 2006年2月7日
2006年2月7日
时间和日子在无知无觉中过去,问自己收获了什么?
每天无所事事。
列个标题,挖个坑,希望每天能来挑一点土。
《解读eclipse_3.50_galileo 源码》
从第一次使用eclipse(大概是03年的事,那时比较好用的是2.1版还是1.4版已记不清了)就想看看这么巧妙的一个玩意儿是怎么实现的,一直懒散无度,从未下手。
这段时间用SWT做个小工具,是边找边抄,为什么要那么写,不知道--真是有违一惯的作风。
每天下班后,都不是为什么奔忙着,网页?网游?都不知道自己看了些什么,玩了些什么。
eclipse 的jar很多,核心的是core.runtime和osgi(早些版本里,是没有osgi的),core.runtime比较小,就几个类,先攻击小的少的--毛主席真是伟大的军事家呀。
敬礼,睡觉去。
前言
一直想学习C,在刚知道有计算机的时候就想学习C,上学时,偷上计算机专业的课,学了半年Turbo C,学到指针时,晕了,也就没有下文。工作之后,时有心血来潮之时,但还是没怎么学习,Java还是比较简单,Java几乎占据了工作全部,更少有学习C了。用Java,研究到Java的核心,发觉还是得学C,学呀,学吧。
今天也是一时的心血来潮了,趁着有股劲,开始动手,记录一下,以期待和方便下次来潮。
写出的代码,得编译才可以运行,这个编译环境,得先搭起来。VC、Visual Studio,都微软的东西,有点抵触,也有些大,不安装了,手工配一套环境吧。
网上搜了一下,Windows系统配C的编译环境,得要MinGW或者cygWin,以前都下载过,但一直不知道它们本身是个什么东西,再查,知道大概:二者均基于GCC(GNU Compiler Collection -格努编译套件),再加一些基本的类库。去各自的官网分别下载安装,感受:cygWin更象是一个linux的模拟器,把linux环境下的GCC给模拟出来,其它的就都一样需要基本的编译器、类库,其它的如make工具。使用的时候,个人取向选择minGW,在环境变量中指向{$minGW}\bin,gcc和make就可以在cmd中运行了。
写个简单的hello world源程序,gcc一把,生产可执行文件,运行,结果出来,OK!
注,下载minGW时,我选择了自动安装下载,一个个的下载,点来点去,累的慌。
单独下载minGW,要如下几个包,再分别解开放在同一目录中。
gcc-core | C语言编译器 |
gcc-c++ | C++语言编译器 |
mingw-runtime | MinGW的运行时库(这个必须安装) |
win32api | win32的API函数头文件和连接库 |
binutils | MinGW的汇编器和连接器等基础工具 |
gdb | MinGW中的调试工具 |
mingw32-make | Make工具,用以更好的管理你的项目 |
make解后,没有通常的make.exe,只有一个mingw32-make.exe文件,其实,把这个文件改名为make.exe就行。
1978:第一个关键的年份
1988:虽然是第一个十年,但十岁的生日没多少印象了,更多的是开始注意的第一个年份。
1993:初中结束了,
1997:高中结束了,
2000/06/30:大学毕业了,世纪之交呀!
2000/08/03:子身跑到汕头的一个小镇开始第一份工作,真正的人生地不熟。到目的地时,身上只有20块钱了,还是年青的老板给我付的“摩的”费。
2001/11/03:混到一份跟自己所学专业,所做的工作一点也不相关的工作,毅然一个人跑到北京。首都呀!当时天很冷,比我想象的要冷,下车后把能穿的都穿上,不知象什么熊。打22块钱的车找到公司,竞然还没到上班时间。
2004/06/xx:一个伤感的月份,也注定要离开这个做了好几年有公司。
2004/08/04:换了一个比较远的公司,在朝阳,自己租住在西直门。
2005/02/28:一个没有29日的月份,还没开始工作,就没有选择的离开了。
2005/07/03:
2006/07/03:换了一份工作,不知什么感受。
与Velocity的第一次见面,是03年,有个新同事推荐使用,因当时我在做别的项目,也没怎么仔细了解,简单的知晓类似如模板一类的东西。之后有过几次接触,但,都没花时间仔细看,前段时间,帮朋友做一个小东西,觉得用个模板做,会省很多事,想到Velocity。东西很小,做完了都没时间看Velocity,今天正好有时间,研究研究。
Velocity是apache下的一个开源项目,其网址:http://velocity.apache.org/;下载地址:http://velocity.apache.org/download.cgi,可直接下载源码,也可通过SVN获取源码。
在eclipse中创建一个web应用工程,把Velocity的源码拷到java资源目录下,自动编译后,报几个错,拷贝下载的Velocity源码lib目录下的commons-collections-3.1.jar、oro-2.0.8.jar、commons-lang-2.1.jar这个三类包到web应用工程的lib目录下即可。
准备就绪,就写个例子跑跑试试。写一个hello.vm的模板文件,创建一个对应的Servlet,就可以运行了。两文件源码贴出如下:
hello.vm
<html>
<body>
#set($greet = "你好哇!")
