#
无门面模式时:
有门面模式时:
package pattern.facade;
/**
* 门面模式/外观模式:Facade Pattern
*
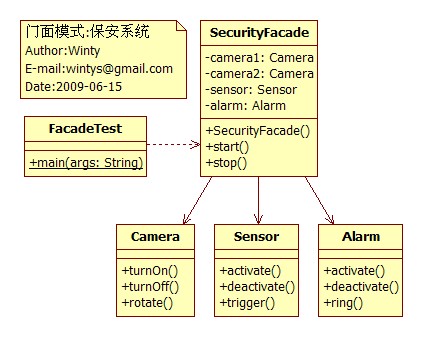
* 保安系统:
* 一个保安系统由两个录像机、一个感应器和一个报警器组成。
* 由保安操作仪器的启动和关闭:没有使用门面模式时,保安必须亲自启动每个仪器。
* @version 2009-6-15
* @author Winty(wintys@gmail.com)
*/
public class FacadeTest{
public static void main(String[] args){
//无门面模式
Camera camera1,camera2;
camera1 = new Camera();
camera2 = new Camera();
Sensor sensor;
sensor = new Sensor();
Alarm alarm;
alarm = new Alarm();
//启动仪器
camera1.turnOn();
camera2.turnOn();
sensor.activate();
alarm.activate();
System.out.println("");
/////////////////////////////////
//使用门面模式
SecurityFacade security = new SecurityFacade();
security.start();
}
}
/**
* 门面:Facade
*/
class SecurityFacade{
private Camera camera1;
private Camera camera2;
private Sensor sensor;
private Alarm alarm;
public SecurityFacade(){
camera1 = new Camera();
camera2 = new Camera();
sensor = new Sensor();
alarm = new Alarm();
}
//启动
public void start(){
camera1.turnOn();
camera2.turnOn();
sensor.activate();
alarm.activate();
}
//停止
public void stop(){
camera1.turnOff();
camera2.turnOff();
sensor.deactivate();
alarm.deactivate();
}
}
class Camera{
public void turnOn(){
System.out.println("turn on the Camera.");
}
public void turnOff(){
System.out.println("turn off the Camera.");
}
//转动
public void rotate(){
System.out.println("rotate the Camera.");
}
}
class Sensor{
public void activate(){
System.out.println("activate the sensor.");
}
public void deactivate(){
System.out.println("deactivate the sensor.");
}
//触发感应器
public void trigger(){
System.out.println("trigger the sensor.");
}
}
class Alarm{
public void activate(){
System.out.println("activate the alarm.");
}
public void deactivate(){
System.out.println("deactivate the alarm.");
}
//拉响报警器
public void ring(){
System.out.println("ring the alarm.");
}
}
运行结果:
turn on the Camera.
turn on the Camera.
activate the sensor.
activate the alarm.
turn on the Camera.
turn on the Camera.
activate the sensor.
activate the alarm.
