
2012年8月12日
js通过ajax传给后台一个json数组字符串:
[{'prjcode':'4209222012A00','countyname':'大悟县','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'},{'prjcode':'4209222005A03','countyname':'大悟县','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'},{'prjcode':'4209222005B00','countyname':'大悟县','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'}]
String jsonstr = request.getParameter("jsonstr");
JSONArray json = JSONArray.fromObject(jsonstr);
Object[] obj=json.toArray();
for(int i=0;i<obj.length;i++){
JSONObject object = JSONObject.fromObject(obj[i]);
String prjcode=object.get("prjcode").toString();
String countyname=object.getString("countyname").toString();
String pro_1=object.getString("pro_1").toString();
String pro_2=object.getString("pro_2").toString();
String pro_3=object.getString("pro_3").toString();
String pro_4=object.getString("pro_4").toString();
String pro_5=object.getString("pro_5").toString();
String pro_6=object.getString("pro_6").toString();
String pro_7=object.getString("pro_7").toString();
String pro_8=object.getString("pro_8").toString();
String pro_9=object.getString("pro_9").toString();
String pro_10=object.getString("pro_10").toString();
String pro_11=object.getString("pro_11").toString();
String pro_12=object.getString("pro_12").toString();
String pro_13=object.getString("pro_13").toString();
String pro_14=object.getString("pro_14").toString();
String pro_15=object.getString("pro_15").toString();
}
posted @
2012-08-16 22:36 zhanghu198901 阅读(2508) |
评论 (0) |
编辑 收藏
CSS之所以会如此流行,是它具备以下的优点
1、符合W3C标准。保证网站不会因为将来网络应用的升级而被淘汰。
2、支持浏览器的向后兼容,也就是无论未来的浏览器大战,胜利的是IE、chrome或者是火狐,网站都能很好的兼容。
3、搜索引擎更加友好。相对与传统的table, 采用DIV+CSS技术的网页,更加容易被搜索引擎找到。
4、样式的调整更加方便。内容和样式的分离,使页面和样式的调整变得更加方便,可以一次性修改多个网页的样式,只修改样式不需要重新发布。
5、降低网页大小,对于一个大型网站来说,可以节省大量带宽,大大提高用户体验,这是非常重要的一点——用户至上。
posted @
2012-08-16 22:36 zhanghu198901 阅读(1142) |
评论 (0) |
编辑 收藏在网上会有很多关于struts2结合autocomplet插件的实例,但是不怎么完整,让人感觉不清楚,刚刚在公司做了一个关于这个的项目,页面也用到了这个插件,所以把详细的步骤和注意事项贴出来和大家分享,废话不多说,贴铁代码:本文代码下载地址:http://download.csdn.net/detail/harderxin/4504612
一、我的资源中有autcomplet的json实例和autocomplet的源代码,也是copy网上的,大家可以免费下载,下载地址:http://download.csdn.net/detail/harderxin/4504288
二、开始我们的案例旅程
1、编写页面index.jsp
<body>
自动提示:
<!-- autocomplete防止一些浏览器的自动提示完成功能 -->
<input type="text" name="content" id="content" autocomplete="off" onkeyup="value=value.replace(/[^\a-\z\A-\Z0-9\u4E00-\u9FA5]/g,'')"/>
