#
Jspxcms-5.2.0-release今天正式发布。
更新列表:
1、增加广告管理的标签
2、描述去除空格。
3、tag增加栏目参数。
4、InfoList标签中加上模型参数。
5、select字段支持key、value。
6、支持可查询字段。
7、文档管理左边栏及列表页显示所属模型。
8、栏目管理左边栏及列表页显示所属模型。
9、修复会员投稿上传获取图片目录问题。
10、修复IE8下视频无法播放。
11、更新新浪采集规则,适用采集改版后的新浪网。
12、后台默认给予欢迎页权限。
13、默认的新浪采集报错(内容没有图片)的内容报错。
14、投稿编辑器改为ueditor。
15、投稿更新时,栏目是否允许投稿判读有误。
16、采集是否提交没有默认值。
17、新闻模型默认增加标题图字段。
18、增加默认专题模型。
19、专题管理上传控件改为swfupload。
20、彻底删除文章后,评论没有删除。
21、会员投稿报错。
22、全局自定义表邮件数据有重复数据及无效数据。
23、文章翻页第二页标题缺失。
可独立管理的站群:
支持多组织、多站点、独立管理的网站群,各个站点可以有独立的管理员,对本站用户、组织、模型、栏目等信息进行独立管理,互不干扰。
无侵入式二次开发:
支持无侵入式插件和二次开发,无需修改系统原有代码,即可无缝整合Entity、Service、Controller、功能菜单、权限、标签、国际化等功能。查看教程。
高并发:
jspxcms有近乎完美的性能表现,在没有做特殊优化、纯动态页下,支持高并发访问。
对 http://demo.jspxcms.com/ 测试结果简要描述:5000次请求,500次并发,全部成功,总耗时31.124秒,每秒处理160.65个请求,每个请求耗时6.225毫秒。
对 http://demo.jspxcms.com/node/40.jspx 测试结果简要描述:5000次请求,500次并发,全部成功,总耗时11.969秒,每秒处理417.73个请求,每个请求耗时2.394毫秒。
详细测试报告http://bbs.jspxcms.com/thread-35-1-1.html
百万级数据支持:
很多cms在小数据量下可以运行的不错,但在日积月累的数据量增加,会让这些cms运行缓慢、不堪重负。
jspxcms在不需要任何特殊处理和优化的情况下,轻松支持百万级数据量,且在纯动态页访问的情况下,一样快速如飞。
全站静态化:
可以对所有的栏目页、文档页做静态化处理,在数据量大的情况下,可以设置前n页静态化,后面n页为动态页。
下载及演示:
下载地址:http://www.jspxcms.com
演示站:http://demo.jspxcms.com 后台:http://demo.jspxcms.com/cmscp/index.do
主要技术:SpringMVC3.2、Spring3.2、JPA2.0、JSP2.0、Freemarker2.3、Spring Data JPA,QueryDSL、Shiro、Lucene等。
技术亮点:JPA、Spring Data JPA、QueryDSL组成的无比简洁高效的持久化技术;Shiro安全框架;Lucene近实时检索;Freemarker模板技术;仿Gmail验证码等。
功能列表:
1、文档。(新闻、图集、下载、视频、作品、文库、招聘等)
2、栏目。(无限级数栏目管理)
3、文件。(zip上传自解压、zip打包下载、模板、图片、js、css)
4、生成。(全文检索、页面静态化、定时任务、任务管理)
5、模块。(文档属性管理、专题类别管理、专题管理、TAG管理、评论管理、敏感词管理、评分组管理、附件管理)
6、扩展。(友情链接类型管理、友情链接管理、留言板类型管理、留言板管理、广告版位管理、广告管理、投票管理)
7、插件。(简历管理、数据库备份)
8、统计。(流量分析、受访访问、访问日志)
9、用户。(用户管理、角色管理、会员组管理、组织管理、全局用户管理、全局组织管理)
10、系统。(网站设置、系统设置、站点管理、模型管理、文档属性、工作流组、工作流、发布点、操作日志)
前台模板:
后台界面:
摘要:在IT行业,开发和测试之间的关系一直是一个大家津津乐道的话题。那在周兆熊眼中,开发和测试是什么样的?他进行了细致的说明,并就两者的关系给出了一些建议。
在IT行业,开发和测试之间的关系一直是一个大家津津乐道的话题。在整个软件产品的生命周期中,开发和测试人员所做的工作分别对应不同的阶段,如图1所示。
图1 开发和测试人员的分工
工作内容 从图1可以看出,开发和测试是一个上下游的关系。
具体而言,开发人员主要做这几件事情:
第一,对软件需求说明书进行详细评审,弄清楚要开发一个什么样的软件。
第二,编写软件详细设计、单元测试和集成测试规程文档。软件详细设计文档是最重要的文档,在里面,要写清楚自己程序的流程、函数设计、异常保护考虑等。在动手写程序之前,一定要将软件详细设计文档写好,等评审通过了再写代码。
第三,编写代码,用程序实现软件的功能。很多人认为的软件开发就是写代码,其实这是一种很狭隘的理解,写代码在整个开发流程中,只占了很小的部分。
