#
-
install ZeroMQ
wget http://download.zeromq.org/historic/zeromq-2.1.7.tar.gz
tar -xzf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
./configure
//在configure时可能会报缺包,安装即可:sudo apt-get install g++ uuid-dev
make
sudo make install
-
install JZMQ
git clone https://github.com/nathanmarz/jzmq.git
cd jzmq
./autogen.sh
./configure
make
sudo make install
-
下载并解压STORM
-
编辑conf/storm.yaml
storm.zookeeper.servers:
- "1.2.3.5"
- "1.2.3.6"
- "1.2.3.7"
storm.local.dir: "/opt/folder"
nimbus.host: "54.72.4.92"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 编辑/etc/profile
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
export STORM_HOME=/home/ubuntu/java/storm-0.8.1
export KAFKA_HOME=/home/ubuntu/java/kafka_2.9.2-0.8.1.1
export ZOOKEEPER_HOME=/home/ubuntu/java/zookeeper-3.4.6
export PATH=$JAVA_HOME/bin:$STORM_HOME/bin:$KAFKA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
-
制作启动命令: start-storm.sh
storm nimbus &
storm supervisor &
storm ui &
安装途中如果遇到问题
http://my.oschina.net/mingdongcheng/blog/43009
有时候不知道java安装在哪里了 通过whereis java命令不能知道java真是的安装路径
可以通过 update-alternatives --config java 命令察看
bean@ubuntu :~$ update-alternatives --config java
There is only one alternative in link group java: /usr/lib/jvm/java-7-oracle/jre/bin/java
Nothing to configure.
bean@ubuntu :~$
或者这种方法也可以:
进入到相应的目录:cd /usr/bin
查看java链接到了哪里:ls -l java
localhost:bin root# ls -l java
lrwxr-xr-x 1 root wheel 74 May 18 10:26 java -> /System/Library/Frameworks/JavaVM.framework/Versions/Current/Commands/java
Question: I’m unable to do su – on Ubuntu. It says “su: Authentication failure”. How do I fix it? Also, is it possible for me to login to Ubuntu using root account directly?
Answer: Let us address these two question one by one.
Warning: Enabling root is not recommended. If possible, you should always try to perform all administrative tasks using sudo.
Question 1: I’m unable to login using su command. How to fix this?
By default, root account password is locked in Ubuntu. So, when you do su -, you’ll get Authentication failure error message as shown below.
$ su - Password: su: Authentication failure
Enable super user account password on Ubuntu
First, set a password for root user as shown below.
$ sudo passwd root [sudo] password for ramesh: Enter new UNIX password: Retype new UNIX password: passwd: password updated successfully
Now with the new password you can login as super user with su command
使用JERSEY框架输出JSON,需捕获所有的HTTP错误,如404等,业务错误及其他未定义的错误,将这些错误输出JSON,而不是TOMCAT的错误。
JERSEY已和SPRING整合。
web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://java.sun.com/xml/ns/javaee">
<display-name>Restful Web Application</display-name>
<servlet>
<servlet-name>jersey-serlvet</servlet-name>
<servlet-class>
com.sun.jersey.spi.spring.container.servlet.SpringServlet
</servlet-class>
<init-param>
<param-name>com.sun.jersey.config.property.packages</param-name>
<param-value>restfullapi.rest.service,restfullapi.common.provider,restful.web</param-value>
</init-param>