<input type="button" id="button" name="button" value="提交" onclick="" />
<br />
<p>
</p>
</body>
显示效果如下: 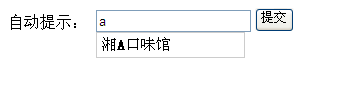
posted @
2012-08-16 22:34 zhanghu198901 阅读(1293) |
评论 (0) |
编辑 收藏PS:在所有例子中正则表达式匹配结果包含在源文本中的【和】之间,有的例子会使用java来实现,如果是java本身正则表达式的用法,会在相应的地方说明。所有java例子都在JDK1.6.0_13下测试通过。
一、对特殊字符进行转义
元字符是一些在正则表达式里有着特殊含义的字符。因为元字符在正则表达式里有着特殊的含义,所以这些字符就无法用来代表它们本身。在元字符前面加上一个反斜杠就可以对它进行转义,这样得到的转义序列将匹配那个字符本身而不是它特殊的元字符含义。如,如果想要匹配[和],就必须对它进行转义:\[和\]。
对元字符转义需要用到斜杠\字符,这就意味着\字符本向也是一个元字符,要匹配\字符本身,必须转义成\\。如匹配windows文件路径。
二、匹配空白字符
元字符大致可以分为两种:一种是用来匹配文本的(如.),另一种是正则表达式的语法所要求的(如[和])。
在进行正则表达式搜索的时候,我们经常会遇到需要对原始文本中里的非打印空白字符进行匹配的情况。比如说,我们可能需要把所有的制表符找出来,或者我们需要把换行符找出来,这类字符很难被直接输入到一个正则表达式里,这时我们可以使用如下列出的特殊元字符来输入它们:
\b 回退(并删除)一个字符(Backspace键)
\f 换页符
\n 换行符
\r 回车符
\t 制表符(Tab键)
\v 垂直制表符
来看一个例子,把文件中的空白行去掉:
文本:
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 26 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
正则表达式:\r\n\r\n
分析:\r\n匹配一个回车+换行组合,windows操作系统中把它作为文本行的结束标签。使用正则表达式\r\n\r\n进行的搜索将匹配两个连续的行尾标签,而这正好是空白行。
注意:Unix和Linux操作系统中只使用一个换行符来结束一个文本行,换句话说,在Unix或Linux系统中匹配空白行只使用\n\n即可,不需要加上\r。同时适用于windows和Unix/Linux的正则表达式应该包括一个可先的\r和一个必须匹配的\n,即\r?\n\r?\n,这将会在后面的文章中讲到。
Java代码如下:
public static void matchBlankLine() throws Exception{
BufferedReader br = new BufferedReader(new FileReader(new File("E:/九宫格.txt")));
StringBuilder sb = new StringBuilder();
char[] cbuf = new char[1024];
int len = 0;
while(br.ready() && (len = br.read(cbuf)) > 0){
br.read(cbuf);
sb.append(cbuf, 0, len);
}
String reg = "\r\n\r\n";
System.out.println("原内容:\n" + sb.toString());
System.out.println("处理后:-----------------------------");
System.out.println(sb.toString().replaceAll(reg, "\r\n"));
}
运行结果如下:原内容:
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 2 6 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
处理后:-----------------------------
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 2 6 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
三、匹配特定的字符类别
字符集合(匹配多个字符中的某一个)是最常见的匹配形式,而一些常用的字符集合可以用特殊元字符来代替。这些元字符匹配的是某一类别的字符(类元字符),类元字符并不是必不可少的,因为可以通过逐一列举有关字符或通过定义一个字符区间来匹配某一类字符,但是使用它们构造出来的正则表达式简明易懂,在实际应用中很常用。
1、匹配数字与非数字
\d 任何一个数字,等价于[0-9]或[0123456789]
\D 任何一个非数字,等价于[^0-9]或[^0123456789]
2、匹配字母和数字与非字母和数字
字母(A-Z不区分大小写)、数字、下划线是一种常用的字符集合,可用如下类元字符:
\w 任何一个字母(不区分大小写)、数字、下划线,等价于[0-9a-zA-Z_]
\W 任何一个非字母数字和下划线,等价于[^0-9a-zA-Z_]
3、匹配空白字符与非空白字符
\s 任何一下空白字符,等价于[\f\n\r\t\v]
\S 任何一下空白字符,等价于[^\f\n\r\t\v]
注意:退格元字符\b没有不在\s的范围之内。
4、匹配十六进制或八进制数值
十六进制:用前缀\x来给出,如:\x0A对应于ASCII字符10(换行符),其效果等价于\n。
八进制:用前缀\0来给出,数值本身可以是两位或三位数字,如:\011对应于ASCII字符9(制表符),其效果等价于\t。
四、使用POSIX字符类
POSIX字符类是很多正则表达式实现都支持的一种简写形式。Java也支持它,但JavaScript不支持。POSIX字符如下所示:
[:alnum:] 任何一个字母或数字,等价于[a-zA-Z0-9]
[:alpha:] 任何一个字母,等价于[a-zA-Z]
[:blank:] 空格或制表符,等价于[\t]
[:cntrl:] ASCII控制字符(ASCII 0到31,再加上ASCII 127)
[:digit:] 任何一个数字,等价于[0-9]
[:graph:] 任何一个可打印字符,但不包括空格
[:lower:] 任何一个小写字母,等价于[a-z]
[:print:] 任何一个可打印字符
[:punct:] 既不属于[:alnum:]和[:cntrl:]的任何一个字符
[:space:] 任何一个空白字符,包括空格,等价于[^\f\n\r\t\v]
[:upper:] 任何一个大写字母,等价于[A-Z]
[:xdigit:] 任何一个十六进制数字,等价于[a-fA-F0-9]
POSIX字符和之前见过的元字符不太一样,我们来看一个前面利用正则表达式来匹配网页中的颜色的例子:
文本:<span style="background-color:#3636FF;height:30px;width:60px;">测试</span>
正则表达式:#[[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]]
结果:<span style="background-color:【#3636FF】;height:30px;width:60px;">测试</span>
注意:这里使用的模式以[[开头、以]]结束,这是使用POSIX字符类所必须的,POSIX字符必须括在[:和:]之间,外层[和]字符用来定义一个集合,内层的[和]字符是POSIX字符类本身的组成部分。
在java中的POSIX字符表示有所不同,不是包括在[:和:]之间,而是以\p开头,包括在{和}之间,且大小写有区别,同时增加了\p{ASCII},如下所示:
\p{Alnum} 字母数字字符:[\p{Alpha}\p{Digit}]
\p{Alpha} 字母字符:[\p{Lower}\p{Upper}]
\p{ASCII} 所有 ASCII:[\x00-\x7F]
\p{Blank} 空格或制表符:[ \t]
\p{Cntrl} 控制字符:[\x00-\x1F\x7F]
\p{Digit} 十进制数字:[0-9]
\p{Graph} 可见字符:[\p{Alnum}\p{Punct}]
\p{Lower} 小写字母字符:[a-z]
\p{Print} 可打印字符:[\p{Graph}\x20]
\p{Punct} 标点符号:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
\p{Space} 空白字符:[ \t\n\x0B\f\r]
\p{Upper} 大写字母字符:[A-Z]
\p{XDigit} 十六进制数字:[0-9a-fA-F]
posted @
2012-08-12 23:00 zhanghu198901 阅读(2124) |
评论 (2) |
编辑 收藏PS:在所有例子中正则表达式匹配结果包含在源文本中的【和】之间,有的例子会使用java来实现,如果是java本身正则表达式的用法,会在相应的地方说明。所有java例子都在JDK1.6.0_13下测试通过。
一、有多少个匹配
前面几篇讲的都是匹配一个字符,但是一个字符或字符集合要匹配多次,应该怎么做呢?比如要匹配一个电子邮件地址,用之前说到的方法,可能有人会写出像\w@\w\.\w这样的正则表达式,但这个只能匹配到像a@b.c这样的地址,明显是不正确的,接下来就来看看如何匹配电子邮件地址。
首先要知道电子邮件地址的组成:以字母数字或下划线开头的一组字符,后面跟@符号,再后面是域名,即用户名@域名地址。不过这也跟具体的邮箱服务提供商有关,有的在用户名中也允许.字符。
1、匹配一个或多个字符
要想匹配同一个字符(或字符集合)的多次重复,只要简单地给这个字符(或字符集合)加上一个+字符作为后缀就可以了。+匹配一个或多个字符(至少一个)。如:a匹配a本身,a+将匹配一个或多个连续出现的a;[0-9]+匹配多个连续的数字。
注意:在给一个字符集合加上+后缀的时候,必须把+放在字符集合的外面,否则就不是重复匹配了。如[0-9+]这样就表示数字或+号了,虽然语法上正确,但不是我们想要的了。
文本:Hello, mhmyqn@qq.com or mhmyqn@126.com is my email.