Hello!$name, $greet
</body>
</html>
HelloServlet.java
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.Hashtable;
import java.util.Properties;
import javax.servlet.ServletConfig;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.velocity.Template;
import org.apache.velocity.app.Velocity;
import org.apache.velocity.context.Context;
import org.apache.velocity.servlet.VelocityServlet;
public class HelloServlet extends VelocityServlet {
protected Properties loadConfiguration(ServletConfig config)
throws IOException, FileNotFoundException {
Properties p = new Properties();
String path = config.getServletContext().getRealPath("/");
if (path == null) {
path = "/";
}
p.setProperty(Velocity.FILE_RESOURCE_LOADER_PATH, path);
p.setProperty("runtime.log", path + "velocity.log");
p.setProperty(Velocity.INPUT_ENCODING, "GBK");
p.setProperty(Velocity.OUTPUT_ENCODING, "GBK");
return p;
}
public Template handleRequest(HttpServletRequest request,
HttpServletResponse response, Context ctx) {
Template template = null;
try {
ctx.put("name","Velocity");
template = Velocity.getTemplate("/hello.vm");
} catch (Exception e) {
e.printStackTrace();
}
return template;
}
}
创建servelt要注意的几个地方。
1、新建的Servlet要扩展Velocity的VelocityServlet
2、在servlet中要实现 public Template handleRequest(HttpServletRequest request,HttpServletResponse response, Context ctx)
A)把要返回到页面上的数据放到context中对应到指定键值(键值名为对应模板中定义的变量名)
B)引入指定模板文件
3、导入配置文件的方法protected Properties loadConfiguration(ServletConfig config),是否实现,是可选的 ,其作用在后面说明。
发布运行后,访问http://localhost:8080/vt/HelloServelt,就可看到结果了。
运行起来,看到结果,是觉得很简单,其运行过程,就要跟踪看源码才能知道了。
看源码,先看的,肯定是VelocityServlet.java。发现源码注释中,这个类已不推荐使用,推荐使用Velocity的一个子项目tool中的VelocityViewServlet.java,我没有当tool子项目,就先看这个“过时的”实现。
VelocityServlet.java,扩展了HttpServlet,实现了doGet、doPost、init基本方法,前两个方法都直接调用新实现的doRequest方法,这些都是很常规的操作。
doRequest方法做如下几件事:创建上下文、设置响应内容文件类型、获取模板(调用每个请求中的具体实现)、合并数据做出响应、出错处理及资源清理。看到这儿,整个请求和响应过程很清晰,并没什么特别的处理。
接下来,看看它的初始化做了些什么事。就做了三件事,超类初始化、自己的初始化、缓存内容类型数据。自己的初始化,也就是(i)导入配置信息,(ii)根据配置信息做初始化设置。导入配置信息,是根据指定的几个地方,获取配置数据(在提供的样例中,重载了它的获取配置数据的方法,自己灵活的写入一些配置信息);根据配置信息做初始化的工作,应用单例设计模式,保证初始化工作的处理唯一。
VelocityServlet自已的初始化,调用另一个类org.apache.velocity.app.Velocity的init( Properties p )方法,就看看Velocity里做了些什么。Velocity里全是静态方法。主要有如下几个方法:
1、初始化;2、预演传入的数据(发现在应用中没有使用,只在单元测试代码中引用到);3、合并数据和模板;4、设置/获取属性;5、操作信息提示(不过,都不推荐使用了),整个的看下来,有两点:1、主要的还是初始化和数据合并了;2、这个类只是一个中转类,所有的方法,最终都是调另一个类org.apache.velocity.runtime.RuntimeSingleton的方法。
打开RuntimeSingleton的代码,看一看,发现它同Velocity类差不多,类本身不做实际的处理操作。它与Velocity不同的是,它是申明一个静态的实例,再调用这个实例,个别地方(init())加了同步控制。如此处理体现它这个类的名字--单例,核心的还是这个静态实例org.apache.velocity.runtime.RuntimeInstance。
到RuntimeInstance,就开始接触到Velocity的处理核心了。
写到这儿,突然没有写下去的冲动了,暂切休息一下。
抽时间看了一下Velocity子项目tool下的VelocityViewServlet的源码,比VelocityServlet要实现的好多了,与struct接合的比较好。
Velocity,不仅仅适合于web应用,还可以作生成SQL、XML的模板,内容比较多,待一一挖掘。
在网上看到“
盖茨北大演讲遭开源人士抗议”一事,对开源兄的行为,我选择不置可否,但对软件而言,我选择开源。
现在的局面是,商业化的软件比开源的软件,要活地滋润、舒展多了,所以也会发生这次事件。
为什么会出面这种局面?为什么需要开源?在这里我不阐述自己的观点--持有同感的人都有自己的想法。
开源如果想要活得不那么艰难,我想:需要一个良好的商业模式支持。
开源不是免费!
开源要生存发展,也需要营养供应,不能仅靠一部分怀开源激情的人或者组织无偿奉献能支撑起来的。
linux、jboss的生存模式算是比较成功的,但还不能够同商业化软件相比较,还需要更充足的营养源。
这二者的模式也是一定范围内有效,不能做到推而广之。
开源软件生存模式的探索之路还很广,还很远,需要有志之士共同努力。
上次看centric crm,是一年多前的事了,这一年中,忙忙碌碌的,都不知道做了些什么,但还是一直关注crm的相关信息。
年初,有个朋友需要一套CRM软件,我就给他推荐centric crm,但他不懂技术,希望我帮他搞搞,这就应了下来,又一次开始认真的看centric crm。
[温故而知新]
看以前贴的关于centric crm的blog,心有惭愧,希望产生误导的影响不会很大。
今天作一些更正,算是补偿。
1、获取centric crm源码,得先注册,注册地址:http://www.centriccrm.com/Register.do
先输入你的邮箱地址(登录用这个);
个人名称可随便填写;
注册成功后,密码会发送到你邮箱中,
2、官方用SubVersion管理centic crm的源码,可以当一个subverion的客户端,指定到要下载版本的链接,
输入注册的邮箱和密码,就可以获取源码。
现在有4.0和4.1两个版本,subverion链接分别如下,
4.1源码:https://svn.centricsuite.com/webapp/branches/branch-41
4.0源码:https://svn.centricsuite.com/webapp/tags/rel-200611151353-402
我使用eclipse,装了个SVN插件,配好后,直接check out成eclipse的项目。
SVN eclipse plugin是subclipse,插件获取网站:http://subclipse.tigris.org/update_1.2.x
3、源码获取下来目录如下图
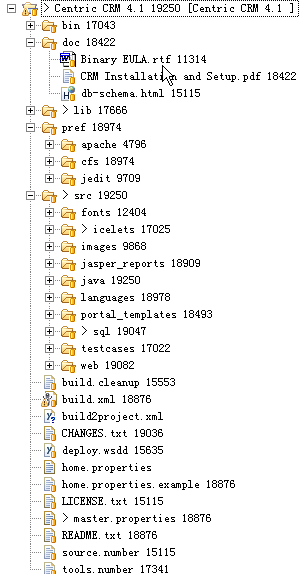
[源码check out到eclipse后,把整个项目编码方式改为UTF-8,因源文件注释中有些时间戳是中文简体字,不设成UTF-8,就显示为乱码,看起来没什么大碍,但若修改源文件再保存就会弹出编码格式不正确错误信息]
bin:暂没看这个目录中的内容
doc:基本文件目录
Binary EULA.rtf:版权申明的文件;
CRM Installation and Setup.pdf:安装配置文件,描述的比较简单;
db-schema.html:库表设计说明文件,了解centric CRM表结构这个文件最佳参考资料
lib:项目需要的jar文件目录
pref:特定情况下需要的配置文件目录
src:源码基本目录
src目录内有下面四个主要目录:
java:java源文件目录
web:web展示源文件目录
sql:库表脚本文件目录
testcases:单元测试文件目录
