#
先把项目背景简单说一下,项目A可以认为是在原有业务系统的基础上衍生出来的新需求(派生的新业务),原有业务系统是一个比较大的系统,在公司也是一个拳头产品,卖了几十套,目前也有好几个人在上面维护+二次开发+缺陷修复等(人力资源紧张)。早期公司高层只是说肯定要做这个项目,但由于人力资源的问题迟迟没有决定要开工(还有一个重要原因是领导希望能够签下1-2个典型客户再启动项目A的开发),而仅仅是上销售去那几十家客户那里兜售新业务,吹的天花乱坠的,比较市场有些竞争,需要先拉单子。这些事情是年中的事情。
等到下半年的时候,市场对这个新的业务反应比较强烈,已经有客户说要看原型再签合同,原因是竞争对手已经出原型了。而此刻,公司以为高层决定要即刻启动项目开发,说先把原型做出来,限期一个月。而中层领导还是由于人手紧张,就随便抽调了4个开发人员,一半是1年工作经验以内的新手,就这样匆忙上阵。由于人手有限、时间紧迫、业务需求虽然已经明确,但很多业务细节这4个开发人员都不清楚,只有一个懂业务的但也谈不上精通。
项目计划就定了一个月,基本上按天把计划排好了,1个月后系统原型出来了。但比较粗糙,缺陷也比较多,设计基本没有做,代码质量也比较差。拿去客户那里安装后,客户认为这个系统太粗糙了,【到客户那里,客户就不会认为这是个原型系统了】
至此,按常规项目管理的做法,应该重新梳理真实的客户需求、业务流程和功能设计、架构设计、概要设计。。。。
但事情的发展却不是这样进行的。由于客户迫切系统以周为单位看到项目的进展,于是领导决定就在原型系统上扩展和修改,其结果就是计划制定后很难执行,变成了按周来排计划,主要就是按客户的需求来改。
好不容易在年底前把版本基本上稳定了,但只是业务流程和功能比较温度,缺陷开始收敛了。
但元旦后到客户现场安装测试版本,客户对此版本又提了很多需求变更和新模块。此刻麻烦就比较大了,因为系统的架构灵活性比较差,改起来对原有代码影响比较大,改动范围大。于是又是时间紧张,又是工作量,刚把功能实现,客户就开始催啥时候测试。缺陷一直居高不小,于是决定花2周时间专门修改缺陷。
到现在为止,开发基本完成了。但问题也比较突出:
系统的性能存在问题(有些模块客户的意见很大,但这个从技术上讲,改动会比较大,不是1周能解决的)
系统的稳定性(与1相关)
功能的可用性(有些功能早期按照开发人员的思维来设计的,到客户那里客户提出新的想法,开发时把这种体验需求压住了,但在后续还是要改)
马上要启动二期的需求开发,这个更麻烦
---------------------
至此,整个项目风险还是比较大的,我总结有以下几个原因:
1. 项目的目标、业务流程、大体需求是很明确的,但细节需求在项目中前期,整个项目组都是一知半解的,造成后续返工较大,客户和开发人员包括公司领导对质量的意见都较大;
2. 项目从开始到现在领导和项目经理的分工不明确;由于人是凑起来的,大家之前没有合作过不了解;
3. 原型系统出来后,项目经理大部分时间都去解决客户的需求沟通和售前支持了,少部分时间在真正项目开发上;
4. 一直对项目的总体计划和推进情况估计不足,造成项目计划形同虚设,完全是开发人员做到哪算哪;
5. 中前期领导对这个项目不重视,等到元旦后发现问题比较严重,就临时抽调人手进来协助,而刚进来的人一方面不是项目经理想要的人(仍然是新手),另外一方面由于系统的业务性比较强,新手加进来后1-2周内根本不起作用;
6. 测试工程师,派过来的2名测试工程师是后期加进来的,业务都不熟悉,培养的2周后才慢慢熟悉,而且在客户现场,测试工程师根本应付不了客户的问题,即客户讲的需求测试工程师根本不懂或不熟悉;
大致就这些吧。
第三话按照原计划是要写写平常心的,因为飞跃计划要交作业,所以就改为写自己对项目管理的一些经验总结,刚好前一段时间那些年我们一起追过的女孩很是流行,这一话的名字就叫做那些年我们一起做过的项目。
