也相信对方相信自己对密钥的信任。
有了这些简单却强大的工具后,接下来这篇paper开始着手分析一些协议,包括Kerberos协议,Andrew Secure RPC 握手协议等,还指出了其中的一些问题和改进措施,例如CCITT X.509 协议中可以通过重复发送一条老的信息来模仿成加密双方中的一员。
具体的分析不贴上来了,一方面对于我这个不熟悉TeX的人来说码公式实在麻烦,另一方面我实在困死了 =_=
建议有兴趣的朋友好好看看这篇经典paper
Some notes on
lock-free and wait-free algorithms
http://www.audiomulch.com/~rossb/code/lockfree/
NOBLE
-
a library of non-blocking synchronization
protocols
http://www.cs.chalmers.se/~noble/
An
optimistic approach to lock-free FIFO queues
(Distributed Computing 2008)
http://people.csail.mit.edu/edya/publications/OptimisticFIFOQueue-journal.pdf
High performance
dynamic lock-free hash tables and list-based sets
http://portal.acm.org/citation.cfm?id=564870.564881
Concurrent
Programming Without Locks
http://www.cl.cam.ac.uk/research/srg/netos/papers/2007-cpwl.pdf
Simple,
Fast, and Practical Non-Blocking and Blocking
Concurrent Queue Algorithms
http://www.research.ibm.com/people/m/michael/podc-1996.pdf
2009-01-08 以前碰到这个问题都得先重启PieTTY然后用screen -x恢复到原来的工作界面,今天不知怎么的emacs里C-x C-s按了就挂起,只能google。 传说中,早期的终端会遇到显示字符的速度慢于接收字符的速度,为了解决这个问题,C-s用于先挂起当前终端,在数据传输之后用C-q恢复显示。所以最简单的解决方法就是在挂起后按C-q。 不过我的WinXP中C-q已经和快速启动工具(寝室里是Turbo Launcher,实验室的是Launchy)绑定了,也懒得为了这么个问题改操作习惯,于是再次google,终于找到一个一劳永逸的方法,以bash为例,在~/.bashrc中加入一行 stty -ixoff -ixon 即可。另外这样设置后似乎恢复了C-s在bash中正向增量查找的功能。恩。
今年的ASPLOS '09上zhou yuanyuan也有一篇关于如何concurrent program中发现隐藏的atomicity violation bugs的paper,里面提到了这篇paper
2008-11-30
OSDI '08上MSR发的paper,针对并发编程中难以发现的bug问题。
paper的内容主要分两大块。
一是如何在发现bug的时候记录下线程的运行先后(thread
interleaving),途径是在线程API和用户程序多写一层wrapper
functions,这里还有一些其他的问题,比如只记录下了thread interleaving的话出现data race怎么解决等。
另外一块内容是如何遍历出给定程序运行后所能产生的结果的集合,加入这个能实现的话那就能把所有隐藏的bug都找出来了。但是这个搜索空间很大,是
指数级的,的一个结论就是:给定一个程序有n个的线程,所有线程共完成k条指令,那么c次占先调度后线程的排列情况数的复杂度是 的,所以在实现遍历代码的时候必须有效的降低k和c的值。 的,所以在实现遍历代码的时候必须有效的降低k和c的值。
问题现象:上校内、一些国内论坛时经常出现连接重置(Connect reset)错误,而上google baidu等网站却没什么问题。ping那些有问题的网站的结果很正常。
google了一堆关键词后终于发现问题出在MTU上,至少在偶的本本上运行
sudo ifconfig eth1 mtu 1412
就没问题了(eth1是无线网卡)
p.s 多谢万熊 XD
摘要: 发信人: linelf (水水), 信区: Real_Estate
标 题: 苏南经济模式兴衰亲历记zz
发信站: 日月光华 (2009年01月15日20:39:22 星期四)
阅读全文
Bruce Eckel的一篇日志建议把self从方法的参数列表中移除,并把它作为一个关键字使用。
http://www.artima.com/weblogs/viewpost.jsp?thread=239003
Guido的这篇日志说明了self作为参数是必不可少的。
http://neopythonic.blogspot.com/2008/10/why-explicit-self-has-to-stay.html
第一个原因是保证foo.meth(arg)和C.meth(foo, arg)这两种方法调用的等价(foo是C的一个实例),关于后者可以参见Python Reference Manual 3.4.2.3。这个原因理论上的意义比较大。
第二个原因在于通过self参数我们可以动态修改一个类的行为:
#
Define an empty class:
class
C:
pass
#
Define a global function:
def
meth(myself, arg):
myself.val
=
arg
return
myself.val
#
Poke the method into the class:
C.meth
=
meth
这样类C就新增了一个meth方法,并且所有C的实例都可以通过c.meth(newval)调用这个方法。
前面两个原因或许都可以通过一些workaround使得不使用self参数时实现同样的效果,但是在存在decorator的代码中Bruce的方法存在致命的缺陷。(关于decorator的介绍可以参见http://www.python.org/dev/peps/pep-0318/)
根据修饰对象,decorator分两种,类方法和静态方法。两者在语法上没有什么区别,但前者需要self参数,后者不需要。而Python在实
现上也没有对这两种方法加以区分。Bruce日志评论中有一些试图解决decorator问题的方法,但这些方法都需要修改大量底层的实现。
最后提到了另一种语法糖实现,新增一个名为classmethod的decorator,为每个方法加上一个self参数,当然这种实现也没必要把self作为关键字使用了。不过我觉得这么做还不如每次写类方法时手工加个self =_=
2008年评出了1998年最具影响力的PLDI论文,获奖论文的作者将分摊1000美元的奖金(还没一等奖学金多 -_-b)
2008 (for 1998): The Implementation of the Cilk-5 Multithreaded Language, Matteo Frigo, Charles E. Leiserson, and Keith H. Randall
Citation
“The 1998 PLDI paper “Implementation of the Cilk-5 Multithreaded
Language” by Matteo Frigo, Charles E. Leiserson, and Keith H. Randall
introduced an efficient form of thread-local deques to control
scheduling of multithreaded programs. This innovation not only opened
the way to faster and simpler runtimes for fine-grained parallelism,
but also provided a basis for simpler parallel recursive programming
techniques that elegantly extend those of sequential programming. The
stack-like side of a deque acts just like a standard procedure stack,
while the queue side enables breadth-first work-stealing by other
threads. The work-stealing techniques introduced in this paper are
beginning to influence common practice, such as the Intel Threading
Building Blocks project, an upcoming standardized fork-join framework
for Java, and a variety of projects at Microsoft.”
另外前几年的获奖paper有:
2007 (for 1997): Exploiting Hardware Performance Counters with Flow and
Context Sensitive Profiling, Glenn Ammons, Thomas Ball, and James R.
Larus
2006 (for 1996): TIL: A Type-Directed Optimizing Compiler for ML,
David Tarditi, Greg Morrisett, Perry Cheng, Christopher Stone, Robert
Harper, and Peter Lee
2005 (for 1995): Selective Specialization for Object-Oriented Languages, Jeffrey Dean, Craig Chambers, and David Grove
2004 (for 1994): ATOM: a system for building customized program analysis tools, Amitabh Srivastava and Alan Eustace
2003 (for 1993): Space Efficient Conservative Garbage Collection, Hans Boehm
2002 (for 1992): Lazy Code Motion, Jens Knoop, Oliver Rüthing, Bernhard Steffen.
2001 (for 1991): A data locality optimizing algorithm, Michael E. Wolf and Monica S. Lam.
2000 (for 1990): Profile guided code positioning, Karl Pettis and Robert C. Hansen.
两者配合,更完美的知识管理方案
http://hi.baidu.com/qq303520912/blog/item/de5cba082db83e36e924889e.html
Endnote是目前国内科研人员使用最多的文献管理软件,功能最完备,各数据库或大学图书馆等和它的兼容也是最好。它的Filter和style
也最为丰富,而且可以自己创建修改。看看周围的人,大部分都是Endnote的用户。
Zotero作为一个新的文件管理系统,与Endnote相比还是稚嫩了些,特别对于国内数据库的支持不佳,更是限制了它的应用。
不过,Zotero作为Firefox浏览器的插件,还是有一些特别之处。
第一,便携。Firefox是有Portable版本的,当然Zotero也就是Portable了,也就是说可以把火狐和Zotero放到U盘里,在任何一台电脑上都可以 使用。而Endnote就没有这么方便了。
第二,便利。使用电脑时,我们使用浏览器的时间要大大多于Endnote的时间,遇到有用的文献、网页或者需要做笔记,直接使用Zotero更加省时省力。而且它自动收集网页中文献信息的功能也大大方便了操作。
第三,
分享。EndnoteX以后可以把一个library发送成一个档案文件(.enlx),使得文献交换更为方便。不过有时我们只需要几条文献时,这样操作
就大动干戈了。当然Endnote也支持所选部分文献的导出,但这样有不能够导出附件,包括图片、PDF等(此处为个人经验,是否Endnote也能导出
附件来还望您不吝赐教)。而Zotero就可以实现某条文献所有内容(题录、笔记、附件)的全部导出,而且可以为另一Zotero用户所完整接受。
第四,跟踪文献的收集。很多数据都支持检索式或者引文的提醒,会随时把新的内容发送到邮箱或者以RSS的形式发布。一般来说,查看这些都需要浏览器。有了Zotero,我们可以在查看的同时收集下有用的文献信息。
Zotero更适合于在日常工作、学习甚至娱乐时使用,而Endnote更适合在有明确目的时使用。有人说Zotero更像“知识管理软件”,
而
Endnote就是为文献服务的。两者可以实现互补,在日常工作中使用Zotero收集零散的资料,积累一定量之后将文献信息导入到Endnote中,使
用Endnote管理、引用文献信息。至于PDF、图片等附件的管理,我还是建议使用Zotero,方便且可以完整导出。
下面谈一下Zotero和Endnote中文献的互相导入。
Zotero导入Endnote:
1 选定文献,右键点选”export selected items”;如果是导入整个Library或者cellection可在相应图标上右键点选;
2 在弹出的对话框中选择导出的格式为”Refer/BibIX”, 选择文件目录,保存文件,格式为.txt;
3 在Endnote中打开一个library,执行“files-import”;
4 在对话框中选择刚才的.txt文件, Impott Option选Refer/BibIX,Text Translation选Unicode(UTF-8)。点确定后即可导入。
Endnote导入Zotero:
1 选择文献后,执行“files-export”;
2 选择Output Style为Endnote Export,命名后导入,得到.txt文件。
3 在Zotero中执行“actions-import” ,选择得到的文件,点确定即可导入。
上述导入方式仅能实现文献题录的导入。
BBS上的一个帖子,问题是 def a():
def b():
x += 1
x = 1
print "a: ", x
b()
print "b: ", x
def c():
def d():
x[0] = [4]
x = [3]
print "c: ", x[0]
d()
print "d: ", x[0] 运行a()会报UnboundLocalError: local variable ‘x’ referenced before assignment
但是运行c()会正确地显示3和4。 原因在于原因在于CPython实现closure的方式和常见的functional language不同,采用了flat closures实现。 “If a name is bound anywhere within a code block, all uses of the
name within the block are treated as references to the current block.” 在第一个例子中,b函数x += 1对x进行赋值,rebind了这个对象,于是Python查找x的时候只会在local environment中搜索,于是就有了UnboundLocalError。 换句话说,如果没有修改这个值,比如b中仅仅简单的输出了x,程序是可以正常运行的,因为此时搜索的范围是nearest enclosing function region。 而d方法并没有rebind x变量,只是修改了x指向的对象的值而已。如果把赋值语句改成x = [4],那么结果就和原来不一样了,因为此时发生了x的rebind。 所以Python中的closure可以理解为是只读的。 另外第二个例子也是这篇文章中提到的一种workaround:把要通过inner function修改的变量包装到数组里,然后在inner function中访问这个数组。 至于为什么Python中enclosed function不能修改enclosing function的binding,文中提到了主要原因还是在于Guido反对这么做。因为这样会导致本应该作为类的实例保存的对象被声明了本地变量。 参考网站:http://www.python.org/dev/peps/pep-0227/
acm queue 9月的杂志的主题是The Concurrency Problem,力推了Erlang这个语言,其中有篇文章简单的介绍了下这个message-oriented语言。 查了下这个名字的读法,正确的读法应该是air-lang,这里元音a的发音和bang中的a一样。 文章中的第一个程序就有点令人费解,主要原因在于Erlang的语法和一般的imperative language差别很大,和functional language比较类似,但是本质上也有很大的不同。 以Java的一个计数程序为例 // A shared counter.
public class Sequence {
private int nextVal = 0;
// Retrieve counter and increment.
public synchronized int getNext() {
return nextVal++;
}
// Re-initialize counter to zero.
public synchronized void reset() {
nextVal = 0;
}
} 这个程序的功能不用多说了,一个同步的计数程序。它的Erlang翻译版的代码为 -module(sequence1).
-export([make_sequence/0, get_next/1, reset/1]).
% Create a new shared counter.
make_sequence() ->
spawn(fun() -> sequence_loop(0)end).
sequence_loop(N) ->
receive
{From, get_next} ->
From!{self(), N},
sequence_loop(N + 1)<SEMI>
reset ->
sequence_loop(0)
end.
% Retrieve counter and increment.
get_next(Sequence) ->
Sequence!{self(), get_next},
receive
{Sequence, N} -> N
end.
% Re-initialize counter to zero.
reset(Sequence) ->
Sequence! reset. 初看这个程序自然是一头雾水,不过程序的函数式风格味还是很浓的。 前面提到,Erlang是基于message的,或者说message sending机制是包含在语言系统内部的,语法就是 pid ! message 接下来再来分析这个简单的程序。开头两行是模块和函数声明,略去。make_sequence开始这个进程,spawn/1内置函数创建一个新的进程,并返回pid到调用者。 初始时运行的函数是sequence_loop(0),这个函数接收两种信息,用receive表达式声明:如果收到形式是{From,
get_next}的信息,就返回当前的N并调用sequence_loop(N+1),这样下一次收到同样的信息时就能返回N+1了;reset则等价
于Java版本中的n=0语句。 get_next/1则是发送给pid为Sequence的进程 {self(), get_next}
这样一个信息,上面解释的sequence_loop/1函数收到这个信息后会返回一个 {self(), N}
的tuple给get_next/1,收到这个信息后get_next/1就能返回N这个值了。 最后reset/1函数则是发送给Sequence一个reset信息。 这个简单的程序里能大致窥见一些Erlang的特点,尤其是它基于信息发送的本质。
09月 18, 2008 第一个testkernel在Xen中的载入The Definitive Guide to Xen中第二章的例子,make成功后运行xen create domain_config,报错 Error: (2, ‘Invalid kernel’, ‘xc_dom_compat_check: guest type xen-3.0-x86_32 not supported by xen kernel, sorry\n’)
google之后发现是虚拟机类型设置的问题,运行xm info可以看到 xen_caps : xen-3.0-x86_32p
末尾的p表示Xen内核开启了PAE模式,所以载入的kernel也必须开启PAE,在bootstrap.x86_32.S中加入PAE=yes选项即可。 09月 25, 2008 DomainU中调用do_console_ioThe Definitive Guide to Xen第二章的Exercise,通过调用hypercall page中的console_io项输出Hello World。 void start_kernel(start_info_t * start_info)
{
HYPERVISOR_console_io(CONSOLEIO_write,12,"Hello World\n");
while(1);
} 但是默认选项编译和启动的Xen是不会保留DomainU中输出的信息。参考drivers/char/console.c,可以看到主要有两个选项控制了DomainU的do_console_io输出: #ifndef VERBOSE
/* Only domain 0 may access the emergency console. */
if ( current->domain->domain_id != 0 )
return -EPERM;
#endif
if ( opt_console_to_ring )
{
for ( kptr = kbuf; *kptr != '\0'; kptr++ )
putchar_console_ring(*kptr);
send_guest_global_virq(dom0, VIRQ_CON_RING);
} VERBOSE选项可以在编译Xen的时候开启debug选项,而opt_console_to_ring则是一个启动选项,在grub的启动选项中增加loglvl=all guest_loglvl=all console_to_ring即可。 重启Xen后就能通过xm dmesg看到Hello World了。 09月 25, 2008 Xen: Remove support for non-PAE 32-bit看来我还是用Xen 3.1吧 = = Subject: [Xen-devel] [PATCH] xen: remove support for non-PAE 32-bitLink to this message From: Jeremy Fitzhardinge (jer…@goop.org) Date: 05/09/2008 04:05:34 AM List: com.xensource.lists.xen-devel Non-PAE operation has been deprecated in Xen for a while, and is rarely tested or used. xen-unstable has now officially dropped non-PAE support. Since Xen/pvops’ non-PAE support has also been broken for a while, we may as well completely drop it altogether. 10月 07, 2008 IA-32 Memory Virtualizationhttp://www.intel.com/technology/itj/2006/v10i3/3-xen/4-extending-with-intel-vt.htm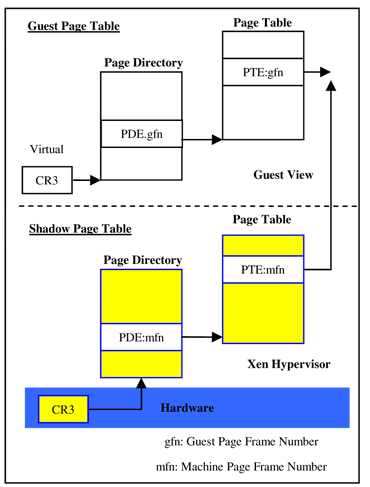 上图为full virtulization的情况,即不修改Guest OS的行为时的解决方案。Xen为每个Guest OS维护了一张shadow page table,其中映射的地址为machine address。一种比较高效的方案是设置Guest OS的page table为只读,当Guest OS试图修改这个虚拟页表时,发生page fault被Xen截获,Xen修改shadow page table中相应的数据(把pseudo-physical address转化成machine address)。另外一个优化是guest page table被修改时不修改shadow page table,只是把它放到一个待更新列表中,等Guest OS执行了刷新tlb的指令后再一次性更新。 The Definitive Guide to Xen上还提到了另一种基于full paravirtulization和shadow page table之间的方案。Xen把Guest OS的page table置为只读,当Guest OS试图修改page table时,Xen捕获到page fault,把page directory中对应的入口置为无效,再把page table改成可写让Guest OS修改。由于page directory中对应的入口被设成无效了,下次访问该地址时还是会发生page fault,这时候Xen再修改page directory和page table的对应项就行了。 这种方法意味着Guest OS中内核管理模块直接和machine address打交道,而其他部分则仍然使用pseudo-physical address。另外这种情况下page directory不能被Guest OS修改。 另外Xen还用到了段机制,用来为Xen保留地址空间开始的64M内存。
好不容易找到的一个php,直接贴这儿了,方便其他网友。 wordpress的wp-syntax插件用的也是geshi,所以同样也适用于wp-syntax <?php
/*************************************************************************************
* erlang.php
* --------
* Author: Uwe Dauernheim (uwe@dauernheim.net)
* Copyright: (c) 2008 Uwe Dauernheim (http://www.kreisquadratur.de/)
* Release Version: 1\.0\.0
* Date Started: 2008-09-27
*
* Erlang language file for GeSHi.
*
* CHANGES
* -------
* 2008-09-27 (1.0.0)
* [ ] First Release
*
* 2008-09-28 (1.0.0.1)
* [!] Bug fixed with keyword module.
* [+] Added more function names
*
* TODO (updated 2008-09-27)
* -------------------------
* [!] Stop ';' from being transformed to '<SEMI>'
*
************************************************************************************/
$language_data = array (
'LANG_NAME' => 'Erlang',
'COMMENT_SINGLE' => array(1 => '%'),
'CASE_KEYWORDS' => GESHI_CAPS_NO_CHANGE,
'QUOTEMARKS' => array('"'),
'HARDQUOTE' => array("'", "'"),
'HARDESCAPE' => array('\\\'',),
'ESCAPE_CHAR' => '\\',
'KEYWORDS' => array(
1 => array(
'module', 'export', 'import', 'author', 'behaviour'
),
2 => array(
'case', 'of', 'if', 'end', 'receive', 'after'
),
3 => array(
// erlang
'set_cookie', 'get_cookie',
// io
'format', 'fwrite', 'fread',
// gen_tcp
'listen', 'accept', 'close',
// gen_server
'call', 'start_link'
)
),
'SYMBOLS' => array(
':', '=', '!', '|'
),
'CASE_SENSITIVE' => array(
GESHI_COMMENTS => false,
1 => true,
2 => true,
3 => true
),
'STYLES' => array(
'KEYWORDS' => array(
1 => 'color: #b1b100;',
2 => 'color: #b1b100;',
3 => 'color: #000066;'
),
'COMMENTS' => array(
1 => 'color: #666666; font-style: italic;',
2 => 'color: #009966; font-style: italic;',
3 => 'color: #0000ff;',
4 => 'color: #cc0000; font-style: italic;',
5 => 'color: #0000ff;',
'MULTI' => 'color: #666666; font-style: italic;'
),
'ESCAPE_CHAR' => array(
0 => 'color: #000099; font-weight: bold;',
'HARD' => 'color: #000099; font-weight: bold;'
),
'BRACKETS' => array(
0 => 'color: #009900;'
),
'STRINGS' => array(
0 => 'color: #ff0000;',
'HARD' => 'color: #ff0000;'
),
'NUMBERS' => array(
0 => 'color: #cc66cc;'
),
'METHODS' => array(
1 => 'color: #006600;',
2 => 'color: #006600;'
),
'SYMBOLS' => array(
0 => 'color: #339933;'
),
'REGEXPS' => array(
0 => 'color: #0000ff;',
4 => 'color: #009999;',
),
'SCRIPT' => array(
)
),
'URLS' => array(
1 => '',
2 => '',
3 => 'http://www.erlang.org/doc/man/{FNAMEL}.html'
),
'OOLANG' => true,
'OBJECT_SPLITTERS' => array(
1 => '->',
2 => ':'
),
'REGEXPS' => array(
// Variable
0 => '[A-Z][_a-zA-Z0-9]*',
// File Descriptor
4 => '<[a-zA-Z_][a-zA-Z0-9_]*>'
),
'STRICT_MODE_APPLIES' => GESHI_NEVER,
'TAB_WIDTH' => 4
);
?>
依然是内网日志的汇总
1. sysenter的介绍
http://www.codeguru.com/cpp/w-p/system/devicedriverdevelopment/article.php/c8223
System Call Optimization with the SYSENTER Instruction
by John Gulbrandsen
Windows下的
2. The SLUB allocator
slab的改进版本
http://lwn.net/Articles/229984/
http://lwn.net/Articles/229096/
Christoph’s response is the SLUB allocator, a drop-in replacement for the slab code. SLUB promises better performance and scalability by dropping most of the queues and related overhead and simplifying the slab structure in general, while retaining the current slab allocator interface.
Wider use may be in the cards: the SLUB allocator is in the -mm tree now and could hit the mainline as soon as 2.6.22. The simplified code is attractive, as is the claimed 5-10% performance increase. If merged, SLUB is likely to coexist with the current slab allocator (and the SLOB allocator intended for small systems) for some time. In the longer term, the current slab code may be approaching the end of its life.
3. Compilers and More: Parallel Programming Made Easy?
http://www.hpcwire.com/features/Compilers_and_More_Parallel_Programming_Made_Easy.html
by Michael Wolfe, Compiler Engineer, The Portland Group, Inc.
4. OpenCL slides, SIGGRAPH '08
发信人: jjgod (while(!asleep()) sheep++;), 信区: CSArch
标 题: SIGGRAPH 08 上的 OpenCL slides
发信站: 水木社区 (Mon Sep 15 01:32:03 2008), 站内
※ 来源:·水木社区 newsmth.net·[FROM: 125.33.176.*]
附件: munshi-opencl.pdf (1338 KB) 链接:
http://att.newsmth.net/att.php?p.272.35430.226.pdf
全文链接:http://www.newsmth.net/bbscon.php?bid=272&id=35430
5. linux-gate.so
http://www.trilithium.com/johan/2005/08/linux-gate/
linux下使用sysenter的机制
发信人: Zellux (null), 信区: Software_06 标 题: OSLab之中断处理 发信站: 日月光华 (2008年08月30日20:15:58 星期六), 站内信件 1. 准备工作 在开始分析Support Code之前,先配置下我们的Source Insight,使它能够支持.s文件的搜索。 在Options->Document Options->Document Types中选择x86 Asm Source File,在File fileter中增加一个*.s,变成*.asm;*.inc;*.s 然后在Project->Add and Remove Project Files中重新将整个oslab的目录加入,这样以后进行文本搜索时.s文件也不会漏掉了。 2. Source Insight使用 接下来简单分析下内核启动的过程,在浏览代码的过程中可以迅速的掌握Source Insight的使用技巧。 lib/multiboot /multiboot.s完成了初始化工作,可以看到其中一句call EXT(multiboot_main)调用了C函数multiboot_main,使用ctrl+/搜索包含multiboot_main的所有文件,最终base_multiboot_main.c中找到了它的定义。依次进行cpu、内存的初 始化,然后开启中断,跳转到kernel_main函数,也是Lab1中所要改写的函数之一。另外 在这里可以通过ctrl+单击或者ctrl+=跳转到相应的函数定义处,很方便。 3. irq处理初始化工作 来看下Lab 1的重点之一,irq的处理。跟踪multiboot_main->base_cpu_setup->base_cp u_init->base_irq_init,可以看到这行代码 gate_init(base_idt, base_irq_inittab, KERNEL_CS); 继续使用ctrl+/找到base_irq_inittab的藏身之处:base_irq_inittab.s 4. base_irq_inittab.s 这个汇编文件做了不少重复性工作,方便我们在c语言级别实现各种handler。 GATE_INITTAB_BEGIN(base_irq_inittab) /* irq处理函数表的起始,还记得jump table 吗? */ MASTER(0, 0) /* irq0 对应的函数 */ 来看看这个MASTER(0, 0)宏展开后是什么样子: #define MASTER(irq, num) \ GATE_ENTRY(BASE_IRQ_MASTER_BASE + (num), 0f, ACC_PL_K|ACC_INTR_GATE) ;\ P2ALIGN(TEXT_ALIGN) ;\ 0: ;\ pushl $(irq) /* error code = irq vector */ ;\ pushl $BASE_IRQ_MASTER_BASE + (num) /* trap number */ ;\ pusha /* save general registers */ ;\ movl $(irq),%ecx /* irq vector number */ ;\ movb $1 << num,%dl /* pic mask for this irq */ ;\ jmp master_ints 依次push irq号,trap号(0x20+irq号),通用寄存器(eax ecx等)入栈,把irq号保 存到ecx寄存器,然后跳转到master_ints,master_ints是所有master interrupts公用 的代码。 跳过master_ints的前几行,从第七行开始 /* Acknowledge the interrupt */ movb $0x20,%al outb %al,$0x20 /* Save the rest of the standard trap frame (oskit/x86/base_trap.h). */ pushl %ds pushl %es pushl %fs pushl %gs /* Load the kernel's segment registers. */ movw %ss,%dx movw %dx,%ds movw %dx,%es /* Increment the hardware interrupt nesting counter */ incb EXT(base_irq_nest) /* Load the handler vector */ movl EXT(base_irq_handlers)(,%ecx,4),%esi 注释写得很详细,首先发送0x20到0x20端口,也就是Lab1文档上所说的发送INT_CTL_DON E到INT_CTL_REG,看来这一步support code已经替我们完成了。接下来保存四个段寄存 器ds es fs gs,并读入kernel态的段寄存器信息。 最后一句很关键,把base_irq_handlers + %ecx * 4这个值保存到了esi寄存器中,%ecx 中保存了irq号,而*4则是一个函数指针的大小,那么base_irq_handlers是什么呢?继 续用ctrl+/搜索,可以在base_irq.c中找到这个数组的定义 unsigned int (*base_irq_handlers[BASE_IRQ_COUNT])(struct trap_state *ts) 且初始时这个数组的每一项都是base_irq_default_handler 看来这句汇编代码的功能是把处理irq对应的函数地址保存到了esi寄存器中。 为了证实这一点,继续看base_irq_inittab.s的代码: #else /* Call the interrupt handler with the trap frame as a parameter */ pushl %esp call *%esi popl %edx #endif 果然,在保存了esp值后,紧接着就调用了esi指向的那个函数。而从那个函数返回后, 之前在栈上保存的相关信息都被恢复了: /* blah blah blah */ /* Return from the interrupt */ popl %gs popl %fs popl %es popl %ds popa addl $4*2,%esp /* Pop trap number and error code */ iret 这样就恢复到了进入这个irq处理单元前的状态,文档中所要求的保存通用寄存器这一步 其实在这里也已经完成了,不需要我们自己写代码。 好了,这样一分析后,我们要做的事情就很简单,就是把base_irq_handlers数组中的对 应项改成相应的handler函数就行了。 注意index是相应的idt_entry号减去BASE_IRQ_SLAVE_BASE,或者直接使用IRQ号。 另外这个数组的初始值都是base_irq_default_handler,用ctrl+左键跳到这个函数的定 义,可以看到这个函数只有一句简单的输出语句: printf("Unexpected interrupt %d\n", ts->err); 而这就是没有注册handler前我们所看到的那句Unexpected interrupt 0的来源了。 5. struct trap_state *ts 所有的handler函数的参数都是一个struct trap_state *ts,这个参数是哪来的呢? 注意call *%esi的前一行 /* Call the interrupt handler with the trap frame as a parameter */ pushl %esp 这里把当前的esp当作指向ts的指针传给了handler,列一下从esp指向的地址开始的内容 ,也就是在此之前push入栈的内容: pushl $(irq) /* error code = irq vector */ ;\ pushl $BASE_IRQ_MASTER_BASE + (num) /* trap number */ ;\ pusha /* save general registers */ ;\ pushl %ds pushl %es pushl %fs pushl %gs 再看一下trap_state的定义,你会发现正好和push的顺序相反: /* Saved segment registers */ unsigned int gs; unsigned int fs; unsigned int es; unsigned int ds; /* PUSHA register state frame */ unsigned int edi; unsigned int esi; unsigned int ebp; unsigned int cr2; /* we save cr2 over esp for page faults */ unsigned int ebx; unsigned int edx; unsigned int ecx; unsigned int eax; /* Processor trap number, 0-31. */ unsigned int trapno; /* Error code pushed by the processor, 0 if none. */ unsigned int err; 而这个定义后面的 /* Processor state frame */ unsigned int eip; unsigned int cs; unsigned int eflags; unsigned int esp; unsigned int ss; 则是发生interrupt时硬件自动push的五个数据(参见Understand the Linux Kernel) 也就是说,ts指针指向的是调用当前handler前的寄存器状态,也是当前handler结束后 用来恢复的寄存器状态,了解这一点对以后的几个lab帮助很大。 p.s. 另外提一句和这个lab无关的话,非vm86模式下栈上是不会有v86_es等四个寄存器 信息的,所以以后根据task_struct指针计算*ts的地址时使用的偏移量不应该是sizeof( struct trap_state) 6. The End 这样差不多就把support code中处理interrupt的方法过了一遍(另外还有base_trap_in ittab.s,不过和irq的处理很相似) 了解这些后Lab1就比较简单了,不需要任何内嵌汇编代码即可完成。
摘要: 美国为什么需要这么多大学生,而中国培育出这么多优秀大学生为什么失业?难道是我们学生程度不够?难道是我们同学不够用功?难道是我们同学专业不对口?那我告诉所有读者,为什么大学生就业难…… 阅读全文
用ctags -R或者ctags * -R的时候只能生成当前目录下的tag,检查了半天发现原来这个版本的ctags的参数顺序只能老老实实的来:ctags -R *
太囧了,总归要bs下的,虽说也有那么一点点可能是bash解析参数时的问题,不过我猜问题来源还是这个低版本的ctags = =
话说我也挺圡的,不习惯用source insight,还是喜欢用vim写代码
没心思看离散,也不准备坚持看没有荷兰的欧洲杯决赛。闲着点好友的Q-Zone,原来Q-Zone首先会判断你的浏览器,如果是Firefox它会重定向到RSS阅读界面。
安然在开学后2个月写的一篇日志,“记忆里的名单”,惊喜的看到有我。也列出了一张属于我的名单。好,等待时间的遴选。
“于是想 如果有个妹妹 我要告诉她 好好放肆猖狂 做不可思议的事情 为友情和少年青涩的爱情花心思 做只是喜欢没有功利目的的事情 这么好的年华 就是用来这样浪费 和珍惜的~”
可惜我只保持了四五个月的这种疯狂,现在依然纠结于功利的选择。有时候曾想,或许那次失败更适合我,或许我终将把这么一条平淡无奇的路走到尽头。“表面强者”,或许还是很有道理的。
看到fofo的博的文字,“我要去杭州,把所有的事情抛掉,不管后果。这个地方太让人压抑,尽管有很玩得来的室友,有很好的足球队的队友,可以看很多以前爸妈不让看的喜欢的书还有过米的比赛,吃的东西也都很习惯,还是会在天气很好的星期天下午突然想起曾经在冬日的阳光照射下一家人在阳台上围着一张桌子吃饭的情景,还是会在一个人骑在去计算机协会的路上很难过地想着再也不会有那么四个或者五个人在一起吃完小炒放肆地在铺满夕阳的校园小路上勾肩搭背地行走了,还是会在一百多个人的课堂上怀念起那些艰苦却简单的日子里所有的笑声,还是会在网吧包夜的时候想起初中时捏着饭钱偷偷摸摸地去电脑房玩星际……想找找朋友们,调整一下自己的心情。”
真的找不回来了。在写这篇博文时也找不到以前写字的感觉了。
明天离散考试,某个记录或许将要因此打破。
摘要: 一篇关于函数式编程的介绍,在水木Java版引起了热烈讨论。 阅读全文
1. framwork/policies/Singleton.h Singleton模式,可以指定相应的线程模型、创建策略和生命期控制策略。 对于全局范围的Singleton实例,定义了若干个宏便于访问,例如  #define sLog MaNGOS::Singleton<Log>::Instance() #define sLog MaNGOS::Singleton<Log>::Instance()
#define sMaster MaNGOS::Singleton<Master>::Instance()
Singleton的定义:  
namespace MaNGOS
{
template
<
typename T,
class ThreadingModel = MaNGOS::SingleThreaded<T>,
class CreatePolicy = MaNGOS::OperatorNew<T>,
class LifeTimePolicy = MaNGOS::ObjectLifeTime<T>
>
class MANGOS_DLL_DECL Singleton
{
public:
static T& Instance();
protected:
Singleton() {};
private:
// Prohibited actions this does not prevent hijacking. this does not prevent hijacking.
Singleton(const Singleton &);
Singleton& operator=(const Singleton &);
// Singleton Helpers
static void DestroySingleton();
// data structure
typedef typename ThreadingModel::Lock Guard;
static T *si_instance;
static bool si_destroyed;
};
}
#endif
不知道这里的注释Prohibited actions...this does not prevent hijacking.是什么意思,copy constructor和hijacking有什么关系呢?
另外注意这行typedef typename ThreadingModel::Lock Guard;,原来typedef还可以用在函数上。
Singleton的Instance方法用的是标准的double-checked lock方法,关于DCL可以参考这篇博文http://www.blogjava.net/zellux/archive/2008/04/07/191365.html
2. Explicit Constructors
game/WorkPacket.h中看到的语法,防止构造函数中参数的隐式转型
比如explicit String(int n); 用String('c')声明时就会报错
一套基于文件系统的安全方案,主要通过隔离运行不可信任的程序、taint记录、事故恢复。
我的presentation:
http://docs.google.com/Presentation?id=dcjk4xx7_473cv5ddgc8
出于时间考虑没有提到paper中进程间通信的解决方法
摘要: 一篇介绍一种全新的Web架构,另一篇介绍虚拟机的探测方法 阅读全文
摘要: 发信人: NetMD (C++), 信区: CPlusPlus
标 题: [FAQ] C/C++中的序列点
发信站: 水木社区 (Wed Feb 7 01:13:41 2007), 站内 阅读全文
VIM Calender是个很好用的写日记的插件( http://www.vim.org/scripts/script.php?script_id=52) 水木上的rmrf写了一个同步VIM Calender和Google Calender的脚本( http://code.google.com/p/diaryvgc/downloads/list) 想到blogger.com支持通过发送邮件发布日志,于是我也写了个把VIM Calender中的日记发布到blogger.com的脚本。 这个脚本把发布情况记录在diary/poster.log中,以后每次执行只会发布最新的日志,同时考虑到当天的日记可能会被修改(blogger.com似乎不支持通过email修改日志),所以当天的日记不会被发布。 使用的时候修改开头几行的配置信息即可 #!/usr/bin/python
# A script for posting diaries created by VIM Calender to blogger.com
# Author: Wang Yuanxuan <zellux@gmail.com>
import smtplib, os, re, datetime
from email.mime.text import MIMEText
fromaddr = xxxxx@fudan.edu.cn'
toaddr = xxxx.xxxx@blogger.com'
smtpserver = 'mail.fudan.edu.cn'
diarydir = '/home/user_name/diary'
username = 'xxxxxx'
password = 'xxxxxx'
logpath = diarydir + '/poster.log'
def PostMail(title, content):
msg = MIMEText(content + '\r\n#end\r\n')
msg['Subject'] = title
msg['From'] = fromaddr
msg['To'] = toaddr
server = smtplib.SMTP(smtpserver)
server.login(username, password)
# server.set_debuglevel(1)
server.sendmail(fromaddr, [toaddr], msg.as_string())
server.quit()
# Load log file. Create a new one if not exist.
posted = []
if os.path.isfile(logpath):
temp = open(logpath, 'r')
posted = [line[:-1] for line in temp.readlines()]
log = open(logpath, 'a')
else:
print "A new poster log has been created at " + logpath
log = open(logpath, 'w')
pattern = r'(\d{4})/(\d{1,2})/(\d{1,2}).cal$'
scanner = re.compile(pattern)
for (top, dirname, filenames) in os.walk(diarydir):
for filename in filenames:
fullpath = os.path.join(top, filename)
if scanner.search(fullpath):
(year, month, day) = scanner.search(fullpath).groups()
filedate = datetime.date(int(year), int(month), int(day))
title = filedate.isoformat()
if filedate == datetime.date.today():
continue
if fullpath not in posted:
log.write(fullpath + '\n')
text = open(fullpath).read()
PostMail(title, text)
print 'The diary ' + title + ' has been posted'
log.close()
这书的数学分析方面有点过于简单了,连绝对值、二维坐标系是个什么东东都会给你解释一下,所以看起来很快。
第一章 经济学十大原理
第二章 像经济学家一样思考
生产可能性边界(production possibilites frontier)通常是凹向原点的形状。
实证表述(positive statements):企图描述世界是什么的观点。经济学的许多内容是实证的。
规范表述(normative statements):企图描述世界应该是什么的观点。
第三章 相互依赖性与贸易的好处
机会成本与比较优势
第四章 供给与需求的市场力量
第五章 弹性及其应用
需求价格弹性 = 需求量变动百分比 / 价格变动百分比
供给价格弹性 = 供给变动百分比 / 价格变动百分比
例:由于毒品的需求缺乏弹性,禁毒引起的毒品价格提高的比例大于毒品使用减少的比例,因此禁毒会增加与毒品相关的犯罪。(短期)
第六章 供给、需求与政府政策
限制性价格上限导致短缺,限制性价格下限导致过剩。
例:最低工资法导致失业。
一旦市场达到新均衡,无论向谁征税,都是买者与卖者分摊税收负担。
例:由于劳动的供给远比劳动的需求缺乏弹性,是工人而不是企业承担了大部分工薪税的负担。
发信人: bluegene (蓝色基因||多看paper才是王道), 信区: Quant
标 题: 美国次贷危机之通俗演义 zz (转载)
发信站: BBS 未名空间站 (Fri Mar 21 01:24:10 2008)
【 以下文字转载自 ChinaNews 讨论区 】
发信人: chaoz (饭局局长), 信区: ChinaNews
标 题: 美国次贷危机之通俗演义 zz
发信站: BBS 未名空间站 (Thu Mar 20 23:49:57 2008)
在美国,贷款是非常普遍的现象,从房子到汽车,从信用卡到电话账单,贷款无处不在。当地人很少全款买房,通常都是长时间贷款。可是我们也知道,在这里失业
和再就业是很常见的现象。这些收入并不稳定甚至根本没有收入的人,他们怎么买房呢?因为信用等级达不到标准,他们就被定义为次级贷款者。
大约从10年前开始,那个时候贷款公司漫天的广告就出现在电视上、报纸上、街头,抑或在你的信箱里塞满诱人的传单:
“你想过中产阶级的生活吗?买房吧!”
“积蓄不够吗?贷款吧!”
“没有收入吗?找阿牛贷款公司吧!”
“首付也付不起?我们提供零首付!”
“担心利息太高?头两年我们提供3%的优惠利率!”
“每个月还是付不起?没关系,头24个月你只需要支付利息,贷款的本金可以两年后再付!想想看,两年后你肯定已经找到工作或者被提升为经理了,到时候还怕付不起!”
“担心两年后还是还不起?哎呀,你也真是太小心了,看看现在的房子比两年前涨了多少,到时候你转手卖给别人啊,不仅白住两年,还可能赚一笔呢!再说了,又不用你出钱,我都相信你一定行的,难道我敢贷,你还不敢借?”
在这样的诱惑下,无数美国市民毫不犹豫地选择了贷款买房。(你替他们担心两年后的债务?向来自我感觉良好的美国市民会告诉你,演电影的都能当上州长,两年后说不定我还能竞选总统呢。)
阿牛贷款公司短短几个月就取得了惊人的业绩,可是钱都贷出去了,能不能收回来呢?公司的董事长——阿牛先生,那也是熟读美国经济史的人物,不可能不知道房
地产市场也是有风险的,所以这笔收益看来不能独吞,要找个合伙人分担风险才行。于是阿牛找到美国经济界的带头大哥——投行。这些家伙可都是名字响当当的主
儿(美林、高盛、摩根),他们每天做什么呢?就是吃饱了闲着也是闲着,于是找来诺贝尔经济学家,找来哈佛教授,用上最新的经济数据模型,一番鼓捣之后,弄
出几份分析报告,从而评价一下某某股票是否值得买进,某某国家的股市已经有泡沫了,一群在风险评估市场里面骗吃骗喝的主儿,你说他们看到这里面有风险没?
用脚都看得到!可是有利润啊,那还犹豫什么,接手搞吧!于是经济学家、大学教授以数据模型、老三样评估之后,重新包装一下,就弄出了新产品——CDO
(注: Collateralized Debt
Obligation,债务抵押债券),说穿了就是债券,通过发行和销售这个CDO债券,让债券的持有人来分担房屋贷款的风险。
光这样卖,风险太高还是没人买啊,假设原来的债券风险等级是6,属于中等偏高。于是投行把它分成高级和普通CDO两个部分,发生债务危机时,高级CDO享
有优先赔付的权利。这样两部分的风险等级分别变成了4和8,总风险不变,但是前者就属于中低风险债券了,凭投行三寸不烂“金”舌,当然卖了个满堂彩!可是
剩下的风险等级8的高风险债券怎么办呢?
于是投行找到了对冲基金,对冲基金又是什么人,那可是在全世界金融界买空卖多、呼风唤雨的角色,过的就是刀口舔血的日子,这点风险小意思!于是凭借着老关
系,在世界范围内找利率最低的银行借来钱,然后大举买入这部分普通CDO债券,2006年以前,日本央行贷款利率仅为1.5%;普通CDO利率可能达到
12%,所以光靠利息差对冲基金就赚得盆满钵满了。
这样一来,奇妙的事情发生了,2001年末,美国的房地产一路飙升,短短几年就翻了一倍多,这样一来就如同阿牛贷款公司开头的广告一样,根本不会出现还不
起房款的事情,就算没钱还,把房子一卖还可以赚一笔钱。结果是从贷款买房的人,到阿牛贷款公司,到各大投行,到各个银行,到对冲基金人人都赚钱,但是投行
却不太高兴了!当初是觉得普通CDO风险太高,才扔给对冲基金的,没想到这帮家伙比自己赚的还多,净值一个劲地涨,早知道自己留着玩了,于是投行也开始买
入对冲基金,打算分一杯羹了。这就好像“老黑”家里有馊了的饭菜,正巧看见隔壁邻居那只讨厌的小花狗,本来打算毒它一把,没想到小花狗吃了不但没事,反而
还越长越壮了,“老黑”这下可蒙了,难道馊了的饭菜营养更好,于是自己也开始吃了!
这下又把对冲基金乐坏了,他们是什么人,手里有1块钱,就能想办法借10块钱来玩的土匪啊,现在拿着抢手的CDO还能老实?于是他们又把手里的CDO债券
抵押给银行,换得10倍的贷款,然后继续追着投行买普通CDO。嘿,当初可是签了协议,这些CDO都归我们的!!!投行心里那个不爽啊,除了继续闷声买对
冲基金之外,他们又想出了一个新产品,就叫CDS (注:Credit Default
Swap,信用违约交换)好了,华尔街就是这些天才产品的温床:不是都觉得原来的CDO风险高吗,那我投保好了,每年从CDO里面拿出一部分钱作为保金,
白送给保险公司,但是将来出了风险,大家一起承担。
保险公司想,不错啊,眼下CDO这么赚钱,1分钱都不用出就分利润,这不是每年白送钱给我们吗?干了!
对冲基金想,不错啊,已经赚了几年了,以后风险越来越大,光是分一部分利润出去,就有保险公司承担一半风险,干了!
于是再次皆大欢喜,CDS也卖火了!但是事情到这里还没有结束:因为“聪明”的华尔街人又想出了基于CDS的创新产品!我们假设CDS已经为我们带来了
50亿元的收益,现在我新发行一个“三毛”基金,这个基金是专门投资买入CDS的,显然这个建立在之前一系列产品之上的基金的风险是很高的,但是我把之前
已经赚的50亿元投入作为保证金,如果这个基金发生亏损,那么先用这50亿元垫付,只有这50亿元亏完了,你投资的本金才会开始亏损,而在这之前你是可以
提前赎回的,首发规模500亿元。天哪,还有比这个还爽的基金吗?1元面值买入的基金,亏到0.90元都不会亏自己的钱,赚了却每分钱都是自己的!评级机
构看到这个天才设想,简直是毫不犹豫:给予AAA评级!
结果这个“三毛”可卖疯了,各种养老基金、教育基金、理财产品,甚至其他国家的银行也纷纷买入。虽然首发规模是原定的500亿元,可是后续发行了多少亿,
简直已经无法估算了,但是保证金50亿元却没有变。如果现有规模5000亿元,那保证金就只能保证在基金净值不低于0.99元时,你不会亏钱了。
当时间走到了2006年年底,风光了整整5年的美国房地产终于从顶峰重重摔了下来,这条食物链也终于开始断裂。因为房价下跌,优惠贷款利率的时限到了之
后,先是普通民众无法偿还贷款,然后阿牛贷款公司倒闭,对冲基金大幅亏损,继而连累保险公司和贷款的银行,花旗、摩根相继发布巨额亏损报告,同时投资对冲
基金的各大投行也纷纷亏损,然后股市大跌,民众普遍亏钱,无法偿还房贷的民众继续增多……最终,美国次贷危机爆发。(屈直言)
次贷危机是否会酿成全球危机?
--
只要功夫深, 一夜夫妻百日恩.
※ 来源:·WWW 未名空间站 海外: mitbbs.com 中国: mitbbs.cn·[FROM: 141.219.]
摘要: 一种利用虚拟机进行的攻击手段(下篇) 阅读全文
 Fight Club
Fight Club
1. 不能谈论斗阵俱乐部。 2. 不能谈论斗阵俱乐部。 3. 只要有人喊停,或者受伤,快累死了,打斗就得停。 4. 一次只能两人打 5. 一次一场 6. 脱掉衬衫和鞋子 7. 打斗没有时限 8. 只要你是初次参加,就一定得打。 太混乱了
 秒速5センチメートル
秒速5センチメートル
“樱花飘落的速度,是每秒5厘米。” 凄美无奈的故事,有点像村上的《国境以南》,只是主人公最后仍然在寻找着对方。 新海诚的动画色彩很斑斓,很华丽。 写到这里,千千静听里正好随机播放到了那首One More Time, One More Chance,几百分之一的概率,呵呵。 晚上看风格截然不同的National Trasure: Book of Secrets
在机房电脑的Arch Linux上搭了个MediaWiki,作为自己的知识库。
前几天在水木上看到的想法,觉得这样很有成就感,尽管现在还没学多少东西。
一步一个脚印,慢慢扩充。
Mika的歌还真是好听。
Problem
Every bus in the Ekaterinburg city has a special man (or woman) called
conductor. When you ride the bus, you have to give money to the conductor.
We know that there are more then P% conductors and less then Q% conductors.
Your task is to determine a minimal possible number of Ekaterinburg citizens.
我只能说太挫了。。。精度问题搞了半天,看来浮点还是要尽量化成整型再算啊。
1 #include <iostream>
2 #include <cmath>
3
4 using namespace std;
5
6 int main()
7 {
8 double dp, dq;
9 cin >> dp >> dq;
10 int p = floor(dp * 100 + 0.5);
11 int q = floor(dq * 100 + 0.5);
12 for (int i = 1; ; i++) {
13 int a = p * i / 10000;
14 int b = q * i / 10000;
15 if ((a < b) && (q * i % 10000 > 0)) {
16 cout << i << endl;
17 return 0;
18 }
19 }
20 return 0;
21 }
22 还有个问题就是q*i是开区间还是闭区间,总之Wrong Answer了无数次后总算过了。。。
摘要: 算法导论第27章,在并行处理的条件下高效的排序算法。 阅读全文
因为MSN一开始会尝试连接crl.microsoft.com,把这个网站屏蔽了就行。
在hosts文件中加入
127.0.0.1 crl.microsoft.com
~/.vim/ftplugin/ 下有c.vim和cpp.vim
但是vim打开cpp和c文件时使用的配置都是c.vim中指定的
使用vim xxx.cpp -V跟踪了打开的配置列表,发现有这么一段
line 17: sourcing "/usr/share/vim/ftplugin/cpp.vim"
Searching for "ftplugin/c.vim ftplugin/c_*.vim ftplugin/c/*.vim" in "/home/wyx/.vim,/usr/share/vim,/usr/share/vim,
/usr/share/vim/after,/home/wyx/.vim/after"
Searching for "/home/wyx/.vim/ftplugin/c.vim"
line 12: sourcing "/home/wyx/.vim/ftplugin/c.vim"
原来/usr/share/vim/ftplugin/cpp.vim中直接调用了c.vim
runtime! ftplugin/c.vim ftplugin/c_*.vim ftplugin/c/*.vim
把这行注释掉,问题解决
要提高效率果然得远离网络,躺床上看paper理解起来快多了
总算把晚上要讲的ppt做出来了,囧
下午打球直到体力极限,一路淋雨跑回寝室,洗澡,感冒,低落。想回家。
有时候会想,几年后,真的就要在上海这个地方工作立足吗?
我想看一堆电影 想读一堆书 想学C# Lisp Python 想上ACM OJ网站切题 想参加一次TopCoder比赛 想学埙 想学钢琴 想睡觉 想看微经 想练英语 想看内核 想到处旅游
终会和现实冲突。于是我想退实验室。几个小时后又放弃这个决定。
终究是怕这怕那保守着缓慢前进的人。
计算机科学论坛最近举办了一个阅读样章,提交书评的活动,具体内容请见http://www.ieee.org.cn/dispbbs.asp?boardID=42&ID=61162。
这里我想针对样章上的一个问题谈谈自己的理解。
问题很简单,求二进制中1的个数。对于一个字节(8bit)的变量,求其二进制表示中"1"的个数,要求算法的执行效率尽可能的高。
先来看看样章上给出的几个算法:
解法一,每次除二,看是否为奇数,是的话就累计加一,最后这个结果就是二进制表示中1的个数。
解法二,同样用到一个循环,只是里面的操作用位移操作简化了。
1: int Count(int v)
2: {
3: int num = 0;
4: while (v) {
5: num += v & 0x01;
6: v >>= 1;
7: }
8: return num;
9: }
解法三,用到一个巧妙的与操作,v & (v -1 )每次能消去二进制表示中最后一位1,利用这个技巧可以减少一定的循环次数。
解法四,查表法,因为只有数据8bit,直接建一张表,包含各个数中1的个数,然后查表就行。复杂度O(1)。
1: int countTable[256] = { 0, 1, 1, 2, 1, ..., 7, 7, 8 };
2:
3: int Count(int v) {
4: return countTable[v];
5: }
好了,这就是样章上给出的四种方案,下面谈谈我的看法。
首先是对算法的衡量上,复杂度真的是唯一的标准吗?尤其对于这种数据规模给定,而且很小的情况下,复杂度其实是个比较次要的因素。
查表法的复杂度为O(1),我用解法一,循环八次固定,复杂度也是O(1)。至于数据规模变大,变成32位整型,那查表法自然也不合适了。
其次,我觉得既然是这样一个很小的操作,衡量的尺度也必然要小,CPU时钟周期可以作为一个参考。
解法一里有若干次整数加法,若干次整数除法(一般的编译器都能把它优化成位移),还有几个循环分支判断,几个奇偶性判断(这个比较耗时间,根据CSAPP上的数据,一般一个branch penalty得耗掉14个左右的cycle),加起来大概几十个cycle吧。
再看解法四,查表法看似一次地址计算就能解决,但实际上这里用到一个访存操作,而且第一次访存的时候很有可能那个数组不在cache里,这样一个cache miss导致的后果可能就是耗去几十甚至上百个cycle(因为要访问内存)。所以对于这种“小操作”,这个算法的性能其实是很差的。
这里我再推荐几个解决这个问题的算法,以32位无符号整型为例。
1: int Count(unsigned x) {
2: x = x - ((x >> 1) & 0x55555555);
3: x = (x & 0x33333333) + ((x >> 2) & 0x33333333);
4: x = (x + (x >> 4)) & 0x0F0F0F0F;
5: x = x + (x >> 8);
6: x = x + (x >> 16);
7: return x & 0x0000003F;
8: }
这里用的是二分法,两两一组相加,之后四个四个一组相加,接着八个八个,最后就得到各位之和了。
还有一个更巧妙的HAKMEM算法
1: int Count(unsigned x) {
2: unsigned n;
3:
4: n = (x >> 1) & 033333333333;
5: x = x - n;
6: n = (n >> 1) & 033333333333;
7: x = x - n;
8: x = (x + (x >> 3)) & 030707070707;
9: x = modu(x, 63);
10: return x;
11: }
首先是将二进制各位三个一组,求出每组中1的个数,然后相邻两组归并,得到六个一组的1的个数,最后很巧妙的用除63取余得到了结果。
因为2^6 = 64,也就是说 x_0 + x_1 * 64 + x_2 * 64 * 64 = x_0 + x_1 + x_2 (mod 63),这里的等号表示同余。
这个程序只需要十条左右指令,而且不访存,速度很快。
由此可见,衡量一个算法实际效果不单要看复杂度,还要结合其他情况具体分析。
关于后面的两道扩展问题,问题一是问32位整型如何处理,这个上面已经讲了。
问题二是给定两个整数A和B,问A和B有多少位是不同的。
这个问题其实就是数1问题多了一个步骤,只要先算出A和B的异或结果,然后求这个值中1的个数就行了。
总体看来这本书还是很不错的,比较喜欢里面针对一个问题提出不同算法并不断改进的风格。这里提出一点个人的理解,望大家指正 ;-)
(by ZelluX http://www.blogjava.net/zellux)
摘要: 以下简单的整理来自游侠 netshow论坛的帖子 部分补充 阅读全文
摘要: 问题:
给定n个32位无符号整数,求出其中异或结果最大的两个整数。 阅读全文
转载请注明 作者 ZelluX
http://www.blogjava.net/zellux
看OOP教材时,提到了一个双检测锁定(Double-Checked Lock, DCL)的问题,但是书上没有多介绍,只是说这是一个和底层内存机制有关的漏洞。查阅了下相关资料,对这个问题大致有了点了解。
从头开始说吧。
在多线程的情况下Singleton模式会遇到不少问题,一个简单的例子
1: class Singleton {
2: private static Singleton instance = null;
3:
4: public static Singleton instance() {
5: if (instance == null) {
6: instance = new Singleton();
7: }
8: return instance;
9: }
10: }
假设这样一个场景,有两个线程调用Singleton.instance(),首先线程一判断instance是否等于null,判断完后一瞬间虚拟机把线程二调度为运行线程,线程二再次判断instance是否为null,然后创建一个Singleton实例,线程二的时间片用完后,线程一被唤醒,接下来它执行的代码依然是instance = new Singleton();
两次调用返回了不同的对象,出现问题了。
最简单的方法自然是在类被载入时就初始化这个对象:private static Singleton instance = new Singleton();
JLS(Java Language Specification)中规定了一个类只会被初始化一次,所以这样做肯定是没问题的。
但是如果要实现延迟初始化(Lazy initialization),比如这个实例初始化时的参数要在运行期才能确定,应该怎么做呢?
依然有最简单的方法:使用synchronized关键字修饰初始化方法:
public synchronized static Singleton instance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
这里有一个性能问题:多个线程同时访问这个方法时,会因为同步而导致每次只有一个线程运行,影响程序性能。而事实上初始化完毕后只需要简单的返回instance的引用就行了。
DCL是一个“看似”有效的解决方法,先把对应代码放上来吧:
1 : class Singleton {
2 : private static Singleton instance = null ;
3 :
4 : public static Singleton instance() {
5 : if (instance == null ) {
6 : synchronized (this) {
7 : if (instance == null)
8 : instance = new Singleton();
9 : }
10 : }
11 : return instance;
12 : }
13 : }
用JavaWorld上对应文章的标题来评论这种做法就是smart, but broken。来看原因:
Java编译器为了提高程序性能会进行指令调度,CPU在执行指令时同样出于性能会乱序执行(至少现在用的大多数通用处理器都是out-of-order的),另外cache的存在也会改变数据回写内存时的顺序[2]。JMM(Java Memory Model, 见[1])指出所有的这些优化都是允许的,只要运行结果和严格按顺序执行所得的结果一样即可。
Java假设每个线程都跑在自己的处理器上,享有自己的内存,和共享的主存交互。注意即使在单核上这种模型也是有意义的,考虑到cache和寄存器会保存部分临时变量。理论上每个线程修改自己的内存后,必须立即更新对应的主存内容。但是Java设计师们认为这种约束会影响程序性能,他们试着创造了一套让程序跑得更快、但又保证线程之间的交互与预期一致的内存模型。
synchronized关键字便是其中一把利器。事实上,synchronized块的实现和Linux中的信号量(semaphore)还是有区别的,前者过程中锁的获得和释放都会都会引发一次Memory Barrier来强制线程本地内存和主存之间的同步。通过这个机制,Java中的同步机制保证了synchronized块中指令的原子性(atomic)。
好了,回过头来看DCL问题。看起来访问一个未同步的instance字段不会产生什么问题,我们再次来假设一个场景:
线程一进入同步块,执行instance = new Singleton(); 线程二刚开始执行getResource();
按照顺序的话,接下来应该执行的步骤是 1) 分配新的Singleton对象的内存 2) 调用Singleton的构造器,初始化成员字段 3) instance被赋为指向新的对象的引用。
前面说过,编译器或处理器都为了提高性能都有可能进行指令的乱序执行,线程一的真正执行步骤可能是1) 分配内存 2) instance指向新对象 3) 初始化新实例。如果线程二在2完成后3执行前被唤醒,它看到了一个不为null的instance,跳出方法体走了,带着一个还没初始化的Singleton对象。
错误发生的一种情形就是这样,关于更详细的编译器指令调度导致的问题,可以参看这个网页 [4]。
[3] 中提供了一个编译器指令调度的证据
instance = new Singleton(); 这条命令在Symantec JIT中被编译成
0206106A mov eax,0F97E78h
0206106F call 01F6B210 ; 分配空间
02061074 mov dword ptr [ebp],eax ; EBP中保存了instance的地址
02061077 mov ecx,dword ptr [eax] ; 解引用,获得新的指针地址
02061079 mov dword ptr [ecx],100h ; 接下来四行是inline后的构造器
0206107F mov dword ptr [ecx+4],200h
02061086 mov dword ptr [ecx+8],400h
0206108D mov dword ptr [ecx+0Ch],0F84030h
可以看到,赋值完成在初始化之前,而这是JLS允许的。
另一种情形是,假设线程一安稳地完成Singleton对象的初始化,退出了同步块,并同步了和本地内存和主存。线程二来了,看到一个非空的引用,拿走。注意线程二没有执行一个Read Barrier,因为它根本就没进后面的同步块。所以很有可能此时它看到的数据是陈旧的。
还有很多人根据已知的几种提出了一个又一个fix的方法,但最终还是出现了更多的问题。可以参阅[3]中的介绍。
[5]中还说明了即使把instance字段声明为volatile还是无法避免错误的原因。
由此可见,安全的Singleton的构造一般只有两种方法,一是在类载入时就创建该实例,二是使用性能较差的synchronized方法。
(by ZelluX http://www.blogjava.net/zellux )
参考资料:
[1] Java Language Specification, Second Edition, 第17章介绍了Java中线程和内存交互关系的具体细节。
[2] out-of-order与cache的介绍可以参阅Computer System, A Programmer's Perspective的第四、五章。
[3] The "Double-Checked Locking is Broken" Declaration, http://www.cs.umd.edu/~pugh/java/memoryModel/DoubleCheckedLocking.html
[4] Synchronization and the Java Memory Model, http://gee.cs.oswego.edu/dl/cpj/jmm.html
[5] Double-checked locking: Clever, but broken, http://www.javaworld.com/javaworld/jw-02-2001/jw-0209-double.html?page=1
[6] Holub on Patterns, Learning Design Patterns by Looking at Code
感冒发烧。
把不应该存在的博文全删了。
我知道我在和自己赌气。
那又如何。
回过头来,这两年我所得到的,不过是可以随手扔掉的东西。
最后,acm的那些人们加油。
翘课大半,作业一半不交一半抄,总之太不像学生了。
搞得现在Super Scalar都只知道个大概,tableaux也知其然而不知所以然。
下星期好好参与一次,上课、作业一个都不能少,恩。
至于之后么,再说咯。
这语言真不错,不像Java那么呆,可惜不开源。 入门看的书是CLR via C#中文版,翻译质量不错,起码到现在还没觉得有必要翻一翻原版(不过为什么中文书都喜欢把“栈”叫成“堆栈”呢)。 前面几章粗略看了下,从第四章类型基础开始重点阅读。 继续漫无目的的学习感兴趣的东西,学习之中经常会惊喜的发现,自己看问题的角度已经不同于之前了。 1. 类的new操作会递归调用该类的所有父类构造器,直到System.Object,后者的构造器只是简单返回,用ILDasm查看MSCorLib.dll可以证实这一点。
.method public hidebysig specialname rtspecialname
instance void .ctor() cil managed
{
 .custom instance void System.Runtime.ConstrainedExecution.ReliabilityContractAttribute::.ctor(valuetype System.Runtime.ConstrainedExecution.Consistency, .custom instance void System.Runtime.ConstrainedExecution.ReliabilityContractAttribute::.ctor(valuetype System.Runtime.ConstrainedExecution.Consistency,
valuetype System.Runtime.ConstrainedExecution.Cer) = ( 01 00 03 00 00 00 01 00 00 00 00 00 )
// Code size 1 (0x1)
.maxstack 8
IL_0000: ret
 } // end of method Object::.ctor } // end of method Object::.ctor
2. is和as操作符,is类似于Java中的instanceof,as会先检查类型,如果兼容返回该对象的引用,反之返回null。 Emplooee e = o as Employee;
if (e != null) {
// blah
} 利用as可以做到只检验一次对象类型,提高程序性能。这本书的很多地方都提到了性能因素。 3. 方法调用和x86上汇编语言调用机制很类似。先是参数入栈,接着返回地址入栈,返回的时候也差不多。 不知道x64等寄存器较多的架构上会不会使用寄存器传参呢,呵呵。
4. 作为方法的prologue的一部分,CLR会自动将所有局部变量初始化为null或0。 感觉这个自动初始化没什么必要,在第五章可以看到。 SomeVal v1;
SomeVal v1 = new SomeVal(); 这里的SomeVal都是值类型,CLR都会将它们初始化为0。区别在于C#认为前者没有初始化,直接使用这个值会报错;而后者在不赋值的情况下使用这个值。 可能这是CLR和C#之间不统一导致的冗余步骤吧。 5. CLR开始在一个进程中运行时,会给System.Type类型创建一个实例,每个类都会包含指向System.Type类型的指针。 6. CLR提供了执行溢出检查的计算指令,例如add.ovf对应add,mul.ovf对应mul。C#中默认关闭溢出检查。 可以使用checked关键字使用溢出检查。一般情况下,对预计可能发生溢出的代码放到checked块中,对允许溢出的代码(比如计算hash值)放到一个unchecked块中,其他情况,Debug时打开编译器的/checked+开关,Release版本关闭。 7. 所有的值类型都是从System.ValueType继承的。后者重写了Equals方法,比较两个值对象是否完全相等。 8. boxing和unboxing。 boxing:托管堆中分配内存,复制值类型,然后返回对象地址。 unboxing:相当于一个通过指针取值的过程,不过这个指针是已装箱部分中的实际值部分。 9. FCL(Framework Class Library)中包含了支持值类型的泛型容器类,不需要对容器中的元素进行boxing/unboxing处理。 不过这里就有个问题了,值类型的话是放在栈上的,生命周期小于容器的,这个怎么处理呢?第16章才详细解释泛型,先把这个问题留着吧 =,= 10. 依然是性能问题。有时候编译器会反复对一个值类型boxing,此时手动boxing会提高一些性能。 Int32 v = 5;
// 需三次boxing
Console.WriteLine("{0}, {1}, {2}", v, v, v);
// 只需一次boxing
Object o = v;
Console.WriteLine("{0}, {1}, {2}", o, o, o);
接下来书上举了个很搞的例子说明boxing和unboxing的各种情况,其实也很容易理解。
火车缓缓地开着,混杂的人群。此时的我不属于两边世界中的任何一个,孤立于这种空间和从属感的交界处。理下思路,趁着记忆的新鲜,在手机上敲下这四天的感受,以弥补将来的某天可能发生的对这次旅行的淡忘。
Zijingang Campus: A Fudaner's Perspective
1. Abstract
一次课堂电影(话剧《暗恋桃花源》[5])
旁听两节课,图形学和线性代数。图形学课上回答一次问题 =_=
一场越剧,小百花越剧团的《春琴传》
一场话剧,黑白剧社[1]的《我在天堂等你》[2]
半天图书馆自修,读了半章SICP[4]和一篇paper
半天机房灌水,水木C版版主上任后的第一个操作居然是在浙大完成的
半天在“风雨操场”打球
一晚上在浙大战网打了十盘星际,九胜一负
2. Introduction
K900到车管所,一站的路程后到达正门。紫金港的正门没有试图制造一种空间隔离感,宽敞的道路上横躺着一块刻有“浙江大学”的石块,构成了形式上的正门。步行百余部后,回头才意识到原来百余步前的所处位置竟是一个入口。
这个入口给人一种宽广、松驰的感觉,与复旦的正门放置伟人像不同,紫金港的封面很平坦。除了草坪就无其他,可以望到天际。整个紫金港都给我这样的感觉:草坪、树、湖的世界中,点缀着几幢风格各异的建筑。
3. Details
3.1 上课
其实到浙大吃完饭后做的第一件事就是旁听了一节数媒专业的图形学,上的是三维空间的坐标变换。老师上课进度偏慢,绝大部分学生上课都很认真。感到那么一点点的压力 >,<
3.2 图书馆
一直觉得图书馆是大学的灵魂组成部分之一。甚至大一的时候觉得有个好的图书馆和一套优秀的借阅制度就足以成为一个好的大学了。也因此新到一个大学后总是特别关注那里的图书馆。
紫金港图书馆依傍在高耸的行政楼旁,可以把它比成计算中心,行政楼对应于光华主楼,较之后者它们靠得更紧密些。浙大同学说外校同学来看图书馆时,第一反应总是误把行政楼当图书馆。喜欢图书馆的这种低调。
