2009年5月31日
#
摘要: 之前遇到几次现场故障,都是和class文件有关,比如版本不兼容造成Bad Version错误之类,需要检查class文件的编译版本信息。 今天无意中发现, jdk自带的javap 命令其实可以方便的搞定这个事情
阅读全文
摘要: 前几次的编码最佳实践系列,我们都着眼于Java代码,今天我们换个话题,看看另外一个领域,和Java代码大相径庭的SQL。
阅读全文
摘要: 本期的案例依然是来自实际项目,很寻常的代码,却意外遭遇传说中的Java"内存溢出"。
阅读全文
摘要: 昨晚继续折腾俺的小站http://www.javauniversity.net,准备给它加上SEO支持,安装了SEO tools模块和相应的依赖模块。
结果安装完成之后就陷入重定向循环了,每个页面都被重定向到新地址,然后新地址再次被重定向。chrome浏览器会稍后报错说太多重定向,而ie则傻傻的一直在死循环。
阅读全文
摘要: 折腾了两天,终于将Java University这个站点开通,过程真不容易的,决定写下来吐吐 糟,以纪念TIANCHAO和谐之光普照下P民的美好生活
阅读全文
摘要: 这是一个来自实际项目的例子,在这个案例中,有同事基于jdk中的LinkedHashMap设计了一个LRUCache,为了提高性能,使用了 ReentrantReadWriteLock 读写锁:写锁对应put()方法,而读锁对应get()方法,期望通过读写锁来实现并发get()。
阅读全文
摘要: 这里将要讲述的是一系列的类似案例,都是在各个产品进行performance tuning时被发现的,非常具有普适性。可以说在日常开发中,有非常大的概率遇到相同或者类似的情形,因此需要对其保持警惕以便避免陷入类似的性能问题。 我们从JAXBContext这个对象开始...
阅读全文
摘要: 这是一个真实案例,曾经惹出硕大风波,故事的起因却很简单,就是需要实现一个简单的计数器,每次取值然后加1......
阅读全文
摘要: 最近在公司内部做了一些收集和整理的工作,关于trouble shooting和performace tuning 中遇到并解决的典型问题,做了一些内部分享。我整理了一下,准备陆续放上来分享给大家。
这些问题,单个看每个问题都不算复杂或高深,但是都是在实际项目开发中出现并一度造成困扰的,而且带有一定的普适性,具体表现为不知道这些问题的同学很容易在日常开发中中招。因此我们开了一个专题,叫做编码最佳实践,似乎名字起的有点大......
先来看看第一个,如何做compare。
阅读全文
摘要: 今天用jetty做嵌入式web container,来做web项目的integration test,结果发现出现在渲染使用EL表达式的jsp页面时出现异常:
javax.el.ExpressionFactory.newInstance()Ljavax/el/ExpressionFactory;
检查了一下,发现javax.el.ExpressionFactory.newInstance()这个方法是EL2.2版本之后才有的方法,而在EL2.1之中是没有这个方法的,问题很明显:org.apache.jasper中试图调用2.2版本的EL,当时提供的EL的版本是2.1版本,所以解决的方式无非就是两个,要不降低org.apache.jasper的版本,要不提升el的版本。考虑到现在使用的jetty已经是最新的版本8.1.2.v20120308,因此提升EL的版本为2.2更为合适。
阅读全文
摘要: 在jenkins上建立了一个job,通过标准的maven命令来执行打包测试和上传artifact到nexus仓库。随后发现有些性能问题:sonar的job执行时,需要重新update SCM,然后需要再次执行test,之后才能进行真正属于sonar的任务如代码检测等。明显update SCM 和执行test是重复了原有job,纯属浪费。这个重复执行问题随着测试案例和测试执行时间的增加,会越来越明显。因此需要考虑消除这里的重复问题,减少build的时间,并节约jenkins的资源。
阅读全文
使用maven填写依赖的时候,常会遇到需要查一下groupId/artifactId和version,有时候还要看看有没有新的版本更新。
原来一直用http://mvnrepository.com/ 这个网站来搜索,最近发现maven官网也提供了类似的功能,http://search.maven.org/。
简单试用了一下search.maven.org,功能基本和mvnrepository.com相同,而且界面更简洁友好。推荐使用。
摘要: cloudfoundry是vmvare新推出来的开源PaaS平台,我试用了一下,发现还是很不错的,申请过程很简单。发出来分享给大家,有需要的可以去申请,毕竟可以支持java的免费的空间实在太难得了。
阅读全文
摘要: 初学gradle,一切都还在摸索的过程中。今天刚刚试图将之前基于ant + ivy的一个小项目转移到gradle下,结果在和sonar集成时出现问题.
