 2005年9月7日
2005年9月7日
应朋友邀请,周六早从上海出发往杭州参加阿里巴巴网侠大会。同行四人,有锐道的macro chen、杨光(还是我师弟)、移动的王伟旭(特长是linux和网络安全,也是中国linux推广的先驱)。一路上,言谈甚欢。老庄给我们订的票,他一早肠胃有恙,仍然坚持把票送到火车站,之后去吊盐水,下午又出现在会场。确实精神可嘉,建议阿里巴巴颁发“最佳精神奖”。
到杭州已是中午,错过了上午大会。下午Robbin进行Java技术展望和RoR实现REST的演讲,既然是朋友,肯定是要捧场的。Robbin旁征博引,以其深厚的技术功底和对新技术的敏锐洞察赢得了听众。
晚上一堆人去聚会,各路豪杰纷至:有阿里巴巴的,有自己创业的,有技术大牛,还有媒体(Infoq),出版社(博文的周总领3员大将赴会)。大家互换名片,认识的不免寒暄几句,不认识的也很快就熟捻了,还不时有“原来你就是×××”的惊呼,原来网上就“互通心曲”,只是一直没机会认识罢了。
席间觥筹交错,具体内容暂且不表,只说一件令我感受颇深之事。一个阿里巴巴的员工表现出对公司的无比忠诚,讲起公司的奖惩制度,说是一个员工的绩效不仅跟所在项目相关,还与部门、其它部门甚至整个公司的业绩相关。所以只要是对公司有利的事情,即使与自己现在的工作无关,他们也会去做。按常理来说,这有点不公平,我只能努力做好自己的事情,而如果别人不努力,我就是白做。但如果大家都努力,又变成了共赢。
这里让我讲一个简单的博弈问题,就是“囚徒困境”。A和B两个同犯被抓,因为没有其它任何证据和证人,只能让2人分别交供。如果A和B都矢口否认,那么两人无罪释放。如果A承认,B不承认;A是坦白从宽,判1年;B抗拒从严,判5年,反之亦然。如果2人都承认,ok证据确凿,各判2年。如果2人都是理性人,且没有互通消息,按照博弈,每个人的最优解就是承认,也就是各判2年。其实对2人真正有利的就是打死不承认然后都无罪释放,而这种状态在理性人的假设下是很难实现的--除非有一个教父,一直灌输他们不要出卖同伙。
马云就是这个“教父”!
卡内基有篇文章,我总结成一句话就是:用崇高的理想打动别人。据说马云一直是以个人魅力及“创造中国电子商务的明天”类似的理想,激励员工的。有了统一的企业文化,员工都不计较个人得失,努力奋进,最终企业和所有员工取得共赢,这绝对是摆脱“囚徒困境”的典型案例。
话说回来,阿里巴巴能让你感受到团队的力量,一群精英在一块做很有价值的事情,对每个人也是很好的锻炼。个人认为,如果有吃苦耐劳的打算,眼光放长远点,又没有其它方面的束缚,阿里巴巴的确是不错的选择。(得向阿里巴巴收代言费,呵呵!)
第二天听了多场论道,主要是SAAS,搜索,分词方面。结合阿里巴巴的战略,我把几点融合起来讲一下。这个下篇再细细道来。
这次给
openfans
做网摘功能,主体程序倒是很快就写完了,另外要做个
IE
插件,却碰到了不少问题。
IE
插件其实很简单,就是用
js
获得页面的标题、
url
和选择的内容,然后通过弹出窗口,将其送到服务器。这里就有中文的问题了,开始使用
escape
,如
escape(title)
形式,
request.getParameter
碰到中文就为
null
,网上搜了一通,说是可以通过
java
编码搞定,但拿到就为
null
了,还怎么换编码?忙活了好几个小时,又是
alert
,又是
document.write
,看上去也没什么问题。不
escape
,直接在浏览器中输入带中文的
url
,拿到的不为
null
了,拿到后,通过
new String(str.getBytes("ISO-8859-1"), "UTF-8");
还真显示正常了。但用
window.open
又出乱码了。看到文章说还有
encodeURIComponent
方法可用,就试了下,把
escape
换成
encodeURIComponent
居然搞定了,服务端还是得用
new String(str.getBytes("ISO-8859-1"), "UTF-8")
进行处理。注意这里用的
tomcat
,它的默认编码就是
"ISO-8859-1"
,如果改了编码程序也得做相应的改动了。
今天为了在本机装个wordpress玩玩,搞了搞php5+mysql5+apache2。网上搜了一篇文档,很快就让php与apache跑起来了,但连mysql始终不行。报错:Call to undefined function mysql_connect()。查了一下半天,就是php关于mysql的ext没配好,但我改了php.ini啊,也把"extension=php_mysql.dll"放出来了。查了好久,看到一篇说php5需要加上"extension=php_mysqli.dll",试了下果然好了。
然后需要以index.php作为默认的welcomefile(不知道怎么叫,web.xml里是这个),需要在"DirectoryIndex index.html index.html.var"后加上 index.php就行。
然后飞快的装了phpmyadmin、dvbbs的php版。发现php应用的安装的确很是方便,解压,拷贝到htdocs下,马上就能运行了,比java应用简单的多,更别提复杂的要死的企业应用了。这点上java要好好向php学习啊。
项目需要,开始研究电子支付。国外的电子支付提供商,得好好研究它的文档和api。全是e文,只能慢慢看了。
学习了下spring2.0。对openfans而言,有2个比较重要的改进。首先是aspectj的支持,可以方便的使用aspectj语法定义aspect和pointcut了,openfans准备在domain object的自动注入上和权限等方面使用aop。另外就是spring form标签库的引入,现在springmvc也有自己的标签库,以前自己给checkbox和radio写的request.getParameter可以改写了。
摘要: 应项目需要做了一个定时更新的
cache
框架,采用
spring+quartz
很方便的实现,可以适用任何需要定时才更新的地方,比如静态网页
cache
等。代码很简单:
---------------------------------QuartzCacheHandler-------------------...
阅读全文
接着前面的写。上文主要写了
ajax
在
portal
中的使用,这篇写集群方面的体会。现在比较流行的架构就是前端
F5
做负载均衡,后面
2
台
websphere server
做成集群,各自都有
HttpServer
,每个
HttpServer
都向
2
台
was
做转发。这样每台都能独立完成从
HttpServer
到
was
的流程。一台出现故障,
F5
首先进行切换,只向正常
server
的
HttpServer
发起请求,这台
HttpServer
再进行切换只向同一台
server
上的
was
做转发。这次
portal
就是采用的这种架构,不妨称为架构
A
。
另一种简单点的架构就是只做
F5
负载均衡,不做
was
集群,每台
websphere server
上的
HttpServer
接受
F5
转发的请求,只向本
server
的
was
转发。这样每台
websphere server
保持独立,相互间没有数据交换和转发。不妨称为架构
B
。
架构
A
和
B
各有优劣,适合不同的需要,下面进行些比较:
Ø
从应用部署上看:
A
使用了
websphere
集群,由一个
DeployManager
进行分发,部署应用,只需部署一次,由
DM
分发到几个节点上。而
B
每个
server
都是独立的,部署应用只能一台台部署,如果
server
较少差别还不明显,如果达到
10
台以上,一台台部署将是一个比较痛苦的事情。
Ø
从
session
上看:
A
使用了
websphere
集群,可以使用集群提供的
session
复制,对于一些关键应用(某台服务器宕机,
session
也必须保持的应用)很有必要。而对于一些能够允许
session
丢失的应用,才可以使用
B
。当然
A
也可以关闭
session
复制,因为
session
复制不管是使用数据库方式还是内存方式,总会消耗一定的性能。具体消耗多少性能,就要看不同的
application server
的
session
复制方案了,想深入了解,可以看集群方面的文档,我也只记得一个比较简单的
round robbin
了。
Ø
从架构复杂性看:
B
更为简单,因为没有
DM
的概念,每台
server
都保持独立。而使用了
DM
有时也会出现莫名奇妙的问题,这当然是由于不了解
DM
的机制所致,但总归也增加了复杂度,这点在后面的教训中进行说明。
Ø
从水平扩展性上看:
B
肯定更胜一筹。只要
F5
能支持,多少台
server
都没关系。而
A
多台
server
做集群,要看
websphere
支持的节点数量,应该不会太大。这个如果哪位同学知道,敬请告知。
当然
A
和
B
在服务器较多的情况下是可以共存的,可以考虑几台机器做集群,然后集群间做负载均衡,这样既可以减少部署的复杂度,又可以带来较好的水平扩展。由于没做过更大型的项目,这个也只是我的假象,请做过的同学斧正。
说一说集群中碰到的问题。
Ø
首先是对各节点的同步:
有时为了方便测试,我们只对其中一个节点进行更改,测试通过再放到其它节点。而如果测试周期较长,有时就会造成节点的不同步,出现各种各样莫名其妙的问题。一个经验就是:无论如何,在每天下班前要保证各节点的同步,不同步的现象不要过夜。
Ø
然后是对
DM
的理解:
我现在还只是实践阶段,没有看过相关文档。从意义上看,它控制了相关的配置文件,如果进行节点同步,就会由它把配置文件同步到它管理的节点上。这对配置文件的修改提出了要求。我们开始只修改节点的配置文件而没有修改
DM
的,结果进行节点同步就会覆盖修改的配置文件,带来很多不必要的工作。经验就是:或者修改
DM
的配置文件,然后进行节点同步,或者直接同时修改所有节点和
DM
的。
Ø
还有关于
cache
的:
Cache
是性能优化的一个有效手段。在单机环境下,最简单的就是内存
cache
,使用
static
的
Map
就行。而在集群环境中,
cache
就变的比较复杂了。首先还是从应用需求入手,是否要保持每台机器的
cache
同步。如果只是信息展示等要求不高的
cache
,不需保证
cache
的同步,问题也比较简单,自己写内存
cache
,或者使用开源的
cache
组件如
ehcache,oscache
等就可以很好的解决问题。而如果需要
cache
在几个节点保持同步,就需要特殊的机制了,
ehcache
等号称支持分布式
cache
,但好像需要
jgroup
,配置比较麻烦,我没有用过,有用过的同学请指教。我本来想使用
session
保存,然后进行
session
同步,后来
IBM
建议使用数据库
cache
,即自己写代码,
cache
在数据库中。这样不需要
session
同步,对象不大,性能也能得到保证,现在用下来效果还可以。
这次做
ibm
的
portal
,算是临危受命。做了几个月的
SA
离职,留下一个功能和性能都有很多问题的项目,临时让我顶上。经过一个多月的紧张工作(经常加班,上班上不了网,也没时间上网),总算功能和性能上都能达到客户要求了。而我也由一个不懂
portal
的人,经过项目中实战,不说成为高手,一般的概念、开发、配置、优化等也都有了很多体会。
这次技术上值得推荐的就是合理的使用
ajax
,既加快了首页的
load
速度,又带来了很好的用户体验。开始首页上所有
portlet
都是串行加载,有的
portlet
比如新邮件,依赖于
mail
系统提供的接口。开始这个接口在较大压力下就出现性能瓶颈,后在我们的要求下替换了协议,性能也在
1s-2s
之间。如果采用常规的办法,加上
wps
验证、运算,显示主题、皮肤,加载所有
portlet
,响应时间肯定在
10s
以上。
我在
openfans
中使用了
ajax
,有些经验,所以决定采用异步加载:首页
load
时一些
portlet
直接显示正在
loading
的字样,在
body onload
时再使用
ajax
填充内容;使用
iframe
的
portlet
,也是
src
先指向一个静态的正在
loading
页面,
body onload
时再替换
src