图书馆的书架分类很笼统,所有的理工类书橱都被贴上了“自然科学”的标签,恐怕找书的时候要很依赖电脑。抽样调查了计算机类书籍,书目较小,重复率较大,甚至会有十几册同本书罢占一层书架的情况。阅读环境很不错,落地窗,明亮。窗外便是那片湖,一如图书馆般地平静。若是把座椅换成摇椅,再加上一杯咖啡,最愉悦的享受莫过于此。
离开图书馆时还让同学代借了本SICP[4],本想带回上海以此要胁该同学五一来复旦,到时候再还的。无奈多带本书太麻烦,回来之前还是还掉了。
3.3 付费
住宿楼旁有几家小吃店,其中不少店都是设置了一个单独的付费窗,而这个付费机制里没有任何凭证,或者说点了吃的却不付钱是很容易做到。别的不多说,这样一种店与客之间的信任给人一种亲切感。当然这也和紫金港地理位置较偏远,外人较少有关。
3.4 话剧
看了黑白剧社[1]的《我在天堂等你》[2]。话剧在一个可容纳百人左右的小书屋里进行。由于一个月前刚看过人艺的《榆树下的欲望》[3],相比之下学生的功底自然略逊一筹,尤其是对老年人的刻划上。不过总体还是很不错的。
记忆最深的是社员的那份激情,话剧结束后,演员和工作人员挨个自我介绍完毕,然后跑出书屋,站在门口等待出来的观众,齐喊“再见”“谢谢”。下楼走出百余米后,听到后面三声击掌,接着是社员们高喊“谢谢你们”,如此重复几遍,一阵高过一阵。被这种热情所震撼。
3.5 肆
一位同学的寝室门口贴着一张记录着这个班级同学的奋斗目标之类的墙纸,中间是一个硕大的草体“肆”。奋斗目标都很直接,譬如要被Stanford商学院录取,要进入某某大公司云云。不怎么喜欢这种过于外露的上进心,更欣赏复旦略带散漫的风格。
3.6 还是课
浙大课比较多。上下午各5节,每节45分钟,中间休息5/15分。同时周末有课也是很常见的现象,为了提高绩点而重修的同学通常周末的课表也很满。个人不喜欢这种课多的生活,喜欢兴趣驱动的学习,不喜欢自己的学习方向太受外力的牵引。
4. The End
总是有一种声音提醒自己,我不属于这里,注定不属于。太多的不应该出现的巧合,太多的主观的或是客观的借口。我有自己的天地,那里与浙大没有交集,即便我希望会有。
5. Acknowledgements
感谢浙大那些被我折腾、蹭吃蹭喝的同学。
感谢版主的m或b。
6. References
[1] 黑白剧社 http://www.qsc.zju.edu.cn/heibai/
[2] 我在天堂等你 http://www.douban.com/subject/1310322/
[3] 榆树下的欲望 Desire Under the Elms, http://www.douban.com/subject/1297393/
[4] Structure and Interpretation of Computer Programs, http://www.douban.com/subject/1451622/
[5] 暗恋桃花源,富含搞笑因素却又错综复杂值得深深体味的一部话剧,推荐一看 http://www.douban.com/subject/1299889/
[6] 春琴传,较传统的日本爱情故事 http://www.douban.com/subject/1949657/
其实理解了 Regular Expression -> NFA -> DFA 这个过程,大致的复杂度确定也不难
发信人: styc (styc), 信区: Algorithm
标 题: Re: 请问一下大家正则表达式的时间复杂度
发信站: 水木社区 (Wed Mar 26 20:37:02 2008), 站内
NFA构造O(n),匹配O(nm)
DFA构造O(2^n),最小化O(kn'logn')(N'=O(2^n)),匹配O(m)
n=regex长度,m=串长,k=字母表大小,n'=原始的dfa大小
大概是这样子吧
一个用Lattice Boltzmann Method模拟三维空间中不可压缩流体的程序,示意图见底部。 转这个程序实在是太耗体力了 -_-b Brook本身的不少缺陷、bug,加上不习惯科学计算程序的代码风格,导致大多数时间都在fix bug。 其中de掉以后最有快感的一个bug:(只能这么形容了 >,<) 每个cell都有一个flag值,尽管类型是double,但是程序中是用一个MAGIC_CAST宏把它当作整型处理的。 初始情况,每个cell的flag都为~f,也就是一个1~28位都是1,29~32位为0的double型浮点。根据IEEE标准,应该是个NaN。 CPU上没有问题,放到GPU上问题就出来了,GPU不支持这种转型操作,在对这个double型进行运算操作的时候,所有结果都会变成NaN。 解决方法: 在把数据传给GPU之前可以先把这些flag值转换为GPU可以操作的double型,最简单的方法就是都先转成int(会有truncating),然后取反,再传给GPU。 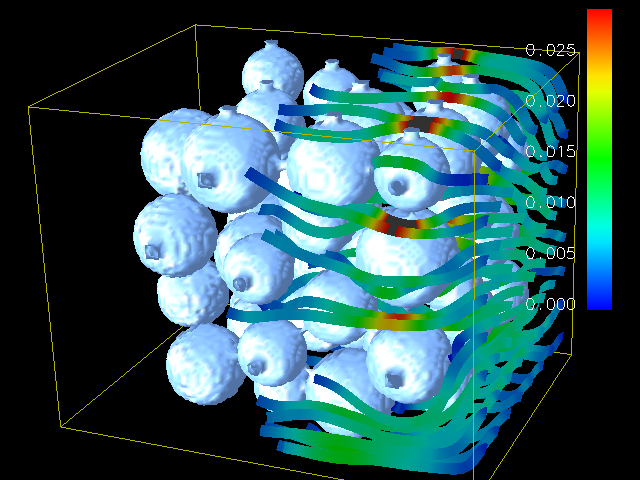
看来这年头Stream Programming要越来越热哈,恩,期待~~
发信人: freelife (陪你一起老), 信区: METech
标 题: Intel披露CPU/GPU混合芯片细节和时间 zz
发信站: 水木社区 (Tue Mar 18 22:54:49 2008), 站内
估计AMD和NV要急了~~
3月18日消息,英特尔2008年春季开发商论坛会议下个月将在中国上海召开。英特尔在会前的新闻发布会上简单地介绍了英特尔即将推出的图形芯片内核“Larrabee”的状况。
“Larrabee”与AMD的Radeon和NVIDIA的GeForce处理器有很大区别。“Larrabee”是以中央处理器架构中使用的 x86指令集为基础的。英特尔副总裁Steve Smith强调说,
“Larrabee”不仅是一个图形处理器,而且是能够完成任何流处理任务的多核芯片。
Smith没有详细说明“Larrabee”芯片中有多少个内核,不过,英特尔2006年披露的早期方案是采用16个内核。每个内核的运行速度都超过2GHz。
“Larrabee”芯片显然能够升级到数千个内核,共享与英特尔的Tera级计划相同的研究成果。除了x86的方式之外,英特尔将很快发布一个名为 “Advanced Vector
Extensions”(高级矢量扩展)的另一种像SSE扩展那样的扩展集。这些扩展可能把“Larrabee”芯片的x86指令集与Core 2 Duo和Phenom处理器的x86指令区别开来。Smith说,
“Larrabee”将支持OpenGL、 DirectX控件和光跟踪指令。
英特尔把处理器与图形处理器混合在一起的芯片将有两种版本。这两种版本都采用Nehalem处理器架构。第一种版本代号为“Havendale”,是一种台式电脑芯片,第二种版
本代号为“Auburndale”,是一种笔记本电脑芯片。
“Auburndale”和“Havendale”这两种芯片将采用两个Nehalem内核和一个图形子系统。两个内核共享4MB二级缓存和一个集成的双通道内存控制器,支持内存配置最高可
达DDR3-1333。
图形子系统最初是采用英特尔G45集成图形芯片。这表明上述两种芯片都没有强大的图形处理能力,只不过是集成图形芯片的替代品。
事实上,这两种图形芯片内核都省略了支持DirectX 9和DirectX 10的关键功能。这个基于G45图形芯片的内核最终将被高级的“Larrabee”图形处理器所取代。
根据英特尔的产品路线图,这种新的处理器预计将在2009年上半年进入市场。这将早于AMD Fusion处理器预计推出的时间。Fusion处理器计划在2009年下半年推出。
Smith许诺说,“Larrabee”芯片最终推出的时候将比Radeon和GeForce芯片更有竞争力。
摘要: 包括各种paper, survey以及workshop上的讲座等内容 阅读全文
禅 意--之二
当一切都会过去
我知道 我会
慢慢地将你忘记
心上的重担卸落
请你原谅我
生命原是要
不断地受伤和不断地复原
世界仍然是一个
在温柔地等待着我成熟的果园
天这样蓝 树这样绿
生活原来可以
这样的安宁和 美丽
摘要: 转载自水木KernelTech版。关于hack系统调用表的一篇文章,里面还涉及了上学期ICS Lab中的二进制代码注入,很好很强大。略作整理(为什么技术博客默认的字体不是等宽的 T.T)=-|================================================-{ www.enye-sec.org }-====|=-[ LKM Rootkits on Linux x86... 阅读全文
摘要: 越狱第三季最后一幕的歌曲蛮不错的,查到歌名叫Llorando,西班牙中“哭泣”的意思。google过程中还发现了这是某部叫做《穆赫兰道》的电影中的曲子,于是对这部电影也产生了兴趣。 阅读全文
这学期想上这门课,纯属娱乐,不准备深入。 主要还是考虑到有机会和安然小朋友合作一个大程 ;-) 关于计算机图形学的学习注意: 本文尽量避免理论化的描述,试图用最通俗的语言介绍一下计算机图形学的学习,以及一些参考书目和网络资源; 本文不涉及对概念的定义,以免陷入学术讨论之中 本文是作者学习计算机图形学的体会,如果有不同的意见,请不要攻击和漫骂 本文合适的题目应当是:白话说学计算机图形学? 1. 引言 什么是计算机图形学? 本文尽量避免给它做严格的定义,但是通常来说,计算机图形学是数字图象处理的逆过程,这只是一个不确切的定义,后面我们会看到,实际上,计算机图形学、数字图象处理和计算机视觉在很多地方的区别不是非常清晰的,很多概念是相通的。 计算机图形学是用计算机来画东西的学科,数字图象处理是把外界获得的图象用计算机进行处理的学科。在法国,图形图象是一门课程。 如何学习计算机图形学呢?除了计算机图形学的基础知识以外,你还需要有以下的知识,你懂的越多,当然做的越好。 * 英语, 你一定要把英语学好,如果你想学习计算机图形学的话,尽量看英文的书籍和资料 * 数学, 计算机图形学里面的数学用的比较多,,我们可以列举一些常用的: 高等数学,数值分析,微分几何,拓扑,概率, 插值理论,(偏)微分方程… * 物理, 如果你要进行基于物理的建模,一些物理理论是要学习的: 力学(运动学,动力学,流体力学…),光学,有限元… * 编程语言: C或C++是计算机图形学最通用的‘普通话’, * 数据结构: 你需要数据结构来描述你的图形对象,除了通用的链表、树等数据结构外,图形学还有自己特殊的数据结构 * 其他类别: 有的时候你需要其他学科的知识,根据你的需要去学习吧 上面列举的不是你必须学习的东西,而是计算机图形学可能会用到的东西,一定要记住,不要指望通过一本教材就学会计算机图形学,它比你想象的要复杂的多。 2. 图形学的问题 每个学科都有自己学科的特定问题,图形学要解决的是如何画出图来,得到需要的效果,当然这是图形学最大的一个问题。 在开始学习计算机图形学的时候,找一本简单的书看,对计算机图形学有个大概的认识,你就可以开始图形学之旅了: OpenGL Programming Guide: The Official Guide to Learning OpenGL, Version 1.4, Fourth Edition OpenGL SuperBible (3rd Edition) 是比较好的学习计算机图形学的入门教材,在练中去学,一开始就去啃 Foley的 Computer Graphics: Principles and Practice, Second Edition in C 不是好主意,会看的一头雾水,一本什么都讲的书的结果往往是什么都没讲清楚。 当你把OpenGL的基本内容掌握之后,你对图形学就有了大概的了解了 那么下面你可以来学习一下计算机图形学的数据结构和算法,下面的书比较适合 Joseph O'Rourke 的Computational Geometry in C,书里面有C的源代码,讲述简单,清晰,适合程序员学习 总的来说,计算机图形学涉及到2大部分:建模和渲染 2.1建模 你想画一个东西,首先要有它的几何模型,那么这个几何模型从什么地方来呢?下面的书很不错的: Gerald Farin 的Curves and Surfaces for CAGD: A Practical Guide 这本书就有一点的难度了,呵呵,要努力看啊 这本书算是CAGD (计算机辅助几何设计)的经典图书,CAGD方面的全貌,还有2本很好的讲述曲面的书Bezier和Nurbs的书 Les A. Piegl, Wayne Tiller 的The Nurbs Book 书里面有NURBS曲线、曲面的程序伪代码,很容易改成C的,书讲的通俗、易懂,但是你要有耐心看的:) 曲线与曲面的数学 这本书是法国人写的中文翻译版,里面还有Bezie本人写的序J,翻译的很不错的,看了你就掌握Bezier曲面技术了 //另外一些你想知道的事情:其他的造型方式-开始 注意:在后面会有这样的章节,标明 //另外一些你想知道的事情:其他的造型方式-开始 //另外一些你想知道的事情:其他的造型方式-结束 里面是我认为的一些高级话题,跳过他们不影响你学习计算机图形学,但是要学好就要注意了,呵呵 还有其他的一些造型技术,比如: 隐式曲面(Implicit Surface)的造型: 就是用函数形式为F( x ,y ,z ) = 0的曲面进行造型,这样的造型技术适合描述动物器官一样的肉乎乎的东西,有2本书推荐大家 Jules Bloomenthal编辑的Introduction to Implicit Surfaces,是一本专著,讲述了Implicit Surface建模型(Modeling),面片化(Polygonization),渲染(Rendering)的问题 Luiz Velho 的 Implicit Objects Computer Graphics 也是一本专著,讲述个更新的一些进展 细分曲面(Subdivision Surface)造型 当用NURBS做造型的时候,曲面拼接是复杂的问题,在动画的时候,可能产生撕裂或者褶皱,Subdivision Surface用来解决这个问题 Joe Warren的Subdivision Methods for Geometric Design: A Constructive Approach就是这方面的专著 从实际物体中得到造型,现在的技术可以用三维扫描仪得到物体表面的点,然后根据这些点把物体的表面计算出来,称为重建(Reconstruction),因为这些技术之在文章中论述,所以我们省略对它的描述 //另外一些你想知道的事情:其他的造型方式-结束 下面还是一个高级话题:) //另外一些你想知道的事情:光有造型是不够的!-开始 在你的几何模型做好之后,有一些问题需要对这个模型进一步处理,得到适合的模型,当面片很多的时候,或者模型很复杂的时候,需要对几何模型进行简化,才可以满足一些实时绘制的需要,这个技术叫做层次细节(LOD-Level of Detail)。下面的书就是讲这个的: David Luebke编著的 Level of Detail for 3D Graphics //另外一些你想知道的事情:光有造型是不够的!-结束 2.2渲染 有了模型,怎么把这个几何模型画出来呢?这个步骤就是渲染啦 如果你看了上面的OpenGL的书,那么你就知道一些渲染的知识了,但是别高兴的太早,OpenGL使用的是局部光照模型(Local Illumination Model),不要被这个词吓住了 Local illumination Model指的是在做渲染的时候只考虑光源和物体之间的相互作用,不考虑物体和物体之间的影响,所以OpenGL不支持阴影,一个(半)透明物体的效果..,这些需要考虑物体之间的影响才可以实现。 //另外一些你想知道的事情:OpenGL可以实现阴影-开始 OpenGL本身不支持,但是通过一些方法可以实现的:),用Google搜索一下 Shadow Volume, OpenGL就找到答案啦 //另外一些你想知道的事情:OpenGL可以实现阴影-结束 Global Illumination Model 这类模型考虑的就比较全啦。现在关于Global Illumination的技术有3大类,具体的技术就不在这里介绍了,如果想了解,可以联系我,大家一起讨论: 光线追踪(Ray Tracing) 关于Ray Tracing的好书有2本: Andrew Glassner 的An Introduction to Ray tracing Glasser是图形界的名人,这本书也是Ray Tracing的经典 R. Keith Morley, Peter Shirley 的Realistic Ray Tracing, Second Edition 这本书第一版是伪代码,第二版是C代码。它的结构不是很清楚,虎头蛇尾的感觉。 辐射度(Radiosity) 关于Radiosity的好书有4本: Michael Cohen 的Radiosity and Realistic Image Synthesis , Cohen获得SIGGRAPH 1998计算机图形学成就奖,他把Radiosity变成实际可用,现在Cohen在MSR图形  http://research.microsoft.com/~cohen/CohenSmallBW2.jpg http://research.microsoft.com/~cohen/CohenSmallBW2.jpgFrancois X. Sillion的Radiosity and Global Illumination , Sillion是法国人,他的主要研究方向是Radiosity,这本书写的很不错的,非常清晰 Philip Dutre 的新书Advanced Global Illumination ,看起来还不错,刚拿到手,还没看,呵呵,所以不好评价 Ian Ashdown的Radiosity: A Programmer's Perspective 有源代码的书啊!! 就凭这个,得给5***** Photon mapping 这个我也不知道怎么翻译,呵呵。这个技术出现的比较晚,一本好书! Henrik Wann Jensen的Realistic Image Synthesis Using Photon Mapping Henrik Wann Jensen是Photon mapping技术的发明者 3.3这些也是图形学吗? 图形和图象的区别模糊了:( 除了上面讲的‘经典’的计算机图形学,还有下面的一些东西,它们也叫计算机图形学吗?是的!!! 3.3.1非真实性图形学(Non-Photorealistic Graphics) 真实性不是计算机图形学的唯一要求,比如:你给我画一个卡通效果的图出来,或者我要用计算机画水彩画怎么办?或者:把图象用文字拼出来怎么做?,解决这些问题要用到非真实性图形学, 好书继续推荐!!! Bruce Gooch, Amy Ashurst Gooch的 Non-Photorealistic Rendering 3.3.2体图形学(Volume Graphics) 用CT机做很多切片(比如头骨),那么能通过这些切片得到3D的头骨吗?Volume Graphics就是解决这样的问题的 Min Chen 编著的Volume Graphics 上面的2个图形学技术就和图象的界限不明显了,实际上他们是图形图象的综合 4 .还有其他的书吗? 还有一些好书啊,呵呵,好书看不完的:),继续放送: Graphics Gems I ~ V,一大帮子人写的书,包括研究人员,程序员… 有计算机图形学的各种数据结构,编程技巧 Tomas Akenine-Moller 等人编著的Real-Time Rendering (2nd Edition) 许多最新的计算机图形学进展 David Ebert等人的Texturing & Modeling: A Procedural Approach, Third Edition 讲述如何通过程序实现纹理、山、地形等图形学要素 F. Kenton Musgrave号称分形狂(Fractal Mania) Ken Perlin就是Perlin噪声的发明者,用过3d软件的人对Perlin Noise不会陌生的 关于图形学的特定对象,有特定的专题图书, Evan Pipho Focus On 3D Models,对于图形学的常用模型格式,进行了讲解 Trent Polack的 Focus On 3D Terrain Programming ,讲地形的 Donald H. House 的Cloth Modeling and Animation ,讲布料的 Nik Lever的Real-time 3D Character Animation with Visual C++ ,讲角色动画的 …… 还有:) Richard Parent的 Computer Animation: Algorithms and Techniques,当然是讲动画的啦,呵呵。 David H. Eberly的3D Game Engine Design : A Practical Approach to Real-Time Computer Graphics ,有代码的啊!呵呵:) 最后,没事情的时候,看看下面的书吧 Alan H. Watt, 3D Computer Graphics (3rd Edition) James D. Foley等人的 Computer Graphics: Principles and Practice in C (2nd Edition) ,这本圣经没事的时候再看吧,呵呵 累了:( 不说了,上面的书差不多了,还有一些shader的书,我不了解,以后会补上的:) 5.从哪里找到这些书啊?还有什么资源啊? 我保证,上面的书在www.amazon.com 都可以买到:) 别打我 那好,大部分的书在国家图书馆可以复印到,北京的兄弟有福啦,3年前的书借出来复印,1角/页,但是新书要早图书馆里复印,5~6角/页,还是比Amazon便宜啊,呵呵。 不行大家就到国外买,合买吧,还负担的起。 我对DirectX不了解,所以没有涉及关于DirectX的内容:)
摘要: Unix - semaphore examplehttp://docs.linux.cz/programming/c/unix_examples/semab.htmlCode highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->/**//* semabinit.c ... 阅读全文
摘要: ipc/shm.c:
sys_shmat 连接共享内存
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->
... 阅读全文
能用上非盗版的Visual Studio了。。。 https://downloads.channel8.msdn.com/Default.aspxWelcome to Microsoft DreamSpark Professional Developer and Designer tools DreamSpark is simple, it's all about giving students Microsoft professional-level developer and design tools at no charge so you can chase your dreams and create the next big breakthrough in technology - or just get a head start on your career. Who can get this right now?We are kicking this off in 11 countries/regions, giving DreamSpark to millions of students in the United States, the United Kingdom, Canada, China, Germany, France, Finland, Spain, Sweden, Switzerland and Belgium. If you are not residing in one of the countries listed keep checking back, we will be adding more countries throughout the year. Does that mean that I might not get in?Possibly, if you are not residing in one of the countries listed, not attending an accredited university or not a member of one of the student organizations that we're connected with. But keep checking back, as we're working on adding more ways to verify your student status all the time. What do I have to do to get this software? Not much really, just select a product and follow the steps below.- Sign In with your Windows Live ID. If you don't have one, go get one here. Pretty basic stuff.
- Get verified as a student. The system is linked to schools and organizations around the world that can confirm student status. Simply choose your country and school, enter your info and hit submit.
- Download your products. Now remember these are professional tools. This means they are pretty big files so make sure you have the bandwidth and space to bring them to your machine. We support the latest versions of both Internet Explorer and Firefox for your download.
《边干边学》上一个简单的共享内存的例程:
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <errno.h>
#include <stdio.h>
#include <string.h>
#define KEY 1234
#define SIZE 1024
int main()
{
int shmid;
char *shmaddr;
struct shmid_ds buf;
shmid = shmget(KEY, SIZE, IPC_CREAT | 0600);
  if (shmid == -1) { if (shmid == -1) {
printf("Failed in creating shared memory: %s\n", strerror(errno));
return 0;
 } }
if (fork() == 0) {
shmaddr = (char *) shmat(shmid, NULL, 0);
if (shmaddr == (void *) -1) {
printf("Failed in connecting to the shared memory: %s\n", strerror(errno));
return 0;
}
strcpy(shmaddr, "Hello, this is child process!\n");
shmdt(shmaddr);
return 0;
} else {
sleep(3);
shmctl(shmid, IPC_STAT, &buf);
printf("Size of the shared memory: ");
printf("shm_segsz = %d bytes\n", buf.shm_segsz);
printf("Process id of the creator: ");
printf("shm_cpid = %d\n", buf.shm_cpid);
printf("Process id of the last operator: ");
printf("shm_lpid = %d\n", buf.shm_lpid);
shmaddr = (char *) shmat(shmid, NULL, 0);
if (shmaddr == (void *) -1) {
printf("Failed in connecting the shared memory: %s\n", strerror(errno));
return 0;
}
printf("The content of the shared memory: %s\n", shmaddr);
shmdt(shmaddr);
shmctl(shmid, IPC_RMID, NULL);
}
}
主要的API: shmget 创建一块共享内存 shmat 将一块已经存在的共享内存映射到一个进程的地址空间 shmdt 取消一个进程的地址空间中的一块共享块的映射 shmctl 管理共享内存,和ioctl的风格很像 每一个新创建的共享都由一个shmid_ds{}表示。struct shmid_ds在linux/shm.h中的定义:
/**//* Obsolete, used only for backwards compatibility and libc5 compiles */
struct shmid_ds {
struct ipc_perm shm_perm; /**//* operation perms */
int shm_segsz; /**//* size of segment (bytes) */
__kernel_time_t shm_atime; /**//* last attach time */
__kernel_time_t shm_dtime; /**//* last detach time */
__kernel_time_t shm_ctime; /**//* last change time */
__kernel_ipc_pid_t shm_cpid; /**//* pid of creator */
__kernel_ipc_pid_t shm_lpid; /**//* pid of last operator */
unsigned short shm_nattch; /**//* no. of current attaches */
unsigned short shm_unused; /**//* compatibility */
void *shm_unused2; /**//* ditto - used by DIPC */
void *shm_unused3; /**//* unused */
};其中存放权限信息的ipc_perm{}的定义为: include/linux/ipc.h
/**//* Obsolete, used only for backwards compatibility and libc5 compiles */
struct ipc_perm
{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};mode为该共享的内存的读写权限,和chmod的参数有点像。mode低九位定义了访问许可,解释如下:
0400 用户可读 0200用户可写 0040 组成员可读 0020 组成员可写 0004 其他用户可读 0002 其他用户可写
没有执行位 0100 0010 和 0001
_syscall 宏:
最简单的没有参数的系统调用的实现: /**//* XXX - _foo needs to be __foo, while __NR_bar could be _NR_bar. */
#define _syscall0(type,name) \
type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name)); \
__syscall_return(type,__res); \
}
以getuid()为例,_syscall0(int, getuid)展开后就变成 int getuid(void)
{
long __res;
__asm__ volatile("int $0x80"
:"=a" (__res)
:"0" (__NR_getuid));
__syscall_return(int, __res);
}
程序把系统调用号__NR_getuid放入eax寄存器,然后调用软中断。 include/asm-i386/hw_irq.h中的定义: 00025 #define SYSCALL_VECTOR 0x80;
arch/i386/kernel/traps.c中把该中断号绑定到system_call函数: 00944 set_system_gate(SYSCALL_VECTOR,&system_call);
system_call函数在arch/i386/kernel/entry.S中: ENTRY(system_call)
pushl %eax # save orig_eax
SAVE_ALL
GET_CURRENT(%ebx)
testb $0x02,tsk_ptrace(%ebx) # PT_TRACESYS
jne tracesys
cmpl $(NR_syscalls),%eax
jae badsys
call *SYMBOL_NAME(sys_call_table)(,%eax,4)
movl %eax,EAX(%esp) # save the return value
ENTRY(ret_from_sys_call)
cli # need_resched and signals atomic test
cmpl $0,need_resched(%ebx)
jne reschedule
cmpl $0,sigpending(%ebx)
jne signal_return
restore_all:
RESTORE_ALL 主要步骤: 1. 保留一份系统调用号的最初拷贝 2. 保存堆栈环境(SAVE_ALL) 3. 得到当前task_struct的地址,保存到ebx中 4. 检查系统调用号 5. 根据%eax调用号计算地址,调用相应函数 6. 在entry.S后面可以看到, .data
ENTRY(sys_call_table)
.long SYMBOL_NAME(sys_ni_syscall) /* 0 - old "setup()" system call*/
.long SYMBOL_NAME(sys_getuid16)
.long SYMBOL_NAME(sys_stime) /* 25 */
.long SYMBOL_NAME(sys_ptrace)
sys_call_table + %eax * 4是sys_getuid16地址,kernel/uid16.c中:
asmlinkage long sys_getuid16(void)
{
return high2lowuid(current->uid);
} 很简单的处理代码,返回当前进程的uid。这里asmlinkage修饰符表示函数必须从堆栈中,而不是从寄存器中拿参数(防止gcc用寄存器传参优化)。 7. 保存返回值eax到堆栈中的eax 8. RESTORE_ALL 另外这里再提一下GET_CURRENT的实现 #define GET_CURRENT(reg) \
movl $-8192, reg; \
andl %esp, reg 很巧妙的实现,把栈指针与掩码-8192做与操作,末尾13位清零,就是当前的进程的task_struct地址了。 接下来是利用内核模块动态添加一个系统调用的例程,由于2.4.20以后sys_call_table符号不再被导出了,要获得这个地址得手动hack。尚未成功,下次回过头来看看。
Mars: A MapReduce Framework on Graphics Processors
by Bingsheng He @ Hong Kong Univ. of Sci. & Tech.
Nage K. Govindaraju @ Microsoft Corp.
Qiong Luo, Tuyong Wang @ Sina Corp.
一些重点摘记:
1. Introduction
Three challenges in implementing the MapReduce framework on the GPU:
First, the synchronization overhead in the run-time system of the framework must be low.
Second, a fine-grained load balancing scheme is required.
Third, the core tasks of MapReduce, including string processing, file manipulation and concurrent reads and writes, are unconventional to GPUs and must be handled efficiently.
Each thread is responsible for a Map or a Reduce task with a small number of key/value pairs as input.
Performance improvement: 1.5-16 times
2. Priliminary and Related Work
2.1. Graphics Processors
It is desirable to schedule the tasks between the CPU and the GPU to fully exploit their computation power.
Given a kernel program, the occupancy of the GPU is the ratio of active schedule units to the maximum number of schedule units supported on the GPU.
The GPU has a hardware feature called coalesced access to exploit the spatial locality of memory accesses among threads.
2.2. GPGPU
2.3. MapReduce
Map: (k1, v1) -> (k2, v2)*
Reduce: (k2, v2*) -> v3*
3. Design and Immplementation
3.1. Design Goals
3.2. System Workflow and Configuration
3.3. APIs
3.4. Implementation Techniques
Based on this compilation information and the total computation resources on the GPU, we set the number of threads per thread group and the number of thread groups to achieve a high occupancy at run time.
4. Evaluation
4.1. Experimental Setup
作者是豆瓣上的草薰风暖
http://www.douban.com/people/1299430/
长大以后,不会仅仅因为文笔而喜欢一个作家,也不会因为情节曲折而喜欢一部书。有一种读者和作者之间的传神,我领会为“心跳的合拍”,从字里行间,从遣词造句,从审美风格,从情感表达,从思维方式……我深信,如果喜欢一本书,必然和这本书的作者在性情上有某种程度的相似或者共鸣。
我不喜欢杜拉斯的语言,只记得她说过的一种偏爱,她说她喜欢只写过一部作品的作家。我的体会是,我只喜欢至少有过一部作品使我感到“心跳的合拍”的作家。比如陈丹燕,那个被朋友称之为面目阴暗的女子,却因为她的一部《女中学生之死》令我坚持喜欢,尽管她后来的上海系列再不能打动我。(可能今天的我再去读《女》就不会那么感慨,可能。)
相对于欧美小说的叙述笔调,我更能体会和揣摩部分日本小说里的情欲,不是说前者不能明白,只是对后者的玩味更得心应手。比如村上春树,尽管他的作品除了幽微蓝调、内心独白的风格之外,也透着阴郁潮湿的气味,我想,恐怕算得上微微一点病态而不至于变态的美感,像爵士乐,村上春树的抒情深沉而敏感。
是的,安静下来,你能够听到心脏的声音。听到一个沉静又自命不凡的男子从12岁到37岁的心脏的声音。手边的这本《国境以南,太阳以西》是很早就借的,在这样热的夏天读起来却格外喜欢。
这部小说不妨说是一个人的成长史,而里面的每个人,初君,岛本,泉,有纪子,也都不能说不是可爱的。
【岛本】
两个12岁的被群体隔膜的独生子女成为好朋友,那种心灵共振的好朋友。恐怕谁都会觉得那样一种场景无限美好,两个孩子坐在一起一下午,听李斯特的钢琴,说话。我宁可把他们的交谈称之为说话,说心里想的话,说思考过的话,说简单又蕴藏真切感受的话。两个相似的独生子女,在一起说话,在一起听话,宁静的,专注的,不被周围的人打扰,陪伴彼此安静的时间和声音,缓缓的,淡淡的,一点一点的,就像异常漂亮但腿有点跛的岛本走路的情状,耐心而从容。
【初君】
不用说,若有细心人细心观察,应该不难看出初君是免不了有其自身问题的,然而说到底,世界上又哪里存在没有其自身问题的少年呢?初君是一个异常孤独而傲慢的少年,需要和同伴配合的体育项目他无论如何喜欢不来,同他人抢分的竞赛也不屑一顾。但也不是彻头彻尾的孤独。尽管为数不多,还是交了几个要好的朋友。假如身边没有那样的朋友,一个人在通过二十岁以前那段不安稳岁月的过程中难免受到更深的伤害。
初君的第一个女朋友泉指出他是一个独生子,并非说他是被宠坏了的孩子,而是指他有孤独倾向的个性,很难走出一个人的世界。从某种意义上,岛本为了保护自己会使得自己微笑,而初君连随和的微笑都觉得累赘。
恐怕我们每个人多少都会认同独生子女有着强烈的自我意识,并略感悲哀我们难以向别人敞开心扉。假如不是通过书,我们不可能分享初君那样一个独生子从12岁到37岁内心隐秘的情感和意象,这也是我曾经喜欢陈丹燕《一个女孩》的原因。虽然都不过是孩子,也未尝不具备某种“思想家”和“艺术家”的潜质。而通过他们的内心独白,你大概会觉得自己不孤单,甚至连那些白日梦都让你觉得可亲和会心,后来明白,一个孩子苦心经营的白日梦,不外乎是自我中心的或者连接着某个重要的人,不外乎是自己变得不同寻常出色厉害或者沉溺于悲伤惨淡的情境情结中……我不知道有多少人是如此,或者说生活太吵闹而这些人又隐匿在自我里,所以彼此看不见。 但我想总是有一部分人如此。
国境以南,太阳以西,看见,人生的样子。时光,是很冷的东西。一个人,一个个人,从遇事不知所措的懦弱的少年走到平和的微笑的知足惜福的也带一点伤感的中年,尽管途经波涛暗涌,最后仍只剩下沙漠。岁月这东西是要把人变成各种样子的,有纪子其后遇上了初君,而泉大概谁也没有遇上。而无论初君说什么,岛本都浮现出将所有感情吞噬一尽的迷人微笑看着他,就好像在说“没关系的,这样可以的。”“活法林林总总,死法种种样样,都没什么大不了的。剩下来的唯独沙漠,真正活着的只有沙漠。”
小说里几乎每个人物的性格都透着一点清冷,读起来却有一股温暖的温柔的温情的东西在。也许人是难以活得过分自我的,即使有心也不能。岛本的幽微美丽荡漾着死的气息,美人对男人有安抚的作用,初君也期待“专为我准备”的一个女子,可惜时间不能挽回,她所要求的全部非死不能成全。有纪子对初君并非完完全全,而他们最终在沙漠里好端端活下去。既非生气,又不悲伤,有纪子仅仅是将事实作为事实说出口来。“你的确是个自私自利的人、不地道的人……但这些都不是问题。你肯定什么都不明白。”有纪子是懂得初君的。
(这不见得是一部多么精彩的书,不过可以从中窥见几许人性自然,但很令人不爽的一点是,最终作者也不肯告诉我们岛本过去究竟有着怎样的经历现在有着怎样的身份!!他不想说就不要卖关子!!!)
人和人是不同的,有些人是写字的,有些人是看字的,事实上这两种人又有相通的潜质,否则不会懂得。世间,一直有像村上春树,像普鲁斯特,像卡夫卡那样曲径通幽的灵魂,因而也就一直有读他们灵魂的人,虽然,艺术气质永不是生存的主流。
不想一天到晚呆坐电脑前,灌灌水,聊聊天
还是读点村上的
《挪威的森林》估计是因为太喜欢,带到学校里了
那就先重读《国境以南,太阳以西》
当时应该是一行推荐我看安妮的书,然后我看到99的书单上安妮推荐了这本书,于是我就没买安妮的,买了这本 =_=
从此就迷上村上的小说了。尽管这本和《挪威的森林》与村上其他作品的风格还是有一定出入的。
发现自己对Python的语法的兴趣远比对使用Python本身的兴趣浓厚得多
为什么水木上的帖子每行末尾都是用空格填充的,每次转载还要先放到vim里面处理一下。。。
by ilovecpp
让Python支持true closure有多难?
只需修改11行代码。
如果你不知道什么是true closure,这里简单解释一下。Python支持lexicalscope:
>>> def add_n(n):
... def f(m):
... return n+m
... return f
>>> add_2 = add_n(2)
>>> add_2(0)
2
>>> add_2(2)
4
f引用了外层函数add_n的局部变量n。有趣的是,f引用n的时候,add_n已经结束,n似乎不存在了。f所以能正常工作,是因为创建它的时候就把n作为f的上下文(closure)保存了下来,并不随add_n结束而消失。
但是,Python的lexical scope和Scheme/Smalltalk/Ruby还有一点区别:不能在内层函数中rebind外层函数的局部变量。
>>> def f():
... def g():
... n=1
... n=0
... g()
... return n
...
>>> f()
0
这是因为Python没有变量声明, n=1 自动使n成为g的局部变量,也就无法rebind f中的n了。可以说Python的closure是只读的。如果你听到有人说"Python不支持true closure",就是指这个。其实,Python VM能够支持true closure。因为,Python支持内层函数看见外层函数的name rebinding:
>>> def f():
... def g():
... yield n
... yield n
... x = g()
... n = 0
... print x.next()
... n = 1
... print x.next()
...
>>> f()
0
1
对于Python的closure实现(flat closure),"外层函数rebind name"和"内层函数rebind name"其实没有区别。我们知道用global关键字可以rebind module scopename。如果增加一个类似的outer关键字,就可以支持rebind outer scope name。真正的限制是Guido不愿意为支持true closure增加关键字。
也可以不增加关键字,而是把global n的语义改为"如果outer scope定义了n,rebind outer scope n;否则rebind module scope n"。简单起见,我没有修改Python的built-in compiler,而是修改了compiler module(用Python实现的Python compiler)。你只需把下面这个patch打到compiler/symbols.py(Python 2.5.1)就可以体验true closure了:
C:\Python\Lib>diff -u compiler/symbols.py.orig compiler/symbols.py
--- compiler/symbols.py.orig Thu Aug 17 10:28:56 2006
+++ compiler/symbols.py Mon Feb 11 12:03:01 2008
@@ -21,6 +21,7 @@
self.params = {}
self.frees = {}
self.cells = {}
+ self.outers = {}
self.children = []
# nested is true if the class could contain free variables,
# i.e. if it is nested within another function.
@@ -54,8 +55,10 @@
if self.params.has_key(name):
raise SyntaxError, "%s in %s is global and parameter" % \
(name, self.name)
- self.globals[name] = 1
- self.module.add_def(name)
+ if self.nested:
+ self.outers[name] = 1
+ else:
+ self.globals[name] = 1
def add_param(self, name):
name = self.mangle(name)
@@ -90,6 +93,8 @@
"""
if self.globals.has_key(name):
return SC_GLOBAL
+ if self.outers.has_key(name):
+ return SC_FREE
if self.cells.has_key(name):
return SC_CELL
if self.defs.has_key(name):
@@ -107,6 +112,7 @@
return ()
free = {}
free.update(self.frees)
+ free.update(self.outers)
for name in self.uses.keys():
if not (self.defs.has_key(name) or
self.globals.has_key(name)):
@@ -134,6 +140,9 @@
free.
"""
self.globals[name] = 1
+ if self.outers.has_key(name):
+ self.module.add_def(name)
+ del self.outers[name]
if self.frees.has_key(name):
del self.frees[name]
for child in self.children:
因为我们没有修改built-in compiler,所以程序要写在字符串里,用compiler.compile编译,用exec执行:
>>> from compiler import compile
>>> s = '''
... def counter():
... n = 0
... def inc():
... global n
... n += 1
... def dec():
... global n
... n -= 1
... def get():
... return n
... return inc, dec, get
... '''
>>> exec compile(s, '', 'exec')
>>> inc, dec, get = counter()
>>> get()
0
>>> inc()
>>> get()
1
>>> dec()
>>> get()
0
后记
1 搞这个东西的缘起是Selfless Python(http://www.voidspace.org.uk/python/weblog/arch_d7_2006_12_16.shtml#e583)。很有趣的bytecode hack,给一个类中的所有函数补上self参数。既然PythonVM支持true closure,能不能用类似的手法让Python支持true closure呢?不过很快就明白这个在bytecode层面不好弄,还是得修改编译器。不过改起来还真是出乎意料地简单。
2 Guido早已明确表示不能改变global的语义(因为会影响现有代码),所以这个只是玩玩而已,不用指望成为现实。当然你可以只发布bytecode,大概还能把反编译器搞挂掉。:-)
3 我可以理解Guido的决定。除非你之前一直在用Scheme,否则我觉得像上面counter例子那种一组共享状态的函数还是写成class为好,至少共享状态是什么一目了然。Lexical scope太implicit,用在开头add_n那种地方挺方便,再复杂就不好了。
又:很抱歉"幕后的故事"拖了这么久。写起来才发现自己还是不懂descriptor。
不过我肯定不会让它烂尾的。
zz from 游侠
http://game.ali213.net/viewthread.php?tid=1874905
转自巴哈姆特,原帖主clover0425
原帖地址
http://forum.gamer.com.tw/C.php?bsn=01223&snA=9101
==============(等级~等级)============================
怪物(分类)等级+怪物(分类)等级=怪物(分类)等级
合成结果如下:
==============(LV.1~LV.10)============================
青蛙(生物)LV.1+蟾蜍(生物)LV.1=蟾蜍(生物)LV.1
青蛙(生物)LV.1+刺胡蜂(生物)LV.3=蟾蜍(生物)LV.1
青蛙(生物)LV.1+通臂猖猿(精怪)LV.4=青蛙(生物)LV.1
草妖(精怪)LV.1+草妖(精怪)LV.1=泥童(活尸)LV.2
泥童(活尸)LV.2 +草妖(精怪)LV.1=青蛙(生物)LV.1
泥童(活尸)LV.2 +泥童(活尸)LV.2=草妖(精怪)LV.1
蟾蜍(生物)LV.1+蟾蜍(生物)LV.1=蟾蜍(生物)LV.1
蟾蜍(生物)LV.1+草妖(精怪)LV.1=蟾蜍(生物)LV.1
蟾蜍(生物)LV.1+刺胡蜂(生物)LV.3=蟾蜍(生物)LV.1
蟾蜍(生物)LV.1+通臂猖猿(精怪)LV.4=蟾蜍(生物)LV.1
蟾蜍(生物)LV.1+长颈鬼(活尸)LV.5=毒蛇(生物)LV.2
★备注:魏国士兵无法收服,所以无法炼化。
蝙蝠(生物) LV.1+蝙蝠(生物) LV.1=蟾蜍(生物)LV.1
蝙蝠(生物) LV.1+蟾蜍(生物)LV.1=蟾蜍(生物)LV.1
蝙蝠(生物) LV.1+毒蛇(生物)LV.2=蟾蜍(生物)LV.1
蝙蝠(生物) LV.1+刺胡蜂(生物)LV.3=蟾蜍(生物)LV.1
蝙蝠(生物) LV.1+通臂猖猿(精怪)LV.4=蟾蜍(生物)LV.1
刺胡蜂(生物)LV.3+刺胡蜂(生物)LV.3=魏国亡兵(鬼魂)LV.7
刺胡蜂(生物)LV.3+通臂猖猿(精怪)LV.4=魏国亡兵(鬼魂)LV.7
毒蛇(生物)LV.2+蟾蜍(生物)LV.1=蟾蜍(生物)LV.1
毒蛇(生物)LV.2+毒蛇(生物)LV.2=蟾蜍(生物)LV.1
毒蛇(生物)LV.2+刺胡蜂(生物)LV.3=蟾蜍(生物)LV.1
毒蛇(生物)LV.2+通臂猖猿(精怪)LV.4=蟾蜍(生物)LV.1
蜘蛛(生物) LV.2+蝙蝠(生物) LV.1=蟾蜍(生物)LV.1
蜘蛛(生物) LV.2+蜘蛛(生物) LV.2=魏国亡兵(鬼魂)LV.7
蜘蛛(生物) LV.2+通臂猖猿(精怪)LV.4=魏国亡兵(鬼魂)LV.7
蜘蛛(生物) LV.2+魏国亡兵(鬼魂)LV.7=青蛙(生物)LV.1
狐精(妖灵) LV.2+狐精(妖灵)LV.2=蟾蜍(生物)LV.1
狐精(妖灵) LV.2+魏国亡兵(鬼魂)LV.7=青蛙(生物)LV.1
通臂猖猿(精怪)LV.4+泥童(生物)LV.2 =长颈鬼(活尸)LV.5
通臂猖猿(精怪)LV.4+通臂猖猿(精怪)LV.4=魏国亡兵(鬼魂)LV.7
魏国亡兵(鬼魂)LV.7+毒蛇(生物)LV.2=青蛙(生物)LV.1
魏国亡兵(鬼魂)LV.7+通臂猖猿(精怪)LV.4=青蛙(生物)LV.1
魏国亡兵(鬼魂)LV.7+魏国亡兵(鬼魂)LV.7=角鹰(生物)LV.10
芙蕖精(仙灵)LV.10+污泥怪(活尸)LV.25=玄龟(神兽)LV.39
芙蕖精(仙灵)LV.10+雨女(妖灵)LV.11=颙(妖灵)LV.21
角鹰(生物)LV.10+角鹰(生物)LV.10=等活狱兵(?)LV.?
獍(魔兽)LV.10+碧鬼魔(魔神)LV.22=娥仙(仙灵)LV.17
==============(LV.11~LV.20)============================
雨女(妖灵)LV.11+雨女(妖灵)LV.11=赑屃(神兽)LV.30
九曜神兵(天神)LV.13+角鹰(生物)LV.10=赑屃(神兽)LV.30
娥仙(仙灵)LV.17+仙芝(仙灵)LV.14=蛟蝮魔(魔兽)LV.24
髑髅(活尸)LV.18+仙芝(仙灵)LV.14=玄龟(神兽)LV.39
无头鬼(鬼魂)LV.19+鬼瞳(鬼魂)LV.22=马面(魔神)LV.42
==============(LV.21~LV.30)============================
颙(妖灵)LV.21+獍(魔兽)LV.10=牛头(魔神)LV.42
颙(妖灵)LV.21+白玉琼浆(?)LV.30=赤焰仙子(仙灵)LV.31
颙(妖灵)LV.21+鹿皮靴(?)LV.14=马面(魔神)LV.42
碧鬼魔(魔神)LV.22+罴(生物)LV.14=污泥怪(活尸)LV.25
碧鬼魔(魔神)LV.22+碧鬼魔(魔神)LV.22=希夷(?)LV.28
竦斯(妖灵)LV.23+蛟蝮魔(魔兽)LV.24=马面(?)LV.42
蛟蝮魔(魔兽)LV.24+药草(?)LV.1=牛头(魔神)LV.42
博木妖(精怪)LV.25+博木妖(精怪)LV.25=阴颅(活尸)LV.36
锁爷(鬼魂)LV.26+锁爷(鬼魂)LV.26=黑血巨蟒(生物)LV.36
巨怪(魔兽)LV.26+蛟蝮魔(魔兽)LV.24=丹顶(仙灵)Lv.32
化虎(?)LV.27+武虎虎王(?)LV.35=夜叉(?)LV.44
魔剑客(妖灵)LV.29+化虎(妖灵)LV.27=英招(神兽)LV.42
魔剑客(妖灵)LV.29+五方天兵(天神)LV.18=金线草妖(精怪)LV.30
魔剑客(妖灵)LV.29+苞娘(精怪)lv.30=灵目鬼(鬼魂)lv.35
魔剑客(妖灵)LV.29+食人妖花(精怪)lv.23=怨魂(鬼魂)lv.29
魔剑客(妖灵)LV.29+赤焰仙子(仙灵)lv.31=山神(仙灵)lv.33
魔剑客(妖灵)LV.29+蝶仙(仙灵)LV.32=晶硥(妖灵)LV.32
==============(LV.31~LV.40)============================
赤焰仙子(仙灵)LV.31+赤焰仙子(仙灵)LV.31=虣虎王(?)LV.35
赤焰仙子(仙灵)LV.31+硥(妖灵)LV.25=蝶仙(仙灵)LV.32
蝶仙(仙灵)LV.32+怨魂(鬼魂)LV.27=鬼菇(精怪)LV..38
蝶仙(仙灵)LV.32+鬼朣(鬼魂)LV..22=寒玉藤(精怪)LV..32
阴颅(活尸)LV.36+黑血巨莽(生物)LV.36)=殍髅(活尸LV.40
巨灵神将(天神)LV.38+巨?怪(魔兽)LV.20=青尾凤友(生物)LV.50
巨灵神将(天神)LV.38+苞娘(精怪)LV.30=女英(仙灵)LV.35
巨灵神将(天神)LV.38+金线草妖(精怪)LV.30=娥皇(仙灵)LV.35
巨灵神将(天神)LV.38+食人妖花(精怪)LV.23=镇山元帅(仙灵)LV.34
九天玄女(仙灵)LV.38+娥皇(仙灵)LV.35=炎罴兽(魔兽)LV.40
九天玄女(仙灵)LV.38+山神(仙灵)LV.35=天火假猿(魔兽)LV.38
九天玄女(仙灵)LV.38+食火蛛(妖灵)LV.36=朱[舌鸟](仙灵)LV.36
黑绳狱卒(鬼魂)LV.38+苞娘(精怪)LV.30=枷爷(鬼魂)LV.40
鴸(妖灵)LV.40+苞娘(精怪)LV.30=冥府鬼焰(鬼魂LV.40
鴸(妖灵)LV.40+金线草妖(精怪)LV.30=吴兵亡灵(鬼魂)LV.42
鴸(妖灵)LV.40+山神(仙灵)LV.35=朱[舌鸟](仙灵)LV.30
==============(LV.41~LV.50)============================
牛头(魔神)LV.42+镇山元帅(?)LV.?=阿鼻狱使(鬼魂)LV.49
英昭(神兽)LV.42+蛟腹魔(魔兽)LV.24=玄龟(神兽)LV.39
夜叉(魔神)LV.44+蝶仙(仙灵)LV.32=阿鼻狱使(鬼魂)LV.49
夜叉(魔神)LV.44+玄龟(天神)LV.39=战死尸鬼(活尸)LV.45
夜叉(魔神)LV.44+枷爷(鬼魂)LV.40=赤滕(妖灵)LV.47
夜叉(魔神)LV.44+吴兵亡灵(鬼魂)LV.42=鬼魈(妖灵)LV.48
夜叉(魔神)LV.44+殍髅(活尸)LV.42=蝮魔王(魔兽)LV.44
诸怀(神兽)LV.45+蝮魔王(魔兽)LV.44=白虎(神兽)LV.52
诸怀(神兽)LV.45+独目鬼(魔兽)LV.46=青龙(神兽)LV.52
诸怀(神兽)LV.45+吴兵亡灵(鬼魂)LV.42=上元夫人(仙灵)LV.52
诸怀(神兽)LV.45+炎罴兽(魔兽)LV.40=开明兽(仙灵)LV.52
雷电灵霸(魔兽)LV.50+开明兽(神兽)LV.52=麒麟(神兽)LV.55
雷电灵霸(魔兽)LV.50+诛怀(神兽)LV.45=黑龙(神兽)LV.55
雷电灵霸(魔兽)LV.50+黑龙(神兽)LV.55)=兕(魔兽)LV.58
==============(LV.51~LV.60)============================
青龙(神兽)LV.52+黑龙(神兽)LV.55=奇[仓鸟](妖灵)LV.56
青龙(神兽)LV.52+蛟腹魔(魔兽)LV.24=希有(神兽)LV.49
青龙(神兽)LV.52+鬼火(鬼魂)LV.20=朱舌鸟(仙灵)LV.36
上元夫人(仙灵)LV.52+骑督亡灵(鬼魂)LV.47=鬼蔷(精怪)LV.56
阿修罗(魔神)LV.55+夜叉(魔神)LV.44=托塔天王(天神)LV.58
麒麟(神兽)LV.55+蛟腹魔(魔兽)LV.24=哮天犬(神兽)LV.50
云生兽(神兽)LV.55+殍髅(活尸)LV.40=焰尾朱鸟(生物)LV.54
云生兽(神兽)LV.55+蛊使(鬼魂)LV.45=镇元大仙(仙灵)LV.52
云生兽(神兽)LV.55+炎罴兽(魔兽)LV.40=黑龙(神兽)LV.55
云生兽(神兽)LV.55+蝮魔王(魔兽)LV.44=犎魔元帅(魔兽)LV.55
云生兽(神兽)LV.55+天火假元(魔兽)LV.38=雷电灵霸(魔兽)LV.50
云生兽(神兽)LV.55+兕(魔兽)LV.58=龙王(神兽)LV.62
托塔天王(天神)LV.58+阿修罗(魔神)LV.52=菩提祖师(天神)LV.62
托塔天王(天神)LV.58+焰尾朱鸟(生物)LV.54)=云生兽(神兽)LV.55
兕(魔兽)LV.58+开明兽(神兽)LV.52=凤凰(神兽)LV.60
zz from 游侠
http://game1.ali213.net/thread-1874977-1-1.html
转自巴哈姆特,原帖主fitbtm6810,修正部分错字加重新排版。
原帖地址
http://forum.gamer.com.tw/C.php?bsn=01223&snA=9714
http://forum.gamer.com.tw/C.php?bsn=01223&snA=9751
==========================================================
武器:
炼化规则:
神兽+饰品 & 鬼魂+饰品 & 活尸+防具 & 奇物+防具 & 饰品+饰品 & 武器+防具 (出现武器或防具)
剑:
昆吾剑15级=泥童+沉胜衣
雁翎刀20级=月隐服+振心散 & 赑屃+金牛角
青釭剑26级=无法利用炼化出现
龙鳞32级=玄雀+沉胜衣 & 金刚月牙+沉胜衣
纯钧剑40级=无法利用炼化出现
百辟48级=青龙+云隐戒指 & 神臂弓+九霄连摆甲
封魔刀55级=纯钩剑+银狐裘 & 百辟+神影游龙服
刃:
五毒刀13级=振心散+诫袍
炎突18级=铁甲+振心散
星驰24级=无法利用炼化出现
玄雀30级=雁翎刀+水镜银衫 & 火神弓+须弥琉璃甲
九绝38级=无法利用炼化出现
鬼眼46级=无法利用炼化出现
翔风53级=百辟+九霄连摆甲 & 百辟+赤焰霓裳
戟:
玄铁枪16级=无法利用炼化出现
透甲枪21级=樊木+铁甲 & 赤焰连环甲+抑神粉
蛇矛27级=无法利用炼化出现
铁戟33级=龙鳞+天星甲 & 玄龟+明日香包
百胜戟41级=玄雀+九霄连摆甲 & 金星白玉锤+水镜银衫
竞月勾49级=青龙+蓝玉戒指 & 青龙+琥珀戒指 & 九绝+神影游龙服
逐日戟56级=护法神杖+玄溟战甲 & 振心粉+水镜银衫
镇魂神枪60级=封魔刀+银狐裘
杖:
夜叉杵13级=等活狱兵+金牛角
樊木18级=无法利用炼化出现
天师诚24级=无法利用炼化出现
金刚月牙30级=污泥怪+沉胜衣 & 火神弓+沉胜衣
冲霄神杖38级=无法利用炼化出现
太虚神杖46级=百战戟+水镜银衫 & 九霄连摆甲+龙鳞
无极53级=百战戟+御灵圣环铠
护法神杖56级=封魔刀+神影游龙服 & 翔风+银狐裘
弓:
桑弧弓14级=无法利用炼化出现
火神弓19级=等活狱兵+神草结 & 振心散+天羽彩衣
伏魔弓25级=无法利用炼化出现
逐日弓31级=蓝玉戒指+鬼瞳 & 透甲枪+沉胜衣
神臂弓39级=金星白玉锤+天星甲 & 铁戟+须弥琉璃甲
刚侯弓47级=金刚月牙+神影游龙服 & 太虚神杖+水镜银衫
斧:
开明斧19级=无法利用炼化出现
诛剌25级=沉胜衣+抑神粉
金星白玉锤39级=逐日弓+水镜银衫
狂章47级=无法利用炼化出现
雷公震54级=无法利用炼化出现
==========================================================
防具:
炼化规则:
天神+武器 & 精怪+灵药 & 生物+灵药 & 武器+足具 & 灵药+灵药 & 武器+防具 (出现武器或防具)
武士:
铣甲17级=药草+返魂香
赤焰连环甲21级=跌打伤药+返魂香
天星甲27级=白玉琼浆+返魂香 & 雁翎刀+沉胜衣
须弥琉璃甲33级=逐日弓+沉胜衣 & 金刚月牙+天星甲
九霄连摆甲41级=龙鳞+赤焰霓裳 & 神臂弓+水镜银衫
御灵圣环铠49级=太虚神杖+九霄连摆甲 & 龙鳞+银狐裘
玄冥战甲56级=无极+神影游龙服 & 翔风+御灵圣环铠
法师:
天羽彩衣15级=解毒草+返魂香
月隐服20级=消疲丸+返魂香
沉胜衣26级=活络散(灵仙酒)+返魂香 & 返魂香+返魂香
水镜银衫32级=雁翎刀+须弥琉璃甲 & 白玉琼浆+白玉琼浆
赤焰霓裳40级=龙鳞+水镜银衫 & 铁戟+水镜银衫
神影游龙服48级=百胜戟+九霄连摆甲 & 百胜戟+赤焰霓裳
银狐裘55级=神影游龙服+太虚神杖 & 百辟+攀云踏风鞋
==========================================================
足具:
炼化规则:
神兽+防具 & 饰品+防具 & 鬼魂+防具 & 活尸+奇物 & 奇物+奇物 & 奇物+足具 (出现足具或奇物)
鹿皮靴14级=铁甲+金牛角
驰云履19级=振心散+抑神粉
鬼爪履25级=沉胜衣+神草结 & 沉胜衣+汉兵亡灵
龙麟百足靴31级=赑屃+天星甲 & 水镜银衫+汉兵亡灵
追风流光鞜39级=须弥琉璃甲+赑屃 & 九霄连摆甲+蓝玉戒指
攀云踏风鞋47级=玄龟+九霄连摆甲 & 玄龟+赤焰霓裳
疾风鞮54级=诸怀+神影游龙服 & 云生兽+40级以上防具
==========================================================
饰品:
炼化规则:
天神+灵药 & 生物+足具 & 精怪+足具 & 武器+武器 & 灵药+足具
金牛角03级=草药+布鞋
防御手环03级=短刃+短刃
防毒香包08级=跌打药伤+布鞋
驱邪香包08级=消疲丸+布鞋
天仙符10级=返魂香+布鞋
凰羽10级=活络散+布鞋
醒脑香包12级=九曜神兵+活络散
神草结15级=五方神兵+返魂香
明目香包15级=五方神兵+活络散
照妖镜18级=龙鳞+雁翎刀
芭蕉扇18级=金刚月牙+雁翎刀
太极护符18级=龙鳞+金星白玉锤
镇心炼18级=龙鳞+龙鳞
万宝节环20级=
护身令牌20级=
云隐戒指22级=金星白玉锤+金星白玉锤
玄冥戒25级=
龟蛇旗25级=
蓝玉戒指25级=
琥珀戒指25级=
天女丝巾28级=
北斗挂日链30级=
白玉龙纹佩35级=镇魂神枪+护法神杖
==========================================================
灵药:
炼化原则:
神兽+奇物 & 活尸+饰品 & 鬼魂+奇物 & 防具+防具 & 奇物+饰品
恢复生命:
跌打伤药15级=赤焰连环甲+铁甲
金创药24级=抑神粉+玄龟
天创药32级=九霄连摆甲+九霄连摆甲(须弥琉璃甲)
地脉血泉08级=赤焰连环甲+藤甲
不死泉水18级=赑屃+振心散
破元仙露26级=须弥琉璃甲+天星甲(水镜银衫)
恢复体力:
消疲丸10级=镇心炼+长颈鬼
活络散20级=沉胜衣+沉胜衣
活骨灵药28级=九霄连摆甲+天星甲
灵山雪参35级=
恢复灵力:
金蜂蜜10级=天羽彩衣+天羽彩衣
灵仙酒20级=天星甲+天星甲
蟠桃28级=水镜银衫+赤焰连环甲
归元花露水35级=赤焰霓裳+赤焰霓裳
恢复生命&体力&灵力:
九命猫脑浆40级=
状态恢复:
返思铃01级=藤甲+护身短甲
绝情膏12级=铁甲+铁甲
润喉丸06级=护身短甲+护身短甲
龙爪花15级=赤焰连环甲+赤焰连环甲
目药粉06级=诫袍+诫袍
溶石魔羽15级=天星甲+铁甲
返魂香25级=九霄连摆甲+赤焰连环甲
白玉琼浆30级=
轮回盘40级=
==========================================================
奇物:
炼化原则:
天神+足具 & 武器+生物 & 足具+足具 & 武器+精怪 & 武器+灵药 & 足具+奇物
土地神符8级=草药+铜剑
诱敌女娃8级=跌打伤药+铜剑
振心散15级=消疲丸+铜剑
抑神粉15级=活络散(返魂香)+昆吾剑
神秘果60级=无法炼化
雪肌冰饱60级=无法炼化
新绝代双骄的插曲,当时蛮有感觉的,突然想起来我还没听过完整的。
http://www.whjsr.com/dc.mp3
我的双脚陷进爱中
等了已好久好久
你的手从指间经过
只能碰却不能握
心里好多话对你说
你却看着我沉默
这样的相爱那儿有错
连云也难说服我
我不是个稻草人
不能动不能说
已把爱紧紧绑心中
我不是个稻草人
没人爱没人懂
再难再疯我要结果
我不是个稻草人
看天亮看日落
就等你给我一双手
我不是个稻草人
不做梦不还手
别用泪水逼我放手
就算全界都笑我
爱个人谁敢说错
就算全世界都怪我
我只要你跟我走
借用里面的话来说,就是
连年动众,未能成功——盖应变、将略,非其所长!
摘要: /proc文件系统不是直接从内核的存储区中读写数据,二是通过回调函数实现文件读写的。struct proc_dir_entry有一对读写操作函数指针read_proc_t, write_proc_t。
一个编写内核模块操作proc文件系统的例子,书上的源程序是在2.4.18下跑起来的,改了三个地方在2.6.23下成功运行。当然Makefile也按照2.6中make modules的方式写了。
... 阅读全文
作者:晏渭川
随着Linux2.6的发布,由于2.6内核做了新的改动,各个设备的驱动程序在不同程度上要进行改写。为了方便各位Linux爱好者我把自己整理的这分 文档share出来。该文当列举了2.6内核同以前版本的绝大多数变化,可惜的是由于时间和精力有限没有详细列出各个函数的用法。
1、 使用新的入口
必须包含 <linux/init.h>
module_init(your_init_func);
module_exit(your_exit_func);
老版本:int init_module(void);
void cleanup_module(voi);
2.4中两种都可以用,对如后面的入口函数不必要显示包含任何头文件。
2、 GPL
MODULE_LICENSE("Dual BSD/GPL");
老版本:MODULE_LICENSE("GPL");
3、 模块参数
必须显式包含<linux/moduleparam.h>
module_param(name, type, perm);
module_param_named(name, value, type, perm);
参数定义
module_param_string(name, string, len, perm);
module_param_array(name, type, num, perm);
老版本:MODULE_PARM(variable,type);
MODULE_PARM_DESC(variable,type);
4、 模块别名
MODULE_ALIAS("alias-name");
这是新增的,在老版本中需在/etc/modules.conf配置,现在在代码中就可以实现。
5、 模块计数
int try_module_get(&module);
module_put();
老版本:MOD_INC_USE_COUNT 和 MOD_DEC_USE_COUNT
http://www.fsl.cs.sunysb.edu/~sean/parser.cgi?modules
In 2.4 modules, the MOD_INC_USE_COUNT macro is used to prevent unloading of the module while there is an open file. The 2.6 kernel, however, knows not to unload a module that owns a character device that's currently open.
However, this requires that the module be explicit in specifying ownership of character devices, using the THIS_MODULE macro.
You also have to take out all calls to MOD_INC_USE_COUNT and MOD_DEC_USE_COUNT.
static struct file_operations fops =
{
.owner = THIS_MODULE,
.read = device_read,
.write = device_write,
.open = device_open,
.release = device_release
}
The 2.6 kernel considers modules that use the deprecated facility to be unsafe, and does not permit their unloading, even with rmmod -f.
2.6,2.5的kbuild不需要到处加上MOD_INC_USE_COUNT来消除模块卸载竞争(module unload race)
6、 符号导出
只有显示的导出符号才能被其他模块使用,默认不导出所有的符号,不必使用EXPORT_NO_SYMBOLS
老板本:默认导出所有的符号,除非使用EXPORT_NO_SYMBOLS
7、 内核版本检查
需要在多个文件中包含<linux/module.h>时,不必定义__NO_VERSION__
老版本:在多个文件中包含<linux/module.h>时,除在主文件外的其他文件中必须定义__NO_VERSION__,防止版本重复定义。
8、 设备号
kdev_t被废除不可用,新的dev_t拓展到了32位,12位主设备号,20位次设备号。
unsigned int iminor(struct inode *inode);
unsigned int imajor(struct inode *inode);
老版本:8位主设备号,8位次设备号
int MAJOR(kdev_t dev);
int MINOR(kdev_t dev);
9、 内存分配头文件变更
所有的内存分配函数包含在头文件<linux/slab.h>,而原来的<linux/malloc.h>不存在
老版本:内存分配函数包含在头文件<linux/malloc.h>
10、 结构体的初试化
gcc开始采用ANSI C的struct结构体的初始化形式:
static struct some_structure = {
.field1 = value,
.field2 = value,
..
};
老版本:非标准的初试化形式
static struct some_structure = {
field1: value,
field2: value,
..
};
11、 用户模式帮助器
int call_usermodehelper(char *path, char **argv, char **envp, int wait);
新增wait参数
12、 request_module()
request_module("foo-device-%d", number);
老版本:
char module_name[32];
printf(module_name, "foo-device-%d", number);
request_module(module_name);
13、 dev_t引发的字符设备的变化
1、取主次设备号为
unsigned iminor(struct inode *inode);
unsigned imajor(struct inode *inode);
2、老的register_chrdev()用法没变,保持向后兼容,但不能访问设备号大于256的设备。
3、新的接口为
a)注册字符设备范围
int register_chrdev_region(dev_t from, unsigned count, char *name);
b)动态申请主设备号
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count, char *name);
看了这两个函数郁闷吧^_^!怎么和file_operations结构联系起来啊?别急!
c)包含 <linux/cdev.h>,利用struct cdev和file_operations连接
struct cdev *cdev_alloc(void);
void cdev_init(struct cdev *cdev, struct file_operations *fops);
int cdev_add(struct cdev *cdev, dev_t dev, unsigned count);
(分别为,申请cdev结构,和fops连接,将设备加入到系统中!好复杂啊!)
d)void cdev_del(struct cdev *cdev);
只有在cdev_add执行成功才可运行。
e)辅助函数
kobject_put(&cdev->kobj);
struct kobject *cdev_get(struct cdev *cdev);
void cdev_put(struct cdev *cdev);
这一部分变化和新增的/sys/dev有一定的关联。
14、 新增对/proc的访问操作
<linux/seq_file.h>
以前的/proc中只能得到string, seq_file操作能得到如long等多种数据。
相关函数:
static struct seq_operations 必须实现这个类似file_operations得数据中得各个成员函数。
seq_printf();
int seq_putc(struct seq_file *m, char c);
int seq_puts(struct seq_file *m, const char *s);
int seq_escape(struct seq_file *m, const char *s, const char *esc);
int seq_path(struct seq_file *m, struct vfsmount *mnt,
struct dentry *dentry, char *esc);
seq_open(file, &ct_seq_ops);
等等
15、 底层内存分配
1、<linux/malloc.h>头文件改为<linux/slab.h>
2、分配标志GFP_BUFFER被取消,取而代之的是GFP_NOIO 和 GFP_NOFS
3、新增__GFP_REPEAT,__GFP_NOFAIL,__GFP_NORETRY分配标志
4、页面分配函数alloc_pages(),get_free_page()被包含在<linux/gfp.h>中
5、对NUMA系统新增了几个函数:
a) struct page *alloc_pages_node(int node_id, unsigned int gfp_mask, unsigned int order);
b) void free_hot_page(struct page *page);
c) void free_cold_page(struct page *page);
6、 新增Memory pools
<linux/mempool.h>
mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn, mempool_free_t *free_fn, void *pool_data);
void *mempool_alloc(mempool_t *pool, int gfp_mask);
void mempool_free(void *element, mempool_t *pool);
int mempool_resize(mempool_t *pool, int new_min_nr, int gfp_mask);
16、 per-CPU变量
get_cpu_var();
put_cpu_var();
void *alloc_percpu(type);
void free_percpu(const void *);
per_cpu_ptr(void *ptr, int cpu)
get_cpu_ptr(ptr)
put_cpu_ptr(ptr)
老版本使用
DEFINE_PER_CPU(type, name);
EXPORT_PER_CPU_SYMBOL(name);
EXPORT_PER_CPU_SYMBOL_GPL(name);
DECLARE_PER_CPU(type, name);
DEFINE_PER_CPU(int, mypcint);
2.6内核采用了可剥夺得调度方式这些宏都不安全。
17、 内核时间变化
1、现在的各个平台的HZ为
Alpha: 1024/1200; ARM: 100/128/200/1000; CRIS: 100; i386: 1000; IA-64: 1024; M68K: 100; M68K-nommu: 50-1000; MIPS: 100/128/1000; MIPS64: 100; PA-RISC: 100/1000; PowerPC32: 100; PowerPC64: 1000; S/390: 100; SPARC32: 100; SPARC64: 100; SuperH: 100/1000; UML: 100; v850: 24-100; x86-64: 1000.
2、由于HZ的变化,原来的jiffies计数器很快就溢出了,引入了新的计数器jiffies_64
3、#include <linux/jiffies.h>
u64 my_time = get_jiffies_64();
4、新的时间结构增加了纳秒成员变量
struct timespec current_kernel_time(void);
5、他的timer函数没变,新增
void add_timer_on(struct timer_list *timer, int cpu);
6、新增纳秒级延时函数
ndelay();
7、POSIX clocks 参考kernel/posix-timers.c
18、 工作队列(workqueue)
1、任务队列(task queue )接口函数都被取消,新增了workqueue接口函数
struct workqueue_struct *create_workqueue(const char *name);
DECLARE_WORK(name, void (*function)(void *), void *data);
INIT_WORK(struct work_struct *work,
void (*function)(void *), void *data);
PREPARE_WORK(struct work_struct *work,
void (*function)(void *), void *data);
2、申明struct work_struct结构
int queue_work(struct workqueue_struct *queue, struct work_struct *work);
int queue_delayed_work(struct workqueue_struct *queue, struct work_struct *work,
unsigned long delay);
int cancel_delayed_work(struct work_struct *work);
void flush_workqueue(struct workqueue_struct *queue);
void destroy_workqueue(struct workqueue_struct *queue);
int schedule_work(struct work_struct *work);
int schedule_delayed_work(struct work_struct *work, unsigned long delay);
19、 新增创建VFS的"libfs"
libfs给创建一个新的文件系统提供了大量的API.
主要是对struct file_system_type的实现。
参考源代码:
drivers/hotplug/pci_hotplug_core.c
drivers/usb/core/inode.c
drivers/oprofile/oprofilefs.c
fs/ramfs/inode.c
fs/nfsd/nfsctl.c (simple_fill_super() example)
20、 DMA的变化
未变化的有:
void *pci_alloc_consistent(struct pci_dev *dev, size_t size, dma_addr_t *dma_handle);
void pci_free_consistent(struct pci_dev *dev, size_t size, void *cpu_addr, dma_addr_t dma_handle);
变化的有:
1、 void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, int flag);
void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t dma_handle);
2、列举了映射方向:
enum dma_data_direction {
DMA_BIDIRECTIONAL = 0,
DMA_TO_DEVICE = 1,
DMA_FROM_DEVICE = 2,
DMA_NONE = 3,
};
3、单映射
dma_addr_t dma_map_single(struct device *dev, void *addr, size_t size, enum dma_data_direction direction);
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma_data_direction direction);
4、页面映射
dma_addr_t dma_map_page(struct device *dev, struct page *page, unsigned long offset, size_t size, enum dma_data_direction direction);
void dma_unmap_page(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma_data_direction direction);
5、有关scatter/gather的函数:
int dma_map_sg(struct device *dev, struct scatterlist *sg, int nents, enum dma_data_direction direction);
void dma_unmap_sg(struct device *dev, struct scatterlist *sg, int nhwentries, enum dma_data_direction direction);
6、非一致性映射(Noncoherent DMA mappings)
void *dma_alloc_noncoherent(struct device *dev, size_t size, dma_addr_t *dma_handle, int flag);
void dma_sync_single_range(struct device *dev, dma_addr_t dma_handle, unsigned long offset, size_t size,
enum dma_data_direction direction);
void dma_free_noncoherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t dma_handle);
7、DAC (double address cycle)
int pci_dac_set_dma_mask(struct pci_dev *dev, u64 mask);
void pci_dac_dma_sync_single(struct pci_dev *dev, dma64_addr_t dma_addr, size_t len, int direction);
21、 互斥
新增seqlock主要用于:
1、少量的数据保护
2、数据比较简单(没有指针),并且使用频率很高
