 2006年9月21日
2006年9月21日
Java的内存模型中Thread会附有自己的堆栈,寄存器,必要时需要和主存即heap之间同步。
可以使用Synchornized关键字和Concurrent包中的Lock可以保证线程互斥和可见性。
互斥性体现在类锁或者对象锁上,每个对象自身都包含一个监视器,该监视器是一个每次只能被一个线程所获取进入的临界区,可以通过wait和notify来退出和准入临界区。可以看出这是一个生产者-消费者的模型。而Concurrent包中的Lock为了能够获得更好的性能和更好的扩展性,以及不依赖于关键字的可读代码,自己实现了这样一个生产消费队列,也就是AbstractQueuedSynchronizer,被称为AQS的机制。每个Lock都内置了一个AbstractQueuedSynchronizer。需要说明的是AbstractQueuedSynchronizer内部实现采用了CAS机制,通过getState, setState, compareAndSetState访问控制一个32bit int的形式进行互斥。
那么可见性是如何保证的呢?
对于关键字的同步机制,其实可见性就是线程和主存之间的同步时机问题。共有4个时间点需要注意:
1 获取或释放类锁/对象锁的时候。Thread保证reload/flush全部变更
2 volatile就是flush on write或者reload on read
3 当线程首次访问共享变量时,可以得到最新的结果。
题外:所以在构造方法中公布this时很危险的。简单的说,就是构造时不逃脱任何变量,不开启新的线程,只做封装。关于安全构造,请参考
http://www.ibm.com/developerworks/cn/java/j-jtp0618/#resources
4 线程结束时,所有变更会写回主存
关于Concurrent Lock如何实现可见性的问题,Doug Lea大侠,只在他的论文中提到,按照JSR133,Unsafe在getState, setState, compareAndSetState时保证了线程的变量的可见性,不需要额外的volatile支持,至于具体这些native做了哪些magic就不得而知了,总之,最后的contract就是保证lock区间的共享变量可见性。开发团队被逼急了就这样回答:
There seems to be a real reluctance to explain the dirty details. I think the question was definitely understood on the concurrent interest thread, and the answer is that synchronized and concurrent locking are intended to be interchangable in terms of memory semantics when implemented correctly. The answer to matfud's question seems to be "trust us.”
不过这个地方的确是开发团队给我们用户迷惑的地方,在同样应用了CAS机制的Atomic类中,都内嵌了volatile变量,但是再lock块中,他告诉我们可以保证可见性。
感兴趣的同学可以下面的两个thread和Doug Lea的thesis:
http://altair.cs.oswego.edu/pipermail/concurrency-interest/2005-June/001587.html
http://forums.sun.com/thread.jspa?threadID=631014&start=15&tstart=0
http://gee.cs.oswego.edu/dl/papers/aqs.pdf
ThreadLocal是一种confinement,confinement和local及immutable都是线程安全的(如果JVM可信的话)。因为对每个线程和value之间存在hash表,而线程数量未知,从表象来看ThreadLocal会存在内存泄露,读了代码,发现实际上也可能会内存泄露。
事实上每个Thread实例都具备一个ThreadLocal的map,以ThreadLocal Instance为key,以绑定的Object为Value。而这个map不是普通的map,它是在ThreadLocal中定义的,它和普通map的最大区别就是它的Entry是针对ThreadLocal弱引用的,即当外部ThreadLocal引用为空时,map就可以把ThreadLocal交给GC回收,从而得到一个null的key。
这个threadlocal内部的map在Thread实例内部维护了ThreadLocal Instance和bind value之间的关系,这个map有threshold,当超过threshold时,map会首先检查内部的ThreadLocal(前文说过,map是弱引用可以释放)是否为null,如果存在null,那么释放引用给gc,这样保留了位置给新的线程。如果不存在slate threadlocal,那么double threshold。除此之外,还有两个机会释放掉已经废弃的threadlocal占用的内存,一是当hash算法得到的table index刚好是一个null key的threadlocal时,直接用新的threadlocal替换掉已经废弃的。另外每次在map中新建一个entry时(即没有和用过的或未清理的entry命中时),会调用cleanSomeSlots来遍历清理空间。此外,当Thread本身销毁时,这个map也一定被销毁了(map在Thread之内),这样内部所有绑定到该线程的ThreadLocal的Object Value因为没有引用继续保持,所以被销毁。
从上可以看出Java已经充分考虑了时间和空间的权衡,但是因为置为null的threadlocal对应的Object Value无法及时回收。map只有到达threshold时或添加entry时才做检查,不似gc是定时检查,不过我们可以手工轮询检查,显式调用map的remove方法,及时的清理废弃的threadlocal内存。需要说明的是,只要不往不用的threadlocal中放入大量数据,问题不大,毕竟还有回收的机制。
综上,废弃threadlocal占用的内存会在3中情况下清理:
1 thread结束,那么与之相关的threadlocal value会被清理
2 GC后,thread.threadlocals(map) threshold超过最大值时,会清理
3 GC后,thread.threadlocals(map) 添加新的Entry时,hash算法没有命中既有Entry时,会清理
那么何时会“内存泄露”?当Thread长时间不结束,存在大量废弃的ThreadLocal,而又不再添加新的ThreadLocal(或新添加的ThreadLocal恰好和一个废弃ThreadLocal在map中命中)时。
文档应该包括两大部分,一部分是清晰的代码结构和注释,比如Concurrent API就是这样,还有一部分是文字文档,包括三个小部分:一是开发文档,应该讲架构和功能;二是索引文档,详细介绍功能和参数,三是用户文档,包括安装和使用说明
文档最困难的莫过于版本的一致性,当软件升级后,一些obsolete的内容和新的feature很难同步。要是架构发生了变化,那就更困难了。一般document team都不是太精于技术,所以也会产生一些问题。
只能说任何事物永远都有改进的空间,但是同样也永远没有达到完美的程度
摘要: 1 根据cpu core数量确定selector数量
2 用一个selector服务accept,其他selector按照core-1分配线程数运行
3 accept selector作为生产者把获得的请求放入队列
4 某个selector作为消费者从blocking queue中取出请求socket channel,并向自己注册
5 当获得read信号时,selector建立工作...