我的第一个项目是在2005年,那是一家市场占有率前三的本地化翻译公司,公司的信息部门只有两个人:老大和我,我们一起开发公司内部的协同办公系统。要解决的问题很简单:由于公司发展迅速,以前单纯依靠纸质单据和邮件分派和追踪任务已经越来越让项目经理和财务不堪重负,迫切需要将这些工作给自动化。系统的技术架构也很简单:
jsp+javabean+mysql。没有专门的开发计划,基本开发流程是这样的:每周一我们访谈一个业务部门经理,了解他的需求,周中开发,开发中有任何问题都可以直接找业务经理,周五的时候系统上测试环境,再和业务经理坐到一起看一下是否满足了他的需求。系统就一直这样不紧不慢的开发着,老板办公室就在我们身后,一有时间老板就会和我们一起使用该系统。整个开发过程只有一个细节让我印象深刻,就是对任务估算工作量时,不管我估算多少,老大都会给我乘以3,一次要给业务表单增加一个字段,老大问我需要多长时间,我说不就是增加数据库字段吗10分钟,结果老大给了我半天时间,老大说,增加字段确实只需要几分钟,但打开编辑器需要时间吧,集中注意力需要时间吧,改完了启动系统测试需要时间吧,测试完了和业务经理确认需求需要时间吧,我们估算的是完成整个事情的时间而不仅仅是编码的时间。
这个项目完成时获得了公司上下的一致好评,从公司老板到业务经理,每个人都非常满意,而让我感到唯一遗憾的却是身为IT人员竟然从来都没有加过班。
回想起来,这个项目之所以成功固然是因为技术简单和系统不复杂(我们甚至都不需要 SVN,完全依靠脚本同步代码),但最重要的还是持续交付和持续的用户反馈,老板和业务经理每周都能看到新功能的上线,这增强了他们的信心,同时反馈几乎每天都在进行,并且他们很快都能看到这是否是他们想要的。
第二个项目在2006年,这一年我换工作了,因为当时我认为不加班的程序员不是好程序员。新公司在上地,是一家做协同办公业务平台的公司,最开始去的是项目部,一开始很为业务平台这个概念着迷,因为当写程序时最先不是写代码而是用代码生成器生成代码,并且生成完的代码马上可以运行!第一个项目是丰田公司的销售管理系统,我们创新的使用了当时最热的Ajax技术,我们完全是用技术热情加上周末时间完成对原有功能的 Ajax增强,这个项目获得了用户极高的评价,因为当大多数web系统还在使用点击 /刷新的方式进行交互时,我们却可以直接拖拽完成操作了。如果在当时,我会认为是技术的创新让项目获得了成功,但是现在,我会用渐进式增强这个词,即只有在完成用户所需要的核心功能(什么叫核心功能,即缺少这个功能系统不能工作)后才开始对系统用户体验、性能进行渐进式优化。
第三个项目是在公司的平台部,这里部门经理正准备对原有的业务平台进行重写,原先业务平台的技术框架是:jsp+struts+ojb+sqlserver,新的技术框架定义为: ajax+freemarker+webwork+spring+hibernate。这让我兴奋,因为新的技术框架几乎是当时最流行的技术。加部门经理共有三个开发人员(所以沟通一直不是问题),老大使用project来管理项目,每个人负责一个模块,估算以周为单位,最初计划是 5个月交付,功能直接就是老平台的翻版换的只是技术实现,但是 5个月后进行测试和项目试用时却发现了大量缺陷,最后几乎用了半年时间才将缺陷收敛,产品发布计划延期半年。回顾这个项目,需求没有进行详细的分解和评审导致实现与需求不一致 似乎是项目延期最重要的问题,然而更深的思考却是我们需不需因为技术原因开始新产品的开发,在不影响用户使用的情况下对原业务平台进行渐进式增强是否更加合适。即我们在启动项目时更多关注的应该是用户价值(只有有用户价值用户才会买单公司才有收益)。