src目录内有下面四个主要文件:
build.xml:项目编译、发布的ant配置文件
home.properties.example:build.xml的辅助文件样例,定义一些基本路径信息,如:服务发布目录
master.properties:build.xml的辅助文件,定义系统的一些属性配置
README.txt:比较详细的安装配置文件(我就是看这个文件进行安装配置的,有时间可以把安翻译成中文)
4、开始安装配置
1)安装需求Java JDK,就不用说了,1.4以上都可以,1.4以下行不行,我也没试,有兴趣的朋友可试试,测试结果能告之当是感激了。我装的是JDK 5.0。
2)应用服务用tomcat 5.0,5.5都可以(不过tomcat5.5得在JDK5.0上才能运行起来),Jboss、Weblogic、WebSphere、Resin也可以运行。我用Tomcat 5.5.3。
3)数据库支持DB、MSSQL、MySQL、Oracle等,具体信息可看README.txt。我用的是MySQL 5.0.21。驱动jar是MySQL官网下载的 mysql-connector-java-5.0.4-bin.jar。
4)还需要有ant工具,申明是要1.6的,我用eclipse自带的1.6.5。
5)centric CRM中用到WebServices,可去下载一个,
下载地址:http://apache.downlod.in/ws/axis/1_4/axis-src-1_4.zip。
解开zip包,把webapp下面的axis目录拷贝到$tomcat/webapps/目录下。
准备好上几步要求的,可以开始配置build.xml运行的两个属性文件。
复制home.properties.example文件为 home.properties,相关属性做如下修改:
## The following properties can be set instead of using environment variables
## Declare the webapp server's directory to compile using web app server libraries
## based on the webapp type configured in build.properties
## 设置Tomcat安装路径
CATALINA_HOME=D:/java/tomcat5.5.3
#GERONIMO_HOME=/path/to/geronimo or websphere ce
#JBOSS_HOME=/path/to/jboss
#WEBLOGIC_HOME=/path/to/weblogic
#WEBSPHERE_HOME=/path/to/websphere
## CENTRIC_HOME can be used to compile directly to the webapp's deployment
## directory (for development), or to any directory for later generating a .war
## 设置centric CRM 发布到tomcat中的路径
CENTRIC_HOME=D:/java/tomcat5.5.3/webapps/centric
#CENTRIC_HOME=/path/to/weblogic/domain/autodeploy/directory
## At times, scripts will need to install or upgrade fileLibrary documents when
## deploying from source
## 设置项目中配置文件存放目录
CENTRIC_FILELIBRARY=D:/Project.java/Centric CRM 4.1/fileLibrary
## To skip web based GUI the fileLibrary must be in the WEB-INF folder, useful
## for development
## 设置配置文件发布目录
CENTRIC_FILELIBRARY=D:/java/tomcat5.5.3/webapps/centric/WEB-INF/fileLibrary
## If using Axis Web Services, then declare the webapp home so that the
## Centric CRM descriptors can be installed with "ant ws"
## 设置axis在tomcat中的发布目录
AXIS_HOME=D:/java/tomcat5.5.3/webapps/axis
master.properties 相关属性做如下修改:
##
## NOTE: Do not edit "master.properties" -- edit a copy of it
## These settings are used by ant for the build and installation process
##
## PART 1: Are you reading the instructions? (required)
## The following is a control, uncomment the following line after modifying
## these properties... we just want to make sure you're paying attention and
## the build process doesn't do something it shouldn't!
## 确认修改过此配置文件标识
PROPERTIES=configured
## PART 2: Deployment settings (required for compiling)
## Default language setting: even though any locale can be specified, the
## following have Centric CRM translations and supporting database data
## args="de_DE,en_US,es_VE,fr_FR,it_IT,ja_JP,nl_NL,pt_BR,ro_RO,ru_RU,sl_SI"/>
SYSTEM.LANGUAGE=en_US
## Web server debug level:
## Extended debug information can be displayed in the web server's log file
## Comment out for no debugging, especially production server
DEBUGLEVEL=2
#DEBUG=true
#DEBUGLEVEL=lines,vars,source
## Specify the web server to build/deploy against (required):
## Use catalina for Tomcat
## Use geronimo for WAS-CE or Apache Geronimo
## All others untested but planned for
## 指定Web Server 应用服务类型
WEBSERVER.TYPE=catalina
#WEBSERVER.TYPE=geronimo
#WEBSERVER.TYPE=jboss
#WEBSERVER.TYPE=weblogic
#WEBSERVER.TYPE=websphere
## A self-signed SSL Certificate will be generated with the following parameters,
## which can then be added to Tomcat's SSL configuration and/or
## signed by an authority
## Common name should be a domain name
## Ex. *.yourcompany.com or www.yourcompany.com
KEYSTORE.COMMONNAME=127.0.0.1
KEYSTORE.ORGANIZATION=Company
KEYSTORE.ORGANIZATIONALUNIT=Unit
KEYSTORE.CITY=City
KEYSTORE.STATE=State
KEYSTORE.COUNTRY=US
KEYSTORE.VALIDITY=1000
## Force users to use SSL in Centric CRM
## The web server must be configured for SSL if this option is set to true as
## Centric CRM will redirect non-secure URLs to the secure URL
FORCESSL=false
## PART 3: Database installation settings (required for database installation)
## Uncomment and set the connection information for your specific database
## NOTE: The gatekeeper URL includes your database name, the site URL does not;
## The ant script will insert the database name after the specified url
## DB2
## CREATE DATABASE centric USING CODESET UTF-8 TERRITORY US pagesize 32 k
#GATEKEEPER.DBTYPE=db2
