突然要做一个相关的编译优化项目,先放一点国外网的IPA的资料上来,教育网出国不方便
GCC wiki:
Analysis and optimizations that work on more than one procedure at a time. This is usually done by making walking the Strongly Connected Components of the call graph, and performing some analysis and optimization across some set of procedures (be it the whole program, or just a subset) at once.
GCC has had a callgraph for a few versions now (since GCC 3.4 in the FSF releases), but the procedures didn't have control flow graphs (CFGs) built. The tree-profiling-branch in GCC CVS now has a CFG for every procedure built and accessible from the callgraph, as well as a basic IPA pass manager. It also contains in-progress interprocedural optimizations and analyses: interprocedural constant propagation (with cloning for specialization) and interprocedural type escape analysis.
IBM的XL Fortran V10.1 for Linux:
Benefits of interprocedural analysis (IPA)
Interprocedural Analysis (IPA) can analyze and optimize your application as a whole, rather than on a file-by-file basis. Run during the link step of an application build, the entire application, including linked libraries, is available for interprocedural analysis. This whole program analysis opens your application to a powerful set of transformations available only when more than one file or compilation unit is accessible. IPA optimizations are also effective on mixed language applications.
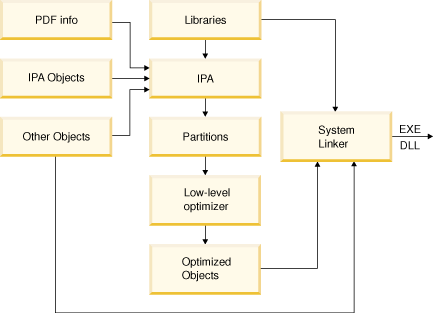
Figure 2. IPA at the link step
The following are some of the link-time transformations that IPA can use to restructure and optimize your application:
- Inlining between compilation units
- Complex data flow analyses across subprogram calls to eliminate parameters or propagate constants directly into called subprograms.
- Improving parameter usage analysis, or replacing external subprogram calls to system libraries with more efficient inline code.
- Restructuring data structures to maximize access locality.
In order to maximize IPA link-time optimization, you must use IPA at both the compile and link step. Objects you do not compile with IPA can only provide minimal information to the optimizer, and receive minimal benefit. However when IPA is active on the compile step, the resulting object file contains program information that IPA can read during the link step. The program information is invisible to the system linker, and you can still use the object file and link without invoking IPA. The IPA optimizations use hidden information to reconstruct the original compilation and can completely analyze the subprograms the object contains in the context of their actual usage in your application.
During the link step, IPA restructures your application, partitioning it into distinct logical code units. After IPA optimizations are complete, IPA applies the same low-level compilation-unit transformations as the -O2 and -O3 base optimizations levels. Following those transformations, the compiler creates one or more object files and linking occurs with the necessary libraries through the system linker.
It is important that you specify a set of compilation options as consistent as possible when compiling and linking your application. This includes all compiler options, not just -qipa suboptions. When possible, specify identical options on all compilations and repeat the same options on the IPA link step. Incompatible or conflicting options that you specify to create object files, or link-time options in conflict with compile-time options can reduce the effectiveness of IPA optimizations.
Using IPA on the compile step only
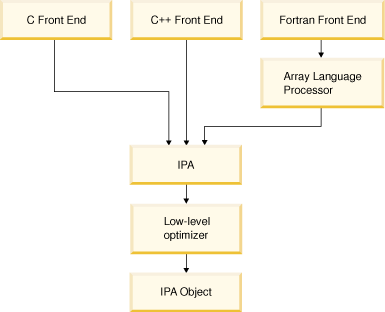
IPA can still perform transformations if you do not specify IPA on the link step. Using IPA on the compile step initiates optimizations that can improve performance for an individual object file even if you do not link the object file using IPA. The primary focus of IPA is link-step optimization, but using IPA only on the compile-step can still be beneficial to your application without incurring the costs of link-time IPA.
Figure 3. IPA at the compile step
IPA Levels and other IPA suboptions
You can control many IPA optimization functions using the -qipa option and suboptions. The most important part of the IPA optimization process is the level at which IPA optimization occurs. Default compilation does not invoke IPA. If you specify -qipa without a level, or specify -O4, IPA optimizations are at level one. If you specify -O5, IPA optimizations are at level two.
Table 5. The levels of IPA
|
IPA Level
|
Behaviors
|
|
qipa=level=0 |
- Automatically recognizes standard library functions
- Localizes statically bound variables and procedures
- Organizes and partitions your code according to call affinity, expanding the scope of the -O2 and -O3 low-level compilation unit optimizer
- Lowers compilation time in comparison to higher levels, though limits analysis
|
|
qipa=level=1 |
- Level 0 optimizations
- Performs procedure inlining across compilation units
- Organizes and partitions static data according to reference affinity
|
|
qipa=level=2 |
- Level 0 and level 1 optimizations
- Performs whole program alias analysis which removes ambiguity between pointer references and calls, while refining call side effect information
- Propagates interprocedural constants
- Eliminates dead code
- Performs pointer analysis
- Performs procedure cloning
- Optimizes intraprocedural operations, using specifically:
- Value numbering
- Code propagation and simplification
- Code motion, into conditions and out of loops
- Redundancy elimination techniques
|
IPA includes many suboptions that can help you guide IPA to perform optimizations important to the particular characteristics of your application. Among the most relevant to providing information on your application are:
-
lowfreq which allows you to specify a list of procedures that are likely to be called infrequently during the course of a typical program run. Performance can increase because optimization transformations will not focus on these procedures.
-
partition which allows you to specify the size of the regions within the program to analyze. Larger partitions contain more procedures, which result in better interprocedural analysis but require more storage to optimize.
-
threads which allows you to specify the number of parallel threads available to IPA optimizations. This can provide an increase in compilation-time performance on multi-processor systems.
-
clonearch which allows you to instruct the compiler to generate duplicate subprograms with each tuned to a particular architecture.
Using IPA across the XL compiler family
The XL compiler family shares optimization technology. Object files you create using IPA on the compile step with the XL C, C++, and Fortran compilers can undergo IPA analysis during the link step. Where program analysis shows that objects were built with compatible options, such as -qnostrict, IPA can perform transformations such as inlining C functions into Fortran code, or propagating C++ constant data into C function calls.