3、对不产生任何副作用的数据的访问
4、访问时写者不被饿死
<linux/seqlock.h>
初始化
seqlock_t lock1 = SEQLOCK_UNLOCKED;
或seqlock_t lock2; seqlock_init(&lock2);
void write_seqlock(seqlock_t *sl);
void write_sequnlock(seqlock_t *sl);
int write_tryseqlock(seqlock_t *sl);
void write_seqlock_irqsave(seqlock_t *sl, long flags);
void write_sequnlock_irqrestore(seqlock_t *sl, long flags);
void write_seqlock_irq(seqlock_t *sl);
void write_sequnlock_irq(seqlock_t *sl);
void write_seqlock_bh(seqlock_t *sl);
void write_sequnlock_bh(seqlock_t *sl);
unsigned int read_seqbegin(seqlock_t *sl);
int read_seqretry(seqlock_t *sl, unsigned int iv);
unsigned int read_seqbegin_irqsave(seqlock_t *sl, long flags);
int read_seqretry_irqrestore(seqlock_t *sl, unsigned int iv, long flags);
22、 内核可剥夺
<linux/preempt.h>
preempt_disable();
preempt_enable_no_resched();
preempt_enable_noresched();
preempt_check_resched();
23、 眠和唤醒
1、原来的函数可用,新增下列函数:
prepare_to_wait_exclusive();
prepare_to_wait();
2、等待队列的变化
typedef int (*wait_queue_func_t)(wait_queue_t *wait, unsigned mode, int sync);
void init_waitqueue_func_entry(wait_queue_t *queue, wait_queue_func_t func);
24、 新增完成事件(completion events)
<linux/completion.h>
init_completion(&my_comp);
void wait_for_completion(struct completion *comp);
void complete(struct completion *comp);
void complete_all(struct completion *comp);
25、 RCU(Read-copy-update)
rcu_read_lock();
void call_rcu(struct rcu_head *head, void (*func)(void *arg),
void *arg);
26、 中断处理
1、中断处理有返回值了。
IRQ_RETVAL(handled);
2、cli(), sti(), save_flags(), 和 restore_flags()不再有效,应该使用local_save
_flags() 或local_irq_disable()。
3、synchronize_irq()函数有改动
4、新增int can_request_irq(unsigned int irq, unsigned long flags);
5、 request_irq() 和free_irq() 从 <linux/sched.h>改到了 <linux/interrupt.h>
27、 异步I/O(AIO)
<linux/aio.h>
ssize_t (*aio_read) (struct kiocb *iocb, char __user *buffer, size_t count, loff_t pos);
ssize_t (*aio_write) (struct kiocb *iocb, const char __user *buffer, size_t count, loff_t pos);
int (*aio_fsync) (struct kiocb *, int datasync);
新增到了file_operation结构中。
is_sync_kiocb(struct kiocb *iocb);
int aio_complete(struct kiocb *iocb, long res, long res2);
28、 网络驱动
1、struct net_device *alloc_netdev(int sizeof_priv, const char *name, void (*setup)(struct net_device *));
struct net_device *alloc_etherdev(int sizeof_priv);
2、新增NAPI(New API)
void netif_rx_schedule(struct net_device *dev);
void netif_rx_complete(struct net_device *dev);
int netif_rx_ni(struct sk_buff *skb);
(老版本为netif_rx())
29、 USB驱动
老版本struct usb_driver取消了,新的结构体为
struct usb_class_driver {
char *name;
struct file_operations *fops;
mode_t mode;
int minor_base;
};
int usb_submit_urb(struct urb *urb, int mem_flags);
int (*probe) (struct usb_interface *intf,
const struct usb_device_id *id);
30、 block I/O 层
这一部分做的改动最大。不祥叙。
31、 mmap()
int remap_page_range(struct vm_area_struct *vma, unsigned long from, unsigned long to, unsigned long size, pgprot_t prot);
int io_remap_page_range(struct vm_area_struct *vma, unsigned long from, unsigned long to, unsigned long size, pgprot_t prot);
struct page *(*nopage)(struct vm_area_struct *area, unsigned long address, int *type);
int (*populate)(struct vm_area_struct *area, unsigned long address, unsigned long len, pgprot_t prot, unsigned long pgoff, int nonblock);
int install_page(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long addr, struct page *page, pgprot_t prot);
struct page *vmalloc_to_page(void *address);
32、 零拷贝块I/O(Zero-copy block I/O)
struct bio *bio_map_user(struct block_device *bdev, unsigned long uaddr, unsigned int len, int write_to_vm);
void bio_unmap_user(struct bio *bio, int write_to_vm);
int get_user_pages(struct task_struct *task, struct mm_struct *mm, unsigned long start, int len, int write, int force, struct page **pages, struct vm_area_struct **vmas);
33、 高端内存操作kmaps
void *kmap_atomic(struct page *page, enum km_type type);
void kunmap_atomic(void *address, enum km_type type);
struct page *kmap_atomic_to_page(void *address);
老版本:kmap() 和 kunmap()。
34、 驱动模型
主要用于设备管理。
1、 sysfs
2、 Kobjects
推荐文章:
http:/www-900.ibm.com/developerWorks/cn/linux/kernel/l-kernel26/index.shtml
http:/www-900.ibm.com/developerWorks/cn/linux/l-inside/index.shtml
2.6里不需要再定义“__KERNEL__”和“MODULE”了。
用下面的Makefile文件编译:
代码:
obj-m := hello.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KDIR) M=$(PWD) modules
4.2. Data Structures
The GPU Memory Model
通常使用二维的texture保存,一是因为一维texture能存放的东西很少,二是因为现在的GPU很难高效地写入一列3维texture。
Iteration
stream编程模型包含了一种隐式的流的并行遍历。
Generalized Arrays via Address Translation
在GPGPU编程中主要使用的数据结构是随机访问的多位容器,包括稀疏/稠密数组等。每个结构定义了一个虚拟域virual grid domain和一个物理域physical grid domaiin,以及之间相互转换的address translator。
4.2.1. Dense Arrays
多维数组通常先映射到一维,然后再到二维。
4.2.2. Sparse Arrays
根据非零元素的位置和数量是否变化分两种,静态和动态。
4.2.3. Adaptive Structures
4. GPGPU Techniques
4.1. Stream Operations
4.1.1. Map
Given a stream of data elements and a function, map will apply the function to every element in the stream.
4.1.2. Reduce
Sometimes a computation requires computing a smaller stream from a larger input stream, possibly to a single element stream. This type of computation is called a reduction. For example, computing the sum or maximum of all the elements in a stream.
On GPUs, reductions can be performed by alternately rendering to and reading from a pair of textures.
也就是用分治法,不断切换输入和输出数据,每次都能减少一定比例的数据规模。
4.1.3. Scatter and Gather
If the write and read operations access memory indirectly, they are called scatter and gather respectively.
4.1.4. Stream Filtering
This stream fitering operation is essentially a nonuniform reduction.
4.1.5. Sort
Classic sorting algorithms are data-dependent and generally require scatter operations.
主要的几个算法都和Sorting Network有关,还有一种adaptive sort,和原来序列的有序度相关。
4.1.6. Search
4.2. Data Structures
注册表
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Drivers32
新建一个字符串值
名为 wavemapper
值为 msacm32.drv
2.4 GPU Program Flow Control
最新的GPU支持多种形式的分支,但是由于它们的高度并行化的本质,使用这些分支的时候一定要注意。
2.4.1 Hardware Machanisms for Flow Control
三种主要实现:
Predication 并非真正的data-dependent branch
MIMD branching
SIMD branching 同时进行的指令唯一,即各个点的分支选择应该一致
2.4.2 Moving Branching Up The Pipeline
2.4.2.1 Static Branch Resolution
静态分析,避免循环内部的分支。这里举了一个在离散空间点格(discrete spatial grid)上解偏微分方程的例子,不过没怎么看懂,大致是把循环拆成两部分的做法。
2.4.2.2 Pre-computation
有时候一段时间内或者几次循环中某个分支的结果会是一个常数。这时候就只要在知道结果会改变的时候重新计算即可。
2.4.2.3 Z-Cull
现代GPU有一系列用于避免处理不会被看到的像素的技术,其中之一就是Z-cull。简单的说Z-cull把没有通过深度测试(Z轴覆盖)点直接放弃。在流体模拟中,把land-locked障碍单元的Z深度标记为0,即可跳过这些点的计算。
2.4.2.4 Data-Dependent Looping With Occlusion Queries
同样是避免处理不可见的点的技术
3 Programming Systems
GPU的架构发展非常迅速,使得profiling和tuning需要由GPU生产商解决。
3.1 High-level Shading Languages
Cg, HLSL 和底层硬件很接近
OpenGL Shading Language 有一些不直接映射到硬件的特性,比如整数支持
Sh, Ashli, ...
3.2 GPGPU Languages and Libraries
上面提到的几个语言在使用时都要求编程人员站在几何元素的视角写代码。下面的几个系统试着把一些GPGPU功能抽象出来,隐藏底层的GPU实现。
Brook 前几星期打过交道的东东
Scout, Glift 都没听说过。。。
3.3 Debugging Tools
GPU的调试功能很受局限。它必须提供在某一时刻显示多个点的调试信息的功能。一种printf-style的方法是把他们直接显示在屏幕上(汗,如果是GPGPU编程岂不是花屏了 >,<)。
实验室的寒假任务 =_=
No.1
A Survey of General-Purpose Computation on Graphics Hardware
on EUROGRAPHICS 2005
1. Why GP-GPU?
1.1 Powerful and Inexpensive
高内存带宽:Nvidia GeForce 6800 Ultra - 35.2GB/sec
强大的计算能力:ATI X800 XT - 63GFLOPS, Intel Pentium4 SSE unit(3.7GHz) - 14.8GFLOPS
尖端处理科技的应用:最新公布(指该survey发布的时间)的GPU包含三亿个晶体管,由0.011微米技术制作
快速发展:GeForce 6800的throughput为5900的两倍。通常GPU的计算能力平均每年增长速度为1.7x(pixels/second)和2.3x(vertices/second),而根据摩尔定律,CPU的对应数值大概为每年1.4x。粗略的说,GPU性能每六个月增长一倍。
1.2 Flexible and Programmable
1.3 Limitations and Difficulties
GPU的强大计算性能是建立在它高度针对的架构上的,因此很多应用都不适合放到GPU上做。比如文字处理,主要包括内存通信,而且很难并行化。
如今的GPU也缺少一些基本的计算功能,比如整数运算。而且很多只支持32位浮点数(貌似最近的R670指令集可以处理double类型了),这样导致很多科学计算都没法在GPU上做。
另外即使对于适合GPU这些特性的问题,真正使用GPU做时也有不少问题。GPU的编程模型很不一样,高效的GPU编程不仅仅是说多学一门高级语言。如今要借助GPU的计算能力,需要编程人员同时掌握相应的科学计算知识和计算机图形学知识。尽管如此,GPU对性能提升的帮助还是很诱人的。
1.4 GPGPU Today
http://gpgpu.org
一些GPGPU的应用包括
Dense and sparse matrix multiplication 计算领域
Multigrid and conjugate-gradient solves for systems partial differential equations 计算领域
Ray tracing 图像处理
Photon mapping 图像处理
Fluid mechanics solvers 物理模拟
Datamining operations 数据库/数据挖掘
2. Overview of Programmable Graphics Hardware
2.1 Overview of the Graphics Pipeline
当今的GPU都采用了称为graphics pipeline的架构。pipeline被分成不同的stage,硬件上每个stage都被放到task-parallel machine organization上实现。
2.2 Programmable Hardware
显卡商们把固定功能的pipeline转化成了一个更灵活的可编程的pipeliine。主要在geometry stage和fragment stage。原来的固定的操作被用户定义的vertex program和fragment program代替
通常来说,这些可编程阶段读入一组含有限数量的 有4个32位浮点的向量 数组并输出一组含有限数量的4*32浮点向量的数组。每个可编程阶段都可以访问常数寄存器,也可以读写对应的寄存器。
2.3 Introduction to the GPU Programming Model
典型的GPGPU程序都使用了fragment processor作为计算引擎。通常的结构为:
a. 程序员确定该应用的并行部分。应用程序被分成几个独立的可并行段,每段都被看成是一个kernel,被当成fragment program实现。每个kernel的输入输出都是一个或多个数据数组,以texture形式保存在GPU内存中。用流相关的术语表述的话,这些在texture中的数据组成了stream,每个stream上的元素都要被kernel分别处理。
b. 调用kernel前要先确定计算范围,程序员可以传递点的数据给GPU。注意GPU在处理一维数组时性能有所局限。
c. rasterizer为每个像素生成一个fragment。
d. 每个fragment被 同一个活动的kernel程序处理。fragment程序可以读入任意的全局内存,但只能写到rasterizer决定的frame buffer中。 这块还没怎么搞懂
e. 每个fragment的输出是一个值或者向量值,可以作为作中的程序结果,也可以保存为一个texture,用于后面的计算,复杂的应用通常需要多个pipeline之间的传递(multipass)
http://web.mat.bham.ac.uk/R.W.Kaye/minesw/ordmsw.htm
居然是NPC...
如果一些文章的链接失效,google相应的标题应该还是很容易找到其他网站的转载的。
中断处理:
Interrupt in Linux
相当不错的中文资料
内核调度:
Inside the Linux scheduler
讲的是用expired/active两个数组维护的O(1)算法,大多数讲2.6内核的书上都会提到的调度算法 (2008-02-06)
Multiprocessing with the Completely Fair Scheduler
最新的2.6.23采用的CFS,还没搞懂 (2008-02-06)
http://www.ibm.com/developerworks/cn/linux/l-cn-scheduler/index.html
Linux 调度器发展简述 (2008-02-13)
内核模块:
2.6 内核中的模块注入 (2008-02-17)
http://www.linuxforum.net/forum/showflat.php?Cat=&Board=security&Number=536404&page=0&view=collapsed&sb=5&o=31&fpart
系统调用:
Linux 2.6 新增的 vsyscall 系统服务调用机制 (2008-02-18)
http://blog.csdn.net/wishfly/archive/2005/01/23/264435.aspx
Linux on-the-fly kernel patching without LKM (2008-02-19)
http://doc.bughunter.net/rootkit-backdoor/kernel-patching.html
内存管理:
http://linux-mm.org/LinuxMM
Linux-mm.org is a wiki for documenting how memory management works and for coordinating new memory management development projects. (2008-02-21)
并发同步:
http://hi.baidu.com/charleswen/blog/item/61f3e40ebc26dcce7acbe1c8.html
Linux内核中的同步和互斥分析报告 (2008-02-21)
http://www-128.ibm.com./developerworks/cn/linux/kernel/sync/index.html
Linux 2.4.x内核同步机制 (2008-02-22)
Big Picture:
http://www.linuxdriver.co.il/kernel_map
Interactive Linux kernel map (2008-02-16)
把内核中的函数相互调用做成了一张可放大缩小的地图,单击相应函数名会跳转到lxr的相应代码链接。
编程资料:
http://www.jegerlehner.ch/intel/
Intel Assembler CodeTable 80x86 (2008-02-21)
相关站点:
http://kernelnewbies.org
Linux Kernel Newbies
http://bbs4.newsmth.net/bbsdoc.php?board=KernelTech
水木KernelTech版
http://www.phrack.org
Phrack is an underground ezine made by and for hackers.
有不少和内核相关的hack资料
以前认识的水木KernelTech版版大luohandsome,居然也是余姚人,太神奇了,不可思议。
这个世界果然很小
继续聊,突然又发现他和安然小朋友也很熟,囧。而且安然小朋友以前和我提过他。
很好,很神奇。
硕大的Open64居然从早上11点编译到现在,囧
期间离散出成绩了,更囧,两次quiz未参加 + n次作业不交,期末还有半道题目没做出来,居然还混了个A-,liyi真不错,下学期的算法分析不知道怎样,嘿嘿
编译期间都不敢和GPU打交道,万一给我来个蓝屏我就悲剧了
啊啊啊,就是这种感觉,似曾相识的轻快,太赞了
再次激发我学一种乐器的冲动
看来冬天去体育馆打球一定得带好衣服,打完里面马上洗完澡再出来。今天全身湿透跑回寝室又差点感冒了 =_=
按期完成proposal应该问题不大,浙大那边也快放了,昨天的一些问题今天也突然一个个被解决了
nice
似乎是直接生成二进制安装文件的,很好很强大
http://www.moxiu.com/
做了一个,下载了两个感觉还不错的
搞到火车票了,还突然听说旅馆已经有人帮我们订好了,赞啊赞。
BBS上被老大那么伤地骂了句,囧。还好这几天心情好得很,算了。(不过如果我心情不好又能怎么办呢  ) )
接下来嘛,先干活,然后如此如此,接着,最终,恩。
最后攒下人品,明天考试的孩子们好运,没了。
剩下的两星期
我负责的主要是Fortran -> IL的部分
主要的几个问题
Fortran转成High WHIRL后,怎么写成IL?
1. 参考brook,看看能不能代码重用
2. 或者试试直接将WHIRL转成Brook IR,然后调用那几个routines自动转IL?
如何在Fortran中调用CAL?
1. 如何实现F77调用库函数?
2. 调用的overhead如何呢?
一些优化相关的paper,CC已经收集了几篇
1. Alan Leung on 6th Workshop on Compiler-Driven Performance
2. RapidMind Development Platform
3. LiquidSIMD
其他一些问题
1. 决定是否放到GPU里面做的那个tradeoff如何控制?或者动态控制?
暂时想到这些,一步一步来
离散啊离散,高中时如此痴迷,以至于保送志愿填了数学系,现在看都不想看 =,=
关键是教的东西太抽象,结合点现实估计会好不少
不过这几天做的事情比复习有意义多了,考试都能pass了我也就瞑目了
酱紫
一大早起来考Java,还是一个状态,懒懒散散地写完,交卷。
回寝,写完最后一页,把东西寄出了,满怀期待,希望能带给我想要的
出来一门2分的C,过了就好
不过想想如果到时候离散真给我个C的话还是有点小不爽的,不过也罢,毕竟没复习,这学期又没付出多少
开始收集一些东东,呵呵
主要是三件事情
1 搞一个proposal出来
2 制定一份旅行计划
3 做一个web3d项目
coding多了,画画都不会了 =,=
当年初中时候还被美术老师建议去读美院来着,sigh
一个下午差不多没干什么事
看了篇vectorization的paper,没怎么明白那个detection算法,更不用说后面的转换了,差不多等于没看。
然后看离散,三分钟后发现太无聊了,不就是堆定理定义吗,继续仍到一边
同时我继续着把光华所有收藏的版面扫了一遍,水木的几个主题也批了一遍
然后找快递公司电话,找到了,算是第一件做成事情
百度地图看看旅游路线,看了会儿就回寝室了
这效率不是一般的低啊,连老大都说我太坐不住了,不适合debug,囧
一大早起来去参加什么数据结构期末考,题目做得没胃口,二十分钟交了卷。
居然说我用了HashSet查找元素的平均复杂度会是O(n)。。。什么跟什么啊。。。
不管他,跑出考场挑了一上午围巾,选中了一条不错的(thanks to anran again~),小朋友应该会喜欢,吃好午饭就把它拍下来了
接下来开始看Fortran,搞个proposal也不容易啊,早点做出来早点出去玩,恩
明天开始考试的同学们加油了~
p.s. 突然发现编译原理成绩出来了,最后一个project没交果然就拿不到A了。最想拿A的课没拿到A。。。sigh。。。剩下的什么DS DM随他去吧,别给我挂了就行
小朋友兴冲冲地打电话过来叫嚷着说那里下雪了,几刻钟前还说在食堂背政治的
高二的那场雪仗,至今记忆犹新。昨天滑冰温习了一下 水的固体 的触感
不知道这边的雪什么时候会舍得落下来
bless考试的人们,也bless我的寒假
纠结了一下午,被一个电话惊醒了,不可颓废。
绩点么,能拿A当然最好
拿不了么,混个B啊C的都可以,关键是不能因为要绩点而花时间复习
恩,就是这样,离散就不复习了,混个及格了事
早上滑冰到现在膝盖还疼,悲剧
明天看微经,顺便搞搞proposal
讲到out-of-bounds detection时,有这么一段
One may say, by way of excuse, "but the language in which, I program has the kind of address arithmetics that makes it impossible to know the bounds of an array." Yes, and the man who shot his mother and father threw himself upon the mercy of the court because he was an orphan.
很强大,很贴切
发信人: lingcore (), 信区: CSArch
标 题: Three Reading Groups
发信站: 水木社区 (Sat Jan 5 05:34:59 2008), 站内
MIT Compiler Reading Group
http://cag.csail.mit.edu/crg/
Toronto Compiler and Architecture Reading Group (CARG)
http://www.eecg.toronto.edu/~steffan/carg/
Reconfigurable Reading Group
http://wiki.ittc.ku.edu/rcreading/Main_Page
发信人: lxfind (静下心来踏踏实实地学习), 信区: Arch_Compiler
标 题: Re: Three Reading Groups [zz]
发信站: 日月光华 (2008年01月05日11:16:46 星期六), 站内信件
搭车贴一个我很喜欢的。。UPenn architecture组的Reading group
http://www.cis.upenn.edu/acg/reading.html
摘要: http://wikipedia.answers.com/vectorization
阅读全文
复习,还是继续自顾自学呢。。。
|
编译原理
|
|
1月10日 9:00-11:00
|
|
计算机系统基础
|
|
1月10日 13:30-3:30
|
|
数据结构与算法设计
|
Z2107
|
1月14日 9:00-11:00
|
|
Java程序设计
|
HGX307
|
1月15日 8:30-10:30
|
|
离散数学
|
Z2306
|
1月16日 9:00-11:00
|
小结下,恩
一月初拿到选课书,发现非软院学生可以选Web应用课,意味着转系可以不留级,最终在转CS和转SS之间选择了后者,现在看来这个决定很明智,恩。
寒假里草草地补了下Java知识,看了半本Thinking in Java,加上几章Core Java I,算是入了门,另外在笔记本上弄了个Ubuntu玩玩,使用vim写Java程序,算是第一次正式接触Linux吧。
记得当时对Java的感觉很不错,写代码比Pascal/Delphi容易多了,配上一个好的IDE经常第一次运行就能通过。
开了学,接触J2EE,啃了一本JSP & servlet的入门书,接触了一些Hibernate / Struts方面的东东,当时觉得软件工程学的东西就是这样,不需要算法,主要是框架、设计。那个学期接触了很多东西,Ruby Python ASP.NET 都很浮躁地玩了一把,结果就是到现在除了Python都忘得差不多了。。。
逐渐对Linux熟悉起来,熟悉了一些基本的工具,发现Linux下大多数软件都可以通过配置文件定制,比较cool。
学的东西总是一阵一阵的,解决掉web project3后,接了个web项目,之后一段时间就抛掉web相关的概念,一心学算法了,一个人参加校内的组队编程赛,拿了个三等奖,不过这个比赛ACM队员都没有参加。期末的时候参加了ACM队的选拔,通过了,想暑假留下一段时间参加集训,但最终由于本部条件太差还是躲回家了。
简单的说那个学期很没方向,一直在怀疑自己当前学的东西有没有用,换了一个又一个内容,最后啥都没学会,不过了解了很多比较新的概念和技术。
这个学期其他方面的收获倒是蛮多的,参加了学院的调研小组,后来一篇文章好像还拿去评了奖。做了一期班刊,参与了其中的约稿、制作、拉赞助、印刷各个过程。
无视了绩点的结果就是差点连3.0都不到了。
暑假军训,略,搬到张江。这边玩的地方太少,一开始不习惯,一心看书。
这学期学的东西还是蛮基础的。选了门编译原理,事实证明提前选这课很正确,尽管现在还搞不定最后的project。继续啃算法导论,到现在看了半本左右,有个大致感觉,书后题目还是不会做的多。还看了些内核的东西,以及网络基础,不过11月底就被召去实验室了,后来就没时间看。
感觉fd软院和其他学校的差别比较大,最有特色的两门课,ICS和OS都是比较基础比较底层的。
PPI很不错,每周要制定自己的schedule,每周都有小组会议,每人报告自己的进度,所以一般想混过去是不可能的。实验室牛人很多,也很nice,有问题去问基本上都能得到一个满意的答案。另外每周有sports day。而且PPI很注重读paper,尽管现在还没读多少,但这似乎是一种更好的学习方法,可以很快的了解一些技术。
在PPI接触到了第一个比较正式的项目,GP-GPU的编译优化,有点意思。
我觉得自己剩下几年的方向差不多就是这个了,系统底层,编译,可能还有网络。
感觉软院和其他学校的差别比较大
Linux几乎每天都会接触,但只是用ssh,图形界面差不多几个月没碰了。不喜欢Unix版上整天讨论的诸如wine模拟office、pidgin配置的话题,对自己没什么用还折腾人,Vista + Pietty,这样才比较爽,呵呵。
学期初学C++,花了不少时间,但还是放弃了,这语言太难 =_=,偶还是老老实实地用C/Java/Python算了
这个月底学了点lisp,主要是想锻炼下思维,学点函数式编程还可以把Python/Ruby用得更好。
最后还是上了dota的贼船,星际差不多荒废掉了,不过还是在对北大和交大的两场友谊赛中2:0干掉对手。
差不多就是这样,接下来想做的,就是继续啃CLRS,看内核。
http://blog.csdn.net/wooin
http://blog.csdn.net/wooin/category/156101.aspx
《Linux设备设备驱动程序(第三版)》学习笔记之一:scull设备的使用
《Linux设备设备驱动程序(第三版)》学习笔记之三:sleepy设备的使用
利用enumerate
for i, obj in enumerate(list):
print i, obj
Help on class enumerate in module __builtin__:
class enumerate(object)
| enumerate(iterable) -> iterator for index, value of iterable
|
| Return an enumerate object. iterable must be an other object that supports
| iteration. The enumerate object yields pairs containing a count (from
| zero) and a value yielded by the iterable argument. enumerate is useful
| for obtaining an indexed list: (0, seq[0]), (1, seq[1]), (2, seq[2]), ...
|
| Methods defined here:
|
| __getattribute__(...)
| x.__getattribute__('name') <==> x.name
|
| __iter__(...)
| x.__iter__() <==> iter(x)
|
| next(...)
| x.next() -> the next value, or raise StopIteration
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __new__ = <built-in method __new__ of type object at 0xb7f35d20>
| T.__new__(S, ...) -> a new object with type S, a subtype of T
CAL样例程序里面出现很多sample指令,google到的简单介绍:
Antialias
(抗锯齿)
虽然减小像素的大小可以使图像可以更加精细,一定程度上减轻了锯齿,但是只要像素的大小大到可以互相彼此区分,那么锯齿的产生是不可避免的!抗锯齿的方法一般是多点(注意此处是“点”而不是“像素”,后面可以看出它们间的区别)采样。
一、
理论与方法:
1
.
Oversampling
(重复取样):
(
1
)方法:
首先,将场景以比你的显示器(前缓冲)更高分辨率进行渲染:
假设当前的(前
/
后缓冲)的分辨率是
800
×
600
,那么可以先将场景渲染到
1600
×
1200
的渲染目标上(纹理);
然后,从高分辨率的渲染目标得到低分辨率的场景渲染结果:
此时取每
2
×
2
个像素块颜色的平均值为最终渲染的像素颜色值。
(
2
)优点:可以显著地改善锯齿导致的失真。
(
3
)缺点:需要更大的缓冲,同时填充缓冲导致性能消耗变大;
进行多个像素的取样,导致性能下降;
由于以上缺点,
D3D
并没有采用这种抗锯齿方法。
2
.
Multisampling
(多取样):
(
1
)方法:
只需要对像素进行一次取样,而是在每个像素中取
N
个点(取决于具体的取样模型),该像素的最终颜色
=
该像素原先的颜色
*
多边形覆盖的点数
/
总的取样点数;
(
2
)优点:可以改善锯齿带来的失真的同时而不会增加取样次数,同时比起
Oversampling
它也不需要更大的后备缓冲。
(
3
)缺点:原本当一个多边形覆盖了一个像素的中心点时,该像素的颜色才会由该多边形决定(在像素管线阶段典型的就是寻址到合适的纹理颜色与顶点管线输出的颜色进行调制),但是
Multisampling
中,如果该多边形覆盖了其中一部分取样点却未覆盖像素中心点,该像素颜色仍然由此多边形决定。如此一来,纹理寻址可能出现错误,这对于纹理集(
atlas
)会出现另一种失真效果:多边形边缘颜色错误!
3
.
Centriod Sampling
(质心采样):
(
1
)方法:
为了解决在使用
Multisampling
导致的在纹理集中进行纹理寻址带来的错误,不再采用像素中心的颜色作为“该像素原先的颜色”,而是用“该像素中被多边形覆盖的那些取样点的中心点的颜色”。这样就保证了被渲染的像素点始终是多边形的内部(也就是说纹理地址不会超出多边形的范围)。
(
2
)如何使用:
①任何有COLOR语义作为输入的Pixel Shader会自动运用质心采样;
②在Pixel Shader的输入参数的语义后中手动加入
_centroid
扩展,例如:
float4 TexturePointCentroidPS( float4 TexCoord : TEXCOORD0_centroid ) : COLOR0
{
return tex2D( PointSampler, TexCoord );
}
(
3
)注意:
质心采样主要用于采用纹理集的
Multisampling
,对于一整张纹理对应一个的多边形网格的情况,采用质心采样反而会导致错误!
CS:APP P521
在CC同学的帮助下终于看懂这个程序了
关键在于P488的Generic Cache Memory Organization,以前看过,没留下什么印象
cache是有多个(2s个)大小为block size的片组成的
这样在访问B[k][j]时,B[k][j] - B[k][j + bsize - 1]这条内存就被cache了
重复bsize次后B[k][k] - b[k + bsize - 1][k + bsize - 1]这块内存被cache
后面做乘法就快很多的
lambda真是王道啊
#!/usr/bin/env python
d={'a':1,'b':5,'c':4}
print sorted(d.items(), key=lambda (k,v): (v,k))
Help on built-in function sorted in module __builtin__:
sorted(...)
sorted(iterable, cmp=None, key=None, reverse=False) --> new sorted list
Subject: Re: Explanation, please!
Summary: Original citation
From: td@alice.UUCP (Tom Duff)
Organization: AT&T Bell Laboratories, Murray Hill NJ
Date: 29 Aug 88 20:33:51 GMT
Message-ID: <8144@alice.UUCP>
I normally do not read comp.lang.c, but Jim McKie told me that ``Duff's device'' had come up in comp.lang.c again. I have lost the version that was sent to netnews in May 1984, but I have reproduced below the note in which I originally proposed the device. (If anybody has a copy of the netnews version, I would gratefully receive a copy at research!td or td@research.att.com.)
To clear up a few points:
- The point of the device is to express general loop unrolling directly in C. People who have posted saying `just use memcpy' have missed the point, as have those who have criticized it using various machine-dependent memcpy implementations as support. In fact, the example in the message is not implementable as memcpy, nor is any computer likely to have an memcpy-like idiom that implements it.
- Somebody claimed that while the device was named for me, I probably didn't invent it. I almost certainly did invent it. I had definitely not seen or heard of it when I came upon it, and nobody has ever even claimed prior knowledge, let alone provided dates and times. Note the headers on the message below: apparently I invented the device on November 9, 1983, and was proud (or disgusted) enough to send mail to dmr. Please note that I do not claim to have invented loop unrolling, merely this particular expression of it in C.
- The device is legal dpANS C. I cannot quote chapter and verse, but Larry Rosler, who was chairman of the language subcommittee (I think), has assured me that X3J11 considered it carefully and decided that it was legal. Somewhere I have a note from dmr certifying that all the compilers that he believes in accept it. Of course, the device is also legal C++, since Bjarne uses it in his book.
- Somebody invoked (or more properly, banished) the `false god of efficiency.' Careful reading of my original note will put this slur to rest. The alternative to genuflecting before the god of code-bumming is finding a better algorithm. It should be clear that none such was available. If your code is too slow, you must make it faster. If no better algorithm is available, you must trim cycles.
- The same person claimed that the device wouldn't exhibit the desired speed-up. The argument was flawed in two regards: first, it didn't address the performance of the device, but rather the performance of one of its few uses (implementing memcpy) for which many machines have a high-performance idiom. Second, the poster made his claims in the absence of timing data, which renders his assertion suspect. A second poster tried the test, but botched the implementation, proving only that with diligence it is possible to make anything run slowly.
- Even Henry Spencer, who hit every other nail square on the end with the flat round thing stuck to it, made a mistake (albeit a trivial one). Here is Henry replying to bill@proxftl.UUCP (T. William Wells):
>>... Dollars to doughnuts this
>>was written on a RISC machine.
>Nope. Bell Labs Research uses VAXen and 68Ks, mostly.
I was at Lucasfilm when I invented the device.
- Transformations like this can only be justified by measuring the resulting code. Be careful when you use this thing that you don't unwind the loop so much that you overflow your machine's instruction cache. Don't try to be smarter than an over-clever C compiler that recognizes loops that implement block move or block clear and compiles them into machine idioms.
Here then, is the original document describing Duff's device:
From research!ucbvax!dagobah!td Sun Nov 13 07:35:46 1983
Received: by ucbvax.ARPA (4.16/4.13) id AA18997; Sun, 13 Nov 83 07:35:46 pst
Received: by dagobah.LFL (4.6/4.6b) id AA01034; Thu, 10 Nov 83 17:57:56 PST
Date: Thu, 10 Nov 83 17:57:56 PST
From: ucbvax!dagobah!td (Tom Duff)
Message-Id: <8311110157.AA01034@dagobah.LFL>
To: ucbvax!decvax!hcr!rrg, ucbvax!ihnp4!hcr!rrg, ucbvax!research!dmr, ucbvax!research!rob
Consider the following routine, abstracted from code which copies an array of shorts into the Programmed IO data register of an Evans & Sutherland Picture System II:
send(to, from, count)
register short *to, *from;
register count;
 { {
do
*to = *from++;
while (--count>0);
}
(Obviously, this fails if the count is zero.)
The VAX C compiler compiles the loop into 2 instructions (a movw and a sobleq,
I think.) As it turns out, this loop was the bottleneck in a real-time animation playback program which ran too slowly by about 50%. The standard way to get more speed out of something like this is to unwind the loop a few times, decreasing the number of sobleqs. When you do that, you wind up with a leftover partial loop. I usually handle this in C with a switch that indexes a list of copies of the original loop body. Of course, if I were writing assembly language code, I'd just jump into the middle of the unwound loop to deal with the leftovers. Thinking about this yesterday, the following implementation occurred to me:
send(to, from, count)
register short *to, *from;
register count;
{
register n=(count+7)/8;
switch(count%8) {
case 0: do { *to = *from++;
case 7: *to = *from++;
case 6: *to = *from++;
case 5: *to = *from++;
case 4: *to = *from++;
case 3: *to = *from++;
case 2: *to = *from++;
case 1: *to = *from++;
} while(--n>0);
}
}
Disgusting, no? But it compiles and runs just fine. I feel a combination of pride and revulsion at this discovery. If no one's thought of it before, I think I'll name it after myself.
It amazes me that after 10 years of writing C there are still little corners that I haven't explored fully. (Actually, I have another revolting way to use switches to implement interrupt driven state machines but it's too horrid to go into.)
Many people (even bwk?) have said that the worst feature of C is that switches don't break automatically before each case label. This code forms some sort of argument in that debate, but I'm not sure whether it's for or against.
yrs trly
Tom
ORC (Open Research Compiler) 的一个讲座,里面有不少IPA的内容 http://www.blogjava.net/Files/zellux/ORC-PACT02-tutorial.rar然后貌似龙书第二版里也讲了大量的IPA优化和call graph方面的东西,啃啊啃
University of Houston, Computer Science Department, High Performance Computing Tools Group的一篇论文:
Overview of the Open64 Compiler Infrastructure
VI.4. Interprocedural Analysis
Interprocedural Analysis (IPA) is performed in the following phases of Open64:
• Inliner phase
• IPA local summary phase
• IPA analysis phase
• IPA optimization phase
• IPA miscellaneous
By default the IPA does the function inlining in the inliner facility. The local summary phase is done in the IPL module and the analysis phase and optimization phase in the ipa-link module.
During the analysis phase, it does the following:
• IPA_Padding Analysis (common blocks Padding/Split Analysis)
• Construction of the Callgraph
Then it does space and multigot partitioning of the Callgraph. The partitioning algorithm takes into account whether it is doing partitioning for solving space or the multigot problem.
During the optimization phase the following phases are performed:
• IPA Global Variable Optimization
• IPA Dead function elimination
• IPA Interprocedural Alias Analysis
• IPA Cloning Analysis (It propagates information about formal parameters used as symbolic terms in array section summaries. This information is later used to trigger cloning.
• IPA Interprocedural Constant propagation
• IPA Array_Section Analysis
• IPA Inlining Analysis
• Array section summaries arrays for the Dependence Analyzer of the Loop Nest Optimizer.
突然要做一个相关的编译优化项目,先放一点国外网的IPA的资料上来,教育网出国不方便
GCC wiki:
Analysis and optimizations that work on more than one procedure at a time. This is usually done by making walking the Strongly Connected Components of the call graph, and performing some analysis and optimization across some set of procedures (be it the whole program, or just a subset) at once.
GCC has had a callgraph for a few versions now (since GCC 3.4 in the FSF releases), but the procedures didn't have control flow graphs (CFGs) built. The tree-profiling-branch in GCC CVS now has a CFG for every procedure built and accessible from the callgraph, as well as a basic IPA pass manager. It also contains in-progress interprocedural optimizations and analyses: interprocedural constant propagation (with cloning for specialization) and interprocedural type escape analysis.
IBM的XL Fortran V10.1 for Linux:
Benefits of interprocedural analysis (IPA)
Interprocedural Analysis (IPA) can analyze and optimize your application as a whole, rather than on a file-by-file basis. Run during the link step of an application build, the entire application, including linked libraries, is available for interprocedural analysis. This whole program analysis opens your application to a powerful set of transformations available only when more than one file or compilation unit is accessible. IPA optimizations are also effective on mixed language applications.
Figure 2. IPA at the link step
The following are some of the link-time transformations that IPA can use to restructure and optimize your application:
- Inlining between compilation units
- Complex data flow analyses across subprogram calls to eliminate parameters or propagate constants directly into called subprograms.
- Improving parameter usage analysis, or replacing external subprogram calls to system libraries with more efficient inline code.
- Restructuring data structures to maximize access locality.
In order to maximize IPA link-time optimization, you must use IPA at both the compile and link step. Objects you do not compile with IPA can only provide minimal information to the optimizer, and receive minimal benefit. However when IPA is active on the compile step, the resulting object file contains program information that IPA can read during the link step. The program information is invisible to the system linker, and you can still use the object file and link without invoking IPA. The IPA optimizations use hidden information to reconstruct the original compilation and can completely analyze the subprograms the object contains in the context of their actual usage in your application.
During the link step, IPA restructures your application, partitioning it into distinct logical code units. After IPA optimizations are complete, IPA applies the same low-level compilation-unit transformations as the -O2 and -O3 base optimizations levels. Following those transformations, the compiler creates one or more object files and linking occurs with the necessary libraries through the system linker.
It is important that you specify a set of compilation options as consistent as possible when compiling and linking your application. This includes all compiler options, not just -qipa suboptions. When possible, specify identical options on all compilations and repeat the same options on the IPA link step. Incompatible or conflicting options that you specify to create object files, or link-time options in conflict with compile-time options can reduce the effectiveness of IPA optimizations.
Using IPA on the compile step only
IPA can still perform transformations if you do not specify IPA on the link step. Using IPA on the compile step initiates optimizations that can improve performance for an individual object file even if you do not link the object file using IPA. The primary focus of IPA is link-step optimization, but using IPA only on the compile-step can still be beneficial to your application without incurring the costs of link-time IPA.
Figure 3. IPA at the compile step
IPA Levels and other IPA suboptions
You can control many IPA optimization functions using the -qipa option and suboptions. The most important part of the IPA optimization process is the level at which IPA optimization occurs. Default compilation does not invoke IPA. If you specify -qipa without a level, or specify -O4, IPA optimizations are at level one. If you specify -O5, IPA optimizations are at level two.
Table 5. The levels of IPA
|
IPA Level
|
Behaviors
|
|
qipa=level=0 |
- Automatically recognizes standard library functions
- Localizes statically bound variables and procedures
- Organizes and partitions your code according to call affinity, expanding the scope of the -O2 and -O3 low-level compilation unit optimizer
- Lowers compilation time in comparison to higher levels, though limits analysis
|
|
qipa=level=1 |
- Level 0 optimizations
- Performs procedure inlining across compilation units
- Organizes and partitions static data according to reference affinity
|
|
qipa=level=2 |
- Level 0 and level 1 optimizations
- Performs whole program alias analysis which removes ambiguity between pointer references and calls, while refining call side effect information
- Propagates interprocedural constants
- Eliminates dead code
- Performs pointer analysis
- Performs procedure cloning
- Optimizes intraprocedural operations, using specifically:
- Value numbering
- Code propagation and simplification
- Code motion, into conditions and out of loops
- Redundancy elimination techniques
|
IPA includes many suboptions that can help you guide IPA to perform optimizations important to the particular characteristics of your application. Among the most relevant to providing information on your application are:
-
lowfreq which allows you to specify a list of procedures that are likely to be called infrequently during the course of a typical program run. Performance can increase because optimization transformations will not focus on these procedures.
-
partition which allows you to specify the size of the regions within the program to analyze. Larger partitions contain more procedures, which result in better interprocedural analysis but require more storage to optimize.
-
threads which allows you to specify the number of parallel threads available to IPA optimizations. This can provide an increase in compilation-time performance on multi-processor systems.
-
clonearch which allows you to instruct the compiler to generate duplicate subprograms with each tuned to a particular architecture.
Using IPA across the XL compiler family
The XL compiler family shares optimization technology. Object files you create using IPA on the compile step with the XL C, C++, and Fortran compilers can undergo IPA analysis during the link step. Where program analysis shows that objects were built with compatible options, such as -qnostrict, IPA can perform transformations such as inlining C functions into Fortran code, or propagating C++ constant data into C function calls.
摘要: from IBM developerWorks 原文的代码部分很乱,整理了一下
Although users usually think of Python as a procedural and object-oriented language, it actually contains everything you need for a completely func... 阅读全文
这个lab主要考察gdb的使用和对汇编代码的理解。后者在平时的作业中涉及得较多,这里不再赘述,主要介绍一下gdb
其实偶对这个也不是很熟,有错误请指正 @@
简单的说,gdb是一款强大的调试工具,尽管它只有文本界面(需要图形界面可以使用ddd,不过区别不大),但是功能却比eclipse等调试环境强很多。
接下来看看怎样让它为lab2拆炸弹服务,在命令行下运行gdb bomb就能开始调试这个炸弹程序,提高警惕,恩
首先最重要的,就是如何阻止炸弹的引爆,gdb自然提供了一般调试工具都包括的断点功能——break命令
在gdb中输入help break能够看到相关的信息
(gdb) help break
Set breakpoint at specified line or function.
Argument may be line number, function name, or "*" and an address.
If line number is specified, break at start of code for that line.
If function is specified, break at start of code for that function.
If an address is specified, break at that exact address.
With no arg, uses current execution address of selected stack frame.
This is useful for breaking on return to a stack frame.
Multiple breakpoints at one place are permitted, and useful if conditional.
Do "help breakpoints" for info on other commands dealing with breakpoints.
可以看到break允许我们使用行号、函数名或地址设置断点
按ctrl+z暂时挂起当前的gdb进程,运行objdump –d bomb | more 查看反编译后的炸弹文件,可以看到里面有这么一行(开始的那个地址每个人都不同):
08049719 <explode_bomb>:
这个就是万恶的引爆炸弹的函数了,运行fg返回gdb环境,在这个函数设置断点:
break explode_bomb (可以使用tab键自动补齐)
显示
Breakpoint 1 at 0x8049707
接下来你可以喘口气,一般情况下炸弹是不会引爆的了
下面我们来拆第一个炸弹,首先同样是设置断点,bomb.c中给出了各个关卡的函数名,第一关就是phase_1,使用break phase_1在第一关设置断点
接下来就开始运行吧,输入run
Welcome to my fiendish little bomb. You hava 6 phases with
which to blow yourself up. Hava a nice day!
我们已经设置了炸弹断点,这些恐吓可以直接无视。
输入ABC继续(输入这个是为了方便在后面的测试中找到自己的输入串地址)
提示Breakpoint 2, 0x08048c2e in phase_1 (),说明现在程序已经停在第一个关了
接下来就是分析汇编代码,使用disassemble phase_1显示这个函数的汇编代码
注意其中关键的几行:
8048c2e:68 b4 99 04 08 push $0x80499b4
8048c33:ff 75 08 pushl 0x8(%ebp)
8048c36:e8 b1 03 00 00 call 8048fec <strings_not_equal>
这个lab很厚道的一点就是函数名很明确地说明了函数的功能 ^_^
估计这三行代码的意思就是比较两个字符串相等,不相等的话应该就会让炸弹爆炸了
因为字符串很大,所以传递给这个比较函数的肯定是他们的地址,分别为0x80499b4和0x8(%ebp)
我们先来看后者,使用p/x *(int*)($ebp + 8)查看字符串所在的地址
$1 = 0x804a720,继续使用p/x *0x804a720查看内存中这个地址的内容
$2 = 0x434241,连续的三个数,是不是想起什么了?把这三个数分别转换为十进制,就是67 66 65,分别为CBA的ASCII码,看来这里保存了我们输入的串。
接下来0x80499b4里肯定保存着过关的密码
p/x *0x80499b4,显示$3 = 0x62726556,c中的字符串是以0结尾的,看来这个字符串还不止这个长度,继续使用
p/x *0x80499b4@10查看这个地址及其后面36个字节的内容,终于在第二行中出现了终结符”0x0”(不一定是四个字节)
$4 = {0x62726556, 0x7469736f, 0x656c2079, 0x20736461, 0x75206f74, 0x656c636e, 0x202c7261, 0x72616e69,
0x75636974, 0x6574616c, 0x69687420, 0x2e73676e, 0x0, 0x21776f57, 0x756f5920, 0x20657627, 0x75666564,
0x20646573, 0x20656874, 0x72636573}
把开头到0x0的所有信息字节下来,通过手算或者自己写程序得出最后的密码串(注意little endian中字符的排列方式!)
输入run重新运行,输入刚才得出的密码串,如果前面的计算正确的话,就会提示
Phase 1 defused. How about the next one?
关于这个lab的一些其他心得:
1. VMware中开发很不舒服,屏幕小、字体丑@@、需要Ctrl+Alt切换回windows,不怎么方便,推荐在windows下使用pietty登录虚拟机中的linux系统(RedHat 9默认安装了sshd),个人觉得这样比较方便。
2. ASCII查询可以在linux终端中运行man ascii。
3. 退出gdb后,再次进入时一定要注意使用break给explode_bomb上断点,不可大意 ~.~
4. 后面的几关涉及递归等内容,也有和前面几次作业很相似的东东。
5. gdb中还有一个很好用的jump指令,可以在运行时任意跳转。
6. 看汇编代码时,使用objdump -d bomb > bomb.asm把汇编代码保存到bomb.asm中,然后使用sftp工具把这个文件下载到windows或者直接在vim中查看,这样比在gdb中看方便一些。
7. 个人认为lab2和期中考试不冲突,这个lab2可以帮你理清很多汇编语言的概念
其他补充:
sfox:
可以通过GDB中的 x /s addr输出以\0结尾的字符串
ICSLab:
为了防止每次拆的时候都不停的输入之前的stage的key,可以把key存入文本文件,一行一个key,不要有多余字符
然后GDB run 的时候用 gdb bomb 回车
(gdb) b .... ....
(gdb) r password.txt
这样bomb就会自动从password.txt中读入之前的密码
直到到达最后一个空行处,如Lab2的说明文档中所述。
http://www.wiki.cn/wiki/Exponentiation_by_squaring
Exponentiating by squaring is an algorithm used for the fast computation of large integer powers of a number. It is also known as the square-and-multiply algorithm or binary exponentiation. In additive groups the appropriate name is double-and-add algorithm. It implicitly uses the binary expansion of the exponent. It is of quite general use, for example in modular arithmetic.
1. 纯虚函数的声明:将函数赋值为0
virtual void gen_elems(int pos) = 0;
2. 通常情况下,定义了一个或多个虚函数的基类要定义一个虚析构函数,因为在释放子类内存时具体析构函数需要在运行期才能确定。
作者也不建议把析构函数定义为纯虚的,即使没有任何具体的实现。
恩,睡觉
Pitfall 1:判断x的奇偶性
public static boolean isOdd(int x) {
return x % 2 == 1;
}
当x为负奇数时,x % 2的值为负数。
Note:把 x % 2 == 1 改为 x % 2 != 0
Pitfall 2:长整数计算
long MICROS_PER_DAY = 24 * 60 * 60 * 1000 * 1000;
这个表达式先计算左边几个int的乘积,然后再把值转换为long,因此仍会溢出
Note:把24改成24L
Pitfall 3:看看这句话的结果
System.out.println(12345+5432l);
Note:5432后面的l很容易被看成1,因此建议使用L表示长整形时都使用大写。
Pitfall 4:下面这句话又会是什么结果
System.out.println(Long.toHexString(0x100000000L + 0xcafebabe));
Java计算时先用sign-extension把后面一个数转成long,然后再计算
Note:尽量避免混合类型计算
Pitfall 5:这句话呢?
System.out.println((int) (char) (byte) -1);
结果是65535
Note:char是无符号类型,将char转为int时使用zero-extension
Pitfall 6:交换变量值
int x = 1984;
int y = 2001;
x ^= y ^= x ^= y;
最终结果是x == 0, y == 1984
Note:Java中操作符是从左往右计算的 (JLS 15.7)
改成 y = (x ^ (y ^= x) ^ y; 就可以,但是永远不要这么做
Pitfall 7:问号操作符
char x = 'X';
int i = 0;
System.out.print(true ? x : 0);
System.out.print(false ? i : x);
输出结果为X88
Note:同样是混合类型计算导致的问题,建议在条件表达式中使用类型相同的第二和第三操作符。
Pitfall 8:看似相同的表达式的不同结果
short x = 0;
int i = 123456;
1) x += i; // 隐含了类型转换,结果为-7616
2) x = x + i; // 编译无法通过,因为损失了精度
第一次接触后缀树应该是在某次省队集训,徐串大牛做的讲座。
不过当时只是有了个印象。
现在发现这东东还是很好用的 @,@
http://www.blogjava.net/Files/zellux/SuffixT1withFigs.rar
On–line construction of suffix trees
by Esko Ukkonen
Key Words.
Linear time algorithm, suffix tree, suffix trie, suffix automaton, DAWG.
Abstract.
An on–line algorithm is presented for constructing the suffix tree for a given string in time linear in the length of the string. The new algorithm has the desirable property of processing the string symbol by symbol from left to right. It has always the suffix tree for the scanned part of the string ready. The method is developed as a linear–time version of a very simple algorithm for (quadratic size) suffix tries. Regardless of its quadratic worst-case this latter algorithm can be a good practical method when the string is not too long. Another variation of this method is shown to give in a natural way the well–known algorithms for constructing suffix automata (DAWGs).
发现居然还是Pascal描述,亲切啊亲切
http://iprai.hust.edu.cn/icl2002/algorithm/datastructure/basic/binary_tree/chapter5_4.htm
线索二叉树
当用二叉链表作为二叉树的存储结构时,因为每个结点中只有指向其左、右儿子结点的指针,所以从任一结点出发只能直接找到该结点的左、右儿子。在一般情况下靠它无法直接找到该结点在某种遍历序下的前驱和后继结点。如果在每个结点中增加指向其前驱和后继结点的指针,将降低存储空间的效率。
我们可以证明:在n个结点的二叉链表中含有n+1个空指针。因为含n个结点的二叉链表中含有个指针,除了根结点,每个结点都有一个从父结点指向该结点的指针,因此一共使用了n-1个指针,所以在n个结点的二叉链表中含有n+1个空指针。
因此可以利用这些空指针,存放指向结点在某种遍历次序下的前驱和后继结点的指针。这种附加的指针称为线索,加上了线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树。为了区分一个结点的指针是指向其儿子的指针,还是指向其前驱或后继结点的线索,可在每个结点中增加两个线索标志。这样,线索二叉树结点类型定义为:
|
type
TPosition=^thrNodeType;
thrNodeType=record
Label:LabelType;
ltag,rtag:0..1;
LeftChild,RightChild:TPosition;
end;
|
其中ltag为左线索标志,rtag为右线索标志。它们的含义是:
- ltag=0,LeftChild是指向结点左儿子的指针;
- ltag=1,LeftChild是指向结点前驱的左线索。
- rtag=0,RightChild是指向结点右儿子的指针;
- rtag=1,RihgtChild是指向结点后继的右线索。
例如图13(a)是一棵中序线索二叉树,它的线索链表如图13(b)所示。