阅读全文
摘要: 虽然easymock中提供了大量的方法来进行参数匹配,但是对于一些特殊场合比如参数是复杂对象而又不能简单的通过equals()方法来比较,这些现有的参数匹配器就无能为力了。easymock为此提供了IArgumentMatcher 接口来让我们实现自定义的参数匹配器。
阅读全文
摘要: 在easymock中,对于mock对象的同一个方法,可以为每一次的调用定制不同的行为。在record阶段easymock会精确的记录我们录入的行为,基于每一次的方法调用。
阅读全文
摘要: 前面的教程中,我们看到easymock可以通过expect方法来设定mock方法的返回值或者异常,但是注意这些案例中设置的返回值都是在调用被测试的类的方法前就已经确定下来的,即我们其实在测试类的代码运行前(实际是在EasyMock.replay()方法调用前)就已经"预知"了返回结果。
但是在某些情况下,我们可能无法预知返回值,比如我们需要根据输入的参数值来决定返回什么,而这个参数可能无法在record阶段获得。因此在mock方法中我们无法在record阶段就决定应该返回什么。
对于这种场景,easymock提供了IAnswer接口和andAnswer()方法来提供运行时决定返回值或者异常的机制。
阅读全文
摘要: easymock中提供对于类的mock功能,我们可以方便的mock这个类的某些方法,指定预期的行为以便测试这个类的调用者。这种场景下被mock的类在测试案例中扮演的是次要测试对象或者说依赖的角色,主要测试对象是这个mock类的调用者。但是有时候我们需要将这个测试类作为主要测试对象,我们希望这个类中的部分(通常是大部分)方法保持原有的正常行为,只有个别方法被我们mock掉以便测试。
阅读全文
摘要: easymock中提供了非常多的方法来实现参数匹配,基本能满足一般参数匹配的要求。
阅读全文
摘要: 在创建mock对象的时候,我们可以命名mock对象。
命名mock对象有什么好处呢?其实就是一点,即在当测试案例因为某个mock对象的状态或行为不符合要求而失败的时候,在异常信息里面可以输出这个mock对象的名称。
阅读全文
摘要: 对于mock对象上的mock方法的调用,easymock支持指定次数,默认为1.同时easymock提供了其他的方法,用于指定具体调用次数或者放宽调用次数检验。
阅读全文
摘要: easymock并不是万能的,在使用easymock时有一些限制需要注意。
阅读全文
摘要:
前面教程中有个章节讨论到mock和stub的概念差别,一般来说easymock如其名所示,主要是用来做mock用的,但是easymock中也提供有对stub的支持, 主要体现在andStubAnswer(),andStubDelegateTo(),andStubReturn(),andStubThrow()和asStub()等方法的使用上。
阅读全文
大家都知道sonar是个好东东,在有CI支持的情况下,使用好了可以非常好的控制代码的质量,诸如代码覆盖率,代码规则检查等。
而解决violation的办法,除了正统的修改代码来满足规则外,还有一个变通的方法, NOSONAR。这个标记本意是在一些特殊情况,有不得已的理由不得不违反规则,为了避免sonar继续报错而不得已做了一个"变通"。
NOSONAR本意虽好,但要是有人滥用,变通就会变成取巧,因为解决sonar violation的最简单的方法,就是直接NOSONAR!
当问题很简单时,一般人都会选择正常的方式修改代码,如果只是举手之劳基本上还是能遵守规则的。但是当问题复杂时,或者说当解决问题不再是举手之劳时,每个人都要受到NOSONAR的诱惑。而NOSONAR的底线在哪里?没有人定义,没有人检测,自然不会每个人都坚守,NOSONAR的底线随着一个一个的NOSONAR慢慢的在降低。退五十步的人,是没有资格笑百步的。
返回到现实代码中,不知道是大家都没有顶住诱惑,还是说我们开启的规则不大合理,总之越来越频繁的在代码中看到NOSONAR了,虽然还没有到泛滥的地步,但是已经让我有些不安了。简单搜索了一下刚才让我感觉到很多NOSONAR的project,结果是58个。
更糟糕的是,每个NOSONAR后面都不会带有注释说明为什么要NOSONAR,因此一个个飞舞的NOSONAR就变成了一个个谜团。想知道为什么要NOSONAR吗?恩,你猜......
我没有办法去检查这个58个NOSONAR是不是都合理的,都站得住脚的。出于程序员的习惯,对于一切不可确认性都报以怀疑的眼光和质疑的姿态,我总觉得这58个NOSONAR让我总是没有底,每次我看到sonar上100%的规则检测通过率时,我总是禁不住在心里浮现NOSONAR的字样。
好吧,我承认,我是个心里有些阴暗的家伙......
摘要: 在easymock的使用过程中,当创建mock对象时,我们会遇到 strict mock和nice mock的概念。上述的测试案例验证了strict mock和nice mock的基本使用,对于同一个mock对象,strict模式下多个方法之间的调用顺序在record阶段和replay阶段下是需要保持一致的。但是故事并不是到此结束,更有意思的内容在后面:如果出现多个mock对象,那么这些不同mock对象的方法之间,他们的调用顺序是否检测?普通mock和nice mock模式下自然是不会检测顺序,但是strict模式下呢?
阅读全文
摘要: IMocksControl接口容许创建多个mock对象,这些创建的对象自动关联到这个mocksControl实例上,以后再调用replay()/verify()/reset()时就不需要逐个列举出每个mock对象。当mock对象比较多,尤其是原有代码上新增mock 对象时非常方便。
阅读全文
摘要: 前面的例子中,mock的对象都是基于interface,虽然说我们总是强调要面对接口编程,而不要面对实现,但是实际开发中不提取interface而直接使用class的场景非常之多。尤其是一些当前只有一个明确实现而看不到未来扩展的类,是否应该提取interface或者说是否应该现在就提取interface,总是存在争论。
这种情况下,我们就会面临主要测试对象依赖到一个具体类而不是interface的情况,easymock中通过class extension 来提供对class mocking的支持。
阅读全文
摘要: 关于easymock的典型使用方式,在easymock的官网文档中,有非常详尽的讲解,文档地址为 http://easymock.org/EasyMock3_0_Documentation.html,文档的开头一部分内容都是easymock中最基本的使用介绍,虽然是英文,但是非常容易看懂,适用新学者入门。
这里只罗列一些简单的常用功能。
阅读全文
摘要: record-replay-verify 模型容许记录mock对象上的操作然后重演并验证这些操作。这是目前mock框架领域最常见的模型,几乎所有的mock框架都是用这个模型,有些是现实使用如easymock,有些是隐式使用如jmockit。
record-replay-verify 模型非常好的满足了大多数测试场景的需要:先指定测试的期望,然后执行测试,再验证期望是否被满足。这个模型简单直接,易于实现,也容易被开发人员理解和接受,因此被各个mock框架广泛使用。
阅读全文
摘要: 在单元测试中,通常我们都会有一个明确的测试对象,我们测试的主要目的就是为了验证这个类的工作如我们预期。
阅读全文
摘要: easymock是目前java mock 工具中比较流行的工具,这个教程将系统的介绍easymock的使用。
主要内容来自easymock的官网教程,针对日常使用进行了一些筛选和补充,另外增加一些个人的理解和认识。
另外考虑到网络上已有不少分散的教程,我将适当的链接进来。
教程的内容将在随后逐渐添加,目前计划的目录如下,相应内容完成之后我将逐个更新此文的链接。
阅读全文
近期发现一个问题,hudson执行任务时,经常不能获取到最新的代码,从而导致出现各种问题。
日常开发中的典型例子:发现一个bug,修改代码,本地测试通过,提交代码到subversion,手工激活hudson构建,原本期望hudson获取到刚刚提交的代码并测试/打包/发布。结果事与愿违,测试的结果发现刚刚做出的修改似乎没有生效。正费解之时,再执行一次hudson构建,又成功了...
