|
2018年1月4日
#
摘要: 前阵子从支付宝转账1万块钱到余额宝,这是日常生活的一件普通小事,但作为互联网研发人员的职业病,我就思考支付宝扣除1万之后,如果系统挂掉怎么办,这时余额宝账户并没有增加1万,数据就会出现不一致状况了。上述场景在各个类型的系统中都能找到相似影子,比如在电商系统中,当有用户下单后,除了在订单表插入一条记录外,对应商品表的这个商品数量必须减1吧,怎么保证?!在搜索广告系统中,当用户点击某广告后,除了在点击... 阅读全文
2017年12月31日
#
微服务架构采用Scale Cube方法设计应用架构,将应用服务按功能拆分成一组相互协作的服务。每个服务负责一组特定、相关的功能。每个服务可以有自己独立的数据库,从而保证与其他服务解耦。 微服务优点 1、通过分解巨大单体式应用为多个服务方法解决了复杂性问题,每个微服务相对较小 2、每个单体应用不局限于固定的技术栈,开发者可以自由选择开发技术,提供API服务。 3、每个微服务独立的开发,部署 4、单一职责功能,每个服务都很简单,只关注于一个业务功能 5、易于规模化开发,多个开发团队可以并行开发,每个团队负责一项服务 6、改善故障隔离。一个服务宕机不会影响其他的服务 微服务缺点: 1.开发者需要应对创建分布式系统所产生的额外的复杂因素 l 目前的IDE主要面对的是单体工程程序,无法显示支持分布式应用的开发 l 测试工作更加困难 l 需要采用服务间的通讯机制 l 很难在不采用分布式事务的情况下跨服务实现功能 l 跨服务实现要求功能要求团队之间的紧密协作 2.部署复杂 3.内存占用量更高
2017年12月24日
#
JDK 的 HashMap 中使用了一个 hash 方法来做 bit shifting,在注释中说明是为了防止一些实现比较差的hashCode() 方法,请问原理是什么?JDK 的源码参见:GrepCode: java.util.HashMap (.java) /** * Applies a supplemental hash function to a given hashCode, which * defends against poor quality hash functions. This is critical * because HashMap uses power-of-two length hash tables, that * otherwise encounter collisions for hashCodes that do not differ * in lower bits. Note: Null keys always map to hash 0, thus index 0. */ static int hash(int h) { // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } PS:网上看见有人说作者本人说原理需要参见圣经《计算机程序设计艺术》的 Vol.3 里头的介绍,不过木有看过神书,求达人介绍 这段代码叫“扰动函数”。 题主贴的是Java 7的HashMap的源码,Java 8中这步已经简化了,只做一次16位右位移异或混合,而不是四次,但原理是不变的。下面以Java 8的源码为例解释, //Java 8中的散列值优化函数staticfinalinthash(Objectkey){inth;return(key==null)?0:(h=key.hashCode())^(h>>>16);//key.hashCode()为哈希算法,返回初始哈希值} 大家都知道上面代码里的key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。理论上散列值是一个int型,如果直接拿散列值作为下标访问HashMap主数组的话,考虑到2进制32位带符号的int表值范围从-2147483648到2147483648。前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。你想,HashMap扩容之前的数组初始大小才16。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标。源码中模运算是在这个indexFor( )函数里完成的。 bucketIndex = indexFor(hash, table.length);indexFor的代码也很简单,就是把散列值和数组长度做一个"与"操作, static int indexFor(int h, int length) { return h & (length-1);}顺便说一下,这也正好解释了为什么HashMap的数组长度要取2的整次幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。 10100101 11000100 00100101& 00000000 00000000 00001111---------------------------------- 00000000 00000000 00000101 //高位全部归零,只保留末四位 但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,就无比蛋疼。这时候“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图, 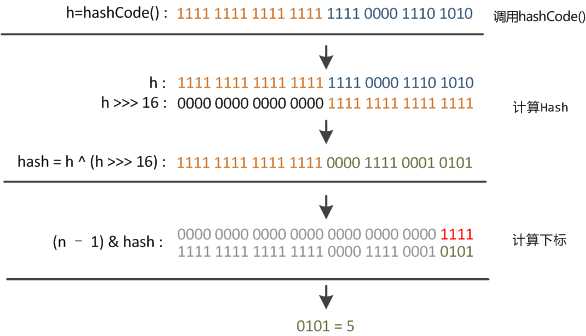 右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。最后我们来看一下PeterLawley的一篇专栏文章《An introduction to optimising a hashing strategy》里的的一个实验:他随机选取了352个字符串,在他们散列值完全没有冲突的前提下,对它们做低位掩码,取数组下标。 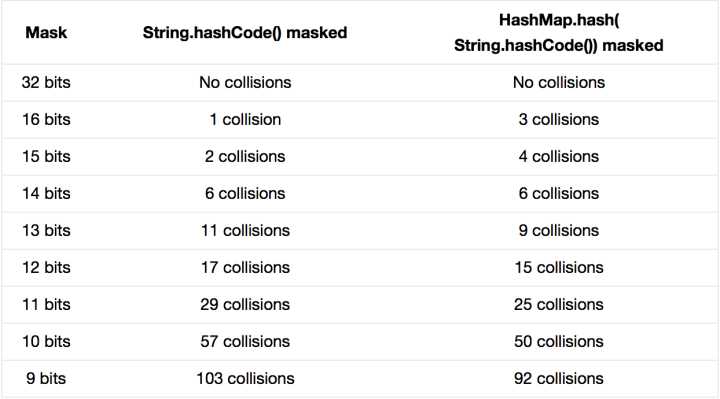 结果显示,当HashMap数组长度为512的时候,也就是用掩码取低9位的时候,在没有扰动函数的情况下,发生了103次碰撞,接近30%。而在使用了扰动函数之后只有92次碰撞。碰撞减少了将近10%。看来扰动函数确实还是有功效的。但明显Java 8觉得扰动做一次就够了,做4次的话,多了可能边际效用也不大,所谓为了效率考虑就改成一次了。 ------------------------------------------------------ https://www.zhihu.com/question/20733617
2017年8月3日
#
Go语言没有沿袭传统面向对象编程中的诸多概念,比如继承、虚函数、构造函数和析构函数、隐藏的this指针等。 方法 Go 语言中同时有函数和方法。方法就是一个包含了接受者(receiver)的函数,receiver可以是内置类型或者结构体类型的一个值或者是一个指针。所有给定类型的方法属于该类型的方法集。
如下面的这个例子,定义了一个新类型Integer,它和int一样,只是为它内置的int类型增加了个新方法Less() type Integer int func (a Integer) Less(b Integer) bool { return a < b } func main() { var a Integer = 1 if a.Less(2) { fmt.Println("less then 2") } } 可以看出,Go语言在自定义类型的对象中没有C++/Java那种隐藏的this指针,而是在定义成员方法时显式声明了其所属的对象。 method的语法如下: func (r ReceiverType) funcName(parameters) (results) 当调用method时,会将receiver作为函数的第一个参数: 所以,receiver是值类型还是指针类型要看method的作用。如果要修改对象的值,就需要传递对象的指针。 指针作为Receiver会对实例对象的内容发生操作,而普通类型作为Receiver仅仅是以副本作为操作对象,并不对原实例对象发生操作。 func (a *Ingeger) Add(b Integer) { *a += b } func main() { var a Integer = 1 a.Add(3) fmt.Println("a =", a) // a = 4 } 如果Add方法不使用指针,则a返回的结果不变,这是因为Go语言函数的参数也是基于值传递。 注意:当方法的接受者是指针时,即使用值类型调用那么方法内部也是对指针的操作。 之前说过,Go语言没有构造函数的概念,通常使用一个全局函数来完成。例如: func NewRect(x, y, width, height float64) *Rect { return &Rect{x, y, width, height} } func main() { rect1 := NewRect(1,2,10,20) fmt.Println(rect1.width) }
匿名组合 Go语言提供了继承,但是采用了组合的语法,我们将其称为匿名组合,例如: type Base struct { name string } func (base *Base) Set(myname string) { base.name = myname } func (base *Base) Get() string { return base.name } type Derived struct { Base age int } func (derived *Derived) Get() (nm string, ag int) { return derived.name, derived.age } func main() { b := &Derived{} b.Set("sina") fmt.Println(b.Get()) } 例子中,在Base类型定义了get()和set()两个方法,而Derived类型继承了Base类,并改写了Get()方法,在Derived对象调用Set()方法,会加载基类对应的方法;而调用Get()方法时,加载派生类改写的方法。 组合的类型和被组合的类型包含同名成员时, 会不会有问题呢?可以参考下面的例子: type Base struct { name string age int } func (base *Base) Set(myname string, myage int) { base.name = myname base.age = myage } type Derived struct { Base name string } func main() { b := &Derived{} b.Set("sina", 30) fmt.Println("b.name =",b.name, "\tb.Base.name =", b.Base.name) fmt.Println("b.age =",b.age, "\tb.Base.age =", b.Base.age) }
