1、介绍
通过证书验证用户身份(浏览器),其核心是利用cookie实现http和https的信息共享(同域名)。如http://test.abc.com/app/index.html 发现未验证后,跳转到https://test.abc.com:443/app/checkCrt.html身份验证,要求出去证书,确认后将身份信息带入http请求头部,跳转到原请求页面(http://test.abc.com/app/index.html ),读取身份信息后进入页面(出于安全考虑Cookie需要加密)。
流程图
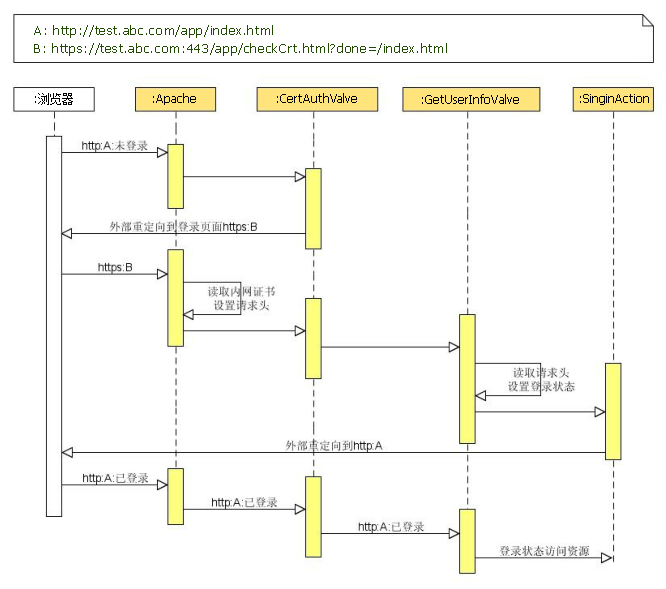
流程说明:
登录流程详细介绍:
1). 未登录用户访问页面 如:http://test.abc.com/app/index.html
2). 【CertAuthValve】判断是否访问受限制资源,如访问受限制的资源则判断用户身份是否已验证,未验证则将用户重定向到身份验证页面,原始请求的url做为
query的一部分,登录成功后可以跳转回来, 如:https://test.abc.com:443/app/checkCrt.htm?done=/index.html。
3). 【CertAuthValve】对于https请求,apache读取请求提供的用户证书,获取证书中的邮件地址,并将该信息写入请求头中。
4). 【GetUserInfoValve】读取请求头,获取刚刚设置的用户邮件地址信息,进一步获取用户的详细信息,然后将这些信息加密后放入cookie中。
5). 登录完成,将用户外部重定向回原始页面。
2、具体实现
1)、安装apache、ssh、java、jboss等环境,略。
2)、生成服务证书和服务密码
openssl req -new -x509 -nodes -out /home/admin/app/conf/ssl.crt/server.crt -keyout /home/admin/app/conf/ssl.crt/server.key -days 3600
因为要和内网证书交互,所以需要一个内网证书公钥文件,可以通过以下方式获取:
获取方法:IE->工具->Internet选项->内容->证书->受信任的根证书颁发机构,找到intranet行,点击导出,选择下一步,选择Base64编码X.509,将证书文件保存为intranet-ca.crt,拷贝到目录/home/admin/app/conf/ssl.crt/。
3)、apache(httpd.conf)配置
应用和身份验证页面放在一起,所以需要同时配置两个虚拟主机,同时监听80(处理http请求)、443(处理https请求)端口。
#监听端口Listen 80Listen 443#app的虚拟主机配置NameVirtualHost *:80
<VirtualHost *:80>
ServerAdmin sa@abc.com
ServerName test.abc.com
DocumentRoot /home/admin/app/target/app/htdocs/
</VirtualHost>#身份验证的虚拟主机配置NameVirtualHost *:443
<VirtualHost *:443>
ServerAdmin sa@abc.com
ServerName test.abc.com
DocumentRoot /home/admin/app/target/app/htdocs/
SSLEngine on
SSLCipherSuite ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+SSLv3:+EXP:+eNULL
#该指令为虚拟主机指定证书文件名。
SSLCertificateFile /home/
admin/app/conf/ssl.crt/server.crt
#该指令为证书指定一个对应的私钥文件
SSLCertificateKeyFile /home
/admin/app/conf/ssl.crt/server.key
#该指令为指定一个包含Certificate Authority证书的文件
SSLCACertificateFile /home/admin/app/conf/ssl.crt/intranet-ca.cer
SSLProxyEngine on
RewriteEngine on
#设置客户端证书验证为必须
SSLVerifyClient require
#因为一个CA证书能够被另一个CA证书验证,所以可以形成一个CA证书链.使用该指令可指定服务器验证用户证书时可以查找多少个CA证明。
#设置认证深度:一般用默认10。
SSLVerifyDepth 10
#把mod_ssl里的变量变为全局环境的变量
RequestHeader unset SSL_CLIENT_S_DN_Email
RequestHeader add SSL_CLIENT_S_DN_Email %{SSL_CLIENT_S_DN_Email}e
</VirtualHost>
4)、代码片段
//CertAuthValve.java
//判断session中是否有用户邮箱地址
SessionValue session = SessionHelper.getSessionValue(rundata);
if (StringUtil.isNotEmpty(session.getCropEmail())) {
return null;
}
// 从内网证书中获取用户邮箱地址: SSL_CLIENT_S_DN_Email
String cropEmail = rundata.getRequest().getHeader(SSL_CLIENT_HEADER_MAIL);
if (StringUtil.isNotEmpty(cropEmail)) {
//将邮箱地址保存到session
session.setCropEmail(cropEmail);
SessionHelper.saveSessionValue(rundata, session);
if (log.isDebugEnabled()) {
log.debug("用户" + session.getCropEmail() + "已经通过证书验证");
}
return null;
}
URIBrokerService uriBrokerService = (URIBrokerService) getWebxComponent().getService(
URIBrokerService.SERVICE_NAME);
URIBroker noPermissionUriBroker = uriBrokerService.getURIBroker(CHECK_CRT_URL);
//请求的原始URL & 验证的URL
String requestPath = rundata.getPathInfo().replace("_", "");
String checkCrtUrl = (String) noPermissionUriBroker.getPath().get(
noPermissionUriBroker.getPath().size() - 1);
try {
//原始请求判断
if (requestPath.equalsIgnoreCase(checkCrtUrl)) {
//当前是https请求,但是依然不能得到证书信息,转到禁止页面
//(要将禁止页面加入到允许访问的配置文件中,不然会导致循环重定向)
URIBroker uriBroker = uriBrokerService.getURIBroker("forbidden");
rundata.setRedirectLocation(uriBroker.render());
} else {
//转到证书验证页面
rundata.setRedirectLocation(noPermissionUriBroker.render() + "?done=" + rundata.getPathInfo());
}
} catch (IOException e) {
log.error("权限验证重定向出错", e);
}
return new BreakPipeline();
//GetUserInfoValve.java
Object user = rundata.getSession().getAttribute("userInfo");
if (user == null) {
SessionValue session = SessionHelper.getSessionValue(rundata);
String email = session.getCropEmail();
Employe employe = PersonInfoUtil.getPersonInfoByEmail(email);
// 写入cookie
session.setEmployeeId(employe.getEmployeId());
session.setName(employe.getName());
session.setCropEmail(employe.getEmail());
SessionHelper.saveSessionValue(rundata, session);
}
采集到花瓣
posted @
2011-12-09 16:09 josson 阅读(2480) |
评论 (0) |
编辑 收藏
受限于证书的原因,以前经常不得已用IE打开一些应用。其实有一工具可以帮助我们导出IE证书,用于firefox,解决证书的困惑。
采集到花瓣
posted @
2011-12-09 13:54 josson 阅读(3160) |
评论 (1) |
编辑 收藏 互联网的产品大都是面向海量用户的服务,且用户分布区域广泛,其教育水平、习惯也大多不同,具有高度不确定性,我们必须非常关注用户的行为和反馈。因而,在互联网产品服务的整个用户研究,需求分析、产品研发及交付服务的过程中,都采用探索式、适应性的研发理念进行产品的研发。通常,会把整个产品研发周期划分为若干个迭代,采用迭代式的演进过程,不断的去交付新的产品特性,并通过观察用户的行为和反馈获取,进而随时调整产品的思路和方向。一切以用户价值为核心是互联网产品最核心的特点,而以价值驱动的敏捷开发方法非常符合这一特点。
一、敏捷项目管理实践 
从阿里软件开始,内贸团队就一直在实行着敏捷项目管理实践,通过小步快跑,快速迭代、增量交付用户价值,不断获取用户反馈,持续、快速的调整产品,验证并适合用户价值。正是通过这些实践活动,我们以迭代的、增量的交付用户价值,最大限度的保证产品朝着符合用户实际需求方向发展。目前,在内贸团队应用较成熟的敏捷实践活动有:
1)、迭代计划(Sprint Planning Meeting)
2)、每日晨会(Daily Scrum Meeting) & 任务墙(Task Wall)
3)、功能预演(Spring Review)
4)、项目总结(Retrospect Meeting)
5)、结对编程(Pair Programming)
6)、其他技术实践活动等
二、敏捷团队
1)、自组织文化
如google、facebook等互联网企业,他们很少甚至没有特定的项目流程,通常怎么敏捷怎么做,具有浓厚的工程师驱动文化。我们则有较完整的开发流程指导和规范我们的项目研发工作,相比而言,丧失了一些灵活性和积极性,不利于我们工程师自我管理、自我驱动意识的培养。臃肿、缺乏灵活性的流程同互联网产品快速更新、快速发展是不相适应的,同时也弱化我们的责任心意识。除了遵守详尽的流程,我们是否可以换个角度、换种方法,提倡和营造一种自我管理、自我驱动的开发文化,省却一些并不能给我们带来帮助却影响效率的流程呢?
敏捷团队的自组织特性弱化了团队技术领导这个角色,强调自我管理和自我驱动。虽然这对工程师的素质要求更高,相对技术能力更难提高。但是,团队导向很重要,我们努力营造这样的氛围,从小团队做起,逐渐锻炼和培养自组织团队。相信在这样的开发氛围下,会让我们做的更高效、更敏捷,可以走的更稳、更远。
2)、追求一体化
一体化团队作为敏捷开发方法中最具精益思想基因的实践,是指每个项目团队包括分析,开发,测试等角色,使团队满足一个需求从设计,开发到测试各个阶段顺利完成,达到符合质量标准并满足需求的软件。这种以项目/产品为单位的虚拟团队,坐在一起,全身心的为共同的目标而努力,可以更好的凝聚项目组中的各种角色,消除部门墙。
3)、追求全功能
这里所指的全功能是希望项目团队能打破工程师角色之间的边界,如研发、测试和前端工程师的界线,消除开发、测试流程中一些潜在浪费,提高效率。在项目团队内部通过角色互换,不限角色的结对工作,加强不同角色,不同模块间的知识传递,打破技术壁垒,帮助员工从不同视角理解项目,锻炼技能,进而增加团队均衡生产的能力。
为什么要提倡打破边界?项目整体效率依赖于项目过程中各环节的工作效率,而整体效率的优化往往依赖于均衡生产(精益思想的按需生产),即消除生产的波峰(过度生产)和波谷(生产不足),只有局部效率的增加无法直接转换为整体效率的增加(就象桶能装多少水,决定于最短的那块板)。整体效率的优化要求IT团队消除技能壁垒,培养多面手,根据计划的的变动,弹性地调整任务,达到各角色和流程之间的平衡。
三、质量保证
我们追求开发效率,同时也注重项目质量。如何去保证质量?就象美国的一位教授爱德化.戴明(W.Edwards Deming)所说:“我们应该停止依靠大量检验来保证质量,而是要改进工艺流程,从一开始就生产出优质的产品”。我们要在整个开发过程中多个环节去保证质量。同时,质量保证是整个团队的责任,就如同前面所说的追求全功能团队,打破边界。
至于在哪些环节采用哪些实践,我们先做个分类,按是否能被系统用户感知将质量问题区分内部质量和外部质量。外部质量指能直接被系统用户感知,如运行缓慢,不可操作或是操作复杂就属于外部质量低劣。而不能直接为系统用户所直接感知的要素,对产品键壮性、可维护性有深远影响的问题就属于外部质量,如系统设计的一致性、代码可读性、逻辑完整性等。内部质量对用户的影响比较间接,但比外部质量意义更深远。一般来说,系统内部质量优秀,外部质量仍有可能很差。而内部质量差的系统,外部质量肯定也不怎么样。
1)、外部质量保证
在外部质量保证上,大部分会在开发后期介入,可以通过性能测试、自动化测试及工程师的功能测试来保证,通过这些实践活动发现并保证例如运行缓慢、不可操作等质量问题不会存在。针对交互特别复杂的web应用,可以更多的考虑采用webui自动化测试工具,如selenium、pwaitr(b2b)、automan(淘宝)等,可以很好的完成那些简单、重复的TC用例,可以大大提高测试效率,解决测试工程师的资源瓶颈。
2)、内部质量保证
相对于外部质量,内部质量问题影响更为深远,在开发开始阶段就应该去保证。如通过单元测试、静态代码扫描(PMD\findbugs)、持续集成、重构、结对编程、code review等多种实践活动来保证项目代码的健康。
除了一些实践活动去检查代码质量外,更为重要的是研发工程师对内部质量的重视,如果工程师没有形成良好的质量意识,很可能这些实践也只是停留于形式,并不能带来较好的结果。如我们在开发过程中的编码规范、单元测试的质量及覆盖率,code review的及时性及问题是否持续跟进等等。此外,有选择的采用结对编程实践,有助于质量的提高。
本文以敏捷、精益(消除浪费、按需生产)思想的角度试图去探讨一种适合互联网公司的产品开发体系,上述概要的介绍了项目管理、团队、质量方面的一些敏捷实践活动,主要涉及了我们对敏捷方面的经验分享或者是些正在研究探讨的课题。文中涉及的实践活动,后续我将逐一展开详细介绍,帮助大家更好的理解和认识。希望本文的分享能成为一个引子,引起大家对敏捷开发的思考和讨论,或者更好的了解敏捷和精益思想。
posted @
2011-06-13 15:53 josson 阅读(569) |
评论 (0) |
编辑 收藏 以下为本人在公司内部关于项目质量和工作效率邮件回复的一此意见和想法。
1、 谈流程
不可否认流程的重要性,但我们需要根据具合格情况分析,不断的梳理和优化我们的流程,让流程更好的指导我们工作,而不是束缚。目前,我们的流程慢慢多了起来,感觉不如以前敏捷了。经过rpm改造后,无论在测试环节还是发布阶段,较之前失去了很大的灵活性。测试阶段,开发bugfix后想在测试环境验证,每次必须重走aone的流程及打包布署,相比之前的build效率真的差了好多。当然,也许是我们项目组对这个流程熟练度、方法还不够,很多环节有待改进。
发布阶段,目前统一由SCM来发布,必然会导致开发对线上环境及发流程更加陌生,同我们提倡的打破边界,敏捷响应有些相背。再者,SCM资源有限的原因,要支持ITU众多产品线,能否应付的过来,始终是个问题。发布统一管理有好处,同样也带来了弊端,ITU不同于网站,大多数的技术团队共同在维护在几个应用,而itu的应用多、规模相对小、环境各异,这样的产品线采用统一管理性价比不高。希望相应的owner,能不定期的搜集各产品线的意见和反馈,不断的优化,让我们的流程更合理。
2、 谈自测
我们团队一直在强调自测意识,也在这方面不断的总结和改进。我觉的要提高自测,首先应让每位开发同学形成较好的自测意识,而不是自上而下的命令式管理,只有自己有这方面的意,才会去思考、去想办法,去实践。再者,需要PM或技术经理去思考,目前阶段实行自测会有什么困难,如没有系统的自测方法、时间不充足(需要熟悉下阶段的UC、下迭代的设计、单元测试补写等),找到这些困难或问题,就容易对症下药了。最后,不断总结和积累自测方式,优化项目流程。自测不是一种形式,而要追求效果,开发自测同样需要计划和方法,所以我们需要向QA同学请教,总结过去 bug常犯的错误,整理自己的check项。相信通过这样的一些自测方法,能真正提高我们的项目质量,打破同QA的界线,我们的开发、测试资源比例可以得到更大的优化,将以前开发阶段紧,测试阶段松的状况加以改善,使整个项目过程中的紧张度趋于平缓。