经历过几次上述蹊跷遭遇之后,发现这个问题不是偶然。之后检查hudson的日志,发现问题的发现在最开始update / check out subversion代码时,明明已经提交的代码,hudson做update / check out时,居然没有update / check out下来!显示的subversion版本号也和subversion上实际的最新版本不一致,hudson总是要小一些,换言之,hudson update / check out的代码要比当前最新代码老一些。
google一番,发现这个问题之前就有人遭遇过,hudson上甚至已经有了好几个关于这个问题的bug,比如 http://issues.hudson-ci.org/browse/HUDSON-1241 "force using HEAD SVN version for build"。问题的根源在于hudson 获取subversion代码的方式,hudson是通过时间戳的方式来获取代码,而不是我们一般认为的"最新代码"即"HEAD"。这种方式通常没有问题,因为获取当前时间戳,然后要求update / checkout这个时间戳前的代码,理论上也是可以拿到最新代码的。
但是,如果hudson所在的服务器和subversion服务器时间不一致,这个机制就会出现问题:
我们假设subversion服务器的时间是准确的,再假设当时时间是15:10分,开发人员A提交代码,subversion上当前这个最新提交的代码时间戳为15:10:00。然后开发人员A手工激活hudson进行构建。hudson在15:10:20时开始check out代码。如果hudson时间无误,则hudson会发出请求说要求获取时间戳在15:10:20之前的代码,这样这个实际提交时间为15:10:00的新代码就可以如期的被check out。但是如果hudson的时钟有误,由于某些原因导致时钟偏慢2分钟,即在hudson上,"当前时间"为"15:08:20",则hudson获取代码的请求为:获取时间戳为15:08:20之前的代码,此时时间戳为15:10:00的新代码就无法checkout。
几分钟之后,疑惑的开发人员A再次激活hudson再次构建,假设此时时间时间是15:15:00,hudson慢两分钟为15:13:00。此时hudson发出请求: 获取时间戳为15:13:00之前的代码, 因此实际提交时间为15:10:00的新代码可以正常checkout,问题又在不知不觉被回避了。
总结说,hudson 获取代码的机制不是我们直觉中的获取最新代码(即subversion中HEAD checkout),而是基于时间戳。由于这个方式通常如HEAD般工作,因此我们总是容易误解为是获取最新代码。当hudson的时钟晚于subversion时,悲剧就出现了。
对这个问题,有几点疑惑:
1. 不明白为什么hudson不采用最直接最简单最容易被人理解最不容易出误解的HEAD checkout,而要基于时间戳
2. 这个问题很早就发生了,上面提到的bug 08年就被人提出, "Created: 31/Jan/08 05:37 AM Updated: 01/Jul/10 11:06 AM",三年了类似的bug被多次提出,但是就是始终没有修复。
修复的方式很简单,就改一个类的一行代码
in Class: hudson.scm.SubversionSCM
line 377:
final SVNRevision revision = SVNRevision.create(timestamp);
replace to:
final SVNRevision revision = SVNRevision.HEAD;
hudson拒绝修复的理由是什么?
Maven 3.0 的第一个RC版本终于发布了,下面是sonatype给出的发布信息:
Maven 在apache上的页面目前还没有放出RC1版本。下面是关于mavne3.*版本相对于2.* 版本的改进列表:
https://cwiki.apache.org/confluence/display/MAVEN/Maven+3.x+Compatibility+Notes
PS: 坦言说,改进很少,尤其没有大的功能改进,有点失望。
修订:上面的URL是兼容性列表,因此看起来和2.*差别不大,是我理解错了,抱歉。
摘要: 最新版本的confluence 3.3.1 linux 安装笔记。
阅读全文
摘要: 之前安装的fisheye2.2.1,破解不是很好用,最近看到fisheye2.3.6版本有出新的破解方式,特地尝试了一下,成功安装。现在将过程简单分享给大家。
阅读全文
摘要: 作为测试的基本概念,在开发测试中经常遇到mock和stub。之前认为自己对这两个概念已经很明白了,但是当决定要写下来并写清楚以便能让不明白的人也能弄明白,似乎就很有困难。
试着写下此文,以检验自己是不是真的明白mock和stub。
阅读全文
讲个笑话吧,关于"keep it simple"
这其实是个真实的故事,发生在两年前,当我从上一家公司离职时。
当时我移交了一个重要模块,后来不久,记不清了,大概一两个月后吧,有关系不错的同事告诉我说:某某人大肆宣扬,***模块我只找个了***的人,*天就接手了,云云。
言下之意自不必说。
而我,则将上述评论视为对自己的嘉奖,深以为荣。
*******************************************************************************
为了大家能看懂这个笑话,罗嗦一点介绍两个背景故事:
1. 最骄傲的事
工作9年了,回首看最令自己骄傲的事情,就是在07年的夏天,加班加点的工作了1个半月,将上述模块的新需求完成。开发模式是我最喜爱的TDD + 持续重构,完备的unit测试案例覆盖。后面测试中,3位负责测试同事用了三天的时间,测试完成所有的测试案例,全部一次性通过,没有一个bug,哪怕是小bug。
此记录本人之后两年中一直试图复制,至今没有成功。
2. 荒谬的问题
发生在离职做上述模块移交时,被接收人问了一个问题:项目代码里面,test目录下是什么东西啊?
