做任何一个应用系统,比如银行核心、ERP核心、订票系统等等,应用系统都包括三个架构:1)业务架构;2)系统架构;3)实施架构。
1)业务架构
业务架构是应用系统的业务范围的具体划分和体现。业务架构与将要落地的系统平台无关。
业务架构的搭建,可以在概设阶段完成轮廓的搭建,对一些具体的细节,可以没有,或将会存在。但是,要在架构搭建过程中,把控着,或设计者,要留有充分的包容余地。
业务架构具体内容,要有粗细业务流的体现。每个业务流肯定要行得通。对综合或交叉的业务流要详细划分,按通用性,或者特殊性,划分为各自的子集。
业务架构要包括应用系统项目的当前实施范围,或将要实施的范围。
业务架构应该做到,业务范围内容的增加,不影响已经搭建好的业务架构,并且,比较容易地融合到业务架构中。
在业务架构搭建过程中,对熟悉的、惯例的业务用细业务流按模块划分,进行描述。对没有落地的业务内容,按粗业务流进行模块划分描述。划分好的业务功能模块,在业务架构中是唯一的,不能重叠。
2)系统架构
系统架构是业务架构落实到具体硬件平台的应用,硬件平台如HP-UX、RS6000、ES9000、AS400等等,操作系统如UNIX、AIX、390 Z系统、OS400、LINUX等等。
架构师的责任就是把业务架构的各个模块在一个单独硬件平台上,或一个整体,包括多个层次复杂的综合硬件系统平台上,把应用系统落实在最能体现硬件平台运行效率的地方。
业务架构是有范围的,在现有状况下,或将来一定时间段,实现的业务架构都会满足现有项目需求。
优秀的架构师,整体观要非常强,精通当今至少一条行业技术方向和主要技术,熟悉当今IT潮流硬件平台,和在此之下的潮流软件实施技术。
架构师不是万能的,但是,在架构师的统帅下,各分支的模块架构实现,要根据架构师规划和设计的系统架构轮廓进行实施,具体模块实现要team leader,根据模块特征,做具体技术设计和实现。
架构师职责之一,就是把控应用系统项目实施规范。
打个比方,IT架构师,就像建筑总体架构师,业务架构就像一个建筑架构,比如一个社区的建筑规划,哪里是居住区?哪里是电影院?哪里是超市?等等,这些都是在社区建设初期,架构师就要设计和规划出轮廓。对具体细节操作,比如社区中有一块区域要建筑一座楼房,第三层要实现中式复古装修;第四层要实现欧式宫廷式装修,等等,每一层都有各自熟悉精通这方面的team leader设计领导实施。
架构师的职责之一,就是会懂得用人,把各team leader放在最能发挥作用的地方。
一个好的应用系统,不会因为业务扩充或变化,而影响应用系统运行和运行效率。不提倡打补丁的做法。功能唯一,包括功能代码唯一,是好的系统架构的保障,同时也是评价一个优秀架构师的标准。
3)实施架构
实施架构是系统架构具体实现手段,是体系项目实施提升效率的具体实施行为。
背景:
某电信项目中采用HBase来存储用户终端明细数据,供前台页面即时查询。HBase无可置疑拥有其优势,但其本身只对rowkey支持毫秒级的快速检索,对于多字段的组合查询却无能为力。针对HBase的多条件查询也有多种方案,但是这些方案要么太复杂,要么效率太低,本文只对基于Solr的HBase多条件查询方案进行测试和验证。
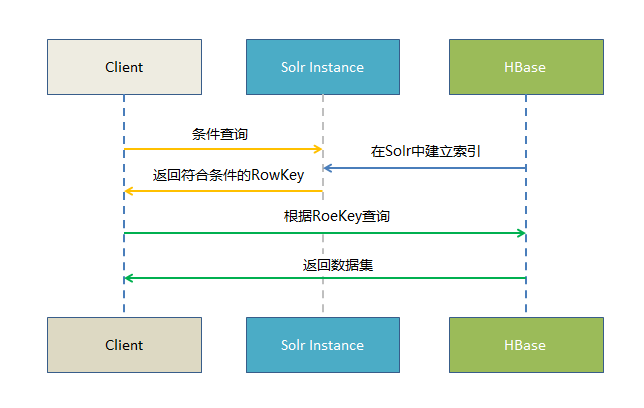
原理:
基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。
测试环境:
solr 4.0.0版本,使用其自带的jetty服务端容器,单节点;
hbase-0.94.2-cdh4.2.1,10台Lunux服务器组成的HBase集群。
HBase中2512万条数据172个字段;
Solr索引HBase中的100万条数据;
测试结果:
1、100万条数据在Solr中对8个字段建立索引。在Solr中最多8个过滤条件获取51316条数据的rowkey值,基本在57-80毫秒。根据Solr返回的rowkey值在HBase表中获取所有51316条数据12个字段值,耗时基本在15秒;
2、数据量同上,过滤条件同上,采用Solr分页查询,每次获取20条数据,Solr获得20个rowkey值耗时4-10毫秒,拿到Solr传入的rowkey值在HBase中获取对应20条12个字段的数据,耗时6毫秒。
以下列出测试环境的搭建、以及相关代码实现过程。
一、Solr环境的搭建
因为初衷只是测试Solr的使用,Solr的运行环境也只是用了其自带的jetty,而非大多人用的Tomcat;没有搭建Solr集群,只是一个单一的Solr服务端,也没有任何参数调优。
1)在Apache网站上下载Solr 4:http://lucene.apache.org/solr/downloads.html,我们这里下载的是“apache-solr-4.0.0.tgz”;
2)在当前目录解压Solr压缩包:
-xvzf apache-solr-..tgz
3)修改Solr的配置文件schema.xml,添加我们需要索引的多个字段(配置文件位于“/opt/apache-solr-4.0.0/example/solr/collection1/conf/”)
<field name="rowkey" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="time" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="tebid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="tetid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="puid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="mgcvid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="mtcvid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="smaid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="mtlkid" type="string" indexed="true" stored="true" required="false" multiValued="false" />