1.filehosting

filehosting的免费存储空间,无空间大小限制,无文件大小限制,无流量限制,直接WEB方式上传文件,方便快捷。
2.Savefile

Savefile是美国的一家免费网络硬盘,无限空间、无限流量,单个文件100M以内,你上传的文件30天内无人下载将被删除。无需注册为 Savefile会员即可上传文件,使用方便,但下载的时候广告较多。
3.Wiki upload

不用注册,可直接上传文档,支持上传5G的单个文件。
4.FileSend

FileSend提供免费网络文件存储空间,无需注册可直接上传,单个文件最大支持120M,注册用户单个文件最大支持300M,
5.File Save

你可以从myspace、facebook、bebo page上连接到这个文件或发送链接到你的博客或论坛或自己留着。
6.InfiniteMb

提供5G ,支持PHP+MYSQL空间,它可以使你上传并且分享不受限制的文件、图片、视频和音乐给全世界的人。
zRoom与User存在一对多的关系,如果要在取得Room的同时取得User,则在Room中加入Set,List或Map类型的集合成员,Set中的元素不可以重复,List中的元素可以重复,Map是鍵值对类型的集合。
在HIBERNATE的配置文件中象这样配置:
<set name="users" table="user" cascade="all" inverse="true" lazy="extra">
<key column="room_id"/>
<one-to-many class="paul.com.User"/>
</set>
- 指定users私有成员的类型为SET:set name="users"
- 指定集合中的对象类型为User:<one-to-many class="paul.com.User"/>
- 指定User对应的表:table="user"
- 指定外键:<key column="room_id"/>
- 指定如果同时新增、修改、删除关联的Room和User对象时,是否需要HIBERNATE执行两次操作:cascade="all"
- 指定 lazy="extra"时,则集合中的元素不会被一起取出,而且要读SIZE时,只会发送一条COUNT的SQL语句至后台
- 指定 inverse="true"时,当保存一的对象时,对应的多的对象不会同时被保存。
如果要在取得User对象的同时取得Room对象,则在User中加入私有成员Room,在HIBERNATE的配置文件中如下配置:
<many-to-one name="room"
column="room_id"
class="paul.com.Room"
cascade="all"
outer-join="true"/>
- 指定名称为room成员的类型:many-to-one name="room"
- 指定room对应的类名:class="paul.com.Room"
- 指定外键:column="room_id"
- 指定如果同时新增、修改、删除关联的Room和User对象时,是否需要HIBERNATE执行两次操作:cascade="all"
- 指定关联两个表时的查询是否使用left-outer关键字:outer-join="true"
User和Server是多对多的关系,如要在取得User对象的同时取得Server,可以User中加入Set私有成员,在HIBERNATE中如下配置:
<set name="servers"
table="user_server"
cascade="save-update">
<key column="user_id"/>
