|
|
2010年1月13日
1、http://www.jar114.com/site.html
该网站可以提供我们项目中经常需要的jar包,如果缺少包,就可以在这里查找。
流程定义文件*.jpdl.xml中如果有中文乱码,肯定是task中有中文。
需要在eclipse安装软件下,即E:\eclipse\eclipse.ini增加
-Dfile.encoding=UTF-8
然后重启eclipse即可解决。
配置jbpm4工程的运行环境:
1、添加依赖库。
E:\JBPM\jbpm-4.3\jbpm.jar
E:\JBPM\jbpm-4.3\lib下的jar包。
2、添加配置文件。
E:\JBPM\jbpm-4.3\examples\src下的配置文件拷贝到自己java工程的src下。
---------------------------------------------------------------
管理流程定义:发布流程定义、查看流程定义、删除流程定义。
RepositoryService repositoryService = processEngine.getRepositoryService();
String deploymentId = repositoryService.createDeployment().addResourceFromClasspath
("helloworld.jpdl.xml").deploy();
List<ProcessDefinition> list = repositoryService.createProcessDefinitionQuery().list();
repositoryService.deleteDeploymentCascade(deploymentId);
---------------------------------------------------------------
管理流程实例:发起新流程、执行等待的流程、查看流程实例、终止流程实例、删除流程实例。
ExecutionService executionService = processEngine.getExecutionService();
ProcessInstance pi = executionService.startProcessInstanceByKey("helloworld");
ProcessInstance pi = executionService.signalExecutionById(pi.getId()); //执行等待的流程.
List<ProcessInstance> list = executionService.createProcessInstanceQuery().list();
executionService.endProcessInstance(pi.getId(), "cancel");
executionService.deleteProcessInstanceCascade(pi.getId());
TaskService taskService = processEngine.getTaskService();
taskService.completeTask(taskId, map);
控制流程的活动:Start、End、Decision、Fork、Join、Sub-process、State、task.
原子活动:java、script、sql、hql、email。
配置开发环境:
1、jbpm4:http://sourceforge.net/projects/jbpm/files/ 下选择jbpm-4.3.zip 137.9M
2、eclipse3.5版本以上 : http://www.eclipse.org/downloads/ 下选择 Eclipse IDE for Java EE 190M
3、GPD (Graphical Process Designer)插件,路径:E:\jbpm-4.3\install\src\gpd\jbpm-gpd-site.zip。
通过Eclipse-->help-->Install New Software-->Add-->Archive到插件所在路径。
java.lang.NullPointerException
at jxl.read.biff.File.<init>(File.java:77)
at jxl.Workbook.getWorkbook(Workbook.java:250)
at jxl.Workbook.getWorkbook(Workbook.java:235)
at org.drools.decisiontable.parser.xls.ExcelParser.parseFile(ExcelParser.java:76)
at org.drools.decisiontable.SpreadsheetCompiler.compile(SpreadsheetCompiler.java:89)
at org.drools.decisiontable.SpreadsheetCompiler.compile(SpreadsheetCompiler.java:68)
at com.sample.DecisionTableTest.readDecisionTable(DecisionTableTest.java:59)
at com.sample.DecisionTableTest.main(DecisionTableTest.java:36)
Drools调用readDecisionTable()方法里面一处为:
InputStream is = DecisionTableTest.class.getResourceAsStream("rules\\Sample.xls");
final String drl = converter.compile( is, InputType.XLS );
需改为如下,取的class即错误解决。
InputStream is = DecisionTableTest.class.getClassLoader().getResourceAsStream("rules\\Sample.xls");
final String drl = converter.compile( is, InputType.XLS );
org.mvel.CompileException: can not resolve identifier: 'declr'
at org.mvel.ASTNode.getReducedValue(ASTNode.java:315)
at org.mvel.ast.PropertyASTNode.getReducedValue(PropertyASTNode.java:29)
at org.mvel.MVELInterpretedRuntime.parseAndExecuteInterpreted(MVELInterpretedRuntime.java:103)
at org.mvel.MVELInterpretedRuntime.parse(MVELInterpretedRuntime.java:51)
at org.mvel.TemplateInterpreter.execute(TemplateInterpreter.java:428)
at org.mvel.TemplateInterpreter.parse(TemplateInterpreter.java:320)
at org.drools.rule.builder.dialect.java.AbstractJavaBuilder.generatTemplates(AbstractJavaBuilder.java:113)
at org.drools.rule.builder.dialect.java.JavaConsequenceBuilder.build(JavaConsequenceBuilder.java:95)
at org.drools.rule.builder.RuleBuilder.build(RuleBuilder.java:67)
at org.drools.compiler.PackageBuilder.addRule(PackageBuilder.java:446)
at org.drools.compiler.PackageBuilder.addPackage(PackageBuilder.java:304)
at org.drools.compiler.PackageBuilder.addPackageFromDrl(PackageBuilder.java:167)
at com.sample.DecisionTableTest.readDecisionTable(DecisionTableTest.java:63)
at com.sample.DecisionTableTest.main(DecisionTableTest.java:36)
替换mvel.jar为mvel14-1.2.10.jar后不再报错,好像是jar包的问题。
看了下jar包里面的org.mvel.ASTNode.getReducedValue方法已经注释掉了。
WARNING: Wasn't able to correctly close stream for decision table. nulljava.lang.NullPointerException
at jxl.read.biff.File.<init>(File.java:77)
at jxl.Workbook.getWorkbook(Workbook.java:250)
at jxl.Workbook.getWorkbook(Workbook.java:235)
at org.drools.decisiontable.parser.xls.ExcelParser.parseFile(ExcelParser.java:76)
at org.drools.decisiontable.SpreadsheetCompiler.compile(SpreadsheetCompiler.java:89)
at org.drools.decisiontable.SpreadsheetCompiler.compile(SpreadsheetCompiler.java:68)
at org.drools.decisiontable.SpreadsheetCompiler.compile(SpreadsheetCompiler.java:110)
at com.sample.DecisionTableTest.readDecisionTable(DecisionTableTest.java:57)
at com.sample.DecisionTableTest.main(DecisionTableTest.java:35)
在web项目中的原先的写法为:
final String drl = converter.compile( "rules\\Sample.xls", InputType.XLS );
参考了下别人的写法,改为下面的方式进行处理:
InputStream is = DecisionTableTest.class.getClassLoader().getResourceAsStream("rules\\Sample.xls");
final String drl = converter.compile( is, InputType.XLS );
由于drools有新版本了,所以与MyEclipse整合进行了解下。
整合步骤如下:
1、下载MyEclipse 8.5;
2、在http://www.jboss.org/drools/downloads.html下载Drools Eclipse 3.5 Workbench 5.1 插件;
3、在E:\MyEclipse8.5下新建2个文件:links、myplugins。
E:\MyEclipse 8.5\links:放drools.link配置文件,内容为path=E:\\MyEclipse 8.5\\myplugins\\drools\\
E:\MyEclipse 8.5\myplugins:放drools文件,该E:\MyEclipse 8.5\myplugins\drools\eclipse下放置从网上下载的drools插件的features和plugins。
4、重启MyEclipse 8.5即可看见drools图标。
5、安装Jboss:下载jboss-5.0.0.GA,解压即可。
打开MyEclipse->window->Preference->MyEclipse->Servers->JBoss->JBoss 5.x进行jre及相关配置。
在命令行下运行java程序,出现如上异常Exception in thread "main" java.lang.UnsupportedClassVersionError。
主要是jdk的版本被oracle给换成低版本了。
可以在命令行下输入:javac -version 查看版本,最后把%JAVA_HOME%\bin;添加到Oracle之前,再重开启电脑,编译,运行即可。
可以查考:http://hi.baidu.com/tianxingacer/blog/item/e628b947ffc54f016a63e5ac.html/cmtid/1fe1e9ae1dc5b9f6faed50d9
我的机器以前装的是offices2003自带的js调试工具,昨天按照上IE8后,js调试工具有时候是ie8的调试界面,有时是ie6的调试界面,经网上查找已找到原因。
主要是我把IE8的‘脚本’下的“启动调试”给关了,所以最后只出现ie6的调试界面。
解决方法:打开IE8后,点击"工具"->"开发人员工具",或者快捷键F12,会打开页面调试窗口。
今天用反编译工具查看java源代码,发现反编译的java文件有错误,在网上了解了下,是原先开发人员对代码做了一下加密处理。下面介绍一下java的混淆器Proguard。
ProGuard 是一个免费的 Java类文件的压缩,优化,混肴器。它删除没有用的类,字段,方法与属性。使字节码最大程度地优化,使用简短且无意义的名字来重命名类、字段和方法 。eclipse已经把Proguard集成在一起了。
其他地方也有介绍,如下:http://blog.csdn.net/alex197963/archive/2008/07/07/2620603.aspx
1、当处理多个访问相同数据的用户时,通常可能出现三种问题:
脏读
当应用程序使用了被另一个应用程序修改过的数据,而这个数据处于未提交状态时,就会发生脏读。第二个应用程序随后会请求回滚被其修改的数据。第一个事务使用的数据就会被损坏,或者“变脏”。
不可重复的读
当一个事务获得了数据,而该数据随后被一个单独的事务所更改时,若第一个事务再次读取更改后的数据,就会发生不可重复的读。这样,第一个事务进行了一个不可重复的读。
虚读
当事务通过某种查询获取了数据,另一个事务修改了部分该数据,原来的事务第二次获取该数据时,就会发生虚读。第一个事务现在会有不同的结果集,它可能包含虚读。
2、Java.sql.Connection接口定义的隔离级别
TRANSACTION_NONE 说明不支持事务
TRANSACTION_READ_UNCOMMITTED 说明在提交前一个事务可以看到另一个事务的变化。这样脏读、不可重复的读和虚读都是允许的。
TRANSACTION_READ_COMMITTED 说明读取未提交的数据是不允许的。这个级别仍然允许不可重复的读和虚读产生。
TRANSACTION_REPEATABLE_READ 说明事务保证能够再次读取相同的数据而不会失败,但虚读仍然会出现。
TRANSACTION_SERIALIZABLE 是最高的事务级别,它防止脏读、不可重复的读和虚读。
3、事务的隔离级别
在J2EE中,通过java.sql.Connection接口设置事务隔离级别,这一接口为连接的隔离级别提供了getter()和setter()
Int getTransactionIsolation() throws SQLException
void setTransactionIsolation() throws SQLException
Connection对象负责事务,一旦收到事务请求,事务将自动提交,因为Connection对象已定义为自动提交方式,可通过setAutoCommit(false)禁用自动提交模式
另外java.sql.DatabaseMetaData接口为数据存储提供支持的隔离级别查找方法:getTransactionIsolation(),supportsTransactionIsolationLevel()
对多个库操作的分布式事务必须在所有库中执行同一个隔离级别,否则会出现意想不到的结果
4、事务提交和回滚
为了完成提交事务和回滚事务,JDBC API包括了两个方法作为 Connection 接口的一部分。若将 Connection 对象名称指定为 con,通过调用 con.commit(); 可以保存程序状态;
通过调用 con.rollback(); 可以返回到以前保存的状态。如果数据库实际运行操作时有错误发生,这两个方法都会抛出 SQLExceptions,所以您需要在 try ... catch 块中包装它们。
5、批处理和事务
缺省情况下,JDBC 驱动程序运行在被称为自动提交的模式下,可禁用自动提交模式
con.setAutoCommit(false);
批处理操作中通过在一次单独的操作(或批处理)中执行多个数据库更新操作
{con.setAutoCommit(false) ;
Statement stmt = connection.createStatement() ; stmt.addBatch("INSERT INTO people VALUES('Joe Jackson', 0.325, 25, 105) ; stmt.addBatch("INSERT INTO people
VALUES('Jim Jackson', 0.349, 18, 99) ; stmt.addBatch("INSERT INTO people VALUES('Jack Jackson', 0.295, 15, 84) ;
int[] updateCounts = stmt.executeBatch() ; con.commit() ;
Initial Capacity:池的连接数量,在启动时创建
Maximun Capacity:这是池可以打开的连接的最大数量
Capacity Increment:成组地打开增量连接
Login Delay Seconds:池驱动程序在启动时打开每一个新的连接需要等待的时间
Refresh Period(刷新周期)
Supports Local Transaction:只用于XA连接池
Allow Shrinking and Shrink Period(允许收缩和收缩期):如果池的数量太大,超过了初始,且如果任何一个连接在收缩期内空闲,那么空闲的连接将在收缩期末关闭
监控JDBC连接池:
Waiters Hight字段指明了最多有多少客户等待数据库连接
Waiters字段告诉你当前有多少客户正在等待连接
Connections Hight字段给出最大的并发连接数。
Wait Seconds Hight字段显示了客户等待数据库连接的最长时间
1、连接:
直接连接(direct connection)
池连接(pooled connection)
连接复用 ,避免了数据库连接频繁建立、关闭的开销 ;
对JDBC中的原始连接进行了封装 ,隔离了应用的本身的处理逻辑和具体数据库访问逻辑 。
2、什么是连接池?
连接池是在Weblogic启动时候预先建立的数据库连接,由Weblogic在运行时负责维护。
可以减少程序每次数据库请求都要新创建数据库物理连接的时间及资源。
对数据库属性的更改只需通过控制台进行,不需改动客户端代码
MultiPool
可以使用MultiPool为高用户访问量提供数据库负载均衡,它使用简单的循环算法将连接请求平衡分配MultiPool中的每一个池。
多池的作用:为防数据库连接失败提供冗余,备份或高有效池;为高用户访问量提供数据库负载均衡,负载均衡池。
备份池:一个备份池由一个有顺序的连接池列表组成。
负载均衡池:使用简单的循环算法将连接请求平衡地分到在列表中的每一个池。
3、DataSource
数据源对应一个数据库连接池。客户程序可以通过数据源绑定的JNDI名字得到该数据源的引用,并通过数据源对象得到数据库连接。
JDBC的API:
java.sql.DriverManager
java.sql.Connection
java.sql.ResultSet
Javax.sql.RowSet:
javax.sql.Statement
java.sql.PreparedStatement:用于执行预编译的SQL语句
java.sql.CallableStatement:用于执行在数据库中定义的存储过程
Javax.sql.DataSource是java.sql.Connectioin对象的工厂并使用一个JNDI服务注册它.
1、Type 1类型驱动,JDBC-ODBC桥
通常运行Windows平台,需要在客户端安装ODBC驱动,早期Java访问数据库的主要方式,效率较低。
适用于快速的原型系统,没有提供JDBC驱动的数据库如Access ,由于包含多个驱动程序层,其性能一般不适合生产系统
Java-->JDBC-ODBC Bridge---->JDBC-ODBC Library--->ODBC Driver-->Database
驱动程序的类名称是 sun.jdbc.odbc.JdbcOdbcDriver
JDBC URL 的形式为 jdbc:odbc:dsn(dsn 是使用 ODBC 管理员注册数据库的数据源名称)
不是100%JAVA程序,与ODBC之间的接口采用非JAVA方式调用,因此不能在APPLET中使用
{
String url = "jdbc:odbc:jdbc" ;
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection con = DriverManager.getConnection(url, "java", "sun");
}
2、Type 2类型驱动,需要在客户端安装数据库的本地驱动,JDBC请求会转换为对数据库本地API的调用。
利用开发商提供的本地库来直接与数据库通信。
Java-->JDBC-Driver-->DB Client Library-->Database
绕过了ODBC层,性能优于Type1
也称为部分 Java 驱动程序,因为它们直接将 JDBC API 翻译成具体数据库的API
使用第二种模型将开发者限制在数据库厂商的客户机库支持的客户机平台和操作系统
Oracle的OCI驱动就属于Type2
3、Type 3类型驱动,DBC请求通过网络服务器层实现,在网络服务器层可以实现负载均衡,连接池管理等。
第三种驱动程序是纯 Java 驱动程序,它将 JDBC API 转换成独立于数据库的协议。JDBC 驱动程序并没有直接和数据库进行通讯;它和一个中间件服务器通讯,然后这个中间件服务器和数据库进行通讯。这种额外的中间层次提供了灵活性:可以用相同的代码访问不同的数据库,因为中间件服务器隐藏了 Java 应用程序的细节。要转到不同的数据库,您只需在中间件服务器上改变参数。(有一点需要注意:中间件服务器必须支持您访问的数据库格式。)
第三种驱动程序的缺点是,额外的中间层次可能有损整体系统性能。另一方面,如果应用程序需要和不同的数据库格式进行交互,第三种驱动程序是个有效的方法,因为不管底层的数据库是什么,都使用同样的 JDBC 驱动程序。另外,因为中间件服务器可以安装在专门的硬件平台上,可以利用总的结果进行一些优化。
Java--->Jdbc Driver(Type3 jdbc driver)----->java middleware--->JDBC Driver---->Database
Weblogic的Pool驱动程序就是一个Type3的JDBC驱动程序。
4、Type 4类型驱动,为纯Java实现,不需要任何客户端设置。
OCI驱动程序利用Java本地化接口(JNI),通过Oracle客户端软件与数据库进行通讯。Thin驱动程序是纯Java驱动程序,它直接与数据库进行通讯。
JDBC应用的两种架构
两层架构:客户程序直接对数据库发起JDBC请求,Type1、2、4支持两层架构。
多层架构:客户程序将JDBC请求发送到中间层,中间层再将请求发送到数据库。
通常应用系统会根据用户数、并发数、用户的行为等等来确定具体的性能目标,如果确定应用程序不能满足性能目标,那么就需要优化、重构程序并调整JVM、应用服务器、数据库、OS 或者改变硬件配置等等。
影响Java 性能的主要因素:
硬件,如CPU、内存、体系结构等等
操作系统
数据库系统
JVM
应用服务器
数据库服务器
网络环境
应用架构及程序编写水平
性能调整的步骤:
1、 使用工具测试系统是否满足性能目标
2、 发现性能瓶颈
3、 假设瓶颈的原因
4、 测试你的假设
5、 如果假设成立,更改这一部分
6、 测试确定更改是否可以提高性能,衡量性能提高的程度
7、重复以上步骤,直到获得可以接受的性能。
J2EE性能不好时的现象,主要表现在对客户端的请求响应很慢:
一向很慢:应用的响应总是很慢,改变环境(如应用负载、数据库的连接池数量等等),对响应时间的影响不大。
越来越慢:在相同的负载情况下,随着系统运行的时间的增长,系统越来越慢,这可能是系统已到达极限或是系统死锁和错误引起的。
低于负载时会越来越慢(Slower and slower under load):.
偶尔的挂起或异常错误(Sporadic hangs or aberrant errors):有时这可能是由于负载的变化或其他情况引起的可以预测的死锁(Foreseeable lock ups): 挂起或最初只有少量错误,但随着时间的推移整个系统都锁上了,典型地这可能是为的适应"management by restarts.“
突发性的混乱(Sudden chaos): 系统已运行了一段时间(如一个小时或可能是三、四天),性能稳定并可以接受, 突然没有任何理由,开始出错或死锁了。
监控工具:
WebLogic Server的控制台
cpu
内存
JDBC
辅助的工具
Jprobe
Optimizit
Vtune
TowerJ Performance
WebLogic Server 10的下载地址:
http://www.oracle.com/technology/software/products/ias/htdocs/wls_main.html
1、域(Domains)
域是管理的单元或边界;
作为一个单元来管理的,并相互关联的一组Weblogic 服务器资源被称为域;
域由单一的管理服务器来管理。
2、机器(Machines)
可以对应到服务器所在的物理硬件;
可以是Unix或non-Unix类型;
可以用来远程管理和监控;
3、服务器(Servers)
服务器是执行在单一Java虚拟机 (JVM)中weblogic.Server类的实例。
服务器:最多和一个WLS机器关联;占用一定数量的RAM ;是多线程的。
4、管理服务器(Administration server)
对整个域的集中控制
XML配置存储库的保存者
日志信息的集中保存
5、被管理服务器(Managed Server)
WebLogicServer的一个实例;
从管理服务器远程加载配置信息‘;
可以是也可以不是集群的一部分。
6、集群 (Clustering)
WebLogic集群技术指通过一组服务器共同 工作,在多台机器间复制应用表示层和应用逻辑层的能力,实现关键业务系统的负载分布,消除个别故障点;集群用来实现负载均衡和容错。
1、J2EE应用开发的核心组件。
Servlet: 处理HTTP请求,产生响应。
JSP:Java Server Pages ,同Servlet。其中包含了HTML和JSP标签、Java代码和其他信息。
EJB:EJB服务端组件模型简化了具有交互性、扩展性和移植性中间组件的开发。EJB一般用于实现系统的业务逻辑。
2、J2EE的相关技术
核心:Servlet 、JSP、EJB
数据库:JDBC
命名和目录服务:JNDI
消息服务:JMS( Java Message Service )
Email:Java Mail
分布式计算:RMI、RMI-IIOP
事务:JTA(Java Transaction API)
数据格式化:XML、HTML、XSL
协议:TCP/IP、HTTP(S)、IIOP、SSL
安全:JAAS
3、J2EE的4层结构
客户层(浏览器)
Web层(HTML、Servlet、JSP)
业务层(EJB)
EIS层(关系数据库)
4、J2EE的Application Server:
Tomcat
BEA Weblogic
IBM Websphere
Oracle Application Server
Sun Java System
Jboss
Borland AppServer
Sybase Application Server
HP Application Server
Apusic
5、集成开发工具:
Borland:JBuilder
Oracle :JDeveloper
Bea :WebLogic Workshop
IBM:Websphere Studio
Sun:NetBeans
MyEclipse
在小型的应用系统或者有特殊需要的系统中,可以使用一个免费的Web服务器Tomcat,该服务器支持全部JSP以及Servlet规范,但是目前还不支持EJB。
在Java相关的开发领域中,常用的是3种数据库:Oracle、DB2和MySQL。有时候也使用微软公司的SQL Server数据库服务器 。
DateUtils.compareYear(regDate, base.getTInsrncBgnTm()) // 新旧车标志【保险起期 - 初登年月】 单位:年
//显示输入框录入的字符位数。 ztf 10.07.19
function displayLength(obj) {
var lenSpan = document.getElementById("lenSpan");
if (lenSpan == null) {
lenSpan = document.createElement("SPAN");
lenSpan.id = "lenSpan";
obj.parentNode.appendChild(lenSpan);
}
lenSpan.innerText = "已输入" + obj.value.length + "位";
}
onkeyup="displayLength(this)"进行js调用。
--情况1:多个参数的传递,由于多个文件编码不一致,可能出现乱码。
window.open(base+"/policy/universal/pop/flat_vhl_inf_query.jsp?
cLcnNo="+objPlateNo.value+"&cEngNo="+objEngNo.value+"&cVhlFrm="+objFrmNo.value+"&cPlateTy
p="+objPlateTyp+"&cProdNo="+objCProdNo+"&cDptCde="+objCDptCde+"&cNewMrk="+objNewMrk.value
+"&cEcdemicMrk="+objEcdemicMrk.value,"","scrollbars=yes,left=100,top=150,Toolbar=no,Locat
ion=no,Direction=no,Resizeable=no,Width="+800+" ,Height="+400);
--相应的jsp获得参数
<%
String CProdNo = request.getParameter("prodNo");
String CDptCde = request.getParameter("dptCde");
String CPlateNo = request.getParameter("plateNo");
String CFrmNo = request.getParameter("frmNo");
if("".equals(CPlateNo)&&"".equals(CFrmNo)){
return;
}
String dwName = "policy.pub.flat_vhl_inf_DW";
%>
--情况2:解决乱码的问题。
function tool_uploadFile(clmNo,billType,maxFileNum,fileType,singleLimit,totalLimit) {//解决乱码的问题,增加变量paramObj。ztf 10.06.01
var paramObj = {
"clmNo" : clmNo,
"billType" : billType,
"maxFileNum" : maxFileNum,
"fileType" : fileType,
"singleLimit" : singleLimit,
"totalLimit" : totalLimit
};
var r = window.showModalDialog(global.WEB_APP_NAME+"/core/jsp/common/uploadFile.jsp",paramObj,"dialogHeight:610px;dialogWidth:530px;center:1;help: 0; status: 0;");
return r;
}
--在相应的jsp页面通过js获得参数:
<html>
<head>
<title>文件上传</title>
</head>
<script type="text/javascript" src="<%=webApp%>/core/js/core/Tool.js"></script>
<body bgcolor="#85b7ec">
<script>
var paramObj = window.dialogArguments;
var clmNo = paramObj.clmNo;
var billType = paramObj.billType;
var maxFileNum = paramObj.maxFileNum;
var fileType = paramObj.fileType;
var singleLimit = paramObj.singleLimit;
var totalLimit = paramObj.totalLimit;
tool.loadApplet('<%=agentIp%>','<%=agentPort%>','<%=orgId%>',clmNo,billType,maxFileNum,fileType,singleLimit,totalLimit);
</script>
</body>
</html>
vReturnValue = window.showModalDialog(sURL [, vArguments] [, sFeatures])
1、具体业务中用到的sql,这个是查找最近标志为1,且有多条记录的数据。 (这个sql查找错误比较有用。)
select a.c_ply_no ,count(1) from web_ply_base a
where a.c_latest_mrk='1'
group by a.c_ply_no
having count(1)>1
背景count(*) count(1) 两者比较,主要还是要count(1)所相对应的数据字段:
如果你的数据表没有主键,那么count(1)比count(*)快
如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快
如果你的表只有一个字段的话那count(*)就是最快的啦
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*),自动会优化指定到那一个字段。所以没必要去count(?),用count(*),sql会帮你完成优化的.
其他语句:select * from 表名 where 条件 order by 字段名 asc\desc // asc 升序 desc 降序
2、C_Nme_En匹配多个 like 查询。
select distinct C_Spec_No
from WEB_Prd_Fix_Spec
WHERE C_Spec_No in (SELECT C_Spec_No
FROM web_Prd_Prod_Spec_Rel
WHERE C_Prod_No = '0326'
and C_Spec_No like '89%')
and (C_Nme_En like '%000000%' or C_Nme_En like '%030006%' or
C_Nme_En like '%030061%')
--递归,树状结构的存储与展示
drop table article;
create table article
(
id number primary key,
count varchar2(4000),
pid number,
isleaf number(1), --0 代表非叶子节点,1代表叶子节点
alevel number(2)
);
insert into article values(1,'蚂蚁大战大象',0,0,0);
insert into article values(2,'大象被打趴下',1,0,1);
insert into article values(3,'蚂蚁也不好过',2,1,2);
insert into article values(4,'瞎说',2,0,2);
insert into article values(5,'没有瞎说',4,1,3);
insert into article values(6,'怎么可能',1,0,1);
insert into article values(7,'怎么没有可能',6,1,2);
insert into article values(8,'可能性是很大的',6,1,2);
insert into article values(9,'大象进医院了',2,0,2);
insert into article values(10,'护士是蚂蚁',9,1,3);
commit;
蚂蚁大战大象
大象被打趴下了
蚂蚁也不好过
瞎说
没有瞎说
大象进医院了
护士是蚂蚁
怎么可能
怎么没有可能
可能性是很大的
--用存储过程展现树状结构。
create or replace procedure p(v_pid article.pid%type,v_level binary_integer) is
cursor c is select * from article where pid = v_pid;
v_preStr varchar2(1024) := '';
begin
for i in 0..v_level loop
v_preStr := v_preStr || '****';
end loop;
for v_article in c loop
dbms_output.put_line(v_preStr ||v_article.cont);
if(v_article.isleaf=0) then
p(v_artile.id,v_levle +1);
end if;
end loop;
end;
--触发器
create table emp2_log
(
uname varchar2(20);
action varchar2(10);
atime date
);
create or replace trigger trig
after insert or delete or update on emp2 for each row
begin
if inserting then
insert into emp2_log values (USER,'insert',sysdate); --USER关键字,用户。
elsif updating then
insert into emp2_log values (USER,'update',sysdate);
elsif deleting then
insert into emp2_log values (USER,'delete',sysdate);
end if;
end;
update emp2 set sal = sal*2 where deptno = 30;
select * from emp2_log;
drop trigger trig;
--直接执行时,出现违反完整约束条件,已找到子记录。
update dept set deptno = 99 where deptno = 10;
--使用下面的,把子表一起更新。
create or replace trigger trig
after update on dept for each row
begin
update emp set deptno =:NEW.deptno where deptno =:OLD.deptno;
end;
update dept set deptno = 99 where deptno = 10;
select * from emp;
rollback;
--函数
create or replace function sal_tax
(v_sal number)
return number
is
begin
if(v_sal < 2000) then
return 0.10;
elsif(v_sal < 2750) then
return 0.15;
else
return 0.20;
end if;
end;
数据库定义的函数money_to_chinese ,把数字转换正中文输出。
create or replace function money_to_chinese(money in VARCHAR2)
return varchar2 is
c_money VARCHAR2(12);
m_string VARCHAR2(60) := '分角圆拾佰仟万拾佰仟亿';
n_string VARCHAR2(40) := '壹贰叁肆伍陆柒捌玖';
b_string VARCHAR2(80);
n CHAR;
len NUMBER(3);
i NUMBER(3);
tmp NUMBER(12);
is_zero BOOLEAN;
z_count NUMBER(3);
l_money NUMBER;
l_sign VARCHAR2(10);
BEGIN
l_money := abs(money);
IF money < 0 THEN
l_sign := '负' ;
ELSE
l_sign := '';
END IF;
tmp := round(l_money, 2) * 100;
c_money := rtrim(ltrim(to_char(tmp, '999999999999')));
len := length(c_money);
is_zero := TRUE;
z_count := 0;
i := 0;
WHILE i < len LOOP
i := i + 1;
n := substr(c_money, i, 1);
IF n = '0' THEN
IF len - i = 6 OR len - i = 2 OR len = i THEN
IF is_zero THEN
b_string := substr(b_string, 1, length(b_string) - 1);
is_zero := FALSE;
END IF;
IF len - i = 6 THEN
b_string := b_string || '万';
END IF;
IF len - i = 2 THEN
b_string := b_string || '圆';
END IF;
IF len = i THEN
IF (len = 1) THEN
b_string := '零圆整';
ELSE
b_string := b_string || '整';
END IF;
END IF;
z_count := 0;
ELSE
IF z_count = 0 THEN
b_string := b_string || '零';
is_zero := TRUE;
END IF;
z_count := z_count + 1;
END IF;
ELSE
b_string := b_string || substr(n_string, to_number(n), 1) ||
substr(m_string, len - i + 1, 1);
z_count := 0;
is_zero := FALSE;
END IF;
END LOOP;
b_string := l_sign || b_string ;
RETURN b_string;
exception
--异常处理
WHEN OTHERS THEN
RETURN(SQLERRM);
END;
--创建存储过程:
create or replace procedure p
is
cursor c is
select * from emp2 for update;
begin
for v_temp in c loop
if(v_temp.deptno = 10) then
update emp2 set sal = sal+10 where current of c;
elsif(v_temp.deptno = 20) then
update emp2 set sal = sal+20 where current of c;
else
update emp2 set sal = sal+50 where current of c;
end if;
end loop;
commit;
end;
--执行:
exec p;
begin
p;
end;
--带参数的存储过程,in传入参数,默认为传入,out传出。
create or replace procedure p
(v_a in number,v_b number,v_ret out number,v_temp in out number)
is
begin
if(v_a >v_b) then
v_ret := v_a;
else
v_ret := v_b;
end if;
v_temp :=v_temp +1;
end;
declare
v_a number := 3;
v_b number := 4;
v_ret number;
v_temp number := 5;
begin
p(v_a,v_b,v_ret,v_temp);
dbms_output.put_line(v_ret);
dbms_output.put_line(v_temp);
end;
--游标
declare
cursor c is
select * from emp;
v_emp c%rowtype;
begin
open c;
loop
fetch c into v_emp;
exit when(c%notfound);
dbms_output.put_line(v_emp.ename);
end loop;
close c;
end;
declare
cursor c is
select * from emp;
v_emp emp%rowtype;
begin
open c;
fetch c into v_emp;
while(c%found) loop
dbms_output.put_line(v_emp.ename);
fetch c into v_emp;
--fetch c into v_emp; 导致第一条没有打印,最后一条打印2遍。
--dbms_output.put_line(v_emp.ename);
end loop;
close c;
end;
declare
cursor c is
select * from emp;
begin
for v_emp in c loop
dbms_output.put_line(v_emp.ename);
end loop;
end;
--带参数的游标
declare
cursor c(v_deptno emp.deptno%type,v_job emp.job%type)
is
select ename,sal from emp where deptno =v_deptno and job= v_job;
--v_temp c%rowtype;
begin
for v_temp in c(30,'CLERK') loop --for自动打开游标。
dbms_output.put_line(v_temp.ename);
end loop;
end;
--可更新的游标
declare
cursor c
is
select * from emp2 for update;
--v_temp c%rowtype;
begin
for v_temp in c loop
if(v_temp.sal <2000) then
update emp2 set sal = sal*2 where current of c;
elsif(v_temp.sal = 5000) then
delete from emp2 where current of c;
end if;
end loop;
commit;
end;
PLSql是SQL的补充,PL过程语言procedure language,SQL:Structured Query Language。
PLSql 带有分支、循环的语言,SQL没有分支、循环的语言。
set serveroutput on;
-- 简单的PL/SQL语句块
declare
v_name varchar2(20);
begin
v_name :='myname';
dbms_output.put_line(v_name);
end;
/
--语句块的组成
declare
v_num number := 0 ;
begin
v_num := 2/v_num;
dbms_output.put_line(v_num);
exception
when others then
dbms_output.put_line('error');
end;
/
--变量声明的规则
1、变量名不能够使用保留字,如from、select等
2、第一个字符必须是字母
3、变量名最多包含30个字符
4、不要与数据库的表或者列同名
5、每一行只能声明一个变量
--常用变量类型
1、binary_integer:整数,主要用来计数而不是用来表示字段类型
2、number:数字类型
3、char:定长字符串
4、varchar2:变长字符串
5、date:日期
6、long:长字符串,最长2GB
7、boolean:布尔类型,可以取值true、false和null值
--变量声明
declare
v_temp number(1);
v_count binary_integer :=0;
v_sal number(7,2):= 4000.00;
v_date date:= sysdate;
v_pi constant number(3,2) := 3.14; --constant相当java的final常量
v_valid boolean := false;
v_name varchar2(20) not null :='MyName';
begin
dbms_output.put_line('v_temp value:'|| v_temp);
end;
--变量声明,使用%type属性
declare
v_empno number(4);
v_empno2 emp.empno%type;
v_empno3 v_empno2%type;
begin
dbms_output.put_line('Test');
end;
--简单变量赋值
declare
v_name varchar2(20);
v_sal number(7,2);
v_sal2 number(7,2);
v_valid boolean :=false;
v_date date;
begin
va_name :='MyName';
v_sal :=23.77;
v_sal2 :=23.77;
v_valid:=(v_sal = v_sal2);
v_date:=to_date('1999-08-12 12:23:38','YYYY-MM-DD HH24:MI:SS');
end;
--Table变量类型,定义一种新的类型,是数组。
declare
type type_table_emp_empno is table of emp.empno%type index by binary_integer;
v_empno type_table_emp_empno;
begin
v_empnos(0) := 7369;
v_empnos(2) := 7839;
v_empnos(-1) := 9999;
dbms_output.put_line(v_empnos(-1));
end;
--Record变量类型,类似java的类的概念。
declare
type type_record_dept is record
(
deptno dept.deptno%type,
dname dept.dname%type,
loc dept.loc%type
);
v_tmp type_record_dept;
begin
v_tmp.deptno := 50;
v_tmp.dname := 'aaaa';
v_tmp.loc := 'bj';
dbms_output.put_line(v_temp.deptno||''||v_temp.dname);
end;
--使用%rowtype声明Record变量
declare
v_temp dept%rowtype;
begin
v_tmp.deptno := 50;
v_tmp.dname := 'aaaa';
v_tmp.loc := 'bj';
dbms_output.put_line(v_temp.deptno||''||v_temp.dname);
end;
--SQL语句的运用,返回数据有且只有一条记录。
declare
v_ename emp.ename%type;
v_sal emp.sal%type;
begin
select ename,sal into v_ename,v_sal from emp where empno = 7369;
dbms_output.put_line(v_ename||''||v_sal);
end;
declare
v_emp emp%rowtype;
begin
select * into v_emp from emp where empno = 7369;
dbms_output.put_line(v_emp.ename);
end;
declare
v_deptno dept.deptno%type := 50;
v_dname dept.dname%type := 'aaaa';
v_loc dept.loc%type := 'bj';
begin
insert into dept2 values (v_deptno,v_dname,v_loc);
commit;
end;
declare
v_deptno emp2.deptno%type := 10;
v_count number ;
begin
--update emp2 set sal = sal/2 where deptno = v_deptno;
--select deptno into v_deptno from emp2 where empno = 7369;
select count(*) into v_count from emp2;
dbms_output.put_line(sql%rowcount||'条记录被影响');
commit;
end;
DDL语句:
begin
execute immediate 'create table T(nnn varchar2(20) default ''aaa'')';
end;
--if语句:取出7369的薪水,如果<1200,则输出'low',如果<2000则输出'middle',否则'high'
declare
v_sal emp.sal%type;
begin
select sal into v_sal from emp where empno = 7369;
if(v_sal < 1200) then
dbms_output.put_line('low');
elsif(v_sal < 2000) then
dbms_output.put_line('middle');
else
dbms_output.put_line('high');
end if;
end;
--循环
declare
i binary_integer := 1;
begin
loop
dbms_output.put_line(i);
i := i+ 1;
exit when (i >= 11);
end loop;
end;
declare
j binary_integer := 1;
begin
while j< 11 loop
dbms_output.put_line(j);
j := j+ 1;
end loop;
end;
begin
for k in 1..10 loop
dbms_output.put_line(k);
end loop;
for k in reverse 1..10 loop
dbms_output.put_line(k);
end loop;
end;
--错误处理
declare
v_temp number(4);
begin
select empno into v_temp from emp where deptno = 10;
exception
when too_many_rows then
dbms_output.put_line('太多记录了');
when others then
dbms_output.put_line('error');
end;
declare
v_temp number(4);
begin
select empno into v_temp from emp where empno = 2222;
exception
when no_data_found then
dbms_output.put_line('没数据');
end;
create table errorlog
(
id number primary key,
errcode number,
errmsg varchar2(1024),
errdate date
);
create sequence seq_errorlog_id start with 1 increment by 1;
declare
v_deptno dept.deptno%type := 10;
v_errmsg varchar2(1024);
begin
delete from dept where deptno = v_deptno;
commit;
exception
when others then
rollback;
v_errcode := SQLCODE; --关键字,代表出错的代码。
v_errmsg := SQLERRM;
insert into errorlog values (seq_errorlog_id.nextval,v_errcode,v_errmsg,sysdate);
commit;
end;
构造数据库必须遵循一定的规则。在关系数据库中,这种规则就是范式。关系数据库中的关系必须满足一定的要求,即满足不同的范式。目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、第四范式(4NF)、第五范式(5NF)和第六范式(6NF)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
第一范式(1NF):无重复的列。
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
第二范式(2NF):属性完全依赖于主键[消除部分子函数依赖]。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是属性完全依赖于主键。
第三范式(3NF):属性不依赖于其它非主属性[消除传递依赖]。
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。
所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。
序列:sequence,产生一个独一无二的序列,是oracle特有的。
create table article
(
id number,
title varchar2(1024),
cont long
);
insert into article values(seq.nextval,'a','b');
select * from user_sequences; --查询序列
create sequence seq; --创建序列seq对象
select seq.nextval from dual;
drop sequence seq;
视图:一个虚表,也是一个子查询,是存储在数据字典里的一条select语句。
视图:基于一个表或多个表或视图的逻辑表,本身不包含数据,通过它可以对表里面的数据进行查询和修改,视图基于的表称为基表。
视图的优点:
1、对数据库的访问,可以有选择性的选取数据库里的一部分信息,整张表的信息不对外开放。2.用户通过简单的查询可以从复杂查询中得到结果。
视图的缺点:
如果一个表的结构改了,相应的视图如果用到了该表的字段,也要进行修改,增加维护工作量。
简单视图:只从单表里获取数据,不包含函数和数据组,可以实现DML操作。
复杂视图:从多表获取数据,包含函数和数据组,不可以DML操作。
视图的创建:
CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW view_name
[(alias[, alias]...)]
