|
2012年11月27日
#
摘要: 前阵子从支付宝转账1万块钱到余额宝,这是日常生活的一件普通小事,但作为互联网研发人员的职业病,我就思考支付宝扣除1万之后,如果系统挂掉怎么办,这时余额宝账户并没有增加1万,数据就会出现不一致状况了。上述场景在各个类型的系统中都能找到相似影子,比如在电商系统中,当有用户下单后,除了在订单表插入一条记录外,对应商品表的这个商品数量必须减1吧,怎么保证?!在搜索广告系统中,当用户点击某广告后,除了在点击... 阅读全文
微服务架构采用Scale Cube方法设计应用架构,将应用服务按功能拆分成一组相互协作的服务。每个服务负责一组特定、相关的功能。每个服务可以有自己独立的数据库,从而保证与其他服务解耦。 微服务优点 1、通过分解巨大单体式应用为多个服务方法解决了复杂性问题,每个微服务相对较小 2、每个单体应用不局限于固定的技术栈,开发者可以自由选择开发技术,提供API服务。 3、每个微服务独立的开发,部署 4、单一职责功能,每个服务都很简单,只关注于一个业务功能 5、易于规模化开发,多个开发团队可以并行开发,每个团队负责一项服务 6、改善故障隔离。一个服务宕机不会影响其他的服务 微服务缺点: 1.开发者需要应对创建分布式系统所产生的额外的复杂因素 l 目前的IDE主要面对的是单体工程程序,无法显示支持分布式应用的开发 l 测试工作更加困难 l 需要采用服务间的通讯机制 l 很难在不采用分布式事务的情况下跨服务实现功能 l 跨服务实现要求功能要求团队之间的紧密协作 2.部署复杂 3.内存占用量更高
JDK 的 HashMap 中使用了一个 hash 方法来做 bit shifting,在注释中说明是为了防止一些实现比较差的hashCode() 方法,请问原理是什么?JDK 的源码参见:GrepCode: java.util.HashMap (.java) /** * Applies a supplemental hash function to a given hashCode, which * defends against poor quality hash functions. This is critical * because HashMap uses power-of-two length hash tables, that * otherwise encounter collisions for hashCodes that do not differ * in lower bits. Note: Null keys always map to hash 0, thus index 0. */ static int hash(int h) { // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } PS:网上看见有人说作者本人说原理需要参见圣经《计算机程序设计艺术》的 Vol.3 里头的介绍,不过木有看过神书,求达人介绍 这段代码叫“扰动函数”。 题主贴的是Java 7的HashMap的源码,Java 8中这步已经简化了,只做一次16位右位移异或混合,而不是四次,但原理是不变的。下面以Java 8的源码为例解释, //Java 8中的散列值优化函数staticfinalinthash(Objectkey){inth;return(key==null)?0:(h=key.hashCode())^(h>>>16);//key.hashCode()为哈希算法,返回初始哈希值} 大家都知道上面代码里的key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。理论上散列值是一个int型,如果直接拿散列值作为下标访问HashMap主数组的话,考虑到2进制32位带符号的int表值范围从-2147483648到2147483648。前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。你想,HashMap扩容之前的数组初始大小才16。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标。源码中模运算是在这个indexFor( )函数里完成的。 bucketIndex = indexFor(hash, table.length);indexFor的代码也很简单,就是把散列值和数组长度做一个"与"操作, static int indexFor(int h, int length) { return h & (length-1);}顺便说一下,这也正好解释了为什么HashMap的数组长度要取2的整次幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。 10100101 11000100 00100101& 00000000 00000000 00001111---------------------------------- 00000000 00000000 00000101 //高位全部归零,只保留末四位 但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,就无比蛋疼。这时候“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图, 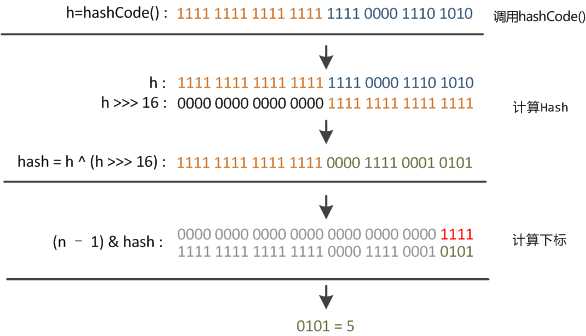 右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。最后我们来看一下PeterLawley的一篇专栏文章《An introduction to optimising a hashing strategy》里的的一个实验:他随机选取了352个字符串,在他们散列值完全没有冲突的前提下,对它们做低位掩码,取数组下标。 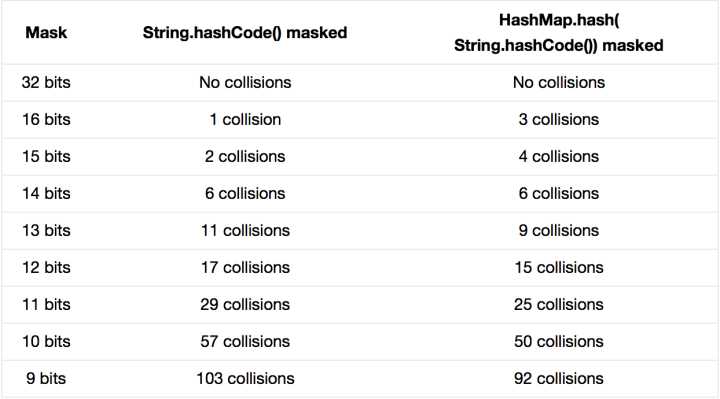 结果显示,当HashMap数组长度为512的时候,也就是用掩码取低9位的时候,在没有扰动函数的情况下,发生了103次碰撞,接近30%。而在使用了扰动函数之后只有92次碰撞。碰撞减少了将近10%。看来扰动函数确实还是有功效的。但明显Java 8觉得扰动做一次就够了,做4次的话,多了可能边际效用也不大,所谓为了效率考虑就改成一次了。 ------------------------------------------------------ https://www.zhihu.com/question/20733617
Go语言没有沿袭传统面向对象编程中的诸多概念,比如继承、虚函数、构造函数和析构函数、隐藏的this指针等。 方法 Go 语言中同时有函数和方法。方法就是一个包含了接受者(receiver)的函数,receiver可以是内置类型或者结构体类型的一个值或者是一个指针。所有给定类型的方法属于该类型的方法集。
如下面的这个例子,定义了一个新类型Integer,它和int一样,只是为它内置的int类型增加了个新方法Less() type Integer int func (a Integer) Less(b Integer) bool { return a < b } func main() { var a Integer = 1 if a.Less(2) { fmt.Println("less then 2") } } 可以看出,Go语言在自定义类型的对象中没有C++/Java那种隐藏的this指针,而是在定义成员方法时显式声明了其所属的对象。 method的语法如下: func (r ReceiverType) funcName(parameters) (results) 当调用method时,会将receiver作为函数的第一个参数: 所以,receiver是值类型还是指针类型要看method的作用。如果要修改对象的值,就需要传递对象的指针。 指针作为Receiver会对实例对象的内容发生操作,而普通类型作为Receiver仅仅是以副本作为操作对象,并不对原实例对象发生操作。 func (a *Ingeger) Add(b Integer) { *a += b } func main() { var a Integer = 1 a.Add(3) fmt.Println("a =", a) // a = 4 } 如果Add方法不使用指针,则a返回的结果不变,这是因为Go语言函数的参数也是基于值传递。 注意:当方法的接受者是指针时,即使用值类型调用那么方法内部也是对指针的操作。 之前说过,Go语言没有构造函数的概念,通常使用一个全局函数来完成。例如: func NewRect(x, y, width, height float64) *Rect { return &Rect{x, y, width, height} } func main() { rect1 := NewRect(1,2,10,20) fmt.Println(rect1.width) }
匿名组合 Go语言提供了继承,但是采用了组合的语法,我们将其称为匿名组合,例如: type Base struct { name string } func (base *Base) Set(myname string) { base.name = myname } func (base *Base) Get() string { return base.name } type Derived struct { Base age int } func (derived *Derived) Get() (nm string, ag int) { return derived.name, derived.age } func main() { b := &Derived{} b.Set("sina") fmt.Println(b.Get()) } 例子中,在Base类型定义了get()和set()两个方法,而Derived类型继承了Base类,并改写了Get()方法,在Derived对象调用Set()方法,会加载基类对应的方法;而调用Get()方法时,加载派生类改写的方法。 组合的类型和被组合的类型包含同名成员时, 会不会有问题呢?可以参考下面的例子: type Base struct { name string age int } func (base *Base) Set(myname string, myage int) { base.name = myname base.age = myage } type Derived struct { Base name string } func main() { b := &Derived{} b.Set("sina", 30) fmt.Println("b.name =",b.name, "\tb.Base.name =", b.Base.name) fmt.Println("b.age =",b.age, "\tb.Base.age =", b.Base.age) }
值语义和引用语义 值语义和引用语义的差别在于赋值,比如 如果b的修改不会影响a的值,那么此类型属于值类型;如果会影响a的值,那么此类型是引用类型。 Go语言中的大多数类型都基于值语义,包括: - 基本类型,如byte、int、bool、float32、string等;
- 复合类型,如arry、struct、pointer等;
C语言中的数组比较特别,通过函数传递一个数组的时候基于引用语义,但是在结构体定义数组变量的时候基于值语义。而在Go语言中,数组和基本类型没有区别,是很纯粹的值类型,例如: var a = [3] int{1,2,3} var b = a b[1]++ fmt.Println(a, b) // [1 2 3] [1 3 3] 从结果看,b=a赋值语句是数组内容的完整复制,要想表达引用,需要用指针: var a = [3] int{1,2,3} var b = &a // 引用语义 b[1]++ fmt.Println(a, b) // [1 3 3] [1 3 3]
接口 Interface 是一组抽象方法(未具体实现的方法/仅包含方法名参数返回值的方法)的集合,如果实现了 interface 中的所有方法,即该类/对象就实现了该接口。 Interface 的声明格式: type interfaceName interface { //方法列表 } Interface 可以被任意对象实现,一个类型/对象也可以实现多个 interface;
interface的变量可以持有任意实现该interface类型的对象。 如下面的例子:  package main import "fmt" type Human struct { name string age int phone string } type Student struct { Human //匿名字段 school string loan float32 } type Employee struct { Human //匿名字段 company string money float32 } //Human实现SayHi方法 func (h Human) SayHi() { fmt.Printf("Hi, I am %s you can call me on %s\n", h.name, h.phone) } //Human实现Sing方法 func (h Human) Sing(lyrics string) { fmt.Println("La la la la...", lyrics) } //Employee重载Human的SayHi方法 func (e Employee) SayHi() { fmt.Printf("Hi, I am %s, I work at %s. Call me on %s\n", e.name, e.company, e.phone) } // Interface Men被Human,Student和Employee实现 // 因为这三个类型都实现了这两个方法 type Men interface { SayHi() Sing(lyrics string) } func main() { mike := Student{Human{"Mike", 25, "222-222-XXX"}, "MIT", 0.00} paul := Student{Human{"Paul", 26, "111-222-XXX"}, "Harvard", 100} sam := Employee{Human{"Sam", 36, "444-222-XXX"}, "Golang Inc.", 1000} tom := Employee{Human{"Tom", 37, "222-444-XXX"}, "Things Ltd.", 5000} //定义Men类型的变量i var i Men //i能存储Student i = mike fmt.Println("This is Mike, a Student:") i.SayHi() i.Sing("November rain") //i也能存储Employee i = tom fmt.Println("This is tom, an Employee:") i.SayHi() i.Sing("Born to be wild") //定义了slice Men fmt.Println("Let's use a slice of Men and see what happens") x := make([]Men, 3) //这三个都是不同类型的元素,但是他们实现了interface同一个接口 x[0], x[1], x[2] = paul, sam, mike for _, value := range x{ value.SayHi() } } 空接口 空interface(interface{})不包含任何的method,正因为如此,所有的类型都实现了空interface。空interface对于描述起不到任何的作用(因为它不包含任何的method),但是空interface在我们需要存储任意类型的数值的时候相当有用,因为它可以存储任意类型的数值。它有点类似于C语言的void*类型。 // 定义a为空接口 var a interface{} var i int = 5 s := "Hello world" // a可以存储任意类型的数值 a = i a = s interface的变量里面可以存储任意类型的数值(该类型实现了interface),那么我们怎么反向知道这个interface变量里面实际保存了的是哪个类型的对象呢?目前常用的有两种方法:switch测试、Comma-ok断言。 switch测试如下: type Element interface{} type List [] Element type Person struct { name string age int } //打印 func (p Person) String() string { return "(name: " + p.name + " - age: "+strconv.Itoa(p.age)+ " years)" } func main() { list := make(List, 3) list[0] = 1 //an int list[1] = "Hello" //a string list[2] = Person{"Dennis", 70} for index, element := range list{ switch value := element.(type) { case int: fmt.Printf("list[%d] is an int and its value is %d\n", index, value) case string: fmt.Printf("list[%d] is a string and its value is %s\n", index, value) case Person: fmt.Printf("list[%d] is a Person and its value is %s\n", index, value) default: fmt.Println("list[%d] is of a different type", index) } } } 如果使用Comma-ok断言的话: func main() { list := make(List, 3) list[0] = 1 // an int list[1] = "Hello" // a string list[2] = Person{"Dennis", 70} for index, element := range list { if value, ok := element.(int); ok { fmt.Printf("list[%d] is an int and its value is %d\n", index, value) } else if value, ok := element.(string); ok { fmt.Printf("list[%d] is a string and its value is %s\n", index, value) } else if value, ok := element.(Person); ok { fmt.Printf("list[%d] is a Person and its value is %s\n", index, value) } else { fmt.Printf("list[%d] is of a different type\n", index) } } } 嵌入接口 正如struct类型可以包含一个匿名字段,interface也可以嵌套另外一个接口。 如果一个interface1作为interface2的一个嵌入字段,那么interface2隐式的包含了interface1里面的method。 反射 所谓反射(reflect)就是能检查程序在运行时的状态。 使用reflect一般分成三步,下面简要的讲解一下:要去反射是一个类型的值(这些值都实现了空interface),首先需要把它转化成reflect对象(reflect.Type或者reflect.Value,根据不同的情况调用不同的函数)。这两种获取方式如下: t := reflect.TypeOf(i) //得到类型的元数据,通过t我们能获取类型定义里面的所有元素 v := reflect.ValueOf(i) //得到实际的值,通过v我们获取存储在里面的值,还可以去改变值 转化为reflect对象之后我们就可以进行一些操作了,也就是将reflect对象转化成相应的值,例如 tag := t.Elem().Field(0).Tag //获取定义在struct里面的标签 name := v.Elem().Field(0).String() //获取存储在第一个字段里面的值 获取反射值能返回相应的类型和数值 var x float64 = 3.4 v := reflect.ValueOf(x) fmt.Println("type:", v.Type()) fmt.Println("kind is float64:", v.Kind() == reflect.Float64) fmt.Println("value:", v.Float()) 最后,反射的话,那么反射的字段必须是可修改的,我们前面学习过传值和传引用,这个里面也是一样的道理。反射的字段必须是可读写的意思是,如果下面这样写,那么会发生错误 var x float64 = 3.4 v := reflect.ValueOf(x) v.SetFloat(7.1) 如果要修改相应的值,必须这样写 var x float64 = 3.4 p := reflect.ValueOf(&x) v := p.Elem() v.SetFloat(7.1) 上面只是对反射的简单介绍,更深入的理解还需要自己在编程中不断的实践。 参考文档: http://se77en.cc/2014/05/05/methods-interfaces-and-embedded-types-in-golang/ http://se77en.cc/2014/05/04/choose-whether-to-use-a-value-or-pointer-receiver-on-methods/
http://www.cnblogs.com/chenny7/p/4497969.html
不可或缺的函数,在Go中定义函数的方式如下: func (p myType ) funcName ( a, b int , c string ) ( r , s int ) { return }
通过函数定义,我们可以看到Go中函数和其他语言中的共性和特性 共性- 关键字——func
- 方法名——funcName
- 入参——— a,b int,b string
- 返回值—— r,s int
- 函数体—— {}
特性Go中函数的特性是非常酷的,给我们带来不一样的编程体验。 为特定类型定义函数,即为类型对象定义方法在Go中通过给函数标明所属类型,来给该类型定义方法,上面的 p myType 即表示给myType声明了一个方法, p myType 不是必须的。如果没有,则纯粹是一个函数,通过包名称访问。packageName.funcationName 如: //定义新的类型double,主要目的是给float64类型扩充方法 type double float64 //判断a是否等于b func (a double) IsEqual(b double) bool { var r = a - b if r == 0.0 { return true } else if r < 0.0 { return r > -0.0001 } return r < 0.0001 } //判断a是否等于b func IsEqual(a, b float64) bool { var r = a - b if r == 0.0 { return true } else if r < 0.0 { return r > -0.0001 } return r < 0.0001 } func main() { var a double = 1.999999 var b double = 1.9999998 fmt.Println(a.IsEqual(b)) fmt.Println(a.IsEqual(3)) fmt.Println( IsEqual( (float64)(a), (float64)(b) ) ) }
上述示例为 float64 基本类型扩充了方法IsEqual,该方法主要是解决精度问题。 其方法调用方式为: a.IsEqual(double) ,如果不扩充方法,我们只能使用函数IsEqual(a, b float64) 入参中,如果连续的参数类型一致,则可以省略连续多个参数的类型,只保留最后一个类型声明。如 func IsEqual(a, b float64) bool 这个方法就只保留了一个类型声明,此时入参a和b均是float64数据类型。 这样也是可以的: func IsEqual(a, b float64, accuracy int) bool 变参:入参支持变参,即可接受不确定数量的同一类型的参数如 func Sum(args ...int) 参数args是的slice,其元素类型为int 。经常使用的fmt.Printf就是一个接受任意个数参数的函数 fmt.Printf(format string, args ...interface{}) 支持多返回值前面我们定义函数时返回值有两个r,s 。这是非常有用的,我在写C#代码时,常常为了从已有函数中获得更多的信息,需要修改函数签名,使用out ,ref 等方式去获得更多返回结果。而现在使用Go时则很简单,直接在返回值后面添加返回参数即可。 如,在C#中一个字符串转换为int类型时逻辑代码 int v=0; if ( int.TryPase("123456",out v) ) { //code }
而在Go中,则可以这样实现,逻辑精简而明确 if v,isOk :=int.TryPase("123456") ; isOk { //code }
同时在Go中很多函数充分利用了多返回值 - func (file *File) Write(b []byte) (n int, err error)
- func Sincos(x float64) (sin, cos float64)
那么如果我只需要某一个返回值,而不关心其他返回值的话,我该如何办呢? 这时可以简单的使用符号下划线”_“ 来忽略不关心的返回值。如: _, cos = math.Sincos(3.1415) //只需要cos计算的值
命名返回值前面我们说了函数可以有多个返回值,这里我还要说的是,在函数定义时可以给所有的返回值分别命名,这样就能在函数中任意位置给不同返回值复制,而不需要在return语句中才指定返回值。同时也能增强可读性,也提高godoc所生成文档的可读性 如果不支持命名返回值,我可能会是这样做的 func ReadFull(r Reader, buf []byte) (int, error) { var n int var err error for len(buf) > 0 { var nr int nr, err = r.Read(buf) n += nr if err !=nil { return n,err } buf = buf[nr:] } return n,err }
但支持给返回值命名后,实际上就是省略了变量的声明,return时无需写成return n,err 而是将直接将值返回 func ReadFull(r Reader, buf []byte) (n int, err error) { for len(buf) > 0 && err == nil { var nr int nr, err = r.Read(buf) n += nr buf = buf[nr:] } return }
函数也是“值”和Go中其他东西一样,函数也是值,这样就可以声明一个函数类型的变量,将函数作为参数传递。 声明函数为值的变量(匿名函数:可赋值个变量,也可直接执行) //赋值 fc := func(msg string) { fmt.Println("you say :", msg) } fmt.Printf("%T \n", fc) fc("hello,my love") //直接执行 func(msg string) { fmt.Println("say :", msg) }("I love to code")
输出结果如下,这里表明fc 的类型为:func(string) func(string) you say : hello,my love say : I love to code
将函数作为入参(回调函数),能带来便利。如日志处理,为了统一处理,将信息均通过指定函数去记录日志,且是否记录日志还有开关 func Log(title string, getMsg func() string) { //如果开启日志记录,则记录日志 if true { fmt.Println(title, ":", getMsg()) } } //---------调用-------------- count := 0 msg := func() string { count++ return "您没有即使提醒我,已触犯法律" } Log("error", msg) Log("warring", msg) Log("info", msg) fmt.Println(count)
这里输出结果如下,count 也发生了变化 error : 您没有即使提醒我,已触犯法律 warring : 您没有即使提醒我,已触犯法律 info : 您没有即使提醒我,已触犯法律 3
函数也是“类型”你有没有注意到上面示例中的 fc := func(msg string)... ,既然匿名函数可以赋值给一个变量,同时我们经常这样给int赋值 value := 2 ,是否我们可以声明func(string) 类型 呢,当然是可以的。 //一个记录日志的类型:func(string) type saveLog func(msg string) //将字符串转换为int64,如果转换失败调用saveLog func stringToInt(s string, log saveLog) int64 { if value, err := strconv.ParseInt(s, 0, 0); err != nil { log(err.Error()) return 0 } else { return value } } //记录日志消息的具体实现 func myLog(msg string) { fmt.Println("Find Error:", msg) } func main() { stringToInt("123", myLog) //转换时将调用mylog记录日志 stringToInt("s", myLog) }
这里我们定义了一个类型,专门用作记录日志的标准接口。在stringToInt函数中如果转换失败则调用我自己定义的接口函数进行日志处理,至于最终执行的哪个函数,则无需关心。 defer 延迟函数defer 又是一个创新,它的作用是:延迟执行,在声明时不会立即执行,而是在函数return后时按照后进先出的原则依次执行每一个defer。这样带来的好处是,能确保我们定义的函数能百分之百能够被执行到,这样就能做很多我们想做的事,如释放资源,清理数据,记录日志等 这里我们重点来说明下defer的执行顺序 func deferFunc() int { index := 0 fc := func() { fmt.Println(index, "匿名函数1") index++ defer func() { fmt.Println(index, "匿名函数1-1") index++ }() } defer func() { fmt.Println(index, "匿名函数2") index++ }() defer fc() return func() int { fmt.Println(index, "匿名函数3") index++ return index }() } func main() { deferFunc() }
这里输出结果如下, 0 匿名函数3 1 匿名函数1 2 匿名函数1-1 3 匿名函数2
有如下结论: - defer 是在执行完return 后执行
- defer 后进先执行
另外,我们常使用defer去关闭IO,在正常打开文件后,就立刻声明一个defer,这样就不会忘记关闭文件,也能保证在出现异常等不可预料的情况下也能关闭文件。而不像其他语言:try-catch 或者 using() 方式进行处理。 file , err :=os.Open(file) if err != nil { return err } defer file.Close() //dosomething with file
后续,我将讨论: 作用域、传值和传指针 以及 保留函数init(),main() 本笔记中所写代码存储位置:
以前关注的数据存储过程不太懂其中奥妙,最近遇到跨数据库,同时对多个表进行CURD(Create增、Update改、Read读、Delete删),怎么才能让繁琐的数据CURD同步变得更容易呢?相信很多人会首先想到了MySQL存储过程、触发器,这种想法确实不错。于是饶有兴趣地亲自写了CUD(增、改、删)触发器的实例,用触发器实现多表数据同步更新。  定义: 何为MySQL触发器? 在MySQL Server里面也就是对某一个表的一定的操作,触发某种条件(Insert,Update,Delete 等),从而自动执行的一段程序。从这种意义上讲触发器是一个特殊的存储过程。下面通过MySQL触发器实例,来了解一下触发器的工作过程吧! 一、创建MySQL实例数据表: 在mysql的默认的测试test数据库下,创建两个表t_a与t_b:
/*Table structure for table `t_a` */
DROP TABLE IF EXISTS `t_a`;
CREATE TABLE `t_a` (
`id` smallint(1) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`groupid` mediumint(8) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=16 DEFAULT CHARSET=latin1;
/*Data for the table `t_a` */
LOCK TABLES `t_a` WRITE;
UNLOCK TABLES;
/*Table structure for table `t_b` */
DROP TABLE IF EXISTS `t_b`;
CREATE TABLE `t_b` (
`id` smallint(1) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`groupid` mediumint(8) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=57 DEFAULT CHARSET=latin1;
/*Data for the table `t_b` */
LOCK TABLES `t_b` WRITE;
UNLOCK TABLES;
在t_a表上分创建一个CUD(增、改、删)3个触发器,将t_a的表数据与t_b同步实现CUD,注意创建触发器每个表同类事件有且仅有一个对应触发器,为什么只能对一个触发器,不解释啦,看MYSQL的说明帮助文档吧。 二、创建MySQL实例触发器: 在实例数据表t_a上依次按照下面步骤创建tr_a_insert、tr_a_update、tr_a_delete三个触发器 1、创建INSERT触发器trigger_a_insert:
DELIMITER $$
USE `test`$$
--判断数据库中是否存在tr_a_insert触发器
DROP TRIGGER /*!50032 IF EXISTS */ `tr_a_insert`$$
--不存在tr_a_insert触发器,开始创建触发器
--Trigger触发条件为insert成功后进行触发
CREATE
/*!50017 DEFINER = 'root'@'localhost' */
TRIGGER `tr_a_insert` AFTER INSERT ON `t_a`
FOR EACH ROW BEGIN
--Trigger触发后,同时对t_b新增同步一条数据
INSERT INTO `t_b` SET username = NEW.username, groupid=NEW.groupid;
END;
$$
DELIMITER;
2、创建UPDATE触发器trigger_a_update:
DELIMITER $$
USE `test`$$
--判断数据库中是否存在tr_a_update触发器
DROP TRIGGER /*!50032 IF EXISTS */ `tr_a_update`$$
--不存在tr_a_update触发器,开始创建触发器
--Trigger触发条件为update成功后进行触发
CREATE
/*!50017 DEFINER = 'root'@'localhost' */
TRIGGER `tr_a_update` AFTER UPDATE ON `t_a`
FOR EACH ROW BEGIN
--Trigger触发后,当t_a表groupid,username数据有更改时,对t_b表同步一条更新后的数据
IF new.groupid != old.groupid OR old.username != new.username THEN
UPDATE `t_b` SET groupid=NEW.groupid,username=NEW.username WHEREusername=OLD.username AND groupid=OLD.groupid;
END IF;
END;
$$
DELIMITER ;
3、创建DELETE触发器trigger_a_delete:
DELIMITER $$
USE `test`$$
--判断数据库中是否存在tr_a_delete触发器
DROP TRIGGER /*!50032 IF EXISTS */ `tr_a_delete`$$
--不存在tr_a_delete触发器,开始创建触发器
--Trigger触发条件为delete成功后进行触发
CREATE
/*!50017 DEFINER = 'root'@'localhost' */
TRIGGER `tr_a_delete` AFTER DELETE ON `t_a`
FOR EACH ROW BEGIN
--t_a表数据删除后,t_b表关联条件相同的数据也同步删除
DELETE FROM `t_b` WHERE username=Old.username AND groupid=OLD.groupid;
END;
$$
DELIMITER ;
三、测试MySQL实例触发器: 分别测试实现t_a与t_b实现数据同步CUD(增、改、删)3个Triggers 1、测试MySQL的实例tr_a_insert触发器: 在t_a表中新增一条数据,然后分别查询t_a/t_b表的数据是否数据同步,测试触发器成功标志,t_a表无论在何种情况下,新增了一条或多条记录集时,没有t_b表做任何数据insert操作,它同时新增了一样的多条记录集。 下面来进行MySQL触发器实例测试:
--t_a表新增一条记录集
INSERT INTO `t_a` (username,groupid) VALUES ('sky54.net',123)
--查询t_a表
SELECT id,username,groupid FROM `t_a`
--查询t_b表
SELECT id,username,groupid FROM `t_b`
2、测试MySQL的实例tr_a_update、tr_a_delete触发器: 这两个MySQL触发器测试原理、步骤与tr_a_insert触发器一样的,先修改/删除一条数据,然后分别查看t_a、t_b表的数据变化情况,数据变化同步说明Trigger实例成功,否则需要逐步排查错误原因。 世界上任何一种事物都其其优点和缺点,优点与缺点是自身一个相对立的面。当然这里不是强调“世界非黑即白”式的“二元论”,“存在即合理”嘛。当然 MySQL触发器的优点不说了,说一下不足之处,MySQL Trigger没有很好的调试、管理环境,难于在各种系统环境下测试,测试比MySQL存储过程要难,所以建议在生成环境下,尽量用存储过程来代替 MySQL触发器。 本篇结束前再强调一下,支持触发器的MySQL版本需要5.0以上,5.0以前版本的MySQL升级到5.0以后版本方可使用触发器哦! http://blog.csdn.net/hireboy/article/details/18079183
摘要: 在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。缓存的目的是提升系统访问速度和增大系统能处理的容量,可谓是抗高并发流量的银弹;而降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉,待高峰或者问题解决后再打开;而有些场景并不能用缓存和降级来解决,比如稀缺资源(秒杀、抢购)、写服务(如评论、下单)、频繁的复杂查询(评论的最后几页),因此需有一种手段来限制这些场景的并发/请求量,即限... 阅读全文
Install the Command Line ClientIf you prefer command line client, then you can install it on your Linux with the following command. Debiansudo apt-get install python-pip sudo pip install shadowsocks UbuntuYes, you can use the above commands to install shadowsocks client on ubuntu. But it will install it under ~/.local/bin/ directory and it causes loads of trouble. So I suggest using su to become root first and then issue the following two commands. apt-get install python-pip pip install shadowsocks Fedora/Centossudo yum install python-setuptools or sudo dnf install python-setuptools sudo easy_install pip sudo pip install shadowsocks OpenSUSEsudo zypper install python-pip sudo pip install shadowsocks Archlinuxsudo pacman -S python-pip sudo pip install shadowsocks As you can see the command of installing shadowsocks client is the same to the command of installing shadowsocks server, because the above command will install both the client and the server. You can verify this by looking at the installation script output Downloading/unpacking shadowsocks Downloading shadowsocks-2.8.2.tar.gz Running setup.py (path:/tmp/pip-build-PQIgUg/shadowsocks/setup.py) egg_info for package shadowsocks Installing collected packages: shadowsocks Running setup.py install for shadowsocks Installing sslocal script to /usr/local/bin Installing ssserver script to /usr/local/bin Successfully installed shadowsocks Cleaning up... sslocal is the client software and ssserver is the server software. On some Linux distros such as ubuntu, the shadowsocks client sslocal is installed under /usr/local/bin. On Others such as Archsslocal is installed under /usr/bin/. Your can use whereis command to find the exact location. user@debian:~$ whereis sslocal sslocal: /usr/local/bin/sslocal Create a Configuration Filewe will create a configuration file under /etc/ sudo vi /etc/shadowsocks.json Put the following text in the file. Replace server-ip with your actual IP and set a password. {
"server":"server-ip",
"server_port":8000,
"local_address": "127.0.0.1",
"local_port":1080,
"password":"your-password",
"timeout":600,
"method":"aes-256-cfb"
}Save and close the file. Next start the client using command line sslocal -c /etc/shadowsocks.json To run in the backgroundsudo sslocal -c /etc/shadowsocks.json -d start Auto Start the Client on System BootEdit /etc/rc.local file sudo vi /etc/rc.local Put the following line above the exit 0 line: sudo sslocal -c /etc/shadowsocks.json -d start Save and close the file. Next time you start your computer, shadowsocks client will automatically start and connect to your shadowsocks server. Check if It WorksAfter you rebooted your computer, enter the following command in terminal: sudo systemctl status rc-local.service If your sslocal command works then you will get this ouput: ● rc-local.service - /etc/rc.local
Compatibility Loaded: loaded (/etc/systemd/system/rc-local.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2015-11-27 03:19:25 CST; 2min 39s ago
Process: 881 ExecStart=/etc/rc.local start (code=exited, status=0/SUCCESS)
CGroup: /system.slice/rc-local.service
├─ 887 watch -n 60 su matrix -c ibam
└─1112 /usr/bin/python /usr/local/bin/sslocal -c /etc/shadowsocks.... As you can see from the last line, the sslocal command created a process whose pid is 1112 on my machine. It means shadowsocks client is running smoothly. And of course you can tell your browser to connect through your shadowsocks client to see if everything goes well. If for some reason your /etc/rc.local script won’t run, then check the following post to find the solution. If you prefer command line client, then you can install it on your Linux with the following command. Debiansudo apt-get install python-pip
sudo pip install shadowsocks
UbuntuYes, you can use the above commands to install shadowsocks client on ubuntu. But it will install it under ~/.local/bin/ directory and it causes loads of trouble. So I suggest using su to become root first and then issue the following two commands. apt-get install python-pip
pip install shadowsocks Fedora/Centossudo yum install python-setuptools or sudo dnf install python-setuptools
sudo easy_install pip
sudo pip install shadowsocks
OpenSUSEsudo zypper install python-pip
sudo pip install shadowsocks
Archlinuxsudo pacman -S python-pip
sudo pip install shadowsocks
As you can see the command of installing shadowsocks client is the same to the command of installing shadowsocks server, because the above command will install both the client and the server. You can verify this by looking at the installation script output Downloading/unpacking shadowsocks
Downloading shadowsocks-2.8.2.tar.gz
Running setup.py (path:/tmp/pip-build-PQIgUg/shadowsocks/setup.py) egg_info for package shadowsocks
Installing collected packages: shadowsocks
Running setup.py install for shadowsocks
Installing sslocal script to /usr/local/bin
Installing ssserver script to /usr/local/bin
Successfully installed shadowsocks
Cleaning up... sslocal is the client software and ssserver is the server software. On some Linux distros such as ubuntu, the shadowsocks client sslocal is installed under /usr/local/bin. On Others such as Archsslocal is installed under /usr/bin/. Your can use whereis command to find the exact location. user@debian:~$ whereis sslocal
sslocal: /usr/local/bin/sslocal Create a Configuration Filewe will create a configuration file under /etc/ sudo vi /etc/shadowsocks.json Put the following text in the file. Replace server-ip with your actual IP and set a password. {
"server":"server-ip",
"server_port":8000,
"local_address": "127.0.0.1",
"local_port":1080,
"password":"your-password",
"timeout":600,
"method":"aes-256-cfb"
}Save and close the file. Next start the client using command line sslocal -c /etc/shadowsocks.json To run in the backgroundsudo sslocal -c /etc/shadowsocks.json -d start
Auto Start the Client on System BootEdit /etc/rc.local file sudo vi /etc/rc.local Put the following line above the exit 0 line: sudo sslocal -c /etc/shadowsocks.json -d start Save and close the file. Next time you start your computer, shadowsocks client will automatically start and connect to your shadowsocks server. Check if It WorksAfter you rebooted your computer, enter the following command in terminal: sudo systemctl status rc-local.service If your sslocal command works then you will get this ouput: ● rc-local.service - /etc/rc.local Compatibility
Loaded: loaded (/etc/systemd/system/rc-local.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2015-11-27 03:19:25 CST; 2min 39s ago
Process: 881 ExecStart=/etc/rc.local start (code=exited, status=0/SUCCESS)
CGroup: /system.slice/rc-local.service
├─ 887 watch -n 60 su matrix -c ibam
└─1112 /usr/bin/python /usr/local/bin/sslocal -c /etc/shadowsocks.... As you can see from the last line, the sslocal command created a process whose pid is 1112 on my machine. It means shadowsocks client is running smoothly. And of course you can tell your browser to connect through your shadowsocks client to see if everything goes well. If for some reason your /etc/rc.local script won’t run, then check the following post to find the solution. How to enable /etc/rc.local with Systemd
废话少说,直接上代码,以前都是调用别人写好的,现在有时间自己弄下,具体功能如下: 1、httpClient+http+线程池: 2、httpClient+https(单向不验证证书)+线程池: https在%TOMCAT_HOME%/conf/server.xml里面的配置文件 <Connector port="8443" protocol="HTTP/1.1" SSLEnabled="true" maxThreads="150" scheme="https" secure="true" clientAuth="false" keystoreFile="D:/tomcat.keystore" keystorePass="heikaim" sslProtocol="TLS" executor="tomcatThreadPool"/> 其中 clientAuth="false"表示不开启证书验证,只是单存的走https package com.abin.lee.util;
import org.apache.commons.collections4.MapUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.http.*;
import org.apache.http.client.HttpRequestRetryHandler;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.config.Registry;
import org.apache.http.config.RegistryBuilder;
import org.apache.http.conn.ConnectTimeoutException;
import org.apache.http.conn.socket.ConnectionSocketFactory;
import org.apache.http.conn.socket.PlainConnectionSocketFactory;
import org.apache.http.conn.ssl.NoopHostnameVerifier;
import org.apache.http.conn.ssl.SSLConnectionSocketFactory;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.message.BasicHeader;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.protocol.HttpContext;
import org.apache.http.util.EntityUtils;
import javax.net.ssl.*;
import java.io.IOException;
import java.io.InterruptedIOException;
import java.net.UnknownHostException;
import java.nio.charset.Charset;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.util.*;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 16-4-18
* Time: 上午10:24
* To change this template use File | Settings | File Templates.
*/
public class HttpClientUtil {
private static CloseableHttpClient httpsClient = null;
private static CloseableHttpClient httpClient = null;
static {
httpClient = getHttpClient();
httpsClient = getHttpsClient();
}
public static CloseableHttpClient getHttpClient() {
try {
httpClient = HttpClients.custom()
.setConnectionManager(PoolManager.getHttpPoolInstance())
.setConnectionManagerShared(true)
.setDefaultRequestConfig(requestConfig())
.setRetryHandler(retryHandler())
.build();
} catch (Exception e) {
e.printStackTrace();
}
return httpClient;
}
public static CloseableHttpClient getHttpsClient() {
try {
//Secure Protocol implementation.
SSLContext ctx = SSLContext.getInstance("SSL");
//Implementation of a trust manager for X509 certificates
TrustManager x509TrustManager = new X509TrustManager() {
public void checkClientTrusted(X509Certificate[] xcs,
String string) throws CertificateException {
}
public void checkServerTrusted(X509Certificate[] xcs,
String string) throws CertificateException {
}
public X509Certificate[] getAcceptedIssuers() {
return null;
}
};
ctx.init(null, new TrustManager[]{x509TrustManager}, null);
//首先设置全局的标准cookie策略
// RequestConfig requestConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD_STRICT).build();
ConnectionSocketFactory connectionSocketFactory = new SSLConnectionSocketFactory(ctx, hostnameVerifier);
Registry<ConnectionSocketFactory> socketFactoryRegistry = RegistryBuilder.<ConnectionSocketFactory>create()
.register("http", PlainConnectionSocketFactory.INSTANCE)
.register("https", connectionSocketFactory).build();
// 设置连接池
httpsClient = HttpClients.custom()
.setConnectionManager(PoolsManager.getHttpsPoolInstance(socketFactoryRegistry))
.setConnectionManagerShared(true)
.setDefaultRequestConfig(requestConfig())
.setRetryHandler(retryHandler())
.build();
} catch (Exception e) {
e.printStackTrace();
}
return httpsClient;
}
// 配置请求的超时设置
//首先设置全局的标准cookie策略
public static RequestConfig requestConfig(){
RequestConfig requestConfig = RequestConfig.custom()
.setCookieSpec(CookieSpecs.STANDARD_STRICT)
.setConnectionRequestTimeout(20000)
.setConnectTimeout(20000)
.setSocketTimeout(20000)
.build();
return requestConfig;
}
public static HttpRequestRetryHandler retryHandler(){
//请求重试处理
HttpRequestRetryHandler httpRequestRetryHandler = new HttpRequestRetryHandler() {
public boolean retryRequest(IOException exception,int executionCount, HttpContext context) {
if (executionCount >= 5) {// 如果已经重试了5次,就放弃
return false;
}
if (exception instanceof NoHttpResponseException) {// 如果服务器丢掉了连接,那么就重试
return true;
}
if (exception instanceof SSLHandshakeException) {// 不要重试SSL握手异常
return false;
}
if (exception instanceof InterruptedIOException) {// 超时
return false;
}
if (exception instanceof UnknownHostException) {// 目标服务器不可达
return false;
}
if (exception instanceof ConnectTimeoutException) {// 连接被拒绝
return false;
}
if (exception instanceof SSLException) {// ssl握手异常
return false;
}
HttpClientContext clientContext = HttpClientContext.adapt(context);
HttpRequest request = clientContext.getRequest();
// 如果请求是幂等的,就再次尝试
if (!(request instanceof HttpEntityEnclosingRequest)) {
return true;
}
return false;
}
};
return httpRequestRetryHandler;
}
//创建HostnameVerifier
//用于解决javax.net.ssl.SSLException: hostname in certificate didn't match: <123.125.97.66> != <123.125.97.241>
static HostnameVerifier hostnameVerifier = new NoopHostnameVerifier(){
@Override
public boolean verify(String s, SSLSession sslSession) {
return super.verify(s, sslSession);
}
};
public static class PoolManager {
public static PoolingHttpClientConnectionManager clientConnectionManager = null;
private static int maxTotal = 200;
private static int defaultMaxPerRoute = 100;
private PoolManager(){
clientConnectionManager.setMaxTotal(maxTotal);
clientConnectionManager.setDefaultMaxPerRoute(defaultMaxPerRoute);
}
private static class PoolManagerHolder{
public static PoolManager instance = new PoolManager();
}
public static PoolManager getInstance() {
if(null == clientConnectionManager)
clientConnectionManager = new PoolingHttpClientConnectionManager();
return PoolManagerHolder.instance;
}
public static PoolingHttpClientConnectionManager getHttpPoolInstance() {
PoolManager.getInstance();
// System.out.println("getAvailable=" + clientConnectionManager.getTotalStats().getAvailable());
// System.out.println("getLeased=" + clientConnectionManager.getTotalStats().getLeased());
// System.out.println("getMax=" + clientConnectionManager.getTotalStats().getMax());
// System.out.println("getPending="+clientConnectionManager.getTotalStats().getPending());
return PoolManager.clientConnectionManager;
}
}
public static class PoolsManager {
public static PoolingHttpClientConnectionManager clientConnectionManager = null;
private static int maxTotal = 200;
private static int defaultMaxPerRoute = 100;
private PoolsManager(){
clientConnectionManager.setMaxTotal(maxTotal);
clientConnectionManager.setDefaultMaxPerRoute(defaultMaxPerRoute);
}
private static class PoolsManagerHolder{
public static PoolsManager instance = new PoolsManager();
}
public static PoolsManager getInstance(Registry<ConnectionSocketFactory> socketFactoryRegistry) {
if(null == clientConnectionManager)
clientConnectionManager = new PoolingHttpClientConnectionManager(socketFactoryRegistry);
return PoolsManagerHolder.instance;
}
public static PoolingHttpClientConnectionManager getHttpsPoolInstance(Registry<ConnectionSocketFactory> socketFactoryRegistry) {
PoolsManager.getInstance(socketFactoryRegistry);
// System.out.println("getAvailable=" + clientConnectionManager.getTotalStats().getAvailable());
// System.out.println("getLeased=" + clientConnectionManager.getTotalStats().getLeased());
// System.out.println("getMax=" + clientConnectionManager.getTotalStats().getMax());
// System.out.println("getPending="+clientConnectionManager.getTotalStats().getPending());
return PoolsManager.clientConnectionManager;
}
}
public static String httpPost(Map<String, String> request, String httpUrl){
String result = "";
CloseableHttpClient httpClient = getHttpClient();
try {
if(MapUtils.isEmpty(request))
throw new Exception("请求参数不能为空");
HttpPost httpPost = new HttpPost(httpUrl);
List<NameValuePair> nvps = new ArrayList<NameValuePair>();
for(Iterator<Map.Entry<String, String>> iterator=request.entrySet().iterator(); iterator.hasNext();){
Map.Entry<String, String> entry = iterator.next();
nvps.add(new BasicNameValuePair(entry.getKey(), entry.getValue()));
}
httpPost.setEntity(new UrlEncodedFormEntity(nvps, Consts.UTF_8));
System.out.println("Executing request: " + httpPost.getRequestLine());
CloseableHttpResponse response = httpClient.execute(httpPost);
result = EntityUtils.toString(response.getEntity());
System.out.println("Executing response: "+ result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
public static String httpPost(String json, String httpUrl, Map<String, String> headers){
String result = "";
CloseableHttpClient httpClient = getHttpClient();
try {
if(StringUtils.isBlank(json))
throw new Exception("请求参数不能为空");
HttpPost httpPost = new HttpPost(httpUrl);
for(Iterator<Map.Entry<String, String>> iterator=headers.entrySet().iterator();iterator.hasNext();){
Map.Entry<String, String> entry = iterator.next();
Header header = new BasicHeader(entry.getKey(), entry.getValue());
httpPost.setHeader(header);
}
httpPost.setEntity(new StringEntity(json, Charset.forName("UTF-8")));
System.out.println("Executing request: " + httpPost.getRequestLine());
CloseableHttpResponse response = httpClient.execute(httpPost);
result = EntityUtils.toString(response.getEntity());
System.out.println("Executing response: "+ result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
public static String httpGet(String httpUrl, Map<String, String> headers) {
String result = "";
CloseableHttpClient httpClient = getHttpClient();
try {
HttpGet httpGet = new HttpGet(httpUrl);
System.out.println("Executing request: " + httpGet.getRequestLine());
for(Iterator<Map.Entry<String, String>> iterator=headers.entrySet().iterator();iterator.hasNext();){
Map.Entry<String, String> entry = iterator.next();
Header header = new BasicHeader(entry.getKey(), entry.getValue());
httpGet.setHeader(header);
}
CloseableHttpResponse response = httpClient.execute(httpGet);
result = EntityUtils.toString(response.getEntity());
System.out.println("Executing response: "+ result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
public static String httpGet(String httpUrl) {
String result = "";
CloseableHttpClient httpClient = getHttpClient();
try {
HttpGet httpGet = new HttpGet(httpUrl);
System.out.println("Executing request: " + httpGet.getRequestLine());
CloseableHttpResponse response = httpClient.execute(httpGet);
result = EntityUtils.toString(response.getEntity());
System.out.println("Executing response: "+ result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
maven依赖: <!--httpclient--> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpcore</artifactId> <version>4.4.4</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpmime</artifactId> <version>4.5.2</version> </dependency> <dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.1</version>
</dependency>
1、twemproxy explore 当我们有大量 Redis 或 Memcached 的时候,通常只能通过客户端的一些数据分配算法(比如一致性哈希),来实现集群存储的特性。虽然Redis 2.6版本已经发布Redis Cluster,但还不是很成熟适用正式生产环境。 Redis 的 Cluster 方案还没有正式推出之前,我们通过 Proxy 的方式来实现集群存储。 Twitter,世界最大的Redis集群之一部署在Twitter用于为用户提供时间轴数据。Twitter Open Source部门提供了Twemproxy。 Twemproxy,也叫nutcraker。是一个twtter开源的一个redis和memcache代理服务器。 redis作为一个高效的缓存服务器,非常具有应用价值。但是当使用比较多的时候,就希望可以通过某种方式 统一进行管理。避免每个应用每个客户端管理连接的松散性。同时在一定程度上变得可以控制。 Twemproxy是一个快速的单线程代理程序,支持Memcached ASCII协议和更新的Redis协议: 它全部用C写成,使用Apache 2.0 License授权。项目在Linux上可以工作,而在OSX上无法编译,因为它依赖了epoll API. Twemproxy 通过引入一个代理层,可以将其后端的多台 Redis 或 Memcached 实例进行统一管理与分配,使应用程序只需要在 Twemproxy 上进行操作,而不用关心后面具体有多少个真实的 Redis 或 Memcached 存储。 2、twemproxy特性: 另外可以修改redis的源代码,抽取出redis中的前半部分,作为一个中间代理层。最终都是通过linux下的epoll 事件机制提高并发效率,其中nutcraker本身也是使用epoll的事件机制。并且在性能测试上的表现非常出色。 3、twemproxy问题与不足
Twemproxy 由于其自身原理限制,有一些不足之处,如: - 不支持针对多个值的操作,比如取sets的子交并补等(MGET 和 DEL 除外)
- 不支持Redis的事务操作
- 出错提示还不够完善
- 也不支持select操作
4、安装与配置 Twemproxy 的安装,主要命令如下: apt-get install automake
apt-get install libtool
git clone git://github.com/twitter/twemproxy.git
cd twemproxy
autoreconf -fvi
./configure --enable-debug=log
make
src/nutcracker -h
通过上面的命令就算安装好了,然后是具体的配置,下面是一个典型的配置 redis1:
listen: 127.0.0.1:6379 #使用哪个端口启动Twemproxy
redis: true #是否是Redis的proxy
hash: fnv1a_64 #指定具体的hash函数
distribution: ketama #具体的hash算法
auto_eject_hosts: true #是否在结点无法响应的时候临时摘除结点
timeout: 400 #超时时间(毫秒)
server_retry_timeout: 2000 #重试的时间(毫秒)
server_failure_limit: 1 #结点故障多少次就算摘除掉
servers: #下面表示所有的Redis节点(IP:端口号:权重)
- 127.0.0.1:6380:1
- 127.0.0.1:6381:1
- 127.0.0.1:6382:1
redis2:
listen: 0.0.0.0:10000
redis: true
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: false
timeout: 400
servers:
- 127.0.0.1:6379:1
- 127.0.0.1:6380:1
- 127.0.0.1:6381:1
- 127.0.0.1:6382:1 你可以同时开启多个 Twemproxy 实例,它们都可以进行读写,这样你的应用程序就可以完全避免所谓的单点故障。
http://blog.csdn.net/hguisu/article/details/9174459/
Linux is a powerhouse when it comes to networking, and provides a full featured and high performance network stack. When combined with web front-ends such asHAProxy, lighttpd, Nginx, Apache or your favorite application server, Linux is a killer platform for hosting web applications. Keeping these applications up and operational can sometimes be a challenge, especially in this age of horizontally scaled infrastructure and commodity hardware. But don't fret, since there are a number of technologies that can assist with making your applications and network infrastructure fault tolerant. One of these technologies, keepalived, provides interface failover and the ability to perform application-layer health checks. When these capabilities are combined with the Linux Virtual Server (LVS) project, a fault in an application will be detected by keepalived, and the virtual interfaces that are accessed by clients can be migrated to another available node. This article will provide an introduction to keepalived, and will show how to configure interface failover between two or more nodes. Additionally, the article will show how to debug problems with keepalived and VRRP. What Is Keepalived?
The keepalived project provides a keepalive facility for Linux servers. This keepalive facility consists of a VRRP implementation to manage virtual routers (aka virtual interfaces), and a health check facility to determine if a service (web server, samba server, etc.) is up and operational. If a service fails a configurable number of health checks, keepalived will fail a virtual router over to a secondary node. While useful in its own right, keepalived really shines when combined with the Linux Virtual Server project. This article will focus on keepalived, and a future article will show how to integrate the two to create a fault tolerant load-balancer. Installing KeepAlived From Source Code
Before we dive into configuring keepalived, we need to install it. Keepalived is distributed as source code, and is available in several package repositories. To install from source code, you can execute wget or curl to retrieve the source, and then run "configure", "make" and "make install" compile and install the software: $ wget http://www.keepalived.org/software/keepalived-1.1.17.tar.gz $ tar xfvz keepalived-1.1.17.tar.gz $ cd keepalived-1.1.17 $ ./configure --prefix=/usr/local $ make && make install In the example above, the keepalived daemon will be compiled and installed as /usr/local/sbin/keepalived. Configuring KeepAlived
The keepalived daemon is configured through a text configuration file, typically named keepalived.conf. This file contains one or more configuration stanzas, which control notification settings, the virtual interfaces to manage, and the health checks to use to test the services that rely on the virtual interfaces. Here is a sample annotated configuration that defines two virtual IP addresses to manage, and the individuals to contact when a state transition or fault occurs: # Define global configuration directives global_defs { # Send an e-mail to each of the following # addresses when a failure occurs notification_email { matty@prefetch.net operations@prefetch.net } # The address to use in the From: header notification_email_from root@VRRP-director1.prefetch.net # The SMTP server to route mail through smtp_server mail.prefetch.net # How long to wait for the mail server to respond smtp_connect_timeout 30 # A descriptive name describing the router router_id VRRP-director1 } # Create a VRRP instance VRRP_instance VRRP_ROUTER1 { # The initial state to transition to. This option isn't # really all that valuable, since an election will occur # and the host with the highest priority will become # the master. The priority is controlled with the priority # configuration directive. state MASTER # The interface keepalived will manage interface br0 # The virtual router id number to assign the routers to virtual_router_id 100 # The priority to assign to this device. This controls # who will become the MASTER and BACKUP for a given # VRRP instance. priority 100 # How many seconds to wait until a gratuitous arp is sent garp_master_delay 2 # How often to send out VRRP advertisements advert_int 1 # Execute a notification script when a host transitions to # MASTER or BACKUP, or when a fault occurs. The arguments # passed to the script are: # $1 - "GROUP"|"INSTANCE" # $2 = name of group or instance # $3 = target state of transition # Sample: VRRP-notification.sh VRRP_ROUTER1 BACKUP 100 notify "/usr/local/bin/VRRP-notification.sh" # Send an SMTP alert during a state transition smtp_alert # Authenticate the remote endpoints via a simple # username/password combination authentication { auth_type PASS auth_pass 192837465 } # The virtual IP addresses to float between nodes. The # label statement can be used to bring an interface # online to represent the virtual IP. virtual_ipaddress { 192.168.1.100 label br0:100 192.168.1.101 label br0:101 } } The configuration file listed above is self explanatory, so I won't go over each directive in detail. I will point out a couple of items: - Each host is referred to as a director in the documentation, and each director can be responsible for one or more VRRP instances
- Each director will need its own copy of the configuration file, and the router_id, priority, etc. should be adjusted to reflect the nodes name and priority relative to other nodes
- To force a specific node to master a virtual address, make sure the director's priority is higher than the other virtual routers
- If you have multiple VRRP instances that need to failover together, you will need to add each instance to a VRRP_sync_group
- The notification script can be used to generate custom syslog messages, or to invoke some custom logic (e.g., restart an app) when a state transition or fault occurs
- The keepalived package comes with numerous configuration examples, which show how to configure numerous aspects of the server
Starting Keepalived
Keepalived can be executed from an RC script, or started from the command line. The following example will start keepalived using the configuration file /usr/local/etc/keepalived.conf: $ keepalived -f /usr/local/etc/keepalived.conf If you need to debug keepalived issues, you can run the daemon with the "--dont-fork", "--log-console" and "--log-detail" options: $ keepalived -f /usr/local/etc/keepalived.conf --dont-fork --log-console --log-detail These options will stop keepalived from fork'ing, and will provide additional logging data. Using these options is especially useful when you are testing out new configuration directives, or debugging an issue with an existing configuration file. Locating The Router That is Managing A Virtual IP
To see which director is currently the master for a given virtual interface, you can check the output from the ip utility: VRRP-director1$ ip addr list br0 5: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN link/ether 00:24:8c:4e:07:f6 brd ff:ff:ff:ff:ff:ff inet 192.168.1.6/24 brd 192.168.1.255 scope global br0 inet 192.168.1.100/32 scope global br0:100 inet 192.168.1.101/32 scope global br0:101 inet6 fe80::224:8cff:fe4e:7f6/64 scope link valid_lft forever preferred_lft forever VRRP-director2$ ip addr list br0 5: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN link/ether 00:24:8c:4e:07:f6 brd ff:ff:ff:ff:ff:ff inet 192.168.1.7/24 brd 192.168.1.255 scope global br0 inet6 fe80::224:8cff:fe4e:7f6/64 scope link valid_lft forever preferred_lft forever In the output above, we can see that the virtual interfaces 192.168.1.100 and 192.168.1.101 are currently active on VRRP-director1. Troubleshooting Keepalived And VRRP
The keepalived daemon will log to syslog by default. Log entries will range from entries that show when the keepalive daemon started, to entries that show state transitions. Here are a few sample entries that show keepalived starting up, and the node transitioning a VRRP instance to the MASTER state: Jul 3 16:29:56 disarm Keepalived: Starting Keepalived v1.1.17 (07/03,2009) Jul 3 16:29:56 disarm Keepalived: Starting VRRP child process, pid=1889 Jul 3 16:29:56 disarm Keepalived_VRRP: Using MII-BMSR NIC polling thread... Jul 3 16:29:56 disarm Keepalived_VRRP: Registering Kernel netlink reflector Jul 3 16:29:56 disarm Keepalived_VRRP: Registering Kernel netlink command channel Jul 3 16:29:56 disarm Keepalived_VRRP: Registering gratutious ARP shared channel Jul 3 16:29:56 disarm Keepalived_VRRP: Opening file '/usr/local/etc/keepalived.conf'. Jul 3 16:29:56 disarm Keepalived_VRRP: Configuration is using : 62990 Bytes Jul 3 16:29:57 disarm Keepalived_VRRP: VRRP_Instance(VRRP_ROUTER1) Transition to MASTER STATE Jul 3 16:29:58 disarm Keepalived_VRRP: VRRP_Instance(VRRP_ROUTER1) Entering MASTER STATE Jul 3 16:29:58 disarm Keepalived_VRRP: Netlink: skipping nl_cmd msg... If you are unable to determine the source of a problem with the system logs, you can use tcpdump to display the VRRP advertisements that are sent on the local network. Advertisements are sent to a reserved VRRP multicast address (224.0.0.18), so the following filter can be used to display all VRRP traffic that is visible on the interface passed to the "-i" option: $ tcpdump -vvv -n -i br0 host 224.0.0.18 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on br0, link-type EN10MB (Ethernet), capture size 96 bytes 10:18:23.621512 IP (tos 0x0, ttl 255, id 102, offset 0, flags [none], proto VRRP (112), length 40) \ 192.168.1.6 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20, addrs: 192.168.1.100 auth "19283746" 10:18:25.621977 IP (tos 0x0, ttl 255, id 103, offset 0, flags [none], proto VRRP (112), length 40) \ 192.168.1.6 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20, addrs: 192.168.1.100 auth "19283746" ......... The output contains several pieces of data that be useful for debugging problems: authtype - the type of authentication in use (authentication configuration directive) vrid - the virtual router id (virtual_router_id configuration directive) prio - the priority of the device (priority configuration directive) intvl - how often to send out advertisements (advert_int configuration directive) auth - the authentication token sent (auth_pass configuration directive) Conclusion
In this article I described how to set up a host to use the keepalived daemon, and provided a sample configuration file that can be used to failover virtual interfaces between servers. Keepalived has a slew of options not covered here, and I will refer you to the keepalived source code and documentation for additional details
在Keepalived集群中,其实并没有严格意义上的主、备节点,虽然可以在Keepalived配置文件中设置“state”选项为“MASTER”状态,但是这并不意味着此节点一直就是Master角色。控制节点角色的是Keepalived配置文件中的“priority”值,但并它并不控制所有节点的角色,另一个能改变节点角色的是在vrrp_script模块中设置的“weight”值,这两个选项对应的都是一个整数值,其中“weight”值可以是个负整数,一个节点在集群中的角色就是通过这两个值的大小决定的。 在一个一主多备的Keepalived集群中,“priority”值最大的将成为集群中的Master节点,而其他都是Backup节点。在Master节点发生故障后,Backup节点之间将进行“民主选举”,通过对节点优先级值“priority”和““weight”的计算,选出新的Master节点接管集群服务。
在vrrp_script模块中,如果不设置“weight”选项值,那么集群优先级的选择将由Keepalived配置文件中的“priority”值决定,而在需要对集群中优先级进行灵活控制时,可以通过在vrrp_script模块中设置“weight”值来实现。下面列举一个实例来具体说明。
假定有A和B两节点组成的Keepalived集群,在A节点keepalived.conf文件中,设置“priority”值为100,而在B节点keepalived.conf文件中,设置“priority”值为80,并且A、B两个节点都使用了“vrrp_script”模块来监控mysql服务,同时都设置“weight”值为10,那么将会发生如下情况。
在两节点都启动Keepalived服务后,正常情况是A节点将成为集群中的Master节点,而B自动成为Backup节点,此时将A节点的mysql服务关闭,通过查看日志发现,并没有出现B节点接管A节点的日志,B节点仍然处于Backup状态,而A节点依旧是Master状态,在这种情况下整个HA集群将失去意义。
下面就分析一下产生这种情况的原因,这也就是Keepalived集群中主、备角色选举策略的问题。下面总结了在Keepalived中使用vrrp_script模块时整个集群角色的选举算法,由于“weight”值可以是正数也可以是负数,因此,要分两种情况进行说明。
1. “weight”值为正数时 在vrrp_script中指定的脚本如果检测成功,那么Master节点的权值将是“weight值与”priority“值之和,如果脚本检测失败,那么Master节点的权值保持为“priority”值,因此切换策略为: Master节点“vrrp_script”脚本检测失败时,如果Master节点“priority”值小于Backup节点“weight值与”priority“值之和,将发生主、备切换。 Master节点“vrrp_script”脚本检测成功时,如果Master节点“weight”值与“priority”值之和大于Backup节点“weight”值与“priority”值之和,主节点依然为主节点,不发生切换。
2. “weight”值为负数时 在“vrrp_script”中指定的脚本如果检测成功,那么Master节点的权值仍为“priority”值,当脚本检测失败时,Master节点的权值将是“priority“值与“weight”值之差,因此切换策略为: Master节点“vrrp_script”脚本检测失败时,如果Master节点“priority”值与“weight”值之差小于Backup节点“priority”值,将发生主、备切换。 Master节点“vrrp_script”脚本检测成功时,如果Master节点“priority”值大于Backup节点“priority”值时,主节点依然为主节点,不发生切换。
在熟悉了Keepalived主、备角色的选举策略后,再来分析一下刚才实例,由于A、B两个节点设置的“weight”值都为10,因此符合选举策略的第一种,在A节点停止Mysql服务后,A节点的脚本检测将失败,此时A节点的权值将保持为A节点上设置的“priority”值,即为100,而B节点的权值将变为“weight”值与“priority”值之和,也就是90(10+80),这样就出现了A节点权值仍然大于B节点权值的情况,因此不会发生主、备切换。
对于“weight”值的设置,有一个简单的标准,即“weight”值的绝对值要大于Master和Backup节点“priority”值之差。对于上面A、B两个节点的例子,只要设置“weight”值大于20即可保证集群正常运行和切换。由此可见,对于“weight值的设置,要非常谨慎,如果设置不好,将导致集群角色选举失败,使集群陷于瘫痪状态。
如果你在读这篇文章,说明你跟大多数开发者一样对GIT感兴趣,如果你还没有机会来试一试GIT,我想现在你就要了解它了。 GIT不仅仅是个版本控制系统,它也是个内容管理系统(CMS),工作管理系统等。如果你是一个具有使用SVN背景的人,你需要做一定的思想转换,来适应GIT提供的一些概念和特征。所以,这篇文章的主要目的就是通过介绍GIT能做什么、它和SVN在深层次上究竟有什么不同来帮助你认识它。 那好,这就开始吧… 1.GIT是分布式的,SVN不是: 这是GIT和其它非分布式的版本控制系统,例如SVN,CVS等,最核心的区别。如果你能理解这个概念,那么你就已经上手一半了。需要做一点声明,GIT并不是目前第一个或唯一的分布式版本控制系统。还有一些系统,例如Bitkeeper, Mercurial等,也是运行在分布式模式上的。但GIT在这方面做的更好,而且有更多强大的功能特征。 GIT跟SVN一样有自己的集中式版本库或服务器。但,GIT更倾向于被使用于分布式模式,也就是每个开发人员从中心版本库/服务器上chect out代码后会在自己的机器上克隆一个自己的版本库。可以这样说,如果你被困在一个不能连接网络的地方时,就像在飞机上,地下室,电梯里等,你仍然能够提 交文件,查看历史版本记录,创建项目分支,等。对一些人来说,这好像没多大用处,但当你突然遇到没有网络的环境时,这个将解决你的大麻烦。 同样,这种分布式的操作模式对于开源软件社区的开发来说也是个巨大的恩赐,你不必再像以前那样做出补丁包,通过email方式发送出去,你只需要创建一个分支,向项目团队发送一个推请求。这能让你的代码保持最新,而且不会在传输过程中丢失。GitHub.com就是一个这样的优秀案例。 有些谣言传出来说subversion将来的版本也会基于分布式模式。但至少目前还看不出来。 2.GIT把内容按元数据方式存储,而SVN是按文件: 所有的资源控制系统都是把文件的元信息隐藏在一个类似.svn,.cvs等的文件夹里。如果你把.git目录的 体积大小跟.svn比较,你会发现它们差距很大。因为,.git目录是处于你的机器上的一个克隆版的版本库,它拥有中心版本库上所有的东西,例如标签,分 支,版本记录等。 3.GIT分支和SVN的分支不同: 分支在SVN中一点不特别,就是版本库中的另外的一个目录。如果你想知道是否合并了一个分支,你需要手工运行像这样的命令svn propget svn:mergeinfo,来确认代码是否被合并。感谢Ben同学指出这个特征。所以,经常会发生有些分支被遗漏的情况。 然而,处理GIT的分支却是相当的简单和有趣。你可以从同一个工作目录下快速的在几个分支间切换。你很容易发现未被合并的分支,你能简单而快捷的合并这些文件。
4.GIT没有一个全局的版本号,而SVN有: 目前为止这是跟SVN相比GIT缺少的最大的一个特征。你也知道,SVN的版本号实际是任何一个相应时间的源代 码快照。我认为它是从CVS进化到SVN的最大的一个突破。因为GIT和SVN从概念上就不同,我不知道GIT里是什么特征与之对应。如果你有任何的线 索,请在评论里奉献出来与大家共享。 更新:有些读者指出,我们可以使用GIT的SHA-1来唯一的标识一个代码快照。这个并不能完全的代替SVN里容易阅读的数字版本号。但,用途应该是相同的。 5.GIT的内容完整性要优于SVN: GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。这里有一个很好的关于GIT内容完整性的讨论 –http://stackoverflow.com/questions/964331/git-file-integrity GIT和SVN之间只有这五处不同吗?当然不是。我想这5个只是“最基本的”和“最吸引人”的,我只想到这5点。如果你发现有比这5点更有趣的,请共享出来,欢迎。
mysql中 myisam 引擎不支持事务的概念,多用于数据仓库这样查询多而事务少的情况,速度较快。
mysql中 innoDB 引擎支持事务的概念,多用于web网站后台等实时的中小型事务处理后台。
而oracle没有引擎的概念,oracle有OLTP和OLAP模式的区分,两者的差别不大,只有参数设置上的不同。
oracle无论哪种模式都是支持事务概念的,oracle是一个不允许读脏的数据库系统。
当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果.
OLTP:
也称为面向交易的处理系统,其基本特征是顾客的原始数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果。
这样做的最大优点是可以即时地处理输入的数据,及时地回答。也称为实时系统(Real time System)。衡量联机事务处理系统的一个重要性能指标是系统性能,具体体现为实时响应时间(Response Time),即用户在终端上送入数据之后,到计算机对这个请求给出答复所需要的时间。OLTP是由数据库引擎负责完成的。
OLTP 数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务。
OLAP:
简写为OLAP,随着数据库技术的发展和应用,数据库存储的数据量从20世纪80年代的兆(M)字节及千兆(G)字节过渡到现在的兆兆(T)字节和千兆兆(P)字节,同时,用户的查询需求也越来越复杂,涉及的已不仅是查询或操纵一张关系表中的一条或几条记录,而且要对多张表中千万条记录的数据进行数据分析和信息综合,关系数据库系统已不能全部满足这一要求。在国外,不少软件厂商采取了发展其前端产品来弥补关系数据库管理系统支持的不足,力图统一分散的公共应用逻辑,在短时间内响应非数据处理专业人员的复杂查询要求。
联机分析处理(OLAP)系统是数据仓库系统最主要的应用,专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况,了解对象的需求,制定正确的方案。
第一种:直接启动 安装: tar zxvf redis-2.8.9.tar.gz cd redis-2.8.9 #直接make 编译 make #可使用root用户执行`make install`,将可执行文件拷贝到/usr/local/bin目录下。这样就可以直接敲名字运行程序了。 make install 启动: #加上`&`号使redis以后台程序方式运行 ./redis-server & 检测: #检测后台进程是否存在 ps -ef |grep redis #检测6379端口是否在监听 netstat -lntp | grep 6379 #使用`redis-cli`客户端检测连接是否正常 ./redis-cli 127.0.0.1:6379> keys * (empty list or set) 127.0.0.1:6379> set key "hello world" OK 127.0.0.1:6379> get key "hello world" 停止: #使用客户端 redis-cli shutdown #因为Redis可以妥善处理SIGTERM信号,所以直接kill -9也是可以的 kill -9 PID 第二种:通过指定配置文件启动 配置文件 可为redis服务启动指定配置文件,配置文件 redis.conf 在Redis根目录下。 #修改daemonize为yes,即默认以后台程序方式运行(还记得前面手动使用&号强制后台运行吗)。 daemonize no #可修改默认监听端口 port 6379 #修改生成默认日志文件位置 logfile "/home/futeng/logs/redis.log" #配置持久化文件存放位置 dir /home/futeng/data/redisData
启动时指定配置文件 redis-server ./redis.conf #如果更改了端口,使用`redis-cli`客户端连接时,也需要指定端口,例如: redis-cli -p 6380
其他启停同 直接启动 方式。配置文件是非常重要的配置工具,随着使用的逐渐深入将显得尤为重要,推荐在一开始就使用配置文件。 第三种: 使用Redis启动脚本设置开机自启动 启动脚本 推荐在生产环境中使用启动脚本方式启动redis服务。启动脚本 redis_init_script 位于位于Redis的 /utils/ 目录下。 #大致浏览下该启动脚本,发现redis习惯性用监听的端口名作为配置文件等命名,我们后面也遵循这个约定。 #redis服务器监听的端口 REDISPORT=6379 #服务端所处位置,在make install后默认存放与`/usr/local/bin/redis-server`,如果未make install则需要修改该路径,下同。 EXEC=/usr/local/bin/redis-server #客户端位置 CLIEXEC=/usr/local/bin/redis-cli #Redis的PID文件位置 PIDFILE=/var/run/redis_${REDISPORT}.pid #配置文件位置,需要修改 CONF="/etc/redis/${REDISPORT}.conf" 配置环境 1. 根据启动脚本要求,将修改好的配置文件以端口为名复制一份到指定目录。需使用root用户。 mkdir /etc/redis cp redis.conf /etc/redis/6379.conf 2. 将启动脚本复制到/etc/init.d目录下,本例将启动脚本命名为redisd(通常都以d结尾表示是后台自启动服务)。 cp redis_init_script /etc/init.d/redisd 3. 设置为开机自启动 此处直接配置开启自启动 chkconfig redisd on 将报错误: service redisd does not support chkconfig 参照 此篇文章 ,在启动脚本开头添加如下两行注释以修改其运行级别: #!/bin/sh # chkconfig: 2345 90 10 # description: Redis is a persistent key-value database # 再设置即可成功。 #设置为开机自启动服务器 chkconfig redisd on #打开服务 service redisd start #关闭服务 service redisd stop http://www.tuicool.com/articles/aQbQ3u
mysql mysqldump 只导出表结构 不导出数据 mysqldump --opt -d 数据库名 -u root -p > xxx.sql 备份数据库
#mysqldump 数据库名 >数据库备份名 #mysqldump -A -u用户名 -p密码 数据库名>数据库备份名 #mysqldump -d -A --add-drop-table -uroot -p >xxx.sql 1.导出结构不导出数据
mysqldump --opt -d 数据库名 -u root -p > xxx.sql 2.导出数据不导出结构 mysqldump -t 数据库名 -uroot -p > xxx.sql 3.导出数据和表结构 mysqldump 数据库名 -uroot -p > xxx.sql 4.导出特定表的结构
mysqldump -uroot -p -B 数据库名 --table 表名 > xxx.sql 导入数据:
由于mysqldump导出的是完整的SQL语句,所以用mysql客户程序很容易就能把数据导入了: #mysql 数据库名 < 文件名 #source /tmp/xxx.sql
Haproxy根目录:F:\SysWork\openSource\haproxy\haproxy1.5.12 配置文件haproxy.cfg如下: global log 127.0.0.1 local0 # maxconn 4096 chroot F:\SysWork\openSource\haproxy\haproxy1.5.12 # uid 99 # gid 99 # daemon nbproc 1 pidfile F:\SysWork\openSource\haproxy\haproxy1.5.12\haproxy.pid debug quiet defaults log 127.0.0.1 local3 mode http option httplog option httpclose option dontlognull option forwardfor option redispatch retries 3 maxconn 8192 balance roundrobin timeout connect 50000 timeout client 50000 timeout server 50000 timeout check 20000 listen httpweb :8100 mode http balance roundrobin option httpclose option forwardfor option httpchk GET /index.html #心跳检测的文件 server httpweb1 localhost:9200 cookie 1 weight 5 check inter 2000 rise 2 fall 3 server httpweb2 localhost:9300 cookie 2 weight 3 check inter 2000 rise 2 fall 3 listen httpservice :8200 mode http balance roundrobin option httpclose option forwardfor option httpchk GET /index.html #心跳检测的文件 server httpservice1 localhost:9200 cookie 3 weight 5 check inter 2000 rise 2 fall 3 server httpservice2 localhost:9300 cookie 4 weight 3 check inter 2000 rise 2 fall 3 listen tcpservice bind 0.0.0.0:8400 mode tcp server tcpservice1 localhost:20880 cookie 5 weight 3 check inter 2000 rise 2 fall 3 listen status 127.0.0.1:8300 stats enable stats uri /status stats auth admin:123456 stats realm (Haproxy\ statistic) 启动命令: F:\SysWork\openSource\haproxy\haproxy1.5.12>haproxy.exe -f haproxy.cfg [WARNING] 240/200829 (11260) : parsing [haproxy.cfg:14] : 'option httplog' not usable with proxy 'tcpservice' (needs 'mo de http'). Falling back to 'option tcplog'. [WARNING] 240/200829 (11260) : config : 'option forwardfor' ignored for proxy 'tcpservice' as it requires HTTP mode. [WARNING] 240/200829 (11260) : config : proxy 'tcpservice' : ignoring cookie for server 'tcpservice1' as HTTP mode is di sabled. Available polling systems : poll : pref=200, test result OK select : pref=150, test result FAILED Total: 2 (1 usable), will use poll. Using poll() as the polling mechanism. [WARNING] 240/200829 (11260) : [haproxy.main()] Cannot raise FD limit to 4019. [WARNING] 240/200829 (11260) : [haproxy.main()] FD limit (256) too low for maxconn=2000/maxsock=4019. Please raise 'ulim it-n' to 4019 or more to avoid any trouble. [WARNING] 240/200830 (11260) : Server httpweb/httpweb1 is DOWN, reason: Layer4 connection problem, info: "Connection ref used", check duration: 1000ms. 1 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. [WARNING] 240/200831 (11260) : Server httpweb/httpweb2 is DOWN, reason: Layer4 connection problem, info: "Connection ref used", check duration: 1000ms. 0 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. [ALERT] 240/200831 (11260) : proxy 'httpweb' has no server available! [WARNING] 240/200831 (11260) : Server httpservice/httpservice1 is DOWN, reason: Layer4 connection problem, info: "Connec tion refused", check duration: 1000ms. 1 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. [WARNING] 240/200831 (11260) : Server httpservice/httpservice2 is DOWN, reason: Layer4 connection problem, info: "Connec tion refused", check duration: 998ms. 0 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. [ALERT] 240/200831 (11260) : proxy 'httpservice' has no server available! 监控页面地址:http://127.0.0.1:8300/status 现在配置文件除了http代理之外,还有tcp代理,http代理就是简单的代理tomcat的请求。把haproxy的请求分发给多个tomcat,而tcp代理我这里是代理的dubbo请求,dubbo启动起来的时候20880端口,但是我们可以通过这里的8400端口提供请求 我们之前都是通过telnet localhost 20880可以看到dubbo控制台,现在可以通过telnet localhost 8400查看dubbo控制台
nginx的根目录是:D:\Sys\server\nginx\nginx-1.9.4\ nginx配置文件目录:D:\Sys\server\nginx\nginx-1.9.4\conf nginx.conf 配置文件如下: #user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #gzip on; include vhosts/*.conf; }
这个主目录只保留基本配置 include vhosts/*.conf;这句话就是引用虚拟主机目录的配置文件 在该目录下面创建vhosts目录: D:\Sys\server\nginx\nginx-1.9.4\conf\vhosts 虚拟主机(实际里面就是配置upstream和server,然后server里面配置监听端口和serverName,还有location)目录里面的配置文件分别为: www.abin.com.conf www.lee.com.conf www.abin.com.conf的配置为: upstream abin { server localhost:9200 weight=10; } # another virtual host using mix of IP-, name-, and port-based configuration server { listen 8000; server_name www.abin.com abin.com; location / { #反向代理的地址 proxy_pass http://abin; root html; index index.html index.htm; } location /abin { #反向代理的地址 proxy_pass http://abin; root html; index index.html index.htm; } } www.lee.com.conf的配置为: upstream lee { server localhost:9300 weight=10;//这个配置为tomcat的请求地址 } # another virtual host using mix of IP-, name-, and port-based configuration server { listen 8000; server_name www.lee.com lee.com; location / { #反向代理的地址 proxy_pass http://lee; root html; index index.html index.htm; } location /abin { #反向代理的地址 proxy_pass http://lee; root html; index index.html index.htm; } } 测试: http://www.lee.com:8000/ http://www.lee.com:8000/abin
http://lee.com:8000/abin http://www.lee.com:8000/ http://www.lee.com:8000/lee
http://lee.com:8000/lee
我的tomcat服务器的web.xml都配置了<webcome-list>index.html</welcome-list>,
tomcat:9200配置了abin这个java工程,它里面的index.html内容为hello,abin
tomcat:9300配置了abin这个java工程,它里面的index.html内容为hello,lee 那么上面的第二个地址打印hello,abin 那么上面的第四个地址打印hello,lee 本地hosts文件配置为: 127.0.0.1 localhost 127.0.0.1 www.abin.com abin.com 127.0.0.1 www.lee.com lee.com
支付宝这次面试,直接是一波流搞定,没有HR问为毛辞职,职业规划之类的问题,都是直接上干货的,技术. 笔试40分钟,然后带上试卷直接去面试,面试时间长短就不清楚了,我大概面了1个小时左右. 笔试: 1. cookie 和 session 的区别 2. JVM 内存模型 3. SQL注入的原理 4. 悲观锁 和 乐观锁 5. 读程序,输出结果. 关于treemap的 6. linux 基础命令,统计日志中的信息 7. java 分布式集群 8. 一道设计题,具体到数据库的表.大概是淘宝的搜索中,输入手机,会出来很多类型,按品牌按价格区间按手机种类. 还有2道题我记不住了. 面试: 1.介绍你做过的项目,用到的技术,涉及到的模块,然后从项目中问各种技术实现的细节(为了确保你是真的懂了). 2.看你的试卷,喊你讲解做题的思路,以及这样结果的原因.(考的是各位的java基础知识了,这点是绕不过去的,懂了就懂了啊,只有平时多看书) 3.团购6位验证码以及团购成功后,发送到你手机上的条码的实现方式.(第一个问题我说用随机数+时间来验证.第二个问题老实说,我也没答上来,我说用序列,面试官说序列到后期20位以上的时候,用户体验很差的) 4.淘宝上是如何保证库存和订单之间的数据准确性的.(CICS Tuxedo,考点是分布式事务,这个问题我也没答上来,最后他问我有什么问题问他的时候,我就反问的这个问题,面试官人挺好的,给我耐心的讲解了一遍淘宝的实现方式以及 epay的实现方式. 淘宝是通过分布式事物,中间用了一个叫协调者角色的程序,当那边点击购买时,会库存减一,保存一条预扣的状态,但是是个预准备状态,然后做成功后,协调者会在另一个数据库生成订单,然后这个订单也是预状态,等两边都准备好以后,通知协调者,又协调者统一完成这2个数据库的事物,从而达到完成一笔交易的目的,若其中一方失败,则将预扣的数字返回到库存从而实现类似回滚的操作.) 5.索引的原理.能否构建时间索引.时间索引构建后会存在什么问题.(索引原理我是回答的堆表索引的构建原理以及查询原理,但是关于时间索引的问题,我也没回答出个所以然来,看面试官的反馈,好像回答得不够好吧) 6.你们数据库的数据量有多大,(回答:我们是电信方面的系统,表上亿的数据很正常).问:如果保证效率? (我是如此回答的,各位自行结合自身的情况参考.答:后台J OB程序会定期备份,把生产表数据移走,然后备份表也会再备份一次,如此剃度的备份,保证生产库的数据是最小的.然后备份表采用分区和子分区,加上构建战略索引(分析系统的sql,常用 查询字段构建复合索引,以减少每次查询时对表的访问次数)). 7.SQL注入的原理以及如何预防,并举例.(这个相对简单,网上一搜一大片) 8.使用过Memcache么? 用在项目中哪些地方? (答,在门户主机上使用,缓存session,分布式的时候,统一访问这台主机验证用户session是否存在,来维持回话的状态和实现回话同步.又追问:java代码中如何实现访问门户服务器的这个session池子的? 几年前的代码,确实忘记了..于是坦白的说,记不清楚了 ) 这些是主要的问题,当你回答一个大问题时中间还有很多比较碎的追问性质的小问题,总体给我的感觉是,氛围很轻松+愉快的,技术层面上还是需要你真正的理解透彻一些关键技术点,才能做到应付各种追问和给出满意的答案吧.如果只是一知半解想去蒙混过关肯定是不行的,毕竟在支付宝的技术大牛面前,多追问几句,也就把你逼到死角了. 还有一点比较重要的感觉就是,他们比较在意你是否了解当下的一些比较热的技术点,比如淘宝的秒杀,是如何保证高并发下的安全性和性能,新浪微博那种大数据量的发送,怎么就保证正确性和时效性的. 自我感觉面试得很一般,估计希望比较小吧,共享这些希望能给各位小伙伴带来实际上的帮助.
