1、介绍
通过证书验证用户身份(浏览器),其核心是利用cookie实现http和https的信息共享(同域名)。如http://test.abc.com/app/index.html 发现未验证后,跳转到https://test.abc.com:443/app/checkCrt.html身份验证,要求出去证书,确认后将身份信息带入http请求头部,跳转到原请求页面(http://test.abc.com/app/index.html ),读取身份信息后进入页面(出于安全考虑Cookie需要加密)。
流程图
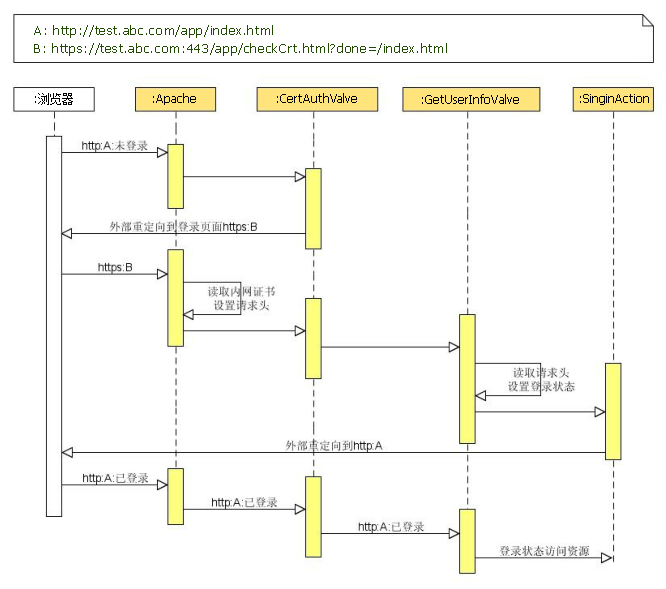
流程说明:
登录流程详细介绍:
1). 未登录用户访问页面 如:http://test.abc.com/app/index.html
2). 【CertAuthValve】判断是否访问受限制资源,如访问受限制的资源则判断用户身份是否已验证,未验证则将用户重定向到身份验证页面,原始请求的url做为
query的一部分,登录成功后可以跳转回来, 如:https://test.abc.com:443/app/checkCrt.htm?done=/index.html。
3). 【CertAuthValve】对于https请求,apache读取请求提供的用户证书,获取证书中的邮件地址,并将该信息写入请求头中。
4). 【GetUserInfoValve】读取请求头,获取刚刚设置的用户邮件地址信息,进一步获取用户的详细信息,然后将这些信息加密后放入cookie中。
5). 登录完成,将用户外部重定向回原始页面。
2、具体实现
1)、安装apache、ssh、java、jboss等环境,略。
2)、生成服务证书和服务密码
openssl req -new -x509 -nodes -out /home/admin/app/conf/ssl.crt/server.crt -keyout /home/admin/app/conf/ssl.crt/server.key -days 3600
因为要和内网证书交互,所以需要一个内网证书公钥文件,可以通过以下方式获取:
获取方法:IE->工具->Internet选项->内容->证书->受信任的根证书颁发机构,找到intranet行,点击导出,选择下一步,选择Base64编码X.509,将证书文件保存为intranet-ca.crt,拷贝到目录/home/admin/app/conf/ssl.crt/。
3)、apache(httpd.conf)配置
应用和身份验证页面放在一起,所以需要同时配置两个虚拟主机,同时监听80(处理http请求)、443(处理https请求)端口。
#监听端口Listen 80Listen 443#app的虚拟主机配置NameVirtualHost *:80
<VirtualHost *:80>
ServerAdmin sa@abc.com
ServerName test.abc.com
DocumentRoot /home/admin/app/target/app/htdocs/
</VirtualHost>#身份验证的虚拟主机配置NameVirtualHost *:443
<VirtualHost *:443>
ServerAdmin sa@abc.com
ServerName test.abc.com
DocumentRoot /home/admin/app/target/app/htdocs/
SSLEngine on
SSLCipherSuite ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+SSLv3:+EXP:+eNULL
#该指令为虚拟主机指定证书文件名。
SSLCertificateFile /home/
admin/app/conf/ssl.crt/server.crt
#该指令为证书指定一个对应的私钥文件
SSLCertificateKeyFile /home
/admin/app/conf/ssl.crt/server.key
#该指令为指定一个包含Certificate Authority证书的文件
SSLCACertificateFile /home/admin/app/conf/ssl.crt/intranet-ca.cer
SSLProxyEngine on
RewriteEngine on
#设置客户端证书验证为必须
SSLVerifyClient require
#因为一个CA证书能够被另一个CA证书验证,所以可以形成一个CA证书链.使用该指令可指定服务器验证用户证书时可以查找多少个CA证明。
#设置认证深度:一般用默认10。
SSLVerifyDepth 10
#把mod_ssl里的变量变为全局环境的变量
RequestHeader unset SSL_CLIENT_S_DN_Email
RequestHeader add SSL_CLIENT_S_DN_Email %{SSL_CLIENT_S_DN_Email}e
</VirtualHost>
4)、代码片段
//CertAuthValve.java
//判断session中是否有用户邮箱地址
SessionValue session = SessionHelper.getSessionValue(rundata);
if (StringUtil.isNotEmpty(session.getCropEmail())) {
return null;
}
// 从内网证书中获取用户邮箱地址: SSL_CLIENT_S_DN_Email
String cropEmail = rundata.getRequest().getHeader(SSL_CLIENT_HEADER_MAIL);
if (StringUtil.isNotEmpty(cropEmail)) {
//将邮箱地址保存到session
session.setCropEmail(cropEmail);
SessionHelper.saveSessionValue(rundata, session);
if (log.isDebugEnabled()) {
log.debug("用户" + session.getCropEmail() + "已经通过证书验证");
}
return null;
}
URIBrokerService uriBrokerService = (URIBrokerService) getWebxComponent().getService(
URIBrokerService.SERVICE_NAME);
URIBroker noPermissionUriBroker = uriBrokerService.getURIBroker(CHECK_CRT_URL);
//请求的原始URL & 验证的URL
String requestPath = rundata.getPathInfo().replace("_", "");
String checkCrtUrl = (String) noPermissionUriBroker.getPath().get(
noPermissionUriBroker.getPath().size() - 1);
try {
//原始请求判断
if (requestPath.equalsIgnoreCase(checkCrtUrl)) {
//当前是https请求,但是依然不能得到证书信息,转到禁止页面
//(要将禁止页面加入到允许访问的配置文件中,不然会导致循环重定向)
URIBroker uriBroker = uriBrokerService.getURIBroker("forbidden");
rundata.setRedirectLocation(uriBroker.render());
} else {
//转到证书验证页面
rundata.setRedirectLocation(noPermissionUriBroker.render() + "?done=" + rundata.getPathInfo());
}
} catch (IOException e) {
log.error("权限验证重定向出错", e);
}
return new BreakPipeline();
//GetUserInfoValve.java
Object user = rundata.getSession().getAttribute("userInfo");
if (user == null) {
SessionValue session = SessionHelper.getSessionValue(rundata);
String email = session.getCropEmail();
Employe employe = PersonInfoUtil.getPersonInfoByEmail(email);
// 写入cookie
session.setEmployeeId(employe.getEmployeId());
session.setName(employe.getName());
session.setCropEmail(employe.getEmail());
SessionHelper.saveSessionValue(rundata, session);
}
采集到花瓣
posted @
2011-12-09 16:09 josson 阅读(2482) |
评论 (0) |
编辑 收藏
受限于证书的原因,以前经常不得已用IE打开一些应用。其实有一工具可以帮助我们导出IE证书,用于firefox,解决证书的困惑。
采集到花瓣
posted @
2011-12-09 13:54 josson 阅读(3162) |
评论 (1) |
编辑 收藏 互联网的产品大都是面向海量用户的服务,且用户分布区域广泛,其教育水平、习惯也大多不同,具有高度不确定性,我们必须非常关注用户的行为和反馈。因而,在互联网产品服务的整个用户研究,需求分析、产品研发及交付服务的过程中,都采用探索式、适应性的研发理念进行产品的研发。通常,会把整个产品研发周期划分为若干个迭代,采用迭代式的演进过程,不断的去交付新的产品特性,并通过观察用户的行为和反馈获取,进而随时调整产品的思路和方向。一切以用户价值为核心是互联网产品最核心的特点,而以价值驱动的敏捷开发方法非常符合这一特点。
一、敏捷项目管理实践 
从阿里软件开始,内贸团队就一直在实行着敏捷项目管理实践,通过小步快跑,快速迭代、增量交付用户价值,不断获取用户反馈,持续、快速的调整产品,验证并适合用户价值。正是通过这些实践活动,我们以迭代的、增量的交付用户价值,最大限度的保证产品朝着符合用户实际需求方向发展。目前,在内贸团队应用较成熟的敏捷实践活动有:
1)、迭代计划(Sprint Planning Meeting)
2)、每日晨会(Daily Scrum Meeting) & 任务墙(Task Wall)
3)、功能预演(Spring Review)
4)、项目总结(Retrospect Meeting)
5)、结对编程(Pair Programming)
6)、其他技术实践活动等
二、敏捷团队
1)、自组织文化
如google、facebook等互联网企业,他们很少甚至没有特定的项目流程,通常怎么敏捷怎么做,具有浓厚的工程师驱动文化。我们则有较完整的开发流程指导和规范我们的项目研发工作,相比而言,丧失了一些灵活性和积极性,不利于我们工程师自我管理、自我驱动意识的培养。臃肿、缺乏灵活性的流程同互联网产品快速更新、快速发展是不相适应的,同时也弱化我们的责任心意识。除了遵守详尽的流程,我们是否可以换个角度、换种方法,提倡和营造一种自我管理、自我驱动的开发文化,省却一些并不能给我们带来帮助却影响效率的流程呢?