AS subquery
[WITH CHECK OPTION [CONSTRAINT constraint]]
[WITH READ ONLY]
其中:
OR REPLACE:若所创建的试图已经存在,ORACLE自动重建该视图;
FORCE:不管基表是否存在ORACLE都会自动创建该视图;
NOFORCE:只有基表都存在ORACLE才会创建该视图:
alias:为视图产生的列定义的别名;
subquery:一条完整的SELECT语句,可以在该语句中定义别名;
WITH CHECK OPTION :插入或修改的数据行必须满足视图定义的约束;
WITH READ ONLY :该视图上不能进行任何DML操作。
例如:
CREATE OR REPLACE VIEW dept_sum_vw
(name,minsal,maxsal,avgsal)
AS SELECT d.dname,min(e.sal),max(e.sal),avg(e.sal)
FROM emp e,dept d
WHERE e.deptno=d.deptno
GROUP BY d.dname;
查询视图:select * from user_views;
修改视图:通过OR REPLACE 重新创建同名视图即可。
删除视图:DROP VIEW VIEW_NAME;
视图的定义原则:
1.视图的查询可以使用复杂的SELECT语法,包括连接/分组查询和子查询;
2.在没有WITH CHECK OPTION和 READ ONLY 的情况下,查询中不能使用ORDER BY 子句;
3.如果没有为CHECK OPTION约束命名,系统会自动为之命名,形式为SYS_Cn;
4.OR REPLACE选项可以不删除原视图便可更改其定义并重建,或重新授予对象权限。
视图上的DML操作,应遵循的原则:
1.简单视图可以执行DML操作;
2.在视图包含GROUP 函数,GROUP BY子句,DISTINCT关键字时不能删除数据行;
3.在视图不出现下列情况时可通过视图修改基表数据或插入数据:
a.视图中包含GROUP 函数,GROUP BY子句,DISTINCT关键字;
b.使用表达式定义的列;
c .ROWNUM伪列。
d.基表中未在视图中选择的其他列定义为非空且无默认值。
WITH CHECK OPTION 子句限定:
通过视图执行的INSERTS和UPDATES操作不能创建该视图检索不到的数据行,因为它会对插入或修改的数据行执行完整性约束和数据有效性检查。
例如:
CREATE OR REPLACE VIEW vw_emp20
AS SELECT * FROM emp
WHERE deptno=20
WITH CHECK OPTION constraint vw_emp20_ck;
视图 已建立。
查询结果:
SELECT empno,ename,job FROM vw_emp20;
EMPNO ENAME JOB
--------------------- -------------- -------------
7369 SMITH CLERK
7566 JONES MANAGER
7902 FORD ANALYST
修改:
UPDATE vw_emp20
SET deptno=20
WHERE empno=7902;
将产生错误:
UPDATE vw_emp20
*
ERROR 位于第一行:
ORA-01402:视图WITH CHECK OPTION 违反WHERE 子句
索引:--像字典里面的索引。
表建立索引后在插入数据时,一要把数据写入表里,二要把该数据记入索引里面,因此查询效率高、但插入效率低。
create index idx_stu_email on stu(email,class); --组合索引,查询效率高。
drop index idx_stu_email;
select * from user_indexes; -- 查询索引
Oracle的数据库对象分为五种:表,视图,序列,索引和同义词。
select * from user_tables -- 当前用户下有多少张表
select * from user_views -- 当前用户下有多少张视图
select * from user_sequences; --查询序列
select * from user_indexes; -- 查询索引
select * from user_constraints -- 当前用户下有多少约束
select * from dictionary --数据字典表的表
DDL(data definition language):DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
数据类型:VARCHAR2(50)最大4K(4096字节)、CHAR(1)最大2k、NUMBER(10,6)、NUMBER(6)、DATE、
LONG 变长字符串,最大长度达2G。
约束条件有5个:非空、唯一、主键、外键、check。
create table stu
(
id number(6), --primary key
name varchar2(20) constraint stu_name_nn not null, --stu_name_nn别名
sex number(1),
age number(3),
sdate date,
grade number(2) default 1,
class number(4), --references class(id)
email varchar2(50),
--email varchar2(50) unique --字段级约束,不能有重复值
constraint stu_name_email_uni unique(name,email), --表级约束
constraint stu_id_pk primary key(id), --表级约束
constraint stu_class_fk foreign key(class) references class(id) --被参考字段必须是主键
);
create table class
(
id number(4) primary key,
name varchar2(20) not null
)
alter table stu add(addr varchar2(100)); --对已存在的表新增字段
alter table stu modify(addr varchar2(150)); --对字段修改
alter table stu drop (addr); --删除一个字段
alter table stu drop constraint stu_class_fk;
delete from class;
drop table class;
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
DML(data manipulation language):它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言。
conn sys/sys as sysdba;
drop user pcisv6 cascade;
exp --备份scott用户下的表
--创建用户,identified为认证相当是密码,quota配额就是分配空间。
create user pcisv6 identified by 11 default tablespace core6 quota 10M on corev6
grant create session,create table,create view to pcisv6; --授权,session是用于登录的
imp --导入scott用户下的表
SELECT:
select rownum r,ename from emp; --rownum行数,目前只能使用<、<=, 而没有直接>、=的写法。
select ename, sal --求薪水最高的前5人
from (select ename, sal from emp order by sal desc)
where rownum <= 5;
--求薪水最高的前6到10人
select ename,sal,rownum r from emp order by sal desc; --r 排序混乱
select ename,sal,rownum r from (select ename,sal from emp order by sal desc); --此时r序号按新表排序
select ename, sal -- 此处为结果
from (select ename, sal, rownum r
from (select ename, sal from emp order by sal desc))
where r >= 6
and r <= 10;
INSERT:
insert into dept values(50,'game','bj'); --整条记录
rollback;
create table dept2 as selet * from emp; --创建dept2表
insert into dept2(deptno,dname) values(60,'game2'); --有选择的字段插入
insert into dept2 select * from dept; --插入一个表, 2个表结构一样
UPDATE:
update emp2 set sal=sal*12,ename=ename||'-' where deptno=10;
DELETE:
delete from dept2 where deptno<25;
rollback;
TRANSACTION:
transaction 起始一条dml语句,在commit、rollback时完成。
transaction 在执行dml后,在其后有执行了ddl、dcl时,事务自动提交。
在正常退出exit时,事务自动提交。
在非正常退出时,事务回滚。
------------------------------------------------------------
例子:
有3个表S,C,SC
S(SNO,SNAME)代表(学号,姓名)
C(CNO,CNAME,CTEACHER)代表(课号,课名,教师)
SC(SNO,CNO,SCGRADE)代表(学号,课号成绩)
问题:
1,找出没选过“黎明”老师的所有学生姓名。
2,列出2门以上(含2门)不及格学生姓名及平均成绩。
3,即学过1号课程有学过2号课所有学生的姓名。
请用标准SQL语言写出答案,方言也行(请说明是使用什么方言)。
1.
select sname froms
join sc on (s.sno = sc.sno)
join c(c.cno = sc.cno)
where c.cteacher <> 'liming';
2.
select sname
where sno in (select sno
from sc
where scgrade < 60
group by sno
having count(*) >= 2);
3.
select sname
where sno in (select sno
from sc
where cno = 1
and sno in (select sno from sc where cno = 2));
错误原因:在Oracle新建了一个表,名为“QueryHistory",用来保存用户的查询记录,这时,再用"Select * from QueryHistory"来查询,报 "ORA-00942: 表或视图不存在 "。
错误分析:利用Google搜索找到了原因,
oracle是大小写敏感的,如果定义表名称或列名称的时候没有用引号引起来的话 oracle会把他们全部转换为大写,这时就会出现错误了。
解决方法:将语句改为"Select * from "QueryHistory" 或是语句全部大写。
PCIS[2010-07-08 18:08:02,531]>> ERROR>> [BizControllerImpl异常堆栈{事务ID/用户代码}:[1278583679437325]/[00000210]:com.fwk.service.BusinessServiceException: com.fwk.dao.DaoException: 保存保单, saveOrUpdatePolicy()时出错; nested exception is org.springframework.dao.DataIntegrityViolationException: Could not execute JDBC batch update; nested exception is org.hibernate.exception.ConstraintViolationException: Could not execute JDBC batch update
at com.pcis.policy.dm.PolicyDAO.saveOrUpdatePolicy(PolicyDAO.java:193)
at com.pcis.policy.app.newbusiness.service.PolicyAppService.savePolicy(PolicyAppService.java:343)
at com.pcis.policy.app.underwrite.bm.UnderwriteBM.submitUnderwrite(UnderwriteBM.java:139)
at com.pcis.policy.app.underwrite.action.UnderwriteBizAction.submitUnderwrite(UnderwriteBizAction.java:548)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
...
Caused by: org.springframework.dao.DataIntegrityViolationException: Could not execute JDBC batch update; nested exception is org.hibernate.exception.ConstraintViolationException: Could not execute JDBC batch update
at org.springframework.orm.hibernate3.SessionFactoryUtils.convertHibernateAccessException(SessionFactoryUtils.java:624)
at org.springframework.orm.hibernate3.HibernateAccessor.convertHibernateAccessException(HibernateAccessor.java:412)
at org.springframework.orm.hibernate3.HibernateTemplate.execute(HibernateTemplate.java:379)
at org.springframework.orm.hibernate3.HibernateTemplate.flush(HibernateTemplate.java:841)
at com.fwk.dao.BaseDao.flush(Unknown Source)
at com.pcis.policy.dm.PolicyDAO.saveOrUpdatePolicy(PolicyDAO.java:174)
... 80 more
Caused by: java.sql.BatchUpdateException: ORA-00001: unique constraint (PCISV6_TS.UI_PLY_CVRG) violated
at oracle.jdbc.driver.DatabaseError.throwBatchUpdateException(DatabaseError.java:602)
at oracle.jdbc.driver.OraclePreparedStatement.executeBatch(OraclePreparedStatement.java:9350)
at oracle.jdbc.driver.OracleStatementWrapper.executeBatch(OracleStatementWrapper.java:210)
at org.apache.commons.dbcp.DelegatingStatement.executeBatch(DelegatingStatement.java:297)
at org.hibernate.jdbc.BatchingBatcher.doExecuteBatch(BatchingBatcher.java:48)
at org.hibernate.jdbc.AbstractBatcher.executeBatch(AbstractBatcher.java:246)
... 90 more
分析及解决:
在页面保存的时候,后台提示是违反唯一索引,通过UI_PLY_CVRG 查询相应的表,
select * from user_indexes where index_name='UI_PLY_CVRG'
该表是WEB_PLY_CVRG ,而该表的唯一索引UI_PLY_CVRG 是由该表的3个字段组成 C_PLY_NO、N_EDR_PRJ_NO、 N_SEQ_NO,然后看下页面发现是N_SEQ_NO有4个重复,删除多余的记录即可保存成功。
在项目中经常需要处理一些输入字符,往往我们也需要对其进行校验,而使用正则表达式是一个很好的处理方法。下面介绍一款处理正则表达式的软件 Match Tracer v2.0,MTracer最有用的特性是中文的正则式分析树。
下载地址:http://www.52z.com/down/30160.Html
官网:http://www.regexlab.com/zh/mtracer/
在平时的项目中,经常需要开一下别人写的源码,而此时别人提供的往往是jar文件,根本看不了,很是不爽。最近很偶然的看见一个同事在eclipse下查看class文件,很是兴奋。下面讲下是如何安装下插件的。
打开class文件,我目前了解的有2种类型的软件:
一、 在eclipse外部打开jar文件。
Java Decompiler.exe,主页JD home page: http://java.decompiler.free.fr ,该软件可以打开整个jar包,功能很强大。
二、 在eclipse内部打开jar文件。
net.sf.jadclipse_3.3.0.jar、jad158g.win.zip,需要这两个文件。
准备工作:
1、下载jad.exe文件: http://www.varaneckas.com/jad
2、下载jadeclipse插件: http://sourceforge.net/projects/jadclipse/files/
安装如下:
1、将jadeclipse插件net.sf.jadclipse_3.3.0.jar 拷贝到myeclipse安装目录E:\MyEclipse 6.0\eclipse\myplugins\jad\eclipse\plugins目录下,并在目录E:\MyEclipse 6.0\eclipse\links下新建文件jad.link,内容如下path=E:\\MyEclipse 6.0\\eclipse\\myplugins\\jad\\
2、将jad.exe解压到指定目录。如:D:\tools
3、在eclipse窗口下,点击Window > Preferences > Java > JadClipse > Path to Decompiler。(设置jad的绝对路径,如 D:\tools\jad\jad.exe)。Use Eclipse code formatter(overrides Jad formatting instructions)选项打勾,与格式化出来的代码样式一致。
4、在eclipse窗口下,点击Window > Preferences > Java > JadClipse > Misc,将Convert Unicode strings into ANSI strings选项打勾,避免反编译后可能出现的中文乱码。
5、重新启动myeclipse,eclipse自动将JadClipse Class File Viewer设置成class文件的缺省打开方式。如果没有默认,可以在Eclipse的Window > Preferences >General >Editors> File Associations中修改“*.class”默认关联的编辑器为“JadClipse Class File Viewer”。设置完成后,双击*.class文件,eclipse将自动反编译。
select e1.ename,e2.ename from emp e1 join emp e2 on (e1.mgr=e2.empno); --自连接,从e2中取出e1的经理人。
select ename,dname from emp e left join dept d on (e.deptno=d.deptno); --左外连接
select ename,dname from emp e right outer join dept d on (e.deptno=d.deptno); --右外连接
select ename,dname from emp e full join dept d on (e.deptno=d.deptno); --全连接
--求部门中哪些人的薪水最高
select ename,sal from emp
join (select max(sal) max_sal,deptno from emp group by deptno) t
on (emp.sal = t.max_sal and emp.deptno = t.deptno);
--求部门平均薪水的等级
select deptno,avg_sal,grade from
(select deptno,avg(sal) avg_sal from emp group by deptno) t
join salgrade s on (t.avg_sal between s.losal and s.hisal);
--求部门平均的薪水等级
select avg(grade) from
(select deptno,ename,grade from emp join salgrade s on (emp.sal between s.losal and s.hisal )) t
group by deptno;
--雇员中有哪些人是经理人
select ename from emp where empno in (select distinct mgr from emp);
--不准用组函数,求薪水的最高值。采用的是自连接。
select distinct sal from emp where sal not in
(select distinct e1.sal from emp e1 join emp e2 on (e1.sal < e2.sal));
--求平均薪水最高的部门的部门编号。嵌套的组函数。
select deptno,avg_sal from
(select avg(sal) avg_sal,deptno from emp group by deptno)
where avg_sal =
(select max(avg(sal)),deptno from emp group by deptno;
--求平均薪水的等级最低的部门的部门名称。
select dname,t1.deptno,grade,avg_sal from
(
select deptno,grade,avg_sal from
(select deptno,avg(sal) avg_sal from emp group by deptno) t
join salgrade s on (t.avg_sal between s.losal and s.hisal)
)
t1
join dept on (t1.deptno = dept.deptno)
)
where t1.grade =
(
select min(grade) from
(select deptno,grade,avg_sal from
(select deptno,grade,avg(sal) avg_sal from emp group by deptno) t
join salgrade s on (t.avg_sal between s.losal and s.hisal)
)
)
--求平均薪水的等级最低的部门的部门名称。采用视图。
conn sys/sys as sysdba;
grant create table,create view to scott;
create view v$_dept_avg_sal_info as
select deptno,grade,avg_sal from
(select deptno,grade,avg(sal) avg_sal from emp group by deptno) t
join salgrade s on (t.avg_sal between s.losal and s.hisal);
select dname,t1.deptno,grade,avg_sal from
v$_dept_avg_sal_info t1
join dept on (t1.deptno = dept.deptno)
)
where t1.grade =
(
select min(grade) from v$_dept_avg_sal_info
)
-- 比普通员工的最高薪水还要高的经理人名称。
select ename from emp
where empno in (select distinct mgr from emp where mgr is not null)
and sal >
(
select max(sal) from emp where empno not in
(select distinct mgr from emp where mgr is not null)
)
--1992年sql标准,连接条件和过滤条件写在一起。
select ename,dname,grade
from emp e,dept d,salgrade s
where e.deptno = d.deptno and e.sal between s.losal and s.hisal and job<>'CLERK';
--1999年sql标准,连接条件和过滤条件分开
select ename,dname,grade
from emp e join dept d on (e.deptno = d.deptno)
join salgrade s on (e.sal between s.losal and s.hisal)
where ename not like '_A%';
increase the size of the pool and retry..] - [org.hibernate.util.JDBCExceptionReporter] -950125750 [[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kernel.Default (self-tuning)']
PCIS[2010-07-01 12:51:47,456]>> WARN>> [SQL Error: 0, SQLState: null] - [org.hibernate.util.JDBCExceptionReporter] -950125750 [[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kernel.Default (self-tuning)']
PCIS[2010-07-01 12:51:47,456]>>ERROR>> [Cannot obtain connection: driverURL = jdbc:weblogic:pool:pcis_ts, props = {EmulateTwoPhaseCommit=false, connectionPoolID=pcis_ts, jdbcTxDataSource=true, LoggingLastResource=false, dataSourceName=pcis_ts}] - [org.hibernate.util.JDBCExceptionReporter] -950125750 [[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kernel.Default (self-tuning)']
PCIS[2010-07-01 12:51:47,456]>> WARN>> [SQL Error: 0, SQLState: null] - [org.hibernate.util.JDBCExceptionReporter] -950125750 [[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kernel.Default (self-tuning)']
PCIS[2010-07-01 12:51:47,456]>>ERROR>> [weblogic.common.resourcepool.ResourceLimitException: No resources currently available in pool pcis_ts to allocate to applications, please increase the size of the pool and retry..] - [org.hibernate.util.JDBCExceptionReporter] -950125750 [[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kernel.Default (self-tuning)']
PCIS[2010-07-01 12:51:47,456]>> WARN>> [SQL Error: 0, SQLState: null] - [org.hibernate.util.JDBCExceptionReporter] -950125750 [[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kernel.Default (self-tuning)']
PCIS[2010-07-01 12:51:47,456]>>ERROR>> [Cannot obtain connection: driverURL = jdbc:weblogic:pool:pcis_ts, props = {EmulateTwoPhaseCommit=false, connectionPoolID=pcis_ts, jdbcTxDataSource=true, LoggingLastResource=false, dataSourceName=pcis_ts}] - [org.hibernate.util.JDBCExceptionReporter] -950125750 [[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kerne
l.Default (self-tuning)']
[com.pcis.premium.service.PremiumService] -950125750 [[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kernel.Default (self-tuning)']
org.springframework.jdbc.UncategorizedSQLException: Hibernate operation: Cannot open connection; uncategorized SQLException for SQL [???]; SQL state [null]; error code [0]; weblogic.common.resourcepool.ResourceLimitException: No resources currently available in pool pcis_ts to allocate to applications, please increase the size of the pool and retry..; nested exception is weblogic.jdbc.extensions.PoolLimitSQLException: weblogic.common.resourcepool.ResourceLimitException: No resources currently available in pool pcis_ts to allocate to applications, please increase the size of the pool and retry..
at org.springframework.jdbc.support.SQLStateSQLExceptionTranslator.translate(SQLStateSQLExceptionTranslator.java:124)
at org.springframework.jdbc.support.SQLErrorCodeSQLExceptionTranslator.translate(SQLErrorCodeSQLExceptionTranslator.java:322)
at org.springframework.orm.hibernate3.HibernateAccessor.convertJdbcAccessException(HibernateAccessor.java:424)
at org.springframework.orm.hibernate3.HibernateAccessor.convertHibernateAccessException(HibernateAccessor.java:410)
at org.springframework.orm.hibernate3.HibernateTemplate.execute(HibernateTemplate.java:379)
at org.springframework.orm.hibernate3.HibernateTemplate.find(HibernateTemplate.java:872)
at org.springframework.orm.hibernate3.HibernateTemplate.find(HibernateTemplate.java:868)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:727)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:820)
at weblogic.servlet.internal.StubSecurityHelper$ServletServiceAction.run(StubSecurityHelper.java:226)
at weblogic.servlet.internal.StubSecurityHelper.invokeServlet(StubSecurityHelper.java:124)
at weblogic.servlet.internal.ServletStubImpl.execute(ServletStubImpl.java:283)
at weblogic.servlet.internal.TailFilter.doFilter(TailFilter.java:26)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at org.springframework.security.util.FilterChainProxy.doFilter(FilterChainProxy.java:168)
at org.springframework.web.filter.DelegatingFilterProxy.invokeDelegate(DelegatingFilterProxy.java:183)
at org.springframework.web.filter.DelegatingFilterProxy.doFilter(DelegatingFilterProxy.java:138)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at org.jasig.cas.client.session.SingleSignOutFilter.doFilter(SingleSignOutFilter.java:99)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at com.isoftstone.iaeap.web.filter.SetCharacterEncodingFilter.doFilter(Unknown Source)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at weblogic.servlet.internal.WebAppServletContext$ServletInvocationAction.run(WebAppServletContext.java:3393)
at weblogic.security.acl.internal.AuthenticatedSubject.doAs(AuthenticatedSubject.java:321)
at weblogic.security.service.SecurityManager.runAs(Unknown Source)
at weblogic.servlet.internal.WebAppServletContext.securedExecute(WebAppServletContext.java:2140)
at weblogic.servlet.internal.WebAppServletContext.execute(WebAppServletContext.java:2046)
at weblogic.servlet.internal.ServletRequestImpl.run(ServletRequestImpl.java:1366)
at weblogic.work.ExecuteThread.execute(ExecuteThread.java:200)
at weblogic.work.ExecuteThread.run(ExecuteThread.java:172)
Caused by: weblogic.jdbc.extensions.PoolLimitSQLException: weblogic.common.resourcepool.ResourceLimitException: No resources currently available in pool pcis_ts to allocate to applications, please increase the size of the pool and retry..
at weblogic.jdbc.common.internal.JDBCUtil.wrapAndThrowResourceException(JDBCUtil.java:242)
at weblogic.jdbc.pool.Driver.connect(Driver.java:160)
at weblogic.jdbc.jts.Driver.getNonTxConnection(Driver.java:642)
at weblogic.jdbc.jts.Driver.connect(Driver.java:124)
at weblogic.jdbc.common.internal.RmiDataSource.getConnection(RmiDataSource.java:339)
at org.springframework.orm.hibernate3.LocalDataSourceConnectionProvider.getConnection(LocalDataSourceConnectionProvider.java:82)
at org.hibernate.jdbc.ConnectionManager.openConnection(ConnectionManager.java:423)
at org.hibernate.jdbc.ConnectionManager.getConnection(ConnectionManager.java:144)
at org.hibernate.jdbc.AbstractBatcher.prepareQueryStatement(AbstractBatcher.java:139)
at org.hibernate.loader.Loader.prepareQueryStatement(Loader.java:1547)
at org.hibernate.loader.Loader.doQuery(Loader.java:673)
at org.hibernate.loader.Loader.doQueryAndInitializeNonLazyCollections(Loader.java:236)
at org.hibernate.loader.Loader.doList(Loader.java:2213)
at org.hibernate.loader.Loader.listIgnoreQueryCache(Loader.java:2104)
at org.hibernate.loader.Loader.list(Loader.java:2099)
at org.hibernate.loader.hql.QueryLoader.list(QueryLoader.java:378)
at org.hibernate.hql.ast.QueryTranslatorImpl.list(QueryTranslatorImpl.java:338)
at org.hibernate.engine.query.HQLQueryPlan.performList(HQLQueryPlan.java:172)
at org.hibernate.impl.SessionImpl.list(SessionImpl.java:1121)
at org.hibernate.impl.QueryImpl.list(QueryImpl.java:79)
at org.springframework.orm.hibernate3.HibernateTemplate$30.doInHibernate(HibernateTemplate.java:881)
at org.springframework.orm.hibernate3.HibernateTemplate.execute(HibernateTemplate.java:374)
... 31 more
原因:主要是weblogic的连接池已满,需要重新设置或者重启weblogic的AdminServer服务器进行释放连接。
操作:进入weblogic控制台,选择:域-->Services-->JDBC-->Data Source-->点击control-->选中AdminServer,对其重启即可。
select chr(65) from dual;
select ascii('A') from dual; --求编码
select ename from emp where lower(ename) like '_a%' -- upper大写
select round(23.652,2) from dual; -- 四舍五入 23.65,round(23.652)为24
select substr(ename,1,3) from emp; --从第一个开始,总接取3个。
select ename,sal,deptno from emp where length(sal)>3;
select to_char(sal,'$99,999.9999') from emp; --'L00000.0000'千位不够补0
select to_char(sysdate,'YYYY-MM-DD HH24:MI:SS') from dual;
select ename,hiredate from emp where hiredate>to_date('1981-2-20 12:34:56','YYYY-MM-DD HH24:MI:SS');
select sal from emp where sal>to_number('$1,250.00','$9,999.99');
select ename,sal*12 + nvl(comm,0) from emp; --对空值处理
组函数:
select max(sal) from emp;
select min(sal) from emp;
select avg(sal) from emp;
select sum(sal) from emp;
select count(*) from emp; -- *求出总记录数, count(comm)求出该列不为空的值。
select deptno,job,max(sal) from emp group by deptno,job; --按照条件组合分组
select ename from emp where sal =(select max(sal) from emp); --子查询
update Web_Bas_Edr_Rsn set c_rsn_txt=REPLACE(c_rsn_txt,'天津','北京') where c_rsn_txt like '%天津%' --批量替换
-- having对分组进行限制,where对单行限制
select avg(sal) from emp where sal>1000 group by deptno having avg(sal) >1500 order by avg(sal) desc;
sqlplus sys/sys as sysdba;
alert user scott account unlock;
desc emp;
select ename,sal*12 from emp;
select sysdate from dual; --dual为空表
select ename,sal*12 annual_sal from emp; --别名
--数值+null 为null
select ename||sal from emp; --拼串
select ename||'aaa''bbb' from emp; --含'的拼串,''替换为'
select distinct deptno,job from emp; --去掉2个字段值的组合
select * from emp where deptno=10 and ename='CLARK';
select ename,sal from emp where sal>1500;
select ename,sal from emp where deptno<>10;
select ename,sal from emp where sal between 800 and 1500; -- sal>=800 and sal<=1500
select ename,sal,comm from emp where comm is null; --is not null
select ename,sal,comm from emp where sal in (800,1500); -- not in (800,1500)
select ename from emp where ename like '_A%' -- %为0个或多个,-为1个
select ename from emp where ename like '%\%%' -- 名字含有%,需要\为转义字符处理
select ename from emp where ename like '%$%%' escape '$' -- 可以使用$作为转义字符
select ename,sal,deptno from emp order by deptno asc,ename desc; -- 升序asc,降序 desc
今天想把tomcat下的程序迁移到weblogic92上,可是程序在发布到weblogic92时报下面的异常:
Home > Summary of Deployments > Summary of JDBC Data Sources > myDataSource > Summary of Deployments :
Messages
An error occurred during activation of changes, please see the log for details.
[HTTP:101064][WebAppModule(nonvhl:WebRoot)] Error parsing descriptor in Web appplication "E:\workspace\nonvhl_policy_TS\WebRoot"
weblogic.application.ModuleException: VALIDATION PROBLEMS WERE FOUND E:\workspace\nonvhl_policy_TS\WebRoot\WEB-INF\web.xml:133:5:133:5: problem: cvc-complex
-type.2.4a: Expected elements 'servlet-class@http://java.sun.com/xml/ns/j2ee jsp-file@http://java.sun.com/xml/ns/j2ee' instead of 'display-
name@http://java.sun.com/xml/ns/j2ee' here in element servlet@http://java.sun.com/xml/ns/j2ee: at weblogic.servlet.internal.WebAppModule.loadDescriptor
(WebAppModule.java:784) at weblogic.servlet.internal.WebAppModule.prepare(WebAppModule.java:275) at
weblogic.application.internal.flow.ScopedModuleDriver.prepare(ScopedModuleDriver.java:176) at
weblogic.application.internal.flow.ModuleListenerInvoker.prepare(ModuleListenerInvoker.java:93) at
weblogic.application.internal.flow.DeploymentCallbackFlow$1.next(DeploymentCallbackFlow.java:360) at weblogic.application.utils.StateMachineDriver.nextState
(StateMachineDriver.java:26) at weblogic.application.internal.flow.DeploymentCallbackFlow.prepare(DeploymentCallbackFlow.java:56) at
weblogic.application.internal.flow.DeploymentCallbackFlow.prepare(DeploymentCallbackFlow.java:46) at weblogic.application.internal.BaseDeployment$1.next
(BaseDeployment.java:621) at weblogic.application.utils.StateMachineDriver.nextState(StateMachineDriver.java:26) at
weblogic.application.internal.BaseDeployment.prepare(BaseDeployment.java:208) at weblogic.application.internal.DeploymentStateChecker.prepare
(DeploymentStateChecker.java:147) at weblogic.deploy.internal.targetserver.AppContainerInvoker.prepare(AppContainerInvoker.java:61) at
weblogic.deploy.internal.targetserver.operations.ActivateOperation.createAndPrepareContainer(ActivateOperation.java:189) at
weblogic.deploy.internal.targetserver.operations.ActivateOperation.doPrepare(ActivateOperation.java:87) at
weblogic.deploy.internal.targetserver.operations.AbstractOperation.prepare(AbstractOperation.java:217) at
weblogic.deploy.internal.targetserver.DeploymentManager.handleDeploymentPrepare(DeploymentManager.java:718) at
weblogic.deploy.internal.targetserver.DeploymentManager.prepareDeploymentList(DeploymentManager.java:1185) at
weblogic.deploy.internal.targetserver.DeploymentManager.handlePrepare(DeploymentManager.java:247) at
原因:经过分析是web.xml配置的问题,有些servlet上面配置了'display-name',这个weblogic是不支持的。
解决:在web.xml中把'display-name'删除掉,工程就可以在weblogic下成功发布。
在配置weblogic的数据源时,提示一下信息:
Home > Summary of Deployments > Summary of JDBC Data Sources:
Messages
An error occurred during activation of changes, please see the log for details.
weblogic.application.ModuleException:
weblogic.common.ResourceException: Could not create pool connection. The DBMS driver exception was: Io 异常: The Network Adapter could not establish the connection
解决:主要是我在配置数据源时没有把Oracle的服务启动造成的。
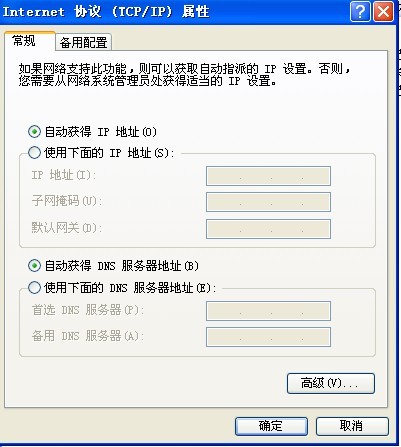
1、今天到客户现场,输入系统地址,发现登录不上,后来查了下是DNS域名的问题。
原因:客户的机器域名解析地址是:google的DNS,首选DNS服务器和备用DNS服务器分别设置为 8.8.8.8和8.8.4.4。由于我们是在本地局域网设置的域名,公网的域名解析器不识别,导致登录不了系统。
解决:设置自动获取DNS。
2、登录系统后,打来相关的页面,又出现页面加载失败
原因:主要是域名解析后,对相应的ip地址有限制。
解决:把域名、ip地址都加入为可信任站点,调低安全级别即可。

1、声明式事务配置
* 配置SessionFactory
* 配置事务管理器
* 事务的传播特性
* 那些类那些方法使用事务
2、编写业务逻辑方法
* 继承HibernateDaoSupport类,使用HibernateTemplate来持久化,HibernateTemplate是
Hibernate Session的轻量级封装
* 默认情况下运行期异常才会回滚(包括继承了RuntimeException子类),普通异常是不会滚的
* 编写业务逻辑方法时,最好将异常一直向上抛出,在表示层(struts)处理
* 关于事务边界的设置,通常设置到业务层,不要添加到Dao上
3、了解事务的几种传播特性
1. PROPAGATION_REQUIRED: 如果存在一个事务,则支持当前事务。如果没有事务则开启
2. PROPAGATION_SUPPORTS: 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行
3. PROPAGATION_MANDATORY: 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
4. PROPAGATION_REQUIRES_NEW: 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
5. PROPAGATION_NOT_SUPPORTED: 总是非事务地执行,并挂起任何存在的事务。
6. PROPAGATION_NEVER: 总是非事务地执行,如果存在一个活动事务,则抛出异常
7. PROPAGATION_NESTED:如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务,
则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行
4、Spring事务的隔离级别
1. ISOLATION_DEFAULT: 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
另外四个与JDBC的隔离级别相对应
2. ISOLATION_READ_UNCOMMITTED: 这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。
这种隔离级别会产生脏读,不可重复读和幻像读。
3. ISOLATION_READ_COMMITTED: 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
4. ISOLATION_REPEATABLE_READ: 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。
它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
5. ISOLATION_SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
除了防止脏读,不可重复读外,还避免了幻像读。
对于出现的乱码有2种解决方法:
1、在JS中,window.showModalDialog传递对象。
  function tool_uploadFile(clmNo,billType,maxFileNum,fileType,singleLimit,totalLimit) function tool_uploadFile(clmNo,billType,maxFileNum,fileType,singleLimit,totalLimit)  {//解决乱码的问题,增加变量paramObj。10.06.01 {//解决乱码的问题,增加变量paramObj。10.06.01
  var paramObj = { var paramObj = {
 "clmNo" : clmNo, "clmNo" : clmNo,
"billType" : billType,
"maxFileNum" : maxFileNum,
"fileType" : fileType,
"singleLimit" : singleLimit,
"totalLimit" : totalLimit
 }; };
var r = window.showModalDialog(global.WEB_APP_NAME+"/core/jsp/common/uploadFile.jsp",paramObj,"dialogHeight:610px;dialogWidth:530px;center:1;help: 0; status: 0;");
return r;
 } }
在uploadFile.jsp中,通过js获得参数。
 <script> <script>
var paramObj = window.dialogArguments;
var clmNo = paramObj.clmNo;
var billType = paramObj.billType;
var maxFileNum = paramObj.maxFileNum;
var fileType = paramObj.fileType;
var singleLimit = paramObj.singleLimit;
var totalLimit = paramObj.totalLimit;
tool.loadApplet('<%=agentIp%>','<%=agentPort%>','<%=orgId%>',clmNo,billType,maxFileNum,fileType,singleLimit,totalLimit);
</script>
2、在JS中,window.showModalDialog通过?传递参数。
function tool_uploadFile(clmNo,billType,maxFileNum,fileType,singleLimit,totalLimit) {
billType = encodeURIComponent(billType);
var r = window.showModalDialog(global.WEB_APP_NAME+"/core/jsp/common/uploadFile.jsp?clmNo="+clmNo+"&billType="+billType+"&maxFileNum="+maxFileNum+"&fileType="+fileType+"&singleLimit="+singleLimit+"&totalLimit="+totalLimit,"","dialogHeight:610px;dialogWidth:530px;center:1;help: 0; status: 0;");
return r;
}
在uploadFile.jsp中,通过java解析获得参数。
String paramStr = request.getQueryString();
if (paramStr == null || paramStr.equals("")) {
return;
}
HashMap<String, ArrayList<String>> parameter = new HashMap<String, ArrayList<String>>();
String[] paramArr = paramStr.split("&+");
String[] arr = null;
for (int i = 0; i < paramArr.length; i++) {
arr = paramArr[i].split("=", 2);
ArrayList<String> lst = parameter.get(arr[0]);
if (lst == null) {
lst = new ArrayList<String>();
parameter.put(arr[0], lst);
}
if (arr.length < 2) {
lst.add("");
} else {
lst.add(URLDecoder.decode(arr[1], "UTF-8"));
}
}
ArrayList<String> paramlst = parameter.get("billType");
String billType = paramlst.get(0);
以上两种方法,对应用服务器设置的url编码没有关系。
还有一种方法,就是转换成GB2312,不过此种方法跟服务器编码设置还有关系,有时还会出现乱码:
billType = new String(billType.getBytes(" ISO-8859-1"),"GB2312");
一:WebLogic配置问题:
由于WebLogic的配置问题,我们的系统运行出现了失败情况。原因是为WebLogic分配的内存太少了。通过修改commom\bin\commEnv.cmd文件来增加内存分配。
修改的部分如下:
:bea
if "%PRODUCTION_MODE%" == "true" goto bea_prod_mode
set JAVA_VM=-jrockit
set MEM_ARGS=-Xms768m -Xmx1024m
set JAVA_OPTIONS=%JAVA_OPTIONS% -Xverify:none
goto continue
:bea_prod_mode
set JAVA_VM=-jrockit
set MEM_ARGS=-Xms768m -Xmx1024m //原来是128M~256M,太小了,数据太大
goto continue
结果修改后,没有效果。还是有失败的情况。
发现,原来,在:bea下面还有一段配置信息如下:
:sun
if "%PRODUCTION_MODE%" == "true" goto sun_prod_mode
set JAVA_VM=-client
set MEM_ARGS=-Xms768m -Xmx1024m -XX:MaxPermSize=256m
set JAVA_OPTIONS=%JAVA_OPTIONS% -Xverify:none
goto continue
:sun_prod_mode
set JAVA_VM=-server
set MEM_ARGS=-Xms768m -Xmx1024m -XX:MaxPermSize=256m
goto continue
将这里的内存分配修改后见效。
原因是,上面对第一段代码是为bea自己的JVM设置的,下面的是为Sun的设置的。而WebLogic默认的是Sun的,所以出了毛病。
二,domain中的相关配置:
1,修改bea\user_projects\domains\base_domain\bin\setDomainEnv.cmd文件.
2,修改如下几个位置:以下蓝色部分是需修改的内存大小
set MEM_ARGS=-Xms256m -Xmx512m @最主要将这两个值改大,这是此域启动后,虚拟机可使用的内存
if "%JAVA_VENDOR%"=="Sun" ( @使用sun服务器开发模式下的JVM配置
if "%PRODUCTION_MODE%"=="" (
set MEM_DEV_ARGS=-XX:CompileThreshold=8000 -XX ermSize=48m
)
)
if "%JAVA_VENDOR%"=="Sun" ( @使用sun服务器生产模式下的JVM配置
set MEM_ARGS=%MEM_ARGS% %MEM_DEV_ARGS% -XX:MaxPermSize=128m
)
if "%JAVA_VENDOR%"=="HP" ( @使用hp服务器生产模式下的JVM配置
set MEM_ARGS=%MEM_ARGS% -XX:MaxPermSize=128m
)
weblogic在运行一段时间后,出现以下的错误:
<2010-5-28 上午11时46分17秒 CST> <Error> <HTTP> <BEA-101017> <[weblogic.servlet.internal.WebAppServletContext@
1b0d235 - appName: 'rules', name: 'rules', context-path: '/rules'] Root cause of ServletException.
java.lang.OutOfMemoryError: PermGen space
>
解决方法:
重新启动weblogic,系统恢复正常。
这里以tomcat环境为例,其它WEB服务器如jboss,weblogic等是同一个道理。
一、java.lang.OutOfMemoryError: PermGen space PermGen space的全称是Permanent Generation space,是指内存的永久保存区域, 这块内存主要是被JVM存放Class和Meta信息的,Class在被Loader时就会被放到PermGen space中, 它和存放类实例(Instance)的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对 PermGen space进行清理,所以如果你的应用中有很多CLASS的话,就很可能出现PermGen space错误, 这种错误常见在web服务器对JSP进行pre compile的时候。如果你的WEB APP下都用了大量的第三方jar, 其大小超过了jvm默认的大小(4M)那么就会产生此错误信息了。
解决方法: 手动设置MaxPermSize大小修改TOMCAT_HOME/bin/catalina.sh 在“echo "Using CATALINA_BASE: $CATALINA_BASE"”上面加入以下行: JAVA_OPTS="-server -XX:PermSize=64M -XX:MaxPermSize=128m
建议:将相同的第三方jar文件移置到tomcat/shared/lib目录下,这样可以达到减少jar 文档重复占用内存的目的。
二、java.lang.OutOfMemoryError: Java heap space Heap size 设置 JVM堆的设置是指java程序运行过程中JVM可以调配使用的内存空间的设置.JVM在启动的时候会自动设置Heap size的值,其初始空间(即-Xms)是物理内存的1/64,最大空间(-Xmx)是物理内存的1/4。可以利用JVM提供的-Xmn -Xms -Xmx等选项可进行设置。Heap size 的大小是Young Generation 和Tenured Generaion 之和。提示:在JVM中如果98%的时间是用于GC且可用的Heap size 不足2%的时候将抛出此异常信息。提示:Heap Size 最大不要超过可用物理内存的80%,一般的要将-Xms和-Xmx选项设置为相同,而-Xmn为1/4的-Xmx值。
解决方法:手动设置Heap size 修改TOMCAT_HOME/bin/catalina.sh 在“echo "Using CATALINA_BASE: $CATALINA_BASE"”上面加入以下行: JAVA_OPTS="-server -Xms800m -Xmx800m -XX:MaxNewSize=256m"
三、实例,以下给出1G内存环境下java jvm 的参数设置参考:
JAVA_OPTS="-server -Xms800m -Xmx800m -XX:PermSize=64M -XX:MaxNewSize=256m -XX:MaxPermSize=128m -Djava.awt.headless=true "
四、 可以配置下Tomcat。
修改TOMCAT_HOME/bin/tomcat6w.exe 双击打开,在“Java "下设置如下:
Initial memory pool:768 MB
Maximum memory pool:1024 MB
Thread stack size:64KB
Java 堆 - 这是 JVM 用来分配 java 对象的内存。
如果JVM不能在java堆中获得更多内存来分配更多java对象,将会抛出java内存不足(java.lang.OutOfMemoryError)错误。默认情况下,应用程序崩溃。
本地内存 - 这是 JVM 用于其内部操作的内存。
如果 JVM 无法获得更多本地内存,它将抛出本地内存不足(本地 OutOfMemoryError)错误。当进程到达操作系统的进程大小限值,或者当计算机用完 RAM 和交换空间时,通常会发生这种情况。
进程大小 - 进程大小将是 java 堆、本地内存与加载的可执行文件和库所占用内存的总和。在 32 位操作系统上,进程的虚拟地址空间最大可达到 4 GB。从这 4 GB 内存中,操作系统内核为自己保留一部分内存(通常为 1 - 2 GB)。剩余内存可用于应用程序。
--项目中的用法。
1、StringUtils.join
List dwVoListInTab = this.prodService.getPicTabVOList(picId);
List dwNameListInTab = new ArrayList();
for (PrdTabVO dwVo : dwVoListInTab) {
String dwName = this.prodService.cvtTabNo2DWName(useProdNo, picId,
dwVo.getCTabNo());
dwNameListInTab.add(dwName);
dwNameMap.put(dwVo.getCNmeEn(), dwName);
}
((List)plyDwNameList).addAll(dwNameListInTab);
String dwNameListStr = "['" + StringUtils.join(dwNameListInTab.toArray(), "','") + "']";
其它:
StringUtils.join(new String[]{"cat","dog","carrot","leaf","door"}, ":")
// cat:dog:carrot:leaf:door
2、StringUtils.isNotEmpty //Checks if a String is not empty ("") and not null.
if (StringUtils.isNotEmpty(onload))
onload = sub.replace(onload);
else {
onload = "";
}
public String replace(char oldChar,char newChar)返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的。
如果 oldChar 在此 String 对象表示的字符序列中没有出现,则返回对此 String 对象的引用。
3、StringUtils.equals //StringUtils.equals(null, null) = true
if (!StringUtils.equals(prodKindNo, "00")) {
}
4、StringUtils.isBlank //Checks if a String is whitespace, empty ("") or null.
if (StringUtils.isBlank(taskId))
jsBuffer.append("var taskId='';\n");
else {
jsBuffer.append("var taskId='" + taskId + "';\n");
}
5、StringUtils.leftPad(String str, int size,String padStr) --左填充
//投保年度【保险起期 - 初登年月】 单位:年
String ply_year = StringUtils.leftPad(String.valueOf(DateUtils.compareYear(regDate,base.getTInsrncBgnTm())), 2, '0');
/**
4260 * <p>Left pad a String with a specified String.</p>
4261 *
4262 * <p>Pad to a size of <code>size</code>.</p>
4263 *
4264 * <pre>
4265 * StringUtils.leftPad(null, *, *) = null
4266 * StringUtils.leftPad("", 3, "z") = "zzz"
4267 * StringUtils.leftPad("bat", 3, "yz") = "bat"
4268 * StringUtils.leftPad("bat", 5, "yz") = "yzbat"
4269 * StringUtils.leftPad("bat", 8, "yz") = "yzyzybat"
4270 * StringUtils.leftPad("bat", 1, "yz") = "bat"
4271 * StringUtils.leftPad("bat", -1, "yz") = "bat"
4272 * StringUtils.leftPad("bat", 5, null) = " bat"
4273 * StringUtils.leftPad("bat", 5, "") = " bat"
4274 * </pre>
4275 *
4276 * @param str the String to pad out, may be null
4277 * @param size the size to pad to
4278 * @param padStr the String to pad with, null or empty treated as single space
4279 * @return left padded String or original String if no padding is necessary,
4280 * <code>null</code> if null String input
4281 */
4282 public static String leftPad(String str, int size, String padStr) {
4283 if (str == null) {
4284 return null;
4285 }
4286 if (isEmpty(padStr)) {
4287 padStr = " ";
4288 }
4289 int padLen = padStr.length();
4290 int strLen = str.length();
4291 int pads = size - strLen;
4292 if (pads <= 0) {
4293 return str; // returns original String when possible
4294 }
4295 if (padLen == 1 && pads <= PAD_LIMIT) {
4296 return leftPad(str, size, padStr.charAt(0));
4297 }
4298
4299 if (pads == padLen) {
4300 return padStr.concat(str);
4301 } else if (pads < padLen) {
4302 return padStr.substring(0, pads).concat(str);
4303 } else {
4304 char[] padding = new char[pads];
4305 char[] padChars = padStr.toCharArray();
4306 for (int i = 0; i < pads; i++) {
4307 padding[i] = padChars[i % padLen];
4308 }
4309 return new String(padding).concat(str);
4310 }
4311 }
---------------------------------------------
详见:http://commons.apache.org/lang/api/org/apache/commons/lang/StringUtils.html
isEmpty
public static boolean isEmpty(CharSequence str)
Checks if a String is empty ("") or null.
StringUtils.isEmpty(null) = true
StringUtils.isEmpty("") = true
StringUtils.isEmpty(" ") = false
StringUtils.isEmpty("bob") = false
StringUtils.isEmpty(" bob ") = false
NOTE: This method changed in Lang version 2.0. It no longer trims the String. That
functionality is available in isBlank().
Parameters:
str - the String to check, may be null
Returns:
true if the String is empty or null
isNotEmpty
public static boolean isNotEmpty(CharSequence str)
Checks if a String is not empty ("") and not null.
StringUtils.isNotEmpty(null) = false
StringUtils.isNotEmpty("") = false
StringUtils.isNotEmpty(" ") = true
StringUtils.isNotEmpty("bob") = true
StringUtils.isNotEmpty(" bob ") = true
Parameters:
str - the String to check, may be null
Returns:
true if the String is not empty and not null
isBlank
public static boolean isBlank(CharSequence str)
Checks if a String is whitespace, empty ("") or null.
StringUtils.isBlank(null) = true
StringUtils.isBlank("") = true
StringUtils.isBlank(" ") = true
StringUtils.isBlank("bob") = false
StringUtils.isBlank(" bob ") = false
Parameters:
str - the String to check, may be null
Returns:
true if the String is null, empty or whitespace
Since:
2.0
isNotBlank
public static boolean isNotBlank(CharSequence str)
Checks if a String is not empty (""), not null and not whitespace only.
StringUtils.isNotBlank(null) = false
StringUtils.isNotBlank("") = false
StringUtils.isNotBlank(" ") = false
StringUtils.isNotBlank("bob") = true
StringUtils.isNotBlank(" bob ") = true
Parameters:
str - the String to check, may be null
Returns:
true if the String is not empty and not null and not whitespace
Since:
2.0
trim
public static String trim(String str)
Removes control characters (char <= 32) from both ends of this String, handling null by
returning null.
The String is trimmed using String.trim(). Trim removes start and end characters <= 32.
To strip whitespace use strip(String).
To trim your choice of characters, use the strip(String, String) methods.
StringUtils.trim(null) = null
StringUtils.trim("") = ""
StringUtils.trim(" ") = ""
StringUtils.trim("abc") = "abc"
StringUtils.trim(" abc ") = "abc"
Parameters:
str - the String to be trimmed, may be null
Returns:
the trimmed string, null if null String input
trimToNull
public static String trimToNull(String str)
Removes control characters (char <= 32) from both ends of this String returning null if
the String is empty ("") after the trim or if it is null.