3、 谈故障分
“尽量不要让故障分成为大家包袱,可以考虑被实施产品对事故级和A类才对个人计故障分,B和C类故障分记在主管头上!”,个人也比较支持骆驼的观点。目前大家对线上故障都小心翼翼,大家对质量的意识很高,这当然是好事,但同时带来的影响是效率低了。我的观点是,作为增值服务的互联网产品,我们更需要快速迭代增量提供用户价值,尽快获取用户反馈并改善产品,产品推出的迟早,不仅影响获得回报的时间,还影响到获得价值的多少,错过了一个时间窗口,产品可能就不再有任何价值。所以,我们需要找到一个平衡量点,可接受的质量状况达到最大的效率。
从客户第一角度谈质量,某些时候,客户可以接受服务偶而不可用重启下,却不能接受产品没价值、交互性太差,操作太复杂。所以,对于客户来说什么对他们更重要,就需要我们每个人去分析和评估。所以,我们一味只注重质量,而忽略客户真实需求,那就太悲哀。我的观点是,case by case,带着这样的观点去思考和解决问题。
4、谈敏捷项目团队
从打破边界,我想到了一体化的敏捷项目管理团队,一个目标一致、自我管理的团队,应该具备良好的目标意识和执行力,不仅能管好自己的一亩三分地,同时也能站在项目、团队的角度看待问题。PD出现了问题,开发积极去弥补;开发出现了问题,QA积极去弥补,项目团队的目标非常一致。每位项目组成员一定要把好每一关,万不可把问题向下抛,因为还有开发或QA会把关,所以差不多就行了,这样往往就是灾难的开始。
posted @
2011-05-20 16:39 josson 阅读(524) |
评论 (0) |
编辑 收藏
2010已成为历史,记忆里2010年变化很多、做的很多、收获也很多。2010是个转型期、创业期,从年初开始,就在新的Marking中努力耕耘。前半年,以新产品研发为主;后半年,结合客户使用产品后的反馈,不断的优化和改进产品功能,努力提升产品价值和用户体验。通过大家的努力,几款新产品还是彼受用户欢迎的,最欣喜的是我们提前完成了2010年的KPI目标。
过去的一年,有着太多的痛苦和艰辛,为了新产品的上线,晚上、周未都没了,唯一想的和做的就是确保产品如期上线。过程虽然很艰苦,但大家都努力坚持,齐心协力,确保任务如期完成,我们保持了一贯的说到做到、如期交付的作风。因为这样的磨练,我和我们的团队得到了更多成长。困难并不可怕,熬过去,明天的太阳会更加灿烂。
1、谈谈成长和不足:
1)、职业转型,开发到管理
虽然Team Leader已经做了几年了,但一直停留在项目上,多为管事不管人,对细节问题关注较多,所以之前谈不上管理,只能算是积累些项目管理经验。经过这一年的学习和发展,有了更多的管理意识,逐渐关注团队建设、团队成长,注意给小组成员更多的机会和空间,让他们得到锻炼和成长,承担更多团队或项目中的重要事项,而他们通过完成这些重要任务,不仅得到了磨练,同时在团队中建立了自己的影响力。
放在以前,我会认为有风险,或者自己做更快,更省事,或最有把握的人去。现在想来,以前认识太肤浅了,我们需要的团队战斗力,而不是个别人的能力,若平常不注重团队成员的培养,团队的战斗力永远不行,承担不了关键任务。
谈到成长和培养,团队需要什么样的人呢?作为互联网企业,同一般软件企业不同,产品在推出之前,谁也无法肯定是否会受用户欢迎,只能快速推出,让市场来验证,不断的改进和适应用户的需要。因而,需要我们技术人员也具备技术判断力,改变命令式管理体制下的工作习惯,充分发挥主观能动性和创新意识,共同做好产品。
2)、学会拥抱变化;
2010年变化很多,有些也许对个人、团队没有影响或影响很小,有些直接关系自己或团队,如团队的核心成员不断的被抽调、人员调整、KPI的271考评等,每次的变化都会带来不同的问题。持续输血,新人补允,使团队战斗力大打折扣,很长一段时间非常的纠结和无耐。事情总是具有两面性,往好处看,这对我、对团队也未必是件坏事,没有经验过挫折和磨练,又怎能成佛呢?既然是组织需要或Boss的决定,那就多些理解和支持,支持和协助上级完成也是每个下属的职责;况且,某些变化至少对于一些同学也是件好事,他们有更多的机会和更大的平台去一展才华。
大概人都是喜欢按习惯办事的缘故,每每有变化都觉的很痛苦。我觉的如何拥抱变化关键在于心态,我们需要理性看待变化,多往积极的方向思考,不仅更容易调整好心态,而且可以在变化中吸取经验和教训,鞭策我们成长。
3)、提升项目管理能力
虽然在项目管理知识上没有太多的时间和精力去系统的学习,但通过不断实践和总结,还是有了不少的积累和沉淀,对项目管理有了更多的理解和把握,对敏捷项目管理也有不同的认识,结合团队自身寻找适合我们的实践方式。在项目管理方面,还有很多需要去提升和学习,2011年希望安排更多的时间系统的学习项目管理知识及敏捷项目管理,并结合实际应用到工作中。
4)、提升向上沟通力
在拥抱变化的同时,同样需要理性的分析和积极的向上沟通。在过去,虽然会尽可能的去表达和反馈自己的想法和意见,但我重新审视下,总觉得表达还不够明确或不是那么的到位,或许在表达时还有更好的方式,至少还有提升的必要。向上沟通也是门学问,需要好好研究下。
5)、提升团队建设和辅导能力
相对来说,过去的一年所有的同学都会关注到,但领悟能力和基础较好的同学成长更快,基础稍弱的没有太大变化。显然,平常辅导工作没有做好或做到位,关注程度不够。越是基础差些的同学需要关注和帮助的点越多,需要帮助他们找到不足和问题所在,一起找改进办法,并给予必要的督促和检查,养成好的学习习惯,促进成长。2011年,这方面需要做的还有更多。
2、谈谈2011年的期望
1)、团队
解决目前团队新人多,有效资源少的问题;积极关注和帮助新人溶入团队,熟悉业务,以减少对项目开展的影响;
抓好梯队建设,关注和辅导基础较差同学的,共同制定改进计划和Action,做好必要的监督和指导,促进成长;
2)、能力
系统学习项目管理和敏捷软件开发方面的知识,并应用到项目管理实践中;同时积极参与相关方面的分享和讨论。
3)、影响
推动兴趣小组活动的开展,借开发工具的发展和分享,建立团队在部门或技术部的影响;
鼓励团队成员积极参与技术部的公共事务,提升影响力。
给力2010,加油2011!!!
posted @
2011-02-02 21:46 josson 阅读(360) |
评论 (0) |
编辑 收藏
iteration和release是两个不同的概念,但在敏捷实践活动中,我们往往认识的比较模糊,一个Iteration就是一次release,其实不然。那么,具体有什么区别和联系呢?
Iteration(迭代):在固定的周期内,经过需求分析、设计、实现、测试等活动,完成计划的的业务需求,迭代结束提供一个可工作的产品。计划的业务需求,可能是一个完整的User Story,也可能是一个Story中的若干task。
Release(发布):经过一个或若干个iteration后,完成计划中的所有User Story,经过测试后才release,最终真正交付给客户使用。
在我们的实践活动中,一个User Story所需的工作量超过我们的有效资源,无法安排在一个iteration内。我们就会想当然的会去延长迭代周期,增加有效资源以适应所需工作量。殊不知,这更象是形式上的迭代开发,无异于瀑布式项目开发过程。
2、建立固定的迭代周期,保持稳定的开发节奏
Scurm方法也非常强调稳定的迭代节奏,一个稳定的迭代节奏就如同项目的的心跳。Simon Baker描述说:"就像心脏有规律地跳动来保持身体运行,固定的迭代长度提供了一个恒量,有助于建立开发和交付的节奏。根据我的经验,节奏是帮助取得不变的步幅的重要因素"(2004)。对于敏捷开发的团队而言,稳定的迭代节奏可以让产品保持更稳定的交付。
3、如何保持稳定的开发节奏?
当一个迭代期内可提供的有效资源无法实现一个User Story时,我们如何按排呢? 在 谈迭代周期控制的困惑 中已谈到,这里不在细述。
4、如何选择适合自己团队的迭代周期?
一般需要考虑以下因素:
1)、整个项目周期长度(完成计划的商业需求所需时间)
较短的迭代周期将会有以下一些好处:更频繁的向客户展示/交付可用的软件;更频繁的度量开发进度;更频繁的取得反馈并改进;一般大的项目最好有多次(3次或以上)获取反馈、修正的机会,根据项目周期调整迭代周期长度。
2)、不确定性的多少
不确定性有多种形式,客户到底想要的是什么?小组的工作效率,时间?技术门槛等都不存在不确定性,不确定性越多,迭代就应该越短。
3)、获得反馈的难易程度
指小组获取反馈数量、频度和及时性,视所处的环境不同,选择合适的迭代长度;
4)、优先级要以多久保持不变
开发小组承诺在一次迭代中完成一组特定的功能,重要的是不要改变他们的目标方向,优先级不会被改变的时间长度是选择迭代长度时需要考虑的因素。
5)、迭代的系统开销
每次迭代的成本(时间),如迭代中进行的完整回归测试。最佳迭代周期的目标之一就是减少或近似消除每次迭代的系统开销。如每次回归时间成本很高,那决定周期长度时更倾向于长一些。
6)、团队成员的紧迫感
Niels Malotaux指出:"只要项目的结束日期还在遥远的将来,我们就不会感到任何压力,并从容不迫的工作。当结束日期逼近时,我们才会开始更努力的工作"。意思指项目开始大家比较放松,而越临近结束,工作越忙压力越大。因此,选择一个合适的迭代周期长度,让团队成员在整个迭代过程中感受到的压力更平均,不是给团队更多的压力,而是压力总量平均分布在迭代过程中。
每个团队根据所在环境和条件确定一个合适的迭代长度,一般建议2~4周。在我们的实践中,以2周一次迭代的频率,保持相对稳定的开发和交付的节奏。
5、参考资料:
《敏捷估计与规划》 Mike Cohn
posted @
2011-01-31 14:26 josson 阅读(3478) |
评论 (0) |
编辑 收藏
敏捷宣言中说到:"最好的架构、需求和设计来自于自组织的团队"。在自组织团队中,我们每个人既是团队/项目的管理者,又是执行者,要取得优异的结果,必须加强自我管理。
如何做好自我管理呢?
1、平和的心态:我们会不断的遇到各类或好事或坏事、或成功或挫折,什么样的心态去对待决定了我们成长的方向及高度,"态度决定一切"。
2、目标感:大到个人职业规划,小到每件事的期望,对于目标(期望)的制定和管理,都需要我们认真的去对待;
3、执行力:目标是方向,不能执行就不会有结果,好的执行力是优秀个人或团队的必要条件。
4、时间管理:工作需要区分轻重缓急,不能对事情没有计划和按排,对事需要分析重要性和紧急程度,分别对待;
5、学习能力:"学历代表过去,能力代表现在,学习能力代表将来。",一个人的学习能力决定他将来的成绩;
任何人都不希望自己被人管着,但要想不被人管只有一种办法:时时严格要求自己,主动、出色的完成每项工作,努力学习,与团队共成长。





posted @
2011-01-28 18:56 josson 阅读(300) |
评论 (0) |
编辑 收藏
昨日PM小组例会,谈到了需求评估工作量远大于有效资源情况下,如何保证迭代周期稳定的问题。讨论的内容,对于PM如何控制、保持迭代周期稳定有较大的参考价值。
| |
有效资源 |
评估工作量 |
| 1 |
多 |
少 |
| 2 |
少 |
多 |
| 3 |
相同 |
相同 |
注:
有效资源:指迭代周期内,开发团队所能提供的有效工作日,单位人/天。
评估工作量:指迭代周期内,产品经理提供需要实现的业务需求所评估的工作量之和。
上表描述以固定周期为两周的迭代中,可能会出现的有效资源和评估工作量对比情况。其中,1、3两种情况因为评估工作量小于或等同能提供的有效资源,所以不会影响迭代周期。重点需讨论的是有效资源小于评估工作量时,如何保持固定周期?
例举:一迭代周期,能提供有效资源20人/天,需求评估工作量30人/天。
1、功能较独立,需求不能拆分发布;
安排一个release,两个iterative。这种情况需要在迭代2中附加一些技术改造或低优先级的小需求、bugfix,release日期相对会慢几天。
2、一个迭代中包括多个产品的需求(需要各位产品经理协商,决定需求优先级);
a)、以保证质量为重:
忽略商业优先级,先处理一个迭代中就能全部完成的需求。
b)、保证价值
分两个迭代完成,一次release。
通常情况下,我们尽力保证迭代周期的稳定,但也允许例外,如:商业需求,产品上确定了发布时间点,或者节假期间团队请假比较多,一个迭代所能提供的有效资源相对比较少的情况。
保持迭代周期稳定,其核心是:
固定Timebox和可提供的资源,让产品经理来决定需求的优先级,每迭代只接纳(开发/QA资源)可承受的需求。
posted @
2011-01-13 15:31 josson 阅读(1100) |
评论 (0) |
编辑 收藏
对于互联网行业来说,快速推出产品占领市场、快速检验产品的价值和方向性、快速调整及优化是极期重要的。因此,采用小步快跑、持续迭代的敏捷实践一种不错的项目管理方法。我们团队在敏捷项目管理方面持续开展了二年多时间,在scrum、xp等敏捷最佳实践的基础上,结合团队自身的基础和条件,不断的偿试和优化,总结和积累了一些经验。目前,这些敏捷项目管理实践在项目组开展情况良好,得到了大多数团队成员的认同,特别是业务方、QA等合作方的认可。
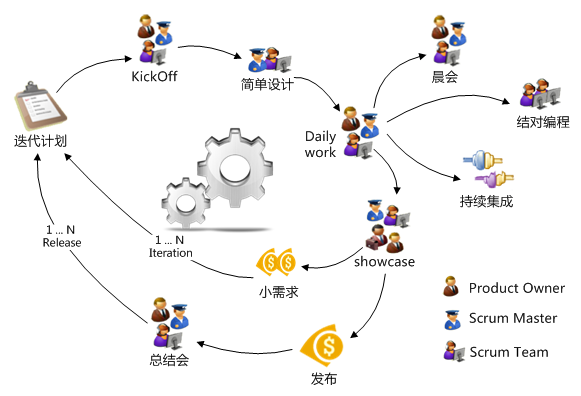
上图描述了一个基本项目迭代流程,其中涉及三个角色,其职责同等于Scrum中的Product Owner、Scrum Master、Scrum Team。迭代流程中分别包含了以下敏捷实践:
1)、迭代计划会议,按商业优先级筛选需求列表,确定本项目需求范围;
2)、确认本次迭代需求、资源、时间的具体情况;
3)、简单设计,对关键技术点进行必要的设计;
4)、晨会;
5)、结对编程;
6)、持续集成;
7)、showcase;
8)、项目总结会;
9)、新迭代的开始... ...
以上具体实践活动内容及组织形式,后续将逐一介绍,敬请关注。
posted @
2010-12-16 15:57 josson 阅读(389) |
评论 (0) |
编辑 收藏1、什么是java序列化
Java
序列化
API
提供一种处理对象序列化的标准机制。序列化(Serialization)是指将java对象用一连串字节描述的一个过程;反序列化(deserialization)是一种将这一串字节构建成一个对象的过程。
2、序列化的作用(必要性)
Java中,一切都是对象,在分布式环境中经常需要将对象从这一端网络或设备传递到另一端。Java
序列化机制就是一种解决在网络两端传输数据的问题而产生的协议。下图表示客户端/服务器之间通信,一个对象是从客户端传送到服务器通过序列化的视图。

3、如何序列化一个对象
为序列化一个对象,你需确保对象类实现Serializable接口。Serializable接口没有方法,只要实现了序列化接口,Class
就能被序列化机制处理。
示例代码,需序列化的java对象:
1 import java.io.Serializable;
2
3 public class TestClassSerial implements Serializable {
4 public byte version = 100;
5 public byte count = 0;
6 }
示例代码,
把TestClassSerial对照象
输出成
Byte
流,存储到
temp.out
文件里:
1 public static void main(String args[]) throws IOException {
2 FileOutputStream fos = null;
3 ObjectOutputStream oos = null;
4 try {
5 fos = new FileOutputStream("c:/temp.out");
6 oos = new ObjectOutputStream(fos);
7 TestClassSerial tcs = new TestClassSerial();
8 oos.writeObject(tcs);
9 oos.flush();
10 }
11 finally {
12 if(oos != null) {
13 oos.close();
14 }
15 if(fos != null) {
16 fos.close();
17 }
18 }
19 }
示例代码,
从持久的文件中读取
Bytes
重建对象:
1 public static void main1(String args[]) throws IOException {
2 FileInputStream fis = null;
3 ObjectInputStream oin = null;
4 try {
5 fis = new FileInputStream("c:/temp.out");
6 oin = new ObjectInputStream(fis);
7 TestClassSerial tcs = (TestClassSerial) oin.readObject();
8 System.out.println("version="+tcs.version);
9 }
10 finally {
11 if(fis != null) {
12 fis.close();
13 }
14 if(oin != null) {
15 oin.close();
16 }
17 }
18 }
执行结果为:100.