敏捷团队的自组织特性弱化了团队技术领导这个角色,强调自我管理和自我驱动。虽然这对工程师的素质要求更高,相对技术能力更难提高。但是,团队导向很重要,我们努力营造这样的氛围,从小团队做起,逐渐锻炼和培养自组织团队。相信在这样的开发氛围下,会让我们做的更高效、更敏捷,可以走的更稳、更远。
2)、追求一体化
一体化团队作为敏捷开发方法中最具精益思想基因的实践,是指每个项目团队包括分析,开发,测试等角色,使团队满足一个需求从设计,开发到测试各个阶段顺利完成,达到符合质量标准并满足需求的软件。这种以项目/产品为单位的虚拟团队,坐在一起,全身心的为共同的目标而努力,可以更好的凝聚项目组中的各种角色,消除部门墙。
3)、追求全功能
这里所指的全功能是希望项目团队能打破工程师角色之间的边界,如研发、测试和前端工程师的界线,消除开发、测试流程中一些潜在浪费,提高效率。在项目团队内部通过角色互换,不限角色的结对工作,加强不同角色,不同模块间的知识传递,打破技术壁垒,帮助员工从不同视角理解项目,锻炼技能,进而增加团队均衡生产的能力。
为什么要提倡打破边界?项目整体效率依赖于项目过程中各环节的工作效率,而整体效率的优化往往依赖于均衡生产(精益思想的按需生产),即消除生产的波峰(过度生产)和波谷(生产不足),只有局部效率的增加无法直接转换为整体效率的增加(就象桶能装多少水,决定于最短的那块板)。整体效率的优化要求IT团队消除技能壁垒,培养多面手,根据计划的的变动,弹性地调整任务,达到各角色和流程之间的平衡。
三、质量保证
我们追求开发效率,同时也注重项目质量。如何去保证质量?就象美国的一位教授爱德化.戴明(W.Edwards Deming)所说:“我们应该停止依靠大量检验来保证质量,而是要改进工艺流程,从一开始就生产出优质的产品”。我们要在整个开发过程中多个环节去保证质量。同时,质量保证是整个团队的责任,就如同前面所说的追求全功能团队,打破边界。
至于在哪些环节采用哪些实践,我们先做个分类,按是否能被系统用户感知将质量问题区分内部质量和外部质量。外部质量指能直接被系统用户感知,如运行缓慢,不可操作或是操作复杂就属于外部质量低劣。而不能直接为系统用户所直接感知的要素,对产品键壮性、可维护性有深远影响的问题就属于外部质量,如系统设计的一致性、代码可读性、逻辑完整性等。内部质量对用户的影响比较间接,但比外部质量意义更深远。一般来说,系统内部质量优秀,外部质量仍有可能很差。而内部质量差的系统,外部质量肯定也不怎么样。
1)、外部质量保证
在外部质量保证上,大部分会在开发后期介入,可以通过性能测试、自动化测试及工程师的功能测试来保证,通过这些实践活动发现并保证例如运行缓慢、不可操作等质量问题不会存在。针对交互特别复杂的web应用,可以更多的考虑采用webui自动化测试工具,如selenium、pwaitr(b2b)、automan(淘宝)等,可以很好的完成那些简单、重复的TC用例,可以大大提高测试效率,解决测试工程师的资源瓶颈。
2)、内部质量保证
相对于外部质量,内部质量问题影响更为深远,在开发开始阶段就应该去保证。如通过单元测试、静态代码扫描(PMD\findbugs)、持续集成、重构、结对编程、code review等多种实践活动来保证项目代码的健康。
除了一些实践活动去检查代码质量外,更为重要的是研发工程师对内部质量的重视,如果工程师没有形成良好的质量意识,很可能这些实践也只是停留于形式,并不能带来较好的结果。如我们在开发过程中的编码规范、单元测试的质量及覆盖率,code review的及时性及问题是否持续跟进等等。此外,有选择的采用结对编程实践,有助于质量的提高。
本文以敏捷、精益(消除浪费、按需生产)思想的角度试图去探讨一种适合互联网公司的产品开发体系,上述概要的介绍了项目管理、团队、质量方面的一些敏捷实践活动,主要涉及了我们对敏捷方面的经验分享或者是些正在研究探讨的课题。文中涉及的实践活动,后续我将逐一展开详细介绍,帮助大家更好的理解和认识。希望本文的分享能成为一个引子,引起大家对敏捷开发的思考和讨论,或者更好的了解敏捷和精益思想。
posted @
2011-06-13 15:53 josson 阅读(571) |
评论 (0) |
编辑 收藏 以下为本人在公司内部关于项目质量和工作效率邮件回复的一此意见和想法。
1、 谈流程
不可否认流程的重要性,但我们需要根据具合格情况分析,不断的梳理和优化我们的流程,让流程更好的指导我们工作,而不是束缚。目前,我们的流程慢慢多了起来,感觉不如以前敏捷了。经过rpm改造后,无论在测试环节还是发布阶段,较之前失去了很大的灵活性。测试阶段,开发bugfix后想在测试环境验证,每次必须重走aone的流程及打包布署,相比之前的build效率真的差了好多。当然,也许是我们项目组对这个流程熟练度、方法还不够,很多环节有待改进。
发布阶段,目前统一由SCM来发布,必然会导致开发对线上环境及发流程更加陌生,同我们提倡的打破边界,敏捷响应有些相背。再者,SCM资源有限的原因,要支持ITU众多产品线,能否应付的过来,始终是个问题。发布统一管理有好处,同样也带来了弊端,ITU不同于网站,大多数的技术团队共同在维护在几个应用,而itu的应用多、规模相对小、环境各异,这样的产品线采用统一管理性价比不高。希望相应的owner,能不定期的搜集各产品线的意见和反馈,不断的优化,让我们的流程更合理。
2、 谈自测
我们团队一直在强调自测意识,也在这方面不断的总结和改进。我觉的要提高自测,首先应让每位开发同学形成较好的自测意识,而不是自上而下的命令式管理,只有自己有这方面的意,才会去思考、去想办法,去实践。再者,需要PM或技术经理去思考,目前阶段实行自测会有什么困难,如没有系统的自测方法、时间不充足(需要熟悉下阶段的UC、下迭代的设计、单元测试补写等),找到这些困难或问题,就容易对症下药了。最后,不断总结和积累自测方式,优化项目流程。自测不是一种形式,而要追求效果,开发自测同样需要计划和方法,所以我们需要向QA同学请教,总结过去 bug常犯的错误,整理自己的check项。相信通过这样的一些自测方法,能真正提高我们的项目质量,打破同QA的界线,我们的开发、测试资源比例可以得到更大的优化,将以前开发阶段紧,测试阶段松的状况加以改善,使整个项目过程中的紧张度趋于平缓。
3、 谈故障分
“尽量不要让故障分成为大家包袱,可以考虑被实施产品对事故级和A类才对个人计故障分,B和C类故障分记在主管头上!”,个人也比较支持骆驼的观点。目前大家对线上故障都小心翼翼,大家对质量的意识很高,这当然是好事,但同时带来的影响是效率低了。我的观点是,作为增值服务的互联网产品,我们更需要快速迭代增量提供用户价值,尽快获取用户反馈并改善产品,产品推出的迟早,不仅影响获得回报的时间,还影响到获得价值的多少,错过了一个时间窗口,产品可能就不再有任何价值。所以,我们需要找到一个平衡量点,可接受的质量状况达到最大的效率。
从客户第一角度谈质量,某些时候,客户可以接受服务偶而不可用重启下,却不能接受产品没价值、交互性太差,操作太复杂。所以,对于客户来说什么对他们更重要,就需要我们每个人去分析和评估。所以,我们一味只注重质量,而忽略客户真实需求,那就太悲哀。我的观点是,case by case,带着这样的观点去思考和解决问题。
