#
这篇也是转载,改了中间部分内。
在基于注解方式配置Spring
的配置文件中,你可能会见到<context:annotation-config/>这样一条配置,他的作用是式地向 Spring
容器注册
AutowiredAnnotationBeanPostProcessor、CommonAnnotationBeanPostProcessor、
PersistenceAnnotationBeanPostProcessor 以及 RequiredAnnotationBeanPostProcessor 这 4 个BeanPostProcessor。
注册这4个 BeanPostProcessor的作用,就是为了你的系统能够识别相应的注解。
例如:
如果你想使用@Autowired注解,那么就必须事先在 Spring 容器中声明 AutowiredAnnotationBeanPostProcessor Bean。传统声明方式如下:
- <bean class="org.springframework.beans.factory.annotation. AutowiredAnnotationBeanPostProcessor "/>
如果想使用@ Resource 、@ PostConstruct、@ PreDestroy等注解就必须声明CommonAnnotationBeanPostProcessor
如果想使用@PersistenceContext注解,就必须声明PersistenceAnnotationBeanPostProcessor的Bean。
如果想使用 @Required的注解,就必须声明RequiredAnnotationBeanPostProcessor的Bean。同样,传统的声明方式如下:
- <bean class="org.springframework.beans.factory.annotation.RequiredAnnotationBeanPostProcessor"/>
一般来说,这些注解我们还是比较常用,尤其是Antowired的注解,在自动注入的时候更是经常使用,所以如果总是需要按照传统的方式一条一条配置显得有些繁琐和没有必要,于是spring给我们提供<context:annotation-config/>的简化配置方式,自动帮你完成声明。
不过,呵呵,我们使用注解一般都会配置扫描包路径选项
- <context:component-scan base-package=”XX.XX”/>
该配置项其实也包含了自动注入上述processor的功能,因此当使用 <context:component-scan/> 后,就可以将 <context:annotation-config/> 移除了。
本文转载:http://mushiqianmeng.blog.51cto.com/3970029/723880
有一段时间没有关注spring了,spring2.5就蛮够用的,spring3出来后一直没怎么关注。
这几天抽空关注一下。干咱这行的还是要紧跟时代变化啊。
下边这些内容是转载51cto的一篇文章。
1、项目结构与构建变化
解压后的立即发现,Spring 3.0的项目结构已经发现了巨大变化:
1、Spring3采用多项目结构源码组织,不再是以前的单一方式,共26个项目,差不多每个项目对于一个分发的jar包,不过有些项目是空的,或者是为了构建而设。
2、不再提供完整打包文件spring.jar,而是20个jar(或称bundle),一方面应该也是向osgi靠拢。
Spring 3.0的readme中说道:
Note that this release does not contain a 'spring.jar' file anymore, in contrast to previous Spring generations. Furthermore, the jar file names follow bundle repository conventions now.
(51CTO编辑快译:与之前的Spring版本相反,此次发布不再包括spring.jar文件了。新版本中的jar文件命名由bundle版本库的规则所决定。)
3、采用Ivy为主构建方式,当然仍然有Maven,项目结构由Maven管理。另外没有打包全部的依赖包了,整个下载包比2.5的小了近一半
4、Spring3已经完全采用Java5/6开发和编译构建,因此应该是不再支持Java1.4及更早版本了
2、框架结构的变化
框架结构的架构图也进一步演变了,不再是原来那个简单的方块图:

Spring3架构图
跟原来的相比,DAO、ORM、JEE等模块被划归到了一起,成为“数据访问/集成”部分,Web层突出了自己的MVC(Servlet)和Portlet,核心容器增加了表达式语言。另外,对测试的支持也放到了整个架构中来了。所以整个框架重新划分成了五部分。
因此,典型的全应用场景也相应变化,并提示使用自家的Tomcat:

关于eclipse的一些应用,开发过程中用到了就随手记下。
1.Web App Libraries and Eclipse Build Path
在eclipse下创建web项目,在build path下会对应包含Web App Libraries 动态加载项目下/WebContent/WEB-INF/lib所有的jar文件。
好处是在项目增加或删除jar包时不用总是修改build path配置文件,从cvs同步代码的时候保持这部分不变。
2.system library
有些jar在开发的时候要用到,但是部署的时候不用部署到服务器。
比如:jsp-api.jar,servelet.jar,这些文件在tomcat jboss 下已经包含,重复部署的话会引起错误。
我以前的做法是在anr build.xml文件中打包生成war时删除对应的jar包。
刚发现还有这么一种用法,在eclipse添加system library把jar添加到该库下就不会部署到服务器。
如图:主要tomcat-jar 一定要设置成system library
关于在创业公司工作的话题,以前跟同事讨论过,刚看到这么一篇,转载一下。
有人在Quora问了这个问题:What startup could make me a millionaire in four years if I got hired as an emplyee today?