<init-param>
<param-name>com.sun.jersey.api.json.POJOMappingFeature</param-name>
<param-value>true</param-value>
</init-param>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>jersey-serlvet</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
<listener>
<listener-class>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
<listener>
<listener-class>
org.springframework.web.context.request.RequestContextListener
</listener-class>
</listener>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/mvc-dispatcher-servlet.xml</param-value>
</context-param>
<!-- spring logback -->
<context-param>
<param-name>logbackConfigLocation</param-name>
<param-value>classpath:logback.xml</param-value>
</context-param>
<listener>
<listener-class>ch.qos.logback.ext.spring.web.LogbackConfigListener</listener-class>
</listener>
<context-param>
<param-name>webAppRootKey</param-name>
<param-value>restfull-api</param-value>
</context-param>
<welcome-file-list>
<welcome-file>/index.jsp</welcome-file>
</welcome-file-list>
</web-app>
AbstractBaseRestfulException.java
public abstract class AbstractBaseRestfulException extends Exception{
private static final long serialVersionUID = 6779508767332777451L;
public AbstractBaseRestfulException()
{
}
public AbstractBaseRestfulException(String message)
{
super(message);
}
public abstract String getErrcode();
public abstract void setErrcode(String errcode);
public abstract String getDescription();
public abstract void setDescription(String description);
}
AbstractBaseRestfulExceptionMapper.java
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.Response;
import javax.ws.rs.core.Response.Status;
import javax.ws.rs.ext.ExceptionMapper;
import javax.ws.rs.ext.Provider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.paul.common.exception.AbstractBaseRestfulException;
import com.paul.common.json.DefaultJsonResponse;
@Provider
public class AbstractBaseRestfulExceptionMapper implements ExceptionMapper<AbstractBaseRestfulException>{
private Logger logger = LoggerFactory.getLogger(AbstractBaseRestfulExceptionMapper.class);
public Response toResponse(AbstractBaseRestfulException exception) {
logger.error(exception.getMessage(), exception);
DefaultJsonResponse<Object> response = new DefaultJsonResponse<Object>();
response.setDescription(exception.getDescription());
response.setErrcode(exception.getErrcode());
response.setResult(null);
return Response.status(Status.BAD_REQUEST)
.entity(response)
.type(MediaType.APPLICATION_JSON + ";charset=utf-8")
.build();
}
}
OtherExceptionMapper.java
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.Response;
import javax.ws.rs.core.Response.Status;
import javax.ws.rs.ext.ExceptionMapper;
import javax.ws.rs.ext.Provider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.paul.common.json.DefaultJsonResponse;
import com.paul.common.json.JsonResponseStatus;
@Provider
public class OtherExceptionMapper implements ExceptionMapper<Exception>{