4、对象的序列化格式
TestClassSerial对象序列化输出的
temp.out
文件,以
16
进制方式显示,内容如下:
AC ED 00 05 73 72 00 0A 53 65 72 69 61 6C 54 65
73 74 A0 0C 34 00 FE B1 DD F9 02 00 02 42 00 05
63 6F 75 6E 74 42 00 07 76 65 72 73 69 6F 6E 78
70 00 64
这些二进制字节就是用来描述序列化以后的TestClassSerial对象的,我们注意到
TestSerial
类中只有两个域:
1 public byte version = 100;
2 public byte count = 0;
都是
byte
型,理论上存储这两个域只需要
2
个
byte
,但是实际上
temp.out
占据空间为
51bytes
,也就是说除了数据以外,还包括了对序列化对象的其他描述。
5、Java
的序列化算法
序列化算法一般会按步骤做如下事情:
1、将对象实例相关的类的元数据输出;
2、递归地输出类的超类元数据描述直到不再有超类;
3、类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值;
4、从上至下递归输出实例的数据;
更多序例化事例及二进制字节含义参考文档:http://my.oschina.net/god/blog/1291
posted @
2010-12-16 14:52 josson 阅读(856) |
评论 (0) |
编辑 收藏
1、员工激励
通过各种外部或内部的刺激,以激发员工的需要、动机、欲望,调动人的工作积极性,充分挖掘潜力,全力达到预期目标的过程。
2、激励形式、方法:
广义的分物质激励和精神激励(职务、荣誉、目标、信任、情感等)。

3、原则:
1)、精神激励为主;
2)、只激励该激励的人;
3)、只激励该激励的事;
4)、激励方法、手段因人而异,把握按需激励;
5)、鼓励公开竞争、和谐竞争;
4、案例:
1)、压力非常大的时候,采用激励手段 -- 目标激励
2)、当前员工不开心,采用的手段 -- 先沟通,明确原因
3)、表现好的员工 -- 信任激励,肯定
4)、推行新方法 -- 目标激励,竞赛
5、附:
马斯洛需求层次理论(Maslow's hierarchy of needs),亦称“基本需求层次理论”,是行为科学的理论之一,由美国心理学家亚伯拉罕·马斯洛于1943年在《人类激励理论》论文中所提出。
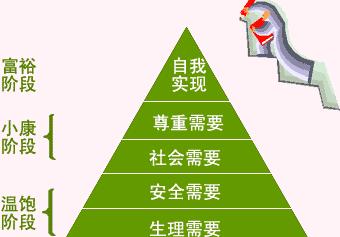
安全、生理需要属于物质性价值需求;社会需要、尊重需要、自我实现属于精神价值需求;
posted @
2010-12-09 16:17 josson 阅读(439) |
评论 (0) |
编辑 收藏
解决冲突的法则
- 在不了解对方动机之前千万不要表明自己的立场
- 准确把握自己的需求底线
- 解决冲突的最好办法是谈判
决策的法则
- 首先,以事实而后数据为依据,如果没有,
- 以严密的逻辑推理为依据,如果没有,
- 以民主评议,如果没有,
- 以最终负责人来决断
奖惩制度
- 在构建奖励制度的同时不要忘记处罚制度的建设
- 物质与非物质的奖励(以非物质的奖励)
- 侧重奖励行为还是结果?
表扬要及时(3天为限)、有理有据、真诚。
表扬是最不花钱最辞旧的激励手段,表扬是为下一个成功设立起点。
不要过度的物质奖励,在这种方式的激励下,员工永远得不到激励。
要注重精神上的奖励,只有精神是永存的。
posted @
2010-11-24 10:31 josson 阅读(449) |
评论 (0) |
编辑 收藏
垃圾收集的目的在于清除不再使用的对象,释放那些不再使用的对象所占用的内存。GC两种常用的方法是引用计数和对象引用遍历,早期的jvm使用引用计数,现在大多数jvm采用对象引用遍历。
1、对象引用计数:
当应用程序创建引用以及引用超出作用域(范围)时,jvm必须适当增减引用数。当某对象的引用数为0时,对象便可以进行垃圾收集。
2、对象引用遍历:
(1)、标记(marking)对象:从一组对象开始,沿着整个对象图上的引用链,递归确定可到达的对象,GC将标记这些可到达的对象。如果某对象不能从这些根对象的一个(至少一个)到达,则表示它可被收集。
(2)、清除(sweeping)对象:GC删除不可到达的对象,删除时,有些GC只是简单的扫描堆栈,删除未标记的对象,并释放它们的内存以生成新的对象。这种方法的问题在于内存会分成好多小段,而它们不足以用于新的对象,但是组合起来却很大。因此,许多gc可以重新组织内存中的对象,并进行压缩(compact),形成可利用的空间。
不一定要将所有的真话讲出来,但你讲的每一句真话必须是真话。(white
lie)
posted @
2010-07-28 14:37 josson 阅读(282) |
评论 (0) |
编辑 收藏最近一个项目主要涉及前端的交互优化,由于UED资源不足,所以一起做了一些前端的工作,
由于各浏览器的标准不一样,如要兼容像ie6,7,8及firefox,样式调整比较费事,现在css相关
的一些技巧分享一下,希望对大家有所帮助。
1、什么是css hack.
针对不同的浏览器去写不同的CSS,让它能够同时兼容不同的浏览器,能在不同的浏览器中也
能得到我们想要的页面效果,这种针对不同的浏览器写不同的CSS code的过程,称之为CSS hack。
通过下表中的hack
code就可以实现不同版本ie浏览器间的兼容:
|
hack code
|
ie6
|
ie7
|
firefox
|
|
_
|
√
|
×
|
×
|
|
*
|
√
|
√
|
×
|
|
!import
|
×
|
√
|
√
|
‘_’ : 只有ie6能识别_,如ie7,8下”width:100px; “的样式是OK,但ie6不够宽时,可以在”width:100px”后面增加一段”_width:105px;” 那么ie7,8不会解析_width:105px,但ie6会执行。
‘*’ : ie6,7都能识别*,但firefox不能识别;
‘!import’ : ie 6不能识别,ie7和ie8都能识别;
2、css调试工具
(1). ie8的调试工具,ie8下按F12能呼出开发人员开发工具,如下图:
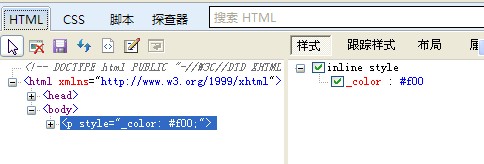
选中图中的箭头鼠标按钮,在浏览器中选中需要优化的HTML对象,HTML窗口就会
定位到选中HTML对象的代码上(如上图左),则右窗口中则显示当前对象的所有样式,
通过对右窗口中的样式调整,达到预期效果后,找到css文件的class,并作相同修
改。通过这个工具,修改样式后所见即所得,确定样式后再修改样式文件。
(2). Firebug,firefox下可以通过Firebug工具,来定位HTML对象并调试该对象的样式,如下图:
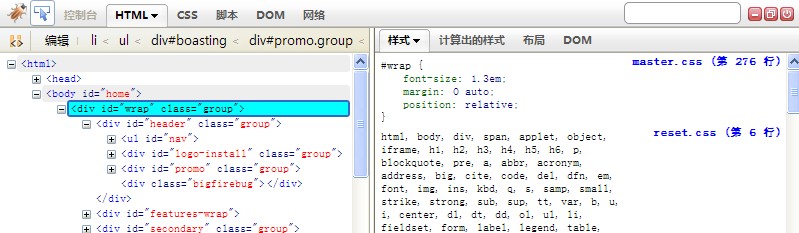
posted @
2010-06-29 11:03 josson 阅读(2272) |
评论 (0) |
编辑 收藏
| 事件 |
解说 |
| 一般事件 |
onclick |
鼠标点击时触发此事件 |
| ondblclick |
鼠标双击时触发此事件 |
| onmousedown |
按下鼠标时触发此事件 |
| onmouseup |
鼠标按下后松开鼠标时触发此事件 |
| onmouseover |
当鼠标移动到某对象范围的上方时触发此事件 |
| onmousemove |
鼠标移动时触发此事件 |
| onmouseout |
当鼠标离开某对象范围时触发此事件 |
| onkeypress |
当键盘上的某个键被按下并且释放时触发此事件. |
| onkeydown |
当键盘上某个按键被按下时触发此事件 |
| onkeyup |
当键盘上某个按键被按放开时触发此事件 |
| 页面相关事件 |
onabort |
图片在下载时被用户中断 |
| onbeforeunload |
当前页面的内容将要被改变时触发此事件 |
| onerror |
出现错误时触发此事件 |
| onload |
页面内容完成时触发此事件 |
| onmove |
浏览器的窗口被移动时触发此事件 |
| onresize |
当浏览器的窗口大小被改变时触发此事件 |
| onscroll |
浏览器的滚动条位置发生变化时触发此事件 |
| onstop |
浏览器的停止按钮被按下时触发此事件或者正在下载的文件被中断 |
| oncontextmenu |
当弹出右键上下文菜单时发生 |
| onunload |
当前页面将被改变时触发此事件 |
| 表单相关事件 |
onblur |
当前元素失去焦点时触发此事件 |
| onchange |
当前元素失去焦点并且元素的内容发生改变而触发此事件 |
| onfocus |
当某个元素获得焦点时触发此事件 |
| onreset |
当表单中RESET的属性被激发时触发此事件 |
| onsubmit |
一个表单被递交时触发此事件 |
posted @
2010-04-11 13:05 josson 阅读(178) |
评论 (0) |
编辑 收藏
1、让用户随时了解系统的状态;
2、系统应与真实世界相符合;
3、给予用户控制权和自主权;
4、提倡一致性和标准化;
5、帮助用户识别、诊断和修复错误;
6、预防错误;
7、依赖识别而不是记忆;
8、强调使用的灵活性及有效性;
9、最小化设计;
10、提供帮助及文档;
posted @
2010-04-11 13:05 josson 阅读(228) |
评论 (0) |
编辑 收藏
1、新建 archetype 项目(模板项目):
mvn archetype:genera -DgroupId=org.simple -DartifactId=simple -DarchetypeArtifactId=maven-archetype-archetype
2、修改主要模板文件:archetype-resources/pom.xml
1)修改 META-INF/maven/archetype.xml 中相关的 sources
2)安装此项目:mvn install
3、根据模板项目创建新项目:
mvn archetype:generate
-DarchetypeGroupId=org.simple\
-DarchetypeArtifactId= simple \
-DarchetypeVersion=1.0-SNAPSHOT
【安装私有库】
1、复制 mylib-1.2.3.jar 到本地代码库
2、编写 mylib-1.2.3.pom 文件:
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.mylib</groupId>
<artifactId>mylib</artifactId>
<version>1.2.3</version>
</project>
如果有依赖关系,可以将依赖关系描述在 pom 中
3、用Ant 来生成 jar 包和 pom 文件的 checksum 文件:
build.xml:
<project default="checksum">
<target name="checksum">
<checksum file="mylib-1.2.3.jar" algorithm="SHA" fileext=".sha1"/>
<checksum file="mylib-1.2.3.pom" algorithm="SHA" fileext=".sha1"/>
</target>
</project>
4、生成 mylib-1.2.3.jar.sha1 和 mylib-1.2.3.pom.sha1 文件
ant build.xml
【使用版本控制】
提交:mvn scm:checkin -Dmessage="Message"
检出:mvn scm:checkout
更新:mvn scm:update
posted @
2010-04-11 13:02 josson 阅读(892) |
评论 (0) |
编辑 收藏
作为一名开发者,通常会忽视系统可用性及用户体验。但系统的可用性和用户体验对于一个真正优秀的Web-based系统却至关重要,因此,我们有必要花一些时间来了解和学习一下。
一、相关的概念:
用户体验,user experience(或称ux/ue),指用户访问或使用一个产品/服务时的全部感受。具有主观性,不同的用户本身的知识、爱好、价值观等会有不同的结果,因人而异。
可用性,指产品是否易学、使用是否有效果,以及通用性是否良好等。衡量一个产品的可用性,可以通过一些具体目标来评判,相对用户体验而言,比较客观。考察产品可用性的目标可分为:
1、可行性,指产品使用的效果;
2、有效性,产品使用的工作效率;
3、安全性,指产品能否安全的使用,或称为容错性;
4、通用性,指产品是否具备良好的通用性;
5、易学性,指产品的是否容易上手,易操作;
6、易记性,指产品的操作方法简单,易记性;
二、开发人员的特点
作为一名开发者,通常会对目标用户的判断有较大的偏差,往往高估实际用户的操作能力和理解能力,忽视产品的易学性和易操作性。再者,作为技术人员,开发工作者通常重视功能实现,忽视产品界面、视觉外观,不重视用户体验。
三、一些案例
1、iPhone的成功
iPhone的成功,产品的可用度及用户体验有者至关重要的作用。其产品的很多细节,都凝聚着apple公司的创新。如3.5吋屏幕上触摸输入,比较费轻且易出错,但iphone在输入过程中,会放大选中的字符,便于用户确认,同时,作一些输入校验,进行容错处理,避免用户输入错误字符引起的麻烦。
2、在线订票、论坛注册
再如个在线订票系统,用户兴冲冲的跑上来想体验一把,千辛万苦输入一大段信息,终于注册成功,想下单的时候,即发现自己有的银行卡不支持,试想此时用户的心情会多么的糟糕。试想一下,如果在用户注册前,提示系统当前支持的银行卡的话,用户可以第一时间选择其他的方式来实现自己的目的。
再谈论坛的会员管理机制,网上这种案例也很多。用户费了好大的劲完成注册后,即告知新注册用户不能立即发言,很可能这个用户就这样失去了。
所以要做好一个产品,需要每位项目成员的投入,从用户角度出度,解决用户的实际问题。
posted @
2009-11-18 11:32 josson 阅读(384) |
评论 (0) |
编辑 收藏Codereivew是开发团队中经常采用的,为提高代码质量、提高编码规范的一种手段。针对实际工作组织review过程中的一些想法、见解,作一下总结。
关于CodeReview的几点作用:
1、提高团队的编码规范,培养良好的coding风格
旨在提高整个团队的编码规范程度,统一编码风格。通过每次的codereivew,发现团队成员在实际开发中的一些细节问题,如不良的编码习惯、错误的调用方式等。通过多次的发现、解决问题,使大家都养成良好的编码习惯。review的内容一般包括:
1)、异常、日志的处理;
2)、常量的定义及使用;
3)、字符串处理、BigDecimal.ZERO等;
4)、代码的封装,提高重用性;
5)、代码注释情况;
6)、javascript文件的抽取情况;
2、检查业务逻辑
对项目实现的功能逻辑进行一次reivew,结合众人发散思维,检查业务逻辑是否有盲点或错误。通常需要参与review的成员能够静下心来深入地认真分析,比较耗费时间。
3、分享和培训
每个项目的工作安排相对来说都是比较紧凑的,所以每个团队成员在完成自己的开发任务完,没有太多的时间去了解或熟悉其他成员的功能实现。但对于敏捷开发来说,每个功能模块的开发者并不是固定的,根据项目需要,很有可能由非原开发人员来完成增值功能或重构,所以codereivew是一次不错的培训及分享机会,特别是对功能相对复杂的需求实现。可以让团队成员了解或熟悉基本的设计思想和相关的类定义,确保在今后接手这一块工作时,可以更快的上手或找到最到最合适的人去了解更深层的逻辑。
关于reivew的方式:
1、集体review;
项目成员一起参与codereive,成本比较大,一般一个项目组织一次。比较适合开发经验分享,以及新功能的实现介绍,利于其他成员了解、熟悉实现者的设计思路及代码结构,在后续项目接手这些新功能时,更加从容。
2、TM组织若干开发经验丰富的一起review;
3、分组、交叉review;
具有较好的灵活性,根据情况随时找相关人员一起对已实现的代码进行review,及时发现过程中问题并予以修正。比较适合分组\抱团开发,以2-3人为单位,对具体的功能模块负责,一起分析、设计、编码,每位成员对于功能逻辑都比较逻辑,对业务逻辑reivew有比较好的效果。
实际工作中,根据实际情况灵活选择合适的review方式,不应拘于某种形式。review过程,应有明确的目的,具有针对性,而不是停留于表面,避免逐渐成为一种负担,流于形式。另外,应对每次review结果,整理出一份问题列表,进行分析和总结,避免相同问题的重复出现。同时,也应按排相关人员跟进并解决问题。总之,通过codereivew这一手段,尽可能的在提交测试之前去发现代码中存在的一些实际问题,从项目经历中得到成长。
posted @
2009-09-20 16:50 josson 阅读(461) |
评论 (0) |
编辑 收藏
因项目需要,实现系统对IE8的支持,安装了ie8版本。安装完后,发现一个奇怪问题,打开一个窗口(window.open方式)后,再打开时,新窗口的页面显示空白,无法加载其内容。关闭ie后,重新偿亦是如此,第一次能打开,第二次就不行。无论是ie7模式,还是兼容模式。
网上搜了很多内容,都没有找相应的解决方案。后来偿试了一下,ie设置重置(工具-Internet选项-高级-重置),删除所有个性化设置,完成后,重试后该问题不再出现,窗口能正常打开。回想,可能是装完ie后,ie设置向导中做了某些不当的设置有关,但具体是哪项尚不得而知。
posted @
2009-09-12 15:01 josson 阅读(4109) |
评论 (2) |
编辑 收藏
在原网页窗口高度根据内容自适应的基础上,做了一些调整:
1、解决窗口底部靠近任务栏时,
window.resizeBy 不能调整窗口高度问题;
1、增加宽度自适功能(注:只针对宽度不足,进行扩展的情况;无法调整窗口宽度比实际内容宽的情况)
Ext.util.ResizeWin = function() {
try {
var sh = document.documentElement.scrollHeight
|| document.body.scrollHeight;
var ch = document.documentElement.clientHeight
|| document.body.clientHeight;
var sw = document.documentElement.scrollWidth
|| document.body.scrollWidth
var cw = document.documentElement.clientWidth
|| document.body.scrollWidth;
var xHeight = 55;//任务栏高度(double).