Symbolic Analytics的创始人Brandon Smietana在下面做了很长的回答,内容很精彩,不过请勿对号入座:
大多数创业公司的退出(exit),都是通过M&A(并购),而不是通过IPO(首次公开募股),现在大多数的M&A价格都低于3000万美元,最典型的价格是1500万美元,现在我们来假设一个最乐观的退出案例,从其中的数据中算出,我作为创始人和CEO,能够拿多少钱;从而计算出,你,作为一个员工可能赚得的利益。
(一)
假定案例
1)我拿到1000万的投资。
2)投资人拥有公司50%的股权(乐观估计)。
3)我将公司以3000万的价格出售。
4)我拥有30%的外流通股(Outstanding Share) ,非常乐观的估计。
投资人还拥有优先股,通过并购,他们首先把自己投入的钱收回来,然后再参与省下的股权收益分红。
1)在3000万的退出中,投资人首先拿回他们投入的1000万,剩下2000万。
2)然后,优先股股东吃掉省下2000万的50%的利益分红,于是他们拿走另外1000万。
3)现在,整个脱售的现金只剩下1000万,分享这份利益的关系者包括大众股东,公司员工,创始人和管理团队。
我,作为创始人和CEO,享有最多的普通股股权,价值这1000万美元的大概600万。省下的400万利益归属其他所有的普通股股东(包括所有的公司员工)
最典型的早期员工,在利益分红中能拿到的资产不足CEO的1/30,因此,一位非常重要的早期员工,能够从脱售中取得20万美元的利益。
现在,让我设想得不那么乐观,相对实际一点。70%进入A轮融资的创业者,除了工资,其他什么利益都无法从公司获得。因此作为一名员工,
1)有70%的可能,如果你在A轮融资的时候加入创业公司,你的普通股是没有价值的。
2)与A轮以前的早期员工相比,A轮以后的员工通过股权或者期权能拿到的利益要少很多。
3)在A轮融资以后,新员工能够拿到的最好的股权大概在0.3%左右。
4)无论什么样的员工,他们的股权都会在管理层更换或者新一轮融资中被稀释。
(二)
如果我进入的公司是”下一个Facebook”呢?
硅谷在过去的十年里发生了惊天动地的变化。这些变化,同时作用并且影响着IT员工们能从公司那里获取的利益。
如果你在1998年以前(包含1998年)加入了一家在将来很成功的创业公司,那你一定已经赚了很多钱。但是,如果你加入的是Facebook,你所能获取的利益价值可能就无法跟前者媲美了。那么,那些加入“下一个Facebook“的哥们儿,希望可能就更小了,以下是原因:
谷歌的早期员工在加入时,谷歌的估值还很低。
1)谷歌的估值,一路从4000万涨到了2000亿。
2)那些最早加入谷歌的清洁工,从谷歌获得价值1000美元的股权,在2008年也价值400万美元。
3)一个获得了5万美元股权的工程师,他的股权在2008年价值1亿美元。
4)谷歌的大厨也获得了价值2800万的股权。
有四点原因说明,谷歌的员工为何能够金融上收益如此好:
1)他们在公司处于很低估值的时候获得股票期权。
2)从A轮融资到现在,谷歌的估值涨了4000倍。
3)公司员工以人为的超低协议价格获得购买期权(大概只相当于每股股价的1/10还要低),因为当时IRS(美国国税局)的409(a)条款还不存在呢。
4)由于协议价格足够低,因此员工在行权时,缴纳的是资本利得税15%(Capital Gain Tax),而不是收入税50%(Income Tax treatment)。
当谷歌发行股票给他的员工时:
1)公司处于低估值阶段,而非后来的顶峰估值阶段。
2)那时,美国国税局还没有执行409(a)条款,409(a)条款明确规定了员工期权的估值。
在十年以前,创业公司都会以低于估值的协议价格发给员工期权,以吸引有识之士。员工因此有可能通过公司IPO而一夜致富,他们行权的协议价格大概之相当于估值价的1/10。
而到今天,这么做就是不合法的了。现在,公司的主管们,依据83(b)条款,依然有权通过限制性股票(restricted stock)获得低估股票(undervalued stock);但是,现在获得将理性期权(Incentive Stock Options)的员工,就必须遵循IRS的的409(a)条款。同时,现在的员工,在行权时更可能缴纳50%的收入税,而不是15%的资本利得税。
随着更高的早期估值,现在的员工已经不太有可能有现金能够行权,而且也不太有可能缴纳资本利得税,一般都缴纳收入税。409(a)条款通过明确规定,也防止了员工行权价像十年前那么低。现在,一个创业公司的员工,如果行使价值200万美元的ISO期权(国际标准期权),在缴纳了加州税或者德州税之后,仍然可能面临50%的收入税。
一般情况下:创始人和主管们获得的是依据83(b)条款的限制性股票(Restricted Stock),并且缴纳的是15%的资本利得税,员工则更可能时取得福利期权(Incentive Options), 税率相对更高。
因此,作为一名员工,即便有一天你的公司被卖了,你也可能要缴纳50%的收入税。
200万瞬间就只剩100万,而现在,旧金山的房价是300万。
(三)创业公司估值之于员工的影响
以前所有关于谷歌员工胜出的理由,现在都有可能不复存在了。
新的创业公司,如Facebook,获得很高的早期估值,因此,早期员工能获得的利益相比以前的创业公司,就少很多了。
更重要的是,现在只有越来越少的大型IPO,取而代之的是越来越多的小型M&A。