到实际地址(这是
ajax
模式的一种)。这样首页登录实际上只经过
wps
内部的验证和显示,所有业务逻辑都是加载成功后再并行进行。实际表现效果就是:头上的主题很快出来,一块块区域显示正在
loading
字样,性能快的
portlet
很快出来,需要几秒的
portlet
随后出来,而不是让用户傻等
10
多
s
再一下全部显示。
使用
ajax
同时也能解决页面刷新问题和获取返回值的问题。比如前面显示新邮件的
portlet
,用户点击了一封邮件,新邮件数应该减
1
,刚点击的邮件也应该上页面上消失。原始的做法就是刷新整个页面,既加大服务器压力,又带来很差的用户体验。使用
ajax
,在点击后
1s
(或者更长,这取决于邮件系统对点击操作的响应快慢)刷新
div
的内容,用户甚至感觉不到内容已经更新。其它
portlet
也不需要重新载入,大大减轻服务器的压力。有的操作需要提交给其它系统,而且可能成功可能失败,这就需要获得返回值。如果使用普通的
form
提交,需要更新整个页面。而使用
ajax
提交,可以方便的获得其返回值,进而显示不同的提示。
另一个架构上的特点就是
portal
服务器职责单一
。开始所有的业务逻辑都是写在
portlet
里,加重了
portlet
服务器的压力。我进来后做的一个大的规划就是,把业务逻辑抽离到其它
server
上,然后通过
ajax
加载到
portlet
中。这样既可以充分利用服务器资源(新的
server
使用单独的内存空间和线程池),又使得
portal
服务器职责更单一:仅进行验证、权限控制、主题、皮肤和
portlet
的展示。
先写这么多。因为使用了
2
台
server
做集群,在分布式环境下,开发也有了更多的要求(比如
cache
),后一篇文章再细细道来。
难得有空,写篇程序之外的文章,关于压力的,也是自己近来的亲身体会。
众所周知软件这行压力是很大的。各种各样的问题层出不穷,每天上班工作内容都是排的满满的,遇到突发问题就得加班。如果不及时进行疏解,积累到一定的程度,就可能产生一定的负面问题,比如上班精神状态差、注意力不能集中、遇事喜欢逃避等等。我就亲身经历了这样的状况,明知自己工作积极性差、效率很低,但也很难一下子找回自我。
一次偶然的出游让我从中很快走了出来。一个亲戚考上厦大的博士,我请了
2
天的假,利用周末时间顺便去厦门旅游。厦门依山傍海,的确是旅游的好去处。晚上到海边,凉风习习,光脚沿着沙滩走过,任起落的潮水在腿上脚上留下层层薄沙。内心也变得平静,能够感受到海的呼吸。天地间仿佛只剩下我和大海,在进行心灵的交流,俗世烦扰皆抛诸脑后,只剩下对海的依恋。白天去爬南普陀山,并不太高,慢慢爬到山顶,整个思明区尽收眼底,远处一艘快艇在海面掠过,留下一条美丽的浪花。然后顺山而下到植物园,途径无数奇花异草、层天老树,走得累了,找个湖边石凳休息一下,人也觉得轻松愉快。
经过大自然的洗礼,回到单位,人的精神面貌焕然一新,抱着积极的心态处理事情,很多问题迎刃而解。压力测试做的很累,经常要熬夜,但通过一轮轮的测试,逐步定位到性能问题所在,自己也学了不少相关知识,想想也就没那么烦了。
做事的方式,也有了长进。我现在信奉人一时只做一件事效率最高的原则。事情再多,也是一件件做,每天安排好近日的工作,并排个优先级,什么是要亲自处理的,什么是让别人处理的,什么是需要预先通知他人的,需要什么资源,每件事情的预计时间如何,需要如何
check
等等。做好一件事就打个勾,做到心中有数。如果事情有延误,分析是什么原因,该如何补救,而不要有太大的心理负担,自己尽力了就好,是自己的责任就要勇敢扛下,死不了人的。这其实是很简单的原则,谁都能够学会,但的确很管用。
总结:压力是无处不在的,关键在于如何应对和排解。用积极的心态和恰当的方法面对,压力也就没那么大了。感觉压力积累到一定程度,在还未影响正常工作之前就先想办法排解,出去旅游、运动等都是缓解压力的好办法。
最近对项目组的一些较差的代码进行了些重构,同时灵光一闪,对代码有些比较形象的比喻。
坏的代码就象揉面团,管什么接口什么实现全揉成一团,一个方法几百行,注释写再多也是面团(夹了些小纸条而已)。然后需要重用了,就是从中抓起一把面团,然后放到其它的面团里继续揉。这样重复代码一堆,什么易读性、扩展性、可维护性都是无从谈起。
好的代码就象堆积木,接口实现定义清清楚楚,每个接口只做一件事情,重复代码都是通过更细的接口来消除。重用就是把积木块往该放的地方堆,这样的代码,几个大块几个小块一目了然,只要方法命名规范,连注释都可以省去。这样耦合性低,易读性、扩展性、可维护性都可以得到保证。
把面团变成积木并不复杂,定义好模具,面团一团团往里面填充,待稳定下来,就成了一块块积木。这里关键就是模具的制作,推荐制作宝典:
martin fowler
的那本重构。还得有模具的丈量工具,就非
junit
莫属了。
项目需要写了几个数据库同步用的
trigger
,就是记录用户的操作到一个
temp
表,然后每天通过
webservice
同步到其它系统,同步成功清空该
temp
表。自认为写的还行,做个记录。是
db2
的。
--
用户组新增触发器
--DROP TRIGGER TG_USERG;
CREATE TRIGGER LIBING.TG_USERG AFTER INSERT ON LIBING.TM_USERG
REFERENCING NEW AS NROW
FOR EACH ROW
MODE DB2SQL
BEGIN ATOMIC
declare @groupId integer;
declare @name varchar(30);
declare @descn varchar(100);
declare @syntype varchar(4);
declare @ddlsql varchar(1024);
declare @isprimary char(1);
declare @updateTime timestamp;
declare @createTime timestamp;
declare @createBy integer;
declare @updateBy integer;
declare @groupType integer;
declare @adminType integer;
declare @appId integer;
declare @oldGroupId integer;
set @groupId=NROW.GROUP_ID;
set @name=NROW.name;
set @descn=NROW.descn;
set @syntype=NROW.syn_type;
set @ddlsql=NROW.ddlsql;
set @isprimary=NROW.isprimary;
set @updateTime=NROW.update_time;
set @createTime=NROW.create_time;
set @createBy=NROW.create_by;
set @updateBy=NROW.update_by;
set @groupType=NROW.group_type;
set @adminType=NROW.admin_type;
set @appId=NROW.app_id;
INSERT INTO TM_USERG_TEMP(GROUP_ID,NAME,DESCN,DDLSQL,ISPRIMARY,UPDATE_TIME,CREATE_TIME,
CREATE_BY,UPDATE_BY,GROUP_TYPE,ADMIN_TYPE,APP_ID,ACTION) VALUES (@groupId,@name,@descn,
@ddlsql,@isprimary,@updateTime,@createTime,@createBy,@updateBy,@groupType,@adminType,@appId,'INSERT');
END;
--
更新用户组数据的触发器
-- DROP TRIGGER TG_USERG_UPDATE;
CREATE TRIGGER TG_USERG_UPDATE AFTER UPDATE ON TM_USERG
REFERENCING NEW AS NROW
FOR EACH ROW
MODE DB2SQL
BEGIN ATOMIC
declare @groupId integer;
declare @name varchar(30);
declare @descn varchar(100);
declare @syntype varchar(4);
declare @ddlsql varchar(1024);
declare @isprimary char(1);
declare @updateTime timestamp;
declare @createTime timestamp;
declare @createBy integer;
declare @updateBy integer;
declare @groupType integer;
declare @adminType integer;
declare @appId integer;
set @groupId=NROW.GROUP_ID;
set @name=NROW.name;
set @descn=NROW.descn;
set @syntype=NROW.syn_type;
set @ddlsql=NROW.ddlsql;
set @isprimary=NROW.isprimary;
set @updateTime=NROW.update_time;
set @createTime=NROW.create_time;
set @createBy=NROW.create_by;
set @updateBy=NROW.update_by;
set @groupType=NROW.group_type;
set @adminType=NROW.admin_type;
set @appId=NROW.app_id;
--
如果已经有
update
则只记录最后一条
update
IF EXISTS(SELECT GROUP_ID FROM TM_USERG_TEMP WHERE GROUP_ID=@groupId AND ACTION='UPDATE') THEN
UPDATE TM_USERG_TEMP SET GROUP_ID=@groupId,
NAME=@name,DESCN=@descn,DDLSQL=@ddlsql,
ISPRIMARY=@isprimary,UPDATE_TIME=@updateTime,
CREATE_TIME=@createTime,CREATE_BY=@createBy,
UPDATE_BY=@updateBy,GROUP_TYPE=@groupType,
ADMIN_TYPE=@adminType,APP_ID=@appId,ACTION='UPDATE'
where GROUP_ID=@groupId AND ACTION='UPDATE';
--
如果有
insert
则把后面的
update
当作
insert
ELSEIF EXISTS(SELECT GROUP_ID FROM TM_USERG_TEMP WHERE GROUP_ID=@groupId AND ACTION='INSERT') THEN
UPDATE TM_USERG_TEMP SET GROUP_ID=@groupId,
NAME=@name,DESCN=@descn,DDLSQL=@ddlsql,
ISPRIMARY=@isprimary,UPDATE_TIME=@updateTime,
CREATE_TIME=@createTime,CREATE_BY=@createBy,
UPDATE_BY=@updateBy,GROUP_TYPE=@groupType,
ADMIN_TYPE=@adminType,APP_ID=@appId,ACTION='INSERT'
where GROUP_ID=@groupId AND ACTION='INSERT';
ELSE INSERT INTO TM_USERG_TEMP(GROUP_ID,NAME,DESCN,DDLSQL,ISPRIMARY,UPDATE_TIME,CREATE_TIME,