(a)

(b)
图13 线索二叉树及其线索链表
图13(b)中,在二叉树的线索链表上增加了一个头结点,其LeftChild指针指向二叉树的根结点,其RightChild指针指向中序遍历时的最后一个结点。另外,二叉树中依中序列表的第一个结点的LeftChild指针,和最后一个结点的RightChild指针都指向头结点。这就像为二叉树建立了一个双向线索链表,既可从第一个结点起,顺着后继进行遍历,也可从最后一个结点起顺着前驱进行遍历。
如何在线索二叉树中找结点的前驱和后继结点?以图13的中序线索二叉树为例。树中所有叶结点的右链是线索,因此叶结点的RightChild指向该结点的后继结点,如图13中结点"b"的后继为结点"*"。当一个内部结点右线索标志为0时,其RightChild指针指向其右儿子,因此无法由RightChild得到其后继结点。然而,由中序遍历的定义可知,该结点的后继应是遍历其右子树时访问的第一个结点,即右子树中最左下的结点。例如在找结点"*"的后继时,首先沿右指针找到其右子树的根结点"-",然后沿其LeftChild指针往下直至其左线索标志为1的结点,即为其后继结点(在图中是结点"c")。类似地,在中序线索树中找结点的前驱结点的规律是:若该结点的左线索标志为1,则LeftChild为线索,直接指向其前驱结点,否则遍历左子树时最后访问的那个结点,即左子树中最右下的结点为其前驱结点。由此可知,若线索二叉树的高度为h,则在最坏情况下,可在O(h)时间内找到一个结点的前驱或后继结点。在对中序线索二叉树进行遍历时,无须像非线索树的遍历那样,利用递归引入栈来保存待访问的子树信息。
对一棵非线索二叉树以某种次序遍历使其变为一棵线索二叉树的过程称为二叉树的线索化。由于线索化的实质是将二叉链表中的空指针改为指向结点前驱或后继的线索,而一个结点的前驱或后继结点的信息只有在遍历时才能得到,因此线索化的过程即为在遍历过程中修改空指针的过程。为了记下遍历过程中访问结点的先后次序,可附设一个指针pre始终指向刚刚访问过的结点。当指针p指向当前访问的结点时,pre指向它的前驱。由此也可推知pre所指结点的后继为p所指的当前结点。这样就可在遍历过程中将二叉树线索化。对于找前驱和后继结点这二种运算而言,线索树优于非线索树。但线索树也有其缺点。在进行插人和删除操作时,线索树比非线索树的时间开销大。原因在于在线索树中进行插人和删除时,除了修改相应的指针外,还要修改相应的线索。
要做个和Java3D有关的项目,需要稍微了解下相关的知识。
看的资料是The Java3d Tutorial,版本有点早,凑合着看了。
Java 3D 的虚拟环境是从场景图(scene graph)中建立的,场景图聚合(assemble)了各种定义几何、声音、光、位置、方位等元素的类。
一种常用的定义图的数据结构由结点(node)和弧(arc)组成。结点都是Java 3D类的实例,而弧则代表了实例间两种不同的关系。
最常见的关系是父子(parent-child)关系。一个组结点(group node)可以包含任意多的子结点,但只能有一个父结点。
另一种关系是引用(reference),引用通过一个场景图的结点关联了一个NodeComponent类,NodeComponent类定义了各种视图对象的几何和外观属性。
这种结构可以用树来描述,从根结点到任一叶子结点的路成为场景图路径(scene graph path). 每条路径都完整地描述了它的叶子结点的状态。