图片一: 1992年 — 2009年 风险投资也IPO和M&A交易的比例
大多数公司并没有谷歌和Facebook那样做得很好。即便在Facebook,也只有一小部分员工积累财富。
Zuckerberg在Facebook的股权大致相当于Facebook所有非主管的员工股权的总和(24%vs30%).。前50个Facebook的非主管员工所获得的股权,差不多相当于后面25000个员工的总和。
股权就是金字塔,越升一级,差俱就越大。
在一个以3000万被并购的公司退出案例里(见上),一个很成功的M&A退出。公司的CEO也差不多只能赚600万美元。
(四)创业领域与员工回报的关系
有很多创业公司扎根在大众互联网领域(Customer Internet Space), 但是这个领域的投资回报率也最低。就拿Facebook举例(最成功的消费者互联网公司之一),它从每一个月度活跃用户那里只能产生3美元/年的利益。
很少的大众互联网公司能够通过广告获得盈利,像Ad.ly, Digg, Myspace, Twitter,还有很多其他的公司都很难达到大规模盈利,即便是用户量非常庞大。
一个大众互联网公司,如果每个月的活跃用户数有50万,依照Facebook的盈利推算,一年的盈利也只有150万美元。因此,不要把大众互联网当做救命稻草。
现如今,B2B/SaaS模式,以及生物技术市场,仍然能够在市场上攫取上亿的资金,但是,很少有人能有能力和经验在这个市场里把公司做起来。但是,在这领域,却有比大众互联网市场更多的盈利机会。
最有盈利空间的市场,最难发现创业公司。特别是,金融领域每年攫取的利润占全美公司利益的70%,但是,在硅谷却很难发现金融创业公司,即便有,也基本是大众金融服务。
Protip: 从数据和理论上看,如果你是A轮以后加入大众互联网公司的员工一枚,你的股权几乎就不值钱了。
Hadoop最近很火,到处都能看到,查了一下资料大概先了解一下其运行原理。
google在05年公开了Map/Reduce论文,MapReduce在处理巨量数据方面有明显优势。
google公司一个技术大牛jefffery Dean提出的这个算法,随后很多小牛纷纷实现了Mapreduce,Hadoop是它的java实现,MapReduce概念直接推动了云计算概念的火爆。
没有优秀算法云是没法搞的。
这篇文章对Map/Reduce原理讲的很清楚。
http://www.chinacloud.cn/download/Tech/MapReduceOverview.pdf
这个是Apache关系Hadoop的文档,安装、开发示例都有。
http://hadoop.apache.org/common/docs/r0.19.2/cn/mapred_tutorial.html
因为一直在做企业信息化方面的开发,有必要了解一下相关的理论。
同事推荐的几本书。
霍顿(F.W.Horton)的信息资源管理(IRM)理论
威廉。德雷尔的数据管理(DA)理论
詹姆斯马丁的信息工程方法论(IEM)
看了之后有些吃惊,很多概念和理论都是上世纪80年代,还有60年代就提出的概念,做了这么久的开发居然没听说过,在规划方面没有一定的理论指导,都是些野路子方法。
还有许多平时用到的概念和方法找到了渊源,原来是这哥们或那哥们提出,老外的版权意识就是强对几十年前提出的理论都会整理出哪个观点是哪个人提出的。
不然很多方法一直觉得理所当然是那么用的,看过这些资料才知道理论提出的背景,除了这种理论解决哪些问题还有哪些方法,各有什么优缺点。
信息工程理论总结起来,就是以数据规划为基础,自定向下规划。并提供了一系列的技术用于自下向上的设计方法。对企业信息化中比较重要的业务流程有很大的篇幅。
目前的收获是,1.在系统规划方面有了完整的理论指导;2.了解了规划、分析、设计阶段会有哪些技术,哪些已掌握的技术需要加强、哪些技术需要学习。
老外的书翻译过来的在中文版看着费劲,找了本国内编译出版的,写得不错。
信息工程与总体规划概述。
本书讨论计算机信息系统总体规划的方法论,重点是总体数据规划。
第一章是本文的综述,目的是使读者尽快了解信息工程概念和总体数据规划方法的大意,因此是全书的提纲。
第二章到第四章是信息工程产生的背景和方法论的分析。这三章按三个主题展开:数据处理危机与转折;信息工程的原理、方法与工具;信息工程与结构化方法。
第五章到第十章比较全面深入地介绍总体数据规划的一整套方法,是本书的主体。编者根据近几年参与中大型企业计算机信息系统总体规划设计工作的实践,深感探讨先进科学的方法论的极端重要性,特别是总体数据规划的内容、方法,以及与后续开发工作的衔接等问题,更是迫切需要解决的。为此,我们较全面地翻译介绍了詹姆斯·马丁所倡导的一整套方法,供有兴趣的读者参考,从而尽快形成适合我国国情的总体规划方法论。
第一章
从需求分析开始的传统生命周期开发方法论
数据结构和数据是相对稳定的,而数据的处理过程则是经常变化的。总体数据规划方法。
软件工程仅仅是关于计算机软件的规范说明、设计和编制程序的学科,实际上信息工程的一个组成部分。
信息工程的基本原理和前提是:
1.数据位于数据处理的中心。
2.数据是稳定的,处理是多变的。数据类型是不变的。
只有建立的稳定的数据结构,才能是行政管理或者业务管理上的变化为计算机信息系统所适应,这正是面向数据系统所具有的灵活性,面向过程系统往往不能适应管理上的变化需求。
3.用户必须真正参与开发工作。Design with,not design for.