CREATE_BY,UPDATE_BY,GROUP_TYPE,ADMIN_TYPE,APP_ID,ACTION) VALUES (@groupId,@name,@descn,
@ddlsql,@isprimary,@updateTime,@createTime,@createBy,@updateBy,@groupType,@adminType,@appId,'UPDATE');
end if;
END;
--
删除用户组触发器
--DROP TRIGGER TG_USERG_DELETE;
CREATE TRIGGER TG_USERG_DELETE AFTER DELETE ON TM_USERG
REFERENCING OLD AS OROW
FOR EACH ROW
MODE DB2SQL
BEGIN ATOMIC
declare @groupId integer;
declare @name varchar(30);
declare @descn varchar(100);
declare @syntype varchar(4);
declare @ddlsql varchar(1024);
declare @isprimary char(1);
declare @updateTime timestamp;
declare @createTime timestamp;
declare @createBy integer;
declare @updateBy integer;
declare @groupType integer;
declare @adminType integer;
declare @appId integer;
set @groupId=OROW.GROUP_ID;
set @name=OROW.name;
set @descn=OROW.descn;
set @syntype=OROW.syn_type;
set @ddlsql=OROW.ddlsql;
set @isprimary=OROW.isprimary;
set @updateTime=OROW.update_time;
set @createTime=OROW.create_time;
set @createBy=OROW.create_by;
set @updateBy=OROW.update_by;
set @groupType=OROW.group_type;
set @adminType=OROW.admin_type;
set @appId=OROW.app_id;
--
如果没有操作记录,则插入
delete
记录
IF NOT EXISTS(SELECT GROUP_ID FROM TM_USERG_TEMP WHERE GROUP_ID=@groupId) THEN
INSERT INTO TM_USERG_TEMP(GROUP_ID,NAME,DESCN,DDLSQL,ISPRIMARY,UPDATE_TIME,CREATE_TIME,
CREATE_BY,UPDATE_BY,GROUP_TYPE,ADMIN_TYPE,APP_ID,ACTION) VALUES (@groupId,@name,@descn,
@ddlsql,@isprimary,@updateTime,@createTime,@createBy,@updateBy,@groupType,@adminType,@appId,'DELETE');
--
如果有
insert
记录,则整体结果相当于没有进行任何操作
ELSEIF EXISTS(SELECT GROUP_ID FROM TM_USERG_TEMP WHERE GROUP_ID=@groupId and ACTION='INSERT') THEN
DELETE FROM TM_USERG_TEMP WHERE GROUP_ID=@groupId and ACTION='INSERT';
--
如果没有
insert
记录,则只需记录最后的
delete
操作
ELSE
UPDATE TM_USERG_TEMP set ACTION='DELETE' where GROUP_ID=@groupId;
END IF;
END;
在项目中碰到一些重用上的问题,有些想法,就先写一点。
重用应该是高层的复用,逻辑的复用,接口的复用,而不是具体实现的复用。
我们项目开始讲复用,就是大家把别人的代码拿过来,可用的地方就用,不同的地方改改,结果问题一堆。说到底就是接口没有定义清楚的,很多该复用的逻辑隐藏在了具体的实现中。这样导致无法进行接口的复用,转而使用具体的实现复用。从程序员的角度看,他们总会使用成本最小的方法完成任务。所以我们要时刻思考如何能让最正确的方法在他们看来同时也是成本最小。
这里有一个较为简单的办法,就是尽量使用方法封装实现,使接口的粒度最小。如果一个实现需要几百行,且其中包含多个逻辑,就最好抽取出多个方法,然后在主体接口内进行调用。这样的代码逻辑清晰易读,可重用性也高。看看大师们对代码的不断重构,很大程度上就是重构出粒度最细,复用性最高的接口。
如何达到最大程度的复用,其实是非常复杂的问题,还需要在今后的项目中不断体会。
最近做
portal
的压力测试,一个字“累”。其中犯了不少错误,白白加了几天班,也有一些体会,就记录下来,希望对大家有所帮助。
首先讲压力测试环境。这个很是关键,我们就是在这个上面吃了苦头。我们用的
loadrunner
,原理也很简单,一台主控机,控制多台客户机,模拟并发用户访问应用。然后需要能实时监控各相关应用服务器,
ldap
服务器等的性能。这里每台客户机最好能使用同样的配置,使用足够带宽的网络,给予同样的负载(模拟同样数量的用户)。同时要注意监控客户机的
cpu
和网络状况,时刻保证
cpu
和网络利用率低于
100%
。我们犯的很大错误就是使用各自的笔记本,而且都使用的是一个
10M hub
牵出的网线,这样导致实际的网络阻塞,既没有给予服务器足够的负载,又导致报告的响应时间比实际更长,从而带来了后续很多的无用测试。
然后讲测试方法。用的较多的还是持续压力测试,就是持续给予服务器一段时间的并发量(一般为
5
到
10
分钟),然后看平均响应时间是否在可以接受的范围内。这个“可接受”要视应用类型和实际的并发用户而定,如何估计并发就要靠经验了。对于
portal
而言,由于要与众多的应用接口,如进行
SSO
,获取数据等,有很大程度也依赖于其它应用的性能,其性能要求不会太高。我们测试首页的性能,在放上全部的
portlet
的情况下,
100
个并发的平均响应时间就在
17s
左右,这肯定是不能接受的(
10s
只能算勉强可以)。接下来就是发现性能瓶颈,并尝试进行优化了。
初步的发现瓶颈的方法也很简单,通过对
portlet
的增减,发现最影响性能的
portlet
,然后不断优化,直至达到可以接受范围。发现瓶颈所在了,就得进一步确定是什么原因:是我们本身程序的问题,还是其它应用接口性能不佳等等。这里光靠猜是不行的,要讲数据讲事实,记录时间日志就是简单有效的办法,我们对各个时间点打印了日志,比如
doview
方法的全部执行时间,
jsp
的载入时间,具体接口的执行时间等。有些接口可能在压力较小的情况下性能不错,而在大压力情况下出现性能隐患,所以一定要在进行压力测试后查看日志。我们就是这样发现了性能隐患,同时更进一步对各方面进行优化,直至达到客户可以接受为止。
由于不是专门的测试人员,很多地方都是实际项目中的体会,也没什么理论基础。有什么不对的地方,大家多交流。
接着昨天的写。今天写我认为的一个
javaEE
项目中应该提倡的做法。
1.
开发流程尽量简化,采用迭代增量的模式,做适合项目需要的文档。很多时候千言不如一图,原型开发我认为也非常重要。
2.
采用成熟的框架,
ssh
组合或更多
full-stack
的框架如
seam
等都是不错的选择。如果一定要用公司的框架,至少
SA
要非常熟悉这个框架,在出现问题时要能快速的解决。
3.
对业务的分析做到越细越好,如果有条件让更多的开发人员参与业务的分析,同时形成项目通用的业务语言(实在不行,精简的
user story
也可以)。对于每个达成共识的业务都要能记录下来,并能方便的进行查阅。业务模型和业务规则要始终与当前需求、代码和数据库保持一致。
4.
在团队的建设上,需要更多的投入。不要为了节约成本,让很多程序员老后面才加入团队。一个稳定、团结、有冲劲的团队能比松散而人数更多的团队,完成的更快更好。然后要加强沟通,比如每天开个小的茶话会,大家交流下各自的工作情况,有什么困惑和疑难,提出来大家一起解决,避免大家各自做相同的逻辑(很多东西经过抽象可能就是一个)。在工作之余大家一块吃吃饭,打打游戏等都是增进感情的好方法,大家彼此熟悉了,工作上也能更好的协作。
5.
对程序员要有更高的要求,
SA
有责任让程序员了解更多的东西,如面向对象的
5
大原则、一些模式、
junit
、重构等,这些其实并不是什么高深的东西,仅仅是掌握一些方面也能对代码质量和开发中的愉悦度产生很大促进。要激发他们对技术的热爱和对代码质量的追求,因为最终受益的还是他们。
XP
所提倡的结对编程也是快速进行知识传递的好办法。
6.
采用
wiki
进行项目进度跟踪和一些文档的展示。这次用
excel+cvs
的方式感觉很是麻烦,在
spring
翻译中我们采用
wiki
的方式就感觉很好。
暂时先想到这么多,有更多体会,再来补充!
摘要: 在程序员发表的一篇maven文章,跟大家共享。用
Maven
做项目管理
在
Java世界中我们很多的开发人员选择用
Ant来构建项目,一个
build.xml能够完成编译、测试、打包、部署等很多任务,但我们...
阅读全文
开发进行到尾声了,但
bug
仍然层出不穷。总的来说,算是一个比较失败的项目,原因很多,有外在因素也有我作为一个
SA
不可推卸的责任。正好借加班的时间写点总结,也算是在失败总吸取教训,从错误中感受更多吧。
首先是开发流程。我是
xp
的坚定支持者,但在项目中由于外界原因还是采用了传统的开发流程,没有迭代,就是需求
->
设计
->
程序员进场开发
->
改
bug
。由于程序员进场时间较晚,一上来就开始开发,没有时间进行培训和团队的融合。然后开发中缺少沟通,就是一个人负责一块,开发完了再做其它。结果开发到现在,还有人不清楚我们项目的全貌,到底是为了解决什么业务。
然后是开发框架。使用了公司的框架,而我们作为
SA
(我们是双
SA
),都是第一次接触,程序员也就一个人用过。我们最早是达成共识采用
SSH
的组合(我至少还算是了解吧,其它人也都用过),但由于上层因素没有实施(这也导致我好长一段时间进入不了状态)。开发前期大家都在探索这个框架(的确很难用,出错机制较差,配置文件很多,耦合较强
...
),在一堆莫名奇妙的问题中摸索前行,花费大量的精力。而比较搞笑的是,在大家开始学习这个框架之时,我作为
SA
,因为要写一堆只为应付客户的设计文档(后面就没人看过),错过了和大家共同进步的机会,后面总是感觉“低人一等”。
在业务方面也存在很多问题。很多业务逻辑并没有以很好的载体保存下来,在需求文档中很多逻辑并没有体现。我维护了一套
pd
的业务模型,从概念模型
->
物理模型
->
数据库,这解决了后面的一些沟通问题,但由于更多体现的是静态的实体及关联,对于一些动态的业务流程没法体现。我们
SA
之间有时在一些问题上的理解还存在分歧(讨论过也达成过共识,但没有记录下来,后面可能就忘了),程序员就更是无所适从。谈到这,我更感受到
DDD
这本书的价值,他所提倡的开发人员参加模型的讨论,形成项目的模型语言,并不断随着业务进行演化。。。好多理念都是项目经验的结晶啊。
在开发管理上我也是无所作为。
Junit
都没有推广下去,更别说
TDD
了,这也与框架相关,它就没提供写
test case
的地方,等我搞明白一堆配置文件,做出脱离
web
容器的
test
框架,都开发一大半了,说起
test
的好处,大家也表示不理解(或者表示理解但没时间
=
没理解),就让他们慢慢
debug
吧!代码的质量也没有保证,程序员不明白代码的味道,更别说理解重构的意义以及进行恰当的重构了。一个函数写上
100
多行,什么逻辑都混在一块,但由于时间较紧,我也只好睁一只眼闭一只眼“功能完成就行吧!也不是我一个人在管”,到现在很多代码混成一团,展现层直接调用
dao
(又是框架惹得祸),相同的逻辑
copy
到
n
处,我也是后悔莫及。
今天先写失误,明天写从中学到的东西,从错误中学到的也许更多!