阅读全文
多线程的优点:
1 多核利用
2 为单个任务建模方便
3 异步处理不同事件,不必盲等
4 现代的UI也需要它
风险:
1 同步变量易错误
2 因资源限制导致线程活跃性问题
3 因2导致的性能问题
用途:
框架,UI,Backend
线程安全的本质是什么:
并非是线程和锁,这些只是基础结构,本质是如何控制共享变量访问的状态
什么是线程安全:
就是线程之间的执行
还没有发生错误,就是没有发生意外
一个线程安全的类本身封装了对类内部方法和变量的异步请求,调用方无需考虑线程安全问题
无状态的变量总是线程安全的
原子性:
完整执行的单元,如不加锁控制,则会发生竞态条件,如不加锁的懒汉单例模式,或者复合操作。
锁,内在锁,重入:
利用synchronized关键字控制访问单元,同一线程可以重入锁内部,避免了面向对象产生的问题。同一变量的所有出现场合应该使用同一个锁来控制。synchronized(lock)。
即使所有方法都用synchronized控制也不能保证线程安全,它可能在调用时编程复合操作。
活跃性和性能问题:
过大的粒度会导致这个问题,用锁进行异步控制,导致了线程的顺序执行。
简单和性能是一对矛盾,需要适当的取舍。不能在没有考虑成熟的情况下,为了性能去牺牲简洁性。
要尽量避免耗时操作,IO和网络操作中使用锁
Store包含两个数据缓存 - snapshot和data,grid,combo等控件的显示全部基于data,而snapshot是数据的完整缓存,当首次应用过滤器时,snapshot从data中备份数据,当应用过滤器时,filter从snapshot获取一份完整的数据,并在其中进行过滤,过滤后的结果形成了data并传递给展示,及data总是过滤后的数据,而snapshot总是完整的数据,不过看名字让人误以为它们的作用正好相反。
相应地,当进行store的增删改时,要同时维护两个缓存。
问题
Store包含两个增加Record的方法,即insert和add,其中的insert没有更新snapshot所以当重新应用filter时,即data被重新定义时,在data中使用insert新增的记录是无效的。
解决方法
用add不要用insert,如果用insert,记得把数据写进snapshot: store.snapshot.addAll(records)
摘要: 在Extjs中构造N级联动下拉的麻烦不少,需定制下拉数据并设定响应事件。通过对Combo集合的封装,无需自己配置Combo,只需设定数据和关联层级,即可自动构造出一组支持正向和逆向过滤的联动下拉并获取其中某一个的实例。
如:
数据:
Ext.test = {};
Ext.test.lcbdata&nb...
阅读全文
目前主流的SSH开发架构中,为减轻开发者工作,便于管理开发过程,往往用到一些公共代码和组件,或者采用了基于模版的代码生成机制,对于后台的DAO,Service等因为架构决定,代码生成必不可少,但是在前端页面的实现上,却可以有两种不同的思路,一种是把配置信息直接封装成更高级别的组建,一种是进行代码生成。请大家讨论一下这两种方案的优劣,这里先抛砖引玉了。
相同点:
配置信息:XML OR 数据库
控件化:
优点:
1 易于添加公共功能
2 修改配置数据直接生效
3 代码结构清晰,对开发者友好
缺点:
1 重组内存中对象结构,性能没有代码生成好(但渲染时间相同)
2 仅能控制组件自身封装的配置,不支持个性化修改,如果配置文件不支持的参数,则控件不支持
3 必须保证每个控件一个配置
代码生成:
优点:
1 性能较好
2 易于定制内容
3 可以只配置一个模版,然后做出多个简单的修改
缺点:
1 不能针对多个页面同时添加公共功能
2 业务修改需要重新生成代码
3 开发者需要修改自动生成的代码,并需要了解一些底层的实现结构
=====================20091029
代码生成并不能提高工作效率,尤其是针对复杂的富客户端开发
开发组件可提提供一种有效的选项,但是在运行效率和内存处理上需要细心处理
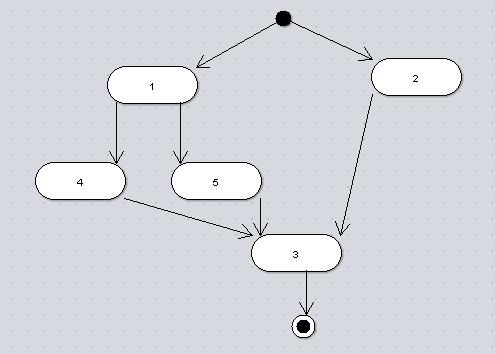
最近在学习jBPM和Javascript,所以按照一些相关概念自己写了下面的200行代码的“工作流引擎”,工作流管理系统包含了流程定义,引擎,及应用系统三个主要部分,下面的代码实现了流程的分支合并,目前只支持一种环节上的迁移。拷贝到html,双击就可以跑起来。
var workflowDef = {
start:{
fn:"begin", //对应处理方法可以在内部定义,也可以在外部定义
next:["task1","task2"]
},
end:"end",
tasks:[{
id:"task1",
fn:function(){
alert("执行任务一");
},
before:function(){
alert("执行任务一前");
},
after:function(){
alert("执行任务一后");
},
next:["task4","task5"]
},{
id:"task2",
fn:function(){
alert("执行任务二");
},
before:function(){
alert("执行任务二前");
},
after:function(){
alert("执行任务二后");
},
next:["task3"]
},{
id:"task3",
fn:function(){
alert("执行任务三");
},
before:function(){
alert("执行任务三前");
},
after:function(){
alert("执行任务三后");
},
//定义合并的数量
merge: 3,
next:"EOWF"
},{
id:"task4",
fn:function(){
alert("执行任务四");
},
before:function(){
alert("执行任务四前");
},
after:function(){
alert("执行任务四后");
},
next:["task3"]
},{
id:"task5",
fn:function(){
alert("执行任务五");
},
before:function(){
alert("执行任务五前");
},
after:function(){
alert("执行任务五后");
},
next:["task3"]
}]
}
//////////定义引擎////////////
Yi = {};
Yi.Utils = {};
Yi.Utils.execute = function(o){
if(typeof o != 'function')
eval(o)();
else
o();
}
//工作流类
Yi.Workflow = function(workflowDef){
this.def = workflowDef;
this.tasks = this.def.tasks;
}
//public按照环节id查找查找
Yi.Workflow.prototype.findTask = function(taskId){
for(var i=0;i<this.tasks.length;i++){
if(this.tasks[i].id == taskId)
return this.tasks[i];
}
}
//public启动工作流
Yi.Workflow.prototype.start = function(){
this.currentTasks = [];
Yi.Utils.execute(this.def.start.fn);
for(var i=0;i<this.def.start.next.length;i++){
this.currentTasks[i] = this.findTask(this.def.start.next[i]);
Yi.Utils.execute(this.currentTasks[i].before);
}
}
//private
Yi.Workflow.prototype.findCurrentTaskById = function(taskId){
for(var i=0;i<this.currentTasks.length;i++){
if(this.currentTasks[i].id == taskId)
return this.currentTasks[i];
}
return null;
}
//private
Yi.Workflow.prototype.removeFromCurrentTasks = function(task){
var temp = [];
for(var i=0;i<this.currentTasks.length;i++){
if(!(this.currentTasks[i] == task))
temp.push(this.currentTasks[i]);
}
this.currentTasks = temp;
temp = null;
}
//public触发当前环节
Yi.Workflow.prototype.signal = function(taskId){
//只处理当前活动环节
var task = this.findCurrentTaskById(taskId);
if(task == null){
