|
2009年8月13日
#
用SAX解析XML实例
实例:以下输出中的所有属性和标签值
package com.meixin.xml;
import java.io.File;
import java.util.HashMap;
import java.util.Vector;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
public class PraseXML extends DefaultHandler
{
private Vector<String> tagName;
private Vector<String> tagValue;
private int step;
// 开始解析XML文件
public void startDocument() throws SAXException
{
tagName = new Vector<String>();
tagValue = new Vector<String>();
step = 0;
}
// 结束解析XML文件
public void endDocument() throws SAXException
{
for (int i = 0; i < tagName.size(); i++)
{
if (!tagName.get(i).equals("") || tagName.get(i) != null)
{
System.out.println("节点名称:" + tagName.get(i));
System.out.println("节点值:" + tagValue.get(i));
}
}
}
/**
* 在解释到一个开始元素时会调用此方法.但是当元素有重复时可以自己写算法来区分
* 这些重复的元素.qName是什么? <name:page ll=""></name:page>这样写就会抛出SAXException错误
* 通常情况下qName等于localName
*/
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException
{
// 节点名称
tagName.add(qName);
// 循环输出属性
for (int i = 0; i < attributes.getLength(); i++)
{
// 获取属性名称
System.out.println("属性名称:" + attributes.getQName(i));
// 获取属性值
System.out.println("属性值:"
+ attributes.getValue(attributes.getQName(i)));
}
}
/**
* 在遇到结束标签时调用此方法
*/
public void endElement(String uri, String localName, String qName)
throws SAXException
{
step = step + 1;
}
/**
* 读取标签里的值,ch用来存放某行的xml的字符数据,包括标签,初始大小是2048,
* 每解释到新的字符会把它添加到char[]里。 * 注意,这个char字符会自己管理存储的字符,
* 并不是每一行就会刷新一次char,start,length是由xml的元素数据确定的,
* 暂时找不到规律,以后看源代码.
*
* 这里一个正标签,反标签都会被执行一次characters,所以在反标签时不用获得其中的值
*/
public void characters(char ch[], int start, int length)
throws SAXException
{
// 只要当前的标签组的长度一至,值就不赋,则反标签不被计划在内
if (tagName.size() - 1 == tagValue.size())
{
tagValue.add(new String(ch, start, length));
}
}
public static void main(String[] args)
{
String filename = "MyXml.xml";
SAXParserFactory spf = SAXParserFactory.newInstance();
try
{
SAXParser saxParser = spf.newSAXParser();
saxParser.parse(new File(filename), new PraseXML());
}
catch (Exception e)
{
e.printStackTrace();
}
}
public Vector getTagName()
{
return tagName;
}
public void setTagName(Vector tagName)
{
this.tagName = tagName;
}
public Vector getTagValue()
{
return tagValue;
}
public void setTagValue(Vector tagValue)
{
this.tagValue = tagValue;
}
}
输出结果:
属性名称:personid
属性值:e01
属性名称:enable
属性值:true
属性名称:personid
属性值:e02
属性名称:enable
属性值:false
属性名称:personid
属性值:e03
属性名称:enable
属性值:true
节点名称:people
节点值:
节点名称:person
节点值:
节点名称:name
节点值:张三
节点名称:tel
节点值:5128
节点名称:email
节点值:txq512@sina.com
节点名称:person
节点值:
节点名称:name
节点值:meixin
节点名称:tel
节点值:5252525
节点名称:email
节点值:wnight88@sina.com
节点名称:person
节点值:
节点名称:name
节点值:yu
节点名称:tel
节点值:5389654
节点名称:email
节点值:yu@188.net
文件内容
<?xml version="1.0" encoding="UTF-8"?>
<people>
<person personid="e01" enable="true">
<name>张三</name>
<tel>5128</tel>
<email>txq512@sina.com</email>
</person>
<person personid="e02" enable="false">
<name>meixin</name>
<tel>5252525</tel>
<email>wnight88@sina.com</email>
</person>
<person personid="e03" enable="true">
<name>yu</name>
<tel>5389654</tel>
<email>yu@188.net</email>
</person>
</people>
http://wnight88.blog.51cto.com/512204/163197/
简介: Spring
作为现在最优秀的框架之一,已被广泛的使用,并且有很多对其分析的文章。本文将从另外一个视角试图剖析出 Spring 框架的作者设计 Spring
框架的骨骼架构的设计理念,有那几个核心组件?为什么需要这些组件?它们又是如何结合在一起构成 Spring 的骨骼架构? Spring 的
AOP 特性又是如何利用这些基础的骨骼架构来工作的? Spring
中又使用了那些设计模式来完成它的这种设计的?它的这种设计理念对对我们以后的软件设计有何启示?本文将详细解答这些问题。
Spring 的骨骼架构
Spring 总共有十几个组件,但是真正核心的组件只有几个,下面是 Spring 框架的总体架构图:
图 1 .Spring 框架的总体架构图

从上图中可以看出 Spring 框架中的核心组件只有三个:Core、Context 和 Beans。它们构建起了整个 Spring 的骨骼架构。没有它们就不可能有 AOP、Web 等上层的特性功能。下面也将主要从这三个组件入手分析 Spring。
Spring 的设计理念
前面介绍了 Spring 的三个核心组件,如果再在它们三个中选出核心的话,那就非 Beans 组件莫属了,为何这样说,其实 Spring
就是面向 Bean 的编程(BOP,Bean Oriented Programming),Bean 在 Spring 中才是真正的主角。
Bean 在 Spring 中作用就像 Object 对 OOP 的意义一样,没有对象的概念就像没有面向对象编程,Spring 中没有
Bean 也就没有 Spring 存在的意义。就像一次演出舞台都准备好了但是却没有演员一样。为什么要 Bean 这种角色 Bean 或者为何在
Spring 如此重要,这由 Spring 框架的设计目标决定,Spring 为何如此流行,我们用 Spring 的原因是什么,想想你会发现原来
Spring 解决了一个非常关键的问题他可以让你把对象之间的依赖关系转而用配置文件来管理,也就是他的依赖注入机制。而这个注入关系在一个叫
Ioc 容器中管理,那 Ioc 容器中有又是什么就是被 Bean 包裹的对象。Spring 正是通过把对象包装在 Bean
中而达到对这些对象管理以及一些列额外操作的目的。
它这种设计策略完全类似于 Java 实现 OOP 的设计理念,当然了 Java 本身的设计要比 Spring
复杂太多太多,但是都是构建一个数据结构,然后根据这个数据结构设计他的生存环境,并让它在这个环境中按照一定的规律在不停的运动,在它们的不停运动中设
计一系列与环境或者与其他个体完成信息交换。这样想来回过头想想我们用到的其他框架都是大慨类似的设计理念。
核心组件如何协同工作
前面说 Bean 是 Spring 中关键因素,那 Context 和 Core 又有何作用呢?前面吧 Bean
比作一场演出中的演员的话,那 Context 就是这场演出的舞台背景,而 Core
应该就是演出的道具了。只有他们在一起才能具备能演出一场好戏的最基本的条件。当然有最基本的条件还不能使这场演出脱颖而出,还要他表演的节目足够的精
彩,这些节目就是 Spring 能提供的特色功能了。
我们知道 Bean 包装的是 Object,而 Object 必然有数据,如何给这些数据提供生存环境就是 Context 要解决的问题,对
Context 来说他就是要发现每个 Bean 之间的关系,为它们建立这种关系并且要维护好这种关系。所以 Context 就是一个 Bean
关系的集合,这个关系集合又叫 Ioc 容器,一旦建立起这个 Ioc 容器后 Spring 就可以为你工作了。那 Core
组件又有什么用武之地呢?其实 Core 就是发现、建立和维护每个 Bean 之间的关系所需要的一些列的工具,从这个角度看来,Core 这个组件叫
Util 更能让你理解。
它们之间可以用下图来表示:
图 2. 三个组件关系

核心组件详解
这里将详细介绍每个组件内部类的层次关系,以及它们在运行时的时序顺序。我们在使用 Spring 是应该注意的地方。
Bean 组件
前面已经说明了 Bean 组件对 Spring 的重要性,下面看看 Bean 这个组件式怎么设计的。Bean 组件在 Spring 的
org.springframework.beans 包下。这个包下的所有类主要解决了三件事:Bean 的定义、Bean 的创建以及对 Bean
的解析。对 Spring 的使用者来说唯一需要关心的就是 Bean 的创建,其他两个由 Spring 在内部帮你完成了,对你来说是透明的。
Spring Bean 的创建时典型的工厂模式,他的顶级接口是 BeanFactory,下图是这个工厂的继承层次关系:
图 4. Bean 工厂的继承关系

BeanFactory 有三个子类:ListableBeanFactory、HierarchicalBeanFactory 和
AutowireCapableBeanFactory。但是从上图中我们可以发现最终的默认实现类是
DefaultListableBeanFactory,他实现了所有的接口。那为何要定义这么多层次的接口呢?查阅这些接口的源码和说明发现,每个接口
都有他使用的场合,它主要是为了区分在 Spring 内部在操作过程中对象的传递和转化过程中,对对象的数据访问所做的限制。例如
ListableBeanFactory 接口表示这些 Bean 是可列表的,而 HierarchicalBeanFactory 表示的是这些
Bean 是有继承关系的,也就是每个 Bean 有可能有父 Bean。AutowireCapableBeanFactory 接口定义 Bean
的自动装配规则。这四个接口共同定义了 Bean 的集合、Bean 之间的关系、以及 Bean 行为。
Bean 的定义主要有 BeanDefinition 描述,如下图说明了这些类的层次关系:
图 5. Bean 定义的类层次关系图

Bean 的定义就是完整的描述了在 Spring 的配置文件中你定义的 <bean/> 节点中所有的信息,包括各种子节点。当
Spring 成功解析你定义的一个 <bean/> 节点后,在 Spring 的内部他就被转化成 BeanDefinition
对象。以后所有的操作都是对这个对象完成的。
Bean 的解析过程非常复杂,功能被分的很细,因为这里需要被扩展的地方很多,必须保证有足够的灵活性,以应对可能的变化。Bean 的解析主要就是对 Spring 配置文件的解析。这个解析过程主要通过下图中的类完成:
图 6. Bean 的解析类

当然还有具体对 tag 的解析这里并没有列出。
Context 组件
Context 在 Spring 的 org.springframework.context 包下,前面已经讲解了 Context 组件在
Spring 中的作用,他实际上就是给 Spring 提供一个运行时的环境,用以保存各个对象的状态。下面看一下这个环境是如何构建的。
ApplicationContext 是 Context 的顶级父类,他除了能标识一个应用环境的基本信息外,他还继承了五个接口,这五个接口主要是扩展了 Context 的功能。下面是 Context 的类结构图:
图 7. Context 相关的类结构图

(查看 图 7 的清晰版本。)
从上图中可以看出 ApplicationContext 继承了 BeanFactory,这也说明了 Spring 容器中运行的主体对象是
Bean,另外 ApplicationContext 继承了 ResourceLoader 接口,使得 ApplicationContext
可以访问到任何外部资源,这将在 Core 中详细说明。
ApplicationContext 的子类主要包含两个方面:
- ConfigurableApplicationContext 表示该 Context 是可修改的,也就是在构建 Context
中用户可以动态添加或修改已有的配置信息,它下面又有多个子类,其中最经常使用的是可更新的 Context,即
AbstractRefreshableApplicationContext 类。
- WebApplicationContext 顾名思义,就是为 web 准备的 Context 他可以直接访问到 ServletContext,通常情况下,这个接口使用的少。
再往下分就是按照构建 Context 的文件类型,接着就是访问 Context 的方式。这样一级一级构成了完整的 Context 等级层次。
总体来说 ApplicationContext 必须要完成以下几件事:
- 标识一个应用环境
- 利用 BeanFactory 创建 Bean 对象
- 保存对象关系表
- 能够捕获各种事件
Context 作为 Spring 的 Ioc 容器,基本上整合了 Spring 的大部分功能,或者说是大部分功能的基础。
Core 组件
Core 组件作为 Spring 的核心组件,他其中包含了很多的关键类,其中一个重要组成部分就是定义了资源的访问方式。这种把所有资源都抽象成一个接口的方式很值得在以后的设计中拿来学习。下面就重要看一下这个部分在 Spring 的作用。
下图是 Resource 相关的类结构图:
图 8. Resource 相关的类结构图

(查看 图 8 的清晰版本。)
从上图可以看出 Resource
接口封装了各种可能的资源类型,也就是对使用者来说屏蔽了文件类型的不同。对资源的提供者来说,如何把资源包装起来交给其他人用这也是一个问题,我们看到
Resource 接口继承了 InputStreamSource 接口,这个接口中有个 getInputStream 方法,返回的是
InputStream 类。这样所有的资源都被可以通过 InputStream
这个类来获取,所以也屏蔽了资源的提供者。另外还有一个问题就是加载资源的问题,也就是资源的加载者要统一,从上图中可以看出这个任务是由
ResourceLoader 接口完成,他屏蔽了所有的资源加载者的差异,只需要实现这个接口就可以加载所有的资源,他的默认实现是
DefaultResourceLoader。
下面看一下 Context 和 Resource 是如何建立关系的?首先看一下他们的类关系图:
图 9. Context 和 Resource 的类关系图

从上图可以看出,Context 是把资源的加载、解析和描述工作委托给了 ResourcePatternResolver 类来完成,他相当于一个接头人,他把资源的加载、解析和资源的定义整合在一起便于其他组件使用。Core 组件中还有很多类似的方式。
Ioc 容器如何工作
前面介绍了 Core 组件、Bean 组件和 Context 组件的结构与相互关系,下面这里从使用者角度看一下他们是如何运行的,以及我们如何让 Spring 完成各种功能,Spring 到底能有那些功能,这些功能是如何得来的,下面介绍。
如何创建 BeanFactory 工厂
正如图 2 描述的那样,Ioc 容器实际上就是 Context 组件结合其他两个组件共同构建了一个 Bean
关系网,如何构建这个关系网?构建的入口就在 AbstractApplicationContext 类的 refresh
方法中。这个方法的代码如下:
清单 1. AbstractApplicationContext.refresh
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
}
}
|
这个方法就是构建整个 Ioc 容器过程的完整的代码,了解了里面的每一行代码基本上就了解大部分 Spring 的原理和功能了。
这段代码主要包含这样几个步骤:
- 构建 BeanFactory,以便于产生所需的“演员”
- 注册可能感兴趣的事件
- 创建 Bean 实例对象
- 触发被监听的事件
下面就结合代码分析这几个过程。
第二三句就是在创建和配置 BeanFactory。这里是 refresh 也就是刷新配置,前面介绍了 Context
有可更新的子类,这里正是实现这个功能,当 BeanFactory 已存在是就更新,如果没有就新创建。下面是更新 BeanFactory
的方法代码:
清单 2. AbstractRefreshableApplicationContext. refreshBeanFactory
protected final void refreshBeanFactory() throws BeansException {
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException(
"I/O error parsing bean definition source for "
+ getDisplayName(), ex);
}
}
|
这个方法实现了 AbstractApplicationContext 的抽象方法
refreshBeanFactory,这段代码清楚的说明了 BeanFactory 的创建过程。注意 BeanFactory
对象的类型的变化,前面介绍了他有很多子类,在什么情况下使用不同的子类这非常关键。BeanFactory 的原始对象是
DefaultListableBeanFactory,这个非常关键,因为他设计到后面对这个对象的多种操作,下面看一下这个类的继承层次类图:
图 10. DefaultListableBeanFactory 类继承关系图

(查看 图 10 的清晰版本。)
从这个图中发现除了 BeanFactory 相关的类外,还发现了与 Bean 的 register 相关。这在
refreshBeanFactory 方法中有一行 loadBeanDefinitions(beanFactory)
将找到答案,这个方法将开始加载、解析 Bean 的定义,也就是把用户定义的数据结构转化为 Ioc 容器中的特定数据结构。
这个过程可以用下面时序图解释:
图 11. 创建 BeanFactory 时序图

(查看 图 11 的清晰版本。)
Bean 的解析和登记流程时序图如下:
图 12. 解析和登记 Bean 对象时序图

(查看 图 12 的清晰版本。)
创建好 BeanFactory 后,接下去添加一些 Spring 本身需要的一些工具类,这个操作在 AbstractApplicationContext 的 prepareBeanFactory 方法完成。
AbstractApplicationContext 中接下来的三行代码对 Spring
的功能扩展性起了至关重要的作用。前两行主要是让你现在可以对已经构建的 BeanFactory 的配置做修改,后面一行就是让你可以对以后再创建
Bean 的实例对象时添加一些自定义的操作。所以他们都是扩展了 Spring 的功能,所以我们要学习使用 Spring 必须对这一部分搞清楚。
其中在 invokeBeanFactoryPostProcessors 方法中主要是获取实现 BeanFactoryPostProcessor 接口的子类。并执行它的 postProcessBeanFactory 方法,这个方法的声明如下:
清单 3. BeanFactoryPostProcessor.postProcessBeanFactory
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory)
throws BeansException;
|
它的参数是 beanFactory,说明可以对 beanFactory 做修改,这里注意这个 beanFactory 是
ConfigurableListableBeanFactory 类型的,这也印证了前面介绍的不同 BeanFactory
所使用的场合不同,这里只能是可配置的 BeanFactory,防止一些数据被用户随意修改。
registerBeanPostProcessors 方法也是可以获取用户定义的实现了 BeanPostProcessor
接口的子类,并执行把它们注册到 BeanFactory 对象中的 beanPostProcessors
变量中。BeanPostProcessor
中声明了两个方法:postProcessBeforeInitialization、postProcessAfterInitialization
分别用于在 Bean 对象初始化时执行。可以执行用户自定义的操作。
后面的几行代码是初始化监听事件和对系统的其他监听者的注册,监听者必须是 ApplicationListener 的子类。
如何创建 Bean 实例并构建 Bean 的关系网
下面就是 Bean 的实例化代码,是从 finishBeanFactoryInitialization 方法开始的。
清单 4. AbstractApplicationContext.finishBeanFactoryInitialization
protected void finishBeanFactoryInitialization(
ConfigurableListableBeanFactory beanFactory) {
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
// Allow for caching all bean definition metadata, not expecting further changes.
beanFactory.freezeConfiguration();
// Instantiate all remaining (non-lazy-init) singletons.
beanFactory.preInstantiateSingletons();
}
|
从上面代码中可以发现 Bean 的实例化是在 BeanFactory 中发生的。preInstantiateSingletons 方法的代码如下:
清单 5. DefaultListableBeanFactory.preInstantiateSingletons
public void preInstantiateSingletons() throws BeansException {
if (this.logger.isInfoEnabled()) {
this.logger.info("Pre-instantiating singletons in " + this);
}
synchronized (this.beanDefinitionMap) {
for (String beanName : this.beanDefinitionNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton()
&& !bd.isLazyInit()) {
if (isFactoryBean(beanName)) {
final FactoryBean factory =
(FactoryBean) getBean(FACTORY_BEAN_PREFIX+ beanName);
boolean isEagerInit;
if (System.getSecurityManager() != null
&& factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
new PrivilegedAction<Boolean>() {
public Boolean run() {
return ((SmartFactoryBean) factory).isEagerInit();
}
}, getAccessControlContext());
}
else {
isEagerInit = factory instanceof SmartFactoryBean
&& ((SmartFactoryBean) factory).isEagerInit();
}
if (isEagerInit) {
getBean(beanName);
}
}
else {
getBean(beanName);
}
}
}
}
}
|
这里出现了一个非常重要的 Bean —— FactoryBean,可以说 Spring 一大半的扩展的功能都与这个 Bean
有关,这是个特殊的 Bean 他是个工厂 Bean,可以产生 Bean 的 Bean,这里的产生 Bean 是指 Bean
的实例,如果一个类继承 FactoryBean 用户可以自己定义产生实例对象的方法只要实现他的 getObject 方法。然而在 Spring
内部这个 Bean 的实例对象是 FactoryBean,通过调用这个对象的 getObject 方法就能获取用户自定义产生的对象,从而为
Spring 提供了很好的扩展性。Spring 获取 FactoryBean 本身的对象是在前面加上 & 来完成的。
如何创建 Bean 的实例对象以及如何构建 Bean 实例对象之间的关联关系式 Spring 中的一个核心关键,下面是这个过程的流程图。
图 13.Bean 实例创建流程图

(查看 图 13 的清晰版本。)
如果是普通的 Bean 就直接创建他的实例,是通过调用 getBean 方法。下面是创建 Bean 实例的时序图:
图 14.Bean 实例创建时序图

(查看 图 14 的清晰版本。)
还有一个非常重要的部分就是建立 Bean 对象实例之间的关系,这也是 Spring 框架的核心竞争力,何时、如何建立他们之间的关系请看下面的时序图:
图 15.Bean 对象关系建立

(查看 图 15 的清晰版本。)
Ioc 容器的扩展点
现在还有一个问题就是如何让这些 Bean 对象有一定的扩展性,就是可以加入用户的一些操作。那么有哪些扩展点呢? Spring 又是如何调用到这些扩展点的?
对 Spring 的 Ioc 容器来说,主要有这么几个。BeanFactoryPostProcessor,
BeanPostProcessor。他们分别是在构建 BeanFactory 和构建 Bean 对象时调用。还有就是
InitializingBean 和 DisposableBean 他们分别是在 Bean
实例创建和销毁时被调用。用户可以实现这些接口中定义的方法,Spring 就会在适当的时候调用他们。还有一个是 FactoryBean
他是个特殊的 Bean,这个 Bean 可以被用户更多的控制。
这些扩展点通常也是我们使用 Spring 来完成我们特定任务的地方,如何精通 Spring 就看你有没有掌握好 Spring 有哪些扩展点,并且如何使用他们,要知道如何使用他们就必须了解他们内在的机理。可以用下面一个比喻来解释。
我们把 Ioc
容器比作一个箱子,这个箱子里有若干个球的模子,可以用这些模子来造很多种不同的球,还有一个造这些球模的机器,这个机器可以产生球模。那么他们的对应关
系就是 BeanFactory 就是那个造球模的机器,球模就是 Bean,而球模造出来的球就是 Bean
的实例。那前面所说的几个扩展点又在什么地方呢? BeanFactoryPostProcessor
对应到当造球模被造出来时,你将有机会可以对其做出设当的修正,也就是他可以帮你修改球模。而 InitializingBean 和
DisposableBean 是在球模造球的开始和结束阶段,你可以完成一些预备和扫尾工作。BeanPostProcessor
就可以让你对球模造出来的球做出适当的修正。最后还有一个
FactoryBean,它可是一个神奇的球模。这个球模不是预先就定型了,而是由你来给他确定它的形状,既然你可以确定这个球模型的形状,当然他造出来
的球肯定就是你想要的球了,这样在这个箱子里尼可以发现所有你想要的球
Ioc 容器如何为我所用
前面的介绍了 Spring 容器的构建过程,那 Spring 能为我们做什么,Spring 的 Ioc 容器又能做什么呢?我们使用
Spring 必须要首先构建 Ioc 容器,没有它 Spring 无法工作,ApplicatonContext.xml 就是 Ioc
容器的默认配置文件,Spring 的所有特性功能都是基于这个 Ioc 容器工作的,比如后面要介绍的 AOP。
Ioc 它实际上就是为你构建了一个魔方,Spring
为你搭好了骨骼架构,这个魔方到底能变出什么好的东西出来,这必须要有你的参与。那我们怎么参与?这就是前面说的要了解 Spring
中那有些扩展点,我们通过实现那些扩展点来改变 Spring 的通用行为。至于如何实现扩展点来得到我们想要的个性结果,Spring
中有很多例子,其中 AOP 的实现就是 Spring 本身实现了其扩展点来达到了它想要的特性功能,可以拿来参考。
回页首
Spring 中 AOP 特性详解
动态代理的实现原理
要了解 Spring 的 AOP 就必须先了解的动态代理的原理,因为 AOP 就是基于动态代理实现的。动态代理还要从 JDK 本身说起。
在 Jdk 的 java.lang.reflect 包下有个 Proxy 类,它正是构造代理类的入口。这个类的结构入下:
图 16. Proxy 类结构

从上图发现最后面四个是公有方法。而最后一个方法 newProxyInstance 就是创建代理对象的方法。这个方法的源码如下:
清单 6. Proxy. newProxyInstance
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
throws IllegalArgumentException {
if (h == null) {
throw new NullPointerException();
}
Class cl = getProxyClass(loader, interfaces);
try {
Constructor cons = cl.getConstructor(constructorParams);
return (Object) cons.newInstance(new Object[] { h });
} catch (NoSuchMethodException e) {
throw new InternalError(e.toString());
} catch (IllegalAccessException e) {
throw new InternalError(e.toString());
} catch (InstantiationException e) {
throw new InternalError(e.toString());
} catch (InvocationTargetException e) {
throw new InternalError(e.toString());
}
}
|
这个方法需要三个参数:ClassLoader,用于加载代理类的 Loader 类,通常这个 Loader 和被代理的类是同一个
Loader
类。Interfaces,是要被代理的那些那些接口。InvocationHandler,就是用于执行除了被代理接口中方法之外的用户自定义的操作,
他也是用户需要代理的最终目的。用户调用目标方法都被代理到 InvocationHandler 类中定义的唯一方法 invoke
中。这在后面再详解。
下面还是看看 Proxy 如何产生代理类的过程,他构造出来的代理类到底是什么样子?下面揭晓啦。
图 17. 创建代理对象时序图

其实从上图中可以发现正在构造代理类的是在 ProxyGenerator 的 generateProxyClass 的方法中。ProxyGenerator 类在 sun.misc 包下,感兴趣的话可以看看他的源码。
假如有这样一个接口,如下:
清单 7. SimpleProxy 类
public interface SimpleProxy {
public void simpleMethod1();
public void simpleMethod2();
}
|
代理来生成的类结构如下:
清单 8. $Proxy2 类
public class $Proxy2 extends java.lang.reflect.Proxy implements SimpleProxy{
java.lang.reflect.Method m0;
java.lang.reflect.Method m1;
java.lang.reflect.Method m2;
java.lang.reflect.Method m3;
java.lang.reflect.Method m4;
int hashCode();
boolean equals(java.lang.Object);
java.lang.String toString();
void simpleMethod1();
void simpleMethod2();
}
|
这个类中的方法里面将会是调用 InvocationHandler 的 invoke 方法,而每个方法也将对应一个属性变量,这个属性变量 m 也将传给 invoke 方法中的 Method 参数。整个代理就是这样实现的。
Spring AOP 如何实现
从前面代理的原理我们知道,代理的目的是调用目标方法时我们可以转而执行 InvocationHandler 类的 invoke 方法,所以如何在 InvocationHandler 上做文章就是 Spring 实现 Aop 的关键所在。
Spring 的 Aop 实现是遵守 Aop 联盟的约定。同时 Spring 又扩展了它,增加了如 Pointcut、Advisor 等一些接口使得更加灵活。
下面是 Jdk 动态代理的类图:
图 18. Jdk 动态代理的类图

上图清楚的显示了 Spring 引用了 Aop Alliance 定义的接口。姑且不讨论 Spring 如何扩展 Aop
Alliance,先看看 Spring 如何实现代理类的,要实现代理类在 Spring 的配置文件中通常是这样定一个 Bean 的,如下:
清单 9. 配置代理类 Bean
<bean id="testBeanSingleton"
class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="proxyInterfaces">
<value>
org.springframework.aop.framework.PrototypeTargetTests$TestBean
</value>
</property>
<property name="target"><ref local="testBeanTarget"></ref> </property>
<property name="singleton"><value>true</value></property>
<property name="interceptorNames">
<list>
<value>testInterceptor</value>
<value>testInterceptor2</value>
</list>
</property>
</bean>
|
配置上看到要设置被代理的接口,和接口的实现类也就是目标类,以及拦截器也就在执行目标方法之前被调用,这里 Spring 中定义的各种各样的拦截器,可以选择使用。
下面看看 Spring 如何完成了代理以及是如何调用拦截器的。
前面提到 Spring Aop 也是实现其自身的扩展点来完成这个特性的,从这个代理类可以看出它正是继承了 FactoryBean 的
ProxyFactoryBean,FactoryBean 之所以特别就在它可以让你自定义对象的创建方法。当然代理对象要通过 Proxy
类来动态生成。
下面是 Spring 创建的代理对象的时序图:
图 19.Spring 代理对象的产生

Spring 创建了代理对象后,当你调用目标对象上的方法时,将都会被代理到 InvocationHandler 类的 invoke
方法中执行,这在前面已经解释。在这里 JdkDynamicAopProxy 类实现了 InvocationHandler 接口。
下面再看看 Spring 是如何调用拦截器的,下面是这个过程的时序图:
图 20.Spring 调用拦截器

以上所说的都是 Jdk 动态代理,Spring 还支持一种 CGLIB 类代理,感兴趣自己看吧。
回页首
Spring 中设计模式分析
Spring 中使用的设计模式也很多,比如工厂模式、单例模式、模版模式等,在《 Webx 框架的系统架构与设计模式》、《 Tomcat 的系统架构与模式设计分析》已经有介绍,这里就不赘述了。这里主要介绍代理模式和策略模式。
代理模式
代理模式原理
代理模式就是给某一个对象创建一个代理对象,而由这个代理对象控制对原对象的引用,而创建这个代理对象就是可以在调用原对象是可以增加一些额外的操作。下面是代理模式的结构:
图 21. 代理模式的结构

- Subject:抽象主题,它是代理对象的真实对象要实现的接口,当然这可以是多个接口组成。
- ProxySubject:代理类除了实现抽象主题定义的接口外,还必须持有所代理对象的引用
- RealSubject:被代理的类,是目标对象。
Spring 中如何实现代理模式
Spring Aop 中 Jdk 动态代理就是利用代理模式技术实现的。在 Spring 中除了实现被代理对象的接口外,还会有
org.springframework.aop.SpringProxy 和
org.springframework.aop.framework.Advised 两个接口。Spring 中使用代理模式的结构图如下:
图 22. Spring 中使用代理模式的结构图

$Proxy 就是创建的代理对象,而 Subject 是抽象主题,代理对象是通过 InvocationHandler 来持有对目标对象的引用的。
Spring 中一个真实的代理对象结构如下:
清单 10 代理对象 $Proxy4
public class $Proxy4 extends java.lang.reflect.Proxy implements
org.springframework.aop.framework.PrototypeTargetTests$TestBean
org.springframework.aop.SpringProxy
org.springframework.aop.framework.Advised
{
java.lang.reflect.Method m16;
java.lang.reflect.Method m9;
java.lang.reflect.Method m25;
java.lang.reflect.Method m5;
java.lang.reflect.Method m2;
java.lang.reflect.Method m23;
java.lang.reflect.Method m18;
java.lang.reflect.Method m26;
java.lang.reflect.Method m6;
java.lang.reflect.Method m28;
java.lang.reflect.Method m14;
java.lang.reflect.Method m12;
java.lang.reflect.Method m27;
java.lang.reflect.Method m11;
java.lang.reflect.Method m22;
java.lang.reflect.Method m3;
java.lang.reflect.Method m8;
java.lang.reflect.Method m4;
java.lang.reflect.Method m19;
java.lang.reflect.Method m7;
java.lang.reflect.Method m15;
java.lang.reflect.Method m20;
java.lang.reflect.Method m10;
java.lang.reflect.Method m1;
java.lang.reflect.Method m17;
java.lang.reflect.Method m21;
java.lang.reflect.Method m0;
java.lang.reflect.Method m13;
java.lang.reflect.Method m24;
int hashCode();
int indexOf(org.springframework.aop.Advisor);
int indexOf(org.aopalliance.aop.Advice);
boolean equals(java.lang.Object);
java.lang.String toString();
void sayhello();
void doSomething();
void doSomething2();
java.lang.Class getProxiedInterfaces();
java.lang.Class getTargetClass();
boolean isProxyTargetClass();
org.springframework.aop.Advisor; getAdvisors();
void addAdvisor(int, org.springframework.aop.Advisor)
throws org.springframework.aop.framework.AopConfigException;
void addAdvisor(org.springframework.aop.Advisor)
throws org.springframework.aop.framework.AopConfigException;
void setTargetSource(org.springframework.aop.TargetSource);
org.springframework.aop.TargetSource getTargetSource();
void setPreFiltered(boolean);
boolean isPreFiltered();
boolean isInterfaceProxied(java.lang.Class);
boolean removeAdvisor(org.springframework.aop.Advisor);
void removeAdvisor(int)throws org.springframework.aop.framework.AopConfigException;
boolean replaceAdvisor(org.springframework.aop.Advisor,
org.springframework.aop.Advisor)
throws org.springframework.aop.framework.AopConfigException;
void addAdvice(org.aopalliance.aop.Advice)
throws org.springframework.aop.framework.AopConfigException;
void addAdvice(int, org.aopalliance.aop.Advice)
throws org.springframework.aop.framework.AopConfigException;
boolean removeAdvice(org.aopalliance.aop.Advice);
java.lang.String toProxyConfigString();
boolean isFrozen();
void setExposeProxy(boolean);
boolean isExposeProxy();
}
|
策略模式
策略模式原理
策略模式顾名思义就是做某事的策略,这在编程上通常是指完成某个操作可能有多种方法,这些方法各有千秋,可能有不同的适应的场合,然而这些操作方法都有可能用到。各一个操作方法都当作一个实现策略,使用者可能根据需要选择合适的策略。
下面是策略模式的结构:
图 23. 策略模式的结构

- Context:使用不同策略的环境,它可以根据自身的条件选择不同的策略实现类来完成所要的操作。它持有一个策略实例的引用。创建具体策略对象的方法也可以由他完成。
- Strategy:抽象策略,定义每个策略都要实现的策略方法
- ConcreteStrategy:具体策略实现类,实现抽象策略中定义的策略方法
Spring 中策略模式的实现
Spring 中策略模式使用有多个地方,如 Bean 定义对象的创建以及代理对象的创建等。这里主要看一下代理对象创建的策略模式的实现。
前面已经了解 Spring 的代理方式有两个 Jdk 动态代理和 CGLIB 代理。这两个代理方式的使用正是使用了策略模式。它的结构图如下所示:
图 24. Spring 中策略模式结构图

在上面结构图中与标准的策略模式结构稍微有点不同,这里抽象策略是 AopProxy 接口,Cglib2AopProxy 和
JdkDynamicAopProxy 分别代表两种策略的实现方式,ProxyFactoryBean 就是代表 Context
角色,它根据条件选择使用 Jdk 代理方式还是 CGLIB 方式,而另外三个类主要是来负责创建具体策略对象,ProxyFactoryBean
是通过依赖的方法来关联具体策略对象的,它是通过调用策略对象的 getProxy(ClassLoader classLoader)
方法来完成操作。
回页首
总结
本文通过从 Spring 的几个核心组件入手,试图找出构建 Spring 框架的骨骼架构,进而分析 Spring
在设计的一些设计理念,是否从中找出一些好的设计思想,对我们以后程序设计能提供一些思路。接着再详细分析了 Spring
中是如何实现这些理念的,以及在设计模式上是如何使用的。
通过分析 Spring 给我一个很大的启示就是其这套设计理念其实对我们有很强的借鉴意义,它通过抽象复杂多变的对象,进一步做规范,然后根据它定义的这套规范设计出一个容器,容器中构建它们的复杂关系,其实现在有很多情况都可以用这种类似的处理方法。
虽然我很想把我对 Spring 的想法完全阐述清楚,但是所谓“书不尽言,言不尽意。”,有什么不对或者不清楚的地方大家还是看看其源码吧。
|
原文地址
http://www.ibm.com/developerworks/cn/java/j-lo-spring-principle/index.html
摘要: Java的反射机制是Java特性之一,反射机制是构建框架技术的基础所在。灵活掌握Java反射机制,对大家以后学习框架技术有很大的帮助。
那么什么是Java的反射呢?
大家都知道,要让Java程序能够运行,那么就得让Java类要被Java虚拟机加载。Java类如果不被Java虚拟机加载,是不... 阅读全文
在网上看了很多有关序列化的文
章,我自己也写了两篇,现在感觉这些文章都没有很好的把序列化说清楚(包括我自己在内),所以在此我将总结前人以及自己的经验,用更浅显易懂的语言来描述
该机制,当然,仍然会有不好的地方,希望你看后可以指出,作为一名程序员应该具有不断探索的精神和强烈的求知欲望!
序列化概述:
简单来说序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化,流的概念这里不用多说(就是I/O),我们可以对流化后的对象进行
读写操作,也可将流化后的对象传输于网络之间(注:要想将对象传输于网络必须进行流化)!在对对象流进行读写操作时会引发一些问题,而序列化机制正是用来
解决这些问题的!
问题的引出:
如上所述,读写对象会有什么问题呢?比如:我要将对象写入一个磁盘文件而后再将其读出来会有什么问题吗?别急,其中一个最大的问题就是对象引用!举个例子
来说:假如我有两个类,分别是A和B,B类中含有一个指向A类对象的引用,现在我们对两个类进行实例化{ A a = new A(); B b =
new B();
},这时在内存中实际上分配了两个空间,一个存储对象a,一个存储对象b,接下来我们想将它们写入到磁盘的一个文件中去,就在写入文件时出现了问题!因为
对象b包含对对象a的引用,所以系统会自动的将a的数据复制一份到b中,这样的话当我们从文件中恢复对象时(也就是重新加载到内存中)时,内存分配了三个
空间,而对象a同时在内存中存在两份,想一想后果吧,如果我想修改对象a的数据的话,那不是还要搜索它的每一份拷贝来达到对象数据的一致性,这不是我们所
希望的!
以下序列化机制的解决方案:
1.保存到磁盘的所有对象都获得一个序列号(1, 2, 3等等)
2.当要保存一个对象时,先检查该对象是否被保存了。
3.如果以前保存过,只需写入"与已经保存的具有序列号x的对象相同"的标记,否则,保存该对象
通过以上的步骤序列化机制解决了对象引用的问题!
序列化的实现:
将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements
Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个
ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object
obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
例子:
import java.io.*;
public class Test
{
public static void main(String[] args)
{
Employee harry = new Employee("Harry Hacker", 50000);
Manager manager1 = new Manager("Tony Tester", 80000);
manager1.setSecretary(harry);
Employee[] staff = new Employee[2];
staff[0] = harry;
staff[1] = manager1;
try
{
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("employee.dat"));
out.writeObject(staff);
out.close();
ObjectInputStream in = new ObjectInputStream(
new FileInputStream("employee.dat"));
Employee[] newStaff = (Employee[])in.readObject();
in.close();
/**
*通过harry对象来加薪
*将在secretary上反映出来
*/
newStaff[0].raiseSalary(10);
for (int i = 0; i < newStaff.length; i++)
System.out.println(newStaff[i]);
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
class Employee implements Serializable
{
public Employee(String n, double s)
{
name = n;
salary = s;
}
/**
*加薪水
*/
public void raiseSalary(double byPercent)
{
double raise = salary * byPercent / 100;
salary += raise;
}
public String toString()
{
return getClass().getName()
+ "[name = "+ name
+ ",salary = "+ salary
+ "]";
}
private String name;
private double salary;
}
class Manager extends Employee
{
public Manager(String n, double s)
{
super(n, s);
secretary = null;
}
/**
*设置秘书
*/
public void setSecretary(Employee s)
{
secretary = s;
}
public String toString()
{
return super.toString()
+ "[secretary = "+ secretary
+ "]";
}
//secretary代表秘书
private Employee secretary;
}
修改默认的序列化机制:
在
序列化的过程中,有些数据字段我们不想将其序列化,对于此类字段我们只需要在定义时给它加上transient关键字即可,对于transient字段序
列化机制会跳过不会将其写入文件,当然也不可被恢复。但有时我们想将某一字段序列化,但它在SDK中的定义却是不可序列化的类型,这样的话我们也必须把他
标注为transient,可是不能写入又怎么恢复呢?好在序列化机制为包含这种特殊问题的类提供了如下的方法定义:
private void readObject(ObjectInputStream in) throws
IOException, ClassNotFoundException;
private void writeObject(ObjectOutputStream out) throws
IOException;
(注:这些方法定义时必须是私有的,因为不需要你显示调用,序列化机制会自动调用的)
使用以上方法我们可以手动对那些你又想序列化又不可以被序列化的数据字段进行写出和读入操作。
下面是一个典型的例子,java.awt.geom包中的Point2D.Double类就是不可序列化的,因为该类没有实现Serializable接口,在我的例子中将把它当作LabeledPoint类中的一个数据字段,并演示如何将其序列化!
import java.io.*;
import java.awt.geom.*;
public class TransientTest
{
public static void main(String[] args)
{
LabeledPoint label = new LabeledPoint("Book", 5.00, 5.00);
try
{
System.out.println(label);//写入前
ObjectOutputStream out = new ObjectOutputStream(new
FileOutputStream("Label.txt"));
out.writeObject(label);
out.close();
System.out.println(label);//写入后
ObjectInputStream in = new ObjectInputStream(new
FileInputStream("Label.txt"));
LabeledPoint label1 = (LabeledPoint)in.readObject();
in.close();
System.out.println(label1);//读出并加1.0后
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
class LabeledPoint implements Serializable
{
public LabeledPoint(String str, double x, double y)
{
label = str;
point = new Point2D.Double(x, y);
}
private void writeObject(ObjectOutputStream out) throws IOException
{
/**
*必须通过调用defaultWriteObject()方法来写入
*对象的描述以及那些可以被序列化的字段
*/
out.defaultWriteObject();
out.writeDouble(point.getX());
out.writeDouble(point.getY());
}
private void readObject(ObjectInputStream in)
throws IOException, ClassNotFoundException
{
/**
*必须调用defaultReadObject()方法
*/
in.defaultReadObject();
double x = in.readDouble() + 1.0;
double y = in.readDouble() + 1.0;
point = new Point2D.Double(x, y);
}
public String toString()
{
return getClass().getName()
+ "[label = "+ label
+ ", point.getX() = "+ point.getX()
+ ", point.getY() = "+ point.getY()
+ "]";
}
private String label;
transient private Point2D.Double point;
}
- String[] projection = new String[] {
- People._ID,
- People.NAME,
- People.NUMBER,
- };
-
- Uri contactUri = People.CONTENT_URI;
-
- Cursor peopleCursor = managedQuery (contactUri,
- projection,
- null,
- null,
- People.DEFAULT_SORT_ORDER);
-
- peopleCursor.moveToFirst();
-
-
-
- long personId = peopleCursor.getLong(peopleCursor.getColumnIndex("_id"));
-
- Uri personUri = ContentUris.withAppendedId(contactUri, personId );
-
- Uri phoneUri=
- Uri.withAppendedPath(personUri, Contacts.People.Phones.CONTENT_DIRECTORY);
-
-
- Cursor phonesCursor = managedQuery(phoneUri,
- null,
- null,
- null,
- Phones.DEFAULT_SORT_ORDER);
-
- phonesCursor.moveToFirst();
 android 2.2 获取联系人,电话,并拨号 收藏 android 2.2 获取联系人,电话,并拨号 收藏
该demo是第一次基于android开发。
主要功能有: 读取联系人姓名、号码,并lisetview 显示,获取listview数据,并发短信、或者拨号
package com.android.hello;
import android.app.Activity;
import android.content.Intent;
import android.database.Cursor;
import android.graphics.Color;
import android.net.Uri;
import android.os.Bundle;
import android.telephony.PhoneNumberUtils;
import android.util.Log;
import android.view.View;
import android.widget.AdapterView;
import android.widget.LinearLayout;
import android.widget.ListAdapter;
import android.widget.ListView;
import android.widget.RelativeLayout;
import android.widget.TextView;
import android.widget.Toast;
import android.provider.ContactsContract;
import java.util.ArrayList;
import java.util.HashMap;
import android.widget.SimpleAdapter;
@SuppressWarnings("deprecation")
public class hello extends Activity {
/** Called when the activity is first created. */
// @SuppressWarnings("deprecation")
// @Override
//
private static final String TAG="App";
ListView listView;
ListAdapter adapter;
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// setContentView(R.layout.main);
LinearLayout linearLayout=new LinearLayout(this);
linearLayout.setOrientation(LinearLayout.VERTICAL);
linearLayout.setBackgroundColor(Color.BLACK);
LinearLayout.LayoutParams param=new LinearLayout.LayoutParams(LinearLayout.LayoutParams.FILL_PARENT,LinearLayout.LayoutParams.WRAP_CONTENT);
listView=new ListView(this);
listView.setBackgroundColor(Color.BLACK);
linearLayout.addView(listView,param);
this.setContentView(linearLayout);
//生成动态数组,加入数据
ArrayList<HashMap<String, Object>> listItem = new ArrayList<HashMap<String, Object>>();
ArrayList<HashMap<String, Object>> listItemRead = new ArrayList<HashMap<String, Object>>();
Cursor cursor = getContentResolver().query(ContactsContract.Contacts.CONTENT_URI,null, null, null, null);
while (cursor.moveToNext())
{
HashMap<String, Object> map = new HashMap<String, Object>();
String phoneName = cursor.getString(cursor.getColumnIndex(ContactsContract.Contacts.DISPLAY_NAME));
map.put("ItemTitle", phoneName);//电话姓名
String contactId = cursor.getString(cursor.getColumnIndex(ContactsContract.Contacts._ID));
String hasPhone = cursor.getString(cursor.getColumnIndex(ContactsContract.Contacts.HAS_PHONE_NUMBER));
if (hasPhone.compareTo("1") == 0)
{
Cursor phones = getContentResolver().query(ContactsContract.CommonDataKinds.Phone.CONTENT_URI,null,ContactsContract.CommonDataKinds.Phone.CONTACT_ID +" = "+ contactId,null, null);
while (phones.moveToNext())
{
String phoneNumber = phones.getString(phones.getColumnIndex(ContactsContract.CommonDataKinds.Phone.NUMBER));
String phoneTpye = phones.getString(phones.getColumnIndex(ContactsContract.CommonDataKinds.Phone.TYPE));
map.put("ItemText", phoneNumber); // 多个号码如何处理
Log.d(TAG,"testNum="+ phoneNumber + "type:"+phoneTpye);
}
phones.close();
}
Cursor emails = getContentResolver().query(ContactsContract.CommonDataKinds.Email.CONTENT_URI,null,ContactsContract.CommonDataKinds.Email.CONTACT_ID + " = " + contactId,null, null);
while (emails.moveToNext())
{
String emailAddress = emails.getString(emails.getColumnIndex(ContactsContract.CommonDataKinds.Email.DATA));
String emailType = emails.getString(emails.getColumnIndex(ContactsContract.CommonDataKinds.Email.TYPE));
Log.d(TAG,"testNum="+ emailAddress + "type:"+emailType);
}
emails.close();
listItem.add(map);
}
//生成适配器的Item和动态数组对应的元素
SimpleAdapter listItemAdapter = new SimpleAdapter(this,listItem,//数据源
android.R.layout.simple_list_item_2,//ListItem的XML实现
//动态数组与ImageItem对应的子项
new String[] {"ItemTitle", "ItemText"},
//ImageItem的XML文件里面的一个ImageView,两个TextView ID
new int[] {android.R.id.text1,android.R.id.text2}
);
listView.setAdapter(listItemAdapter);
cursor.close();
//listView.setEmptyView(findViewById(R.id.empty));
listView.setOnItemSelectedListener(new AdapterView.OnItemSelectedListener(){
public void onItemSelected(AdapterView<?> arg0, View arg1,
int arg2, long arg3) {
// TODO Auto-generated method stub
//openToast("滚动到:"+arg0.getSelectedItemId());
//短信发送
setTitle("选择"+arg2+"项目");
openToast("选择"+arg0.getSelectedItemId()+"项目");
RelativeLayout lr = (RelativeLayout) arg1;
TextView mText = (TextView) lr.getChildAt(1);
openToast(mText.getText().toString());
String number = mText.getText().toString();
Log.d(TAG, "number=" + number);
// 判断电话号码的有效性
if (PhoneNumberUtils.isGlobalPhoneNumber(number)) {
Intent intent = new Intent(Intent.ACTION_SENDTO, Uri
.parse("smsto://" + number));
intent.putExtra("sms_body", "The SMS text");
startActivity(intent);
}
}
public void onNothingSelected(AdapterView<?> arg0) {
// TODO Auto-generated method stub
}
});
listView.setOnItemClickListener(new AdapterView.OnItemClickListener(){
public void onItemClick(AdapterView<?> arg0, View arg1,
int position, long arg3) {
// TODO Auto-generated method stub
// openToast("Click"+Integer.toString(position+1)+"项目");
RelativeLayout lr = (RelativeLayout) arg1;
TextView mText = (TextView) lr.getChildAt(1);
openToast(mText.getText().toString());
String number = mText.getText().toString();
Log.d(TAG, "number=" + number);
// 判断电话号码的有效性
if (PhoneNumberUtils.isGlobalPhoneNumber(number)) {
Intent intent = new Intent(Intent.ACTION_DIAL, Uri
.parse("tel://" + number));
startActivity(intent);
}
}
});
}
private void openToast(String str){
Toast.makeText(this,str,Toast.LENGTH_SHORT).show();
}
}
// Collator 类是用来执行区分语言环境的 String 比较的,这里选择使用CHINA
Comparator cmp = Collator.getInstance(java.util.Locale.CHINA);
TreeMap tree=new TreeMap(cmp);
String[] arr = {"张三", "李四", "王五"};
// 使根据指定比较器产生的顺序对指定对象数组进行排序。
Arrays.sort(arr, cmp);
for (int i = 0; i < arr.length; i++)
System.out.println(arr[i]);
<script>
names = ["张三", "李四", "王五", "刘六"];
names.sort(function(a,b){return a.localeCompare(b)});//a,b 为数组a的某两个值,自动传入
alert(names);
</script>
另:
示例文本:
String [] test = new String[] {
"作业",
"测试",
"test",
"我们",
"。空",
"镂空",
"[",
"浏",
"皙"
};
jdk 版本:
1.5.6
开发平台:
Eclipse 3.1
关键字: 中文排序
概述
我们在应用程序中可能会经常遇到对中文排序的问题,例如姓名列表,词汇表等等。对中文排序,我们使用比较多的是根据汉语拼音发音来确定顺序。
我们可能会经常使用
接口,
- java.util.Arrays
.sort((T[] a, Comparator
<? super
T> c))
等类或方法对含有中文字符的对象进行排序,但是这些在默认情况下都是调用
方法,这个方法是比较2个字符的 codepoint value,如果第一个字符的值小于第二个,则在排序结果中第一个会在前面,反之亦然。
接口及其实现类
其实 java 中提供了和语言相关的类,即 Collator 接口及其实现类。
是一个具体类,它实现了 Comparator 接口中的 compare(Object, Object) 方法。
RuleBasedCollator 根据根据特定语言的默认规则比较字符,也可以按照指定的规则来比较,请参阅 java API 获取此类的详细信
息。
如果我们需要对一个有中文的数组进行排序,则可以使用这个类。请看如下示例代码:
以上代码的输出结果为:
============
[
test
。空
测试
我们
作业
浏
镂空
皙
大家可能会发现只有一部分汉字是按照汉语拼音排序了,还有几个没有。
问题分析:
GB2312:
在简体中文中我们使用比较多的字符集是 GB2312-80,简称为 GB2312,这个字符集包含了目前最常用的汉字共计 6736 个。其中的汉字分为两大类:
常用汉字按照汉语拼音来排序,而次常用汉字按照笔画部首进行排序。
简体汉字在 Unicode 中一般是按照 gb2312 的码点值的顺序来放置的,所以如果是常用汉字 java 就能够很准确的进行排序,但如果是次常用汉字,则就会出现问题。在以上示例中,"镂","皙" 属于次常用字。
解决方案:
RuleBasedCollator 类 getRules() 方法可以返回对应语言的规则设置。简体中文对应的规则是 gb2312 所对应的字符。
我们可以把其中的全部汉字提取出来
对这些汉字重新排序
利用RuleBasedCollator(String rules) 构造器新建一个定制的 RuleBasedCollator
参考代码
在以下的代码中,我把排过序的汉字直接作为 String 对象放在类里面了,如果要让代码变得简洁一些,则可以把完整的规则(特殊字符+排序汉字)存为文件。
- package
sorting;
- import
java.util.*;
- import
java.text.*;
- /**
- * @author GaoJianMin
- *
- */
- public
class
ChineseGB2312Collator
- {
- /**
- * @return a customized RuleBasedCollator with Chinese characters (GB2312) sorted correctly
- *
- */
- public
static
final
RuleBasedCollator
getFixedGB2312Collator()
- {
- RuleBasedCollator
fixedGB2312Collator =null
;
- try
- {
- fixedGB2312Collator = new
java.text.RuleBasedCollator
(
- ChineseGB2312Collator.getGB2312SpecialChars() +
- GB2312Chars
- );
- }catch
(ParseException
e)
- {
- e.printStackTrace();
- }
- return
fixedGB2312Collator;
- }
-
- /**
- * @return the special characters in GB2312 charset.
- *
- */
- public
static
final
String
getGB2312SpecialChars()
- {
- RuleBasedCollator
zh_CNCollator = (RuleBasedCollator
)Collator
.getInstance(Locale
.CHINA);
- //index 2125 is the last symbol "╋"
- return
zh_CNCollator.getRules().substring(0,2125);
- }
-
- /**
- * 6763 Chinese characters in GB2312 charset
- */
- public
static
final
String
GB2312Chars =
- "<吖<阿<啊<
锕<嗄<哎<哀<唉<埃<挨<锿<捱<皑<癌<嗳<矮<蔼<
霭<艾<爱<砹<隘<嗌<嫒<碍<暧<瑷<安<桉<氨<庵<
谙<鹌<鞍<俺<埯<铵<揞<犴<岸<按<案<胺<暗<黯<
肮<昂<盎<凹<坳<敖<嗷<廒<獒<遨<熬<翱<聱<螯<
鳌<鏖<拗<袄<媪<岙<傲<奥<骜<澳<懊<鏊"
+
- "<八<巴<叭<
扒<吧<岜<芭<疤<捌<笆<粑<拔<茇<菝<跋<魃<把<
钯<靶<坝<爸<罢<鲅<霸<灞<掰<白<百<佰<柏<捭<
摆<呗<败<拜<稗<扳<班<般<颁<斑<搬<瘢<癍<阪<
坂<板<版<钣<舨<办<半<伴<扮<拌<绊<瓣<邦<帮<
梆<浜<绑<榜<膀<蚌<傍<棒<谤<蒡<磅<镑<勹<包<
孢<苞<胞<煲<龅<褒<雹<宝<饱<保<鸨<堡<葆<褓<
报<抱<豹<趵<鲍<暴<爆<陂<卑<杯<悲<碑<鹎<北<
贝<狈<邶<备<背<钡<倍<悖<被<惫<焙<辈<碚<蓓<
褙<鞴<鐾<奔<贲<锛<本<苯<畚<坌<笨<崩<绷<嘣<
甭<泵<迸<甏<蹦<逼<荸<鼻<匕<比<吡<妣<彼<秕<
俾<笔<舭<鄙<币<必<毕<闭<庇<畀<哔<毖<荜<陛<
毙<狴<铋<婢<庳<敝<萆<弼<愎<筚<滗<痹<蓖<裨<
跸<辟<弊<碧<箅<蔽<壁<嬖<篦<薜<避<濞<臂<髀<
璧<襞<边<砭<笾<编<煸<蝙<鳊<鞭<贬<扁<窆<匾<
碥<褊<卞<弁<忭<汴<苄<拚<便<变<缏<遍<辨<辩<
辫<灬<杓<彪<标<飑<髟<骠<膘<瘭<镖<飙<飚<镳<
表<婊<裱<鳔<憋<鳖<别<蹩<瘪<宾<彬<傧<斌<滨<
缤<槟<镔<濒<豳<摈<殡<膑<髌<鬓<冫<冰<兵<丙<
邴<秉<柄<炳<饼<禀<并<病<摒<拨<波<玻<剥<钵<
饽<啵<脖<菠<播<伯<孛<驳<帛<泊<勃<亳<钹<铂<
舶<博<渤<鹁<搏<箔<膊<踣<薄<礴<跛<簸<擘<檗<
逋<钸<晡<醭<卜<卟<补<哺<捕<不<布<步<怖<钚<
部<埠<瓿<簿"
;
- }
- package
sorting;
- import
java.util.*;
- import
java.text.*;
- /**
- * @author GaoJianMin
- *
- */
- public
class
ChineseGB2312Comparator implements
Comparator
<String
>, Comparable
<String
> {
- private
RuleBasedCollator
GB2312Collator =
- ChineseGB2312Collator.getFixedGB2312Collator();
- private
String
str1;
-
- /**
- * @param str1
- */
- public
ChineseGB2312Comparator(String
str1) {
- this
.str1 = str1;
- }
- /**
- *
- */
- public
ChineseGB2312Comparator() {
- this
.str1=""
;
- }
- /**
- * @param str1
- * @param str2
- * @return an integer indicatint the comparison result
- * @see java.util.Comparator#compare(Object, Object)
- */
- public
int
compare(String
str1, String
str2) {
- return
GB2312Collator.compare(str1, str2);
- }
- /**
- * @param str2
- * @return an integer indicatint the comparison result
- * @see java.lang.Comparable#compareTo(Object)
- */
- public
int
compareTo(String
str2) {
- return
GB2312Collator.compare(str1, str2);
- }
- }
测试代码及结果
代码:
- import
java.util.*;
- import
java.text.*;
- public
class
Test
- {
- String
[] test = new
String
[] {
- "作业"
,
- "测试"
,
- "test"
,
- "我们"
,
- "。空"
,
- "镂空"
,
- "["
,
- "浏"
,
- "皙"
- };
- java.util.Arrays
.sort(test, new
ChineseGB2312Comparator());
- System
.out.println("============"
);
- for
(String
key : test)
- System
.out.println(key);
- }
ChineseGB2312Comparator 类同时实现了 Comparator, Comparable 接口,这样以后能够使用 compare, compareTo 方法的时候都可以使用这个类。
Action 类:
• Struts1要求Action类继承一个抽象基类。Struts1的一个普遍问题是使用抽象类编程而不是接口。
• Struts 2 Action类可以实现一个Action接口,也可实现其他接口,使可选和定制的服务成为可能。Struts2提供一个ActionSupport基类去 实现 常用的接口。Action接口不是必须的,任何有execute标识的POJO对象都可以用作Struts2的Action对象。
线程模式:
• Struts1 Action是单例模式并且必须是线程安全的,因为仅有Action的一个实例来处理所有的请求。单例策略限制了Struts1 Action能作的事,并且要在开发时特别小心。Action资源必须是线程安全的或同步的。
• Struts2 Action对象为每一个请求产生一个实例,因此没有线程安全问题。(实际上,servlet容器给每个请求产生许多可丢弃的对象,并且不会导致性能和垃圾回收问题)
Servlet 依赖:
• Struts1 Action 依赖于Servlet API ,因为当一个Action被调用时HttpServletRequest 和 HttpServletResponse 被传递给execute方法。
• Struts 2 Action不依赖于容器,允许Action脱离容器单独被测试。如果需要,Struts2 Action仍然可以访问初始的request和response。但是,其他的元素减少或者消除了直接访问HttpServetRequest 和 HttpServletResponse的必要性。
可测性:
• 测试Struts1 Action的一个主要问题是execute方法暴露了servlet API(这使得测试要依赖于容器)。一个第三方扩展--Struts TestCase--提供了一套Struts1的模拟对象(来进行测试)。
• Struts 2 Action可以通过初始化、设置属性、调用方法来测试,“依赖注入”支持也使测试更容易。
捕获输入:
• Struts1 使用ActionForm对象捕获输入。所有的ActionForm必须继承一个基类。因为其他JavaBean不能用作ActionForm,开发者经 常创建多余的类捕获输入。动态Bean(DynaBeans)可以作为创建传统ActionForm的选择,但是,开发者可能是在重新描述(创建)已经存 在的JavaBean(仍然会导致有冗余的javabean)。
• Struts 2直接使用Action属性作为输入属性,消除了对第二个输入对象的需求。输入属性可能是有自己(子)属性的rich对象类型。Action属性能够通过 web页面上的taglibs访问。Struts2也支持ActionForm模式。rich对象类型,包括业务对象,能够用作输入/输出对象。这种 ModelDriven 特性简化了taglib对POJO输入对象的引用。
表达式语言:
• Struts1 整合了JSTL,因此使用JSTL EL。这种EL有基本对象图遍历,但是对集合和索引属性的支持很弱。
• Struts2可以使用JSTL,但是也支持一个更强大和灵活的表达式语言--"Object Graph Notation Language" (OGNL).
绑定值到页面(view):
• Struts 1使用标准JSP机制把对象绑定到页面中来访问。
• Struts 2 使用 "ValueStack"技术,使taglib能够访问值而不需要把你的页面(view)和对象绑定起来。ValueStack策略允许通过一系列名称相同但类型不同的属性重用页面(view)。
类型转换:
• Struts 1 ActionForm 属性通常都是String类型。Struts1使用Commons-Beanutils进行类型转换。每个类一个转换器,对每一个实例来说是不可配置的。
• Struts2 使用OGNL进行类型转换。提供基本和常用对象的转换器。
校验:
• Struts 1支持在ActionForm的validate方法中手动校验,或者通过Commons Validator的扩展来校验。同一个类可以有不同的校验内容,但不能校验子对象。
• Struts2支持通过validate方法和XWork校验框架来进行校验。XWork校验框架使用为属性类类型定义的校验和内容校验,来支持chain校验子属性
Action执行的控制:
• Struts1支持每一个模块有单独的Request Processors(生命周期),但是模块中的所有Action必须共享相同的生命周期。
• Struts2支持通过拦截器堆栈(Interceptor Stacks)为每一个Action创建不同的生命周期。堆栈能够根据需要和不同的Action一起使用。
花了整整一天时间,研究怎么通过在Android应用程序中添加Admob广告来赚钱。网上也有些教程,不过说得不够详细,自己还得花时间摸索。为了让后来者能更快开始Admob广告赚钱,所以写个详细一点的教程,供大家参考。
例子工程源码下载地址:(建议使用浏览器自带的下载工具下载)http://cid-cb78b387364ae9a7.skydrive.live.com/browse.aspx/.Public/%e8%bd%af%e4%bb%b6/Andoroid
当然,我也参考了一些网上的资料,主要有:
AdMob:在android应用中嵌入广告的方案
如何在Android Market赚钱 part 2 - 免费app附带广告
Publisher Starter Kit
面向开发者 Wiki 的 AdMob
好了,现在让我从头开始说起……在这之前,你不需要有任何的帐号,唯一需要的就是有一个有效的email邮箱。只要按照下面的步骤一步步来,你就能通过将Admob的广告插到自己的程序中赚钱啦!
首先,当然是需要注册一个Admob的帐号。Admob的主页是:http://www.admob.com/ 。 当然,如果你对于浏览英文网页还有些障碍的话,可以登录中文网站:http://zhcn.admob.com/
。如果网站的文字还是英文,你可以在网站主页的右下角的“Language”处,选择“中文(简体)”。点击进入注册页面后,有一些栏目需要填写,不要太
过疑虑,就像你注册一个论坛一样,随便填下就好了。最关键的是保证填写的email地址有效,另外就是填上姓名,选择语言。帐户类型我选择的“不确定”,
语言“中文(简体)”~ 提交注册申请之后,不久你就会收到用于确认并激活帐号的电子邮件,点击激活链接,就可以了激活你的Admob帐号了~
第二步就是设置你的Android应
用程序信息,并获得Admob的插入代码。登录你的Admob帐号后,在主页的左上方(Logo上面)点击“Marketplace(手机广告市场)”,
进入页面后,在“Sites&Apps(站点和应用程序)”标签下,点击“Add Site/App”。选择我们熟悉的图标——" Android App ” 。这时会出现需要你填写一个“详细信息”,随便填上一些信息。(不要太过在意现在填写的东西,因为这些以后都是可以修改的)。比如“Android Package URL” 我到现在都还没有填写,描述之类的,想写就写点吧。填好详细信息后,点击“继续”,就可以到AdMob Android SDK 的下载页面了。下载这个SDK(当然,这个很重要)。
The AdMob Android SDK includes:
README: Get started with AdMob Android ads!
AdMob Jar file: Required for publishing ads. Follow the documentation in
javadoc/index.html and drop the AdMob Jar file into your project.
Sample Projects: Examples of AdMob Android ads shown in the LunarLander application.
第三步获取你的应用程序对应的Publisher ID。在下载页面点击"Go to Sites/Apps"就可以到你应用程序的管理界面了。这时你会发现在这个页面醒目的位置会有一个叫你填写详细信息的提示:
在我们发送任何有待收入之前,您需要填写技术联系详细信息和付款首选项。
我们暂时可以不用管它,因为钱是会存在我们的Admob的账户上的,等我们需要提现的时候,或者你想填的时候再填就可以了。在下面的列表中,选择你
的应用程序并进入。这个界面就是你的应用程序广告的管理界面了,里面有比较多的功能,以后可以慢慢了解,现在我们只需要知道两个东西,一个是发布者
ID(Publisher ID),一个是你程序的状态。Publisher
ID是一个15个字符的字符串,而你程序的状态现在应该还是不活动(Inactive)。我们下面要做的就是怎么让它变为Active。
第四步代码编写——在你的应用程序中插入Admob广告。经过上面的步骤,我们在网站上的设置就告一个段落了,现在我们终于要进入主题了,如何在自己的Android应用程序中插入Admob广告。如果你不健忘的话,一定还记得我们之前下载的那个AdMob Android SDK 。解压它,看看里面有些什么东西。这里面最重要的就是那个名为“admob-sdk-android.jar”的包啦,Admob将如何把广告加载到Android应用程序中的代码集成在这个包里,我们编写程序的时候就需要将这个包导入到我们的工程里面去。另外,解压出来的文件夹中还有一个名为“javadoc”的文件夹,打开它里面的index.html。它是关于Admob Android SDK的帮助文档,在Package 下的Setup下,有详细完整的在自己的应用程序中插入广告的方法介绍,在这里我就偷懒,引用一下~
Including the Jar
Add the Jar file included with the SDK to your Android
project as an external library. In your project's root directory create
a subdirectory libs (this will already be done for you if you used Android's activitycreator). Copy the AdMob Jar file into that directory. For Eclipse projects:
Go to the Properties of your project (right-click on your project from the Package Explorer tab and select Properties)
Select "Java Build Path" from left panel
Select "Libraries" tab from the main window
Click on "Add JARs..."
Select the JAR copied to the libs directory
Click "OK" to add the SDK to your android project
注意:需要首先在你工程的根目录下新建一个叫做“libs”的文件夹,并把之前所说的最重要的东西“admob-sdk-android.jar”复制到里面。
AndroidManifest.xml
Your AdMob publisher ID was given to you when creating your publisher account on www.admob.com
before downloading this code. It is a 15-character code like
a1496ced2842262. Just before the closing </application> tag add a
line to set your publisher ID:
<!-- The application's publisher ID assigned by AdMob -->
<meta-data android:value="YOUR_ID_HERE" android:name="ADMOB_PUBLISHER_ID" />
</application>
Set any permissions not already included just before the closing </manifest> tag:
<!-- AdMob SDK permissions -->
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION" />
</manifest>
Only the INTERNET permission is required. Setting
ACCESS_COARSE_LOCATION (and/or ACCESS_FINE_LOCATION) allows narrowly
geo-targeted ads be shown.
这里需要注意的是,<meta-data android:value="YOUR_ID_HERE" android:name="ADMOB_PUBLISHER_ID"
/>中,我们只需要改的是"YOUR_ID_HERE"。这里需要你填上的ID就是我们之前在Admob网站我们的应用程序管理页面上看到的
Publisher ID,而name="ADMOB_PUBLISHER_ID"是不应该改的。程序需要这个Key来查找对应的Value。
attrs.xml
The attrs.xml file specifies custom AdView attributes in XML layout
files. If your application does not already have an
/res/values/attrs.xml file then create one and copy-and-paste the
following into it. If you do have that file then just add the
declare-styleable element:
<?xml version="1.0" encoding="utf-8"?>
<resources>
<declare-styleable name="com.admob.android.ads.AdView">
<attr name="testing" format="boolean" />
<attr name="backgroundColor" format="color" />
<attr name="textColor" format="color" />
<attr name="keywords" format="string" />
<attr name="refreshInterval" format="integer" />
<attr name="isGoneWithoutAd" format="boolean" />
</declare-styleable>
</resources>
这个,没什么说的。
Placing an AdView in a Layout
AdView widgets can be put into any XML layout now. The first step is to
reference attrs.xml in your layout element by adding an xmlns line that
includes your package name specified in AndroidManifest.xml:
xmlns:yourapp=http://schemas.android.com/apk/res/yourpackage
For example a simple screen with only an ad on it would look like:
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:admobsdk="http://schemas.android.com/apk/res/com.admob.android.example"
android:orientation="vertical"
android:layout_width="fill_parent"
android:layout_height="fill_parent">
<com.admob.android.ads.AdView
android:id="@+id/ad"
android:layout_width="fill_parent"
android:layout_height="wrap_content"
admobsdk:backgroundColor="#000000"
admobsdk:textColor="#FFFFFF"
admobsdk:keywords="Android application"
/>
</LinearLayout>
这里好像也没什么需要特别注意的,注意加上xmlns,另外知道这里可以设置一个keywords
Test Mode
When you start integrating AdMob ads into your application it is
recommended to use test mode. This always returns the same ad. Normal ad
requests are not deterministic making it harder to be sure the ad view
looks like you want (e.g. ad requests can timeout or may not fill).
Once the ad shows up as you expect be sure to turn test mode off to get real ads. Never put your application into the Android Market with test mode enabled.
Test mode can be enabled either by calling
AdManager.setInTestMode(true) or by adding a "admobsdk:testing="true""
property to the ad in your XML layout (where "admobsdk" is the XML
namespace for your application).
设置Test Mode这个很关键,千万别将处于Test Mode的程序发布出去了,那样可赚不了钱啊~!如果在AdView的属性中不加上admobsdk:testing="false",似乎程序也是不处于Test Mode的,不过最好还是加上吧~
第五步编译运行,并激活程序。编译运行你的程序,在模拟器上就可以看到效果啦~(当然你的模拟器需要能上网,关于怎么让模拟器上网呢?用路由的应该
可以直接上,如果不是用路由,那么可能需要设置下,具体方法大家自己网上搜吧,具体忘了)。如果你的应用程序能显示出广告,那么恭喜你,你的应用程序很快
就会在Admob上被激活了(需要一定的时间,我的好像花了一个小时不到)!
第六步在Admob网站上查看应用程序赚了多少钱~“手机广告市场”—>“报告”—>“站点和应用程序报告”。选择你的应用程序,然后点击页面最下面的“创建报告”~ OK,赚钱啦~
最后,我把我自己写的一个例子工程上传上来,大家可以下载来参考下。另外,我的工程将广告作为移动的,并且改变了它默认的宽度和背景,希望对如何在应用程序中摆放广告,起到一个抛砖引玉的作用。效果图如下(哈哈,在模拟器跑的~):
1.http://www.admob.com/注册一个帐号,
添加Add Mobile Site/app,输入相关信息后,提交完成,
下载Android平台使用的JAR,查看发布者 ID。
2.然后将JAR添加到你的项目中
Properties->Java Build Path->Libraries->Add JARs…->Select the JAR->OK
3.编辑AndroidManifest.xml
application节点中添加
<!– The application’s publisher ID assigned by AdMob –>
<meta-data android:value=”a14ae1ce0357305″ android:name=”ADMOB_PUBLISHER_ID” />
manifest节点添加权限申请
<!– AdMob SDK permissions –>
<uses-permission android:name=”android.permission.INTERNET” />
4.添加attrs.xml
/res/values/attrs.xml
<?xml version=”1.0″ encoding=”utf-8″?>
<resources>
<declare-styleable name=”com.admob.android.ads.AdView”>
<attr name=”testing” format=”boolean” />
<attr name=”backgroundColor” format=”color” />
<attr name=”textColor” format=”color” />
<attr name=”keywords” format=”string” />
<attr name=”refreshInterval” format=”integer” />
<attr name=”isGoneWithoutAd” format=”boolean” />
</declare-styleable>
</resources>
5.添加广告组件
<?xml version=”1.0″ encoding=”utf-8″?>
<LinearLayout xmlns:android=”http://schemas.android.com/apk/res/android”
xmlns:admobsdk=”http://schemas.android.com/apk/res/com.moandroid.livesports”
android:orientation=”vertical”
android:layout_width=”fill_parent”
android:layout_height=”fill_parent”
>
<TextView
android:layout_width=”fill_parent”
android:layout_height=”wrap_content”
android:text=”@string/hello”
/>
<com.admob.android.ads.AdView
android:id=”@+id/ad”
android:layout_width=”fill_parent”
android:layout_height=”wrap_content”
admobsdk:backgroundColor=”#000000″
admobsdk:textColor=”#FFFFFF”
admobsdk:keywords=”Android application”
admobsdk:refreshInterval=”60″
/>
</LinearLayout>
6.显示效果
为免费app嵌入Admob广告,进而获得广告收入。

http://marshal.easymorse.com/archives/2950
在多Activity开发中,有可能是自己应用之间的Activity跳转,或者夹带其他应用的可复用Activity。可能会希望跳转到原来某个Activity实例,而不是产生大量重复的Activity。
这需要为Activity配置特定的加载模式,而不是使用默认的加载模式。
加载模式分类及在哪里配置
Activity有四种加载模式:
- standard
- singleTop
- singleTask
- singleInstance
设置的位置在AndroidManifest.xml文件中activity元素的android:launchMode属性:
<activity android:name="ActB" android:launchMode="singleTask"></activity>
也可以在Eclipse ADT中图形界面中编辑:

区分Activity的加载模式,通过示例一目了然。这里编写了一个Activity A(ActA)和Activity B(ActB)循环跳转的例子。对加载模式修改和代码做稍微改动,就可以说明四种模式的区别。
standard
首先说standard模式,也就是默认模式,不需要配置launchMode。先只写一个名为ActA的Activity:
package com.easymorse.activities;
import android.app.Activity;
import android.content.Intent;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
import android.widget.LinearLayout;
import android.widget.TextView;
public class ActA extends Activity {
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
TextView textView = new TextView(this);
textView.setText(this + "");
Button button = new Button(this);
button.setText("go actA");
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
Intent intent = new Intent();
intent.setClass(ActA.this, ActA.class);
startActivity(intent);
}
});
LinearLayout layout = new LinearLayout(this);
layout.setOrientation(LinearLayout.VERTICAL);
layout.addView(textView);
layout.addView(button);
this.setContentView(layout);
}
}
例子中都没有用layout,免得看着罗嗦。可见是ActA –> ActA的例子。在界面中打印出对象的toString值可以根据hash code识别是否创建新ActA实例。
第一个界面:

点击按钮后:

可以多点几次。发现每次都创建了该Activity的新实例。standard的加载模式就是这样的,intent将发送给新的实例。
现在点Android设备的回退键,可以看到是按照刚才创建Activity实例的倒序依次出现,类似退栈的操作,而刚才操作跳转按钮的过程是压栈的操作。如下图:

singleTop
singleTop和standard模式,都会将intent发送新的实例(后两种模式不发送到新的实例,如果已经有了的话)。不
过,singleTop要求如果创建intent的时候栈顶已经有要创建的Activity的实例,则将intent发送给该实例,而不发送给新的实例。
还是用刚才的示例,只需将launchMode改为singleTop,就能看到区别。
运行的时候会发现,按多少遍按钮,都是相同的ActiA实例,因为该实例在栈顶,因此不会创建新的实例。如果回退,将退出应用。

singleTop模式,可用来解决栈顶多个重复相同的Activity的问题。
如果是A Activity跳转到B Activity,再跳转到A Activity,行为就和standard一样了,会在B Activity跳转到A Activity的时候创建A Activity的新实例,因为当时的栈顶不是A Activity实例。
ActA类稍作改动:
package com.easymorse.activities;
import android.app.Activity;
import android.content.Intent;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
import android.widget.LinearLayout;
import android.widget.TextView;
public class ActA extends Activity {
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
TextView textView = new TextView(this);
textView.setText(this + "");
Button button = new Button(this);
button.setText("go actB");
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
Intent intent = new Intent();
intent.setClass(ActA.this, ActB.class);
startActivity(intent);
}
});
LinearLayout layout = new LinearLayout(this);
layout.setOrientation(LinearLayout.VERTICAL);
layout.addView(textView);
layout.addView(button);
this.setContentView(layout);
}
}
ActB类:
package com.easymorse.activities;
import android.app.Activity;
import android.content.Intent;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
import android.widget.LinearLayout;
public class ActB extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
Button button=new Button(this);
button.setText("go actA");
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
Intent intent=new Intent();
intent.setClass(ActB.this, ActA.class);
startActivity(intent);
}
});
LinearLayout layout=new LinearLayout(this);
layout.addView(button);
this.setContentView(layout);
}
}
ActB类使用默认(standard)加载,ActA使用singleTop加载。结果类似下图:

如果把ActA的加载模式改为standard,情况一样。
singleTask
singleTask模式和后面的singleInstance模式都是只创建一个实例的。
当intent到来,需要创建singleTask模式Activity的时候,系统会检查栈里面是否已经有该Activity的实例。如果有直接将intent发送给它。
把上面singleTop的实例中的ActA的launchMode改为singleTask,ActB的改为standard。那么会发现在ActA界面中按一次按钮:

然后在ActB1界面中按按钮,因为ActA是singleTask,会使用原来的ActA1实例。这时候栈内的情况:

如果多次按按钮跳转,会发现始终只有ActA1这一个ActA类的实例。
singleInstance
解释singleInstance模式比较麻烦。
首先要说一下Task(任务)的概念。
如果是Swing或者Windows程序,可能有多个窗口可以切换,但是你无法在自己程序中复用人家的窗口。注意是直接复用人家的二进制代码,不是你拿到人家api后的源代码级调用。
Android可以做到,让别人的程序直接复用你的Activity(类似桌面程序的窗口)。
Android为提供这种机制,就引入了Task的概念。Task可以认为是一个栈,可放入多个Activity。比如启动一个应用,那么
Android就创建了一个Task,然后启动这个应用的入口Activity,就是intent-filter中配置为main和launch的那个
(见一个APK文件部署产生多个应用安装的效果)。这个Activity是根(Root)Activity,可能会在它的界面调用其他Activity,这些Activity如果按照上面那三个模式,也会在这个栈(Task)中,只是实例化的策略不同而已。
验证的办法是调用和打印Activity的taskId:
TextView textView2 = new TextView(this);
textView2.setText("task id: "+this.getTaskId());
会发现,无论切换Activity,taskId是相同的。
当然也可以在这个单一的Task栈中,放入别人的Activity,比如google地图,这样用户看过地图按回退键的时候,会退栈回到调用地图的Activity。对用户来说,并不觉得在操作多个应用。这就是Task的作用。
但是,有这样的需求,多个Task共享一个Activity(singleTask是在一个task中共享一个Activity)。
现成的例子是google地图。比如我有一个应用是导游方面的,其中调用的google地图Activity。那么现在我比如按home键,然后到应用列表中打开google地图,你会发现显示的就是刚才的地图,实际上是同一个Activity。
如果使用上面三种模式,是无法实现这个需求的。google地图应用中有多个上下文Activity,比如路线查询等的,导游应用也有一些上下文Activity。在各自应用中回退要回退到各自的上下文Activity中。
singleInstance模式解决了这个问题(绕了这么半天才说到正题)。让这个模式下的Activity单独在一个task栈中。这个栈只有一个Activity。导游应用和google地图应用发送的intent都由这个Activity接收和展示。
这里又有两个问题:
- 如果是这种情况,多个task栈也可以看作一个应用。比如导游应用启动地图Activity,实际上是在导游应用task栈之上
singleInstance模式创建的(如果还没有的话,如果有就是直接显示它)一个新栈,当这个栈里面的唯一Activity,地图Activity
回退的时候,只是把这个栈移开了,这样就看到导游应用刚才的Activity了;
- 多个应用(Task)共享一个Activity要求这些应用都没有退出,比如刚才强调要用home键从导游应用切换到地图应用。因为,如果退出导游应用,而这时也地图应用并未运行的话,那个单独的地图Activity(task)也会退出了。
如果还是拿刚才的ActA和ActB的示例,可以把ActB的模式改为singleInstance,ActA为standard,如果按一次按钮切换到ActB,看到现象用示意图类似这样:

如果是第一次按钮切换到ActB,在ActB在按按钮切换到ActA,然后再回退,示意图是:

另外,可以看到两个Activity的taskId是不同的。
摘要: 转自:http://blog.csdn.net/Android_Tutor/archive/2010/04/20/5508615.aspx
今天我们的教程是根据前面一节扩展进行的,如果你没有看,请点击 Android高手进阶教程(三) 查看第三课,这样跟容易方便你的理解!
在xml 文件里定义控件的属性,我们已经习惯了android:attrs="" ,那么我们能不能定... 阅读全文
摘要: 转自:http://blog.csdn.net/Android_Tutor/archive/2010/04/21/5513869.aspx
大家好我们这一节讲的是LayoutInflater的使用,在实际开发种LayoutInflater这个类还是非常有用的,它的作用类似于 findViewById(),
不同点是LayoutInflater是用来找layout下xml布局文件,并且实例化... 阅读全文
OverView:
程序通过后台每天检查是否有最新版本,如果需要更新当前版本,将弹出对话框让用户选择是否在当前通过Market来更新 软件。
Knowledge Points:
- SharedPreferences: 一个轻量级的存储方法,类似于经常使用的.ini文件,它也是通过检索关键字来取得相应的数值。之所以是成为轻量级,是因为它所能应用的数值类型有限,对于存储较大数值,效率相对较低。官方参考
- System.currentTimeMillis:将当前时间以毫秒作为单位来表示,用于比较两个时间的先后顺序。(其数值表示从1970-01-01 00:00:00直到当前时间的总毫秒数)官方参考
- 通过网络来读取信息:在checkUpdate()方法中包含了通过制定的URL来读取网络资源。具体操作步骤,请参考源代码。
- Runnable: 在其内部的Run()方法中实现所要执行的任何代码,当这个runnable interface被调用后可以视作为新的线程。
Source Code:
- public class hello extends Activity {
- /** Called when the activity is first created. */
- private Handler mHandler;
-
- @Override
- public void onCreate(Bundle savedInstanceState) {
- super.onCreate(savedInstanceState);
- setContentView(R.layout.main);
-
- mHandler = new Handler();
-
- /* Get Last Update Time from Preferences */
- SharedPreferences prefs = getPreferences(0);
- long lastUpdateTime = prefs.getLong("lastUpdateTime", System.currentTimeMillis());
-
- int curVersion = 0;
- try {
- curVersion = getPackageManager().getPackageInfo("linhai.com.hello", 0).versionCode;
- } catch (NameNotFoundException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- Log.i("DEMO",String.valueOf(curVersion));
- /* Should Activity Check for Updates Now? */
- if ((lastUpdateTime + (24 * 60 * 60 * 1000)) < System.currentTimeMillis()) {
-
- /* Save current timestamp for next Check*/
- lastUpdateTime = System.currentTimeMillis();
- SharedPreferences.Editor editor = getPreferences(0).edit();
- editor.putLong("lastUpdateTime", lastUpdateTime);
- editor.commit();
-
- /* Start Update */
- // checkUpdate.start();
- }
- }
-
- /* This Thread checks for Updates in the Background */
- private Thread checkUpdate = new Thread()
- {
- public void run() {
- try {
- URL updateURL = new URL("http://my.company.com/update");
- URLConnection conn = updateURL.openConnection();
- InputStream is = conn.getInputStream();
- BufferedInputStream bis = new BufferedInputStream(is);
- ByteArrayBuffer baf = new ByteArrayBuffer(50);
-
- int current = 0;
- while((current = bis.read()) != -1){
- baf.append((byte)current);
- }
-
- /* Convert the Bytes read to a String. */
- final String s = new String(baf.toByteArray());
-
- /* Get current Version Number */
- int curVersion = getPackageManager().getPackageInfo("your.app.id", 0).versionCode;
- int newVersion = Integer.valueOf(s);
-
- /* Is a higher version than the current already out? */
- if (newVersion > curVersion) {
- /* Post a Handler for the UI to pick up and open the Dialog */
- mHandler.post(showUpdate);
- }
- } catch (Exception e) {
- }
- }
- };
-
- /* This Runnable creates a Dialog and asks the user to open the Market */
- private Runnable showUpdate = new Runnable(){
- public void run(){
- new AlertDialog.Builder(hello.this)
- .setIcon(R.drawable.ok)
- .setTitle("Update Available")
- .setMessage("An update for is available!\n\nOpen Android Market and see the details?")
- .setPositiveButton("Yes", new DialogInterface.OnClickListener() {
- public void onClick(DialogInterface dialog, int whichButton) {
- /* User clicked OK so do some stuff */
- Intent intent = new Intent(Intent.ACTION_VIEW, Uri.parse("market://search?q=pname:your.app.id"));
- startActivity(intent);
- }
- })
- .setNegativeButton("No", new DialogInterface.OnClickListener() {
- public void onClick(DialogInterface dialog, int whichButton) {
- /* User clicked Cancel */
- }
- })
- .show();
- }
- };
-
- }
复制代码
分为三个部分:
- 置于onCreate()方法中的程序用于判断当前时间是否需要检查更新(如果距离上次更新时间大于1天,将启动检查更新)
- 当以上条件满足时,启动checkUpdate来检查当前程序是否为最新版本。
- 如果确定版本已过期,那么将登录market,并直接指向当前程序页面。
*******************************************************************************************
向上言:
本人在 论坛曾经发过一关于此问题的 求助帖,虽然大至的思路和上文差不多,关键点是在于程序如何更新,现在看到它这里指出的更新方法居然是登录market。不过以后发布的程序都是在market中,问题就不存在。
- Intent intent = new Intent(Intent.ACTION_VIEW, Uri.parse("market://search?q=pname:your.app.id"));
- startActivity(intent);
复制代码
大家都是在eclipse上 开发吧,在每次更新代码, 运行模拟器时,大家是否有注意到console的提示信息:
- [2009-06-06 19:53:50 - Hello] Android Launch!
- [2009-06-06 19:53:50 - Hello] adb is running normally.
- [2009-06-06 19:53:50 - Hello] Performing linhai.com.hello.hello activity launch
- [2009-06-06 19:53:50 - Hello] Automatic Target Mode: using existing emulator 'emulator-5554' running compatible AVD 'avd'
- [2009-06-06 19:53:50 - Hello] WARNING: Application does not specify an API level requirement!
- [2009-06-06 19:53:50 - Hello] Device API version is 3 (Android 1.5)
- [2009-06-06 19:53:50 - Hello] Uploading Hello.apk onto device 'emulator-5554'
- [2009-06-06 19:53:50 - Hello] Installing Hello.apk...
- [2009-06-06 19:54:05 - Hello] Application already exists. Attempting to re-install instead...
- [2009-06-06 19:54:31 - Hello] Success!
复制代码
分析:
1。 android正常运行
2。通过配置文件AndroidManifest.xml中运行我们的程序
3。 Uploading Hello.apk onto device 'emulator-5554'这句是关键,更新我们的程序
4。 Installing Hello.apk...
5。 Application already exists. Attempting to re-install instead...//程序已经存在,尝试重新安装
所以如果我们的程序要 自动更新,本人初步猜想是和上面的步骤是一样的。
详看logcat中的log
- 06-06 11:54:02.567: DEBUG/PackageParser(582): Scanning package: /data/app/vmdl12464.tmp
- 06-06 11:54:08.048: INFO/PackageManager(582): Removing non-system package:linhai.com.hello
- 06-06 11:54:08.187: DEBUG/PackageManager(582): Removing package linhai.com.hello
- 06-06 11:54:08.286: DEBUG/PackageManager(582): Activities: linhai.com.hello.hello
- 06-06 11:54:11.136: DEBUG/PackageManager(582): Scanning package linhai.com.hello
- 06-06 11:54:11.301: INFO/PackageManager(582): /data/app/vmdl12464.tmp changed; unpacking
- 06-06 11:54:11.626: DEBUG/installd(555): DexInv: --- BEGIN '/data/app/vmdl12464.tmp' ---
- 06-06 11:54:12.987: DEBUG/dalvikvm(7756): DexOpt: load 224ms, verify 265ms, opt 1ms
- 06-06 11:54:13.047: DEBUG/installd(555): DexInv: --- END '/data/app/vmdl12464.tmp' (success) ---
- 06-06 11:54:13.057: DEBUG/PackageManager(582): Activities: linhai.com.hello.hello
- 06-06 11:54:15.608: INFO/installd(555): move
/data/dalvik-cache/data@app@vmdl12464.tmp@classes.dex ->
/data/dalvik-cache/data@app@linhai.com.hello.apk@classes.dex
- 06-06 11:54:15.737: DEBUG/PackageManager(582): New package installed in /data/app/linhai.com.hello.apk
复制代码
关于此类的自动更新的第三方管理软件已经有了叫 aTrackDog,其原理就是使用上面的方式。
关于得到版本号,使用:
- int curVersion = getPackageManager().getPackageInfo("your.app.id", 0).versionCode;
复制代码
程序版本号的是放在AndroidManifest.xml文件中:
- <manifest xmlns:android="http://schemas.android.com/apk/res/android"
- package="linhai.com.hello" android:versionCode="2" android:versionName="2.0.1">
复制代码
主点是关于:getPackageManager()在这个下面有很多方法,你可以通过它得,得到当前终端安装的程序等。关于安装包的函数是:getPackageManager().installPackage(packageURI)
动手试验:
在dos状态下运行:


查看logcat下的信息,大致和刚才相同,分析流程:
- 06-06 12:18:58.827: INFO/jdwp(8368): received file descriptor 20 from ADB
- 06-06 12:19:02.546: DEBUG/PackageParser(582): Scanning package: /data/app/vmdl12465.tmp
- 06-06 12:19:07.738: INFO/PackageManager(582): /data/app/vmdl12465.tmp changed; unpacking
- 06-06 12:19:07.978: DEBUG/installd(555): DexInv: --- BEGIN '/data/app/vmdl12465.tmp' ---
- 06-06 12:19:09.617: DEBUG/dalvikvm(8378): DexOpt: load 254ms, verify 564ms, opt 3ms
- 06-06 12:19:09.697: DEBUG/installd(555): DexInv: --- END '/data/app/vmdl12465.tmp' (success) ---
- 06-06 12:19:11.907: INFO/installd(555): move
/data/dalvik-cache/data@app@vmdl12465.tmp@classes.dex ->
/data/dalvik-cache/data@app@com.example.android.snake.apk@classes.dex
- 06-06 12:19:11.956: DEBUG/PackageManager(582): New package installed in /data/app/com.example.android.snake.apk
- 06-06 12:19:14.746: DEBUG/dalvikvm(8368): VM cleaning up
- 06-06 12:19:14.857: DEBUG/dalvikvm(8368): LinearAlloc 0x0 used 628420 of 4194304 (14%)
- 06-06 12:19:15.897: DEBUG/dalvikvm(582): GC freed 17704 objects / 903984 bytes in 615ms
- 06-06 12:19:15.936: DEBUG/HomeLoaders(625): application intent received: android.intent.action.PACKAGE_ADDED, replacing=false
- 06-06 12:19:15.936: DEBUG/HomeLoaders(625): --> package:com.example.android.snake
- 06-06 12:19:15.936: DEBUG/HomeLoaders(625): --> add package
复制代码
1。接收 数据,保存到临时文件中/data/app/vmdl12465.tmp
2。解压此文件,注意路径/data/dalvik-cache/data@ app@vmdl12465.tmp@classes.dex
它是在data下的dalvik-cache下
3.安装文件[这个步骤还包括查找程序是否已经安装等]
4.使用GC清理内存
查看DDMS中的结构

看到此文件结构,应该可以想起linux下的文件 系统和它的权限管理,也就可以理解,为什么我们的程序无法在data下创建文件之类的问题了。
转载: http://www.androidres.com/?p=349
ndroid中,你的应用程序程序与View类组件有着一种固定的联系,例如按钮(Button)、 文本框(TextView), 可编辑文本框(EditText), 列表框(ListView), 复选框(CheckBox), 单选框(RadioButton), 滚动条(Gallery), 微调器(Spinner), 等等,还有一些比较先进的有着特殊用途的View组件,例如 AutoCompleteTextView, ImageSwitcher和 TextSwitcher。除此之外,种类繁多的像 线性布局(LinearLayout), 框架布局(FrameLayout), 这样的布局组件(Layout)也被认为是View组件,他们是从View类派生过来的。
你的应用程序就是这些控制组件和布局组件以某种方式结合显示在屏幕上,一般来说这些组件对你来说基本够用,但是你也应该知道你是可以通过类继承创建
属于自己的组件,一般可以继承像View、Layouts(布局组件)这样的组件,甚至可以是一些比较高级的控制类组件。下面我们说一下为什么要继承:
- 你可以为实现某种功能创建一个完全自定义风格的组件,例如用二维的图形创建控制组件实现声音的控制,就像电子控制一样。
- 你可以把几种组件结合形成一个新的组件,你的组件可能同时包含ComboBox(一个能输入的文本列表)和dual-pane selector control(左右两个List窗口,你可以分配窗口每一项的从属关系)等等。
- 你可以创建自己的布局组件(Layout)。SDK中的布局组件已经提供了一系列的选项让你打造属于自己的应用程序,但是高级的开发人员会发现根据现有的Layout组件开发新的Layout组件是很有必要的,甚至是完全从底层开发新的组件。
- 你可以覆盖一个现有组件的显示或功能。例如,改变EditText(可编辑文本)组件在屏幕上的显示方式(可以参考Notepad的例子,里面教你如何创建一个下划线的显示页面)。
- 你可以捕获像按键按下这样的事件,以一些通用的方法来处理这些事件(一个游戏的例子)。
为了实现某种目标你可能很有必要扩展一个已经存在的View组件,下面我们结合一些例子教你如何去做。
内容:
- 基本方法(The Basic Approach )
- 完全自定义组件(Fully Customized Components )
- 定制组件的例子(Customized Component Example )
- 组件的混合(或者控制类的混合) (Compound Components (or Compound Controls) )
- 修改现有组件(Tweaking an Existing Component )
- 小结(Go Forth and Componentize )
基本方法(The Basic Approach )
下面的一些步骤都比较概括,教你如何创建自己的组件:
- 让你的类(Class)继承一个现有的View 类或View的子类。
- 重载父类的一些方法:需要重载的父类方法一般以‘
on’开头,如onDraw(), onMeasure()和 onKeyDown()等等。
- 使用你的继承类:一旦你的继承类创建完成,你可以在基类能够使用的地方使用你的继承类,但完成功能就是你自己编写的了。
继承类能够定义在activities里面,这样你能够方便的调用,但是这并不是必要的(或许在你的应用程序中你希望创建一个所有人都可以使用的组件)。
完全自定义组件(Fully Customized Components)
完全自定义组件的方法可以创建一些用于显示的图形组件(graphical components),也许是一个像电压表的图形计量器,或者想卡拉OK里面显示歌词的小球随着音乐滚动。无论那种方式,你也不能单纯的利用组件的结合完成,无论你怎么结合这些现有的组件。
幸运的是,你可以以你自己的要求轻松地创建完全属于自己的组件,你会发现不够用的只是你的想象力、屏幕的尺寸和处理器的性能(记住你的应用程序最后只会在那些性能低于桌面电脑的平台上面运行)。
下面简单介绍如何打造完全自定义的组件:
- 最为通用的VIEW类的父类毫无疑问是View类,因此,最开始你要创建一个基于此类的一个子类。
- 你可以写一个构造函数从XML文件中提取属性和参数,当然你也可以自己定义这些属性和参数(也许是图形计量器的颜色和尺寸,或者是指针的宽度和幅度等等)
- 你可能有必要写自己的事件监听器,属性的访问和修改函数和一些组件本身的功能上的代码。
- 如果你希望组件能够显示什么东西,你很有可能会重载
onMeasure() 函数,因而你就不得不重载 onDraw() 函数。当两个函数都用默认的,那么 onDraw() 函数将不会做任何事情,并且默认的 onMeasure() 函数自动的设置了一个100x100 —的尺寸,这个尺寸可能并不是你想要的。
- 其他有必要重载的
on... 系列函数都需要重新写一次。
onDraw()和onMeasure()
onDraw()函数将会传给你一个 Canvas 对象,通过它你可以在二维图形上做任何事情,包括其他的一些标准和通用的组件、文本的格式,任何你可以想到的东西都可以通过它实现。
注意: 这里不包括三维图形如果你想使用三维的图形,你应该把你的父类由View改为SurfaceView类,并且用一个单独的线程。可以参考GLSurfaceViewActivity 的例子。
onMeasure() 函数有点棘手,因为这个函数是体现组件和容器交互的关键部分,onMeasure()应该重载,让它能够有效而准确的表现它所包含部分的测量值。这就有点复杂了,因为我们不但要考虑父类的限制(通过onMeasure()传过来的),同时我们应该知道一旦测量宽度和高度出来后,就要立即调用setMeasuredDimension() 方法。
概括的来讲,执行onMeasure()函数分为一下几个阶段:
- 重载的
onMeasure()方法会被调用,高度和宽度参数同时也会涉及到(widthMeasureSpec 和heighMeasureSpec两个参数都是整数类型),同时你应该考虑你产品的尺寸限制。这里详细的内容可以参考View.onMeasure(int, int) (这个连接内容详细的解释了整个measurement操作)。
- 你的组件要通过
onMeasure()计算得到必要的measurement长度和宽度从而来显示你的组件,它应该与规格保持一致,尽管它可以实现一些规格以外的功能(在这个例子里,父类能够选择做什么,包括剪切、滑动、提交异常或者用不同的参数又一次调用onMeasure()函数)。
- 一旦高度和宽度计算出来之后,必须调用
setMeasuredDimension(int width, int height),否则就会导致异常。
一个自定义组件的例子(A Customized Component Example)
在 API Demos 中的CustomView提供了以一个自定义组件的例子,这个自定义组件在 LabelView 类中定义。
LabelView例子涉及到了自定义组件的方方面面:
- 首先让自定义组件从View类中派生出来。
- 编写带参数的构造函数(参数可以来源于XML文件)。这里面的一些处理都已经在View父类中完成,但是任然有些Labelview使用的自定义组件特有的新的参数需要处理。
- 一些标准的Public函数,例如
setText(), setTextSize(), setTextColor()
- 重载
onMeasure()方法来确定组件的尺寸(注意:在LabelView中是通过一个私有函数measureWidth()来实现的)
- 重载
onDraw()函数把Lable显示在提供的canvas上。
在例子中,你可以通过custom_view_1.xml看到自定义组件LabelView的用法。在XML文件中特别要注意的是android:和app:两个参数的混合运用,app:参数表示应用程序中被认为是LabelView组件的个体,这些也会作为资源在R类中定义。
组件混合技术Compound Components (or Compound Controls)
如果你不想创建一个完全自定义的组件,而是由几个现有组件的组合产生的新的组件,那么混合组件技术就更加适合。简单的来
说,这样把几个现有的组件融合到一个逻辑组合里面可以封装成一个新的组件。例如,一个Combo
Box组件可以看作是是一个EditText和一个带有弹出列表的Button组件的混合体。如果你点击按钮为列表选择一项,
在Android中,其实还有其他的两个View类可以做到类似的效果: Spinner和AutoCompleteTextView,,但是Combo Box作为一个例子更容易让人理解。
下面简单的介绍如何创建组合组件:
- 一般从Layout类开始,创建一个Layout类的派生类。也许在Combo
box我们会选择水平方向的LinearLayout作为父类。记住,其他的Layout类是可以嵌套到里面的,因此混合组件可以是任何组件的混合。注
意,正如Activity一样,你既可以使用外部XML文件来声明你的组件,也可以嵌套在代码中。
- 在新的混合组件的构造函数中,首先,调用所有的父类的构造函数,传入对应的参数。然后可以设置你的混合组件的其他的一些方面,在哪创建
EditText组件,又在哪创建PopupList组件。注意:你同时也可以在XML文件中引入一些自己的属性和参数,这些属性和参数也可以被你的混合
组件所使用。
- 你也可以创建时间监听器去监听新组件中View类触发的事件,例如,对List选项单击事件的监听,你必须在此时间发生后更新你EditText的值。
- 你可能创建自己的一些属性,带有访问和修改方法。例如,允许设置EditText初始值并且提供访问它的方法。
- 在Layout的派生类中,你没有必要去重载
onDraw()和onMeasure()方法,因为Layout会有比较好的默认处理。但是,如果你觉得有必要你也可以重载它。
- 你也可能重载一些
on系列函数,例如通过onKeyDown()的重载,你可以通过按某个键去选择列表中的对应的值。
总之,把Layout类作为基类有下面几个优点:
- 正如activity一样,你也可以通过XML文件去声明你的新组件,或者你也可以在代码中嵌套。
onDraw()函数和onMeasure()函数是没有必要重载的,两个函数已经做得很好了。 - 你可以很快的创建你的混合组件,并且可以像单一组件那样使用。
混合组件的例子(Examples of Compound Controls)
In the API Demos project 在API Demos工程中,有两个List类的例子——Example 4和Example 6,里面的SpeechView组件是从LinearLayout类派生过来,实现显示演讲显示功能,对应的原代码是List4.java和List6.java。
调整现有组件(Tweaking an Existing Component)
在某些情况下,你可能有更简单的方法去创建你的组件。如果你应经有了一个非常类似的组件,你所要做的只是简单的从这个组件派生出你的组件,重在其中
一些有必要修改的方法。通过完全自定义组件的方法你也可以同样的实现,但通过冲View派生产生新的组件,你可以简单获取一些已经存在的处理机制,这些很
可能是你所想要的,而没有必要从头开始。
例如,在SDK中有一个NotePad的例子(NotePad application )。该例子演示了很多Android平台实用的细节,例如你会学到从EditView派生出能够自动换行的记事本。这还不是一个完美的例子,因为相比早期的版本来说,这些API已经感变了很多,但它确实说明了一些问题。
如果你还未查看该程序,现在你就可以在Eclipse中导入记事本例程(或仅通过提供的链接查看相应的源代码)。特别是查看NoteEditor.java 中的MyEditText的定义。
下面有几点要注意的地方:
- 声明(The Definition)
这个类是通过下面一行代码来定义的:
public static class MyEditText extends EditText
- 它是定义在
NoteEditor activity类里面的,但是它是共有的(public),因此如果有必要,它可以通过NoteEditor.MyEditText从NoteEditor外面来调用。
- 它是
static类(静态类),意味着不会出现所谓的通过父类访问数据的“虚态方法”, 这样就使该类成为一个可以不严重依赖NoteEditor的单独类。对于不需要从外部类访问的内联类的创建,这是一个很清晰地思路,保证所产生的类很小,并且允许它可以被其他的类方便的调用。
- 它是
EditText类的扩展,它是我们选择的用来自定义的父类。当我们完成以后,新的类就可以作为一个普通的EditText来使用。
- 类的初始化
一般来说,父类是首先调用的。进一步来说,这不是一个默认的构造函数,而是一个带参数的构造函数。因为EditText是使用从XML布局文件提取出来的参数进行创建,因此我们的构造函数也要取出参数并且将这些参数传递给父类。
- 方法重载
在本例中,仅对onDraw()一个方法进行重载。但你可以很容易地为你的定制组件重载其他需要的方法。
对于记事本例子来说,通过重载onDraw()方法我们可以在EidtView的画布(canvas)上绘制蓝色的线条(canvas类是通过重写的onDraw()方法传递)。该函数快要结束时要调用super.onDraw()函数。父类的方法是应该调用,但是在这个例子里面,我们是在我们划好了蓝线之后调用的。
- 使用定制组件
现在,我们已经有自己定制的组件了,但是应该怎样使用它呢?在记事本例子中,定制的组件直接在预定义的布局文件中使用,让我们看一看res/layout目录中的note_editor.xml文件。
<view xmlns:android="http://schemas.android.com/apk/res/android"
class="com.android.notepad.NoteEditor$MyEditText"
id="@+id/note"
android:layout_width="fill_parent"
android:layout_height="fill_parent"
android:background="@android:drawable/empty"
android:padding="10dip"
android:scrollbars="vertical"
android:fadingEdge="vertical" />
- 该自定义组件在XML中是作为一个一般的View类来创建的,并且是通过全路径包来描述的。注意这里内联类是通过
NoteEditor$MyEditText来表示的,这是Java编程中引用内联类的标准方法。
- 在定义中的其他属性和参数将传递给定制组件的构造函数,然后才传到EditText构造函数中,因此这些参数也是你使用EditText组件的参数。注意,这里你也可以增加你自己的参数,我们将在下面讨论这个问题。
这就是你全部需要做的,诚然这是一个简单的例子。但问题的关键是:你的需求有多复杂,那么你的自定义组件就有多么复杂。
一个更为复杂的组件可能需要重载更多的on系列函数,并且还要很多特有的函数来充分实现自定义组件的功能。唯一的限制就是你的想象力和你需要组件去执行什么工作。
现在开始你的组件化之旅吧
如你所见,Android提供了一种精巧而又强大的组件模型,让你尽可能的完成你的工作。从简单的组件调整到组件混合,甚至完全自定义组件,灵活的运用这些技术,你应该可以得到一个完全符合你外观要求的的Android程序
http://apphu.com/androidmarket
APP虎大讲堂:
android market就是程序应用商店。在2008年8月29日,谷歌推出了Android Market,为使用Android操作系统的手机用户提供第三方应用。
这个平台相似于Apple的App Store,可以连接最新的Google在线 服务器。由于其本土化的设计,Android Market可以让用户下载和安装支持Android系统的第三方软件。
Google作为Android Market的东道主,却一再强调Android Market的扮演的角色仅仅是“软件销售和传播的中心”而不是“软件过滤器”。
为什么Google选择 android market 而不是Store?
Google选择“’Market’”这个词而不是“Store”,是因为其觉得开发者需要的是一个开放的、毫无阻碍的环境来创造内容。Google希望 Android Market最终会像YouTube那样,只需要注册一个发行人资格和软件的类别就可以发布软件。
Google并没有表示会对android market进行监管,只是表示Android
Market里的软件将拥有反馈系统以及类似YouTube上的等级系统。Google
将通过追踪工具获得软件的反馈,如果某个软件有危险性,将会有标识提醒用户注意。但是其中的隐私问题却在前不久的SMobile 的分析报告>中显露无疑,而且普通用户很难注意到有些软件会侵犯他们的隐私,况且让谷歌android手机用户去辨别生涩的专业名词,实在太强人所难了。
Android Market学习了App Store开创的软件销售模式,对iPhone以及App Store是一个冲击;更重要的一方面是 Google选择的Market模式与苹果的App Store之间的差异会逐渐显现出来。
国内三大类android market知多少
自从android在中国大大的火了一把之后,android market也如雨后春笋般的不断涌现出来。总的来说android market有如下几类:
第一类: 谷歌创建的android market
谷歌android market,只此一家,别无其他官方market。
第二类: 国内有头有脸的手机厂商和移动运营商创建的android market
- MOTO的智件园:
摩托罗拉也是通过去年转型生产一系列android手机,才着实大赚了一把,流转了不利局面,倒是Nokia迟缓的反应速度让其市场份额半年几乎损失过
半,虽然只在英国占有主导地位,可以在美国的市场份额远不及iphone和android手机,MOTO的Milestone更是让其重新站上历史的舞
台。不甘于被谷歌android market 控制的摩托罗拉自然在寻出路,建造自己的android market
- 中移动的Mobile Market
中移动的MM简单来说是在android1.0/android1.5的基础上改良版的android系统,虽然当时可以跑动大部分android
软件,但是这个market仍处于不愠不火的状态。不过不久前,中国移动在原来版本的基础上进行了许多创新和改进,推出的OPhone2,0,还完全兼容
Android2.1,甚至三星“奥斯卡I7680”也搭载了OMS系统。目前MM已经初具规模,中国移动Mobile
Market拥有16400款应用。
- 联通的UniStore
联通应用商店(UniStore)已经完成了漫长的“内测阶段”,将于7月中旬正式发布,该应用商店在支付模式上将采用“中间账户”的模式,用户注
册联通应用商店时会自动注册“中间账户”,便可绑定话费支付或者支付宝、财付通等第三方支付工具。据悉,联通应用商店将采用开放平台的模式,也就是说不仅
支持中国联通手机用户使用,也支持中国移动和中国电信的手机用户使用,目前仅有775款。
- 中国电信的天翼软件工厂
中国电信的天翼空间更是时刻处在升级状态,虽然使出浑身解数,也仍然难见起色,天翼空间拥有1054款
- 酷派的Android Coolmart为了支撑新机器的上市,宇龙酷派也正在进行着Android Coolmart的招兵买马中。
第三类: 独立第三方创建的android market
虽然可用的谷歌android市场越来越多,但是同质化越来越严重的Market只能让用户无所适从,也无法产生类似App
Store一样的用户黏性。怎么样教育用户用自家的market是最大的问题,让我们期待中国的android市场是如何演绎他们自己的故事。当然APP
虎的软件在各类市场都可以通过搜索APPhu下载。
http://www.iteeyan.com/2010/07/play-android-app-on-emulator/
前几天,Jackeroo给大家介绍了一个Android模拟器,可以让大家在PC机上玩Android 2.2。不过,该模拟器中少了一个精华的东西,那就是“Android Market(电子市场)”。目前,iPhone手机玩的是操控感、时尚,而Android手机玩的则是软件,少了“Android Market”的Android模拟器,无异于自废了一半的功力……
其实,要想在Android 2.2模拟器中使用“Android Market(电子市场)”,认真说来还是有点麻烦。网上虽然也有地方介绍过,但很多细节部分语焉不详。Jackeroo就以自己的实战操作,帮助大家温习一下。
Step 01 新建Android 2.2虚拟机
首先,安装Android SDK,新建一台Android 2.2虚拟机。不知道该去哪里下载Android SDK或者不清楚该如何使用虚拟机的朋友,请先阅读“Google手机免费玩·在PC上装Android 2.2”博文。

Step 02 命令行方式启动新建虚拟机
把SDK包下的System.img文件(F:\android-sdk-windows\platforms\android-8\images)拷贝到的%UserProfile%\.android\avd\Android-2.2下。
然后打开命令行窗口,切换到SDK包的Tools目录下,加参数“-partition-size 96”启动虚拟机,才能让/system有足够的空间安装“Android Market(电子市场)”。
cd /d f:\android-sdk-windows\tools
emulator.exe -avd Android-2.2 -partition-size 96

Step 03 让Android启动Checkin服务
要正常使用“Android Market(电子市场)”,必须启动Checkin服务。等Android 2.2虚拟机启动完毕,看到正常的界面。

这时候,我们可以把配置文件build.prop取回来编辑(如果你有真实的Android连在电脑上,一定要先取下来再进行以下操作)。
cd /d f:\android-sdk-windows\tools
adb pull /system/build.prop .