最近看了看领域模型驱动这本书,只看了前面几章,但也深切的感受到了模型的重要性。通过与代码同步的模型,能够维护一个很好的知识共享的空间,包括设计者与程序员之间,客户与设计者之间
……
而且模型应该尽可能简单,让不同背景的人都能够很快学会,并都能对模型有所增益。
那么这个模型应该是什么样的?书我没有细看,只说说自己的体会。关于设计,很早就有数据驱动和对象驱动的提法。在
Without EJB
里,
Rod
也有讲:数据驱动或者说面向数据库设计更成熟,工具更多;而对象驱动更符合面向对象程序的特性,但由于掌握的人较少,风险较大。而通过模型驱动,我认为很大程度填补了
2
种方式的鸿沟,核心是模型,具体是对象模型还是数据模型并不重要,重要的是这个模型能够与需求、代码、数据库保持一致。
说到这里,顺便谈一谈我对文档的理解。我一直是
XP
的坚定支持者,甚至有点偏执。而由于文档不易阅读和沟通,且经常会出现与设计和代码的脱节,导致其可读性更差,所以我一向对文档不大感冒,更倾向于使用代码说话。但在目前的公司项目中,由于更多采用传统的软件过程,我也写了很多的文档,包括需求规格说明书、概要设计文档、详细设计文档等等。从对项目的帮助来看,文档作用并不太大,或者说是付出收益比太低,更多的是给客户写的,而不是给程序员写的。从程序员的需要来看,他关心的是每个实体的属性和关联,核心的接口、输入和输出,页面间的跳转和数据流,然后有一个统一的框架和编程模式。我的体会是:如果以文档为核心,很难描述清楚这些东西,且难以应对变化。
而通过以模型为核心(项目现在采用的
power designer
的概念模型为基础),辅以适当的描述,既能够加快大家对项目的认识(程序员是后面才加入),又能够节省一些写文档的时间,更早投入开发。
说到
power designer
,我也比较惭愧。用了好久,一直只是把它当成看数据库的工具。项目一开始就是从物理模型入手,结果举步维艰。后面从概念模型入手,就感受到了它的好处。使用概念模型,不用考虑太多关联表、外键什么的,而是从实体出发,然后确定相互间的关联,是一对一、一对多还是多对多。然后自动转成物理模型,并直接与相应的数据库挂钩。从这点上看与从对象设计出发真的非常相似。其实这也是合情合理的,正体现了这个世界的统一性吧(物理学界不也在搞什么统一场理论的证明吗)。
Power designer
也做了
conceptual model, physical model, object-oriented model
和
xml model
的自动转换,我现在还没全部摸熟。
openfans
则是从对象入手,并通过
hibernate
建立与数据库的联系,也体现了一定的方便灵活性。但比较糟糕的是,只有代码和配置文件,没有清晰的便于交流的模型,谁要想参与只能先去慢慢看代码。所以我先通过
together reverse
出来一个类图,然后适当加以文字进行说明。类图已经做好,但比较乱,还需要更多的图例加以说明。文字说明就是下一篇
blog
的工作了。也算是预告吧!
近来在一个项目做
SA
,也是第一次做比较大的项目的设计,感觉比较吃力。同时又要参与
spring
文档的翻译,一直没时间写
blog
。今天终于有点时间,就写一下最近的感悟。
首先是不适应。要参与需求阶段,因为需求初期并不确定,客户都不清楚他们需要什么东西,只是有一个很模糊的概念。我们得不断调研、讨论、出方案、出原型
……
而这都是我比较不擅长的。还好有个职务较高的老大带着我们,才能逐渐把需求理顺。我也从他身上学到不少,准备写一篇“如何做需求”,但毕竟是第一次做较大的需求,理解还不很深刻,怕贻笑大方,所以只拿
MindManager
列了个提纲。
其次还是不适应。项目开始好几个月,没写过一行代码。项目没有采用
XP
的方式,而是普通的瀑布。需求就做了几个月,然后做概设、详设。我是
XP
的支持者,所以对这种方式持反对态度,但老大不同意,没办法!写文档,我也是很不情愿,但转念一想:
Rod
写
Without EJB
,但他
ejb
的理解比谁都深,什么方式都实践下可能更好。由于同时在看
Joel on software
,他对需求规格说明书却很是强调,我也就听听大师的话,好好写需求,顺便把他的一招用上了
-------
写的有趣点,就当写故事吧。
最后还是不适应。以前做程序员,可以好好研究很多东西,现在不行了。有个
xml
与
bean
转换的技术要解决,我能研究不?不行,我得写文档,这种比较
detail
的事情得给程序员做。看着程序员兴高采烈的比较各种开源工具,最后选定
JIBX
(
openfans
发挥了一定的作用),然后跟我讲这个如何如何好,我只有附和的份。
讲到这里,让我想到一则小故事:有一个学钢琴的拜一个牛人为师。牛人交给他一个曲谱,说:“回去练好,一个月再过来。”他好歹把这个曲练熟了,还想展示一下,牛人又交给他一个更难的曲谱,又是同样的话。他只好回去继续苦练,每次都感觉不适应。这样往返多次,他忍不住了,问牛人:“你是不是故意整我,每次都给我更难的,还不给我表现的机会”。牛人让他把上次的曲弹弹,他感觉不错,让弹再上次的,更是轻松,最后弹第一次,他弹的是出神入化。他明白了!
大家都明白没:只有不断的感到不适应,才能进步。如果一切感觉良好,没什么挑战,就该考虑。。。。。。(此处省略
2
字)了。
不经意看到了程序员的一期算法专题,细细研读多位高手(包括李开复)的文字之后,对算法的重要性重新进行了反思。我研究生毕业
2
年,一直从事
J2EE
开发,由于项目的原因,很少需要自己去设计算法,甚至
stack
,
tree
这些数据结构都很少使用。还好自己也不甘于平淡,如
Effective Java
,
Practical Java
,
Refactory
,
Design Pattern
等等这些流行书还是抽空学习,这些书的确很是经典,对我的编码风格,模式的理解,设计能力都起到了很好的促进。也快速的由一个程序员成长为架构师(只是公司的,离真正的架构师还差得远)。
因为项目需要,去年下半年开始全面接触开源软件,使用了
spring
,
maven
,
hibernate
,
ibatis
等众多开源软件,也对开源软件产生了浓厚的兴趣,于是拿这些开源软件做了
openfans
,一方面是推进开源软件在中国的使用的交流,一方面也为自己在实践中更多使用这些软件(因为没有项目和利益因素,可以做想做的事,用想用的软件)。使用这些开源软件倒很是顺利,很多软件拿来就能用,都有
sample
,简单使用还是不难的。
但一些关键的问题一直悬而未决!比如
tag
的设计:我现在简单的使用平铺的模型,
tag
没有层次之分,
tag
间产生双向关联。但这样是最符合
tag
特性的模型吗?如何对这些
tag
进行分类,如何定义
tag
的多级关联(如
spring
和
hibernate
有关联,
hibernate
又与持久层关联,
spring
是否与持久层有间接关联,依次类推)。。。。。。而做出一个好的
tag
模型,可能就需要图论方面的知识。再比如用户相似度设计(号称是豆瓣的核心,难以复制):每个用户拥有了一些
tag
,如何根据这些
tag
定义用户的相似度,一个用户有
spring
,
hibernate
这
2
个
tag
,一个用户有
spring
,
ibatis
这
2
个
tag
,他们相似度为多少,如果每个人
tag
都很多,再加上权重的概念,问题又复杂的多。简单的做法就是每个用户
tag
一个个匹配,匹配的越多相似度越大,但这样设计一是不准确,二是时间复杂度很大,最坏情况为
n*n*m*m
,
n
为用户数,
m
为每个用户的
tag
数。
这些都需要扎实的算法基础。而我的基础就很薄弱:本科学的比文科还文科的专业,研究生又学的比较上层的东西(
UML
,
RUP
,
PM
等,也都一知半解),选修了一门算法导论,又被
1000
多页的经典英文教材吓趴下了,上了几次课就直接放弃,没敢参加最后考试。现在想临时抱佛脚,谈何容易。
所以算法也并非没有用处,关键要看你在做什么,想做什么。想去
google
、百度不用会
spring
,算法基础扎实,只会
c
语言都行;一些行业如电信、金融也很是需要算法高手。而国内更多的企业做企业应用,一般是连连数据库,写写页面,最多引入些开源框架和软件,如
spring
,
hibernate
,
struts
等。这方面的需求较大,会了
spring
,省了公司的培训成本,自然还是给找工作加了一些砝码。
所以有时听到某些人对某项技术不以为然,说“这些东西有什么是我在几个星期学不会的”的时候,一方面是对其狂妄进行些鄙视,一方面也真要问问自己,我的核心价值到底在哪。这个问题很重要,涉及面很广,选择也很多,而我也只是有些模糊的答案,等以后再仔细写写。
不管如何,我是要开始研究算法了,得解决问题阿!先在
openfans
开个算法的
tag
,一边学一边积累,对算法有兴趣的同学也可以跟我一块进步。
PS
:做个广告,
blogjava
很多好的
bloger
,能否到
www.openfans.net
导入下
blog
,跟大家分享下你的感悟,谢谢!