另外关键的一点是修改原有的uniqueKey,本文设置HBase表的rowkey字段为Solr索引的uniqueKey:
<uniqueKey>rowkey</uniqueKey>
type 参数代表索引数据类型,我这里将type全部设置为string是为了避免异常类型的数据导致索引建立失败,正常情况下应该根据实际字段类型设置,比如整型字段设置为int,更加有利于索引的建立和检索;
indexed 参数代表此字段是否建立索引,根据实际情况设置,建议不参与条件过滤的字段一律设置为false;
stored 参数代表是否存储此字段的值,建议根据实际需求只将需要获取值的字段设置为true,以免浪费存储,比如我们的场景只需要获取rowkey,那么只需把rowkey字段设置为true即可,其他字段全部设置flase;
required 参数代表此字段是否必需,如果数据源某个字段可能存在空值,那么此属性必需设置为false,不然Solr会抛出异常;
multiValued 参数代表此字段是否允许有多个值,通常都设置为false,根据实际需求可设置为true。
4)我们使用Solr自带的example来作为运行环境,定位到example目录,启动服务监听:
cd /opt/apache-solr-4.0.0/example java -jar ./start.jar
如果启动成功,可以通过浏览器打开此页面:http://192.168.1.10:8983/solr/
二、读取HBase源表的数据,在Solr中建立索引
一种方案是通过HBase的普通API获取数据建立索引,此方案的缺点是效率较低每秒只能处理100多条数据(或许可以通过多线程提高效率):
package com.ultrapower.hbase.solrhbase;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.KeyValue;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.ResultScanner;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.util.Bytes;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.HttpSolrServer;import org.apache.solr.common.SolrInputDocument;public class SolrIndexer { /** * @param args * @throws IOException * @throws SolrServerException */ public static void main(String[] args) throws IOException, SolrServerException { final Configuration conf; HttpSolrServer solrServer = new HttpSolrServer( "http://192.168.1.10:8983/solr"); // 因为服务端是用的Solr自带的jetty容器,默认端口号是8983 conf = HBaseConfiguration.create(); HTable table = new HTable(conf, "hb_app_xxxxxx"); // 这里指定HBase表名称 Scan scan = new Scan(); scan.addFamily(Bytes.toBytes("d")); // 这里指定HBase表的列族 scan.setCaching(500); scan.setCacheBlocks(false); ResultScanner ss = table.getScanner(scan); System.out.println("start ..."); int i = 0; try { for (Result r : ss) { SolrInputDocument solrDoc = new SolrInputDocument(); solrDoc.addField("rowkey", new String(r.getRow())); for (KeyValue kv : r.raw()) { String fieldName = new String(kv.getQualifier()); String fieldValue = new String(kv.getValue()); if (fieldName.equalsIgnoreCase("time") || fieldName.equalsIgnoreCase("tebid") || fieldName.equalsIgnoreCase("tetid") || fieldName.equalsIgnoreCase("puid") || fieldName.equalsIgnoreCase("mgcvid") || fieldName.equalsIgnoreCase("mtcvid") || fieldName.equalsIgnoreCase("smaid") || fieldName.equalsIgnoreCase("mtlkid")) { solrDoc.addField(fieldName, fieldValue); } } solrServer.add(solrDoc); solrServer.commit(true, true, true); i = i + 1; System.out.println("已经成功处理 " + i + " 条数据"); } ss.close(); table.close(); System.out.println("done !"); } catch (IOException e) { } finally { ss.close(); table.close(); System.out.println("erro !"); } } }另外一种方案是用到HBase的Mapreduce框架,分布式并行执行效率特别高,处理1000万条数据仅需5分钟,但是这种高并发需要对Solr服务器进行配置调优,不然会抛出服务器无法响应的异常:
Error: org.apache.solr.common.SolrException: Server at http://192.168.1.10:8983/solr returned non ok status:503, message:Service Unavailable
MapReduce入口程序:
package com.ultrapower.hbase.solrhbase;import java.io.IOException;import java.net.URISyntaxException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.hbase.util.Bytes;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;public class SolrHBaseIndexer { private static void usage() { System.err.println("输入参数: <配置文件路径> <起始行> <结束行>"); System.exit(1); } private static Configuration conf; public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException { if (args.length == 0 || args.length > 3) { usage(); } createHBaseConfiguration(args[0]); ConfigProperties tutorialProperties = new ConfigProperties(args[0]); String tbName = tutorialProperties.getHBTbName(); String tbFamily = tutorialProperties.getHBFamily(); Job job = new Job(conf, "SolrHBaseIndexer"); job.setJarByClass(SolrHBaseIndexer.class); Scan scan = new Scan(); if (args.length == 3) { scan.setStartRow(Bytes.toBytes(args[1])); scan.setStopRow(Bytes.toBytes(args[2])); } scan.addFamily(Bytes.toBytes(tbFamily)); scan.setCaching(500); // 设置缓存数据量来提高效率 scan.setCacheBlocks(false); // 创建Map任务 TableMapReduceUtil.initTableMapperJob(tbName, scan, SolrHBaseIndexerMapper.class, null, null, job); // 不需要输出 job.setOutputFormatClass(NullOutputFormat.class); // job.setNumReduceTasks(0); System.exit(job.waitForCompletion(true) ? 0 : 1); } /** * 从配置文件读取并设置HBase配置信息 * * @param propsLocation * @return */ private static void createHBaseConfiguration(String propsLocation) { ConfigProperties tutorialProperties = new ConfigProperties( propsLocation); conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", tutorialProperties.getZKQuorum()); conf.set("hbase.zookeeper.property.clientPort", tutorialProperties.getZKPort()); conf.set("hbase.master", tutorialProperties.getHBMaster()); conf.set("hbase.rootdir", tutorialProperties.getHBrootDir()); conf.set("solr.server", tutorialProperties.getSolrServer()); } }对应的Mapper:
