1.总体介绍:
CMS(Concurrent Mark-Sweep)是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。在启动JVM参数加上
-XX:+UseConcMarkSweepGC ,这个参数表示对于老年代的回收采用CMS。CMS采用的基础算法是:标记—清除。
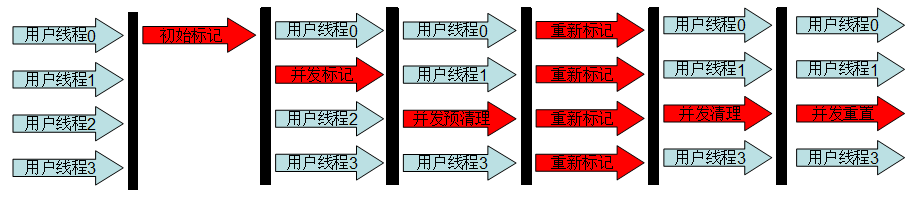
2.CMS过程:
- 初始标记(STW initial mark)
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark)
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)
初始标记 :在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的"根对象"开始,只扫描到能够和"根对象"直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
并发标记 :这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
并发预清理 :并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代,或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段"重新标记"的工作,因为下一个阶段会Stop The World。
重新标记 :这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从"跟对象"开始向下追溯,并处理对象关联。
并发清理 :清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
并发重置 :这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
CSM执行过程:
3.CMS缺点
- CMS回收器采用的基础算法是Mark-Sweep。所有CMS不会整理、压缩堆空间。这样就会有一个问题:经过CMS收集的堆会产生空间碎片。 CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。为了解决堆空间浪费问题,CMS回收器不再采用简单的指针指向一块可用堆空间来为下次对象分配使用。而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象。
- 需要更多的CPU资源。从上面的图可以看到,为了让应用程序不停顿,CMS线程和应用程序线程并发执行,这样就需要有更多的CPU,单纯靠线程切换是不靠谱的。并且,重新标记阶段,为空保证STW快速完成,也要用到更多的甚至所有的CPU资源。当然,多核多CPU也是未来的趋势!
- CMS的另一个缺点是它需要更大的堆空间。因为CMS标记阶段应用程序的线程还是在执行的,那么就会有堆空间继续分配的情况,为了保证在CMS回收完堆之前还有空间分配给正在运行的应用程序,必须预留一部分空间。也就是说,CMS不会在老年代满的时候才开始收集。相反,它会尝试更早的开始收集,已避免上面提到的情况:在回收完成之前,堆没有足够空间分配!默认当老年代使用68%的时候,CMS就开始行动了。 – XX:CMSInitiatingOccupancyFraction =n 来设置这个阀值。
总得来说,CMS回收器减少了回收的停顿时间,但是降低了堆空间的利用率。
4.啥时候用CMS
如果你的应用程序对停顿比较敏感,并且在应用程序运行的时候可以提供更大的内存和更多的CPU(也就是硬件牛逼),那么使用CMS来收集会给你带来好处。还有,如果在JVM中,有相对较多存活时间较长的对象(老年代比较大)会更适合使用CMS。
JBOSS默认配置会有一个后台漏洞,漏洞发生在
jboss.deployment命名空间 中的