很不好意思,不是原创技术。做个广告,有不妥,欢迎管理员从首页拿掉。
你是开源软件的爱好者,平时学习和使用这些软件,也不时写写
blog
,记下些心得。
你是开源软件的传播者,你希望更多的人了解和使用开源软件,希望你的文章被更多的人阅读,并展开更深刻的讨论。
你是开源软件的参与者,平时参与参与国外的开源项目,也希望中国能有更多的开源团体,大家一起做国人自己的开源软件。。。。。。
只要你对开源软件保持着一份热爱,欢迎来到
openfans(www.openfans.net)
。
非常方便的注册后,你就可以点击“提交
feed
”,只要输入你的
rss
地址(由于时间原因,还没做直接从
web
地址发现
feed
),就可以将你的
feed
加入,同时我们对一些网站提供了简单的匹配(如
blogjava
,只需输入你在
blogjava
的用户名,系统会自动匹配成你在
blogjava
的
feed
)。完成后,点击“立即导入”,就可以将你的文章入库,点击“最新日志”可以查看。以后系统会每日定期读取你的
feed
,自动将新的文章加入。由于你提供的是
rss
,内容应该是文章的简短描述(视你的
blog
提供商而定),而且我们会为每篇文章提供原文链接,直接指向你的
blog
原文。
导入的日志一般是没有进行分类的,不方便大家的查找。在每篇日志上都有个“我要推荐”链接,点击并输入你认为适合的标签(如
spring
,
hibernate
,
cms
)等,就可以把这篇日志形成文章,放在相应的标签下,永久保存。需要学习
spring
,
hibernate
,
cms
的后来者,可以方便的查找到标签和软件,找到你的文章,进而进入你的
blog
。
同时你也可以发表文章,推荐软件,创建和加入小组,进行评论。。。。。。我们会不断完善功能,给大家提供更方便的功能和更好的用户体验。
由于现在人员较少,开发进度较慢。但先做个广告,下一步会做
digg
,提供对软件、文章、用户等的
digg
。做对一些标签的
rss
,如
springframework
网站的
rss
,自动获取
spring
的版本更新信息。还要完善小组功能和好友功能,给大家提供一个方便交流的平台。
网站拿
java
的一堆开源软件做成,同时本身也是开源软件,希望参与的同学可以
email
给
pesome@gmail.com
,大家一块为推动开源软件在中国的发展做出自己的贡献。
前面openfans用的JDK1.4,今天下决心换成1.5了。运行倒是好好的,在jetty下也没有什么问题。一不小心点了下eclipse里我做的mvn eclipse:eclipse的External Tools,就开始maven了。停也没用了,等着吧。结果报错:D:\javaproject\openfans\main\src\org\openfans\domain\Group.java:[29,19] -source 1.3 中不支持泛型(请尝试使用 -source 1.5 以启用泛型)。看了看maven的bat,会自动使用环境变量配置的jdk,应该没问题啊。还好我网上认识人多,想起alin用的jdk1.5,就问他怎么回事。发过来这个:
<
plugin
>
<
artifactId
>
maven-compiler-plugin
</
artifactId
>
<
configuration
>
<
source
>
1.5
</
source
>
<
target
>
1.5
</
target
>
</
configuration
>
</
plugin
>
我一看就明白了,
mvn
时是用
1.3
给我编译的,得告诉它用
1.5
。拷到
pom
文件中,再
mvn eclipse:eclipse
搞定。问题是很快解决了,同时却留下了很多思考:
1.
技术没有止境,做人一定要谦虚。
Maven2
我用的也算比较早,还曾经被白衣说是对maven2的推广做了贡献的,自己也颇以为然。而现在这个简单的问题却不知道了,还得google或问人解决。还好我一直比较谦虚(本身也没啥可骄傲的资本),否则要狂被鄙视了。
2.
技术的推广要不遗余力,好的东西要让大家都知道。
Maven2
我也只是使用,了解并不深入(项目中碰到了的知道,没碰到的就不懂了),但我是到处推荐,碰到个人就说这个好。这下很多朋友都知道了,也引入项目实践了。一方面他们用的舒服,提高了效率,有点问题还可以向我这个所谓的maven2高手请教,我自是“知无不言,言无不尽”;另一方面,他们也许就碰到其它问题了,然后知道如何解决,在我碰到类似问题时,就可以向他们请教了。你看,多好的良性循环,想想都美滋滋的。
3.
多进行知识共享,大家的智慧比个人强。
这是从更高的角度看了,通过知识的共享,能迅速集合大家的经验和智慧,让个体更快的进行学习,少走弯路。你共享自己知识的同时,也能获得别人的成果。如果你知道谁spring比较强,谁hibernate比较强,谁在用maven,而且碰到问题能看他们的文章或直接向他们请教,做起项目来是不是都安心的多。可能有人说有google,但google信息量太大,而且很多文章是处处转载千篇一律,经常半天找不到东西。我是深有体会,所以想到做openfans,做一个知识共享的平台,并做到去糟取精。现在还远远达不到要求,但我会努力的。
领域模型驱动(
Domain Driven Design
),很热的名词。
Openfans
,不太热的网站。今天俺就借着很热的
ddd
,给不太热的
openfans
再造点势。
Openfans
就不多介绍了,网站用
spring+hibernate
为核心的一堆开源软件构建。有了
spring
的
IOC
和
hibernate
的
ORM
,打着
ddd
的旗号也就名正言顺了很多。先声明其实俺对
ddd
的理解也多是道听途说,没有什么系统的学习过,倒是和
Joe
阿牛讨论过几次,颇有受益,他对这个理解还是很深刻的。
言归正传,就讲
openfans
现在经
ddd
思想改造过的模型。整体上看还是普通的三层架构体系:展现层、业务层、持久层。展现层用
spring mvc
,力图做到只是展示相关,避免出现业务逻辑。再具体细分,就是
jsp
页面只有展示逻辑,主要使用
jstl
完成显示功能。
Controller
负责从页面获得参数、把数据传回页面、控制页面流传和调用业务层的接口。持久层使用
hibernate
,在设计上我不是按
dao
方式为每个对象建立相应的
dao
,也不是
ddd
推荐的每个
domain
一个
repository
,而是分成了
Persistence
和
Fetcher2
个接口。
Persistence
处理持久相关如
save
和
remove
方法,
Fetcher
则处理
get
相关。这样分的原因也很简单,
persistence
是很稳固的,对象都可以共用一个接口如
save
(
Object
),而
fetcher
就千变万化,需要分页、排序等接口。
这样设计是与业务层架构相关的。我采用的是
domain
对象(简称
DO
)
+
一层薄薄
façade
的方式。
DO
处理自身的逻辑,包括持久功能。本身
DO
是没有持久能力的,需要依靠注入的
persistence
接口,这里就体现按
Persistence
和
Fetcher
分开的一个好处,
persistence
所有
DO
可以共用一个,给编程带来了方便。
Openfans
中采用的是
DO
继承一个抽象
PersistentObject
类的方式,这样
DO
方便的获得了注入的能力和持久的能力。这样做有何优缺点还需要做些讨论,为了方便我也就先这么用。
PersistentObject
代码如下:
public abstract class PersistentObject implements NeedPersist {
private Persistence persistence;
public void save() {
persistence.save(this);
}
public void remove() {
persistence.remove(this);
}
public void setPersistence(Persistence persistence) {
this.persistence = persistence;
}
public Persistence getPersistence() {
return persistence;
}
}
这样
DO
只需要注入
persistence
就获得了持久的能力,而且可以把这种能力往下传递。
DO
获得了持久能力,就有点接近富血模型的想法了,他能够处理一些业务,做持久然后调用引用对象的业务和持久方法
(
从另外的角度看持久与业务其实是分不开的
)
。这样把业务封装在了领域本身,更适于用领域对象出发的方式去思考问题。领域层的
façade
主要是为了
Transaction
管理和隐藏
DO
接口。这样
DO
的业务方法都可以设置成
friendly
,仅相互间可见。
Façade
就放在
domain
包中,它负责给
DO
注入
persistence bean
,调用
DO
的接口,提供给
controller
一个
use case
级别的接口,同时它也代理
fetcher
的接口。
有了这个架构,实现起来也不复杂,要配置的
bean
很少(现在还没有使用
spring 2.0
将
DO
配置在容器中)。设计就从
DO
出发,明确它的属性和方法,让
hibernate
自己生成数据库表。
这样设计也算是一次尝试吧,其中肯定有很多考虑不周的地方,需要不断的讨论和改进。
摘要: 自己做个小项目,使用了
maven2
,一直使用
tomcat
,但很不方便。采用直接改
server.xml
指向项目路径的方法,但这样要求把编译路径改向
WEB-INF/classes
,而且要求把需要的
jar
放到
WEB-I...
阅读全文
今天下午去参加了上海的
bea usergroup
大会,主题是深入极限编程,感觉还是受益良多的。这次大会有
yanger
主持,少了很多的商业气息,只是在中间休息阶段问了一些有关
bea
产品的问题。关于
bea
我也不大熟,平时用的都是
ibm
的一套,也就不多评论了。
一共
3
个
speaker
,第一个是
thoughtworks
的资深顾问,讲了些
xp
要注意的地方,并配了些照片和图表,讲如何实施
xp
,还是有些收获的。第二个是阿里巴巴的性能测试专家,讲了如何进行性能测试,如模拟用户,确定负载等等。人挺牛的,但想想阿里巴巴每天
1
个亿的
pv(page view)
,他都搞得定,咱也没话说。
第三个出场的就是这篇文章的重点了,讲的的确很好,而且很有新意。这位是红工厂的老板,在中国工作几年,然后去加拿大开始了他的
xper
之路,回国后做出了自己的
JDO
实现。他的主题就是结合自己的经历,讲授一个
xper
的成长过程。因为是亲身所感,他讲出来很是实在,加上时不时幽它一默,如:上班让打游戏感觉很爽,跟印度美媚
pair programmer
却感觉很累。。。。。。让人在会意的微笑中体味他当时的感受和成长,同时加深对
xp
的一些实践的实际认识。
他并没有讲
xp
所涉及的所有要素,只是强调了
pp
和沟通的重要性以及测试优先和重构是程序员的基本素质这几个方面。他很是关注沟通的精神甚至一个人的性格要素,他认为好的
programmer
应该乐于去沟通,勇于承认不足,并能主动去向同伴或团队寻求解答(而不是首先去
google
)。同时他对
xp
的精神提出了自己的看法,也是以人为本,但是另一种意义上的以人为本。他半开玩笑的说,以人为本并不是给你更多的工资,让你上班打游戏,让你
happy
的工作,而是把以前对流程的关注更多转到开发人员上面,让开发人员具备一个
xper
应有的素质。他通过亲身体验说明了一个好的
xper
即使不在
xp
的团队中,也能创造更快的开发效率,更高的代码质量和更少的加班。关于这点我也很是认同并有一些亲身的实践:通过测试先行,不断重构和努力消除重复代码,是能大大优化代码结构,提高代码质量,减少
bug
率的,而相应的反而会提高开发效率。
也许目前国内还较少有真正能实施
xp
的团队,我们也很难真的在项目中进行
xp
的完整实践。但只要我们接受
xp
的思想,在平时的实践中就采用一些
xp
推荐的方式,如测试优先、重构、持续集成、乐于沟通等等,先把自己变成一个合格的
xper
,那么在真的有机会实施
xp
的时候,我们就能更快的融入团队,更好的用
xp
的精髓指引项目走向成功。
接着昨天的写。
出了大楼,师弟带我们到新建好的南门去看看。这不是凯旋门的模仿吗?厚重的大理石砌出中间一大两边一小的空透长门,再加上一些简单的雕饰,中间的下面却立了很大石碑,刻上学校的名字,再围上一些花,阻止人的通行,顿时减少了很多宏伟的气势。但这样却便于照相,好多同学三五成群往石碑前一站,然后很好取景:人面鲜花相映,加上“凯旋门”的气势和石碑的明喻,很有纪念意义。“凯旋门”两旁是弧形的长廊,仿欧洲古典主义建筑风格,一排排石柱过去,凭添了不少文化气息。