第四个项目是我负责的,这个项目几乎是上一个项目的翻版,重写公司的工作流产品:支持更多的工作流模式,更易集成的api和管理界面,唯一不同的是这个项目采用了很多敏捷里的实践:持续集成、单元测试、站会、迭代,但这些实践均不影响这个项目最终的失败。同样是该不该重写这个项目的问题,在公司资金链紧张、时间要求紧、新产品相比竞品没有突出特性的情况下,这个项目从一开始就决定了失败。如果没有特别充足的理由就不要重写产品,这几乎成为我目前最重要的一条原则,尤其要从公司全局的角度看待产品不能局限在技术。现在,只要谁一说到要重写产品,而给出的仅仅是技术原因,我就会两股加紧,冷汗直流。在对项目完全负责的情况下,我另一点深刻感受就是人的重要性,对团队中的每个人员,作为leader 你都需要知道他的需求是什么,没有人愿意做机器人,在一次对某一技术方案简单粗暴拍板后,一个核心技术人员流失了,这成了压垮这个项目的最后一根稻草。
08年底去了一家新公司,新公司采用敏捷实践。第一个项目很成功,几乎是敏捷项目的一个成功范例,需求分析、迭代、持续集成、结对、客户 showcase、持续交付,项目甚至提前半个月完成。唯一美中不足的是项目二期时新团队由于一期文档很少带来了很多困扰。突出的感受是:团队人员有了角色、有了分工也就有了流程。现在,到了一个新的部门或中心,第一件事情往往就是梳理项目开发流程,定义出每个人的角色,职责不清是互相埋怨之源。
第二个项目是咨询项目,略去不表。第三个项目是分布式团队,一部分团队在国外,一部分团队在国内,最开始一切顺利,但在上线前一个月遇到了严重的性能问题,陷入了一片混乱当中,所有人都不知道我们离上线还有多远,还有哪些工作需要完成,优先级都是什么,项目经理甚至自己都失去对整个项目的把控,她不知道项目上线究竟需要满足什么条件,于是一次次在等待国外团队优化后的测试结果,于是一次次的测试结果不满意,于是项目在一次次的下周二上线的空头承诺中成了整个公司的笑柄。这个项目回顾起来就是团队遇到挫折时放弃了计划,迭代没有了,故事墙没有了,所有人都在等待,而项目经理为了不让开发人员被公司收回还不得不想一些优先级不高的任务给团队完成装着我们很忙。教训就是,任何情况下都不能放弃计划,计划是项目之本。其他包括团队能不分布式就不要分布式,如果必须分布式那么一定要从架构开发任务上进行隔离,尽量减少两个团队之间的交互(很多项目经理进入到部门之后推进项目制,其实也是同样的原则,团队大了就要拆解,产品代码多了也要模块化,尽量减少团队之间、模块之间的交互,做到能够各自独立演进和发布)。尽早进行实际环境的测试,越早越好。测试越早进行越好,测试环境越贴近产品环境越好,这一原则什么时候强调都不过分(我们上线前的测试才发现严重的性能问题)。
第三个项目是幸运的,因为他们有钱,能够等待,在多等待了大半年后系统终于上线。而第四个项目就没有这么走运了,这个项目是一个在线 saas CRM系统的重写,而且有着强时间约束(如果半年不能交付,将错过该系统客户每年做预算的窗口期),看吧,又是重写,又是时间约束,这几乎总预示着它厄运难逃。表面上看项目是在一次中期的架构重写中崩溃了,重写耗去了团队太多的时间,而由于对未知领域知识的不正确估算(需要学习)再次令项目雪上加霜,项目目标又不能变化,要在六个月后上线,但更深层的原因还是项目开始之前没有决策正确,真的要重写产品吗?老产品确实界面很丑、一些功能没有,但这些不能渐进式增强进行吗,一定要重新开始吗?重写使用新团队,他们对该业务领域并没有经验,过去系统遇到的坑他们不清楚,他们的计划因为少考虑了一些情况是否显得过于乐观?这个项目的其他问题包括项目计划一直没有发生变化,尽管所有人都认为在规定日期到来之前不可能交付,但这个日期却没有发生变化。最后不得不说这是一个技术强大的团队,一切都做到了自动化,甚至部署产品环境也是一键完成,但是这些在项目目标失败的情况下显得黯然失色。而客户贷款做这个项目则让很多团队成员良心不安。
来到腾讯,来到soso,最重要的收获是对运维有了新的认识,以前曾经认为devops就是自动化部署,全功能团队,现在发现它关乎架构:一条搜索的badcase是否能够很快找出错误的原因?是抓取失败,是索引时丢失,还是相关性排序不好?关乎监控和报警,我们能否很快从监控中定位出原因?关乎组织结构,前台开发,后台架构,基础架构,运维测试团队都是分离的,如何协作才能使团队合作的成本最低而整体利益最大化?