<many-to-many class="paul.com.Server"
column="server_id"/>
</set>
- 指定名称为servers的私有成员的类型为SET:set name="servers"
- 指定中间表为:table="user_server"
- 指定User表与中间表关联的外键:key column="user_id"
- 指定集合中的对象类型为:many-to-many class="paul.com.Server"
- 指定中间表与Server关联的外键:column="server_id"
- 指定如果同时新增、修改、删除关联的Room和User对象时,是否需要HIBERNATE执行两次操作:cascade="save-update"
如此配置后,将大量减少SQL语句的撰写。
无论采用什么方法论和体系,一个项目管理的过程往往涉及了如下这些过程组。
把提纲列一下有助于我们检查项目管理的遗漏:
启动过程组:
1制定项目章程
2制定初步范围说明书
规划过程组:
1制定项目管理计划
2范围规划
3范围定义
4制作工作分解结构
5活动定义
6活动排序
7活动资源估算
8活动持续时间估算
9进度表制定
10费用估算
11费用预算
12质量规划
13人力资源规划
14沟通规划
15风险管理规划
16风险识别
17定性风险分析
18定量风险分析
19风险应对规划
20采购规划
21发包规划
执行过程组
1指导与管理项目执行
2实施质量保证
3项目团队组建
4项目团队建设
5信息发布
6询价
7卖方选择
监控过程组
1监控项目工作
2整体变更控制
3范围核实
4范围控制
5进度控制
6费用控制
7实施质量控制
8项目团队管理
9绩效报告
10利害关系者管理
11风险控制
12合同管理
收尾过程组
1项目收尾
2合同收尾
如果一个男人,把自己超过三分之一的总收入,用在了你身上,那么姑且请相信,这个男人爱你。哪怕他在演戏。要考虑,他的实际收入。他要消费,他要储蓄,他要应酬,能花三分之一收入在你身上,那就是真的。
如果一个女人,把自己超过三分之一的时间,用在了你身上,那么请姑且相信,这个女人爱你。哪怕,她在演戏,她还在和其他男人暧昧,她还在和其他男人选择和被选择的演戏,她还在挂,还在挑,还在选。
如果男人真心欺骗,如果女人真心演戏,那么一切就是真的。
女人不要说,你没有遇到你想遇到的人,你想嫁的人,如果你的容貌身材姿色收入家庭条件出生没有发生改变的话,按照常理和规律,你就应该和现在的人在一起。男人不要说,等我有了钱,等我成功了,等我有了权,如果你的相貌身材收入家庭姿色没有发生根本转变的话按照常理和规律,你就应该和现在的人在一起。你现在能遇到的,能交往的,就是你可以找到的人。所以,你不要想以后怎样,以后是以后的事情。
现在,就是现在。
没有多少男人会泡mm了,这个年头,男人负担太重,活得太累。所以,即便一个是想泡你,他也是真心在泡你。如果真是为了性,为了身体,这个时代可以解决的途径和方式很多,直接迅速廉价。
没有多少女人会真心在男人身上花时间了,甚至奉献青春和身体,现在女人都功利,现实,如果你不是百万千万富翁,就别以为女人是想你的钱财。何况这个时代,女人想赚钱,途径很多,方法很多,直接迅速快截。
所以,泡你的人,和陪你的人,都是在真心的逢场作戏,至少他们还相信爱情,还期待感情,还很纯真,还很善良。
那些为你赶路,为你计划,为你安排,为你消费,为你安排,为你安排的男人,请你珍惜。也许他们并不富裕,但是甘愿为你花费一周乃至数周的薪水,博取你一笑,和彼此的开心快乐,那么他是爱你的,他是一个有道德的人,他演技高超。