4、谈敏捷项目团队
从打破边界,我想到了一体化的敏捷项目管理团队,一个目标一致、自我管理的团队,应该具备良好的目标意识和执行力,不仅能管好自己的一亩三分地,同时也能站在项目、团队的角度看待问题。PD出现了问题,开发积极去弥补;开发出现了问题,QA积极去弥补,项目团队的目标非常一致。每位项目组成员一定要把好每一关,万不可把问题向下抛,因为还有开发或QA会把关,所以差不多就行了,这样往往就是灾难的开始。
posted @
2011-05-20 16:39 josson 阅读(526) |
评论 (0) |
编辑 收藏
2010已成为历史,记忆里2010年变化很多、做的很多、收获也很多。2010是个转型期、创业期,从年初开始,就在新的Marking中努力耕耘。前半年,以新产品研发为主;后半年,结合客户使用产品后的反馈,不断的优化和改进产品功能,努力提升产品价值和用户体验。通过大家的努力,几款新产品还是彼受用户欢迎的,最欣喜的是我们提前完成了2010年的KPI目标。
过去的一年,有着太多的痛苦和艰辛,为了新产品的上线,晚上、周未都没了,唯一想的和做的就是确保产品如期上线。过程虽然很艰苦,但大家都努力坚持,齐心协力,确保任务如期完成,我们保持了一贯的说到做到、如期交付的作风。因为这样的磨练,我和我们的团队得到了更多成长。困难并不可怕,熬过去,明天的太阳会更加灿烂。
1、谈谈成长和不足:
1)、职业转型,开发到管理
虽然Team Leader已经做了几年了,但一直停留在项目上,多为管事不管人,对细节问题关注较多,所以之前谈不上管理,只能算是积累些项目管理经验。经过这一年的学习和发展,有了更多的管理意识,逐渐关注团队建设、团队成长,注意给小组成员更多的机会和空间,让他们得到锻炼和成长,承担更多团队或项目中的重要事项,而他们通过完成这些重要任务,不仅得到了磨练,同时在团队中建立了自己的影响力。
放在以前,我会认为有风险,或者自己做更快,更省事,或最有把握的人去。现在想来,以前认识太肤浅了,我们需要的团队战斗力,而不是个别人的能力,若平常不注重团队成员的培养,团队的战斗力永远不行,承担不了关键任务。
谈到成长和培养,团队需要什么样的人呢?作为互联网企业,同一般软件企业不同,产品在推出之前,谁也无法肯定是否会受用户欢迎,只能快速推出,让市场来验证,不断的改进和适应用户的需要。因而,需要我们技术人员也具备技术判断力,改变命令式管理体制下的工作习惯,充分发挥主观能动性和创新意识,共同做好产品。
2)、学会拥抱变化;
2010年变化很多,有些也许对个人、团队没有影响或影响很小,有些直接关系自己或团队,如团队的核心成员不断的被抽调、人员调整、KPI的271考评等,每次的变化都会带来不同的问题。持续输血,新人补允,使团队战斗力大打折扣,很长一段时间非常的纠结和无耐。事情总是具有两面性,往好处看,这对我、对团队也未必是件坏事,没有经验过挫折和磨练,又怎能成佛呢?既然是组织需要或Boss的决定,那就多些理解和支持,支持和协助上级完成也是每个下属的职责;况且,某些变化至少对于一些同学也是件好事,他们有更多的机会和更大的平台去一展才华。
大概人都是喜欢按习惯办事的缘故,每每有变化都觉的很痛苦。我觉的如何拥抱变化关键在于心态,我们需要理性看待变化,多往积极的方向思考,不仅更容易调整好心态,而且可以在变化中吸取经验和教训,鞭策我们成长。
3)、提升项目管理能力
虽然在项目管理知识上没有太多的时间和精力去系统的学习,但通过不断实践和总结,还是有了不少的积累和沉淀,对项目管理有了更多的理解和把握,对敏捷项目管理也有不同的认识,结合团队自身寻找适合我们的实践方式。在项目管理方面,还有很多需要去提升和学习,2011年希望安排更多的时间系统的学习项目管理知识及敏捷项目管理,并结合实际应用到工作中。
4)、提升向上沟通力
在拥抱变化的同时,同样需要理性的分析和积极的向上沟通。在过去,虽然会尽可能的去表达和反馈自己的想法和意见,但我重新审视下,总觉得表达还不够明确或不是那么的到位,或许在表达时还有更好的方式,至少还有提升的必要。向上沟通也是门学问,需要好好研究下。
5)、提升团队建设和辅导能力
相对来说,过去的一年所有的同学都会关注到,但领悟能力和基础较好的同学成长更快,基础稍弱的没有太大变化。显然,平常辅导工作没有做好或做到位,关注程度不够。越是基础差些的同学需要关注和帮助的点越多,需要帮助他们找到不足和问题所在,一起找改进办法,并给予必要的督促和检查,养成好的学习习惯,促进成长。2011年,这方面需要做的还有更多。
2、谈谈2011年的期望
1)、团队
解决目前团队新人多,有效资源少的问题;积极关注和帮助新人溶入团队,熟悉业务,以减少对项目开展的影响;
抓好梯队建设,关注和辅导基础较差同学的,共同制定改进计划和Action,做好必要的监督和指导,促进成长;
2)、能力
系统学习项目管理和敏捷软件开发方面的知识,并应用到项目管理实践中;同时积极参与相关方面的分享和讨论。
3)、影响
推动兴趣小组活动的开展,借开发工具的发展和分享,建立团队在部门或技术部的影响;
鼓励团队成员积极参与技术部的公共事务,提升影响力。
给力2010,加油2011!!!
posted @
2011-02-02 21:46 josson 阅读(362) |
评论 (0) |
编辑 收藏
iteration和release是两个不同的概念,但在敏捷实践活动中,我们往往认识的比较模糊,一个Iteration就是一次release,其实不然。那么,具体有什么区别和联系呢?
Iteration(迭代):在固定的周期内,经过需求分析、设计、实现、测试等活动,完成计划的的业务需求,迭代结束提供一个可工作的产品。计划的业务需求,可能是一个完整的User Story,也可能是一个Story中的若干task。
Release(发布):经过一个或若干个iteration后,完成计划中的所有User Story,经过测试后才release,最终真正交付给客户使用。
在我们的实践活动中,一个User Story所需的工作量超过我们的有效资源,无法安排在一个iteration内。我们就会想当然的会去延长迭代周期,增加有效资源以适应所需工作量。殊不知,这更象是形式上的迭代开发,无异于瀑布式项目开发过程。
2、建立固定的迭代周期,保持稳定的开发节奏
Scurm方法也非常强调稳定的迭代节奏,一个稳定的迭代节奏就如同项目的的心跳。Simon Baker描述说:"就像心脏有规律地跳动来保持身体运行,固定的迭代长度提供了一个恒量,有助于建立开发和交付的节奏。根据我的经验,节奏是帮助取得不变的步幅的重要因素"(2004)。对于敏捷开发的团队而言,稳定的迭代节奏可以让产品保持更稳定的交付。
3、如何保持稳定的开发节奏?
当一个迭代期内可提供的有效资源无法实现一个User Story时,我们如何按排呢? 在 谈迭代周期控制的困惑 中已谈到,这里不在细述。
4、如何选择适合自己团队的迭代周期?