第四,程序写好之后,开发人员要对它进行单元测试和集成测试也叫(自测),确保程序的正确性。这里就出现了“测试”二字,但与软件测试所做的“测试”是不同的,他们做的是“系统测试”。等自测通过之后,并且相关文档也写好之后,就可以提交程序版本,供测试人员进行测试了。
相对开发,测试人员主要做这几件事情:
第一,参与软件需求说明书的评审,对软件要实现的功能有一个大致的了解。
第二,搭建测试环境。这个是很重要的,也是比较难的事情。什么是“测试环境”呢?就是说,不管什么软件,都有个运行的条件,如操作系统类型、参数设置及配套软硬件设施等,这些统称为“环境”。为了保证程序功能的正确性,要在软件发布之前,尽量模拟软件实际的运行环境,这就是搭建测试环境时要做的事情。很多软件在正式商用之后出问题,就是测试的时候没有还原现场环境所致。
第三,对软件进行系统测试并输出测试报告。所谓系统测试,就是指将配套的所有软件都运行起来,看一下所有的功能是否正常。当出现问题的时候,要及时和开发人员联系,以修正软件缺陷。
第四,指导现场人员安装软件程序,并在必要的时候亲自出差到现场去安装软件。因此,测试人员也可能会经常出差的。
“三足鼎立” 开发人员的主要任务是用程序完成软件需求,而测试人员的主要任务则是保证程序功能的正确性,他们做事的依据都是需求开发工程师编写的需求说明书。
在实际的软件开发项目中,需求开发工程师、软件开发工程师和软件测试工程师之间的交流是很频繁的,如图2所示。
图2 三类角色的“三足鼎立”
就像“三国时期”的魏蜀吴“三足鼎立”一样,需求开发工程师、软件开发工程师和软件测试工程师所站的立场不同,对软件的认识也不同。大家需要相互讨论、协商,挑选出一套最佳的软件实现方案。
一些建议 在完成软件研发的过程中,开发和测试之间的关系非常的“微妙”,时而合作如亲人,时而争论如敌人。我认为,为了做出高质量的软件产品来,开发和测试需要做到:
第一,共同参与软件需求文档的评审,对程序要实现的功能有一个清晰的认识。如果对需求有疑问,一定要当面提出来。
第二,在对需求达成共识之后,软件开发人员严格按照软件需求文档上的描述来编写程序,如果在程序实现上有困难,要提出来和大家讨论。软件测试人员严格按照需求的描述来验证程序的功能,如果发现程序实现与需求不符,要及时与软件开发人员联系,大家共同将程序问题解决掉。
第三,如果开发时间紧张、人手不足,那么在开发人员编写程序的时候,测试人员可以帮忙把测试环境搭建好。等程序编写好之后,开发人员便可以立即进行单元测试和集成测试。
第四,不管是需求有问题,还是程序有缺陷,大家都可以指出来。但注意要就事论事,不可将软件问题上升为对特定个人的人身攻击。
第五,虽然是各司其职,也许还身处不同的部门,但大家的共同目标是一致的:做出让客户满意的、高质量的软件产品。开发和测试人员要为了这个目标,一起努力。
结束语 一个软件产品的成功需要从各个环节上去把握,因此用人的左手和右手的关系来比喻开发和测试之间的关系更为恰当。好的软件产品需要开发和测两手抓,两手都要硬。
什么是系统架构?
从字面上理解,系统架构是系统的框架结构,是系统进行抽象之后的一个草图。它包含了系统中各个抽象组件的协作方式。
为什么需要架构?
好的架构能够降低系统的创造和维护成本,特别是维护成本。一个系统的创造成本低,而维护的成本大,特别是互联网应用,一般情况下把一个系统搞上线只需要一个月,但是有的系统搞下线缺需要几个月,而维护则需要数年。好的设计师不会在系统上线后对系统进行大的修改,从而减少系统的维护成本。
如果区分创造和维护两个阶段的话,架构师分为系统架构师和维护架构师,架构新的系统的是系统架构师,而维护老系统的则是维护架构师,程序员大多数愿意做新系统不愿意维护老系统,因为感觉没什么技术含量,但是维护老的系统反而更难,因为老系统的重构和改进更加复杂,维护架构师不仅需要读懂老系统架构设计,还要在不影响老系统功能的情况下,进行功能新增和重构。我的一位同事在对一个旧的系统进行重构之前,读了几个星期的代码,然后才开始设计改进方案。
架构设计的目标
设计的目标围绕着降低成本这个需求进行。设计的目标非常多,不同的系统架构目标也不一致,但是我觉得比较重要的架构目标有以下几个,可扩展性,灵活性和可插入性。
可扩展性,新的功能容易加入到系统里,降低创造成本。
灵活性,一处修改不会波及其他的地方,降低维护成本。
可插入性,同样的功能可方便的替换,降低创造和维护成本。
那么如何实现这三个目标
提高可扩展性:把不易变的抽象出来。抽象层要比实现层要更稳定,抽象层的变化要少。把变化的集中起来,比如把容易变化的功能放在单独一个系统或者一个模块里。
灵活性:模块化,每个模块相互独立,减少模块之间的藕合度,修改不会互相传递。
提高可插入性:模块化,服务化。
如何开始架构
当一块新业务放在你面前时,如何进行系统架构?我觉得需要进行以下几个步骤的思考:
业务分析:输出业务架构图,这个系统里有多少个业务模块,从前台用户到底层一共有多少层。
系统划分:根据业务架构图输出系统架构图,需要思考的是这块业务划分成多少个系统,可能一个系统能支持多个业务。基于什么原则将一个系统拆分成多个系统?又基于什么原则将两个系统合并成一个系统?