值语义和引用语义 值语义和引用语义的差别在于赋值,比如 如果b的修改不会影响a的值,那么此类型属于值类型;如果会影响a的值,那么此类型是引用类型。 Go语言中的大多数类型都基于值语义,包括: - 基本类型,如byte、int、bool、float32、string等;
- 复合类型,如arry、struct、pointer等;
C语言中的数组比较特别,通过函数传递一个数组的时候基于引用语义,但是在结构体定义数组变量的时候基于值语义。而在Go语言中,数组和基本类型没有区别,是很纯粹的值类型,例如: var a = [3] int{1,2,3} var b = a b[1]++ fmt.Println(a, b) // [1 2 3] [1 3 3] 从结果看,b=a赋值语句是数组内容的完整复制,要想表达引用,需要用指针: var a = [3] int{1,2,3} var b = &a // 引用语义 b[1]++ fmt.Println(a, b) // [1 3 3] [1 3 3]
接口 Interface 是一组抽象方法(未具体实现的方法/仅包含方法名参数返回值的方法)的集合,如果实现了 interface 中的所有方法,即该类/对象就实现了该接口。 Interface 的声明格式: type interfaceName interface { //方法列表 } Interface 可以被任意对象实现,一个类型/对象也可以实现多个 interface;
interface的变量可以持有任意实现该interface类型的对象。 如下面的例子:  package main import "fmt" type Human struct { name string age int phone string } type Student struct { Human //匿名字段 school string loan float32 } type Employee struct { Human //匿名字段 company string money float32 } //Human实现SayHi方法 func (h Human) SayHi() { fmt.Printf("Hi, I am %s you can call me on %s\n", h.name, h.phone) } //Human实现Sing方法 func (h Human) Sing(lyrics string) { fmt.Println("La la la la...", lyrics) } //Employee重载Human的SayHi方法 func (e Employee) SayHi() { fmt.Printf("Hi, I am %s, I work at %s. Call me on %s\n", e.name, e.company, e.phone) } // Interface Men被Human,Student和Employee实现 // 因为这三个类型都实现了这两个方法 type Men interface { SayHi() Sing(lyrics string) } func main() { mike := Student{Human{"Mike", 25, "222-222-XXX"}, "MIT", 0.00} paul := Student{Human{"Paul", 26, "111-222-XXX"}, "Harvard", 100} sam := Employee{Human{"Sam", 36, "444-222-XXX"}, "Golang Inc.", 1000} tom := Employee{Human{"Tom", 37, "222-444-XXX"}, "Things Ltd.", 5000} //定义Men类型的变量i var i Men //i能存储Student i = mike fmt.Println("This is Mike, a Student:") i.SayHi() i.Sing("November rain") //i也能存储Employee i = tom fmt.Println("This is tom, an Employee:") i.SayHi() i.Sing("Born to be wild") //定义了slice Men fmt.Println("Let's use a slice of Men and see what happens") x := make([]Men, 3) //这三个都是不同类型的元素,但是他们实现了interface同一个接口 x[0], x[1], x[2] = paul, sam, mike for _, value := range x{ value.SayHi() } } 空接口 空interface(interface{})不包含任何的method,正因为如此,所有的类型都实现了空interface。空interface对于描述起不到任何的作用(因为它不包含任何的method),但是空interface在我们需要存储任意类型的数值的时候相当有用,因为它可以存储任意类型的数值。它有点类似于C语言的void*类型。 // 定义a为空接口 var a interface{} var i int = 5 s := "Hello world" // a可以存储任意类型的数值 a = i a = s interface的变量里面可以存储任意类型的数值(该类型实现了interface),那么我们怎么反向知道这个interface变量里面实际保存了的是哪个类型的对象呢?目前常用的有两种方法:switch测试、Comma-ok断言。 switch测试如下: type Element interface{} type List [] Element type Person struct { name string age int } //打印 func (p Person) String() string { return "(name: " + p.name + " - age: "+strconv.Itoa(p.age)+ " years)" } func main() { list := make(List, 3) list[0] = 1 //an int list[1] = "Hello" //a string list[2] = Person{"Dennis", 70} for index, element := range list{ switch value := element.(type) { case int: fmt.Printf("list[%d] is an int and its value is %d\n", index, value) case string: fmt.Printf("list[%d] is a string and its value is %s\n", index, value) case Person: fmt.Printf("list[%d] is a Person and its value is %s\n", index, value) default: fmt.Println("list[%d] is of a different type", index) } } } 如果使用Comma-ok断言的话: func main() { list := make(List, 3) list[0] = 1 // an int list[1] = "Hello" // a string list[2] = Person{"Dennis", 70} for index, element := range list { if value, ok := element.(int); ok { fmt.Printf("list[%d] is an int and its value is %d\n", index, value) } else if value, ok := element.(string); ok { fmt.Printf("list[%d] is a string and its value is %s\n", index, value) } else if value, ok := element.(Person); ok { fmt.Printf("list[%d] is a Person and its value is %s\n", index, value) } else { fmt.Printf("list[%d] is of a different type\n", index) } } } 嵌入接口 正如struct类型可以包含一个匿名字段,interface也可以嵌套另外一个接口。 如果一个interface1作为interface2的一个嵌入字段,那么interface2隐式的包含了interface1里面的method。 反射 所谓反射(reflect)就是能检查程序在运行时的状态。 使用reflect一般分成三步,下面简要的讲解一下:要去反射是一个类型的值(这些值都实现了空interface),首先需要把它转化成reflect对象(reflect.Type或者reflect.Value,根据不同的情况调用不同的函数)。