package com.ultrapower.hbase.solrhbase;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.KeyValue;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.io.ImmutableBytesWritable;import org.apache.hadoop.hbase.mapreduce.TableMapper;import org.apache.hadoop.io.Text;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.HttpSolrServer;import org.apache.solr.common.SolrInputDocument;public class SolrHBaseIndexerMapper extends TableMapper<Text, Text> { public void map(ImmutableBytesWritable key, Result hbaseResult, Context context) throws InterruptedException, IOException { Configuration conf = context.getConfiguration(); HttpSolrServer solrServer = new HttpSolrServer(conf.get("solr.server")); solrServer.setDefaultMaxConnectionsPerHost(100); solrServer.setMaxTotalConnections(1000); solrServer.setSoTimeout(20000); solrServer.setConnectionTimeout(20000); SolrInputDocument solrDoc = new SolrInputDocument(); try { solrDoc.addField("rowkey", new String(hbaseResult.getRow())); for (KeyValue rowQualifierAndValue : hbaseResult.list()) { String fieldName = new String( rowQualifierAndValue.getQualifier()); String fieldValue = new String(rowQualifierAndValue.getValue()); if (fieldName.equalsIgnoreCase("time") || fieldName.equalsIgnoreCase("tebid") || fieldName.equalsIgnoreCase("tetid") || fieldName.equalsIgnoreCase("puid") || fieldName.equalsIgnoreCase("mgcvid") || fieldName.equalsIgnoreCase("mtcvid") || fieldName.equalsIgnoreCase("smaid") || fieldName.equalsIgnoreCase("mtlkid")) { solrDoc.addField(fieldName, fieldValue); } } solrServer.add(solrDoc); solrServer.commit(true, true, true); } catch (SolrServerException e) { System.err.println("更新Solr索引异常:" + new String(hbaseResult.getRow())); } } }读取参数配置文件的辅助类:
package com.ultrapower.hbase.solrhbase;import java.io.File;import java.io.FileReader;import java.io.IOException;import java.util.Properties;public class ConfigProperties { private static Properties props; private String HBASE_ZOOKEEPER_QUORUM; private String HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT; private String HBASE_MASTER; private String HBASE_ROOTDIR; private String DFS_NAME_DIR; private String DFS_DATA_DIR; private String FS_DEFAULT_NAME; private String SOLR_SERVER; // Solr服务器地址 private String HBASE_TABLE_NAME; // 需要建立Solr索引的HBase表名称 private String HBASE_TABLE_FAMILY; // HBase表的列族 public ConfigProperties(String propLocation) { props = new Properties(); try { File file = new File(propLocation); System.out.println("从以下位置加载配置文件: " + file.getAbsolutePath()); FileReader is = new