import junit.***, extends TestCase...
无言以对。
摘要: Tokyo Tyrant基本规范,翻译自Tokyo Tyrant官网。
本节为Tokyo Tyrant的基础教程。
阅读全文
摘要:
Tokyo Tyrant基本规范,翻译自Tokyo Tyrant官网。
本节介绍Tokyo Tyrant的远程数据库API,Lua扩展和协议。部分细节内容没有翻译。
阅读全文
摘要:
Tokyo Tyrant基本规范,翻译自Tokyo Tyrant官网。
本节介绍Tokyo Tyrant的客户端程序。
阅读全文
摘要: Tokyo Tyrant基本规范,翻译自tt官网,地址为http://fallabs.com/tokyotyrant/spex.html。
本节介绍Tokyo Tyrant的服务器程序。
阅读全文
摘要: Tokyo Tyrant基本规范,翻译自tt官网,地址为http://fallabs.com/tokyotyrant/spex.html。
本节介绍Tokyo Tyrant的基本知识和安装方法。
阅读全文
摘要: Solr是一个基于Lucene java库的企业级搜索服务器,本文记录了solr的安装过程,版本为最新的1.4.1。
阅读全文
摘要: Tokyo Tyrant是目前评价最高的key-value数据库之一,本文记录在linux(suse11)上的安装过程。
阅读全文
摘要: 一直在使用easymock作为mock工具,但是easymock有一个一直令我极其恼火的地方:easymock将interface和class的mock区分开,给出了针对interface mock的easyMock和针对class mock的easyMock class extension。两种mock被严格区分开,连jar包都是两个,使用时不能混用,比如不能用easymock (非class extension)来mock class。
easymock已经发布了新的3.0版本,该版本的主要改进就是消除上述的问题,新版本中可以直接mock class,不再强制使用easyMock class extension。
强烈推荐还在使用2.*的朋友们升级到3.0版本。
阅读全文
摘要: 有遇到类似的TortoiseSVN / subversive 信息无法识别的问题的朋友,可以这个方法。
阅读全文
摘要: sonar 安装配置笔记, 基于SUSE SLSE11, mysql.
阅读全文
摘要: 近期自己折腾自己,放着正统的maven + junit不用,却准备用ant + ivy 替代maven做依赖管理,用testng替代junit做单元测试。
阅读全文
摘要: 众所周知,对于高动态高可扩展的应用,OSGI是一个非常好的平台。但是,也因此增加了复杂性,开发中对service的依赖变得复杂。这也是 service的关系管理成为OSGI中一个非常重要的部分,我们来看看OSGI中service依赖关系管理的方式。篇幅原因,只关注发展历程,不具体介绍每个方式的详细实现细节。
概括的说,目前在OSGI中主要有以下几种service依赖关系管理的方法:
1. Service listener
2. Service binder
3. Dependency Manager
4. Declarative Services
5. iPOJO
6. blueprint
阅读全文
摘要: 当时实际上,我们在检查ThreadDeath的调用信息时,说明这个出现init()错误的filter还是被glassfish正常调用去执行doFilter()方法,这里和j2ee API的要求是不符合的。有点奇怪的是,glassfish一向是以严格遵循j2ee规范而著称,居然在这里一反常态。
而更令人 郁闷的是,glassfish在处理这个有filter初始化出现ServletException异常的webapp时的前后表现:首先这个 webapp的启动没有问题,状态正常。filter也被认为可以正常工作并加入了filter链。webapp中的功能正常,可以正常的接收请求并转发给内容业务处理模块。从这些迹象看这个webapp基本没有问题。但是后面glassfish却莫名其妙的认定,“this web application instance has been stopped already”,从而以ThreadDeath这种非常规的error来报错。
阅读全文
摘要: 对比最近遇到的两个事情,明显感觉sun有力不从心或者心不在焉的感觉,oracle对sun收购的负面影响至少在开源社区方面是显而易见的,个人甚至怀疑oracle正在逐渐放弃之前sun一直努力支撑的开源社区。
阅读全文
摘要: 刚刚鄙视完sun,继续performance tuning,结果又发现问题。
有点怀疑metro是不是根本就没有做过性能测试,我们的测试场景,openESB下通过bepl调用4个我们称为common service的webservice,目前大概做到1200个tps,算下来common service的webservice的tps大概是1200*4 = 5K附近,上面的问题就非常明显,之前tps没有上去前没有这么严重。
可以参考我之前的一个blog, http://www.blogjava.net/aoxj/archive/2010/04/29/319706.html,在解决这里提到的http long connection 和 TIME_AIT的问题之前,我们的tps比较低,cpu压不上去,当时好像这个问题不明显。后来搞定之后tps上来了才暴露出来。
考虑上一个blog中 == 比较无效导致cache失效的bug,我对metro的代码质量真是很没有信息。按说这样的大型项目,release之前怎么也要做做压力测试,稳定性测试之
阅读全文
摘要: 依然是近期工作中发现的问题,真实案例,写下来分享给大家。
总结:用 == 来比较非enum或者类型安全枚举的对象实例,这种错误一般只有初学者才犯,万万没有想到,能在metro这样级别的代码中也能出现。无限感叹啊,再次援引同事的评语作为本文的结束语:
sun的程序员也是程序员啊!