回顾往事,保尔柯察金说:如何才能不虚度光阴,只有为共产主义奋斗终身;柯景腾说:唯有沈佳宜让我怀念;而我想说的是:
做任何项目之前一定要想清楚为什么要做这个项目,一定要想清楚这个项目的价值是对用户和公司的(尤其需要跳出站到一个比较高的层次看项目),一定要想清楚项目的约束(时间约束、人员约束),不仅是项目开始之前要想,过程中要不断回顾;;
项目任何时候都必须有计划,对所有干系人透明;
项目一定是持续交付和持续反馈的,不允许黑盒出现;
测试和运维一定要尽早介入;
从每个团队成员的角度出发关注所有人的利益实现共赢。
年轻时,不犹豫,年长时,不后悔。年轻时要尽早的给自己定位,是鸟就飞的更高,是鱼就游得更快。
发挥自己的特长,有所专一,不能什么都会。根据别人的经验为自己找方法。
趁自己还年轻,把想干的事都干了,只要对自己能力有提升的,别犹豫。不能等到年长时后悔当年
自己没有干什么事,不能等到年老时再聊发少年狂。
年轻时,努力的探索自己,发掘自己,积极的上进,努力的学习,积攒技能,学习人事。
要努力学习,以开放积极的心态来面对困难与挑战。
三十岁时,让自己能够独当一面,能够为人所用。跟着一群优秀的人合作共赢,积攒人脉,让自己
变得更优秀。
四十岁时,让优秀的人为自己工作,五十岁时,让优秀的人变得更加优秀。
年轻时,积累自己的耐心,价值,能力,知识,创造,付出,原则
年轻时,靠的是努力。重点是学习如何成为一员有专业素养的精兵,找到立身之本的根。
年轻时,最困难在于要在最耐不住寂寞的年纪做耐得住寂寞的事。
或许某些努力看上去是无望的,但是不要放弃,坚持不懈怠,有傻×一样的努力才有牛叉一样的结果。
三十岁,靠的是实力。重点是学习如何成为一名有管理能力的猛将,要能独挡一面。
这时,要将专业的深度,人格的成熟度,人情的练达度拧成自己的综合实力。
四十岁,靠资历。重点是学习如何成为一位有经营水平的名帅,建设枝繁叶茂的系统。
这时,你的经验,资格,见识,荣誉都要上得了台面。
五十岁,靠势力。重点是学习如何成为一位成就组织的王者,培育众木成林的势力生态。
桃李满天下,知交遍天下,关系满天下。成为培育组织,保护组织,成长组织的人。
依靠以前铺好的轨迹走自己的路。
年轻时跟优秀的人工作,三十岁跟优秀的人合作,四十岁找优秀的人为你工作,五十岁
努力是别人成为更加优秀的人。
年轻时可教,三十岁可用,四十岁有资格可捧,五十岁可敬。
五十岁的功德是自己成就的,是自己人生经验财富的积累。
作者:邹振文
初六的早晨,刚从老家回来,坐在出租屋的阳台上,阳光灿烂,竟然是北京难得的好天气。距离上次写年终总结已经过去好久,打开博客,发现上次写年终总结已经是四年前的事情。上次写总结的时候还是在东直门温暖的办公室里,随着年龄的增长,觉得时间过得越来越快,四年时间,发生了太多太多的事情:有小孩了,换工作了,最重要的,是三十了。三十,意味着很多事情,古人说,三十而立,对我来说,更重要的是有了更多的责任,不仅仅是家庭,工作也如是。
年初负责的第一个项目是配置管理组的运维自动化项目,简单的说就是将之前手工管理的20多台机器使用puppet管理起来。想一想,命运真是讽刺,就在一年前,在上一家公司,自己还对持续集成工具不太感冒,不愿去学,甚至认为有些太难:机器环境的管理、构建工具、jenkins、puppet/chef、shell,觉得这些东西太琐碎,一心只想写代码。换了工作,阴差阳错,先到配置管理组工作一段时间,必须学习这些东西,过程就不多说了,只有一个感悟:很多时候,你觉得太难,只是因为你不了解它。用了两周时间,将整个puppet环境搭建起来,一切皆SVN,一切皆代码。
接下来的第二个项目是负责调研搜索新架构的自动化发布方案,这是跨部门的合作项目,大大小小跨越20多个项目组,这其中还包括了运维同事、测试同事和云计算基础服务的同事,调研一礼拜,实际上事前准备了很长时间,仅仅那一周的调研计划就修改了四版,系统整理了整个新架构的架构方式,和对方领导达成一致,取得他们的支持,了解大家的期望:开发同事希望能够更快更有效率的发布代码,测试同事希望测试的代码与发布的代码同源,运维同事希望发布过程能够遵从规范可控,当大家对共同的目标达成一致时,方案就顺理成章了:持续集成服务器负责一键编译测试打包上传到包服务器,包服务器保存所有的预发布包,预发布包经过测试后才转为发布包,发布包透过发布系统一键推送到Torca集群调度系统,Torca完成最终集群的发布调度。相比老架构,感觉新架构最明显的提升是:下载、索引和检索三大模块被分离成各自独立的服务,独立演进;统一的数据管理平台,以前追踪badcase很难判定是哪个模块处理数据出了问题,现在透过数据管理平台,数据处理过程被可视化可追踪;统一的脚本执行系统,所有脚本以及执行过程透明可视化;云计算平台,XFS文件系统、Xcube数据库、Torca集群调度、mapreduce并行计算,这些服务大大简化了上层应用的开发。越来越体会到架构的本质:随着系统的演进,我们需要不断进行系统的分解,做到服务的独立演化。当然当时也有困惑:当所有的希望都被压在新架构身上,毕其功于一役,现网老架构停止开发运营时,项目的风险可想而知。做完这个项目,感悟有两个:一是机会只青睐有准备的人;二是跨部门沟通一定要找到共同的利益点,一定要多换位思考。