alert("工作流未流转到此环节!");
return;
}
//对于合并的处理
if(task.merge != undefined){
if(task.merge != 0){
alert("工作流流转条件不充分!");
return;
}else{
Yi.Utils.execute(task.before);
}
}
//触发当前环节
Yi.Utils.execute(task.fn);
//触发后动作
Yi.Utils.execute(task.after);
//下一步如果工作流结束
if(task.next === "EOWF"){
Yi.Utils.execute(this.def.end);
delete this.currentTasks;
return;
}
//遍历下一步环节
this.removeFromCurrentTasks(task);
for(var i=0;i<task.next.length;i++){
var tempTask = this.findTask(task.next[i]);
if(!tempTask.inCurrentTasks)
this.currentTasks.push(tempTask);
if(tempTask.merge != undefined){
tempTask.merge--;
tempTask.inCurrentTasks = true;
}
else
Yi.Utils.execute(tempTask.before);
}
}
//public获取当前的活动环节
Yi.Workflow.prototype.getCurrentTasks = function(){
return this.currentTasks;
}
//public获取流程定义
Yi.Workflow.prototype.getDef = function(){
return this.def;
}
////////应用系统///////////////
var wf = new Yi.Workflow(workflowDef);
alert("启动工作流");
wf.start();
alert("尝试手工执行任务3,返回工作流没有流转到这里");
wf.signal("task3");
alert("分支开始");
alert("手工执行任务1");
wf.signal("task1");
alert("手工执行任务2");
wf.signal("task2");
alert("手工执行任务4");
wf.signal("task4");
alert("手工执行任务5");
wf.signal("task5");
alert("手工执行任务3");
wf.signal("task3");
function begin(){
alert("流程开始,该函数在外部定义");
}
function end(){
alert("流程结束");
}
1 对于类型是checkboxgroup的数据,数据库中保存数据的格式是value1,value2...valueN,其中1~N的数据有可能不存在,如果选中则存在,最后拼接成一个串。
在Ext中,通过Record对象向FormPanel中的内置对象BasicForm加载数据时,采用的是setValues方法,而setValues第一步要通过Record中定义的name使用findField方法找到表单元素,遗憾的是,继承了Field的checkboxgroup组件并不能正确的通过getName返回自身引用,所以,需要对getName方法进行重写,此外,为了适应我们采用的数据格式,对于该组件的setValue(被setValues调用)和getValue(获取到已加工的数据,此事后话)也要进行重写。故而对于形如:
{
xtype: 'checkboxgroup',
name: 'biztype',
width: 220,
columns: 3,
fieldLabel: '业务类别',
items: [
{boxLabel: '类别1', inputValue: '01'},
{boxLabel: '类别2', inputValue: '02'},
{boxLabel: '类别3', inputValue: '03'},
{boxLabel: '类别4', inputValue: '04'}
]
}
的checkboxgroup定义,需重写类如下:
Ext.override(Ext.form.CheckboxGroup,{
//在inputValue中找到定义的内容后,设置到items里的各个checkbox中
setValue : function(value){
this.items.each(function(f){
if(value.indexOf(f.inputValue) != -1){
f.setValue(true);
}else{
f.setValue(false);
}
});
},
//以value1,value2的形式拼接group内的值
getValue : function(){
var re = "";
this.items.each(function(f){
if(f.getValue() == true){
re += f.inputValue + ",";
}
});
return re.substr(0,re.length - 1);
},
//在Field类中定义的getName方法不符合CheckBoxGroup中默认的定义,因此需要重写该方法使其可以被BasicForm找到
getName : function(){
return this.name;
}
});
2 通过内置对象basicForm的getValues方法可以获取到一个form的完整json数据,但遗憾的事,这里取到的是dom的raw数据,类似emptyText的数据也会被返回,而Field的getValue方法不存在这个问题,所以如果想要返回一个非raw的json集合,可以给formpanel添加如下方法:
getJsonValue:function(){
var param = '{';
this.getForm().items.each(function(f){
var tmp = '"' + f.getName() + '":"' + f.getValue() + '",';
param += tmp;
});
param = param.substr(0,param.length - 1) + '}';
return param;
}
这个方法同样适用于上面定义的checkboxgroup,如此就可以把前后台的数据通过json统一起来了
摘要: 当前的富客户端可以包含两部分:分别为JSP页面和通过富客户端js组件(如extjs)渲染的组件化窗口页。针对这两部分分别做如下处理:
对于JSP页面的部分采用JSTL标准库的fmt标签,如通过:
<fmt:message key="page.login.title"/>这样的形式进行展现,其中message对应的文本在服务端配置,并在web.xml中配置资源文件的位置,也可以采用s...
阅读全文
看此文前请保证jar包中有至少一个Main方法入口,及图形化的界面。
并保证META-INF/MANIFEST文件中的Main-Class已经指向之前实现的main方法入口。
最近硬盘坏了,于是重新安装了OS,发现拷贝后的jdk或jre(未经安装的版本),不能打开jar文件执行(jdk版本1.6_11),
于是在打开方式中指向了javaw程序,发现无效,并提示"cannot find main class", 与此同时windows把jar类型的文件关联到了
指定的javaw程序上,上网找了一通,没有人提及这个问题的解决办法,而显然这个问题又不是由开篇中提到的问题导致的。
于是在注册表中当前用户配置中删除了当前jar类型的定义。但是重新尝试后依然无效。
于是重新安装了jdk,发现这次可以打开jar文件了,并且这次用来打开的程序从打开方式来看仍然是javaw。
比较注册表中文件类型的定义,并没有差别。从文件夹选项 -> 文件类型来看终于看到了差别,
高级里面的open操作定义如下:
"C:\Program Files\Java\jre6\bin\javaw.exe" -jar "%1" %*
而如果我们自己选择javaw,默认的open操作是没有 -jar参数的,必须手工加进去。
我们知道java启动jar包的参数是 -jar,但是记得以前javaw是可以直接打开jar的,不知什么时候起也需要带有-jar参数了。
所以对于一个拷贝的绿色jre只要修改一下open操作的定义就可以解决上面的问题了。
解决了上面的问题,又产生了新的问题,之前选择打开的javaw程序在打开方式中丢不掉了,比较多余,这个可以在注册表中修改
在HKEY_CLASSES_ROOT\Applications下面找到响应的程序删除就可以了,原来每次用一个程序打开一个类型的文件windows都会在
注册表中这个地方留下相关的记录
偶然间注意到一个困扰了我很久的问题,那就是如果我不通过Socket而通过应用层的某种基于文本的协议,比如SOAP进行通信的话,
如何传递二进制的数据呢?现在SOA,Web Service等很火,应该会遇到这种问题吧?