#GATEKEEPER.DRIVER=com.ibm.db2.jcc.DB2Driver
#GATEKEEPER.URL=jdbc:db2://127.0.0.1:50000/centric
#GATEKEEPER.USER=db2admin
#GATEKEEPER.PASSWORD=
#SITE.DBTYPE=db2
#SITE.DRIVER=com.ibm.db2.jcc.DB2Driver
#SITE.URL=jdbc:db2://127.0.0.1:50000/
#SITE.USER=db2admin
#SITE.PASSWORD=
## POSTGRESQL
## createdb -E UNICODE centric_crm
#GATEKEEPER.DBTYPE=postgresql
#GATEKEEPER.DRIVER=org.postgresql.Driver
#GATEKEEPER.URL=jdbc:postgresql://127.0.0.1:5432/centric_crm
#GATEKEEPER.USER=postgres
#GATEKEEPER.PASSWORD=
#SITE.DBTYPE=postgresql
#SITE.DRIVER=org.postgresql.Driver
#SITE.URL=jdbc:postgresql://127.0.0.1:5432/
#SITE.USER=postgres
#SITE.PASSWORD=
## MySQL
## CREATE DATABASE centric_crm CHARACTER SET utf8 COLLATE utf8_general_ci
## 指定数据库类型及连接配置
GATEKEEPER.DBTYPE=mysql
GATEKEEPER.DRIVER=com.mysql.jdbc.Driver
GATEKEEPER.URL=jdbc:mysql://127.0.0.1:3306/my_centric_crm
GATEKEEPER.USER=my_centric_crm
GATEKEEPER.PASSWORD=crm
SITE.DBTYPE=mysql
SITE.DRIVER=com.mysql.jdbc.Driver
SITE.URL=jdbc:mysql://127.0.0.1:3306/
SITE.USER=my_centric_crm
SITE.PASSWORD=crm
## MS SQL SERVER
#GATEKEEPER.DBTYPE=mssql
#GATEKEEPER.DRIVER=net.sourceforge.jtds.jdbc.Driver
#GATEKEEPER.URL=jdbc:jtds:sqlserver://127.0.0.1:1433/centric_crm
#GATEKEEPER.USER=centric_crm
#GATEKEEPER.PASSWORD=
#SITE.DBTYPE=mssql
#SITE.DRIVER=net.sourceforge.jtds.jdbc.Driver
#SITE.URL=jdbc:jtds:sqlserver://127.0.0.1:1433/
#SITE.USER=centric_crm
#SITE.PASSWORD=
## CodeGear's InterBase (formally owned by Borland) www.codegear.com
## Do NOT put the database in the centric file library, or at least the root,
## as the build.xml copies its prefs into there using the same name as your database file!
## "e:/centriccrm_db" is only an example
#GATEKEEPER.DBTYPE=interbase
#GATEKEEPER.DRIVER=interbase.interclient.Driver
#GATEKEEPER.URL=jdbc:interbase://127.0.0.1:3050/e:/centriccrm_db/centric_crm.ib
#GATEKEEPER.USER=sysdba
#GATEKEEPER.PASSWORD=masterkey
#SITE.DBTYPE=interbase
#SITE.DRIVER=interbase.interclient.Driver
#SITE.URL=jdbc:interbase://127.0.0.1:3050/e:/centriccrm_db/
#SITE.USER=sysdba
#SITE.PASSWORD=masterkey
## FIREBIRD SQL
#GATEKEEPER.DBTYPE=firebird
#GATEKEEPER.DRIVER=org.firebirdsql.jdbc.FBDriver
#GATEKEEPER.URL=jdbc:firebirdsql:127.0.0.1/3050:${CENTRIC_FILELIBRARY}/centric_crm.fdb
#GATEKEEPER.USER=sysdba
#GATEKEEPER.PASSWORD=masterkey
#SITE.DBTYPE=firebird
#SITE.DRIVER=org.firebirdsql.jdbc.FBDriver
#SITE.URL=jdbc:firebirdsql:127.0.0.1/3050:${CENTRIC_FILELIBRARY}/
#SITE.USER=sysdba
#SITE.PASSWORD=masterkey
## DAFFODIL DB EMBEDDED
#GATEKEEPER.DBTYPE=daffodildb
#GATEKEEPER.DRIVER=in.co.daffodil.db.jdbc.DaffodilDBDriver
## YOU MUST EDIT THE path in the following line to where you want the database
## created.
## The user and password must be set to daffodil
#GATEKEEPER.URL=jdbc:daffodilDB_embedded:centric_crm;create=true;path=/home/fileLibrary/centric_crm/daffodildb
#GATEKEEPER.USER=daffodil
#GATEKEEPER.PASSWORD=daffodil
#SITE.DBTYPE=daffodildb
#SITE.DRIVER=in.co.daffodil.db.jdbc.DaffodilDBDriver
#SITE.URL=jdbc:daffodilDB_embedded:
## YOU MUST EDIT THE path in the following line to where you want the database
## created.
## Ex. Use the same path as Centric CRM's deployed file library, then the name of
## the database, then end in daffodildb
## The user and password must be set to daffodil
#SITE.APPEND=;create=true;path=/home/fileLibrary/centric_crm/daffodildb
#SITE.USER=daffodil
#SITE.PASSWORD=daffodil
## ORACLE
## During installdb, use XE (or whatever you add under gatekeeper) for the
## database name since the install has not been adjusted for Oracle yet
#GATEKEEPER.DBTYPE=oracle
#GATEKEEPER.DRIVER=oracle.jdbc.driver.OracleDriver
#GATEKEEPER.URL=jdbc:oracle:thin:@//127.0.0.1:1521/XE
#GATEKEEPER.USER=
#GATEKEEPER.PASSWORD=
#SITE.DBTYPE=oracle
#SITE.DRIVER=oracle.jdbc.driver.OracleDriver
#SITE.URL=jdbc:oracle:thin:@//127.0.0.1:1521/
#SITE.USER=
#SITE.PASSWORD=
## Derby
#GATEKEEPER.DBTYPE=derby
#GATEKEEPER.DRIVER=org.apache.derby.jdbc.EmbeddedDriver
## YOU MUST EDIT THE path in the following line to where you want the database
## created.
#GATEKEEPER.URL=jdbc:derby:/home/fileLibrary/centric_crm/derbydb;create=true;upgrade=true