那些为你化妆,为你精心准备服饰,为你推掉应酬约会,在黄金时间和重大节假日陪你的女人,请你珍惜。也许她们并不国色天香,品味非凡,气质高雅,但是甘愿在人生最宝贵的时间,一年最郑重和值得纪念的日子,陪伴你,和你在一起,让你不寂寞,让彼此愉悦,相信感情和彼此温暖,那么她是爱你的,因为女人的青春最宝贵,一去不复返,她成功欺骗了你,欺骗了自己,丧失了机会。
也许,你不相信爱情,也许,你不能再爱,也许你觉得世界庸俗,也许,你觉得没有什么可以相信。那么请相信一切都是真的。那个男人深夜里给你发来短信和问候,再很多时间,牵挂着你,哪怕他在莺莺燕燕的包围里,只要他还记得你。
也许,你觉得这个世界物质,这个世界残酷,这个世界没有真爱,这个世界虚伪,这个人生虚幻,那么请相信一切都是真的。那个女人为了你玩弄许多花样,谈论起自己很多男人追逐,很抢手,谈论自己过去有很多有钱人垂涎,谈论自己的家常生活,甚至只是需要一件嫁衣。哪怕,她还在左顾右盼,还在瞻前顾后,只要她还在哄骗你。
那么,请认真地逢场作戏。请善待那个真实欺骗你的人。请珍惜为你演戏的人。哪怕她的骗术拙劣,哪怕他的演戏低劣。请相信,他是真的。至少当时是真的,是因为他相信感情很好,爱情很美好。
至于以后,以后谁也不知道。也许他真的腰缠万贯,在依红偎翠时,仍然忘不了你,舍不得你,或者你是他的发妻,你永远是no1,是第一位,是同患难的,是可以欺骗他一生的女人。也许你以后一文不名,穷困潦倒,众生无望,但是有一个女人,会围绕你身边,不离不弃,因为你是她的丈夫,你永远是归宿,你演技高超,是可以和她一生做对手的那个人。
所以,欺骗是好的,只要彼此相信,心照不宣,就没有问题。所以,演戏是好的,只要你们,彼此投入,人生不过百年,幕起幕落而已。
1.吃了辣的东西,感觉就要被辣死了,就往嘴里放上少许盐,含一下,漱下口,就不辣了;
2.牙齿黄,可以把花生嚼碎后含在嘴里,并刷牙三分钟,很有效;
3.若有小面积皮肤损伤或者烧伤、烫伤,抹上少许牙膏,可立即止血止痛;
4.经常装茶的杯子里面留下难看的茶渍,用牙膏洗之,非常干净;
5.仰头点眼药水时微微张嘴,这样眼睛就不会乱眨了;
6.嘴里有溃疡,就用维生素C贴在溃疡处,等它溶化后溃疡基本就好了;
7.眼睛进了小灰尘,闭上眼睛用力咳嗽几下,灰尘就会自己出来;
8.洗完脸后,用手指沾些细盐在鼻头两侧轻轻按摩,然后再用清水冲洗,黑头和粉刺就会清除干净,毛细孔也会变小
9.刚刚被蚊子咬完时,涂上肥皂就不会痒了;
10.如果嗓子、牙龈发炎了,在晚上把西瓜切成小块,沾着盐吃,记得一定要是晚上,当时症状就会减轻,第二天就好了;
11.吹风机对着标签吹,等吹到商标的胶热了,就可以很容易的把标签撕下来;
12.旅行带衣服时如果怕压起褶皱,可以把每件衣服都卷成卷;
13.打打嗝时就喝点醋,立杆见影;
14.吃了有异味的东西,如大蒜、臭豆腐,吃几颗花生米就好了;
15.治疗咳嗽,特别是干咳,晚上睡觉前,用纯芝麻香油煎鸡蛋,油放稍多些,什么调味料都不要放,趁热吃过就去睡觉,连吃几天效果很明显;
16.手腕长粗的MM想带较细的手镯,就不能硬带,应把手上套上一个塑料袋再带上手镯,非常好带,也不会把手弄疼,取下也是同样的方法;
17.栗子皮难剥,先把外壳剥掉,再把它放进微波炉转一下,拿出后趁热一搓,皮就掉了;
18.插花时,在水里滴上一滴洗洁精,可以维持好几天;
19.把核桃放进锅里蒸十分钟,取出放在凉水里再砸开,就能取出完整的桃核仁了;
20.把虾仁放进碗里,加一点精盐、食用碱粉,用手抓搓一会儿后用清水浸泡,然后再用清水冲洗,即能使炒出的虾仁透明如水晶,爽嫩可口;
21.炒肉时,先把肉用小苏打水浸泡十几分钟,倒掉水,再入味,炒出来会很嫩滑;
22.将残茶叶浸入水中数天后,浇在植物根部,可促进植物生长;
23.把残茶叶晒干,放到厕所或者沟渠里燃熏,可消除恶臭,具有驱除蚊子苍蝇的功能;
24.夹生饭重煮法:可用筷子在饭内扎些直通锅底的孔,洒入少许黄酒重焖,