现在已知的方法可以通过Base64进行编码,其原理和方法见:
http://baike.baidu.com/view/469071.htm
这种方法采用了字节中的6位进行文本转换,并且在其他论坛上也看到了帖子说淘宝的搜索也采用了这种编码方式进行处理。
但是采用了5位进行转换。并且大胆地给出了5位转码的算法,见:
http://www.javaeye.com/topic/286240
不过这种5位的转换会产生更多多余的字节,6位的转码充分利用了现今的可读文本,可是5位却没有,因为5和8的最小公倍数是40,
所以当每转换40位即5个字节的二进制数据需要8个字节来表示,这样就多产生3个字节,浪费的效率是3/5, 而6位转码浪费的效率是
1/3。而且随着字节增多,转化效率也在下降。可见采用5位转码是一种既浪费空间,又浪费效率的解决方案。在不增加url长度的情况下充分提高效率,6位编码是最佳的。如果可以任意的饿牺牲url长度,
可以把0-9全部拿出来当做标记位,0-9不会单独出现,这样一共有10*26 + 26 = 286 种可能还不包括小写字母,
此外还有=,+,-什么的至少256可以编码8位的字节了,这样处理效率就提高了。
现在把问题优化一下,人类可读无歧义的文本码有0-9,A-Z,a-z共62个
设取出x个作为标志位则(62-x) * x + (62 - x) >= 256
解这个二元一次方程得到:
3.366<=X<=57.634
考虑到编码的文本长度,取x的最小值,即 4
最优解:
用0, 1, 2, 3做为标志位
4-9,A-Z, a-z参与编码并与标志位配合实现8位字节的文本化
可以看到这种方法的转码效率会比较高,但是空间冗余大。
此外其实可用的文本不知62个,包括感叹号等用上后补足64 = 2^6
它的高位是 00
那么只要再找到三个文本符保存其他三个高位01 10 11就可以了
这样的转码空间可以更小一些。
想法还很不成熟,欢迎大家批评
摘要: 最近在学习JavaScript,发现不论是ext还是prototype都很推崇json这种通信协议的格式,但是这两个框架都是比较偏前端的,和dwr不同,dwr是一个一站式的ajax框架,不仅提供了客户端的工具方法,也包括服务端的配置和通信的处理。
而ext和prototype等仅仅设置好了json的接口并对ajax通信做了封装,相对而言是一种比较“纯粹”的AJAX实现,当...
阅读全文
学过软件工程的都知道,软件产品的生产周期是一个经历若干阶段的漫长过程,包括需求获取 - 设计 - 开发 - 维护等等。
需求阶段 - 总想考虑到所有的问题,或是一切按合同办事。但在现实中根本不得能,因此很多公司开始提倡“随需而变”的能力,希望快速的响应用户的需求变化
维护阶段 - 总希望自己开发出来的东西一劳永逸,永远不要再产生任何麻烦,产生了麻烦也不要找到我。甚至有些项目组的人员开发出来一大堆不成熟的产品、项目后撒手不管,走人了事,毫无职业操守,亦是对自身行业声誉(至少是国内IT服务提供商声誉)的一个打击。真正的项目开发不应该这样,一定是非常易于维护的,能够快速地找出问题的所在,或是新需求切入点的所在,然后解决
很明显,前面提到的两个问题都要也只能通过设计和开发来解决。问题来了,怎样开发出的软件才能快速地响应需求,易于维护?可以有很多不相冲突的说法,比如解耦,比如通过POJO封装数据等等。这些东西流行开来以后,很多人有疑问,为什么我的项目中一定要用这些框架?我不用这些框架也可以快速的开发出我要的功能,而且更加简单,等等。如果孤立地从设计和开发的角度看这些问题,这种说法并没有错误,但是如果从整个软件开发的生命周期来看,则不是这样。当然,这里还有一个是否“过度设计”的trade-off在里面,不过那又是另一个话题了。
再说说各种各样的平台吧,它们和框架不同,软件体系结构中有一种架构模型即层次模型,我们现在的TCP/IP协议栈即属于这种模型,我们的软件对于平台产品的依赖是一种朝向稳定的依赖,就好像我们在调试代码时往往不会去调试操作系统API的bug一样,因此在开发这种平台层次级别的产品时就没有必要再去采用那些为了保障“企业应用”Web软件生命周期中所采用的方法了,完全可以用最基础,最底层的手段。只要能够做到高效、稳定即可。因此,平台中间件产品的开发必须和应用软件产品分开来看,虽然它们可能都在用Java这种编程语言。
本科读书时,曾听过离散数学老师一句很精彩的论断:“只要能够形式化的东西,就可以自动化”。可是今天我不谈离散数学,倒想说说其他不相关的东西。
你一定听到过“一流的企业卖标准,二流的企业卖品牌,三流的企业卖产品”。
什么是形式化?为什么形式化的东西就可以自动化呢?撇开数学符号不谈,对企业来说,形式化的东西可以是一些规章及做事的方法,生产产品的方法等等。为什么人民币稍一升值,中国的中小制造型企业就要痛苦不堪?因为我们每既没有品牌,更没有标准,拿生产DVD机为例,最初的90年代生产DVD机卖到欧美很赚,可是现在据说不赔钱就不错了,因为要缴纳一大笔的专利费。中国的大多数企业处在整个产业链的最下端,所得的利润的大多数被其他企业剥夺了,因为我们用的是别人的品牌,别人的标准。我们的公司在全球经济中处于“民工”的境地。
回到我们的问题中来,一流企业所做的标准,是生产一种产品的方式和规约,这一层面是抽象世界的最高层次,无法对这层抽象的产生进行形式化,所以是一种创造性的劳动;二流企业所卖的品牌是对一种产品具体生产方法的规约,通过“模板方法模式”的应用,这一层次的抽象的模板可以从上一个层次的形式化中自动化,然后只需形式化具体的操作细节,对于生产细节的形式化,也需要一定的创造性的劳动;三流的企业是一部机器,因为到此为止一切的东西都已经形式化了,只需要有时间和精力的机器去自动完成而已。
让我们好好想想在一个知识经济的社会里,什么事物是创造性的,是只能被形式化而不能被自动化的。因为只有人类的创造性思想不能被机器所取代,这也是为什么机器人无法取代人类的原因。
80年代出生的人应该记得历史教科书中的论述,工业革命时,一些工人去砸毁机器,觉得这些机器剥夺了他们的工作。如果有一天,老板突然来告诉您:你可以离开了,请不要沮丧和懊悔,因为您早该意识到您其实就是一部机器。当然为了防止上面悲剧的发生,早点去从事有创造性的工作吧,停止对于各种软件自动化辅助工具的抱怨和担忧,勇敢地迎接明天。
还记得小时候常看的电影《神鞭》吧!