#GATEKEEPER.USER=centric_crm
#GATEKEEPER.PASSWORD=
#SITE.DBTYPE=derby
#SITE.DRIVER=org.apache.derby.jdbc.EmbeddedDriver
## YOU MUST EDIT THE path in the following line to where you want the database
## created.
#SITE.URL=jdbc:derby:/home/fileLibrary/centric_crm/
#SITE.APPEND=;create=true;upgrade=true
#SITE.USER=centric_crm
#SITE.PASSWORD=
## PART 4: Advanced configuration (optional)
## Web-based configuration is recommended and is the default setting
##
## If you uncomment the following CONTROL line then you must configure the
## remaining parameters yourself. You will also have to create a new Centric
## CRM user and password before using Centric CRM.
##
## If you DO NOT uncomment the CONTROL line, then the first time you use
## Centric CRM, you will be presented with a configuration wizard which will
## assist you in defining these parameters and creating a new Centric CRM
## user and password.
##
#CONTROL=BYPASS_WEB-BASED_APPLICATION_SETUP
## The following are methods for working with multiple development databases
## The APPCODE must be the same for the following Gatekeeper prefs and Site prefs
GATEKEEPER.APPCODE=centric
SITE.APPCODE=centric
## Define the web address used in communications when using a single development
## database
#WEBSERVER.URL=127.0.0.1:8080/centric
## Define the web address used in communications when using multiple development
## databases
#WEBSERVER.ASPMODE=true
#WEBSERVER.PORT=8080
#WEBSERVER.CONTEXT=/centric
## The server's default timezone for new users (using standard Java names)
SYSTEM.TIMEZONE=America/New_York
## Default currency for all users
SYSTEM.CURRENCY=USD
## Default country for all users
SYSTEM.COUNTRY=UNITED STATES
## External Servers used by the system
MAILSERVER=127.0.0.1
FAXSERVER=127.0.0.1
FAXENABLED=false
PROXYSERVER=false
PROXYSERVER.HOST=
PROXYSERVER.PORT=
## Apache Axis Web Services
## 指定WebService 服务路径
AXIS.WEBAPP=/axis
AXIS.HOST=127.0.0.1
AXIS.PORT=8080
## Asterisk integration
ASTERISK.OUTBOUND.ENABLED=false
ASTERISK.INBOUND.ENABLED=false
ASTERISK.URL=
ASTERISK.USERNAME=
ASTERISK.PASSWORD=
ASTERISK.CONTEXT=from-internal
## XMPP/Jabber integration
XMPP.ENABLED=false
XMPP.CONNECTION.SSL=false
XMPP.CONNECTION.URL=
XMPP.CONNECTION.PORT=5222
XMPP.MANAGER.USERNAME=
XMPP.MANAGER.PASSWORD=
## LDAP integration
LDAP.ENABLED=false
# Validate username OR email against LDAP: username|email
LDAP.CENTRIC_CRM.FIELD=username
LDAP.FACTORY=com.sun.jndi.ldap.LdapCtxFactory
LDAP.SERVER=ldap://127.0.0.1:389
# Search by attribute, otherwise composite DN: true|false
LDAP.SEARCH.BY_ATTRIBUTE=true
LDAP.SEARCH.USERNAME=cn=admin,ou=IT,o=COMPANY
LDAP.SEARCH.PASSWORD=
LDAP.SEARCH.CONTAINER=o=COMPANY
LDAP.SEARCH.ORGPERSON=inetOrgPerson
LDAP.SEARCH.SUBTREE=true
LDAP.SEARCH.ATTRIBUTE=mail
#LDAP.SEARCH.BY_ATTRIBUTE=false
#LDAP.SEARCH.PREFIX=cn=
#LDAP.SEARCH.POSTFIX=,o=COMPANY
## Define the system's email address
EMAILADDRESS=Centric CRM <noreply@127.0.0.1>
## Timed events, definitely turn on for a production server
CRON.ENABLED=true
## Connection Pool Settings
CONNECTION_POOL.DEBUG=false
CONNECTION_POOL.TEST_CONNECTIONS=false
CONNECTION_POOL.ALLOW_SHRINKING=true
CONNECTION_POOL.MAX_CONNECTIONS=10
CONNECTION_POOL.MAX_IDLE_TIME.SECONDS=60
CONNECTION_POOL.MAX_DEAD_TIME.SECONDS=300
## Layout Settings
## Template replaces the following files which MUST exist:
## CSS:
## template1.css
## template1-8pt.css
## template1-10pt.css
## JSP:
## template1nav.jsp
## template1style.jsp
## template1styleNoSession.jsp
## template1styleContainer.jsp
LAYOUT.TEMPLATE=template1
LAYOUT.JSP.WELCOME=welcome.jsp
LAYOUT.JSP.LOGIN=login.jsp
#LAYOUT.JSP.LOGIN.LOGO=<img src="images/centric/logo-centric.gif" width="295" height="66" alt="" border="0" />
#LAYOUT.JSP.LOGIN.TEXT=Centric CRM
## Max Imports that can run concurrently
IMPORT_QUEUE_MAX=1
## Opportunity behavior
# OPPORTUNITY.DEFAULT_TERM=52
# OPPORTUNITY.DEFAULT_UNITS=W
# OPPORTUNITY.MULTIPLIER=52
# OPPORTUNITY.CLOSE_PROBABILITY=25,50,75
完成上述两文件的修改后,打开eclipse的ant视图,
运行:
ant deploy 完成项目的编译发布工作。
下一步是创建库表,可运行 ant installdb 创建库表。
运行 ant installdb前,先在启动MySQL,创建一个表空间及用户,
CREATE DATABASE my_centric_crm CHARACTER SET utf8 COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON my_centric_crm.* TO my_centric_crm@"%" IDENTIFIED BY "crm"; 创建库表时,若出现类似"
Specified key was too long; max key length is 765bytes"的错误,是因为标识"UNIQUE NOT NULL"的字段长度>255(255=765/3)了。MySQL数据库的unique类字段长度限制比较短,视不同版本,有的限制为765个字节,有的限制为1000个字节,UTF是占用3个字节位的,所以在这个限制上还要除以3。centric CRM的mysql库脚本中,unique类字段的长度是设为300长字符的,出现上述问题一个可行的妥协办法是修改脚本unique类字段的长度。
建完表后,可以启动tomcat服务,运行 ant ws 激活WebService,应用服务配置安装完成!