一般需要考虑以下因素:
1)、整个项目周期长度(完成计划的商业需求所需时间)
较短的迭代周期将会有以下一些好处:更频繁的向客户展示/交付可用的软件;更频繁的度量开发进度;更频繁的取得反馈并改进;一般大的项目最好有多次(3次或以上)获取反馈、修正的机会,根据项目周期调整迭代周期长度。
2)、不确定性的多少
不确定性有多种形式,客户到底想要的是什么?小组的工作效率,时间?技术门槛等都不存在不确定性,不确定性越多,迭代就应该越短。
3)、获得反馈的难易程度
指小组获取反馈数量、频度和及时性,视所处的环境不同,选择合适的迭代长度;
4)、优先级要以多久保持不变
开发小组承诺在一次迭代中完成一组特定的功能,重要的是不要改变他们的目标方向,优先级不会被改变的时间长度是选择迭代长度时需要考虑的因素。
5)、迭代的系统开销
每次迭代的成本(时间),如迭代中进行的完整回归测试。最佳迭代周期的目标之一就是减少或近似消除每次迭代的系统开销。如每次回归时间成本很高,那决定周期长度时更倾向于长一些。
6)、团队成员的紧迫感
Niels Malotaux指出:"只要项目的结束日期还在遥远的将来,我们就不会感到任何压力,并从容不迫的工作。当结束日期逼近时,我们才会开始更努力的工作"。意思指项目开始大家比较放松,而越临近结束,工作越忙压力越大。因此,选择一个合适的迭代周期长度,让团队成员在整个迭代过程中感受到的压力更平均,不是给团队更多的压力,而是压力总量平均分布在迭代过程中。
每个团队根据所在环境和条件确定一个合适的迭代长度,一般建议2~4周。在我们的实践中,以2周一次迭代的频率,保持相对稳定的开发和交付的节奏。
5、参考资料:
《敏捷估计与规划》 Mike Cohn
posted @
2011-01-31 14:26 josson 阅读(3482) |
评论 (0) |
编辑 收藏
敏捷宣言中说到:"最好的架构、需求和设计来自于自组织的团队"。在自组织团队中,我们每个人既是团队/项目的管理者,又是执行者,要取得优异的结果,必须加强自我管理。
如何做好自我管理呢?
1、平和的心态:我们会不断的遇到各类或好事或坏事、或成功或挫折,什么样的心态去对待决定了我们成长的方向及高度,"态度决定一切"。
2、目标感:大到个人职业规划,小到每件事的期望,对于目标(期望)的制定和管理,都需要我们认真的去对待;
3、执行力:目标是方向,不能执行就不会有结果,好的执行力是优秀个人或团队的必要条件。
4、时间管理:工作需要区分轻重缓急,不能对事情没有计划和按排,对事需要分析重要性和紧急程度,分别对待;
5、学习能力:"学历代表过去,能力代表现在,学习能力代表将来。",一个人的学习能力决定他将来的成绩;
任何人都不希望自己被人管着,但要想不被人管只有一种办法:时时严格要求自己,主动、出色的完成每项工作,努力学习,与团队共成长。





posted @
2011-01-28 18:56 josson 阅读(302) |
评论 (0) |
编辑 收藏
昨日PM小组例会,谈到了需求评估工作量远大于有效资源情况下,如何保证迭代周期稳定的问题。讨论的内容,对于PM如何控制、保持迭代周期稳定有较大的参考价值。
| |
有效资源 |
评估工作量 |
| 1 |
多 |
少 |
| 2 |
少 |
多 |
| 3 |
相同 |
相同 |
注:
有效资源:指迭代周期内,开发团队所能提供的有效工作日,单位人/天。
评估工作量:指迭代周期内,产品经理提供需要实现的业务需求所评估的工作量之和。
上表描述以固定周期为两周的迭代中,可能会出现的有效资源和评估工作量对比情况。其中,1、3两种情况因为评估工作量小于或等同能提供的有效资源,所以不会影响迭代周期。重点需讨论的是有效资源小于评估工作量时,如何保持固定周期?
例举:一迭代周期,能提供有效资源20人/天,需求评估工作量30人/天。
1、功能较独立,需求不能拆分发布;
安排一个release,两个iterative。这种情况需要在迭代2中附加一些技术改造或低优先级的小需求、bugfix,release日期相对会慢几天。
2、一个迭代中包括多个产品的需求(需要各位产品经理协商,决定需求优先级);
a)、以保证质量为重:
忽略商业优先级,先处理一个迭代中就能全部完成的需求。
b)、保证价值
分两个迭代完成,一次release。
通常情况下,我们尽力保证迭代周期的稳定,但也允许例外,如:商业需求,产品上确定了发布时间点,或者节假期间团队请假比较多,一个迭代所能提供的有效资源相对比较少的情况。
保持迭代周期稳定,其核心是:
固定Timebox和可提供的资源,让产品经理来决定需求的优先级,每迭代只接纳(开发/QA资源)可承受的需求。
posted @
2011-01-13 15:31 josson 阅读(1102) |
评论 (0) |
编辑 收藏
对于互联网行业来说,快速推出产品占领市场、快速检验产品的价值和方向性、快速调整及优化是极期重要的。因此,采用小步快跑、持续迭代的敏捷实践一种不错的项目管理方法。我们团队在敏捷项目管理方面持续开展了二年多时间,在scrum、xp等敏捷最佳实践的基础上,结合团队自身的基础和条件,不断的偿试和优化,总结和积累了一些经验。目前,这些敏捷项目管理实践在项目组开展情况良好,得到了大多数团队成员的认同,特别是业务方、QA等合作方的认可。
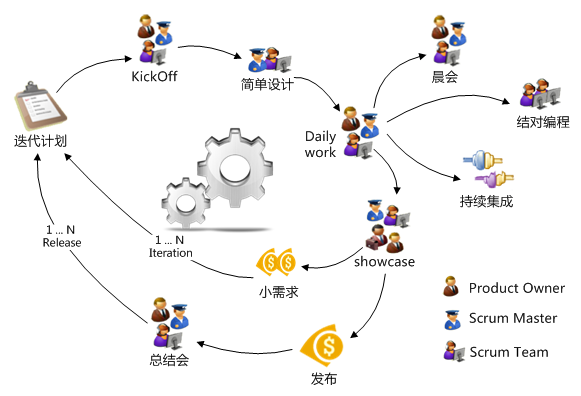
上图描述了一个基本项目迭代流程,其中涉及三个角色,其职责同等于Scrum中的Product Owner、Scrum Master、Scrum Team。迭代流程中分别包含了以下敏捷实践:
1)、迭代计划会议,按商业优先级筛选需求列表,确定本项目需求范围;
2)、确认本次迭代需求、资源、时间的具体情况;
3)、简单设计,对关键技术点进行必要的设计;
4)、晨会;
5)、结对编程;
6)、持续集成;
7)、showcase;
8)、项目总结会;
9)、新迭代的开始... ...
以上具体实践活动内容及组织形式,后续将逐一介绍,敬请关注。
posted @
2010-12-16 15:57 josson 阅读(391) |
评论 (0) |
编辑 收藏1、什么是java序列化
Java
序列化
API
提供一种处理对象序列化的标准机制。序列化(Serialization)是指将java对象用一连串字节描述的一个过程;反序列化(deserialization)是一种将这一串字节构建成一个对象的过程。
2、序列化的作用(必要性)
Java中,一切都是对象,在分布式环境中经常需要将对象从这一端网络或设备传递到另一端。Java
序列化机制就是一种解决在网络两端传输数据的问题而产生的协议。下图表示客户端/服务器之间通信,一个对象是从客户端传送到服务器通过序列化的视图。

3、如何序列化一个对象
为序列化一个对象,你需确保对象类实现Serializable接口。Serializable接口没有方法,只要实现了序列化接口,Class
就能被序列化机制处理。
示例代码,需序列化的java对象:
1 import java.io.Serializable;
2
3 public class TestClassSerial implements Serializable {
4 public byte version = 100;
5 public byte count = 0;
6 }
示例代码,
把TestClassSerial对照象
输出成
Byte
流,存储到
temp.out
文件里:
1 public static void main(String args[]) throws IOException {
2 FileOutputStream fos = null;
3 ObjectOutputStream oos = null;
4 try {
5 fos = new FileOutputStream("c:/temp.out");
6 oos = new ObjectOutputStream(fos);
7 TestClassSerial tcs = new TestClassSerial();
8 oos.writeObject(tcs);
9 oos.flush();
10 }
11 finally {
12 if(oos != null) {
13 oos.close();
14 }
15 if(fos != null) {
16 fos.close();
17 }
18 }
19 }
示例代码,
从持久的文件中读取
Bytes
重建对象:
1 public static void main1(String args[]) throws IOException {
2 FileInputStream fis = null;
3 ObjectInputStream oin = null;
4 try {
5 fis = new FileInputStream("c:/temp.out");
6 oin = new ObjectInputStream(fis);
7 TestClassSerial tcs = (TestClassSerial) oin.readObject();
8 System.out.println("version="+tcs.version);
9 }
10 finally {
11 if(fis != null) {
12 fis.close();
13 }
14 if(oin != null) {
15 oin.close();
16 }
17 }
18 }
执行结果为:100.