环境 配置Mysql的MasterSlave至少需要两台机器。我这里使用三台虚拟机进行测试。三台机器配置完全一样,MySQL安装的路径也是一样: 第一台:10.1.5.181; Windows 2008 DataCenter + MySQL Community Server 5.6.10.1 第二台:10.1.5.182; Windows 2008 DataCenter + MySQL Community Server 5.6.10.1 第三台:10.1.5.183; Windows 2008 DataCenter + MySQL Community Server 5.6.10.1 第一台10.1.5.181用作master,其他两台用做slave。 配置Master 在10.1.5.181这台服务器上找到MySQL的配置文件my.ini。我的具体路径是在C:\ProgramData\MySQL\MySQL Server 5.6下。 打开配置文件,在最下面添加如下配置: ************************************************************************************ #Master start
#日志输出地址 主要同步使用
log-bin=master-bin.log
#同步数据库
binlog-do-db=test
#主机id 不能和从机id重复
server-id=1
#Master end ************************************************************************************ master的配置比较少,server-id是为这一组master/slave服务器定的唯一id,master/slave服务器中不能重复。在binlog-do-db中填写对象要同步的数据库,如果有多个,用逗号分隔,或再写一行如binlog-do-db=test2。 配置Slave 同样在第二台机器上10.1.5.181找到配置文件my.ini。打开配置文件,在最下面添加如下配置: ***************************************************************************** report-host = 10.1.5.181
report-user = root
report-password = root123
log-bin = slave-bin.log
replicate-do-db = test server-id = 2 ***************************************************************************** 这里需要添加master的IP,连接master的用户名和密码,生产环境中需要新建一个用户专门来处理replication,这里没有新建用户,用root做测试。端口没有配置,就是使用默认的3306,如果端口有变化,则通过report-port=?来配置。log-bin是记录日志的位置。 然后通过命令start slave来启动mysql的复制功能。如果在start slave过程中出现异常: The server is not configured as slave; fix in config file or with CHANGE MASTER TO 可以通过下面语句解决: change master to master_host='10.1.5.181',master_user='root',master_password='root123',master_log_file='master-bin.000001' ,master_log_pos=120; 使用show slave status 命令来查来看运行状态。特别关注两个属性,是否为“Yes”,如果都为“Yes”,则说明运行正常。 Slave_IO_Running:连接到主库,并读取主库的日志到本地,生成本地日志文件 Slave_SQL_Running:读取本地日志文件,并执行日志里的SQL命令。 同样的配置再在第三台机器上配置一下,server-id修改成3。重启slave和master的mysqld服务。然后测试,在三台服务器上都确保有数据库test,然后在master服务器的test数据库上建表和数据,之后再两台slave上面都会看见数据的同步。 Mysql的MasterSlave同步时通过二进制文件进行同步的。在Master端,你可以在C:\ProgramData\MySQL\MySQL Server 5.6\data的master-bin.log日志文件里看见所有同步的sql脚本,master-bin.log是配置master时候输入的。在slave端,你可以在MySQL02-relay-bin类似的文件中找到日志。
http://www.cnblogs.com/haoxinyue/archive/2013/04/02/2995280.html
最近因为项目需要,简单的试用了两款高可用开源方案:Keepalived和Heartbeat。两者都很流行,但差异还是很大的,现将试用过程中的感受以及相关知识点简单总结一下,供大家选择方案的时候参考。 1)Keepalived使用更简单:从安装、配置、使用、维护等角度上对比,Keepalived都比Heartbeat要简单得多,尤其是Heartbeat2.1.4后拆分成3个子项目,安装、配置、使用都比较复杂,尤其是出问题的时候,都不知道具体是哪个子系统出问题了;而Keepalived只有1个安装文件、1个配置文件,配置文件也简单很多; 2)Heartbeat功能更强大:Heartbeat虽然复杂,但功能更强大,配套工具更全,适合做大型集群管理,而Keepalived主要用于集群倒换,基本没有管理功能; 3)协议不同:Keepalived使用VRRP协议进行通信和选举,Heartbeat使用心跳进行通信和选举;Heartbeat除了走网络外,还可以通过串口通信,貌似更可靠; 4)使用方式基本类似:如果要基于两者设计高可用方案,最终都要根据业务需要写自定义的脚本,Keepalived的脚本没有任何约束,随便怎么写都可以;Heartbeat的脚本有约束,即要支持service start/stop/restart这种方式,而且Heartbeart提供了很多默认脚本,简单的绑定ip,启动apache等操作都已经有了; 使用建议:优先使用Keepalived,当Keepalived不够用的时候才选择Heartbeat
1、StatefulJobimplements StatefulJob使Job成为有状态的,顺序执行 同一个有状态的job实例不存在并发,无状态的job的并发数由上面配置的线程数决定。不想并发的话,设置成1,第二个线程在前一个执行完以后触发执行。 线程数大于1时,如果存在空闲线程,则到执行时间点即触发执行。
2、MethodInvokingJobDetailFactoryBean MethodInvokingJobDetailFactoryBean的并发问题 大家在使用quartz的时候,一般只设置了“targetObject”和“targetMethod”,MethodInvokingJobDetailFactoryBean类默认是并发执行的,这时候如果不设置“concurrent”为false,很可能带来并发或者死锁的问题,而且几率较小,不容易复现,请大家使用的时候注意设置“concurrent”。 <bean id="cpm.MessageJobFactoryBean" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean"> <property name="targetObject" ref="cpm.MessageJob"/> <property name="targetMethod" value="execute"/> <property name="concurrent" value="false"/> </bean> concurrent 同时发生 concurrent:对于相同的JobDetail,当指定多个Trigger时, 很可能第一个job完成之前,第二个job就开始了。 定concurrent设为false,多个job不会并发运行,第二个job将不会在第一个job完成之前开始
防止job并行运行的几种解决方案 一、JOB State 在通过MethodInvokingJobDetailFactoryBean在运行中动态生成的Job,配置的xml文件有个concurrent属性,表示job是否可以并行运行:如果一个job的业务处理发费的时间超过了job的启动的间隔时间(repeatInterval),这个属性非常有用。如果为false,那么,在这种情况下,当前job还在运行,那么下一个job只能延时运行。如果为true,那么job就会并行运行。在实际的应用中应该配置为true/false,要根据需要了(废话)。 二、如果通过继承QuartzJobBean实现job的话,默认情况下QuartzJobBean是implements org.quartz.Job接口的,也就是说job示例是stateless的,会出现前面所述的并行情况。而代码中却要求job任务必需串行,解决办法:在job子类中继续implements org.quartz.StatefulJob。那么这个job实例变成了Stateful,job任务也就是串行的了。 注: 在Quartz中,如果实现org.quartz.Job接口,那么这个job是stateless的,job实例的参数不能在多个任务之间共享,如果实现org.quartz.StatefulJob,这个job是个单例的,job实例的属性可以从当前任务传递到下一个任务。
spring和quartz的整合对版本是有要求的。 spring3.1以下的版本必须使用quartz1.x系列,3.1以上的版本才支持quartz 2.x,不然会出错。
至于原因,则是spring对于quartz的支持实现,org.springframework.scheduling.quartz.CronTriggerBean继承了org.quartz.CronTrigger,在quartz1.x系列中org.quartz.CronTrigger是个类,而在quartz2.x系列中org.quartz.CronTrigger变成了接口,从而造成无法用spring的方式配置quartz的触发器(trigger)。 在Spring中使用Quartz有两种方式实现:第一种是任务类继承QuartzJobBean,第二种则是在配置文件里定义任务类和要执行的方法,类和方法可以是普通类。很显然,第二种方式远比第一种方式来的灵活。 MethodInvokingJobDetailFactoryBean中concurrent和shouldRecover属性的作用 解释 concurrent为true,则允许一个QuartzJob并发执行,否则就是顺序执行。例如QuartzJob A执行时间为15秒,配置为每10秒执行一次;如果concurrent为true,则0秒的时候启动一次A,10秒的时候再启动一次A,20秒的时候再启动一次A,不管前面启动的A有没有执行完;如果concurrent为false,则0秒的时候启动一次A,15秒的时候A执行完毕,再第二次启动A。 shouldRecover属性为true,则当Quartz服务被中止后,再次启动或集群中其他机器接手任务时会尝试恢复执行之前未完成的所有任务。例如QuartzJob B,在每次00秒的时候启动,假如在03:00的任务执行完之后服务器1被中止,服务器2在05:15的时候才接手;如果shouldRecover属性为true,则服务器2会尝试着补回原来在04:00和05:00的时候应该做的任务,如果shouldRecover属性为false,则服务器2只会从06:00的时候再执行B。 Quartz集群只支持JDBCJobStore存储方式,而MethodInvokingJobDetailFactoryBean不能序列化存储job数据到数据库, 重写 quartz 的 QuartzJobBean 类 原因是在使用 quartz+spring 把 quartz 的 task 实例化进入数据库时,会产生: serializable 的错误,原因在于: 这个 MethodInvokingJobDetailFactoryBean 类中的 methodInvoking 方法,是不支持序列化的,因此在把 QUARTZ 的 TASK 序列化进入数据库时就会抛错。网上有说把 SPRING 源码拿来,修改一下这个方案,然后再打包成 SPRING.jar 发布,这些都是不好的方法,是不安全的。 必须根据 QuartzJobBean 来重写一个自己的类 。
QRTZ_CALENDARS 以 Blob 类型存储 Quartz 的 Calendar 信息 QRTZ_CRON_TRIGGERS 存储 Cron Trigger,包括 Cron表达式和时区信息 QRTZ_FIRED_TRIGGERS 存储与已触发的 Trigger 相关的状态信息,以及相联 Job的执行信息QRTZ_PAUSED_TRIGGER_GRPS 存储已暂停的 Trigger 组的信息 QRTZ_SCHEDULER_STATE 存储少量的有关 Scheduler 的状态信息,和别的 Scheduler实例(假如是用于一个集群中) QRTZ_LOCKS 存储程序的悲观锁的信息(假如使用了悲观锁) QRTZ_JOB_DETAILS 存储每一个已配置的 Job 的详细信息 QRTZ_JOB_LISTENERS 存储有关已配置的 JobListener 的信息 QRTZ_SIMPLE_TRIGGERS 存储简单的Trigger,包括重复次数,间隔,以及已触的次数 QRTZ_BLOG_TRIGGERS Trigger 作为 Blob 类型存储(用于 Quartz 用户用 JDBC创建他们自己定制的 Trigger 类型,JobStore 并不知道如何存储实例的时候) QRTZ_TRIGGER_LISTENERS 存储已配置的 TriggerListener 的信息 QRTZ_TRIGGERS 存储已配置的 Trigger 的信息 -------------------------------------------------------------------------------------------------- quartz 持久化数据库表格字段解释 建表,SQL语句在quartz-1.6.6\docs\dbTables文件夹中可以找到,介绍下主要的几张表:
表qrtz_job_details: 保存job详细信息,该表需要用户根据实际情况初始化
job_name:集群中job的名字,该名字用户自己可以随意定制,无强行要求
job_group:集群中job的所属组的名字,该名字用户自己随意定制,无强行要求
job_class_name:集群中个note job实现类的完全包名,quartz就是根据这个路径到classpath找到该job类
is_durable:是否持久化,把该属性设置为1,quartz会把job持久化到数据库中
job_data:一个blob字段,存放持久化job对象
表qrtz_triggers: 保存trigger信息
trigger_name: trigger的名字,该名字用户自己可以随意定制,无强行要求
trigger_group:trigger所属组的名字,该名字用户自己随意定制,无强行要求
job_name: qrtz_job_details表job_name的外键
job_group: qrtz_job_details表job_group的外键
trigger_state:当前trigger状态,设置为ACQUIRED,如果设置为WAITING,则job不会触发
trigger_cron:触发器类型,使用cron表达式
表qrtz_cron_triggers:存储cron表达式表
trigger_name: qrtz_triggers表trigger_name的外键
trigger_group: qrtz_triggers表trigger_group的外键
cron_expression:cron表达式
表qrtz_scheduler_state:存储集群中note实例信息,quartz会定时读取该表的信息判断集群中每个实例的当前状态
instance_name:之前配置文件中org.quartz.scheduler.instanceId配置的名字,就会写入该字段,如果设置为AUTO,quartz会根据物理机名和当前时间产生一个名字
last_checkin_time:上次检查时间
checkin_interval:检查间隔时间
步骤4:
配置quartz.properties文件:
#调度标识名 集群中每一个实例都必须使用相同的名称 org.quartz.scheduler.instanceName = scheduler #ID设置为自动获取 每一个必须不同 org.quartz.scheduler.instanceId = AUTO #数据保存方式为持久化 org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX #数据库平台 org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.oracle.weblogic.WebLogicOracleDelegate #数据库别名 随便取org.quartz.jobStore.dataSource = myXADS #表的前缀 org.quartz.jobStore.tablePrefix = QRTZ_ #设置为TRUE不会出现序列化非字符串类到 BLOB 时产生的类版本问题 org.quartz.jobStore.useProperties = true #加入集群 org.quartz.jobStore.isClustered = true #调度实例失效的检查时间间隔 org.quartz.jobStore.clusterCheckinInterval = 20000 #容许的最大作业延长时间 org.quartz.jobStore.misfireThreshold = 60000 #ThreadPool 实现的类名 org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool #线程数量 org.quartz.threadPool.threadCount = 10 #线程优先级 org.quartz.threadPool.threadPriority = 5 #自创建父线程 org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true #设置数据源org.quartz.dataSource.myXADS.jndiURL = CT #jbdi类名 org.quartz.dataSource.myXADS.java.naming.factory.initial = weblogic.jndi.WLInitialContextFactory #URLorg.quartz.dataSource.myXADS.java.naming.provider.url = t3://localhost:7001
【注】:在J2EE工程中如果想用数据库管理Quartz的相关信息,就一定要配置数据源,这是Quartz的要求。
1、下载一个jrebel的文件,解压到D:\Sys\jrebel6.0.0-crack,在eclipse的classpath路径下面配置rebel.xml <?xml version="1.0" encoding="UTF-8"?> <application xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.zeroturnaround.com" xsi:schemaLocation="http://www.zeroturnaround.com http://www.zeroturnaround.com/alderaan/rebel-2_0.xsd"> <classpath> <dir name="D:\SystemFile\EclipseWorkspace\SpringAQConsume\target"> </dir> </classpath> <web> <link target="/"> <dir name="D:\SystemFile\EclipseWorkspace\SpringAQConsume\src\main\webapp"> </dir> </link> </web> </application> 2、在tomcat里面配置 -javaagent:D:\Sys\jrebel6.0.0-crack\jrebel.jar -noverify -Xbootclasspath/p:D:\Sys\jrebel6.0.0-crack\rebelboot.jar -javaagent:D:\Sys\jrebel-6.0.2\jrebel.jar -noverify -Xbootclasspath/p:D:\Sys\jrebel-6.0.2\rebelboot.jar *********6.2.2需要以下设置********** -noverify -Djavaagent:D:/Sys\server/JRebel/JRebel6.2.0/jrebel.jar -DXbootclasspath/p:D:\Sys\server\JRebel\JRebel6.2.0\rebelboot.jar -Drebel.generate.show=true -Drebel.spring_plugin=true -Drebel.aspectj_plugin=true -Drebel.cxf_plugin=true -Drebel.logback_plugin=true -Drebel.mybatis_plugin=true -Xdebug -Djava.compiler=NONE -DXrunjdwp:transport=dt_socket,address=8787,server=y,suspend=n -Drebel.dirs=D:\SystemFile\EclipseWorkspace\integrate-svr\integrate-main\target\classes -Dmyproject.root=D:\SystemFile\EclipseWorkspace\integrate-svr -Drebel.disable_update=true
《秒杀系统架构优化思路》
上周参加Qcon,有个兄弟分享秒杀系统的优化,其观点有些赞同,大部分观点却并不同意,结合自己的经验,谈谈自己的一些看法。
一、为什么难 秒杀系统难做的原因:库存只有一份,所有人会在集中的时间读和写这些数据。 例如小米手机每周二的秒杀,可能手机只有1万部,但瞬时进入的流量可能是几百几千万。 又例如12306抢票,亦与秒杀类似,瞬时流量更甚。
二、常见架构 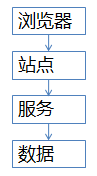
流量到了亿级别,常见站点架构如上:
1)浏览器端,最上层,会执行到一些JS代码 2)站点层,这一层会访问后端数据,拼html页面返回给浏览器 3)服务层,向上游屏蔽底层数据细节 4)数据层,最终的库存是存在这里的,mysql是一个典型
三、优化方向 1)将请求尽量拦截在系统上游:传统秒杀系统之所以挂,请求都压倒了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,流量虽大,下单成功的有效流量甚小【一趟火车其实只有2000张票,200w个人来买,基本没有人能买成功,请求有效率为0】 2)充分利用缓存:这是一个典型的读多些少的应用场景【一趟火车其实只有2000张票,200w个人来买,最多2000个人下单成功,其他人都是查询库存,写比例只有0.1%,读比例占99.9%】,非常适合使用缓存
四、优化细节 4.1)浏览器层请求拦截 点击了“查询”按钮之后,系统那个卡呀,进度条涨的慢呀,作为用户,会不自觉的再去点击“查询”,继续点,继续点,点点点。。。有用么?平白无故的增加了系统负载(一个用户点5次,80%的请求是这么多出来的),怎么整? a)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求 b)JS层面,限制用户在x秒之内只能提交一次请求 如此限流,80%流量已拦
4.2)站点层请求拦截与页面缓存 浏览器层的请求拦截,只能拦住小白用户(不过这是99%的用户哟),高端的程序员根本不吃这一套,写个for循环,直接调用你后端的http请求,怎么整? a)同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面 b)同一个item的查询,例如手机车次,做页面缓存,x秒内到达站点层的请求,均返回同一页面 如此限流,又有99%的流量会被拦截在站点层
4.3)服务层请求拦截与数据缓存 站点层的请求拦截,只能拦住普通程序员,高级黑客,假设他控制了10w台肉鸡(并且假设买票不需要实名认证),这下uid的限制不行了吧?怎么整? a)大哥,我是服务层,我清楚的知道小米只有1万部手机,我清楚的知道一列火车只有2000张车票,我透10w个请求去数据库有什么意义呢?对于写请求,做请求队列,每次只透过有限的写请求去数据层,如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完” b)对于读请求,还用说么?cache来抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的 如此限流,只有非常少的写请求,和非常少的读缓存mis的请求会透到数据层去,又有99.9%的请求被拦住了
4.4)数据层闲庭信步 到了数据这一层,几乎就没有什么请求了,单机也能扛得住,还是那句话,库存是有限的,小米的产能有限,透过过多请求来数据库没有意义。
五、总结 没什么总结了,上文应该描述的非常清楚了,对于秒杀系统,再次重复下笔者的两个架构优化思路: 1)尽量将请求拦截在系统上游 2)读多写少的常用多使用缓存
java 有for(;;)和 for(Object obj : List/Array)
最明显的一个:前者是有范围;后者是全部。
就编码来说各有好处:for更灵活,foreach更简便
for和foreach都是java中重要的集合遍历方法
for循环中 你可以选择从前往后遍历,也可以从后往前遍历,也可以不遍历默写值
但是foreach只能从前往后遍历,而且每一个都会遍历一次,他们之间的选择得看你项目程序中的需求而定 JVM在解释执行行,都会将for与foreach解释成iterator。
总结如下: 1.如果只是遍历集合或者数组,用foreach好些,快些。 2.如果对集合中的值进行修改,就要用for循环了。
其实foreach的内部原理其实也是Iterator,但它不能像Iterator一样可以人为的控制,而且也不能调用iterator.remove();
更不能使用下标来访问每个元素,所以不能用于增加,删除等复杂的操作。
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。 生成的ID是64Bits整型数,同时满足高性能(>10K ids/s),低延迟(<2ms)和高可用。
在分布式系统中,需要生成全局UID的场合还是比较多的,twitter的snowflake解决了这种需求,实现也还是很简单的,除去配置信息,核心代码就是毫秒级时间41位+机器ID
10位+毫秒内序列12位。 该项目地址为:https://github.com/twitter/snowflake是用Scala实现的。 python版详见开源项目https://github.com/erans/pysnowflake。 核心代码为其IdWorker这个类实现,其原理结构如下,我分别用一个0表示一位,用—分割开部分的作用: 0---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---0000000000 00 在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。 这样的好处是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
1.
41位的时间序列(精确到毫秒,41位的长度可以使用69年) 2. 10位的机器标识(10位的长度最多支持部署1024个节点,支持多机房的分布式,需要使用zookeeper) 3. 12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号) 最高位是符号位,始终为0。 //64--------63-----------22-----------12----------0
//符号位 |41位时间 |10位机器码 |12位自增码|
对twitter而言这样的ID生成方案满足: 1.每秒能够生成足够的ID数。 2.生成的ID按照时间大致有序。 用zookeeper的原因是需要获取一个workerId,当然你也可以给分布式节点手工指定不同的workderId,那样就不需要用zookeeper了。
一个server一个workerid, 用zookeeper做保证.
除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。
1.Http作为web服务的首选协议,居有4大优点:
1)http非常简单,以纯文本(超文本)形式编码的请求和响应组成
2)http是无状态的。一旦发送了一个http请求,客户和服务器之间的连接信息就会被释放,有利于减少服务器资源的消耗。
3)http的运行端口80,在大多数防火墙上是公开的
4)行业认可。
但是Http的缺点:
1)缺少对异步消息的支持
2)消息传输的不可靠性
web service相对http (post/get)有好处吗? 1.接口中实现的方法和要求参数一目了然 2.不用担心大小写问题 3.不用担心中文urlencode问题 4.代码中不用多次声明认证(账号,密码)参数 5.传递参数可以为数组,对象等...
http和webservice的区别: 1、http是采用get,post等方式传输数据,而webservice是采用xml格式打包数据,传输是基于http协议进行传输。 2、http直接传输数据,而webservice是采用xml编解码数据,所以能速度上面有些慢。 3、webservice可以直接传输数组或者对象的数据格式,实际现在常用的http+json也可以的,只是需要进行字符串和各种格式的转换。 4、http传输占用的带宽要比webservice占用的带宽少。 5、webservice支持用户权限的验证,而http不支持直接的用户权限验证。 6、webservice 接口中实现的方法和要求参数一目了然。
HTTPS和HTTP的区别: https协议需要到ca申请证书,一般免费证书很少,需要交费。 http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议 http和https使用的是完全不同的连接方式用的端口也不一样,前者是80,后者是443。 http的连接很简单,是无状态的 HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议 要比http协议安全 SSL协议基础 SSL协议位于TCP/IP协议与各种应用层协议之间,本身又分为两层: SSL记录协议(SSL Record Protocol):建立在可靠传输层协议(TCP)之上,为上层协议提供数据封装、压缩、加密等基本功能。 SSL握手协议(SSL Handshake Procotol):在SSL记录协议之上,用于实际数据传输前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。 HTTPS通信过程: 1.在服务器端存在一个公钥及私钥 2.客户端从服务器取得这个公钥 3.客户端产生一个随机的密钥 4.客户端通过公钥对密钥加密(非对称加密) 5.客户端发送到服务器端 6.服务器端接受这个密钥并且以后的服务器端和客户端的数据全部通过这个密钥加密(对称加密)
Zookeeper有两种运行模式: 独立模式(standalone mode):只运行在一台服务器上,适合测试环境 复制模式(replicated mode):运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”(ensemble)。Zookeeper通过复制来实现高可用性,只要集合体中半数以上的机器处于可用状态,它就能够保证服务继续。为什么一定要超过半数呢?这跟Zookeeper的复制策略有关:zookeeper确保对znode树的每一个修改都会被复制到集合体中超过半数的机器上。 生产环境,zookeeper集群的服务器数目应该是奇数。 Zookeeper集群中的角色及其职责 领导者 1.管理写请求 跟随者 1.响应客户端的读请求 2.负责把客户端提交的写请求转发给领导者 znode的观察机制 znode以某种方式发生变化时,“观察”(watch)机制可以让客户端得到通知。可以针对ZooKeeper服务的“操作”来设置观察,该服务的其他操作可以触发观察。比如,客户端可以对某个客户端调用exists操作,同时在它上面设置一个观察,如果此时这个znode不存在,则exists返回false,如果一段时间之后,这个znode被其他客户端创建,则这个观察会被触发,之前的那个客户端就会得到通知。
sync: 将客户端的znode视图与ZooKeeper同步 SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。 跨客户端视图的并发一致性:
ZooKeeper并不保证在某时刻,两个不同的客户端具有一致的数据视图。因为网络延迟的原因,一个客户端可能在另一个客户端得到修改通知之前进行更新。假定有两个客户端A和B。如果客户端A将一个节点/a的值从0修改为1,然后通知客户端B读取/a,客户端B读取到的值可能还是0,这取决于它连接到了哪个服务器。如果客户端A和B读取到相同的值很重要,那么客户端B应该在执行读取之前调用sync()方法。 所以,ZooKeeper本身不保证修改在多个服务器间同步地发生,但是可以使用ZooKeeper原语来构建高层功能,提供有用的客户端同步。
设计目的 1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。 2 .可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。 3 .实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。 4 .等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。 5.原子性:更新只能成功或者失败,没有中间状态。 6 .顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
节点宕机:
应用集群中,我们常常需要让每一个机器知道集群中(或依赖的其他某一个集群)哪些机器是活着的,并且在集群机器因为宕机,网络断链等原因能够不在人工介入的情况下迅速通知到每一个机器。 Zookeeper同样很容易实现这个功能,比如我在zookeeper服务器端有一个znode叫/APP1SERVERS,那么集群中每一个机器启动的时候都去这个节点下创建一个EPHEMERAL类型的节点,比如server1创建/APP1SERVERS/SERVER1(可以使用ip,保证不重复),server2创建/APP1SERVERS/SERVER2,然后SERVER1和SERVER2都watch /APP1SERVERS这个父节点,那么也就是这个父节点下数据或者子节点变化都会通知对该节点进行watch的客户端。因为EPHEMERAL类型节点有一个很重要的特性,就是客户端和服务器端连接断掉或者session过期就会使节点消失,那么在某一个机器挂掉或者断链的时候,其对应的节点就会消失,然后集群中所有对/APP1SERVERS进行watch的客户端都会收到通知,然后取得最新列表即可。
zookeeper是一个高可用性,高性能的协调服务 解决哪些问题 在分布式应用中,经常会出现部分失败的情况,即当节点间传递消息的时候由于网络或者接收者进程死掉等原因,发送者无法知道接收者是否收到消息。 由于部分失败是分布式系统固有的特征因此zookeeper并不能避免部分失败,但是它可以帮你在部分失败的时候进行正确处理 为了解决这个问题zookeeper具有以下特征: 1:zookeeper提供丰富的构件(building block)来实现很多协调数据结构和协议 2:访问原子性,客户端要么读到所有数据,要么读取失败,不会出现只读取部分的情况 3:zookeeper运行在一组机器上,具有高可用性,帮助系统避免单点故障,同时删掉故障服务器 4:顺序一致性:任意客户端的更新请求会被按照发送顺序提交 5:单一系统映像:当一台服务器故障,导致它的客户端需要连接其它服务器的时候,所有更新晚于故障服务器的服务器都不会接收请求,一直到更新赶上故障服务器 6:及时性:任何客户端能看到的滞后都是有限的,不会超过几十秒,且提供sync操作强制客户端所连的服务器与领导者同步 7:会话:每个客户端连接时会尝试连接到配置列表中的一台服务器,一旦失败会自动连接另一台服务器依次类推,知道成功连接一台服务器,从而创建一个会话,客户端可以位每个会话设置超时时间,一旦会话过期,则所有短暂znode会丢失,因为zookeeper会自动发送心跳包,所以很少发生 8:约会机制(rendezvous),在交互的过程中,被协调的各方不许要事先彼此了解,甚至不必同时存在 9:ACL:zookeeper提供了digest(通过用户名密码),host(通过主机名),ip(通过ip地址)3种身份验证模式,依赖与zookeeper的身份验证机制每个ACL都是一个身份对应一组权限,如果我们要给demo.com的客户端域一个读权限在java语言中可以这样创建: new ACL(Perms.READ, new Id("host", "demo.com")); Ids.OPEN_ACL_UNSAFE是将所有ADMIN之外的权限授予每个人 另zookeeper还可以集成第三方的身份验证系统 10:提供关于通用协调模式的开源共享资源库 11:高性能的(官方数据)对以写为主的工作负载来说使用5台不错的机器基准吞吐量达到10000+
各种设计模式--应用场景:
装饰器模式: 1、类继承会导致类的膨胀,这时候装饰器就派上用场了 责任链模式: 1、ifelse 用责任链来实现 状态模式: 1、ifelse 适配器模式:目的是在原来代码的基础上面,增加一些修饰的东西。 1、订单信息,比如增加了活动了之后,返回结果中要包含活动信息,在原来代码的基础上面给返回的Bean里面增加一些活动信息。 代理模式: 比如吧,我有一个业务,同时要调用外部系统的http实现的接口和webservice实现的接口,可以做一个代理类, 代理webservice接口和http接口, 代理类帮我判断该用哪个, 我直接调用代理类就行了。代理类专门屏蔽后面的接口或者协议。 模板方法模式: 1、比如订单的下单还有退款操作,都需要同时判断使用的金额和红包。 2、支付的时候,调用不同的支付方式,都需要去做判断。 策略模式: 策略模式和装饰器模式区别: 策略模式偏向于对实现方法或策略的封装,调用者不需要考虑具体实现,只要指定使用的策略即可。 装饰器模式一般用于需要对功能进行扩展的场合,每一种装饰都是一种扩展或增强。 看起来两个模式好像没有必然的联系,但是在实际使用过程中,发现了一个让我困惑的地方。 先看一个典型的场景: 商场对客户打折,老客户8折,新客户9折,新客户购物满3000,打8.5折 对这个基本场景,一般给的经典模式是策略模式,很多书也以这个作为策略模式的的经典案例。 但是,如果我把每一种折扣看作是一种对原有价格的装饰,这个场景也是可以用装饰器模式实现的。 两个模式都需要花费一些代码去判断策略或装饰器的类型,而且实现难度也旗鼓相当。 我用两种模式都实现了相同的功能,但是却没有发现明显的区别,不知道大家对这两个模式怎么看, 欢迎讨论。 策略模式更倾向是N选1的模式,也即根据条件选择相应的算法,但各种算法是互斥的,比如:团体客户和个人客户的优惠政策必然是非此即彼的;
装饰模式是在主体逻辑的基础上的附加逻辑,比如,个人客户有的属于同城客户,支持送货上门。 谢谢您的回复,如果按照策略模式,每一种打折方案是一种策略,而且只能选择一个,这是没有问题的。
按照装饰模式,每一种折扣都是在购买金额上的附加,在没有折上折或者送货上门这些附加值的时候,我感觉装饰模式也是实用的,当然,当折上折和送货这种附加体现的时候,装饰起的模式就体现去来了。
所以,我感觉在当前描述的问题中,这两个模式应该都可以很恰当的实现需求,但是没感觉到本质的区别。
于是就有些困惑了,看了您的总结,我感觉自己有点钻牛角了。
如果这个场景新增附加需求,比如新增vip客户,那么策略模式就比较合适了。
但是如果进行折上折或者送货上门这类附加需求,很明显装饰模式会更好一些了。
看来具体的模式还得根据实际需求确定,不能死搬硬套。 尽管楼主可以使用两种模式实现自己说的场景,但是两者还是有本质的区别。 策略模式,已经说的很清楚, 就不多说了。 装饰模式是主题逻辑的基础上的加强。可以看看JAVA IO的设计。 就像楼上说的, 如果客户购买满5000, 不只可以享受7折优惠, 还可以送货上门。 这里有两项功能: 1) 7折优惠, 2)送货上门 如果使用策略模式, 我们势必把两项功能都写在一个策略的实现类里面。 假使现在有新的场景出现,就是老客户购买满3000, 也享受送货上门。(或者说这里面的还蕴藏一些其他的优惠,比如说返券等等) 难道我们又把这些功能添加到我们的策略里面, 这样代码就很生硬而且不容易修改。 但是使用装饰模式就不一样,装饰模式能动态的给对象增加特有的功能。 比如说IO里面可以添加Buffer的功能。 同样在我们的场景里面,我们也可以将送货上门、返券等也动态的增强, new 送货上门(new 返券())...., 这样子就很灵活了。 策略实现可能类似: do7折(); do送货上门(); do返券() 装饰的实现可能了类似: new 7折( new 送货上门(new 返券())), 能随意组合; 所有的优惠都享受上了, 看上去还是爽一点。 其实装饰模式, 还是更符合设计的一条原则: 少继承, 多组合
JAR上传到NEXUS mvn deploy:deploy-file -DgroupId=org.csource.fastdfs -DartifactId=fastdfs-client -Dversion=1.24 -Dpackaging=jar -Dfile=D:\\fastdfs-client-1.24.jar -Durl=http://172.16.6.214:8081/nexus/content/groups/public/ -DrepositoryId=nexus JAR创建到本地 mvn install:install-file -DgroupId=com.home.link -DartifactId=fastdfs-client -Dversion=1.24 -Dpackaging=jar -Dfile=D:\\fastdfs-client-1.24.jar
RAID 是“独立磁盘冗余阵列”(最初为“廉价磁盘冗余阵列”)的缩略语,1987 年由Patterson, Gibson 和Katz 在加州大学伯克利分院的一篇文章中定义。RAID 阵列技术允许将一系列磁盘分组,以实现提高可用性的目的,并提供为实现数据保护而必需的数据冗余,有时还有改善性能的作用。我们将对七个RAID 级别: 0,1,3,5,10,30 和50 作些说明。最前面的4 个级别0,1,3,5,)已被定为工业标准,10 级、30 级和50 级则反应了ACCSTOR2000 磁盘阵列可以提供的功能。了解每个级别的特征将有助于您判断哪个级别最适合您的需要,本文的最后一部分将提供一份指导方针,帮助您选择最适合您需要的RAID 级别。RAID 级别可以通过软件或硬件实现。许多但不是全部网络操作系统支持的RAID 级别至少要达到5 级,RAID10、30和50 在ACCSTOR2000 磁盘阵列控制下才能实现。基于软件的RAID 需要使用主机CPU 周期和系统内存,从而增加了系统开销,直接影响系统的性能。磁盘阵列控制器把RAID 的计算和操纵工作由软件移到了专门的硬件上,一般比软件实现RAID 的系统性能要好。
RAID 0
1、RAID 0又称为Stripe(条带化)或Striping,它代表了所有RAID级别中最高的存储性能。RAID 0提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。
2、系统向三个磁盘组成的逻辑硬盘(RADI 0 磁盘组)发出的I/O数据请求被转化为3项操作,其中的每一项操作都对应于一块物理硬盘。我们从图中可以清楚的看到通过建立RAID 0,原先顺序的数据请求被分散到所有的三块硬盘中同时执行。从理论上讲,三块硬盘的并行操作使同一时间内磁盘读写速度提升了3倍。 但由于总线带宽等多种因素的影响,实际的提升速率肯定会低于理论值,但是,大量数据并行传输与串行传输比较,提速效果显著显然毋庸置疑。
3、RAID 0的缺点是不提供数据冗余,因此一旦用户数据损坏,损坏的数据将无法得到恢复。
4、RAID 0具有的特点,使其特别适用于对性能要求较高,而对数据安全不太在乎的领域,如图形工作站等。对于个人用户,RAID 0也是提高硬盘存储性能的绝佳选择。
RAID 1
1、RAID 1又称为Mirror或Mirroring(镜像),它的宗旨是最大限度的保证用户数据的可用性和可修复性。 RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。
2、当读取数据时,系统先从RAID 0的源盘读取数据,如果读取数据成功,则系统不去管备份盘上的数据;如果读取源盘数据失败,则系统自动转而读取备份盘上的数据,不会造成用户工作任务的中断。当然,我们应当及时地更换损坏的硬盘并利用备份数据重新建立Mirror,避免备份盘在发生损坏时,造成不可挽回的数据损失。
3、由于对存储的数据进行百分之百的备份,在所有RAID级别中,RAID 1提供最高的数据安全保障。同样,由于数据的百分之百备份,备份数据占了总存储空间的一半,因而Mirror(镜像)的磁盘空间利用率低,存储成本高。
4、Mirror虽不能提高存储性能,但由于其具有的高数据安全性,使其尤其适用于存放重要数据,如服务器和数据库存储等领域。
RAID 10=RAID 0+1
1、正如其名字一样RAID 0+1是RAID 0和RAID 1的组合形式,也称为RAID 10。
2、以四个磁盘组成的RAID 0+1为例,其数据存储方式如图所示:RAID 0+1是存储性能和数据安全兼顾的方案。它在提供与RAID 1一样的数据安全保障的同时,也提供了与RAID 0近似的存储性能。
3、由于RAID 0+1也通过数据的100%备份功能提供数据安全保障,因此RAID 0+1的磁盘空间利用率与RAID 1相同,存储成本高。
4、RAID 0+1的特点使其特别适用于既有大量数据需要存取,同时又对数据安全性要求严格的领域,如银行、金融、商业超市、仓储库房、各种档案管理等。
RAID 5
1、RAID 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。 以四个硬盘组成的RAID 5为例,其数据存储方式如图4所示:图中,P0为D0,D1和D2的奇偶校验信息,其它以此类推。由图中可以看出,RAID 5不对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
2、RAID 5可以理解为是RAID 0和RAID 1的折衷方案。RAID 5可以为系统提供数据安全保障,但保障程度要比Mirror低而磁盘空间利用率要比Mirror高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较低。
JDK中的实现
在JDK中LinkedHashMap可以作为LRU算法以及插入顺序的实现,LinkedHashMap继承自HashMap,底层结合hash表和双向链表,元素的插入和查询等操作通过计算hash值找到其数组位置,在做插入或则查询操作是,将元素插入到链表的表头(当然得先删除链表中的老元素),如果容量满了,则删除LRU这个元素,在链表表尾的元素即是。 LinkedHashMap的时间复杂度和HashMap差不多,双向链表的删除和表头插入等操作都是O(1)复杂度,故不会影响HashMap的操作性能,插入,查询,删除LRU元素等操作均是O(1)的时间复杂度。
LinkedHashMap不是线程安全的类,用于多线程缓存则需要花点心思去同步它了,JDK中有支持并发的高性能ConcurrenHashMap,没有ConcurrenListHashMap的实现,故要使用支持并发的高性能LRU算法还得靠自己去继承ConcurrenHashMap或则其他方式实现。Google以及其它资深研发团队已有ConcurrenListHashMap的实现 当然知道了原理,我们自己也可以来实现LRU算法
1.简单的计数或则LU时间标记法 底层使用hash表,插入和访问的时间都可以做到O(1)复杂度,容量满了需要删除LRU,则需要遍历一遍数组,通过计数或则LU时间得到LRU,删除之,时间复杂度O(n)。此算法简单容易实现,适合数据量不大的需求
2.通过栈或双向链表 这种算法通过维护元素的在链表中的顺序来达到计算元素的访问热度,不需要额外的空间来计数或则记录访问时间。 插入时,先检查改元素存在此链表中没有,有的删除之,然后再将元素插入表头。 访问时,遍历数组查找该元素,然后将该元素移动至表头。 这样一来,最近被访问的元素都在表头,故要找出LRU则只需要删除表尾元素即可。插入和访问的时间复杂度均为O(n),如果用来作为缓存(查询操作频繁),相比hash表的实现,性能相当不好啊
3.结合HashMap和双向链表 通过上面可知道HashMap可实现读写O(1)复杂度,但是找出LRU需要遍历整个数组,而通过维护链表则相反,仅需要O(1)就可以找出LRU,故将两者结合起来,实现综合复杂度为O(1)的LRU算法 使用数组来存放元素,插入时通过hash计算出其位置,然后改变该元素在链表中的指针,两个操作的时间复杂度均为1。具体实现可参考JDK的LinkedHashMap http://www.360doc.com/content/14/0402/09/10504424_365635496.shtml
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。 为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。 每个Server在工作过程中有三种状态: LOOKING:当前Server不知道leader是谁,正在搜寻 LEADING:当前Server即为选举出来的leader FOLLOWING:leader已经选举出来,当前Server与之同步 Leader选举流程: 当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。先介绍basic paxos流程: 1 .选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server; 2 .选举线程首先向所有Server发起一次询问(包括自己); 3 .选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息( id,zxid),并将这些信息存储到当次选举的投票记录表中; 4. 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server; 5. 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。 通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1. 每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。 fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。 zookeeper数据同步过程: 选完leader以后,zk就进入状态同步过程。 1. leader等待server连接; 2 .Follower连接leader,将最大的zxid发送给leader; 3 .Leader根据follower的zxid确定同步点; 4 .完成同步后通知follower 已经成为uptodate状态; 5 .Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。 工作流程 Leader工作流程 Leader主要有三个功能: 1 .恢复数据; 2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型; 3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。 PING消息是指Learner的心跳信息;REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;ACK消息是Follower的对提议的回复,超过半数的Follower通过,则commit该提议;REVALIDATE消息是用来延长SESSION有效时间。Leader的工作流程简图如下所示,在实际实现中,流程要比下图复杂得多,启动了三个线程来实现功能。 2.3.2 Follower工作流程 Follower主要有四个功能: 1. 向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息); 2 .接收Leader消息并进行处理; 3 .接收Client的请求,如果为写请求,发送给Leader进行投票; 4 .返回Client结果。 Follower的消息循环处理如下几种来自Leader的消息: 1 .PING消息:心跳消息; 2 .PROPOSAL消息:Leader发起的提案,要求Follower投票; 3 .COMMIT消息:服务器端最新一次提案的信息; 4 .UPTODATE消息:表明同步完成; 5 .REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息; 6 .SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。 Follower的工作流程简图如下所示,在实际实现中,Follower是通过5个线程来实现功能的。 http://www.it165.net/admin/html/201405/2997.html
静态代理 静态代理相对来说比较简单,无非就是聚合+多态: 参考:设计模式笔记 – Proxy 代理模式 (Design Pattern) 动态代理 我们知道,通过使用代理,可以在被代理的类的方法的前后添加一些处理方法,这样就达到了类似AOP的效果。而JDK中提供的动态代理,就是实现AOP的绝好底层技术。 JDK动态代理 JDK动态代理主要涉及到java.lang.reflect包中的两个类:Proxy和InvocationHandler。InvocationHandler是一个接口,通过实现该接口定义横切逻辑,并通过反射机制调用目标类的代码,动态将横切逻辑和业务逻辑编制在一起。 Proxy利用InvocationHandler动态创建一个符合某一接口的实例,生成目标类的代理对象。 例子:Java笔记 – 反射 动态代理 CGLib动态代理 还有一个叫CGLib的动态代理,CGLib全称为Code Generation Library,是一个强大的高性能,高质量的代码生成类库,可以在运行期扩展Java类与实现Java接口,CGLib封装了asm,可以再运行期动态生成新的class。和JDK动态代理相比较:JDK创建代理有一个限制,就是只能为接口创建代理实例,而对于没有通过接口定义业务方法的类,则可以通过CGLib创建动态代理。 CGLib采用非常底层的字节码技术,可以为一个类创建子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,并顺势织入横切逻辑。 JDK动态代理和CGLib的比较 CGLib所创建的动态代理对象的性能比JDK所创建的代理对象性能高不少,大概10倍,但CGLib在创建代理对象时所花费的时间却比JDK动态代理多大概8倍,所以对于singleton的代理对象或者具有实例池的代理,因为无需频繁的创建新的实例,所以比较适合CGLib动态代理技术,反之则适用于JDK动态代理技术。另外,由于CGLib采用动态创建子类的方式生成代理对象,所以不能对目标类中的final,private等方法进行处理。所以,大家需要根据实际的情况选择使用什么样的代理了。 同样的,Spring的AOP编程中相关的ProxyFactory代理工厂内部就是使用JDK动态代理或CGLib动态代理的,通过动态代理,将增强(advice)应用到目标类中。 JDK动态代理主要用到java.lang.reflect包中的两个类:Proxy和InvocationHandler. InvocationHandler是一个接口,通过实现该接口定义横切逻辑,并通过反射机制调用目标类的代码,动态的将横切逻辑和业务逻辑编织在一起。 Proxy利用InvocationHandler动态创建一个符合某一接口的实例,生成目标类的代理对象。
Cookie攻击:
防止Cookie被抓包了之后攻击:
就是验证的东西尽量多就行了,比如里面添加IP验证,添加一些MAC地址,添加有效期,添加
NIO通常采用Reactor模式,AIO通常采用Proactor模式。AIO简化了程序的编写,stream的读取和写入都有OS来完成,不需 要像NIO那样子遍历Selector。Windows基于IOCP实现AIO,Linux只有eppoll模拟实现了AIO。
Java7之前的JDK只支持NIO和BIO,从7开始支持AIO。
你说的IO应该指BIO,这种模式需要阻塞线程,一个IO需要一个线程,NIO由一个thread来监听connect事件,另外多个thread来监听读写事件,带来性能上很大提高。
基于原生nio的socket通信时一种很好的解决方案,基于事件的通知模式使得多并发时不用维持高数量的线程,高并发的socket服务器的java实现成为现实。不过原生nio代码十分复杂,无论编写还是修改都是一件头疼的事。“屏蔽底层的繁琐工作,让程序员将注意力集中于业务逻辑本身”,有需求就有生产力进步,
状态模式(state pattern)和策略模式(strategy pattern)的实现方法非常类似,都是利用多态把一些操作分配到一组相关的简单的类中,因此很多人认为这两种模式实际上是相同的。然而 •在现实世界中,策略(如促销一种商品的策略)和状态(如同一个按钮来控制一个电梯的状态,又如手机界面中一个按钮来控制手机)是两种完全不同的思想。当我们对状态和策略进行建模时,这种差异会导致完全不同的问题。例如,对状态进行建模时,状态迁移是一个核心内容;然而,在选择策略时,迁移与此毫无关系。另外,策略模式允许一个客户选择或提供一种策略,而这种思想在状态模式中完全没有。 •一个策略是一个计划或方案,通过执行这个计划或方案,我们可以在给定的输入条件下达到一个特定的目标。策略是一组方案,他们可以相互替换;选择一个策略,获得策略的输出。策略模式用于随不同外部环境采取不同行为的场合。我们可以参考微软企业库底层Object Builder的创建对象的strategy实现方式。 •而状态模式不同,对一个状态特别重要的对象,通过状态机来建模一个对象的状态;状态模式处理的核心问题是状态的迁移,因为在对象存在很多状态情况下,对各个business flow,各个状态之间跳转和迁移过程都是及其复杂的。例如一个工作流,审批一个文件,存在新建、提交、已修改、HR部门审批中、老板审批中、HR审批失败、老板审批失败等状态,涉及多个角色交互,涉及很多事件,这种情况下用状态模式(状态机)来建模更加合适;把各个状态和相应的实现步骤封装成一组简单的继承自一个接口或抽象类的类,通过另外的一个Context来操作他们之间的自动状态变换,通过event来自动实现各个状态之间的跳转。在整个生命周期中存在一个状态的迁移曲线,这个迁移曲线对客户是透明的。我们可以参考微软最新的WWF 状态机工作流实现思想。 •在状态模式中,状态的变迁是由对象的内部条件决定,外界只需关心其接口,不必关心其状态对象的创建和转化;而策略模式里,采取何种策略由外部条件(C)决定。
Spring什么时候实例化bean,首先要分2种情况 第一:如果你使用BeanFactory作为Spring Bean的工厂类,则所有的bean都是在第一次使用该Bean的时候实例化 第二:如果你使用ApplicationContext作为Spring Bean的工厂类,则又分为以下几种情况: (1):如果bean的scope是singleton的,并且lazy-init为false(默认是false,所以可以不用设置),则ApplicationContext启动的时候就实例化该Bean,并且将实例化的Bean放在一个map结构的缓存中,下次再使用该Bean的时候,直接从这个缓存中取 (2):如果bean的scope是singleton的,并且lazy-init为true,则该Bean的实例化是在第一次使用该Bean的时候进行实例化 (3):如果bean的scope是prototype的,则该Bean的实例化是在第一次使用该Bean的时候进行实例化
1、lazy init 在getBean时实例化 2、非lazy的单例bean 容器初始化时实例化 3、prototype等 getBean时实例化
<!--applicationContext.xml配置:-->
<bean id="personService" class="cn.mytest.service.impl.PersonServiceBean"></bean>
id是对象的名称,class是要实例化的类,然后再通过正常的方式进调用实例化的类即可,比如:public void instanceSpring(){ //加载spring配置文件 ApplicationContext ac = new ClassPathXmlApplicationContext( new String[]{ "/conf/applicationContext.xml" }); //调用getBean方法取得被实例化的对象。 PersonServiceBean psb = (PersonServiceBean) ac.getBean("personService"); psb.save(); } 采用这种实例化方式要注意的是:要实例化的类中如果有构造器的话,一定要有一个无参的构造器。 二、使用静态工厂方法实例化; 根据这个中实例化方法的名称就可以知道要想通过这种方式进行实例化就要具备两个条件:(一)、要有工厂类及其工厂方法;(二)、工厂方法是静态的。OK,知道这两点就好办了,首先创建工程类及其静态方法: package cn.mytest.service.impl; /** *创建工厂类 * */ public class PersonServiceFactory { //创建静态方法 public static PersonServiceBean createPersonServiceBean(){ //返回实例化的类的对象 return new PersonServiceBean(); } } 然后再去配置spring配置文件,配置的方法和上面有点不同,这里也是关键所在<!--applicationContext.xml配置:--> <bean id="personService1" class="cn.mytest.service.impl.PersonServiceFactory" factory-method="createPersonServiceBean"></bean> id是实例化的对象的名称,class是工厂类,也就实现实例化类的静态方法所属的类,factory-method是实现实例化类的静态方法。 然后按照正常的调用方法去调用即可: public void instanceSpring(){ //加载spring配置文件 ApplicationContext ac = new ClassPathXmlApplicationContext( new String[]{ "/conf/applicationContext.xml" }); //调用getBean方法取得被实例化的对象。 PersonServiceBean psb = (PersonServiceBean) ac.getBean("personService1"); psb.save(); } 三、使用实例化工厂方法实例化。 这个方法和上面的方法不同之处在与使用该实例化方式工厂方法不需要是静态的,但是在spring的配置文件中需要配置更多的内容,,首先创建工厂类及工厂方法: package cn.mytest.service.impl; /** *创建工厂类 * */ public class PersonServiceFactory { //创建静态方法 public PersonServiceBean createPersonServiceBean1(){ //返回实例化的类的对象 return new PersonServiceBean(); } } 然后再去配置spring配置文件,配置的方法和上面有点不同,这里也是关键所在<!--applicationContext.xml配置:--> <bean id="personServiceFactory" class="cn.mytest.service.impl.PersonServiceFactory"></bean> <bean id="personService2" factory-bean="personServiceFactory" factory-method="createPersonServiceBean1"></bean> 这里需要配置两个bean,第一个bean使用的构造器方法实例化工厂类,第二个bean中的id是实例化对象的名称,factory-bean对应的被实例化的工厂类的对象名称,也就是第一个bean的id,factory-method是非静态工厂方法。 然后按照正常的调用方法去调用即可: public void instanceSpring(){ //加载spring配置文件 ApplicationContext ac = new ClassPathXmlApplicationContext( new String[]{ "/conf/applicationContext.xml" }); //调用getBean方法取得被实例化的对象。 PersonServiceBean psb = (PersonServiceBean) ac.getBean("personService2"); psb.save(); }
所谓原子操作,就是"不可中断的一个或一系列操作" 。
硬件级的原子操作:
在单处理器系统(UniProcessor)中,能够在单条指令中完成的操作都可以认为是" 原子操作",因为中断只能发生于指令之间。这也是某些CPU指令系统中引入了test_and_set、test_and_clear等指令用于临界资源互斥的原因。
在对称多处理器(Symmetric Multi-Processor)结构中就不同了,由于系统中有多个处理器在独立地运行,即使能在单条指令中完成的操作也有可能受到干扰。
在x86 平台上,CPU提供了在指令执行期间对总线加锁的手段。CPU芯片上有一条引线#HLOCK pin,如果汇编语言的程序中在一条指令前面加上前缀"LOCK",经过汇编以后的机器代码就使CPU在执行这条指令的时候把#HLOCK pin的电位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的CPU就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中的
原子性。
软件级的原子操作:
软件级的原子操作实现依赖于硬件原子操作的支持。
对于linux而言,内核提供了两组原子操作接口:一组是针对整数进行操作;另一组是针对单独的位进行操作。
2.1. 原子整数操作
针对整数的原子操作只能对atomic_t类型的数据处理。这里没有使用C语言的int类型,主要是因为:
1) 让原子函数只接受atomic_t类型操作数,可以确保原子操作只与这种特殊类型数据一起使用
2) 使用atomic_t类型确保编译器不对相应的值进行访问优化
3) 使用atomic_t类型可以屏蔽不同体系结构上的数据类型的差异。尽管Linux支持的所有机器上的整型数据都是32位,但是使用atomic_t的代码只能将该类型的数据当作24位来使用。这个限制完全是因为在SPARC体系结构上,原子操作的实现不同于其它体系结构:32位int类型的低8位嵌入了一个锁,因为SPARC体系结构对原子操作缺乏指令级的支持,所以只能利用该锁来避免对原子类型数据的并发访问。
原子整数操作最常见的用途就是实现计数器。原子整数操作列表在中定义。原子操作通常是内敛函数,往往通过内嵌汇编指令来实现。如果某个函数本来就是原子的,那么它往往会被定义成一个宏。
在编写内核时,操作也简单:
atomic_t use_cnt;
atomic_set(&use_cnt, 2);
atomic_add(4, &use_cnt);
atomic_inc(use_cnt);
2.2. 原子性与顺序性
原子性确保指令执行期间不被打断,要么全部执行,要么根本不执行。而顺序性确保即使两条或多条指令出现在独立的执行线程中,甚至独立的处理器上,它们本该执行的顺序依然要保持。
2.3. 原子位操作
原子位操作定义在文件中。令人感到奇怪的是位操作函数是对普通的内存地址进行操作的。原子位操作在多数情况下是对一个字长的内存访问,因而位号该位于0-31之间(在64位机器上是0-63之间),但是对位号的范围没有限制。
编写内核代码,只要把指向了你希望的数据的指针给操作函数,就可以进行位操作了:
unsigned long word = 0;
set_bit(0, &word); /*第0位被设置*/
set_bit(1, &word); /*第1位被设置*/
clear_bit(1, &word); /*第1位被清空*/
change_bit(0, &word); /*翻转第0位*/
为什么关注原子操作?
1)在确认一个操作是原子的情况下,多线程环境里面,我们可以避免仅仅为保护这个操作在外围加上性能开销昂贵的锁。
2)借助于原子操作,我们可以实现互斥锁。
3)借助于互斥锁,我们可以把一些列操作变为原子操作。
GNU C中x++是原子操作吗?
答案不是。x++由3条指令完成。x++在单CPU下不是原子操作。
对应3条汇编指令
movl x, %eax
addl $1, %eax
movl %eax, x
在vc2005下对应
++x;
004232FA mov eax,dword ptr [x]
004232FD add eax,1
00423300 mov dword ptr [x],eax
仍然是3条指令。
所以++x,x++等都不是原子操作。因其步骤包括了从内存中取x值放入寄存器,加寄存器,把值写入内存三个指令。
如何实现x++的原子性?
在单处理器上,如果执行x++时,禁止多线程调度,就可以实现原子。因为单处理的多线程并发是伪并发。
在多处理器上,需要借助cpu提供的Lock功能。锁总线。读取内存值,修改,写回内存三步期间禁止别的CPU访问总线。同时我估计使用Lock指令锁总线的时候,OS也不会把当前线程调度走了。要是调走了,那就麻烦了。
在多处理器系统中存在潜在问题的原因是:
不使用LOCK指令前缀锁定总线的话,在一次内存访问周期中有可能其他处理器会产生异常或中断,而在异常处理中有可能会修改尚未写入的地址,这样当INC操作完成后会产生无效数据(覆盖了前面的修改)。
spinlock 用于CPU同步, 它的实现是基于CPU锁定数据总线的指令.
当某个CPU锁住数据总线后, 它读一个内存单元(spinlock_t)来判断这个spinlock 是否已经被别的CPU锁住. 如果否, 它写进一个特定值, 表示锁定成功, 然后返回. 如果是, 它会重复以上操作直到成功, 或者spin次数超过一个设定值. 锁定数据总线的指令只能保证一个机器指令内, CPU独占数据总线.
单CPU当然能用spinlock, 但实现上无需锁定数据总线.
spinlock在锁定的时候,如果不成功,不会睡眠,会持续的尝试,单cpu的时候spinlock会让其它process动不了.
AOP 面向切面编程(AOP)通过提供另外一种思考程序结构的途经来弥补面向对象编程(OOP)的不足。在OOP中模块化的关键单元是类(classes),而在AOP中模块化的单元则是切面。切面能对关注点进行模块化,例如横切多个类型和对象的事务管理。(在AOP术语中通常称作横切(crosscutting)关注点。) AOP框架是Spring的一个重要组成部分。但是Spring IoC容器并不依赖于AOP,这意味着你有权利选择是否使用AOP,AOP做为Spring IoC容器的一个补充,使它成为一个强大的中间件解决方案。
AOP即Aspect-Oriented Programming的缩写,中文意思是面向切面(或方面)编程。AOP实际上是一种编程思想,可以通过预编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种思想。 AOP在Spring Framework中的作用 目前AOP主要有:Spring AOP ,JBOSS AOP ,AspectJ AOP AOP与OOP:可以理解为OOP是纵向的采用继承树形式的。而AOP是横向的
Spring AOP: 由于Spring AOP是容易实现的,如果你计划在Spring Beans之上将横切关注点模块化,Spring的这一目标将是要点之一。但同样的目标也可能成为一个限制,如果你用的是普通的Java对象而不是Spring beans,并基于此将横切关注点模块化的话。另一方面,AspectJ可用于基于普通Java对象的模块化,但在实施之前需要良好的关于这个主题的知识。 Spring AOP致力于提供一种能够与Spring IoC紧密集成的面向方面框架的实现,以便于解决在开发企业级项目时面临的常见问题。明确你在应用横切关注点(cross-cutting concern)时(例如事物管理、日志或性能评估),需要处理的是Spring beans还是POJO。如果正在开发新的应用,则选择Spring AOP就没有什么阻力。但是如果你正在维护一个现有的应用(该应用并没有使用Spring框架),AspectJ就将是一个自然的选择了。为了详细说明这一点,假如你正在使用Spring AOP,当你想将日志功能作为一个通知(advice)加入到你的应用中,用于追踪程序流程,那么该通知(Advice)就只能应用在Spring beans的连接点(Joinpoint)之上。 AspectJ AOP: 使用“AspectJ”你可以在任何Java对象上应用通知,而不需要在任何文件中创建或配置任何bean。
另一个需要考虑的因素是,你是希望在编译期间进行织入(weaving),还是编译后(post-compile)或是运行时(run-time)。Spring只支持运行时织入。如果你有多个团队分别开发多个使用Spring编写的模块(导致生成多个jar文件,例如每个模块一个jar文件),并且其中一个团队想要在整个项目中的所有Spring bean(例如,包括已经被其他团队打包了的jar文件)上应用日志通知(在这里日志只是用于加入横切关注点的举例),那么通过配置该团队自己的Spring配置文件就可以轻松做到这一点。之所以可以这样做,就是因为Spring使用的是运行时织入。
因为Spring基于代理模式(使用CGLIB),它有一个使用限制,即无法在使用final修饰的bean上应用横切关注点。因为代理需要对Java类进行继承,一旦使用了关键字final,这将是无法做到的。 在这种情况下,你也许会考虑使用AspectJ,其支持编译期织入且不需要生成代理。
于此相似,在static和final方法上应用横切关注点也是无法做到的。因为Spring基于代理模式。如果你在这些方法上配置通知,将导致运行时异常,因为static和final方法是不能被覆盖的。在这种情况下,你也会考虑使用AspectJ,因为其支持编译期织入且不需要生成代理。 缺点: 使用AspectJ的一个间接局限是,因为AspectJ通知可以应用于POJO之上,它有可能将通知应用于一个已配置的通知之上。对于一个你没有注意到这方面问题的大范围应用的通知,这有可能导致一个无限循环。 面向切面编程,把散落在程序中的公共部分提取出来,做成切面类,这样的好处在于,代码的可重用,一旦涉及到该功能的需求发生变化,只要修改该代码就行,否则,你要到处修改,如果只要修改1、2处那还可以接受,万一有1000处呢。
AOP底层的东西就是JDK动态代理和CGLIB代理,说白了就是增强类的功能。
最常用的AOP应用在数据库连接以及事务处理上。
AOP:面向切面编程。(Aspect-Oriented Programming)
AOP可以说是对OOP的补充和完善。OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
将程序中的交叉业务逻辑(比如安全,日志,事务等),封装成一个切面,然后注入到目标对象(具体业务逻辑)中去。 实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码. AOP(Aspect Orient Programming),作为面向对象编程的一种补充,广泛应用于处理一些具有横切性质的系统级服务,如事务管理、安全检查、缓存、对象池管理等。 AOP 实现的关键就在于 AOP 框架自动创建的 AOP 代理,AOP 代理则可分为静态代理和动态代理两大类,其中静态代理是指使用 AOP 框架提供的命令进行编译,从而在编译阶段就可生成 AOP 代理类,因此也称为编译时增强;而动态代理则在运行时借助于 JDK 动态代理、CGLIB 等在内存中"临时"生成 AOP 动态代理类,因此也被称为运行时增强。
先建立表: CREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(100) DEFAULT NULL COMMENT 'name', `ban` varchar(100) DEFAULT NULL COMMENT 'ban', `score` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `inx_ban` (`ban`) ) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=latin1 name:学生名 ban:班级 score:分数 1、按班级分组排序,取出分数前两名的同学。 select t.ban,t.score,t.name from student t where 2<(select count(*) from student k where k.ban=t.ban and t.score>k.score order by k.ban desc) order by t.ban,t.score desc; 示例如下: one 100 abin1 one 99 abin2 three 100 varyall1 three 99 varyall2 two 100 lee1 two 99 lee2 2、按组统计出来每组的所有分组,用逗号隔开 select t.ban,group_concat(t.score) from student t group by t.ban 示例如下: one 100,99,97,95,91 three 100,99,97,95,91 two 100,99,97,95,91
Spring控制反转(IoC)的理解 Spring框架的核心就是控制反转(Inversion of Control)和依赖注入(Dependency Injection),通过这两方面来实现松耦合。 使用IoC,对象是被动的接受依赖类,而不是自己主动的去找。容器在实例化的时候主动将它的依赖类注入给它。可以这样理解:控制反转将类的主动权转移到接口上,依赖注入通过xml配置文件在类实例化时将其依赖类注入。
依赖类(Dependency)是通过外部(xml)来注入的,而不是由使用它的类(Business)来自己制造,这就是依赖的注入。另一方面,Business对类Dependency的依赖转移到对接口IDependency的依赖,控制权由类转移到了接口,即由"实现"转移到"抽象"中。这就是控制反转。 使用IoC,对象是被动的接受依赖类,而不是自己主动的去找。容器在实例化的时候主动将它的依赖类注入给它。可以这样理解:控制反转将类的主动权转移到接口上,依赖注入通过xml配置文件在类实例化时将其依赖类注入。 控制反转即IoC (Inversion of Control),它把传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的“控制反转”概念就是对组件对象控制权的转移,从程序代码本身转移到了外部容器。
依赖注入(Dependency Injection)和控制反转(Inversion of Control)是同一个概念。具体含义是:当某个角色(可能是一个Java实例,调用者)需要另一个角色(另一个Java实例,被调用者)的协助时,在传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在Spring里,创建被调用者的工作不再由调用者来完成,因此称为控制反转;创建被调用者实例的工作通常由Spring容器来完成,然后注入调用者,因此也称为依赖注入。
简而言之:所谓控制反转就是应用本身不负责依赖对象的创建及维护,依赖对象的创建及维护是由外部容器负责的。这样控制权就由应用转移到了外部容器,控制权的转移就是所谓反转;所谓依赖注入就是指:在运行期,由外部容器动态地将依赖对象注入到组件中。
传统编程和IoC的对比 传统编程:决定使用哪个具体的实现类的控制权在调用类本身,在编译阶段就确定了。 IoC模式:调用类只依赖接口,而不依赖具体的实现类,减少了耦合。控制权交给了容器,在运行的时候才由容器决定将具体的实现动态的“注入”到调用类的对象中。
应用控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体将其所依赖的对象的引用传递给它。也可以说,依赖被注入到对象中。所以,控制反转是,关于一个对象如何获取他所依赖的对象的引用,这个责任的反转。
IoC核心理念: 1.在类当中不创建对象,在代码中不直接与对象和服务连接 2.在配置文件中描述创建对象的方式,以及各个组件之间的联系 3.外部容器通过解析配置文件,通过反射来将这些联系在一起 The Hollywood principle:Don’t call us,we’ll call you. 即,所有组件都是被动的、不主动联系(调用)外部代码, 要等着外部代码的调用--------所有的组件的初始化和相互调用都由容器负责实现。 简单的说,就是整个程序之间的关系,都由容器来控制:将程序的控制权反转给容器,就是所谓的外转 而在我们传统代码中,由程序代码直接控制
优缺点:
IoC最大的好处是什么?
因为把对象生成放在了XML里定义,所以当我们需要换一个实现子类将会变成很简单(一般这样的对象都是实现于某种接口的),只要修改XML就可以了,这样我们甚至可以实现对象的热插拔(有点象USB接口和SCSI硬盘了)。 IoC最大的缺点是什么?
(1)生成一个对象的步骤变复杂了(事实上操作上还是挺简单的),对于不习惯这种方式的人,会觉得有些别扭和不直观。
(2)对象生成因为是使用反射编程,在效率上有些损耗。但相对于IoC提高的维护性和灵活性来说,这点损耗是微不足道的,除非某对象的生成对效率要求特别高。
(3)缺少IDE重构操作的支持,如果在Eclipse要对类改名,那么你还需要去XML文件里手工去改了,这似乎是所有XML方式的缺憾所在。
IOC的意思是控件反转也就是由容器控制程序之间的关系,把控件权交给了外部容器,之前的写法,由程序代码直接操控,而现在控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。
下载一个dubbo.xsd文件 windows->preferrence->xml->xmlcatalog add->catalog entry ->file system 选择刚刚下载的文件路径 修改key值和配置文件的  http://code.alibabatech.com/schema/dubbo/dubbo.xsd 相同 保存。。在xml文件右键validate ok解决了。 http://my.oschina.net/u/1455908/blog/343437
初级优化: 1、select这些关键字大写,否则,系统会自动的转化为大写才去执行sql的解释执行计划。 2、如果需要字段少的话选择select a,b,c from table ,尽量少用select * from table. 3、尽量少使用!=和<>因为不会使用到索引。 4、尽量少使用or,不会使用到索引. 5、避免使用is not null 和not in,like,不会使用到索引。 6、避免全表扫描,在where和order by 上面建立索引。 7、应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2 8、应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。 9、不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
二叉树->b-树,解决的是读索引的IO次数问题 在真实的数据库中往往索引本身的数据量也是非常庞大的 树的查找,其实是每一层需要做一次判断因为索引很大,只能存在文件里,不能一次加载,所以没判断一层,都需要有一次磁盘IO,所以查找IO次数最坏的情况 就是树的高度-1,加入你要的节点在最后一层的话 二叉树,是只有两个子节点的一单数据量一大的话 树高会很恐怖B-Tree,的度是没有限制的 可以打打减少这个数的高度,从而减少磁盘读的次数b-tree -> b+tree :这个是针对IO的再次优化 b+tree,的父节点是不存数据的 数据库索引,其实一个节点刚好占的是硬盘的一页空间 由于索引节点不存数据 一个硬盘页,也就是一个节点的度就可以更大 可以最大程度减少树的高度 之所以一个节点刚好占一页,也是IO的问题,一次硬盘IO只能读一页 这是结构上的改进 效果就是一个节点一次IO的度更大了 他这个意思就是说,如果有索引,一次索引查找,基本不会超过2次硬盘IO 这还只是b-tree b-tree这玩意儿就读B树 很多人读B减数是误读
1、JVM类装载机制,JVM内存模型,JVM垃圾回收算法,JVM垃圾回收器。 2、spring IOC和AOP机制。 3、http的get,post,put,delete,option。 4、Mybatis复杂数据类型实现,自增id返回机制。 5、多线程的ThreadLocal实现机制,volatile,线程池使用。 6、memcached的分片存储机制,redis优化。 7、mysql的myisam和innodb的区别,索引的概念和优化,mysql的主键索引和普通索引的区别,以及唯一索引。 主键的数据域存储了整行的数据, 普通索引的数据域存的是主键 联合索引这个,A=X AND C=X能用到的索引长度是A列的长度
A=X And B=X用到的索引长度是两列的长度和
8、sql查询实现,以及优化sql。 9、数据库连接池异常怎么处理。
服务端编程的性能杀手: 1、大量线程导致的线程切换开销。 2、锁和竞争条件。 3、非必要的内存拷贝。
4、网络IO
5、磁盘IO
6、CPU核心数
7、网络带宽
8、内存大小
9、
1、线程问题 由于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起 Memcached,还是稍有逊色。 因为 Redis 的操作都非常快速——它的数据全部在内存里,完全不需要访问磁盘。至于并发,Redis 使用多路 I/O 复用技术,本身的并发效率不成问题。 当然,单个 Redis 进程没办法使用多核(任一时刻只能跑在一个 CPU 核心上),但是它本来就不是非常计算密集型的服务。如果单核性能不够用,可以多开几个进程。 Redis 单线程-多路复用io模型
、 2、内存使用效率对比: 使用简单的key-value存储的话,Memcached的内存利用率更高,而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached。 3、数据类型: Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached 里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的 GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。 4、安全机制 memcached采用cas机制,而redis有事务机制。 5、事件模型 memcached采用了libevent事件模型,多线程模型可以发挥多核作用,Redis实现了自己的一套和libevent类似的事件驱动机制,两者都采用了epoll通信模型和非阻塞机制。 epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。 最后讲讲 为什么epoll会比select高效,主要从三方面来进行论述。 (1)elect对描述符状态的改变是通过轮询来进行查找的;而epoll是当描述符状态发生改变时主动进行通知内核,这就是所谓的Reactor事件处理机制。可以用“好莱坞原则”进行描述:不要打电话给我们,我们会打电话通知你。相比之下,select的机制就好比面试结束后不停给面试官打电话询问面试结果。效率孰高孰低,可见一 斑。 (2)select的文件描述符是使用链表进行组织的;而epoll是使用红黑树这一高效数据结构组织的。 (3)select从内核到用户空间传递文件描述符上发送的信息是使用内存复制的方式进行的;而epoll是采用共享内存的方式。
6、内存管理方面 Memcached使用预分配的内存池的方式,使用slab和大小不同的chunk来管理内存,Item根据大小选择合适的chunk存储,内存池的方式可以省去申请/释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被剔除,原因可以参考Timyang的文章:http://timyang.net/data/Memcached-lru-evictions/ Redis使用现场申请内存的方式来存储数据,并且很少使用free-list等方式来优化内存分配,会在一定程度上存在内存碎片,Redis跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致swap也不会剔除任何非临时数据(但会尝试剔除部分临时数据),这点上Redis更适合作为存储而不是cache。 7、redis并发 Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类keyvalue存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Python,Ruby,Erlang,PHP客户端,使用很方便。 性能测试结果: SET操作每秒钟 110000 次,GET操作每秒钟 81000 次,服务器配置如下: Linux 2.6, Xeon X3320 2.5Ghz. stackoverflow 网站使用 Redis 做为缓存服务器。
中央仓库(官方和非官方) https://repo1.maven.org/maven2 http://repo.maven.apache.org/maven2/ http://maven.oschina.net/content/groups/public/ http://download.java.net/maven/2/ https://repository.jboss.com/nexus/content/repositories/root_repository/maven2/ http://repository.jboss.com/maven2/ http://mirrors.ibiblio.org/maven2/ http://repository.sonatype.org/content/groups/public/ 私有仓库 http://repository.codehaus.org/ http://snapshots.repository.codehaus.org/ http://people.apache.org/repo/m2-snapshot-repository/ http://people.apache.org/repo/m2-incubating-repository/
反射只能读取类信息,而 ASM 除了读还能写。 反射读取类信息时需要进行类加载处理,而 ASM 则不需要将类加载到内存中。 反射相对于 ASM 来说使用方便,想直接操纵 ASM 的话需要有 JVM 指令基础。 反射是读取持久堆上存储的类信息。而 ASM 是直接处理 .class 字节码的小工具(工具虽小,但是功能非常强大!)
If you are not sure about the string pool usage, try -XX:+PrintStringTableStatistics JVM argument. It will print you the string pool usage when your program terminates.
基本概念: 在软件系统中,“ 行为请求者”与“ 行为实现者”通常呈现一种“ 紧耦合”。但在 某些场合,比如要对行为进行“记录、撤销/重做、事务”等处理,这种无法抵御变化的紧耦合是不合适的。在这种情况下,如何将“行为请求者”与“行为实现者”解耦?将 一组行为抽象为对象, 实现二者之间的松耦合。这就是 命令模式(Command Pattern)。
将来自客户端的请求传入一个对象,从而使你可用不同的请求对客户进行参数化。用于“行为请求者”与“行为实现者”解耦,可实现二者之间的松耦合,以便适应变化。分离变化与不变的因素。 在面向对象的程序设计中,一个对象调用另一个对象,一般情况下的调用过程是:创建目标对象实例;设置调用参数;调用目标对象的方法。 但在有些情况下有必要使用一个专门的类对这种调用过程加以封装,我们把这种专门的类称作command类。 特点 1)、command模式将调用操作的对象和实现该操作的对象解耦 2)、可以将多个命令装配成一个复合命令,复合命令是Composite模式的一个实例 3)、增加新的command很容易,无需改变已有的类 应用场景: 我们来分析下命令模式的使用场景吧,一般情况下如下几类场景中使用命令模式会达到很好的效果: 1、当一个应用程序调用者与多个目标对象之间存在调用关系时,并且目标对象之间的操作很类似的时候。 2、例如当一个目标对象内部的方法调用太复杂,或者内部的方法需要协作才能完成对象的某个特点操作时。 3、有时候调用者调用目标对象后,需要回调一些方法。
命令模式是将行为请求者和行为实现者解耦合的方式。对命令进行封装,将命令和执行命令分隔开。请求的一方发出命令,要求执行某些操作,接受一方收到命令,执行这些操作的真正实现。请求的一方不必知道接受方的接口,以及如何被操作。
命令模式可以应用到很多场景,比如实现do/undo功能、实现导航功能。
ApplicationContext 是 BeanFactory 接口的子接口,它增强了 BeanFactory 的功能,处于 context 包下。很多时候, ApplicationContext 允许以声明式方式操作容器,无须手动创建。可利用如 ContextLoader 的支持类,在 Web 应用启动时自动创建 ApplicationContext。当然,也可以采用编程方式创建 ApplicationContext。 ApplicationContext包括BeanFactory的全部功能,因此建议优先使用ApplicationContext。除非对于某些内存非常关键的应用,才考虑使用 BeanFactory。 spring为ApplicationContext提供的3种实现分别为: 1、 ClassPathXmlApplicationContext:利用类路径的XML文件来载入Bean定义的信息 [1] ApplicationContext ctx = new ClassPathXmlApplicationContext("bean.xml"); [2] String[] locations = {"bean1.xml", "bean2.xml", "bean3.xml"}; ApplicationContext ctx = new ClassPathXmlApplication(locations); 2、 FileSystemXmlApplicationContext:利用文件系统中的XMl文件来载入Bean 定义的信息 [1] ApplicationContext ctx = new FileSystemXmlApplicationContext("bean.xml"); //加载单个配置文件 [2] String[] locations = {"bean1.xml", "bean2.xml", "bean3.xml"}; ApplicationContext ctx = new FileSystemXmlApplicationContext(locations ); //加载多个配置文件 [3] ApplicationContext ctx =new FileSystemXmlApplicationContext("D:/project/bean.xml"); //根据具体路径加载 3、 XmlWebApplicationContext:从Web系统中的XML文件来载入Bean定义的信息。 ServletContext servletContext = request.getSession().getServletContext(); ApplicationContext ctx = WebApplicationContextUtils.getWebApplicationContext(servletContext); 配置WebApplicationContext的两种方法: (1) 利用Listener接口来实现 <listener> <listener-class> org.springframework.web.context.ContextLoaderListener </listener-class> </listener> <context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:applicationContext</param-value> </context-param> (2) 利用Servlet接口来实现 <context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:applicationContext</param-value> </context-param> <Servlet> <servlet-name>context</servlet-name> <servlet-class> org.springframework.web.context.ContextLoaderServlet </servlet-class> </servlet>
装饰者模式(Decorator Pattern),是在不必改变原类文件和使用继承的情况下,动态的扩展一个对象的功能。它是通过创建一个包装对象,也就是装饰来包裹真实的对象。
使用装饰者模式的时候需要注意一下几点内容:
(1)装饰对象和真实对象有相同的接口。这样客户端对象就可以以和真实对象相同的方式和装饰对象交互。
(2)装饰对象包含一个真实对象的引用。
(3)装饰对象接受所有的来自客户端的请求,它把这些请求转发给真实的对象。
(4)装饰对象可以在转发这些请求以前或以后增加一些附加功能。这样就确保了在运行时,不用修改给定对象的结构就可以在外部增加附加的功能。在面向对象的设计中,通常是通过继承来实现对给定类的功能扩展。然而,装饰者模式,不需要子类可以在应用程序运行时,动态扩展功能,更加方便、灵活。
适用装饰者模式场合:
1.当我们需要为某个现有的对象,动态的增加一个新的功能或职责时,可以考虑使用装饰模式。
2.当某个对象的职责经常发生变化或者经常需要动态的增加职责,避免为了适应这样的变化,而增加继承子类扩展的方式,因为这种方式会造成子类膨胀的速度过快,难以控制。
推荐你一本设计模式方面的优秀书籍:郑阿奇 主编的《软件秘笈-设计模式那点事》。里面讲解很到位,实例通俗易懂,看了收获很大!