4月份,准备调回项目管理组,去云计算基础架构部做项目经理。在配置管理组的最后一个项目是Jenkins的报表系统,只有一周半时间,最开始准备使用scala,考虑到后续维护最后使用了java,好久没有编码了,找回久违的感觉:打印出IDE的快捷键,搭建开发环境、测试环境和产品环境,jenkins一键自动部署,数据库版本管理,TDD,一周半的时间就上线第一个版本,最后还不得不赞一下jenkins的rest api。感悟是:感谢一期开发时间只有一周半,这使得我们不断思考到底我们要做些什么,哪些是我们最紧急最需要的,哪些是锦上添花的,一期上线后,唯一也是最大的好处就是:我们再也不用手动统计和发送构建周报了,每个礼拜一再也不用那么忙碌了。时间盒,很重要。
终于转回了项目经理,去云计算,牛人聚集的地方。首先仍旧是补课:计算机原理、Linux系统编程、C++ primer,一个都不能少。去了没多久,出现了一起事故:搜索模块对云计算SDK的依赖是源代码依赖,云计算有5个产品,但是一个产品单独发布时与之前的SDK不兼容,一发布就直接导致了大量搜索模块的无法编译。正好由我负责来推动解决这个问题,立了一个发布流程规范化项目:通过规范化发布流程、增加自动化集成测试,减少云计算平台的发布风险。所有SDK统一打基线发布,发布前必须进行自动化集成测试,server发布时也要与所有SDK版本进行兼容性测试。随着项目的进行,逐渐融入了这个部门:这是一个工程师文化非常强烈的部门,所有人都在技术上追求卓越,加班到10点以后是非常常见的事情,单元测试覆盖率令人惊讶的全部达到85%,但是很多同事一听到规范和流程就头疼,项目计划也是比较随意,延期比较常见,另外因为之前发布版本升级比较随意,也会经常受到上游兄弟部门的投诉,有很多次出现问题,兄弟部门抱怨云计算平台不稳定,而仔细检查后发现很多时候是使用的方式不对,比如查找文件时使用了遍历。逐渐意识到,部门最大的问题其实是缺少产品运营,大家的关注点全部集中在产品本身上(吞吐量、最大存放文件数、强一致性),或多或少的忽略了用户。5月下旬,风神项目启动,项目目标是搭建台风统一的监控平台和自动化部署框架,打造一站式的台风服务。开始在项目中引入项目管理的实践,WBS是最基本的了,迭代计划找到开发节奏、回顾、每个迭代结束后都努力向线上发布版本,实现持续交付,工程上则将开发环境与线上环境进行了隔离。效果都还不错,但思考更多的还是,我们还应该做些什么。产品发布规范化,必须通过自动兼容性测试和周知用户;集群环境的修改必须可被审计,暂时不能自动化,那么先必须周知部门内同事或结对操作;监控有风神项目,但集群运营、用户数据、可用率日报也需要发送;开发、测试和线上环境互相隔离;定期和用户进行主动沟通,了解他们的问题。这段经历的感悟很简单:产品的核心在于运营,作为服务部门,我们交付的一定是用户满意度而不是产品。
紧跟着,新架构还未上线,组织结构调整来了,喜欢ls的直率:我现在的任务很简单,就是看到哪里有山头就把它给平了,所有人都必须听我的,所有人的思路必须一致。
在敏捷中国大会发表了演讲《百年历史看管理》,这个session足足准备了2个月时间,重新思考了流程、组织结构和人之间的关系。从20世纪初到40年代,管理科学完成了从无到有的第一个阶段发展,这个阶段最重要的成就就是将管理作为一门科学建立起来,发现了管理的三要素:工作流程、组织结构和人,并振聋发聩的告诉所有人:管理是可以学习的。我们可以看到,所谓管理,都不过是在流程、组织结构和人这三者之中进行权衡调节,管理没有固定模式,只有不同企业根据不同情况在这三者间权衡裁剪罢了。如果说管理科学的第一个阶段是在探讨如何正确的做事,如何提高工作的效率,那么50到60年代这二十年管理科学的第二个阶段则是在探讨如何做正确的事:以顾客为中心、做事之前一定要想清楚做事的目的。管理至此也终于有了一个完整的定义:做正确的事、正确的做事。从70年代开始,管理科学进入第三个发展阶段,在这个阶段,首先提出的思想就是没有银弹,管理是一门艺术需要柔性,接下来就是流程的内涵开始延伸,不再是单纯的工作流程,而是面向顾客,强调端到端满足顾客需求的整个过程,这个过程在全球化背景下越来越强调企业之间的协调、强调整个面向交付生态系统的协调,业务流程的概念被提出。进入新世纪,不管是更合理组织结构的思考(扁平化),还是对人的推崇(乔布斯、创新)抑或是业务流程效率的竞争(供应链),都明白无误的告诉我们:管理只有恒久的问题,没有终结的答案。
9月份调整到新的部门:搜搜问问。先负责的是后台组的项目管理。新团队,老人只有一个,士气低下,缺少文档,上百个服务,光维护就非常困难,重写计划。从回顾会议开始,持续改进。这段时间的感悟是:提升团队士气的最好方式就是帮助大家成功,任何一点成绩都值得鼓励。我们引入了持续集成和自动化发布,鼓励同事做总结和分享;引入了自动化测试,鼓励同事做汇报,帮助review ppt;积极的让大家做有态度的程序员,对产品进行思考和反馈,把团队精神传递到部门经理,让部门经理进行鼓励。可以自豪的说,后台组是现在问问最有战斗力的团队。还有一点最重要的感悟是:一定是团队leader决定团队是否给力,幸运的是,我们有一个非常优秀的leader。