var statHeigth = 30;//状态栏高度
var maxHeight = window.screen.height - xHeight; //最大可显示网页高度
var wHeight = window.screenTop + sh + statHeigth;
if(wHeight > maxHeight){
//窗口位置过底时,向上移动若干象素,使窗口状态栏在任务栏上面.
var newTop = (window.screenTop - xHeight) + (maxHeight - wHeight);
if(newTop < 0) newTop = 0;
window.moveTo(window.screenLeft, newTop);
}
//宽度调整时,实际内容不够宽可以适用,过宽无法调整.
window.resizeBy((sw-cw),(sh-ch));
}catch (e){}
};
以下从网上收集的一些相关资料:
1、关于网页窗口高、宽示意图:

2、更多属性:
网页可见区域宽:document.body.clientWidth
网页可见区域高:document.body.clientHeight
网页可见区域宽:document.body.offsetWidth (包括边线的宽)
网页可见区域高:document.body.offsetHeight (包括边线的宽)
网页正文全文宽:document.body.scrollWidth
网页正文全文高:document.body.scrollHeight
网页被卷去的高:document.body.scrollTop
网页被卷去的左:document.body.scrollLeft
网页正文部分上:window.screenTop
网页正文部分左:window.screenLeft
屏幕分辨率的高:window.screen.height
屏幕分辨率的宽:window.screen.width
屏幕可用工作区高度:window.screen.availHeight
屏幕可用工作区宽度:window.screen.availWidth
HTML精确定位:scrollLeft,scrollWidth,clientWidth,offsetWidth
scrollHeight: 获取对象的滚动高度。
scrollLeft:设置或获取位于对象左边界和窗口中目前可见内容的最左端之间的距离
scrollTop:设置或获取位于对象最顶端和窗口中可见内容的最顶端之间的距离
scrollWidth:获取对象的滚动宽度
offsetHeight:获取对象相对于版面或由父坐标 offsetParent 属性指定的父坐标的高度
offsetLeft:获取对象相对于版面或由 offsetParent 属性指定的父坐标的计算左侧位置
offsetTop:获取对象相对于版面或由 offsetTop 属性指定的父坐标的计算顶端位置
event.clientX 相对文档的水平座标
event.clientY 相对文档的垂直座标
event.offsetX 相对容器的水平坐标
event.offsetY 相对容器的垂直坐标
document.documentElement.scrollTop 垂直方向滚动的值
event.clientX+document.documentElement.scrollTop 相对文档的水平座标+垂直方向滚动的量
IE,FireFox 差异如下:
IE6.0、FF1.06+:
clientWidth = width + padding
clientHeight = height + padding
offsetWidth = width + padding + border
offsetHeight = height + padding + border
IE5.0/5.5:
clientWidth = width - border
clientHeight = height - border
offsetWidth = width
offsetHeight = height
(需要提一下:CSS中的margin属性,与clientWidth、offsetWidth、clientHeight、offsetHeight均无关)
网页可见区域宽: document.body.clientWidth
网页可见区域高: document.body.clientHeight
网页可见区域宽: document.body.offsetWidth (包括边线的宽)
网页可见区域高: document.body.offsetHeight (包括边线的高)
网页正文全文宽: document.body.scrollWidth
网页正文全文高: document.body.scrollHeight
网页被卷去的高: document.body.scrollTop
网页被卷去的左: document.body.scrollLeft
网页正文部分上: window.screenTop
网页正文部分左: window.screenLeft
屏幕分辨率的高: window.screen.height
屏幕分辨率的宽: window.screen.width
屏幕可用工作区高度: window.screen.availHeight
屏幕可用工作区宽度: window.screen.availWidt
posted @
2009-09-05 18:15 josson 阅读(482) |
评论 (0) |
编辑 收藏
1、ssh 登录linux时,报: ssh_exchange_identification: Connection closed by remote host
google了好一阵,才找到线索。主要由于我前晚写shell脚本调试的时候,误将一些系统文件的宿主为新用户了。后来新的会话怎么都登录不上去了,好在还有一个root登录的会话,找到/var/empty/sshd,修改宿主及权限。
chown -R root:root /var/empty/sshd
chmod 700 /var/empty/sshd
2、su 切换用户,输入密码总是提示:密码不正确。
也是权限问题,root切到其他账号时没有问题;其他账号之间切换就是不行,密码输入也正确。后来其到/bin/su 文件的权限不正确,调整如下解决问题:
-rwsr-xr-x 1 root root 61144 Jul 30 2007 /bin/su
posted @
2009-08-13 18:34 josson 阅读(255) |
评论 (0) |
编辑 收藏
一般业务系统中总会存在一些基础数据,在其他的业务单据中会被套引用。因此,系统必须保证这些被业务单据引用的基础数据不能任意的删除。最常见的做法就是,在删除基础数据时,预先校验该类数据是否在相关业务表中存在,若不存在才允许用户删除,否则给用户以提示。
但这样的处理方法,有些缺点,就是需要编码对每个业务类提供查询方法,或在删除逻辑中增加判断逻辑。因此,每次引用关系变化,增加或减少时免不了要修改原来的逻辑,时间越长,系统的维护成本就越来越高了。因此,有必要对系统进行重构,将这类的处理逻辑进行抽象,单独封装成一个服务,当引用关系有变更时,不用再修改原有逻辑,通过配置就可以完成变更。
通用引用关系查询服务,主要就是通过db表或xml配置文件,对系统中每个基础数据有引用的所有关系进行定义,定义属性主要是引用的表及字段名称。查询时,从配置文件中读取指定类别的引用关系,并逐一查询这些表中的记录,以确定数据是否被引用。这种处理方法的优点为,易扩展、可维护性强,引用关系变更时,仅通过维护配置文件,不必进行编码,就能实现,这样能大大的提高系统的稳定性。
xml配置文件如下:
<rule bizName='product' desc="产品关联项定义">
<item>
<refTable>sale_item</refTable>
<refField>product_id</refField>
<!-- 用于查询条件的扩展,允许为空 -->
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
<item>
<refTable>sale_order_item</refTable>
<refField>product_id</refField>
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
</rule>
<rule bizName='customer' desc="客户关联项定义">
<item>
<refTable>sale_order</refTable>
<refField>cust_id</refField>
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
<item>
<refTable>sale_bill</refTable>
<refField>cust_id</refField>
<extCondition></extCondition>
</item>
... ...
</rule>
通用业务引用查询类代码片段如下:
public class BizReferenceService implements IBizReferenceService {
private static Map<String,List<BizReferenceRule>> ruleMaps;
private static final String PATTERN = "#[\\w]+#";
private static final String CFG_FILE = "bizReferenceRule.xml";
... ...
/**
* 查询指定业务数据是否被其他业务表关联依赖.
* @param bizName 关联业务名称
* @param bizId 关联业务ID.
* @param extParam 扩展条件
* @return true 被关联/false 未被关联.
*/
public boolean isBizReference(String bizName,String bizId,Map<String,Object>extParam) throws ServiceException {
Assert.notNull(bizName, "业务名称不能为空,bizName is NULL。");
Assert.notNull(bizId, "记录ID不能为空,bizId is NULL。");
try {
//逐个检查依赖项是否有数据关联.
List<BizReferenceRule> rules = getBizRelationRule(bizName);
for(BizReferenceRule rule : rules){
StringBuilder sqlBuilder = new StringBuilder();
sqlBuilder.append("select count(*) from ").append(rule.getRelTable()).append(" where ")
.append(rule.getRelField()).append("='").append(bizId).append("' ");
String extConditon = rule.getExtCondition();
if(StringUtil.isNotBlank(extConditon)){
initTenantParam(extParam);
sqlBuilder.append(" and ").append(getExtParamSql(extConditon,extParam));
}
logger.debug(sqlBuilder);
int nCount = bizReferenceDao.getBizRelationCount(sqlBuilder.toString());
if (nCount != 0) return true;
}
return false;
}
catch(Exception ex){
logger.error("调用业务关联服务错误。"+bizName+",bizId:"+bizId+",extParam"+LogUtil.parserBean(extParam),ex);
throw new ServiceException("调用业务关联服务错误。");
}
}
/**
* 组装扩展查询条件的sql
* @param condition
* @param extParam
* @return
* @throws Exception
*/
private String getExtParamSql(String condition,Map<String,Object>extParam) throws Exception {
List<String> paramList = parseDyncParam(condition);
for(String param : paramList){
String simpleParam = simpleName(param);
if(!extParam.containsKey(simpleParam)){
throw new ServiceException("动态参数值未设置! param:"+param+",extParam:"+LogUtil.parserBean(extParam));
}
condition = condition.replaceAll(param, "'"+String.valueOf(extParam.get(simpleParam))+"'");
}
return condition;
}
/**
* 解析扩展查询条件中的动态参数名.
* @param condition
* @return
* @throws Exception
*/
private List<String> parseDyncParam(String condition) throws Exception {
PatternCompiler compiler = new Perl5Compiler();
PatternMatcher matcher = new Perl5Matcher();
MatchResult result = null;
PatternMatcherInput input = null;
List<String> paramList = new ArrayList<String>();
input = new PatternMatcherInput(condition);
Pattern pattern = compiler.compile(PATTERN,Perl5Compiler.CASE_INSENSITIVE_MASK);
while (matcher.contains(input, pattern)){
result = matcher.getMatch();
input.setBeginOffset(result.length());
paramList.add(result.group(0));
}
return paramList;
}
/**
* 获取业务关联查询规则.
*/
private List<BizReferenceRule> getBizRelationRule(String bizName){
Assert.notNull(bizName, "业务名称不能为空,bizName is NULL。");
//配置定义未加载到内存时,读取配置文件
if(ruleMaps == null){
parseRuleConfig();
if(ruleMaps == null) return null;
}
return ruleMaps.get(bizName);
}
/**
* 读取业务关联规则配置文件
*/
@SuppressWarnings("unchecked")
private synchronized void parseRuleConfig(){
if(ruleMaps != null){
return;
}
//解析业务引用定义文件.

}
/**
* 读取Xml文档
* @return
*/
private Document getXmlDocument(){
InputStream is = null;
try {
ClassLoader loader = Thread.currentThread().getContextClassLoader();
is = loader.getResourceAsStream(CFG_FILE);
SAXBuilder sb = new SAXBuilder();
return sb.build(new BufferedInputStream(is));
}
catch(Exception ex) {
logger.error("读取配置文件错误. file:"+CFG_FILE, ex);
return null;
}
finally {
try {
if(is != null){
is.close();
is = null;
}
}
catch(Exception ex) {
logger.error(ex);
}
}
}
}
其他的一些可选处理方法:
b. 在客户表增加引用计数字段;
需额外维护引用计数字段,在引用的业务逻辑增加或删除记录时,需对该字段的数值进行更新。适用于需要直接查询记录被引用次数的场景,但在集群环境下,需注意并发问题。
posted @
2009-07-14 14:42 josson 阅读(419) |
评论 (0) |
编辑 收藏
在IE、FireFox、Netscape等不同的浏览器里,对于document.body 的 clientHeight、offsetHeight 和 scrollHeight 有着不同的含义,比较容易搞混,现整理一下相关的内容:
clientHeight:在上述浏览器中, clientHeight 的含义是一致的,定义为网页内容可视区域的高度,即在浏览器中可以看到网页内容的高度,通常是工具条以下到状态栏以上的整个区域高度,与具体的网页页面内容无关。可以理解为,
在屏幕上通过浏览器窗口所能看到网页内容的高度。
offsetHeight:关于offsetHeight,ie和firefox等不同浏览中意义有所不同,需要加以区别。在ie中,offsetHeight 的取值为 clientHeight加上滚动条及边框的高度;而firefox、netscape中,其取值为是实际网页内容的高度,可能会小于clientHeight。
scrollHeight:scrollHeight都表示浏览器中网页内容的高度,但稍有区别。在ie里为实际网页内容的高度,可以小于 clientHeight;在firefox 中为网页内容高度,最小值等于 clientHeight,即网页实际内容比clientHeight时,取clientHeight。
clientWidth、offsetWidth 和 scrollWidth 的含义与上述内容雷同,不过是高度变成宽度而已。
若希望clientHeight、offsetHeight和scrollHeight三个属性能取值一致的话,可以通过设置DOCTYPE,启用不同的解析器,如:<!DOCTYPE HTML PUBLIC "DTD XHTML 1.0 Transitional">,设置DOCTYPE后,这三个属性都表示实际网页内容的高度。
通过以下HTML代码,可以了解一下这三个属性的含义:
<!DOCTYPE HTML PUBLIC "DTD XHTML 1.0 Transitional"> //设置DOCTYPE
<HTML>
<HEAD>
<TITLE> 测试。 </TITLE>
</HEAD>
<script type='text/javascript'>
window.onload = function(){
var ch = document.body.clientHeight;
var sh = document.body.offsetHeight;
var ssh = document.body.scrollHeight;
alert('clientHeight:'+ch+'; offsetHeight:'+sh+"; scrollHeight:"+ssh);
}
</script>
<BODY style='margin:0px'>
<div style='background-color:#ccc; height:400px; padding:0px'>
text
</div>
</BODY>
</HTML>
根据页面内容调整窗口高度的方法:
Ext.util.ResizeWin = function() {
try {
var sh = document.documentElement.scrollHeight
|| document.body.scrollHeight;
var ch = document.documentElement.clientHeight
|| document.body.clientHeight;
window.resizeBy(0,(sh-ch));
}catch (e){}
};
posted @
2009-06-14 16:48 josson 阅读(1542) |
评论 (0) |
编辑 收藏
我们通常依赖单元测试工具Luntbuild,来发现代码中有许多隐藏的错误或不良的编码,然后再去修正。这样从发现问题,到解决问题花费很多功夫。其实我们可以利用一些java代码分析工具,来及时发现相关的问题。如findbugs,luntbuild就是集成了findbugs插件来发现一些代码上的问题。
findbugs 当前版本为:1.3.9,其下载地址如下(包括eclipse插件):
findbugs :http://findbugs.sourceforge.net/index.html
findbugs for eclipse : http://findbugs.sourceforge.net/downloads.html
documents: http://findbugs.sourceforge.net/manual/
插件安装比较简单,将findbugs for eclipse 插件文件(zip)下载后,直接解压至$eclipse.home$/plugins/目录下,重启eclipse即可使用。你可以通过查看:(eclipse 3.4) about ecliplse platform -> plug-ins details 中找到findbugs 插件安装信息。
Findbugs 的使用:
在Package Explorer或Navigator视图中,选中你的Java项目,右键,可以看到“Find Bugs”菜单项,子菜单项里有“Find Bugs”和“Clear Bug Markers”等项。点击Find Bugs 后,开始分析项目中隐藏的代码问题,发现的问题会在相应的代码行上进行标记,或者在Bug Explorer中显示所有的问题(findbug视图,window -> show view -> others 可以找到Bug Explorer.) 我们就可以根据findbugs发现的问题,进行逐一解决,提高代码质量。
Findbugs 的一些配置说明:
FindBugs是一个基于“Bug Patterns”进行分析并找出Java程序中隐藏的Bugs。打开 Window -> preferences ,对findbugs 的分析规则进行定义,如图:
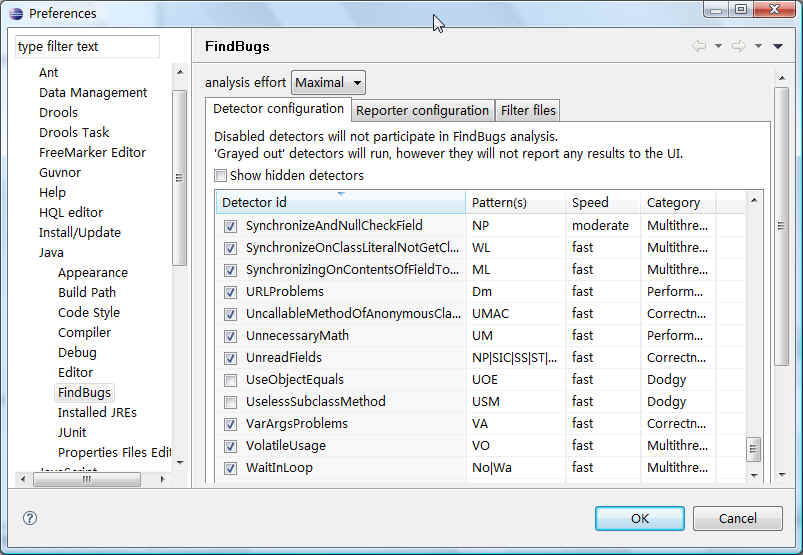
posted @
2009-06-13 23:55 josson 阅读(1275) |
评论 (0) |
编辑 收藏
http://java.decompiler.free.fr/
一个不错的java反编译工具,有gui及eclipse插件。
posted @
2009-05-21 08:34 josson 阅读(268) |
评论 (0) |
编辑 收藏
实现javascript文件压缩的批处理脚本,脚本完成的内容:
1、利用一个windows script 删除js文件中的空白字符及注释;
2、通过gzip.exe 将js文件压缩打包成gzjs文件。gzip.exe 下载地址:
http://www.gzip.org
相关文件请下载附件:
js 压缩批处理 。
使用方法:
a. 双击运行 gzjs.bat ,提示输入javascript文件名(带路径).