The String is trimmed using String.trim(). Trim removes start and end characters <= 32.
To strip whitespace use stripToNull(String).
StringUtils.trimToNull(null) = null
StringUtils.trimToNull("") = null
StringUtils.trimToNull(" ") = null
StringUtils.trimToNull("abc") = "abc"
StringUtils.trimToNull(" abc ") = "abc"
Parameters:
str - the String to be trimmed, may be null
Returns:
the trimmed String, null if only chars <= 32, empty or null String input
Since:
2.0
trimToEmpty
public static String trimToEmpty(String str)
Removes control characters (char <= 32) from both ends of this String returning an empty
String ("") if the String is empty ("") after the trim or if it is null.
The String is trimmed using String.trim(). Trim removes start and end characters <= 32.
To strip whitespace use stripToEmpty(String).
StringUtils.trimToEmpty(null) = ""
StringUtils.trimToEmpty("") = ""
StringUtils.trimToEmpty(" ") = ""
StringUtils.trimToEmpty("abc") = "abc"
StringUtils.trimToEmpty(" abc ") = "abc"
Parameters:
str - the String to be trimmed, may be null
Returns:
the trimmed String, or an empty String if null input
Since:
2.0
equals
public static boolean equals(String str1,
String str2)
Compares two Strings, returning true if they are equal.
nulls are handled without exceptions. Two null references are considered to be equal. The
comparison is case sensitive.
StringUtils.equals(null, null) = true
StringUtils.equals(null, "abc") = false
StringUtils.equals("abc", null) = false
StringUtils.equals("abc", "abc") = true
StringUtils.equals("abc", "ABC") = false
Parameters:
str1 - the first String, may be null
str2 - the second String, may be null
Returns:
true if the Strings are equal, case sensitive, or both null
See Also:
String.equals(Object)
startsWith
public static boolean startsWith(String str,
String prefix)
Check if a String starts with a specified prefix.
nulls are handled without exceptions. Two null references are considered to be equal. The
comparison is case sensitive.
StringUtils.startsWith(null, null) = true
StringUtils.startsWith(null, "abc") = false
StringUtils.startsWith("abcdef", null) = false
StringUtils.startsWith("abcdef", "abc") = true
StringUtils.startsWith("ABCDEF", "abc") = false
Parameters:
str - the String to check, may be null
prefix - the prefix to find, may be null
Returns:
true if the String starts with the prefix, case sensitive, or both null
Since:
2.4
See Also:
String.startsWith(String)
1.去除尾部换行符,使用函数:StringUtils.chomp(testString)
函数介绍:去除testString尾部的换行符
例程:
String input = "Hello\n";
System.out.println( StringUtils.chomp( input ));
String input2 = "Another test\r\n";
System.out.println( StringUtils.chomp( input2 ));
输出如下:
Hello
Another test
2.判断字符串内容的类型,函数介绍:
StringUtils.isNumeric( testString ) :如果testString全由数字组成返回True
StringUtils.isAlpha( testString ) :如果testString全由字母组成返回True
StringUtils.isAlphanumeric( testString ) :如果testString全由数字或数字组成返回True
StringUtils.isAlphaspace( testString ) :如果testString全由字母或空格组成返回True
例程:
String state = "Virginia";
System.out.println( "Is state number? " + StringUtils.isNumeric(state ) );
System.out.println( "Is state alpha? " + StringUtils.isAlpha( state ));
System.out.println( "Is state alphanumeric? " +StringUtils.isAlphanumeric( state ) );
System.out.println( "Is state alphaspace? " + StringUtils.isAlphaSpace( state ) );
输出如下:
Is state number? false
Is state alpha? true
Is state alphanumeric? true
Is state alphaspace? true
3.查找嵌套字符串,使用函数:
StringUtils.substringBetween(testString,header,tail)
函数介绍:在testString中取得header和tail之间的字符串。不存在则返回空
例程:
String htmlContent = "ABC1234ABC4567";
System.out.println(StringUtils.substringBetween(htmlContent, "1234", "4567"));
System.out.println(StringUtils.substringBetween(htmlContent, "12345", "4567"));
输出如下:
ABC
null
4.颠倒字符串,使用函数:StringUtils.reverse(testString)
函数介绍:得到testString中字符颠倒后的字符串
例程:
System.out.println( StringUtils.reverse("ABCDE"));
输出如下:
EDCBA
5.部分截取字符串,使用函数:
StringUtils.substringBetween(testString,fromString,toString ):取得两字符之间的字符串
StringUtils.substringAfter( ):取得指定字符串后的字符串
StringUtils.substringBefore( ):取得指定字符串之前的字符串
StringUtils.substringBeforeLast( ):取得最后一个指定字符串之前的字符串
StringUtils.substringAfterLast( ):取得最后一个指定字符串之后的字符串
函数介绍:上面应该都讲明白了吧。
例程:
String formatted = " 25 * (30,40) [50,60] | 30";
System.out.print("N0: " + StringUtils.substringBeforeLast( formatted, "*" ) );
System.out.print(", N1: " + StringUtils.substringBetween( formatted, "(", "," ) );
System.out.print(", N2: " + StringUtils.substringBetween( formatted, ",", ")" ) );
System.out.print(", N3: " + StringUtils.substringBetween( formatted, "[", "," ) );
System.out.print(", N4: " + StringUtils.substringBetween( formatted, ",", "]" ) );
System.out.print(", N5: " + StringUtils.substringAfterLast( formatted, "|" ) );
输出如下:
N0: 25 , N1: 30, N2: 40, N3: 50, N4: 40) [50,60, N5: 30
MethodUtils的简单用法。
package com.ztf;
import java.util.Map;
import org.apache.commons.beanutils.MethodUtils;
import org.apache.commons.beanutils.PropertyUtils;
public class TestMethodUtils {
public static void main(String[] args) throws Exception{
Entity entity = new Entity();
entity.setId(1) ;
entity.setName("断点");
// 通过MethodUtils的invokeMethod方法,执行指定的entity中的方法(无参的情况)
MethodUtils.invokeMethod(entity, "sayHello", null);
// 通过MethodUtils的invokeMethod方法,执行指定的entity中的方法(1参的情况)
MethodUtils.invokeMethod(entity, "sayHello", "断点");
// 通过MethodUtils的invokeMethod方法,执行指定的entity中的方法(多参的情况)
Object[] params = new Object[]{new Integer(10),new Integer(12)};
MethodUtils.invokeMethod(entity, "sayHello", params);
}
}
实体:
package com.ztf;
public class Entity {
private Integer id;
private String name;
public void sayHello(){
System.out.println("sayHello()---> 无参");
}
public void sayHello(String s){
System.out.println("sayHello()---> 有1个参数" );
}
public void sayHello(Integer a,Integer b){
System.out.println("sayHello()---> 有2个参数");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
}
输出:
sayHello()---> 无参
sayHello()---> 有1个参数
sayHello()---> 有2个参数
实体bean。
package com.ztf;
public class Entity {
private Integer id;
private String name;
public void sayHello(){
System.out.println("sayHello()---> 无参");
}
public void sayHello(String s){
System.out.println("sayHello()---> 有1个参数" );
}
public void sayHello(Integer a,Integer b){
System.out.println("sayHello()---> 有2个参数");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
}
package com.ztf;
import java.util.Map;
import org.apache.commons.beanutils.MethodUtils;
import org.apache.commons.beanutils.PropertyUtils;
public class TestPropertyUtils {
public static void main(String[] args) throws Exception{
Entity entity = new Entity();
entity.setId(1) ;
entity.setName("断点");
// 通过PropertyUtils的getProperty方法获取指定属性的值
Integer id = (Integer)PropertyUtils.getProperty(entity, "id");
String name = (String)PropertyUtils.getProperty(entity, "name");
System.out.println("id = " + id + " name = " + name);
// 调用PropertyUtils的setProperty方法设置entity的指定属性
PropertyUtils.setProperty(entity, "name", "每天进步一点");
System.out.println("name = " + entity.getName());
// 通过PropertyUtils的describe方法把entity的所有属性与属性值封装进Map中
Map map = PropertyUtils.describe(entity);
System.out.println("id = " + map.get("id") + " name = " + map.get("name"));
}
}
输出:
id = 1 name = 断点
name = 每天进步一点
id = 1 name = 每天进步一点
其它例子:
import org.apache.commons.beanutils.PropertyUtils;
List<Map<String, Object>> data = new ArrayList<Map<String, Object>>();
for(BaseGrpMemberVO member : MemberVO){
Map m = new HashMap();
for(Map.Entry<String, String> entry: fieldMap.entrySet()){
String key = entry.getKey();
fieldList.add(key); //记录字段名
String[] keyArray = key.split("\\.");
if(keyArray.length == 2){//成员信息
Object o =PropertyUtils.getProperty(member, keyArray[1]);
m.put(key, o==null?"":o.toString());
}else if(keyArray.length == 3){//险别信息
List<BaseGrpCvrgVO> cvrgVoList = mgr.getRelCvrgById(member.getCPkId());
String cvrgNo = keyArray[0];
for(BaseGrpCvrgVO cvrgVo : cvrgVoList){
if(cvrgNo.equals(cvrgVo.getCCvrgNo())){
Object o =PropertyUtils.getProperty(cvrgVo, keyArray[2]);
m.put(key, o==null?"":o.toString());
}
}
}
}
data.add(m);
}
apache.commons.beanutils.BeanUtils
该class提供了一系列的静态方法操作已存在的符合JavaBean规范定义的Java Class.这里强调的JavaBean规范,简单来说就是一个Java Class通过一系列getter和setter的方法向外界展示其内在的成员变量(属性)。
通过BeanUtils的静态方法,我们可以:
复制一个JavaBean的实例--BeanUtils.cloneBean();
在一个JavaBean的两个实例之间复制属性--BeanUtils.copyProperties(),BeanUtils.copyProperty();
为一个JavaBean的实例设置成员变量(属性)值--BeanUtils.populate(),BeanUtils.setProperty();
从一个JavaBean的实例中读取成员变量(属性)的值--BeanUtils.getArrayProperty(),BeanUtils.getIndexedProperty(),BeanUtils.getMappedProperty(),BeanUtils.getNestedProperty(),BeanUtils.getSimpleProperty(),BeanUtils.getProperty(),BeanUtils.describe();
1、BeanUtils.cloneBean(java.lang.object bean)
为bean创建一个clone对象,方法返回类型为Object.此方法的实现机制建立在bean提供的一系列的getters和setters的基础之上.此方法的正常使用代码非常简单,故略掉.
2、BeanUtils.copyProperties(java.lang.Object dest, java.lang.Object orig)
一个bean class有两个实例:orig和dest,将orig中的成员变量的值复制给dest,即将已经存在的dest变为orig的副本.与BeanUtils.cloneBean(java.lang.object bean)的区别就在于是不是需要创建新的实例了.
原文如下:Copy property values from the origin bean to the destination bean for all cases where the property names are the same.
3、BeanUtils.setProperty(java.lang.Object bean,java.lang.String name,java.lang.Object value)
这个方法简单的说就是将bean中的成员变量name赋值为value.
BeanUtils.populate(java.lang.Object bean, java.util.Map properties)
使用一个map为bean赋值,该map中的key的名称与bean中的成员变量名称相对应.注意:只有在key和成员变量名称完全对应的时候,populate机制才发生作用;但是在数量上没有任何要求,如map中的key如果是成员变量名称的子集,那么成员变量中有的而map中不包含的项将会保留默认值;同样,如果成员变量是map中key的子集,那么多余的key不会对populate的结果产生任何影响.恩,结果就是populate只针对map中key名称集合与bean中成员变量名称集合的交集产生作用。
4、BeanUtils.getArrayProperty(java.lang.Object bean,java.lang.String name)
获取bean中数组成员变量(属性)的值.
如果我们指定的name不是数组类型的成员变量,结果会如何?会不会抛出类型错误的exception呢?回答是不会,仍然会返回一个String的数组,数组的第一项就是name对应的值(如果不
是String类型的话,JVM会自动的调用toString()方法的).
BeanUtils.getIndexedProperty(java.lang.Object bean,java.lang.String name)
BeanUtils.getIndexedProperty(java.lang.Object bean,java.lang.String name,int index)
这两个方法都是获取数组成员变量(属性)中的单一元素值的方法.
比如,我想得到SampleObject中words[1]的值,用法如下:
BeanUtils.getIndexedProperty(sampleOjbectInstance,"words[1]");
BeanUtils.getIndexedProperty(sampleOjbectInstance,"words",1);
BeanUtils.getMappedProperty(java.lang.Object bean,java.lang.String name)
BeanUtils.getMappedProperty(java.lang.Object bean,java.lang.String name,java.lang.String key)
BeanUtils.describe(java.lang.Object bean)
将一个bean以map的形式展示。
来源:http://www.chinaitpower.com/A/2005-07-03/150232.html
原因:在这两天的时间里,weblogic92把我很是郁闷了一把,原因是我本地的工程走业务流程没有问题,而到它上面去跑流程就是 处理失败!真正的问题就是2个jar包的有冲突,一样的class文件,名字分别为pcis_reinsure.jar、pcis_reinsure_open.jar 。在我提交svn的时候,把pcis_reinsure.jar删除了,把pcis_reinsure_open.jar 新增了,结果weblogic92的缓存中含有pcis_reinsure.jar、pcis_reinsure_open.jar 。
注:pcis_reinsure.jar 旧包、pcis_reinsure_open.jar 新包,其中一个类IRiskUnitService有方法divideRiskUnit,而另一个没有这个方法,所以老是提示
Caused by: java.lang.NoSuchMethodError: com..pcis.riskunit.service.IRiskUnitService.divideRiskUnit(L
com/isoftstone/pcis/policy/dm/bo/PolicyApplication;)V
解决:
在Tomcat中,我们知道%catalina_home%\work是存放缓存文件的地方,可以通过删除这里面的文件,让它重新编译,以便代码生效。
weblogic92的缓存文件存放在哪里呢?
weblogic92的发布项目缓存临时文件路径是
D:\bea\user_projects\domains\nonvhl_policy\servers\AdminServer\tmp\_WL_user\nonvhl_policy\4huf50\war\WEB-INF\lib,在此路径下把pcis_reinsure.jar删除就可以了。
注意:
1、要停服务后再删除缓存文件,运行时它已经加载到内存了。
2、缓存只加载新增的文件,对于工程删除的jar文件它不做删除。
.
JAVA Memory arguments: -Xms512m -Xmx768m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=256m
.
WLS Start Mode=Development
.
CLASSPATH=D:\bea\weblogic_crack.jar;;d:\bea\patch_weblogic920\profiles\default\sys_manifest_classpath\weblogic
_patch.jar;d:\bea\JDK150~1\lib\tools.jar;D:\bea\WEBLOG~1\server\lib\weblogic_sp.jar;D:\bea\WEBLOG~1\server\lib
\weblogic.jar;D:\bea\WEBLOG~1\server\lib\webservices.jar;;D:\bea\WEBLOG~1\common\eval\pointbase\lib\pbclient51
.jar;D:\bea\WEBLOG~1\server\lib\xqrl.jar;;
.
PATH=d:\bea\patch_weblogic920\profiles\default\native;D:\bea\WEBLOG~1\server\native\win\32;D:\bea\WEBLOG~1\ser
ver\bin;d:\bea\JDK150~1\jre\bin;d:\bea\JDK150~1\bin;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;D:
\bea\WEBLOG~1\server\native\win\32\oci920_8
.
***************************************************
* To start WebLogic Server, use a username and *
* password assigned to an admin-level user. For *
* server administration, use the WebLogic Server *
* console at http:\\hostname:port\console *
***************************************************
starting weblogic with Java version:
java version "1.5.0_04"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_04-b05)
Java HotSpot(TM) Client VM (build 1.5.0_04-b05, mixed mode)
Starting WLS with line:
d:\bea\JDK150~1\bin\java -client -Xms512m -Xmx768m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSi
ze=256m -Xverify:none -da -Dplatform.home=D:\bea\WEBLOG~1 -Dwls.home=D:\bea\WEBLOG~1\server -Dwli.home=D:\be
a\WEBLOG~1\integration -Dweblogic.management.discover=true -Dwlw.iterativeDev= -Dwlw.testConsole= -Dwlw.logE
rrorsToConsole= -Dweblogic.ext.dirs=d:\bea\patch_weblogic920\profiles\default\sysext_manifest_classpath -Dwebl
ogic.Name=AdminServer -Djava.security.policy=D:\bea\WEBLOG~1\server\lib\weblogic.policy weblogic.Server
<2010-5-24 上午09时42分56秒 CST> <Notice> <WebLogicServer> <BEA-000395> <Following extensions directory conten
ts added to the end of the classpath:
D:\bea\weblogic92\platform\lib\p13n\p13n-schemas.jar;D:\bea\weblogic92\platform\lib\p13n\p13n_common.jar;D:\be
a\weblogic92\platform\lib\p13n\p13n_system.jar;D:\bea\weblogic92\platform\lib\wlp\netuix_common.jar;D:\bea\web
logic92\platform\lib\wlp\netuix_schemas.jar;D:\bea\weblogic92\platform\lib\wlp\netuix_system.jar;D:\bea\weblog
ic92\platform\lib\wlp\wsrp-common.jar>
<2010-5-24 上午09时42分56秒 CST> <Info> <WebLogicServer> <BEA-000377> <Starting WebLogic Server with Java HotS
pot(TM) Client VM Version 1.5.0_04-b05 from Sun Microsystems Inc.>
<2010-5-24 上午09时42分57秒 CST> <Info> <Management> <BEA-141107> <Version: WebLogic Server 9.2 Fri Jun 23 20
:47:26 EDT 2006 783464 >
<2010-5-24 上午09时43分00秒 CST> <Info> <WebLogicServer> <BEA-000215> <Loaded License : d:\bea\license.bea>
<2010-5-24 上午09时43分00秒 CST> <Notice> <WebLogicServer> <BEA-000365> <Server state changed to STARTING>
<2010-5-24 上午09时43分00秒 CST> <Info> <WorkManager> <BEA-002900> <Initializing self-tuning thread pool>
<2010-5-24 上午09时43分00秒 CST> <Notice> <Log Management> <BEA-170019> <The server log file D:\bea\user_proje
cts\domains\nonvhl_policy\servers\AdminServer\logs\AdminServer.log is opened. All server side log events will
be written to this file.>
<2010-5-24 上午09时43分00秒 CST> <Error> <Socket> <BEA-000438> <Unable to load performance pack. Using Java I/
O instead. Please ensure that wlntio.dll is in: 'd:\bea\JDK150~1\bin;.;C:\WINDOWS\system32;C:\WINDOWS;d:\bea\p
atch_weblogic920\profiles\default\native;D:\bea\WEBLOG~1\server\native\win\32;D:\bea\WEBLOG~1\server\bin;d:\be
a\JDK150~1\jre\bin;d:\bea\JDK150~1\bin;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;D:\bea\WEBLOG~1
\server\native\win\32\oci920_8'
>
<2010-5-24 上午09时43分02秒 CST> <Notice> <Security> <BEA-090082> <Security initializing using security realm
myrealm.>
<2010-5-24 上午09时43分03秒 CST> <Critical> <Deployer> <BEA-149618> <Unable to deploy an internal management W
eb application - bea_wls_management_internal2. Managed servers may be unable to start.
weblogic.management.DeploymentException: weblogic.management.DeploymentException:
at weblogic.deploy.internal.InternalAppProcessor.stageFilesAndCreateBeansForInternalApp(InternalAppPro
cessor.java:258)
at weblogic.deploy.internal.InternalAppProcessor.updateConfiguration(InternalAppProcessor.java:196)
at weblogic.management.deploy.internal.DeploymentServerService.init(DeploymentServerService.java:144)
at weblogic.management.deploy.internal.DeploymentPreStandbyServerService.start(DeploymentPreStandbySer
verService.java:32)
at weblogic.t3.srvr.SubsystemRequest.run(SubsystemRequest.java:64)
Truncated. see log file for complete stacktrace
java.util.zip.ZipException: Error opening file - D:\bea\WEBLOG~1\server\lib\bea_wls_management_internal2.war M
essage - 系统找不到指定的文件。
at weblogic.servlet.utils.WarUtils.existsInWar(WarUtils.java:65)
at weblogic.servlet.utils.WarUtils.isWar(WarUtils.java:44)
at weblogic.servlet.internal.WarDeploymentFactory.findOrCreateComponentMBeans(WarDeploymentFactory.jav
a:54)
at weblogic.application.internal.MBeanFactoryImpl.findOrCreateComponentMBeans(MBeanFactoryImpl.java:48
)
at weblogic.application.internal.MBeanFactoryImpl.createComponentMBeans(MBeanFactoryImpl.java:110)
Truncated. see log file for complete stacktrace
>
<2010-5-24 上午09时43分03秒 CST> <Critical> <WebLogicServer> <BEA-000362> <Server failed. Reason:
There are 1 nested errors:
weblogic.management.provider.UpdateException: [Deployer:149616]A critical internal application bea_wls_managem
ent_internal2 was not deployed. Error: weblogic.management.DeploymentException:
at weblogic.deploy.internal.InternalAppProcessor.handleErr(InternalAppProcessor.java:211)
at weblogic.deploy.internal.InternalAppProcessor.updateConfiguration(InternalAppProcessor.java:198)
at weblogic.management.deploy.internal.DeploymentServerService.init(DeploymentServerService.java:144)
at weblogic.management.deploy.internal.DeploymentPreStandbyServerService.start(DeploymentPreStandbySer
verService.java:32)
at weblogic.t3.srvr.SubsystemRequest.run(SubsystemRequest.java:64)
at weblogic.work.ExecuteThread.execute(ExecuteThread.java:209)
at weblogic.work.ExecuteThread.run(ExecuteThread.java:181)
Caused by: java.util.zip.ZipException: Error opening file - D:\bea\WEBLOG~1\server\lib\bea_wls_management_inte
rnal2.war Message - 系统找不到指定的文件。
at weblogic.servlet.utils.WarUtils.existsInWar(WarUtils.java:65)
at weblogic.servlet.utils.WarUtils.isWar(WarUtils.java:44)
at weblogic.servlet.internal.WarDeploymentFactory.findOrCreateComponentMBeans(WarDeploymentFactory.jav
a:54)
at weblogic.application.internal.MBeanFactoryImpl.findOrCreateComponentMBeans(MBeanFactoryImpl.java:48
)
at weblogic.application.internal.MBeanFactoryImpl.createComponentMBeans(MBeanFactoryImpl.java:110)
at weblogic.application.inter
解决方法:
1、把自己以前安装的bea目录下的
D:\bea\WEBLOG~1\server\lib\bea_wls_management_internal2.war Message 文件重新复制一份放在当前bea下即可。
2、还有一种就是重新装下bea。
ArrayUtils类帮我们完成数组的打印、查找、克隆、倒序、以及值型/对象数组之间的转换等操作。
1import org.apache.commons.lang.ArrayUtils;
2
3public class TestArrayUtils {
4
5 public static void main(String[] args) {
6 /** *//**
7 * 打印数组中的内容
8 */
9 int[] intArray = new int[] { 2, 3, 4, 5, 6 };
10 int[][] multiDimension = new int[][] { { 1, 2, 3 }, { 2, 3 }, {5, 6, 7} };
11
12 System.out.println( "intArray: " + ArrayUtils.toString( intArray ) );
13 System.out.println( "multiDimension: " + ArrayUtils.toString( multiDimension ) );
14 }
15}
输出:
intArray: {2,3,4,5,6}
multiDimension: {{1,2,3},{2,3},{5,6,7}}
CollectionUtils 中四个方法对集合操作: union(),intersection(),disjunction();,subtract()。
1import java.util.Arrays;
2import java.util.Collection;
3import java.util.Collections;
4import java.util.List;
5
6import org.apache.commons.collections.CollectionUtils;
7import org.apache.commons.lang.ArrayUtils;
8
9public class TestCollectionUtils {
10 @SuppressWarnings("unchecked")
11 public static void main(String[] args) {
12 String[] arrayA = new String[] { "1", "2", "3", "3", "4", "5" };
13 String[] arrayB = new String[] { "3", "4", "4", "5", "6", "7" };
14
15 List<String> a = Arrays.asList(arrayA);
16 List<String> b = Arrays.asList(arrayB);
17 // 并集
18 Collection<String> union = CollectionUtils.union(a, b);
19 // 交集
20 Collection<String> intersection = CollectionUtils.intersection(a, b);
21 // 交集的补集
22 Collection<String> disjunction = CollectionUtils.disjunction(a, b);
23 // 集合相减
24 Collection<String> subtract = CollectionUtils.subtract(a, b);
25
26 Collections.sort((List<String>) union);
27 Collections.sort((List<String>) intersection);
28 Collections.sort((List<String>) disjunction);
29 Collections.sort((List<String>) subtract);
30
31 System.out.println("A: " + ArrayUtils.toString(a.toArray()));
32 System.out.println("B: " + ArrayUtils.toString(b.toArray()));
33 System.out.println("--------------------------------------------");
34 System.out.println("Union(A, B): " + ArrayUtils.toString(union.toArray()));
35 System.out.println("Intersection(A, B): " + ArrayUtils.toString(intersection.toArray()));
36 System.out.println("Disjunction(A, B): " + ArrayUtils.toString(disjunction.toArray()));
37 System.out.println("Subtract(A, B): " + ArrayUtils.toString(subtract.toArray()));
38 }
39}
输出:
A: {1,2,3,3,4,5}
B: {3,4,4,5,6,7}
--------------------------------------------
Union(A, B): {1,2,3,3,4,4,5,6,7}
Intersection(A, B): {3,4,5}
Disjunction(A, B): {1,2,3,4,6,7}
Subtract(A, B): {1,2,3}
转载:http://blog.csdn.net/ofofw/archive/2009/06/26/4300964.aspx
2010-5-4 9:55:00 org.apache.catalina.session.StandardManager doLoad
严重: IOException while loading persisted sessions: java.io.EOFException
java.io.EOFException
at java.io.ObjectInputStream$PeekInputStream.readFully(ObjectInputStream.java:2228)
at java.io.ObjectInputStream$BlockDataInputStream.readShort(ObjectInputStream.java:2694)
at java.io.ObjectInputStream.readStreamHeader(ObjectInputStream.java:761)
at java.io.ObjectInputStream.<init>(ObjectInputStream.java:277)
at org.apache.catalina.util.CustomObjectInputStream.<init>(CustomObjectInputStream.java:58)
at org.apache.catalina.session.StandardManager.doLoad(StandardManager.java:362)
at org.apache.catalina.session.StandardManager.load(StandardManager.java:321)
at org.apache.catalina.session.StandardManager.start(StandardManager.java:637)
at org.apache.catalina.core.ContainerBase.setManager(ContainerBase.java:438)
at org.apache.catalina.core.StandardContext.start(StandardContext.java:4258)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:791)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:771)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:525)
at org.apache.catalina.startup.HostConfig.deployDirectory(HostConfig.java:920)
at org.apache.catalina.startup.HostConfig.deployDirectories(HostConfig.java:883)
at org.apache.catalina.startup.HostConfig.deployApps(HostConfig.java:492)
at org.apache.catalina.startup.HostConfig.start(HostConfig.java:1138)
at org.apache.catalina.startup.HostConfig.lifecycleEvent(HostConfig.java:311)
at org.apache.catalina.util.LifecycleSupport.fireLifecycleEvent(LifecycleSupport.java:117)
at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1053)
at org.apache.catalina.core.StandardHost.start(StandardHost.java:719)
at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1045)
at org.apache.catalina.core.StandardEngine.start(StandardEngine.java:443)
at org.apache.catalina.core.StandardService.start(StandardService.java:516)
at org.apache.catalina.core.StandardServer.start(StandardServer.java:710)
at org.apache.catalina.startup.Catalina.start(Catalina.java:566)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:585)
at org.apache.catalina.startup.Bootstrap.start(Bootstrap.java:288)
at org.apache.catalina.startup.Bootstrap.main(Bootstrap.java:413)
解决:
删除Tomcat里面的work\Catalina\localhost下的内容即可解决。
今天测试工程的时候,我用本地“承保工程”调用另外一个同事的“规则工程”,也报了上面的错误。
网上相关解决如下:
java.lang.UnsupportedClassVersionError: Bad version number in .class file异常,检查了一下我的myEclipse,发现不知道啥时候不小心将编译器改成JDK6.0了,那个工程是从同事的机上拷贝过来的,用的编译器是JDK5.0,试了一下,果然是这个问题引起。
那次在Linux上部署工程时也出现过因为版本不同引起的问题,那时我们用的IDE的编译器是JDK5.0,而那台Linux装的是JDK6.0,部署后发现很多功能都出错,看来有些东西还是得注意一下啊。
附,在myEclipse中改变编译器的方法:Project->Properties->Java Compiler->Configure Workspace Setting,在弹出的页面中可以进行设置。
在操作Drools的测试例子时,Eclipse后台报以下错误:
org.drools.RuntimeDroolsException: Unable to load dialect 'org.drools.rule.builder.dialect.java.JavaDialectConfiguration:java'
at org.drools.compiler.PackageBuilderConfiguration.addDialect(PackageBuilderConfiguration.java:160)
at org.drools.compiler.PackageBuilderConfiguration.buildDialectConfigurationMap(PackageBuilderConfiguration.java:146)
at org.drools.compiler.PackageBuilderConfiguration.init(PackageBuilderConfiguration.java:121)
at org.drools.compiler.PackageBuilderConfiguration.<init>(PackageBuilderConfiguration.java:98)
at org.drools.compiler.PackageBuilder.<init>(PackageBuilder.java:124)
at org.drools.compiler.PackageBuilder.<init>(PackageBuilder.java:86)
at com.sample.DecisionTableTest.readDecisionTable(DecisionTableTest.java:58)
at com.sample.DecisionTableTest.main(DecisionTableTest.java:35)
Caused by: java.lang.RuntimeException: The Eclipse JDT Core jar is not in the classpath
at org.drools.rule.builder.dialect.java.JavaDialectConfiguration.setCompiler(JavaDialectConfiguration.java:91)
at org.drools.rule.builder.dialect.java.JavaDialectConfiguration.init(JavaDialectConfiguration.java:52)
at org.drools.compiler.PackageBuilderConfiguration.addDialect(PackageBuilderConfiguration.java:156)
... 7 more
主要是缺少一个jar包:org.eclipse.jdt.core_3.3.1.v_780_R33x.jar而引起的。
package org.jbpm.helloworld;
import junit.framework.TestCase;
import org.jbpm.graph.def.ProcessDefinition;
import org.jbpm.graph.exe.ProcessInstance;
import org.jbpm.graph.exe.Token;
public class HelloWorldTest extends TestCase {
public void testHelloWorldProcess() {
ProcessDefinition processDefinition = ProcessDefinition.parseXmlResource("helloWorld.xml");
/* 从这里可以看出,是对流程定义的XML进行解析*/
ProcessInstance processInstance = new ProcessInstance(processDefinition);
Token token = processInstance.getRootToken();
assertSame(processDefinition.getStartState(), token.getNode());
token.signal();
assertSame(processDefinition.getNode("s"), token.getNode());
token.signal();
assertSame(processDefinition.getNode("end"), token.getNode());
}
流程定义文件:helloWorld.xml
<?xml version="1.0" encoding="UTF-8"?>
<process-definition xmlns="urn:jbpm.org:jpdl-3.1" name="Helloworld">
<start-state>
<transition to='s' />
</start-state>
<state name='s'>
<transition to='end' />
</state>
<end-state name='end' />
</process-definition>
package rules;
import java.io.InputStream;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import org.drools.RuleBase;
import org.drools.RuleBaseFactory;
import org.drools.WorkingMemory;
import org.drools.compiler.PackageBuilder;
import org.drools.decisiontable.InputType;
import org.drools.decisiontable.SpreadsheetCompiler;
import org.drools.rule.Package;
public class TestPremium {
public static final String path = "rules\\premium\\0326\\02\\030006\\rate.xls";
public static void main(String[] args) throws Exception {
try {
RuleBase ruleBase = readDecisionTable();
WorkingMemory workingMemory = ruleBase.newStatefulSession();
int flag = path.indexOf("FormulaOrder");
ElementResultVO r = new ElementResultVO();
PremiumHelper helper = new PremiumHelper();
workingMemory.setGlobal("r", r);
workingMemory.setGlobal("helper", helper);
AppBaseVO base = new AppBaseVO();
AppVhlVO vhl = new AppVhlVO();
AppPrmCoefVO prmCoef = new AppPrmCoefVO();
base.setCAmtCur("01");
base.setNAmt(4000000d);
workingMemory.insert(base);
workingMemory.insert(vhl);
workingMemory.insert(prmCoef);
workingMemory.fireAllRules();
System.out.println("==========compile success!===========");
} catch (Exception e) {
System.out.println("==========compile failure!===========");
e.printStackTrace();
}
}
private static RuleBase readDecisionTable() throws Exception {
final SpreadsheetCompiler converter = new SpreadsheetCompiler();
InputStream is = TestPremium.class.getClassLoader().getResourceAsStream(path);
final String drl = converter.compile( is, InputType.XLS );
PackageBuilder builder = new PackageBuilder();
builder.addPackageFromDrl( new StringReader( drl ) );
Package pkg = builder.getPackage();
RuleBase ruleBase = RuleBaseFactory.newRuleBase();
ruleBase.addPackage( pkg );
return ruleBase;
}
}
++++++++++++++++++++++++++++++++++++++
执行后的一部分:
#From row number: 369
rule "_369"
salience 65167
activation-group "x"
when
vhl:AppVhlVO(CUsageCde == "374015", CVhlTyp == "365012",
eval(helper.getVhlYear(vhl.getCFstRegYm())>=4 && helper.getVhlYear(vhl.getCFstRegYm())<1000))
then
r.putCoef("rate",0.67);
r.putField("Table.col","Cvrg.NRate");
end
package com.premium.rules;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.Reader;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import org.apache.log4j.Logger;
import org.drools.compiler.DroolsParserException;
import org.drools.compiler.PackageBuilder;
import org.drools.decisiontable.InputType;
import org.drools.decisiontable.SpreadsheetCompiler;
import org.drools.rule.Package;
public class DrlPackageManager {
// 用于缓存Drools的Package,key为Excel的完整路径,value为此文件编译过后的Package
static Map<String, Package> pkgMap = new HashMap<String, Package>();
private static Logger logger = Logger.getLogger(DrlPackageManager.class);
/**
* 通过Excel的文件名缓存Drools的Package
*
* @param fileName
* @return
* @throws Exception
*/
public static Package getPackageByXsl(String fileName) throws Exception {
Package pkg = (Package) pkgMap.get(fileName);
if (pkg != null)
return pkg;
final SpreadsheetCompiler converter = new SpreadsheetCompiler();
InputStream is = null;
try {
is = DrlPackageManager.class.getResourceAsStream(fileName);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
is.close();
throw new Exception("====读取规则的资源文件" + fileName + "出错,请检查文件"+ fileName + "=====", e);
}
String drl = null;
try {
drl = converter.compile(is, InputType.XLS);
logger.debug("Drools Excel规则文件:" + fileName + "编译成.drl文件的结果:"+ drl);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
is.close();
throw new Exception("xls文件编译成drl文件出错", e);
}
PackageBuilder builder = new PackageBuilder();
StringReader srd = new StringReader(drl);
builder.addPackageFromDrl(srd);
pkg = builder.getPackage();
pkgMap.put(fileName, pkg);
is.close();
return pkg;
}
}
1、Drools是什么?
Drools 是一个基于Charles Forgy's的Rete算法的,专为Java语言所设计的规则引擎。Rete算法应用于面向对象的接口将使基于商业对象的商业规则的表达更为自然。Drools是用Java写的,但能同时运行在Java和.Net上。
一路到底的框架:
大多数开发者都有自己喜爱的框架。无特定顺序,它们包括表现层框架(Struts, JSF, Cocoon和Spring),持久化框架(JDO, Hibernate, Cayenne and Entity Beans)以及结构框架(EJB, 又是Spring, Pico和Excalibur), 还有其它很多。每种框架都各有所长,给开发者提供子许多“即开即用”的功能。使用框架来部署应用意味着你避免了许多让人厌烦的细节,让你集中注意力到关键之处。
到目前为直,在框架所能做的事中仍然有一个缺口,那就是商业逻辑没有框架。像EJB和Spring这样的工具虽好,但它们却几乎没有提及怎么组织你的那些if …then语句。把Drools加到你的开发工具箱中意味着现在你可以“一路到底”的使用框架来构建你的应用程序。
2.Drools4.0版本:
JBoss Drools是一款开源的业务规则引擎,目前已经发布了4.0版本。在4.0版本中主要的特色和改进如下:
1.更高的性能:较之于之前的版本,Drools 4.0更为高效并且占用更少的内存空间。内部的性能测试表明,性能的提升已经从几分钟缩减为若干秒钟。
2.提升的表达能力:当前的发布版引入了更为强大且的业务行为脚本语言(MVFlex表达式语言)。
3.友好的业务分析工具:一个具备向导功能的规则编辑器的增加,使得非程序员用户可以设计复杂的业务规则,并在没有编写任何代码的情况下自动绑定企业数据。提供带有菜单提示和下拉列表的向导来帮助用户完成设计过程。
4.规则流的能力:可视化的建模技术可以使用户声明式地为相应规则的执行路径建立访问模型。它同样还允许在单个工作内存中存在多个并发工作流,并根据控制典型的业务处理过程的需求,从根本上组织规则的执行。 5.多应用支撑:对于有状态和无状态处理过程增强的支持以及全面的线程安全性,辅助Drools更轻易的嵌入在Java平台,JavaEE以及面向服务的商业应用之中。
6.直接可和Hibernate集成:用户可以直接在Hibernate驱动的RDBMS查询中对数据(facts)进行判断。现有的Hibernate组件可以直接用在规则引擎里,减少编码的工作量。
7.为非程序员设计的BRMS:从技术角度来看,新的BRMS基于Web开发,使用AJAX呈现,便于协作,是一个编写、版本化控制和管理规则的系统。业务分析师目前可以交互式的授权或修改自动转换的规则。管理员目前具备完全的生命周期控制能力,包含何种规则在QA阶段,分段(staging),以及实施(production)阶段等等。
3.Drools的总体架构:
我们使用Drools就是为了让它处理数据与规则的关系,因此Drools要获得数据和获得规则,然后进行执行。因此Drools分为编制和运行时两个部分。
编制是指产生rule的过程,Drools用DRL,或者XML来描述规则。编制的过程包括为规则建立DRL 或XML 文件,传入一个由Antlr 3 文法器定义的解析器中。解析器对文件中规则文法的正确性进行检查并为descr 建立一个中间结构,在AST 中的descr 代表规则的描述。AST 然后将descr 传入Package Builder中,由其进行打包。Package Builder 同时负责包括打包中用到的所有代码产生器和编译器。Package 对象是自包含并可配置的,它是一个包含规则的序列化的对象。
RuleBase 是运行时组件,包含一个或多个Package。Package 在任何时候都可以向RuleBase中添加或删除。一个RuleBase 可以同时初始化多个Working Memory,在其间维护着一个弱引用,除非重新进行配置。Working Memory 包含许多子组件,如Working Memory Event Support(事件支持),Truth Maintenance System(真值维护系统), Agenda 和 Agenda Event Support(事件支持)。向Working Memory 中设置对象的工作可能要在建立了一个或多个激活的规则后才结束。Agenda 负有规划激活规则运行的责任。
4.Drools主要有以下类实现:
编制:
XmlParser,DrlParser 分别用来解析XML描述的规则文件和DRL描述的规则文件。
PackageBuilder 创建package实例。
例如:
PackageBuilder builder = new PackageBuilder();
builder.addPackageFromDrl( new InputStreamReader( getClass().getResourceAsStream( "package1.drl" ) ) );
builder.addPackageFromXml( new
InputStreamReader( getClass().getResourceAsStream( "package2.xml" ) ) );
Package pkg = builder.getPackage();
运行时的类:
RuleBase 使用RuleBaseFactory 实例化,默认情况下返回一个ReteOO 的RuleBase。Package通过使用addPackage 方法按顺序加入。你可以指定任何名称空间的Packages 或者同一名称的多个包加入RuleBase。
RuleBase ruleBase = RuleBaseFactory.newRuleBase();
ruleBase.addPackage( pkg );
事实数据相关类:
WorkingMemory 保存运行时事实数据的地方。
由ruleBase产生:WorkingMemory wm= ruleBase.newStatefulSession();
加载事实数据:
wm.insert(object );
insert方法返回一个FactHandle对象指向workingMemory中对象的引用。如果要对Object进行修改删除等操作都要通过FactHander对象来完成。
在准备好Rule,和Fact后 就可以调用 WorkingMemory对象的 fireAllRules()方法执行规则引擎。
Agenda上面提到过它负有规划激活规则运行的责任。
它运行过程分两个阶段:
1) WorkingMemory Actions : assert 新的 facts ,修改存在的 facts 和 retract facts 都是 WorkingMemory Actions 。通过在应用程序中调用 fireAllRules() 方法,会使引擎 转换到 Agenda Evaluatioin 阶段。
2) Agenda Evaluation :尝试选择一条规则进行激发( fire )。如果规则没有找到就 退出,否则它就尝试激发这条规则,然后转换到 WorkingMemory Actions 阶段,直到 Agenda中为空。
Eval 是Javascript 中一个非常有用而奇特的预定义函数,它的概念和作用也像C 语言中的指针一样较难理解,因而在实际应用中常常不能运用得当。函数Eval的功能是把一个字符串参数转换成Javascript的代码,这个被转换的代码可以是一个变量名,也可以是一个算术表达式,甚至是一个函数表达式。如i = eval("name1")是把名为name1 的变量赋值给变量i;i=eval("3+2")是把表达式3+2 的值5 赋给变量i ; i = eval("funname(n)")是把函数funname(n)返回值传给变量i。这时,你也许要问了,这不是多此一举吗?直接写成i=name1;i=3+2;i=funname(n)不就行了吗?是的,如果我们仅仅把字符串值当作参数,是一点作用都不起。但如果我们把字符串变量作为参数,Eval 的作用就大了。如i=eval(str)(其中,str 是字符串变量),str 作为一个变量,其值可以动态地发生变更,从而使i = eval(str)产生不同的结果。这时str是不是像C语言的指针?它“指”向name1(即str 的值是"name1" 字串),i得到的是变量name1 的值。它“指”向一个函数名,就调用该函数并返回值给i(但该函数必须事先定义好,Javascript 引擎要找得到才行)。此外,它比“指针”更有用的是,还可解析执行动态生成的运算表达式。
下面通过一个Web仿真计算器实例来描述它的这个作用。这是一个基于Web的计算器仿真程序。用户可以像操作一个现实世界中的计算器一样,通过单击按钮输入数据和运算符号,当输入等号后在文本框中得到最终结果。它的原理很简单,就是记录用户输入的运算式字串,然后用Eval 函数把该字串转成运算式交给Javascript 执行即可。先手动建立一个简单的HTML 文件,只要<html>、head>和<body>元素即可。接着在<body></body>间插入以下html 代码,设置好该程序界面。
<input type="text" name=textdisp value="" ><br>
<input type="button" name=leftk value="(" onclick="yunsuan(value)">
<input type="button" name=rightk value=")" onclick="yunsuan(value)">
<input type="button" name=op1 value="1" onclick="yunsuan(value)">
<input type="button" name=op2 value="2" onclick="yunsuan(value)">
<input type="button" name=op3 value="3" onclick="yunsuan(value)">
<input type="button" name=op4 value="4" onclick="yunsuan(value)">
<br><p>
<input type="button" name=op5 value="5" onclick="yunsuan(value)">
<input type="button" name=op6 value="6" onclick="yunsuan(value)">
<input type="button" name=op7 value="7" onclick="yunsuan(value)">
<input type="button" name=op8 value="8" onclick="yunsuan(value)">
<input type="button" name=op9 value="9" onclick="yunsuan(value)">
<input type="button" name=op0 value="0" onclick="yunsuan(value)">
<br><p>
<input type="button" name=oppoint value="." onclick="yunsuan(value)">
<input type="button" name=opadd value="+" onclick="yunsuan(value)">
<input type="button" name=opsub value="-" onclick="yunsuan(value)">
<input type="button" name=opmul value="*" onclick="yunsuan(value)">
<input type="button" name=opdiv value="/" onclick="yunsuan(value)">
<input type="button" name=opeql value="=" onclick="yunsuan(value)">
<br><p>
<input type="button" name=cle value="restar" onclick="res()">
现在用IE6 打开它,就会得到如图所示的效果。再接再厉,现在在<head></head>中输入以下Javascript
代码:
<TITLE>test</TITLE>
<script language="javascript">
var expstring="";
var numstring="";
function yunsuan(btn){
if(btn=="=")
textdisp.value=eval(expstring);
else
{if(((btn>="0")&&(btn<="9"))||(btn=="."))