4、对象的序列化格式
TestClassSerial对象序列化输出的
temp.out
文件,以
16
进制方式显示,内容如下:
AC ED 00 05 73 72 00 0A 53 65 72 69 61 6C 54 65
73 74 A0 0C 34 00 FE B1 DD F9 02 00 02 42 00 05
63 6F 75 6E 74 42 00 07 76 65 72 73 69 6F 6E 78
70 00 64
这些二进制字节就是用来描述序列化以后的TestClassSerial对象的,我们注意到
TestSerial
类中只有两个域:
1 public byte version = 100;
2 public byte count = 0;
都是
byte
型,理论上存储这两个域只需要
2
个
byte
,但是实际上
temp.out
占据空间为
51bytes
,也就是说除了数据以外,还包括了对序列化对象的其他描述。
5、Java
的序列化算法
序列化算法一般会按步骤做如下事情:
1、将对象实例相关的类的元数据输出;
2、递归地输出类的超类元数据描述直到不再有超类;
3、类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值;
4、从上至下递归输出实例的数据;
更多序例化事例及二进制字节含义参考文档:http://my.oschina.net/god/blog/1291
posted @
2010-12-16 14:52 josson 阅读(859) |
评论 (0) |
编辑 收藏
1、员工激励
通过各种外部或内部的刺激,以激发员工的需要、动机、欲望,调动人的工作积极性,充分挖掘潜力,全力达到预期目标的过程。
2、激励形式、方法:
广义的分物质激励和精神激励(职务、荣誉、目标、信任、情感等)。

3、原则:
1)、精神激励为主;
2)、只激励该激励的人;
3)、只激励该激励的事;
4)、激励方法、手段因人而异,把握按需激励;
5)、鼓励公开竞争、和谐竞争;
4、案例:
1)、压力非常大的时候,采用激励手段 -- 目标激励
2)、当前员工不开心,采用的手段 -- 先沟通,明确原因
3)、表现好的员工 -- 信任激励,肯定
4)、推行新方法 -- 目标激励,竞赛
5、附:
马斯洛需求层次理论(Maslow's hierarchy of needs),亦称“基本需求层次理论”,是行为科学的理论之一,由美国心理学家亚伯拉罕·马斯洛于1943年在《人类激励理论》论文中所提出。
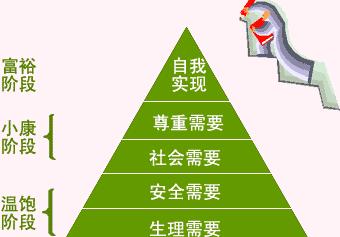
安全、生理需要属于物质性价值需求;社会需要、尊重需要、自我实现属于精神价值需求;
posted @
2010-12-09 16:17 josson 阅读(439) |
评论 (0) |
编辑 收藏
解决冲突的法则
- 在不了解对方动机之前千万不要表明自己的立场
- 准确把握自己的需求底线
- 解决冲突的最好办法是谈判
决策的法则
- 首先,以事实而后数据为依据,如果没有,
- 以严密的逻辑推理为依据,如果没有,
- 以民主评议,如果没有,
- 以最终负责人来决断
奖惩制度
- 在构建奖励制度的同时不要忘记处罚制度的建设
- 物质与非物质的奖励(以非物质的奖励)
- 侧重奖励行为还是结果?
表扬要及时(3天为限)、有理有据、真诚。
表扬是最不花钱最辞旧的激励手段,表扬是为下一个成功设立起点。
不要过度的物质奖励,在这种方式的激励下,员工永远得不到激励。
要注重精神上的奖励,只有精神是永存的。
posted @
2010-11-24 10:31 josson 阅读(449) |
评论 (0) |
编辑 收藏
垃圾收集的目的在于清除不再使用的对象,释放那些不再使用的对象所占用的内存。GC两种常用的方法是引用计数和对象引用遍历,早期的jvm使用引用计数,现在大多数jvm采用对象引用遍历。
1、对象引用计数:
当应用程序创建引用以及引用超出作用域(范围)时,jvm必须适当增减引用数。当某对象的引用数为0时,对象便可以进行垃圾收集。
2、对象引用遍历:
(1)、标记(marking)对象:从一组对象开始,沿着整个对象图上的引用链,递归确定可到达的对象,GC将标记这些可到达的对象。如果某对象不能从这些根对象的一个(至少一个)到达,则表示它可被收集。
(2)、清除(sweeping)对象:GC删除不可到达的对象,删除时,有些GC只是简单的扫描堆栈,删除未标记的对象,并释放它们的内存以生成新的对象。这种方法的问题在于内存会分成好多小段,而它们不足以用于新的对象,但是组合起来却很大。因此,许多gc可以重新组织内存中的对象,并进行压缩(compact),形成可利用的空间。
不一定要将所有的真话讲出来,但你讲的每一句真话必须是真话。(white
lie)
posted @
2010-07-28 14:37 josson 阅读(283) |
评论 (0) |
编辑 收藏最近一个项目主要涉及前端的交互优化,由于UED资源不足,所以一起做了一些前端的工作,
由于各浏览器的标准不一样,如要兼容像ie6,7,8及firefox,样式调整比较费事,现在css相关
的一些技巧分享一下,希望对大家有所帮助。
1、什么是css hack.