阅读全文
摘要: 近日做性能调优,主要是针对web service,运行于glassfish之上
最终的结果,还是比较理想的,修改了两个参数之后,cpu终于压上去了,tps也有了巨大的提升,而且TIME_WAIT的连接也大为减少。
但是这两个max connections参数的名称,注释和实际测试中的效果,都有名不副实的感觉,令人极度困惑。
阅读全文
摘要: fisheye2.2.1 & Crucible 2.2.1 安装配置笔记。
阅读全文
摘要: 今天,尝试使用slf4j + logback的黄金组合,结果发现有点问题,slf4j和logback的最新版本不兼容。当然slf4j是1.6.0-RC0,正式发布时 logback应该会跟进发布新的版本吧。
阅读全文
摘要: 这是一个真实案例,本周在工作中发现的,案例情况比较极端,因此显得很滑稽很搞笑。但是深入一下,还是有些东西值得思考:
下一次,如果我面对一个函数/接口,要求传入一个大对象,我手头只有一个pk,还有一个现成的函数可以一行代码就搞定查询,我要如何才能挡住诱惑?
阅读全文
摘要:
在SUSE SLES11 下安装好tomcat6后,考虑方便需要设置tomcat为开机自动运行。
找到tomcat官方的安装文档 http://tomcat.apache.org/tomcat-6.0-doc/setup.html,按照要求安装,中间发现有些问题,记录下来备忘。
阅读全文
摘要: 这段时间简单的试用了一下jira,非常满意。准备作为个人之后开发的首选缺陷管理工具,但是当时采用的是windows的全集成安装方式,因此考虑在linux上正式的安装一下,同时将数据库换成mysql。
虽然最后的结果不大好,不过上面的这个安装过程,已经远比当前google上能找到的资料要多了。如果其他朋友有打算用jira4 + resin4 + mysql的,可以稍微参考,少走弯路。如果最后能安装成功正确使用,希望能告知正确的安装方法,谢谢!
阅读全文
摘要: 前面的blog有提到,在选择CMS系统时试用java版本的magnolia,结果很失望的放弃了。
重新将目光投向php + mysql的传统CMS,我选择了drupal,下面是drupal的安装配置笔记。
阅读全文
摘要: SUSE SLES11 上安装配置mysql的笔记,分享并备忘。
阅读全文
摘要: 最近想找个cms系统来用用,做点简单的东西,因为自己比较熟悉java,因此考虑试试java版本的cms系统先,记得之前hibernate网站改版,是换了一个java版本的cms的,特地找过去看了一下,magnolia,google了一下似乎好评还不少。于是下载下来开始研究。
延续这些年的习惯,安装过程一定要详细记录下来,避免日后再次安装时浪费时间,呵呵。
试用的结果很不好,还没有正式开始使用就决定放弃,原因请见下文。
阅读全文
摘要: 安装SUSE sles11的过程记录,分享给有类似需要的朋友,同时备忘。
阅读全文
摘要: 有两年多没有使用resin了,最近打算在机器上安装一个web container跑点java web app,同时也可能需要支持php,原本打算用apache + tomcat,apache可以加载php模块来提供php支持,tomcat作为java web container。但突然想到resin,似乎是可以直接支持php的,而且resin的速度也是稍微快于tomcat,于是跑到resin的官网看了一下,恩,新出了4.0版本(惭愧,两年前用的是3.0或者3.1)。
决定用resin试试,老朋友了。但是在安装过程中,发现了一系列问题,尤其是设置开机自动启动,记录下来提供大家参考。
阅读全文
摘要: 在windows上安装jira 4.0.2的简单过程记录,备忘。
阅读全文
摘要: 从网上找到的一个设计模式快速参考,感觉做的非常的好,分享给大家。
阅读全文
摘要: 在application server下,比如常见的weblogic,glassfish,jboss等,由于javaee规范的要求,一般不容许直接启动线程。因此在常见的异步/并行任务执行上,会遭遇到比普通javase程序更多的麻烦。
阅读全文
摘要: 这是近期工作中遇到的一个问题,cxf在glassfish下timeout设置出现问题,进而引发的关于classloader, JAX-WS的一些小故事,很惊讶的发现cxf在这种情况下根本没有办法运行于glassfish平台。
关键字:glassfish, cxf, classloader, JAX-WS, metro。
阅读全文
摘要: 如题,osgi 资料收集贴,随时收集,随时更新。
阅读全文
摘要: 在讨论这个问题前,先简单的介绍一下双重解析器的工作原理:顾名思义,双重解析是双重的:它由一个ivyResolver和一个 artifactResolver组成,其中ivyResolver负责解析ivy的模块描述符,而artifactResolver则用于解析制品。换言之,ivyResolver用来指明需要什么,而artifactResolver则负责获取具体的制品文件。
第一次在学习ivy的过程中看到ivy中的双重解析器,就感觉设计非常的不错,可以比较好的解决这方面的问题。只要维护好ivyResolver中的依赖,则整个系统中的依赖都被限制在这个范围中。比如如果有人想用spring2.5.6之外的版本,哼哼,ivyResolver解析器会不工作的......