这两种获取方式如下: t := reflect.TypeOf(i) //得到类型的元数据,通过t我们能获取类型定义里面的所有元素 v := reflect.ValueOf(i) //得到实际的值,通过v我们获取存储在里面的值,还可以去改变值 转化为reflect对象之后我们就可以进行一些操作了,也就是将reflect对象转化成相应的值,例如 tag := t.Elem().Field(0).Tag //获取定义在struct里面的标签 name := v.Elem().Field(0).String() //获取存储在第一个字段里面的值 获取反射值能返回相应的类型和数值 var x float64 = 3.4 v := reflect.ValueOf(x) fmt.Println("type:", v.Type()) fmt.Println("kind is float64:", v.Kind() == reflect.Float64) fmt.Println("value:", v.Float()) 最后,反射的话,那么反射的字段必须是可修改的,我们前面学习过传值和传引用,这个里面也是一样的道理。反射的字段必须是可读写的意思是,如果下面这样写,那么会发生错误 var x float64 = 3.4 v := reflect.ValueOf(x) v.SetFloat(7.1) 如果要修改相应的值,必须这样写 var x float64 = 3.4 p := reflect.ValueOf(&x) v := p.Elem() v.SetFloat(7.1) 上面只是对反射的简单介绍,更深入的理解还需要自己在编程中不断的实践。 参考文档: http://se77en.cc/2014/05/05/methods-interfaces-and-embedded-types-in-golang/ http://se77en.cc/2014/05/04/choose-whether-to-use-a-value-or-pointer-receiver-on-methods/
http://www.cnblogs.com/chenny7/p/4497969.html
2017年8月2日
#
不可或缺的函数,在Go中定义函数的方式如下: func (p myType ) funcName ( a, b int , c string ) ( r , s int ) { return }
通过函数定义,我们可以看到Go中函数和其他语言中的共性和特性 共性- 关键字——func
- 方法名——funcName
- 入参——— a,b int,b string
- 返回值—— r,s int
- 函数体—— {}
特性Go中函数的特性是非常酷的,给我们带来不一样的编程体验。 为特定类型定义函数,即为类型对象定义方法在Go中通过给函数标明所属类型,来给该类型定义方法,上面的 p myType 即表示给myType声明了一个方法, p myType 不是必须的。如果没有,则纯粹是一个函数,通过包名称访问。packageName.funcationName 如: //定义新的类型double,主要目的是给float64类型扩充方法 type double float64 //判断a是否等于b func (a double) IsEqual(b double) bool { var r = a - b if r == 0.0 { return true } else if r < 0.0 { return r > -0.0001 } return r < 0.0001 } //判断a是否等于b func IsEqual(a, b float64) bool { var r = a - b if r == 0.0 { return true } else if r < 0.0 { return r > -0.0001 } return r < 0.0001 } func main() { var a double = 1.999999 var b double = 1.9999998 fmt.Println(a.IsEqual(b)) fmt.Println(a.IsEqual(3)) fmt.Println( IsEqual( (float64)(a), (float64)(b) ) ) }
上述示例为 float64 基本类型扩充了方法IsEqual,该方法主要是解决精度问题。 其方法调用方式为: a.IsEqual(double) ,如果不扩充方法,我们只能使用函数IsEqual(a, b float64) 入参中,如果连续的参数类型一致,则可以省略连续多个参数的类型,只保留最后一个类型声明。如 func IsEqual(a, b float64) bool 这个方法就只保留了一个类型声明,此时入参a和b均是float64数据类型。 这样也是可以的: func IsEqual(a, b float64, accuracy int) bool 变参:入参支持变参,即可接受不确定数量的同一类型的参数如 func Sum(args ...int) 参数args是的slice,其元素类型为int 。经常使用的fmt.Printf就是一个接受任意个数参数的函数 fmt.Printf(format string, args ...interface{}) 支持多返回值前面我们定义函数时返回值有两个r,s 。这是非常有用的,我在写C#代码时,常常为了从已有函数中获得更多的信息,需要修改函数签名,使用out ,ref 等方式去获得更多返回结果。而现在使用Go时则很简单,直接在返回值后面添加返回参数即可。 如,在C#中一个字符串转换为int类型时逻辑代码 int v=0; if ( int.TryPase("123456",out v) ) { //code }
而在Go中,则可以这样实现,逻辑精简而明确 if v,isOk :=int.TryPase("123456") ; isOk { //code }
同时在Go中很多函数充分利用了多返回值 - func (file *File) Write(b []byte) (n int, err error)
- func Sincos(x float64) (sin, cos float64)
那么如果我只需要某一个返回值,而不关心其他返回值的话,我该如何办呢? 这时可以简单的使用符号下划线”_“ 来忽略不关心的返回值。如: _, cos = math.Sincos(3.1415) //只需要cos计算的值
命名返回值前面我们说了函数可以有多个返回值,这里我还要说的是,在函数定义时可以给所有的返回值分别命名,这样就能在函数中任意位置给不同返回值复制,而不需要在return语句中才指定返回值。同时也能增强可读性,也提高godoc所生成文档的可读性 如果不支持命名返回值,我可能会是这样做的 func ReadFull(r Reader, buf []byte) (int, error) { var n int var err error for len(buf) > 0 { var nr int nr, err = r.Read(buf) n += nr if err !=nil { return n,err } buf = buf[nr:] } return n,err }
但支持给返回值命名后,实际上就是省略了变量的声明,return时无需写成return n,err 而是将直接将值返回 func ReadFull(r Reader, buf []byte) (n int, err error) { for len(buf) > 0 && err == nil { var nr int nr, err = r.Read(buf) n += nr buf = buf[nr:] } return }
函数也是“值”和Go中其他东西一样,函数也是值,这样就可以声明一个函数类型的变量,将函数作为参数传递。 声明函数为值的变量(匿名函数:可赋值个变量,也可直接执行) //赋值 fc := func(msg string) { fmt.Println("you say :", msg) } fmt.Printf("%T \n", fc) fc("hello,my love") //直接执行 func(msg string) { fmt.Println("say :", msg) }("I love to code")
输出结果如下,这里表明fc 的类型为:func(string) func(string) you say : hello,my love say : I love to code
将函数作为入参(回调函数),能带来便利。如日志处理,为了统一处理,将信息均通过指定函数去记录日志,且是否记录日志还有开关 func Log(title string, getMsg func() string) { //如果开启日志记录,则记录日志 if true { fmt.Println(title, ":", getMsg()) } } //---------调用-------------- count := 0 msg := func() string { count++ return "您没有即使提醒我,已触犯法律" } Log("error", msg) Log("warring", msg) Log("info", msg) fmt.Println(count)
这里输出结果如下,count 也发生了变化 error : 您没有即使提醒我,已触犯法律 warring : 您没有即使提醒我,已触犯法律 info : 您没有即使提醒我,已触犯法律 3
函数也是“类型”你有没有注意到上面示例中的 fc := func(msg string)... ,既然匿名函数可以赋值给一个变量,同时我们经常这样给int赋值 value := 2 ,是否我们可以声明func(string) 类型 呢,当然是可以的。 //一个记录日志的类型:func(string) type saveLog func(msg string) //将字符串转换为int64,如果转换失败调用saveLog func stringToInt(s string, log saveLog) int64 { if value, err := strconv.ParseInt(s, 0, 0); err != nil { log(err.Error()) return 0 } else { return value } } //记录日志消息的具体实现 func myLog(msg string) { fmt.Println("Find Error:", msg) } func main() { stringToInt("123", myLog) //转换时将调用mylog记录日志 stringToInt("s", myLog) }