针对不同的浏览器去写不同的CSS,让它能够同时兼容不同的浏览器,能在不同的浏览器中也
能得到我们想要的页面效果,这种针对不同的浏览器写不同的CSS code的过程,称之为CSS hack。
通过下表中的hack
code就可以实现不同版本ie浏览器间的兼容:
|
hack code
|
ie6
|
ie7
|
firefox
|
|
_
|
√
|
×
|
×
|
|
*
|
√
|
√
|
×
|
|
!import
|
×
|
√
|
√
|
‘_’ : 只有ie6能识别_,如ie7,8下”width:100px; “的样式是OK,但ie6不够宽时,可以在”width:100px”后面增加一段”_width:105px;” 那么ie7,8不会解析_width:105px,但ie6会执行。
‘*’ : ie6,7都能识别*,但firefox不能识别;
‘!import’ : ie 6不能识别,ie7和ie8都能识别;
2、css调试工具
(1). ie8的调试工具,ie8下按F12能呼出开发人员开发工具,如下图:
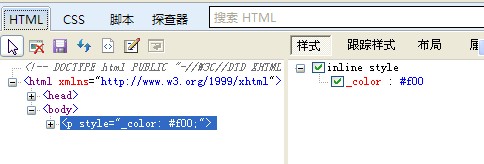
选中图中的箭头鼠标按钮,在浏览器中选中需要优化的HTML对象,HTML窗口就会
定位到选中HTML对象的代码上(如上图左),则右窗口中则显示当前对象的所有样式,
通过对右窗口中的样式调整,达到预期效果后,找到css文件的class,并作相同修
改。通过这个工具,修改样式后所见即所得,确定样式后再修改样式文件。
(2). Firebug,firefox下可以通过Firebug工具,来定位HTML对象并调试该对象的样式,如下图:
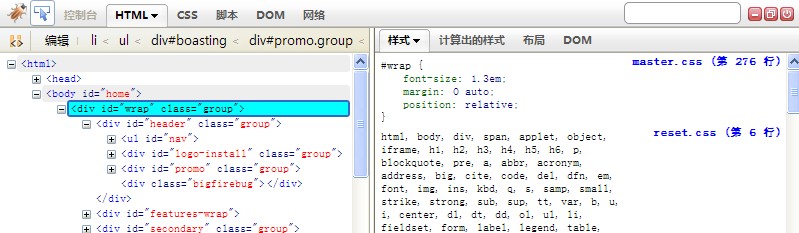
posted @
2010-06-29 11:03 josson 阅读(2273) |
评论 (0) |
编辑 收藏
| 事件 |
解说 |
| 一般事件 |
onclick |
鼠标点击时触发此事件 |
| ondblclick |
鼠标双击时触发此事件 |
| onmousedown |
按下鼠标时触发此事件 |
| onmouseup |
鼠标按下后松开鼠标时触发此事件 |
| onmouseover |
当鼠标移动到某对象范围的上方时触发此事件 |
| onmousemove |
鼠标移动时触发此事件 |
| onmouseout |
当鼠标离开某对象范围时触发此事件 |
| onkeypress |
当键盘上的某个键被按下并且释放时触发此事件. |
| onkeydown |
当键盘上某个按键被按下时触发此事件 |
| onkeyup |
当键盘上某个按键被按放开时触发此事件 |
| 页面相关事件 |
onabort |
图片在下载时被用户中断 |
| onbeforeunload |
当前页面的内容将要被改变时触发此事件 |
| onerror |
出现错误时触发此事件 |
| onload |
页面内容完成时触发此事件 |
| onmove |
浏览器的窗口被移动时触发此事件 |
| onresize |
当浏览器的窗口大小被改变时触发此事件 |
| onscroll |
浏览器的滚动条位置发生变化时触发此事件 |
| onstop |
浏览器的停止按钮被按下时触发此事件或者正在下载的文件被中断 |
| oncontextmenu |
当弹出右键上下文菜单时发生 |
| onunload |
当前页面将被改变时触发此事件 |
| 表单相关事件 |
onblur |
当前元素失去焦点时触发此事件 |
| onchange |
当前元素失去焦点并且元素的内容发生改变而触发此事件 |
| onfocus |
当某个元素获得焦点时触发此事件 |
| onreset |
当表单中RESET的属性被激发时触发此事件 |
| onsubmit |
一个表单被递交时触发此事件 |
posted @
2010-04-11 13:05 josson 阅读(178) |
评论 (0) |
编辑 收藏
1、让用户随时了解系统的状态;
2、系统应与真实世界相符合;
3、给予用户控制权和自主权;
4、提倡一致性和标准化;
5、帮助用户识别、诊断和修复错误;
6、预防错误;
7、依赖识别而不是记忆;
8、强调使用的灵活性及有效性;
9、最小化设计;
10、提供帮助及文档;
posted @
2010-04-11 13:05 josson 阅读(228) |
评论 (0) |
编辑 收藏
1、新建 archetype 项目(模板项目):
mvn archetype:genera -DgroupId=org.simple -DartifactId=simple -DarchetypeArtifactId=maven-archetype-archetype
2、修改主要模板文件:archetype-resources/pom.xml
1)修改 META-INF/maven/archetype.xml 中相关的 sources
2)安装此项目:mvn install
3、根据模板项目创建新项目:
mvn archetype:generate
-DarchetypeGroupId=org.simple\
-DarchetypeArtifactId= simple \
-DarchetypeVersion=1.0-SNAPSHOT
【安装私有库】
1、复制 mylib-1.2.3.jar 到本地代码库
2、编写 mylib-1.2.3.pom 文件:
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.mylib</groupId>
<artifactId>mylib</artifactId>
<version>1.2.3</version>
</project>
如果有依赖关系,可以将依赖关系描述在 pom 中
3、用Ant 来生成 jar 包和 pom 文件的 checksum 文件:
build.xml:
<project default="checksum">
<target name="checksum">
<checksum file="mylib-1.2.3.jar" algorithm="SHA" fileext=".sha1"/>
<checksum file="mylib-1.2.3.pom" algorithm="SHA" fileext=".sha1"/>
</target>
</project>
4、生成 mylib-1.2.3.jar.sha1 和 mylib-1.2.3.pom.sha1 文件
ant build.xml
【使用版本控制】
提交:mvn scm:checkin -Dmessage="Message"
检出:mvn scm:checkout
更新:mvn scm:update
posted @
2010-04-11 13:02 josson 阅读(892) |
评论 (0) |
编辑 收藏
作为一名开发者,通常会忽视系统可用性及用户体验。但系统的可用性和用户体验对于一个真正优秀的Web-based系统却至关重要,因此,我们有必要花一些时间来了解和学习一下。
一、相关的概念:
用户体验,user experience(或称ux/ue),指用户访问或使用一个产品/服务时的全部感受。具有主观性,不同的用户本身的知识、爱好、价值观等会有不同的结果,因人而异。
可用性,指产品是否易学、使用是否有效果,以及通用性是否良好等。衡量一个产品的可用性,可以通过一些具体目标来评判,相对用户体验而言,比较客观。考察产品可用性的目标可分为:
1、可行性,指产品使用的效果;
2、有效性,产品使用的工作效率;
3、安全性,指产品能否安全的使用,或称为容错性;
4、通用性,指产品是否具备良好的通用性;
5、易学性,指产品的是否容易上手,易操作;
6、易记性,指产品的操作方法简单,易记性;
二、开发人员的特点
作为一名开发者,通常会对目标用户的判断有较大的偏差,往往高估实际用户的操作能力和理解能力,忽视产品的易学性和易操作性。再者,作为技术人员,开发工作者通常重视功能实现,忽视产品界面、视觉外观,不重视用户体验。
三、一些案例
1、iPhone的成功
iPhone的成功,产品的可用度及用户体验有者至关重要的作用。其产品的很多细节,都凝聚着apple公司的创新。如3.5吋屏幕上触摸输入,比较费轻且易出错,但iphone在输入过程中,会放大选中的字符,便于用户确认,同时,作一些输入校验,进行容错处理,避免用户输入错误字符引起的麻烦。
2、在线订票、论坛注册
再如个在线订票系统,用户兴冲冲的跑上来想体验一把,千辛万苦输入一大段信息,终于注册成功,想下单的时候,即发现自己有的银行卡不支持,试想此时用户的心情会多么的糟糕。试想一下,如果在用户注册前,提示系统当前支持的银行卡的话,用户可以第一时间选择其他的方式来实现自己的目的。
再谈论坛的会员管理机制,网上这种案例也很多。用户费了好大的劲完成注册后,即告知新注册用户不能立即发言,很可能这个用户就这样失去了。
所以要做好一个产品,需要每位项目成员的投入,从用户角度出度,解决用户的实际问题。
posted @
2009-11-18 11:32 josson 阅读(384) |
评论 (0) |
编辑 收藏Codereivew是开发团队中经常采用的,为提高代码质量、提高编码规范的一种手段。针对实际工作组织review过程中的一些想法、见解,作一下总结。
关于CodeReview的几点作用:
1、提高团队的编码规范,培养良好的coding风格
旨在提高整个团队的编码规范程度,统一编码风格。通过每次的codereivew,发现团队成员在实际开发中的一些细节问题,如不良的编码习惯、错误的调用方式等。通过多次的发现、解决问题,使大家都养成良好的编码习惯。review的内容一般包括:
1)、异常、日志的处理;
2)、常量的定义及使用;
3)、字符串处理、BigDecimal.ZERO等;
4)、代码的封装,提高重用性;
5)、代码注释情况;
6)、javascript文件的抽取情况;
2、检查业务逻辑
对项目实现的功能逻辑进行一次reivew,结合众人发散思维,检查业务逻辑是否有盲点或错误。通常需要参与review的成员能够静下心来深入地认真分析,比较耗费时间。
3、分享和培训
每个项目的工作安排相对来说都是比较紧凑的,所以每个团队成员在完成自己的开发任务完,没有太多的时间去了解或熟悉其他成员的功能实现。但对于敏捷开发来说,每个功能模块的开发者并不是固定的,根据项目需要,很有可能由非原开发人员来完成增值功能或重构,所以codereivew是一次不错的培训及分享机会,特别是对功能相对复杂的需求实现。可以让团队成员了解或熟悉基本的设计思想和相关的类定义,确保在今后接手这一块工作时,可以更快的上手或找到最到最合适的人去了解更深层的逻辑。
关于reivew的方式:
1、集体review;
项目成员一起参与codereive,成本比较大,一般一个项目组织一次。比较适合开发经验分享,以及新功能的实现介绍,利于其他成员了解、熟悉实现者的设计思路及代码结构,在后续项目接手这些新功能时,更加从容。
2、TM组织若干开发经验丰富的一起review;
3、分组、交叉review;
具有较好的灵活性,根据情况随时找相关人员一起对已实现的代码进行review,及时发现过程中问题并予以修正。比较适合分组\抱团开发,以2-3人为单位,对具体的功能模块负责,一起分析、设计、编码,每位成员对于功能逻辑都比较逻辑,对业务逻辑reivew有比较好的效果。
