#
@Min and @Max are used for validating numeric fields which could be String(representing number), int, short, byte etc and their respective primitive wrappers.
@Size is used to check the length constraints on the fields.
As per documentation @Size supports String, Collection, Map and arrays while @Min and @Max supports primitives and their wrappers. See the documentation.
手动触发:
https://blog.csdn.net/justyman/article/details/89857577
如果是自动触发BUILD时,则可以以最新建立的TAG为基础进行BUILD,而无需人手选TAG进行BUILD。
配置,注意应取消参数化配置工程:
- Add the following refspec to the Git plugin:
+refs/tags/*:refs/remotes/origin/tags/*
- Add the following branch specifier:
*/tags/*
- Enable SCM polling, so that the job detects new tags.
定义一个事件,因SPRING中可以有不同的事件,需要定义一个类以作区分:
import lombok.Getter;
import org.springframework.context.ApplicationEvent;
@Getter
public class JavaStackEvent extends ApplicationEvent {
/**
* Create a new {@code ApplicationEvent}.
*
* @param source the object on which the event initially occurred or with
* which the event is associated (never {@code null})
*/
public JavaStackEvent(Object source) {
super(source);
}
}
定义一个此事件观察者,即感兴趣者:
import lombok.NonNull;
import lombok.RequiredArgsConstructor;
import org.springframework.context.ApplicationListener;
import org.springframework.scheduling.annotation.Async;
/**
* 观察者:读者粉丝
*/
@RequiredArgsConstructor
public class ReaderListener implements ApplicationListener<JavaStackEvent> {
@NonNull
private String name;
private String article;
@Async
@Override
public void onApplicationEvent(JavaStackEvent event) {
// 更新文章
updateArticle(event);
}
private void updateArticle(JavaStackEvent event) {
this.article = (String) event.getSource();
System.out.printf("我是读者:%s,文章已更新为:%s\n", this.name, this.article);
}
}
注册感兴趣者(将自身注入SPRING容器则完成注册),并制定发布机制(通过CONTEXT发布事件):
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Slf4j
@Configuration
public class ObserverConfiguration {
@Bean
public CommandLineRunner commandLineRunner(ApplicationContext context) {