b. 输入待压缩的js文件,或者拖动js文件到command窗口(可直接在eclipse视图中拖动js文件到cmd窗口)。
c. 回车后,在js文件所在目录会生成一个相同文件名的gzjs文件。
批处理文件内容如下:
 @echo off
@echo off
if not "%1" == "" (
set JSFILE=%1
goto ZIPING
)
:INPUT_FILENAME
set /P JSFILE=请输入待压缩的JS文件名:
if "%JSFILE%"=="" (
echo ERROR: JS文件名称必须指定!
goto INPUT_FILENAME
)
:ZIPING
set MINJS_FILENAME=c-ziped.js
if not exist %JSFILE% (
echo ERROR: 文件:%JSFILE%不存在!
goto INPUT_FILENAME
)
rem 压缩Javascript文件.
if exist %MINJS_FILENAME% del %MINJS_FILENAME%
CScript /nologo pack.wsf %JSFILE% >> %MINJS_FILENAME%
if not "%ERRORLEVEL%"=="0" (
echo ERROR: JS文件压缩失败:%JSFILE%
goto END
)
rem 打包js文件为.gzjs
gzip -9 %MINJS_FILENAME%
for %%i in ("%JSFILE%") do (
set FILENAME=%%~ni
set JS_FILEPATH=%%~di%%~pi
rem echo %JS_FILEPATH%
)
rem 压缩文件名及重命名的文件名.
set GZIPED_FILE=%FILENAME%.gzjs
set TMP_GZIPED_FILE="%MINJS_FILENAME%.gz"
rem 重命名.
if exist %GZIPED_FILE% del %GZIPED_FILE%
call ren %TMP_GZIPED_FILE% %GZIPED_FILE%
if not "%ERRORLEVEL%"=="0" (
echo ERROR: JS压缩文件打包失败:%TMP_GZIPED_FILE%
goto END
)
rem 移动压缩文件到源目录.
set TARGET_GZJS=%JS_FILEPATH%%GZIPED_FILE%
call move /Y %GZIPED_FILE% %TARGET_GZJS%
echo done. %TARGET_GZJS%
:END
pause
Apache配置,以支持gzjs文件格式(http header的Content-Encoding=gzip):
<FilesMatch "\.gzjs$">
Header add Content-Encoding gzip
</FilesMatch>
posted @
2009-03-19 22:22 josson 阅读(1128) |
评论 (0) |
编辑 收藏
一、Use Case 概述 Use Case,它描述的是一个操作,而不是一个功能。传统的软件模型设计喜欢在需求分析把业务分解成功能模块,这样的弊端就是混淆了需求和设计的界限,因为功能模块的划分牵涉到系统的概要设计。在RUP里面提倡用use case来代替功能模块的划分。与功能模块不同的是,用例是站在用户的角度来分解系统,用户并不想了解系统的内部结构和设计,他们关心的是系统所能提供的服务,即系统是如何去操作的,这就是用例的基本思想。用例模型主要由以下元素组成:
1、参与者(Actor):参与者是与系统发生交互的外部用户、系统或其他硬件设备,参与者可以是人、另一个计算机系统或一些可运行的进程等。
2、用例(Use Case):用例用于表示系统所提供的服务,它定义了系统是如何被参与者所使用的,它描述的是参与者为了使用系统所提供的某一完整功能而与系统之间发生的一段对话。
3、通讯关联(Communication Association) :通讯关联用于表示参与者和用例之间的对应关系,它表示参与者使用了系统中的哪些服务(用例),或者说系统所提供的服务(用例)是被哪些参与者所使用的。
二、用例之间的关系
1、包含(include),将若干用例中一些相同的行为,单独抽象成一个的用例,然后其他用例来包含这个用例。这样避免在多个用例里面重复设计同一个操作,也避免同一个操作在不同的用例里面的描述出现不一致。需要修改的时候,也只需要一个用例,避免修改多个用例出现的不一致和重复工作。例如:银行ATM系统,用户取款、存款时,都会打印凭证,我们将打印凭证抽象出来,取款、存款等操作时包含打印任证这个行为。

2、扩展(extend),扩展是将事件流中一些相对独立并且可选的行为扩展为新的用例,并且在基用例上的扩展点进行扩展。与包含关系不同的是,包含的事件是必须存在的动作,并且该用例的事件流一定要插入到基础用例中;而扩展是提供一些备选动作,可根据条件来决定是否将扩展用例的事件流插入基础用例的事件流中。扩展也可以抽象为基用例的备选流,扩展出来的用例可以让基用例变得更加简练。例如:在通话业务的基础上可扩展一些增值业务,如语音信箱、呼叫转移等。

3、泛化(generalization) ,也叫继承(泛化是分析领域术语,继承是设计和实现领域术语,通常用继承来解决泛化问题)。当多个用例拥有相同的结构、行为时,我们可以把它们的共性部份抽象出来成为父用例,而其他用例作为泛化关系中的子用例。在泛化关系中,子用例是父用例的特殊形式,子用例继承了父用例所有的结构、行为以及关系。例如:订票是网上订票用例和电话订票用例的抽象。

三、建立用例模型
1、确定参与者,可以从以下问题入手:
系统开发完成之后,有哪些人会使用这个系统?
系统需要从哪些人或其他系统中获得数据?
系统会为哪些人或其他系统提供数据?
系统会与哪些其他系统相关联?
系统是由谁来维护和管理的?
2、确定用例,寻找用例可以从以下问题入手(针对每一个参与者):
参与者为什么要使用该系统?
参与者是否会在系统中创建、修改、删除、访问、存储数据?如果是的话,参与者又是如何来完成这些操作的?
参与者是否会将外部的某些事件通知给该系统?
系统是否会将内部的某些事件通知该参与者?
posted @
2009-03-19 22:21 josson 阅读(541) |
评论 (1) |
编辑 收藏UML(统一建模语言 Unified Modeling Language)是一种标准的图形化建模语言,是面向对象分析与设计的一种标准表示。
UML体系统比较复杂,内容较多,我们可以根据实际情况选择性的学习,部份内容可日后再做深入学习。首先了解一下UMl中相关的一些概念:
UML视图
视图只是表达系统某一方面特征的U M L建模组件的子集。按结构划分,描述系统中的结构成员及其相互关系,包括静态视图、用例视图和实现视图。按动态行为划分,描述系统随时间变化的行为,包括状态机视图、活动视图和交互视图。模型管理,说明了模型的分层组织结构,包括模型管理视图。
|
主要的域
|
视图
|
图
|
主要概念
|
|
结构
|
静态视图
|
类图
|
类、关联、泛化、依赖关系、实现、接口
|
|
用例视图
|
用例图
|
用例、角色、关联、扩展、包括、用例泛化
|
|
实现视图
|
构件图
|
构件、接口、依赖关系、实现
|
|
部署视图
|
部署图
|
节点、构件、依赖关系、位置
|
|
状态
|
状态机视图
|
状态图
|
状态、事件、转换、动作
|
|
活动视图
|
活动图
|
状态、活动、完成转换、分叉、结合
|
|
交互视图
|
顺序图
|
交互、对象、消息、激活
|
|
|
协作图
|
协作、交互、协作角色、消息
|
|
模型管理
|
模型管理视图
|
类图
|
包、子系统、模型
|
|
可扩展性
|
所有
|
所有
|
约束、构造型、标记值
|
UML 图
图是一个具体视图的组成部分,由模型元素的符号化的图片组成。UML中包含以下9种:
1、用例图(use-case diagram),用于显示若干角色(actor)以及这些角色与系统提供的用例之间的连接关系。角色代表外部实体,如用户、硬件设备或与系统发生交互的另一个外部系统。
2、类图(class diagram),用来表示系统中的类和类与类之间的关系,是对系统静态结构的描述。
3、对象图,类似于类图,区别在于对象图表示类的对象实例,而不是类。
4、状态图,描述类的所有对象可能具有的状态,以及引起状态变化的事件。
5、序列图,反映若干个对象之间的动态协作关系,也就是随着时间的流逝,对象之间是如何交互的。
6、协作图,其作用同序列图,除了显示消息变化外,协作图还显示对象及其之间的关系。
7、活动图(activity diagram),描述某个操作执行时的活动状况。
8、组件图(component diagram),反应代码的物理结构,可为源代码、二进制文件或可执行文件组件。
9、展开图(deployment diagram),用来显示系统中软件和硬件的物理架构,通常在图中以结点的形式显示实际的计算机和设备,以及各个结点之间的关系。
UML建模工具
1、StarUML http://staruml.sourceforge.net/en/
小巧的建模工具,才20来M,目前版本是 5.0 。是一个韩国人用delphi写的,免费很关键。
2、JUDE http://jude.change-vision.com/jude-web/download/index.html
posted @
2009-03-19 22:21 josson 阅读(345) |
评论 (0) |
编辑 收藏
近日,有同事遇到一个奇怪问题:在开发环境,apache能正常支持中文文件下载,但切换到测试环境就404错误,找不文件,两个环境都是linux系统。我起先怀疑的是linux下需要对apache进行配置,以支持中文名。但研究了一下两个环境的配置,开发环境除apache版本高了点外,并没有其他特殊配置。所以怀疑版本问题,又把开发环境的apache及配置同步到了测试环境,重启依然无效。
折腾半天,基本上可以判定这个问题应该与apache配置和版本无关了。
网上google了一把,有很多关于mod_encoding.so模块实现中文支持和IE浏览器中取消"发送UTF-8 URL"的设置,考虑到开发环境并没有加入额外的module,也没设置IE选项,所以也没在意这些方案,况且这两个方案也不便于生产环境布署或实际应用。
后来,又请教了SA和其他同学,还是没有结果。只能继续摸索,查找原因。通过两个环境的反复比较,终于发现了问题所在:
通过 locale 查看了系统的字符集,开发机上是en_US.UTF-8,而测试机上是zh_CN.GBK;开发机上显示的中文文件名是乱码,测试机上显示正常,但反而显示为乱码的开发机上能被下载,而测试机上显示正常的文件不能被下载。后来,将测试环境的字符集也设为:en_US.UTF-8,并从svn重新迁出了中文名的文件,发现确实可以被读取到。
分析一下原因,ie客户是发送"UTF-8 URL"到apache,apache以utf-8编码的文件名查找相关目录下的文件,如果此时中文文件是以GBK或其他字符集保存时,就无法找到匹配的文件。所以网上说的IE浏览器中取消"发送UTF-8 URL"的设置就有效的说法就可以解释了。
结论:linux环境下apache中文文件下载支持与该文件的字符集有关,只要创建或从svn迁出中文文件文件时,linux系统为UTF-8的字符集,或中文文件名以UTF-8编码的文件,即能被apache正确读取。网上有资料说,apache 2.x 以上版本即支持中文文件名,虽然未经验证,但至少可以肯定apache 2.0.55、2.0.63是没有问题的。
posted @
2009-03-13 21:37 josson 阅读(1191) |
评论 (0) |
编辑 收藏1、常用命令
mvn compile
编译主程序源代码,不会编译test目录的源代码。第一次运行时,会下载相关的依赖包,可能会比较费时。
mvn test-compile
编译测试代码,compile之后会生成target文件夹,主程序编译在classes下面,测试程序放在test-classes下。
mvn test
运行应用程序中的单元测试
mvn site
生成项目相关信息的网站
mvn clean
清除目标目录中的生成结果
mvn package
依据项目生成 jar 文件,打包之前会进行编译,测试。
mvn install
在本地 Repository 中安装 jar。
mvn eclipse:eclipse
生成 Eclipse 项目文件及包引用定义,注意,需确保定义Classpath Variables: M2_REPO,指向本地maven类库目录。
2、pom.xml 说明
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorial.struts2</groupId>
<artifactId>tutorial</artifactId>
<packaging>war</packaging>
<version>1.0-SNAPSHOT</version>
<name>Struts 2 Starter</name>
<url>http://www.myComp.com</url>
<description>Struts 2 Starter</description>
<dependencies>
<!-- Junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
<version>2.5.5</version>
</dependency>
</dependencies>
</project>
说明:
modelversion pom.xml 使用的对象模型版本
groupId 创建项目的组织或团体的唯一 Id
artifactId> 项目唯一Id, 项目名
packaging 打包扩展名(JAR、WAR、EAR)
version 项目版本号
name 显示名,用于生成文档
url 组织站点,用于生成文档
description 项目描述,用于生成文档
dependency之scope 管理依赖部署,取值如下:
compile 缺省值,用于所有阶段,随项目一起发布;
provided 期望JDK、容器或使用者提供此依赖。如servlet.jar;
runtime 只在运行时使用;
test 只在测试时使用,不随项目发布;
system 需显式提供本地jar,不在代码仓库中查找;
3、创建Maven Web项目
mvn archetype:generate -DgroupId=com.demo -DartifactId=web-app -DarchetypeArtifactId=maven-archetype-webapp
groupId 组织名,对应项目的package;artifactId 项目名;archetypeArtifactId 项目类型
posted @
2009-02-27 17:42 josson 阅读(1137) |
评论 (0) |
编辑 收藏
查看/etc/inittab文件,其主要内容如下:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:5:initdefault:
... ...
0:停机(不要设置为启动默认级别)
1:单用户模式
2:多用户,无NFS(如果您没有配置网络,该级别与3一样)
3:完全多用户模式
4:不使用
5:X11图形模式
6:重启(不要设置为启动默认级别)
如果想让系统不用图形模式登陆可将id:5:initdefault: 中的5改为3即可。
2、Linux运行级别
Linux 启动时,运行一个叫做init 的程序,然后由它来启动后面的任务,包括多用户环境,网络等。
那么,到底什么是运行级别呢?简单的说,运行级就是操作系统当前正在运行的功能级别。这个级别从1 到6 ,具有不同的功能。这些级别在/etc/inittab 文件里指定。这个文件是init 程序寻找的主要文件,最先运行的服务是那些放在/etc/rc.d 目录下的文件。
大多数的Linux 发行版本中,启动脚本放在/etc/rc.d/init.d,这些脚本被ln 命令来连接到 /etc/rc.d/rcn.d 目录(这里的n 就是运行级0-6)。如:/etc/rc.d/rc5.d 下面的S10network 就是连接到/etc/rc.d/init.d下的network 脚本的。因此,我们可以知道,rc5.d 下面的文件就是和运行级5 有关的。
3、Samba的自启动
samba安装完后,默认是不会自启动的。通过查看/etc/rc.d/rcn.d/目录下的文件或通过chkconfig命令查询,如:
[alisoft@kplan-dev8 ~]$ ll /etc/rc.d/rc5.d
总用量 272
lrwxrwxrwx 1 root root 22 8月 13 11:17 K30spamassassin -> ../init.d/spamassassin
lrwxrwxrwx 1 root root 13 8月 18 21:59 K35smb -> ../init.d/smb
lrwxrwxrwx 1 root root 19 8月 13 11:17 K35vncserver -> ../init.d/vncserver
lrwxrwxrwx 1 root root 17 8月 13 11:17 S10network -> ../init.d/network
文件开头的S 代表start 就是启动服务,K代表kill。后面的数字10 就是启动的顺序。例如,有S80postfix 文件,80 就是顺序在 10 以后,表示postfix启动需先启动网络。/etc/rc.d/rc5.d/K35smb ,K 代表 kill。标准的Linux运行级别为3 或者5 ,Linux启动时,init 就会执行 K35smb 脚本。
[alisoft@kplan-dev8 ~]$ /sbin/chkconfig --list | grep smb
smb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
0~6 表示运行级别。on 表示启动;off 表示关闭。
要设置Samba自启动,需通过chkconfig命令进行设置:
[alisoft@kplan-dev8 ~]/sbin/chkconfig --level 35 smb on
[alisoft@kplan-dev8 ~]$ /sbin/chkconfig --list | grep smb
smb 0:off 1:off 2:off 3:on 4:off 5:on 6:off
Linux系统运行级别为3 或者5时,系统就会自启动Samba服务。
posted @
2009-01-07 11:14 josson 阅读(4453) |
评论 (2) |
编辑 收藏
在K-system中,需通过域名来访问,在各个测试环境及开发环境中访问时,需在本地做hosts域名绑定。这在开发、测试过程中就会经常的修改hosts文件,来完成在开发、测试、预发及正式环境之间切换。修改hosts文件并不是件复杂的事,但频繁的修改,也是挺累人的事。因此,写个批处理,自动完成环境域名绑定的工作,也可以省不少心。
域名绑定,包括k-system的域名及依赖环境的域名(如AEP、支付宝等)。不同的开发、测试环境只需变更k-system的变更,依赖环境的域名相同;预发环境只需绑定k-system的域名,不需依赖环境的域名绑定;生产环境则取消所有的域名绑定。基于此,一个hosts文件可分成几个部份:与K-system无关的其他域名绑定;K-system依赖环境的域名绑定;预发环境K-system域名的绑定;开发、测试环境的K-system域名绑定。
根据上述分析,预定义若干hosts文件,分别对应上述列的几部份内容。为每个环境建一个批处理文件,根据环境需要将这些预定义的hosts文件进行组合,并动态替换系统的hosts(C:\WINDOWS\system32\drivers\etc)文件。同时,调用IE,打开K-system登录页面。这样,通过一个批处理,可以很方便的在各个环境中切换,免去经常要去编辑hosts文件的烦扰。
考虑到开发和测试会在多个本地测试环境切换,建立过多的批处理也不是个好办法。这时,可以考虑将本地开发、测试环境的切换用同一个脚本实现,不同的环境由用户提供运行参数来指定。如:"test_env.bat 10.2.225.87",则表示将K-system环境切换到87服务器。
部份批处理内容如下,test_env.bat:
@echo off
rem 根据实际情况,修改windows的安装目录
set WIN_DIR=C:\WINDOWS
echo 生成测试hosts文件.
if exist .env_temp del .env_temp
if "%1"=="" (
type inc\local.default >> .env_temp
goto endl
)
echo #FI 开发、测试环境 >> .env_temp
rem 指定其他的IP
echo %1 fi.alisoft.com image.alisoft.com >> .env_temp
:endl
rem 合并hosts文件
call inc\merger.bat env.host inc\.env_base inc\.env_local .env_temp
rem 备份系统的hosts
set SYS_HOST=%WIN_DIR%\system32\drivers\etc\hosts
set SYS_HOST_BAK=%SYS_HOST%-bak0
if not exist %SYS_HOST_BAK% (
copy %SYS_HOST% %SYS_HOST_BAK%
)
rem 复制hosts文件到系统目录
move env.host %SYS_HOST%
del .env_temp
rem 打开浏览器.
call cmd /c start iexplore https://fi.alisoft.com
echo done!