实际工作中,根据实际情况灵活选择合适的review方式,不应拘于某种形式。review过程,应有明确的目的,具有针对性,而不是停留于表面,避免逐渐成为一种负担,流于形式。另外,应对每次review结果,整理出一份问题列表,进行分析和总结,避免相同问题的重复出现。同时,也应按排相关人员跟进并解决问题。总之,通过codereivew这一手段,尽可能的在提交测试之前去发现代码中存在的一些实际问题,从项目经历中得到成长。
posted @
2009-09-20 16:50 josson 阅读(461) |
评论 (0) |
编辑 收藏
因项目需要,实现系统对IE8的支持,安装了ie8版本。安装完后,发现一个奇怪问题,打开一个窗口(window.open方式)后,再打开时,新窗口的页面显示空白,无法加载其内容。关闭ie后,重新偿亦是如此,第一次能打开,第二次就不行。无论是ie7模式,还是兼容模式。
网上搜了很多内容,都没有找相应的解决方案。后来偿试了一下,ie设置重置(工具-Internet选项-高级-重置),删除所有个性化设置,完成后,重试后该问题不再出现,窗口能正常打开。回想,可能是装完ie后,ie设置向导中做了某些不当的设置有关,但具体是哪项尚不得而知。
posted @
2009-09-12 15:01 josson 阅读(4109) |
评论 (2) |
编辑 收藏
在原网页窗口高度根据内容自适应的基础上,做了一些调整:
1、解决窗口底部靠近任务栏时,
window.resizeBy 不能调整窗口高度问题;
1、增加宽度自适功能(注:只针对宽度不足,进行扩展的情况;无法调整窗口宽度比实际内容宽的情况)
Ext.util.ResizeWin = function() {
try {
var sh = document.documentElement.scrollHeight
|| document.body.scrollHeight;
var ch = document.documentElement.clientHeight
|| document.body.clientHeight;
var sw = document.documentElement.scrollWidth
|| document.body.scrollWidth
var cw = document.documentElement.clientWidth
|| document.body.scrollWidth;
var xHeight = 55;//任务栏高度(double).
var statHeigth = 30;//状态栏高度
var maxHeight = window.screen.height - xHeight; //最大可显示网页高度
var wHeight = window.screenTop + sh + statHeigth;
if(wHeight > maxHeight){
//窗口位置过底时,向上移动若干象素,使窗口状态栏在任务栏上面.
var newTop = (window.screenTop - xHeight) + (maxHeight - wHeight);
if(newTop < 0) newTop = 0;
window.moveTo(window.screenLeft, newTop);
}
//宽度调整时,实际内容不够宽可以适用,过宽无法调整.
window.resizeBy((sw-cw),(sh-ch));
}catch (e){}
};
以下从网上收集的一些相关资料:
1、关于网页窗口高、宽示意图:

2、更多属性:
网页可见区域宽:document.body.clientWidth
网页可见区域高:document.body.clientHeight
网页可见区域宽:document.body.offsetWidth (包括边线的宽)
网页可见区域高:document.body.offsetHeight (包括边线的宽)
网页正文全文宽:document.body.scrollWidth
网页正文全文高:document.body.scrollHeight
网页被卷去的高:document.body.scrollTop
网页被卷去的左:document.body.scrollLeft
网页正文部分上:window.screenTop
网页正文部分左:window.screenLeft
屏幕分辨率的高:window.screen.height
屏幕分辨率的宽:window.screen.width
屏幕可用工作区高度:window.screen.availHeight
屏幕可用工作区宽度:window.screen.availWidth
HTML精确定位:scrollLeft,scrollWidth,clientWidth,offsetWidth
scrollHeight: 获取对象的滚动高度。
scrollLeft:设置或获取位于对象左边界和窗口中目前可见内容的最左端之间的距离
scrollTop:设置或获取位于对象最顶端和窗口中可见内容的最顶端之间的距离
scrollWidth:获取对象的滚动宽度
offsetHeight:获取对象相对于版面或由父坐标 offsetParent 属性指定的父坐标的高度
offsetLeft:获取对象相对于版面或由 offsetParent 属性指定的父坐标的计算左侧位置
offsetTop:获取对象相对于版面或由 offsetTop 属性指定的父坐标的计算顶端位置
event.clientX 相对文档的水平座标
event.clientY 相对文档的垂直座标
event.offsetX 相对容器的水平坐标
event.offsetY 相对容器的垂直坐标
document.documentElement.scrollTop 垂直方向滚动的值
event.clientX+document.documentElement.scrollTop 相对文档的水平座标+垂直方向滚动的量
IE,FireFox 差异如下:
IE6.0、FF1.06+:
clientWidth = width + padding
clientHeight = height + padding
offsetWidth = width + padding + border
offsetHeight = height + padding + border
IE5.0/5.5:
clientWidth = width - border
clientHeight = height - border
offsetWidth = width
offsetHeight = height
(需要提一下:CSS中的margin属性,与clientWidth、offsetWidth、clientHeight、offsetHeight均无关)
网页可见区域宽: document.body.clientWidth
网页可见区域高: document.body.clientHeight
网页可见区域宽: document.body.offsetWidth (包括边线的宽)
网页可见区域高: document.body.offsetHeight (包括边线的高)
网页正文全文宽: document.body.scrollWidth
网页正文全文高: document.body.scrollHeight
网页被卷去的高: document.body.scrollTop
网页被卷去的左: document.body.scrollLeft
网页正文部分上: window.screenTop
网页正文部分左: window.screenLeft
屏幕分辨率的高: window.screen.height
屏幕分辨率的宽: window.screen.width
屏幕可用工作区高度: window.screen.availHeight
屏幕可用工作区宽度: window.screen.availWidt
posted @
2009-09-05 18:15 josson 阅读(482) |
评论 (0) |
编辑 收藏
1、ssh 登录linux时,报: ssh_exchange_identification: Connection closed by remote host
google了好一阵,才找到线索。主要由于我前晚写shell脚本调试的时候,误将一些系统文件的宿主为新用户了。后来新的会话怎么都登录不上去了,好在还有一个root登录的会话,找到/var/empty/sshd,修改宿主及权限。
chown -R root:root /var/empty/sshd
chmod 700 /var/empty/sshd
2、su 切换用户,输入密码总是提示:密码不正确。
也是权限问题,root切到其他账号时没有问题;其他账号之间切换就是不行,密码输入也正确。后来其到/bin/su 文件的权限不正确,调整如下解决问题:
-rwsr-xr-x 1 root root 61144 Jul 30 2007 /bin/su
posted @
2009-08-13 18:34 josson 阅读(256) |
评论 (0) |
编辑 收藏
一般业务系统中总会存在一些基础数据,在其他的业务单据中会被套引用。因此,系统必须保证这些被业务单据引用的基础数据不能任意的删除。最常见的做法就是,在删除基础数据时,预先校验该类数据是否在相关业务表中存在,若不存在才允许用户删除,否则给用户以提示。
但这样的处理方法,有些缺点,就是需要编码对每个业务类提供查询方法,或在删除逻辑中增加判断逻辑。因此,每次引用关系变化,增加或减少时免不了要修改原来的逻辑,时间越长,系统的维护成本就越来越高了。因此,有必要对系统进行重构,将这类的处理逻辑进行抽象,单独封装成一个服务,当引用关系有变更时,不用再修改原有逻辑,通过配置就可以完成变更。
通用引用关系查询服务,主要就是通过db表或xml配置文件,对系统中每个基础数据有引用的所有关系进行定义,定义属性主要是引用的表及字段名称。查询时,从配置文件中读取指定类别的引用关系,并逐一查询这些表中的记录,以确定数据是否被引用。这种处理方法的优点为,易扩展、可维护性强,引用关系变更时,仅通过维护配置文件,不必进行编码,就能实现,这样能大大的提高系统的稳定性。
xml配置文件如下:
<rule bizName='product' desc="产品关联项定义">
<item>
<refTable>sale_item</refTable>
<refField>product_id</refField>
<!-- 用于查询条件的扩展,允许为空 -->
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
<item>
<refTable>sale_order_item</refTable>
<refField>product_id</refField>
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
</rule>
<rule bizName='customer' desc="客户关联项定义">
<item>
<refTable>sale_order</refTable>
<refField>cust_id</refField>
<extCondition>CORP_ID = #corpId#</extCondition>
</item>
<item>
<refTable>sale_bill</refTable>
<refField>cust_id</refField>
<extCondition></extCondition>
</item>
... ...