{numstring=numstring+btn;
textdisp.value=numstring;
}
else
numstring="";
expstring=expstring+btn;
}
}
function res(){
expstring="";
textdisp.value="";
numstring="";
}
</script>
这样,我们利用Eval 函数,仅仅十几行代码就做好了这个计算器。
转载:http://school.cfan.com.cn/pro/pother/2006-08-28/1156732532d14455.shtml
目前来看,JS框架以及一些开发包和库类有如下几个:Dojo 、Scriptaculous 、Prototype 、yui-ext 、Mochikit、mootools 、moo.fx 、jQuery。
Dojo (JS library and UI component ):
Dojo是目前最为强大的j s框架,它在自己的Wiki上给自己下了一个定义,dojo是一个用JavaScript编写的开源的DHTML工具箱。dojo很想做一个“大一统”的 工具箱,不仅仅是浏览器层面的,野心还是很大的。Dojo包括ajax, browser, event, widget等跨浏览器API,包括了JS本身的语言扩展,以及各个方面的工具类库,和比较完善的UI组件库,也被广泛 应用在很多项目中,他的UI组件的特点是通过给html标签增加tag的方式进行扩展,而不是通过写JS来生成,dojo的API模仿Java类库的组织 方式。 用dojo写Web OS可谓非常方便。dojo现在已经4.0了,dojo强大的地方在于界面和特效的封装,可以让开发者快速构建一些兼容标准的界面。
优点:库相当完善,发展时间也比较长,功能强大,据说利用dojo的io.bind()可以实现comet,看见其功能强大非一般,得到IBM和SUN的支持。
缺点:文件体积比较大,200多KB,初次下载相当慢,此外,dojo的类库使用显得不是那么易用,j s语法增强方面不如prototype。
Prototype (JS OO library):
是一个非常优雅的JS库,定义了JS的面向对象扩展,DOM操作API,事件等等,以prototype为核心,形成了一个外围的各种各样 的JS扩展库,是相当有前途的JS底层框架,值得推荐,感觉也是现实中应用最广的库类(RoR集成的AJAX JS库),之上还有 Scriptaculous 实现一些JS组件功能和效果。
优点:基本底层,易学易用,甚至是其他一些js特效开发包的底层,体积算是最小的了。
缺点:如果说缺点,可能就是功能是他的弱项
Scriptaculous (JS UI component based on prototype):
Scriptaculous是基于prototype.js框架的JS效果。包含了6个js文件,不同的文件对应不同的js效果,所以说,如果底层用 prototype的话,做js效果用Scriptaculous那是再合适不过的了,连大名鼎鼎的digg都在用他。
优点:基于prototype是最大的优点,由于使用prototype的广泛性,无疑对用户书锦上添花,并且在《ajax in action》中就拿Scriptaculous来讲述js效果。
缺点:刚刚兴起,需要时间的磨练。
yui-ext (JS UI component):
基于Yahoo UI的扩展包yui-ext是具有CS风格的Web用户界面组件 能实现复杂的Layout布局,界面效果可以和backbase媲美,而且使用纯javascript代码开发。真正的可编辑的表格Edit Grid,支持XML和Json数据类型,直接可以迁入grid。许多组件实现了对数据源的支持,例如动态的布局,可编辑的表格控件,动态加载的Tree 控件、动态拖拽效果等等。1.0 beta版开始同Jquery合作,推出基于jQuery的Ext 1.0,提供了更多有趣的功能。
优点:结构化,类似于java的结构,清晰明了,底层用到了Jquery的一些函数,使整合使用有了选择,最重要的一点是界面太让让人震撼了。
缺点:太过复杂,整个界面的构造过于复杂。
Mochikit :
MochiKit自称为一个轻量级的js框架。MochiKit 主要受到 Python 和 Python 标准库提供的很多便利之处的启发,另外还缓解了浏览器版本之间的不一致性。其中的 MochiKit.DOM 尤其方便,能够以比原始 JavaScript 更友好的方式处理 DOM 对象。MochiKit.DOM 大部分都是针对 XHTML 文档定制的,如果与 MochiKit 和 Ajax 结合在一起,使用 XHTML 包装的微格式尤其方便。Mochikit可以直接对字符串或者数字格式化输出,比较实用和方便。它还有自己的 js 代码解释器。
优点:MochiKit.DOM这部分很实用,简介也是很突出的。
缺点:轻量级的缺点。
mootools :
MooTools是一个简洁,模块化,面向对象的JavaScript框架。它能够帮助你更快,更简单地编写可扩展和兼容性强的JavaScript代码。Mootools跟prototypejs相类似,语法几乎一样。但它提供的功能要比prototypejs多,而且更强大。比如增加了动画特效、拖放操作等等。
优点:可以定制自己所需要的功能,可以说是prototypejs的增强版。
缺点:不大不小,具体应用具体分析。
moo.fx :
moo.fx是一个超级轻量级的javascript特效库(7k),能够与prototype.js或mootools框架一起使用。它非常快、易于使用、跨浏览器、符合标准,提供控制和修改任何HTML元素的CSS属性,包括颜色。它内置检查器能够防止用户通过多次或疯狂点击来破坏效果。moo.fx整体采用模块化设计,所以可以在它的基础上开发你需要的任何特效。
优点:小块头有大能耐。
缺点:这么小了,已经不错了。
jQuery:
jQuery是一款同prototype一样优秀js开发库类,特别是对css和XPath的支持,使我们写js变得更加方便!如果你不是个js高手又想写出优秀的js效果,jQuery可以帮你达到目的!并且简介的语法和高的效率一直是jQuery追求的目标。
优点:注重简介和高效,js效果有yui-ext的选择,因为yui-ext 重用了很多jQuery的函数。
缺点:据说太嫩,历史不悠久。
IMP-00017: 由于 ORACLE 的 600 错误,以下的语句失败
"CREATE PACKAGE BODY quest_soo_util wrapped"
IMP-00003: 遇到 ORACLE 错误 600
ORA-00600: 内部错误代码,参数: [16201], [], [], [], [], [], [], []
IMP-00017: 由于 ORACLE 的 600 错误,以下的语句失败
"CREATE PACKAGE BODY QUEST_SOO_PKG wrapped"
以上是imp导入Oracle是出现的错误。
转载,其他情况出现的ORACLE 的 600 错误:
这个错误是 drop 用户时产生的,用户无法 drop。既然如此,登录该用户删除其中的procedure,结果也出现了该错误。有个帖子介绍说这是 Oracle 的一个 bug(No. 2422726),并给出了解决办法。这里记录一下:
1. 错误现象:
SQL> show user
USER 为"SYS"
SQL> select * from v$version;
BANNER
------------------------------------------------------------
Oracle8i Release 8.1.6.0.0 - Production
PL/SQL Release 8.1.6.0.0 - Production
CORE 8.1.6.0.0 Production
TNS for 32-bit Windows: Version 8.1.6.0.0 - Production
NLSRTL Version 3.4.1.0.0 - Production
SQL> drop user hos_kf_hl cascade;
drop user hos_kf_hl cascade
*
ERROR 位于第 1 行:
ORA-00600: 内部错误代码,自变量: [16201], [], [], [], [], [], [], []
SQL> conn hos_kf_hl/test@qmyb
已连接。
SQL> drop procedure kill_session;
drop procedure kill_session
*
ERROR 位于第 1 行:
ORA-00600: 内部错误代码,自变量: [16201], [], [], [], [], [], [], []
2. 查询视图 procedure$,确认该错误:
SQL> select obj#,owner#,type# from sys.obj$ where name ='KILL_SESSION' and owner#=96;
OBJ# OWNER# TYPE#
---------- ---------- ----------
55491 96 7
SQL> select * from procedure$ where obj# = 55491;
OBJ# AUDIT$ STORAGESIZE OPTIONS
---------- -------------------------------------- ----------- ----------
3. 解决
SQL> insert into procedure$ values (55491, '----------------', null, 2);
1 row inserted
SQL> commit;
Commit complete
SQL> drop procedure kill_session;
过程已丢弃。
SQL> conn sys/password@s177 as sysdba
已连接。
SQL> drop user hos_kf_hl cascade;
用户已丢弃
Error 500--Internal Server Error
java.lang.NoSuchMethodError: org.springframework.web.util.WebUtils.exposeErrorRequestAttributes
(Ljavax/servlet/http/HttpServletRequest;Ljava/lang/Throwable;Ljava/lang/String;)V
at org.springframework.web.servlet.DispatcherServlet.processHandlerException(DispatcherServlet.java:1119)
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:896)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:809)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:571)
at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:511)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:763)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:856)
at org.jasig.cas.web.init.SafeDispatcherServlet.service(SafeDispatcherServlet.java:115)
at weblogic.servlet.internal.StubSecurityHelper$ServletServiceAction.run(StubSecurityHelper.java:227)
at weblogic.servlet.internal.StubSecurityHelper.invokeServlet(StubSecurityHelper.java:125)
at weblogic.servlet.internal.ServletStubImpl.execute(ServletStubImpl.java:283)
at weblogic.servlet.internal.TailFilter.doFilter(TailFilter.java:26)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at org.inspektr.common.web.ClientInfoThreadLocalFilter.doFilterInternal(ClientInfoThreadLocalFilter.java:48)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:75)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at weblogic.servlet.internal.WebAppServletContext$ServletInvocationAction.run(WebAppServletContext.java:3242)
at weblogic.security.acl.internal.AuthenticatedSubject.doAs(AuthenticatedSubject.java:321)
at weblogic.security.service.SecurityManager.runAs(SecurityManager.java:121)
at weblogic.servlet.internal.WebAppServletContext.securedExecute(WebAppServletContext.java:2010)
at weblogic.servlet.internal.WebAppServletContext.execute(WebAppServletContext.java:1916)
at weblogic.servlet.internal.ServletRequestImpl.run(ServletRequestImpl.java:1366)
at weblogic.work.ExecuteThread.execute(ExecuteThread.java:209)
at weblogic.work.ExecuteThread.run(ExecuteThread.java:181)
处理方法参考:
在IE菜单-->工具-->Internet选项->高级选项卡-->显示友好的HTTP错误信息, 把钩选去掉。调整设置后,你可以看到更多的有关错误的细节。
Error 500--Internal Server Error 错误是一个通常的错误,原因可能有很多,往往是服务器进程内组件、模块或服务器调用的进程外组件等造成的错误。
我的这个问题的原因是:不同的用户在本机的多个IE上登录造成的错误。
IMP-00003: 遇到 ORACLE 错误 1658
ORA-01658: 无法为表空间COREV6中的段创建 INITIAL 区
IMP-00017: 由于 ORACLE 的 1658 错误,以下的语句失败
"CREATE TABLE "WEB_VCH_APP" ("C_APP_ID" VARCHAR2(30) NOT NULL ENABLE, "C_VCH"
"_TYPE" VARCHAR2(30), "C_APP_DPT" VARCHAR2(30) NOT NULL ENABLE, "T_APP_TM" D"
"ATE NOT NULL ENABLE, "C_APP_CDE" VARCHAR2(50) NOT NULL ENABLE, "N_APP_NUM" "
"NUMBER(8, 0) NOT NULL ENABLE, "N_STORE_NUM" NUMBER(8, 0), "C_APP_REMARK" VA"
"RCHAR2(500), "C_STATUS" CHAR(1), "N_CHK_TMS" NUMBER(4, 0), "C_CRT_CDE" VARC"
"HAR2(30) NOT NULL ENABLE, "T_CRT_TM" DATE NOT NULL ENABLE, "C_UPD_CDE" VARC"
"HAR2(30) NOT NULL ENABLE, "T_UPD_TM" DATE NOT NULL ENABLE, "C_TRANS_MRK" CH"
"AR(1), "T_TRANS_TM" DATE) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 ST"
"ORAGE(INITIAL 65536 FREELISTS 1 FREELIST GROUPS 1) TABLESPACE "COREV6" LOGG"
"ING NOCOMPRESS"
主要是表空间已经用完,重新扩大表空间,即可。
1.在web项目WEB-INF/下创建weblogic.xml文件。
weblogic.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<weblogic-web-app xmlns="http://www.bea.com/ns/weblogic/90">
<context-root>/pcis</context-root>
</weblogic-web-app>
其中:<context-root>/pcis</context-root>中pcis该web项目文件夹名称;
2.在web项目中找到spring的配置文件applicationContext.xml,并在其中配置数据源。
<bean id="myDataSource" class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName">
<value>jdbc/pcis</value>
</property>
<property name="jndiEnvironment">
<props>
<prop key="java.naming.provider.url">t3://localhost:7001</prop>
<prop key="java.naming.factory.initial">weblogic.jndi.WLInitialContextFactory</prop>
</props>
</property>
</bean>
3.启动E:\bea\user_projects\domains\base_domain\bin下的startWebLogic.cmd,登录:http://localhost:7001/console/ 。
(1)在左边的Domain Structure下base_domain/Services/JDBC/Data Sources下配置数据源,如jdbc/pcis。
(2)在左边的Domain Structure下base_domain/Deployments中配置发布的工程。
注意:在出现这个“What do you want to name this deployment?”的地方,填上工程的发布名,如:pcis
4.在base_domain/Deployments下,选择要启动的工程,点击“Start”。
5.工程启动完以后,在IE上输入 http://localhost:7001/pcis ,验证是否成功登录。
错误提示1:
<Server failed. Reason:
Unable to start WebLogic Server!
Error: license signature validation error.
Please make sure you have a valid license.bea
file in the BEA home directory associated with this
installation. For more information about the license.bea
file, see the installation guide for the version of the
software you are using at http://e-docs.bea.com.
>
错误提示2:
The Server is not licensed for this operation.Connection rejected, the server license allows connections from only 5 unique IP addresses.
操作方法:
运行开始 -> 程序 -> BEA Products -> WebLogic Server 9.2
解决方法:
1.找到对应的文件:E:\bea\weblogic92\samples\domains\wl_server\bin\startWebLogic.cmd
2.修改配置:startWebLogic.cmd 中的CLASSPATH为
set CLASSPATH=E:\bea\weblogic_crack.jar;%CLASSPATH%;%MEDREC_WEBLOGIC_CLASSPATH%
3.把weblogic_crack.jar 加到 E:\bea 路径下。
查看是否正常启动:
双击 WebLogic Server 9.2,然后再IE上输入http://localhost:7001/,检查服务器是否启动成功。
win下的使用方法:
1.将license.bea和weblogic_crack.jar拷贝到bea安装目录下,例如E:\bea
2.修改E:\bea\user_projects\domains\base_domain\bin\startWeblogic.cmd
把set CLASSPATH=%CLASSPATH%;%MEDREC_WEBLOGIC_CLASSPATH%
改为
set CLASSPATH=E:\bea\weblogic_crack.jar;%CLASSPATH%;%MEDREC_WEBLOGIC_CLASSPATH%
3. 重启weblogic。
linux下使用方法:
1.将license.bea和weblog_crack.jar拷贝到bea安装目录下,例如:/opt/bea
2.修改/opt/bea/user_projects/domains/base_domain/bin/startWebLogic.sh
修改
CLASSPATH="${CLASSPATH}${CLASSPATHSEP}${MEDREC_WEBLOGIC_CLASSPATH}"
为
CLASSPATH="/opt/bea/weblogic_crack.jar:${CLASSPATH${CLASSPATHSEP${MEDREC_WEBLOGIC_CLASSPATH}"
3. 重启weblogic。
本文所用环境:MyEclipse 6.0GA + WebLogic 9.2
一、选择 WebLogic 9.2 的原因
①WebLogic 8 支持的是 J2EE 1.3,也就是 Servlet 2.3 规范。若在 MyEclipse 中建立 Web Project 时选择了 J2EE 1.4[default],在部署的时候就会出现异常,提示部署描述符 web.xml 是畸形的,也就是未通过 DTD 检验。因为 J2EE 1.4 使用的是 Servlet 2.4 规范,这直接体现在 web.xml 部署描述符的头部引用中。这就是有些朋友遇到的,部署在 Tomcat 和 JBoss 中能够运行的 JSP 程序,部署到 WebLogic 8 就无法运行的原因之一。解决这个问题,需要将 WebLogic 升级到 9.2 版本;或者使用 J2EE 1.3。
②若在上一个问题选择了 J2EE 1.3 进行开发后,在部署时会出现另外的异常,提示“Unsupported major.minor version 49.0”—— 又是版本问题,这次是由于 JDK 版本不支持造成的。WebLogic 8 不支持 JDK 1.5,由 JDK 1.5 编译的程序无法部署到只支持 JDK 1.4 的服务器上运行。解决的办法也有两个:用 JDK 1.4 重新编译;或者换用支持 JDK 1.5 的服务器,也就是升级到 WebLogic 9.2。
Servlet 2.3 规范生成的 web.xml 头部:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
...
</web-app>
Servlet 2.4 规范生成的 web.xml 头部:
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
...
</web-app>
二、配置 WebLogic 9.2 的域。
①运行开始 -> 程序 -> BEA Products -> Tools -> Configuration Wizard。
②选择 Create a new WebLogic domain,Next。
③在 Select Domain Source 界面保持默认,Next。
④在 User name 处输入 weblogic,两个 password 都输入 weblogic(密码要求 8 位),Next。
⑤ 在 Configure Server Start Mode and JDK 界面中保持默认,即 JDK 选择的是“Sun SDK 1.5.0_04 @ C:\BEA\jdk150_04”,注意这里若选择“Other JDK”配置比 SDK 1.5.0_04 更高的版本,服务器启动时将会出现异常,所以最好保持默认,然后 Next。
⑥在 Customize Environment and Services Settings 界面中默认为 No,Next。
⑦在 Domain name 处为默认base_domain,点击 Create。
⑧完成后点击 Done ,关闭 Configuration Wizard 对话框。
三、修改WebLogic 9.2 的文件配置。
修改E:\bea\user_projects\domains\base_domain\bin\startWeblogic.cmd
在文件中找到 “set CLASSPATH=%CLASSPATH%;%MEDREC_WEBLOGIC_CLASSPATH%”,加入weblogic_crack.jar的路径,改为:
set CLASSPATH=E:\bea\weblogic_crack.jar;%CLASSPATH%;%MEDREC_WEBLOGIC_CLASSPATH%
四、MyEclipse6.0 集成WebLogic 9.2。
启动 Eclipse,选择“Window -> Preferences”菜单,打开首选项对话框。展开 MyEclipse 下的 Application Servers 节点,点击 WebLogic 9,选中右边的 Enable 单选按钮,启用 WebLogic 服务器。配置如下:
①BEA home directory:E:\bea(假定 WebLogic 安装在 E:\bea目录中)
②WebLogic installation directory:E:\bea\weblogic92
③Admin username:weblogic(来自 WebLogic 中的配置)
④Admin password:weblogic(来自 WebLogic 中的配置)
⑤Execution domain root:E:\bea\user_projects\domains\base_domain
⑥Execution server name:AdminServer
⑦Security policy file:E:\bea\weblogic92\server\lib\weblogic.policy
⑧JAAS login configuration file:(Null)
接着展开 WebLogic 9 节点,点击 JDK,在右边的 WLS JDK name 处选择 WebLogic 9 的默认 JDK。这里组合框中缺省为单独安装的 JRE。单击 Add 按钮,弹出 WebLogic -> Add JVM 对话框,在 JRE 主目录处选择 WebLogic 安装文件夹中的 JDK 文件夹,我的版本为 E:\bea\jdk150_04,程序会自动填充其他选项。单击确定按钮关闭对话框。这时候就可以在 WLS JDK name 组合框中选择 jdk150_04 了。
五、重要补充配置 :
点击 Paths,在右边的 Prepend to classpath 列表框中,通过 Add JAR/ZIP 按钮,加入:
E:\bea\weblogic92\server\lib\weblogic.jar
E:\bea\weblogic92\server\lib\webservices.jar
E:\bea\weblogic_crack.jar
E:\bea\weblogic92\server\lib\classes12.jar
六、查看是否正常启动。
运行开始 -> 程序 -> BEA Products -> WebLogic Server 9.2,然后再IE上输入http://localhost:7001/,检查服务器是否启动成功。
1、学习Linux的基本要求:
1). 掌握至少50个以上的常用命令。
2). 熟悉Gnome/KDE等X-windows桌面环境操作 。
3). 掌握.tgz、.rpm等软件包的常用安装方法
4). 学习添加外设,安装设备驱动程序(比如网卡)
5). 熟悉Grub/Lilo引导器及简单的修复操作 。
6). 熟悉Linux文件系统 和目录结构。
7). 掌握vi,gcc,gdb等常用编辑器,编译器,调试器 。
8). 理解shell别名、管道、I/O重定向、输入和输出以及shell脚本编程。
9). 学习Linux环境下的组网
2、Linux服务器领域:
----代理服务器,使用的是Linux的iptables功能;
----电影服务器,使用的是Linux的samba服务的功能,文件和打印共享服务器
----游戏服务器,cs服务器,在Linux系统下使用cs的Linux版本建立的服务器
----客户存档服务器,采用的Linux的ftp服务器,常用的有:wu-ftp,pro-ftp软件建立的
----www服务器,使用的是Linux下的apache服务器软件
----ftp服务器,下载服务器,使用的是Linux下的wu-ftp,pro-ftp,vs-ftp软件
----mail服务器,采用的是Linux下的sendmail,qmail软件
----dns服务器,使用的是Linux下的bind软件
----数据库服务器,使用的是mysql或者oracle软件
----防火墙,软件防火墙服务器,使用的是Linux的iptables功能建立的
----路由器,软路由器,使用的是Linux下的routed软件建立的
----拨号服务器,vpn服务器等等
3、Linux学习三步走:
第一,网络服务器阶段;
第二,应用软件的开发;
第三,内核研究与操作系统的开发阶段。
需求:对WEB_CUS_CLENT机构为空的进行修改,通过WEB_CUS_CLENT客户编码查找投保人WEB_PLY_APPLICANT的申请单号,通过申请单号查找web_PLY_BASE查找承保机构。
CREATE OR REPLACE PROCEDURE V6.P_WEB_CUS_CLINT_DPT
IS
--增量抽取客户信息数据
v_task_start_date date ;
v_task_end_date date ;
v_sql_code number :=0 ;
v_sql_msg VARCHAR2(4000) := '' ; --sql错误信息
V_Cus_Client Web_Cus_Client%rowtype ;
V_UPD_TM date;
V_APP_NO varchar2(50);
V_DPT_CDE varchar2(50);
V_COUNT number(4,0);
cursor CUR_WEB_CUS_ADD is
select *
from Web_Cus_Client
a where a.C_DPT_CDE is null;
BEGIN
SELECT SYSDATE INTO v_task_start_date FROM dual; --任务开始时间和任务结束时间
SELECT SYSDATE INTO v_task_end_date FROM dual;
v_sql_msg := '对WEB_CUS_CLENT机构为空的进行修改';
open CUR_WEB_CUS_ADD;
loop
fetch CUR_WEB_CUS_ADD into V_Cus_Client;
exit when CUR_WEB_CUS_ADD% notfound;
v_sql_msg := V_Cus_Client.c_Clnt_Cde||'对WEB_CUS_CLENT机构为空的进行修改';
V_COUNT :=0;
select count(1) into V_COUNT from WEB_PLY_APPLICANT a where a.C_APP_CDE=V_Cus_Client.c_Clnt_Cde;
if(V_COUNT>0) then
select max(T_CRT_TM) into V_UPD_TM from WEB_PLY_APPLICANT a where a.C_APP_CDE=V_Cus_Client.c_Clnt_Cde;
select max(C_APP_NO) into V_APP_NO from WEB_PLY_APPLICANT a where a.T_CRT_TM=V_UPD_TM and a.C_APP_CDE=V_Cus_Client.c_Clnt_Cde;
select C_DPT_CDE into V_DPT_CDE from web_PLY_BASE a where a.C_APP_NO=V_APP_NO;
update WEB_CUS_CLIENT a set a.C_DPT_CDE=V_DPT_CDE where a.C_CLNT_CDE=V_Cus_Client.c_Clnt_Cde;
end if;
commit;
end loop;
close CUR_WEB_CUS_ADD;
--写任务日志
v_sql_code :=0;
v_sql_msg := 'NORMAL, SUCCESSFUL COMPLETION';
SELECT SYSDATE INTO v_task_end_date FROM dual;
INSERT INTO LOAD_HIS_LOG
( SYS
,JOBNAME
,START_DATE
,END_DATE
,RUN_DATE
,SQL_CODE
,SQL_STATE
)
VALUES
('V5_MID'
,'P_WEB_CUS_CLINT_DPT'
,v_task_start_date
,v_task_end_date
,to_char((v_task_end_date - v_task_start_date) * 86400)
,v_sql_code
,v_sql_msg
);
COMMIT;
EXCEPTION
WHEN OTHERS THEN
v_sql_code := SQLCODE;
v_sql_msg := v_sql_msg || ' ' || ' : ' || SQLERRM;
SELECT SYSDATE INTO v_task_end_date FROM dual; --任务结束时间
ROLLBACK;
INSERT INTO LOAD_HIS_LOG
( SYS
,JOBNAME
,START_DATE
,END_DATE
,RUN_DATE
,SQL_CODE
,SQL_STATE
)
VALUES
('V5_MID'
,'P_WEB_CUS_CLINT_DPT'
,v_task_start_date
,v_task_end_date
,to_char((v_task_end_date - v_task_start_date) * 86400)
,v_sql_code
,v_sql_msg
);
COMMIT;
END ;
在Linux中有7种启动级别,默认是X-Window,像是Windows的窗口模式,而Linux的操作和配置一般我们都采用输入命令的方式来完成,像DOS操作系统一样,如何让Linux一启动就进入这种模式呢?
方法:以管理员身份进入Linux,修改文件:/etc/inittab文件,找到“id:5:initdefault:”,其中的5就是X-Window,
为默认运行级别,一般我们把5改为3即可。
一共有7种启动级别,分别为:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
各个运行级的详细解释:
0 为停机,机器关闭。
1 为单用户模式,就像Win9x下的安全模式类似。
2 为多用户模式,但是没有NFS支持。
3 为完整的多用户模式,是标准的运行级。
4 一般不用,在一些特殊情况下可以用它来做一些事情。例如在笔记本电脑的电池用尽时,可以切换到这个模式来做一些设置。
5 就是X11,进到X Window系统了。
6 为重启,运行init 6机器就会重启。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Linux启动顺序:
1.load bios(hardware informantion)
2.read MBR's config to find out the OS
硬盘上的数据由五大部分组成,它们分别是:MBR区、DBR区,FAT区,DIR区和DATA区。
MBR - Main Boot Record 主引导记录区,位于整个硬盘的0磁道0柱面1扇区。
3.load the kernel of the OS
4.init process starts...
5.execute /etc/rc.d/sysinit
rc - run command
d - 后台运行的进程
6.start other modules (/etc/modules.conf)
7.execute the run level scripts
0 - 系统停机状态
1 - 单用户工作
2 - 多用户状态(没有nfs)
3 - 多用户状态(有nfs)network file system
4 - 系统未使用,留给用户
5 - 图形界面
6 - 系统正常关闭并重新启动.
8.execute /etc/rc.d/rc.local
9.execute /bin/login
10.shell started...
通过这些基础命令的学习我们可以进一步理解Linux系统:
安装和登录命令:login、 shutdown、 halt、 reboot 、mount、umount 、chsh
文件处理命令:file、 mkdir、 grep、dd、 find、 mv 、ls 、diff、 cat、 ln
系统管理相关命令:df、top、 free、quota 、at、 lp、adduser、 groupadd kill、crontab、tar、unzip、 gunzip 、last
网络操作命令:ifconfig、 ip 、ping 、 netstat 、telnet、 ftp、 route、 rlogin rcp 、finger 、mail 、nslookup
系统安全相关命令: passwd 、su、 umask 、chgrp、 chmod、chown、chattr、sudo、 pswho
第0节
# exit 退出terminal
# man shutdown 按q退出man
# shutdown --help
# shutdown --?
# shutdown now
# shutdown 0
ctrl+c 退出当前正在运行的程序
第1节
# ls -l //列显示
# ls -m //行显示
# cd, cd.. 退到上级目录
# pwd 显示当前路径
# mkdir test
# rmdir test 目录必须是空目录
# rm -r test 被询问依次删除
# rm -rf test 强制删除
# touch 1 创建文件,linux文件的后缀名称,从技术角度讲,没有意义
第2节
# cp file1 file2 把文件file1拷贝一份,命名为file2
# cp -r directory1 directory2 递归recursion,把目录directory1拷贝一份,命名为directory2
# mv directory1 directory2 把目录directory1移动到directory2目录下
# mv -r
# vi fileName
(
esc 编辑模式-->命令模式
:w 命令模式下,保存
:q 命令模式下,退出
:q! 命令模式下,不保存退出
:wq 命令模式下,保存退出
dd 命令模式下,删除光标所在行
dw 命令模式下,删除光标所在单词word
O 上插入一行
o 下插入一行
a 命令模式下,在当前位置插入,转为输入模式,append添加
)
第3节
# more fileName 列出文件内容
# cat fileName 列出文件内容 正序
# tac fileName 列出文件内容 逆序
# head -3 fileName 列出文件头三行
# tail -3 fileName 列出文件末三行
# clear 清屏
# find / -name *local 在/目录下查找名字后五个字母为local的文件
# whereis ls 显示ls命令来自哪个文件,及帮助文档。
# echo $PATH 系统path包括哪些路径
# ln file1 file2 file2和file1硬连接起来。一个文件变,另一个也变(这是和复制的区别)
# ln -s file1 file3 file3软连接到file1 //symbol符号,软连接相当与快捷方式。
(
删除硬连接时,一个被删,另一个还在
删除软件接时(被指向的文件,软连接文件还在,只是不指向任何文件)
ls时,软连接文件最开头是l,最后会显示指向谁
)
第4节 用户管理
$ 一般用户下显示的符号;
# 超级用户下显示的符号。
# useradd ztf 添加一个用户 (没指定组的话,则增加一个和用户名一样的组)
# passwd ztf 设置密码
(
然后 # cd /etc
# more passwd
最后一行显示:
testuser:x:501:502::/home/ztf:/bin/bash
用户名 :x:组号:用户号::用户主目录:用户shell
)
# bash
# bsh
# csh
# sh
(四种shell的相互切换)
# groupadd testg 添加一个组
# useradd testuser2 -g testg 添加一个用户到指定的组中
# usermod -g testg testuser1 用户testuser1修改到组testg中
# userdel testuser
# cd /home
# rm -rf testuser
以上三行是删除一个用户的步骤。删除用户,再删除用户的文件夹
# su testuser 切换用户
第5节 文件权限
drwxrwxrwx ‘—’表示无权限,read write execute
文件所有者,同组用户,其他用户
# chmod +x fileName 给文件加x权限,change module改变模式
# chmod -x fileName 给文件减x权限
# chmod u+x fileName 给文件给用户自己加上权限
# chmod g+x fileName 给文件给同组加上权限
# chmod o+x fileName 给others用户加x
# chmod 755 fileName 755 rwxr-xr-x
# chmod 777 fileName 777 rwxrwxrwx //7为111
# chmod testuser2 fileName 给文件改变所有者
第6节
# wc fileName 用来统计文本文件的行数,字数,字符数 word count
# grep asdf fileName 查询文件中,哪一行有asdf,返回这些行
# date 显示日期
# stat 显示指定文件信息
# who,w 显示在线登陆用户
# whoami 显示用户自己身份
# id 显示当前用户信息
# hostname 显示主机名
# uname 显示操作系统信息
# dmesg 显示系统启动信息
# du 显示指定文件目录已使用的磁盘信息
# df 显示文件系统磁盘空间使用情况
# free 显示当前内存和交换空间的使用情况
# fdisk -l 显示磁盘信息
# locale 显示当前语言信息
管道:将一个命令的输出传送给另一个命令,作为另一个命令的输入。使用方法:命令1|命令2|命令3|命令4|...命令n
# ls -ri /etc | more
# cat /etc/passwd | wc
# cat /etc/passwd | grep lrj
# dmesg | grep eth0
# man bash |col -b>bash.txt //shell特殊字符">"和">>",把说明文件的内容输出成纯文本文件时,控制字符会变成乱码,col指令则能有效滤除这些控制字符。
# ls -l | grep "^d" 只列出目录
# ls -l* | grep "^-" | wc -l
第7节 命令替换
# wall message 通知所有用户 message
# wall ~date~ 通知所有用户命令的执行结果
# ls > cmd.txt 把命令执行的结果输入到文件中
# ls >> cmd.txt 把命令执行结果输入到文件中两遍
# lsss 2> cmd.txt 错误输出重定向
# wall < aa.txt 输入重定向.把文件内容广播给所有用户
出现这个问题,主要是我把“我的电脑---计算机名”给改了,导致监听启动后自动退出。
解决方法有以下两种:
1.改配置文件。
打开E:\oracle\ora92\network\admin\listener.ora文件,将listener.ora 中的HOST值改成现在的机器名或IP 地址,然后再启动监听。
2.通过图形界面设置。
打开Net Manager,如下图把“主机”改成现在新的机器名,就OK啦。
前些天发现电脑的时间与手机的时间差10多分钟,电脑时间不准,修改了好几次,电脑改完后又马上还原了,怎么也修改不了电脑的时间,郁闷。。。
今天上网在网上搜了一大片信息,终于找到了方法,现在电脑的时间已修改过来了!
现分享出来:
1.先下载360的顽固木马专杀大全 SuperKiller.exe,下载后进行全电脑杀毒;
2.重启电脑,再下载360的 360TimeProt.exe,进行时间修改。
posted @ 2009-11-30 15:23 断点 阅读(115) | 评论 (0)
常用命令:
一、ls 只列出文件名 (相当于dir,dir也可以使用)
-A:列出所有文件,包含隐藏文件。
-l:列表形式,包含文件的绝大部分属性。
-R:递归显示。
--help:此命令的帮助。
二、cd 改变目录
cd /:进入根目录
cd :回到自己的目录(用户不同则目录也不同,root为/root,xxt为/home/xxt
cd ..:回到上级目录
pwd:显示当前所在的目录
三.less 文件名:查看文件内容。
四.q 退出打开的文件。
五.上传文件: rz 选择要传送的文件,确定。
六.下载文件: sz 指定文件名,enter敲,即下载到了secureCRT/download目录下。
七:删除文件: rm 删除文件 ,rmdir 删除空目录。
八.显示 最近输入的20条命令:history 20
九.获得帮助命令 --help查看命令下详细参数: 如:rz --help , sz --help 。
十.cd 进入某个文件夹的命令:
mkdir+文件夹名 创建某个文件夹的命令
sz+文件名 从服务器端向本机发送文件的命令
rz 从本机向服务器端传送文件的命令
ll 列出当前目录下的所有文件,包括每个文件的详细信息
dir 对当前文件夹
vi 打开当前文件
十一.在编辑某个文件的时候:
a 切换到编辑模式
ctrl+c 退出编辑模式
dd 删除整行
:q 退出当前文件
:w 写入并保存当前文件
-f 强行xx的参数。。。
其它命令:
1.ps -ef //查看server的进程,以列表形式显示的server进程。
ps 显示当前在系统运行的进程 /usr/bin/ps [选项] -e 显示每个现在运行的进程 -f 生成一个完全的列表
实际操作:
--------------------------------------
1 SSH客户端连接到10.5.1.55系统(参见《启动远程客户端说明SecureCRT.doc》)
$ cd /home/bea2/user_projects/csdomain/bin
2 查看weblogic92服务进程
$ ps -eaf | grep weblogic
bea2 327926 331940 0 13:08:45 pts/4 0:00 grep weblogic
webadmin 421908 368956 0 Sep 24 - 4:13 /usr/java5_64/bin/java -Xms256m -Xmx512m -da -Dplatform.home=/home/weblogic/bea/weblogic92 -Dwls.home=/home/weblogic/bea/weblogic92/server -Dwli.home=/home/weblogic/bea/weblogic92/integration -Dweblogic.management.discover=true -Dwlw.iterativeDev=false -Dwlw.testConsole=false -Dwlw.logErrorsToConsole= -Dweblogic.ext.dirs=/home/weblogic/bea/patch_weblogic923/profiles/default/sysext_manifest_classpath -Dweblogic.Name=AdminServer -Djava.security.policy=/home/weblogic/bea/weblogic92/server/lib/weblogic.policy weblogic.Server
bea2 491796 385044 17 00:12:50 pts/6 182:55 /usr/java5_64/bin/java -Xms6g -Xmx8g -javaagent:/home/bea2/user_projects/csdomain/Introscope/wily/Agent.jar -Dcom.wily.introscope.agentProfile=/home/bea2/user_projects/csdomain/Introscope/wily/IntroscopeAgent.profile -Dcom.wily.introscope.agent.agentName=AdminServer -da -Dplatform.home=/home/weblogic/bea/weblogic92 -Dwls.home=/home/weblogic/bea/weblogic92/server -Dwli.home=/home/weblogic/bea/weblogic92/integration -Dweblogic.management.discover=true -Dwlw.iterativeDev= -Dwlw.testConsole= -Dwlw.logErrorsToConsole= -Dfile.encoding=GBK -Dibm.stream.nio=true -Dweblogic.ext.dirs=/home/weblogic/bea/patch_weblogic923/profiles/default/sysext_manifest_classpath -Dweblogic.Name=AdminServer -Djava.security.policy=/home/weblogic/bea/weblogic92/server/lib/weblogic.policy weblogic.Server
说明:根据以上提示查看登陆用户bea2启动的进程,注意标红的bea2为进程拥有着, 491796为进程号
3 执行如下命令杀掉进程
$ kill -9 491796(根据2操做查找到得系统进程号)
说明:执行后再执行$ ps -eaf | grep weblogic命令将不会看到该进程号的weblogic进程
4 启动服务
$ ./quickRun.sh
-------------------------------------------------------------------
2.ant -buildfile CMS_MainTrunk.xml //build 包
3.vi test.txt //浏览文件内容
i {insert写输入}
esc 退出insert
:wq! write 保存并退出vi模式
:q! 不保存退出vi模式
4.我一般习惯用ps –ef命令,这样看到以列表形式显示的server进程;用命令pstree来查看server的进程,这样看到以树的形式显示的server进程。
Pstree命令的优点在于可以立即找出某进程的父进程。您可能会需要使用 -p 选项显示每个进程的 PID,以及 -u 选项来显示启动该进程的用户名。
一般来说,这一树结构比较长,您就需要这么执行 pstree –up | less 这将让您纵览整个进程树结构。
5.secureCRT中乱码解决:Options->SessionOptions->Appearance->font把default改成UTF-8,就可以显示中文字体了。
6.hostname:查hostname
7.ifconfig 查询主机IP
8.在S-CRT下用ctrl+c 和ctrl+v:
Options---Global Options---Edit default Settings进去后点Terminal---Emulation然后点Mapped Keys,点中低部的,use windows copy and paste key,点确认。
9.进入vi的命令:
vi filename :打开或新建文件,并将光标置于第一行首
vi +n filename :打开文件,并将光标置于第n行首
vi + filename :打开文件,并将光标置于最后一行首
vi +/pattern filename:打开文件,并将光标置于第一个与pattern匹配的串处
10.移动光标类命令:
}:光标移至段落开头
{:光标移至段落结尾
nG:光标移至第n行首
n+:光标下移n行
n-:光标上移n行
n$:光标移至第n行尾
H :光标移至屏幕顶行
M :光标移至屏幕中间行
L :光标移至屏幕最后行
0:(注意是数字零)光标移至当前行首
$:光标移至当前行尾
11.屏幕翻滚类命令:
Ctrl+u:向文件首翻半屏
Ctrl+d:向文件尾翻半屏
Ctrl+f:向文件尾翻一屏 //好像是 r
Ctrl+b;向文件首翻一屏
12.搜索命令:
/pattern:从光标开始处向文件尾搜索pattern
?pattern:从光标开始处向文件首搜索pattern
n:在同一方向重复上一次搜索命令
N:在反方向上重复上一次搜索命令
postgres使用:
1.进入sql运行环境。
[test@test bin]$ ./psql -n dbname -U usrname
stay81=# select count(*) from table1;
count
-------
5986
(1 row)
2. 退出,使用结束后退出,不然连接一直被挂起。
stay81=# \q
3.postgres 数据导出。
[postgres@test bin]$ ./pg_dump -U postgres -t testTable -d testDB > testTable.dump
或[postgres@test bin]$ ./pg_dump -U postgres -d testDB -t testTable -F c -v > testTable.dump
4. postgres 数据导入。
[postgres@test bin]$ ./psql -U postgres -d testDB < testTable.dump
或[postgres@test bin]$ ./pg_restore -U postgres -d testDB < testTable.dump
5.一台主机上将数据库目录转储到另一台主机上。
pg_dump -h host1 -p 5432 dbname | psql -h host2 -p post1 dbname
或./pg_dump -U postgres -d testDB1 -t testTable | ./psql -U postgres -d testDB2
-U 为用户名 ,-d 为DB名,-t 为表名称,如果整个数据库导出,不需此项。
6.php执行。
[test@test bin]$ /usr/bin/php -q ./batchstart.php
实战操作:
/home/absys6$ ls
dvlp dvlp_bak20090413 personal tmp
/home/absys6$ cd dvlp
/home/absys6/dvlp$ ls
/home/absys6/dvlp$ cd SV_POLICY
/home/absys6/dvlp/SV_POLICY$ ls
include src
/home/absys6/dvlp/SV_POLICY$ cd src
/home/absys6/dvlp/SV_POLICY/src$ ls
/home/absys6/dvlp/SV_POLICY/src$ ls *pc //对文件进行筛选
/home/absys6/dvlp/SV_POLICY/src$ grep VIP *pc //列出包含VIP的所有.pc的文件的代码的一部分。
/home/absys6/dvlp/SV_POLICY/src$ vi PlyPrmCnt.pc //查看整个文件。
还可见其它命令:http://www.zjgzx.com/blog/user1/1/archives/2008/4607.html
posted @ 2009-09-11 19:42 断点 阅读(556) | 评论 (0)
问题:我重装操作系统后,不知道怎么把我的电脑左侧菜单没了,现在打开我的电脑C盘、D盘及其它项,都顶到了最左头。
解决方法:
方法一:右键单击我的电脑-属性-高级-性能设置-视觉效果-选择“在文件夹中使用常见任务”
方法二:工具-文件夹选项---常规-任务里选择“在文件夹中显示常见任务"即可。
posted @ 2009-10-31 14:05 断点 阅读(14) | 评论 (0)
1.首先有一个主页面main.jsp,包含以下信息:
<IMG id="IMG_DESIGN_SETTING" style="cusor:hand" onclick="javascript:qqhelp()" border="0" src="./skin/<%=skin%>/blue_skin/images/qqhelp.png"/>
<IMG id="IMG_DESIGN_SETTING" style="cusor:hand" onclick="javascript:helpdoc()" border="0" src="./skin/<%=skin%>/blue_skin/images/lookhelp.png"/>
<script>
function qqhelp(){
window.showModalDialog("<%=request.getContextPath()%>/core/common/help/qqhelp.html",window,"help:no;font-size:9pt;dialogWidth:210px;dialogHeight:365px;status:no;scroll:true;resizable:no");
}
function helpdoc(){
window.showModalDialog("<%=request.getContextPath()%>/core/common/help/doc/helpdoc.html",window,"help:no;font-size:9pt;dialogWidth:1024px;dialogHeight:768px;status:no;scroll:true;resizable:no");
}
</script>
2.子页面qqhelp.html:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>QQ在线帮助</title>
<style ></style>
<script></script>
</head>
<body >
<script>var online= new Array();</script>
<table border="0" cellpadding="0" cellspacing="0" style="margin-left: 2px;margin-top: 3px;height: 323px">
<script src="http://webpresence.qq.com/getonline?Type=1&422407700:13284200:277069500:275597200:30781800:"></script>
<tr>
<td align="left" background="./menumiddle.png">
<script>
if (online[0]==0)
document.write(" <img src=./QQoffline.gif border=0 align=center style=margin-left:30px><a class='qqb' target=blank href='http://wpa.qq.com/msgrd?V=1&Uin=422407700&Site='在线咨询'&Menu=no' title='飞哥不在线,请留言'>承保管理(飞哥)</a>");
else
document.write(" <img src=./QQonline.png border=0 align=center style=margin-left:30px><a class='qqa' target=blank href='http://wpa.qq.com/msgrd?V=1&Uin=422407700&Site='在线咨询'&Menu=no' title='在线即时交谈'>承保管理(飞哥)</a>");
</script >
</td>
</tr>
<tr>
<td align="left" background="./menumiddle.png">
<script>
if (online[1]==0)
document.write(" <img src=./QQoffline.gif border=0 align=center style=margin-left:30px><a class='qqb' target=blank href='http://wpa.qq.com/msgrd?V=1&Uin=13284200&Site='在线咨询'&Menu=no' title='飞哥不在线,请留言'>见费出单(飞哥)</a>");
else
document.write(" <img src=./QQonline.png border=0 align=center style=margin-left:30px><a class='qqa' target=blank href='http://wpa.qq.com/msgrd?V=1&Uin=13284200&Site='在线咨询'&Menu=no' title='在线即时交谈'>见费出单(飞哥)</a>");
</script >
</td>
</tr>
<td align="left" background="./menumiddle.png">
<font style="margin-left:30px;font-size:15px; font-weight: bolder; color:#000"> V6QQ群号(30781800)</font>
</td>
</tr>
</table>
</body>
</html>
posted @ 2009-09-10 14:50 断点 阅读(675) | 评论 (0)
常用快捷键:
F3 默认情况下,当你按F3的时候UE可以查找现在选中的内容,F3是下一个符合的内容;
CTRL+F3 是上一个符合的内容。
F7 插入当前日期/时间
CTRL+R 查找文件
Ctrl+E 删除整行,Ctrl+F11 删除到行首,Ctrl+F12 删除到行尾。
Ctrl+F2 移到需要标记的行按下,标记好了;走到文件的任意其他行,按F2,回到标记处。
CTRL + W 自动换行
CTRL + B 找到匹配的括号 (,[,{ or },],)
CTRL + T 段落重新格式化
CTRL + F8 显示Tag 列表
CTRL + F5 转换所选文字为小写
Alt + F5 转换所选文字为大写
F8 显示函数列表
Tip 1: 如何去掉所编辑文本中包含特定字符串的行?