文件合并批处理 merger.bat:
@echo off
set output=%1
if exist %output% del %output%
:getfile
shift
if "%1"=="" goto end
type %1 >> %output%
goto getfile
:end
set todir=
posted @
2008-12-24 15:09 josson 阅读(649) |
评论 (0) |
编辑 收藏
我们的项目都是基于https协议访问的,由于费用问题,在开发、测试环境中使了一个过期证书。所以每天得面对浏览器提示证书过期问题,若只是页面访问,多确认一下就完了,但遇到系统间的页面跳转、互相调用,就玩不转了。没折,干脆自已做证书。
通过Openssl建立根证书和服务器证书,并用根证书对服务器证书进行签名。
1、使用Openssl的CA脚本来建立根证书(/usr/share/ssl/misc/CA)
运行CA -newca,Openssl会找CA自己的私有密钥密码文件。如果没有这个文件?按回车会自动创建,输入密码来保护这个密码文件。之后会提示你输入公司信息来做CA.crt文件。最后,在当前目录下多了一个demoCA目录,demoCA/private/cakey.pem就是CA的key文件了,而demoCA/cacert.pem就是CA的crt文件了。具体如下:
[root@xplan-dev8 ca]# ./CA -newca
CA certificate filename (or enter to create)
Making CA certificate
Generating a 1024 bit RSA private key
.++++++
++++++
writing new private key to './demoCA/private/./cakey.pem'
Enter PEM pass phrase:
Verifying - Enter PEM pass phrase:
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [GB]:CN
State or Province Name (full name) [Berkshire]:Zhejiang
Locality Name (eg, city) [Newbury]:Hangzhou
Organization Name (eg, company) [My Company Ltd]:Mysoft.com corpration
Organizational Unit Name (eg, section) []:Mysoft.com
Common Name (eg, your name or your server's hostname) []:Mysoft.com
Email Address []:
2、生成服务器证书
生成服务器私钥Key文件,openssl genrsa -des3 -out server.key 1024,并输入保护密码:
[root@xplan-dev8 ca]# openssl genrsa -des3 -out server.key 1024
Generating RSA private key, 1024 bit long modulus
..++++++
..++++++
e is 65537 (0x10001)
Enter pass phrase for server.key:
Verifying - Enter pass phrase for server.key:
生成服务器证书(注:输入Common Name一项时,若需对泛域名支持证书时,需用*.mysoft.com):
[root@xplan-dev8 ca]# openssl req -new -key server.key -out server.csr -days 365
Enter pass phrase for server.key:
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [GB]:CN
State or Province Name (full name) [Berkshire]:Zhejiang
Locality Name (eg, city) [Newbury]:Hangzhou
Organization Name (eg, company) [My Company Ltd]:Mysoft.com
Organizational Unit Name (eg, section) []:Mysoft.com
Common Name (eg, your name or your server's hostname) []:*.mysoft.com
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
3、用根证书对服务器证书进行签名
把server.crt文件重命名成newreq.pem,然后用CA脚本进行签名,期间会提示要求输入cakey.pem的保护密码。
[root@xplan-dev8 ca]# mv server.csr newreq.pem
[root@xplan-dev8 ca]# ./CA -sign
Using configuration from /usr/share/ssl/openssl.cnf
Enter pass phrase for ./demoCA/private/cakey.pem:
Check that the request matches the signature
Signature ok
Certificate Details:
Serial Number: 1 (0x1)
Validity
Not Before: Dec 8 12:27:14 2008 GMT
Not After : Dec 8 12:27:14 2009 GMT
Subject:
countryName = CN
stateOrProvinceName = Zhejiang
localityName = Hangzhou
organizationName = Mysoft.com
organizationalUnitName = Mysoft.com
commonName = *.mysoft.com
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
0F:0C:46:82:EB:68:61:CE:6F:06:10:78:BC:7B:2F:10:F8:96:7E:09
X509v3 Authority Key Identifier:
keyid:E0:01:2C:50:62:87:8D:10:7A:17:6D:AB:2C:43:0A:79:EB:5F:26:0C
DirName:/C=CN/ST=Zhejiang/L=Hangzhou/O=Mysoft.com corpration/OU=Mysoft.com/CN=Mysoft.com
serial:00
Certificate is to be certified until Dec 8 12:27:14 2009 GMT (365 days)
Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]y
Write out database with 1 new entries
Data Base Updated
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 1 (0x1)
Signature Algorithm: md5WithRSAEncryption
Issuer: C=CN, ST=Zhejiang, L=Hangzhou, O=Mysoft.com corpration, OU=Mysoft.com, CN=Mysoft.com
Validity
Not Before: Dec 8 12:27:14 2008 GMT
Not After : Dec 8 12:27:14 2009 GMT
Subject: C=CN, ST=Zhejiang, L=Hangzhou, O=Mysoft.com, OU=Mysoft.com, CN=*.mysoft.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
RSA Public Key: (1024 bit)
Modulus (1024 bit):
00:f0:46:a7:a3:9d:8d:ce:09:da:f1:02:a0:fd:1f:
5c:df:a5:08:66:ea:13:0d:17:ac:49:92:9f:65:21:
cf:ec:f8:79:73:a1:73:0a:3e:d6:d0:c3:a4:d4:36:
22:b8:4c:82:51:fe:5d:e1:13:22:99:5f:4c:ef:c6:
65:3a:5d:de:1f:83:f2:17:a5:2b:f3:03:94:9a:31:
bc:09:c8:1c:9e:4d:ad:3b:90:2d:dc:65:0c:e3:04:
9b:8a:d5:c2:93:b7:51:8e:fe:92:1d:ee:55:6e:a0:
77:25:e1:a1:24:7f:55:7a:b4:4d:f4:84:83:13:56:
8d:62:be:2d:db:f8:1a:de:35
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
0F:0C:46:82:EB:68:61:CE:6F:06:10:78:BC:7B:2F:10:F8:96:7E:09
X509v3 Authority Key Identifier:
keyid:E0:01:2C:50:62:87:8D:10:7A:17:6D:AB:2C:43:0A:79:EB:5F:26:0C
DirName:/C=CN/ST=Zhejiang/L=Hangzhou/O=Mysoft.com corpration/OU=Mysoft.com/CN=Mysoft.com
serial:00
Signature Algorithm: md5WithRSAEncryption
0b:dc:15:f3:87:5c:e0:07:23:0e:78:47:af:56:fb:43:31:4b:
0d:12:76:57:95:cd:d7:2a:75:00:01:21:96:9d:d4:bf:9d:e9:
b6:26:cc:70:98:95:fd:ca:af:ad:68:fb:10:79:09:05:32:20:
02:7a:84:53:2f:e0:d5:cd:ed:4d:42:e7:d5:9d:90:78:9a:2e:
d8:72:cb:7f:f7:29:30:24:25:f2:0f:2d:b4:9d:a2:b3:24:00:
b4:f7:e9:de:5c:1a:50:d3:59:a4:9c:1d:03:15:04:17:6d:c2:
ab:95:a8:1f:28:e5:ad:3c:a9:a8:c8:30:3a:09:3f:75:5d:70:
2e:af
-----BEGIN CERTIFICATE-----
MIIDfDCCAuWgAwIBAgIBATANBgkqhkiG9w0BAQQFADCBgDELMAkGA1UEBhMCQ04x
ETAPBgNVBAgTCFpoZWppYW5nMREwDwYDVQQHEwhIYW5nemhvdTEfMB0GA1UEChMW
QWxpc29mdC5jb20gY29ycHJhdGlvbjEUMBIGA1UECxMLQWxpc29mdC5jb20xFDAS
BgNVBAMTC0FsaXNvZnQuY29tMB4XDTA4MTIwODEyMjcxNFoXDTA5MTIwODEyMjcx
NFowdzELMAkGA1UEBhMCQ04xETAPBgNVBAgTCFpoZWppYW5nMREwDwYDVQQHEwhI
YW5nemhvdTEUMBIGA1UEChMLQWxpc29mdC5jb20xFDASBgNVBAsTC0FsaXNvZnQu
Y29tMRYwFAYDVQQDFA0qLmFsaXNvZnQuY29tMIGfMA0GCSqGSIb3DQEBAQUAA4GN
ADCBiQKBgQDwRqejnY3OCdrxAqD9H1zfpQhm6hMNF6xJkp9lIc/s+HlzoXMKPtbQ
w6TUNiK4TIJR/l3hEyKZX0zvxmU6Xd4fg/IXpSvzA5SaMbwJyByeTa07kC3cZQzj
BJuK1cKTt1GO/pId7lVuoHcl4aEkf1V6tE30hIMTVo1ivi3b+BreNQIDAQABo4IB
DDCCAQgwCQYDVR0TBAIwADAsBglghkgBhvhCAQ0EHxYdT3BlblNTTCBHZW5lcmF0
ZWQgQ2VydGlmaWNhdGUwHQYDVR0OBBYEFA8MRoLraGHObwYQeLx7LxD4ln4JMIGt
BgNVHSMEgaUwgaKAFOABLFBih40QehdtqyxDCnnrXyYMoYGGpIGDMIGAMQswCQYD
VQQGEwJDTjERMA8GA1UECBMIWmhlamlhbmcxETAPBgNVBAcTCEhhbmd6aG91MR8w
HQYDVQQKExZBbGlzb2Z0LmNvbSBjb3JwcmF0aW9uMRQwEgYDVQQLEwtBbGlzb2Z0
LmNvbTEUMBIGA1UEAxMLQWxpc29mdC5jb22CAQAwDQYJKoZIhvcNAQEEBQADgYEA
C9wV84dc4AcjDnhHr1b7QzFLDRJ2V5XN1yp1AAEhlp3Uv53ptibMcJiV/cqvrWj7
EHkJBTIgAnqEUy/g1c3tTULn1Z2QeJou2HLLf/cpMCQl8g8ttJ2isyQAtPfp3lwa
UNNZpJwdAxUEF23Cq5WoHyjlrTypqMgwOgk/dV1wLq8=
-----END CERTIFICATE-----
Signed certificate is in newcert.pem
这样就生成了server的证书newcert.pem,把newcert.pem 重命名为server.crt。
4、配置apache
NameVirtualHost *:443
<VirtualHost *:443>
ServerAdmin sa@mysoft.com
ServerName xplan.mysoft.com
DocumentRoot /home/admin/project/htdocs
SSLEngine on
SSLCipherSuite ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+SSLv3:+EXP:+eNULL
SSLCertificateFile /home/admin/modules/crt/server.crt
SSLCertificateKeyFile /home/admin/modules/crt/server.key
SSLProxyEngine on
RewriteEngine on
RewriteRule ^/$ /xplan/user/login!login.jspa [L,P]
</VirtualHost>
重启apache时,会提示要求输入服务端证书的密码。如下:
[root@localhost]# bin/apachectl restart
httpd not running, trying to start
Apache/2.2.0 mod_ssl/2.2.0 (Pass Phrase Dialog)
Some of your private key files are encrypted for security reasons.
In order to read them you have to provide the pass phrases.
Server xplan.mysoft.com:443 (RSA)
Enter pass phrase:
OK: Pass Phrase Dialog successful.
5、客户端(IE)导入根证书(ca.cert)
在"选项"->"内容"->"证书"->"受信任根证书颁发机构"中点击"导入",选中"ca.crt",完成导入。或者,直接在点ca.crt文件右键,选择安装即可。
6、重启apache,要求输入密码的问题解决
1)、去掉bin/apachectl start启动的pass phrase,用空pass phrase启动apache
(while preserving the original file):
[root@xplan-dev8 ca]$ cp server.key server.key.org
[root@xplan-dev8 ca]$ openssl rsa -in server.key.org -out server.key
确认server.key 文件为root可读
[root@xplan-dev8 ca]$ chmod 400 server.key
2、编辑
[root@xplan-dev8 ca]$ vi conf/extra/httpd-ssl.conf
注释SSLPassPhraseDialog builtin
在后添加:SSLPassPhraseDialog exec:/usr/local/apache2/conf/apache_pass.sh
[root@xplan-dev8 ca]$ vi conf/apache_pass.sh
#!/bin/sh
echo "密码"
[root@xplan-dev8 ca]$ chmod +x /usr/local/apache2/conf/apache_pass.sh
posted @
2008-12-08 21:19 josson 阅读(2687) |
评论 (1) |
编辑 收藏1、Spket for eclipse
spket支持JavaScript、XUL/XBL、Laszlo、SVG and Yahoo! Widget等新产品,具有代码自动完成、语法高亮、内容概要等功能特点,可以帮助开发人员高效地创建JavaScript程序,它可以以一个独立的桌面应用程序运行或者以Eclipse的插件运行,从它的官方网站http://www.spket.com/可以下载。
插件安装地址:http://www.spket.com/update
相关资料:
Spket Eclipse Plugin & IDE(Ext在Spket上的安装方法)
spket 1.6.6 破解
2、Propedit for eclipse
不错的编写properties文件的Eclipse插件(plugin),有了它我们在编辑一些简体中文、繁体中文等Unicode文本时,就不必再使用native2ascii编码了。
插件安装地址:http://propedit.sourceforge.jp/eclipse/updates/
3、Velocity for eclipse
http://veloeclipse.googlecode.com/svn/trunk/update/
posted @
2008-11-28 10:04 josson 阅读(570) |
评论 (0) |
编辑 收藏
现有需求如下:需对若干服务器做相同的环境配置,且配置工作相当复杂,若人工一台一台的处理比较耗时且容易出错。我们可以考虑先完成一台服务器的配置工作,确认配置无误后,再通过脚本,将相应的配置工作同步到其他所有的服务器中。设有已完成配置的服务器:A (192.168.0.2) 和 待配置的服务器B ~ Z(192.168.0.101 ~ 126)。
实现上述需求,关键有两点:1). 通过ssh信任登录,避免每次同步时要求输入密码;2). 通过rsync命令实现服务器之间文件的同步。具体实现细节如下:
1. 完成单向Trusted SSH Authorized
首先在A产生public/private dsa key pair:
……………………………………………………………………………………………………
[root@kplan-test3 .ssh]# ssh-keygen -d
Generating public/private dsa key pair.
Enter file in which to save the key (/root/.ssh/id_dsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
f3:47:3b:b0:2a:50:f8:77:7e:ca:29:85:e8:d9:05:9b root@kplan-test3
[root@kplan-test3 .ssh]#
……………………………………………………………………………………………………
完成上述命令后,会在系统/root/.ssh目录生成两个文件:id_dsa与id_dsa.pub。现在复制id_dsa.pub到B服务器,并更名为 authorized_keys2
……………………………………………………………………………………………………
[root@kplan-test3 .ssh]# scp id_dsa.pub 192.168.0.101:/root/.ssh/authorized_keys2
root@192.168.0.101's password:
id_dsa.pub 100% |*****************************************************| 612 00:00
[root@kplan-test3 .ssh]#
……………………………………………………………………………………………………
如果上述步骤顺利完成的话,现在您可以执行”ssh 192.168.0.101”,无需输入登录密码,即可登录到B服务器了。
2.使用rsync 做Remote sync﹕
rsync特性简介: rsync是unix-like系统下的数据镜像备份工具,从命名上就可以看出来了remote sync。它的特性如下:
1、可以镜像保存整个目录树和文件系统。
2、可以很容易做到保持原来文件的权限、时间等等。
3、无须特殊权限即可安装。
4、优化的流程,文件传输效率高。
5、可以使用rcp、ssh等方式来传输文件,当然也可以通过直接的socket连接。
6、支持匿名传输。
参数意义如下﹕
-a, --archive
It is a quick way of saying you want recursion and want to preserve almost everything.