注意:第一次执行adb指令,会加载adb相关服务,然后提示“device offline(设备不在线)”。此时,需要再次执行上面的adb指令就可以了。
这样一来,build.prop就放在了f:\android-sdk-windows\tools目录下,用文本编辑软件比如EmEditor、UltraEdit之类的打开它。将“ro.config.nocheckin=yes”前面加“#”号注释掉。
#ro.config.nocheckin=yes
然后再传到Android虚拟机上,重新启动虚拟机,Checkin服务就启动了(在上传之前,需要执行“adb remount”指令使/system目录可写)。
adb remount
adb push build.prop /system/build.prop

Step 04 安装“Android Market”到虚拟机
首先,下载一个为各种手机开发的定制版Android 2.2,比如Jackeroo曾经用过的Android 2.2 for
HTC。将它解压缩,将system/app/GoogleServicesFramework.apk
和system/app/Vending.apk放到f:\android-sdk-windows\tools下。
Android 2.2 for Legend :远程下载
然后执行以下指令安装这两个apk安装包,并且删除Android虚拟机上的SdkSetup.apk(注意大小写):
adb push GoogleServicesFramework.apk /system/app
adb push Vending.apk /system/app
adb shell rm /system/app/SdkSetup.apk

Step 05 清理现场
关闭虚拟机, 把产生的 image: userdata-qemu.img, userdata.img, cache.img都删除,重新启动虚拟机它就会自动初始化。
Step 06 “Android Market”现身
打开SDK Setup.exe,按照常规方式启动刚才新创建的Android 2.2虚拟机,就可以看到“Android Market”。

点击“Market”,就需要进行Google登录了,用你自己的Google账号登录吧。

登录以后,理论上说就可以使用“Android Market(电子市场)”尝试各种软件了,但由于网络无法连接,暂时还搜索不到。
有连接上的朋友,请告诉我解决方法。
http://dev.10086.cn/cmdn/bbs/thread-17136-1-1.html
最近看论坛上有人问如何挂断电话,实际上1.1版本后.Google已经把该API隐藏掉
今天看资料,发现可以通过AIDL(Android远程方法)及反射,调用hide API,废话不多说了.附上过程
一:在你的项目中新建包com.android.internal.telephony,因为要使用AIDL,该包与ITelephony.aidl一致
在该包下新建文件ITelephony.aidl
首先
package com.android.internal.telephony;
/* * Copyright (C) 2007 The Android Open Source Project
* * Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
* * [url=http://www.apache.org/licenses/LICENSE-2.0]http://www.apache.org/licenses/LICENSE-2.0[/url]
* * Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
/**
* Interface used to interact with the phone. Mostly this is used by the
* TelephonyManager class. A few places are still using this directly.
* Please clean them up if possible and use TelephonyManager insteadl.
* * {@hide}
*/
interface ITelephony {
/** * End call or go to the Home screen *
* @return whether it hung up
*/
boolean endCall();
/** * Answer the currently-ringing call.
* * If there's already a current active call, that call will be
* automatically put on hold. If both lines are currently in use, the
* current active call will be ended. *
* TODO: provide a flag to let the caller specify what policy to use
* if both lines are in use. (The current behavior is hardwired to
* "answer incoming, end ongoing", which is how the CALL button
* is specced to behave.) *
* TODO: this should be a oneway call (especially since it's called
* directly from the key queue thread). */
void answerRingingCall();
}
之后会在gen下面自动生成ITelephony.java
二.通过反射生成ITelephony实例
TelephonyManager telMgr = (TelephonyManager)getSystemService(
TELEPHONY_SERVICE);
//初始化iTelephony
Class <TelephonyManager> c = TelephonyManager.class;
Method getITelephonyMethod = null;
try {
getITelephonyMethod = c.getDeclaredMethod("getITelephony", (Class[])null);
getITelephonyMethod.setAccessible(true);
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (NoSuchMethodException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
iTelephony = (ITelephony) getITelephonyMethod.invoke(telMgr, (Object[])null);
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
这样可以调用iTelephony的endCall()方法
三.在AndroidManifest.xml中增加权限
<uses-permission android:name="android.permission.CALL_PHONE"/>
摘要: http://blog.csdn.net/maxleng/archive/2010/04/15/5490770.aspx
IPC框架分析 Binder,Service,Service manager
我首先从宏观的角度观察Binder,Service,Service Manager,并阐述各自的概念。从Linux的概念空间中,Android的设计Acti... 阅读全文
摘要: 建立AIDL服务的步骤(3)
(4)编写一个MyService类,代码如下:
package net.blogjava.mobile.complex.type.aidl;
import java.util.HashMap;
import java.util.Map; &nb... 阅读全文
摘要: 8.4.2 建立AIDL服务的步骤(2)
在编写上面代码时应注意如下两点:
使用bindService方法来绑定AIDL服务。其中需要使用Intent对象指定AIDL服务的ID,也就是<action>标签中android:name属性的值。
在绑定时需要一个ServiceConnection对象。创建ServiceConnection对象的过程中如果绑定成功,系统会调... 阅读全文
摘要: http://book.51cto.com/art/201006/207070.htm
建立AIDL服务的步骤(1)
建立AIDL服务要比建立普通的服务复杂一些,具体步骤如下:
(1)在Eclipse Android工程的Java包目录中建立一个扩展名为aidl的文件。该文件的语法类似于Java代码,但会稍有不同。详细介绍见实例52的内容。
(2)如果aidl文件的内容是正确的,ADT... 阅读全文
摘要: http://blog.chinaunix.net/u3/90876/showart_2200991.html
在Android中, 每个应用程序都可以有自己的进程. 在写UI应用的时候, 经常要用到Service. 在不同的进程中, 怎样传递对象呢? 显然, Java中不允许跨进程内存共享. 因此传递对象, 只能把对象拆分成操作系统能理解的简单形式, 以达到跨界对象访问的目的. 在J2EE中,... 阅读全文
http://zenz.ourcafe.mobi/archives/216
在有APKTool之前,Android软件的汉化是一件非常痛苦的事情。例如汉化狂人的汉化工具,那都是直接修改二进制文件的,首先
是寻找需要修改的字符串苦难(当然汉化狂人已经做得不错了),然后修改的字符串长度还要注意中文长度不能长过原来的文字……个中郁闷就不细说了。
APKTool可以说是一个革命性的工具,有了APKTool之后,可以说,俺拽软件的汉化工作到了一个前所未有的简单程度。
闲话不说,我们用汉化实例来证明APKTool的方便简单,在动手之前,需要去 APKTool 的网站把工具下载下来。当然也可以下载我已经打包的 APKTool.zip(Windows下使用)。
确保你的电脑已经安装了JDK1.6(JRE1.6也可以),而且安装了一个优秀的编辑软件(推荐UltraEdit),把APKTool解压到随便哪个你认为操作起来方便的目录。如果都好了,我们动手吧:

第一步,把需要汉化的文件(以汉化ColorNote为例)放到APKTool所在目录,然后命令行进入APKTool目录,执行下面的命令:
apktool d ColorNote.apk ColorNote
这句命令的意思是,对ColorNote.apk这个程序进行反编译,获得的文件放在当前目录下的ColorNote目录中。正常反编译的话,能看到下面的提示:
I: Baksmaling…
I: Decoding resource table…
I: Decoding resources…
I: Copying assets and libs…
反编译完成,会在APKTool的目录下面,出现一个名叫ColorNote的目录,进去看看,是这个样子的!

用UltraEdit打开这个AndroidManifest.xml看看?哈哈,是纯文本文件呀!在打开res目录中的values中随便一个文
件看看?也是纯文本文件啊!也就是说,只要一个UltraEdit,我们就可以轻轻松松进行汉化了(就把需要的字符串转换成中文就可以了,也不用考虑长度
了!)至于要汉化哪些内容,这个大家自己研究吧,不用我详细说,也没有办法详细说的吧?(事实上,除了XML的文本资源文件外,老外写的很多程序,字符串
都是hard
coding在执行代码里面的,APKTool反编译会得到smali伪代码,有些在XML资源里面找不到的字符串,去看看smali的代码吧。)
中间的翻译过程我们跳过去,例如我们已经翻译好了,就在APKTool目录下执行下面的命令行:
apktool b ColorNote
这条命令是告诉APKTool,把这个ColorNote目录里的东西编译打包成APK程序
I: Checking whether sources has changed…
I: Smaling…
I: Checking whether resources has changed…
I: Building resources…
I: Building apk file…
生成的APK程序在哪里呢?在ColorNote\Dist目录里面,名字是out.apk
我们把这个out.apk文件签名之后安装看看?哈哈!完美中文汉化的俺拽程序来了!(当然,这要看汉化者的功力了。)
Popularity: 76%
http://www.cn-java.com/www1/?action-viewnews-itemid-3054
...
set CATALINA_HOME=C:\Tomcat4.1.29
set CLASSPATH=%JAVA_HOME%\lib\tools.jar
set CLASSPATH=%JAVA_HOME%\soap-2.3.1\lib\soap.jar
set CLASSPATH=%CLASSPATH%;%JAVA_HOME%\javamail-1.3.1\mail.jar
set CLASSPATH=%CLASSPATH%;%JAVA_HOME%\jaf-1.0.2\activation.jar
set CLASSPATH=%CLASSPATH%;%JAVA_HOME%\xerces-2_6_0\xercesImpl.jar
set CLASSPATH=%CLASSPATH%;%JAVA_HOME%\xerces-2_6_0\xercesSamples.jar
set CLASSPATH=%CLASSPATH%;%JAVA_HOME%\xerces-2_6_0\xml-apis.jar
set CLASSPATH=%CLASSPATH%;%JAVA_HOME%\xerces-2_6_0\xmlParserAPIs.jar
set CLASSPATH=%CLASSPATH%;%CATALINA_HOME%\common\lib\servlet.jar
set CLASSPATH=%CLASSPATH%;%CATALINA_HOME%\common\lib\tools.jar
...
如果你的安装路径(installation
paths)和上面使用的不同,你需要更正它们,然后关闭和重启Tomcat以使它们生效。这样,你就有为运行SOAP作好了准备。但是现在,我要忘记有
关的技术部分,来学一点理论知识。
SOAP意思是简单对象访问协议(Simple Object Access
Protocol)。的确如它的名字一样,SOAP是很简单的。它是一个基于XML的协议,允许程序组件和应用程序彼此使用一种标准的Internet协
议--HTTP来通讯。SOAP是一种独立的平台,它不依赖程序语言,它是简单的,弹性的,很容易扩展的。目前,应用程序能够彼此使用一种基于DCOM和
CORBA技术的远程过程调用(RPC)来进行相互通讯,但HTTP不被设计为这个目的。RPC在Internet上应用是非常困难的,它们会出现许多兼
容性和安全性的问题,因为防火墙和代理服务器通常都会阻断(block)这些类型的流量。应用程序之间最好的通讯方式是通过HTTP协议,因为HTTP是
支持所有Internet浏览器和服务器的。基于这个目的,SOAP协议被创建出来。
那么,它们是如何运作的呢?比如,一个应用程序(A)需要和另一个应用程序(B)在SOAP的帮助下进行彼此通讯。它们将使用下面的框架图来完成这个
过程:

这个SOAP信封(SOAP envelope)是一个包含以下内容的XML文档:

正如你看到的,它是非常简单的。它看起来确实就象一个普通的信封或者你的email。你想看看它们是如何动作的吗?下面跟我们一起来吧。其实我们有很多方
法是不用SOAP来在创建和运行我们自己的“Hello
World”应用程序的,但是因为我们要保持它的简单性,我会给你一个它运作方式的框架图(scheme)。
我们的“Hello World”范例会包含一个SOAP Service。我们的SOAP Client将发送它们的名字到该SOAP
Service,并试图得到一些答复或响应。这个SOAP Service需要部署到一个SOAP
Admin的工具,以至重定位所有请求的SOAP(Proxy) RPC
Router能够知道它们应该使用哪种服务来运作。总而言之,这个是以下面的方式来运作的:

现在,我们来一步步的看看到底发生了什么。在Step 1里,HelloWorldClient将连接一个SOAP RPC
Router,请求我们的SOAP Service并将包含我们名字的一个字符串传递给它。该SOAP RPC
Router会检查是否它已经部署了这个SOAP Service。如果它被发现是被部署的,那么它将传递数据到这个SOAP
Service并调用特定的方法,这个是Step 2。然后SOAP Service方法会被执行,将返回某个字符串值(该值就是SOAP
Client的答复或者响应)(Step 3)。在Step4中,SOAP RPC Router将仅仅只是重定向这个数据到SOAP
Client。所有在Step1和Step4里传输的数据是通过SOAP
Envelope来完成的。正如你所看到的,算法是相当简单的,因此我们只准备关心实际的代码。
首先,我们要创建一个SOAP Service。下面是它的代码,请不要忘记将它放入HelloWorld/
目录中(必须被包含在你的CLASSPATH中):
1: // SOAPService.java
2: package HelloWorld;
3: public class SOAPService {
4: public String sayHi(String x) {
5: return("Hello my friend, " + x + "! Glad to see you!");
6: }
7: }
添加任何注释也是很容易的。要编译它,只需要用下列命令:
javac SOAPService.java
第二步,一旦我们准备好了SOAP Service,我们需要用SOAP Service
Manager来部署它。这个可以通过很多方式来实现,但是为了能让初学SOAP的读者更容易理解SOAP,我提供了一个最容易的方式。我们假设你的
Web
Server(Tomcat或其他)已经正常运行,并且你已经正确安装了SOAP。那么当浏览器访问http://localhost:8080
/soap/,你会看见Apache SOAP的欢迎页面。点击Run the admin client ,然后
Deploy。你会得到一个屏幕显示,在那里你需要填入ID,Scope,Method,Provider Type和JAVA
Provider的信息到表单域中。你能忽略其他所有的表单域,除非你真的需要它们的信息。我们的“HelloWorld”例子不需要它们,所以,我们填
的下面的值:
ID: urn:HelloWorld_SOAPService
Scope: Application
Methods: sayHi
Provider Type: java
Java Provider - Provider Class: HelloWorld.SOAPService
Java Provider - Static? No
一些注释:ID是我们要从SOAP Client标识我们的SOAP Service的唯一名字。Method包含SOAP
Service提供的一系列方法。JAVA Provider-Provider Class是SOAP Service Java类的名字。
现在,点击Deploy
按钮,那么你的服务会被部署。再次强调,请注意正确设置CLASSPATH环境变量。然后,你的HelloWorld.SOAPService类能够被找
到,并且所有必需的jar包也能被找到。这是个几乎每个人都会犯的普通错误。现在,你能够点击 List ,将会看见你的服务已经被部署进来。恭喜!
最后,让我们来创建一个SOAP Client。代码看起来有点复杂,但是在现实中不会只有这么点长。
1: // HelloWorldClient.java
2: import java.io.*;
3: import java.net.*;
4: import java.util.*;
5: import org.apache.soap.*;
6: import org.apache.soap.rpc.*;
7: public class HelloWorldClient {
8: public static void main(String[] arg) throws Exception {
9: Call c = null;
10: URL url = null;
11: Vector params = null;
12: Response rep = null;
13: String ourName = "Superman";
14: String ourUrn = "urn:HelloWorld_SOAPService";
15: String ourMethod = "sayHi";
16: url = new URL("http://localhost:8080/soap/servlet/
rpcrouter");
17: System.out.println("Passing to our deployed "+ourUrn+"
our name ("+ourName+"): ");
18: c = new Call();
19: c.setTargetObjectURI(ourUrn);
20: c.setMethodName(ourMethod);
21: c.setEncodingStyleURI(Constants.NS_URI_SOAP_ENC);
22: params = new Vector();
23: params.addElement(new Parameter("ourName", String.class,
ourName, null));
24: c.setParams(params);
25: System.out.print("and its answer is: ");
26: rep = c.invoke(url, "");
27: if (rep.generatedFault()) {
28: Fault fault = rep.getFault();
29: System.out.println("\nCall failed!");
30: System.out.println("Code = " + fault.getFaultCode());
31: System.out.println("String = " + fault.getFaultString());
32: } else {
33: Parameter result = rep.getReturnValue();
34: System.out.print(result.getValue());
35: System.out.println();
36: }
37: }
38:}
下面我要做一些解释。在第13行,我们设置了我们的名字,这个名字将会传递给SOAP
Service。在第14行,我们设置了我们将要调用的服务的ID(service ID),和第15行里设置的服务方法(service
method)。有了这个ID,服务能够被部署到SOAP服务管理器(SOAP Service
Manager)中。我们没有设置任何其他值,仅仅只用刚才那些基础值就可以正常运作了。你能从SOAP的官方文档上得到相关信息,该文档来自SOAP包
中,它们的解释超出了本文的范围。
用以下方式编译这个SOAP Client:
javac HelloWorldClient.java
为了圆满完成它,让我们检查一下针对我们的测试,是否所有事情都准备就绪。Tomcat正在运行,所有的环境变量都正确,SOAP
Service被编译和部署,SOAP Client被成功编译。OK,让我们运行它,你将看到这个屏幕:

正如你所看到的,我们的SOAP Client使用SOAP协议成功发送它的名字和接收了一个答复。正如前面所说的,SOAP Service发送和接收的是SOAP envelope。这个是SOAP envelope的源代码。
被发送到SOAP Service的SOAP Envelope
<?xml version=1.0 encoding=UTF-8?>
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/
soap/envelope/"
xmlns:xsi="http://www.w3.org/2001/
XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<SOAP-ENV:Body>
<ns1:sayHi xmlns:ns1="urn:HelloWorld_SOAPService"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/
soap/encoding/">
<ourName xsi:type="xsd:string">Superman</ourName>
</ns1:sayHi>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>:
从SOAP Service接收的SOAP Envelope
<?xml version=1.0 encoding=UTF-8?>
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/
soap/envelope/"
xmlns:xsi="http://www.w3.org/2001/
XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<SOAP-ENV:Body>
<ns1:sayHiResponse xmlns:ns1="urn:HelloWorld_SOAPService"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.
org/soap/encoding/">
<return xsi:type="xsd:string">Hello my friend, Superman!
Glad to see you!</return>
</ns1:sayHiResponse>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
要理解SOAP Envelope中的所有标签的含义,我建议你花一点时间阅读 http://www.w3.org/2001/06/soap-envelope 命名空间规范。
我希望本文能够在你理解SOAP技术上有一定帮助。这个技术是简单的,有趣的,强大的,弹性的。它被用在许多Web
做客户端有必要对soap做基本的了解,开发手机的程序员可能对web service不是太了解。
soap简单说是基于xml的,建立在http协议上的协议,用来调用web server提供的service。
这里转载一个对soap的简单原理,希望对大家有帮助
什么是Web Services
从表面上看,Web service 就是一个应用程序,它向外界暴露出一个能够通过Web进行调用的API。也就是说,可以利用编程的方法通过Web来调用这个应用程序。
对Web service 更精确的解释: Web services是建立可互操作的分布式应用程序的新平台。Web service平台是一套标准,它定义了应用程序如何在Web上实现互操作性。你可以用任何你喜欢的语言,在任何你喜欢的平台上写Web service ,只要我们可以通过Web service标准对这些服务进行查询和访问。
不管你的Web service是用什么工具,什么语言写出来的,只要你用SOAP协议通过HTTP来调用它,总体结构都一致。通常,你用你自己喜欢的语言(如VB 6或者VB.NET)来构建你的Web service,然后用SOAP Toolkit或者.NET的内建支持来把它暴露给Web客户。于是,任何语言,任何平台上的客户都可以阅读其WSDL文档,以调用这个Web service。客户根据WSDL描述文档,会生成一个SOAP请求消息。Web service都是放在Web服务器 (如IIS) 后面的,客户生成的SOAP请求会被嵌入在一个HTTP POST请求中,发送到Web服务器来。Web服务器再把这些请求转发给Web service请求处理器。请求处理器的作用在于,解析收到的SOAP请求,调用Web service,然后再生成相应的SOAP应答。Web服务器得到SOAP应答后,会再通过HTTP应答的方式把它送回到客户端。
iGoogle 发表于 2010-10-24 17:00
基本概念
SOAP
XML和XSD
WSDL(Web Services Description Language)
WSML(Web Services Meta Language)
什么时候使用Web Services
Web service是创建可互操作的分布式应用程序的新平台。Web service 的主要目标是跨平台的可互操作性。为了达到这一目标,Web service 是完全基于XML、XSD等独立于平台、独立于软件供应商的标准的。
Web service在应用程序跨平台和跨网络进行通信的时候是非常有用的。Web service适用于应用程序集成、B2B集成、代码和数据重用,以及通过Web进行客户端和服务器的通信的场合。
当然,Web service也不是万能的,你不能到处滥用Web service。在有些情况下,Web service 会降低应用程序的性能,而不会带来任何好处。例如,一台机器或一个局域网里面运行的同构应用程序就不应该用Web service 进行通信。
如何调用Web Services
客户端:取得服务端的服务描述文件WSDL,解析该文件的内容,了解服务端的服务信息,以及调用方式。根据需要,生成恰当的SOAP请求消息(指定调用的方法,已经调用的参数),发往服务端。等待服务端返回的SOAP回应消息,解析得到返回值。
服务端:生成服务描述文件,以供客户端获取。接收客户端发来的SOAP请求消息,解析其中的方法调用和参数格式。根据WSDL和WSML的描述,调用相应的COM对象来完成指定功能,并把返回值放入SOAP回应消息返回给用户。
高层接口
使用高层接口,不需要知道SOAP和XML的任何信息,就可以生成和使用一个WebService。Soap Toolkit 2.0通过提供两个COM对象――SoapClient和SoapServer,来完成这些功能。
在客户端,只需要生成一个SoapClient实例,并用WSDL作为参数来调用其中的mssoapinit方法。SoapClient对象会自动解析 WSDL文件,并在内部生成所有Web Service的方法和参数信息。之后,你就可以像调用IDispatch接口里的方法一样,调用里面所有的方法。在VB或是脚本语言里,你甚至可以直接在SoapClient对象名后面直接加上.方法(参数…)进行调用。
低层接口
要使用低层接口,你必须对SOAP和XML有所了解。你可以对SOAP的处理过程进行控制,特别是要做特殊处理的时候。
在客户端,首先要创建一个HttpConnector对象,负责HTTP连接。设定Connector的一些头部信息,比如EndPoinURL和 SoapAction等。如果网络连接需要使用代理服务器,那也要在这里设定相关的信息。接着创建SoapSerializer对象,用于生成Soap消息。按照WSDL里定义,把所有参数按顺序序列化,得到一个完整的SOAP请求消息。该Soap消息,作为Payload通过HttpConnector 被发送到服务端。最后,生成一个
摘要: Activity
Android中,Activity是所有程序的根本,所有程序的流程都运行在Activity之中,Activity具有自己的生命周期(见http://www.cnblogs.com/feisky/archive/2010/01/01/1637427.html,由系统控制生命周期,程序无法改变,但可以用onSaveInstanceState保存其状态)。
对于Activity,关... 阅读全文
手机上的应用程序,别人的界面设计的很漂亮,很想知道别人的怎么设计的,我应该怎么做呢?
在没有遇到这个工具前 我是通过破解别人的程序去查看他的设计的。
那天无意中在 tools这个文件夹下发现这个文件 hierarchyviewer.bat,Google一下发现帮你分析应用程序UI布局。
现在我们开始使用它吧:
第一步,双击(废话),出现一个灰色的界面,大家不要急,这是因为它没有发现运行的android程序呢
第二步:启动android程序,(或者连接android手机),你会发现在 Hierarchy Viewer 的 Devices里有 emulator-5554(这个是我的模拟器),然后选择 start servier
如图

选择 MainActivity,点击Load view Hierarchy
如图

你还可以通过左下角的按钮交换到界面视图

这就是你手机上看到的效果,看到蓝色的细线没有?你可以拖动他,右边会显示他的颜色的坐标
你也可以把这些东西导出来,怎么样 好用吧
摘要: 转载自:http://www.cnblogs.com/allin/archive/2010/05/11/1732200.html
在android开发中ListView是比较常用的组件,它以列表的形式展示具体内容,并且能够根据数据的长度自适应显示。抽空把对ListView的使用做了整理,并写了个小例子,如下图。
列表的显示需要三个元素:
1.ListVeiw ... 阅读全文
javac -classpath的使用:
javac:如果当前你要编译的java文件中引用了其它的类(比如说:继承),但该引用类的.class文件不在当前目录下,这种情况下就需要在javac命令后面加上-classpath参数,通过使用以下三种类型的方法 来指导编译器在编译的时候去指定的路径下查找引用类。
(1).绝对路径:javac -classpath c:\junit3.8.1\junit.jar Xxx.java
(2).相对路径:javac -classpath ..\junit3.8.1\Junit.javr Xxx.java
(3).系统变量:javac -classpath %CLASSPATH% Xxx.java (注意:%CLASSPATH%表示使用系统变量CLASSPATH的值进行查找,这里假设Junit.jar的路径就包含在CLASSPATH系统变量中)
javac 绝对路径的使用:
javac:假设你要编译的类文件名叫:HelloWorld.java,其完全路径为:D:\java\HelloWorld.java。但你所在的当前目录是:C:\Documents and Settings\peng>。如果想在这里执行编译,会有什么结果呢?
(1).C:\Documents and Settings\peng> javac HelloWorld.java 这时编译器会给出如下的错误提示信息:
error: cannot read: HelloWorld.java
这是因为默认情况下javac是在当前目录下查找类文件,很明显这个路径不是我们存放类文件的地方,所以就会报错了
(2).C:\Documents and Settings\peng>javac D:\java\HelloWorld.java
这时编译成功。
所以,只要你执行javac命令的目录不是类文件存放的目录,你就必须在javac命令中显式地指定类文件的路径。
java -classpath的使用:
java:假设我们的CLASSPATH设置为:D:\peng\java\pro ,在该目录下有三个文件:HelloWorld.java / HelloWorldExtendsTestCase / HelloWorldExtendsHelloWorld。这三个文件的类声明分别如下:
HelloWorld.java :public class HelloWorld
HelloWorldExtendsHelloWorld.java :public class HelloWorldExtendsHelloWorld extends HelloWorld
HelloWorldExtendsTestCase.java:public class HelloWorldExtendsTestCase extends junit.framework.TestCase
假设我们已经按照上面关于javac -classpath和javac 绝对路径的使用,顺利地完成了三个文件地编译。现在我们在C:\Documents and Settings\peng>目录下执行这三个.class文件
(1).C:\Documents and Settings\peng>java HelloWorld
Hello World
可以看到执行成功。为什么我们在 C:\Documents and Settings\peng>执行命令,JVM能够找到D:\peng\java\pro\HelloWorld.class文件呢?这是因为我们配置了系统变量CLASSPATH,并且指向了目录:D:\peng\java\pro 。所以JVM会默认去该目录下加载类文件,而不需要指定.class文件的绝对路径了。
(2).C:\Documents and Settings\peng>java HelloWorldExtendsHelloWorld
Hello World
可以看到执行成功了。HelloWorldExtendsHelloWorld继承了HelloWorld类,所以在执行时JVM会先查找在CLASSPATH下是否存在一个HelloWorld.class文件,因为我们已经成功编译了HelloWorld 类了,所以可以成功执行HelloWorldExtendsHelloWorld.class
(3).C:\Documents and Settings\peng>java HelloWorldExtendsTestCase
Exception in thread "main" java.lang.NoClassDefFoundError: junit/framework/TestCase
可以看到程序抛出异常了,提示找不到junit.framework.TestCase文件。为什么同样在:\peng\java\pro 下,HelloWorldExtendsHelloWorld.class就可以成功执行,而这个就不行了呢?这是因为: junit.framework.TestCase.class文件并不存在于当前目录下,所以为了能够让程序成功运行,我们必须通过指定CLASSPATH的方式,让JVM可以找到junit.framework.TestCase这个类,如(4):
(4). C:\Documents and Settings\peng>java -classpath %CLASSPATH% HelloWorldExtendsTestCase
Hello World
总结:
(1).何时需要使用-classpath:当你要编译或执行的类引用了其它的类,但被引用类的.class文件不在当前目录下时,就需要通过-classpath来引入类
(2).何时需要指定路径:当你要编译的类所在的目录和你执行javac命令的目录不是同一个目录时,就需要指定源文件的路径(CLASSPATH是用来指定.class路径的,不是用来指定.java文件的路径的)
[转自:
http://blog.csdn.net/pengpenglin/
http://www.blogjava.net/pengpenglin/
]
下面的讨论以Windows平台的Sun MicroSystem实现的java5虚拟机为蓝本,其他操作系统或其他公司实现的虚拟机参数会有部分不同,但大部分含义都和Windows上的类似。Java5与以前版本相比,虚拟机参数大部分保持了向前兼容,同时也增加了一些新的参数,本文将对这些参数的作用作详细描述,使虚拟机能更符合运行环境的需要,获得更好的性能和稳定性。
Java在运行已编译完成的类时,是通过java虚拟机来装载和执行的,java虚拟机通过操作系统命令JAVA_HOME\bin\java –option 来启动,-option为虚拟机参数,JAVA_HOME为JDK安装路径,通过这些参数可对虚拟机的运行状态进行调整,掌握参数的含义可对虚拟机的运行模式有更深入理解。
虚拟机参数分为基本和扩展两类,在命令行中输入JAVA_HOME\bin\java 就可得到基本参数列表,
在命令行输入JAVA_HOME\bin\java –X 就可得到扩展参数列表。
基本参数说明:
-client,-server
这两个参数用于设置虚拟机使用何种运行模式,client模式启动比较快,但运行时性能和内存管理效率不如server模式,通常用于客户端应用程序。相反,server模式启动比client慢,但可获得更高的运行性能。
在windows上,缺省的虚拟机类型为client模式,如果要使用server模式,就需要在启动虚拟机时加-server参数,以获得更高性能,对服务器端应用,推荐采用server模式,尤其是多个CPU的系统。在Linux,Solaris上缺省采用server模式。
-hotspot
含义与client相同,jdk1.4以前使用的参数,jdk1.4开始不再使用,代之以client。
-classpath,-cp
虚拟机在运行一个类时,需要将其装入内存,虚拟机搜索类的方式和顺序如下:
Bootstrap classes,Extension classes,User classes。
Bootstrap 中的路径是虚拟机自带的jar或zip文件,虚拟机首先搜索这些包文件,用System.getProperty("sun.boot.class.path")可得到虚拟机搜索的包名。
Extension是位于jre\lib\ext目录下的jar文件,虚拟机在搜索完Bootstrap后就搜索该目录下的jar文件。用System. getProperty("java.ext.dirs”)可得到虚拟机使用Extension搜索路径。
User classes搜索顺序为当前目录、环境变量 CLASSPATH、-classpath。
-classpath告知虚拟机搜索目录名、jar文档名、zip文档名,之间用分号;分隔。
例如当你自己开发了公共类并包装成一个common.jar包,在使用common.jar中的类时,就需要用-classpath common.jar 告诉虚拟机从common.jar中查找该类,否则虚拟机就会抛出java.lang.NoClassDefFoundError异常,表明未找到类定义。
在运行时可用System.getProperty(“java.class.path”)得到虚拟机查找类的路径。
使用-classpath后虚拟机将不再使用CLASSPATH中的类搜索路径,如果-classpath和CLASSPATH都没有设置,则虚拟机使用当前路径(.)作为类搜索路径。
推荐使用-classpath来定义虚拟机要搜索的类路径,而不要使用环境变量CLASSPATH的搜索路径,以减少多个项目同时使用CLASSPATH时存在的潜在冲突。例如应用1要使用a1.0.jar中的类G,应用2要使用a2.0.jar中的类G,a2.0.jar是a1.0.jar的升级包,当a1.0.jar,a2.0.jar都在CLASSPATH中,虚拟机搜索到第一个包中的类G时就停止搜索,如果应用1应用2的虚拟机都从CLASSPATH中搜索,就会有一个应用得不到正确版本的类G。
-D<propertyName>=value
在虚拟机的系统属性中设置属性名/值对,运行在此虚拟机之上的应用程序可用System.getProperty(“propertyName”)得到value的值。
如果value中有空格,则需要用双引号将该值括起来,如-Dname=”space string”。
该参数通常用于设置系统级全局变量值,如配置文件路径,应为该属性在程序中任何地方都可访问。
-verbose[:class|gc|jni]
在输出设备上显示虚拟机运行信息。
verbose和verbose:class含义相同,输出虚拟机装入的类的信息,显示的信息格式如下:
[Loaded java.io.FilePermission$1 from shared objects file]
当虚拟机报告类找不到或类冲突时可用此参数来诊断来查看虚拟机从装入类的情况。
-verbose:gc在虚拟机发生内存回收时在输出设备显示信息,格式如下:
[Full GC 268K->168K(1984K), 0.0187390 secs]
该参数用来监视虚拟机内存回收的情况。
-verbose:jni在虚拟机调用native方法时输出设备显示信息,格式如下:
[Dynamic-linking native method HelloNative.sum ... JNI]
该参数用来监视虚拟机调用本地方法的情况,在发生jni错误时可为诊断提供便利。
-version
显示可运行的虚拟机版本信息然后退出。一台机器上装有不同版本的JDK时
-showversion
显示版本信息以及帮助信息。
-ea[:<packagename>...|:<classname>]
-enableassertions[:<packagename>...|:<classname>]
从JDK1.4开始,java可支持断言机制,用于诊断运行时问题。通常在测试阶段使断言有效,在正式运行时不需要运行断言。断言后的表达式的值是一个逻辑值,为true时断言不运行,为false时断言运行,抛出java.lang.AssertionError错误。
上述参数就用来设置虚拟机是否启动断言机制,缺省时虚拟机关闭断言机制,用-ea可打开断言机制,不加<packagename>和classname时运行所有包和类中的断言,如果希望只运行某些包或类中的断言,可将包名或类名加到-ea之后。例如要启动包com.foo.util中的断言,可用命令 –ea:com.foo.util 。
-da[:<packagename>...|:<classname>]
-disableassertions[:<packagename>...|:<classname>]
用来设置虚拟机关闭断言处理,packagename和classname的使用方法和-ea相同。
-esa | -enablesystemassertions
设置虚拟机显示系统类的断言。
-dsa | -disablesystemassertions
设置虚拟机关闭系统类的断言。
-agentlib:<libname>[=<options>]
该参数是JDK5新引入的,用于虚拟机装载本地代理库。
Libname为本地代理库文件名,虚拟机的搜索路径为环境变量PATH中的路径,options为传给本地库启动时的参数,多个参数之间用逗号分隔。在Windows平台上虚拟机搜索本地库名为libname.dll的文件,在Unix上虚拟机搜索本地库名为libname.so的文件,搜索路径环境变量在不同系统上有所不同,Linux、SunOS、IRIX上为LD_LIBRARY_PATH,AIX上为LIBPATH,HP-UX上为SHLIB_PATH。
例如可使用-agentlib:hprof来获取虚拟机的运行情况,包括CPU、内存、线程等的运行数据,并可输出到指定文件中,可用-agentlib:hprof=help来得到使用帮助列表。在jre\bin目录下可发现hprof.dll文件。
-agentpath:<pathname>[=<options>]
设置虚拟机按全路径装载本地库,不再搜索PATH中的路径。其他功能和agentlib相同。
-javaagent:<jarpath>[=<options>]
虚拟机启动时装入java语言设备代理。Jarpath文件中的mainfest文件必须有Agent-Class属性。代理类要实现public static void premain(String agentArgs, Instrumentation inst)方法。当虚拟机初始化时,将按代理类的说明顺序调用premain方法。
参见:java.lang.instrument
扩展参数说明
-Xmixed
设置-client模式虚拟机对使用频率高的方式进行Just-In-Time编译和执行,对其他方法使用解释方式执行。该方式是虚拟机缺省模式。
-Xint
设置-client模式下运行的虚拟机以解释方式执行类的字节码,不将字节码编译为本机码。
-Xbootclasspath:path
-Xbootclasspath/a:path
-Xbootclasspath/p:path
改变虚拟机装载缺省系统运行包rt.jar而从-Xbootclasspath中设定的搜索路径中装载系统运行类。除非你自己能写一个运行时,否则不会用到该参数。
/a:将在缺省搜索路径后加上path 中的搜索路径。
/p:在缺省搜索路径前先搜索path中的搜索路径。
-Xnoclassgc
关闭虚拟机对class的垃圾回收功能。
-Xincgc
启动增量垃圾收集器,缺省是关闭的。增量垃圾收集器能减少偶然发生的长时间的垃圾回收造成的暂停时间。但增量垃圾收集器和应用程序并发执行,因此会占用部分CPU在应用程序上的功能。
-Xloggc:<file>
将虚拟机每次垃圾回收的信息写到日志文件中,文件名由file指定,文件格式是平文件,内容和-verbose:gc输出内容相同。
-Xbatch
虚拟机的缺省运行方式是在后台编译类代码,然后在前台执行代码,使用-Xbatch参数将关闭虚拟机后台编译,在前台编译完成后再执行。
-Xms<size>
设置虚拟机可用内存堆的初始大小,缺省单位为字节,该大小为1024的整数倍并且要大于1MB,可用k(K)或m(M)为单位来设置较大的内存数。初始堆大小为2MB。
例如:-Xms6400K,-Xms256M
-Xmx<size>
设置虚拟机内存堆的最大可用大小,缺省单位为字节。该值必须为1024整数倍,并且要大于2MB。可用k(K)或m(M)为单位来设置较大的内存数。缺省堆最大值为64MB。
例如:-Xmx81920K,-Xmx80M
当应用程序申请了大内存运行时虚拟机抛出java.lang.OutOfMemoryError: Java heap space错误,就需要使用-Xmx设置较大的可用内存堆。
-Xss<size>
设置线程栈的大小,缺省单位为字节。与-Xmx类似,也可用K或M来设置较大的值。通常操作系统分配给线程栈的缺省大小为1MB。
另外也可在java中创建线程对象时设置栈的大小,构造函数原型为Thread(ThreadGroup group, Runnable target, String name, long stackSize)。
-Xprof
输出CPU运行时的诊断信息。
-Xfuture
对类文件进行严格格式检查,以保证类代码符合类代码规范。为保持向后兼容,虚拟机缺省不进行严格的格式检查。
-Xrs
减少虚拟机中操作系统的信号(singals)的使用。该参数通常用在虚拟机以后台服务方式运行时使用(如Servlet)。
-Xcheck:jni
调用JNI函数时进行附加的检查,特别地虚拟机将校验传递给JNI函数参数的合法性,在本地代码中遇到非法数据时,虚拟机将报一个致命错误而终止。使用该参数后将造成性能下降。
Sitman PC复读机7月24日发布了最新的2.3版(官方网站:http://www.sitmansoft.com/),但安装程序中附带了“百度”等垃圾,最近官方又发布了绿色版,其中祛除了垃圾软件,下载地址:
复读机下载地址:http://www.sitmansoft.com/down/SitMan23.zip
以前版本的注册码在2.3版下不好用!
注册方法:
方法一:
在sitman目录中config.ini文件中加入以下一项。
[RegInfo]
RegisterCode=8ac1000323ulgyeq5x
UserName=学英语
方法二:
打开Sitman→单击“帮助”菜单→单击“关于Sitman”→双击左下角的“软件授权”→然后在注册窗口填上:用户名:学英语 注册码:8ac1000323ulgyeq5x→最后点“注册”按钮,OK注册成功。(我觉得这个方法好,我用的就是这个,装好了)
 axis2 java.lang.reflect.InvocationTargetException
收藏
axis2 java.lang.reflect.InvocationTargetException
收藏
http://loshamo.javaeye.com/blog/627020
[i][/i]在使用codegen1.3插件来从WSDL生成代码,到了最后一步竟然出然
了"An error occurred while completing process
-java.lang.reflect.InvocationTargetException"的错误
产生这种错误的原因一般有2种:首先关闭eclipse。
1.jar包缺失
从AXIS2的LIB库中复制"geronimo-stax-api_1.0_spec-1.0.1.jar"和"backport-util-concurrent-3.1.jar"文件到Codegen的lib目录中,同时修改plugin.xml文件,添加
<library name="lib/geronimo-stax-api_1.0_spec-1.0.1.jar">
<export name="*"/>
</library>
<library name="lib/backport-util-concurrent-3.1.jar">
<export name="*"/>
</library>
2.版本问题
F:\Program Files\MyEclipse 6.0\eclipse\plugins\Axis2_Codegen_Wizard_1.3.0\plugin.xml中
<plugin
id="Axis2_Codegen_Wizard"
name="Axis2 Codegen Wizard Plug-in"
version="1.3.0"
provider-name="Apache Software Foundation"
class="org.apache.axis2.tool.codegen.eclipse.plugin.CodegenWizardPlugin"&
gt;看看自己下载的axis2版本是否和这个配置一致,像我的是axis2-1.5.1则需修改上面的配置为<plugin
id="Axis2_Codegen_Wizard"
name="Axis2 Codegen Wizard Plug-in"
version="1.5.1" //对应的版本号
provider-name="Apache Software Foundation"
class="org.apache.axis2.tool.codegen.eclipse.plugin.CodegenWizardPlugin">
然后再将文件夹的名字Axis2_Codegen_Wizard_1.3.0改为Axis2_Codegen_Wizard_1.5.1
修改完以上2步重新启动eclipse即可。
摘要: 使用Axis编写WebService比较简单,就我的理解,WebService的实现代码和编写Java代码其实没有什么区别,主要是将哪些Java类发布为WebService。下面是一个从编写测试例子到发布WebService,以及编写测试代码的过程介绍。
本例子的WebService提供了两个方法,分别是sayHello和sayHelloTo... 阅读全文
最近在研究openmeetings,使用的是mysql5,但在切换简体中文的时候老出问题,后来发现库中不存在中文的配置文件,找到简体中文利用提供的语言导入功能,发现中文无法写入,导入英文的配置文件完全没有问题。
在网上查到的方法:
找到“my.ini”这个文件,就在MYSQL的安装目录下,如果找不到的话,用搜索也行!
用记事本打开,找到下面这一行文本
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
注意,可能不太一样,但前面肯定是 sql-mode 只有这么一行。
在它的前面加上一个“#”号,即
#sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
保存文件,最后是重新启动一下MYSQL服务。
试完后中文还是无法保存,后来发现字段属性的字符集是latin1,改成utf8后就好了.
http://blog.csdn.net/wjp553650958/archive/2009/08/30/4499540.aspx
读取容器配置参数---context-param和init-param区别
web.xml里面可以定义两种参数:
(1)application范围内的参数,存放在servletcontext中,在web.xml中配置如下: <context-param>
<param-name>context/param</param-name>
<param-value>avalible during application</param-value>
<param-name>name1</param-name>
<param-value>value1</param-value>
</context-param>
(2)servlet范围内的参数,只能在servlet的init()方法中取得,在web.xml中配置如下:
<servlet>
<servlet-name>MainServlet</servlet-name>
<servlet-class>com.wes.controller.MainServlet</servlet-class>
<init-param>
<param-name>param1</param-name>
<param-value>avalible in servlet init()</param-value>
</init-param>
<load-on-startup>0</load-on-startup>
</servlet>
在servlet中可以通过代码分别取用:
package com.wes.controller;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
public class MainServlet extends HttpServlet ...{
public MainServlet() ...{
super();
}
public void init() throws ServletException ...{
System.out.println("下面的两个参数param1是在servlet中存放的");
System.out.println(this.getInitParameter("param1"));
System.out.println("下面的参数是存放在servletcontext中的");
System.out.println(getServletContext().getInitParameter("context/param"));
}
}
第
一种参数在servlet里面可以通过getServletContext().getInitParameter("context/param")得
到?(在servlet的init()方法中通过this.getInitParameter("param1")取得)
第二种参数只能在servlet的init()方法中通过this.getInitParameter("param1")取得
---------------------------------------------------------------------
ServletContextListener实现读取web.xml中context-param信息 2009年03月27日 星期五 22:37
用部署文件来存储配置参数在Java中是一种很流行的做法。
配置参数一般存放在context-param元素中,每一个context-param元素代表了一个键值对。
我
们可以通过实现ServletContextListener接口读取该键值对中的值,在web应用程序初始化的时候,调用
ServletContextListener的contextInitialized()方法,所以我们我们可以重写该方法,实现读取操作。可以这样实
现:
public class AppListener implements ServletContextListener {
public void contextInitialized(ServletContextEvent sce) {
try {
MyConfig config = new MyConfig();//存放配置信息,用Map实现
Enumeration parameters = sce.getServletContext().getInitParameterNames();
while(parameters.hasMoreElements()){
String name = (String) parameters.nextElement();
config.addKeyTValue(name, sce.getServletContext().getInitParameter(name));
}
//相应的键值对存到map中
config.addKeyValue(parameter, sc.getInitParameter(parameter));
}
} catch(Exception e) {
System.out.println("com.shou error:" + e.getMessage());
}
}
public void contextDestroyed(ServletContextEvent arg0) {
}
}
MyConfig类:(Singleton Config)
package com.myapp;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
*
* @author Administrator
*/
public class MyConfig{
public static MyConfig myconfig;
public static HashMap config = new HashMap();
public static HashMap getConfig() {
return config;
}
public static MyConfig getInstance(){
if(myconfig==null){
myconfig = new MyConfig();
}
return myconfig;
}
public static void setConfig(HashMap config) {
MyConfig.config = config;
}
public HashMap addKeyTValue(String name,String value){
this.config.put(name, value);
return this.config;
}
}
接着,必须在web.xml中配置相应的监听类,才能在初始化的时候,自动调用该方法。如:
<listener>
<listener-class>com.myapp.MyListener</listener-class>
</listener>
这样就可以在任何一个JSP页面,通过EL表达式或JSTL读到context-param中的内容。
有的网友说在web.xml内定义<listener>元素时得注意下列两点:
<listener>元素必须出现在任何Context起始参数(由<context-param>元素所定义)之后。
<listener>元素必须出现在任何Servlet实体(由<servlet>元素所定义)之前。
但是我在TOMCAT5.5 + J2EE 5下配置web.xml并没有按照上述的严格限制也能成功读取信息。
难道是版本的问题吗。
在Struts 1.X下,通过一个自定义的Singleton Config类,可以让web.xml中的配置参数在整个应用程序里都能被共享。
http://zhxing.javaeye.com/blog/399668
在项目中总会遇到一些关于加载的优先级问题,近期也同样遇到过类似的,所以自己查找资料总结了下,下面有些是转载其他人的,毕竟人家写的不错,自己也就不重复造轮子了,只是略加点了自己的修饰。
首先可以肯定的是,加载顺序与它们在 web.xml 文件中的先后顺序无关。即不会因为 filter 写在 listener 的前面而会先加载 filter。最终得出的结论是:listener -> filter -> servlet
同时还存在着这样一种配置节:context-param,它用于向 ServletContext
提供键值对,即应用程序上下文信息。我们的 listener, filter 等在初始化时会用到这些上下文中的信息,那么
context-param 配置节是不是应该写在 listener 配置节前呢?实际上 context-param 配置节可写在任意位置,因此真正的加载顺序为:context-param -> listener -> filter -> servlet
对于某类配置节而言,与它们出现的顺序是有关的。以 filter 为例,web.xml 中当然可以定义多个 filter,与
filter 相关的一个配置节是 filter-mapping,这里一定要注意,对于拥有相同 filter-name 的 filter 和
filter-mapping 配置节而言,filter-mapping 必须出现在 filter 之后,否则当解析到
filter-mapping 时,它所对应的 filter-name 还未定义。web 容器启动时初始化每个 filter 时,是按照
filter 配置节出现的顺序来初始化的,当请求资源匹配多个 filter-mapping 时,filter 拦截资源是按照 filter-mapping 配置节出现的顺序来依次调用 doFilter() 方法的。
servlet 同 filter 类似,此处不再赘述。
由此,可以看出,web.xml 的加载顺序是:context-param -> listener -> filter -> servlet ,而同个类型之间的实际程序调用的时候的顺序是根据对应的 mapping 的顺序进行调用的。
web.xml文件详解
Web.xml常用元素
<web-app>
<display-name></display-name>定义了WEB应用的名字
<description></description> 声明WEB应用的描述信息
<context-param></context-param> context-param元素声明应用范围内的初始化参数。
<filter></filter> 过滤器元素将一个名字与一个实现javax.servlet.Filter接口的类相关联。
<filter-mapping></filter-mapping> 一旦命名了一个过滤器,就要利用filter-mapping元素把它与一个或多个servlet或JSP页面相关联。
<listener></listener>servlet API的版本2.3增加了对事件监听程序的支持,事件监听程序在建立、修改和删除会话或servlet环境时得到通知。
Listener元素指出事件监听程序类。
<servlet></servlet> 在向servlet或JSP页面制定初始化参数或定制URL时,必须首先命名servlet或JSP页面。Servlet元素就是用来完成此项任务的。
<servlet-mapping></servlet-mapping> 服务器一般为servlet提供一个缺省的URL:http://host/webAppPrefix/servlet/ServletName。
但是,常常会更改这个URL,以便servlet可以访问初始化参数或更容易地处理相对URL。在更改缺省URL时,使用servlet-mapping元素。
<session-config></session-config> 如果某个会话在一定时间内未被访问,服务器可以抛弃它以节省内存。
可通过使用HttpSession的setMaxInactiveInterval方法明确设置单个会话对象的超时值,或者可利用session-config元素制定缺省超时值。
<mime-mapping></mime-mapping>如果Web应用具有想到特殊的文件,希望能保证给他们分配特定的MIME类型,则mime-mapping元素提供这种保证。
<welcome-file-list></welcome-file-list> 指示服务器在收到引用一个目录名而不是文件名的URL时,使用哪个文件。
<error-page></error-page> 在返回特定HTTP状态代码时,或者特定类型的异常被抛出时,能够制定将要显示的页面。
<taglib></taglib> 对标记库描述符文件(Tag Libraryu Descriptor file)指定别名。此功能使你能够更改TLD文件的位置,
而不用编辑使用这些文件的JSP页面。
<resource-env-ref></resource-env-ref>声明与资源相关的一个管理对象。
<resource-ref></resource-ref> 声明一个资源工厂使用的外部资源。
<security-constraint></security-constraint> 制定应该保护的URL。它与login-config元素联合使用
<login-config></login-config> 指定服务器应该怎样给试图访问受保护页面的用户授权。它与sercurity-constraint元素联合使用。
<security-role></security-role>给出安全角色的一个列表,这些角色将出现在servlet元素内的security-role-ref元素
的role-name子元素中。分别地声明角色可使高级IDE处理安全信息更为容易。
<env-entry></env-entry>声明Web应用的环境项。
<ejb-ref></ejb-ref>声明一个EJB的主目录的引用。
< ejb-local-ref></ ejb-local-ref>声明一个EJB的本地主目录的应用。
</web-app>
相应元素配置
1、Web应用图标:指出IDE和GUI工具用来表示Web应用的大图标和小图标
<icon>
<small-icon>/images/app_small.gif</small-icon>
<large-icon>/images/app_large.gif</large-icon>
</icon>
2、Web 应用名称:提供GUI工具可能会用来标记这个特定的Web应用的一个名称
<display-name>Tomcat Example</display-name>
3、Web 应用描述: 给出于此相关的说明性文本
<disciption>Tomcat Example servlets and JSP pages.</disciption>
4、上下文参数:声明应用范围内的初始化参数。
<context-param>
<param-name>ContextParameter</para-name>
<param-value>test</param-value>
<description>It is a test parameter.</description>
</context-param>
在servlet里面可以通过getServletContext().getInitParameter("context/param")得到
5、过滤器配置:将一个名字与一个实现javaxs.servlet.Filter接口的类相关联。
<filter>
<filter-name>setCharacterEncoding</filter-name>
<filter-class>com.myTest.setCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>GB2312</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>setCharacterEncoding</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
6、监听器配置
<listener>
<listerner-class>listener.SessionListener</listener-class>
</listener>
7、Servlet配置
基本配置
<servlet>
<servlet-name>snoop</servlet-name>
<servlet-class>SnoopServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>snoop</servlet-name>
<url-pattern>/snoop</url-pattern>
</servlet-mapping>
高级配置
<servlet>
<servlet-name>snoop</servlet-name>
<servlet-class>SnoopServlet</servlet-class>
<init-param>
<param-name>foo</param-name>
<param-value>bar</param-value>
</init-param>
<run-as>
<description>Security role for anonymous access</description>
<role-name>tomcat</role-name>
</run-as>
</servlet>
<servlet-mapping>
<servlet-name>snoop</servlet-name>
<url-pattern>/snoop</url-pattern>
</servlet-mapping>
元素说明
<servlet></servlet> 用来声明一个servlet的数据,主要有以下子元素:
<servlet-name></servlet-name> 指定servlet的名称
<servlet-class></servlet-class> 指定servlet的类名称
<jsp-file></jsp-file> 指定web站台中的某个JSP网页的完整路径
<init-param></init-param> 用来定义参数,可有多个init-param。在servlet类中通过getInitParamenter(String name)方法访问初始化参数
<load-on-startup></load-on-startup>指定当Web应用启动时,装载Servlet的次序。
当值为正数或零时:Servlet容器先加载数值小的servlet,再依次加载其他数值大的servlet.
当值为负或未定义:Servlet容器将在Web客户首次访问这个servlet时加载它
<servlet-mapping></servlet-mapping> 用来定义servlet所对应的URL,包含两个子元素
<servlet-name></servlet-name> 指定servlet的名称
<url-pattern></url-pattern> 指定servlet所对应的URL
8、会话超时配置(单位为分钟)
<session-config>
<session-timeout>120</session-timeout>
</session-config>
9、MIME类型配置
<mime-mapping>
<extension>htm</extension>
<mime-type>text/html</mime-type>
</mime-mapping>
10、指定欢迎文件页配置
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
</welcome-file-list>
11、配置错误页面
一、 通过错误码来配置error-page
<error-page>
<error-code>404</error-code>
<location>/NotFound.jsp</location>
</error-page>
上面配置了当系统发生404错误时,跳转到错误处理页面NotFound.jsp。
二、通过异常的类型配置error-page
<error-page>
<exception-type>java.lang.NullException</exception-type>
<location>/error.jsp</location>
</error-page>
上面配置了当系统发生java.lang.NullException(即空指针异常)时,跳转到错误处理页面error.jsp
12、TLD配置
<taglib>
<taglib-uri>http://jakarta.apache.org/tomcat/debug-taglib</taglib-uri>
<taglib-location>/WEB-INF/jsp/debug-taglib.tld</taglib-location>
</taglib>
如果MyEclipse一直在报错,应该把<taglib> 放到 <jsp-config>中
<jsp-config>
<taglib>
<taglib-uri>http://jakarta.apache.org/tomcat/debug-taglib</taglib-uri>
<taglib-location>/WEB-INF/pager-taglib.tld</taglib-location>
</taglib>
</jsp-config>
13、资源管理对象配置
<resource-env-ref>
<resource-env-ref-name>jms/StockQueue</resource-env-ref-name>
</resource-env-ref>
14、资源工厂配置
<resource-ref>
<res-ref-name>mail/Session</res-ref-name>
<res-type>javax.mail.Session</res-type>
<res-auth>Container</res-auth>
</resource-ref>
配置数据库连接池就可在此配置:
<resource-ref>
<description>JNDI JDBC DataSource of shop</description>
<res-ref-name>jdbc/sample_db</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
15、安全限制配置
<security-constraint>
<display-name>Example Security Constraint</display-name>
<web-resource-collection>
<web-resource-name>Protected Area</web-resource-name>
<url-pattern>/jsp/security/protected/*</url-pattern>
<http-method>DELETE</http-method>
<http-method>GET</http-method>
<http-method>POST</http-method>
<http-method>PUT</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>tomcat</role-name>
<role-name>role1</role-name>
</auth-constraint>
</security-constraint>
16、登陆验证配置
<login-config>
<auth-method>FORM</auth-method>
<realm-name>Example-Based Authentiation Area</realm-name>
<form-login-config>
<form-login-page>/jsp/security/protected/login.jsp</form-login-page>
<form-error-page>/jsp/security/protected/error.jsp</form-error-page>
</form-login-config>
</login-config>
17、安全角色:security-role元素给出安全角色的一个列表,这些角色将出现在servlet元素内的security-role-ref元素的role-name子元素中。
分别地声明角色可使高级IDE处理安全信息更为容易。
<security-role>
<role-name>tomcat</role-name>
</security-role>
18、Web环境参数:env-entry元素声明Web应用的环境项
<env-entry>
<env-entry-name>minExemptions</env-entry-name>
<env-entry-value>1</env-entry-value>
<env-entry-type>java.lang.Integer</env-entry-type>
</env-entry>
19、EJB 声明
<ejb-ref>
<description>Example EJB reference</decription>
<ejb-ref-name>ejb/Account</ejb-ref-name>
<ejb-ref-type>Entity</ejb-ref-type>
<home>com.mycompany.mypackage.AccountHome</home>
<remote>com.mycompany.mypackage.Account</remote>
</ejb-ref>
20、本地EJB声明
<ejb-local-ref>
<description>Example Loacal EJB reference</decription>
<ejb-ref-name>ejb/ProcessOrder</ejb-ref-name>
<ejb-ref-type>Session</ejb-ref-type>
<local-home>com.mycompany.mypackage.ProcessOrderHome</local-home>
<local>com.mycompany.mypackage.ProcessOrder</local>
</ejb-local-ref>
21、配置DWR
<servlet>
<servlet-name>dwr-invoker</servlet-name>
<servlet-class>uk.ltd.getahead.dwr.DWRServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>dwr-invoker</servlet-name>
<url-pattern>/dwr/*</url-pattern>
</servlet-mapping>
22、配置Struts
<display-name>Struts Blank Application</display-name>
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>
org.apache.struts.action.ActionServlet
</servlet-class>
<init-param>
<param-name>detail</param-name>
<param-value>2</param-value>
</init-param>
<init-param>
<param-name>debug</param-name>
<param-value>2</param-value>
</init-param>
<init-param>
<param-name>config</param-name>
<param-value>/WEB-INF/struts-config.xml</param-value>
</init-param>
<init-param>
<param-name>application</param-name>
<param-value>ApplicationResources</param-value>
</init-param>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
<!-- Struts Tag Library Descriptors -->
<taglib>
<taglib-uri>struts-bean</taglib-uri>
<taglib-location>/WEB-INF/tld/struts-bean.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>struts-html</taglib-uri>
<taglib-location>/WEB-INF/tld/struts-html.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>struts-nested</taglib-uri>
<taglib-location>/WEB-INF/tld/struts-nested.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>struts-logic</taglib-uri>
<taglib-location>/WEB-INF/tld/struts-logic.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>struts-tiles</taglib-uri>
<taglib-location>/WEB-INF/tld/struts-tiles.tld</taglib-location>
</taglib>
23、配置Spring(基本上都是在Struts中配置的)
<!-- 指定spring配置文件位置 -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
<!--加载多个spring配置文件 -->
/WEB-INF/applicationContext.xml, /WEB-INF/action-servlet.xml
</param-value>
</context-param>
<!-- 定义SPRING监听器,加载spring -->
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<listener>
<listener-class>
org.springframework.web.context.request.RequestContextListener
</listener-class>
</listener>
Tomcat中web.xml文件的详细说明
<?xml version="1.0" encoding="GB2312"?> <!--
Web.xml依次定议了如下元素:
<web-app>
<display-name></display-name> 定义了WEB应用的名字
<description></description> 声明WEB应用的描述信息
<filter></filter>
<filter-mapping></filter-mapping>
<servlet></servlet>
<servlet-mapping></servlet-mapping>
<session-config></session-config>
<welcome-file-list></welcome-file-list>
<taglib></taglib>
<resource-ref></resource-ref>
<security-constraint></security-constraint>
<login-config></login-config>
</web-app>
在web.xml中元素定义的先后顺序不能颠倒,否则Tomcat服务器可能会抛出SAXParseException.
-->
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems,Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<display-name>Sample Application</display-name>
<description>
This is a Sample Application
</description>
<!--
filter 配置Servlet过滤器
filter-name 定义过滤器的名字。当有多个过滤器时,不能同名
filter-class 指定实现这一过滤的类,这个类负责具体的过滤事务
-->
<filter>
<filter-name>SampleFilter</filter-name>
<filter-class>mypack.SampleFilter</filter-class>
</filter>
<!--
filter-mapping 设定过滤器负责过滤的URL
filter-name 过滤器名。这里的名字一定要和filter中的过滤器名匹配
url-pattern 指定过滤器负责过滤的URL
-->
<filter-mapping>
<filter-name>SampleFilter</filter-name>
<url-pattern>*.jsp</url-pattern>
</filter-mapping>
<!--
servlet 配置Servlet.
servlet-name 定义Servlet的名字
servlet-class 指定实现这个servlet的类
init-param 定义Servlet的初始化参数和参数值,可有多个init-param。在servlet类中通过getInitParamenter(String name)方法访问初始化参数
load-on-startup 指定当Web应用启动时,装载Servlet的次序。
当值为正数或零时:Servlet容器先加载数值小的servlet,再依次加载其他数值大的servlet.
当值为负或未定义:Servlet容器将在Web客户首次访问这个servlet时加载它
-->
<servlet>
<servlet-name>SampleServlet</servlet-name>
<servlet-class>mypack.SampleServlet</servlet-class>
<init-param>
<param-name>initParam1</param-name>
<param-value>2</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<!--
配置servlet映射(下面代码为SampleServlet指定的相对URL为"/sample":
servlet-name 指定servlet的名字,这里的名字应该和<Servlet>元素中定义的名字匹配。
url-pattern 指定访问这个servlet的URL。只需给出相对路径。
-->
<servlet-mapping>
<servlet-name>SampleServlet</servlet-name>
<url-pattern>/sample</url-pattern>
</servlet-mapping>
<!--配置session session用来设定HttpSession的生命周期。单位(秒)-->
<session-config>
<session-timeout>30</session-timeout>
</session-config>
<!--配置Wel0come0文件清单-->
<welcome-file-list>
<welcome-file>login.jsp</welcome-file>
<welcome-file>index.htm</welcome-file>
</welcome-file-list>
<!--
配置Tag Library
taglib-uri 设定Tag Library的唯一标识符,在Web应用中将根据这一标识符来引用Tag Library
taglib-location 指定和Tag Library对应的TLD文件的位置
-->
<taglib>
<taglib-uri>/mytaglib</taglib-uri>
<taglib-location>/WEB-INF/mytaglib.tld</taglib-location>
</taglib>
<!--
配置资源引用
description 对所引用的资源的说明
res-ref-name 指定所引用资源的JNDI名字
res-type 指定所引用资源的类名字
res-auth 指定管理所引用资源的Manager,它有两个可选值:
Container:由容器来创建和管理resource
Application:同WEB应用来创建和管理Resource
-->
<resource-ref>
<description>DB Connection</description>
<res-ref-name>jdbc/sampleDB</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
<!--
配置安全约束(以下代码指定当用户访问该WEB应用下的所有资源时,必须具备guest角色)
web-resource-collection 声明受保护的WEB资源
auth-constraint 声明可以访问受保护资源的角色,可以包含多个<role-name>子元素
web-resource-name 标识受保护的WEB资源
url-pattern 指定受保护的URL路径
-->
<Security-constraint>
<web-resource-collection>
<web-resource-name>sample appliction</web-resource-name>
<url-pattern>/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>guest</role-name>
</auth-constraint>
</Security-constraint>
<!--
配置安全验证登录界面:指定当WEB客户访问受保护的WEB资源时,系统弹出的登录对话框的类型。
auth-method 指定验证方法,它有三个可选值:BASIC(基本验证)、DIGEST(摘要验证)、FORM(表单验证)
realm-name 设定安全域的名称
form-login-config 当验证方法为FORM时,配置验证网页和出错网页
form-login-page 当验证方法为FORM时,设定验证网页
form-error-page 当验证方法为FORM时,设定出错网页
-->
<login-config>
<auth-method>FORM</auth-method>
<realm-name>
Tomcat Server Configuration form-Based Authentication Area
</realm-name>
<form-login-config>
<form-login-page>/login.jsp</form-login-page>
<form-error-page>/error.jsp</form-error-page>
</form-login-config>
</login-config>
<!--配置对安全验证角色的引用-->
<security-role>
<description>
The role that is required to log into the sample application
</description>
<role-name>guest</role-name>
</security-role>
</web-app>
http://wangguorui89.javaeye.com/blog/428345
关键字: java, 定时器, timertask
在web中,定时器的启动一般随web server的启动而启动,一般有两种方法.
方法一:在web.xml里配置一个Servlet,并设置其随web server的启动而启动。然后在该Servlet的init()方法里启动定时器,在destory()方法里销毁定时器。
方法二:在web.xml里配置一个Listener,然后在该Listener的初始化方法里启动定时器,在其销毁的方法朝左销毁定时器。
在servlet中启动定时器
java 代码
- import java.io.IOException;
- import java.util.Timer;
- import javax.servlet.RequestDispatcher;
- import javax.servlet.ServletContext;
- import javax.servlet.ServletException;
- import javax.servlet.http.HttpServlet;
- import javax.servlet.http.HttpServletRequest;
- import javax.servlet.http.HttpServletResponse;
-
- import org.apache.commons.lang.StringUtils;
-
- public class ConvergeDataServlet extends HttpServlet {
-
- private static final long serialVersionUID = 1L;
-
- private Timer timer1 = null;
-
- private Task task1;
-
- /**
- * Constructor of the object.
- */
- public ConvergeDataServlet() {
- super();
- }
-
- /**
- * Destruction of the servlet.
- */
- public void destroy() {
- super.destroy();
- if(timer1!=null){
- timer1.cancel();
- }
- }
-
-
- public void doGet(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
-
- }
-
-
- public void doPost(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
- doGet(request, response);
- }
-
- // init方法启动定时器
- public void init() throws ServletException {
-
- ServletContext context = getServletContext();
-
- // (true为用定时间刷新缓存)
- String startTask = getInitParameter("startTask");
-
- // 定时刷新时间(分钟)
- Long delay = Long.parseLong(getInitParameter("delay"));
-
- // 启动定时器
- if(startTask.equals("true")){
- timer1 = new Timer(true);
- task1 = new Task(context);
- timer1.schedule(task1, delay * 60 * 1000, delay * 60 * 1000);
- }
- }
- }
定时执行操作
java 代码
-
- /**
- *
- * @author callan
- */
- import java.util.TimerTask;
-
- import javax.servlet.ServletContext;
-
- public class Task extends TimerTask{
-
- private ServletContext context;
-
- private static boolean isRunning = true;
-
- public Task(ServletContext context){
- this.context = context;
- }
-
-
- @Override
- public void run() {
- if(isRunning){
-
- }
- }
-
- }
在web.xml配置这个servlet为服务启动时就调用servlet
<servlet></servlet>
< servlet >
< servlet-name >taskservlet< / servlet-name >
< servlet-class >com.task< /servlet-class >
< init-param >
< param-name >startTask< /param-name >
< param-value >true< /param-value >
< /init-param >
< init-param >
< param-name >intervalTime< /param-name >
< param-value >1< /param-value >
< /init-param >
< load-on-startup >300< /load-on-startup >
< /servlet >
<servlet></servlet>
http://callan.javaeye.com/blog/123374
关键字: java, 定时器, timertask
在web中,定时器的启动一般随web server的启动而启动,一般有两种方法.
方法一:在web.xml里配置一个Servlet,并设置其随web server的启动而启动。然后在该Servlet的init()方法里启动定时器,在destory()方法里销毁定时器。
方法二:在web.xml里配置一个Listener,然后在该Listener的初始化方法里启动定时器,在其销毁的方法朝左销毁定时器。
在servlet中启动定时器
java 代码
- import java.io.IOException;
- import java.util.Timer;
- import javax.servlet.RequestDispatcher;
- import javax.servlet.ServletContext;
- import javax.servlet.ServletException;
- import javax.servlet.http.HttpServlet;
- import javax.servlet.http.HttpServletRequest;
- import javax.servlet.http.HttpServletResponse;
-
- import org.apache.commons.lang.StringUtils;
-
- public class ConvergeDataServlet extends HttpServlet {
-
- private static final long serialVersionUID = 1L;
-
- private Timer timer1 = null;
-
- private Task task1;
-
- /**
- * Constructor of the object.
- */
- public ConvergeDataServlet() {
- super();
- }
-
- /**
- * Destruction of the servlet.
- */
- public void destroy() {
- super.destroy();
- if(timer1!=null){
- timer1.cancel();
- }
- }
-
-
- public void doGet(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
-
- }
-
-
- public void doPost(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
- doGet(request, response);
- }
-
- // init方法启动定时器
- public void init() throws ServletException {
-
- ServletContext context = getServletContext();
-
- // (true为用定时间刷新缓存)
- String startTask = getInitParameter("startTask");
-
- // 定时刷新时间(分钟)
- Long delay = Long.parseLong(getInitParameter("delay"));
-
- // 启动定时器
- if(startTask.equals("true")){
- timer1 = new Timer(true);
- task1 = new Task(context);
- timer1.schedule(task1, delay * 60 * 1000, delay * 60 * 1000);
- }
- }
- }
定时执行操作
java 代码
-
- /**
- *
- * @author callan
- */
- import java.util.TimerTask;
-
- import javax.servlet.ServletContext;
-
- public class Task extends TimerTask{
-
- private ServletContext context;
-
- private static boolean isRunning = true;
-
- public Task(ServletContext context){
- this.context = context;
- }
-
-
- @Override
- public void run() {
- if(isRunning){
-
- }
- }
-
- }
在web.xml配置这个servlet为服务启动时就调用servlet
<servlet></servlet>
< servlet >
< servlet-name >taskservlet< / servlet-name >
< servlet-class >com.task< /servlet-class >
< init-param >
< param-name >startTask< /param-name >
< param-value >true< /param-value >
< /init-param >
< init-param >
< param-name >intervalTime< /param-name >
< param-value >1< /param-value >
< /init-param >
< load-on-startup >300< /load-on-startup >
< /servlet >
<servlet></servlet>
最近,公司用servlet做一个跟踪图片点击技术的模块,我个人略有心得想和大家分享,
不知大家愿意审视。
这个模块挺大,我仅说说用servlet显示图片部分。我先说说用servlet显示图片的一个流程:
1. 设置response的输出类型:
对应的语句--response.setContentType("image/gif;charset=GB2312") ,response
便能输出gif图片,"image/gif;charset=GB2312"便是输出类型,当然你可以输出
"image/jpg;charset=GB2312"类型文件。
2. 得到文件流:
servlet是以流的形式件图片文件从服务器读出,通过response将流发到浏览器的。
3. 得到输出流:
对应的语句--OutputStream output = response.getOutputStream();
当然,处理图片文件需要以二进制形式的流。
4. 文件流的编码(但也不一定必须编码的,如果不是文件流,则必须编码)
所以我给大家一个用编码的代码和不用编码的代码.
顺便说一句,sun公司仅提供了jpg图片文件的编码api。
我想基本流程都讲完了,下面我把代码拿给大家看一下,大家自然一目了然了:
package xjw.personal.servet;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import com.sun.image.codec.jpeg.*;//sun公司仅提供了jpg图片文件的编码api
import javax.imageio.stream.*;
import java.awt.*;
import java.awt.image.BufferedImage;
public class ShowPicture extends HttpServlet
{
private static final String GIF="image/gif;charset=GB2312";//设定输出的类型
private static final String JPG="image/jpeg;charset=GB2312";
public void init() throws ServletException
{
}
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException
{
doPost(request, response);
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException
{
String spec=request.getParameter("spec");//输出图片的类型的标志
int int_spec=Integer.parseInt(spec);
if(spec==1)
{
String imagePath="/jfgg/b1.jpg";//图片相对web应用的位置
}
else
{
String imagePath="/jfgg/b2.gif";//图片相对web应用的位置
}
OutputStream output = response.getOutputStream();//得到输出流
if(imagePath.toLowerCase().endsWith(".jpg"))//使用编码处理文件流的情况:
{
response.setContentType(JPG);//设定输出的类型
//得到图片的真实路径
imagePath = getServletContext().getRealPath(imagePath);
//得到图片的文件流
InputStream imageIn = new FileInputStream(new File(imagePath));
//得到输入的编码器,将文件流进行jpg格式编码
JPEGImageDecoder decoder = JPEGCodec.createJPEGDecoder(imageIn);
//得到编码后的图片对象
BufferedImage image = decoder.decodeAsBufferedImage();
//得到输出的编码器
JPEGImageEncoder encoder = JPEGCodec.createJPEGEncoder(output);
encoder.encode(image);//对图片进行输出编码
imageIn.close();//关闭文件流
}
if(imagePath.toLowerCase().endsWith(".gif"))//不使用编码处理文件流的情况:
{
response.setContentType(GIF);
ServletContext context = getServletContext();//得到背景对象
InputStream imageIn=context.getResourceAsStream(imagePath);//文件流
BufferedInputStream bis=new BufferedInputStream(imageIn);//输入缓冲流
BufferedOutputStream bos=new BufferedOutputStream(output);//输出缓冲流
byte data[]=new byte[4096];//缓冲字节数
int size=0;
size=bis.read(data);
while (size!=-1)
{
bos.write(data,0,size);
size=bis.read(data);
}
bis.close();
bos.flush();//清空输出缓冲流
bos.close();
}
output.close();
}
}
最后是如何调用,你可以简单的映射一下servelt,我就将servet的名映射为
ShowPic, 于是下代码调用
<html>
<body>
<img src="ShowPic?spec=2"></a>
</body>
</html>
这样图片便显示在htm上了,本人研究java的时间不长,如有问题,尽情指正。
一、完整的自我介绍1
Good morning !
It is really my honor to have this
opportunity for an interview,I hope I can make a good performance today.
I’m confident that I can succeed.Now I will introduce myself briefly.
I
am 26 years old,born in shandong province .I was graduated from qingdao
university. My major is electronic and i got my bachelor degree after
my graduation in the year of 2003.I spend most of my time on study,I
have passed CET4/6 . and I have acquired basic knowledge of my major
during my school time.In July 2003, I began work for a small private
company as a technical support engineer in QingDao city.Because I’m
capable of more responsibilities, so I decided to change my job.And in
August 2004,I left QingDao to BeiJing and worked for a foreign
enterprise as a automation software test engineer.Because I want to
change my working environment, I’d like to find a job which is more
challenging. Morover Motorola is a global company, so I feel I can gain
the most from working in this kind of company ennvironment. That is the
reason why I come here to compete for this position.
I think I’m a good team player and I’m a person of great honesty to others. Also I am able to work under great pressure.
That’s all. Thank you for giving me the chance.
完整的自我介绍2
good
morning, my name is jack, it is really a great honor to have this
opportunity for a interview, i would like to answer whatever you may
raise, and i hope i can make a good performance today, eventually enroll
in this prestigious university in september. now i will introduce
myself briefly.
i am 21 years old,born in heilongjiang province
,northeast of china,and i am curruently a senior student at beijing XX
uni.my major is packaging engineering.and i will receive my bachelor
degree after my graduation in june.in the past 4 years,i spend most of
my time on study,i have passed CET4/6 with an ease. and i have acquired
basic knowledge of packaging and publishing both in theory and in
practice. besides, i have attend several packaging exhibition hold in
Beijing, this is our advantage study here, i have taken a tour to some
big factory and company. through these i have a deeply understanding of
domestic packaging industry. compared to developed countries such as us,
unfortunately, although we have made extraordinary progress since
1978,our packaging industry are still underdeveloped, mess, unstable,
the situation of employees in this field are awkard.
but i have
full confidence in a bright future if only our economy can keep the
growth pace still. i guess you maybe interested in the reason itch to
law, and what is my plan during graduate study life, i would like to
tell you that pursue law is one of my lifelong goal,i like my major
packaging and i won’t give up,if i can pursue my master degree here i
will combine law with my former education. i will work hard in
thesefields ,patent ,trademark, copyright, on the base of my years study
in department of p&p.
my character? i cannot describe it
well, but i know i am optimistic and confident. sometimes i prefer to
stay alone, reading, listening to music, but i am not lonely, i like to
chat with my classmates, almost talk everything ,my favorite pastime is
valleyball,playing cards or surf online. through college life,i learn
how to balance between study and entertainment. by the way, i was a
actor of our amazing drama club. i had a few glorious memory on stage.
that is my pride.
二、模板1:自我介绍(self-introduction)
Good morning. I am glad to be here for this interview.
First
let me introduce myself. My name is ***, 24. I come from ******,the
capital of *******Province. I graduated from the ******* department of
*****University in July ,2001.In the past two years I have been
preparing for the postgraduate examination while I have been teaching
*****in NO.****middle School and I was a head-teacher of a class in
junior grade two.Now all my hard work has got a result since I have a
chance to be interview by you . I am open-minded ,quick in thought and
very fond of history.In my spare time,I have broad interests like many
other youngsters.I like reading books, especially those about
*******.Frequently I exchange with other people by making comments in
the forum on line.In addition ,during my college years,I was once a
Net-bar technician.So, I have a comparatively good command of network
application.I am able to operate the computer well.I am skillful in
searching for information in Internet.I am a football fan for
years.Italian team is my favorite.
Anyway,I feel great pity for
our country’s team. I always believe that one will easily lag behind
unless he keeps on learning .Of course, if I am given a chance to study
****** in this famous University,I will stare no effort to master a good
command of advance ******.
模板2:自我介绍(self-introduction)
Good afternoon .I am of great hornor to stand here and introduce myself to you .
First
of all ,my english name is …and my chinese name is ..If you are going
to have a job interview ,you must say much things which can show your
willness to this job ,such as ,it is my long cherished dream to be …and I
am eager to get an opportunity to do…and then give some examples which
can give evidence to .then you can say something about your hobbies .and
it is best that the hobbies have something to do with the job.
What
is more important is do not forget to communicate with the
interviewee,keeping a smile and keeping your talks interesting and funny
can contribute to the success.
I hope you will give them a wonderful speech .Good luck to you !
三、面试现场提问环节:
1. What is your greatest strength?(你最突出的优点是什么?)
这是很多面试
考官喜欢问的一个问题,这是你展示自己的最佳机会,不要吹嘘自己或过于自负,但要让雇主知道你相信自己,你知道自己的优点。如可答:“我认为我最大的优点
是能够执着地尽力把事情办好。当做完一件工作而其成果又正合我的预想时,我会有一种真正的成就感。我给自己定了一些高目标。比如说,我要成为出色的毕业
生。尽管在大学一年级时我启动慢了些,但最终我以优等论文完成了学业。”
I feel that my strongest asset is
my ability to stick to things to get them done. I feel a real sense of
accomplishment when I finish a job and it turns out just as I’d planned.
I’ve set some high goals for myself. For example, I want to graduate
with highest distinction. And even though I had a slow start in my
freshman year, I made up for it by doing an honor’s thesis.
2. What is your greatest weakness?(你最大的弱点是什么?)
你不应该说你没有任何弱点,以此来回避这个问题。每个人都有弱点,最佳策略是承认你的弱点,但同时表明你在予以改进,并有克服弱点的计划。可能的话,你可说出一项可能会给公司带来好处的弱点,如可说:“我是一个完美主义者。工作做得不漂亮,我是不会撒手的。”
I’m such a perfectionist that I will not stop until a job is well done.
I'm married and I have two beautiful children. I'm interested in cricket, history and bird watching.
I graduated from university with a Business Management degree with high marks. I studied
courses such as accounting and English. I've got two years' work experience, first as a clerk and
then as a manager in a factory in the capital, so I can easily do the duties of this job. I'm also very
skilled with computers.
我
结婚了,有两个漂亮的孩子。我喜欢打板球,喜欢历史,喜欢观察野鸟。我的大学专业是商务管理,并且成绩优秀。在校时我研读的课程有会计,英语等。我有两年
的工作经验。第一份工作是做一名普通的职员,第二次是在工厂里做管理人员。所以我可以胜任这份工作。另外,我的电脑技术也很不错。
I'm efficient; when I have a project to do, I do it thoroughly and on
time. For example, I always double-check my reports. I like to be
organized; in my last managerial position I had many duties so I
organized a schedule and prioritized my jobs. I'm a fast learner: I
didn't know anything about computers before university, it was difficult
at first but I studied hard, got high marks and can use it effectively
now…. I believe that problems are really challenges and that I can solve
them.
我做事有效率。当我做一个项目时,我考虑很周到并且按时完工。比如,我总是对报告进行二度确认。我做事有条理。在我
上一份工作中,我是管理人员,我有许多事情要做,所以我自己列了一个做事提纲并且按事情的轻重缓急来安排时间。我学习能力很强。在大学前我不懂电脑,对我
来说,起初很困难,但我用功学习电脑并且得到了高分,所以现在对电脑驾轻就熟。我认为,工作中的问题是有挑战性的,但我可以解决。
老师点评:
This is an excellent answer. It gives a lot of additional information which is not on the CV
It gives specific details, examples and evidence of key skills and qualities
It reveals the personality and values of the candidate (for example, 'problems are really challenges')
It shows a problem-solving approach and self-management skills.
摘要: 为了便于管理,先引入个基础类:
package algorithms;
/**
* @author yovn
*
*/
public abstract class Sorter<E extends Comparable<E>> {... 阅读全文
经常在论坛上面看到覆写hashCode函数的问题,很多情况下是一些开发者不了解hash code,或者和equals一起用的时候不太清楚为啥一定要复写hashCode。
对于hash code的理论我不想多说,这个话题太大。我只想说用hash code的原因只有一个:效率。理论的说法它的复杂度只有O(1)。试想我们把元素放在线性表里面,每次要找一个元素必须从头一个一个的找它的复杂度有O(n)。如果放在平衡二叉树,复杂度也有O(log n)。
为啥很多地方说“覆写equals的时候一定要覆写hashCode”。说到这里我知道很多人知道有个原则:如果a.equals(b)那么要确保a.hashCode()==b.hashCode()。为什么?hashCode和我写的程序的业务逻辑毫无关系,为啥我要override? 要我说如果你的class永远不可能放在hash code为基础的容器内,不必劳神,您真的不必override hashCode() :)
说得准确一点放在HashMap和Hashtable里面如果是作为value而不是作为key的话也是不必override
hashCode了。至于HashSet,实际上它只是忽略value的HashMap,每次HashSet.add(o)其实就是
HashMap.put(o, dummyObject)。
那为什么放到Hash容器里面要overide hashCode呢?因为每次get的时候HashMap既要看equals是不是true也要看hash code是不是一致,put的时候也是要看equals和hash code。
如果说到这里您还是不太明白,咱就举个例子:
譬如把一个自己定义的class
Foo{...}放到HashMap。实际上HashMap也是把数据存在一个数组里面,所以在put函数里面,HashMap会调
Foo.hashCode()算出作为这个元素在数组里面的下标,然后把key和value封装成一个对象放到数组。等一下,万一2个对象算出来的
hash
code一样怎么办?会不会冲掉?先回答第2个问题,会不会冲掉就要看Foo.equals()了,如果equals()也是true那就要冲掉了。万一
是false,就是所谓的collision了。当2个元素hashCode一样但是equals为false的时候,那个HashMap里面的数组的这
个元素就变成了链表。也就是hash code一样的元素在一个链表里面,链表的头在那个数组里面。
回过来说get的时候,HashMap也先调key.hashCode()算出数组下标,然后看equals是不是true,所以就涉及了equals。
反观假设如果a.equals(b)但是a.hashCode()!=b.hashCode()的话,在put元素a之后,我们又用一个
a.equals(b)但是b.hashCode()!=a.hashCode()的b元素作为key来get的时候就找不到a了。如果
a.hashCode()==b.hashCode()但是!a.equals(b)倒是不要紧,这2个元素会collision然后被放到链表,只是效
率变差。
这里有个非常简化版的HashMap实现帮助大家理解。
- /*
- * Just to demonstrate hash map mechanism,
- * Please do not use it in your commercial product.
- *
- * @author Shengyuan Lu 卢声远 <michaellufhl@yahoo.com.cn>
- */
- public class SimpleHashMap {
- ArrayList<LinkedList<Entry>> entries = new ArrayList<LinkedList<Entry>>();
-
- /**
- * Each key-value is encapsulated by Entry.
- */
- static class Entry {
- Object key;
- Object value;
- public Entry(Object key, Object value) {
- this.key = key;
- this.value = value;
- }
- }
- void put(Object key, Object value) {
- LinkedList<Entry> e = entries.get(key.hashCode());
- if (e != null) {
- for (Entry entry : e) {
- if (entry.key.equals(key)) {
- entry.value = value;// Match in lined list
- return;
- }
- }
- e.addFirst(new Entry(key, value));// Add the entry to the list
- } else {
- // Put the new entry in array
- LinkedList<Entry> newEntry = new LinkedList<Entry>();
- newEntry.add(new Entry(key, value));
- entries.add(key.hashCode(), newEntry);
- }
- }
- Object get(Object key) {
- LinkedList<Entry> e = entries.get(key.hashCode());
- if (e != null) {
- for (Entry entry : e) {
- if (entry.key.equals(key)) {
- return entry.value;
- }
- }
- }
- return null;
- }
-
- /**
- * Do we need to override equals() and hashCode() for SimpleHashMap itself?
- * I don't know either:)
- */
- }
这个问题的权威阐释可以参考Bloch的<Effective Java>的 Item 9: Always override hashCode when you override equals
责怪糟糕的代码(或不良代码对象)并不能帮助您发现瓶颈,提高 Java™ 应用程序速度,猜测也不能帮您解决。Ted Neward 引导您关注 Java 性能监控工具,从5 个技巧开始,使用Java 5 的内置分析器JConsole 收集和分析性能数据。
当应用程序性能受到损害时,大多数开发人员都惊慌失措,这在情理之中。跟踪 Java 应用程序瓶颈来源一直以来都是很麻烦的,因为 Java 虚拟机有黑盒效应,而且 Java 平台分析工具一贯就有缺陷。
然而,随着 Java 5 中 JConsole 的引入,一切都发生了改变。JConsole 是一个内置 Java
性能分析器,可以从命令行或在 GUI shell
中运行。它不是完美的,但是当尖头老板来问你关于性能的问题时,用它来应对还是绰绰有余的——这比查询 Papa Google 要好得多。
在本期 5 件事 系列中,我将向您展示 5 个方法,使您可以轻松地使用 JConsole(或者,它更高端的 “近亲” VisualVM )来监控 Java 应用程序性能和跟踪 Java 中的代码。
1. JDK 附带分析器
许多开发人员没有意识到从 Java 5 开始 JDK 中包含了一个分析器。JConsole(或者 Java
平台最新版本,VisualVM)是一个内置分析器,它同 Java 编译器一样容易启动。如果是从命令行启动,使 JDK 在 PATH 上,运行
jconsole 即可。如果从 GUI shell 启动,找到 JDK 安装路径,打开 bin 文件夹,双击 jconsole。
当分析工具弹出时(取决于正在运行的 Java 版本以及正在运行的 Java 程序数量),可能会出现一个对话框,要求输入一个进程的 URL 来连接,也可能列出许多不同的本地 Java 进程(有时包含 JConsole 进程本身)来连接。
使用 JConsole 进行工作
在 Java 5 中,Java 进程并不是被设置为默认分析的,而是通过一个命令行参数 —
-Dcom.sun.management.jmxremote — 在启动时告诉 Java 5 VM 打开连接,以便分析器可以找到它们;当进程被
JConsole 捡起时,您只能双击它开始分析。
分析器有自己的开销,因此最好的办法就是花点时间来弄清是什么开销。发现 JConsole
开销最简单的办法是,首先独自运行一个应用程序,然后在分析器下运行,并测量差异。(应用程序不能太大或者太小;我最喜欢使用 JDK 附带的
SwingSet2 样本。)因此,我使用 -verbose:gc 尝试运行 SwingSet2 来查看垃圾收集清理,然后运行同一个应用程序并将
JConsole 分析器连接到它。当 JConsole 连接好了之后,一个稳定的 GC 清理流出现,否则不会出现。这就是分析器的性能开销。
2. 远程连接进程
因为 Web 应用程序分析工具假设通过一个套接字进行连通性分析,您只需要进行少许配置来设置 JConsole(或者是基于 JVMTI 的分析器,就这点而言),监控/分析远程运行的应用程序。
如果 Tomcat 运行在一个名为 “webserve” 的机器上,且 JVM 已经启动了 JMX 并监听端口 9004,从
JConsole(或者任何 JMX 客户端)连接它需要一个 JMX URL
“service:jmx:rmi:///jndi/rmi://webserver:9004/jmxrmi”。
基本上,要分析一个运行在远程数据中心的应用程序服务器,您所需要的仅仅是一个 JMX URL。更多关于使用 JMX 和 JConsole 远程监控和管理的信息,参见 参考资料。)
3. 跟踪统计
JConsole 有许多对收集统计数据有用的选项卡,包括:
Memory:在 JVM 垃圾收集器中针对各个堆跟踪活动。
Threads:在目标 JVM 中检查当前线程活动。
Classes:观察 VM 已加载类的总数。
这些选项卡(和相关的图表)都是由每个 Java 5 及更高版本 VM 在 JMX 服务器上注册的 JMX 对象提供的,是内置到 JVM
的。一个给定 JVM 中可用 bean 的完整清单在 MBeans
选项卡上列出,包括一些元数据和一个有限的用户界面来查看数据或执行操作。(然而,注册通知是在 JConsole 用户界面之外。)
使用统计数据
假设一个 Tomcat 进程死于 OutOfMemoryError。如果您想要弄清楚发生了什么,打开 JConsole,单击
Classes 选项卡,过一段时间查看一次类计数。如果数量稳定上升,您可以假设应用程序服务器或者您的代码某个地方有一个 ClassLoader
漏洞,不久之后将耗尽 PermGen 空间。如果需要更进一步的确认问题,请看 Memory 选项卡。
4. 为离线分析创建一个堆转储
生产环境中一切都在快速地进行着,您可能没有时间花费在您的应用程序分析器上,相反地,您可以为 Java 环境中的每个事件照一个快照保存下来过后再看。在 JConsole 中您也可以这样做,在 VisualVM 中甚至会做得更好。
先找到 MBeans 选项卡,在其中打开 com.sun.management 节点,接着是 HotSpotDiagnostic
节点。现在,选择 Operations,注意右边面板中的 “dumpHeap” 按钮。如果您在第一个(“字符串”)输入框中向 dumpHeap
传递一个文件名来转储,它将为整个 JVM 堆照一个快照,并将其转储到那个文件。
稍后,您可以使用各种不同的商业分析器来分析文件,或者使用 VisualVM 分析快照。(记住,VisualVM 是在 Java 6 中可用的,且是单独下载的。)
5. JConsole 并不是高深莫测的
作为一个分析器实用工具,JConsole 是极好的,但是还有更好的工具。一些分析插件附带分析器或者灵巧的用户界面,默认情况下比 JConsole 跟踪更多的数据。
JConsole 真正吸引人的是整个程序是用 “普通旧式 Java ” 编写的,这意味着任何 Java
开发人员都可以编写这样一个实用工具。事实上,JDK 其中甚至包括如何通过创建一个插件来定制 JConsole 的示例(参见 参考资料)。建立在
NetBeans 顶部的 VisualVM 进一步延伸了插件概念。
如果 JConsole(或者
VisualVM,或者其他任何工具)不符合您的需求,或者不能跟踪您想要跟踪的,或者不能按照您的方式跟踪,您可以编写属于自己的工具。如果您觉得
Java 代码很麻烦,Groovy 或 JRuby 或很多其他 JVM 语言都可以帮助您更快完成。
您真正需要的是一个快速而粗糙(quick-and-dirty)的由 JVM 连接的命令行工具,可以以您想要的方式确切地跟踪您感兴趣的数据。
结束语
Java 性能监控不止于 JConsole 或 VisualVM — 在 JDK 中隐藏着一整套工具,只是大多数开发人员并不知道。 本系列
中的下一篇文章将深入探究一些实验性的命令行工具,可以帮助您挖掘更多的您所需要的性能数据。因为这些工具通常只关注特殊数据,比一个完整的分析器更小更
轻巧,所以它们的性能开销要小一些。
Velocity是什么?
Velocity是一个基于java的模板引擎(template engine)。它允许任何人仅仅简单的使用模板语言(template language)来引用由java代码定义的对象。
当Velocity应用于web开发时,界面设计人员可以和java程序开发人员同步开发一个遵循MVC架构的web站点,也就是说,页面设计人
员可以只关注页面的显示效果,而由java程序开发人员关注业务逻辑编码。Velocity将java代码从web页面中分离出来,这样为web站点的长
期维护提供了便利,同时也为我们在JSP和PHP之外又提供了一种可选的方案。
Velocity的能力远不止web站点开发这个领域,例如,它可以从模板(template)产生SQL和PostScript、XML,它也
可以被当作一个独立工具来产生源代码和报告,或者作为其他系统的集成组件使用。Velocity也可以为Turbine
web开发架构提供模板服务(template
service)。Velocity+Turbine提供一个模板服务的方式允许一个web应用以一个真正的MVC模型进行开发。
Velocity能为我们作什么?
The Mud Store Example
假设你是一家专门出售Mud的在线商店的页面设计人员,让我们暂且称它为“在线MUD商店”。你们的业务很旺,客户下了各种类型和数量的mud订
单。他们都是通过输入用户名和密码后才登陆到你的网站,登陆后就允许他们查看订单并购买更多的mud。现在,一种非常流行的mud正在打折销售。另外有一
些客户规律性的购买另外一种也在打折但是不是很流行的Bright Red
Mud,由于购买的人并不多所以它被安置在页面的边缘。所有用户的信息都是被跟踪并存放于数据库中的,所以某天有一个问题可能会冒出来:为什么不使用
velocity来使用户更好的浏览他们感兴趣的商品呢?
Velocity使得web页面的客户化工作非常容易。作为一个web site的设计人员,你希望每个用户登陆时都拥有自己的页面。
你会见了一些公司内的软件工程师,你发现他们每个人都同意客户应该拥有具有个性化的信息。那让我们把软件工程师应该作的事情发在一边,看一看你应该作些什么吧。
你可能在页面内嵌套如下的VTL声明:
<html>
<body>
Hello $customer.Name!
<table>
#foreach( $mud in $nudsOnSpecial )
#if ( $customer.hasPurchased( $mud ) )
<tr><td>$flogger.getPromo( $mud )</td></tr>
#end
#end
</table>
Velocity Template Language(VTL):AN introduction
VTL意味着提供最简单、最容易并且最整洁的方式合并页面动态内容。
VTL使用references来在web
site内嵌套动态内容,一个变量就是一种类型的reference。变量是某种类型的refreence,它可以指向java代码中的定义,或者从当前
页面内定义的VTL statement得到值。下面是一个VTL statement的例子,它可以被嵌套到HTML代码中:
#set ( $a = “Velocity” )
和所有的VTL
statement一样,这个statement以#字符开始并且包含一个directive:set。当一个在线用户请求你的页面时,Velocity
Templating Engine将查询整个页面以便发现所有#字符,然后确定哪些是VTL statement,哪些不需要VTL作任何事情。
#字符后紧跟一个directive:set时,这个set directive使用一个表达式(使用括号封闭)――一个方程式分配一个值给变量。变量被列在左边,而它的值被列在右边,最后他们之间使用=号分割。
在上面的例子中,变量是$a,而它的值是Velocity。和其他的references一样以$字符开始,而值总是以双引号封闭。Velocity中仅有String可以被赋值给变量。
记住以下的规则:
使用$字符开始的references用于得到什么;使用#字符开始的directives用于作些什么。
Hello Velocity World!
一旦某个变量被分配了一个值,那么你就可以在HTML文件的任何地方引用它。在下面的例子中,一个值被分配给$foo变量,并在其后被引用。
<html>
<body>
#set ( $foo = “Velocity” )
Hello $foo World!
</body>
</html>
上面的实现结果是在页面上打印“Hello Velocity World!”
为了使包含VTL directives的statement更具有可读性,我们鼓励你在新行开始每个VTL statement,尽管你不是必须这么作。Set directive将在后面详细描述。
注释
单行注释:
## This is a single line comment.
多行注释:
#*
Thus begins a multi-line comment. Online visitors won’t
see this text because the Velocity Templating Engine will
ignore it.
*#
文档格式:
#**
This is a VTL comment block and
may be used to store such information
as the document author and versioning
information:
@version 5
@author
*#
References
在VTL中有三种类型的references:变量(variables)、属性(properties)、方法(methods)。作为一个使
用VTL的页面设计者,你和你的工程师必须就references的名称达成共识,以便你可以在你的template中使用它们。
Everything coming to and from a reference被作为一个String对象处理。如果有一个对象$foo是一个Integer对象,那么Velocity将调用它的toString()方法将这个对象转型为String类型。
变量
格式要求同java。
属性
例子:
$customer.Address
$purchase.Total
$customer.Address有两种含义。它可以表示:查找hashtable对象customer中以Address为关键字的值;也可
以表示调用customer对象的getAddress()方法。当你的页面被请求时,Velocity将确定以上两种方式选用那种,然后返回适当的值。
方法
一个方法就是被定义在java中的一段代码,并且它有完成某些有用工作的能力,例如一个执行计算和判断条件是否成立、满足等。方法是一个由$开始并跟随VTL标识符组成的References,一般还包括一个VTL方法体。例如:
$customer.getAddress()
$purchase.getTotal()
$page.setTitle( “My Home Page” )
$person.setAttributes( [“Strange”, “Weird”, “Excited”] )
前两个例子$customer.getAddress()和$purchase.getTotal()看起来挺想上面的属性$customer.Address 和 $purchase.Total。如果你觉得他们之间有某种联系的话,那你是正确的。
VTL属性可以作为VTL方法的缩写。$customer.Address属性和使用$customer.getAddress()方法具有相同的效果。如果可能的话使用属性的方式是比较合理的。属性和方法的不同点在于你能够给一个方法指定一个参数列表。
正式reference标记
reference的正是格式如下:
${mudSlinger} 变量
${customer.Address} 属性
${purchase.getTotal()} 方法
非正是格式更见常用,但是有时还是使用正是格式比较适合。例如:你希望通过一个变量$vice来动态的组织一个字符串。
Jack is a $vicemaniac.
本来变量是$vice现在却变成了$vicemaniac,这样Veloctiy就不知道您到底要什么了。所以,应该使用正是格式书写
Jack is a ${vice}maniac
现在Velocity知道变量是$vice而不是$vicemaniac。
Quiet reference notation
例如:
<input type=”text” name=”email” value=”$email” />
当页面的form被初始加载时,变量$email还没有值,这时你肯定是希望它能够显示一个blank text来代替输出”$email”这样的字段。那么使用quiet reference notation就比较合适。
<input type=”text” name=”email” value=”$!email”/>
这样文本框的初始值就不会是email而是空值了。
正式和quiet格式的reference notation也可一同使用,像下面这样:
<input type=”text” name=”email” value=”$!{email}”/>
Getting literal
Velocity使用特殊字符$和#来帮助它工作,所以如果要在template里使用这些特殊字符要格外小心。本节将讨论$字符。
货币字符
在VTL中使用$2.5这样的货币标识是没有问题得的,VTL不会将它错认为是一个reference,因为VTL中的reference总是以一个大写或者小写的字母开始。
Escaping valid VTL reference
VTL中使用“"”作为逃逸符。
例如:
#set( $email = “foo” )
$email
"$email
""$email
"""$email
将render为:
foo
$email
"foo
""$email
如果email变量没有被定义则
$email
"$email
""$email
"""$email
将被render为:
$email
"$email
""$email
"""$email
注意:VTL中未被定义的变量将被认为是一个字符串,所以以下例子:
#set( $foo = “gibbous” )
$moon = $foo
的输出结果是:
$moon = gibbous
Case substitution
现在你已经对reference比较熟悉了,你可以将他们高效的应用于你的template了。Velocity利用了很多java规范以方便了设计人员的使用。例如:
$foo
$foo.getBar()
## is the same as
$foo.Bar
$data.getUser(“jon”)
## is the same as
$data.User(“jon”)
$data.getRequest().getServerName()
# is the same as
$data.Request.ServerName
## is the same as
${data.Request.ServerName}
但是,注意VTL中不会将reference解释为对象的实例变量。例如:$foo.Name将被解释为Foo对象的getName()方法,而不是Foo对象的Name实例变量。
Directives
Reference允许设计者使用动态的内容,而directive使得你可以应用java代码来控制你的显示逻辑,从而达到你所期望的显示效果。
#set
#set directive被用于设置一个reference的值。例如:
#set ( $primate = “monkey” )
#set ( $customer.Behavior = $primate )
赋值左侧的(LHS)必须是一个变量或者属性reference。右侧(RHS)可以是以下类型中一种:
l 变量reference
l String literal
l 属性reference
l 方法reference
l number literal
l ArrayList
下面是应用各种类型的RHS的例子:
#set ( $monkey = $bill ) ##变量reference
#set ( $monkey.Friend = “monica” ) ##String literal
#set ( $monkey.Blame = $whitehouse.Leak )##属性reference
#set ( $monkey.Plan = $spindoctor.weave($web) )##方法reference
#set ( $monkey.Number = 123 )##Number literal
#set ( $monkey.Say = [“Not”, $my, “fault”] )##ArrayList
注意:最后一个例子的取值方法为:$monkey.Say.get(0)
RHS也可以是一个简单的算术表达式:
#set ( $value = $foo + 1 )
#set ( $value = $bar -1 )
#set ( $value = $foo * $bar )
#set ( $value = $foo / $bar )
如果你的RHS是一个null,VTL的处理将比较特殊:它将指向一个已经存在的reference,这对初学者来讲可能是比较费解的。例如:
#set ( $resut = $query.criteria(“name”) )
The result of the first query is $result
#set ( $resut = $query.criteria(“address”) )
The result of the second query is $result
如果$query.criteria(“name”)返回一个“bill”,而$query.criteria(“address”)返回的是null,则显示的结果如下:
The result of the first query is bill
The result of the first query is bill
看看下面的例子:
#set( $criteria = ["name", "address"] )
#foreach( $criterion in $criteria )
#set( $result = $query.criteria($criterion) )
#if( $result )
Query was successful
#end
#end
在上面的例子中,程序将不能智能的根据$result的值决定查询是否成功。在$result被#set后(added to the
context),它不能被设置回null(removed from the
context)。打印的结果将显示两次查询结果都成功了,但是实际上有一个查询是失败的。
为了解决以上问题我们可以通过预先定义的方式:
#set( $criteria = [“name”, “address”] )
#foreach( $criterion in $criteria )
#set( $result = false )
#set( $result = $query.criteria( $criterion ) )
#if( $result )
Query was successful
#end
#end
String Literals
当你使用#set directive,String literal封闭在一对双引号内。
#set ( $directoryRoot = “www” )
#set ( $templateName = “index.vm” )
#set ( $template = “$directoryRoot/$tempateName” )
$template
上面这段代码的输出结果为:www/index.vm
但是,当string literal被封装在单引号内时,它将不被解析:
#set ( $foo = “bar” )
$foo
#set ( $blargh = ‘$foo’ )
结果:
bar
$foo
上面这个特性可以通过修改velocity.properties文件的stringliterals.interpolate = false的值来改变上面的特性是否有效。
条件语句
if/elseif/else
当一个web页面被生成时使用Velocity的#if directrive,如果条件成立的话可以在页面内嵌入文字。例如:
#if ( $foo )
<strong>Velocity!</strong>
#end
上例中的条件语句将在以下两种条件下成立:
l $foo是一个boolean型的变量,且它的值为true
l $foo变量的值不为null
这里需要注意一点:Velocity context仅仅能够包含对象,所以当我们说“boolean”时实际上代表的时一个Boolean对象。即便某个方法返回的是一个boolean值,Velocity也会利用内省机制将它转换为一个Boolean的相同值。
如果条件成立,那么#if和#end之间的内容将被显示。
#elseif和#else元素可以同#if一同使用。例如:
#if( $foo < 10 )
<strong> Go North </strong>
#elseif( $foo == 10 )
<strong> Go East </strong>
#elseif( $foo == 6 )
<strong> Go South </strong>
#else
<strong> Go West </strong>
#end
注意这里的Velocity的数字是作为Integer来比较的――其他类型的对象将使得条件为false,但是与java不同它使用“==”来比较两个值,而且velocity要求等号两边的值类型相同。
关系、逻辑运算符
Velocity中使用等号操作符判断两个变量的关系。例如:
#set ( $foo = “deoxyribonucleic acid” )
#set ( $bar = “ribonucleic acid” )
#if ( $foo == $foo )
In this case it’s clear they aren’t equivalent.So…
#else
They are not equivalent and this will be the output.
#end
Velocity有AND、OR和NOT逻辑运算符。下面是一些例子:
## logical AND
#if( $foo && $bar )
<strong> This AND that </strong>
#end
## logical OR
#if ( $foo || $bar )
<strong>This OR That </strong>
#end
##logical NOT
#if ( !$foo )
<strong> NOT that </strong>
#end
循环
Foreach循环
例子:
<ul>
#foreach ( $product in $allProducts )
<li> $product </li>
#end
</ul>
每次循环$allProducts中的一个值都会赋给$product变量。
$allProducts可以是一个Vector、Hashtable或者Array。分配给$product的值是一个java对象,并且可以
通过变量被引用。例如:如果$product是一个java的Product类,并且这个产品的名字可以通过调用他的getName()方法得到。
现在我们假设$allProducts是一个Hashtable,如果你希望得到它的key应该像下面这样:
<ul>
#foreach ( $key in $allProducts.keySet() )
<li>Key: $key -> Value: $allProducts.get($key) </li>
#end
</ul>
Velocity还特别提供了得到循环次数的方法,以便你可以像下面这样作:
<table>
#foreach ( $customer in $customerList )
<tr><td>$velocityCount</td><td>$customer.Name</td></tr>
#end
</table>
$velocityCount变量的名字是Velocity默认的名字,你也可以通过修改velocity.properties文件来改变它。
默认情况下,计数从“1”开始,但是你可以在velocity.properties设置它是从“1”还是从“0”开始。下面就是文件中的配置:
# Default name of loop counter
# variable reference
directive.foreach.counter.name = velocityCount
# Default starting value of the loop
# counter variable reference
directive.foreach.counter.initial.value = 1
include
#include script element允许模板设计者引入本地文件。被引入文件的内容将不会通过模板引擎被render。为了安全的原因,被引入的本地文件只能在TEMPLATE_ROOT目录下。
#inclued ( “one.txt” )
如果您需要引入多个文件,可以用逗号分隔就行:
#include ( “one.gif”, “two.txt”, “three.htm” )
在括号内可以是文件名,但是更多的时候是使用变量的:
#inclue ( “greetings.txt”, $seasonalstock )
parse
#parse script element允许模板设计者一个包含VTL的本地文件。Velocity将解析其中的VTL并render模板。
#parse( “me.vm” )
就像#include,#parse接受一个变量而不是一个模板。任何由#parse指向的模板都必须包含在TEMPLATE_ROOT目录下。与#include不同的是,#parse只能指定单个对象。
你可以通过修改velocity.properties文件的parse_direcive.maxdepth的值来控制一个template可以包含的最多#parse的个数――默认值是10。#parse是可以递归调用的,例如:如果dofoo.vm包含如下行:
Count down.
#set ( $count = 8 )
#parse ( “parsefoo.vm” )
All done with dofoo.vm!
那么在parsefoo.vm模板中,你可以包含如下VTL:
$count
#set ( $count = $count – 1 )
#if ( $count > 0 )
#parse( “parsefoo.vm” )
#else
All done with parsefoo.vm!
#end
的显示结果为:
Count down.
8
7
6
5
4
3
2
1
0
All done with parsefoo.vm!
All done with dofoo.vm!
Stop
#stop script element允许模板设计者停止执行模板引擎并返回。把它应用于debug是很有帮助的。
#stop
Velocimacros
#macro script element允许模板设计者定义一段可重用的VTL template。例如:
#macro ( d )
<tr><td></td></tr>
#end
在上面的例子中Velocimacro被定义为d,然后你就可以在任何VTL directive中以如下方式调用它:
#d()
当你的template被调用时,Velocity将用<tr><td></td></tr>替换为#d()。
每个Velocimacro可以拥有任意数量的参数――甚至0个参数,虽然定义时可以随意设置参数数量,但是调用这个Velocimacro时必须指定正确的参数。下面是一个拥有两个参数的Velocimacro,一个参数是color另一个参数是array:
#macro ( tablerows $color $somelist )
#foreach ( $something in $somelist )
<tr><td bgcolor=$color>$something</td</tr>
#end
#end
调用#tablerows Velocimacro:
#set ( $greatlakes = [ “Superior”, “Michigan”, “Huron”, “Erie”, “Ontario” ] )
#set ( $color = “blue” )
<table>
#tablerows( $color $greatlakes )
</table>
经过以上的调用将产生如下的显示结果:
<table>
<tr><td bgcolor=” blue”> Superior </td></tr>
<tr><td bgcolor=” blue”> Michigan </td></tr>
<tr><td bgcolor=” blue”> Huron </td></tr>
<tr><td bgcolor=” blue”> Erie </td></tr>
<tr><td bgcolor=” blue”> Ontario </td></tr>
</table>
Velocimacros可以在Velocity模板内实现行内定义(inline),也就意味着同一个web
site内的其他Velocity模板不可以获得Velocimacros的定义。定义一个可以被所有模板共享的Velocimacro显然是有很多好处
的:它减少了在一大堆模板中重复定义的数量、节省了工作时间、减少了出错的几率、保证了单点修改。
上面定义的#tablerows( $color $list
)Velocimacro被定义在一个Velocimacros模板库(在velocity.properties中定义)里,所以这个macro可以在
任何规范的模板中被调用。它可以被多次应用并且可以应用于不同的目的。例如下面的调用:
#set ( $parts = [ “volva”, “stipe”, “annulus”, “gills”, “pileus” ] )
#set ( $cellbgcol = “#CC00FF” )
<table>
#tablerows( $cellbgcol $parts )
</table>
上面VTL将产生如下的输出:
<table>
<tr><td bgcolor=”#CC00FF”> volva </td</tr>
<tr><td bgcolor=”#CC00FF”> stipe </td</tr>
<tr><td bgcolor=”#CC00FF”> annulus </td</tr>
<tr><td bgcolor=”#CC00FF”> gills </td</tr>
<tr><td bgcolor=”#CC00FF”> pileus </td</tr>
</table>
Velocimacro arguments
Velocimacro可以使用以下任何元素作为参数:
l Reference:任何以$开头的reference
l String literal:
l Number literal:
l IntegerRange:[1….3]或者[$foo….$bar]
l 对象数组:[“a”,”b”,”c”]
l boolean值:true、false
当将一个reference作为参数传递给Velocimacro时,请注意reference作为参数时是以名字的形式传递的。这就意味着参数
的值在每次Velocimacro内执行时才会被产生。这个特性使得你可以将一个方法调用作为参数传递给Velocimacro,而每次
Velocimacro执行时都是通过这个方法调用产生不同的值来执行的。例如:
#macro ( callme $a )
$a $a $a
#end
#callme( $foo.bar() )
执行的结果是:reference $foo的bar()方法被执行了三次。
如果你不需要这样的特性可以通过以下方法:
#set ( $myval = $foo.bar() )
#callme ( $myval )
Velocimacro properties
Velocity.properties文件中的某几行能够使Velocimacros的实现更加灵活。注意更多的内容可以看Developer Guide。
Velocity.properties文件中的velocimacro.libraary:一个以逗号分隔的模板库列表。默认情况下,velocity查找唯一的一个库:VM_global_library.vm。你可以通过配置这个属性来指定自己的模板库。
Velocity.properties文件中的velocimacro.permissions.allow.inline属性:有两个可选的
值true或者false,通过它可以确定Velocimacros是否可以被定义在regular
template内。默认值是ture――允许设计者在他们自己的模板中定义Velocimacros。
Velocity.properties文件中的
velocimacro.permissions.allow.inline.replace.global属性有两个可选值true和
false,这个属性允许使用者确定inline的Velocimacro定义是否可以替代全局Velocimacro定义(比如在
velocimacro.library属性中指定的文件内定义的Velocimacro)。默认情况下,此值为false。这样就阻止本地
Velocimacro定义覆盖全局定义。
Velocity.properties文件中的
velocimacro.permissions.allow.inline.local.scale属性也是有true和false两个可选
值,默认是false。它的作用是用于确定你inline定义的Velocimacros是否仅仅在被定义的template内可见。换句话说,如果这个
属性设置为true,一个inline定义的Velocimacros只能在定义它的template内使用。你可以使用此设置实现一个奇妙的VM敲
门:a template can define a private implementation of the second VM that
will be called by the first VM when invoked by that template. All other
templates are unaffected。
Velocity.properties文件中的velocimacro.context.localscope属性有true和false两个
可选值,默认值为false。当设置为true时,任何在Velocimacro内通过#set()对context的修改被认为是针对此
velocimacro的本地设置,而不会永久的影响内容。
Velocity.properties文件中的velocimacro.library.autoreload属性控制Velocimacro
库的自动加载。默认是false。当设置为ture时,对于一个Velocimacro的调用将自动检查原始库是否发生了变化,如果变化将重新加载它。这
个属性使得你可以不用重新启动servlet容器而达到重新加载的效果,就像你使用regular模板一样。这个属性可以使用的前提就是resource
loader缓存是off状态(file.resource.loader.cache = false)。注意这个属性实际上是针对开发而非产品的。
Velocimacro Trivia
Velocimacro必须被定义在他们被使用之前。也就是说,你的#macro()声明应该出现在使用Velocimacros之前。
特别要注意的是,如果你试图#parse()一个包含#macro()的模板。因为#parse()发生在运行期,但是解析器在
parsetiem决定一个看似VM元素的元素是否是一个VM元素,这样#parse()-ing一组VM声明将不按照预期的样子工作。为了得到预期的结
果,只需要你简单的使用velocimacro.library使得Velocity在启动时加载你的VMs。
Escaping VTL directives
VTL directives can be escaped with “"”号,使用方式跟VTL的reference使用逃逸符的格式差不多。
## #include( “a.txt” ) renders as <ontents of a.txt>(注释行)
#include( “a.txt” )
## "#include( “a.txt” ) renders as "#include( “a.txt” )
"#include( “a.txt” )
## ""#include ( “a.txt” ) renders as "<contents of a.txt>
""#include( “a.txt” )
在对在一个directive内包含多个script元素的VTL directives使用逃逸符时要特别小心(比如在一个if-else-end statement内)。下面是VTL的if-statement的典型应用:
#if ( $jazz )
Vyacheslav Ganelin
#end
如果$jazz是ture,输出将是:
Vyacheslav Ganelin
如果$jazz是false,将没有输出。使用逃逸符将改变输出。考虑一下下面的情况:
"#if ( $jazz )
Vyacheslav Ganelin
"#end
现在无论$jazz是true还是false,输出结果都是:
#if ( $jazz )
Vyacheslav Ganelin
#end
事实上,由于你使用了逃逸符,$jazz根本就没有被解析为boolean型值。在逃逸符前使用逃逸符是合法的,例如:
""#if ( $jazz )
Vyacheslav Ganelin
""#end
以上程序的显示结果为:
" Vyacheslav Ganelin
但是如果$jazz为false,那么将没有输出。(书上说会没有输出,但是我觉得应该还有有“"”字符被输出。)
VTL:Formatting issues
尽管在此用户手册中VTL通常都开始一个新行,如下所示:
#set ( $imperial = [ “Munetaka”, “Koreyasu”, “Hisakira”, “Morikune” ] )
#foreach ( $shogun in $imperial )
$shogun
#end
但是像下面这种写法也是可以的:
Send me #set($foo = [“$10 and”,”a cake”])#foreach($a in $foo)$a #end please.
上面的代码可以被改写为:
Send me
#set ( $foo = [“$10 and “,”a cake”] )
#foreach ( $a in $foo )
$a
#end
please.
或者
Send me
#set($foo = [“$10 and “,”a cake”])
#foreach ($a in $foo )$a
#end please.
这两种的输出结构将一样。
其他特性和杂项
math 在模板中可以使用Velocity内建的算术函数,如:加、减、乘、除
#set ( $foo = $bar + 3 )
#set ( $foo = $bar - 4 )
#set ( $foo = $bar * 6 )
#set ( $foo = $bar / 2 )
当执行除法时将返回一个Integer类型的结果。而余数你可以使用%来得到:
#set ( $foo = $bar % 5 )
在Velocity内使用数学计算公式时,只能使用像-n,-2,-1,0,1,2,n这样的整数,而不能使用其它类型数据。当一个非整型的对象被使用时它将被logged并且将以null作为输出结果。
Range Operator
Range operator可以被用于与#set和#foreach statement联合使用。对于处理一个整型数组它是很有用的,Range operator具有以下构造形式:
[n..m]
m和n都必须是整型,而m是否大于n则无关紧要。例子:
First example:
#foreach ( $foo in [1..5] )
$foo
#end
Second example:
#foreach ( $bar in [2..-2] )
$bar
#end
Third example:
#set ( $arr = [0..1] )
#foreach ( $i in $arr )
$i
#end
Fourth example:
[1..3]
上面四个例子的输出结果为:
First example:
1 2 3 4 5
Second example:
2 1 0 -1 -2
Third example:
0 1
Fourth example:
[1..3]
注意:range operator只在#set和#foreach中有效。
Advanced Issue:Escaping and!
当一个reference被“!”分隔时,并且在它之前有逃逸符时,reference将以特殊的方式处理。注意这种方式与标准的逃逸方式时不同的。对照如下:
#set ( $foo = “bar” )
特殊形式 标准格式
Render前 Render后 Render前 Render后
$"!foo $!foo "$foo "$foo
$"!{foo} $!{foo} "$!foo "$!foo
$""!foo $"!foo "$!{foo} "$!{foo}
$"""!foo $""!foo ""$!{foo} "bar
Velocimacro杂记
Can I user a directive or another VM as an argument to a VM?
例如:#center ( #bold( “hello” ) )
不可以。一个directive的参数使用另外一个directive是不合法的。
但是,还是有些事情你可以作的。最简单的方式就是使用双引号:
#set ( $stuff = “#bold( ‘hello’ )” )
#center ( $stuff )
上面的格式也可以缩写为一行:
#center ( “#bold( ‘hello’ ) )
请注意在下面的例子中参数被evaluated在Velocimacro内部,而不是在calling level。例子:
#macro ( inner $foo )
inner : $foo
#end
#macro ( outer $foo )
#set ( $bar = “outerlala” )
outer : $foo
#end
#set ( $bar = ‘calltimelala’ )
#outer( “#inner($bar)” )
输出结果为:
outer : inner : outerlala
记住Veloctiy的特性:参数的传递是By Name的。例如:
#macro ( foo $color )
<tr bgcolor = $color ><td>Hi</td></tr>
<tr bgcolor = $color ><td>There</td></tr>
#end
#foo ( $bar.rowColor() )
以上代码将导致rowColor()方法两次调用,而不是一次。为了避免这种现象的出现,我们可以按照下面的方式执行:
#set ( $color = $bar.rowColor() )
#foo ( $color )
can I register velocimacros via #parse()?
目前,Velocimacros必须在第一次被模板调用前被定义。这就意味着你的#macro()声明应该出现在使用Velocimacros之前。
如果你试图#parse()一个包含#macro()
directive的模板,这一点是需要牢记的。因为#parse()发生在运行期,但是解析器在parsetiem决定一个看似VM元素的元素是否是一
个VM元素,这样#parse()-ing一组VM声明将不按照预期的样子工作。为了得到预期的结果,只需要你简单的使用
velocimacro.library使得Velocity在启动时加载你的VMs。
What is velocimacro autoreloading?
velocimacro.library.autoreload是专门为开发而非产品使用的一个属性。此属性的默认值是false。
String concatenation
开发人员最常问的问题是我如何作字符拼接?在java中是使用“+”号来完成的。
在VTL里要想实现同样的功能你只需要将需要联合的reference放到一起就行了。例如:
#set ( $size = “Big” )
#set ( $name = “Ben” )
The clock is $size$name.
输出结果将是:The clock is BigBen.。更有趣的情况是:
#set ( $size = “Big” )
#set ( $name = “Ben” )
#set ( $clokc = “$size$name” )
The clock is $clock.
上例也会得到同样的结果。最后一个例子,当你希望混合固定字段到你的reference时,你需要使用标准格式:
#set ( $size = “Big” )
#set ( $name = “Ben” )
#set ( $clock = “${size}Tall$name” )
The clock is $clock.
输出结果是:The clock is BigTallBen.。使用这种格式主要是为了使得$size不被解释为$sizeTall。
开始学习在 Java™ 平台上使用诸如 Spring、Hibernate 或 MySQL
之类的开放源码工具时可能非常困难。再加上 Ant 或 Maven,以及与 DWR 一起的小 Ajax,还有 Web 框架 —— 即
JSF,我们必须睁大眼睛盯着如何配置应用程序。AppFuse
减少了集成开放源码项目的痛苦。它可以把测试变成一等公民,让我们可以从数据库表生成整个 UI,并使用 XFire 来支持 Web
服务。另外,AppFuse 的社区也非常健全,这是不同 Web 框架用户可以一起融洽相处的地方之一。
AppFuse
是一个开放源码的项目和应用程序,它使用了在 Java 平台上构建的开放源码工具来帮助我们快速而高效地开发 Web
应用程序。我最初开发它是为了减少在为客户构建新 Web 应用程序时所花费的那些不必要的时间。从核心上来说,AppFuse
是一个项目骨架,类似于通过向导创建新 Web 项目时 IDE 所创建的东西。当我们使用 AppFuse
创建一个项目时,它会提示我们将使用开放源码框架,然后才创建项目。它使用 Ant
来驱动测试、代码生成、编译和部署。它提供了目录和包结构,以及开发基于 Java 语言的 Web 应用程序所需要的库。
与大部分 “new project” 向导不同,AppFuse
创建的项目从最开始就包含很多类和文件。这些文件用来实现特性,不过它们同时也会在您开发应用程序时被用作示例。通过使用 AppFuse
启动新项目,我们通常可以减少一到两周的开发时间。我们不用担心如何将开放源码框架配置在一起,因为这都已经完成了。我们的项目都已提前配置来与数据库进
行交互,它会部署到应用服务器上,并对用户进行认证。我们不必实现安全特性,因为这都早已集成了。
当我最初开发 AppFuse 时,它只支持 Struts 和 Hibernate。经过几年的努力,我发现了比 Struts 更好的 Web
框架,因此我还添加了为这些 Web 框架使用的选项。现在,AppFuse 可以支持 Hibernate 或 iBATIS 作为持久性框架。对于
Web 框架来说,我们可以使用 JavaServer Faces(JSF)、Spring MVC、Struts、Tapestry 或
WebWork。
AppFuse 提供了很多应用程序需要的一些特性,包括:
- 认证和授权
- 用户管理
- Remember Me(这会保存您的登录信息,这样就不用每次都再进行登录了)
- 密码提醒
- 登记和注册
- SSL 转换
- E-mail
- URL 重写
- 皮肤
- 页面修饰
- 模板化布局
- 文件上载
这种 “开箱即用” 的功能是 AppFuse 与其他 CRUD 代 框架的区别之一(CRUD 取自创建、检索、更新 和删除 几个操作的英文首字母),包括 Ruby on Rails、Trails 和 Grails。上面提到的这些框架,以及 AppFuse,都让我们可以从数据库表或现有的模型对象中生成主页/细节页。
图 1 阐述了一个典型 AppFuse 应用程序的概念设计:
图 1. 典型的 AppFuse 应用程序