通过 http://localhost:8080/centric,第一次进入centric crm系统。
第一次进入系统时,是一个登录界面,用户是dhvadmin,密码是admin,登录进入,是一步步的系统参数设置操作,操页面提示,就可完成设置。最后是创建应用系统公司名称和管理员用户密码的界面,再次使用系统时,就以管理员名称和密码登录,对系统进行设置及添加管理其他用户。(至此,告一段落。)
有一段时间没写blog了,个中的理由就是这段时间心情浮躁,沉不下来。
毕业后参加工作已整整6个年头了。从一个只知道找父母要钱花,不知道社会是什么样的“弱冠”到现在刚开始意识到要靠自己养家糊口,照顾父母的准“而立”,要考虑的事情比以前复杂的多了,这段时间工作也是动荡的,没有一个稳定的基础考虑自己要考虑的问题,愈是浮萍一样的没有根。
今,得空闲一会,浏览blog,看到一个blog,它的公告图片上是一个漂亮的小女孩,它的ICO是卡通的唐老鸭,抑郁的心情忽的开阔了。想那小女孩肯定是作者的女儿,唐老鸭肯定是作者女儿的所爱。如果年青的妈妈,她的blog上放这些,是很容易理解的,而作者是一个大老爷们,他的blog上放这些与“大老爷们”身份有巨大的反差,但正是这种反差,让我看到一位父亲对女儿的喜爱。
粗读王永强的
解析管理信息化的“十大陷阱” ,最有同感的是“买方决定性陷阱”。
中国信息化的现状说:邓小平提出建设有中国特色的社会主义,或许是因为中国的政治宣传力度比较强,企业的发展管理策略也带上“特色”,信息化就自然而然的要有自己的特色,如果拷贝另一企业的信息化经验成果,就是没有特色--你用你的枪,我用我的炮。
企业信息化软件实施说:信息化是一把手工程,如果一把手支持稍有松懈,所有的工作就有可能失败,原因什么呢 ?县官不如现管,现管的人不支持,这工作就开展不了。而上一个新系统,对于现管的人来说,就如同是一次革命,牵扯到的利益太多,稍有一点不均衡,不满意的人出来了,你的工作就得暂停一下。所以,新系统必须考虑到企业的实际情况,现有的模式,你再先进、再科学,也得适合我的脚,我才穿。
信息化系统提供商说:我们是公司行为,先生存,再发展;客户要什么东西,我们就做什么东西;先做项目,再做产品。
圈内流传消息说:中国软件不如印度,更比不上欧美。欧美做内核,简单重复的劳力就支援第三世界发展,换句话说是中国帮外国做产品,但没有自己的产品,而且作为劳动关系雇员还不如同桌。
在这条“生态链”中,谁是谁非?作为一个局外人看其中的问题很清楚,但身处某一个链节中时,没有谁能是我这是问题。如果企业说,我要一个产品,不要项目,这样,中国肯定会出现一些响当当的产品;如果系统提供商说,我有非常好的产品,可以做实施,不做项目,产品有吸引力应能取到市场的一杯羹。
在web.xml文件中,可以发现
<servlet-mapping>
<servlet-name>com.metaparadigm.jsonrpc.JSONRPCServlet</servlet-name>
<url-pattern>/JSON-RPC</url-pattern>
</servlet-mapping>
所有的请求提交到这个Servlet后分发处理并做出响应。
JSONRPCServlet.java中实现了init()和service(),
init() 中只是取了些配置参数作了相关设置;
service() 中实现了请求处理;
1.从session中创建/获取JSONRPCBridge对象;
2.把提交的数据装入一个JSONObject对象中;
3.用JSONRPCBridge对象的call方法处理JSONObject对象并返回JSONRPCResult对象。
这个处理较ajax-buffalo 中的处理单调了不少。
再来看看JSONRPCBridge.java是如何构建的。
1.内置6个内部类:CallbackData、ClassData、LocalArgResovleData、MethodCandidate、MethodKey、ObjectInstance;
2.还有一些辅助处理的方法,比较多(提取为一个或者多个辅助类比较好);
3.核心的就是call()方法了。运用的是java反射机制,进行方法调用。这个方法写的也比较长,没仔细看,只看到有它两个可取的地方,一个就返回对象的序列化,另一个是对不同异常,给出相应返回的处理比较细致,这样有利于找到异常在什么地方,估计是原因引起的。
在客户端的处理,是把各方法、对象串连在一起,封装后,便于应用。
它把请求的数据对象化再以串的形式提交,后端再做一个反向操作,方便了数据处理。这种方式比ajax-buffalo 中把数据组织成一个XML结构的数据包提交、处理效率高。
--沉浸在技术之中,如同喝高度白酒,比较麻醉人。
工作中,遇到比较复杂的SQL语句,也挺费时间的。今天有时间就研究一下,找到如下几个资源链(比较懒,也懒得COPY,避嫌抄袭)
http://www.51one.net/study/Oracle/list1.htm
学习两个关键字的用法,intersect(取交集),minus(取差集)
(select a.name from a) intersect (select b.name from b)
(select a.name from a) minus (select b.name from b)
{重学高等数学,全还给老师了,现在自己去要回来,上Google:)
并集:A和B相加的全部;交集:A和B相交叠的部分;差集:并集-交集;补集:如果集合B是集合I的子集,我们把I看作全集,那么I与B的差集I-B,叫做B在I中的补集}
SQL语句优化技术分析
http://www.pconline.com.cn/pcjob/other/data/oracle/0501/536463.html
避免用
| 避免使用 |
替代方法 |
| field in(a,b,c) |
field=a or field = b or field=c |
| field is null /is not null |
field > ' ' 、field > 0 |
|
select * from a
union
select * from b
先取两表,再合并
|
select * from a
union all
select * from b
简单的将两个结果合并后就返回
|
| |
|
1kg?
1kg代表什么?
一公斤么?对!
一公斤什么?