系统分层:系统是几层架构,基于什么原则将一个系统进行分层,分成多少层?
模块化:系统里有多少个模块,哪些需要模块化?基于什么原则将一类代码变成一个模块。
首先,他们的测试方法不同:
单元测试属于白盒测试;
集成测试属于灰盒测试的范畴;
系统测试属于黑盒测试。
其次,他们的考察范围不同,也就是他们测试的重点不同:
单元测试主要测试单元内部的数据结构、逻辑控制、异常处理等等;
集成测试主要测试模块之间的接口和接口数据传递的关系,以及模块组合后的整体功能;
系统测试主要测试整个系统相对于需求的符合度。
再次,他们的基准不同:
单元测试评估的主要是逻辑覆盖率;
集成测试评估的主要是接口覆盖率;
系统测试评估的是测试用例对需求规格的覆盖率。
摘要: HTTP SESSION的管理通常是由容器来做,但如果是在PAAS环境下,服务器不能做变更,则需要由WEB应用来做处理HTTP SESSION。同样,如果是分布式的环境下,SESSION的管理也会带来性能问题。SPRING推出了处理SESSION的框架:SPRING-SESSION。
SPRING会重写HTTP SESSION的那一套,使用SESSION也同样还是用
Code ...
阅读全文
1、BI与数据仓库(DW)之间的关系是怎么样的?
回答这个问题有一个很恰当的比喻,房子和地基——数据仓库是BI的地基:数据仓库将数据抽取过来,清洗完,整合到主题域和多维模型里,然后BI就可以基于主题域和多维模型做各种分析了。如果这个地基(数据仓库)没做好,整个房子(BI项目)就很容易倒塌。
2、BI系统主要是为了帮助企业解决什么样的问题?如何解决?
1)以前发生了什么——可以用固定报表、各种图标、仪表盘、计分卡等实现;
2)为什么发生——可以用例外分析、即席查询、OLAP分析和数据挖掘实现;
3)现在发生了什么——可以用EII技术、预警和自动激发短信等工具来实现;
4)将来会发生什么——可以用预测分析、数据挖掘等来实现;
5)控制未来发展的方向,将活动控制到正确的道路上来——可以用过程分析、过程监控、统计过程控制(SPC)等实现。
从另一方面来看,可以这样看:
支持战略决策,通过数据反映宏观和公司的运营状况,帮助领导做出正确的战略决策,起到参谋的作用。
优化业务,通过数据与业务的结合,发现可优化的环节和总结出优化方法,提高运营效率和公司输出。
业务管控,业务模式成熟后,通过BI系统与其它系统对接,打通,形成循环,通过数据化管理,保证业务运营行在正确的轨道上。
3、大数据、云计算和商业智能这三者的关系到底如何,以后的发展前景有什么看法?
云计算:着重于存储(物理内存,存储)
大数据:着重于数据,在云计算的基础上将数据整合与存储
商业智能:在大数据的基础上,进行数据建模,数据挖掘,然后在Dashboard上展示出规律
4、BI中的多维数据模型和OLAP的实用价值在哪?
1)让分析人员可以快速地从不同的角度感知数据的情况。 在数据量大且维度指标众多的情况下,人的记忆力往往有限,只能记住某些方面,无法客观地了解全局多个角度,OLAP可以提供帮助
2)在决策时,可以方便让参与决策的人员(不一定是专业分析人员)汇聚讨论的焦点。 通过维度组合及条件过滤,很容易抽丝剥茧,验证各自的想法。 而对静态的固定报表,由于无法深入下去,所以讨论往往没有达到关键点就作罢
原文出自FineBI商业智能解决方案官网 www.finebi.com
使用SPRING的定时任务框架,如果是在分布式的环境下,由于有多台节点,会产生相同的任务,会被多个节点执行,这时需引入分布式的QUARTZ。
触发器:存放时间排程
任务:蔟业务代码
排程器:负责调度,即在指定的时间执行对应的任务
如果是分布式QUARTZ,则各个节点会上报任务,存到数据库中,执行时会从数据库中取出触发器来执行,如果触发器的名称和执行时间相同,则只有一个节点去执行此任务。
如果此节点执行失败,则此任务则会被分派到另一节点执行。
quartz.properties
#============================================================================
# Configure JobStore
# Using Spring datasource in quartzJobsConfig.xml
# Spring uses LocalDataSourceJobStore extension of JobStoreCMT
#============================================================================
org.quartz.jobStore.useProperties=true
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.isClustered = true
org.quartz.jobStore.clusterCheckinInterval = 5000
org.quartz.jobStore.misfireThreshold = 60000
org.quartz.jobStore.txIsolationLevelReadCommitted = true
# Change this to match your DB vendor
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#============================================================================
# Configure Main Scheduler Properties
# Needed to manage cluster instances
#============================================================================
org.quartz.scheduler.instanceId=AUTO
org.quartz.scheduler.instanceName=MY_CLUSTERED_JOB_SCHEDULER
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
#============================================================================
# Configure ThreadPool
#============================================================================
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 10
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
web-schedule-applicationcontext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:mongo="http://www.springframework.org/schema/data/mongo"
xsi:schemaLocation="http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/data/mongo
http://www.springframework.org/schema/data/mongo/spring-mongo-1.3.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<!-- 增加定时器配置 -->
<!-- 线程执行器配置,用于任务注册 -->
<bean id="executor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="10" />
<property name="maxPoolSize" value="100" />
<property name="queueCapacity" value="500" />
</bean>
<!-- 设置调度 -->
<bean id="webScheduler"
class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="configLocation" value="classpath:/properties/config/quartz.properties" />
<property name="dataSource" ref="dataSourceCMS" />
<property name="transactionManager" ref="txManager" />
<!-- This name is persisted as SCHED_NAME in db. for local testing could
change to unique name to avoid collision with dev server -->
<property name="schedulerName" value="quartzScheduler" />
<!-- Will update database cron triggers to what is in this jobs file on
each deploy. Replaces all previous trigger and job data that was in the database.