清单 1 给出了我们在创建 devworks 项目时所使用的命令行交互操作,同时还给出了所生成的结果。这个项目使用了 WebWork 作为自己的 Web 框架(请参考下面 参考资料 一节给出的链接)。
清单 1. 使用 AppFuse 创建新项目
alotta:~/dev/appfuse mraible$ ant new
Buildfile: build.xml
clean:
[echo] Cleaning build and distribution directories
init:
new:
[echo]
[echo] +-------------------------------------------------------------+
[echo] | -- Welcome to the AppFuse New Application Wizard! -- |
[echo] | |
[echo] | To create a new application, please answer the following |
[echo] | questions. |
[echo] +-------------------------------------------------------------+
[input] What would you like to name your application [myapp]?
devworks
[input] What would you like to name your database [mydb]?
devworks
[input] What package name would you like to use [org.appfuse]?
com.ibm
[input] What web framework would you like to use [webwork,tapestry,spring,js
f,struts]?
webwork
[echo] Creating new application named 'devworks'...
[copy] Copying 359 files to /Users/mraible/Work/devworks
[copy] Copying 181 files to /Users/mraible/Work/devworks/extras
[copy] Copying 1 file to /Users/mraible/Work/devworks
[copy] Copying 1 file to /Users/mraible/Work/devworks
install:
[echo] Copying WebWork JARs to ../../lib
[copy] Copying 6 files to /Users/mraible/Work/devworks/lib
[echo] Adding WebWork entries to ../../lib.properties
[echo] Adding WebWork classpath entries
[echo] Removing Struts-specific JARs
[delete] Deleting directory /Users/mraible/Work/devworks/lib/struts-1.2.9
[delete] Deleting directory /Users/mraible/Work/devworks/lib/strutstest-2.1.3
[echo] Deleting struts_form.xdt for XDoclet
[delete] Deleting directory /Users/mraible/Work/devworks/metadata/templates
[echo] Deleting Struts merge-files in metadata/web
[delete] Deleting 7 files from /Users/mraible/Work/devworks/metadata/web
[echo] Deleting unused Tag Libraries and Utilities
[delete] Deleting 2 files from /Users/mraible/Work/devworks/src/web/org/appfu
se/webapp
[echo] Modifying appgen for WebWork
[copy] Copying 12 files to /Users/mraible/Work/devworks/extras/appgen
[echo] Replacing source and test files
[delete] Deleting directory /Users/mraible/Work/devworks/src/web/org/appfuse/
webapp/form
[delete] Deleting directory /Users/mraible/Work/devworks/src/web/org/appfuse/
webapp/action
[copy] Copying 13 files to /Users/mraible/Work/devworks/src
[delete] Deleting directory /Users/mraible/Work/devworks/test/web/org/appfuse
/webapp/form
[delete] Deleting directory /Users/mraible/Work/devworks/test/web/org/appfuse
/webapp/action
[copy] Copying 5 files to /Users/mraible/Work/devworks/test
[echo] Replacing web files (images, scripts, JSPs, etc.)
[delete] Deleting 1 files from /Users/mraible/Work/devworks/web/scripts
[copy] Copying 34 files to /Users/mraible/Work/devworks/web
[delete] Deleting: /Users/mraible/Work/devworks/web/WEB-INF/validator-rules-c
ustom.xml
[echo] Modifying Eclipse .classpath file
[echo] Refactoring build.xml
[echo] ----------------------------------------------
[echo] NOTE: It's recommended you delete extras/webwork as you shouldn't ne
ed it anymore.
[echo] ----------------------------------------------
[echo] Repackaging info written to rename.log
[echo]
[echo] +-------------------------------------------------------------+
[echo] | -- Application created successfully! -- |
[echo] | |
[echo] | Now you should be able to cd to your application and run: |
[echo] | > ant setup test-all |
[echo] +-------------------------------------------------------------+
BUILD SUCCESSFUL
Total time: 15 seconds
|
 |
为什么使用 WebWork?
Struts 社区最近在热情地拥抱 WebWork,这种结合导致为 Java 平台提供了一个非常优秀的新 Web 框架:Struts
2。当然,Spring MVC 是一个非常优秀的基于请求的框架,但是它不能像 Struts 2 一样支持 JSF。基于内容的框架(例如 JSF 和
Tapestry)也都很好,但是我发现 WebWork 更为直观,更容易使用(更多有关 Structs 2 和 JSF 的内容请参看 参考资料)。
|
|
在创建一个新项目之后,我们就得到了一个类似于图 2 所示的目录结构。Eclipse 和 Intellij IDEA 项目文件都是作为这个过程的一部分创建的。
图 2. 项目的目录结构

这个目录结构与 Sun 为 Java 2 Platform Enterprise Edition(J2EE)Web
应用程序推荐的目录结构非常类似。在 2.0 版本的 AppFuse 中,这个结构会变化成适合 Apache Maven
项目的标准目录结构(有关这两个目录介绍的内容,请参看 参考资料
中的链接)。AppFuse 还会从 Ant 迁移到 Maven 2 上,从而获得相关下载的能力和对生成 IDE 项目文件的支持。目前基于
Ant 的系统要求提交者维护项目文件,而 Maven 2 可以通过简单地使用项目的 pom.xml 文件生成 IDEA、Eclipse 和
NetBeans 项目文件。(这个文件位于您项目的根目录中,是使用 Maven 构建应用程序所需要的主要组件)。它与利用 Ant 所使用的
build.xml 文件非常类似。)
现在我们对 AppFuse 是什么已经有一点概念了,在本文剩下的部分中,我们将介绍使用 AppFuse 的 7 点理由。即使您选择不使用
AppFuse 来开始自己的项目,也会看到 AppFuse 可以为您提供很多样板代码,这些代码可以在基于 Java 语言的 Web
应用程序中使用。由于它是基于 Apache 许可证的,因此非常欢迎您在自己的应用程序中重用这些代码。
理由 1:测试
测试是在软件开发项目中很少被给予足够信任的一个环节。注意我并不是说在软件开发的一些刊物中没有得到足够的信任!很多文章和案例研究都给出了测试
优先的开发方式和足够的测试覆盖面以提高软件的质量。然而,测试通常都被看作是一件只会延长项目开发时间的事情。实际上,如果我们使用测试优先的方法在编
写代码之前就开始撰写测试用例,我相信我们可以发现这实际上会加速 开发速度。另外,测试优先也可以使维护和重用更加 容易。如果我们不编写代码来测试自己的代码,那么就需要手工对应用程序进行测试 —— 这通常效率都不高。自动化才是关键。
当我们首次开始使用 AppFuse 时,我们可能需要阅读这个项目 Web 站点上提供的快速入门指南和教程(请参看 参考资料
中的链接)。这些教程的编写就是为了您可以首先编写测试用例;它们直到编写接口和/或实现之后才能编译。如果您有些方面与我一样,就会在开始编写代码之前
就已经编写好测试用例了;这是真正可以加速编写代码的惟一方式。如果您首先编写了代码的实现,通过某种方式验证它可以工作,那么您可能会对自己说,“哦,
看起来不错 —— 谁需要测试呢?我还有更多的代码需要编写!”这种情况不幸的一面是您通常都会做一些事情 来测试自己的代码;您简单地跳过了可以自动化进行测试的地方。
AppFuse 的文档展示了如何测试应用程序的所有 层次。它从数据库层开始入手,使用了 DbUnit(请参看 参考资料)在运行测试之前提前使用数据来填充自己的数据库。在数据访问(DAO)层,它使用了 Spring 的 AbstractTransactionalDataSourceSpringContextTests 类(是的,这的确是一个类的名字!)来允许简单地加载 Spring 上下文文件。另外,这个类对每个 testXXX() 方法封装了一个事务,并当测试方法存在时进行回滚。这种特性使得测试 DAO 逻辑变得非常简单,并且不会对数据库中的数据造成影响。
在服务层,jMock (请参看 参考资料)用来编写那些可以消除 DAO 依赖的真正 单元测试。这允许进行验证业务逻辑正确的快速测试;我们不用担心底层的持久性逻辑。
|
HtmlUnit 支持
HtmlUnit 团队在 1.8 发行版中已经完成了相当多的工作来确保包可以与流行的 Ajax 框架(Prototype 和 Scriptaculous)很好地工作。
|
|
在 Web 层,测试会验证操作(Struts/WebWork)、控件(Spring MVC)、页面(Tapestry)和管理
bean(JSF)如我们所期望的一样进行工作。Spring 的 spring-mock.jar
可以非常有用地用来测试所有这些框架,因为它包含了一个 Servlet API 的仿真实现。如果没有这个有用的库,那么测试 AppFuse 的
Web 框架就会变得非常困难。
UI 通常是开发 Web 应用程序过程中最为困难的一部分。它也是顾客最经常抱怨的地方 ——
这既是由于它并不是非常完美,也是由于它的工作方式与我们期望的并不一样。另外,没有什么会比在客户面前作演示的过程中看到看到异常堆栈更糟糕的了!您的
应用程序可能会非常可怕,但是客户可能会要求您做到十分完美。永远不要让这种事情发生。Canoo WebTest 可以对 UI 进行测试。它使用了
HtmlUnit 来遍历测试 UI,验证所有的元素都存在,并可以填充表单的域,甚至可以验证一个假想的启用 Ajax 的 UI
与我们预期的工作方式一样。(有关 WebTest 和 HTMLUnit 的链接请参看 参考资料。)
为了进一步简化 Web 的测试,Cargo(请参看 参考资料)对 Tomcat 的启动和停止(分别在运行 WebTest 测试之前和之后)进行了自动化。
理由 2:集成
正如我在本文简介中提到的一样,很多开放源码库都已经预先集成到 AppFuse 中了。它们可以分为以下几类:
- 编译、报告和代码生成:Ant、Ant Contrib Tasks、Checkstyle、EMMA、Java2Html、PMD 和 Rename Packages
- 测试框架:DbUnit、Dumbster、jMock、JUnit 和 Canoo WebTest
- 数据库驱动程序:MySQL 和 PostgreSQL
- 持久性框架:Hibernate 和 iBATIS
- IoC 框架:Spring
- Web 框架:JSF、Spring MVC、Struts、Tapestry 和 WebWork
- Web 服务:XFire
- Web 工具:Clickstream、Display Tag、DWR、JSTL、SiteMesh、Struts Menu 和 URL Rewrite Filter
- Security:Acegi Security
- JavaScript 和 CSS:Scriptaculous、Prototype 和 Mike Stenhouse 的 CSS Framework
除了这些库之外,AppFuse 还使用 Log4j 来记录日志,使用 Velocity 来构建 e-mail 和菜单模板。Tomcat
可以支持最新的开发,我们可以使用 1.4 或 5 版本的 Java 平台来编译或构建程序。我们应该可以将 AppFuse 部署到任何 J2EE
1.3 兼容的应用服务器上;这已经经过了测试,我们知道它在所有主要版本的 J2EE 服务器和所有主要的 servlet 容器上都可以很好地工作。
图 3 给出了上面创建的 devworks 项目的 lib 目录。这个目录中的 lib.properties 文件控制了每个依赖性的版本号,这意味着我们可以简单地通过把这些包的新版本放到这个目录中并执行诸如 ant test-all -Dspring.version=2.0 之类的命令来测试这些包的新版本。
图 3. 项目依赖性

预先集成这些开放源码库可以在项目之初极大地提高生产效率。尽管我们可以找到很多文档介绍如何集成这些库,但是定制工作示例并简单地使用它来开发应用程序要更加简单。
除了可以简化 Web 应用程序的开发之外,AppFuse 让我们还可以将 Web 服务简单地集成到自己的项目中。尽管 XFire 也在 AppFuse 下载中一起提供了,不过如果我们希望,也可以自己集成 Apache Axis(请参看 参考资料 中有关 Axis 集成的教程)。另外,Spring 框架和 XFire 可以一起将服务层作为 Web 服务非常简单地呈现出来,这就为我们提供了开发面向服务架构的能力。
另外,AppFuse 并不会将我们限定到任何特定的 API
上。它只是简单地对可用的最佳开放源码解决方案重新进行打包和预先集成。AppFuse 中的代码可以处理这种集成,并实现了 AppFuse
的基本安全性和可用性特性。只要可能,就会减少代码,以便向 AppFuse 的依赖框架添加一个特性。例如,AppFuse 自带的 Remember
Me 和 SSL 切换特性最近就因为类似的特性而从 Acegi Security 中删除了。
理由 3:自动化
Ant 使得简化了从编译到构建再到部署的自动化过程。Ant 是 AppFuse 中的一等公民,这主要是因为我发现在命令行中执行操作比从 IDE 中更加简单。我们可以使用 Ant 实现编译、测试、部署和执行任何代码生成的任务。
尽管这种能力对于有些人来说非常重要,但是它并不适用于所有的人。很多 AppFuse 用户目前都使用 Eclipse 或 Intellij
IDEA 来构建和测试自己的项目。在这些 IDE 中运行 Ant 的确可以工作,但是这样做的效率通常都不如使用 IDE 内置的 JUnit
支持来运行测试效率高。
幸运的是,AppFuse 支持在 IDE 中运行测试,不过管理这种特性对于 AppFuse 开发人员来说就变得非常困难了。最大的痛苦在于
XDoclet 用来生成 Hibernate 映射文件和 Web 框架所使用的一些工件(例如 ActionForms 和 Struts 使用的
struts-config.xml)。IDE 并不知道需要生成的代码,除非我们配置使用 Ant 来编译它们,或者安装了一些可以认识
XDoclet 的插件。
这种对知识的缺乏是 AppFuse 2.0 切换到 JDK 5 和 Maven 2 上的主要原因。JDK 5、注释和 Struts 2
将让我们可以摆脱 XDoclet。Maven 2 将使用这些生成的文件和动态类路径来生成 IDE
项目文件,这样对项目的管理就可以进行简化。目前基于 Ant 的编译系统已经为不同的层次生成了一些工件(包括
dao.jar、service.jar 和 webapp.war),因此切换到 Maven 的模型上应该是一个非常自然的调整。
除了 Ant 之外(它对于编译、测试、部署和报告具有丰富的支持),对于 CruiseControl 的支持也构建到了 AppFuse
中。CruiseControl 是一个 Continuous Integration
应用程序,让我们可以在源代码仓库中代码发生变化时自动运行所有的测试。extras/cruisecontrol 目录包含了我们为基于
AppFuse 的项目快速、简单地设置 Continuous Integration 时所需要的文件。
设置 Continuous Integration 是软件开发周期中我们首先要做的事情之一。它不但激发程序员去编写测试用例,而且还通过 “You broke the build!” 游戏促进了团队之间的合作和融合。
理由 4:安全特性和可扩展性
AppFuse 最初是作为我为 Apress 编写的书籍 Pro JSP
中示例应用程序的一部分开发的。这个示例应用程序展示了很多安全特性和用于简化 Struts 开发的特性。这个应用程序中的很多安全特性在 J2EE
的安全框图中都不存在。使用容器管理认证(CMA)的认证方法非常简单,但是 Remember Me、密码提示、SSL
切换、登记和用户管理等功能却都不存在。另外,基于角色的保护方法功能在非 EJB 环境中也是不可能的。
最初,AppFuse 使用自己的代码和用于 CMA 的解决方案完全实现了这些特性。我在 2004 年年初开始学习 Spring
时就听说过有关 Acegi Security 的知识。我对 Acegi 所需要的 XML 的行数(175)与 web.xml 中所需要的 CMA
的行数(20)进行了比较,很快就决定丢弃 Acegi 了,因为它太过复杂了。
一年半之后 —— 在为另外一本书 Spring Live 中编写了一章有关使用 Acegi Security 的内容之后 —— 我就改变了自己的想法。Acegi 的确(目
前仍然)需要很多 XML,但是一旦我们理解了这一点,它实际上是相当简单的。当我们最终作出改变,使用 Acegi Security
的特性来全部取代 AppFuse 的特性之后,我们最终删除了大量的代码。类之上的类都已经没有了,“Acegi handles that now”
中消失的部分现在全部进入了 CVS 的 Attic 中了。
Acegi Security 是 J2EE 安全模型中曾经出现过的最好模型。它让我们可以实现很多有用的特性,这些特性在 Servlet
API 的安全模型中都不存在:认证、授权、角色保护方法、Remember Me、密码加密、SSL
切换、用户切换和注销。它让我们还可以将用户证书存储到 XML 文件、数据库、LDAP 或单点登录系统(例如 Yale 的 Central
Authentication Service (CAS) 或者 SiteMinder)中。
AppFuse 对很多与安全性相关的特性的实现从一开始都是非常优秀的。现在 AppFuse 使用了 Acegi Security,这些特性
—— 以及更多特性 —— 都非常容易实现。Acegi 有很多地方都可以进行扩充:这是它使用巨大的 XML
配置文件的原因。正如我们已经通过去年的课程对 Acegi 进行集成一样,我们已经发现对很多 bean 的定义进行定制可以更加紧密地与
AppFuse 建立联系。
Spring IoC 容器和 Acegi Security 所提供的简单开发、容易测试的代码和松耦合特性的组合是 AppFuse
是这么好的一种开发平台的主要原因。这些框架都是不可插入的,允许生成干净的可测试代码。AppFuse
集成了很多开放源码项目,依赖注入允许对应用程序层进行简单的集成。
理由 5:使用 AppGen 生成代码
有些人会将代码生成称为代码气味的散播(code smell)。在他们的观点中,如果我们需要生成代码,那么很可能就会做一些错事。我倾向于这种确定自己代码使用的模式和自动化生成代码的能力应该称为代码香味的弥漫(code perfume)。如果我们正在编写类似的 DAO、管理器、操作或控件,并且不想为它们生成代码,那么这就需要根据代码的气味来生成代码。当然,当语言可以为我们提供可以简化任务的特性时,一切都是那么美好;不过代码生成通常都是一个必需 —— 通常其生产率也非常高 —— 的任务。
AppFuse 中提供了一个基于 Ant 和 XDoclet 的代码生成工具,名叫 AppGen。默认情况下,常见的 DAO 和管理器都可以允许我们对任何普通老式 Java 对象(POJO)进行 CRUD 操作,但是在 Web 层上这样做有些困难。AppGen 有几个特性可以用来执行以下任务:
- (使用 Middlegen 和 Hibernate 工具)从数据库表中生成 POJO
- 从 POJO 生成 UI
- 为 DAO、管理器、操作/控制器和 UI 生成测试
在运行 AppGen 时,您会看到提示说 AppGen 要从数据库表或 POJO 中生成代码。如果在命令行中执行 ant install-detailed,AppGen 就会安装 POJO 特定的 DAO、管理器以及它们的测试。运行 ant install 会导致 Web 层的类重用通用的 DAO 和默认存在的管理器。
为了阐述 AppGen 是如何工作的,我们在 devworks MySQL 数据库中创建了如清单 2 所示的表:
清单 2. 创建一个名为 cat 的数据库表
create table cat (
cat_id int(8) auto_increment,
color varchar(20) not null,
name varchar(20) not null,
created_date datetime not null,
primary key (cat_id)
) type=InnoDB;
|
在 extras/appgen 目录中,运行 ant install-detailed。这个命令的输出结果对于本文来说实在太长了,不过我们在清单 3 中给出了第一部分的内容:
清单 3. 运行 AppGen 的 install-detailed 目标
$ ant install-detailed
Buildfile: build.xml
init:
[mkdir] Created dir: /Users/mraible/Work/devworks/extras/appgen/build
[echo]
[echo] +-------------------------------------------------------+
[echo] | -- Welcome to the AppGen! -- |
[echo] | |
[echo] | Use the "install" target to use the generic DAO and |
[echo] | Manager, or use "install-detailed" to general a DAO |
[echo] | and Manager specifically for your model object. |
[echo] +-------------------------------------------------------+
[input] Would you like to generate code from a table or POJO? (table,pojo)
table
[input] What is the name of your table (i.e. person)?
cat
[input] What is the name, if any, of the module for your table (i.e. organization)?
[echo] Running Middlegen to generate POJO...
|
要对 cat 表使用这个新生成的代码,我们需要修改
src/dao/com/ibm/dao/hibernate/applicationContext-hibernate.xml,来为
Hibernate 添加 Cat.hbm.xml 映射文件。清单 3 给出了我们修改后的 sessionFactory bean 的样子:
清单 4. 将 Cat.hbm.xml 添加到 sessionFactory bean 中
<bean id="sessionFactory" class="...">
<property name="dataSource" ref="dataSource"/>
<property name="mappingResources">
<list>
<value>com/ibm/model/Role.hbm.xml</value>
<value>com/ibm/model/User.hbm.xml</value>
<value>com/ibm/model/Cat.hbm.xml</value>
</list>
</property>
...
</bean>
|
在运行 ant setup deploy 之后,我们就应该可以在部署的应用程序中对 cat 表执行 CRUD 操作了:
图 4. Cat 列表
 图 5. Cat 表单
图 5. Cat 表单