这里我们定义了一个类型,专门用作记录日志的标准接口。在stringToInt函数中如果转换失败则调用我自己定义的接口函数进行日志处理,至于最终执行的哪个函数,则无需关心。 defer 延迟函数defer 又是一个创新,它的作用是:延迟执行,在声明时不会立即执行,而是在函数return后时按照后进先出的原则依次执行每一个defer。这样带来的好处是,能确保我们定义的函数能百分之百能够被执行到,这样就能做很多我们想做的事,如释放资源,清理数据,记录日志等 这里我们重点来说明下defer的执行顺序 func deferFunc() int { index := 0 fc := func() { fmt.Println(index, "匿名函数1") index++ defer func() { fmt.Println(index, "匿名函数1-1") index++ }() } defer func() { fmt.Println(index, "匿名函数2") index++ }() defer fc() return func() int { fmt.Println(index, "匿名函数3") index++ return index }() } func main() { deferFunc() }
这里输出结果如下, 0 匿名函数3 1 匿名函数1 2 匿名函数1-1 3 匿名函数2
有如下结论: - defer 是在执行完return 后执行
- defer 后进先执行
另外,我们常使用defer去关闭IO,在正常打开文件后,就立刻声明一个defer,这样就不会忘记关闭文件,也能保证在出现异常等不可预料的情况下也能关闭文件。而不像其他语言:try-catch 或者 using() 方式进行处理。 file , err :=os.Open(file) if err != nil { return err } defer file.Close() //dosomething with file
后续,我将讨论: 作用域、传值和传指针 以及 保留函数init(),main() 本笔记中所写代码存储位置:
2016年8月18日
#
以前关注的数据存储过程不太懂其中奥妙,最近遇到跨数据库,同时对多个表进行CURD(Create增、Update改、Read读、Delete删),怎么才能让繁琐的数据CURD同步变得更容易呢?相信很多人会首先想到了MySQL存储过程、触发器,这种想法确实不错。于是饶有兴趣地亲自写了CUD(增、改、删)触发器的实例,用触发器实现多表数据同步更新。  定义: 何为MySQL触发器? 在MySQL Server里面也就是对某一个表的一定的操作,触发某种条件(Insert,Update,Delete 等),从而自动执行的一段程序。从这种意义上讲触发器是一个特殊的存储过程。下面通过MySQL触发器实例,来了解一下触发器的工作过程吧! 一、创建MySQL实例数据表: 在mysql的默认的测试test数据库下,创建两个表t_a与t_b:
/*Table structure for table `t_a` */
DROP TABLE IF EXISTS `t_a`;
CREATE TABLE `t_a` (
`id` smallint(1) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`groupid` mediumint(8) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=16 DEFAULT CHARSET=latin1;
/*Data for the table `t_a` */
LOCK TABLES `t_a` WRITE;
UNLOCK TABLES;
/*Table structure for table `t_b` */
DROP TABLE IF EXISTS `t_b`;
CREATE TABLE `t_b` (
`id` smallint(1) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`groupid` mediumint(8) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=57 DEFAULT CHARSET=latin1;
/*Data for the table `t_b` */
LOCK TABLES `t_b` WRITE;
UNLOCK TABLES;
在t_a表上分创建一个CUD(增、改、删)3个触发器,将t_a的表数据与t_b同步实现CUD,注意创建触发器每个表同类事件有且仅有一个对应触发器,为什么只能对一个触发器,不解释啦,看MYSQL的说明帮助文档吧。 二、创建MySQL实例触发器: 在实例数据表t_a上依次按照下面步骤创建tr_a_insert、tr_a_update、tr_a_delete三个触发器 1、创建INSERT触发器trigger_a_insert:
DELIMITER $$
USE `test`$$
--判断数据库中是否存在tr_a_insert触发器
DROP TRIGGER /*!50032 IF EXISTS */ `tr_a_insert`$$
--不存在tr_a_insert触发器,开始创建触发器
--Trigger触发条件为insert成功后进行触发
CREATE
/*!50017 DEFINER = 'root'@'localhost' */
TRIGGER `tr_a_insert` AFTER INSERT ON `t_a`
FOR EACH ROW BEGIN
--Trigger触发后,同时对t_b新增同步一条数据
INSERT INTO `t_b` SET username = NEW.username, groupid=NEW.groupid;
END;
$$
DELIMITER;
2、创建UPDATE触发器trigger_a_update:
DELIMITER $$
USE `test`$$
--判断数据库中是否存在tr_a_update触发器
DROP TRIGGER /*!50032 IF EXISTS */ `tr_a_update`$$
--不存在tr_a_update触发器,开始创建触发器
--Trigger触发条件为update成功后进行触发
CREATE
/*!50017 DEFINER = 'root'@'localhost' */
TRIGGER `tr_a_update` AFTER UPDATE ON `t_a`
FOR EACH ROW BEGIN
--Trigger触发后,当t_a表groupid,username数据有更改时,对t_b表同步一条更新后的数据
IF new.groupid != old.groupid OR old.username != new.username THEN
UPDATE `t_b` SET groupid=NEW.groupid,username=NEW.username WHEREusername=OLD.username AND groupid=OLD.groupid;
END IF;
END;
$$
DELIMITER ;
3、创建DELETE触发器trigger_a_delete:
DELIMITER $$
USE `test`$$
--判断数据库中是否存在tr_a_delete触发器
DROP TRIGGER /*!50032 IF EXISTS */ `tr_a_delete`$$
--不存在tr_a_delete触发器,开始创建触发器
--Trigger触发条件为delete成功后进行触发
CREATE
/*!50017 DEFINER = 'root'@'localhost' */
TRIGGER `tr_a_delete` AFTER DELETE ON `t_a`
FOR EACH ROW BEGIN
--t_a表数据删除后,t_b表关联条件相同的数据也同步删除
DELETE FROM `t_b` WHERE username=Old.username AND groupid=OLD.groupid;
END;
$$
DELIMITER ;
三、测试MySQL实例触发器: 分别测试实现t_a与t_b实现数据同步CUD(增、改、删)3个Triggers 1、测试MySQL的实例tr_a_insert触发器: 在t_a表中新增一条数据,然后分别查询t_a/t_b表的数据是否数据同步,测试触发器成功标志,t_a表无论在何种情况下,新增了一条或多条记录集时,没有t_b表做任何数据insert操作,它同时新增了一样的多条记录集。 下面来进行MySQL触发器实例测试:
--t_a表新增一条记录集
INSERT INTO `t_a` (username,groupid) VALUES ('sky54.net',123)
--查询t_a表
SELECT id,username,groupid FROM `t_a`
--查询t_b表
SELECT id,username,groupid FROM `t_b`
2、测试MySQL的实例tr_a_update、tr_a_delete触发器: 这两个MySQL触发器测试原理、步骤与tr_a_insert触发器一样的,先修改/删除一条数据,然后分别查看t_a、t_b表的数据变化情况,数据变化同步说明Trigger实例成功,否则需要逐步排查错误原因。 世界上任何一种事物都其其优点和缺点,优点与缺点是自身一个相对立的面。当然这里不是强调“世界非黑即白”式的“二元论”,“存在即合理”嘛。当然 MySQL触发器的优点不说了,说一下不足之处,MySQL Trigger没有很好的调试、管理环境,难于在各种系统环境下测试,测试比MySQL存储过程要难,所以建议在生成环境下,尽量用存储过程来代替 MySQL触发器。 本篇结束前再强调一下,支持触发器的MySQL版本需要5.0以上,5.0以前版本的MySQL升级到5.0以后版本方可使用触发器哦! http://blog.csdn.net/hireboy/article/details/18079183
2016年6月14日