二分查找的基本思想是将n个元素分成大致相等的两部分,去a[n/2]与x做比较,如果x=a[n/2],则找到x,算法中止;如果x<a[n/2],则只要在数组a的左半部分继续搜索x,如果x>a[n/2],则只要在数组a的右半部搜索x. 时间复杂度无非就是while循环的次数! 总共有n个元素, 渐渐跟下去就是n,n/2,n/4,....n/2^k,其中k就是循环的次数 由于你n/2^k取整后>=1 即令n/2^k=1 可得k=log2n,(是以2为底,n的对数) 所以时间复杂度可以表示O()=O(logn)
Static 静态:这里主要记录的是静态程序块和静态方法 如果有些代码必须在项目启动的时候就执行,就需要使用静态代码块,这种代码是主动执行的;需要在项目启动的时候就初始化但是不执行,在不创建对象的情况下,可以供其他程序调用,而在调用的时候才执行,这需要使用静态方法,这种代码是被动执行的. 静态方法在类加载的时候 就已经加载 可以用类名直接调用。 静态代码块和静态方法的区别是: 静态代码块是自动执行的; 静态方法是被调用的时候才执行的. 静态方法:如果我们在程序编写的时候需要一个不实例化对象就可以调用的方法,我们就可以使用静态方法,具体实现是在方法前面加上static,如下: public static void method(){} 在使用静态方法的时候需要注意一下几个方面: 在静态方法里只能直接调用同类中其他的静态成员(包括变量和方法),而不能直接访问类中的非静态成员。这是因为,对于非静态的方法和变量,需要先创建类的实例对象后才可使用,而静态方法在使用前不用创建任何对象。(备注:静态变量是属于整个类的变量而不是属于某个对象的) 静态方法不能以任何方式引用this和super关键字,因为静态方法在使用前不用创建任何实例对象,当静态方法调用时,this所引用的对象根本没有产生。 静态程序块:当一个类需要在被载入时就执行一段程序,这样可以使用静态程序块。 public class DemoClass { private DemoClass(){} public static DemoClass _instance; static{ if(null == _instance ){ _instance = new DemoClass(); } } public static DemoClass getInstance(){ return _instance; } } 这样的程序在类被加载的时候就执行了static中的代码。 Ps:java中类的装载步骤: 在Java中,类装载器把一个类装入Java虚拟机中,要经过三个步骤来完成:装载、链接和初始化,其中链接又可以分成校验、准备和解析三步,除了解析外,其它步骤是严格按照顺序完成的,各个步骤的主要工作如下: 所谓装载就是寻找一个类或是一个接口的二进制形式并用该二进制形式来构造代表这个类或是这个接口的class对象的过程。其中类或接口的名称是给定了的。 装载:查找和导入类或接口的二进制数据; 链接:执行下面的校验、准备和解析步骤,其中解析步骤是可以选择的; 校验:检查导入类或接口的二进制数据的正确性; 准备:给类的静态变量分配并初始化存储空间; 解析:将符号引用转成直接引用; 初始化:激活类的静态变量的初始化Java代码和静态Java代码块
replication的限制:一旦数据库过于庞大,尤其是当写入过于频繁,很难由一台主机支撑的时候,我们还是会面临到扩展瓶颈。数据切分(sharding):通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。。数据的切分同时还可以提高系统的总体可用性,因为单台设备Crash之后,只有总体数据的某部分不可用,而不是所有的数据。 数据的切分(Sharding)模式
一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。 垂直切分:一个架构设计较好的应用系统,其总体功能肯定是由很多个功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一个或者多个表。而在架构设计中,各个功能模块相互之间的交互点越统一越少,系统的耦合度就越低,系统各个模块的维护性以及扩展性也就越好。这样的系统,实现数据的垂直切分也就越容易。 一般来说,如果是一个负载相对不是很大的系统,而且表关联又非常的频繁,那可能数据库让步,将几个相关模块合并在一起减少应用程序的工作的方案可以减少较多的工作量,这是一个可行的方案。一个垂直拆分的例子: 1.用户模块表:user,user_profile,user_group,user_photo_album 2.群组讨论表:groups,group_message,group_message_content,top_message 3.相册相关表:photo,photo_album,photo_album_relation,photo_comment 4.事件信息表:event - 群组讨论模块和用户模块之间主要存在通过用户或者是群组关系来进行关联。一般关联的时候都会是通过用户的id或者nick_name以及group的id来进行关联,通过模块之间的接口实现不会带来太多麻烦;
- 相册模块仅仅与用户模块存在通过用户的关联。这两个模块之间的关联基本就有通过用户id关联的内容,简单清晰,接口明确;
- 事件模块与各个模块可能都有关联,但是都只关注其各个模块中对象的ID信息,同样可以做到很容易分拆。
垂直切分的优点 - 数据库的拆分简单明了,拆分规则明确;
- 应用程序模块清晰明确,整合容易;
- 数据维护方便易行,容易定位;
垂直切分的缺点 - 部分表关联无法在数据库级别完成,需要在程序中完成;
- 对于访问极其频繁且数据量超大的表仍然存在性能瓶颈,不一定能满足要求;
- 事务处理相对更为复杂;
- 切分达到一定程度之后,扩展性会遇到限制;
- 过读切分可能会带来系统过渡复杂而难以维护。
水平切分将某个访问极其频繁的表再按照某个字段的某种规则来分散到多个表之中,每个表中包含一部分数据。 对于上面的例子:所有数据都是和用户关联的,那么我们就可以根据用户来进行水平拆分,将不同用户的数据切分到不同的数据库中。 现在互联网非常火爆的Web2.0类型的网站,基本上大部分数据都能够通过会员用户信息关联上,可能很多核心表都非常适合通过会员ID来进行数据的水平切分。而像论坛社区讨论系统,就更容易切分了,非常容易按照论坛编号来进行数据的水平切分。切分之后基本上不会出现各个库之间的交互。
水平切分的优点 - 表关联基本能够在数据库端全部完成;
- 不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
- 应用程序端整体架构改动相对较少;
- 事务处理相对简单;
- 只要切分规则能够定义好,基本上较难遇到扩展性限制;
水平切分的缺点 - 切分规则相对更为复杂,很难抽象出一个能够满足整个数据库的切分规则;
- 后期数据的维护难度有所增加,人为手工定位数据更困难;
- 应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
两种切分结合用:一般来说,我们数据库中的所有表很难通过某一个(或少数几个)字段全部关联起来,所以很难简单的仅仅通过数据的水平切分来解决所有问题。而垂直切分也只能解决部分问题,对于那些负载非常高的系统,即使仅仅只是单个表都无法通过单台数据库主机来承担其负载。我们必须结合“垂直”和“水平”两种切分方式同时使用 每一个应用系统的负载都是一步一步增长上来的,在开始遇到性能瓶颈的时候,大多数架构师和DBA都会选择先进行数据的垂直拆分,因为这样的成本最先,最符合这个时期所追求的最大投入产出比。然而,随着业务的不断扩张,系统负载的持续增长,在系统稳定一段时期之后,经过了垂直拆分之后的数据库集群可能又再一次不堪重负,遇到了性能瓶颈。 如果我们再一次像最开始那样继续细分模块,进行数据的垂直切分,那我们可能在不久的将来,又会遇到现在所面对的同样的问题。而且随着模块的不断的细化,应用系统的架构也会越来越复杂,整个系统很可能会出现失控的局面。 这时候我们就必须要通过数据的水平切分的优势,来解决这里所遇到的问题。而且,我们完全不必要在使用数据水平切分的时候,推倒之前进行数据垂直切分的成果,而是在其基础上利用水平切分的优势来避开垂直切分的弊端,解决系统复杂性不断扩大的问题。而水平拆分的弊端(规则难以统一)也已经被之前的垂直切分解决掉了,让水平拆分可以进行的得心应手。 示例数据库: 假设在最开始,我们进行了数据的垂直切分,然而随着业务的不断增长,数据库系统遇到了瓶颈,我们选择重构数据库集群的架构。如何重构?考虑到之前已经做好了数据的垂直切分,而且模块结构清晰明确。而业务增长的势头越来越猛,即使现在进一步再次拆分模块,也坚持不了太久。 ==>选择了在垂直切分的基础上再进行水平拆分。 ==>在经历过垂直拆分后的各个数据库集群中的每一个都只有一个功能模块,而每个功能模块中的所有表基本上都会与某个字段进行关联。如用户模块全部都可以通过用户ID进行切分,群组讨论模块则都通过群组ID来切分,相册模块则根据相册ID来进切分,最后的事件通知信息表考虑到数据的时限性(仅仅只会访问最近某个事件段的信息),则考虑按时间来切分。 数据切分以及整合方案.数据库中的数据在经过垂直和(或)水平切分被存放在不同的数据库主机之后,应用系统面临的最大问题就是如何来让这些数据源得到较好的整合,其中存在两种解决思路: - 在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个数据库,在模块内完成数据的整合;
- 通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;
第二种方案,虽然短期内需要付出的成本可能会相对更大一些,但是对整个系统的扩展性来说,是非常有帮助的。针对第二种方案,可以选择的方法和思路有: 1.利用MySQLProxy 实现数据切分及整合.可用来监视、分析或者传输他们之间的通讯信息。他的灵活性允许你最大限度的使用它,目前具备的功能主要有连接路由,Query分析,Query过滤和修改,负载均衡,以及基本的HA机制等。MySQLProxy 本身并不具有上述所有的这些功能,而是提供了实现上述功能的基础。要实现这些功能,还需要通过我们自行编写LUA脚本来实现。 原理:MySQLProxy 实际上是在客户端请求与MySQLServer 之间建立了一个连接池。所有客户端请求都是发向MySQLProxy,然后经由MySQLProxy 进行相应的分析,判断出是读操作还是写操作,分发至对应的MySQLServer 上。对于多节点Slave集群,也可以起做到负载均衡的效果。 2.利用Amoeba实现数据切分及整合Amoeba是一个基于Java开发的,专注于解决分布式数据库数据源整合Proxy程序的开源框架,Amoeba已经具有Query路由,Query过滤,读写分离,负载均衡以及HA机制等相关内容。Amoeba主要解决的以下几个问题: - 数据切分后复杂数据源整合;
- 提供数据切分规则并降低数据切分规则给数据库带来的影响;
- 降低数据库与客户端的连接数;
- 读写分离路由;
AmoebaFor MySQL 主要是专门针对MySQL数据库的解决方案,前端应用程序请求的协议以及后端连接的数据源数据库都必须是MySQL。对于客户端的任何应用程序来说,AmoebaForMySQL 和一个MySQL数据库没有什么区别,任何使用MySQL协议的客户端请求,都可以被AmoebaFor MySQL 解析并进行相应的处理。 Proxy程序常用的功能如读写分离,负载均衡等配置都在amoeba.xml中进行。Amoeba已经支持了实现数据的垂直切分和水平切分的自动路由,路由规则可以在rule.xml进行设置。
3.利用HiveDB实现数据切分及整合HiveDB同样是一个基于Java针对MySQL数据库的提供数据切分及整合的开源框架,只是目前的HiveDB仅仅支持数据的水平切分。主要解决大数据量下数据库的扩展性及数据的高性能访问问题,同时支持数据的冗余及基本的HA机制。 HiveDB的实现机制与MySQLProxy 和Amoeba有一定的差异,他并不是借助MySQL的Replication功能来实现数据的冗余,而是自行实现了数据冗余机制,而其底层主要是基于HibernateShards 来实现的数据切分工作。数据切分与整合中可能存在的问题 引入分布式事务的问题?一旦数据进行切分被分别存放在多个MySQLServer中之后,不管我们的切分规则设计的多么的完美(实际上并不存在完美的切分规则),都可能造成之前的某些事务所涉及到的数据已经不在同一个MySQLServer 中了。 ==>将一个跨多个数据库的分布式事务分拆成多个仅处于单个数据库上面的小事务,并通过应用程序来总控各个小事务。
跨节点Join的问题?==>先从一个节点取出数据,然后根据这些数据,再到另一个表中取数据. ==>使用Federated存储引擎,问题是:乎如果远端的表结构发生了变更,本地的表定义信息是不会跟着发生相应变化的。 跨节点合并排序分页问题?==>Join本身涉及到的多个表之间的数据读取一般都会存在一个顺序关系。但是排序分页就不太一样了,排序分页的数据源基本上可以说是一个表(或者一个结果集),本身并不存在一个顺序关系,所以在从多个数据源取数据的过程是完全可以并行的。这样,排序分页数据的取数效率我们可以做的比跨库Join更高,所以带来的性能损失相对的要更小。
前言有人反馈之前几篇文章过于理论缺少实际操作细节,这篇文章就多一些可操作性的内容吧。 注:这篇文章是以 MySQL 为背景,很多内容同时适用于其他关系型数据库,需要有一些索引知识为基础。 优化目标 1.减少 IO 次数 IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当然,也是收效最明显的优化手段。 2.降低 CPU 计算 除了 IO 瓶颈之外,SQL优化中需要考虑的就是 CPU 运算量的优化了。order by, group by,distinct … 都是消耗 CPU 的大户(这些操作基本上都是 CPU 处理内存中的数据比较运算)。当我们的 IO 优化做到一定阶段之后,降低 CPU 计算也就成为了我们 SQL 优化的重要目标 优化方法 改变 SQL 执行计划 明确了优化目标之后,我们需要确定达到我们目标的方法。对于 SQL 语句来说,达到上述2个目标的方法其实只有一个,那就是改变 SQL 的执行计划,让他尽量“少走弯路”,尽量通过各种“捷径”来找到我们需要的数据,以达到 “减少 IO 次数” 和 “降低 CPU 计算” 的目标 常见误区 1.count(1)和count(primary_key) 优于 count(*) 很多人为了统计记录条数,就使用 count(1) 和 count(primary_key) 而不是 count(*) ,他们认为这样性能更好,其实这是一个误区。对于有些场景,这样做可能性能会更差,应为数据库对 count(*) 计数操作做了一些特别的优化。 2.count(column) 和 count(*) 是一样的 这个误区甚至在很多的资深工程师或者是 DBA 中都普遍存在,很多人都会认为这是理所当然的。实际上,count(column) 和 count(*) 是一个完全不一样的操作,所代表的意义也完全不一样。 count(column) 是表示结果集中有多少个column字段不为空的记录 count(*) 是表示整个结果集有多少条记录 3.select a,b from … 比 select a,b,c from … 可以让数据库访问更少的数据量 这个误区主要存在于大量的开发人员中,主要原因是对数据库的存储原理不是太了解。 实际上,大多数关系型数据库都是按照行(row)的方式存储,而数据存取操作都是以一个固定大小的IO单元(被称作 block 或者 page)为单位,一般为4KB,8KB… 大多数时候,每个IO单元中存储了多行,每行都是存储了该行的所有字段(lob等特殊类型字段除外)。 所以,我们是取一个字段还是多个字段,实际上数据库在表中需要访问的数据量其实是一样的。 当然,也有例外情况,那就是我们的这个查询在索引中就可以完成,也就是说当只取 a,b两个字段的时候,不需要回表,而c这个字段不在使用的索引中,需要回表取得其数据。在这样的情况下,二者的IO量会有较大差异。 4.order by 一定需要排序操作 我们知道索引数据实际上是有序的,如果我们的需要的数据和某个索引的顺序一致,而且我们的查询又通过这个索引来执行,那么数据库一般会省略排序操作,而直接将数据返回,因为数据库知道数据已经满足我们的排序需求了。 实际上,利用索引来优化有排序需求的 SQL,是一个非常重要的优化手段 延伸阅读:MySQL ORDER BY 的实现分析,MySQL 中 GROUP BY 基本实现原理以及 MySQL DISTINCT 的基本实现原理这3篇文章中有更为深入的分析,尤其是第一篇 5.执行计划中有 filesort 就会进行磁盘文件排序 有这个误区其实并不能怪我们,而是因为 MySQL 开发者在用词方面的问题。filesort 是我们在使用 explain 命令查看一条 SQL 的执行计划的时候可能会看到在 “Extra” 一列显示的信息。 实际上,只要一条 SQL 语句需要进行排序操作,都会显示“Using filesort”,这并不表示就会有文件排序操作。 基本原则1.尽量少 join MySQL 的优势在于简单,但这在某些方面其实也是其劣势。MySQL 优化器效率高,但是由于其统计信息的量有限,优化器工作过程出现偏差的可能性也就更多。对于复杂的多表 Join,一方面由于其优化器受限,再者在 Join 这方面所下的功夫还不够,所以性能表现离 Oracle 等关系型数据库前辈还是有一定距离。但如果是简单的单表查询,这一差距就会极小甚至在有些场景下要优于这些数据库前辈。 2.尽量少排序 排序操作会消耗较多的 CPU 资源,所以减少排序可以在缓存命中率高等 IO 能力足够的场景下会较大影响 SQL 的响应时间。 对于MySQL来说,减少排序有多种办法,比如: 上面误区中提到的通过利用索引来排序的方式进行优化 减少参与排序的记录条数 非必要不对数据进行排序 … 3.尽量避免 select * 很多人看到这一点后觉得比较难理解,上面不是在误区中刚刚说 select 子句中字段的多少并不会影响到读取的数据吗? 是的,大多数时候并不会影响到 IO 量,但是当我们还存在 order by 操作的时候,select 子句中的字段多少会在很大程度上影响到我们的排序效率,这一点可以通过我之前一篇介绍 MySQL ORDER BY 的实现分析的文章中有较为详细的介绍。 此外,上面误区中不是也说了,只是大多数时候是不会影响到 IO 量,当我们的查询结果仅仅只需要在索引中就能找到的时候,还是会极大减少 IO 量的。 4.尽量用 join 代替子查询 虽然 Join 性能并不佳,但是和 MySQL 的子查询比起来还是有非常大的性能优势。MySQL 的子查询执行计划一直存在较大的问题,虽然这个问题已经存在多年,但是到目前已经发布的所有稳定版本中都普遍存在,一直没有太大改善。虽然官方也在很早就承认这一问题,并且承诺尽快解决,但是至少到目前为止我们还没有看到哪一个版本较好的解决了这一问题。 5.尽量少 or 当 where 子句中存在多个条件以“或”并存的时候,MySQL 的优化器并没有很好的解决其执行计划优化问题,再加上 MySQL 特有的 SQL 与 Storage 分层架构方式,造成了其性能比较低下,很多时候使用 union all 或者是union(必要的时候)的方式来代替“or”会得到更好的效果。 6.尽量用 union all 代替 union union 和 union all 的差异主要是前者需要将两个(或者多个)结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的 CPU 运算,加大资源消耗及延迟。所以当我们可以确认不可能出现重复结果集或者不在乎重复结果集的时候,尽量使用 union all 而不是 union。 7.尽量早过滤 这一优化策略其实最常见于索引的优化设计中(将过滤性更好的字段放得更靠前)。 在 SQL 编写中同样可以使用这一原则来优化一些 Join 的 SQL。比如我们在多个表进行分页数据查询的时候,我们最好是能够在一个表上先过滤好数据分好页,然后再用分好页的结果集与另外的表 Join,这样可以尽可能多的减少不必要的 IO 操作,大大节省 IO 操作所消耗的时间。 8.避免类型转换 这里所说的“类型转换”是指 where 子句中出现 column 字段的类型和传入的参数类型不一致的时候发生的类型转换: 人为在column_name 上通过转换函数进行转换 直接导致 MySQL(实际上其他数据库也会有同样的问题)无法使用索引,如果非要转换,应该在传入的参数上进行转换 由数据库自己进行转换 如果我们传入的数据类型和字段类型不一致,同时我们又没有做任何类型转换处理,MySQL 可能会自己对我们的数据进行类型转换操作,也可能不进行处理而交由存储引擎去处理,这样一来,就会出现索引无法使用的情况而造成执行计划问题。 9.优先优化高并发的 SQL,而不是执行频率低某些“大”SQL 对于破坏性来说,高并发的 SQL 总是会比低频率的来得大,因为高并发的 SQL 一旦出现问题,甚至不会给我们任何喘息的机会就会将系统压跨。而对于一些虽然需要消耗大量 IO 而且响应很慢的 SQL,由于频率低,即使遇到,最多就是让整个系统响应慢一点,但至少可能撑一会儿,让我们有缓冲的机会。 10.从全局出发优化,而不是片面调整 SQL 优化不能是单独针对某一个进行,而应充分考虑系统中所有的 SQL,尤其是在通过调整索引优化 SQL 的执行计划的时候,千万不能顾此失彼,因小失大。 11.尽可能对每一条运行在数据库中的SQL进行 explain 优化 SQL,需要做到心中有数,知道 SQL 的执行计划才能判断是否有优化余地,才能判断是否存在执行计划问题。在对数据库中运行的 SQL 进行了一段时间的优化之后,很明显的问题 SQL 可能已经很少了,大多都需要去发掘,这时候就需要进行大量的 explain 操作收集执行计划,并判断是否需要进行优化。 原文地址:http://isky000.com/database/mysql-performance-tuning-sql
一,单一Bean 1. 实例化;
2. 设置属性值;
3. 如果实现了BeanNameAware接口,调用setBeanName设置Bean的ID或者Name;
4. 如果实现BeanFactoryAware接口,调用setBeanFactory 设置BeanFactory;
5. 如果实现ApplicationContextAware,调用setApplicationContext设置ApplicationContext
6. 调用BeanPostProcessor的预先初始化方法;
7. 调用InitializingBean的afterPropertiesSet()方法;
8. 调用定制init-method方法;
9. 调用BeanPostProcessor的后初始化方法; 1. 调用DisposableBean的destroy();
2. 调用定制的destroy-method方法; 二,多个Bean的先后顺序 - 优先加载BeanPostProcessor的实现Bean
- 按Bean文件和Bean的定义顺序按bean的装载顺序(即使加载多个spring文件时存在id覆盖)
- “设置属性值”(第2步)时,遇到ref,则在“实例化”(第1步)之后先加载ref的id对应的bean
- AbstractFactoryBean的子类,在第6步之后,会调用createInstance方法,之后会调用getObjectType方法
- BeanFactoryUtils类也会改变Bean的加载顺序
关于springmvc的几个注解,基本都在org.springframework:spring-webmvc:3.1.4.REALEASE这个包里面处理的,具体是在org.springframework.web.servlet.mvc.annotation这个包里面的AnnotationMethodHandlerAdapter这个类里面处理的。
1、使用<context:annotation-config />简化配置
Spring2.1添加了一个新的context的Schema命名空间,该命名空间对注释驱动、属性文件引入、加载期织入等功能提供了便捷的配置。我们知道注释本身是不会做任何事情的,它仅提供元数据信息。要使元数据信息真正起作用,必须让负责处理这些元数据的处理器工作起来。 AutowiredAnnotationBeanPostProcessor和CommonAnnotationBeanPostProcessor就是处理这些注释元数据的处理器。但是直接在Spring配置文件中定义这些Bean显得比较笨拙。Spring为我们提供了一种方便的注册这些BeanPostProcessor的方式,这就是<context:annotation-config />:
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd"> <context:annotation-config /> </beans> <context:annotationconfig />将隐式地向Spring容器注册AutowiredAnnotationBeanPostProcessor、CommonAnnotationBeanPostProcessor、 PersistenceAnnotationBeanPostProcessor以及RequiredAnnotationBeanPostProcessor这4个BeanPostProcessor。 2、使用<context:component-scan />让Bean定义注解工作起来 <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd"> <context:component-scan base-package="com.kedacom.ksoa" /> </beans> 这里,所有通过<bean>元素定义Bean的配置内容已经被移除,仅需要添加一行<context:component-scan />配置就解决所有问题了——Spring XML配置文件得到了极致的简化(当然配置元数据还是需要的,只不过以注释形式存在罢了)。<context:component-scan />的base-package属性指定了需要扫描的类包,类包及其递归子包中所有的类都会被处理。 < context:component-scan />还允许定义过滤器将基包下的某些类纳入或排除。Spring支持以下4种类型的过滤方式: 过滤器类型 表达式范例 说明 注解 org.example.SomeAnnotation将所有使用SomeAnnotation注解的类过滤出来 类名指定 org.example.SomeClass过滤指定的类 正则表达式 com\.kedacom\.spring\.annotation\.web\..*通过正则表达式过滤一些类 AspectJ表达式 org.example..*Service+通过AspectJ表达式过滤一些类 以正则表达式为例,我列举一个应用实例: <context:component-scan base-package="com.casheen.spring.annotation"> <context:exclude-filter type="regex" expression="com\.casheen\.spring\.annotation\.web\..*" /> </context:component-scan> 值得注意的是<context:component-scan />配置项不但启用了对类包进行扫描以实施注释驱动Bean定义的功能,同时还启用了注释驱动自动注入的功能(即还隐式地在内部注册了AutowiredAnnotationBeanPostProcessor和CommonAnnotationBeanPostProcessor),因此当使用<context:component-scan />后,就可以将<context:annotation-config />移除了.
Java 虚拟机(JVM)是可运行Java 代码的假想计算机。只要根据JVM规格描述将解释器移植到特定的计算机上,就能保证经过编译的任何Java代码能够在该系统上运行。本文首先简要介绍从Java文件的编译到最终执行的过程,随后对JVM规格描述作一说明。 一.Java源文件的编译、下载 、解释和执行 Java应用程序的开发周期包括编译、下载 、解释和执行几个部分。Java编译程序将Java源程序翻译为JVM可执行代码?字节码。这一编译过程同C/C++ 的 编译有些不同。当C编译器编译生成一个对象的代码时,该代码是为在某一特定硬件平台运行而产生的。因此,在编译过程中,编译程序通过查表将所有对符号的引 用转换为特定的内存偏移量,以保证程序运行。Java编译器却不将对变量和方法的引用编译为数值引用,也不确定程序执行过程中的内存布局,而是将这些符号 引用信息保留在字节码中,由解释器在运行过程中创立内存布局,然后再通过查表来确定一个方法所在的地址。这样就有效的保证了Java的可移植性和安全 性。 运行JVM字节码的工作是由解释器来完成的。解释执行过程分三部进行:代码的装入、代码的校验和代码的执行。装入代码的工作由"类装载器"(class loader)完成。类装载器负责装入运行一个程序需要的所有代码,这也包括程序代码中的类所继承的类和被其调用的类。当类装载器装入一个类时,该类被放 在自己的名字空间中。除了通过符号引用自己名字空间以外的类,类之间没有其他办法可以影响其他类。在本台计算机上的所有类都在同一地址空间内,而所有从外 部引进的类,都有一个自己独立的名字空间。这使得本地类通过共享相同的名字空间获得较高的运行效率,同时又保证它们与从外部引进的类不会相互影响。当装入 了运行程序需要的所有类后,解释器便可确定整个可执行程序的内存布局。解释器为符号引用同特定的地址空间建立对应关系及查询表。通过在这一阶段确定代码的 内存布局,Java很好地解决了由超类改变而使子类崩溃的问题,同时也防止了代码对地址的非法访问。 随后,被装入的代码由字节码校验器进行检查。校验器可发现操作数栈溢出,非法数据类型转化等多种错误。通过校验后,代码便开始执行了。 Java字节码的执行有两种方式: 1.即时编译方式:解释器先将字节码编译成机器码,然后再执行该机器码。 2.解释执行方式:解释器通过每次解释并执行一小段代码来完成Java字节码程 序的所有操作。 通常采用的是第二种方法。由于JVM规格描述具有足够的灵活性,这使得将字节码翻译为机器代码的工作 具有较高的效率。对于那些对运行速度要求较高的应用程序,解释器可将Java字节码即时编译为机器码,从而很好地保证了Java代码的可移植性和高性能。 二.JVM规格描述 JVM的设计目标是提供一个基于抽象规格描述的计算机模型,为解释程序开发人员提很好的灵活性,同时也确保Java代码可在符合该规范的任何系统上运 行。JVM对其实现的某些方面给出了具体的定义,特别是对Java可执行代码,即字节码(Bytecode)的格式给出了明确的规格。这一规格包括操作码 和操作数的语法和数值、标识符的数值表示方式、以及Java类文件中的Java对象、常量缓冲池在JVM的存储 映象。这些定义为JVM解释器开发人员提供了所需的信息和开发环境。Java的设计者希望给开发人员以随心所欲使用Java的自由。 JVM定义了控制Java代码解释执行和具体实现的五种规格,它们是: JVM指令系统 JVM寄存器 JVM栈结构 JVM碎片回收堆 JVM存储 区 2.1JVM指令系统 JVM指令系统同其他计算机的指令系统极其相似。Java指令也是由 操作码和操作数两部分组成。操作码为8位二进制数,操作数进紧随在操作码的后面,其长度根据需要而不同。操作码用于指定一条指令操作的性质(在这里我们采 用汇编符号的形式进行说明),如iload表示从存储器中装入一个整数,anewarray表示为一个新数组分配空间,iand表示两个整数的" 与",ret用于流程控制,表示从对某一方法的调用中返回。当长度大于8位时,操作数被分为两个以上字节存放。JVM采用了"big endian"的编码方式来处理这种情况,即高位bits存放在低字节中。这同 Motorola及其他的RISC CPU采用的编码方式是一致的,而与Intel采用的"little endian "的编码方式即低位bits存放在低位字节的方法不同。 Java指令系统是以Java语言的实现为目的设计的,其中包含了用于调用方法和监视多先程系统的指令。Java的8位操作码的长度使得JVM最多有256种指令,目前已使用了160多种操作码。 2.2JVM指令系统 所有的CPU均包含用于保存系统状态和处理器所需信息的寄存器组。如果虚拟机定义较多的寄存器,便可以从中得到更多的信息而不必对栈或内存进行访问,这 有利于提高运行速度。然而,如果虚拟机中的寄存器比实际CPU的寄存器多,在实现虚拟机时就会占用处理器大量的时间来用常规存储器模拟寄存器,这反而会降 低虚拟机的效率。针对这种情况,JVM只设置了4个最为常用的寄存器。它们是: pc程序计数器 optop操作数栈顶指针 frame当前执行环境指针 vars指向当前执行环境中第一个局部变量的指针 所有寄存器均为32位。pc用于记录程序的执行。optop,frame和vars用于记录指向Java栈区的指针。 2.3JVM栈结构 作为基于栈结构的计算机,Java栈是JVM存储信息的主要方法。当JVM得到一个Java字节码应用程序后,便为该代码中一个类的每一个方法创建一个栈框架,以保存该方法的状态信息。每个栈框架包括以下三类信息: 局部变量 执行环境 操作数栈 局部变量用于存储一个类的方法中所用到的局部变量。vars寄存器指向该变量表中的第一个局部变量。 执行环境用于保存解释器对Java字节码进行解释过程中所需的信息。它们是:上次调用的方法、局部变量指针和操作数栈的栈顶和栈底指针。执行环境是一个 执行一个方法的控制中心。例如:如果解释器要执行iadd(整数加法),首先要从frame寄存器中找到当前执行环境,而后便从执行环境中找到操作数栈, 从栈顶弹出两个整数进行加法运算,最后将结果压入栈顶。 操作数栈用于存储运算所需操作数及运算的结果。 2.4JVM碎片回收堆 Java类的实例所需的存储空间是在堆上分配的。解释器具体承担为类实例分配空间的工作。解释器在为一个实例分配完存储空间后,便开始记录对该实例所占用的内存区域的使用。一旦对象使用完毕,便将其回收到堆中。 在Java语言中,除了new语句外没有其他方法为一对象申请和释放内存。对内存进行释放和回收的工作是由Java运行系统承担的。这允许Java运行 系统的设计者自己决定碎片回收的方法。在SUN公司开发的Java解释器和Hot Java环境中,碎片回收用后台线程的方式来执行。这不但为运行系统提供了良好的性能,而且使程序设计人员摆脱了自己控制内存使用的风险。 2.5JVM存储区 JVM有两类存储区:常量缓冲池和方法区。常量缓冲池用于存储类名称、方法和字段名称以及串常量。方法区则用于存储Java方法的字节码。对于这两种存 储区域具体实现方式在JVM规格中没有明确规定。这使得Java应用程序的存储布局必须在运行过程中确定,依赖于具体平台的实现方式。 JVM是为Java字节码定义的一种独立于具体平台的规格描述,是Java平台独立性的基础。目前的JVM还存在一些限制和不足,有待于进一步的完善,但无论如何,JVM的思想是成功的。 对比分析:如果把Java原程序想象成我们的C++ 原 程序,Java原程序编译后生成的字节码就相当于C++原程序编译后的80x86的机器码(二进制程序文件),JVM虚拟机相当于80x86计算机系 统,Java解释器相当于80x86CPU。在80x86CPU上运行的是机器码,在Java解释器上运行的是Java字节码。 Java解释器相当于运行Java字节码的“CPU”,但该“CPU”不是通过硬件实现的,而是用软件实现的。Java解释器实际上就是特定的平台下的一 个应用程序。只要实现了特定平台下的解释器程序,Java字节码就能通过解释器程序在该平台下运行,这是Java跨平台的根本。当前,并不是在所有的平台 下都有相应Java解释器程序,这也是Java并不能在所有的平台下都能运行的原因,它只能在已实现了Java解释器程序的平台下运行。
Java主要靠Java虚拟机(JVM)在目标码级实现平台无关性。JVM是一种抽象机器,它附着在具体操作系统之上,本身具有一套虚机器指令,并有自己的栈、寄存器组等。但JVM通常是在软件上而不是在硬件上实现。(目前,SUN系统公司已经设计实现了Java芯片,主要使用在网络计算机NC上。另外,Java芯片的出现也会使Java更容易嵌入到家用电器中。)JVM是Java平台无关的基础,在JVM上,有一个Java解释器用来解释Java编译器编译后的程序。Java编程人员在编写完软件后,通过Java编译器将Java源程序编译为JVM的字节代码。任何一台机器只要配备了Java解释器,就可以运行这个程序,而不管这种字节码是在何种平台上生成的(过程如图1所示)。另外,Java采用的是基于IEEE标准的数据类型。通过JVM保证数据类型的一致性,也确保了Java的平台无关性。
简单说,java的解释器只是一个基于虚拟机jvm平台的程序
由于JDK的安全检查耗时较多.所以通过setAccessible(true)的方式关闭安全检查就可以达到提升反射速度的目的
在面向对象编程中, 最通常的方法是一个new操作符产生一个对象实例,new操作符就是用来构造对象实例的。但是在一些情况下, new操作符直接生成对象会带来一些问题。举例来说, 许多类型对象的创造需要一系列的步骤: 你可能需要计算或取得对象的初始设置; 选择生成哪个子对象实例; 或在生成你需要的对象之前必须先生成一些辅助功能的对象。 在这些情况,新对象的建立就是一个 “过程”,不仅是一个操作,像一部大机器中的一个齿轮传动。 模式的问题:你如何能轻松方便地构造对象实例,而不必关心构造对象实例的细节和复杂过程呢? 解决方案:建立一个工厂来创建对象 实现: 一、引言
1)还没有工厂时代:假如还没有工业革命,如果一个客户要一款宝马车,一般的做法是客户去创建一款宝马车,然后拿来用。
2)简单工厂模式:后来出现工业革命。用户不用去创建宝马车。因为客户有一个工厂来帮他创建宝马.想要什么车,这个工厂就可以建。比如想要320i系列车。工厂就创建这个系列的车。即工厂可以创建产品。
3)工厂方法模式时代:为了满足客户,宝马车系列越来越多,如320i,523i,30li等系列一个工厂无法创建所有的宝马系列。于是由单独分出来多个具体的工厂。每个具体工厂创建一种系列。即具体工厂类只能创建一个具体产品。但是宝马工厂还是个抽象。你需要指定某个具体的工厂才能生产车出来。 4)抽象工厂模式时代:随着客户的要求越来越高,宝马车必须配置空调。于是这个工厂开始生产宝马车和需要的空调。 最终是客户只要对宝马的销售员说:我要523i空调车,销售员就直接给他523i空调车了。而不用自己去创建523i空调车宝马车. 这就是工厂模式。 二、分类
工厂模式主要是为创建对象提供过渡接口,以便将创建对象的具体过程屏蔽隔离起来,达到提高灵活性的目的。
工厂模式可以分为三类: 1)简单工厂模式(Simple Factory)
2)工厂方法模式(Factory Method)
3)抽象工厂模式(Abstract Factory) 这三种模式从上到下逐步抽象,并且更具一般性。
GOF在《设计模式》一书中将工厂模式分为两类:工厂方法模式(Factory Method)与抽象工厂模式(Abstract Factory)。 将简单工厂模式(Simple Factory)看为工厂方法模式的一种特例,两者归为一类。 三、区别
工厂方法模式:
一个抽象产品类,可以派生出多个具体产品类。
一个抽象工厂类,可以派生出多个具体工厂类。
每个具体工厂类只能创建一个具体产品类的实例。
抽象工厂模式:
多个抽象产品类,每个抽象产品类可以派生出多个具体产品类。
一个抽象工厂类,可以派生出多个具体工厂类。
每个具体工厂类可以创建多个具体产品类的实例。
区别:
工厂方法模式只有一个抽象产品类,而抽象工厂模式有多个。
工厂方法模式的具体工厂类只能创建一个具体产品类的实例,而抽象工厂模式可以创建多个。
两者皆可。
http://blog.csdn.net/jason0539/article/details/23020989
重排序通常是编译器或运行时环境为了优化程序性能而采取的对指令进行重新排序执行的一种手段。重排序分为两类:编译期重排序和运行期重排序,分别对应编译时和运行时环境
在并发程序中,程序员会特别关注不同进程或线程之间的数据同步,特别是多个线程同时修改同一变量时,必须采取可靠的同步或其它措施保障数据被正确地修改,这里的一条重要原则是:不要假设指令执行的顺序,你无法预知不同线程之间的指令会以何种顺序执行。 但是在单线程程序中,通常我们容易假设指令是顺序执行的,否则可以想象程序会发生什么可怕的变化。理想的模型是:各种指令执行的顺序是唯一且有序的,这个顺序就是它们被编写在代码中的顺序,与处理器或其它因素无关,这种模型被称作顺序一致性模型,也是基于冯·诺依曼体系的模型。当然,这种假设本身是合理的,在实践中也鲜有异常发生,但事实上,没有哪个现代多处理器架构会采用这种模型,因为它是在是太低效了。而在编译优化和CPU流水线中,几乎都涉及到指令重排序。 编译期重排序 编译期重排序的典型就是通过调整指令顺序,在不改变程序语义的前提下,尽可能减少寄存器的读取、存储次数,充分复用寄存器的存储值。 假设第一条指令计算一个值赋给变量A并存放在寄存器中,第二条指令与A无关但需要占用寄存器(假设它将占用A所在的那个寄存器),第三条指令使用A的值且与第二条指令无关。那么如果按照顺序一致性模型,A在第一条指令执行过后被放入寄存器,在第二条指令执行时A不再存在,第三条指令执行时A重新被读入寄存器,而这个过程中,A的值没有发生变化。通常编译器都会交换第二和第三条指令的位置,这样第一条指令结束时A存在于寄存器中,接下来可以直接从寄存器中读取A的值,降低了重复读取的开销。
重排序对于流水线的意义 现代CPU几乎都采用流水线机制加快指令的处理速度,一般来说,一条指令需要若干个CPU时钟周期处理,而通过流水线并行执行,可以在同等的时钟周期内执行若干条指令,具体做法简单地说就是把指令分为不同的执行周期,例如读取、寻址、解析、执行等步骤,并放在不同的元件中处理,同时在执行单元EU中,功能单元被分为不同的元件,例如加法元件、乘法元件、加载元件、存储元件等,可以进一步实现不同的计算并行执行。 流水线架构决定了指令应该被并行执行,而不是在顺序化模型中所认为的那样。重排序有利于充分使用流水线,进而达到超标量的效果。
确保顺序性 尽管指令在执行时并不一定按照我们所编写的顺序执行,但毋庸置疑的是,在单线程环境下,指令执行的最终效果应当与其在顺序执行下的效果一致,否则这种优化便会失去意义。 通常无论是在编译期还是运行期进行的指令重排序,都会满足上面的原则。 Java存储模型中的重排序 在Java存储模型(Java Memory Model, JMM)中,重排序是十分重要的一节,特别是在并发编程中。JMM通过happens-before法则保证顺序执行语义,如果想要让执行操作B的线程观察到执行操作A的线程的结果,那么A和B就必须满足happens-before原则,否则,JVM可以对它们进行任意排序以提高程序性能。 volatile关键字可以保证变量的可见性,因为对volatile的操作都在Main Memory中,而Main Memory是被所有线程所共享的,这里的代价就是牺牲了性能,无法利用寄存器或Cache,因为它们都不是全局的,无法保证可见性,可能产生脏读。 volatile还有一个作用就是局部阻止重排序的发生,对volatile变量的操作指令都不会被重排序,因为如果重排序,又可能产生可见性问题。 在保证可见性方面,锁(包括显式锁、对象锁)以及对原子变量的读写都可以确保变量的可见性。但是实现方式略有不同,例如同步锁保证得到锁时从内存里重新读入数据刷新缓存,释放锁时将数据写回内存以保数据可见,而volatile变量干脆都是读写内存。
Java 内存模型由于 ConcurrentHashMap 是建立在 Java 内存模型基础上的,为了更好的理解 ConcurrentHashMap,让我们首先来了解一下 Java 的内存模型。 Java 语言的内存模型由一些规则组成,这些规则确定线程对内存的访问如何排序以及何时可以确保它们对线程是可见的。下面我们将分别介绍 Java 内存模型的重排序,内存可见性和 happens-before 关系。 重排序内存模型描述了程序的可能行为。具体的编译器实现可以产生任意它喜欢的代码 -- 只要所有执行这些代码产生的结果,能够和内存模型预测的结果保持一致。这为编译器实现者提供了很大的自由,包括操作的重排序。 编译器生成指令的次序,可以不同于源代码所暗示的“显然”版本。重排序后的指令,对于优化执行以及成熟的全局寄存器分配算法的使用,都是大有脾益的,它使得程序在计算性能上有了很大的提升。 重排序类型包括: - 编译器生成指令的次序,可以不同于源代码所暗示的“显然”版本。
- 处理器可以乱序或者并行的执行指令。
- 缓存会改变写入提交到主内存的变量的次序。
内存可见性由于现代可共享内存的多处理器架构可能导致一个线程无法马上(甚至永远)看到另一个线程操作产生的结果。所以 Java 内存模型规定了 JVM 的一种最小保证:什么时候写入一个变量对其他线程可见。 在现代可共享内存的多处理器体系结构中每个处理器都有自己的缓存,并周期性的与主内存协调一致。假设线程 A 写入一个变量值 V,随后另一个线程 B 读取变量 V 的值,在下列情况下,线程 B 读取的值可能不是线程 A 写入的最新值: - 执行线程 A 的处理器把变量 V 缓存到寄存器中。
- 执行线程 A 的处理器把变量 V 缓存到自己的缓存中,但还没有同步刷新到主内存中去。
- 执行线程 B 的处理器的缓存中有变量 V 的旧值。
Happens-before 关系happens-before 关系保证:如果线程 A 与线程 B 满足 happens-before 关系,则线程 A 执行动作的结果对于线程 B 是可见的。如果两个操作未按 happens-before 排序,JVM 将可以对他们任意重排序。 下面介绍几个与理解 ConcurrentHashMap 有关的 happens-before 关系法则: - 程序次序法则:如果在程序中,所有动作 A 出现在动作 B 之前,则线程中的每动作 A 都 happens-before 于该线程中的每一个动作 B。
- 监视器锁法则:对一个监视器的解锁 happens-before 于每个后续对同一监视器的加锁。
- Volatile 变量法则:对 Volatile 域的写入操作 happens-before 于每个后续对同一 Volatile 的读操作。
- 传递性:如果 A happens-before 于 B,且 B happens-before C,则 A happens-before C。
1.希望复用一些现存的类,但是接口又与复用环境要求不一致。
2.其实适配器模式有点无奈之举,在前期设计的时候,我们就不应该考虑适配器模式,而应该考虑通过重构统一接口。
想使用一个已存在的类,但是该类不符合接口需求;或者需要创建一个可重用的类,适配没有提供合适接口的其它类。
适配器模式主要解决的问题就是我们要调用的接口类型,无法满足我们新系统的使用需求,这时候,我们需要将旧系统的接口,通过适配器进行转配,达到支持新接口调用的目的。
对于这样的要求,我们通过适配器就可以完成,当然如果有多个接口需要转配,那么我们就需要为每一个接口提供一个适配器去完成转换的工作。当然具体的调用过程,我们可以进行相应的封装。达到比较通用的方式去调用适配器,完成适配服务。
我们来看看适配的过程。
我们根据上面的适配器的特点的介绍中,我们来分析下适配器模式的几类比较适用的使用场景:
1、我们在使用第三方的类库,或者说第三方的API的时候,我们通过适配器转换来满足现有系统的使用需求。
2、我们的旧系统与新系统进行集成的时候,我们发现旧系统的数据无法满足新系统的需求,那么这个时候,我们可能需要适配器,完成调用需求。
3、我们在使用不同数据库之间进行数据同步。(我这里只是分析的是通过程序来说实现的时候的情况。还有其他的很多种方式[数据库同步])。
我们本节给出适配器模式的经典实现代码,我们这里结合项目中的查询服务来进行说明,旧系统中提供一个查询服务方法Query();但是我新系统定义底层的数据访问服务层
的时候,却是使用的GetList()方法,并且将之前的返回结果集合进行包装成泛型的形式来进行。
枚举单例模式:
关于单例模式的实现有很多种,网上也分析了如今实现单利模式最好用枚举,好处不外乎三点:1.线程安全 2.不会因为序列化而产生新实例 3.防止反射攻击
1.线程安全
下面这段代码就是声明枚举实例的通常做法,它可能还包含实例变量和实例方法,但是为了简单起见,我并没有使用这些东西,仅仅需要小心的是如果你正在使用实例方法,那么你需要确保线程安全(如果它影响到其他对象的状态的话)。默认枚举实例的创建是线程安全的,但是在枚举中的其他任何方法由程序员自己负责。
关于线程安全的保证,其实是通过类加载机制来保证的,我们看看INSTANCE的实例化时机,是在static块中,JVM加载类的过程显然是线程安全的。 static {}; Code: 0: new #12; //class com/abin/lee/spring/util/Singleton$1 3: dup 4: ldc #14; //String INSTANCE 6: iconst_0 7: invokespecial #15; //Method com/abin/lee/spring/util/Singleton$1."<init>":(Ljava/lang/String;I)V 10: putstatic #19; //Field INSTANCE:Lcom/abin/lee/spring/util/Singleton; 13: iconst_1 14: anewarray #1; //class com/abin/lee/spring/util/Singleton 17: dup 18: iconst_0 19: getstatic #19; //Field INSTANCE:Lcom/abin/lee/spring/util/Singleton; 22: aastore 23: putstatic #21; //Field ENUM$VALUES:[Lcom/abin/lee/spring/util/Singleton; 26: return 线程安全,从反编译后的类源码中可以看出也是通过类加载机制保证的,应该是这样吧
2.不会因为序列化而产生新实例
枚举自己处理序列化 传统单例存在的另外一个问题是一旦你实现了序列化接口,那么它们不再保持单例了,因为readObject()方法一直返回一个新的对象就像java的构造方法一样,你可以通过使用readResolve()方法来避免此事发生,看下面的例子:
//readResolve to prevent another instance of Singleton private Object readResolve(){ return INSTANCE; } 这样甚至还可以更复杂,如果你的单例类维持了其他对象的状态的话,因此你需要使他们成为transient的对象。但是枚举单例,JVM对序列化有保证。
优点:不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象
3.防止反射攻击
反射攻击,我有自己试着反射攻击了以下,不过报错了...看了下方的反编译类源码,明白了,因为单例类的修饰是abstract的,所以没法实例化。(解决)
静态内部类: // Correct lazy initialization in Java @ThreadSafe class Foo { private static class HelperHolder { public static Helper helper = new Helper(); } public static Helper getHelper() { return HelperHolder.helper; } } 它利用了内部静态类只有在被引用的时候才会被加载的规律。 这样一来,一旦内部的HelperHolder被引用了,它就会首先被JVM加载,进行该类的静态域的初始化,从而使得Helper这一单例类被初始化。它之所以是线程安全的,也是托了JVM的福,因为JVM对于类的加载这一过程是线程安全的。
在看 Java并发包(java.util.concurrent)中大量使用了CAS操作,CAS即 Compare And Swap(CAS),比较并交换,其中由sun.misc.Unsafe实现,Unsafe类提供了硬件级别的原子操作,Java无法直接访问到操作系统底层(如系统硬件等),为此Java使用native方法来扩展Java程序的功能。具体实现使用c++。 牛B,**Unsafe类提供了硬件级别的原子操作**,但到底是什么意思呢?CAS从字面意思上就有两部分:1、读取并比较;2、判断并决定是否交换。然后把这两步骤作为原子操作,这样就能保证线程安全 几句关于 Unsafe的并发性。compareAndSwap方法是 原子的,并且可用来实现高性能的、无锁的数据结构。比如,考虑问题:在使用大量线程的共享对象上增长值。... Java是一门安全的编程语言,防止程序员犯很多愚蠢的错误,它们大部分是基于内存管理的。但是,有一种方式可以有意的执行一些不安全、容易犯错的操作,那就是使用 Unsafe类。 CAS操作有3个操作数,内存值M,预期值E,新值U,如果M==E,则将内存值修改为B,否则啥都不做。 sun.misc.Unsafe这个类是如此地不安全,以至于JDK开发者增加了很多特殊限制来访问它。它的构造器是私有的,工厂方法 getUnsafe()的调用器只能被Bootloader加载。如你在下面代码片段的第8行所见,这个家伙甚至没有被任何类加载器加载,所以它的类加载器是 null。它会抛出 SecurityException 异常来阻止侵入者。 public final class Unsafe { ... private Unsafe() {} private static final Unsafe theUnsafe = new Unsafe(); ... public static Unsafe getUnsafe() { Class cc = sun.reflect.Reflection.getCallerClass(2); if (cc.getClassLoader() != null) throw new SecurityException("Unsafe"); return theUnsafe; } ... public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
return (Unsafe)f.get(null);
} catch (Exception e) {
/* ... */
}
}
Unsafe一些有用的特性 - 虚拟机“集约化”(VM intrinsification):如用于无锁Hash表中的CAS(比较和交换)。再比如compareAndSwapInt这个方法用JNI调用,包含了对CAS有特殊引导的本地代码。在这里你能读到更多关于CAS的信息:http://en.wikipedia.org/wiki/Compare-and-swap。
- 主机虚拟机(译注:主机虚拟机主要用来管理其他虚拟机。而虚拟平台我们看到只有guest VM)的sun.misc.Unsafe功能能够被用于未初始化的对象分配内存(用allocateInstance方法),然后将构造器调用解释为其他方法的调用。
- 你可以从本地内存地址中追踪到这些数据。使用java.lang.Unsafe类获取内存地址是可能的。而且可以通过unsafe方法直接操作这些变量!
- 使用allocateMemory方法,内存可以被分配到堆外。例如当allocateDirect方法被调用时DirectByteBuffer构造器内部会使用allocateMemory。
- arrayBaseOffset和arrayIndexScale方法可以被用于开发arraylets,一种用来将大数组分解为小对象、限制扫描的实时消耗或者在大对象上做更新和移动。
Unsafe.java是jdk并发类库java.util.concurrent包中使用的底层类,该类中的方法都是通过native方法调用操作系统命令。 在多线程环境下,主要存在两种特殊的场景: 1;多个线程同时访问某个对象的方法,由于操作系统对线程调度的不确定性,存在使该对象的状态处于不一致的状态,为了避免这种情况的发生,我们可以声明该方法为同步方法(synchronized)。保证某一时刻只有一个线程调用该方法,其它调用线程则被阻塞。这种方法在并发性很高的情况下会产生大量的线程调度开销。从而影响程序的并发性能。在java.util.concurrent包中通过使用非阻塞原子方法,减少操作系统的无用线程调度开销,从而提高并发性能。 2;多线程通过某个对象进行通信,即常见的生产者消费者模型。在以前的jdk版本中是通过wait,notify方法实现的。该方法也是通过底层在某个信号量上的阻塞队列实现的。而Unsafe类中直接提供操作系统调度命令park,unpark,减少信号量的开销,提高新能。 从上面可以看出,Unsafe类是通过提供底层的操作系统命令接口给开发者,从而提供程序的性能。
【51CTO精选译文】G1垃圾回收器(简称G1 GC)是JDK 7中Java HotSpot VM新引入的垃圾回收器,Java SE 6 Update 14中已经包含了一个G1的体验版本(据51CTO之前的报导,在Java SE 6 u14于6月初登场时,原本Sun的声明是:G1垃圾回收器需要收费方能使用。然而之后不久,Sun表示这是一个误会,修改了原本的发布声明,并表示现在以及将来对G1的使用都是完全免费的),G1是设计用于替代HotSpot低延迟的并行标记/清除垃圾回收器(也叫做CMS)的。 Java 7 G1属性 G1是一个服务端垃圾回收器,有以下属性: ◆并行和并发性:G1利用了当今硬件中存在的并行性,当Java应用程序的线程被停止时,它使用所有可用的CPU(核心,硬件线程等)加速其停止,在停止过程中运行Java线程最小化整个堆栈。 ◆代:和其他HotSpot GC一样,G1是一代,意味着它在处理新分配的对象(年轻代)和已经生存了一段时间的对象(年老代)时会不同,它主要集中于新对象上的垃圾回收活动,因为它们是最可能回收的,旧对象只是偶尔访问一下,对于大多数Java应用程序,代的垃圾回收对于替代方案具有重要优势。 ◆压缩:和CMS不同,G1会随时间推移对堆栈进行压缩,压缩消除了潜在的碎片问题,确保长时间运行的操作流畅和一致。 ◆可预测性:G1比CMS预测性更佳,这都是由于消除了碎片问题带来的好处,再也没有CMS中停止期间出现的负面影响,另外,G1有一个暂停预测模型,允许它满足(或很少超过)暂停时间目标。 Java 7 G1描述 和其它HotSpot GC相比,G1采用了一个非常不同的堆栈布局方法,在G1中,年轻代和年老代之间没有物理隔离,相反,它们之间有一个连续的堆栈,被分成大小一样的区域(region),年轻代可能是一套非连续的区域,年老代也一样,这就允许G1在年轻代和年老代之间灵活地移动资源。 G1中的回收是通过消除暂停发生的,在此期间,幸存者指的是回收集被转移到另一个区域,以便回收区域可以再生,消除暂停是并行的,所有可用的CPU都会参加,大多数消除暂停收集可用的年轻区域,和其它HotSpot GC中的年轻回收是一样的,在暂停期间偶尔也会选择年老区域回收,因为G1在年轻一代回收上还肩负了年老代的回收活动。 和CMS相同的是,G1会定期执行一个并发标记暂停,这个阶段的主要职责是识别哪一个年老区域的垃圾对象是最完整的,因为这些是最有效和最值得回收的,和CMS不同的是,G1不会执行并发清除暂停,相反,最有用的年老区域是通过并发标记暂停标识的,在随后的消除暂停期间进行回收。 使用G1 G1仍然被看做是试验品,可以使用下面两个参数开启它: -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC 为了设置一个GC暂停时间目标,使用下面的参数: -XX:MaxGCPauseMillis =50 (暂停时间目标50ms) 使用G1时还可以指定时间间隔,当GC暂停持续时间没有上面给出的时间长时可以这么用: -XX:GCPauseIntervalMillis =200 (暂停间隔目标200ms) 注意上面两个选项表示的目标,没有承诺和保证,在某些情况下它们可能能够工作,GC不是总是能够执行它们。 另外,年轻代的大小可以明确指定影响消除暂停时间: -XX:+G1YoungGenSize=512m (年轻代大小512M) G1也使用幸存空间(可能是非连续的区域),它们的大小可以使用一个常见的参数指定,如: -XX:SurvivorRatio=6 最后,为了运行G1充分发挥其潜力,尝试设置以下两个默认被禁用了的参数,因为它们可能会暴露一个罕见的竞争状态: -XX:+G1ParallelRSetUpdatingEnabled -XX:+G1ParallelRSetScanningEnabled 注意当设置了-XX:+PrintGCDetails后,G1比起其它HotSpot GC要啰嗦得多,因为它会打印每个GC线程的计时和其它有助于进行故障排除的信息,如果你想使GC日志更简单,请使用-verbosegc参数。 Java 7 G1最新进展 G1开发现在主要集中在遗留的可靠性问题和改善性能,同时也在逐步移除下面的限制: ◆G1不能完全支持JVM工具接口(JVM TI)或Java管理扩展(JMX),因此关于G1的监视和管理工具很可能不能正常工作; ◆G1不支持增量永久性代回收,如果一个应用程序产生了许多类转储,需要永久性代回收,这在完整GC期间是可以实现的; ◆从GC暂停时间来说,G1有时表现比CMS好有时比CMS差。 原文:Java HotSpot Garbage Collection
centos端口转发神器:socat安装及使用 sudo nohup socat tcp-l:6666,reuseaddr,fork tcp:114.80.***.***:80 & sudo nohup socat tcp-l:外部访问端口,reuseaddr,fork tcp:192.168.xxx.xxx:内部转发端口 Linux下Iptables端口转发功能的解决 将881请求发至10.10.2.00:881端口 iptables -t nat -A PREROUTING -p tcp -m tcp --dport 881 -j DNAT --to-destination 10.10.2.200:881
package com.cp.common.aop; import java.lang.reflect.Method; import org.aopalliance.intercept.MethodInterceptor; import org.aopalliance.intercept.MethodInvocation; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; public class TimeHandler implements MethodInterceptor { private static final Log log = LogFactory.getLog(TimeHandler.class); private int error; private int warn; private int info; public TimeHandler() { this.error = 200; this.warn = 100; this.info = 50; } public Object invoke(MethodInvocation methodInvocation) throws Throwable { long procTime = System.currentTimeMillis(); try { Object result = methodInvocation.proceed(); return result; } finally { procTime = System.currentTimeMillis() - procTime; String msg = "Process method " + methodInvocation.getMethod().getName() + " successful! Total time: " + procTime + " milliseconds!"; if (procTime > this.error) if (log.isErrorEnabled()) log.error(msg); else if (procTime > this.warn) if (log.isWarnEnabled()) log.warn(msg); else if (procTime > this.info) if (log.isInfoEnabled()) log.info(msg); else if (log.isDebugEnabled()) log.debug(msg); } } public void setError(int error) { this.error = error; } public void setWarn(int warn) { this.warn = warn; } public void setInfo(int info) { this.info = info; } } /* 对于上面的代码需要说明的是下面两行代码: Object result = methodInvocation.proceed(); return result; 整个程序的流程是这样的: 1,先是执行在Object result = methodInvocation.proceed();前面的代码; 2,接着执行Object result = methodInvocation.proceed();,它把执行控制权交给了interceptor stack(拦截器栈)内的下一个interceptor,如果没有了就交给真正的业务方法; 3,然后执行return result;之前的代码; 4,最后执行return result;,它把控制权交回它之上的interceptor,如果没有了就退出interceptor stack。 */
HashMap is implemented as a hash table, and there is no ordering on keys or values.
TreeMap is implemented based on red-black tree structure, and it is ordered by the key.
LinkedHashMap preserves the insertion order
Hashtable is synchronized, in contrast to HashMap.
方法一: 直接执行命令: mysql> select count(1) from table into outfile '/tmp/test.xls'; Query OK, 31 rows affected (0.00 sec) 在目录/tmp/下会产生文件test.xls 遇到的问题: mysql> select count(1) from table into outfile '/data/test.xls'; 报错: ERROR 1 (HY000): Can't create/write to file '/data/test.xls' (Errcode: 13) 可能原因:mysql没有向/data/下写的权限,没有深究 方法二: 查询都自动写入文件: mysql> pager cat > /tmp/test.txt ; PAGER set to 'cat > /tmp/test.txt' 之后的所有查询结果都自动写入/tmp/test.txt',并前后覆盖 mysql> select * from table ; 30 rows in set (0.59 sec) 在框口不再显示查询结果 以上参考:http://blog.163.com/cpu_driver/blog/static/117663448201111295420990/ 方法三: 跳出mysql命令行 [root@SHNHDX63-146 ~]# mysql -h127.0.0.1 -uroot -pXXXX -P3306 -e"select * from table" > /tmp/test/txt
select FQQ,FScoreCount from Tbl_User into outfile "/tmp/terminatedtest.txt" fields terminated by ",";
select * from test into outfile '/home/user/test.txt'
在linux(centos)下 ,启动了mysql 并给用户文件读写的权利
grant file on *.* to root@localhost;
在linux系统上,目录的权限全部是 rwxrwxrwx
chmod 777 ...
/home/user/test
drwxrwxrwx 4 root root 4096 Sep 3 18:42 home
drwxrwxrwx 10 mapuser mapuser 4096 Sep 4 03:41 user
drwxrwxrwx 5 mapuser mapuser 4096 Sep 3 17:57 test
在mysql下输入
select * from test into outfile '/home/user/test.txt'
出现错误信息:
ERROR 1 (HY000): Can't create/write to file '/home/user/test.txt' (Errcode: 13)
当时如果是tmp目录的话就不会有这个错误
select * from test into outfile '/tmp/test.txt'
Query OK, 0 rows test(0.00 sec)
难道只能是tmp目录吗?
有什么地方可以修改的吗?
后来吧home的所有者改成了mysql
drwxrwxrwx 5 mysql mysql 4096 Sep 4 10:08 home
select * from test into outfile '/home/test.txt'
ERROR 1 (HY000): Can't create/write to file '/home/test.txt' (Errcode: 13)
也是同样出错。
这个有什么办法可以写入home目录下面吗?或者其他什么目录,只要不是tmp目录,有人说先写入tmp目录,再cp到想要的
目录,这样做是可以,不过比较麻烦,文件比较大,2-3G呢,
修改mysql的配置能实现吗?还是修改文件的权限,这个是什么问题呢?
select * from test into outfile '/tmp/test.txt'
Query OK, 0 rows test(0.00 sec)
看一下产生的这个文件的owner 是谁。
[root@localhost /]# ls -l
drwxrwxrwx 4 root root 4096 9月 4 21:03 home
drwxrwxrwt 10 root root 4096 9月 4 21:03 tmp
[root@localhost /]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 27
Server version: 5.1.14-beta MySQL Community Server (GPL)
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select user from user;
+--------+
| user |
+--------+
| system |
| root |
+--------+
2 rows in set (0.03 sec)
mysql> select user from user into outfile '/home/test.txt';
Query OK, 2 rows affected (0.02 sec)
[root@localhost home]# ls -l
-rw-rw-rw- 1 mysql mysql 12 9月 4 21:12 test.txt
[root@localhost home]# cat /home/test.txt
system
root
select * from test into outfile '/home/test.txt'
ERROR 1 (HY000): Can't create/write to file '/home/test.txt' (Errcode: 13)
------------------------
从Errcode: 13来看是没权限
你执行上面语句时,是用什么用户执行的呢?检查下这个用户是否有权限吧
估计和权限没关系,因为已经是777了。
看看是不是selinux打开了,如果没什么特别需要的话,关了为好。
非root用户,在mysql下执行的select * from test into outfile '/home/user/test.txt'
select * from test into outfile '/home/user/test.txt'该语句产生的文件是
-rw-rw-rw- 1 mysql mysql 12 9月 4 21:12 test.txt
mysql组的mysql用户的。
貌似和权限没什么关系,我用root用户登陆系统,执行mysql的语句,其结果还是一样,写入/home目录时
select * from test into outfile '/home/test.txt'
ERROR 1 (HY000): Can't create/write to file '/home/test.txt' (Errcode: 13)
还是有这个问题。
selinux会阻止其他程序写入操作??
具体怎么改变一下selinx的配置呢
我理清是什么问题了。
在red hat系列的linux中selinux对哪些daemon可以进行怎么样的操作是有限制的,mysql的select into outfile的命令是mysql的daemon来负责写文件操作的。写文件之前当然要具有写文件的权限。而selinux对这个权限做了限制。如果 selinux是关闭的吧,这个命令执行是没有问题的
mysql> select user from user into outfile '/home/test.txt';
Query OK, 2 rows affected (0.02 sec)
当时selinux开启时
selinux对mysql的守护进程mysqld进行了限制。
mysql> select user from user into outfile '/home/test.txt';
ERROR 1 (HY000): Can't create/write to file '/home/test.txt' (Errcode: 13)
出现了没有权限写的error。
解决方法,可以关闭selinux。
可以在/etc/selinux中找到config
root用户,
shell>vi /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - SELinux is fully disabled.
SELINUX=enforcing
修改SELINUX=disabled关闭selinux就可以了,这个问题就可以解决了。
不过全部关闭SELINUX有带来一些安全问题。
当然也可以,单独给mysql的守护进程权限,
shell>getsebool -a可以查看当前的对系统一系列守护进程的权限情况。
lpd_disable_trans --> off
mail_read_content --> off
mailman_mail_disable_trans --> off
mdadm_disable_trans --> off
mozilla_read_content --> off
mysqld_disable_trans --> off
nagios_disable_trans --> off
named_disable_trans --> off
named_write_master_zones --> off
nfs_export_all_ro --> on
nfs_export_all_rw --> on
nfsd_disable_trans --> off
nmbd_disable_trans --> off
nrpe_disable_trans --> off
shell>setsebool -P mysqld_disable_trans=1
开启对mysql守护进程的权限,这样
mysql> select user from user into outfile '/home/test.txt';
写入到自定义的目录就没有问题了。
-P表示 是永久性设置,否则重启之后又恢复预设值。
getsebool setsebool命令在root用户下有权限。
除了对selinux的权限,当然首先要保证该目录拥有读写权限。
在ubuntu下 ,可以对AppArmor(/etc/apparmor.d/usr.sbin.mysqld) 修改,类似selinux。
添加/etc/squid/lists/eighties.txt w,类似。
input.py : 代码如下: import sys one = sys.argv[1] print one
执行控制台命令:
[root@root ~] python input.py mypython
结果为
[root@root ~]
mypython
并发问题可归纳为以下几类: A.丢失更新:撤销一个事务时,把其他事务已提交的更新数据覆盖(A和B事务并发执行,A事务执行更新后,提交;B事务在A事务更新后,B事务结束前也做了对该行数据的更新操作,然后回滚,则两次更新操作都丢失了)。
B.脏读:一个事务读到另一个事务未提交的更新数据(A和B事务并发执行,B事务执行更新后,A事务查询B事务没有提交的数据,B事务回滚,则A事务得到的数据不是数据库中的真实数据。也就是脏数据,即和数据库中不一致的数据)。
C.不可重复读:一个事务读到另一个事务已提交的更新数据(A和B事务并发执行,A事务查询数据,然后B事务更新该数据,A再次查询该数据时,发现该数据变化了)。
D. 覆盖更新:这是不可重复读中的特例,一个事务覆盖另一个事务已提交的更新数据(即A事务更新数据,然后B事务更新该数据,A事务查询发现自己更新的数据变了)。 E.虚读(幻读):一个事务读到另一个事务已提交的新插入的数据(A和B事务并发执行,A事务查询数据,B事务插入或者删除数据,A事务再次查询发现结果集中有以前没有的数据或者以前有的数据消失了)。
数据库系统提供了四种事务隔离级别供用户选择:
A.Serializable(串行化):一个事务在执行过程中完全看不到其他事务对数据库所做的更新(事务执行的时候不允许别的事务并发执行。事务串行化执行,事务只能一个接着一个地执行,而不能并发执行。)。
B.Repeatable Read(可重复读):一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,但是不能看到其他其他事务对已有记录的更新。
C.Read Commited(读已提交数据):一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,而且能看到其他事务已经提交的对已有记录的更新。
D.Read Uncommitted(读未提交数据):一个事务在执行过程中可以看到其他事务没有提交的新插入的记录,而且能看到其他事务没有提交的对已有记录的更新。 | 丢失更新 | 脏读 | 非重复读 | 覆盖更新 | 幻像读 | 未提交读 | Y | Y | Y | Y | Y | 已提交读 | N | N | Y | Y | Y | 可重复读 | N | N | N | N | Y | 串行化 | N | N | N | N | N |
隔离级别 数据库系统有四个隔离级别(大多数数据库默认级别为read commited)。对数据库使用何种隔离级别要审慎分析,因为 1. 维护一个最高的隔离级别虽然会防止数据的出错,但是却导致了并行度的损失,以及导致死锁出现的可能性增加。 2. 然而,降低隔离级别,却会引起一些难以发现的bug。 SERIALIZABLE(序列化) 添加范围锁(比如表锁,页锁等,关于range lock,我也没有很深入的研究),直到transaction A结束。以此阻止其它transaction B对此范围内的insert,update等操作。 幻读,脏读,不可重复读等问题都不会发生。 REPEATABLE READ(可重复读) 对于读出的记录,添加共享锁直到transaction A结束。其它transaction B对这个记录的试图修改会一直等待直到transaction A结束。 可能发生的问题:当执行一个范围查询时,可能会发生幻读。 READ COMMITTED(提交读) 在transaction A中读取数据时对记录添加共享锁,但读取结束立即释放。其它transaction B对这个记录的试图修改会一直等待直到A中的读取过程结束,而不需要整个transaction A的结束。所以,在transaction A的不同阶段对同一记录的读取结果可能是不同的。 可能发生的问题:不可重复读。 READ UNCOMMITTED(未提交读) 不添加共享锁。所以其它transaction B可以在transaction A对记录的读取过程中修改同一记录,可能会导致A读取的数据是一个被破坏的或者说不完整不正确的数据。 另外,在transaction A中可以读取到transaction B(未提交)中修改的数据。比如transaction B对R记录修改了,但未提交。此时,在transaction A中读取R记录,读出的是被B修改过的数据。 可能发生的问题:脏读。 问题 我们看到,当执行不同的隔离级别时,可能会发生各种各样不同的问题。下面对它们进行总结并举例说明。 幻读 幻读发生在当两个完全相同的查询执行时,第二次查询所返回的结果集跟第一个查询不相同。 发生的情况:没有范围锁。 例子: | 事务1 | 事务2 | SELECT * FROM users WHERE age BETWEEN 10 AND 30 |
|
| INSERT INTO users VALUES ( 3 , 'Bob' , 27 ); COMMIT; | SELECT * FROM users WHERE age BETWEEN 10 AND 30; |
如何避免:实行序列化隔离模式,在任何一个低级别的隔离中都可能会发生。 不可重复读 在基于锁的并行控制方法中,如果在执行select时不添加读锁,就会发生不可重复读问题。 在多版本并行控制机制中,当一个遇到提交冲突的事务需要回退但却被释放时,会发生不可重复读问题。 | 事务1 | 事务2 | SELECT * FROM users WHERE id = 1; |
|
| UPDATE users SET age = 21 WHERE id = 1 ; COMMIT; /* in multiversion concurrency*/ control, or lock-based READ COMMITTED * | SELECT * FROM users WHERE id = 1; |
|
| COMMIT; /* lock-based REPEATABLE READ */ |
在上面这个例子中,事务2提交成功,它所做的修改已经可见。然而,事务1已经读取了一个其它的值。在序列化和可重复读的隔离级别中,数据库管理系统会返回旧值,即在被事务2修改之前的值。在提交读和未提交读隔离级别下,可能会返回被更新的值,这就是“不可重复读”。 有两个策略可以防止这个问题的发生: 1. 推迟事务2的执行,直至事务1提交或者回退。这种策略在使用锁时应用。(悲观锁机制,比如用select for update为数据行加上一个排他锁) 2. 而在多版本并行控制中,事务2可以被先提交。而事务1,继续执行在旧版本的数据上。当事务1终于尝试提交时,数据库会检验它的结果是否和事务1、事务2顺序执行时一样。如果是,则事务1提交成功。如果不是,事务1会被回退。(乐观锁机制) 脏读 脏读发生在一个事务A读取了被另一个事务B修改,但是还未提交的数据。假如B回退,则事务A读取的是无效的数据。这跟不可重复读类似,但是第二个事务不需要执行提交。 | 事务1 | 事务2 | SELECT * FROM users WHERE id = 1; |
|
| UPDATE users SET age = 21 WHERE id = 1 | SELECT FROM users WHERE id = 1; |
|
| COMMIT; /* lock-based DIRTY READ */ |
ANSI/ISO SQL的四个isolation levelSERIALIZABLE这是最高层次isolation level,这个层次的isolation实现了串行化的效果,即:几个Transcation在执行时,其执行效果和某个串行序执行这几个Transaction的效果是一样的。使用Serializable层次的事务,其中的查询语句在每次都必须在同样的数据上执行,从而防止了phantom read,其实现机制是range lock。与下一个层次的不同之处在于range lock。 在基于锁的DBMS中,Serializable直到事务结束才释放select数据集上的读、写锁。而且select查询语句必须首先获得range-locks才能执行。在非锁并行的DBMS中,系统每当检测到write collision时,一次只有一个write能被写入。
range lockRange lock记录Serializable Transaction所读取的key值范围,阻止其他在这个key值范围内的记录被插入到表中。Range lock位于Index上,记录一个起始Index和一个终止Index。在Range lock锁定的Index范围内,任何Update、Insert和Delete操作都是被禁止的,从而保证了Serializable中的操作每次都在同样的数据集上进行。
REPEATABLE READS在基于锁的DBMS中,Repeatable Reads直到事务结束才释放select数据集上的读、写锁。但不会使用range lock,因此会产生Phantom Read。
READ COMMITTED在基于锁的DBMS中,Read Committed直到事务结束才释放select数据集上的写锁,但读锁会在一个select完成后才被释放。和Repeatable Read一样,Read Committed不使用range lock,会产生Phantom read和Unrepeatable read。(注:这段主要参考wikipedia,我也搜索过Read Committed,基本都采用了这种说法。但我有一个疑问,既然write锁直到事务提交才释放,那么在这个阶段是不会发生update操作的,在一个事务中的多个读应该也不会产生不同的结果才对。望知之者指点一二,小弟不胜感激。)
READ UNCOMMITTED这是Isolation Level的最底层,不仅会产生Phantom Read、Unrepeatable Read,还会有Dirty Read的风险。
Read phenomenaSQL 92标准将事务T1读写T2的操作分为三种,Phantom Read、Unrepeatable Read和Dirty Read Users
Dirty reads (Uncommitted Dependency)事务T1在读取事务T2已经修改、但T2还未提交的数据时会发生Dirty Read。这个Isolation Level唯一能保证的是Update操作按顺序执行,即事务中前面的update一定比后面的update先执行。 下面的这个例子是一个典型的Dirty Read
| Transaction 1 | Transaction 2 |
|---|
/* Query 1 */
SELECT age FROM users WHERE id = 1;
/* will read 20 */
| | | | /* Query 2 */
UPDATE users SET age = 21 WHERE id = 1;
/* No commit here */
| /* Query 1 */
SELECT age FROM users WHERE id = 1;
/* will read 21 */
| | | | ROLLBACK; /* lock-based DIRTY READ */
|
Non-repeatable reads在一个事务T1中,如果对同一条记录读取两次而值不一样,那么就发生了Non-repeatable read。 在基于锁的DBMS中,Non-repeatable read可能在未获得read lock时进行select操作,或在select操作刚结束就释放read lock时发生。在多版本并行控制的DBMS中,non-repeatable read可能在违背“受commit conflict影响的事务必须回滚“的原则时发生。
| Transaction 1 | Transaction 2 |
|---|
/* Query 1 */ SELECT * FROM users WHERE id = 1; | | | | /* Query 2 */ UPDATE users SET age = 21 WHERE id = 1; COMMIT; /* in multiversion concurrency control, or lock-based READ COMMITTED */ | /* Query 1 */ SELECT * FROM users WHERE id = 1; COMMIT; /* lock-based REPEATABLE READ */ |
有两种方式来防止non-repeatable read。第一种方式用锁使T1和T2串行。另外一种方式是在多版本并行控制的DBMS中使用的。在这里,T2可以提交,而先于T2启动的T1则在自己的Snapshot(快照)里继续执行,在T1提交时,系统会检查其结果是否与T1、T2序执行的结果一样,如果一样,则T1提交,否则T1必须回滚并生成一个serialization failure。
Phantom readsPhantom read是指在一个事务中,执行两个或多个同样的查询返回的结果集却不相同的现象。这种现象发生在没获得range lock即进行select... where....操作时,解决方法是使用range lock。
| Transaction 1 | Transaction 2 |
|---|
/* Query 1 */ SELECT * FROM users WHERE age BETWEEN 10 AND 30; | | | | /* Query 2 */ INSERT INTO users VALUES ( 3, 'Bob', 27 ); COMMIT; | /* Query 1 */ SELECT * FROM users WHERE age BETWEEN 10 AND 30; | |
参考: http://msdn.microsoft.com/en-us/library/ms191272.aspx
http://en.wikipedia.org/wiki/Isolation_%28database_systems%29
import MySQLdb import csv try: conn=MySQLdb.connect(host='localhost',user='root',passwd='',db='abin',port=3306) cursor=conn.cursor() result = cursor.execute('select * from tabin') info=cursor.fetchmany(result) writer = csv.writer(file('your.csv','wb')) writer.writerow(['id','name','time']) for line in info: writer.writerow(line) except MySQLdb.Error,e: print 'MySQLError is : ',e.args[0]
import MySQLdb import time try: conn=MySQLdb.connect(host='localhost',user='root',passwd='',db='abin',port=3306) cur=conn.cursor() result=cur.execute('select * from tabin') print result print '-------' info=cur.fetchmany(result) for ii in info: currentTime = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())) values=[ii[1],currentTime] cur.execute('insert into sabin (name,create_time) values (%s,%s)',values) print '====' cur.close() conn.commit() conn.close() except MySQLdb.Error,e: print "Mysql Error %d: %s % ()e.args[0],e.args[1]" import urllib params = urllib.urlencode({'type':'mobile','parameter':'13521502037','pageNum':1,'pageSize':10}) conn = urllib.urlopen("http://test.qunar.com:7400/complaints/find.action",params); result = conn.read() print result
一 前言 tomcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或者启动日志.或者登录他们的默认页面http://localhost:8080/查看其中的服务器状态。 二 bio 默认的模式 blocking IO,性能非常低下,没有经过任何优化处理和支持. 三 nio 利用java的异步io护理技术,no blocking IO技术. 想运行在该模式下,直接修改server.xml里的Connector节点,修改protocol为 <Connector port="80" protocol="org.apache.coyote.http11.Http11NioProtocol" connectionTimeout="20000" URIEncoding="UTF-8" useBodyEncodingForURI="true" enableLookups="false" redirectPort="8443" /> 启动后,就可以生效。性能得到初步优化但与apr相比,还是有一些差距。 四 apr 安装起来最困难,但是从操作系统级别来解决异步的IO问题,大幅度的提高性能. 必须要安装apr和native,直接启动就支持apr。 下面的修改纯属多余,仅供大家扩充知识,但仍然需要安装apr和native 如nio修改模式,修改protocol为org.apache.coyote.http11.Http11AprProtocol 五 补充 1)安装APR的方法,请看我另一篇博客http://phl.iteye.com/blog/910984; 2)关于性能数据请读者们自行研究,笔者不是在写教科书在此只是给出思路,性能研究是个很深的领域,请各位按需自行搭建环境测试; 3)总的来说,bio是不推荐使用的,apr的模式推荐; | item | protocol | Requests per second | | BIO | org.apache.coyote.http11.Http11Protocol | 916.06 [#/sec] (mean) | | NIO | org.apache.coyote.http11.Http11NioProtocol | 2102.26 [#/sec] (mean) | | APR | org.apache.coyote.http11.Http11AprProtocol | 1997.24 [#/sec] (mean) |
http://phl.iteye.com/blog/910996
先来个例子理解一下概念,以银行取款为例: 同步 : 自己亲自出马持银行卡到银行取钱(使用同步IO时,Java自己处理IO读写)。 异步 : 委托一小弟拿银行卡到银行取钱,然后给你(使用异步IO时,Java将IO读写委托给OS处理,需要将数据缓冲区地址和大小传给OS(银行卡和密码),OS需要支持异步IO操作API)。 阻塞 : ATM排队取款,你只能等待(使用阻塞IO时,Java调用会一直阻塞到读写完成才返回)。 非阻塞 : 柜台取款,取个号,然后坐在椅子上做其它事,等号广播会通知你办理,没到号你就不能去,你可以不断问大堂经理排到了没有,大堂经理如果说还没到你就不能去(使用非阻塞IO时,如果不能读写Java调用会马上返回,当IO事件分发器会通知可读写时再继续进行读写,不断循环直到读写完成)。
Java对BIO、NIO、AIO的支持: Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。 Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。 Java AIO(NIO.2) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,
BIO、NIO、AIO适用场景分析: BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。 NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。 AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
另外,I/O属于底层操作,需要操作系统支持,并发也需要操作系统的支持,所以性能方面不同操作系统差异会比较明显。
本文出自 “力量来源于赤诚的爱!” 博客,请务必保留此出处http://stevex.blog.51cto.com/4300375/1284437
一、线程池的创建 我们可以通过ThreadPoolExecutor来创建一个线程池。
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, milliseconds,runnableTaskQueue, handler); 创建一个线程池需要输入几个参数: - corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
- runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。 可以选择以下几个阻塞队列。
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
- LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
- maximumPoolSize(线程池最大大小):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。
- ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
- RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。以下是JDK1.5提供的四种策略。
- AbortPolicy:直接抛出异常。
- CallerRunsPolicy:只用调用者所在线程来运行任务。
- DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
- DiscardPolicy:不处理,丢弃掉。
- 当然也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化不能处理的任务。
- keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
- TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
二、Executors提供了一些方便创建ThreadPoolExecutor的常用方法,主要有以下几个: 1、 Executors.newFixedThreadPool(int nThreads);创建固定大小(nThreads,大小不能超过int的最大值)的线程池 //线程数量 int nThreads = 20; //创建executor 服务 ExecutorService executor = Executors.newFixedThreadPool(nThreads) ; 重载后的版本,需要多传入实现了ThreadFactory接口的对象。 ExecutorService executor = Executors. newFixedThreadPool(nThreads,threadFactory); 说明:创建固定大小(nThreads,大小不能超过int的最大值)的线程池,缓冲任务的队列为LinkedBlockingQueue,大小为整型的最大数,当使用此线程池时,在同执行的任务数量超过传入的线程池大小值后,将会放入LinkedBlockingQueue,在LinkedBlockingQueue中的任务需要等待线程空闲后再执行,如果放入LinkedBlockingQueue中的任务超过整型的最大数时,抛出RejectedExecutionException。 2、Executors.newSingleThreadExecutor():创建大小为1的固定线程池。 ExecutorService executor = Executors.newSingleThreadExecutor(); 重载后的版本,需要多传入实现了ThreadFactory接口的对象。 ExecutorService executor = Executors. newSingleThreadScheduledExecutor(ThreadFactory threadFactory) 说明:创建大小为1的固定线程池,同时执行任务(task)的只有一个,其它的(任务)task都放在LinkedBlockingQueue中排队等待执行。 3、Executors.newCachedThreadPool();创建corePoolSize为0,最大线程数为整型的最大数,线程keepAliveTime为1分钟,缓存任务的队列为SynchronousQueue的线程池。 ExecutorService executor = Executors.newCachedThreadPool(); 当然也可以以下面的方式创建,重载后的版本,需要多传入实现了ThreadFactory接口的对象。 ExecutorService executor = Executors.newCachedThreadPool(ThreadFactory threadFactory) ; 说明:使用时,放入线程池的task任务会复用线程或启动新线程来执行,注意事项:启动的线程数如果超过整型最大值后会抛出RejectedExecutionException异常,启动后的线程存活时间为一分钟。 4、Executors.newScheduledThreadPool(int corePoolSize):创建corePoolSize大小的线程池。 //线程数量 int corePoolSize= 20; //创建executor 服务 ExecutorService executor = Executors.newScheduledThreadPool(corePoolSize) ; 重载后的版本,需要多传入实现了ThreadFactory接口的对象。 ExecutorService executor = Executors.newScheduledThreadPool(corePoolSize, threadFactory) ; 说明:线程keepAliveTime为0,缓存任务的队列为DelayedWorkQueue,注意不要超过整型的最大值。
1、volatile
volatile字段的写入操作happens-before于每一个后续的同一个字段的读操作。
因为实际上put、remove等操作也会更新count的值,所以当竞争发生的时候,volatile的语义可以保证写操作在读操作之前,也就保证了写操作对后续的读操作都是可见的,这样后面get的后续操作就可以拿到完整的元素内容。
使用建议:在两个或者更多的线程访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量时,不必使用。
volatile实际上只有在多cpu或者多核下才有用。当读取数据时,他不会cache缓存中读取,而是强制从内从中读取,这样读到的就是最新值。当写入数据的时候,会直接将数据写入内存中,并刷新所有其他核中的缓存,这样其他核看到的就是最新写入的值,也就是说,其他线程就看到了最新写入的值。
一般说来,volatile用在如下的几个地方:
1、中断服务程序中修改的供其它程序检测的变量需要加volatile;
2、多任务环境下各任务间共享的标志应该加volatile;
3、存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
声明方式为 volatile declaration
备注
系统总是在 volatile
对象被请求的那一刻读取其当前值,即使上一条指令从同一对象请求值。而且,该对象的值在赋值时立即写入。
volatile 修饰符通常用于由多个线程访问而不使用 lock 语句来序列化访问的字段。使用 volatile
修饰符能够确保一个线程检索由另一线程写入的最新值。
读文件的方法: 第一步: 将文件的内容通过管道(|)或重定向(<)的方式传给while 第二步: while中调用read将文件内容一行一行的读出来,并付值给read后跟随的变量。变量中就保存了当前行中的内容。 例如读取文件/sites/linuxpig.com.txt 1)管道的方式:
cat /sites/linuxpig.com.txt |while read LINE
do
echo $LINE
done 当然也可以将cat /sites/linuxpig.com.txt 写成一些复杂一些的,比如:
示例1:
find -type f -name "*.txt" -exec cat |while read LINE
do
echo $LINE
done
可以将当前目录所有以 .txt 结尾的文件读出
示例2:
grep -r "linuxpig.com" ./ | awk -F":" '{print $1}' | cat |while read LINE
do
echo $LINE
done 可以将含有 "linuxpig.com" 字符串的所有文件打开并读取。。 示例没有实际测试,如果使用请先测试。。。。。:-)
2)重定向的方式: 2.1 利用重定向符< while read LINE
do
echo $LINE
done < /sites/linuxpig.com.txt 2.2 利用文件描述符(0~9)和重定向符 < exec 3<&0
exec 0</sites/linuxpig.com.txt
while read LINE
do
echo $LINE
done
exec 0<&3
ZooKeeper是一个高可用的分布式数据管理与系统协调框架。基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得ZooKeeper解决很多分布式问题。网上对ZK的应用场景也有不少介绍,本文将结合作者身边的项目例子,系统地对ZK的应用场景进行一个分门归类的介绍。 值得注意的是,ZK并非天生就是为这些应用场景设计的,都是后来众多开发者根据其框架的特性,利用其提供的一系列API接口(或者称为原语集),摸索出来的典型使用方法。因此,也非常欢迎读者分享你在ZK使用上的奇技淫巧。 ZooKeeper典型应用场景一览 | | 数据发布与订阅(配置中心) | | 发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到ZK节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,服务式服务框架的服务地址列表等就非常适合使用。 | 1. 应用中用到的一些配置信息放到ZK上进行集中管理。这类场景通常是这样:应用在启动的时候会主动来获取一次配置,同时,在节点上注册一个Watcher,这样一来,以后每次配置有更新的时候,都会实时通知到订阅的客户端,从来达到获取最新配置信息的目的。
2. 分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在ZK的一些指定节点,供各个客户端订阅使用。
3. 分布式日志收集系统。这个系统的核心工作是收集分布在不同机器的日志。收集器通常是按照应用来分配收集任务单元,因此需要在ZK上创建一个以应用名作为path的节点P,并将这个应用的所有机器ip,以子节点的形式注册到节点P上,这样一来就能够实现机器变动的时候,能够实时通知到收集器调整任务分配。
4. 系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息的发问。通常是暴露出接口,例如JMX接口,来获取一些运行时的信息。引入ZK之后,就不用自己实现一套方案了,只要将这些信息存放到指定的ZK节点上即可。
注意:在上面提到的应用场景中,有个默认前提是:数据量很小,但是数据更新可能会比较快的场景。 | | 负载均衡 | | 这里说的负载均衡是指软负载均衡。在分布式环境中,为了保证高可用性,通常同一个应用或同一个服务的提供方都会部署多份,达到对等服务。而消费者就须要在这些对等的服务器中选择一个来执行相关的业务逻辑,其中比较典型的是消息中间件中的生产者,消费者负载均衡。 | 消息中间件中发布者和订阅者的负载均衡,linkedin开源的KafkaMQ和阿里开源的metaq都是通过zookeeper来做到生产者、消费者的负载均衡。这里以metaq为例如讲下: 生产者负载均衡:metaq发送消息的时候,生产者在发送消息的时候必须选择一台broker上的一个分区来发送消息,因此metaq在运行过程中,会把所有broker和对应的分区信息全部注册到ZK指定节点上,默认的策略是一个依次轮询的过程,生产者在通过ZK获取分区列表之后,会按照brokerId和partition的顺序排列组织成一个有序的分区列表,发送的时候按照从头到尾循环往复的方式选择一个分区来发送消息。 消费负载均衡: 在消费过程中,一个消费者会消费一个或多个分区中的消息,但是一个分区只会由一个消费者来消费。MetaQ的消费策略是: 1. 每个分区针对同一个group只挂载一个消费者。
2. 如果同一个group的消费者数目大于分区数目,则多出来的消费者将不参与消费。
3. 如果同一个group的消费者数目小于分区数目,则有部分消费者需要额外承担消费任务。
在某个消费者故障或者重启等情况下,其他消费者会感知到这一变化(通过 zookeeper watch消费者列表),然后重新进行负载均衡,保证所有的分区都有消费者进行消费。 | | 命名服务(Naming Service) | | 命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务地址,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架中的服务地址列表。通过调用ZK提供的创建节点的API,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。 | 阿里巴巴集团开源的分布式服务框架Dubbo中使用ZooKeeper来作为其命名服务,维护全局的服务地址列表,点击这里查看Dubbo开源项目。在Dubbo实现中: 服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,这个操作就完成了服务的发布。 服务消费者启动的时候,订阅/dubbo/${serviceName}/providers目录下的提供者URL地址, 并向/dubbo/${serviceName} /consumers目录下写入自己的URL地址。 注意,所有向ZK上注册的地址都是临时节点,这样就能够保证服务提供者和消费者能够自动感应资源的变化。 另外,Dubbo还有针对服务粒度的监控,方法是订阅/dubbo/${serviceName}目录下所有提供者和消费者的信息。 | | 分布式通知/协调 | | ZooKeeper中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能够收到通知,并作出相应处理 | 1. 另一种心跳检测机制:检测系统和被检测系统之间并不直接关联起来,而是通过zk上某个节点关联,大大减少系统耦合。
2. 另一种系统调度模式:某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了ZK上某些节点的状态,而ZK就把这些变化通知给他们注册Watcher的客户端,即推送系统,于是,作出相应的推送任务。
3. 另一种工作汇报模式:一些类似于任务分发系统,子任务启动后,到zk来注册一个临时节点,并且定时将自己的进度进行汇报(将进度写回这个临时节点),这样任务管理者就能够实时知道任务进度。
总之,使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合 | | 集群管理与Master选举 | 1. 集群机器监控:这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。 这种做法可行,但是存在两个比较明显的问题:
1. 集群中机器有变动的时候,牵连修改的东西比较多。
2. 有一定的延时。
利用ZooKeeper有两个特性,就可以实现另一种集群机器存活性监控系统: 1. 客户端在节点 x 上注册一个Watcher,那么如果 x?的子节点变化了,会通知该客户端。
2. 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
例如,监控系统在 /clusterServers 节点上注册一个Watcher,以后每动态加机器,那么就往 /clusterServers 下创建一个 EPHEMERAL类型的节点:/clusterServers/{hostname}. 这样,监控系统就能够实时知道机器的增减情况,至于后续处理就是监控系统的业务了。 2. Master选举则是zookeeper中最为经典的应用场景了。
在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行,其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能,于是这个master选举便是这种场景下的碰到的主要问题。 利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建 /currentMaster 节点,最终一定只有一个客户端请求能够创建成功。利用这个特性,就能很轻易的在分布式环境中进行集群选取了。 另外,这种场景演化一下,就是动态Master选举。这就要用到EPHEMERAL_SEQUENTIAL类型节点的特性了。 上文中提到,所有客户端创建请求,最终只有一个能够创建成功。在这里稍微变化下,就是允许所有请求都能够创建成功,但是得有个创建顺序,于是所有的请求最终在ZK上创建结果的一种可能情况是这样: /currentMaster/{sessionId}-1 ,/currentMaster/{sessionId}-2,/currentMaster/{sessionId}-3 ….. 每次选取序列号最小的那个机器作为Master,如果这个机器挂了,由于他创建的节点会马上小时,那么之后最小的那个机器就是Master了。 | 1. 在搜索系统中,如果集群中每个机器都生成一份全量索引,不仅耗时,而且不能保证彼此之间索引数据一致。因此让集群中的Master来进行全量索引的生成,然后同步到集群中其它机器。另外,Master选举的容灾措施是,可以随时进行手动指定master,就是说应用在zk在无法获取master信息时,可以通过比如http方式,向一个地方获取master。
2. 在Hbase中,也是使用ZooKeeper来实现动态HMaster的选举。在Hbase实现中,会在ZK上存储一些ROOT表的地址和HMaster的地址,HRegionServer也会把自己以临时节点(Ephemeral)的方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的存活状态,同时,一旦HMaster出现问题,会重新选举出一个HMaster来运行,从而避免了HMaster的单点问题 | | 分布式锁 | 分布式锁,这个主要得益于ZooKeeper为我们保证了数据的强一致性。锁服务可以分为两类,一个是保持独占,另一个是控制时序。 1. 所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看作是一把锁,通过create znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。
2. 控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。 | | 分布式队列 | | 队列方面,简单地讲有两种,一种是常规的先进先出队列,另一种是要等到队列成员聚齐之后的才统一按序执行。对于第一种先进先出队列,和分布式锁服务中的控制时序场景基本原理一致,这里不再赘述。 第二种队列其实是在FIFO队列的基础上作了一个增强。通常可以在 /queue 这个znode下预先建立一个/queue/num 节点,并且赋值为n(或者直接给/queue赋值n),表示队列大小,之后每次有队列成员加入后,就判断下是否已经到达队列大小,决定是否可以开始执行了。这种用法的典型场景是,分布式环境中,一个大任务Task A,需要在很多子任务完成(或条件就绪)情况下才能进行。这个时候,凡是其中一个子任务完成(就绪),那么就去 /taskList 下建立自己的临时时序节点(CreateMode.EPHEMERAL_SEQUENTIAL),当 /taskList 发现自己下面的子节点满足指定个数,就可以进行下一步按序进行处理了。 |
本文出自 “专栏:Paxos与ZooKeeper” 博客,请务必保留此出处http://nileader.blog.51cto.com/1381108/1040007
1、free -m
2、uptime
3、vmstat 1 5
4、iostat -x -h -t
5、mpstat -P ALL
6、netstat -natp | grep 8080
7、netstat -natp | find "80"(windows)
8、ps -aux | grep java
9、ps -ef | grep java
10、top -H -p 9768
1、把命令结果赋值给变量 #!/bash/bin echo "1 2 3 4"|awk '{print $1}' temp=`echo "1 2 3 4"|awk '{print $1}'`; echo $temp;
2、
for in 格式
for 无$变量 in 字符串
do
$变量
done
| 一简单的字符串 枚举遍历法,利用for in格式对字符串按空格切份的功能
SERVICES="80 22 25 110 8000 23 20 21 3306 "
for x in $SERVICES
do
iptables -A INPUT -p tcp --dport $x -m state --state NEW -j ACCEPT
done
|
for variable in values --------字符串数组依次赋值
#!/bin/sh
for i in a b c 字符串列表A B C
字符串用空格分隔,没有括号,没有逗号, 然后循环将其依次赋给变量i
变量没有$
do
echo "i is $i"
done | [macg@machome ~]$ sh test.sh
i is a
i is b
i is c
|
for in 里,变量和*不等价
#!/bin/bash
for i in *.h ;
do
cat ${i}.h
done
| [macg@vm test]$ ./tip.sh
cat: *.h.h: No such file or directory
$i代表的是整个路径,而不是*.h里的.h前面的部分
| 改正
#!/bin/bash
for i in *.h
do
cat $i
done
| [macg@vm test]$ echo hahaha >>1.h
[macg@vm test]$ echo ha >>2.h
[macg@vm test]$ ./tip.sh
hahaha
ha
| 例2:
for i in /etc/profile.d/*.sh
do
$i
done
| $i代表的是/etc/profile.d/color.sh,
/etc/profile.d/alias.sh, /etc/profile.d/default.sh |
for in 对(命令行,函数)参数遍历
test()
{
local i
for i in $* ; do
echo "i is $i"
done
}
$*是字符串:以"参数1 参数2 ... " 形式保存所有参数
$i是变量i的应用表示
| [macg@machome ~]$ sh test.sh p1 p2 p3 p4
i is p1
i is p2
i is p3
i is p4
|
for in语句与通配符*合用,批量处理文件
批量改文件名
[root@vm testtip]# ls
aaa.txt ccc.txt eee.txt ggg.txt hhh.txt jjj.txt lll.txt nnn.txt
bbb.txt ddd.txt fff.txt go.sh iii.txt kkk.txt mmm.txt ooo.txt
| [root@vm testtip]# cat go.sh
for i in *.txt *.txt相当于一个字符串数组,依次循环赋值给i
do
mv "$i" "$i.bak"
done
| [root@vm testtip]# sh go.sh
[root@vm testtip]# ls
aaa.txt.bak ccc.txt.bak eee.txt.bak ggg.txt.bak hhh.txt.bak jjj.txt.bak lll.txt.bak nnn.txt.bak bbb.txt.bak ddd.txt.bak fff.txt.bak go.sh iii.txt.bak kkk.txt.bak mmm.txt.bak ooo.txt.bak
|
for in语句与` `和$( )合用,利用` `或$( )的将多行合为一行的缺陷,实际是合为一个字符串数组
for i in $(ls *.txt)
do
echo $i
done
| [macg@machome ~]$ sh test
111-tmp.txt
111.txt
22.txt
33.txt
| 或者说,利用for in克服` `和$( ) 的多行合为一行的缺陷
利用for in 自动对字符串按空格遍历的特性,对多个目录遍历
LIST="rootfs usr data data2"
for d in $LIST; do
mount /backup/$d
rsync -ax --exclude fstab --delete /$d/ /backup/$d/
umount /backup/$d
done
|
1、 #!/bin/bash mysql -u* -h* -p* <<EOF Your SQL script. EOF 2、 准备一个sql脚本,如update.sql,然后执行如下命令:mysql -uroot -ppassword < update.sql 3、 mysql -Dftp -uroot -proot -e"select user FROM users" >users.txt catfilename="users.txt" for i in `cat $catfilename`; do echo "$i" done 4、 echo "select user FROM ftp.users" | mysql -u root -proot 5、 使用mysql参数的方法mysql -u$user -p$pass -D $db -e "select host from user;"6、忽略mysql列名 #!/bin/bash
MYSQL=mysql #选用mysql程序
USER=root #设定用户名
PASSWORD="123456" #设定数据库的用户密码
DB=eucalyptus_auth #选定需要的数据库
COMMAND="select auth_user_query_id, auth_user_secretkey from auth_users where auth_user_name=\"admin\" " #查找需要的数据sql语句
declare count=`$MYSQL -u${USER} -p${PASSWORD} -D ${DB} -e "${COMMAND}" --skip-column-name` #执行mysql的查询,并将其记录到count中
for list in $count
do
echo " the item is $list"
done #读取得到的数据 7、取出数据表里面的一行的第一列 #!/bin/sh HOST="192.168.111.11" PORT="3306" USERNAME="root" PWD="root" DBNAME="abin" TNAME="city" select_sql="select * from ${TNAME}" mysql -h${HOST} -P${PORT} -u${USERNAME} -p${PWD} ${DBNAME} -e "set names utf8; ${select_sql}" --skip-column-name| while read line; do midd=`echo "$line" | awk '{print $1}'`; echo ${midd}; done; ~ 8、 mysql database -u $user -p $password -e "SELECT A, B, C FROM table_a"|while read a b c
do
echo $a $b $c
don 9、 exec 8<>file
mysql database -u $user -p $password -e "SELECT A, B, C FROM table_a"
while read a b c
do
echo $a $b $c
done<&8 10、 #!/bin/sh HOST="localhost" PORT="3306" USERNAME="root" PWD="" DBNAME="abin" CITYNAME="city" BNAME="bussiness" HNAME="height" parameter=$1 type=$2 echo "parameter=${parameter},type=${type}" select_sql="select * from ${CITYNAME} t where t.code='${parameter}'" mysql -h${HOST} -P${PORT} -u${USERNAME} -p${PWD} ${DBNAME} -e "set names utf8; ${select_sql}" --skip-column-name| while read a b c; do id=${a}; echo "id=${id}" if [ $type = 1 ];then echo "type=${type},id=${id}" bus_sql="select * from ${BNAME} t where t.ccode=${id}" mysql -h${HOST} -P${PORT} -u${USERNAME} -p${PWD} ${DBNAME} -e "set names utf8; ${bus_sql}" --skip-column-name | while read d e f g; do echo "bussiness=${e},city_code=${g},bussiness_code=${f}" done elif [ $type = 2 ];then echo "type=${type},id=${id}" hei_sql="select * from ${HNAME} t where t.ccode=${id}" mysql -h${HOST} -P${PORT} -u${USERNAME} -p${PWD} ${DBNAME} -e "set names utf8; ${hei_sql}" --skip-column-name | while read h i j k; do echo "sex=${i},height=${j},city_code=${k}" done else echo "others" fi; done
以 MySQL 为例:
mysql -e "select * from tbl" | while read line ; do echo "$line" ; done
在linux下用shell脚本读取mysql结果集中值的二种方法,按行读取sql结果,将sql执行结果读取到shell变量中,然后读取。
| shell脚本读取mysql结果集的值 | 按行读取sql结果: while read -a row do echo "..${row[0]}..${row[1]}..${row[2]}.." done < <(echo "SELECT A, B, C FROM table_a" mysql database -u $user -p $password) 将sql执行结果读取到shell变量中: while read a b c do echo "..${a}..${b}..${c}.." done < <(echo "SELECT A, B, C FROM table_a" mysql database -u $user -p $password) |
|
|
经常要在shell下查询数据库的东西,数据库有中文,shell显示就是乱码,有几个方法看看结果首先linux中文字体要安装,这个自己装,数据库的字符集要支持中文,我的支持啊,然后就是在写shell的时候的问题了 mysql -u root -p --default-character-set=utf8 db -e "select * from tb where A=10;" 这个显示的就是乱码 mysql -u root -p db -e "set names utf8 ;select * from tb where A=10;" 这个还是乱码 mysql -u root -p db -e "set names Latin1 ;select * from tb where A=10;" 这个也是乱码 mysql -u root -p db -e "set names gbk ;select * from tb where A=10;" 最后这个却显示中文了!!!! http://wdegang.blog.51cto.com/134120/1137929
1、接收linuxshell控制台输入的字符串参数: #!/bash/bin parameter=$1 if [ $parameter = "a" ];then echo "equals" elif [ $parameter = "b" ];then echo "not" else echo "kong" fi
2、接收linuxshell控制台输入的数字参数: #!/bash/bin parameter=$1 if [ $parameter = 1 ];then echo "input is $parameter" elif [ $parameter = 2 ];then echo "input is $parameter" else echo "input is other: $parameter" fi 3、接收linuxshell控制台输入的时间参数:
为什么ImmutableMap是不可变集合,是线程安全的? 首先介绍一下基本概念,什么事immutable 何为Immutable对象? 简单地说,如果一个对象实例不能被更改就是一个Immutable的对象,Java SDK提供的大量值对象,比如String等都是Immutable的对象。 如何使对象Immutable? 按照Effective Java的说明,需要满足下面几条规则: - 保证类不能被继承 - 为了避免其继承的类进行mutable的操作
- 移调所有setter/update等修改对象实例的操作
- 保证所有的field是private和final的
不可变对象(immutable objects),后面文章我将使用immutable objects来代替不可变对象! 那么什么是immutable objects?什么又是mutable Objects呢? immutable Objects就是那些一旦被创建,它们的状态就不能被改变的Objects,每次对他们的改变都是产生了新的immutable的对象,而mutable Objects就是那些创建后,状态可以被改变的Objects. 举个例子:String和StringBuilder,String是immutable的,每次对于String对象的修改都将产生一个新的String对象,而原来的对象保持不变,而StringBuilder是mutable,因为每次对于它的对象的修改都作用于该对象本身,并没有产生新的对象。 但有的时候String的immutable特性也会引起安全问题,这就是密码应该存放在字符数组中而不是String中的原因! immutable objects 比传统的mutable对象在多线程应用中更具有优势,它不仅能够保证对象的状态不被改变,而且还可以不使用锁机制就能被其他线程共享。 实际上JDK本身就自带了一些immutable类,比如String,Integer以及其他包装类。为什么说String是immutable的呢?比如:java.lang.String 的trim,uppercase,substring等方法,它们返回的都是新的String对象,而并不是直接修改原来的对象。 如何在Java中写出Immutable的类? 要写出这样的类,需要遵循以下几个原则: 1)immutable对象的状态在创建之后就不能发生改变,任何对它的改变都应该产生一个新的对象。 2)Immutable类的所有的属性都应该是final的。 3)对象必须被正确的创建,比如:对象引用在对象创建过程中不能泄露(leak)。 4)对象应该是final的,以此来限制子类继承父类,以避免子类改变了父类的immutable特性。 5)如果类中包含mutable类对象,那么返回给客户端的时候,返回该对象的一个拷贝,而不是该对象本身(该条可以归为第一条中的一个特例) 当然不完全遵守上面的原则也能够创建immutable的类,比如String的hashcode就不是final的,但它能保证每次调用它的值都是一致的,无论你多少次计算这个值,它都是一致的,因为这些值的是通过计算final的属性得来的! 有时候你要实现的immutable类中可能包含mutable的类,比如java.util.Date,尽管你将其设置成了final的,但是它的值还是可以被修改的,为了避免这个问题,我们建议返回给用户该对象的一个拷贝,这也是Java的最佳实践之一。 使用Immutable类的好处:1)Immutable对象是线程安全的,可以不用被synchronize就在并发环境中共享 2)Immutable对象简化了程序开发,因为它无需使用额外的锁机制就可以在线程间共享 3)Immutable对象提高了程序的性能,因为它减少了synchroinzed的使用 4)Immutable对象是可以被重复使用的,你可以将它们缓存起来重复使用,就像字符串字面量和整型数字一样。你可以使用静态工厂方法来提供类似于valueOf()这样的方法,它可以从缓存中返回一个已经存在的Immutable对象,而不是重新创建一个。 immutable也有一个缺点就是会制造大量垃圾,由于他们不能被重用而且对于它们的使用就是”用“然后”扔“,字符串就是一个典型的例子,它会创造很多的垃圾,给垃圾收集带来很大的麻烦。当然这只是个极端的例子,合理的使用immutable对象会创造很大的价值。 Guava提供的ImmutableMap是一个支持多线程环境下面的安全的Map,同时效率也是很高的Key-Value集合,为什么他就是安全的呢。 先看下面例子: ImmutableMap.Builder<String, Object> request = ImmutableMap.builder(); request.put("one","1"); request.put("two","2"); request.put("three","3"); Map<String, Object> map = request.build(); 让我们首先从Builder<T,T>入手进行分析 public static class Builder<K, V> { TerminalEntry<K, V>[] entries; int size; public ImmutableMap<K, V> build() { switch (size) { case 0: return of(); case 1: return of(entries[0].getKey(), entries[0].getValue()); default: return new RegularImmutableMap<K, V>(size, entries); } } } 上面的 ImmutableMap.Builder<String, Object> request = ImmutableMap.builder(); 这个实例创建的时候,只是创建了一个空的对象。 那么实际效用的是build() @SuppressWarnings("unchecked") Builder(int initialCapacity) { this.entries = new TerminalEntry[initialCapacity]; this.size = 0; }
没事干,写点小东西,练练手(Java <T> T): import java.util.List; import java.util.concurrent.CopyOnWriteArrayList; public class GenericsTest { public static void main(String[] args) { String[] arr = new String[]{"1","2","3","4"}; List<String> list = get(arr); System.out.println("list= "+list); String result = transfer(true, "abin", "lee"); System.out.println("result= "+result); } public static <T> List<T> get(T... t){ List<T> list = new CopyOnWriteArrayList<T>(); for(T s:t){ list.add(s); } return list; } public static <T> T transfer(boolean flag,T first,T second){ T t = flag ? first : second; return t; }
}
在windows下 : 启动: 1.cd c:/mysql/bin 2.mysqld --console 关闭: 1.cd c:/mysql/bin 2.mysqladmin -uroot shutdown 还可以: 启动: 1.cd c:/mysql/bin 2.net start mysql5 关闭: 1.cd c:/mysql/bin 2.net stop mysql5 在linux下: 采用netstat -nlp查看mysql服务的状态 命令行方式: 开启 ./mysqld_safe & 关闭 mysqladmin -uroot shutdown rpm方式安装的 开启 service mysql start 关闭 service mysql stop 在命令行启动mysql时,如不加"--console",启动、关闭信息不在界面中显示,而是记录在安装目录下的data目录里,文件名一般是hostname.err,通过此文件查看mysql的控制台信息。
innodb作为事务型数据库的首选引擎,支持ACID事务,支持行级锁定,支持外键。并且InnoDB默认地被包含在MySQL二进制分发中,已经成为绝大多数OLTP系统的直选存储引擎。 索引作为数据库开发的一个重要方面,对于访问性能以及能否支持高并发,高tps的应用,起着决定性作用。Innodb存储引擎支持B+树索引以及自适应哈希索引,其中后者是由innodb引擎根据表的使用情况自动生成,无法进行人为创建。 B+树索引是目前关系型数据库中最常见最有效的索引,是基于二分查找而形成的一棵平衡术结构。我们来逐步了解。
MySQL就普遍使用B+Tree实现其索引结构
索引的主要作用:
1、快速定位记录
2、避免排序和使用临时表
3、可以将随机IO变为顺序IO
分布式领域CAP理论, Consistency(一致性), 数据一致更新,所有数据变动都是同步的 Availability(可用性), 好的响应性能 Partition tolerance(分区容错性) 可靠性 定理:任何分布式系统只可同时满足二点,没法三者兼顾。 忠告:架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。 关系数据库的ACID模型拥有 高一致性 + 可用性 很难进行分区: Atomicity原子性:一个事务中所有操作都必须全部完成,要么全部不完成。 Consistency一致性. 在事务开始或结束时,数据库应该在一致状态。 Isolation隔离层. 事务将假定只有它自己在操作数据库,彼此不知晓。 Durability. 一旦事务完成,就不能返回。 跨数据库事务:2PC (two-phase commit), 2PC is the anti-scalability pattern (Pat Helland) 是反可伸缩模式的,JavaEE中的JTA事务可以支持2PC。因为2PC是反模式,尽量不要使用2PC,使用BASE来回避。 BASE模型反ACID模型,完全不同ACID模型,牺牲高一致性,获得可用性或可靠性: Basically Available基本可用。支持分区失败(e.g. sharding碎片划分数据库) Soft state软状态 状态可以有一段时间不同步,异步。 Eventually consistent最终一致,最终数据是一致的就可以了,而不是时时高一致。 BASE思想的主要实现有 1.按功能划分数据库 2.sharding碎片 BASE思想主要强调基本的可用性,如果你需要High 可用性,也就是纯粹的高性能,那么就要以一致性或容错性为牺牲,BASE思想的方案在性能上还是有潜力可挖的。 现在NoSQL运动丰富了拓展了BASE思想,可按照具体情况定制特别方案,比如忽视一致性,获得高可用性等等,NOSQL应该有下面两个流派: 1. Key-Value存储,如Amaze Dynamo等,可根据CAP三原则灵活选择不同倾向的数据库产品。 2. 领域模型 + 分布式缓存 + 存储 (Qi4j和NoSQL运动),可根据CAP三原则结合自己项目定制灵活的分布式方案,难度高。 这两者共同点:都是关系数据库SQL以外的可选方案,逻辑随着数据分布,任何模型都可以自己持久化,将数据处理和数据存储分离,将读和写分离,存储可以是异步或同步,取决于对一致性的要求程度。 不同点:NOSQL之类的Key-Value存储产品是和关系数据库头碰头的产品BOX,可以适合非Java如PHP RUBY等领域,是一种可以拿来就用的产品,而领域模型 + 分布式缓存 + 存储是一种复杂的架构解决方案,不是产品,但这种方式更灵活,更应该是架构师必须掌握的。 http://www.jdon.com/37625
工厂方法模式:
一个抽象产品类,可以派生出多个具体产品类。
一个抽象工厂类,可以派生出多个具体工厂类。
每个具体工厂类只能创建一个具体产品类的实例。
抽象工厂模式:
多个抽象产品类,每个抽象产品类可以派生出多个具体产品类。
一个抽象工厂类,可以派生出多个具体工厂类。
每个具体工厂类可以创建多个具体产品类的实例。
区别:
工厂方法模式只有一个抽象产品类,而抽象工厂模式有多个。
工厂方法模式的具体工厂类只能创建一个具体产品类的实例,而抽象工厂模式可以创建多个。
工厂方法模式: 一个抽象产品类,可以派生出多个具体产品类。 一个抽象工厂类,可以派生出多个具体工厂类。 每个具体工厂类只能创建一个具体产品类的实例。 抽象工厂模式: 多个抽象产品类,每个抽象产品类可以派生出多个具体产品类。 一个抽象工厂类,可以派生出多个具体工厂类。 每个具体工厂类可以创建多个具体产品类的实例。 区别: 工厂方法模式只有一个抽象产品类,而抽象工厂模式有多个。 工厂方法模式的具体工厂类只能创建一个具体产品类的实例,而抽象工厂模式可以创建多个。 GOF《设计模式》写的很清楚,工厂方法是由子类自行决定实例化那个类,而抽象工厂是自己决定实例化哪个类。至于是组合还是继承还是实现接口都无所谓。根本区别在于是自己实例化还是子类实例化。
在jvm中堆空间划分为三个代:年轻代(Young Generation)、年老代(Old Generation)和永久代(Permanent Generation)。年轻代和年老代是存储动态产生的对象。永久带主要是存储的是java的类信息,包括解析得到的方法、属性、字段等等。永久带基本不参与垃圾回收。我们这里讨论的垃圾回收主要是针对年轻代和年老代。具体如下图。
年轻代又分成3个部分,一个eden区和两个相同的survior区。刚开始创建的对象都是放置在eden区的。分成这样3个部分,主要是为了生命周期短的对象尽量留在年轻带。当eden区申请不到空间的时候,进行minorGC,把存活的对象拷贝到survior。年老代主要存放生命周期比较长的对象,比如缓存对象。具体jvm内存回收过程描述如下(可以结合上图): 1、对象在Eden区完成内存分配
2、当Eden区满了,再创建对象,会因为申请不到空间,触发minorGC,进行young(eden+1survivor)区的垃圾回收
3、minorGC时,Eden不能被回收的对象被放入到空的survivor(Eden肯定会被清空),另一个survivor里不能被GC回收的对象也会被放入这个survivor,始终保证一个survivor是空的
4、当做第3步的时候,如果发现survivor满了,则这些对象被copy到old区,或者survivor并没有满,但是有些对象已经足够Old,也被放入Old区 XX:MaxTenuringThreshold
5、当Old区被放满的之后,进行fullGC 在知道垃圾回收机制以后,大家可以在对jvm中堆的各个参数进行优化设置,来提高性能。
哈希(hash)是一种非常快的查找方法,一般情况下查找的时间复杂度为O(1)。常用于连接(join)操作,如SQL Server和Oracle中的哈希连接(hash join)。但是SQL Server和Oracle等常见的数据库并不支持哈希索引(hash index)。MySQL的Heap存储引擎默认的索引类型为哈希,而InnoDB存储引擎提出了另一种实现方法,自适应哈希索引(adaptive hash index)。 InnoDB存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应(adaptive)的。自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。 根据InnoDB的官方文档显示,启用自适应哈希索引后,读取和写入速度可以提高2倍;对于辅助索引的连接操作,性能可以提高5倍。在我看来,自适应哈希索引是非常好的优化模式,其设计思想是数据库自优化(self-tuning),即无需DBA对数据库进行调整。 通过命令SHOW ENGINE INNODB STATUS可以看到当前自适应哈希索引的使用状况,如下所示: - mysql> show engine innodb status\G;
- *************************** 1. row ***************************
- Status:
- =====================================
- 090922 11:52:51 INNODB MONITOR OUTPUT
- =====================================
- Per second averages calculated from the last 15 seconds
- ......