private Logger logger = LoggerFactory.getLogger(OtherExceptionMapper.class);
public Response toResponse(Exception exception) {
logger.error(exception.getMessage(), exception);
DefaultJsonResponse<Object> response = new DefaultJsonResponse<Object>();
response.setDescription(JsonResponseStatus.OTHER_ERROR.getMessage() + exception.getMessage());
response.setErrcode(JsonResponseStatus.OTHER_ERROR.getCode());
response.setResult(null);
return Response.status(Status.BAD_REQUEST)
.entity(response)
.type(MediaType.APPLICATION_JSON + ";charset=utf-8")
.build();
}
}
WebApplicationExceptionMapper.java
import javax.ws.rs.WebApplicationException;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.Response;
import javax.ws.rs.ext.ExceptionMapper;
import javax.ws.rs.ext.Provider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.paul.common.json.DefaultJsonResponse;
@Provider
public class WebApplicationExceptionMapper implements ExceptionMapper<WebApplicationException >{
private Logger logger = LoggerFactory.getLogger(WebApplicationExceptionMapper.class);
public Response toResponse(WebApplicationException exception) {
logger.error(exception.getMessage(), exception);
DefaultJsonResponse<Object> response = new DefaultJsonResponse<Object>();
response.setDescription(exception.getMessage());
response.setErrcode(String.valueOf(exception.getResponse().getStatus()));
response.setResult(null);
return Response.status(exception.getResponse().getStatus())
.entity(response)
.type(MediaType.APPLICATION_JSON + ";charset=utf-8")
.build();
}
}
Controller中无须再处理异常
import javax.ws.rs.DefaultValue;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.QueryParam;
import javax.ws.rs.core.MediaType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import com.paul.common.json.DefaultJsonResponse;
import com.paul.common.json.JsonResponseStatus;
import com.paul.program.stbstart.valueobject.StbStart;
import com.paul.stbstart.valueobject.StbStartRequest;
import com.paul.restfullapi.rest.service.AdvertisementRestfulService;
@Path("/advertisement")
@Controller
public class AdvertisementRestfulController {
private Logger logger = LoggerFactory.getLogger(AdvertisementRestfulController.class);
@Autowired
AdvertisementRestfulService advertisementRestfulService;
@Path("/getAdvertisement")
@Produces({MediaType.APPLICATION_JSON + ";charset=utf-8"})
@GET
public DefaultJsonResponse<StbStart> getAdvertisement(
@DefaultValue("") @QueryParam("version")String version,
@QueryParam("token")String token) throws Exception
{
DefaultJsonResponse<StbStart> response = new DefaultJsonResponse<StbStart>();
StbStartRequest request = new StbStartRequest();
logger.info(version);
request.setVersion(version);
request.setToken(token);
StbStart result = advertisementRestfulService.findByVersion(request);
response.setResult(result);
response.setDescription(JsonResponseStatus.SUCCESS.getMessage());
response.setErrcode(JsonResponseStatus.SUCCESS.getCode());
logger.info("----------------");
// double i = 1/0;