#
摘要: 在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。缓存的目的是提升系统访问速度和增大系统能处理的容量,可谓是抗高并发流量的银弹;而降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉,待高峰或者问题解决后再打开;而有些场景并不能用缓存和降级来解决,比如稀缺资源(秒杀、抢购)、写服务(如评论、下单)、频繁的复杂查询(评论的最后几页),因此需有一种手段来限制这些场景的并发/请求量,即限... 阅读全文
2016年5月13日
#
Install the Command Line ClientIf you prefer command line client, then you can install it on your Linux with the following command. Debiansudo apt-get install python-pip sudo pip install shadowsocks UbuntuYes, you can use the above commands to install shadowsocks client on ubuntu. But it will install it under ~/.local/bin/ directory and it causes loads of trouble. So I suggest using su to become root first and then issue the following two commands. apt-get install python-pip pip install shadowsocks Fedora/Centossudo yum install python-setuptools or sudo dnf install python-setuptools sudo easy_install pip sudo pip install shadowsocks OpenSUSEsudo zypper install python-pip sudo pip install shadowsocks Archlinuxsudo pacman -S python-pip sudo pip install shadowsocks As you can see the command of installing shadowsocks client is the same to the command of installing shadowsocks server, because the above command will install both the client and the server. You can verify this by looking at the installation script output Downloading/unpacking shadowsocks Downloading shadowsocks-2.8.2.tar.gz Running setup.py (path:/tmp/pip-build-PQIgUg/shadowsocks/setup.py) egg_info for package shadowsocks Installing collected packages: shadowsocks Running setup.py install for shadowsocks Installing sslocal script to /usr/local/bin Installing ssserver script to /usr/local/bin Successfully installed shadowsocks Cleaning up... sslocal is the client software and ssserver is the server software. On some Linux distros such as ubuntu, the shadowsocks client sslocal is installed under /usr/local/bin. On Others such as Archsslocal is installed under /usr/bin/. Your can use whereis command to find the exact location. user@debian:~$ whereis sslocal sslocal: /usr/local/bin/sslocal Create a Configuration Filewe will create a configuration file under /etc/ sudo vi /etc/shadowsocks.json Put the following text in the file. Replace server-ip with your actual IP and set a password. {
"server":"server-ip",
"server_port":8000,
"local_address": "127.0.0.1",
"local_port":1080,
"password":"your-password",
"timeout":600,
"method":"aes-256-cfb"
}Save and close the file. Next start the client using command line sslocal -c /etc/shadowsocks.json To run in the backgroundsudo sslocal -c /etc/shadowsocks.json -d start Auto Start the Client on System BootEdit /etc/rc.local file sudo vi /etc/rc.local Put the following line above the exit 0 line: sudo sslocal -c /etc/shadowsocks.json -d start Save and close the file. Next time you start your computer, shadowsocks client will automatically start and connect to your shadowsocks server. Check if It WorksAfter you rebooted your computer, enter the following command in terminal: sudo systemctl status rc-local.service If your sslocal command works then you will get this ouput: ● rc-local.service - /etc/rc.local
Compatibility Loaded: loaded (/etc/systemd/system/rc-local.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2015-11-27 03:19:25 CST; 2min 39s ago
Process: 881 ExecStart=/etc/rc.local start (code=exited, status=0/SUCCESS)
CGroup: /system.slice/rc-local.service
├─ 887 watch -n 60 su matrix -c ibam
└─1112 /usr/bin/python /usr/local/bin/sslocal -c /etc/shadowsocks.... As you can see from the last line, the sslocal command created a process whose pid is 1112 on my machine. It means shadowsocks client is running smoothly. And of course you can tell your browser to connect through your shadowsocks client to see if everything goes well. If for some reason your /etc/rc.local script won’t run, then check the following post to find the solution. If you prefer command line client, then you can install it on your Linux with the following command. Debiansudo apt-get install python-pip
sudo pip install shadowsocks
UbuntuYes, you can use the above commands to install shadowsocks client on ubuntu. But it will install it under ~/.local/bin/ directory and it causes loads of trouble. So I suggest using su to become root first and then issue the following two commands. apt-get install python-pip
pip install shadowsocks Fedora/Centossudo yum install python-setuptools or sudo dnf install python-setuptools
sudo easy_install pip
sudo pip install shadowsocks
OpenSUSEsudo zypper install python-pip
sudo pip install shadowsocks
Archlinuxsudo pacman -S python-pip