第二章
信息工程的组成部分
自定向下规划和自下向上设计方法论
重点分为三个部分:
企业模型、实体关系分析和数据模型的建立(即主题数据库的规划),以及数据分布规划。
总体数据规划简介
四类数据库环境
1.数据文件;
2.应用数据库
3.主题数据库
4.信息检索系统
规划方法
1.进行业务分析建立企业模型
2.进行实体分析建立主题数据库模型
3.进行数据分布分析
第三章
信息工程概貌
1.关于全面开放的规划
2.关于业务分析
3.关于数据分析,数据可以表达成与使用无关
4.关于自动化工具
信息工程的基本组成
1.企业模型,企业模型的开发是在战略数据规划期间进行的。
2.借助实体关系分析,建立信息资源规划。这是自顶向下的数据类型分析,这些数据是必须被保存起来的,还要分析他们之间是如何联系的。
3.数据模型的建立,产生详细的数据库逻辑设计
导致信息工程产生的一个重要认识,是组织中存在的数据可以描述成与这些数据如何使用无关的形式,而且数据需要建立起一定的结构。这一点较面向对象的思想很接近,可以把数据模型任务是数据对象。
信息工程的建设基础
战略的数据规划工作
信息工程方法论
1.关于企业信息化战略规划的方法
2.关于信息系统设计实现的方法
3.关于自动化开发工具
第四章结构化方法与信息工程
信息工程是在进行战略需求规划,信息需求规划,总体数据规划和数据分布规划的基础上,使用结构化设计和结构化编程的方法。
结构化系统分析
数据流图
结构化系统设计
信息工程是面向数据的方法,结构化方法是面向过程的方法。前者可以使用未来,后者只能使用过去和现在。
战略需求规划
战略需求规划是信息工程的基础工作,不仅要对现有需求规划,还要对未来需求规划。
1.加强用户之间的沟通合作。
2.加强高层领导者之间的沟通并为之提供支持。
3.提高资源需求预测和分配的准确性。
4.提供内部mis的可行点。
5.提出新颖而高质量的应用系统。
信息需求规划
信息需求:
1.事务处理工作的管理信息需求;
2.高层领导者的管理信息需求;
3.企业发展和改革发展方面的信息需求;
传统的软件工程和数据库技术尽管有分析设计方法,但缺乏自顶向下的规划,不能适应大型复杂系统的建设。信息工程强调总体规划,形成了一套自顶向下规划与自下向上设计的完成的方法学,为大型复杂系统的建设提供了保障。
第五章总体数据规划的组织
战略规划
1.战略业务规划
2.战略信息技术规划
3.战略数据规划
战略数据规划,即总体数据规划是信息工程规划工作的核心和基础,需要研究它的组织方法。
战略规划的目的是使信息系统的各部分能共同工作。
对战略规划的详细程度要有恰当的理解。
第六章 企业模型
..........................