FileReader(file); props.load(is); HBASE_ZOOKEEPER_QUORUM = props.getProperty("HBASE_ZOOKEEPER_QUORUM"); HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT = props.getProperty("HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT"); HBASE_MASTER = props.getProperty("HBASE_MASTER"); HBASE_ROOTDIR = props.getProperty("HBASE_ROOTDIR"); DFS_NAME_DIR = props.getProperty("DFS_NAME_DIR"); DFS_DATA_DIR = props.getProperty("DFS_DATA_DIR"); FS_DEFAULT_NAME = props.getProperty("FS_DEFAULT_NAME"); SOLR_SERVER = props.getProperty("SOLR_SERVER"); HBASE_TABLE_NAME = props.getProperty("HBASE_TABLE_NAME"); HBASE_TABLE_FAMILY = props.getProperty("HBASE_TABLE_FAMILY"); } catch (IOException e) { throw new RuntimeException("加载配置文件出错"); } catch (NullPointerException e) { throw new RuntimeException("文件不存在"); } } public String getZKQuorum() { return HBASE_ZOOKEEPER_QUORUM; } public String getZKPort() { return HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT; } public String getHBMaster() { return HBASE_MASTER; } public String getHBrootDir() { return HBASE_ROOTDIR; } public String getDFSnameDir() { return DFS_NAME_DIR; } public String getDFSdataDir() { return DFS_DATA_DIR; } public String getFSdefaultName() { return FS_DEFAULT_NAME; } public String getSolrServer() { return SOLR_SERVER; } public String getHBTbName() { return HBASE_TABLE_NAME; } public String getHBFamily() { return HBASE_TABLE_FAMILY; } }参数配置文件“config.properties”:
HBASE_ZOOKEEPER_QUORUM=slave-1,slave-2,slave-3,slave-4,slave-5HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT=2181HBASE_MASTER=master-1:60000HBASE_ROOTDIR=hdfs:///hbaseDFS_NAME_DIR=/opt/data/dfs/name DFS_DATA_DIR=/opt/data/d0/dfs2/data FS_DEFAULT_NAME=hdfs://192.168.1.10:9000SOLR_SERVER=http://192.168.1.10:8983/solrHBASE_TABLE_NAME=hb_app_m_user_te HBASE_TABLE_FAMILY=d
三、结合Solr进行HBase数据的多条件查询:
可以通过web页面操作Solr索引,
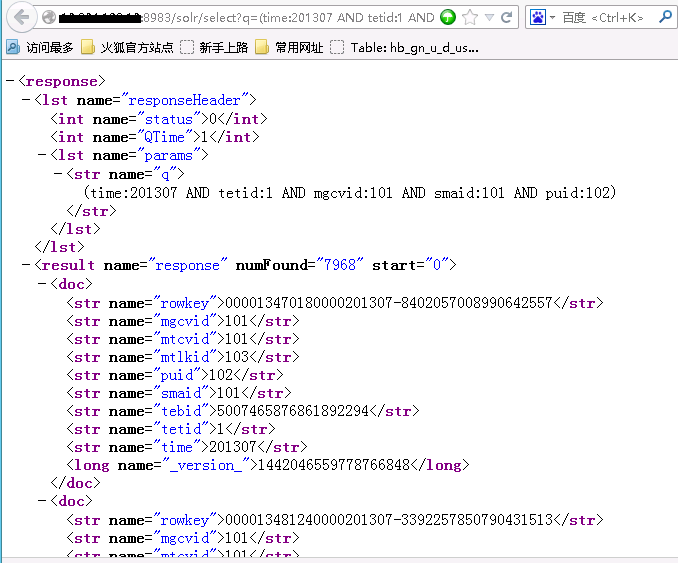
查询:
http://192.168.1.10:8983/solr/select?(time:201307 AND tetid:1 AND mgcvid:101 AND smaid:101 AND puid:102)
删除所有索引:
http://192.168.1.10:8983/solr/update/?stream.body=<delete><query>*:*</query></delete>&stream.contentType=text/xml;charset=utf-8&commit=true
通过java客户端结合Solr查询HBase数据:
package com.ultrapower.hbase.solrhbase;import java.io.IOException;import java.nio.ByteBuffer;import java.util.ArrayList;import java.util.List;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Get;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.util.Bytes;import org.apache.solr.client.solrj.SolrQuery;import org.apache.solr.client.solrj.SolrServer;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.HttpSolrServer;import org.apache.solr.client.solrj.response.QueryResponse;import org.apache.solr.common.SolrDocument;import org.apache.solr.common.SolrDocumentList;public class QueryData { /** * @param args * @throws SolrServerException * @throws IOException */ public static void main(String[] args) throws SolrServerException, IOException { final Configuration conf; conf = HBaseConfiguration.create(); HTable table = new HTable(conf, "hb_app_m_user_te"); Get get = null; List<Get> list = new ArrayList<Get>(); String url = "http://192.168.1.10:8983/solr"; SolrServer server = new HttpSolrServer(url); SolrQuery query = new SolrQuery("time:201307 AND tetid:1 AND mgcvid:101 AND smaid:101 AND puid:102"); query.setStart(0); //数据起始行,分页用 query.setRows(10); //返回记录数,分页用 QueryResponse response = server.query(query); SolrDocumentList docs = response.getResults(); System.out.println("文档个数:" + docs.getNumFound()); //数据总条数也可轻易获取 System.out.println("查询时间:" + response.getQTime()); for (SolrDocument doc : docs) { get = new Get(Bytes.toBytes((String) doc.getFieldValue("rowkey"))); list.add(get); } Result[] res = table.get(list); byte[] bt1 = null; byte[] bt2 = null; byte[] bt3 = null; byte[] bt4 = null; String str1 = null; String str2 = null; String str3 = null; String str4 = null; for (Result rs : res) { bt1 = rs.getValue("d".getBytes(), "3mpon".getBytes()); bt2 = rs.getValue("d".getBytes(), "3mponid".getBytes()); bt3 = rs.getValue("d".getBytes(), "amarpu".getBytes()); bt4 = rs.getValue("d".getBytes(), "amarpuid".getBytes()); if (bt1 != null && bt1.length>0) {str1 = new String(bt1);} else {str1 = "无数据";} //对空值进行new String的话会抛出异常 if (bt2 != null && bt2.length>0) {str2 = new String(bt2);} else {str2 = "无数据";} if (bt3 != null && bt3.length>0) {str3 = new String(bt3);} else {str3 = "无数据";} if (bt4 != null && bt4.length>0) {str4 = new String(bt4);} else {str4 = "无数据";} System.out.print(new String(rs.getRow()) + " "); System.out.print(str1 + "|"); System.out.print(str2 + "|"); System.out.print(str3 + "|"); System.out.println(str4 + "|"); } table.close(); } }小结:
通过测试发现,结合Solr索引可以很好的实现HBase的多条件查询,同时还能解决其两个难点:分页查询、数据总量统计。
实际场景中大多都是分页查询,分页查询返回的数据量很少,采用此种方案完全可以达到前端页面毫秒级的实时响应;若有大批量的数据交互,比如涉及到数据导出,实际上效率也是很高,十万数据仅耗时10秒。
另外,如果真的将Solr纳入使用,Solr以及HBase端都可以不断进行优化,比如可以搭建Solr集群,甚至可以采用SolrCloud基于hadoop的分布式索引服务。
总之,HBase不能多条件过滤查询的先天性缺陷,在Solr的配合之下可以得到较好的弥补,难怪诸如新蛋科技、国美电商、苏宁电商等互联网公司以及众多游戏公司,都使用Solr来支持快速查询。
----end