sudo pip install shadowsocks
As you can see the command of installing shadowsocks client is the same to the command of installing shadowsocks server, because the above command will install both the client and the server. You can verify this by looking at the installation script output Downloading/unpacking shadowsocks
Downloading shadowsocks-2.8.2.tar.gz
Running setup.py (path:/tmp/pip-build-PQIgUg/shadowsocks/setup.py) egg_info for package shadowsocks
Installing collected packages: shadowsocks
Running setup.py install for shadowsocks
Installing sslocal script to /usr/local/bin
Installing ssserver script to /usr/local/bin
Successfully installed shadowsocks
Cleaning up... sslocal is the client software and ssserver is the server software. On some Linux distros such as ubuntu, the shadowsocks client sslocal is installed under /usr/local/bin. On Others such as Archsslocal is installed under /usr/bin/. Your can use whereis command to find the exact location. user@debian:~$ whereis sslocal
sslocal: /usr/local/bin/sslocal Create a Configuration Filewe will create a configuration file under /etc/ sudo vi /etc/shadowsocks.json Put the following text in the file. Replace server-ip with your actual IP and set a password. {
"server":"server-ip",
"server_port":8000,
"local_address": "127.0.0.1",
"local_port":1080,
"password":"your-password",
"timeout":600,
"method":"aes-256-cfb"
}Save and close the file. Next start the client using command line sslocal -c /etc/shadowsocks.json To run in the backgroundsudo sslocal -c /etc/shadowsocks.json -d start
Auto Start the Client on System BootEdit /etc/rc.local file sudo vi /etc/rc.local Put the following line above the exit 0 line: sudo sslocal -c /etc/shadowsocks.json -d start Save and close the file. Next time you start your computer, shadowsocks client will automatically start and connect to your shadowsocks server. Check if It WorksAfter you rebooted your computer, enter the following command in terminal: sudo systemctl status rc-local.service If your sslocal command works then you will get this ouput: ● rc-local.service - /etc/rc.local Compatibility
Loaded: loaded (/etc/systemd/system/rc-local.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2015-11-27 03:19:25 CST; 2min 39s ago
Process: 881 ExecStart=/etc/rc.local start (code=exited, status=0/SUCCESS)
CGroup: /system.slice/rc-local.service
├─ 887 watch -n 60 su matrix -c ibam
└─1112 /usr/bin/python /usr/local/bin/sslocal -c /etc/shadowsocks.... As you can see from the last line, the sslocal command created a process whose pid is 1112 on my machine. It means shadowsocks client is running smoothly. And of course you can tell your browser to connect through your shadowsocks client to see if everything goes well. If for some reason your /etc/rc.local script won’t run, then check the following post to find the solution. How to enable /etc/rc.local with Systemd
2016年4月27日
#
废话少说,直接上代码,以前都是调用别人写好的,现在有时间自己弄下,具体功能如下: 1、httpClient+http+线程池: 2、httpClient+https(单向不验证证书)+线程池: https在%TOMCAT_HOME%/conf/server.xml里面的配置文件 <Connector port="8443" protocol="HTTP/1.1" SSLEnabled="true" maxThreads="150" scheme="https" secure="true" clientAuth="false" keystoreFile="D:/tomcat.keystore" keystorePass="heikaim" sslProtocol="TLS" executor="tomcatThreadPool"/> 其中 clientAuth="false"表示不开启证书验证,只是单存的走https package com.abin.lee.util;
import org.apache.commons.collections4.MapUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.http.*;
import org.apache.http.client.HttpRequestRetryHandler;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.config.Registry;
import org.apache.http.config.RegistryBuilder;
import org.apache.http.conn.ConnectTimeoutException;
import org.apache.http.conn.socket.ConnectionSocketFactory;
import org.apache.http.conn.socket.PlainConnectionSocketFactory;
import org.apache.http.conn.ssl.NoopHostnameVerifier;
import org.apache.http.conn.ssl.SSLConnectionSocketFactory;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.message.BasicHeader;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.protocol.HttpContext;
import org.apache.http.util.EntityUtils;
import javax.net.ssl.*;
import java.io.IOException;
import java.io.InterruptedIOException;
import java.net.UnknownHostException;
import java.nio.charset.Charset;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.util.*;
/**
* Created with IntelliJ IDEA.
* User: abin
* Date: 16-4-18
* Time: 上午10:24
* To change this template use File | Settings | File Templates.