今天看了五章的内容,休息一下。
忙完手头工作继续学习,2012-2-28
总体数据规划的第一步是进行业务分析,建立企业模型。(编者按:目前电信行业都已经建立起了完善的企业模型,其他行业还没看到)
企业模型是对企业结构和业务活动 本质的、概况的认识。
用职能区域--业务过程--业务活动 这样的层次结构来描述。
1.研制一个表示企业各职能区域的模型;
2.扩展上述模型,使它能表现企业的各项业务过程;
3.继续扩展上述模型,使它能够表现企业的各项业务活动。
依靠企业高层,分析企业的现行业务和长远目标,按照企业内部的各种业务的逻辑关系,将他们划分为不同的只能区域,弄清各职能区域包括的全部业务过程,再将各个业务过程细分为一些业务活动。
建立分析企业模型的过程,是对现行业务系统再认识的过程。
职能区域
职能范围、业务范围,是指一些主要的业务活动区域,如销售、市场、财务、认识、生产。
职能模型,职能区域图表
业务过程
企业模型的二级结构是业务过程的识别、命名、定义。这项工作主要由分析人员来完成。
1.业务过程与组织结构
2.识别业务过程的参考模式
产品、服务和资源四阶段生命周期
计划,获得,保管,处置(编者按:原书有一张图表,这里就不列出来了),模式的每一阶段都有一些业务过程的类型。
3.业务过程与负责人
4.经验
业务活动
每个业务过程中都存在一定数量的业务活动
业务活动分析
1.功能分解的程度
2.凝聚性活动,1.产生清晰可识别的结果,2.有清楚的边界,3.是一个执行单元,4.自封闭的,独立于其他活动。
3.冗余活动和功能组合,
企业模型的建立过程
可以理解为逻辑模型
企业模型的特点
完整性、适用性、永久性
关键成功因素
3~6个决定成功与否的因素
1.关键成功因素的确定
关键成功因素应该成为最高层管理人员管理控制企业系统的基础,对一个行业来讲关键成功因素差不多是相同的。
如食品公司:广告效果,货物分发,产品革新
2.关键成功因素的审查
第七章主题数据库
独立于应用的数据
数据库环境的原则
1.企业的数据应该得到直接管理,与使用的职能分开;
2.数据描述不应由使用数据的应用包含,而应当由独立的数据管理员设计;
3.数据应该独立于现有机器资源;
4.使用统一的工具和设施管理资源;
5.有适当的安全和保密控制;
6.高层管理人员要参与数据库的总体规划和决策。
面向过程的系统分析方法
面向数据的系统分析方法
主题数据库与组织内各类人、事、物相关,而不是与传统的应用相关。
总的来说这部分没什么干货,就是对前面方法论的细化和再次说明。
这本书侧重于方法论和理论概念。在规划部分有具体的指导,在具体分析和设计技术上着墨不多。
第八章实体活动分析
第九章数据分布规划
第十章规划与开发建议
这两天比较忙,后边章先顾不上看了。
第八章和第九章应该跟软件工程里的内容是一致的,原来项目开发时经常要用到。第十章讨论BSP方法,要了解一下。
因为项目需要做了一个简单的工作流引擎,用于集成订单管理(IOM)的生产调度。之前的文章有提到。原想着有这样一个引擎来进行生产调度,设计好业务流程后就可以面朝大海,春暖花开。在还生产系统对接的时候发现有一部分还是人工处理更好,毕竟不是所有的流程都能那么细致合理。
下面是我们的解决方案,图片是从wps里另存出来的,不知道咋就变成黑底了。
1.1 问题描述
工作流引擎处理流程调度部分的内容。客户下订单之后,协调各生产部门进行工作。
最理想化的情况是对客户发起的每一种操作都定义一组流程,在流程执行的过程中每种状下态当有新的操作进来也相应定义一组流程,但这样一来流程设计工作极其繁琐,容易出错,不利于降低管理难度减轻管理工作量。
一个折中的方案是对执行中的流程进行流程合并。选择对一部分操作不创建新流程,给用户提示信息,由用户觉得如何进行手工操作。
1.2 问题分析
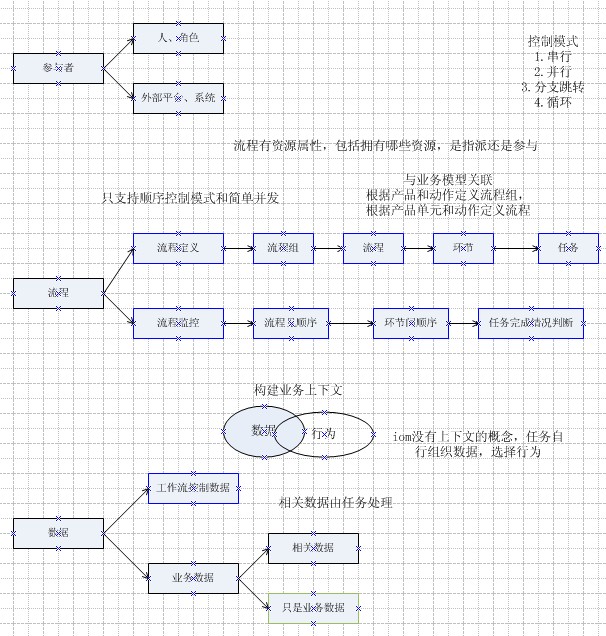
1.2.1 概念定义
生产平台:生产平台是由人和机器构成的,能将一定输入转化为特定输出的有机整体。对应于工厂中的生产车间概念。
生产线:生产是与相关的一个部门或一组操作对应的组织。类似于项目组的概念,是依据生产流程对生产能力的一种划分方式。