正则表达式:\w+@(\w+\.)+\w+
结果:Hello, 【mhmyqn@qq.com】 or 【mhmyqn@126.com】 is my email.
分析:\w+可以匹配一个或多个字符,而子表达式(\w+\.)+可匹配像xxxx.edu.这样的字符串,而最后不会是.字符结尾,所以后面还会有一个\w+。像mhmyqn@xxxx.edu.cn这样的邮件地址也会匹配到。
2、匹配零个或多个字符
匹配零个或多个字符使用元符*,它的用法和+完全一样,只要把它放在一下字符或字符集合的后面,就可以匹配该字符(或字符集合)连续出现零次或多次。如正则表达式ab*c可以匹配ac、abc、abbbbbc等。
3、匹配零个或一个字符
匹配零个或一个字符使用元字符?。像上一篇说到的匹配一个空白行使用正则表达式\r\n\r\n,但在Unix和Linux中不需要\r,就可以使用元字符?,\r?\n\r?\n这样既可匹配windows中的空白行,也可匹配Unix和Linux中的空白行。下面来看一个匹配http或https协议的URL的例子:
文本:The URL is http://www.mikan.com, to connect securely use https://www.mikan.cominstead.
正则表达式:https?://(\w+\.)+\w+
结果:The URL is 【http://www.mikan.com】, to connect securely use 【https://www.mikan.com】 instead.
分析:这个模式以https?开头,表示?之前的一个字符可以有,也可以没有,所以它能匹配http或https,后面部分和前一个例子一样。
二、匹配的重复次数
正则表达式里的+、*和?解决了很多问题,但是:
1)+和*匹配的字符个数没有上限。我们无法为它们将匹配的字符个数设定一个最大值。
2)+、*和?至少匹配一个或零个字符。我们无法为它们将匹配的字符个数另行设定一个最小值。
3)如果只使用*和+,我们无法把它们将匹配的字符个数设定为一个精确的数字。
正则表达式里提供了一个用来设定重复次数的语法,重复次数要用{和}字符来给出,把数值写在它们中间。
1、为重复匹配次数设定一个精确值
如果想为重复匹配次数设定一个精确的值,把那个数字写在{和}之间即可。如{4}表示它前面的那个字符(或字符集合)必须在原始文本中连续重复出现4次才算是一个匹配,如果只出现了3次,也不算是一个匹配。
如前面几篇中说到的匹配页面中颜色的例子,就可以用重复次数来匹配:#[[:xdigit:]]{6}或#[0-9a-fA-F]{6},POSIX字符在java中是#\\p{XDigit}{6}。
2、为重复匹配次数设定一个区间
{}语法还可以用来为重复匹配次数设定一个区间,也就是为重复匹配次数设定一个最小值和最大值。这种区间必须以{n, m}这样的形式给出,其中n>=m>=0。如检查日期格式是否正确(不检查日期的有效性)的正则表达式(如日期2012-08-12或2012-8-12):\d{4}-\d{1,2}-\d{1,2}。
3、匹配至少重复多少次
{}语法的最后一种用法是给出一个最小的重复次数(但不必给出最大重复次数),如{3,}表示至少重复3次。注意:{3,}中一定要有逗号,而且逗号后不能有空格。否则会出错。
来看一个例子,使用正则表达式把所有金额大于$100的金额找出来:
文本:
$25.36
$125.36
$205.0
$2500.44
$44.30
正则表达式:$\d{3,}\.\d{2}
结果:
$25.36
【$125.36】
【$205.0】
【$2500.44】
$44.30
+、*、?可以表示成重复次数:
+等价于{1,}
*等价于{0,}
?等价于{0,1}
三、防止过度匹配
?只能匹配零个或一个字符,{n}和{n,m}也有匹配重复次数的上限,但是像*、+、{n,}都没有上限值,这样有时会导致过度匹配的现象。
来看匹配一个html标签的例子
文本:
Yesterday is <b>history</b>,tomorrow is a <B>mystery</B>, but today is a <b>gift</b>.