return response;
}
}
一、Mongodb数据更新命令
Mongodb更新有两个命令:update、save。
1.1update命令
update命令格式:
db.collection.update(criteria,objNew,upsert,multi)
参数说明:
criteria:查询条件
objNew:update对象和一些更新操作符
upsert:如果不存在update的记录,是否插入objNew这个新的文档,true为插入,默认为false,不插入。
multi:默认是false,只更新找到的第一条记录。如果为true,把按条件查询出来的记录全部更新。
示例:
Shell代码

- > db.classes.insert({"name":"c1","count":30})
- > db.classes.insert({"name":"c2","count":30})
- > db.classes.find()
- { "_id" : ObjectId("5030f3a3721e16c4ab180cd9"), "name" : "c1", "count" : 30 }
- { "_id" : ObjectId("5030f3ab721e16c4ab180cda"), "name" : "c2", "count" : 30 }
- >
示例1:把count大于20的class name修改为c3
Shell代码
- > db.classes.update({"count":{$gt:20}},{$set:{"name":"c3"}})
- > db.classes.find()
- { "_id" : ObjectId("5030f3a3721e16c4ab180cd9"), "name" : "c3", "count" : 30 }
- { "_id" : ObjectId("5030f3ab721e16c4ab180cda"), "name" : "c2", "count" : 30 }
- >
由于没有指定upsert和multi的值,所以全部默认为false,由结果可以看出,只修改了第一条符合条件的记录。
示例2:把count大于20的class name修改为c4,设置multi为true
Shell代码
- > db.classes.update({"count":{$gt:20}},{$set:{"name":"c4"}},false,true)
- > db.classes.find()
- { "_id" : ObjectId("5030f3a3721e16c4ab180cd9"), "name" : "c4", "count" : 30 }
- { "_id" : ObjectId("5030f3ab721e16c4ab180cda"), "name" : "c4", "count" : 30 }
- >
由于指定了multi为true,所以对两条符合条件的记录都进行了更新。
示例3: 把count大于50的class name修改为c5,设置upsert为true
Shell代码
- > db.classes.update({"count":{$gt:50}},{$set:{"name":"c5"}},true,false)
- > db.classes.find()
- { "_id" : ObjectId("5030f3a3721e16c4ab180cd9"), "name" : "c4", "count" : 30 }
- { "_id" : ObjectId("5030f3ab721e16c4ab180cda"), "name" : "c4", "count" : 30 }
- { "_id" : ObjectId("5030f589ce8fa8884e6cd441"), "name" : "c5" }
- >
在集合中没有count大于50的记录,但是由于指定了upsert为true,如果找不到则会插入一条新记录。
1.2save命令
Mongodb另一个更新命令是save,格式如下:
db.collection.save(obj)
obj代表需要更新的对象,如果集合内部已经存在一个和obj相同的"_id"的记录,Mongodb会把obj对象替换集合内已存在的记录,如果不存在,则会插入obj对象。
这条命令比较简单,示例就省略了。
二、数据更新操作符
1.$inc
用法:{$inc:{field:value}}
作用:对一个数字字段的某个field增加value
示例:将name为chenzhou的学生的age增加5
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "name" : "chenzhou", "age" : 22 }
- #查询结果显示年龄为22
- > db.students.update({name:"chenzhou"},{$inc:{age:5}})
- #执行修改,把age增加5
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "name" : "chenzhou", "age" : 27 }
- >
- #查询结果显示年龄为27,修改成功
2.$set
用法:{$set:{field:value}}
作用:把文档中某个字段field的值设为value
示例: 把chenzhou的年龄设为23岁
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "name" : "chenzhou", "age" : 27 }
- > db.students.update({name:"chenzhou"},{$set:{age:23}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "name" : "chenzhou", "age" : 23 }
- >
从结果可以看到,更新后年龄从27变成了23
3.$unset
用法:{$unset:{field:1}}
作用:删除某个字段field
示例: 将chenzhou的年龄字段删除
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "name" : "chenzhou", "age" : 23 }
- > db.students.update({name:"chenzhou"},{$unset:{age:1}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "name" : "chenzhou" }
- >
4.$push
用法:{$push:{field:value}}
作用:把value追加到field里。注:field只能是数组类型,如果field不存在,会自动插入一个数组类型