- -------------------------------------
- INSERT BUFFER AND ADAPTIVE HASH INDEX
- -------------------------------------
- Ibuf: size 2249, free list len 3346, seg size 5596,
- 374650 inserts, 51897 merged recs, 14300 merges
- Hash table size 4980499, node heap has 1246 buffer(s)
- 1640.60 hash searches/s, 3709.46 non-hash searches/s
- ......
现在可以看到自适应哈希索引的使用信息了,包括自适应哈希索引的大小、使用情况、每秒使用自适应哈希索引搜索的情况。值得注意的是,哈希索引只能用来搜索等值的查询,如select * from table where index_col = 'xxx',而对于其他查找类型,如范围查找,是不能使用的。因此,这里出现了non-hash searches/s的情况。用hash searches : non-hash searches命令可以大概了解使用哈希索引后的效率。 由于自适应哈希索引是由InnoDB存储引擎控制的,所以这里的信息只供我们参考。不过我们可以通过参数innodb_adaptive_hash_index来禁用或启动此特性,默认为开启。 转自http://www.cnblogs.com/ylqmf/archive/2011/09/16/2179166.html
通过什么方法来排查是否linux服务器的负载过大? 通过top命令来查看服务器负载 再对此Linux服务器性能分析之前,先了解下Linux系统Load average负载的知识,负载均值在uptime 或者top 命令中可以看到,它们可能会显示成这个样子:load average: 0.15, 0.14, 0.11
很多人会这样理解负载均值:三个数分别代表不同时间段的系统平均负载(一分钟、五分钟、以及十五分钟),它们的数字当然是越小越好。数字越高,说明服务器的负载越大,这也可能是服务器出现某种问题的信号。
一个单核的处理器可以形象得比喻成一条单车道。如果前面没有车辆在等待,那么你可以告诉后面的司机通过。如果车辆众多,那么需要告知他们可能需要稍等一会。 因此,需要些特定的代号表示目前的车流情况,例如:
0.00 表示目前桥面上没有任何的车流。实际上这种情况与0.00 和1.00 之间是相同的,总而言之很通畅,过往的车辆可以丝毫不用等待的通过。
1.00 表示刚好是在这座桥的承受范围内。这种情况不算糟糕,只是车流会有些堵,不过这种情况可能会造成交通越来越慢。
超过1.00,那么说明这座桥已经超出负荷,交通严重的拥堵。那么情况有多糟糕?例如2.00 的情况说明车流已经超出了桥所能承受的一倍,那么将有多余过桥一倍的车辆正在焦急的等待。3.00 的话情况就更不妙了,说明这座桥基本上已经快承受不了,还有超出桥负载两倍多的车辆正在等待。 上面的情况和处理器的负载情况非常相似。一辆汽车的过桥时间就好比是处理器处理某线程的实际时间。Unix 系统定义的进程运行时长为所有处理器内核的处理时间加上线程在队列中等待的时间。 和收过桥费的管理员一样,你当然希望你的汽车(操作)不会被焦急的等待。所以,理想状态下,都希望负载平均值小于1.00 。当然不排除部分峰值会超过1.00,但长此以往保持这个状态,就说明会有问题,这时候你应该会很焦急。 “所以你说的理想负荷为1.00 ?” 嗯,这种情况其实并不完全正确。负荷1.00 说明系统已经没有剩余的资源了。在实际情况中,有经验的系统管理员都会将这条线划在0.70: “需要进行调查法则”:如果长期你的系统负载在0.70 上下,那么你需要在事情变得更糟糕之前,花些时间了解其原因。 “现在就要修复法则”:1.00 。如果你的服务器系统负载长期徘徊于1.00,那么就应该马上解决这个问题。否则,你将半夜接到你上司的电话,这可不是件令人愉快的事情。 “凌晨三点半锻炼身体法则”:5.00。如果你的服务器负载超过了5.00 这个数字,那么你将失去你的睡眠,还得在会议中说明这情况发生的原因,总之千万不要让它发生。 那么多个处理器呢?我的均值是3.00,但是系统运行正常!哇喔,你有四个处理器的主机?那么它的负载均值在3.00 是很正常的。在多处理器系统中,负载均值是基于内核的数量决定的。以100% 负载计算,1.00 表示单个处理器,而2.00 则说明有两个双处理器,那么4.00 就说明主机具有四个处理器。 回到我们上面有关车辆过桥的比喻。1.00 我说过是“一条单车道的道路”。那么在单车道1.00 情况中,说明这桥梁已经被车塞满了。而在双处理器系统中,这意味着多出了一倍的负载,也就是说还有50% 的剩余系统资源- 因为还有另外条车道可以通行。 所以,单处理器已经在负载的情况下,双处理器的负载满额的情况是2.00,它还有一倍的资源可以利用。 从上图的top命令可以了解到,Linux服务器运行了5天23小时20分,在load average的数据来看,这台快吧Linux无盘服务器可以说是压力为零,运行十分流畅。 方法二:输入iostat -x -k -t 说明:%util:一秒中有百分之多少的时间用于I/O操作,或者说一秒中有多少时间I/O队列是非空的。
即delta(use)/s/1000 (因为use的单位为毫秒)
如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。 方法三: 如果玩游戏很卡,可以用hdparm –t /dev/磁盘名称来测试磁盘性能是否达标,下图是单个希捷1T的盘测试的结果说明:sd表示硬盘是SATA,SCSI或者SAS,a表示串口的第一块硬盘 本文转摘自:http://www.flybaaa.com/help/69_1.html
一直以来以为通过top然后按数字1键,查到的cpu个数是服务器的物理cpu个数,今天在看服务器的硬件配置清单中发现一服务器的物理cpu个数是4个,我就奇怪了,这台机子我的影响很深,明明是48啊,当时通过top 1查看cpu信息还提示 “Sorry ,terminal is not big enough”。想当初服务器只能识别到32个。还是重新编译内核搞定的。后来经过查询原来不是这样滴,top 1查看的是逻辑cpu个数,一下为记。
查看Linux服务器的CPU详细情况
判断Linux服务器CPU情况的依据如下:
具有相同core id的CPU是同一个core的超线程。(Any cpu with the same core id are hyperthreads in the same core.)
具有相同physical id的CPU是同一个CPU封装的线程或核心。(Any cpu with the same physical id are threads or cores in the same physical socket.)
下面举例说明。
物理CPU个数如下: [root@dbabc.net ~]# cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l 4 每个物理CPU中core的个数(即核数)如下: [root@dbabc.net ~]# cat /proc/cpuinfo| grep "cpu cores"| uniq cpu cores : 12 逻辑CPU的个数如下: [root@dbabc.net ~]#cat /proc/cpuinfo| grep "processor"| wc -l 48 按理说物理CPU个数×核数就应该等于逻辑CPU的 Dbabc.Net [http://dbabc.net]
本文链接:http://dbabc.net/archives/2012/02/13/linux-cpu-info-count.shtml
JVM在装载class文件的时候,会有一步是将符号引用解析为直接引用的过程。 那么这里的直接引用到底是什么呢? 对于指向“类型”【Class对象】、类变量、类方法的直接引用可能是指向方法区的本地指针。 指向实例变量、实例方法的直接引用都是偏移量。实例变量的直接引用可能是从对象的映像开始算起到这个实例变量位置的偏移量。实例方法的直接引用可能是方法表的偏移量。 在《深入java虚拟机》书的第197页我们可以看到,子类中方法表的偏移量和父类中的方法表的偏移量是一致的。比如说父类中有一个say()方法的偏移量是7,那么子类中say方法的偏移量也是7。 书中第199页说,通过“接口引用”来调用一个方法,jvm必须搜索对象的类的方法表才能找到一个合适的方法。这是因为实现同一个接口的这些类中,不一定所有的接口中的方法在类方法区中的偏移量都是一样的。他们有可能会不一样。这样的话可能就要搜索方法表才能确认要调用的方法在哪里。 而通过“类引用”来调用一个方法的时候,直接通过偏移量就可以找到要调用的方法的位置了。【因为子类中的方法的偏移量跟父类中的偏移量是一致的】 所以,通过接口引用调用方法会比类引用慢一些。 下面介绍下什么是接口引用。 interface A{void say();} class B implements A{} class C{public static void main(String []s){A a=new B();a.say()}} 在上面的第三行代码中,就是用“接口引用”来调用方法。 -------------------------------------------------------------------- 符号引用: 符号引用是一个字符串,它给出了被引用的内容的名字并且可能会包含一些其他关于这个被引用项的信息——这些信息必须足以唯一的识别一个类、字段、方法。这样,对于其他类的符号引用必须给出类的全名。对于其他类的字段,必须给出类名、字段名以及字段描述符。对于其他类的方法的引用必须给出类名、方法名以及方法的描述符。
总结:JVM对于直接引用和符号引用的处理是有区别的,可以看到符号引用时,JVM将使用StringBuilder来完成字符串的 添加,而直接引用时则直接使用String来完成;直接引用永远比符号引用效率更快,但实际应用开发中不可能全用直接引用,要提高效能可以考虑按虚拟机的思维来编写你的程序。 1.0 直接引用: public class StringAndStringBuilder{
public static void main(String[] args){
System.out.println ("s=" + "asdfa");
}
} 反编译后的: F:\java\res\字节码>javap -c StringAndStringBuilder
Compiled from "StringAndStringBuilder.java"
public class StringAndStringBuilder extends java.lang.Object{
public StringAndStringBuilder();
Code:
0: aload_0
1: invokespecial #1; //Method java/lang/Object."<init>":()V
4: return public static void main(java.lang.String[]);
Code:
0: ldc #2; //String asdfa
2: astore_1
3: getstatic #3; //Field java/lang/System.out:Ljava/io/PrintStream;
6: ldc #4; //String s=asdfa
8: invokevirtual #5; //Method java/io/PrintStream.println:(Ljava/lang/Str
ing;)V
11: return } 2.0 符号引用: public class StringAndStringBuilder{
public static void main(String[] args){
String s="asdfa";
System.out.println ("s=" + s);
}
} 反编译后的: F:\java\res\字节码>javap -c StringAndStringBuilder
Compiled from "StringAndStringBuilder.java"
public class StringAndStringBuilder extends java.lang.Object{
public StringAndStringBuilder();
Code:
0: aload_0
1: invokespecial #1; //Method java/lang/Object."<init>":()V
4: return public static void main(java.lang.String[]);
Code:
0: ldc #2; //String asdfa
2: astore_1
3: getstatic #3; //Field java/lang/System.out:Ljava/io/PrintStream;
6: new #4; //class java/lang/StringBuilder
9: dup
10: invokespecial #5; //Method java/lang/StringBuilder."<init>":()V
13: ldc #6; //String s=
15: invokevirtual #7; //Method java/lang/StringBuilder.append:(Ljava/lang/
String;)Ljava/lang/StringBuilder;
18: aload_1
19: invokevirtual #7; //Method java/lang/StringBuilder.append:(Ljava/lang/
String;)Ljava/lang/StringBuilder;
22: invokevirtual #8; //Method java/lang/StringBuilder.toString:()Ljava/la
ng/String;
25: invokevirtual #9; //Method java/io/PrintStream.println:(Ljava/lang/Str
ing;)V
28: return }
MySQL 的默认设置下,当一个连接的空闲时间超过8小时后,MySQL 就会断开该连接,而 c3p0 连接池则以为该被断开的连接依然有效。在这种情况下,如果客户端代码向 c3p0 连接池请求连接的话,连接池就会把已经失效的连接返回给客户端,客户端在使用该失效连接的时候即抛出异常。解决这个问题的办法有三种:1. 增加 MySQL 的 wait_timeout 属性的值。修改 /etc/mysql/my.cnf 文件,在 [mysqld] 节中设置: # Set a connection to wait 8 hours in idle status. # Set a connection to wait 8 hours in idle status.
wait_timeout = 86400# How long to keep unused connections around(in seconds)
# Note: MySQL times out idle connections after 8 hours(28,800 seconds)
# so ensure this value is below MySQL idle timeout
cpool.maxIdleTime=25200 在 Spring 的配置文件中:<bean id="dataSource"
class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="maxIdleTime" value="${cpool.maxIdleTime}" />
<!-- other properties -->
</bean> 3. 定期使用连接池内的连接,使得它们不会因为闲置超时而被 MySQL 断开。修改 c3p0 的配置文件,设置:# Prevent MySQL raise exception after a long idle time
cpool.preferredTestQuery='SELECT 1'
cpool.idleConnectionTestPeriod=18000
cpool.testConnectionOnCheckout=true <bean id="dataSource"
class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="preferredTestQuery"
value="${cpool.preferredTestQuery}" />
<property name="idleConnectionTestPeriod"
value="${cpool.idleConnectionTestPeriod}" />
<property name="testConnectionOnCheckout"
value="${cpool.testConnectionOnCheckout}" />
<!-- other properties -->
</bean>
#!/bin/awk
BEGIN {
FS="=";
}
{
if (NF == 2) {
if ((x=index($1, ".")) > 0) {
property_name = substr($1, x+1, length($1));
} else {
property_name = $1;
}
printf("<property name="%s" value="${%s}"/> ", property_name, $1);
}
}
java.lang.OutOfMemoryError: unable to create new native thread
引发此问题的原因有两个:
1.线程数超过了操作系统的限制。
* 使用top命令查看系统资源,如果发现剩余内存很多,而又出现此异常,则基本可以肯定是由于操作系统线程数限制引起的。
[root@jack ~]# top
top - 11:36:52 up 5 days, 1:34, 4 users, load average: 0.00, 0.00, 0.07
Tasks: 131 total, 1 running, 130 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.2%us, 0.2%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 3821320k total, 3122236k used, 699084k free, 112636k buffers
Swap: 6062072k total, 571760k used, 5490312k free, 840728k cached
* 在linux下,可以通过 ulimit -a 查看系统限制
[root@jack ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 29644
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240
cpu time (seconds, -t) unlimited
max user processes (-u) 1024
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
max user process即系统可创建最大线程数。
* 可以使用 ulimit -u 4096 修改max user processes的值,但是只能在当前终端的这个session里面生效,重新登录后仍然是使用系统默认值。
正确的修改方式是修改/etc/security/limits.d/90-nproc.conf文件中的值。
[root@jack ~]# cat /etc/security/limits.d/90-nproc.conf
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 1024
2.系统内存不足
如果通过top命令确认到是内存不足,则可以通过java启动参数 -Xss修改每个线程栈大小。减小此参数,可以提高最大线程数。当然,要保证你的线程使用的内存不会超过这个数。
当然,如果不是因为系统级别的问题,那就的优化程序了,检查有没有泄露的内存,有没有业务逻辑存在大量并发等等。
StackOverflow上面给出的解释是: The reason for the HotSpot JVM's two survivor spaces is to reduce the need to deal with fragmentation. New objects are allocated in eden space. All well and good. When that's full, you need a GC, so kill stale objects and move live ones to a survivor space, where they can mature for a while before being promoted to the old generation. Still good so far. The next time we run out of eden space, though, we have a conundrum. The next GC comes along and clears out some space in both eden and our survivor space, but the spaces aren't contiguous. So is it better to - Try to fit the survivors from eden into the holes in the survivor space that were cleared by the GC?
- Shift all the objects in the survivor space down to eliminate the fragmentation, and then move the survivors into it?
- Just say "screw it, we're moving everything around anyway," and copy all of the survivors from both spaces into a completely separate space--the second survivor space--thus leaving you with a clean eden and survivor space where you can repeat the sequence on the next GC?
Sun's answer to the question is obvious.
对于如何达到“无碎片”的目的,理解上可能有些困难,下面我把新生代回收机制详细解释一下: 注意,两个survivor是交替使用的,在任意一个时刻,必定有一个survivor为空,一个survivor中存放着对象(连续存放,无碎片)。回收过程如下: S1、GC,将eden中的live对象放入当前不为空的survivor中,将eden中的非live对象回收。如果survivor满了,下次回收执行S2;如果survivor未满,下次回收仍然以S1的方式回收; S2、GC,将eden和存放着对象的survivor中的live对象放入当前为空的survivor中,将非live对象回收。 可以看到,上述的新生代回收机制保证了一个survivor为空,另一个非空survivor中无碎片。 在执行一定次数的minor GC后,会通过Full GC将新生代的survivor中的对象移入老年代。
对于理解GC的整个机制,推荐一篇非常好的文章:http://www.cubrid.org/blog/dev-platform/understanding-java-garbage-collection/
下面的例子全是以抓取eth0接口为例,如果不加”-i eth0”是表示抓取所有的接口包括lo。
首先安装tcpdump包:yum install -y tcpdump
1、抓取包含172.16.1.122的数据包
# tcpdump -i eth0 -vnn host 172.16.1.122
2、抓取包含172.16.1.0/24网段的数据包
# tcpdump -i eth0 -vnn net 172.16.1.0/24
3、抓取包含端口22的数据包
# tcpdump -i eth0 -vnn port 22
4、抓取udp协议的数据包
# tcpdump -i eth0 -vnn udp
5、抓取icmp协议的数据包
# tcpdump -i eth0 -vnn icmp
6、抓取arp协议的数据包
# tcpdump -i eth0 -vnn arp
7、抓取ip协议的数据包
# tcpdump -i eth0 -vnn ip
8、抓取源ip是172.16.1.122数据包。
# tcpdump -i eth0 -vnn src host 172.16.1.122
9、抓取目的ip是172.16.1.122数据包
# tcpdump -i eth0 -vnn dst host 172.16.1.122
10、抓取源端口是22的数据包
# tcpdump -i eth0 -vnn src port 22
11、抓取源ip是172.16.1.253且目的ip是22的数据包
# tcpdump -i eth0 -vnn src host 172.16.1.253 and dst port 22
12、抓取源ip是172.16.1.122或者包含端口是22的数据包
# tcpdump -i eth0 -vnn src host 172.16.1.122 or port 22
13、抓取源ip是172.16.1.122且端口不是22的数据包
[root@ ftp]# tcpdump -i eth0 -vnn src host 172.16.1.122 and not port 22
14、抓取源ip是172.16.1.2且目的端口是22,或源ip是172.16.1.65且目的端口是80的数据包。
# tcpdump -i eth0 -vnn \( src host 172.16.1.2 and dst port 22 \) or \( src host 172.16.1.65 and dst port 80 \)
15、抓取源ip是172.16.1.59且目的端口是22,或源ip是172.16.1.68且目的端口是80的数据包。
# tcpdump -i eth0 -vnn 'src host 172.16.1.59 and dst port 22' or ' src host 172.16.1.68 and dst port 80 '
16、把抓取的数据包记录存到/tmp/fill文件中,当抓取100个数据包后就退出程序。
# tcpdump –i eth0 -vnn -w /tmp/fil1 -c 100
17、从/tmp/fill记录中读取tcp协议的数据包
# tcpdump –i eth0 -vnn -r /tmp/fil1 tcp
18、从/tmp/fill记录中读取包含172.16.1.58的数据包
# tcpdump –i eth0 -vnn -r /tmp/fil1 host 172.16.1.58 tcpdump抓包并保存成cap文件 首选介绍一下tcpdump的常用参数 tcpdump采用命令行方式,它的命令格式为:
tcpdump [ -adeflnNOpqStvx ] [ -c 数量 ] [ -F 文件名 ]
[ -i 网络接口 ] [ -r 文件名] [ -s snaplen ]
[ -T 类型 ] [ -w 文件名 ] [表达式 ] 1. tcpdump的选项介绍
-a 将网络地址和广播地址转变成名字;
-d 将匹配信息包的代码以人们能够理解的汇编格式给出;
-dd 将匹配信息包的代码以c语言程序段的格式给出;
-ddd 将匹配信息包的代码以十进制的形式给出;
-e 在输出行打印出数据链路层的头部信息;
-f 将外部的Internet地址以数字的形式打印出来;
-l 使标准输出变为缓冲行形式;
-n 不把网络地址转换成名字;
-t 在输出的每一行不打印时间戳;
-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息;
-vv 输出详细的报文信息;
-c 在收到指定的包的数目后,tcpdump就会停止;
-F 从指定的文件中读取表达式,忽略其它的表达式;
-i 指定监听的网络接口;
-r 从指定的文件中读取包(这些包一般通过-w选项产生);
-w 直接将包写入文件中,并不分析和打印出来;
-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc(远程过程
调用)和snmp(简单网络管理协议;) 当网络出现故障时,由于直接用tcpdump抓包分析有点困难,而且当网络中数据比较多时更不容易分析,使用tcpdump的-w参数+ethereal分析会很好的解决这个问题,具体参数如下: tcpdump -i eth1 -c 2000 -w eth1.cap -i eth1 只抓eth1口的数据 -c 2000代表数据包的个数,也就是只抓2000个数据包 -w eth1.cap 保存成cap文件,方便用ethereal分析 抓完数据包后ftp到你的FTP服务器,put一下,然后用ethereal软件打开就可以很直观的分析了 注:有时将.cap文件上传到FTP服务器后,发现用ethreal打开时提示数据包大于65535个,这是你在ftp上传或者下载的时候没有用bin的模式上传的原因。 另:有的网站提示在tcpdump中用-s 0命令,例如 tcpdump -i eth1 -c 2000 -s0 -w eth1.cap,可实际运行该命令时系统却提示无效的参数,去掉-s 0参数即可 例子: [root@localhost cdr]#tcpdump -i eth0 -t tcp -s 60000 -w diaoxian.cap
[root@localhost cdr]# tcpdump host 58.240.72.195 -s 60000 -w x.cap |
tcpdump 的抓包保存到文件的命令参数是-w xxx.cap
抓eth1的包
tcpdump -i eth1 -w /tmp/xxx.cap
抓 192.168.1.123的包
tcpdump -i eth1 host 192.168.1.123 -w /tmp/xxx.cap
抓192.168.1.123的80端口的包
tcpdump -i eth1 host 192.168.1.123 and port 80 -w /tmp/xxx.cap
抓192.168.1.123的icmp的包
tcpdump -i eth1 host 192.168.1.123 and icmp -w /tmp/xxx.cap
抓192.168.1.123的80端口和110和25以外的其他端口的包
tcpdump -i eth1 host 192.168.1.123 and ! port 80 and ! port 25 and ! port 110 -w /tmp/xxx.cap
抓vlan 1的包
tcpdump -i eth1 port 80 and vlan 1 -w /tmp/xxx.cap
抓pppoe的密码
tcpdump -i eth1 pppoes -w /tmp/xxx.cap
以100m大小分割保存文件, 超过100m另开一个文件 -C 100m
抓10000个包后退出 -c 10000
后台抓包, 控制台退出也不会影响:
nohup tcpdump -i eth1 port 110 -w /tmp/xxx.cap &
抓下来的文件可以直接用ethereal 或者wireshark打开。 wireshark就是新版的ethereal,程序换名了 sudo tcpdump -s0 -A host 192.168.234.249 sudo tcpdump -i eth0 -vnn port 8100
转载自: http://blog.sina.com.cn/s/blog_4a071ed80100sv13.html
设x[1…n],y[1…n]为两个数组,每个包含n个已知的排好序的数,给出一个数组x和y中所有2n个元素的中位数,要求时间复杂度为O(lgN) 这是算法导论上面的一道题目: public class FindMedianTwoSortedArray { public static int median(int[] arr1, int l1, int h1, int[] arr2, int l2, int h2) { System.out.println("-----------"); int mid1 = (h1 + l1 ) / 2; int mid2 = (h2 + l2 ) / 2; if (h1 - l1 == 1) return (Math.max(arr1[l1] , arr2[l2]) + Math.min(arr1[h1] , arr2[h2]))/2; else if (arr1[mid1] > arr2[mid2]) return median(arr1, l1, mid1 , arr2, mid2 , h2); else return median(arr1, mid1 , h1, arr2, l2 , mid2 ); } public static void main(String[] args) { int[] a = new int[]{0,1,2}; int[] b = new int[]{1,2,3}; int result = median(a, 0, a.length-1,b,0,b.length-1); System.out.println(result); } }
package com.abin.lee.algorithm.insert; import java.util.Arrays; public class InsertSort { public static void main(String[] args) { int[] input = {6,1,4,2,5,8,3,7,9,0}; input = InsertSort.sort(input); System.out.println(Arrays.toString(input)); } public static int[] sort(int[] input){ int temp = 0; for(int i=0;i<input.length;i++){ temp = input[i]; int j=i-1; for(;j>=0&&temp<input[j];j--){ input[j+1] = input[j]; } input[j+1] = temp; } return input; } }
package com.abin.lee.algorithm.merge; import java.util.Arrays; /** * 归并排序 */ public class MergeSort { public static void main(String[] args) { int[] input = {2,7,3,9,1,6,0,5,4,8}; MergeSort.sort(input, 0, input.length-1); System.out.println("input="+Arrays.toString(input)); } //首先分而自治 /** * 归并排序 * 简介:将两个(或两个以上)有序表合并成一个新的有序表 即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列 * 时间复杂度为O(nlogn) * 稳定排序方式 * @param nums 待排序数组 * @return 输出有序数组 */ public static int[] sort(int[] input,int low,int high){ int middle = (low+high)/2; if(low<high){ //左边 sort(input,low,middle); //右边 sort(input,middle+1,high); //左右归并 merge(input,low,high,middle); } return input; } public static void merge(int[] input,int low,int high,int middle){ int[] temp = new int[high-low+1]; int i = low;//左指针 int j = middle+1;//右指针 int k=0; // 把较小的数先移到新数组中 while(i<=middle&&j<=high){ if(input[i]<input[j]){ temp[k++] = input[i++]; }else{ temp[k++] = input[j++]; } } // 把左边剩余的数移入数组 while(i<=middle){ temp[k++] = input[i++]; } // 把右边边剩余的数移入数组 while(j<=high){ temp[k++] = input[j++]; } // 把新数组中的数覆盖input数组 for(int m=0;m<temp.length;m++){ input[m+low] = temp[m]; } } }
//递归性
package com.abin.lee.algorithm.binary; public class BinarySearch { public static void main(String[] args) { int[] input = new int[]{2,3,4,5,6,7,8,9}; int result = search(input, 5, 0, input.length-1); System.out.println("result="+result); } public static int search(int[] input,int data,int low,int high){ int middle = (low+high)/2; if(data == input[middle]){ return middle; }else if(data > input[middle]){ return search(input, data, middle+1, high); }else if(data < input[middle]){ return search(input, data, low, middle-1); }else{ return -1; } } } //while循环型 public static int binary(int[] input,int low,int high,int target){ while(low <= high){ int middle = (low+high)/2; if(input[middle]>target){ high = middle-1; }else if(input[middle]<target){ low = middle+1; }else{ return middle; } } return -1; }
package com.abin.lee.algorithm.fast; public class SpeedSort { public static void main(String[] args) { int[] input = new int[]{1,6,3,5,2,4}; quickSort(input, 0, input.length-1); for(int i=0;i<input.length;i++){ System.out.println("input["+i+"]="+input[i]); } } //分为参照物的大小两组 public static int getMiddle(int[] input,int low,int high){ int temp = input[low]; while(low<high){ while(low<high && input[high]>temp){ high--; } input[low]=input[high]; while(low<high && input[low]<temp){ low++; } input[high]=input[low]; } input[low]=temp; return low; } //分而自治 public static void quickSort(int[] input,int low,int high){ if(low<high){ int middle = getMiddle(input, low, high); quickSort(input,low,middle-1); quickSort(input,middle+1,high); } } } 快速排序 对冒泡排序的一种改进,若初始记录序列按关键字有序或基本有序,蜕化为冒泡排序。使用的是递归原理,在所有同数量级O(n longn) 的排序方法中,其平均性能最好。就平均时间而言,是目前被认为最好的一种内部排序方法
基本思想是:通过一躺排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
三个指针: 第一个指针称为pivotkey指针(枢轴),第二个指针和第三个指针分别为left指针和right指针,分别指向最左边的值和最右边的值。left指针和right指针从两边同时向中间逼近,在逼近的过程中不停的与枢轴比较,将比枢轴小的元素移到低端,将比枢轴大的元素移到高端,枢轴选定后永远不变,最终在中间,前小后大。
需要两个函数:
① 递归函数 public static void quickSort(int[]n ,int left,int right)
② 分割函数(一趟快速排序函数) public static int partition(int[]n ,int left,int right)
JAVA源代码(成功运行):
package testSortAlgorithm; public class QuickSort { public static void main(String[] args) { int [] array = {49,38,65,97,76,13,27}; quickSort(array, 0, array.length - 1); for (int i = 0; i < array.length; i++) { System.out.println(array[i]); } } /*先按照数组为数据原型写出算法,再写出扩展性算法。数组{49,38,65,97,76,13,27} * */ public static void quickSort(int[]n ,int left,int right){ int pivot; if (left < right) { //pivot作为枢轴,较之小的元素在左,较之大的元素在右 pivot = partition(n, left, right); //对左右数组递归调用快速排序,直到顺序完全正确 quickSort(n, left, pivot - 1); quickSort(n, pivot + 1, right); } } public static int partition(int[]n ,int left,int right){ int pivotkey = n[left]; //枢轴选定后永远不变,最终在中间,前小后大 while (left < right) { while (left < right && n[right] >= pivotkey) --right; //将比枢轴小的元素移到低端,此时right位相当于空,等待低位比pivotkey大的数补上 n[left] = n[right]; while (left < right && n[left] <= pivotkey) ++left; //将比枢轴大的元素移到高端,此时left位相当于空,等待高位比pivotkey小的数补上 n[right] = n[left]; } //当left == right,完成一趟快速排序,此时left位相当于空,等待pivotkey补上 n[left] = pivotkey; return left; } }
package com.abin.lee.list.test; public class SingleList { private Object obj; private transient SingleList singleList; private SingleList next; private SingleList pre; private transient int size; public SingleList() { singleList = new SingleList(null,null,null); singleList.next = singleList.pre = singleList; size=0; } public SingleList(Object obj,SingleList next,SingleList pre) { this.obj=obj; this.next=next; this.pre=pre; } public void add(Object obj){ SingleList current = new SingleList(obj,singleList,singleList.pre); current.next.pre = current; current.pre.next = current; size++; singleList = current; } public int size(){ return size; } public Object get(int index){ SingleList current = singleList.next; for(int i=0;i<index;i++){ current = current.next; } return current.obj; } public static void main(String[] args) { SingleList single = new SingleList(); for(int i=0;i<5;i++){ single.add("abin"+i); } System.out.println("single="+single); int size = single.size(); System.out.println("size="+size); Object element = single.get(0); System.out.println("element="+element); } }
摘要: 最近对程序占用内存方面做了一些优化,取得了不错的效果,总结了一些经验简要说一下,相信会对大家写出优质的程序有所帮助下面的论述针对32位系统,对64位系统不适用,后叙经常你写了一个程序,一测试,功能没问题,一看内存占用也不多,就不去考虑其它的东西了。但可能程序使用了一个什么数据结构,会当数据规模变大时,内存占用激增。基本&&关键的问题是,Java里各种东东占多少内存?????????... 阅读全文
1、查看Web服务器(Nginx Apache)的并发请求数及其TCP连接状态: netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' netstat -n|grep ^tcp|awk '{print $NF}'|sort -nr|uniq -c 或者: netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"t",state[key]}' 返回结果一般如下: LAST_ACK 5 (正在等待处理的请求数) SYN_RECV 30 ESTABLISHED 1597 (正常数据传输状态) FIN_WAIT1 51 FIN_WAIT2 504 TIME_WAIT 1057 (处理完毕,等待超时结束的请求数) 其他参数说明: CLOSED:无连接是活动的或正在进行 LISTEN:服务器在等待进入呼叫 SYN_RECV:一个连接请求已经到达,等待确认 SYN_SENT:应用已经开始,打开一个连接 ESTABLISHED:正常数据传输状态 FIN_WAIT1:应用说它已经完成 FIN_WAIT2:另一边已同意释放 ITMED_WAIT:等待所有分组死掉 CLOSING:两边同时尝试关闭 TIME_WAIT:另一边已初始化一个释放 LAST_ACK:等待所有分组死掉 2、查看Nginx运行进程数 ps -ef | grep nginx | wc -l 返回的数字就是nginx的运行进程数,如果是apache则执行 ps -ef | grep httpd | wc -l 3、查看Web服务器进程连接数: netstat -antp | grep 80 | grep ESTABLISHED -c 4、查看MySQL进程连接数: ps -axef | grep mysqld -c
第一方面:30种mysql优化sql语句查询的方法 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 3.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20 5.下面的查询也将导致全表扫描: select id from t where name like '%abc%' 若要提高效率,可以考虑全文检索。 6.in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3 7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t where num=@num 可以改为强制查询使用索引: select id from t with(index(索引名)) where num=@num 8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2 9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)='abc'--name以abc开头的id select id from t where datediff(day,createdate,'2005-11-30')=0--'2005-11-30'生成的id 应改为: select id from t where name like 'abc%' select id from t where createdate>='2005-11-30' and createdate<'2005-12-1' 10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。 11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。 12.不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(...) 13.很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num) 14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。 15.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。 16.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。 17.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。 18.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。 19.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。 20.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。 21.避免频繁创建和删除临时表,以减少系统表资源的消耗。 22.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。 23.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。 24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。 25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。 26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。 27.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。 28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。 29.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。 30.尽量避免大事务操作,提高系统并发能力。 上面有几句写的有问题。 第二方面: select Count (*)和Select Count(1)以及Select Count(column)区别 一般情况下,Select Count (*)和Select Count(1)两着返回结果是一样的 假如表沒有主键(Primary key), 那么count(1)比count(*)快, 如果有主键的話,那主键作为count的条件时候count(主键)最快 如果你的表只有一个字段的话那count(*)就是最快的 count(*) 跟 count(1) 的结果一样,都包括对NULL的统计,而count(column) 是不包括NULL的统计 第三方面: 索引列上计算引起的索引失效及优化措施以及注意事项 创建索引、优化查询以便达到更好的查询优化效果。但实际上,MySQL有时并不按我们设计的那样执行查询。MySQL是根据统计信息来生成执行计划的,这就涉及索引及索引的刷选率,表数据量,还有一些额外的因素。 Each table index is queried, and the best index is used unless the optimizer believes that it is more efficient to use a table scan. At one time, a scan was used based on whether the best index spanned more than 30% of the table, but a fixed percentage no longer determines the choice between using an index or a scan. The optimizer now is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size. 简而言之,当MYSQL认为符合条件的记录在30%以上,它就不会再使用索引,因为mysql认为走索引的代价比不用索引代价大,所以优化器选择了自己认为代价最小的方式。事实也的确如此
是MYSQL认为记录是30%以上,而不是实际MYSQL去查完再决定的。都查完了,还用什么索引啊?!
MYSQL会先估算,然后决定是否使用索引。
第四方面: 一,如何判断SQL的执行效率? 通过explain 关键字分析效率低的SQL执行计划。 比如: explain select sum(moneys) from sales a, company b where a.company_id = b.company_id and a.year = 2006; id : 1 select_type: SIMPLE table: type: 1.row: id select_type table type possible_keys key key_len ref rows Extra 1 SIMPLE a ALL NULL NULL NULL NULL 1000 Using where 2.row id select_type table type possible_keys key key_len ref rows Extra 1 SIMPLE b ref ind_company_id ind_company_id 5 sakila.a.company_id 1 Using where;Using index select_type: SIMPLE, 简单表,不使用表连接或子查询;PRIMARY,主查询,即外层的查询;UNION,UNION中的第二个查询或后面的查询;SUMQUERY,子查询中的第一个SELECT。 table: 输出结果集的表。 type: 表示表的连接类型,性能由好到坏,依次为, system,表中只有一行,常量表。 const,单表中最多有一行匹配,如pramary key 或者 unique index eq_ref,对于前面的每一行,此表中只查询一条记录,比如多表连接中,使用primary key 或 unique index ref,与eq_ref 类似,区别在于不是primary key 或qunique index, 而是普通索引。 ref_or_null,与ref 类似,区别在于查询中包含对null的查询。 index_merge,索引合并优化 unique_subquery,in的后面是一个查询主键字段的子查询。 index_subquery,与unique_subquery类似,区别在于是查询非唯一索引字段的子查询。 range,单表中的范围查询。 index,对于前面的每一行,都通过查询索引来得到数据。 all,全表扫描。 possible_keys: 表示查询时,可能使用的索引。 key:表示实际使用的索引。 key_len:索引字段的长度。 rows:扫描行的数量。 Extra:执行情况的说明和描述。 二,如何通过查询数据库各操作的比例及索引使用次数来判断数据库索引及使用是否合理? 1, 命令: >show status like 'Com_%'; 结果:Com_xxx 表示每个xxx语句的执行次数。如: Com_select, Com_insert,Com_update,Com_delete。 特别的,针对InnoDB: Innodb_rows_read,select查询返回的行数 Innodb_rows_inserted,执行insert操作插入的行数 等等。 通过以上可以查看该数据库的读写比例,以便优化。 2, 命令:>show status like 'Handler_read%' 查看索引使用次数。 三,何时匹配到索引? 明确第一索引,第二索引的含义。回表,覆盖索引等优化方法。这里不再赘述。特别的,组合索引只能前缀匹配。同样,like 关键字也只能前缀匹配索引,通配符不能放在第一个字符。 四,何时不走索引? 1,如果mysql 估计索引使用比全表扫描更慢,则不使用索引。例如几乎获取全表数据的范围查询等等。 2,or 分开的条件,OR前的条件列有索引,后面的没有索引,那么涉及的索引都不会用到。 3,条件不是组合索引的第一部分,即不满足前缀左匹配的条件。 4,like 条件以%开始,则不走索引。 5,where 条件后如果是字符串,则一定要用引号括起来,不然自动转换其他类型后,不会走索引。 五,常用SQL优化 1,大批量插入数据,使用多值语句插入。 insert into test values (1,2),(2,3),(2,4)...... 2, 优化group by, 默认情况下,mysql 会对所有group by C1,C2,C3 ... 的字段排序,与order by C1,C2,C3 类似,所以在group by 中增加相同列的order by 性能没什么影响。 如果用户想避免排序带来的影响,可以显式指定不排序,后面加上order by NULL。 3,order by 后面的顺序与索引顺序相同,且与where 中使用的条件相同,且是索引,则才会走真正索引。 4,in + 子查询的 SQL 尽量用join 连接来代替。 5,OR 之间的每个条件列都必须用到索引。 六,深层一些的优化 考虑每次查询时的IO消耗,回表次数;考虑表设计时,数据结构的不同,比如varchar ,char 区别;考虑表设计时每行数据的大小,尽量保持在128K以内,让其在一页内,避免跨页,大数据行。
我这里使用的是Centos6.4的环境下面测试的:
ulimit -SHn 65535
安装:libevent-2.0.12-stable.tar.gz
wget http://httpsqs.googlecode.com/files/libevent-2.0.12-stable.tar.gz
tar zxvf libevent-2.0.12-stable.tar.gz
cd libevent-2.0.12-stable/
./configure --prefix=/usr/local/libevent-2.0.12-stable/
make
make install
cd ../
安装:tokyocabinet-1.4.47.tar.gz wget http://httpsqs.googlecode.com/files/tokyocabinet-1.4.47.tar.gz
tar zxvf tokyocabinet-1.4.47.tar.gz
cd tokyocabinet-1.4.47/
./configure --prefix=/usr/local/tokyocabinet-1.4.47/
#Note: In the 32-bit Linux operating system, compiler Tokyo cabinet, please use the ./configure --enable-off64 instead of ./configure to breakthrough the filesize limit of 2GB.
#./configure --enable-off64 --prefix=/usr/local/tokyocabinet-1.4.47/
make
make install
cd ../
##执行上面这个tokyocabinet-1.4.47.tar.gz软件包安装的时候,对于32bit的机器,需要使用
#./configure --enable-off64 --prefix=/usr/local/tokyocabinet-1.4.47/ 这个命令,此外我安装的过程中,出现了这个错误提示,提示tokyocabinet-1.4.47.tar.gz安装不成功,解决办法是,安装需要的软件包就可以了.
错误提示一:
configure: error: zlib.h is required
解决方法是: # yum install zlib-devel
configure: error: bzlib.h is required 解决方法是: # yum install bzip2-devel
下面进入到了正式环节,上面装的两个都是为了httpsqs的安装做的前提准备:
安装:httpsqs-1.7.tar.gz wget http://httpsqs.googlecode.com/files/httpsqs-1.7.tar.gz
tar zxvf httpsqs-1.7.tar.gz
cd httpsqs-1.7/
make
make install
cd ../
至此安装已经结束:
[root@xoyo ~]# httpsqs -h -l <ip_addr> 监听的IP地址,默认值为 0.0.0.0
-p <num> 监听的TCP端口(默认值:1218)
-x <path> 数据库目录,目录不存在会自动创建(例如:/opt/httpsqs/data)
-t <second> HTTP请求的超时时间(默认值:3)
-s <second> 同步内存缓冲区内容到磁盘的间隔秒数(默认值:5)
-c <num> 内存中缓存的最大非叶子节点数(默认值:1024)
-m <size> 数据库内存缓存大小,单位:MB(默认值:100)
-i <file> 保存进程PID到文件中(默认值:/tmp/httpsqs.pid)
-a <auth> 访问HTTPSQS的验证密码(例如:mypass123)
-d 以守护进程运行
-h 显示这个帮助
[root@localhost ~]# ulimit -SHn 65535
[root@localhost ~]# httpsqs -d -p 1218 -x /data0/queue -a mypass123
[root@localhost ~]# ps -aux | grep httpsqs
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
root 14378 0.0 0.0 396420 500 pts/0 S 10:44 0:00 [httpsqs: master process] /usr/bin/httpsqs -d -p 1218 -x /data0/queue -a mypass123
root 14379 0.0 0.0 406664 716 pts/0 Sl 10:44 0:00 [httpsqs: worker process] /usr/bin/httpsqs -d -p 1218 -x /data0/queue -a mypass123
root 14382 0.0 0.0 4356 756 pts/0 S+ 10:44 0:00 grep httpsqs
1、put a queue
[root@localhost ~]# curl "http://192.168.59.129:1218/?name=your_queue_name&opt=put&data=url_encoded_text_message&auth=mypass123"
HTTPSQS_PUT_OK
[root@localhost ~]# 如果入队列成功,返回:HTTPSQS_PUT_OK 如果入队列失败,返回:HTTPSQS_PUT_ERROR 如果队列已满,返回:HTTPSQS_PUT_END
http://192.168.59.129:1218/?name=your_queue_name&opt=get&auth=mypass123
http://192.168.59.129:1218/?name=your_queue_name&opt=status&auth=mypass123 HTTP Simple Queue Service v1.7
------------------------------
Queue Name: your_queue_name
Maximum number of queues: 1000000
Put position of queue (1st lap): 5
Get position of queue (1st lap): 0
Number of unread queue: 5 4、使用json格式查看队列内容
http://192.168.59.129:1218/?name=your_queue_name&opt=status_json&auth=mypass123 {"name":"your_queue_name","maxqueue":1000000,"putpos":5,"putlap":1,"getpos":1,"getlap":1,"unread":4}
http://code.google.com/p/httpsqs/
//oracle解释执行计划
SQL> explain plan for select t.* from abin1 t where t.id<200; Explained SQL> select * from table(dbms_xplan.display); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- Plan hash value: 1270356885 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 98 | 1862 | 2 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| ABIN1 | 98 | 1862 | 2 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("T"."ID"<200) 13 rows selected SQL> //mysql解释执行计划 explain select t.* from user_rest t where id<>8 //oracle收集表的统计信息 analyze table abin1 compute statistics;
数据类型 大小(二进制位数) 范围 默认值
byte(字节) 8 -128 - 127 0
shot(短整型) 16 -32768 - 32768 0
int(整型) 32 -2147483648-2147483648 0
long(长整型) 64 -9233372036854477808-9233372036854477808 0
float(浮点型) 32 -3.40292347E+38-3.40292347E+38 0.0f
double(双精度) 64 -1.79769313486231570E+308-1.79769313486231570E+308 0.0d
char(字符型) 16 ‘ \u0000 - u\ffff ’ ‘\u0000 ’
boolean(布尔型) 1 true/false false
JAVA基本数据类型所占字节数是多少?byte 1字节 short 2字节 int 4字节 long 8字节 char 2字节(C语言中是1字节)可以存储一个汉字 float 4字节 double 8字节 boolean false/true(理论上占用1bit,1/8字节,实际处理按1byte处理) JAVA是采用Unicode编码。每一个字节占8位。你电脑系统应该是 32位系统,这样每个int就是 4个字节
其中一个字节由8个二进制位组成
Java一共有8种基本数据类型(原始数据类型):
类型 存储要求 范围(包含) 默认值 包装类
整 int 4字节(32位) -231~ 231-1 0 Integer
数 short 2字节(16位) -215~215-1 0 Short
类 long 8字节(64位) -263~263-1 0 Long
型 byte 1字节(8位) -27~27-1 0 Byte
浮点 float 4字节(32位) -3.4e+38 ~ 3.4e+38 0.0f Float
类型 double 8字节(64位) -1.7e+308 ~ 1.7e+308 0 Double
字符 char 2字节(16位) u0000~uFFFF(‘’~‘?’) ‘0’ Character
(0~216-1(65535))
布尔 boolean 1/8字节(1位) true, false FALSE Boolean
在移动开发中由于移动设备内存的局限性,往往需要考虑使用的数据类型所占用的字节数。下面简单介绍下Java中几种基本数据类型,以加深记忆。
在Java中一共有8种基本数据类型,其中有4种整型,2种浮点类型,1种用于表示Unicode编码的字符单元的字符类型和1种用于表示真值的boolean类型。(一个字节等于8个bit)
1.整型
类型 存储需求 bit数 取值范围 备注
int 4字节 4*8
short 2字节 2*8 -32768~32767
long 8字节 8*8
byte 1字节 1*8 -128~127
2.浮点型
类型 存储需求 bit数 取值范围 备注
float 4字节 4*8 float类型的数值有一个后缀F(例如:3.14F)
double 8字节 8*8 没有后缀F的浮点数值(如3.14)默认为double类型
3.char类型
类型 存储需求 bit数 取值范围 备注
char 2字节 2*8
4.boolean类型
类型 存储需求 bit数 取值范围 备注
boolean 1字节 1*8 false、true
补充:Java有一个能够表示任意精度的算书包,通常称为“大数值”(big number)。虽然被称为大数值,但它并不是一种Java类型,而是一个Java对象。 如果基本的整数和浮点数精度不能够满足需求,那么可以使用java.math包中的两个很有用的类:BigIntegerBigDecimal(Android SDK中也包含了java.math包以及这两个类)这两个类可以处理包含任意长度数字序列的数值。BigInteger类实现了任意精度的整数运算,BigDecimal实现了任意精度的浮点数运算。具体的用法可以参见Java API。 http://blog.csdn.net/witsmakemen/article/details/8974200
int常见为4个字节,跟操作系统有关系。
turbo c(以及Turbo c的一些衍生编译器,他们用的一套编译程序)是dos时代的编译器,是上世纪80年代的产物,严重过时,属于老掉牙的产品,他们编译出来的程序是16位操作系统dos下的程序,所以长度为16位,即两个字节。windows为了兼容dos,所以turbo c生成的文件也可以在windows中运行。
其他一般就都是4个字节了。 操作系统16位的时候,int 2字节,操作系统32位的时候,int 4字节,由于32位系统之前占主流地位,实际现在就算是64位系统,出于兼容性考虑,int也是4字节的
文件上传方面的: plupload+fastdfs plupload负责上传,fastdfs 负责存储
二叉树相关的问的比较多 二分查找 treemap和某些数据库索引的的底层是红黑树 链表的相交和闭环 针对二叉树,比如分层遍历,找最近父节点 在字符串中找回文串,数组中寻找重复的数字或相邻之和的最大串 红黑树不就是B树么 如果没有遇到专业考算法的公司,只能说还没面试过牛公司,就相当于编程感觉不到数据结构,相当于编程还没入门 是对称二叉B树
还是有点不一样,是其子集,误导你了
try {
response.setContentType("application/vnd.ms-excel;charset=UTF-8");
response.setHeader("Content-Disposition", "attachment; filename=" +teamQuery.getTeamId()+ new String(" 项目销量.xls".getBytes("gbk"), "iso8859-1"));
Boolean flag = manteamService.downFile(teamQuery,response.getOutputStream());
if (flag) {
resutMap.put("success", true);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace(); //To change body of catch statement use File | Settings | File Templates.
} catch (IOException e) {
e.printStackTrace(); //To change body of catch statement use File | Settings | File Templates.
}
一定要有response.getOutputStream()
百度 T2:7k~10k T3:11k~13k T4:14k~16k T5:16k~20k T6:20k~25k
年青代=新生代(eden space)+2个survivor
年青代用来存放新近创建的对象,尺寸随堆大小的增大和减小而相应的变化,默认值是保持为堆大小的1/15,可以通过-Xmn参数设置年青代为固定大小,也可以通过-XX:NewRatio来设置年青代与年老代的大小比例,年青代的特点是对象更新速度快,在短时间内产生大量的“死亡对象”。
年轻代的特点是产生大量的死亡对象,并且要是产生连续可用的空间, 所以使用复制清除算法和并行收集器进行垃圾回收. 对年轻代的垃圾回收称作初级回收 (minor gc)
初级回收将年轻代分为三个区域, 一个新生代 , 2个大小相同的复活代, 应用程序只能使用一个新生代和一个复活代, 当发生初级垃圾回收的时候,gc挂起程序, 然后将新生代和复活代中的存活对象复制到另外一个非活动的复活代中,然后一次性清除新生代和复活代,将原来的非复活代标记成为活动复活代. 将在指定次数回收后仍然存在的对象移动到年老代中, 初级回收后,得到一个空的可用的新生代.
昨天,看一个build Standalone中databrusher的一个脚本,发现一个Java类似乎没有在classpath中,好像也可一直运行了。很疑惑,问了对应的开发同学,然后自己好好看了下它的代码,才知道了原理。 命令是:$JAVA_HOME/bin/java $JAVA_OPTS com.alibaba.standalone.AppStartor com.alibaba.intl.standalone.databrusher.Startor "$main_class" "$signal_file" "$recivers" 原理是:Java根据classpath找到,com.alibaba.standalone.AppStartor这个class,运行这个class,会启动一个classloader来加载com.alibaba.intl.standalone.databrusher.Startor(在里面会指定到WORLDS-INF目录下加载类),然后com.alibaba.intl.standalone.databrusher.Startor会启动对应的"$main_class". 然后,花了挺多时间好好看了一下Java的classloader,了解一下其中的原理和看了下代码。下面也简单总结一下吧。 java虚拟机是由sun.misc.Launcher来初始化的,也就是java(或java.exe)这个程序来做的.虚拟机按以下顺序搜索并装载所有需要的类: 1,引导类:组成java平台的类,包含rt.jar和i18n.jar等基础jar包中的类. 2,扩展类:使用java扩展机制的类,都是位于扩展目录($JAVA_HOME/jre/lib/ext)中的.jar档案包. 3,用户类:开发者定义的类或者没有使用java扩展机制的第三方产品.你必须在命令行中使用-classpath选项或者使用CLASSPATH环境变量来确定这些类的位,或者自己写ClassLoader加载。 Java的class loader的大致情况如下图所示: http://renyongjie668.blog.163.com/prevPhDownload.do?host=renyongjie668&albumId=197449439&photoId=6568564371 bootstrap classloader -->extension classloader-->system classloader 虚拟机一启动,会先做一些初始化的动作。一旦初始化动作完成之后,就会 产生第一个类别加载器,即所谓的Bootstrap Loader,Bootstrap Loader 是由C++ 所撰写而成,这个Bootstrap Loader所做的初始工作中,除了也做一些基本的初始化动作之外,最重要的就是加载定义在sun.misc 命名空间底下的Launcher.java 之中的ExtClassLoader( 因为是inner class ,所以编译之后会变成Launcher$ExtClassLoader.class) ,并设定其Parent 为null,代表其父加载器为Bootstrap Loader 。然后Bootstrap Loader ,再要求加载定义于sun.misc 命名空间底下的Launcher.java 之中的AppClassLoader( 因为是inner class,所以编译之后会变成Launcher$AppClassLoader.class) ,并设定其Parent 为之前产生的ExtClassLoader 实例。 a. Bootstrap ClassLoader/启动类加载器 主要负责java_home/jre/lib目录下的核心 api 或 -Xbootclasspath 选项指定的jar包装入工作. b. Extension ClassLoader/扩展类加载器 主要负责java_home/jre/lib/ext目录下的jar包或 -Djava.ext.dirs 指定目录下的jar包装入工作 c. System ClassLoader/系统类加载器 主要负责java -classpath/-Djava.class.path或$CLASSPATH变量所指的目录下的类与jar包装入工作.(这里需要说明的是,如果$CLASSPATH为空,jdk会默认将被运行的Java类的当前路径作为一个默认的$CLASSPATH,一但设置了$CLASSPATH变量,则会到$CLASSPATH对应的路径下去寻找相应的类,找不到就会报错。这个结论,我已经经过测试,并且看了下类加载器中源代码) d. User Custom ClassLoader/用户自定义类加载类(java.lang.ClassLoader的子类)在程序运行期间, 通过java.lang.ClassLoader的子类动态加载class文件, 体现java动态实时类装入特性. 为了有更多的了解,写了个简单的Java程序对前面三种classloader能加载类的路径及其parent类进行了测试。代码如下: import java.net.URL; import java.net.URLClassLoader; /** * @className: IClassLoader * @description: 测试三种classloader加载类的路径,及其parent * @author: 笑遍世界 * @createTime: 2010-11-17 下午07:33:40 */ public class IClassLoader { public static void main(String[] args) { // 测试bootstrap classloader 的类加载路径 URL[] urls=sun.misc.Launcher.getBootstrapClassPath().getURLs(); for (int i = 0; i < urls.length; i++) { System.out.println(urls[i].toExternalForm()); } // 测试extension classloader 的类加载路径,先打印一个路径,再打印出其parent,然后再打印出类加载路径中的所有jar包 System.out.println("-------------------------------------"); System.out.println(System.getProperty("java.ext.dirs")); ClassLoader extensionClassloader=ClassLoader.getSystemClassLoader().getParent(); System.out.println("the parent of extension classloader : "+extensionClassloader.getParent()); System.out.println("extension classloader can use thess jars:"); URL[] extURLs = ((URLClassLoader)ClassLoader.getSystemClassLoader().getParent()).getURLs(); for (int i = 0; i < extURLs.length; i++) { System.out.println(extURLs[i]); } // 测试system classloader 的类加载路径,其实也就时classpath的路径,并打印出它的parent System.out.println("-------------------------------------"); System.out.println(System.getProperty("java.class.path")); System.out.println(ClassLoader.getSystemResource("")); ClassLoader systemClassloader=ClassLoader.getSystemClassLoader(); System.out.println("the parent of system classloader : "+systemClassloader.getParent()); } } 本机(linux+jdk1.5)运行结果如下: file:/usr/ali/java/jre/lib/rt.jar file:/usr/ali/java/jre/lib/i18n.jar file:/usr/ali/java/jre/lib/sunrsasign.jar file:/usr/ali/java/jre/lib/jsse.jar file:/usr/ali/java/jre/lib/jce.jar file:/usr/ali/java/jre/lib/charsets.jar file:/usr/ali/java/jre/classes ------------------------------------- /usr/ali/java/jre/lib/ext the parent of extension classloader : null extension classloader can use thess jars: file:/usr/ali/java/jre/lib/ext/emma.jar file:/usr/ali/java/jre/lib/ext/localedata.jar file:/usr/ali/java/jre/lib/ext/dnsns.jar file:/usr/ali/java/jre/lib/ext/sunpkcs11.jar file:/usr/ali/java/jre/lib/ext/sunjce_provider.jar ------------------------------------- .:/usr/ali/java/lib/dt.jar:/usr/ali/java/lib/tools.jar file:/home/master/workspace/2010_11/bin/ the parent of system classloader : sun.misc.Launcher$ExtClassLoader@1a5ab41 //ps:当前路径.即是/home/master/workspace/2010_11/bin/ 关于Java的classloader其原理还是需要好好理解才能清楚的,仅通过一天的了解,记录为上面那么多吧。更多详细信息,可以参考如下资料: http://snandy.javaeye.com/blog/307083 http://haofenglemon.javaeye.com/blog/426382 http://blog.csdn.net/zdwzzu2006/archive/2008/04/05/2253982.aspx http://wuquanyin1011.javaeye.com/blog/703842 http://hi.baidu.com/yangzhibin_bai/blog/item/78846cce1cb86b0992457ead.html http://www.blogjava.net/clraychen/archive/2008/02/20/180868.html
第一种: 最基本的作为一个本本分分的函数声明使用。
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>Validate Page</title>
</head>
<script type="text/javascript">
function validate(abin){
var lee=function(parameter){
return 'hello,'+abin;
}(abin);
document.getElementById("spanId").innerHTML=lee;
}
</script>
<body>
<div id="divId" class="divs">
<input id="button" type="button" value="请猛击" onclick="validate('varyall')"/>
</div>
<br/>
<span id="spanId" class="spans"></span>
</body>
</html> 第二种: <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" " http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>Validate Page</title> </head> <script type="text/javascript"> var validate=function(abin){ var lee=function(parameter){ return 'hello,'+parameter; }(abin); document.getElementById("spanId").innerHTML=lee; }; </script> <body> <div id="divId" class="divs"> <input id="button" type="button" value="请猛击" onclick="validate('varyall')"/> </div> <br/> <span id="spanId" class="spans"></span> </body> </html> 第三种: <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" " http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>Validate Page</title> </head> <script type="text/javascript"> var validate=new Function("abin", "var lee=function(parameter){return 'hello,'+parameter;}(abin);document.getElementById('spanId').innerHTML=lee;"); </script> <body> <div id="divId" class="divs"> <input id="button" type="button" value="请猛击" onclick="validate('who')"/> </div> <br/> <span id="spanId" class="spans"></span> </body> </html>
语言只是把具体的算法实现出来而已。据我了解的排序算法11-13种。排序算法嘛 主要就是个思想而已。不同的算法时间复杂度不一样,空间复杂度也不一样,当然执行的效率也不一样。当然采用哪种算法还取决于你要实现什么样的功能。就好比说:要同时尽快的找出最大最小,或者尽快的找出最值的位置等等。
冒泡排序(bubble sort) — O(n2)
鸡尾酒排序 (Cocktail sort, 双向的冒泡排序) — O(n2)
插入排序 (insertion sort)— O(n2)
桶排序 (bucket sort)— O(n); 需要 O(k) 额外 记忆体
计数排序 (counting sort) — O(n+k); 需要 O(n+k) 额外 记忆体
归并排序 (merge sort)— O(n log n); 需要 O(n) 额外记忆体
原地归并排序 — O(n2)
二叉树排序 (Binary tree sort) — O(n log n); 需要 O(n) 额外记忆体
鸽巢排序 (Pigeonhole sort) — O(n+k); 需要 O(k) 额外记忆体
基数排序 (radix sort)— O(n·k); 需要 O(n) 额外记忆体
Gnome sort — O(n2)
Library sort — O(n log n) with high probability, 需要 (1+ε)n 额外记忆体不稳定
选择排序 (selection sort)— O(n2)
希尔排序 (shell sort)— O(n log n) 如果使用最佳的现在版本
Comb sort — O(n log n)
堆排序 (heapsort)— O(n log n)
Smoothsort — O(n log n)
快速排序 (quicksort)— O(n log n) 期望时间, O(n2) 最坏情况; 对於大的、乱数串列一般相信是最快的已知排序
1、冒泡排序: 冒泡排序(BubbleSort)的基本概念是:依次比较相邻的两个数,将小数放在前面,大数放在后面。即在第一趟:首先比较第1个和第2个数,将小数放前,大数放后。然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放前,大数放后。至此第一趟结束,将最大的数放到了最后。在第二趟:仍从第一对数开始比较(因为可能由于第2个数和第3个数的交换,使得第1个数不再小于第2个数),将小数放前,大数放后,一直比较到倒数第二个数(倒数第一的位置上已经是最大的),第二趟结束,在倒数第二的位置上得到一个新的最大数(其实在整个数列中是第二大的数)。如此下去,重复以上过程,直至最终完成排序。 具体代码例一:
package com.abin.lee.algorithm.bubble;
public class BubbleSort {
public static void main(String[] args) {
int[] start={5,2,1,3,6,4};
int[] end=sort(start);
for(int i=0;i<end.length;i++){
System.out.println("end["+i+"]="+end[i]);
}
}
public static int[] sort(int[] input){
int temp=0;
//最多做n-1趟排序 for(int i=0;i<input.length-1;i++){ //对当前无序区间score[0......length-i-1]进行排序(j的范围很关键,这个范围是在逐步缩小的) for(int j=0;j<input.length-i-1;j++){ //把大的值交换到后面 if(input[j]>input[j+1]){ temp=input[j]; input[j]=input[j+1]; input[j+1]=temp; } StringBuffer stb=new StringBuffer(); for(int k=0;k<input.length;k++){ stb.append("input["+k+"]="+input[k]+" "); } System.out.println("i="+i+",j="+j+" = "+stb.toString()); } } return input; }
}
2、选择排序: 选择排序(Straight Select Sorting) 也是一种简单的排序方法,它的基本思想是:第一次从R[0]~R[n-1]中选取最小值,与R[0]交换,第二次从R{1}~R[n-1]中选取最小值,与R[1]交换,...., 第i次从R[i-1]~R[n-1]中选取最小值,与R[i-1]交换,.....,第n-1次从R[n-2]~R[n-1]中选取最小值,与R[n-2]交换,总共通过n-1次,得到一个按排序码从小到大排列的有序序列. 具体代码:
package com.abin.lee.algorithm.select;
public class SelectSort {
public static void main(String[] args) {
int[] start={5,2,3,1,6,4};
start=sort(start);
for(int i=0;i<start.length;i++){
System.out.println("start["+i+"]="+start[i]);
}
}
public static int[] sort(int[] input){
int temp=0;
for(int i=0;i<input.length;i++){
for(int j=i+1;j<input.length;j++){
if(input[i]>input[j]){
temp=input[i];
input[i]=input[j];
input[j]=temp;
}
StringBuffer stb=new StringBuffer();
for(int k=0;k<input.length;k++){
stb.append("input["+k+"]="+input[k]+" ");
}
System.out.println("i="+i+",j="+j+" = "+stb.toString());
}
}
return input;
}
}
3、请输入一个数字,比如4,输出为: 1 2 3 4 5 6 7 8 9 10 代码如下:
package com.abin.lee.photo;
public class TestInputNumber {
public static void main(String[] args) {
int n=4;
output(n);
}
public static void output(int n){
int temp=1;
for(int i=1;i<=n;i++){
for(int j=0;j<i;j++){
System.out.print(temp+" ");
temp++;
}
System.out.println("");
}
}
}
4.二叉树算法
package com.abin.lee.algorithm.binary;
public class BinaryNode {
public int data;//根节点
BinaryNode left;//左节点
BinaryNode right;//右节点
public BinaryNode(int data,BinaryNode left,BinaryNode right) {
this.data=data;
this.left=left;
this.right=right;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public BinaryNode getLeft() {
return left;
}
public void setLeft(BinaryNode left) {
this.left = left;
}
public BinaryNode getRight() {
return right;
}
public void setRight(BinaryNode right) {
this.right = right;
}
}
package com.abin.lee.algorithm.binary;
public class BinaryTree {
//前序遍历
public static void preOrder(BinaryNode root){
if(null!=root){
System.out.print(root.data+"-");
preOrder(root.left);
preOrder(root.right);
}
}
//中序遍历
public static void inOrder(BinaryNode root){
if(null!=root){
inOrder(root.left);
System.out.print(root.data+"--");
inOrder(root.right);
}
}
//后序遍历
public static void postOrder(BinaryNode root){
if(null!=root){
postOrder(root.left);
postOrder(root.right);
System.out.print(root.data+"---");
}
}
public static void main(String[] args) {
BinaryNode one=new BinaryNode(1,null,null);
BinaryNode three=new BinaryNode(3,null,null);
BinaryNode two=new BinaryNode(2,three,one);
BinaryNode four=new BinaryNode(4,one,two);
BinaryNode five=new BinaryNode(5,four,one);
System.out.println("preOrder");
preOrder(five);
System.out.println();
System.out.println("inOrder");
inOrder(five);
System.out.println();
System.out.println("postOrder");
postOrder(five);
System.out.println();
}
}
输出结果:
preOrder
5-4-1-2-3-1-1-
inOrder
1--4--3--2--1--5--1--
postOrder
1---3---1---2---4---1---5---
5、java插入排序
插入式排序法——插入排序法 插入排序(Insertion Sortion)的基本思想是:把n个待排序的元素看成一个有序表和一个无序表,开始有序表只包含一个元素,无序表中包含n-1个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码依次与有序表元素的排序码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表。 public class InjectionSort //定义一个 InjectionSort 类
public static void injectionSort(int[] number) //传数组
for(int j = 1;j<number.length;j++)//循环
int tmp = number[j]; //循环把数组第二个值放到tmp里
int i = j-1//给i 赋值
while(tmp<number[i]) //tmp值和数组第一个值比较谁小
number[i+1] = number[i]; //如果小于就把第一个值赋值给第二个
i--;
if(i == -1)//如果i值=-1
break; //退出循环
number[i+1] = tmp //因为比较数组里的前一个比后一个这样就换交了实现了把小的放在前面
这是第一次,因为循环是一个数组,后边的就一次往下循环,最后就把数组里的顺序从小到大排序了
public static void main(String[] args){
int[] num = {5,46,26,67,2,35};//定义数组num
injectionSort(num);//调用方法
for(int i = 0;i<num.length;i++){
System.out.println(num[i]);//显示排序后的数组,一行显示一个值
简单说就是数组里第二个和第一个比谁小,把小的放到第一个里,大的放到第二个里,然后第二个再和第三个比,小的还是放在前,一直比到这个数组结束,这样就实现了从小到大,希望我说的够详细 插入排序代码while循环: package com.abin.lee.algorithm.insert; public class InsertSort { public static void main(String[] args) { int[] input = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 }; input=sort(input); for (int i = 0; i < input.length; i++) { System.out.print(input[i] + " "); } } public static int[] sort(int[] input) { for (int i = 1; i < input.length; i++) { int insertVal = input[i]; // insertValue准备和前一个数比较 int index = i - 1; while (index >= 0 && insertVal < input[index]) { // 将把input[index]向后移动 input[index + 1] = input[index]; // 让index向前移动一位 index--; } // 将insertValue插入到适当位置 input[index + 1] = insertVal; //下面这个循环是为了打印一下中间的循环看看是不是插入排序的正确算法 StringBuffer stb=new StringBuffer(); for(int k=0;k<input.length;k++){ stb.append(input[k]+" "); } System.out.println("i="+i+" = "+stb.toString()); } return input; } } 插入排序for循环代码: package com.abin.lee.algorithm.insert; public class DoInsertSort { public static void main(String[] args) { int[] input={5,4,6,3,7,2,8,1,0,9}; input=sort(input); for(int i=0;i<input.length;i++){ System.out.print("input["+i+"]="+input[i]+" "); } } public static int[] sort(int[] input){ for(int i=1;i<input.length;i++){ int temp=input[i]; int j; for(j=i;j>0;j--){ if(temp<input[j-1]){ input[j]=input[j-1]; }else{ break; } } input[j]=temp; //下面这个循环是为了打印一下中间的循环看看是不是插入排序的正确算法 StringBuffer stb=new StringBuffer(); for(int k=0;k<input.length;k++){ stb.append(input[k]+" "); } System.out.println("i="+i+" = "+stb.toString()); } return input; } } 二分查找又称折半查找,它是一种效率较高的查找方法。 折半查找的算法思想是将数列按有序化(递增或递减)排列,查找过程中采用跳跃式方式查找,即先以有序数列的中点位置为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。 折半查找是一种高效的查找方法。它可以明显减少比较次数,提高查找效率。但是,折半查找的先决条件是查找表中的数据元素必须有序。
package com.abin.algorithm.template.half;
public class BinarySearch { public static void main(String[] args) { int[] src=new int[]{1,3,5,7,9,11}; int result=binarySearch(src, 3); System.out.println("result="+result); int status=binarySearch(src, 9 ,0 ,src.length); System.out.println("status="+status); } //循环实现 public static int binarySearch(int[] src,int key){ int low=0; int high=src.length-1; while(low<=high){ int middle=(low+high)/2; if(key==src[middle]){ return middle; }else if(key<src[middle]){ high=middle-1; }else{ low=middle+1; } } return -1; } //递归实现 public static int binarySearch(int[] src,int key,int low,int high){ int middle=(low+high)/2; if(src[middle]==key){ return middle; }else if(low>=high){ return -1; }else if(src[middle]>key){ return binarySearch(src, key, low, middle-1); }else if(src[middle]<key){ return binarySearch(src, key, middle+1, high); } return -1; }
}
<style type="text/css">
div.remark
{
white-space:nowrap;
width:6em;
overflow:hidden;
text-overflow:ellipsis;
}
</style>
<div class="remark">${refundApply.remarks }</div>
repcached实现memcached的复制功能:
repcached是日本人开发的实现memcached复制功能,它是一个单 master单 slave的方案,但它的 master/slave都是可读写的,而且可以相互同步,如果 master坏掉, slave侦测到连接断了,它会自动 listen而成为 master;而如果 slave坏掉, master也会侦测到连接断,它就会重新 listen等待新的 slave加入
安装:
先安装memcached(我安装的1.2.8)
有两种方式:
方式一、下载对应的repcached版本
#wget http://downloads.sourceforge.net/repcached/memcached-1.2.8-repcached-2.2.tar.gz
#tar zxf memcached-1.2.8-repcached-2.2.tar.gz
#cd memcached-1.2.8-repcached-2.2
方式二、下载对应patch版本
#wget http://downloads.sourceforge.net/repcached/repcached-2.2-1.2.8.patch.gz
#gzip -cd ../repcached-2.2-1.2.8.patch.gz | patch -p1
#./configure --enable-replication
# make
# make install
启动:
启动master
#memcached -v -l 192.168.50.240 -p 11211 -uroot
replication: listen (master监听)
启动salve
#memcached -v -l 192.168.50.241 -p 11213 -uroot -x 127.0.0.1 -X 11212
replication: connect (peer=192.168.50.240:11212)
replication: marugoto copying
replication: start
启动正常后,master将accept。测试:
操作master
#telnet 192.168.50.240 11211
#set key1 0 0 3
111
查看slave
#telnet 192.168.50.241 11213
#get key1
如果正常表示,配置成功
应用:
可以实现cache冗余 注意:如果master down机,slave接管并成为master,这时down机的master只能启用slave,他们之间互换角色,才能保持复制功能。换句话说,master没有抢占功能。
一、Memcache内存分配机制
关于这个机制网上有很多解释的,我个人的总结如下。
- Page为内存分配的最小单位。
Memcached的内存分配以page为单位,默认情况下一个page是1M,可以通过-I参数在启动时指定。如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区 -
-
-
-
域。page一旦被分配在重启前不会被回收或者重新分配(page ressign已经从1.2.8版移除了)
- Slabs划分数据空间。
Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储。如下图,每个slab只存储大于其上一个slab的size并小于或者等于自己最大size的数据。例如:slab 3只存储大小介于137 到 224 bytes的数据。如果一个数据大小为230byte将被分配到slab 4中。从下图可以看出,每个slab负责的空间其实是不等的,memcached默认情况下下一个slab的最大值为前一个的1.25倍,这个可以通过修改-f参数来修改增长比例。 
-
-
- Chunk才是存放缓存数据的单位。
Chunk是一系列固定的内存空间,这个大小就是管理它的slab的最大存放大小。例如:slab 1的所有chunk都是104byte,而slab 4的所有chunk都是280byte。chunk是memcached实际存放缓存数据的地方,因为chunk的大小固定为slab能够存放的最大值,所以所有分配给当前slab的数据都可以被chunk存下。如果时间的数据大小小于chunk的大小,空余的空间将会被闲置,这个是为了防止内存碎片而设计的。例如下图,chunk size是224byte,而存储的数据只有200byte,剩下的24byte将被闲置。 
-
-
-
- Slab的内存分配。
Memcached在启动时通过-m指定最大使用内存,但是这个不会一启动就占用,是随着需要逐步分配给各slab的。
如果一个新的缓存数据要被存放,memcached首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;如果没有则要进行申请。slab申请内存时以page为单位,所以在放入第一个数据,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk的数组,在从这个chunk数组中选择一个用于存储数据。如下图,slab 1和slab 2都分配了一个page,并按各自的大小切分成chunk数组。 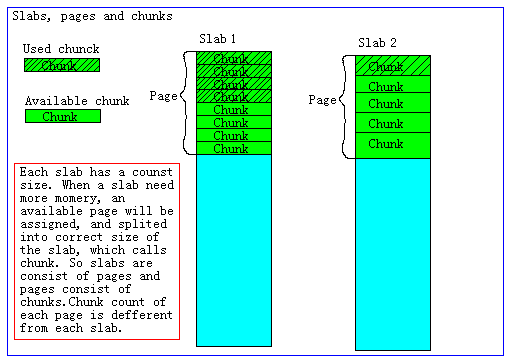
-
-
-
- Memcached内存分配策略。
综合上面的介绍,memcached的内存分配策略就是:按slab需求分配page,各slab按需使用chunk存储。
这里有几个特点要注意,
- Memcached分配出去的page不会被回收或者重新分配
- Memcached申请的内存不会被释放
- slab空闲的chunk不会借给任何其他slab使用
每一个slab=1M 切分的chunk个数=1M/最小的chunk大小
下一个chunk=上一个chunk大小*增长因子 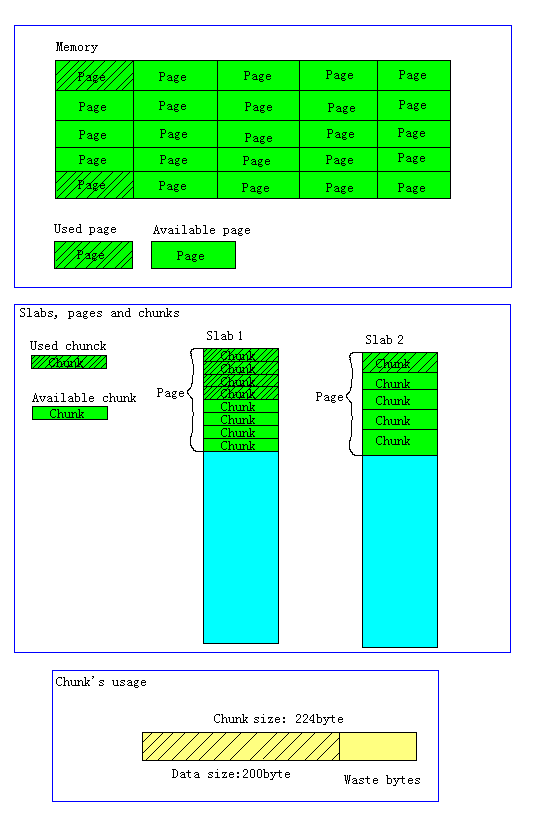
知道了这些以后,就可以理解为什么总内存没有被全部占用的情况下,memcached却出现了丢失缓存数据的问题了。
*******************
当存储的值item大于1M的时候:
按照官方解释,当大于1M时,按现有的 slab allocation内存分配管理机制,memcache的存取效率会下降很多,就失去了使用memcache的意义,之所以用memcache,一大原因就是它比数据库速度快,如果失去了速度优势,就没意思了。 支持大于1M的方法 官方也给出了:一个是还是使用slab allocation 机制修改源代码中 POWER_BLOCK 的值,然后重新编译。另一个方法是使用低效的 malloc/free 分配机制。 如果某个常用slab满了 而且又没开启LRU,会出现命中低的情况· 1M/最小的chunk=存储的个数
然后第二个chunk=第一个chunk*1.25
这样1M被不断的分
切到最后1M只能存一个chunk 1M 用完会申请一个新的 1M 但是 不能超过你的最大内存数 超过了 就开始回收 也就是LRU 当memcache每次在get的时候会检测key所对应的value过期时间 那么当检测到此item过期了 value会被清除 key呢 保留 还是也会被清除 ?