我们在上面的屏幕快照中看到的记录都是作为代码生成的一部分创建的,因此现在就有测试数据了。
理由 6:文档
我们可以找到 AppFuse 各个风味的教程,并且它们都以 6 种不同的语言给出了:中文、德语、英语、韩语、葡萄牙语和西班牙语。使用风味(flavor)
一词,我的意思是不同框架的组合,例如 Spring MVC 加上 iBATIS、Spring MVC 加上 Hibernate 或 JSF
加上 Hibernate。使用这 5 种 Web 框架和两种持久框架,可以有好几种组合。有关它们的翻译,AppFuse 为自己的默认特性提供了 8
种翻译。可用语言包括中文、荷兰语、德语、英语、法语、意大利语、葡萄牙语和西班牙语。
除了核心教程之外,还添加了很多教程(请参看 参考资料) 来介绍与各种数据库、应用服务器和其他开放源码技术(包括 JasperReports、Lucene、Eclipse、Drools、Axis 和 DWR)的集成。
理由 7:社区
Apache 软件基金会对于开放源码有一个有趣的看法。它对围绕开放源码项目开发一个开放源码社区最感兴趣。它的成员相信如果社区非常强大,那么产生高质量的代码就是一个自然的过程。下面的内容引自 Apache 主页:
“我们认为自己不仅仅是一组共享服务器的项目,而且是一个开发人员和用户的社区。”
AppFuse 社区从 2003 年作为 SourceForge 上的一个项目(是 struts.sf.net
的一部分)启动以来,已经获得了极大的增长。通过在 2004 年 3 月转换到 java.net 上之后,它已经成为这里一个非常流行的项目,从
2005 年 1 月到 3 月成为访问量最多的一个项目。目前它仍然是一个非常流行的项目(有关 java.net 项目统计信息的链接,请参看 参考资料),不过在这个站点上它正在让位于 Sun 赞助的很多项目。
在 2004 年年末,Nathan Anderson 成为继我之后第一个提交者。此后有很多人都加入了进来,包括 Ben
Gill、David Carter、Mika G?ckel、Sanjiv Jivan 和 Thomas
Gaudin。很多现有的提交者都已经通过各种方式作出了自己的贡献,他们都帮助 AppFuse 社区成为一个迅速变化并且非常有趣的地方。
邮件列表非常友好,我们试图维护这样一条承诺 “没有问题是没有人理会的问题”。我们的邮件列表归档文件中惟一一条 “RTFM”
是从用户那里发出的,而不是从开发者那里发出的。我们绝对信奉 Apache 开放源码社区的哲学。引用我最好的朋友 Bruce Snyder
的一句话,“我们为代码而来,为人们而留下”。目前,大部分开发者都是用户,我们通常都喜欢有一段美妙的时间。另外,大部分文档都是由社区编写的;因此,
这个社区的知识是非常渊博的。
结束语
我们应该尝试使用 AppFuse 进行开发,这是因为它允许我们简单地进行测试、集成、自动化,并可以安全地生成 Web 应用程序。其文档非常丰富,社区也非常友好。随着其支撑框架越来越好,AppFuse 也将不断改进。
从 AppFuse 2.0 开始,我们计划迁移到 JDK 5(仍然支持部署到 1.4)和 Maven 2 上去。这些工具可以简化使用
AppFuse 的开发、安装和升级。我们计划充分利用 Maven 2 的功能来处理相关依赖性。我们将碰到诸如
appfuse-hibernate-2.0.jar 和 appfuse-jsf-2.0.jar 之类的工件。这些工件都可以在 pom.xml
文件中进行引用,它们负责提取其他相关依赖性。除了在自己的项目中使用 AppFuse 基类之外,我们还可以像普通的框架一样在 JAR
中对这些类简单地进行扩展,这应该会大大简化它的升级过程,并鼓励更多用户将自己希望的改进提交到这个项目中。
如果没有其他问题,使用 AppFuse 可以让您始终处于 Java Web 开发的技术前沿上 —— 就像我们一样!
参考资料
学习
获得产品和技术
讨论
摘要: http://smc.sourceforge.net/SmcManSec1g.htm
教程第一部分:.sm文件的布局
1.1任务类(对象)
SMC生成有限状态机的对象-而不是进程或应用程序,而是一个单独的对象,如果你有对象的接收或者异步回调,以及基于对象的状态如何应对这些回调,SMC提供了一个强大的解决方案.
(注:这个例子是基于Java和简单容易翻译成其他语言。此外,这个例子假设你知道面... 阅读全文
引言
数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除
(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
设计范式是不是很难懂呢?非也,大学教材上给我们一堆数学公式我们当然看不懂,也记不住。所以我们很多人就根本不按照范式来设计数据库。
实质上,设计范式用很形象、很简洁的话语就能说清楚,道明白。本文将对范式进行通俗地说明,并以笔者曾经设计的一个简单论坛的数据库为例来讲解怎样将这
些范式应用于实际工程。
范式说明
第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属性
由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
例如,如下的数据库表是符合第一范式的:
而这样的数据库表是不符合第一范式的:
| 字段1 |
字段2 |
字段3 |
字段4 |
| |
|
字段3.1 |
字段3.2 |
|
很显然,在当前的任何关系数据库管理系
统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中
设计出不符合第一范式的数据库都是不可能的。
第二范式(2NF):数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部
分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。
假定选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),关键字为组合关键字(学号,
课程名称),因为存在如下决定关系:
(学号, 课程名称) → (姓名, 年龄, 成绩, 学分)
这个数据库表
不满足第二范式,因为存在如下决定关系:
(课程名称) → (学分)
(学号) → (姓名, 年龄)
即存在组合关键字中的字段决定非关键字的情况。
由于不符合2NF,这个选课关系表会存在如下问题:
(1)
数据冗余:
同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。
(2) 更新异常:
若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
(3) 插入异常:
假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据
库。
(4) 删除异常:
假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同
时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
把选课关系表SelectCourse改为如下三个表:
学生:Student(学号, 姓名, 年龄);
课程:Course(课程名称, 学分);
选课关
系:SelectCourse(学号, 课程名称, 成绩)。
这样的数据库表是符合第二范式的,消除了数据冗余、更新异常、插入异常
和删除异常。
另外,所有单关键字的数据库表都符合第二范式,因为不可能存在组合关键字。
第三范式(3NF):在
第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如果存在"A → B →
C"的决定关系,则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系:
关键字段 → 非关键字段x →
非关键字段y
假定学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号) →
(姓名, 年龄, 所在学院, 学院地点, 学院电话)
这个数据库是
符合2NF的,但是不符合3NF,因为存在如下决定关系:
(学号) → (所在学院) → (学院地点, 学院电话)
即存在非关键
字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依
赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况,读者可自行分析得知。
把学生关系表分为如下两个
表:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 地点, 电话)。
这样的数据库表是符合第三范式的,消除了数据冗余、更
新异常、插入异常和删除异常。
鲍依斯-科得范式(BCNF):在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段
的传递函数依赖则符合第三范式。
假设仓库管理关系表为
StorehouseManage(仓库ID, 存储物品ID, 管理员ID,
数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID,
存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,
(仓库ID, 存储物品ID)和(管理员ID,
存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以
其不符合BCNF范式。它会出现如下异常情况:
(1) 删除异常:
当仓库被清空后,所有"存储物品ID"和"数
量"信息被删除的同时,"仓库ID"和"管理员ID"信息也被删除了。
(2) 插入异常:
当仓库没有存储任何物
品时,无法给仓库分配管理员。
(3) 更新异常:
如果仓库换了管理员,则表中所有行的管理员ID都要修改。
把仓库管理关系表分解为二个关系表:
仓库管理:StorehouseManage(仓库ID, 管理员ID);
仓库:Storehouse(仓库ID, 存储物品ID, 数量)。
这样的数据库表是符合BCNF范式的,消除了删除异常、插入异
常和更新异常。
范式应用
我们来逐步搞定一个论
坛的数据库,有如下信息:
(1) 用户:用户名,email,主页,电话,联系地址
(2)
帖子:发帖标题,发帖内容,回复标题,回复内容
第一次我们将数据库设计为仅仅存在表:
| 用户名 |
email |
主页 |
电话 |
联系地址 |
发帖标题 |
发帖内容 |
回复标题 |
回复内容 |
这个数据库表符合第一范式,但是没有任何一组候选关键字能决定数据库表的整行,唯一的关键字段用户名也不能完全决定整个元组。我们需要增加"
发帖ID"、"回复ID"字段,即将表修改为:
| 用户名 |
email |
主页 |
电话 |
联系地址 |
发帖ID |
发帖标题 |
发帖内容 |
回复ID |
回复标题 |
回复内容 |
这样数据表中的关键字(用户名,发帖ID,回复ID)能决定整行:
(用户名,发帖ID,回复ID) →
(email,主页,电话,联系地址,发帖标题,发帖内容,回复标题,回复内容)
但是,这样的设计不符合第二范式,因为存在如下决定
关系:
(用户名) → (email,主页,电话,联系地址)
(发帖ID) → (发帖标题,发帖内容)
(回复ID) → (回复标题,回复内容)
即非关键字段部分函数依赖于候选关键字段,很明显,这个设计会导致大量的数据冗余和操作
异常。
我们将数据库表分解为(带下划线的为关键字):
(1) 用户信息:用户名,email,主页,电话,联系地址
(2) 帖子信息:发帖ID,标题,内容
(3) 回复信息:回复ID,标题,内容
(4)
发贴:用户名,发帖ID
(5) 回复:发帖ID,回复ID
这样的设计是满足第1、2、3范式和BCNF范式要求
的,但是这样的设计是不是最好的呢?
不一定。
观察可知,第4项"发帖"中的"用户名"和"发帖ID"之间是
1:N的关系,因此我们可以把"发帖"合并到第2项的"帖子信息"中;第5项"回复"中的"发帖ID"和"回复ID"之间也是1:N的关系,因此我们可以
把"回复"合并到第3项的"回复信息"中。这样可以一定量地减少数据冗余,新的设计为:
(1)
用户信息:用户名,email,主页,电话,联系地址
(2) 帖子信息:用户名,发帖ID,标题,内容
(3)
回复信息:发帖ID,回复ID,标题,内容
数据库表1显然满足所有范式的要求;
数据库表2中存在非关键字段"标
题"、"内容"对关键字段"发帖ID"的部分函数依赖,即不满足第二范式的要求,但是这一设计并不会导致数据冗余和操作异常;
数据库
表3中也存在非关键字段"标题"、"内容"对关键字段"回复ID"的部分函数依赖,也不满足第二范式的要求,但是与数据库表2相似,这一设计也不会导致数
据冗余和操作异常。
由此可以看出,并不一定要强行满足范式的要求,对于1:N关系,当1的一边合并到N的那边后,N的那边就不再满足
第二范式了,但是这种设计反而比较好!
对于M:N的关系,不能将M一边或N一边合并到另一边去,这样会导致不符合范式要求,同时导致
操作异常和数据冗余。
对于1:1的关系,我们可以将左边的1或者右边的1合并到另一边去,设计导致不符合范式要求,但是并不会导致操作异常和数
据冗余。
结论
满足范式要求的数据库设计是结构清晰的,同时可避免数据冗余和操作异常。这并意味着不符合范式要求
的设计一定是错误的,在数据库表中存在1:1或1:N关系这种较特殊的情况下,合并导致的不符合范式要求反而是合理的。
在我们设计数
据库的时候,一定要时刻考虑范式的要求。
从零开始。
>1 下载Android SDK
,然后带着不求甚解的态度去阅读 SDK 里的官方文档。
没有手机软件开发经验、Java 以及 eclipse
使用经验的朋友不必担心,我也是一样。
刚开始接触不可能一下就看明白,先大体扫一下官方文档,了解一下基本概念,不需要完全理解,
有点印象就行了。
>2 去
http://www.eoeandroid.com/viewthread.php?tid=772&extra=page%3D1
下载 eoe 特刊~ 写的很不错,你首先需要看完第一期,就可以把开发环境搭建好了。
其他几期可以稍后再看。
>3
查阅官方文档,按照里边的 hello world 教程一步一步做,很快你的第一个 android 项目就可以
成功运行了!
>4
接下来你应该学习官方文档里的记事本了,这个要稍微花点时间,做的过程可能有一些疑问,没关系,
大胆忽略,只要可以成功运行即可。
>5
看了一大堆英文的东西,也有不少疑问了,应该看一些中文的文档来加深理解了。
强烈推荐 深入淺出 Android --
Google 手持設備應用程式設計入門
http://code.google.com/p/androidbmi/wiki/DiveIntoAndroid
虽然是繁体的,但是文章的质量相当高,看完之后基本上就可以算是入门了!
>6 接下来,建议把 eoe
特刊的其它几期都看完,相信你对一些常见的开发需求就很有把握了。
>7 请加入hong老大建的群,这里有很多对android
感兴趣 的兄弟,大家可以一起探讨。
http://groups.google.com/group/china-android-dev
>8
推荐几个不错的博客,
http://haric.javaeye.com/
http://rayleung.javaeye.com/
>9 可以经常去
http://www.eoeandroid.com/forumdisplay.php?fid=27 这里逛逛。
>10
想开始做app赚钱了? 呵呵,把 javaeye 里移动编程板块的精华良好贴都翻一遍吧~ 祝福你!
转自:http://www.javaeye.com/topic/473980
在使用<c:out value="${map[key]}" /> 求对应的KEY中的,value
必须注意:key的类型必须和map中存放的key的类型一致,否则不能得到预期的结果
1、迭代
当forEach
的items属性中的表达式的值是java.util.Map时,则var中命名的变量的类型就是java.util.Map.Entry。这时
var=entry的话,用表达式${entry.key}取得键名。用表达式${entry.value}得到每个entry的值。这是因为
java.util.Map.Entry对象有getKey和getValue方法,表达式语言遵守JavaBean的命名约定。
例:
- <c:forEach items="${map}" var="entry">
- <c:out value="${entry.key}" />
- <c:out value="${entry.value}" />
- </c:forEach>
<c:forEach items="${map}" var="entry">
<c:out value="${entry.key}" />
<c:out value="${entry.value}" />
</c:forEach>
2、根据key求值
如果事先知道key那么很容易根据${map.key值}就可以得到值对象,但是如果key是一个变量呢?有一个问题,如果给定一个key的变量如何使用
EL得到对象呢,这里需要使用EL表达式中的[]来解决。
例:
- <c:out value="${map[key]}" />
- <!-- 这里的map就是 java.util.Map对像,key是这个map里的一个
key -->
<c:out value="${map[key]}" />
<!-- 这里的map就是 java.util.Map对像,key是这个map里的一个key -->
1、迭代
Map的每个对象以key=value的形式给出
当forEach
tag的item属性中的表达式的值是java.util.Map时,在var中命名的变量被设置为类型是java.util.Map.Entry的
item。这时,迭代变量被称为entry,因此,用表达式${entry.key}取得键名。
在下面的例子中你会看到,可以用表达
式${entry.value}得到每个entry的值。这是因为java.util.Map.Entry对象有getKey和getValue方法,表
达式语言遵守JavaBean的命名约定。
通常,JSP
EL表达式${a.b.c.d}是用代码a.getB().getC().getD()来计算的。这种表达式是对JavaBean属性的相继调用的简化。
示例:
- <%@ page language="java" pageEncoding="utf-8"%>
- <jsp:directive.page import="com.xaccp.vo.BookAdapter"/>
- <%@ taglib prefix="c" uri="/WEB-INF/c.tld" %>
- <jsp:directive.page import="java.util.Hashtable"/>
- <jsp:directive.page import="com.xaccp.vo.Book"/>
- <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
- <html:html locale="true">
- <head>
- <%
- Hashtable table=new Hashtable();
- BookAdapter ba=new BookAdapter();
- table.put("aaa",new Book(1,"abc"));
- table.put("bbb",new Book(2,"bbb"));
- table.put("ccc",new Book(3,"cccc"));
- pageContext.setAttribute("table",table);
- %>
- </head>
-
- <body>
-
- <hr>
- <c:forEach items="${table}" var="aaa">
- <c:set var="key" value="${aaa.key}" ></c:set>
- <c:set var="book" value="${aaa.value}"></c:set>
- ${key }=${book }111 name:${book.bookID}<br>
-
- </c:forEach>
- </body>
- </html:html>
-
-
<%@ page language="java" pageEncoding="utf-8"%>
<jsp:directive.page import="com.xaccp.vo.BookAdapter"/>
<%@ taglib prefix="c" uri="/WEB-INF/c.tld" %>
<jsp:directive.page import="java.util.Hashtable"/>
<jsp:directive.page import="com.xaccp.vo.Book"/>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html:html locale="true">
<head>
<%
Hashtable table=new Hashtable();
BookAdapter ba=new BookAdapter();
table.put("aaa",new Book(1,"abc"));
table.put("bbb",new Book(2,"bbb"));
table.put("ccc",new Book(3,"cccc"));
pageContext.setAttribute("table",table);
%>
</head>
<body>
<hr>
<c:forEach items="${table}" var="aaa">
<c:set var="key" value="${aaa.key}" ></c:set>
<c:set var="book" value="${aaa.value}"></c:set>
${key }=${book }111 name:${book.bookID}<br>
</c:forEach>
</body>
</html:html>
2、根据key变量求值
如果事先知道key那么很容易根据${map.key值}就可以得到值对象,但是如果key是一个变量呢?
有一
个问题,如果给定一个key的变量如何使用EL得到对象呢,这里需要使用EL表达式中的[]来解决,解决方法如示例:
- <%@ page language="java" pageEncoding="utf-8"%>
- <jsp:directive.page import="com.xaccp.vo.BookAdapter"/>
- <%@ taglib prefix="c" uri="/WEB-INF/c.tld" %>
- <jsp:directive.page import="java.util.Hashtable"/>
- <jsp:directive.page import="com.xaccp.vo.Book"/>
- <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
- <html:html locale="true">
- <head>
- <%
- Hashtable table=new Hashtable();
- table.put("aaa",new Book(1,"abc"));
- table.put("bbb",new Book(2,"bbb"));
- table.put("ccc",new Book(3,"cccc"));
- pageContext.setAttribute("table",table);
- %>
- </head>
-
- <body>
- This a struts page. <br>
- <c:set var="keys" value="bbb" ></c:set>
- <c:set var="book" value="${pageScope.table[pageScope.keys]}"></c:set>
- ${keys }=${book}
- <!-- 这里的${book就是对应于key值得book对象} -->
- <br>
- </body>
- </html:html>
google app engin Text字段可保存任意长的字符(可能有人说用String,不好意思engin不支持500字符以上的String)
持久化字段需这样才能保存
@Persistent(defaultFetchGroup="true")
private Text text;
可用text.getValue()获取其保存的字符串
注意:用jstl标签<c:out value="${text}" />会进行转义
如果不想转义,即是原封不动的将字符串输出,用${text}即可
1.对于JSTL先了解下:
sevlet2.4 jsp2.0规范 需使用jstl1.1 tomcat5.X
:使用标签需在jsp头部引用<%@ taglib prefix="c" uri=" http://java.sun.com/jsp/jstl/core"
%>
sevlet2.5 需使用jstl1.2 tomcat6.X
<%@ page contentType="text/html;charset=UTF-8" language="java" isELIgnored="false" import="java.util.*"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
isELIgnored="false"表示使用EL表达式
EL表达式可参见:http://www.cnblogs.com/hya1109/archive/2007/10/02/912947.html
2.在google app engine中使用JSTL,需在jsp中加入:
<%@ isELIgnored="false" %>
<%@
taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>(这句代码在myeclipse中会报错不用管)
因为在web.xml中其实sevlet2.5
${article.title}====article.getTile();
http://homelink.javaeye.com/blog/293328#comments
参考文档 http://www.ibm.com/developerworks/cn/web/wa-lo-comet/
comet是HTTP长连接,就是在HTTP发送请求时,服务器不立刻发送响应信息给客户端,
而是保持着连接,等待一定情况发生后才把数据发送回去给客户端。所以用comet可以实现服务器端的数据实时地发送给客户端。
本文主要是用java和js来简单地实现comet,最后附上源码和使用例子。
在客户端用XMLRequest发送请求到服务器,在服务器端用一个servlet来接收XMLRequest的请求,当接收到请
求时,并不立刻响应客户端,而是把该servlet线程阻塞,等到一定事件发生后,再响应客户端。当客户端接收到服务端的响应后,调用自定义的回调函数来
处理服务器发送回来的数据,处理完成后,再发送一个XMLRequest请求到服务端,这样循环下去,就可以实现数据的实时更新,又不必要在客户端不断地
轮循(polling)。
利用该comet的实现(以后简称为keeper)时,只要在客户端注册事件和写一个处理返回数据的回调函数,然后在服务端实现
keeper中的EventListener接口,调用Controller.action(eventListener,eventType)就可以
了。
keeper分成两大部分,第一部分为客户端的javascript,第二部分是服务端的servlet和事件处理。
一.客户端
建立一个XMLRequest对象池,每发送一次请求,从对象池中取一个XMLRequest对象,如果没有可用的对象,则创建一
个,把它加入到对象池中。这部分的代码来自于网络。
为了使用方便,再添加一些方法,用来注册事件。这样只要调用注册函数来注册事件,并且把回调函数传给注册事件函数就行了,处理数据
的事情,交给回调函数,并由用户来实现。
keeper为了方便使用,把客户端的javascript代码集成在servlet中,当配置好keeper的servlet,
启动HTTP服务器时,keeper会根据用户的配置,在相应的目录下生成客户端的javascript代码。
二.服务端
服务端的servlet初始化时,根据配置来生成相应的客户端javascript代码。
servlet的入口由keeper.servlet.Keeper.java中的doGet进入。在Keeper的doGet
中,从请求中获取用户注册事件的名称(字符串类型),然后根据事件的名称,构造一个事件(Event类型),再把它注册到NameRegister中,注
册完成后,该servlet线程调用wait(),把自已停止。等待该servlet线程被唤醒后,从Event中调用事件的EventListener
接口的process(request,response)来处理客户端的请求。
- protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
- String eventName = request.getParameter("event");
- NameRegister reg = NameRegister.getInstance();
- Event event = null;
- try {
- event = reg.getEvent(eventName);
- if(event == null) {
- event = new Event(eventName,this);
- reg.registeEvent(eventName, event);
- }
- if(event.getServlet() == null) {
- event.setServlet(this);
- }
-
- } catch (RegistException e1) {
- e1.printStackTrace();
- }
- synchronized(this) {
- while(!event.isProcess()) {
- try {
- wait();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- EventListener listener = event.getListener();
- if(listener != null) {
- listener.process(request,response);
- }
- }
在服务端处理事件时,调用了keeper.control.Controller中的静态方法
action(EventListener listener,String eventName)来处理。如下所示。
- public static boolean action(EventListener listener,String eventName){
- NameRegister reg = NameRegister.getInstance();
- HttpServlet servlet = null;
- Event e = null;
- try {
- e = reg.getEvent(eventName,true);
- if(e == null) {
- return false;
- }
- e.setListener(listener);
- servlet = e.getServlet();
- e.setProcess(true);
- synchronized(servlet) {
- servlet.notifyAll();
- }
- } catch (RegistException ex) {
- ex.printStackTrace();
- }
- if(servlet != null && e != null) {
- e = null;
- return true;
- } else {
- return false;
- }
- }
下面开始用keeper来写一个简单的网页聊天程序和基于服务端的时间。
1.客户端设置
注册两个事件,一个用于是时间事件,一个是消息事件。同时还要写两个回调函数,用于处理服务
端返回的时间和聊天消息。如下所于:
- <script type="text/javascript">
- Keeper.addListener('timer',showTime);//注册时间事件
- function showTime(obj){ //时间处理回调函数
- var sp = document.getElementById("dateTime");
- if(sp){
- sp.innerHTML = obj.responseText;
- }
- }
- function startOrStop(obj){
- var btn = document.getElementById("controlBtn")
- btn.value=obj.responseText;
- }
- Keeper.addListener('msg',showMsg,"GBK");//注册消息事
件,最后一个参数是
- //字符串编码
- function showMsg(obj){//处理消息的回调函数
- var msg = document.getElementById("msg");
- if(msg){
-
- msg.value = obj.responseText+""n"+msg.value;
-
- }
- }
- function sendMsg() {
- var msg = document.getElementById("sendMsg");
- if(msg){
- var d = "msg="+msg.value;
- sendReq('POST','./demo',d,startOrStop);
- msg.value = "";
- }
- }
-
- </script>
2.配置服务端
服务端的配置在
web.xml文件中,如下所示
- <servlet>
- <servlet-name>keeper</servlet-name>
- <servlet-class>keeper.servlet.Keeper</servlet-class>
- <init-param>
- <!--可选项,设置生成客户端的JavaScript路径和名字,默认置为
/keeper.js-->
- <param-name>ScriptName</param-name>
- <param-value>/keeperScript.js</param-value>
- </init-param>
- <!--这个一定要设置,否则不能生成客户端代码-->
- <load-on-startup>1</load-on-startup>
- </servlet>
- <servlet-mapping>
- <servlet-name>keeper</servlet-name>
- <url-pattern>/keeper</url-pattern>
- </servlet-mapping>
用<script type="text/javascript"
src="./keeperScript.js"></script>在页面包含JavaScript时,这里的src一定要和上面配
置的一至。上面的设置除了<init-param></init-param>为可选的设置外,其他的都是必要的,而且不能改
变。
3.编写事件处理代码,消息的处理代码如下:
- protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
- System.out.println("Post..");
- String msg = request.getParameter("msg");
- Controller.action(new SendMsg(msg),"msg");
- }
- class SendMsg implements EventListener{
- private String msg;
- public SendMsg(String msg) {
- this.msg = msg;
- }
- @Override
- public void process(HttpServletRequest request, HttpServletResponse response) {
- response.setCharacterEncoding("UTF-8");
- PrintWriter out = null;
- try {
- out = response.getWriter();
- if(msg!=null){
- out.write(msg);
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
- finally{
- if(out != null) {
- out.close();
- }
- }
- }
- }
到这时,一个基本的keeper应用就完成了。其它部分请参考附件中的例子源码。
互联网服务的特点就是面向海量级的用户,面向海量级的用户如何提供稳定的服务呢?这里,对这几年的一些经验积累和平时接触的一些理念做一个总结。
一、原则
1.Web服务的CAP原理
CAP指的是三个要素:一致性(Consistency)、可用性(Availability)、分区容忍性(Partition
tolerance)。CAP原理指的是这三个要素最多只能同时实现两点,不可能三者兼顾,对于海量级服务,一般这是一条常记心中的基准准则。
如下是《 Web服务的CAP
》关于CAP的定义:
- 一致性:可以参考数据库的一致性。每次信息的读取都需要反映最新更新后的数据。
- 可用性:高可用性意味着每一次请求都可以成功完成并受到响应数据
- 分区宽容度:这个是容错机制的要求。一个服务需要在局部出错的情况下,没有出错的那部分被复制的数据分区仍然可以支持部分服务的操作,可以简单的
理解为可以很容易的在线增减机器以达到更高的扩展性,即所谓的横向扩展能力。
面向海量级的分布式服务设计,基本上分区容忍性(Partition
tolerance)是第一要素,因此根据业务的情况,我们需要在一致性(Consistency)和可用性(Availability)之间做取舍。对
于一些业务,譬如支付宝或财付通,一致性会是第一考虑要素,即使是延迟的不一致也是不可接受的,这种时候只能牺牲可用性以保证一致性。对于一些应用,譬如
淘宝或拍拍交易中的评价信息,一般用户是可以接受延迟的一致性,这种时候可以优先考虑可用性,而用最终一致性来保证数据一致,譬如通过某种对帐机制。对于
一些应用,甚至一致性都并非要求,只需要保证差不多一致性即可,譬如Q-zone中的农场游戏中的偷菜。
根据我们应用的业务需求,选择合适的一致性级别,以更好地保证系统的分区容忍性和可用性。
2.柔性可用
面向海量级的分布式服务设计,我们要意识到,一切都是不可靠的,在不可靠的环境的环境中构建可靠的应用,其中最重要的一点就是保持系统的柔性。
1)不可靠的环境
我们可能已经见惯一个远程服务提供不了服务了,运行一段时间后WebServer突然不响应了,数据库随着负载的不断增加再放上一条SQL语句就会垮掉。
但是,硬盘坏掉、电源断掉、光纤中断,听起来似乎多么不可思议,然而,当一个海量服务需要成千上万台服务器、需要部署全国各地的数十个数据中心、需要横跨
电信网通教育网三大网络的时候,一切听起来不可思议的事情会变成常态。一切都是不可靠的,唯一可靠的就是不可靠本身。
2)划分服务级别
我们应该意识到,在这种不可靠的环境中提供完美的服务,本身就是一个神话,即使不是说完全不可能,但至少是代价高昂的,因此,当某些问题发生(环境变地不
可靠的时候),我们必须做出取舍,选择为用户提供用户最关心的服务,这种服务虽然听起来是有损的(至少是不完美的),但却能在一定程度上满足用户大部分的
需求。譬如,当网络带宽无法为用户提供最好的体验而扩容又不是短期可以达到的时候,选择降低一些非重要服务的体验是一个比较好的选择。
在面向海量互联网的设计当中,对服务进行分级,当系统变地不可靠的时候,优先提供重要优先级的服务。
3)尽快响应
互联网用户的耐心是非常有限的,如果一个页面需要3秒以上才能看到,也许大部分用户的第一选择就是关掉浏览器。在构建柔性可用的互联网服务的时候,响应时
间大部分情况下都是需要最优先考虑。还是一句话,环境是不可靠的,当我们无法尽快从远程服务获得数据、当数据库已经慢如蜗牛,也许当后台还在吭哧吭哧干活
的时候,用户老早已经关闭了页面,处理返回的数据也只是在浪费表情,面向互联网用户,响应就是生命。
二、策略
如何让我们的应用提供更高质量的服务呢,这里是一些在日常开发使用到或者观察到的一些策略的总结:
1.数据sharding
海量服务相应也意味着海量的用户和海量的用户数据,大家都知道,即使是再强大的数据库、再强大服务器,在单表上亿规模的数据足够让一条简单的SQL语句慢
如蜗牛(甚至于在百万、千万级别上,如果没有采取合适的策略,都无法满足服务要求),一般处理这种千万上亿级数据的大家基本上都会想到的就是数据
sharding,将数据切割成多个数据集,分散到多个数据库的多个表中(譬如将用户数据按用户ID切割成4个数据库每个数据库100个表共400个
表),由于每个表数据足够小可以让我们的SQL语句快速地执行。而至于如何切割,实际上跟具体的业务策略有关系。
当然,我们要认识到,这种数据sharding并非全无代价的,这也意味着我们需要做出一些折中,譬如可能很难进行跨表数据集的查询、联表和排序也变地非
常困难、同时数据库client程序编写也会变地更加复杂、保证数据一致性在某些情况下会变地困难重重。sharding并非万能药,选择是否
sharding、如何sharding、为sharding如何换用一个近似的业务描述方式,这是业务设计需要仔细考虑的问题。
2.Cache
经验会告诉我们,基本上大部分系统的瓶颈会集中在IO/数据库上,常识也告诉我们,网络和内存的速度比IO/数据库会提升甚至不止一个数量级。面向海量服
务,Cache基本上是一个必选项,分布式Cache更是一个不二选择,根据我们的需要,我们可以选择memcached(非持久化)、
memcachedb/Tokyo Tyrant(持久化),甚至构建自己的cache平台。
在使用Cache上,下面是需要仔细考虑的点:
- 选择合适的Cache分布算法,基本上我们会发现使用取模方式决定Cache位置是不可靠的,因为坏节点的摘除或者节点扩量会让我们的Cache
命中率在短时间内下降到冰点,甚至会导致系统在短期内的负载迅速增长甚至于崩溃,选择一种合适的分布算法非常重要,譬如稳定的一致性哈希
- Cache管理:为每个应用配置独立的Cache通常不是一个好主意,我们可以选择在大量的机器上,只要有空闲内存,则运行Cache实例,将
Cache实例分成多个组,每个组就是一个完整的Cache池,而多个应用共享一个Cache池
- 合理的序列化格式:使用紧凑的序列化方案存储Cache数据,尽量少存储冗余数据,一方面可以最大能力地榨取Cache的存储利用率,另一方面,
可以更方便地进行容量预估。此外,不可避免地,随着业务的升级,存储的数据的格式有可能会变更,序列化也需要注意向上兼容的问题,让新格式的客户端能够支
持旧的数据格式。
- 容量估算:在开始运行之前,先为自己的应用可能使用到的容量做一个容量预估,以合理地分配合适的Cache池,同时为可能的容量扩充提供参考。
- 容量监控:Cache命中率怎么样,Cache的存储饱和度怎么样,Client的Socket连接数等等,对这些数据的采集和监控,将为业务的
调整和容量的扩充提供了数据支持。
- 选择在哪层上进行Cache,譬如数据层Cache、应用层Cache和Web层Cache,越靠近数据,Cache的通用性越高,越容易保持
Cache数据的一致性,但相应的处理流程也越长,而越靠近用户,Cache的通用性越差,越难保证Cache数据的一致性,但是响应也越快,根据业务的
特点,选择合适的Cache层是非常重要的。一般而言,我们会选择将粗粒度、极少变更、数据对用户不敏感(即可以一定程度上接受误差)、并且非针对用户级
的数据,在最靠近用户的层面上Cache,譬如图片Cache、TOP
X等数据;而将一些细粒度、变更相对频繁、用户相对敏感的数据或者是针对用户级的数据放在靠近数据的一段,譬如用户的Profile、关系链等。
3.服务集群
面向海量服务,系统的横向扩展基本上是第一要素,在我的经验和经历中,服务集群需要考虑如下因素:
- 分层:合理地对系统进行分层,将系统资源要求不同的部分进行合理地逻辑/物理分层,一般对于简单业务,Client层、WebServer层和
DB层已经足够,对于更复杂业务,可能要切分成Client层、WebServer层、业务层、数据访问层(业务层和数据访问层一般倾向于在物理上处于同
一层)、数据存储层(DB),太多的分层会导致处理流程变长,但相应系统地灵活性和部署性会更强。
- 功能细粒度化:将功能进行细粒度的划分,并使用独立的进程部署,一方面能更有利于错误的隔离,另一方面在功能变更的时候避免一个功能对其他功能产
生影响
- 按数据集部署:如果每一层都允许对下一层所有的服务接口进行访问,将存在几个严重的缺陷,一是随着部署服务的增长,会发现下一层必须允许数量非常
庞大的Socket连接进来,二是我们可能必须把不同的服务部署在不同的数据中心(DC)的不同机房上,即便是上G的光纤专线,机房间的穿梭流量也会变地
不可接受,三是每个服务节点都是全数据容量接入,并不利于做一些有效的内部优化机制,四是只能采用代码级控制的灰度发布和部署。当部署规模达到一定数量级
的时候,按数据集横向切割成多组服务集合,每组服务集合只为特定的数据集服务,在部署上,每组服务集合可以部署在独立的相同的数据中心(DC)上。
- 无状态:状态将为系统的横向扩容带来无穷尽的烦恼。对于状态信息比少的情况,可以选择将全部状态信息放在请求发器端,对于状态信息比较多的情况,
可以考虑维持一个统一的Session中心。
- 选择合适的负载均衡器和负载均衡策略:譬如在L4上负载均衡的LVS、L7上负载均衡的Nginx、甚至是专用的负载均衡硬件F5(L4),对于
在L7上工作的负载均衡器,选择合适的负载均衡策略也非常重要,一般让用户总是负载均衡到同一台后端Server是一个很好的方式
4.灰度发布
当系统的用户增长到一定的规模,一个小小功能的发布也会产生非常大的影响,这个时候,将功能先对一小部分用户开放,并慢慢扩展到全量用户是一个稳妥的做
法,使用灰度化的发布将避免功能的BUG产生大面积的错误。如下是一些常见的灰度控制策略:
- 白名单控制:只有白名单上的用户才允许访问,一般用于全新功能Alpha阶段,只向被邀请的用户开放功能
- 准入门槛控制:常见的譬如gmail出来之初的邀请码、QQ农场开始阶段的X级的黄钻准入,同样一般用于新功能的Beta阶段,慢慢通过一步一步
降低门槛,避免在开始之处由于系统可能潜在的问题或者容量无法支撑导致整个系统的崩溃。
- 按数据集开放:一般常用于成熟的功能的新功能开发,避免新功能的错误产生大面积的影响
5.设计自己的通信协议:二进制协议、向上/下兼容
随着系统的稳定运行访问量的上涨,慢慢会发现,一些看起来工作良好的协议性能变地不可接受,譬如基于xml的协议xml-rpc,将会发现xml解析和包
体的增大变地不可接受,即便是接近于二进制的hessian协议,多出来的字段描述信息(按我的理解,hessian协议是类似于map结构的,包含字段
的名称信息)和基于文本的http头将会使协议效率变地低下。也许,在开始合适的时候而不是到最后不得已的时候,去设计一个良好的基于二进制的高效的内部
通信协议是一个好的方式。按我的经验,设计自己的通信协议需要注意如下几点:
- 协议紧凑性,否则早晚你会为你浪费的空间痛心疾首
- 协议扩展性,早晚会发现旧的协议格式不能适应新的业务需求,而在早期预留变地非常地重要,基本上,参见一些常用的规范,魔术数(对于无效果的请求
可以迅速丢弃)、协议版本信息、协议头、协议Body、每个部分(包括结构体信息中的对象)的长度这些信息是不能省的
- 向下兼容和向上兼容:但功能被大规模地调用的时候,发布一个新的版本,让所有的client同时升级基本上是不可接受的,因此在设计之处就需要考
虑好兼容性的问题
6.设计自己的Application Server
事情进行到需要自己设计通信协议,自己构建Application Server也变地顺理成章,下面是在自己开发Application
Server的时候需要处理的常见的问题:
- 过载保护:当系统的某个部件出现问题的时候,最常见的情况是整个系统的负载出现爆炸性的增长而导致雪崩效应,在设计application
server的时候,必须注意进行系统的过载保护,当请求可以预期无法处理的时候(譬如排队满载或者排队时间过长),丢弃是一个明智的选择,TCP的
backlog参数是一个典型的范例。
- 频率控制:即便是同一系统中的其他应用在调用,一个糟糕的程序可能会将服务的所有资源占完,因此,应用端必须对此做防范措施,频率控制是其中比较
重要的一个
- 异步化/无响应返回:对于一些业务,只需要保证请求会被处理即可,客户端并不关心什么时候处理完,只要最终保证处理就行,甚至最终没有处理也不是
很严重的事情,譬如邮件,对于这种应用,应快速响应避免占着宝贵的连接资源,而将请求进入异步处理队列慢慢处理。
- 自我监控:Application
Server本身应该具备自我监控的功能,譬如性能数据采集、为外部提供内部状态的查询(譬如排队情况、处理线程、等待线程)等
- 预警:譬如当处理变慢、排队太多、发生请求丢弃的情况、并发请求太多的时候,Application
Server应该具备预警的能力以快速地对问题进行处理
- 模块化、模块间松耦合、机制和策略分离:如果不想一下子面对所有的复杂性或不希望在修改小部分而不得不对所有的测试进行回归的话,模块化是一个很
好的选择,将问题进行模块切割,每个模块保持合理的复杂度,譬如对于这里的Application
Server,可以切分成请求接收/管理/响应、协议解析、业务处理、数据采集、监控和预警等等模块。这里同时要注意块间使用松耦合的方式交互,譬如,请
求接收和业务处理之间则可以使用阻塞队列通信的方式降低耦合。另外还需要注意的是机制和策略的分离,譬如协议可能会变更、性能采集和告警的方式可能会变化
等等,事先的机制和策略分离,策略变更的处理将变地更加简单。
7.Client
很多应用会作为服务的Client,去调用其他的服务,如下是在做为Client应该注意的一些问题:
- 服务不可靠:作为Client永远要记住的一点就是,远程服务永远是不可靠的,因此作为Client自己要注意做自我保护,当远程服务如果无法访
问时,做折中处理
- 超时保护:还是上面所说的,远程服务永远都是不可靠的,永远也无法预测到远程什么时候会响应,甚至可能不会响应(譬如远程主机宕机),请求方要做
好超时保护,譬如对于主机不可达的情况,在linux环境下,有时会让客户端等上几分钟TCP层才会最终告诉你服务不可到达。
- 并发/异步:为了提速响应,对于很多可以并行获取的数据,我们总是应该并行地去获取,对于一些我们无法控制的同步接口——譬如读数据库或同步读
cache——虽然不是很完美,但多线程并行去获取是一个可用的选择,而对于服务端都是使用自构建的Application
Server,使用异步Client接口至关重要,将请求全部发送出去,使用异步IO设置超时等待返回即可,甚至于更进一步异步anywhere,在将
client与application
server整合到一块的时候,请求发送出去之后立即返回,将线程/进程资源归还,而在请求响应回来符合条件的时候,触发回调做后续处理。
8.监控和预警
基本上我们会见惯了各种网络设备或服务器的监控,譬如网络流量、IO、CPU、内存等监控数据,然而除了这些总体的运行数据,应用的细粒度化的数据也需要
被监控,服务的访问压力怎么样、处理速度怎么样、性能瓶颈在哪里、带宽主要是被什么应用占、Java虚拟机的CPU占用情况怎么样、各内存区的内存占用情
况如何,这些数据将有利于我们更好的了解系统的运行情况,并对系统的优化和扩容提供数据指导。
除了应用总体监控,特定业务的监控也是一个可选项,譬如定时检查每个业务的每个具体功能点(url)访问是否正常、访问速度如何、页面访问速度如何(用户
角度,包括服务响应时间、页面渲染时间等,即网页测速)、每个页面的PV、每个页面(特别是图片)每天占用的总带宽等等。这些数据将为系统预警和优化提供
数据上的支持,例如对于图片,如果我们知道哪些图片占用的带宽非常大(不一定是图片本身比较大,而可能是访问比较大),则一个小小的优化会节省大量的网络
带宽开销,当然,这些事情对于小规模的访问是没有意义的,网络带宽开销节省的成本可能都没有人力成本高。
除了监控,有效的预警机制也是必不可少,应用是否在很好地提供服务、响应时间是否能够达到要求、系统容量是否达到一个阀值。有效的预警机制将让我们尽快地
对问题进行处理。
9.配置中心化
当系统错误的时候,我们如何尽快地恢复呢,当新增服务节点的时候,如何尽快地让真个系统感知到呢?当系统膨胀之后,如果每次摘除服务节点或者新增节点都需
要修改每台应用配置,那么配置和系统的维护将变地越来越困难。
配置中心化是一个很好的处理这个问题的方案,将所有配置进行统一地存储,而当发生变更的时候(摘除问题节点或者扩量增加服务节点或新增服务),使用一些通
知机制让各应用刷新配置。甚至于,我们可以自动地检测出问题节点并进行智能化的切换。
三、最后
构建面向海量用户的服务,可以说是困难重重挑战重重,一些原则和前人的设计思路可以让我们获得一些帮助,但是更大的挑战会来源于细节部分,按我们技术老大
的说法,原则和思路只要看几本书是个技术人员都会,但决定一个系统架构师能力的,往往却是对细节的处理能力。因此,在掌握原则和前人的设计思路的基础上,
更深入地挖掘技术的细节,才是面向海量用户的服务的制胜之道。
刚换了项目组,接触到了htmlunit,就把官方示例翻译一下,作为入门:
先下载依赖的相关JAR包:http://sourceforge.net/projects/htmlunit/files/
示例1:获取javaeye网站的title
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public static void getHomeTile() throws FailingHttpStatusCodeException, MalformedURLException, IOException{
final WebClient webClient = new WebClient();
final HtmlPage htmlPage = webClient.getPage("http://www.javaeye.com");
System.out.println(htmlPage.getTitleText());
System.out.println(htmlPage.getTextContent());
}
可以看见打印出:JavaEye Java编程 Spring框架 AJAX技术 Agile敏捷软件开发 ruby on rails实践 - JavaEye做最棒的软件开发交流社区
和javaeye首页的title属性一样
示例二:获取一个特定的浏览器版本
public void homePage_Firefox() throws Exception {
final WebClient webClient = new WebClient(BrowserVersion.FIREFOX_2);
final HtmlPage page = webClient.getPage("http://htmlunit.sourceforge.net");
assertEquals("HtmlUnit - Welcome to HtmlUnit", page.getTitleText());
}
示例三:获取特定ID的DIV或者锚链接
public void getElements() throws Exception {
final WebClient webClient = new WebClient();
final HtmlPage page = webClient.getPage("http://some_url");
final HtmlDivision div = page.getHtmlElementById("some_div_id");
final HtmlAnchor anchor = page.getAnchorByName("anchor_name");
}
实例四:模拟页面提交一个form
public void submittingForm() throws Exception {
final WebClient webClient = new WebClient();
// Get the first page
final HtmlPage page1 = webClient.getPage("http://some_url");
// Get the form that we are dealing with and within that form,
// find the submit button and the field that we want to change.
final HtmlForm form = page1.getFormByName("myform");
final HtmlSubmitInput button = form.getInputByName("submitbutton");
final HtmlTextInput textField = form.getInputByName("userid");
// Change the value of the text field
textField.setValueAttribute("root");
// Now submit the form by clicking the button and get back the second page.
final HtmlPage page2 = button.click();
}
Eclipse 快捷键(1)
Ctrl+1 快速修复(最经典的快捷键,就不用多说了)
Ctrl+D: 删除当前行
Ctrl+Alt+↓ 复制当前行到下一行(复制增加)
Ctrl+Alt+↑ 复制当前行到上一行(复制增加)
Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)
Alt+↑ 当前行和上面一行交互位置(同上)
Alt+← 前一个编辑的页面
Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)
Alt+Enter 显示当前选择资源(工程,or 文件 or文件)的属性
Shift+Enter 在当前行的下一行插入空行(这时鼠标可以在当前行的任一位置,不一定是最后)
Shift+Ctrl+Enter 在当前行插入空行(原理同上条)
Ctrl+Q 定位到最后编辑的地方
Ctrl+L 定位在某行 (对于程序超过100的人就有福音了)
Ctrl+M 最大化当前的Edit或View (再按则反之)
Ctrl+/ 注释当前行,再按则取消注释
Ctrl+O 快速显示 OutLine
Ctrl+T 快速显示当前类的继承结构
Ctrl+W 关闭当前Editer
Ctrl+K 参照选中的Word快速定位到下一个
Ctrl+E 快速显示当前Editer的下拉列表(如果当前页面没有显示的用黑体表示)
Ctrl+/(小键盘) 折叠当前类中的所有代码
Ctrl+×(小键盘) 展开当前类中的所有代码
Ctrl+Space 代码助手完成一些代码的插入(但一般和输入法有冲突,可以修改输入法的热键,也可以暂用Alt+/来代替)
Ctrl+Shift+E 显示管理当前打开的所有的View的管理器(可以选择关闭,激活等操作)
Ctrl+J 正向增量查找(按下Ctrl+J后,你所输入的每个字母编辑器都提供快速匹配定位到某个单词,如果没有,则在stutes
line中显示没有找到了,查一个单词时,特别实用,这个功能Idea两年前就有了)
Ctrl+Shift+J 反向增量查找(和上条相同,只不过是从后往前查)
Ctrl+Shift+F4 关闭所有打开的Editer
Ctrl+Shift+X 把当前选中的文本全部变味小写
Ctrl+Shift+Y 把当前选中的文本全部变为小写
Ctrl+Shift+F 格式化当前代码
Ctrl+Shift+P 定位到对于的匹配符(譬如{}) (从前面定位后面时,光标要在匹配符里面,后面到前面,则反之)
下面的快捷键是重构里面常用的,本人就自己喜欢且常用的整理一下(注:一般重构的快捷键都是Alt+Shift开头的了)
Alt+Shift+R 重命名 (是我自己最爱用的一个了,尤其是变量和类的Rename,比手工方法能节省很多劳动力)
Alt+Shift+M 抽取方法 (这是重构里面最常用的方法之一了,尤其是对一大堆泥团代码有用)
Alt+Shift+C 修改函数结构(比较实用,有N个函数调用了这个方法,修改一次搞定)
Alt+Shift+L 抽取本地变量( 可以直接把一些魔法数字和字符串抽取成一个变量,尤其是多处调用的时候)
Alt+Shift+F 把Class中的local变量变为field变量 (比较实用的功能)
Alt+Shift+I 合并变量(可能这样说有点不妥Inline)
Alt+Shift+V 移动函数和变量(不怎么常用)
Alt+Shift+Z 重构的后悔药(Undo)
Ctrl + Z 返回到修改前的状态(编写代码时的后悔药)
Ctrl + Y 与上面的操作相反 (即刚后悔完又后悔)
Shift + / 自动导入类包 (在你写好的类名的右边用这个可导入包)
Ctrl + Shif + / 自动注释代码
Ctrl + Shif + "自动取消已经注释的代码
Ctrl + Shif +O 自动引导类包
MyEclipse 快捷键(2)[b][/b][color=#FF0000][/color]
(1)Ctrl+M切换窗口的大小
(2)Ctrl+Q跳到最后一次的编辑处
(3)F2当鼠标放在一个标记处出现Tooltip时候按F2则把鼠标移开时Tooltip还会显示即Show Tooltip
Description。
F3跳到声明或定义的地方。
F5单步调试进入函数内部。
F6单步调试不进入函数内部,如果装了金山词霸2006则要把“取词开关”的快捷键改成其他的。
F7由函数内部返回到调用处。
F8一直执行到下一个断点。
(4)Ctrl+Pg~对于XML文件是切换代码和图示窗口
(5)Ctrl+Alt+I看Java文件中变量的相关信息
(6)Ctrl+PgUp对于代码窗口是打开“Show List”下拉框,在此下拉框里显示有最近曾打开的文件
(7)Ctrl+/ 在代码窗口中是这种//~注释。
Ctrl+Shift+/ 在代码窗口中是这种/*~*/注释,在JSP文件窗口中是<!--~-->。
(8)Alt+Shift+O(或点击工具栏中的Toggle Mark Occurrences按钮)
当点击某个标记时可使本页面中其他地方的此标记黄色凸显,并且窗口的右边框会出现白色的方块,点击此方块会跳到此标记处。
(9)右击窗口的左边框即加断点的地方选Show Line Numbers可以加行号。
(10)Ctrl+I格式化激活的元素Format Active Elements。
Ctrl+Shift+F格式化文件Format Document。
(11)Ctrl+S保存当前文件。
Ctrl+Shift+S保存所有未保存的文件。
(12)Ctrl+Shift+M(先把光标放在需导入包的类名上) 作用是加Import语句。
Ctrl+Shift+O作用是缺少的Import语句被加入,多余的Import语句被删除。
(13)Ctrl+Space提示键入内容即Content
Assist,此时要将输入法中Chinese(Simplified)IME-Ime/Nonlme
Toggle的快捷键(用于切换英文和其他文字)改成其他的。
Ctrl+Shift+Space提示信息即Context Information。
(14)双击窗口的左边框可以加断点。
(15)Ctrl+D删除当前行。
前不久做的一个笔记本BIOS相关的项目,操作对BOIS文件里面的内容时进行较多的位运算,于是顺手整理了一份位运算相关的内容。
Java 定义的位运算(bitwise operators
)直接对整数类型的位进行操作,这些整数类型包括long,int,short,char,and byte 。
所有的整数类型(除了char 类型之外)都是有符号的整数。这意味着他们既能表示正数,又能表示负数。Java 使用采用补码来表示负数。
为什么采用补码吗?这是考虑到零的交叉(zero crossing )问题。
原码:
将最高位作为符号位(以0代表正,1代表负),其余各位代表数值本身的绝对值(以二进制表示)。这个时候有一个问题:表示0的时候正0和负0表示并不一
样,所以在计算机中没有采用原码的表示形式。
反码:
一个数如果为正,则它的反码与原码相同;一个数如果为负,则符号位为1,其余各位是对原码取反。问题和上面一样的。所以,计算机中也没有采用反码来表示数
字。
补码:
一个数如果为正,则它的原码、反码、补码相同;一个数如果为负,则符号位为1,其余各位是对原码取反,然后再加1。也就是通过将与其对应的正数的二进制代
码取反(即将1变成0,将0变成1),然后对其结果加1。例如,-42就是通过将42的二进制代码的各个位取反,即对00101010
取反得到11010101 ,然后再加1,得到11010110 ,即-42
。要对一个负数解码,首先对其所有的位取反,然后加1。例如-42,或11010110 取反后为00101001
,或41,然后加1,这样就得到了42。
在计算机中,如果我们用1个字节表示一个数,一个字节有8位,超过8位就进1,在内存中情况为:1
00000000。进位1被丢弃。这种情况,我们叫溢出。在计算机中,假定byte 类型的值零为0000 0000,反码为1111 1111
补码为1 0000 0000,在计算-0的补码的时候因为溢出,导致-0和+0是一样的表示,所以计算机中采用补码的形式表示数字。
数的最大值和最小值:由于最高位为符号位,所以最大值和最小值时要去掉最高位。如一个byte为8位.最大值为0111 1111 ,即 (2的7次方)
-1 = 127.最小值为1000 0000,即-( 2的7次方)
=-128。char为无符号数,没有符号位,所以最小值为0,最大值为1111 1111 1111 1111 ,即(2的16次方)
-1。
移位运算符
包括:
“>> 右移,高位补符号位”;
“>>> 无符号右移,高位补0”;
“<< 左移”;
例子:
-5>>3=-1
1111 1111 1111 1111 1111 1111 1111 1011
1111 1111 1111 1111 1111 1111 1111 1111
其结果与 Math.floor((double)-5/(2*2*2)) 完全相同。
-5<<3=-40
1111 1111 1111 1111 1111 1111 1111 1011
1111 1111 1111 1111 1111 1111 1101 1000
其结果与 -5*2*2*2 完全相同。
5>>3=0
0000 0000 0000 0000 0000 0000 0000 0101
0000 0000 0000 0000 0000 0000 0000 0000
其结果与 5/(2*2*2) 完全相同。
5<<3=40
0000 0000 0000 0000 0000 0000 0000 0101
0000 0000 0000 0000 0000 0000 0010 1000
其结果与 5*2*2*2 完全相同。
-5>>>3=536870911
1111 1111 1111 1111 1111 1111 1111 1011
0001 1111 1111 1111 1111 1111 1111 1111
无论正数、负数,它们的右移、左移、无符号右移 32 位都是其本身,比如
-5<<32=-5、-5>>32=-5、-5>>>32=-5。
一个有趣的现象是,把 1 左移 31 位再右移 31 位,其结果为 -1。
0000 0000 0000 0000 0000 0000 0000 0001
1000 0000 0000 0000 0000 0000 0000 0000
1111 1111 1111 1111 1111 1111 1111 1111
位逻辑运算符
包括:
& 与;
| 或;
~ 非(也叫做求反);
^ 异或
“& 与”、“| 或”、“~ 非”是基本逻辑运算,由此可以演变出“与非”、“或非”、“与或非”复合逻辑运算。“^
异或”是一种特殊的逻辑运算,对它求反可以得到“同或”,所以“同或”逻辑也叫“异或非”逻辑。
例子:
5&3=1
0000 0000 0000 0000 0000 0000 0000 0101
0000 0000 0000 0000 0000 0000 0000 0011
0000 0000 0000 0000 0000 0000 0000 0001
-5&3=1
1111 1111 1111 1111 1111 1111 1111 1011
0000 0000 0000 0000 0000 0000 0000 0011
0000 0000 0000 0000 0000 0000 0000 0011
5|3=7
0000 0000 0000 0000 0000 0000 0000 0101
0000 0000 0000 0000 0000 0000 0000 0011
0000 0000 0000 0000 0000 0000 0000 0111
-5|3=-5
1111 1111 1111 1111 1111 1111 1111 1011
0000 0000 0000 0000 0000 0000 0000 0011
1111 1111 1111 1111 1111 1111 1111 1011
~5=-6
0000 0000 0000 0000 0000 0000 0000 0101
1111 1111 1111 1111 1111 1111 1111 1010
~-5=4
1111 1111 1111 1111 1111 1111 1111 1011
0000 0000 0000 0000 0000 0000 0000 0100
5^3=6
0000 0000 0000 0000 0000 0000 0000 0101
0000 0000 0000 0000 0000 0000 0000 0011
0000 0000 0000 0000 0000 0000 0000 0110
-5^3=-8
1111 1111 1111 1111 1111 1111 1111 1011
0000 0000 0000 0000 0000 0000 0000 0011
1111 1111 1111 1111 1111 1111 1111 1000
参考:
http://blog.csdn.net/zdmilan/archive/2005/10/30/519634.aspx
应用程序服务器通过各种协议,可以包括HTTP,把商业逻辑暴露给客户端应用程序。Web服务器主要是处理向浏览器发送HTML以供浏览,而应用程序服务
器提供访问商业逻辑的途径以供客户端应用程序使用。应用程序使用此商业逻辑就象你调用对象的一个方法一样。
通俗的讲,Web服务器传送(serves)页面使浏览器可以浏览,然而应用程序服务器提供的是客户端应用程序可以调用(call)的方法
(methods)。确切一点,你可以说:Web服务器专门处理HTTP请求(request),但是应用程序服务器是通过很多协议来为应用程序提供
(serves)商业逻辑(business logic)。
下面让我们来细细道来:
Web服务器
(Web Server)
Web服务器可以解析(handles)HTTP协议。当Web服务器接收到一个HTTP请求(request),会返回一个HTTP响应
(response),例如送回一个HTML页面。为了处理一个请求(request),Web服务器可以响应(response)一个静态页面或图片,
进行页面跳转(redirect),或者把动态响应(dynamic
response)的产生委托(delegate)给一些其它的程序例如CGI脚本,JSP(JavaServer
Pages)脚本,servlets,ASP(Active Server
Pages)脚本,服务器端(server-side)JavaScript,或者一些其它的服务器端(server-side)技术。无论它们(译者
注:脚本)的目的如何,这些服务器端(server-side)的程序通常产生一个HTML的响应(response)来让浏览器可以浏览。
要知道,Web服务器的代理模型(delegation
model)非常简单。当一个请求(request)被送到Web服务器里来时,它只单纯的把请求(request)传递给可以很好的处理请求
(request)的程序(译者注:服务器端脚本)。Web服务器仅仅提供一个可以执行服务器端(server-side)程序和返回(程序所产生的)响
应(response)的环境,而不会超出职能范围。服务器端(server-side)程序通常具有事务处理(transaction
processing),数据库连接(database connectivity)和消息(messaging)等功能。
虽然
Web服务器不支持事务处理或数据库连接池,但它可以配置(employ)各种策略(strategies)来实现容错性(fault
tolerance)和可扩展性(scalability),例如负载平衡(load
balancing),缓冲(caching)。集群特征(clustering—features)经常被误认为仅仅是应用程序服务器专有的特征。
应用程序服务器(The Application Server)
根据我们的定义,作为应用程序服务器,
它通过各种协议,可以包括HTTP,把商业逻辑暴露给(expose)客户端应用程序。Web服务器主要是处理向浏览器发送HTML以供浏览,而应用程序
服务器提供访问商业逻辑的途径以供客户端应用程序使用。应用程序使用此商业逻辑就象你调用对象的一个方法(或过程语言中的一个函数)一样。
应用程序服务器的客户端(包含有图形用户界面(GUI)的)可能会运行在一台PC、一个Web服务器或者甚至是其它的应用程序服务器上。在应用程序服务
器与其客户端之间来回穿梭(traveling)的信息不仅仅局限于简单的显示标记。相反,这种信息就是程序逻辑(program logic)。
正是由于这种逻辑取得了(takes)数据和方法调用(calls)的形式而不是静态HTML,所以客户端才可以随心所欲的使用这种被暴露的商业逻辑。
在大多数情形下,应用程序服务器是通过组件(component)的应用程序接口(API)把商业逻辑暴露(expose)(给客户端应用程序)的,例
如基于J2EE(Java 2 Platform, Enterprise Edition)应用程序服务器的EJB(Enterprise
JavaBean)组件模型。此外,应用程序服务器可以管理自己的资源,例如看大门的工作(gate-keeping
duties)包括安全(security),事务处理(transaction processing),资源池(resource
pooling),
和消息(messaging)。就象Web服务器一样,应用程序服务器配置了多种可扩展(scalability)和容错(fault
tolerance)技术。
一个例子
例如,设想一个在线商店(网站)提供实时定价(real-time
pricing)和有效性(availability)信息。这个站点(site)很可能会提供一个表单(form)让你来选择产品。当你提交查询
(query)后,网站会进行查找(lookup)并把结果内嵌在HTML页面中返回。网站可以有很多种方式来实现这种功能。我要介绍一个不使用应用程序
服务器的情景和一个使用应用程序服务器的情景。观察一下这两中情景的不同会有助于你了解应用程序服务器的功能。
情景
1:不带应用程序服务器的Web服务器
在此种情景下,一个Web服务器独立提供在线商店的功能。Web服务器获
得你的请求(request),然后发送给服务器端(server-side)可以处理请求(request)的程序。此程序从数据库或文本文件
(flat file,译者注:flat
file是指没有特殊格式的非二进制的文件,如properties和XML文件等)中查找定价信息。一旦找到,服务器端(server-side)程序
把结果信息表示成(formulate)HTML形式,最后Web服务器把会它发送到你的Web浏览器。
简而言之,Web服务器只是简
单的通过响应(response)HTML页面来处理HTTP请求(request)。
情景2:带应用程序服务器的
Web服务器
情景2和情景1相同的是Web服务器还是把响应(response)的产生委托
(delegates)给脚本(译者注:服务器端(server-side)程序)。然而,你可以把查找定价的商业逻辑(business
logic)放到应用程序服务器上。由于这种变化,此脚本只是简单的调用应用程序服务器的查找服务(lookup
service),而不是已经知道如何查找数据然后表示为(formulate)一个响应(response)。
这时当该脚本程序产生HTML响应(response)时就可以使用该服务的返回结果了。
在此情景中,应用程序服务器提供
(serves)了用于查询产品的定价信息的商业逻辑。(服务器的)这种功能(functionality)没有指出有关显示和客户端如何使用此信息的细
节,相反客户端和应用程序服务器只是来回传送数据。当有客户端调用应用程序服务器的查找服务(lookup
service)时,此服务只是简单的查找并返回结果给客户端。
通过从响应产生(response-generating)HTML的
代码中分离出来,在应用程序之中该定价(查找)逻辑的可重用性更强了。其他的客户端,例如收款机,也可以调用同样的服务(service)来作为一个店员
给客户结帐。相反,在情景1中的定价查找服务是不可重用的因为信息内嵌在HTML页中了。
总而言之,在情景2的模型中,在Web服务器
通过回应HTML页面来处理HTTP请求(request),而应用程序服务器则是通过处理定价和有效性(availability)请求
(request)来提供应用程序逻辑的。
警告(Caveats)
现在,XML Web
Services已经使应用程序服务器和Web服务器的界线混淆了。通过传送一个XML有效载荷(payload)给服务器,Web服务器现在可以处理数
据和响应(response)的能力与以前的应用程序服务器同样多了。
另外,现在大多数应用程序服务器也包含了Web服务器,这就意味
着可以把Web服务器当作是应用程序服务器的一个子集(subset)。虽然应用程序服务器包含了Web服务器的功能,但是开发者很少把应用程序服务器部
署(deploy)成这种功能(capacity)(译者注:这种功能是指既有应用程序服务器的功能又有Web服务器的功能)。相反,如果需要,他们通常
会把Web服务器独立配置,和应用程序服务器一前一后。这种功能的分离有助于提高性能(简单的Web请求(request)就不会影响应用程序服务器
了),分开配置(专门的Web服务器,集群(clustering)等等),而且给最佳产品的选取留有余地。
HTTPS(Secure Hypertext Transfer Protocol)安全超文本传输协议
它是一个安全通信通道,它基于HTTP开发,用于在客户计算机和服务器之间交换信息。它使用安全套接字层(SSL)进行信息交换,简单来说它是HTTP的
安全版。
它是由Netscape开发并内置于其浏览器中,用于对数据进行压缩和解压操作,并返回网络上传送回的结果。HTTPS实际上应用了Netscape的安
全全套接字层(SSL)作为HTTP应用层的子层。(HTTPS使用端口443,而不是象HTTP那样使用端口80来和TCP/IP进行通信。)SSL使
用40
位关键字作为RC4流加密算法,这对于商业信息的加密是合适的。HTTPS和SSL支持使用X.509数字认证,如果需要的话用户可以确认发送者是谁。
HTTPS和HTTP的区别:
https协议需要到ca申请证书,一般免费证书很少,需要交费。
http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议
http和https使用的是完全不同的连接方式用的端口也不一样,前者是80,后者是443。
http的连接很简单,是无状态的
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议 要比http协议安全
HTTPS解决的问题:
1 . 信任主机的问题. 采用https 的server 必须从CA 申请一个用于证明服务器用途类型的证书. 改证书只有用于对应的server
的时候,客户度才信任次主机. 所以目前所有的银行系统网站,关键部分应用都是https 的. 客户通过信任该证书,从而信任了该主机.
其实这样做效率很低,但是银行更侧重安全. 这一点对我们没有任何意义,我们的server ,采用的证书不管自己issue
还是从公众的地方issue, 客户端都是自己人,所以我们也就肯定信任该server.
2 . 通讯过程中的数据的泄密和被窜改
1. 一般意义上的https, 就是 server 有一个证书.
a) 主要目的是保证server 就是他声称的server. 这个跟第一点一样.
b) 服务端和客户端之间的所有通讯,都是加密的.
i. 具体讲,是客户端产生一个对称的密钥,通过server 的证书来交换密钥. 一般意义上的握手过程.
ii. 加下来所有的信息往来就都是加密的. 第三方即使截获,也没有任何意义.因为他没有密钥. 当然窜改也就没有什么意义了.
2. 少许对客户端有要求的情况下,会要求客户端也必须有一个证书.
a) 这里客户端证书,其实就类似表示个人信息的时候,除了用户名/密码, 还有一个CA 认证过的身份.
应为个人证书一般来说上别人无法模拟的,所有这样能够更深的确认自己的身份.
b) 目前少数个人银行的专业版是这种做法,具体证书可能是拿U盘作为一个备份的载体.
HTTPS 一定是繁琐的.
a) 本来简单的http协议,一个get一个response. 由于https 要还密钥和确认加密算法的需要.单握手就需要6/7 个往返.
i. 任何应用中,过多的round trip 肯定影响性能.
b) 接下来才是具体的http协议,每一次响应或者请求, 都要求客户端和服务端对会话的内容做加密/解密.
i. 尽管对称加密/解密效率比较高,可是仍然要消耗过多的CPU,为此有专门的SSL 芯片. 如果CPU
信能比较低的话,肯定会降低性能,从而不能serve 更多的请求.
ii. 加密后数据量的影响. 所以,才会出现那么多的安全认证提示
早早就听说过开发方向的笔试面试都是以算法和数据结构这些基础为主,我自恃着那么一丁点项目经验,一直没放在心上。
连日下来的笔试彻底印证了师兄们的话,笔试基本不过。最可惜的是淘宝,笔试中发挥不错终于能进一面,一开始聊家常聊框架聊开源技术还聊得不错,突然
间,连续问了三个问题:
1.多线程访问hashtable和hashmap有什么不一样?我只答出线程安全不一样,具体怎么不一样就有一句每一句了(回来google一
下,这种java基础还真TM简单,枉称精通java了)
2.平衡二叉树查找算法的复杂度?再次雷响,随便蒙了个归并排序的复杂度给他。
3.对于100W条数据的排序和查找有什么效率高的方式?完了,结结巴巴的说一通,最后自认不会……
原本以为技术面会比笔试好过的,回学校的路上我泪流满面啊我。这些都不是RP问题了,铁了心恶补数据结构……
Java线
程安全同步解决方案
1、 问题描述:
如果一个资源或对象可能被多个线程同时访问,它就是一个共享资源;例如
类的成员变量,包括类变量和实例变量,再比如对一个文件进行写操作等。一般情况下,对共享资源的访问需要考虑线程安全的问题。
如果一个对象的完整生命周期只在一个线程内,则不需要考虑线程安全,例
如一个局部变量。下面为一个示例代码:
- public class C1 {
- public static java.text.SimpleDateFormat
sdf = new java.text.SimpleDateFormat("yyyy-MM-dd");
- //其他代码
-
}
假如在一个JSP中这样的去调用:
- <a.jsp>:
- <%
- Java.util.Date date =
C1.sdf.parse(“2003-4-15”);
-
%>
则这样的代码不是线程安全的。因为java.text.SimpleDateFormat
不是线程安全的,a.jsp中的代码将会有若干个线程同时执行,而都访问的是同一个线程不安全的对象,这样就不是一个线程安全的代码。正确的写法应该如
下:
- <a.jsp>:
- <%
- java.text.SimpleDateFormat sdf =
new java.text.SimpleDateFormat("yyyy-MM-dd");
- Java.util.Date date =
sdf.parse(“2003-4-15”);
-
%>
2、 原因分析:
此时,sdf对象从创建到销毁都位于一个方法中,相当于一个局部变量,不是一个共享资源,因此则没有线程不安全的问题。
3、 解决方法或过程:
1) 如果对象是immutable,则是线程安全的,例如:String,可以放心使用。
2) 如果对象是线程安全的,则放心使用
3) 有
条件线程安全,对于Vector和Hashtable一般情况下是线程安全的,但是对于某些特殊情况,需要通过额外的synchronized保证线程安
全。
4) 使用synchronized关键字;
对于上例中可以改写jsp代码,在sdf上进行同步,而不需要每次创建一个新的对象来保证线程安全,代码如下:
- <%
- synchronized(C1.sdf){
- Java.util.Date date =
C1.sdf.parse(“2003-4-15”);
- }
-
%>
这种写法是在一个对象级别上进行同步,也就是说任何时候,对于这个对象,最多只能有一个线程在执行同步方法。
另外一种写法是在Class级别上进行同步,写法如下:
- public class C1 {
- public static java.text.SimpleDateFormat
sdf = new java.text.SimpleDateFormat("yyyy-MM-dd");
- public void method(){
- synchronized(C1.class){
- //synchronized code
- }
- }
-
}
这种写法表示无论C1有多少个实例,在任何一个时间点,最多只能有一个线程和一个实例进入同步块中。这种同步会比较大的影响性能。
5) 有些对象不能在多线程间共享,则只能在方法内部使用,或者只在一个线程内部使用。
synchronized详解
Java对多线程的支持与同步机制深受大家的喜爱,似乎看起来使用了synchronized关键字就可以轻松地解决多线程共享数据同步问题。到底如何?――还得对synchronized关键字的作用进行深入了解才可定论。
总的说来,synchronized关键字可以作为函数的修饰符,也可作为函数内的语句,也就是平时说的同步方法和同步语句块。如果再细的分类,synchronized可作用于instance变量、object
reference(对象引用)、static函数和class literals(类名称字面常量)身上。
在进一步阐述之前,我们需要明确几点:
A.无论synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁――而且同步方法很可能还会被其他线程的对象访问。
B.每个对象只有一个锁(lock)与之相关联。
C.实现同步是要很大的系统开销作为代价的,甚至可能
造成死锁,所以尽量避免无谓的同步控制。
接着来讨论synchronized
用到不同地方对代码产生的影响:
假设P1、P2是同一个类的不同对象,这个类中定义了以下几种情况的同步块或同步方法,P1、P2就都可以调用它们。
1. 把synchronized当作函数修饰符时,示例代码如下:
Public synchronized void methodAAA()
{
//….
}
这也就是同步方法,那这时synchronized锁定的是哪个对象呢?它锁定的是调用这个同步方法对象。也就是说,当一个对象P1在不
同的线程中执行这个同步方法时,它们之间会形成互斥,达到同步的效果。但是这个对象所属的Class所
产生的另一对象P2却可以任意调用这个被加了synchronized关键字的方法。
上边的示例代码等同于如下代码:
public void methodAAA()
{
synchronized (this) // (1)
{
//…..
}
}
(1)处
的this指的是什么呢?它指的就是调用这个方法的对象,如P1。可见
同步方法实质是将synchronized作用于object
reference。――那个拿到了P1对象
锁的线程,才可以调用P1的同步方法,而对P2而
言,P1这个锁与它毫不相干,程序也可能在这种情形下摆脱同步机制的控制,造成数据混乱:(
2.同步块,示例代码如下:
public void method3(SomeObject so)
{
synchronized(so)
{
//…..
}
}
这时,锁就是so这个对象,谁拿到这个锁谁就可以运行它所控制的那段代码。当有一个明确的对象作为锁时,就可以这样写程序,但当没有明确的对象作为
锁,只是想让一段代码同步时,可以创建一个特殊的instance变量(它得是一个对象)来充当锁:
class Foo implements Runnable
{
private byte[] lock = new
byte[0]; // 特殊的instance变量
Public void methodA()
{
synchronized(lock) { //… }
}
//…..
}
注:零长度的byte数
组对象创建起来将比任何对象都经济――查看编译后的字节码:生成零长度的byte[]对
象只需3条操作码,而Object lock = new Object()则
需要7行操作码。
3.将synchronized作用于static 函数,示例代码如下:
Class Foo
{
public synchronized static void methodAAA() // 同步的static 函数
{
//….
}
public void methodBBB()
{
synchronized(Foo.class) // class literal(类名称字面常量)
}
}
代码中的methodBBB()方法是把class literal作为锁的情况,它和同步的static函
数产生的效果是一样的,取得的锁很特别,是当前调用这个方法的对象所属的类(Class,
而不再是由这个Class产生的某个具体对象了)。
记得在《Effective Java》一书中看到过将 Foo.class和 P1.getClass()用于作同步锁还不一样,不能用P1.getClass()来达到锁这个Class的目的。P1指的是由Foo类产生的对象。
可以推断:如果一个类中定义了一个synchronized的static函数A,也定
义了一个synchronized 的instance函数B,那么这个类的同一对象Obj在多线程中分别访问A和B两个方法时,不会构成同步,因为它们的锁都不一样。A方法的锁
是Obj这个对象,而B的锁是Obj所属的那个Class。
小结如下:
搞清楚synchronized锁定的是哪个对象,就能帮助我们设计更安全的多线程程序。
还有一些技巧可以让我们对共享资源的同步访问更加安全:
1. 定义private 的instance变量+它的 get方法,而不要定义public/protected的instance变量。如果将变量定义为public,对象在外界可以绕过同步方法的控制而
直接取得它,并改动它。这也是JavaBean的标准实现方式之一。
2. 如果instance变量是一个对象,如数组或ArrayList什么的,那上述方法仍然不安全,
因为当外界对象通过get方法拿到这个instance对象的引用后,又将其指向另一个对象,那么这个private变量也就变了,岂不是很危险。这个时候就需要将get方法
也加上synchronized同步,并且,只返回这个private对象的clone()――这样,调用端得到的就是对象副本的引用了。
字符,字节和编码
转载自:http://www.regexlab.com/zh/encoding.htm
级别:中级
摘要:本文介绍了字符与编码的发展过程,相关概念的正确理解。举例说明了一些实际应用中,编码的实现方法。然后,本文
讲述了通常对字符与编码的几种误解,由于这些误解而导致乱码产生的原因,以及消除乱码的办法。本文的内容涵盖了“中文问题”,“乱码问题”。
掌握编码问题的关键是正确地理解相关概念,编码所涉及的技术其实是很简单的。因此,阅读本文时需要慢读多想,多思考。
引言
“字符与编码”是一个被经常讨论的话题。即使这样,时常出现的乱码仍然困扰着大家。虽然我们有很多的办法可以用来消除乱
码,但我们并不一定理解这些办法的内在原理。而有的乱码产生的原因,实际上由于底层代码本身有问题所导致的。因此,不仅是初学者会对字符编码感到模糊,有
的底层开发人员同样对字符编码缺乏准确的理解。
1. 编码问题的由来,相关概念的理解
1.1 字符与编码的发展
从计算机对多国语言的支持角度看,大致可以分为三个阶段:
| 系统内码 |
说明 |
系统 |
| 阶段一 |
ASCII |
计算机刚开始只支持英语,其它语言不能够在计算机上存储和显示。 |
英文 DOS |
| 阶段二 |
ANSI编码
(本地化) |
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2
个字节来表示 1 个字符。比如:汉字 '中' 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2
个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312
编码,在日文操作系统下,ANSI 编码代表 JIS 编码。
不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI
编码的文本中。 |
中文 DOS,中文 Windows 95/98,日文 Windows
95/98 |
| 阶段三 |
UNICODE
(国际化) |
为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,
为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。 |
Windows NT/2000/XP,Linux,Java |
字符串在内存中的存放方法:
在 ASCII 阶段,单字节字符串使用一个字节存放一个字符(SBCS)。比如,"Bob123"
在内存中为:
| 42 |
6F |
62 |
31 |
32 |
33 |
00 |
 |
|
|
|
|
|
|
| B |
o |
b |
1 |
2 |
3 |
"0 |
在使用 ANSI
编码支持多种语言阶段,每个字符使用一个字节或多个字节来表示(MBCS),因此,这种方式存放的字符也被称作多字节字符。比如,"中文
123" 在中文 Windows 95 内存中为7个字节,每个汉字占2个字节,每个英文和数字字符占1个字节:
| D6 |
D0 |
CE |
C4 |
31 |
32 |
33 |
00 |
|
|
|
|
|
|
| 中 |
文 |
1 |
2 |
3 |
"0 |
在 UNICODE 被采用之后,计算机存放字符串时,改为存放每个字符在 UNICODE
字符集中的序号。目前计算机一般使用 2 个字节(16 位)来存放一个序号(DBCS),因此,这种方式存放的字符也被称作宽字节字符。
比如,字符串 "中文123" 在 Windows 2000 下,内存中实际存放的是 5 个序号:
| 2D |
4E |
87 |
65 |
31 |
00 |
32 |
00 |
33 |
00 |
00 |
00 |
← 在 x86 CPU 中,低字节在前 |
|
|
|
|
|
|
|
| 中 |
文 |
1 |
2 |
3 |
"0 |
一共占 10 个字节。
1.2 字符,字节,字符串
理解编码的关键,是要把字符的概念和字节的概念理解准确。这两个概念容易混淆,我们在此做一下区分:
| 概念描述 |
举例 |
| 字符 |
人们使用的记号,抽象意义上的一个符号。 |
'1', '中', 'a', '$', '¥', …… |
| 字节 |
计算机中存储数据的单元,一个8位的二进制数,是一个很具体的存储空间。 |
0x01, 0x45, 0xFA, …… |
ANSI
字符串 |
在内存中,如果“字符”是以 ANSI 编码形式存在的,一个字符
可能使用一个字节或多个字节来表示,那么我们称这种字符串为 ANSI 字符串或者多字节字符串。 |
"中文123"
(占7字节) |
UNICODE
字符串 |
在内存中,如果“字符”是以在 UNICODE
中的序号存在的,那么我们称这种字符串为 UNICODE 字符串或者宽字节字符串。 |
L"中文123"
(占10字节) |
由于不同 ANSI 编码所规定的标准是不相同的,因此,对于一个给定的多字节字符串,我们必须知道它采用
的是哪一种编码规则,才能够知道它包含了哪些“字符”。而对于 UNICODE 字符串来说,不管在什么环境下,它所代表的“字符”内容总
是不变的。
1.3 字符集与编码
各个国家和地区所制定的不同 ANSI
编码标准中,都只规定了各自语言所需的“字符”。比如:汉字标准(GB2312)中没有规定韩国语字符怎样存储。这些 ANSI
编码标准所规定的内容包含两层含义:
- 使用哪些字符。也就是说哪些汉字,字母和符号会被收入标准中。所包含“字符”的集合就叫做“字符集”。
- 规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。
各个国家和地区在制定编码标准的时候,“字符的集合”和“编码”一般都是同时制定的。因此,平常我们所说的“字符集”,比
如:GB2312, GBK, JIS 等,除了有“字符的集合”这层含义外,同时也包含了“编码”的含义。
“UNICODE 字符集”包含了各种语言中使用到的所有“字符”。用来给 UNICODE
字符集编码的标准有很多种,比如:UTF-8, UTF-7, UTF-16, UnicodeLittle, UnicodeBig 等。
1.4 常用的编码简介
简单介绍一下常用的编码规则,为后边的章节做一个准备。在这里,我们根据编码规则的特点,把所有的编码分成三类:
| 分类 |
编码标准 |
说明 |
| 单字节字符编码 |
ISO-8859-1 |
最简单的编码规则,每一个字节直接作为一个 UNICODE
字符。比如,[0xD6, 0xD0] 这两个字节,通过 iso-8859-1 转化为字符串时,将直接得到 [0x00D6, 0x00D0] 两个
UNICODE 字符,即 "ÖÐ"。
反之,将 UNICODE 字符串通过 iso-8859-1 转化为字节串时,只能正常转化 0~255
范围的字符。 |
| ANSI 编码 |
GB2312,
BIG5,
Shift_JIS,
ISO-8859-2 …… |
把 UNICODE 字符串通过 ANSI
编码转化为“字节串”时,根据各自编码的规定,一个 UNICODE 字符可能转化成一个字节或多个字节。
反之,将字节串转化成字符串时,也可能多个字节转化成一个字符。比如,[0xD6, 0xD0] 这两个字节,通过
GB2312 转化为字符串时,将得到 [0x4E2D] 一个字符,即 '中' 字。
“ANSI 编码”的特点:
1. 这些“ANSI 编码标准”都只能处理各自语言范围之内的 UNICODE 字符。
2. “UNICODE 字符”与“转换出来的字节”之间的关系是人为规定的。 |
| UNICODE
编码 |
UTF-8,
UTF-16, UnicodeBig …… |
与“ANSI 编码”类似的,把字符串通过 UNICODE
编码转化成“字节串”时,一个 UNICODE 字符可能转化成一个字节或多个字节。
与“ANSI 编码”不同的是:
1. 这些“UNICODE 编码”能够处理所有的 UNICODE 字符。
2. “UNICODE 字符”与“转换出来的字节”之间是可以通过计算得到的。 |
我们实际上没有必要去深究每一种编码具体把某一个字符编码成了哪几个字节,我们只需要知道“编码”的概念就是把“字符”转
化成“字节”就可以了。对于“UNICODE 编码”,由于它们是可以通过计算得到的,因此,在特殊的场合,我们可以去了解某一种“UNICODE
编码”是怎样的规则。
2. 字符与编码在程序中的实现
2.1 程序中的字符与字节
在 C++ 和 Java 中,用来代表“字符”和“字节”的数据类型,以及进行编码的方法:
| 类型或操作 |
C++ |
Java |
| 字符 |
wchar_t |
char |
| 字节 |
char |
byte |
| ANSI
字符串 |
char[] |
byte[] |
| UNICODE
字符串 |
wchar_t[] |
String |
| 字节串→字符串 |
mbstowcs(), MultiByteToWideChar() |
string = new String(bytes, "encoding") |
| 字符串→字节串 |
wcstombs(), WideCharToMultiByte() |
bytes = string.getBytes("encoding") |
以上需要注意几点:
- Java 中的 char 代表一个“UNICODE 字符(宽字节字符)”,而 C++ 中的 char
代表一个字节。
- MultiByteToWideChar() 和 WideCharToMultiByte() 是
Windows API 函数。
2.2 C++ 中相关实现方法
声明一段字符串常量:
// ANSI 字符串,内容长度 7 字节
char sz[20] = "中文123";
// UNICODE 字符串,内容长度 5 个 wchar_t(10 字节)
wchar_t wsz[20] = L""x4E2D"x6587"x0031"x0032"x0033"; |
UNICODE 字符串的 I/O 操作,字符与字节的转换操作:
// 运行时设定当前 ANSI 编码,VC
格式
setlocale(LC_ALL, ".936");
// GCC 中格式
setlocale(LC_ALL, "zh_CN.GBK");
// Visual C++ 中使用小写 %s,按照 setlocale
指定编码输出到文件
// GCC 中使用大写 %S
fwprintf(fp, L"%s"n", wsz);
// 把 UNICODE 字符串按照 setlocale
指定的编码转换成字节
wcstombs(sz, wsz, 20);
// 把字节串按照 setlocale 指定的编码转换成 UNICODE 字符串
mbstowcs(wsz, sz, 20); |
在 Visual C++ 中,UNICODE 字符串常量有更简单的表示方法。如果源程序的编码与当前默认 ANSI
编码不符,则需要使用 #pragma setlocale,告诉编译器源程序使用的编码:
// 如果源程序的编码与当前默认 ANSI
编码不一致,
// 则需要此行,编译时用来指明当前源程序使用的编码
#pragma setlocale(".936")
// UNICODE 字符串常量,内容长度 10 字节
wchar_t wsz[20] = L"中文123"; |
以上需要注意 #pragma setlocale 与 setlocale(LC_ALL, "")
的作用是不同的,#pragma setlocale 在编译时起作用,setlocale() 在运行时起作用。
2.3 Java 中相关实现方法
字符串类 String 中的内容是 UNICODE 字符串:
// Java 代码,直接写中文
String string = "中文123";
// 得到长度为 5,因为是 5 个字符
System.out.println(string.length()); |
字符串 I/O 操作,字符与字节转换操作。在 Java 包 java.io.*
中,以“Stream”结尾的类一般是用来操作“字节串”的类,以“Reader”,“Writer”结尾的类一般是用来操作“字符串”的类。
// 字符串与字节串间相互转化
// 按照 GB2312 得到字节(得到多字节字符串)
byte [] bytes = string.getBytes("GB2312");
// 从字节按照 GB2312 得到 UNICODE 字符串
string = new String(bytes,
"GB2312");
// 要将 String 按照某种编码写入文本文件,有两种方法:
// 第一种办法:用 Stream 类写入已经按照指定编码转化好的字节串
OutputStream os = new
FileOutputStream("1.txt");
os.write(bytes);
os.close();
// 第二种办法:构造指定编码的 Writer 来写入字符串
Writer ow = new
OutputStreamWriter(new FileOutputStream("2.txt"), "GB2312");
ow.write(string);
ow.close();
/* 最后得到的 1.txt 和 2.txt 都是 7 个字节 */ |
如果 java 的源程序编码与当前默认 ANSI 编码不符,则在编译的时候,需要指明一下源程序的编码。比如:
| E:">javac -encoding
BIG5 Hello.java |
以上需要注意区分源程序的编码与 I/O 操作的编码,前者是在编译时起作用,后者是在运行时起作用。
3. 几种误解,以及乱码产生的原因和解决办法
3.1 容易产生的误解
| 对编码的误解 |
| 误解一 |
在将“字节串”转化成“UNICODE
字符串”时,比如在读取文本文件时,或者通过网络传输文本时,容易将“字节串”简单地作为单字节字符串,采用每“一个字节”就是“一个字
符”的方法进行转化。
而实际上,在非英文的环境中,应该将“字节串”作为 ANSI 字符串,采用适当的编码来得到 UNICODE
字符串,有可能“多个字节”才能得到“一个字符”。
通常,一直在英文环境下做开发的程序员们,容易有这种误解。 |
| 误解二 |
在 DOS,Windows 98 等非 UNICODE 环境下,字符串都是以
ANSI 编码的字节形式存在的。这种以字节形式存在的字符串,必须知道是哪种编码才能被正确地使用。这使我们形成了一个惯性思维:“字符串的编码”。
当 UNICODE 被支持后,Java 中的 String
是以字符的“序号”来存储的,不是以“某种编码的字节”来存储的,因此已经不存在“字符串的编码”这个概念了。只有在“字符串”与“字节串”转化时,或
者,将一个“字节串”当成一个 ANSI 字符串时,才有编码的概念。
不少的人都有这个误解。 |
第一种误解,往往是导致乱码产生的原因。第二种误解,往往导致本来容易纠正的乱码问题变得更复杂。
在这里,我们可以看到,其中所讲的“误解一”,即采用每“一个字节”就是“一个字符”的转化方法,实际上也就等同于采用
iso-8859-1 进行转化。因此,我们常常使用 bytes = string.getBytes("iso-8859-1")
来进行逆向操作,得到原始的“字节串”。然后再使用正确的 ANSI 编码,比如 string = new String(bytes,
"GB2312"),来得到正确的“UNICODE 字符串”。
3.2 非 UNICODE 程序在不同语言环境间移植时的乱码
非 UNICODE 程序中的字符串,都是以某种 ANSI
编码形式存在的。如果程序运行时的语言环境与开发时的语言环境不同,将会导致 ANSI 字符串的显示失败。
比如,在日文环境下开发的非 UNICODE
的日文程序界面,拿到中文环境下运行时,界面上将显示乱码。如果这个日文程序界面改为采用 UNICODE
来记录字符串,那么当在中文环境下运行时,界面上将可以显示正常的日文。
由于客观原因,有时候我们必须在中文操作系统下运行非 UNICODE
的日文软件,这时我们可以采用一些工具,比如,南极星,AppLocale 等,暂时的模拟不同的语言环境。
3.3 网页提交字符串
当页面中的表单提交字符串时,首先把字符串按照当前页面的编码,转化成字节串。然后再将每个字节转化成 "%XX"
的格式提交到 Web 服务器。比如,一个编码为 GB2312 的页面,提交 "中" 这个字符串时,提交给服务器的内容为 "%D6%D0"。
在服务器端,Web 服务器把收到的 "%D6%D0" 转化成 [0xD6, 0xD0] 两个字节,然后再根据
GB2312 编码规则得到 "中" 字。
在 Tomcat 服务器中,request.getParameter()
得到乱码时,常常是因为前面提到的“误解一”造成的。默认情况下,当提交 "%D6%D0" 给 Tomcat
服务器时,request.getParameter() 将返回 [0x00D6, 0x00D0] 两个 UNICODE 字符,而不是返回一个
"中" 字符。因此,我们需要使用 bytes = string.getBytes("iso-8859-1") 得到原始的字节串,再用
string
= new String(bytes, "GB2312") 重新得到正确的字符串 "中"。
3.4 从数据库读取字符串
通过数据库客户端(比如 ODBC 或 JDBC)从数据库服务器中读取字符串时,客户端需要从服务器获知所使用的
ANSI 编码。当数据库服务器发送字节流给客户端时,客户端负责将字节流按照正确的编码转化成 UNICODE 字符串。
如果从数据库读取字符串时得到乱码,而数据库中存放的数据又是正确的,那么往往还是因为前面提到的“误解一”造成的。解决
的办法还是通过 string = new String( string.getBytes("iso-8859-1"), "GB2312")
的方法,重新得到原始的字节串,再重新使用正确的编码转化成字符串。
3.5 电子邮件中的字符串
当一段 Text 或者 HTML 通过电子邮件传送时,发送的内容首先通过一种指定的字符编码转化成“字
节串”,然后再把“字节串”通过一种指定的传输编码(Content-Transfer-Encoding)进行转化得到另一串“字节
串”。比如,打开一封电子邮件源代码,可以看到类似的内容:
Content-Type: text/plain;
charset="gb2312"
Content-Transfer-Encoding: base64
sbG+qcrQuqO17cf4yee74bGjz9W7+b3wudzA7dbQ0MQNCg0KvPKzxqO6uqO17cnnsaPW0NDEDQoNCg== |
最常用的 Content-Transfer-Encoding 有 Base64 和
Quoted-Printable 两种。在对二进制文件或者中文文本进行转化时,Base64 得到的“字节串”比 Quoted-Printable
更短。在对英文文本进行转化时,Quoted-Printable 得到的“字节串”比 Base64 更短。
邮件的标题,用了一种更简短的格式来标注“字符编码”和“传输编码”。比如,标题内容为
"中",则在邮件源代码中表示为:
// 正确的标题格式
Subject: =?GB2312?B?1tA=?= |
其中,
- 第一个“=?”与“?”中间的部分指定了字符编码,在这个例子中指定的是 GB2312。
- “?”与“?”中间的“B”代表 Base64。如果是“Q”则代表 Quoted-Printable。
- 最后“?”与“?=”之间的部分,就是经过 GB2312 转化成字节串,再经过 Base64
转化后的标题内容。
如果“传输编码”改为 Quoted-Printable,同样,如果标题内容为 "中":
// 正确的标题格式
Subject: =?GB2312?Q?=D6=D0?= |
如果阅读邮件时出现乱码,一般是因为“字符编码”或“传输编码”指定有误,或者是没有指定。比如,有的发邮件组件在发送邮
件时,标题 "中":
// 错误的标题格式
Subject: =?ISO-8859-1?Q?=D6=D0?= |
这样的表示,实际上是明确指明了标题为 [0x00D6, 0x00D0],即 "ÖÐ",而不是 "中"。
4. 几种错误理解的纠正
误解:“ISO-8859-1 是国际编码?”
非也。iso-8859-1 只是单字节字符集中最简单的一种,也就是“字节编号”与“UNICODE
字符编号”一致的那种编码规则。当我们要把一个“字节串”转化成“字符串”,而又不知道它是哪一种 ANSI
编码时,先暂时地把“每一个字节”作为“一个字符”进行转化,不会造成信息丢失。然后再使用 bytes =
string.getBytes("iso-8859-1") 的方法可恢复到原始的字节串。
误解:“Java 中,怎样知道某个字符串的内码?”
Java 中,字符串类 java.lang.String 处理的是 UNICODE 字符串,不是 ANSI
字符串。我们只需要把字符串作为“抽象的符号的串”来看待。因此不存在字符串的内码的问题。
想写个struts 2.0+tiles模版玩玩,没有想到找资料还麻烦,于是自己把通宵弄好的过程记下来,以供大家有急需,不足的地方欢迎交流。
1.在WEB-INF/lib下加入所需的jar包
commons-digester-1.6.jar,
tiles-core-2.0-20070207.130156-4.jar,
tiles-api-2.0-20070207.130156-4.jar,
struts2-tiles-plugin-2.0.6.jar,
struts2-core-2.0.6.jar
xwork-2.0.1.jar,
2. 以下内容添加到web.xml
<context-param>
<param-name>org.apache.tiles.CONTAINER_FACTORY</param-name>
<param-value>
org.apache.struts2.tiles.StrutsTilesContainerFactory
</param-value>
</context-param>
<context-param>
<param-name>
org.apache.tiles.impl.BasicTilesContainer.DEFINITIONS_CONFIG
</param-name>
<param-value>/WEB-INF/tiles.xml</param-value>
</context-param>
<listener>
<listener-class>
org.apache.struts2.tiles.StrutsTilesListener
</listener-class>
</listener>
3.在WEB-INF下添加和tiles.tld和tiles.xml文件,其中tiles.tld内容为tiles-core-
2.0-20070207.130156-4.jar包中META_INF/tiles-core.tld的内容。
tiles.xml内容:
<?xml version="1.0" encoding="GB2312" ?>
<!DOCTYPE tiles-definitions PUBLIC
"-//Apache Software
Foundation//DTD Tiles Configuration 2.0//EN"
"http://jakarta.apache.org/struts/dtds/tiles-config.dtd">
<tiles-definitions>
<definition name="myapp.homepage" template="layout.jsp">
<put name="title" value="Tiles tutorial homepage" />
<put name="header" value="/tiles/header.jsp" />
<put name="menu" value="/tiles/menu.jsp" />
<put name="body" value="/tiles/cBody.jsp" />
<put name="footer" value="/tiles/footer.jsp" />
</definition>
</tiles-definitions>
4.struts.xml 为:
<!DOCTYPE struts PUBLIC
"-//Apache Software
Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="default" extends="tiles-default">
<action name="go"
class="com.action.MyAction">
<!--result
name="success">/next.jsp</result-->
<result name="success" type="tiles">myapp.homepage</result>
</action>
</package>
</struts>
红色部分根据自己项目
定。注意extends="tiles-default"
5创建layout.jsp:
<%@ page contentType="text/html;
charset=UTF-8"%>
<%@ taglib uri="WEB-INF/tiles.tld " prefix="tiles"%>
<html>
<head>
<title></title>
</head>
<body>
<table width="768px" height="800px" border="2"
align="center">
<tr>
<td colspan="2" align="center" valign="top" width="768px" height="100px" bgcolor="#80ff80">
<tiles:insertAttribute
name="header" />
</td>
</tr>
<tr>
<td align="center" width="150px" height="800px"
bgcolor="#00ff00">
<tiles:insertAttribute
name="menu" />
</td>
<td align="right" width="618px" height="800px"
bgcolor="#ff80c0">
<tiles:insertAttribute
name="body" />
</td>
</tr>
<tr>
<td colspan="2" bgcolor="#00ff40" height="100px">
<tiles:insertAttribute
name="footer" />
</td>
</tr>
</table>
</body>
</html>
6.根据
<put name="title" value="Tiles tutorial
homepage" />
<put name="header" value="/tiles/header.jsp" />
<put name="menu" value="/tiles/menu.jsp" />
<put name="body" value="/tiles/cBody.jsp" />
<put name="footer" value="/tiles/footer.jsp" />
在WebRoot下创
建tiles目录和相应jsp文件
null
获取
MIME:HttpContext.Current.Request.Files[fileKey].ContentLength
MIME类型就是设定某种扩展名
的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。
下面列出常用的文件对应的MIME类型:
| Mime-
Types(mime类型) |
Dateiendung(扩
展名) |
Bedeutung |
| application/msexcel |
*.xls *.xla |
Microsoft Excel Dateien |
| application/mshelp |
*.hlp *.chm |
Microsoft Windows Hilfe Dateien |
| application/mspowerpoint |
*.ppt *.ppz *.pps *.pot |
Microsoft Powerpoint Dateien |
| application/msword |
*.doc *.dot |
Microsoft Word Dateien |
|
application/octet-stream
|
*.exe |
exe |
| application/pdf |
*.pdf |
Adobe PDF-Dateien |
| application/post****** |
*.ai *.eps *.ps |
Adobe Post******-Dateien |
| application/rtf |
*.rtf |
Microsoft RTF-Dateien |
| application/x-httpd-php |
*.php *.phtml |
PHP-Dateien |
| |
|
|
| application/x-java****** |
*.js |
serverseitige Java******-Dateien |
| application/x-shockwave-flash |
*.swf *.cab |
Flash Shockwave-Dateien |
| application/zip |
*.zip |
ZIP-Archivdateien |
| audio/basic |
*.au *.snd |
Sound-Dateien |
| audio/mpeg |
*.mp3 |
MPEG-Dateien |
| audio/x-midi |
*.mid *.midi |
MIDI-Dateien |
| audio/x-mpeg |
*.mp2 |
MPEG-Dateien |
| audio/x-wav |
*.wav |
Wav-Dateien |
| image/gif |
*.gif |
GIF-Dateien |
| image/jpeg |
*.jpeg *.jpg *.jpe |
JPEG-Dateien |
| image/x-windowdump |
*.xwd |
X-Windows Dump |
| text/css |
*.css |
CSS Stylesheet-Dateien |
| text/html |
*.htm *.html *.shtml |
-Dateien |
| text/java****** |
*.js |
Java******-Dateien |
| text/plain |
*.txt |
reine Textdateien |
| video/mpeg |
*.mpeg *.mpg *.mpe |
MPEG-Dateien |
| video/vnd.rn-realvideo |
*.rmvb |
realplay-Dateien |
| video/quicktime |
*.qt *.mov |
Quicktime-Dateien |
| video/vnd.vivo |
*viv *.vivo |
Vivo-Dateien |
更多....查找请用ctrl+F
MIME类型大全
application/vnd.lotus-1-2-3
3gp video/3gpp
aab application/x-authoware-bin
aam application/x-authoware-map
aas application/x-authoware-seg
ai application/post******
aif audio/x-aiff
aifc audio/x-aiff
aiff audio/x-aiff
als audio/X-Alpha5
amc application/x-mpeg
ani application/octet-stream
asc text/plain
asd application/astound
asf video/x-ms-asf
asn application/astound
asp application/x-asap
asx video/x-ms-asf
au audio/basic
avb application/octet-stream
avi video/x-msvideo
awb audio/amr-wb
bcpio application/x-bcpio
bin application/octet-stream
bld application/bld
bld2 application/bld2
bmp application/x-MS-bmp
bpk application/octet-stream
bz2 application/x-bzip2
cal image/x-cals
ccn application/x-cnc
cco application/x-cocoa
cdf application/x-netcdf
cgi magnus-internal/cgi
chat application/x-chat
class application/octet-stream
clp application/x-msclip
cmx application/x-cmx
co application/x-cult3d-object
cod image/cis-cod
cpio application/x-cpio
cpt application/mac-compactpro
crd application/x-mscardfile
csh application/x-csh
csm chemical/x-csml
csml chemical/x-csml
css text/css
cur application/octet-stream
dcm x-lml/x-evm
dcr application/x-director
dcx image/x-dcx
dhtml text/html
dir application/x-director
dll application/octet-stream
dmg application/octet-stream
dms application/octet-stream
doc application/msword
dot application/x-dot
dvi application/x-dvi
dwf drawing/x-dwf
dwg application/x-autocad
dxf application/x-autocad
dxr application/x-director
ebk application/x-expandedbook
emb chemical/x-embl-dl-nucleotide
embl chemical/x-embl-dl-nucleotide
eps application/post******
eri image/x-eri
es audio/echospeech
esl audio/echospeech
etc application/x-earthtime
etx text/x-setext
evm x-lml/x-evm
evy application/x-envoy
exe application/octet-stream
fh4 image/x-freehand
fh5 image/x-freehand
fhc image/x-freehand
fif image/fif
fm application/x-maker
fpx image/x-fpx
fvi video/isivideo
gau chemical/x-gaussian-input
gca application/x-gca-compressed
gdb x-lml/x-gdb
gif image/gif
gps application/x-gps
gtar application/x-gtar
gz application/x-gzip
hdf application/x-hdf
hdm text/x-hdml
hdml text/x-hdml
hlp application/winhlp
hqx application/mac-binhex40
htm text/html
html text/html
hts text/html
ice x-conference/x-cooltalk
ico application/octet-stream
ief image/ief
ifm image/gif
ifs image/ifs
imy audio/melody
ins application/x-NET-Install
ips application/x-ip******
ipx application/x-ipix
it audio/x-mod
itz audio/x-mod
ivr i-world/i-vrml
j2k image/j2k
jad text/vnd.sun.j2me.app-de******or
jam application/x-jam
jar application/java-archive
jnlp application/x-java-jnlp-file
jpe image/jpeg
jpeg image/jpeg
jpg image/jpeg
jpz image/jpeg
js application/x-java******
jwc application/jwc
kjx application/x-kjx
lak x-lml/x-lak
latex application/x-latex
lcc application/fastman
lcl application/x-digitalloca
lcr application/x-digitalloca
lgh application/lgh
lha application/octet-stream
lml x-lml/x-lml
lmlpack x-lml/x-lmlpack
lsf video/x-ms-asf
lsx video/x-ms-asf
lzh application/x-lzh
m13 application/x-msmediaview
m14 application/x-msmediaview
m15 audio/x-mod
m3u audio/x-mpegurl
m3url audio/x-mpegurl
ma1 audio/ma1
ma2 audio/ma2
ma3 audio/ma3
ma5 audio/ma5
man application/x-troff-man
map magnus-internal/imagemap
mbd application/mbedlet
mct application/x-mascot
mdb application/x-msaccess
mdz audio/x-mod
me application/x-troff-me
mel text/x-vmel
mi application/x-mif
mid audio/midi
midi audio/midi
mif application/x-mif
mil image/x-cals
mio audio/x-mio
mmf application/x-skt-lbs
mng video/x-mng
mny application/x-msmoney
moc application/x-mocha
mocha application/x-mocha
mod audio/x-mod
mof application/x-yumekara
mol chemical/x-mdl-molfile
mop chemical/x-mopac-input
mov video/quicktime
movie video/x-sgi-movie
mp2 audio/x-mpeg
mp3 audio/x-mpeg
mp4 video/mp4
mpc application/vnd.mpohun.certificate
mpe video/mpeg
mpeg video/mpeg
mpg video/mpeg
mpg4 video/mp4
mpga audio/mpeg
mpn application/vnd.mophun.application
mpp application/vnd.ms-project
mps application/x-mapserver
mrl text/x-mrml
mrm application/x-mrm
ms application/x-troff-ms
mts application/metastream
mtx application/metastream
mtz application/metastream
mzv application/metastream
nar application/zip
nbmp image/nbmp
nc application/x-netcdf
ndb x-lml/x-ndb
ndwn application/ndwn
nif application/x-nif
nmz application/x-scream
nokia-op-logo image/vnd.nok-oplogo-color
npx application/x-netfpx
nsnd audio/nsnd
nva application/x-neva1
oda application/oda
oom application/x-AtlasMate-Plugin
pac audio/x-pac
pae audio/x-epac
pan application/x-pan
pbm image/x-portable-bitmap
pcx image/x-pcx
pda image/x-pda
pdb chemical/x-pdb
pdf application/pdf
pfr application/font-tdpfr
pgm image/x-portable-graymap
pict image/x-pict
pm application/x-perl
pmd application/x-pmd
png image/png
pnm image/x-portable-anymap
pnz image/png
pot application/vnd.ms-powerpoint
ppm image/x-portable-pixmap
pps application/vnd.ms-powerpoint
ppt application/vnd.ms-powerpoint
pqf application/x-cprplayer
pqi application/cprplayer
prc application/x-prc
proxy application/x-ns-proxy-autoconfig
ps application/post******
ptlk application/listenup
pub application/x-mspublisher
pvx video/x-pv-pvx
qcp audio/vnd.qcelp
qt video/quicktime
qti image/x-quicktime
qtif image/x-quicktime
r3t text/vnd.rn-realtext3d
ra audio/x-pn-realaudio
ram audio/x-pn-realaudio
rar application/x-rar-compressed
ras image/x-cmu-raster
rdf application/rdf+xml
rf image/vnd.rn-realflash
rgb image/x-rgb
rlf application/x-richlink
rm audio/x-pn-realaudio
rmf audio/x-rmf
rmm audio/x-pn-realaudio
rmvb audio/x-pn-realaudio
rnx application/vnd.rn-realplayer
roff application/x-troff
rp image/vnd.rn-realpix
rpm audio/x-pn-realaudio-plugin
rt text/vnd.rn-realtext
rte x-lml/x-gps
rtf application/rtf
rtg application/metastream
rtx text/richtext
rv video/vnd.rn-realvideo
rwc application/x-rogerwilco
s3m audio/x-mod
s3z audio/x-mod
sca application/x-supercard
scd application/x-msschedule
sdf application/e-score
sea application/x-stuffit
sgm text/x-sgml
sgml text/x-sgml
sh application/x-sh
shar application/x-shar
shtml magnus-internal/parsed-html
shw application/presentations
si6 image/si6
si7 image/vnd.stiwap.sis
si9 image/vnd.lgtwap.sis
sis application/vnd.symbian.install
sit application/x-stuffit
skd application/x-Koan
skm application/x-Koan
skp application/x-Koan
skt application/x-Koan
slc application/x-salsa
smd audio/x-smd
smi application/smil
smil application/smil
smp application/studiom
smz audio/x-smd
snd audio/basic
spc text/x-speech
spl application/futuresplash
spr application/x-sprite
sprite application/x-sprite
spt application/x-spt
src application/x-wais-source
stk application/hyperstudio
stm audio/x-mod
sv4cpio application/x-sv4cpio
sv4crc application/x-sv4crc
svf image/vnd
svg image/svg-xml
svh image/svh
svr x-world/x-svr
swf application/x-shockwave-flash
swfl application/x-shockwave-flash
t application/x-troff
tad application/octet-stream
talk text/x-speech
tar application/x-tar
taz application/x-tar
tbp application/x-timbuktu
tbt application/x-timbuktu
tcl application/x-tcl
tex application/x-tex
texi application/x-texinfo
texinfo application/x-texinfo
tgz application/x-tar
thm application/vnd.eri.thm
tif image/tiff
tiff image/tiff
tki application/x-tkined
tkined application/x-tkined
toc application/toc
toy image/toy
tr application/x-troff
trk x-lml/x-gps
trm application/x-msterminal
tsi audio/tsplayer
tsp application/dsptype
tsv text/tab-separated-values
tsv text/tab-separated-values
ttf application/octet-stream
ttz application/t-time
txt text/plain
ult audio/x-mod
ustar application/x-ustar
uu application/x-uuencode
uue application/x-uuencode
vcd application/x-cdlink
vcf text/x-vcard
vdo video/vdo
vib audio/vib
viv video/vivo
vivo video/vivo
vmd application/vocaltec-media-desc
vmf application/vocaltec-media-file
vmi application/x-dreamcast-vms-info
vms application/x-dreamcast-vms
vox audio/voxware
vqe audio/x-twinvq-plugin
vqf audio/x-twinvq
vql audio/x-twinvq
vre x-world/x-vream
vrml x-world/x-vrml
vrt x-world/x-vrt
vrw x-world/x-vream
vts workbook/formulaone
wav audio/x-wav
wax audio/x-ms-wax
wbmp image/vnd.wap.wbmp
web application/vnd.xara
wi image/wavelet
wis application/x-InstallShield
wm video/x-ms-wm
wma audio/x-ms-wma
wmd application/x-ms-wmd
wmf application/x-msmetafile
wml text/vnd.wap.wml
wmlc application/vnd.wap.wmlc
wmls text/vnd.wap.wml******
wmlsc application/vnd.wap.wml******c
wml****** text/vnd.wap.wml******
wmv audio/x-ms-wmv
wmx video/x-ms-wmx
wmz application/x-ms-wmz
wpng image/x-up-wpng
wpt x-lml/x-gps
wri application/x-mswrite
wrl x-world/x-vrml
wrz x-world/x-vrml
ws text/vnd.wap.wml******
wsc application/vnd.wap.wml******c
wv video/wavelet
wvx video/x-ms-wvx
wxl application/x-wxl
x-gzip application/x-gzip
xar application/vnd.xara
xbm image/x-xbitmap
xdm application/x-xdma
xdma application/x-xdma
xdw application/vnd.fujixerox.docuworks
xht application/xhtml+xml
xhtm application/xhtml+xml
xhtml application/xhtml+xml
xla application/vnd.ms-excel
xlc application/vnd.ms-excel
xll application/x-excel
xlm application/vnd.ms-excel
xls application/vnd.ms-excel
xlt application/vnd.ms-excel
xlw application/vnd.ms-excel
xm audio/x-mod
xml text/xml
xmz audio/x-mod
xpi application/x-xpinstall
xpm image/x-xpixmap
xsit text/xml
xsl text/xml
xul text/xul
xwd image/x-xwindowdump
xyz chemical/x-pdb
yz1 application/x-yz1
z application/x-compress
zac application/x-zaurus-zac
zip application/zip
HttpClient 是 Apache Jakarta Common
下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP
协议最新的版本和建议。本文首先介绍 HTTPClient,然后根据作者实际工作经验给出了一些常见问题的解决方法。
HttpClient简介
HTTP 协议可能是现在 Internet 上使用得最多、最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP
协议来访问网络资源。虽然在 JDK 的 java.net 包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK
库本身提供的功能还不够丰富和灵活。HttpClient 是 Apache Jakarta Common
下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP
协议最新的版本和建议。HttpClient 已经应用在很多的项目中,比如 Apache Jakarta 上很著名的另外两个开源项目 Cactus
和 HTMLUnit 都使用了 HttpClient,更多使用 HttpClient 的应用可以参见http://wiki.apache.org/jakarta-httpclient/HttpClientPowered。HttpClient
项目非常活跃,使用的人还是非常多的。目前 HttpClient 版本是在 2005.10.11 发布的 3.0 RC4 。
HttpClient 功能介绍
以下列出的是 HttpClient 提供的主要的功能,要知道更多详细的功能可以参见 HttpClient 的主页。
- 实现了所有 HTTP 的方法(GET,POST,PUT,HEAD 等)
- 支持自动转向
- 支持 HTTPS 协议
- 支持代理服务器等
下面将逐一介绍怎样使用这些功能。首先,我们必须安装好 HttpClient。
HttpClient 基本功能的使用
GET 方法
使用 HttpClient 需要以下 6 个步骤:
1. 创建 HttpClient 的实例
2. 创建某种连接方法的实例,在这里是 GetMethod。在 GetMethod 的构造函数中传入待连接的地址
3. 调用第一步中创建好的实例的 execute 方法来执行第二步中创建好的 method 实例
4. 读 response
5. 释放连接。无论执行方法是否成功,都必须释放连接
6. 对得到后的内容进行处理
根据以上步骤,我们来编写用GET方法来取得某网页内容的代码。
- 大部分情况下 HttpClient 默认的构造函数已经足够使用。
HttpClient httpClient = new HttpClient();
|
- 创建GET方法的实例。在GET方法的构造函数中传入待连接的地址即可。用GetMethod将会自动处理转发过程,如果想要把自动处理
转发过程去掉的话,可以调用方法setFollowRedirects(false)。
GetMethod getMethod = new GetMethod("http://www.ibm.com/");
|
- 调用实例httpClient的executeMethod方法来执行getMethod。由于是执行在网络上的程序,在运行
executeMethod方法的时候,需要处理两个异常,分别是HttpException和IOException。引起第一种异常的原因主要可能是
在构造getMethod的时候传入的协议不对,比如不小心将"http"写成"htp",或者服务器端返回的内容不正常等,并且该异常发生是不可恢复
的;第二种异常一般是由于网络原因引起的异常,对于这种异常
(IOException),HttpClient会根据你指定的恢复策略自动试着重新执行executeMethod方法。HttpClient的恢复
策略可以自定义(通过实现接口HttpMethodRetryHandler来实现)。通过httpClient的方法setParameter设置你实
现的恢复策略,本文中使用的是系统提供的默认恢复策略,该策略在碰到第二类异常的时候将自动重试3次。executeMethod返回值是一个整数,表示
了执行该方法后服务器返回的状态码,该状态码能表示出该方法执行是否成功、需要认证或者页面发生了跳转(默认状态下GetMethod的实例是自动处理跳
转的)等。
//设置成了默认的恢复策略,在发生异常时候将自动重试3次,在这里你也可以设置成自定义的恢复策略
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
new DefaultHttpMethodRetryHandler());
//执行getMethod
int statusCode = client.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
}
|
-
在返回的状态码正确后,即可取得内容。取得目标地址的内容有三种方法:第一种,getResponseBody,该方法返回的是目标的二进制的byte
流;第二种,getResponseBodyAsString,这个方法返回的是String类型,值得注意的是该方法返回的String的编码是根据系
统默认的编码方式,所以返回的String值可能编码类型有误,在本文的"字符编码"部分中将对此做详细介绍;第三
种,getResponseBodyAsStream,这个方法对于目标地址中有大量数据需要传输是最佳的。在这里我们使用了最简单的
getResponseBody方法。
byte[] responseBody = method.getResponseBody();
|
- 释放连接。无论执行方法是否成功,都必须释放连接。
method.releaseConnection();
|
- 处理内容。在这一步中根据你的需要处理内容,在例子中只是简单的将内容打印到控制台。
System.out.println(new String(responseBody));
|
下面是程序的完整代码,这些代码也可在附件中的test.GetSample中找到。
package test;
import java.io.IOException;
import org.apache.commons.httpclient.*;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams;
public class GetSample{
public static void main(String[] args) {
//构造HttpClient的实例
HttpClient httpClient = new HttpClient();
//创建GET方法的实例
GetMethod getMethod = new GetMethod("http://www.ibm.com");
//使用系统提供的默认的恢复策略
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
new DefaultHttpMethodRetryHandler());
try {
//执行getMethod
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
//读取内容
byte[] responseBody = getMethod.getResponseBody();
//处理内容
System.out.println(new String(responseBody));
} catch (HttpException e) {
//发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
//发生网络异常
e.printStackTrace();
} finally {
//释放连接
getMethod.releaseConnection();
}
}
}
|
POST方法
根据RFC2616,对POST的解释如下:POST方法用来向目的服务器发出请求,要求它接受被附在请求后的实体,并把它当作请求队列
(Request-Line)中请求URI所指定资源的附加新子项。POST被设计成用统一的方法实现下列功能:
- 对现有资源的注释(Annotation of existing resources)
- 向电子公告栏、新闻组,邮件列表或类似讨论组发送消息
- 提交数据块,如将表单的结果提交给数据处理过程
- 通过附加操作来扩展数据库
调用HttpClient中的PostMethod与GetMethod类似,除了设置PostMethod的实例与GetMethod有些
不同之外,剩下的步骤都差不多。在下面的例子中,省去了与GetMethod相同的步骤,只说明与上面不同的地方,并以登录清华大学BBS为例子进行说
明。
- 构造PostMethod之前的步骤都相同,与GetMethod一样,构造PostMethod也需要一个URI参数,在本例中,登录
的地址是http://www.newsmth.net/bbslogin2.php。在创建了PostMethod的实例之后,需要给method实例
填充表单的值,在BBS的登录表单中需要有两个域,第一个是用户名(域名叫id),第二个是密码(域名叫passwd)。表单中的域用类
NameValuePair来表示,该类的构造函数第一个参数是域名,第二参数是该域的值;将表单所有的值设置到PostMethod中用方法
setRequestBody。另外由于BBS登录成功后会转向另外一个页面,但是HttpClient对于要求接受后继服务的请求,比如POST和
PUT,不支持自动转发,因此需要自己对页面转向做处理。具体的页面转向处理请参见下面的"自动转向"部分。代码如下:
String url = "http://www.newsmth.net/bbslogin2.php";
PostMethod postMethod = new PostMethod(url);
// 填入各个表单域的值
NameValuePair[] data = { new NameValuePair("id", "youUserName"),
new NameValuePair("passwd", "yourPwd") };
// 将表单的值放入postMethod中
postMethod.setRequestBody(data);
// 执行postMethod
int statusCode = httpClient.executeMethod(postMethod);
// HttpClient对于要求接受后继服务的请求,象POST和PUT等不能自动处理转发
// 301或者302
if (statusCode == HttpStatus.SC_MOVED_PERMANENTLY ||
statusCode == HttpStatus.SC_MOVED_TEMPORARILY) {
// 从头中取出转向的地址
Header locationHeader = postMethod.getResponseHeader("location");
String location = null;
if (locationHeader != null) {
location = locationHeader.getValue();
System.out.println("The page was redirected to:" + location);
} else {
System.err.println("Location field value is null.");
}
return;
}
|
完整的程序代码请参见附件中的test.PostSample
使用HttpClient过程中常见的一些问题
下面介绍在使用HttpClient过程中常见的一些问题。
字符编码
某目标页的编码可能出现在两个地方,第一个地方是服务器返回的http头中,另外一个地方是得到的html/xml页面中。
- 在http头的Content-Type字段可能会包含字符编码信息。例如可能返回的头会包含这样子的信息:Content-Type:
text/html;
charset=UTF-8。这个头信息表明该页的编码是UTF-8,但是服务器返回的头信息未必与内容能匹配上。比如对于一些双字节语言国家,可能服务
器返回的编码类型是UTF-8,但真正的内容却不是UTF-8编码的,因此需要在另外的地方去得到页面的编码信息;但是如果服务器返回的编码不是UTF-
8,而是具体的一些编码,比如gb2312等,那服务器返回的可能是正确的编码信息。通过method对象的getResponseCharSet()方
法就可以得到http头中的编码信息。
- 对于象xml或者html这样的文件,允许作者在页面中直接指定编码类型。比如在html中会有<meta
http-equiv="Content-Type" content="text/html;
charset=gb2312"/>这样的标签;或者在xml中会有<?xml version="1.0"
encoding="gb2312"?>这样的标签,在这些情况下,可能与http头中返回的编码信息冲突,需要用户自己判断到底那种编码类型应该
是真正的编码。
自动转向
根据RFC2616中对自动转向的定义,主要有两种:301和302。301表示永久的移走(Moved
Permanently),当返回的是301,则表示请求的资源已经被移到一个固定的新地方,任何向该地址发起请求都会被转到新的地址上。302表示暂时
的转向,比如在服务器端的servlet程序调用了sendRedirect方法,则在客户端就会得到一个302的代码,这时服务器返回的头信息中
location的值就是sendRedirect转向的目标地址。
HttpClient支持自动转向处理,但是象POST和PUT方式这种要求接受后继服务的请求方式,暂时不支持自动转向,因此如果碰到
POST方式提交后返回的是301或者302的话需要自己处理。就像刚才在POSTMethod中举的例子:如果想进入登录BBS后的页面,必须重新发起
登录的请求,请求的地址可以在头字段location中得到。不过需要注意的是,有时候location返回的可能是相对路径,因此需要对
location返回的值做一些处理才可以发起向新地址的请求。
另外除了在头中包含的信息可能使页面发生重定向外,在页面中也有可能会发生页面的重定向。引起页面自动转发的标签是:<meta
http-equiv="refresh" content="5;
url=http://www.ibm.com/us">。如果你想在程序中也处理这种情况的话得自己分析页面来实现转向。需要注意的是,在上面那
个标签中url的值也可以是一个相对地址,如果是这样的话,需要对它做一些处理后才可以转发。
处理HTTPS协议
HttpClient提供了对SSL的支持,在使用SSL之前必须安装JSSE。在Sun提供的1.4以后的版本中,JSSE已经集成到
JDK中,如果你使用的是JDK1.4以前的版本则必须安装JSSE。JSSE不同的厂家有不同的实现。下面介绍怎么使用HttpClient来打开
Https连接。这里有两种方法可以打开https连接,第一种就是得到服务器颁发的证书,然后导入到本地的keystore中;另外一种办法就是通过扩
展HttpClient的类来实现自动接受证书。
方法1,取得证书,并导入本地的keystore:
- 安装JSSE
(如果你使用的JDK版本是1.4或者1.4以上就可以跳过这一步)。本文以IBM的JSSE为例子说明。先到IBM网站上下载JSSE的安装包。然后解
压开之后将ibmjsse.jar包拷贝到<java-home>"lib"ext"目录下。
- 取得并且导入证书。证书可以通过IE来获得:
1. 用IE打开需要连接的https网址,会弹出如下对话框:

2. 单击"View Certificate",在弹出的对话框中选择"Details",然后再单击"Copy to
File",根据提供的向导生成待访问网页的证书文件

3. 向导第一步,欢迎界面,直接单击"Next",

4. 向导第二步,选择导出的文件格式,默认,单击"Next",

5. 向导第三步,输入导出的文件名,输入后,单击"Next",

6. 向导第四步,单击"Finish",完成向导

7. 最后弹出一个对话框,显示导出成功

-
用keytool工具把刚才导出的证书倒入本地keystore。Keytool命令在<java-home>"bin
"下,打开命令行窗口,并到<java-home>"lib"security"目录下,运行下面的命令:
keytool -import -noprompt -keystore cacerts -storepass changeit -alias yourEntry1 -file your.cer
|
其中参数alias后跟的值是当前证书在keystore中的唯一标识符,但是大小写不区分;参数file后跟的是刚才通过IE导出的证
书所在的路径和文件名;如果你想删除刚才导入到keystore的证书,可以用命令:
keytool -delete -keystore cacerts -storepass changeit -alias yourEntry1
|
- 写程序访问https地址。如果想测试是否能连上https,只需要稍改一下GetSample例子,把请求的目标变成一个https地
址。
GetMethod getMethod = new GetMethod("https://www.yourdomain.com");
|
运行该程序可能出现的问题:
1. 抛出异常java.net.SocketException: Algorithm SSL not
available。出现这个异常可能是因为没有加JSSEProvider,如果用的是IBM的JSSE Provider,在程序中加入这样的一行:
if(Security.getProvider("com.ibm.jsse.IBMJSSEProvider") == null)
Security.addProvider(new IBMJSSEProvider());
|
或者也可以打开<java-home>"lib"security"java.security,在行
security.provider.1=sun.security.provider.Sun
security.provider.2=com.ibm.crypto.provider.IBMJCE
|
后面加入security.provider.3=com.ibm.jsse.IBMJSSEProvider
2. 抛出异常java.net.SocketException: SSL implementation not
available。出现这个异常可能是你没有把ibmjsse.jar拷贝到<java-home>"lib"ext"目录下。
3. 抛出异常javax.net.ssl.SSLHandshakeException: unknown
certificate。出现这个异常表明你的JSSE应该已经安装正确,但是可能因为你没有把证书导入到当前运行JRE的keystore中,请按照前
面介绍的步骤来导入你的证书。
方法2,扩展HttpClient类实现自动接受证书
因为这种方法自动接收所有证书,因此存在一定的安全问题,所以在使用这种方法前请仔细考虑您的系统的安全需求。具体的步骤如下:
- 提供一个自定义的socket
factory(test.MySecureProtocolSocketFactory)。这个自定义的类必须实现接口
org.apache.commons.httpclient.protocol.SecureProtocolSocketFactory,在实现接口
的类中调用自定义的X509TrustManager(test.MyX509TrustManager),这两个类可以在随本文带的附件中得到
- 创建一个org.apache.commons.httpclient.protocol.Protocol的实例,指定协议名称和默认
的端口号
Protocol myhttps = new Protocol("https", new MySecureProtocolSocketFactory (), 443);
|
- 注册刚才创建的https协议对象
Protocol.registerProtocol("https ", myhttps);
|
- 然后按照普通编程方式打开https的目标地址,代码请参见test.NoCertificationHttpsGetSample
处理代理服务器
HttpClient中使用代理服务器非常简单,调用HttpClient中setProxy方法就可以,方法的第一个参数是代理服务器地
址,第二个参数是端口号。另外HttpClient也支持SOCKS代理。
httpClient.getHostConfiguration().setProxy(hostName,port);
|
结论
从上面的介绍中,可以知道HttpClient对http协议支持非常好,使用起来很简单,版本更新快,功能也很强大,具有足够的灵活性和扩
展性。对于想在Java应用中直接访问http资源的编程人员来说,HttpClient是一个不可多得的好工具。
参考资料
- Commons
logging包含了各种各样的日志API的实现,读者可以通过站点http://jakarta.apache.org/commons
/logging/得到详细的内容
- Commons
codec包含了一些一般的解码/编码算法。包含了语音编码、十六进制、Base64和URL编码等,通过http:
//jakarta.apache.org/commons/codec/可以得到详细的内容
- rfc2616是关于
HTTP/1.1的文档,可以在http://www.faqs.org/rfcs/rfc2616.html上得到详细的内容,另外rfc1945是关
于HTTP/1.0的文档,通过http://www.faqs.org/rfcs/rfc1945.html可以得到详细内容
- SSL――SSL
是由 Netscape Communications Corporation 于 1994 年开发的,而 TLS V1.0 是由
Internet Engineering Task Force(IETF)定义的标准,它基于 SSL
V3.0,并且在使用的加密算法上与其有些许的不同。例如,SSL 使用 Message Authentication
Code(MAC)算法来生成完整性校验值,而 TLS 应用密钥的 Hashing for Message Authentication
Code(HMAC)算法。
- IBM JSSE提供了SSL(Secure Sockets
Layer)和TLS(Transport Layer
Security)的java实现,在http://www-03.ibm.com/servers/eserver/zseries/software
/java/jsse.html中可以得到详细的信息
- Keytool是一个管理密钥和证书的工具。关于它详细的使用信
息可以在http://www.doc.ic.ac.uk/csg/java/1.3.1docs/tooldocs/solaris
/keytool.html上得到
- HTTPClient的主页是http://jakarta.apache.org
/commons/httpclient/,你可以在这里得到关于HttpClient更加详细的信息
http://update1.aptana.org/studio/3.2/024747/index.html
在以上网址中可以下载插件或者在线安装插件:
End of Life Aptana Studio 1.2
This update site is for Aptana Studio 1.2 users. There is already a
newer version of Aptana Studio available. Please check it out at
http://aptana.org/studio/download
Aptana Studio 3.2 and 3.3 Update Site
This site is designed to be used inside Eclipse 3.2 or manually update
an old version of Aptana Studio.
If you have Aptana Studio installed, it is recommended you use the
internal update mechanism available via the
Help menu => Check for Aptana Updates...
Install Aptana Studio as a Plugin
For Eclipse 3.2 or Eclipse 3.3
If you're already familiar with installing plugins from Eclipse, you
can use this URL for the update site:
http://update.aptana.com/update/studio/3.2
For detailed instructions click here.
For Eclipse 3.4
For Eclipse 3.4 installation instructions click here
From a Local File

- Save the above file to an easy to find location.
- Open Eclipse, and go to Help > Software Updates >
Find and Install
- Search for new features to install, then click "Next" then choose
"New Archived Site". Choose the file you saved in step 1.
- Select the appropriate plugins to install, then click "Next",
accept the license agreements, and click "Next" again.
- Click "Change location". If no appropriate location is already
available, click "Add Location" and choose something like
"D:"dev"extensions"pluginname" or "extesnions"aptana".
- Click "Finish".
Update Aptana Studio Standalone from a Local File
- Save the above file to an easy-to-find location, preferably in the
root of your drive.
- Unzip the file into a folder.
- Make sure fix_policy.sh (OS X and Linux) or fix_policy.vbs
(Windows) is executable
- Run fix_policy.sh (OS X and Linux) or fix_policy.vbs (Windows)
- Open policy_url.txt and copy the URL into your clipboard.
- Open Aptana Studio, and go to Window > Preferences >
Install/Update
- Paste the URL from policy_url.txt (something similar to
file:///path/to/policy.xml) into the Policy URL field
- Click "OK".
- Go to Help > Check for Aptana Studio Updates now...
- In the "Updates" window, check the box next to the name of the
plug-in, and click the "Next" button.
- Choose the option to accept the terms of the license agreement,
and click the "Next" button.
- Click the "Finish" button.
- Click the "Install All" button.
如果按照以上方法安装有冲突,即可将其下载的插件解压(比如我解压到D:/myeclipse6.0.1/eclipse/aptana_update_3.3),并把对应的文件复制features和plugins,并在D:/myeclipse6.0.1/eclipse/links目录下新建aptana.link文件,并编辑:path=D:\\myeclipse6.0.1\\eclipse\\aptana_update_3.3
解决开启后报错java.lang.NullPointerException的问题
开启后弹出对话框报错java.lang.NullPointerException,点击details,他报错:
java.lang.NullPointerException
at
com.aptana.ide.xul.FirefoxBrowser.createControl(FirefoxBrowser.java:314)
at
com.aptana.ide.server.portal.ui.MyAptanaEditor.createPartControl(MyAptanaEditor.java:261)
at
org.eclipse.ui.internal.EditorReference.createPartHelper(EditorReference.java:596)
...........
省略.............
这时,虽我已经安装了firefox,但还是要选择windows->Preferences->My
Aptana/Message Center-> "Use Firefox as the Aptana Home Page
Browser",去掉勾子就解决了,My Aptana的庐山真面目就欣赏到了
* struts1.2和webwork的区别
* hibernate和ibatis的区别
* spring工作机制,IOC容器
* servlet的一些相关问题
* webservice相关
* java基础:jvm,HashSet等等
* 考察学习新技术的能力
1.hibernate中配置int和integer的区别
2.手写,spring+hibernate配置
3.JavaScript时间和如何实现继承
其他略忘了
下面的安装以myeclipse6.0为例
一、下载:
http://jadclipse.sourceforge.net/wiki/index.php/Main_Page#Download(jdaclipse插件主页)
下载插件:
- JadClipse 3.3
This release stream is appropriate for Eclipse 3.3.
- JadClipse 3.2
This release stream is appropriate for Eclipse 3.2.
- JadClipse 3.1
This release stream is appropriate for Eclipse 3.1.
| Filename
| Size
| Description
|
| jadclipse_3.1.0.jar
|
54 KB
|
JadClipse for Eclipse 3.1 (including milestone builds starting
from 3.1M6 up to 3.2M2)
|
myeclipse6.0 就下载JadClipse 3.3
下载Jad反编译工具:
http://www.varaneckas.com/jad,在该页中找到适合自己操作系统平台的jad下载。下载后解压,然后将解压后的jad.exe文件复制到%JAVA_HOME%"bin目录下面(可以将jad.exe放到任意位置,只要记住其存放路径就好,下面要用到)。
二、安装:
Eclipse中的插件安装可以参考:
方法1、直接将x.x.x.jar(x.x.x.代表版本号)复制到%ECLIPSE_HOME%"plugins目录下。
方法2、使用link方式安装,建立D:"Myplugins"jadclipse3.2.4"eclipse"plugins的目录结构,将jadclipse_3.2.4.jar放到plugins目录下面(注:其中D:"Myplugins为你自己定义的一个专门放置插件的目录)。再在%ECLIPSE_HOME%"links目录下面建立一个jadclipse3.2.4.link文件(该文件名随便取)。文件里面内容为:path=D:/Myplugins/jadclipse3.2.4.
三、
使用:
启动eclipse,点击反编译的类文件,此时会激活jadclipse插件,在eclipse菜单中会多出一个jadclipse菜单,
如下图所示:

一般地它会自动
反编译相应的class文件,如果没有自动反编译,请点击
jadclipse->Decompile
如下图所示:

常见问题及解决:
(一)启动eclipse,打开Window->Preferences->Java->JadClipse,如果没有找到JadClipse,即JadClipse插件没有激活。
(1)检查插件安装的版
本是否与你安装的eclipse版本对应
(2)使用 –clean参数来启动eclipse
(二)在使用JadClipse插件反编译class文件时出现如下类似错误:
/*jadclipse*/
/*
DECOMPILATION REPORT
Decompiled from: D:"Program Files"Java"jdk1.5.0_12"jre"lib"rt.jar
Total time: 16 ms
Jad reported messages/errors:
Exit status: 0
Caught exceptions:
java.io.IOException: CreateProcess: (...)
请确保你的Jad路径在eclipse中正确制定。
启动eclipse,打开:Window->Preferences->Java->JadClipse.
1、Path to decompiler,这里设置反编译工具jad的全路径名,比如:%JAVA_HOME%"bin"jad.exe.
2、Directory for temporary files,这里设置临时
文件路径。
至于Window->Preferences->Java->JadClipse目录下的Debug,Directives,Formatting,Misc目录中的参数
设置,就不再罗嗦了。
(三)安装完成后,eclipse没有自动将JadClipse Class File
Viewer设置成class文件的缺省打开方式。
如果没有默认,可以在Eclipse的Windows—>
Perference—>General->Editors->File Associations中修改“*.class”默认关联的编辑器为“JadClipse Class File
Viewer”。设置完成后,双击*.class文件,eclipse将自动反编译。
OGNL介绍
OGNL是Object-Graph Navigation
Language的缩写,它是一种功能强大的表达式语言(Expression
Language,简称为EL),通过它简单一致的表达式语法,可以存取对象的任意属性,调用对象的方法,遍历整个对象的结构图,实现字段类型转化等功
能。它使用相同的表达式去存取对象的属性。
XWork遵循“不要重复地发明同一个轮子”的理论,它的表达式语言核心用的就是这个OGNL。我们先
来看看一个简单的例子:
还记得我们用户注册的那个例子吗?我们输入框的name用到的名字就是OGNL的表达式,比如:用户名的输入
框:“<input type="text"
name="user.username">”,在用户注册成功之后我们要显示用户注册的信息,用了“<ww:property
value="user.username"/>”。Input输入框里的“user.username”,它解析成Java语句
为:getUser().setUsername();,property标签里的“user.username”解析为Java语
句:getUser.getUsername();。
我们的两个表达式都是相同的,但前一个保存对象属性的值,后一个是取得对象属性的值。表达式
语言简单、易懂却又功能强大,关于OGNL更多的介绍可以去http://www.ognl.org,
那里有很详细的文档
值堆栈-OgnlValueStack
OGNL在框架中的应用,最主要是支持我们的值堆栈(Value
Stack)——OgnlValueStack,它主要的功能是通过表达式语言来存取对象的属性。用户界面输入数据,它会根据保存表达式将数据依次保存到
它堆栈的对象中,业务操作完成,结果数据会通过表达式被获取、输出。
还记得我们用户注册的例子吗?下面我们用一段程序来演示它向
OgnlValueStack中保存、取得数据的步骤:
// DemoRegisterValueStack
package
example.register;
import com.opensymphony.xwork.util.OgnlValueStack;
public
class DemoRegisterValueStack {
public void demo(){
RegisterAction action = new RegisterAction();
OgnlValueStack
valueStack= new OgnlValueStack();
valueStack.push(action);
valueStack.setValue("user.username","Babydavic");
System.out.println("username =
"+valueStack.findValue("user.username"));
}
public
static void main(String[] args) {
DemoRegisterValueStack
demoValueStack = new DemoRegisterValueStack();
demoValueStack.demo();
}
}
我们来看一看它的demo()方法:
1、
创建我们的Action(RegisterAction)类的对象action,将action对象压入堆栈valueStack中。在WebWrok中
Action的创建、入栈是在DefaultActionInvocation构造函数中进行的,详细介绍见:ServletDispatcher原理。
2、
通过表达式语言,调用堆栈对象的get()、set()方法,设置该对象的值。
public void setValue(String
expr, Object value)
语句:valueStack.setValue("user.username","Babydavic");
的作用等同于:action.getUser().setUsername("Babydavic");
3、
通过表达式语言,去堆栈对象中查找我们前面保存的值,并在控制台打印。valueStack.findValue("user.username")等同
与语句:
action.getUser().getUsername()
最后控制台打印的结果:
username = Babydavic
CompoundRoot
在OgnlValueStack中,一个堆栈其
实是一个List。查看OgnlValueStack你会发现,堆栈就是
com.opensymphony.xwork.util.CompoundRoot类的对象:
public class
CompoundRoot extends ArrayList {
//~ Constructors
/////////////////////////////////////
public CompoundRoot() {
}
public CompoundRoot(List list) {
super(list);
}
//~ Methods ////////////////////////////////////////////
public
CompoundRoot cutStack(int index) {
return new
CompoundRoot(subList(index, size()));
}
public Object
peek() {
return get(0);
}
public Object pop() {
return remove(0);
}
public void push(Object o) {
add(0, o);
}
}
我们通过表达式向堆栈对象操作时,我们并不知道堆栈中有哪些对象。OgnlValueStack会根据堆栈由上向下的顺序(先入栈在下面,最后入栈
在最上面)依次去查找与表达式匹配的对象方法,找到即进行相应的存取操作。假设后面对象也有相同的方法,将不会被调用。
下面我们看一个对
OgnlValueStack操作的程序,它主要演示了如何对Map对象的存取和OgnlValueStack堆栈的原理
package
example.register;
import
com.opensymphony.xwork.util.OgnlValueStack;
public class
DemoGroupValueStack {
public void demoAction(){
DemoGroupAction action = new DemoGroupAction();
OgnlValueStack valueStack= new OgnlValueStack();
valueStack.push(action);
User zhao = new User();
zhao.setUsername("zhao");
zhao.setEmail("zhao@yahoo.com.cn");
User qian = new User();
qian.setUsername("qian");
qian.setEmail("qian@yahoo.com.cn");
valueStack.setValue("users['zhao']",zhao);
valueStack.setValue("users['qian']",qian);
System.out.println("users['zhao'] =
"+valueStack.findValue("users['zhao']"));
System.out.println("users['qian'] =
"+valueStack.findValue("users['qian']"));
System.out.println("users size = "+valueStack.findValue("users.size"));
System.out.println("allUserName[0] =
"+valueStack.findValue("allUserName[0]"));
}
public void demoModels(){
User model_a = new
User();
model_a.setUsername("model_a");
User
model_b = new User();
model_b.setUsername("model_b");
User model_c = new User();
model_c.setUsername("model_c");
OgnlValueStack valueStack= new OgnlValueStack();
valueStack.push(model_a);
valueStack.push(model_b);
valueStack.push(model_c);
System.out.println("username = "+valueStack.findValue("username"));
System.out.println("[1].username =
"+valueStack.findValue("[1].username"));
System.out.println("[0].toString = "+valueStack.findValue("[0]"));
System.out.println("[1].toString = "+valueStack.findValue("[1]"));
System.out.println("[2].toString = "+valueStack.findValue("[2]"));
}
public static void main(String[] args) {
DemoGroupValueStack demoValueStack = new DemoGroupValueStack();
demoValueStack.demoAction();
demoValueStack.demoModels();
}
}
package example.register;
import
java.util.ArrayList;
import java.util.HashMap;
import
java.util.List;
import java.util.Map;
public class
DemoGroupAction {
private Map users = new HashMap();
public Map getUsers(){
return this.users;
}
public List getAllUserName(){
return new
ArrayList(users.keySet());
}
public String execute(){
//执行业务操作
return null;
}
public String
toString(){
return users.toString();
}
}
注意:1、
Map属性的存取,它的表达式语言如:users['zhao'],注意它用’’来引用HashMap的key字符串。
2、
demoModels()方法演示了OgnlValueStack中堆栈的原理,请特别注意它的
[0].toString、[1].toString、[2].toString,它们依次调用堆栈中对象的toString()方法,并逐一的减少堆栈
最上面的对象。
控制台输出的结果如下:
users['zhao'] =
username=zhao;password=null;email=zhao@yahoo.com.cn;age=0
users['qian']
= username=qian;password=null;email=qian@yahoo.com.cn;age=0
users
size = 2
allUserName[0] = qian
username = model_c
[1].username
= model_b
[0].toString =
[username=model_c;password=null;email=null;age=0,
username=model_b;password=null;email=null;age=0,
username=model_a;password=null;email=null;age=0]
[1].toString =
[username=model_b;password=null;email=null;age=0,
username=model_a;password=null;email=null;age=0]
[2].toString =
[username=model_a;password=null;email=null;age=0]
axis2创建web service(一)
http://blog.csdn.net/chnic/archive/2008/03
/13/2179760.aspx
http://www.javaeye.com/topic/284387
axis2 是新一代的web service开发工具,它会让你的web
service开发变得轻松,快捷。下面让我们以一个实际的例子来体验一下。
首先,工欲善其事,必先利其器。就让我们先做好一些必备的准备工作吧。
1.下载axis2 的2进制的包和war,现在的最新版本是1.4.1
发布时间是2008-8-25
地址 http://ws.apache.org/axis2
具体的1.4.1版本的http://ws.apache.org/axis2/download/1_4_1/download.cgi
2.把下载后的war放入tomcat的webapps目录里,然后启动tomcat,这样war包就会自动解压为目录axis2
在浏览器中输入http://localhost:8080/axis2/ ,如果一切正常你会看到下面的画面
3,就开始准备一下axis2的eclispe的插件
了。axis2的eclispe插件分为2个,一个是帮助我们生成aar文件的,另一个是帮
我们用wsdl文件生成stub代码的。
下载地址是
http://www.apache.org/dyn/mirrors/mirrors.cgi/ws/axis2/tools/1_4_1/axis2-eclipse-service-archiver-wizard.zip
http://www.apache.org/dyn/mirrors/mirrors.cgi/ws/axis2/tools/1_4_1/axis2-eclipse-codegen-wizard.zip
下载完2个压缩文件后,可以直接把解压后的文件拷贝到plugins目录中,也可以在links目录中写文件路径的方式来安装插件,安装完插件后,
打开eclipse,在package explorer 中点击右键--->选择new---->other
如果安装正确你会看到

这样准备工作就都做好了。接下来就是正式开发了。
开发的过程,下回分解。。。。。
工具都已经准备齐全了。我们来动手做一个小例子来小试牛刀!
这一节我们先利用axis2来发布一个web service 的服务,然后在下一节我们做一客户端来调用这个服务。
我们的服务很简单的,就是输入一个字符串,然后打印出一段字符串。
代码很简单,主要是测试用。
- package com.deltaj.server;
-
- public class SimpleServer {
-
- /**
- * 简
单的测试方法
- *
- */
- public String simpleMethod(String name) {
- return name + "Say this is a Simple method ^-^";
- }
-
- }
package com.deltaj.server;
public class SimpleServer {
/**
* 简单的测试方法
*
*/
public String simpleMethod(String name) {
return name + "Say this is a Simple method ^-^";
}
}
主要的过程就是如何利用axis2的eclispe插件来发布这个服务啦。
1。在eclispe 的package Explorer
中点击右键,在菜单中选择新建--->other...----->Axis2 Service Archiver

2.然后点击next进入了类选择页面,在这个页面中的Class File Location选择框中选择类所在的文件夹。

3.点击next之后进入了选择 wsdl文件,这里我们选择skip wsdl。
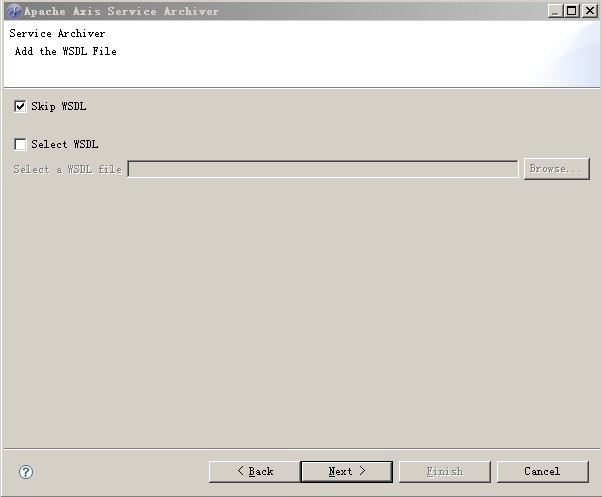

4. 点击next之后,进入的是选择jar文件的页面,这里我们没有外部的jar,所以点击next直接跳过这个页面。

4.点击next之后,进入的是选择xml页面,这里我们选择的是自动生成xml,也就是勾选
Generate the service xml automatically这一项


5.点击next之后,进入的是生成xml文件的页面,在service name
里填写这个服务所起的名字,这里我起名为simpleServer,然后在class name
中填写要发布的类,这里一定要写全路径,写好后就可以点击load 按钮,如果一切ok的话,你会看到如下画面
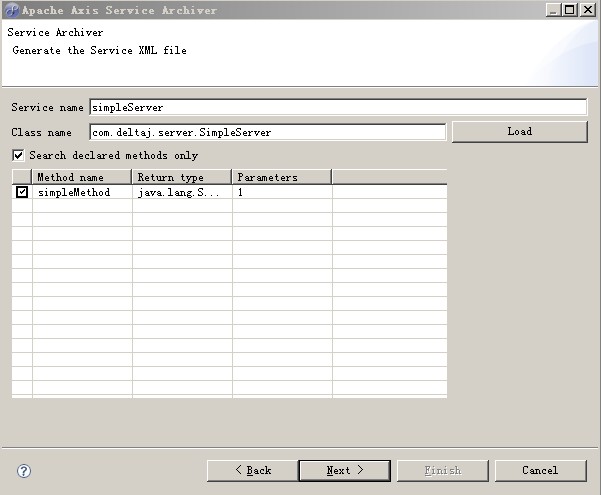

6 点击next 后,进入的是输出artiver文件的页面,先要在output File location 中选择要输出的路径,
在output File Name中输入artiver文件的名称。我起的名字是simpleServer


7.点击finish ,如果看到如下的画面,恭喜你,服务发布成功啦
8.接下来,我们就可以把这个aar文件放入tomcat中发布,首先把生成的aar文件拷贝到tomcat目录中的axis2项目的
service目录中位置如图。

9.接下来启动tomcat,在地址栏中输入http://localhost:8080/axis2 ,
你会看到axis2的欢迎画面
 
10.点击Service连接,你会看到发布的服务列表。这里面就能看到我们发布的simpleService


11.点击我们的服务simpleServer的连接,我们会看到。至此,服务发布成功。

 这节我们就来写一个客户端来调用一下这个服务。主要关注一下如何用elispe的axis2的插件来生成stub代码。
1.在eclispe 的package Explorer
中点击右键,在菜单中选择新建--->other...----->Axis2 Code Generator
2.点击next,进入下一个页面,选择从wsdl文件来产生java文件。
3. 点击next,然后选择wsdl文件,注意此处要填写上一节我们
4.点击next,进入设置页面,这里我们就用默认的设置。

5. 点击next,选择输出文件的路径。

(出错解决方案:
除了把backport-util-
concurrent-2.2.jar加到lib中, 加<library
name="lib/backport-util-concurrent-2.2.jar">
<export name="*"/>
</library> 到plugsin.xml
还要
1.
把Axis2_Codegen_wizard_1.3.0(eclipse/plugins/Axis2_Codegen_wizard_1.3.0)的
名字改成Axis2_Codegen_wizard_1.4.0
2. 在plugin.xml中在<plugin>中
把Axis2_Codegen_wizard的version="1.3.0"改成version="1.3.0"
在MyEclipse6.5中会报错:
An error ocurred while completing process
-java.lang.reflect.InvocationTargetException
主要的问题在于 Code Generator plugin 内缺少了 backport-util-concurrent-3.1.jar
包和geronimo-stax-api_1.0_spec-1.0.1.jar 包。
[解决方案] :
1.关闭 Eclipse
2.copy %AXIS2_HOME%"lib" 下的
backport-util-concurrent-3.1.jar 和 backport-util-concurrent-3.1.jar
复制到 MyEclipse 6.5"eclipse"plugins"Axis2_Codegen_Wizard_1.3.0"lib
文件夹下。
3.注册此 jar 包:
修改MyEclipse
6.5"eclipse"plugins"Axis2_Codegen_Wizard_1.3.0"plugin.xml 文件
在 <runtime> 內加入下面的字串
<library name="lib/geronimo-stax-api_1.0_spec-1.0.1.jar">
<export name="*"/>
</library>
<library name="lib/backport-util-concurrent-3.1.jar">
<export name="*"/>
</library>
到plugin.xml文件中,保存后重新启动Eclipse即可。
)
6.点击next,如果看到这个页面,恭喜你已经生成代码成功。
7.在package
Explorer中刷新一下项目,然后你发现出现2个新的文件SimpleServerStub和
SimpleServerCallbackHandler 。打开SimpleServerStub你会惊喜的发现。著名的小红叉一个接一个的
这是因为没有axis2的类包。我们可以在下载的axis2-1.4.1-bin中找到lib包,把其中的jar都加入我们的工程中。
然后重新编译一下工程,这时我们发现SimpleServerStub还是有几个小红叉。这个是因为这个插件有个小bug。
生成的代码没有实现序列化方法。我们可以自己来加上,在小红叉上点一下,弹出一个小菜单,选择
Add unimplemented methods .

8.
- /**
- * 调
用发布的服务。
- *
- */
- public class SimpleClient {
-
- public static void main(String[] args) throws Exception{
-
- //初始化桩文件
- SimpleServerStub stub = new SimpleServerStub();
- //初始化SimpleMethod方法。
- SimpleServerStub.SimpleMethod request = new SimpleServerStub.SimpleMethod();
- //调用simpleMethod的setName方法。
- request.setName("zt");
- //
- System.out.println(stub.simpleMethod(request).get_return());
-
-
- }
- }
/**
* 调用发布的服务。
*
*/
public class SimpleClient {
public static void main(String[] args) throws Exception{
//初始化桩文件
SimpleServerStub stub = new SimpleServerStub();
//初始化SimpleMethod方法。
SimpleServerStub.SimpleMethod request = new SimpleServerStub.SimpleMethod();
//调用simpleMethod的setName方法。
request.setName("zt");
//
System.out.println(stub.simpleMethod(request).get_return());
}
}
如果一切正常,你就会看到结果
log4j:WARN No appenders could be found for logger
(org.apache.axis2.description.AxisService).
log4j:WARN Please
initialize the log4j system properly.
ztSay this is a Simple method
^-^。
调用服务成功。这是个简单的例子,下节我们再做一个复杂一点的例子,来更好的学习axis2
我们2005年底就做了一个Wap网站 “WAP一把刀实用查询大全”,当
时没有统计、没有广告,只有简单的免费服务功能。
2007年Google推出AdSense for
Mobile的时候,我们对Wap网站代码进行了一些整理,以方便统一加入广告代码,同时我们也加入了一段某公司提供的Wap统计代码,可惜做Wap统计
这样的免费功能只有投入没有收入,一般公司都不愿意长久做,所以都没能用很长时间,换了1、2次统计代码后我们也放弃了统计,就从AdSense中的分渠
道统计移动广告收入的数据来大概知道网站的访问流量。
今年从Analytics的英文官方博客中看到Google终于承担起这个免费的Wap统计任务,不过我忙于其它事情,一直没有加上代
码试试。
前些天AdSense移动广告的代码要求更新,但我们用新代码却无法正常访问,已经给Google的人写邮件询问去了,等待答复中。
昨天在为其它Web网站添加Google
Webmastertools中的站点地图时,顺便把wap.18dao.com也验证加入了,然后试着将Analytics的移动统计代码加入,这个代
码可以从“Analytics(分析)设置 - 配置文件设置 - 检查状态 - 跟踪代码 -
高级”中选择“针对手机创建的网站”,可以提供“选择您的移动网站的服务器端语言”为:
我们以前是用JSP开发的,选择JSP后提示:
将代码粘贴到您的移动网站
请注意:请勿在使用移动跟踪的网页上使用台式机跟踪代码。
第 1 步:复制下列代码,然后将其粘贴到您要跟踪的每个网页的 <html> 标记之前,并使其紧邻此标记。
<%@ page import="java.io.UnsupportedEncodingException,
java.net.URLEncoder" %>
<%!
// Copyright 2009 Google Inc. All Rights Reserved.
private static final String GA_ACCOUNT = "MO-241337-53";
private static final String GA_PIXEL = "ga.jsp";
private String googleAnalyticsGetImageUrl(
HttpServletRequest request) throws UnsupportedEncodingException {
StringBuilder url = new StringBuilder();
url.append(GA_PIXEL + "?");
url.append("utmac=").append(GA_ACCOUNT);
url.append("&utmn=").append(Integer.toString((int) (Math.random() * 0x7fffffff)));
String referer = request.getHeader("referer");
String query = request.getQueryString();
String path = request.getRequestURI();
if (referer == null || "".equals(referer)) {
referer = "-";
}
url.append("&utmr=").append(URLEncoder.encode(referer, "UTF-8"));
if (path != null) {
if (query != null) {
path += "?" + query;
}
url.append("&utmp=").append(URLEncoder.encode(path, "UTF-8"));
}
url.append("&guid=ON");
return url.toString().replace("&", "&");
}
%>
第 2 步:复制下列代码,然后将其粘贴到您要跟踪的每个网页的 </body> 标记之前,并使其紧邻此标记。
<% String googleAnalyticsImageUrl = googleAnalyticsGetImageUrl(request); %>
<img src="<%= googleAnalyticsImageUrl %>" />
将此文件复制到您的根目录
下载 ga.jsp 并将其保存到您的网络服务器的根目录 ("/")。请确保将您的根目录配置为执行服务器端代码。
我们以前开发时,用的wml
1.x,根本就没有<html>和</body>标记,不过有对应的<wml>和</card>,我一
步一步按照上面的要求设置了。顺便还把以前浏览器报错的地方统一批量修改替换掉。
有几个特别说明的地方:
从实际运行的情况看,对Wap网站没有特别的影响,也没有像以前其他小公司搞的统计代码都带个图标链接,Analytics的wap和web版
本一样,都不在网页中显示任何内容。
登录Analytics后台已经可以看到有统计数据产生了,wap网站的统计数据和web网站的统计数据差不多全面,比以前的其它免费
wap统计都强很多,不仅仅是简单的访问数据统计,更重要的还有各种分析功能。我准备打开Analytics与AdSense结合的功能看看能否还统计出
AdSense的情况,另外也打开内部搜索统计试一试,有新的发现后再补充在日志中。
用Analytics中的Wap统计有一点最放心:不用害怕Google过一阵子不再提供这个服务了。
有关插件安装问题,四种常用的方法在此特别注明:
1. “帮助”->“软件更新”->“查找并安装”->“搜索要安装的新功能部件”->“新建远程站点”(此种方式用于在线更新)
2. “帮助”->“软件更新”->“查找并安装”->“搜索要安装的新功能部件”->“新建本地站点”(如果插件已经下载到了本地,请不要用第一种方法)
3. 直接拷贝plugins和features两个目录下的内容置于$Eclipse_Home$/对应的plugins和features下面
4. 用link外链接与外部插件关联
前三种方法都会将插件文件拷贝至相$Eclipse_Home$/对应的plugins和
features目录下,从本质上看,没多大区别,并且插件只能安装和禁用,不能卸载(当然,如果你对插件对应的目录和文件都很熟悉的话,可以通过直接删
除拷进去的文件来达到卸载插件的目的),但方法一和方法二在安装插件的时候很容易出错或者是产生冲突,特别是当你用了Myeclipse插件、中文包的同
时,又想安装HibernateSynchronizer、 Jode Compiler(Class反编译工具)、Visual
Editor等插件时,及有可能导致Myeclipse插件和中文包失效。
所以,如果插件已经下载到了本地,请直接拷贝至$Eclipse_Home$/对应的plugins和features目录下,也就是用方法三,这样能避免冲突。
方法四是将所有的插件用一个外部目录存放起来,假如是D:\plug-in,将上面所示的插件目录文件全部拷贝到该目录下,比如Tomcat插件,
此时的文件路径就是D:\plug-in\tomcat_plug\eclipse\plugins\
com.sysdeo.eclipse.tomcat_3.1.0.beta(请注意,方法四一定要严格这样的目录路径放置文件)。然后在$
Eclipse_Home$下新建一个links目录,并在links目录下建立关联文件,假如是tomcat.link,在建立的关联文件中加入如下语
句:
path=D:\\plug-in\\tomcat_plug
也可以写成下面的形式
path=D:/plug-in/tomcat_plug
还可以写成相对路径的形式
用SAX解析xml文件的例子
2008-07-15 09:46
1. Xml技术简介
Xml文件有两种约束类型,包括文档类型定义(DTD)和Xml 模式(Schema)。Xml
DTD被包含在xml1的标准里。Xml 模式被包含在W3C的标准中。在xml 数据和xml 模式两者之间有很多的区别。
A. xml模式支持的数据类型比xml DTD多;
B. xml模式在无序的情况下使用起来比xml DTD更方便;
C. xml模式支持名字空间,可以在不同的文件中定义相同的方法等。
D. xml模式形成的文档可以被多种标准解析,如dom,sax或者jdom等,而xml DTD方式下确不行。
2. Xml文件解析
在java语言环境里可以使用三种方法解析xml文件:dom(document object model),sax(simple api for
xml)和jdom(java document object model)。
SAX提供了基于事件的方式进行解析,适合于快速,数据量小的解析情况。SAX解析有几个缺陷:A.它的解析是连续的;B.数据无法回朔。
DOM解析不同于SAX。它提供了内存中完整的xml数据映像,数据被存储在树状结构中。DOM解析方式更容易获得和处理数据。
JDOM是java语言中特有的,主要用来支持xpath标准。
3. SAX解析方式
上面我简要介绍了几种解析xml文件的技术,这里我们使用SAX技术给出一个小例子,大家可以从这个例子中发现如果你能够掌握一些开源软件包,你就可以很
快掌握解析xml数据的技术。
3.1制作一个简单的xml文件component.xml
<?xml version="1.0"?>
<XmlComponents>
<XmlComponent>
<ComNo>1</ComNo>
</XmlComponent>
</XmlComponents>
3.2下载xerces.jar软件包
在Apache网站上×××下载xerces.jar软件包,这个包中包含了上面我们列举的几种解析xml数据的API。然后将这个软件包加入到程序的
classpath中。
3.3制作解析类MySaxParser.java
import java.io.IOException;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class MySaxParser extends DefaultHandler {
private static int INDENT = 2;
// 运行主方法
public static void main(String[] argv) {
// if (argv.length != 1) {
// System.out.println("Usage: java ds.MySaxParser [URI]");
// System.exit(0);
// }
System.setProperty("javax.xml.parsers.SAXParserFactory", "org.apache.xerces.jaxp.SAXParserFactoryImpl");
// String uri = argv[0];
String uri = "Components.xml";
try {
SAXParserFactory parserFactory = SAXParserFactory.newInstance();
parserFactory.setValidating(false);
parserFactory.setNamespaceAware(false);
MySaxParser MySaxParserInstance = new MySaxParser();
SAXParser parser = parserFactory.newSAXParser();
parser.parse(uri, MySaxParserInstance);
}
catch(IOException ex) {
ex.printStackTrace();
}
catch(SAXException ex) {
ex.printStackTrace();
}
catch(ParserConfigurationException ex) {
ex.printStackTrace();
}
catch(FactoryConfigurationError ex) {
ex.printStackTrace();
}
}
private int idx = 0; //indent
// 处理各种分隔符号
public void characters(char[] ch, int start, int length) throws SAXException {
//instantiates s, indents output, prints character values in element
String s = new String(ch, start, length);
if (!s.startsWith("\n")) //空的value不打印
System.out.println(getIndent()+ " Value: " + s);
}
// 处理文档尾
public void endDocument() throws SAXException {
idx -= INDENT;
System.out.println(getIndent() + "end document");
System.out.println("...PARSING ends");
}
// 处理标记尾
public void endElement(String uri, String localName, String qName) throws SAXException {
idx -= INDENT;
}
// 处理文档的起始点
public void startDocument() throws SAXException {
idx += INDENT;
System.out.println("PARSING begins...");
System.out.println(getIndent() + "start document: ");
}
// 处理标记头
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
idx += INDENT;
System.out.println('\n' + getIndent() + "start element: " + qName);
}
private String getIndent() {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < idx; i++)
sb.append(" ");
return sb.toString();
}
}
总结,虽然解析xml数据很复杂,因为涉及了很多的递归算法,但是我们可以使用业界比较成熟的解析API来进行xml数据处理。我现在只是给出了一个非常
简单的例子,但是在真实系统中远比这个要复杂的多,大家以后在使用的使用会发现还是有很多的工作要做的。
一、 前言
用
Java解析XML文档,最常用的有两种方法:使用基于事件的XML简单API(Simple API for
XML)称为SAX和基于树和节点的文档对象模型(Document Object Module)称为DOM。Sun公司提供了Java API
for XML Parsing(JAXP)接口来使用SAX和DOM,通过JAXP,我们可以使用任何与JAXP兼容的XML解析器。
JAXP接口包含了三个包:
(1) org.w3c.dom W3C推荐的用于XML标准规划文档对象模型的接口。
(2) org.xml.sax 用于对XML进行语法分析的事件驱动的XML简单API(SAX)
(3) javax.xml.parsers解析器工厂工具,程序员获得并配置特殊的特殊语法分析器。
二、 前提
DOM编程不要其它的依赖包,因为JDK里自带的JDK里含有的上面提到的org.w3c.dom、org.xml.sax 和javax.xml.parsers包就可以满意条件了。
三、 使用SAX解析XML文档
SAX是基于事件的简单API,同样的我们也是用一个最简单的例子来看看SAX是如何解析XML的
先来看看我们要解析的XML代码吧
<?xml version="1.0" encoding="gb2312"?>
<books>
<book email="zhoujunhui">
<name addr="address">rjzjh</name>
<price>jjjjjj</price>
</book>
</books>
简单的不能再简单了。但是该有的都有了,根元素、属性、子节点。好了,能反应问题就行了,下面来看看解析这个XML文件的Java代码吧!
1 public class SaxParse {
2 public SaxParse(){
3 SAXParserFactory saxfac=SAXParserFactory.newInstance();
4 try {
5 SAXParser saxparser=saxfac.newSAXParser();
6 InputStream is=new FileInputStream("bin/library.xml");
7 saxparser.parse(is,new MySAXHandler());
8 } catch (ParserConfigurationException e) {
9 e.printStackTrace();
10 } catch (SAXException e) {
11 e.printStackTrace();
12 } catch (FileNotFoundException e) {
13 e.printStackTrace();
14 } catch (IOException e) {
15 e.printStackTrace();
16 }
17 }
18 public static void main(String[] args) {
19 new SaxParse();
20 }
21 }
这段代码比较短,因为SAX是事件驱动的,它的大部分实现在在另一个Java文件中,先别管另一个文件,我们来一个个地分析吧!
(1)得到SAX解析器的工厂实例
3 SAXParserFactory saxfac=SAXParserFactory.newInstance();
这是一个javax.xml.parsers.SAXParserFactory类的实例
(2)从SAX工厂实例中获得SAX解析器
5 SAXParser saxparser=saxfac.newSAXParser();
使用javax.xml.parsers.SAXParserFactory工厂的newSAXParser()方法
(3)把要解析的XML文档转化为输入流,以便DOM解析器解析它
6 InputStream is=new FileInputStream("bin/library.xml");
InputStream是一个接口。
(4)解析XML文档
7 saxparser.parse(is,new MySAXHandler());
后面就不用看了,都是些没用的代码(相对而言),够简单的吧!
注意了,我们新建了一个实例new MySAXHandler()这个实例里面又有什么东西呢?
这个实例就是SAX的精华所在。我们使用SAX解析器时,必须实现内容处理器ContentHandler接口中的一些回调方法,然而我们不须要全部地实现这些方法,还好,我们有org.xml.sax.helpers.DefaultHandler类,看它的类申明:
public class DefaultHandler
implements EntityResolver, DTDHandler, ContentHandler, ErrorHandler
实现了这么多接口啊,其它的先不管了,至少它实现了ContentHandler这一接口。
好了,看看这个类有些什么吧?下面是它的Java代码!
public class MySAXHandler extends DefaultHandler {
boolean hasAttribute=false;
Attributes attributes=null;
/* (非 Javadoc)
* @see org.xml.sax.helpers.DefaultHandler#startDocument()
*/
public void startDocument() throws SAXException {
System.out.println("文档开始打印了");
}
/* (非 Javadoc)
* @see org.xml.sax.helpers.DefaultHandler#endDocument()
*/
public void endDocument() throws SAXException {
System.out.println("文档打印结束了");
}
/* (非 Javadoc)
* @see
org.xml.sax.helpers.DefaultHandler#startElement(java.lang.String,
java.lang.String, java.lang.String, org.xml.sax.Attributes)
*/
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if(qName.equals("books")){
return;
}
if(qName.equals("book")){
System.out.println(attributes.getQName(0)+attributes.getValue(0));
}
if(attributes.getLength()>0){
this.attributes=attributes;
this.hasAttribute=true;
}
}
/* (非 Javadoc)
* @see org.xml.sax.helpers.DefaultHandler#endElement(java.lang.String, java.lang.String, java.lang.String)
*/
public void endElement(String uri, String localName, String qName)
throws SAXException {
if(hasAttribute&&(attributes!=null)){
for(int i=0;i<attributes.getLength();i++){
System.out.println(attributes.getQName(0)+attributes.getValue(0));
}
}
}
/* (非 Javadoc)
* @see org.xml.sax.helpers.DefaultHandler#characters(char[], int, int)
*/
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.println(new String(ch,start,length));
}
}
不要看它一大堆,我一一分解给大家看。我们说SAX是基于事件的API,我们这个类实到了ContentHandler接口中的如下方法:
(1)startDocument() 用于处理文档解析开始事件
public void startDocument() throws SAXException {
System.out.println("文档开始打印了");
}
(2)endDocument() 用于处理文档解析结束事件
public void endDocument() throws SAXException {
System.out.println("文档打印结束了");
}
(3)startElement 用于处理元素开始事件
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if(qName.equals("books")){
return;
}
if(qName.equals("book")){
System.out.println(attributes.getQName(0)+attributes.getValue(0));
}
if(attributes.getLength()>0){
this.attributes=attributes;
this.hasAttribute=true;
}
}
第二个参数String qName表示这个元素的名字,如:
根节点 <books></books> 它的qName为“books”
最底层节点 <price>jjjjjj</price> 它的qName为“price”
知道这一点上面程序就好解释了,当遇到根元素“books”时就什么也不做跳过,当遇到“book”元素时就打出它的属性(它只有一个属性<book email="zhoujunhui"></book>)。
当是其它节点时(这下只剩下最底层的两个节点“name”和“price”了),就把它的属性取出来存到this.attributes域中,以后中元素结束事件好处理。
(4)endElement 用于处理元素结束事件
public void endElement(String uri, String localName, String qName)
throws SAXException {
if(hasAttribute&&(attributes!=null)){
for(int i=0;i<attributes.getLength();i++){
System.out.println(attributes.getQName(0)+attributes.getValue(0));
}
}
}
代码的作用是如果这个元素的属性不为空(hasAttribute&&(attributes!=null)),就把它们打印出来。
(5)characters(char[] ch, int start, int length) 处理元素字符的内容
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.println(new String(ch,start,length));
}
我们只用了这么几个事件,其它还有其的的一些事件,我们只要看一下ContentHandler这个接口就行了,如:
(6)startPrefixMapping(String prefix,String URI) 处理前缀映射开始事件,参数表示前缀名称和所指向的URI
(7)endPrefixMapping(String prefix,String URI) 处理前缀映射结束事件,参数表示前缀名称和所指向的URI
(8)ignorableWhitespace(Char[] ch,int start,int length) 处理元素中可忽略的空格
(9)processingInstruction(String target,String data) 处理解析中产生的处理指令事件。
当你需要处理XML文档时,你的首要选择是使用DOM(文档对象模型)还是使用SAX(用于XML的简单API),即当前使用的两个主要的XML
API。你可以使用任何一种(或者在同一时间使用两种)来处理XML文档,然而DOM将文档载入到内存中处理,而SAX则相反,它可以检测一个即将到来的
XML流,由此并不需要所有的XML代码同时载入到内存中。
选择DOM与SAX,与在一个数据库中的表单与视图之前选择一样:选择适合于当前实际情况的方法。如果你只是想简单地查看XML文档而不处理它,那么请选择使用SAX。
SAX与DOM之间有一些显著区别,包括:
DOM是复杂对象处理的首选,比如当XML比较复杂的时候,或者当你需要随机处理文档中数据的时候。SAX从文档的开始通过每一节点移动,以定位一个特定的节点。
DOM
为载入到内存的文档节点建立类型描述。最终,这些描述呈现了可容易横向移动、潜在巨大、树型结构。如果XML很冗长,DOM就会显示出无法控制的胀大。例
如,一个300KB的XML文档可以导致RAM或者虚拟内存中的3,000,000KB的DOM树型结构。通过比较就会发现,一个SAX文档根本就没有被
解构,它也没有隐藏在内存空间中(当然当XML流被读入时,会有部分文档暂时隐藏在内存中)。SAX就是一种“更轻巧的”技术──它可以给你的系统带来更
轻的负担。SAX相当于观看一场马拉松比赛,而DOM就好比邀请所有的比赛选手到家里参加晚餐。
所以,你如何选择SAX和DOM?如果你处理复杂的东西,比如高级XSLT转换,或者Xpath过滤,请选择使用DOM。如果你建立或者更改XML文档,你也可以选择DOM。
相反,你可以使用SAX来查询或者阅读XML文档。SAX可以快速扫描一个大型的XML文档,当它找到查询标准时就会立即停止,然后再处理之。
在某些情况下,在一个方案中,最佳的选择是使用DOM和SAX处理不同的部分。例如,你可以使用DOM将XML载入到内存并改变它,然后通过从DOM树中发送一个SAX流而转移最后的结果。
SAX概念
SAX是Simple API for XML的缩写,它并不是由W3C官方所提出的标准,可以说是“民间”的事实标准。实际上,它是一种社区性质的讨论产物。虽然如此,在XML中对SAX的应用丝毫不比DOM少,几乎所有的XML解析器都会支持它。
与DOM比较而言,SAX是一种轻量型的方法。我们知道,在处理DOM的时候,我们需要读入整个的XML文档,然后在内存中创建DOM树,生成
DOM树上的每个Node对象。当文档比较小的时候,这不会造成什么问题,但是一旦文档大起来,处理DOM就会变得相当费时费力。特别是其对于内存的需
求,也将是成倍的增长,以至于在某些应用中使用DOM是一件很不划算的事(比如在applet中)。这时候,一个较好的替代解决方法就是SAX。
SAX在概念上与DOM完全不同。首先,不同于DOM的文档驱动,它是事件驱动的,也就是说,它并不需要读入整个文档,而文档的读入过程也就
是SAX的解析过程。所谓事件驱动,是指一种基于回调(callback)机制的程序运行方法。(如果你对Java新的代理事件模型比较清楚的话,就会很
容易理解这种机制了)
在XMLReader接受XML文档,在读入XML文档的过程中就进行解析,也就是说读入文档的过程和解析的过程是同时进行的,这和DOM区
别很大。解析开始之前,需要向XMLReader注册一个ContentHandler,也就是相当于一个事件监听器,在ContentHandler中
定义了很多方法,比如startDocument(),它定制了当在解析过程中,遇到文档开始时应该处理的事情。当XMLReader读到合适的内容,就
会抛出相应的事件,并把这个事件的处理权代理给ContentHandler,调用其相应的方法进行响应
本文引自:http://blog.csdn.net/allenzue/archive/2008/12/18/3549959.aspx
另有:http://wiki.ubuntu.org.cn/JBoss_5.0.0GA安装指南
一.下载与安装JBoss
在本文中,我下载的JBoss版本为:JBOSS5.0 Beta4。
下载地址: http://www.jboss.org/jbossas/downloads/
在如上的下载页中下载JBOSS5.0 Beta4.zip文件。
下载完成后,将其解压缩后即可完成安装,解压
缩后将其放置到一个不带空格的目录(若目录带有空格,例如:C:"Program
Files,日后可能会产生一些莫名的错误),eg:E:"JBossJBOSS5.0
Beta4。同时在“环境变量设置”中设置名为JBOSS_HOME的环境变量,值为JBoss的安装路径,如下图所示:

在此,JBoss的安装工作已经结束,可通过如下方式测试安装是否成功:
运行JBoss安装目
录"bin"run.bat,如果窗口中没有出现异常,且出现:10:16:19,765 INFO [Server] JBoss (MX
MicroKernel) [5.0.Beta4 (build: SVNTag=5.0.Beta4 date=20080831605)]
Started in 30s:828ms字样,则表示安装成功。
我们可以通过访问: http://localhost:8080/ 进入JBoss的欢迎界面,点击JBoss Management下的JMX Console可进入JBoss的控制台。
若启动失败,可能由以下原因引起:
1)
JBoss所用的端口(8080,1099,1098,8083等)被占用。一般情况下为8080端口被占用(例如,Oracle占用了8080端口),
此时需要修改JBoss的端口,方法为进入JBoss安装目录"server"default"deployer"jboss-web.deployer
目录,修改其下的server.xml目录,在此文件中搜索8080,将其改成你想要的端口即可(例如8088);
2) JDK安装不正确;
3) JBoss下载不完全。
二. JBoss 的目录结构说明
|
目录
|
描述
|
|
bin
|
启动和关闭 JBoss 的脚本( run.bat 为 windows 系统下的启动脚本, shutdown.bat 为 windows 系统下的关闭脚本)。
|
|
client
|
客户端与 JBoss 通信所需的 Java 库( JARs )。
|
|
docs
|
配置的样本文件(数据库配置等)。
|
|
docs/dtd
|
在 JBoss 中使用的各种 XML 文件的 DTD 。
|
|
lib
|
一些 JAR , JBoss 启动时加载,且被所有 JBoss 配置共享。(不要把你的库放在这里)
|
|
server
|
各种 JBoss 配置。每个配置必须放在不同的子目录。子目录的名字表示配置的名字。 JBoss 包含 3 个默认的配置: minimial , default 和 all ,在你安装时可以进行选择。
|
|
server/all
|
JBoss 的完全配置,启动所有服务,包括集群和 IIOP 。
|
|
server/default
|
JBoss 的默认配置。在没有在 JBoss 命令行中指定配置名称时使用。 ( 我们下载的 JBOSS5.0 Beta4 版本默认采用此配置 ) 。
|
|
server/default/conf
|
JBoss 的配置文件。
|
|
server/default/data
|
JBoss 的数据库文件。比如,嵌入的数据库,或者 JBossMQ
|
|
server/default /deploy
|
JBoss 的热部署目录。放到这里的任何文件或目录会被 JBoss 自动部署。 EJB 、 WAR 、 EAR ,甚至服务。
|
|
server/default /lib
|
一些 JAR , JBoss 在启动特定配置时加载他们。 (default 和 minimial 配置也包含这个和下面两个目录。 )
|
|
server/default/log
|
JBoss 的日志文件。
|
|
server/default/tmp
|
JBoss 的临时文件。
|
三. JBoss 的配置
1. 日志文件设置
若需要修改JBoss默认的log4j设置,
可修改JBoss安装目录"server"default"conf下的jboss-log4j.xml文件,在该文件中可以看到,log4j的日志输出
在JBoss安装目录"server"default"log下的server.log文件中。对于log4j的设置,读者可以在网上搜索更加详细的信
息。
2. web 服务的端口号的修改
这点在前文中有所提及,即修改JBoss安装目录"server"default"deployer"jboss-web.deployer下的server.xml文件,内容如下:
<Connector port="8080" address="${jboss.bind.address}"
maxThreads="250" maxHttpHeaderSize="8192"
emptySessionPath="true" protocol="HTTP/1.1"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" />
将上面的8080端口修改为你想要的端口即可。重新启动JBoss后访问:http://localhost/:新设置的端口,可看到JBoss的欢迎界面。
3. JBoss 的安全设置
1) jmx-console 登录的用户名和密码设置
默认情况访问 http://localhost:8080/jmx-console 就可以浏览jboss的部署管理的一些信息,不需要输入用户名和密码,使用起来有点安全隐患。下面我们针对此问题对jboss进行配置,使得访问jmx-console也必须要知道用户名和密码才可进去访问。步骤如下:
i) 找到JBoss安装目录/server/default/deploy/jmx-console.war/WEB-INF/jboss-web.xml文件,去掉<security-domain>java:/jaas/jmx-console</security-domain>的注释。修改后的该文件内容为:
 <jboss-web> <jboss-web>
<!-- Uncomment the security-domain to enable security. You will
need to edit the htmladaptor login configuration to setup the
login modules used to authentication users.-->
<security-domain>java:/jaas/jmx-console</security-domain>
</jboss-web>
ii)修改与i)中的jboss-web.xml同级目录下的web.xml文件,查找到<security-constraint/>节点,去掉它的注释,修改后该部分内容为:
<!-- A security constraint that restricts access to the HTML JMX console
to users with the role JBossAdmin. Edit the roles to what you want and
uncomment the WEB-INF/jboss-web.xml/security-domain element to enable
secured access to the HTML JMX console.-->
<security-constraint>
<web-resource-collection>
<web-resource-name>HtmlAdaptor</web-resource-name>
<description>An example security config that only allows users with the
role JBossAdmin to access the HTML JMX console web application
</description>
<url-pattern>/*</url-pattern>
<http-method>GET</http-method>
<http-method>POST</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>JBossAdmin</role-name>
</auth-constraint>
</security-constraint>
在此处可以看出,为登录配置了角色JBossAdmin。
iii) 在第一步中的jmx-console安全域和第二步中的运行角色JBossAdmin都是在login-config.xml中配置,我们在JBoss安装目录/server/default/config下找到它。查找名字为:jmx-console的application-policy:
<application-policy name = "jmx-console">
<authentication>
<login-module code="org.jboss.security.auth.spi.UsersRolesLoginModule"
flag = "required">
<module-option name="usersProperties">props/jmx-console-users.properties</module-option>
<module-option name="rolesProperties">props/jmx-console-roles.properties</module-option>
</login-module>
</authentication>
</application-policy>
在此处可以看出,登录的角色、用户等的信息分别在props目录下的jmx-console-roles.properties和jmx-console-users.properties文件中设置,分别打开这两个文件。
其中jmx-console-users.properties文件的内容如下:
# A sample users.properties file for use with the UsersRolesLoginModule
admin=admin
该文件定义的格式为:用户名=密码,在该文件中,默认定义了一个用户名为admin,密码也为admin的用户,读者可将其改成所需的用户名和密码。
jmx-console-roles.properties的内容如下:
# A sample roles.properties file for use with the UsersRolesLoginModule
admin=JBossAdmin, HttpInvoker
该文件定义的格式为:用户名=角色,多个角色以“,”隔开,该文件默认为admin用户定义了JBossAdmin和HttpInvoker这两个角色。
配置完成后读者可以通过访问: http://localhost:8088/jmx-console/ ,输入jmx-console-roles.properties文件中定义的用户名和密码,访问jmx-console的页面。
四. 在MyEclipse 中配置JBoss
笔者的MyEclipse版本:6.5 GA
JBoss版本:5.0
JDK版本:1.6
进入Window-> Preferences-> MyEclipse -> Application Servers -> JBoss5,进行如下设置:

选择JBoss 5下的JDK设置所用的JDK.
好了,开始JBoss之旅吧.
摘 要 本文在分析对象池技术基本原理的基础上,给出了对象池技术的两种实现方式。还指出了使用对象池技术时所应注意的问题。
关键词 对象池;对象池技术;Java 对象;性能
Java对象的生命周期分析
Java对象的生命周期大致包括三个阶段:对象的创建,对象的使用,对象的清除。因此,对象的生命周期长度可用如下的表达式表示:T = T1 + T2 +T3。其中T1表示对象的创建时间,T2表示对象的使用时间,而T3则表示其清除时间。由此,我们可以看出,只有T2是真正有效的时间,而T1、T3则是对象本身的开销。下面再看看T1、T3在对象的整个生命周期中所占的比例。
我们知道,Java对象是通过构造函数来创建的,在这一过程中,该构造函数链中的所有构造函数也都会被自动调用。另外,默认情况下,调用类的构造函数时,Java会把变量初始化成确定的值:所有的对象被设置成null,整数变量(byte、short、int、long)设置成0,float和double变量设置成0.0,逻辑值设置成false。所以用new关键字来新建一个对象的时间开销是很大的,如表1所示。
表1 一些操作所耗费时间的对照表
| 运算操作 |
示例 |
标准化时间 |
| 本地赋值 |
i = n |
1.0 |
| 实例赋值 |
this.i = n |
1.2 |
| 方法调用 |
Funct() |
5.9 |
| 新建对象 |
New Object() |
980 |
| 新建数组 |
New int[10] |
3100 |
从表1可以看出,新建一个对象需要980个单位的时间,是本地赋值时间的980倍,是方法调用时间的166倍,而若新建一个数组所花费的时间就更多了。
再看清除对象的过程。我们知道,Java语言的一个优势,就是Java程序员勿需再像C/C++程序员那样,显式地释放对象,而由称为垃圾收集器(Garbage Collector)的自动内存管理系统,定时或在内存凸现出不足时,自动回收垃圾对象所占的内存。凡事有利总也有弊,这虽然为Java程序设计者提供了极大的方便,但同时它也带来了较大的性能开销。这种开销包括两方面,首先是对象管理开销,GC为了能够正确释放对象,它必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等。其次,在GC开始回收“垃圾”对象时,系统会暂停应用程序的执行,而独自占用CPU。
因此,如果要改善应用程序的性能,一方面应尽量减少创建新对象的次数;同时,还应尽量减少T1、T3的时间,而这些均可以通过对象池技术来实现。
对象池技术的基本原理
对象池技术基本原理的核心有两点:缓存和共享,即对于那些被频繁使用的对象,在使用完后,不立即将它们释放,而是将它们缓存起来,以供后续的应用程序重复使用,从而减少创建对象和释放对象的次数,进而改善应用程序的性能。事实上,由于对象池技术将对象限制在一定的数量,也有效地减少了应用程序内存上的开销。
实现一个对象池,一般会涉及到如下的类:
1)对象池工厂(ObjectPoolFactory)类
该类主要用于管理相同类型和设置的对象池(ObjectPool),它一般包含如下两个方法:
·createPool:用于创建特定类型和设置的对象池;
·destroyPool:用于释放指定的对象池;
同时为保证ObjectPoolFactory的单一实例,可以采用Singleton设计模式,见下述getInstance方法的实现:
public static ObjectPoolFactory getInstance() {
if (poolFactory == null) {
poolFactory = new ObjectPoolFactory();
}
return poolFactory;
} |
2)参数对象(ParameterObject)类
该类主要用于封装所创建对象池的一些属性参数,如池中可存放对象的数目的最大值(maxCount)、最小值(minCount)等。
3)对象池(ObjectPool)类
用于管理要被池化对象的借出和归还,并通知PoolableObjectFactory完成相应的工作。它一般包含如下两个方法:
·getObject:用于从池中借出对象;
·returnObject:将池化对象返回到池中,并通知所有处于等待状态的线程;
4)池化对象工厂(PoolableObjectFactory)类
该类主要负责管理池化对象的生命周期,就简单来说,一般包括对象的创建及销毁。该类同ObjectPoolFactory一样,也可将其实现为单实例。
通用对象池的实现
对象池的构造和管理可以按照多种方式实现。最灵活的方式是将池化对象的Class类型在对象池之外指定,即在ObjectPoolFactory类创建对象池时,动态指定该对象池所池化对象的Class类型,其实现代码如下:
. . .
public ObjectPool createPool(ParameterObject paraObj,Class clsType) {
return new ObjectPool(paraObj, clsType);
}
. . . |
其中,paraObj参数用于指定对象池的特征属性,clsType参数则指定了该对象池所存放对象的类型。对象池(ObjectPool)创建以后,下面就是利用它来管理对象了,具体实现如下:
public class ObjectPool {
private ParameterObject paraObj;//该对象池的属性参数对象
private Class clsType;//该对象池中所存放对象的类型
private int currentNum = 0; //该对象池当前已创建的对象数目
private Object currentObj;//该对象池当前可以借出的对象
private Vector pool;//用于存放对象的池
public ObjectPool(ParameterObject paraObj, Class clsType) {
this.paraObj = paraObj;
this.clsType = clsType;
pool = new Vector();
}
public Object getObject() {
if (pool.size() <= paraObj.getMinCount()) {
if (currentNum <= paraObj.getMaxCount()) {
//如果当前池中无对象可用,而且已创建的对象数目小于所限制的最大值,就利用
//PoolObjectFactory创建一个新的对象
PoolableObjectFactory objFactory =PoolableObjectFactory.getInstance();
currentObj = objFactory.create Object (clsType);
currentNum++;
} else {
//如果当前池中无对象可用,而且所创建的对象数目已达到所限制的最大值,
//就只能等待其它线程返回对象到池中
synchronized (this) {
try {
wait();
} catch (InterruptedException e) {
System.out.println(e.getMessage());
e.printStackTrace();
}
currentObj = pool.firstElement();
}
}
} else {
//如果当前池中有可用的对象,就直接从池中取出对象
currentObj = pool.firstElement();
}
return currentObj;
}
public void returnObject(Object obj) {
// 确保对象具有正确的类型
if (obj.isInstance(clsType)) {
pool.addElement(obj);
synchronized (this) {
notifyAll();
}
} else {
throw new IllegalArgumentException("该对象池不能存放指定的对象类型");
}
}
} |
从上述代码可以看出,ObjectPool利用一个java.util.Vector作为可扩展的对象池,并通过它的构造函数来指定池化对象的Class类型及对象池的一些属性。在有对象返回到对象池时,它将检查对象的类型是否正确。当对象池里不再有可用对象时,它或者等待已被使用的池化对象返回池中,或者创建一个新的对象实例。不过,新对象实例的创建并不在ObjectPool类中,而是由PoolableObjectFactory类的createObject方法来完成的,具体实现如下:
. . .
public Object createObject(Class clsType) {
Object obj = null;
try {
obj = clsType.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
return obj;
}
. . . |
这样,通用对象池的实现就算完成了,下面再看看客户端(Client)如何来使用它,假定池化对象的Class类型为StringBuffer:
. . .
//创建对象池工厂
ObjectPoolFactory poolFactory = ObjectPoolFactory. getInstance ();
//定义所创建对象池的属性
ParameterObject paraObj = new ParameterObject(2,1);
//利用对象池工厂,创建一个存放StringBuffer类型对象的对象池
ObjectPool pool = poolFactory.createPool(paraObj,String Buffer.class);
//从池中取出一个StringBuffer对象
StringBuffer buffer = (StringBuffer)pool.getObject();
//使用从池中取出的StringBuffer对象
buffer.append("hello");
System.out.println(buffer.toString());
. . . |
可以看出,通用对象池使用起来还是很方便的,不仅可以方便地避免频繁创建对象的开销,而且通用程度高。但遗憾的是,由于需要使用大量的类型定型(cast)操作,再加上一些对Vector类的同步操作,使得它在某些情况下对性能的改进非常有限,尤其对那些创建周期比较短的对象
专用对象池的实现
由于通用对象池的管理开销比较大,某种程度上抵消了重用对象所带来的大部分优势。为解决该问题,可以采用专用对象池的方法。即对象池所池化对象的Class类型不是动态指定的,而是预先就已指定。这样,它在实现上也会较通用对象池简单些,可以不要ObjectPoolFactory和PoolableObjectFactory类,而将它们的功能直接融合到ObjectPool类,具体如下(假定被池化对象的Class类型仍为StringBuffer,而用省略号表示的地方,表示代码同通用对象池的实现):
public class ObjectPool {
private ParameterObject paraObj;//该对象池的属性参数对象
private int currentNum = 0; //该对象池当前已创建的对象数目
private StringBuffer currentObj;//该对象池当前可以借出的对象
private Vector pool;//用于存放对象的池
public ObjectPool(ParameterObject paraObj) {
this.paraObj = paraObj;
pool = new Vector();
}
public StringBuffer getObject() {
if (pool.size() <= paraObj.getMinCount()) {
if (currentNum <= paraObj.getMaxCount()) {
currentObj = new StringBuffer();
currentNum++;
}
. . .
}
return currentObj;
}
public void returnObject(Object obj) {
// 确保对象具有正确的类型
if (StringBuffer.isInstance(obj)) {
. . .
}
} |
结束语
恰当地使用对象池技术,能有效地改善应用程序的性能。目前,对象池技术已得到广泛的应用,如对于网络和数据库连接这类重量级的对象,一般都会采用对象池技术。但在使用对象池技术时也要注意如下问题:
·并非任何情况下都适合采用对象池技术。基本上,只在重复生成某种对象的操作成为影响性能的关键因素的时候,才适合采用对象池技术。而如果进行池化所能带来的性能提高并不重要的话,还是不采用对象池化技术为佳,以保持代码的简明。
·要根据具体情况正确选择对象池的实现方式。如果是创建一个公用的对象池技术实现包,或需要在程序中动态指定所池化对象的Class类型时,才选择通用对象池。而大部分情况下,采用专用对象池就可以了。
AppFuse是一个集成了众多当前最流行开源框架与工具(包括Hibernate、ibatis、Struts、Spring、DBUnit、Ant、Log4J、Struts Menu、Xdoclet、SiteMesh、OSCache、JUnit、JSTL)于一身的Web开发框架。AppFuse提供了Web系统开发过程中都需要开发的一些功能,如登陆、用户密码加密,用户管理、根据不同的用户可以展现不同的菜单.J2EE开发者也可以在此基础上开发加入自己的功能模块。利用这个框架可以大幅度的提高开发速度。
转自:http://blog.chinaunix.net/u/11409/showart_436247.html
http://blog.csdn.net/changzhang/category/369570.aspx可参考这个网址
AppFuse是一个集成了当前最流行的Web应用框架的一个更高层次的Web开发框架,也可以说是一个Web开发基础平台,它与它所集成的各种框架相比,它提供了一部分所有Web系统开发过程中都需要开发的一些功能,如登陆、用户密码加密,用户管理、根据不同的用户可以展现不同的菜单,可以自动生成 40%-60%左右的代码,自带了默认的一些在CSS中设定的样式,使用这些样式能很快的改变整个系统的外观,还有自动化测试的功能。
它最大的价值就是为我们提供了一个Web开发的新的方式和思路,尽管这些技术在国外都已进很流行了,但在国内能够将Hibernate、Struts、 Spring、DBUnit、Ant、Log4J、Struts Menu、Xdoclet、SiteMesh、Velocity、JUnit、JSTL、WebWork这些技术集成到一个框架中的还不多见,所以即使不使用它的全部功能,它也给我们提供了一个很好的借鉴、学习的机会。
通过关注AppFuse,我们可以看到目前国外的主流开发都使用了哪些技术,开发方式是什么样的,可能达到什么样的结果,而在以前,是很少能够看到这样完整的例子的。
AppFuse的另一个启示是:我们可以依靠开源软件的功能降低开发成本,而且可以阅读开源软件的代码提高所在团队的整体实力。
AppFuse 的作者 Matt Raible是当今开源世界一个比较活跃的开发者,它是AppFuse、Struts Menu的作者,也是XDoclet、DisplayTag等一些著名开源项目的积极参与者,《Hibernate In Action》的作者就在感谢的名单里面提到他,XDoclet的下载版本中所带的Hibernate标签部分的例子就是他写的,他还是2004年 Apache技术年会的主讲人之一。
但是通过2个月的实际学习和使用,我也遇到一系列的问题,因为AppFuse是将其他的一些类库或者框架集成在一起的,集成的技术众多,而且有一些技术在国内甚至很少有人知道,资料也比较少,所以虽然作者经过了一些测试,但都是基于英文编码的,而对于中文编码来说,还潜在的存在着一些问题,虽然不是AppFuse的问题,但却降低了开发速度,下面是我在开发过程中遇到过的问题,有些解决了,有些还没有解决:
一.Struts
1. AppFuse中默认的MVC框架是Struts,而且使用的是LookupDispatchAction,并且使用的是按钮(button),在XP下用IE浏览效果还可以,但如果在2000或者98下,就使外观很难看,而且当时我还遇到一个问题:如果按钮显示中文,则在DisplayTag中翻页失灵,而且报错,后来我把BaseAction的相关方法改变了,才可以使用,因为国内的客户都比较重视界面,所以后来我将那些按钮都改成图片了,当然也要添加一些方法了,有点麻烦!
2. Struts中的标签如今推荐使用的只有html部分的标签了,其他的标签或者可以使用JSTL替代,或者已经不推荐使用了,而且AppFuse中推荐使用JSTL,而JSTL和struts的标签的联合使用时,需要的不是<html:标签>,而是<html-el:标签>,这个问题曾经困扰了我整整2天。
3. Struts的Validation的校验规则并不完善,比如如果使用客户端的javascript校验,则在邮箱中输入汉字根本校验不出来,到了服务器端报错。
4.最严重的问题是AppFuse生成的Struts的validation.xml文件中有许多多余的“.”,如果你去掉了,常常在执行ant的 deploy任务时又恢复原样。这样是提交表单的时候经常会报javascript的脚本错误或者缺少对象或者缺少value,所以我会手工的修改这个文件,然后把修改后的文件备份,当重新生成有错误的文件时,我会用备份的没有错误的文件去覆盖。
5. Struts的validatioin对于使用同一个FormBean的Action的校验方式比较复杂。(待解决)。
二.Hibernate
1. Hibernate是现在受到越来越多的人推崇的一个ORM工具(框架、类库),它将我们从繁琐的使用JDBC的开发过程中解放出来,但同时也带来了新的问题,如学习曲线,执行效率,数据库设计优化,还有最重要的灵活性。Hibernate不是一个很容易上手的东西,要完全驾驭它还需要读很多资料,但好的资料却很少。
2. 使用Xdoclet可以很方便的生成Hibernate中的持久类的配置文件(*.hbm.xml),但对一些特殊的映射却无能为力,如使用序列的id生成规则,序列的名字没有地方写,所以也只好先利用它生成主要的内容,然后手工修改。
3. 同样还是id的生成策略问题,如果使用序列、hilo等需要一些数据库机制支持的策略时,schemaExport并不能自动生成序列或者保存当前id的表,这项工作仍然要手工解决。
4. Hibernate中提供了几种关联,一对一、一对多、多对多,但对于怎样调整效率却没有一个很明确的提示,还要根据情况判定,这就带来和一些弹性的设计。
5. Hibernate中可以选择的操作数据库的方式有3种,其中HQL功能最强大,但有些功能使用标准查询可能会更方便,但会有一些限制,所以虽然它很灵活,但易用性不如JDBC好。
三.Spring
在AppFuse的过程中,Spring完全隐藏在幕后,除了一些配置外,几乎感觉不到它的存在,所以我在使用它的过程中并没有遇到什么麻烦,这里只是简单的介绍一下它在AppFuse中起到的作用。
1. Spring在AppFuse中起到的主要作用是对Hibernate的Session和事务的管理,利用Spring封装的Hibernate模板类,我们大大地减少了实现DAO的代码行数。
2. Spring还起到了连接映射文件和类之间的关联,及接口和实现类之间的关联,这些都依赖于Spring的IoC的机制的实现。
3. 对于字符进行编码和解码部分用到了Spring自带的Filter,只需要在配置文件中配置就好了。
四.SiteMesh
SiteMesh是一个基于Decorator模式的技术,它可以修饰返回的网页文件,它的工作方式受到越来越多的人的推崇,这点从Manning出版的一些技术书籍中可以看出来。
我在使用SiteMesh的过程中并不顺利,我参考了《Java Open Source Programming》,这本书中说SiteMesh在默认的情况下不对下载文件进行装饰,但我在下载文件时发现,我的文件内容被丢弃了,取而代之的是 SiteMesh的模板的内容,后来我通过修改SiteMesh的配置文件解决了这个问题,但感觉还有一些不太清楚的地方需要学习。
五.DisplayTag
DisplayTag 是一个优秀的显示内容的标签,从SourceForge的访问量来看,它是很活跃的项目,仅次于Ant、Hibernate、Xdoclet等几个著名的项目,我总结,它的主要功能有4项:显示、分页、排序、将显示的数据写入指定类型的文件中,然后下载。
1. 据我使用的情况看,我只使用了分页和显示的功能,因为当时我没有很好的解决中文编码的问题,所以排序会有问题,直到昨天,我在朋友的帮助下解决了这个问题,至此我可以放心使用的功能又增加了排序(我昨天简单的测试了一下是可以的)。
2. 但对于将显示的内容生成到一个指定格式的文件中的功能却有着很多缺陷,如:
(1) 生成的文件中只有显示的数据,那些没有显示在界面上的的数据,则不会被写到文件中。
(2) 如果修改了DisplayTag的显示的内容,比如添加一列,在这列中的内容不是字符,而是HTML的标签,则生成的文件只有这些HTML标签,而没有数据。
(3) 即使DisplayTag中没有我们定制的HTML脚本,生成的文件偶尔也有问题,比如:它会把“007”生成为“7”,把字符串自动的转换为整型值。有时候还生成空白内容的文件。
(4) DisplayTag生成的Excel文件兼容性不好,有时在Excel2003中不能正常打开,或者在XP下打开报错。
后来,我看了作者写的《Spring Live》,书中说如果想实现稳定的Excel,推荐使用POI,于是我使用POI生成Excel,稳定性和兼容性都不错。
六.DBUnit
DBUnit是一个可以被Ant集成的向数据库中添加数据和备份数据的一个类库,配置很方便,因为AppFuse已经集成好了,所以使用也很容易。
但是如果你使用EditPlus之类的工具手工修改了AppFuse生成的内容,则执行Ant的setup、setup-db或者deploy的任务时,常常报错,说无效的格式,这是因为这个被手工修改的文件再次被AppFuse执行后,它的第一行的文件声明的前几个字母是无效的,是因为本地的字符集编码的原因而引起了乱码,如果把这几个无效的字母去掉,问题就解决了。
七.Struts Menu
Struts Menu也是AppFuse的作者开发的一个开源软件,它可以根据配置文件读取当前用户可以使用的功能菜单,这个功能是我一直以来都想要的,我也找到了一些代码,但实现的都不如这个完善,没什么好说的,使用简单,配置容易,很好的解决了我的问题。
问题是我只使用了AppFuse提供的2个角色,对于多个角色的实验我还没有做。
八.XDoclet
在AppFuse中,使用Xdoclet生成了几乎一切的配置文件:Struts-config.xml、web.xml、validation.xml、*.hbm.xml等文件,如果使用AppGen的话,还会生成更多的文件,这一切都是使用Xdoclet实现的。
问题是我在Struts部分提到的,生成的Validation.xml文件中会多生成一个“.”,另外在生成资源文件时也会多生成一个“.”,目前我没有很好的阅读这段代码,不知道是不是Xdoclet的问题。
九.Ant
Ant并没有什么问题,但在执行作者写的Ant任务的时候,有一些任务不能正常执行,比如,运行模拟对象测试的任务,作者也在1.7版本的修复列表中提到以前版本有些ant任务不能执行,在1.7中修改了一些ant任务,使他们能够正常的执行了。
实际上,我们如果使用AppGen进行开发的话,使用的任务一般不超过8个。
十.JSTL
JSTL 是个好东西,我常用的有<c:>和<fmt:>部分的标签,但是如果使用JSTL进行逻辑判断,我并没有感觉比使用JSP的代码块优雅多少。另外,熟悉JSTL也需要一段时间,我就经历了面对着JSP页面不知道该怎么写JSTL语法的困境。当然,AppFuse中使用的基本都是 JSTL,包括向DisplayTag传递显示的数据,使用的都是JSTL语法,这方面的资料挺多,我参考的是电子工业出版社出的《JSP2.0技术》,说的很详细。
十一.Tomcat
你也许会说:“Tomcat就不用说了吧?”,是的,Tomcat一般都会使用,但是 ―――――――――――――Tomcat5和Tomcat4.X对于中文编码使用了不同的机制,这个问题困扰了我好久,我解决了页面上写入汉字显示乱码的问题,我也曾经以为DisplayTag对汉字不能排序,也不能正常分页是因为DisplayTag的开发者都是老外,是因为他们没有考虑中文的关系的原因。
直到昨天,我才知道这一切都是因为Tomcat5对汉字编码的实现的方式和Tomcat4不一样的原因,如果感兴趣,可以看看这个帖子: http://www.javaworld.com.tw/jute/post/view?bid=9&id=44042&sty=1&tpg=1&age=0
十二.JavaScript
JavaScript简单易学,但想运用自如就不太容易了。AppFuse中嵌入了几个js文件,里面包含了许多函数,值得我们好好的研究一下,比如,如果有一个必填字段没有填写,AppFuse会自动的聚焦在那个input上,类似的小技巧有很多,你可以自己去翻看。
但AppFuse 自带的JavaScript脚本有一个Bug,就是当DisplatyTag中没有可以显示的数据时,你用鼠标单击,它会报JavaScript错误,你仔细研究一下function highlightTableRows(tableId) 就知道了:我的解决办法是在location.href = link.getAttribute("href");前面添加一行判断:if (link != null)。
十三.资源文件国际化
对于Struts和DisplayTag都涉及到资源文件国际化AppFuse1.6.1很好的解决了Struts资源映射文件国际化的问题,你只需要在对应本国语言的资源文件中写入汉字,Ant中有一项执行native2ascii的任务,AppFuse自动的为你进行了资源文件的编码转换,而对于 DisplayTag的资源文件问题,还要自己执行native2ascii命令,为了避免每次都输入一串命令,我用Delphi写了个小工具,可视化的选择资源文件,点击按钮自动执行该命令,底层依赖于JDK。
经过2个多月的学习,我感觉这个框架非常不错,它为我以后的项目开发指出了一个新的方向,但如果想很熟练的使用这个框架进行开发,至少要对以下几种技术比较熟练:Struts(或者WebWork、Spring及其他的已经整合进来的MVC框架)、Hibernate(或者ibatis)、JSTL,当然其他的技术至少也要知道一点,否则遇到问题都不知道出在哪里。
目前我还没有解决的问题有:
1. 如何在翻页的时候才读取下面的数据?
2. 怎样对使用同一个FormBean的多个Form进行客户端校验?
3. 怎样优化Hibernate的效率?《Hibernate In Action》中提供了多种策略,有些时候应该使用lazy,有些时候应该使用outer-join。
4.在什么时机生成导出文件?目前我是在查询的Action中同时生成了导出文件,否则,到了下一页,我就不知道查询条件了,当然,如果把拼装后的HQL存储在Session或者Hidden中也可以解决这个问题,但是这样就破坏了DAO的封装,要把DAO封装后的HQL发送给Action,然后发送的到 Web界面层,所以目前我还在犹豫生成导出文件的时机选择在哪里?
5. 什么时候应该自己获取数据库连接,执行native SQL?具体需要注意些什么?
6. SiteMesh的模板优化?
7. DisplayTag的底层实现?
每个问题都比较棘手,要一个一个解决!
这个框架的优点是:如果熟悉了开发流程,可以大幅度的提高开发速度,如果业务不是很复杂,使用AppGen可以生成60%左右的代码,而且程序可维护性好,因为作者使用了多个设计模式对各个层面进行了封装,所以不同的模块代码风格出奇的一致,有利于开发人员快速上手,也有利于接收其他开发人员遗留的代码。
兔八哥
2004-2-3下午15:51
++++++++++++++++++++
引用:
有没有成功的项目同我们分享一下?
我已经使用AppFuse开发了2个项目了,都是教育系统的,系统都不大,我一个人用实际开发一个月,因为是公司的项目,源码不好外发,但主要的东西都是一样的,对于AppFuse我也没有修改多少,否则,往新版本移植就会有问题了。
我遇到的问题,能想起来的我都写下来了,如果有其他的问题,我们可以一起讨论。
最近我有个朋友在使用WebWork的AppFuse版本进行开发,他遇到的问题和我基本差不多,有交流才有进步,呵呵!
Very Happy
感谢楼上几位的热心解答,谢谢!
+++++++++++++++++++++++
引用:
目前我还没有解决的问题有:
1. 如何在翻页的时候才读取下面的数据?
2. 怎样对使用同一个FormBean的多个Form进行客户端校验?
3. 怎样优化Hibernate的效率?《Hibernate In Action》中提供了多种策略,有些时候应该使用lazy,有些时候应该使用outer-join。
4.在什么时机生成导出文件?目前我是在查询的Action中同时生成了导出文件,否则,到了下一页,我就不知道查询条件了,当然,如果把拼装后的HQL存储在Session或者Hidden中也可以解决这个问题,但是这样就破坏了DAO的封装,要把DAO封装后的HQL发送给Action,然后发送的到 Web界面层,所以目前我还在犹豫生成导出文件的时机选择在哪里?
5. 什么时候应该自己获取数据库连接,执行native SQL?具体需要注意些什么?
6. SiteMesh的模板优化?
7. DisplayTag的底层实现?
1.关于翻页的问题,如果你刚开始使用AppFuse开发的话,推荐使用valuelist,它可以和Hibernate很好的集成,我的一个网友用的就是这个东西,虽然界面没有DisplayTag漂亮,但关于分页却不用你操太多的心,
因为这几天天天开会,所以也没有做些技术实验,另一个朋友告诉我有一个老外把DisplayTag分页部分修改了,在JIRA上有源码下载,我下来了,还没有看,还有一个思路,就是分析DisplayTag的分页的格式,然后用Filter解析,然后把当前页号传入DAO,然后使用标准查询进行查询分页,但要对AppFuse的接口和方法添加参数,正在犹豫中,还有更简单的方法,直接在Session中放入当前的页号,每次都刷新,就不用Filter了,然后同样修改方法和接口。
2.对于Struts的使用同一个FormBean的多个Form进行客户端校验,在孙卫琴的Struts的书中已经提到了,即使她的方法不管用,也可以手写JavaScript来解决,只是我不愿意而已,如果别无他法,则只能如此了。
3. 优化Hibernate的效率,其实对我的程序来说问题不大,我的表比较少,基本只有3层的级联,而且对于数据字典和业务表之间的关联,我采用的是业务表到数据字典表的many-to-one,这样的单向关联比较简单,也能够满足我的要求,性能会好一点点,再加上分页功能,只查询当前也内容,然后参考《Hibernate In Action》的第七章的内容,提高接收效率应该是没有问题的。
4.关于到处文件的时机,我正在看关于模式的书籍,正在找答案,其实还有个简单的办法,就是把生成导出文件单独的实现,用户点击按钮才生产,当然这样就要把用户的查询条件记下来,当然也涉及到修改接口和方法了,AppFuse中,修改接口和方法很麻烦,如果代码生成后再修改,要改动很多处,所以前期设计很重要。
5.关于这一点,我一直在找一个硬性的标准,比如关联表超过多少个等等条件就应该自己获取数据库连接,但现在看来这也不是绝对的,如果能够大幅度提高效率,或者使用 native SQL可以减少工作量或者节省时间的话,那就可以使用,只是要对这种方式的利弊要有所了解,不幸的是,我还没有这样试过,试过的朋友请提供些建议,谢谢!
6.SiteMesh的优化,我看到一片文章,也是个老外写的,忘了出处,说SiteMesh对性能影响不大,可以放心使用,那我就暂时不考虑它了,呵呵。
7.DisplayTag的底层的原理我早就知道,而且它的文档的流程图也有,只是我需要知道更详细的实现细节,最近在读源码,应该很快就有结果了,如果我有好消息,会来这里把解决方案贴出来。
上面的文字只是我目前的一些思路,因为天天开会,也没有做技术实验,还不知道可行的程度,但我想应该都可以实现,我只不过是在找更好的办法,如果你有任何好的思路或者建议,请不吝告知,谢谢,任何建议和意见都是受欢迎的,只是要详细些,不要拿些空洞的模式来敷衍我,呵呵,目前这样的“高手”不少,我有些受够了,呵呵
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/changzhang/archive/2008/03/12/2172675.aspx

注意
Filter虽然很常用,但是覆盖的范围太广,这里我们只介绍设置编码和控制权限的过滤器,其他的使用方式还需要大家自行积累。
如果你不满足以下任一条件,请继续阅读,否则请跳过此后的部分,进入下一章:第 8 章 配置listener监听器。
编码问题会不会成为中国人学java的标志呢?
通过之前的讨论第 2.2.2 节 “POST乱码”,我们知道为了避免提交数据的乱码问题,需要在每次使用请求之前设置编码格式。在你复制粘贴了无数次request.setCharacterEncoding("gb2312");后,有没有想要一劳永逸的方法呢?能不能一次性修改所有请求的编码呢?
用Filter吧,它的名字是过滤器,可以批量拦截修改servlet的请求和响应。
我们编写一个EncodingFilter.java,来批量设置请求编码。
package anni;
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class EncodingFilter implements Filter {
public void init(FilterConfig config) throws ServletException {}
public void destroy() {}
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException {
request.setCharacterEncoding("gb2312");
chain.doFilter(request, response);
}
}
在此EncodingFilter实现了Filter接口,Filter接口中定义的三个方法都要在EncodingFilter中实现,其中doFilter()的代码实现主要的功能:为请求设置gb2312编码并执行chain.doFilter()继续下面的操作。
与servlet相似,为了让filter发挥作用还需要在web.xml进行配置。
<filter>
<filter-name>EncodingFilter</filter-name>
<filter-class>anni.EncodingFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>EncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
filter标签部分定义使用的过滤器,filter-mapping标签告诉服务器把哪些请求交给过滤器处理。这里的/*表示所有请求,/表示根路径,*(星号)代表所有请求,加在一起就变成了根路径下的所有请求。
这样,所有的请求都会先被EncodingFilter拦截,并在请求里设置上指定的gb2312编码。
例子在lingo-sample/07-01目录下,这次我们不需要在test.jsp中为请求设置编码也可以得到正常的中文参数了,EncodingFilter圆满的完成了它的工作。
出于信息安全和其他一些原因的考虑,项目中的一些页面要求用户满足了一定条件之后才能访问。比如,让用户输入帐号和密码,如果输入的信息正确就在session里做一个成功登录的标记,其后在请求保密信息的时候判断session中是否有已经登录成功的标记,存在则可以访问,不存在则禁止访问。
如07-02例子中所示,进入首页看到的就是登录页面。
现在用户还没有登录,如果直接访问保密信息,就会显示无法访问保密信息的页面,并提醒用户进行注册。
返回登录页面后,输入正确的用户名和密码,点击登录。
后台程序判断用户名和密码正确无误后,在session中设置已登录的标记,然后跳转到保密信息页面。
我们要保护的页面是admin/index.jsp,为此我们在web.xml进行如下配置。
<filter>
<filter-name>SecurityFilter</filter-name>
<filter-class>anni.SecurityFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>SecurityFilter</filter-name>
<url-pattern>/admin/*</url-pattern>
</filter-mapping>
定义SecurityFilter过滤器,让它过滤匹配/admin/*的所有请求,这就是说,对/admin/路径下的所有请求都会接受SecurityFilter的检查,那么SecurityFilter里到底做了些什么呢?
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse res = (HttpServletResponse) response;
HttpSession session = req.getSession();
if (session.getAttribute("username") != null) {
chain.doFilter(request, response);
} else {
res.sendRedirect("../failure.jsp");
}
}
首先要将ServletRequest和ServletResponse转换成HttpServletRequest和HttpServletResponse,因为Filter本来设计成为多种协议服务,http协议仅仅是其中一部分。不过我们接触到的也只有http,而且也只有转换成对应HttpServletRequest和HttpServletResponse才能进行下面的session操作和页面重定向。
得到了http请求之后,可以获得请求对应的session,判断session中的username变量是否为null,如果不为null,说明用户已经登录,就可以调用doFilter继续请求访问的资源。如果为null,说明用户还没有登录,禁止用户访问,并使用页面重定向跳转到failure.jsp页面显示提示信息。
session中的username实在登录的时候设置进去的,值就是登录用户使用的用户名,详细代码可以参考07-02/WEB-INF/src/LoginServlet.java,登录和注销都写成了servlet并映射到/login.do和/logout.do这两个请求路径上。源代码和web.xml配置请自行参考07-02中的例子,这里就不复述了。
我们再来看看页面重定向的写法,res.sendRedirect()中使用的是"../failure.jsp",两个点(..)代表当前路径的上一级路径,这是因为SecurityFilter负责处理的是/admin/下的请求,而/failure.jsp的位置在/admin/目录的上一级,所以加上两个点才能正确跳转到failure.jsp。当然这里使用forward()也可以,但是要注意在不同路径下做请求转发会影响页面中相对路径的指向。相关讨论在:第 3.4.2 节 “forward导致找不到图片”。
filter-mapping和servlet-mapping都是将对应的filter或servlet映射到某个url-pattern上,当客户发起某一请求时,服务器先将此请求与web.xml中定义的所有url-pattern进行匹配,然后执行匹配通过的filter和servlet。
你可以使用三种方式定义url-pattern。
-
直接映射一个请求。
<servlet-mapping>
<servlet-name>ContactServlet</servlet-name>
<url-pattern>/contact.do</url-pattern>
</servlet-mapping>
像第 6.3 节 “使用servlet改写联系簿”中对servlet的映射,只有当请求是/contact.do的时候才会执行ContactServlet。/contact.do?id=1或/contact.do?method=list&id=1的请求也可以匹配到ContactServlet,这是因为根据http规范,请求的路径不包含问号以后的部分。
-
映射一个路径下的所有请求。
<servlet-mapping>
<servlet-name>EncodingFilter</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
像第 7.1 节 “批量设置请求编码”中这样使用星号(*)的形式,可以将某个路径下的所有请求都映射到EncodingFilter过滤器下,如果这个路径下还有子路径,那么子路径下的请求也会被EncodingFilter过滤。所以 /*这种写法就会过滤应用下所有的请求。
如果像第 7.2 节 “用filter控制用户访问权限”中那样把映射配置成/admin/*,就会只处理/admin/路径下的请求,不会处理根路径下的/index.jsp和/failure.jsp。
需要注意的是,这种写法必须以/开头,写成与绝对路径的形式,即便是映射所有请求也要写成/*,不能简化成*。
-
映射结尾相同的一类请求。
<servlet-mapping>
<servlet-name>ControllerServlet</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
具体效果请参考07-03的例子,index.jsp中有四个链接,分别指向/a1.do, /a2.do, /xx/b1.do, /xx/yy/c1.do。
web.xml中的ControllerServlet会接收以.do结尾的请求,并使用forward将请求转发到/test.jsp。
点击/a1.do的情况。
点击/xx/yy/c1.do的情况。
这样做的一个好处是语义更清楚,只要看到以.do结尾的请求就知道肯定是交给ControllerServlet处理了,不管这个请求是在根路径还是子路径下,都会准确无误的找到对应的servlet。
缺点就是不同路径之间进行forward,jsp里就不能再使用相对路径了,所以我们在test.jsp中使用request.getContextPath()获得当前应用在服务器中的位置(例子中是/07-03)将相对路径都组装成绝对路径,这种用法在以后也会经常用到。
<%
pageContext.setAttribute("ctx", request.getContextPath());
%>
<p><a href="${ctx}/index.jsp">返回</a></p>
最后需要注意的是,这种请求映射就不能指定某一路径了,它必须是以星号(*)开始字母结尾,不能写成/*.do的形式。
现在咱们也发现java的请求映射有多傻了,灵活配置根本是不可能的任务。
想要获得所有以user开头.do结尾的请求吗?user*.do在url-pattern是无法识别的,只能配置成*.do,再去servlet中对请求进行筛选。
想要让一个servlet负责多个请求吗?/user/*,/admin/*,*.do写在一起url-pattern也不认识,只能配成多个servlet-mapping。
<servlet-mapping>
<servlet-name>ControllerServlet</servlet-name>
<url-pattern>/user/*</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>ControllerServlet</servlet-name>
<url-pattern>/admin/*</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>ControllerServlet</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
java的复杂性在此处显露无疑。实际使用时,最好不要依赖web.xml中的配置,在自己的类中实现灵活配置才是正途。
其实在07-02这个例子里,我们使用了两个过滤器,EncodingFilter负责设置编码,SecurityFilter负责控制权限,那这两个过滤器是怎么起作用的呢?它们两个同时过滤一个请求时谁先谁后呢?
下面这个图会告诉我们答案。
所有的奥秘就在Filter中的FilterChain中。服务器会按照web.xml中过滤器定义的先后循序组装成一条链,然后一次执行其中的doFilter()方法。执行的顺序就如上图所示,执行第一个过滤器的chain.doFilter()之前的代码,第二个过滤器的chain.doFilter()之前的代码,请求的资源,第二个过滤器的chain.doFilter()之后的代码,第一个过滤器的chain.doFilter()之后的代码,最后返回响应。
因此在07-02中执行的代码顺序是:
-
执行EncodingFilter.doFilter()中chain.doFilter()之前的部分:request.setCharacterEncoding("gb2312");
-
执行SecurityFilter.doFilter()中chain.doFilter()之前的部分:判断用户是否已登录。
如果用户已登录,则访问请求的资源:/admin/index.jsp。
如果用户未登录,则页面重定向到:/failure.jsp。
-
执行SecurityFilter.doFilter()中chain.doFilter()之后的部分:这里没有代码。
-
执行EncodingFilter.doFilter()中chain.doFilter()之后的部分:这里也没有代码。
过滤链的好处是,执行过程中任何时候都可以打断,只要不执行chain.doFilter()就不会再执行后面的过滤器和请求的内容。而在实际使用时,就要特别注意过滤链的执行顺序问题,像EncodingFilter就一定要放在所有Filter之前,这样才能确保在使用请求中的数据前设置正确的编码。
我们已经了解了filter的基本用法,还有一些细节配置在特殊情况下起作用。
在servlet-2.3中,Filter会过滤一切请求,包括服务器内部使用forward转发请求和<%@ include file="/index.jsp"%>的情况。
到了servlet-2.4中Filter默认下只拦截外部提交的请求,forward和include这些内部转发都不会被过滤,但是有时候我们需要forward的时候也用到Filter,这样就需要如下配置。
<filter>
<filter-name>TestFilter</filtername>
<filter-class>anni.TestFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>TestFilter</filtername>
<url-pattern>/*</url-pattern>
<dispatcher>REQUEST</dispatcher>
<dispatcher>FORWARD</dispatcher>
<dispatcher>INCLUDE</dispatcher>
<dispatcher>EXCEPTION</dispatcher>
</filter-mapping>
这样TestFilter就会过滤所有状态下的请求。如果我们没有进行设置,默认使用的就是REQUEST。而EXCEPTION是在isErrorPage="true"的情况下出现的,这个用处不多,看一下即可。
这里FORWARD是解决request.getDispatcher("index.jsp").forward(request, response);无法触发Filter的关键,配置上这个以后再进行forward的时候就可以触发过滤器了。
Filter还有一个有趣的用法,在filter-mapping中我们可以直接指定servlet-mapping,让过滤器只处理一个定义在web.xml中的servlet。
<filter-mapping>
<filter-name>TestFilter</filter-name>
<servlet-name>TestServlet</servlet-name>
</filter-mapping>
<servlet>
<servlet-name>TestServlet</servlet-name>
<servlet-class>anni.TestServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>TestServlet</servlet-name>
<url-pattern>/TestServlet</url-pattern>
</servlet-mapping>
直接指定servlet-name,TestFilter便会引用TestServlet配置的url-pattern,在某些filter与servlet绑定的情况下不失为一个好办法。
1.UTF-8
原来用惯了GBK,被大家一再怂恿,才下定决心整个项目换用UTF-8编码。
编码问题几乎与所有国内Java项目相伴而生,不同内核的Linux、英文版日文版的WindowsXP总是让GBK很头痛,而改用UTF-8后,忽然就轻爽了,UTF-8,全世界语系连马尔代夫语都有自己的座位,实在找不到理由为什么还要用只支持大中华的GBK。
而且Springside也成了一个带有大量UTF-8中文注释的项目。
原GBK项目的转换方法
把自己当成车衣厂女工,机械的使用UltraEdit和EditPlus的转换功能,忙活一两个小时,怎么都可以转完所有文件了。
其中UltraEdit的转换方法是文件--〉转换--〉ASCII to UTF-8(Unicode编辑)。最好在Advanced-〉本地代码页那里也设一下UTF-8。
然后就可以用设了UTF-8选项的IDE如IDEA,Eclipse直接编辑了。
2.国际化 I18N
后台的menu.jsp 和 editBook.jsp 还有业务异常类,演示了i18N的应用。
2.1 i18N基础
1.编写messages.zh_CN.properties
用中文写完后,用java带的native2ascii.exe或者ant的native任务把它转成非人类的Unicode编码。
2.在纯Java API里,国际化是这样做的:
ResourceBundle rb = ResourceBundle.getBundle("messages");
String welcome = rb.getString("welcome");
String welcomeCalvin = MessageFormat.format(welcome,new
String[]{"calvin"});
第一二句从classpath里找到messages_zh_CN.properties,读出"欢迎你,{0}"字样。
第三局把上文格式化成"欢迎你,calvin"
3.在Servlet环境下,国际化是这样做的
  则靠<fmt:message>tag
<%@ taglib uri="http://java.sun.com/jstl/fmt" prefix="fmt" %>
<fmt:message key="welcome"/>
可以用context-param来定义默认的properties文件
<context-param>
<param-name>javax.servlet.jsp.jstl.fmt.localizationContext</param-name>
<param-value>messages</param-value>
</context-param>
不过这样定义的缺点是只能定义一个文件,如果所有信息都集中在一个文件会好长,而如果有多个properties,就惟有在页面用<fmt:bundle>绑定了。
2.2 Spring的messageSource增强
Spring增加了MessageSource的概念
一是ApplicationContext将充当一个单例的角色,不再需要每次使用i18时都初始化一次ResourceBundle
二是可以代表多个Resource Bundle.
在ApplicationContext的定义文件中,增加如下节点:
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource">
<property name="basename" value= "messages"/>
</bean>
在pure Java中
context.getMessage("welcome", null, LocaleContextHolder.getLocale())
而经Spring MVC JSTL ViewResolver调用的JSP,<fmt:message>将继续发挥它的功效。
不过这里挺麻烦的,第一如果不是从MVC JSTL转的,messageSource的定义就会失效。而如果定义了<context-param>,则messageSource的定义又会失效.......
还有,<spring:message> 鸡肋一块,因为它如果找不到key对应的就会抛异常,好恐怖。
还还有,spring还有有趣的theme机制,和i18n一样的原理,解决了"做成图片的文字"的国际化,让不同语言的美术字图片的路径分别定义在theme_zh_CN.properties和theme_en_US.properties里面。
一句话概括:==比较的是两个对象的引用(即内存地址)是否相等,而equals()比较的是两个对象的值(即内存地址里存放的值)是否相等。当然equals()在个别类中被重写了那就例外了。
详细论述:eqauls 与 = =之异同
1)比较方式角度:
= =是面向过程的操作符;equals是面向对象的操作符
= =不属于任何类,equals则是任何类(在Java中)的一个方法;
我们可以1)Primitive1 (基本类型)= = Primitive2(基本类型);
2)Object Reference1(对象引用)= = Object Reference2(对象引用)
3)Object Reference1 (对象引用) .equals(Object Reference2 (对象引用))
这三种比较
但却不能Primitive1 (基本类型).equals( Primitive2(基本类型));
对于基本类型,没有面向对象中发送消息一说,自然也不会有
方法成员。
2)比较目的角度:
1) 如果要比较两个基本类型是否相等,请用= =;
2) 如果要比较两个对象引用是否相等,请用= =;
3) 如果要比较两个对象(逻辑上)是否一致,请用equals;
对两个对象(逻辑上)是否一致的阐释:
有人会问:在C++中, 比较两个对象相等不是也可以用==吗?我知道您是指运算符重载,但是很遗憾,Java中不支持运算符重载(java中亦有重载过运算符,他们是“+”,“+=”,不过也仅此两个,而且是内置实现的);所以,对象的是否相等的比较这份责任就交由 equals()来实现 。
这个“逻辑上”其实就取决于人类的看法,实际开发中,就取决于用户的需求;
第三节:equals()缘起:
equals()是每个对象与生俱来的方法,因为所有类的最终基类就是Object(除去Object本身);而equals()是Object的方法之一。
我们不妨观察一下Object中equals()的source code:
public boolean equals(Object obj) {
return (this == obj);
}
注意 “return (this == obj)”
this与obj都是对象引用,而不是对象本身。所以equals()的缺省实现就是比较
对象引用是否一致;为何要如此实现呢? 前面我们说过:对象是否相等,是由我们的需求决定的,世界上的类千奇百怪(当然,这些类都是我们根据模拟现实世界而创造的),虽然Object是他们共同的祖先,可他又怎能知道他的子孙类比较相等的标准呢?但是他明白,任何一个对象,自己总是等于自己的,何谓“自己总是等于自己”呢,又如何判断“自己总是等于自己”呢?一个对象在内存中只有一份,但他的引用却可以有无穷多个,“对象自己的引用1=对象自己的引用2”,不就能判断“自己总是等于自己”吗?所以缺省实现实现自然也就是
“return (this == obj)”;
而到了我们自己编写的类,对象相等的标准由我们确立,于是就不可避免的要覆写
继承而来的public boolean equals(Object obj);
如果您有过编覆写过equals()的经验(没有过也不要紧),请您思考一个问题:
“两个对象(逻辑上)是否一致”实际上是比较什么?没错,或许您已脱口而出:
就是对象的属性(即field,或称数据成员)的比较。方法是不可比较的哦。(这个问题是不是有些弱智呢?哈哈)
第四节:对一个推论的思考
推论如下:一言以蔽之:欲比较栈中数据是否相等,请用= =;
欲比较堆中数据是否相等,请用equals;
因为(根)基本类型,(根)对象引用都在栈中; 而对象本身在堆中;
这句话又对又不对,问题出在哪,就是“数据”二字,先看栈中,数据或为基本类型,或为对象引用,用==比较当然没错;但是堆中呢?对象不是堆中吗?不是应该用equals比较吗?可是,我们比较的是堆中“数据”,堆中有对象,对象由什么构成呢?可能是对象引用,可能是基本类型,或两者兼而有之。如果我们要比较他们,该用什么呢,用”equals()”?不对吧,只能是”= =”!所以正确的结论是:欲比较栈中数据是否相等,请用= =; 欲比较堆中数据是否相等,请用equals;
因为(根)基本类型,(根)对象引用都在栈中(所谓“根”,指未被任何其他对象所包含); 而对象本身在堆中。
文章出处:DIY部落(http://www.diybl.com/course/3_program/java/javajs/2007917/71587.html#)
1. 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
2. 栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第3点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
3. Java中的数据类型有两种。
一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
另外,栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义:
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。 4. String是一个特殊的包装类数据。即可以用String str = new String("abc");的形式来创建,也可以用String str = "abc";的形式来创建(作为对比,在JDK 5.0之前,你从未见过Integer i = 3;的表达式,因为类与字面值是不能通用的,除了String。而在JDK 5.0中,这种表达式是可以的!因为编译器在后台进行Integer i = new Integer(3)的转换)。前者是规范的类的创建过程,即在Java中,一切都是对象,而对象是类的实例,全部通过new()的形式来创建。Java中的有些类,如DateFormat类,可以通过该类的getInstance()方法来返回一个新创建的类,似乎违反了此原则。其实不然。该类运用了单例模式来返回类的实例,只不过这个实例是在该类内部通过new()来创建的,而getInstance()向外部隐藏了此细节。那为什么在String str = "abc";中,并没有通过new()来创建实例,是不是违反了上述原则?其实没有。
5. 关于String str = "abc"的内部工作。Java内部将此语句转化为以下几个步骤:
(1)先定义一个名为str的对String类的对象引用变量:String str;
(2)在栈中查找有没有存放值为"abc"的地址,如果没有,则开辟一个存放字面值为"abc"的地址,接着创建一个新的String类的对象o,并将o的字符串值指向这个地址,而且在栈中这个地址旁边记下这个引用的对象o。如果已经有了值为"abc"的地址,则查找对象o,并返回o的地址。
(3)将str指向对象o的地址。
值得注意的是,一般String类中字符串值都是直接存值的。但像String str = "abc";这种场合下,其字符串值却是保存了一个指向存在栈中数据的引用!
为了更好地说明这个问题,我们可以通过以下的几个代码进行验证。
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true |
注意,我们这里并不用str1.equals(str2);的方式,因为这将比较两个字符串的值是否相等。==号,根据JDK的说明,只有在两个引用都指向了同一个对象时才返回真值。而我们在这里要看的是,str1与str2是否都指向了同一个对象。
结果说明,JVM创建了两个引用str1和str2,但只创建了一个对象,而且两个引用都指向了这个对象。
我们再来更进一步,将以上代码改成:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
System.out.println(str1 + "," + str2); //bcd, abc
System.out.println(str1==str2); //false |
这就是说,赋值的变化导致了类对象引用的变化,str1指向了另外一个新对象!而str2仍旧指向原来的对象。上例中,当我们将str1的值改为"bcd"时,JVM发现在栈中没有存放该值的地址,便开辟了这个地址,并创建了一个新的对象,其字符串的值指向这个地址。
事实上,String类被设计成为不可改变(immutable)的类。如果你要改变其值,可以,但JVM在运行时根据新值悄悄创建了一个新对象,然后将这个对象的地址返回给原来类的引用。这个创建过程虽说是完全自动进行的,但它毕竟占用了更多的时间。在对时间要求比较敏感的环境中,会带有一定的不良影响。
再修改原来代码:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
String str3 = str1;
System.out.println(str3); //bcd
String str4 = "bcd";
System.out.println(str1 == str4); //true |
str3这个对象的引用直接指向str1所指向的对象(注意,str3并没有创建新对象)。当str1改完其值后,再创建一个String的引用str4,并指向因str1修改值而创建的新的对象。可以发现,这回str4也没有创建新的对象,从而再次实现栈中数据的共享。
我们再接着看以下的代码。
String str1 = new String("abc");
String str2 = "abc";
System.out.println(str1==str2); //false |
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1==str2); //false |
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
以上两段代码说明,只要是用new()来新建对象的,都会在堆中创建,而且其字符串是单独存值的,即使与栈中的数据相同,也不会与栈中的数据共享。
6. 数据类型包装类的值不可修改。不仅仅是String类的值不可修改,所有的数据类型包装类都不能更改其内部的值。 7. 结论与建议:
(1)我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,我们创建了String类的对象str。担心陷阱!对象可能并没有被创建!唯一可以肯定的是,指向String类的引用被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑,除非你通过new()方法来显要地创建一个新的对象。因此,更为准确的说法是,我们创建了一个指向String类的对象的引用变量str,这个对象引用变量指向了某个值为"abc"的String类。清醒地认识到这一点对排除程序中难以发现的bug是很有帮助的。
(2)使用String str = "abc";的方式,可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String("abc");的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。这个思想应该是享元模式的思想,但JDK的内部在这里实现是否应用了这个模式,不得而知。
(3)当比较包装类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==。
(4)由于String类的immutable性质,当String变量需要经常变换其值时,应该考虑使用StringBuffer类,以提高程序效率。
JAVA语言中的反射机制:
在Java 运行时 环境中,对于任意一个类,能否知道这个类有哪些属性和方法?
对于任意一个对象,能否调用他的方法?这些答案是肯定的,这种动态获取类的信息,以及动态调用类的方法的功能来源于JAVA的反射。从而使java具有动态语言的特性。
JAVA反射机制主要提供了以下功能:
1.在运行时判断任意一个对象所属的类
2.在运行时构造任意一个类的对象
3.在运行时判断任意一个类所具有的成员变量和方法(通过反射甚至可以调用private方法)
4.在运行时调用任意一个对象的方法(*****注意:前提都是在运行时,而不是在编译时)
Java 反射相关的API简介:
位于java。lang。reflect包中
--Class类:代表一个类
--Filed类:代表类的成员变量
--Method类:代表类的方法
--Constructor类:代表类的构造方法
--Array类:提供了动态创建数组,以及访问数组的元素的静态方法。该类中的所有方法都是静态方法
----Class类
在 java 的Object类中的申明了数个应该在所有的java类中被改写的methods:
hashCode(), equals(),clone(),toString(),getClass()等,其中的getClass()返回yige
Class 类型的对象。
Class类十分的特殊,它和一般的类一样继承自Object,其实体用以表达java程序运行
时的 class和 interface,也用来表达 enum,array,primitive,Java Types 以及关键字void
,当加载一个类,或者当加载器(class loader)的defineClass()被JVM调用,便产生一个Class
对象,
Class是Reflection起源,针对任何你想探勘的class(类),唯有现为他产生一个Class
的对象,接下来才能经由后者唤起为数十多个的反射API。
Java允许我们从多种途径为一个类class生成对应的Class对象。
--运用 getClass():Object类中的方法,每个类都拥有此方法
String str="abc";
Class cl=str.getClass();
--运用 Class。getSuperclass():Class类中的方法,返回该Class的父类的Class
--运用 Class。forName()静态方法:
--运用 ,Class:类名.class
--运用primitive wrapper classes的TYPE语法: 基本类型包装类的TYPE,如:Integer.TYPE
注意:TYPE的使用,只适合原生(基本)数据类型
----运行时生成instance
想生成对象的实体,在反射动态机制中有两种方法,一个针对无变量的构造方法,一个针对带参数的
构造方法,,如果想调用带参数的构造方法,就比较的麻烦,不能直接调用Class类中的newInstance()
,而是调用Constructor类中newInstance()方法,首先准备一个Class[]作为Constructor的参数类型。
然后调用该Class对象的getConstructor()方法获得一个专属的Constructor的对象,最后再准备一个
Object[]作为Constructor对象昂的newInstance()方法的实参。
在这里需要说明的是 只有两个类拥有newInstance()方法,分别是Class类和Constructor类
Class类中的newInstance()方法是不带参数的,而Constructro类中的newInstance()方法是带参数的
需要提供必要的参数。
例:
Class c=Class.forName("DynTest");
Class[] ptype=new Class[]{double.class,int.class};
Constructor ctor=c.getConstructor(ptypr);
Object[] obj=new Object[]{new Double(3.1415),new Integer(123)};
Object object=ctor.newInstance(obj);
System.out.println(object);
----运行时调用Method
这个动作首先准备一个Class[]{}作为getMethod(String name,Class[])方法的参数类型,接下来准备一个
Obeject[]放置自变量,然后调用Method对象的invoke(Object obj,Object[])方法。
注意,在这里调用
----运行时调用Field内容
变更Field不需要参数和自变量,首先调用Class的getField()并指定field名称,获得特定的Field对象后
便可以直接调用Field的 get(Object obj)和set(Object obj,Object value)方法
java 代码
- package cn.com.reflection;
-
- import java.lang.reflect.Field;
- import java.lang.reflect.InvocationTargetException;
- import java.lang.reflect.Method;
-
- public class ReflectTester {
-
-
-
-
-
-
-
-
-
-
-
- public Object copy(Object obj) throws IllegalArgumentException, SecurityException, InstantiationException, IllegalAccessException, InvocationTargetException, NoSuchMethodException{
-
-
- Class classType=obj.getClass();
- System.out.println("该对象的类型是:"+classType.toString());
-
-
- Object objectCopy=classType.getConstructor(new Class[]{}).newInstance(new Object[]{});
-
-
- Field[] fields=classType.getDeclaredFields();
-
- for(int i=0;i
-
- Field field=fields[i];
-
- String fieldName=field.getName();
- String stringLetter=fieldName.substring(0, 1).toUpperCase();
-
-
- String getName="get"+stringLetter+fieldName.substring(1);
- String setName="set"+stringLetter+fieldName.substring(1);
-
-
- Method getMethod=classType.getMethod(getName, new Class[]{});
- Method setMethod=classType.getMethod(setName, new Class[]{field.getType()});
-
-
- Object value=getMethod.invoke(obj, new Object[]{});
- System.out.println(fieldName+" :"+value);
-
-
- setMethod.invoke(objectCopy,new Object[]{value});
-
-
- }
-
- return objectCopy;
-
- }
-
-
- public static void main(String[] args) throws IllegalArgumentException, SecurityException, InstantiationException, IllegalAccessException, InvocationTargetException, NoSuchMethodException {
- Customer customer=new Customer();
- customer.setName("hejianjie");
- customer.setId(new Long(1234));
- customer.setAge(19);
-
- Customer customer2=null;
- customer2=(Customer)new ReflectTester().copy(customer);
- System.out.println(customer.getName()+" "+customer2.getAge()+" "+customer2.getId());
-
- System.out.println(customer);
- System.out.println(customer2);
-
-
- }
-
- }
-
-
- class Customer{
-
- private Long id;
-
- private String name;
-
- private int age;
-
-
- public Customer(){
-
- }
-
- public int getAge() {
- return age;
- }
-
-
- public void setAge(int age) {
- this.age = age;
- }
-
-
- public Long getId() {
- return id;
- }
-
-
- public void setId(Long id) {
- this.id = id;
- }
-
-
- public String getName() {
- return name;
- }
-
-
- public void setName(String name) {
- this.name = name;
- }
-
- }
java 代码
- package cn.com.reflection;
-
- import java.lang.reflect.Array;
-
- public class ArrayTester1 {
-
-
-
-
-
- public static void main(String[] args) throws ClassNotFoundException {
-
- Class classType=Class.forName("java.lang.String");
-
- Object array= Array.newInstance(classType,10);
-
-
- Array.set(array, 5, "hello");
-
- String s=(String)Array.get(array, 5);
-
- System.out.println(s);
-
-
-
- for(int i=0;i<((String[])array).length;i++){
-
- String str=(String)Array.get(array, i);
-
- System.out.println(str);
- }
-
- }
-
- }
声明:JavaEye文章版权属于作者,受法律保护。没有作者书面许可不得转载。
看到这个标题大家可能又想:哎,又一个重新发明轮子的人。在这里很想先声明一下,写这篇文章只是想让大家了解一下Spring到底是怎么运行的,并不是想重造轮子噢,希望大家看完这篇文章后能对Spring有更深入的了解,希望这篇文章对你有所帮助喔!好,言归正传,让我们来一起探索吧!
我们先从最常见的例子开始吧
- public static void main(String[] args) {
- ApplicationContext context = new FileSystemXmlApplicationContext(
- "applicationContext.xml");
- Animal animal = (Animal) context.getBean("animal");
- animal.say();
- }
public static void main(String[] args) {
ApplicationContext context = new FileSystemXmlApplicationContext(
"applicationContext.xml");
Animal animal = (Animal) context.getBean("animal");
animal.say();
}
这段代码你一定很熟悉吧,不过还是让我们分析一下它吧,首先是applicationContext.xml
- <bean id="animal" class="phz.springframework.test.Cat">
- <property name="name" value="kitty" />
- </bean>
<bean id="animal" class="phz.springframework.test.Cat">
<property name="name" value="kitty" />
</bean>
他有一个类phz.springframework.test.Cat
- public class Cat implements Animal {
- private String name;
- public void say() {
- System.out.println("I am " + name + "!");
- }
- public void setName(String name) {
- this.name = name;
- }
- }
public class Cat implements Animal {
private String name;
public void say() {
System.out.println("I am " + name + "!");
}
public void setName(String name) {
this.name = name;
}
}
实现了phz.springframework.test.Animal接口
- public interface Animal {
- public void say();
- }
public interface Animal {
public void say();
}
很明显上面的代码输出I am kitty!
那么到底Spring是如何做到的呢?
接下来就让我们自己写个Spring 来看看Spring 到底是怎么运行的吧!
首先,我们定义一个Bean类,这个类用来存放一个Bean拥有的属性
-
- private String id;
-
- private String type;
-
- private Map<String, Object> properties = new HashMap<String, Object>();
/* Bean Id */
private String id;
/* Bean Class */
private String type;
/* Bean Property */
private Map<String, Object> properties = new HashMap<String, Object>();
一个Bean包括id,type,和Properties。
接下来Spring 就开始加载我们的配置文件了,将我们配置的信息保存在一个HashMap中,HashMap的key就是Bean 的 Id ,HasMap 的value是这个Bean,只有这样我们才能通过context.getBean("animal")这个方法获得Animal这个类。我们都知道Spirng可以注入基本类型,而且可以注入像List,Map这样的类型,接下来就让我们以Map为例看看Spring是怎么保存的吧
Map配置可以像下面的
- <bean id="test" class="Test">
- <property name="testMap">
- <map>
- <entry key="a">
- <value>1</value>
- </entry>
- <entry key="b">
- <value>2</value>
- </entry>
- </map>
- </property>
- </bean>
<bean id="test" class="Test">
<property name="testMap">
<map>
<entry key="a">
<value>1</value>
</entry>
<entry key="b">
<value>2</value>
</entry>
</map>
</property>
</bean>
Spring是怎样保存上面的配置呢?,代码如下:
- if (beanProperty.element("map") != null) {
- Map<String, Object> propertiesMap = new HashMap<String, Object>();
- Element propertiesListMap = (Element) beanProperty
- .elements().get(0);
- Iterator<?> propertiesIterator = propertiesListMap
- .elements().iterator();
- while (propertiesIterator.hasNext()) {
- Element vet = (Element) propertiesIterator.next();
- if (vet.getName().equals("entry")) {
- String key = vet.attributeValue("key");
- Iterator<?> valuesIterator = vet.elements()
- .iterator();
- while (valuesIterator.hasNext()) {
- Element value = (Element) valuesIterator.next();
- if (value.getName().equals("value")) {
- propertiesMap.put(key, value.getText());
- }
- if (value.getName().equals("ref")) {
- propertiesMap.put(key, new String[] { value
- .attributeValue("bean") });
- }
- }
- }
- }
- bean.getProperties().put(name, propertiesMap);
- }
if (beanProperty.element("map") != null) {
Map<String, Object> propertiesMap = new HashMap<String, Object>();
Element propertiesListMap = (Element) beanProperty
.elements().get(0);
Iterator<?> propertiesIterator = propertiesListMap
.elements().iterator();
while (propertiesIterator.hasNext()) {
Element vet = (Element) propertiesIterator.next();
if (vet.getName().equals("entry")) {
String key = vet.attributeValue("key");
Iterator<?> valuesIterator = vet.elements()
.iterator();
while (valuesIterator.hasNext()) {
Element value = (Element) valuesIterator.next();
if (value.getName().equals("value")) {
propertiesMap.put(key, value.getText());
}
if (value.getName().equals("ref")) {
propertiesMap.put(key, new String[] { value
.attributeValue("bean") });
}
}
}
}
bean.getProperties().put(name, propertiesMap);
}
接下来就进入最核心部分了,让我们看看Spring 到底是怎么依赖注入的吧,其实依赖注入的思想也很简单,它是通过反射机制实现的,在实例化一个类时,它通过反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。让我们看看具体它是怎么做的吧。
首先实例化一个类,像这样
- public static Object newInstance(String className) {
- Class<?> cls = null;
- Object obj = null;
- try {
- cls = Class.forName(className);
- obj = cls.newInstance();
- } catch (ClassNotFoundException e) {
- throw new RuntimeException(e);
- } catch (InstantiationException e) {
- throw new RuntimeException(e);
- } catch (IllegalAccessException e) {
- throw new RuntimeException(e);
- }
- return obj;
- }
public static Object newInstance(String className) {
Class<?> cls = null;
Object obj = null;
try {
cls = Class.forName(className);
obj = cls.newInstance();
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
return obj;
}
接着它将这个类的依赖注入进去,像这样
- public static void setProperty(Object obj, String name, String value) {
- Class<? extends Object> clazz = obj.getClass();
- try {
- String methodName = returnSetMthodName(name);
- Method[] ms = clazz.getMethods();
- for (Method m : ms) {
- if (m.getName().equals(methodName)) {
- if (m.getParameterTypes().length == 1) {
- Class<?> clazzParameterType = m.getParameterTypes()[0];
- setFieldValue(clazzParameterType.getName(), value, m,
- obj);
- break;
- }
- }
- }
- } catch (SecurityException e) {
- throw new RuntimeException(e);
- } catch (IllegalArgumentException e) {
- throw new RuntimeException(e);
- } catch (IllegalAccessException e) {
- throw new RuntimeException(e);
- } catch (InvocationTargetException e) {
- throw new RuntimeException(e);
- }
- }
public static void setProperty(Object obj, String name, String value) {
Class<? extends Object> clazz = obj.getClass();
try {
String methodName = returnSetMthodName(name);
Method[] ms = clazz.getMethods();
for (Method m : ms) {
if (m.getName().equals(methodName)) {
if (m.getParameterTypes().length == 1) {
Class<?> clazzParameterType = m.getParameterTypes()[0];
setFieldValue(clazzParameterType.getName(), value, m,
obj);
break;
}
}
}
} catch (SecurityException e) {
throw new RuntimeException(e);
} catch (IllegalArgumentException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
} catch (InvocationTargetException e) {
throw new RuntimeException(e);
}
}
最后它将这个类的实例返回给我们,我们就可以用了。我们还是以Map为例看看它是怎么做的,我写的代码里面是创建一个HashMap并把该HashMap注入到需要注入的类中,像这样,
- if (value instanceof Map) {
- Iterator<?> entryIterator = ((Map<?, ?>) value).entrySet()
- .iterator();
- Map<String, Object> map = new HashMap<String, Object>();
- while (entryIterator.hasNext()) {
- Entry<?, ?> entryMap = (Entry<?, ?>) entryIterator.next();
- if (entryMap.getValue() instanceof String[]) {
- map.put((String) entryMap.getKey(),
- getBean(((String[]) entryMap.getValue())[0]));
- }
- }
- BeanProcesser.setProperty(obj, property, map);
- }
if (value instanceof Map) {
Iterator<?> entryIterator = ((Map<?, ?>) value).entrySet()
.iterator();
Map<String, Object> map = new HashMap<String, Object>();
while (entryIterator.hasNext()) {
Entry<?, ?> entryMap = (Entry<?, ?>) entryIterator.next();
if (entryMap.getValue() instanceof String[]) {
map.put((String) entryMap.getKey(),
getBean(((String[]) entryMap.getValue())[0]));
}
}
BeanProcesser.setProperty(obj, property, map);
}
好了,这样我们就可以用Spring 给我们创建的类了,是不是也不是很难啊?当然Spring能做到的远不止这些,这个示例程序仅仅提供了Spring最核心的依赖注入功能中的一部分。
本文参考了大量文章无法一一感谢,在这一起感谢,如果侵犯了你的版权深表歉意,很希望对大家有帮助!
附件中包含该山寨Spring的源码,核心只有五个类,还有一个测试程序,phz.springframework.test.AnimalSayApp,可以直接运行。
文章分类:招聘求职
一个用户的请求是通ActionServlet来处理和转发的。那么,ActionServlet如何决定把用户请求转发给哪个Action对象呢?这就需要一些描述用户请求路径和Action衍射关系的配置信息了。在 Struts中,这些配置映射信息都存储在特定的XML文件 Struts- config.xml中。在该配置文件中,每一个Action的映射信息都通过一个<Action>元素来配置。
这些配置信息在系统启动的时候被读入内存,供 Struts在运行期间使用。在内存中,每一个<action>元素都对应一个org.apache. struts.action.ActionMapping类的实例。
对于采用 Struts框架的web应用,在web应用启动时就会加载并初始化ActionServlet,ActionServlet从 struts- config.xml文件中读取配置信息,把它们存放到各个配置对象中,例如Action的映射信息存放在ActionMapping对象中。
当ActionServlet接收到一个客户请求时,将执行如下流程:
1.检索和用户请求相匹配的ActionMapping实例,如果不存在,就返回用户请求路径无效信息。
2.如ActionForm实例不存在,就创建一个ActionForm对象,把客户提交的表单数据保存到ActionForm对象中。
3.根据配置信息决定是否需要表单验证。如果需要验证,就调用ActionForm的Validate()方法。
4.如果ActionForm的Validate()方法返回null或返回一个不包含ActionMessage的ActionErrors对象,就表示表单验证成功。
5.ActionServlet根据ActionMapping实例包含的映射信息决定将请求转发给哪个Action。如果相应的Action实例不存在,就先创建这个实例,然后调用Action的execute()方法。
6.Action的execute()方法返回一个ActionForward对象,ActionServlet再把客户请求转发给ActionForward对象指向的JSP组件。
7.ActionForward对象指向的JSP组件生成动态网页,返回给客户。