从“凯旋门”往校园里走,眼前一片开阔,是一大片草坪,有几个足球场大。草坪上有不少学生,或站成一圈玩飞盘,或几个人围坐打扑克,或几个人乱卧其上感受草的气息。我们走进看看,一块块醒目的小牌上都有一句颇有意味的话语“小草在休息,请勿打扰”。本意大家都明白,但看这么多人在上面,也就暂且从众一把。我们也打扰了一下小草,我还忍不住在上面打了个滚。同时在想:这么大的一块草坪,花费不菲,如果只是看看,未免可惜了点,好像国外的草坪也并不禁止人踩踏的,只要不在上面做剧烈运动,如踢足球之类,应该也不会带来很大的影响。
沿着路往东走,右边都是新建的教学区和学院大楼,风格很是统一。经过一座小桥,往下看去,河水缓缓流过,旁边一个小的岸边广场,河岸边有沿河走道,一直往远方延续。在草坪的绿色基调下又多出一些点缀,真是风景这边独好。我又在心底感叹:真是适合谈情说爱的好地方,可惜我们那时没有,只有西边一个小的人工湖,晚上拥挤的很。再往东就看到一个红漆的仿古大门,是把老校区的大门
copy
过来了。照样门前一对石狮,也是适合摄影留恋的地方。
大家到这也就慢慢散去了,大部分打的走了。我的爱车还在学院门口停着呢,于是又跟几个同学往里走。一边聊聊工作的事情,一边大家好像有默契的往以前的宿舍楼所在走去。走了好远,过了一个地道,来到以前的宿舍楼下。又翻新了,涂上浅黄色涂料,加上四角的红砖墙装饰。可惜原本就整体感觉不佳,就好像一个丑媳妇,涂上再多胭脂水粉也变不成美女一样。忍不住从下往上张量以前我住的宿舍,阳台挂了件运动衫,里面还是有位运动健将的。
又得睡觉了,还没写完,明天继续。
今天是母校
110
周年校庆,同学一块回去看看阔别了快
2
年的校园。我可是有车一族,便开车回去看看,不远的路,开了
1
个小时,挺累,是自行车。早听说短短
2
年,学校扩大了好几倍,但真的到了还是颇有感慨。从东边一个门进去,一直往西骑,新造的大楼一座座被抛在后面,完全是陌生的感觉。好久才唤回一些熟悉的记忆,原来是到了以前的东区了。我以前在西区住,到东区的新教学楼上课,就感觉远的厉害,走路需要十多分钟的。现在看来,自行车应该是每个学生的必需品。到了西边还是热闹了很多,有了校庆的气氛,随处可见坐满校友的大巴和各种款式的轿车。等俺有钱了,也开辆小车来显显,我心里嘀咕着。
因为赶时间去聚会,所以也无心流连,骑车直奔饭店。老同学好久不见,免不了一些客套寒暄,
2
年时间毕竟太短,大家也没有太大的变化,没有谁一下飞黄腾达的。席间觥筹交错,自不必说。有
2
个研二的师弟,便吃完带我们四处走走,首先就去看我们毕业后才落成的软件大楼。
这时我的车发挥优势了,他们得做校内巴士,绕好大一圈的,我就沿着一条直线直接骑过去。根据师弟的描述,来到一座银灰色玻璃幕墙的大楼前,停好车,他们还没到,便在外面转悠转悠。五层楼高,挺现代的设计,对一些细部处理的也不错,有挑台,凹进,凸出,显得整个立面挺丰满。这里插一句:我本科是在这学建筑设计的,可惜没天赋,学了个半吊子,只好改行。
等了会,他们才姗姗来迟,大家一块进去看看。厅很大,展出了很多学生的成果,挺不错的,有自己开发的工作流,有拿
spring+hibernate+velocity
做的项目,有自己做的负载均衡服务器。。。。。。二点感受,一是学校教的还不错,是在培养学生的实际能力,跟社会接轨;二是开源软件深入人心,在校的学生也都在使用了。看了他们的实验室,全
dell
的液晶,空间按公司的
cube
方式布置,大家议论说比他们的办公环境还好,于是纷纷感叹,生不逢时,晚来几年就好了。
得睡觉了,先写这么多,明天接着写。
Sf
的
cvs
一直不好,也不知道什么原因
.
前面听白衣说过,可以一键切换到
svn.
今天就试了试,找了半天,在
admin-> svn
下找到了
migrate
这个链接,点一下进入
migrate
界面,什么都不用改,直接点下面的确认按钮就搞定。这时的状态是
wating
,号称要等
1-3
小时才能搞定。我等不及,隔了一会就刷新,结果状态已经变成
complete
了。
svn
地址为
:https://svn.sourceforge.net/svnroot/openfans/
然后拿小海龟试了下
,
可以访问
.
拿
svn
的
eclipse
插件下载也成功了
,
通过
updatesite
可以下载这个插件
(http://www.polarion.org/projects/subversive/download/update-site/)
。打开插件窗口,界面跟
cvs
基本类似,我先试
commit
功能,正好把前面
cvs
的本机改动提交上去。
结果报
403 forbiden
错。
Google
,看到白衣也碰到同样问题,结果迁到
scud
上去了。我只好点些老外的论坛回复看,看到一个解决问题的回复。号称要
admin->member
,我便照做,一看多了个
svn
的
permission
框,把自己的先勾上,
Update
。然后重新
commit
,搞定。
Sf
的
svn
速度飞快,比
cvs
快多了,这下也省得自己搞
svn
了。把这个成功经验写出来,也可以给后面的人一个参考。
应牛牛和
lucky
的要求,写一份
openfans
的快速配置指南,也就是介绍如何在你的机器上把下载下来的
openfans
跑起来。首先使用
maven
,需要下载
maven
,
www.openfans.net
里可以输入
maven
进行搜索,有它的介绍和主页,还有我写的一篇简单的
maven
上手文章。
如果使用
eclipse
,在项目根目录,也就是
pom.xml
所在目录,运行
mvn eclipse:eclipse(
如初次使用,会花较长时间到网上下载
plugin
和
jar
,建议去喝杯咖啡
)
。
mvn eclipse:eclipse
会生成
.class
和
.project
文件,可以进入项目的
build path
查看,会自动将
output
路径设为
target/classes
。默认数据库使用
mysql
,如果希望马上运行,则创建一个新数据库,可以命名为
openfans
,如果
mysql
采用默认安装,则用户名
root
,密码为空,可以无需更改
jdbc
配置文件。要更改也很简单,在
main/src
下面有一个
jdbc.properties
文件,可以在这里更改数据库类型和用户名密码。这里有一句
hibernate.hbm2ddl.auto=update
,表示
hibernate
会自动更新建表语句,也就是新运行或更新了
hbm
文件再运行,
hibernate
都会自动帮你完成数据表的重建工作,这样你可以不用再考虑数据库建表脚本了。
如果想在
tomcat
里直接运行,则可以执行
mvn package
,会运行所有
test case
。目前的
test case
通过继承
AbstractTransactionalDataSourceSpringContextTests
,能够方便的实现数据库回滚,在
BaseTest
类下有一句
this.setDefaultRollback(false)
,如果希望通过程序填充数据,就
uncomment
它。这里有一个地方要注意一下,就是
web/WEB-INF/urlrewrite.xml
,这是
urlrewrite
的配置文件,
urlrewrite
的描述在
openfans
网站里有,可以通过搜索
urlrewrite
快速的找到。因为我把文档根设为“
/
”,所以有
<to type="redirect">/view$1.html\?id=$2</to>
,如果文档根是
openfans
则需在
/view
前加上
/openfans
,然后再运行
mvn package
。测试全部通过,就会在
target
目录下生成
openfans-o.1.war
,将这个
war
放到
tomcat
的
webapps
下,启动
tomcat
,应该就能通过
http://localhost:8080/openfans
访问了(假定你采用默认端口
8080
)。
如果进行开发,可以安装
eclipse-tomcat
插件,插件也可以在
openfans
网站输入
tomcat
进行搜索。可以在
tomcat
的
conf/Catalina/localhost
下创建一个
openfans.xml
,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<Context path="/openfans" reloadable="true" docBase="D:/javaproject/openfans/web">
</Context>
docBase
改成你的
openfans
所在的路径。
这里因为pom文件定义的默认输出位置为target,需改为web-inf/classes,这时会有一个src冲突,需把src/web/里的web-inf/classes exclude掉就可以了。
然后在
eclipse
启动
tomcat
,同样可以通过
http://localhost:8080/openfans
访问了。用这种方式启动
tomcat
可以进行调试。
先说一下openfans最早版本的整体设计。首先是用Equinox直接new出项目来,它默认是springmvc+spring+hibernate再加上一些常用的组件,如sitemesh,common-validator,dwr等。而这些都是我们想要的。
有了这个大的框架,我们可以进行业务建模了,我们采用的是领域模型驱动的设计方案。首先考虑的是对象以及对象间的关联,我们也没用什么建模工具和自动生成工具,先自己写java类,写好属性,用eclipse生成get和set。然后手写hibernate的hbm配置文件,有点土,这也是我第一正式的使用hibernate。开始我用了dao模式,写了好多dao,后来和oofrank讨论,一直认为hibernate就是我们的持久层,完全没有必要为了移植性(如将来使用ibatis)而引入dao。所以抛弃了dao模式,而由一个façade处理持久。这样的设计跟一般的三层模型略有不同,hibernate就是我们的持久层,然后通过一个façade提供对上层的接口。领域模型和mvc中的c充当我们的业务层。我们的对象不是贫血模型,而是有能力的。当然现在这种能力更多是对象间的关联,而对持久层无能为力,但也已经方便了很多。Controller现在具有较多的功能,它能调领域对象,也能直接使用façade。然后是jsp+jstl+el做纯粹的展现层。C和V的分类原则是这样的:一类是查看,一类是form提交。所有查看由一个viewController统一处理(这样增加了一些耦合,但效果还可以),一个对象的增、删、改由一个formController处理。
有了这些设计原则,做起来倒是很快,几天就核心功能出来了。对于数据库,只要建一个库就行,其余的如建表,改表等都由hibernate来自动帮你完成,数据库就是在写hbm时关心下,其它完全对我们透明,感觉还是挺爽的。 最初版一共就20几个类,完成了很多的功能,可以具体看
www.openfans.org 下一篇写怎么使用maven和tomcat,让openfans在自己机器上跑起来。先去吃饭了,^_^。大家有任何疑问和好的改进意见,都可以提,跟帖。
本网站旨在推动opensource软件在中国的传播和使用。应用web2.0的思想,提倡大家都来参与和有收获有贡献的风气。注册后就可以直接登录(将来需发email进行验证),登录近来就可以进行所有的操作了。
操作很简单,先可以点击上面的修改用户链接,补充自己的信息(现在只要填入blog地址、简单描述和所在地),这样能够让其它用户更好的了解你,还可以加一个你喜欢的图像上传(现在大小限制在10k以内)。
点击推荐软件链接,可以推荐你喜欢的开源软件。填入名称,主页,加上你的介绍或官方的介绍,然后给它个图标,就可以了。图标可以在它的主页上找到,然后将其url拷贝下来,就可以了。
在浏览软件时,你可以随时增加认为与其相关的标签(我们把软件认为是一种特殊的标签)。标签标题是不带空格的,我们可以填入用空格分割的多个标签,系统会依次增加这些标签关联。如hibernate,你认为它是持久层,也可以认为是O/Rmapping,已经关联的标签也可以再加,我们会增加其关联度。一个标签下的相关标签会按关联度从高到低排列。
更重要的是你说明自己对这个软件的使用情况,如熟练掌握、正在使用还是准备使用。简单的点击,会给软件和你增加有用的信息。我们会看到一个软件有多少人熟练掌握,有多少人正在使用,在进行同类软件横向比较时非常有用。而如果你在准备使用一个软件时,就可以看看有谁熟练掌握了这个软件,可以看他(她)的blog,或直接跟他(她)联系,更快的掌握这个软件。
如果你有好的心得体会或看到网上有好得相关文章,也可以在浏览标签的页面,点击发表文章链接,跟大家进行分享。别人也许就因为你的一篇文章快速入门了呢,呵呵!