YMMV -->
<property name="overwriteExistingJobs" value="true" />
<property name="startupDelay" value="5"/>
<property name="applicationContextSchedulerContextKey" value="applicationContext" />
<property name="jobFactory">
<bean class="com.tcl.project7.boss.common.scheduling.AutowiringSpringBeanJobFactory" />
</property>
<property name="triggers">
<list>
<ref bean="springQuertzClusterTaskSchedulerTesterTigger" />
</list>
</property>
<property name="jobDetails">
<list>
<ref bean="springQuertzClusterTaskSchedulerTesterJobDetail" />
</list>
</property>
<property name="taskExecutor" ref="executor" />
</bean>
<!-- 触发器 -->
<bean id="springQuertzClusterTaskSchedulerTesterTigger" class="common.scheduling.PersistableCronTriggerFactoryBean">
<property name="jobDetail" ref="springQuertzClusterTaskSchedulerTesterJobDetail"/>
<property name="cronExpression" value="* * * * * ?" />
</bean>
<bean id="springQuertzClusterTaskSchedulerTesterJobDetail" class="org.springframework.scheduling.quartz.JobDetailBean">
<property name="jobClass" value="common.scheduling.SpringQuertzClusterTaskSchedulerTester" />
<!-- fail-over 重写执行失败的任务,default=false -->
<property name="requestsRecovery" value="false"/>
</bean>
</beans>
JOB文件:SpringQuertzClusterTaskSchedulerTester.java
package common.scheduling;
import java.util.Date;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.quartz.QuartzJobBean;
import com.tcl.project7.boss.common.util.UrlUtil;
import com.tcl.project7.boss.common.util.time.TimeUtils;
/**
* <p>Title:SpringQuertzClusterTaskSchedulerTester</p>
* <p>Description:
* 应为要持久化等特性操作,需要继承 QuartzJobBean
* <br>由于要被持久化,所以不能存放xxxxManager类似对象,
* 只能从每次从QuartzJobBean注入的ApplicationContext 中去取出
*
* </p>
*
*
*/
public class SpringQuertzClusterTaskSchedulerTester extends QuartzJobBean {
private static Logger logger = LoggerFactory.getLogger(SpringQuertzClusterTaskSchedulerTester.class);
@Autowired
private UrlUtil urlUtil;
protected void executeInternal(JobExecutionContext arg0)
throws JobExecutionException {
logger.info("------" + TimeUtils.formatTime(new Date()) + "------" + urlUtil.getNginxHost());
System.out.println("------" + TimeUtils.formatTime(new Date()) + "------" + urlUtil.getNginxHost());
}
}
如果JOB中有需要调用SPRING的BEAN,则需要此文件AutowiringSpringBeanJobFactory.java
package common.scheduling;
import org.quartz.spi.TriggerFiredBundle;
import org.springframework.beans.factory.config.AutowireCapableBeanFactory;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.scheduling.quartz.SpringBeanJobFactory;
/**
* Autowire Quartz Jobs with Spring context dependencies
* @see http://stackoverflow.com/questions/6990767/inject-bean-reference-into-a-quartz-job-in-spring/15211030#15211030
*/
public final class AutowiringSpringBeanJobFactory extends SpringBeanJobFactory implements ApplicationContextAware {
private transient AutowireCapableBeanFactory beanFactory;
public void setApplicationContext(final ApplicationContext context) {
beanFactory = context.getAutowireCapableBeanFactory();
}
@Override
protected Object createJobInstance(final TriggerFiredBundle bundle) throws Exception {
final Object job = super.createJobInstance(bundle);
beanFactory.autowireBean(job);
return job;
}
}
由于JOB需要存储到数据库中,会产生PROPERTY的问题,需剔除JOB-DATA,需此文件PersistableCronTriggerFactoryBean.java
package common.scheduling;
import org.springframework.scheduling.quartz.CronTriggerFactoryBean;
import org.springframework.scheduling.quartz.JobDetailAwareTrigger;
/**
* Needed to set Quartz useProperties=true when using Spring classes,
* because Spring sets an object reference on JobDataMap that is not a String
*
* @see http://site.trimplement.com/using-spring-and-quartz-with-jobstore-properties/
* @see http://forum.springsource.org/showthread.php?130984-Quartz-error-IOException
*/
public class PersistableCronTriggerFactoryBean extends CronTriggerFactoryBean {