这就是一个简单的场景图的结构,其中包括VisualUniverse Locale GroupNode Leaf 等元素
每个场景图都有单一的VirtualUniverse,后者包含一串Locale对象。一个程序可以包含多个VirtualUniverse对象,但是没有一种简单的方法实现它们相互之间的通信。
写Java3D程序的通常步骤:
1. 创建一个Canvas3D对象
2. 创建一个VirtualUniverse对象
3. 创建一个Locale对象,将其与VirtualUniverse相关联
4. 构造视图分支(view branch graph):分别创建一个View ViewPlatform PhysicalBody PhysicalEnvironment对象,将后面三个及Canvas3D与View对象关联
5. 构造内容分支(content branch graph)
6. 编译(compile)各个分支
7. 将子图(subgraph)插入Locale中
使用SimpleUniverse可以简化这些步骤
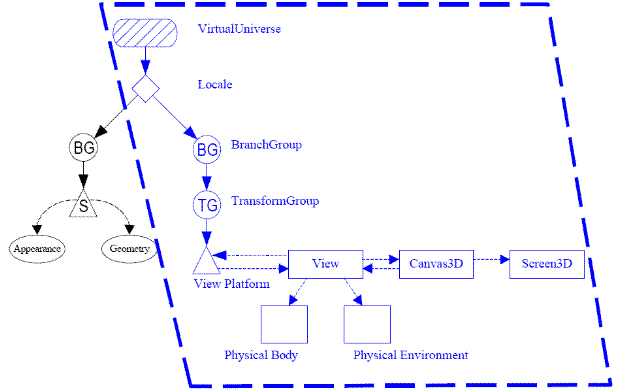
虚线框起来的部分就是SimpleUniverse中提供的内容
通过它可以将步骤简化为
1. 创建一个Canvas3D对象
2. 创建一个引用了之前的Canvas3D对象的SimpleUniverse类,并定制该类
3. 构造一个内容分支,编译后插入SimpleUniverse的Locale
什么是编译(compile):通过编译BranchGroup,可以将它及其祖先转换为一种更高效的实现方式。建议在最后一步中做编译。
摘要: 问题:
有两堆石子,数量任意,可以不同。游戏开始由两个人轮流取石子。游戏规定,每次有两种不同的取法,一是可以在任意的一堆中取走任意多的石子;二是可以在两堆中同时取走相同数量的石子。最后把石子全部取完者为胜者。现在给出初始的两堆石子的数目,如果轮到你先取,假设双方都采取最好的策略,问最后你是胜者还是败者。 阅读全文
摘要: 水木上看到的
一个K位的数N (K<=2000,N<=10^20)
找出一个比N大且最接近的数,这个数的每位之和与N相同
用代码实现之
如:
0050 所求数为0104
112 所求数为121
阅读全文
maillist上有人问关于这个函数的问题,回复中有人推荐去看它的源代码
memcpy调用了__memcpy函数执行内存的复制(__memcpy3d就先不管了),下面是这个这两个函数的代码
void *memcpy(void *to, const void *from, size_t n)
{
#ifdef CONFIG_X86_USE_3DNOW
return __memcpy3d(to, from, n);
#else
return __memcpy(to, from, n);
#endif
}
static __always_inline void * __memcpy(void * to, const void * from, size_t n)
{
int d0, d1, d2;
__asm__ __volatile__(
"rep ; movsl\n\t"
"movl %4,%%ecx\n\t"
"andl $3,%%ecx\n\t"
#if 1 /* want to pay 2 byte penalty for a chance to skip microcoded rep? */
"jz 1f\n\t"
#endif
"rep ; movsb\n\t"
"1:"
: "=&c" (d0), "=&D" (d1), "=&S" (d2)
: "0" (n/4), "g" (n), "1" ((long) to), "2" ((long) from)
: "memory");
return (to);
}
看了一本内联汇编的书,总算把这段代码搞懂了。
起始时,把n/4保存在%ecx寄存器中,并把to和from的地址分别存入%edi和%esi (引用占位符)
然后重复调用movsl n/4次,接下来应该还有(n mod 4)个字节尚未复制,这里用了一个比较巧妙的方法
movl %4, %%ecx 把n的值保存到%ecx
andl $3, %%ecx n与3做逻辑与,得到n mod 4
jz 1f 如果4 | n,跳过后面的复制
rep movsb 再复制(n mod 4)个字节
由于是按四个字节复制的,因此效率上memcpy肯定比strcpy高不少。
睡前过一道,睡觉睡得香  不管这题多简单,咔咔
按照木块的长度或质量排序,之后贪心即可,后面和NOIP的拦截导弹一样。
我的做法是枚举最远到达的湖,减去相应的时间后贪心。
贪心时需要建立一个堆,用了STL中的priority_queue,然后就不知道如何设置less<>方法了。。。
最后是通过自定义一个类node解决的
一开始写的operator<方法逻辑上有问题,VS 2005跑了一会儿就冒出个 Debug assert error,这个挺赞的
导致我WA的几个数据:
1) 收益为0的几组数据。由于一开始设置的max值为0,因此当正解也是0时并没有记录下当前的最优解。max初始为负值即可。
2) 同样是0导致的问题。0收益的钓鱼点也可能出现在堆中,此时应该放弃这个点,把时间保留给序数大的钓鱼点。
另外我有这次比赛的测试数据和标程,需要的朋友留言即可。
#include <iostream>
#include <fstream>
#include <vector>
#include <queue>
using namespace std;
class node {
public:
int first, second;
node(int x, int y)
{
first = x;
second = y;
}
bool operator< (const node &rhs) const
{
if (second < rhs.second)
return true;
else if (second > rhs.second)
return false;
else return (first > rhs.first);
}
};
int main()
{
int n, h;
int d[26], t[26], f[26];
priority_queue<node, vector<node>, less<vector<node>::value_type> > heap;
vector<int> best(26);
cin >> n;
while (true) {
if (n == 0) break;
cin >> h;
for (int i = 1; i <= n; i++)
cin >> f[i];
for (int i = 1; i <= n; i++)
cin >> d[i];
t[0] = 0;
for (int i = 1; i < n; i++)
cin >> t[i];
best.clear();
int max = -1;
// i indicates the last lake
for (int i = 1; i <= n; i++) {
vector<int> tempBest(26);
int valueGet = 0;
int timeLeft = h * 12;
for (int j = 1; j <= i; j++)
timeLeft -= t[j - 1];
if (timeLeft <= 0) break;
while (!heap.empty())
heap.pop();
for (int j = 1; j <= i; j++)
heap.push(node(j, f[j]));
while ((!heap.empty()) && (timeLeft > 0)) {
int next = heap.top().first;
if (heap.top().second > 0) {
timeLeft--;
tempBest[next]++;
valueGet += heap.top().second;
}
int valueLeft = heap.top().second - d[next];
heap.pop();
if (valueLeft > 0)
heap.push(node(next, valueLeft));
}
if (valueGet > max) {
max = valueGet;
best = tempBest;
if (timeLeft > 0)
best[1] += timeLeft;
}
}
printf("%d", best[1] * 5);
for (int i = 2; i <= n; i++)
printf(", %d", best[i] * 5);
printf("\nNumber of fish expected: %d\n", max);
cin >> n;
if (n != 0) cout << endl;
}
return 0;
}
安装samba服务可以与Windows进行文件的共享
下面是在Arch下的简单安装方法:
- pacman -Sy samba
- (root) cp /etc/samba/smb.conf.default /etc/samba/smp.conf
- (root) vim /etc/samba/smb.conf (或者使用其他的编辑器)
[globle]选项块
workgroup = HOME # 组名,在Windows中默认是MSHOME或者WORKGROUP
netbios name = ZelluX # 在网上邻居中显示的机器名
encrypt passwords = yes # 应该设为yes。但是如果要在Windows 98/95上访问你的服务器,得把这个设为no,因为它们不支持密码的加密传输。
[homes]选项块
最简单的配置(登陆后方可访问):
browseable = no
read only = no # 或者writable = yes
匿名可读,登陆后可以修改:
public = yes
writable = yes
write list = @staff
如果想让Windows用户看到一个清晰的目录(隐藏.开头的文件,比如~/.bashrc):
[homes]
path = /home/%u/smb
browseable = no
read only = no
同时要在每位用户的主目录下建立一个smb目录。可以通过在/etc/skel目录下建立smb,从而自动在所有用户目录下建立该目录
mkdir /etc/skel/smb
要共享其他的目录也很容易,只要设置path和valid users属性即可
[music]
path = /mnt/windows/Music/
browseable = yes
read only = yes
valid users = Bryan, Michael, David, Jane
valid users属性指定登陆后有权限访问到这个目录的用户
- (root) 使用 smbpasswd -a 用户名 增加允许登陆的用户,并指定他们的登陆密码
- (root) /etc/rc.d/samba stop 停止samba服务
- (root) /etc/rc.d/samba start 启动samba服务
刚做完了Java课布置的homework,其中有一题是打印日历
February 2007
---------------------------
Sun Mon Tue Wed Thu Fri Sat
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28
用GregorianCalendar类几分钟就做好了
Java的确很方便,主要是很多库都集成在jdk中,查一份手册就可以使用
如果这个用C++写,除非去找个开源的库,否则估计就得自己计算了,印象中日期方面的竞赛题都属于难度不大,但是很容易出错的题目。
话虽如此,还是想学好C++ -,-|||
更详细的分析google Nim Game
http://www.math.ucla.edu/~tom/Game_Theory/comb.pdf
发信人: flyskyf (flysky), 信区: Algorithm
标 题: 拿糖果问题
发信站: 水木社区 (Mon Oct 15 19:07:51 2007), 站内
现有4堆糖果.分别为1,2,4,8
甲乙两人分别从中拿糖果
规则:
1 每人可以从某一堆中拿任意多个
2 甲乙两人交替拿
3 谁拿到最后一个糖果或最后几个糖果算赢.
请问谁有必胜把握?怎样实现?
发信人: meeme (米鸣), 信区: Algorithm
标 题: Re: 拿糖果问题
发信站: 水木社区 (Mon Oct 15 19:26:32 2007), 站内
转成二进制
1 =0001
2 =0010
4 =0100
8-1 =0111 +
-----------
0222
这样每个位上都有两个1。
比如个位上,1和7在个位上都有一个1
对方不可能同时把这两个1拿走。所以对方是拿不完的。
对方拿完之后,自己再拿若干个调整成这种状态。
中间应该有不少证明...
http://www.ekany.com/wdg98/zhsx/2/2_6.htm
Ferrers图像
一个从上而下的n层格子,mi 为第i层的格子数,当mi>=mi+1(i=1,2,...,n-1)
,即上层的格子数不少于下层的格子数时,称之为Ferrers图像,如图(2-6-2)示。

图 (2-6-2)
Ferrers图像具有如下性质:
1.每一层至少有一个格子。
2.第一行与第一列互换,第二行于第二列互换,…,即图(2-6-3)绕虚线轴旋转所得的图仍然是Ferrers图像。两个Ferrers
图像称为一对共轭的Ferrers图像。
利用Ferrers图像可得关于整数拆分的十分有趣的结果。
(a)整数n拆分成k个数的和的拆分数,和数n拆分成个数的和的拆分数相等。
因整数n拆分成k个数的和的拆分可用一k行的图像表示。所得的Ferrers图像的共轭图像最上面一行有k个格子。例如:

图 (2-6-3)
(b)整数n拆分成最多不超过m个数的和的拆分数,和n拆分成最大不超过m的拆分数相等。
理由和(a)相类似。
因此,拆分成最多不超过m个数的和的拆分数的母函数是

拆分成最多不超过m-1个数的和的拆分数的母函数是

所以正好拆分成m个数的和的拆分数的母函数为

(c)整数n拆分成互不相同的若干奇数的和的的拆分数,和n拆分成自共轭的Ferrers图像的拆分数相等.
设

其中n1>n2>...>nk
构造一个Ferrers图像,其第一行,第一列都是n1+1格,对应于2n1+1,第二行,第二列各n2+1格,对应于2n2+1。以此类推。由此得到的Ferres图像是共轭的。反过来也一样。
例如 17=9+5+3 对应为Ferrers图像为

图 (2-6-4)
费勒斯(Ferrers)图象
假定n拆分为n=n1+n2+n3+……+nk,且n1>=n2>=n3>=……>=nk
我们将它排列成阶梯形,左边看齐,我们可以得到一个类似倒阶梯图像,这种图像我们称之为Ferrers图像,如对于20=10+5+4+1,我们有图像:
对于Ferrers图像,我们很容易知道以下两条性质:
(1) 每层至少一个格子
(2) 行列互换,所对应的图像仍为Ferrers图像,他应该为该图像的共轭图像
任意的Ferrers图像对应一个整数的拆分,而可用Ferrers图像方便地证明:
(1) n拆分为k个整数的拆分数,与n拆分成最大数为k的拆分数相等
(2) n拆分为最多不超过k个数的拆分数,与n拆分成最大数不超过k的拆分数相等
(3) n拆分为互不相同的若干奇数的拆分数,与n拆分成图像自共轭的拆分的拆分数相等
这两星期里得看懂Robocode代码,然后自己做个类似小霸王坦克大战的游戏出来@@ 只能老老实实啃了
首先要了解了一些常用的设计模式,由于时间有限,就不去看四人帮的那本书了,偷懒google别人的文章快速入门算了
Robocode中有不少Manager类,其实就是Façade模式的应用。
http://www.fish888.com/Facade-t126336
1、官方描述:
为子系统中的一组接口提供一个一致的界面,Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
2、实例讨论:
我们可以通过电视机遥控器的作用来理解该模式的价值和作用,电视机的内部很复杂,包括频道调节和处理系统、图像色彩调节处理系统、声音调节系统等等,每个系统又包括多个类进行操作,如果把这些系统都暴露给用户使用,而不是通过遥控器进行封装,那么每个电视机用户都可能需要进行一个《电视机操作使用》培训才能使用了。相对而言,现在通过遥控器,电视机用户在很短的时间就可以掌握常规的使用方法。
电视机遥控器及电视机内部的结构图如下所示:

3、适用性:
1)为复杂的子系统提供一个简单的接口,子系统可能为了通用性目标,实现为可以根据使用情况进行各种定制的复杂系统,可是按照2/8法则,80%的用户可能只是使用简单的20%的功能,这样通过提供Facade对子系统进行高层概括,便极大的简化了这80%用户的易用性;
2)子系统存在多种实现,通过Facade在用户和子系统内部实现之间进行分离,减弱了用户对子系统的实现依赖性,这样就便于对子系统进行扩展和维护;
3)降低子系统之间的依赖性;
4、实现特征:
1)Facade不提供新的功能,仅作为子系统的高层概括和代理;
2)子系统不知道Facade的存在,即子系统中没有对Facade的关联,而只是Facade了解子系统内部结构;
3)Facade原则上并不禁止用户直接访问子系统中的对象,Facade在子系统的可定制性上层建立了一个简单视图;
5、Java代码演示:
下面代码演示了电视机遥控器的程序结构:
1)子系统部分代码:
类ChannelManager(频道管理器),负责电视频道的相关调整和操作:
package qinysong.pattern.facade.subsystem;
public class ChannelManager ...{
//当前频道编号
private int currentChannelNumber;
//设置频道(可能还会调用其它辅助类)
public void chooseChannel(int channelNumber) ...{
System.out.println("ChannelManager.chooseChannel(): 设置频道(可能还会调用其它辅助类)");
currentChannelNumber = channelNumber;
}
//上调频道(可能还会调用其它辅助类)
public void upSkipChannel()...{
System.out.println("ChannelManager.upSkipChannel(): 上调频道(可能还会调用其它辅助类)");
currentChannelNumber++;
}
//下调频道(可能还会调用其它辅助类)
public void downSkipChannel()...{
System.out.println("ChannelManager.downSkipChannel(): 下调频道(可能还会调用其它辅助类)");
currentChannelNumber--;
}
public void otherMethod()...{
System.out.println("ChannelManager.otherMethod(): 其他方法");
}
}
类AudioManager(声频管理器),负责声音的相关调整和操作,该类还用到其他类,如类Volume等:
package qinysong.pattern.facade.subsystem;
public class AudioManager ...{
//当前音量
private Volume currentVolume;
//加重音量
public void aggravateVolume()...{
System.out.println("AudioManager.aggravateVolume(): 加重音量(可能还会调用其它辅助类)");
currentVolume.aggravate();
}
//降低音量
public void weakenVolume()...{
System.out.println("AudioManager.weakenVolume(): 降低音量(可能还会调用其它辅助类)");
currentVolume.weaken();
}
public void otherMethod()...{
System.out.println("AudioManager.otherMethod(): 其他方法");
}
}
类ColorManager(色彩管理器),负责图像色彩的相关调整和操作,该类还用到其他类,如类Color等:
package qinysong.pattern.facade.subsystem;
public class ColorManager ...{
//当前色彩度
private Color currentColor;
//加重色彩度
public void aggravateColor()...{
System.out.println("ColorManager.aggravateColor(): 加重色彩度(可能还会调用其它辅助类)");
currentColor.aggravate();
}
//降低色彩度
public void weakenColor()...{
System.out.println("ColorManager.weakenColor(): 降低色彩度(可能还会调用其它辅助类)");
currentColor.weaken();
}
public void otherMethod()...{
System.out.println("ColorManager.otherMethod(): 其他方法");
}
}
2)视图代码:
类RemoteDevice(遥控器),对电视机的日常使用操作进行封装,以便用户使用:
package qinysong.pattern.facade;
import qinysong.pattern.facade.subsystem.AudioManager;
import qinysong.pattern.facade.subsystem.ColorManager;
import qinysong.pattern.facade.subsystem.ChannelManager;
public class RemoteDevice ...{
private AudioManager audioManager;
private ColorManager colorManager;
private ChannelManager channelManager;
//加重音量
public void aggravateVolume()...{
//取得 audioManager
audioManager.aggravateVolume();
}
//降低音量
public void weakenVolume()...{
//取得 audioManager
audioManager.weakenVolume();
}
//加重色彩度
public void aggravateColor()...{
//取得 colorManager
colorManager.aggravateColor();
}
//降低色彩度
public void weakenColor()...{
//取得 colorManager
colorManager.weakenColor();
}
//设置频道(可能还会调用其它辅助类)
public void chooseChannel(int channelNumber) ...{
//取得 channelManager
channelManager.chooseChannel(channelNumber);
}
//上调频道(可能还会调用其它辅助类)
public void upSkipChannel()...{
//取得 channelManager
channelManager.upSkipChannel();
}
//下调频道(可能还会调用其它辅助类)
public void downSkipChannel()...{
//取得 channelManager
channelManager.downSkipChannel();
}
}
开始用Word 2007发布日志
发现书上很多加了星号的题目我都得看Instructor's Manual才会做 =_=
Problem: Show how to solve the fractional knapsack problem in O(n) time. Assume that you have a solution to Problem 9-2.
Problem 9-2就是在最差情况下也能在O(n)时间内求出第k大元素的算法。
解答:
使用线性算法找出Vi / Wi的中位数
将物体分成三个集合,G = { i : Vi / Wi > m } E = { i : Vi / Wi = m} L : { i : Vi / Wi < m},同样能在线性时间内完成
计算WG = Sigma(Wi), i ∈ G; WE = Sigma(Wi), i ∈ E
-
如果WG > W,则不在G中取出任何物体,而是继续递归分解G
-
如果WG <= W,取出G中所有物体,并尽可能多得取出E中物体
-
如果WG + WE >= W,也就是说步骤2以后背包已经放满,则问题解决
-
否则如果尚未放满,则继续在L上递归调用查找W – WG - WE的方案
以上所有调用都在线性时间内完成,每次递归调用都能减少一半的数据规模
因此运行时间的递归式为
T(n) <= T(n/2) + Omega(n)
有Master Theorem可得
T(n) = O(n)
问题:
已知一些活动的起止时间{Si}, {Fi},把它们安排在若干个大厅中进行,要求任一大厅任意时间段内不能有两项活动同时进行,求出所需的最少的大厅数。
分析:(from CLRS Instructor's Manual)
这是一个区间图的着色问题(Interval-graph Coloring Problem),用点表示活动,把时间冲突的活动连起来,然后进行点的着色,要求同一线段的两端不能有相同颜色的点。
首先最容易想到的就是用书上的Greedy-Activity-Selector找出可安排在大厅1的最长序列,然后删去这些活动,再次调用该方法,找出安排在大厅2的活动,以此类推。
复杂度O(n*n)
还有一个O(n*logn)的算法,甚至在起止时间都是比较小的数字时复杂度只有O(n)。
主要思想是依次遍历每个活动,把它们安排到不同的大厅中。
维护两张表,一张记录当前时间t已经安排了活动的大厅,另一张记录当前时间空闲的大厅
然后从头扫描排序后的时间点序列(如果事件a的结束时间等于时间b的开始时间,那么前者应该排在后者后面)
碰到开始时间t,把该活动放到空闲列表的第一个大厅中(如果空闲列表为空则新加一个大厅),然后把该大厅放入已安排的大厅列表中;
碰到结束时间t,从已安排的大厅列表中移出相应大厅到空闲列表。
复杂度分析:
排序:O(n logn),如果时间范围有限制还可以做到O(n)
处理:O(n)
发信人: CJC (蓝色雪狐), 信区: 05SS
标 题: OS_Lab3 指南 List
发信站: 复旦燕曦BBS (2007年10月11日03:55:12 星期四), 转信
先写点List的东西吧,这个其实在以前并不作为重点讲,不过好像大家对它还是有些偏
见,所以这次稍微讲下吧。作用是为到时候建立进程关系列表做准备。
讲的内容都在/usr/src/linux.../include/linux/list.h中,大家只要把一些不必要的
ifdef和一些prefetch的东西删掉就好了。
首先讲讲历史。在没有范型的Java里面我们用的链表往往会这样(如果转成C的话):
typedef struct list_head {
struct list_node *prev;
void *data;
struct list_node *next;
} list_t;
通过这个结构,我们就能完成链表的功能了。但是我觉得这个数据结构不好,原因有二
:
第一:这个结构比较容易引起内存碎片。
┌──┬─┬──┐
│prev│ │next│<----多余内存消耗
└──┴┼┴──┘
│ ┌───┐
└─>│ data │
└───┘
这种设计每一个节点都会引起一块多余的内存消耗。
第二:类型不明确,因为现在没办法用范型。如果写明了类型,那么还要为每种类型的
list自己再做一整套函数,得不偿失。
当然,还会考虑类似于我们希望用别人写得比较好的代码之类的原因。
那让我们来看看我们版本里的list_t是怎么定义的
typedef struct list_head {
struct list_head *next, *prev;
} list_t;
乍一看,这个list_head里面什么都没包含,只有一对前后指针,没有指向数据的指针
。那怎么用呢?这里的做法我叫做:反包含。我们来看一个具体的使用例子:
typedef struct test_struct {
int val1;
int val2;
char vals[4];
list_t all_tests; //千万注意,这里是list_t,不是list_t *
} test_t;
那么我们声明了这个数据结构在内存中是什么样的呢?
(test_list) ┌─────┐┬ <--my_test_struct_p(test_t *)
┌──┬──┐ │ val1 ││
│prev│next├┐ ├─────┤│
└──┴──┘│ │ val2 ││h
│ ├─────┤│
│ │ vals ││
表示指向首地址└──>├──┬──┤┴ <--my_list_p(list_t *)
│prev│next│ //这里如果是list_t *就不是这样画了!
└──┴──┘
上图就是一个test_t的结构图。小地址在上,大地址在下,val1上面的那条分界线作为
val1的起始地址(请注意我my_test_struct_p及其它指针的画法,是指向上面那根线,表示
为那个东西的起始地址,为清楚起见推荐大家以后这样画)
然后为了把所有的test_t数据结构串起来,我们需要一个全局变量:test_list,类行
为list_t(如果这里声明list_t *的话一定要为它分配空间!如果是死的全局变量、全局数
组和一些临时数组,推荐直接声明成类型而不是指针,因为编译器会放在dat/bss和stack段
里。但是如果这个数据结构是返回类型的分配空间,一定要malloc!否则回去就会错。这里
也提醒一下)
我们可以看到test_list.next是指向my_test_struct_p->all_tests,而不是my_test_s
truct。但是对我有用的应该是my_test_struct。所以一般处理方法有二,
第一种比较死板,就是在数据结构的一开始就放一个list_t(命名为list),那么&lis
t=&stru,可以直接(xxx *)list_p。但是问题是如果一个数据结构可以同属两个链表,如pc
b,又要是run_list的成员,又要是all_tasks的成员,还要是父进程children的成员……这
种方法显然是不够的。
第二种方法就相对好些。大家可以看,
((unsigned int)my_list_p)-h=(unsigned int)my_test_struct_p
而怎么得到h呢?是不是需要每个数据结构都定义一个h呢?不需要,可以这样看
h=(unsigned int)(&(((test_t *)0)->all_tests))
就是把0地址当作是test_t数据结构的开始地址,那么这个数据结构的all_tests所在的
地址就是h了。
通过把这两个算式结合,我们可以得到一个宏:
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
在这里的用法就是:
my_test_struct_p = list_entry(test_list.next, test_t, all_tests);
(如果使用类似于Simics的编辑器的话,all_tests的显示会是类似于没有定义变量,
不用管它,的确是这样的。最后编译成功就对了)。
看过了最精妙的list_entry之后我们就可以来看一些简单的操作了
#define INIT_LIST_HEAD(ptr) do { \
(ptr)->next = (ptr); (ptr)->prev = (ptr); \
} while (0)
为什么要加while(0)可以参见lab2指南里面的一些define帮助。其大致概念如下:
┌─────────┐
│ │
└->┌──┬──┐ │
┌─┤prev│next├─┘ //这里为了画清逻辑,不把指针放在首地址
│ └──┴──┘<-┐
│ │
└─────────┘
这是一个环状链表。一般这个作为头指针,链表为空的判断依据就是:
static inline int list_empty(struct list_head *head)
{
return head->next == head;
}
然后是添加,先有一个辅助函数:
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
这个是添加在第一个:
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
┌───────────────────┐
│ ┌─────┐ │
└->┌──┬──┐┌─>├──┬──┤ │
┌─┤prev│next├┘ ┌┤prev│next├-─┘ //这里的数据结构就省略画了
│ └──┴──┘<─┘├──┴──┤ <-┐
│ └─────┘ │
└───────────────────┘
ori_first
┌────────────────────────────┐
│ ┌─────┐ ┌─────┐ │
└->┌──┬──┐┌─>├──┬──┤┌─>├──┬──┤ │
┌─┤prev│next├┘ ┌┤prev│next├┘ ┌┤prev│next├─┘
│ └──┴──┘<─┘├──┴──┤<─┘├──┴──┤<-┐
│ └─────┘ └─────┘ │
└────────────────────────────┘
new ori_first
这个是添加在head->prev,由于是环状的,那么就是添在了最后一个
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
┌────────────────────────────┐
│ ┌─────┐ ┌─────┐ │
└->┌──┬──┐┌─>├──┬──┤┌─>├──┬──┤ │
┌─┤prev│next├┘ ┌┤prev│next├┘ ┌┤prev│next├─┘
│ └──┴──┘<─┘├──┴──┤<─┘├──┴──┤<-┐
│ └─────┘ └─────┘ │
└────────────────────────────┘
ori_first new
接下来是删除:
这是辅助方法
static inline void __list_del(struct list_head *prev, struct list_head *next)
{
next->prev = prev;
prev->next = next;
}
这个是用了辅助方法__list_del并且把entry的前后都设为NULL,是为了安全起见
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = (void *) 0;
entry->prev = (void *) 0;
}
个人觉得list_del_init, list_move, list_move_tail, list_splice没啥太大作用…
…不过后面两个非常重要:
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev, prefetch(pos->prev); pos != (head); \
pos = pos->prev, prefetch(pos->prev))
使用方法:
list_t *pos;
list_for_each(pos, &test_list) {
test_t *tmp = list_entry(pos, test_t, all_tests);
//do something on tmp
}
=======================================================================
list_t *pos, *n;
list_for_each_safe(pos, n, &test_list) {
test_t *tmp = list_entry(pos, test_t, all_tests);
//do something on tmp
}
======================================================================
那么这两个有什么差别呢?我们可以来看这个例子:
list_for_each(pos, &test_list) {
list_del(pos);
}
首先,我们得到pos=test_list.next,然后删除,此时pos->next=0,如果按照list_fo
r_each的话下一个循环的pos就是NULL,再访问下去就出错了!同样的,修改位置也是。所
以在需要修改队列结构的时候,一定要使用list_for_each_safe。如果只修改对应的数据结
构其他字段,可以用list_for_each,因为这个效率比较高。
有了这些方法基本上就可以使用了。我们可以来看一个物理内存管理的例子:
#define USER_MEM_SIZE (256*1024*1024)
#define USER_MEM_START (16*1024*1024)
#define PAGE_SHIFT 12
#define PAGE_SIZE (1<<(PAGE_SHIFT))
#define PAGE_COUNT (((USER_MEM_SIZE)-(USER_MEM_START))>>(PAGE_SHIFT))
#define PAGE_START(ptr) (((ptr)-(all_pages))<<(PAGE_SHIFT)+(USER_MEM_START))
//获取这个page数据结构对应的起始地址
#define PAGE_STRU(addr) (&all_pages[((addr)-(USER_MEM_START))<<(PAGE_SHIFT)])
typedef struct page_struct {
unsigned long use_count;
list_t mem_list;
} page_t;
list_t free_list, lru_list; //lru是用作换出的,最近使用在队首,换出队尾页
//如果编译器不肯让我们这样定义的话用lmm_alloc或者out_alloc也可以。
page_t all_pages[PAGE_COUNT];
void init()
{
int i;
INIT_LIST_HEAD(&free_list);
INIT_LIST_HEAD(&lru_list); //初始化两个链表
for (i = 0; i < PAGE_COUNT; i++) {
all_pages[i] = 0;
list_add_tail(&all_pages[i].mem_list, &free_list); //加入free_list
}
}
//此处返回值作为错误信息,addr作为所需返回的物理内存起始地址
int get_page(unsigned int *addr)
{
if (list_empty(&free_list)) //没有空页
return -1;
list_t *lst = free_list.next;
list_del(lst);
list_add(lst, &lru_list); //最近使用,放到队首
*addr = PAGE_START(list_entry(lst, page_t, mem_list);
return 0;
}
void use_page(unsigned int addr)
{
page_t *pg = PAGE_STRU(addr);
list_del(&pg->mem_list);
list_add(&pg->mem_list, &lru_list); //将页面放到lru队列首
}
void return_page(unsigned int addr)
{
page_t *pg = PAGE_STRU(addr);
list_del(&pg->mem_list);
list_add(&pg->mem_list, &free_list); //将页面放到free队列首,下次取时用
}
物理页面管理基本上就类似于此。我们接下来来看一个稍微复杂些的例子,就是进程父
子关系的例子,去年又同学跟我反映这是一个交错链接或者说是嵌套链接,其实不然。我们
拆分开来看:
┌─────────-┐
│┌-────────┼───┐
│ ↘ A->children │ │
┌───-┼─>┌──┬──┐ │ │
│ └-─┤prev│next├┐│ │
│ └──┴──┘││ │
│┌────────────┘│ │
││ ┌-───┘ │
││ ┌─────┐ ↘┌─────┐│
│└>├──┬──┤┌─>├──┬──┤│
└-─┤prev│next├┘ ┌┤prev│next├┘
├──┴──┤<─┘├──┴──┤
└─────┘ └─────┘
B C
由图可知,A有BC两个子进程,分别连接到A进程的children上。此时,处理A的childre
n又有两种方法,第一种是增加指针,第二种是作为A进程的一部分。利用上面的思考方法,
我们可以知道,如果按照第一种做法,那么势必会引起更多的内存碎片,不方便。于是我们
把children作为pcb的一个field。那么B和C里面的prev/next该叫什么呢?因为B和C也是pc
b的数据结构,已经不可能再叫children了(而且他们也应该有children节点,因为他们也
可能有子进程)。那么我们就叫它为sibling吧。因为在这个链表里,除了A是父进程,其余
的都是兄弟进程。
所以pcb的父子关系可以这样写:
#define TASK_STATE_RUNNING 0
#define TASK_STATE_ZOMBIE 1
//调用了wait指令,等待子进程结束
#define TASK_STATE_WAIT_CHILD 2
typedef struct pcb_struct{
struct pcb_struct *parent; 父进程
unsigned long state;
list_t children;
list_t sibling;
list_t all_tasks;
} pcb_t;
//init是一个非常特殊的进程,一般我们的kernel一起来,就只负责两个进程:init和idle
//init的作用是先fork,子进程运行shell,它自身while(1) {wait(...);}就是负责回收
//孤儿进程。
//并且在此,我们可以把所有的进程都连接在init的all_tasks上面,这样又可以节省一个
//相当于前例test_list的全局变量。找所有进程只须遍历init->all_tasks即可。
//所以在生成init的时候应该是INIT_LIST_HEAD(&task->all_tasks)
void init_pcb(pcb_t *task, pcb_t *init)
{
INIT_LIST_HEAD(&task->children);
INIT_LIST_HEAD(&task->sibling);
task->parent = NULL;
task->state = TASK_STATE_RUNNING;
list_add_tail(&task->all_tasks, &init->all_tasks);
}
void add_child(pcb_t *parent, pcb_t *child)
{
child->parent = parent;
list_add_tail(&child->sibling, &parent->children); //想想为什么
}
void do_exit(pcb_t *task, pcb_t *init)
{
//exit_mem_first_part
list_t *pos, *n;
list_for_each_safe(pos, n, &task->children) //将所有子进程交给init
{ //~~~~
task_t *child = list_entry(pos, task_t, sibling); //这里是sibling
child->parent = init;
list_del(&child->sibling);
list_add_tail(&child->sibling, &init_children);
if (child->state == TASK_STATE_ZOMBIE && init->state != TASK_STATE_WAIT_
CHILD)
{
//这里激活init,并把init放到进程列表的尾端
}
}
//然后切换到父进程运行
}
如果看懂了以上的所有例子,那么链表结构应该就差不多了。由于篇幅关系,PCB的构
建就单列开来吧。这里专门讲LIST好了。:)
如果有代码觉得看的郁闷的,拿张纸画画对应的内存结构应该就会好些了
--
※ 修改:·CJC 于 Oct 11 03:57:46 修改本文·[FROM: 穿梭而来]
※ 来源:·复旦燕曦BBS yanxibbs.cn·[FROM: 穿梭而来]
http://10.132.140.73/lxr/http/blurb.html
在机房搭了一个,原本以为有笔记的功能,装好以后才发现只能阅读用,不过搜索功能还是很强大的。
转载,部分修改(标为红色)
我们在阅读linux源代码时都有这样的体会:核心的组织相对松散,在看一个文件时往往要牵涉到其他的头文件、源代码文件。如此来回跳转寻找变量、常量、函数的定义十分不方便,这样折腾几次,便使读代码的心情降到了低点。
lxr(linux cross reference)就是一个解决这个问题的工具:他对你指定的源代码文件建立索引数据库,利用perl脚本CGI动态生成包含源码的web页面,你可以用任何一种浏览器查阅。在此web页中,所有的变量、常量、函数都以超连接的形式给出,十分方便查阅。比如你在阅读/usr/src/linux/net/socket.c的源代码,发现函数 get_empty_inode不知道是如何以及在哪里定义的,这时候你只要点击get_empty_inode,lxr将返回此函数的定义、实现以及各次引用是在什么文件的哪一行,注意,这些信息也是超连接,点击将直接跳转到相应的文件相应的行。另外lxr还提供标识符搜索、文件搜索,结合程序 glimpse还可以提供对所有的源码文件进行全文检索,甚至包括注释!
下面将结合实例介绍一下lxr和glimpse的基本安装和使用,由于glimpse比较简单,就从它开始:
首先访问站点: http://glimpse.cs.arizona.edu/ 得到glimpse的源码
,比如我得到的是glimpse-4.12.5.tar.gz . 用root登录,在任一目录下用tar zxvf glimpse-4.12.5.tar.gz解开压缩包,在当前目录下出现新目录glimpse-4.12.5 .
进入该目录,执行
./configure
make
make install
如果单独使用glimpse,那么只要简单的执行glimpseindex foo即可,其中foo是你想要索引的目录,比如说是/usr/src/linux .glimpseindex的执行结果是在你的起始目录下产生若干.glimpse*的索引文件。
然后你只要执行glimpse yourstring即可查找/usr/src/linux下所有包含字符串yourstring的文件。
对于lxr,你可以访问lxr.linux.no得到它的源代码解包后,遵循如下步骤:
/*下面的文字来源于lxr的帮助文档以及本人的安装体会*/
1)修改Makefile中的变量PERLBIN和INSTALLPREFIX,使它们分别为 perl程序的位置和你想lxr安装的位置.在我的机器上,PERLBIN的值为/usr/bin/perl .至于INSTALLPREFIX,有如下原则,lxr的安装路径必须是web服务器能有权限访问。因此它的值简单一点可取 /home/httpd/html/lxr (对于Apache web server)。
2)执行 make install
3)修改$INSTALLPREFIX/http/lxr.conf :
baseurl : http://yourIP/lxr/http/
htmlhead: /home/httpd/html/lxr/http/template-head
htmltail: /home/httpd/html/lxr/http/template-tail
htmldir: /home/httpd/html/lxr/http/template-dir
sourceroot : /usr/src/linux # 假如对linux核心代码索引
dbdir : /home/httpd/html/lxr/dbdir/ #dbdirk可任意起名,且位置任意 glimpsebin: /usr/bin/glimpse #可执行程序glimpse的位置
4)在$INSTALLPREFIX/http/下增加一个文件.htaccess内容:
<Files ~ (source|search|ident|diff|find)$> ***
SetHandler cgi-script
</Files>
上面这个文件保证Apache server将几个perl文件作为cgi-script.
5)按照lxr.conf中的设置建立dbdir ,按照上例,建立目录
/home/httpd/html/lxr/dbdir
进入这个目录执行$INSTALLPREFIX/bin/genxref yourdir
其中yourdir是源码目录,比如/usr/src/linux
如果要结合glimpse,则执行glimpseindex -H . yourdir
6)修改 /etc/httpd/conf/ httpd.conf ,加入
<Directory /home/httpd/html/lxr/http>
Options All
AllowOverride All
order allow,deny
allow from all
</Directory>
7)进入/etc/rc.d/init.d/ 执行
killall httpd
./httpd start
进入X ,用浏览器 http://yourIP/lxr/http/blurb.html
大功告成 ,这下你可以舒心的读源码了。
Problem: You are given n real numbers - they are NOT sorted. Develop a linear time(O(n))algorithm to find the largest gap between consecutive numbers when the n numbers are sorted. For example, given:
10 23 7 1 35 27 50 41
the algorithm should produce 13 as its result, since the sorted list is:
1 7 10 23 27 35 41 50
and the largest gap is 13 (between 10 and 23).
Please note that your algorithm cannot actually sort the n numbers.
Macsy (真心) 于 (Fri Oct 5 11:59:16 2007) 提到:
有一个方法需要额外的O(n)的空间。
首先找到最大最小数max,min
max gap 肯定不小于 (max-min)/n 。
然后以(max-min)/n为步长,建立n个桶
每个桶里面记录落在这个桶中的最大最小值。
最后顺序扫描这n个桶中的值就可以了。
大概代码是
input: a[n];
min=min_of(a[1..n]);
max=max_of(a[1..n]);
step=(max-min)/n;
b[0..n].min=maxfloat; b[0..n].max=-maxfloat;
for i=1 to n
ind = (a[i]-min)/step;
b[ind].min=min(b[ind].min, a[i]);
b[ind].max=max(b[ind].max, a[i]);
maxgap=step;
last=b[0].max;
for i=1 to n
if (b[i].min != maxfloat)
maxgap=max(maxgap, b[i].min-last);
last=b[i].max;
output maxgap
proftpd.conf中增加两行设置:
UseReverseDNS off
IdentLookups off
Come From Alacner Blog:http://blog.alacner.com/post/168.htm
同目录下包含这三个文件即可
mingwm10.dll
QtCore4.dll
QtGui4.dll
以下转载自《Linux kernel》
核心源码的顶层是/usr/src/linux目录,在此目录下你可以看到大量子目录:
arch
这个子目录包含了所有体系结构相关的核心代码。它还包含每种支持的体系结构的子目录,如i386。
include
这个目录包括了用来重构核心的大多数include文件。对于每种支持的体系结构分别有一个子目录。 此目录中的asm子目录中是对应某种处理器的符号连接,如include/asm-i386。要修改处理器结构 则只需编辑核心的makefile并重新运行Linux核心配置程序。
init
此目录包含核心启动代码。
mm
此目录包含了所有的内存管理代码。与具体体系结构相关的内存管理代码位于arch/*/mm目录下, 如arch/i386/mm/fault.c 。
drivers
系统中所有的设备驱动都位于此目录中。它又进一步划分成几类设备驱动,如block。
ipc
此目录包含了核心的进程间通讯代码。
modules
此目录仅仅包含已建好的模块。
fs
所有的文件系统代码。它也被划分成对应不同文件系统的子目录,如vfat和ext2。
kernel
主要核心代码。同时与处理器结构相关代码都放在arch/*/kernel目录下。
net
核心的网络部分代码。
lib
此目录包含了核心的库代码。与处理器结构相关库代码被放在arch/*/lib/目录下。
scripts
此目录包含用于配置核心的脚本文件(如awk和tk脚本)。
主要是做DS Project 1时碰到的问题
1. 泛型方法push(elemType &x)无法接受常数等const类型,必须将形参声明为const elemType &x
2. 在给泛型类SimpleList增加operator<<方法时,把实现代码放在类的声明外部会报错,直接放在里面就可以,不知道是不是必须是内联inline的才可以。
水木问了下,答案是
除非在友元声明中显式指定了模板参数,否则与函数模板同名的友元函数的声明不会引用该函数模板.如果未指定模板参数,则友元声明将声明一个非模板函数。
3. C++中可以throw很多东西,比如String, int等。catch (...)表示把所有的异常都捕捉到。
from 水木
1. 两两比较,找出最大的,n-1次
2. 从找最大的这条路线回溯,次大的必然在这条路线上,找到它需要logn - 1次(败者树的最大高度为logn)
其实就是一个锦标赛排序
水木上的帖子
s 是全局数据区,
s1 是函数的栈空间区域,函数执行完成,这个空间就没了
------------------------------------------------------------------------------------------
7.2 可是我听说 char a[ ] 和 char *a 是一样的。
并非如此。(你所听说的应该跟函数的形式参数有关;参见问题 6.4) 数组不是指针。 数组定义 char a[6] 请求预留 6 个字符的位置, 并用名称 ``a" 表示。也就是说, 有一个称为 ``a" 的位置, 可以放入 6 个字符。 而指针申明 char *p, 请求一个位置放置一个指针, 用名称 ``p" 表示。 这个指针几乎可以指向任何位置: 任何字符和任何连续的字符, 或者哪里也不指(参见问题 5.1 和 1.10)。
一个图形胜过千言万语。声明
char a[] = "hello";
char *p = "world";
将会初始化下图所示的数据结果:
+---+---+---+---+---+---+
a: | h | e | l | l | o |\0 |
+---+---+---+---+---+---+
+-----+ +---+---+---+---+---+---+
p: | *======> | w | o | r | l | d |\0 |
+-----+ +---+---+---+---+---+---+
根据 x 是数组还是指针, 类似 x[3] 这样的引用会生成不同的代码。认识到这一点大有裨益。以上面的声明为例, 当编译器看到表达式 a[3] 的时候, 它生成代码从 a 的位置开始跳过 3 个, 然后取出那个字符. 如果它看到 p[3], 它生成代码找到 ``p" 的位置, 取出其中的指针值, 在指针上加 3 然后取出指向的字符。换言之, a[3] 是 名为 a 的对象 (的起始位置) 之后 3 个位置的值, 而 p[3] 是 p 指向的对象的 3 个位置之后的值. 在上例中, a[3] 和 p[3] 碰巧都是 'l' , 但是编译器到达那里的途径不尽相同。本质的区别在于类似 a 的数组和类似 p 的指针一旦在表达式中出现就会按照不同的方法计算, 不论它们是否有下标。下一问题继续深入解释。 参见问题 1.13。
参考资料: [K&R2, Sec. 5.5 p. 104]; [CT&P, Sec. 4.5 pp. 64-5]。
7.3 那么, 在 C 语言中 ``指针和数组等价" 到底是什么意思 ?
在 C 语言中对数组和指针的困惑多数都来自这句话。说数组和指针 ``等价" 不表示它们相同, 甚至也不能互换。它的意思是说数组和指针的算法定义可以用指针方便的访问数组或者模拟数组。
特别地, 等价的基础来自这个关键定义:
一个 T 的数组类型的左值如果出现在表达式中会蜕变为一个指向数组第一个成员的指针(除了三种例外情况); 结果指针的类型是 T 的指针。
这就是说, 一旦数组出现在表达式中, 编译器会隐式地生成一个指向数组第一个成员地指针, 就像程序员写出了 &a[0] 一样。例外的情况是, 数组为 sizeof 或 & 操作符的操作数, 或者为字符数组的字符串初始值。
作为这个这个定义的后果, 编译器并那么不严格区分数组下标操作符和指针。在形如 a[i] 的表达式中, 根据上边的规则, 数组蜕化为指针然后按照指针变量的方式如 p[i] 那样寻址, 如问题 6.2 所述, 尽管最终的内存访问并不一样。 如果你把数组地址赋给指针:
p = a;
那么 p[3] 和 a[3] 将会访问同样的成员。
参见问题 6.6 和 6.11。
------------------------------------------------------------------------------------------
char *s1 = "hello";
char s2[6] = "hello";
类型指针与类型数组名在很多场合中可等价使用。容易给人造成的印象是两者是等价。
这话不尽然。首先我们要明白这是两个不同的东西。
s1的类型char *,而s2的类型是array of char。
s1初始化为一个指针值,指向一个内存区域,该处有6个字符的数据,
即'h', 'e', 'l', 'l', 'o', '\0'。 在运行过程中,s1的值可改变,指向其他任何允许的地址。
但上面的数据("hello")不会在程序退出之前销毁[注:这是另外一个比较迷惑人的细节],
即使s1变量生命周期结束。
s2初始化为6个字符的数组,也是'h', 'e', 'l', 'l', 'o', '\0'。在运行过程中,s2的内容可改变,
也就是存储在s2中的hello也就"消失"了。
但为什么容易给人造成类型指针与类型数组名可等价的疑惑呢?虽然类型不同,但C规定(为了
追求简洁与灵活性,C假设使用者知道自己代码会有什么结果。)在很多场合下,认为数组名
与类型指针类型兼容。记忆中只有2中情况下,数组名不可等同视为数组指针,&与sizeof操作符。
void foo1(const char *str) {...};
void foo2(int size) {return size};
...
char *s1 = "hello";
char s2[6] = "hello";
foo1(s1); // ok
foo1(s2); // ok
foo1(&s2); // incompatible
foo2(&s2[0]); // ok
s1[0] = 0; // error
s2[0] = 0; // ok
s1 = s2; // ok
s2 = s1; // error
// 下面假设在ia32平台上运行
foo2(sizeof(s1)); // return 4, pointer size
foo2(sizeof(s2)); // return 6, array size
只记得上面的这些内容,不知道对错,与大家共同提高。
C++ 学习笔记(6)
1. 类声明中定义的函数都被自动处理为inline函数。
2. Triangular t5(); 这句话似乎声明了一个类的实例,但事实上,C++为了保持与C语法的一致,该语句会被解释成一个返回Triangular对象的函数;正确的声明应该去掉()。
3. 考虑下面一段代码
class Matrix {
public:
Matrix( int row, int col ) // ...
~Matrix() { delete [] _pmat; }
private:
int _row, _col;
double *_pmat;
};
{
Matrix mat(4, 4);
{
Matrix mat2 = mat;
}
}
把mat复制给mat2后,mat2中的_pmat与mat的_pmat指向同一个数组,在mat2所在的域结束后,mat2被释放,同时删除了_pmat指针指向的内容。错误发生。
解决办法是在Matrix::Matrix( const Matrix &rhs )中详细指出深层拷贝的方法,同时实现赋值操作符的重载。
4. mutable 和 const
const方法无法修改类的成员,mutable成员除外。
1. 查看某个类型的最大最小值:
#include <limits>
int max_int = numeric_limits<int>::max();
double min_dbl = numeric_limits<double>::max();
2. A struct is simply a class whose members are public by default.
3. 类的似有成员的保护依赖于对成员名使用的限制,也就是说,通过地址操作、强制类型转换等技术可以被访问,C++可以防止意外的发生,但不能阻止这种故意的欺骗。只有硬件层面才有可能防止这种恶意访问,但通常在现实中也很难做到。
4. 使用类的初始化列表代替代码体中的赋值语句可以节省很多时间。而且,如果一个数据成员是const的,那么它只能在初始化列表中进行初始化;如果一个数据成员是不具有零参数的构造函数的类类型,那么它也必须在初始化列表中进行初始化。
还是做一点笔记,记得牢一些
有了follow和first集合后,就可以构造一张预测解析表(predictive parsing table)了。
具体方法是:
对于任一产生式X -> ƒ,找到first(ƒ)中的每一个元素T,把X -> ƒ填充到X行T列中去;
如果ƒ nullable,还要把X -> ƒ填充到X行follow(ƒ)列中去
预测解析表构造完成后,如果某格中不止一个产生式,则说明该语法不适用于预测解析表;
如果每格至多一个产生式,则该语法被称为LL(1) Left-to-right parse, Leftmost-derivation, 1-symbol lookahead
开始看lkd,不过最新可以抽出来的时间不多,下星期Java课还有project,还要写一份robocode的项目文档,然后编译课也得跟上,英语高口课还得准备资料。。。先转一篇学习计划过来
发信人: ccedcced (turing), 信区: KernelTech
标 题: 整理的内核学习计划
发信站: 水木社区 (Fri Jan 6 18:15:35 2006), 转信
内核学习现在开始
方法就是:
读书(lkd)+源代码阅读-->项目
先从基础做起!
希望大家都能积极地参与讨论,写读书笔记和源码阅读笔记!
------------------------------
内核学习第一周计划--Are you ready?
时间:11月2号--11月5日
阅读内容:前言和第一章
导读:这是比较容易阅读的开头部分,内容比较少而且常识性的内容比较多。请在阅读的过程中考虑如下的问题:
1.linux和unix相比有哪些特点?
2.内核编程和用户空间编程相比有哪些不同之处?
3.自己编译一下内核,你编译成功了么?如果不成功,有什么问题?使用你新编译的内核,
能顺利启动么?有什么问题?
4.linux内核源代码树中你能找到sg设备驱动是在那个文件中实现的么?sg是什么含意?
清楚地了解一下内核中源代码树的结构。
Are you ready?
------------------------------
内核学习第二周计划
时间:11.7-11.13
内容:
主要是lkd中文版第一版第二章(英文第二版版第三章)的内容,比较重要。
1.和进程管理相关的内核文件都有哪些?找出来大致浏览一下.
2.什么是进程和线程?在Linux中有什么独特的地方?
3.什么是进程描述符?怎样得到当前进程的进程描述符?进程的内核栈有多大?
4.进程的状态都有哪些?在什么情况下发生转化?
5.Linux中所有进程之间的关系是怎么样的?
6.用户线程和内核线程的区别和联系?
7.Linux是怎样创建进程和线程的?
8.Linux怎样终结进程?
9.对照相应的内核源代码文件,分析一下问题3、5、6、7。
------------------------------
内核学习第三、四周计划
内核学习第三、四周计划:
时间:11.14-11.27
调度是操作系统中非常重要的部分,也是最核心的东西。通过学习这一章,希望大家都能大致掌握Linux的调度策略,以及为什么要这么做,Linux相比其它的系统有什么优点。重点多分析源代码中的算法实现!!我希望我能有时间和大家一起分析代码,也希望大家积极主动地分析一些代码片断。
学习内容:
1.进程调度最基本的原理是什么?
2.列举出几个I/O消耗性和处理器消耗型的进程。
3.Linux都采用了哪些调度的算法?详细解释一下这些算法。
4.进程什么时间进入运行态?什么时间进入休眠(阻塞)状态?
5.了解进程抢占的算法;
6.讨论一下Linux进程调度的实时性怎么样,还有哪些需要提高的地方?
7.自己查找进程调度的相关文件,分析为题3-6。
------------------------------
内核学习第五周计划
时间:11.28--12.5
1、什么是系统调用?
2、为什么需要系统调用?
3、实现系统调用相关的代码有哪些,找出来浏览一下
4、详细阅读getuid()这一下系统调用的实现代码
5、如何导出sys_call_table,有几种方法,注意不同内核版本的区别
6、尝试自己给kernel添加一个简单的系统调用
功能要求:调用这个系统调用,使用户的uid等于0。(这个题目取自《边干边学》)
7、采用添加系统调用的方式实现一个新功能的利弊有哪些,替代方法是什么?
------------------------------
内核学习第六周计划
这一周就总结了一下中断和下半部相关的知识点,供大家参考一下!同时附件里有我以前学习时候的笔记,写的不好请多多指教。
内核学习第六周计划:
1、如何理解中断、中断上下文和进程上下文的区别、为何中断不能睡眠
2、关于x86中选择子、描述符和各种门的理解
3、查阅相关资料和内核源码理解:
中断是如何发生以及硬件和内核是如何相应的,如何返回的
x86上中断发生时上下文(寄存器)如何保存以及中断返回时上下文如何恢复的,系统的第一个任务是如何启动的
4、内核中安排下半部的理由
5、软中断及其他的下半部策略适用于什么样的任务和场合?
6、下半部可以睡眠么?为什么?
7、2.4和2.6内核中下半部包括哪些部分,为何2.6内核相比2.4内核会做这样的改进
8、阅读内核中关于软中断、tasklet以及工作队列的代码、相关书籍和资料,总结如下两个问题:
软中断、tasklet以及工作队列是如何初始化,注册以及触发的,使用了哪些关键的数据结构及内核变量?
软中断、tasklet以及工作队列都在什么场合下使用?
------------------------------
内核学习第七周计划
内核学习第七周计划:
时间:12月13日--12月19日
内容:内核同步的理论知识。
问题:
1.为什么要进行内核的同步?
2.内核中怎么定义原子操作?
3.竞争产生的条件与加锁的顺序?
4.要保护的对象?
5.死锁产生的条件与解决办法?
6.你有什么比较好的方法来调试多线程的程序?
7.据一个内核中产生竞争的例子。
------------------------------
内核学习第八周计划
第八周:
内容:
上一周我们分析了内核中的同步,这一次我们要接触的是内核中怎么进行同步和互斥。
问题:
1.原子操作的粒度问题;
2.自旋锁的设计及其应用场合,分析自旋锁;
3.信号量及其应用,信号量怎么使用?
4.锁的粒度以及其分类;
5.内核可抢占性的实现及其与锁的关系;
6.smp中需要考虑哪些同步与互斥;
------------------------------
内核学习第九周计划
前面的话:
内核学习已经进行了两个月的时间,LKD这本书我们基本上已经进行了一半。希望大家在下面多用功。
我们在这个计划里面列出来的只是一些比较基本的问题,而且我们没有给出问题的答案,但是只要你在下面
用功了,我想答案就在这本书里和源代码里面。
本周内容:TIMERS AND TIME MANAGEMENT
1.HZ和jiffies值的定义?
2.内核中怎样解决jiffies的回绕?为什么这样可以解决jiffies回绕?
3.时钟中断处理程序有哪些值得注意的地方?
4.xtime_lock锁和seqlock锁?
5.定时器的实现、使用和竞争条件?
6.udelay()&mdelay()?
------------------------------
内核学习第十周计划:
内存管理
学习内容
内存管理是比较庞大的一个部分,在lkd这本书中用了很少的篇幅,从这里面我们基本能看清楚 内存管理的概貌。《情景分析》一书关于内存管理的部分讲得比较多,代码分析比较透彻也比较深入。 但是相对的难度也比较大,建议先看看lkd这本书,然后再看《情景分析》一书的内存管理。
问题:
1.内核中内存的分页、分区;
2.内核中有哪些函数来获得内存?内核中分配内存要注意什么?
3.为什么使用slab?slab对象的详细分析。
4.内核栈上内存的静态分配问题;
太笨了,看了好久才明白。。。
first集合没有问题
follow集合:
以A -> aBb为例,如果b nullable,则follow(B)包括follow(A),原因很简单,把A看成一个整体,当作为production的右式时它后面直接跟的元素自然也可能是B后面直接跟的元素,因为b可能为空。
理解follow集合的定义后,虎书上给出的算法
if Yi+1 ... Yk are all nullable
then FOLLOW(Yi) = FOLLOW(Yi) U FOLLOW(X)
if Yi+1 ... Yj-1 are all nullable
then FOLLOW(Yi) = FOLLOW(Yi) U FIRST(Yj)
就不难理解了
关于表示32位整型中最小的数-2147483648的一篇文章,from CSAPP http://csapp.cs.cmu.edu/public/tmin.html
Summary
Due to one of the rules for processing integer constants in ANSI C,
the numeric constant -2147483648 is handled in a peculiar
way on a 32-bit, two's complement machine.
The problem can be corrected by writing
-2147483647-1, rather than
-2147483648 in any C code.
Description of Problem
The ANSI C standard requires that an integer constant too large to be
represented as a signed integer be ``promoted'' to an unsigned value.
When GCC encounters the value 2147483648, it gives a warning message:
`` warning: decimal constant is so large that it is
unsigned.'' The result is the same as if the value had been
written 2147483648U.
ANSI C标准中要求太大的整型常量都表示为unsigned
The compiler processes an expression of the form -X
by first reading the expression X and then
negating it. Thus, when the C compiler encounters the constant
-2147483648, it first processes 2147483648,
yielding 2147483648U, and then negates it. The unsigned
negation of this value is also 2147483648U. The bit
pattern is correct, but the type is wrong!
书上的一个小错误
Writing TMin in Code
The ANSI C standard states that the maximum and minimum integers
should be declared as constants INT_MAX and
INT_MIN in the file limits.h. Looking at
this file on an IA32 Linux machine (in the directory
/usr/include), we find the following declarations:
/* Minimum and maximum values a `signed int' can hold. */
#define INT_MAX 2147483647
#define INT_MIN (-INT_MAX - 1)
This method of declaring INT_MIN avoids accidental
promotion and also avoids any warning messages by the C compiler about
integer overflow.
The following are ways to write TMin_32 for a 32-bit machine that give
the correct value and type, and don't cause any error messages:
- -2147483647-1
- (int) 2147483648U
- 1<<31
The first method is preferred, since it indicates that the
result will be a negative number.
表示-2147483648的几种方法
原来只给机房电脑的Arch配了20G的空间,现在想装个virtualbox,空间自然不够了,于是到windows下删了一个分区用于挂载/home的内容。
然后问题就出来了,由于少了一个分区,原来arch所在的分区(sda8)向前移了一位(sda7),结果grub启动出错,无法进入系统。
从机房管理员那借来Redhat的安装盘,进入rescue模式,挂在好/dev/sda7后,修改boot/grub/menu.lst中的盘符,重启,问题依旧。
只好先恢复winxp再说,用winxp工具盘启动后,fdisk /mbr,重启,安装grub for dos,再重启,进入grub
grub> root (hd0,6)
grub> setup (hd0)
报错,估计是dos下的问题,只好手动进入arch
grub> root (hd0,6)
grub> kernel /boot/vmlinuz26 root=/dev/sda7 ro
grub> initrd /boot/kernel26.img
grub> boot
进入后仍然有错误,说是sda8无法访问,这时才想起fstab还没改过,但是当前的挂载的sda7还是只读的,只好再用redhat的启动盘启动,挂载sda7后修改fstab中的信息。
问题解决。
n个不同的物体按固定次序入栈,随时可以出栈,求最后可能的出栈序列的总数。
只想到这个问题等价于把n个push和n个pop操作排列,要求任意前几个操作中push数都不能少于pop数,至于这个排列数怎么求就不知道了。请教了peter大牛后,原来这就是一个Catalan数的应用。
Wikipedia上的Catalan numbers:
In combinatorial mathematics, the Catalan numbers form a sequence of natural numbers that occur in various counting problems, often involving recursively defined objects. They are named for the Belgian mathematician Eugène Charles Catalan (1814–1894).
The nth Catalan number is given directly in terms of binomial coefficients by

The first Catalan numbers (sequence A000108 in OEIS) for n = 0, 1, 2, 3, … are
- 1, 1, 2, 5, 14, 42, 132, 429, 1430, 4862, 16796, 58786, 208012, 742900, 2674440, 9694845, 35357670, 129644790, 477638700, 1767263190, 6564120420, 24466267020, 91482563640, 343059613650, 1289904147324, 4861946401452, …
Properties
An alternative expression for Cn is

This shows that Cn is a natural number, which is not a priori obvious from the first formula given. This expression forms the basis for André's proof of the correctness of the formula (see below under second proof).
The Catalan numbers satisfy the recurrence relation

They also satisfy:

which can be a more efficient way to calculate them.
Asymptotically, the Catalan numbers grow as

in the sense that the quotient of the nth Catalan number and the expression on the right tends towards 1 for n → ∞. (This can be proved by using Stirling's approximation for n!.)
Applications in combinatorics
There are many counting problems in combinatorics whose solution is given by the Catalan numbers. The book Enumerative Combinatorics: Volume 2 by combinatorialist Richard P. Stanley contains a set of exercises which describe 66 different interpretations of the Catalan numbers. Following are some examples, with illustrations of the case C3 = 5.
- Cn is the number of Dyck words of length 2n. A Dyck word is a string consisting of n X's and n Y's such that no initial segment of the string has more Y's than X's (see also Dyck language). For example, the following are the Dyck words of length 6:
XXXYYY XYXXYY XYXYXY XXYYXY XXYXYY.
- Re-interpreting the symbol X as an open parenthesis and Y as a close parenthesis, Cn counts the number of expressions containing n pairs of parentheses which are correctly matched:
((())) ()(()) ()()() (())() (()())
- Cn is the number of different ways n + 1 factors can be completely parenthesized (or the number of ways of associating n applications of a binary operator). For n = 3 for example, we have the following five different parenthesizations of four factors:
- Successive applications of a binary operator can be represented in terms of a binary tree. It follows that Cn is the number of rooted ordered binary trees with n + 1 leaves:
If the leaves are labelled, we have the quadruple factorial numbers.
- Cn is the number of non-isomorphic full binary trees with n vertices that have children, usually called internal vertices or branches. (A rooted binary tree is full if every vertex has either two children or no children.)
- Cn is the number of monotonic paths along the edges of a grid with n × n square cells, which do not cross the diagonal. A monotonic path is one which starts in the lower left corner, finishes in the upper right corner, and consists entirely of edges pointing rightwards or upwards. Counting such paths is equivalent to counting Dyck words: X stands for "move right" and Y stands for "move up". The following diagrams show the case n = 4:
- Cn is the number of different ways a convex polygon with n + 2 sides can be cut into triangles by connecting vertices with straight lines. The following hexagons illustrate the case n = 4:
Error creating thumbnail:
- Cn is the number of stack-sortable permutations of {1, ..., n}. A permutation w is called stack-sortable if S(w) = (1, ..., n), where S(w) is defined recursively as follows: write w = unv where n is the largest element in w and u and v are shorter sequences, and set S(w) = S(u)S(v)n, with S being the identity for one-element sequences.
Proof of the formula
There are several ways of explaining why the formula

solves the combinatorial problems listed above. The first proof below uses a generating function. The second and third proofs are examples of bijective proofs; they involve literally counting a collection of some kind of object to arrive at the correct formula.
First proof
We start with the observation that several of the combinatorial problems listed above can easily be seen to satisfy the recurrence relation
For example, every Dyck word w of length ≥ 2 can be written in a unique way in the form
- w = Xw1Yw2
with (possibly empty) Dyck words w1 and w2.
The generating function for the Catalan numbers is defined by

As explained in the article titled Cauchy product, the sum on the right side of the above recurrence relation is the coefficient of xn in the product

Therefore

Multiplying both sides by x, we get

So we have

and hence

The square root term can be expanded as a power series using the identity

which can be proved, for example, by the binomial theorem, (or else directly by considering repeated derivatives of  ) together with judicious juggling of factorials. Substituting this into the above expression for c(x) produces, after further manipulation, ) together with judicious juggling of factorials. Substituting this into the above expression for c(x) produces, after further manipulation,

Equating coefficients yields the desired formula for Cn.
Second proof
This proof depends on a trick due to D. André, which is now more generally known as the reflection principle (not to be confused with the Schwarz reflection theorem in complex analysis). It is most easily expressed in terms of the "monotonic paths which do not cross the diagonal" problem (see above).

Figure 1. The green portion of the path is being flipped.
Suppose we are given a monotonic path in an n × n grid that does cross the diagonal. Find the first edge in the path that lies above the diagonal, and flip the portion of the path occurring after that edge, along a line parallel to the diagonal. (In terms of Dyck words, we are starting with a sequence of n X's and n Y's which is not a Dyck word, and exchanging all X's with Y's after the first Y that violates the Dyck condition.) The resulting path is a monotonic path in an (n − 1) × (n + 1) grid. Figure 1 illustrates this procedure; the green portion of the path is the portion being flipped.
Since every monotonic path in the (n − 1) × (n + 1) grid must cross the diagonal at some point, every such path can be obtained in this fashion in precisely one way. The number of these paths is equal to
 . .
Therefore, to calculate the number of monotonic n × n paths which do not cross the diagonal, we need to subtract this from the total number of monotonic n × n paths, so we finally obtain

which is the nth Catalan number Cn.
Third proof
The following bijective proof, while being more involved than the previous one, provides a more natural explanation for the term n + 1 appearing in the denominator of the formula for Cn.

Figure 2. A path with exceedance 5.
Suppose we are given a monotonic path, which may happen to cross the diagonal. The exceedance of the path is defined to be the number of pairs of edges which lie above the diagonal. For example, in Figure 2, the edges lying above the diagonal are marked in red, so the exceedance of the path is 5.
Now, if we are given a monotonic path whose exceedance is not zero, then we may apply the following algorithm to construct a new path whose exceedance is one less than the one we started with.
- Starting from the bottom left, follow the path until it first travels above the diagonal.
- Continue to follow the path until it touches the diagonal again. Denote by X the first such edge that is reached.
- Swap the portion of the path occurring before X with the portion occurring after X.
The following example should make this clearer. In Figure 3, the black circle indicates the point where the path first crosses the diagonal. The black edge is X, and we swap the red portion with the green portion to make a new path, shown in the second diagram.

Figure 3. The green and red portions are being exchanged.
Notice that the exceedance has dropped from three to two. In fact, the algorithm will cause the exceedance to decrease by one, for any path that we feed it.