将来还会有更多更好更酷的功能出来,我们永远会从用户角度出发,力求做到最好的用户体验。欢迎进入openfans的世界!
注册网站
www.openfans.org以及
www.openfans.net(现在www.openfans.net开通了
),提供对开源软件的介绍和评论。应用web
2.0思想,体现社区自管理的原则,提倡对开源软件学习和交互。期望成为中国开源软件介绍和交流的主流平台之一,为开源软件在中国的传播和使用贡献自己的力量。
roadmap(暂定):
0.1(4月底完成)--注册,登陆,权限管理,标签功能,发表软件介绍和文章
0.5(5月底完成)--评分体系,同城,小组和朋友管理
0.8(7月底完成)--sns功能,投票功能
1.0(9月底完成)--开始形成专家小组,提供项目外包和咨询管理平台
更多--随着平台的使用和更多的成员加入,不断加入新的功能
同时启动开源项目openfans,使用开源软件:eclipse,
maven2, spring(包括spring mvc), hibernate,
mysql,common-validator,sitemesh.....
目的是提供web2.0应用的基本模型,同步在www.openfans.net上进行验证和使用,并能够方便的移植到其它领域。
目前项目在sourceforge上,由pesome和oofrank共同管理。0.1版基本完成。
cvs -d:pserver:anonym...@cvs.sourceforge.net:/cvsroot/openfans login
希望参与开发的同学请mailto:pes...@gmail.com,简单介绍自己并注明在sf上的用户名。
在google上开了一个站务论坛:http://groups.google.com/group/openfans
欢迎大家多来访问,推荐软件和文章,方便大家更快更好的找到自己最需要的东西!
项目组对log和exception的讨论结果。希望更多的人参与讨论。
1 log
1.1 用log.error表示系统级错误
1.2 用log.warn表示应用级错误
1.3 服务初始化或结束用log.info
1.4 用log.debug替代out,debug要判断isDebugEnable
1.5 用log.warn("",e)替代e.printstack
1.6 用log4e生成log相关代码
1.7 Log信息要保证可读性,需记录现场信息,如当前处理id等
2 exception
2.1 try catch内的代码不要太长
2.2 因为性能原因,try catch少放循环内
2.3 尽量避免catch(Exception)这样的写法
2.4 不同模块定义不同的exception
2.5 建议创建应用的基类exception,特别是有定义error code需要的应用
2.6 只要catch就要log error message
2.7 catch并封装成另一种exception,如果不nest原来的exception就要log stackTrace
2.8 持久层throw dataAccessException,业务层throw checked exception,展现层只显示exception信息
2.9 规范的exception流程定义如下:
业务层不需处理的runtime exception,由展现层定义的exception controller捕获,交给相应的error页面显示并记录stack信息。业务层捕获下层的exception,并封装成业务层的checked exception,如果nest所捕获的exception,则仅log error message,如果不nest就需要用log.warn(“”,e)记录stack信息。展现层捕获业务层的exception,应由处理业务层exception的error页面来处理。
对spring框架和开发模式进行了验证。大家有什么问题或好的建议,请回复,大家一起讨论!
一、 项目目标及完成情况
|
目标 |
完成情况 |
|
技术验证和推广 |
完成较好。
1. 共有7人实际参与项目开发,我们引入maven2作为构建工具,eclipse作为ide环境。大家都能在很短的时间初始化项目,并快速掌握各自需要的技术(如spring,spring mvc等)进行开发。
2. 对分层开发的模式也进行了探讨,证明它是可行的:可以各层并行开发,提高开发效率;而通过分层可以隔离关注点,使得各层开发人员可以只关注本层相关技术和接口,减轻开发人员负担,提高效率。
3. 在项目活动中碰到一些技术难点,我们将解决方案文档化,然后项目内共享,这样能在碰到同样问题时快速解决。现在还是碰到问题才解决,以后需要建立预研机制,较早发现可能出现的难点,尽早解决,避免对项目进展产生影响。
4. 平台还处于建设阶段,对项目的支持还不够,需要形成一些通用的组件。 |
|
过程和管理实施 |
有待提高。
1. 测试1.0版已发布,目前开发1。1版,完善分页功能和采用更好的验证方式。由于对规范开发的项目周期估计不足,加上管理上的一些问题,导致项目有所延期,需要对实际的项目开发进行量化分析,确立比较准确的人员和时间计划。
2. UC文档规范和编码规范等的引入,为项目提供了较好的支持。
3. 在实施中比较缺乏必要的文档支持,如设计文档等;同时各层的接口定义也出现较多问题,导致一些开发瓶颈的出现,这都需要在正式迭代中改进。 |
|
系统功能 |
完成较好。
1. 完成了UC文档确定的功能点,页面美观,使用方便,能给用户较好的页面体验。
2. 采用较好的面向对象设计,能提供一定的可重用性和扩展性。 |
二、展现层总结
经验与教训
1. SpringMVC是一个简洁、标准的MVC实现,结构清晰,功能强大(主要体现在对日常WEB开发中可能遇到的各种常见问题的解决方案),有一定学习曲线,但是有其它MVC框架基础的开发人员可以较快上手;
2. 根据业务功能尽早确定接口,接口由展现层确定,由业务层实现;
3. 合理选择Controller可以减少开发工作量,前提是充分理解每种Controller的处理机制及其回调方法细节,Controller的编写更多的精力主要花在校验、出错处理上;
4. 页面工作量很大,特别是需要比较复杂javascript的页面;
5. UI的流转设计等对于Controller的编写和业务层的接口有着很大的影响,应尽早明确,否则会产生较大的返工;
6. 展现层开发可以与业务层同步进行,推荐确定接口后,就编写业务层接口的mock实现,放在展现层的test包内,同时写单独的测试用spring配置文件;
待解决问题
1. Controller是否应写test case,本次开发未做;
2. 如何减少校验的工作量,对于有业务逻辑的服务端校验如何实现,是否需要采用一些validator框架,如sun的JEF的validator组件,目前我们进行了研究,通过使用commons validator组件能够较方便的实现validator;
三、业务层总结
经验与教训:
1. Spring,iBatis的应用还是很成功的,学习曲线比较平滑,好的框架好掌握;
2. 比较重视测试,编写很多测试案例,并频繁使用maven运行所有测试,使得问题能够及早发现,保证了各层能够快速成功集成
3. 对于很多问题都需要经过各层间的讨论来确定;
4. 接口由展现层定义,由业务层实现;
5. 持久层数据模型和领域模型是有区别的,但简单的情况下可以合二为一;
6. Façade模式还是很有价值的;
7. 一些开源软件的使用需要比较小心,如iBatis的null的问题等,如果处理不当会花费较多的人力物力,需要技术较强的人对开源软件花费一定时间进行源码级的研究,才能找出较好的解决方案;
8. 认识到设计的重要性,需要对前置、后置条件等进行分析;
9. 数据类型分析简单,造成数据库设计对业务层产生不良影响;
待解决问题:
1. 沟通不够,需要建立沟通渠道,是否可以有专门的场合和时间讨论项目中的进度和问题;
2. 计划不明确,对于要完成哪些功能,完成到什么程度,没有明确的定义,需要设置里程碑目标。在正式迭代开始前,要明确每次迭代的任务和目标,需要结合业务需求进行计划;
四、持久层总结
经验与教训:
1. 通过代码生成工具,能够大大提高开发效率;
2. 工具使用者要求对ibatis和sql比较了解;
3. 在使用过程中对工具进行了完善,这对正式使用工具提供了保证;
4. 与业务层的接口,应该由业务层确定,由持久层实现,而不是由持久层决定;
待解决问题:
1. 持久层的测试该如何进行,才能真的有用;
2. 一些通用功能如分页代码生成,还在开发中;
今天跟SUN的高级工程师有了些交流,感触颇多。首先要谈到它的一个产品(其实不能叫产品)JEF,也就是Java Enterprise Framework。JEF可以说是很多框架和组件的有机结合,有opensource的,有商业的,也有sun自己写的,其实也是SUN在多个大规模项目中不断实践的基础上发展起来的。它通过定义良好的分层和封装,能够提供应用开发非常坚实的基础。下图是JEF的整体架构图:
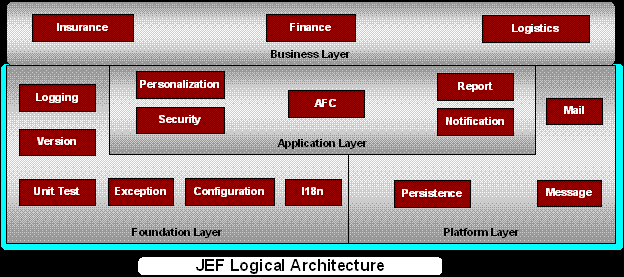

有机会再进行对它整体架构和各个组件功能的详谈吧。
再谈一谈对真正的系统架构师的认识。JEF的2个主要设计者我都见过了,都是香港人,都温文尔雅,学识渊博,经验丰富。能够聆听它们对软件架构的理解,对项目实际问题的分析和解决,真的是受益匪浅,对自己将来进行设计时思考问题的深度和广度都有很大的提高。这才是真正的架构师!他需要对各种框架,组件都了如指掌,在面对具体的项目需求时能正确的选择最适用的技术;他需要对软件整体架构有清晰的认识和理解,知道在面对实际项目时该使用何种架构,包括thin client还是rich client,with EJB还是without EJB等等;他需要有一种严谨求证的性格,对任何东西不是盲目下结论,而是根据具体的分析和实证进行取舍。。。。。。通往真正的架构师的路还很长,需要经历的项目,需要做的事情还很多。我们不能盲目尊大(拿spring+hibernate做个小项目就以为很牛),也不能丧失信心(经验和领会都是靠项目做出来的)。我们应该时刻保持向上的心态,去主动参与项目,去沟通,去交流,去总结,去思考。即使将来成不了真正的架构师,我们也可以自豪的说:“我每一步都是踏实的走下来的,我每一个项目都是用心在做的,我的代码都是注释详实,简单易懂,为后来者提供很好的可重用基础的而不是被人咒骂的,我做的是可用的软件而不是垃圾软件。”希望与所有有志于成为真正的系统架构师的同学共勉。
摘要: 项目很小,主体部分也完成的差不多了,但麻雀虽小,五脏具全,我在其中用到了spring的IoC和transaction管理,也用到了简单的AOP功能,同时使用了spring mvc,下面我对它们做一些总结,也跟和我一样刚刚踏入spring大门的兄弟们探讨探讨:
(一)spring IoC探讨
先还是谈谈spring IoC的使用。IoC也就是控制反转,即由容器来调用你的代码,而你不用去使用容器的...