偶然间看到下面有一个网友慨叹普元的强大,而开发人员的渺小。
小弟刚刚参加工作,也在项目中接触到了普元的EOS。普元的这个东西怎么说呢,就是乱用XML然后Spring没做好就变成那个样子的,同时失去了类型的表述,一部机器要进行装配需要组件和零件,软件应该自上而下,分而治之,这是上个世纪70年代,学者们就达成的共识,所以关于“银弹”神话的唯一结论就是——“没有银弹”。
为什么说EOS是没有做好的Spring?
Spring简化了对象的装配,强调重用,是建立在面向对象基础上的,是建立在敏捷测试基础上的,是建立在强类型基础上的;
而EOS则是建立在面向过程的基础上的,建立在不可测试的基础上的,建立在毫无类型基础上的(全是String)
然而EOS也有很多的优点(据小弟不完全发现):
1)EOS固化的开发流程强制一个team从一种易于维护的结构组织Web,包括页面,表示层,逻辑层等等。否则的话就需要一个架构师来做出规约,但仍不易于管理;
2)EOS的画图功能让人耳目一新,从“代码即文档”的哲学出发,这些画图很好地诠释了代码表述的内容和结构,给程序的维护带来便利。
3)相对于OO和J2EE传统开发,EOS易于上手,学习曲线较短。但是这一点有争议,EOS的知识不具备通用性。
综上,根据2-8的关系法则,在某些领域EOS的确有其优点,但是认为EOS完全“解放”了程序员,则是不负责任的说法。
这只是我的个人看法,欢迎大家就此话题讨论。
联合国是国家间的标准化组织,可惜一超多强们只把它当作是一个道具,需要时拿来用一下,不需要时完全可以踢到一边。
历史上,每个朝代都认识到失败的教训,却最终都迎来了相似的结局。
有人说,软件行业是一个天生的垄断行业,其特质是,产品研发的过程异常的复杂,但产品一旦出炉,就可以疯狂而不计成本地生产。只有NRE Cost,眼下的软件行业也出现了群雄逐鹿的场面,上游产业被几家大公司所瓜分,这些大公司如果能互相牵制,则会坐在一起,成立一个组织。如果一家独大,则我行我素,称王称霸。
看看他们的一路成长:
初始:
他们想占有你,最初都会很乖。就像女孩在成为家庭主妇之前总能收到男孩的礼物。
成长:
大公司们也渐渐从规范的参与者,变成规范+的树立者,比如IE,Office,再比如Oracle的特性等等。
称霸:
市场占有的差不多了,可以不顾客户的意志做自己喜欢的事情,反正你已经离不开我。
消亡:
客户们怨声载道,新的“符合规范”或简洁明了的产品出现市场。
希望这些大软件厂商们能够吸取教训,也希望小软件厂商们将来不要走入历史的怪圈。
在远古时期人们靠结绳纪事,据说美洲的玛雅文明在覆灭之前都一直没有自己的文字,而采用这种古老的方法。
后来我们的祖先发明了文字,在竹简上,布帛上书写文字,竹简和布帛就是信息的载体,这样的载体造价不菲,所以我们的文言和白话就有这么大的差距,留下的论语也要微言大义。再后来我们的祖先发明了纸张,严重地降低了承载信息的开销,于是人类的文明得以更好地记录和更快地发展。今天,我们的信息载体又有了新的变化,一张光盘,一个硬盘都可以承载无数的学问。
信息有了载体,随之产生了信息管理的问题:
如何对信息进行增删改查的操作?如何处理附加在信息上的工作流?如何管理权限?
在IT系统出现之前,人们通过图书馆管理图书,通过搬运工进行信息流动,通过钥匙和锁头管理权限。
在IT系统出现之后,人类可以通过计算机来完成这些操作。这其中数据库系统,工作流系统帮了我们大忙。
IT系统处理信息的过程是:
多样式的文档(抽象为XML)-> 内存数据 -> 持久化(文件数据库)->内存数据 -> 多样式的文档(抽象为XML)
我们让用户在我们设定的UI窗口进行输入,然后通过报表的形式产生各种各样的输出。中间一个步骤一个步骤,一个环节一个环节的走下去。
这其中,我们把很大一部分精力消耗在,如何让用户舒服的输入,和产生用户所需要的输出上。
于是人们就要思考,难道不可以直接编辑一种全世界认可的文档形式(大家现在正在和MS争吵的东西)通过网络流转,然后获得结果吗?为什么要从程序员的角度加给用户数据库,工作流,录入界面这些繁杂的东西?
从这点意义上说,我推崇Sharepoint或者Google sites。
就拿google docs来说吧,在线编辑word,每个环节通过分享的形式进行编辑,授权这部分可以通过历史记录来找到,随时恢复到历史版本,因此也不怕误操作和无权限操作,真正的所见即所得,支持50人同时在线编辑。这难道不是OA的杀手级应用吗?