示例:给chenzhou添加别名"michael"
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "name" : "chenzhou" }
- > db.students.update({name:"chenzhou"},{$push:{"ailas":"Michael"}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "Michael" ], "name" : "chenzhou" }
- >
由结果可以看到,记录中追加了一个数组类型字段alias,且字段有一个为"Michael"的值
5.pushAll
用法:{$pushAll:{field:value_array}}
作用:用法同$push一样,只是$pushAll可以一次追加多个值到一个数组字段内。
示例:给chenzhou追加别名A1,A2
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "Michael" ], "name" : "chenzhou" }
- > db.students.update({name:"chenzhou"},{$pushAll:{"ailas":["A1","A2"]}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "Michael", "A1", "A2" ], "name" : "chenzhou" }
- >
6.$addToSet
用法:{$addToSet:{field:value}}
作用:加一个值到数组内,而且只有当这个值在数组中不存在时才增加。
示例:往chenzhou的别名字段里添加两个别名A3、A4
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "Michael", "A1", "A2" ], "name" : "chenzhou" }
- > db.students.update({name:"chenzhou"},{$addToSet:{"ailas":["A3","A4"]}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "Michael", "A1", "A2", [ "A3", "A4" ] ], "name" : "chenzhou" }
- >
由结果可以看出,更新后ailas字段里多了一个对象,这个对象里包含2个数据,分别是A3、A4
7.$pop
用法:删除数组内第一个值:{$pop:{field:-1}}、删除数组内最后一个值:{$pop:{field:1}}
作用:用于删除数组内的一个值
示例: 删除chenzhou记录中alias字段中第一个别名
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "Michael", "A1", "A2", [ "A3", "A4" ] ], "name" : "chenzhou" }
- > db.students.update({name:"chenzhou"},{$pop:{"ailas":-1}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "A1", "A2", [ "A3", "A4" ] ], "name" : "chenzhou" }
- >
由结果可以看书,第一个别名Michael已经被删除了。
我们再使用命令删除最后一个别名:
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "A1", "A2", [ "A3", "A4" ] ], "name" : "chenzhou" }
- > db.students.update({name:"chenzhou"},{$pop:{"ailas":1}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "A1", "A2" ], "name" : "chenzhou" }
- >
由结果可以看出,alias字段中最后一个别名["A3","A4"]被删除了。
8.$pull
用法:{$pull:{field:_value}}
作用:从数组field内删除一个等于_value的值
示例:删除chenzhou记录中的别名A1
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "A1", "A2" ], "name" : "chenzhou" }
- > db.students.update({name:"chenzhou"},{$pull:{"ailas":"A1"}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "A2" ], "name" : "chenzhou" }
- >
9.$pullAll
用法:{$pullAll:value_array}
作用:用法同$pull一样,可以一次性删除数组内的多个值。
示例: 删除chenzhou记录内的所有别名
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ "A1", "A2" ], "name" : "chenzhou" }
- > db.students.update({name:"chenzhou"},{$pullAll:{"ailas":["A1","A2"]}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ ], "name" : "chenzhou" }
- >
可以看到A1和A2已经全部被删除了
10.$rename
用法:{$rename:{old_field_name:new_field_name}}
作用:对字段进行重命名
示例:把chenzhou记录的name字段重命名为sname
Shell代码
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ ], "name" : "chenzhou" }
- > db.students.update({name:"chenzhou"},{$rename:{"name":"sname"}})
- > db.students.find()
- { "_id" : ObjectId("5030f7ac721e16c4ab180cdb"), "ailas" : [ ], "sname" : "chenzhou" }
- >
由结果可以看出name字段已经被更新为sname了。