*/
public class HttpClientUtil {
private static CloseableHttpClient httpsClient = null;
private static CloseableHttpClient httpClient = null;
static {
httpClient = getHttpClient();
httpsClient = getHttpsClient();
}
public static CloseableHttpClient getHttpClient() {
try {
httpClient = HttpClients.custom()
.setConnectionManager(PoolManager.getHttpPoolInstance())
.setConnectionManagerShared(true)
.setDefaultRequestConfig(requestConfig())
.setRetryHandler(retryHandler())
.build();
} catch (Exception e) {
e.printStackTrace();
}
return httpClient;
}
public static CloseableHttpClient getHttpsClient() {
try {
//Secure Protocol implementation.
SSLContext ctx = SSLContext.getInstance("SSL");
//Implementation of a trust manager for X509 certificates
TrustManager x509TrustManager = new X509TrustManager() {
public void checkClientTrusted(X509Certificate[] xcs,
String string) throws CertificateException {
}
public void checkServerTrusted(X509Certificate[] xcs,
String string) throws CertificateException {
}
public X509Certificate[] getAcceptedIssuers() {
return null;
}
};
ctx.init(null, new TrustManager[]{x509TrustManager}, null);
//首先设置全局的标准cookie策略
// RequestConfig requestConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD_STRICT).build();
ConnectionSocketFactory connectionSocketFactory = new SSLConnectionSocketFactory(ctx, hostnameVerifier);
Registry<ConnectionSocketFactory> socketFactoryRegistry = RegistryBuilder.<ConnectionSocketFactory>create()
.register("http", PlainConnectionSocketFactory.INSTANCE)
.register("https", connectionSocketFactory).build();
// 设置连接池
httpsClient = HttpClients.custom()
.setConnectionManager(PoolsManager.getHttpsPoolInstance(socketFactoryRegistry))
.setConnectionManagerShared(true)
.setDefaultRequestConfig(requestConfig())
.setRetryHandler(retryHandler())
.build();
} catch (Exception e) {
e.printStackTrace();
}
return httpsClient;
}
// 配置请求的超时设置
//首先设置全局的标准cookie策略
public static RequestConfig requestConfig(){
RequestConfig requestConfig = RequestConfig.custom()
.setCookieSpec(CookieSpecs.STANDARD_STRICT)
.setConnectionRequestTimeout(20000)
.setConnectTimeout(20000)
.setSocketTimeout(20000)
.build();
return requestConfig;
}
public static HttpRequestRetryHandler retryHandler(){
//请求重试处理
HttpRequestRetryHandler httpRequestRetryHandler = new HttpRequestRetryHandler() {
public boolean retryRequest(IOException exception,int executionCount, HttpContext context) {
if (executionCount >= 5) {// 如果已经重试了5次,就放弃
return false;
}
if (exception instanceof NoHttpResponseException) {// 如果服务器丢掉了连接,那么就重试
return true;
}
if (exception instanceof SSLHandshakeException) {// 不要重试SSL握手异常
return false;
}
if (exception instanceof InterruptedIOException) {// 超时
return false;
}
if (exception instanceof UnknownHostException) {// 目标服务器不可达
return false;
}
if (exception instanceof ConnectTimeoutException) {// 连接被拒绝
return false;
}
if (exception instanceof SSLException) {// ssl握手异常
return false;
}
HttpClientContext clientContext = HttpClientContext.adapt(context);
HttpRequest request = clientContext.getRequest();
// 如果请求是幂等的,就再次尝试
if (!(request instanceof HttpEntityEnclosingRequest)) {
return true;
}
return false;
}
};
return httpRequestRetryHandler;
}
//创建HostnameVerifier
//用于解决javax.net.ssl.SSLException: hostname in certificate didn't match: <123.125.97.66> != <123.125.97.241>
static HostnameVerifier hostnameVerifier = new NoopHostnameVerifier(){
@Override
public boolean verify(String s, SSLSession sslSession) {
return super.verify(s, sslSession);
}
};
public static class PoolManager {
public static PoolingHttpClientConnectionManager clientConnectionManager = null;
private static int maxTotal = 200;
private static int defaultMaxPerRoute = 100;
private PoolManager(){
clientConnectionManager.setMaxTotal(maxTotal);
clientConnectionManager.setDefaultMaxPerRoute(defaultMaxPerRoute);
}
private static class PoolManagerHolder{
public static PoolManager instance = new PoolManager();
}
public static PoolManager getInstance() {
if(null == clientConnectionManager)
clientConnectionManager = new PoolingHttpClientConnectionManager();
return PoolManagerHolder.instance;
}
public static PoolingHttpClientConnectionManager getHttpPoolInstance() {
PoolManager.getInstance();
// System.out.println("getAvailable=" + clientConnectionManager.getTotalStats().getAvailable());
// System.out.println("getLeased=" + clientConnectionManager.getTotalStats().getLeased());
// System.out.println("getMax=" + clientConnectionManager.getTotalStats().getMax());
// System.out.println("getPending="+clientConnectionManager.getTotalStats().getPending());
return PoolManager.clientConnectionManager;
}
}
public static class PoolsManager {
public static PoolingHttpClientConnectionManager clientConnectionManager = null;
private static int maxTotal = 200;
private static int defaultMaxPerRoute = 100;
private PoolsManager(){
clientConnectionManager.setMaxTotal(maxTotal);
clientConnectionManager.setDefaultMaxPerRoute(defaultMaxPerRoute);
}
private static class PoolsManagerHolder{
public static PoolsManager instance = new PoolsManager();
}
public static PoolsManager getInstance(Registry<ConnectionSocketFactory> socketFactoryRegistry) {
if(null == clientConnectionManager)
clientConnectionManager = new PoolingHttpClientConnectionManager(socketFactoryRegistry);
return PoolsManagerHolder.instance;
}
public static PoolingHttpClientConnectionManager getHttpsPoolInstance(Registry<ConnectionSocketFactory> socketFactoryRegistry) {
PoolsManager.getInstance(socketFactoryRegistry);