学习这些框架技术,我觉得归根结底就是做什么的,为什么做,如何做
前人说读书有三个层次,我看这大概可以总结为是新的三个层次:)
因为没有搞清楚为什么要用,就会误用,用了还不如没用。其实我觉得学spring读读rod那个原著挺好的,比单纯学spring有帮助,最好自己有体会。比如你开发网站很熟练了,自然就知道为什么要用spring了。等完全领会了他那两本书后,再读读他们的reference book应该差不多了。
这个过程其实就是做什么->为什么->怎么做的过程
最近在研究关于系统的基于日志的故障恢复,无意间在网上发现一篇论文中对于系统日志模型的精彩论述,翻译过来并附上我的思路:
『
一个系统是一个具有明显的边界的实体,它根据一定的输入,自身运行逻辑及系统的内部时钟变化来产生相应的输出。
所谓“明显的边界”是指系统所产生的输出是明确而无二义性的。我们称这个边界为系统的设计规范(specification)。一个系统通过与其所处环境进行交互,从而获取输入并产生输出。一个系统可以被拆解为不同的子系统。这些子系统通常被称为系统模块(system components),每个模块又独立地成为一个系统,作为一个系统,这个模块又会和它的相关环境进行交互(比如,一个更大的系统中的其他的模块组件)来获取输入并产生输出,这些模块还可以继续被分解为更小的子系统。
一个系统可以被建模为一个状态机(state machine),其中的状态包含了系统所持有并处理的数据。这些状态的迁移被分为两大类:由系统内部逻辑所触发且对外部环境透明的迁移和直接与外部环境相接触的迁移。前者的例子如内存数据和寄存器数据的转换,内存中数据结构的重组。第二种迁移的例子包含了各种各样的系统和环境之间的交互,一般来说,如果这个过程能被建模成系统的I/O操作,则应属于这一类别。因此,一个消息内容的形成是一个或多个第一类别状态迁移的结果,但将消息输出到系统的环境则是属于第二类迁移。
第二类别的状态迁移可以捕获交互事件(interaction events),或者简单的事件(events)。这些事件可以由系统外部的观察者(observer)来获取。显然,这里的事件是消息、信号、数据及其内容以及一切系统和其环境交互(如机器人运动手脚,报警器报警,打印机打印等等)的发送和接受的模型。此外事件还可以用来描述系统缺乏交互的时间,比如一个计时器在日志中输出系统的空闲时间等。
当一个大的系统被拆分成多个模块时,每个模块都被赋予了整个系统所处理数据的一部分,正因为模块和模块间的接口衔接和数据感知,一些原来属于第一类别的状态转换,因为系统的拆分在更低的层次上变成了第二类别,成为系统和环境之间的交互。
对于一个特定的系统,他对于输入的形式和获取时间是不可预知的,但是这个系统却应该能够做到根据一个特定的输入以及系统当前的特定状态获取一个特定的输出。因此系统的执行可以被建模为状态转换序列,每个状态的输入是一个不确定性事件。为了记录日志并做到故障恢复,我们还应做到能够在环境中捕获这个不确定性事件输入。
此外,在系统与系统间进行交互式,事件的传递时间也应该是不确定性的。
』
怎样用日志来预防系统崩溃,在崩溃后如何还原系统,我想关键问题就是怎么做好内存的快照,这样,在断电重启后可以通过日志来还原内存的信息这样第一步就是确认内存中的数据结构,哪些是必不可少的。确定系统恢复的粒度,按照子系统的分割和事件的记录来进行replay,根据子系统的划分,可以找出每个子系统中第二类别的事件进行记录。
以向数据库系统提交作业为例,实际上在整个作业提交的过程中,每个层次都要做到可以在失败的情况下重现,这个功能在完善的数据库系统和集群批处理系统中当然已经很完善。但如果是针对web系统的作业提交,则需要针对Web的作业持久方案,做一个日志恢复处理。需要特别指出的是,对于数据的查询是不需要做备份的。
在具体实现上,我想应该包括:日志记录,故障检测,日志持久三个部分。一份日志就是一个对于系统检查点(checkpoint)的连续记录。日志记录者负责记录日志到日志持久者,故障检测器随时监控系统,发现故障后,从日志持久者中读取日志,进行replay.
总算找到了工作.
我会好好努力的.
此时此刻,更加明白,以往的一切荣与辱都成为过去.
又要踏上新的征程.
刚看了myeclipse,eclipse是一个很可怕的东西,它试图让所有的开发人员一打开电脑就不能够离开它,还要在里面完成所有的工作。人们不至于反感它的原因是它是开源的,不受商业控制的。如果我们对于myeclipse过度依赖,必然最终走向对微软严重依赖的老路。我不反对利用软件盈利。但是自由的精神不应被改变。
微软和我们
是原始的猎人与猎物之间的关系,虎与伥的关系,最终极的占有。我们这才生是MS的人,死是MS的鬼。
摘要: 这篇随笔谈一谈如何在Java环境下利用Unix/Linux的用户名和密码对用户的权限作出过滤。为方便大家学习交流,本文中给出了源代码,借此抛砖引玉,欢迎大家对这个简单的登录模型做出改进或者设计出自己的技术方案。
由标题我们不难看出,与本文相关的知识点主要有3个:
1 JAAS这个解耦设计的多层验证方法(1.4后已归入Java核心库中)
2 应用JNI访问底层代码,及JNI中简单的类型匹配
3 在shadow模式下,Unix/Linux系统的用户验证
阅读全文
O/R映射框架的延迟加载技术实现大体上有这么4种(参看Martin Fowler的意见):
(http://www.martinfowler.com/eaaCatalog/lazyLoad.html)
There are four main varieties of lazy load. Lazy Initialization uses a special marker value (usually null) to indicate a field isn't loaded. Every access to the field checks the field for the marker value and if unloaded, loads it. Virtual Proxy is an object with the same interface as the real object. The first time one of its methods are called it loads the real the object and then delegates. Value Holder is an object with a getValue method. Clients call getValue to get the real object, the first call triggers the load. A ghost is the real object without any data. The first time you call a method the ghost loads the full data into its fields.
通过阅读源代码,发现iBATIS中的延迟加载是用上述方式中的虚拟代理实现的.
在动态代理的实现上, iBATIS有Java动态代理和CGLIB两种实现方案,iBATIS把用CGLIB实现的方案称为Enhanced的方案,可见CGLIB的效率会比java的动态代理效率要高.
在iBATIS首先判断是否定义了延迟加载,如果定义了,则利用Lazy的Loader来提取数据(返回一个Proxy).如没有执行对这个的任何操作,或者只是不再使用(finalize),则不做处理,否者就加载真正的对象.
可以通过阅读类
com.ibatis.sqlmap.engine.mapping.result.loader.LazyResultLoader
的源码获取更多的细节.