一,抽象类:abstract
1,只要有一个或一个以上抽象方法的类,必须用abstract声明为抽象类;
2,抽象类中可以有具体的实现方法;
3,抽象类中可以没有抽象方法;
4,抽象类中的抽象方法必须被它的子类实现,如果子类没有实现,则该子类继续为抽象类
5,抽象类不能被实例化,但可以由抽象父类指向的子类实例来调用抽象父类中的具体实现方法;通常作为一种默认行为;
6,要使用抽象类中的方法,必须有一个子类继承于这个抽象类,并实现抽象类中的抽象方法,通过子类的实例去调用;
二,接口:interface
1,接口中可以有成员变量,且接口中的成员变量必须定义初始化;
2,接口中的成员方法只能是方法原型,不能有方法主体;
3,接口的成员变量和成员方法只能public(或缺省不写),效果一样,都是public
4,实现接口的类必须全部实现接口中的方法(父类的实现也算,一般有通过基类实现接口中个异性不大的方法来做为适配器的做法)
三,关键字:final
1,可用于修饰:成员变量,非抽象类(不能与abstract同时出现),非抽象的成员方法,以及方法参数
2,final方法:不能被子类的方法重写,但可以被继承;
3,final类:表示该类不能被继承,没有子类;final类中的方法也无法被继承.
4,final变量:表示常量,只能赋值一次,赋值后不能被修改.final变量必须定义初始化;
5,final不能用于修饰构造方法;
6,final参数:只能使用该参数,不能修改该参数的值;
四,关键字:static
1,可以修饰成员变量和成员方法,但不能修饰类以及构造方法;
2,被static修饰的成员变量和成员方法独立于该类的任何对象。也就是说,它不依赖类特定的实例,被类的所有实例共享
3,static变量和static方法一般是通过类名直接访问,但也可以通过类的实例来访问(不推荐这种访问方式)
4,static变量和static方法同样适应java访问修饰符.用public修饰的static变量和static方法,在任何地方都可以通过类名直接来访问,但用private修饰的static变量和static方法,只能在声明的本类方法及静态块中访问,但不能用this访问,因为this属于非静态变量.
五,static和final同时使用
1,static final用来修饰成员变量和成员方法,可简单理解为“全局常量”!
2,对于变量,表示一旦给值就不可修改,并且通过类名可以访问。
3,对于方法,表示不可覆盖,并且可以通过类名直接访问。
HTTP 状态代码
如果向您的服务器发出了某项请求要求显示您网站上的某个网页(例如,当用户通过浏览器访问您的网页或在 Googlebot 抓取该网页时),那么,您的服务器会返回 HTTP 状态代码以响应该请求。
此状态代码提供了有关请求状态的信息,且为 Googlebot 提供了有关您网站和请求的网页的信息。
一些常见的状态代码为:
- 200 - 服务器成功返回网页
- 404 - 请求的网页不存在
- 503 - 服务器暂时不可用
以下提供了 HTTP 状态代码的完整列表。点击链接可了解详细信息。您也可以访问有关 HTTP 状态代码的 W3C 页来了解详细信息。
1xx(临时响应)
用于表示临时响应并需要请求者执行操作才能继续的状态代码。
| 代码 |
说明 |
| 100(继续) |
请求者应当继续提出请求。服务器返回此代码则意味着,服务器已收到了请求的第一部分,现正在等待接收其余部分。 |
| 101(切换协议) |
请求者已要求服务器切换协议,服务器已确认并准备进行切换。 |
2xx(成功)
用于表示服务器已成功处理了请求的状态代码。
| 代码 |
说明 |
| 200(成功) |
服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。如果您的 robots.txt 文件显示为此状态,那么,这表示 Googlebot 已成功检索到该文件。 |
| 201(已创建) |
请求成功且服务器已创建了新的资源。 |
| 202(已接受) |
服务器已接受了请求,但尚未对其进行处理。 |
| 203(非授权信息) |
服务器已成功处理了请求,但返回了可能来自另一来源的信息。 |
| 204(无内容) |
服务器成功处理了请求,但未返回任何内容。 |
| 205(重置内容) |
服务器成功处理了请求,但未返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如清除表单内容以输入新内容)。 |
| 206(部分内容) |
服务器成功处理了部分 GET 请求。 |
3xx(已重定向)
要完成请求,您需要进一步进行操作。通常,这些状态代码是永远重定向的。Google 建议您在每次请求时使用的重定向要少于 5 个。您可以使用网站管理员工具来查看 Googlebot 在抓取您已重定向的网页时是否会遇到问题。诊断下的抓取错误页中列出了 Googlebot 由于重定向错误而无法抓取的网址。
| 代码 |
说明 |
| 300(多种选择) |
服务器根据请求可执行多种操作。服务器可根据请求者 (User agent) 来选择一项操作,或提供操作列表供请求者选择。 |
| 301(永久移动) |
请求的网页已被永久移动到新位置。服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码通知 Googlebot 某个网页或网站已被永久移动到新位置。 |
| 302(临时移动) |
服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。但由于 Googlebot 会继续抓取原有位置并将其编入索引,因此您不应使用此代码来通知 Googlebot 某个页面或网站已被移动。 |
| 303(查看其他位置) |
当请求者应对不同的位置进行单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。 |
| 304(未修改) |
自从上次请求后,请求的网页未被修改过。服务器返回此响应时,不会返回网页内容。
如果网页自请求者上次请求后再也没有更改过,您应当将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。由于服务器可以告诉 Googlebot 自从上次抓取后网页没有更改过,因此可节省带宽和开销
。 |
| 305(使用代理) |
请求者只能使用代理访问请求的网页。如果服务器返回此响应,那么,服务器还会指明请求者应当使用的代理。 |
| 307(临时重定向) |
服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。但由于 Googlebot 会继续抓取原有位置并将其编入索引,因此您不应使用此代码来通知 Googlebot 某个页面或网站已被移动。 |
4xx(请求错误)
这些状态代码表示,请求可能出错,已妨碍了服务器对请求的处理。
| 代码 |
说明 |
| 400(错误请求) |
服务器不理解请求的语法。 |
| 401(未授权) |
请求要求进行身份验证。登录后,服务器可能会返回对页面的此响应。 |
| 403(已禁止) |
服务器拒绝请求。如果在 Googlebot 尝试抓取您网站上的有效网页时显示此状态代码(您可在 Google 网站管理员工具中诊断下的网络抓取页面上看到此状态代码),那么,这可能是您的服务器或主机拒绝 Googlebot 对其进行访问。 |
| 404(未找到) |
服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的网页进行的,那么,服务器通常会返回此代码。
如果您的网站上没有 robots.txt 文件,而您在 Google 网站管理员工具"诊断"标签的 robots.txt 页上发现此状态,那么,这是正确的状态。然而,如果您有 robots.txt 文件而又发现了此状态,那么,这说明您的 robots.txt 文件可能是命名错误或位于错误的位置。(该文件应当位于顶级域名上,且应当名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址上发现此状态(位于"诊断"标签的 HTTP 错误页上),那么,这表示 Googlebot 所追踪的可能是另一网页中的无效链接(旧链接或输入有误的链接)。
|
| 405(方法禁用) |
禁用请求中所指定的方法。 |
| 406(不接受) |
无法使用请求的内容特性来响应请求的网页。 |
| 407(需要代理授权) |
此状态代码与 401(未授权)类似,但却指定了请求者应当使用代理进行授权。如果服务器返回此响应,那么,服务器还会指明请求者应当使用的代理。 |
| 408(请求超时) |
服务器等候请求时超时。 |
| 409(冲突) |
服务器在完成请求时发生冲突。服务器必须包含有关响应中所发生的冲突的信息。服务器在响应与前一个请求相冲突的 PUT 请求时可能会返回此代码,同时会提供两个请求的差异列表。 |
| 410(已删除) |
如果请求的资源已被永久删除,那么,服务器会返回此响应。该代码与 404(未找到)代码类似,但在资源以前有但现在已经不复存在的情况下,有时会替代 404 代码出现。如果资源已被永久删除,那么,您应当使用 301 代码指定该资源的新位置。 |
| 411(需要有效长度) |
服务器不会接受包含无效内容长度标头字段的请求。 |
| 412(未满足前提条件) |
服务器未满足请求者在请求中设置的其中一个前提条件。 |
| 413(请求实体过大) |
服务器无法处理请求,因为请求实体过大,已超出服务器的处理能力。 |
| 414(请求的 URI 过长) |
请求的 URI(通常为网址)过长,服务器无法进行处理。 |
| 415(不支持的媒体类型) |
请求的格式不受请求页面的支持。 |
| 416(请求范围不符合要求) |
如果请求是针对网页的无效范围进行的,那么,服务器会返回此状态代码。 |
| 417(未满足期望值) |
服务器未满足"期望"请求标头字段的要求。 |
5xx(服务器错误)
这些状态代码表示,服务器在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错。
| 代码 |
说明 |
| 500(服务器内部错误) |
服务器遇到错误,无法完成请求。 |
| 501(尚未实施) |
服务器不具备完成请求的功能。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。 |
| 502(错误网关) |
服务器作为网关或代理,从上游服务器收到了无效的响应。 |
| 503(服务不可用) |
目前无法使用服务器(由于超载或进行停机维护)。通常,这只是一种暂时的状态。 |
| 504(网关超时) |
服务器作为网关或代理,未及时从上游服务器接收请求。 |
| 505(HTTP 版本不受支持) |
服务器不支持请求中所使用的 HTTP 协议版本。 |
| |
| java工厂模式 |
|
[ 2009-2-6 16:15:00 | By: 孙大峰 ]
|
|
一、引子
话说十年前,有一个爆发户,他家有三辆汽车(Benz(奔驰)、Bmw(宝马)、Audi(奥迪)看来这人比较爱国,没有日本车),还雇了司机为他开车。不过,爆发户坐车时总是这样:上Benz车后跟司机说"开奔驰车!",坐上Bmw后他说"开宝马车!",坐上Audi后他说"开奥迪车!"。你一定说:这人有病!直接说开车不就行了?! 而当把这个爆发户的行为放到我们程序语言中来,我们发现C语言一直是通过这种方式来坐车的!幸运的是,这种有病的现象在OO语言中可以避免了。下面以Java语言为基础来引入我们本文的主题:工厂模式!!
二、简介
工厂模式主要是为创建对象提供了接口。工厂模式按照《Java与模式》中的提法分为三类:
1. 简单工厂模式(Simple Factory)
2. 工厂方法模式(Factory Method)
3. 抽象工厂模式(Abstract Factory)
这三种模式从上到下逐步抽象,并且更具一般性。还有一种分类法,就是将简单工厂模式看为工厂方法模式的一种特例,两个归为一类。下面是使用工厂模式的两种情况:
1.在编码时不能预见需要创建哪种类的实例。
2.系统不应依赖于产品类实例如何被创建、组合和表达的细节
三、简单工厂模式
顾名思义,这个模式本身很简单,而且使用在业务较简单的情况下。
它由三种角色组成(关系见下面的类图):
1、工厂类角色:这是本模式的核心,含有一定的商业逻辑和判断逻辑。在java中它往往由一个具体类实现。
2、抽象产品角色:它一般是具体产品继承的父类或者实现的接口。在java中由接口或者抽象类来实现。
3、具体产品角色:工厂类所创建的对象就是此角色的实例。在java中由一个具体类实现。

那么简单工厂模式怎么用呢?我来举个例子吧,我想这个比讲一大段理论上的文字描述要容易理解的多!下面就来给那个暴发户治病: P
在使用了简单工厂模式后,现在暴发户只需要坐在车里对司机说句:"开车"就可以了。来看看怎么实现的:
//抽象产品角色
public interface Car{
public void drive();
}
//具体产品角色
public class Benz implements Car{
public void drive() {
System.out.println("Driving Benz ");
}
}
public class Bmw implements Car{
public void drive() {
System.out.println("Driving Bmw ");
}
}
。。。(奥迪我就不写了:P)
//工厂类角色
public class Driver{
//工厂方法
//注意 返回类型为抽象产品角色
public static Car driverCar(String s)throws Exception {
//判断逻辑,返回具体的产品角色给Client
if(s.equalsIgnoreCase("Benz")) return new Benz();
else if(s.equalsIgnoreCase("Bmw"))
return new Bmw();
......
else throw new Exception();
。。。
//欢迎暴发户出场......
public class Magnate{
public static void main(String[] args){
try{
//告诉司机我今天坐奔驰
Car car = Driver.driverCar("benz");
//下命令:开车
car.drive();
。。。
如果将所有的类放在一个文件中,请不要忘记只能有一个类被声明为public。 程序中类之间的关系如下:
这便是简单工厂模式了。下面是其好处:
首先,使用了简单工厂模式后,我们的程序不在"有病",更加符合现实中的情况;而且客户端免除了直接创建产品对象的责任,而仅仅负责"消费"产品(正如暴发户所为)。
下面我们从开闭原则上来分析下简单工厂模式。当暴发户增加了一辆车的时候,只要符合抽象产品制定的合同,那么只要通知工厂类知道就可以被客户使用了。那么对于产品部分来说,它是符合开闭原则的--对扩展开放、对修改关闭;但是工厂部分好像不太理想,因为每增加一辆车,都要在工厂类中增加相应的商业逻辑和判断逻辑,这显自然是违背开闭原则的。
对于这样的工厂类(在我们的例子中是为司机师傅),我们称它为全能类或者上帝类。
我们举的例子是最简单的情况,而在实际应用中,很可能产品是一个多层次的树状结构。由于简单工厂模式中只有一个工厂类来对应这些产品,所以这可能会把我们的上帝类坏了,进而累坏了我们可爱的程序员:(
正如我前面提到的简单工厂模式适用于业务将简单的情况下。而对于复杂的业务环境可能不太适应阿。这就应该由工厂方法模式来出场了!!
四、工厂方法模式
先来看下它的组成吧:
1、抽象工厂角色:这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。在java中它由抽象类或者接口来实现。
2、具体工厂角色:它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。在java中它由具体的类来实现。
3、抽象产品角色:它是具体产品继承的父类或者是实现的接口。在java中一般有抽象类或者接口来实现。
4、具体产品角色:具体工厂角色所创建的对象就是此角色的实例。在java中由具体的类来实现。
来用类图来清晰的表示下的它们之间的关系:

我们还是老规矩使用一个完整的例子来看看工厂模式各个角色之间是如何来协调的。话说暴发户生意越做越大,自己的爱车也越来越多。这可苦了那位司机师傅了,什么车它都要记得,维护,都要经过他来使用!于是暴发户同情他说:看你跟我这么多年的份上,以后你不用这么辛苦了,我给你分配几个人手,你只管管好他们就行了!于是,工厂方法模式的管理出现了。代码如下:
//抽象产品角色,具体产品角色与简单工厂模式类似,只是变得复杂了些,这里略。
//抽象工厂角色
public interface Driver{
public Car driverCar();
}
public class BenzDriver implements Driver{
public Car driverCar(){
return new Benz();
}
}
public class BmwDriver implements Driver{
public Car driverCar() {
return new Bmw();
}
}
......//应该和具体产品形成对应关系,这里略...
//有请暴发户先生
public class Magnate
{
public static void main(String[] args)
{
try{
Driver driver = new BenzDriver();
Car car = driver.driverCar();
car.drive();
}catch(Exception e)
{ }
}
}
工厂方法使用一个抽象工厂角色作为核心来代替在简单工厂模式中使用具体类作为核心。让我们来看看工厂方法模式给我们带来了什么?使用开闭原则来分析下工厂方法模式。当有新的产品(即暴发户的汽车)产生时,只要按照抽象产品角色、抽象工厂角色提供的合同来生成,那么就可以被客户使用,而不必去修改任何已有的代码。看来,工厂方法模式是完全符合开闭原则的!
使用工厂方法模式足以应付我们可能遇到的大部分业务需求。但是当产品种类非常多时,就会出现大量的与之对应的工厂类,这不应该是我们所希望的。所以我建议在这种情况下使用简单工厂模式与工厂方法模式相结合的方式来减少工厂类:即对于产品树上类似的种类(一般是树的叶子中互为兄弟的)使用简单工厂模式来实现。
当然特殊的情况,就要特殊对待了:对于系统中存在不同的产品树,而且产品树上存在产品族,那么这种情况下就可能可以使用抽象工厂模式了。
五、小结
让我们来看看简单工厂模式、工厂方法模式给我们的启迪:
如果不使用工厂模式来实现我们的例子,也许代码会减少很多--只需要实现已有的车,不使用多态。但是在可维护性上,可扩展性上是非常差的(你可以想象一下,添加一辆车后要牵动的类)。因此为了提高扩展性和维护性,多写些代码是值得的。
六、抽象工厂模式
先来认识下什么是产品族:位于不同产品等级结构中,功能相关联的产品组成的家族。如果光看这句话就能清楚的理解这个概念,我不得不佩服你啊。还是让我们用一个例子来形象地说明一下吧。
图中的BmwCar和BenzCar就是两个产品树(产品层次结构);而如图所示的BenzSportsCar和BmwSportsCar就是一个产品族。他们都可以放到跑车家族中,因此功能有所关联。同理BmwBussinessCar和BenzSportsCar也是一个产品族。
回到抽象产品模式的话题上,可以这么说,它和工厂方法模式的区别就在于需要创建对象的复杂程度上。而且抽象工厂模式是三个里面最为抽象、最具一般性的。抽象工厂模式的用意为:给客户端提供一个接口,可以创建多个产品族中的产品对象。而且使用抽象工厂模式还要满足一下条件:
1.系统中有多个产品族,而系统一次只可能消费其中一族产品
2.同属于同一个产品族的产品以其使用。
来看看抽象工厂模式的各个角色(和工厂方法的如出一辙):
抽象工厂角色:这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。在java中它由抽象类或者接口来实现。
具体工厂角色:它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。在java中它由具体的类来实现。
抽象产品角色:它是具体产品继承的父类或者是实现的接口。在java中一般有抽象类或者接口来实现。
具体产品角色:具体工厂角色所创建的对象就是此角色的实例。在java中由具体的类来实现。
看过了前两个模式,对这个模式各个角色之间的协调情况应该心里有个数了,我就不举具体的例子了。只是一定要注意满足使用抽象工厂模式的条件哦,不然即使存在了多个产品树,也存在产品族,但是不能使用的。
|
|
|
围剿 Flash 的不仅有 HTML 5,还有 JavaScript,著名的 JavaScript 框架 jQuery 在运动特效方面已经越来越流畅,有时候你需要点一下右键来确认它不是 Flash。本文介绍了10个非常出色的 jQuery 运动特效,这些效果可以更有效地展示你的内容。
1. 流感导航菜单
下面的导航菜单,当鼠标在上面移动的时候,会很流畅地垂下解释菜单,当你将鼠标在上面快速左右移动的时候,会怀疑这是 Flash。

2. 转花灯
Roundabout 是一个 jQuery 插件,可以将一组 HTML 对象转换为旋转花灯的效果。

3. 拉洋片
拉洋片也许是 jQuery 最拿手的效果了。该效果在遇到 JavaScript 被禁用的场合会自动降级使用。

4. jQuery Quicksand 插件
这个让人赞叹的插件,可以对一组 HTML 对象重新洗牌,效果非常出众。

5. 导航滑块
这种风格的导航已经见于很多站点,鼠标在导航菜单上移动的时候,一个高亮指示条随着鼠标滑动,指示当前的导航位置。

6. 文字的移动纹理
在文字上,显示移动的纹理,效果美轮美奂。原理是,做一个带透明文字的 PNG 图像放在一个容器里,容器的背景放一张图案,用 jQuery 移动容器的背景,很简单,不过,不支持 IE6,因为 IE6 不支持 PNG。

7. jDiv: jQuery 导航 Tab
一个可以显示丰富内容的下拉导航菜单(演示要翻墙)。

8. 基于 CSS3 和 jQuery 的半透明导航系统
鼠标在导航菜单上移动,显示半透明的指示图标。CSS3 做这个实在太容易了。

9. 云台式拉洋片
常规的拉洋片效果要么左到右,要么右到左,或者垂直上下,这个 jQuery 效果可以象云台那样扫镜头。

10. SlideDeck
SlideDeck 是一种新颖的内容展示方式,有点类似 Outlook 的手风琴菜单,但视觉效果和用户体验更好一些。

本文来源:http://devsnippets.com/article/10-jquery-transition-effects.html
FCKeditor 是个开源的HTML 文本编辑器,可以让web 程序拥有如MS Word 这样强大的编辑功能。等等。但是,它有一个不足之处是只有三个皮肤。而且看起来也都不怎么好看。针对此问题,我们就来探讨一下FCKeditor如何更换与创建皮肤。
我们找到FCKeditor目录里的fckconfig.js文件,用记事本打开。找到下面这一句
1. FCKConfig.SkinPath = FCKConfig.BasePath + 'skins/default/' ;
这就是默认的皮肤文件设置。可以将后面的default设置成其它的。自带的三套皮肤目录分别是:default、office2003和silver。更改完成后清空一下缓存。再次打开带有编缉器的网页。我们可以发现编缉器的风格已经改变了。
由于FckEditor for java 2.4相对于2.3而言做了许多改变,这些改变使得我们的Fckeditor配置起来更方便。例如:
基础包名从:com.fredck.FCKeditor 改为 net.fckeditor.
文件上传SimpleUploaderServle整合到了ConnectorServlet里面,WEB,XML的配置就简单多了,下面通过一个实例说明配置详细步骤
1、首先登陆www.fckeditor.net/download下载FCKeditor的最新版本,需要下载2个压缩包,一个是基本应用。另一个是在为在jsp下所准备的配置。
最新版本为:FckEditor2.6.3和FckEditor for java 2.4
FCKeditor 2.6.3下载地址:sourceforge.net/project/downloading.php
具体下载地址:http://easynews.dl.sourceforge.net/sourceforge/fckeditor/FCKeditor_2.6.3.zip
FCKeditor for Java 下载地址:sourceforge.net/project/downloading.php
具体下载地址:http://switch.dl.sourceforge.net/sourceforge/fckeditor/fckeditor-java-2.4-bin.zip(发行版,如果需要源码或者demo包请另行下载)
请下载demo包,否则会出现留言中那位朋友的错误!
下载之后分别为:FCKeditor_2.6.3.zip 和 fckeditor-java-2.4-bin.zip(fckeditor-java-demo-2.4.war)将它们分别解压。
2、首先在MyEclipse(或者其他的IDE)下建立一个新项目例如:FckedtiorTest 即http://localhost:8080/FckeditorTest
现在将解压后的FCKeditor_2.6.3.zip 里面的fckeditor文件夹拷贝到当前的项目文件夹里面。我的demo项目目录结构如下:

3、配置web.xml。配置文件如下,这就是全部了,其他的不需要再配置,由于SimpleUploaderServle整合到了ConnectorServlet里面,所以文件上传等都不需要再配置。
|
<servlet>
<servlet-name>Connector</servlet-name>
<servlet-class>
net.fckeditor.connector.ConnectorServlet
</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Connector</servlet-name>
<url-pattern>
/fckeditor/editor/filemanager/connectors/*
</url-pattern>
</servlet-mapping>
|
4、在src目录下面建立fckeditor.properties资源文件,在里面写入这么一行“connector.userActionImpl=net.fckeditor.requestcycle.impl.UserActionImpl”
5、下面写测试页面:
index.jsp
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<%@ taglib uri="http://java.fckeditor.net" prefix="FCK" %>
<html>
<head>
<title>FckEditor测试</title>
</head>
<body style="text-align: center;">
<div style="text-align: center;width: 600pt">
<h2>FckEditor测试</h2>
<hr>
<form action="ShowData.jsp" method="post">
<FCK:editor instanceName="test" height="400pt">
<jsp:attribute name="value"> 这里是<a href="http://hi.baidu.com/huqiwen">数据测试</a>
</jsp:attribute>
</FCK:editor>
<input type="submit" value="提交"/>
<input type="reset" value="重置"/>
</form>
</div>
</body>
</html> |
显示数据的页面:ShowData.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<head>
<title>FCKeditor - 显示数据</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<%
request.setCharacterEncoding("UTF-8");
String data = request.getParameter("test");
%>
<body>
<h1>FCKeditor - 显示数据</h1>
<hr/><br />
<%=data%>
</body>
</html> |
6、结果截图
index.jsp

ShowData.jsp
7、给FckEditor瘦身
删除fckeditor目录下面所有以“_”开头的文件或者文件夹,像"_samples"、"_documentation.html“等
删除fckeditor目录下面除了,fckconfig.js fckpackage.xml fckstyles.xml fcktemplates.xml外的所有文件,当然要保留editor文件夹
删除fckeditor/editor/lang目录下面除了en.js、 zh-cn.js外的所有文件
删除fckeditor\editor\filemanager目录下面的connectors文件夹
删除editor\skins目录下面除了default下面的文件夹,这个里面是皮肤,共有三种,可以在fckconfig.js里面设置。
PS:demo下载:http://www.namipan.com/d/7218d2c0bf3e33e8aedf972b41d5d09f3efab0d8f53b0900
再PS:有关中文乱码问题请参考:http://hi.baidu.com/huqiwen/blog/item/c709aa18fa187a0135fa4103.html
现在要求您诊断 WebLogic J2EE 应用程序中的性能问题。因为 Java 系统是如此复杂,所以诊断 WebLogic J2EE 应用程序中的性能问题就有点像诊断疑难杂症。
为了正确地找到问题所在,您需要对症状有全面了解,要做好准备进行大量研究工作,最后您需要制定正确的治疗方案。本文讨论了 J2EE 应用程序性能问题的一些最常见类型和它们产生的原因,以及如何正确地诊断和消除它们的推荐指导原则。
症状
WebLogic 应用程序性能问题的症状是什么?您看到的症状可以指导您在所有可能的问题中进行搜索。请准备一个笔记本并开始向人们调查。试着把对问题根本原因的推测和假设与系统行为的实际证据分离。下面是一个常见症状集的列表: 持续缓慢:应用程序一直特别慢。改变环境因素(负载、数据库连接数量)对整体响应时间的改变很小。 随着时间推进越来越慢:系统运行时间越长(负载相对均衡不变的情况下),就变得越慢。有可能是(最后)达到了某个阈值,系统被锁定或者由于大量错误而崩溃。 随着负载增加越来越慢:每增加一个额外用户,应用程序就变得越慢。如果用户离开系统,系统就“冷却下来”,恢复正常。 零星的挂起或者异常错误:偶尔(可能由于负载或某些其它原因),在页面无法完成或者出现追踪到异常和堆栈的错误页时,用户会看到挂起的情况。挂起的数量可能不同,但总是无法完全消除,甚至在强化 (“burn in”) 期间之后也是如此。 可以预见的锁定:首先出现一些挂起或错误,然后加速出现,直到系统完全被锁定。通常这些问题可以通过“重新启动来管理”的方式解决。 突然混乱:系统一直运行正常,相当一段时间里(可能一个小时,也可能是三天)性能都还差强人意,但是“突然某个时候,根本没有任何原因的”,系统开始出现大量错误,或者被锁定。
为什么问题诊断如此复杂? 软件开发网
对于 WebLogic 应用程序的某个具体应用模式来说,没有既定的公式可以用来推导出它的性能(在严格的实时工程当中,速度单调分析这类技术确实可以做这项工作,但是在本文里还是让我们忘记它吧)。网络上是否存在另外一个系统正在密集使用一个共享的后端服务,对于实际产生的性能有很大影响。性能也许还取决于 JDBC 驱动程序版本和数据库的正确匹配。也许开发人员三年前写的一些代码恰巧在这个时候才出现特定类型的异常,而您急切需要的解决问题回馈,却恰恰包含在这个异常里。
从本质上说,典型业务系统的性能是由成千上万交互的变量和决策共同作用的结果。就像人体一样,有太多连锁着的部分和过程,所以很难理解系统的整体。因此我们进行了简化,并求助于拱形模式。
疾病
您看到的症状的根本原因是什么?它是初级流行性感冒或者是肺炎的开始吗?是应用程序内部的底层问题还是它所在的 JVM 外部的问题?请参阅表 1 中应用程序性能低下的一些最常见原因。
http://www.mscto.com
表1
毛病 描述 症状 原因或治法 线性内存泄漏 每单位(每事务、每用户等)泄漏造成内存随着时间或负载线性增长。这会随着时间或负载增长降低系统性能。只有重启才有可能恢复。 随着时间越来越慢
随着负载越来越慢 虽然可能有多种外部原因,但最典型的是与资源泄漏有关(例如,每单位数据的链表存储,或者没有回收的回收/增长缓冲区)。 指数方式内存泄漏 双倍增长策略的泄漏造成系统内存消耗表现为时间的指数曲线 随着时间越来越慢
随着负载越来越慢 通常是由于向集合(Vector,HashMap) 中加入永远不删除的元素造成的。 糟糕的编码:无限循环 线程在 while(true) 语句以及类似的语句里阻塞。 可以预见的锁定 您需要对循环进行大刀阔斧的删剪。 资源泄漏 JDBC 语句,CICS 事务网关连接,以及类似的东西被泄漏了,造成对 Java 桥接层和后端系统的影响。 随着时间越来越慢
可以预见的锁定
突然混乱 通常情况下,这是由于遗漏了 finally 块,或者更简单点,就是忘记用 close() 关闭代表外部资源的对象所造成的。 外部瓶颈问题 后端或者其他外部系统(如鉴权)越来越慢,同样减缓了 J2EE 应用服务器和应用程序 持续缓慢
随着负载越来越慢 咨询专家(负责的第三方或者系统管理员),获取解决外部瓶颈问题的方法。 外部系统 J2EE 应用程序通过太大或太多的请求滥用后端系统。 持续缓慢
随着负载越来越慢 清除冗余的工作请求 ,成批处理相似的工作请求,把大的请求分解成若干个更小的请求,调整工作请求或后端系统(例如,公共查询关键字的索引)等。 糟糕的编码:CPU密集的组件 这是 J2EE 世界中常见的感冒。一些糟糕的代码或大量代码之间一次糟糕的交互,就挂起了 CPU,把吞吐速度减慢到爬行的速度。 持续缓慢
随着负载越来越慢 典型的解决方案就是数据高速缓存或者性能计数。 中间层问题 实现得很糟糕的桥接层(JDBC 驱动程序,到传统系统的 CORBA 连接),由于对数据和请求不断的排列、解除排列,从而把所有通过它的流量减慢到爬行速度。这个毛病在早期阶段很容易与外部瓶颈混淆。 持续缓慢
随着负载越来越慢 检查桥接层和外部系统的版本兼容性。如果有可能,评估不同的桥接供应商。如果重新规划架构,有可能完全不需要桥接。 内部资源瓶颈:过度使用或分配不足 内部资源(线程、放入池的对象)变得稀缺。是在正确使用的情况下加大负载时出现过度使用还是因为泄漏? 随着负载越来越慢
零星的挂起或异常错误 分配不足:根据预期的最大负载提高池的最大尺寸。过度使用:请参阅外部系统的过度使用。 不停止的重试 这包括对失败请求连续的(或者在极端情况下无休止的)重试。 可以预见的锁定
突然混乱 可能就是后端系统完全宕机。在这里,可用性监控会有帮助,或者就是把尝试与成功分开。 线程:阻塞点 线程在过于积极的同步点上备份,造成交通阻塞。 随着负载越来越慢
零星的挂起或异常错误
可以预见的锁定
突然混乱 可能同步是不必要的(只要重新设计),或者比较外在的锁定策略(例如,读/写锁)也许会有帮助。 线程:死锁/活动锁 最普遍,这是您基本的“获得顺序”的问题。 突然混乱 处理选项包括:主锁,确定的获得顺序,以及银行家算法。
测量关键的统计指标
当您负责诊断问题的时候,您应当能够跟踪关于您的 WebLogic 应用程序健康情况的关键统计指标。您能测量什么?有什么工具可以提供帮助呢?
使用的全部内存:在不同级别上 (JVM 堆栈,操作系统),Java 堆栈 profiler 对堆栈的正确使用提供了可见性;像 top ,vmstat 以及 Windows Perfmon 这样的工具在操作系统级别上为内存使用提供可见性。察看 Java 堆栈的一个简单的聚合视图,请打开—verbose:gc 开关(如果在您的 JVM 上可以使用的话)。 CPU 时间:合并(可以通过使用 top 等方式得到)每个组件或每种方法。其中某些指标可以通过 WebLogic 管理控制台得到。也可以通过 Java profile 使用它们。 计时 (a.k.a.“实” 时):每事务,每组件,每方法;可以按统计平均值或单独的数据点查看。Java profiler 可以产生一些这样的数据,但是使用程序监控解决方案可能是您的最佳选择。 内部资源:
分配的数量,使用的数量,等待的客户数量,获得资源的平均等待时间,使用资源平均消耗的时间,使用资源完成请求工作时使用的平均时间。应用程序服务器通常会给出这些数字的最小可视性。 外部资源:分配的数量,使用的数量,等待的客户数量,平均等待时间,加上对这些外部系统的直接测量(例如查看它能多快完成请求的工作)。不要忘记运行应用程序服务器的操作系统和硬件也是“外部资源”-例如,是否您使用了太多的进程或端口?可以用两种形式测试这些资源—从 JVM 内部测试提供资源的桥接层,用外部资源本身的工具测量外部资源。 网络应用:带宽使用,延迟。虽然操作系统自带的工具(例如 netstat)也有助于做这些工作,但是网络嗅探器设备可以深入了解这些信息。 系统状态:用线程清除,日志和跟踪文件,堆栈跟踪等等。或者在更深层次上,就像调试器中查看的那样使用变量的值。
实验工作
有的时候,在一次标杆运行中获得的数据,不足以揭示答案。那么找到答案的机会就在于您还有些有限的预算,可以运行试验或者做实验工作,来完成诊断。您可以运行什么类型的试验呢?您可以修改、观察什么变量呢?
http://www.mscto.com
尝试观察系统行为在一段时间上的变化。应用一个衡定的负载,并观察您的指标随时间发生的变化。您可能会看到某些趋势,短则一小时就可看到,长则二三天。例如,您可以看到内存使用随着时间而增长。随着使用的内存数量达到上限, JVM 花在搜索垃圾上的时间和操作系统花在分配内存页面上的时间开始减少用户事务的整体响应时间。当抛开 GC 的时候,垃圾搜集的整个过程可能过长,从而造成执行中的事务超时和异常。现在可以开始查找资源泄漏或内存泄漏了。 尝试在系统上改变负载。 采用三到四种工作负载(例如,10个,50个和100个用户),并搜集每个负载的数据。分析一下您对这些负载的测量情况。例如,您可能发现,当您的账户登录 servlet 的响应时间无论如何都会低于 50 毫秒的时候,计算销售税的 EJB 却随着用户数据的增长,速度呈线性下降。如果这个 EJB 性能在负载下的差异能解释整体响应时间性能在负载下的增长,那么现在就是深入分析这个组件的时候了。谨记一定还要把负载恢复原状,并查看系统是否复原。 尝试把系统分成小单元,针对每个单元轮流进行压力测试。 选择一个或多个坐标系对系统进行划分。主要的一个是系统面上的层:负载均衡器、Web 服务器、WebLogic Server,以及后端。其它示例包括用户账户,内部组件,事务类型,以及单独的页面。假设您选择了用户账户。在用户 A 的账户下运行一些负载,然后再在用户 B 的账户(应当非常不同)下运行某些负载;比较两次运行间不同的测量结果。或者,轮流选择您使用的后端系统,分别对使用每个后端系统比较重的应用程序组件进行压力测试。具体要选择哪个坐标进行划分,完全取决于您要证明或者否定哪个假设。下面是一些具体想法:
- 如果某个用户的登录看起来造成了问题,那么有可能是这个用户账户档案(例如,装入 2,000 个订单的完整采购历史),或者可能是他使用系统的方式(例如,页面访问的顺序,或者他用来查找某个文档的查询字符串的正确性)。
- 如果您使用的是一个集群系统,请尝试以单台机器为单位划分。尽管尽了最大努力,有的时候还会有一些机器没有安装最新的应用服务器或者操作系统补丁,这就会造成不同的性能特征。而且,还请注意负载均衡器,或者保姆进程,查看它们是否公平地分配了工作并跟踪了进入请求。
诊断:测试您的推测
在这个时候,您应当已经有了足够的信息,可以形成关于性能瓶颈原因的推测了(请参阅表 1)。为了验证您的推测是否正确或者在多个备选的推测之间进行筛选,您需要分析更多的信息或者在系统上运行更多的标杆测试。这里是一些可以帮助您的指导意见:
区分糟糕的编码(或者是应用程序组件或者是桥接层)和瓶颈 (内部的或外部的),请查看整体的 CPU 使用情况。如果它在负载下没变化,但是整体响应时间变化了,那么就是应用程序花费了它的大多数时间来等待。 仅仅是因为好像是外部资源的问题,不代表您就可以立刻把责任推到资源上。 例如,分层或联网的问题,也能造成数据库看起来很慢,虽然实际上它并不慢。或者,更简单一点,您对数据库的请求可能是不合理的(每次用户登录的时候,都要进行三个表之间的 200 万行记录合并)。应当一直把桥接层的响应时间(例如,JDBC 驱动器)和资源提供的时间或者工具提供的时间进行比较(例如,DBA Studio)。 结构化的图表有助于您理解系统内部的整体交互,但是不要忘记地图并不是领地。.编码错误或者对架构意图的误解,有可能使系统的实际行为与期望的行为不同。请相信性能工作提供的实际数据,而不要相信一个声称“每个用户事务将只会发布一个 SQL 语句”这样的文档。 使用 Occam 军刀。 假设您有两个备选推测,一个是:在 200 万行代码里,有一个编码糟糕的组件,直到上周这个组件才集成进来;另一个是 JVM 的即时编译器生成了糟糕的机器码,破坏了这个变量的内存完整性。除非您有具体的数据来证实,否则(我已经看到了第二种情况发生),请更详细地检查第一个假设。J2EE 系统确实容易出错,但是不要让这一点就妨碍您先测试一个更简单的假设。 日志文件中没有错误不代表不存在错误。 有许多原因可以造成不在日志里写下异常;可能是因为程序员认为某件事“永远不会发生”,于是就排除了这个异常;也可能是因为某些组件可以使用故障恢复机制,所以就没有记录第一次故障。
示例诊断
让我们来实际研究一个示例。您的 WebLogic 应用程序表现出在负载下越来越慢的症状。您加入的用户越多,系统越慢。一旦消除负载,系统就冷静下来,没有任何后遗症。您对这一主要症状进行测试,发现并得到图 2 所示的以下结果(时间测量针对的是单一典型事务的端到端完成时间)。
表2
负载(用户数) 来回用时(毫秒) 10 300 50 471 100 892 150 1067
应用程序性能在负载下越来越慢
http://www.mscto.com
您形成了几个假设。也许这里的毛病是一个糟糕编码的组件,也许是后端系统的瓶颈。它可能是一个同步阻塞点。您怎样才能分清它们的不同呢?假设您还测试了应用程序服务器在负载运行期间的CPU整体使用情况,并得到了表 3 所示的结果。
表3
负载(用户数) 来回用时(毫秒) 整体 CPU 时间(%) 10 300 30 50 471 33 100 892 37 150 1067 41
问题看起来好像是“等待”瓶颈
现在看起来,系统不是 CPU 密集型的,这就是说它的多数时间都花在等待上了。那么是它的内部(例如,同步交通阻塞)或外部(缓慢的数据库)的问题?好,让我们假设我们还稍微多搜集了一些数据,如表 4 所示。
表4
负载(用户数) 等待数据库连接的线程数量 JDBC 查询用时(毫秒) 10 2 58 50 3 115 100 3 489 150 4 612
问题是否出在一个缓慢的 SQL 语句上呢?
现在看起来并不是内部等待数据库连接的瓶颈,相反,好像是 JDBC 查询本身的问题。JDBC 查询不仅随整体事务时间的不同而不同,而且它糟糕的性能还解释了整体性能糟糕的原因。但是,我们还不能完全确定。您仍然还有三个主要的假设要排序:是否数据库本身慢?应用程序是否对数据库进行了不合理的请求?或者问题是不是出在应用程序和数据库之间的某个层上?您拿出数据库供应商专用的工具,从它的角度查看响应时间。假设您看到如表 5 所示的数字。
表5
负载(用户数) JDBC 查询计时(毫秒) DB SQL 执行的时间(毫秒) 10 58 43 50 115 97 100 489 418 150 612 589
实际是数据库中的 SQL 语句慢
如果您没有看到这条信息,那么您可能要返回 JDBC 驱动程序,期待能够发现其中的某些同步问题(请记住,CPU 没有被抑制)。幸运的是,在这个案例里,您已经把具体问题的范围缩小到数据库查询上。找出查询请求是否足够合理,需要一些相关领域的知识,需要熟悉系统,但是在这个案例里,它也许就是发现查询把非索引字段和外键进行了比较。您和 DBA 协作,它修改索引方案,让查询变得更快,而您则找到了您的药方。
结束语
诊断 WebLogic J2EE 应用程序的性能瓶颈是一个艰苦的旅程。请随时保持清醒,把事实与推测分开,总是用实际的证据来确认您的推测。我希望给您带来了思考和实践问题的一些有用的想法的分类。就像调试,这仍然是一项不明确的艺术,但是深思熟虑会带您走出困境。祝您好运!
关于作者
John Bley 是 Wily Technology 的软件工程师。他有丰富的 Java 编程和架构经验。为了撰写本文,他总结了 Wily 的企业客户的经验,Wily负责管理复杂的 J2EE 环境。(更多)
原文出处 http://www.sys-con.com/story/?storyid=43024&DE=1
Google近日推出了一款网站性能优化工具:Page Speed(http://code.google.com/speed/page-speed/)。它旨在帮助站长与网站开发者分析网站中存在的性能方面的问题,并有针对性地提出改进意见。Page Speed在功能方面极其类似于Yahoo!的网站性能优化YSlow,不过YSlow要比Page Speed推出早得的多。它们都是基于Firebug的Fireffox插件,使用方法也类似。这里我主要介绍一下Google新推出的Page Speed的使用,对Yslow感兴趣的朋友可以参照我以前的这篇文章《你的网站为什么会慢?——用YSlow为你的网站提速》,同时还有我翻译的Yahoo!的文章Yahoo!网站性能最佳体验的34条黄金守则——内容、JavaScript和CSS、服务器、图片、Coockie与移动应用,相信一定会对你提高网站性能有帮助。
一、Page Speed的安装及使用
Page Speed是一款Firefox插件,同时他依附于别款插件Firebug,也就是说你的Firefox浏览器中必须已经安装了Firebug才能安装Page Speed。安装环境为Firefox 3.0.4以上,Fireug 1.3.3以上。
Page Speed的使用也很简单,在Firefox中点击右下角的Firebug图标启动后,再点击Page Speed选项卡即可。要注意的是,你要对你网站内的某个页面进行性能分析,你必须先把该页面加载完成后才能使用Page Speed,也就是说只有在浏览器左下角出现“Done”或者"完成"之后才可以启用Page Speed进行分析。如果页面中流媒体,可能不会现在“完成”,这种情况要等到流媒体可以播放。

然后点击“Analyze Performance”(性能分析),这时Page Speed会根据web performance best practices (网页性能最佳实践)进行逐项打分。然后根据重要程序和优先级对每项进行排列。

此外,你还可以点击每条建议前面的“加号”展开查看详细的描述,或者直接点击每条规则相看该规则的具体内容,还可以点击“Show Resource”(查看来源)来查看每条建议是针对页面中哪部分内容提出的。
对于分析结果中的符号说明一下:
- 红色感叹号代表高优先级提示,表示这一项严重影响了你的页面性能,你需要优先对其进行性能优化;
- 橙色三角代表此项提示需要引起你的注意,并进行适当改进;
- 绿色的对号代表该项规则在你的网站中应用得到,你在修改了前面两部分的提示之后,它们有可能变为绿色的对号;
- 蓝色消息符号是为你提供了额外的帮助信息,请稍加留意(需要注意的是,如果你的页面中出现了大量的此类符号,可能是因为你在页面加载完成之前就进行了网站性能分析)。
二、活动记录
活动记录是一条页面活动的时间轴,它记录了包括网络事件、JavaScript运行在内的所有浏览器活动。你可以使用它并配合性能分析中的数据进一步对网站性能做出评估。
- 查看页面运行过程中所耗费的时间,以毫秒计算;
- 查看浏览器事件,包括页面加载完成后的事件;
- 区分造成页面响应缓慢的原因,其中包括网络来时、DNS查找、连接建立、JavaScript运行等;
- 获取在特定时间或者事件下才响应的JavaScript事件列表;
- 可以对其它标签或者窗口中打开的页面进行分析;
- 多页面加载时的页面加载顺序;
- 对根据Page Speed优化前后的表现进行对比。

三、理解Page Speed中的事件
页面记录选项卡下是通过时间线来记录各种资源加载到页面所有需要的时间。事件的记录时间间隔为10毫秒,如果事件需要的时间少于10毫秒那么它将用较短的色块来表示。时间线中没有任何颜色的表示,在浏览器事件的运行依赖于其它进程,如DOM和CSS渲染、Flash ActionScript、渲染、操作系统事件等。
| 网络事件 |
描述 |
|
|
DNS |
浏览器查找DNS所需要的时间 |
|
|
t连接等待 |
浏览器与网站服务器建立连接(TCP)需要一定的时间。由于浏览器可以打开的连接数目是有限的,如果达到这个限制他必须等其它连接关闭之后才能再重新建立一个新的连接。(更多关于浏览器连接的信息可以参照Parallel downloads across hostnames)。 这个事件显示了浏览器等其它连接完成的时间。 |
|
|
连接 |
浏览器和web服务器建立连接。这个事件只有打开新连接时出现,已有连接重新打开使用不包含在内。 |
|
|
请求发送 |
浏览器发送的HTTP请求。只显示GET方式的请求。 |
|
|
已连接 |
浏览器通过网络等待接收数据。事件随着浏览器TCP连接的结束而结束。 |
| 本地事件 |
描述 |
|
|
缓存 |
浏览器成功将内容加入到缓存中。 |
|
|
可用数据 |
可用于浏览器呈现的数据。由于web服务器发送大量的数据,如果文件很大那么有可能一个资源会出现多个该事件。 |
|
|
获取JS |
浏览器获取JavaScript。该事件可能会延缓其它事件,如果此种情况出现,将会在其下一行列出。 |
|
|
运行JS |
浏览器执行JavaScript。该事件可能会延缓其它事件,如果此种情况出现,将会在其下一行列出。如果获取JS和运行JS中间有时间间隔,这说明源文件中包括有延时功能的函数。 |
此外,Page Speed还包括了对已完成的JavaScript函数的信息搜集功能,当页面中的JS函数一旦运行,PageSpeed就会捕捉到相关信息。不通过对Page Speed进行设置还可以对未触发函数、延时加载函数等进行收集。
下面的图片显示了7800毫秒时已经加载但还未触发的函数列表:

而下面则显示是已经触发运行了的JS函数:

此外Pge Speed还有诸如JavaScript函数控制、浏览器User Agent设置等更高级功能。具体使用大家可以与YSlow对比一下。
相信,用好这两款工具,对于站长和网站开发者来说会有极大的帮助。
本文网址: http://www.dudo.org/article/NewSoftware/using_google_page_speed.htm
转载请注意出处
最近在项目中需要用到用到JavaScript开发工具的支持,于是乎找到了曾经了解过但是并没有具体用过的aptana。
Aptana是一个开发Ajax的很好的ide,甚至该公司已经有自己的单独的Ajax Server和框架的支持。而且,至少到目前为止笔者所用过的支持JavaScript的ide中,aptana是最好的一个。且aptana提供了eclpse的插件,用起来几乎很上手而且很简单、方便,没有理由不去爱它。
但是在MyEclipse下安装aptana总会遇到一些问题,笔者 也一样遇到了许多问题。现在这里就做一个总结,安装aptana遇到的问题:
1、安装以后必须有Firefox支持。
因为aptana需要firefox 的JavaScript调试工具做调试,因此如果你安装过了aptana之后系统没有安装firefox,那么,还是推荐你安装一个firefox吧。即使不用这个浏览器也可以安装上,省的出现一些其他的不可预料的问题。
2、安装过程中出现无法下载或者不兼容的问题。
这个问题正式困扰我好几天的问题。如果aptana安装不上或者安装之后出现错误,一般都是aptana和myeclipse或者eclipse的版本问题,因此请下载之前认真阅读官方网站的资料以及版本的限制。一般说来,你使用的myeclipse版本越高,那么对应的aptana的版本就需要越高。笔者使用的MyEclipse完整版6.0,配上最新的aptana的eclipse插件。
3、是自动在线下载安装?还是link方式安装?
笔者推荐使用后者,也就是手动配置link的方式安装aptana插件。这样可以避免许多问题。笔者前几次安装aptana插件都失败,原因就在于是自动下载安装的,可每次都会出现错误,而改用手动配置link的方式安装后,一切问题迎刃而解了。
那么,跟着我一起来试试吧。
1、先去aptana的官方网站下载eclipse的插件
地址:http://update.aptana.com/update/studio/3.2/
强烈推荐手动下载插件的方式而不是在线升级的方式,尤其你用的不是eclipse而是完整安装版的myeclipse。
2、手动以link方式安装aptana插件
首先在你的myeclipse目录下打开eclipse文件夹:

然后将下载后的aptana插件文件解压缩到任何目录(笔者解压缩到了eclipse所在的目录)。再在links文件夹中新建一个文本文件aptana.link,其内容形式为:
path={aptana插件存放的位置}
例如笔者的link文件内容为:
path=C:\\Program Files\\Eclipse-6.0M1\\eclipse\\Aptana
然后,重启myeclipse就可以发现可爱的aptana的界面菜单了

(如果安装过程中出现问题,请留言。)
接下来就可以发现其伟大的特点了。

将Aptana编辑器设置成myeclipse默认的编辑器
如果我们想把aptana的编辑器设置成myeclipse默认的编辑器的话,那么可以在多做一点事情,这样方便我们今后的开发了。笔者也正式如此。
在Window菜单中找到Preferences,打开的菜单中左边的树中展开General,找到editor
点击File Associations,然后在上边选择要设置的文件后缀名,在下边找到aptana相应的编辑器,然后点“default”即可完成默认的设置了。很简单的,试试吧。
相关链接:eclipse在线更新地址http://update.aptana.com/update/studio/3.2/
官方相关介绍:http://www.aptana.com/docs/index.php/Plugging_Aptana_into_an_existing_Eclipse_configuration
原文地址:http://werr1985.javaeye.com/blog/288777
如果上述操作还不能安装的话:
请将aptana插件中的features,plugins的文件复制或者剪切到E:\MyEclipse 6.0\eclipse下面的相应文件夹里面,以后保准能运行
而且需要再windows-属性-aptana-my aptana/message center
把use firefox...前面的复选框的狗狗去掉
即可正常使用啦
我并不是说阅读英文有困难才这么做的,只是觉得如果有英汉两种界面,对我以后学习英文肯定有帮助,因为你可以对照者英文找对应的中文菜单。
时间长了,自己的英文水平肯定有所提高,以后遇到一些英文原版 软件就可以很快熟练掌握。虽然你有可能是计算机专业的,但是你有了这些积累之后,你就有可能翻译出专业的计算机词汇。
我们处在一个开源的时代,本人本着开源、好东西要大家分享的理念。
今天我要把这个汉化方法与大家共享,希望更多的人能从中受益。
下面就是汉化的具体方法:
1. 首先到Eclipse官方 网站下载一个语言 包---Eclipse 3.2多国语言 包
我最近刚下载的,我下载时的名字叫NLpack1-eclipse-SDK-3.2-win32.zip
它 包括的语言有German(德语), Spanish(西班牙语), French(法语), Italian(意大利语), Japanese (日语), Korean(韩语),Traditional Chinese(繁体中文) and Simplified Chinese(简体中 文).然后将其解压到硬盘的任意目录。
注意: 1. 解压的目录最好不要太深,目录中最好不要出现中文字符,建议都用英 文字符。
2. 为了避免无意中删除所需要的eclipse文件夹,造成日后汉化启动的失败,
建议解压到Aptana目录,例如我的就是:D:\Java\AptanaStudio\aptana\eclipse
2. 在Aptana目录下面建立一个子目录links,记住名字为links。
在目录里面建一个文本文件在里面输入以下内容:
path=D:\\Java\\AptanaStudio\\aptana 并保存。
(注:这里path指定的位置应该为刚才解压的文件夹eclipse的位置,我的就是 D:\Java\AptanaStudio\aptana)最后将文本文件改名为“com.genuitec.eclipse.NLpack1.link”
3. 找到AptanaStudio.exe所在文件夹,在AptanaStudio.exe上面右击选择“创建快捷方式”,并命名为 Aptana_CN。右击该快捷方式选择“属性”,在快捷方式选项 卡的“目标”中的AptanaStudio.exe后面加上-clean -vm保存即可。使用此快捷方式重新启动Aptana即可,这时你就会看到熟悉的中文界面了。
到此,汉化过程完成。
如果你是位英文高手的话,你还想继续用英文界面的话,可能就有人说,我的已经汉化成中文的了,难道还要我再下载一个英文的不成。
其实没有那么麻烦,你只需按照步骤3再建一个快捷方式,并命名为Aptana_EN,
把其中的-clean -vm改为-nl en保存即可。
以后你就可以用Aptana_EN启动英文版AptanaStudio,用Aptana_CN启动中文版AptanaStudio,想用哪个就用哪个,中英文界面随便你切换,而且还可以两个对照学习英文呢!
主菜单栏中点击 "help" -> "software update" --> "find and install";
search for new featrues to install -> 点击 next;
点击 New Remote Site;
Name:language URL:http://download.eclipse.org/technology/babel/update-site/europa -> 点击 OK -> 点击 Finish;
稍候片刻,弹出 Update Site Mirrors 窗口 -> 点选下拉框最下端的 language -> 点击 OK;
稍候片刻,弹出 Updates 窗口,在 Select the features to install 中点击 language 左侧三角形图标以便展开目录 -> 勾选 Babel Language Packs in Simple Chinese -> 点击 next;
等候下载,弹出选择安装路径对话框,默认即可,点击 Finish;
下载完毕,提示安装,点击 install all,安装完毕,提示关闭 MyEclipse,确认即可;
到程序安装目录下,将 X:\Program Files\MyEclipse 6.5\eclipse\eclipse.ini 配置文件中的 -Duser.language=en 删除 -> 保存 -> 关闭配置文件;
文章出处:DIY部落(http://www.diybl.com/course/3_program/java/javajs/20090208/154947.html)
Aptana
简单的说:Aptana 也就是一个WEB开发IDE,包含了HTML,CSS,JAVASCRIPT等的强大的提示功能以及断点调试。并且有eclipse的插件,插件安装以及下载地址:http://update15.aptana.org/studio/26124/index.html
原文:
Aptana Studio is a complete web development environment that combines powerful authoring tools for HTML, CSS, and JavaScript, along with thousands of additional plugins created by the community.
Aptana Update Site
This site is designed to be used though the Eclipse or Aptana update manager.
Installing this Plugin via Aptana or Eclipse
- From the Help menu, select Install New Software... to open an Install pop-up window.
- In the Work with: text box of the Install window, type the URL http://update15.aptana.org/studio/26124/for the update site, and hit the Enter key.
- In the populated table below, check the box next to the name of the plug-in, and click the Next button.
- Click the Next button to go to the license page.
- Choose the option to accept the terms of the license agreement, and click the Finish button.
Manual Installation
- Save the above file to an easy-to-find location.
- Open Eclipse distribution, and go to Help -> Install New Software....
- Click the Add... button to open the Add Site window.
- Click the Archive... button, and select the file saved in step 1.
- Select the appropriate plugins to install, and click Next -> Next.
- Click the Finish button.
Aptana Studio支持中文的方法 :
在Windows 菜单 → Preferences → General → Content Types,选择 Text ,在下方指定默认编码为UTF-8,并在File associations下
面添加文件类型,如 *.js
如果文档的编码不是UTF-8 就指定成相应的编码。不过还是建议使用 UTF-8 编码
|
一、准备工作
1、ghost是著名的备份工具,在DOS下运行,因此需准备DOS启动盘一张(如98启动盘)
2、下载ghost8.0程序,大小1.362K,各大软件站均有免费下载,推荐下载后将它复制到一张空白软盘上,如果你的硬盘上有FAT32或FAT文件系统格式的分区,也可把它放在该分区的根目录,便于DOS下读取这个命令。
3、为了减小备份文件的体积,建议禁用系统还原、休眠,清理临时文件和垃圾文件,将虚拟内存设置到非系统区。
二、用ghost8.0备份分区
使用Ghost进行系统备份,有整个硬盘和分区硬盘两种方式。下面以备份我的C盘为例,推荐当你的C盘新装(重装)系统后,都要用GHOST备份一下,以防不测,以后恢复时10分钟还你一个全新系统!ghost8.0支持FAT、FAT32和NTFS文件系统。
将软驱设为第一启动盘,扦入DOS启动盘重启电脑进入DOS。
启动进入DOS后,取出DOS启动软盘,再插入含有ghost.exe的软盘。在提示符“A:\>_”下输入“ghost”后回车,即可开启ghost程序,显示如下图1

图1 已经进入 Ghost
图1中显示程序信息,直接按回车键后,显示主程序界面,如下图2所示

图2 打开程序菜单
主程序有四个可用选项∶Quit(退出)、Help(帮助)、Options(选项)和Local(本地)。在菜单中点击 Local(本地)项,在右面弹出的菜单中有3个子项,其中 Disk表示备份整个硬盘(即硬盘克隆)、Partition 表示备份硬盘的单个分区、Check 表示检查硬盘或备份的文件,查看是否可能因分区、硬盘被破坏等造成备份或还原失败。我这里要对本地磁盘进行操作,应选Local;当前默认选中“Local”(字体变白色),按向右方向键展开子菜单,用向上或向下方向键选择,依次选择Local(本地)→Partition(分区)→To Image(产生镜像) (这步一定不要选错)如下图3所示

图3 依次选择产生镜像
确定“To Image”被选中(字体变白色),然后回车,显示如下图4所示

图4 选择本地硬盘
弹出硬盘选择窗口,因为我这里只有一个硬盘,所以不用选择了,直接按回车键后,显示如下图5所示

图5 逻辑分区

图8 文件名
选择备份存放的分区、目录路径及输入备份文件名称。上图中有五个框∶最上边框(Look jn)选择分区;第二个(最大的)选择目录;第三个(File narne)输入影像文件名称,注意影像文件的名称带有 GHO 的后缀名;第四个(File of type)文件类型,默认为GHO不用改。
这里首先选择存放影像文件的分区∶按Tab键约8次切换到最上边框(Look jn)(使它被白色线条显示,如下图9所示

图9 切换到最上边框
按回车键确认选择,显示如下图10所示

图10 出现下拉菜单
弹出了分区列表,在列表中没有显示要备份的分区。注意∶在列表中显示的分区盘符(C、D、E)与实际盘符会不相同,但盘符后跟着的1:2(即第一个磁盘的第二个分区)与实际相同,选分区时留意了。要将影像文件存放在有足够空间的分区,我将用原系统的F盘,这里就用向下方向键选(E:1:4口FAT drive)第一个磁盘的第四个分区(使其字体变白色),如下图11所示

图11 选择分区
选好分这后按回车键确认选择,显示如下图12所示

图12 出现分区内容
确认选择分区后,第二个框(最大的)内即显示了该分区的目录,从显示的目录列表中可以进一步确认所选择的分区是否正确。如果要将影像文件存放在这个分区的目录内,可用向下方向键选择目录后回车确认即可。我这里要将影像文件放在根目录,所以不用选择目录,直接按Tab键切换到第三个框(File name),如下图13所示

图13 切换到 File name
这里输入影像文件名称,我要备份C盘的XP系统,影像文件名称就输入cxp.GHO,注意影像文件的名称带有 GHO 的后缀名;如下图14所示

图14 起一个映像名字
输入影像文件名称后,下面两个框不用输入了,按回车键后准备开始备份,显示如下图15所示

图15 准备开始备份!
接下来,程序询问是否压缩备份数据,并给出3个选择:No 表示不压缩,Fast表示压缩比例小而执行备份速度较快(推荐),High 就是压缩比例高但执行备份速度相当慢。如果不需要经常执行备份与恢复操作,可选High 压缩比例高,所用时间多3至5分钟但影像文件的大小可减小约700M。我这里用向右方向键选High,如下图16所示

图16 是否压缩映像文件
选择好压缩比后,按回车键后即开始进行备份,显示如下图17所示

图17 开始备份
整个备份过程一般需要五至十几分钟(时间长短与C盘数据多少,硬件速度等因素有关), 完成后显示如下图18所示

图18 备份完成!
提示操作已经完成,按回车键后,退出到程序主画面,显示如下图19所示

图19 准备退出
要退出Ghost程序,用向下方向键选择Quit, 如下图20所示

图20 退出
按回车键后,显示如下图21所示

图21 确认退出
问是否要退出ghost程序,按回车键后即完全退出ghost程序,返回Dos下显示提示符A:>_,取出软盘后按Ctrl+Alt+Del组合键重新启动电脑进入XP系统,打开E盘后查看,如下图22所示

图22 图为映像文件生成好了
三、用Ghost8.0恢复分区备份
如果硬盘中已经备份的分区数据受到损坏,用一般数据修复方法不能修复,以及系统被破坏后不能启动,都可以用备份的数据进行完全的复原而无须重新安装程序或系统。当然,也可以将备份还原到另一个硬盘上。
这里介绍将存放在E盘根目录的原C盘的影像文件cxp.GHO恢复到C盘的过程∶要恢复备份的分区,进入Dos下,运行ghost.exe启动进入主程序画面,如下图23所示

图23 准备恢复
依次选择Local(本地)→Partition(分区)→From Image(恢复镜像) (这步一定不要选错)如下图24所示

图24 选择恢复镜像
按回车键确认后,显示如下图25所示

图25 下拉菜单
选择镜像文件所在的分区,我将影像文件cxp.GHO存放在E盘(第一个磁盘的第四个分区)根目录,所以这里选“E:1:4囗FAT drive”,按回车键确认后,显示如下图26所示

图26 选择源文件所在分区
确认选择分区后,第二个框(最大的)内即显示了该分区的目录,用方向键选择镜像文件cxp.GHO后,输入镜像文件名一栏内的文件名即自动完成输入,按回车键确认后,显示如下图27所示

图27 原分区文件信息
显示出选中的镜像文件备份时的备份信息(从第1个分区备份,该分区为NTFS格式,大小4000M,已用空间1381M)!确认无误后,按回车键,显示如下图28所示

图28 选择目的硬盘
选择将镜像文件恢复到那个硬盘。我这里只有一个硬盘,不用选,直接按回车键,显示如下图29所示

图29 选择目的硬盘中的分区
选择要恢复到的分区,这一步要特别小心。我要将镜像文件恢复到C盘(即第一个分区),所以这里选第一项(第一个分区),按回车键,显示如下图30所示

图30 是否恢复
提示即将恢复,会复盖选中分区破坏现有数据!选中“Yes”后,按回车键开始恢复,显示如下图31所示

图31 开始恢复
正在将备份的镜像恢复,完成后显示如下图32所示

图32 克隆完成
取出软盘,直接按回车键后,计算机将重新启动!启动后你就可见到效果了,恢复后和原备份时的系统一模一样,而且磁盘碎片整理也免了。
注意:在恢复前请备份你现有系统的“输入法自定义词库、杀毒软件(以免再次升级)、我的文件夹、QQ文件夹等”
备份前几点建议:
一、转移或删除页面文件
二、关闭休眠和系统还原
三、删除暂时不需要的字库、临时文件等
四、扫描磁盘和整理磁盘碎片
五、注册好MSN、杀毒软件等
|
|
.
|
软件使用教程
|
|