不会被清除,只会返回空
直到lru覆盖这个过期值
那就是当我程序弃用了大量的key时 cmd_get时 这些key 还会被扫描到?
不会
只是还存在内存里 占着内存
有些符号在URL中是不能直接传递的,如果要在URL中传递这些特殊符号,那么就要使用他们的编码了。下表中列出了一些URL特殊符号及编码
十六进制值
| 1 |
+ |
URL 中+号表示空格 |
%2B |
| 2 |
空格 |
URL中的空格可以用+号或者编码 |
%20 |
| 3 |
/ |
分隔目录和子目录 |
%2F |
| 4 |
? |
分隔实际的 URL 和参数 |
%3F |
| 5 |
% |
指定特殊字符 |
%25 |
| 6 |
# |
表示书签 |
%23 |
| 7 |
& |
URL 中指定的参数间的分隔符 |
%26 |
| 8 |
= |
URL 中指定参数的值 |
%3D |
解决的方法:
replace() 方法如果直接用str.replace("-","!") 只会替换第一个匹配的字符.
而str.replace(/\-/g,"!")则可以替换掉全部匹配的字符(g为全局标志)。
replace()
js中替换字符变量如下:
data2=data2.replace(/\%/g,"%25");
data2=data2.replace(/\#/g,"%23");
data2=data2.replace(/\&/g,"%26");
如何用jquery获取<input id="test" name="test" type="text"/>中输入的值? $("#test").val()
$("input[name='test']").val()
$("input[type='text']").val()
$("input[type='text']").attr("value")
1.struts的toke原理
Struts本身有一套完善的防止重复提交表单的Token(令牌)机制,但笔者目前的项目自写的framework没有用到Struts,故也得自写防止用户因为后退或者刷新来重复提交表单内容的Token机制。不难,容易实现。实现原理:一致性。jsp生成表单时,在表单中插入一个隐藏<input>字段,该字段就是保存在页面端的token字符串,同时把该字符串存入session中。等到用户提交表单时,会一并提交该隐藏的token字符串。在服务器端,查看下是否在session中含有与该token字符串相等的字符串。如果有,那么表明是第一次提交该表单,然后删除存放于session端的token字符串,再做正常业务逻辑流程;如果没有,那么表示该表单被重复提交,做非正常流程处理,可以警告提示也可以什么也不做。
2.
行级锁:
select * from abin1 t where t.id=21 for update;
表级锁:
lock table abin1 IN EXCLUSIVE MODE (nowait);
memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。但是它并不提供冗余(例如,复制其hashmap条目);当某个服务器S停止运行或崩溃了,所有存放在S上的键/值对都将丢失。 Memcached官方:http://danga.com/memcached/ 关于Memcached的介绍请参考:Memcached深度分析 下载Windows的Server端 下载地址:http://code.jellycan.com/memcached/ windows服务端下载地址:
http://code.jellycan.com/files/memcached-1.2.6-win32-bin.zip windows服务端安装: http://www.cnblogs.com/xd502djj/archive/2012/09/25/2701800.htmlhttp://www.cnblogs.com/wucg/archive/2011/03/01/1968185.html ehcache集群的相关文章: http://www.cnblogs.com/yangy608/archive/2011/10/07/2200669.htmlhttp://www.cnblogs.com/hoojo/archive/2012/07/19/2599534.htmlhttp://www.open-open.com/lib/view/open1345651870876.html
以图为例 Cache A、Cache B,Cache C为三台Memcached服务器 根据三台Memcached的IP和端口,计算出他们的Hash值,然后分布在整个圆环上 每两台Memcached服务器的Hash值之间为一个区间 Key1、Key2、Key3、Key4 为要存储在Memcached里的4个Key 根据4个Key计算出他们的Hash值,同样也落在这个圆环上 在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。 根据上面的方法,对象 key1 将被存储到 cache A 上; key2 和 key3 对应到 cache C ; key4 对应到 cache B; 同一个key不是三台服务器上面都有映射, 只会映射到其中一台服务器上面 集群中其中一个Memcached节点宕机,会导致存在着上面的Key全部失效而重新对这些key进行hash
对其他活着的Memcached节点上的key没有影响
如果是集群 Set和Get时触发操作的是否为同一个配置 如果是多个应用服务器触发Set、Get操作,每一个的Memcached节点配置顺序是否相同 可以通过telnet的方式,去Memcached节点上Get一下响应的Key,看是否真的过期 你分析一下你的slab构成,看看每个slab分配了多少page页,加起来是不是跟总分配内存一样,如果是一样的表示你的内存已经分配完了,每个slab只能使用已分配的大小,不能再增涨。再分析一下存这个value的slab的大小,如果比较小,且hits量很大,就会出现你这样的情况,刚存没多久的数据没到过期就会被挤掉。
失效就几种可能:
1,cache满了,刚插进去就被lru剔出来
2,失效时间设置不对,导致数据一插进去就失效(不能超过30天) 使用了64的操作系统,能分配2GB以上的内存。32位操作系统中,每个进程最多只能使用2GB内存。可以启动多个分配2GB以下内存的进程,但这样一台服务器上的TCP连接数就会成倍增加,管理上也变得复杂,所以尽量统一使用了64位操作系统。 另外,最好分配内存为3GB,是因为内存分配量超过这个值,就有可能导致内存交换(swap),memcached的内存存储“slab”, memcached启动时指定的内存分配量是memcached用于保存数据的量,没有包括“slab”本身占用的内存、以及为了保存数据而设置的管理空间。因此,memcached进程的实际内存分配量要比指定的容量要大。 如果在memcached中的数据大部分都比较小。这样,进程的大小要比指定的容量大很多。因此,改变内存分配量进行验证,确认了3GB的大小不会引发swap。 64位操作系统不受限制(小于你的物理内存大小即可),不过得注意Memcache软件本身是有内存消耗的(相比可以忽略),但这点还是注意一下。
<script type="text/javascript" >
var EventUtil = {
addHandler: function (element, type, handler) {
if (element.addEventListener) {
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent("on" + type, handler);
} else {
element["on" + type] = handler;
}
}
};
EventUtil.addHandler(document, "DOMContentLoaded", function (event) {
setTimeout(function(){
var imgs=document.getElementsByTagName("img");
for (var i =0; i<=imgs.length;i++){
var img=imgs[i];
var height,width;
height=img.naturalHeight;
width=img.naturalWidth;
if((height==0&&width==0)){
img.src="";
img.parentNode.parentNode.hidden=true;
var nid=img.getAttribute('nid');
document.getElementById('divNoneImg'+nid).style.display="block";
}
}
}, 2000);
});
</script>
//spring-mvc.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:cache="http://www.springframework.org/schema/cache"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc" xmlns:oxm="http://www.springframework.org/schema/oxm"
xmlns:p="http://www.springframework.org/schema/p" xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.1.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd
http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-3.1.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-3.1.xsd">
<!-- 指定系统寻找controller路径 -->
<!-- json 数据格式转换
<mvc:annotation-driven>
<mvc:message-converters>
<bean id="jsonConverter" class="com.abin.lee.ssh.util.json.fastjson.FastjsonHttpMessageConverter">
<property name="supportedMediaTypes" value="application/json" />
<property name="serializerFeature">
<list>
<value>WriteMapNullValue</value>
<value>QuoteFieldNames</value>
</list>
</property>
</bean>
</mvc:message-converters>
</mvc:annotation-driven>
-->
<!-- 搜索的包路径 -->
<context:component-scan base-package="com.abin.lee.ssh"
use-default-filters="false">
<context:include-filter type="annotation"
expression="org.springframework.stereotype.Controller" />
</context:component-scan>
<!-- jsp视图解释器 -->
<bean id="jspViewResolver"
class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="viewClass"
value="org.springframework.web.servlet.view.JstlView" />
<property name="prefix" value="/page/" />
<property name="suffix" value=".jsp" />
</bean>
</beans>
//web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xmlns=" http://java.sun.com/xml/ns/javaee" xmlns:web=" http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" xsi:schemaLocation=" http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" id="WebApp_ID" version="2.5"> <display-name>front</display-name> <!-- spring MVC --> <servlet> <servlet-name>spring-mvc</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value>classpath*:spring-mvc.xml</param-value> </init-param> <load-on-startup>2</load-on-startup> </servlet> <servlet-mapping> <servlet-name>spring-mvc</servlet-name> <url-pattern>/mvc/*</url-pattern> </servlet-mapping> <welcome-file-list> <welcome-file>index.html</welcome-file> <welcome-file>index.htm</welcome-file> <welcome-file>index.jsp</welcome-file> <welcome-file>default.html</welcome-file> <welcome-file>default.htm</welcome-file> <welcome-file>default.jsp</welcome-file> </welcome-file-list> </web-app> //UnivernalController.java package com.abin.lee.ssh.controller;
import java.util.ArrayList;
import java.util.List;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Controller;
import org.springframework.ui.ModelMap;
import org.springframework.web.bind.annotation.RequestMapping;
import com.abin.lee.ssh.entity.UniversalBean;
@Scope("prototype")
@Controller
@RequestMapping("/sky/")
public class UniversalController {
@RequestMapping("/activity")
public String activity(ModelMap map){
List<UniversalBean> list=new ArrayList<UniversalBean>();
UniversalBean bean=null;
for(int i=0;i<=5;i++){
bean=new UniversalBean();
bean.setId(i);
bean.setName("abin"+i);
bean.setImageUrl("http://localhost:7700/front/"+i+".jpg");
list.add(bean);
}
map.put("list", list);
return "mobile/show";
}
}
//show.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<%@ taglib uri="http://java.sun.com/jsp/jstl/functions" prefix="fn"%>
</head>
<script language="javascript" type="text/javascript" src="../script/js/share.js" ></script>
<script type="text/javascript">
</script>
<body>
<div id="content">
<c:forEach items="${list}" var="obj">
<div id="" class="lb">
<c:choose>
<c:when test="${empty obj.name}">
I am Empty
</c:when>
<c:when test="${obj.name=='abin1'}">
${obj.name} is a boy
</c:when>
<c:otherwise>
${obj.name } is normally
</c:otherwise>
</c:choose>
<img alt="显示不出来" src="${obj.imageUrl }"></img>
</div>
</c:forEach>
</div>
</body>
</html>
window的load事件会在页面中的一切都加载完毕时触发,但这个过程可能会因为要加载外部资源过多而颇费周折。而DOMContentLoaded事件则在形成完整的DOM树之后就会触发,不理会图像、JavaScript文件、CSS文件或其他资源是否已经下载完毕。与load事件不同,DOMContentLoaded支持在页面下载的早期添加事件处理程序,这也就意味着用户能够尽早地与页面进行交互。
要处理DOMContentLoaded事件,可以为document或window添加相应的事件处理程序(尽管这个事件会冒泡到window,但它的目标实际上是document)。来看下面的例子: var EventUtil = {
addHandler: function (element, type, handler) {
if (element.addEventListener) {
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent("on" + type, handler);
} else {
element["on" + type] = handler;
}
}
};
EventUtil.addHandler(document, "DOMContentLoaded", function (event) {
alert("Content loaded.");
});
DOMContentLoaded事件对象不会提供任何额外的信息(其target属性是document)。
Firefox、Chrome、Safari 3.1及更高的版本和Opera 9及更高版本都支持DOMContentLoaded事件,通常这个事件既可以添加事件处理程序,也可以执行其它DOM操作。这个事件始终都会在load事件之前触发。
对于不支持DOMContLoaded的浏览器,我们建议在页面加载期间设置一个事件为0毫秒的超时调用,如下面的例子所示: sentTimeout(function () {
//在此添加事件处理程序
}, 0);
这段代码实际意思是:“在当前JavaScript处理完成后立即运行这个函数。”在页面下载和构建期间,只有一个JavaScript处理过程,因此超时调用会在该过程结束时立即触发。至于这个事件与DOMContentLoaded被触发的时间是否同步,主要还是取决与用户使用的浏览器页面中的其它代码。为了确保这个方法有效,必须将其作为页面中的第一个超时调用;即便如此,也还是无法保证在所有浏览器中该超时调用一定会遭遇load事件被触发。
package com.abin.lee.wechat; import java.awt.Color; import java.awt.Font; import java.awt.Graphics2D; import java.awt.image.BufferedImage; import java.io.File; import java.text.SimpleDateFormat; import java.util.HashMap; import java.util.Map; import javax.imageio.ImageIO; import javax.imageio.stream.FileImageOutputStream; public class WeChatPhoto { public String createzPicture(Map<String,String> request){ String timeStamp=new SimpleDateFormat("yyyyMMddHHmmssSSS").format(new java.util.Date()); File fileOne = new File("E:\\pament\\wechat\\photo\\"+timeStamp+".png"); try { BufferedImage d = ImageIO.read(new File("E:\\pament\\wechat\\photo\\flight-model.png")); Graphics2D graohics =d.createGraphics(); //写字往图片上面 String startPlace=request.get("startPlace"); String arrivalPlace=request.get("arrivalPlace"); String flightNo=request.get("flightNo"); String startTime=request.get("startTime"); String arrivalTime=request.get("arrivalTime"); Font font = new Font("粗体", Font.PLAIN, 18);// 添加字体的属性设置 graohics.setColor(Color.BLACK); graohics.setFont(font); graohics.drawString(flightNo, 300, 20); graohics.drawString(startPlace, 30, 100); graohics.drawString(arrivalPlace, 555, 100); graohics.drawString(startTime, 50, 145); graohics.drawString(arrivalTime, 600, 145); ImageIO.write(d, "png", new FileImageOutputStream(fileOne)); } catch (Exception e) { e.printStackTrace(); } return timeStamp; } public static void main(String[] args) { WeChatPhoto we=new WeChatPhoto(); Map<String,String> request=new HashMap<String, String>(); request.put("startPlace", "北京首都T2"); request.put("arrivalPlace", "上海虹桥T1"); request.put("startTime", "08:58"); request.put("arrivalTime", "10:23"); request.put("flightNo", "MU5183"); String timeStamp=we.createzPicture(request); System.out.println("timeStamp="+timeStamp); } }
最近因项目存在内存泄漏,故进行大规模的JVM性能调优 , 现把经验做一记录。
一、JVM内存模型及垃圾收集算法
1.根据Java虚拟机规范,JVM将内存划分为:
- New(年轻代)
- Tenured(年老代)
- 永久代(Perm)
其中New和Tenured属于堆内存,堆内存会从JVM启动参数(-Xmx:3G)指定的内存中分配,Perm不属于堆内存,有虚拟机直接分配,但可以通过-XX:PermSize -XX:MaxPermSize 等参数调整其大小。
- 年轻代(New):年轻代用来存放JVM刚分配的Java对象
- 年老代(Tenured):年轻代中经过垃圾回收没有回收掉的对象将被Copy到年老代
- 永久代(Perm):永久代存放Class、Method元信息,其大小跟项目的规模、类、方法的量有关,一般设置为128M就足够,设置原则是预留30%的空间。
New又分为几个部分:
- Eden:Eden用来存放JVM刚分配的对象
- Survivor1
- Survivro2:两个Survivor空间一样大,当Eden中的对象经过垃圾回收没有被回收掉时,会在两个Survivor之间来回Copy,当满足某个条件,比如Copy次数,就会被Copy到Tenured。显然,Survivor只是增加了对象在年轻代中的逗留时间,增加了被垃圾回收的可能性。
2.垃圾回收算法
垃圾回收算法可以分为三类,都基于标记-清除(复制)算法:
JVM会根据机器的硬件配置对每个内存代选择适合的回收算法,比如,如果机器多于1个核,会对年轻代选择并行算法,关于选择细节请参考JVM调优文档。
稍微解释下的是,并行算法是用多线程进行垃圾回收,回收期间会暂停程序的执行,而并发算法,也是多线程回收,但期间不停止应用执行。所以,并发算法适用于交互性高的一些程序。经过观察,并发算法会减少年轻代的大小,其实就是使用了一个大的年老代,这反过来跟并行算法相比吞吐量相对较低。
还有一个问题是,垃圾回收动作何时执行?
- 当年轻代内存满时,会引发一次普通GC,该GC仅回收年轻代。需要强调的时,年轻代满是指Eden代满,Survivor满不会引发GC
- 当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代
- 当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载
另一个问题是,何时会抛出OutOfMemoryException,并不是内存被耗空的时候才抛出
- JVM98%的时间都花费在内存回收
- 每次回收的内存小于2%
满足这两个条件将触发OutOfMemoryException,这将会留给系统一个微小的间隙以做一些Down之前的操作,比如手动打印Heap Dump。
二、内存泄漏及解决方法
1.系统崩溃前的一些现象:
- 每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s
- FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC
- 年老代的内存越来越大并且每次FullGC后年老代没有内存被释放
之后系统会无法响应新的请求,逐渐到达OutOfMemoryError的临界值。
2.生成堆的dump文件
通过JMX的MBean生成当前的Heap信息,大小为一个3G(整个堆的大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成该文件。
3.分析dump文件
下面要考虑的是如何打开这个3G的堆信息文件,显然一般的Window系统没有这么大的内存,必须借助高配置的Linux。当然我们可以借助X-Window把Linux上的图形导入到Window。我们考虑用下面几种工具打开该文件:
- Visual VM
- IBM HeapAnalyzer
- JDK 自带的Hprof工具
使用这些工具时为了确保加载速度,建议设置最大内存为6G。使用后发现,这些工具都无法直观地观察到内存泄漏,Visual VM虽能观察到对象大小,但看不到调用堆栈;HeapAnalyzer虽然能看到调用堆栈,却无法正确打开一个3G的文件。因此,我们又选用了Eclipse专门的静态内存分析工具:Mat。
4.分析内存泄漏
通过Mat我们能清楚地看到,哪些对象被怀疑为内存泄漏,哪些对象占的空间最大及对象的调用关系。针对本案,在ThreadLocal中有很多的JbpmContext实例,经过调查是JBPM的Context没有关闭所致。
另,通过Mat或JMX我们还可以分析线程状态,可以观察到线程被阻塞在哪个对象上,从而判断系统的瓶颈。
5.回归问题
Q:为什么崩溃前垃圾回收的时间越来越长?
A:根据内存模型和垃圾回收算法,垃圾回收分两部分:内存标记、清除(复制),标记部分只要内存大小固定时间是不变的,变的是复制部分,因为每次垃圾回收都有一些回收不掉的内存,所以增加了复制量,导致时间延长。所以,垃圾回收的时间也可以作为判断内存泄漏的依据
Q:为什么Full GC的次数越来越多?
A:因此内存的积累,逐渐耗尽了年老代的内存,导致新对象分配没有更多的空间,从而导致频繁的垃圾回收
Q:为什么年老代占用的内存越来越大?
A:因为年轻代的内存无法被回收,越来越多地被Copy到年老代
三、性能调优
除了上述内存泄漏外,我们还发现CPU长期不足3%,系统吞吐量不够,针对8core×16G、64bit的Linux服务器来说,是严重的资源浪费。
在CPU负载不足的同时,偶尔会有用户反映请求的时间过长,我们意识到必须对程序及JVM进行调优。从以下几个方面进行:
- 线程池:解决用户响应时间长的问题
- 连接池
- JVM启动参数:调整各代的内存比例和垃圾回收算法,提高吞吐量
- 程序算法:改进程序逻辑算法提高性能
1.Java线程池(java.util.concurrent.ThreadPoolExecutor)
大多数JVM6上的应用采用的线程池都是JDK自带的线程池,之所以把成熟的Java线程池进行罗嗦说明,是因为该线程池的行为与我们想象的有点出入。Java线程池有几个重要的配置参数:
- corePoolSize:核心线程数(最新线程数)
- maximumPoolSize:最大线程数,超过这个数量的任务会被拒绝,用户可以通过RejectedExecutionHandler接口自定义处理方式
- keepAliveTime:线程保持活动的时间
- workQueue:工作队列,存放执行的任务
Java线程池需要传入一个Queue参数(workQueue)用来存放执行的任务,而对Queue的不同选择,线程池有完全不同的行为:
SynchronousQueue: 一个无容量的等待队列,一个线程的insert操作必须等待另一线程的remove操作,采用这个Queue线程池将会为每个任务分配一个新线程LinkedBlockingQueue : 无界队列,采用该Queue,线程池将忽略 maximumPoolSize参数,仅用corePoolSize的线程处理所有的任务,未处理的任务便在LinkedBlockingQueue中排队ArrayBlockingQueue: 有界队列,在有界队列和 maximumPoolSize的作用下,程序将很难被调优:更大的Queue和小的maximumPoolSize将导致CPU的低负载;小的Queue和大的池,Queue就没起动应有的作用。
其实我们的要求很简单,希望线程池能跟连接池一样,能设置最小线程数、最大线程数,当最小数<任务<最大数时,应该分配新的线程处理;当任务>最大数时,应该等待有空闲线程再处理该任务。
但线程池的设计思路是,任务应该放到Queue中,当Queue放不下时再考虑用新线程处理,如果Queue满且无法派生新线程,就拒绝该任务。设计导致“先放等执行”、“放不下再执行”、“拒绝不等待”。所以,根据不同的Queue参数,要提高吞吐量不能一味地增大maximumPoolSize。
当然,要达到我们的目标,必须对线程池进行一定的封装,幸运的是ThreadPoolExecutor中留了足够的自定义接口以帮助我们达到目标。我们封装的方式是:
- 以SynchronousQueue作为参数,使maximumPoolSize发挥作用,以防止线程被无限制的分配,同时可以通过提高maximumPoolSize来提高系统吞吐量
- 自定义一个RejectedExecutionHandler,当线程数超过maximumPoolSize时进行处理,处理方式为隔一段时间检查线程池是否可以执行新Task,如果可以把拒绝的Task重新放入到线程池,检查的时间依赖keepAliveTime的大小。
2.连接池(org.apache.commons.dbcp.BasicDataSource)
在使用org.apache.commons.dbcp.BasicDataSource的时候,因为之前采用了默认配置,所以当访问量大时,通过JMX观察到很多Tomcat线程都阻塞在BasicDataSource使用的Apache ObjectPool的锁上,直接原因当时是因为BasicDataSource连接池的最大连接数设置的太小,默认的BasicDataSource配置,仅使用8个最大连接。
我还观察到一个问题,当较长的时间不访问系统,比如2天,DB上的Mysql会断掉所以的连接,导致连接池中缓存的连接不能用。为了解决这些问题,我们充分研究了BasicDataSource,发现了一些优化的点:
- Mysql默认支持100个链接,所以每个连接池的配置要根据集群中的机器数进行,如有2台服务器,可每个设置为60
- initialSize:参数是一直打开的连接数
- minEvictableIdleTimeMillis:该参数设置每个连接的空闲时间,超过这个时间连接将被关闭
- timeBetweenEvictionRunsMillis:后台线程的运行周期,用来检测过期连接
- maxActive:最大能分配的连接数
- maxIdle:最大空闲数,当连接使用完毕后发现连接数大于maxIdle,连接将被直接关闭。只有initialSize < x < maxIdle的连接将被定期检测是否超期。这个参数主要用来在峰值访问时提高吞吐量。
- initialSize是如何保持的?经过研究代码发现,BasicDataSource会关闭所有超期的连接,然后再打开initialSize数量的连接,这个特性与minEvictableIdleTimeMillis、timeBetweenEvictionRunsMillis一起保证了所有超期的initialSize连接都会被重新连接,从而避免了Mysql长时间无动作会断掉连接的问题。
3.JVM参数
在JVM启动参数中,可以设置跟内存、垃圾回收相关的一些参数设置,默认情况不做任何设置JVM会工作的很好,但对一些配置很好的Server和具体的应用必须仔细调优才能获得最佳性能。通过设置我们希望达到一些目标:
- GC的时间足够的小
- GC的次数足够的少
- 发生Full GC的周期足够的长
前两个目前是相悖的,要想GC时间小必须要一个更小的堆,要保证GC次数足够少,必须保证一个更大的堆,我们只能取其平衡。
(1)针对JVM堆的设置一般,可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,我们通常把最大、最小设置为相同的值
(2)年轻代和年老代将根据默认的比例(1:2)分配堆内存,可以通过调整二者之间的比率NewRadio来调整二者之间的大小,也可以针对回收代,比如年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。同样,为了防止年轻代的堆收缩,我们通常会把-XX:newSize -XX:MaxNewSize设置为同样大小
(3)年轻代和年老代设置多大才算合理?这个我问题毫无疑问是没有答案的,否则也就不会有调优。我们观察一下二者大小变化有哪些影响
- 更大的年轻代必然导致更小的年老代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的年老代会导致更频繁的Full GC
- 更小的年轻代必然导致更大年老代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的年老代会减少Full GC的频率
- 如何选择应该依赖应用程序对象生命周期的分布情况:如果应用存在大量的临时对象,应该选择更大的年轻代;如果存在相对较多的持久对象,年老代应该适当增大。但很多应用都没有这样明显的特性,在抉择时应该根据以下两点:(A)本着Full GC尽量少的原则,让年老代尽量缓存常用对象,JVM的默认比例1:2也是这个道理 (B)通过观察应用一段时间,看其他在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给年老代至少预留1/3的增长空间
(4)在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法: -XX:+UseParallelOldGC ,默认为Serial收集
(5)线程堆栈的设置:每个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太了,一般256K就足用。理论上,在内存不变的情况下,减少每个线程的堆栈,可以产生更多的线程,但这实际上还受限于操作系统。
(4)可以通过下面的参数打Heap Dump信息
- -XX:HeapDumpPath
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:/usr/aaa/dump/heap_trace.txt
通过下面参数可以控制OutOfMemoryError时打印堆的信息
- -XX:+HeapDumpOnOutOfMemoryError
请看一下一个时间的Java参数配置:(服务器:Linux 64Bit,8Core×16G)
JAVA_OPTS="$JAVA_OPTS -server -Xms3G -Xmx3G -Xss256k -XX:PermSize=128m -XX:MaxPermSize=128m -XX:+UseParallelOldGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/aaa/dump -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/usr/aaa/dump/heap_trace.txt -XX:NewSize=1G -XX:MaxNewSize=1G"
经过观察该配置非常稳定,每次普通GC的时间在10ms左右,Full GC基本不发生,或隔很长很长的时间才发生一次
通过分析dump文件可以发现,每个1小时都会发生一次Full GC,经过多方求证,只要在JVM中开启了JMX服务,JMX将会1小时执行一次Full GC以清除引用,关于这点请参考附件文档。
4.程序算法调优:本次不作为重点
参考资料:
http://java.sun.com/javase/technologies/hotspot/gc/gc_tuning_6.html
AOP有三种植入切面的方法:其一是编译期织入,这要求使用特殊的Java编译器,AspectJ是其中的代表者;其二是类装载期织入,而这要求使用特殊的类装载器,AspectJ和AspectWerkz是其中的代表者;其三为动态代理织入,在运行期为目标类添加增强生成子类的方式,Spring AOP采用动态代理织入切面。
Spring AOP使用了两种代理机制,一种是基于JDK的动态代理,另一种是基于CGLib的动态代理,之所以需要两种代理机制,很大程度上是因为JDK本身只提供基于接口的代理,不支持类的代理。
Spring的三种注入方式: 接口注入(不推荐) getter,setter方式注入(比较常用) 构造器注入(死的应用) 什么是AOP?
面向切面编程(AOP)完善spring的依赖注入(DI),面向切面编程在spring中主要表现为两个方面
1.面向切面编程提供声明式事务管理
2.spring支持用户自定义的切面 面向切面编程(aop)是对面向对象编程(oop)的补充,
面向对象编程将程序分解成各个层次的对象,面向切面编程将程序运行过程分解成各个切面。
AOP从程序运行角度考虑程序的结构,提取业务处理过程的切面,oop是静态的抽象,aop是动态的抽象,
是对应用执行过程中的步骤进行抽象,,从而获得步骤之间的逻辑划分。 aop框架具有的两个特征:
1.各个步骤之间的良好隔离性
2.源代码无关性 什么是DI机制?
依赖注入(Dependecy Injection)和控制反转(Inversion of Control)是同一个概念,具体的讲:当某个角色
需要另外一个角色协助的时候,在传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在spring中
创建被调用者的工作不再由调用者来完成,因此称为控制反转。创建被调用者的工作由spring来完成,然后注入调用者
因此也称为依赖注入。
spring以动态灵活的方式来管理对象 , 注入的两种方式,设置注入和构造注入。
设置注入的优点:直观,自然
构造注入的优点:可以在构造器中决定依赖关系的顺序。 spring 的优点都有哪些?
1.降低了组件之间的耦合性 ,实现了软件各层之间的解耦
2.可以使用容易提供的众多服务,如事务管理,消息服务等
3.容器提供单例模式支持
4.容器提供了AOP技术,利用它很容易实现如权限拦截,运行期监控等功能
5.容器提供了众多的辅助类,能加快应用的开发
6.spring对于主流的应用框架提供了集成支持,如hibernate,JPA,Struts等
7.spring属于低侵入式设计,代码的污染极低
8.独立于各种应用服务器
9.spring的DI机制降低了业务对象替换的复杂性
10.Spring的高度开放性,并不强制应用完全依赖于Spring,开发者可以自由选择spring的部分或全部 一、spring工作原理: 1.spring mvc请所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责负责对请求进行真正的处理工作。
2.DispatcherServlet查询一个或多个HandlerMapping,找到处理请求的Controller.
3.DispatcherServlet请请求提交到目标Controller
4.Controller进行业务逻辑处理后,会返回一个ModelAndView
5.Dispathcher查询一个或多个ViewResolver视图解析器,找到ModelAndView对象指定的视图对象
6.视图对象负责渲染返回给客户端。 描述一下Spring中实现DI(Dependency Injection)的几种方式 方式一:接口注入,在实际中得到了普遍应用,即使在IOC的概念尚未确立时,这样的方法也已经频繁出现在我们的代码中。 方式二:Type2 IoC: Setter injection对象创建之后,将被依赖对象通过set方法设置进去 方式三:Type3 IoC: Constructor injection对象创建时,被依赖对象以构造方法参数的方式注入 简单描述下IOC(inversion of control)的理解一个类需要用到某个接口的方法,我们需要将类A和接口B的实现关联起来,最简单的方法是类A中创建一个对于接口B的实现C的实例,但这种方法显然两者的依赖(Dependency)太大了。而IoC的方法是只在类A中定义好用于关联接口B的实现的方法,将类A,接口B和接口B的实现C放入IoC的 容器(Container)中,通过一定的配置由容器(Container)来实现类A与接口B的实现C的关联。spring提供的事务管理可以分为两类:编程式的和声明式的。编程式的,比较灵活,但是代码量大,存在重复的代码比较多;声明式的比编程式的更灵活。编程式主要使用transactionTemplate。省略了部分的提交,回滚,一系列的事务对象定义,需注入事务管理对象.void add(){transactionTemplate.execute( new TransactionCallback(){pulic Object doInTransaction(TransactionStatus ts){ //do sth}}}声明式:使用TransactionProxyFactoryBean:PROPAGATION_REQUIRED PROPAGATION_REQUIRED PROPAGATION_REQUIRED,readOnly围绕Poxy的动态代理 能够自动的提交和回滚事务org.springframework.transaction.interceptor.TransactionProxyFactoryBeanPROPAGATION_REQUIRED–支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。PROPAGATION_SUPPORTS–支持当前事务,如果当前没有事务,就以非事务方式执行。PROPAGATION_MANDATORY–支持当前事务,如果当前没有事务,就抛出异常。PROPAGATION_REQUIRES_NEW–新建事务,如果当前存在事务,把当前事务挂起。PROPAGATION_NOT_SUPPORTED–以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。PROPAGATION_NEVER–以非事务方式执行,如果当前存在事务,则抛出异常。PROPAGATION_NESTED–如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。spring中的核心类有那些,各有什么作用?BeanFactory:产生一个新的实例,可以实现单例模式BeanWrapper:提供统一的get及set方法ApplicationContext:提供框架的实现,包括BeanFactory的所有功能spring的ioc及di代表什么意思?控制权由代码转向容器,通过容器动态将某些对象加入。如何在spring中实现国际化?在applicationContext.xml加载一个beanmessage.properties是一个键名加键值的文件,
Java堆,分配对象实例所在空间,是GC的主要对象。分为 新生代(Young Generation/New) 老年代(Tenured Generation/Old) 新生代又划分成 Eden Space From Survivor/Survivor 0 To Survivor/Survivor 1 新生代要如此划分是因为新生代使用的GC算法是复制收集算法。这种算法效率较高,而GC主要是发生在对象经常消亡的新生代,因此新生代适合使用这种复制收集算法。由于有一个假设:在一次新生代的GC(Minor GC)后大部分的对象占用的内存都会被回收,因此留存的放置GC后仍然活的对象的空间就比较小了。这个留存的空间就是Survivor space:From Survivor或To Survivor。这两个Survivor空间是一样大小的。例如,新生代大小是10M(Xmn10M),那么缺省情况下(-XX:SurvivorRatio=8),Eden Space 是8M,From和To都是1M。 在new一个对象时,先在Eden Space上分配,如果Eden Space空间不够就要做一次Minor GC。Minor GC后,要把Eden和From中仍然活着的对象们复制到To空间中去。如果To空间不能容纳Minor GC后活着的某个对象,那么该对象就被promote到老年代空间。从Eden空间被复制到To空间的对象就有了age=1。此age=1的对象如果在下一次的Minor GC后仍然存活,它还会被复制到另一个Survivor空间(如果认为From和To是固定的,就是又从To回到了From空间),而它的age=2。如此反复,如果age大于某个阈值(-XX:MaxTenuringThreshold=n),那个该对象就也可以promote到老年代了。 如果Survivor空间中相同age(例如,age=5)对象的总和大于等于Survivor空间的一半,那么age>=5的对象在下一次Minor GC后就可以直接promote到老年代,而不用等到age增长到阈值。 在做Minor GC时,只对新生代做回收,不会回收老年代。即使老年代的对象无人索引也将仍然存活,直到下一次Full GC。
切分(Sharding)并不是特定数据库产品所附属的功能,而是在具体技术细节之上的抽象处理。是水平扩展(Scale Out)的解决方案,主要目的是解决单节点数据库服务器的能力限制,以及整个应用其架构的可扩展性(Scalability)。
切分主要有两种方式:水平切分(Horizental Sharding)和垂直切分(Vertical Sharding)。
水平切分所指的是通过一系列的切分规则将数据水平分布到不同的DB或table中,在通过相应的DB路由 或者table路由规则找到需要查询的具体的DB或者table以进行Query操作,比如根据用户ID将用户表切分到多台数据库上。
垂直切分指的是按业务、产品切分,将不同类型的数据且分到不同的服务器上,通过数据库代理疏通程序与多个数据库的通讯、降低应用的复杂度。
读写分离简单的说是把对数据库读和写的操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力。主数据库提供写操作,从数据库提供读操作,这样既避免了主数据库服务器(Master)的过载,也有效地利用了从数据库服务器(Slave)的资源。 这里ebay工程师的文章:《可伸缩性最佳实践:来自eBay的经验》更详细地介绍了一些概念及业务场景。 --End--
Java内存分配: 1. 寄存器:我们在程序中无法控制
2. 栈:存放基本类型的数据和对象的引用,但对象本身不存放在栈中,而是存放在堆中
3. 堆:存放用new产生的数据
4. 静态域:存放在对象中用static定义的静态成员
5. 常量池:存放常量
6. 非RAM(随机存取存储器)存储:硬盘等永久存储空间
---------------------------------------------------------------------------------------------------------------------- a.在函数中定义的一些基本类型的变量数据和对象的引用变量都在函数的栈内存中分配。
当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当该变量退出该作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
b.堆内存用来存放由new创建的对象和数组。 在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。 引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。引用变量就相当于是为 数组或者对象起的一个名称。引用变量是普通的变量,定义时在栈中分配,引用变量在程序运行到其作用域之外后被释放。而数组和对象本身在堆中分配,即使程序运行到使用 new 产生数组或者对象的语句所在的代码块之外,数组和对象本身占据的内存不会被释放,数组和对象在没有引用变量指向它的时候,才变为垃圾,不能在被使用,但仍然占据内存空间不放,在随后的一个不确定的时间被垃圾回收器收走(释放掉)。这也是 Java 比较占内存的原因。
实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
c.常量池(constant pool)指的是在编译期被确定,并被保存在已编译的.class文件中的一些数据。除了包含代码中所定义的各种基本类型(如int、long等等)和对象型(如String及数组)的常量值(final)还包含一些以文本形式出现的符号引用,比如: 类和接口的全限定名; 字段的名称和描述符; 方法和名称和描述符。 虚拟机必须为每个被装载的类型维护一个常量池。常量池就是该类型所用到常量的一个有序集和,包括直接常量(string,integer和floating point常量)和对其他类型,字段和方法的符号引用。对于String常量,它的值是在常量池中的。而JVM中的常量池在内存当中是以表的形式存在的,对于String类型,有一张固定长度的CONSTANT_String_info表用来存储文字字符串值,注意:该表只存储文字字符串值,不存储符号引用。说到这里,对常量池中的字符串值的存储位置应该有一个比较明了的理解了。 在程序执行的时候,常量池会储存在Method Area,而不是堆中.
d.Java的堆是一个运行时数据区,类的(对象从中分配空间。这些对象通过new、newarray、anewarray和multianewarray等指令建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量数据(int, short, long, byte, float, double, boolean, char)和对象句柄(引用)。
栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义:
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找栈中是否有3这个值,如果没找到,就将3存放进来,然后将a指向3。接着处理int b = 3;在创建完b的引用变量后,因为在栈中已经有3这个值,便将b直接指向3。这样,就出现了a与b同时均指向3的情况。
这时,如果再令a=4;那么编译器会重新搜索栈中是否有4值,如果没有,则将4存放进来,并令a指向4;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
要注意这种数据的共享与两个对象的引用同时指向一个对象的这种共享是不同的,因为这种情况a的修改并不会影响到b, 它是由编译器完成的,它有利于节省空间。而一个对象引用变量修改了这个对象的内部状态,会影响到另一个对象引用变量。 /*****************************************************************************/ String是一个特殊的包装类数据。可以用:
String str = new String("abc");
String str = "abc";
两种的形式来创建,第一种是用new()来新建对象的,它会在存放于堆中。每调用一次就会创建一个新的对象。
而第二种是先在栈中创建一个对String类的对象引用变量str,然后通过符号引用去字符串常量池里找有没有"abc",如果没有,则将"abc"存放进字符串常量池,并令str指向”abc”,如果已经有”abc” 则直接令str指向“abc”。
比较类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==,下面用例子说明上面的理论。
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true
可以看出str1和str2是指向同一个对象的。
String str1 =new String ("abc");
String str2 =new String ("abc");
System.out.println(str1==str2); // false
用new的方式是生成不同的对象。每一次生成一个。
因此用第二种方式创建多个”abc”字符串,在内存中其实只存在一个对象而已. 这种写法有利与节省内存空间. 同时它可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String("abc");的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。
另一方面, 要注意: 我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,创建了String类的对象str。担心陷阱!对象可能并没有被创建!而可能只是指向一个先前已经创建的对象。只有通过new()方法才能保证每次都创建一个新的对象。
由于String类的immutable性质,当String变量需要经常变换其值时,应该考虑使用StringBuffer类,以提高程序效率。
1. 首先String不属于8种基本数据类型,String是一个对象。
因为对象的默认值是null,所以String的默认值也是null;但它又是一种特殊的对象,有其它对象没有的一些特性。
2. new String()和new String(”")都是申明一个新的空字符串,是空串不是null;
3. String str=”kvill”;String str=new String (”kvill”)的区别
看例1:
String s0="kvill";
String s1="kvill";
String s2="kv" + "ill";
System.out.println( s0==s1 );
System.out.println( s0==s2 );
结果为:
true
true
首先,我们要知结果为道Java会确保一个字符串常量只有一个拷贝。
因为例子中的s0和s1中的”kvill”都是字符串常量,它们在编译期就被确定了,所以s0==s1为true;而”kv”和”ill”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被解析为一个字符串常量,所以s2也是常量池中” kvill”的一个引用。所以我们得出s0==s1==s2;用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。
看例2:
String s0="kvill";
String s1=new String("kvill");
String s2="kv" + new String("ill");
System.out.println( s0==s1 );
System.out.println( s0==s2 );
System.out.println( s1==s2 );
结果为:
false
false
false
例2中s0还是常量池中"kvill”的应用,s1因为无法在编译期确定,所以是运行时创建的新对象”kvill”的引用,s2因为有后半部分 new String(”ill”)所以也无法在编译期确定,所以也是一个新创建对象”kvill”的应用;明白了这些也就知道为何得出此结果了。
4. String.intern():
再补充介绍一点:存在于.class文件中的常量池,在运行期被JVM装载,并且可以扩充。String的intern()方法就是扩充常量池的 一个方法;当一个String实例str调用intern()方法时,Java查找常量池中是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在常量池中增加一个Unicode等于str的字符串并返回它的引用;看例3就清楚了
例3:
String s0= "kvill";
String s1=new String("kvill");
String s2=new String("kvill");
System.out.println( s0==s1 );
System.out.println( "**********" );
s1.intern();
s2=s2.intern(); //把常量池中"kvill"的引用赋给s2
System.out.println( s0==s1);
System.out.println( s0==s1.intern() );
System.out.println( s0==s2 );
结果为:
false
**********
false //虽然执行了s1.intern(),但它的返回值没有赋给s1
true //说明s1.intern()返回的是常量池中"kvill"的引用
true
最后我再破除一个错误的理解:有人说,“使用 String.intern() 方法则可以将一个 String 类的保存到一个全局 String 表中 ,如果具有相同值的 Unicode 字符串已经在这个表中,那么该方法返回表中已有字符串的地址,如果在表中没有相同值的字符串,则将自己的地址注册到表中”如果我把他说的这个全局的 String 表理解为常量池的话,他的最后一句话,”如果在表中没有相同值的字符串,则将自己的地址注册到表中”是错的:
看例4:
String s1=new String("kvill");
String s2=s1.intern();
System.out.println( s1==s1.intern() );
System.out.println( s1+" "+s2 );
System.out.println( s2==s1.intern() );
结果:
false
kvill kvill
true
在这个类中我们没有声名一个”kvill”常量,所以常量池中一开始是没有”kvill”的,当我们调用s1.intern()后就在常量池中新添加了一个”kvill”常量,原来的不在常量池中的”kvill”仍然存在,也就不是“将自己的地址注册到常量池中”了。
s1==s1.intern()为false说明原来的”kvill”仍然存在;s2现在为常量池中”kvill”的地址,所以有s2==s1.intern()为true。
5. 关于equals()和==:
这个对于String简单来说就是比较两字符串的Unicode序列是否相当,如果相等返回true;而==是比较两字符串的地址是否相同,也就是是否是同一个字符串的引用。
6. 关于String是不可变的
这一说又要说很多,大家只要知道String的实例一旦生成就不会再改变了,比如说:String str=”kv”+”ill”+” “+”ans”; 就是有4个字符串常量,首先”kv”和”ill”生成了”kvill”存在内存中,然后”kvill”又和” ” 生成 “kvill “存在内存中,最后又和生成了”kvill ans”;并把这个字符串的地址赋给了str,就是因为String的”不可变”产生了很多临时变量,这也就是为什么建议用StringBuffer的原因了,因为StringBuffer是可改变的。 /*******************************************************************************/ 下面是一些String相关的常见问题: String中的final用法和理解
final StringBuffer a = new StringBuffer("111");
final StringBuffer b = new StringBuffer("222");
a=b;//此句编译不通过 final StringBuffer a = new StringBuffer("111");
a.append("222");//编译通过 可见,final只对引用的"值"(即内存地址)有效,它迫使引用只能指向初始指向的那个对象,改变它的指向会导致编译期错误。至于它所指向的对象的变化,final是不负责的。 String 常量池问题的几个例子 下面是几个常见例子的比较分析和理解:
[1]
String a = "a1";
String b = "a" + 1;
System.out.println((a == b)); //result = true
String a = "atrue";
String b = "a" + "true";
System.out.println((a == b)); //result = true
String a = "a3.4";
String b = "a" + 3.4;
System.out.println((a == b)); //result = true 分析:JVM对于字符串常量的"+"号连接,将程序编译期,JVM就将常量字符串的"+"连接优化为连接后的值,拿"a" + 1来说,经编译器优化后在class中就已经是a1。在编译期其字符串常量的值就确定下来,故上面程序最终的结果都为true。 [2]
String a = "ab";
String bb = "b";
String b = "a" + bb;
System.out.println((a == b)); //result = false 分析:JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + bb无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给b。所以上面程序的结果也就为false。 [3]
String a = "ab";
final String bb = "b";
String b = "a" + bb;
System.out.println((a == b)); //result = true 分析:和[3]中唯一不同的是bb字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + bb和"a" + "b"效果是一样的。故上面程序的结果为true。 [4]
String a = "ab";
final String bb = getBB();
String b = "a" + bb;
System.out.println((a == b)); //result = false
private static String getBB() {
return "b";
} 分析:JVM对于字符串引用bb,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和"a"来动态连接并分配地址为b,故上面程序的结果为false。 通过上面4个例子可以得出得知:
String s = "a" + "b" + "c";
就等价于String s = "abc";
String a = "a";
String b = "b";
String c = "c";
String s = a + b + c; 这个就不一样了,最终结果等于:
StringBuffer temp = new StringBuffer();
temp.append(a).append(b).append(c);
String s = temp.toString(); 由上面的分析结果,可就不难推断出String 采用连接运算符(+)效率低下原因分析,形如这样的代码: public class Test {
public static void main(String args[]) {
String s = null;
for(int i = 0; i < 100; i++) {
s += "a";
}
}
} 每做一次 + 就产生个StringBuilder对象,然后append后就扔掉。下次循环再到达时重新产生个StringBuilder对象,然后 append 字符串,如此循环直至结束。 如果我们直接采用 StringBuilder 对象进行 append 的话,我们可以节省 N - 1 次创建和销毁对象的时间。所以对于在循环中要进行字符串连接的应用,一般都是用StringBuffer或StringBulider对象来进行append操作。 String对象的intern方法理解和分析: public class Test4 {
private static String a = "ab";
public static void main(String[] args){
String s1 = "a";
String s2 = "b";
String s = s1 + s2;
System.out.println(s == a);//false
System.out.println(s.intern() == a);//true
}
} 这里用到Java里面是一个常量池的问题。对于s1+s2操作,其实是在堆里面重新创建了一个新的对象,s保存的是这个新对象在堆空间的的内容,所以s与a的值是不相等的。而当调用s.intern()方法,却可以返回s在常量池中的地址值,因为a的值存储在常量池中,故s.intern和a的值相等 总结: a.栈中用来存放一些原始数据类型的局部变量数据和对象的引用(String,数组.对象等等)但不存放对象内容 b.堆中存放使用new关键字创建的对象. c.字符串是一个特殊包装类,其引用是存放在栈里的,而对象内容必须根据创建方式不同定(常量池和堆).有的是编译期就已经创建好,存放在字符串常量池中,而有的是运行时才被创建.使用new关键字,存放在堆中。 本文转自:http://zy19880423.javaeye.com/blog/434179
1. Snapshot版本代表不稳定、尚处于开发中的版本
2. Release版本则代表稳定的版本
3. 什么情况下该用SNAPSHOT?
协同开发时,如果A依赖构件B,由于B会更新,B应该使用SNAPSHOT来标识自己。这种做法的必要性可以反证如下:
a.如果B不用SNAPSHOT,而是每次更新后都使用一个稳定的版本,那版本号就会升得太快,每天一升甚至每个小时一升,这就是对版本号的滥用。
b.如果B不用SNAPSHOT, 但一直使用一个单一的Release版本号,那当B更新后,A可能并不会接受到更新。因为A所使用的repository一般不会频繁更新release版本的缓存(即本地repository),所以B以不换版本号的方式更新后,A在拿B时发现本地已有这个版本,就不会去远程Repository下载最新的B
4. 不用Release版本,在所有地方都用SNAPSHOT版本行不行?
不行。正式环境中不得使用snapshot版本的库。 比如说,今天你依赖某个snapshot版本的第三方库成功构建了自己的应用,明天再构建时可能就会失败,因为今晚第三方可能已经更新了它的snapshot库。你再次构建时,Maven会去远程repository下载snapshot的最新版本,你构建时用的库就是新的jar文件了,这时正确性就很难保证了。
1、ReentrantLock 拥有Synchronized相同的并发性和内存语义,此外还多了 锁投票,定时锁等候和中断锁等候
线程A和B都要获取对象O的锁定,假设A获取了对象O锁,B将等待A释放对O的锁定,
如果使用 synchronized ,如果A不释放,B将一直等下去,不能被中断
如果 使用ReentrantLock,如果A不释放,可以使B在等待了足够长的时间以后,中断等待,而干别的事情
ReentrantLock获取锁定与三种方式:
a) lock(), 如果获取了锁立即返回,如果别的线程持有锁,当前线程则一直处于休眠状态,直到获取锁
b) tryLock(), 如果获取了锁立即返回true,如果别的线程正持有锁,立即返回false;
c)tryLock(long timeout,TimeUnit unit), 如果获取了锁定立即返回true,如果别的线程正持有锁,会等待参数给定的时间,在等待的过程中,如果获取了锁定,就返回true,如果等待超时,返回false;
d) lockInterruptibly:如果获取了锁定立即返回,如果没有获取锁定,当前线程处于休眠状态,直到或者锁定,或者当前线程被别的线程中断
2、synchronized是在JVM层面上实现的,不但可以通过一些监控工具监控synchronized的锁定,而且在代码执行时出现异常,JVM会自动释放锁定,但是使用Lock则不行,lock是通过代码实现的,要保证锁定一定会被释放,就必须将unLock()放到finally{}中
3、在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
MySQL 当记录不存在时插入,当记录存在时更新.........具体解决办法如下: 1、INSERT INTO… ON DUPLICATE KEY UPDATE 如果您指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则执行旧行UPDATE。 使用环境: 例如,如果列a被定义为UNIQUE,并且包含值1,则以下两个语句具有相同的效果: 首先建表(先说UNIQUE): create table abin1(
id int not null unique,
username varchar(100),
password varchar(100)
) insert into abin1 (id,username,password) values (1,'abin1','varyall1') on duplicate key update username='abin12',password='varyall12';
其次再说主键(primary key)类型的:
create table abin2(
id int not null,
username varchar(100),
password varchar(100),
constraint pk_abin2 primary key(id)
)
insert into abin2 (id,username,password) values (1,'abin1','varyall1') on duplicate key update username='abin12',password='varyall12'; 2、插入单行记录:如果不存在插入记录,如果存在记录的话,就不再插入 insert into abin2 (id,username,password) select 1,'abin12','varyall12' from dual where not exists (select k.* from abin2 k where k.id=1) 3、 示例一:插入多条记录假设有一个主键为 id 的 abin2表,可以使用下面的语句: insert into abin2 (id,username,password) select 1,'abin12','varyall12' from dual
where not exists (select k.* from abin2 k where k.id=1)
4、我们在使用数据库时可能会经常遇到这种情况。如果一个表在一个字段上建立了唯一索引,当我们再向这个表中使用已经存在的键值插入一条记录,那将会抛出一个主键冲突的
错误。当然,我们可能想用新记录的值来覆盖原来的记录值。如果使用传统的做法,必须先使用DELETE语句删除原先的记录,然后再使用INSERT插入新的记录。而在MySQL中为
我们提供了一种新的解决方案,这就是REPLACE语句。使用REPLACE插入一条记录时,如果不重复,REPLACE就和INSERT的功能一样,如果有重复记录,REPLACE就使用新记录的值
来替换原来的记录值。
具体用法:
replace into abin2 (id,username,password) values (2,'abin','varyall')
http://blog.csdn.net/kesaihao862/article/details/6718443
1)ArrayBlockingQueue:规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小.其所含的对象是以FIFO(先入先出)顺序排序的.
2)LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制,若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定.其所含的对象是以FIFO(先入先出)顺序排序的
3)PriorityBlockingQueue:类似于LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序.
4)SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的,是之前提过的BlockingQueue的又一实现。它给我们提供了在线程之间交换单一元素的极轻量级方法.
其中LinkedBlockingQueue和ArrayBlockingQueue比较起来,它们背后所用的数据结构不一样,导致LinkedBlockingQueue的数据吞吐量要大于ArrayBlockingQueue,但在线程数量很大时其性能的可预见性低于ArrayBlockingQueue.
http://www.2cto.com/kf/201212/175028.html
1.根据ROWID来分
select * from t_xiaoxi where rowid in(select rid from (select rownum rn,rid from(select rowid rid,cid from t_xiaoxi order by cid desc) where rownum<10000) where rn>9980) order by cid desc;
执行时间0.03秒
2.按分析函数来分
select * from (select t.*,row_number() over(order by cid desc) rk from t_xiaoxi t) where rk<10000 and rk>9980;
执行时间1.01秒
3.按ROWNUM来分
select * from(select t.*,rownum rn from(select * from t_xiaoxi order by cid desc) t where rownum<10000) where rn>9980;执行时间0.1秒
其中t_xiaoxi为表名称,cid为表的关键字段,取按CID降序排序后的第9981-9999条记录,t_xiaoxi表有70000多条记录
个人感觉1的效率最好,3次之,2最差
锁:
- 内置锁 (监视器锁): 每个java对象都可以做一个实现同步的锁,这些锁被成为内置锁. 获得锁的唯一途径就是进入有这个锁保护的代码块或方法
- 重入锁: 由于内置锁是可重入的,因此如果某个线程试图获得一个以已经由他自己持有的锁, 那么这个请求就会成功.重入意味着获取锁的操作粒度是"线程",而不是"调用"
volatile 使用条件(必须同时满足所有条件):
- 对变量的写入操作不依赖变量的当前值,或者你能确保只有单个线程更新变量的值
- 该变量不会与其他状态变量一起纳入不变性条件中
- 在访问变量时间不需要加锁
高并发术语
|
术语 |
英文单词 |
描述 |
|
比较并交换 |
Compare and Swap |
CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。 |
|
CPU流水线 |
CPU pipeline |
CPU流水线的工作方式就象工业生产上的装配流水线,在CPU中由5~6个不同功能的电路单元组成一条指令处理流水线,然后将一条X86指令分成5~6步后再由这些电路单元分别执行,这样就能实现在一个CPU时钟周期完成一条指令,因此提高CPU的运算速度。 |
|
内存顺序冲突 |
Memory order violation |
内存顺序冲突一般是由假共享引起,假共享是指多个CPU同时修改同一个缓存行的不同部分而引起其中一个CPU的操作无效,当出现这个内存顺序冲突时,CPU必须清空流水线。 |
|
共享变量 |
|
在多个线程之间能够被共享的变量被称为共享变量。共享变量包括所有的实例变量,静态变量和数组元素。他们都被存放在堆内存中,Volatile只作用于共享变量。 |
|
内存屏障 |
Memory Barriers |
是一组处理器指令,用于实现对内存操作的顺序限制。 |
|
缓冲行 |
Cache line |
缓存中可以分配的最小存储单位。处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期。 |
|
原子操作 |
Atomic operations |
不可中断的一个或一系列操作。 |
|
缓存行填充 |
cache line fill |
当处理器识别到从内存中读取操作数是可缓存的,处理器读取整个缓存行到适当的缓存(L1,L2,L3的或所有) |
|
缓存命中 |
cache hit |
如果进行高速缓存行填充操作的内存位置仍然是下次处理器访问的地址时,处理器从缓存中读取操作数,而不是从内存。 |
|
写命中 |
write hit |
当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存,这个操作被称为写命中。 |
synchronized
volatile
concurrent
在并发编程中很常用的实用工具类。此包包括了几个小的、已标准化的可扩展框架,以及一些提供有用功能的类,没有这些类,这些功能会很难实现或实现起来冗长乏味。下面简要描述主要的组件。另请参阅 locks 和 atomic 包。
执行程序接口。Executor 是一个简单的标准化接口,用于定义类似于线程的自定义子系统,包括线程池、异步 IO 和轻量级任务框架。根据所使用的具体 Executor 类的不同,可能在新创建的线程中,现有的任务执行线程中,或者调用 execute() 的线程中执行任务,并且可能顺序或并发执行。ExecutorService 提供了多个完整的异步任务执行框架。ExecutorService 管理任务的排队和安排,并允许受控制的关闭。ScheduledExecutorService 子接口及相关的接口添加了对延迟的和定期任务执行的支持。ExecutorService 提供了安排异步执行的方法,可执行由 Callable 表示的任何函数,结果类似于 Runnable。Future 返回函数的结果,允许确定执行是否完成,并提供取消执行的方法。RunnableFuture 是拥有 run 方法的 Future,run 方法执行时将设置其结果。
实现。类 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 提供可调的、灵活的线程池。Executors 类提供大多数 Executor 的常见类型和配置的工厂方法,以及使用它们的几种实用工具方法。其他基于 Executor 的实用工具包括具体类 FutureTask,它提供 Future 的常见可扩展实现,以及 ExecutorCompletionService,它有助于协调对异步任务组的处理。
队列java.util.concurrent ConcurrentLinkedQueue 类提供了高效的、可伸缩的、线程安全的非阻塞 FIFO 队列。java.util.concurrent 中的五个实现都支持扩展的 BlockingQueue 接口,该接口定义了 put 和 take 的阻塞版本:LinkedBlockingQueue、ArrayBlockingQueue、SynchronousQueue、PriorityBlockingQueue 和 DelayQueue。这些不同的类覆盖了生产者-使用者、消息传递、并行任务执行和相关并发设计的大多数常见使用的上下文。BlockingDeque 接口扩展 BlockingQueue,以支持 FIFO 和 LIFO(基于堆栈)操作。LinkedBlockingDeque 类提供一个实现。
计时TimeUnit 类为指定和控制基于超时的操作提供了多重粒度(包括纳秒级)。该包中的大多数类除了包含不确定的等待之外,还包含基于超时的操作。在使用超时的所有情况中,超时指定了在表明已超时前该方法应该等待的最少时间。在超时发生后,实现会“尽力”检测超时。但是,在检测超时与超时之后再次实际执行线程之间可能要经过不确定的时间。接受超时期参数的所有方法将小于等于 0 的值视为根本不会等待。要“永远”等待,可以使用 Long.MAX_VALUE 值。
同步器四个类可协助实现常见的专用同步语句。Semaphore 是一个经典的并发工具。CountDownLatch 是一个极其简单但又极其常用的实用工具,用于在保持给定数目的信号、事件或条件前阻塞执行。CyclicBarrier 是一个可重置的多路同步点,在某些并行编程风格中很有用。Exchanger 允许两个线程在 collection 点交换对象,它在多流水线设计中是有用的。
并发 Collection除队列外,此包还提供了设计用于多线程上下文中的 Collection 实现:ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet、CopyOnWriteArrayList 和 CopyOnWriteArraySet。当期望许多线程访问一个给定 collection 时,ConcurrentHashMap 通常优于同步的 HashMap,ConcurrentSkipListMap 通常优于同步的 TreeMap。当期望的读数和遍历远远大于列表的更新数时,CopyOnWriteArrayList 优于同步的 ArrayList。
此包中与某些类一起使用的“Concurrent&rdquo前缀;是一种简写,表明与类似的“同步”类有所不同。例如,java.util.Hashtable 和Collections.synchronizedMap(new HashMap()) 是同步的,但 ConcurrentHashMap 则是“并发的”。并发 collection 是线程安全的,但是不受单个排他锁的管理。在 ConcurrentHashMap 这一特定情况下,它可以安全地允许进行任意数目的并发读取,以及数目可调的并发写入。需要通过单个锁不允许对 collection 的所有访问时,“同步”类是很有用的,其代价是较差的可伸缩性。在期望多个线程访问公共 collection 的其他情况中,通常“并发”版本要更好一些。当 collection 是未共享的,或者仅保持其他锁时 collection 是可访问的情况下,非同步 collection 则要更好一些。
大多数并发 Collection 实现(包括大多数 Queue)与常规的 java.util 约定也不同,因为它们的迭代器提供了弱一致的,而不是快速失败的遍历。弱一致的迭代器是线程安全的,但是在迭代时没有必要冻结 collection,所以它不一定反映自迭代器创建以来的所有更新。
Java Language Specification 第 17 章定义了内存操作(如共享变量的读写)的 happen-before 关系。只有写入操作 happen-before 读取操作时,才保证一个线程写入的结果对另一个线程的读取是可视的。synchronized 和 volatile 构造 happen-before 关系,Thread.start() 和Thread.join() 方法形成 happen-before 关系。尤其是:
- 线程中的每个操作 happen-before 稍后按程序顺序传入的该线程中的每个操作。
- 一个解除锁监视器的(
synchronized 阻塞或方法退出)happen-before 相同监视器的每个后续锁(synchronized 阻塞或方法进入)。并且因为 happen-before 关系是可传递的,所以解除锁定之前的线程的所有操作 happen-before 锁定该监视器的任何线程后续的所有操作。 - 写入
volatile 字段 happen-before 每个后续读取相同字段。volatile 字段的读取和写入与进入和退出监视器具有相似的内存一致性效果,但不 需要互斥锁。 - 在线程上调用
start happen-before 已启动的线程中的任何线程。 - 线程中的所有操作 happen-before 从该线程上的
join 成功返回的任何其他线程。
java.util.concurrent 中所有类的方法及其子包扩展了这些对更高级别同步的保证。尤其是:
- 线程中将一个对象放入任何并发 collection 之前的操作 happen-before 从另一线程中的 collection 访问或移除该元素的后续操作。
- 线程中向
Executor 提交 Runnable 之前的操作 happen-before 其执行开始。同样适用于向 ExecutorService 提交 Callables。 - 异步计算(由
Future 表示)所采取的操作 happen-before 通过另一线程中 Future.get() 获取结果后续的操作。 - “释放”同步储存方法(如
Lock.unlock、Semaphore.release 和 CountDownLatch.countDown)之前的操作 happen-before 另一线程中相同同步储存对象成功“获取”方法(如 Lock.lock、Semaphore.acquire、Condition.await 和 CountDownLatch.await)的后续操作。 - 对于通过
Exchanger 成功交换对象的每个线程对,每个线程中 exchange() 之前的操作 happen-before 另一线程中对应 exchange() 后续的操作。 - 调用
CyclicBarrier.await 之前的操作 happen-before 屏障操作所执行的操作,屏障操作所执行的操作 happen-before 从另一线程中对应await 成功返回的后续操作。
Condition
Condition 将 Object 监视器方法(wait、notify 和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待 set(wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。
条件(也称为条件队列 或条件变量)为线程提供了一个含义,以便在某个状态条件现在可能为 true 的另一个线程通知它之前,一直挂起该线程(即让其“等待”)。因为访问此共享状态信息发生在不同的线程中,所以它必须受保护,因此要将某种形式的锁与该条件相关联。等待提供一个条件的主要属性是:以原子方式 释放相关的锁,并挂起当前线程,就像 Object.wait 做的那样。
Condition 实例实质上被绑定到一个锁上。要为特定 Lock 实例获得 Condition 实例,请使用其 newCondition() 方法。
作为一个示例,假定有一个绑定的缓冲区,它支持 put 和 take 方法。如果试图在空的缓冲区上执行 take 操作,则在某一个项变得可用之前,线程将一直阻塞;如果试图在满的缓冲区上执行 put 操作,则在有空间变得可用之前,线程将一直阻塞。我们喜欢在单独的等待 set 中保存 put 线程和 take 线程,这样就可以在缓冲区中的项或空间变得可用时利用最佳规划,一次只通知一个线程。可以使用两个 Condition 实例来做到这一点。 class BoundedBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
Object x = items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
(ArrayBlockingQueue 类提供了这项功能,因此没有理由去实现这个示例类。)
Condition 实现可以提供不同于 Object 监视器方法的行为和语义,比如受保证的通知排序,或者在执行通知时不需要保持一个锁。如果某个实现提供了这样特殊的语义,则该实现必须记录这些语义。
注意,Condition 实例只是一些普通的对象,它们自身可以用作 synchronized 语句中的目标,并且可以调用自己的 wait 和notification 监视器方法。获取 Condition 实例的监视器锁或者使用其监视器方法,与获取和该 Condition 相关的 Lock 或使用其 waiting 和 signalling 方法没有什么特定的关系。为了避免混淆,建议除了在其自身的实现中之外,切勿以这种方式使用Condition 实例。
除非另行说明,否则为任何参数传递 null 值将导致抛出 NullPointerException。
实现注意事项
在等待 Condition 时,允许发生“虚假唤醒”,这通常作为对基础平台语义的让步。对于大多数应用程序,这带来的实际影响很小,因为 Condition 应该总是在一个循环中被等待,并测试正被等待的状态声明。某个实现可以随意移除可能的虚假唤醒,但建议应用程序程序员总是假定这些虚假唤醒可能发生,因此总是在一个循环中等待。
三种形式的条件等待(可中断、不可中断和超时)在一些平台上的实现以及它们的性能特征可能会有所不同。尤其是它可能很难提供这些特性和维护特定语义,比如排序保证。更进一步地说,中断线程实际挂起的能力在所有平台上并不是总是可行的。
因此,并不要求某个实现为所有三种形式的等待定义完全相同的保证或语义,也不要求其支持中断线程的实际挂起。
要求实现清楚地记录每个等待方法提供的语义和保证,在某个实现不支持中断线程的挂起时,它必须遵从此接口中定义的中断语义。
由于中断通常意味着取消,而又通常很少进行中断检查,因此实现可以先于普通方法的返回来对中断进行响应。即使出现在另一个操作后的中断可能会释放线程锁时也是如此。实现应记录此行为。
第一部分:JMOCK测试接口
package com.abin.lee.mock.jmock;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-5-6
* Time: 下午12:23
* To change this template use File | Settings | File Templates.
*/
public interface UserService {
public String getMessage(String message);
}
package com.abin.lee.mock.jmock;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-5-6
* Time: 下午12:24
* To change this template use File | Settings | File Templates.
*/
public class UserServiceImpl implements UserService {
@Override
public String getMessage(String message) {
String result="";
result="hello "+message;
return result;
}
}
package com.abin.lee.mock.jmock;
import junit.framework.TestCase;
import org.jmock.Expectations;
import org.jmock.Mockery;
import org.junit.BeforeClass;
import org.junit.Test;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-5-6
* Time: 下午12:29
* To change this template use File | Settings | File Templates.
*/
public class UserManageTest {
@Test
public void testUserManage(){
Mockery mockery= new Mockery();
final UserService userService=mockery.mock(UserService.class);
final String message="abin";
final String expectValue="hello abin";
mockery.checking(new Expectations(){{
oneOf(userService).getMessage(message);
will(returnValue(expectValue));
}});
String actual=userService.getMessage(message);
System.out.println("actual="+actual);
TestCase.assertEquals(expectValue,actual);
mockery.assertIsSatisfied();
}
}
第二部分:JMOCK测试普通类
package com.abin.lee.mock.jmock;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-5-6
* Time: 下午12:43
* To change this template use File | Settings | File Templates.
*/
public class UserManage {
public String getMessage(String message){
String result="hello "+message;
System.out.println("result="+result);
return result;
}
}
package com.abin.lee.mock.jmock;
import junit.framework.TestCase;
import org.jmock.Expectations;
import org.jmock.Mockery;
import org.jmock.integration.junit4.JUnit4Mockery;
import org.jmock.lib.legacy.ClassImposteriser;
import org.junit.Test;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-5-6
* Time: 下午12:47
* To change this template use File | Settings | File Templates.
*/
public class UserManageTest {
@Test
public void testUserManage(){
Mockery mockery=new Mockery();
mockery.setImposteriser(ClassImposteriser.INSTANCE);
final UserManage userManage=mockery.mock(UserManage.class);
final String message="abin";
final String expectValue="hello abin";
mockery.checking(new Expectations(){{
oneOf(userManage).getMessage(message);
will(returnValue(expectValue));
}});
String expect=userManage.getMessage(message);
System.out.println("expect="+expect);
TestCase.assertEquals(expectValue,expect);
mockery.assertIsSatisfied();
}
}
实例一:
package com.abin.lee.async;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.nio.client.DefaultHttpAsyncClient;
import org.apache.http.nio.client.HttpAsyncClient;
import org.apache.http.nio.reactor.IOReactorException;
import org.junit.Test;
import java.io.IOException;
import java.util.concurrent.Future;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-23
* Time: 下午6:13
* To change this template use File | Settings | File Templates.
*/
public class HttpAsyncClientTest {
private static final String HttpUrl="http://localhost:8100/MyThread/HttpClientPostProxyServlet";
@Test
public void testHttpAsyncClient() throws IOException {
HttpAsyncClient httpAsyncClient=new DefaultHttpAsyncClient();
httpAsyncClient.start();
HttpPost request=null;
try {
request=new HttpPost(HttpUrl);
Future<HttpResponse> future=httpAsyncClient.execute(request,null);
HttpResponse response=future.get();
System.out.println("response="+response);
}catch(Exception e){
e.printStackTrace();
}finally {
if(!request.isAborted()){
request.abort();;
}
httpAsyncClient.getConnectionManager().shutdown();
}
}
}
实例二:
package com.abin.lee.async;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.concurrent.FutureCallback;
import org.apache.http.impl.nio.client.DefaultHttpAsyncClient;
import org.apache.http.nio.client.HttpAsyncClient;
import org.junit.Test;
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.Future;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-23
* Time: 下午6:13
* To change this template use File | Settings | File Templates.
*/
public class HttpAsyncClientFutureCallBackTest {
private static final String HttpUrl="http://localhost:8100/MyThread/HttpClientGetProxyServlet";
private static final String HttpOneUrl="http://localhost:8100/MyThread/HttpClientGetOneServlet";
private static final String HttpTwoUrl="http://localhost:8100/MyThread/HttpClientGetTwoServlet";
@Test
public void testHttpAsyncClientFutureCallBack() throws IOException {
HttpAsyncClient httpAsyncClient=new DefaultHttpAsyncClient();
httpAsyncClient.start();
HttpGet[] requests=null;
try {
requests=new HttpGet[]{new HttpGet(HttpUrl),new HttpGet(HttpOneUrl),new HttpGet(HttpTwoUrl)};
final CountDownLatch latch=new CountDownLatch(requests.length);
for(final HttpGet request:requests){
httpAsyncClient.execute(request,new FutureCallback<HttpResponse>() {
@Override
public void completed(HttpResponse httpResponse) {
latch.countDown();
System.out.println(request.getRequestLine()+"--->"+httpResponse.getStatusLine());
//To change body of implemented methods use File | Settings | File Templates.
}
@Override
public void failed(Exception e) {
latch.countDown();
System.out.println(request.getRequestLine()+"-->"+e.getMessage());
//To change body of implemented methods use File | Settings | File Templates.
}
@Override
public void cancelled() {
latch.countDown();
System.out.println(request.getRequestLine()+"--->"+" cancelled");
//To change body of implemented methods use File | Settings | File Templates.
}
}) ;
}
latch.await();
System.out.println("shutting down");
}catch(Exception e){
e.printStackTrace();
}finally {
httpAsyncClient.getConnectionManager().shutdown();
}
}
}
查看oracle表结构:
desc ABIN_LEE;
select * from user_tab_columns where table_name='ABIN_LEE';
select dbms_metadata.get_ddl('TABLE','ABIN_LEE') from dual;
select * from cols where table_name= 'ABIN_LEE';
//EasyMockServlet.java
package com.abin.lee.easymock.servlets;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-22
* Time: 下午3:12
* To change this template use File | Settings | File Templates.
*/
public class EasyMockServlet extends HttpServlet {
public void doPost(HttpServletRequest request,HttpServletResponse response) throws IOException, ServletException {
System.out.println("doPost come in");
String userName=request.getParameter("userName");
String passWord=request.getParameter("passWord");
System.out.println("userName="+userName+",passWord="+passWord);
if("abin".equals(userName)&&"varyall".equals(passWord)){
System.out.println("come in");
ServletContext context=this.getServletContext();
RequestDispatcher dispatcher=context.getNamedDispatcher("dispatcher");
dispatcher.forward(request,response);
}else{
throw new RuntimeException("Login failed.");
}
}
}
//EasyMockServletFailedTest.java
package com.abin.lee.easymock.servlets;
import org.easymock.EasyMock;
import org.easymock.IMocksControl;
import org.junit.Test;
import javax.servlet.http.HttpServletRequest;
import static junit.framework.TestCase.assertEquals;
import static org.junit.Assert.fail;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-22
* Time: 下午5:08
* To change this template use File | Settings | File Templates.
*/
public class EasyMockServletFailedTest {
@Test
public void testEasyMockServletFailed(){
HttpServletRequest request=EasyMock.createMock(HttpServletRequest.class);
EasyMock.expect(request.getParameter("userName")).andReturn("abin");
EasyMock.expect(request.getParameter("passWord")).andReturn("varyall").times(1);
EasyMock.replay(request);
EasyMockServlet easyMockServlet=new EasyMockServlet();
try {
easyMockServlet.doPost(request,null);
fail("Not caught exception!");
}catch(Exception e){
assertEquals("Login failed.", e.getMessage());
e.printStackTrace();
}
EasyMock.verify(request);
}
}
//EasyMockServletSuccessTest
package com.abin.lee.easymock.servlets;
import org.easymock.EasyMock;
import org.easymock.IMocksControl;
import org.junit.Test;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-22
* Time: 下午7:49
* To change this template use File | Settings | File Templates.