摘要:企业科技正在以不可思议的速度向前发展,本文预测的9大技术或许在2015年甚至以后将会对我们产生深远影响。无论是Docker容器还是机器学习,开源都是未来的一大趋势,也是企业获得竞争优势的首选。
【编者按】预测未来本来就是一件非常疯狂的事情,而且现在企业科技的发展速度永远超越我们的想象。infoworld主编Eric Knorr为我们预测了在2015年或是未来一段时间内9大技术将大行其道。他认为开源是企业获得竞争优势的首选,作为开发人员应该关注技术热点,并围绕核心技术构建一个类似Docker、Hadoop等的生态系统。
以下为译文: 1.公有云将获得成功 今年,IaaS和PaaS的融合使得在公有云平台上更容易构建、测试和部署应用程序。随着AWS现在提供多重PaaS选项,所有主流的公有云都将提供类似集成方式。
与此同时,私有云由于成本和复杂的企业部署以及维护整个内部堆栈将会止步不前。云计算创新是企业科技发生重大变革的领域,所以我不得不怀疑任何业务都可以跟上技术变化的速度。除了监管障碍和支付成本,为什么不简单地迁移到公有云呢?毕竟,紧随科技潮流是每个公有云厂商应该做的事。至于企业,则并非如此。当然,迁移需要时间,但像GE这样的公司已经宣布他们全力投入。
2.疯狂的容器技术 Docker是目前这个星球上最热门的开源项目,它使你可以打包应用程序,以便将让其运行构建在Linux内核上的容器中。之所以它如此重要是因为这意味着真正的应用程序可移植——使用轻量级包来替代一个完整的虚拟机。此外,Docker公司正在与微软Windows上创建Docker驱动的容器。很多人都在探讨使用Docker从开发到测试以及生产阶段迁移应用程序,但我相信Docker也将被用来在云中迁移生产应用程序。
将一个打包应用程序从一个容器迁移到另一个容器是很容易的,但是涉及多重容器的复杂应用程序将会变得更加困难。Docker管理和编排工具将帮助你装配和迁移复杂的App。Docker顶级项目包括Kubernetes、
Mesos 、StackEngine、
Google Cloud Platform 和AWS上个月添加了他们自己的容器管理系统。
3.微服务架构 在当代网络和移动App开发时代,开发人员往往从服务构建应用程序,而不是从头开始编写所有程序。通常情况下,这些服务就是微服务——专用API,可获得API的App已经成为更大应用程序的构建模块。Docker通过提供一个便捷的打包和部署方式在一定程度上加快了微服务的发展趋势。
如果你还记得十年前的SOA趋势,微服务架构可能听起来很熟悉。主要的区别在于微服务架构是从开发者的角度来看服务而不是企业架构师的角度,因此服务是细粒度的。服务之间的沟通也很简单:JSON取代XML,REST代替SOAP,另外重型中间件并不包含在内。
4.流体计算 InfoWorld”的主编Galen Gruman创造了“流体计算”的短语来描述ad hoc(点对点)网络在个人设备上的影响,在那里你可以在智能手机、笔记本电脑、平板电脑以及台式机之间迁移时保存状态。例如,如果你正在参加一个会议,并在平板电脑上修改了你的描述,当你回到办公室,你会发现那个描述已经提供在你的台式机前面。第一个推出这个切换特性的是OS X Yosemite和iOS 8,但微软和谷歌正在为他们的设备生态系统打造类似的功能;三星最近也宣布自己的版本。
5.多重云管理 云的趋势是更大、更复杂的平台。你构建在之上的平台越多,你就越依赖于其独特的特性,如果是一个公有云,你就会将自己完全锁定在一个由别人控制的平台上。很少有大型企业会把所有的鸡蛋放在同一个篮子里,而这就是多重云管理的价值所在。
跨多重云部署工具已经出现有一段时间了,当下获得了更多的关注。CliQr,一个由谷歌风险投资公司支持多重云管理初创公司声称能够动态决定哪个云应该运行哪个工作负载。但值得关注的还有RightScale,他们声称能够让你在多重云环境下管理和优化资源以及成本。
6.端点安全创新 企业安全仍将处于绝望的状态,只要用户还会继续不小心下载恶意软件。尽管如此,我还是对今年出现的一些新的安全解决方案留下了深刻的印象。首先,Tanium在整个企业将创新搜索技术应用于查询端点。Tanium可以获得近实时查看成千上万的端点来检测异常情况,并且确定哪些软件缺乏最新的补丁——全部显示到仪表板视图上。
手机上也出现了有趣的解决方案,而不仅仅是指纹阅读。一些蓝牙LE近距离解决方案使你能够用你的智能手机作为安全密钥,或作为其他移动设备的物理标记来用于近距离身份验证。最近,Android 5.0 Lollipop引入“可信任地点”技术,当你在一个区域你感觉是安全的,比如你的家或办公室,这项技术使用定位来消除密码或pincode gates。
7.机器学习 这差不多是人工智能的新名称。一方面,重要的是不要对近期机器学习的潜力承诺太多;另一方面,理解大数据是必需的,开源项目Mahout 和Spark / MLlib会带来帮助。正如James Kobielus在今年早些时候注意到的一样,机器学习是如此的普遍,我们甚至经常假设其存在于大数据应用程序中。IBM是这一思想的主要支持者,并且开源了
Watson APIs ,而初创公司例如Andreessen投资的 Adatao今天正在应用强大的计算能力来恢复神经网络算法。
8.devops的回归 这种 “开发”和“运维”的融合实际上是通过提高操作效率来实现敏捷开发。devops趋势五年前首次出现,但是供应商让其重新焕发生机。当下,其正在应用程序生命周期管理、自动化测试工具、数据库虚拟化、自动化、配置管理、应用程序性能监控、平台即服务以及相关技术领域以其原有的方式运行。
在某些圈子里,devops被认为是一种让开发人员持续为生产中的应用程序负责的一种方式,但这并不普遍。对devops最好的理解是对现代高效配置开发和测试环境的速写,这必须延伸概念以满足更多更好应用程序几乎通用的商业需求。