产品:产品是指中企动力运用营销手段,将业务或业务组合附加上销售对象、销售地域、资费计划、销售渠道、服务水平及配套资源属性后的产物,是向客户最终交付的、客户可以购买的产品单元组合实例。
产品单元:产品单元是业务在生产系统的具体表现。
产品单元与生产线之间是多对多的关系。如果一个产品单元需要跨多个生产线,引擎需要调度产品单元在不同生产线的生产过程。
流程组:流程组指由一系列操作流程组成的流程集合,有流程间的先后顺序。流程组在此是由产品和操作类型共同决定的。
流程:流程是一系列操作环节的集合。环节间有并行和串行的关系。流程在此处是由平台和操作类型决定的。
环节:环节是一系列操作的集合。环节此处定义是由一个人的一个或多个可并行的操作决定的。
任务:任务是可执行的最小单位。任务具有原子性,是环节的组成部分。一般一个任务完成一个事务。
一个环节包含多个任务,一个流程包含多个环节,一个流程组包含多个流程。
1.2.2 问题描述
以一件定制服装的过程为例,只是为了说明问题对流程做了简化。见下图。
定制服装生产流程:

最简化的情况,客户在提交了定制服装生产的要求后便不再干预,生产线就按流程走就可以了。
但是客户可能会在生产的各个环节提出变更要求,已经制作完成了客户要求加个兜,已经质检完成了客户要求加个纽扣,已经包装好了客户要求领子样式改改。
如果把每一种可能都定义一组流程,就这个简化流程全部列出来也够贴一面墙了。所以我们采取了一种折中的方案,在大多数情况下正在生产时客户要求有变化,通过一个描述性的工单告诉生产线负责人暂停生产、并由负责人来决定回退到那个环节重新进行。
如果都包装好了客户还要改,那就暂停当前流程,走和客户打官司的流程了,这种情况下需要一个流程。
本方案通过对生产中的流程进行合并,减少流程定义的工作量和复杂程性度。
1.3 问题解决
1.3.1 工单
1.3.1.1 逻辑模型
订单生成工单的过程,称为合单。
|
订单工单关系 |
工单属性 |
|

|

|
现在所描述的都是对同一个订购实例所下各种订单的合单处理情况。
1.订购实例第一次下订单,根据订单生成工单和工单明细。
2.订购实例第二次下订单
a) 之前生成的工单已经竣工,生成新工单和新工单明细。
b) 之前生成的工单还未生产,废弃该工单,生成新工单和新工单明细
c) 之前生成的工单生产中,废弃该工单,继续沿用原工单编号,合并生成新工单和新工单明细。新工单状态为生产中。
在工单明细表增加字段“产品单元变更标识”,如果产品单元对应的属性内容在两次订单中没有变化,引擎不暂定产品单元触发的流程。
1.3.2 流程实例化
1.3.2.1 逻辑模型
流程定义模型见下图,概念定义部分对名词有描述。
|
流程定义 |
流程实例化 |
|

|

|
在业务支撑系统经常使用的一个概念,实例化。
用户购买一个产品后,就产生一个产品的实例化,区别于别的客户购买的同类产品,称为订购实例。
定义一组流程用来处理产品生产过程,具体到某个订购实例的生产过程的实例化,就有了流程组实例、流程实例、环节实例和任务实例。
1.3.2.2 流程定义过程
有了流程定义的模型,我们就是可以设计或者叫定义产品的生产流程。
完成一件复杂的工作,总是需要一个步骤一个步骤的完成,每个步骤称为一个环节,在这个环节下可能需要做几个事情,每个要做的事情称为一个任务。
1.根据生产部门划分生产线
2.根据生产线+操作,定义流程,把流程中的任务根据负责人划分为不同的环节。
3.按照产品涉及的流程划分为不同的流程组。
1.3.2.3 流程实例化
1.实例化约束
a) 一个订购实例当前只有一个运行中的流程组实例;
b) 流程合并前先暂停,避免和引擎并发竞争。
2.实例化过程
a) 接收工单,检查订购实例当前是否有流程组实例在运行中;
i. 无,实例化一个新的流程组实例
ii. 检查是否属于同一个流程组定义
1. 是同一个流程组,进行流程合并。
2. 不是同一个流程组,暂不实例化,待下一次轮询再处理。
流程合并细节见《流程合并详细设计》
1.3.3 流程引擎
1.3.3.1 模型状态