|
一键GHOST下载
|
|
|
 |
史上最完整详细的GHOST使用教程+名词解释和详细图解:
教程说明:下面的GHOST的教程对于熟悉一点电脑的人来说或贻笑大方,因为此教程虽然十分简单但也可算十分实用的教程,也算是专门为菜鸟所写的,老鸟可以飞过咯,希望能对没有接触过GHOST的朋友有所帮助。
大家都知道GHOST是一个备份软件它能将一个分区内所有文件 通常我们是将系统盘C盘 制作成一个“压缩文件” 存放在电脑其它安全的分区内 再在系统出现任意已知或未知的问题时候再启动GHOST 提取此备份文件 再还原到系统盘C盘 以保证到系统正常安全运行 GHOST适用于各种操作系统 .
名词解释
镜像文件 此处泛指GHOST软件制作成的压缩文件 以.gho 为后缀 在ghost中显示为黄色
源盘 即将要备份的磁盘 在一般的情况下我们泛指 操作系统盘 C盘
镜像盘 存放备份镜像的磁盘 在一般的情况下我们泛指 文件存放盘 D盘 或 E F G 盘
打包 制作镜像文件 通常是指将 操作系统盘 C盘 经压缩后存放在其它盘 如D盘里面
解包 还原镜像文件 通常在系统盘C盘 出现错误或病毒木马后 将存放在其它盘里面的镜 像文件 还原到系统盘内 以求能恢复干净 良好的操作系统
一 使用GHOST之前必定要注意到的事
1.在备份系统时 单个的备份文件最好不要超过 2GB 如果超过了2GB 程序会自动产生一个后缀名为 如00100001.GHS 的文件 请您切记不要保留此文件与镜像文件在同一文件夹内 没有此文件是不能还原成功的 建议您 新建一个文件夹 名为 001 (如果您不断备份您可以依次新建文件夹名为 002 003 004 依此类推) 将镜像放置在里面 GHOST 建议您选用选用最新的版本号 需要最少 GHOST8.0版本 或以上的版本
2.在备份系统前 最好将一些无用的文件删除以减少Ghost文件的体积 通常无用的文件有:Windows的临时文件夹 如果您不是太了解 只建议您删除C:WINDOWSTEMP 下面的文件
镜像文件应尽量保持“干净” “基本”。应用软件安装得越多,系统被修改得越严重 安装新软件也就越容易出错 所以在制作镜像文件前 千万不要安装过多的应用软件
建议您分层次一步一步打包 系统刚刚做完安装完驱动打一个 如是001 再安装一些必要的软件再打一个 如是002 以后再安装了新软件再打 如是003 如果安装新软件或硬件 使用一时间后发现容易出错或死机的话 回复到前一个版本的包后 再安装新软件或硬件
一定要到没有任意问题才算好的 否则不可以删除前一个安全良好的包(有些朋友们硬盘空间比较小 有时会为了空间删除 镜像文件 )通常建议您将镜像文件复制一下 放在安全的地方比如说放在另外的盘里面 或设置为只读或隐藏 防止误删除
3.在备份系统前 进行磁盘碎片整理 整理源盘和镜像盘,以加快备份速度。
4.在备份系统前及恢复系统前 源盘和镜像盘 进行磁盘检查错误 如有修复磁盘错误 系统备份之前必定要升级杀毒软件后 仔细完全查杀一次毒如有可能 下载好各种系统安全补丁 确定系统运行得十分正常且安全 再备份
5.在恢复系统时 最好先检查一下要恢复的目标盘是否有重要的文件还未转移(切记切记) 目标盘上的原有数据将全部被覆盖 使用任何反删除法都无法恢复 我们要养成一个良好的习惯 不要在系统盘C盘 放任意需要保存的资料 下载软件的下载默认一定要设置到D盘或其它盘里面
6.在选择压缩率时 建议不要选择最高压缩率 因为最高压缩率非常耗时 而压缩率又没有明显的提高 建议选取 适度压缩 就是中间的一个
7 通常建议电脑上保存二个或以上的镜像文件 在新安装了软件和硬件后 最好重新制作映像文件
二 软件下载 安装
1 您可以点击 下载
●Ghost
也可以本地下载
●Ghost
此处以本站本地下载的 ●Ghost 为例子 右击——另存为 或用 ●网际快车下载
下载下来后是一个自动解压缩文件 双击打开 点击 安装
2 完成后会在同一目录下出现一个名叫 GHOST的文件夹 双击打开 里面有六个文件
3 对于我们而言 有用的是那个 ghost 大小1.32M其它的文件 初学者可以忽略不计
4 将这个文件复制到您的放文件的盘里面 不能放在可能误操作的盘里面 通常我们放在D盘 记住 直接放在D盘目录下 一定不能放在中文名字的文件夹里面(在DOS下不能识别中文)
5 为了便于操作 将这个文件改名字 通常我们改正成 G
三 进入GHOST软件界面
此处以windows98为例
1 重新启动计算机
2 在电脑启动时 快速 连续 按键盘最上一排的 F8
3 按了后会显示 黑底白字的 系统选项 通常上面有6 个选项
4 此处我们需要了解的是1 正常模式 3 安全模式 6 进入DOS界面
5 ghost通常必须要在dos 运行 因此选取 6 进入dos 界面 按上下选择箭头 选定 6 回车
6 进入后会出现DOS 提示符 如 C:> 此处意思为 现在显示的是C盘
7 在c:> 后面输入d:此处的意思为进入D盘 输入后回车 出现d:>
8 再在d:> 后面输入 g 此处意思为运行 g 程序 此处的g 实际上就是原有的 ghost程序
9 输入后回车 就会进入GHOST 的操作界面 见 图一
附 DOS 下基本操作命令 每一个命令输入完毕后回车进入下一个操作
1 c :进入C盘 同样的道理 D :进入D盘 E: F: 进入E盘F盘
2 dir 查看 查看目录下面的文件 如c:> dir 是指查看 C盘里面的文件
3 cd 文件夹名字 打开文件夹 如cd 123 意思是说 打开123这个文件夹
4 exe 是程序的意思 如这ghost 改名字后为g 在dos下面就叫 g.exe
5 在dos下面 如果要执行程序的话 输入程序名字 回车即可 如 运行g.exe 输入g回车
6 cd ..进入上一个目录 如此时是c:> windows是表示在C盘的windowd 中 如果说此时输入 cd .. 则会进入C盘 屏幕上显示出c:>
三 打包 制作镜像文件
对于通常用户来说 仅仅只是使用GHOST里的分区备份功能 故此此处只讲解分区备份部分
1 按上所说处理好打包前的工作(系统状况最好 驱动安装好 相关软件安装好 清理垃圾文件 磁盘查错 磁盘碎片整理……) 后 重新启动 快速按F8 进入DOS界面 运行 G.exe
2 注意:若要使用备份分区功能 (如要备份C盘)必须有两个分区(最少要有C D二个分区)以上 而且C盘所用容量必须大于D盘的未用容量(通常C盘用了二GB 则D盘必定要有二GB以上的空间) 保证D盘上有足够的空间储存镜像
同时你尽量做到少往主分区上安装不是十分必要重要的软件 有相当多的工具性软件 (金山快译金山词霸……)可以放在D盘里面的 只要在C盘里注册一下就可以了 这样制作的映像文件就不会太大了
但必要的软件或有重大安全性的软件 如QQ MSN 杀毒软件 网络游戏………… 必定要放在C盘里面
3 进入图一所示GHOST 界面后 由于是在DOS下 只能用键盘操作按回车 进入下一个界面
4 DOS界面下 键盘操作:TAB键进行切换 回车键进行确认 方向键进行选择
如图二 用方向键选择
此处操作
选择菜单 Local(本机)--Partition(分区)--To Image(到镜像)
通俗一点说就是1-2-2
先选中 1 再选取 弹出选项 2再选取弹出选项 2
5 选中后回车 将出现如图三
选择硬盘 此处第一次是显示的第一个硬盘的信息
如果有二个硬盘的话 回车后会出现二个硬盘的信息选项 通常我们只一个硬盘
此处操作
回车
6 选中后回车 将出现下一个操作界面 如图四
选择要备份的分区 通常我们是选择C盘 也就是系统盘
此处操作
1 选择分区(可以用方向键上下选择 用TAB选择项目 )通常选择第一个就是C盘 分区
2 选定分区 回车确定
3 按一下TAB 再次确定 回车 就表示已经选定为 备份C盘 如果说您不能确定是不是备份的C盘
建议您在WINDOWS的时候 查看一下您的各个分区的大小 再对照就可以知道的
因此处是借鉴别的人的图 所以需要到您区别一下
7 选中后回车 将出现如图5
此处需要是输入备份文件名字
此处操作
1 按TAB选定到图片下面的输入名字的地方 在空格内输入您确定的名字 回车
2 此处选择的名字为 windows 当然您也可以选择别的名字的
3 通常我选择的是001
8 输入后回车 就会进入如下所示 见 图6
此处是提示您选择压缩模式 上面共有三个选择:
No表示不压缩,Fast表示适量压缩,High高压缩
限于适用与速度 通常我们选择适量压缩 Fast
此处操作
1 按TAB或左右方向键 选定Fast 回车
9 输入后回车 就会进入下一操作界面 见 图7
此处是提示您选择是否开始备份 共有二个选择 YES 是 NO 不 我们需要选定YES
此处操作
1 按左右方向键 选定YES 回车
10 输入后回车 就会进入下一个操作界面 见 图8
此处是提示GHOST根据您的指示 开始备份
此处操作
1 此处请不要做任意动作 您的任意动作都会带来不可预见之后果
请1 不要按键盘 2 不要关机
静心等待到进度条走完
11 进度条跑完后会进入到下一个 操作界面 见 图9
此处是提示GHOST根据您的指示 已经备份完毕 回车退出
此处操作
1 回车
备份完毕 重新启动就可以了
备份的文件以GHO后缀名储存在设定的目录中 如上所述
您的这个文件名叫 windows.gho
此文件在windows界面下是不显示什么的 在DOS下运行GHOST显示为黄色
您的这个 windows.gho保存在D盘目录下 就是和 G.EXE 一个目录下
通常建议您将镜像文件复制一下 放在安全的地方防止误删除
三 解包 还原镜像文件
要提醒您注意的是在使用 GHSOT 软件恢复系统时,请勿中途中止!如果您在恢复过程中重新启动了计算机那么您的计算机将无法启动!必定要接双硬盘或用光盘系统启动才可恢复
在您的系统遇到以下的情况之一怀疑或确定您的系统中了病毒或木马 系统运行了半个月以上 或出现无故死机 变慢 及相关类别
您需要还原您的系统镜像文件 以保证到系统的安全与良好运行
1 重新启动 快速按F8 进入DOS界面 运行G.exe 进入GHOST界面 回车
2 回车后 就会进入GHOST 的操作界面 见 图10
此处操作
选择菜单到 Local(本机)--Partition(分区)--From Image
通俗一点说就是1-2-3
先选中 1 再选弹出选项 2 再选项弹出选项 3
3 选定后回车 就会进入下一个操作界面 见 图11
处是提示您 选择 需要还原的镜像文件 如上所述 我们打的包是 windows.gho
所以我们这里选择windows.gho
此处操作
1 按上下方向键 选择好windows.gho
回车
4 输入后回车 就会进入下一个操作界面 见 图12
此处显示硬盘信息 不需要处理 直接回车
此处操作
1 回车
5 输入后回车 就会进入下一个操作界面 见 图13
此处显示硬盘信息 不需要处理 直接回车
如果您是双盘操作 此处必定要选择好硬盘 切记切记 通常是选择第二块硬盘
此处操作
1 回车
6 输入后回车 就会进入下一个操作界面 见 图14
此处显示分区信息 提示您是需要还原到哪珍上分区 默认是还原第一个分区 也就是C盘系统盘 如果您是要还原到此分区 不需要处理 直接回车
此处操作
1 回车
7 输入后回车 就会进入下一个操作界面 见 图15
此处显示信息 此处是为了防止误操作 再次提醒您是不是一定要还原镜像文件
您到了这一步 如果说没有十分的把握 这是最后一次机会 默认是NO 按下可以退出到起始界面 如果选择YES 将进行还原操作 此操作到了此处已经不可逆转 此处需要的是用左右方向键 选择YES 回车
此处操作
1 用左右方向键 选择YES 回车
8 输入后回车 就会进入GHOST 的操作界面 见 图16
此处是提示GHST根据您的指示 开始还原镜像文件 此时千万不要进行操作
此处操作
1 此处请不要做任意动作 您的任意动作都会带来不可预见之后果 包括系统不能启动
请 1 不要按键盘 2 不要关机
静心等待到进度条走完
9 输入后回车 就会进入下一个操作界面 见 图17
此处是提示GHST根据您的指示 已经备份完毕 给出的二个选择 一 默认为重新启动
二 以后再重新启动 此处需要的是重新启动
此处操作
1 回车
至此 您已经成功的还原了您的系统镜像 您的系统又和原来最最良好的时候是一样的了
恭喜您的电脑有了百毒不侵 之身 有了可以防止误操作的万事无忧之方法
有了以上的说明 在通常的情况下 您可以随时随地将您的系统还原到最良好运行之境地
五 双盘解包
此操作需要到您稍稍了解电脑 不建议初学者操作 建议在有了解电脑的朋友在边上时操作
1 此方法适用于还原镜像的时候 失败或突然停电 致使系统无法启动 理论上只要是可以进入DOS 界面 就可以还原GHOST的
2 您必定要有二个硬盘 初学者建议一个硬盘一个数据线安在主板上 可以进入系统就表示您选取的是好的硬盘上的系统 如果进不了 表示进错了盘 将主板上的二个硬盘的数据线对换一下就可以了
3 进入了后 按上述操作说明操作 要注意的是图13 的地方 需要到选择第二块硬盘 如果您是双盘操作 此处必定要选择好硬盘 切记切记 通常是选择第二块硬盘 请在懂电脑一点的人在身边时操作
六 光盘使用GHOST
此操作需要到您稍稍了解电脑 不建议初学者操作 建议在有了解电脑的朋友在边上时操作
1 此方法适用于还原镜像的时候 失败或突然停电 致使系统无法启动 理论上只要是可以进入DOS 界面 就可以还原GHOST的
2 您必定要有光驱 要有带启动文件的光盘 最好光盘里面有GHOST 7.0以上
3 在主板的启动设置里面设置成光盘启动 启动后进入DOS界面
4 再如上操作就可以了
七 XP系统使用GHOST说明
此操作需要到您稍稍了解电脑 不建议初学者操作 建议在有了解电脑的朋友在边上时操作
如果您是XP系统 也可以使用GHOST的 前题是必定要让系统能够在启动时 进入 纯DOS 系统进入DOS后 如是选择手动操作的话 就和上面所说的 win98 进入GHOST后的操作一样的
XP系统 进入 纯DOS 系统 的方法
您的系统在安装XP系统前 最好是格式化时 复制系统文件
如果您用的FDISK分的区 格式化时请选取 format c: /s
如果您是用的双硬盘格式化的 请在复制系统文件前打 对钩
如果你在C盘复制了系统文件 在您的XP启动的时候会有双项选择 一个是进入 XP 一个是进入DOS
如果说您要使用GHOST 请选择 MS DOS 启动选项 再如上操作
如果您在本机上无法操作GHOST 也可以接双硬盘或光盘 做好XP系统的GHOST备份或还原
如果您的XP系统不能进入纯DOS界面 您可以尝试安装以下软件 可以实现XP DOS 双启动
您可以点击 本地下载 矮人DOS工具箱4.2
矮人DOS工具箱说明 是为2k以上系统加上纯DOS启动支持的工具!方便没有光软驱的朋友 全中文操作界面,为普通用户着想 软件中已经预装有GHOST8.2版 支持NTFS分区 软件在DOS下以虚拟磁盘存在 以免去 NTFS文件系统不能为DOS系统所识别 对初学者尤为重要
此处以本站本地下载的 矮人DOS工具箱4.2为例子 右击—另存为 或用 ●网际快车下载
下载下来后是一个自动解压缩文件 双击打开 点击 安装
10 完成后会在同一目录下出现一个名叫 dosgz 的文件夹 双击打开 里面有一个XP2Kargzs文件夹 再双击打开后出一个名叫 airenDOS_4.2的安装文件
11 双击安装 依次点下一步 我同意 下一步 下一步 下一步 直到安装完成
12 查看您的磁盘是FAT32 格式 还是 NTFS 格式
1> 显示桌面 -----打开 我的电脑 -----找到 本地磁盘 C盘
2> 右击C盘----选择 属性 ---打开
3> 上面会显示您的 文件系统 您的上面显示的为FAT32 或 NTFS 盘此处是说明您的分区格式
4> 不管是什么格式 您必定要注意到记下来 同时也需要查看一下其它磁盘格式通常是相同格式
矮人DOS工具箱使用方法
1 安装完成后 做好所有上述备份前的工作后 以及上述需要注意到的事情 详细请查看上面所说 一 使用GHOST之前必定要注意到的事处 请仔细查看
2 确定您C盘所有重要文件都已经备份到其它磁盘 确定您的存放镜像文件的磁盘空间够用(最少要有C盘的所有已用文件空间大)确定您已经知道您磁盘文件系统格式为FAT32 或 NTFS 确定您已经做好相关准备工作
3 重新启动计算机
4 在您进入系统之前 在黑底白字之时会在您的屏幕最上面会出现二个系统启动选项
一为 WINDOWSXP 正常启动 二为下面的 我的DOS工具箱
5 选择进入 我的DOS工具箱 进入后会有中文菜单选择,主要是前两项,
1、矮人工作室DOS工具盘 2、GHOST 8.2 向导工具盘
到了此处都是全中文操作界面 您应当说能理解此处此时是选择GHOST 8.2 向导工具盘
6 GHOST工具盘进入后 有多个选项 如下图
备份操作
1 一键备份系统 支持NTFS (如果您的文件系统为NTFS格式 请选择此项)
3 全自动备份系统 仅FAT32(如果您的文件系统为FAT32格式 请选择此项)
选择后会有中文提示 如图
此处通常是选择第一个硬盘
如有需要也可以安装双硬盘后备份到第二个硬盘上
选择第一个硬盘后会出现下一个操作界面 如图
按此所说意思可能为 您的系统盘将被制作为镜像文件
文件名字为 bak.gho默认存放在D盘的目录下 您可以进入了WINDOWS后查找到此文件的
不要移动此文件 或文件夹
还原操作
此处意思或为 经过您一键备份了系统后 您的镜像文件bak.gho 备份在了D盘指定目录下
此时软件直接从指定目录中提取此镜像文件来还原系统盘C盘
2 一键恢复系统 支持NTFS (如果您的文件系统为NTFS格式 请选择此项)
4 全自动恢复系统 仅FAT32 (如果您的文件系统为FAT32格式 请选择此项)
5 启动GHOST8。2版 手工操作
如果您选此选项 您将直接进入到GHOST8。2 您可以按以上所说操作您的系统备份和还原
切切需要记住的是 必定要记住放置和还原镜像文件的地方 看清盘符了再操作 使用 TAB键 选择
6 7 二项不建议初学者使用
八 使用电脑上已有的GHOST镜像文件还原系统
通常做系统的师付 在与您做系统的时候 一般都做了系统备份的 只是没有与你说清楚罢了 但或您每次电脑出了问题他都或以在几分钟内最多“半小时”内给你重新装好系统 (如果可能 您可以要求师付与您做一个GHOST镜像文件 )其实不然 真正做好一个系统没有三五个小时是难做好的 通常他们都是还原了GHOST镜像文件 而GHOST 对于初学者来说 还原镜像远比制作镜像文件容易得多
您可以通过查找您的电脑上的 *.gho 可以查找到您的系统上的备份的
1 点击电脑桌面的最左下的 开始----查找-----文件或文件夹 就会跳出一个 查找 所有文件的框
2 找到 名称 在名称后面的空白处输入 *.gho
3 找到下面的搜索 点中后面的下行键 选中 本地硬盘驱动器(C:,D(如果您有多个分区后面将有E:F:甚至更多)
4 找到 开始查找左键单击 系统就会自动开始查找电脑上的所有GHOST系列文件
5 在找到的结果当中 您可以看见到有 GHOST 镜像文件如果您的电脑上可以找到这 就表示您的系统是备份过了的 如图18
6 注意到 此文件通常比较大 最初的镜像文件通常在370M上下 如果说后来不断的备份的话 此文件会加大 如果是您的最新打的包 此文件或为您的C盘已经使用了的容量的一半或稍大一点
7 找到此文件后 将此文件复制到您的GHOST程序目录下 如GHOST在D盘下 此文件也要复制到D盘下 不能放在文件夹内 尤其是不是放在中文名字的文件夹内 切记切记 如是XP系统 切记要您存放镜像文件的盘的分区格式为 FAT32格式
8 再在您的系统出现任意问题后 请您按上面所说仔细操作一下 最好多实习一下 如果没有到最后现YES的地方都可以取消操作的 实习后 确定无误了 您到操作一下 大不了再同您以前一下 出钱让人上门维护一下
九 使用别的电脑上的GHOST镜像文件 还原您的系统
如果您的电脑上没有备份而您不会做 或者说有朋友们有比较好的系统 或朋友们系统里有比较好的软件或大软件 您也可以使用他人的电脑上的GHOST镜像文件来还原您的系统的
1 建议您将您的电脑上的所有驱动 全部放在您的D盘或E盘 建议所有的朋友们 在您新电脑买回家后 装系统的第一件事 必定要将您的电脑上的随机光盘 随机软件 所有必要的软件的安装文件 切记 必定要是安装文件 用光驱拷在您的电脑硬盘上 此为电脑装机第一步 不要怕麻烦 一定要注意
此操作前您必定要找到您的网卡驱动
在您的驱动光盘文件里面 有一个LAN 的文件夹通常 是网卡驱动 切记切记 如果不能确定 您可以在 ●驱动之家 找到您的网卡驱动 通常的是8139 您需要下载 如不能确定 请多下载几个网卡驱动
2 您的电脑上 必定要有您的系统安装文件 切记 如 您是WIN98系统 必定要在硬盘上保留一个WIN98的安装文件
3 复制人家的电脑上的GHOST镜像文件 到您的电脑上 您可以通过网络或双硬盘拷上去
切切需要记住的是 如果您是使用的别人的电脑上的XP系统GHOST 必定要作相关处理 不然不能启动
详细方法请您必定要 点击此处查看 制作XP系统 GHOST文件方法 切记切记切记切记
4 下载GHOST 软件 再将此GHOST镜像文件 同放在D或E盘目录 不能放在文件夹内 尤其是不是放在中文名字的文件夹内 切记切记 如是XP系统 初学者切记要您存放镜像文件的盘的分区格式为 FAT32格式
5 按上面的操作 还原您的系统盘 C盘 还原 重新启动
6 在电脑启动时 快速 连续 按键盘最上一排的 F8
7 按了后会显示 黑底白字的 系统选项 通常上面有6 个选项
8 此处我们需要了解的是1 正常模式 3 安全模式 6 进入DOS界面 按上下方向键 选定3 进入安全模式
9 进入安全模式后 桌面四周会显示安全模式 选中桌面上的 我的电脑 右击---- 属性 会跳出一个系统属性的框
10 选中最左上的 设备管理器 默认为 按类型查看设备
11 找到里面的 声音 视频和游戏控制器双击打开 将所有弹出的子选项 全部删除
12 找到里面的 网络适配器双击打开 将所有弹出的子选项 全部删除 有时此项不能删除 删除后进入不了系统 您可以选择不删除
13 找到里面的 显示适配器 双击打开 将所有弹出的子选项 全部删除
14 重新启动计算机
15 进入系统后 系统会自动找到新硬件 自动安装 如果系统找不到的 就需要您手动指向驱动的地方
16 如果您的电脑上的驱动完备 通常 可以正常安装完所有的驱动 如果有的没有 请上网后在 ●驱动之家 里面找到安装
17 有时可能出现安装驱动时候死机 蓝屏的现像 此或为几个驱动冲突而引的 此时需要到您
重新启动计算机----快速按F8----进入系统启动选项---选取3 进入安全模式----进入桌面
通常的系统更新如在正常模式下无法更新 而安全模式下可以的更新的 更新后再正常启动
18 安装完成后 重新启动 确定您的系统完好 再按以上所述制作一个镜像文件
19 如果您是还原的XP系统的GHOST包 通常会自动安装所有驱动 完了重新启动就可以了
注意到 GHOST 不管怎么样操作 只要到最后重复提示 YES NO 的时候 选中NO的话 都可以取消操作的 您是初学者 可以试着看见上面的所说 多操作三五次 三五十次 只要最后不按 YES 都不会对系统有任意伤害的 确定正确后再正常操作
• 有系统地设计档案目录﹐不要随便到处保存档案以至以后不知道放哪里了﹐ 或找到档案也不知道为何物。
• 养成一个做记录的习惯。尤其是发现问题的时候﹐把错误信息和引发状况以及 解决方法记录清楚﹐同时最后归类几定期整理。别以为您还年轻﹐ 等你再弄多几年计算机了﹐您将会非常庆幸您有此一习惯。
• 如果看在网络上看到任何好文章﹐可以为自己留一份copy﹐同时定好题目﹐归类存档。
• 作为一个使用者﹐人要迁就机器﹔做为一个开发者﹐要机器迁就人。
• 学写 script 的确没设定 server 那么好玩﹐不过以我自己的感觉是﹕ 关键是会得“偷”﹐偷了会得改﹐改了会得变﹐变则通矣。
• 在Windows里面﹐设定不好设备﹐您可以骂它﹔在Linux里面﹐如果设定好设备了﹐您得要感激
一,ping
它是用来检查网络是否通畅或者网络连接速度的命令。作为一个生活在网络上的管理员或者黑客来说,ping命令是第一个必须掌握的DOS命令,它所利用的原理是这样的:网络上的机器都有唯一确定的IP地址,我们给目标IP地址发送一个数据包,对方就要返回一个同样大小的数据包,根据返回的数据包我们可以确定目标主机的存在,可以初步判断目标主机的操作系统等。下面就来看看它的一些常用的操作。先看看帮助吧,在DOS窗口中键入:ping /? 回车,。所示的帮助画面。在此,我们只掌握一些基本的很有用的参数就可以了(下同)。
-t 表示将不间断向目标IP发送数据包,直到我们强迫其停止。试想,如果你使用100M的宽带接入,而目标IP是56K的小猫,那么要不了多久,目标IP就因为承受不了这么多的数据而掉线,呵呵,一次攻击就这么简单的实现了。
-l 定义发送数据包的大小,默认为32字节,我们利用它可以最大定义到65500字节。结合上面介绍的-t参数一起使用,会有更好的效果哦。
-n 定义向目标IP发送数据包的次数,默认为3次。如果网络速度比较慢,3次对我们来说也浪费了不少时间,因为现在我们的目的仅仅是判断目标IP是否存在,那么就定义为一次吧。
说明一下,如果-t 参数和 -n参数一起使用,ping命令就以放在后面的参数为标准,比如"ping IP -t -n 3",虽然使用了-t参数,但并不是一直ping下去,而是只ping 3次。另外,ping命令不一定非得ping IP,也可以直接ping主机域名,这样就可以得到主机的IP。
下面我们举个例子来说明一下具体用法。
这里time=2表示从发出数据包到接受到返回数据包所用的时间是2秒,从这里可以判断网络连接速度的大小。从TTL的返回值可以初步判断被ping主机的操作系统,之所以说"初步判断"是因为这个值是可以修改的。这里TTL=32表示操作系统可能是 win98。
(小知识:如果TTL=128,则表示目标主机可能是Win2000;如果TTL=250,则目标主机可能是Unix)
至于利用ping命令可以快速查找局域网故障,可以快速搜索最快的QQ服务器,可以对别人进行ping攻击……这些就靠大家自己发挥了。
二,nbtstat
该命令使用TCP/IP上的NetBIOS显示协议统计和当前TCP/IP连接,使用这个命令你可以得到远程主机的NETBIOS信息,比如用户名、所属的工作组、网卡的MAC地址等。在此我们就有必要了解几个基本的参数。
-a 使用这个参数,只要你知道了远程主机的机器名称,就可以得到它的NETBIOS信息(下同)。
-A 这个参数也可以得到远程主机的NETBIOS信息,但需要你知道它的IP。
-n 列出本地机器的NETBIOS信息。
当得到了对方的IP或者机器名的时候,就可以使用nbtstat命令来进一步得到对方的信息了,这又增加了我们入侵的保险系数。
三,netstat
这是一个用来查看网络状态的命令,操作简便功能强大。
-a 查看本地机器的所有开放端口,可以有效发现和预防木马,可以知道机器所开的服务等信息,如图4。
这里可以看出本地机器开放有FTP服务、Telnet服务、邮件服务、WEB服务等。用法:netstat -a IP。
-r 列出当前的路由信息,告诉我们本地机器的网关、子网掩码等信息。用法:netstat -r IP。
四,tracert
跟踪路由信息,使用此命令可以查出数据从本地机器传输到目标主机所经过的所有途径,这对我们了解网络布局和结构很有帮助。如图5。
这里说明数据从本地机器传输到192.168.0.1的机器上,中间没有经过任何中转,说明这两台机器是在同一段局域网内。用法:tracert IP。
五,net
这个命令是网络命令中最重要的一个,必须透彻掌握它的每一个子命令的用法,因为它的功能实在是太强大了,这简直就是 微软为我们提供的最好的入侵工具。首先让我们来看一看它都有那些子命令,键入net /?回车如图6。
在这里,我们重点掌握几个入侵常用的子命令。
net view
使用此命令查看远程主机的所以共享资源。命令格式为net view \IP。
net use
把远程主机的某个共享资源影射为本地盘符,图形界面方便使用,呵呵。命令格式为net use x: \IP\sharename。上面一个表示把192.168.0.5IP的共享名为magic的目录影射为本地的Z盘。下面表示和192.168.0.7 建立IPC$连接(net use \IP\IPC$ "password" /user:"name"),
建立了IPC$连接后,呵呵,就可以上传文件了:copy nc.exe \192.168.0.7\admin$,表示把本地目录下的nc.exe传到远程主机,结合后面要介绍到的其他DOS命令就可以实现入侵了。
net start
使用它来启动远程主机上的服务。当你和远程主机建立连接后,如果发现它的什么服务没有启动,而你又想利用此服务怎么办?就使用这个命令来启动吧。用法:net start servername,如图9,成功启动了telnet服务。
net stop
入侵后发现远程主机的某个服务碍手碍脚,怎么办?利用这个命令停掉就ok了,用法和net start同。
net user
查看和帐户有关的情况,包括新建帐户、删除帐户、查看特定帐户、激活帐户、帐户禁用等。这对我们入侵是很有利的,最重要的,它为我们克隆帐户提供了前提。键入不带参数的net user,可以查看所有用户,包括已经禁用的。下面分别讲解。
1,net user abcd 1234 /add,新建一个用户名为abcd,密码为1234的帐户,默认为user组成员。
2,net user abcd /del,将用户名为abcd的用户删除。
3,net user abcd /active:no,将用户名为abcd的用户禁用。
4,net user abcd /active:yes,激活用户名为abcd的用户。
5,net user abcd,查看用户名为abcd的用户的情况
net localgroup
查看所有和用户组有关的信息和进行相关操作。键入不带参数的net localgroup即列出当前所有的用户组。在入侵过程中,我们一般利用它来把某个帐户提升为administrator组帐户,这样我们利用这个帐户就可以控制整个远程主机了。用法:net localgroup groupname username /add。
现在我们把刚才新建的用户abcd加到administrator组里去了,这时候abcd用户已经是超级管理员了,呵呵,你可以再使用net user abcd来查看他的状态,和图10进行比较就可以看出来。但这样太明显了,网管一看用户情况就能漏出破绽,所以这种方法只能对付菜鸟网管,但我们还得知道。现在的手段都是利用其他工具和手段克隆一个让网管看不出来的超级管理员,这是后话。有兴趣的朋友可以参照《黑客防线》第30期上的《由浅入深解析隆帐户》一文。
net time
这个命令可以查看远程主机当前的时间。如果你的目标只是进入到远程主机里面,那么也许就用不到这个命令了。但简单的入侵成功了,难道只是看看吗?我们需要进一步渗透。这就连远程主机当前的时间都需要知道,因为利用时间和其他手段(后面会讲到)可以实现某个命令和程序的定时启动,为我们进一步入侵打好基础。用法:net time \IP。
六,at
这个命令的作用是安排在特定日期或时间执行某个特定的命令和程序(知道net time的重要了吧?)。当我们知道了远程主机的当前时间,就可以利用此命令让其在以后的某个时间(比如2分钟后)执行某个程序和命令。用法:at time command \computer。
表示在6点55分时,让名称为a-01的计算机开启telnet服务(这里net start telnet即为开启telnet服务的命令)。
七,ftp
大家对这个命令应该比较熟悉了吧?网络上开放的ftp的主机很多,其中很大一部分是匿名的,也就是说任何人都可以登陆上去。现在如果你扫到了一台开放 ftp服务的主机(一般都是开了21端口的机器),如果你还不会使用ftp的命令怎么办?下面就给出基本的ftp命令使用方法。
首先在命令行键入ftp回车,出现ftp的提示符,这时候可以键入"help"来查看帮助(任何DOS命令都可以使用此方法查看其帮助)。
大家可能看到了,这么多命令该怎么用?其实也用不到那么多,掌握几个基本的就够了。
首先是登陆过程,这就要用到open了,直接在ftp的提示符下输入"open 主机IP ftp端口"回车即可,一般端口默认都是21,可以不写。接着就是输入合法的用户名和密码进行登陆了,这里以匿名ftp为例介绍。
用户名和密码都是ftp,密码是不显示的。当提示**** logged in时,就说明登陆成功。这里因为是匿名登陆,所以用户显示为Anonymous。
接下来就要介绍具体命令的使用方法了。
dir 跟DOS命令一样,用于查看服务器的文件,直接敲上dir回车,就可以看到此ftp服务器上的文件。
cd 进入某个文件夹。
get 下载文件到本地机器。
put 上传文件到远程服务器。这就要看远程ftp服务器是否给了你可写的权限了,如果可以,呵呵,该怎么 利用就不多说了,大家就自由发挥去吧。
delete 删除远程ftp服务器上的文件。这也必须保证你有可写的权限。
bye 退出当前连接。
quit 同上。
八,telnet
功能强大的远程登陆命令,几乎所有的入侵者都喜欢用它,屡试不爽。为什么?它操作简单,如同使用自己的机器一样,只要你熟悉DOS命令,在成功以 administrator身份连接了远程机器后,就可以用它来干你想干的一切了。下面介绍一下使用方法,首先键入telnet回车,再键入help查看其帮助信息。
然后在提示符下键入open IP回车,这时就出现了登陆窗口,让你输入合法的用户名和密码,这里输入任何密码都是不显示的。
当输入用户名和密码都正确后就成功建立了telnet连接,这时候你就在远程主机上具有了和此用户一样的权限,利用DOS命令就可以实现你想干的事情了。这里我使用的超级管理员权限登陆的。
到这里为止,网络DOS命令的介绍就告一段落了,这里介绍的目的只是给菜鸟网管一个印象,让其知道熟悉和掌握网络DOS命令的重要性。其实和网络有关的DOS命令还远不止这些,这里只是抛砖引玉,希望能对广大菜鸟网管有所帮助。学好DOS对当好网管有很大的帮助,特别的熟练掌握了一些网络的DOS命令。
另外大家应该清楚,任何人要想进入系统,必须得有一个合法的用户名和密码(输入法漏洞差不多绝迹了吧),哪怕你拿到帐户的只有一个很小的权限,你也可以利用它来达到最后的目的。所以坚决消灭空口令,给自己的帐户加上一个强壮的密码,是最好的防御弱口令入侵的方法。
最后,由衷的说一句,培养良好的安全意识才是最重要的。
=========================================
开始→运行→命令集锦
winver---------检查Windows版本
wmimgmt.msc----打开windows管理体系结构(WMI)
wupdmgr--------windows更新程序
wscript--------windows脚本宿主设置
write----------写字板
winmsd---------系统信息
wiaacmgr-------扫描仪和照相机向导
winchat--------XP自带局域网聊天
mem.exe--------显示内存使用情况
Msconfig.exe---系统配置实用程序
mplayer2-------简易widnows media player
mspaint--------画图板
mstsc----------远程桌面连接
mplayer2-------媒体播放机
magnify--------放大镜实用程序
mmc------------打开控制台
mobsync--------同步命令
dxdiag---------检查DirectX信息
drwtsn32------ 系统医生
devmgmt.msc--- 设备管理器
dfrg.msc-------磁盘碎片整理程序
diskmgmt.msc---磁盘管理实用程序
dcomcnfg-------打开系统组件服务
ddeshare-------打开DDE共享设置
dvdplay--------DVD播放器
net stop messenger-----停止信使服务
net start messenger----开始信使服务
notepad--------打开记事本
nslookup-------网络管理的工具向导
ntbackup-------系统备份和还原
narrator-------屏幕"讲述人"
ntmsmgr.msc----移动存储管理器
ntmsoprq.msc---移动存储管理员操作请求
netstat -an----(TC)命令检查接口
syncapp--------创建一个公文包
sysedit--------系统配置编辑器
sigverif-------文件签名验证程序
sndrec32-------录音机
shrpubw--------创建共享文件夹
secpol.msc-----本地安全策略
syskey---------系统加密,一旦加密就不能解开,保护windows xp系统的双重密码
services.msc---本地服务设置
Sndvol32-------音量控制程序
sfc.exe--------系统文件检查器
sfc /scannow---windows文件保护
tsshutdn-------60秒倒计时关机命令
tourstart------xp简介(安装完成后出现的漫游xp程序)
taskmgr--------任务管理器
eventvwr-------事件查看器
eudcedit-------造字程序
explorer-------打开资源管理器
packager-------对象包装程序
perfmon.msc----计算机性能监测程序
progman--------程序管理器
regedit.exe----注册表
rsop.msc-------组策略结果集
regedt32-------注册表编辑器
rononce -p ----15秒关机
regsvr32 /u *.dll----停止dll文件运行
regsvr32 /u zipfldr.dll------取消ZIP支持
cmd.exe--------CMD命令提示符
chkdsk.exe-----Chkdsk磁盘检查
certmgr.msc----证书管理实用程序
calc-----------启动计算器
charmap--------启动字符映射表
cliconfg-------SQL SERVER 客户端网络实用程序
Clipbrd--------剪贴板查看器
conf-----------启动netmeeting
compmgmt.msc---计算机管理
cleanmgr-------垃圾整理
ciadv.msc------索引服务程序
osk------------打开屏幕键盘
odbcad32-------ODBC数据源管理器
oobe/msoobe /a----检查XP是否激活
lusrmgr.msc----本机用户和组
logoff---------注销命令
iexpress-------木马捆绑工具,系统自带
Nslookup-------IP地址侦测器
fsmgmt.msc-----共享文件夹管理器
utilman--------辅助工具管理器
gpedit.msc-----组策略
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/ccsbb/archive/2010/01/27/5261954.aspx
java反编译工具Jode Decompiler的Eclipse插件安装与使用
- Jode Decompiler的安装:
安装非常的简单,在ECLIPSE上的help => Software Updates => Find and Install... => Search for new features to install,单击"New Remote Site..." 在URL栏输入 http://www.technoetic.com/eclipse/update,然后下一步,就可以看到“jode decompiler plugin *.*”了,选上安装就可以了,由于Jode Decompiler是纯Java编写的所以也不需要其他的什么组件来支持了;
- 配置:
安装好了可以看到Window => Preferences... => Java => Jode Decompiler选项卡。安装好了再设置一下文件关联就可以了,Window => Preferences... => General => Editors => File Associations找到"*.class"在"Associated editors"里面可以看到"Jode class file viewer"选中它再单击Default按钮就OK了.
- 使用:
现在就可以开始使用了,建立一个project然后引用你的组件,在组件中找到你所要反编译的类文件打开就可以看到反编译后得到的代码了.
注:现在版本只支持3.0或者3.1的,3.2安装以后可能会有错误。
推荐一款Java反编译器,也使用了挺久的了,感觉还是很好用,就拿出和大家分享一下。
这款反编译器叫 "Java Decompiler", 由 Pavel Kouznetsov开发,目前最新版本为0.2.5.
它由 C++开发,并且 官方可以下载 windows、linux和苹果Mac Os三个平台的可执行程序。
本人之所以认为它还不错,是其有下面几个功能:
1. 支持对整个Jar文件进行反编译,并本源代码可直接点击进行相关代码的跳转
2. 支持众多Java编译器的反编译(支持泛型, Annotation和enum枚举类型)
- jdk1.1.8
- jdk1.3.1
- jdk1.4.2
- jdk1.5.0
- jdk1.6.0
- jikes-1.22
- harmony-jdk-r533500
- Eclipse Java Compiler v_677_R32x, 3.2.1 release
- jrockit90_150_06
图示:
3. 快速查找源文件功能(Ctrl+Shift+T)
4. 安装方便.只有600K,直接运行即可。
5. 支持文件的拖放功能,源代码高亮显示
当然对于反编译的效果,感觉还可以。当然在本人使用过程也出现过,编译效果不佳的情况。但从总体上来看已经让我挺满意了,呵呵。
最近不少Web技术圈内的朋友在讨论协议方面的事情,有的说web开发者应该熟悉web相关的协议,有的则说不用很了解。个人认为这要分层次来看待这个问题,对于一个新手或者刚入门的web开发人员而言,研究协议方面的东西可能会使得web开发失去趣味性、抹煞学习积极性,这类人应该更多的了解基本的Web技术使用。而对于在该行业工作多年的老鸟来说,协议相关的内容、标准相关内容应该尽量多些的了解,因为只有这样才能使得经手的web系统更加优秀(安全、漂亮、快速、兼容性好、体验好……)。本文我们来说一下MIME 协议的一个扩展 Content-disposition。
我们在开发web系统时有时会有以下需求:
- 希望某类或者某已知MIME 类型的文件(比如:*.gif;*.txt;*.htm)能够在访问时弹出“文件下载”对话框
- 希望以原始文件名(上传时的文件名,例如:山东省政府1024号文件.doc)提供下载,但服务器上保存的地址却是其他文件名(如:12519810948091234_asdf.doc)
- 希望某文件直接在浏览器上显示而不是弹出文件下载对话框
- ……………………
要解决上述需求就可以使用Content-disposition来解决。第一个需求的解决办法是
Response.AddHeader "content-disposition","attachment; filename=fname.ext"
将上述需求进行归我给出如下例子代码:
public static void ToDownload(string serverfilpath,string filename)
{
FileStream fileStream = new FileStream(serverfilpath, FileMode.Open);
long fileSize = fileStream.Length;
HttpContext.Current.Response.ContentType = "application/octet-stream";
HttpContext.Current.Response.AddHeader("Content-Disposition", "attachment; filename=\"" + UTF_FileName(filename) + "\";");
////attachment --- 作为附件下载
////inline --- 在线打开
HttpContext.Current.Response.AddHeader("Content-Length", fileSize.ToString());
byte[] fileBuffer = new byte[fileSize];
fileStream.Read(fileBuffer, 0, (int)fileSize);
HttpContext.Current.Response.BinaryWrite(fileBuffer);
fileStream.Close();
HttpContext.Current.Response.End();
}
public static void ToOpen(string serverfilpath, string filename)
{
FileStream fileStream = new FileStream(serverfilpath, FileMode.Open);
long fileSize = fileStream.Length;
HttpContext.Current.Response.ContentType = "application/octet-stream";
HttpContext.Current.Response.AddHeader("Content-Disposition", "inline; filename=\"" + UTF_FileName(filename) + "\";");
HttpContext.Current.Response.AddHeader("Content-Length", fileSize.ToString());
byte[] fileBuffer = new byte[fileSize];
fileStream.Read(fileBuffer, 0, (int)fileSize);
HttpContext.Current.Response.BinaryWrite(fileBuffer);
fileStream.Close();
HttpContext.Current.Response.End();
}
private static string UTF_FileName(string filename)
{
return HttpUtility.UrlEncode(filename, System.Text.Encoding.UTF8);
}
简单的对上述代码做一下解析,ToDownload方法为将一个服务器上的文件(serverfilpath为服务器上的物理地址),以某文件名(filename)在浏览器上弹出“文件下载”对话框,而ToOpen是将服务器上的某文件以某文件名在浏览器中显示/打开的。注意其中我使用了UTF_FileName方法,该方法很简单,主要为了解决包含非英文/数字名称的问题,比如说文件名为“衣明志.doc”,使用该方法客户端就不会出现乱码了。
需要注意以下几个问题:
- Content-disposition是MIME协议的扩展,由于多方面的安全性考虑没有被标准化,所以可能某些浏览器不支持,比如说IE4.01
- 我们可以使用程序来使用它,也可以在web服务器(比如IIS)上使用它,只需要在http header上做相应的设置即可
可参看以下几篇文档:
如果是使用的catalina.sh(linux)或Catalina.bat(win)启动的:修改这两个文件,加上下面这句: SET CATALINA_OPTS= -Xms64m -Xmx128m 如果使用的winnt服务启动:打开C:\WINNT\system32\regedt32.exe,在HKEY_LOCAL_MACHINE-->SOFTWARE-->Apache Software Foundation-->Process Runner 1.0-->Tomcat5-->Parameters 修改属性: -Xms64m -Xmx128m 有人建议Xms和Xmx的值取成一样比较好,说是可以加快内存回收速度。但未经本人验证过。有兴趣可以试试。 加大tomcat连接数: 在tomcat配置文件server.xml中的配置中,和连接数相关的参数有: minProcessors:最小空闲连接线程数,用于提高系统处理性能,默认值为10 maxProcessors:最大连接线程数,即:并发处理的最大请求数,默认值为75 acceptCount:允许的最大连接数,应大于等于maxProcessors,默认值为100 enableLookups:是否反查域名,取值为:true或false。为了提高处理能力,应设置为false connectionTimeout:网络连接超时,单位:毫秒。设置为0表示永不超时,这样设置有隐患的。通常可设置为30000毫秒。 其中和最大连接数相关的参数为maxProcessors和acceptCount。如果要加大并发连接数,应同时加大这两个参数。 web server允许的最大连接数还受制于操作系统的内核参数设置,通常Windows是2000个左右,Linux是1000个左右。
问题表现:
当用户执行一个大数据的应用时(净字节码量约为5M)时,系统会提示出错:
前台错误为:HTTP Status 500-Dispatch[EAITool] to method listCurTree retrun an exception
(以下省略)
………………………………………………………
………………………………………………………
后台错误为:java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start(Native Method)
at org.apache.catalina.loader.WebappLoader.notifyContext(WebappLoader.ja
va:847)
(以下省略)
………………………………………………………
………………………………………………………
问题分析:
由于TOMCAT内存溢出而引发的问题,主要原因是JVM的虚拟内存默认为128M,当超过这个值时就把先前占用的内存释放,而导致好象TCP/IP丢包的假象,出现HTTP500的错误。
解决方法主要是加大TOMCAT可利用内存,并在程序当中加大内存使用。
解决方法:
方法:加大TOMCAT可利用内存:
在TOMCAT的目录下,也就是在TOMCAT41/bin/catalina.bat文件最前面加入
set JAVA_OPTS=-Xms800m -Xmx800m
表现效果是当你启动TOMCAT时,系统内存会增加近800M使用
操作方法:
1)、先关掉WINDOWS服务当中的TOMCAT4服务。
2)、再找到TOMCAT/BIN目录下startup.bat,双击打开它,你会发现现WINDOWS内存占用会增加近800M。
3)、执行程序,因为是TOMCAT重新编译程序,所以第一次会比较慢。
结论:
经过测试,我们得出如下数据:
当系统传输约2000条数据时,大约近12M的净数据(不压缩时),系统辅助运行的内存大约占用150M左右的空间,也就是近200M的内存占用,而我们扩大了近800M的JAVA内存使用,这对于业务本身来说是足够了。所以你们不用担心大数据量的传递问题。
基于JAVA虚拟机的原理,JAVA自动有垃圾回收机制,也就是在你对一些内存长时间不使用时(近2分钟,取决于使用频度和优先级等),就会自动垃圾回收,从而释放不用的内存占用。
单态定义:
Singleton模式主要作用是保证在Java应用程序中,一个类Class只有一个实例存在。
在很多操作中,比如建立目录 数据库连接都需要这样的单线程操作。
还有, singleton能够被状态化; 这样,多个单态类在一起就可以作为一个状态仓库一样向外提供服务,比如,你要论坛中的帖子计数器,每次浏览一次需要计数,单态类能否保持住这个计数,并且能synchronize的安全自动加1,如果你要把这个数字永久保存到数据库,你可以在不修改单态接口的情况下方便的做到。
另外方面,Singleton也能够被无状态化。提供工具性质的功能,
Singleton模式就为我们提供了这样实现的可能。使用Singleton的好处还在于可以节省内存,因为它限制了实例的个数,有利于Java垃圾回收(garbage collection)。
我们常常看到工厂模式中类装入器(class loader)中也用Singleton模式实现的,因为被装入的类实际也属于资源。
如何使用?
一般Singleton模式通常有几种形式:
|
public class Singleton {
private Singleton(){}
//在自己内部定义自己一个实例,是不是很奇怪?
//注意这是private 只供内部调用
private static Singleton instance = new Singleton();
//这里提供了一个供外部访问本class的静态方法,可以直接访问
public static Singleton getInstance() {
return instance;
}
}
|
第二种形式:
| public class Singleton {
private static Singleton instance = null;
public static synchronized Singleton getInstance() {
if (instance==null)
instance=new Singleton();
return instance; }
}
|
使用Singleton.getInstance()可以访问单态类。
上面第二中形式是lazy initialization,也就是说第一次调用时初始Singleton,以后就不用再生成了。
注意到lazy initialization形式中的synchronized,这个synchronized很重要,如果没有synchronized,那么使用getInstance()是有可能得到多个Singleton实例。关于lazy initialization的Singleton有很多涉及double-checked locking (DCL)的讨论,有兴趣者进一步研究。
一般认为第一种形式要更加安全些。
使用Singleton注意事项:
有时在某些情况下,使用Singleton并不能达到Singleton的目的,如有多个Singleton对象同时被不同的类装入器装载;在EJB这样的分布式系统中使用也要注意这种情况,因为EJB是跨服务器,跨JVM的。
我们以SUN公司的宠物店源码(Pet Store 1.3.1)的ServiceLocator为例稍微分析一下:
在Pet Store中ServiceLocator有两种,一个是EJB目录下;一个是WEB目录下,我们检查这两个ServiceLocator会发现内容差不多,都是提供EJB的查询定位服务,可是为什么要分开呢?仔细研究对这两种ServiceLocator才发现区别:在WEB中的ServiceLocator的采取Singleton模式,ServiceLocator属于资源定位,理所当然应该使用Singleton模式。但是在EJB中,Singleton模式已经失去作用,所以ServiceLocator才分成两种,一种面向WEB服务的,一种是面向EJB服务的。
Singleton模式看起来简单,使用方法也很方便,但是真正用好,是非常不容易,需要对Java的类 线程 内存等概念有相当的了解。
总之:如果你的应用基于容器,那么Singleton模式少用或者不用,可以使用相关替代技术。
进一步深入可参考:
Double-checked locking and the Singleton pattern
When is a singleton not a singleton?
Singleton是邪恶的
关于web应用的static变量
Jive中的单例模式
更多单例专题
更多本模式专题
更多线程安全专题
更多同步或锁专题
更多对象生命周期专题
c:forEach标签的使用
在JSP的开发中,迭代是经常要使用到的操作。例如,逐行的显示查询的结果等。在早期的JSP中,通常使用Scriptlets来实现Iterator或者Enumeration对象的迭代输出。现在,通过JSTL的迭代标签可以在很大的程度上简化迭代操作。
JSTL所支持的迭代标签有两个,分别是c:forEach和c:forTokens。在这里介绍的是c:forEach标签。
简单点说,<c:forEach>标签的作用就是迭代输出标签内部的内容。它既可以进行固定次数的迭代输出,也可以依据集合中对象的个数来决定迭代的次数。
c:forEach标签的语法定义如下所示。
xml 代码
- <c:forEach var="name" items="expression" varStatus="name"
-
- begin="expression" end="expression" step="expression">
-
- body content
-
- </c:forEach>
<c:forEach>标签具有以下一些属性:
l var:迭代参数的名称。在迭代体中可以使用的变量的名称,用来表示每一个迭代变量。类型为String。
l items:要进行迭代的集合。对于它所支持的类型将在下面进行讲解。
l varStatus:迭代变量的名称,用来表示迭代的状态,可以访问到迭代自身的信息。
l begin:如果指定了items,那么迭代就从items[begin]开始进行迭代;如果没有指定items,那么就从begin开始迭代。它的类型为整数。
l end:如果指定了items,那么就在items[end]结束迭代;如果没有指定items,那么就在end结束迭代。它的类型也为整数。
l step:迭代的步长。
<c:forEach>标签的items属性支持Java平台所提供的所有标准集合类型。此外,您可以使用该操作来迭代数组(包括基本类型数组)中的元素。它所支持的集合类型以及迭代的元素如下所示:
l java.util.Collection:调用iterator()来获得的元素。
l java.util.Map:通过java.util.Map.Entry所获得的实例。
l java.util.Iterator:迭代器元素。
l java.util.Enumeration:枚举元素。
l Object实例数组:数组元素。
l 基本类型值数组:经过包装的数组元素。
l 用逗号定界的String:分割后的子字符串。
l javax.servlet.jsp.jstl.sql.Result:SQL查询所获得的行。
不论是对整数还是对集合进行迭代,<c:forEach>的varStatus属性所起的作用相同。和var属性一样,varStatus用于创建限定了作用域的变量(改变量只在当前标签体内起作用)。不过,由varStatus属性命名的变量并不存储当前索引值或当前元素,而是赋予javax.servlet.jsp.jstl.core.LoopTagStatus类的实例。该类包含了一系列的特性,它们描述了迭代的当前状态,如下这些属性的含义如下所示:
l current:当前这次迭代的(集合中的)项。
l index:当前这次迭代从0开始的迭代索引。
l count:当前这次迭代从1开始的迭代计数。
l first:用来表明当前这轮迭代是否为第一次迭代,该属性为boolean类型。
l last:用来表明当前这轮迭代是否为最后一次迭代,该属性为boolean类型。
l begin:begin属性的值。
l end:end属性的值
l step:step属性的值
下面就来看一个个基本的例子,表格隔行背景色变化
xml 代码
- <c:forEach var="item" items="${contents}" varStatus="status">
- <tr <c:if test="${status.count%2==0}">bgcolor="#CCCCFE"</c:if> align="left">
- xxx
- </tr>
配置的前提是要有装oracle的驱动程序,如果有装oracle服务器端或客户端就自动安装上的oracle的驱动程序
1、database->generate database
2、general->Direct generation 如果没有配置好数据源,就要点数据库的图标
3、配置Data Sourcce
选择ODBC machine data source
选择Configure
4、点击添加data source 选择用户数据源(只用于当前机器)
5、选择oracle驱动,填写新建的数据源的名字即可!
Hex number system
是计算机中数据的一种表示方法.同我们日常中的十进制表示法不一样.它由0-9,A-F,组成.与10进制的对应关系是:
0-9对应0-9;
A-F对应10-15;
N进制的数可以用0---(N-1)的数表示超过9的用字母A-F
例如:
10进制的32表示成16进制就是:20
16进制的32表示成10进制就是:3×16^1+2×16^0=50
6.1 为什么需要八进制和十六进制?
编程中,我们常用的还是10进制……毕竟C/C++是高级语言。
比如:
int a = 100,b = 99;
不过,由于数据在计算机中的表示,最终以二进制的形式存在,所以有时候使用二进制,可以更直观地解决问题。
但,二进制数太长了。比如int 类型占用4个字节,32位。比如100,用int类型的二进制数表达将是:
0000 0000 0000 0000 0110 0100
面对这么长的数进行思考或操作,没有人会喜欢。因此,C,C++ 没有提供在代码直接写二进制数的方法。
用16进制或8进制可以解决这个问题。因为,进制越大,数的表达长度也就越短。不过,为什么偏偏是16或8进制,而不其它的,诸如9或20进制呢?
2、8、16,分别是2的1次方,3次方,4次方。这一点使得三种进制之间可以非常直接地互相转换。8进制或16进制缩短了二进制数,但保持了二进制数的表达特点。在下面的关于进制转换的课程中,你可以发现这一点。
6.2 二、八、十六进制数转换到十进制数
6.2.1 二进制数转换为十进制数
二进制数第0位的权值是2的0次方,第1位的权值是2的1次方……
所以,设有一个二进制数:0110 0100,转换为10进制为:
下面是竖式:
0110 0100 换算成 十进制
第0位 0 * 2^0 = 0
第1位 0 * 2^1 = 0
第2位 1 * 2^2 = 4
第3位 0 * 2^3 = 0
第4位 0 * 2^4 = 0
第5位 1 * 2^5 = 32
第6位 1 * 2^6 = 64
第7位 0 * 2^7 = 0 +
---------------------------
100
用横式计算为:
0 * 2^0 + 0 * 2^1 + 1 * 2^2 + 0 * 2^3 + 0 * 2^4 + 1 * 2^5 + 1 * 2^6 + 0 * 2^7 = 100
0乘以多少都是0,所以我们也可以直接跳过值为0的位:
1 * 2^2 + 1 * 2^3 + 1 * 2^5 + 1 * 2^6 = 100
上面错的,改
1 * 2^2 + 1 * 2^5 + 1 * 2^6 = 100
4 + 32 + 64 =100
6.2.2 八进制数转换为十进制数
八进制就是逢8进1。
八进制数采用 0~7这八数来表达一个数。
八进制数第0位的权值为8的0次方,第1位权值为8的1次方,第2位权值为8的2次方……
所以,设有一个八进制数:1507,转换为十进制为:
用竖式表示:
1507换算成十进制。
第0位 7 * 8^0 = 7
第1位 0 * 8^1 = 0
第2位 5 * 8^2 = 320
第3位 1 * 8^3 = 512 +
--------------------------
839
同样,我们也可以用横式直接计算:
7 * 8^0 + 0 * 8^1 + 5 * 8^2 + 1 * 8^3 = 839
结果是,八进制数 1507 转换成十进制数为 839
6.2.3 八进制数的表达方法
C,C++语言中,如何表达一个八进制数呢?如果这个数是 876,我们可以断定它不是八进制数,因为八进制数中不可能出7以上的阿拉伯数字。但如果这个数是123、是567,或12345670,那么它是八进制数还是10进制数,都有可能。
所以,C,C++规定,一个数如果要指明它采用八进制,必须在它前面加上一个0,如:123是十进制,但0123则表示采用八进制。这就是八进制数在C、C++中的表达方法。
由于C和C++都没有提供二进制数的表达方法,所以,这里所学的八进制是我们学习的,CtC++语言的数值表达的第二种进制法。
现在,对于同样一个数,比如是100,我们在代码中可以用平常的10进制表达,例如在变量初始化时:
int a = 100;
我们也可以这样写:
int a = 0144; //0144是八进制的100;一个10进制数如何转成8进制,我们后面会学到。
千万记住,用八进制表达时,你不能少了最前的那个0。否则计算机会通通当成10进制。不过,有一个地方使用八进制数时,却不能使用加0,那就是我们前面学的用于表达字符的“转义符”表达法。
6.2.4 八进制数在转义符中的使用
我们学过用一个转义符\'\\'加上一个特殊字母来表示某个字符的方法,如:\'\n\'表示换行(line),而\'\t\'表示Tab字符,\'\\'\'则表示单引号。今天我们又学习了一种使用转义符的方法:转义符\'\\'后面接一个八进制数,用于表示ASCII码等于该值的字符。
比如,查一下第5章中的ASCII码表,我们找到问号字符(?)的ASCII值是63,那么我们可以把它转换为八进值:77,然后用 \'\77\'来表示\'?\'。由于是八进制,所以本应写成 \'\077\',但因为C,C++规定不允许使用斜杠加10进制数来表示字符,所以这里的0可以不写。
事实上我们很少在实际编程中非要用转义符加八进制数来表示一个字符,所以,6.2.4小节的内容,大家仅仅了解就行。
6.2.5 十六进制数转换成十进制数
2进制,用两个阿拉伯数字:0、1;
8进制,用八个阿拉伯数字:0、1、2、3、4、5、6、7;
10进制,用十个阿拉伯数字:0到9;
16进制,用十六个阿拉伯数字……等等,阿拉伯人或说是印度人,只发明了10个数字啊?
16进制就是逢16进1,但我们只有0~9这十个数字,所以我们用A,B,C,D,E,F这五个字母来分别表示10,11,12,13,14,15。字母不区分大小写。
十六进制数的第0位的权值为16的0次方,第1位的权值为16的1次方,第2位的权值为16的2次方……
所以,在第N(N从0开始)位上,如果是是数 X (X 大于等于0,并且X小于等于 15,即:F)表示的大小为 X * 16的N次方。
假设有一个十六进数 2AF5, 那么如何换算成10进制呢?
用竖式计算: 2AF5换算成10进制:
第0位: 5 * 16^0 = 5
第1位: F * 16^1 = 240
第2位: A * 16^2 = 2560
第3位: 2 * 16^3 = 8192 +
-------------------------------------
10997
直接计算就是:
5 * 16^0 + F * 16^1 + A * 16^2 + 2 * 16^3 = 10997
(别忘了,在上面的计算中,A表示10,而F表示15)
现在可以看出,所有进制换算成10进制,关键在于各自的权值不同。
假设有人问你,十进数 1234 为什么是 一千二百三十四?你尽可以给他这么一个算式:
1234 = 1 * 10^3 + 2 * 10^2 + 3 * 10^1 + 4 * 10^0
6.2.6 十六进制数的表达方法
如果不使用特殊的书写形式,16进制数也会和10进制相混。随便一个数:9876,就看不出它是16进制或10进制。
C,C++规定,16进制数必须以 0x开头。比如 0x1表示一个16进制数。而1则表示一个十进制。另外如:0xff,0xFF,0X102A,等等。其中的x也也不区分大小写。(注意:0x中的0是数字0,而不是字母O)
以下是一些用法示例:
int a = 0x100F;
int b = 0x70 + a;
至此,我们学完了所有进制:10进制,8进制,16进制数的表达方式。最后一点很重要,C/C++中,10进制数有正负之分,比如12表示正12,而-12表示负12,;但8进制和16进制只能用达无符号的正整数,如果你在代码中里:-078,或者写:-0xF2,C,C++并不把它当成一个负数。
6.2.7 十六进制数在转义符中的使用
转义符也可以接一个16进制数来表示一个字符。如在6.2.4小节中说的 \'?\' 字符,可以有以下表达方式:
\'?\' //直接输入字符
\'\77\' //用八进制,此时可以省略开头的0
\'\0x3F\' //用十六进制
同样,这一小节只用于了解。除了空字符用八进制数 \'\0\' 表示以外,我们很少用后两种方法表示一个字符。
6.3 十进制数转换到二、八、十六进制数
6.3.1 10进制数转换为2进制数
给你一个十进制,比如:6,如果将它转换成二进制数呢?
10进制数转换成二进制数,这是一个连续除2的过程:
把要转换的数,除以2,得到商和余数,
将商继续除以2,直到商为0。最后将所有余数倒序排列,得到数就是转换结果。
听起来有些糊涂?我们结合例子来说明。比如要转换6为二进制数。
“把要转换的数,除以2,得到商和余数”。
那么:
要转换的数是6, 6 ÷ 2,得到商是3,余数是0。 (不要告诉我你不会计算6÷3!)
“将商继续除以2,直到商为0……”
现在商是3,还不是0,所以继续除以2。
那就: 3 ÷ 2, 得到商是1,余数是1。
“将商继续除以2,直到商为0……”
现在商是1,还不是0,所以继续除以2。
那就: 1 ÷ 2, 得到商是0,余数是1 (拿笔纸算一下,1÷2是不是商0余1!)
“将商继续除以2,直到商为0……最后将所有余数倒序排列”
好极!现在商已经是0。
我们三次计算依次得到余数分别是:0、1、1,将所有余数倒序排列,那就是:110了!
6转换成二进制,结果是110。
把上面的一段改成用表格来表示,则为:
被除数 计算过程 商 余数
6 6/2 3 0
3 3/2 1 1
1 1/2 0 1
(在计算机中,÷用 / 来表示)
如果是在考试时,我们要画这样表还是有点费时间,所更常见的换算过程是使用下图的连除:
(图:1)
请大家对照图,表,及文字说明,并且自己拿笔计算一遍如何将6转换为二进制数。
说了半天,我们的转换结果对吗?二进制数110是6吗?你已经学会如何将二进制数转换成10进制数了,所以请现在就计算一下110换成10进制是否就是6。
6.3.2 10进制数转换为8、16进制数
非常开心,10进制数转换成8进制的方法,和转换为2进制的方法类似,唯一变化:除数由2变成8。
来看一个例子,如何将十进制数120转换成八进制数。
用表格表示:
被除数 计算过程 商 余数
120 120/8 15 0
15 15/8 1 7
1 1/8 0 1
120转换为8进制,结果为:170。
非常非常开心,10进制数转换成16进制的方法,和转换为2进制的方法类似,唯一变化:除数由2变成16。
同样是120,转换成16进制则为:
被除数 计算过程 商 余数
120 120/16 7 8
7 7/16 0 7
120转换为16进制,结果为:78。
请拿笔纸,采用(图:1)的形式,演算上面两个表的过程。
6.4 二、十六进制数互相转换
二进制和十六进制的互相转换比较重要。不过这二者的转换却不用计算,每个C,C++程序员都能做到看见二进制数,直接就能转换为十六进制数,反之亦然。
我们也一样,只要学完这一小节,就能做到。
首先我们来看一个二进制数:1111,它是多少呢?
你可能还要这样计算:1 * 2^0 + 1 * 2^1 + 1 * 2^2 + 1 * 2^3 = 1 * 1 + 1 * 2 + 1 * 4 + 1 * 8 = 15。
然而,由于1111才4位,所以我们必须直接记住它每一位的权值,并且是从高位往低位记,:8、4、2、1。即,最高位的权值为2^3 = 8,然后依次是 2^2 = 4,2^1=2, 2^0 = 1。
记住8421,对于任意一个4位的二进制数,我们都可以很快算出它对应的10进制值。
下面列出四位二进制数 xxxx 所有可能的值(中间略过部分)
仅4位的2进制数 快速计算方法 十进制值 十六进值
1111 = 8 + 4 + 2 + 1 = 15 F
1110 = 8 + 4 + 2 + 0 = 14 E
1101 = 8 + 4 + 0 + 1 = 13 D
1100 = 8 + 4 + 0 + 0 = 12 C
1011 = 8 + 0 + 2 + 1 = 11 B
1010 = 8 + 0 + 2 + 0 = 10 A
1001 = 8 + 0 + 0 + 1 = 10 9
....
0001 = 0 + 0 + 0 + 1 = 1 1
0000 = 0 + 0 + 0 + 0 = 0 0
二进制数要转换为十六进制,就是以4位一段,分别转换为十六进制。
如(上行为二制数,下面为对应的十六进制):
1111 1101 , 1010 0101 , 1001 1011
F D , A 5 , 9 B
反过来,当我们看到 FD时,如何迅速将它转换为二进制数呢?
先转换F:
看到F,我们需知道它是15(可能你还不熟悉A~F这五个数),然后15如何用8421凑呢?应该是8 + 4 + 2 + 1,所以四位全为1 :1111。
接着转换 D:
看到D,知道它是13,13如何用8421凑呢?应该是:8 + 4 + 1,即:1101。
所以,FD转换为二进制数,为: 1111 1101
由于十六进制转换成二进制相当直接,所以,我们需要将一个十进制数转换成2进制数时,也可以先转换成16进制,然后再转换成2进制。
比如,十进制数 1234转换成二制数,如果要一直除以2,直接得到2进制数,需要计算较多次数。所以我们可以先除以16,得到16进制数:
被除数 计算过程 商 余数
1234 1234/16 77 2
77 77/16 4 13 (D)
4 4/16 0 4
结果16进制为: 0x4D2
然后我们可直接写出0x4D2的二进制形式: 0100 1101 0010。
其中对映关系为:
0100 -- 4
1011 -- D
0010 -- 2
同样,如果一个二进制数很长,我们需要将它转换成10进制数时,除了前面学过的方法是,我们还可以先将这个二进制转换成16进制,然后再转换为10进制。
下面举例一个int类型的二进制数:
01101101 11100101 10101111 00011011
我们按四位一组转换为16进制: 6D E5 AF 1B
6.5 原码、反码、补码
结束了各种进制的转换,我们来谈谈另一个话题:原码、反码、补码。
我们已经知道计算机中,所有数据最终都是使用二进制数表达。
我们也已经学会如何将一个10进制数如何转换为二进制数。
不过,我们仍然没有学习一个负数如何用二进制表达。
比如,假设有一 int 类型的数,值为5,那么,我们知道它在计算机中表示为:
00000000 00000000 00000000 00000101
5转换成二制是101,不过int类型的数占用4字节(32位),所以前面填了一堆0。
现在想知道,-5在计算机中如何表示?
在计算机中,负数以其正值的补码形式表达。
什么叫补码呢?这得从原码,反码说起。
原码:一个整数,按照绝对值大小转换成的二进制数,称为原码。
比如 00000000 00000000 00000000 00000101 是 5的 原码。
反码:将二进制数按位取反,所得的新二进制数称为原二进制数的反码。
取反操作指:原为1,得0;原为0,得1。(1变0; 0变1)
比如:将00000000 00000000 00000000 00000101每一位取反,得11111111 11111111 11111111 11111010。
称:11111111 11111111 11111111 11111010 是 00000000 00000000 00000000 00000101 的反码。
反码是相互的,所以也可称:
11111111 11111111 11111111 11111010 和 00000000 00000000 00000000 00000101 互为反码。
补码:反码加1称为补码。
也就是说,要得到一个数的补码,先得到反码,然后将反码加上1,所得数称为补码。
比如:00000000 00000000 00000000 00000101 的反码是:11111111 11111111 11111111 11111010。
那么,补码为:
11111111 11111111 11111111 11111010 + 1 = 11111111 11111111 11111111 11111011
所以,-5 在计算机中表达为:11111111 11111111 11111111 11111011。转换为十六进制:0xFFFFFFFB。
再举一例,我们来看整数-1在计算机中如何表示。
假设这也是一个int类型,那么:
1、先取1的原码:00000000 00000000 00000000 00000001
2、得反码: 11111111 11111111 11111111 11111110
3、得补码: 11111111 11111111 11111111 11111111
可见,-1在计算机里用二进制表达就是全1。16进制为:0xFFFFFF。
一切都是纸上说的……说-1在计算机里表达为0xFFFFFF,我能不能亲眼看一看呢?当然可以。利用C++ Builder的调试功能,我们可以看到每个变量的16进制值。
6.6 通过调试查看变量的值
下面我们来动手完成一个小小的实验,通过调试,观察变量的值。
我们在代码中声明两个int 变量,并分别初始化为5和-5。然后我们通过CB提供的调试手段,可以查看到程序运行时,这两个变量的十进制值和十六进制值。
首先新建一个控制台工程。加入以下黑体部分(就一行):
//---------------------------------------------------------------------------
#pragma hdrstop
//---------------------------------------------------------------------------
#pragma argsused
int main(int argc, char* argv[])
{
int aaaa = 5, bbbbb = -5;
return 0;
}
//---------------------------------------------------------------------------
没有我们熟悉的的那一行:
getchar();
所以,如果全速运行这个程序,将只是DOS窗口一闪而过。不过今天我们将通过设置断点,来使用程序在我们需要的地儿停下来。
设置断点:最常用的调试方法之一,使用程序在运行时,暂停在某一代码位置,
在CB里,设置断点的方法是在某一行代码上按F5或在行首栏内单击鼠标。
如下图:
在上图中,我们在return 0;这一行上设置断点。断点所在行将被CB以红色显示。
接着,运行程序(F9),程序将在断点处停下来。
(请注意两张图的不同,前面的图是运行之前,后面这张是运行中,左边的箭头表示运行运行到哪一行)
当程序停在断点的时,我们可以观察当前代码片段内,可见的变量。观察变量的方法很多种,这里我们学习使用Debug Inspector (调试期检视),来全面观察一个变量。
以下是调出观察某一变量的 Debug Inspector 窗口的方法:
先确保代码窗口是活动窗口。(用鼠标点一下代码窗口)
按下Ctrl键,然后将鼠标挪到变量 aaaa 上面,你会发现代码中的aaaa变蓝,并且出现下划线,效果如网页中的超链接,而鼠标也变成了小手状:
点击鼠标,将出现变量aaaa的检视窗口:
(笔者使用的操作系统为WindowsXP,窗口的外观与Win9X有所不同)
从该窗口,我可以看到:
aaaa :变量名
int :变量的数据类型
0012FF88:变量的内存地址,请参看5.2 变量与内存地址;地址总是使用十六进制表达
5 : 这是变量的值,即aaaa = 5;
0x00000005 :同样是变量的值,但采用16进制表示。因为是int类型,所以占用4字节。
首先先关闭前面的用于观察变量aaaa的Debug Inspector窗口。
现在,我们用同样的方法来观察变量bbbb,它的值为-5,负数在计算机中使用补码表示。
正如我们所想,-5的补码为:0xFFFFFFFB。
再按一次F9,程序将从断点继续运行,然后结束。
6.7 本章小结
很难学的一章?
来看看我们主要学了什么:
1)我们学会了如何将二、八、十六进制数转换为十进制数。
三种转换方法是一样的,都是使用乘法。
2)我们学会了如何将十进制数转换为二、八、十六进制数。
方法也都一样,采用除法。
3)我们学会了如何快速的地互换二进制数和十六进制数。
要诀就在于对二进制数按四位一组地转换成十六进制数。
在学习十六进制数后,我们会在很多地方采用十六进制数来替代二进制数。
4)我们学习了原码、反码、补码。
把原码的0变1,1变0,就得到反码。要得到补码,则先得反码,然后加1。
以前我们只知道正整数在计算机里是如何表达,现在我们还知道负数在计算机里使用其绝对值的补码表达。
比如,-5在计算机中如何表达?回答是:5的补码。
5)最后我们在上机实验中,这会了如何设置断点,如何调出Debug Inspector窗口观察变量。
以后我们会学到更多的调试方法。
daiqionghui 修改一部分错的。、
十六进制
rkb-irir rtrt*-7-759-9urelurugf 44ihub 十六进制
交换两个变量的值,不使用第三个变量(2009-09-16 18:19:18)
|
通常我们的做法是(尤其是在学习阶段):定义一个新的变量,借助它完成交换。代码如下:
int a,b;
a=10; b=15;
int t;
t=a; a=b; b=t;
这种算法易于理解,特别适合帮助初学者了解计算机程序的特点,是赋值语句的经典应用。在实际软件开发当中,此算法简单明了,不会产生歧义,便于程序员之间的交流,一般情况下碰到交换变量值的问题,都应采用此算法(以下称为标准算法)。
上面的算法最大的缺点就是需要借助一个临时变量。那么不借助临时变量可以实现交换吗?答案是肯定的!这里我们可以用三种算法来实现:1)算术运算;2)指针地址操作;3)位运算。
1) 算术运算
简单来说,就是通过普通的+和-运算来实现。代码如下:
int a,b;
a=10;b=12;
a=b-a; //a=2;b=12
b=b-a; //a=2;b=10
a=b+a; //a=10;b=10
通过以上运算,a和b中的值就进行了交换。表面上看起来很简单,但是不容易想到,尤其是在习惯标准算法之后。
它的原理是:把a、b看做数轴上的点,围绕两点间的距离来进行计算。
具体过程:第一句“a=b-a”求出ab两点的距离,并且将其保存在a中;第二句“b=b-a”求出a到原点的距离(b到原点的距离与ab两点距离之差),并且将其保存在b中;第三句“a=b+a”求出b到原点的距离(a到原点距离与ab两点距离之和),并且将其保存在a中。完成交换。
此算法与标准算法相比,多了三个计算的过程,但是没有借助临时变量。(以下称为算术算法)
2) 指针地址操作
因为对地址的操作实际上进行的是整数运算,比如:两个地址相减得到一个整数,表示两个变量在内存中的储存位置隔了多少个字节;地址和一个整数相加即“a+10”表示以a为基地址的在a后10个a类数据单元的地址。所以理论上可以通过和算术算法类似的运算来完成地址的交换,从而达到交换变量的目的。即:
int *a,*b; //假设
*a=new int(10);
*b=new int(20); //&a=0x00001000h,&b=0x00001200h
a=(int*)(b-a); //&a=0x00000200h,&b=0x00001200h
b=(int*)(b-a); //&a=0x00000200h,&b=0x00001000h
a=(int*)(b+int(a)); //&a=0x00001200h,&b=0x00001000h
通过以上运算a、b的地址真的已经完成了交换,且a指向了原先b指向的值,b指向原先a指向的值了吗?上面的代码可以通过编译,但是执行结果却令人匪夷所思!原因何在?
首先必须了解,操作系统把内存分为几个区域:系统代码/数据区、应用程序代码/数据区、堆栈区、全局数据区等等。在编译源程序时,常量、全局变量等都放入全局数据区,局部变量、动态变量则放入堆栈区。这样当算法执行到“a=(int*)(b-a)”时,a的值并不是0x00000200h,而是要加上变量a所在内存区的基地址,实际的结果是:0x008f0200h,其中0x008f即为基地址,0200即为a在该内存区的位移。它是由编译器自动添加的。因此导致以后的地址计算均不正确,使得a,b指向所在区的其他内存单元。再次,地址运算不能出现负数,即当a的地址大于b的地址时,b-a<0,系统自动采用补码的形式表示负的位移,由此会产生错误,导致与前面同样的结果。
有办法解决吗?当然!以下是改进的算法:
if(a<b)
{
a=(int*)(b-a);
b=(int*)(b-(int(a)&0x0000ffff));
a=(int*)(b+(int(a)&0x0000ffff));
}
else
{
b=(int*)(a-b);
a=(int*)(a-(int(b)&0x0000ffff));
b=(int*)(a+(int(b)&0x0000ffff));
}
算法做的最大改进就是采用位运算中的与运算“int(a)&0x0000ffff”,因为地址中高16位为段地址,后16位为位移地址,将它和0x0000ffff进行与运算后,段地址被屏蔽,只保留位移地址。这样就原始算法吻合,从而得到正确的结果。
此算法同样没有使用第三变量就完成了值的交换,与算术算法比较它显得不好理解,但是它有它的优点即在交换很大的数据类型时,它的执行速度比算术算法快。因为它交换的时地址,而变量值在内存中是没有移动过的。(以下称为地址算法)
3) 位运算
通过异或运算也能实现变量的交换,这也许是最为神奇的,请看以下代码:
int a=10,b=12; //a=1010^b=1100;
a=a^b; //a=0110^b=1100;
b=a^b; //a=0110^b=1010;
a=a^b; //a=1100=12;b=1010;
此算法能够实现是由异或运算的特点决定的,通过异或运算能够使数据中的某些位翻转,其他位不变。这就意味着任意一个数与任意一个给定的值连续异或两次,值不变。
即:a^b^b=a。将a=a^b代入b=a^b则得b=a^b^b=a;同理可以得到a=b^a^a=b;轻松完成交换。
以上三个算法均实现了不借助其他变量来完成两个变量值的交换,相比较而言算术算法和位算法计算量相当,地址算法中计算较复杂,却可以很轻松的实现大类型(比如自定义的类或结构)的交换,而前两种只能进行整形数据的交换(理论上重载“^”运算符,也可以实现任意结构的交换)。
介绍这三种算法并不是要应用到实践当中,而是为了探讨技术,展示程序设计的魅力。从中可以看出,数学中的小技巧对程序设计而言具有相当的影响力,运用得当会有意想不到的神奇效果。而从实际的软件开发看,标准算法无疑是最好的,能够解决任意类型的交换问题
|
摘要: 转载自:http://www.ibm.com/developerworks/cn/java/j-drools/
使用声明性编程方法编写程序的业务逻辑
... 阅读全文
第一章 介绍与导览
本文描述Weblogic Server的域以及如何配置域。域是WebLogic Server的基本管理单元。一个域可以包括一个或多个WebLogic Server实例以及相关资源,只需使用一个Administration Server进行管理。
以下章节描述该指南的内容与结构——理解域配置。
文档范围与读者
文档向导
相关文档
示例与指南
该发布版本中新的域特性
文档范围与读者
文档主要适用于基于一个或多个Weblogic server域开发和部署Web应用的J2EE系统架构师、应用开发人员和系统管理员。
文档的主题仅和软件项目的设计与开发阶段相关,不涉及产品过程管理、监控或者性能调整。对于这些主题的WebLogic Server文档和资源链接,参见“相关文档”。
文档假定读者熟悉J2EE,XML的基本概念以及应用管理的一般概念。
文档向导
本章“介绍与导览”,介绍该指南的目的、结构和上下文关系。
第二章“理解WebLogic Server域”介绍Weblogic Server域。
第三章“使用WebLogic工具配置域”,展示你可以用来修改域配置的几种工具。
第四章“域配置文件”描述维护域和域的内容的磁盘表现形式的配置与目录。
第五章“管理配置变更”描述如何变更Weblogic Server的管理特性。
相关文档
关于用于创建和配置Weblogic Server域的工具的更多信息,参见:
使用配置向导创建WebLogic域
WebLogic脚本工具
使用JMX部署可管理的应用
WebLogic Server命令参考
管理控制台在线帮助
关于其他系统管理任务的信息,参见系统管理文档,尤其是:
设计和配置WebLogic Server环境
使用WebLogic Server集群
示例和向导
BEA系统公司为本文档提供了和域配置、管理相关的以下代码示例和指南:
BEA WebLogic Server的示例安装(可选)于目录WL_HOME/samples/server/examples/src/examples,WL_HOME是你安装WebLogic Server的顶级目录,这些示例也可以通过Windows开始菜单使用。集群示例会在BEA WebLogic Server集群指南示例中描述,指导你掌握使用WebLogic配置向导和管理控制台来创建和配置一个新的server实例集群的整个过程。
本版中新的域特性
Weblogic Server 9.0在Weblogic Server域配置中引入了几项重要变化:
config.xml的XML Schema
域目录结构
配置变更管理
config.xml的XML Schema
WebLogic Server域和实例配置的磁盘表现形式在本版本中有所不同。在原版本中,配置信息被保存在单个XML仓库文件config.xml中,默认位于user_projects/domains/domain_name目录下。在本版的WebLogic Server中,config.xml文件符合XML Schema定义(用来验证域配置文件格式的有效性)。而且,config.xml融合了其他配置文件(符合各自的XML Schema)的配置信息。在本版中,config.xml默认位于user_projects/domains/domain_name/config目录下,config.xml核心文件涉及的辅助配置文件位于user_projects/domains/domain_name/config目录的子目录中。更多信息,参见第四章“域配置文件”。
域目录结构
本版中,Weblogic Server域在磁盘上的目录结构有了改变。域的父目录命名为domains。域的配置信息保存在domains/domain_name/config目录和config目录的子目录中。更多信息,参见“域目录内容”。
配置变更管理
WebLogic Server提供了一些新特性用来管理服务配置变更,这使你可以安全、可预知地实现分发某个域的配置变更。当然这要求你在使用控制台进行配置变更前获得管理员控制台锁。
WebLogic Server中的变更管理过程和数据库事务有些类似。由管理服务器维护一个独立的,可编辑的域配置表现形式,称为编辑层。server实例并不涉及编辑层。相反,server实例使用只读层来发现配置。为了开启编辑过程,你应当可以获得一个编辑层的锁以防止其他人更改。当你完成更改后,你保存并将其分发至域中的所有server实例。分发完成后,每一个server来决定自己是否接受该变更。一旦所有的server都接受该变更,则更新运行的配置层,变更才完成。
现在的管理控制台包括一个名为Change Center(变更中心)的区域。当你使用管理控制台进行配置变更时,你必须首先通过点击Change Center的Lock & Make Changes(锁且变更)获得锁。进行期望的配置变更以后,然后可以在Change Center:
点击Activate Changes(激活变更)接受更改,向域中的sever实例分发,或者
点击Undo All Changes(撤销所有变更),释放锁。
WebLogic Server一般采用相同方式控制配置变更,无论变更是使用管理控制台实现,还是WebLogic 脚本工具、配置管理服务或者JMX API。
更多信息,参见第五章“管理配置变更”。
第二章 理解Weblogic Server域
以下章节介绍Weblogic Server域和域的内容:
域是什么
组织域
域的内容
域约束
域是什么?
一个Weblogic Server管理域是逻辑上相关的Weblogic Server资源组。域包括一个特殊的Weblogic Server实例,叫做管理服务器(Administration Server),这是你配置和管理域的所有资源的关键。通常,你配置的一个域会加入另外的WebLogic Server实例,叫作托管服务器(Managed Server)。你的Web应用、EJB和其他资源会部署在托管服务器上,而管理服务器只是用于配置和管理。
多个托管服务器可以组织成集群(clusters),这使你能够保持负载平衡和对于临界的应用提供失败保护,同时只使用一个管理服务器会使托管服务器实例的管理变得简单。
组织域
如何将WebLogic Server装置组织成域,这取决于你的业务需求。你可以基于系统管理员职责、应用边界或者server运行的地理位置的不同定义多个域。与之相反,你也可以决定将所有WebLogic Server管理行为集中于一个域。
根据你特定的业务需求和系统管理实际,你可以按照如下标准决定如何组织你的域:
应用的逻辑区分。比如,你可以有一个域用于类似购物车的终端用户功能,另一个域用于后台记账。
物理位置。你可以为业务的不同地理位置和分支分别建域。
大小。你会发现域被组织成更小的单元可能会使不同的系统管理员管理效率更高。反之,你也会发现维护单个域或者少量的域,配置更容易保持一致。
一个域由一个管理服务器和一个或多个托管服务器组成,也可以只由单个孤立的server组成,既扮演管理服务器的角色又驻留应用。
由分散的托管服务器组成的域:简单的产品环境由几个驻留应用的托管服务器,一个执行管理操作的管理服务器组成。在这种配置下,应用和资源部署在各自的托管服务器中;类似地,访问应用的客户端与各自的托管服务器连接。
如果产品环境对增强应用性能、吞吐量或者可用性有要求,那么应该将两个或者更多的托管服务器配置成集群。机群允许多个托管服务器作为单个个体驻留应用和资源。关于在孤立的和集群托管服务器之间差异的更多信息,参见“托管服务器和托管服务器集群”。
孤立的server域:对于开发或测试环境而言,你可能想在部署单个应用和server独立于产品域中的server。这种情况下,你可以部署一个简单域,只由单个server实例组成,既作为管理服务器,又驻留你开发的应用。你用WebLogic Server安装的wl_server域就是一个孤立server域的例子。
注意:在产品环境中,BEA建议你只在域中的托管服务器部署应用,管理服务器应当只负责管理任务。
域的内容

尽管域的范围与目的会有很大差异,但是大多数 WebLogic Server域都包含本章节中描述的组件。
下图展示了产品环境,包括一个管理服务器,三个孤立的托管服务器和三个托管服务器组成的集群。
管理服务器
每个Weblogic Server域都必须有一个server实例作为管理服务器。你使用管理服务器(编程或者通过管理服务器)来配置域中的所有其他server实例和资源。
管理服务器的角色
在启动域的托管服务器之前,应先启动管理服务器。当你启动一个孤立或集群托管服务器时,它会按配置信息与管理服务器相联。这种方式下,管理服务器在整个域配置中充当核心控制体。
当管理服务器启动时,加载域的config.xml文件,除非你在创建域时指定另一个目录存储config.xml。
BEA_HOME/user_projects/domains/mydomain/config
这里mydomain是特定域的目录,名称与域相同。config.xml引用的其他配置文件,位于域的config目录的子目录下。
管理服务器每一次成功启动后,将在域目录中创建一份命名为config-booted.jar的备份配置文件。万一配置文件在server实例生命周期内有损坏,有可能恢复原先的配置。
如果管理服务器出错会发生什么?
域的管理服务器出错不会影响域中的托管服务器的操作。如果域的管理服务器变得不可用,而它所管理的server实例——集群或者其他方式——仍在运行,那么那些托管服务器将继续运行。如果该域包含集群server实例,那么由域配置支持的负载平衡和失败性能保持可用,即使管理服务器出错。如果域的管理服务器停止运行而托管服务器继续运行,那么每一个托管服务器会周期性地尝试重新连接管理服务器,周期由ServerMBean属性AdminReconnectIntervalSecs指定。AdminReconnectIntervalSecs默认为10秒。
如果管理服务器因为主机的硬件或软件错误而失败,同一台机器的其它server实例都可能受到同样的影响。然而,管理服务器自身的失败不会中断域的托管服务器的运行。而且即使管理服务器不在运行状态,你也可以启动托管服务器。这种情况下,托管服务器使用配置文件的本地拷贝来作为它的启动配置,然后周期性地向管理服务器作连接尝试,连接后利用管理服务器来同步配置状态。
对于重启管理服务器的指令,参见“管理服务器启动与关闭”。
托管服务器和托管服务器集群
在域中,非管理服务器的server实例,指向托管服务器。托管服务器驻留构成你应用的组件和相关资源,比如JSP和EJB。当某个托管服务器启动后,它会连接域的管理服务器来获得配置和部署设置。
注意:即使管理服务器不可用,域中的托管服务器也可以独立于管理服务器启动。更多信息参见“管理server启动与关闭”中的“避免server失败与恢复”。
两个或更多的托管服务器可以配置成一个WebLogic Server集群,来增加应用的可伸缩性与可用性。在WebLogic Server集群中,大多数资源与服务平均部署给每一个托管服务器(与单个托管服务器相反),来使失败与负载平衡。要想了解哪种组件类型和服务可以进行集群(部署给集群中的所有server实例),参见“使用WebLogic Server集群”中的“理解WebLogic Server集群”。
你可以创建一个非集群的托管服务器,然后通过配置有关server实例和集群的参数将其加入集群。你也可以通过重新配置参数从集群中删除某个托管服务器。在集群与非集群托管服务器之间的根本区别在于对失败和负载平衡的支持。这些特性仅在集群托管服务器中可用。
你对于可伸缩性与可靠性的要求将决定你是否采用集群托管服务器。比如,如果你的应用不常遇到易变的加载,应用服务中可能的中断也是可以接受的,那么就没有必要采用集群。
关于WebLogic Server集群的好处与性能的更多信息,参见“使用WebLogic Server集群”中的“理解WebLogic Server集群”。单个域可以包含多个WebLogic Server集群,同样多个托管服务器也可以不被配置成集群。
资源与服务
除了管理服务器和托管服务器之外,域还包括托管服务器所需的资源和服务及部署在该域上的应用。
域配置包括域运行的网络计算机环境信息,比如:
机器定位依靠硬件上某个特定的物理片段来识别。机器定位被用来关联驻留托管服务器的计算机。该信息由节点管理器(Node Manager)重启一台出错的托管服务器,集群的托管服务器选择存储重复的会话数据的最好位置时使用。关于节点管理器的更多信息,参见“设计与配置WebLogic Server环境”的“使用节点管理器控制服务器”。
网络通道,一个可以用来定义默认端口、协议和协议设置的可选资源。在创建一个网络通道后,可以将它分配给域中任意一个托管服务器和集群。更多信息,参见“设计与配置WebLogic Server环境”中的“配置网络资源”。
域配置还包括与驻留在域中应用相关的资源和服务信息。这些资源和服务的例子包括:
应用组件,比如EJB
连接器
JDBC连接池
JMS server
启动类
资源和服务可能被限制于域中一个或多个托管服务器,而不是对于整个域可用。你可以选择托管服务器或者集群进行部署资源与服务。
域约束
WebLogic Server环境可以由单个域组成,包括驻留应用所需的所有托管服务器,也可以是多个域。你可以选择创建多个域,根据组织单元、系统管理员职责、应用边界或者其它要考虑的事项来划分。在设计域配置时,注意以下约束:
每一个域都需要自身的管理服务器执行管理操作。当你使用管理控制台执行管理和监控任务时,你可以在域中来回切换,同时你会连接不同的管理服务器。
同一个集群中的所有托管服务器必须位于相同的域,你不能将集群拆分至多个域。
同一个域中的所有托管服务器运行的WebLogic Server软件版本必须相同。域中的管理服务器可以和托管服务器运行相同的版本,也可以是更新的版本。
你不能在域中共享配置资源与子系统。比如,如果你在一个域中创建了一个JDBC连接池,你就不可能在另一个域中的托管服务器或集群中使用。代之,你必须在第二个域中创建一个类似的连接池。
第三章 使用Weblogic工具配置域
WebLogic包括了你可以用来创建、修改或者复制域配置的一系列工具。包括以下工具:
域配置向导——域配置向导是创建一个新的域或集群的推荐工具。关于使用域配置向导的更多信息,参见“使用配置向导创建WebLogic域”。
WebLogic Server管理控制台——管理控制台是管理服务器的图形化用户界面(GUI)。管理控制台描述参见“管理控制台在线帮助”。
WebLogic脚本工具(WLST)——你可以使用命令行脚本接口来创建、管理和维护WebLogic Server配置变更。WebLogic脚本工具描述参见“WebLogic脚本工具”。
WebLogic Server应用编程接口(API)—— 你可以使用WebLogic Server提供的API编写程序修改配置属性。JMX API描述参见“使用JMX开发可管理的应用”。
WebLogic Server命令行工具——该工具允许你创建脚本来自动进行域管理。关于该工具的更多信息,参见“WebLogic Server命令参考”。
对于大多数方式而言,要修改域配置域的管理服务器必须运行。然而,你如果使用 WLST 来进行域配置变更不需要运行管理服务器。这种情况下,WLST造成的变更也不会立即生效直到管理服务器和托管服务器重启。
第四章 域配置文件
本章节描述如何在文件系统中表示域。它包括以下部分:
配置文件概览
config.xml
域域目录概览

域目录内容
域配置文件概览
WebLogic Server管理和配置服务通过Java管理扩展(JMX)API来访问。域的配置保存在域目录下的配置目录中。这些配置目录中的文件用来持久化存储WebLogic Server在使用JMX API运行期间创建和修改的托管对象。config.xml的目的是存储托管配置对象的变更以使得WebLogic Server重启时可以访问。
域的核心配置文件为domain_name/config/config.xml文件。它指定域的名称和域中每一个server实例、集群、资源和服务的配置参数。域的一些主要子系统配置保存在domain_name/config目录的子目录中。
域目录还包括你用来启动域的管理服务器和托管服务器的默认脚本文件。
config.xml
域的核心配置文件为/domains/domain_name/config/config.xml文件。它指定域的名称和域中每一个server实例、集群、资源与服务的配置参数。
config.xml文件符合XML Schema,URL为 http://www.bea.com/ns/weblogic/config。schema位于文件系统中的JAR文件BEA_HOME/weblogic90/server/lib/schema/configuration-binding.jar中,即META-INF/schemas/schema-0.xsd。XML编辑工具可以使用XML Schema来修改和验证config.xml文件。
编辑配置文件
大多数情况下,你不应该直接修改config.xml或其他配置文件,而应该使用管理控制台或者用第三章“使用WebLogic工具配置域”中列出的某个工具来修改域配置。配置变更将会映射到配置文件中。
如果你选择放置配置文件,安装的其他组件在源控制之下(使用WLST管理),直接修改配置文件可能是合适的。
警告:当WebLogic Server运行时你不能编辑配置文件,因为WebLogic Server会周期性地重写该文件。你的更改将会丢失,也可能造成WebLogic Server失败,这取决于你的平台。
WebLogic Server配置文件是格式友好的XML文件,因此它有可能使用XML解析应用比如 Apache Xerces, or JDOM来使某个重复性的变更脚本实现。
确保完整测试所创建的脚本,在作变更之前对每一个配置文件作备份性拷贝。
辅助配置文件
在原版本中,config.xml文件存放了所有配置信息。新版本中,几个WebLogic Server子系统被配置在辅助配置文件中,由核心的config.xml来引用。这些辅助配置文件位于/domains/domain_name/config目录的子目录中。关于辅助配置文件的更多信息,参见“域目录概览”和“域目录内容”。
配置文件压缩包
WebLogic Server对配置文件作备份拷贝。万一配置变更需要推倒重来或者配置文件被破坏(当然这种情况不太可能),这使得恢复很容易。当管理服务器启动时,它将配置文件保存在一个命名为config-booted.jar的JAR文件中。当你变更配置文件时,旧文件以JAR文件的形式保存在域目录下的configArchive目录中,命名带数字序列,比如config-1.jar。
域目录概览
图4-1是域目录树型结构的概览。 domain-name 、deployment-name和server-name目录名称不是字面所示,实际上替换成任何指定的名称都是可以的;其他的目录名称则是字面所示。概览只显示目录,不含目录内的文件。任何实际的特定域目录树,整个结构都可能不会是这样。
域目录内容
本节描述域目录和子目录的内容,以斜体表示的目录名称不是实际的名称,而是要以适当的具体名称来替代,非斜体的名称则是字面上所示的名称。
domain-name
该目录的名称为域的名称。
applications
该目录提供了一种在部署服务器上部署应用的快速方式。当Weblogic Server实例以开发模式运行时,它会自动部署你放置在该目录的任何应用与模块。
你放置在目录的文件可以是:
一个J2EE应用
一个EAR文件
一个WAR、EJB JAR、RAR或者CAR的压缩模块
一个应用或者一个模块的解压目录
bin
该目录包括了一些用来启动或终止域中的管理服务器和托管服务器进程的脚本。它也可以包括一些其他广义上的域脚本,比如启动和终止数据库管理系统、全文检索引擎进程等的脚本。更多信息,参见管理server启动和终止。
config
该目录包含域的当前配置和部署状态,核心域配置文件config.xml即位于本目录中。
config/deployments
保存域部署应用的目录。
config/deployments/library_modules
保存类库模块的目录,也就是说,该目录中的任何文件都将以类库模块自动注册。
config/deployments/deployment-name-1
该目录包含一个应用或者可发布的模块。它所含的子级目录可以包含一个压缩文件(EAR或WAR),一个部署清单,扩展描述符等等。
config/diagnostics
该目录包含WebLogic诊断服务(WebLogic Diagnostic Service)系统模块。更多信息,参见“理解WebLogic诊断服务”。
config/jdbc
该目录包含JDBC系统模块:所有JDBC模块都可以通过JMX直接配置(和JSR-88不同)。更多信息,参见“数据库连接(JDBC)”。
config/jms
该目录包含JMS系统模块:所有JMS模块都可以通过JMX直接配置。更多信息,参见“消息与数据库连接(JDBC)”。
config/nodemanager
该目录保存与节点管理器连接的的配置信息。更多信息,参见“设计与配置WebLogic Server环境”中的“使用节点管理器管理服务”。
config/security
该目录包含安全框架系统模块。包含了当前域的每一种安全供应器的安全供应器配置扩展。更多信息,参见理解“WebLogic 安全”。
config/startup
该目录包含含启动计划的系统模块。启动计划被用来生成shell脚本,作为server启动的一部分。
configArchive
该目录包含一组用于保存域配置状态的JAR文件。在未决的配置变更激活前,域的当前配置状态,包括config.xml文件和其他相关文件,保存在带版本号的JAR文件中,命名成config.jar#1,config.jar#2等等。
带版本号的JAR文件的最大数量由DomainMBean的archiveConfigurationCount属性指定。一旦达到最大数,在新版本创建之前删除最旧的版本。
lib
放置在该目录中的任何JAR文件在sever的Java虚拟机启动时都会添加至域中每一个server实例的系统classpath。
pending
该目录包含的域配置文件表示已请求,但还没有激活的配置变更。一旦配置变更被激活,该目录中的配置文件将被删除。更多信息,参见“管理配置变更”。
security
该目录保存的安全相关文件对于域中的每一个WebLogic Server实例来说都是相同的。
SerializedSystemIni.dat
该目录还保存只有域管理服务器需要的安全相关文件:
DefaultAuthorizerInit.ldift
DefaultAuthenticatorInit.ldift
DefaultRoleMapperInit.ldift
更多信息,参见“理解WebLogic安全”。
servers
该目录为域中每一个WebLogic Server实例设置一个子目录。
servers/server-name
该目录为server目录,名称和WebLogic Server实例的名称相同。
servers/server-name/bin
该目录存放可执行的或shell文件,对于不同的server可能会不同。server环境脚本(setServerEnv.sh或setServerEnv.cmd)是位于此处的一个文件示例,因为它能区分一个WebLogic Server实例与下一个实例的不同,这取决于server实例是否有自己的启动计划。
servers/server-name/cache
该目录存放包含缓存数据的目录和文件。这里“缓存(cached)”表示该数据是其他数据的拷贝,可能是进程中的形式(已编译,已翻译或重新格式化的)。
servers/server-name/cache/EJBCompilerCache
该目录为已编译的EJB缓存。
servers/server-name/data
和临时的、缓存的或者历史信息相反,该目录存放的文件维护持久化的预服务状态,而不是安全状态,用于运行WebLogic Server实例。该目录中的文件非常重要,必须存在于WebLogic Server实例开始,停止,崩溃,重启或升级至新版本的整个过程中。
servers/server-name/data/ldap
该目录存放内嵌的LDAP数据库。WebLogic Server实例的运行时安全状态持久化于该目录。
servers/server-name/data/store
该目录存放JMS持久化存储。对于每一个持久化存储,都有一个子目录存放表示持久化存储的文件。子目录的名称为持久化存储的名称。照例有一个存储命名为default。
servers/server-name/logs
该目录存放日志和诊断信息。实际上只是一些历史信息,对于server的运行并非至关重要,可以删除(不过至少WebLogic Server实例应该终止)而不影响正确的运行。然而,这些信息对于调试和检查相当有用,如果没有好的理由不应当删除。
servers/server-name/logs/diagnostic_images
该目录存放WebLogic诊断服务(WebLogic Diagnostic Service)的Server图片捕获器(Server Image Capture)组件创建的信息。更多信息,参见“理解WebLogic诊断服务”。
servers/server-name/logs/jmsServers
该目录为WebLogic Server实例中的每一个JMS服务提供一个子目录。每一个那样的子目录包含JMS服务的日志。子目录的名称为JMS服务的名称。
servers/server-name/logs/connector
该目录是连接器模块(JCA资源适配器)日志的默认基目录。
servers/server-name/security
该目录存放安全相关文件,每一个WebLogic Server实例都可能不同。文件boot.properties是位于此处的一个文件示例,因为它能区分一个server实例与下一个实例的不同。该目录还维护与SSL key相关的文件。
servers/server-name/tmp
该目录存放server实例运行时创建的临时目录与文件。server运行时该目录中的文件应当保留,但可以在server实例终止后随意删除。
第五章 管理配置变更
为了提供一个安全、可预期的方式来分发域的配置变更,WebLogic Server采用了大致类似于数据库事务的变更管理进程。域的配置在文件系统中表示为一组XML配置文件,核心为config.xml文件,在运行时表示为配置MBean(Configuration MBeans)树。当你编辑域配置时,你实际上编辑的是分离的管理服务器的配置MBeans树。要开始编辑过程,你应获得编辑树的锁以阻止其他人进行变更。完成变更后,保存变更。不过变更不会生效直到你激活它们,分发给域中的所有server实例。激活变更后,每一个server都决定是否接受变更。如果所有server都可以接受该变更,则更新运行着的配置层,变更完成。
注意WebLogic Server的变更管理过程适用于域的变更和server配置数据,不适用于安全或应用数据。
关于如何通过JMX和配置MBean来实现配置变更的更多详细信息,参见“使用JMX开发可管理的应用”中的“理解WebLogic Server MBeans”
如第三章“使用WebLogic工具配置域”中的描述,你可以使用一系列不同的WebLogic Server工具进行配置变更:
管理控制台
WebLogic 脚本工具
JMX API
无论你使用哪一个工具进行配置变更,WebLogic Server都采用大体相同的方式来处理变更过程。
以下章节描述配置变更管理:
管理控制台的变更管理

配置变更管理过程
配置管理状态图
管理控制台的变更管理
WebLogic管理控制台将配置变更管理过程集中于Change Center:
如果你想使用管理控制台进行配置变更,你必须先点击Change Center中的Lock & Edit(锁定并编辑)按钮。当你点击Lock & Edit后,你会获得域中所有server的配置MBean的可编辑层(编辑树)的锁。
在你使用管理控制台进行配置变更后,在适当的页面点击Save(保存)(某些情况下为Finish(完成)),这些不会使变更立即生效,而是在你点击Save时,将变更保存至编辑树,domain-name/pending/config.xml文件和相关的配置文件。只有在你点击Change Center的Activate Changes(激活变更)时变更才会生效,此时,配置变更分发至域中的每一个server。只有每一个server都接受该变更,变更才会生效。如果有任何server不接受该变更,那么域中的所有server的所有变更全部回滚。变更保持为未决状态,你既可以编辑该未决变更以解决问题或者恢复未决变更。
配置变更管理过程

以下步骤详细描述该过程,从你首先导入域的管理服务器开始:
1.服务器启动时读取域配置文件,包括config.xml文件和config.xml文件涉及的所有附属配置文件,使用这些数据对随后的MBean树进行实例化:
–一个配置 MBean的只读树包含管理服务器的当前资源配置。
–域中所有服务器的所有配置 MBean的可编辑树。
注意:管理服务器也会实例化一个运行时MBean树和一个域运行时MBean树,但是这些不用于配置管理。
2. 按以下步骤开始配置变更:
a. 获得当前配置锁。
b. 使用你选择的工具(管理控制台,WLST,JMX API等),按你的要求变更。
c. 将变更保存至config.xml文件的未决版本。
3. 配置管理器服务将来自编辑MBean树的所有数据保存成一份独立的配置文件,目录名为pending。参见图5-2。
pending目录直接位于域的根目录下。比如说,如果你的域命名为mydomain,那么未决的config.xml文件的默认路径名为mydomain/pending/config.xml。
4. 进行其它变更或者取消已做出的变更。
5. 当你准备激活域的变更时,使用管理控制台Change Center的Activate Changes按钮或者使用ConfigurationManagerMBean。
激活变更(参见图 5-3):
a. 对于域的每一个server实例,配置管理器服务将未决配置文件拷贝至server的根目录下的pending目录。
如果托管服务器和管理服务器共享根目录,ConfigurationManagerMBean不必拷贝未决的配置文件,托管服务器直接使用管理服务器的未决文件。
b. 每一个server实例将它的当前配置和未决文件中的配置进行比较。
c. 每一个server内部的子系统将对自身是否能接受新配置进行投票。
只有要任一子系统表示它不能接受该变更,整个的激活过程将回滚,ConfigurationManagerMBean抛出异常。你可以修改变更,再次进行变更激活,或者放弃锁,编辑配置MBean树和未决配置文件恢复至只读配置MBean树和配置文件的配置。
d. 如果所有server的所有子系统都能接受该变更,配置管理器服务将域的每一个server实例的只读配置文件替换成未决配置文件。
e. 每一个server实例都会更新bean和只读配置MBean树以和新的配置文件的变更保持一致。
f. 然后未决配置文件从pending目录中删除。
6. 你可以保持锁以进行其它的变更或者释放锁以使其他人可以更新配置。你也可以设置超时时限使配置管理器服务放弃锁。
注意:配置变更锁不会防止你在使用相同的管理员账号造成的配置编辑冲突。比如,如果你使用管理控制台获得配置变更锁,然后以相同的用户帐号使用WebLogic脚本工具,你将访问的是在管理控制台中打开的相同的编辑会话,你不会因为使用脚本工具而被锁定。由于这可能造成配置变更的混乱和冲突,这不是一种受推荐的手段。你应该通过为每一个管理员身份的用户维护一个独立的管理员账号来减少发生这种情况是造成的风险。不过如果你有使用相同的用户帐号的多个相同脚本实例,相同的问题仍然会发生,
处理变更冲突
这种情况,你保存的多个变更没有被激活,某个变更会使前一个变更无效,变更管理器服务需要你在保存变更前手动解决该无效问题。
配置管理状态图