*/
public class EasyMockServletSuccessTest {
@Test
public void testEasyMockServletSuccess() throws ServletException, IOException {
IMocksControl control= EasyMock.createControl();
HttpServletRequest request=control.createMock(HttpServletRequest.class);
// HttpServletResponse response=control.createMock(HttpServletResponse.class);
final ServletContext servletContext=control.createMock(ServletContext.class);
RequestDispatcher requestDispatcher=control.createMock(RequestDispatcher.class);
EasyMock.expect(request.getParameter("userName")).andReturn("abin").once();
EasyMock.expect(request.getParameter("passWord")).andReturn("varyall").once();
EasyMock.expect(servletContext.getNamedDispatcher("dispatcher")).andReturn(requestDispatcher).times(1);
requestDispatcher.forward(request,null);
EasyMock.expectLastCall();
control.replay();
EasyMockServlet easyMockServlet=new EasyMockServlet(){
public ServletContext getServletContext(){
return servletContext;
}
} ;
easyMockServlet.doPost(request,null);
control.verify();
}
}
//UserDao.java
package com.abin.lee.jmock;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-23
* Time: 上午11:07
* To change this template use File | Settings | File Templates.
*/
public interface UserDao {
public String getMessage(String message);
}
//UserService.java
package com.abin.lee.jmock;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-23
* Time: 上午11:06
* To change this template use File | Settings | File Templates.
*/
public class UserService {
private UserDao userDao;
public String findMessage(String message){
return this.userDao.getMessage(message);
}
public void setUserDao(UserDao userDao){
this.userDao=userDao;
}
}
//UserManageTest.java
package com.abin.lee.jmock;
import junit.framework.TestCase;
import org.jmock.Expectations;
import org.jmock.Mockery;
import org.junit.Test;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-23
* Time: 上午11:08
* To change this template use File | Settings | File Templates.
*/
public class UserManageTest {
@Test
public void testUserManage(){
// 建立一个test上下文对象。
Mockery mockery=new Mockery();
// 生成一个mock对象
final UserDao userDao=mockery.mock(UserDao.class);
// 设置期望。
mockery.checking(new Expectations(){
{
// 当参数为"abin"的时候,userDao对象的getMessage方法被调用一次,并且返回西安。
oneOf(userDao).getMessage("abin");
will(returnValue("abin"));
}
});
UserService userService=new UserService();
userService.setUserDao(userDao);
String message=userService.findMessage("abin");
System.out.println("message="+message);
TestCase.assertEquals("abin",message);
}
}
手头的项目越来越大,很多以前不会出现的问题开始浮现。 比如:我修改了一个基础的类库,却意外的影响了九重天外的客户项目,直接导致一个功能无法实现。我郁闷啊!!! 因此开始要有组织、有预谋、有计划的对项目过程进行测试驱动了。最终目标是,我修改了底层某个dll的某个方法,测试框架能够自动帮我找出来所有收到影响的类,全部执行一次回归测试,并发送一份漂亮的报告到我手里。 这个目标估计1、2个星期才能实现,不过现在先放出一个非常漂亮的MOCK核心代码。 研究过程 在不断收集各种资料过程中,学习了很多,例如以下关键字,有兴趣的兄弟可以自己搜索一下: testdriven.net, nunit, typemock, cruiseControl.net, Confluence, JIRE, NUnitForms, WatiN, MBUnit, CSUnit, NBehave, Gallio ranorex, dynamicProxy... 估计各位有时间看看上面的简介,就能够掌握现在测试驱动的大致发展。 - nunit的核心代码非常容易理解,大伙自己下载看看就行了。
- testdriven.net 的前身是:NUnitAddin, 如果要研究如何testdriven集成到vs,看看不错。
- WatiN的核心代码虽然我没有看,不过猜也能猜到,就是调用了IE的核,然后搜索上面的html标签操作。
- typeMock有点混蛋,源码混淆了,无法拿到核心技术,不过从介绍来看是源自了castle.DynamicProxy,那么各位可以参观一下一篇非常垃圾的文章,但是起码让我入门了: http://www.cublog.cn/u/23701/showart_1414436.html
- 最后,我来到了Moq,开始因为听说是.net3.5,就没有看源码,不过刚才研究了一下顿时非常兴奋。起码Moq能让我解决了50%的工作。
接下来就说下Mock技术和测试驱动中的作用。 Mock技术 我最不喜欢老外造名词,所以会用自己的体会去介绍。 mock的本质就是模拟目标对象的一个假对象。 这个性质在测试驱动中非常有用,例如我的代码是:  代码 代码 public DateTime GetNextFiredDate(DateTime now, IOrmScheduleTrigger trigger, int triggeredtimes)
{
return GetNextFiredDate(now, trigger.TriggerType, trigger.TriggerExpression, triggeredtimes);
} 现在要测试这个代码,就需要传入一个IOrmScheduleTrrigger的接口对象。但是不幸的是,这个对象是个ORM,要启动这个对象,就涉及到了数据库。。。。 老大,我只是想测试一下一辆宝马的玻璃是否坚硬,不需要启动我的宝马加速到120km,然后再用手去翘翘那块玻璃吧。 所以,我希望能够有个模拟对象,继承了这个接口, 同时提供了我期望的返回值,让这个方法能够顺利执行。 传统的傻逼方法,就是自己写一个类,继承了这个接口,然后才传入进去。例如: public class OrmScheduleTriggerTestObject : IOrmScheduleTrigger
{
// some method here
} 这样不就更加的傻逼了?我为了测一块玻璃,还亲自造了另外一台简易的宝马出来? 于是我开始翻阅各种文献,甚至考虑使用动态代理(DynamicProxy)。动态代理的核心思想就是在代码运行中写IL生成一个继承类。这个技术很有用,但是现在我还用不上(就像martin fowler说的,typemock就等于把核武器交给了一个4岁小孩)。 于是我继续寻找,终于翻开了Moq的源码,找到了答案。 先看看以下一段代码,是我摘自Moq源码的核心部分,稍加改造了: 代码 using System;
using System.Collections.Generic;
using System.Text;
using System.Runtime.Remoting.Proxies;
using System.Runtime.Remoting.Messaging;
namespace Pixysoft.Framework.TestDrivens
{
public class Mock<TInterface> : RealProxy
{
public Mock()
: base(typeof(TInterface))
{
}
public TInterface Value
{
get
{
return (TInterface)this.GetTransparentProxy();
}
}
public override IMessage Invoke(IMessage msg)
{
IMethodCallMessage methodCall = msg as IMethodCallMessage;
//我返回int = 1
return new ReturnMessage(1, null, 0, null, methodCall);
}
}
public interface IMock
{
int Devide(int a, int b);
}
public class testrealproxy //测试代码在这里!!!
{
public void test()
{
IMock mock = new Mock<IMock>().Value;
Console.WriteLine(mock.Devide(1, 2));
//输出 = 1
}
}
}
这段代码就是Moq的核心思想。 大概意思是:我希望调用接口IMock的方法Devide,但是我压根不想写这个接口的实现。 那么我先写一个通用的模拟对象Mock<TInterface>,继承了RealProxy。 然后通过调用Value就可以返回需要的接口对象。而这个对象就是 return (TInterface)this.GetTransparentProxy();是个透明代理。 最后当我调用了 int Devide(int a, int b); 方法的时候,等于调用了public override IMessage Invoke(IMessage msg)方法(有点点的AOP感觉)。 后记 上文就是Moq的核心思想了。非常的精彩!估计有了思路,各位就可以制造自己的原子弹了。 这里插句题外话,很多人抨击重复造轮子。我就奇怪了。如果我造一个轮子花费的时间和学习用一个轮子的时间差不远,为什么不造一个? 而且,用别人的轮子,经常出现的情况是:很多轮子不知道挑哪个。一旦挑上了,项目进展到一般才发现不适合、有bug,于是又重头挑另外的轮子。 这个经历是真实的。当年读大学,我的室友就是典型的挑轮子,他懂得很多框架(java),webwork,hibernate, spring。和人砍起来朗朗上口,但是需要深入做项目了,出现问题基本上不知所措,不是翻文献,就是问师兄,最后整个项目组从来就没有一个成品。 我自从学电脑依赖,从来就没有用过别人的轮子,即使是hibernate,我的确也没有用过,不过他的核心文档倒是看过,对比之下,和oracle的toplink相比简直就是小孩。 比我牛逼的兄弟大有人在,希望各位牛人不要浪费自己的时间去挑别人的轮子,直接自己造一个算了。 最后说说接下来的工作。 基于接口的测试驱动完成了,剩下的就是面对sealed class 等顽固分子了, 必然需要动用非常规武器,DynamicProxy。下回再见。
1 现有的单元测试框架
单元测试是保证程序正确性的一种有效的测试手段,对于不同的开发语言,通常都能找到相应的单元框架。 
借助于这些单测框架的帮助,能够使得我们编写单元测试用例的过程变得便捷而优雅。框架帮我们提供了case的管理,执行,断言集,运行参数,全局事件工作,所有的这些使得我们只需关注:于对于特定的输入,被测对象的返回是否正常。
那么,这些xUnit系列的单元测试框架是如何做到这些的了?分析这些框架,发现所有的单元测试框架都是基于以下的一种体系结构设计的。

如上图所示,单测框架中通常包括TestRunner, Test, TestResult, TestCase, TestSuite, TestFixture六个组件。
TestRuner:负责驱动单元测试用例的执行,汇报测试执行的结果,从而简化测试
TestFixture:以测试套件的形式提供setUp()和tearDown()方法,保证两个test case之间的执行是相互独立,互不影响的。
TestResult:这个组件用于收集每个test case的执行结果
Test:作为TestSuite和TestCase的父类暴露run()方法为TestRunner调用
TestCase:暴露给用户的一个类,用户通过继承TestCase,编写自己的测试用例逻辑
TestSuite:提供suite功能管理testCase
正因为相似的体系结构,所以大多数单元测试框架都提供了类似的功能和使用方法。那么在单测中引入单元测试框架会带来什么好处,在现有单元测试框架下还会存在什么样不能解决的问题呢?
2 单元测试框架的优点与一些问题
在单元测试中引入单测框架使得编写单测用例时,不需要再关注于如何驱动case的执行,如何收集结果,如何管理case集,只需要关注于如何写好单个测试用例即可;同时,在一些测试框架中通过提供丰富的断言集,公用方法,以及运行参数使得编写单个testcase的过程得到了最大的简化。
那这其中会存在什么样的疑问了?
我在单元测试框架中写一个TestCase,与我单独写一个cpp文件在main()方法里写测试代码有什么本质却别吗?用了单元测试框架,并没有解决我在对复杂系统做单测时遇到的问题。
没错,对于单个case这两者从本质上说是没有区别的。单元测试框架本身并没有告诉你如何去写TestCase,在这一点上他是没有提供任何帮助的。所以对于一些复杂的场景,只用单元测试框架是有点多少显得无能为力的。
使用单元测试框架往往适用于以下场景的测试:单个函数,一个class,或者几个功能相关class的测试,对于纯函数测试,接口级别的测试尤其适用,如房贷计算器公式的测试。
但是,对于一些复杂场景:
被测对象依赖复杂,甚至无法简单new出这个对象
对于一些failure场景的测试
被测对象中涉及多线程合作
被测对象通过消息与外界交互的场景
…
单纯依赖单测框架是无法实现单元测试的,而从某种意义上来说,这些场景反而是测试中的重点。
以分布式系统的测试为例,class 与 function级别的单元测试对整个系统的帮助不大,当然,这种单元测试对单个程序的质量有帮助;分布式系统测试的要点是测试进程间的交互:一个进程收到客户请求,该如何处理,然后转发给其他进程;收到响应之后,又修改并应答客户;同时分布式系统测试中通常更关注一些异常路径的测试,这些场景才是测试中的重点,也是难点所在。
Mock方法的引入通常能帮助我们解决以上场景中遇到的难题。
3 Mock的引入带来了什么
在维基百科上这样描述Mock:In object-oriented programming, mock objects are simulated objects that mimic the behavior of real objects in controlled ways. A computer programmer typically creates a mock object to test the behavior of some other object, in much the same way that a car designer uses a crash test dummy to simulate the dynamic behavior. of a human in vehicle impacts.
Mock通常是指,在测试一个对象A时,我们构造一些假的对象来模拟与A之间的交互,而这些Mock对象的行为是我们事先设定且符合预期。通过这些Mock对象来测试A在正常逻辑,异常逻辑或压力情况下工作是否正常。
引入Mock最大的优势在于:Mock的行为固定,它确保当你访问该Mock的某个方法时总是能够获得一个没有任何逻辑的直接就返回的预期结果。
Mock Object的使用通常会带来以下一些好处:
隔绝其他模块出错引起本模块的测试错误。
隔绝其他模块的开发状态,只要定义好接口,不用管他们开发有没有完成。
一些速度较慢的操作,可以用Mock Object代替,快速返回。
对于分布式系统的测试,使用Mock Object会有另外两项很重要的收益:
通过Mock Object可以将一些分布式测试转化为本地的测试
将Mock用于压力测试,可以解决测试集群无法模拟线上集群大规模下的压力
4 Mock的应用场景
在使用Mock的过程中,发现Mock是有一些通用性的,对于一些应用场景,是非常适合使用Mock的:
真实对象具有不可确定的行为(产生不可预测的结果,如股票的行情)
真实对象很难被创建(比如具体的web容器)
真实对象的某些行为很难触发(比如网络错误)
真实情况令程序的运行速度很慢
真实对象有用户界面
测试需要询问真实对象它是如何被调用的(比如测试可能需要验证某个回调函数是否被调用了)
真实对象实际上并不存在(当需要和其他开发小组,或者新的硬件系统打交道的时候,这是一个普遍的问题)
当然,也有一些不得不Mock的场景:
一些比较难构造的Object:这类Object通常有很多依赖,在单元测试中构造出这样类通常花费的成本太大。
执行操作的时间较长Object:有一些Object的操作费时,而被测对象依赖于这一个操作的执行结果,例如大文件写操作,数据的更新等等,出于测试的需求,通常将这类操作进行Mock。
异常逻辑:一些异常的逻辑往往在正常测试中是很难触发的,通过Mock可以人为的控制触发异常逻辑。
在一些压力测试的场景下,也不得不使用Mock,例如在分布式系统测试中,通常需要测试一些单点(如namenode,jobtracker)在压力场景下的工作是否正常。而通常测试集群在正常逻辑下无法提供足够的压力(主要原因是受限于机器数量),这时候就需要应用Mock去满足。
在这些场景下,我们应该如何去做Mock的工作了,一些现有的Mock工具可以帮助我们进行Mock工作。
5 Mock工具的介绍
手动的构造 Mock 对象通常带来额外的编码量,而且这些为创建 Mock 对象而编写的代码很有可能引入错误。目前,有许多开源项目对动态构建 Mock 对象提供了支持,这些项目能够根据现有的接口或类动态生成,这样不仅能避免额外的编码工作,同时也降低了引入错误的可能。
C++: GoogleMock http://code.google.com/p/googlemock/
Java: EasyMock http://easymock.org/ 通常Mock工具通过简单的方法对于给定的接口生成 Mock 对象的类库。它提供对接口的模拟,能够通过录制、回放、检查三步来完成大体的测试过程,可以验证方法的调用种类、次数、顺序,可以令 Mock 对象返回指定的值或抛出指定异常。通过这些Mock工具我们可以方便的构造 Mock 对象从而使单元测试顺利进行,能够应用于更加复杂的测试场景。
以EasyMock为例,通过 EasyMock,我们可以为指定的接口动态的创建 Mock 对象,并利用 Mock 对象来模拟协同模块,从而使单元测试顺利进行。这个过程大致可以划分为以下几个步骤:
使用 EasyMock 生成 Mock 对象
设定 Mock 对象的预期行为和输出
将 Mock 对象切换到 Replay 状态
调用 Mock 对象方法进行单元测试
对 Mock 对象的行为进行验证
EasyMock的使用和原理: http://www.ibm.com/developerworks/cn/opensource/os-cn-easymock/ EasyMock 后台处理的主要原理是利用 java.lang.reflect.Proxy 为指定的接口创建一个动态代理,这个动态代理,就是我们在编码中用到的 Mock 对象。EasyMock 还为这个动态代理提供了一个 InvocationHandler 接口的实现,这个实现类的主要功能就是将动态代理的预期行为记录在某个映射表中和在实际调用时从这个映射表中取出预期输出。
借助类似于EasyMock这样工具,大大降低了编写Mock对象的成本,通常来说Mock工具依赖于单元测试框架,为用户编写TestCase提供便利,但是本身依赖于单元测试框架去驱动,管理case,以及收集测试结果。例如EasyMock依赖于JUint,GoogleMock依赖于Gtest。
那么有了单元测试框架和相应的Mock工具就万事俱备了,还有什么样的问题?正如单元测试框架没有告诉你如何写TestCase一样,Mock工具也没有告诉你如何去选择Mock的点。
6 如何选择恰当的mock点
对于Mock这里存在两个误区,1.是Mock的对象越多越好;2.Mock会引入巨大的工作量,通常得不偿失。这都是源于不恰当的Mock点的选取。
这里说的如何选择恰当的mock点,是说对于一个被测对象,我们应当在外围选择恰当的mock对象,以及需要mock的接口。因为对于任意一个对象,任意一段代码逻辑我们都是有办法进行Mock的,而Mock点选择直接决定了我们Mock的工作量以及测试效果。从另外一种意义上来说,不恰当Mock选择反而会对我们的测试产生误导,从而在后期的集成和系统测试中引入更多的问题。
在mock点的选择过程中,以下的一些点会是一些不错的选择
网络交互:如果两个被测模块之间是通过网络进行交互的,那么对于网络交互进行Mock通常是比较合适的,如RPC
外部资源:比如文件系统、数据源,如果被测对象对此类外部资源依赖性非常强,而其行为的不可预测性很可能导致测试的随机失败,此类的外部资源也适合进行Mock。
UI:因为UI很多时候都是用户行为触发事件,系统本身只是对这些触发事件进行相应,对这类UI做Mock,往往能够实现很好的收益,很多基于关键字驱动的框架都是基于UI进行Mock的
第三方API:当接口属于使用者,通过Mock该接口来确定测试使用者与接口的交互。
当然如何做Mock一定是与被系统的特性精密关联的,一些强制性的约束和规范是不合适的。这里介绍几个做的比较好的mock的例子。
1. 杀毒软件更新部署模块的Mock
这个例子源于一款杀毒产品的更新部署模块的测试。对于一个杀毒软件客户端而言,需要通过更新检查模块与病毒库Server进行交互,如果发现病毒库有更新则触发病毒库部署模块的最新病毒库的数据请求和部署工作,要求部署完成后杀毒软件客户端能够正常工作。

对于这一场景的测试,当时受限于这样一个条件,通常的病毒库server通常最多一天只更新一次病毒库,也就是说如果使用真实的病毒库server,那么针对更新部署模块的测试一天只能被触发一次。这是测试中所不能容忍的,通过对病毒库server进行mock可以解决这个问题。
对于这个场景可以采取这样一种Mock方式:用一个本地文件夹来模拟病毒库server,选择更新部署模块与病毒库server之间交互的两个函数checkVersion(),reqData()函数进行Mock。
checkVersion()工作原先的工作是检查病毒库Server的版本号,以决定是否触发更新,将其行为Mock为检查一个本地文件夹中病毒库的版本号;reqData()原有的行为是从病毒库Server拖取病毒库文件,将其Mock为从本地文件夹中拖取病毒库文件。通过这种方式我们用一个本地文件夹Mock病毒库Server的行为,其带来的产出是:我们可以随意的触发病毒库更新操作以及各种异常。通过这种方式发现了一个在更新部署过程中,病毒库Server的病毒库版本发生改变造成出错的严重bug,这个是在原有一天才触发一次更新操作的情况下永远也无法发现的。
2. 分布式系统中对NameNode模块的测试

在测试NameNode模块的过程中存在这样一个问题,在正常逻辑无压力条件下NameNode模块都是工作正常的。但是线上集群在大压力的情况下,是有可能触发NameNode的问题的。但是原有的测试方法下,我们是无法对NameNode模拟大压力的场景的(因为NameNode的压力主要来源于DateNode数量,而我们测试集群是远远无法达到线上几千台机器的规模的),而NameNode单点的性能瓶颈问题恰恰是测试的重点,真实的DataNode是无法满足测试需求的,我们必须对DataNode进行Mock。

如何对DateNode进行Mock了,最直观的想法是选择NameNode与DataNode之间的交互接口进行Mock,也就是他们之间的RPC交互,但是由于NameNode与DataNode之间的交互信息种类很多,所以其实这并不是一种很好的选择。
换个角度来想,NameNode之上的压力是源于对HDFS的读写操作造成的NameNode上元数据的维护,也就是说,对于NameNode而言,其实他并不关心数据到底写到哪里去了,只关心数据是否读写成功。如果是这种场景Mock就可以变的简单了,我们可以直接将DataNode上对块的操作进行mock,比如,对一次写请求,DataNode并不触发真实的写操作,而直接返回成功。通过这种方式,DataNode去除了执行功能,只保留了消息交互功能,间接的实现了我们的测试需求,且工作量比之第一种方案小很多。
3. 开源社区提供的MRUnit测试框架
在原有框架下,对于MapReduce程序的测试通常是无法在本地验证的,更不用说对MapReduce程序进行单测了。而MRUnit通过一个简单而优雅的Mock,却实现了一个基于MapReduce程序的单测框架。 基于MRUINT框架可以将单测写成如下形式: 
在这个框架中定义了MapDriver,ReducerDriver,MapReduceDriver三个有点类似容器的driver,通过driver来驱动map,reduce或者整个mapreduce过程的执行。
如上例,在driver中设定mapper为IdentityMapper,通过withInput方法设定输入数据,通过withOutput方法设定预期结果,通过runTest方法来触发执行并进行结果检测
他的实现原理是将outputCollector做Mock,outputCollectort中的emit方法实现的逻辑是将数据写到文件系统中,Mock后是通过另外一个进程去收集数据并保存在内存中,从而实现最终结果的可检验(在自己的数据结构中比对结果)。
实现的原理很简单,这样做mock就会精巧,只选择最底层的一些简单却又依赖广泛的点(依赖广泛指模块间的数据流通常都走这样的点过)做mock,这样通常效果很好且简单
当然这个例子中也有一些缺陷:1.因为在outputcollector层做mock的数据截取,使得无法过partition的分桶逻辑;2.这个框架是写内存的,无法最终改成压力性能测试工具。
7 附录
1. EasyMock示例:

|
1、什么情况下会使用mock技术 (1)需要将当前被测单元和其依赖模块独立开来,构造一个独立的测试环境,不关注被测单元的依赖对象,只关注被测单元的功能逻辑 ----------比如被测代码中需要依赖第三方接口返回值进行逻辑处理,可能因为网络或者其他环境因素,调用第三方经常会中断或者失败,无法对被测单元进行测试,这个时候就可以使用mock技术来将被测单元和依赖模块独立开来,使得测试可以进行下去。 (2)被测单元依赖的模块尚未开发完成,而被测单元需要依赖模块的返回值进行后续处理 ----------比如service层的代码中,包含对Dao层的调用,但是,DAO层代码尚未实现 (3)被测单元依赖的对象较难模拟或者构造比较复杂 ----------比如,支付宝支付的异常条件有很多,但是模拟这种异常条件很复杂或者无法模拟,比如,查询聚划算的订单结果,无法在测试环境进行模拟 2、Mock技术分类 (1)手动构造mock对象 ---------------比如,可以自己写某个接口方法的实现,根据需要编写返回值,测试代码中使用该实现类对象 缺点:会增加代码量,在写mock对象代码时,有可能引入错误 (2)使用开源代码提供的构造mock方法 --------------比如easyMock,提供了对接口类的模拟,能够通过录制、回放、检查三步来完成大体的测试过程,可以验证方法的调用种类、次数、顺序,可以令Mock对象返回指定的值或抛出指定异常 3、EasyMock使用 (1)引入easyMock ------------在maven工程中,通过pom配置依赖关系 <dependency>
<groupId>org.easymock</groupId>
<artifactId>easymock</artifactId>
<version>3.0</version>
<scope>test</scope>
</dependency> | ------------在普通java工程中,通过添加外部包的方式 (2)使用easyMock过程 1)使用EasyMock生成Mock对象;
pingJiaDao = mockControl.createMock(IPingJiaDao.class); 2)设定Mock对象的预期行为和输出;
EasyMock.expect(pingJiaDao.getGoodPingJiaRate(storeId)).andReturn(0.11); 3)将Mock对象切换到Replay状态;
EasyMock.replay(pingJiaDao); 4)调用Mock对象方法进行单元测试;
storeService.setStoredao(pingJiaDao);
double rate = storeService.getStoreGoodRate(storeId); 5)对Mock对象的行为进行验证。
EasyMock.verify(pingJiaDao); 4、其他easyMock功能 (1)特殊的mock对象:niceMock
(2)参数匹配器
(3)重置mock对象
(4)模拟异常抛出
(5)设置调用次数
/** * HTTP DELETE方法进行删除操作 * @param url * @param map * @return * @throws ClientProtocolException * @throws IOException */ public static String remoteDelete(String url, Map<String, String> map) throws ClientProtocolException, IOException{ url = JETSUM_PLATFORM_SERVER+url; HttpClient httpclient = new DefaultHttpClient(); HttpDelete httpdelete= new HttpDelete(); List<NameValuePair> formparams = setHttpParams(map); String param = URLEncodedUtils.format(formparams, "UTF-8"); httpdelete.setURI(URI.create(url + "?" + param)); HttpResponse response = httpclient.execute(httpdelete); String httpEntityContent = GetHttpEntityContent(response); httpdelete.abort(); return httpEntityContent; } /** * 设置请求参数 * @param map * @return */ private static List<NameValuePair> setHttpParams(Map<String, String> map) { List<NameValuePair> formparams = new ArrayList<NameValuePair>(); Set<Map.Entry<String, String>> set = map.entrySet(); for (Map.Entry<String, String> entry : set) { formparams.add(new BasicNameValuePair(entry.getKey(), entry.getValue())); } return formparams; } /** * 获得响应HTTP实体内容 * @param response * @return * @throws IOException * @throws UnsupportedEncodingException */ private static String GetHttpEntityContent(HttpResponse response) throws IOException, UnsupportedEncodingException { HttpEntity entity = response.getEntity(); if (entity != null) { InputStream is = entity.getContent(); BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8")); String line = br.readLine(); StringBuilder sb = new StringBuilder(); while (line != null) { sb.append(line + "\n"); line = br.readLine(); } return sb.toString(); } return ""; }
怎么配置Tomcat支持HTTP Delete和Put 方法
如何配置Tomcat支持HTTP Delete和Put 方法
在tomcat web.xml文件中配置org.apache.catalina.servlets.DefaultServlet的
<init-param>
<param-name>readonly</param-name>
<param-value>false</param-value>
</init-param> readonly参数默认是true,即不允许delete和put操作,所以通过XMLHttpRequest对象的put或者delete方法访问就会报告http 403错误。为REST服务起见,应该设置该属性为false。
逻辑: String url = "http://www.baidu.com"; //将要访问的url字符串放入HttpPost中 HttpPost httpPost = new HttpPost(url); //请求头 放置一些修改http请求头和cookie httpPost.setHeader("Accept", "application/json"); ...... //如果是HttpPost或者HttpPut请求需要在请求里加参数,而HttpGet或者HttpDelete请求则可以直接拼接到url字符串后面 //向HttpPost中加入参数 List<NameValuePair> values = new ArrayList<NameValuePair>(); values.add(new NameValuePair("id", "1")); values.add(new NameValuePair("name", "xiaohong")); httpPost.setEntity(new UrlEncodeFormEntity(values, HTTP.UTF_8)); //进行转码 //实例HttpClient 并执行带有HttpPost的方法,返回HttpResponse 响应,再进行操作 HttpClient httpClient = new DefaultHttpClient(); HttpResponse httpResponse = httpClient.execute(httpPost); int statusCode = httpResponse.getStatusLine().getStatusCode(); //返回状态码 ,用来进行识别或者判断访问结果 if(statusCode == 200){ Instream in = httpResponse.getEntity().getContent(); //要处理该数据流是否为GZIP流 } 示例代码如下: package cn.dratek.haoyingsheng.manager.client; import cn.dratek.haoyingsheng.manager.util.ResourceUtil;
import net.dratek.browser.http.Cookie;
import net.dratek.browser.http.CookieManager;
import net.dratek.browser.http.URL;
import org.apache.http.*;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpDelete;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.methods.HttpPut;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.protocol.HTTP; import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.util.List;
public class HttpNetClient {
/**
* 所有get 请求底层调用方法
*
* @param url 请求url
* @return byte[] response data
*/
public static byte[] doGet(String url) {
InputStream in;
byte[] bre = null;
HttpResponse response;
CookieManager manager = CookieManager.getInstance();
if (url != null && url.length() != 0) {
URL myURL = URL.parseString(url);
Cookie[] cookies = manager.getCookies(myURL);
HttpGet httpGet = new HttpGet(url);
if (cookies != null && cookies.length > 0) {
StringBuilder sb = new StringBuilder();
for (Cookie ck : cookies) {
sb.append(ck.name).append('=').append(ck.value).append(";");
}
String sck = sb.toString();
if (sck.length() > 0) {
httpGet.setHeader("Cookie", sck);
}
}
httpGet.setHeader("Accept-Encoding", "gzip, deflate");
httpGet.setHeader("Accept-Language", "zh-CN");
httpGet.setHeader("Accept", "application/json, application/xml, text/html, text/*, image/*, */*");
try {
response = new DefaultHttpClient().execute(httpGet);
if (response != null) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200 || statusCode == 403) {
Header[] headers = response.getHeaders("Set-Cookie");
if (headers != null && headers.length > 0) {
for (Header header : headers) {
manager.setCookie(myURL, header.getValue());
}
}
in = response.getEntity().getContent();
if (in != null) {
bre = ResourceUtil.readStream(in);
} }
}
} catch (IOException e) {
e.printStackTrace();
}
}
return bre;
} /**
* 所有Post 请求底层调用方法
*
* @param url 请求url
* @param values 传递的参数
* @return byte[] 返回数据 or null
*/
public static byte[] doPost(String url, List<NameValuePair> values) {
System.out.println("url = " + url);
byte[] bytes = null;
HttpResponse response;
InputStream inputStream = null;
CookieManager manager = CookieManager.getInstance();
if (url != null && url.length() != 0) {
URL myurl = URL.parseString(url);
Cookie[] cookies = manager.getCookies(myurl);
HttpPost post = new HttpPost(url);
if (cookies != null && cookies.length > 0) {
StringBuilder sb = new StringBuilder();
for (Cookie ck : cookies) {
sb.append(ck.name).append('=').append(ck.value).append(";");
}
String sck = sb.toString();
if (sck.length() > 0) {
post.setHeader("Cookie", sck);
} }
post.setHeader("Accept-Encoding", "gzip, deflate");
post.setHeader("Accept-Language", "zh-CN");
post.setHeader("Accept", "application/json, application/xml, text/html, text/*, image/*, */*");
DefaultHttpClient client = new DefaultHttpClient();
try {
if (values != null && values.size() > 0) {
post.setEntity(new UrlEncodedFormEntity(values, HTTP.UTF_8));
}
response = client.execute(post);
if (response != null) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200 || statusCode == 403) {
Header[] headers = response.getHeaders("Set-Cookie");
if (headers != null && headers.length > 0) {
for (Header header : headers) {
manager.setCookie(myurl, header.getValue());
}
}
inputStream = response.getEntity().getContent();
}
} } catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
if (inputStream != null) {
bytes = ResourceUtil.readStream(inputStream);
}
}
return bytes;
} /**
* PUT基础请求
*
* @param url 请求地址
* @param values 提交参数
* @return byte[] 请求成功后的结果
*/
public static byte[] doPut(String url, List<NameValuePair> values) {
byte[] ret = null; CookieManager manager = CookieManager.getInstance();
if (url != null && url.length() > 0) {
URL myUrl = URL.parseString(url);
StringBuilder sb = new StringBuilder();
Cookie[] cookies = manager.getCookies(myUrl);
if (cookies != null && cookies.length > 0) {
for (Cookie cookie : cookies) {
sb.append(cookie.name).append("=").append(cookie.value).append(";");
} }
HttpPut request = new HttpPut(url);
String sck = sb.toString();
if (sck.length() > 0) {
request.setHeader("Cookie", sck);
}
request.setHeader("Accept-Encoding", "gzip, deflate");
request.setHeader("Accept-Language", "zh-CN");
request.setHeader("Accept", "application/json, application/xml, text/html, text/*, image/*, */*"); DefaultHttpClient client = new DefaultHttpClient();
if (values != null && values.size() > 0) {
try {
UrlEncodedFormEntity entity;
entity = new UrlEncodedFormEntity(values);
request.setEntity(entity);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
try {
HttpResponse response = client.execute(request);
if (response != null) {
StatusLine statusLine = response.getStatusLine();
int statusCode = statusLine.getStatusCode();
if (statusCode == 200 || statusCode == 403) {
Header[] headers = response.getHeaders("Set-Cookie");
if (headers != null && headers.length > 0) {
for (Header header : headers) {
manager.setCookie(myUrl, header.getValue());
}
}
HttpEntity entity = response.getEntity();
InputStream inputStream = entity.getContent();
if (inputStream != null) {
ret = ResourceUtil.readStream(inputStream);
inputStream.close();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
return ret;
} /**
* Delete基础请求
*
* @param url 请求地址
* @return 请求成功后的结果
*/
public static byte[] doDelete(String url) { InputStream in;
byte[] bre = null;
HttpResponse response;
CookieManager manager = CookieManager.getInstance();
if (url != null && url.length() != 0) {
URL myurl = URL.parseString(url);
Cookie[] cookies = manager.getCookies(myurl);
HttpDelete delete = new HttpDelete(url);
if (cookies != null && cookies.length > 0) {
StringBuilder sb = new StringBuilder();
for (Cookie ck : cookies) {
sb.append(ck.name).append('=').append(ck.value).append(";");
}
String sck = sb.toString();
if (sck.length() > 0) {
delete.setHeader("Cookie", sck);
} }
delete.setHeader("Accept-Encoding", "gzip, deflate");
delete.setHeader("Accept-Language", "zh-CN");
delete.setHeader("Accept", "application/json, application/xml, text/html, text/*, image/*, */*");
try {
response = new DefaultHttpClient().execute(delete);
if (response != null) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200 || statusCode == 403) {
Header[] headers = response.getHeaders("Set-Cookie");
if (headers != null && headers.length > 0) {
for (Header header : headers) {
manager.setCookie(myurl, header.getValue());
}
}
in = response.getEntity().getContent();
if (in != null) {
bre = ResourceUtil.readStream(in);
} }
}
} catch (IOException e) {
e.printStackTrace();
}
}
return bre;
}
}
http://www.cnblogs.com/lianghui66/archive/2013/03/06/2946495.html
我是一个初学者. 我建了一个classes表和一个students表,表示班级和学生,其中学生里面有一个外键关联到班级表. 然后学生类里面建了一个classes的属性, 用session取出学生后,如果关闭session的话,就无法读取到学生类里的classes值,没有关闭就能读取到. 请问这个session会不会影响到其他用户的访问呢? 就是说如果有两个用户并行操作数据库的话,一个用户的session不关闭影不影响另一个用户呢?
J2EE中最大的一个观念就是分层..
session是持久层的东东.不可窜到别的层..
你的这个问题其实就是延迟加载的问题.
从理论的角度讲,最好是用一个就关一个.防止资源消耗.
但由于hibernate中的延迟加载,所以出现了你的关闭session的话,就无法读取到学生类里的classes值问题.
这个问题可以用Hibernate.initialize()来解决.也可就使用opensessionview的方式.spring中提供了这样的filter
不知道这在使用中有没有使用spring.用了就比较方便,也不会出现你所说的
引用 一个用户的session不关闭影不影响另一个用户 因为session由spring来管理,很安全,不会出现这个种并发问题. 如果只是使用了Hibernate的话,那得注意了.你在servlet中直接创建session就可能出现并发问题,因为session不是线程安全的,而servlet是多线程的. 这时可以使用ThreadLocal来解决这个问题. 希望对你有所帮助!
在一个应用程序中,如果DAO层使用Spring的hibernate模板,通过Spring来控制session的生命周期,则首选getCurrentSession 使用Hibernate的大多数应用程序需要某种形式的“上下文相关的”session,特定的session在整个特定的上下文范围内始终有效。然而,对不同类型的应用程序而言,要给为什么是组成这种“上下文”下一个定义通常是困难的;不同的上下文对“当前”这个概念定义了不同的范围。在3.0版本之前,使用Hibernate的程序要么采用自行编写的基于ThreadLocal的上下文session(如下面代码),要么采用HibernateUtil这样的辅助类,要么采用第三方框架(比如Spring或Pico),它们提供了基于代理(proxy)或者基于拦截器(interception)的上下文相关session 从3.0.1版本开始,Hibernate增加了SessionFactory.getCurrentSession()方法。一开始,它假定了采用JTA事务,JTA事务 定义了当前session的范围和上下文(scope and context)。Hibernate开发团队坚信,因为有好几个独立的JTA TransactionManager实现稳定可用,不论是否被部署到一个J2EE容器中,大多数(假若不是所有的)应用程序都应该采用JTA事务管理。 基于这一点,采用JTA的上下文相关session可以满足你一切需要。 更好的是,从3.1开始,SessionFactory.getCurrentSession()的后台实现是可拔插的。因此,我们引入了新的扩展接口 (org.hibernate.context.CurrentSessionContext)和新的配置参数 (hibernate.current_session_context_class),以便对什么是“当前session”的范围和上下文(scope and context)的定义进行拔插。 org.hibernate.context.JTASessionContext - 当前session根据JTA来跟踪和界定。这和以前的仅支持JTA的方法是完全一样的。 org.hibernate.context.ThreadLocalSessionContext - 当前session通过当前执行的线程来跟踪和界定。 这两种实现都提供了“每数据库事务对应一个session”的编程模型,也称作一请求一事务。即Hibernate的session的生命周期由数据库事务的生存来控制。假若你采用自行编写代码来管理事务(比如,在纯粹的J2SE,或者 JTA/UserTransaction/BMT),建议你使用Hibernate Transaction API来把底层事务实现从你的代码中隐藏掉。如果你在支持CMT的EJB容器中执行,事务边界是声明式定义的,你不需要在代码中进行任何事务或session管理操作。 1、getCurrentSession()与openSession()的区别 * 采用getCurrentSession()创建的session会绑定到当前线程中,而采用openSession() 创建的session则不会 * 采用getCurrentSession()创建的session在commit或rollback时会自动关闭,而采用openSession()创建的session必须手动关闭 2、使用getCurrentSession()需要在hibernate.cfg.xml文件中加入如下配置: * 如果使用的是本地事务(jdbc事务) <property name="hibernate.current_session_context_class">thread</property> * 如果使用的是全局事务(jta事务) <property name="hibernate.current_session_context_class">jta</property> 在SessionFactory启动的时候,Hibernate会根据配置创建相应的CurrentSessionContext,在 getCurrentSession()被调用的时候,实际被执行的方法是CurrentSessionContext.currentSession()。在currentSession()执行时,如果当前Session 为空,currentSession 会调用SessionFactory 的openSession。所以getCurrentSession() 对于Java EE 来说是更好的获取Session 的方法。 sessionFactory.getCurrentSession()可以完成一系列的工作,当调用时,hibernate将session绑定到当前线程,事务结束后,hibernate将session从当前线程中释放,并且关闭session,当再次调用getCurrentSession()时,将得到一个新的session,并重新开始这一系列工作。 这样调用方法如下:
Session session = HibernateUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Event theEvent = new Event();
theEvent.setTitle(title);
theEvent.setDate(theDate);
session.save(theEvent);
session.getTransaction().commit(); 不需要close session了 利于ThreadLocal模式管理Session 早在Java1.2推出之时,Java平台中就引入了一个新的支持:java.lang.ThreadLocal,给我们在编写多线程程序时提供了一种新的选择。ThreadLocal是什么呢?其实ThreadLocal并非是一个线程的本地实现版本,它并不是一个Thread,而是thread local variable(线程局部变量)。也许把它命名为ThreadLocalVar更加合适。线程局部变量(ThreadLocal)其实的功用非常简单,就是为每一个使用某变量的线程都提供一个该变量值的副本,是每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。从线程的角度看,就好像每一个线程都完全拥有一个该变量。ThreadLocal是如何做到为每一个线程维护变量的副本的呢?其实实现的思路很简单,在ThreadLocal类中有一个Map,用于存储每一个线程的变量的副本。 public class HibernateUtil {
private static String CONFIG_FILE_LOCATION = "/hibernate.cfg.xml";
//创建一个局部线程变量
private static final ThreadLocal<Session> THREAD_LOCAL = new ThreadLocal<Session>();
private static final Configuration cfg = new Configuration();
private static SessionFactory sessionFactory;
/*
* 取得当前session对象
*/
@SuppressWarnings("deprecation")
public static Session currentSession() throws HibernateException {
Session session = (Session)THREAD_LOCAL.get();
if (session == null) {
if (sessionFactory == null) {
try {
cfg.configure(CONFIG_FILE_LOCATION);
sessionFactory = cfg.buildSessionFactory();
} catch (Exception e) {
System.out.println("【ERROR】创建SessionFactory对象出错,原因是:");
e.printStackTrace();
}
}
session = sessionFactory.openSession();
THREAD_LOCAL.set(session);
}
return session;
}
public static void closeSession() throws HibernateException {
Session session = (Session) THREAD_LOCAL.get();
THREAD_LOCAL.set(null);
if(session != null){
session.close();
}
}
}
package com.abin.lee.hack;
import java.io.BufferedInputStream;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.DefaultHttpClient;
import org.junit.Test;
public class HttpClientVisitTest {
private static final String HttpUrl = "http://111.111.111.111/vote/ticket";
private static final String HttpHost = "111.111.111.111";
@Test
public void testHttpClientVisit() {
HttpClient httpClient = new DefaultHttpClient();
HttpPost httpPost = new HttpPost(HttpUrl);
httpPost.addHeader("Accept", "*/*");
httpPost.addHeader("Accept-Language", "zh-cn");
httpPost.addHeader("Referer", HttpUrl);
httpPost.addHeader("Content-Type", "application/x-www-form-urlencoded");
httpPost.addHeader("Cache-Control", "no-cache");
httpPost.addHeader("Accept-Encoding", "gzip, deflate");
httpPost.addHeader("User-Agent",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)");
httpPost.addHeader("Host", HttpHost);
httpPost.addHeader("Connection", "Keep-Alive");
// HttpHost httpProxy = new HttpHost("222.222.222.222", 1443, "http");
// httpClient.getParams().setParameter(AllClientPNames.DEFAULT_PROXY,httpProxy);
StringBuffer params = new StringBuffer();
String userName = "abin";
String passWord= "varyall";
String userAge= "12345";
String homeTown= "china beijing";
params.append("__userName ").append("=").append(userName )
.append("&").append(passWord").append("=")
.append(passWord).append("&").append("userAge")
.append("=").append(userAge).append("&")
.append("homeTown").append("=")
.append(homeTown);
HttpResponse httpResponse = null;
String result = "";
try {
StringEntity reqEntity = new StringEntity(params.toString());
httpPost.setEntity(reqEntity);
HttpHost httpTarget = new HttpHost(HttpHost, 80, "http");
httpResponse = httpClient.execute(httpTarget, httpPost);
System.out.println("httpResponse=" + httpResponse.getStatusLine());
BufferedInputStream buffer = new BufferedInputStream(httpResponse
.getEntity().getContent());
byte[] bytes = new byte[1024];
int line = 0;
StringBuilder builder = new StringBuilder();
while ((line = buffer.read(bytes)) != -1) {
builder.append(new String(bytes, 0, line));
}
result = new String(builder.toString());
} catch (Exception e) {
e.printStackTrace();
} finally {
if (httpPost.isAborted()) {
httpPost.abort();
}
httpClient.getConnectionManager().shutdown();
}
// System.out.println("result="+result);
}
}
//研究了一下午,终于发现一个问题,写这个代码不是很难的,难的是找一个能代理的IP地址,实际网上的好多代码都可以用滴,只是代理IP和Port有问题而已,废话少说,直接上代码: 1、先说Get的代理(首先提供一个Servlet的Get的http服务)
package com.abin.lee.servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-18
* Time: 上午8:39
* To change this template use File | Settings | File Templates.
*/
public class HttpClientGetProxyServlet extends HttpServlet {
public void init(ServletConfig config) throws ServletException {
super.init(config);
}
public void doGet(HttpServletRequest request,HttpServletResponse response)throws IOException {
System.out.println("receive httpGet request");
String userName=request.getParameter("userName");
String passWord=request.getParameter("passWord");
String localIp=request.getLocalAddr();
String localName=request.getLocalName();
int localPort=request.getLocalPort();
int ServerPort=request.getServerPort();
String leeHeader=request.getHeader("lee");
System.out.println("userName="+userName+",passWord="+passWord+",localIp="+localIp+",localName="+localName+",localPort="+localPort);
System.out.println("ServerPort="+ServerPort+",leeHeader="+leeHeader);
String remoteIp=request.getRemoteAddr();
String remoteHost=request.getRemoteHost();
int remotePort=request.getRemotePort();
System.out.println("remoteIp="+remoteIp+",remoteHost="+remoteHost+",remotePort="+remotePort);
ServletOutputStream out=response.getOutputStream();
BufferedWriter writer=new BufferedWriter(new OutputStreamWriter(out));
writer.write("success");
writer.flush();
writer.close();
}
}
HttpGet代理测试类:
package com.abin.lee.ssh.senior.proxy.httpclient;
import org.apache.http.Header;
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.conn.params.ConnRoutePNames;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
import org.junit.Test;
public class HttpClientGetProxyServletTest {
public static final String HttpGetProxyUrl="http://localhost:8100/MyThread/HttpClientGetProxyServlet";
@Test
public void testHttpClientPostProxyServlet()throws Exception {
HttpHost proxy = new HttpHost("10.10.10.10", 1443, "http");
DefaultHttpClient httpclient = new DefaultHttpClient();
try {
httpclient.getParams().setParameter(ConnRoutePNames.DEFAULT_PROXY, proxy);
HttpHost target = new HttpHost("localhost", 8100, "http");
HttpGet request = new HttpGet(HttpGetProxyUrl+"?"+"userName=abin&passWord=varyall");
request.setHeader("lee", "lee");
System.out.println("executing request to " + target + " via " + proxy);
HttpResponse rsp = httpclient.execute(target, request);
HttpEntity entity = rsp.getEntity();
System.out.println("----------------------------------------");
System.out.println(rsp.getStatusLine());
Header[] headers = rsp.getAllHeaders();
for (int i = 0; i<headers.length; i++) {
System.out.println(headers[i]);
}
System.out.println("----------------------------------------");
if (entity != null) {
System.out.println(EntityUtils.toString(entity));
}
} finally {
// When HttpClient instance is no longer needed,
// shut down the connection manager to ensure
// immediate deallocation of all system resources
httpclient.getConnectionManager().shutdown();
}
}
}
//正常测试代码,非代理
package com.abin.lee.ssh.senior.proxy.httpclient;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.DefaultHttpClient;
import org.junit.Test;
public class HttpClientGetServletTest {
public static final String HttpGetUrl = "http://localhost:8100/MyThread/HttpClientGetProxyServlet";
@Test
public void HttpClientGetServlet() {
HttpClient httpClient = new DefaultHttpClient();
StringEntity reqEntity = null;
HttpGet httpGet = null;
try {
HttpGet request = new HttpGet(HttpGetUrl+"?"+"userName=abin&passWord=varyall");
request.setHeader("lee", "lee");
// 目标地址
System.out.println("请求: " + httpGet.getRequestLine());
// 执行
HttpResponse response = httpClient.execute(httpGet);
HttpEntity entity = response.getEntity();
System.out.println("----------------------------------------");
System.out.println(response.getStatusLine());
if (entity != null) {
System.out.println("Response content length: "
+ entity.getContentLength());
}
// 显示结果
BufferedReader reader = new BufferedReader(new InputStreamReader(
entity.getContent(), "UTF-8"));
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (!httpGet.isAborted()) {
httpGet.abort();
}
httpClient.getConnectionManager().shutdown();
}
}
}
//servlet配置 <servlet> <servlet-name>HttpClientGetProxyServlet</servlet-name> <servlet-class>com.abin.lee.servlet.HttpClientGetProxyServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>HttpClientGetProxyServlet</servlet-name> <url-pattern>/HttpClientGetProxyServlet</url-pattern> </servlet-mapping> 我这里的IP和端口不一定能用哟,自己找能用的!!代码是100%没问题的,经过生产环境测试的哟!!!
//研究了一下午,终于发现一个问题,写这个代码不是很难的,难的是找一个能代理的IP地址,实际网上的好多代码都可以用滴,只是代理IP和Port有问题而已,废话少说,直接上代码: 1、先说Post的代理 //HttpClientPostProxyServlet
package com.abin.lee.servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 13-4-18
* Time: 上午8:39
* To change this template use File | Settings | File Templates.
*/
public class HttpClientPostProxyServlet extends HttpServlet {
public void init(ServletConfig config) throws ServletException {
super.init(config);
}
public void doPost(HttpServletRequest request,HttpServletResponse response)throws IOException {
System.out.println("receive httpPost request");
String userName=request.getParameter("userName");
String passWord=request.getParameter("passWord");
String localIp=request.getLocalAddr();
String localName=request.getLocalName();
int localPort=request.getLocalPort();
int serverPort=request.getServerPort();
String leeHeader=request.getHeader("lee");
System.out.println("userName="+userName+",passWord="+passWord+",localIp="+localIp+",localName="+localName+",localPort="+localPort);
System.out.println("serverPort="+serverPort+",leeHeader="+leeHeader);
String remoteIp=request.getRemoteAddr();
String remoteHost=request.getRemoteHost();
int remotePort=request.getRemotePort();
String remoteUser=request.getRemoteUser();
System.out.println("remoteIp="+remoteIp+",remoteHost="+remoteHost+",remotePort="+remotePort+",remoteUser="+remoteUser);
ServletOutputStream out=response.getOutputStream();
BufferedWriter writer=new BufferedWriter(new OutputStreamWriter(out));
writer.write("success");
writer.flush();
writer.close();
}
}
Post代理测试类: //HttpClientPostProxyServletTest.java
package com.abin.lee.ssh.senior.proxy.httpclient;
import org.apache.http.Header;
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.conn.params.ConnRoutePNames;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
import org.junit.Test;
public class HttpClientPostProxyServletTest {
public static final String HttpPostProxyUrl="http://localhost:8100/MyThread/HttpClientPostProxyServlet";
@Test
public void testHttpClientPostProxyServlet()throws Exception {
HttpHost proxy = new HttpHost("10.10.10.10", 1443, "http");
DefaultHttpClient httpclient = new DefaultHttpClient();
try {
httpclient.getParams().setParameter(ConnRoutePNames.DEFAULT_PROXY, proxy);
HttpHost target = new HttpHost("localhost", 8100, "http");
HttpPost request = new HttpPost(HttpPostProxyUrl);
StringEntity reqEntity = new StringEntity("userName=abin&passWord=varyall");
reqEntity.setContentType("application/x-www-form-urlencoded");
request.setEntity(reqEntity);
request.setHeader("lee", "lee");
System.out.println("executing request to " + target + " via " + proxy);
HttpResponse rsp = httpclient.execute(target, request);
HttpEntity entity = rsp.getEntity();
System.out.println("----------------------------------------");
System.out.println(rsp.getStatusLine());
Header[] headers = rsp.getAllHeaders();
for (int i = 0; i<headers.length; i++) {
System.out.println(headers[i]);
}
System.out.println("----------------------------------------");
if (entity != null) {
System.out.println(EntityUtils.toString(entity));
}
} finally {
// When HttpClient instance is no longer needed,
// shut down the connection manager to ensure
// immediate deallocation of all system resources
httpclient.getConnectionManager().shutdown();
}
}
}
//正常测试代码,非代理
package com.abin.lee.ssh.senior.proxy.httpclient;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.DefaultHttpClient;
import org.junit.Test;
public class HttpClientPostServletTest {
public static final String HttpPostUrl="http://localhost:8100/MyThread/HttpClientPostProxyServlet";
@Test
public void testHttpClientPostServlet(){
HttpClient httpClient = new DefaultHttpClient();
HttpPost httpPost = new HttpPost(HttpPostUrl);
try {
// 目标地址
System.out.println("请求: " + httpPost.getRequestLine());
// 构造最简单的字符串数据
StringEntity reqEntity = new StringEntity("userName=abin&passWord=varyall");
// 设置类型
reqEntity.setContentType("application/x-www-form-urlencoded");
// 设置请求的数据
httpPost.setEntity(reqEntity);
httpPost.setHeader("lee", "lee");
// 执行
HttpResponse response = httpClient.execute(httpPost);
HttpEntity entity = response.getEntity();
System.out.println("----------------------------------------");
System.out.println(response.getStatusLine());
if (entity != null) {
System.out.println("Response content length: " + entity.getContentLength());
}
// 显示结果
BufferedReader reader = new BufferedReader(new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(!httpPost.isAborted()){
httpPost.abort();
}
httpClient.getConnectionManager().shutdown();
}
}
}
//servlet配置
<servlet>
<servlet-name>HttpClientPostProxyServlet</servlet-name>
<servlet-class>com.abin.lee.servlet.HttpClientPostProxyServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HttpClientPostProxyServlet</servlet-name>
<url-pattern>/HttpClientPostProxyServlet</url-pattern>
</servlet-mapping>
我这里的IP和端口不一定能用哟,自己找能用的!!代码是100%没问题的,经过生产环境测试的哟!!!
摘要: Introduction
EasyMock (http://www.easymock.org/)使用Java的proxy机制即时为接口提供Mock Object (和扩展类的object)。因EasyMock独特的期望记录方式,大部分重构不会印象Mock Object,故EasyMock很适合于TDD。
EasyMock的license为Apache 2.0 (details see... 阅读全文
使用simple-spring-memcached统一缓存的使用如何在一个中型的Java应用中使用Memcached缓存数据不是个简单的问题。当某个缓存数据需要在多个系统间共享和失效时,必须要有统一的规划才能保证不出错。经过各种实践,目前系统在使用Memcached缓存数据全部采用Simple-Spring-Memcached框架来完成,并统一规划各系统Spring和Cache key的配置。
下面对在使用过程中需要注意的点做一个详细说明: Cache整体规划目前我们系统中有两个不同的Memcached服务器: - session memcached服务器:主要存储用户的session
- app memcached服务器: 主要用于缓存应用数据
由于应用所有的缓存数据都放在app缓存上,为避免各应用的缓存数据出现冲突,必须规划好它们的命名空间。所幸Simple-Spring-Memcached支持namespace的概念,因此对各应用的namespace前缀规定如下: | 应用 | NAMESPACE前缀 | |
|---|
| goodscenter | goodscenter | | | trade | trade | | | uic | uic | |
这个namespace在生成key时,将放在最前面,稍后会有例子详述。
同一个应用中存在许多需要缓存的对象,因此约定namespace前缀之后再加上缓存对象的类名。
例子如下: | 应用 | 缓存对象 | 完整的NAMESPACE | 最终生成的KEY |
|---|
| trade | TcRate (id为42) | trade:TcRate | trade:TcRate:12 | | goodscenter | GoodsDo(id为42) | goodscenter:GoodsDo | goodscenter:GoodsDo:12 |
key的生成规则Simple-Spring-Memcached提供的针对单个对象的注解接口提供了两种key生成方式,详情见此文 - AssignCache类注解通过assignKey指定cache的key
- SingleCache类注解通过ParameterValueKeyProvider注解指定生成key的方法
对于第一种只要求必须保证key不与其它的冲突,且namesapce符合规则。
第二种时,约定缓存的数据对象必须实现有带CacheKeyMethod的cacheKey方法,参考实现如下: @CacheKeyMethod public String cacheKey() { return this.getId(); } | 目前@CacheKeyMethod只支持返回String的方法,需要改造成可接受Long,Integer型的。当前必须有单独的方法来作为缓存Key的生成器 |
 | 真实存放到Memcached的key的生成规则是:namespace:key。
如goodscenter的id为42的domain对象GoodsDo,按上述方式生成的key为:goodscenter:GoodsDo:42 |
spring配置说明关于Simple-Spring-Memcached具体XML配置如下: <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd"> <import resource="classpath:simplesm-context.xml"/> <aop:aspectj -autoproxy/> <context:annotation -config/> <bean name="appCache" class="com.google.code.ssm.CacheFactory"> <property name="cacheClientFactory"> <bean class="com.google.code.ssm.providers.xmemcached.MemcacheClientFactoryImpl"/> </property> <property name="addressProvider"> <bean class="com.google.code.ssm.config.DefaultAddressProvider"> <!--memcached服务器ip:port 可以是多个,格式为: 127.0.0.1:11211,192.168.100.11:11211--> <property name="address" value="{memcached.server}"/> </bean> </property> <property name="configuration"> <!-- memcached连接器的配置,具体的配置项参考这个类 --> <bean class="com.google.code.ssm.providers.XMemcachedConfiguration"> <!--是否使用一致性哈希--> <property name="consistentHashing" value="true"/> <!--连接池--> <property name="connectionPoolSize" value="10"/> <property name="optimizeGet" value="true"/> </bean> </property> <property name="cacheName"> <!-- 该Memcached配置的Cache名称 一个应用中存在多个Memcached时,各个配置的cacheName必须不同。如果该值未设,系统默认为default --> <value>appCache</value> </property> </bean> </beans>Java代码中使用说明a. 注解方式使用直接使用注解来处理缓存及失效非常简单,下面是相应的例子:
读取缓存: EventGoodsServiceClientImpl.java @Override @ReadThroughSingleCache(namespace = "goodscenter:EventGoodsDo", expiration = 60) @CacheName("appCache") public EventGoodsDo queryEventGoodsDo(@ParameterValueKeyProvider(order = 0) long goodsId, @ParameterValueKeyProvider(order = 1) long eventId) { return getRemoteServiceBean().queryEventGoodsDo(goodsId, eventId); }更新缓存: EventGoodsDaoImpl.java @BridgeMethodMappings(value = {@BridgeMethodMapping(erasedParamTypes ={Object.class},targetParamTypes = {com.hqb360.promotion.dao.entity.EventGoods.class},methodName = "update")}) public class EventGoodsDaoImpl<EventGoods> extends BaseDaoImpl<EventGoods> implements EventGoodsDao<EventGoods> { @Override public DaoStatementName getDaoStatementName() { return new DefaultDaoStatementName() { public String getDomainName() { return "EventGoods"; } }; } @Override @InvalidateSingleCache(namespace = "goodscenter:EventGoodsDo") @CacheName("appCache") public void update(@ParameterValueKeyProvider EventGoods obj) throws DataAccessException { super.update(obj); } }EventGoods.java @CacheKeyMethod public String getCacheKey() { return goodsId + CACHE_ID_SEPARATOR + eventId; } public static final String CACHE_ID_SEPARATOR = "/";上述代码需要注意的点- 多个方法参数都作为cacheKey时,ParameterValueKeyProvider必须指明其order值
- 多个方法参数作为cacheKey时,参数之间在 / 号分隔
- EventGoodsDaoImpl类中的update方法参数接收的是一个泛型对象,因此必须在该类上配置BridgeMethodMappings。具体配置见示例
b. 以bean的方式使用Cache对象某些场景我们希望更便捷地自己手动来管理缓存数据,此时需要使用Simple-Spring-Memcached配置中定义的bean。以上面的配置文件为例,使用方法如下
bean的注入: @Autowired private Cache appCache; bean的使用: appCache.set(Constants.CACHE_KEY + members.getMemberId(), 3600,cacheValue);
@CacheName: 指定缓存实例注解 @CacheKeyMethod:缓存key生成注解 ---------------------------------读取------------------------------------------- @ReadThroughAssignCache(assignedKey = "SomePhatKey", namespace = "Echo", expiration = 3000): 读取指定key缓存 @ReadThroughSingleCache(namespace = SINGLE_NS, expiration = 0):读取单个缓存 @ReadThroughMultiCache(option = @ReadThroughMultiCacheOption(generateKeysFromResult = true)):读取多个缓存 @ReadThroughMultiCacheOption(generateKeysFromResult = true) 读取多个缓存操作generateKeysFromResult 通过结果生成key ---------------------------------更新------------------------------------------- @UpdateAssignCache(assignedKey = "SomePhatKey", namespace = "Echo", expiration = 3000): 指定key更新缓存 @UpdateSingleCache(namespace = SINGLE_NS, expiration = 2): 更新单个缓存(namespace 命名空间, expiration 失效时间单位秒) @UpdateMultiCache(namespace = "Bravo", expiration = 300): 更新多个缓存 ---------------------------------失效------------------------------------------- @InvalidateAssignCache(assignedKey = "SomePhatKey", namespace = "Echo") : 指定key失效缓存 @InvalidateSingleCache(namespace = SINGLE_NS):失效单个缓存 @InvalidateMultiCache(namespace = "Delta") : 失效多个缓存 ---------------------------------参数------------------------------------------- @ParameterDataUpdateContent: 标记方法的参数作为更新内容。这个注解应结合Update*Cache注解使用 @ParameterValueKeyProvider: 标记将方法的参数做为计算缓存key.如果方法被注解的对象标记CacheKeyMethod的方法将会用来生成缓存key否则调用toString()生成 @ParameterValueKeyProvider(order=0) 属性表示如果多个参数做为key时需提供参数顺序 与@ParameterValueKeyProvider类似的注解有: { @ReturnValueKeyProvider: 返回值对象中计算key } ---------------------------------泛型处理------------------------------------------- @BridgeMethodMappings({ @BridgeMethodMapping(methodName = "updateUser", erasedParamTypes = { Object.class }, targetParamTypes = { AppUser.class }) }): 泛型桥接注解 methodName : 指定方法 erasedParamTypes : 擦除对象类型 targetParamTypes : 目标转换类型 ---------------------------------计数器------------------------------------------- @InvalidateAssignCache :在给的计算器上加1. 如果不存在则初始化为1 @DecrementCounterInCache : 在给的计数器上减1 @ReadCounterFromCache :读取计数器 @UpdateCounterFromCache : 更新计数器 Simple-Spring-Memcached代码阅读之BridgeMethod http://www.colorfuldays.org/program/java/bridgemethod%E7%9A%84%E4%BD%9C%E7%94%A8/ http://www.colorfuldays.org/tag/ssm/ 这个系列不错 b. 以bean的方式使用Cache对象某些场景我们希望更便捷地自己手动来管理缓存数据,此时需要使用Simple-Spring-Memcached配置中定义的bean。以上面的配置文件为例,使用方法如下
bean的注入: @Autowired private Cache appCache; bean的使用: appCache.set(Constants.CACHE_KEY + members.getMemberId(), 3600,cacheValue);
主要是思维方式的不同:
显然,RPC是以方法调用的方式描述WebSerivce的,也就是说,你要说清楚调用的那个方法,以及各个参数的名称和值。要描述这些东东,SOAP消息就要有一个统一的规范,指出那一部分是方法名,哪个部分是参数,哪个部分是返回值。换句话说,RPC方式调用的SOAP消息格式是有章可循的,固定的。(比如说,每个Parameter必须对应一个Part,Part的name必须和参数名一致)。
而Document则是以文档传输的方式描述WebService,只要你的SoapBody里面是一个可以用Schema描述的合法的Xml文档就行了,对具体的格式没有什么要求(Schema要在WSDL里面写)。
可以看出,Document形式要更加灵活——尤其是需要传输特定格式的Xml文档的时候,而RPC的Soap消息实际上也可以用Document形式模拟(只要Schema定义得当)。所以目前Document方式应用更广泛一些(也是.NET里面的缺省方式)。
对Namespace,我觉得两者应该没有明显的区别。主要是RPC通常与Encoding模式结合使用,这就要引用Soap的namespace了;而Document只要引用XmlSchema的Namespace定义类型就成了。
尽管是转载的,但是原文中几处错误或者不规范的表达,我已经进行了修改。
大部分 Web 服务都是围绕着远程过程调用而构建的,而 WSDL 规范允许另外一种 Web 服务体系结构:文档样式( document style )。在该体系结构中,整个文档在服务客户端和服务器之间进行交换。在本文中, James McCarthy 将向您解释文档样式以及应该何时使用它。
在 Web 服务描述语言( Web Service Definition Language , WDSL )规范中隐含着一个非常巧妙的转换开关,它可以将 Web 服务的 SOAP 绑定从远程过程调用转换成 pass-through 文档。在 SOAP 协议绑定中的样式属性可以包含这两个值中的一个: rpc 或 document 。当属性被设定为文档样式时,客户端知道应该使用 XML 模式而不是远程过程调用约定。本文将提供对这个 WSDL 转换开关的说明,描述它的好处,并将解释应该何时使用 pass-through 文档。
首先,让我们简要地谈谈 WSDL 的一些要点,来理解这个巧妙的转换是如何发生的。 WSDL 是一项 XML 规范,它被用来描述Web服务以及对于到达端点(服务)的协议相关的需求。 WSDL 用抽象术语来描述服务;通过可扩展的绑定定义,它能够为使用具体术语调用服务定义协议和数据格式规范。下面的语法是直接从 WSDL 规范中摘 录出来的,展示了在绑定中所包含的可扩展性元素:
|
<wsdl:definitions .... >
<wsdl:binding name="nmtoken" type="qname"> *
<-- extensibility element (1) --> *
<wsdl:operation name="nmtoken"> *
<-- extensibility element (2) --> *
<wsdl:input name="nmtoken"? > ?
<-- extensibility element (3) -->
</wsdl:input>
<wsdl:output name="nmtoken"? > ?
<-- extensibility element (4) --> *
</wsdl:output>
<wsdl:fault name="nmtoken"> *
<-- extensibility element (5) --> *
</wsdl:fault>
</wsdl:operation>
</wsdl:binding>
</wsdl:definitions> |
WSDL 规范通常描述三种绑定扩展: HTTP GET/POST 、 MIME 以及 SOAP version 1.1 。 HTTP GET/POST 和 MIME 中定义的绑定扩展用来定义与标准的 Web 应用程序进行通信的需
求,这些应用程序可能返回(也可能不返回) XML 文档。在发送或返回 XML 文档时, HTTP GET/POST 绑定的扩展是隐式的文档样式。
SOAP 绑定扩展用来定义支持 SOAP 信封协议的服务。 SOAP 信封是一种简单模式,它设计成能包含 XML 消息,提供特定于应用程序的消息头和消息体。 SOAP 绑定的扩展使 WSDL 文档能够声明 SOAP 消息的需求,这样应用程序就能够与服务正确通信。 SOAP 扩展允许将 SOAP 消息的样式声明为文档或 RPC 。如果在 soap:binding 元素中声明了样式属性,那么该样式将成为所有没有显式声明的样式属性的 soap:operation 元素的缺省值。如果在 soap:binding 元素中没有声明样式属性,那么缺省的样式就是文档。下面是文档样式的显式声明:
|
<soap:binding style="document" transport="uri"> |
不管 soap:binding 元素中的声明如何, soap:operation 元素可以覆盖每个操作的声明,就像这样的:
|
<soap:operation soapAction="uri" style="document"> |
在声明了文档样式的 SOAP 消息中,原始( as-is )或编码( encoded )的消息被直接放置在 SOAP 信封的体部。
如果样式声明为 RPC ,消息就封装在包装器元素中,同时带有从操作名属性中提取的的元素的名称以及从操作名称空间属性中提取的名称空间。
勿庸置疑,使用 XML 调用跨平台的远程过程调用的能力是非常有用的,它是使用 Web 服务的非常有说服力的理由。但是如果 Web 服务仅仅局限于 RPC 消息传递,这项技术的影响将是有限的。幸运的是,开发人员可以选择是使用 RPC 还是文档样式的消息传递,并且能够使用适合的技术来完成他们面临的任务。
XML 规范开发用来使通常锁定于专有格式的常规数据可以以一种人易读的、自描述的、自验证的开放格式来描述。当 Web 服务使用文档消息传递时,它可以利用 XML 的全部能力来描述和验证高级业务文档。当服务使用 RPC 消息格式化时, XML 描述方法以及为方法调用编码的参数,但是却不能用来执行高级业务规则。为了执行这些规则, RPC 消息必须包含 XML 文档作为字符串参数并且在被调用的方法中隐藏验证。出于这个原因, XML 的某些好处就丧失了,或者至少是被隐藏在后台应用程序里了。
使用文档消息传递的另外一个原因在于,远程过程调用必须是相对静态的,并且对接口的任何变化都将破坏服务和应用程序之间的契约。如果服务是广泛分布的,那么很可能大量的应用程序已经从它的 WSDL 文档中产生了存根代码。改变 WSDL 将会导致所有依赖于特定方法签名的应用程序被破坏,而且许多支持行产生问题。好的设计要求 RPC 消息服务的方法签名不应该改变。使用文档消息传递,规则更严格,并且可以使 XML 模式得到显著增强和改变,同时又不会破坏调用应用程序。
当业务使用基于 Web 的应用程序通过 Internet 交换信息时,应用程序应该能够使用有保证的交付机制来提高它的可靠性、可伸缩性和性能。为了达到这个目的,应用程序通常将使用异步消息队列。由于文档消息通常是自包含的,所以它更适合于异步处理,并且可以直接放到队列中。之所以说应用程序的可靠性得到了提高,是因为即使目标应用程序当前不是活动的,消息队列也可以保证消息的交付;之所以说性能得到了提高,是因为 Web 应用程序只是把文档发送到队列中,然后便可以自由地执行其他的任务;之所以说可扩展性得到了提高,是因为文档被下传到一个或多个应用程序的实例以进行处理。
业务文档的设计通常很好地适于面向对象的体系结构。结果,两个应用程序可以设计成通过使用 XML 交换对象的状态。与对象序列化相比,在对象交换中,交换的每个端点都可以自由地设计它认为合适的对象,只要交换符合达成协议的 XML 文件格式即可。不使用对象序列化的一个原因是为了支持对象在客户端和服务器端的实现。许多现有的特定于行业的 XML 模式被设计成客户端 / 服务器体系结构,在这种体系结构中,在客户端上完成的处理与预定在服务器上完成的处理是分离的。通常的情况是,客户端仅仅以服务器要求的特定文档格式请求或保存信息。当然,这种类型的交换也能用 RPC 消息完成,但是这种消息的编码方式限制了每个端点上的对象的设计。在文档样式中就不会出现这些限制问题。
什么时候应该使用文档样式呢?简单地说:只要没有连接到已存在的远程过程调用,任何时候都可以使用文档方式。使用文档方式比起通常花费额外的工作来连接服务,好处要大得多。不过需要提醒的是:一般来说,构建一个使用文档消息传递的服务的工作量要比构建一个 RPC 消息服务所需的工作量大。这些额外的工作通常包括 XML 模式的设计或对已存在的模式的支持、以及从文档中提取相关的信息。模式设计是重要的,因为 XML 解析器使用这个模式来验证文档,支持预定的业务规则。服务需要进行额外的工作来从文档中提取用于处理请求的相关信息。相比之下, RPC 消息只需要设计方法的接口,通过方法的接口, RPC 消息就可以自动地编组和解组参数。
当您决定发布一项服务时,您可能应该考虑下列问题。我将在下面的部分中分析您的答案的结果。
- 这项服务是连接到已存在的过程调用,并且这个过程调用是无状态的吗?
- 这项服务是仅在您的组织内部使用,还是也可以被外部用户所使用?
- 参数之一仅仅是 XML 文档规范吗?
- 这项服务需要请求 / 响应体系结构吗?
- 参数表示了可以从用于验证的 XML 文档模式受益的复杂结构吗?
- 所有需要进行交换的信息都能够合理地存放在内存中吗?
如果必须以特定的顺序调用多个过程来维护应用程序状态,您应该考虑在您的服务中使用文档体系结构。如果需要多个过程调用,那么过程就不是无状态的,并且服务必须维护应用程序状态。在 Web 服务中维护状态可能是困难的;在远程过程调用的情况下,很少有客户端平台会产生能够支持状态信息的存根代码。一个可能的解决方案是使用文档体系结构,并在文档内部传送整个事务的内容。在这种情况下,服务将执行调用,以确保服务内部保持正确的顺序,并且状态信息的维护不超出单个事务的范围。如果仍然需要状态信息,可以将状态信息记录在最终得到的文档中,客户端应用程序也可以维护一个用于服务识别它的状态的令牌。
如果一个应用程序被发布到组织以外,发布者就很难控制谁正依赖于这个服务,以及如果做出任何改动后果会怎样。在这种情况下,使用文档消息传递和支持像 ebXML 这样的通用交换协议可能更加有利。通用交换协议正发展成能改善外部交换的管理,因此新的贸易合作伙伴协定就可以快速地部署。同样,如果您的服务不需要请求 / 响应体系结构,那么通用交换协议就可以更好地设计来处理认证、可靠消息交付以及异步请求 / 响应。
如果您的服务正使用字符串参数来传递或返回 XML 文档,或者它的参数之一是一个具有复杂结构且需要自定义处理的对象,那么文档消息传递就可能是较好的选择。将参数的真实含义隐藏在字符串里经常会导致带有无效参数的有效调用。如果服务发布了 XML 文档模式,那么在调用服务之前根据这个模式进行验证就会更加容易。复杂结构经常用来传递组成完整事务的数百条信息。在处理复杂的结构时,远程过程服务可能不得不处理自定义的编组代码,同时应用程序仍然负责仔细地验证结构的每个元素。如果使用文档消息传递,那么应用程序程序员就可以使用 XML 模式来将验证下传到文档设计器,并且不需要自定义的编组代码。
择使用文档样式的消息传递还是 RPC 样式的消息传递时,需要考虑的最后一个因素是需要处理的信息量大小。由于采用 RPC 样式的消息传递来编组参数的大部分(如果不是全部的话)实现都是在内存中执行这项操作,所以内存约束可能会使得 RPC 消息传递行不通。许多文档消息传递服务能够选择是用 DOM 还是用 SAX 来处理文档,因而能够最小化内存中的处理。这对于 Web 服务尤为关键,因为它可能需要处理成千上万的请求,而且其中许多是同时发生的。
在您设计下一个 Web 服务时,您需要考虑当前的 WSDL 规范为您提供的所有选择。在开始创建过程性的接口之前,考虑好将如何使用服务,谁将使用它,以及需要交换的数据的类型和数量。设计开发文档样式的 Web 服务可能需要稍多一些的工作量,但是在很多情况下,这些额外的工作量将会换取更高的信息质量和更可靠的交换性能。
TCP/IP:
数据链路层:ARP,RARP
网络层: IP,ICMP,IGMP
传输层:TCP ,UDP,UGP
应用层:Telnet,FTP,SMTP,SNMP.
OSI:
物理层:EIA/TIA-232, EIA/TIA-499, V.35, V.24, RJ45, Ethernet, 802.3, 802.5, FDDI, NRZI, NRZ, B8ZS
数据链路层:Frame Relay, HDLC, PPP, IEEE 802.3/802.2, FDDI, ATM, IEEE 802.5/802.2
网络层:IP,IPX,AppleTalk DDP
传输层:TCP,UDP,SPX
会话层:RPC,SQL,NFS,NetBIOS,names,AppleTalk,ASP,DECnet,SCP
表示层:TIFF,GIF,JPEG,PICT,ASCII,EBCDIC,encryption,MPEG,MIDI,HTML
应用层:FTP,WWW,Telnet,NFS,SMTP,Gateway,SNMP
应用层
1.主要功能 :用户接口、应用程序
application 2.典型设备:网关
3.典型协议、标准和应用:TELNET, FTP, HTTP
表示层
1.主要功能 :数据的表示、压缩和加密
presentation2.典型设备:网关
3.典型协议、标准和应用:ASCLL、PICT、TIFF、JPEG、 MIDI、MPEG
会话层
1.主要功能 :会话的建立和结束
session2.典型设备:网关
3.典型协议、标准和应用:RPC、SQL、NFS 、X WINDOWS、ASP
传输层
1.主要功能 :端到端控制
transport 2.典型设备:网关
3.典型协议、标准和应用:TCP、UDP、SPX
网络层
1.主要功能 :路由,寻址
network2.典型设备:路由器
3.典型协议、标准和应用:IP、IPX、APPLETALK、ICMP
数据链路层
1.主要功能 :保证误差错的数据链路
data link 2.典型设备:交换机、网桥、网卡
3.典型协议、标准和应用:802.2、802.3ATM、HDLC、FRAME RELAY
物理层
1.主要功能 :传输比特流
physical2.典型设备:集线器、中继器
3.典型协议、标准和应用:V.35、EIA/TIA-232
从下到上,物理层最低的!!!!应用层最高。
什么是TCP/IP协议,划为几层,各有什么功能?
TCP/IP协议族包含了很多功能各异的子协议。为此我们也利用上文所述的分层的方式来剖析它的结构。TCP/IP层次模型共分为四层:应用层、传输层、网络层、数据链路层。
TCP/IP网络协议
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网间网协议)是目前世界上应用最为广泛的协议,它的流行与Internet的迅猛发展密切相关—TCP/IP最初是为互联网的原型ARPANET所设计的,目的是提供一整套方便实用、能应用于多种网络上的协议,事实证明TCP/IP做到了这一点,它使网络互联变得容易起来,并且使越来越多的网络加入其中,成为Internet的事实标准。
* 应用层—应用层是所有用户所面向的应用程序的统称。ICP/IP协议族在这一层面有着很多协议来支持不同的应用,许多大家所熟悉的基于Internet的应用的实现就离不开这些协议。如我们进行万维网(WWW)访问用到了HTTP协议、文件传输用FTP协议、电子邮件发送用SMTP、域名的解析用DNS协议、远程登录用Telnet协议等等,都是属于TCP/IP应用层的;就用户而言,看到的是由一个个软件所构筑的大多为图形化的操作界面,而实际后台运行的便是上述协议。
* 传输层—这一层的的功能主要是提供应用程序间的通信,TCP/IP协议族在这一层的协议有TCP和UDP。
* 网络层—是TCP/IP协议族中非常关键的一层,主要定义了IP地址格式,从而能够使得不同应用类型的数据在Internet上通畅地传输,IP协议就是一个网络层协议。
* 网络接口层—这是TCP/IP软件的最低层,负责接收IP数据包并通过网络发送之,或者从网络上接收物理帧,抽出IP数据报,交给IP层。
1.TCP/UDP协议
TCP (Transmission Control Protocol)和UDP(User Datagram Protocol)协议属于传输层协议。其中TCP提供IP环境下的数据可靠传输,它提供的服务包括数据流传送、可靠性、有效流控、全双工操作和多路复用。通过面向连接、端到端和可靠的数据包发送。通俗说,它是事先为所发送的数据开辟出连接好的通道,然后再进行数据发送;而UDP则不为IP提供可靠性、流控或差错恢复功能。一般来说,TCP对应的是可靠性要求高的应用,而UDP对应的则是可靠性要求低、传输经济的应用。TCP支持的应用协议主要有:Telnet、FTP、SMTP等;UDP支持的应用层协议主要有:NFS(网络文件系统)、SNMP(简单网络管理协议)、DNS(主域名称系统)、TFTP(通用文件传输协议)等。
IP协议的定义、IP地址的分类及特点
什么是IP协议,IP地址如何表示,分为几类,各有什么特点?