这则技巧是在UltraEdit的帮助文件里提到.CTRL+R 调出来替换(Replace)窗口,选中"使用正则表达式";然后用查找 %*你的字符串*^p 替换成空内容即可.如,我当前有个文本文件,需要去掉所有包含 http://www.dbanotes.net/ 这个字符串的行,查找 %*http://www.dbanotes.net/*^p 替换成空即可.注意,^p 是 DOS 文件类型的换行符.如果是 Unix 类型文件,则用 ^n.
Tip 2: 如何在行末添加特定字符,比如逗号?
有了上面的经验(其实我第一次是从同事那里学到的),CTRL+R 调出来替换(Replace)窗口,选中"使用正则表达式".然后可以查找 ^p(或者^n,如果是Unix 文件),用 ,^p(或者,^n)进行"全部替换"即可.补充一点,如果是 MAC(Apple) 类型文件,则换行符号为 ^r .
Tip 3: 如何删除空行?
参考上面两个例子,查找 ^p$ 然后替换为空即可.
看来,正则表达式需要学习一下喽.
Tip 4: 编辑文件如何加入时间戳 ?
F7 快捷键即可.你试试看?
Tip 5: 为何 拷贝(Copy)/粘贴(Paste)功能不能用了?
不怕大家笑话,我有几次使用 UltraEdit 的过程中发现拷贝与粘贴的内容是不匹配的.不知所以然,干脆重新启动了笔记本.今天翻看手册才恍然大悟:UltraEdit有10个剪切板 (clipboard),分别用Ctrl+0 - Ctrl+9 切换. Ctrl+0 是 Windows 的,其他则为用户自定义的.我在使用的过程中错调用了 CTRL+n, 结果内容就有问题了.你遇到过没?
Tip 6: 即使是打开小文件也有迟延?
这是我遇到过的问题.每次打开文件的时候总有几秒钟的耽搁.我的机器性能可不算差.怎么回事? 网络打印机搞得鬼! 打开"高级"->"设置"->"编辑器"->"高级",看看是不是选中了"载入/恢复打印机设置"?如果是的话,去掉(不同的版本/汉 化与否可能该位置所在有差别).
Tip 7: 删除当前行内容 CTRL+e
Tip 8: 把常用的菜单功能做成快捷按钮放在面板上。
菜单路径:Advanced-Configuration-Toolbar,选中左边喜欢的功能菜单,选中右边的位置,点击Insert即可。比如” Dos to Unix”用于把dos下的回车键去掉,“Compare files”用来比对文件,”Display Ruler”,”Display Line Numbers”,最让人惊喜的居然还有一个”ASCII table”的功能,不用每次查ASCII码的时候都去翻箱倒柜了,呵呵。不过可显示字符的 ASCII值可以通过直接查看16进制模式看到,不用这么麻烦。
Tip 9: 列模式(快捷键:Alt+C)
当你需要批量修改数据或者造数据的时候,这个功能显示了强大威力。试试打开一个文件,按下Alt+C,Ctrl+A,开始写字,你会发现文件中所有的行都在执行相同的动作,一排相同的数据就出现了。动动脑筋你会发现各种奇妙的用法。
Tip 10: 做行标记
移到需要标记的行按下Ctrl+F2,标记好了;走到文件的任意其他行,按F2,回到标记处。可以做多个标记,这时F2在各个标记中循环走动。F2:Next Bookmark,Alt+F2:Previous Bookmark。
Tip 11: 列标志
写后台程序的时候不希望一行写的太长,一般要小于80个字节,但即使显示了标尺也看不大清楚屏幕中下部的行是否已经到了80字节,除非看下部状态条的列 号。这时这个东西就起作用了。菜单路径:View-Set Column Markers,可以设置两个列标志,我们先设第一个,在第一个编辑框中填入80,再选择View-Show Column Marker 1,看到了?第80字节的地方出现了一条竖线。
Tip 12: 注释
有时调试程序时需要把连续的多行用“//”注释,然后还要放开注释,一行一行写太土了吧,有现成的东西用。选定要注释的行,Edit-Comment
Add增加注释,Edit-Comment Remove。
Tip 13:编辑
选定整个单词当然可以用鼠标双击,用键盘Ctrl+J。删除整行Ctrl+E,删除到行首Ctrl+F11,删除到行尾Ctrl+F12。
Tip 14:别让它老问你是否把unix文件转换尾dos文件
到了9.0版本打开unix文件的时候它总是会问是否转换为dos文件,实在很烦。不过可以屏蔽,Advanced-Configuration-General,把右中部的Auto Convert Unix Files点上就好了。
Tip 15:
打开文件内容中的文件 如果文件的内容里面有 "c:\test.txt" 或者"http://www.test.com/js/test.js"
这样的内容你可以把鼠标定位到上面,点右键。弹出的菜单最上边会多个选项 "c:\test.txt" 或者"http://www.test.com/.../test.js"
点击它,打开相应文件。
ctrl+b 写程序的时候,括号一般要一一对应的,但是如果嵌套太多,看花眼了,怎么办?你把光标放在括号开始的地方,按ctrl+b,UE 会帮你找到相对应的括号结尾的地方。你还可以试试连着多按几次ctrl+b。 [Stick Out Tongue]
F3
默认情况下,当你按F3的时候UE可以查找现在选中的内容,F3是下一个符合的内容,ctrl+f3是上一个符合的内容.(请查 看advanced/configuration/Find标签)
ctrl+f2
程序会有很多行你当然可以记得你要到的行数,然后用ctrl+g,然后输入行号,到所在的行。但是用ctrl+f2我觉得更方便。比如说你要频繁在多个 function中切换。可以在function开始的地方,按一下ctrl+f2,给这一行加一个书签。然后再另外的function开始的地方,也来 一下ctrl+f2,有书签的地方,字的背景色会不同。当你想换到下一个书签的时候,就按f2,但是想到上一个标签怎么办?ctrl+f2?不对,嘿嘿,
再按就是加书签或者取消当前行的书签了。应该是alt +f2.
简单的用正则表达式的查找替换
有时候会有一些简单文本处理的工作。比如你手头有一个文本,需要给所有行后边添加一个";"。用查找替换来完成ctrl +r,查找 '^p' 替换为'^p;',(记得选中regular Expressions,这样才能用正则表达式的功能。)然后你可以选replace all(alt+a),或者点开始,一个一个的查找,替换,这样的好处是知道都替换了那些,有些时候你可能不想全部替换
把类似'{$abc}'替换为'var abc=abc;',abc有可能是其他字符ctrl+r,查找 '{^$^(*^)}' 替换为'var ^1=^1;'(记得选中regular Expressions,这样才能用正则表达式的功能。)然后你可以选replace all(alt+a),或者点开始,一个一个的查找,替换。
自定义快捷键
UE很多功能都有快捷键,但不是所有的都有。11.00有一个Text2html的功能。我工作中遇到了要对大量代码进行这种操 作的情况。我就想自己定一个快捷键。
advanced/configuration/key mapping
在commands 里面找到你要用的command.我这里是HTMLConvertSpecialChars,然后点Pres s new key下面的输入框,设置一个自己觉得爽,不冲突的快捷键。比如ctrl+alt+s.然后点ok.这样用常用的功能,可以成倍 提高效率。
计算选中区域数字的和
比如如下文本
2
23a1
4 1.1
5
6
先选中,然后Column/(sum column/Selection),UE会以空格,字母分割数字,告诉你一个总数
UE的列编辑功能
首先要alt+c,进入列编辑模式。进入后,你可以用鼠标选择一个方形的区域。删除,复制全看你喜欢了。
如果你想在每一行第二个字符开始加入一个'test',在列编辑模式下,定位光标到第一行,第二列。
Column/(Insert/Fill column)
,你还可以用这个功能插入行数。在列编辑状态下的复制粘贴都很有意思,某些情况下可以取得意想不到的效果。
UE的比较
UE内置一个比较功能,可以帮你比较2个文件的不同
file/compare files...
如果你打开了2个要比较的文件,UE会把这2个文件自动填入2个要比较的文件位置,不然,你要用browse功能去找到那2个文件,设置一下text还是 bin,是否要ignore一些你不关心的东西。然后点击compare就到比较界面。你可以设置只显示不同或者相同或者都显示。日常的应用是可以了。 (有点像BC,不知道谁抄谁的 )
加入当前时间
有时候写代码要注释,比如那天改的,按一下F7试试。
打开的文件中切换
如果打开多个文件,要在多个文件中切换,用鼠标点,麻烦,试一下ctrl+tab。好多多窗口的软件都支持这个功能。
恢复到上次存盘状态
一个文件改动多了,想undo到最初状态,file/revert to saved.
文件备份,重命名
一个文件要备份,你如果选save as了,那当前打开的就是你save as之后的文件了。
用fle/(make copy/backup),你还可以直接重命名当前编辑的文件 file/Rename file
UE的project功能
11.00 以后有了一个自动打开上次关闭时打开着的文件这个功能了,以前好像没有。这就可以用到Project功能。其实就是定 义一组相关的文件。project/(new project/workspace) UE会要求你存一个*.prj的文件。下次你可以打开UE的时候,project/ (o pen project/workspace),继续上次的那个project的session工作。也可以file/(recent project/workspace)
UE的function列表功能
打开一个程序文件,比如*.js,确保view/view as(*)/Javascript。选择view/(view/lists)/function list.也可以用F8
大块代码缩进的调整
选中要调整的代码块 按tab,进行缩进,你再按一下shift+tab。效果咋样?
UE的右键功能
1)去处行末的空格
选中要去空格的区域。点右键/format/menu../trim trailing spaces
2)删除整行
定位光标要删除的行。点右键/delete/delete line,(也可以用ctrl+e)
3)给代码加注释
首先要确定选中了正确的语法加亮显示 view/view as(*)/Javascript 然后选中要注释的部分
点右键/delete/comment add 或者comment remove
4)格式化代码
首先要确定选中了正确的语法加亮显示 view/view as(*)/Javascript
然后选中要格式化的部分,就是让代码的缩进好看点,点右键/format menu/reIndent selection
不过,如果你的代码是一行,没有按照句子分号。好像没啥效果。
5)复制当前编辑文件的路径如果你要把当前文件作其他处理,需要这个文件的路径,这个
功能可以不用再去敲路径点右键 copy file path/name
6)复制当前编辑文件的路径::点右键copy file path/name
7)打开文件内容中的文件: 如果文件的内容里面有"c:test.txt" 或者"http://www.test.com/js/test.js"
这样的内容。你可以把鼠标定位到上面,点右键。弹出的菜单最上边会多个选项
"c:test.txt" 或者"http://www.test.com/.../test.js",点击它,打开相应文件。
调整,添加语法高亮显示
advanced/configuration/syntax Highlighting 点击下边的full path name for word list后边的open
打开的文件如:d:Program FilesUltraEditWORDFILE.TXT,就是UE语法高亮显示的配置文件
/L1"C/C++" 就是第一种语言,/L2就是第二种。目前这些word files 可以从下面连接下载到
http://www.ultraedit.com/index.php?...id=40#wordfiles
用的时候,下载相应的word file,复制出来,粘贴到d:Program Files\UltraEdit\WORDFILE.TXT,注意修改刚开始的/L1和你现有系统匹配。好像对xml.xsl的显示不是很好,不够准确
运行dos命令,直接得到结果
F9,会跳出来一个窗口,让你输入命令和工作目录。比如 dir c: 会列出来c盘的目录。如果你要给朋友发目录列表,除了从dos窗口复制过来,还可以用这个简单的方法。加上一下简单的列编辑。结 果就更好看了。
内置的ascii table
view/ascii table
有时候需要知道某个字母的ascii值,从这里就能查出来
!是33
A是65
。。。
内置的多个剪贴板 你点右键可以看到
clipboards,里面内置了10个剪贴板。按说windows的copy只能复制一个内容。如果你要复制多个内容,跟据不 同的情况进行粘贴,这10个剪贴板,应该够你用了。ctrl+0-9的数字键,是在剪贴板之间切换。比如 ctrl+1,然后copy了内容"a";ctrl+2,然后copy了内容"b" 你如果想paste a,就要先按1下ctrl+1再ctrl+v,要paste
b,就按一下ctrl+2再 ctrl+v。我有时候不小心更换了剪贴板,就奇怪从别的地方复制的东西粘贴不过来。这种情况要注意。
转载:http://hi.baidu.com/oracle_10g/blog/item/52e4ab1e2f28a51c4034170a.html
posted @ 2009-07-17 19:16 断点 阅读(468) | 评论 (0)
根据全国计算机技术与软件专业技术资格(水平)考试的安排,其中作为高级工程师级别的职位有项目管理师、系统分析师和系统架构师(这里的系统架构主要是指软件系统的架构)。考试大纲对这三个职位的要求和职责定义如下:
(1)项目管理师:掌握信息系统项目管理的知识体系,具备管理大型、复杂信息系统项目和多项目的经验和能力;能根据需求组织制定可行的项目管理计划;能够组织项目实施,对项目的人员、资金、设备、进度和质量等进行管理,并能根据实际情况及时做出调整,系统地监督项目实施过程的绩效,保证项目在一定的约束条件下到达既定的项目目标;能分析和评估项目管理计划和成果;能在项目管理进展的早期发现问题,并有预防问题的措施;能协调项目所涉及的相关人员。即项目管理师的主要职责是负责整个项目的实施和控制,协调各种资源(包括组织内部资源和客户资源)。
(2)系统分析师:熟悉应用领域的业务,能分析用户的需求和约束条件,写出信息系统需求规格说明书,制订项目开发计划,协调项目开发与运行所涉及的各类人员;能指导制订企业的战略数据规划,组织开发项目;能评估和选用适宜的开发方法和工具;能按照标准规范编写系统分析、设计文档;能对开发过程进行质量控制与进度控制;能具体指导项目开发。即系统分析师的主要职责是获取并分析用户的需求,形成规范化的文档,指导整个项目的开发,需要与客户不断的交流,熟悉应用领域的业务。
(3)系统架构师:能够根据用户需求,结合用户应用领域的实际情况,设计正确、合理的软件构架,维护系统构件及其接口,并确保系统构架具有良好的性能;能够对项目进行系统构架级的描述、分析、设计与评估;能够按照相关标准编写相应的设计文档;具有扎实的理论功底、广博的知识面,能够与系统分析师、项目管理师相互协作、配合工作。即系统架构师的职责是负责整体的、宏观的系统设计,重点在架构级别上。还要对架构进行描述、分析和评估,属于纯技术性的工作。
转载出处:http://blog.csdn.net/SmartTony/archive/2007/12/03/1914062.aspx
posted @ 2009-06-22 20:11 断点 阅读(204) | 评论 (0)
如何成为软件架构师?
那么要成为架构师的途径似乎只有现在较为流行的软件学院和个人自我培养了。关于软件学院我接触过不少,其宗旨绝大部分都是造就(or打造)企业 需要的软件架构师(or程序员or人才)。教师来源与企业、学员来源与企业、人才输送到企业是他们办学的手段。尽管各个如雨后春笋般出现的软件学院口号差 不多,但恐怕大多只是为了圈钱卖学位了事...
架构师不是通过理论学习可以搞出来的,不过不学习相关知识那肯定是不行的。参考软件企业架构师需求、结合目前架构师所需知识,总结架构师自我培养过程大致如下仅供参考:
1、架构师胚胎(程序员)学习的知识是语言基础、设计基础、通信基础等,应该在大学完成,内容包括java、c、c++、uml、RUP、XML、socket通信(通信协议)——学习搭建应用系统所必须的原材料。
2、架构师萌芽(高级程序员)学习分布式系统、组建等内容,可以在大学或第一年工作时间接触,包括分布式系统原理、ejb、corba、com/com+、webservice(研究生可以研究网络计算机、高性能并发处理等内容)
3、架构师幼苗(设计师)应该在掌握上述基础之上,结合实际项目经验,透彻领会应用设计模式,内容包括设计模式(c++版本、java版本)、 ejb设计模式、J2EE架构、UDDI、软件设计模式等。在此期间,最好能够了解软件工程在实际项目中的应用以及小组开发、团队管理。
4、软件架构师的正式成型在于机遇、个人努力和天赋,软件架构师其实是一种职位,但一个程序员在充分掌握软架构师所需的基本技能后,如何得到这 样的机会、如何利用所掌握的技能进行应用的合理架构、如何不断的抽象和归纳自己的架构模式、如何深入行业成为能够胜任分析、架构为一体的精英人才这可不是 每个人都能够遇上的馅饼……
然而学海无涯,精力有限,个人如何能够很快将这些所谓的架构师知识掌握?这是秘密,每个人都有自己的独门家传秘笈就不敢一一暴露了。不过有一点就是广泛学习的基础之上一定要根据个人兴趣、从事领域确定一条自己的主线来努力。
转载出处:http://blog.csdn.net/SmartTony/archive/2007/12/03/1914041.aspx
posted @ 2009-06-22 20:02 断点 阅读(93) | 评论 (0)
一、常规键盘快捷键
Ctrl + C 复制。
Ctrl + X 剪切。
Ctrl + V 粘贴。
Ctrl + Z 撤消。
DELETE 删除。
Shift + Delete 永久删除所选项,而不将它放到“回收站”中。
CTRL + SHIFT + 任何箭头键 突出显示一块文本。
Ctrl + A 选中全部内容。
F3 搜索文件或文件夹。
F5 刷新当前窗口。
Alt + Enter 查看所选项目的属性。
Alt + F4 关闭当前项目或者退出当前程序。
ALT + Enter 显示所选对象的属性。
Ctrl + F4 在允许同时打开多个文档的程序中关闭当前文档。
Alt + Tab 在打开的项目之间切换。
Alt + Esc 以项目打开的顺序循环切换。
Alt + 空格键 显示当前窗口的“系统”菜单。
Ctrl + Esc 显示“开始”菜单。
CTRL + 向右键 将插入点移动到下一个单词的起始处。
CTRL + 向左键 将插入点移动到前一个单词的起始处。
CTRL + 向下键 将插入点移动到下一段落的起始处。
CTRL + 向上键 将插入点移动到前一段落的起始处。
二、自然键盘快捷键
WIN 显示或隐藏"开始"菜单。
WIN+ BREAK 显示"系统属性"对话框。
WIN+ D 显示桌面。
WIN+ E 打开"我的电脑"。
WIN+ F 搜索文件或文件夹。
WIN+ F1 显示 Windows 帮助。
WIN+ L 锁定计算机。
WIN+ R 打开"运行"对话框。
posted @ 2009-04-07 20:03 断点 阅读(46) | 评论 (0)
前段时间公司说要sap方面的人,要我们熟悉一下这方面的,但现在另有安排。因此,我想了,得把我这段时间搜集的知识贴出来与别人分享一下。
sap 打油诗:
sap是庞大的,模块是多多的,功能是强大的,搞懂是没门的。
sd是灵巧的,五脏是俱全的,满足是不能的,报表是经常的。
pp是复杂的,相同是很少的,mrp是要的,精确是不能的。
mm是重要的,数据是多多的,做好是稀有的,目前是紧缺的。
fi是核心的,记账是主要的,工作是轻松的,地位是高高的。
co是控制的,与fi是配合的,凭证是很多的,成本是不准的。
abap是必须的,开发是经常的,地位是没有的,作用是点缀的。
basis是装机的,debug是常有的,精通是困难的,abap是兼职的。
HR是搞人的,会作是很少的,研究是需要的,潜力是无穷的。
workflow是神奇的,功能是炫目的,做通是很少的,因而是不做的。
qm是质量的,上的是不多的,思路是奇特的,冲突是必然的。
pm是见过的,功能是明显的,做做是蛮好的,培训是需要的。
apo是传说的,上的是没有的,目标是理想的,成功是偶然的。
crm是起步的,客户是听说的,用好是没有的,完善是需要的。
bw是早有的,产品是多样的,需求是渐多的,招人是必要的。
市场是巨大的,erp是需要的,签单是可能的,打折是一定的。
kick off是要有的,首期是会付的,蓝图是要做的,确认是艰苦的。
实施是痛苦的,修改是经常的,说服是需要的,项目是继续的。
数据是庞大的,整理是艰苦的,手输是不能的,batch是要编的。
客户是刁蛮的,要求是无理的,说话是牛逼的,干活是不行的。
key user是难做的,加班是经常的,工资是不多的,衰老是优先的。
上线是被逼的,不逼是不行的,时间是紧张的,恐惧是不必的。
SAP包含以下模块:
FI 财务会计 集中公司有关会计的所有资料,提供完整的文献和全面的资讯,同时作为企业实行控制和规划的最新基础。
TR 财务管理 是一个高效率财务管理完整解决方案,确保公司在世界范围的周转,对财务资产结构实行盈利化组合,并限制风险。
CO 管理会计 是公司管理系统中规划与控制工具的完整体系,具有统一的报表系统,协调公司内部处理业务的内容和过程。
EC 企业控制 根据特制的管理资讯,连续监控公司的成功因素和业绩指标。
IM 投资管理 提供投资手段和专案,从规划到结算的综合性管理和处理,包括投资前分析和折旧模拟。
PP 生产计划 提供各种制造类型的全面处理:从重覆性生产、订制生产、订装生产,加工制造、批量及订存生产直至过程生产,具有扩展MPRⅡ的功能。另外还可以选择连接PDC、制程控制系统,CAD和PDM。
MM 物料管理 以工作流程为导向的处理功能对所有采购处理最佳化,可自动评估供应商,透过精确的库存和仓储管理降低采购和仓储成本,并与发票核查相整合。
PM 工厂维护 提供对定期维护、检查、耗损维护与服务管理的规划、控制和处理,以确保各操作性系统的可用性。
QM 品质管理 监控、输入和管理整个供应链与品质保证相关的各类处理、协调检查处理、启动校正措施、以及与实验室资讯系统整合。
PS 专案管理 协调和控制专案的各个阶段,直接与采购及控制合作,从报价、设计到批准以及资源管理与结算。
SD 销售与分销 积极支援销售和分销活动,具有出色的定价、订单快速处理、按时交货,交互式多层次可变配置功能,并直接与盈利分析和生产计划模组连接。
HR 人力资源管理 采用涵盖所有人员管理任务和帮助简化与加速处理的整合式应用程式,为公司提供人力资源规划和管理解决方案。
开放式资讯仓储 包括智能资讯系统,该系统把来自R/3应用程式和外部来源的数据归纳成为主管人员资讯,不仅支援使用者部门决策和控制,同时也支援对成功具有关键作用的高阶控制和监控。
FI 应收、应付、总帐、合并、投资、基金、现金等;
CO 利润及成本中心,产品成本、项目会计、获利分析等;
AM 固定资产、技术资产、投资控制等;
SD 销售计划、询价报价、定单管理、运输发货、发票等;
MM 采购、库房管理、库存管理、MRP、供应商评价等;
PP 工厂数据、生产计划、MRP、能力计划、成本核算等;
QM 质量计划、质量检测、质量控制、质量文档等;
PM 维护及检测计划、单据处理、历史数据、报告分析等;
HR 薪资、差旅、工时、招聘、发展计划、人事成本等;
PS 项目计划、预算、能力计划、资源管理、结果分析等;
WF 工作定义、流程管理、电子邮件、信息传送自动化等;
IS 针对不同行业提供特殊应用。
基础部分:R/3系统内核、数据库、支持各类平台的接口、ABAP/4工具语言等。
posted @ 2009-03-30 18:55 断点 阅读(132) | 评论 (0)
一直以来习惯用EditPlus查看.xml文件,但EditPlus总是自动生成一个.BAK文件。
其实想去掉EditPlus的自动备份功能也简单,方法如下:
打开菜单栏上的:工具(T)->参数选择(P)->文件
取消“保存时自动创建备份文件”前的复选框中选择状态即可。
或
Tools-->Preference-->选中Files-->Create backup file when saving的复选框中的勾去掉即可。
posted @ 2009-03-17 10:14 断点 阅读(680) | 评论 (3)
基本概念:
工作流:两个或两个以上的人,为了共同的目标,连续的以串行或并行的方式去完成某一业务。
工作流管理系统的定义:是解释已定义好的工作流,产生并管理触发请求、警告,并且与外部系统进行交互。其实,工作流管理系统的核心是工作流引擎。说白了,工作流引擎就是一段程序,负责一些东西的流转。
两个或两个以上的人:一个人处理的业务不称其为工作流,只有任务从一个人"流"向另一个人的时候,才有工作流。
共同的目标:个体参与工作流必须是为了同一个工作目标。
在工作流自动化出现以前,所有的工作流都是通过手工实现的。
例子:较典型的是某项任务中的步骤要求参与者批阅文档或表格组成的文件。完成批阅及填写完表格中的相关内容后,文件被人工地传到下一步的执行者。需要对进程的参与者进行关于进程路由的培训,否则文件就会留在文件夹里得不到处理。
缺点:
高度依赖纸张;
劳动强度大;
流程不严密,任务执行不易贯彻;
无法对流程的过程进行监控;
无法度量进程时间和统计进程的成本。
工作流解决方案与传统管理软件的关系:
1、传统的管理软件注重解决企业应用层现存的问题(例如提高企业的资源配置率或提高单一员工的生产效率)。
EXCEL可以提高员工画表格的效率、财务软件可以规范财务人员的工作并提高帐目查询的效率、CRM可以规范客户管理从而使客户资源掌握在公司手中而不是被一部分业务人员把持并提高客户响应时间、ERP解决的是如何配置企业资源使企业的人力资源、财力资源和物资资源能够根据业务的需求实现最大化配置。
2、workflow关注的是如何缩短流程闲置时间,从而提高企业的业务处理能力并使企业能够关注于真正对企业有意义的增值业务上。
3、传统软件不能解决工作流的问题,例如ERP关注的是企业的资源配置,但不可能解决资源传输过程中的损耗和降低传输(流程)的成本;同样workflow也不能完全解决传统管理软件所能解决的问题,例如对生产管理的MRP系统所能解决的生产过程控制通过workflow很难实现。
一个好的工作流自动化解决方案:
能够画出工作流程图,当然以图形化界面设计的为佳;
能为每个步骤设计电子表格;
能将外部应用程序结合为工作流自动化的一部分;
能与电子表格及企业数据库相连接;
能设计基于复杂业务规则的条件型路由的工作流程图,最好无须编程;
能根据功能、用户名称或上下级关系按规则传递信息;
能够监控工作流执行状况;
能够对工作流进行调节;
能够模拟并测试工作流的行为;
工作流的应用必须支持多用户并具高度可靠性;
工作流的应用必须支持内部网或英特网及跨多种平台。
工作流自动化瞄准的是滞后时间。
工作流系统编程步骤总结:
创建流程定义;
部署流程定义;
启动流程定义;
获取流程实例;
执行任务;
结束任务。
看工作流的文档,经常会出现interface n这一说法,下面解释一下这些interface(一共5个)的内容:
1、Process Definitions
这一层的关键是Process Definition Language,目前的标准为XPDL。
API中有关过程定义语言的处理内容:
会话处理(连接,断开与参与系统的会话连接)
工作流定义操作(获得过程定义的名称,提供会话句柄以供对象级的操作,读取、写入第一级的过程定义对象)
工作流定义对象操作(根据工作流定义创建、获得和删除对象,获得、设置和删除对象属性)
2、Workflow APIs
API中有关工作流客户端应用接口(Interface 2)的处理内容:
1会话处理(连接,断开与参与系统的会话连接)
2工作流定义操作(获得过程定义的名称和属性)
3过程控制功能(创建、开始、中介一个独立过程实例,悬挂、恢复一个独立的过程实例,改变独立过程实例或活动实例的状态,指派、查询一个过程或活动的属性)
4过程状态功能(打开、关闭一个过程或活动实例的查询,设置可选的过滤器,根据情况获得过滤后的过程或活动实例的细节,获得特定的过程或活动的细节)
5工作表/工作项处理功能(打开、关闭一个工作表查询,设置可选的过滤器,根据情况获得工作表中的项,选择、重新指派、结束一个工作项时的通知,指派或查询一个工作项的属性)
6过程管理功能(改变过程定义和过程实例的操作状态,改变所有特定类型的过程和活动实例的状态,指派属性给所有特定类型的过程和活动的实例,结束全部过程实例)
7数据处理功能(获得/返回工作流相关数据或应用数据)
3、API中有关应用调用接口的处理内容:
会话处理(连接,断开与参与系统的会话连接)
活动管理功能([工作流引擎-->应用] 开始活动,悬挂、恢复、退出活动 [应用-->工作流引擎]活动结束通知,信号事件,查询活动属性)
数据处理功能(为工作流提供相关数据,提供应用数据或数据地址)
4、Inter-Engine Workflow
这一层描述了多个工作流引擎交互的方面,并且,各个引擎间的交互对用户是透明的。
5、Audit and Monitoring (Interface 5)
The support of this specification in workflow products allows analysis of consistent audit data across heterogeneous workflow products. During the initialization and execution of a process instance, multiple events occur which are of interest to a business, including WAPI events, internal workflow management engine operations and other system and application functions.
posted @ 2009-03-18 18:14 断点 阅读(211) | 评论 (0)
Caused by: java.lang.OutOfMemoryError: Java heap space
org.apache.jasper.JasperException: javax.servlet.ServletException: java.lang.OutOfMemoryError: Java heap space
2009-4-2 14:32:37 org.apache.catalina.core.ApplicationContext log
信息: javax.servlet.ServletException: java.lang.OutOfMemoryError: Java heap space
at org.apache.jasper.servlet.JspServletWrapper.handleJspException(JspServletWrapper.java:505)
at org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:417)
at org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:320)
at org.apache.jasper.servlet.JspServlet.service(JspServlet.java:266)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:803)
原因:
使用Java程序从数据库中查询大量的数据时出现异常:java.lang.OutOfMemoryError: Java heap space
在JVM中如果98%的时间是用于GC且可用的 Heap size 不足2%的时候将抛出此异常信息。
JVM堆的设置是指java程序运行过程中JVM可以调配使用的内存空间的设置.JVM在启动的时候会自动设置Heap size的值,其初始空间(即-Xms)是物理内存的1/64,最大空间(-Xmx)是物理内存的1/4。可以利用JVM提供的-Xmn -Xms -Xmx等选项可进行设置。
MyEclipse下解决办法:
Window-->Preference-->MyEclipse-->Application Servers-->Tomcat-->Tomcat 6.x-->JDK-->Optional Java VM arguments下填上:
-Xms100m -Xmx200m -XX:PermSize=256m -XX:MaxPermSize=600m
posted @ 2009-04-02 20:50 断点 阅读(2174) | 评论 (0)
严重: Servlet.service() for servlet jsp threw exception
java.lang.LinkageError: loader constraints violated when linking javax/el/ExpressionFactory class
at org.apache.jsp.login_jsp._jspInit(login_jsp.java:23)
at org.apache.jasper.runtime.HttpJspBase.init(HttpJspBase.java:52)
at org.apache.jasper.servlet.JspServletWrapper.getServlet(JspServletWrapper.java:159)
at org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:329)
at org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:320)
at org.apache.jasper.servlet.JspServlet.service(JspServlet.java:266)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:803)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:290)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:233)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:175)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:128)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:102)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:109)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:263)
at org.apache.coyote.http11.Http11Processor.process(Http11Processor.java:844)
at org.apache.coyote.http11.Http11Protocol$Http11ConnectionHandler.process(Http11Protocol.java:584)
at org.apache.tomcat.util.net.JIoEndpoint$Worker.run(JIoEndpoint.java:447)
at java.lang.Thread.run(Thread.java:595)
解释:
加载时违背约束条件。
错误的原因:
tomcat/lib下的el-api.jar与项目WEB-INF/lib目录下的el-api.jar冲突。
解决方式:
把项目目录下的el-api.jar删除即可。
posted @ 2009-03-17 09:53 断点 阅读(903) | 评论 (0)
1.警告: Failed to register in JMX: javax.naming.NamingException: Could not load resource factory class [Root exception is java.lang.ClassNotFoundException: org.apache.commons.dbcp.BasicDataSourceFactory]
2.Caused by: java.lang.NoClassDefFoundError: org/apache/commons/pool/impl/GenericObjectPool
我今天遇到这个错误了,不过在网上终于找到了答案,主要是一个包没有导入进去,除了需要commons-dbcp.jar之外还需要commons-pool.jar这个包,把后面这个commons-pool.jar包导入C:\Program Files\Apache Software Foundation\Tomcat 6.0\lib进去就应该行了。
总结:凡是看到ClassNotFoundException、NoClassDefFoundError等之类的,基本都是缺少什么包的,把相应的包导进去就行了。
posted @ 2009-03-09 11:00 断点 阅读(365) | 评论 (0)
异常如下:
org.apache.commons.dbcp.SQLNestedException: Cannot create PoolableConnectionFactory (Io 异常: The Network Adapter could not establish the connection)
at org.apache.commons.dbcp.BasicDataSource.createDataSource(BasicDataSource.java:1225)
at org.apache.commons.dbcp.BasicDataSource.getConnection(BasicDataSource.java:880)
Caused by: java.sql.SQLException: Io 异常: The Network Adapter could not establish the connection
at oracle.jdbc.dbaccess.DBError.throwSqlException(DBError.java:180)
at oracle.jdbc.dbaccess.DBError.throwSqlException(DBError.java:222)
at oracle.jdbc.dbaccess.DBError.throwSqlException(DBError.java:335)
主要原因:
1.可能是server.xml文件的DataSource配置出错。
(1).如果用到的是本机上的数据,本地数据源里的部分配置为: username="pcisv62" password="11" url="jdbc:oracle:thin:@localhost:1521:orcl"
(2).如果用到的是服务器上的数据,则数据源里的部分配置为: username="pcisv62" password="11" url="jdbc:oracle:thin:@dbserver:1521:corev6"
(dbserver为服务器的名字,corev6为服务器上Oracle的SID)
2.可能是oracle的tnsnames.ora文件配置出错。
oracle的安装目录E:\oracle\ora92\network\admin下的tnsnames.ora:
本地配置:
ORCL =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 主机名)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
)
)
或服务器配置:
COREV6_DBSERVER =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = dbserver)(PORT = 1521))
)
(CONNECT_DATA =
(SID = COREV6)
(SERVER = DEDICATED)
)
)
posted @ 2009-03-04 17:33 断点 阅读(3508) | 评论 (0)
tomcat 连接池泄露的问题
Caused by: org.apache.commons.dbcp.SQLNestedException: Cannot get a connection, pool exhausted
转载:
1 问题描述
Web程序在tomcat刚开始运行时速度很快,但过一段时间后发现速度变得很慢。
检查日志输出,发现异常如下:
org.apache.commons.dbcp.SQLNestedException: Cannot get a connection, pool exhausted, cause:
java.util.NoSuchElementException: Timeout waiting for idle object
2 问题解决
tomcat 的数据源定义提供了三个参数:
a. 如果设为true则tomcat自动检查恢复重新利用,没有正常关闭的Connection.(默认是false)
<parameter>
<name>removeAbandoned</name>
<value>true</value>
</parameter>
b. 设定连接在多少秒内被认为是放弃的连接,即可进行恢复利用。
<parameter>
<name>removeAbandonedTimeout</name>
<value>60</value>
</parameter>
c. 输出回收的日志,可以详细打印出异常从而发现是在那里发生了泄漏
<parameter>
<name>logAbandoned</name>
<value>true</value>
</parameter>
posted @ 2009-02-17 16:03 断点 阅读(738) | 评论 (0)
现在做个项目老是出现这个问题:
Cannot create JDBC driver of class '' for connect URL 'null'
在网上搜寻一番,现把它整理如下。
Tomcat5版本的数据源的配置如下:
<Resource name="jdbc/mldn" auth="Container" type="javax.sql.DataSource"/>
<ResourceParams name="jdbc/mldn">
<parameter>
<name>factory</name>
<value>org.apache.commons.dbcp.BasicDataSourceFactory</value>
</parameter>
<parameter>
<name>maxActive</name>
<value>100</value>
</parameter>
<parameter>
<name>maxIdle</name>
<value>30</value>
</parameter>
<parameter>
<name>maxWait</name>
<value>5000</value>
</parameter>
<parameter>
<name>username</name>
<value>root</value>
</parameter>
<parameter>
<name>password</name>
<value>root</value>
</parameter>
<parameter>
<name>driverClassName</name>
<value>com.mysql.jdbc.Driver</value>
</parameter>
<parameter>
<name>url</name>
<value>jdbc:mysql://localhost:3306/mldn</value>
</parameter>
</ResourceParams>
Tomcat6版本的数据源的配置如下:
第一步:在%Tomcat_HOME%conf\server.xml的 <Host>标签里当前位置下的<Context>里添加如下代码。
<Resource name="jdbc/mldn"
auth="Container"
type="javax.sql.DataSource"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
username="root"
password="root"
url="jdbc:mysql://localhost:3306/mldn"
driverClassName="com.mysql.jdbc.Driver"
maxIdle="30"
maxWait="5000"
maxActive="100"/>
第二步:配置应用目录下的web.xml文件,在<web-app></web-app>之间加入以下代码:
<resource-ref>
<description>DB Connection</description>
<res-ref-name>jdbc/mldn</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
注意:要求<res-ref-name>jdbc/mldn</res-ref-name>中的“jdbc/mldn”一定要与在server.xml中配置的Resource中的name一致,不然会出错。
第三步:在测试之前,要确保将数据库的驱动jar包放到,你的应用目录\WEB-INF\lib目录下和%Tomcat_HOME%c\lib目录下。
下面重启Tomcat就OK了!