@Override
public void afterPropertiesSet() {
super.afterPropertiesSet();
//Remove the JobDetail element
getJobDataMap().remove(JobDetailAwareTrigger.JOB_DETAIL_KEY);
}
}
建表语句,MYSQL:quartzTables.sql
#
# Quartz seems to work best with the driver mm.mysql-2.0.7-bin.jar
#
# In your Quartz properties file, you'll need to set
# org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#
DROP TABLE IF EXISTS QRTZ_JOB_LISTENERS;
DROP TABLE IF EXISTS QRTZ_TRIGGER_LISTENERS;
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
CREATE TABLE QRTZ_JOB_DETAILS
(
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_VOLATILE VARCHAR(1) NOT NULL,
IS_STATEFUL VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_JOB_LISTENERS
(
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
JOB_LISTENER VARCHAR(200) NOT NULL,
PRIMARY KEY (JOB_NAME,JOB_GROUP,JOB_LISTENER),
FOREIGN KEY (JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_TRIGGERS
(
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
IS_VOLATILE VARCHAR(1) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(200) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_SIMPLE_TRIGGERS
(
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_CRON_TRIGGERS
(
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
CRON_EXPRESSION VARCHAR(200) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_BLOB_TRIGGERS
(
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_TRIGGER_LISTENERS
(
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
TRIGGER_LISTENER VARCHAR(200) NOT NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_LISTENER),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_CALENDARS
(
CALENDAR_NAME VARCHAR(200) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (CALENDAR_NAME)
);
CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS
(
TRIGGER_GROUP VARCHAR(200) NOT NULL,
PRIMARY KEY (TRIGGER_GROUP)
);
CREATE TABLE QRTZ_FIRED_TRIGGERS
(
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
IS_VOLATILE VARCHAR(1) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(200) NULL,
JOB_GROUP VARCHAR(200) NULL,
IS_STATEFUL VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (ENTRY_ID)
);
CREATE TABLE QRTZ_SCHEDULER_STATE
(
INSTANCE_NAME VARCHAR(200) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (INSTANCE_NAME)
);
CREATE TABLE QRTZ_LOCKS
(
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (LOCK_NAME)
);
INSERT INTO QRTZ_LOCKS values('TRIGGER_ACCESS');
INSERT INTO QRTZ_LOCKS values('JOB_ACCESS');
INSERT INTO QRTZ_LOCKS values('CALENDAR_ACCESS');
INSERT INTO QRTZ_LOCKS values('STATE_ACCESS');
INSERT INTO QRTZ_LOCKS values('MISFIRE_ACCESS');
commit;
参考:
http://wenku.baidu.com/view/82e3bcbdfd0a79563c1e7223.htmlQuartz集成springMVC 的方案二(持久化任务、集群和分布式)
http://blog.csdn.net/congcong68/article/details/39256307
摘要: Bootstrap是快速开发Web应用程序的前端工具包。它是一个CSS和HTML的集合,它使用了最新的浏览器技术,给你的Web开发提供了时尚的版式,表单,buttons,表格,网格系统等等。本文向你推荐 50 个 Bootstrap 的插件,可以考虑在你下一个项目中使用它们。1. Bootstrap Multiselect 2. Bootstrap Dialog 3. Boot...
阅读全文
https://github.com/wandoulabs/codis
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有明显的区别 (不支持的命令列表), 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务.
Codis 由四部分组成:
Codis Proxy (codis-proxy)
Codis Manager (codis-config)
Codis Redis (codis-server)
ZooKeeper
codis-proxy 是客户端连接的 Redis 代理服务, codis-proxy 本身实现了 Redis 协议, 表现得和一个原生的 Redis 没什么区别 (就像 Twemproxy), 对于一个业务来说, 可以部署多个 codis-proxy, codis-proxy 本身是无状态的.
codis-config 是 Codis 的管理工具, 支持包括, 添加/删除 Redis 节点, 添加/删除 Proxy 节点, 发起数据迁移等操作. codis-config 本身还自带了一个 http server, 会启动一个 dashboard, 用户可以直接在浏览器上观察 Codis 集群的运行状态.
codis-server 是 Codis 项目维护的一个 Redis 分支, 基于 2.8.13 开发, 加入了 slot 的支持和原子的数据迁移指令. Codis 上层的 codis-proxy 和 codis-config 只能和这个版本的 Redis 交互才能正常运行.
Codis 依赖 ZooKeeper 来存放数据路由表和 codis-proxy 节点的元信息, codis-config 发起的命令都会通过 ZooKeeper 同步到各个存活的 codis-proxy.