为了便于寻址和层次化地构造网络,IP地址被分为A、B、C、D、E五类,商业应用中只用到A、B、C三类。
IP协议(Internet Protocol)又称互联网协议,是支持网间互连的数据报协议,它与TCP协议(传输控制协议)一起构成了TCP/IP协议族的核心。它提供网间连接的完善功能, 包括IP数据报规定互连网络范围内的IP地址格式。
Internet 上,为了实现连接到互联网上的结点之间的通信,必须为每个结点(入网的计算机)分配一个地址,并且应当保证这个地址是全网唯一的,这便是IP地址。
目前的IP地址(IPv4:IP第4版本)由32个二进制位表示,每8位二进制数为一个整数,中间由小数点间隔,如159.226.41.98,整个IP地址空间有4组8位二进制数,由表示主机所在的网络的地址(类似部队的编号)以及主机在该网络中的标识(如同士兵在该部队的编号)共同组成。
为了便于寻址和层次化的构造网络,IP地址被分为A、B、C、D、E五类,商业应用中只用到A、B、C三类。
* A类地址:A类地址的网络标识由第一组8位二进制数表示,网络中的主机标识占3组8位二进制数,A类地址的特点是网络标识的第一位二进制数取值必须为 “0”。不难算出,A类地址允许有126个网段,每个网络大约允许有1670万台主机,通常分配给拥有大量主机的网络(如主干网)。
* B类地址:B类地址的网络标识由前两组8位二进制数表示,网络中的主机标识占两组8位二进制数,B类地址的特点是网络标识的前两位二进制数取值必须为“10”。B类地址允许有16384个网段,每个网络允许有65533台主机,适用于结点比较多的网络(如区域网)。
* C类地址:C类地址的网络标识由前3组8位二进制数表示,网络中主机标识占1组8位二进制数,C类地址的特点是网络标识的前3位二进制数取值必须为“110”。具有C类地址的网络允许有254台主机,适用于结点比较少的网络(如校园网)。
为了便于记忆,通常习惯采用4个十进制数来表示一个IP地址,十进制数之间采用句点“.”予以分隔。这种IP地址的表示方法也被称为点分十进制法。如以这种方式表示,A类网络的IP地址范围为1.0.0.1-127.255.255.254;B类网络的IP地址范围为:128.1.0.1-191.255.255.254;C类网络的IP地址范围为:192.0.1.1-223.255.255.254。
由于网络地址紧张、主机地址相对过剩,采取子网掩码的方式来指定网段号。
TCP/IP协议与低层的数据链路层和物理层无关,这也是TCP/IP的重要特点。正因为如此 ,它能广泛地支持由低两层协议构成的物理网络结构。目前已使用TCP/IP连接成洲际网、全国网与跨地区网。
OSP与TCP/IP的参考层次图:

OSP与TCP/IP的比较:
分层结构
OSI参考模型与TCP/IP协议都采用了分层结构,都是基于独立的协议栈的概念。OSI参考模型有7层,而TCP/IP协议只有4层,即TCP/IP协议没有了表示层和会话层,并且把数据链路层和物理层合并为网络接口层。不过,二者的分层之间有一定的对应关系
标准的特色
OSI参考模型的标准最早是由ISO和CCITT(ITU的前身)制定的,有浓厚的通信背景,因此也打上了深厚的通信系统的特色,比如对服务质量(QoS)、差错率的保证,只考虑了面向连接的服务。并且是先定义一套功能完整的构架,再根据该构架来发展相应的协议与系统。
TCP/IP协议产生于对Internet网络的研究与实践中,是应实际需求而产生的,再由IAB、IETF等组织标准化,而并不是之前定义一个严谨的框架。而且TCP/IP最早是在UNIX系统中实现的,考虑了计算机网络的特点,比较适合计算机实现和使用。
连接服务
OSI的网络层基本与TCP/IP的网际层对应,二者的功能基本相似,但是寻址方式有较大的区别。
OSI的地址空间为不固定的可变长,由选定的地址命名方式决定,最长可达160byte,可以容纳非常大的网络,因而具有较大的成长空间。根据OSI的规定,网络上每个系统至多可以有256个通信地址。
TCP/IP网络的地址空间为固定的4byte(在目前常用的IPV4中是这样,在IPV6中将扩展到16byte)。网络上的每一个系统至少有一个唯一的地址与之对应。
传输服务
OSI与TCP/IP的传输层都对不同的业务采取不同的传输策略。OSI定义了五个不同层次的服务:TP1,TP2,TP3,TP4,TP5。TCP/IP定义了TCP和UPD两种协议,分别具有面向连接和面向无连接的性质。其中TCP与OSI中的TP4,UDP与OSI中的TP0在构架和功能上大体相同,只是内部细节有一些差异。
应用范围
OSI由于体系比较复杂,而且设计先于实现,有许多设计过于理想,不太方便计算机软件实现,因而完全实现OSI参考模型的系统并不多,应用的范围有限。而TCP/IP协议最早在计算机系统中实现,在UNIX、Windows平台中都有稳定的实现,并且提供了简单方便的编程接口(API),可以在其上开发出丰富的应用程序,因此得到了广泛的应用。TCP/IP协议已成为目前网际互联事实上的国际标准和工业标准。
数据库连接池在初始化的时候会创建initialSize个连接,当有数据库操作时,会从池中取出一个连接。如果当前池中正在使用的连接数等于maxActive,则会等待一段时间,等待其他操作释放掉某一个连接,如果这个等待时间超过了maxWait,则会报错;如果当前正在使用的连接数没有达到maxActive,则判断当前是否空闲连接,如果有则直接使用空闲连接,如果没有则新建立一个连接。在连接使用完毕后,不是将其物理连接关闭,而是将其放入池中等待其他操作复用。
对于一个数据库连接池,一般包括一下属性。
名称 说明 备注
minIdle 最小活跃数 可以允许的空闲连接数目
maxActive 最大连接数 相当于池的大小
initialSize 初始化连接大小
maxWait 获取连接的最大等待时间
timeBetweenEvictionRunsMillis 空闲连接的最大生存时间 指定空闲连接在空闲多长时间后,关闭其物理连接
testWhileIdle 是否在空闲时检测连接可用性 由于网络或者数据库配置的原因(比如mysql连接的8小时限制),开启这个开关可以定期检测连接的可用性
锁:
- 内置锁 (监视器锁): 每个java对象都可以做一个实现同步的锁,这些锁被成为内置锁. 获得锁的唯一途径就是进入有这个锁保护的代码块或方法
- 重入锁: 由于内置锁是可重入的,因此如果某个线程试图获得一个以已经由他自己持有的锁, 那么这个请求就会成功.重入意味着获取锁的操作粒度是"线程",而不是"调用"
volatile 使用条件(必须同时满足所有条件):
- 对变量的写入操作不依赖变量的当前值,或者你能确保只有单个线程更新变量的值
- 该变量不会与其他状态变量一起纳入不变性条件中
- 在访问变量时间不需要加锁
高并发术语
|
术语 |
英文单词 |
描述 |
|
比较并交换 |
Compare and Swap |
CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。 |
|
CPU流水线 |
CPU pipeline |
CPU流水线的工作方式就象工业生产上的装配流水线,在CPU中由5~6个不同功能的电路单元组成一条指令处理流水线,然后将一条X86指令分成5~6步后再由这些电路单元分别执行,这样就能实现在一个CPU时钟周期完成一条指令,因此提高CPU的运算速度。 |
|
内存顺序冲突 |
Memory order violation |
内存顺序冲突一般是由假共享引起,假共享是指多个CPU同时修改同一个缓存行的不同部分而引起其中一个CPU的操作无效,当出现这个内存顺序冲突时,CPU必须清空流水线。 |
|
共享变量 |
|
在多个线程之间能够被共享的变量被称为共享变量。共享变量包括所有的实例变量,静态变量和数组元素。他们都被存放在堆内存中,Volatile只作用于共享变量。 |
|
内存屏障 |
Memory Barriers |
是一组处理器指令,用于实现对内存操作的顺序限制。 |
|
缓冲行 |
Cache line |
缓存中可以分配的最小存储单位。处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期。 |
|
原子操作 |
Atomic operations |
不可中断的一个或一系列操作。 |
|
缓存行填充 |
cache line fill |
当处理器识别到从内存中读取操作数是可缓存的,处理器读取整个缓存行到适当的缓存(L1,L2,L3的或所有) |
|
缓存命中 |
cache hit |
如果进行高速缓存行填充操作的内存位置仍然是下次处理器访问的地址时,处理器从缓存中读取操作数,而不是从内存。 |
|
写命中 |
write hit |
当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存,这个操作被称为写命中。 |
synchronized
volatile
concurrent
在并发编程中很常用的实用工具类。此包包括了几个小的、已标准化的可扩展框架,以及一些提供有用功能的类,没有这些类,这些功能会很难实现或实现起来冗长乏味。下面简要描述主要的组件。另请参阅 locks 和 atomic 包。
执行程序接口。Executor 是一个简单的标准化接口,用于定义类似于线程的自定义子系统,包括线程池、异步 IO 和轻量级任务框架。根据所使用的具体 Executor 类的不同,可能在新创建的线程中,现有的任务执行线程中,或者调用 execute() 的线程中执行任务,并且可能顺序或并发执行。ExecutorService 提供了多个完整的异步任务执行框架。ExecutorService 管理任务的排队和安排,并允许受控制的关闭。ScheduledExecutorService 子接口及相关的接口添加了对延迟的和定期任务执行的支持。ExecutorService 提供了安排异步执行的方法,可执行由 Callable 表示的任何函数,结果类似于 Runnable。Future 返回函数的结果,允许确定执行是否完成,并提供取消执行的方法。RunnableFuture 是拥有 run 方法的 Future,run 方法执行时将设置其结果。
实现。类 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 提供可调的、灵活的线程池。Executors 类提供大多数 Executor 的常见类型和配置的工厂方法,以及使用它们的几种实用工具方法。其他基于 Executor 的实用工具包括具体类 FutureTask,它提供 Future 的常见可扩展实现,以及 ExecutorCompletionService,它有助于协调对异步任务组的处理。
队列java.util.concurrent ConcurrentLinkedQueue 类提供了高效的、可伸缩的、线程安全的非阻塞 FIFO 队列。java.util.concurrent 中的五个实现都支持扩展的 BlockingQueue 接口,该接口定义了 put 和 take 的阻塞版本:LinkedBlockingQueue、ArrayBlockingQueue、SynchronousQueue、PriorityBlockingQueue 和 DelayQueue。这些不同的类覆盖了生产者-使用者、消息传递、并行任务执行和相关并发设计的大多数常见使用的上下文。BlockingDeque 接口扩展 BlockingQueue,以支持 FIFO 和 LIFO(基于堆栈)操作。LinkedBlockingDeque 类提供一个实现。
计时TimeUnit 类为指定和控制基于超时的操作提供了多重粒度(包括纳秒级)。该包中的大多数类除了包含不确定的等待之外,还包含基于超时的操作。在使用超时的所有情况中,超时指定了在表明已超时前该方法应该等待的最少时间。在超时发生后,实现会“尽力”检测超时。但是,在检测超时与超时之后再次实际执行线程之间可能要经过不确定的时间。接受超时期参数的所有方法将小于等于 0 的值视为根本不会等待。要“永远”等待,可以使用 Long.MAX_VALUE 值。
同步器四个类可协助实现常见的专用同步语句。Semaphore 是一个经典的并发工具。CountDownLatch 是一个极其简单但又极其常用的实用工具,用于在保持给定数目的信号、事件或条件前阻塞执行。CyclicBarrier 是一个可重置的多路同步点,在某些并行编程风格中很有用。Exchanger 允许两个线程在 collection 点交换对象,它在多流水线设计中是有用的。
并发 Collection除队列外,此包还提供了设计用于多线程上下文中的 Collection 实现:ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet、CopyOnWriteArrayList 和 CopyOnWriteArraySet。当期望许多线程访问一个给定 collection 时,ConcurrentHashMap 通常优于同步的 HashMap,ConcurrentSkipListMap 通常优于同步的 TreeMap。当期望的读数和遍历远远大于列表的更新数时,CopyOnWriteArrayList 优于同步的 ArrayList。
此包中与某些类一起使用的“Concurrent&rdquo前缀;是一种简写,表明与类似的“同步”类有所不同。例如,java.util.Hashtable 和Collections.synchronizedMap(new HashMap()) 是同步的,但 ConcurrentHashMap 则是“并发的”。并发 collection 是线程安全的,但是不受单个排他锁的管理。在 ConcurrentHashMap 这一特定情况下,它可以安全地允许进行任意数目的并发读取,以及数目可调的并发写入。需要通过单个锁不允许对 collection 的所有访问时,“同步”类是很有用的,其代价是较差的可伸缩性。在期望多个线程访问公共 collection 的其他情况中,通常“并发”版本要更好一些。当 collection 是未共享的,或者仅保持其他锁时 collection 是可访问的情况下,非同步 collection 则要更好一些。
大多数并发 Collection 实现(包括大多数 Queue)与常规的 java.util 约定也不同,因为它们的迭代器提供了弱一致的,而不是快速失败的遍历。弱一致的迭代器是线程安全的,但是在迭代时没有必要冻结 collection,所以它不一定反映自迭代器创建以来的所有更新。
Java Language Specification 第 17 章定义了内存操作(如共享变量的读写)的 happen-before 关系。只有写入操作 happen-before 读取操作时,才保证一个线程写入的结果对另一个线程的读取是可视的。synchronized 和 volatile 构造 happen-before 关系,Thread.start() 和Thread.join() 方法形成 happen-before 关系。尤其是:
- 线程中的每个操作 happen-before 稍后按程序顺序传入的该线程中的每个操作。
- 一个解除锁监视器的(
synchronized 阻塞或方法退出)happen-before 相同监视器的每个后续锁(synchronized 阻塞或方法进入)。并且因为 happen-before 关系是可传递的,所以解除锁定之前的线程的所有操作 happen-before 锁定该监视器的任何线程后续的所有操作。 - 写入
volatile 字段 happen-before 每个后续读取相同字段。volatile 字段的读取和写入与进入和退出监视器具有相似的内存一致性效果,但不 需要互斥锁。 - 在线程上调用
start happen-before 已启动的线程中的任何线程。 - 线程中的所有操作 happen-before 从该线程上的
join 成功返回的任何其他线程。
java.util.concurrent 中所有类的方法及其子包扩展了这些对更高级别同步的保证。尤其是:
- 线程中将一个对象放入任何并发 collection 之前的操作 happen-before 从另一线程中的 collection 访问或移除该元素的后续操作。
- 线程中向
Executor 提交 Runnable 之前的操作 happen-before 其执行开始。同样适用于向 ExecutorService 提交 Callables。 - 异步计算(由
Future 表示)所采取的操作 happen-before 通过另一线程中 Future.get() 获取结果后续的操作。 - “释放”同步储存方法(如
Lock.unlock、Semaphore.release 和 CountDownLatch.countDown)之前的操作 happen-before 另一线程中相同同步储存对象成功“获取”方法(如 Lock.lock、Semaphore.acquire、Condition.await 和 CountDownLatch.await)的后续操作。 - 对于通过
Exchanger 成功交换对象的每个线程对,每个线程中 exchange() 之前的操作 happen-before 另一线程中对应 exchange() 后续的操作。 - 调用
CyclicBarrier.await 之前的操作 happen-before 屏障操作所执行的操作,屏障操作所执行的操作 happen-before 从另一线程中对应await 成功返回的后续操作。
Condition
Condition 将 Object 监视器方法(wait、notify 和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待 set(wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。
条件(也称为条件队列 或条件变量)为线程提供了一个含义,以便在某个状态条件现在可能为 true 的另一个线程通知它之前,一直挂起该线程(即让其“等待”)。因为访问此共享状态信息发生在不同的线程中,所以它必须受保护,因此要将某种形式的锁与该条件相关联。等待提供一个条件的主要属性是:以原子方式 释放相关的锁,并挂起当前线程,就像 Object.wait 做的那样。
Condition 实例实质上被绑定到一个锁上。要为特定 Lock 实例获得 Condition 实例,请使用其 newCondition() 方法。
作为一个示例,假定有一个绑定的缓冲区,它支持 put 和 take 方法。如果试图在空的缓冲区上执行 take 操作,则在某一个项变得可用之前,线程将一直阻塞;如果试图在满的缓冲区上执行 put 操作,则在有空间变得可用之前,线程将一直阻塞。我们喜欢在单独的等待 set 中保存 put 线程和 take 线程,这样就可以在缓冲区中的项或空间变得可用时利用最佳规划,一次只通知一个线程。可以使用两个 Condition 实例来做到这一点。 class BoundedBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
Object x = items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
(ArrayBlockingQueue 类提供了这项功能,因此没有理由去实现这个示例类。)
Condition 实现可以提供不同于 Object 监视器方法的行为和语义,比如受保证的通知排序,或者在执行通知时不需要保持一个锁。如果某个实现提供了这样特殊的语义,则该实现必须记录这些语义。
注意,Condition 实例只是一些普通的对象,它们自身可以用作 synchronized 语句中的目标,并且可以调用自己的 wait 和notification 监视器方法。获取 Condition 实例的监视器锁或者使用其监视器方法,与获取和该 Condition 相关的 Lock 或使用其 waiting 和 signalling 方法没有什么特定的关系。为了避免混淆,建议除了在其自身的实现中之外,切勿以这种方式使用Condition 实例。
除非另行说明,否则为任何参数传递 null 值将导致抛出 NullPointerException。
实现注意事项
在等待 Condition 时,允许发生“虚假唤醒”,这通常作为对基础平台语义的让步。对于大多数应用程序,这带来的实际影响很小,因为 Condition 应该总是在一个循环中被等待,并测试正被等待的状态声明。某个实现可以随意移除可能的虚假唤醒,但建议应用程序程序员总是假定这些虚假唤醒可能发生,因此总是在一个循环中等待。
三种形式的条件等待(可中断、不可中断和超时)在一些平台上的实现以及它们的性能特征可能会有所不同。尤其是它可能很难提供这些特性和维护特定语义,比如排序保证。更进一步地说,中断线程实际挂起的能力在所有平台上并不是总是可行的。
因此,并不要求某个实现为所有三种形式的等待定义完全相同的保证或语义,也不要求其支持中断线程的实际挂起。
要求实现清楚地记录每个等待方法提供的语义和保证,在某个实现不支持中断线程的挂起时,它必须遵从此接口中定义的中断语义。
由于中断通常意味着取消,而又通常很少进行中断检查,因此实现可以先于普通方法的返回来对中断进行响应。即使出现在另一个操作后的中断可能会释放线程锁时也是如此。实现应记录此行为。
http://blog.csdn.net/fh13760184/article/details/8551546#
java处理高并发高负载类网站中数据库的设计方法(java教程,java处理大量数据,java高负载数据)
一:高并发高负载类网站关注点之数据库
没错,首先是数据库,这是大多数应用所面临的首个SPOF。尤其是Web2.0的应用,数据库的响应是首先要解决的。
一般来说MySQL是最常用的,可能最初是一个mysql主机,当数据增加到100万以上,那么,MySQL的效能急剧下降。常用的优化措施是M-S(主-从)方式进行同步复制,将查询和操作和分别在不同的服务器上进行操作。我推荐的是M-M-Slaves方式,2个主Mysql,多个Slaves,需要注意的是,虽然有2个Master,但是同时只有1个是Active,我们可以在一定时候切换。之所以用2个M,是保证M不会又成为系统的SPOF。
Slaves可以进一步负载均衡,可以结合LVS,从而将select操作适当的平衡到不同的slaves上。
以上架构可以抗衡到一定量的负载,但是随着用户进一步增加,你的用户表数据超过1千万,这时那个M变成了SPOF。你不能任意扩充Slaves,否则复制同步的开销将直线上升,怎么办?我的方法是表分区,从业务层面上进行分区。最简单的,以用户数据为例。根据一定的切分方式,比如id,切分到不同的数据库集群去。
全局数据库用于meta数据的查询。缺点是每次查询,会增加一次,比如你要查一个用户nightsailer,你首先要到全局数据库群找到nightsailer对应的cluster id,然后再到指定的cluster找到nightsailer的实际数据。
每个cluster可以用m-m方式,或者m-m-slaves方式。这是一个可以扩展的结构,随着负载的增加,你可以简单的增加新的mysql cluster进去。
需要注意的是:
1、禁用全部auto_increment的字段
2、id需要采用通用的算法集中分配
3、要具有比较好的方法来监控mysql主机的负载和服务的运行状态。如果你有30台以上的mysql数据库在跑就明白我的意思了。
4、不要使用持久性链接(不要用pconnect),相反,使用sqlrelay这种第三方的数据库链接池,或者干脆自己做,因为php4中mysql的链接池经常出问题。
二:高并发高负载网站的系统架构之HTML静态化
其实大家都知道,效率最高、消耗最小的就是纯静态化 http://www.ablanxue.com/shtml/201207/776.shtml的html页面,所以我们尽可能使我们的网站上的页面采用静态页面来实现,这个最简单的方法其实也是 最有效的方法。但是对于大量内容并且频繁更新的网站,我们无法全部手动去挨个实现,于是出现了我们常见的信息发布系统CMS,像我们常访问的各个门户站点 的新闻频道,甚至他们的其他频道,都是通过信息发布系统来管理和实现的,信息发布系统可以实现最简单的信息录入自动生成静态页面,还能具备频道管理、权限 管理、自动抓取等功能,对于一个大型网站来说,拥有一套高效、可管理的CMS是必不可少的。
除了门户和信息发布类型的网站,对于交互性要求很高的社区类型网站来说,尽可能的静态化也是提高性能的必要手段,将社区内的帖子、文章进行实时的静态化,有更新的时候再重新静态化也是大量使用的策略,像Mop的大杂烩就是使用了这样的策略,网易社区等也是如此。
同时,html静态化也是某些缓存策略使用的手段,对于系统中频繁使用数据库查询但是内容更新很小的应用,可以考虑使用html静态化来实现,比如论坛 中论坛的公用设置信息,这些信息目前的主流论坛都可以进行后台管理并且存储再数据库中,这些信息其实大量被前台程序调用,但是更新频率很小,可以考虑将这 部分内容进行后台更新的时候进行静态化,这样避免了大量的数据库访问请求高并发。
网站HTML静态化解决方案
当一个Servlet资源请求到达WEB服务器之后我们会填充指定的JSP页面来响应请求:
HTTP请求---Web服务器---Servlet--业务逻辑处理--访问数据--填充JSP--响应请求
HTML静态化之后:
HTTP请求---Web服务器---Servlet--HTML--响应请求
静态访求如下
Servlet:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
if(request.getParameter("chapterId") != null){
String chapterFileName = "bookChapterRead_"+request.getParameter("chapterId")+".html";
String chapterFilePath = getServletContext().getRealPath("/") + chapterFileName;
File chapterFile = new File(chapterFilePath);
if(chapterFile.exists()){response.sendRedirect(chapterFileName);return;}//如果有这个文件就告诉浏览器转向
INovelChapterBiz novelChapterBiz = new NovelChapterBizImpl();
NovelChapter novelChapter = novelChapterBiz.searchNovelChapterById(Integer.parseInt(request.getParameter("chapterId")));//章节信息
int lastPageId = novelChapterBiz.searchLastCHapterId(novelChapter.getNovelId().getId(), novelChapter.getId());
int nextPageId = novelChapterBiz.searchNextChapterId(novelChapter.getNovelId().getId(), novelChapter.getId());
request.setAttribute("novelChapter", novelChapter);
request.setAttribute("lastPageId", lastPageId);
request.setAttribute("nextPageId", nextPageId);
new CreateStaticHTMLPage().createStaticHTMLPage(request, response, getServletContext(),
chapterFileName, chapterFilePath, "/bookRead.jsp");
}
}
生成HTML静态页面的类:
package com.jb.y2t034.thefifth.web.servlet;
import java.io.ByteArrayOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpServletResponseWrapper;
/**
* 创建HTML静态页面
* 功能:创建HTML静态页面
* 时间:2009年1011日
* 地点:home
* @author mavk
*
*/
public class CreateStaticHTMLPage {
/**
* 生成静态HTML页面的方法
* @param request 请求对象
* @param response 响应对象
* @param servletContext Servlet上下文
* @param fileName 文件名称
* @param fileFullPath 文件完整路径
* @param jspPath 需要生成静态文件的JSP路径(相对即可)
* @throws IOException
* @throws ServletException
*/
public void createStaticHTMLPage(HttpServletRequest request, HttpServletResponse response,ServletContext servletContext,String fileName,String fileFullPath,String jspPath) throws ServletException, IOException{
response.setContentType("text/html;charset=gb2312");//设置HTML结果流编码(即HTML文件编码)
RequestDispatcher rd = servletContext.getRequestDispatcher(jspPath);//得到JSP资源
final ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();//用于从ServletOutputStream中接收资源
final ServletOutputStream servletOuputStream = new ServletOutputStream(){//用于从HttpServletResponse中接收资源
public void write(byte[] b, int off,int len){
byteArrayOutputStream.write(b, off, len);
}
public void write(int b){
byteArrayOutputStream.write(b);
}
};
final PrintWriter printWriter = new PrintWriter(new OutputStreamWriter(byteArrayOutputStream));//把转换字节流转换成字符流
HttpServletResponse httpServletResponse = new HttpServletResponseWrapper(response){//用于从response获取结果流资源(重写了两个方法)
public ServletOutputStream getOutputStream(){
return servletOuputStream;
}
public PrintWriter getWriter(){
return printWriter;
}
};
rd.include(request, httpServletResponse);//发送结果流
printWriter.flush();//刷新缓冲区,把缓冲区的数据输出
FileOutputStream fileOutputStream = new FileOutputStream(fileFullPath);
byteArrayOutputStream.writeTo(fileOutputStream);//把byteArrayOuputStream中的资源全部写入到fileOuputStream中
fileOutputStream.close();//关闭输出流,并释放相关资源
response.sendRedirect(fileName);//发送指定文件流到客户端
}
}
三:高并发高负载类网站关注点之缓存、负载均衡、存储
缓存是另一个大问题,我一般用memcached来做缓存集群,一般来说部署10台左右就差不多(10g内存池)。需要注意一点,千万不能用使用
swap,最好关闭linux的swap。
负载均衡/加速
可能上面说缓存的时候,有人第一想的是页面静态化,所谓的静态html,我认为这是常识,不属于要点了。页面的静态化随之带来的是静态服务的
负载均衡和加速。我认为Lighttped+Squid是最好的方式了。
LVS <------->lighttped====>squid(s) ====lighttpd
上面是我经常用的。注意,我没有用apache,除非特定的需求,否则我不部署apache,因为我一般用php-fastcgi配合lighttpd,
性能比apache+mod_php要强很多。
squid的使用可以解决文件的同步等等问题,但是需要注意,你要很好的监控缓存的命中率,尽可能的提高的90%以上。
squid和lighttped也有很多的话题要讨论,这里不赘述。
存储
存储也是一个大问题,一种是小文件的存储,比如图片这类。另一种是大文件的存储,比如搜索引擎的索引,一般单文件都超过2g以上。
小文件的存储最简单的方法是结合lighttpd来进行分布。或者干脆使用Redhat的GFS,优点是应用透明,缺点是费用较高。我是指
你购买盘阵的问题。我的项目中,存储量是2-10Tb,我采用了分布式存储。这里要解决文件的复制和冗余。
这样每个文件有不同的冗余,这方面可以参考google的gfs的论文。
大文件的存储,可以参考nutch的方案,现在已经独立为hadoop子项目。(你可以google it)
其他:
此外,passport等也是考虑的,不过都属于比较简单的了。
四:高并发高负载网站的系统架构之图片服务器分离
大家知道,对于Web 服务器来说,不管是Apache、IIS还是其他容器,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上大型网站都会采用的策略,他 们都有独立的图片服务器,甚至很多台图片服务器。这样的架构可以降低提供页面访问请求的服务器系统压力,并且可以保证系统不会因为图片问题而崩溃,在应用 服务器和图片服务器上,可以进行不同的配置优化,比如apache在配置ContentType的时候可以尽量少支持,尽可能少的LoadModule, 保证更高的系统消耗和执行效率。
利用Apache实现图片服务器的分离
缘由:
起步阶段的应用,都可能部署在一台服务器上(费用上的原因)
第一个优先分离的,肯定是数据库和应用服务器。
第二个分离的,会是什么呢?各有各的考虑,我所在的项目组重点考虑的节约带宽,服务器性能再好,带宽再高,并发来了,也容易撑不住。因此,我这篇文章的重点在这里。这里重点是介绍实践,不一定符合所有情况,供看者参考吧,
环境介绍:
WEB应用服务器:4CPU双核2G, 内存4G
部署:Win2003/Apache Http Server 2.1/Tomcat6
数据库服务器:4CPU双核2G, 内存4G
部署:Win2003/MSSQL2000
步骤:
步骤一:增加2台配置为:2CPU双核2G,内存2G普通服务器,做资源服务器
部署:Tomcat6,跑了一个图片上传的简单应用,(记得指定web.xml的<distributable/>),并指定域名为res1.***.com,res2.***.com,采用ajp协议
步骤二:修改Apache httpd.conf配置
原来应用的文件上传功能网址为:
1、/fileupload.html
2、/otherupload.html
在httpd.conf中增加如下配置
<VirtualHost *:80>
ServerAdmin webmaster@***.com
ProxyPass /fileupload.html balancer://rescluster/fileupload lbmethod=byrequests stickysession=JSESSIONID nofailover=Off timeout=5 maxattempts=3
ProxyPass /otherupload.html balancer://rescluster/otherupload.html lbmethod=byrequests stickysession=JSESSIONID nofailover=Off timeout=5 maxattempts=3
#<!--负载均衡-->
<Proxy balancer://rescluster/>
BalancerMember ajp://res1.***.com:8009 smax=5 max=500 ttl=120 retry=300 loadfactor=100 route=tomcat1
BalancerMember ajp://res2.***.com:8009 smax=5 max=500 ttl=120 retry=300 loadfactor=100 route=tomcat2
</Proxy>
</VirtualHost>
步骤三,修改业务逻辑:
所有上传文件在数据库中均采用全url的方式保存,例如产品图片路径存成:http://res1.***.com/upload/20090101/product120302005.jpg
现在,你可以高枕无忧了,带宽不够时,增加个几十台图片服务器,只需要稍微修改一下apache的配置文件,即可。
五:高并发高负载网站的系统架构之数据库集群和库表散列
大型网站都有复杂的应用,这些应用必须使用数据库,那么在面对大量访问的时候,数据库的瓶颈很快就能显现出来,这时一台数据库将很快无法满足应用,于是我们需要使用数据库集群或者库表散列。
在数据库集群方面,很多数据库都有自己的解决方案,Oracle、Sybase等都有很好的方案,常用的MySQL提供的Master/Slave也是类似的方案,您使用了什么样的DB,就参考相应的解决方案来实施即可。
上面提到的数据库集群由于在架构、成本、扩张性方面都会受到所采用DB类型的限制,于是我们需要从应用程序的角度来考虑改善系统架构,库表散列是常用并 且最有效的解决方案。我们在应用程序中安装业务和应用或者功能模块将数据库进行分离,不同的模块对应不同的数据库或者表,再按照一定的策略对某个页面或者 功能进行更小的数据库散列,比如用户表,按照用户ID进行表散列,这样就能够低成本的提升系统的性能并且有很好的扩展性。sohu的论坛就是采用了这样的 架构,将论坛的用户、设置、帖子等信息进行数据库分离,然后对帖子、用户按照板块和ID进行散列数据库和表,最终可以在配置文件中进行简单的配置便能让系 统随时增加一台低成本的数据库进来补充系统性能。
集群软件的分类:
一般来讲,集群软件根据侧重的方向和试图解决的问题,分为三大类:高性能集群(High performance cluster,HPC)、负载均衡集群(Load balance cluster, LBC),高可用性集群(High availability cluster,HAC)。
高性能集群(High performance cluster,HPC),它是利用一个集群中的多台机器共同完成同一件任务,使得完成任务的速度和可靠性都远远高于单机运行的效果。弥补了单机性能上的不足。该集群在天气预报、环境监控等数据量大,计算复杂的环境中应用比较多;
负载均衡集群(Load balance cluster, LBC),它是利用一个集群中的多台单机,完成许多并行的小的工作。一般情况下,如果一个应用使用的人多了,那么用户请求的响应时间就会增大,机器的性能也会受到影响,如果使用负载均衡集群,那么集群中任意一台机器都能响应用户的请求,这样集群就会在用户发出服务请求之后,选择当时负载最小,能够提供最好的服务的这台机器来接受请求并相应,这样就可用用集群来增加系统的可用性和稳定性。这类集群在网站中使用较多;
高可用性集群(High availability cluster,HAC),它是利用集群中系统 的冗余,当系统中某台机器发生损坏的时候,其他后备的机器可以迅速的接替它来启动服务,等待故障机的维修和返回。最大限度的保证集群中服务的可用性。这类系统一般在银行,电信服务这类对系统可靠性有高的要求的领域有着广泛的应用。
2 数据库集群的现状
数据库集群是将计算机集群技术引入到数据库中来实现的,尽管各厂商宣称自己的架构如何的完美,但是始终不能改变Oracle当先,大家追逐的事实,在集群的解决方案上Oracle RAC还是领先于包括微软在内的其它数据库厂商,它能满足客户高可用性、高性能、数据库负载均衡和方便扩展的需求。
Oracle’s Real Application Cluster (RAC)
Microsoft SQL Cluster Server (MSCS)
IBM’s DB2 UDB High Availability Cluster(UDB)
Sybase ASE High Availability Cluster (ASE)
MySQL High Availability Cluster (MySQL CS)
基于IO的第三方HA(高可用性)集群
当前主要的数据库集群技术有以上六大类,有数据库厂商自己开发的;也有第三方的集群公司开发的;还有数据库厂商与第三方集群公司合作开发的,各类集群实现的功能及架构也不尽相同。
RAC(Real Application Cluster,真正应用集群)是Oracle9i数据库中采用的一项新技术,也是Oracle数据库支持网格计算环境的核心技术。它的出现解决了传统数据库应用中面临的一个重要问题:高性能、高可伸缩性与低价格之间的矛盾。在很长一段时间里,甲骨文都以其实时应用集群技术(Real Application Cluster,RAC)统治着集群数据库市场
六:高并发高负载网站的系统架构之缓存
缓存一词搞技术的都接触过,很多地方用到缓存。网站架构和网站开发中的缓存也是非常重要。这里先讲述最基本的两种缓存。高级和分布式的缓存在后面讲述。
架构方面的缓存,对Apache比较熟悉的人都能知道Apache提供了自己的缓存模块,也可以使用外加的Squid模块进行缓存,这两种方式均可以有效的提高Apache的访问响应能力。
网站程序开发方面的缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用,比如用Java开发的时候就可以调用MemoryCache对一些数据进行缓存和通讯共享,一些大 型社区使用了这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java就更多 了,.net不是很熟悉,相信也肯定有。
Java开源缓存框架
JBossCache/TreeCache JBossCache是一个复制的事务处理缓存,它允许你缓存企业级应用数据来更好的改善性能。缓存数据被自动复制,让你轻松进行Jboss服务器之间的集群工作。JBossCache能够通过Jboss应用服务或其他J2EE容器来运行一个Mbean服务,当然,它也能独立运行。 JBossCache包括两个模块:TreeCache和TreeCacheAOP。 TreeCache --是一个树形结构复制的事务处理缓存。 TreeCacheAOP --是一个“面向对象”缓存,它使用AOP来动态管理POJO
OSCache OSCache标记库由OpenSymphony设计,它是一种开创性的JSP定制标记应用,提供了在现有JSP页面之内实现快速内存缓冲的功能。OSCache是个一个广泛采用的高性能的J2EE缓存框架,OSCache能用于任何Java应用程序的普通的缓存解决方案。OSCache有以下特点:缓存任何对象,你可以不受限制的缓存部分jsp页面或HTTP请求,任何java对象都可以缓存。 拥有全面的API--OSCache API给你全面的程序来控制所有的OSCache特性。 永久缓存--缓存能随意的写入硬盘,因此允许昂贵的创建(expensive-to-create)数据来保持缓存,甚至能让应用重启。 支持集群--集群缓存数据能被单个的进行参数配置,不需要修改代码。 缓存记录的过期--你可以有最大限度的控制缓存对象的过期,包括可插入式的刷新策略(如果默认性能不需要时)。
JCACHE JCACHE是一种即将公布的标准规范(JSR 107),说明了一种对Java对象临时在内存中进行缓存的方法,包括对象的创建、共享访问、假脱机(spooling)、失效、各JVM的一致性等。它可被用于缓存JSP内最经常读取的数据,如产品目录和价格列表。利用JCACHE,多数查询的反应时间会因为有缓存的数据而加快(内部测试表明反应时间大约快15倍)。
Ehcache Ehcache出自Hibernate,在Hibernate中使用它作为数据缓存的解决方案。
Java Caching System JCS是Jakarta的项目Turbine的子项目。它是一个复合式的缓冲工具。可以将对象缓冲到内存、硬盘。具有缓冲对象时间过期设定。还可以通过JCS构建具有缓冲的分布式构架,以实现高性能的应用。 对于一些需要频繁访问而每访问一次都非常消耗资源的对象,可以临时存放在缓冲区中,这样可以提高服务的性能。而JCS正是一个很好的缓冲工具。缓冲工具对于读操作远远多于写操作的应用性能提高非常显著。
SwarmCache SwarmCache是一个简单而功能强大的分布式缓存机制。它使用IP组播来有效地在缓存的实例之间进行通信。它是快速提高集群式Web应用程序的性能的理想选择。
ShiftOne ShiftOne Object Cache这个Java库提供了基本的对象缓存能力。实现的策略有先进先出(FIFO),最近使用(LRU),最不常使用(LFU)。所有的策略可以最大化元素的大小,最大化其生存时间。
WhirlyCache Whirlycache是一个快速的、可配置的、存在于内存中的对象的缓存。它能够通过缓存对象来加快网站或应用程序的速度,否则就必须通过查询数据库或其他代价较高的处理程序来建立。
Jofti Jofti可对在缓存层中(支持EHCache,JBossCache和OSCache)的对象或在支持Map接口的存储结构中的对象进行索引与搜索。这个框架还为对象在索引中的增删改提供透明的功能同样也为搜索提供易于使用的查询功能。
cache4j cache4j是一个有简单API与实现快速的Java对象缓存。它的特性包括:在内存中进行缓存,设计用于多线程环境,两种实现:同步与阻塞,多种缓存清除策略:LFU, LRU, FIFO,可使用强引用(strong reference)与软引用(soft reference)存储对象。
Open Terracotta 一个JVM级的开源群集框架,提供:HTTP Session复制,分布式缓存,POJO群集,跨越群集的JVM来实现分布式应用程序协调(采用代码注入的方式,所以你不需要修改任何)。
sccache SHOP.COM使用的对象缓存系统。sccache是一个in-process cache和二级、共享缓存。它将缓存对象存储到磁盘上。支持关联Key,任意大小的Key和任意大小的数据。能够自动进行垃圾收集。
Shoal Shoal是一个基于Java可扩展的动态集群框架,能够为构建容错、可靠和可用的Java应用程序提供了基础架构支持。这个框架还可以集成到不希望绑定到特定通信协议,但需要集群和分布式系统支持的任何Java产品中。Shoal是GlassFish和JonAS应用服务器的集群引擎。
Simple-Spring-Memcached Simple-Spring-Memcached,它封装了对MemCached的调用,使MemCached的客户端开发变得超乎寻常的简单。
http://www.ablanxue.com/prone_1020_1.html
//客户端代码,用来测试访问Servlet:
package com.abin.lee.ssh.basic.unionpay;
import java.io.BufferedInputStream;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.List;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSocket;
import javax.net.ssl.TrustManager;
import javax.net.ssl.X509TrustManager;
import org.apache.http.HttpResponse;
import org.apache.http.HttpVersion;
import org.apache.http.NameValuePair;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.params.AllClientPNames;
import org.apache.http.conn.scheme.Scheme;
import org.apache.http.conn.ssl.SSLSocketFactory;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.params.BasicHttpParams;
import org.apache.http.params.HttpParams;
import org.apache.http.protocol.HTTP;
import org.junit.Test;
public class GetUnionpayMessages1Test {
private static final String HTTPURL = "https://124.288.188.28:1443/stsf/deal/unionpay/UnionPayDeal";
@Test
public void testGetMessageState() throws Exception {
HttpClient httpClient = new DefaultHttpClient();
HttpPost httpPost = new HttpPost(HTTPURL);
httpClient.getParams().setParameter(AllClientPNames.PROTOCOL_VERSION,
HttpVersion.HTTP_1_1);
httpClient.getParams().setParameter(
AllClientPNames.USE_EXPECT_CONTINUE, Boolean.TRUE);
httpClient.getParams().setParameter(
AllClientPNames.HTTP_CONTENT_CHARSET, "UTF_8");
httpClient.getParams().setParameter(
AllClientPNames.CONN_MANAGER_TIMEOUT, 10000l);
httpClient.getParams().setParameter(AllClientPNames.CONNECTION_TIMEOUT,
2000);
httpClient.getParams().setParameter(AllClientPNames.SO_TIMEOUT, 10000);
try {
TrustManager easyTrustManager = new X509TrustManager() {
public void checkClientTrusted(X509Certificate[] chain,
String authType) throws CertificateException {
// 哦,这很简单!
}
public void checkServerTrusted(X509Certificate[] chain,
String authType) throws CertificateException {
//哦,这很简单!
}
public X509Certificate[] getAcceptedIssuers() {
return null;
}
};
SSLContext sslcontext = SSLContext.getInstance("TLS");
sslcontext
.init(null, new TrustManager[] { easyTrustManager }, null);
SSLSocketFactory sf = new SSLSocketFactory(sslcontext);
SSLSocket socket = (SSLSocket) sf.createSocket();
socket.setEnabledCipherSuites(new String[] { "SSL_RSA_WITH_RC4_128_MD5" });
HttpParams params = new BasicHttpParams();
Scheme sch = new Scheme("https", 1443, sf);
sf.connectSocket(socket, "124.288.188.28", 1443, null, -1, params);
httpClient.getConnectionManager().getSchemeRegistry().register(sch);
List<NameValuePair> nvps = new ArrayList<NameValuePair>();
nvps.add(new BasicNameValuePair("userName", "abin"));
nvps.add(new BasicNameValuePair("createTime", new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss").format(new java.util.Date())));
HttpResponse httpResponse = null;
String result = "";
try {
httpPost.setEntity(new UrlEncodedFormEntity(nvps, HTTP.UTF_8));
httpResponse = httpClient.execute(httpPost);
BufferedInputStream buffer = new BufferedInputStream(
httpResponse.getEntity().getContent());
byte[] bytes = new byte[1024];
int line = 0;
StringBuilder builder = new StringBuilder();
while ((line = buffer.read(bytes)) != -1) {
builder.append(new String(bytes, 0, line, "UTF-8"));
}
result = builder.toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (httpPost.isAborted()) {
httpPost.abort();
}
httpClient.getConnectionManager().shutdown();
}
System.out.println("result=" + result);
} finally {
// When HttpClient instance is no longer needed,
// shut down the connection manager to ensure
// immediate deallocation of all system resources
httpClient.getConnectionManager().shutdown();
}
}
}
//在%TOMCAT_HOME%/conf/server.xml里面添加的内容
<Connector port="1443" protocol="HTTP/1.1" SSLEnabled="true"
maxThreads="150" scheme="https" secure="true"
clientAuth="false" keystoreFile="D:/tomcat.keystore"
keystorePass="longcode" sslProtocol="TLS" />
//UnionPayDeal.java
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
*
* @author Administrator
*
*/
public class UnionPayDeal extends HttpServlet {
private static final long serialVersionUID = -1370581177759574628L;
public void init(ServletConfig config) throws ServletException {
super.init(config);
}
public void doPost(HttpServletRequest request,HttpServletResponse response) throws IOException{
System.out.println("接收到银联的异步通知");
String accept=null;
BufferedReader reader=new BufferedReader(new InputStreamReader(request.getInputStream()));
int num=0;
char[] buffer=new char[1024];
while((num=reader.read(buffer))!=-1){
accept=new String(buffer,0,num);
System.out.println("accept="+accept);
}
}
public void destroy() {
super.destroy();
}
}
//客户端代码,用来测试访问Servlet:
package com.abin.lee.ssh.basic.https;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.security.KeyStore;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.HttpResponse;
import org.apache.http.HttpVersion;
import org.apache.http.NameValuePair;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.params.AllClientPNames;
import org.apache.http.conn.scheme.Scheme;
import org.apache.http.conn.ssl.SSLSocketFactory;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.protocol.HTTP;
import org.junit.Test;
public class GetUnionpayMessageTest {
private static final String HTTPURL = "https://124.288.188.28:1443/stsf/deal/unionpay/UnionPayDeal";
@Test
public void testGetMessageState() throws Exception {
HttpClient httpClient = new DefaultHttpClient();
HttpPost httpPost =new HttpPost(HTTPURL);
httpClient.getParams().setParameter(AllClientPNames.PROTOCOL_VERSION,HttpVersion.HTTP_1_1);
httpClient.getParams().setParameter(AllClientPNames.USE_EXPECT_CONTINUE, Boolean.TRUE);
httpClient.getParams().setParameter(AllClientPNames.HTTP_CONTENT_CHARSET,"UTF_8");
httpClient.getParams().setParameter(AllClientPNames.CONN_MANAGER_TIMEOUT, 10000l);
httpClient.getParams().setParameter(AllClientPNames.CONNECTION_TIMEOUT, 2000);
httpClient.getParams().setParameter(AllClientPNames.SO_TIMEOUT, 10000);
try {
KeyStore trustStore = KeyStore.getInstance(KeyStore
.getDefaultType());
FileInputStream instream = new FileInputStream(new File(
"D:/tomcat.keystore"));
try {
trustStore.load(instream, "longcode".toCharArray());
} finally {
try {
instream.close();
} catch (Exception ignore) {
}
}
SSLSocketFactory socketFactory = new SSLSocketFactory(trustStore);
Scheme sch = new Scheme("https", 1443, socketFactory);
httpClient.getConnectionManager().getSchemeRegistry().register(sch);
List<NameValuePair> nvps = new ArrayList<NameValuePair>();
nvps.add(new BasicNameValuePair("userName", "abin"));
nvps.add(new BasicNameValuePair("createTime", new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss").format(new java.util.Date())));
HttpResponse httpResponse = null;
String result = "";
try {
httpPost.setEntity(new UrlEncodedFormEntity(nvps, HTTP.UTF_8));
httpResponse = httpClient.execute(httpPost);
BufferedInputStream buffer = new BufferedInputStream(
httpResponse.getEntity().getContent());
byte[] bytes = new byte[1024];
int line = 0;
StringBuilder builder = new StringBuilder();
while ((line = buffer.read(bytes)) != -1) {
builder.append(new String(bytes, 0, line, "UTF-8"));
}
result = builder.toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (httpPost.isAborted()) {
httpPost.abort();
}
httpClient.getConnectionManager().shutdown();
}
System.out.println("result=" + result);
} finally {
// When HttpClient instance is no longer needed,
// shut down the connection manager to ensure
// immediate deallocation of all system resources
httpClient.getConnectionManager().shutdown();
}
}
}
//在%TOMCAT_HOME%/conf/server.xml里面添加的内容
<Connector port="1443" protocol="HTTP/1.1" SSLEnabled="true"
maxThreads="150" scheme="https" secure="true"
clientAuth="false" keystoreFile="D:/tomcat.keystore"
keystorePass="longcode" sslProtocol="TLS" />
//UnionPayDeal.java
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
*
* @author Administrator
*
*/
public class UnionPayDeal extends HttpServlet {
private static final long serialVersionUID = -1370581177759574628L;
public void init(ServletConfig config) throws ServletException {
super.init(config);
}
public void doPost(HttpServletRequest request,HttpServletResponse response) throws IOException{
System.out.println("接收到银联的异步通知");
String accept=null;
BufferedReader reader=new BufferedReader(new InputStreamReader(request.getInputStream()));
int num=0;
char[] buffer=new char[1024];
while((num=reader.read(buffer))!=-1){
accept=new String(buffer,0,num);
System.out.println("accept="+accept);
}
}
public void destroy() {
super.destroy();
}
}
这段时间遇到一个问题,程序里明明插入了一条记录,但在后边的一段Procedure中却查不到刚刚插入的记录,最后发现这个Procedure的定义中加入了PRAGMA AUTONOMOUS_TRANSACTION。
PRAGMA AUTONOMOUS_TRANSACTION中文翻译过来叫“自治事务”(翻译的还算好理解),对于定义成自治事务的Procedure,实际上相当于一段独立运行的程序段,这段程序不依赖于主程序,也不干涉主程序
自治事务的特点
第一,这段程序不依赖于原有Main程序,比如Main程序中有未提交的数据,那么在自治事务中是查找不到的。
第二,在自治事务中,commit或者rollback只会提交或回滚当前自治事务中的DML,不会影响到Main程序中的DML。
Autonomous Transaction Demo 1
Without Pragma Autonomous Transaction
CREATE TABLE t ( test_value VARCHAR2(25)); CREATE OR REPLACE PROCEDURE child_block IS BEGIN INSERT INTO t (test_value) VALUES ('Child block insert'); COMMIT; END child_block; / CREATE OR REPLACE PROCEDURE parent_block IS BEGIN INSERT INTO t (test_value) VALUES ('Parent block insert'); child_block; ROLLBACK; END parent_block; / -- run the parent procedure exec parent_block -- check the results SELECT * FROM t;
Output:
Parent block insert
Child block insert
With Pragma Autonomous Transaction
CREATE OR REPLACE PROCEDURE child_block IS
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
INSERT INTO t
(test_value)
VALUES
('Child block insert');
COMMIT;
END child_block;
/
CREATE OR REPLACE PROCEDURE parent_block IS
BEGIN
INSERT INTO t
(test_value)
VALUES
('Parent block insert');
child_block;
ROLLBACK;
END parent_block;
/
-- empty the test table
TRUNCATE TABLE t;
-- run the parent procedure
exec parent_block;
-- check the results
SELECT * FROM t;
Output:
Child block insert
Autonomous Transaction Demo 2Without Pragma Autonomous Transaction DROP TABLE t; CREATE TABLE t (testcol NUMBER); CREATE OR REPLACE FUNCTION howmanyrows RETURN INTEGER IS i INTEGER; BEGIN SELECT COUNT(*) INTO i FROM t; RETURN i; END howmanyrows; / CREATE OR REPLACE PROCEDURE testproc IS a INTEGER; b INTEGER; c INTEGER; BEGIN SELECT COUNT(*) INTO a FROM t; INSERT INTO t VALUES (1); COMMIT; INSERT INTO t VALUES (2); INSERT INTO t VALUES (3); b := howmanyrows; INSERT INTO t VALUES (4); INSERT INTO t VALUES (5); INSERT INTO t VALUES (6); COMMIT; SELECT COUNT(*) INTO c FROM t; dbms_output.put_line(a); dbms_output.put_line(b); dbms_output.put_line(c); END testproc; / set serveroutput on exec testproc
Output:
0
3
6
Total execution time 2.782 sec.
With Pragma Autonomous Transaction CREATE OR REPLACE FUNCTION howmanyrows RETURN INTEGER IS
i INTEGER;
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
SELECT COUNT(*)
INTO i
FROM t;
RETURN i;
END howmanyrows;
/
-- empty the test table
TRUNCATE TABLE t;
exec testproc;
Output:
0
1
6 转载请注明出处: http://blog.csdn.net/pan_tian/article/details/7675800
package com.abin.lee.ssh.basic.train;
import java.io.BufferedInputStream;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.HttpResponse;
import org.apache.http.HttpVersion;
import org.apache.http.NameValuePair;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.params.AllClientPNames;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.protocol.HTTP;
import org.junit.Test;
public class CityToCityTest {
private static final String HTTPURL="http://localhost:7500/train/mvc/train/searchTrain2";
@Test
public void testCityToCity(){
HttpClient httpClient = new DefaultHttpClient();
HttpPost httpPost =new HttpPost(HTTPURL);
httpClient.getParams().setParameter(AllClientPNames.PROTOCOL_VERSION,HttpVersion.HTTP_1_1);
httpClient.getParams().setParameter(AllClientPNames.USE_EXPECT_CONTINUE, Boolean.TRUE);
httpClient.getParams().setParameter(AllClientPNames.HTTP_CONTENT_CHARSET,HTTP.UTF_8);
httpClient.getParams().setParameter(AllClientPNames.CONN_MANAGER_TIMEOUT,1000l);
httpClient.getParams().setParameter(AllClientPNames.CONNECTION_TIMEOUT, 2000);
httpClient.getParams().setParameter(AllClientPNames.SO_TIMEOUT, 10000);
List<NameValuePair> nvps = new ArrayList<NameValuePair>();
nvps.add(new BasicNameValuePair("terminalId", "132456"));
nvps.add(new BasicNameValuePair("startCity", "北京"));
nvps.add(new BasicNameValuePair("endCity", "上海"));
nvps.add(new BasicNameValuePair("trainNumber", "T284"));
nvps.add(new BasicNameValuePair("searchType", "0"));
HttpResponse httpResponse =null;
String result="";
try {
httpPost.setEntity(new UrlEncodedFormEntity(nvps, HTTP.UTF_8));
httpResponse = httpClient.execute(httpPost);
BufferedInputStream buffer=new BufferedInputStream(httpResponse.getEntity().getContent());
byte[] bytes=new byte[1024];
int line=0;
StringBuilder builder=new StringBuilder();
while((line=buffer.read(bytes))!=-1){
builder.append(new String(bytes,0,line,"UTF-8"));
}
result=builder.toString();
} catch (Exception e) {
e.printStackTrace();
}finally{
if(httpPost.isAborted()){
httpPost.abort();
}
httpClient.getConnectionManager().shutdown();
}
System.out.println("result="+result);
}
}
十八. 和系统运行状况相关的Shell命令:
1. Linux的实时监测命令(watch):
watch 是一个非常实用的命令,可以帮你实时监测一个命令的运行结果,省得一遍又一遍的手动运行。该命令最为常用的两个选项是-d和-n,其中-n表示间隔多少秒执行一次"command",-d表示高亮发生变化的位置。下面列举几个在watch中常用的实时监视命令:
/> watch -d -n 1 'who' #每隔一秒执行一次who命令,以监视服务器当前用户登录的状况
Every 1.0s: who Sat Nov 12 12:37:18 2011
stephen tty1 2011-11-11 17:38 (:0)
stephen pts/0 2011-11-11 17:39 (:0.0)
root pts/1 2011-11-12 10:01 (192.168.149.1)
root pts/2 2011-11-12 11:41 (192.168.149.1)
root pts/3 2011-11-12 12:11 (192.168.149.1)
stephen pts/4 2011-11-12 12:22 (:0.0)
此时通过其他Linux客户端工具以root的身份登录当前Linux服务器,再观察watch命令的运行变化。
Every 1.0s: who Sat Nov 12 12:41:09 2011
stephen tty1 2011-11-11 17:38 (:0)
stephen pts/0 2011-11-11 17:39 (:0.0)
root pts/1 2011-11-12 10:01 (192.168.149.1)
root pts/2 2011-11-12 11:41 (192.168.149.1)
root pts/3 2011-11-12 12:40 (192.168.149.1)
stephen pts/4 2011-11-12 12:22 (:0.0)
root pts/5 2011-11-12 12:41 (192.168.149.1)
最后一行中被高亮的用户为新登录的root用户。此时按CTRL + C可以退出正在执行的watch监控进程。
#watch可以同时运行多个命令,命令间用分号分隔。
#以下命令监控磁盘的使用状况,以及当前目录下文件的变化状况,包括文件的新增、删除和文件修改日期的更新等。
/> watch -d -n 1 'df -h; ls -l'
Every 1.0s: df -h; ls -l Sat Nov 12 12:55:00 2011
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 5.8G 3.3G 2.2G 61% /
tmpfs 504M 420K 504M 1% /dev/shm
total 20
-rw-r--r--. 1 root root 10530 Nov 11 23:08 test.tar.bz2
-rw-r--r--. 1 root root 183 Nov 11 08:02 users
-rw-r--r--. 1 root root 279 Nov 11 08:45 users2
此时通过另一个Linux控制台窗口,在watch监视的目录下,如/home/stephen/test,执行下面的命令
/> touch aa #在执行该命令之后,另一个执行watch命令的控制台将有如下变化
Every 1.0s: df -h; ls -l Sat Nov 12 12:57:08 2011
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 5.8G 3.3G 2.2G 61% /
tmpfs 504M 420K 504M 1% /dev/shm
total 20
-rw-r--r--. 1 root root 0 Nov 12 12:56 aa
-rw-r--r--. 1 root root 0 Nov 12 10:02 datafile3
-rw-r--r--. 1 root root 10530 Nov 11 23:08 test.tar.bz2
-rw-r--r--. 1 root root 183 Nov 11 08:02 users
-rw-r--r--. 1 root root 279 Nov 11 08:45 users2
其中黄色高亮的部分,为touch aa命令执行之后watch输出的高亮变化部分。
2. 查看当前系统内存使用状况(free):
free命令有以下几个常用选项:
| 选项 |
说明 |
| -b |
以字节为单位显示数据。 |
| -k |
以千字节(KB)为单位显示数据(缺省值)。 |
| -m |
以兆(MB)为单位显示数据。 |
| -s delay |
该选项将使free持续不断的刷新,每次刷新之间的间隔为delay指定的秒数,如果含有小数点,将精确到毫秒,如0.5为500毫秒,1为一秒。 |
free命令输出的表格中包含以下几列:
| 列名 |
说明 |
| total |
总计物理内存的大小。 |
| used |
已使用的内存数量。 |
| free |
可用的内存数量。 |
| Shared |
多个进程共享的内存总额。 |
| Buffers/cached |
磁盘缓存的大小。 |
见以下具体示例和输出说明:
/> free -k
total used free shared buffers cached
Mem: 1031320 671776 359544 0 88796 352564
-/+ buffers/cache: 230416 800904
Swap: 204792 0 204792
对于free命令的输出,我们只需关注红色高亮的输出行和绿色高亮的输出行,见如下具体解释:
红色输出行:该行使从操作系统的角度来看待输出数据的,used(671776)表示内核(Kernel)+Applications+buffers+cached。free(359544)表示系统还有多少内存可供使用。
绿色输出行:该行则是从应用程序的角度来看输出数据的。其free = 操作系统used + buffers + cached,既:
800904 = 359544 + 88796 + 352564
/> free -m
total used free shared buffers cached
Mem: 1007 656 351 0 86 344
-/+ buffers/cache: 225 782
Swap: 199 0 199
/> free -k -s 1.5 #以千字节(KB)为单位显示数据,同时每隔1.5刷新输出一次,直到按CTRL+C退出
total used free shared buffers cached
Mem: 1007 655 351 0 86 344
-/+ buffers/cache: 224 782
Swap: 199 0 199
total used free shared buffers cached
Mem: 1007 655 351 0 86 344
-/+ buffers/cache: 224 782
Swap: 199 0 199
3. CPU的实时监控工具(mpstat):
该命令主要用于报告当前系统中所有CPU的实时运行状况。
#该命令将每隔2秒输出一次CPU的当前运行状况信息,一共输出5次,如果没有第二个数字参数,mpstat将每隔两秒执行一次,直到按CTRL+C退出。
/> mpstat 2 5
Linux 2.6.32-71.el6.i686 (Stephen-PC) 11/12/2011 _i686_ (1 CPU)
04:03:00 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
04:03:02 PM all 0.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.50
04:03:04 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:03:06 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:03:08 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:03:10 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Average: all 0.00 0.00 0.10 0.00 0.00 0.00 0.00 0.00 99.90
第一行的末尾给出了当前系统中CPU的数量。后面的表格中则输出了系统当前CPU的使用状况,以下为每列的含义:
| 列名 |
说明 |
| %user |
在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100 |
| %nice |
在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100 |
| %sys |
在internal时间段里,内核时间(%) (system/total)*100 |
| %iowait |
在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100 |
| %irq |
在internal时间段里,硬中断时间(%) (irq/total)*100 |
| %soft |
在internal时间段里,软中断时间(%) (softirq/total)*100 |
| %idle |
在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100 |
计算公式:
total_cur=user+system+nice+idle+iowait+irq+softirq
total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq
user=user_cur – user_pre
total=total_cur-total_pre
其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。
/> mpstat -P ALL 2 3 #-P ALL表示打印所有CPU的数据,这里也可以打印指定编号的CPU数据,如-P 0(CPU的编号是0开始的)
Linux 2.6.32-71.el6.i686 (Stephen-PC) 11/12/2011 _i686_ (1 CPU)
04:12:54 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
04:12:56 PM all 0.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.50
04:12:56 PM 0 0.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.50
04:12:56 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
04:12:58 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:12:58 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:12:58 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
04:13:00 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:13:00 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
Average: all 0.00 0.00 0.17 0.00 0.00 0.00 0.00 0.00 99.83
Average: 0 0.00 0.00 0.17 0.00 0.00 0.00 0.00 0.00 99.83
4. 虚拟内存的实时监控工具(vmstat):
vmstat命令用来获得UNIX系统有关进程、虚存、页面交换空间及CPU活动的信息。这些信息反映了系统的负载情况。vmstat首次运行时显示自系统启动开始的各项统计信息,之后运行vmstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
/> vmstat 1 3 #这是vmstat最为常用的方式,其含义为每隔1秒输出一条,一共输出3条后程序退出。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 531760 67284 231212 108 0 0 260 111 148 1 5 86 8 0
0 0 0 531752 67284 231212 0 0 0 0 33 57 0 1 99 0 0
0 0 0 531752 67284 231212 0 0 0 0 40 73 0 0 100 0 0
/> vmstat 1 #其含义为每隔1秒输出一条,直到按CTRL+C后退出。
下面将给出输出表格中每一列的含义说明:
有关进程的信息有:(procs)
r: 在就绪状态等待的进程数。
b: 在等待状态等待的进程数。
有关内存的信息有:(memory)
swpd: 正在使用的swap大小,单位为KB。
free: 空闲的内存空间。
buff: 已使用的buff大小,对块设备的读写进行缓冲。
cache: 已使用的cache大小,文件系统的cache。
有关页面交换空间的信息有:(swap)
si: 交换内存使用,由磁盘调入内存。
so: 交换内存使用,由内存调入磁盘。
有关IO块设备的信息有:(io)
bi: 从块设备读入的数据总量(读磁盘) (KB/s)
bo: 写入到块设备的数据总理(写磁盘) (KB/s)
有关故障的信息有:(system)
in: 在指定时间内的每秒中断次数。
sy: 在指定时间内每秒系统调用次数。
cs: 在指定时间内每秒上下文切换的次数。
有关CPU的信息有:(cpu)
us: 在指定时间间隔内CPU在用户态的利用率。
sy: 在指定时间间隔内CPU在核心态的利用率。
id: 在指定时间间隔内CPU空闲时间比。
wa: 在指定时间间隔内CPU因为等待I/O而空闲的时间比。
vmstat 可以用来确定一个系统的工作是受限于CPU还是受限于内存:如果CPU的sy和us值相加的百分比接近100%,或者运行队列(r)中等待的进程数总是不等于0,且经常大于4,同时id也经常小于40,则该系统受限于CPU;如果bi、bo的值总是不等于0,则该系统受限于内存。
5. 设备IO负载的实时监控工具(iostat):
iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
其中该命令中最为常用的使用方式如下:
/> iostat -d 1 3 #仅显示设备的IO负载,其中每隔1秒刷新并输出结果一次,输出3次后iostat退出。
Linux 2.6.32-71.el6.i686 (Stephen-PC) 11/16/2011 _i686_ (1 CPU)
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 5.35 258.39 26.19 538210 54560
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
/> iostat -d 1 #和上面的命令一样,也是每隔1秒刷新并输出一次,但是该命令将一直输出,直到按CTRL+C退出。
下面将给出输出表格中每列的含义:
| 列名 |
说明 |
| Blk_read/s |
每秒块(扇区)读取的数量。 |
| Blk_wrtn/s |
每秒块(扇区)写入的数量。 |
| Blk_read |
总共块(扇区)读取的数量。 |
| Blk_wrtn |
总共块(扇区)写入的数量。 |
iostat还有一个比较常用的选项-x,该选项将用于显示和io相关的扩展数据。
/> iostat -dx 1 3
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 5.27 1.31 2.82 1.14 189.49 19.50 52.75 0.53 133.04 10.74 4.26
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
还可以在命令行参数中指定要监控的设备名,如:
/> iostat -dx sda 1 3 #指定监控的设备名称为sda,该命令的输出结果和上面命令完全相同。
下面给出扩展选项输出的表格中每列的含义:
| 列名 |
说明 |
| rrqm/s |
队列中每秒钟合并的读请求数量 |
| wrqm/s |
队列中每秒钟合并的写请求数量 |
| r/s |
每秒钟完成的读请求数量 |
| w/s |
每秒钟完成的写请求数量 |
| rsec/s |
每秒钟读取的扇区数量 |
| wsec/s |
每秒钟写入的扇区数量 |
| avgrq-sz |
平均请求扇区的大小 |
| avgqu-sz |
平均请求队列的长度 |
| await |
平均每次请求的等待时间 |
| util |
设备的利用率 |
下面是关键列的解释:
util是设备的利用率。如果它接近100%,通常说明设备能力趋于饱和。
await是平均每次请求的等待时间。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
avgqu-sz是平均请求队列的长度。毫无疑问,队列长度越短越好。
6. 当前运行进程的实时监控工具(pidstat):
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
在正常的使用,通常都是通过在命令行选项中指定待监控的pid,之后在通过其他具体的参数来监控与该pid相关系统资源信息。
| 选项 |
说明 |
| -l |
显示该进程和CPU相关的信息(command列中可以显示命令的完整路径名和命令的参数)。 |
| -d |
显示该进程和设备IO相关的信息。 |
| -r |
显示该进程和内存相关的信息。 |
| -w |
显示该进程和任务时间片切换相关的信息。 |
| -t |
显示在该进程内正在运行的线程相关的信息。 |
| -p |
后面紧跟着带监控的进程id或ALL(表示所有进程),如不指定该选项,将监控当前系统正在运行的所有进程。 |
#监控pid为1(init)的进程的CPU资源使用情况,其中每隔3秒刷新并输出一次,3次后程序退出。
/> pidstat -p 1 2 3 -l
07:18:58 AM PID %usr %system %guest %CPU CPU Command
07:18:59 AM 1 0.00 0.00 0.00 0.00 0 /sbin/init
07:19:00 AM 1 0.00 0.00 0.00 0.00 0 /sbin/init
07:19:01 AM 1 0.00 0.00 0.00 0.00 0 /sbin/init
Average: 1 0.00 0.00 0.00 0.00 - /sbin/init
%usr: 该进程在用户态的CPU使用率。
%system:该进程在内核态(系统级)的CPU使用率。
%CPU: 该进程的总CPU使用率,如果在SMP环境下,该值将除以CPU的数量,以表示每CPU的数据。
CPU: 该进程所依附的CPU编号(0表示第一个CPU)。
#监控pid为1(init)的进程的设备IO资源负载情况,其中每隔2秒刷新并输出一次,3次后程序退出。
/> pidstat -p 1 2 3 -d
07:24:49 AM PID kB_rd/s kB_wr/s kB_ccwr/s Command
07:24:51 AM 1 0.00 0.00 0.00 init
07:24:53 AM 1 0.00 0.00 0.00 init
07:24:55 AM 1 0.00 0.00 0.00 init
Average: 1 0.00 0.00 0.00 init
kB_rd/s: 该进程每秒的字节读取数量(KB)。
kB_wr/s: 该进程每秒的字节写出数量(KB)。
kB_ccwr/s: 该进程每秒取消磁盘写入的数量(KB)。
#监控pid为1(init)的进程的内存使用情况,其中每隔2秒刷新并输出一次,3次后程序退出。
/> pidstat -p 1 2 3 -r
07:29:56 AM PID minflt/s majflt/s VSZ RSS %MEM Command
07:29:58 AM 1 0.00 0.00 2828 1368 0.13 init
07:30:00 AM 1 0.00 0.00 2828 1368 0.13 init
07:30:02 AM 1 0.00 0.00 2828 1368 0.13 init
Average: 1 0.00 0.00 2828 1368 0.13 init
%MEM: 该进程的内存使用百分比。
#监控pid为1(init)的进程任务切换情况,其中每隔2秒刷新并输出一次,3次后程序退出。
/> pidstat -p 1 2 3 -w
07:32:15 AM PID cswch/s nvcswch/s Command
07:32:17 AM 1 0.00 0.00 init
07:32:19 AM 1 0.00 0.00 init
07:32:21 AM 1 0.00 0.00 init
Average: 1 0.00 0.00 init
cswch/s: 每秒任务主动(自愿的)切换上下文的次数。主动切换是指当某一任务处于阻塞等待时,将主动让出自己的CPU资源。
nvcswch/s: 每秒任务被动(不自愿的)切换上下文的次数。被动切换是指CPU分配给某一任务的时间片已经用完,因此将强迫该进程让出CPU的执行权。
#监控pid为1(init)的进程及其内部线程的内存(r选项)使用情况,其中每隔2秒刷新并输出一次,3次后程序退出。需要说明的是,如果-t选项后面不加任何其他选项,缺省监控的为CPU资源。结果中黄色高亮的部分表示进程和其内部线程是树状结构的显示方式。
/> pidstat -p 1 2 3 -tr
Linux 2.6.32-71.el6.i686 (Stephen-PC) 11/16/2011 _i686_ (1 CPU)
07:37:04 AM TGID TID minflt/s majflt/s VSZ RSS %MEM Command
07:37:06 AM 1 - 0.00 0.00 2828 1368 0.13 init
07:37:06 AM - 1 0.00 0.00 2828 1368 0.13 |__init
07:37:06 AM TGID TID minflt/s majflt/s VSZ RSS %MEM Command
07:37:08 AM 1 - 0.00 0.00 2828 1368 0.13 init
07:37:08 AM - 1 0.00 0.00 2828 1368 0.13 |__init
07:37:08 AM TGID TID minflt/s majflt/s VSZ RSS %MEM Command
07:37:10 AM 1 - 0.00 0.00 2828 1368 0.13 init
07:37:10 AM - 1 0.00 0.00 2828 1368 0.13 |__init
Average: TGID TID minflt/s majflt/s VSZ RSS %MEM Command
Average: 1 - 0.00 0.00 2828 1368 0.13 init
Average: - 1 0.00 0.00 2828 1368 0.13 |__init
TGID: 线程组ID。
TID: 线程ID。
以上监控不同资源的选项可以同时存在,这样就将在一次输出中输出多种资源的使用情况,如:pidstat -p 1 -dr。
7. 报告磁盘空间使用状况(df):
该命令最为常用的选项就是-h,该选项将智能的输出数据单位,以便使输出的结果更具可读性。
/> df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 5.8G 3.3G 2.2G 61% /
tmpfs 504M 260K 504M 1% /dev/shm
8. 评估磁盘的使用状况(du):
| 选项 |
说明 |
| -a |
包括了所有的文件,而不只是目录。 |
| -b |
以字节为计算单位。 |
| -k |
以千字节(KB)为计算单位。 |
| -m |
以兆字节(MB)为计算单位。 |
| -h |
是输出的信息更易于阅读。 |
| -s |
只显示工作目录所占总空间。 |
| --exclude=PATTERN |
排除掉符合样式的文件,Pattern就是普通的Shell样式,?表示任何一个字符,*表示任意多个字符。 |
| --max-depth=N |
从当前目录算起,目录深度大于N的子目录将不被计算,该选项不能和s选项同时存在。
|
#仅显示子一级目录的信息。
/> du --max-depth=1 -h
246M ./stephen
246M .
/> du -sh ./* #获取当前目录下所有子目录所占用的磁盘空间大小。
352K ./MemcachedTest
132K ./Test
33M ./thirdparty
#在当前目录下,排除目录名模式为Te*的子目录(./Test),输出其他子目录占用的磁盘空间大小。
/> du --exclude=Te* -sh ./*
352K ./MemcachedTest
33M ./thirdparty
http://www.cnblogs.com/stephen-liu74/archive/2011/12/05/2257887.html
因为在日常的工作中,出问题的时候查看日志是每个管理员的习惯,作为初学者,为了以后的需要,我今天将下面这些查看命令共享给各位
cat
tail -f
日 志 文 件 说 明
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信息
/var/log/cron 与定时任务相关的日志信息
/var/log/spooler 与UUCP和news设备相关的日志信息
/var/log/boot.log 守护进程启动和停止相关的日志消息
系统:
# uname -a # 查看内核/操作系统/CPU信息
# cat /etc/issue
# cat /etc/redhat-release # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量
资源:
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh <目录名> # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载
磁盘和分区:
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况
网络:
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息
进程:
# ps -ef # 查看所有进程
# top # 实时显示进程状态(另一篇文章里面有详细的介绍)
用户:
# w # 查看活动用户
# id <用户名> # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户
# cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务
服务:
# chkconfig –list # 列出所有系统服务
# chkconfig –list | grep on # 列出所有启动的系统服务
程序:
# rpm -qa # 查看所有安装的软件包
pl/sql中设置:
tools->preferences->sql window->AutoSelect statement
然后光标放在一行,按F8就可以了, 注意: 每个语句结尾还要分号标注一下!