addURL()函数,该函数可以远程下载一个war压缩包并解压访问http://www.safe3.com.cn:8080/jmx-console/ 后台,如下图

下拉找到如下图所示

点击
flavor=URL,type=DeploymentScanner进入

在输入框中写入war压缩文件webshell的url地址,如上图点击invoke执行界面获得一个jsp的webshell,如下图
 临时漏洞修补办法
临时漏洞修补办法:给jmx-console加上访问密码
1.在
${jboss.server.home.dir}/deploy下面找到jmx-console.war目录编辑WEB-INF/web.xml文件 去掉 security-constraint 块的注释,使其起作用 2.编辑WEB-INF/classes/jmx-console-users.properties或server/default/conf/props/jmx-console-users.properties (version >=4.0.2)和 WEB-INF/classes/jmx-console-roles.properties 或server/default/conf/props/jmx-console-roles.properties(version >=4.0.2) 添加用户名密码 3.编辑WEB-INF/jboss-web.xml去掉 security-domain 块的注释 ,security-domain值的映射文件为 login-config.xml (该文件定义了登录授权方式)

这是一份历尽千辛万苦,迟来却依旧让人无比激动的圣诞礼物。就在大约1个小时之前,Pod 2g的博客终于迎来了更新,标题更是醒目的“A4 release”,等待终于结束了。
Pod 2g在博客中称,基于他的研发成果,Chronic Dev Team(带头大哥p0sixninja,代表作绿毒)和iPhone Dev Team(带头大哥肌肉男,代表作红雪)经过测试后,于今天正式发布A4设备的iOS 5.0.1完美
越狱。
无论是已经不完美
越狱的用户,还是从未使用RedSn0w
越狱的用户,均可使用本次
越狱方案进行完美
越狱。支持设备:iPhone 3GS/4,iPad1代,iPod touch 3/4。与此同时,Pod 2g建议大家在苹果发布iOS 5.0.2时不要升级,以免
越狱漏洞被封堵。
越狱工具下载,请点击跳转。 使用最新版RedSn0w完美
越狱iOS 5.0.1教程:
首先当然是要将手上的设备升级到iOS 5.0.1了。向小白温馨提示:不要直接连接iTunes之后点击升级5.0.1,因为这样一来设备上的部分软件还会保留,不利于后面的
越狱。正确做法:直接通过iTunes安装苹果官方的5.0.1固件即可。
 第一步:
第一步:从我们给出的链接地址下载Mac/Windows版RedSn0w 0.9.10b1。解压后打开redsn0w.exe,点击Jailbreak。
 第二步:
第二步:此时要确保需要
越狱的设备与电脑连接,点击Next
 第三步:
第三步:进入DFU模式。具体操作方法RedSn0w已经给出:先按电源键三秒左右,等待跳转之后再按下Home键,此时不要放开电源键,再次跳转之后放开电源键,Home键保持不动。
 第四步:
第四步:最后放开Home键之后就是验证设备和准备
越狱的过程了,需要花上一点时间。

 第五步:
第五步:验证完成后,出弹出以下图框,第一个打勾选项为安装Cydia,此时点击Next。这时候RedSn0w会上传RAM Disk和Kernel,最后就是进行
越狱了,整个过程估计耗时5分钟左右。

 第六步:
第六步:此时iPod touch 4(iOS 5.0.1)已完美
越狱。
iOS 5.0.1完美
越狱方法2:
以上是使用最新版本的RedSn0w v0.9.10b1进行的完美
越狱。假如你的设备之前已经升级iOS 5.0.1,并且已通过RedSn0w进行过不完美
越狱,那么这里还有一种来自绿毒团队Chronic Dev Team的方法,支持iPhone 3GS/4, iPhone 4 CDMA, iPad 1, iPod touch 3/4。这种方法更为简单直接:
 第一步:
第一步:进入Cydia,搜索到Corona Untether 5.0.1
第二步:点击安装,Cydia会帮你完成接下来的工作
没有第三步了。
完美
越狱完成,你现在已经可以安全重启这些设备了。
Cydia成功出现在iOS 5.0.1系统当中,还只是第一步而已。各位在
越狱之后,先不要急着进入Cydia,因为Cydia在IOS5.0+的固件下,添加源会闪退,以下是处理方法:
点击设备中的设置→通用→多语言环境→语言中,选择English(英文),进入英文环境。这时候Cydia不会出现闪退,所以可以在这个时候添加源。
加入源的步骤如下:
第一步:点击下方Manage(管理),进入Source(软件源)
 第二步:
第二步:点击右上方Edit(编辑)
 第三步:
第三步:点击左上方Add(加入)
 第四步:
第四步:弹入方框后输入apt.weiphone.com(威锋源)后,点击Add Source(加入软件源)
 第五步:
第五步:如果弹出一个警告窗口,请无视它,点击Add Anyway(仍然加入),之后就会进入源的安装中了。
 第六步:
第六步:安装完成之后,点击右下的Search(搜索),输入afc2,就会出现一个叫做“afc2服务补丁”的文件。
 第七步:
第七步:点击进入“afc2服务补丁”的文件之后,点击右上的Install(安装),跳转页面之后在点击右上角的Confirm,之后就是安装文件了。
 第八步:
第八步:到了这步,大家可以下载iFunBox了(
iFunBox下载地址请点击跳转)。下载完成后,打开iFunBox,选择路径文件系统/var/mobile/Library中找到Keyboard文件夹,并将其拖出桌面。
 第九步:
第九步:然后再选择路径文件系统/var/root/Library,将桌面的Keyboard文件夹拖入其中。

OK了,完成这步之后,就解决了你在简体中文环境下,iOS5.0+系统使用Cydia崩溃的情况。之后就能在切换回简体中文了。最后可不要忘了安装 AppSync for iOS 5.0,只要在搜索中搜索就能看见,点击安装之后就能安装破解过后的后缀名为ipa的软件了。

最后,我们仍然要再次重申的是,本次
越狱仅支持iOS 5.0.1。大神的博客里写得很清楚了,5.0的完美
越狱目前还在测试之中,相信不久之后就会放出。另外,两个版本的
越狱都不支持iPhone 4S和iPad 2,希望大家注意了。
周末听了项目管理的课程,很有感触,有很多记忆深刻的点,比如不要揣摩要提问,要先管理后产品,胜者先胜而后战,败者先战而求胜。然而,让我印象最深的是估算工时这点事,不禁让我想起自己的经历来。
最开始刚参加工作时是在一家翻译公司做它内部的协同系统,两个程序员,老大和我,老大是30岁的老程序员,安排工作很随性,每天早上,点点系统,然后想想接下来要做什么,然后,叫上我,说,把这棵树实现一下吧,然后,再说,需要多长时间?我想一会儿,不就是一棵树吗,说,1小时。老大点点头,说,好,1天。再一天,老大又交给我一项任务,这次任务量大一些,要实现一个完整的模块,我同样是想了想,说3天,老大点点头,说,好,9天。老大总是这样,只要是我作出的估算,他总要乘以3,对此我是不以为然的,这也太保守了。不过好消息是,一年下来我们从未加过班,几乎所有的工作都按计划完成了,日子过得轻松而又悠闲,经常有些时间写点自己喜欢的其他代码,一点也不像程序员。
第二份工作就是IT公司了,做企业应用开发。老大使用干特图来进行工期管理,项目开始之前,老大已经分好大的模块了,这些模块比我第一家公司所谓的模块要大的多,需要以周来估算。这天,老大叫上我,问,这个门户的模块需要几周完成?我想一想,门户以前没有接触过,学习需要一周,开发需要两周,再留一周测试,说,四周。老大点点头,说,好,我再给你加一周学习时间,于是用鼠标在project上拖出一条长长的蓝线来。几个程序员每个都拖出一条蓝线来,三个程序员,八个模块,蓝线短的就再估算一个模块,这样,一条一条蓝线拼起来,最长的那条就成了关键路径,也决定了交付日期,交付日期定在五个月以后。