posted @ 2009-02-11 16:49 断点 阅读(376) | 评论 (0)
我也遇到了这个问题,所以把它贴出来,大家了解一下。
在tomcat5下jsp中出现此错误一般都是在jsp中使用了输出流(如输出图片验证码,文件下载等),
没有妥善处理好的原因。
具体的原因:
在tomcat中jsp编译成servlet之后在函数_jspService(HttpServletRequest request, HttpServletResponse response)的最后
有一段这样的代码
finally {
if (_jspxFactory != null) _jspxFactory.releasePageContext(_jspx_page_context);
}
这里是在释放在jsp中使用的对象,会调用response.getWriter(),因为这个方法是和
response.getOutputStream()相冲突的!所以会出现以上这个异常。
在使用完输出流以后调用以下两行代码即可:
out.clear();
out = pageContext.pushBody();
最后这里是一个输出彩色验证码例子(这样的例子几乎随处可见),以下为代码的一部分:
ImageIO.write(image, " JPEG " ,os);
os.flush();
os.close();
os = null ;
response.flushBuffer();
out.clear();
out = pageContext.pushBody();
来源:http://chenlb.blogjava.net/archive/2007/05/26/104714.html#
posted @ 2009-02-11 15:34 断点 阅读(236) | 评论 (0)
1、Tomcat默认可以使用的内存为128MB,在较大型的应用项目中,这点内存是不够的,有可能导致系统无法运行。常见的问题是报Tomcat内存溢出错误,Out of Memory(系统内存不足)的异常,从而导致客户端显示500错误,一般调整Tomcat的使用内存即可解决此问题。
Windows环境下修改“%TOMCAT_HOME%\bin\catalina.bat”文件,在文件开头增加如下设置:set JAVA_OPTS=-Xms256m -Xmx512m
Linux环境下修改“%TOMCAT_HOME%\bin\catalina.sh”文件,在文件开头增加如下设置:JAVA_OPTS=’-Xms256m -Xmx512m’
其中,-Xms设置初始化内存大小,-Xmx设置可以使用的最大内存。
2、Tomcat6版本已经没有catalina.bat文件了。这个时候我们需要运行%TOMCAT_HOME%\bin\tomcat6w.exe文件,修改其中的Initial memory pool和Maximum memory pool的值,分别为256、512。
posted @ 2008-12-17 18:11 断点 阅读(1564) | 评论 (2)
SELECT *
FROM (SELECT COUNT (c_nme_en) as cus , c_nme_en
FROM web_prod
WHERE c_prod_no = '0325' AND c_tab_no != '0040'
GROUP BY c_nme_en)
WHERE cus > 1
order by c_nme_en
这个就是对c_nme_en列的不同内容进行统计。
可以参考:http://www.w3school.com.cn/sql/sql_groupby.asp
posted @ 2009-06-03 11:11 断点 阅读(56) | 评论 (0)
数据类型:
数字类型:
Number用来表示可变长的数值列,语法为Number(p, s),p是指所有有效数字的位数,s是指小数点以后的位数;p和s的取值分别是p=1 to 38,s=-84 to 127;
有效数位:从左边第一个不为0的数算起,小数点和负号不计入有效位数。
p>0,对s分3种情况:
1. s>0
精确到小数点右边s位,并四舍五入。然后检验有效数位是否<=p;如果s>p,小数点右边至少有s-p个0填充。
2. s<0
精确到小数点左边s位,并四舍五入。然后检验有效数位是否<=p+|s|
3.s是0或者未指定,四舍五入到最近整数。
注意:当p小于s时候,表示数字是绝对值小于1的数字,且从小数点右边开始的前s-p 位必须是0,保留s位小数。
比如
Value Datatype Stored Value
123.2564 NUMBER 123.2564
1234.9876 NUMBER(6) 1235
1234.9876 NUMBER(6,2) 1234.99
12345.12345 NUMBER(6,2) Error
12345.345 NUMBER(5,-2) 12300
1234567 NUMBER(5,-2) 1234600
12345678 NUMBER(5,-2) Error
12345.58 NUMBER(*, 1) 12345.6
0.1 NUMBER(4,5) Error
0.01234567 NUMBER(4,5) 0.01235
0.09999 NUMBER(4,5) 0.09999
0.099996 NUMBER(4,5) <>
用法如下:
create table t_n(id number(5,2));
insert into t_n values(123.455);
insert into t_n values(1.234);
insert into t_n values(.001);
select * from t_n 结果为:
Number类型存储实数,PLS_Integer和BINARY_Integer只能存储整数。
字符类型:
Char表示定长的字符串,语法Char(L),L是可选的。如果没有指定L值,默认为1;最大长度为32767。
VarChar2用来存储可变的字符串,语法VarChar2(L),L是必须的。最大长度为32767。
布尔类型:
Boolean类型的合法赋值为True、False和Null。
类型转换:
To_Char:可以将Number和Date类型转换为Varchar2类型;
To_Date:将Char类型转换Date类型;
To_Number:将Char类型转换Number类型;
变量和常量:
变量名称:1.必须以字母开头;2.其后可以跟一个或多个字母、数字(0~9)、特殊字符$、#或_ ;
3.变量长度不超过30个字符;4.变量名中不能有空格。
1.变量的声明:
DECLARE
v_StudentName VARCHAR2(20),
v_CurrentDate DATE;
v_NumberCredits NUMBER(3);
2.自定义的数据类型:
DECLARE
TYPE t_StudentRecord IS RECORD (FirstName Varchar2(10),LastName Varchar2(10),
CurrentCredits NUMBER(3));
v_Student t_StudentRecord;
3.变量属性:
下面介绍常见的几种复合数据类型变量的定义。
(1)使用%type定义变量
为了让PL/SQL中变量的类型和数据表中的字段的数据类型一致,Oracle 9i提供了%type定义方法。这样当数据表的字段类型修改后,PL/SQL程序中相应变量的类型也自动修改。如下:
declare
mytable emp.empno%type;
begin
select a.empno into mytable
from emp a
where a.ename='SCOTT';
dbms_output.put_line(mytable);
end;
(2)使用%rowtype定义变量
使用%type可以使变量获得字段的数据类型,使用%rowtype可以使变量获得整个记录的数据类型。
比较两者定义的不同:变量名 数据表.列名%type,变量名 数据表%rowtype。
declare
mytable emp%rowtype;
begin
select * into mytable
from emp a
where a.ename='SCOTT';
dbms_output.put_line(mytable.empno||' '||mytable.job);
end;
流程控制:
待续。。。
posted @ 2009-02-03 11:33 断点 阅读(176) | 评论 (0)
SELECT b.c_dpt_cde as CDptCde,
a.c_prod_no as CProdNo,
a.c_ply_no as CPlyNo,
a.c_edr_no as CEdrNo,
a.c_insrnt_cde as CInsrntCde,
a.c_bs_cur as CBsCur,
a.n_bs_amt as NBsAmt,
a.n_exch_rate as NExchRate,
a.c_rp_cur as CRpCur,
a.n_rp_amt as NRpAmt,
a.n_orig_cur_amt as NOrigCurAmt,
a.c_main_con_cde as CMainConCde,
a.c_sls_cde as CSlsCde,
a.c_cha_cls as CChaCls,
a.c_cha_cde as CChaCde,
b.c_oper_cde as COperCde,
b.t_cav_tm as TCavTm,
b.t_upd_tm as TUpdTm,
a.c_cav_pk_id as CCavPkId,
c.c_rp_type as CRpType,
b.c_check_cde as CCheckCde,
b.t_check_tm as TCheckTm,
b.c_check_flag as CCheckFlag,
b.c_check_memo as CCheckMemo,
a.c_prmdue_pk_id as CPrmduePkId,
a.c_paydue_pk_id as CPayduePkId,
a.c_clmdue_pk_id as CClmduePkId,
a.c_cavdoc_pk_id as CCavdocPkId,
a.c_clm_no as CClmNo,
a.c_bill_flag as CBillFlag,
a.c_feetyp_cde as CFeetypCde
FROM web_fin_cav_doc a
left join web_fin_cav_bill b on a.c_cav_pk_id = b.c_cav_pk_id
left join web_fin_cav_rptyp c on a.c_cav_pk_id = c.c_cav_pk_id
WHERE 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1
AND 1 = 1;
上面实现的是三个数据表之间的左连接。以前看见过两个表的左连接,而要实现三个表之间的左连接,还真有点困难,搞了半天才做出来。。。
posted @ 2009-02-27 09:50 断点 阅读(356) | 评论 (0)
1.集合操作:
Union 用第二个查询结果合并第一个查询结果,同时不显示重复的行。
Union all 检索出所有的行,包括重复的行。
intersect 返回两个查询所检索出的共有行。
minus 返回将第二个查询检索出的行从第一个查询检索出的行中减去之后剩余的行。
select ename,dname,job
from dept t,emp p
where t.deptno=p.deptno and t.dname='SALES'
union/intersect/minus
select ename,dname,job
from dept t,emp p
where t.deptno=p.deptno and p.job='MANAGER';
2.子查询:
可以在一个select语句中嵌入另一个完整的select语句,但此句的子查询的返回结果只能有一个,如想返回多个可用 in 。
select ename,dname,job
from dept t,emp p
where t.deptno=p.deptno and t.dname=
(
select dname
from dept t,emp p
where t.deptno=p.deptno and p.sal=1600.00
);
select ename,dname,job
from dept t,emp p
where t.deptno=p.deptno and t.dname in
(
select dname
from dept t,emp p
where t.deptno=p.deptno and p.sal>3000.00
);
3.表的连接:
select t.dname
from emp p,dept t
where p.deptno=t.deptno and p.ename='SMITH';
由于实施了关系连接的两表是任何连接的,所有需要在where子句中设置主关键字等于外部关键字的条件,否则查询结果不对。
4.case语句:
*简单case语句,使用表达式确定返回值,但case后的变量只有一个;
select t.dname,t.loc,t.deptno,
case t.deptno
when 10 then 'ACCOUNTING'
when 20 then 'RESEARCH'
when 30 then 'SALES'
else 'T'
end
from dept t;
*搜索case语句,使用条件确定返回值,但when后面可以跟多个条件。
select t.dname,t.loc,t.deptno,
case
when t.deptno=10 and t.loc='CHICAGO' then 'ACCOUNTING'
when t.deptno=20 then 'RESEARCH'
when t.deptno=30 then 'SALES'
else 'T'
end
from dept t;
5.decode函数:
decode(value,search_value,result,default_value)
如果value和search_value相等,则返回result,否则返回default_value。
select t.dname,t.loc,t.deptno,
decode(t.deptno,
10,'ACCOUNTING',
20,'RESEARCH',
30,'SALES',
'T'
)
from dept t;
posted @ 2009-01-13 17:15 断点 阅读(240) | 评论 (0)
1.在where子句中使用比较运算符:= ,!=(不等于) , <> (不等于), < ,> ,<= ,>= ,like。
2.使用比较运算符like:%通配符可以匹配任何长度的字符;_每个下划线匹配一个字母。
3.or:或的意思。
4.and:连接的两个条件必须同时满足。
5.not 非:select * from web_fin_dcr t where not t.n_item_no in(1,2);
6.between...and:指定某个范围内的所有值,包括指定值本身。
7.in用来指定一条列值:select * from web_fin_dcr t where t.n_item_no in(1,2);
8.order by:对检索到的数据进行排序,默认为升序asc(ascend),降序为desc(descend)。
select * from web_fin_dcr t where t.n_item_no in(1,2,3) order by t.n_item_no desc;
9.distinct来检索唯一的表列值,也就是检索哪些不同的数据:
select distinct t.c_cav_flag from web_fin_dcr t where t.n_item_no in(1,2,3);
posted @ 2009-01-12 16:19 断点 阅读(61) | 评论 (0)
<beans>
<bean id="person" class="org.spring.bean.Person">
<property name="name">
<value>zhangsan</value>
/property>
<property name="age">
<value>23</value>
</property>
</bean>
</beans>
注意:配置bean的开始,注意在property里name的属性值要和你在bean类里面的那个name成员变量一样。
从上面.xml的文档说明我们可以知道id属性是一个bean的唯一标示符,这个id在管理Bean的BeanFactory或者ApplicationContext中必须是唯一的标示符。用法如下
Person p = (Person) a.getBean("person");在getBean()方法里所传递的参数就是bean的id属性值。
当然我们也可以使用name属性来指定Bean的id演示代码如下:
<beans>
<bean name="person,user" class="org.spring.bean.Person">
<property name="name">
<value>zhangsan</value>
</property>
<property name="age">
<value>23</value>
</property>
</bean>
</beans>
使用bean的id和name来指定bean的id的区别:
id属性允许我们指定一个Bean的id,并且它在XML DTD中作为一个真正的XML元素的ID属性被标记,所以XML解析器能够在其他元素指向它的时候做一些额外的效验;name属性则与id相反,如果我们在开发中有必要使用一些非法的字符,那么我们可以通过name属性指定一个或多个id。当我们指定多个id时要用逗号(,)或者(;)来进行分隔。
用法如下:Person p = (Person) a.getBean("person"); 或改写为Person p = (Person) a.getBean("user");
posted @ 2009-02-11 10:35 断点 阅读(1005) | 评论 (0)
数据库使用锁(lock)来保证任何给定时刻最多只有一个事务在修改给定的一段数据。实质上讲,正是锁机制才使并发控制成为可能。
ORACLE的封锁策略:
1、只有当修改时,Oracle在行级上锁定数据,不要把锁定上升到块或表级。
2、Oracle决不会为读取而锁定数据,简单读取不能在数据行上设置锁定。
3、数据的写入器不会阻塞数据读取器。
4、只有当另一个数据写入器已经锁定了某行数据后,才阻塞其他人对该行数据的写入。数据的读取器决不会阻塞数据的写入器。
-------------------------------------------------------------------------
Oracle并发处理机制的简单看法。http://www.51testing.com/html/97/n-131297.html
转载内容如下:
在Oracle开发过程中,如果你只是独立地测试你的应用,然后部署,并交给数十个并发用户使用,就很有可能痛苦地遭遇原先未能检测到的并发问题。例如,2个用户同时修改某张订单,首先他们会查询这张订单存在不存在,如果存在,那么修改它的状态。在并发操作中,用户1会很奇怪的发现他的修改丢失了。当然,除此之外,在未能够很好的处理并发问题可能遭遇的情况还有:
◆破坏数据的完整性。
◆随着用户数的增多,应用的运行速度减慢。
◆不能很好地扩缩应用来支持大量用户。
为解决这些问题。首先要引入的是ORACLE的锁机制。数据库使用锁(lock)来保证任何给定时刻最多只有一个事务在修改给定的一段数据。实质上讲,正是锁机制才使并发控制成为可能。对ORACLE的锁机制可以查看ORACLE官方文档介绍。以下是对ORACLE锁的一点总结。
Oracle只在修改时才对数据加行级锁。正常情况下不会升级到块级锁或表级锁(不过两段提交期间的一段很短的时间内除外,这是一个不常见的操作)。
◆如果只是读数据,Oracle绝不会对数据锁定。不会因为简单的读操作在数据行上锁定。
◆写入器(writer)不会阻塞读取器(reader)。换种说法:读(read)不会被写(write)阻塞。这一点几乎与其他所有数据库都不一样。在其他数据库中,读往往会被写阻塞。尽管听上去这个特性似乎很不错(一般情况下确实如此),但是,如果你没有充分理解这个思想,而且想通过应用逻辑对应用施加完整性约束,就极有可能做得不对。
◆写入器想写某行数据,但另一个写入器已经锁定了这行数据,此时该写入器才会被阻塞。读取器绝对不会阻塞写入器。
开发人员要尽可能的考虑以上因素。而且还要意识到这些事ORACLE独有的。针对其他数据库,在锁的应用上略有不同。
以DB2为例
1.Oracle通过具有意向锁的多粒度封锁机制进行并发控制,保证数据的一致性。其DML锁(数据锁)分为两个层次(粒度):即表级和行级。通常的DML操作在表级获得的只是意向锁(RS或RX),其真正的封锁粒度还是在行级;DB2也是通过具有意向锁的多粒度封锁机制进行并发控制,保证数据的一致性。
其DML锁(数据锁)分为两个层次(粒度):即表级和行级。通常的DML操作在表级获得的只是意向锁(IS,SIX或IX),其真正的封锁粒度也是在行级;另外,在Oracle数据库中,单纯地读数据(SELECT)并不加锁,这些都提高了系统的并发程度,Oracle强调的是能够“读”到数据,并且能够快速的进行数据读取。而DB2的锁强调的是“读一致性”,进行读数据(SELECT)时会根据不同的隔离级别(RR,RS,CS)而分别加S,IS,IS锁,只有在使用UR隔离级别时才不加锁。从而保证不同应用程序和用户读取的数据是一致的。
2. 在支持高并发度的同时,DB2和Oracle对锁的操纵机制有所不同:Oracle利用意向锁及数据行上加锁标志位等设计技巧,减小了Oracle维护行级锁的开销,使其在数据库并发控制方面有着一定的优势。而DB2中对每个锁会在锁的内存(locklist)中申请分配一定字节的内存空间,具体是X锁64字节内存,S锁32字节内存(注:DB2 V8之前是X锁72字节内存而S锁36字节内存)。
3. Oracle数据库中不存在锁升级,而DB2数据库中当数据库表中行级锁的使用超过locklist*maxlocks会发生锁升级。
4. 在Oracle中当一个session对表进行insert,update,delete时候,另外一个session仍然可以从Orace回滚段或者还原表空间中读取该表的前映象(before image); 而在DB2中当一个session对表进行insert,update,delete时候,另外一个session仍然在读取该表数据时候会处于lock wait状态,除非使用UR隔离级别可以读取第一个session的未提交的值;所以Oracle同一时刻不同的session有读不一致的现象,而DB2在同一时刻所有的session都是“读一致”的。
posted @ 2009-11-28 17:50 断点 阅读(24) | 评论 (0)
今天在选择一条记录进行做删除操作时,碰见index失败的问题,如下:
处理失败!错误信息:[SQLException ORA-01502 index VHL_V6.PK_WEB_APP_TGT_OBJ or partition of such index is in unusable state ]
在网上查询了下,知道原因,就上数据库查了一下,结果如下:
1 PK_WEB_APP_TGT_OBJ NORMAL VHL_V6 TABLE UNUSABLE。
显然是UNUSABLE状态,那也就知道原因了,呵呵,解决!
以下为参考文件:
SQL> create table t(a number);
Table created.
1、现在,我们建立一个唯一索引来看看:
SQL> create unique index idx_t on t(a);
Index created.
SQL> select index_name,index_type,tablespace_name,table_type,status from user_indexes where index_name='T';
no rows selected
SQL> select index_name,index_type,tablespace_name,table_type,status from user_indexes where index_name='IDX_T';
INDEX_NAME INDEX_TYPE TABLESPACE_NAME TABLE_TYPE STATUS
------------------------------ --------------------------- ------------------------------ ----------- --------
IDX_T NORMAL DATA_DYNAMIC TABLE VALID
SQL> insert into t values(1);
1 row created.
SQL> commit;
Commit complete.
2、将索引手工修改为unusable状态(模拟发生索引失效的情况):
SQL> alter index idx_t unusable;
Index altered.
SQL> select index_name,index_type,tablespace_name,table_type,status from user_indexes where index_name='IDX_T';
INDEX_NAME INDEX_TYPE TABLESPACE_NAME TABLE_TYPE STATUS
------------------------------ --------------------------- ------------------------------ ----------- --------
IDX_T NORMAL DATA_DYNAMIC TABLE UNUSABLE
我们看到这是,已经不能正常往表中插入数据:
SQL> insert into t values(2);
insert into t values(2)
*
ERROR at line 1:
ORA-01502: index 'MISC.IDX_T' or partition of sUCh index is in unusable state
3、首先,我们通过重建索引(rebuild index)的方法来解决问题:
SQL> alter index idx_t rebuild;
Index altered.
SQL> select index_name,index_type,tablespace_name,table_type,status from user_indexes where index_name='IDX_T';
INDEX_NAME INDEX_TYPE TABLESPACE_NAME TABLE_TYPE STATUS
------------------------------ --------------------------- ------------------------------ ----------- --------
IDX_T NORMAL DATA_DYNAMIC TABLE VALID
SQL> insert into t values(2);
1 row created.
SQL> commit;
Commit complete.
SQL>
4、现在我们再次模拟索引失效(unusable状态):
SQL> alter index idx_t unusable;
Index altered.
SQL> select index_name,index_type,tablespace_name,table_type,status from user_indexes where index_name='IDX_T';
INDEX_NAME INDEX_TYPE TABLESPACE_NAME TABLE_TYPE STATUS
------------------------------ --------------------------- ------------------------------ ----------- --------
IDX_T NORMAL DATA_DYNAMIC TABLE UNUSABLE
SQL> insert into t values(3);
insert into t values(3)
*
ERROR at line 1:
ORA-01502: index 'MISC.IDX_T' or partition of such index is in unusable state
5、然后,看看是否可以通过设置参数skip_unusable_indexes=true来解决问题:
SQL> alter session set skip_unusable_indexes=true;
Session altered.
SQL> insert into t values(3);
insert into t values(3)
*
ERROR at line 1:
ORA-01502: index 'MISC.IDX_T' or partition of such index is in unusable state
SQL> select index_name,index_type,tablespace_name,table_type,status from user_indexes where index_name='IDX_T';
INDEX_NAME INDEX_TYPE TABLESPACE_NAME TABLE_TYPE STATUS
------------------------------ --------------------------- ------------------------------ ----------- --------
IDX_T NORMAL DATA_DYNAMIC TABLE UNUSABLE
SQL> alter index idx_t rebuild;
Index altered.
SQL> select index_name,index_type,tablespace_name,table_type,status from user_indexes where index_name='IDX_T';
INDEX_NAME INDEX_TYPE TABLESPACE_NAME TABLE_TYPE STATUS
------------------------------ --------------------------- ------------------------------ ----------- --------
IDX_T NORMAL DATA_DYNAMIC TABLE VALID
SQL> insert into t values(3);
1 row created.
SQL> commit;
Commit complete.
SQL>
总结:对于unique index,通过简单的设置参数是不能解决问题的,要解决unique index 失效的问题,只能通过重建索引来实现。
资料引用:http://www.knowsky.com/388811.html
posted @ 2009-09-26 21:36 断点 阅读(80) | 评论 (0)
1、用户
查看当前用户的缺省表空间:SQL>select username,default_tablespace from user_users;
查看当前用户的角色:SQL>select * from user_role_privs;
查看当前用户的系统权限和表级权限
SQL>select * from user_sys_privs;
SQL>select * from user_tab_privs;
显示当前会话所具有的权限:SQL>select * from session_privs;
显示指定用户所具有的系统权限:SQL>select * from dba_sys_privs where grantee='GAME';
显示特权用户:select * from v$pwfile_users;
显示用户信息(所属表空间)
select default_tablespace,temporary_tablespace
from dba_users where username='GAME';
显示用户的PROFILE :select profile from dba_users where username='GAME';
2、表
查看用户下所有的表 SQL>select * from user_tables;
查看名称包含log字符的表
SQL>select object_name,object_id from user_objects where instr(object_name,'LOG')>0;
查看某表的创建时间
SQL>select object_name,created from user_objects where object_name=upper('&table_name');
查看某表的大小
SQL>select sum(bytes)/(1024*1024) as "size(M)" from user_segments
where segment_name=upper('&table_name');
查看放在ORACLE的内存区里的表
SQL>select table_name,cache from user_tables where instr(cache,'Y')>0;
3、索引
查看索引个数和类别
SQL>select index_name,index_type,table_name from user_indexes order by table_name;
查看索引被索引的字段
SQL>select * from user_ind_columns where index_name=upper('&index_name');
查看索引的大小
SQL>select sum(bytes)/(1024*1024) as "size(M)" from user_segments
where segment_name=upper('&index_name');
4、序列号
查看序列号,last_number是当前值
SQL>select * from user_sequences;
5、视图
查看视图的名称 SQL>select view_name from user_views;
查看创建视图的select语句
SQL>set view_name,text_length from user_views;
SQL>set long 2000; 说明:可以根据视图的text_length值设定set long 的大小
SQL>select text from user_views where view_name=upper('&view_name');
6、同义词
查看同义词的名称
SQL>select * from user_synonyms;
7、约束条件
查看某表的约束条件
SQL>select constraint_name, constraint_type,search_condition, r_constraint_name
from user_constraints where table_name = upper('&table_name');
SQL>select c.constraint_name,c.constraint_type,cc.column_name
from user_constraints c,user_cons_columns cc
where c.owner = upper('&table_owner') and c.table_name = upper('&table_name')
and c.owner = cc.owner and c.constraint_name = cc.constraint_name
order by cc.position;
8、存储函数和过程
查看函数和过程的状态
SQL>select object_name,status from user_objects where object_type='FUNCTION';
SQL>select object_name,status from user_objects where object_type='PROCEDURE';
查看函数和过程的源代码
SQL>select text from all_source where owner=user and name=upper('&plsql_name');
转载:http://www.javaeye.com/topic/264639
posted @ 2009-09-14 17:29 断点 阅读(28) | 评论 (0)
最近看C语言的程序,程序里面带有sql语句,其中就有这么一句:
EXEC SQL select upper(nvl(c_grant_dpt_cde,'0')),nvl(C_CTCT_CDE,'0') into :sGrantCde,:sCtctCde from t_department where c_dpt_cde = :sDptCde;
if (sqlca.sqlcode!=0) {
printf("[ppPlyNewCountPrm]ERROR:sqlca.sqlerrmc = %s\n", sqlca.sqlerrm.sqlerrmc);
return(SetUserError(lpInBuffer,2,"取机构部门归属错误!"));
}
不明白 sqlca.sqlcode = 0 是什么意思,搜了搜,记录一下sqlca.sqlcode的各种取值的意义:
0 ——最近一次sql语句执行成功
-1 ——最近一次sql语句执行失败
100 ——最近一次sql语句没有返回数据
posted @ 2009-09-10 19:59 断点 阅读(129) | 评论 (0)
1、SELECT nvl(C_REMARK,chr(0)) into :sRate
from T_COMM_CODE
where c_cde = trim(:sText2) and rownum = 1;
nvl是个函数,作用是如果第一个参数为空值,则返回第二个参数的值,否则返回第一个参数的值。
chr(0)将数字0转化为字符0。
2、Y.YJKSBH=X.ZXKSBH(+) AND Y.ZLXMID=X.ZLXMID(+)
(+)表示左连接,就是在做关联之后,y表中存在而x表中不存在的数据也能查出来。
posted @ 2009-06-13 17:46 断点 阅读(72) | 评论 (0)
原因:出现这个问题,可能有人move过表,或者disable 过索引。
1、alter table xxxxxx move tablespace xxxxxxx 命令后,索引就会失效。
2、alter index index_name unusable,命令使索引失效。
解决办法:
1、重建索引才是解决这类问题的完全的方法。
alter index index_name rebuild (online);
2、如果是分区索引只需要重建那个失效的分区 。
alter index index_name rebuild partition partition_name (online);
说明:
1. alter session set skip_unusable_indexes=true;就可以在session级别跳过无效索引作查询。
2.分区索引应适用user_ind_partitions。
3.状态分4种:
N/A说明这个是分区索引需要查user_ind_partitions或者user_ind_subpartitions来确定每个分区是否可用;
VAILD说明这个索引可用;
UNUSABLE说明这个索引不可用;
USABLE 说明这个索引的分区是可用的。
http://www.sudu.cn/info/html/edu/20071225/20526.html
http://blog.oracle.com.cn/html/65/t-122265.html
posted @ 2009-05-19 19:16 断点 阅读(369) | 评论 (0)
比如定义为number(4,2),却要插入一个值200.12的话,就会出错啊,原因是number(p,s)的问题。
number(p,s),其中p表示该number的总长度,s为小数位。
如果s为负数,则会取相应位数的取整。
例如,如果number(4,-3),则数字1234的存储值为1000;如果number(4,-2),则数字1234的存储值为1200。
在对数据库表中的字段设定类型时,要注意:
NUMBER(10,6) Double 带有小数
NUMBER(4) Long 为整数
posted @ 2009-05-16 17:31 断点 阅读(363) | 评论 (0)
Blob是指二进制大对象也就是英文Binary Large Object的所写;
Clob是指大字符对象也就是英文Character Large Object的所写。
因此这两个类型都是用来存储大量数据而设计的,其中BLOB是用来存储大量二进制数据的;CLOB用来存储大量文本数据。
在JDBC中有两个接口对应数据库中的BLOB和CLOB类型,java.sql.Blob和java.sql.Clob。和你平常使用数据库一样你可以直接通过ResultSet.getBlob()方法来获取该接口的对象。与平时的查找唯一不同的是得到Blob或Clob的对象后,我们并没有得到任何数据,但是我们可以这两个接口中的方法得到数据。
例如:
Blob b=resultSet.getBlob(1);
InputStream bin=b.getBinaryStream();
Clob c=resultSet.getClob(2);
Reader cReader=c.getCharacterStream():
另外还有一种获取方法,不使用数据流,而是使用数据块。
例如
Blob b=resultSet.getBlob(1);
byte data=b.getByte(0,b.length());
Clob c=resultSet.getClob(2);
String str=c.getSubString(0,c.length());
在这里要说明一下,这个方法其实并不安全,如果你很细心的话,那很容易就能发现getByte()和getSubString()两个方法中的第二个参数都是int类型的,而BLOB和CLOB是用来存储大量数据的。而且Bolb.length()和Clob.length()的返回值都是long类型的,所以很不安全。
那么有人肯定要问既然已经有VARCHAR和VARBINARY两中类型,为什么还要再使用另外的两种类型呢?
原因:VARCHAR和VARBINARY两种类型是有自己的局限性的。首先说这两种类型的长度还是有限的不可以超过一定的限额,以VARCHAR在ORA中为例长度不可以超过4000;而LONGVARCHAR类型的一个重要缺陷就是不可以使用LIKE这样的条件检索。
另外就是在数据库中VARCHAR和VARBINARY的存取是将全部内容从全部读取或写入,对于100K或者说更大数据来说这样的读写方式,远不如用流进行读写来得更现实一些。
posted @ 2009-05-16 19:26 断点 阅读(166) | 评论 (0)
在oracle中建有date类型的字段,插入可以采取如下方法:
如果是小时为:1-12 采取如下格式:yyyy-mm-dd HH:MI:SS
insert into test values(to_date('2009-5-7 07:09:37','yyyy-mm-dd HH:MI:SS'));
如果是小时为:1-24 采取如下格式:yyyy-mm-dd HH24:MI:SS
insert into test values(to_date('2009-5-7 17:09:37','yyyy-mm-dd HH24:MI:SS'));
posted @ 2009-05-07 20:14 断点 阅读(145) | 评论 (0)
Caused by: java.sql.BatchUpdateException: ORA-01461: 仅可以为插入 LONG 列的 LONG 值赋值
我在系统的一个页面上加载一个.xml文件时,出现了这个错误。
原因:
当插入数据的长度在1000、2000内,就会抛出这样的错误。
解决方法:
思路:将存储的字符串补上空格,让其超过2000的长度即可,但仅限与紧急解决问题。
1、首先在.java文件中引入import org.apache.commons.lang.StringUtils;
2、在此.java文件的相应的方法里添加如下判断:
// 处理ora-1461问题(clob长度在1000-2000之间会出错)
if (xml.length() >= 1000 && xml.length() <= 2000) {
xml = StringUtils.rightPad(xml, 2008);
}
相关知识:
LONG: 可变长的字符串数据,最长2G,LONG具有VARCHAR2列的特性,可以存储长文本一个表中最多一个LONG列
LONG RAW: 可变长二进制数据,最长2G
CLOB: 字符大对象Clob 用来存储单字节的字符数据
NCLOB: 用来存储多字节的字符数据
BLOB: 用于存储二进制数据
BFILE: 存储在文件中的二进制数据,这个文件中的数据只能被只读访。但该文件不包含在数据库内。bfile字段实际的文件存储在文件系统中,字段中存储的是文件定位指针.bfile对oracle来说是只读的,也不参与事务性控制和数据恢复。
其中CLOB,NCLOB,BLOB都是内部的LOB(Large Object)类型,最长4G,没有LONG只能有一列的限制。要保存图片、文本文件、Word文件各自最好采用那種数据类型呢?BLOB最好,LONG RAW也不错,但Long是oracle将要废弃的类型,因此建议用BLOB。
相关链接:http://www.blogjava.net/allen-zhe/archive/2008/05/06/198627.html
posted @ 2009-04-18 13:01 断点 阅读(676) | 评论 (0)
今天跟新人安装oracle后,打开数据库查看表里面的数据,发现里面的数据全是“靠”字。
这可是以前没有出现过的。因此就查了一下,了解到是注册表的字符级问题。现解决如下:
在注册表里进行修改:
开始-->运行里面输入regedit-->我的电脑\HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\HOME0 里NLS_LANG的值
以前是:American_America.ZHS16GBK
现改为:SIMPLIFIED CHINESE_CHINA.ZHS16GBK
再一次打开oracle时,数据显示一切正常。
posted @ 2009-04-09 15:08 断点 阅读(118) | 评论 (0)
现在在企业中,操作oracle数据库的客户端,除了PL/SQL外,使用的较多的就是TOAD了!
为此,我在网上搜索了下,整理了些简单TOAD的使用技巧,现分享给大家。
常用快捷键:
F8 调出以前执行的sql命令
F9 执行全部sql
Ctrl+t 补全table_name
Ctrl+. 补全table_name
alt+ 箭头上下 看sql history
Ctrl+Enter 直接执行当前sql
Ctrl+Shift+F 格式化sql语句。
如果还觉得不够用的话,可以在系统菜单空白处点击右键,进入menu shortcuts,自行定义快捷键。
toad下修改表中字段的值:
首先在schema Browser下查找到相应的表,在右边点击Data栏,然后选中一条记录,再点击Data栏下面的▲(Edit Record),即可修改字段里的值,然后点击√(Post edit),最后就是Commit了。
posted @ 2009-04-08 20:50 断点 阅读(637) | 评论 (0)
前序:关于Oracle9i数据的导出与导入问题,折腾我好长时间了,尤其是导入。今天在一位同事的指导下,算是终于成功了,为了记住这位同事的帮助,在此仅以“坤”作为记号。
正文:
Oracle数据导出:
如果是导出本机的Oracle数据库:
exp pcisv62/11@ORCL file="d:\pcisv62081226.dmp" full=y
(ORCL为本地数据库监听)
如果是导出服务器端的Oracle数据:
exp pcisv62/11@tnsname file="d:\pcisv62081226.dmp" full=y
(tnsname为COREV6_DBSERVER,SID为COREV6,主机为DBSERVER。)
exp pcisv6_ab/11@COREV6_DBSERVER file=d:\v6100210.dmp rows=y buffer=1024000
注意:必须是 DBA 才能执行完整数据库或表空间导出操作。
Oracle数据导入,分以下步骤:
1.先在Oracle9i的Enterprise Manager Console下,以sys/sys及sysdba身份登陆,在“存储”-->“表空间”下创建表空间COREV6,同时给其分配合适的空间。
2.在“安全性”-->“用户”下创建用户pcisv62,使用户默认的表空间为COREV6,同时在“角色”里授予CONNECT、DBA、EXP_FULL_DATABASE、IMP_FULL_DATABASE、RESOURCE。
3.导入.dmp文件,开始-->运行cmd,导入命令:
imp pcisv6_ab/11@ORCL file=d:\v6100210.dmp full=y ignore=y
注意:如果备份的.dmp文件是以用户pcisv62导出COREV6空间的数据,那么
1.新建的用户最好是pcisv62,否则命令为:
imp pcisv62/11@ORCL file=d:\v6100210.dmp fromuser=pcisv62 touser=pcisv6_ab full=y ignore=y rows=y tablespaces=corev6
2.与新建用户关联的新建空间名必须为COREV6,否则Oracle报找不到COREV6空间的错误。
数据成功导入以后,下一步就是配置Tomcat的server.xml文件:
1.如果用到的是本机上的数据,本地数据源里的部分配置为: username="pcisv62" password="11"
url="jdbc:oracle:thin:@localhost:1521:orcl"
2.如果用到的是服务器上的数据,则数据源里的部分配置为: username="pcisv62" password="11"
url="jdbc:oracle:thin:@dbserver:1521:corev6"(dbserver为服务器的名字,corev6为服务器上Oracle的SID)
oracle的安装目录E:\oracle\ora92\network\admin下的tnsnames.ora:
本地配置:
ORCL =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 主机名)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
)
)
或服务器配置:
COREV6_DBSERVER =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = dbserver)(PORT = 1521))
)
(CONNECT_DATA =
(SID = COREV6)
(SERVER = DEDICATED)
)
)
以下转载:几种导入导出的命令方法,以备以后查阅。
数据导出:
exp qhmis/qhmis@qhmis file='d:\backup\qhmis\qhmis20060526.dmp' grants=y full=n
1 将数据库TEST完全导出,用户名system 密码manager 导出到D:\daochu.dmp中
exp system/manager@TEST file=d:\daochu.dmp full=y
2 将数据库中system用户与sys用户的表导出
exp system/manager@TEST file=d:\daochu.dmp owner=(system,sys)
3 将数据库中的表table1 、table2导出
exp system/manager@TEST file=d:\daochu.dmp tables=(table1,table2)
4 将数据库中的表table1中的字段filed1以"00"打头的数据导出
exp system/manager@TEST file=d:\daochu.dmp tables=(table1) query=\" where filed1 like '00%'\"
数据的导入:
1 将D:\daochu.dmp 中的数据导入 TEST数据库中。
imp system/manager@TEST file=d:\daochu.dmp
上面可能有点问题,因为有的表已经存在,然后它就报错,对该表就不进行导入。
在后面加上 ignore=y 就可以了。
2 将d:\daochu.dmp中的表table1 导入
imp system/manager@TEST file=d:\daochu.dmp tables=(table1)
posted @ 2009-03-04 17:06 断点 阅读(1224) | 评论 (0)
系统环境:WindowXP。
oracle9i 安装到最后,更改了:sys口令:sys system口令:system
现在需要以system身份登陆sql*puls,方法有二:
第一种方法:.进入SQL*Plus后在弹出对话框中直接点击“确定”,
请输入用户名:sys as sysdba
请输入口令:sys
第二种方法:进入Dos窗口,输入一下命令:
c:\>sqlplus /nolog
SQL>conn sys/password as sysdba
注意:sys的权限最大!是默认的DBA!一般不在该用户下建用户表,PACKAGE等!system的权限就差一些。
posted @ 2009-02-27 14:55 断点 阅读(96) | 评论 (0)
有两个简单例子,以说明 “exists”和“in”的效率问题
1) select * from T1 where exists(select * from T2 where T1.a=T2.a) ;
T1数据量小而T2数据量非常大时,T1<<T2 时,1) 的查询效率高。
2) select * from T1 where T1.a in (select T2.a from T2) ;
T1数据量非常大而T2数据量小时,T1>>T2 时,2) 的查询效率高。
exists 用法:
1)句中的“select * from T2 where T1.a=T2.a” 相当于一个关联表查询,
相当于“select * from T1,T2 where T1.a=T2.a”;
“exists(xxx)”它只在乎括号里的数据能不能查找出来,是否存在这样的记录,如果存在,这1)句的where 条件成立。
in的用法:
2)句中的“select * from T1 where T1.a in (select T2.a from T2) ”,这里的“in”后面括号里的语句搜索出来的字段的内容一定要相对应,一般来说,T1和T2这两个表的a字段表达的意义应该是一样的,否则这样查没什么意义。
---------------------------------------------------------------
+++++++++++++ 下面转载 +++++++++++++++++++
---------------------------------------------------------------
今天市场报告有个sql及慢,运行需要20多分钟,如下:
update p_container_decl cd
set cd.ANNUL_FLAG=\'0001\',ANNUL_DATE = sysdate
where exists(
select 1
from (
select tc.decl_no,tc.goods_no
from p_transfer_cont tc,P_AFFIRM_DO ad
where tc.GOODS_DECL_NO = ad.DECL_NO
and ad.DECL_NO = \'sssssssssssssssss\'
) a
where a.decl_no = cd.decl_no
and a.goods_no = cd.goods_no
)
上面涉及的3个表的记录数都不小,均在百万左右。根据这种情况,我想到了前不久看的tom的一篇文章,说的是exists和in的区别,in 是把外表和那表作hash join,而exists是对外表作loop,每次loop再对那表进行查询。
这样的话,in适合内外表都很大的情况,exists适合外表结果集很小的情况。
而我目前的情况适合用in来作查询,于是我改写了sql,如下:
update p_container_decl cd
set cd.ANNUL_FLAG=\'0001\',ANNUL_DATE = sysdate
where (decl_no,goods_no) in
(
select tc.decl_no,tc.goods_no
from p_transfer_cont tc,P_AFFIRM_DO ad
where tc.GOODS_DECL_NO = ad.DECL_NO
and ad.DECL_NO = ‘ssssssssssss’
)
让市场人员测试,结果运行时间在1分钟内。问题解决了,看来exists和in确实是要根据表的数据量来决定使用。
--------------------------------------------------------------------------
posted @ 2009-02-01 17:54 断点 阅读(240) | 评论 (0)
在卸载Oracle时删不干净,搞的要重装系统,本人在工作中总结出如下方法,希望对大家有所帮助。
注意:oracle的源程序的路径必须是英文路径,否则安装会出错!