return (args) -> {
log.info("发布事件:什么是观察者模式?");
context.publishEvent(new JavaStackEvent("什么是观察者模式?"));
};
}
@Bean
public ReaderListener readerListener1(){
return new ReaderListener("小明");
}
@Bean
public ReaderListener readerListener2(){
return new ReaderListener("小张");
}
@Bean
public ReaderListener readerListener3(){
return new ReaderListener("小爱");
}
}
Excel 在读取 csv 的时候是通过读取文件头上的 bom 来识别编码的,这导致如果我们生成 csv 文件的平台输出无 bom 头编码的 csv 文件(例如 utf-8 ,在标准中默认是可以没有 bom 头的),Excel 只能自动按照默认编码读取,不一致就会出现乱码问题了。
掌握了这点相信乱码已经无法阻挡我们前进的步伐了:只需将不带 bom 头编码的 csv 文件,用文本编辑器(工具随意,推荐 notepad++ )打开并转换为带 bom 的编码形式(具体编码方式随意),问题解决。
当然,如果你是像我一样的码农哥哥,在生成 csv 文件的时候写入 bom 头更直接点,用户会感谢你的。
附录:对于 utf-8 编码,unicode 标准中是没有 bom 定义的,微软在自己的 utf-8 格式的文本文件之前加上了EF BB BF三个字节作为识别此编码的 bom 头,这也解释了为啥大部分乱码都是 utf-8 编码导致的原因
SPRING BATCH中生成CSV文件时的解决方案:
new FlatFileItemWriterBuilder<T>()
.name(itemWriterName)
.resource(outputResource)
.lineAggregator(lineAggregator)
.headerCallback(
h -> {
System.out.println(header);
h.write('\uFEFF');//只需加这一行
h.write(header);
}
)
.build();
https://stackoverflow.com/questions/48952319/send-csv-file-encoded-in-utf-8-with-bom-in-java
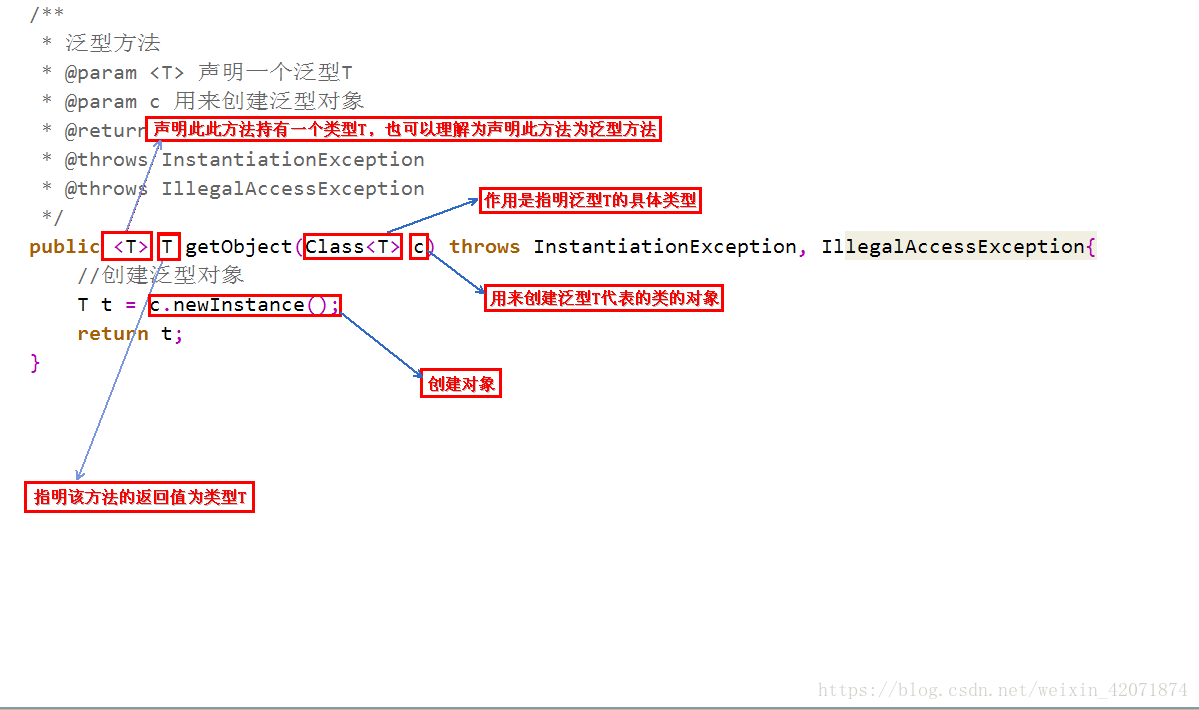
/**
*
* @param <T>声明此方法持有一个类型T,也可以理解为声明此方法为泛型方法
* @param clazz 作用是指明泛型T的具体类型
* @return 指明该方法的返回值为类型T
* @throws InstantiationException
* @throws IllegalAccessException
*/
public <T> T getObject(Class<T> clazz) throws InstantiationException, IllegalAccessException {
T t = clazz.newInstance();//创建对象
return t;
}
方法返回值前的<T>的左右是告诉编译器,当前的方法的值传入类型可以和类初始化的泛型类不同,也就是该方法的泛型类可以自定义,不需要跟类初始化的泛型类相同
领域驱动(DDD,Domain Driven Design)为软件设计提供了一套完整的理论指导和落地实践,通过战略设计和战术设计,将技术实现与业务逻辑分离,来应对复杂的软件系统。本系列文章准备以实战的角度来介绍 DDD,首先编写领域驱动的代码模型,然后再基于代码模型,引入 DDD 的各项概念,先介绍战术设计,再介绍战略设计。
> DDD 实战1 - 基础代码模型
> DDD 实战2 - 集成限界上下文(Rest & Dubbo)
> DDD 实战3 - 集成限界上下文(消息模式)
> DDD 实战4 - 领域事件的设计与使用
> DDD 实战5 - 实体与值对象
> DDD 实战6 - 聚合的设计
> DDD 实战7 - 领域工厂与领域资源库
> DDD 实战8 - 领域服务与应用服务
> DDD 实战9 - 架构设计
> DDD 实战10 - 战略设计