以前在开发webservice服务,都是自己基于HTTP协议,自己写一个测试程序来进行测试,最近在研究RestFul,对以前webservice服务进行了重构,总结了不少经验,今天就给大家介绍下几款Rest Client的测试工具。
REST介绍
所谓REST,是Representational State Transfer,这个词汇的中文翻译很不统一,而且很晦涩,有叫“具象状态传输”,有叫“表象化状态转变”,等等。
REST风格的Web服务,是通过一个简洁清晰的URI来提供资源链接,客户端通过对URI发送HTTP请求获得这些资源,而获取和处理资源的过程让客户端应用的状态发生改变(不像那些远程过程调用那么直接地发生改变)。
常用的对资源进行CRUD(Create, Read, Update 和 Delete)的四种HTTP方法分别是POST, GET, PUT, DELETE。
基于浏览器的Rest Client工具
在chrome或者firefox浏览器都有很多插件,我一般都是使用chrome浏览器,在chrome的webstore中可以搜索到自己想要的插件。这里就讲讲Advance REST Client,Postman-REST Client,DEV HTTP CLIENT,Simple REST Client,火狐下的RESTClient插件。
Advanced REST client
网页开发者辅助程序来创建和测试自定义HTTP请求。它是一款非常强大,使用简单的客户端测试工具,得到了程序员的好评。每周超过50k的开发者使用此应用程序。如此多的人是不会错的! 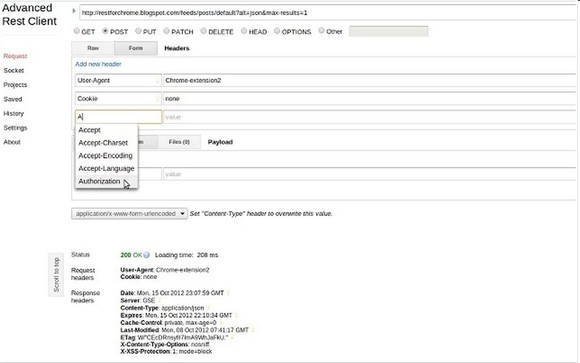
支持的功能
- Make a HTTP request (via XmlHttpRequest level 2)
- Debug socket (via web socket API).
- JSON response viewer
- XML response viewer
- set custom headers - even does not supported by XmlHttpRequest object
- help with filling HTTP headers (hint + code completion)
- add headers list as raw data or via form
- construct POST or PUT body via raw input, form or send file(s) with request
- set custom form encoding
- remember latest request (save current form state and restore on load)
- save (Ctrl+S) and open (Ctrl+O) saved request forms
- history support
- data import/export
Postman -REST client
Postman可以帮助你更有效的针对API工作。Postman是一个scratch-your-own-itch项目。它需要的是开发者有效的在项目中创建APIS,能够对API测试进行收藏保留。 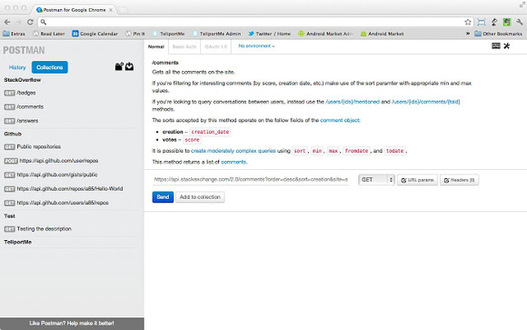
支持功能
- HTTP requests 支持文件上传
- 格式化API响应的JSON and XML
- 打开 responses 的HTML文件在一个新窗口展示
- 支持REST准则的超媒体应用状态的引擎- HATEOS
- 图像预览
- Request history
- 基本oauth 1.0助手
- Autocomplete for URL and header values
- 可以在URL参数中使用 key/value编辑添加参数或header值
- 使用环境变量容易转移之间设置。可用于测试,生产,分期或本地设置。
- 使用全局变量的值是在整个 APIs
- 使用快速查找功能预览变量和它们的值使用状况
- 键盘快捷方式,最大限度地提高您的生产力
Simple REST Client
Simple REST Client插件,提供了一个简单的表单进行各种HTTP操作,并可以看到返回的信息。构建自定义HTTP请求直接测试您的网络服务。 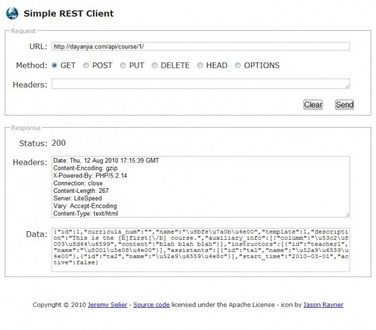
Firefox下的RESTClient
FirefoxRESTClient的插件,这款插件由国人开发,功能上支持Basic和OAuth的登录header发送,并且对于返回的XML数据还可以高亮显示
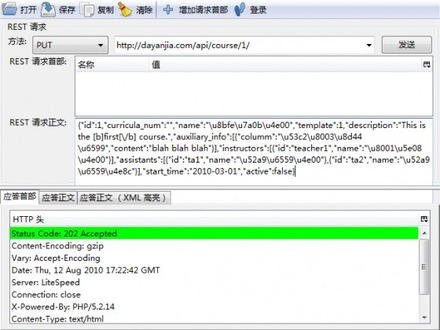
Linux常用的工具CURL
CURL是一个很强大的支持各种协议的文件传输工具,用它来进行RESTful Web Services的测试简直是小菜一碟。
CURL的命令参数非常多,一般用于RESTful Web Services测试要用到下面四种参数:
- -d/–data :POST数据内容
- -X/–request :指定请求的方法(使用-d时就自动设为POST了)
- -H/–header
:设定header信息
- -I/–head:只显示返回的HTTP头信息
Java GUI rest-client
这是一个用Java写的测试小工具,项目主页上提到它有命令行和GUI两种版本。为了方便操作我们选择GUI版本来看看。既然是一款软件,显然就比刚才介绍的浏览器插件功能更加强大。它支持应答正文的JSON和XML缩排和高亮,还可以一键搭建一个RESTful服务端,另外还提供了单元测试的功能。
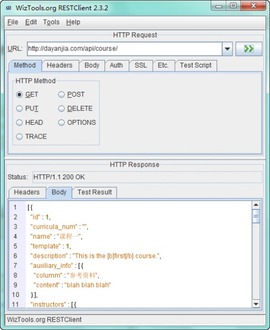
格式化JSON数据
Koala (考拉) 是一款应用在 Java EE 企业级应用开发领域,用于帮助架构师简化系统设计,降低框架耦合度,提高系统灵活性,提供开发工程师工作效率,降低成本的平台工具。

为什么使用 Koala:
- 开源免费的开发平台,允许你任意修改源码并扩展功能
- 以DDD领域驱动思想为核心,抛弃传统的以数据库为中心的四层编码模型
- 丰富的基础组件支持,包括:国际化、异常、缓存等
- 向导式的搭建项目过程,支持各种技术选择,JPA,Mybstis,SpringMVC,struts2MVC等
- 向导式的数据库到实体的生成过程
- 向导式的实体生成CURD功能
- 向导式的服务发布一键无缝发布成war、EJB、webservice(SOAP/REST) 多种服务形式
- 基于RBAC3模型的权限子系统
- 监控子系统轻松协助你监控URL,方法,数据库,内存等状态
- 使用通用查询子系统轻松定制完成查询功能
- 基于IP过滤,用户名验证及方法权限控制的WS安全子系统
- 基于JBPM5的流程子系统