12月份开始负责部门的社区化运营项目。这和今年工作的感悟是一致的,产品的核心在于运营,这正是我想做的。项目立项一定要有一个NB的名字,我们就叫黑暗骑士。这个项目同样面对很多的挑战,目前最大的挑战还是在于人,团队的信心目前还没有建立,年后可能还会有人提出离职,而招人又是如此的困难,所以,上班第二天的第一件事是回顾会议。团队年前第一个版本发的很有挫折感,需求反复修改,开发人员都心灰意冷,所以,感悟是:一份优秀的需求文档是一切合理计划的起点。
1月份组织了技术中心的部门年会节目,我们原创的小品《非问勿扰》获得了二等奖。把新人都变为主角,这也算团队建设的一部分。
依然在不停思考,对问问来说,我们还应该做些什么。传统问答模式作为搜索引擎的补充是否已经走到了尽头?SNS的问答模式是否值得探索?与微博是否有更深的整合方式,或者,它们本身就是一种产品的两种展现方式?新浪微什么的探索是否还不够大胆?在移动端,独立的app没有前景,如何和微信更有力的结合。
终于到了可以结尾的段落,还有一件事情似乎忘了总结,那就是我们写了长达四年的那本书《流程的永恒之道-一个工作流和BPM项目的实战》,什么也不说了,一个例子来说明为什么值得期待:当我们把房管局及各委办局的数据和流程用BPM全部打通后,客户却依旧坚持要手动盖章走人工流程,BPM实施技术根本就不是瓶颈,瓶颈依旧是人啊。今年上半年一定出版。之所以写了四年,是因为写着写着总觉得知道的越来越不够,不断读书和补充内容,真是,那时年少,无知者无畏,唉。
2013,黑暗骑士崛起!
本文为转载:原创地址http://www.software8.co/wzjs/cxyyg/2953.html
这项利器是由CRM领域的领导Saleforce发布的。相当于HBase的JDBC。
具体详见:
https://github.com/forcedotcom/phoenix支持select,from,where,groupby,having,orderby和建表操作,未来将支持二级索引,join操作,动态列簇等功能。
是建立在原生HBASE API基础上的,响应时间10M级别的数据是毫秒,100M级别是秒。
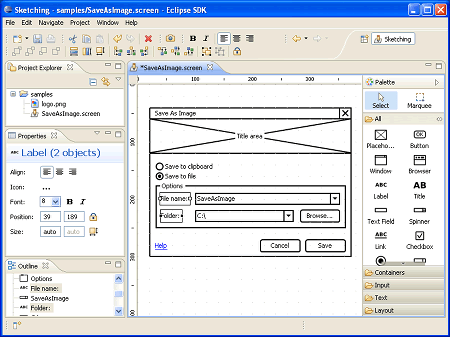
WireframeSketcher是一个Eclipse 插件,用于创建线框图,界面模型和UI原型。
项目正式开发前创建原型可以帮助用户和开发者理解系统,使用WireframeSketcher在Eclipse中创建能够更好的集成进入你的项目开发流程。
WireframeSketcher 如何工作?它提供了一个pre-drawn,text-driven 预制图,文本驱动的widgets,能够展现通用UI界面,你可以拖拽他们进入编辑器迅速画出你的界面。界面用XML存储。
- HBASE的SHELL命令使用
- HBASE的JAVA CLIENT的使用
新增和修改记录用PUT。
PUT的执行流程:
首先会在内存中增加MEMSTORE,如果这个表有N个COLOUMN FAMILY,则会产生N个MEMSTORE,记录中的值属于不同的COLOUMN FAMILY的,会保存到不同的MEMSTORE中。MEMSTORE中的值不会马上FLUSH到文件中,而是到MEMSTORE满的时候再FLUSH,且FLUSH的时候不会写入已存在的HFILE中,而是新增一个HFILE去保存。另外会写WRITE AHEAD LOG,这是由于新增记录时不是马上写入HFILE的,如果中途出现DOWN机时,则HBASE重启时会根据这个LOG来恢复数据。
删除记录用DELETE。
删除时并不会将在HFILE中的内容删除,而是作一标记,然后在查询的时候可以不取这些记录。
读取单条记录用GET。
读取的时候会将记录保存到CAHE中,同样如果这个表有N个COLOUMN FAMILY,则会产生N个CAHE
,记录中的值属于不同的COLOUMN FAMILY的,会保存到不同的CAHE中。这样下次客户端再取记录时会综合CAHE和MEMSTORE来返回数据。
新增表用HADMIN。
查询多条记录用SCAN和FILTER。
- HBASE的分布式计算
为什么会有分布式计算
前面的API是针对ONLINE的应用,即要求低延时的,相当于OLTP。而针对大量数据时这些API就不适用了。
如要针对全表数据进行分析时用SCAN,这样会将全表数据取回本地,如果数据量在100G时会耗几个小时,为了节省时间,引入多线程做法,但要引入多线程时,需遵从新算法:将全表数据分成N个段,每段用一个线程处理,处理完后,交结果合成,然后进行分析。
如果数据量在200G或以上时间就加倍了,多线程的方式不能满足了,因此引入多进程方式,即将计算放在不同的物理机上处理,这时就要考虑每个物理机DOWN机时的处理方式等情况了,HADOOP的MAPREDUCE则是这种分布式计算的框架了,对于应用者而言,只须处理分散和聚合的算法,其他的无须考虑。
HBASE的MAPREDUCE
使用TABLEMAP和TABLEREDUCE。
HBASE的部署架构和组成的组件
架构在HADOOP和ZOOPKEEPER之上。
HBASE的查询记录和保存记录的流程
说见前一编博文。
HBASE作为数据来源地、保存地和共享数据源的处理方式
即相当于数据库中JOIN的算法:REDUCE SIDE JOIN、MAP SIDE JOIN。
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