-v, --verbose
This option increases the amount of information you are given during the transfer.
-l, --links
When symlinks are encountered, recreate the symlink on the destination.
-R, --relative
Use relative paths. 保留相对路径...才不会让子目录跟 parent 挤在同一层...
--delete
是指如果Server端删除了一文件,那客户端也相应把这一文件删除,保持真正的一致。
-e ssh
建立起加密的连接。
3、同步脚本
创建脚本,实现自动配置工作。
……………………………………………………………………………………………………
[root@kplan-test3 backup]# vi install_env.sh
#!/bin/bash
WEBSERVER='kplan-test1 kplan-test2 kplan-test3'
echo "auto install envirment … ------------------------"
for webserver in $WEBSERVER
do
echo "install server:$webserver's envirment."
echo 'transport file : /etc/profile & /etc/hosts'
rsync -v -r -l -H -p -g -t -S -e ssh --delete /etc/profile root@$webserver:/etc/profile
rsync -v -r -l -H -p -g -t -S -e ssh --delete /etc/hosts root@$webserver:/etc/hosts
echo 'run shell command : /home/init_env.sh'
ssh -q -o StrictHostKeyChecking=no root@$webserver "/home/init_env.sh"
ssh -q -o StrictHostKeyChecking=no root@$webserver "rm -f /home/init_env.sh"
echo " $webserver is end ------------------------- "
done
sleep 1
clear
……………………………………………………………………………………………………
4、其他
如果你想用来做自动备份,则在crontab中加入备份脚本即可。如在每天0时0分做备份(设/root目录下已有完成备份的脚本 backup.sh):
……………………………………………………………………………………………………
[root@kplan-test3 backup]# crontab -e
0 0 * * * /root/backup.sh
……………………………………………………………………………………………………
posted @
2008-10-15 16:50 josson 阅读(588) |
评论 (0) |
编辑 收藏
检查SVN设置如下:
右键->TortoiseSVN->Settings->Look and Feel ->Icon Overlays->Driver Types : 选中"Network drives"后,应用即可。
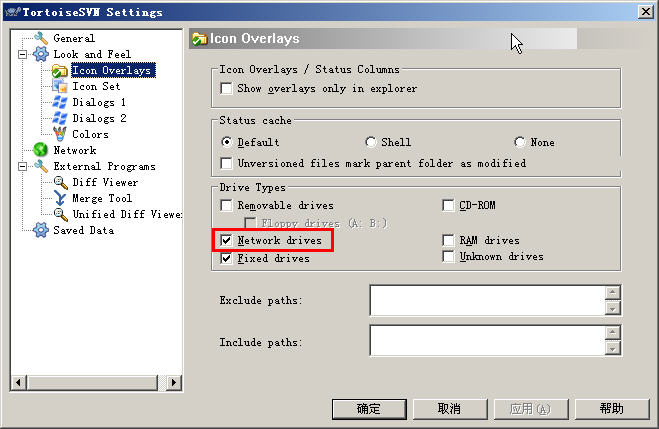
posted @
2008-09-09 15:38 josson 阅读(846) |
评论 (0) |
编辑 收藏
一、相关资源:
Jboss 下载:
http://www.jboss.org/jbossas/downloads/
Apache 下载(包含OpenSSL的版本):
http://httpd.apache.org/download.cgi
Apache与Tomcat的连接器:
jakarta-tomcat-connectors-jk2.0.4-win32-apachex.x.xx.zip
二、Apache 配置
安装过程很简单,按默认安装即可。Apache配置文件conf/httpd.conf 需要做的修改如下:
#监听443端口
Listen 443
ServerName crm.company.com
#确认下列module启用
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_connect_module modules/mod_proxy_connect.so
LoadModule proxy_http_module modules/mod_proxy_http.so
LoadModule rewrite_module modules/mod_rewrite.so
LoadModule ssl_module modules/mod_ssl.so
#需将默认的SSL配置注释(也可将下面虚拟机中关于SSL的配置更改到ssl.conf)
#<IfModule mod_ssl.c>
# Include conf/ssl.conf
#</IfModule>
#定义虚拟主机
NameVirtualHost *:443
<VirtualHost *:443>
ServerAdmin admin@company.com
ServerName crm.company.com
DocumentRoot E:/projects/crm/htdocs
SSLEngine On
SSLCipherSuite ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+SSLv3:+EXP:+eNULL
SSLCertificateFile D:/Services/crt/crm.crt
SSLCertificateKeyFile D:/Services/crt/crm.key
SSLProxyEngine on
RewriteEngine on
RewriteRule ^/$ /crm/login!login.jspa [L,P]
</VirtualHost>
三、Jboss 配置
解压后即完成安装,应用配置需要修改的配置文件为:server\default\conf\jboss-service.xml
#在此配置属性中加入应用所在路径.或者将应用直接布署到deploy目录下面.
<attribute name="URLs">
deploy/, file:/d:/project/crm/deploy/target/
</attribute>
四、Apache 与 Jboss集成
1、将mod_jk2.so文件拷贝到Apache安装目录下的modules文件夹中,并修改Apache的配置文件(httpd.conf),加入如下内容:
#与Jboss集成所需的配置
<IfModule mod_jk2.c>
JkSet config.file ./workers2.properties
</IfModule>
LoadModule jk2_module modules/mod_jk2.so
2、在Apache配置目录conf下新建文件work.properties,并加入如内容:
[channel.socket:localhost:8009]
port=8009
host=127.0.0.1
[ajp13:localhost:8009]
channel=channel.socket:localhost:8009
[uri:/*]
[uri:/*.jsp]
[uri:/*.jspa]
worker=ajp13:localhost:8009
3、JBOSS的server\default\conf目录下,新建一个jk2.properties的文件,内容如下:
# Set the desired handler list
handler.list=apr,request,channelSocket
#
# Override the default port for the socketChannel
channelSocket.port=8009
五、测试
完成上述配置后,分别启动Jboss和Apache,使用https访问应用,如https://crm.company.com,apache收到请求后,按虚拟机中设置的kURL重写规则,转向/crm/login!login.jspa。连接器检测到jspa文件,则将该请求转给Jboss处理。如jspa页面的内容被显示出来,则表示配置成功。
六、小结
配置过程中,httpd.con配置比较容易出现问题,一般使用apache提供的配置文件检测功能,确定httpd.conf正确。其次,可查看apache的log日志文件,按日志文件的错误描述进行处理。
配置过程中,可按步进行:Apache & ssl配置;Jboss 应用配置;集成配置;如此可减少一些问题。
posted @
2008-09-05 14:18 josson 阅读(1485) |
评论 (0) |
编辑 收藏对于任何数据库来说,提供唯一标识数据表中一行记录的能力是至关重要的。几乎所有数据库都提供了为新添加的行自动生成主键的方法。这样再操作数据库的时候比较方便,但它也带来了一个问题,如果我们需要知道新生成的主键值该怎么办?
有的数据库供应商是预先生成(pre-generate)主键的(如Oracle和PostgreSQL),有的则是事后生成(post-generate)的(如SQL Server和MySQL)。不管是哪种方式,我们都可以使用<selectKey>节点来获取<insert>语句所产生的主键。下面的例子演示了这两种方式下的做法:
<!-- Oracle SEQUENCE Example using .NET 1.1 System.Data.OracleClient -->
<insert id="insertProduct-ORACLE" parameterClass="product">
<selectKey resultClass="int" type="pre" property="Id" >
SELECT STOCKIDSEQUENCE.NEXTVAL AS VALUE FROM DUAL
</selectKey>
insert into PRODUCT (PRD_ID,PRD_DESCRIPTION) values (#id#,#description#)
</insert>
<!-- Microsoft SQL Server IDENTITY Column Example -->
<insert id="insertProduct-MSSQL" parameterClass="product">
insert into PRODUCT (PRD_DESCRIPTION)
values (#description#)
<selectKey resultClass="int" type="post" property="id" >
select @@IDENTITY as value
</selectKey>
</insert>
<!-- MySQL Example -->
<insert id="insertProduct-MYSQL" parameterClass="product">
insert into PRODUCT (PRD_DESCRIPTION)
values (#description#)
<selectKey resultClass="int" type="post" property="id" >
select LAST_INSERT_ID() as value
</selectKey>
</insert>
posted @
2008-08-01 14:44 josson 阅读(520) |
评论 (0) |
编辑 收藏
编程式事务:
使用TransactionTemplate进行事务处理(Spring进行commit和rollback),原型定义如下:
public class TransactionTemplate extends DefaultTransactionDefinition implements InitializingBean {
public Object execute(TransactionCallback action) throws TransactionException {
if (this.transactionManager instanceof CallbackPreferringPlatformTransactionManager) {
return ((CallbackPreferringPlatformTransactionManager) this.transactionManager).execute(this, action);
}
else {
TransactionStatus status = this.transactionManager.getTransaction(this);
Object result = null;
try {
// 参数TransactionCallback 是一个接口,接口中定义了doInTransaction方法
// 只要实现TransactionCallback接口,在doInTransaction()方法里编写具体要进行事务处理的代码即可。
result = action.doInTransaction(status);
}
catch (RuntimeException ex) {
// 回滚事务
rollbackOnException(status, ex);
throw ex;
}
catch (Error err) {
// 回滚事务
rollbackOnException(status, err);
throw err;
}
this.transactionManager.commit(status);
return result;
}
}
}
实现TransactionCallback接口。
transactionTemplate.execute(
new TransactionCallback() {
public Object doInTransaction(TransactionStatus ts) {
//代码实现.
}
}
}
配置文件定义:
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource">
<ref bean="myDataSource" />
</property>
</bean>
<bean id="transactionTemplate" class="org.springframework.transaction.support.TransactionTemplate">
<property name="transactionManager">
<ref bean="transactionManager" />
</property>
</bean>
posted @
2008-07-28 14:37 josson 阅读(1108) |
评论 (0) |
编辑 收藏 Shell基本语法
像高级程序设计语言一样,Shell也提供说明和使用变量的功能。对Shell来讲,所有变量的取值都是一个字串,Shell程序采用$var的形式来引用名为var的变量的值。
Shell有以下几种基本类型的变量。
(1)Shell定义的环境变量:
Shell在开始执行时就已经定义了一些和系统的工作环境有关的变量,用户还可以重新定义这些变量,常用的Shell环境变量有:
HOME 用于保存注册目录的完全路径名。
PATH 用于保存用冒号分隔的目录路径名,Shell将按PATH变量中给出的顺序搜索这些目录,找到的第一个与命令名称一致的可执行文件将被执行。
TERM 终端的类型。
UID 当前用户的识别字,取值是由数位构成的字串。
PWD 当前工作目录的绝对路径名,该变量的取值随cd命令的使用而变化。
PS1 主提示符,在特权用户下,默认的主提示符是#,在普通用户下,默认的主提示符是$。
PS2 在Shell接收用户输入命令的过程中,如果用户在输入行的末尾输入“”然后回车,或者当用户按回车键时Shell判断出用户输入的命令没有结束时,就显示这个辅助提示符,提示用户继续输入命令的其余部分,默认的辅助提示符是>。
(2)用户定义的变量:
用户可以按照下面的语法规则定义自己的变量:
变量名=变量值
要注意的一点是,在定义变量时,变量名前不应加符号$,在引用变量的内容时则应在变量名前加$;在给变量赋值时,等号两边一定不能留空格,若变量中本身就包含了空格,则整个字串都要用双引号括起来。
在编写Shell程序时,为了使变量名和命令名相区别,建议所有的变量名都用大写字母来表示。
有时我们想要在说明一个变量并对它设置为一个特定值后就不在改变它的值时,可以用下面的命令来保证一个变量的只读性:
readonly 变量名
在任何时候,创建的变量都只是当前Shell的局部变量,所以不能被Shell运行的其他命令或Shell程序所利用,而export命令可以将一个局部变量提供给Shell执行的其他命令使用,其格式为:
export 变量名
也可以在给变量赋值的同时使用export命令:
export 变量名=变量值
使用export说明的变量,在Shell以后运行的所有命令或程序中都可以访问到。
(3)位置参数:
位置参数是一种在调用Shell程序的命令行中按照各自的位置决定的变量,是在程序名之后输入的参数。位置参数之间用空格分隔,Shell取第一个位置
参数替换程序文件中的$1,第二个替换$2,依次类推。$0是一个特殊的变量,它的内容是当前这个Shell程序的文件名,所以,$0不是一个位置参数,
在显示当前所有的位置参数时是不包括$0的。
(4)预定义变量:
预定义变量和环境变量相类似,也是在Shell一开始时就定义了的变量。所不同的是,用户只能根据Shell的定义来使用这些变量,而不能重定义它。所有预定义变量都是由$符和另一个符号组成的,常用的Shell预定义变量有:
$# 位置参数的数量。
$* 所有位置参数的内容。
$? 命令执行后返回的状态。
$$ 当前进程的进程号。
$! 后台运行的最后一个进程号。
$0 当前执行的进程名。
其中,$?用于检查上一个命令执行是否正确。(在Linux中,命令退出状态为0表示该命令正确执行,任何非0值表示命令出错。)
$$变量最常见的用途是用做暂存文件的名字以保证暂存文件不会重复。
(5)参数置换的变量:
Shell提供了参数置换功能以便用户可以根据不同的条件来给变量赋不同的值。参数置换的变量有4种,这些变量通常与某一个位置参数相联系,根据指定的位置参数是否已经设置类决定变量的取值,它们的语法和功能分别如下。
a. 变量=${参数-word}:如果设置了参数,则用参数的值置换变量的值,否则用word置换。即这种变量的值等于某一个参数的值,如果该参数没有设置,则变量就等于word的值。
b. 变量=${参数=word}:如果设置了参数,则用参数的值置换变量的值,否则把变量设置成word,然后再用word替换参数的值。注意,位置参数不能用于这种方式,因为在Shell程序中不能为位置参数赋值。
c.