阅读全文
今天忙了一天,收获不小。到公司接到个小项目,需求很简单,时间也很宽松,我就想用spring+hibernate来做,其实有点杀鸡用牛刀的味道,但我觉得能通过实践来学习spring和hibernate,也还是不错的。
spring和hibernate我也是刚学,各看了本书,然后搞了搞spring的sample,就是那个jpetstore和petclinic,一个是用ibatis,一个用hibernate做persistence层。同时有一个刚进公司的人跟着我做,我也就得先把项目初始化好,写好配置文件,分好包和层次结构,然后放cvs上。既然用spring+hibernate,配置文件肯定是很多的,我基本是参照petclinic,分了dao, dao.hibernate, model, model.logic, service, web这几个包,配置文件定义了applicationContext.xml,app-servlet.xml(我用spring mvc) , log4j.properties,jdbc.properties, mail.properties,说到spring的配置文件,其实也不复杂,搞懂了它的IoC(DI)和AOP就很容易配了,层次定义清楚,在头脑中对谁ref谁有概念,基本就不大会配错了。错了也没关系,它的log功能强大,定义好log4j,出了什么错都能有详细的记录。我搞spring的sample时就是把这个配置改改,那个删掉,自己写个类,替换它的。。。。。。这样很快就对它的配置文件有了深刻的理解。这次算是我第一个正式用spring的项目,但因为前面在理论上和零星的实践中对它有了较深的认识,也就大大降低了项目的风险(技术预研真的很重要啊!)。
虽然是小项目,但也得规范一下,定好项目计划,统一大家使用的工具和环境,简单交代编程的注意事项,如代码规范,cvs的使用,多写test类等。我们采用eclipse3.1+ myeclipse+tomcat5+mysql作为各自的开发和单元测试环境,上线使用websphere5+db2。我是要求先在mysql上能跑,然后能方便的迁移到db2上的,这样方便进行单元测试,也能在事实上与数据库解耦合,用hibernate很容易做到这一点。
但要能顺利的上线到websphere5,我就没什么把握了,毕竟它还是使用ibm 的jdk1.3,而且很多东西跟tomcat不同,更会不会有什么lib冲突等问题。我先把兼容性测试放在了开发的前面,否则在tomcat上开发好了,websphere不支持或出现难以解决的问题,就麻烦了,严重的可能要推倒重来。因为没在实际项目中使用过spring,周围又没什么人可问(我毕业一年多,没有高手指导,全靠自学和实际项目中领悟),所以有这些疑问也是正常的。不管如何,先把项目在tomcat上跑起来再说。改了一通配置文件,配好tomcat的数据源,往mysql加一个最简单的表(id一个字段),写了2张最简单的jsp(测试spring mvc的multiaction用),一个jsp显示从数据库获得的id。开启和关闭几次tomcat(我比较粗心大意,配错好几处),id就能在页面上显示了。Tomcat上基本配置完成,这也忙了个3、4个小时。
然后就是做兼容性测试了。我们有个websphere的测试环境,先把项目deploy到它上面。测试环境没用ND,我先deploy到server1上,这样能重启应用。Deploy完成,页面都出不来,500错,应用就没起来。先看日志,哇!一堆错。分析日志,好像是先装载的DispatcherServlet, 然后才是ContextLoaderServlet,当然出问题了,不过至少说明它找到了lib下的spring.jar也能work。我使用的Listener而不是Servlet来load context,估计是这个原因导致的,tomcat工作正常,websphere对Listener就不保证先启动了。于是改成使用Servlet,tomcat测试通过,我将改过的web.xml覆盖服务器(这里要覆盖2个地方,一个是应用下的,还有一个config/cells…..下的), 重启应用,再看日志,还是错。不过这次是先启动ContextLoaderServlet了,但一上来就错了,报错:javax.naming.NamingException: Attempted to use a 4.0 DataSource from a 2.3 (or higher) servlet。这不是spring的问题,呵呵!我用的数据源V4,结果用了j2ee2.3,再改web.xml,头上改成用j2ee2.2,再覆盖,再启应用。这次首页出来了,看日志,一切正常。呵呵!没那么多问题嘛,jdk1.3照样跑最新的spring和hibernate。
今天从零开始把spring和hibernate跑了起来,也算是一次不错的实战,就作为spring+hibernate实战的第一篇吧,接下来几天,我在项目中的体会也会记录下来,当成一个一个系列吧。
摘要: 这篇文章源自刚开发的一个小项目。项目中并未使用hibernate,但我还是要把它放在hibernate栏下。理由很简单,技术是死的,而人是活的,能熟练的使用一项技术不算什么,但能恰当的选择相应的技术,甚至自己想出办法来优雅的解决实际问题,就需要一定的积累了。而这种积累就来源自项目实践和对各种技术其实质的理解。我记得在某个论坛上某人(名字忘了)说过一句话:如果学习hibernate只是学会了怎么ma...
阅读全文
今天负责把多个系统的db2数据库迁移到另外一台机器上。同时要修改WebSphere的数据源,让它指向新的数据库。以前没做过,对于数据库操作,我向来是要用的时候再去翻资料的。开始考虑使用备份、还原的方式,但版本不一样,原来是7现在是8,操作系统也不一样,原来是AIX,现在是Windows,这样备份还原是行不通的,于是采用db2move。
看看db2move的命令说明,大致就明白怎么做了,于是我就开始实战了。我采用最简单的方式,原机器上使用db2move &dbname export生成文件,在目标机上ftp拿到生成的文件,然后使用db2move &dbname import。目标机上只要创建一个新库,无需使用DDL生成表。信息显示所有表都ok,很快就搞定一个数据库,connect上去查看,表自动生成,数据也完全一致。然后在WebSphere所在机器上重新catalog新的数据库,语法也是现查的,现记录如下:catalog tcpip node &nodename remote &ip server &port, terminate, catalog db &remotedbname as &dbaliesname at node &nodename,terminate。加&表示根据实际设置的值。Db2 connect试试,新的连接正常。进入Administartor Console修改数据源配置,然后保存。重启server,测试完全正常。一个数据库搞定。
下面一个是我帮别人迁移的数据库,我对其表结构,表空间等都不知道。不管三七二十一,我先照着刚才办法做。Export一切正常,import前面的表都正常,快结束发现报错了,报创建表失败。到相应表的msg文件发现错误描述如下:
SQL3319N 创建表时发生 SQL 错误 "-286"。
SQL0286N 找不到页大小至少为 "8192"、许可使用授权标识 "DB2ADMIN"
的缺省表空间。 SQLSTATE=42727
原来需要8k页大小的表空间。这简单,使用控制中心新建一个8k的表空间。然后需要让出错的表使用这个表空间,也就是说要要使用DDL语句先创建这个表了。连上原来的数据库,生成这个表的DDL语句,修改tablespace名,改为新建的表空间,然后到新的数据库上执行。我不想重新再import所有表了,怎么做到呢,先看看生成的那些文件,有个db2move.lst,然后是每个表的ixf和msg文件,lst文件居然可以用文本打开,发现里面一行就是一个表,估计这就是需要导入表的列表了。删除那些已经正常导入的表信息,只留没导入的表,然后重新运行db2move &dbname import,这下一切正常了。然后就是剩下的同样工作了。
值得注意的是,db2move只导入表的信息,其它如view,trigger等均需通过DDL语句或控制中心添加。忙了一天,是为此记。
吃过午饭,随意溜达,信步走到开发区的一片绿地上去。说是绿地,地方倒也不大,一块草坪,其上点缀几棵小树,树的荫盖稀疏,即使人独躺其下也能感受阳光透过的刺目眩光。幸好今天多云,加上已到秋天,阳光已经失去如夏日那般的威力了。草坪并不禁止践踏,这大概因为并非什么名贵的进口草坪的缘故,也不需要太多的维护费用,可以任其夏荣冬枯。这种草并不抱簇成团,而是一根根坚韧的往外生长,因而躺在上面并不舒服,感觉刺的厉害。但我却喜欢这种草,朴素,随处可见,生命力顽强,令我回忆起小时候在河堤上玩耍的情形来。
躺了会,的确有点刺背,就坐起身来。目光所及,前面草地上有只不知名的小鸟,白头黑身,长长的尾巴,正在草中寻虫吃吧,走几步小嘴一啄,尾巴也上下颤动,可爱的很。它漫无目的的走着,大体向我靠近了,我心中一阵高兴,幻想着它能来到身边,我伸出手掌让它停在上面。我屏住呼吸,尽量不弄出一点动作和声音,只是静静的看着它,欣赏它的美丽。可它又慢慢走远了,可能发现了我,头也不回的一摇一摆的往前走去。小鸟终究是怕人的。
于是我便站起身来。草坪旁边是一个人工湖,湖边是一座叠石流水,水绕着叠石,向下流淌到湖中,倒也别具匠心。叠石不高,顶上好像能上去的样子,我生性好动,就想往上爬。难度不大,但也得手脚并用,看准落脚点,手上抓牢,很快就站在最高点了。可以俯瞰湖面,波光粼粼,水上还有一些睡莲,不由浮想起:“鱼戏莲叶东,鱼戏莲叶西,鱼戏莲叶南,鱼戏莲叶北”的诗句来。但好像没有鱼的动静,也许这个湖也刚建不久,还未长成吧。湖岸对面一个老者,拿根小竹竿在忙活着,应该不是钓鱼吧,鱼都没长大呢!带着一丝好奇,我又爬下叠石,转到对岸去看看。
他旁边放了个盛水的小盒子,里面一些非常小的鱼在游着,我以为是鱼苗呢,就上去问:“你是要把这些鱼放进湖里吗?”他没抬头,旁边又来了几个民工样的人,也凑上身来,其中一个问:“鱼这么小,有什么用?”老者这下答话了:“我去喂小乌龟。”“小乌龟不吃小鱼吧”……原来他是用小网兜把可怜的小鱼捞上来,然后装回家喂小乌龟。我很快走开了,好的心情一下荡然无存。这么小的鱼,好不容易才在这片池塘出生,却因为某人家里不知道吃不吃它的小乌龟,被装到盒子里,注定其灭亡的命运。而我只能幻想鱼群在莲叶下游过的景象。我忽然想起为什么我是走开,而不是将鱼放到湖里去。那样会得罪人,是啊,“少管闲事”的观念已经深入骨髓了。但我也只是想想,头也不回的往公司走去。