接着上次的话题,今天我们聊聊gSOAP这个框架,我们把用C写的旧有系统用gSOAP改造一下,通过SOA的形式发布出去。
上文提到,利用gSOAP可以做到以下3点:
1 一个Stand-alone的服务器外壳
2 一个根据API程序自动生成的Web Services服务
3 一个WSDL描述符文件
客户根据 WSDL 描述文档,会生成一个 SOAP 请求消息。Web Services 都是放在Web服务器后面,客户生成的SOAP请求会被嵌入在一个HTTP POST请求中,发送到 Web 服务器来。Web 服务器再把这些请求转发给 Web Services 请求处理器。请求处理器的作用在于,解析收到的 SOAP 请求,调用 Web Services,然后再生成相应的 SOAP 应答。Web 服务器得到 SOAP 应答后,会再通过 HTTP应答的方式把信息送回到客户端。
WSDL是Web服务中客户端和服务端沟通的桥梁,描述了对象提供的方法。SOAP帮我们制定了一份被官方认可的对象的封装方法。有了WSDL,客户端只关心如何把参数用Soap封装起来发出去,并获取结果。服务端只关心如何对Soap进行拆包->服务->封包。gSOAP可以帮我们实现上述过程中的拆包和封包,而我们可以只关心服务的实现。
言归正传,在这里我们以一个简单的实现加、减、开放的Web Services的服务为例子,介绍gSOAP的使用:
为了发布这个Web服务,首先我们需要把服务的接口定义好,这个服务可能是一个现有服务的Adapter,为此我们定义头文件
calc.h:
typedef double xsd__double;
int ns__add(xsd__double a, xsd__double b, xsd__double &result);
int ns__sub(xsd__double a, xsd__double b, xsd__double &result);
int ns__sqrt(xsd__double a, xsd__double &result);
注意到这里面我们把double定义成了xsd__double(两个下划线),这是为了告诉gSOAP,我们需要的soap格式和WSDL格式是基于Document/literal的而非rpc/encoded.为了不把事情搞复杂,在这里我只能说,Java1.6自带的Web Services工具只支持Document/literal格式的WSDL,所以我们生成这种格式的WSDL。至于这两种格式之间选择和他们的long story,大家可以参考下面的文章:
http://www.ibm.com/developerworks/webservices/library/ws-whichwsdl/
编写好头文件后,我们就可以利用gSOAP提供的工具进行生成了:
/usr/lib/gsoap-2.7/bin/soapcpp2 -S -2 calc.h
生成的主要文件详见附件。
下面我们实现calc.h中定义的函数:
// Contents of file "calc.cpp":
#include "soapH.h"
#include "ns.nsmap"
#include <math.h>
int main()
{
struct soap soap;
int m, s; // master and slave sockets
soap_init(&soap);
m = soap_bind(&soap, "localhost", 9999, 100);
if (m < 0)
soap_print_fault(&soap, stderr);
else
{
fprintf(stderr, "Socket connection successful: master socket = %d\n", m);
for (int i = 1; ; i++)
{
s = soap_accept(&soap);
if (s < 0)
{
soap_print_fault(&soap, stderr);
break;
}
fprintf(stderr, "%d: accepted connection from IP=%d.%d.%d.%d socket=%d", i,
(soap.ip >> 24)&0xFF, (soap.ip >> 16)&0xFF, (soap.ip >> 8)&0xFF, soap.ip&0xFF, s);
if (soap_serve(&soap) != SOAP_OK) // process RPC request
soap_print_fault(&soap, stderr); // print error
fprintf(stderr, "request served\n");
soap_destroy(&soap); // clean up class instances
soap_end(&soap); // clean up everything and close socket
}
}
soap_done(&soap); // close master socket and detach environment
}
// Implementation of the "add" remote method:
int ns__add(struct soap *soap, double a, double b, double &result)
{
result = a + b;
return SOAP_OK;
}
// Implementation of the "sub" remote method:
int ns__sub(struct soap *soap, double a, double b, double &result)
{
result = a - b;
return SOAP_OK;
}
// Implementation of the "sqrt" remote method:
int ns__sqrt(struct soap *soap, double a, double &result)
{
if (a >= 0)
{
result = sqrt(a);
return SOAP_OK;
}
else
{
return soap_sender_fault(soap, "Square root of negative value", "I can only compute the square root of a non-negative value");
}
}
前文提到过,我们不希望为了发布基于Web Services的C语言的API而开发或应用一个大的Web服务器。我们代码中的main函数实现了一个最简单的Web Server(基于Socket).这个Server利用gSOAP生成的API来提供针对SOAP的处理。
下面我们把这个嵌入式的web server编译,编译的时候注意stdsoap2.cpp这个文件是从gSOAP包中拷贝而来,不是自动生成的,大家下载gSOAP后直接就能找到这个文件及其头文件。
g++ -o calcServer calc.cpp soapC.cpp soapServer.cpp stdsoap2.cpp
一个以Web Servers形式提供的C API诞生了。
在server端执行./calcServer
下面讨论如何用Java1.6的自带工具生成一个客户端stub:
把gSOAP生成的WSDL拷贝到我们的Java开发环境中来,按照Web Services Server中定义的端口和服务器,配置参数生成客户端Web Services代码:
/usr/lib/jvm/jdk1.6.0_03/bin/wsimport -extension -httpproxy:localhost:9999 -verbose ns.wsdl
生成后,把这个环境添加到eclipse的编译环境中来,然后在eclipse中建一个新的类:
class Test {
public static void main(String args[]) {
Service service = new Service();
double h = service.getService().sub(20000, 1);
System.out.println(h);
}
}
运行后得到结果19999.0
总结:当集成Java和C两种平台时,我们可以有多种解决方案,但首先我们应该想到gSOAP因为它能够很出色地完成任务。
文中相关代码:
http://www.blogjava.net/Files/yangyi/gsoap.zip
广告:本人明年毕业,正在找工作,个人简历:
http://www.blogjava.net/Files/yangyi/My%20Resume.zip
背景:
对于旧有系统的改造和升级,最苦恼的莫过于跨平台,跨语言。我的一个朋友最近从Java专向了专攻.NET——因为.NET的CLR既有类似Java虚拟机概念这种已经被证明很成功的底层托管能力。又对于Windows的就有桌面应用提供了良好的兼容。
最近我的一个个人项目也面临着这样的需求。一个C语言开发的中间件,通过API暴露给二次开发及插件应用。现在由于对其应用的需求变得日趋复杂,而且正在脱离Unix的管理环境,走向基于JWS这样的BCS管理。有朋友推荐我用JNI,但这样一是增加了耦合度,二是让Java睡在JNI感觉不太安稳。在认知了上下两层的系统平台后,问题变得明朗起来:如何在HTTP协议下实现Java和C之间的交互?
思路:
本人对Java比较熟悉,先从Java的角度入手,Java间的通信方法:
1 通过URL,Applet/JWS访问被影射到URL的动态资源(Servlet)
2 通过URL,Applet/JWS访问共享的静态资源(Server定期更新静态资源)
3 通过序列化和反序列化,实现简单对象的传输(比如Resin的Hessian框架就提供了这种通信的方式)
4 通过一些工具做代码生成,利用Web Services实现客户端和服务端的交互
此外脱离HTTP,还可以做RMI,socket编程
现在问题是通信的一端由Java变成了C/C++, 于是, 解决方案1需要把动态资源由CGI来定义,而方案3变得不再适用。于是方案有:
1 通过URL,Applet/JWS访问被影射到URL的动态资源(CGI)
2 通过URL,Applet/JWS访问共享的静态资源(Server定期更新静态资源)
3 通过一些工具做代码生成,利用Web Services实现客户端和服务端的交互(×××这是我们讨论的重点×××)
解决方案:
现在针对上文提出的3中通信方式中的1和3谈一谈实现的方法,2的实现方案比较灵活,需要发挥大家的想象力了:)
针对CGI:
首先CGI可以配置在各种主流的服务器中作为后端的脚本运行。大家可能对Servlet更熟悉一些。
CGI可以用脚本写,也可以用C来实现。CGI被触发后,通过系统的环境变量来获得输入,在处理完毕后向标准输出中输出结果。
由此可以想见,Web服务器在接受到来自HTTP协议的请求后,首先把请求的参数获取到,然后设置到环境变量里。
根据对访问的URL的解析和服务器自身的配置,找到服务于请求的CGI程序的位置,然后执行这个程序。
这个程序被执行后通过环境变量得到了服务器先前设置在环境变量中的参数。在经过一些复杂的逻辑操作后,向标准输出输出结果。
这个输出又被Web服务器所捕获,转而传递回请求的客户端。
更多关于CGI的知识和理解,大家可以通过google来寻找答案
上述CGI的方式可以让我们直接获取到结果,但是方案比较原始和基础。其缺点有:
1 需要自己制定类型传输协议,做封装和拆封,否则只支持字符串
2 我们不会为了要用C的API就给它装一个或者自己实现一个Web服务器的,这让我们的底层程序显得蠢笨而冗余。我们希望能有一个超薄的Server外壳,
在对API封装后,通过某个端口进行开放即可。
针对Web Servcies:
Based on上面的两个不足,我们只能把希望寄托在Web Services身上了,
笔者在这里推荐给大家的是在C/C++很著名的Web Services工具gSOAP。大家可以到http://gsoap2.sourceforge.net/上去下载这个工具。
通过这个工具,我们可以做到:
1 一个Stand-alone的服务器外壳
2 一个根据API程序自动生成的Web Services服务
3 一个WSDL描述符文件
有关基于gSOAP的Web Services C服务端和Java客户端的运行机理,及通过Java客户端访问gSOAP的Web Services的过程中需要注意的问题(笔者费了一天周折才搞清楚),将在下一篇中描述
广告时间:
本人是哈工大的研究生,明年7月毕业。正在找工作,如果有工作机会,别忘了通知小弟哦(contactyang@163.com)
好久没有更新了,昨天在VMware上安装了一个虚拟的局域网,并在其上 配置了NFS和NIS,以及公司的集群产品LSF
Are you trying to build software that is composed by software components provided by large companies, and still name it a system?