Figure 4. All monotonic paths in a 3×3 grid, illustrating the exceedance-decreasing algorithm.
It is also not difficult to see that this process is reversible: given any path P whose exceedance is less than n, there is exactly one path which yields P when the algorithm is applied to it.
This implies that the number of paths of exceedance n is equal to the number of paths of exceedance n − 1, which is equal to the number of paths of exceedance n − 2, and so on, down to zero. In other words, we have split up the set of all monotonic paths into n + 1 equally sized classes, corresponding to the possible exceedances between 0 and n. Since there are

monotonic paths, we obtain the desired formula

Figure 4 illustrates the situation for n = 3. Each of the 20 possible monotonic paths appears somewhere in the table. The first column shows all paths of exceedance three, which lie entirely above the diagonal. The columns to the right show the result of successive applications of the algorithm, with the exceedance decreasing one unit at a time. Since there are five rows, C3 = 5.
Hankel matrix
The n×n Hankel matrix whose (i, j) entry is the Catalan number Ci+j has determinant 1, regardless of the value of n. For example, for n = 4 we have

Note that if the entries are ``shifted", namely the Catalan numbers Ci+j+1, the determinant is still 1, regardless of the size of n. For example, for n = 4 we have
 . .
The Catalan numbers is the unique sequence with this property.
Quadruple factorial
The quadruple factorial is given by  , or , or  . This is the solution to labelled variants of the above combinatorics problems. It is entirely distinct from the multifactorials. . This is the solution to labelled variants of the above combinatorics problems. It is entirely distinct from the multifactorials.
History
The Catalan sequence was first described in the 18th century by Leonhard Euler, who was interested in the number of different ways of dividing a polygon into triangles. The sequence is named after Eugène Charles Catalan, who discovered the connection to parenthesized expressions. The counting trick for Dyck words was found by D. André in 1887.
10.31: CLRS 22.1-22.3 Elementary Graph Algorithms
10.25: CLRS 18.2 Operations on B-trees
10.22: CLRS 18.1 Definition of B-trees
10.15: CLRS 16.3 Huffman codes
10.14: CLRS 16.2 Elements of the greedy strategy
10.13: CLRS 16.1 An activity-selection problem
10.11-12: LKD 调度 O(1)调度算法
10.10: 虎书 看完Abstract Syntax
10.7~9: LKD 第二章进程管理看完,不过还是没什么感觉,看来代码读的不够多
10.3: 虎书 LR Parsing 看到Error Recovery之前
9.24-25: CLRS 15 Dynamic Programming 看完,习题未做
9.22: CSAPP Chapter1 除浮点部分回顾了一遍
9.19: CSAPP 6.3 The Memory Hierarchy
9.18: CSAPP 6.2 Locality
总进度:
CS: APP
Chapter1(Tour) 泛读一遍
Chapter2(Representing and Manipulating) 除浮点部分已看完
Chapter3(Machine-Level Representation of Programs) 除*部分已看完
Chapter6(The Memory Hierarchy) 正在看,跳过第一节Storage Technologies
Chapter7(Linking) 看过一遍,Symbols and Symbol Tables, Relocation部分还不怎么清楚
Chapter8(Exceptional Control Flow) 看完
Chapter10(Virtual Memory) 看过一点,发现不知道Locality后跳到第6章
CLRS
Part I: Foundation 粗略的看了一遍,主要了解了下Big-Oh Big-Omega Big-Theta的概念,Master Method的应用和简单的Generation Function
Part II: Sorting and Order Statistics 除复杂度证明部分外看了一遍,大多数习题都看过
Part III: Data Structures 翻过一遍,*部分都没看,习题看的不多,红黑书相关的操作还不怎么熟练,后面两章还要再看一下
Part IV: Advanced Design and Analysis Techniques 跳过Amortized Analysis,做了部分习题
Part V: Advanced Data Structures 看了一点B-Tree,二分堆、Fibonacci堆和并查集先跳过了
PartVI: Graph Algorithms 正在看
Modern Compilers Implementation in C
从头看到第四章 Abstract Syntax,略过Burke-Fisher错误恢复
Linux Kernel Development 中文版
刚开始看
1. 安装后reboot,选择Arch Linux Fallback,出现登录提示后键盘无响应,按Num Lock键指示灯也没有变化,此时拔掉键盘再插上即可。
2. Network IP, Gateway, Mask设置都正常,但无法ping到网关,翻了wiki后终于发现是Windows在捣鬼
Windows中关机后会自动将Realtek 8168 8169 8101 8111网卡禁用,直到再次进入Windows后才会恢复
解决方法是在设备管理器->网络适配器->Realtek xxx->高级中把"Wake-On-Lan After Shutdown"设为Enable
3. 几个pacman常用的参数
pacman -Sy 更新本地包的数据库
pacman -S package_name1 package_name2 ... 安装包
pacman -S extra/package_name 指定安装某个版本的包
pacman -Su 更新所有安装的包,通常和Sy参数合并为-Syu
pacman -Ss 搜索
pacman -U *.pkg.tar.gz 安装本地包
4. 好不容易+莫名奇妙地配好了显卡,startx可以跑起来了
然后运行gnome-session,提示Gtk WARNING **: Cannot open display:
找了一堆解决方法,总算有一个可行的:
在~/.xinitrc中增加gnome-session,然后启动startx
http://jefke.free.fr/soft/texttable/
dl: http://jefke.free.fr/soft/texttable/texttable.py
NAME
texttable - module for creating simple ASCII tables
FILE
/usr/lib/python2.3/site-packages/texttable.py
DESCRIPTION
Example:
table = Texttable()
table.header(["Name", "Age"])
table.set_cols_align(["l", "r"])
table.add_row(["Xavier\nHuon", 32])
table.add_row(["Baptiste\nClement", 1])
table.draw()
Result:
+----------+-----+
| Name | Age |
+==========+=====+
| Xavier | 32 |
| Huon | |
+----------+-----+
| Baptiste | 1 |
| Clement | |
+----------+-----+
CLASSES
exceptions.Exception
ArraySizeError
Texttable
class ArraySizeError(exceptions.Exception)
| Exception raised when specified rows don't fit the required size
|
| Methods defined here:
|
| __init__(self, msg)
|
| __str__(self)
|
| ----------------------------------------------------------------------
| Methods inherited from exceptions.Exception:
|
| __getitem__(...)
class Texttable
| Methods defined here:
|
| __init__(self, max_width=80)
| Constructor
| - max_width is an integer, specifying the maximum width of the t
able
| - if set to 0, size is unlimited, therefore cells won't be wrapp
ed
|
| add_row(self, array)
| Add a row in the rows stack
|
| Cells can contain newlines.
|
| draw(self)
| Draw the table
|
| header(self, array)
| Specify the header of the table
|
| reset(self)
| Reset the instance:
| - reset rows and header
|
| set_chars(self, array)
| Set the characters used to draw lines between rows and
| columns.
|
| The array should contain 4 fields:
|
| [horizontal, vertical, corner, header]
|
| Default is set to:
|
| ['-', '|', '+', '=']
|
| set_cols_align(self, array)
| Set the desired columns alignment
|
| The elements of the array should be either "l", "c" or "r"
| - "l": column flushed left
| - "c": column centered
| - "r": column flushed right
|
| set_cols_width(self, array)
| Set the desired columns width
|
| The elements of the array should be integers, specifying the
| width of each column. For example:
|
| [10, 20, 5]
|
| set_deco(self, deco)
| Set the table decoration. 'deco' can be a combinaison of:
|
| Texttable.BORDER: Border around the table
| Texttable.HEADER: Horizontal line below the header
| Texttable.HLINES: Horizontal lines between rows
| Texttable.VLINES: Vertical lines between columns
|
| Example:
|
| Texttable.BORDER | Texttable.HEADER
|
| All of them are enabled by default.
|
| --------------------------------------------------------------------
--
| Data and other attributes defined here:
|
| BORDER = 1
|
| HEADER = 4
|
| HLINES = 8
|
| VLINES = 16
DATA
__all__ = ['Texttable', 'ArraySizeError']
__author__ = 'Gerome Fournier <jefke(at)free.fr>'
__credits__ = 'Jeff Kowalczyk:\n - textwrap improved import\n - ..
.
__license__ = 'GPL'
__revision__ = '$Id: texttable.py,v 1.3 2003/10/05 13:53:39 jef Exp je..
.
__version__ = '0.3'
VERSION
0.3
AUTHOR
Gerome Fournier <jefke(at)free.fr>
CREDITS
Jeff Kowalczyk:
- textwrap improved import
- comment concerning header output
connector.py
import urllib, urllib2, cookielib
class MyConnector:
def __init__(self):
pass
def login(self, url):
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
str = urllib.urlencode({'id': 'guest', 'passwd': ''})
self.sock = urllib2.urlopen(url, str)
def getHTML(self, url):
self.sock = urllib2.urlopen(url)
return self.sock.read()
yanxiparser.py
from sgmllib import SGMLParser
import re
class YanxiURLParser(SGMLParser):
def reset(self):
self.result = []
SGMLParser.reset(self)
def start_a(self, attrs):
for (k, v) in attrs:
if (k == 'href' and (v.find('bbsanc') >= 0)):
self.result.append(v)
class YanxiHTMLParser:
def parse(self, html):
uid = ufrom = ubirth = ufav = ''
html = html.replace(r' ', ' ')
html = html.replace(r'<br />', '')
pattern = '\xbe\xcd\xca\xc7(.*)\xc0\xb2'
matchObject = re.search(pattern, html)
uid = matchObject.group(1)
uid = uid.strip()
pattern = '\xc0\xb4\xd7\xd4(.*)\xa3(\xac|xa1)'
matchObject = re.search(pattern, html)
ufrom = matchObject.group(1)
ufrom = ufrom.strip()
pattern = '\xcf\xb2\xbb\xb6(.*)\n'
matchObject = re.search(pattern, html)
ufav = matchObject.group(1)
ufav = ufav.strip()
pattern = '\n(.*)\xca\xc7\xce\xd2\xb5\xc4\xc9\xfa\xc8\xd5'
matchObject = re.search(pattern, html)
ubirth = matchObject.group(1)
ubirth = ubirth.strip()
return {"id" : uid, "from" : ufrom, "birth" : ubirth, "fav" : ufav}
runner.py
from connector import MyConnector
from yanxiparser import *
rootURL = 'http://yanxibbs.cn'
loginURL = 'http://yanxibbs.cn/bbslogin.php'
url1 = 'http://yanxibbs.cn/cgi-bin/bbs/bbs0an?path=%2Fgroups%2FGROUP%5F3%2F06SS%2Fbyxx%2Fbjcy'
url2 = 'http://yanxibbs.cn/cgi-bin/bbs/bbs0an?path=%2Fgroups%2FGROUP%5F3%2F06SS%2Fbyxx%2Fbjyr'
conn = MyConnector()
conn.login(loginURL)
def printInfo(url):
html = conn.getHTML(url)
urlParser = YanxiURLParser()
htmlParser = YanxiHTMLParser()
urlParser.feed(html)
for targetURL in urlParser.result:
html = conn.getHTML(rootURL + targetURL)
info = htmlParser.parse(html)
print "%(id)s\t%(from)s\t%(birth)s\t%(fav)s" % info
printInfo(url1)
printInfo(url2)
1. 写了个测试脚本,逐个测试testcases目录下的各个tiger程序,并统计出错数
#!/usr/bin/python
from commands import *
countOk = countError = 0
for i in range(1,50):
result = getstatusoutput('./lextest ../testcases/test%s.tig' % i)
if (result[0] == 0):
print('Test case %s: OK' % i)
countOk += 1
else:
print('Error on test case %s with errorno %s' % (i, result[0]))
countError += 1
print("Total cases: %s" % (countOk + countError))
print("Passed cases: %s" % (countOk))
print("Failed cases: %s" % (countError))
2. 状态:
定义的状态名不能与已经定义的变量/宏名冲突。在处理字符串的时候定义了个<STRING>状态,和tokens.h中的STRING冲突了,结果解析的时候被认成了BAD_TOKEN。
发信人: laye (Addict to Goth >_<), 信区: Unix
标 题: 我的 Ubuntu 7.04 Cookbook
发信站: 日月光华 (2007年09月09日09:19:35 星期天), 站内信件
最近装了 Ubuntu 7.04,写了一个简单的 Cookbook,记录了自己遇到的一些问题和解决
方法,希望对大家有帮助。
cook01 中文字体美化
(1) 得到 simsun.ttc tahoma.ttf tahomabd.ttf verdana.ttf verdanab.ttf
verdanai.ttf verdanaz.ttf 几个个字体文件 (可以从 Windows 的 Fonts 文件夹中获
取)
(2) 用 nautilus 打开系统的字体文件夹:nautilus fonts:///
(3) 将第 (1) 步中的几个个字体复制进第 (2) 步打开的字体文件夹中
(4) 创建 /etc/fonts/local.conf 文件,内容如 [附录1] (本文最底端)
(5) 重新启动 X: Ctrl + Alt + Backspace
(6) 打开 gnome 字体设置:gnome-font-properties,设置前四个字体为 Tahoma
(7) 打开 firefox 字体设置:将 Serif 设置为 SimSun,Sans-serif 设置为 Tahoma,
Monospace 设置为 SimSun,并且允许网页自由选择字体
(8) 重新启动 X, enjoy~
点评:该优化方案用 Windows 的 SimSun (衬线) 和 Tahoma (无衬线) 作为 UI 和
Web 中的主要字体使用。并且,解决了字体替换后的几个问题:
(1) 针对中文选字混乱问题 (同一句话中的不同汉字可能用不同字体进行渲染),我将所
有亚洲字符都强制使用 SimSun 显示。
(2) 由于 SimSun 的小字体为点阵字体,所以关闭了 8-17px 字体的抗锯齿以达到理想
的显示效果。
(3) 设置了 SimSun 和 Tahoma 的最小字体尺寸以保证显示效果
已知 Bug: SimSun 英文和数字粗体效果不佳,可以下载网友制作的 SimSunbd 拷贝入
字体目录 (SimSunbd 的英文和数字用的好像是 Tahoma)
cook02 连接 windows 的远程桌面
安装 rdesktop:
sudo apt-get install rdesktop
使用:
rdesktop ip
rdesktop -f ip (全屏)
cook03 使 ntfs 分区可写
安装 ntfs-config:
sudo apt-get install ntfs-config
配置:
sudo ntfs-config
勾选两个选项 (或根据需要勾选)
cook04 访问 Windows 共享文件夹
执行:nautilus-connect-server
填写你要访问的 Windows 共享文件夹的相关信息,这个文件夹就会被 mount 到你的
Desktop 下。同样的方法可以 mount FTP 文件夹等等。
cook05 使 Windows 能访问 ubuntu 的文件 (samba)
执行:shares-admin
按需要设置
cook06 播放各种视频
(1) 下载 mplayer 的 Codec Package:
http://www.mplayerhq.hu/design7/dload.html#binary_codecs
(2) 将下载的 Codec Package 解压到 /usr/lib/win32
(3) 安装 mplayer 或各种 mplayer 的前端程序,我用的是 mplayer 的一个前端:
smplayer
(4) 如果你的 mplayer 的播放画面不正常,请检查你的 Video Output Driver 是否为
x11
(5) 若要显示中文字幕,需要在播放器内设置字幕用字体和字幕编码
cook07 使用 fcitx 替换 scim
由于使用习惯和兼容性原因,许多人不得不使用 fcitx,安装方法如下:
sudo apt-get install im-switch fcitx
im-switch -s fcitx -z default
如果你要在 en 的 locale 下使用 fcitx,请将 /etc/gtk-2.0/gtk.immodules 中的:
“xim” “X Input Method” “gtk20″ “/usr/share/locale” “ko:ja:th:zh”
替换为
“xim” “X Input Method” “gtk20″ “/usr/share/locale” “en:ko:ja:th:zh”
cook08 Panel 中的好东东
ubuntu 桌面上下各有一个 Panel。其实,我们可以自定义 Panel 上面的内容,比如说
:
天气预报,本本的电量显示、亮度调节,CPU 频率监视,系统负载监视,还有一个强制
终止程序的按钮 (Force Quit)等等。
你也可以把自己建立的 Laucher 拖动到 Panel 上,当然,你也可以在别的位置建立自
己的 Panel。
cook09 使用 HP 打印机
ubuntu 自带了 HP 系列打印机的驱动 oo2zjs,但奇怪的是,这个驱动居然是不能用的
。
用户需要卸载掉 ubuntu 自带的 oo2zjs,安装新的 oo2zjs。
具体过程如下:
确认编译环境已安装:
sudo apt-get install build-essential
下载 oo2zjs:
wget -O foo2zjs.tar.gz http://foo2zjs.rkkda.com/foo2zjs.tar.gz
解压:
tar zxf foo2zjs.tar.gz
cd foo2zjs
卸载原有 foo2zjs:
make uninstall
编译,安装:
make
./getweb 1020 这里是你的打印机型号
sudo make install install-hotplug cups
在 ubuntu 的打印机管理中添加你的打印机 (不要选 suggest 的那个驱动):
sudo gnome-cups-manager
最后,重启 cups:
sudo make cups
cook10 开启 Vim 的“简易模式”
ubuntu 中 Vim 只有 console 的版本,且是传统 Unix 的行为模式,即在 INSERT
MODE 下,方向键和退格键是不起作用的。可以手动开启“类 Windows”模式,即在
COMMAND MODE 下输入:
:behave mswin
[附录1]
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<!-- use SimSun to display all Asia character -->
<match target="font">
<test compare="contains" name="lang" >
<string>zh-cn</string>
<string>zh-tw</string>
<string>ja</string>
<string>ko</string>
</test>
<edit name="family"><string>SimSun</string></edit>
</match>
<!-- open anti-alias for all font -->
<match target="font" >
<edit mode="assign" name="antialias"><bool>true</bool></edit>
<edit mode="assign"
name="hintstyle"><const>hintslight</const></edit>
<edit mode="assign" name="hinting"><bool>true</bool></edit>
<edit mode="assign" name="autohint"><bool>false</bool></edit>
</match>
<!-- disable anti-alias for fonts between 8 to 17 pixels -->
<match target="font" >
<test compare="more_eq" name="pixelsize"
qual="any"><double>8</double></test>
<test compare="less_eq" name="pixelsize"
qual="any"><double>17</double></test>
<edit mode="assign" name="antialias"><bool>false</bool></edit>
</match>
<!-- set the minimum size for SimSun and Tahoma -->
<match target="font" >
<test name="family" qual="any">
<string>SimSun</string>
<string>NSimSun</string>
<string>Tahoma</string>
</test>
<test compare="more_eq" name="pixelsize"><int>8</int></test>
<test compare="less_eq" name="pixelsize"><int>12</int></test>
<edit compare="eq" name="pixelsize"><int>12</int></edit>
</match>
</fontconfig>
DFA(deterministic finite automaton): 从同一状态出发的边都标记有不同的符号
可以把一个DFA用一个转置矩阵(transition matrix)表示,矩阵的第i行记录状态i向其他状态跳转的情况,edges[i][j]表示状态i时吃掉一个j符号后跳转到edges[i][j]状态。
DFA的一个好处就是可以识别最长的匹配,比如对于IF8这个字符串,可以被识别为一个变量而不是一个关键字加数字。
处理方法是保留最后一次自动机的终结状态Last-Final及其相对应的字符位置Input-Position-at-Last-Final。
每次进入一个终结状态,就更新这两个变量。
遇到死路(dead state, a nonfinal state with no output transitions),通过这两个变量回复到上一个终结状态。
NFA(nondeterministic finite automaton): 从同一状态出发的边可能标记有相同的符号
由于从同一状态出发选择的路径可能有多条,非确定性自动机总是需要进行“猜测”,而且总要做出正确的猜测。
看了半天总算对这节有了个大致的感觉,首先看几个和sigprocmask相关的函数:
#include <signal.h>
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);
int sigemptyset(sigset_t *set);
int sigfillset(sigset_t *set);
int sigaddset(sigset_t *set, int signum);
int sigdelset(sigset_t *set, int signum); // Return: 0 if OK, -1 on error
int sigismember(const sigset_t *set, int signum); // Return: 1 if member, 0 if not, -1 on error
sigprocmask用于改变当前blocked signals的集合,how参数指定了具体的行为:
SIG_BLOCK 把set中的信号添加到blocked列表(blocked = blocked | set)
SIG_UNBLOCK 把set中的信号从blocked列表中移出(blocked = blocked & ~set)
SIG_SETMASK blocked = set
另外,如果oldset的值不是NULL的话,之前的blocked列表会保存在oldset中。
而sigaddset sigdelset sigfillset sigemptyset都是用于操作sigset_t列表的函数。
sigprocmask适用于在父子进程间同步的情况,以一个典型的UNIX shell程序为例,父进程需要在一个job
list中记录它所有的子进程,当父进程创建一个子进程时,它把子进程加入到job list中;当父进程reap一个子进程时,就从job
list中移出这个进程。
如果不同步父子进程,有可能发生这种情况:
1. 父进程执行fork函数,内核调度新创建的子进程替换父进程运行
2. 在父进程能够再次运行前,子进程终止,成为一个zombie,内核发送SIGCHLD信号给父进程
3. 父进程可以运行前,内核发现了未处理的(pending)SIGCHLD信号,让它由父进程的handler处理
4. handler reap了终止的进程,调用deletejob函数,实际上没有任何作用,因为父进程还没有把该子进程加入列表
5. handler完成后,内核继续运行父进程,后者调用fork完成后继续,错误地把不存在的子进程加入了job list
一种做法是用最差情况下复杂度也是O(n)的算法求出第k大的数,然后把这个数作为pivot进行一次paritition,再排序该数左边的部分。复杂度为O(n + klgk)
http://en.wikipedia.org/wiki/Selection_algorithm
另外,CLRS上Selection in worst-case linear time算法实际上对in expected linear time在选数时做了一个优化,这样在最差情况下也有O(n)的复杂度了,实际应用中没什么用 (thx to Peter大牛 ^_^)
搬到张江了
1. 比较排序法最差情况下至少需要omega(n lgn)
证明:
通过决策树(decision tree)分析比较排序,n!种可能情况都要被该决策树的叶子覆盖。
设树深度为h,有
n! <= l <= 2h
得h >= lg(n!) = omega(n lgn)
2. 计数排序
很简单的排序算法,不过后面的C数组的运用比较技巧。
for i = 1 to k
do c[i] = 0
for j = 1 to length(a)
do c[a[j]] = c[a[j]] + 1
// c 数组记录了各个元素的出现次数
for i = 1 to k
do c[i] = c[i] + c[i - 1]
// c[i] 记录了小于或等于i的元素个数
for j = length(a) downto 1
do b[c[a[j]]] = a[j]
c[a[j]] = c[a[j]] - 1
复杂度: k = O(n)时,复杂度为theta(n)
CSAPP上的例子,但是书中的源码有问题,修改后的版本:
#include "csapp.h"
#define MAXARGS 128
void eval(char *cmdline);
int parseline(char *buf, char **argv);
int buildin_command(char **argv);
int main()
{
char cmdline[MAXLINE];
while (1)
{
printf("> ");
Fgets(cmdline, MAXLINE, stdin);
if (feof(stdin))
exit(0);
eval(cmdline);
}
}
void eval(char *cmdline)
{
char *argv[MAXARGS];
char buf[MAXLINE];
int bg;
pid_t pid;
strcpy(buf, cmdline);
bg = parseline(buf, argv);
if (argv[0] == NULL)
return;
if (!builtin_command(argv))
{
if ((pid = Fork()) == 0)
{
if (execve(argv[0], argv, environ) < 0)
{
printf("%s: Command not found.\n", argv[0]);
exit(0);
}
}
if (!bg)
{
int status;
if (waitpid(pid, &status, 0) < 0)
unix_error("waitfg: waitpid error");
}
else
printf("%d %s", pid, cmdline);
}
return;
}
int builtin_command(char **argv)
{
if (!strcmp(argv[0], "quit"))
exit(0);
if (!strcmp(argv[0], "&"))
return 1;
return 0;
}
int parseline(char *buf, char **argv)
{
char *delim;
int argc;
int bg;
buf[strlen(buf) - 1] = ' ';
while (*buf && (*buf == ' '))
buf++;
argc = 0;
while ((delim = strchr(buf, ' ')))
{
argv[argc++] = buf;
*delim = '\0';
buf = delim + 1;
while (*buf && (*buf == ' '))
buf++;
}
argv[argc] = NULL;
if (argc == 0)
return 1;
if ((bg = (*argv[argc - 1] == '&')) != 0)
argv[--argc] = NULL;
return bg;
}
摘要: http://www.defmacro.org/ramblings/fp.html还是放在Mathematics类吧
Functional Programming For The Rest of Us
Monday, June 19, 2006
Introduction
Programmers are procrastinators. Get in, get some coffee, ... 阅读全文
1. dup和dup2函数
#include <unistd.h>
int dup(int filedes);
int dup2(int filedes, int filedes2);
// Both return: new file descriptor if OK, -1 on error
dup返回的file descriptor(以下简称fd)为当前可用的最低号码,dup2则指定目的fd,如果该fd已被打开,则首先关闭这个fd。
dup后两个fd指向相同的file table entry,这意味着它们共享同一个的file status flag, read, write, append, offset等。
事实上,dup等价于
fcntl(filedes, F_DUPFD, 0);
dup2和也类似于
close(filedes2);
fcntl(filedes, F_DUPFD, filedes2);
但这不是一个原子操作,而且errno也有一定的不同。
Appending to a File 考虑某个单一进程试图在文件追加写入的操作。由于早期的UNIX系统不支持O_APPEND选项,因此得先用lseek将offset置于文件尾部。 if (lseek(fd, 0L, 2) < 0) err_sys("lseek error"); if (write(fd, buf, 100) != 100) err_sys("write error"); 注意这里的lseek函数的第三个参数2等于SEEK_END常量,但是早期UNIX并没有这个常量名(System V中才引进) 这样的处理在多进程试图在同一文件尾部追加写入时就有可能出现问题。 假设两个独立线程A B要在某个文件尾部追加写入,使用了上述方法,并没有使用O_APPEND开关。 首
先A指向了该文件尾部(假设是offset=1500的地方),接着内核切换到B进程,B也指向了该尾部,然后写入了100字节,此时内核把v-node
中当前文件的大小改为了1600。内核再次切换进程,A继续运行,调用write方法,结果就在offset=1500的地方写入了,覆盖了B进程写入的
内容。 这个问题其实和Java中的多线程差不多,指向文件尾部和写入应该作为一个原子操作执行,就像Java中使用synchronized块保护原子操作。使用O_APPEND选项就是一种解决方法。 另一种解决方法时使用XSI extension中的pread和pwrite函数。 #include <unistd.h> ssize_t pread(int filedes, void *buf, size_t nbytes, off_t offset); // Returns: number of bytes read, 0 if end of file, -1 on error ssize_t pwrite(int filedes, const void *buf, size_t nbytes, off_t offset); // Returns: number of bytes read, 0 if end of file, -1 on error 调用pread与调用lseek后再调用read等价,以下情况除外: 1. pread的两个步骤无法被中断。 2. 文件指针尚未被更新时。 pwrite与lseek+write的差别也相似。 Creating a File
当使用O_CREAT和O_EXCL开关调用open函数时,如果文件已经存在,则open函数返回失败值。如果不使用这两个开关,可以这样写:
if ((fd = open(pathname, O_WRONLY)) < 0) {
if (errno == ENOENT) {
if ((fd = creat(pathname, mode)) < 0)
err_sys("creat error");
} else {
err_sys("open error");
}
}
当open函数执行后creat函数执行前另一个进程创建了同名文件的话,该数据就会被擦除。
内核使用三种数据结构表示一个打开的文件,他们之间的关系决定了进程间对于共享文件的作用。 Every process has an entry in the process table. Within each process table entry is a table of open file descriptors, which we can think of as a vector, with one entry per descriptor. Associated with each file descriptor are 1) The file descriptor flags (close-on-exec; refer to Figure 3.6 and Section 3.14) 2) A pointer to a file table entry The kernel maintains a file table for all open files. Each file table entry contains 1) The file status flags for the file, such as read, write, append, sync, and nonblocking 2) The current file offset 3) A pointer to the v-node table entry for the file Each open file (or device) has a v-node structure that contains information about the type of file and pointers to functions that operate on the file. For most files, the v-node also contains the i-node for the file. This information is read from disk when the file is opened, so that all the pertinent information about the file is readily available. For example, the i-node contains the owner of the file, the size of the file, pointers to where the actual data blocks for the file are located on disk, and so on. 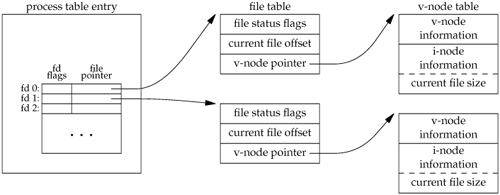 上图为这三种数据结构及其相互联系 其中v-node主要用于提供单个操作系统上的多文件系统支持,Sun把它称为Virtual File System linux中没有v-node,使用了一个generic i-node代替,尽管使用了不同的实现方式,v-node在概念上与generic i-node相同。 下面来讨论两个独立的进程打开同一文件的情况 这种情况下两个进程拥有不同的file table,但其中的两个指针指向了同一个v-node。 知道了这些数据结构的情况以后,我们可以更精确的知道某些操作的结果 1) 每次write操作结束后,当前文件的offset增加,如果这个操作导致当前的offset超出了文件长度,则i-node表中记录的文件大小会被修改为改动后的大小。 2) 使用O_APPEND方式打开文件后,每次调用write函数时,当前文件的offset都会被设置为i-node表中的该文件大小,从而write函数只能在文件尾部追加。 3) lseek 函数只改变在file table中的当前文件offset,并不会产生io操作 注意file descriptor flag和file status flag的作用域差别,前者属于某个单独进程的单独的file descriptor,后者则适用于任意进程中指向给定file table entry的所有descriptor。fcntl函数可以修改这两种flag
1. 貌似和dive into python中的有一定的差异,可能是版本的关系(python 2.2 - 2.5)
minidom.parse("binary.xml")得到的对象是binary.xml的整棵dom树,它的第一个结点包含了DOCTYPE的相关信息,对于它的字节点的firstNode,貌似一般都是空的。
2. unicode 相关
string.encode()
sys.getdefaultencoding()
指定.py文件编码的方法:
在每个文件开头加入编码声明
# -*- coding: UTF-8 -*-
3. python目录的lib/site-packages/sitecustomize.py是一个特殊的脚本,Python会在启动的时候导入它。
4. 搜索元素:
getElementByTagName()
返回的是一个list
5. 元素属性
attributes 是一个xml.dom.minidom.NameNodeMap实例,常用的方法如keys() values(),同时也有__getitem__方法,类似于dictionary
居然要军训两星期后才搬去张江,残念啊。。。
求到了个代理,总算能上外网,却上不了TopCoder
在寝室百无聊赖ing...
算了,还是看会儿书吧
1. 几个常用对象:
os.system 执行命令
sys.stdin sys.stdout
os.path.getsize 获得文件大小
os.path.isdir
os.mkdir
os.listdir
2. walk()函数
很好用的一个函数
os.path.walk(rootdir, f, arg)
rootdir是要访问的目录树的根,f是用户定义的函数,arg是调用f时用的一个参数。
对于每一个"walk"过程中遇到的目录directory,设该目录下的文件列表为filelist,walk函数会调用
f(arg, directory, filelist)
1. 交换x和y的值 [x, y] = [y, x]
2. zip()方法把几个lists的第i个元素合成一个tuple,放在一个新的list中。
zip(seq1 [, seq2 [...]]) -> [(seq1[0], seq2[0] ...), (...)]
函数式编程相关
1. Mapping
map() 方法对序列中的每个元素调用某个函数,返回新生成的结果序列。
有点类似于Ruby的Array.each do | element |
>>> z = map(len, ["abc", "clounds", "rain"])
>>> z
[3, 6, 4]
2. Filtering
过滤掉满足条件的元素,类似与Array.reject do | element |
>>> x = [5,12,-2,13]
>>> y = filter(lambda z: z > 0, x)
>>> y
[5, 12, 13]
3. List Comprehension
来个复杂的例子
>>> y
[[0, 2, 22], [1, 5, 12], [2, 3, 33]]
>>> [a for b in y for a in b[1:]]
[2, 22, 5, 12, 3, 33]
4. Reduction
先看示例
>>> x = reduce(lambda x,y: x+y, range(5))
>>> x
10
执行的顺序是:首先调用函数处理range(5)前两个值,0 + 1 = 1,然后返回的值1作为x,继续与range(5)的第三个值(2,作为y)。
最后的结果是0+1+2+3+4的值
这个常用来代替for循环
两场 Luna ZvP 开局都一样,我12D分矿BH,对手2BG xx rush,两局还都是近点。 第一局show了一下农民卡位,貌似这个因为玩了魔兽提高了不少,愣是把P的第一个狂热卡了好几下,等它到我的分矿6条小狗已经出来了。之后是小狗show,纯小狗一只没死先后杀死6狂热,我都怀疑这是不是自己的操作了  ,然后就是纯A了。。。 第二局没第一局好玩,近点xx rush防住后骗对方升级基地,然后爆狗A掉了
一开始没看清题目,以为是在网状图中找遍历所有点的最短路径  后来才发现是在一棵树中,而且是从根节点出发,这个就简单多了 把所有路径加起来乘以2,就是从根节点到各个路径后再返回根节点所需的最短耗费。 然后再减掉访问最后一个节点后返回所需的耗费即可,既然要求最小的耗费就减去耗费最大的路径即可。
public class PowerOutage {
public static int estimateTimeOut(int[] fromJunction, int[] toJunction, int[] ductLength) {
int sum = 0;
for (int i = 0; i < ductLength.length; i++)
sum += ductLength[i];
sum *= 2;
sum -= findLongestWay(0, fromJunction, toJunction, ductLength);
return sum;
}
public static int findLongestWay(int root, int[] fromJunction,
int[] toJunction, int[] ductLength) {
int max = 0;
for (int i = 0; i < fromJunction.length; i++) {
if (fromJunction[i] == root) {
int temp = findLongestWay(toJunction[i], fromJunction,
toJunction, ductLength) + ductLength[i];
if (temp > max)
max = temp;
}
}
return max;
}
}
1. File hole
The file's offset can be greater than the file's current size, in which case the next write to the file will extend the file. This is referred to as creating a hole in a file and is allowed. Any bytes in a file that not been written are read back as 0.
A
hole in a file isn't required to have storage backing it on disk.
Depending on the file system implementation, when you write after
seeking past the end of the file, new disk blocks might be allocated to
store the data, but there's no need to allocate disk blocks for the
data between the old end of file and t he location where you start
writing.
2. read Function
#include <unistd.h>
ssize_t read(int filedes, void *buf, size_t nbytes);
// Returns: number of bytes read, 0 if end of file, -1 on error
read读取的字节数小于所要求的字节数的几种可能:
1) 从文件中读取,在所要求的字节数读取完成前到达文件尾。
2) 从终端读取,这种情况下通常每次最多读取一行内容。
3) 通过网络读取,网络缓冲可能导致读取到少于要求的字节数。
4) 从管道或者FIFO中读取
5) 从record-oriented设备中读取,如磁带,每次至多返回一个记录。orz...
6) 在一定数量的数据读取后被信号中断。
3. write Function
#include <unistd.h>
ssize_t write(int filedes, const void *buf, size_t nbytes);
// Returns: number of bytes written if OK, -1 on error
导致错误的通常原因是磁盘已满,或者超出了给定进程的文件大小限制。
PS: 看了IEF2007 ipx vs pj, ipx vs lx的四场ZvP,ipx和他们的差距自然很大,细节上lx比pj强不少,包括小狗进入矿区时农民的控制,开局的计算等。推荐ipx vs pj中Luna上的一场,局面一边倒,ipx充分展示了ZvP的关键——灵活,打得很妖。
1. 任何存储字符串size()方法返回的结果的变量必须为string::size_type类型。特别重要的是,不要把size的返回结果赋给一个int变量。string::size_type是一个unsigned型。
同样,在定义用作索引的变量时,最好也用string::size_type类型。
2. vector::const_iterator() 返回只读迭代器。
3.
typedef string *pstring;
const pstring cstr;
等价于string *const cstr;
而不是const string *cstr;
也可以写成pstring const str;
但是大多数人习惯把const写在类型的前面,尽管这种情况把const放在类型后面更容易理解。
把以前跳过去的几节补一下
对齐就是指为了提高处理器的效率,把某些基础类型的地址规定为必须是某个值(通常是2,4或8)的整数倍。
如果不这样处理,例如把一个double值分开存放在地址为8*n的两边,处理器每次从内存中读取8字节,这样就需要读取两次才能得到这个double值了。
Linux的做法是把2字节数据(如short)存放在偶数的地址中,把其他更大的数据(int, int *, float, double)放在以4为约数的地址中。
Windows则使用了相对现代的处理器而言更好的做法,任何k字节的数据必须存放在以k的倍数为起始的地址中,即double必须存放在以8*n为起始的地址中。
GCC的编译开关-malign-double也可以达到这种效果,但因此可能导致与某些假定4字节对齐方式的库的链接错误。
一个简单的例子:
struct S1 {
int i;
char c;
int j;
};
对齐后的保存方式为
0-4: i
4-5: c
8-12: j
1. unbuffered IO是相对于standard IO而言的,unbuffered指每个read和write函数都是通过内核系统调用实现的。这些函数并不是ISO C的一部分,但都属于POSIX.1和Single UNIX Specification.
2. File Descriptors
内
核中所有打开的文件都是通过File Descriptor指向的。file
descriptor是一个非负的整数,按照管理,UNIX系统把0指定为进程的标准输入,1为进程的标准输出,2为标准错误输出。为了程序的通用性考
虑,这些magic number应该由<unistd.h>中的STDIN_FILENO, STDOUT_FILENO,
STRERR_FILENO代替。
file descriptor的范围是从[0, OPEN_MAX],早期系统的上限为19,现在许多已经到达了63,Linux 2.4.22把每个进程打开的文件数上限提升到了2^20.
3. open 函数
#include <fcntl.h>
int open(const char *pathname, int oflag, ..., /* mode_t mode */ );
返回: 正常 - 最小的未被使用的file descriptor,出错 - 0
oflag: O_RDONLY(0), O_WRONLY(1), O_RDWR(2) 括号内为大多数情况下的值,这三个参数中必选一个,剩下的可选参数指定了是否追加、是否创建等信息,具体参见man 2 open
4. File Name and Pathname Truncation
如果创建的文件名长度大于NAME_MAX常量,BSD系统会返回一个错误状态,并把errno设为ENAMETOOLONG。如果只是把文件名截去部分就有可能导致与已存在的文件重名。
POSIX.1中的常量_POSIX_NO_TRUNC指定了长文件名和路径会被截断还是会引发错误
5. 创建文件
#include <fcntl.h>
int creat(const char *pathname, mode_t mode);
事实上这个函数等价于
open (pathname, O_WRONLY | O_CREAT | O_TRUNC, mode);
6. 关闭文件
#include <fcntl.h>
int close(int filedes);
返回: 成功 -1,出错 0
当一个进程结束时,系统会自动关闭该进程打开的所有文件。
7. lseek 函数
每个打开的文件都有一个current file offset属性,通常是一个非负的整数。默认情况下文件打开后该值为0,除非指定了O_APPEND选项。
#include <unistd.h>
off_t lseek(int filedes, off_t offset, int whence);
// Returns: new file offset if OK, -1 on error
可以通过seek 0字节来得到当前的offset
off_t currpos;
currpos = lseek(fd, 0, SEEK_CUR);
这个方法也可以用来判断当前文件是否可以被seek,如果是指向管道(pipe),FIFO,或者socket的file descriptor,lseek把errno设置为ESPIPE并返回-1
某些设备可能允许负值的offset(如FreeBSD上的/dev/kmem),因此在检查返回值时应判断是否等于-1,而不是是否小于0
水木上看到的,
while (i != i) {}
问如何给i赋值使程序进入死循环
一种正确答案是
当i为浮点类型,且值为NAN时
例如
float i = -1;
i = sqrt(i);
1. 静态库(static library)的主要缺陷:
1) 静态库通常需要维护和定期更新,而这些库的使用者就得注意这些变化,并且在库修改后重新将自己的程序和库链接起来
2) 以printf和scanf这两个函数为例,它们的代码在每个运行的进程里都保留了一份,在一个典型的操作系统上运行着50-100个进程,这无疑是对系统资源的严重浪费。(内存的一个有趣的特性是,它永远是一个短缺的资源,无关一个系统里有多大的内存)
2. 共享库(shared library)弥补了静态库的这些缺陷。所谓共享库,就是指在运行时可以被读入到任意的内存地址,并与程序链接的模块。这个过程也被称为动态链接(dynamic linking),由动态链接器(dynamic linker)完成。
Unix系统中共享对象通常后缀为.so,微软的操作系统中大量使用了共享库,通常被称为DLL(dynamic link libraries)
3. 共享库的“共享”表现在两个方面:
1) 在任何一个给定的文件系统中,对于某个特定的库,只有一个.so文件
2) 共享库单独的一份.text域可以由多个不同的运行进程共享。
4. 编译一个共享库:gcc -shared -fPIC -o libvector.so addvec.c multvec.c
-fPIC开关让编译器产生位置独立的代码(PIC, position independent code)
-shared开关使得编译器产生共享对象的文件
5. 动态链接的几个应用:
1) 软件的分布式开发
2) 开发高效的Web服务器
早期的Web服务器通过fork和execve调用子进程来产生动态的内容,被称为CGI,而现代的Web服务器则通过基于动态链接库的一种高效的方式。
主要的方法是把生成动态内容的函数打包到一个共享库中,当服务器端接收到一个请求后,服务器动态地读入并且链接到相应的函数,并直接调用这个函数,而
fork和execve则是在子进程的环境中运行的。函数调用后继续存在,以后的类似请求都只需要一个简单的调用就可以了。另外,方法也可以在不停止服务
器的情况下更新,也可以加入新的函数。
6. Unix系统中读入并链接共享库的方法
#include <dlfcn.h>
void *dlopen(const char *filename, int flag);
// returns: ptr to handle if OK, NULL on error
需要通过-rdynamic编译,具体见CSAPP P569
获得已经打开的库的句柄(handle)
#include <dlfcn.h>
void #dlsym(void *handle, char *symbol);
// returns: ptr to symbol if OK, NULL on error
关闭共享库
#include <dlfcn.h>
int dlclose(void *handle);
// returns: 0 if OK, -1 on error
获得错误信息
#include <dlfcn.h>
const char *dlerror(void);
1. 一个有限非空集合M到自身的一个双射称为置换。
若M的元素个数为n,记M的所有置换的集合记作Sn,则不难得出Sn的元素个数为n个元素的排列数,即
| Sn | = n!
2. Sn的一个把i1变到i2,i2变到i3,……,ik-1变到ik,ik变到i1,而其余的元(如果还有)不变的置换称为k阶循环置换
如
(1 2 3 4 5 6) = (1) = (2) = ... = (6),称为恒等置换
1 2 3 4 5 6
3.几个定理:
1) 设f,g为两个不相交的循环置换,则fg = gf
2) 任意置换均可唯一地分解成不相交循环置换的乘积
这个定理可由构造法证得,该证法同时也给出了分解为循环置换的乘积的方法
3) 任意置换均可分解为对换的乘积(不唯一),例如
(12)(345) = (12)(35)(34) = (12)(14)(41)(35)(34)
4. 置换的奇偶性
1) 设f ∈Sn,规定f的符号为
Sgn f = ∏[ f(i) - f(j) ] / (i - j)
貌似就是逆序对数的奇偶性,奇为-1,偶为1
2) Sgn(fg) = (Sgn f)(Sgn g)
3) n > 1时,Sn中奇置换与偶置换的个数相等,均为n! / 2
可通过分离一组对换积证得
1. The following Vim command will perform a fast code block formatting:
1G=G
We can split it up in simply says:
1G : Go to the first line(you can also use gg)
= : Indent according to the configuration
G : Go to the last line(tell Vim where to end indenting)
2. Another way is to go into visual mode with V and press = to reindent the chosen lines.
3.
=i{ will reindent everything between { and } excluding the brackets.
other similar choices:
a{ : all the code between { and } including the brackets.
i(, a(, i<, a<, i[, a[
APUE上的例程,稍微改了下,在进程开始和结束的时候会分别显示当前的PID和退出状态。 不支持参数 1. fgets命令从标准输入读入命令,当键入文件结束字符(通常是Ctrl+D)时进程结束 2. 以\0替换输入命令的最后一个字符,即去掉换行符,使得execlp能够处理 3. fork函数创建一个新进程,对父进程返回新的子进程的非负PID,对子进程返回0 4. 在子进程中,调用execlp以执行从标准输入读入的命令。fork和exec的组合产生了一个新进程 5. 新的子进程开始执行后,父进程等待子进程的终止,这一要求由waitpid实现 6. 执行这个程序后还可以在这个简易shell中创建新的自身的进程
#include <sys/types.h>
#include <sys/wait.h>
#include "ourhdr.h"
int main(void)
{
char buf[MAXLINE];
pid_t pid;
int status;
printf("%% ");
while (fgets(buf, MAXLINE, stdin) != NULL)
{
buf [strlen(buf) - 1] = 0;
if ( (pid = fork()) < 0)
err_sys("fork error");
else if (pid == 0)
{
execlp(buf, buf, (char *) 0);
err_ret("couldn't execute: %s", buf);
exit(127);
}
printf("*** %d ***\n", status);
/* parent */
if ( (pid = waitpid(pid, &status, 0)) < 0)
err_sys("waitpid error");
printf("*** %d ***\n", pid);
printf("%% ");
}
exit(0);
}
将两个文件放在同一目录中,修改gpa.sh中的账号密码,并用chmod设置为可执行,运行即可。 写得不怎么样,像URPParser里处理标签的时候直接输出了,很不规范,不过懒得改了  urpparser.py:
from sgmllib import SGMLParser
class URPParser(SGMLParser):
def reset(self):
self.tdOpen = 0
self.colCount = -1
self.firstRow = 1
self.pieces = []
SGMLParser.reset(self)
def start_td(self, attrs):
"""
When encountered with tag td, check whether there's
an align property in the tag, which will distinguish
score table from others.
"""
for (k, v) in attrs:
if (k == "align"):
self.tdOpen = 1
break
def end_td(self):
self.tdOpen = 0
def handle_data(self, text):
if (self.tdOpen > 0):
if (len(text.strip()) > 0):
self.colCount += 1
if (self.colCount > 6):
self.colCount = 0
self.firstRow = 0
print
if (self.firstRow):
return
if (self.colCount == 2):
print "\t",
else:
print text.strip(),"\t",
gpa.sh:
#!/usr/bin/python
import urllib, cookielib, urllib2
loginURL = "http://fdis.fudan.edu.cn:58080/amserver/UI/Login?" +\
"goto=http%3A%2F%2Fwww.urp.fudan.edu.cn%3A84%2Feps" +\
"tar%2Fapp%2Ffudan%2FframeSub.jsp%3FaffairNO%3D035067"
scoreURL = "http://www.urp.fudan.edu.cn:84/epstar/app/fudan/S" +\
"coreManger/ScoreViewer/Student/Course.jsp"
logoutURL = "http://www.urp.fudan.edu.cn/logout.jsp"
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
str = urllib.urlencode({'Login.Token1': '06301000000', 'Login.Token2': "yourpassword"})
sock1 = urllib2.urlopen(loginURL, str)
loginHTML = sock1.read()
sock1.close()
sock2 = urllib2.urlopen(scoreURL)
scoreHTML = sock2.read()
sock2.close()
sock3 = urllib2.urlopen(logoutURL)
sock3.close()
from urpparser import URPParser
parser = URPParser()
parser.feed(scoreHTML)
print
如果直接编译myls.c,会报错 /tmp/cceQcwN0.o: In function `main': myls.c:(.text+0x24): undefined reference to `err_quit' myls.c:(.text+0x5b): undefined reference to `err_sys' collect2: ld 返回 1 需要下载随书附带的源代码并编译所需的库文件 源代码下载:http://www.blogjava.net/Files/zellux/apue.linux3.tar.Z.zip (下载后去掉.zip后缀) apue/README 文件中有具体的编译方法,对于Linux系统比较简单,进入lib.rhlin目录,然后运行make,就会在apue目录下生成libmisc.a,以后编译的时候连接这个库就行了。 以书中的第一个程序myls.c为例
#include <sys/types.h>
#include <dirent.h>
#include "ourhdr.h"
int main(int argc, char* argv[])
{
DIR *dp;
struct dirent *dirp;
if (argc != 2)
err_quit("a single argument (the directory name) is required");
if ( (dp = opendir(argv[1])) == NULL)
err_sys("can't open %s", argv[1]);
while ( (dirp = readdir(dp)) != NULL)
printf("%s\n", dirp->d_name);
closedir(dp);
exit(0);
}
$ gcc myls.c libmisc.a 出现几个Warning: libmisc.a(strerror.o): In function `strerror': strerror.c:(.text+0x18): warning: `sys_errlist' is deprecated; use `strerror' or `strerror_r' instead strerror.c:(.text+0xf): warning: `sys_nerr' is deprecated; use `strerror' or `strerror_r' instead 看来这本书的确太老了  $ ./a.out . 就会列出当前目录下的所有文件
《窃听风暴》的男主角乌尔里希·穆埃(Ulrich Mühe)
病逝了。。。好片子,好演员,可惜了。。。CSAPP 第七章Linking太枯燥了  啃了半天总算看到一点实际经历中遇到过的。 在编译阶段,编译器把全局变量标记为strong或者weak,并导出到汇编程序中,由汇编程序把这些信息隐式地添加到relocatable object file的符号表(symbol table)中。 函数和被初始化的全局变量被标记为strong,未初始化的全局变量被标记为weak。 Unix连接器(linker)使用下面的规则来处理多个符号的情况: 1. 不允许多个strong symbol的存在 2. 如果有一个strong symbol和若干个weak symbol,使用strong symbol 3. 只有若干个weak symbol,则使用其中任意一个 几个例子(未特殊说明的情况,变量定义均在全局范围): 1. foo1.c和bar1.c中都有int main()方法,即存在了两个strong symbol,连接器就会产生一条错误信息。 2.
/* foo3.c */
#include <stdio.h>
void f(void);
int x = 15213;
int main()
{
f();
printf("x = %d\n", x);
return 0;
}
/* bar3.c */
int x;
void f()
{
x = 15212;
}
main()方法调用f()后,x变为15212并被输出。 注意这可能不是main()方法的作者原来的意图。类似的情况也可能发生在两个weak symbol同名的时候。 3. 全局变量类型不同的情况:
/* foo5.c */
#include <stdio.h>
void f(void);
int x = 15213;
int y = 15212;
int main()
{
f();
printf("x = 0x%x y = 0x%x \n", x, y);
return 0;
}
/* bar4.c */
double x;
void f()
{
x = -0.0;
}
根据书上的内容, linux> gcc -o foobar5 foo5.c bar5.c linux> ./foobar5 结果应该是 x = 0x0 y = 0x80000000 但是在自己机器上编译时报错了,可能连接器版本较高,会自动找出这种错误  /usr/bin/ld: Warning: alignment 4 of symbol `x' in /tmp/ccupQXSG.o is smaller than 8 in /tmp/ccNNG9XZ.o 是double和int大小不义导致的对齐问题 这些问题都比较细小难以被查觉,通常在程序执行了一段时间后才出现较严重的问题,因此很难被修复,尤其当许多程序员不清楚连接器的工作方式的时候。 另外可以使用GCC的-warn-common标记(flag),使得它在解析多个同名的全局变量时发出警告。 试了下没成功@@ gcc --warn-common提示无法识别的命令行选项,gcc -Wall则不会发出警告。
1.基于dictionary的字符串格式化 >>> params = {"server":"mpilgrim", "database":"master", "uid":"sa", "pwd":"secret"} >>> "%(pwd)s" % params 'secret' 这个东西的用处在于和locals的搭配使用,比如样例程序中
def handle_comment(self, text):
self.pieces.append("<!--%(text)s-->" % locals())
就读取了text变量的内容。
不过这样和直接用text变量有什么区别呢?貌似"<!--%s-->" % text也可以啊
水木上问了一下,得到的答案是
发信人: Essien5 (宝贝晶~), 信区: Python
标 题: Re: 关于locals()的用处
发信站: 水木社区 (Thu Aug 2 11:16:37 2007), 转信
好处就是多个变量是代码很好维护,一一对应
'%s%s.......%s'%(a,b,c,d,....,z)
'%(a)s%(b)s......%(z)s'%locals()
第一种写法前面的%s和后面的变量很难对应起来,bug的源泉
后一个就非常直观了
而且要往中间再随便插变量也方便
2. 自己的类继承了SGMLParser后,需要对特殊标记处理,可以以start_或do_开始命名相关函数。
可以这样做的原因在于python的自醒机制(introspection)
def finish_starttag(self, tag, attrs):
try:
method = getattr(self, 'start_' + tag)
except AttributeError:
try:
method = getattr(self, 'do_' + tag)
except AttributeError:
self.unknown_starttag(tag, attrs)
return -1
else:
self.handle_starttag(tag, method, attrs)
return 0
else:
self.stack.append(tag)
self.handle_starttag(tag, method, attrs)
return 1
程序首先尝试获得start_tagname的方法,如果失败则继续尝试获得do_tagname,如果仍然不能找到,则调用unknown_starttag方法。 感觉这和Java的反射机制很相似,例如Javabean中的getter setter方法,也是通过特殊命名的形式让其他对象了解自己的。 3. import 语句可以写在任何地方。
Software版进不去了,一进去就会自动退出,WEB模式下一看是有个名字乱码的文章
2976 plantxue Aug 1 19:54 ?鶳鹛鶳鹇鶳鸺遭遇文件名不合法 (85)
2977 basic Aug 1 20:08 Adobe.CS3.Production.Premium.Activation-AGAiN (55)
2978 basic Aug 1 20:09 ?鶳鹛鶳鹇鶳鸺遭遇文件名不合法 (49)
看来web模式下发主题带有特殊字符的帖子可以起到一定的效果的 
前 言
软件质量是被大多数程序员挂在嘴上而不是放在心上的东西!
除了完全外行和真正的编程高手外,初读本书,你最先的感受将是惊慌:“哇!我以前捏造的C++/C 程序怎么会有那么多的毛病?”
别难过,作者只不过比你早几年、多几次惊慌而已。
请花一两个小时认真阅读这本百页经书,你将会获益匪浅,这是前面N-1 个读者的建议。
http://www.blogjava.net/Files/zellux/c.zip
转一篇wikipedia上的文章 http://zh.wikipedia.org/wiki/%E7%B4%85%E9%BB%91%E6%A8%B9
红黑树是一种 自平衡二叉查找树,是在 计算机科学中用到的一种 数据结构,典型的用途是实现 关联数组。它是在 1972年由 Rudolf Bayer发明的,他称之为"对称二叉B树",它现代的名字是在 Leo J. Guibas 和 Robert Sedgewick 于 1978年写的一篇论文中获得的。它是复杂的,但它的操作有着良好的最坏情况 运行时间,并且在实践中是高效的: 它可以在 O(log n)时间内做查找,插入和删除,这里的 n是树中元素的数目。
用途和好处
红黑树和AVL树一样都对插入时间、删除时间和查找时间提供了最好可能的最坏情况担保。这不只是使它们在时间敏感的应用如即时应用(real time application)中有价值,而且使它们有在提供最坏情况担保的其他数据结构中作为建造板块的价值;例如,在计算几何中使用的很多数据结构都可以基于红黑树。
红黑树在函数式编程中也特别有用,在这里它们是最常用的持久数据结构之一,它们用来构造关联数组和集合,在突变之后它们能保持为以前的版本。除了O(log n)的时间之外,红黑树的持久版本对每次插入或删除需要O(log n)的空间。
红黑树是 2-3-4树的
一种等同。换句话说,对于每个 2-3-4 树,都存在至少一个数据元素是同样次序的红黑树。在 2-3-4
树上的插入和删除操作也等同于在红黑树中颜色翻转和旋转。这使得 2-3-4
树成为理解红黑树背后的逻辑的重要工具,这也是很多介绍算法的教科书在红黑树之前介绍 2-3-4 树的原因,尽管 2-3-4 树在实践中不经常使用。
性质
红黑树是每个节点都带有颜色属性的二叉查找树,颜色或红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
性质1. 节点是红色或黑色。
性质2. 根是黑色。
性质3. 所有叶子都是黑色(包括NIL)。
性质4. 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
这些约束强制了红黑树的关键性质:
从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的
高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
要知道为什么这些特性确保了这个结果,注意到属性4导致了路径不能有两个毗连的红色节点就足够了。最短的可能路径都是黑色节点,最长的可能路径有交替的红色和黑色节点。因为根据属性5所有最长的路径都有相同数目的黑色节点,这就表明了没有路径能多于任何其他路径的两倍长。
在很多树数据结构的表示中,一个节点有可能只有一个子节点,而叶子节点包含数据。用这种范例表示红黑树是可能的,但是这会改变一些属性并使算法复
杂。为此,本文中我们使用 "nil 叶子"
或"空(null)叶子",如上图所示,它不包含数据而只充当树在此结束的指示。这些节点在绘图中经常被省略,导致了这些树好象同上述原则相矛盾,而实际
上不是这样。与此有关的结论是所有节点都有两个子节点,尽管其中的一个或两个可能是空叶子。
操作
因为每一个红黑树也是一个特化的二叉查找树,因此红黑树上的只读操作与普通二叉查找树上的只读操作相同。然而,在红黑树上进行插入操作和删除操作会导致不再符合红黑树的性质。恢复红黑树的属性需要少量(O(log n))的颜色变更(实际是非常快速的)和不超过三次树旋转(对于插入操作是两次)。虽然插入和删除很复杂,但操作时间仍可以保持为 O(log n) 次。
插入
我们首先以二叉查找树的方法增
加节点并标记它为红色。(如果设为黑色,就会导致根到叶子的路径上有一条路上,多一个额外的黑节点,这个是很难调整的。但是设为红色节点后,可能会导致出
现两个连续红色节点的冲突,那么可以通过颜色调换(color flips)和树旋转来调整。)
下面要进行什么操作取决于其他临近节点的颜色。同人类的家族树中一样,我们将使用术语叔父节点来指一个节点的父节点的兄弟节点。注意:
- 性质1[1]和性质3[2]总是保持着。
- 性质4[3]只在增加红色节点、重绘黑色节点为红色,或做旋转时受到威胁。
- 性质5[4]只在增加黑色节点、重绘红色节点为黑色,或做旋转时受到威胁。
在下面的示意图中,将要插入的节点标为N,N的父节点标为P,N的祖父节点标为G,N的叔父节点标为U。在图中展示的任何颜色要么是由它所处情形所作的假定,要么是这些假定所暗含的。
对于每一种情况,我们将使用 C示例代码来展示。通过下列函数,可以找到一个节点的叔父和祖父节点:
node grandparent(node n) {
return n->parent->parent;
}
node uncle(node n) {
if (n->parent == grandparent(n)->left)
return grandparent(n)->right;
else
return grandparent(n)->left;
}
情形1: 新节点N位于树的根上,没有父节点。在这种情形下,我们把它重绘为黑色以满足性质2[5]。因为它在每个路径上对黑节点数目增加一,性质5[4]符合。
void insert_case1(node n) {
if (n->parent == NULL)
n->color = BLACK;
else
insert_case2(n);
}
情形2: 新节点的父节点P是黑色,所以性质4[3]没有失效(新节点是红色的)。在这种情形下,树仍是有效的。性质5[4]受到威胁,因为新节点N有两个黑色叶子儿子;但是由于新节点N是红色,通过它的每个子节点的路径就都有同通过它所取代的黑色的叶子的路径同样数目的黑色节点,所以这个性质依然满足。
void insert_case2(node n) {
if (n->parent->color == BLACK)
return; /* 树仍旧有效 */
else
insert_case3(n);
}
注意: 在下列情形下我们假定新节点有祖父节点,因为父节点是红色;并且如果它是根,它就应当是黑色。所以新节点总有一个叔父节点,尽管在情形4和5下它可能是叶子。
|
情形3: 如果父节点P和叔父节点U二者都是红色,则我们可以将它们两个重绘为黑色并重绘祖父节点G为红色(用来保持性质5[4])。现在我们的新节点N有了一个黑色的父节点P。因为通过父节点P或叔父节点U的任何路径都必定通过祖父节点G,在这些路径上的黑节点数目没有改变。但是,红色的祖父节点G的父节点也有可能是红色的,这就违反了性质4[3]。为了解决这个问题,我们在祖父节点G上递归地进行情形1的整个过程。
|
void insert_case3(node n) {
if (uncle(n) != NULL && uncle(n)->color == RED) {
n->parent->color = BLACK;
uncle(n)->color = BLACK;
grandparent(n)->color = RED;
insert_case1(grandparent(n));
}
else
insert_case4(n);
}
注意: 在余下的情形下,我们假定父节点P 是其父亲G 的左子节点。如果它是右子节点,情形4和情形5中的左和右应当对调。
|
情形4: 父节点P是红色而叔父节点U是黑色或缺少; 还有,新节点N是其父节点P的右子节点,而父节点P又是其父节点的左子节点。在这种情形下,我们进行一次左旋转调换新节点和其父节点的角色; 接着,我们按情形5处理以前的父节点P。这导致某些路径通过它们以前不通过的新节点N或父节点P中的一个,但是这两个节点都是红色的,所以性质5[4]没有失效。
|
void insert_case4(node n) {
if (n == n->parent->right && n->parent == grandparent(n)->left) {
rotate_left(n->parent);
n = n->left;
} else if (n == n->parent->left && n->parent == grandparent(n)->right) {
rotate_right(n->parent);
n = n->right;
}
insert_case5(n);
}
|
情形5: 父节点P是红色而叔父节点U 是黑色或缺少,新节点N 是其父节点的左子节点,而父节点P又是其父节点G的左子节点。在这种情形下,我们进行针对祖父节点P 的一次右旋转; 在旋转产生的树中,以前的父节点P现在是新节点N和以前的祖父节点G 的父节点。我们知道以前的祖父节点G是黑色,否则父节点P就不可能是红色。我们切换以前的父节点P和祖父节点G的颜色,结果的树满足性质4[3]。性质5[4]也仍然保持满足,因为通过这三个节点中任何一个的所有路径以前都通过祖父节点G ,现在它们都通过以前的父节点P。在各自的情形下,这都是三个节点中唯一的黑色节点。
|
void insert_case5(node n) {
n->parent->color = BLACK;
grandparent(n)->color = RED;
if (n == n->parent->left && n->parent == grandparent(n)->left) {
rotate_right(grandparent(n));
} else {
/* Here, n == n->parent->right && n->parent == grandparent(n)->right */
rotate_left(grandparent(n));
}
}
注意插入实际上是原地算法,因为上述所有调用都使用了尾部递归。
[编辑] 删除
如果需要删除的节点有两个儿子,那么问题可以被转化成删除另一个只有一个儿子的节点的问题(为了表述方便,这里所指的儿子,为非叶子节点的儿子)。对于二叉查找树,在删除带有两个非叶子儿子的节点的时候,我们找到要么在它的左子树中的最大元素、要么在它的右子树中的最小元素,并把它的值转移到要删除的节点中(如在这里所展示的那样)。我们接着删除我们从中复制出值的那个节点,它必定有少于两个非叶子的儿子。因为只是复制了一个值而不违反任何属性,这就把问题简化为如何删除最多有一个儿子的节点的问题。它不关心这个节点是最初要删除的节点还是我们从中复制出值的那个节点。
在本文余下的部分中,我们只需要讨论删除只有一个儿子的节点(如果它两个儿子都为空,即均为叶子,我们任意将其中一个看作它的儿
子)。如果我们删除一个红色节点,它的父亲和儿子一定是黑色的。所以我们可以简单的用它的黑色儿子替换它,并不会破坏属性3和4。通过被删除节点的所有路
径只是少了一个红色节点,这样可以继续保证属性5。另一种简单情况是在被删除节点是黑色而它的儿子是红色的时候。如果只是去除这个黑色节点,用它的红色儿
子顶替上来的话,会破坏属性4,但是如果我们重绘它的儿子为黑色,则曾经通过它的所有路径将通过它的黑色儿子,这样可以继续保持属性4。
需要进一步讨论的是在要删除的节点和它的儿子二者都是黑色的时候,这是一种复杂的情况。我们首先把要删除的节点替换为它的儿子。出于方便,称呼这个儿子为N,称呼它的兄弟(它父亲的另一个儿子)为S。在下面的示意图中,我们还是使用P称呼N的父亲,SL称呼S的左儿子,SR称呼S的右儿子。我们将使用下述函数找到兄弟节点:
node sibling(node n) {
if (n == n->parent->left)
return n->parent->right;
else
return n->parent->left;
}
我们可以使用下列代码进行上述的概要步骤,这里的函数 replace_node 替换 child 到 n 在树中的位置。出于方便,在本章节中的代码将假定空叶子被用不是 NULL 的实际节点对象来表示(在插入章节中的代码可以同任何一种表示一起工作)。
void delete_one_child(node n) {
/* Precondition: n has at most one non-null child */
node child = (is_leaf(n->right)) ? n->left : n->right;
replace_node(n, child);
if (n->color == BLACK) {
if (child->color == RED)
child->color = BLACK;
else
delete_case1(child);
}
free(n);
}
如果 N 和它初始的父亲是黑色,则删除它的父亲导致通过 N 的路径都比不通过它的路径少了一个黑色节点。因为这违反了属性 4,树需要被重新平衡。有几种情况需要考虑:
情况 1: N 是新的根。在这种情况下,我们就做完了。我们从所有路径去除了一个黑色节点,而新根是黑色的,所以属性都保持着。
void delete_case1(node n) {
if (n->parent == NULL)
return;
else
delete_case2(n);
}
注意: 在情况2、5和6下,我们假定 N 是它父亲的左儿子。如果它是右儿子,则在这些情况下的左和右应当对调。
|
情况 2: S 是红色。在这种情况下我们在N的父亲上做左旋转,把红色兄弟转换成N的祖父。我们接着对调 N 的父亲和祖父的颜色。尽管所有的路径仍然有相同数目的黑色节点,现在 N 有了一个黑色的兄弟和一个红色的父亲,所以我们可以接下去按 4、5或6情况来处理。(它的新兄弟是黑色因为它是红色S的一个儿子。)
|
void delete_case2(node n) {
if (sibling(n)->color == RED) {
n->parent->color = RED;
sibling(n)->color = BLACK;
if (n == n->parent->left)
rotate_left(n->parent);
else
rotate_right(n->parent);
}
delete_case3(n);
}
|
情况 3: N 的父亲、S 和 S 的儿子都是黑色的。在这种情况下,我们简单的重绘 S 为红色。结果是通过S的所有路径, 它们就是以前不通
过 N 的那些路径,都少了一个黑色节点。因为删除 N 的初始的父亲使通过 N 的所有路径少了一个黑色节点,这使事情都平衡了起来。但是,通过 P
的所有路径现在比不通过 P 的路径少了一个黑色节点,所以仍然违反属性4。要修正这个问题,我们要从情况 1 开始,在 P 上做重新平衡处理。
|
void delete_case3(node n) {
if (n->parent->color == BLACK &&
sibling(n)->color == BLACK &&
sibling(n)->left->color == BLACK &&
sibling(n)->right->color == BLACK)
{
sibling(n)->color = RED;
delete_case1(n->parent);
}
else
delete_case4(n);
}
|
情况 4: S 和 S 的儿子都是黑色,但是 N 的父亲是红色。在这种情况下,我们简单的交换 N 的兄弟和父亲的颜色。这不影响不通过 N 的路径的黑色节点的数目,但是它在通过 N 的路径上对黑色节点数目增加了一,添补了在这些路径上删除的黑色节点。
|
void delete_case4(node n) {
if (n->parent->color == RED &&
sibling(n)->color == BLACK &&
sibling(n)->left->color == BLACK &&
sibling(n)->right->color == BLACK)
{
sibling(n)->color = RED;
n->parent->color = BLACK;
}
else
delete_case5(n);
}
|
情况 5: S 是黑色,S 的左儿子是红色,S 的右儿子是黑色,而 N 是它父亲的左儿子。在这种情况下我们在 S
上做右旋转,这样 S 的左儿子成为 S 的父亲和 N 的新兄弟。我们接着交换 S 和它的新父亲的颜色。所有路径仍有同样数目的黑色节点,但是现在
N 有了一个右儿子是红色的黑色兄弟,所以我们进入了情况 6。N 和它的父亲都不受这个变换的影响。
|
void delete_case5(node n) {
if (n == n->parent->left &&
sibling(n)->color == BLACK &&
sibling(n)->left->color == RED &&
sibling(n)->right->color == BLACK)
{
sibling(n)->color = RED;
sibling(n)->left->color = BLACK;
rotate_right(sibling(n));
}
else if (n == n->parent->right &&
sibling(n)->color == BLACK &&
sibling(n)->right->color == RED &&
sibling(n)->left->color == BLACK)
{
sibling(n)->color = RED;
sibling(n)->right->color = BLACK;
rotate_left(sibling(n));
}
delete_case6(n);
}
|
情况 6: S 是黑色,S 的右儿子是红色,而 N 是它父亲的左儿子。在这种情况下我们在 N 的父亲上做左旋转,这样 S
成为 N 的父亲和 S 的右儿子的父亲。我们接着交换 N 的父亲和 S 的颜色,并使 S
的右儿子为黑色。子树在它的根上的仍是同样的颜色,所以属性 3 没有被违反。但是,N 现在增加了一个黑色祖先: 要幺 N
的父亲变成黑色,要么它是黑色而 S 被增加为一个黑色祖父。所以,通过 N 的路径都增加了一个黑色节点。
此时,如果一个路径不通过 N,则有两种可能性:
- 它通过 N 的新兄弟。那么它以前和现在都必定通过 S 和 N 的父亲,而它们只是交换了颜色。所以路径保持了同样数目的黑色节点。
- 它通过 N 的新叔父,S 的右儿子。那么它以前通过 S、S 的父亲和 S 的右儿子,但是现在只通过 S,它被假定为它以前的父亲的颜色,和 S 的右儿子,它被从红色改变为黑色。合成效果是这个路径通过了同样数目的黑色节点。
在任何情况下,在这些路径上的黑色节点数目都没有改变。所以我们恢复了属性 4。在示意图中的白色节点可以是红色或黑色,但是在变换前后都必须指定相同的颜色。
|
void delete_case6(node n) {
sibling(n)->color = n->parent->color;
n->parent->color = BLACK;
if (n == n->parent->left) {
/* Here, sibling(n)->color == BLACK &&
sibling(n)->right->color == RED */
sibling(n)->right->color = BLACK;
rotate_left(n->parent);
}
else
{
/* Here, sibling(n)->color == BLACK &&
sibling(n)->left->color == RED */
sibling(n)->left->color = BLACK;
rotate_right(n->parent);
}
}
同样的,函数调用都使用了尾部递归,所以算法是就地的。此外,在旋转之后不再做递归调用,所以进行了恒定数目(最多 3 次)的旋转。
渐进边界的证明
包含n个内部节点的红黑树的高度是 O(log(n))。
定义:
- h(v) = 以节点v为根的子树的高度。
- bh(v) = 从v到子树中任何叶子的黑色节点的数目(如果v是黑色则不计数它)(也叫做黑色高度)。
引理: 以节点v为根的子树有至少2bh(v) − 1个内部节点。
引理的证明(通过归纳高度):
基础: h(v) = 0
如果v的高度是零则它必定是 nil,因此 bh(v) = 0。所以:
2bh(v) − 1 = 20 − 1 = 1 − 1 = 0
归纳假设: h(v) = k 的v有 2bh(v) − 1 − 1 个内部节点暗示了 h(v') = k+1 的 v'有2bh(v') − 1 个内部节点。
因为 v' 有 h(v') > 0 所以它是个内部节点。同样的它有黑色高度要么是 bh(v') 要么是 bh(v')-1 (依据v'是红色还是黑色)的两个儿子。通过归纳假设每个儿子都有至少 2bh(v') − 1 − 1 个内部接点,所以 v' 有:
2bh(v') − 1 − 1 + 2bh(v') − 1 − 1 + 1 = 2bh(v') − 1
个内部节点。
使用这个引理我们现在可以展示出树的高度是对数性的。因为在从根到叶子的任何路径上至少有一半的节点是黑色(根据红黑树属性4),根的黑色高度至少是h(root)/2。通过引理我们得到:
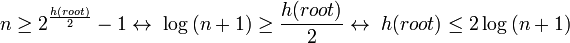
因此根的高度是O(log(n))。
from smth.org
p = malloc(n * sizeof(int));
for (i = 0; i < n; i++)
p[i] = i;
output(p, n);
for (i = n - 1; i > 0; i--)
if (p[i] > p[i - 1])
{
for (j = n - 1; p[j] < p[i - 1]; j--);
swap(&(p[i - 1]), &(p[j]));
for (j = i, k = n - 1; j < k; j++, k--)
swap(&(p[j]), &(p[k]));
ouput(p, n);
i = n;
}
free(p);
把总长度求出来,然后用和背包问题类似的dp算法求是否可以达到这个总长度的一半,但是超时了。
找到一个优化方案,结果0ms就过了,orz http://162.105.81.202/course/problemSolving/dividingProve.doc
以下论证均转自这篇文章。 结论 对于任意一种珠宝的个数n,如果n>=8, 可以将n改写为 11(n为奇数) 或 12(n为偶数)。 证明: 对于任意一组数,6的个数为n(n>=8) 一、如果可以分成两堆,我们可以分成两种情况: 1. 两堆里都有6,那么我们可知:把n改为n-2,仍然可分。 (两堆各减一个6) 2. 只有一堆里有6,设为左边,那么左边的总和不小于6*8=48。 我们观察,5*6=6*5 ,4*3=6*2 , 3*2=6 , 2*3=6 , 1*6=6 而 5*5 + 4*2 + 3*1 + 2*2 + 1*5 = 25 + 8 + 3 + 4 + 5 = 45 < 48 由抽屉原理右边必然存在 (多于5个的5 或者 多于2个的4 或者 多于1个的3 或者 多于2个的2 或者 多于5个的1) 即右边至少存在一组数的和等于若干个6,比如右边有3个4,这样把左边的2个6与右边的3个4交换,则又出现左右都有6的情况。 根据1,我们还是可以把n改为n-2且可分的状态不变。 综合1,2。我们可以看出只要原来n的个数=8,我们就可以把它改为n-2,这样操作一直进行到n<8。我们可以得出结论,对于大于等于8的偶数,可以换成6。 对于大于8的奇数,可以换成7。换完之后仍然可分。 二、如果不能分成两堆: 显然改为n-2时同样也不能分,那么对于大于等于8的偶数,可以换成6;对于大于8的奇数,可以换成7。换完之后仍然不可分。 综合一、二,我们得出结论把不小于8的偶数改为8,大于8的奇数改为7,原来可分与否的性质不会改变。 以上是对6的讨论,同样的方法可以推出 5的个数 6*4 + 4*4 + 3*4 + 2*4 + 1*4 = 64 < 5*13 即5的个数多于12时,偶数换为12,奇数换为11 4的个数 6*1 + 5*3 + 3*3 + 2*1 + 1*3 = 35 < 4*9 即4的个数多于8时,偶数换为8,奇数换为7 3的个数 5*2 + 4*2 + 2*2 + 1*2 = 24 < 3*9 即3的个数多于8时,偶数换为8,奇数换为7 2的个数 5*1 + 3*1 + 1*1 = 9 < 2*5 即2的个数多于4时,偶数换为4,奇数换为3 1的个数 多于5则必然可分(在总数是偶数的前提下) 综上所述, 对于任意一种珠宝的个数n,如果n>=8, 可以将n改写为 11(n为奇数) 或 12(n为偶数)。 进一步分析: 对每个数(1-6),以上只是粗略的估计,可以进一步减少其最大有效取值,例如, 对于6,5*5 + 4*2 + 3*1 + 2*2 + 1*5 = 25 + 8 + 3 + 4 + 5 = 45 就有4和2不能同时出现,5和1不能同时出现,3个5和1个3不能同时出现,4个5不能和1个4同时出现等等,所以组合不出6的整数倍的情况的总价值至多为25,所以当6的个数大于6时,奇数可改为5,偶数可改为6。 1-5 也有类似情况。 为了得出精确值,下面先我们讨论这样一个数论命题。 命题: 可重复的从自然数集中取出n个数(n>=2),其中必有若干个数之和能被n整除。 证明:设取出的n个自然数为a1,a2,a3,.....an 考虑这样的n+1个数 0, a1, a1+a2 , a1+a2+a3 , ...... , a1+a2+a3+...+an, 由于自然数模n的剩余类有n个,所以以上n+1个数中必有两个同余。 这两个数的差必被n整除,而且这两个数的差就是原来的n个数中的一些数的和。 这就证明了命题。 由以上命题 对于6而言,我们至多从{1,2,3,4,5}中可重复的找出5个数使它们不能组合成6的倍数。 所以这些数的和小于等于5*5=25 对于5而言,我们至多从{1,2,3,4,6}中可重复的找出4个数使它们不能组合成5的倍数。 所以这些数的和小于等于6*4=24 对于4而言,我们至多从{1,2,3,5,6}中可重复的找出3个数使它们不能组合成4的倍数。 所以这些数的和小于等于3*6=18 , 然而,两个6就是4的倍数, 所以最多有一个6 此时不能有两个5(2*5+6=16是4的倍数), 最多才6 + 5 + 3 = 14 < 3*5 =15 所以这些数的和小于等于3*5=15 对于3而言,我们至多从{1,2,4,5,6}中可重复的找出2个数使它们不能组合成3的倍数。 所以这些数的和小于等于2*5=10 (6就是3的倍数,所以不能取6) 对于2而言,我们至多从{1,3,4,5,6}中可重复的找出1个数使它们不能组合成6的倍数。 所以这些数的和小于等于1*5=5 考虑到 4*6 < 25 < 5*6 , 我们可以算出6的最大有效个数为5 。 考虑到 4*5 < 24 < 5*5 , 我们可以算出5的最大有效个数为5 。但是其实应该修正为6, 如果遇到如下特殊情况,左边5个6,右边6个5。此时虽然左右可以交换,但是交换后仍然只有一边有5,与(一、2)中讨论情况不符。 考虑到 3*4 < 15 < 4*4 , 我们可以算出5的最大有效个数为4 。但是其实应该修正为5, 如果遇到如下特殊情况,左边4个5,右边5个4。此时虽然左右可以交换,但是交换后仍然只有一边有4,与(一、2)中讨论情况不符。 考虑到 3*3 < 10 < 4*3 , 我们可以算出5的最大有效个数为4 。但是其实应该修正为5, 如果遇到如下特殊情况,左边3个5,右边5个3。此时虽然左右可以交换,但是交换后仍然只有一边有3,与(一、2)中讨论情况不符。 考虑到 2*2 < 5 < 3*2 , 我们可以算出5的最大有效个数为3 。 但是其实应该修正为4,如果遇到如下特殊情况,左边1个3和1个5,右边4个2。此时虽然左右可以交换,但是交换后仍然只有一边有2,与(一、2)中讨论情况不符。 我们得出最后的精确结论: 奇数改为 偶数改为 6的个数大于5 5 4 5的个数大于6 5 6 4的个数大于5 5 4 3的个数大于5 5 4 2的个数大于4 3 4