Hadoop/Hbase是开源版的google Bigtable, GFS, MapReduce的实现,随着互联网的发展,大数据的处理显得越发重要,Hadoop/Hbase的用武之地也越发广泛。为了更好的使用Hadoop/Hbase系统,需要有一套完善的监控系统,来了解系统运行的实时状态,做到一切尽在掌握。Hadoop/Hbase有自己非常完善的metrics framework, 里面包种各种维度的系统指标的统计,另外,这套metrics framework设计的也非常不错,用户可以很方便地添加自定义的metrics。更为重要的一点是metrics的展示方式,目前它支持三种方式:一种是落地到本地文件,一种是report给Ganglia系统,另一种是通过JMX来展示。本文主要介绍怎么把Hadoop/Hbase的metrics report给Ganglia系统,通过浏览器来查看。
介绍后面的内容之前有必要先简单介绍一下Ganglia系统。Ganglia是一个开源的用于系统监控的系统,它由三部分组成:gmond, gmetad, webfrontend, 三部分是这样分工的:
gmond: 是一个守护进程,运行在每一个需要监测的节点上,收集监测统计,发送和接受在同一个组播或单播通道上的统计信息
gmetad: 是一个守护进程,定期检查gmond,从那里拉取数据,并将他们的指标存储在RRD存储引擎中
webfrontend: 安装在有gmetad运行的机器上,以便读取RRD文件,用来做前台展示
简单总结它们三者的各自的功用,gmond收集数据各个node上的metrics数据,gmetad汇总gmond收集到的数据,webfrontend在前台展示gmetad汇总的数据。Ganglia缺省是对系统的一些metric进行监控,比如cpu/memory/net等。不过Hadoop/Hbase内部做了对Ganglia的支持,只需要简单的改配置就可以将Hadoop/Hbase的metrics也接入到ganglia系统中进行监控。
接下来介绍如何把Hadoop/Hbase接入到Ganglia系统,这里的Hadoop/Hbase的版本号是0.94.2,早期的版本可能会有一些不同,请注意区别。Hbase本来是Hadoop下面的子项目,因此所用的metrics framework原本是同一套Hadoop metrics,但后面hadoop有了改进版本的metrics framework:metrics2(metrics version 2), Hadoop下面的项目都已经开始使用metrics2, 而Hbase成了Apache的顶级子项目,和Hadoop成为平行的项目后,目前还没跟进metrics2,它用的还是原始的metrics.因此这里需要把Hadoop和Hbase的metrics分开介绍。
Hadoop接入Ganglia:
1. Hadoop metrics2对应的配置文件为:hadoop-metrics2.properties
2. hadoop metrics2中引用了source和sink的概念,source是用来收集数据的, sink是用来把source收集的数据consume的(包括落地文件,上报ganglia,JMX等)
3. hadoop metrics2配置支持Ganglia:
#*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink30
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
*.sink.ganglia.supportsparse=true
*.sink.ganglia.slope=jvm.metrics.gcCount=zero,jvm.metrics.memHeapUsedM=both
*.sink.ganglia.dmax=jvm.metrics.threadsBlocked=70,jvm.metrics.memHeapUsedM=40
#uncomment as your needs
namenode.sink.ganglia.servers=10.235.6.156:8649
#datanode.sink.ganglia.servers=10.235.6.156:8649
#jobtracker.sink.ganglia.servers=10.0.3.99:8649
#tasktracker.sink.ganglia.servers=10.0.3.99:8649
#maptask.sink.ganglia.servers=10.0.3.99:8649
#reducetask.sink.ganglia.servers=10.0.3.99:8649
这里需要注意的几点:
(1) 因为Ganglia3.1与3.0不兼容,需要根据Ganglia的版本选择使用GangliaSink30或者GangliaSink31
(2) period配置上报周期,单位是秒(s)
(3) namenode.sink.ganglia.servers指定Ganglia gmetad所在的host:port,用来向其上报数据