</rule>
通用业务引用查询类代码片段如下:
public class BizReferenceService implements IBizReferenceService {
private static Map<String,List<BizReferenceRule>> ruleMaps;
private static final String PATTERN = "#[\\w]+#";
private static final String CFG_FILE = "bizReferenceRule.xml";
... ...
/**
* 查询指定业务数据是否被其他业务表关联依赖.
* @param bizName 关联业务名称
* @param bizId 关联业务ID.
* @param extParam 扩展条件
* @return true 被关联/false 未被关联.
*/
public boolean isBizReference(String bizName,String bizId,Map<String,Object>extParam) throws ServiceException {
Assert.notNull(bizName, "业务名称不能为空,bizName is NULL。");
Assert.notNull(bizId, "记录ID不能为空,bizId is NULL。");
try {
//逐个检查依赖项是否有数据关联.
List<BizReferenceRule> rules = getBizRelationRule(bizName);
for(BizReferenceRule rule : rules){
StringBuilder sqlBuilder = new StringBuilder();
sqlBuilder.append("select count(*) from ").append(rule.getRelTable()).append(" where ")
.append(rule.getRelField()).append("='").append(bizId).append("' ");
String extConditon = rule.getExtCondition();
if(StringUtil.isNotBlank(extConditon)){
initTenantParam(extParam);
sqlBuilder.append(" and ").append(getExtParamSql(extConditon,extParam));
}
logger.debug(sqlBuilder);
int nCount = bizReferenceDao.getBizRelationCount(sqlBuilder.toString());
if (nCount != 0) return true;
}
return false;
}
catch(Exception ex){
logger.error("调用业务关联服务错误。"+bizName+",bizId:"+bizId+",extParam"+LogUtil.parserBean(extParam),ex);
throw new ServiceException("调用业务关联服务错误。");
}
}
/**
* 组装扩展查询条件的sql
* @param condition
* @param extParam
* @return
* @throws Exception
*/
private String getExtParamSql(String condition,Map<String,Object>extParam) throws Exception {
List<String> paramList = parseDyncParam(condition);
for(String param : paramList){
String simpleParam = simpleName(param);
if(!extParam.containsKey(simpleParam)){
throw new ServiceException("动态参数值未设置! param:"+param+",extParam:"+LogUtil.parserBean(extParam));
}
condition = condition.replaceAll(param, "'"+String.valueOf(extParam.get(simpleParam))+"'");
}
return condition;
}
/**
* 解析扩展查询条件中的动态参数名.
* @param condition
* @return
* @throws Exception
*/
private List<String> parseDyncParam(String condition) throws Exception {
PatternCompiler compiler = new Perl5Compiler();
PatternMatcher matcher = new Perl5Matcher();
MatchResult result = null;
PatternMatcherInput input = null;
List<String> paramList = new ArrayList<String>();
input = new PatternMatcherInput(condition);
Pattern pattern = compiler.compile(PATTERN,Perl5Compiler.CASE_INSENSITIVE_MASK);
while (matcher.contains(input, pattern)){
result = matcher.getMatch();
input.setBeginOffset(result.length());
paramList.add(result.group(0));
}
return paramList;
}
/**
* 获取业务关联查询规则.
*/
private List<BizReferenceRule> getBizRelationRule(String bizName){
Assert.notNull(bizName, "业务名称不能为空,bizName is NULL。");
//配置定义未加载到内存时,读取配置文件
if(ruleMaps == null){
parseRuleConfig();
if(ruleMaps == null) return null;
}
return ruleMaps.get(bizName);
}
/**
* 读取业务关联规则配置文件
*/
@SuppressWarnings("unchecked")
private synchronized void parseRuleConfig(){
if(ruleMaps != null){
return;
}
//解析业务引用定义文件.

}
/**
* 读取Xml文档
* @return
*/
private Document getXmlDocument(){
InputStream is = null;
try {
ClassLoader loader = Thread.currentThread().getContextClassLoader();
is = loader.getResourceAsStream(CFG_FILE);
SAXBuilder sb = new SAXBuilder();
return sb.build(new BufferedInputStream(is));
}
catch(Exception ex) {
logger.error("读取配置文件错误. file:"+CFG_FILE, ex);
return null;
}
finally {
try {
if(is != null){
is.close();
is = null;
}
}
catch(Exception ex) {
logger.error(ex);
}
}
}
}
其他的一些可选处理方法:
b. 在客户表增加引用计数字段;
需额外维护引用计数字段,在引用的业务逻辑增加或删除记录时,需对该字段的数值进行更新。适用于需要直接查询记录被引用次数的场景,但在集群环境下,需注意并发问题。
posted @
2009-07-14 14:42 josson 阅读(419) |
评论 (0) |
编辑 收藏
在IE、FireFox、Netscape等不同的浏览器里,对于document.body 的 clientHeight、offsetHeight 和 scrollHeight 有着不同的含义,比较容易搞混,现整理一下相关的内容:
clientHeight:在上述浏览器中, clientHeight 的含义是一致的,定义为网页内容可视区域的高度,即在浏览器中可以看到网页内容的高度,通常是工具条以下到状态栏以上的整个区域高度,与具体的网页页面内容无关。可以理解为,
在屏幕上通过浏览器窗口所能看到网页内容的高度。
offsetHeight:关于offsetHeight,ie和firefox等不同浏览中意义有所不同,需要加以区别。在ie中,offsetHeight 的取值为 clientHeight加上滚动条及边框的高度;而firefox、netscape中,其取值为是实际网页内容的高度,可能会小于clientHeight。
scrollHeight:scrollHeight都表示浏览器中网页内容的高度,但稍有区别。在ie里为实际网页内容的高度,可以小于 clientHeight;在firefox 中为网页内容高度,最小值等于 clientHeight,即网页实际内容比clientHeight时,取clientHeight。
clientWidth、offsetWidth 和 scrollWidth 的含义与上述内容雷同,不过是高度变成宽度而已。
若希望clientHeight、offsetHeight和scrollHeight三个属性能取值一致的话,可以通过设置DOCTYPE,启用不同的解析器,如:<!DOCTYPE HTML PUBLIC "DTD XHTML 1.0 Transitional">,设置DOCTYPE后,这三个属性都表示实际网页内容的高度。
通过以下HTML代码,可以了解一下这三个属性的含义:
<!DOCTYPE HTML PUBLIC "DTD XHTML 1.0 Transitional"> //设置DOCTYPE
<HTML>
<HEAD>
<TITLE> 测试。 </TITLE>
</HEAD>
<script type='text/javascript'>
window.onload = function(){
var ch = document.body.clientHeight;
var sh = document.body.offsetHeight;
var ssh = document.body.scrollHeight;
alert('clientHeight:'+ch+'; offsetHeight:'+sh+"; scrollHeight:"+ssh);
}
</script>
<BODY style='margin:0px'>
<div style='background-color:#ccc; height:400px; padding:0px'>
text
</div>
</BODY>
</HTML>
根据页面内容调整窗口高度的方法:
Ext.util.ResizeWin = function() {
try {
var sh = document.documentElement.scrollHeight
|| document.body.scrollHeight;
var ch = document.documentElement.clientHeight
|| document.body.clientHeight;
window.resizeBy(0,(sh-ch));
}catch (e){}
};
posted @
2009-06-14 16:48 josson 阅读(1543) |
评论 (0) |
编辑 收藏