Codis 支持按照 Namespace 区分不同的产品, 拥有不同的 product name 的产品, 各项配置都不会冲突.
目前 Codis 已经是稳定阶段,目前豌豆荚已经在使用该系统。
架构:
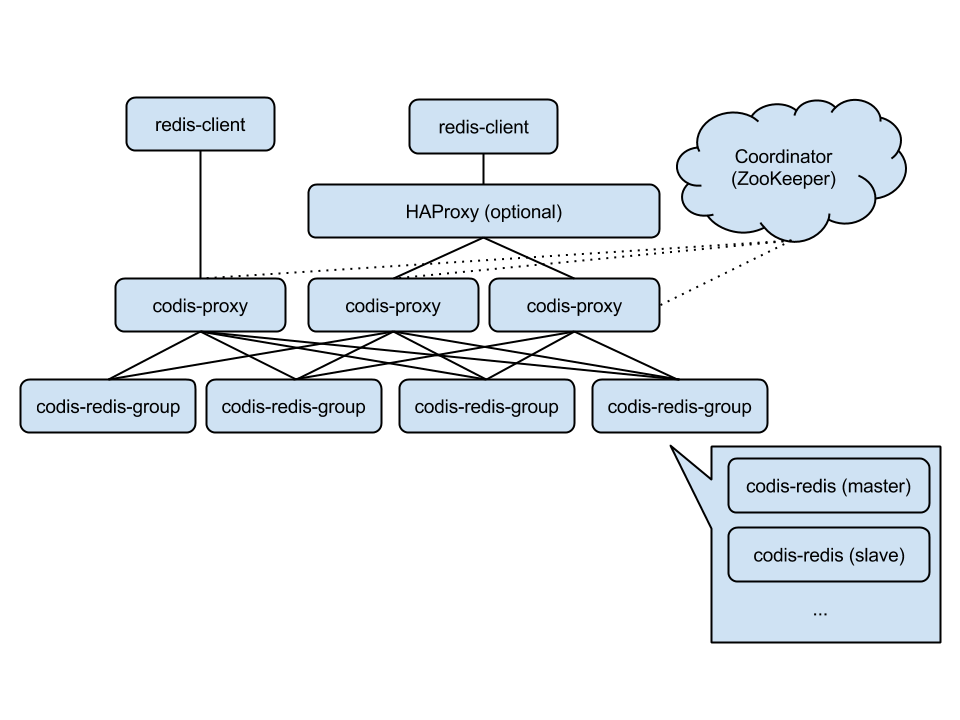
特性:
安装:
界面截图:
Dashboard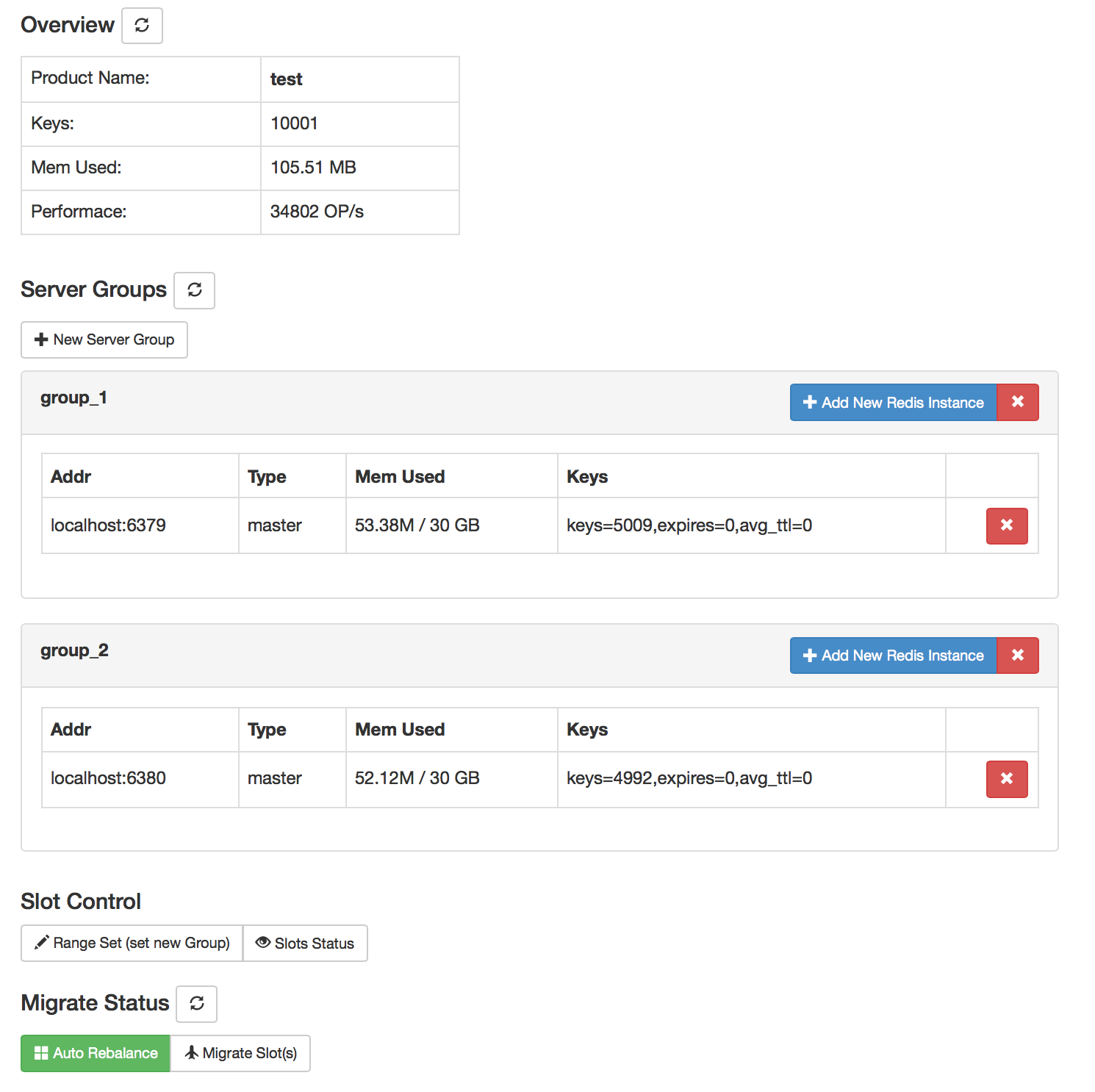
Migrate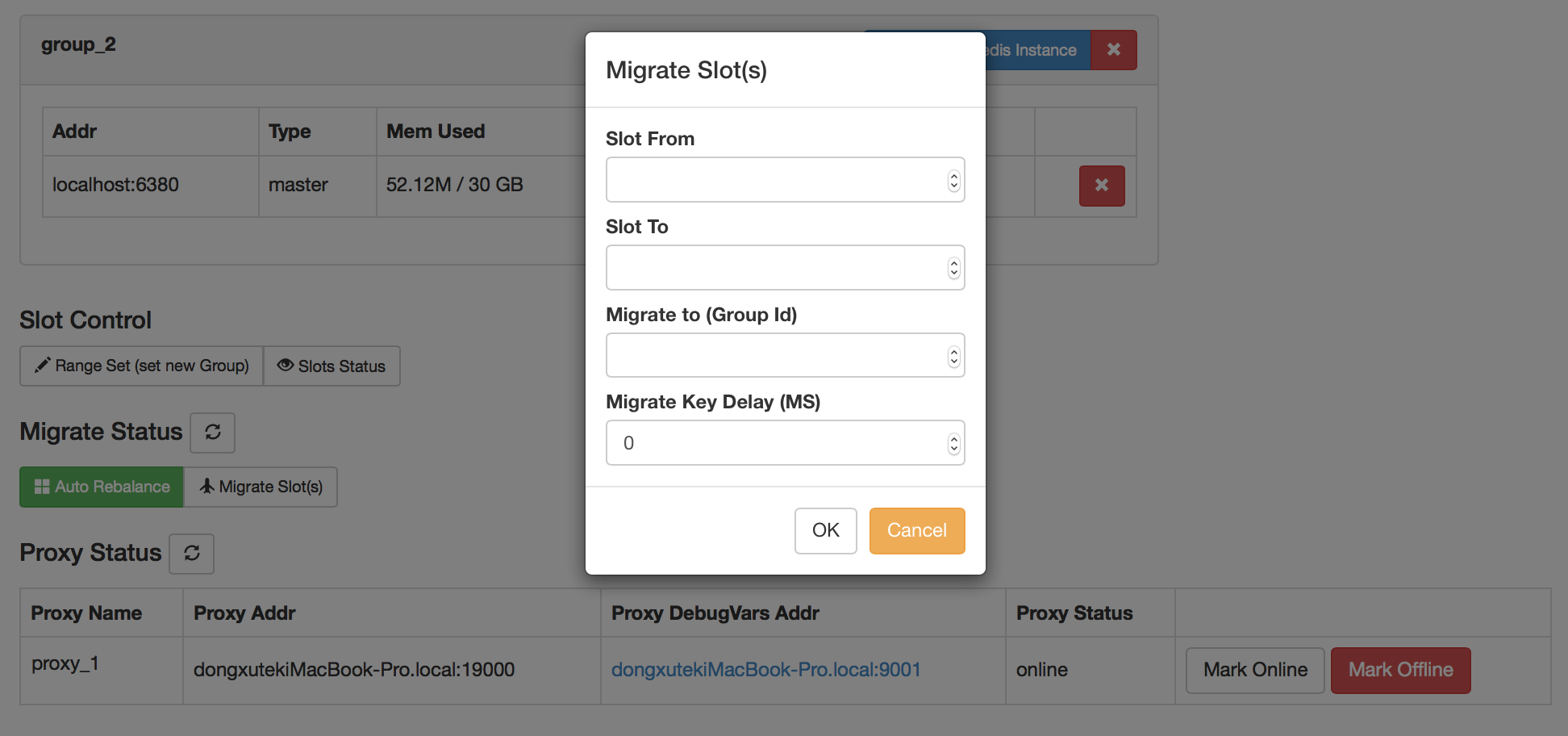