1.已实例化
2.已分配(负责人)
3.执行中
4.暂停
5.已完成

流程启动后按顺序执行,当要回到上一步骤时,监控页面支持回退和回滚两种操作。
回退,当前执行中/暂停的环节设置为已分配,上一环节由已完成设置为执行中。
回滚,对任务可以执行其反任务。
1.3.3.2 功能描述
1.引擎轮询程序,检查处于执行中状态的环节,如果环节下所有关键任务都已完成则环节进入已完成状态,下一环节进入执行中状态。
2.环节实例化后处于已实例化状态,用户在任务分配页面指定环节负责人,环节处于已分配状态,上一环节完成后由引擎设置本环节进入执行中状态。
3.鉴于引擎对执行中的环节进行调度工作,实例化程序和页面监控程序在对执行中的环节操作时,需先暂停环节。
4.监控页面支持对流程、环节的回退,支持对任务的回滚。
之前做了一个简单的工作流引擎,干完了活做点理论总结。
项目见
工作流应用---理论基础篇、
工作流应用---概念、模型这个工作流引擎主要是根据项目需求和网上看到的一些文章提到的概念做出来的,估计比较野路子,想着把概念和名词向大师靠拢。
过了年刚来不忙,这几天抽空看了两本工作流方面的书,《工作流管理技术基础》和《工作流管理:模型、方法和系统》,讲的比较细致、对基础概念讲的很清楚,就是书老了点。
书中对XPDL标准做了详细描述,对新出的BPEL没有涉及。
我自己项目中用到的概念和大师们基本一致,大方向不错,看来网上找到的那几篇文章挺靠谱的,当时应该随手整理出来。
工作流引擎做的比较简单,没有使用主流的petri技术,只支持项目需求更负责的需求就够呛了,回头有空再改一版。看了书才发现有这么多种模型实现方法早都有人研究很多年了。
这两本书在超星网站都能找到电子版。
IPO模型,过程中的每一个活动都由输入(I)、处理(P)、输出(O)三部分组成。
理论来自《科学管理》提出的科学管理原则:
一个组织的工作可以描述为一系列的任务,每个任务都是工人们具体、严谨的活动过程,管理就是在一定的计划下让这些任务以最优的方式进行。
常用的工作流模型:
1.基于活动网络的过程模型
组成模型的元素包括过程、活动、模块、控制连接弧、数据连接弧和条件。
以活动作为构成过程的基本单元,以连接弧体现过程逻辑,可以灵活的实现企业经营过程的建模,我做的那个基本上采用的就是这种模型。
过程:为完成目标而定义的一系列步骤;
活动:过程中的步骤;
模块:跟过程的概念类似;区别在于是否可以多次重复使用
控制链接弧:定义两个活动间的执行顺序
数据连接弧:定义两个活动间的信息流
条件:定义过程执行中的约束
定义在控制连接弧上的条件:转移条件
活动可以执行和活动被执行:开始条件、结束条件。
优点:
从系统分析的角度来看,有利于通过过程模型提取功能视图和信息视图、便于深入分析
从系统实现的角度来看,控制流管理和数据流管理分离,是不同性质的流管理独立。
2.事件驱动的过程链模型
兼顾模型描述能力强和模型易读两个方面。
业务事件、业务功能、控制流、逻辑操作符、信息对象、组织单元
3.基于语言行为理论的工作流模型
IPO模型对于观察信息和物流的流动过程比较合适,但不利于不同角色间的委托和承担行为。
语言行为理论则侧重与解决,数据、物、人协作中IPO模型对人直接协作描述不足的情况。
听上去不错,实际中没有看到用这种模型的,google了一下相关资料,还只是一个理论在软件领域用来进行协作过程建模的很少。
简单了解一下先,等大师们研究明白了咱再学习。
4.基于petri网的工作流模型
这个东西看着挺复杂的,不过好多人都说是好东西,研究一下先。
找了两本有关petri的书,都太理论化看不懂。还是《工作流管理:模型、方法和系统》讲得比较通俗。
petri基本概念很好理解,不同于过程化分析,更接近面向对象的思想。看起来我在这个项目中采用的分析方法更接近与petri,原来俺们朴素的想法跟大师很接近哦。
一般的面向对象分析更侧重与静态结构,在动态模型部分描述的都不够清楚。petri在动态过程方面感觉很细致有效。据说还是经过严格熟悉验证的分析方法,不过那些公式没看懂,太费劲。分析时用petri分析建模方法就可以了。
.....