优化后的代码:
#include <iostream>
using namespace std;
long n[6];
long sum;
const long MAX_N = 60000;
int dividable()
{
int f[MAX_N];
for (int i = 0; i <= sum; i++)
f[i] = 0;
f[0] = 1;
for (int i = 0; i < 6; i++)
{
for (int j = 1; j <= n[i]; j++)
{
int base = j * (i + 1);
if (base > sum) break;
for (int k = sum - (i+1); k >= base - i - 1; k--)
if (f[k])
f[k + i + 1] = 1;
if (f[sum]) return 1;
}
}
return f[sum];
}
int main()
{
long cases = 0;
while (true)
{
sum = 0;
for (long i = 0; i < 6; i++)
{
cin >> n[i];
}
if (n[5] > 5) n[5] = 4 + n[5] % 2;
if (n[4] > 6) n[4] = 6 - n[4] % 2;
if (n[3] > 5) n[3] = 4 + n[3] % 2;
if (n[2] > 5) n[2] = 4 + n[2] % 2;
if (n[1] > 4) n[1] = 4 - n[1] % 2;
for (long i = 0; i < 6; i++)
{
sum += n[i] * (i + 1);
}
if (sum == 0)
break;
cases++;
cout << "Collection #" << cases << ":\n";
if (sum % 2 != 0)
{
cout << "Can't be divided.\n\n";
continue;
}
sum /= 2;
if (dividable())
cout << "Can be divided.\n";
else
cout << "Can't be divided.\n";
cout << endl;
}
return 0;
}
先抄了《Linux编程白皮书》上的代码,貌似不成功;google后改了下,编译成功。 hello.c
#include <linux/kernel.h>
#include <linux/module.h>
MODULE_LICENSE("GPL");
int init_module()
{
printk("Hello, world - this is the kernel speaking\n");
return 0;
}
void cleanup_module()
{
printk("Short is the life of a kernel module\n");
}
Makefile: obj-m := hello.o KERNELBUILD := /lib/modules/`uname -r`/build default: make -C $(KERNELBUILD) M=$(shell pwd) modules 然后
make sudo insmod hello.ko // 载入模块 dmesg // 即可看到Hello, world sudo rmmod hello // 移除模块 dmesg // 看到移除时信息
1. 设A, B为两个集合,若存在从A到B的双射函数,则称A与B是等势的,记为A≈B
N*N ≈ N的一种证明:构造双射函数 n = 2a * (2b - 1)。
2. 设A, B, C为任意的集合,则
(1) A≈A
(2) 若A≈B,则B≈A
(3) 若A≈B且B≈C,则A≈C
3. Cantor定理
(1) N不与R等势
(2) 设A为任意的集合,则A不与P(A)等势
4. 若一个集合A与某个自然数n等势,则称A是有穷集合,否则称A为无穷集合。
1. 数学归纳法证明自然数的性质P:
第一,构造 S = { n | n ∈N ∧ P(n) }
第二,证明S是归纳集
2. 设A为一个集合,如果A中任何元素的元素也是A的元素,则称A为传递集。每个自然数都是传递集。
以下命题等价:
(1) A是传递集
(2) ∪A 包含于 A
(3) 对于任意的y∈A,y包含于A
(4) A包含于P(A)
(5) P(A)为传递集
3. 设A为一个集合,称从A*A到A的函数为A上的二元运算。
另+: N*N -> N,且对于任意的m, n ∈N,+(<m, n>) = Am(n), 记作m + n,称+为N上的加法运算
另·: N*N -> N,且对于任意的m, n ∈N,·(<m, n>) = Mm(n),记作m·n,称·为N上的乘法运算。
1. Peano 系统
Peano系统是满足以下公设的有序三元组<M, F, e>,其中M为一个集合,F为M到M的函数,e为首元素。5条公设为:
(1) e ∈M
(2) M在F下是封闭的
(3) e ¢ ranF (暂时只找到这个符号表示“不属于” 囧)
(4) F是单射的
(5) 如果M的子集A满足 (e属于A) 且 (A在F下是封闭的),则A=M
(5)称为极小性公设
2. 设A为一个集合,称 A∪{A} 为A的后继,记作A+, 并称求集合的后继为后继运算。
3. 设A为一个集合,若A满足:
(1) Ø ∈A,
(2) 若对于一切 a ∈A,则 a+ ∈A,
则称A是归纳集。
4. 从归纳集的定义可以看出,Ø,Ø+, Ø++,... 是所有归纳集的元素,于是可以将它们定义成自然数。
自然数是属于每个归纳集的集合,将Ø,Ø+, Ø++,...分别记为0, 1, 2, ...
设D={v | v是归纳集|,称∩D为全体自然数集合,记为N.
设N为自然数集合,σ: N -> N,且σ(n) = n+, 则<N, σ, Ø>是Peano系统。
这个Peano系统的第(5)条公设提出了证明自然数性质的一种方法,即数学归纳法,称此公设为数学归纳法原理。
1. 考虑表达式3 + 4的语法分析树,exp( exp(number (3)), op(+), exp(number (4)) )。 还有一种更为简单的表示方法,例如将(34 - 3) * 42表示为*(-(34, 3), 42) 后者被称为抽象语法树(abstract syntax tree),它的效率更高,但是不能从中重新得到记号序列。 2. 简单的算术表达式的抽象语法树的数据类型
typedef enum {Plus, Minus, Times} OpKind;
typedef enum {OpKind, ConstKind} ExpKind;
typedef struct streenode
{
ExpKind kind;
OpKind op;
struct streenode *lchild, *rchild;
int val;
} STreeNode;
typedef STreeNode *SyntaxTree;
3. 简单算术文法的二义性解决 例如串34 - 3 * 42,可以有两种不同的分析树: 34 - 3 = 31, 31 * 42 3 * 42 = 126, 34 - 126 解决二义性的方法通常有两种,一种是设置消除二义性规则(disambiguating rule),如设置运算符的优先权;另一种是将文法限制为只能分析成单一的分析树,如将上式表示为34 - (3 * 42)。 设置运算符的优先权 定义如下的简单表达式文法: exp -> exp addop exp | term addop -> + | - term -> term mulop term | factor mulop -> * factor -> (exp) | number 这样乘法被归在term规则下,而加减法被归在exp规则下,因此在分析树和语法树中加减法将更接近于根,由此也就接受了更低一级的优先权。 这样将算符放在不同的优先权级别中的办法是在语法说明中使用BNF的一个标准方法,成为优先级联(precedence cascade)。 接下来的问题就是如何让同级运算从左往右。 可以将表达式文法改为 exp -> exp addop term | term addop -> + | - term -> term mulop factor | factor mulop -> * factor -> (exp) | number 这样就使得加法和减法左结合,而如果写成 exp -> term addop exp | term 这样的形式,则会使得它们右结合。 4. else 悬挂的问题 简单 if 语句的文法 statement -> if-stmt | other if-stmt -> if (exp) statement | if (exp) statement else statement exp -> 0 | 1 考虑串 if (0) if (1) other else other 这时else other的悬挂就出现了二义性,它既可以理解为是if (0)匹配失败后的选择,也可以理解为if (0)匹配成功,if (1) 匹配失败后的结果。 消除二义性的规则是 statement -> matched-stmt | unmatched-stmt matched-stmt -> if (exp) matched-stmt else matched-stmt | other unmatched-stmt -> if (exp) statement | if (exp) matched-stmt else unmatched-stmt exp -> 0|1 由这个定义,上面的串就可以分析为 if (0) // unmatched-stmt if (1) other else other // matched-stmt 另外一种解决方法就是在语法中解决这个问题。 可以要求出现else部分,或者使用一个分段关键字(bracketing keyword),例如 if (1) then if (0) then other else other endif endif
先试着用Apache2.2 + PHP,但是由于上一次删除Apache时没删干净,然后我用注册表手动删除还是有残留,结果Apache就废掉了,装也装不上,卸也卸不掉-,-
正好以前捣鼓.NET时装了IIS,就干脆用这个好了。
复制php5ts.dll和 libmysql.dll到c:\windows\system32
打开IIS配置,默认网站->属性->主目录->配置->添加/编辑应用程序扩展名映射,设置可执行文件指向php5isapi.dll文件,扩展名输入.php,选中脚本引擎和检查文件是否存在。
在IIS网站目录下新建phpinfo.php,内容为<?php phpinfo();?>
访问http://localhost/phpinfo.php ,查看是否正确。
用的是Lv6的小号,对手Lv7的神族,Luna 2Z v 5P
对方bf bn开局,我12D分矿,造气矿,提狗速,另外偷偷地在P主矿高地角落放了个基地。
对手第二次用农民来侦察我的时候,我把12条狗给他看了下,然后说
wo bao gou, bu yong zhen cha le
对方农民在我基地兜了一圈,发现我没骗他,回复曰
hao de wen xi
然后我又补了个基地,继续主矿三基地爆狗,同时偷造的基地也快好了。
一分钟后,8条小狗突然出现在对方基地。
30分钟后,主矿被拆干净。
此时这个P表现的还是挺冷静的,派狂热站高地防守,同时不断地补地堡。
可惜我在狂热堵住高地通道之前把4队狗A了上去。
接着这个P再次表现出了与他Lv7的等级不符的操作能力,守住了这一波进攻(当然和我没操作也有一定的关系)
5秒后后援的两队小狗赶到,再A一把,对方无奈退出。momo~~
问题:
有n个大小各不相同的螺帽及对应的螺钉,要求在O(nlogn)的复杂度内完成配对。螺钉之间、螺帽之间都无法直接比较大小,只能比较一颗螺帽与螺钉,判断他们之间的大小差异。
感觉和快速排序的partition差不多。
首先任选一颗螺钉与各螺帽进行比较,分成大小两组,另外得到与改螺钉相匹配的螺帽。
然后用那个螺帽再和其他螺钉比较,也分成大小两组,然后继续二分递归。
CLRS page 161 伪代码描述: Stooge-sort(A, i, j) if A[i] > A[j] then exchange A[i], A[] if i + 1 >= j then return k = (j - i + 1) / 3 Stooge-sort(A, i, j - k) Stooge-sort(A, i + k , j) Stooge-sort(A, i, j - k) 即先排序前2/3部分,然后是后2/3部分,最后再进行前面1/3的排序。 a. 证明算法正确性 由于是递归算法,而初始状态显然成立,因此只要证明当部分排序正确时,整体也能够被正确排序: 第一次排序后,第二部分每个数都不小于第一部分的所有数; 第二次排序后,第二部分某些数被交换到第三部分中,此时第三部分数都不小于第二部分和第一部分的数,但是第二部分的数并不一定都小于第一部分的(因为可能包含第三部分的数,而这些数与第一部分数的大小关系无法确认); 第三次排序后,第二部分的数都不小于第一部分的数。 这样,第一部分的任意数<=第二部分的任意数<=第三部分的任意数 而且各部分的数都已排序,因此整体已被排序。 b. 复杂度分析 递归式 T(n) = 3T(2n/3) + 1 由Master Theorem 
T(n) = O(n^log(3/2, 3))
各符号的定义与上文中最近处的定义相同。
1. 设R属于A*A,若R是自反的、反对称的和传递的,则称R是A上的偏序关系。 partial order
2. 称一个非空集合A及其A上的一个偏序关系<=组成的有序二元组(a, <=)为一个偏序集。partially ordered set, or simply poset.
3. 若(A, <=)为一个偏序集,若对于一切x,y属于A,如果x<=y或者y<=x成立,则称x与y是可比的。
4. 若x与y是可比的,且x<y(即x<=y且x!=y),但不存在z属于A,使得x<z<y,则称y覆盖x。
5. 哈斯图作法: Hasse diagram
(1) 省去关系图中每个顶点处的环。
(2) 若y覆盖x,则将代表y的顶点放在代表x的顶点之上,并连线,省去有向边的箭头。
6. 若对于一切x,y属于A,x与y均可比,则称<=为A上的全序关系,或线性关系。linear order
7. 若R是反自反的和传递的,则称R为A上的拟序关系,常将R记作<。
8. 最大元 最小元 极大元 极小元 上界 下界 最小上界 最大下界
其实这些词的区别和高数中的很相近,“最”针对自身集合的所有元素,“极”针对自身集合的部分元素,“界”指有一个更大的包含自身集合的参照系下的情况。
9. 线性关系中由于任何两个元素均可比,因此哈斯图中就可以表示为一条直线,从而容易理解线性的由来。又称为链,元素个数称为链的长度。
10. 良序关系:拟全序集(A, <)中任何非空子集均有最小元。
1.闭包 Closure
(1) 自反 reflexive
对称 symmetric
传递 transitive
(2) 其中,设R属于A*A(A为非空集合),则r(R) = R与A上恒等关系的并,s(R) = R与R的逆的并,
t(R) = R 并 R^2 并 R^3 并...并 R^l。
(3) rs(R) = sr(R)
rt(R) = tr(R)
st(R) 属于 ts(R)
2. 等价关系和划分
(1) 设R属于A*A,若R是自反的、对称的和传递的,则称R为A上的等价关系。
(2) 令[x]R为x的关于R的等价类,在不引起混乱时可简记为[x]。
(3) 以关于R的全体不同的等价类为元素的集合称为A关于R的商集,记作A/R。
(4) 设A为非空集合,若存在A的一个子集族S满足
a. S中不包含空集元素
b. 对于一切x,y属于S,且x,y不相等,则x与y不相交的(disjoint)
c. S中所有集合的并为A
则称S为A的一个划分,S中元素称为划分块。
(5) 非空集合A上的等价关系与A的划分是一一对应的。
(6) 第二类Stirling数,表示将n个不同的球放入r个相同的盒子中的方案数,可以由下列递归式计算:
f(n, r) = r * f(n - 1, r) + f(n - 1, r - 1)
很容易理解的一个递归式,其中初始状态为
f(n, 0) = 0, f(n, 1) = 1, f(n, 2) = 2^(n-1) - 1, f(n, n - 1) = C(n, 2), f(n, n) = 1
(7) A上等价关系的数量可以通过Stiring数求出,以A={a,b,c,d}为例
f(4,1) + f(4,2) + f(4,3) + f(4,4) = 15
命令行下使用的程序,和vim整合的很好(回复、发帖都是通过调用vim完成的)
具体配置可以参照/usr/share/doc/slrn/examples/slrn.rc.gz,第一次使用的时候需要
slrn --create生成相应的.jnewsrc文件。
CLRS上第六章的习题,以前感觉挺难的,现在仔细想了发现其实和堆是一样的。
/* Min-Young tableaus on Page 143 */
#include <iostream>
#include <iomanip>
using namespace std;
template <class Type>
class YTable
{
private:
Type** data;
int m, n;
const static int INFINITY = 9999;
public:
YTable(int m = 10, int n = 10);
~YTable();
int Insert(Type x);
int FloatUp(int x, int y);
int Print();
int Extract(int x, int y, Type value);
};
template <class Type>
YTable<Type>::YTable(int m, int n)
{
this->m = m;
this->n = n;
data = new Type*[m];
for (int i = 0; i < m; i++)
data[i] = new Type[n];
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
data[i][j] = INFINITY;
}
template <class Type>
YTable<Type>::~YTable()
{
for (int i = 0; i < m; i++)
delete [] data[i];
delete [] data;
}
template <class Type>
int YTable<Type>::Insert(Type x)
{
if (data[m - 1][n - 1] != INFINITY)
return 0;
data[m - 1][n - 1] = x;
FloatUp(m - 1, n - 1);
return 1;
}
template <class Type>
int YTable<Type>::FloatUp(int x, int y)
{
int maxX = x;
int maxY = y;
if (x > 0 && data[x - 1][y] > data[maxX][maxY])
{
maxX = x - 1;
maxY = y;
}
if (y > 0 && data[x][y - 1] > data[maxX][maxY])
{
maxX = x;
maxY = y - 1;
}
if (maxX != x || maxY != y)
{
swap(data[maxX][maxY], data[x][y]);
FloatUp(maxX, maxY);
}
return 1;
}
template <class Type>
int YTable<Type>::Print()
{
cout.setf(ios::fixed);
for (int i = 0; i < m; i++)
{
for (int j = 0; j < n; j++)
if (data[i][j] != INFINITY)
cout << setw(3) << data[i][j];
else
cout << " X ";
cout << endl;
}
return 1;
}
template <class Type>
int YTable<Type>::Extract(int x, int y, Type value)
{
data[x][y] = value;
FloatUp(x, y);
return 1;
}
int main()
{
YTable<int> myTable(4, 4);
int x[] = {9, 16, 3, 2, 4, 8, 1, 5, 14, 12, 7, 11, 10, 15, 13, 6};
for (int i = 0; i < 16; i++)
myTable.Insert(x[i]);
cout << "Initial state:\n";
myTable.Print();
cout << "\nNow change (4,3) to 5:\n";
myTable.Extract(3, 2, 5);
myTable.Print();
return 0;
}
先用任意的linux启动盘启动,推荐tomsrcbt,一个只有一两兆的发行版,不过我是从硬盘启动了ubuntu7.04的desktop.iso
如果非硬盘启动可能还需要先挂载原linux分区,接着使用chmod 755 /media/sda9/*修改该分区下的目录权限
重启,使用正常的模式进入ubuntu,结果发现无法在图形界面下登录,控制台中使用telnet上bbs求助后才知道还需要开放/tmp的写权限,用sudo chmod a=rwxt /tmp搞定。
移植XP下字体到Ubuntu时,其中的命令
sudo chmod 644 *
被我打成了
sudo chmod 644 /*
然后就开始痛苦了。。。
ls cd cat都不能用,firefox自动关闭,桌面图标全部变成叉,qterm里面的bbs列表也无法访问了。
最郁闷的是sudo这个命令也无法使用了,就像把钥匙留在房间里然后关上了门。
只能请教熊,貌似要用光盘才能恢复。。。
书上的例子,计算行号的,但是书中对行的定义是 line *.\n 貌似不正确,flex无法解析,改成line (.)*\n就可以了。 书上的样例也没有yywrap,写了个空函数。
%{
/* a Lex program that adds line numbers
to lines of text, printing the new text
to the standard output
*/
#include <stdio.h>
int lineno = 1;
%}
line (.)*\n
%%
{line} { printf ("%5d %s", lineno++, yytext); }
%%
main()
{
yylex();
return 0;
}
int yywrap()
{
return 0;
}
生成flex程序:flex linecount.lex 编译:gcc lex.yy.c 利用管道输入刚才的程序:cat linecount.lex | ./a.out
1. 允许将字符放在引号中作为真正的字符匹配。
例如要匹配\*可以写成\\\*,也可以是"\*"
2. 方括号中大多数元字符都可以无需引号直接引出。如("+"|"-")可以写成[-+],但不能写成[+-],因为-在中括号中可以作为表示范围的连字符。
3. 大括号可以指出正则表达式的名字,但不能递归调用。
nat [0-9]+
signedNat (+|-) ? {nat}
from www.BrainBashers.com
1. Intersection 横断,游戏一开始就使用的常见技巧。
 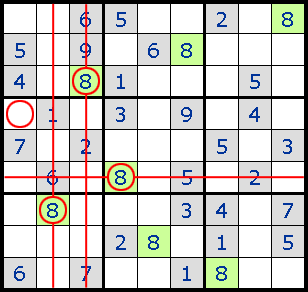
2. Forced Moves 排除所有其他可能性后唯一的答案
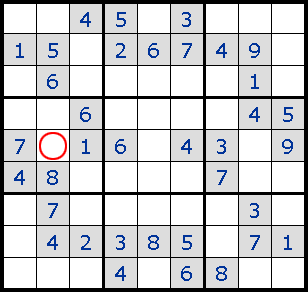 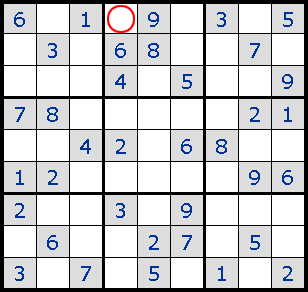
3. Pinned Squares
Intersection 的加强版,根据更多的情况确定某一个数字在该区域的唯一可能位置。
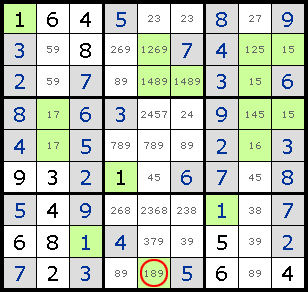 
4. Locked Sets
如图一R5C1和R6C1只能填1或8,由此可排除与他们有关的域中的其他格填1和8的可能性,从而R6C2只能填5。
装了fcitx以后thunderbird罢工了。。。现在只能用Google groups上新闻组了,不过fcitx的确不错的说。
cs书上的一个习题,在执行i=0这样的命令时是用: xorl %edx, %edx
为什么不用 movl $0, %edx呢?
老大: 一般的说立即数的存取是内存操作,而前一条指令是寄存器操作。所以Itanium上有专门的寄存器放0.
SecretVan@smth.org: 可能跟标志位有关系,如xor清零后紧跟一个条件跳转。
先把这些回答放这,以后在回过头来看。
看到汇编中的基本运算这一节,想看看传说中的编译器把a*2优化为a<<1是不是真的呢,写了个函数试了下:
int func(int x)
{
return x * 2;
}
用gcc -O2 -S test.c
编译,发现优化后是用了加法,而不是位移
func:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax
popl %ebp
addl %eax, %eax
ret
BBS上问了,老大说一般加法不会慢。
又试了一下把*2改成*3,仍然是使用leal (%eax,%eax,2), %eax进行加法操作完成的,而改成*4就使用位移了。
其他回答:
SecretVan@smth.org: CISC指令集上更倾向于选择功能一样而长度较短的指令,带了立即数之后指令就长了,如果使用寄存器那更得不偿失
Nineveh@smth.org: 因为 add 的长度短于或等于 sal,速度快于或等于 sal,吞吐量大于或等于 sal。
lib@rygh: 在P4里面我记得一条加法指令是0.5个cycle.移位指令撑死了也要0.5个cycle吧,没听说过有0.25cycle的指令。
1. {a, b, c}上的串S中,任何两个b都不相连,用正则表达式表示为
(a|c|ba|bc)*(b|空)
2. Pascal注释的表示
{(~})*}
{ } 中间为任意非}的符号,注意表达的严谨
3. C注释的表示就困难很多
例如要表示ba ...(没有ab)... ab这样的字符串,不能简单的写成
ba(~(ab))*ab
因为~非运算符通常只适用于单字符,否则容易产生混淆。
b*(a*~(a|b)b*)*a*
像这样的定义很难读,而且难以证明其正确性,因此在真正的扫描程序中通常用特殊方法解决。
今天收获真不小啊  看懂了第一个汇编程序,尽管简单得不能再简单了 然后就是新闻组,尽管以前也去过微软的中文新闻组,但没有太多感兴趣的内容。今天发现了个news.cn99.com,海量的信息(包括反动信息-,-),人气也很高,刚问了个如何查看已经安装的python-doc,10分钟后就有人回复 最后是一个关于bbs的彩色效果,其实qterm登录bbs后本来就只是提供了一个shell,像 <ESC><ESC>[1;31m 之类的ANSI记号不是bbs提供的类似api的东西,而是会保存在bbs的原始数据里,qterm端接收这些符号,然后以指定的效果显示。一个例子就是把这些符号("\033\033[1;31mhello world")显示在gnome-terminal终端的时候就是用红色字体显示的。
突然想通了一开始一直超时的原因。 每次我都是把新的suspect并入第一个元素所在的集合中,但是由于使用了优化后的并集操作,有可能是第一个元素所在的集合并入了新的suspect所在的集合,也就是说此后last变量并没有指向第一个元素所在集合的跟结点。于是在Union方法中,parent[root1]可能得到一个正整数,并导致Find方法死循环(根结点的parent为正) 后来把Find方法放到Union方法中,问题解决了。
#include <iostream>
using namespace std;
const int DEFAULT_SIZE = 100;
class UFSets
{
private:
int *parent;
int size;
public:
UFSets(int s = DEFAULT_SIZE);
~UFSets() { delete [] parent; }
void Union(int root1, int root2);
int Find(int x);
void Clear(int n);
};
UFSets::UFSets(int s)
{
size = s;
parent = new int[size + 1];
for (int i = 0; i <= size; i++)
parent[i] = -1;
}
int UFSets::Find(int x)
{
int result = x;
while (parent[result] >= 0)
result = parent[result];
return result;
}
void UFSets::Union(int root1, int root2)
{
// The old version didn't contain the following 3 setences.
root1 = Find(root1);
root2 = Find(root2);
if (root1 == root2) return;
int temp = parent[root1] + parent[root2];
if (parent[root2] < parent[root1])
{
parent[root1] = root2;
parent[root2] = temp;
}
else
{
parent[root2] = root1;
parent[root1] = temp;
}
}
void UFSets::Clear(int n)
{
for (int i = 0; i < n; i++)
parent[i] = -1;
}
int main()
{
UFSets sets(30000);
int n, m;
while (true)
{
cin >> n >> m;
if (n == 0) break;
sets.Clear(n);
for (int i = 0; i < m; i++)
{
int t;
cin >> t;
int last, x;
cin >> last;
last = sets.Find(last);
for (int j = 1; j < t; j++)
{
cin >> x;
sets.Union(last, x);
// int temp = sets.Find(x);
// if (temp != last)
// sets.Union(last, temp);
}
}
int result = 1;
int target = sets.Find(0);
for (int i = 1; i < n; i++)
if (sets.Find(i) == target)
result ++;
cout << result << endl;
}
return 0;
}
摘要: 转载自http://blog.csdn.net/fisher_jiang/archive/2006/08/25/1116918.aspx并查集 (Union-Find Sets)
并查集: (union-find sets)是一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多。一般采取树形结构来存储并查集,并利用一个rank数组来存储集合的... 阅读全文
PKU1330,普通树的LCA问题。把结点A的所有父结点都保存在一个hash数组中,然后从结点B开始向上搜索,直到发现hash数组中存在的元素为止。
#include <stdio.h>
#include <stdlib.h>
typedef struct TreeNode *pTree;
struct TreeNode
{
int value;
pTree father;
};
main()
{
int cases, n, i;
scanf("%d", &cases);
pTree nodes[10000];
for (i = 0; i < 10000; i++)
{
nodes[i] = malloc(sizeof(struct TreeNode));
nodes[i]->value = i;
}
int flag[10000];
while (cases > 0)
{
cases --;
scanf("%d", &n);
for (i = 0; i < n; i++)
{
nodes[i]->father = NULL;
}
int x, y;
for (i = 0; i < n - 1; i++)
{
scanf("%d %d", &x, &y);
nodes[y - 1]->father = nodes[x - 1];
}
scanf("%d %d", &x, &y);
for (i = 0; i < n - 1; i++)
flag[i] = 0;
pTree p = nodes[x - 1];
while (p != NULL)
{
flag[p->value] = 1;
p = p->father;
}
p = nodes[y - 1];
while (p != NULL)
{
if (flag[p->value])
{
printf("%d\n", p->value + 1);
break;
}
p = p->father;
}
}
return 0;
}
LCA (Lowest Common Ancestor) 一篇转载的文章,是对于二叉搜索树的算法 http://blog.csdn.net/AmiRural/archive/2006/06/07/777966.aspx
[题目]:已知二元搜索树(Binary Search Tree)上两个结点的值,请找出它们的公共祖先。你可以假设这两个值肯定存在。这个函数的调用接口如下所示:
int FindLowestCommonAncestor(node *root, int value1, int value2);
根据树的存储结构,我们可以立刻得到一个这样的算法:从两个给定的结点出发回溯,两条回溯路线的交点就是我们要找的东西。这个算法的具体实现办法是:从根
结点开始,先用这两个结点的全体祖先分别生成两个链表,再把这两个链表第一次出现不同结点的位置找出来,则它们的前一个结点就是我们要找的东西。
这个算法倒没有什么不好的地方,但是它没有利用二元搜索树的任何特征,其他类型的树也可以用这个算法来处理。二元搜索树中左结点的值永远小于或者等于当前
结点的值,而右结点的值永远大于或者等于当前结点的值。仔细研究,4和14的最低公共祖先是8,它与4和14的其他公共祖先是有重要区别的:其他的公共祖
先或者同时大于4和4,或者同时小于4和14,只有8介于4和14之间。利用这一研究成果,我们就能得到一个更好的算法。
从根结点出发,沿着两个给定结点的公共祖先前进。当这两个结点的值同时小于当前结点的值时,沿当前结点的左指针前进;当这两个结点的值同时大于当前结点的
值时,沿当前结点的右指针前进;当第一次遇到当前结点的值介于两个给定的结点值之间的情况时,这个当前结点就是我们要找的最的最低公共祖先了。
这是一道与树有关的试题,算法也有递归的味道,用递归来实现这一解决方案似乎是顺理成章的事,可这里没有这个必要。递归技术特别适合于对树的多个层次进行
遍历或者需要寻找某个特殊结点的场合。这道题只是沿着树结点逐层向下前进,用循环语句来实现有关的过程将更简单明了。
int FindLowestCommonAncestor(node *root, int value1, int value2)
{
node *curnode = root;
while(1)
{
if (curnode->data>value1&&curnode->data>value2)
curnode = curnode->left;
else if(curnode->data<value1&&curnode->data<value2)
curnode = curnode->right;
else
return curnode->data;
}
}
C语言实现:
/*二叉排序树的生成及树,任意两结点的最低公共祖先 Amirural设计*/
#include <stdio.h>
#define null 0
int counter=0;
typedef struct btreenode
{int data;
struct btreenode *lchild;
struct btreenode *rchild;
}bnode;
bnode *creat(int x,bnode *lbt,bnode *rbt) //生成一棵以x为结点,以lbt和rbt为左右子树的二叉树
{bnode *p;
p=(bnode*)malloc(sizeof(bnode));
p->data=x;
p->lchild=lbt;
p->rchild=rbt;
return(p);
}
bnode *ins_lchild(bnode *p, int x) //x作为左孩子插到二叉树中
{bnode *q;
if(p==null)
printf("Illegal insert.");
else
{q=(bnode*)malloc(sizeof(bnode));
q->data=x;
q->lchild=null;
q->rchild=null;
if(p->lchild!=null) //若p有左孩子,则将原来的左孩子作为结点x的右孩子
q->rchild=p->lchild;
p->lchild=q;
}
return(p);
}
bnode *ins_rchild(bnode *p, int x) //x作为右孩子插入到二叉树
{bnode *q;
if(p==null)
printf("Illegal insert.");
else
{q=(bnode*)malloc(sizeof(bnode));
q->data=x;
q->lchild=null;
q->rchild=null;
if(p->rchild!=null) //若x有右孩子,则将原来的右孩子作为结点x的的左孩子
q->lchild=p->rchild;
p->rchild=q;
}
return(p);
}
void prorder(bnode *p)
{if(p==null)
return;
printf("%d\t%u\t%d\t%u\t%u\n",++counter,p,p->data,p->lchild,p->rchild);
if(p->lchild!=null)
prorder(p->lchild);
if(p->rchild!=null)
prorder(p->rchild);
}
void print(bnode *p) //嵌套括号表示二叉树,输出左子树前打印左括号,
{ //输出右子树后打印右括号。
if(p!=null)
{printf("%d",p->data);
if(p->lchild!=null||p->rchild!=null)
{printf("(");
print(p->lchild);
if(p->rchild!=null)
printf(",");
print(p->rchild);
printf(")");
}
}
}
int FindLowestCommonAncestor(bnode *root, int value1, int value2)
{
bnode *curnode = root;
while(1)
{
if (curnode->data>value1&&curnode->data>value2)
curnode = curnode->lchild;
else if(curnode->data<value1&&curnode->data<value2)
curnode = curnode->rchild;
else
return curnode->data;
}
}
main()
{
bnode *bt,*p,*q;
int x,y,v1,v2;
printf("输入根结点:");
scanf("%d",&x);
p=creat(x,null,null);
bt=p; //使bt p都指向根结点
printf("输入新的结点值:");
scanf("%d",&x);
while(x!=-1)
{p=bt;
q=p;
while(x!=p->data&&q!=null) //q记录当前根结点
{p=q;
if(x<p->data)
q=p->lchild;
else
q=p->rchild;
}
if(x==p->data)
{printf("元素%d已经插入二叉树中!\n",x);
}
else
if(x<p->data) ins_lchild(p,x);
else ins_rchild(p,x);
scanf("%d",&x);
}
p=bt;
printf("struct of the binary tree:\n");
printf("number\taddress\tdata\tlchild\trchild\n");
prorder(p);
printf("\n");
printf("用括号形式输出二叉树:");
print(p);
printf("\n请任意输入树中存在的两个结点:");
scanf("%d,%d",&v1,&v2);
y = FindLowestCommonAncestor(p, v1, v2);
printf("输出%d和%d的最低公共祖先:",v1,v2);
printf("%d\n",y);
}
运行结果:
输入根结点:20
输入新的结点值:8 22 4 12 10 14 -1 (以-1结束结点的输入)
struct of the binary tree:
number addresss data lchild rchild
1 4391168 20 4391104 4391040
2 4391104 8 4390976 4399072
3 4390976 4 0 0
4 4399072 12 4399008 4398944
5 4399008 10 0 0
6 4398644 14 0 0
7 4391040 22 0 0
用括号形式输出:20(8(4,12(10,14)),22) (输出左子树打印左括号,输出右子树后打印括号)
请任意输入树中存在的两个结点:4,14
输出4和14的最低祖先:8
1.一行代码解决的辗转相除法 for(;;){if ((m %= n) == 0) return n;if ((n %= m) == 0) return m;}
2.推进式的前缀表达式求值,没见过这种递归@@
char *a; int i;
int eval()
{
int x = 0;
while (a[i] == ' ') i++;
if (a[i] == '+')
{
i++;
return eval() + eval();
}
if (a[i] == '*')
{
i++;
return eval() * eval();
}
while ((a[i] >= '0') && (a[i] <= '9'))
x = 10 * x + (a[i++] - '0');
return x;
}
1. 二维数组内存分配
Algorithm in C上的方法,这种方法好处在于t[i]是指向各行首的指针,类似于Java的数组;而如果直接用malloc分配m*n*sizeof(int)大小的空间,则没有这种效果,类似于C#中的[,]数组
int **malloc2d(int r, int c)
{
int i;
int **t = malloc(r * sizeof(int *));
for (i = 0; i < r; i++)
t[i] = malloc(c * sizeof(int));
return t;
}
1. 函数接收一维数组的形参声明
func1(str)
char str[10];
{
}
表示有界数组,数组的下标只能小于或等于传递数组的大小。10可省略,表示无界数组。
但事实上两者区别很小,编译器只是让函数接收一个指针。
二维数组类似
char str[][10];
2. 宏
#define MIN(a, b) (a<b) ? a : b
使用该宏时表达式被直接替换,增加了代码的速度,但因此增加了程序的长度。
1.
由于Python的判断语句返回值的特殊性,and-or语句可以达到类似三元运算符的效果。
bool ? a : b
可以写成
bool and a or b
2.
print None 不会输出任何信息
需要显示None,要使用print str(None)
很简短,有点trick的感觉,就像小学里写的那些(n-1) mod x + 1。进了大学后很少写类似风格的代码了,这些用在java项目中就要因为可读性被bs了。
1. 计算串长度 strlen(a)
for (i = 0; a[i] != 0; i++); return i;
2. 复制 strcpy(a, b)
for (i = 0; (a[i] = b[i]) != 0; i++);
3. 比较 strcmp(a, b)
for (i = 0; a[i] == b[i]; i++)
if (a[i] == 0) return 0;
return a[i] - b[i];
注意适用于不同长度的字符串
指针版本
1. strlen(a)
b = a; while (*b++); return b - a - 1;
2. strcpy(a, b)
while (*a++ = *b++);
3. strcmp(a, b)
while (*a++ = *b++)
if (*(a-1) == 0) return 0;
return *(a-1) - *(b-1);
wrong answer了几次,总算过了
gdb还是不怎么会用,调试dfs时不知道怎么跳出当前层(finish和up貌似都不管用),以及如何step over
/*
PROG: lamps
ID: 06301031
LANG: C++
*/
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
using namespace std;
struct StateArray
{
bool value[100];
};
int n, c;
int methodCount = 0;
vector<int> reqOn, reqOff;
vector<StateArray> result;
int method[4];
bool state[100]; // On - true, Off - false
bool equalState(const StateArray& s1, const StateArray& s2)
{
for (int i = 0; i < n; i++)
if (s1.value[i] != s2.value[i])
return false;
return true;
}
bool compareState(const StateArray& s1, const StateArray& s2)
{
for (int i = 0; i < n; i++)
if (s1.value[i] != s2.value[i])
return !s1.value[i];
return false;
}
void changeState(int m) // m[0,4] refers to the method
{
switch (m)
{
case 0:
for (int i = 0; i < n; i++)
state[i] = !state[i];
break;
case 1:
for (int i = 0; i < n; i += 2)
state[i] = !state[i];
break;
case 2:
for (int i = 1; i < n; i += 2)
state[i] = !state[i];
break;
case 3:
for (int i = 0; i < n; i += 3)
state[i] = !state[i];
break;
}
}
bool validState()
{
for (int i = 0; i < reqOn.size(); i++)
if (!state[reqOn[i]])
return false;
for (int i = 0; i < reqOff.size(); i++)
if (state[reqOff[i]])
return false;
return true;
}
void DFS(int t) // t: method number
{
if ((methodCount > c) || (t >= 4))
return;
for (int i = 0; i < 2; i++)
{
if (i == 1)
{
methodCount++;
changeState(t);
if (((c - methodCount) % 2 == 0) && validState())
{
StateArray tempState;
for (int j = 0; j < n; j++)
{
tempState.value[j] = state[j];
}
result.push_back(tempState);
}
DFS(t + 1);
methodCount--;
changeState(t);
}
else
{
if (((c - methodCount) % 2 == 0) && validState())
{
StateArray tempState;
for (int j = 0; j < n; j++)
{
tempState.value[j] = state[j];
}
result.push_back(tempState);
}
DFS(t + 1);
}
}
}
int main()
{
ifstream fin("lamps.in");
ofstream fout("lamps.out");
fin >> n >> c;
int x;
while (fin >> x)
if (x == -1)
break;
else
reqOn.push_back(x - 1);
while (fin >> x)
if (x == -1)
break;
else
reqOff.push_back(x - 1);
for (int i = 0; i < n; i++)
state[i] = true;
DFS(0);
if (result.size() < 1)
fout << "IMPOSSIBLE\n";
sort(result.begin(), result.end(), compareState);
vector<StateArray>::iterator iter;
vector<StateArray> uni;
for (iter = result.begin(); iter != result.end(); iter++)
if (uni.empty() || !equalState(uni[uni.size() - 1], *iter))
uni.push_back(*iter);
for (int i = 0; i < uni.size(); i++)
{
for (int j = 0; j < n; j++)
{
fout << uni[i].value[j];
}
fout << endl;
}
return 0;
}
Wrong Answer了半天发现原来是m - 1打成m + 1了。。。
/*
PROG: castle
ID: 06301031
LANG: C++
*/
#include <iostream>
#include <fstream>
using namespace std;
enum Direction {WEST = 0, NORTH = 1, EAST = 2, SOUTH = 3};
// The directions corresponding to the following steps are
// West(0), North(1), East(2) and South(3).
const int dx[] = {0, -1, 0, 1};
const int dy[] = {-1, 0, 1, 0};
int region[50][50];
int colors[50 * 50];
int maze[50][50];
bool canGo(int value, int dirx)
{
int base = 1;
for (int i = 0; i < dirx; i++)
base *= 2;
return ((base & value) == 0);
}
void floodfill(int x, int y, int color)
{
if (region[x][y] < 0)
{
region[x][y] = color;
colors[color]++;
}
//cout << "now paint " << x << ',' << y << endl;
for (int i = 0; i < 4; i++) // dirction
{
if (canGo(maze[x][y], i) && region[x + dx[i]][y + dy[i]] < 0)
{
floodfill(x + dx[i], y + dy[i], color);
}
}
}
int main()
{
ifstream fin("castle.in");
ofstream fout("castle.out");
int m, n;
fin >> n >> m;
for (int i = 0; i < m; i++)
for (int j= 0; j < n; j++)
{
fin >> maze[i][j];
region[i][j] = -1;
}
int colorCount = 0;
int maxCount = 0;
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
if (region[i][j] < 0)
{
colors[colorCount] = 0;
floodfill(i, j, colorCount);
if (maxCount < colors[colorCount])
maxCount = colors[colorCount];
// for (int ii = 0; ii < m; ii++) {
// for (int jj = 0; jj < n; jj++)
// cout << (region[ii][jj] >= 0 ? region[ii][jj] : ' ');
// cout << endl;
// }
// cout << i << ',' << j << ':' << colorCount << ' ' << colors[colorCount] << endl;
colorCount++;
}
fout << colorCount << endl;
fout << maxCount << endl;
int maxCombine = 0, maxD, maxI, maxJ;
for (int j = 0; j < n; j++)
for (int i = m - 1; i >= 0; i--)
for (int d = 1; d < 3; d++)
{
int nx = i + dx[d];
int ny = j + dy[d];
if (nx < 0 || nx >= m || ny < 0 || ny >= n)
continue;
if (region[nx][ny] != region[i][j])
{
if (maxCombine < colors[region[nx][ny]] + colors[region[i][j]])
{
maxCombine = colors[region[nx][ny]] + colors[region[i][j]];
maxD = d;
maxI = i;
maxJ = j;
}
}
}
fout << maxCombine << endl;
fout << maxI + 1 << ' ' << maxJ + 1 << ' ';
switch (maxD)
{
case 0: fout << 'W' << endl;
break;
case 1: fout << 'N' << endl;
break;
case 2: fout << 'E' << endl;
break;
case 3: fout << 'S' << endl;
break;
}
return 0;
}
在水源上看到的,大概的做法是
求前n项和序列S1, S2, ..., Sn,问题即转化为求i, j,使得Si - Sj = X
把{Sk}和{Sk + X}序列中的数都放入hash表中,查找冲突项。
BBS上peter大牛的问题:
char *s = "string1";
strcpy(s, "string2");
这样为什么会segmentation fault?
后面的解答:
char *s="string1" //此时"string1"在常量区 s是指向常量区的一个指针 你不能对
常量区的内容进行修改
char s[]="string2" //此时"string2" 在栈区 此时可以对里面的内容进行修改
所以你可以写成
char s[]="string1";
strcpy(s,"string2");
http://www.aurora-x.net/blog/oasis/?p=92
by opengl@rygh
现在市面上系统的,由浅及深的讲Ruby的书凤毛麟角,这本是分量最重的一本。原书第二版出版到现在也过去两年了,国内刚刚在这个月由博文引进电工发行了译本。
800+页的大部头,一半是核心库和标准库的参考,另外一半分为三个部分——基础、环境、高级。这其中我觉得比较有价值的部分在于“高级这一块”有助于让你从一个更高的层次来理解和掌握这门语言,这一部分也是需要经常参考的部分。
就国内目前引进的唯一一本算是讲Ruby的书,要从这本书开始学习Ruby估计会吓跑不少潜在用户。作者是大牛没错,不过教学则是另一回事了(大家都应有体会,本科上课的时候课讲的最好的老师通常都不是学术最牛的老师)。缺点有两处很明显:
第一是自顶向下,它的顺序是这样的:
对象和类–>容器、集合–>标准类型–>表达式–>异常和模块–>基本输入输出
一个从上降到低又陡然上升的过程。作者自己也说在第一版里这样的效果并不好,因此在第二版里特意增加了一个介绍性章节,粗略的先把所有东西列给读者看一遍。虽然起到些作用,但是实际效果我想对于初学者来说仍然不会太好。C++/Java的书我都读过不少,也没见哪个是一上来就把Class/Object这些东西甩给读者的,总是从基本类型、控制语句过渡。除非你已经对OO这套相当熟悉了,否则上来这个门槛就能把一堆新手挡在门外。
接下来的,谈不上十分晦涩,但也不是什么读来轻快的内容,关键是作者给的例子较少,使得象块、迭代这些特色难以掌握。再有一点,ruby的语法风格有相当部分还保留有Perl的痕迹,而Perl是出了名的以奇怪符号著称于世,这些符号在新手眼里不外天书,而高手们则爱不释手。
所以,要能比较顺利的通过这本书的入门之路,你得事先具有OO的基础,至少一门脚本语言的经验(Perl最佳),函数式编程的一些概念(否则当你看到块的一些用法时会很迷惑)。然后,可以用Ruby笨拙的写一些小程序了。
Ruby作为动态语言之一,它的最大特点自然是“动态”两个字,其著名的“duck typing”就是一大体现(在我看来,就像是基于接口的调用,但却并不用一个给定的接口去事先限制)。这些在高级部分里都有专门讲述,是应该重点学习的部分。
那么入门究竟用什么书更好?我推荐《Everyday Scripting with Ruby》这本。和《Programming Ruby》同一个出版社,今年一月份刚出了原版。它是以相当循序渐进的方式带领读者进入Ruby的世界,尤其是作者精心设计的几个Project是全书亮点(学习一门语言最好的方式还是要动手写程序)。
最后总结如下,首先看《Everyday》这本书,跟着书中的指导摆弄过所有的Project,并完成相应的练习。然后再看《Programmin》一书的Crystallized部分。再之后就主要是当作API参考手册了。花钱去买中文版我个人觉得不是很有必要,总共四部分中,前两部分我觉得蛮鸡肋的,第四部分在电脑上查更方便,只有第三部分有较高的价值。
1. Array#reject 方法遍历一个集合的每个元素,并把符合条件的元素删去。
例如去掉数组中的所有素数
nums = nums.reject do | num |
prime?(num)
end
puts nums
2. String#chomp 方法
str.chomp(separator=$/) => new_str
Returns a new +String+ with the given record separator removed from
the end of _str_ (if present). If +$/+ has not been changed from
the default Ruby record separator, then +chomp+ also removes
carriage return characters (that is it will remove +\n+, +\r+, and
+\r\n+).
"hello".chomp #=> "hello"
"hello\n".chomp #=> "hello"
"hello\r\n".chomp #=> "hello"
"hello\n\r".chomp #=> "hello\n"
"hello\r".chomp #=> "hello"
"hello \n there".chomp #=> "hello \n there"
"hello".chomp("llo") #=> "he"
3. 判断是否在命令行运行脚本
if $0 == __FILE__
check_usage
compare_inventory_files(ARGV[0], ARGV[1])
end
类似于Java类的main方法,在被其他类导入时不会运行其中的代码。
4. Enumerable#any? 方法查找一个集合中是否有满足条件的元素
irb(main):004:0> deposits = [1, 0, 10000]
irb(main):005:0> deposits.any? do | deposit |
irb(main):006:1* deposit > 9999
irb(main):007:1> end
=> true
5. 关于测试
这本书(Everyday Scripting with Ruby)的很多程序都是依循测试驱动开发的思想写出来的,测试单元中的方法通常有两种目的。
一种是direct test,需要测试那个函数就直接调用那个函数,传递的参数都是直接写出来的。
另一种是bootstrapping test,被测试函数的参数也是通过生成这些参数的函数生成的,即一个方法测试了多个对象。
Everyone finds their own balance between testing directly and testing indirectly. You will too.
6. Time#strftime 方法
t = Time.now
t.strftime("Printed on %m/%d/%Y") #=> "Printed on 04/09/2003"
t.strftime("at %I:%M%p") #=> "at 08:56AM"
先把各种热门的东西都走马观花地看一遍,呵呵。
看的是Everyday Scripting with Ruby,风格和In Action系列差不多,大量的实例。
现在学Ruby的主要目的也是everyday scripting,方便数据处理、生成,文件批处理等,RoR之类的暂时不考虑。
1. String.inspect 方法
文档中的说法是
str.inspect => string
Returns a printable version of _str_, with special characters
escaped.
str = "hello"
str[3] = 8
str.inspect #=> "hel\010o"
具体情况试试 myString.inspect.inspect....就能了解一点了
2. Arrays.each 和 Arrays.collect
for_each方法
irb(main):007:0> [1, 2, 3].each do | element |
irb(main):008:1* puts element
irb(main):009:1> end
1
2
3
=> [1, 2, 3]
后者与前者的不同之处在于,在处理数据的同时,每次处理的返回结果都会保存到一个新的数组中返回。
irb(main):036:0> newarray = ["aBC", "B"].collect do |e|
irb(main):037:1* e.downcase
irb(main):038:1> end
=> ["abc", "b"]
3. Messages and Methods
It can be hard to remember the difference between messages and methods. A message is a request sent from some sender object. When the receiver object receives the message, it looks to see whether it has a method with the same name. If so, the Ruby code within the method is run, and the results are returned to the sender. The message is the request; the method fulfills it.
呃,还是没有感性认识。
4. Delimiting Blocks
块的两种表示方式:
array.each do | element |
puts element
end
array.each { | element |
puts element
}
通常使用第一种,但可以用一行写成的情况也可以使用第二种:
array.each { | element | puts element }
摘要: For using taglist plugin,you must install ctags plugin first.1.ctags
(1)到http://ctags.sourceforge.net/下载ctags源码ctags-5.6.tar.gz
http://prdownloads.sourceforge.net/ctags/ctags-5.6.tar.gzwindows user ... 阅读全文
Java跨平台的优势啊。。。
1. 把WinXP下的所有项目文件复制到Ubuntu下
2. 通过EMS导出数据库的sql文件,在Ubuntu下导入
3. 在Ubuntu下用MyEclipse加入该项目,重新设置引用的包的路径(包括数据库的配置)
4. 把所有包含中文的java源程序设置编码方式为GBK
5. 注意linux下的mysql是对大小写敏感的,因此原来windows下配置正确的Hibernate文件可能在linux下需要修改
6. 部署,enjoy
原来vim的复制快捷键是 " +y ,其中+也是要按的,怪不得以前一直不成功
/*
PROG: sort3
ID: 06301031
LANG: C++
*/
#include <fstream>
#include <iostream>
#include <vector>
using namespace std;
int main()
{
ifstream fin("sort3.in");
ofstream fout("sort3.out");
int n;
fin >> n;
vector<int> nums(n);
int numCount[4];
numCount[1] = numCount[2] = numCount[3] = 0;
for (int i = 0; i < n; i++)
{
fin >> nums[i];
numCount[nums[i]]++;
}
numCount[2] += numCount[1];
numCount[3] += numCount[2];
int toBeChanged[4][4];
for (int i = 1; i <= 3; i++)
for (int j = 1; j <= 3; j++)
toBeChanged[i][j] = 0;
for (int i = 0; i < n; i++)
{
int sortedNum = 1;
for (int j = 1; j < 4; j++)
if (i - numCount[j] < 0)
{
sortedNum = j;
break;
}
cout << nums[i] << ":" << sortedNum << endl;
if (nums[i] != sortedNum)
toBeChanged[nums[i]][sortedNum]++;
}
for (int i = 1; i <= 3; i++)
for (int j = 1; j <= 3; j++)
if (toBeChanged[i][j] != 0)
cout << i << "," << j << ":" << toBeChanged[i][j] << endl;
int triangles = 0;
int swaps = 0;
for (int i = 1; i <= 3; i++)
for (int j = 1; j <= 3; j++)
if (toBeChanged[i][j] != 0)
{
int smaller = toBeChanged[i][j];
if (toBeChanged[j][i] < smaller)
smaller = toBeChanged[j][i];
toBeChanged[i][j] -= smaller;
toBeChanged[j][i] -= smaller;
swaps += smaller;
}
for (int i = 1; i <= 3; i++)
for (int j = 1; j <= 3; j++)
if (toBeChanged[i][j] != 0)
triangles += toBeChanged[i][j];
cout << swaps << endl << triangles << endl;
swaps += (triangles / 3 * 2);
fout << swaps << endl;
return 0;
}
第一个接到的Project啊 ^_^ 挺简单的 1. 映射了一对多关系后需要做查询时碰到问题,翻书发现了个好东西Criterion Query。
 Criteria criteria = session.createCriteria(Booking.class); Criteria criteria = session.createCriteria(Booking.class);
criteria.add(Expression.ne("foregift", Foregift.getInstance(1)));
return criteria.list();
这样就得到了已付押金的订单列表
由于复赛只做出一题,所以被安排为单独一队。
Problem A比较简单,模拟,把要改动的坐标点放入一个队列中, 每次处理队列的首个元素。
Problem B先用简单的几何知识转化为着色问题,然后离散化,着色。由于信号的覆盖范围是[0, 1000],在处理边缘的时候有点问题,Wrong Answer了几次,第五次提交总算过了。
然后是Problem F,这题比赛时一直过不了,赛后和其他人交流了下题目理解也没错,一些比较容易错的数据也处理正确了,但就是过不了 =_= 拿到测试数据了再看看吧
就这么进ACM了,暑假留校。
from http://gyq.czszg.net/items/rxk06/words-color.htm
对于做网页的初学者可能更习惯于使用一些漂亮的图片作为自己网页的背景,但浏览一
下大型的商业网站,你会发现他们更多运用的是白色、蓝色、黄色等,使得网页显得典
雅,大方和温馨。更重要的是,这样可以大大加快浏览者打开网页的速度。
一般来说,网页的背景色应该柔和一些、素一些、淡一些,再配上深色的文字,使
人看起来自然、舒畅。而为了追求醒目的视觉效果,可以为标题使用较深的颜色。下面
是我做网页和浏览别人的网页时,对网页背景色和文字色彩搭配积累的经验,这些颜色
可以做正文的底色,也可以做标题的底色,再搭配不同的字体,一定会有不错的效果,
希望对大家在制作网页时有用。
BgcolorΚ″#F1FAFA″---做正文的背景色好,淡雅
BgcolorΚ″#E8FFE8″---做标题的背景色较好
BgcolorΚ″#E8E8FF″---做正文的背景色较好,文字颜色配黑色
BgcolorΚ″#8080C0″---上配黄色白色文字较好
BgcolorΚ″#E8D098″---上配浅蓝色或蓝色文字较好
BgcolorΚ″#EFEFDA″---上配浅蓝色或红色文字较好
BgcolorΚ″#F2F1D7″---配黑色文字素雅,如果是红色则显得醒目
BgcolorΚ″#336699″---配白色文字好看些
BgcolorΚ″#6699CC″---配白色文字好看些,可以做标题
BgcolorΚ″#66CCCC″---配白色文字好看些,可以做标题
BgcolorΚ″#B45B3E″---配白色文字好看些,可以做标题
BgcolorΚ″#479AC7″---配白色文字好看些,可以做标题
BgcolorΚ″#00B271″---配白色文字好看些,可以做标题
BgcolorΚ″#FBFBEA″---配黑色文字比较好看,一般作为正文
BgcolorΚ″#D5F3F4″---配黑色文字比较好看,一般作为正文
BgcolorΚ″#D7FFF0″---配黑色文字比较好看,一般作为正文
BgcolorΚ″#F0DAD2″---配黑色文字比较好看,一般作为正文
BgcolorΚ″#DDF3FF″---配黑色文字比较好看,一般作为正文
浅绿色底配黑色文字,或白色底配蓝色文字都很醒目,但前者突出背景,后者突出
文字。红色底配白色文字,比较深的底色配黄色文字显得非常有效果。
看了bbs上转载自cu的一篇文章,做了一些修改
Ubuntu 7.04
1. 匿名服务器的连接(独立的服务器)
在/etc/vsftpd.conf(原文中是/etc/vsftpd/vsftpd.conf ) 配置文件中添加如下几项:
Anonymous_enable=yes (允许匿名登陆)
Dirmessage_enable=yes (切换目录时,显示目录下.message的内容)
Local_umask=022 (FTP上本地的文件权限,默认是077)
Connect_form_port_20=yes (启用FTP数据端口的数据连接)*
Xferlog_enable=yes (激活上传和下传的日志)
Xferlog_std_format=yes (使用标准的日志格式)
Ftpd_banner=XXXXX (欢迎信息)
Pam_service_name=vsftpd (验证方式)*
Listen=yes (独立的VSFTPD服务器)*
功能:只能连接FTP服务器,不能上传和下传
注:其中所有和日志欢迎信息相关连的都是可选项,打了星号的无论什么帐户都要添加,
是属于FTP的基本选项
2. 开启匿名FTP服务器上传权限
在配置文件中添加以下的信息即可:
Anon_upload_enable=yes (开放上传权限)
Anon_mkdir_write_enable=yes (可创建目录的同时可以在此目录中上传文件)
Write_enable=yes (开放本地用户写的权限)
Anon_other_write_enable=yes (匿名帐号可以有删除的权限)
3. 开启匿名服务器下传的权限
在配置文件中添加如下信息即可:
Anon_world_readable_only=no
注:要注意文件夹的属性,匿名帐户是其它(other)用户要开启它的读写执行的权限
(R)读-----下传 (W)写----上传 (X)执行----如果不开FTP的目录都进不去
4.普通用户FTP服务器的连接(独立服务器)
在配置文件中添加如下信息即可:
Local_enble=yes (本地帐户能够登陆)
Write_enable=no (本地帐户登陆后无权删除和修改文件)
功能:可以用本地帐户登陆vsftpd服务器,有下载上传的权限
注:在禁止匿名登陆的信息后匿名服务器照样可以登陆但不可以上传下传
5. 用户登陆限制进其它的目录,只能进它的主目录
设置所有的本地用户都执行chroot
Chroot_local_user=yes (本地所有帐户都只能在自家目录)
设置指定用户执行chroot
Chroot_list_enable=yes (文件中的名单可以调用)
Chroot_list_file=/任意指定的路径/vsftpd.chroot_list
注意:vsftpd.chroot_list 是没有创建的需要自己添加,要想控制帐号就直接在文件中
加帐号即可
6. 限制本地用户访问FTP
Userlist_enable=yes (用userlistlai 来限制用户访问)
Userlist_deny=no (名单中的人不允许访问)
Userlist_file=/指定文件存放的路径/ (文件放置的路径)
注:开启userlist_enable=yes匿名帐号不能登陆
7. 安全选项
Idle_session_timeout=600(秒) (用户会话空闲后10分钟)
Data_connection_timeout=120(秒) (将数据连接空闲2分钟断)
Accept_timeout=60(秒) (将客户端空闲1分钟后断)
Connect_timeout=60(秒) (中断1分钟后又重新连接)
Local_max_rate=50000(bite) (本地用户传输率50K)
Anon_max_rate=30000(bite) (匿名用户传输率30K)
Pasv_min_port=50000 (将客户端的数据连接端口改在
Pasv_max_port=60000 50000—60000之间)
Max_clients=200 (FTP的最大连接数)
Max_per_ip=4 (每IP的最大连接数)
Listen_port=5555 (从5555端口进行数据连接)
8. 查看谁登陆了FTP,并杀死它的进程
ps –xf |grep ftp
kill 进程号
--
我所做的一切,都是出于一些我自己都无法完全解释的莫名其妙的原因。
我的那些解释都无法让我自己信服。
※ 来源:·日月光华 bbs.fudan.edu.cn·[FROM: 221.137.177.92]
发信人: leemars (03CS·微笑·发光), 信区: Unix
标 题: Re: rrdw 如何在命令行下操作文件名中带空格的文件?
发信站: 日月光华 (2007年06月06日21:16:23 星期三), 站内信件
用双引号引起来
发信人: marcus (Marcus@Fresh_Blood|吴英德勋爵-马凱公爵), 信区: Unix
标 题: Re: rrdw 如何在命令行下操作文件名中带空格的文件?
发信站: 日月光华 (2007年06月06日21:18:14 星期三), 站内信件
用
\blank
可以么?
发信人: medivhet (上局沪段,蓝色永不褪去!), 信区: Unix
标 题: Re: rrdw 如何在命令行下操作文件名中带空格的文件?
发信站: 日月光华 (2007年06月06日21:18:29 星期三), 站内信件
还不如\ (一个空格)...
发信人: DragonZhao (狂抽猛干·抽时间干事业), 信区: Algorithm
标 题: 一个问题
发信站: 日月光华 (2007年05月21日01:26:41 星期一), 站内信件
已知存在二叉树节点结构node{node* left; node* right};,现在给出树的根节点node*
root与自然数int m,要求搜索此树中节点数为m的子树的数量。如何做效率最高?
发信人: wshxzt (WKFB2008), 信区: Algorithm
标 题: Re: 一个问题
发信站: 日月光华 (2007年05月21日01:28:34 星期一), 站内信件
树的动态规划
发信人: lovebei (0124·皮皮和卡卡), 信区: Algorithm
标 题: Re: 一个问题
发信站: 日月光华 (2007年06月06日13:36:43 星期三), 站内信件
以i为根节点 节点数为j的子树个数
p[i][j]=∑{p[left(i)][k]*p[right(i)][j-k-1]} 0<=k<=j-1
发信人: Jeru (柠檬树), 信区: Algorithm
标 题: Re: 一个问题
发信站: 日月光华 (2007年06月06日13:59:36 星期三), 站内信件
没错的。不过硬要说是动态规划也没错,这个概念太宽泛了。
发信人: jesseg (Jesse : 我是花朵,祖国的希望!), 信区: Algorithm
标 题: Re: 一个问题
发信站: 日月光华 (2007年06月06日16:12:04 星期三)
其实这不至于算dp啦,dp的好处没发挥出来,呵呵,树状的搜索不用dp的,要图状的时候
dp才能省计算。
由于体力、实力、发挥等各方面因素,最终还是没把会做的题做出来。
最后凭借微弱的时间优势拿了个三等奖。
赛前也挺有压力的,怕夸下海口最后连个奖都捞不到。
接下来就是好好搞ACM,看Computer System, A Programmer's Perspective,也要兼顾高数和英语,当然也不能让其他课挂了。
恩,总算结束了,本不应该这么有压力的,太自信了吧。
官方的一个很赞的做法,Divide and Conquer,核心部分:
void
genfrac(int n1, int d1, int n2, int d2)
  { {
  if(d1+d2 > n) /**//* cut off recursion */ if(d1+d2 > n) /**//* cut off recursion */
 return; return;
genfrac(n1,d1, n1+n2,d1+d2);
fprintf(fout, "%d/%d\n", n1+n2, d1+d2);
genfrac(n1+n2,d1+d2, n2,d2);
 } }
最朴素的做法
/**//*
PROG: frac1
ID: 06301031
LANG: C++
*/
#include <iostream>
#include <fstream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
class Fraction {
int gcd(int x, int y);
public:
int numerator;
int denominator;
Fraction(int pa, int pb);
bool reductable();
};
bool compareFrac(const Fraction& f1, const Fraction& f2);
int main() {
ifstream fin("frac1.in");
ofstream fout("frac1.out");
int n;
fin >> n;
vector<Fraction> fracs;
int i, j;
fracs.push_back(Fraction(0, 1));
for (i = 1; i <= n; i++) {
for (j = 1; j <= i; j++) {
Fraction frac(j, i);
if (!frac.reductable()) {
fracs.push_back(frac);
 } }
}
}
sort(fracs.begin(), fracs.end(), compareFrac);
vector<Fraction>::iterator iter;
for (iter = fracs.begin(); iter != fracs.end(); iter++) {
fout << iter->numerator << '/' << iter->denominator << endl;
}
return 0;
}
Fraction::Fraction(int pa, int pb) {
numerator = pa;
denominator = pb;
}
bool Fraction::reductable() {
return (gcd(numerator, denominator) != 1);
}
int Fraction::gcd(int x, int y) {
if (x < y) swap(x, y);
if (x % y == 0) return y;
return gcd(y, x % y);
}
bool compareFrac(const Fraction& f1, const Fraction& f2) {
return (long)f1.numerator * (long)f2.denominator < (long)f1.denominator * (long)f2.numerator;
}
USACO上的简单介绍,都快忘了各个术语的中文名了
graph
vertex 顶点 (pl. vertexes / vertices)
edge
edge-weighted 带权图(貌似中文是这么叫的吧)
weight
self-loop 自环
simple graph 简单图,不存在自环或两条(及以上)连接相同两点的边。multigraph 与之相对
degree
adjacent (to)
sparse graph 稀疏图,边数少于最大值(n*(n-1)/2)的图。与之相对的是dense graph。
(un)directed graph (有)无向图
out-degree in-degree 有向图顶点的出度/入度
path
cycle 回路
图的表示:
edge list
adjecency matrix
adjacency list
implict
连通性: connected component 连通分量 strongly connected component 强连通分量 subgraph 子图. The subgraph of G induced by V' is the graph (V', E') bipartite 二分图 complete 任意两点间都有边
1. 关于函数指针
The C++ Programming Language上的一段示例代码:
map<string, int> histogram;
void record(const string& s)
{
histogram[s]++;
}
void print(const pair<const string, int>& r)
{
cout << r.first << ' ' << r.second << '\n\;
}
int main()
{
istream_iterator<string> ii(cin);
istream_iterator<string> eos;
for_each(ii, eos, record);
for_each(histogram.begin(), histogram.end(), print);
}
其中record和print是以函数指针的形式传递给for_each的。感觉这种方法最清晰、直接。
Java似乎更多的是用接口来达到类似的效果的,比如Collections.sort(Comparable),通常通过匿名内部类来进行自定义元素的比较,从而排序。但是这在语义上已经不是函数了,而是将被排序对象解释为实现了Comparable接口的对象。
另外Java反射机制中也有Mehod方法,觉得也可以通过传递Method类,然后在sort方法中调用这个Method的invoke方法,这应该更接近函数指针的语义。但没看到过这样的实例。
C#则引入了委托的概念,通过delegate关键字声明该方法。多一个关键字感觉就是啰唆了点。 -,-
现在开始对第一次在Thinking in Java中看到的Callback回调机制有了一点感觉。当时看的时候很难理解。
看来在学习某一门语言的时候有一定其他语言的背景进行比较,很容易加深理解。
2. 使用地址传递结构,减少开销
学C++最不适应的就是指针的应用,因为没有C的基础,尽管高中竞赛用的是Pascal,也用指针实现了trie、图的链式表示等比较复杂的数据结构,但是也没有像C++这样指针穿插在整个程序中的,当然C更多。
C++传递结构时默认是先复制一份拷贝,然后函数操作的是该拷贝,而不是Java中的传递引用(当然Java没有结构这一类型)。
C++ Primer Plus中指出要
1) 调用函数时传递地址&myStruct
2) 形参声明为指针MyStruct *
3) 访问成员使用操作符 ->
3. 将引用用于结构
同样,为了节省时空开销,在函数返回值时尽量使用引用。
const MyStruct & use(MyStruct & mystruct)
注意最好将返回的引用声明为const,否则可以使用这样的代码:
use(myStruct).used = 10;
容易产生语义混乱。
但在某些时候必须去掉const关键字。
算法:
进入大学后,对算法这些基础的看法改变了好几次。
高中里认为搞ACM没什么意义,觉得和应试差不多。
但是大学里有意无意的一些接触后,发现它涉及了大量应用数学的知识,对基础的提高十分有用。
保送的时候志愿填了数学系,不就是为了打好数学基础吗?
从功利的角度讲,有ACM的经历以后进IT公司自然可以方便不少。
英语:
从小学到高中,英语一直是强项,考试不需要突击,课本单词不需要刻意背诵,语言点很少复习,高中的英语考试让我对自己的英语过于自信了。
然后进了大学,处处受到强人的打击,上学期拿了B+觉得已经不错了。到现在这个英语班已经成为中等偏下的学生了,无论是词汇量还是听说能力。
sigh,暑假要报个补习班了。
至于其他的应用,asp.net ruby 之类的东西,权且当玩具学学吧,等需要应用的时候再好好看未必来不及,关键要有扎实的基础。
希望这个想法在放假前不会改变。
使用SQL登录验证:
1. 在SQL Server Management Studio Express中右击数据库,Properties -> Security,Server authentication选为SQL Server and Windows Authentication mode
2. 返回主界面,在Security的Login中增加用户,分配权限。
BFS,一次通过
/**//*
PROG: milk3
ID: 06301031
LANG: C++
*/
#include <iostream>
#include <fstream>
#include <deque>
#include <set>
using namespace std;
struct Status {
int a;
int b;
int c;
};
void pour(const int from, const int to, const int maxTo, int& newFrom, int& newTo) {
newTo = from + to;
newFrom = 0;
if (newTo > maxTo) {
newFrom = newTo - maxTo;
newTo = maxTo;
}
}
int main() {
int i, j, k;
ifstream fin("milk3.in");
ofstream fout("milk3.out");
Status begin;
int maxA, maxB, maxC;
fin >> maxA >> maxB >> maxC;
begin.a = 0;
begin.b = 0;
begin.c = maxC;
bool hash[21][21][21];
for (i = 0; i <= maxA; i++) {
for (j = 0; j <= maxB; j++) {
for (k = 0; k <= maxC; k++) {
hash[i][j][k] = false;
}
}
}
hash[0][0][maxC] = true;
set<int> result;
deque<Status> queue;
queue.push_back(begin);
while (!queue.empty()) {
deque<Status>::iterator now = queue.begin();
if (now->a == 0) {
result.insert(now->c);
}
Status newStat;
newStat = *now;
pour(now->a, now->b, maxB, newStat.a, newStat.b);
if (!hash[newStat.a][newStat.b][newStat.c]) {
hash[newStat.a][newStat.b][newStat.c] = true;
queue.push_back(newStat);
}
newStat = *now;
pour(now->b, now->a, maxA, newStat.b, newStat.a);
if (!hash[newStat.a][newStat.b][newStat.c]) {
hash[newStat.a][newStat.b][newStat.c] = true;
queue.push_back(newStat);
}
newStat = *now;
pour(now->c, now->a, maxA, newStat.c, newStat.a);
if (!hash[newStat.a][newStat.b][newStat.c]) {
hash[newStat.a][newStat.b][newStat.c] = true;
queue.push_back(newStat);
}
newStat = *now;
pour(now->a, now->c, maxC, newStat.a, newStat.c);
if (!hash[newStat.a][newStat.b][newStat.c]) {
hash[newStat.a][newStat.b][newStat.c] = true;
queue.push_back(newStat);
}
newStat = *now;
pour(now->b, now->c, maxC, newStat.b, newStat.c);
if (!hash[newStat.a][newStat.b][newStat.c]) {
hash[newStat.a][newStat.b][newStat.c] = true;
queue.push_back(newStat);
}
newStat = *now;
pour(now->c, now->b, maxB, newStat.c, newStat.b);
if (!hash[newStat.a][newStat.b][newStat.c]) {
hash[newStat.a][newStat.b][newStat.c] = true;
queue.push_back(newStat);
}
queue.pop_front();
}
set<int>::iterator iter = result.begin();
fout << *iter;
iter++;
for (; iter != result.end(); iter++) {
fout << " " << *iter;
}
fout << endl;
return 0;
}
摘要: 本来想练习了下deque的使用。用BFS,每个结点都记录了到目前为止转动的情况。结果发现内存消耗很大,就只好用DFS了。
/**//*PROG: clocksID: 06301031LANG: C++*/#include <iostream>#include <fstream>#include <deq... 阅读全文
都是最近做usaco时碰到的问题
1. string转int, double
atoi(str.c_str())
atod(str.c_str())
2. std库里已经有swap方法了,难怪我写了以后反应ambiguous method
命令行运行sqlcmd时提示
HResult 0x7E,级别 16,状态 1
VIA 提供程序: 找不到指定的模块。
Sqlcmd: 错误: Microsoft SQL Native Client : 建立到服务器的连接时发生错误。连接到
SQL Server 2005 时,默认设置 SQL Server 不允许远程连接这个事实可能会导致失败。
。
Sqlcmd: 错误: Microsoft SQL Native Client : 登录超时已过期。
google了半天,把VIA, Named Pipes, TCP/IP协议都开启后,还是无法找到。
终于在http://eternity8.bokee.com/viewdiary.13643204.html里找到了解决方法
SQL Server Configuration Manager -> 网络配置 -> 协议
tcp/ip属性
保持活动状态 --> 30000
全部侦听 --> 否
无延迟 --> 否
已启用 --> 是
IP地址
IP地址 --> 你的IP
TCP动态端口 --> 不填
TCP端口 --> 1433
活动 --> 是
已启用 --> 是
题目都不难,都是一看就知道怎么做的,一道模拟,一道深度优先搜索,一道简化了的拓扑排序(其实也谈不上),一道动态规划。
但是手实在是太生疏了,甚至连C(n,m)该如何计算都要回忆一下。。。sigh,加上电脑有问题等客观因素,最后只做出两题。
这东西不做不行啊,赛前几天一定要练下。
Log4j有三个主要的组件:Loggers,Appenders和Layouts,这里可简单理解为日志类别,日志要输出的地方和日志以何种形式输出。综合使用这三个组件可以轻松的记录信息的类型和级别,并可以在运行时控制日志输出的样式和位置。下面对三个组件分别进行说明:
1、 Loggers
Loggers组件在此系统中被分为五个级别:DEBUG、INFO、WARN、ERROR和FATAL。这五个级别是有顺序的,DEBUG < INFO < WARN < ERROR < FATAL,明白这一点很重要,这里Log4j有一个规则:假设Loggers级别为P,如果在Loggers中发生了一个级别Q比P高,则可以启动,否则屏蔽掉。
Java程序举例来说:
//建立Logger的一个实例,命名为“com.foo”
Logger logger = Logger.getLogger("com.foo");
//设置logger的级别。通常不在程序中设置logger的级别。一般在配置文件中设置。
logger.setLevel(Level.INFO);
Logger barlogger = Logger.getLogger("com.foo.Bar");
//下面这个请求可用,因为WARN >= INFO
logger.warn("Low fuel level.");
//下面这个请求不可用,因为DEBUG < INFO
logger.debug("Starting search for nearest gas station.");
//命名为“com.foo.bar”的实例barlogger会继承实例“com.foo”的级别。因此,下面这个请求可用,因为INFO >= INFO
barlogger.info("Located nearest gas station.");
//下面这个请求不可用,因为DEBUG < INFO
barlogger.debug("Exiting gas station search");
这里“是否可用”的意思是能否输出Logger信息。
在对Logger实例进行命名时,没有限制,可以取任意自己感兴趣的名字。一般情况下建议以类的所在位置来命名Logger实例,这是目前来讲比较有效的Logger命名方式。这样可以使得每个类建立自己的日志信息,便于管理。比如:
static Logger logger = Logger.getLogger(ClientWithLog4j.class.getName());
2、 Appenders
禁用与使用日志请求只是Log4j其中的一个小小的地方,Log4j日志系统允许把日志输出到不同的地方,如控制台(Console)、文件(Files)、根据天数或者文件大小产生新的文件、以流的形式发送到其它地方等等。
其语法表示为:
org.apache.log4j.ConsoleAppender(控制台),
org.apache.log4j.FileAppender(文件),
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件),
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
配置时使用方式为:
log4j.appender.appenderName = fully.qualified.name.of.appender.class
log4j.appender.appenderName.option1 = value1
…
log4j.appender.appenderName.option = valueN
这样就为日志的输出提供了相当大的便利。
3、 Layouts
有时用户希望根据自己的喜好格式化自己的日志输出。Log4j可以在Appenders的后面附加Layouts来完成这个功能。Layouts提供了四种日志输出样式,如根据HTML样式、自由指定样式、包含日志级别与信息的样式和包含日志时间、线程、类别等信息的样式等等。
其语法表示为:
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
配置时使用方式为:
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
log4j.appender.appenderName.layout.option1 = value1
…
log4j.appender.appenderName.layout.option = valueN
以上是从原理方面说明Log4j的使用方法,在具体Java编程使用Log4j可以参照以下示例:
1、 建立Logger实例:
语法表示:public static Logger getLogger( String name)
实际使用:static Logger logger = Logger.getLogger (ServerWithLog4j.class.getName ()) ;
2、 读取配置文件:
获得了Logger的实例之后,接下来将配置Log4j使用环境:
语法表示:
BasicConfigurator.configure():自动快速地使用缺省Log4j环境。
PropertyConfigurator.configure(String configFilename):读取使用Java的特性文件编写的配置文件。
DOMConfigurator.configure(String filename):读取XML形式的配置文件。
实际使用:PropertyConfigurator.configure("ServerWithLog4j.properties");
3、 插入日志信息
完成了以上连个步骤以后,下面就可以按日志的不同级别插入到你要记录日志的任何地方了。
语法表示:
Logger.debug(Object message);
Logger.info(Object message);
Logger.warn(Object message);
Logger.error(Object message);
实际使用:logger.info("ServerSocket before accept: " + server);
在实际编程时,要使Log4j真正在系统中运行事先还要对配置文件进行定义。定义步骤就是对Logger、Appender及Layout的分别使用,具体如下:
1、 配置根Logger,其语法为:
log4j.rootLogger = [ level ] , appenderName, appenderName, …
这里level指Logger的优先级,appenderName是日志信息的输出地,可以同时指定多个输出地。如:log4j.rootLogger= INFO,A1,A2
2、 配置日志信息输出目的地,其语法为:
log4j.appender.appenderName = fully.qualified.name.of.appender.class
可以指定上面所述五个目的地中的一个。
3、 配置日志信息的格式,其语法为:
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
这里上面三个步骤是对前面Log4j组件说明的一个简化;下面给出一个具体配置例子,在程序中可以参照执行:
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=
%-4r %-5p %d{yyyy-MM-dd HH:mm:ssS} %c %m%n
这里需要说明的就是日志信息格式中几个符号所代表的含义:
-X号: X信息输出时左对齐;
%p: 日志信息级别
%d{}: 日志信息产生时间
%c: 日志信息所在地(类名)
%m: 产生的日志具体信息
%n: 输出日志信息换行
根据上面的日志格式,某一个程序的输出结果如下:
0 INFO 2003-06-13 13:23:46968 ClientWithLog4j Client socket: Socket[addr=localhost/127.0.0.1,port=8002,localport=2014]
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j Server says: 'Java server with log4j, Fri Jun 13 13:23:46 CST 2003'
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j GOOD
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j Server responds: 'Command 'HELLO' not understood.'
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j HELP
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j Server responds: 'Vocabulary: HELP QUIT'
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j QUIT
5.19
第一反应觉得是个简单的BFS,从最高点开始向四周扩展,最后找到最长的路径即可。
结果Wrong Answer,仔细一想,才意识到并不一定是从最高点开始的。考虑得太不周到了。。
5.31
原来的程序找不到了。。。重新写了一遍,居然写好提交就AC了,恩。这几天进步挺大哈
#include <iostream>
#include <fstream>
#include <algorithm>
#include <vector>
using namespace std;
const int MAX_HEIGHT = 10000;
const int MAX_ROWS = 100;
const int dx[] = {0, 0, -1, 1};
const int dy[] = {1, -1, 0, 0};
struct Point {
int x;
int y;
int height;
};
bool comparePoints(const Point& p1, const Point& p2);
int main() {
//ifstream fin("pku1088.in");
int c, r;
int i, j;
cin >> r >> c;
int h[MAX_ROWS + 2][MAX_ROWS + 2];
int count = 0;
vector<Point> points;
for (i = 1; i <= r; i++) {
for (j = 1; j <= c; j++) {
cin >> h[i][j];
Point temp;
temp.x = i;
temp.y = j;
temp.height = h[i][j];
points.push_back(temp);
}
}
sort(points.begin(), points.end(), comparePoints);
for (i = 0; i <= c; i++) {
h[0][i] = MAX_HEIGHT + 1;
h[r + 1][i] = MAX_HEIGHT + 1;
}
for (i = 0; i <= r; i++) {
h[i][0] = MAX_HEIGHT + 1;
h[i][c + 1] = MAX_HEIGHT + 1;
}
int f[MAX_ROWS + 1][MAX_ROWS + 1];
for (i = 1; i <= r; i++) {
for (int j = 1; j <= c; j++) {
f[i][j] = 1;
}
}
vector<Point>::iterator iter;
for (iter = points.begin(); iter != points.end(); iter++) {
for (i = 0; i < 4; i++) {
int nx = iter->x + dx[i];
int ny = iter->y + dy[i];
if (iter->height > h[nx][ny]) {
if (f[iter->x][iter->y] + 1 > f[nx][ny]) {
f[nx][ny] = f[iter->x][iter->y] + 1;
}
}
}
}
int best = 0;
for (i = 1; i <= r; i++) {
for (j = 1; j <= c; j++) {
if (f[i][j] > best) {
best = f[i][j];
}
}
}
cout << best << endl;
return 0;
}
bool comparePoints(const Point& p1, const Point& p2) {
return (p1.height > p2.height);
}
|