Are you doing the job anybody can do if given enough time to read the technical handbooks and rebuild the system or you have created something?
If you are in the same situation, you are probably a coder instead of a programmer.
I must be an extremely patient user of Linux, for I have been trying to install all versions of Linux distributions lately, and getting used to the shell commands.
I also read some books on the subject. To be honest, it is true that the command lines are more efficient, and this can be verified by the following calculation:
Suppose a mouse have 3 keys, and the keyboard ten times more. The three key mouse can generate actions 3^2 when clicked 2 times, while the keyborad 30^2. Come on, no matter we clicked the keyboard or the mouse, we just clicked 2 times.
摘要: 在 Java SE 6 所提供的诸多新特性和改进中,值得一提的是为 Java 程序提供数据库访问机制的 JDBC 版本升级到了 4.0, 这个以 JSR-221 为代号的版本 , 提供了更加便利的代码编写机制及柔性 , 并且支持更多的数据类型 . 在本文中,我们将从编码的易用性及柔性的角度探讨 JDBC 4.0 所带来的新特性及改进。
JDBC 4.0 的新特性
JDBC 4.0 文档列举了 20 个改进及新特性 , 大小不等 . 本文无法做到尽述其详 , 为此笔者根据其功能特点及应用领域将其分为下述四类:
1. 驱动及连接管理
2. 异常处理
3. 数据类型支持
4. API 的变化
本文按照上述四类展开详述
阅读全文
Zarar Siddiqi写了一篇题为"
Are JSPs Dead?,"的文章,文中不无夸张地建议,JSP技术应该也许根本不该出现在JavaEE开发的前沿阵地上,或许仅仅是ASP的原因吧.他说:
JSP给Java的应用的重用所带来的阻碍是巨大的, J2EE中并没有提供这种机制.而如果你非要这么做的话,则必然以牺牲其他模块或应用的更大的可重用性为代价。对于容器的高度依赖导致了对SE的重用不可实现,同时测试工作也变得举步维艰,您或许不得不建立一些Mock对象来观察结果.JSP和Servlet一对一的绑定,对我来说也不是什么有趣的事情,后台对JSP编译为Java类的处理也毫无意义. 既然可以通过Servlet为网页直接服务,为什么还要多余的推出一种混合的技术呢?
如果您还在考虑用JSP做您的MVC模型中的V部分来开发哪怕是一个中等大小的应用,您已经在犯严重的错误了。特别是,如果您的JSP仅仅作为视图显示的时候(页面中没有实际代码,只有taglibs),因为,您甚至连它仅有的“优点”——内嵌Java代码都没有应用。如果您是那种认为标签库没有想象中那么糟的人,那么您还是可以使用页面脚本,以此来生产您认为合格的软件。您已经无药可救了。
Zarar建议使用Freemarker, Velocity, 以及AJAX 来替换JSP.
这实在是种有趣的想法, 因为不论我们喜欢与否 (Zarar显然属于“否”的行列) JSPs是Java EE中默认的显示技术. JSP是否称职呢? 是否还有其他的可以成为标准的技术呢? 您又在应用何种技术呢? 为什么? (那些还被迫夹在陈旧的项目的中的,仍在使用Struts 1.1和JSPs的“可怜”的朋友们呢?)
摘要: 本文通过几段可以运行的代码示例,让大家在20分钟之内掌握Spring的IoC,AOP这些不易理解的概念
阅读全文
最近学业太过紧张,都没有时间更新blog了,等忙完了这一阵吧。
现在我学习的主打有两个截然不同的方向。一个是工作流技术,一个是移动计算技术。
前一个是我从本科起就一直在搞得东西,想一直钻研下去,多翻译一些,原创一些这方面的文章。
另一方面先在,移动计算方兴未艾,可以预见在不远的将来必定是移动计算的世界。
其实,这两个方向到也是不矛盾的,一个客户端,一个服务器。
记得很久以前,曾经看过一篇帖子说,“完全使用
Linux
,脱离
Windows
”,在最近的一个月时间里,我尝试了这种做法。结论让我不得不说:
Linux
如果作为桌面来使用的话,还远远没有到达实用的程度。
作为开发环境和服务器倒是非常不错的,因此我把
Linux
配置成了一个开发工具,而用
Windows
来娱乐。
vi nano emacs anjuta eclipse都是非常好的编辑开发工具。
现在Java技术在全世界很流行,Java的一个优点是程序员很不容易被一种技术所束缚,而技术的成长在与经验的交流和不断的学习。
欢迎高手和未来的高手,有志于实现四个现代化的青壮年加入技术讨论群:26839664。
我们讨论: Java,Python,Unix/ linux下的C/C++,PHP, Perl,SOA,Web Services,架构,模式,框架,DB,Workflow...
摘要: 原作:Joseph Ottinger, 来自近日的theServerSide,本文是译文。
原作网址:http://www.theserverside.com/news/thread.tss?thread_id=42598
Empathy Box在blog中介绍了编程应该注意的5个问题,这篇文章实际表述了编程时应引起注意的很重要的6个思想
阅读全文
摘要: 做了一个登陆验证码的生成小程序,或许对大家有用。支持背景图和文字旋转
阅读全文