25.若只表面夹生,只要将表层翻到中间再焖即可;
26.巧除纱窗油腻:将洗衣服、吸烟剩下的烟头一起放在水里,待溶解后,拿来擦玻璃窗、纱窗,效果真不错;
27.只要在珠宝盒中放上一节小小的粉笔,即可让首饰常保光泽;
28.桌子、瓶子表面的不干胶痕迹用风油精可以擦拭;
29.出门时随时在包里带一节小的干电池,若裙子带静电,就把电池的正极在裙子上面擦几下即可去掉静电;
30.不管是鞋子的哪个地方磨到了你的脚,你就在鞋子磨脚的地方涂一点点白酒,保证就不磨脚了;
31.烹调蔬菜时,如果必须要焯,焯好菜的水最好尽量利用。如做水饺的菜,焯好的水可适量放在肉馅里,这样既保证营养,又使水饺馅味美有汤;
32.夏天足部容易出汗,每天用淡盐水泡脚可有效应对汗脚;
33.夏天游泳后晒晒太阳,可防肌肤劳损等疾病发生;
34.夏天枕头易受潮滋生霉菌,时常曝晒枕芯有利健康;
35.多吃薏米小豆粥等潮湿健脾,可防暑湿;
36.防失眠:睡前少讲太多话,忌饮浓茶,睡前勿大用脑,可用热水加醋洗脚;
37.金银花有疏散风湿功效,金银花水煎取汁凉后与蜂蜜冲调可解暑;
38.吃过于肥腻的食物后喝茶,能刺激自律神经,促进脂肪代谢;
39.睡眠不足会变笨,一天需要睡眠八小时,有午睡习惯可延缓衰老;
40.双手易变得干燥粗糙,用醋泡手十分钟可护肤;
41.夏天擦拭凉席,用滴加了花露水的清水擦拭凉席,可使凉席保持清爽洁净。当然,擦拭时最好沿着凉席纹路进行,以便花露水渗透到凉席的纹路缝隙,这样清凉舒适的感觉会更持久;
42.早餐多食西红柿、柠檬酸等酸性蔬菜和水果,有益于养肝;
43.爽身止痒洗头或洗澡时,在水中加五六滴花露水,能起到很好的清凉除菌、祛痱止痒作用;
44.葡萄含有睡眠辅助激素,常食有助睡眠;
45.夏天多喝番茄汤既可获得养料,又能补充水分,番茄汤应烧好并冷却后再喝,所含番茄红素有一定的抗前列腺癌和保护心肌的功效,最适合于男子;吃酸性物质马上刷牙会损害牙齿健康;
46.因外伤碰破皮肉时,在伤处涂上牙膏进行消炎、止血,再包扎,作为临时急救药,以药物牙膏效果最为显著;
47.将白醋喷洒在菜板上,放上半小时后再洗,不但能杀菌,还能除味;
48.喝酸奶能解酒后烦躁,酸奶能保护胃黏膜、延缓酒精吸收,并且含钙丰富,对缓解酒后烦躁尤其有效;
49.皮鞋包皮放久了发霉时,可用软布蘸酒精加水(1:1)溶液擦拭即可;
50.发生头痛、头晕时,可在太阳穴涂上牙膏,因为牙膏含有薄荷脑、丁香油可镇痛;
51.蜡烛冷冻二十四小时后,再插到生日蛋糕上,点燃时不会流下烛油;
52.白色衣裤洗后易泛黄,可取一盆清水,滴上二三滴蓝墨水,将洗过的衣裤在浸泡一刻钟,不必拧干,就放在太阳下晒,即可洁白干净;
53.过多食用生葱蒜会刺激口腔肠胃,不利健康,最好加一点醋再食用;
54.及时补充水分但应少喝果汁、可乐、雪碧、汽水等饮料,含有较多的糖精和电解质,喝多了会对肠胃产生不良刺激,影响消化和食欲。因此夏天应多喝白开水或淡盐(糖)水;
55.每天早晨用豆腐摩擦面部几分钟,坚持一个月,面部会变得很滋润;
56.空调室内温差不宜超过五度,即使天气再热,空调室内温度也不宜到24度以下;
57.加酶洗衣粉剂放在温水中需要较长的分解时间才能使洗衣效果更佳;
58.夏天,人的活动时间变长,出汗多,耗能过大,应适当多吃鸡、鸭、瘦肉、鱼类、蛋类等营养食品,以满足人体的代谢需要;
59.头痛时把苹果磨成泥状涂在纱布上,贴在头痛处,症状可减轻;
60.皮包上有污渍,可以用棉花蘸风油精擦拭。
摘要: 软件开发过程中通常会产生各种产品,如代码,文档(需求文档、设计文档等)和交互文档(记录与客户开会情况),而这些产品可能被多人,多次修改过,因此需要管理,如记录谁在什么时候改过什么等,这就叫做配置管理。这些产品就叫做配置项。
阅读全文