1.以Administrators 身份登陆windows系统。
2.停掉Oracle Service服务。
3.通过Oracle installer 卸载任何orcle产品及组件。
4.删除%ORACLE_base%文档和SYSTEM_DRIVE:\program files下的oracle文档。
5.删除SYSTEM_DRIVE:\Documents and Settings\All Users\「开始」菜单\程式中的oracle项。
6.在“开始菜单”—点“运行”—输入“regedit”打开注册表:
到HKEY_CLASSES_ROOT下,删除以Oracle,ORA,ORCL开头的键;
到HKEY_LOCAL_MACHINE\SOFTWARE下,删除ORACLE键和Apache Group键;
到HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services下,删除以Oracle开头的键;
到HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services \Eventlog\Application下,删除以Oracle开头的键;
到HKEY_CURRENT_USER下,删除Oracle键;
到HKEY_CURRENT_USER\SOFTWARE\ORACLE下,删除以Oracle 或 Orcl开头的键(假如有的话);
7.打开系统系统环境变量(我的电脑->右键->系统属性->高级->环境变量),在PATH中删除任何以%ORACLE_HOME%开始的项。
8.重启电脑。
posted @ 2008-12-18 12:37 断点 阅读(68) | 评论 (0)
一、建库和建表以及插入数据的实例。
drop database if exists school; -- 如果存在SCHOOL则删除
create database school; -- 建立库SCHOOL
use school; -- 打开库SCHOOL
create table teacher -- 建立表TEACHER
(
id integer auto_increment not null primary key,
name varchar(10) not null
); -- 建表结束
insert into teacher values(null,'t');
insert into teacher values(null,'j');
在dos下命令不方便调试,你可以将以上命令写入一个文件中取名为school.sql,然后复制到c:\下,并在DOS窗口下键入以下命令:mysql -uroot -p密码 < c:/school.sql。
二、Windows下.sql文件的导入导出。
DOS窗口:开始->运行->cmd
导入为:mysql -uroot -proot<c:/school.sql
导出为:mysqldump -uroot -proot school>c:/school.sql
三、数据的备份(命令在DOS窗口下执行):
1.备份数据库:(将数据库school备份)
mysqldump -uroot -proot school>c:/school.sql
2.将备份数据导入到数据库:(导回school数据库)
mysql -uroot -proot school<c:/school.sql
注意:此时已有数据库school。
注意:另一种方式,就是进入mysql数据库控制台,use school,然后使用source命令source c:/school.sql即可。
四、将文本数据导入到mysql数据库中。
1、文本数据应符合相应的格式:字段数据之间用tab键隔开,null值用\n来代替。
例:取一个文件名为teacher.txt,里面内容如下:
\n w
\n h
2、数据传入命令 load data local infile "c:/teacher.txt" into table teacher;
注意:在mysql命令窗口中,先要用use命令打开此表所在的数据库。
posted @ 2009-03-26 10:05 断点 阅读(90) | 评论 (0)
一、常用命令
列出数据库:show databases;
选择数据库:use databaseName;
列出表格:show tables;
建库create database 库名;
建表create table 表名;
显示数据表的结构:desc 表名;
删库 drop database 库名;
删表 drop table 表名;
将表中记录清空:delete from 表名;
显示表中的记录:select * from 表名;
二、连接MYSQL。
格式: mysql -h主机地址 -u用户名 -p用户密码
1、例1:连接到本机上的MYSQL。
首先在打开DOS窗口,键入命令mysql -uroot -p,回车后提示你输密码。
2、例2:连接到远程主机上的MYSQL。假设远程主机的IP为:192.168.1.5,用户名为root,密码为root。则键入以下命令: mysql -h192.168.1.5 -uroot -proot
3、退出MYSQL命令: exit (回车)
三、其它命令:
查询时间:select now();
查询数据库版本:select version();
查询当前用户:select user();
查询当前使用的数据库:select database();
匹配字符:可以用通配符_代表任何一个字符,%代表任何字符串;
增加一个字段:alter table tabelName add column fieldName dateType;
增加多个字段:alter table tabelName add column fieldName1 dateType,add columns fieldName2 dateType;
修改密码:mysqladmin -u用户名 -p旧密码 password新密码
以下转载:
增加新用户:
格式:grant select on 数据库.* to 用户名@登录主机 identified by "密码"
例1、增加一个用户test1密码为abc,让他可以在任何主机上登录,并对所有数据库有查询、插入、修改、删除的权限。首先用以root用户连入MYSQL,然后键入以下命令:
grant select,insert,update,delete on *.* to test1@"%" Identified by "abc";
但例1增加的用户是十分危险的,你想如某个人知道test1的密码,那么他就可以在internet上的任何一台电脑上登录你的mysql数据库并对你的数据可以为所欲为了,解决办法见例2。
例2、增加一个用户test2密码为abc,让他只可以在localhost上登录,并可以对数据库mydb进行查询、插入、修改、删除的操作(localhost指本地主机,即MYSQL数据库所在的那台主机),这样用户即使用知道test2的密码,他也无法从internet上直接访问数据库,只能通过MYSQL主机上的web页来访问了。
grant select,insert,update,delete on mydb.* to test2@localhost identified by "abc";
例3.如果你不想test2有密码,可以再打一个命令将密码消掉。
grant select,insert,update,delete on mydb.* to test2@localhost identified by "";
例4.增加一个管理员帐户:grant all on *.* to user@localhost identified by "password";
其它命令集:
从已经有的表中复制表的结构create table table2 select * from table1 where 1<>1;
复制表create table table2 select * from table1;
对表重新命名alter table table1 rename as table2;
修改列的类型:
alter table table1 modify id int unsigned;//修改列id的类型为int unsigned
alter table table1 change id sid int unsigned;//修改列id的名字为sid,而且把属性修改为int unsigned
创建索引:
alter table table1 add index ind_id (id);
create index ind_id on table1 (id);
create unique index ind_id on table1 (id);//建立唯一性索引
删除索引:
drop index idx_id on table1;
alter table table1 drop index ind_id;
联合字符或者多个列(将列id与":"和列name和"="连接):
select concat(id,':',name,'=') from students。
limit(选出10到20条)<第一个记录集的编号是0>:
select * from students order by id limit 9,10。
MySQL不支持的功能:事务,视图,外键和引用完整性,存储过程和触发器。
posted @ 2009-03-26 10:02 断点 阅读(79) | 评论 (0)
这个问题主要是MySQL自身的配置问题,修改一下,即可解决。
把E:\MySQL\MySQL Server 5.0里面的my.ini文件,default-character-set项修改为
default-character-set=gbk
注意:default-character-set有两处需要进行修改,且修改后的值一样为gbk。
posted @ 2009-02-12 10:23 断点 阅读(65) | 评论 (0)
项目开始的时候用的是这个my97,选一下日期就能带出来,感觉挺好,但到了后来项目上线了,有一个“保险起期”、“保险止期”联动,发现控件上的日期需要双击才可联动;如果只单击一下“保险起期”,然后离开点页面其他地方,两个时间没有联动起来。经项目组js牛人(wuguojian)努力攻关,终于实现了点击就可以联动的效果。
改造有两个方面的原因:
1.如果业务人员,只单击了“保险起期”,而“保险止期”没有联动,以前的默认的保险期间365天没有发生变化,而保单打印出来的时间“保险起期”、“保险止期”有变化,易引起麻烦。
2.刚才提到双击可以联动,还有单击后点刷新也可以联动,但是在网络慢的情况下,影响出单员的效率。
改造如下:
对文件My97DatePicker.htm部分进行修改,增加一个js方法,在body里面引用:
<head>
<script>
// 增加日历控件关闭事件 2009-10-26
function getObj() {
var divs = document.body.getElementsByTagName("div");
for (var i=0,len=divs.length;i<len;i++) {
if (divs[i].className == 'WdateDiv') {
divs[i].onblur = function () {
$dp.el.onchange();
};
break;
}
}
}
</script>
</head>
<body leftmargin="0" topmargin="0" onload="$c.autoSize();getObj();">
</body>
控件连接地址:http://www.my97.net/dp/demo/index.htm
posted @ 2009-10-31 18:08 断点 阅读(19) | 评论 (0)
什么是正则表达式
简单的说,正则表达式是一种可以用于模式匹配和替换的强有力的工具。
其作用如下:
1、测试字符串的某个模式。例如,可以对一个输入字符串进行测试,看在该字符串是否存在一个电话号码模式或一个信用卡号码模式。这称为数据有效性验证。
2、替换文本。可以在文档中使用一个正则表达式来标识特定文字,然后可以全部将其删除,或者替换为别的文字。
3、根据模式匹配从字符串中提取一个子字符串。可以用来在文本或输入字段中查找特定文字。
正则表达式的形式一般如下:
/love/ 其中位于“/”定界符之间的部分就是将要在目标对象中进行匹配的模式。用户只要把希望查找匹配对象的模式内容放入“/”定界符之间即可。为了能够使用户更加灵活的定制模式内容,正则表达式提供了专门的“元字符”。所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
1、元字符。常用的包括: “+”, “*”,以及 “?”。
“+”元字符规定其前导字符必须在目标对象中连续出现一次或多次。
“*”元字符规定其前导字符必须在目标对象中出现零次或连续多次。
“?”元字符规定其前导对象必须在目标对象中连续出现零次或一次。
\s:用于匹配单个空格符,包括tab键和换行符;
\S:用于匹配除单个空格符之外的所有字符;
\d:用于匹配从0到9的数字;
\w:用于匹配字母,数字或下划线字符;
\W:用于匹配所有与\w不匹配的字符;
. :用于匹配除换行符之外的所有字符。
例子:
/fo+/ 因为上述正则表达式中包含“+”元字符,表示可以与目标对象中的 “fool”, “fo”, 或者 “football”等在字母f后面连续出现一个或多个字母o的字符串相匹配。
/eg*/ 因为上述正则表达式中包含“*”元字符,表示可以与目标对象中的 “easy”, “ego”, 或者 “egg”等在字母e后面连续出现零个或多个字母g的字符串相匹配。
/Wil?/ 因为上述正则表达式中包含“?”元字符,表示可以与目标对象中的 “Win”, 或者“Wilson”,等在字母i后面连续出现零个或一个字母l的字符串相匹配。
/\s+/ 上述正则表达式可以用于匹配目标对象中的一个或多个空格字符。
/\d000/ 如果我们手中有一份复杂的财务报表,那么我们可以通过上述正则表达式轻而易举的查找到所有总额达千元的款项。
2、限定符。有时候不知道要匹配多少字符。为了能适应这种不确定性,正则表达式支持限定符的概念。
{n} n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。
{n,} n 是一个非负整数。至少匹配 n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。
{n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。
3、定位符。定位符用于规定匹配模式在目标对象中的出现位置。 包括: “^”, “$”, “\b” 以及 “\B”。
“^”定位符规定匹配模式必须出现在目标字符串的开头
“$”定位符规定匹配模式必须出现在目标对象的结尾
“\b”定位符规定匹配模式必须出现在目标字符串的开头或结尾的两个边界之一
“\B”定位符则规定匹配对象必须位于目标字符串的开头和结尾两个边界之内。
举例:
/^hell/ 因为上述正则表达式中包含“^”定位符,所以可以与目标对象中以 “hell”, “hello”或“hellhound”开头的字符串相匹配。
/ar$/ 因为上述正则表达式中包含“$”定位符,所以可以与目标对象中以 “car”, “bar”或 “ar” 结尾的字符串相匹配。
/\bbom/ 因为上述正则表达式模式以“\b”定位符开头,所以可以与目标对象中以 “bomb”, 或 “bom”开头的字符串相匹配。
/man\b/ 因为上述正则表达式模式以“\b”定位符结尾,所以可以与目标对象中以 “human”, “woman”或 “man”结尾的字符串相匹配。
4、为了方便用户更加灵活的设定匹配模式,正则表达式允许使用者在匹配模式中指定某一个范围而不局限于具体字符。例如:
/[A-Z]/ 上述正则表达式将会与从A到Z范围内任何一个大写字母相匹配。
/[a-z]/ 上述正则表达式将会与从a到z范围内任何一个小写字母相匹配。
/[0-9]/ 上述正则表达式将会与从0到9范围内任何一个数字相匹配。
/([a-z][A-Z][0-9])+/ 上述正则表达式将会与任何由字母和数字组成的字符串,如 “aB0” 等相匹配。
5、这里需要提醒用户注意的一点就是可以在正则表达式中使用 “()” 把字符串组合在一起。
6、如果我们希望在正则表达式中实现类似编程逻辑中的“或”运算,在多个不同的模式中任选一个进行匹配的话,可以使用管道符 “|”。
例如:/to|too|2/ 上述正则表达式将会与目标对象中的 “to”, “too”, 或 “2” 相匹配。
7、否定符 “[^]”。规定目标对象中不能存在模式中所规定的字符串。例如:/[^A-C]/ 上述字符串将会与目标对象中除A,B,和C之外的任何字符相匹配。
8、当用户需要在正则表达式的模式中加入元字符,可以使用转义符“\”。例如:/Th\*/ 上述正则表达式将会与目标对象中的“Th*”而非“The”等相匹配。
区号:前面一个0,后面跟2-3位数字 : 0\d{2,3}
电话号码:7-8位数字: \d{7,8}
分机号:一般都是3位数字: \d{3,}
这样连接起来就是验证电话的正则表达式了:/^((0\d{2,3})-)(\d{7,8})(-(\d{3,}))?$/
手机号码前面以1开头,第二位现在是3或者5,后面是9位数字,则:/^1[35]\d{9}$/
posted @ 2009-08-15 19:24 断点 阅读(39) | 评论 (0)
有人问 Javascript 中如何截取小数位并实现四舍五入,这是一个很常用的 js 技术,因为觉得比较典型,可能很多新手都会遇到此问题,所以将帖子整理了一下,以备新手查阅。
1、round 方法
作用:返回与给出的数值表达式最接近的整数。
语法:Math.round(number) ,必选项 number 参数是要舍入到最接近整数的值。
说明:如果 number 的小数部分大于等于 0.5,返回值是大于 number 的最小整数。否则,round 返回小于等于 number 的最大整数。
2、在 Javascript 1.5 (IE5.5+,NS6+ 以上版本支持)中,新增了2个专门用于货币流通的函数,Number.toFixed(x) 和 Number.toPrecision(x)。
Number.toFixed(x) 是将指定数字截取小数点后 x 位, Number.toPrecision(x) 是将整个数字截取指定(x)长度。注意,一个是计算小数点后的长度,一个是计算整个数字的长度 。
例如:
<script type="text/javascript">
var aa = 2.3362;
document.write(aa.toFixed(1)); // 2.3
document.write(aa.toFixed(2)); // 2.34
document.write(aa.toPrecision(2)); // 2.3
document.write(aa.toPrecision(3)); // 2.34
document.write(Math.round(aa * 10) / 10); // 2.3
document.write(Math.round(aa * 100) / 100); // 2.34
</script>
由于是新增函数,所以要考虑浏览器支持问题。
posted @ 2009-08-26 13:52 断点 阅读(157) | 评论 (0)
数组分类:
1、从数组的下标分为索引数组、关联数组
/* 索引数组,即通常情况下所说的数组 */
var ary1 = [1,3,5,8];
//按索引去取数组元素,从0开始(当然某些语言实现从1开始),索引实际上就是序数,一个整型数字
alert(ary1[0]);
alert(ary1[1]);
alert(ary1[2]);
alert(ary1[3]);
/* 关联数组,指以非序数类型为下标来存取的数组 python中称为字典 */
var ary2 = {}; //存取时,以非序数(数字),这里是字符串
ary2["one"] = 1;
ary2["two"] = 2;
ary2["thr"] = 3;
ary2["fou"] = 4;
2、从对数据的存储分为静态数组、动态数组
/* java中的静态数组 */
Int[] ary1 = {1,3,6,9}; //定义后数组的长度固定了不能改变,按索引取数组元素
/* java中的动态数组 (java中的ArrayList实现是以Array为基础的。)*/
List<Integer> ary2 = new ArrayList<Integer>();
ary2.add(1);//可以动态的添加元素,数组的长度也随着变化
ary2.add(3);
ary2.add(6);
/* js的数组属于动态数组 */
var ary = [];//定义一个数组,未指定长度
ary[0] = 1;//可以动态的添加元素
ary.push(3);
ary.push(5);
alert(ary.join(","));//输出1,3,5
js的数组同时属于索引数组和动态数组,因为本质上它就是一个js对象,体现着js动态语言特性。但js的索引数组并非“连续分配”内存的,因此索引方法并不会带来很高的效率。而java中的数组则是连续分配内存的。
例子:
function test() { {
 var oneArray=new Array(); var oneArray=new Array();
oneArray["first"]="firstValue";
oneArray["second"]="secondValue";
oneDrapList=document.createElement("select");
  for(att in oneArray){ for(att in oneArray){
var oneOption=document.createElement("option");
oneOption.text=oneArray[att]
oneOption.value=att;
try{
oneDrapList.add(oneOption,null);
 } }
catch(ex){
oneDrapList.add(oneOption);
}
}
 } }
function test(){
var obj = tool.getFilterByName("<%=dwname%>",'VehicleClass');
if(obj){
var cProdNo = '<%=cProdNo%>';
if(cProdNo=="0316"||cProdNo=="0325"){
var array = {"摩托车类":"摩托车类","拖拉机类":"拖拉机类"};
for(var temp in array){
var option = new Option(temp,array[temp]);
obj.add(option);
}
}
}
}
posted @ 2009-08-14 21:28 断点 阅读(202) | 评论 (0)
这几天一直被日期的各种转换缠绕在,现在终于解决,顺便把自己这几天的收获贡献出来,与大家一起共同成长。
1、将日期字符串转换成日期对象。
yyyy-mm-dd这种格式的字符串转化成日期对象,可以用new Date(Date.parse(str.replace(/-/g,"/")));
如下:
var endDateStr = endYear +"-"+ endMonth +"-"+ endDay;
endDate = new Date(Date.parse(endDateStr.replace(/-/g,"/")));
实例显示:
endDateStr:"2010-5-20"
Date.parse(endDateStr.replace(/-/g,"/")):1274284800000
endDate:Thu May 20 00:00:00 UTC+0800 2010
yyyy/mm/dd这种格式转化成日期对象,可以用new Date(str);
如下:
var endDateStr = endYear +"/"+ endMonth +"/"+ endDay;
endDate = new Date(endDateStr);
实例显示:"2010/5/20"、Thu May 20 00:00:00 UTC+0800 2010
yyyymmdd这种格式转换成日期对象,可以用new Date(sDate.replace(/^(\d{4})(\d{2})(\d{2})$/,"$1/$2/$3"));
如下:
var sDate="20090516";
sDate=sDate.replace(/^(\d{4})(\d{2})(\d{2})$/,"$1/$2/$3");
new Date(sDate);
实例显示:"2009/05/16"、Sat May 16 00:00:00 UTC+0800 2009
2、显示当前日期的下一天。
var date = new Date();
var b = date.getDate();
b += 1;
date.setDate(b);
3、求两个日期之间相差的天数。
var Date1 =new Date(2008,6,28); //Mon Jul 28 00:00:00 UTC+0800 2008
var Date2 =new Date(2009,5,16); //Tue Jun 16 00:00:00 UTC+0800 2009
var n = (Date2.getTime()-Date1.getTime())/(24*60*60*1000); //323
var n = (Date2-Date1)/(24*60*60*1000); //直接相减得到的是毫秒数。
4、dateObj.getDay() 返回 Date 对象中用本地时间表示的一周中的日期值。
getDay 方法所返回的值是一个处于 0 到 6 之间的整数,它代表了一周中的某一天,返回值与一周中日期的对应关系如下:
值 星期
0 星期天
1 星期一
2 星期二
3 星期三
4 星期四
5 星期五
6 星期六
此方法可以用来对 ‘工作日’的判断。
posted @ 2009-05-16 15:24 断点 阅读(87) | 评论 (0)
1、(背景:以前在做系统查询的时候,要显示系统当天时间以及下一天,当前时间很容易写出,可下一天不会写,下面是自己试着写的一个。)
function tomorrow(){
var date = new Date();
var year = date.getYear(); //取得当前年份命令
var month = date.getMonth() 1;
var day = date.getDate();
var dateStr=null;
if(year%4==0 && year%100!=0 || year%400==0){ //为闰年
if(month==1||month==3||month==5||month==7||month==8||month==10){
if(day==31){
month = month 1;
if(month < 10){ month ='0' month ; }
dateStr = year "-" month "-" "01" ;
}else if(day!=31){
day = day 1;
if(month < 10){ month ='0' month ; }
if(day < 10){ day ='0' day ; }
dateStr = year "-" month "-" day ;}
}else if(month==4||month==6||month==9||month==11){
if(day==30){
month=month 1;
if(month < 10){ month ='0' month ; }
dateStr = year "-" month "-" "01" ;
}else if(day!=30){
day = day 1;
if(month < 10){ month ='0' month ; }
if(day < 10){ day ='0' day ; }
dateStr = year "-" month "-" day ;}
}else if(month==12){
if(day==31){month="01";dateStr = year 1 "-" month "-" "01" ;}
else if(day!=31){
day = day 1;
if(month < 10){ month ='0' month ; }
if(day < 10){ day ='0' day ; }
dateStr = year "-" month "-" day ;}
}else if(month==2){
if(day==29){month="03";dateStr = year "-" month "-" "01" ;}
else if(day!=29){
day = day 1;
if(month < 10){ month ='0' month ; }
if(day < 10){ day ='0' day ; }
dateStr = year "-" month "-" day ;}
}
}else { //非闰年
if(month==1||month==3||month==5||month==7||month==8||month==10){
if(day==31){
month=month 1;
if(month < 10){ month ='0' month ; }
dateStr = year "-" month "-" "01" ;
}else if(day!=31){
day = day 1;
if(month < 10){ month ='0' month ; }
if(day < 10){ day ='0' day ; }
dateStr = year "-" month "-" day ;}
}else if(month==4||month==6||month==9||month==11){
if(day==30){
month=month 1;
if(month < 10){ month ='0' month ; }
dateStr = year "-" month "-" "01" ;
}else if(day!=30){
day = day 1;
if(month < 10){ month ='0' month ; }
if(day < 10){ day ='0' day ; }
dateStr = year "-" month "-" day ;}
}else if(month==12){
if(day==31){month="01"; dateStr = year 1 "-" month "-" "01" ;}
else if(day!=31){
day = day 1;
if(month < 10){ month ='0' month ; }
if(day < 10){ day ='0' day ; }
dateStr = year "-" month "-" day ;}
}else if(month==2){
if(day==28){month="03";dateStr = year "-" month "-" "01" ;}
else if(day!=28){
day = day 1;
if(month < 10){ month ='0' month ; }
if(day < 10){ day ='0' day ; }
dateStr = year "-" month "-" day ;}
}
}
alert(dateStr); //为了方便查看结果才加上去的
}
2、自己写的特容易出错,调用js自带的函数,使产生的对象自加一,很好的控制了2008-10-32、undefined 、null的产生。
function nextdate(){
var date = new Date();
var b = date.getDate();
b += 1;
date.setDate(b);
var year = date.getYear(); //取得当前年份命令
var month = date.getMonth()+1;
var day = date.getDate();
if(month < 10){ month ='0'+ month ; }
if(day < 10){ day ='0'+ day ; }
var dateStr = year+ "-"+ month+"-"+day ;
alert(dateStr);
}
posted @ 2009-05-09 17:24 断点 阅读(38) | 评论 (0)
1、
string=string.replace(/-/g, "/");
替换字符串中的-为 /。
g 为global,全文查找出现的所有 pattern ;如果没有这个参数只替换第一个。
2、
Date.parse(dateVal)
其中必选项 dateVal 是一个包含以诸如 "Jan 5, 1996 08:47:00" 的格式表示的日期的字符串,或者是一个从 ActiveX(R) 对象或其他对象中获取的 VT_DATE 值。
说明
parse 方法返回一个整数值,这个整数表示 dateVal 中所包含的日期与 1970 年 1 月 1 日午夜之间相间隔的毫秒数。
parse 方法是 Date 对象的一个静态方法。正因为它是一个静态方法,它是通过下面例子中所示的方法被调用的,而不是作为一个已创建 Date 对象的一个方法被调用。
下面是个例子:
var dateBgn = Date.parse(bgnStr.replace(/-/g, "/"));
posted @ 2009-05-09 17:05 断点 阅读(13) | 评论 (0)
parseInt 方法,返回由字符串转换得到的整数。
parseInt(numString, [radix])
参数
numString 必选项。要转换为数字的字符串。
radix 可选项。在 2 和 36 之间的表示 numString 所保存数字的进制的值。如果没有提供,则前缀为 '0x' 的字符串被当作十六进制,前缀为 '0' 的字符串被当作八进制。所有其它字符串都被当作是十进制的。
说明
parseInt 方法返回与保存在 numString 中的数字值相等的整数。如果 numString 的前缀不能解释为整数,则返回 NaN(而不是数字)。
例子如下:
var endDay = parseInt(endStr.substring(8,10),10);
posted @ 2009-05-09 16:25 断点 阅读(33) | 评论 (0)
Microsoft Script Editor,这个程序是Microsoft Office 2003 里的一部分,如果安装时选择了Microsoft Office-->Office工具-->“HTML源文件编辑”的话,
这个冬冬就安装在:C:\Program Files\Microsoft Office\Office11\MSE7.exe
Microsoft Script Editor是很好的js调试工具。使用:右键选择浏览器的属性,进入“高级”,把“禁用脚本调试(Internet Explorer)”和“禁用脚本调试(其他)”前的勾去掉,同时在要调试的js处加上debugger即可使用。
posted @ 2008-12-17 17:48 断点 阅读(175) | 评论 (0)
19:02:31,843 INFO [ServerImpl] Starting JBoss (Microcontainer)...
19:02:31,843 INFO [ServerImpl] Release ID: JBoss [Morpheus] 5.0.0.GA (build: SVNTag=JBoss_5_0_0_GA
date=200812041714)
19:02:31,843 INFO [ServerImpl] Bootstrap URL: null
19:02:31,843 INFO [ServerImpl] Home Dir: E:\jboss-5.0.0.GA
19:02:31,843 INFO [ServerImpl] Home URL: file:/E:/jboss-5.0.0.GA/
19:02:31,843 INFO [ServerImpl] Library URL: file:/E:/jboss-5.0.0.GA/lib/
19:02:31,843 INFO [ServerImpl] Patch URL: null
19:02:31,843 INFO [ServerImpl] Common Base URL: file:/E:/jboss-5.0.0.GA/common/
19:02:31,843 INFO [ServerImpl] Common Library URL: file:/E:/jboss-5.0.0.GA/common/lib/
19:02:31,843 INFO [ServerImpl] Server Name: JBoss
19:02:31,843 INFO [ServerImpl] Server Base Dir: E:\jboss-5.0.0.GA\server
19:02:31,843 INFO [ServerImpl] Server Base URL: file:/E:/jboss-5.0.0.GA/server/
19:02:31,843 INFO [ServerImpl] Server Config URL: file:/E:/jboss-5.0.0.GA/server/JBoss/conf/
19:02:31,843 INFO [ServerImpl] Server Home Dir: E:\jboss-5.0.0.GA\server\JBoss
19:02:31,843 INFO [ServerImpl] Server Home URL: file:/E:/jboss-5.0.0.GA/server/JBoss/
19:02:31,843 INFO [ServerImpl] Server Data Dir: E:\jboss-5.0.0.GA\server\JBoss\data
19:02:31,843 INFO [ServerImpl] Server Library URL: file:/E:/jboss-5.0.0.GA/server/JBoss/lib/
19:02:31,843 INFO [ServerImpl] Server Log Dir: E:\jboss-5.0.0.GA\server\JBoss\log
19:02:31,859 INFO [ServerImpl] Server Native Dir: E:\jboss-5.0.0.GA\server\JBoss\tmp\native
19:02:31,859 INFO [ServerImpl] Server Temp Dir: E:\jboss-5.0.0.GA\server\JBoss\tmp
19:02:31,859 INFO [ServerImpl] Server Temp Deploy Dir: E:\jboss-5.0.0.GA\server\JBoss\tmp\deploy
19:02:34,468 INFO [ServerImpl] Starting Microcontainer, bootstrapURL=file:/E:/jboss-
5.0.0.GA/server/JBoss/conf/bootstrap.xml
Failed to boot JBoss:
java.lang.RuntimeException: Error unmarshalling file:/E:/jboss-5.0.0.GA/server/JBoss/conf/bootstrap.xml
at org.jboss.bootstrap.xml.BootstrapParser.parse(BootstrapParser.java:60)
at org.jboss.bootstrap.microcontainer.ServerImpl.doStart(ServerImpl.java:129)
at org.jboss.bootstrap.AbstractServerImpl.start(AbstractServerImpl.java:394)
at org.jboss.Main.boot(Main.java:209)
at org.jboss.Main$1.run(Main.java:547)
at java.lang.Thread.run(Thread.java:595)
Caused by: org.jboss.xb.binding.JBossXBException: Failed to parse source: file:/E:/jboss-
5.0.0.GA/server/JBoss/conf/bootstrap.xml
at org.jboss.xb.binding.parser.sax.SaxJBossXBParser.parse(SaxJBossXBParser.java:177)
at org.jboss.xb.binding.UnmarshallerImpl.unmarshal(UnmarshallerImpl.java:119)
at org.jboss.bootstrap.xml.BootstrapParser.parse(BootstrapParser.java:53)
... 5 more
Caused by: java.io.FileNotFoundException: E:\jboss-5.0.0.GA\server\JBoss\conf\bootstrap.xml
at org.jboss.net.protocol.file.FileURLConnection.connect(FileURLConnection.java:105)
at org.jboss.net.protocol.file.FileURLConnection.getInputStream(FileURLConnection.java:112)
at org.apache.xerces.impl.XMLEntityManager.setupCurrentEntity(Unknown Source)
at org.apache.xerces.impl.XMLVersionDetector.determineDocVersion(Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse(Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse(Unknown Source)
at org.apache.xerces.parsers.XMLParser.parse(Unknown Source)
at org.apache.xerces.parsers.AbstractSAXParser.parse(Unknown Source)
at org.apache.xerces.jaxp.SAXParserImpl$JAXPSAXParser.parse(Unknown Source)
at org.jboss.xb.binding.parser.sax.SaxJBossXBParser.parse(SaxJBossXBParser.java:173)19:02:35,015 INFO
[ServerImpl] Runtime shutdown hook called, forceHalt: true
... 7 more
19:02:35,078 INFO [ServerImpl] Shutdown complete
Shutdown complete
Halting VM
解决方法:在MyEclipse中的应用服务器中,选中JBoss,将其Server name配置改为default即可。
posted @ 2009-11-28 17:06 断点 阅读(85) | 评论 (0)
我在Jboss5.0下开发MessageDrivenBean时,遇到了一个小错误,提示如下:
javax.naming.NameNotFoundException: QueueConnectionFactory not bound
at org.jnp.server.NamingServer.getBinding(NamingServer.java:771)
at org.jnp.server.NamingServer.getBinding(NamingServer.java:779)
at org.jnp.server.NamingServer.getObject(NamingServer.java:785)
at org.jnp.server.NamingServer.lookup(NamingServer.java:443)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
产生这个错误,主要是因为在Jboss5.0下找不到QueueConnectionFactory。我登陆jboss5.0的http://localhost:8090/jmx-console/,在这个jboss/service=JNDIView/list/Global JNDI Namespace下查找,只有ConnectionFactory!
因此解决办法有了,把发送消息的java类中的QueueConnectionFactory修改一下即可,如下:
QueueConnectionFactory factory = (QueueConnectionFactory)ctx.lookup("QueueConnectionFactory");
改为-->
QueueConnectionFactory factory = (QueueConnectionFactory)ctx.lookup("ConnectionFactory");
OK,搞定!
posted @ 2009-03-27 17:56 断点 阅读(618) | 评论 (3)
昨天试了一下把mysql的数据源配置mysql-ds.xml放在jboss下面跑,成功了;后来我想那oracle数据源配置oracle-ds.xml也可以在jboss下面跑了。我就试了一下, 在启动Eclipse时报以下错误:
11:04:48,078 INFO [SettingsFactory] JDBC driver: Oracle JDBC driver, version: 9.2.0.1.0
11:04:48,125 ERROR [AbstractKernelController] Error installing to Start: name=persistence.unit:unitName=#ztf state=Create
javax.persistence.PersistenceException: [PersistenceUnit: ztf] Unable to build EntityManagerFactory
at org.hibernate.ejb.Ejb3Configuration.buildEntityManagerFactory(Ejb3Configuration.java:677)
at org.hibernate.ejb.HibernatePersistence.createContainerEntityManagerFactory(HibernatePersistence.java:132)
at org.jboss.jpa.deployment.PersistenceUnitDeployment.start(PersistenceUnitDeployment.java:311)
Caused by: org.hibernate.HibernateException: unknown Oracle major version [0]
at org.hibernate.dialect.DialectFactory$1.getDialectClass(DialectFactory.java:173)
at org.hibernate.dialect.DialectFactory.determineDialect(DialectFactory.java:88)
at org.hibernate.dialect.DialectFactory.buildDialect(DialectFactory.java:62)
11:04:48,265 ERROR [ProfileServiceBootstrap] Failed to load profile: Summary of incomplete deployments (SEE PREVIOUS ERRORS
FOR DETAILS):
*** CONTEXTS MISSING DEPENDENCIES: Name -> Dependency{Required State:Actual State}
jboss.j2ee:jar=EntityBean.jar,name=PersonServiceBean,service=EJB3
-> <UNKNOWN jboss.j2ee:jar=EntityBean.jar,name=PersonServiceBean,service=EJB3>{Described:** UNRESOLVED Demands
'persistence.unit:unitName=#ztf' **}
*** CONTEXTS IN ERROR: Name -> Error
persistence.unit:unitName=#ztf -> org.hibernate.HibernateException: unknown Oracle major version [0]
<UNKNOWN jboss.j2ee:jar=EntityBean.jar,name=PersonServiceBean,service=EJB3> -> ** UNRESOLVED Demands
'persistence.unit:unitName=#ztf' **
11:04:48,453 INFO [Http11Protocol] Starting Coyote HTTP/1.1 on http-127.0.0.1-8090
出现这个问题,接着在网上google了一下,在http://forum.hibernate.org/viewtopic.php?p=2373597下找到了答案。
我出现的问题已解决,如下:
1.persistence.xml下<jta-data-source>的数据源配置为java:/ztfDS。
2.在persistence.xml下<properties>加入SQL方言<property name="hibernate.dialect" value="org.hibernate.dialect.Oracle9Dialect"/>
jboss下数据源的配置,分以下几种情况:
1.选择的是mysql-ds.xml,此文件相应位置设为 <jndi-name>ztfDS</jndi-name>,那么在persistence.xml中相应设置为<jta-data-source>java:ztfDS</jta-data-source>。
2.选择的是oracle-ds.xml,此文件相应位置设为<jndi-name>ztfDS</jndi-name>,那么在persistence.xml中相应设置为<jta-data-source>java:/ztfDS</jta-data-source>。
posted @ 2009-03-26 12:43 断点 阅读(1001) | 评论 (0)
eclipse中jboss启动时提示:
Server JBoss v5.0 at localhost was unable to start within 50 seconds. If the server
requires more time, try increasing the timeout in the server editor.
解决办法:
修改 workspace\.metadata\.plugins\org.eclipse.wst.server.core\servers.xml文件。
<servers>
<server hostname="localhost" id="JBoss v5.0 at localhost" name="JBoss v5.0 at
localhost" runtime-id="JBoss v5.0" server-type="org.eclipse.jst.server.generic.jboss5"
server-type-id="org.eclipse.jst.server.generic.jboss5" start-timeout="1000" stop-
timeout="15" timestamp="0">
<map jndiPort="1099" key="generic_server_instance_properties" port="8090"
serverAddress="127.0.0.1" serverConfig="default"/>
</server>
</servers>
把 start-timeout="50" 改为 start-timeout="1000"
重启eclipse就可以了。
其它原因:
我的是因为先前把端口号改为8090,而忽略其他地方的修改,这次我把
C:\jboss-5.0.0.GA\server\default\deploy\jbossweb.sar里面下的server.xml下的相应处也改过
来了即protocol="HTTP/1.1" port="8090"。重启eclipse就可以了,否则Eclipse老在那里work building。
posted @ 2009-03-20 12:36 断点 阅读(1329) | 评论 (5)
数据源可以减少数据库连接对象的创建数量,来提升系统运行性能。
在C:\jboss-5.0.0.GA\docs\examples\jca下有各种数据源配置模板。
数据源的文件命名包含-ds,如:mysql-ds.xml。
以mysql为例:
1.数据源参数的修改。
可以在mysql-ds.xml里配置数据库的可用连接数:
<min-pool-size>0</min-pool-size>
<max-pool-size>20</max-pool-size>
2.数据源的部署。
mysql的连接驱动文件mysql-connector-java-5.0.4-bin.jar拷贝到 jboss的C:\jboss-5.0.0.GA\server\default\lib中。
3.数据源的发布。
把mysql-ds.xml拷贝到C:\jboss-5.0.0.GA\server\default\deploy下,完成发布。
此时在jboss的Console下显示如下:
Bound ConnectionManager 'jboss.jca:service=DataSourceBinding,name=itDS' to JNDI name 'java:itDS'。
注意:在jboss下,数据源可以动态的发布,所以我们修改完mysql-ds.xml里的参数并保存,jboss可以对它进行部署。
posted @ 2009-03-26 10:01 断点 阅读(192) | 评论 (0)
EJB3.0应用需要运行在JDK1.5以上版本。
EJB3.0应用需要运行在EJB容器里,JavaEE应用服务器包含Web容器和EJB容器。
EJB3.0应用需要以下版本的JavaEE应用服务器:
Jboss(4.2.x以上版本)
Weblogic(10以上版本)
注意:Tomcat目前只是Web容器,它不能运行EJB应用。
jboss的下载页面为 http://www.jboss.org/jbossas/downloads/
如果是JDK1.5版本,可选择jboss-5.0.0.GA.zip
如果是JDK6.0版本,可选择jboss-5.0.0.GA-jdk6.zip
下载后直接解压缩文件即可完成安装,点击C:\jboss-5.0.0.GA\bin下的run.bat,启动完成后在浏览器中输入http://localhost:8080/即可以看见JBoss页面。
添加环境变量:
1.在“系统变量”里添加JBOSS_HOME变量,值为Jboss的安装路径,
如:JBOSS_HOME C:\jboss-5.0.0.GA
2.为了方便jboss的命令,需要把jboss的bin目录添加到系统Path路径里,
如: Path ;%JBOSS_HOME%\bin
posted @ 2009-03-19 10:38 断点 阅读(1693) | 评论 (0)
以下是具体cleanerV6.bat的文件内容:
del /f /s /q "%userprofile%\Application Data\Sun\Java\Deployment\cache\*.*"
del /f /s /q "%userprofile%\Local Settings\Temporary Internet Files\*.*"
del /f /s /q "%userprofile%\Local Settings\Temp\*.*"
regsvr32 %systemroot%\system32\jscript.dll /s
regsvr32 %systemroot%\system32\vbscript.dll /s
regsvr32 %systemroot%\system32\Shdocvw.dll /s
regsvr32 %systemroot%\system32\Oleaut32.dll /s
regsvr32 %systemroot%\system32\Actxprxy.dll /s
regsvr32 %systemroot%\system32\Mshtml.dll /s
regsvr32 %systemroot%\system32\Urlmon.dll /s
regsvr32 %systemroot%\system32\browseui.dll /s
posted @ 2009-11-28 18:42 断点 阅读(134) | 评论 (0)
1.vhl.js文件里面的一个js方法里,添加如下:
window.open(base+"/policy/universal/pop/flat_vhl_inf_query.jsp?
all="+url,"","scrollbars=yes,left=0,top=0,Toolbar=no,Location=no,Direction=no,Resizeable=no,Width="+800+" ,Height="+530);
2.在flat_vhl_inf_query.jsp页面的js方法里面,调用:
opener.test(list); // 调用 父窗口 test方法
3.在vhl.js文件里面的一个js方法,名字也就是test,在这个方法里获得弹出窗口的回填数据。
这里调用了非模态窗口用法。
posted @ 2009-11-28 18:13 断点 阅读(4) | 评论 (0)
什么是GZIP压缩 ,网页GZIP压缩是什么意思?
这一般是指WWW服务器中安装的一个功能,当有人来访问这个服务器中的网站时,服务器中的这个功能就将网页内容压缩后传输到来访的电脑浏览器中显示出来。一般对纯文本内容可压缩到原大小的40%。这样传输就快了,效果就是你点击网址后会很快的显示出来。当然这也会增加服务器的负载。一般服务器中都安装有这个功能模块的。
详细请见:http://www.docin.com/p-17644663.html
posted @ 2009-11-28 17:25 断点 阅读(8) | 评论 (0)
1.
String hqlBase = " from AppBaseVO t where t.CAppNo ='" + CAppNo + "'";
rsList = this.commonDao.find(hqlBase);
for(AppBaseVO rt : rsList){//只有一条数据。
baseCBrkrCde = rt.getCBrkrCde();
String hqlCusCha = " from CusChaVO t where t.CChaCde ='" + baseCBrkrCde + "'";
rsCusCha = this.commonDao.find(hqlCusCha);
for(CusChaVO rtCusCha : rsCusCha){//一条数据。
name = rtCusCha.getCChaNme();
}
}
--------------------------------------
2.
public Map<String, String> querySelectList(String str) throws DaoException {
List list = new ArrayList();
Map<String, String> map = new HashMap<String, String>();
try {
String sSQL = " FROM AbstractBaseVO where CPlyNo=?";
list = super.find(sSQL, str);
StringBuffer hql = new StringBuffer();
hql.append(" FROM InqCreditIndivAuditVO");
hql.append(" WHERE CExamMark = '1' "); // 个人客户,'1'为审核通过。
hql.append(" AND CInqNo = ? ");
list2 = super.find(hql.toString(),CInqNo);
super.search语句用问号。
---------------------------------------
3.
String CCoinsurerCde = map.get("CCoinsurerCde");
String sql = "SELECT C_SELF_MRK FROM WEB_RI_COM WHERE C_COM_CDE=?";
SQLPara sqlPara = new SQLPara();
sqlPara.add(CCoinsurerCde);
RowSet rs = this.commonDao.queryNativeSQL(sql, sqlPara, false);
boolean selfFlag = false;
while (rs.next()) {
String sCSelfMrk = rs.getString(1);
if ("1".equals(sCSelfMrk)) {
selfFlag = true;
break;
}
}
-----------------------------------------
4.
List<PlyBaseVO> plyNo = this.find("FROM PlyBaseVO WHERE CAppNo = '" + appNo + "'");
if(plyNo.size() > 0 ){
}
posted @ 2009-11-25 14:28 断点 阅读(12) | 评论 (0)
第一种用法:引用org.apache.commons.logging.Log。
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
private static final Log logger = LogFactory.getLog(PolicyAppBizAction.class); //PolicyAppBizAction.class是自己定义的当前类名。
logger.info("=======================calc start======================");
logger.debug("传递过来的参数 => " + param);
logger.debug("submitToUnderwriting:参数 => " + serviceRequest.getCUST_DATA());
catch (Exception e) {
logger.error("团单险别VO属性拷贝异常. PolicyAppBizAction.procGroupCvrg()");
throw new BusinessServiceException(e);
}
第二种用法:调用log4j。
import org.apache.log4j.Logger;
private Logger logger = Logger.getLogger(this.getClass()); //this.getClass()指当前的类。
public Logger getLogger() {
return this.logger;
}
public void setLogger(Logger logger) {
this.logger = logger;
}
this.logger.info("==============调用平台接口投保预确认出错========================");
posted @ 2009-10-30 01:01 断点 阅读(12) | 评论 (0)
getAttribute:
1.getAttribute()得到的数据是object类型,需要强行转换得到相应类型。这是因为它是获取存放在Web应用特定范围中的数据值。
2.request.setAttribute()和getAttribute()方法传递的数据只会存在于Web容器内部,在具有转发关系的Web组件之间共享。即request.getAttribute()方法返回request范围内存在的对象。
getParameter:
1.getParameter得到的都是String类型的,取得你设在表单或url重定向时的值,如:http://demo.jsp?id=88中的88。
2.request.getParameter()方法传递的数据,会从Web客户端传到Web服务器端,代表HTTP请求数据。
posted @ 2009-02-23 17:33 断点 阅读(122) | 评论 (0)
下面有四种方法,估计好用的应该是第三种吧。
1.用JAVA自带的函数
public static boolean isNumeric(String str){
for (int i = str.length();--i>=0;){
if (!Character.isDigit(str.charAt(i))){
return false;
}
}
return true;
}
2.正则表达式
public static boolean isNumeric(String str){
Pattern pattern = Pattern.compile("[0-9]*");
return pattern.matcher(str).matches();
}
3.还是正则表达式
public static boolean isNumeric(String str){
if(str.matches("\\d*"){
return true;
}else{
return false;
}
}
4.用ascii码
public static boolean isNumeric(String str){
for(int i=str.length();--i>=0;){
int chr=str.charAt(i);
if(chr<48 || chr>57)
return false;
}
return true;
}
posted @ 2009-02-19 10:59 断点 阅读(955) | 评论 (0)
java连接各种数据库
1、Oracle8/8i/9i数据库(thin模式)
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
String url="jdbc:oracle:thin:@localhost:1521:orcl";
//orcl为数据库的SID
String user="test";
String password="test";
Connection conn= DriverManager.getConnection(url,user,password);
2、DB2数据库
Class.forName("com.ibm.db2.jdbc.app.DB2Driver ").newInstance();
String url="jdbc:db2://localhost:5000/sample";
//sample为你的数据库名
String user="admin";
String password="";
Connection conn= DriverManager.getConnection(url,user,password);
3、Sql Server7.0/2000数据库
Class.forName("com.microsoft.jdbc.sqlserver.SQLServerDriver").newInstance();
String url="jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=mydb";
//mydb为数据库
String user="sa";
String password="";
Connection conn= DriverManager.getConnection(url,user,password);
4、Sybase数据库
Class.forName("com.sybase.jdbc.SybDriver").newInstance();
String url =" jdbc:sybase:Tds:localhost:5007/myDB";
//myDB为你的数据库名
Properties sysProps = System.getProperties();
SysProps.put("user","userid");
SysProps.put("password","user_password");
Connection conn= DriverManager.getConnection(url, SysProps);
5、Informix数据库
Class.forName("com.informix.jdbc.IfxDriver").newInstance();
String url =
"jdbc:informix-sqli://123.45.67.89:1533/myDB:INFORMIXSERVER=myserver;
user=testuser;password=testpassword";
//myDB为数据库名
Connection conn= DriverManager.getConnection(url);
6、MySQL数据库
Class.forName("org.gjt.mm.mysql.Driver").newInstance();
String url ="jdbc:mysql://localhost/myDB?user=soft&password=soft1234&useUnicode=true&characterEncoding=8859_1"
//myDB为数据库名
Connection conn= DriverManager.getConnection(url);
7、PostgreSQL数据库
Class.forName("org.postgresql.Driver").newInstance();
String url ="jdbc:postgresql://localhost/myDB"
//myDB为数据库名
String user="myuser";
String password="mypassword";
Connection conn= DriverManager.getConnection(url,user,password);
posted @ 2009-02-05 09:30 断点 阅读(74) | 评论 (0)
1.我在连接数据源后执行报表,老是提示the document has no pages这样的提示,显示的报表什么也没有。
原因及解答:
在ireport里面报表默认没有查到任何数据时,就会显示:the document has no pages,如果想在没有数据时,也出现预览窗口,(假设你的ireport的语言是简体中文的),那就选择“编辑”-->“报表属性”-->“More”在“如果没有数据时”里面选“All sections,no detail”就可以了,如果报表没查出数据,就会显示预览窗口。
2.ireport在执行报表(使用动态连接)时没有提示输入参数的对话框。
主要是在设置参数时,忽略了一个小问题。可以这样解决:选中参数名字,右键点击edit,把这个
Use as a prompt复选框勾上即可。
3.设置ireport输出分页。
在网上找了好半天也没有找到,又回到看报表快速开发入门手册,这次认真看了以后,发现了一个小细节问题。就是可以把detail一栏的宽度调窄一点,这样就可以在PDF的输出页面中多显示几行数据。比如以前一个页面只能显示5行数据,现在可以显示10行了。
posted @ 2009-03-11 12:55 断点 阅读(421) | 评论 (0)
这个问题已经折腾我两天了,今天终于在一位同事(zhangwei)的帮助下解决了。
1.起初没有创建序列s_log,因此需要在Oracle补上s_log序列。
<!-- 增加 日志 -->
<insert id="logSave"
parameterClass="com.reportcenter.sys.dto.OperateLogDto">
INSERT INTO
T_LOG(C_AUTOID,USRCDE,USRADDRESS,OPERATION,BEGINTME,ENDTME,OPERATETIMER,STATE,MESSAGE) VALUES(s_log.nextval,#usrCde#,#usrAddress#,#operation#,#beginTme#,#endTme#,#operateTimer#,#state#,#message#)
</insert>
2.接着就出现下面的问题,主要是usrCde(日志表里的用户代码)属性在系统登陆验证时为空值所致。因此在相应代码处加上对空值的判断,如果为空,就从登陆页面取得userCde值。
if (request.getSession().getAttribute(Constants.usrCde) == null) {
usr = request.getParameter("userCde");
} else {
usr = (String) request.getSession().getAttribute(
Constants.usrCde);
}
Tomcat提示错误如下:
INFO [org.springframework.beans.factory.xml.XmlBeanDefinitionReader] - Loading XML bean definitions from class path resource [org/springframework/jdbc/support/sql-error-codes.xml]
INFO [org.springframework.jdbc.support.SQLErrorCodesFactory] - SQLErrorCodes loaded: [DB2, Derby, H2, HSQL, Informix, MS-SQL, MySQL, Oracle, PostgreSQL, Sybase]
org.springframework.jdbc.UncategorizedSQLException: SqlMapClient operation; uncategorized SQLException for SQL []; SQL state [null]; error code [17004];
--- The error occurred in sqlmap-mapping-log-operate.xml.
--- The error occurred while applying a parameter map.
--- Check the logSave-InlineParameterMap.
--- Check the parameter mapping for the 'usrCde' property.
--- Cause: java.sql.SQLException: 无效的列类型; nested exception is com.ibatis.common.jdbc.exception.NestedSQLException:
--- The error occurred in sqlmap-mapping-log-operate.xml.
--- The error occurred while applying a parameter map.
--- Check the logSave-InlineParameterMap.
--- Check the parameter mapping for the 'usrCde' property.
--- Cause: java.sql.SQLException: 无效的列类型
Caused by: com.ibatis.common.jdbc.exception.NestedSQLException:
--- The error occurred in sqlmap-mapping-log-operate.xml.
--- The error occurred while applying a parameter map.
--- Check the logSave-InlineParameterMap.
--- Check the parameter mapping for the 'usrCde' property.