配置管理服务遵循图 5-4中描述的状态转换。
SVN客户端用户使用手册(完整版)
该文档将逐步教您如何在软件开发过程中使用svn客户端
环境模拟
现有项目名称:test
服务端版本库:test
URL:http://10.155.11.10:81/svn
开发人员:devA,devB
版本库目录结构:
一.基本操作
第一步:安装客户端
到共享文件夹下,下载TortoiseSVN-1.4.0.7501-win32-svn-1.4.0.msi安装程序,双击直接安装即可。安装成功后,右键单击鼠标会多出两个选项,分别是SVN checkout和Tortoise SVN。
第二步:建立工作区
项目开始之前,在本地PC的硬盘上,创建一个文件夹,文件夹命名随意(例如workspace
),该文件夹即作为软件开发者在项目开发过程中的工作区。
第三步:下载版本库
假如现在开发一个项目,配置管理员会在服务端建立一个该项目的版本库test
在workspace文件夹上,右键单击鼠标。选择SVN checkout,会出现如下窗口
在URL of repository中输入版本库地址,http://10.155.11.10:81/svn/test ,在Checkout dir中系统会自动添加第二步所创建的工作区目录。
在Revision中,选中HEAD revision,这样将会下载到版本库的最新版本。如果想下载库中的旧版本文件,可选中Revision,然后填入版本号即可。
如果不想下载整个版本库,而是只想下载自己负责的那部分模块,可以在URL后添加模块名,例如http://10.155.11.10:81/svn/test/Doc 。
单击OK,输入用户名和密码
第四步:修改版本库
对版本库的修改包括修改文件内容,添加删除文件,添加删除目录。
经过第三步的操作,本地的工作区文件夹,即workspace上会有绿色对勾出现,工作区下的文件也会带有绿色对勾,如图2
如果对库中某一个文件进行了修改,系统会自动为这个文件和这个文件所在的各级父文件夹加上红色叹号,代表该文件或目录已经在本地被修改,如图3
图3
当所有对版本库的修改操作完毕后,右键单击工作区文件夹,选择commit提交新版本,输入密码后系统将把修改后的版本库上传到服务端,即完成一次对版本库的更新。
注意:
新版本提交之后,其他拥有写权限的用户也许会重复以上几步的操作,完成对版本库的再一次更新。所以,每次在工作区文件夹下修改本地版本库之前,必须首先对本地版本库执行一次更新(右键单击工作区,选择SVN Updata),将最新的版本下载到本地,然后再进行修改操作。
二.其他操作
在日常的软件开发过程中,除了以上介绍的下载,提交,更新操作外,还有另外几种常用操作。
(1)比较文件的不同之处
当对soc_1做了修改之后,soc_1文件会出现红色叹号,表示已经修改,如果想查看修改后的soc_1文件与修改前有何不同,可以右键单击此文件,选择diff,系统探出一个窗口,如图3,窗口分为两个部分,左边为更改之前的版本,右边为更改之后的版本。并在不同之处作出标记和说明。如图4
如果是word文档的话,选择diff之后,系统会打开一个word文档,并在其中标出修改后的版本与修改前有何不同。如图4.1
(2)查看日志
如果想查看一个文件的日志,例如soc_1,右键单击这个文件,选择show log,系统会踏出一个窗口,并在窗口中显示soc_1各个版本的log。如图4
图5
(3)查看版本树
如果想查看soc_1文件的版本树,右键单击该文件,选择Revision graph,系统将会打开一个窗口,并在窗口中显示该文件的版本树。如图6。
之所以只显示了4.5.6.7四个版本,是因为选择了只显示发生过变化的版本。即1.4.5.6.7每一个版本都有不同的地方,都是经过用户修改后提交的。而2.3两个版本是与版本1相同的。
(4)下载某个文件的旧版本
如果想要得到某个文件的旧版本,只需在该文件上单击右键,选择Updata to revision…即可。系统会提示输入版本号。例如要下载soc_1的第五个版本,只需填入5即可。如图7。查看完版本5的文件后,如果想在此回到最新版本,只需要对soc_1运行Updata即可。
(5)重名名和删除文件
如果要删除一个文件或重名名一个文件,
注意不要在windows下直接操作。只需右键单击该文件,选择Rename或Delete,svn系统便会完成操作。
在workspace中将文件重命名或删除后,服务端的文件结构不会变化,只有当提交新版本库后,即commit后,服务端的文件结构才会被更新。
如果误删除了文件,在没有提交版本库之前,可以通过对版本库的升级将文件重新下载到本地的版本库,也可以通过revert恢复(参考第八条)。如果文件删除,并且已经提交,那么要找回文件只能通过下载旧版本库来完成,参考(4)。
(6)创建分支
版本库中最初的文件soc_1,soc_2,word_1,word_2都是主干文件。如果想要为soc_1创建一个分支,只需右键单击soc_1,选择Branch/Tag,系统会弹出一个窗口,如图8。在窗口中,From URL表示要创建的这个分支是soc_1的分支(系统会自动添加,不必更改)。在To URL中,需要更改一下文件名,在文件名后加一个标志即可,例如“
_branch”,路径不需要更改。在Creat copy in the repository from中,可以选择分支文件是由soc_1的那一个版本拷贝来的。最后填写日志,选择OK。
分支创建完毕,Updata版本库,系统会将soc_1的主干文件和分支文件soc_1_branch同时下载到本地版本库,如图8.1,然后即可在分支文件上进行操作。此时soc_1的版本树如图8.2
(7)合并分支
当需要把soc_1_branc分支文件合并到soc_1主干文件时,右键单击soc_1,选择Merge,会弹出一个窗口,如图9。
在 From输入框中填入主干的URL,在To输入框中填入分支的URL。在From和To中,都有两个选项HEAD Revision和Revision,表示要进行合并的是soc_1的那个版本。合并之后主干文件会标注红色叹号,表示已被修改,并可以提交。如果合并后文件标注的是黄色叹号,表示文件有冲突,处理方法见第三部分“异常处理”。
(8)撤销修改
当对一个文件进行了修改并保存后(注意此处并没有进行提交),如果对修改不满意,想要重新修改,可以右键单击修改过的文件(带红色叹号的那个),然后选择revert,前面的一系列修改便会被撤销,恢复到Updata之后的状态。如果一个文件被误删除,也可通过右键单击该文件所在的目录,选择revert来恢复。
三.异常处理
此处所说的异常主要是指文件发生冲突。以用户devA和用户devB为例,
当两个用户同时下载了最新的版本库,并对库中同一个文件soc_2进行修改提交时,首先提交的用户devA不会发生异常,第二个提交的用户
devB便会出现无法提交的现象。因为服务端的版本库已经被devA更新,devB用户在上传时,系统会提示出错如图10。
在这种情况下,devB用户需要首先对修改的文件进行Updata文件操作。如果两个用户修改了文件soc_2的同一个地方,则在devB用户执行Updata后,系统会将本地的soc_2与从服务端下载soc_2合并到一个文件上,并在该文件图标上标上黄色叹号,表示文件出冲突。在文件中通过“<<<<<<”和“>>>>>>”标识冲突位置和冲突内容。devB用户只有与devA协商,将该冲突处理,之后单击右键,选择Resolve,冲突标记消除,才能够再次提交,否则无法提交。
文件标记冲突的格式:
<<<<<<< .mine
workspsace工作区,等abc工作区提交结束后再提交,应该会出现冲突
=======
在此插入一段话,啊啊aaa,测试冲突
>>>>>>> .r15
绿色部分表示本地文件的修改
蓝色部分表示服务端版本库中的最新版本与本地文件修改发生冲突的地方。
紫色表示是第15个版本发生了冲突
=======
在此插入一段话,啊啊aaa,测试冲突
>>>>>>> .r15
绿色部分表示本地文件的修改
蓝色部分表示服务端版本库中的最新版本与本地文件修改发生冲突的地方。
紫色表示是第15个版本发生了冲突
文章来自[SVN中文技术网]转发请保留本站地址:http://www.svn8.com/svnzixun/20090413/4578.html
最近使用发现了个问题,在下面的介绍使用maven建立web工程的时候有个选项: -DarchetypeArtifactId=maven-archetype-webapp,假如你把这其中的大写A不小心成了小写,则在pom.xml中,生成的将是jar包,而不再是war包了。这两天看了看ant和maven,感觉受益不小,以前总以为自己会ant和maven呢,老认为不用很学习的ant和mvn也有这么大的学问阿,把我的心得写写: maven: 创建一个web-app工程: mvn archetype:create -DgroupID=[类-包的名字] -DartifactID=[应用的名称] -DrarchetypeArtifactID=maven-archetype-webapp 请注意,上面的语句是不正确的,如果这样写了就会出下面的错误: BUILD ERROR Error creating from archetype [INFO] ------------------------------------------------------------------------ [ERROR] BUILD ERROR [INFO] ------------------------------------------------------------------------ [INFO] Error creating from archetype Embedded error: Artifact ID must be specified when creating a new project from an archetype. [INFO] ------------------------------------------------------------------------ [INFO] For more information, run Maven with the -e switch [INFO] ------------------------------------------------------------------------ 这是新手很容易犯的错误!改正方法是把上面的“ID”改为“Id”,这样就可以正确的建立一个工程了!给定两个简单模型: Application: mvn archetype:create -DgroupId=ce.demo.mvn -DartifactId=app |-- pom.xml `-- src |-- main | `-- java | `-- ce | `-- demo | `-- mvn | `-- App.java `-- test `-- java `-- ce `-- demo `-- mvn `-- AppTest.java web-app: mvn archetype:create -DgroupId=ce.demo.mvn -DartifactId=webapp-DarchetypeArtifactId=maven-archetype-webapp |-- pom.xml `-- src `-- main `-- webapp |-- index.jsp |-- WEB-INF `-- web.xml
使用如下命令可以建立一个Struts2 Starter应用程序
mvn archetype:create
-DgroupId=tutorial
-DartifactId=tutorial
-DarchetypeGroupId=org.apache.struts \
-DarchetypeArtifactId=struts2-archetype-starter \
-DarchetypeVersion=2.0.5-SNAPSHOT
-DremoteRepositories=http://people.apache.org/repo/m2-snapshot-repository
参数含义:
参数 含义
groupId 当前应用程序隶属的Group的ID,通常是公司所有应用程序的根目录,例如:com.jpleasure
artifactId 当前应用程序的ID
package 代码生成时使用的根包的名字,如果没有给出,默认使用archetypeGroupId
archetypeGroupId 原型(archetype)的Group ID,因为我们这里使用的是Struts2的原型,所以这里总是org.apache.struts
archetypeArtifactId 原型(archetype)ID
archetypeVersion 原型(archetype)版本
remoteRepositories 包含原型(archetype)的远程资源库的列表,如果部署在标准的maven资源库或者本地,这不需要标记本项
一些相关的Maven命令(注意要再项目目录中运行)
构建
mvn install
创建IntelliJ IDEA项目文件
mvn idea:idea
创建Eclipse项目文件
mvn eclipse:eclipse
运行测试
mvn test
清除
mvn clean
打包
mvn package
获得需要的JAR文件
mvn initialize
使用Jetty运行
mvn jetty:run 在使用此命令之前,需要在xml配置文件中作如下改动:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</span-->modelVersion>
<groupId>com.mycompany.webapp</span-->groupId>
<artifactId>myweb</span-->artifactId>
<packaging>war</span-->packaging>
<version>1.0-SNAPSHOT</span-->version>
<name>myweb Maven Webapp</span-->name>
<url>http://maven.apache.org</span-->url>
<dependencies>
<dependency>
<groupId>junit</span-->groupId>
<artifactId>junit</span-->artifactId>
<version>3.8.1<!--</span-->version>
<scope>test<!--</span-->scope>
</span-->dependency>
</span-->dependencies>
<build>
<finalName>myweb</span-->finalName>
<!-- 添加以下6行插件配置代码 -->
<plugins>
<plugin>
<groupId>org.mortbay.jetty</groupId>
<artifactId>maven-jetty-plugin</artifactId>
</plugin>
</plugins>
<!-- 添加以上6行插件配置代码 -->
</build>
</project>
请注意,在./src/main/目录下面见一个java文件夹,以存放bean,这需要手动来建立:
mkdir $webapp/src/main/java
Maven2较maven1有较大的变化,这里推荐使用maven2并不仅仅因为它是高的版本. 其中变化较大的是在它建立的项目中,只有一个pom.xm配置文件.这里是我的一个工程的配置文件拷贝 attachment/200710/pom.xml.... 你会发现其中的代码如下 <project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.last999</groupId>
<artifactId>bbs</artifactId>
<packaging>war</packaging>
<version>1.3</version>
<name>bbs</name>
<url>last999.com</url>
<description>mybbs</description>
<dependencies>
<!-- Junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
.......................
项目都是在<project>中设定,加入要添加新的开源框架,你只需要到maven源的老家走一趟,查到你需要的版本:比如我们现在需要使用struts.那么我们只需要添加以下几行:
<dependency>
<groupId>org.apache.struts</groupId>
<artifactId>struts2-core</artifactId>
<version>2.0.9</version>
</dependency>
如果再需要和spring集成,除了添加spring需要的包外,你只需要添加:
<dependency>
<groupId>org.apache.struts</groupId>
<artifactId>struts2-spring-plugin</artifactId>
<version>2.0.9</version>
</dependency>
其他一切就 让maven给你自动完成吧!
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/zql2002/archive/2008/06/12/2537770.aspx
每隔一段时间,就会收到些类似的消息:
怎么学好软件开发? 我已经学完了A,我接下来该学B还是C?
其实这样的问题,真的是一言难复。如何学习,是一个很复杂的话题,尤其是眼下业内的技术名词日新月异,乱花迷人眼,使得新人更加看不清。所以才激发了我关于“技术族谱”的设想,本意就是想通过一个机制来理顺知识之间的关系,分享每个人的学习经验,新人借鉴老人的学习路径,从而减少走弯路的现象。
记得2007年的时候,一次团队内部开总结会,我在白板上随手画过一个开发相关知识的结构图,当时还有团队成员拿相机拍下来,现在想想,也许对某些人有一定的指导意义,于是今天整理了一下发出来,如下图所示:

一些相关的解释:
学校里的课程没用吗?
答:肯定有用。
计算机专业的经典理论课,意义非凡:计算机组成原理、计算机体系结构、操作系统、编译原理、数据结构。操作系统中的内存管理算法、进程调度算法、并发控制算法,都是非常经典的,你会在很多其它地方发现这些算法的应用或者变体。编译原理有助于我们理解编程语言是如何工作的,如何用范式来表达复杂的语法,编译原理中的状态机相关知识,也是开发者手中的强大武器。数据结构就更不用说了,List,Map,Tree,是编程中广泛使用的。
快餐式软件开发培训的问题何在?
一个典型的快餐式培训班,先教java语言,然后教SSH,然后给个千篇一律的虚拟项目做一下,最后号称培养出来一批“WEB开发”程序员。我觉得,如果之前没有任何基础,仅靠这样的培训,那么出来真的只能做非常程式化的工作。我一直提倡稳扎稳打,从下向上学起这样的方式,缺点是不如容易出效果。所以从两个方向入手,一边学基础,一边学应用,互相印证,也是不错的学习路径。
软件开发的门槛在提高吗?
我觉得是的,当然,我说的不包括hello world这样的示例程序的开发。虽然现在程序语言比十年前强大很多,工具要好用很多,但要想写出一个有点意义的软件,需要了解的知识多了很多,需要配置的环境复杂了很多。看看有多少初学者被java的ClassPath所困扰,您就明白我说的意思了。
开发不仅仅是学一门语言!
开发的本质是用程序控制计算机做一件事。基本上,任何有价值的程序都有内政和外交。内政就是程序的处理流程、数据加工算法、并发控制。外交就是网络通信、IO、数据库访问,以及通过各种协议和其它系统进行交互。很多知识,尤其是外交相关的知识,仅仅学习一门语言是不够的。
误区:很多人花大量精力关注最上层,比如:新的框架、新的工具、各种处理问题的技巧等等。但偏偏这一部分的变化最快,您在这上面投入的精力保值能力最差。技术有很强的相似性,比如,如果您真正掌握了javascript,那么掌握Ext或者JQuery只是熟悉对方的编程习惯和API而已,没必要为了这些新名词而疲于奔命。
一家之言,欢迎拍砖或者交流。
----
答问:
sun_blackh 发表于2009年9月30日 8:18:27
不好。不知道各种通信协议在什么地方。为什么要把tcp/ip单独拿出来?质量意识显得很突兀,和整体没有关系。虽然它很重要。什么是框架?它应该在哪里?我想LZ没有仔细推敲过。
答:
知识体系中,越是向上,则越是偏向应用层的东西。“各类协议”,只是一个泛指,协议太多了,在一个人的知识结构中,只学习跟自己工作和兴趣需要的即可,比如,如果你做网管,可以关心SNMP,JMX;如果你做WEB开发,可以关心SOAP,AJAX;如果你做SP,可以关注各类短信网关的协议等等。TCP/IP之所以要单拿出来,那绝对是有道理的,TCP/IP是一个协议栈,我觉得只要你想做网络方面的开发,那是必须要学习的,TCP/IP已经是一种不可替代的标准了。
“框架”和刚才对“各类协议”的解释是一样的,并不特指哪种框架,而是一个统称,是根据需要去学习的,比如:SSH,比如:JQUERY,比如:EXT,比如:Reason等等。
质量意识你觉得突兀吗?我觉得它就应该贯穿软件开发的方方面面,它并不是一项具体的技术,但却要时时刻刻挂在心中。
chgaowei 发表于2009年10月2日 星期五 11:08:53 IP:举报
这个模型很不错。我想在补充几个: 1、领域知识。 2、软件工程。 3、算法,数据库,网络基础应该放在下面。 4、质量意识换成软件工程。
答:
您补充的挺好,领域知识,或者说业务知识,的确很重要。
关于“软件工程”,如果代替“质量意识”,这个我觉得值得商榷,因为我觉得软件工程并不能代表高质量软件的全部,你觉得呢。
算法,我个人的意见认为,并不能作为一个底层的东西,对于多数人来说,应该算是可选项,对于某些特殊软件开发,比如视频编解码、搜索引擎等等,可能算法是必须的基础,可能连数学都要算上。
而 网络 和 数据库,按我的原意,应该是程序语言、数据库、网络作为三个并列的知识领域,为了图的紧凑型,所以把数据库和网络竖起来了,但我觉得数据库和网络并不是构成软件开发的必要基础,可以选修。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/jinxfei/archive/2009/09/27/4602449.aspx
前几天看到卢亮的 Larbin 一种高效的搜索引擎爬虫工具 一文提到 Nutch,很是感兴趣,但一直没有时间进行测试研究。趁着假期,先测试一下看看。用搜索引擎查找了一下,发现中文技术社区对 Larbin 的关注要远远大于 Nutch 。只有一年多前何东在他的竹笋炒肉中对 Nutch 进行了一下介绍。
Nutch vs Lucene
Lucene 不是完整的应用程序,而是一个用于实现全文检索的软件库。
Nutch 是一个应用程序,可以以 Lucene 为基础实现搜索引擎应用。
Nutch vs GRUB
GRUB 是一个分布式搜索引擎(参考)。用户只能得到客户端工具(只有客户端是开源的),其目的在于利用用户的资源建立集中式的搜索引擎。
Nutch 是开源的,可以建立自己内部网的搜索引擎,也可以针对整个网络建立搜索引擎。自由(Free)而免费(Free)。
Nutch vs Larbin
"Larbin只是一个爬虫,也就是说larbin只抓取网页,至于如何parse的事情则由用户自己完成。另外,如何存储到数据库以及建立索引的事情 larbin也不提供。[引自这里]
Nutch 则还可以存储到数据库并建立索引。

[引自这里]
Nutch 的早期版本不支持中文搜索,而最新的版本(2004-Aug-04 发布了 0.5)已经做了很大的改进。相对先前的 0.4 版本,有 20 多项的改进,结构上也更具备扩展性。0.5 版经过测试,对中文搜索支持的也很好。
下面是我的测试过程。
前提条件(这里Linux 为例,如果是 Windows 参见手册):
- Java 1.4.x 。因为我的系统上安装的Oracle 10g 已经有 Java 了。设定环境变量:NUTCH_JAVA_HOME 。
[root@fc3 ~]# export NUTCH_JAVA_HOME=/u01/app/oracle/product/10.1.0/db_1/jdk/jre
- Tomcat 4.x 。从这里下载。
- 足够的磁盘空间。我预留了 4G 的空间。
首先下载最新的稳定版:
[root@fc3 ~]# wget http://www.nutch.org/release/nutch-0.5.tar.gz
解压缩:
[root@fc3 ~]# tar -zxvf nutch-0.5.tar.gz
......
[root@fc3 ~]# mv nutch-0.5 nutch
测试一下 nutch 命令:
[root@fc3 nutch]# bin/nutch
Usage: nutch COMMAND
where COMMAND is one of:
crawl one-step crawler for intranets
admin database administration, including creation
inject inject new urls into the database
generate generate new segments to fetch
fetchlist print the fetchlist of a segment
fetch fetch a segment's pages
dump dump a segment's pages
index run the indexer on a segment's fetcher output
merge merge several segment indexes
dedup remove duplicates from a set of segment indexes
updatedb update database from a segment's fetcher output
mergesegs merge multiple segments into a single segment
readdb examine arbitrary fields of the database
analyze adjust database link-analysis scoring
server run a search server
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
[root@fc3 nutch]#
Nutch 的爬虫有两种方式
- 爬行企业内部网(Intranet crawling)。针对少数网站进行。用 crawl 命令。
- 爬行整个互联网。 使用低层的 inject, generate, fetch 和 updatedb 命令。具有更强的可控制性。
以本站(http://www.dbanotes.net)为例,先进行一下针对企业内部网的测试。
在 nutch 目录中创建一个包含该网站顶级网址的文件 urls ,包含如下内容:
http://www.dbanotes.net/
然后编辑conf/crawl-urlfilter.txt 文件,设定过滤信息,我这里只修改了MY.DOMAIN.NAME:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*dbanotes.net/
运行如下命令开始抓取分析网站内容:
[root@fc3 nutch]# bin/nutch crawl urls -dir crawl.demo -depth 2 -threads 4 >& crawl.log
depth 参数指爬行的深度,这里处于测试的目的,选择深度为 2 ;
threads 参数指定并发的进程 这是设定为 4 ;
在该命令运行的过程中,可以从 crawl.log 中查看 nutch 的行为以及过程:
......
050102 200336 loading file:/u01/nutch/conf/nutch-site.xml
050102 200336 crawl started in: crawl.demo
050102 200336 rootUrlFile = urls
050102 200336 threads = 4
050102 200336 depth = 2
050102 200336 Created webdb at crawl.demo/db
......
050102 200336 loading file:/u01/nutch/conf/nutch-site.xml
050102 200336 crawl started in: crawl.demo
050102 200336 rootUrlFile = urls
050102 200336 threads = 4
050102 200336 depth = 2
050102 200336 Created webdb at crawl.demo/db
050102 200336 Starting URL processing
050102 200336 Using URL filter: net.nutch.net.RegexURLFilter
......
050102 200337 Plugins: looking in: /u01/nutch/plugins
050102 200337 parsing: /u01/nutch/plugins/parse-html/plugin.xml
050102 200337 parsing: /u01/nutch/plugins/parse-pdf/plugin.xml
050102 200337 parsing: /u01/nutch/plugins/parse-ext/plugin.xml
050102 200337 parsing: /u01/nutch/plugins/parse-msword/plugin.xml
050102 200337 parsing: /u01/nutch/plugins/query-site/plugin.xml
050102 200337 parsing: /u01/nutch/plugins/protocol-http/plugin.xml
050102 200337 parsing: /u01/nutch/plugins/creativecommons/plugin.xml
050102 200337 parsing: /u01/nutch/plugins/language-identifier/plugin.xml
050102 200337 parsing: /u01/nutch/plugins/query-basic/plugin.xml
050102 200337 logging at INFO
050102 200337 fetching http://www.dbanotes.net/
050102 200337 http.proxy.host = null
050102 200337 http.proxy.port = 8080
050102 200337 http.timeout = 10000
050102 200337 http.content.limit = 65536
050102 200337 http.agent = NutchCVS/0.05 (Nutch; http://www.nutch.org/docs/en/bot.html; n
utch-agent@lists.sourceforge.net)
050102 200337 fetcher.server.delay = 1000
050102 200337 http.max.delays = 100
050102 200338 http://www.dbanotes.net/: setting encoding to GB18030
050102 200338 CC: found http://creativecommons.org/licenses/by-nc-sa/2.0/ in rdf of http:
//www.dbanotes.net/
050102 200338 CC: found text in http://www.dbanotes.net/
050102 200338 status: 1 pages, 0 errors, 12445 bytes, 1067 ms
050102 200338 status: 0.9372071 pages/s, 91.12142 kb/s, 12445.0 bytes/page
050102 200339 Updating crawl.demo/db
050102 200339 Updating for crawl.demo/segments/20050102200336
050102 200339 Finishing update
64,1 7%
050102 200337 parsing: /u01/nutch/plugins/query-basic/plugin.xml
050102 200337 logging at INFO
050102 200337 fetching http://www.dbanotes.net/
050102 200337 http.proxy.host = null
050102 200337 http.proxy.port = 8080
050102 200337 http.timeout = 10000
050102 200337 http.content.limit = 65536
050102 200337 http.agent = NutchCVS/0.05 (Nutch; http://www.nutch.org/docs/en/bot.html;
nutch-agent@lists.sourceforge.net)
050102 200337 fetcher.server.delay = 1000
050102 200337 http.max.delays = 100
......
之后配置 Tomcat (我的 tomcat 安装在 /opt/Tomcat) ,
[root@fc3 nutch]# rm -rf /opt/Tomcat/webapps/ROOT*
[root@fc3 nutch]# cp nutch*.war /opt/Tomcat/webapps/ROOT.war
[root@fc3 webapps]# cd /opt/Tomcat/webapps/
[root@fc3 webapps]# jar xvf ROOT.war
[root@fc3 webapps]# ../bin/catalina.sh start
浏览器中输入 http://localhost:8080 查看结果(远程查看需要将 localhost 换成相应的IP):

搜索测试:

可以看到,Nutch 亦提供快照功能。下面进行中文搜索测试:

注意结果中的那个“评分详解”,是个很有意思的功能(Nutch 具有一个链接分析模块),通过这些数据可以进一步理解该算法。
考虑到带宽的限制,暂时不对整个Web爬行的方式进行了测试了。值得一提的是,在测试的过程中,nutch 的爬行速度还是不错的(相对我的糟糕带宽)。
Nutch 目前还不支持 PDF(开发中,不够完善) 与 图片 等对象的搜索。中文分词技术还不够好,通过“评分详解”可看出,对中文,比如“数据库管理员”,是分成单独的字进行处理的。但作为一个开源搜索引擎软件,功能是可圈可点的。毕竟,主要开发者 Doug Cutting 就是开发 Lucene 的大牛
参考信息
想做一个搜索引擎,最近浏览了许多社区,发现Lucene和Nutch用的很多,而这两个我总感觉难以区分概念,于是在查了些资料。下面是Lucene和Nutch创始人Doug Cutting 的访谈摘录:
Lucene其实是一个提供全文文本搜索的函数库,它不是一个应用软件。它提供很多API函数让你可以运用到各种实际应用程序中。现在,它已经成为Apache的一个项目并被广泛应用着。这里列出一些已经使用Lucene的系统。
Nutch是一个建立在Lucene核心之上的Web搜索的实现,它是一个真正的应用程序。也就是说,你可以直接下载下来拿过来用。它在Lucene的基础上加了网络爬虫和一些和Web相关的东东。其目的就是想从一个简单的站内索引和搜索推广到全球网络的搜索上,就像Google和Yahoo一样。当然,和那些巨人竞争,你得动一些脑筋,想一些办法。我们已经测试过100M的网页,并且它的设计用在超过1B的网页上应该没有问题。当然,让它运行在一台机器上,搜索一些服务器,也运行的很好。
总的来说,我认为LUCENE会应用在本地服务器的网站内部搜索,而Nutch则扩展到整个网络、Internet的检索。当然LUCENE加上爬虫程序等就会成为Nutch,这样理解应该没错吧
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/rokii/archive/2008/03/01/2137450.aspx
浅析HTTP协议
HTTP协议是什么?
简单来说,就是一个基于应用层的通信规范:双方要进行通信,大家都要遵守一个规范,这个规范就是HTTP协议。
HTTP协议能做什么?
很多人首先一定会想到:浏览网页。没错,浏览网页是HTTP的主要应用,但是这并不代表HTTP就只能应用于网页的浏览。HTTP是一种协议,只要通信的双方都遵守这个协议,HTTP就能有用武之地。比如咱们常用的QQ,迅雷这些软件,都会使用HTTP协议(还包括其他的协议)。
HTTP协议如何工作?
大家都知道一般的通信流程:首先客户端发送一个请求(request)给服务器,服务器在接收到这个请求后将生成一个响应(response)返回给客户端。
在这个通信的过程中HTTP协议在以下4个方面做了规定:
1. Request和Response的格式
Request格式:
HTTP请求行
(请求)头
空行
可选的消息体
注:请求行和标题必须以<CR><LF> 作为结尾(也就是,回车然后换行)。空行内必须只有<CR><LF>而无其他空格。在HTTP/1.1 协议中,所有的请求头,除Host外,都是可选的。
实例:
GET / HTTP/1.1
Host: gpcuster.cnblogs.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
If-Modified-Since: Mon, 25 May 2009 03:19:18 GMT
Response格式:
HTTP状态行
(应答)头
空行
可选的消息体
实例:
HTTP/1.1 200 OK
Cache-Control: private, max-age=30
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Expires: Mon, 25 May 2009 03:20:33 GMT
Last-Modified: Mon, 25 May 2009 03:20:03 GMT
Vary: Accept-Encoding
Server: Microsoft-IIS/7.0
X-AspNet-Version: 2.0.50727
X-Powered-By: ASP.NET
Date: Mon, 25 May 2009 03:20:02 GMT
Content-Length: 12173
消息体的内容(略)
详细的信息请参考:RFC 2616。
关于HTTP headers的简要介绍,请查看:Quick reference to HTTP headers
2. 建立连接的方式
HTTP支持2中建立连接的方式:非持久连接和持久连接(HTTP1.1默认的连接方式为持久连接)。
1) 非持久连接
让我们查看一下非持久连接情况下从服务器到客户传送一个Web页面的步骤。假设该贝面由1个基本HTML文件和10个JPEG图像构成,而且所有这些对象都存放在同一台服务器主机中。再假设该基本HTML文件的URL为:gpcuster.cnblogs.com/index.html。
下面是具体步骡:
1.HTTP客户初始化一个与服务器主机gpcuster.cnblogs.com中的HTTP服务器的TCP连接。HTTP服务器使用默认端口号80监听来自HTTP客户的连接建立请求。
2.HTTP客户经由与TCP连接相关联的本地套接字发出—个HTTP请求消息。这个消息中包含路径名/somepath/index.html。
3.HTTP服务器经由与TCP连接相关联的本地套接字接收这个请求消息,再从服务器主机的内存或硬盘中取出对象/somepath/index.html,经由同一个套接字发出包含该对象的响应消息。
4.HTTP服务器告知TCP关闭这个TCP连接(不过TCP要到客户收到刚才这个响应消息之后才会真正终止这个连接)。
5.HTTP客户经由同一个套接字接收这个响应消息。TCP连接随后终止。该消息标明所封装的对象是一个HTML文件。客户从中取出这个文件,加以分析后发现其中有10个JPEG对象的引用。
6.给每一个引用到的JPEG对象重复步骡1-4。
上述步骤之所以称为使用非持久连接,原因是每次服务器发出一个对象后,相应的TCP连接就被关闭,也就是说每个连接都没有持续到可用于传送其他对象。每个TCP连接只用于传输一个请求消息和一个响应消息。就上述例子而言,用户每请求一次那个web页面,就产生11个TCP连接。
2) 持久连接
非持久连接有些缺点。首先,客户得为每个待请求的对象建立并维护一个新的连接。对于每个这样的连接,TCP得在客户端和服务器端分配TCP缓冲区,并维持TCP变量。对于有可能同时为来自数百个不同客户的请求提供服务的web服务器来说,这会严重增加其负担。其次,如前所述,每个对象都有2个RTT的响应延长——一个RTT用于建立TCP连接,另—个RTT用于请求和接收对象。最后,每个对象都遭受TCP缓启动,因为每个TCP连接都起始于缓启动阶段。不过并行TCP连接的使用能够部分减轻RTT延迟和缓启动延迟的影响。
在持久连接情况下,服务器在发出响应后让TCP连接继续打开着。同一对客户/服务器之间的后续请求和响应可以通过这个连接发送。整个Web页面(上例中为包含一个基本HTMLL文件和10个图像的页面)自不用说可以通过单个持久TCP连接发送:甚至存放在同一个服务器中的多个web页面也可以通过单个持久TCP连接发送。通常,HTTP服务器在某个连接闲置一段特定时间后关闭它,而这段时间通常是可以配置的。持久连接分为不带流水线(without pipelining)和带流水线(with pipelining)两个版本。如果是不带流水线的版本,那么客户只在收到前一个请求的响应后才发出新的请求。这种情况下,web页面所引用的每个对象(上例中的10个图像)都经历1个RTT的延迟,用于请求和接收该对象。与非持久连接2个RTT的延迟相比,不带流水线的持久连接已有所改善,不过带流水线的持久连接还能进一步降低响应延迟。不带流水线版本的另一个缺点是,服务器送出一个对象后开始等待下一个请求,而这个新请求却不能马上到达。这段时间服务器资源便闲置了。
HTTP/1.1的默认模式使用带流水线的持久连接。这种情况下,HTTP客户每碰到一个引用就立即发出一个请求,因而HTTP客户可以一个接一个紧挨着发出各个引用对象的请求。服务器收到这些请求后,也可以一个接一个紧挨着发出各个对象。如果所有的请求和响应都是紧挨着发送的,那么所有引用到的对象一共只经历1个RTT的延迟(而不是像不带流水线的版本那样,每个引用到的对象都各有1个RTT的延迟)。另外,带流水线的持久连接中服务器空等请求的时间比较少。与非持久连接相比,持久连接(不论是否带流水线)除降低了1个RTT的响应延迟外,缓启动延迟也比较小。其原因在于既然各个对象使用同一个TCP连接,服务器发出第一个对象后就不必再以一开始的缓慢速率发送后续对象。相反,服务器可以按照第一个对象发送完毕时的速率开始发送下一个对象。
3. 缓存的机制
HTTP/1.1中缓存的目的是为了在很多情况下减少发送请求,同时在许多情况下可以不需要发送完整响应。前者减少了网络回路的数量;HTTP利用一个“过期(expiration)”机制来为此目的。后者减少了网络应用的带宽;HTTP用“验证(validation)”机制来为此目的。
HTTP定义了3种缓存机制:
l Freshness allows a response to be used without re-checking it on the origin server, and can be controlled by both the server and the client. For example, the Expires response header gives a date when the document becomes stale, and the Cache-Control: max-age directive tells the cache how many seconds the response is fresh for.
l Validation can be used to check whether a cached response is still good after it becomes stale. For example, if the response has a Last-Modified header, a cache can make a conditional request using the If-Modified-Since header to see if it has changed.
l Invalidation is usually a side effect of another request that passes through the cache. For example, if URL associated with a cached response subsequently gets a POST, PUT or DELETE request, the cached response will be invalidated.
关于web缓存方面的内容可以参考:Caching Tutorial for Web Authors and Webmasters(英文版)(中文版)
4. 响应授权激发机制
这些机制能被用于服务器激发客户端请求并且使客户端授权。
详细的信息请参考:RFC 2617: HTTP Authentication: Basic and Digest Access
5. 基于HTTP的应用
1 HTTP代理
原理

分类
- 透明代理
- 非透明代理
- 反向代理


2 多线程下载
- 下载工具开启多个发出HTTP请求的线程
- 每个http请求只请求资源文件的一部分:Content-Range: bytes 20000-40000/47000
- 合并每个线程下载的文件
3 HTTPS传输协议原理
两种基本的加解密算法类型
对称加密:密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES等

非对称加密:密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有RSA、DSA等

HTTPS通信过程

优点
- 客户端产生的密钥只有客户端和服务器端能得到
- 加密的数据只有客户端和服务器端才能得到明文
- 客户端到服务端的通信是安全的
4 开发web程序时常用的Request Methods
HEAD
(Head方法)要求响应与相应的GET请求的响应一样,但是没有的响应体(response body)。这用来获得响应头(response header)中的元数据信息(meta-infomation)有(很)帮助,(因为)它不需要传输所有的内容。
TRACE
(Trace方法告诉服务器端)返回收到的请求。客户端可以(通过此方法)察看在请求过程中中间服务器添加或者改变哪些内容。
OPTIONS
返回服务器(在指定URL上)支持的HTTP方法。通过请求“*”而不是指定的资源,这个方法可以用来检查网络服务器的功能。
CONNECT
将请求的连接转换成透明的TCP/IP通道,通常用来简化通过非加密的HTTP代理的SSL-加密通讯(HTTPS)。
5 用户与服务器的交互
- 身份认证
- cookie
- 带条件的GET
6 基于Socket编程编写遵循HTTP的程序
后记:
我这篇文章只是对HTTP协议做了一个大概介绍,很多细节都有遗漏,请有兴趣的朋友阅读RFC 2616。
学习HTTP协议的好书:
1.O'Reilly - HTTP Pocket Reference:这是一本比较简短的介绍HTTP协议的书,可以作为入门读物
2.O'Reilly - HTTP The Definitive Guide:这是一本宝典级别的书,因为它包含的内容实在多,可以作为全面学习的HTTP协议的首选读物
3.Sams - HTTP Developers Handbook:这是比HTTP The Definitive Guide稍微比HTTP The Definitive Guide简单。不过从我的感觉,这本书比HTTP The Definitive Guide要好,因为它篇幅比较少,介绍的是HTTP精髓,我认为这本书应该是web程序员的首选读物
摘要: 轻松为应用程序构建搜索和索引功能
... 阅读全文
关键字: lucene ajax jquery html css
在Web项目的开发过程中,可能对你很有帮助的基本书籍推荐,不要小看基础!
- JFreechat:Web开发中设计到统计曲线,报表显示的,用他吧,不过感觉他的API有点繁杂。
- Java设计模式:设计模式在我们的开发中无处不在,学习他的思路可以说非常重要!
- Javascript权威指南:由于Ajax的出现,Javascript变得越来越重要,是Web开发中的利器!
- JNI:在Web开发中,不可避免的有时会调用dll,Java调用Dll的根本思想在于JNI,举个例子:
-
- public class DllTest
- {
- public static void main(String[] args)
- {
- test a=new test();
- a.HelloWorld();
- System.out.println(a.cToJava());
- }
- }
-
- public class test {
- static
- {
- System.loadLibrary("MyNative");
- }
-
-
- public native static void HelloWorld();
- public native static String cToJava();
-
- }
-
-
- 使用win32 Dynamic-link Library新建一个新空工程,新建一个c++文件,命名为MyNative.cpp,代码如下:
- #include <stdio.h>
- #include "test.h"
- JNIEXPORT void JNICALL Java_test_HelloWorld
- (JNIEnv *env, jclass jobject)
- {
- printf("hello world!\n");
- }
- JNIEXPORT jstring JNICALL Java_test_cToJava
- (JNIEnv *env, jclass obj)
- {
- jstring jstr;
- char str[]="Hello World!\n";
- jstr=env->NewStringUTF(str);
- return jstr;
- }
- 函数申明要和test.h中的函数申明保持一致,否则就出错,使用rebuild all命令,得到MyNative.dll文件,拷贝到test.java同一目录下。
- 运行DllTest类,就得到结果,这里我们就实现用c++来实现具体函数功能的方法,当然这是最简单的JNI应用了。
//编写JAVA文件,其中测试类为DllTest,代码如下:
public class DllTest
{
public static void main(String[] args)
{
test a=new test();
a.HelloWorld();
System.out.println(a.cToJava());
}
}
//编写JNI代码,其中类名为test,如下:
public class test {
static
{
System.loadLibrary("MyNative");
}
//以下函数只做申明,在C中实现
public native static void HelloWorld();
public native static String cToJava();
}
//使用javac得到class文件,然后使用javah命令得到.h文件
//编写C++代码,MyNative如下:
使用win32 Dynamic-link Library新建一个新空工程,新建一个c++文件,命名为MyNative.cpp,代码如下:
#include <stdio.h>
#include "test.h"
JNIEXPORT void JNICALL Java_test_HelloWorld
(JNIEnv *env, jclass jobject)
{
printf("hello world!\n");
}
JNIEXPORT jstring JNICALL Java_test_cToJava
(JNIEnv *env, jclass obj)
{
jstring jstr;
char str[]="Hello World!\n";
jstr=env->NewStringUTF(str);
return jstr;
}
函数申明要和test.h中的函数申明保持一致,否则就出错,使用rebuild all命令,得到MyNative.dll文件,拷贝到test.java同一目录下。
运行DllTest类,就得到结果,这里我们就实现用c++来实现具体函数功能的方法,当然这是最简单的JNI应用了。
关键字: css div 建站
在我个人开发网站的过程中,经常会参考一些网站,我不擅长美工,所以一般页面都喜欢直接拿来用,再自己修饰一下,以下一些网站是我经常访问的,共享给大家:
- 站酷(http://www.zcool.com.cn/ ):拥有丰富的网站资源与模板,很棒
- 51js和blueidea(http://bbs.51js.com ,http://www.blueidea.com ) :主要看一些js高手们探讨的帖子。
- JQuery官网(http://jquery.com ):不用说了
- http://www.freecsstemplates.org/ :很多老外上传的免费模板,有些付费的看看效果图也不错,然后自己动手写,非常有参考价值
不知道大家有没有补充的,在建站的过程中,有没有经常参考的网站呢?欢迎讨论!
网友补充:
- CSS资源和学习网站(http://www.52css.com/ )
- http://www.w3school.com.cn/
JAVA 书籍比较全的网站 http://ajava.org/book/
1)JSON简介
2)JSON/LIST转换
3)JSON/MAP转换
4)JSON/动态Bean转换
5)JSON/静态Bean转换
6)JSON/XML输出
1.JSON简介
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,基于JavaScript,但是不仅仅限于此。
详情可以参考www.json.org
例如一段XML
<?xml version="1.0" encoding="utf-8"?>
<shop>
<name>饭店</name>
<city>北京</city>
</shop>
用JSON表示如下:
{
"name":"饭店",
"city":"北京"
}
XML的解析得考虑子节点父节点关系,而JSON的解析难度相当低,很多控件,尤其是ajax相关的数据交换很多都用json.
2)JSON/LIST转换
本教程解析采用的json-lib,官方网站为http://json-lib.sourceforge.net/,本教程参考官方教程
环境需要配置的jar如下
commons-beanutils和ezmorph控制反射
commons-collections是apachecommons的子项目,扩展了java集合类
commons-lang扩展了java.lang包
commons-logging日志类
xom是xml解析类,可以参考www.xom.nu
junit单元测试用的jar
json-lib核心jar
项目文件夹中拥有货物参数(Shop)和货物参数列表(ShopList)两个实体
Shop包含name和property两个字段,ShopList包含Shop的列表
对应的json是
String s = "[{name:'重量',property:'p1'},{name:'尺寸',property:'p2'},{name:'显卡类型',property:'p3'},{name:'硬盘容量',property:'p4'},{name:'处理器',property:'p5'},{name:'内存',property:'p6'},{name:'型号',property:'p7'},{name:'货号',property:'p8'},{name:'品牌',property:'p9'}]";
把这样的数据结构作为用户定义个人信息存入数据库可以达到个性化参数的作用,
比如shopex的数据库中很多表就是用的json数据类型。因为用户自己添加的参数的长度是不固定的
比如上述例子就拥有9个用户自定义的参数
当用户需要填写这些参数的时候,需要转化为list,然后在struts2的view去显示
完成的代码可以参考附件的ArrayUtil文件
核心代码仅仅就一行JSONArray jsonArray = JSONArray.fromObject(s);
得到这个jsonArray后要转化为ArrayList,需要用循环遍历,如下
for (int i = 0; i < jsonArray.size(); i++) {
Object o = jsonArray.get(i);
JSONObject jsonObject = JSONObject.fromObject(o);
Shop Person = (Shop) JSONObject.toBean(jsonObject, Shop.class);
list.add(Person);
}
然后得到的list就是普通的ArrayList了
3)JSON/MAP转换
当我们初始化完一个map,放入json可以直接放入
Map<String, String> map = new HashMap<String, String>();
map.put("name", "重量");
map.put("property", "p1");
JSONObject jsonObject = JSONObject.fromObject(map);
核心代码为
JSONObject jsonObject = JSONObject.fromObject(map);
JsonLib会自动映射
完成例子见附件MapUtil.java
4)JSON/动态Bean转换
所谓动态bean即是java运行的时候根据情况创建的,而不是程序员已经好了的Bean
JsonLib会自动根据Json格式数据创建字段,然后创建一个包含这些字段的Object
本例子中采用JUNIT做单元测试验证,见DynamicBean.java
String s = "{name:'重量',property:'p1'}";
JSONObject jsonObject = JSONObject.fromObject(s);
Object bean = JSONObject.toBean(jsonObject);
assertEquals(jsonObject.get("name"), PropertyUtils.getProperty(bean,"name"));
assertEquals(jsonObject.get("property"), PropertyUtils.getProperty(bean,"property"));
5)JSON/静态Bean转换(StaticBean.java)
JSONLIB在转换的时候会自动查找关系,比如子类和父类
例如JSON数据源
String s = "{'shopList':[{name:'重量',property:'p1'},{name:'尺寸',property:'p2'},{name:'显卡类型',property:'p3'},{name:'硬盘容量',property:'p4'},{name:'处理器',property:'p5'},{name:'内存',property:'p6'},{name:'型号',property:'p7'},{name:'货号',property:'p8'},{name:'品牌',property:'p9'}]}";
存入Map
map.put("shopList", Shop.class);
ShopList shopList = (ShopList) JSONObject.toBean(JSONObject.fromObject(s), ShopList.class, map);
JSONObject.toBean()方法的三个参数分别表示数据源对应的JSON对象,转化后的对象ShopList和数据源map
然后这样也可以取得ShopList
这种方法和动态转换的区别在于,动态转换仅仅只是转为Object
而静态转换是转换为已经定义过的实体类,会自动映射(这点类似Ibatis)
6)JSON/XML输出
如果自己用String的方法转化为XML输出要写很多代码,然后条用JSONLIB,核心代码仅仅一步
String xmlObject = xmlSerializer.write(object);
比如
String s = "{name:'重量',property:'p1'}";
XMLSerializer xmlSerializer = new XMLSerializer();
JSONObject object = JSONObject.fromObject(s);
String xmlObject = xmlSerializer.write(object);
System.out.println(xmlObject);
输出结果为
<?xml version="1.0" encoding="UTF-8"?>
<o>
<name type="string">重量</name>
<property type="string">p1</property>
</o>
Java EE应用的性能问题对严肃的项目和产品来说是一个非常重要的问题。特别是企业级的应用,并发用户多,数据传输量大,业务逻辑复杂,占用系统资源多,因此性能问题在企业级应用变得至关重要,它和系统的稳定性有着直接的联系。更加重要的是,性能好的应用在完成相同任务的条件下,能够占用更少的资源,获得更好的用户体验,换句话说,就是能够节省费用和消耗,获得更高的利润。
要获得更好的性能,就需要对原来的系统进行性能调优。对运行在Glassfish上的JavaEE应用,调优是一件相对复杂的事情。在调优以前必须要认识到:对JavaEE的系统,调优是多层次的。一个JavaEE的应用其实是整个系统中很少的一部分。开发人员所开发的JavaEE程序,无论是JSP还是 EJB,都是运行在JavaEE应用服务器(Glassfish)之上。而应用服务器本身也是Java语言编写的,需要运行在Java虚拟机之上。 Java虚拟机也只不过是操作系统的一个应用而已,和其他的应用(如Apache)对于操作系统来说没有本质的区别。而操作系统却运行在一定的硬件环境中,包括CPU,内存,网卡和硬盘等等。在这么多的层次中,每一个层次的因素都会影响整个系统的性能。因此,对一个系统的调优,事实上需要同时对每个层次都要调优。JavaEE应用性能调优不仅仅和Glassfish有关,Java语言有关,还要和操作系统以及硬件都有关系,需要调优者有综合的知识和技能。这些不同层面的方法需要综合纵效,结合在一起灵活使用,才能快速有效的定位性能瓶颈。下面是一些具体的案例分析:
内存泄漏问题
某个JavaEE应用运行在8颗CPU的服务器上。上线运行发现性能不稳定。性能随着时间的增加而越来越慢。通过操作系统的工具(mpstat),发现在系统很慢的时候,只有一颗CPU很忙,其他的CPU都很空闲。因此怀疑是Java虚拟机经常进行内存回收,因为虚拟机在内存回收的时候,有的回收算法通常只能运行在一个CPU上。通过Java虚拟机的工具“jstat”可以清楚的看到,Java虚拟机进行内存回收的频率非常高,几乎每5秒中就有一次,每次回收的时间为2秒钟。另外,通过“jstat”的输出还发现每次回收释放的内存非常有限,大多数对象都无法回收。这种现象很大程度上暗示着内存泄漏。使用 Java虚拟机的工具“jmap”来获得当前的一个内存映象。发现有很多(超过10000)个的session对象。这是不正常的一个现象。一般来说, session对应于一个用户的多次访问,当用户退出的时候,session就应该失效,对象应该被回收。当我们和这个系统的开发工程师了解有关 session的设置,发现当他们部署应用的时候,竟然将session的timeout时间设置为50分钟,并且没有提供logout的接口。这样的设置下,每个session的数据都会保存50分钟才会被回收。根据我们的建议,系统提供了logout的链接,并且告诉用户如果退出应用,应该点击这个 logout的链接;并且将session的timeout时间修改为5分钟。通过几天的测试,证明泄漏的问题得到解决。
数据库连接池问题
某财务应用运行在JavaEE服务器上,后台连接Oracle数据库。并发用户数量超过100人左右的时候系统停止响应。通过操作系统层面的进程监控工具发现进程并没有被杀死或挂起,而CPU使用率几乎为零。那么是什么原因导致系统停止响应用户请求呢?我们利用Java虚拟机的工具(kill -3 pid)将当前的所有线程状态DUMP出来,发现JavaEE服务器的大部分处理线程都在等待数据库连接池的连接,而那些已经获得数据库连接的线程却处于阻塞状态。数据库管理员应要求检查了数据库的状态,发现所有的连接的session都处于死锁状态。显然,这是因为数据库端出现了死锁的操作,阻塞了那些有数据库操作的请求,占用了所有数据库连接池中的连接。后续的请求如果还要从连接池中获取连接,就会阻塞在连接池上。当解决数据库死锁的问题之后,性能问题迎刃而解。
大对象缓存问题
电信应用运行在64位Java虚拟机上,系统运行得很不稳定,系统经常停止响应。使用进程工具查看,发现进程并没有被杀死或挂起。利用Java虚拟机的工具发现系统在长时间的进行内存回收,内存回收的时间长达15分钟,整个系统在内存回收的时候就像挂起一样。另外还观察到系统使用了12G的内存(因为是 64位虚拟机所以突破了4G内存的限制)。从开发人员那里了解到,这个应用为了提高性能,大量使用了对象缓存,但是事与愿违,在Java中使用过多的内存,虽然在正常运行的时候能够获得很好的性能,但是会大大增加内存回收的时间。特别是对象缓存,本系统使用了8G的缓存空间,共缓存了6000多万个对象,对这些对象的遍历导致了长时间的内存回收。根据我们的建议,将缓存空间减少到1G,并调整回收算法(使用增量回收的算法),使得系统由于内存回收而造成的最大停顿时间减少到4秒,基本满足用户的需求。
外部命令问题
数字校园应用运行在4CPU的Solaris10服务器上,中间件为JavaEE服务器。系统在做大并发压力测试的时候,请求响应时间比较慢,通过操作系统的工具(mpstat)发现CPU使用率比较高。并且系统占用绝大多数的CPU资源而不是应用本身。这是个不正常的现象,通常情况下用户应用的CPU占用率应该占主要地位,才能说明系统是正常工作。通过Solaris 10的Dtrace脚本,我们查看当前情况下哪些系统调用花费了最多的CPU资源,竟然发现最花费CPU的系统调用是“fork”。众所周知, “fork”系统调用是用来产生新的进程,在Java虚拟机中只有线程的概念,绝不会有进程的产生。这是个非常异常的现象。通过本系统的开发人员,我们找到了答案:每个用户请求的处理都包含执行一个外部shell脚本,来获得系统的一些信息。这是通过Java的“Runtime.getRuntime ().exec”来完成的,但是这种方法在Java中非常消耗资源。Java虚拟机执行这个命令的方式是:首先克隆一个和当前虚拟机一样的进程,再用这个新的进程去执行外部命令,最后再退出这个进程。如果频繁执行这个操作,系统的消耗会很大,不仅在CPU,内存操作也很重。用户根据建议去掉这个shell 脚本执行的语句,系统立刻回复了正常。
文件操作问题
内容管理(CMS)系统运行在JavaEE服务器上,当系统长时间运行以后,性能非常差,用户请求的延时比系统刚上线的时候要大很多,并且用户的并发量很小,甚至是单个用户也很慢。通过操作系统的工具观察,一切都很正常,CPU利用率不高,IO也不是很大,内存很富余,网络几乎没有压力(因为并发用户少)。先不考虑线程互锁的问题,因为单个用户性能也不好。通过Java虚拟机观察也没有发现什么问题(内存回收很少发生)。这使得我们不得不使用代码跟踪器来全程跟踪代码。我们采用了Netbeans的Profiler,跟踪的结果非常意外,用户请求的90%的时间在创建新文件。从系统设计人员了解到,此系统使用了一个目录用于保存所有上传和共享的文件,文件用其命名方式来唯一区别于其他文件。我们查看了那个文件目录,发现该目录下已经拥有80万个文件了。这时候我们才定位到问题了:在同个目录下放置太多的文件,在创建新文件的时候,系统的开销是比较大的,例如为了防止重名,文件系统会遍历当前目录下所有的文件名等等。根据我们的建议,将文件分类保存在不同的目录下,性能有了大幅度的提高。
高速缓存命中率问题
运行在JavaEE服务器上的ERP系统,在CPU充分利用的情况下性能仍然不太好。从操作系统层面上观察不到什么大问题,而且ERP系统过于复杂,代码跟踪比较困难。于是进行了CPU状态的进一步检查,发现CPU的TLB命中率不是很高,于是对Java虚拟机的启动参数进行了修改,强迫虚拟机使用大尺寸的内存页面,提高TLB的命中率。下面的参数是在Sun的HOTSPOT中调整大尺寸(4M)页面的设置:
-XX:+AggressiveHeap
-XX:LargePageSizeInBytes=256m
通过调整,TLB命中明显提高,性能也得到近40%的提升。
转载之:http://developers.sun.com.cn/blog/yutoujava/entry/8
1.使用DNS轮询.
2.使用Apache R-proxy方式。
3.使用Apache mod_jk方式.
DNS轮询的缺点是,当集群中某台服务器停止之后,用户由于dns缓存的缘故,便无法访问服务,
必须等到dns解析更新,或者这台服务器重新启动。
还有就是必须把集群中的所有服务端口暴露给外界,没有用apache做前置代理的方式安全,
并且占用大量公网IP地址,而且tomcat还要负责处理静态网页资源,影响效率。
优点是集群配置最简单,dns设置也非常简单。
R-proxy的缺点是,当其中一台tomcat停止运行的时候,apache仍然会转发请求过去,导致502网关错误。
但是只要服务器再启动就不存在这个问题。
mod_jk方式的优点是,Apache 会自动检测到停止掉的tomcat,然后不再发请求过去。
缺点就是,当停止掉的tomcat服务器再次启动的时候,Apache检测不到,仍然不会转发请求过去。
R-proxy和mod_jk的共同优点是.可以只将Apache置于公网,节省公网IP地址资源。
可以通过设置来实现Apache专门负责处理静态网页,让Tomcat专门负责处理jsp和servlet等动态请求。
共同缺点是:如果前置Apache代理服务器停止运行,所有集群服务将无法对外提供。
R-proxy和mod_jk对静态页面请求的处理,都可以通设置来选取一个尽可能优化的效果。
这三种方式对实现最佳负载均衡都有一定不足,mod_jk相对好些,可以通过设置lbfactor参数来分配请求任务,但又因为mod_jk2方式不被推荐,mod_jk2已经不再被更新了。郁闷中……
为应用程序添加搜索能力经常是一个常见的需求。本文介绍了一个框架,开发者可以使用它以最小的付出实现搜索引擎功能,理想情况下只需要一个配置文件。该框架基于若干开源的库和工具,如 Apache Lucene,Spring 框架,cpdetector 等。它支持多种资源。其中两个典型的例子是数据库资源和文件系统资源。Indexer 对配置的资源进行索引并传输到中央服务器,之后这些索引可以通过 API 进行搜索。Spring 风格的配置文件允许清晰灵活的自定义和调整。核心 API 也提供了可扩展的接口。
引言
为应用程序添加搜索能力经常是一个常见的需求。尽管已经有若干程序库提供了对搜索基础设施的支持,然而对于很多人而言,使用它们从头开始建立一个搜索引擎将是一个付出不小而且可能乏味的过程。另一方面,很多的小型应用对于搜索功能的需求和应用场景具有很大的相似性。本文试图以对多数小型应用的适用性为出发点,用 Java 语言构建一个灵活的搜索引擎框架。使用这个框架,多数情形下可以以最小的付出建立起一个搜索引擎。最理想的情况下,甚至只需要一个配置文件。特殊的情形下,可以通过灵活地对框架进行扩展满足需求。当然,如题所述,这都是借助开源工具的力量。
基础知识
Apache Lucene 是开发搜索类应用程序时最常用的 Java 类库,我们的框架也将基于它。为了下文更好的描述,我们需要先了解一些有关 Lucene 和搜索的基础知识。注意,本文不关注索引的文件格式、分词技术等话题。
什么是搜索和索引
从用户的角度来看,搜索的过程是通过关键字在某种资源中寻找特定的内容的过程。而从计算机的角度来看,实现这个过程可以有两种办法。一是对所有资源逐个与关键字匹配,返回所有满足匹配的内容;二是如同字典一样事先建立一个对应表,把关键字与资源的内容对应起来,搜索时直接查找这个表即可。显而易见,第二个办法效率要高得多。建立这个对应表事实上就是建立逆向索引(inverted index)的过程。
Lucene 基本概念
Lucene 是 Doug Cutting 用 Java 开发的用于全文搜索的工具库。在这里,我假设读者对其已有基本的了解,我们只对一些重要的概念简要介绍。要深入了解可以参考 参考资源 中列出的相关文章和图书。下面这些是 Lucene 里比较重要的类。
Document:索引包含多个 Document。而每个 Document 则包含多个 Field 对象。Document 可以是从数据库表里取出的一堆数据,可以是一个文件,也可以是一个网页等。注意,它不等同于文件系统中的文件。
Field:一个 Field 有一个名称,它对应 Document的一部分数据,表示文档的内容或者文档的元数据(与下文中提到的资源元数据不是一个概念)。一个 Field 对象有两个重要属性:Store ( 可以有 YES, NO, COMPACT 三种取值 ) 和 Index ( 可以有 TOKENIZED, UN_TOKENIZED, NO, NO_NORMS 四种取值 )
Query:抽象了搜索时使用的语句。
IndexSearcher:提供Query对象给它,它利用已有的索引进行搜索并返回搜索结果。
Hits:一个容器,包含了指向一部分搜索结果的指针。
使用 Lucene 来进行编制索引的过程大致为:将输入的数据源统一为字符串或者文本流的形式,然后从数据源提取数据,创建合适的 Field 添加到对应该数据源的 Document 对象之中。
系统概览
要建立一个通用的框架,必须对不同情况的共性进行抽象。反映到设计需要注意两点。一是要提供扩展接口;二是要尽量降低模块之间的耦合程度。我们的框架很简单地分为两个模块:索引模块和搜索模块。索引模块在不同的机器上各自进行对资源的索引,并把索引文件(事实上,下面我们会说到,还有元数据)统一传输到同一个地方(可以是在远程服务器上,也可以是在本地)。搜索模块则利用这些从多个索引模块收集到的数据完成用户的搜索请求。
图 1 展现了整体的框架。可以看到,两个模块之间相对是独立的,它们之间的关联不是通过代码,而是通过索引和元数据。在下文中,我们将会详细介绍如何基于开源工具设计和实现这两个模块。
图 1. 系统架构图
建立索引
可以进行索引的对象有很多,如文件、网页、RSS Feed 等。在我们的框架中,我们定义可以进行索引的一类对象为资源。从实现细节上来说,从一个资源中可以提取出多个 Document 对象。文件系统资源和数据库结果集资源都是资源的代表性例子。
前面提到,从资源中收集到的索引被统一传送到同一个地方,以被搜索模块所用。显然除了索引之外,搜索模块需要有对资源更多的了解,如资源的名称、搜索该资源后搜索结果的呈现格式等。这些额外的附加信息称为资源的元数据。元数据和索引数据一同被收集起来,放置到某个特定的位置。
简要地介绍过资源的概念之后,我们首先为其定义一个 Resource 接口。这个接口的声明如下。
清单 1. Resource 接口
public interface Resource {
// RequestProcessor 对象被动地从资源中提取 Document,并返回提取的数量
public int extractDocuments(ResourceProcessor processor);
// 添加的 DocumentListener 将在每一个 Document 对象被提取出时被调用
public void addDocumentListener(DocumentListener l);
// 返回资源的元数据
public ResourceMetaData getMetaData();
}
其中元数据包含的字段见下表。在下文中,我们还会对元数据的用途做更多的介绍。
表 1. 资源元数据包含的字段
属性 类型 含义
resourceName String 资源的唯一名称
resourceDescription String 资源的介绍性文字
hitTextPattern String 当文档被搜索到时,这个 pattern 规定了结果显示的格式
searchableFields String[] 可以被搜索的字段名称
而 DocumentListener 的代码如下。
清单 2. DocumentListener 接口
public interface DocumentListener extends EventListener {
public void documentExtracted(Document doc);
}
为了让索引模块能够知道所有需要被索引的资源,我们在这里使用 Spring 风格的 XML 文件配置索引模块中的所有组件,尤其是所有资源。您可以在 下载部分 查看一个示例配置文件。
为什么选择使用 Spring 风格的配置文件?
这主要有两个好处:
仅依赖于 Spring Core 和 Spring Beans 便免去了定义配置机制和解析配置文件的负担;
Spring 的 IoC 机制降低了框架的耦合性,并使扩展框架变得简单;
基于以上内容,我们可以大致描述出索引模块工作的过程:
首先在 XML 配置的 bean 中找出所有 Resource 对象;
对每一个调用其 extractDocuments() 方法,这一步除了完成对资源的索引外,还会在每次提取出一个 Document 对象之后,通知注册在该资源上的所有 DocumentListener;
接着处理资源的元数据(getMetaData() 的返回值);
将缓存里的数据写入到本地磁盘或者传送给远程服务器;
在这个过程中,有两个地方值得注意。
第一,对资源可以注册 DocumentListener 使得我们可以在运行时刻对索引过程有更为动态的控制。举一个简单例子,对某个文章发布站点的文章进行索引时,一个很正常的要求便是发布时间更靠近当前时间的文章需要在搜索结果中排在靠前的位置。每篇文章显然对应一个 Document 对象,在 Lucene 中我们可以通过设置 Document 的 boost 值来对其进行加权。假设其中文章发布时间的 Field 的名称为 PUB_TIME,那么我们可以为资源注册一个 DocumentListener,当它被通知时,则检测 PUB_TIME 的值,根据距离当前时间的远近进行加权。
第二点很显然,在这个过程中,extractDocuments() 方法的实现依不同类型的资源而各异。下面我们主要讨论两种类型的资源:文件系统资源和数据库结果集资源。这两个类都实现了上面的 接口。
文件系统资源
对文件系统资源的索引通常从一个基目录开始,递归处理每个需要进行索引的文件。该资源有一个字符串数组类型的 excludedFiles 属性,表示在处理文件时需要排除的文件绝对路径的正则表达式。在递归遍历文件系统树的同时,绝对路径匹配 excludedFiles 中任意一项的文件将不会被处理。这主要是考虑到一般我们只需要对一部分文件夹(比如排除可能存在的备份目录)中的一部分文件(如 doc, ppt 文件等)进行索引。
除了所有文件共有的文件名、文件路径、文件大小和修改时间等 Field,不同类型的文件需要有不同的处理方法。为了保留灵活性,我们使用 Strategy 模式封装对不同类型文件的处理方式。为此我们抽象出一个 DocumentBuilder 的接口,该接口仅定义了一个方法如下:
清单 3. DocumentBuilder 接口
public interface DocumentBuilder {
Document buildDocument(InputStream is);
}
什么是 Strategy 模式?
根据 Design patterns: Elements of reusable object orientated software 一书:Strategy 模式“定义一系列的算法,把它们分别封装起来,并且使它们相互可以替换。这个模式使得算法可以独立于使用它的客户而变化。”
不同的 DocumentBuilder(Strategy) 用于从一个输入流中读取数据,处理不同类型的文件。对于常见的文件格式来说,都有合适的开源工具帮助进行解析。在下表中我们列举一些常见文件类型的解析办法。
文件类型 常用扩展名 可以使用的解析办法
纯文本文档 txt 无需类库解析
RTF 文档 rtf 使用 javax.swing.text.rtf.RTFEditorKit 类
Word 文档(非 OOXML 格式) doc Apache POI (可配合使用 POI Scratchpad)
PowerPoint 演示文稿(非 OOXML 格式) xls Apache POI (可配合使用 POI Scratchpad)
PDF 文档 pdf PDFBox(可能中文支持欠佳)
HTML 文档 htm, html JTidy, Cobra
这里以 Word 文件为例,给出一个简单的参考实现。
清单 4. 解析纯文本内容的实现
// WordDocument 是 Apache POI Scratchpad 中的一个类
Document buildDocument(InputStream is) {
String bodyText = null;
try {
WordDocument wordDoc = new WordDocument(is);
StringWriter sw = new StringWriter();
wordDoc.writeAllText(sw);
sw.close();
bodyText = sw.toString();
} catch (Exception e) {
throw new DocumentHandlerException("Cannot extract text from a Word document", e);
}
if ((bodyText != null) && (bodyText.trim().length() > 0)) {
Document doc = new Document();
doc.add(new Field("body", bodyText, Field.Store.YES, Field.Index.TOKENIZED));
return doc;
}
return null;
}
那么如何选择合适的 Strategy 来处理文件呢?UNIX 系统下的 file(1) 工具提供了从 magicnumber 获取文件类型的功能,我们可以使用 Runtime.exec() 方法调用这一命令。但这需要在有 file(1) 命令的情况下,而且并不能识别出所有文件类型。在一般的情况下我们可以简单地根据扩展名来使用合适的类处理文件。扩展名和类的映射关系写在 properties 文件中。当需要添加对新的文件类型的支持时,我们只需添加一个新的实现 DocumentBuilder 接口的类,并在映射文件中添加一个映射关系即可。
数据库结果集资源
大多数应用使用数据库作为永久存储,对数据库查询结果集索引是一个常见需求。
生成一个数据库结果集资源的实例需要先提供一个查询语句,然后执行查询,得到一个结果集。这个结果集中的内容便是我们需要进行索引的对象。extractDocuments 的实现便是为结果集中的每一行创建一个 Document 对象。和文件系统资源不同的是,数据库资源需要放入 Document 中的 Field 一般都存在在查询结果集之中。比如一个简单的文章发布站点,对其后台数据库执行查询 SELECT ID, TITLE, CONTENT FROM ARTICLE 返回一个有三列的结果集。对结果集的每一行都会被提取出一个 Document 对象,其中包含三个 Field,分别对应这三列。
然而不同 Field 的类型是不同的。比如 ID 字段一般对应 Store.YES 和 Index.NO 的 Field;而 TITLE 字段则一般对应 Store.YES 和 Index.TOKENIZED 的 Field。为了解决这个问题,我们在数据库结果集资源的实现中提供一个类型为 Properties 的 fieldTypeMappings 属性,用于设置数据库字段所对应的 Field 的类型。对于前面的情况来说,这个属性可能会被配置成类似这样的形式:
ID = YES, NO
TITLE = YES, TOKENIZED
CONTENT = NO, TOKENIZED
配合这个映射,我们便可以生成合适类型的 Field,完成对结果集索引的工作。
收集索引
完成对资源的索引之后,还需要让索引为搜索模块所用。前面我们已经说过这里介绍的框架主要用于小型应用,考虑到复杂性,我们采取简单地将分布在各个机器上的索引汇总到一个地方的策略。
汇总索引的传输方式可以有很多方案,比如使用 FTP、HTTP、rsync 等。甚至索引模块和搜索模块可以位于同一台机器上,这种情况下只需要将索引进行本地拷贝即可。同前面类似,我们定义一个 Transporter 接口。
清单 5. Transporter 接口
public interface Transporter {
public void transport(File file);
}
以 FTP 方式传输为例,我们使用 Commons Net 完成传输的操作。
public void transport(File file) throws TransportException {
FTPClient client = new FTPClient();
client.connect(host);
client.login(username, password);
client.changeWorkingDirectory(remotePath);
transportRecursive(client, file);
client.disconnect();
}
public void transportRecursive(FTPClient client, File file) {
if (file.isFile() && file.canRead()) {
client.storeFile(file.getName(), new FileInputStream(file));
} else if (file.isDirectory()) {
client.makeDirectory(file.getName());
client.changeWorkingDirectory(file.getName());
File[] fileList = file.listFiles();
for (File f : fileList) {
transportRecursive(client, f);
}
}
}
对其他传输方案也有各自的方案进行处理,具体使用哪个 Transporter 的实现被配置在 Spring 风格的索引模块配置文件中。传输的方式是灵活的。比如当需要强调安全性时,我们可以换用基于 SSL 的 FTP 进行传输。所需要做的只是开发一个使用 FTP over SSL 的 Transporter 实现,并在配置文件中更改 Transporter 的实现即可。
进行搜索
在做了这么多之后,我们开始接触和用户关联最为紧密的搜索模块。注意,我们的框架不包括一个基于已经收集好的索引进行搜索是个很简单的过程。Lucene 已经提供了功能强大的 IndexSearcher 及其子类。在这个部分,我们不会再介绍如何使用这些类,而是关注在前文提到过的资源元数据上。元数据从各个资源所在的文件夹中读取得到,它在搜索模块中扮演重要的角色。
构建一个查询
对不同资源进行搜索的查询方法并不一样。例如搜索一个论坛里的所有留言时,我们关注的一般是留言的标题、作者和内容;而当搜索一个 FTP 站点时,我们更多关注的是文件名和文件内容。另一方面,我们有时可能会使用一个查询去搜索多个资源的结果。这正是之前我们在前面所提到的元数据中 searchableFields 和 resourceName 属性的作用。前者指出一个资源中哪些字段是参与搜索的;后者则用于在搜索时确定使用哪个或者哪些索引。从技术细节来说,只有有了这些信息,我们才可以构造出可用的 Query 对象。
呈现搜索结果
当从 IndexSearcher 对象得到搜索结果(Hits)之后,当然我们可以直接从中获取需要的值,再格式化予以输出。但一来格式化输出搜索结果(尤其在 Web 应用中)是个很常见的需求,可能会经常变更;二来结果的呈现格式应该是由分散的资源各自定义,而不是交由搜索模块来定义。基于上面两个原因,我们的框架将使用在资源收集端配置结果输出格式的方式。这个格式由资源元数据中的 hitTextPattern 属性定义。该属性是一个字符串类型的值,支持两种语法
形如 ${field_name} 的子字符串都会被动态替换成查询结果中各个 Document 内 Field 的值。
形如 $function(...) 的被解释为函数,括号内以逗号隔开的符号都被解释成参数,函数可以嵌套。
例如搜索“具体”返回的搜索结果中包含一个 Document 对象,其 Field 如下表:
Field 名称 Field 内容
url http://example.org/article/1.html
title 示例标题
content 这里是具体的内容。
那么如果 hitTextPatten 被设置为“${title}
$highlight(${content}, 5, "", "")”,返回的结果经浏览器解释后可能的显示结果如下(这只是个演示链接,请不要点击):
示例标题
这里是具体...
上面提到的 $highlight() 函数用于在搜索结果中取得最匹配的一段文本,并高亮显示搜索时使用的短语,其第一个参数是高亮显示的文本,第二个参数是显示的文本长度,第三和第四个参数是高亮文本时使用的前缀和后缀。
可以使用正则表达式和文本解析来实现前面所提到的语法。我们也可以使用 JavaCC 定义 hitTextPattern 的文法,进而生成词法分析器和语法解析器。这是更为系统并且相对而言不易出错的方法。对 JavaCC 的介绍不是本文的重点,您可以在下面的 阅读资源 中找到学习资料。
下面列出的是一些与我们所提出的框架所相关或者类似的产品,您可以在 学习资料 中更多地了解他们。
IBM?OmniFind?Family
OmniFind 是 IBM 公司推出的企业级搜索解决方案。基于 UIMA (Unstructured Information Management Architecture) 技术,它提供了强大的索引和获取信息功能,支持巨大数量、多种类型的文档资源(无论是结构化还是非结构化),并为 Lotus?Domino?和 WebSphere?Portal 专门进行了优化。
Apache Solr
Solr 是 Apache 的一个企业级的全文检索项目,实现了一个基于 HTTP 的搜索服务器,支持多种资源和 Web 界面管理,它同样建立在 Lucene 之上,并对 Lucene 做了很多扩展,例如支持动态字段及唯一键,对查询结果进行动态分组和过滤等。
Google SiteSearch
使用 Google 的站点搜索功能可以方便而快捷地建立一个站内搜索引擎。但是 Google 的站点搜索基于 Google 的网络爬虫,所以无法访问受保护的站点内容或者 Intranet 上的资源。另外,Google 所支持的资源类型也是有限的,我们无法对其进行扩展。
SearchBlox?
SearchBlox 是一个商业的搜索引擎构建框架。它本身是一个 J2EE 组件,和我们的框架类似,也支持对网页和文件系统等资源进行索引,进而进行搜索。
还需考虑的问题
本文介绍的思想试图利用开源的工具解决中小型应用中的常见问题。当然,作为一个框架,它还有很多不足,下面列举出一些可以进行改进的地方。
性能考虑
当需要进行索引的资源数目不多时,隔一定的时间进行一次完全索引不会占用很长时间。使用一台 2G 内存,Xeon 2.66G 处理器的服务器进行实际测试,发现对数据库资源的索引占用的时间很少,一千多条记录花费的时间在 1 秒到 2 秒之内。而对 1400 多个文件进行索引耗时大约十几秒。但在大型应用中,资源的容量是巨大的,如果每次都进行完整的索引,耗费的时间会很惊人。我们可以通过跳过已经索引的资源内容,删除已不存在的资源内容的索引,并进行增量索引来解决这个问题。这可能会涉及文件校验和索引删除等。
另一方面,框架可以提供查询缓存来提高查询效率。框架可以在内存中建立一级缓存,并使用如 OSCache 或 EHCache 实现磁盘上的二级缓存。当索引的内容变化不频繁时,使用查询缓存更会明显地提高查询速度、降低资源消耗。
分布式索引
我们的框架可以将索引分布在多台机器上。搜索资源时,查询被 flood 到各个机器上从而获得搜索结果。这样可以免去传输索引到某一台中央服务器的过程。当然也可以在非结构化的 P2P 网络上实现分布式哈希表 (DHT),配合索引复制 (Replication),使得应用程序更为安全,可靠,有伸缩性。在阅读资料中给出了 一篇关于构建分布式环境下全文搜索的可行性的论文。
安全性
目前我们的框架并没有涉及到安全性。除了依赖资源本身的访问控制(如受保护的网页和文件系统等)之外,我们还可以从两方面增强框架本身的安全性:
考虑到一个组织的搜索功能对不同用户的权限设置不一定一样,可以支持对用户角色的定义,实行对搜索模块的访问控制。
在资源索引模块中实现一种机制,让资源可以限制自己暴露的内容,从而缩小索引模块的索引范围。这可以类比 robots 文件可以规定搜索引擎爬虫的行为。
通过上文的介绍,我们认识了一个可扩展的框架,由索引模块和搜索模块两部分组成。它可以灵活地适应不同的应用场景。如果需要更独特的需求,框架本身预留了可以扩展的接口,我们可以通过实现这些接口完成功能的定制。更重要的是这一切都是建立在开源软件的基础之上。希望本文能为您揭示开源的力量,体验用开源工具组装您自己的解决方案所带来的莫大快乐。
方法一:
本人解决的方法,保证可用。
添加过滤器(代码如下)
package com.cn.util;
import java.io.* ;
import javax.servlet.* ;
import javax.servlet.http.HttpServletResponse;
public class ForceNoCacheFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException
{
((HttpServletResponse) response).setHeader("Cache-Control","no-cache");
((HttpServletResponse) response).setHeader("Pragma","no-cache");
((HttpServletResponse) response).setDateHeader ("Expires", -1);
filterChain.doFilter(request, response);
}
public void destroy()
{
}
public void init(FilterConfig filterConfig) throws ServletException
{
}
}
然后在web.xml中添加这个过滤器
<filter>
<filter-name>NoCache</filter-name>
<filter-class>com.cn.util.ForceNoCacheFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>NoCache</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
com.cn.util.ForceNoCacheFilter为刚才过滤器的包名.类名,/*为匹配所有请求。
这样你所有的请求都将会传到服务器处理,不会查看缓存了。
方法二:
inComeHttp.url="familyGroup.do?method=query&tmp="+Math.random();
url上随意传一个随机数
flex开发中将各个功能分解到模块中,但在加载各个模块的时候需要注意一下问题:
加载方法:
private function init():void
{
module = mx.modules.ModuleManager.getModule("UIModule/HR/Holiday/Config/frmHolidayMain.swf");
module.addEventListener(mx.events.ModuleEvent.READY,ready);
module.load();
// general=ModuleLoader(mx.managers.PopUpManager.createPopUp(this,ModuleLoader));
//
// general.url="test3.swf";
//
// general.loadModule();
}
private function ready(e:ModuleEvent):void
{
var moduleInfo:IModuleInfo = e.target as IModuleInfo
var wind:MDIWindow = new MDIWindow();
wind.addChild(moduleInfo.factory.create() as DisplayObject);
testcanvas.windowManager.add(wind);
}
需要注意的一点是 module 对象的定义一定要定义为全局的否则ready事件是不能执行的。具体原因不知道,个人理解为到ready方法中无法找到module对象了
flex 装载多个module出现的问题Error #1034: 强制转换类型失败 收藏
摘自http://bzhang.javaeye.com/blog/322148
TypeError: Error #1034: 强制转换类型失败:无法将 Object@1aee90b1 转换为 mx.messaging.messages.IMessage。
需求背景 :
通过树形菜单加载多个不同的module。
问题现象 :module页面存在拖动,Popup,Alert或者colorpicker出现错误信息:
TypeError: Error #1034: 强制转换类型失败:无法将 mx.managers::PopUpManagerImpl@7155ac1 转换为 mx.managers.IPopUpManager。
解决方案 :
在Application加入如下代码引用:
< mx:Script >
<! [CDATA[
import mx.managers.DragManager;
import mx.managers.IPopUpManager;
/* Create dummy variables. */
// 避免出现:无法将 mx.managers::PopUpManagerImpl@52a09a1 转换为 mx.managers.IPopUpManager 错误
private var dragManager : DragManager;
private var popUpManager : IPopUpManager;
//process....
]]>
</mx:Script>
问题原因分析 :
属于ModuleLoader shared code problem .
当Module中使用managers时(如PopUpManager,DragManager, HistoryManager等)则可能出现这个问题(当application里在loader之前没有引入这些manager的引用时)。
manager 的方法是静态方法,整个应用程序中创建了一个该manager接口的singleton实例,但module仅在自己的 Application domain中使用该单例, 当多个module使用同一个单例manager且main application没有使用时,就会出现这个空对象引用问题:第一个引入某manager的module不能将该manager接口的 singleton跟其他module共享,其他module调用该Manager的方法时,应用程序不会再创建该manager接口的实例,这个 module就无法引用到该manager接口的实例,就出现了空对象引用问题.
参考资料:Flex sdk源码。
目前在Application创建了些Application范围内没有使用到的"木偶变量",从代码可读性上来说不是很好。有其他比较好的解决方案的同学麻烦请告之下,:)
posted on 2008-11-22 17:33 钩子 阅读(1118) 评论(1) 编辑 收藏 所属分类: jee 、ria 、工作笔记
<noscript type="text/javascript"> //<![CDATA[ Sys.WebForms.PageRequestManager._initialize('AjaxHolder$scriptmanager1', document.getElementById('Form1')); Sys.WebForms.PageRequestManager.getInstance()._updateControls(['tAjaxHolder$UpdatePanel1'], [], [], 90); //]]> </noscript>
Feedback
# re: FLEX:multiple moduleloader occur #1034 error 2008-11-24 10:14 钩子
同事推荐了个更好的办法:
在ModuleLoader 的creationComplete方法中加入如下代码:
moduleLoader.applicationDomain = ApplicationDomain.currentDomain;
就可以在Application里切换多个module而不需要在Application里明文引用单例manager声明。比我上面所说的方法更好的能解决问题而且,代码可读性更好。
另外,推荐在moduleloader做切换的时候,加上:
moduleLoader.unloadModule再做moduleLoader.loadModule().
在这里做个小记。
http://blog.csdn.net/yzsind/archive/2009/03/27/4031066.aspx
目标:本文主要介绍联系的定义及使用。
一、 联系
联系(Relationship)是指实体集这间或实体集内部实例之间的连接。
实体之间可以通过联系来相互关联。与实体和实体集对应,联系也可以分为联系和联系集,联系集是实体集之间的联系,联系是实体之间的联系,联系是具有方向性的。联系和联系集在含义明确的情况之下均可称为联系。
按照实体类型中实例之间的数量对应关系,通常可将联系分为4类,即一对一(ONE TO ONE)联系、一对多(ONE TO MANY)联系、多对一(MANY TO ONE)联系和多对多联系(MANY TO MANY)。
二、 建立联系
在CDM工具选项板中除了公共的工具外,还包括如下图所示的其它对象产生工具。
在图形窗口中创建两个实体后,单击“实体间建立联系”工具,单击一个实体,在按下鼠标左键的同时把光标拖至别一个实体上并释放鼠标左键,这样就在两个实体间创建了联系,右键单击图形窗口,释放Relationship工具。如下图所示

三、 四种基本的联系
即一对一(ONE TO ONE)联系、一对多(ONE TO MANY)联系、多对一(MANY TO ONE)联系和多对多联系(MANY TO MANY)。如图所示
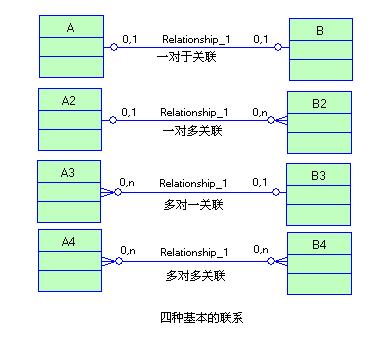
四、 其他几类特殊联系
除了4种基本的联系之外,实体集与实体集之间还存在标定联系(Identify Relationship)、非标定联系(Non-Identify RelationShip)和递归联系(Recursive Relationship)。
标定联系:
每个实体类型都有自己的标识符,如果两个实体集之间发生联系,其中一个实体类型的标识符进入另一个实体类型并与该实体类型中的标识符共同组成其标识符时,这种联系则称为标定联系,也叫依赖联系。反之称为非标定联系,也叫非依赖联系。
注意:
在非标定联系中,一个实体集中的部分实例依赖于另一个实例集中的实例,在这种依赖联系中,每个实体必须至少有一个标识符。而在标定联系中,一个实体集中的全部实例完全依赖于另个实体集中的实例,在这种依赖联系中一个实体必须至少有一个标识符,而另一个实体却可以没有自己的标识符。没有标识符的实体用它所依赖的实体的标识符作为自己的标识符。
换句话来理解,在标定联系中,一个实体(选课)依赖 一个实体(学生),那么(学生)实体必须至少有一个标识符,而(选课)实体可以没有自己的标识符,没有标标识符的实体可以用实体(学生)的标识符作为自己的标识符。
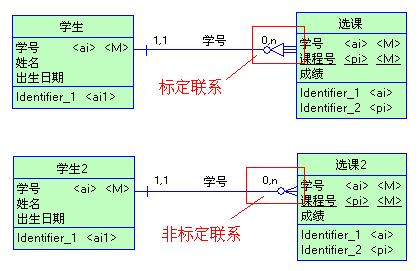
递归联系:
递归联系是实体集内部实例之间的一种联系,通常形象地称为自反联系。同一实体类型中不同实体集之间的联系也称为递归联系。
例如:在“职工”实体集中存在很多的职工,这些职工之间必须存在一种领导与被领导的关系。又如“学生”实体信中的实体包含“班长”子实体集与“普通学生”子实体集,这两个子实体集之间的联系就是一种递归联系。创建递归联系时,只需要单击“实体间建立联系”工具从实体的一部分拖至该实体的别一个部分即可。如图
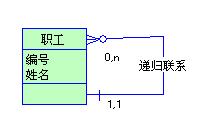
五、 定义联系的特性
在两个实体间建立了联系后,双击联系线,打开联系特性窗口,如图所示。
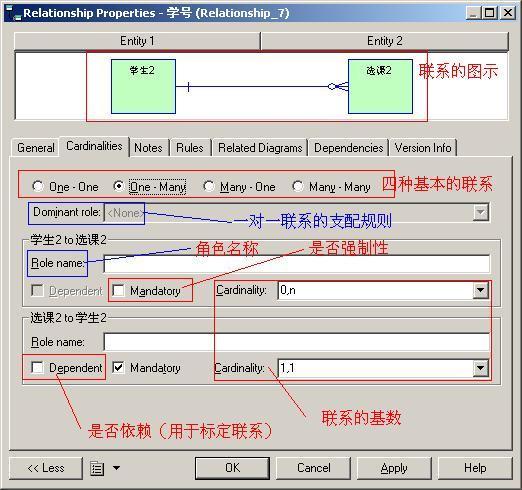
六、 定义联系的角色名
在联系的两个方向上各自包含有一个分组框,其中的参数只对这个方向起作用,Role Name为角色名,描述该方向联系的作用,一般用一个动词或动宾组表。
如:“学生 to 课目 ” 组框中应该填写“拥有”,而在“课目To 学生”组框中填写“属于”。(在此只是举例说明,可能有些用词不太合理)。
七、 定义联系的强制性
Mandatory 表洋这个方向联系的强制关系。选中这个复选框,则在联系线上产生一个联系线垂直的竖线。不选择这个复选框则表示联系这个方向上是可选的,在联系线上产生一个小圆圈。
八、 有关联系的基数
联系具有方向性,每个方向上都有一个基数。
举例,
“系”与“学生”两个实体之间的联系是一对多联系,换句话说“学生”和“系”之间的联系是多对一联系。而且一个学生必须属于一个系,并且只能属于一个系,不能属于零个系,所以从“学生”实体至“系”实体的基数为“1,1”,从联系的另一方向考虑,一个系可以拥有多个学生,也可以没有任何学生,即零个学生,所以该方向联系的基数就为“0,n”,如图所示

待续。
目标:
本文主要介绍数据项、新增数据项、数据项的唯一性代码选项和重用选项等。
一、数据项
数据项(Data Item)是信息存储的最小单位,它可以附加在实体上作为实体的属性。
注意:模型中允许存在没有附加至任何实体上的数据项。
二、新建数据项
1)使用“Model”---> Data Items 菜单,在打开的窗口中显示已有的数据项的列表,点击 “Add a Row”按钮,创建一个新数据项,如图所示
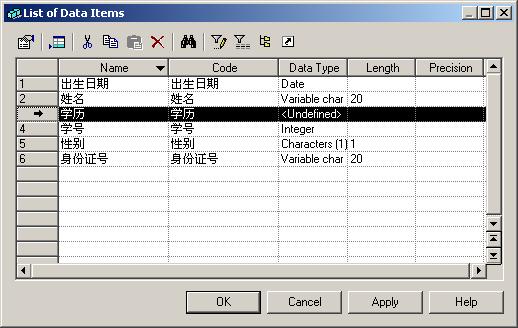
2)当然您可以继续设置具体数据项的Code、DataType、Length等等信息。这里就不再详细说明了。
三、数据项的唯一性代码选项和重用选项
使用Tools--->Model Options->Model Settings。在Data Item组框中定义数据项的唯一性代码选项(Unique Code)与重用选项(Allow Reuse)。
注意:
如果选择Unique Code复选框 ,每个数据项在同一个命名空间有唯一的代码,而选择Allow reuse ,一个数据项可以充当多个实体的属性。
四、在实体中添加数据项
1)双击一个实体符号,打开该实体的属性窗口。
2)单击Attributes选项卡,打开如下图所示窗口
注意:
Add a DataItem 与 Reuse a DataItem的区别在于
Add a DataItem 情况下,选择一个已经存在的数据项,系统会自动复制所选择的数据项。如果您设置了UniqueCode选项,那系统在复制过程中,新数据项的Code会自动生成一个唯一的号码,否则与所选择的数据项完全一致。
Reuse a DataItem情况下,只引用不新增,就是引用那些已经存在的数据项,作为新实体的数据项。
待续。
目标:
本文主要介绍如何定义实体的主、次标识符。
一、标识符
标识符是实体中一个或多个属性的集合,可用来唯一标识实体中的一个实例。要强调的是,CDM中的标识符等价于PDM中的主键或候选键。
每个实体都必须至少有一个标识符。如果实体只有一个标识符,则它为实体的主标识符。如果实体有多个标识符,则其中一个被指定为主标识符,其余的标识符就是次标识符了。
二、如果定义主、次标识符
1)选择某个实体双击弹出实体的属性对话框。在Identifiers选项卡上可以进行实体标识符的定义。如下图所示
2)选择第一行“主标识符”,点击属性按钮或双击第一行“主标识符”,弹出属性对话框,如图所示
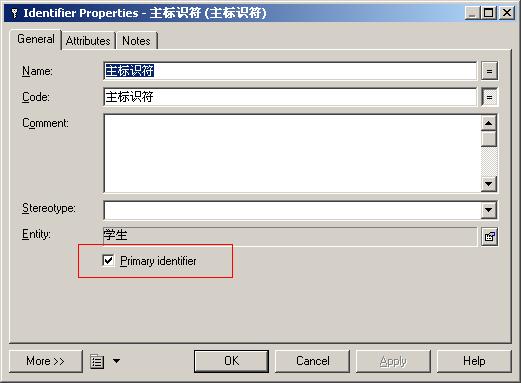
3)选择"Attributes"选项卡,再点击“Add Attributes”工具,弹出如图所示窗口,选择某个属性作为标识符就行了。
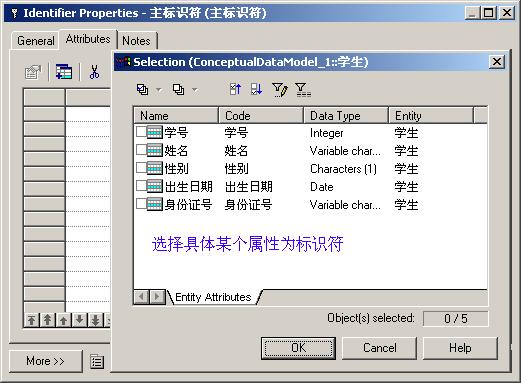
待续。
目标:
本文主要介绍属性的标准检查约束、如何定义属性的附加检查。
一、定义属性的标准检查约束
标准检查约束是一组确保属性有效的表达式。在实体属性的特性窗口,打开如图所示的检查选项卡。
在这个选项卡可以定义属性的标准检查约束,窗口中每项的参数的含义,如下
| 参数 |
说明 |
| Minimum |
属性可接受的最小数 |
| Maximum |
属性可接受的最大数 |
| Default |
属性不赋值时,系统提供的默认值 |
| Unit |
单位,如公里、吨、元 |
| Format |
属性的数据显示格式 |
| Lowercase |
属性的赋值全部变为小写字母 |
| Uppercase |
属性的赋值全部变为大写字母 |
| Cannot modify |
该属性一旦赋值不能再修改 |
| List Of Values |
属性赋值列表,除列表中的值,不能有其他的值 |
| Label |
属性列表值的标签 |
二、定义属性的附加检查
当Standard checks 或Rules 不能满足检查的要求时,可以在Additional Checks选项卡的Server子页上,通过SQL语句中使用%MINMAX%、%LISTVAL%、%RULES%、%UPPER%、%LOWER%几个变量来定义Standard和Rule,如图所示
%MINMAX%、%LISTVAL%、%UPPER%、%LOWER%
在Standard Check中定义的Minimum 和Maximum、List values 、uppervalues、lowervalues
%RULES%
在Rules特性窗口Expression选项卡中定义的有效性规则表达式
待续。
目标:
本文主要介绍PowerDesigner概念数据模型以及实体、属性创建。
一、新建概念数据模型
1)选择File-->New,弹出如图所示对话框,选择CDM模型(即概念数据模型)建立模型。
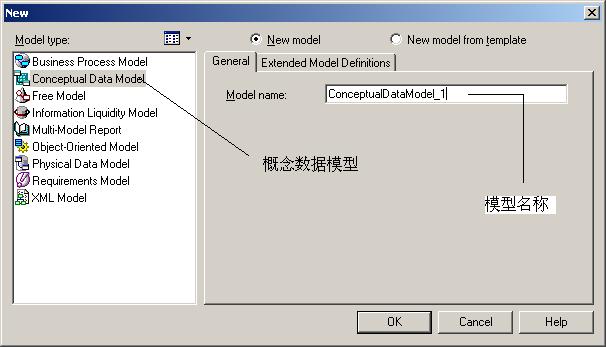
2)完成概念数据模型的创建。以下图示,对当前的工作空间进行简单介绍。(以后再更详细说明)
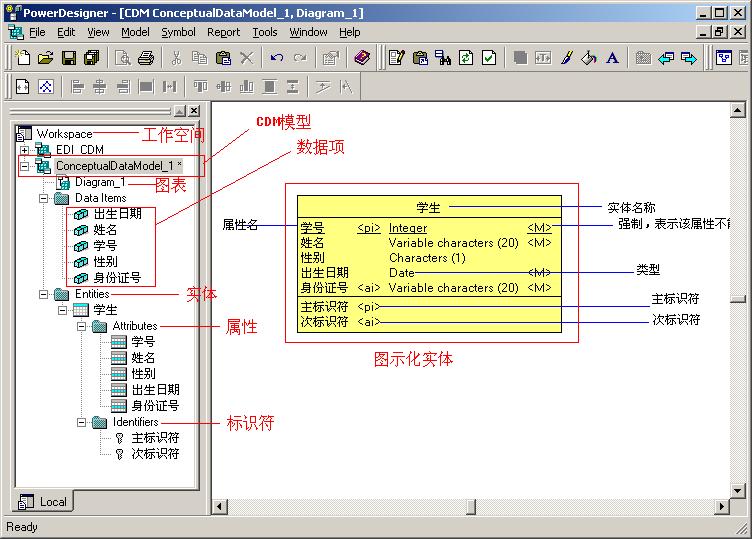
3)选择新增的CDM模型,右击,在弹出的菜单中选择“Properties”属性项,弹出如图所示对话框。在“General”标签里可以输入所建模型的名称、代码、描述、创建者、版本以及默认的图表等等信息。在“Notes”标签里可以输入相关描述及说明信息。当然再有更多的标签,可以点击 "More>>"按钮,这里就不再进行详细解释。
 二、创建新实体
二、创建新实体
1)在CDM的图形窗口中,单击工具选项版上的Entity工具,再单击图形窗口的空白处,在单击的位置就出现一个实体符号。点击Pointer工具或右击鼠标,释放Entitiy工具。如图所示
2)双击刚创建的实体符号,打开下列图标窗口,在此窗口“General”标签中可以输入实体的名称、代码、描述等信息。
 三、添加实体属性
三、添加实体属性
1)在上述窗口的“Attribute”选项标签上可以添加属性,如下图所示。
注意:
数据项中的“添加属性”和“重用已有数据项”这两项功能与模型中Data Item的Unique code 和Allow reuse选项有关。
P列表示该属性是否为主标识符;D列表示该属性是否在图形窗口中显示;M列表示该属性是否为强制的,即该列是否为空值。
如果一个实体属性为强制的,那么, 这个属性在每条记录中都必须被赋值,不能为空。
2)在上图所示窗口中,点击插入属性按钮,弹出属性对话框,如下图所示。
注意:这里涉及到域的概念,即一种标准的数据结构,它可应用至数据项或实体的属性上。在以下的教程中将另立章节详细说明。
待续。
目标:
本文主要介绍PowerDesigner中概念数据模型 CDM的基本概念。
一、概念数据模型概述
数据模型是现实世界中数据特征的抽象。数据模型应该满足三个方面的要求:
1)能够比较真实地模拟现实世界
2)容易为人所理解
3)便于计算机实现
概念数据模型也称信息模型,它以实体-联系(Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库的概念级设计。
通常人们先将现实世界抽象为概念世界,然后再将概念世界转为机器世界。换句话说,就是先将现实世界中的客观对象抽象为实体(Entity)和联系(Relationship),它并不依赖于具体的计算机系统或某个DBMS系统,这种模型就是我们所说的CDM;然后再将CDM转换为计算机上某个DBMS所支持的数据模型,这样的模型就是物理数据模型,即PDM。
CDM是一组严格定义的模型元素的集合,这些模型元素精确地描述了系统的 静态特性、动态特性以及完整性约束条件等,其中包括了 数据结构、数据操作和完整性约束三部分。
1)数据结构表达为实体和属性;
2)数据操作表达为实体中的记录的插入、删除、修改、查询等操作;
3)完整性约束表达为数据的自身完整性约束(如数据类型、检查、规则等)和数据间的参照完整性约束(如联系、继承联系等);
二、实体、属性及标识符的定义
实体(Entity),也称为实例,对应现实世界中可区别于其他对象的“事件”或“事物”。例如,学校中的每个学生,医院中的每个手术。
每个实体都有用来描述实体特征的一组性质,称之为属性,一个实体由若干个属性来描述。如学生实体可由学号、姓名、性别、出生年月、所在系别、入学年份等属性组成。
实体集(Entity Set)是具体相同类型及相同性质实体的集合。例如学校所有学生的集合可定义为“学生”实体集,“学生”实体集中的每个实体均具有学号、姓名、性别、出生年月、所在系别、入学年份等性质。
实体类型(Entity Type)是实体集中每个实体所具有的共同性质的集合,例如“患者”实体类型为:患者{门诊号,姓名,性别,年龄,身份证号.............}。实体是实体类型的一个实例,在含义明确的情况下,实体、实体类型通常互换使用。
实体类型中的每个实体包含唯一标识它的一个或一组属性,这些属性称为实体类型的标识符(Identifier),如“学号”是学生实体类型的标识符,“姓名”、“出生日期”、“信址”共同组成“公民”实体类型的标识符。
有些实体类型可以有几组属性充当标识符,选定其中一组属性作为实体类型的主标识符,其他的作为次标识符。
三、实体、属性及标识符的表达
待续!
|