正则表达式:<[Bb]>.*</[Bb]>
结果:
Yesterday is 【<b>history</b>,tomorrow is a <B>mystery</B>, but today is a <b>gift</b>】.
分析:<[Bb]>匹配<b>标签(不区分大小写),</[Bb]>匹配</b>标签(不区分大小写)。但结果却不是预期的那样有三个,第一个</b>标签之后,一直到最后一个</b>之间的东西全部匹配出来了。
为什么会这样呢?因为*和+都是贪婪型的元字符,它们在匹配时的行为模式是多多益善,它们会尽可能从一段文本的开头一直匹配到这段文本的末尾,而不是从这段文本的开头匹配到碰到第一个匹配时为止。
当不需要这种贪婪行为时,可以使用这些元字符的懒惰型版本。懒惰意思是匹配尽可能少的字符,与贪婪型相反。懒惰型元字符只需要给贪婪型元字符加上一个?后缀即可。下面是贪婪型元字符的对应懒惰型版本:
* *?
+ +?
{n,} {n,}?
所以上面的例子中,正则表达式只需要改成<[Bb]>.*?</[Bb]>即可,结果如下:
<b>history</b>
<B>mystery</B>
<b>gift</b>
四、总结
正则表达式的真下威力体现在重复次数匹配方面。这里介绍了+、*、?几种元字符的用法,如果要精确的确定匹配次数,使用{}。元字符分贪婪型和懒惰型两种,在需要防止过度匹配的场合下,请使用懒惰型元字符来构造正则表达式
posted @
2012-08-12 23:00 zhanghu198901 阅读(13372) |
评论 (1) |
编辑 收藏 根据我近些年在IT行业的摸爬滚打,发现作为一个合格的开发经理需要做的第一件事情是:规范。
1、规范代码
每个公司都有自己的规范文档,但是很少有同学按照规范标准来写自己的代码。这样导致代码风格多元化、代码逻辑可爱化,更有甚者,会有人连自己的代码都看不懂。为什么?原因很简单,虽然写了规范文档,做了规范培训,但是没有强制的执行和跟踪。
我认为作为一个合格的开发经理,需要做如下三件事情。第一步,写代码规范文档,做培训。第二步,按照规范生成开发模版,规定手下的所有开发人员的开发工具中导入此模版。第三步,反复核查开发人员的代码(3-6个月),直到规范成为一种习惯。
2、规范文档
文档在中国IT公司几乎不受太大的重视。
在项目型的公司,要么就是没有文档,要么就是文档泛滥(要知道,有很多文档是做给QA看的,其实都是垃圾),我有时候就想,这样有意义吗?文档的目的是开发人员的辅助工具,尤其对于刚入职公司的新人而言,不会有几个“好心肠”的老员工去帮助新员工讲解项目架构和原理的,进来了就是靠自己摸索,那么文档对于新人就显得尤为重要了。所以,要么就建立一个好的培训机制,要么就写好文档,如果两者都做的很好为最佳。
在互联网公司,对于一些生命周期短暂的小项目不写文档我同意,毕竟需要时间成本。但是这样的项目代码规范一定严格,尽量精细到数据库字段的规范。因为这种类型的项目开发人员一般为1人,如果此人离开,后来人员交接时,能够更快的看懂对方的代码,以节省时间。此外,对于核心项目,一定需要一套完整的API文档,以供各项目组之间的互通,减少不必要的沟通。
总结:正是因为没有合理的规范,某个模块的开发人员离职,会消耗公司的巨大维护成本。如果能够做到以上两点规范,相信能够给公司带来更多的效能。
posted @
2012-08-12 22:58 zhanghu198901 阅读(1921) |
评论 (1) |
编辑 收藏