//方法一:
package com.abin.lir.axis2.client; import org.apache.axiom.om.OMAbstractFactory; import org.apache.axiom.om.OMElement; import org.apache.axiom.om.OMFactory; import org.apache.axiom.om.OMNamespace; import org.apache.axis2.AxisFault; import org.apache.axis2.addressing.EndpointReference; import org.apache.axis2.client.Options; import org.apache.axis2.client.ServiceClient; public class UserClient { public static void main(String[] args) { try { ServiceClient sc = new ServiceClient(); Options opts = new Options(); opts.setTo(new EndpointReference("http://localhost:9090/universal/services/play")); opts.setAction("urn:echo"); opts.setTimeOutInMilliSeconds(10000); sc.setOptions(opts); OMElement res = sc.sendReceive(createPayLoad()); System.out.println(res); } catch (AxisFault e) { e.printStackTrace(); } } public static OMElement createPayLoad(){ OMFactory fac = OMAbstractFactory.getOMFactory(); OMNamespace omNs = fac.createOMNamespace("http://localhost:9090/universal/services/play", "nsl"); OMElement method = fac.createOMElement("getPassengerInfos",omNs); OMElement value = fac.createOMElement("userID",omNs); value.setText("1024"); method.addChild(value); return method; } } //方法二 package com.abin.lir.axis2.client; import javax.xml.namespace.QName; import org.apache.axis2.AxisFault; import org.apache.axis2.addressing.EndpointReference; import org.apache.axis2.client.Options; import org.apache.axis2.rpc.client.RPCServiceClient; public class RPCClient { public static void main(String[] args) throws AxisFault { // 使用RPC方式调用WebService RPCServiceClient serviceClient = new RPCServiceClient(); Options options = serviceClient.getOptions(); // 指定调用WebService的URL EndpointReference targetEPR = new EndpointReference( "http://localhost:9090/universal/services/play"); options.setTo(targetEPR); // 指定方法的参数值 Object[] requestParam = new Object[] {"1024"}; // 指定方法返回值的数据类型的Class对象 Class[] responseParam = new Class[] {String.class}; // 指定要调用的getGreeting方法及WSDL文件的命名空间 QName requestMethod = new QName("http://localhost:9090/universal/services/play", "getPassengerInfos"); // 调用方法并输出该方法的返回值 try { System.out.println(serviceClient.invokeBlocking(requestMethod, requestParam, responseParam)[0]); } catch (AxisFault e) { e.printStackTrace(); } } } //方法三 package com.abin.lir.axis2.client; import org.apache.axiom.om.OMAbstractFactory; import org.apache.axiom.om.OMElement; import org.apache.axiom.om.OMFactory; import org.apache.axiom.om.OMNamespace; import org.apache.axis2.Constants; import org.apache.axis2.addressing.EndpointReference; import org.apache.axis2.client.Options; import org.apache.axis2.client.ServiceClient; public class AXIOMClient { private static EndpointReference targetEPR = new EndpointReference( "http://localhost:9090/universal/services/play"); public static OMElement getPassengerInfos(String symbol) { OMFactory fac = OMAbstractFactory.getOMFactory(); OMNamespace omNs = fac.createOMNamespace( "http://localhost:9090/universal/services/play", "tns"); OMElement method = fac.createOMElement("getPassengerInfos", omNs); OMElement value = fac.createOMElement("userID", omNs); value.addChild(fac.createOMText(value, symbol)); method.addChild(value); return method; } public static void main(String[] args) { try { OMElement getPassenger = getPassengerInfos("1024"); Options options = new Options(); options.setTo(targetEPR); options.setTransportInProtocol(Constants.TRANSPORT_HTTP); ServiceClient sender = new ServiceClient(); sender.setOptions(options); OMElement result = sender.sendReceive(getPassenger); String response = result.getFirstElement().getText(); System.err.println("Current passengers: " + response); } catch (Exception e) { e.printStackTrace(); } } }
http://blog.csdn.net/leo821031/article/details/1545974
http://zhangjunhd.blog.51cto.com/113473/25592/ http://hi.baidu.com/lennydou/item/b57032c0ceb6f5b00c0a7b08 http://www.cnblogs.com/markxue/archive/2012/09/01/2667123.html http://www.blogjava.net/zhaozhenlin1224/archive/2010/02/03/311783.html http://blog.csdn.net/yhhah/article/details/4158487
Axis2生成客户端方式
基于StockQuoteService类创建客户端的四种方式
构建基于AXIOM的客户端;
使用Axis2 Databinding Frame work(ADB)生成客户端;
使用XMLBeans生成客户端;
使用JiBX生成客户端。
ADB:最简单的生成Axis客户端的方法。大部分情况下,这些主要的类都会以内部类的形式创建在stub类中。It is not meant to be a full schema bindingapplication, and has difficulty with structures such as XML Schema element extensions and restrictions。 be meant to:有意要、打算
XMLBeans:与ADB不同,他是一个全功能的schema编译器。他没有ADB的限制。然而,他也比ADB用起来更复杂。他会产成大量的文件,编程模型不如ADB直观。
JiBX:他是一个数据绑定框架。他不仅提供了WSDL-JAVA的转换,而且提供了JAVA-XML的转换。JiBX相当灵活,允许你选择类来代表你的实体,但是这个却不好做,但还句话说,如果这些都能建好,那么使用JiBX就更使用ADB一样容易。
对于简单应用来说ADB已经够用了,如果想用更加强大更加灵活的功能,那么你可能需要使用其他两种方式。
Axis2提供的四种调用模式
Web services可以用来为用户提供广泛的功能,从简单的、少时间消耗的功能到多时间消耗的业务服务。当我们使用(调用客户端的应用程序)这些Web Service时,我们不能用简单的调用机制来针对那些对时间消耗有很大要求的服务操作。例如,如果我们使用一个简单的传输通道(如HTTP)并使用IN-OUT模式来调用一个需要很长时间来完成的Web Service,那么多数情况下,我们得到的结果将是"connection time outs"。另一方面,如果我们从一个简单的客户端应用程序调用一个同步的服务,使用"blocking"的客户端API将会降低客户端应用程序的性能。现在来分析一下一些常用的服务调用形式。
许多Web Service引擎提供给客户Blocking和Non-Blocking的客户端APIs。
1)Blocking API-一旦服务被启用,客户端的应用程序将被挂起,直到operation被执行完毕(表现为收到一个response或fault),才能重新获得控制权。这是调用Web Service最简单的方式,并且这种方式适用于多数业务情形。
2)Non-Blocking API-这是一个回叫或轮询机制的API。因此,一旦服务被起用,客户端应用程序马上得到控制权,通过使用一个callback对象来获得response。这种方式使得客户端应用程序可以很方便的同步启用多个Web Service。
这两种机制都是工作在API层面上的。称将通过使用Non-Blocking API而产生的异步行为方式为API Level 异步。这两种机制都使用单一的传输连接来发送request和接收response。它们的性能远远落后于使用两个传输连接来发送request和接收response(不管是单工还是双工)。所以这两种机制都不能解决需要长时间处理的事务的传输问题(在operation处理完成之前,很有可能你的连接已经超时了)。一种可能的解决方法是使用两个独立的传输连接来发送和接收request&response。这种异步行为,我们称为Transport Level 异步。
通过组合API Level异步和Transport Level 异步,我们可以得到四种调用模式。如下所示。
|
API (Blocking/Non-Blocking) |
Dual Transports (Yes/No) |
Description |
|
Blocking |
No |
最简单和常用的调用模式 |
|
Non-Blocking |
No |
使用回叫或轮询机制 |
|
Blocking |
Yes |
在单工模式下,service operation为IN-OUT时,很有用。(如SMTP) |
|
Non-Blocking |
Yes |
此模式下的异步效果最大 |
Axis2提供了所有上述4种调用Web Service的实现方式。
node.selectNodes("//xml");
node.selectNodes("/xml");
node.selectNodes("xml");
这三个写法有什么区别
问题补充:不是很明白
就举个例子吧
<root>
<xml>1</xml>
<node>
<xml>2</xml>
<AAA>
<xml>3</xml>
</AAA>
</node>
</root>
从node搜索的话,这三种方法分别能搜到1、2、3中的哪几个? nodename 选取此节点的所有子节点
/ 从根节点选取
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
参考资料:http://www.w3school.com.cn/xpath/xpath_syntax.asp
Java所有的类都具有线程的潜力,Java赋予的每个对象一个锁,在计算机内部工作在同一时间,只有一个对象可以持有锁,也就是说程序在同一时间只有一个程序可以运行,这里我把对象比作是一个小的程序。而多处理器,那么就另当别论了。
在这里我们首先学习一下公共方法wait,notify,notifyAll。
wait方法可以使在当前线程的对象等待,直到别的线程调用此对象的notify或notifyAll方法(注意:调用的是此对象的notify和notifyAll),并且当前运行的线程必须具有此对象的对象监视器
package com.abin.lee.thread.thread;
public class CarryTask extends Thread {
public void run() {
try {
synchronized (this) {
Thread t = Thread.currentThread();
System.out.println(t.getId() + t.getName() + ":task start, wait for notify...");
this.wait();
System.out.println(t.getId() + t.getName() + ":task continue...");
}
} catch (InterruptedException ex) {
System.out.println(CarryTask.class.getName());
}
}
}
package com.abin.lee.thread.thread;
public class CarryWait {
public static void main(String[] args) throws InterruptedException {
CarryTask task = new CarryTask();
Thread t = Thread.currentThread();
System.out.println(t.getId() + t.getName() + ":task start...");
task.start();
Thread.sleep(2000);
synchronized (task) {
System.out.println("id="+Thread.currentThread().getId()+",Name="+Thread.currentThread().getName()+",task="+task+",notify");
task.notify();
}
}
}
http://www.iteye.com/topic/1124814
今天试着把SpringMVC与fastjson整合了下,经测试也能解决json含中文乱码的问题,特此分享之。我也是初用,详细文档请见官网。public class MappingFastJsonHttpMessageConverter extends AbstractHttpMessageConverter<Object> { public static final Charset DEFAULT_CHARSET = Charset.forName("UTF-8"); private SerializerFeature[] serializerFeature; public SerializerFeature[] getSerializerFeature() { return serializerFeature; } public void setSerializerFeature(SerializerFeature[] serializerFeature) { this.serializerFeature = serializerFeature; } public MappingFastJsonHttpMessageConverter() { super(new MediaType("application", "json", DEFAULT_CHARSET)); } @Override public boolean canRead(Class<?> clazz, MediaType mediaType) { return true; } @Override public boolean canWrite(Class<?> clazz, MediaType mediaType) { return true; } @Override protected boolean supports(Class<?> clazz) { throw new UnsupportedOperationException(); } @Override protected Object readInternal(Class<?> clazz, HttpInputMessage inputMessage) throws IOException, HttpMessageNotReadableException { ByteArrayOutputStream baos = new ByteArrayOutputStream(); int i; while ((i = inputMessage.getBody().read()) != -1) { baos.write(i); } return JSON.parseArray(baos.toString(), clazz); } @Override protected void writeInternal(Object o, HttpOutputMessage outputMessage) throws IOException, HttpMessageNotWritableException { String jsonString = JSON.toJSONString(o, serializerFeature); OutputStream out = outputMessage.getBody(); out.write(jsonString.getBytes(DEFAULT_CHARSET)); out.flush(); } } SpringMVC关键配置:<mvc:annotation-driven>
<mvc:message-converters register-defaults="true">
<!-- fastjosn spring support -->
<bean id="jsonConverter" class="com.alibaba.fastjson.spring.support.MappingFastJsonHttpMessageConverter">
<property name="supportedMediaTypes" value="application/json" />
<property name="serializerFeature">
<list>
<value>WriteMapNullValue</value>
<value>QuoteFieldNames</value>
</list>
</property>
</bean>
</mvc:message-converters>
</mvc:annotation-driven> http://xyly624.blog.51cto.com/842520/896704
//实例一,这里面用到了信号量Semaphore和FutureTask
package net.abin.lee.mythread.callable;
import java.util.concurrent.Callable;
import java.util.concurrent.Semaphore;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class FutureGo implements Callable<String> {
private String message;
private static final Semaphore semaphore=new Semaphore(3);
private final ReentrantReadWriteLock rwl=new ReentrantReadWriteLock();
public FutureGo(String message) {
this.message = message;
}
public String call() throws InterruptedException {
semaphore.acquire();
Lock read=rwl.readLock();
Lock write=rwl.readLock();
read.lock();
System.out.println("message"+message+",Name"+Thread.currentThread().getName()+"进来了");
read.unlock();
write.lock();
String result=message+"你好!";
Thread.sleep(1000);
System.out.println("message"+message+"Name"+Thread.currentThread().getName()+"离开了");
write.unlock();
semaphore.release();
return result;
}
}
//FutureTaskTest.java
package net.abin.lee.mythread.callable;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.FutureTask;
public class FutureTaskTest {
public static void main(String[] args) throws InterruptedException,
ExecutionException {
Callable<String> go = new FutureGo("abin");
FutureTask<String> task = new FutureTask<String>(go);
ExecutorService executor = Executors.newCachedThreadPool();
if (!executor.isShutdown()) {
executor.execute(task);
}
String result = "";
if (!task.isDone()) {
result = (String) task.get();
System.out.println("result=" + result);
}
executor.shutdown();
}
}
//实例一,这里面用到了信号量Semaphore和FutureTask
package com.abin.lee.junit.httpasyncclient.example;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.conn.ClientConnectionManager;
import org.apache.http.conn.params.ConnManagerParams;
import org.apache.http.conn.scheme.PlainSocketFactory;
import org.apache.http.conn.scheme.Scheme;
import org.apache.http.conn.scheme.SchemeRegistry;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.conn.PoolingClientConnectionManager;
import org.apache.http.params.BasicHttpParams;
import org.apache.http.params.HttpConnectionParams;
import org.apache.http.params.HttpParams;
import org.apache.http.protocol.BasicHttpContext;
import org.apache.http.protocol.HttpContext;
import org.apache.http.util.EntityUtils;
import org.junit.Test;
public class ThreadPoolHttpClient {
// 线程池
private ExecutorService exe = null;
// 线程池的容量
private static final int POOL_SIZE = 20;
private HttpClient client = null;
String[] urls=null;
public ThreadPoolHttpClient(String[] urls){
this.urls=urls;
}
@Test
public void test() throws Exception {
exe = Executors.newFixedThreadPool(POOL_SIZE);
HttpParams params =new BasicHttpParams();
/* 从连接池中取连接的超时时间 */
ConnManagerParams.setTimeout(params, 1000);
/* 连接超时 */
HttpConnectionParams.setConnectionTimeout(params, 2000);
/* 请求超时 */
HttpConnectionParams.setSoTimeout(params, 4000);
SchemeRegistry schemeRegistry = new SchemeRegistry();
schemeRegistry.register(
new Scheme("http", 80, PlainSocketFactory.getSocketFactory()));
//ClientConnectionManager cm = new PoolingClientConnectionManager(schemeRegistry);
PoolingClientConnectionManager cm=new PoolingClientConnectionManager(schemeRegistry);
cm.setMaxTotal(10);
final HttpClient httpClient = new DefaultHttpClient(cm,params);
// URIs to perform GETs on
final String[] urisToGet = urls;
/* 有多少url创建多少线程,url多时机子撑不住
56 // create a thread for each URI
57 GetThread[] threads = new GetThread[urisToGet.length];
58 for (int i = 0; i < threads.length; i++) {
59 HttpGet httpget = new HttpGet(urisToGet[i]);
60 threads[i] = new GetThread(httpClient, httpget);
61 }
62 // start the threads
63 for (int j = 0; j < threads.length; j++) {
64 threads[j].start();
65 }
66
67 // join the threads,等待所有请求完成
68 for (int j = 0; j < threads.length; j++) {
69 threads[j].join();
70 }
71 使用线程池*/
for (int i = 0; i < urisToGet.length; i++) {
final int j=i;
System.out.println(j);
HttpGet httpget = new HttpGet(urisToGet[i]);
exe.execute( new GetThread(httpClient, httpget));
}
//创建线程池,每次调用POOL_SIZE
/*
for (int i = 0; i < urisToGet.length; i++) {
final int j=i;
System.out.println(j);
exe.execute(new Thread() {
@Override
public void run() {
this.setName("threadsPoolClient"+j);
try {
this.sleep(100);
System.out.println(j);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
HttpGet httpget = new HttpGet(urisToGet[j]);
new GetThread(httpClient, httpget).get();
}
});
}
*/
//exe.shutdown();
System.out.println("Done");
}
static class GetThread extends Thread{
private final HttpClient httpClient;
private final HttpContext context;
private final HttpGet httpget;
public GetThread(HttpClient httpClient, HttpGet httpget) {
this.httpClient = httpClient;
this.context = new BasicHttpContext();
this.httpget = httpget;
}
@Override
public void run(){
this.setName("threadsPoolClient");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
get();
}
public void get() {
try {
HttpResponse response = this.httpClient.execute(this.httpget, this.context);
HttpEntity entity = response.getEntity();
if (entity != null) {
System.out.println(this.httpget.getURI()+": status"+response.getStatusLine().toString());
}
// ensure the connection gets released to the manager
EntityUtils.consume(entity);
} catch (Exception ex) {
this.httpget.abort();
}finally{
httpget.releaseConnection();
}
}
}
}
package com.abin.lee.junit.httpasyncclient.service;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Map;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class HttpAsyncClientService extends HttpServlet{
private static final long serialVersionUID = 807336917776643578L;
@SuppressWarnings("rawtypes")
public void service(HttpServletRequest request,HttpServletResponse response) throws IOException{
Map map=request.getParameterMap();
String id=(String)((Object[])map.get("id"))[0].toString();
if(null!=id&&!"".equals(id)){
String result=id+" is response";
System.out.println("result="+result);
ServletOutputStream out=response.getOutputStream();
BufferedWriter writer=new BufferedWriter(new OutputStreamWriter(out,"UTF-8"));
writer.write(result);
writer.flush();
writer.close();
}else{
String result=id+" is null";
System.out.println("result="+result);
ServletOutputStream out=response.getOutputStream();
BufferedWriter writer=new BufferedWriter(new OutputStreamWriter(out,"UTF-8"));
writer.write(result);
writer.flush();
writer.close();
}
}
}
<servlet> <servlet-name>HttpAsyncClientService</servlet-name> <servlet-class>com.abin.lee.junit.httpasyncclient.service.HttpAsyncClientService</servlet-class> </servlet> <servlet-mapping> <servlet-name>HttpAsyncClientService</servlet-name> <url-pattern>/HttpAsyncClientService</url-pattern> </servlet-mapping>
package com.abin.lee.junit.httpasyncclient.example;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.Future;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.concurrent.FutureCallback;
import org.apache.http.impl.nio.client.DefaultHttpAsyncClient;
import org.apache.http.nio.client.HttpAsyncClient;
import org.apache.http.params.CoreConnectionPNames;
import org.apache.http.util.EntityUtils;
public class CreateAsyncClientHttpExchangeFutureCallback {
public static void main(String[] args) throws Exception {
HttpAsyncClient httpclient = new DefaultHttpAsyncClient();
httpclient.getParams()
.setIntParameter(CoreConnectionPNames.SO_TIMEOUT, 3000)
.setIntParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, 3000)
.setIntParameter(CoreConnectionPNames.SOCKET_BUFFER_SIZE, 8 * 1024)
.setBooleanParameter(CoreConnectionPNames.TCP_NODELAY, true);
httpclient.start();
try {
HttpGet[] requests = new HttpGet[] {
new HttpGet("http://localhost:7000/global/HttpAsyncClientService?id=6"),
new HttpGet("http://localhost:7000/global/HttpAsyncClientService?id=8"),
new HttpGet("http://localhost:7000/global/HttpAsyncClientService?id=5")
};
final CountDownLatch latch = new CountDownLatch(requests.length);
for (final HttpGet request: requests) {
httpclient.execute(request, new FutureCallback<HttpResponse>() {
public void completed(final HttpResponse response) {
latch.countDown();
System.out.println(request.getRequestLine() + "->" + response.getStatusLine());
}
public void failed(final Exception ex) {
latch.countDown();
System.out.println(request.getRequestLine() + "->" + ex);
}
public void cancelled() {
latch.countDown();
System.out.println(request.getRequestLine() + " cancelled");
}
});
Future<HttpResponse> future = httpclient.execute(request, null);
HttpResponse response = future.get();
System.out.println("Response: " + response.getStatusLine());
System.out.println("Response1: " + EntityUtils.toString(response.getEntity()));
}
latch.await();
System.out.println("Shutting down");
} finally {
httpclient.shutdown();
}
System.out.println("Done");
}
public static String AsyncHttp(){
return null;
}
}
package com.abin.lee.junit.httpasyncclient.service;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Map;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class HttpAsyncClientService extends HttpServlet{
private static final long serialVersionUID = 807336917776643578L;
@SuppressWarnings("rawtypes")
public void service(HttpServletRequest request,HttpServletResponse response) throws IOException{
Map map=request.getParameterMap();
String id=(String)((Object[])map.get("id"))[0].toString();
if(null!=id&&!"".equals(id)){
String result=id+" is response";
System.out.println("result="+result);
ServletOutputStream out=response.getOutputStream();
BufferedWriter writer=new BufferedWriter(new OutputStreamWriter(out,"UTF-8"));
writer.write(result);
writer.flush();
writer.close();
}else{
String result=id+" is null";
System.out.println("result="+result);
ServletOutputStream out=response.getOutputStream();
BufferedWriter writer=new BufferedWriter(new OutputStreamWriter(out,"UTF-8"));
writer.write(result);
writer.flush();
writer.close();
}
}
}
<servlet> <servlet-name>HttpAsyncClientService</servlet-name> <servlet-class>com.abin.lee.junit.httpasyncclient.service.HttpAsyncClientService</servlet-class> </servlet> <servlet-mapping> <servlet-name>HttpAsyncClientService</servlet-name> <url-pattern>/HttpAsyncClientService</url-pattern> </servlet-mapping>
package com.abin.lee.junit.httpasyncclient.example;
import java.util.concurrent.Future;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.nio.client.DefaultHttpAsyncClient;
import org.apache.http.nio.client.HttpAsyncClient;
import org.apache.http.util.EntityUtils;
public class CreateHttpAsyncClient {
public static void main(String[] args) throws Exception {
HttpAsyncClient httpclient = new DefaultHttpAsyncClient();
httpclient.start();
try {
HttpGet request = new HttpGet("http://localhost:7000/global/HttpAsyncClientService?id=5");
Future<HttpResponse> future = httpclient.execute(request, null);
HttpResponse response = future.get();
System.out.println("Response: " + response.getStatusLine());
System.out.println("Response1: " + EntityUtils.toString(response.getEntity()));
System.out.println("Shutting down");
} finally {
httpclient.shutdown();
}
System.out.println("Done");
}
}
//这个适用于oracle10,11,以前oracle9操作CLOB字段相当的繁琐,记着导入驱动包
package com.abin.wto.dbs.oracle;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class OperateOracle {
public static void main(String[] args) {
Connection conn=null;
PreparedStatement ps=null;
ResultSet rs=null;
try {
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
String url="jdbc:oracle:thin:@localhost:1521:XE";
conn=DriverManager.getConnection(url,"abin","abin");
String sql="insert into bignumber values(?,?)";
ps=conn.prepareStatement(sql);
ps.setInt(1, 1);
oracle.sql.CLOB clob=oracle.sql.CLOB.createTemporary(conn, false, oracle.sql.CLOB.DURATION_SESSION);
clob.open(oracle.sql.CLOB.MODE_READWRITE);
clob.setString(3, "llll");
ps.setClob(2, clob);
int result=ps.executeUpdate();
System.out.println("result="+result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
package com.abin.wto.dbs.oracle;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import oracle.sql.CLOB;
public class OperateOracle {
public static void main(String[] args) {
Connection conn=null;
PreparedStatement ps=null;
ResultSet rs=null;
try {
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
String url="jdbc:oracle:thin:@localhost:1521:XE";
conn=DriverManager.getConnection(url,"abin","abin");
String sql="insert into bignumber values(?,?)";
ps=conn.prepareStatement(sql);
ps.setInt(1, 8888);
java.sql.Clob clob=oracle.sql.CLOB.createTemporary(conn, false, oracle.sql.CLOB.DURATION_SESSION);
clob.setString(1, "55555555555555");
ps.setClob(2, clob);
int result=ps.executeUpdate();
System.out.println("result="+result);
} catch (Exception e) {
e.printStackTrace();
}finally{
if(ps!=null){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
try {
CLOB.freeTemporary(null);
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
摘要: 1、sed使用手册(转载)
sed使用手册(转载) 发信站: BBS 水木清华站 (Wed Sep 25 21:06:36 2002), 站内信件 Sed 命令列可分成编辑指令与文件档部份。其中 , 编辑指令负责控制所有的编 辑工作 ; 文件档表示所处理的档案。 ... 阅读全文
public class CyclicBarrier extends Object 一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。因为该 barrier 在释放等待线程后可以重用,所以称它为循环 的 barrier。 CyclicBarrier 支持一个可选的 Runnable 命令,在一组线程中的最后一个线程到达之后(但在释放所有线程之前),该命令只在每个屏障点运行一次。若在继续所有参与线程之前更新共享状态,此屏障操作 很有用。 以上是jdk文档的说明 * 现在说说我们今天活动的内容、首先我们要在公司大厅集合、然后参观陈云故居 * 参观完后集合、准备去淀水湖参观。(有3辆车、对应3个线程) * * 我们必须等大家都到齐了才能去下个地方、比如说 、在公司集合、3辆车子都到了才能出发 * 要不然人装不下啊。这是我们可以用到java线程并发库的CyclicBarrier类 public class CyclicBarrierTest { public static void main(String[] args) { final CyclicBarrier cb = new CyclicBarrier(3); //final Semaphore semaphore=new Semaphore(1); for (int i = 1; i <= 3; i++) { new Thread(new Runnable() { @Override public void run() { try { //semaphore.acquire(); System.out.println(Thread.currentThread().getName() + "公司大厅集合"); System.out.println(Thread.currentThread().getName() + "公司大厅等待...."); //semaphore.release(); cb.await(); Thread.sleep(2000); //semaphore.acquire(); System.out.println(Thread.currentThread().getName() + "陈云故居集合"); System.out.println(Thread.currentThread().getName() + "陈云故居等待...."); //semaphore.release(); cb.await(); Thread.sleep(2000); //semaphore.acquire(); System.out.println(Thread.currentThread().getName() + "淀水湖集合"); System.out.println(Thread.currentThread().getName() + "淀水湖等待....准备回家了"); //semaphore.release(); cb.await(); Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } } }).start(); } } } 以下是输出结果: Thread-0公司大厅集合 Thread-0公司大厅等待.... Thread-2公司大厅集合 Thread-1公司大厅集合 Thread-1公司大厅等待.... Thread-2公司大厅等待.... Thread-0陈云故居集合 Thread-1陈云故居集合 Thread-2陈云故居集合 Thread-1陈云故居等待.... Thread-0陈云故居等待.... Thread-2陈云故居等待.... Thread-0淀水湖集合 Thread-2淀水湖集合 Thread-1淀水湖集合 Thread-2淀水湖等待....准备回家了 Thread-0淀水湖等待....准备回家了 Thread-1淀水湖等待....准备回家了 ***注意上述代码中的Semaphore类、它也是java线程并发库中的一个类、更多具体作用我们以后再探讨。 以下是使用Semaphore后的输出结果:(相信你已经知道不同的地方了) Thread-0公司大厅集合 Thread-0公司大厅等待.... Thread-1公司大厅集合 Thread-1公司大厅等待.... Thread-2公司大厅集合 Thread-2公司大厅等待.... Thread-2陈云故居集合 Thread-2陈云故居等待.... Thread-1陈云故居集合 Thread-1陈云故居等待.... Thread-0陈云故居集合 Thread-0陈云故居等待.... Thread-2淀水湖集合 Thread-2淀水湖等待....准备回家了 Thread-1淀水湖集合 Thread-1淀水湖等待....准备回家了 Thread-0淀水湖集合 Thread-0淀水湖等待....准备回家了 http://blog.sina.com.cn/s/blog_7f448c520101219g.html
public class Exchanger<V> extends Object 可以在对中对元素进行配对和交换的线程的同步点。每个线程将条目上的某个方法呈现给 exchange 方法,与伙伴线程进行匹配,并且在返回时接收其伙伴的对象。Exchanger 可能被视为 SynchronousQueue 的双向形式。Exchanger 可能在应用程序(比如遗传算法和管道设计)中很有用。 以上是jdk文档的说明。 * 今天公司党委组织活动、12点半call我电话、我以80码的速度狂奔过去、上了一个车子(A车)、 * 戴着眼镜四处瞄了下,没发现什么美女啊。假寐了一会儿,司机说另外一个车子(B车)上要换过来 * 一个人、让车子上的人下去一个去B车。由于地势原因、我就下去了。 * * 一路上突然想到了java线程并发库中的Exchanger类。A车我们可以看作是一个线程、B车我们也可以 * 看作是一个线程,我和B车上的一位美女换位子,就可以用到Exchanger类的exchange方法。 * * 代码如下: public class ExchangerTest { public static void main(String[] args) { final Exchanger<String> exchange=new Exchanger<String>(); //final String a="yupan"; //final String b="a girl"; final String[] carA=new String[]{"zhangsan","lisi","yupan"}; final String[] carB=new String[]{"meinv_a","meinv_b","meinv_c"}; //A车线程 new Thread(new Runnable(){ String[] carA_copy=carA; @Override public void run() { try { System.out.println("交换前:A车上的第三位乘客:"+carA[2]); carA_copy[2]=exchange.exchange(carA_copy[2]); System.out.println("交换后:A车上的第三位乘客:"+carA[2]); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); //B车线程 new Thread(new Runnable(){ String[] carB_copy=carB; @Override public void run() { try { System.out.println("交换前:B车上的第三位乘客:"+carB[2]); carB_copy[2]=exchange.exchange(carB_copy[2]); System.out.println("交换后:B车上的第三位乘客:"+carB[2]); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); } } 输出结果: 交换前:A车上的第三位乘客:yupan 交换前:B车上的第三位乘客:meinv_c 交换后:B车上的第三位乘客:yupan 交换后:A车上的第三位乘客:meinv_c http://blog.sina.com.cn/s/blog_7f448c5201012183.html
Semaphore当前在多线程环境下被扩放使用,操作系统的信号量是个很重要的概念,在进程控制方面都有应用。Java 并发库 的Semaphore 可以很轻松完成信号量控制,Semaphore可以控制某个资源可被同时访问的个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。比如在Windows下可以设置共享文件的最大客户端访问个数。
Semaphore实现的功能就类似厕所有5个坑,假如有10个人要上厕所,那么同时只能有多少个人去上厕所呢?同时只能有5个人能够占用,当5个人中 的任何一个人让开后,其中等待的另外5个人中又有一个人可以占用了。另外等待的5个人中可以是随机获得优先机会,也可以是按照先来后到的顺序获得机会,这取决于构造Semaphore对象时传入的参数选项。单个信号量的Semaphore对象可以实现互斥锁的功能,并且可以是由一个线程获得了“锁”,再由另一个线程释放“锁”,这可应用于死锁恢复的一些场合。
Semaphore维护了当前访问的个数,提供同步机制,控制同时访问的个数。在数据结构中链表可以保存“无限”的节点,用Semaphore可以实现有限大小的链表。另外重入锁 ReentrantLock 也可以实现该功能,但实现上要复杂些。
下面的Demo中申明了一个只有5个许可的Semaphore,而有20个线程要访问这个资源,通过acquire()和release()获取和释放访问许可。
package com.test;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class TestSemaphore {
public static void main(String[] args) {
// 线程池
ExecutorService exec = Executors.newCachedThreadPool();
// 只能5个线程同时访问
final Semaphore semp = new Semaphore(5);
// 模拟20个客户端访问
for (int index = 0; index < 20; index++) {
final int NO = index;
Runnable run = new Runnable() {
public void run() {
try {
// 获取许可
semp.acquire();
System.out.println("Accessing: " + NO);
Thread.sleep((long) (Math.random() * 10000));
// 访问完后,释放
semp.release();
System.out.println("-----------------"+semp.availablePermits());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
exec.execute(run);
}
// 退出线程池
exec.shutdown();
}
}
执行结果如下:
Accessing: 0
Accessing: 1
Accessing: 3
Accessing: 4
Accessing: 2
-----------------0
Accessing: 6
-----------------1
Accessing: 7
-----------------1
Accessing: 8
-----------------1
Accessing: 10
-----------------1
Accessing: 9
-----------------1
Accessing: 5
-----------------1
Accessing: 12
-----------------1
Accessing: 11
-----------------1
Accessing: 13
-----------------1
Accessing: 14
-----------------1
Accessing: 15
-----------------1
Accessing: 16
-----------------1
Accessing: 17
-----------------1
Accessing: 18
-----------------1
Accessing: 19 http://www.cnblogs.com/whgw/archive/2011/09/29/2195555.html
View Code package generate.httpclient; import java.io.ByteArrayOutputStream; import java.io.IOException; import java.io.InputStream; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.concurrent.CountDownLatch; import org.apache.http.HttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.concurrent.FutureCallback; import org.apache.http.impl.nio.client.DefaultHttpAsyncClient; import org.apache.http.nio.client.HttpAsyncClient; import org.apache.http.nio.reactor.IOReactorException; public class AsynClient{ /** * @param args * @throws IOReactorException * @throws InterruptedException */ private List<String> urls; private HandlerFailThread failHandler; public AsynClient(List<String> list){ failHandler=new HandlerFailThread(); urls=list; } public Map<String,String> asynGet() throws IOReactorException, InterruptedException { final HttpAsyncClient httpclient = new DefaultHttpAsyncClient(); httpclient.start(); int urlLength=urls.size(); HttpGet[] requests = new HttpGet[urlLength]; int i=0; for(String url : urls){ requests[i]=new HttpGet(url); i++; } final CountDownLatch latch = new CountDownLatch(requests.length); final Map<String, String> responseMap=new HashMap<String, String>(); try { for (final HttpGet request : requests) { httpclient.execute(request, new FutureCallback<HttpResponse>() { public void completed(final HttpResponse response) { latch.countDown(); responseMap.put(request.getURI().toString(), response.getStatusLine().toString()); try { System.out.println(request.getRequestLine() + "->" + response.getStatusLine()+"->"); //+readInputStream(response.getEntity().getContent()) } catch (IllegalStateException e) { failHandler.putFailUrl(request.getURI().toString(), response.getStatusLine().toString()); e.printStackTrace(); } catch (Exception e) { failHandler.putFailUrl(request.getURI().toString(), response.getStatusLine().toString()); e.printStackTrace(); } } public void failed(final Exception ex) { latch.countDown(); ex.printStackTrace(); failHandler.putFailUrl(request.getURI().toString(), ex.getMessage()); } public void cancelled() { latch.countDown(); } }); } System.out.println("Doing..."); } finally { latch.await(); httpclient.shutdown(); } System.out.println("Done"); failHandler.printFailUrl(); return responseMap; } private String readInputStream(InputStream input) throws IOException{ byte[] buffer = new byte[128]; int len = 0; ByteArrayOutputStream bytes = new ByteArrayOutputStream(); while((len = input.read(buffer)) >= 0) { bytes.write(buffer, 0, len); } return bytes.toString(); } /** * Test * @param args */ public static void main(String[] args) { List<String> urls=new ArrayList<String>(); urls.add(" http://127.0.0.1/examples/servlets/"); urls.add(" http://127.0.0.1/examples/servlets/"); urls.add(" http://127.0.0.1/examples/servlets/"); for(int i=0;i<10;i++){ urls.addAll(urls); } System.out.println(urls.size()); AsynClient client=new AsynClient(urls); try { client.asynGet(); } catch (IOReactorException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("done"); } }
package com.abin.lii.han.limei;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.junit.Test;
public class ImediaRegisterTest {
@Test
public void testImediaRegister(){
String LIMEI_HTTP="http://192.168.3.15:1000/release/mybe";
String appId="fk000";
String udid="3A5S4D6F8G9K_3596140444464123";
String requestUrl=LIMEI_HTTP+"?app="+appId+"&udid="+udid+"&source="+"where"";
System.out.println(requestUrl);
String result="";
try {
URL url=new URL(requestUrl);
HttpURLConnection connection=(HttpURLConnection)url.openConnection();
connection.setDoOutput(true);
connection.setDoInput(true);
connection.setRequestMethod("GET");
connection.setUseCaches(false);
// URLConnection.setInstanceFollowRedirects是成员函数,仅作用于当前函数
connection.setInstanceFollowRedirects(false);
connection.setRequestProperty("Content-Type",
"application/x-www-form-urlencoded");
connection.connect();
//发送执行请求
//接收返回请求
BufferedReader reader=new BufferedReader(new InputStreamReader(connection.getInputStream(),"GBK"));
String line="";
StringBuffer buffer=new StringBuffer();
while((line=reader.readLine())!=null){
buffer.append(line);
}
result=buffer.toString();
System.out.println("result="+result);
connection.disconnect();
} catch (Exception e) {
e.printStackTrace();
}
}
}
1.tomcat下所有应用都强制https访问
在tomcat\conf\web.xml中的</welcome-file-list>后面加上以下配置: <login-config> <!-- Authorization setting for SSL --> <auth-method>CLIENT-CERT</auth-method> <realm-name>Client Cert Users-only Area</realm-name> </login-config> <security-constraint> <!-- Authorization setting for SSL --> <web-resource-collection > <web-resource-name >SSL</web-resource-name> <url-pattern>/*</url-pattern> </web-resource-collection> <user-data-constraint> <transport-guarantee>CONFIDENTIAL</transport-guarantee> </user-data-constraint> </security-constraint>
2.单个应用强制https访问
WEB-INF/web.xml的</welcome-file-list>后面加上以下配置: <login-config> <!-- Authorization setting for SSL --> <auth-method>CLIENT-CERT</auth-method> <realm-name>Client Cert Users-only Area</realm-name> </login-config> <security-constraint> <!-- Authorization setting for SSL --> <web-resource-collection > <web-resource-name >SSL</web-resource-name> <url-pattern>/*</url-pattern> </web-resource-collection> <user-data-constraint> <transport-guarantee>CONFIDENTIAL</transport-guarantee> </user-data-constraint> </security-constraint>
select t.*,t.rowid from abin1 t;
删除重复的记录,只保留一条:
delete from abin1 t where rowid not in (select max(rowid) from abin1 s group by s.id1 );
delete from abin1 t where t.rowid not in (select min(s.rowid) from abin1 s where t.id1=s.id1 group by s.id1)
删除全部重复记录:
delete from abin1 t where t.id1 in (select s.id1 from abin1 s group by s.id1 having count(s.id1)>1 );
delete from abin1 t where exists (select * from abin1 s where t.id1=s.id1 group by s.id1 having count(s.id1)>1)
取出有重复的记录,没有重复的单条记录不取:
select * from abin1 t where t.id1 in (select s.id1 from abin1 s group by s.id1 having(count(s.id1))>1 );
select * from abin1 t where exists (select * from abin1 s where s.id1=t.id1 group by s.id1 having(count(s.id1))>1);
删除重复记录(保留一条):
delete from abin1 t where t.id1 not in(select max(s.id1) from abin1 s group by s.name1 having count(s.name1)>0);
Nginx配置文件详细说明
在此记录下Nginx服务器nginx.conf的配置文件说明, 部分注释收集与网络.
#运行用户
user www-data;
#启动进程,通常设置成和cpu的数量相等
worker_processes 1;
#全局错误日志及PID文件
error_log /var/log/nginx/error.log;
pid /var/run/nginx.pid;
#工作模式及连接数上限
events {
use epoll; #epoll是多路复用IO(I/O Multiplexing)中的一种方式,但是仅用于linux2.6以上内核,可以大大提高nginx的性能
worker_connections 1024;#单个后台worker process进程的最大并发链接数
# multi_accept on;
}
#设定http服务器,利用它的反向代理功能提供负载均衡支持
http {
#设定mime类型,类型由mime.type文件定义
include /etc/nginx/mime.types;
default_type application/octet-stream;
#设定日志格式
access_log /var/log/nginx/access.log;
#sendfile 指令指定 nginx 是否调用 sendfile 函数(zero copy 方式)来输出文件,对于普通应用,
#必须设为 on,如果用来进行下载等应用磁盘IO重负载应用,可设置为 off,以平衡磁盘与网络I/O处理速度,降低系统的uptime.
sendfile on;
#tcp_nopush on;
#连接超时时间
#keepalive_timeout 0;
keepalive_timeout 65;
tcp_nodelay on;
#开启gzip压缩
gzip on;
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
#设定请求缓冲
client_header_buffer_size 1k;
large_client_header_buffers 4 4k;
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
#设定负载均衡的服务器列表
upstream mysvr {
#weigth参数表示权值,权值越高被分配到的几率越大
#本机上的Squid开启3128端口
server 192.168.8.1:3128 weight=5;
server 192.168.8.2:80 weight=1;
server 192.168.8.3:80 weight=6;
}
server {
#侦听80端口
listen 80;
#定义使用www.xx.com访问
server_name www.xx.com;
#设定本虚拟主机的访问日志
access_log logs/www.xx.com.access.log main;
#默认请求
location / {
root /root; #定义服务器的默认网站根目录位置
index index.php index.html index.htm; #定义首页索引文件的名称
fastcgi_pass www.xx.com;
fastcgi_param SCRIPT_FILENAME $document_root/$fastcgi_script_name;
include /etc/nginx/fastcgi_params;
}
# 定义错误提示页面
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /root;
}
#静态文件,nginx自己处理
location ~ ^/(images|javascript|js|css|flash|media|static)/ {
root /var/www/virtual/htdocs;
#过期30天,静态文件不怎么更新,过期可以设大一点,如果频繁更新,则可以设置得小一点。
expires 30d;
}
#PHP 脚本请求全部转发到 FastCGI处理. 使用FastCGI默认配置.
location ~ \.php$ {
root /root;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /home/www/www$fastcgi_script_name;
include fastcgi_params;
}
#设定查看Nginx状态的地址
location /NginxStatus {
stub_status on;
access_log on;
auth_basic "NginxStatus";
auth_basic_user_file conf/htpasswd;
}
#禁止访问 .htxxx 文件
location ~ /\.ht {
deny all;
}
}
}
#以上是一些基本的配置,使用Nginx最大的好处就是负载均衡
#如果要使用负载均衡的话,可以修改配置http节点如下:
#设定http服务器,利用它的反向代理功能提供负载均衡支持
http {
#设定mime类型,类型由mime.type文件定义
include /etc/nginx/mime.types;
default_type application/octet-stream;
#设定日志格式
access_log /var/log/nginx/access.log;
#省略上文有的一些配置节点
#。。。。。。。。。。
#设定负载均衡的服务器列表
upstream mysvr {
#weigth参数表示权值,权值越高被分配到的几率越大
server 192.168.8.1x:3128 weight=5;#本机上的Squid开启3128端口
server 192.168.8.2x:80 weight=1;
server 192.168.8.3x:80 weight=6;
}
upstream mysvr2 {
#weigth参数表示权值,权值越高被分配到的几率越大
server 192.168.8.x:80 weight=1;
server 192.168.8.x:80 weight=6;
}
#第一个虚拟服务器
server {
#侦听192.168.8.x的80端口
listen 80;
server_name 192.168.8.x;
#对aspx后缀的进行负载均衡请求
location ~ .*\.aspx$ {
root /root; #定义服务器的默认网站根目录位置
index index.php index.html index.htm; #定义首页索引文件的名称
proxy_pass http://mysvr ;#请求转向mysvr 定义的服务器列表
#以下是一些反向代理的配置可删除.
proxy_redirect off;
#后端的Web服务器可以通过X-Forwarded-For获取用户真实IP
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 10m; #允许客户端请求的最大单文件字节数
client_body_buffer_size 128k; #缓冲区代理缓冲用户端请求的最大字节数,
proxy_connect_timeout 90; #nginx跟后端服务器连接超时时间(代理连接超时)
proxy_send_timeout 90; #后端服务器数据回传时间(代理发送超时)
proxy_read_timeout 90; #连接成功后,后端服务器响应时间(代理接收超时)
proxy_buffer_size 4k; #设置代理服务器(nginx)保存用户头信息的缓冲区大小
proxy_buffers 4 32k; #proxy_buffers缓冲区,网页平均在32k以下的话,这样设置
proxy_busy_buffers_size 64k; #高负荷下缓冲大小(proxy_buffers*2)
proxy_temp_file_write_size 64k; #设定缓存文件夹大小,大于这个值,将从upstream服务器传
}
}
}
开发的应用采用F5负载均衡交换机,F5将请求转发给5台hp unix服务器,每台服务器有多个webserver实例,对外提供web服务和socket等接口服务。之初,曾有个小小的疑问为何不采用开源的apache、Nginx软件负载,F5设备动辄几十万,价格昂贵?自己一个比较幼稚的问题,后续明白:F5是操作于IOS网络模型的传输层,Nginx、apache是基于http反向代理方式,位于ISO模型的第七层应用层。直白些就是TCP UDP 和http协议的区别,Nginx不能为基于TCP协议的应用提供负载均衡。
了解了二者之间的区别于应用场景,对Nginx产生浓厚的兴趣,阅读张宴的<实战Nginx>(这个85年的小伙子年轻有为羡慕+妒忌),搞明白了大致原理和配置,Ubuntu10.10,window下对Nginx+tomcat负载均衡做了配置尝试,将全部请求转发到tomcat,并未做静态,动态分开,图片防盗链等配置。
Nginx 介绍
Nginx (发音同 engine x)是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行。 其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页伺服器中表现较好.目前中国大陆使用nginx网站用户有:新浪、网易、 腾讯,另外知名的微网志Plurk也使用nginx。
上面的全是Nginx介绍基本上是废话,下面转入正题,图文结合展示基本配置,首先是window环境、其次是Ubuntu环境(Vbox虚拟)。本文主要基于Nginx下配置两台tomcat,结构如下图:

Window xp环境:Nginx+Tomcat6
1、下载地址
http://nginx.org/en/download.html ,这里我们推荐下载稳定版(stable versions),本文采用nginx-0.8.20。
2、目录结构
Nginx-
|_ conf 配置目录
|_ contrib
|_ docs 文档目录
|_ logs 日志目录
|_ temp 临时文件目录
|_ html 静态页面目录
|_ nginx.exe 主程序
window下安装Nginx极其简单,解压缩到一个无空格的英文目录即可(个人习惯,担心中文出问题),双击nginx启动,这里我安装到:D:\server目录,下面涉及到的tomcat也安装在此目录。

DOS环境启动

若果想停止nginx,dos环境运行命令:nginx -s stop
3、nginx.conf配置
Nginx配置文件默认在conf目录,主要配置文件为nginx.conf,我们安装在D:\server\nginx-0.8.20、默认主配置文件为D:\server\nginx-0.8.20\nginx.conf。下面是nginx作为前端反向代理服务器的配置。
#Nginx所用用户和组,window下不指定
#user niumd niumd;
#工作的子进程数量(通常等于CPU数量或者2倍于CPU)
worker_processes 2;
#错误日志存放路径
#error_log logs/error.log;
#error_log logs/error.log notice;
error_log logs/error.log info;
#指定pid存放文件
pid logs/nginx.pid;
events {
#使用网络IO模型linux建议epoll,FreeBSD建议采用kqueue,window下不指定。
#use epoll;
#允许最大连接数
worker_connections 2048;
}
http {
include mime.types;
default_type application/octet-stream;
#定义日志格式
#log_format main '$remote_addr - $remote_user [$time_local] $request '
# '"$status" $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log off;
access_log logs/access.log;
client_header_timeout 3m;
client_body_timeout 3m;
send_timeout 3m;
client_header_buffer_size 1k;
large_client_header_buffers 4 4k;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
#keepalive_timeout 75 20;
include gzip.conf;
upstream localhost {
#根据ip计算将请求分配各那个后端tomcat,许多人误认为可以解决session问题,其实并不能。
#同一机器在多网情况下,路由切换,ip可能不同
#ip_hash;
server localhost:18081;
server localhost:18080;
}
server {
listen 80;
server_name localhost;
location / {
proxy_connect_timeout 3;
proxy_send_timeout 30;
proxy_read_timeout 30;
proxy_pass http://localhost;
}
}
}
代理设置如下: proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 10m;
client_body_buffer_size 128k;
proxy_connect_timeout 300;
proxy_send_timeout 300;
proxy_read_timeout 300;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
gzip压缩相关配置如下: gzip on;
gzip_min_length 1000;
gzip_types text/plain text/css application/x-javascript;
4、Tomcat配置
对于tomcat大家都很熟悉,只需要修改server.xml配置文件即可,这里我们以apache-tomcat-6.0.14为例,分别在server目录,解压缩并命名为:apache-tomcat-6.0.14_1、apache-tomcat-6.0.14_2。
第一处端口修改:
<!-- 修改port端口:18006 俩个tomcat不能重复,端口随意,别太小-->
<Server port="18006" shutdown="SHUTDOWN">
第二处端口修改: <!-- port="18081" tomcat监听端口,随意设置,别太小 -->
<Connector port="18081" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
第三处端口修改: <Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
Engine元素增加jvmRoute属性: <Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat1">
两个tomcat的端口别重复,保证能启动起来,另一个tomcat配置希捷省略,监听端口为18080,附件中我们将上传所有的配置信息。
5、验证配置与测试负载均衡
首先测试nginx配置是否正确,测试命令:nginx -t (默认验证:conf\nginx.conf),也可以指定配置文件路径。
此例nginx安装目录:D:\server\nginx-0.8.20,dos环境下图画面成功示例:

其次验证tomcat,启动两个tomcat,不出现端口冲突即为成功(tomcat依赖的java等搞“挨踢”的就废话不说了);

最后验证配置负载均衡设置,http://localhost/ 或http://localhost/index.jsp 。我修改了index.jsp页面,增加日志输出信息,便于观察。注意:左上角小猫头上的:access tomcat2、access tomcat1。说明访问了不同的tomcat。

至此window下nginx+tomcat负载均衡配置结束,关于tomcat Session的问题通常是采用memcached,或者采用nginx_upstream_jvm_route ,他是一个 Nginx 的扩展模块,用来实现基于 Cookie 的 Session Sticky 的功能。如果tomcat过多不建议session同步,server间相互同步session很耗资源,高并发环境容易引起Session风暴。请根据自己应用情况合理采纳session解决方案。
作者:niumd
Blog:http://ari.iteye.com
//nginx.conf
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
error_log logs/error.log info;
pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
include gzip.conf;
upstream localhost {
#根据ip计算将请求分配各那个后端tomcat,许多人误认为可以解决session问题,其实并不能。
#同一机器在多网情况下,路由切换,ip可能不同
#ip_hash;
server localhost:16300 weight=5;
server localhost:16400 weight=1;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_connect_timeout 3;
proxy_send_timeout 30;
proxy_read_timeout 30;
proxy_pass http://localhost;
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443;
# server_name localhost;
# ssl on;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_timeout 5m;
# ssl_protocols SSLv2 SSLv3 TLSv1;
# ssl_ciphers ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+EXP;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
}
//在%NGINX_HOME%/conf/下面新增proxy.conf proxy_redirect off; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; client_max_body_size 10m; client_body_buffer_size 128k; proxy_connect_timeout 300; proxy_send_timeout 300; proxy_read_timeout 300; proxy_buffer_size 4k; proxy_buffers 4 32k; proxy_busy_buffers_size 64k; proxy_temp_file_write_size 64k; //在%NGINX_HOME%/conf/下面新增gzip.conf gzip on; gzip_min_length 1000; gzip_types text/plain text/css application/x-javascript; //tomcat63 %TOMCAT_HOME%/conf/server.xml
<?xml version='1.0' encoding='utf-8'?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!-- Note: A "Server" is not itself a "Container", so you may not
define subcomponents such as "Valves" at this level.
Documentation at /docs/config/server.html
-->
<Server port="16305" shutdown="SHUTDOWN">
<!--APR library loader. Documentation at /docs/apr.html -->
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<!--Initialize Jasper prior to webapps are loaded. Documentation at /docs/jasper-howto.html -->
<Listener className="org.apache.catalina.core.JasperListener" />
<!-- Prevent memory leaks due to use of particular java/javax APIs-->
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<!-- JMX Support for the Tomcat server. Documentation at /docs/non-existent.html -->
<Listener className="org.apache.catalina.mbeans.ServerLifecycleListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<!-- Global JNDI resources
Documentation at /docs/jndi-resources-howto.html
-->
<GlobalNamingResources>
<!-- Editable user database that can also be used by
UserDatabaseRealm to authenticate users
-->
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<!-- A "Service" is a collection of one or more "Connectors" that share
a single "Container" Note: A "Service" is not itself a "Container",
so you may not define subcomponents such as "Valves" at this level.
Documentation at /docs/config/service.html
-->
<Service name="Catalina">
<!--The connectors can use a shared executor, you can define one or more named thread pools-->
<!--
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="150" minSpareThreads="4"/>
-->
<!-- A "Connector" represents an endpoint by which requests are received
and responses are returned. Documentation at :
Java HTTP Connector: /docs/config/http.html (blocking & non-blocking)
Java AJP Connector: /docs/config/ajp.html
APR (HTTP/AJP) Connector: /docs/apr.html
Define a non-SSL HTTP/1.1 Connector on port 8080
-->
<Connector port="16300" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- A "Connector" using the shared thread pool-->
<!--
<Connector executor="tomcatThreadPool"
port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
-->
<!-- Define a SSL HTTP/1.1 Connector on port 8443
This connector uses the JSSE configuration, when using APR, the
connector should be using the OpenSSL style configuration
described in the APR documentation -->
<!--
<Connector port="8443" protocol="HTTP/1.1" SSLEnabled="true"
maxThreads="150" scheme="https" secure="true"
clientAuth="false" sslProtocol="TLS" />
-->
<!-- Define an AJP 1.3 Connector on port 8009 -->
<Connector port="16309" protocol="AJP/1.3" redirectPort="8443" />
<!-- An Engine represents the entry point (within Catalina) that processes
every request. The Engine implementation for Tomcat stand alone
analyzes the HTTP headers included with the request, and passes them
on to the appropriate Host (virtual host).
Documentation at /docs/config/engine.html -->
<!-- You should set jvmRoute to support load-balancing via AJP ie :
<Engine name="Catalina" defaultHost="localhost" jvmRoute="jvm1">
-->
<Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat63">
<!--For clustering, please take a look at documentation at:
/docs/cluster-howto.html (simple how to)
/docs/config/cluster.html (reference documentation) -->
<!--
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"/>
-->
<!-- The request dumper valve dumps useful debugging information about
the request and response data received and sent by Tomcat.
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.valves.RequestDumperValve"/>
-->
<!-- This Realm uses the UserDatabase configured in the global JNDI
resources under the key "UserDatabase". Any edits
that are performed against this UserDatabase are immediately
available for use by the Realm. -->
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
<!-- Define the default virtual host
Note: XML Schema validation will not work with Xerces 2.2.
-->
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
<!-- SingleSignOn valve, share authentication between web applications
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.authenticator.SingleSignOn" />
-->
<!-- Access log processes all example.
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt" pattern="common" resolveHosts="false"/>
-->
</Host>
</Engine>
</Service>
</Server>
%TOMCAT_HOME%/conf/server.xml
<?xml version='1.0' encoding='utf-8'?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!-- Note: A "Server" is not itself a "Container", so you may not
define subcomponents such as "Valves" at this level.
Documentation at /docs/config/server.html
-->
<Server port="16405" shutdown="SHUTDOWN">
<!--APR library loader. Documentation at /docs/apr.html -->
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<!--Initialize Jasper prior to webapps are loaded. Documentation at /docs/jasper-howto.html -->
<Listener className="org.apache.catalina.core.JasperListener" />
<!-- Prevent memory leaks due to use of particular java/javax APIs-->
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<!-- JMX Support for the Tomcat server. Documentation at /docs/non-existent.html -->
<Listener className="org.apache.catalina.mbeans.ServerLifecycleListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<!-- Global JNDI resources
Documentation at /docs/jndi-resources-howto.html
-->
<GlobalNamingResources>
<!-- Editable user database that can also be used by
UserDatabaseRealm to authenticate users
-->
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<!-- A "Service" is a collection of one or more "Connectors" that share
a single "Container" Note: A "Service" is not itself a "Container",
so you may not define subcomponents such as "Valves" at this level.
Documentation at /docs/config/service.html
-->
<Service name="Catalina">
<!--The connectors can use a shared executor, you can define one or more named thread pools-->
<!--
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="150" minSpareThreads="4"/>
-->
<!-- A "Connector" represents an endpoint by which requests are received
and responses are returned. Documentation at :
Java HTTP Connector: /docs/config/http.html (blocking & non-blocking)
Java AJP Connector: /docs/config/ajp.html
APR (HTTP/AJP) Connector: /docs/apr.html
Define a non-SSL HTTP/1.1 Connector on port 8080
-->
<Connector port="16400" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- A "Connector" using the shared thread pool-->
<!--
<Connector executor="tomcatThreadPool"
port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
-->
<!-- Define a SSL HTTP/1.1 Connector on port 8443
This connector uses the JSSE configuration, when using APR, the
connector should be using the OpenSSL style configuration
described in the APR documentation -->
<!--
<Connector port="8443" protocol="HTTP/1.1" SSLEnabled="true"
maxThreads="150" scheme="https" secure="true"
clientAuth="false" sslProtocol="TLS" />
-->
<!-- Define an AJP 1.3 Connector on port 8009 -->
<Connector port="16409" protocol="AJP/1.3" redirectPort="8443" />
<!-- An Engine represents the entry point (within Catalina) that processes
every request. The Engine implementation for Tomcat stand alone
analyzes the HTTP headers included with the request, and passes them
on to the appropriate Host (virtual host).
Documentation at /docs/config/engine.html -->
<!-- You should set jvmRoute to support load-balancing via AJP ie :
<Engine name="Catalina" defaultHost="localhost" jvmRoute="jvm1">
-->
<Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat64">
<!--For clustering, please take a look at documentation at:
/docs/cluster-howto.html (simple how to)
/docs/config/cluster.html (reference documentation) -->
<!--
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"/>
-->
<!-- The request dumper valve dumps useful debugging information about
the request and response data received and sent by Tomcat.
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.valves.RequestDumperValve"/>
-->
<!-- This Realm uses the UserDatabase configured in the global JNDI
resources under the key "UserDatabase". Any edits
that are performed against this UserDatabase are immediately
available for use by the Realm. -->
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
<!-- Define the default virtual host
Note: XML Schema validation will not work with Xerces 2.2.
-->
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
<!-- SingleSignOn valve, share authentication between web applications
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.authenticator.SingleSignOn" />
-->
<!-- Access log processes all example.
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt" pattern="common" resolveHosts="false"/>
-->
</Host>
</Engine>
</Service>
</Server>
先启动nginx,后启动tomcat。
首先测试nginx配置是否正确,测试命令:nginx -t (默认验证:conf\nginx.conf),也可以指定配置文件路径。
其次验证tomcat,启动两个tomcat,不出现端口冲突即为成功(tomcat依赖的java等搞“挨踢”的就废话不说了);
post提交模拟
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.InetAddress;
import java.net.Socket;
import java.net.URLEncoder;
public class TestSocketPost {
public static void main(String[] args) {
BufferedWriter httpPostWriter = null;
BufferedReader httpResponse = null;
try {
// form域的数据.form域的数据必须以链接形式发送
StringBuffer formDataItems = new StringBuffer();
formDataItems.append(URLEncoder.encode("name", "GBK"));
formDataItems.append("=");
formDataItems.append(URLEncoder.encode("fruitking", "GBK"));
formDataItems.append("&");
formDataItems.append(URLEncoder.encode("company", "GBK"));
formDataItems.append("=");
formDataItems.append(URLEncoder.encode("intohotel", "GBK"));
String hostname = "localhost";// 主机,可以是域名,也可以是ip地址
int port = 8080;// 端口
InetAddress addr = InetAddress.getByName(hostname);
// 建立连接
Socket socket = new Socket(addr, port);
// 创建数据提交数据流
httpPostWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream(), "GBK"));
// 相对主机的请求地址
String httpSubmitPath = "/icbcnet/testpostresult.jsp";
// 发送数据头
httpPostWriter.write("POST " + httpSubmitPath + " HTTP/1.0\r\n");
httpPostWriter.write("Host: socket方式的post提交测试\r\n");
httpPostWriter.write("Content-Length: " + formDataItems.length() + "\r\n");
httpPostWriter.write("Content-Type: application/x-www-form-urlencoded\r\n");
httpPostWriter.write("\r\n"); // 以空行作为分割
// 发送数据
httpPostWriter.write(formDataItems.toString());
httpPostWriter.flush();
// 创建web服务器响应的数据流
httpResponse = new BufferedReader(new InputStreamReader(socket.getInputStream(), "GBK"));
String lineStr = "";
while ((lineStr = httpResponse.readLine()) != null) {
System.out.println(lineStr);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (httpPostWriter != null) {
httpPostWriter.close();
}
if (httpResponse != null) {
httpResponse.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
get模拟
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.InetAddress;
import java.net.Socket;
import java.net.URLEncoder;
public class TestSocketGet {
public static void main(String[] args) {
BufferedWriter httpGetWriter = null;
BufferedReader httpResponse = null;
try {
String hostname = "localhost";// 主机,可以是域名,也可以是ip地址
int port = 8080;// 端口
InetAddress addr = InetAddress.getByName(hostname);
// 建立连接
Socket socket = new Socket(addr, port);
// 创建数据提交数据流
httpGetWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream(), "GBK"));
// 相对主机的请求地址
StringBuffer httpSubmitPath = new StringBuffer("/icbcnet/testpostresult.jsp?");
httpSubmitPath.append(URLEncoder.encode("name", "GBK"));
httpSubmitPath.append("=");
httpSubmitPath.append(URLEncoder.encode("fruitking", "GBK"));
httpSubmitPath.append("&");
httpSubmitPath.append(URLEncoder.encode("company", "GBK"));
httpSubmitPath.append("=");
httpSubmitPath.append(URLEncoder.encode("pubone", "GBK"));
httpGetWriter.write("GET " + httpSubmitPath.toString() + " HTTP/1.1\r\n");
httpGetWriter.write("Host: socket方式的get提交测试\r\n");
httpGetWriter.write("\r\n");
httpGetWriter.flush();
// 创建web服务器响应的数据流
httpResponse = new BufferedReader(new InputStreamReader(socket.getInputStream(), "GBK"));
// 读取每一行的数据.注意大部分端口操作都需要交互数据。
String lineStr = "";
while ((lineStr = httpResponse.readLine()) != null) {
System.out.println(lineStr);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (httpGetWriter != null) {
httpGetWriter.close();
}
if (httpResponse != null) {
httpResponse.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
Web服务器与客户端的通信使用HTTP协议(超文本传输协议),所以也叫做HTTP服务器。用Java构造Web服务器主要用二个类,java.net.Socket和java.net.ServerSocket,来实现HTTP通信。因此,本文首先要讨论的是HTTP协议和这两个类,在此基础上实现一个简单但完整的Web服务器。
一、超文本传输协议
Web服务器和浏览器通过HTTP协议在Internet上发送和接收消息。HTTP协议是一种请求-应答式的协议——客户端发送一个请求,服务器返回该请求的应答。HTTP协议使用可靠的TCP连接,默认端口是80。HTTP的第一个版本是HTTP/0.9,后来发展到了HTTP/1.0,现在最新的版本是HTTP/1.1。HTTP/1.1由 RFC 2616 定义(pdf格式)。
本文只简要介绍HTTP 1.1的相关知识,但应该足以让你理解Web服务器和浏览器发送的消息。如果你要了解更多的细节,请参考RFC 2616。
在HTTP中,客户端/服务器之间的会话总是由客户端通过建立连接和发送HTTP请求的方式初始化,服务器不会主动联系客户端或要求与客户端建立连接。浏览器和服务器都可以随时中断连接,例如,在浏览网页时你可以随时点击“停止”按钮中断当前的文件下载过程,关闭与Web服务器的HTTP连接。
1.1 HTTP请求
HTTP请求由三个部分构成,分别是:方法-URI-协议/版本,请求头,请求正文。下面是一个HTTP请求的例子:
GET /servlet/default.jsp HTTP/1.1
Accept: text/plain; text/html
Accept-Language: en-gb
Connection: Keep-Alive
Host: localhost
Referer: http://localhost/ch8/SendDetails.htm
User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows 98)
Content-Length: 33
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
userName=JavaJava&userID=javaID
请求的第一行是“方法-URI-协议/版本”,其中GET就是请求方法,/servlet/default.jsp表示URI,HTTP/1.1是协议和协议的版本。根据HTTP标准,HTTP请求可以使用多种请求方法。例如,HTTP 1.1支持七种请求方法:GET,POST,HEAD,OPTIONS,PUT,DELETE,和TRACE。在Internet应用中,最常用的请求方法是GET和POST。
URI完整地指定了要访问的网络资源,通常认为它相对于服务器的根目录而言,因此总是以“/”开头。URL实际上是URI 一种类型。最后,协议版本声明了通信过程中使用的HTTP协议的版本。
请求头包含许多有关客户端环境和请求正文的有用信息。例如,请求头可以声明浏览器所用的语言,请求正文的长度,等等,它们之间用一个回车换行符号(CRLF)分隔。
请求头和请求正文之间是一个空行(只有CRLF符号的行),这个行非常重要,它表示请求头已经结束,接下来的是请求的正文。一些介绍Internet编程的书籍把这个CRLF视为HTTP请求的第四个组成部分。
在前面的HTTP请求中,请求的正文只有一行内容。当然,在实际应用中,HTTP请求正文可以包含更多的内容。
1.2 HTTP应答
和HTTP请求相似,HTTP应答也由三个部分构成,分别是:协议-状态代码-描述,应答头,应答正文。下面是一个HTTP应答的例子:
HTTP/1.1 200 OK
Date: Tue, 06 Mar 2012 12:32:58 GMT
Server: Apache/2.2.22 (Win32)
Last-Modified: Tue, 06 Mar 2012 11:46:06 GMT
ETag: “b000000008d9e-57-4ba9196947acd”
Accept-Ranges: bytes
Content-Length: 87
Content-Type: text/html
经过测试,可以使用滴
//实例一:
package com.abin.lii.han.socket;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.InetAddress;
import java.net.Socket;
import java.net.URLEncoder;
public class SocketGetServletTest {
public static void main(String[] args) {
BufferedWriter httpGetWriter = null;
BufferedReader httpResponse = null;
try {
String hostname = "localhost";// 主机,可以是域名,也可以是ip地址
int port = 1443;// 端口
InetAddress addr = InetAddress.getByName(hostname);
// 建立连接
Socket socket = new Socket(addr, port);
// 创建数据提交数据流
httpGetWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream(), "GBK"));
// 相对主机的请求地址
StringBuffer httpSubmitPath = new StringBuffer("/abin/ImediaRegister?");
// StringBuffer httpSubmitPath = new StringBuffer("http://localhost:7200/abin/ImediaRegister?");
httpSubmitPath.append(URLEncoder.encode("app", "GBK"));
httpSubmitPath.append("=");
httpSubmitPath.append(URLEncoder.encode("longcodeimedia", "GBK"));
httpSubmitPath.append("&");
httpSubmitPath.append(URLEncoder.encode("udid", "GBK"));
httpSubmitPath.append("=");
httpSubmitPath.append(URLEncoder.encode("123456789", "GBK"));
httpSubmitPath.append("&");
httpSubmitPath.append(URLEncoder.encode("source", "GBK"));
httpSubmitPath.append("=");
httpSubmitPath.append(URLEncoder.encode("limei", "GBK"));
httpSubmitPath.append("&");
httpSubmitPath.append(URLEncoder.encode("returnFormat", "GBK"));
httpSubmitPath.append("=");
httpSubmitPath.append(URLEncoder.encode("2", "GBK"));
httpGetWriter.write("GET " + httpSubmitPath.toString() + " HTTP/1.1\r\n");
httpGetWriter.write("Host: localhost:7200\r\n");
httpGetWriter.write("UserAgent: IE8.0\r\n");
httpGetWriter.write("Connection: Keep-Alive\r\n");
httpGetWriter.write("\r\n");
httpGetWriter.flush();
// 创建web服务器响应的数据流
httpResponse = new BufferedReader(new InputStreamReader(socket.getInputStream(), "GBK"));
// 读取每一行的数据.注意大部分端口操作都需要交互数据。
String lineStr = "";
while ((lineStr = httpResponse.readLine()) != null) {
System.out.println(lineStr);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (httpGetWriter != null) {
httpGetWriter.close();
}
if (httpResponse != null) {
httpResponse.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
//实例二
package com.abin.lii.han.socket;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.InetAddress;
import java.net.Socket;
public class SocketGetServletTest1 {
public static void main(String[] args) {
try {
Socket socket = new Socket(InetAddress.getLocalHost(), 7200);
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
StringBuffer buffer = new StringBuffer();
buffer.append("GET http://localhost:7200/abin/ImediaRegister?app=2 HTTP/1.1\r\n");
buffer.append("Host: localhost:7200\r\n");
buffer.append("UserAgent: IE8.0\r\n");
buffer.append("Connection: Keep-Alive\r\n");
// 注,这是关键的关键,忘了这里让我搞了半个小时。这里一定要一个回车换行,表示消息头完,不然服务器会等待
buffer.append("\r\n");
writer.write(buffer.toString());
writer.flush();
// --输出服务器传回的消息的头信息
BufferedReader reader=new BufferedReader(new InputStreamReader(socket.getInputStream()));
String line = null;
StringBuilder builder=new StringBuilder();
while((line=reader.readLine())!=null){
builder.append(line);
}
String result=builder.toString();
System.out.println("result="+result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
摘要: MyBatis的动态SQL是基于OGNL表达式的,它可以帮助我们方便的在SQL语句中实现某些逻辑。
MyBatis中用于实现动态SQL的元素主要有:
ifchoose(when,otherwise)trimwheresetforeach
if就是简单的条件判断,利用if语句我们可以实现某些简单的条件选择。先来看如下一个例子:
Xml代码
<... 阅读全文
1.CachedThreadPool
CachedThreadPool首先会按照需要创建足够多的线程来执行任务(Task)。随着程序执行的过程,有的线程执行完了任务,可以被重新循环使用时,才不再创建新的线程来执行任务。我们采用《Thinking In Java》中的例子来分析。
首先,任务定义如下(实现了Runnable接口,并且复写了run方法):
package net.jerryblog.concurrent; public class LiftOff implements Runnable{ protected int countDown = 10; //Default private static int taskCount = 0; private final int id = taskCount++; public LiftOff() {} public LiftOff(int countDown) { this.countDown = countDown; } public String status() { return "#" + id + "(" + (countDown > 0 ? countDown : "LiftOff!") + ") "; } @Override public void run() { while(countDown-- > 0) { System.out.print(status()); Thread.yield(); } } } 采用CachedThreadPool方式执行编写的客户端程序如下: package net.jerryblog.concurrent; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class CachedThreadPool { public static void main(String[] args) { ExecutorService exec = Executors.newCachedThreadPool(); for(int i = 0; i < 10; i++) { exec.execute(new LiftOff()); } exec.shutdown(); } } 上面的程序中,有10个任务,采用CachedThreadPool模式,exec没遇到一个LiftOff的对象(Task),就会创建一个线程来处理任务。现在假设遇到到第4个任务时,之前用于处理第一个任务的线程已经执行完成任务了,那么不会创建新的线程来处理任务,而是使用之前处理第一个任务的线程来处理这第4个任务。接着如果遇到第5个任务时,前面那些任务都还没有执行完,那么就会又新创建线程来执行第5个任务。否则,使用之前执行完任务的线程来处理新的任务。
2.FixedThreadPool
FixedThreadPool模式会使用一个优先固定数目的线程来处理若干数目的任务。规定数目的线程处理所有任务,一旦有线程处理完了任务就会被用来处理新的任务(如果有的话)。这种模式与上面的CachedThreadPool是不同的,CachedThreadPool模式下处理一定数量的任务的线程数目是不确定的。而FixedThreadPool模式下最多 的线程数目是一定的。
采用FixedThreadPool模式编写客户端程序如下: package net.jerryblog.concurrent; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class FixedThreadPool { public static void main(String[] args) { //三个线程来执行五个任务 ExecutorService exec = Executors.newFixedThreadPool(3); for(int i = 0; i < 5; i++) { exec.execute(new LiftOff()); } exec.shutdown(); } }
3.SingleThreadExecutor模式
SingleThreadExecutor模式只会创建一个线程。它和FixedThreadPool比较类似,不过线程数是一个。如果多个任务被提交给SingleThreadExecutor的话,那么这些任务会被保存在一个队列中,并且会按照任务提交的顺序,一个先执行完成再执行另外一个线程。
SingleThreadExecutor模式可以保证只有一个任务会被执行。这种特点可以被用来处理共享资源的问题而不需要考虑同步的问题。
SingleThreadExecutor模式编写的客户端程序如下: package net.jerryblog.concurrent; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class SingleThreadExecutor { public static void main(String[] args) { ExecutorService exec = Executors.newSingleThreadExecutor(); for (int i = 0; i < 2; i++) { exec.execute(new LiftOff()); } } } 这种模式下执行的结果如下: #0(9) #0(8) #0(7) #0(6) #0(5) #0(4) #0(3) #0(2) #0(1) #0(LiftOff!) #1(9) #1(8) #1(7) #1(6) #1(5) #1(4) #1(3) #1(2) #1(1) #1(LiftOff!) 第一个任务执行完了之后才开始执行第二个任务。
1、
最近在网上闲逛,突然发现Liferay的SVN,里面有非常多可用的样例代码,现在分享给大家:
地址:
http://svn.liferay.com/repos/public/plugins/trunk/portlets
用户名/密码: guest/guest http://svn.liferay.com/repos/public/
1.简介
sed是非交互式的编辑器。它不会修改文件,除非使用shell重定向来保存结果。默认情况下,所有的输出行都被打印到屏幕上。
sed编辑器逐行处理文件(或输入),并将结果发送到屏幕。具体过程如下:首先sed把当前正在处理的行保存在一个临时缓存区中(也称为模式空间),然后处理临时缓冲区中的行,完成后把该行发送到屏幕上。sed每处理完一行就将其从临时缓冲区删除,然后将下一行读入,进行处理和显示。处理完输入文件的最后一行后,sed便结束运行。sed把每一行都存在临时缓冲区中,对这个副本进行编辑,所以不会修改原文件。
2.定址
定址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式、或二者的结合。如果没有指定地址,sed将处理输入文件的所有行。
地址是一个数字,则表示行号;是“$"符号,则表示最后一行。例如:
|
sed -n '3p' datafile
只打印第三行
|
只显示指定行范围的文件内容,例如:
# 只查看文件的第100行到第200行
sed -n '100,200p' mysql_slow_query.log
地址是逗号分隔的,那么需要处理的地址是这两行之间的范围(包括这两行在内)。范围可以用数字、正则表达式、或二者的组合表示。例如:
|
sed '2,5d' datafile
#删除第二到第五行
sed '/My/,/You/d' datafile
#删除包含"My"的行到包含"You"的行之间的行
sed '/My/,10d' datafile
#删除包含"My"的行到第十行的内容
|
3.命令与选项
sed命令告诉sed如何处理由地址指定的各输入行,如果没有指定地址则处理所有的输入行。
3.1 sed命令
| 命令 |
功能 |
| a\ |
在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用“\”续行 |
| c\ |
用此符号后的新文本替换当前行中的文本。多行时除最后一行外,每行末尾需用"\"续行 |
| i\ |
在当前行之前插入文本。多行时除最后一行外,每行末尾需用"\"续行 |
| d |
删除行 |
| h |
把模式空间里的内容复制到暂存缓冲区 |
| H |
把模式空间里的内容追加到暂存缓冲区 |
| g |
把暂存缓冲区里的内容复制到模式空间,覆盖原有的内容 |
| G |
把暂存缓冲区的内容追加到模式空间里,追加在原有内容的后面 |
| l |
列出非打印字符 |
| p |
打印行 |
| n |
读入下一输入行,并从下一条命令而不是第一条命令开始对其的处理 |
| q |
结束或退出sed |
| r |
从文件中读取输入行 |
| ! |
对所选行以外的所有行应用命令 |
| s |
用一个字符串替换另一个 |
| g |
在行内进行全局替换 |
| |
|
| w |
将所选的行写入文件 |
| x |
交换暂存缓冲区与模式空间的内容 |
| y |
将字符替换为另一字符(不能对正则表达式使用y命令) |
3.2 sed选项
| 选项 |
功能 |
| -e |
进行多项编辑,即对输入行应用多条sed命令时使用 |
| -n |
取消默认的输出 |
| -f |
指定sed脚本的文件名 |
4.退出状态
sed不向grep一样,不管是否找到指定的模式,它的退出状态都是0。只有当命令存在语法错误时,sed的退出状态才不是0。
5.正则表达式元字符
与grep一样,sed也支持特殊元字符,来进行模式查找、替换。不同的是,sed使用的正则表达式是括在斜杠线"/"之间的模式。
如果要把正则表达式分隔符"/"改为另一个字符,比如o,只要在这个字符前加一个反斜线,在字符后跟上正则表达式,再跟上这个字符即可。例如:sed -n '\o^Myop' datafile
| 元字符 |
功能 |
示例 |
| ^ |
行首定位符 |
/^my/ 匹配所有以my开头的行 |
| $ |
行尾定位符 |
/my$/ 匹配所有以my结尾的行 |
| . |
匹配除换行符以外的单个字符 |
/m..y/ 匹配包含字母m,后跟两个任意字符,再跟字母y的行 |
| * |
匹配零个或多个前导字符 |
/my*/ 匹配包含字母m,后跟零个或多个y字母的行 |
| [] |
匹配指定字符组内的任一字符 |
/[Mm]y/ 匹配包含My或my的行 |
| [^] |
匹配不在指定字符组内的任一字符 |
/[^Mm]y/ 匹配包含y,但y之前的那个字符不是M或m的行 |
| \(..\) |
保存已匹配的字符 |
1,20s/\(you\)self/\1r/ 标记元字符之间的模式,并将其保存为标签1,之后可以使用\1来引用它。最多可以定义9个标签,从左边开始编号,最左边的是第一个。此例中,对第1到第20行进行处理,you被保存为标签1,如果发现youself,则替换为your。 |
| & |
保存查找串以便在替换串中引用 |
s/my/**&**/ 符号&代表查找串。my将被替换为**my** |
| \< |
词首定位符 |
/\<my/ 匹配包含以my开头的单词的行 |
| \> |
词尾定位符 |
/my\>/ 匹配包含以my结尾的单词的行 |
| x\{m\} |
连续m个x |
/9\{5\}/ 匹配包含连续5个9的行 |
| x\{m,\} |
至少m个x |
/9\{5,\}/ 匹配包含至少连续5个9的行 |
| x\{m,n\} |
至少m个,但不超过n个x |
/9\{5,7\}/ 匹配包含连续5到7个9的行 |
6.范例
6.1 p命令
命令p用于显示模式空间的内容。默认情况下,sed把输入行打印在屏幕上,选项-n用于取消默认的打印操作。当选项-n和命令p同时出现时,sed可打印选定的内容。
|
sed '/my/p' datafile
#默认情况下,sed把所有输入行都打印在标准输出上。如果某行匹配模式my,p命令将把该行另外打印一遍。
sed -n '/my/p' datafile
#选项-n取消sed默认的打印,p命令把匹配模式my的行打印一遍。
|
6.2 d命令
命令d用于删除输入行。sed先将输入行从文件复制到模式空间里,然后对该行执行sed命令,最后将模式空间里的内容显示在屏幕上。如果发出的是命令d,当前模式空间里的输入行会被删除,不被显示。
|
sed '$d' datafile
#删除最后一行,其余的都被显示
sed '/my/d' datafile
#删除包含my的行,其余的都被显示
|
6.3 s命令
|
sed 's/^My/You/g' datafile
#命令末端的g表示在行内进行全局替换,也就是说如果某行出现多个My,所有的My都被替换为You。
sed -n '1,20s/My$/You/gp' datafile
#取消默认输出,处理1到20行里匹配以My结尾的行,把行内所有的My替换为You,并打印到屏幕上。
|
|
sed 's#My#Your#g' datafile
#紧跟在s命令后的字符就是查找串和替换串之间的分隔符。分隔符默认为正斜杠,但可以改变。无论什么字符(换行符、反斜线除外),只要紧跟s命令,就成了新的串分隔符。
|
6.4 e选项
-e是编辑命令,用于sed执行多个编辑任务的情况下。在下一行开始编辑前,所有的编辑动作将应用到模式缓冲区中的行上。
|
sed -e '1,10d' -e 's/My/Your/g' datafile
#选项-e用于进行多重编辑。第一重编辑删除第1-3行。第二重编辑将出现的所有My替换为Your。因为是逐行进行这两项编辑(即这两个命令都在模式空间的当前行上执行),所以编辑命令的顺序会影响结果。
|
6.5 r命令
r命令是读命令。sed使用该命令将一个文本文件中的内容加到当前文件的特定位置上。
|
sed '/My/r introduce.txt' datafile
#如果在文件datafile的某一行匹配到模式My,就在该行后读入文件introduce.txt的内容。如果出现My的行不止一行,则在出现My的各行后都读入introduce.txt文件的内容。
|
6.6 w命令
|
sed -n '/hrwang/w me.txt' datafile
|
6.7 a\ 命令
a\ 命令是追加命令,追加将添加新文本到文件中当前行(即读入模式缓冲区中的行)的后面。所追加的文本行位于sed命令的下方另起一行。如果要追加的内容超过一行,则每一行都必须以反斜线结束,最后一行除外。最后一行将以引号和文件名结束。
|
sed '/^hrwang/a\
>hrwang and mjfan are husband\
>and wife' datafile
#如果在datafile文件中发现匹配以hrwang开头的行,则在该行下面追加hrwang and mjfan are husband and wife
|
6.8 i\ 命令
i\ 命令是在当前行的前面插入新的文本。
6.9 c\ 命令
sed使用该命令将已有文本修改成新的文本。
6.10 n命令
sed使用该命令获取输入文件的下一行,并将其读入到模式缓冲区中,任何sed命令都将应用到匹配行紧接着的下一行上。
|
sed '/hrwang/{n;s/My/Your/;}' datafile
|
注:如果需要使用多条命令,或者需要在某个地址范围内嵌套地址,就必须用花括号将命令括起来,每行只写一条命令,或这用分号分割同一行中的多条命令。
6.11 y命令
该命令与UNIX/Linux中的tr命令类似,字符按照一对一的方式从左到右进行转换。例如,y/abc/ABC/将把所有小写的a转换成A,小写的b转换成B,小写的c转换成C。
|
sed '1,20y/hrwang12/HRWANG^$/' datafile
#将1到20行内,所有的小写hrwang转换成大写,将1转换成^,将2转换成$。
#正则表达式元字符对y命令不起作用。与s命令的分隔符一样,斜线可以被替换成其它的字符。
|
6.12 q命令
q命令将导致sed程序退出,不再进行其它的处理。
|
sed '/hrwang/{s/hrwang/HRWANG/;q;}' datafile
|
6.13 h命令和g命令
|
#cat datafile
My name is hrwang.
Your name is mjfan.
hrwang is mjfan's husband.
mjfan is hrwang's wife.
sed -e '/hrwang/h' -e '$G' datafile
sed -e '/hrwang/H' -e '$G' datafile
#通过上面两条命令,你会发现h会把原来暂存缓冲区的内容清除,只保存最近一次执行h时保存进去的模式空间的内容。而H命令则把每次匹配hrwnag的行都追加保存在暂存缓冲区。
sed -e '/hrwang/H' -e '$g' datafile
sed -e '/hrwang/H' -e '$G' datafile
#通过上面两条命令,你会发现g把暂存缓冲区中的内容替换掉了模式空间中当前行的内容,此处即替换了最后一行。而G命令则把暂存缓冲区的内容追加到了模式空间的当前行后。此处即追加到了末尾。
|
7. sed脚本
sed脚本就是写在文件中的一列sed命令。脚本中,要求命令的末尾不能有任何多余的空格或文本。如果在一行中有多个命令,要用分号分隔。执行脚本时,sed先将输入文件中第一行复制到模式缓冲区,然后对其执行脚本中所有的命令。每一行处理完毕后,sed再复制文件中下一行到模式缓冲区,对其执行脚本中所有命令。使用sed脚本时,不再用引号来确保sed命令不被shell解释。例如sed脚本script:
|
#handle datafile
3i\
~~~~~~~~~~~~~~~~~~~~~
3,$s/\(hrwang\) is \(mjfan\)/\2 is \1/
$a\
We will love eachother forever!!
|
|
#sed -f script datafile
My name is hrwang
Your name is mjfan
~~~~~~~~~~~~~~~~~~~~~
mjfan is hrwang's husband. #啦啦~~~
mjfan is hrwang's wife.
We will love eachother forever!!
|
在MYSQL中插入当前时间: NOW()函数以`'YYYY-MM-DD HH:MM:SS'返回当前的日期时间,可以直接存到DATETIME字段中。
CURDATE()以’YYYY-MM-DD’的格式返回今天的日期,可以直接存到DATE字段中。
CURTIME()以’HH:MM:SS’的格式返回当前的时间,可以直接存到TIME字段中。
例:insert into tablename (fieldname) values (now())
now():以'yyyy-mm-dd hh:mm:ss'返回当前的日期时间,可以直接存到datetime字段中。 curdate():’yyyy-mm-dd’的格式返回今天的日期,可以直接存到date字段中。
//获取Mysql系统时间 select now() as systime ; select sysdate() as systime ; select current_date as systime ; select current_time as systime ; select current_timestamp as systime ; select * from abing where to_days(sysdate())=to_days(createtime); select * from abing where to_days(sysdate())=to_days(createtime); select * from abing where str_to_date(now(),'%Y-%m-%d')=str_to_date(createtime,'%Y-%m-%d');
自己写的例子,为了以后忘记了查询用: use abin; create table abin1( id integer not null auto_increment, name varchar(100), create_time datetime , update_time datetime , constraint pk_abin1 primary key(id)); insert into abin1(name,create_time,update_time) values ('abin1',now(),now()); insert into abin1(name,create_time,update_time) values ('abin1',sysdate(),sysdate());
摘要: 删除回滚段 当回滚段不再需要或要重建以改变INITIAL,NEXT或MINEXTENTS参数时,可以将其删除。要删除回滚段,不许使该回滚段离线。 语法: DROP ROLLBACK SEGMENT rollback_segment; 例: DROP ROLLBACK SEGMENT rbs01; 查询回滚段的信息 所用数据字典:DB... 阅读全文
ORA-01555:快照过旧。 一个对于Oracle DBA来说最经典问题。
发生的根本原因:一致性读出了问题。
看到网上有个同学,举例说明,觉得不错,拿来用下:
假设有张表,叫table1,里面有5000万行数据,假设预计全表扫描1次需要1个小时,我们从过程来看:
1、在1点钟,有个用户A发出了select * from table1;此时不管将来table1怎么变化,正确的结果应该是用户A会看到在1点钟这个时刻的内容。这个是没有疑问的。
2、在1点30分,有个用户B执行了update命令,更新了table1表中的第4000万行的这条记录,这时,用户A的全表扫描还没有到达第4000万条。毫无疑问,这个时候,第4000万行的这条记录是被写到了回滚段里去了的,我假设是回滚段RBS1,如果用户A的全表扫描到达了第4000万行,是应该会正确的从回滚段RBS1中读取出1点钟时刻的内容的。
3、这时,用户B将他刚才做的操作commit了,但是这时,系统仍然可以给用户A提供正确的数据,因为那第4000万行记录的内容仍然还在回滚段RBS1里,系统可以根据SCN来到回滚段里找到正确的数据,但是大家注意到,这时记录在RBS1里的第4000万行记录已经发生了一点重大的改变:就是这个第4000万行的在回滚段RBS1里的数据有可能随时被覆盖掉,因为这条记录已经被提交了!!!
4、由于用户A的查询时间漫长,而业务在一直不断的进行,RBS1回滚段在被多个不同的tracnsaction使用着,这个回滚段里的extent循环到了第4000万行数据所在的extent,由于这条记录已经被标记提交了,所以这个extent是可以被其他transaction覆盖掉的!
5、到了1点40分,用户A的查询终于到了第4000万行,而这时已经出现了第4条说的情况,需要到回滚段RBS1去找数据,但是已经被覆盖掉了,于是01555就出现了。
这次出现的ORA-01555,引起的原因很特殊。
报错是回滚段SYSSMU1有问题.
所以断定的是,并不是因为大量的读写,造成的一致性读错误,而且因为回滚段的错误,使快照出现了问题。
首先观察下回滚段:
SQL> select segment_name,tablespace_name,status from dba_rollback_segs;
发现表空间UNDOTBS1的回滚段_SYSSMU1$-10$都是online。
发现表空间UNDOTBS2的回滚段SYSSMU1是竟然是needs recovery,其他都是offline。
最有趣的是这个数据库指定的UNDO是UNDOTBS1,UNDOTBS2实际已经被弃用了。
尝试把该回滚段offline后删除,但是提示非法。
重启数据库后该回滚段状态变成了availabe。
再次尝试offline后删除,还是提示正在使用。
用直接更新数据字典的方法
SQL>update undo$ set status$=2 where name='SYSSMU1';
发现该回滚段状态变更为offline,drop掉即可。
ORA-1555不再出现。
本篇文章来源于 Linux公社网站(www.linuxidc.com) 原文链接:http://www.linuxidc.com/Linux/2012-10/73260.htm
首先说明一下:这是两个2个东西拉 动态代理,不是java语言特性, 只是java提供动态方法拦截的一种方式(工具) 有点类似 hook 动态代理,只是动态的通过反射,动态执行目标的相关操作, 当然要想实现动态代理,必须该类有接口(貌似cglib不需要的) 动态代理,是一种实现方式 多态,是oo语言的特性
多态表现在重载,一个父类的变量可以引用子类的对象
方法一:
package com.abin.lee.thread;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class ThreadSync{
public static List<Object> ThreadSync(final String message) throws InterruptedException{
final List<Object> list=new LinkedList<Object>();
Thread thread=new Thread(){
public void run(){
if(message.equals("one")){
list.add(0, message);
}
}
};
thread.start();
thread.join();
return list;
}
public static void main(String[] args) throws InterruptedException {
List<Object> list=ThreadSync("one1");
System.out.println("size="+list.size());
for(Iterator it=list.iterator();it.hasNext();){
Object obj=(Object)it.next();
System.out.println("obj="+obj);
}
}
}
方法二:
摘要: 教你如何迅速秒杀掉:99%的海量数据处理面试题
作者:July出处:结构之法算法之道blog
前言
一般而言,标题含有“秒杀”,“99%”,“史上最全/最强”等词汇的往往都脱不了哗众取宠之嫌,但进一步来讲,如果读者读罢此文,却无任何收获,那么,我也甘... 阅读全文
1、oracle正则表达式很强大哟,去掉字符串的(如果字符串开头和结尾存在"双引号的话)起头和结尾的双引号
select regexp_replace('"1234"456"','^(")|(")$','') from dual;
2、过滤掉字段里面的所有大小写字母,大小写字母通杀
select regexp_replace(t.address,'^[a-z]+|[A-Z]+$','') from abin7 t;
1、cat命令:
功能:1)显示整个文件。
示例: $ cat fileName
2)把文件串连接后传到基本输出,如将几个文件合并为一个文件或输出到屏幕。
示例: $ cat file1 file2 > file
说明:把档案串连接后传到基本输出(屏幕或加 > fileName 到另一个档案)
cat参数详解:
-n 或 –number 由 1 开始对所有输出的行数编号
-b 或 –number-nonblank 和 -n 相似,只不过对于空白行不编号
-s 或 –squeeze-blank 当遇到有连续两行以上的空白行,就代换为一行的空白行
-v 或 –show-nonprinting
2、more命令:
以百分比的形式查看日志。
3、less命令:
跟more功能差不多,只不过less支持前后翻阅文件。
4、head命令:
功能:从文本文件的头部开始查看,head 命令用于查看一个文本文件的开头部分。
示例如下:
head example.txt 显示文件 example.txt 的前十行内容;
head -n 20 example.txt 显示文件 example.txt 的前二十行内容;
head详解:
-n 指定你想要显示文本多少行。
-n number 这个参数选项必须是十进制的整数,它将决定在文件中的位置,以行为单位。
-c number 这个参数选项必须是十进制的整数,它将决定在文件中的位置,以字节为单位。
5、tail命令:
功能:tail 命令用于显示文本文件的末尾几行。
示例如下:
tail example.txt 显示文件 example.txt 的后十行内容;
tail -n 20 example.txt 显示文件 example.txt 的后二十行内容;
tail -f example.txt 显示文件 example.txt 的后十行内容并在文件内容增加后,自动显示新增的文件内容。
tail -n 50 -f example.txt 显示文件 example.txt 的后50行内容并在文件内容增加后,自动显示新增的文件内容。
注意:
最后一条命令非常有用,尤其在监控日志文件时,可以在屏幕上一直显示新增的日志信息。
tail详解:
-b Number 从 Number 变量表示的 512 字节块位置开始读取指定文件。
-c Number 从 Number 变量表示的字节位置开始读取指定文件。
-f 如果输入文件是常规文件或如果 File 参数指定 FIFO(先进先出),
那么 tail 命令不会在复制了输入文件的最后的指定单元后终止,而是继续
从输入文件读取和复制额外的单元(当这些单元可用时)。如果没有指定 File 参数,
并且标准输入是管道,则会忽略 -f 标志。tail -f 命令可用于监视另一个进程正在写入的文件的增长。
-k Number 从 Number 变量表示的 1KB 块位置开始读取指定文件。
-m Number 从 Number 变量表示的多字节字符位置开始读取指定文件。使用该标志提供在单字节和双字节字符代码集环境中的一致结果。
-n Number 从首行或末行位置来读取指定文件,位置由 Number 变量的符号(+ 或 - 或无)表示,并通过行号 Number 进行位移。
-r 从文件末尾以逆序方式显示输出。-r 标志的缺省值是以逆序方式显示整个文件。如果文件大于 20,480 字节,那么-r标志只显示最后的 20,480 字节。 -r 标志只有
与 -n 标志一起时才有效。否则,就会将其忽略。
create table abin6(id integer,
name nvarchar2(100),
score integer,
constraint pk_abin6 primary key(id));
create table abin7(id integer,
address nvarchar2(100),
sid integer,
constraint pk_abin7 primary key(id),
constraint fk_abin7 foreign key (sid) references abin6(id)
); select * from abin6 t left join abin7 s on t.id=s.sid and t.id=1; select * from abin6 t left join abin7 s on t.id=s.sid where t.id=1; select * from abin6 t,abin7 s where t.id=s.sid(+) ; select * from abin6 t,abin7 s where t.id(+)=s.sid; select * from abin6 t,abin7 s where s.sid(+)=t.id; select * from abin6 t,abin7 s where s.sid=t.id(+); select * from abin6 t inner join abin7 s on t.id=s.sid; select * from abin6 t union select * from abin7 s where exists (select * from abin6 k where s.sid=k.id and k.id =1); select * from abin6 t full join abin7 s on t.id=s.sid; select * from abin7 s full join abin6 t on s.sid=t.id; select * from abin6 natural join abin7; select * from abin6 t cross join abin7; 以下两句是等价查询:
select * from abin6 t where id=1 or id=2; select * from abin6 t where t.id=1 union all select * from abin6 s where s.id=2; 一。查找重复记录 1。查找全部重复记录 select * from abin4 s where s.name in (select t.name from abin4 t group by t.name having count(t.name)>1); select * from abin4 s where exists (select * from abin4 t where t.name=s.name group by t.name having count(t.name)>1 ); 2。过滤重复记录(只显示一条) select * from abin4 s where s.id in (select max(id) from abin4 t group by t.name ); 二。删除重复记录 1。删除全部重复记录(慎用) Delete 表 Where 重复字段 In (Select 重复字段 From 表 Group By 重复字段 Having Count(*)>1) 2。保留一条(这个应该是大多数人所需要的 ^_^) Delete HZT Where ID Not In (Select Max(ID) From HZT Group By Title) 注:此处保留ID最大一条记录 http://blog.csdn.net/csskysea/article/details/6987760
UNION 指令的目的是将两个 SQL 语句的结果合并起来,可以查看你要的查询结果.
例如:
SELECT Date FROM Store_Information
UNION
SELECT Date FROM Internet_Sales
注意:union用法中,两个select语句的字段类型匹配,而且字段个数要相同,如上面的例子,在实际的软件开发过程,会遇到更复杂的情况,具体请看下面的例子
select '1' as type,FL_ID,FL_CODE,FL_CNAME,FLDA.FL_PARENTID from FLDA
WHERE ZT_ID=2006030002
union
select '2' as type,XM_ID,XM_CODE ,XM_CNAME ,FL_ID from XMDA
where exists (select * from (select FL_ID from FLDA WHERE ZT_ID=2006030002 ) a where XMDA.fl_id=a.fl_id)
order by type,FL_PARENTID ,FL_ID
这个句子的意思是将两个sql语句union查询出来,查询的条件就是看XMDA表中的FL_ID是否和主表FLDA里的FL_ID值相匹配,(也就是存在).
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。
在查询中会遇到 UNION ALL,它的用法和union一样,只不过union含有distinct的功能,它会把两张表了重复的记录去掉,而union all不会,所以从效率上,union all 会高一点,但在实际中用到的并不是很多.
表头会用第一个连接块的字段。。。。。。。。。。
而UNION ALL只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用UNION ALL,如下:
尽量使用union all,因为union需要进行排序,去除重复记录,效率低
虽然natural join(自然连接)实际上的用的比较少,但实际上这个连接是非常有用的,若能经常使用一下,实际上是非常方便的。 自然连接是在两张表中寻找那些数据类型和列名都相同的字段,然后自动地将他们连接起来,并返回所有符合条件按的结果。 来看一下自然连接的例子。 Select emp.ename,dept.dname From emp natural join dept; 这里我们并没有指定连接的条件,实际上oracle为我们自作主张的将,emp中的deptno和dept中的deptno做了连接。 也就是实际上相当于 Select emp.ename,dept.dname From emp join dept on emp.deptno = dept.deptno; 因为这两张表的这两个字段deptno的类型个名称完全相同。所以使用natural join时被自然的连接在一起了。 另外: 1.如果做自然连接的两个表的有多个字段都满足有相同名称个类型,那么他们会被作为自然连接的条件。 2.如果自然连接的两个表仅是字段名称相同,但数据类型不同,那么将会返回一个错误。 3.由于oracle中可以进行这种非常简单的natural join,我们在设计表时,应该尽量在不同表中具有相同含义的字段使用相同的名字和数据类型。以方便以后使用natural join 最后我们在前面举的例子都得到以下的结果: SQL> Select emp.ename,dept.dname 2 From emp natural join dept; ENAME DNAME ——————– —————- SMITH RESEARCH ALLEN SALES WARD SALES JONES RESEARCH MARTIN SALES BLAKE SALES CLARK ACCOUNTING SCOTT RESEARCH KING ACCOUNTING TURNER SALES ADAMS RESEARCH JAMES SALES FORD RESEARCH MILLER ACCOUNTING
SQL> create table lee(id number,name varchar2(100),score number,constraint pk_lee primary key(id));
Table created
SQL> desc lee
Name Type Nullable Default Comments
----- ------------- -------- ------- --------
ID NUMBER
NAME VARCHAR2(100) Y
SCORE NUMBER Y
SQL> alter table lee add createtime date;
Table altered
SQL> desc lee
Name Type Nullable Default Comments
---------- ------------- -------- ------- --------
ID NUMBER
NAME VARCHAR2(100) Y
SCORE NUMBER Y
CREATETIME DATE Y
SQL> alter table lee modify createtime nvarchar2(100);
Table altered
SQL> desc lee
Name Type Nullable Default Comments
---------- -------------- -------- ------- --------
ID NUMBER
NAME VARCHAR2(100) Y
SCORE NUMBER Y
CREATETIME NVARCHAR2(100) Y
SQL> alter table lee rename column createtime to mytime;
Table altered
SQL> desc lee
Name Type Nullable Default Comments
------ -------------- -------- ------- --------
ID NUMBER
NAME VARCHAR2(100) Y
SCORE NUMBER Y
MYTIME NVARCHAR2(100) Y
SQL> alter table lee modify mytime date;
Table altered
SQL> desc lee
Name Type Nullable Default Comments
------ ------------- -------- ------- --------
ID NUMBER
NAME VARCHAR2(100) Y
SCORE NUMBER Y
MYTIME DATE Y
SQL> desc lee
Name Type Nullable Default Comments
------ ------------- -------- ------- --------
ID NUMBER
NAME VARCHAR2(100) Y
SCORE NUMBER Y
MYTIME DATE Y
SQL> alter table lee rename column mytime to createtime;
Table altered
SQL> desc lee
Name Type Nullable Default Comments
---------- ------------- -------- ------- --------
ID NUMBER
NAME VARCHAR2(100) Y
SCORE NUMBER Y
CREATETIME DATE Y
SQL> alter table lee drop column createtime;
Table altered
SQL> desc lee
Name Type Nullable Default Comments
----- ------------- -------- ------- --------
ID NUMBER
NAME VARCHAR2(100) Y
SCORE NUMBER Y
SQL>
//这里是测试UserDao userDao=EasyMock.createMock(UserDao.class);这种形式的:
package com.abin.lee.mock;
public class User {
private int id;
private String userName;
private String passWord;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassWord() {
return passWord;
}
public void setPassWord(String passWord) {
this.passWord = passWord;
}
}
package com.abin.lee.mock;
public interface UserDao {
User query(String id);
}
package com.abin.lee.mock;
public class UserDaoImpl implements UserDao{
public User query(String id) {
User user=null;
if(id.equals("1")){
user=new User();
user.setId(1);
user.setUserName("abin1");
user.setPassWord("varyall1");
}
if(id.equals("2")){
user=new User();
user.setId(2);
user.setUserName("abin2");
user.setPassWord("varyall2");
}
return user;
}
}
package com.abin.lee.mock;
public interface UserService {
User query(String id);
}
package com.abin.lee.mock;
public class UserServiceImpl implements UserService{
private UserDao userDao;
public User query(String id){
return this.userDao.query(id);
}
public UserDao getUserDao() {
return userDao;
}
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
}
测试代码:
package com.abin.lee.mock;
import org.easymock.EasyMock;
import org.junit.Assert;
import org.junit.Test;
public class UserMock {
@Test
public void test(){
User expectedUser=new User();
expectedUser.setId(1);
expectedUser.setUserName("abin1");
expectedUser.setPassWord("varyall1");
UserDao userDao=EasyMock.createMock(UserDao.class);
EasyMock.expect(userDao.query("1")).andReturn(expectedUser);
EasyMock.replay(userDao);
UserServiceImpl service=new UserServiceImpl();
service.setUserDao(userDao);
User user=service.query("1");
Assert.assertNotNull(user);
Assert.assertEquals(1, user.getId());
Assert.assertEquals("abin1", user.getUserName());
Assert.assertEquals("varyall1", user.getPassWord());
EasyMock.verify(userDao);
}
}
测试方法2:
package com.abin.lee.mock;
import org.easymock.EasyMock;
import org.easymock.IMocksControl;
import org.junit.Assert;
import org.junit.Test;
public class UsersMock {
@Test
public void test(){
User expectedUser=new User();
expectedUser.setId(2);
expectedUser.setUserName("abin2");
expectedUser.setPassWord("varyall2");
IMocksControl mock=EasyMock.createNiceControl();
UserDao userDao=mock.createMock(UserDao.class);
EasyMock.expect(userDao.query("2")).andReturn(expectedUser);
mock.replay();
UserServiceImpl service=new UserServiceImpl();
service.setUserDao(userDao);
User user=service.query("2");
Assert.assertNotNull(user);
Assert.assertEquals(2, user.getId());
Assert.assertEquals("abin2", user.getUserName());
Assert.assertEquals("varyall2", user.getPassWord());
mock.verify();
mock.resetToNice();
}
}
|