于是就开始开发,那时年轻,无知者无畏,还是单身,加班就不是问题,三个人周六都在公司,吭嗤吭嗤,还真在五个月后给吭嗤完了。于是开始请测试妹妹测试,这一测试问题就来了,很多模块根本就是不可用,只是能够增删改查,很多功能点都没有考虑到,易用性就更别谈了,也难怪,系统设计、实现、测试都被一个只会写代码的程序员包了,既当运动员又当裁判员,能想清楚才怪,于是继续吭嗤,这不吭嗤还好,一吭嗤不得了,又吭嗤出五个月来,再看看jira,几百个bug,每个人都很绝望,老大手一挥,说,哪个软件没有bug,停止开发,修复最重要的bug,然后发布。
第二个项目做完,开始反思,为什么延期这么长估算这么不准,想了很久,觉得是因为估算的粒度太大,时间超过一周,对估算的开发量实际就失去计算了,只剩下一个大概的印象,而为了不成为关键路径不在老大面前丢脸,拍胸脯的情况也发生了,没事,加几个班就搞定了。同时,缺少系统需求说明,这样,在一个错误时间内完成一个不可能完成的任务,质量可想而知,赶进度献礼工程不仅政府在做,程序员同样在做。
这样,到了第三年,自己开始负责一个项目了,吸取了教训,开发估算时,估算的工作量不能超过1周,一旦超过就需要继续分解再进行估算。估算下来,这个项目需要四个月完成,又想起第一个老大的乘三法则,心里颤了一下,难道需要12个月?不能这样,这样这个项目就被取消了。自己带了侥幸的心理,团队的成员都很强,事后也证明这个团队的个人能力都很强,因为有两个人现在在知名外企,一个在淘宝,一个在腾讯,小公司组成这样豪华的阵容是很难得的,唯一不幸的是,我是那个项目经理。我把交付时间定在了四个月之后,开发进度整体还是顺利的,稍微有延期,每周需要延一到两天,这样,我把时间又延长了一个月。天知道,意外发生了,因为我的一句批评,一个成员离职了!我痛哭的发现,项目又要延一个月了,于是,接下来,我就流涕了,六个月时间,公司没有那么多钱投入了!我开始加班,要求其他人也加一些班,意外接着发生,有人生病了,有人有急事要请假了,到最后,终于发现,按估算完成是完全不可能的。最后,项目就被取消了,悲催的项目经理。
继续反思,为什么估算不准,这次我自以为原因很清楚,就是没有考虑项目风险,没有考虑到人会离职,没有考虑到人会请假,没有考虑到人会生病,甚至,没有考虑到人一天工作的产出不是八小时。我太乐观了。我再一次想起来我的第一个老大。
新的公司,新的估算方式,不再一个人估算而是一伙人估算,特性不估算,故事点再估算,没有需求不估算,不一次性估算,迭代估算。这次似乎没有问题了,但客户总是需要一个大的时间点的,于是每个迭代都会排定故事优先级,确保交付前交付的是最有价值的,此外,还有专职的业务分析和漂亮的测试美眉,一切看起来都很好。新公司第一个项目也确实轻松的,但第三个和第四个却都失败了,第三个项目在遇到一个很难解决的性能问题时陷入了一片混乱当中,迭代经理甚至自己都失去对整个项目的可视化了,她不知道项目上线究竟需要满足什么条件,于是项目在一次次的下周二上线的空头承诺中成了整个公司的笑柄。幸福的项目总是相似,不幸的项目各有各的不幸。第四个项目在一次项目中期的架构重写中崩溃了,重写耗去了团队太多的时间,而由于对未知领域知识的不正确估算再次令项目雪上加霜,而更加致命的是,项目目标直到最后一刻也没有发生变化,依旧是要在六个月后上线,于是,程序员们就内存溢出了。
乐观、管理混乱、领域知识不熟,这些都导致了项目延期,工时等于工期吗?不等于,工期永远是假的,工时估计的准确,混乱的管理同样会毁掉它。更严重的不是项目延期,而是项目本来就是老板拍脑袋的结果,想想某个项目,如果不说我们能快速交付就根本得不到它,而得到它后怎么办,那只能拜春哥了!
摘要: 所需软件 Apache :apache_2.0.63 1 个 【apache_2.0.63-win32-x86-no_ssl.msi】 Tomcat: apache-tomcat-5.5.23 (zip版) 2个 mod_jk:: mod_jk-apache-2.0.55.so 1个 部署说明 在同一台机器上部署,即充当Apache负载服务器,又安装两个Tomcat Web服务...