#¥%@&×。
这里(http://www.1kg.cn)有一个答案,一公斤的书籍文具。
这是一项民间发起的公益旅游活动,它通过传递-交流-分享三个简单的步骤带给旅游者丰富的旅游体验,受惠的是每一位参与者的心,更多的是千万双渴望知识的眼睛。
早上刚发现的国产Ajax实现,现在版本是1.2,其网址是:http://www.amowa.net/buffalo。
当下buffalo-1.2.zip 4,770KB ,
解开,发现项目配置文件是eclipse(切喜!eclipse,my love。),
导入eclipse中,红色的报错:三个类库变量没找到,是web服务要的三个包servlet-api.jar、jsp-api.jar、jasper-runtime.jar,在tomcat对应目录可以找到。其实还有第四个类库变量--junit.jar,只不过eclipse中自带的有,如果不用eclipse,找到这四个jar包引入。
项目是以java文件为主的,有一个war目录是演示用的web应用代码目录,web应用项目得自己建,这个感觉不爽,虽然它有一个build.xml文件可以打web应用包,但想调试跟踪,还是缺一步(我站在研究的角度,如果应用的话,加入那几个包,看看使用方法就可以了)。
首先研究了一下ApplicationServlet.java
1.这个Servlet初始化时,创建/获取了一个服务仓库(ServiceRepository);
2.所有的请求、响应都封装成一个自定义的请求上下文本(RequestContext);
3.根据请求的路径调用不同的RequestWorker;(这一点好,又不好)
4.剩下的就是worker开始工作了,初始化、校验、处理。
重要的也是“处理”,现在看看worker的结构。
接口类:interface RequestWorker 定义三个基本方法。
抽象类:abstract class AbstractRequestWorker 实现初始化和校验这两个基本方法,另实现一些其它方法。
具体实现类:ViewWorker、BuffaloWorker、UploadWorker 当然,你也可以写自己的worker
当的项目源码中,ViewWorker、UploadWorker的处理方法中都是抛出UnsupportedOperationException,想处理的话,你也可以加。现在重要的讲讲BuffaloWorker的处理。
1.通过封装的请求上下文件(RequestContext),获取服务仓库(ServiceRepository);
2.通过请求的相对路径(此方法感觉欠妥),获取相应的服务;
3.有了“业务处理方法”、“业务请求”后,就是调用“粗麻布调用(BurlapInvoker)”处理余下的工作了。
前面写的是一些流程,没什么复杂的东西,这最后的 invoker,是比较核心,也很经典的处理。在这里,我也不多写了,再写下去,大家也一路的看下去,没什么感觉。相信看完了 invoker的实现,一定能学到不少东西。
下次看看前端是怎么实现的,今天到此为止,休息一会!
一、下载
下载网站:http://freshmeat.net/projects/json-rpc-java/?branch_id=49217&release_id=214415
下载地址:http://freshmeat.net/redir/json-rpc-java/49217/url_zip/json-rpc-java-1.0rc2.zip (版本1.0rc2)
解压后有三个文件夹、三个文件:
src jsonrpc的核心代码
test 演示用的java代码
webapps 演示用的web代码
build.xml ant文件
jsonrpc.jar 编译好的jsonrpc核心包
jsonrpc.war 编译好的演示web包
二、安装运行
1、如果不想用javaIDE编译发布,配置好ant 和tomcat,用ant运行解压后的build.xml,把jsonrpc的demo发布到tomcat中,启动tomcat,打开http://127.0.0.1:8080/jsonrpc/ 就可以看到演示了。
不过,build.xml文件要做一点适应的改动,
<property name="tomcat" location="../jakarta-tomcat-5.0.19"/>中的location值要设置为tomcat的安装目录
如
<property name="tomcat" location="D:\java\Tomcat5.0"/>
2、用javaIDE的话,我是用eclipse 3.01+myeclipse 3.84
新建一个空的web项目,
web root folder=webapps,
context root url =jsonrpc,OK。
(这两个值可以用默认设置,但用默认设置后面改动比较多,所以就迎合它自己的口味)
把解开的src和test目录放到新建项目的根目录中,webapps/jsonrpc目录下的内容拷贝到项目webapps目录中,eclipse自动编译,会报一些错误,是因为test/src中有一部分java源码未作为java文件编译,鼠标右键点击项目图标->属性->Java编译路径->资源->添加test/src目录到资源中,确定OK。
jsp文件没有因java文件的重新编译而更新所以还会显示一些红色的错误,就得手工让它再编译一次,鼠标右键点击项目中webapps目录->myeclipse->运行校验,OK,剩下的是一些警告信息,如果你不想看到它们,可以去程序中一个个的去掉。
在eclipse中发布jsonrpc、启动tomcat服务,大功告成。
简单的看了一下它的设计实现过,明天接着写。
近日忽有兴致想读钱钟书的《围城》,一时没时间去买书,就在网上搜了一下,果有电子版的。
先看前言,说得多的是第几次印刷,又改了几个错漏--对于这一点,象他们那一辈人给我们的印象都是这样,事不分巨细,都特别认真,再一次感受到他们的这种精神,也增加我接着往下看的兴趣。当读到第一章时,就发现有几个字明显是打词组时带出来的,很简单就能处理的事情,就留它一个结疤在这儿,读得很不顺畅,有几处的用词,意思上差不多可以说过去,但感觉很绕口,为增加读下去的兴致,就自己给自己找借口:钱老那时的白话文跟现在的有差别。不过,读到第三节时,实在没有兴致了。累呀!
前两天网上有关于张海迪的提案事件,事情也是沸沸扬扬的,实情是什么样子的我不知道,但大部分人应是认同张海迪的为人。事件中就提到新闻报到提用人名,要经当事人同意这一点,我想,如果是一个认真的人,这件事情是应该去做的,人云亦云的转抄不去实究更是不该做的事情。
现在的人难道都这么浮躁么!
刚看了《Jboss创始人Marc Fleury:我要为开放源代码辩护》的文章,第一反应就是要为Marc Fleury鼓掌!
我不是计算机专业科班出身,对计算机知识的理解都是基于兴趣爱好--我喜欢,我就做。记得上大学前填报志愿时,好多同学都是没有考虑第一志愿就填的计算机专业(因为他们都喜欢,甚至痴狂),我也非常喜欢计算机,也想跟他们一样,但瞬间的冷静一想,基于计算机会是每一个人的基本工具,懂计算机是必然的事,就报了其它专业。虽然不是学计算机,但课余时间几乎都是在学计算机知识上面,还经常去旁听计算机专业的课。我学习编程,都是看着写好的例子一句句的琢磨,最后就知道怎么用那些方法,关键字,虽然是很原始的学习方法,但还是比较有效的--这也许就是我支持开放源码的“第一”原因吧。
尔后,也接触到很多软件,对那些软件,或多或少有自己的想法,希望能去完善它们,但大部分是编译过的,想完善它们只能是隔靴挠痒的事。有一部分软件也提供二次开发的接口,也有相应的开发接口文档,但发现问题是在它原有程序里的,就没办法。为此,有一段时间特别热中于反编译,觉得那是仅次于做黑客的事情,随后,无奈的知道这是触犯一些商人权利的事(现阶段这些商人创造社会财富,也给制定法律的政府交税,个人还是无法超越在法律之外的)。对此,只有喷墙。
后来,发现开源软件不仅免费使用,更重要的是它的源码是对所有人开放的,这无疑点亮了我学习开源软件中的编程精华、设计思想的光明之路,也促使我更偏爱使用开源软件。
在google上查到两款java的开源ETL工具
Kettle(
http://www.kettle.be/)和
Octopus(
http://www.enhydra.org/tech/octopus/index.html)
先看Kettle
下载kettle的源码(也可以下载BIN的),在eclipse中启动,出现配置Repository的小窗口,在这小窗口中配置的Repository,输入口令后老报口令错误(可能是没配置好),就直接点No Repository进入主窗口,这就开始ETL工作了。
待继。。。
媒婆=政府
女方=企业
男方=IT公司
现在,男方摆出什么家当来,可以让媒婆一上门,女方就高兴的嫁过来呢?