但是,在实际的使用过程中发现,双重解析器的工作模式有点问题:如果目标依赖在ivyResolver中可以找到则情况正常,但是如果目标依赖在 ivyResolver中没有定义,ivy居然会在artifactResolver的继续查找!然后报告说依赖解析成功已下载云云,而不是我
阅读全文
摘要: 在maven中,对于一个依赖,除了groupId,artifactId,version这三个属性来作为标志之外,还有一个特殊的属性可用: classifier。
ivy中依赖对应的有属性org,name,rev,分别对应到maven中的groupId,artifactId,version.
但是dependency没有和maven的classifier属性相对应的属性,因此无法表示dependency的classifier。这样就出现问题了,比如上面的testng 的例子,在ivy中如果将对testng的依赖定义写成上面的样子,则解析时是无法获取到我们想到的依赖 testng-5.10.jar的。
那么,在ivy中如何指定classifier属性呢?
阅读全文
摘要: 如果你已经成功的跟随并理解了所有的教程,可能你还是需要得到更好的关于如何在现实世界中只用ivy的描述。
这里有一些有关系的链接.
阅读全文
摘要: 现在你已经看到从一个已经存在的仓库创建你自己的仓库是如何的简单,你可能会想知道如何处理更加复杂的情况,例如当源仓库和目的地仓库不遵循相同的命名约定。
当你有一个已经存在的仓库并且希望从大量的不遵循相同的命名转换的公共仓库中获益时,这个问题非常常见。或者仅仅是因为你发现你作为基础使用的仓库不够一直- 为什么所有的apache commons模块不适用org.apache.commons 组织?历史原因。但是如果你安装你自己的仓库,你可能不想从历史中蒙受损失。
幸运的是,对于这种问题ivy有一种非常强大的答复:namespaces.
阅读全文
摘要: 在这个步骤中我们使用install任务来从maven2 仓库安装模块到一个基于文件系统的仓库。我们首先安装一个不带依赖的模块,然后安装一个带有依赖的模块。
阅读全文
摘要: install任务让你从一个仓库复制一个模块或者模块集合到另一个仓库。这对于构建和维护一个企业或者团队仓库非常有用。如果你不想你的团队中的开发人员都访问公共的maven2仓库(例如为了控制哪些模块可以在你的公司或者你的团队中使用),答复开发人员的请求来手工增加新的模块或者新的版本在某些时候变得令人厌烦。
幸运的是install任务可以在这里提供帮助: 你可以为你的用于维护目标企业仓库的仓库维护构建使用特定的设置。这些设置将指向另一个仓库(例如maven2 公共仓库),因此你只需要使用简单的命令行要求ivy安装你需要的模块。
为了演示这个我们将首先使用个一些基本的ivy设置文件来展示它是如何工作的,然后我们将使用高级命名空间特性来演示如何在源仓库和目标仓库之间处理命名不匹配。
阅读全文
摘要: 这个教程介绍ivy文件中的模块配置的使用。ivy模块配置事实上是一个非常重要的概念。某些人甚至告诉我使用ivy而不用ivy配置就像吃乳酪而不动就在你旁边的Chateau Margaux 1976!
严肃的说,ivy中的配置可以更好的理解为你的模块的视图,你将可以看到在这里他们将如何被高效地使用。
阅读全文
摘要: 在上一个教程中,你已经看到如何处理两个简单项目之间的依赖。
这个教程将引导你完成在一个更加复杂的环境下的ivy使用。这个教程的所有源文件在ivy发行包的src/example/multi-project下可以得到。
阅读全文
摘要: 这个示例将举例说明在两个项目之间的依赖。
depender项目声明它使用dependee 项目。我们将阐明两个事情:
* 被独立的项目声明的公共类库将被依赖的项目自动获取
* depender项目将获取dependee项目的"最新"版本
阅读全文
摘要: 在一些情况下,会发生这样的事情:你的模块描述符(ivy文件,maven pom, ...)被放置在一个地方,而模块的制品(jars,...)在另外一个地方。
双重解析器用于满足这种类型的需求,而这个教程将展示如何使用它。
阅读全文
摘要: 这个例子演示模块是如何被多解析器获得的。使用多解析器在很多情况下是非常有用的,这里是一些例子:
* 来自发行的单独的集成构建
* 为第三方模块使用公共仓库并且为内部模块使用私有仓库
* 使用一个仓库来存储那些在无法管理的公共仓库里里面的不清晰的模块
* 使用本地仓库来暴露在一个开发人员的位置上生成的构建
在ivy中,多解析器的使用是通过一个名为解析器链的复合解析器来支持的。
在我们的例子中,我们将简单的展示如何使用两个解析器,一个在本地仓库而另一个使用maven2仓库。
阅读全文
摘要: ivy绑定一些默认设置,这使得在通常环境下使用ivy很容易。这个教程,接近于参考文档,解释这些默认设置是什么和他们怎样调整来满足你的需要。
为了完整的理解设置的概念和你可以用它们做什么,我们建议阅读其他和设置相关的教程(如Multiple Resolvers 和 Dual Resolver)或者设置文件的参考文档。
阅读全文
摘要: 在这个例子中,我们将看到使用ivy的一个最简单的方式。不使用任何特殊设置,ivy将使用maven2 仓库来解析你在ivy文件中声明的依赖。让我们来看一眼涉及到的文件的内容。
你将在ivy发行包的src/example/hello-ivy 目录下找到这个教程的源文件。
阅读全文
摘要: 学习的最佳方式是实践!这是ivy教程将帮助你做到的,发现一些伟大的ivy特性。
这里是非常优先的教程,它甚至不需要安装ivy,如果你已经正确安装了ant和jdk,甚至只需要花费不到30秒的时间
阅读全文
摘要: 在ivy中有几个任务被认为是后解析任务(post resolve task),并相应地共享公用行为和设置。
这些任务是:
* retrieve
* cachefileset
* cachepath
* artifactproperty (since 2.0)
* artifactreport (since 2.0)
阅读全文
摘要: cachefileset,为配置构建一个有ivy缓存中的制品组成的ant fileset 从1.2版本起)。
这是一个后解析任务,有所有后解析任务共有的所有行为和属性。注意这个任务不依赖retrieve,因为构建的fileset是由ivy缓存中的制品直接构成的。
阅读全文
摘要: ln命令用于连接文件或目录,lndir命令用于创建目录的符号链接,和ln不同的是lndir会自动为源文件目录下所有的文件和子目录都建立对应的符号链接.