上一篇讲了工作流的主要概念和用途。
知道了要依靠工作流引擎来推动流程向前。
这一篇讲一个具体实现的例子,比较简单,对于复杂的流程关系定义处理不了,上下文参数构建也不支持,这些依赖具体的业务领域模型处理了。
好在工作流基本的概念是有了,对于复杂的应用可以借鉴成熟的产品,知道工作流是怎么回事了其他产品也就容易上手了。
工作流概念这一块,目前也没个统一规范,就自己搞了一套,没采用那些推荐标准太复杂用不上。
要开发一个工作流引擎出来,跟其他开发没有不同,概念、需求、建模。
一、搞清楚都要用到哪些概念
二、能够提供哪些功能、准备用例
三、建模
1.静态模型
依据关键流程的用例推导概念、明确概念定义、支持概念所要用到的数据结构
2.动态模型
定义各功能模块操作,并检查是否覆盖所有关键用例。
实际例子,懒得敲那么多字了,直接上图
1.用例,用来确定系统边界
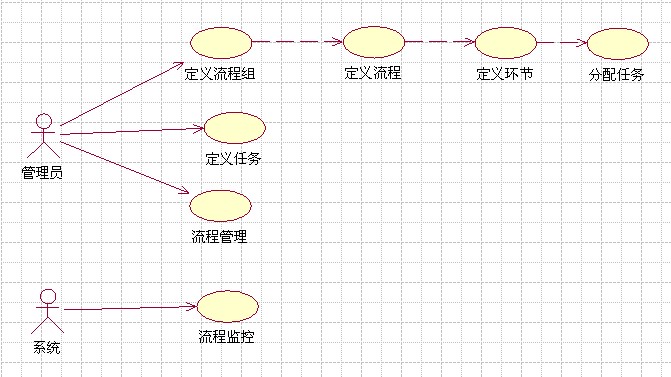
2.主要概念,及概念见关系
3.流程生命周期定义
说明一下,分配状态和运行状态是两个维度的东西,为了省事就定义在一起了。

4.系统架构
描述引擎的内部构成、引擎与外围系统的关系。
这段时间因为项目需要做了一小的工作流引擎,总结一下经验。
大概会分为这么几个阶段来介绍。
1.理论基础
2.实现技术
3.实际开发的一个例子。
如图:
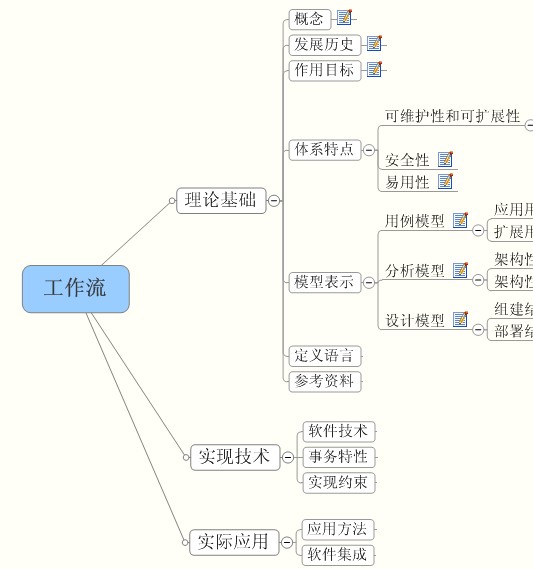 一、理论基础
一、理论基础
只是简单的讨论原理,详细数学理论不再这里讨论,会在附录里列出来,有兴趣的同学自行查看。
1.概念
为了实现业务过程自动化提出的概念。
以前去政府部门办过事大家都有体会,那个迷茫啊困惑啊,很多连个办事指南都没有。
办一件小事要盖十几个章,材料交上去后你根本不知道现在到了哪个部门,审核通过了没人通知你,没通过的话少什么资料也不告诉你,告诉你也不是一次都说,跑一趟说一点。通过了这个部门审核下一步应该去哪也没人告诉你。
这个时候有个对机关门清的人,知道哪里水深水浅,领着你办下来该有多好,该请客请客该送礼送礼,少跑很多冤枉路,还能随时查询状态。
这就是工作流引擎要做的事情。
2.发展历史
工作流技术起源于二十世纪七十年代中期办公自动化领域的研究,由于当时计算机尚未普及,网络技术水平还很低以及理论基础匮乏,这项新技术并未取得成功。
老外也是被扯皮扯怕了试图改进。
3.作用目标
工作流将作为一个公共基础子系统服务于整个平台产品的人力工作流和业务工作流环节。
通过将工作活动分解成定义良好的任务、角色、规则和过程来进行执行和监控,达到提高生产组织水平和工作效率的目的。
人多了事情多了,扯皮的情况也就多了。为了避免扯皮建立一个协调中心,提供办事指南,负责进度管理,公共信息维护。
处理这种有复杂流程的事情目前有两种解决思路:
1.针对业务领域开发一个系统,一个模块处理完成一件事件后根据情况来决定下一步跳到哪个模块,带点什么参数。适应于流程比较固定的业务,像财务系统虽然很复杂,但是各种处理规则都清清楚楚明明白白,也不会随便变动。
2.工作流方式,讲流程跳转规则由工作流引擎统一维护,每个具体执行任务的模块只管干自己的活,干完了告诉一声引擎,由引擎通知下一个模块。目前只能处理相对简单的一些工作流程,OA公文流转,IOM生产系统调度这类规则不是很复杂,流程上下文较简单的情况。
对于特别复杂的流程,开发量反而比定制业务系统还要多。工作流理论需要再有一次提升才能解决这个问题。
4.体系特点
可维护性和可扩展性
与业务系统实际关联低偶合
可以扩充表达式引擎,与界面绑定由界面引擎决定
可以适应与审核等人力流程,也可以适用在无人干预的商业自动化流程
安全性
易用性
5.模型表示
用例模型
应用用例
扩展用例
分析模型
架构性重要分析元素
架构性重要用例实现
设计模型
组件结构
部署结构
6.定义语言
7.参考资料