9.网络交换机的结束 我们不会看到网络交换机在2015年消失。但虚拟网络设备、软件定义网络和强大的服务器将促使我们重新思考数据中心网络。网络的未来沦为“服务器”之间的连接正在变得愈加真实。
Cumulus Linux将网络控制平面带到行业标准硬件和当下的服务器编排工具,同时保留线速网络运营。最近InfoBlox 推出的OpenFlow项目LINCX显示了完全软件可编程网络的潜在力量。同时,NFV(网络功能虚拟化)——利用服务器虚拟化和数据中心编排提供负载平衡、防火墙、广域网加速和其他网络功能作为服务——在服务提供商和云平台诸如OpenStack当中非常受欢迎。
写在最后 综上,一条主线贯穿这九大趋势就是开源。这已经成为初创公司获得竞争优势的首选,作为客户——主要是公司内部的开发人员——应该紧随新技术并提供反馈,最终把它们投入生产。与此同时,其他开发人员应该能看到哪些技术热点,围绕一个核心项目开始构建一个生态系统,就像Docker、Hadoop、OpenStack等等一样。
原文链接:
9 key enterprise tech trends for 2015 and beyond
分布计算系统框架,按照数据集的特点来说,主要分为data-flow和streaming两种。data-flow主要是以数据块为数据源来处理数据,代表有:MR、Spark等,我称作它们为大数据,而streaming主要是处理单位内得到的数据,这种方式,更注重于实时性,主要包括Strom、JStorm和Samza等,我称作它们为快数据。
在这篇文章中,我主要谈论streaming相关的框架。
第一个是Storm,一个实时计算系统,它假定数据源是动态的,可以向流水一样处理数据。
它的特点是:低延迟、高性能、分布式、可扩展和容错性。
架构如下图所示。

Storm的具体概念可以参照:http://blog.csdn.net/hljlzc2007/article/details/12976211,这里不做具体介绍。
Storm目前算是最最稳定的开源流式处理框架,但是个人认为它有两个问题。
1. Storm虽然支持多个语言编写spout和bolt端的代码,但是它的主要技术实现是clojure,这给玩大数据、开源的朋友带来了极大的不变,因为大家会的语言不是以java和C++等大众语言为主,这样的话,变得不可控了,难以深入了解、修改其细节。
2. Storm可以支持在Yarn(Hadoop 2.0)上,可以和其他开源框架共享Hadoop集群的资源,但是性能不佳,这个有待Storm改善
当然无论如何,Storm依然是目前开源流式处理框架的王者。
第二个我想说的是JStorm,这个是阿里做的,算是Storm的另一个实现,它用的语言是Java.
特点:
1. 客户端的API与Storm基本上是一致的,如果从Storm迁移过来,不需要修改bolt和spout的代码
2. Jstrom比Strom稳定,速度更快
3. 提供了一些新的特性
大家有兴趣可以去玩玩,项目地址https://github.com/alibaba/jstorm
第三个是Samza
Samza是由LinkedIn开源的一个技术,它是一个开源的分布式流处理系统,非常类似于Storm。不同的是它运行在Hadoop之上,并且使用了自己开发的Kafka分布式消息处理系统。
这是Linkin开发的一个小而美的项目,如何美呢?
1. 只有几千行代码,完成的功能就可以和Storm媲美,当然目前还有很多的不足
2. 和Kafka结合紧密,更方便的处理数据
3. 运行在Yarn上
之前我做过的一个项目,是Kafka + Storm + ElasticSearch,将来完全可以将Storm替换成Samza,这样的话,还可以利用Hadoop集群的资源,做一些存储、离线分析的功能。将实时处理和离线分析都运行在Hadoop上,不得不说Samza是一个伟大的项目,这样可以减少项目的增长复杂度,利于维护,还是那句话,小而美的东西,更受欢迎一些。
架构:
Samza主要包含三层,
1. 流处理层 --> Kafka
2. 执行层 --> YARN
3. 处理层 --> Samza API
Samza的流处理层和执行层都是可插拔式的,开发人员可以使用其他框架来替代,不局限于上述两种技术。
Samza提供了一个YARN ApplicationMaster,和YARN job,运行在集群之外,下图中不同颜色代表不同的主机。
Samza客户端告诉YARN的Resouce Manager,它想启动一个Samza job, YARN RM 告诉YARN Node manager,分配空间给YARN ApplicationMaster,NM指定完空间后,YARN container会运行Samza Task Runner。

Samza状态管理
流式处理数据对状态的管理是很难的,由于数据是流动的,本身没有状态,这样就需要靠历史数据来记录应用的场合,Samza提供了一个内部的key-value数据库,它是基于LevelDB,运行的JVM之外的,使用它来存储历史数据。这样的做的好处是:
1. 减少JVM的开销
2. 使用内部存储,极大提高的吞吐率
3. 减少并发操作
Samza处理流程.
下图是Samza官方给的一例子,根据Member ID分组,计算页面访问次数。入口消息分别来自Machine1、2,出口是Machine3,我们可以这样理解,消息分散在不同的消息系统中(Kafka),Samza从不同的Kafka中读取topic,在将topic进行处理后,发送到Machine3,这里不做过多分解,具体可以参照官方文档。

项目地址:https://github.com/apache/incubator-samza
官方文件:http://samza.incubator.apache.org/
以上给了我们无限遐想,Storm是否会保持领先地位,Samza能否取而代之呢,无论如何,作为开发者来说,几千行代码,我都迫不及待去要读一下了。