阅读全文
摘要: find命令用于查找文件和目录,任何位于参数之前的字符串都将被视为欲查找的目录。
find 可以指定查找条件如名称,类型,时间,文件大小,权限和所有者查找,针对多个条件进行与或非的逻辑运算。我们可以控制find的查找的行为,还可以和其他命令组合使用。
阅读全文
摘要: 为解析过的模块配置构建一个由在ivy 缓存(或者取决于useOrigin 设置的原始位置)中的制品组成的ant path.
阅读全文
摘要: ls的用法: ls [OPTION]... [FILE]...
列举文件信息(默认当前目录), 如果-cftuvSUX或者--sort没有设置则按照字典顺序排序条目。
阅读全文
摘要: 交付当前模块的解析好的描述符,而且可能执行依赖的递归交付。
这个任务主要做两个事情:
1. 生成一个解析好的ivy 文件
2. 执行递归交付
阅读全文
工作中发现的一个非常奇怪也很有趣事情,有关MANIFEST.MF文件中的分行和空格的格式要求,分享给大家。
对于通常的MANIFEST.MF文件,一般格式是:
Class-Path: lib/a.jar lib/b.jar lib/c.jar lib/d.jar lib/e.jar lib/f.jar
在一行之内将所有的jar包路径写上,空格分隔即可。
但是对于一些大型的项目,因为依赖包众多,比如大于30个,那么如果还写在一行内,就会出现一个长度惊人的行。程序运行倒不会有任何问题,但是对于版本控制就很不友好,如增加或者减少一个依赖包,这行就会被改写。以后compare不同版本时,只能知道这行被修改了确无法直接知道是做了什么修改,必须通过其他方式才能对比出来。
同样的问题发生在code merge时,如果两个分支都修改了这个文件,就必须通过手工来进行merge,而且要对照出来彼此到底改了什么,很困难而且容易出错。
因此一个改进就是将这个文件中的依赖按照一行一个依赖的方式重写,这样以后修改时只会修改改依赖所在的行,很容易就对比出来具体做了哪些感动,code merge时版本控制软件一般也很容易直接自动merge成功。
修改后的文件类似如下:
Class-Path: lib/a.jar
lib/b.jar
lib/c.jar
lib/d.jar
lib/e.jar
lib/f.jar
但是在实际操作时发生了意料之外的问题,会出现异常或者类无法找到,经检查发现问题出现在MANIFEST.MF的格式上,MANIFEST.MF对于分行和空格是有特殊要求的:
1. 每行的最后一个jar的名称后不容许有空格
即" lib/b.jar"在b.jar后必须回车结束本行,不能有空格,一个都不能
2. 每行的开头必须有不少于2个空格
即" lib/b.jar"在b.jar前必须有不下两个空格
以上两个条件有一个不满足都会出现问题,有点古怪。
摘要: 发行当前模块的制品和已解析的描述符(已交付的ivy文件)。
这个任务的目的是发行当前模块描述符和它的声明的发行制品到仓库中。
阅读全文
摘要: configure任务用于通过xml设置文件来配置ivy。
阅读全文
摘要: retrieve任务复制解析好的依赖到你的文件系统的任何位置。
这是一个post resolve任务,带有所有post resolve任务共有的所有的行为和属性。
阅读全文
摘要: 解析任务实际解析在ivy文件中描述的依赖,并将解析后的依赖放置到ivy缓存中。
如果在resolve任务前没有调用configure任务,则将使用默认的configuration (等同于不带参数的调用configure).
阅读全文
摘要: buildlist任务用于获取按照ivy依赖信息从小到大排序的文件(通常是build.xml文件) 列表,或者相反(从1.2之后)
这个任务在结合subant构建相关项目集合时特别有效, 可以确保依赖在其他依赖它的模块之前被构建
阅读全文
摘要: 转一个blog,关于如何使用ivy来处理native的依赖,对于有使用JNI开发的朋友应该很有价值。
原文blog地址:http://www.cooljeff.co.uk/2009/08/01/handling-native-dependencies-with-apache-ivy/
阅读全文
我们的团队一直埋怨说我们的代码规模太大,结构太复杂,维护难度大而成本高。
最明显的一个弊病,就是在clearcase里面打开一个文件的version tree,密密麻麻,横七竖八,我们戏称为"蜘蛛网"。
然而昨天一位出差在外的同事,在维护公司另外一个产品的时候,有了惊喜发现:
我们的代码规模比起来还是差得远!