// System.out.println("getAvailable=" + clientConnectionManager.getTotalStats().getAvailable());
// System.out.println("getLeased=" + clientConnectionManager.getTotalStats().getLeased());
// System.out.println("getMax=" + clientConnectionManager.getTotalStats().getMax());
// System.out.println("getPending="+clientConnectionManager.getTotalStats().getPending());
return PoolsManager.clientConnectionManager;
}
}
public static String httpPost(Map<String, String> request, String httpUrl){
String result = "";
CloseableHttpClient httpClient = getHttpClient();
try {
if(MapUtils.isEmpty(request))
throw new Exception("请求参数不能为空");
HttpPost httpPost = new HttpPost(httpUrl);
List<NameValuePair> nvps = new ArrayList<NameValuePair>();
for(Iterator<Map.Entry<String, String>> iterator=request.entrySet().iterator(); iterator.hasNext();){
Map.Entry<String, String> entry = iterator.next();
nvps.add(new BasicNameValuePair(entry.getKey(), entry.getValue()));
}
httpPost.setEntity(new UrlEncodedFormEntity(nvps, Consts.UTF_8));
System.out.println("Executing request: " + httpPost.getRequestLine());
CloseableHttpResponse response = httpClient.execute(httpPost);
result = EntityUtils.toString(response.getEntity());
System.out.println("Executing response: "+ result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
public static String httpPost(String json, String httpUrl, Map<String, String> headers){
String result = "";
CloseableHttpClient httpClient = getHttpClient();
try {
if(StringUtils.isBlank(json))
throw new Exception("请求参数不能为空");
HttpPost httpPost = new HttpPost(httpUrl);
for(Iterator<Map.Entry<String, String>> iterator=headers.entrySet().iterator();iterator.hasNext();){
Map.Entry<String, String> entry = iterator.next();
Header header = new BasicHeader(entry.getKey(), entry.getValue());
httpPost.setHeader(header);
}
httpPost.setEntity(new StringEntity(json, Charset.forName("UTF-8")));
System.out.println("Executing request: " + httpPost.getRequestLine());
CloseableHttpResponse response = httpClient.execute(httpPost);
result = EntityUtils.toString(response.getEntity());
System.out.println("Executing response: "+ result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
public static String httpGet(String httpUrl, Map<String, String> headers) {
String result = "";
CloseableHttpClient httpClient = getHttpClient();
try {
HttpGet httpGet = new HttpGet(httpUrl);
System.out.println("Executing request: " + httpGet.getRequestLine());
for(Iterator<Map.Entry<String, String>> iterator=headers.entrySet().iterator();iterator.hasNext();){
Map.Entry<String, String> entry = iterator.next();
Header header = new BasicHeader(entry.getKey(), entry.getValue());
httpGet.setHeader(header);
}
CloseableHttpResponse response = httpClient.execute(httpGet);
result = EntityUtils.toString(response.getEntity());
System.out.println("Executing response: "+ result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
public static String httpGet(String httpUrl) {
String result = "";
CloseableHttpClient httpClient = getHttpClient();
try {
HttpGet httpGet = new HttpGet(httpUrl);
System.out.println("Executing request: " + httpGet.getRequestLine());
CloseableHttpResponse response = httpClient.execute(httpGet);
result = EntityUtils.toString(response.getEntity());
System.out.println("Executing response: "+ result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
maven依赖: <!--httpclient--> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpcore</artifactId> <version>4.4.4</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpmime</artifactId> <version>4.5.2</version> </dependency> <dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.1</version>
</dependency>
2015年11月3日
#
1、twemproxy explore 当我们有大量 Redis 或 Memcached 的时候,通常只能通过客户端的一些数据分配算法(比如一致性哈希),来实现集群存储的特性。虽然Redis 2.6版本已经发布Redis Cluster,但还不是很成熟适用正式生产环境。 Redis 的 Cluster 方案还没有正式推出之前,我们通过 Proxy 的方式来实现集群存储。 Twitter,世界最大的Redis集群之一部署在Twitter用于为用户提供时间轴数据。Twitter Open Source部门提供了Twemproxy。 Twemproxy,也叫nutcraker。是一个twtter开源的一个redis和memcache代理服务器。 redis作为一个高效的缓存服务器,非常具有应用价值。但是当使用比较多的时候,就希望可以通过某种方式 统一进行管理。避免每个应用每个客户端管理连接的松散性。同时在一定程度上变得可以控制。 Twemproxy是一个快速的单线程代理程序,支持Memcached ASCII协议和更新的Redis协议: 它全部用C写成,使用Apache 2.0 License授权。项目在Linux上可以工作,而在OSX上无法编译,因为它依赖了epoll API. Twemproxy 通过引入一个代理层,可以将其后端的多台 Redis 或 Memcached 实例进行统一管理与分配,使应用程序只需要在 Twemproxy 上进行操作,而不用关心后面具体有多少个真实的 Redis 或 Memcached 存储。 2、twemproxy特性: 另外可以修改redis的源代码,抽取出redis中的前半部分,作为一个中间代理层。最终都是通过linux下的epoll 事件机制提高并发效率,其中nutcraker本身也是使用epoll的事件机制。并且在性能测试上的表现非常出色。 3、twemproxy问题与不足
Twemproxy 由于其自身原理限制,有一些不足之处,如: - 不支持针对多个值的操作,比如取sets的子交并补等(MGET 和 DEL 除外)
- 不支持Redis的事务操作
- 出错提示还不够完善
- 也不支持select操作
4、安装与配置 Twemproxy 的安装,主要命令如下: apt-get install automake
apt-get install libtool
git clone git://github.com/twitter/twemproxy.git
cd twemproxy
autoreconf -fvi
./configure --enable-debug=log
make
src/nutcracker -h
通过上面的命令就算安装好了,然后是具体的配置,下面是一个典型的配置 redis1:
listen: 127.0.0.1:6379 #使用哪个端口启动Twemproxy
redis: true #是否是Redis的proxy
hash: fnv1a_64 #指定具体的hash函数
distribution: ketama #具体的hash算法
auto_eject_hosts: true #是否在结点无法响应的时候临时摘除结点
timeout: 400 #超时时间(毫秒)
server_retry_timeout: 2000 #重试的时间(毫秒)
server_failure_limit: 1 #结点故障多少次就算摘除掉
servers: #下面表示所有的Redis节点(IP:端口号:权重)
- 127.0.0.1:6380:1
- 127.0.0.1:6381:1
- 127.0.0.1:6382:1
redis2:
listen: 0.0.0.0:10000
redis: true
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: false
timeout: 400
servers:
- 127.0.0.1:6379:1
- 127.0.0.1:6380:1
- 127.0.0.1:6381:1
- 127.0.0.1:6382:1 你可以同时开启多个 Twemproxy 实例,它们都可以进行读写,这样你的应用程序就可以完全避免所谓的单点故障。
http://blog.csdn.net/hguisu/article/details/9174459/
|