--- Cause: java.sql.SQLException: 无效的列类型
at com.ibatis.sqlmap.engine.mapping.statement.GeneralStatement.executeUpdate(GeneralStatement.java:91)
at com.ibatis.sqlmap.engine.impl.SqlMapExecutorDelegate.insert(SqlMapExecutorDelegate.java:447)
at com.ibatis.sqlmap.engine.impl.SqlMapSessionImpl.insert(SqlMapSessionImpl.java:82)
at org.springframework.orm.ibatis.SqlMapClientTemplate$9.doInSqlMapClient(SqlMapClientTemplate.java:370)
at org.springframework.orm.ibatis.SqlMapClientTemplate.execute(SqlMapClientTemplate.java:194)
at org.springframework.orm.ibatis.SqlMapClientTemplate.insert(SqlMapClientTemplate.java:368)
at com.reportcenter.sys.dao.OperateLogDaoImpl.save(OperateLogDaoImpl.java:41)
at com.reportcenter.sys.service.SysLogServiceImpl.save(SysLogServiceImpl.java:52)
at com.reportcenter.util.db.Log.log(Log.java:61)
at com.reportcenter.sys.service.BaseService.doService(BaseService.java:92)
at com.reportcenter.sys.controller.LoginController.handleRequestInternal(LoginController.java:42)
at org.springframework.web.servlet.mvc.AbstractController.handleRequest(AbstractController.java:153)
at org.springframework.web.servlet.mvc.SimpleControllerHandlerAdapter.handle(SimpleControllerHandlerAdapter.java:48)
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:858)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:792)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:476)
at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:441)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:710)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:803)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:290)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at com.reportcenter.util.LoginFilter.doFilter(LoginFilter.java:42)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:235)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:96)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:75)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:235)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:233)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:175)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:128)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:102)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:109)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:263)
at org.apache.coyote.http11.Http11Processor.process(Http11Processor.java:844)
at org.apache.coyote.http11.Http11Protocol$Http11ConnectionHandler.process(Http11Protocol.java:584)
at org.apache.tomcat.util.net.JIoEndpoint$Worker.run(JIoEndpoint.java:447)
at java.lang.Thread.run(Thread.java:595)
Caused by: java.sql.SQLException: 无效的列类型
at oracle.jdbc.dbaccess.DBError.throwSqlException(DBError.java:134)
at oracle.jdbc.dbaccess.DBError.throwSqlException(DBError.java:179)
at oracle.jdbc.dbaccess.DBError.throwSqlException(DBError.java:269)
at oracle.jdbc.driver.OracleStatement.get_internal_type(OracleStatement.java:6164)
at oracle.jdbc.driver.OraclePreparedStatement.setNull(OraclePreparedStatement.java:1316)
at org.apache.commons.dbcp.DelegatingPreparedStatement.setNull(DelegatingPreparedStatement.java:105)
at com.ibatis.sqlmap.engine.mapping.parameter.BasicParameterMap.setParameter(BasicParameterMap.java:171)
at com.ibatis.sqlmap.engine.mapping.parameter.BasicParameterMap.setParameters(BasicParameterMap.java:125)
at com.ibatis.sqlmap.engine.execution.SqlExecutor.executeUpdate(SqlExecutor.java:79)
at com.ibatis.sqlmap.engine.mapping.statement.GeneralStatement.sqlExecuteUpdate(GeneralStatement.java:200)
at com.ibatis.sqlmap.engine.mapping.statement.GeneralStatement.executeUpdate(GeneralStatement.java:78)
... 37 more
com.reportcenter.exception.DaoException: error.sys.log.db.add; nested exception is org.springframework.jdbc.UncategorizedSQLException: SqlMapClient operation; uncategorized SQLException for SQL []; SQL state [null]; error code [17004];
--- The error occurred in sqlmap-mapping-log-operate.xml.
--- The error occurred while applying a parameter map.
--- Check the logSave-InlineParameterMap.
--- Check the parameter mapping for the 'usrCde' property.
--- Cause: java.sql.SQLException: 无效的列类型;
posted @ 2009-03-10 16:53 断点 阅读(2104) | 评论 (0)
在做项目中碰见这样的问题,如下:
Caused by: org.hibernate.NonUniqueObjectException: a different object with the same identifier value was already associated with the session: [com.pcis.cus.vo.CusClientVO#002255207];
原因: 有一个具有相同值的不同对象已经与和 session 相关联。
解决(程序的一部分):
//CusClientVO cusVo = new CusClientVO();
CusClientVO cusVo = null;
IUserDetails user = CurrentUser.getUser();
try {
if ("Same".equals(cusFlag)) {//被保险人和投保人是同一人
cusVo = (CusClientVO)this.getById(CusClientVO.class, applicant.getCAppCde());
if(cusVo==null){ //表示新增客户。
cusVo = new CusClientVO();
}
this.saveCusApplicant(applicant, cusVo);
if(!applicantflag ){
cusVo.setTCrtTm(new Date());
cusVo.setCCrtCde(user.getOpRelCde());
}
}
cusVo.setTUpdTm(new Date());
cusVo.setCUpdCde(user.getOpRelCde());
//
this.saveOrUpdate(cusVo);
} catch (DaoException ex) {
BusinessServiceException e = new BusinessServiceException(ex);
e.setErrorMsg("保存客户信息失败");
}
相关连接:
http://hi.baidu.com/anypcao/blog/item/0db1a41cd3478d8187d6b6d2.html
http://agreal.javaeye.com/blog/339560
posted @ 2009-10-31 13:11 断点 阅读(61) | 评论 (0)
有两张表(question、answer),它们存在着一对多关系(question->answer)和多对一关系(answer->question)。
在Answer.java中定义有:
public class Answer {
private String userid;
private Question question;
private int qid;
}
在answer.hbm.xml中有:
<many-to-one name="question" class="org.lxh.myzngt.vo.Question" fetch="select">
<column name="qid" />
</many-to-one>
所以SQL语句如下:
public List queryByUserAnswer(String userid, int currentPage, int lineSize) {
List all = null;
String hql = "from Question as q where q.qid in(select a.question.qid from Answer as a where a.userid=?)";
Query q = super.getSession().createQuery(hql);
q.setString(0, userid);
// 分页操作。
q.setFirstResult((currentPage - 1) * lineSize);
q.setMaxResults(lineSize); all = q.list();
return all;
}
否则报错:
org.hibernate.QueryException: could not resolve property: qid of: org.lxh.myzngt.vo.Answer [select count(q.qid) from org.lxh.myzngt.vo.Question as q where q.qid in(select a.qid from org.lxh.myzngt.vo.
Answer as a where a.userid=?)]
posted @ 2009-02-23 15:58 断点 阅读(173) | 评论 (0)
org.hibernate.hql.ast.QuerySyntaxError: user is not mapped. [from user as u where u.userid=?]
出现这个问题,主要是hibernate语句不对。
User.hbm.xml为:
<hibernate-mapping>
<class name="org.lxh.myzngt.vo.User" table="user" >
<id name="id" type="java.lang.Integer">
<column name="id" />
<generator class="native"></generator>
</id>
</class>
</hibernate-mapping>
因此,hql 语句如下:
String hql = "from User as u where u.userid=?"
posted @ 2009-02-11 17:55 断点 阅读(109) | 评论 (0)
一个Web 应用发布到Jboss 服务器时需要打成war包。
下面介绍jar命令行及Ant任务两种war文件的打包方式。
1.命令行下进行war 文件打包。
在Dos 窗口中进入到WEB 应用根目录下(WebRoot下),执行如下命令,如:
jar cvf EJBClient.war *,再把打包的EJBClient.war拷贝到C:\jboss-5.0.0.GA\server\default\deploy发布。
2.在Ant 任务中进行war文件打包。
build.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project name="EJBClient" default="war" basedir=".">
<property environment="env" />
<property name="jboss.home" value="${env.JBOSS_HOME}" />
<property name="jboss.server.config" value="default" />
<target name="war" description="创建WEB 发布包">
<war warfile="${basedir}/${ant.project.name}.war" webxml="${basedir}/WebRoot/WEB-INF/web.xml">
<classes dir="${basedir}/WebRoot/WEB-INF/classes">
<include name="**/*.class" />
</classes>
<lib dir="${basedir}/WebRoot/WEB-INF/lib">
<include name="*.jar" />
</lib>
<webinf dir="${basedir}/WebRoot">
<include name="*.*" />
</webinf>
</war>
</target>
<target name="deploy" depends="war" description="发布WAR">
<copy file="${basedir}\${ant.project.name}.war" todir="${jboss.home}\server\${jboss.server.config}\deploy"/>
</target>
<target name="undeploy" description="卸载WAR">
<delete file="${jboss.home}\server\${jboss.server.config}\deploy\${ant.project.name}.war"/>
</target>
</project>
posted @ 2009-03-30 18:15 断点 阅读(145) | 评论 (0)
do not get WebServiceContext property from stateless bean context, it should already have been injected
这个主要原因就在stateless bean的实现类。
仔细查看后发现,原来我在实现类的每个方法前加入了 @WebMethod(指定暴露给外界的方法),因此去掉就可以了。
13:41:39,168 WARN [StatelessBeanContext] EJBTHREE-1337: do not get WebServiceContext property from stateless bean context, it should already have been injected
13:41:39,215 WARN [InterceptorsFactory] EJBTHREE-1246: Do not use InterceptorsFactory with a ManagedObjectAdvisor, InterceptorRegistry should be used via the bean container
13:41:39,215 WARN [InterceptorsFactory] EJBTHREE-1246: Do not use InterceptorsFactory with a ManagedObjectAdvisor, InterceptorRegistry should be used via the bean container
13:41:39,230 WARN [InterceptorRegistry] applicable interceptors is non-existent for public cn.ztf.bean.Order cn.ztf.service.impl.OrderServiceBean.getOrder(java.lang.String)
13:41:39,246 WARN [InterceptorRegistry] applicable interceptors is non-existent for public java.lang.String cn.ztf.service.impl.OrderServiceBean.getUserName(java.lang.String)
13:41:39,246 WARN [InterceptorRegistry] applicable interceptors is non-existent for public java.util.List cn.ztf.service.impl.OrderServiceBean.getOrders()
13:41:39,246 WARN [InterceptorRegistry] applicable interceptors is non-existent for public cn.ztf.bean.Order cn.ztf.service.impl.OrderServiceBean.getOrder(java.lang.String)
13:41:39,261 WARN [InterceptorRegistry] applicable interceptors is non-existent for public java.lang.String cn.ztf.service.impl.OrderServiceBean.getUserName(java.lang.String)
13:41:39,261 WARN [InterceptorRegistry] applicable interceptors is non-existent for public java.util.List cn.ztf.service.impl.OrderServiceBean.getOrders()
13:41:39,293 WARN [StatelessBeanContext] EJBTHREE-1337: do not get WebServiceContext property from stateless bean context, it should already have been injected
13:46:27,043 WARN [StatelessBeanContext] EJBTHREE-1337: do not get WebServiceContext property from stateless bean context, it should already have been injected
13:46:27,043 WARN [StatelessBeanContext] EJBTHREE-1337: do not get WebServiceContext property from stateless bean context, it should already have been injected
posted @ 2009-03-30 14:33 断点 阅读(647) | 评论 (0)
Web服务也是一种分布式技术,属于行业规范,可以跨平台及语言。
EJB属于java平台规范,尽管理论上可以跨平台,但实现起来比较麻烦,所以其应用范围局限在java平台。
二者偏重点不同:
Web服务偏重的是这个系统对外提供什么功能;
EJB偏重的是如何使用一个个组件组装这些功能。
例如:一个硬盘,它对外提供的是存储服务,这是web服务的关注点;对于怎样组装这个硬盘,web服务并不关心,而这些是EJB所关注的。
JavaEE为web service提供了两种不同的编程模型:EJB容器模型、Web容器模型。
下面以最新的JAX-WS2.x规范(Java API for XML-based Web Services)介绍Webservice的开发。
注:JAX-WS的下载路径为https://jax-ws.dev.java.net/servlets/ProjectDocumentList?folderID=7796&expandFolder=7796&folderID=11088
EJB容器模型的WEB服务的客户端开发:
注:首先我们需要建立一个无状态SessionBean,然后把此无状态SessionBean发布为web service。
1.在应用的类路径下放入JAX-WS的全部jar文件,并且把引进的jar文件添加到类路径上,即右击项目名-->Properties-->Java Build Path-->Add JARS。
如果你使用的是JDK6,这一步可以省略,因为JDK6已经绑定了JAX-WS。目前JDK6绑定的JAX-WS版本是2.0。
2.把JAX-WS产品lib目录中找到jaxws-api.jar和jaxb-api.jar,把这两个文件copy到JDK_HOME/jre/lib/endorsed目录下。
3.利用Web Service客户端生成工具(wsimport工具的Ant任务类)生成辅助类。
build.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project name="WSClient" default="wsclientgen" basedir=".">
<property name="src.dir" value="${basedir}/src" />
<path id="build.classpath" description="设置类路径">
<fileset dir="${basedir}/lib">
<include name="*.jar"></include>
</fileset>
</path>
<target name="wsclientgen" description="生成webservice客户端辅助代码,执行后请刷新项目">
<taskdef name="wsimport" classname="com.sun.tools.ws.ant.WsImport"
classpathref="build.classpath"/>
<wsimport wsdl="http://localhost:8090/WebService/OrderServiceBean?wsdl"
sourcedestdir="${src.dir}" package="cn.ztf.ws.client" keep="true"
verbose="true" destdir="${basedir}/bin"/>
</target>
</project>
4.借助辅助类调用Web Service。
posted @ 2009-03-30 14:22 断点 阅读(169) | 评论 (0)
EJB3.0中MessageDrivenBean:
1.java消息驱动bean属于Java消息服务(Java Message Service,简称JMS)。
2.JMS是用于访问企业消息系统的开发商中心的API。企业消息系统可以协助应用软件通过网络进行消息交互。
3.JMS的编程过程简单概括为:应用程序A-->(消息)-->Jboss JMS-->(消息)-->应用程序B。应用程序A和应用程序B没有直接的代码关联,两者实现了解耦。消息传递系统的中心就是消息。
消息驱动Bean(MDB)是设计用来专门处理基于消息请求的组件,它和无状态Session Bean一样也使用了实例池技术,容器可以使用一定数量的bean实例并发处理成百上千个JMS消息。正因为MDB具有处理大量并发消息的能力,所以非常适合应用在一些消息网关产品。如果一个业务执行的时间很长,而执行结果无需实时向用户反馈时,也很适合使用MDB。如订单成功后给用户发送一封电子邮件或发送一条短信等。
消息有下面几种类型,他们都是派生自Message接口。
StreamMessage:一种主体中包含Java基本值流的消息。其填充和读取均按顺序进行。
MapMessage:一种主体中包含一组名-值对的消息。(没有定义条目顺序)
TextMessage:一种主体中包含Java字符串的消息(例如:XML消息)
ObjectMessage:一种主体中包含序列化Java对象的消息。
BytesMessage:一种主体中包含连续字节流的消息。
消息的传递模型:
JMS支持两种消息传递模型:点对点(point-to-point,简称PTP)和发布/订阅(publish/subscribe,简称pub/sub)。
二者有以下区别:
1.PTP 消息传递模型规定了一条消息只能传递给一个接收方。采用javax.jms.Queue表示。
2.Pub/sub 消息传递模型允许一条消息传递给多个接收方。采用javax.jms.Topic表示。
注意:每种模型都通过扩展公用基类来实现。例如,javax.jms.Queue 和javax.jms.Topic都扩展自javax.jms.Destination 类。
开发步骤如下:
一、配置destinations-service.xml文件。
JBOSS使用一个XML文件配置队列地址,文件的取名格式应遵循*-service.xml,我取名为destinations-service.xml。
jboss默认的全局JNDI名称组成为:"queue"+"/"+"目标地址"。
开始JMS编程前,我们需要先配置消息到达的目标地址(Destination),因为只有目标地址存在了,我们才能发送消息到这个地址。由于每个应用服务器关于目标地址的配置方式都有所不同,下面以jboss为例,配置一个queue类型的目标地址。
<?xml version="1.0" encoding="UTF-8"?>
<server>
<mbean code="org.jboss.mq.server.jmx.Queue"
name="jboss.mq.destination:service=Queue,name=ztfQueue">
<attribute name="JNDIName">queue/ztfQueue</attribute>
<depends optional-attribute-
name="DestinationManager">jboss.mq:service=DestinationManager</depends>
</mbean>
<mbean code="org.jboss.mq.server.jmx.Topic"
name="jboss.mq.destination:service=Topic,name=ztfTopic">
<attribute name="JNDIName">topic/ztfTopic</attribute>
<depends optional-attribute-
name="DestinationManager">jboss.mq:service=DestinationManager</depends>
</mbean>
</server>
注意:任何队列或主题被部署之前,应用服务器必须先部署Destination Manager Mbean,所有我们通过<depends>节点声明这一依赖。
二、在java类中发送消息(用到jndi.properties)。
一般发送消息有以下步骤:
1.得到一个JNDI初始化上下文(Context)
InitialContext ctx = new InitialContext();
2.根据上下文查找一个连接工厂ConnectionFactory,改连接工厂是由JMS提供的,不需我们自己创建,每个厂商都为它绑定了一个全局JNDI,我们通过它的全局JNDI便获取它;
QueueConnectionFactory factory = (QueueConnectionFactory)ctx.lookup("ConnectionFactory");
3.从连接工厂得到一个连接QueueConnection。
QueueConnection conn = factory.createQueueConnection();
4.通过连接来建立一个会话(Session);
QueueSession session = conn.createQueueSession(false,QueueSession.AUTO_ACKNOWLEDGE);
这句代码意思是:建立不需要事务的并且能自动确立消息已接收的会话。
5.查找目标地址:
Destination destination=(Destination)ctx.lookup("queue/ztfQueue");
6.根据会话以及目标地址来建立消息生产者MessageProducer(QueueSender和TopicPublisher都扩展自MessageProducer接口):
MessageProducer producer = session.createProducer(destination);
TextMessage msg = session.createTextMessage("您好:荆州,这是我的第一个消息驱动Bean");
producer.send(msg);
三、采用MessageDrivenBean接收消息。
当容器检测到bean守候的目标地址有消息到达时,容器调用onMessage()方法,将消息作为参数传入MDB。MDB在onMessage()中决定如何处理改消息。你可以使用注解指定MDB监听哪一个目标地址(Destination)。当MDB部署时,容器将读取其中的配置信息。
一个MDB通常要实现MessageListener接口,在接口定义了onMessage()方法。Bean通过它来处理收到的JMS消息。
@MessageDriven(activationConfig=
{
@ActivationConfigProperty
(propertyName="destinationType",propertyValue="javax.jms.Queue"),
@ActivationConfigProperty
(propertyName="destination",propertyValue="queue/ztfQueue"),
@ActivationConfigProperty(propertyName="acknowledgeMode",propertyValue="Auto-
acknowledge")
})
public class MessageDrivenBean implements MessageListener{
public void onMessage(Message message) {
TextMessage msg = (TextMessage)message;
try {
System.out.println(msg.getText());
} catch (JMSException e) {
e.printStackTrace();
}
}
}
四、把工程src下的文件打成jar包(用到build.xml),在C:\jboss-5.0.0.GA\server\default\deploy进行部署。
五、运行发送消息的java类,此时在console中就可看见结果了。
六、至此,一个MessageDrivenBean开发就成功了。
posted @ 2009-03-27 17:43 断点 阅读(158) | 评论 (0)
实体bean:
1.它属于java持久化规范(简称JPA)里的技术,Entitybean通过元数据在javabean和数据库表之间建立起映射关系,然后Java程序员就可以使用面向对象的编程思想来操纵数据库。
2.通过注解使实体bean与数据库表相映射。
3.当客户端远程调用EJB时,数据在传送工程中是需要序列化的 ,业务方法是要返回Entitybean对象到客户端,显然Entitybean对象是要进行序列化的过程,所以要实现序列化接口,即对象在交互时需要实现序列化。
4.Entitybean主键值的生成方式。
@GeneratedValue(strategy = GenerationType.IDENTITY)针对Mysql,
@GeneratedValue(strategy = GenerationType.SEQUENCE)针对Oracle,
@GeneratedValue(strategy = GenerationType.AUTO)自动匹配数据库。
5.需要保留一个无参的构造函数,是JPA规范要求的,如果没有,在运行时是要报错的。
6.对象之间的比较,通常采用对象标志属性来进行比较,也就是ID进行比较,因此现在重载hashCode、equals两个方法。
JPA的出现主要是为了简化现有的持久化开发工作和整合ORM技术,目前实现的JPA规范的主流产品有Hibernate、Toplink和OpenJPA,在jboss中采用了Hibernate作为其持久化实现产品。
根据JPA规范的要求:在实体bean应用中,我们需要在应用的类路径下的META-INF目录加入持久化配置文件persistence.xml。
persistence.xml文件用于指定Entitybean使用的数据源及EntityManager对象的默认行为。
persistence.xml的配置说明如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd" version="1.0">
<!-- 一个持久化单元是一个Entitybean的集合,JTA代表全局事物。-->
<persistence-unit name="ztf" transaction-type="JTA">
<jta-data-source>java:/ztfDS</jta-data-source>
<properties>
<!-- 根据元数据生成数据库的表结构。 -->
<property name="hibernate.hbm2ddl.auto" value="update"/>
<!-- 显示执行的SQL。 -->
<property name="hibernate.show_sql" value="true"/>
<!-- 格式化显示的SQL 。 -->
<property name="hibernate.format_sql" value="true"/>
<!-- SQL方言。 -->
<property name="hibernate.dialect" value="org.hibernate.dialect.Oracle9Dialect"/>
</properties>
</persistence-unit>
</persistence>
注意:因为jboss 采用Hibernate,Hibernate 有一项属性hibernate.hbm2ddl.auto,该属性指定实体Bean发布时是否同步数据库结构。
1.如果hibernate.hbm2ddl.auto的值设为create-drop,在实体Bean发布及卸载时将自动创建及删除相应数据库表(注意:Jboss 服务器启动或关闭时也会引发实体Bean 的发布及卸载)。
2.如果hibernate.hbm2ddl.auto的值设为update,以后为了实体bean的改动能反应到数据表,建议使用update,这样实体Bean 添加一个属性时能同时在数据表增加相应字段。
posted @ 2009-03-26 12:35 断点 阅读(166) | 评论 (0)
远程接口调用ejb的过程:
首先客户端需要与ejb建立起socket通信,在通信管道上他们之间需要来回发送IIOP协议消息,因为数据要在网络进行传输,存放数据的java对象必须要进行序列化。这个过程中,有网络通信的开销、协议解析的开销、对象序列化的开销。因为ejb是分布式技术,它允许客户端与ejb应用在不同一机器上面,所以这些开销也是必然的。
本地接口调用ejb的过程:
通过本地接口调用ejb,直接在内存交互,这样就可以避免因网络通信所造成的各种性能开销。
注意:
1.只有客户端与EJB应用都在同一个JVM内运行的时候,我们才能调用本地接口,否则只能调用远程接口。
2.只要客户端与ejb发布在同一个jboss内,我们就认为它们在同一个JVM。
3.客户端可以调用本地接口;也可调用远程接口;当本地接口与远程接口都有同一个方法时,优先调用本地接口中的方法。
开发一个自己的远程接口的无状态会话bean:
1.需要自己开发的EJB的组件.jar包。
注意:在实现类中加入注解,绑定接口。
@Stateless、@Remote(HelloWorld.class) //为接口。
2.需要自己开发出的EJB的客户端,并把客户端工程打成.war文件。
注意:客户端所要知道的JNDI名称,下面的HelloWorld 为远程接口。
InitialContext ctx = new InitialContext();
HelloWorld helloWorld = (HelloWorld)ctx.lookup("HelloWorldBean/remote");
out.println(helloWorld.sayHello("荆州"));
3.把.jar和.war文件拷贝到jboss的deploy区。
4.打开浏览器,输入自己开发出的EJB客户端的.jsp页面,即可。
开发一个自己的本地接口的无状态会话bean:
1.需要自己开发的EJB的组件.jar包。
注意:在实现类中加入注解,绑定接口。
@Stateless、@Local(HelloWorldLocal.class)//接口。
2.需要自己开发出的EJB的客户端,并把客户端工程打成.war文件。
注意:客户端所要知道的JNDI名称,下面的HelloWorldLocal 为本地接口。
InitialContext ctx = new InitialContext();
HelloWorldLocal helloWorld = (HelloWorldLocal)ctx.lookup("HelloWorldLocalBean/local");
out.println(helloWorld.sayHello("荆州"));
3.把.jar和.war文件拷贝到jboss的deploy区。
4.打开浏览器,输入自己开发出的EJB客户端的.jsp页面,即可。
Bean实例的两种管理技术:
1.无状态bean使用实例池技术管理bean;
2.有状态bean使用激活(activation)管理bean。
Jboss生成的JNDI名称,默认命名规则如下:
如果把EJB应用打包成后题为.jar的模块文件,默认的全局JNDI名称是
本地接口:EJB-CLASS-NAME/local
远程接口:EJB-CLASS-NAME/remote
例如:把EJB-HelloWorld(里面包含接口HelloWorld和实现类HelloWorldBean)应用打包成EJB-HelloWorld.jar文件,它的远程接口的JNDI名称是:HelloWorldBean/remote。
jndi.properties的配置:
java.naming.factory.initial=org.jnp.interfaces.NamingContextFactory
java.naming.provider.url=localhost:1099
posted @ 2009-03-26 09:56 断点 阅读(255) | 评论 (0)
要发布EJB 时必须把她打成*.jar 文件,一个EJB 打包后的目录结构如下:
EJB 应用根目录:
| -- com (你的.class 文件)
| -- META-INF
| -- MANIFEST.MF (如果使用工具打包,该文件由工具自动生成)
打包的方式有很多,如:jar 命令行、集成开发环境的打包向导和Ant 任务。
下面介绍Elispse 打包向导和Ant 打包任务。
1. Elispse 打包向导
在Elispse 开发环境下,可以通过向导进行打包。右击项目名称,在跳出的菜单中选择Export-->Java-->JAR file,在"选择要导出的资源"时,选择源目录和用到的资源然,后选择一个存放目录及文件名,点"完成"就结束了打包。
2. Ant 打包任务
主要是在Eclipse下,通过配置build.xml进行ANT 打包,来提高开发效率,也是推荐的打包方式。
下面我们看一个简单的打包任务。
<?xml version="1.0" encoding="UTF-8"?>
<project name="EJB-HelloWorld" basedir=".">
<property name="src.dir" value="${basedir}\src" />
<property environment="env" />
<property name="jboss.home" value="${env.JBOSS_HOME}" />
<property name="jboss.server.config" value="default" />
<property name="build.dir" value="${basedir}\build" />
<path id="build.classpath">
<fileset dir="${jboss.home}\client">
<include name="*.jar"></include>
</fileset>
<pathelement location="${build.dir}"/>
</path>
<target name="prepare">
<delete dir="${build.dir}"/>
<mkdir dir="${build.dir}"/>
</target>
<target name="compile" depends="prepare" description="编译 ">
<javac srcdir="${src.dir}" destdir="${build.dir}">
<classpath refid="build.classpath" />
</javac>
</target>
<target name="ejbjar" depends="compile" description="创建EJB发布包">
<jar jarfile="${basedir}\${ant.project.name}.jar" >
<fileset dir="${build.dir}" >
<include name="**/*.class"></include>
</fileset>
</jar>
</target>
<target name="deploy" depends="ejbjar" description="发布EJB">
<copy file="${basedir}\${ant.project.name}.jar" todir="${jboss.home}\server\${jboss.server.config}\deploy"/>
</target>
<target name="undeploy" description="卸载EJB">
<delete file="${jboss.home}\server\${jboss.server.config}\deploy\${ant.project.name}.jar"/>
</target>
</project>
再右健点击此配置文件build.xml,选择Run As-->Ant Build即可!
posted @ 2009-03-26 09:51 断点 阅读(158) | 评论 (0)
EJB(Enterprise JavaBeans)在JavaEE体系中,通常用来完成商务逻辑层的功能,EJB是一种组件结构。EJB组件要按照EJB规范编写,然后部署到应用服务器上,具体讲是运行在J2EE应用服务器的EJB容器中,该部分软件不单为EJB提供运行时的环境,更重要的是提供事务、会话管理、持久性、安全等服务。EJB容器通过查看EJB描述符(配置文件)确定EJB需要那些服务。客户机要访问EJB组件需要通过JNDI和RMI定位EJB的对外接口。
采用EJB开发基于MVC(包含显示层、控制层和业务层)结构的应用,那么EJB就是用于开发应用的业务层。
开发EJB遵循如下步骤进行:
1.开发构成EJB组件的Java源文件,比如:组件接口、Home接口、企业Bean类、所需的辅助类等。
2.手工完成部署描述符,或者借助与IDE。
3.编译步骤1开发的java源文件.
4.借助于JDK自带的jar使用工具,来创建含有部署描述符和.class文件的EJB-jar文件。
5.通过具体EJb容器提供的部署建议,来完成Ejb-jar文件的部署。
6.配置EJB服务器,使得Ejb-jar含有的Ejb组件能够正常运作。
7.启动EJB服务器。此时,开发者可以验证EJB组件是否部署成功,并运行。
EJB3.0规范定义了如下3种EJB组件类型:
1、会话Bean(SessionBean):无状态会话Bean(Stateless SessionBean)、有状态会话Bean(Stateful SessionBean)。
会话Bean通常有以下属性:
(1)代表单个客户机执行。
(2)可以是事务的。
(3)可以更新共享数据库中的数据。
(4)生存期相对较短。
(5)其生存期通常就是客户机的生存期。
(6)任何持久性数据都有Bean管理。
(7)可以依容器的判断予以删除。
(8)会在EJB服务器失败时被删除。
EJB容器管理无状态会话Bean的生存周期,其方式是通过创建足够多数量的此种Bean适应客户机工作负荷,并在不需要它们的时候将其删除或者将闲置的Bean写到磁盘上。
如果会话Bean在方法调用之前需要保留状态信息,则必须使用有状态的会话Bean(Stateful SessionBean)。
会话Bean在J2EE应用程序中被用来完成一些服务器端的业务操作,例如访问数据库、调用其他EJB组件。
总之,会话Bean代表一种操作:它检索或者存储数据以满足用户的请求。
2、实体Bean(EntityBean),通常有以下属性:
(1)代表数据库的数据。
(2)是事务性的。
(3)允许多个用户共同访问。
(4)可以长期存在。
(5)持久性数据可以由容器管理。
(6)在EJB服务器失败后能继续生存。
实体Bean被用来代表应用数据库中用到的数据。例如在一个电子商务系统中,实体Bean可以被用来代表产品、雇员、信用卡、订单数据等数据对象。
持久性是实体Bean的一个基本属性。EJB规范允许两种形式的实体持久性:Bean管理的持久性(BMP)和容器管理的持久性(CMP)。
实体Bean支持多个用户并发的访问数据。EJB规范说明,维护数据的完整性是容器的责任。容器完成这个任务通常的做法是,锁定数据库中的数据,并使访问串行化,或者通过创建多个实体Bean的实例,并允许在基础数据存储中使用并发控制,来管理访问。
总之,实体Bean代表一种数据集:可以访问这些数据集以满足用户的请求。
3、消息驱动bean(Message DrivenBean)
消息驱动Bean要与JMS结合使用,以提供消息驱动的异步处理功能。例如电子商务系统的交易确认就可以用消息驱动Bean来实现。
消息驱动Bean作为JMS队列和主题的监听器部署,当有JMS消息到达,系统就会调用消息驱动Bean去完成业务逻辑方法。
总之,客户机不能直接调用消息驱动Bean,客户通过发送JMS消息调用消息驱动Bean。
posted @ 2009-03-13 15:11 断点 阅读(122) | 评论 (0)
1、定位文件所在工程的详细路径。
在MyEclipse的视图窗口打开的文件,可以在浏览器窗口中定位到这个文件所在工程的详细路径。
注意:一定要选中浏览器窗口中的 Link with Editer。
posted @ 2009-05-27 13:53 断点 阅读(95) | 评论 (0)
2、关闭MyEclipse Derby服务 。
Eclipse的控制台Console出现 MyEclipse Derby服务,一直想把它去掉,感觉它老是碍事,今天终于有空,就在网上搜索了下,现已解决。如下,Eclipse菜单:
window-->Preferences-->General-->Startup and Shutdown--> MyEclipse Derby
把这个服务关掉就可以了,如果你不需要其它的服务,都可以关掉。
posted @ 2009-09-25 19:11 断点 阅读(86) | 评论 (0)
3、SVN 中导出树形文件目录 。
背景:项目到了试运行阶段,发布版本碰到了很多问题,如果单个的提交文件相当的累,因此运用svn的导出树形目录,再把这个文件放到生产环境,这样就轻松的多。
方法:在项目工程下,如E:\workspace\policy_sc,右键选择TortoiseSVN右边的“Show log”,选中自己提交的文件,右键“compare with previous version”,再选中弹出的自己的文件,右键“Export selection to...”,再自己选中导出目录即可。
posted @ 2009-11-28 17:42 断点 阅读(22) | 评论 (0)
项目启动的时候,有时MyEclipse老是弹出IOConsole Updater error的错误。
解决方法:
右击控制台--》pereferences-->去掉fixed with console前面的勾。
posted @ 2009-05-25 16:07 断点 阅读(219) | 评论 (0)
有时候用Eclipse或者MyEclipse的时候,发现不能自动编译,怎么刷新classes目录下也是空的!
原因:
1、可能是你的自动编译没打开:project->build automatically;
2、要注意你的工程项目上有没有打小红叉,项目报错时,eclipse是不自动编译的。你可以检查一下是否有些类出错,或是检查一下“构建路径”是否完整。
操作方法:
一般先运行project -->clean…,然后再执行build automatically。
注意:eclipse默认是选自动编译。
以下为参考:
http://blog.csdn.net/kkmiao/archive/2008/07/19/2677320.aspx
posted @ 2009-04-24 11:51 断点 阅读(328) | 评论 (0)
使用SVN后,打开MyEclipse工程,有明显的小黄点标识,这样在开发中相当方便,一目了然的知道自己修改了哪个文件。
没有动过的文件以小黄点标识;修改过的以小灰叉标识;新添加的以小问号标识。
首先了解目录:
myplugins文件目录:
-drools
-implementors
-links
-propedit
-SVN
-svn插件.txt
links文件目录:
-com.genuitec.eclipse.MyEclipse.link
-drools.link
-implementors.link
-propedit.link
-SVN.link
配置方法如下:
1.svn插件.txt的内容为:放在MyEclipse的安装目录下 E:\MyEclipse 6.0\eclipse\myplugins
2.把links文件copy到E:\MyEclipse 6.0\eclipse下,修改links文件里面的文件内容。
com.genuitec.eclipse.MyEclipse.link:path=E:\\MyEclipse 6.0\\myeclipse
drools.link:path=E:\\MyEclipse 6.0\\eclipse\\myplugins\\drools\\
implementors.link:path=E:\\MyEclipse 6.0\\eclipse\\myplugins\\implementors
propedit.link:path=E:\\MyEclipse 6.0\\eclipse\\myplugins\\propedit
SVN.link:path=E:\\MyEclipse 6.0\\eclipse\\myplugins\\SVN
注意:drools、implementors、propedit、SVN文件内容其实都是Eclipse的小插件,需要自行下载。
posted @ 2009-04-18 20:32 断点 阅读(948) | 评论 (0)
前些天碰见一个问题,把一个工程导入到MyEclipse里,发现工程里面有的文件上面有红叉标示,整理好长一段时间,现终于解决。
主要原因:
MyEclipse对里面的工程文件进行了多个文件类型的标签或错误验证。
解决方法如下:
Window-->Preferences-->MyEclipse-->Validation-->选中Disable ALL,点击Apply,然后OK,即可。
posted @ 2009-04-18 10:28 断点 阅读(618) | 评论 (1)
远端svn的连接:
1、配置环境变量PATH。
E:\oracle\ora92\bin;C:\Program Files\Oracle\jre\1.3.1\bin;C:\Program Files\Oracle\jre\1.1.8\bin;C:\jdk1.5\bin;C:\Program Files\TortoiseSVN\bin;%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;.;
2、C:\WINDOWS\system32\drivers\etc下的hosts进行修改。
在文件里另起一行输入:122.5.169.130 svn_server
3、可以进行ping一下。
在dos窗口ping一下:ping svn_server
即可看见一些相关信息,说明svn连接好了。
posted @ 2009-04-03 14:36 断点 阅读(330) | 评论 (0)
1. 常用快捷键
Ctrl+Space 输入法的切换
Ctrl+/ 单行注释
Ctrl+Shift+/ 添加多行注释/* */
Ctrl+Shift+\ 解除多行注释
Ctrl+Shift+F 自动格式化代码
Ctrl+F6 工作区的界面切换
Ctril+Shift+O 自动引入当前类所需要得包
Ctrl+Q 定位到最后编辑的地方
Alt+/ 内容辅助,提示完整的信息
Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)
Alt+↑ 当前行和上面一行交互位置(同上)
Alt+← 前一个编辑的页面
Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)
Alt+Tab 切换windows的当前界面
Shift+← 选中光标的前面的一个字符
Shift+→ 选中光标的后面的一个字符
以下为转载:
2. 快捷键列表
编辑
作用域 功能 快捷键
全局 查找并替换 Ctrl+F
文本编辑器 查找上一个 Ctrl+Shift+K
文本编辑器 查找下一个 Ctrl+K
全局 撤销 Ctrl+Z
全局 复制 Ctrl+C
全局 恢复上一个选择 Alt+Shift+↓
全局 剪切 Ctrl+X
全局 快速修正 Ctrl1+1
全局 内容辅助 Alt+/
全局 全部选中 Ctrl+A
全局 删除当前行 Ctrl+D
全局 上下文信息 Alt+?Alt+Shift+?Ctrl+Shift+Space
Java编辑器 显示工具提示描述 F2
Java编辑器 选择封装元素 Alt+Shift+↑
Java编辑器 选择上一个元素 Alt+Shift+←
Java编辑器 选择下一个元素 Alt+Shift+→
文本编辑器 增量查找 Ctrl+J
文本编辑器 增量逆向查找 Ctrl+Shift+J
全局 粘贴 Ctrl+V
全局 重做 Ctrl+Y
查看
作用域 功能 快捷键
全局 放大 Ctrl+=
全局 缩小 Ctrl+-
窗口
作用域 功能 快捷键
全局 激活编辑器 F12
全局 切换编辑器 Ctrl+Shift+W
全局 上一个编辑器 Ctrl+Shift+F6
全局 上一个视图 Ctrl+Shift+F7
全局 上一个透视图 Ctrl+Shift+F8
全局 下一个编辑器 Ctrl+F6
全局 下一个视图 Ctrl+F7
全局 下一个透视图 Ctrl+F8
文本编辑器 显示标尺上下文菜单 Ctrl+W
全局 显示视图菜单 Ctrl+F10
全局 显示系统菜单 Alt+-
导航
作用域 功能 快捷键
Java编辑器 打开结构 Ctrl+F3
全局 打开类型 Ctrl+Shift+T
全局 打开类型层次结构 F4
全局 打开声明 F3
全局 打开外部javadoc Shift+F2
全局 打开资源 Ctrl+Shift+R
全局 后退历史记录 Alt+←
全局 前进历史记录 Alt+→
全局 上一个 Ctrl+,
全局 下一个 Ctrl+.
Java编辑器 显示大纲 Ctrl+O
全局 在层次结构中打开类型 Ctrl+Shift+H
全局 转至匹配的括号 Ctrl+Shift+P
全局 转至上一个编辑位置 Ctrl+Q
Java编辑器 转至上一个成员 Ctrl+Shift+↑
Java编辑器 转至下一个成员 Ctrl+Shift+↓
文本编辑器 转至行 Ctrl+L
搜索
作用域 功能 快捷键
全局 出现在文件中 Ctrl+Shift+U
全局 打开搜索对话框 Ctrl+H
全局 工作区中的声明 Ctrl+G
全局 工作区中的引用 Ctrl+Shift+G
文本编辑
作用域 功能 快捷键
文本编辑器 改写切换 Insert
文本编辑器 上滚行 Ctrl+↑
文本编辑器 下滚行 Ctrl+↓
文件
作用域 功能 快捷键
全局 保存 Ctrl+X Ctrl+S
全局 打印 Ctrl+P
全局 关闭 Ctrl+F4
全局 全部保存 Ctrl+Shift+S
全局 全部关闭 Ctrl+Shift+F4
全局 属性 Alt+Enter
全局 新建 Ctrl+N
项目
作用域 功能 快捷键
全局 全部构建 Ctrl+B
源代码
作用域 功能 快捷键
Java编辑器 格式化 Ctrl+Shift+F //*****************
Java编辑器 取消注释 Ctrl+\
Java编辑器 注释 Ctrl+/
Java编辑器 添加导入 Ctrl+Shift+M
Java编辑器 组织导入 Ctrl+Shift+O
Java编辑器 使用try/catch块来包围 未设置,太常用了,所以在这里列出,建议自己设置。也可以使用Ctrl+1自动修正。
运行
作用域 功能 快捷键
全局 单步返回 F7
全局 单步跳过 F6
全局 单步跳入 F5
全局 单步跳入选择 Ctrl+F5
全局 调试上次启动 F11
全局 继续 F8
全局 使用过滤器单步执行 Shift+F5
全局 添加/去除断点 Ctrl+Shift+B
全局 显示 Ctrl+D
全局 运行上次启动 Ctrl+F11
全局 运行至行 Ctrl+R
全局 执行 Ctrl+U
重构
作用域 功能 快捷键
全局 撤销重构 Alt+Shift+Z
全局 抽取方法 Alt+Shift+M
全局 抽取局部变量 Alt+Shift+L
全局 内联 Alt+Shift+I
全局 移动 Alt+Shift+V
全局 重命名 Alt+Shift+R
全局 重做 Alt+Shift+Y
posted @ 2009-03-19 14:49 断点 阅读(205) | 评论 (0)
今天导入开发的工程,打开后发现java源文件的注释变成了乱码,于是在google上开始了搜索,得到了结论:
出现的原因:因为windows下默认的编码是GBK,而我的java源文件编码是UTF-8所以,所以在windows下的注释,在Myelipse下查看就变成了乱码。
解决方法如下:
1) eclipse->window->preferences->General->Content Types
2) 找到要修改的文件的类型,在下面有个Default encoding,在输入框中输入GBK
3) 点击Update
4) 点击OK
5) 重启eclipse
打开源文件,一切ok,不乱码了!
posted @ 2009-03-17 10:52 断点 阅读(598) | 评论 (1)
现象:在使用ant编译项目的时候经常会遇到“警告:编码 GBK 的不可映射字符”这样的信息。
原因:这个主要是因为我们在写代码的时候加入了一些中文注释,而导致编译时候出现的问题。
解决方式:要处理这个问题,仅仅只需要在 build.xml文件中的调用javac的地方加入encoding的参数。
如下所示:
<target name="compile" description="编译Java文件">
<mkdir dir="${build.dir}" />
<javac encoding="utf-8" destdir="${build.dir}" target="1.5" debug="true" deprecation="false" optimize="false" failonerror="true">
<src path="${src.java.dir}" />
<classpath refid="buildmaster-classpath" />
</javac>
</target>
posted @ 2009-03-09 15:34 断点 阅读(540) | 评论 (0)
我在使用myeclipse6.0的时候遇到了一个问题,在网上搜索一下,现已解决。
我在myeclipse下建了一个WEB项目project,在WebRoot下建了一个文件夹jsp/user,在jsp/user文件下新建了一个文件index.jsp,
写了一个简单的框架应用
<%@ page contentType="text/html;charset=gbk"%>
<html>
<frameset cols="2,8">
<frame src="left.jsp" name="left">
<frame src="userinfo.jsp" name="right">
</frameset>
</html>
当我在写 <frame> 的src属性里的第一个字符l的时候跳出对话框提示
the file /E:/workspace/project/WebRoot/jsp/user/l cannot be found. Please check the location and try again.
每写一个字符都会跳出这个对话框,而我在写其他的jsp文件的html属性时却没有这样的问题。
网上说是平台的原因,反正不清楚,解决方式如下:
关闭它的jsp图形模式。myeclipse6中打开jsp文件时,右键open with 选MyEclipse JSP Editor,不选MyEclipse Visual JSP Editor模式。
posted @ 2009-02-13 17:56 断点 阅读(340) | 评论 (2)
解决方式及说明:
方法1.在写国际化文件或者资源文件的时候,会用到中文,用eclipse首次编辑的时候写中文也不会有问题,但是当你保存后在此打开的时候,中文就会无法显示了,都是问号或者乱码。
这个是因为中文的操作系统中,eclipse对java文件默认的编码是GBK,但是对properties文件默认的字符编码却是ISO-8859-1,所以我们要改变eclipse对properties文件的默认编码。
打开 Window ->Perferences ->General ->Context Types: 在右面的窗口中选择Text-->Java Properties File, 之后在下面的 File association 窗口中选中*.properties(locked) 在把下面的Default encoding从默认的ISO-8859-1更改成GBK,再点击update保存即可。
方法2.通过安装Properties Editor。Properties Editor可以直接编辑Properties文件,直接保存就可以,不用再转换。
如何安装Properties Editor?
在Eclipse的Help菜单中,选择 Software Updates -> Find and Install .... 打开安装插件的向导。
1)选择 Search for new features to install
2)如果是第一次安装Properties Editor,要先点击New Remote Site... ,在出现的New Update Site输入对话框中,Name可以随便输入一个名称。
Name输入:Properties Editor
URL输入:http://propedit.sourceforge.jp/eclipse/updates/
确定后就增加了一个插件网站,接下来一步步按照提示就可以安装,最后会提示重新启动Eclipse,重新启动后就可以了。
posted @ 2008-12-17 18:19 断点 阅读(214) | 评论 (0)
|