有图为证:
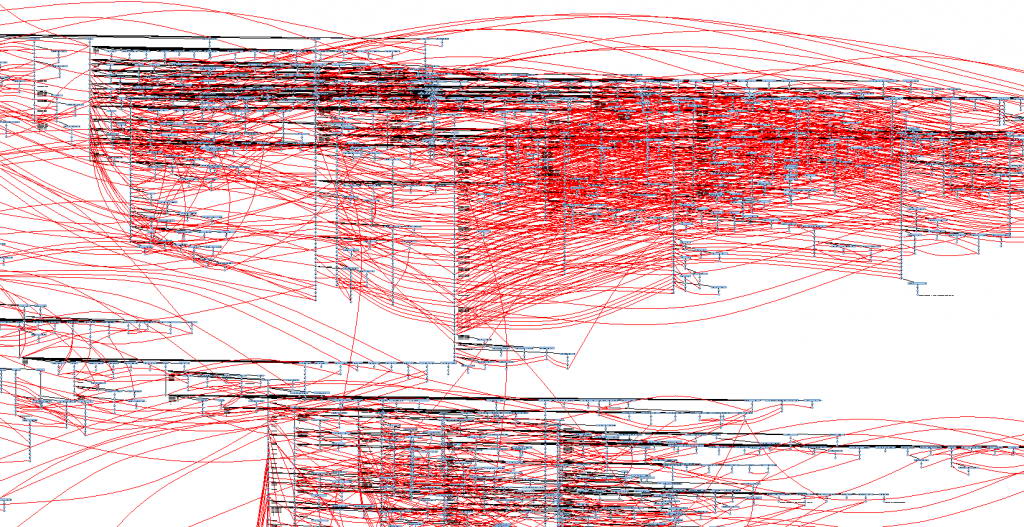
我的评价只有一个字:
晕!
PS:
解释一下,有些朋友没有用过版本控制软件的version tree,可能不大明白。
这个是version tree,是一个文件(注意,只是一个文件)的版本和分支历史,一般的版本控制软件都会提供类似的视图。
图上蓝色直线条的是这个文件的不同分支和这个这个分支下的不同版本,红色的线条是code merge,就是从一个分支的某个版本merge 代码到另外一个分支上时为了表示这种merge关系而增加一种表示方式。
从图上看,这个文件的分支过百了,版本应该过千,红色的merge线在某些地方已经要凝成实体了。这表明在这些版本之间有非常频繁的code merge。
再补充一下:
这个图片里面有些地方红线密集程度有些不大对劲,某些分支几乎每个版本修改都有被merge。正常开发中不应该是这样的,通常都只会是某个或某几个版本被merge。
猜测出现这个情况的可能,有一种解释就是可能在开发时使用了某些自动merge的工具,当该分支每出现一个新版本时就自动merge到某个目标分支,以保证两个分支代码的高度一致。当然这个无法证实,只是我的一个猜测。
摘要: 这个是发生在上周周末的真实案例,因为cxf client 端线程安全导致的错误,总结出来希望其他使用cxf的朋友注意。
阅读全文
摘要: ivy可以非常容易的作为一个单独的程序使用。你所需要的只是一个java1.4+的运行环境(JRE)!
阅读全文
摘要: 使用ivy的主要和最频繁的方式是在ant构建文件中。不过,ivy也可以作为独立的应用被调用。
阅读全文
摘要: ivy的使用完全是基于以"ivy文件"著称的模块描述符。ivy文件是xml文件,通常被称为ivy.xml,包含模块依赖的描述,它发布的制品和它的配置。
阅读全文
摘要: 为了如您所想的工作,ivy有时需要一些设置。实际上,ivy可以在完全没有任何特殊设置的情况下工作,查阅默认设置文档来获取相关的更详尽的信息。但是ivy有能力在完全不同的上下文下工作。你只需要正确的配置它。
阅读全文
摘要: 安装ivy主要有两种方式,手工安装或者自动安装。
阅读全文
摘要: 这里有一些我们从我们的经验和一些客户的顾问工作中收集到的建议和最佳实践。
5) 处理集成版本
6) 是否将依赖内联(inlining)
7) 雇用专家
阅读全文
摘要: 这里有一些我们从我们的经验和一些客户的顾问工作中收集到的建议和最佳实践。
1) 为所有的模块添加模块描述符
2) 使用自己的企业仓库
3) 至少在组织和模块上使用模式
4) 为公共仓库发布ivysettings.xml
阅读全文
摘要: 前面已经介绍了ivy主要的术语和概念,现在是时候说明ivy如何工作的了。
阅读全文
摘要: 在学习ivy的过程中陆陆续续的翻译了一些ivy的参考文档,现在准备将这个工作进行到底,将官方网站上完整的ivy参考文档翻译成中文。上面内容是参考文档的目录,翻译完成的部分我会陆续更新为中文并加入链接。
英文文档地址请见:http://ant.apache.org/ivy/history/latest-milestone/reference.html
水平有限,出现错误的地址请多多指正。
阅读全文
摘要: ivy中引入了一些自己的概念,了解并理会这些概念对ivy的学习使用是有帮助的。这里翻译一下官网的介绍ivy主要概念的文章,原文在此:http://ant.apache.org/ivy/history/2.1.0-rc1/concept.html
因内容太长而拆分,下面是第二部分。
阅读全文
摘要: 日前升级内存容量到8g之后,发现在xp下因为无法全部利用造成浪费,因此考虑安装ramdisk以充分利用资源。
阅读全文
摘要: ivy中引入了一些自己的概念,了解并理会这些概念对ivy的学习使用是有帮助的。这里翻译一下官网的介绍ivy主要概念的文章,原文在此:http://ant.apache.org/ivy/history/2.1.0-rc1/concept.html
因内容太长而拆分,下面是第一部分
阅读全文