第一眼,感觉有很大的空间,可show的东西很多,随便挑一个都成,但要确定一个具体的东西时,张开口不知说哪一个了。
企业信息化?这个题目还是太大。
ERP?是大火过后的冷静,广大中小企业一直也是作避上观。
SCM?政府对企业这方面的东西好象没说话的实质内容。
CRM?政府做的工作是招商引资,投资环境,切实的工作还是得企业自己搬砖砌墙,牵强的说有点表亲关系。
换个思路,现在的女方最看中的是什么呢?看她关注什么。
企业价值最大化,是任何一个企业追求的目标,怎么样才能实现企业价值最大化呢?
提高生产效率、提高产品质量、提高服务质量、提高管理执行力、提高企业竞争力;
扩展市场、提高市场占有率、维系老客户,发展新客户、提升企业品牌价值;
控制成本、减少不必要的支出;
怎么就感觉这些都是站在书堆里说的话呢!
企业公共关系?
写程序也有几个年头了,对程序中变量、方法、目录之类的东西命名,总要花点时间--读书的时候不认真,对不起在上面讲课的老师。对一些命名规则也了解一些,也努力那去做,不过,表意的关键字就没有什么规则好参照,只有自己找资料根据业务找最接近的单词来表述,每每这个时间,就想要努力学习英语。
今天看了几个政府的网站,点到其中的链接,看了半天,愣是没看明白那链接中路径表达的是什么意思,英语太差,惭愧!后来看到网站中栏目分类的名称,一个个的对一下,原来是每个汉字的拼音首字母的组合,一个字,累!尔后看到网站上还标明“中文简体版”、“中文繁体版”、“英文版”。点进繁体版看看,繁简转换得不错,但链接的路径描述还是那样,看来是技术处理的不错;点进英文版瞧瞧,内容跟中文版的完全不一样,是另做的一套网站内容,这时的链接路径描述还可以看出是什么意思来。
今天这事,我想到以前接触的一些项目,其中的表意命名也是这么处理,甚至数据库的字段名也按这个“规则”处理,我想他们工作的时候也是煞费了一番苦心呀。以前还看到一个牛人写的程序,程序中的命名全是汉字,在他的那个编辑器中,还一点问题没有,而且也能跑起来,但把代码一移到其他人的编辑器中,就“万里江山一片红”--汉字命名的全报错,后来那GG一拍屁股走人,他的代码没人能接过来,只有“咔嚓”,项目头头无奈、老板心底流血。
如果在程序中用汉字作变量不出问题的话,估计汉字命名会很风靡。但电脑是洋人发明的,它认识它妈妈的语言很亲切,对于汉字,它也经常头痛,怎么办呢?要用它,就得迁就它--这是我们中国程序员的无奈。
计算机是死的,人是活的,说不定哪天,中国出了一牛人,让计算机认识汉字跟认识英文一样畅通无阻,那时中国程序员就有福了!这只是个期望,现在还没有出现这种情况,我们还没能改变计算机,只有改变自己--跟两个人谈朋友一样,总得有一个人改变,让两个人相处的更和谐!
经过eclipse的好几个发布版本,最先用顺手的是2.1,之后就一直用它。
记得第一次听同事介绍eclipse时,说了很多eclipse的优势,但没体会,自己也是抱着试试的心态拷了一个备份玩玩。
Eclipse 2.1 整个文件包才20多MB,比当时使用的Jbuilder9来说,Jbuilder真是庞然大物。只要把ZIP包解压就就可以运行,不用复杂的安装。做完相关配置后,看到如期的界面了,接近windows界面的颜色比Jbuilder的那种界面颜色更易接受。做了一些简单的应用,操作功能跟Jbuilder差不多,但系统配套的代码开发,eclipse依赖于相关的插件,插件化是一个好的idea,但eclipse这方面的插件还没有一个能达到Jbuilder的那种高度的效果。问题是eclipse是免费的,也不能太高要求,想要高质量的服务,可以花点钱去买个插件MyEclipse装上,使用起来还不错。
时间长了后,Jbuilder快从记忆中消去了(这几天看到Borland要出卖它的IDE部门,甚是为Jbuilder担忧,毕竞是一套不错的产品,也留下过美好的回忆),这期间,eclipse也更新了好几个版本,从2字头的到3字头的,体积变化比较显著,基于eclipse3.01使用比较习惯了,也接受它变得“丰满”。但后面几个版本还是保持在肥胖的状况,而且使用方面,新版本的取向在编辑功能,程序调试的性能大不如前,对此情况,我保持止步不前了。寄希望
| 版本号 |
发布日期 |
文件大小 |
备注 |
| 3.11 |
2005-9-29 |
103.41MB |
|
| 3.1 |
2005-6-27 |
105.47MB |
|
| 3.01 |
2004-9-16 |
88.50MB |
|
| 2.1 |
|
|
|
| 1.0 |
|
19.32MB |
|
注册机是什么颜色的?黑色的。看过很多注册机,都是黑色的界面,挺醒目的。
注册机、破解码、散布的注册码、激活。。。。。
这些都是搜索引擎中热门的词语,因为它们能逾越一些商业软件的保护壳,让复制者不用花什么代价就能使用那些软件。
我对开源、共享软件是比较感兴趣的,也愿意在这方面做出自己的努力。特别欣赏Jboss Group,看到他们,仿佛是看到软件业最终的发展方向和模式。但在当前商业软件为主的状态下,特别是一些软件企业依靠一份份软件换来的钱活命的情况下,我们不能做那种下石头的事吧。
我是一个poor programmer,使用很多free工具,也使用黑色的工具,但我的原则是:自己使用,但不散发。
我很可怜,也可怜别人,留给自己一点尊严。