变量=${参数?word}:如果设置了参数,则用参数的值置换变量的值,否则就显示word并从Shell中退出,如果省略了word,则显示标准信
息。这种变量要求一定等于某一个参数的值。如果该参数没有设置,就显示一个信息,然后退出,因此这种方式常用于出错指示。
d. 变量=${参数+word}:如果设置了参数,则用word置换变量,否则不进行置换。
所有这4种形式中的“参数”既可以是位置参数,也可以是另一个变量,只是用位置参数的情况比较多。Shell程序设计的流程控制
和其他高级程序设计语言一样,Shell提供了用来控制程序执行流程的命令,包括条件分支和循环结构,用户可以用这些命令创建非常复杂的程序。
与传统语言不同的是,Shell用于指定条件值的不是布尔运算式,而是命令和字串。
1.测试命令
test命令用于检查某个条件是否成立,它可以进行数值、字符和文件3个方面的测试,其测试符和相应的功能分别如下。
(1)数值测试:
-eq 等于则为真。
-ne 不等于则为真。
-gt 大于则为真。
-ge 大于等于则为真。
-lt 小于则为真。
-le 小于等于则为真。
(2)字串测试:
= 等于则为真。
!= 不相等则为真。
-z字串 字串长度伪则为真。
-n字串 字串长度不伪则为真。
(3)文件测试:
-e文件名 如果文件存在则为真。
-r文件名 如果文件存在且可读则为真。
-w文件名 如果文件存在且可写则为真。
-x文件名 如果文件存在且可执行则为真。
-s文件名 如果文件存在且至少有一个字符则为真。
-d文件名 如果文件存在且为目录则为真。
-f文件名 如果文件存在且为普通文件则为真。
-c文件名 如果文件存在且为字符型特殊文件则为真。
-b文件名 如果文件存在且为块特殊文件则为真。
另外,Linux还提供了与(!)、或(-o)、非(-a)三个逻辑操作符,用于将测试条件连接起来,其优先顺序为:!最高,-a次之,-o最低。
同时,bash也能完成简单的算术运算,格式如下:
$[expression]
例如:
var1=2
var2=$[var1*10+1]
则var2的值为21。
2.if条件语句
Shell程序中的条件分支是通过if条件语句来实现的,其一般格式为:
if 条件命令串
then
条件为真时的命令串
else
条件为假时的命令串
fi
3.for循环
for循环对一个变量的可能的值都执行一个命令序列。赋给变量的几个数值既可以在程序内以数值列表的形式提供,也可以在程序以外以位置参数的形式提供。for循环的一般格式为:
for变量名 [in数值列表]
do
若干个命令行
done
变量名可以是用户选择的任何字串,如果变量名是var,则在in之后给出的数值将顺序替换循环命令列表中的$var。如果省略了in,则变量var的取值将是位置参数。对变量的每一个可能的赋值都将执行do和done之间的命令列表。
4.while和until循环
while和until命令都是用命令的返回状态值来控制循环的。While循环的一般格式为:
while
若干个命令行1
do
若干个命令行2
done
只要while的“若干个命令行1”中最后一个命令的返回状态为真,while循环就继续执行do...done之间的“若干个命令行2”。
until命令是另一种循环结构,它和while命令相似,其格式如下:
until
若干个命令行1
do
若干个命令行2
done
until循环和while循环的区别在于:while循环在条件为真时继续执行循环,而until则是在条件为假时继续执行循环。
Shell还提供了true和false两条命令用于创建无限循环结构,它们的返回状态分别是总为0或总为非0。
5.case条件选择
if条件语句用于在两个选项中选定一项,而case条件选择为用户提供了根据字串或变量的值从多个选项中选择一项的方法,其格式如下:
case string in
exp-1)
若干个命令行1
;;
exp-2)
若干个命令行2
;;
……
*)
其他命令行
esac
Shell通过计算字串string的值,将其结果依次和运算式exp-1, exp-2等进行比较,直到找到一个匹配的运算式为止。如果找到了匹配项,则执行它下面的命令直到遇到一对分号(;;)为止。
在case运算式中也可以使用Shell的通配符(“*”、“?”、“[ ]”)。通常用 * 作为case命令的最后运算式以便在前面找不到任何相应的匹配项时执行“其他命令行”的命令。
6.无条件控制语句break和continue
break用于立即终止当前循环的执行,而contiune用于不执行循环中后面的语句而立即开始下一个循环的执行。这两个语句只有放在do和done之间才有效。
7.函数定义
在Shell中还可以定义函数。函数实际上也是由若干条Shell命令组成的,因此它与Shell程序形式上是相似的,不同的是它不是一个单独的进程,而是Shell程序的一部分。函数定义的基本格式为:
functionname
{
若干命令行
}
调用函数的格式为:
functionname param1 param2…
Shell函数可以完成某些例行的工作,而且还可以有自己的退出状态,因此函数也可以作为if, while等控制结构的条件。
在函数定义时不用带参数说明,但在调用函数时可以带有参数,此时Shell将把这些参数分别赋予相应的位置参数$1, $2, ...及$*。
8.命令分组
在Shell中有两种命令分组的方法:()和{}。前者当Shell执行()中的命令时将再创建一个新的子进程,然后这个子进程去执行圆括弧中的命令。
当用户在执行某个命令时不想让命令运行时对状态集合(如位置参数、环境变量、当前工作目录等)的改变影响到下面语句的执行时,就应该把这些命令放在圆括弧
中,这样就能保证所有的改变只对子进程产生影响,而父进程不受任何干扰。{}用于将顺序执行的命令的输出结果用于另一个命令的输入(管道方式)。当我们要
真正使用圆括弧和花括弧时(如计算运算式的优先顺序),则需要在其前面加上转义符()以便让Shell知道它们不是用于命令执行的控制所用。
9.信号
trap命令用于在Shell程序中捕捉信号,之后可以有3种反应方式:
(1)执行一段程序来处理这一信号。
(2)接受信号的默认操作。
(3)忽视这一信号。
trap对上面3种方式提供了3种基本形式:
第一种形式的trap命令在Shell接收到与signal list清单中数值相同的信号时,将执行双引号中的命令串。
trap 'commands' signal-list
trap "commands" signal-list
为了恢复信号的默认操作,使用第二种形式的trap命令:
trap signal-list
第三种形式的trap命令允许忽略信号:
trap " " signal-list
注意:
(1)对信号11(段违例)不能捕捉,因为Shell本身需要捕捉该信号去进行内存的转储。
(2)在trap中可以定义对信号0的处理(实际上没有这个信号),Shell程序在其终止(如执行exit语句)时发出该信号。
(3)在捕捉到signal-list中指定的信号并执行完相应的命令之后,如果这些命令没有将Shell程序终止的话,Shell程序将继续执行收到信号时所执行的命令后面的命令,这样将很容易导致Shell程序无法终止。
另外,在trap语句中,单引号和双引号是不同的。当Shell程序第一次碰到trap语句时,将把commands中的命令扫描一遍。此时若
commands是用单引号括起来的话,那么Shell不会对commands中的变量和命令进行替换,否则commands中的变量和命令将用当时具体
的值来替换。运行Shell程序的方法
用户可以用任何编辑程序来编写Shell程序。因为
Shell程序是解释执行的,所以不需要编译成目的程序。按照Shell编程的惯例,以bash为例,程序的第一行一般为“#!/bin/bash”,其
中 # 表示该行是注释,叹号 !
告诉Shell运行叹号之后的命令并用文档的其余部分作为输入,也就是运行/bin/bash并让/bin/bash去执行Shell程序的内容。
执行Shell程序的方法有3种。
1.sh Shell程序文件名
这种方法的命令格式为:
bash Shell程序文件名
这实际上是调用一个新的bash命令解释程序,而把Shell程序文件名作为参数传递给它。新启动的Shell将去读指定的文件,可执行文件中列出的命令,当所有的命令都执行完后结束。该方法的优点是可以利用Shell调试功能。
2.sh
格式为:
bash< Shell程序名
这种方式就是利用输入重定向,使Shell命令解释程序的输入取自指定的程序文件。
3.用chmod命令使Shell程序成为可执行的
一个文件能否运行取决于该文档的内容本身可执行且该文件具有执行权。对于Shell程序,当用编辑器生成一个文件时,系统赋予的许可权都是644(rw-r-r--),因此,当用户需要运行这个文件时,只需要直接键入文件名即可。
在这3种运行Shell程序的方法中,最好按下面的方式选择:当刚创建一个Shell程序,对它的正确性还没有把握时,应当使用第一种方式进行调试。当
一个Shell程序已经调试好时,应使用第三种方式把它固定下来,以后只要键入相应的文件名即可,并可被另一个程序所调用。
4.bash程序的调试
在编程过程中难免会出错,有的时候,调试程序比编写程序花费的时间还要多,Shell程序同样如此。
Shell程序的调试主要是利用bash命令解释程序的选择项。调用bash的形式是:
bash -选择项Shell程序文件名
几个常用的选择项是:
-e 如果一个命令失败就立即退出。
-n 读入命令但是不执行它们。
-u 置换时把未设置的变量看做出错。
-v 当读入Shell输入行时把它们显示出来。
-x 执行命令时把命令和它们的参数显示出来。
上面的所有选项也可以在Shell程序内部用“set -选择项”的形式引用,而“set +选择项”则将禁止该选择项起作用。如果只想对程序的某一部分使用某些选择项时,则可以将该部分用上面两个语句包围起来。
(1)未置变量退出和立即退出
未置变量退出特性允许用户对所有变量进行检查,如果引用了一个未赋值的变量就终止Shell程序的执行。Shell通常允许未置变量的使用,在这种情况
下,变量的值为空。如果设置了未置变量退出选择项,则一旦使用了未置变量就显示错误信息,并终止程序的运行。未置变量退出选择项为-u。
当Shell运行时,若遇到不存在或不可执行的命令、重定向失败或命令非正常结束等情况时,如果未经重新定向,该出错信息会显示在终端屏幕上,而
Shell程序仍将继续执行。要想在错误发生时迫使Shell程序立即结束,可以使用-e选项将Shell程序的执行立即终止。
(2)Shell程序的跟踪
调试Shell程序的主要方法是利用Shell命令解释程序的-v或-x选项来跟踪程序的执行。-v选择项使Shell在执行程序的过程中,把它读入的
每一个命令行都显示出来,而-x选择项使Shell在执行程序的过程中把它执行的每一个命令在行首用一个+加上命令名显示出来。并把每一个变量和该变量所
取的值也显示出来。因此,它们的主要区别在于:在执行命令行之前无-v,则显示出命令行的原始内容,而有-v时则显示出经过替换后的命令行的内容。
除了使用Shell的-v和-x选择项以外,还可以在Shell程序内部采取一些辅助调试的措施。例如,可以在Shell程序的一些关键地方使用
echo命令把必要的信息显示出来,它的作用相当于C语言中的printf语句,这样就可以知道程序运行到什么地方及程序目前的状态。bash的内部命令
bash命令解释套装程序包含了一些内部命令。内部命令在目录列表时是看不见的,它们由Shell本身提供。常用的内部命令有:echo,
eval, exec, export, readonly, read, shift, wait和点(.)。下面简单介绍其命令格式和功能。
1.echo
命令格式:echo arg
功能:在屏幕上显示出由arg指定的字串。
2.eval
命令格式:eval args
功能:当Shell程序执行到eval语句时,Shell读入参数args,并将它们组合成一个新的命令,然后执行。
3.exec
命令格式:exec命令参数
功能:当Shell执行到exec语句时,不会去创建新的子进程,而是转去执行指定的命令,当指定的命令执行完时,该进程(也就是最初的Shell)就终止了,所以Shell程序中exec后面的语句将不再被执行。
4.export
命令格式:export变量名 或:export变量名=变量值
功能:Shell可以用export把它的变量向下带入子Shell,从而让子进程继承父进程中的环境变量。但子Shell不能用export把它的变量向上带入父Shell。
注意:不带任何变量名的export语句将显示出当前所有的export变量。
5.readonly
命令格式:readonly变量名
功能:将一个用户定义的Shell变量标识为不可变。不带任何参数的readonly命令将显示出所有只读的Shell变量。
6.read
命令格式:read变量名表
功能:从标准输入设备读入一行,分解成若干字,赋值给Shell程序内部定义的变量。
7.shift语句
功能:shift语句按如下方式重新命名所有的位置参数变量,即$2成为$1,$3成为$2…在程序中每使用一次shift语句,都使所有的位置参数依次向左移动一个位置,并使位置参数$#减1,直到减到0为止。
8.wait
功能:使Shell等待在后台启动的所有子进程结束。wait的返回值总是真。
9.exit
功能:退出Shell程序。在exit之后可有选择地指定一个数位作为返回状态。
10.“.”(点)
命令格式:. Shell程序文件名
功能:使Shell读入指定的Shell程序文件并依次执行文件中的所有语句。
posted @
2008-07-21 13:14 josson 阅读(332) |
评论 (0) |
编辑 收藏
1、修改linux系统默认的1024个文件上限。
在/root/.bash_profile文件中加入:ulimit -n 4096
2、查看某个进程打开的文件数:
先用ps -aux找到pid,然后运行lsof -p %pid% | wc -l
3、查看80端口的连接数
netstat -nat|grep -i “80″|wc -l
4、查看系统内核版本
uname -a
5、查看Linux版本
登录到服务器执行 lsb_release -a ,即可列出所有版本信息
6、查看目录空间
du -h --max-depth=2 | sort -n
posted @
2008-07-21 11:33 josson 阅读(270) |
评论 (0) |
编辑 收藏作为一个项目构建工具,Maven除具备Ant的功能外,最最要的就是jar包的管理。
相关文章:
http://www.blogjava.net/calvin/archive/2006/03/19/36098.html
http://www.ibm.com/developerworks/cn/opensource/os-maven2/
posted @
2008-06-20 21:25 josson 阅读(319) |
评论 (0) |
编辑 收藏
如果不小心安装了正版验证补丁,可以建一个批处理文件,在安全模式下运行即可删除。批处理文件内容如下:
@echo off
title 删除 Windows Genuine Advantage 脚本
cls
:ClearTemp
echo.
echo.
set choice=
set /p choice= 是否要尝试删除 Windows Genuine Advantage (Y/N)?:
if "%choice%"=="N" goto End
if "%choice%"=="n" goto End
echo.
echo 正在尝试删除 Windows Genuine Advantage ……
echo.
taskkill /f /im wgatray.exe /t
taskkill /f /im wgatray.dll /t
del /f /q %systemroot%\system32\wga*.*
taskkill /f /im wgatray.exe /t
taskkill /f /im wgatray.dll /t
del /f /q %systemroot%\system32\wga*.*
taskkill /f /im wgatray.exe /t
taskkill /f /im wgatray.dll /t
del /f /q %systemroot%\system32\wga*.*
taskkill /f /im wgatray.exe /t
taskkill /f /im wgatray.dll /t
del /f /q %systemroot%\system32\wga*.*
del /f /q %systemroot%\system32\legitcheckcontrol.dll
del /f /q %systemroot%\system32\dllcache\wga*.*
reg delete HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon\Notify\WGALogon /f
reg delete HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\uninstall\wganotify /f
:End
echo.
echo -----------------------处理完毕。请关闭。-----------------------
echo.
echo.
pause>nul
posted @
2008-06-06 12:50 josson 阅读(664) |
评论 (0) |
编辑 收藏
创建.bat文件,输入如下内容:
netsh interface ip set address "本地连接" static 192.9.101.106 255.255.255.0 192.9.101.1 1
netsh interface ip add dns name = "本地连接" addr = 202.101.172.35
netsh interface ip add dns name = "本地连接" addr = 202.101.172.36
posted @
2008-05-28 14:40 josson 阅读(1082) |
评论 (0) |
编辑 收藏
AXIS快速生成客户端调用文件的命令:
java -Djava.ext.dirs=./lib org.apache.axis.wsdl.WSDL2Java -o . -d Session -s -S true -p com.company.webservice.user http://192.9.101.106:8080/cms/services/UserService?wsdl
说明:
1、com.company.webservice.user表示新生成类文件的包名。
2、http://192.9.101.106:8080/cms/services/UserService?wsdl 表示Webservice服务地址。
3、注:相关的依赖包须存放在lib目录下,依赖包包括:
axis.jar
axis-ant.jar
axis-schema.jar
commons-discovery-0.2.jar
commons-logging-1.0.4.jar
jaxrpc.jar
log4j-1.2.8.jar
saaj.jar
wsdl4j-1.5.1.jar
创建bat文件,并将输入上述命令,执行后,即将在当前目录生成相关的类文件。
posted @
2008-05-28 14:30 josson 阅读(1016) |
评论 (0) |
编辑 收藏
1、服务器向指定客户端推送数据
完成聊天室之类的项目时,利用DWR推模式向所有客户端推送数据,的确是很方便,只要客户端的访问页面确定就可以了。但是,若需要对访问同一页面的两个客户端(特别是根据用户身份作不同处理),加以区分,推送不同数据时,就没这么简单了。
有两种方式可以解决这个问题:
a)、服务端不处理,只管往客户端推送数据,由客户端对收到的数据进行过滤,然后再显示出来。但这种方式的缺点很明显,数据包多且不安全。
b)、对每个客户端进行单儿标识。DWR中以ScriptSession来代表一个客户端连接,我们可以通过设置ScriptSession的属性,来达到标识客户端的作用。如将sessionid或用户登录名保存在相应的ScriptSession属性中,向客户端推送数据时,根据这个属性加以过滤。相应的代码片段如下:
/**
* 返回有效的ScriptSession.
* @param user
* @return
*/
@SuppressWarnings("unchecked")
private ScriptSession getCurrentSession(String user){
ScriptSession xSession = null;
Collection<ScriptSession> sessions = new HashSet<ScriptSession>();
sessions.addAll(sctx.getScriptSessionsByPage(PAGE_MAIN));
for (ScriptSession session : sessions) {
//查询与消息接收者相符的客户端页面,并输出消息内容
String xuser = (String)session.getAttribute(SESSION_ATTRNAME_USER);
if(xuser != null && xuser .equals(user)){
xSession = session;
}
}
return xSession;
}
/**
* 清除已有连接, 标识当前连接用户(登录或刷新页面时,进行必要的清理).
* @param user
* @param session
*/
private void cleanDwrConnection(user,ScriptSession session){
String jid = StringUtils.parseBareAddress(user);
ScriptSession oldSession = getCurrentSession(jid);
if(oldSession != null && oldSession != session){
oldSession.invalidate();
oldSession = null;
}
session = WebContextFactory.get().getScriptSession();
session.setAttribute(SESSION_ATTRNAME_USER, jid);
}
2、使用DWR推模式的实现中,刷新页面引起长连接丢失问题
最近在做web版即时消息客户端时,遇到这样一个问题:为了减少无用的服务连接,只在登录后才激活长连接(dwr.engine.setActiveReverseAjax(true),注销后取消长连接)。登录客户端后,用了一段时间后,无法收消息了(消息无法推送到客户端)。后来调试后,发现ScriptSession实例没有绑定物理连接信息(conduits:m:root为空)。测试后发现,当刷新页面后,会产生一个新的ScriptSession实例,而这个ScriptSession的conduits:m:root为空,所以怎么都无法将数据推送到客户端去了。
客户端激活长连接后(dwr.engine.setActiveReverseAjax(true);),对应的ScriptSession实例会绑定物理连接信息,而刷新页面刷新而不重新激活长连接,新产生的ScriptSession是没有绑定物理连接信息的,一旦绑定物理连接信息的ScriptSession被销毁后,就产生了这个问题。
posted @
2008-03-31 16:41 josson 阅读(4165) |
评论 (0) |
编辑 收藏
删除表主键:
ALTER TABLE TABLENAME DROP CONSTRAINT PK_TABLENAME;
新增表主键:
alter table TABLENAME add CONSTRAINT PK_TABLENAME primary key (ID);
posted @
2008-03-19 11:00 josson 阅读(448) |
评论 (0) |
编辑 收藏