(4) 如果同一个物理机器上同时启动了多个hadoop进程(namenode/datanode, etc),根据需要把相应的进程的sink.ganglia.servers配置好即可
Hbase接入Ganglia:
1. Hbase所用的hadoop metrics对应的配置文件是: hadoop-metrics.properties
2. hadoop metrics里核心是Context,写文件有写文件的TimeStampingFileContext, 向Ganglia上报有GangliaContext/GangliaContext31
3. hadoop metrics配置支持Ganglia:
# Configuration of the "hbase" context for ganglia
# Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)
# hbase.class=org.apache.hadoop.metrics.ganglia.GangliaContext
hbase.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
hbase.period=10
hbase.servers=10.235.6.156:8649
这里需要注意几点:
(1) 因为Ganglia3.1和3.0不兼容,所以如果是3.1以前的版本,需要用GangliaContext, 如果是3.1版的Ganglia,需要用GangliaContext31
(2) period的单位是秒(s),通过period可以配置向Ganglia上报数据的周期
(3) servers指定的是Ganglia gmetad所在的host:port,把数据上报到指定的gmetad
(4) 对rpc和jvm相关的指标都可以进行类似的配置
REGIONS SERVER和TASK TRACKER SERVER不要在同一台机器上,最好如果有MAPREDUCE JOB运行的话,应该分开两个CLUSTER,即两群不同的服务器上,这样MAPREDUCE 的线下负载不会影响到SCANER这些线上负载。
如果主要是做MAPREDUCE JOB的话,将REGIONS SERVER和TASK TRACKER SERVER放在一起是可以的。
原始集群模式
10个或以下节点,无MAPREDUCE JOB,主要用于低延迟的访问。每个节点上的配置为:CPU4-6CORE,内存24-32G,4个SATA硬盘。Hadoop NameNode, JobTracker, HBase Master, 和ZooKeeper全都在同一个NODE上。
小型集群模式(10-20台服务器)
HBase Master放在单独一台机器上, 以便于使用较低配置的机器。ZooKeeper也放在单独一台机器上,NameNode和JobTracker放在同一台机器上。
中型集群模式(20-50台服务器)
由于无须再节省费用,可以将HBase Master和ZooKeeper放在同一台机器上, ZooKeeper和HBase Master要三个实例。NameNode和JobTracker放在同一台机器上。
大型集群模式(>50台服务器)
和中型集群模式相似,但ZooKeeper和HBase Master要五个实例。NameNode和Second NameNode要有足够大的内存。
HADOOP MASTER节点
NameNode和Second NameNode服务器配置要求:(小型)8CORE CPU,16G内存,1G网卡和SATA 硬盘,中弄再增加多16G内存,大型则再增加多32G内存。
HBASE MASTER节点
服务器配置要求:4CORE CPU,8-16G内存,1G网卡和2个SATA 硬盘,一个用于操作系统,另一个用于HBASE MASTER LOGS。
HADOOP DATA NODES和HBASE REGION SERVER节点
DATA NODE和REGION SERVER应在同一台服务器上,且不应该和TASK TRACKER在一起。服务器配置要求:8-12CORE CPU,24-32G内存,1G网卡和12*1TB SATA 硬盘,一个用于操作系统,另一个用于HBASE MASTER LOGS。
ZOOPKEEPERS节点
服务器配置和HBASE MASTER相似,也可以与HBASE MASTER放在一起,但就要多增加一个硬盘单独给ZOOPKEEPER使用。
-Xmx8g—设置HEAP的最大值到8G,不建议设到15 GB.
-Xms8g—设置HEAP的最小值到8GS.
-Xmn128m—设置新生代的值到128 MB,默认值太小。
-XX:+UseParNewGC—设置对于新生代的垃圾回收器类型,这种类型是会停止JAVA进程,然后再进行回收的,但由于新生代体积比较小,持续时间通常只有几毫秒,因此可以接受。
-XX:+UseConcMarkSweepGC—设置老生代的垃圾回收类型,如果用新生代的那个会不合适,即会导致JAVA进程停止的时间太长,用这种不会停止JAVA进程,而是在JAVA进程运行的同时,并行的进行回收。
-XX:CMSInitiatingOccupancyFraction—设置CMS回收器运行的频率。