阅读全文
在application server下,比如常见的weblogic,glassfish,jboss等,由于javaee规范的要求,一般不容许直接启动线程。因此在常见的异步/并行任务执行上,会遭遇到比普通javase程序更多的麻烦。
典型例子,在javase中,jdk1.5后就引入了java.util.concurrent包,提供Executor这个非常好用的框架,完美的满足一下典型需求:
1. 同步变异步
请求进来后,将请求封装为task,交给Executor执行,原线程可以立即返回
2. 并行执行
请求进来后,将请求拆分为若干个task,例如下发短信,有100个收件人就可以按照每个收件人一个task来执行,这样可以通过Executor来并行执行这些请求,远比循环执行要快的多。
3. 等待任务结束
有时有要求调用线程必须等待所有任务完成后再继续运行的需要,此外还有超时等细节设置要求。
而在application server,为了避开自己启动线程的弊端,只好通过其他的方式来完成类似的功能。
目前我们的项目开发中主要有三种实现方式:
1. jms queue
通过jms来实现异步和并发,然后自己通过编码方式完成调用线程等待所有任务执行成功。
这个方案比较通用,因为jms是javaee的标准,所有的application server上都支持。因此天然具有跨application server的能力。
缺点就比较多了,首先jms是需要实现串行化的,因此对task是有要求,不能串行化的类是不能传递的。另外串行化的性能损失比较大,造成性能和稳定性问题,这个在大压力下比较突出,基本我们目前在考虑放弃这个方案,而且逐步将原有的实现替换掉。
这个方案还有另外一个缺点,配置麻烦,维护困难:需要创建jsm queque, connection factory, MDB等,如果系统中使用的多了,配置起来很罗嗦,修改时容许出错。
2. commonj work manager
这个是weblogic和WebSphere上支持的一个很实用的解决方案,个人感觉使用上非常舒服,配置简单,只要在weblogic-ejb-jar.xml中间中简单配置:
 < work-manager >
< work-manager >
< name > wm/taskDistributionWorkManager </ name >
< min-threads-constraint >
< name > minthreads </ name >
< count > 1 </ count >
</ min-threads-constraint >
< max-threads-constraint >
< name > maxthreads </ name >
< count > 100 </ count >
</ max-threads-constraint >
</ work-manager > 使用时用jdni lookup到就可以使用了。功能和使用方式和executor框架很类似,同样提供future,而且提供一个非常实用的waitAll()方法论支持等待任务完成。
这个方案的性能非常好,和jms相比提升极大,运行也稳定。缺点就是不是标准,只有weblogic和WebSphere执行,在glassfish,jboss上无法使用。
3. JCA work manager
这个是JCA标准了,glassfish,jboss都支持的,和commonj work manager很像,但是,很遗憾的是没有future的支持,而且也没有类似的waitAll()方法,只能自己编码实现。
spring为glassfish提供了一个工具类"org.springframework.jca.work.WorkManagerTaskExecutor",简化了JCA work manager的使用。
JCA work manager的性能和稳定性都还不错,对比jms要好的多。
JBOSS下的配置
jboss-web.xml
<?xml version="1.0" encoding="UTF-8"?>
<jboss-web>
<resource-ref id="ResourceRef_1163654014164">
<description>WorkManager</description>
<res-ref-name>jboss.jca:service=WorkManager</res-ref-name>
<res-type>org.jboss.resource.work.JBossWorkManager</res-type>
<res-auth>Container</res-auth>
<res-sharing-scope>Shareable</res-sharing-scope>
<jndi-name>WorkManager</jndi-name>
</resource-ref>
</jboss-web>
applicationContext.xml
<bean id="taskExecutor" class="org.springframework.jca.work.jboss.JBossWorkManagerTaskExecutor">
<property name="workManagerName" value="WorkManager"/>
<property name="resourceRef" value="true"/>
</bean>
从目前我们项目的使用经验上看,jms是准备要被淘汰的了(其实我是一直对jms不感冒的,尤其是在有性能要求的地方,想不出用jms的理由)。目前项目要求同时支持weblogic和glassfish,因此commonj work manager和JCA work manager刚好对应于weblogic和glassfish平台。实际使用中,是在这两个work manager上封装了一个通用的接口,然后再有commonj work manager和JCA work manager两个实现,在运行时通过判断平台来自动选择注入其中的一个。
摘要: 用ThreadPoolExecutor的时候,又想知道被执行的任务的执行情况,这时就可以用FutureTask。ThreadPoolTask
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->package com.paul.threadP...
阅读全文