Slots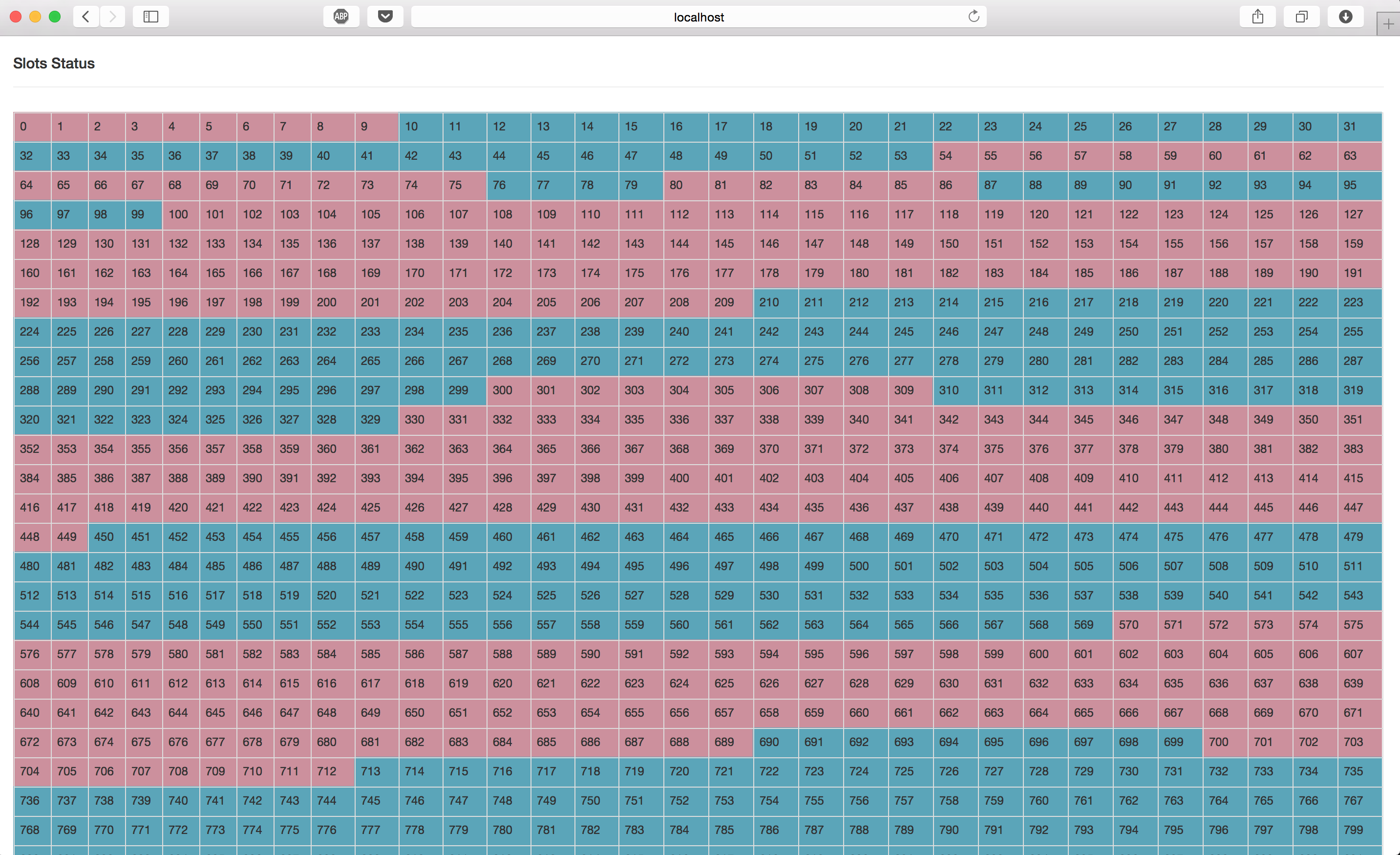
經過幾次搶購,相信有些 unwire 讀者已經買到 Letv X50 Air 超級智能電視,在家享受它的豐富內容,以及準備欣賞 HKTV 直播劇集了吧。
而它提供的內容中,最吸引的肯定是 4K 影片及劇集。相信大家都知道,4K 內容檔案本身容量十分大,還要透過網絡進行串流,一般情況也會「窒下窒下」,但為何在 X50 Air 上會如此順暢?以下小編就為大家解構一下:
好了,謎底揭曉!
其實很多時候欣賞串流內容(streaming)時要等,是因為 cache 時間十分長,導致影響載入時候。
而 Letv 就採用了 CDN(Content Delivery / Distribution Network;內容傳遞網路)網路,它的總承載量比單一骨幹最大的頻寬還要大,而且有異地備援,萬一某個伺服器出現故障,系統就會自動調用其他鄰近地區的伺服器資源,所以可靠度極之接近 100%;
就算沒有故障時,樂視香港的 CDN 網絡亦可有效回避繁忙擠塞的網絡,並自動尋找距離用家最接近的快取伺服器接收內容,因此可以改善內容存取速度,大大縮短下載時間,自然可以用串流網絡,順暢欣賞極致 4K 影片內容啦。