Oracle的内存结构
Oracle
的内存可以分为:
系统全局区
(SGA)
、程序全局区
(PGA)
、用户全局区
(UGA)
其主要用来储存:
1
、程序代码
2
、活动和非活动的
session
信息
3
、程序执行过程中的信息
(
例如
Cursor)
4
、与
Oracle
进程共享和通信的信息
(
例如锁
)
5
、被缓存到内存的信息
一、系统全局区(
SGA
)
SGA
是一组为系统分配的共享内存结构,可以包含多个数据库实例的数据或控制信息。当实例启动时,
SGA
即被自动分配,实例关闭时被自动回收。
SGA
按其作用的不同,可以分为:数据缓冲区、日志缓冲区、共享池、大池、
Java
池、流池等。
查看
SGA
的大小可以使用
:
SQL> select * from v$sga;
NAME VALUE
-------------------- ----------
Fixed Size 453492
Variable Size 109051904
Database Buffers 25165824
Redo Buffers 667648
1
、数据缓冲区(
Database Buffer Cache
)
用户第一次执行查询或修改数据操作时,服务器进程将数据从数据文件中读取出来,并装入到数据缓冲区中,这样操作即在内存中完成,用户下一次访问相同数据时,
Oracle
可以直接将数据缓冲区中的数据返回给用户,大大提高相应速度。
数据缓冲区由许多相同大小的缓存块组成,其大小与数据块相同,从其是否被利用角度可分为三类:
(1)
脏缓存块:保存了已经被修改过的数据,这些数据需等待
DBWR
要重新被写入数据文件中;
(2)
空闲缓存块:不包含任何数据,等待被写入;
(3)
命中缓存块:用户正在访问的缓存块,这些缓存块将被保留在数据缓冲区中。
Oracle
通过最近最少使用列表
(LRU)
和写入列表
(DIRTY)
来管理数据缓冲区中的缓存块。
(1) LRU
:包含所有三类缓存块,使用
LRU
算法将缓冲区中最近一段时间内访问次数最少的缓存块移除缓冲区。
(2) DIRTY
:包含了已经被修改并需要写入数据文件的缓存块
数据缓冲区的工作机制:
(1)
用户提交访问申请,
Oracle
在数据缓冲区中查找,若该数据块位于数据缓冲区中,则直接返回给用户,称之为
“
缓存命中
”
(2)
若数据缓冲区中查找不到所需数据块,则先从数据文件提取到缓存中,再从缓存读取并返回给用户,称之为
“
缓存失败
”
(3)
当
“
缓存失败
”
时,先找到空闲缓存块,若没有空闲块,则将
LRU
列表中的脏缓存块移入
DIRTY
列表
(4)
当
DIRTY
列表到达一定长度时,由
DBWR
将脏数据块的数据写入到磁盘文件,重新刷新数据缓冲区
8i
以前的版本
,
数据缓存的大小由
DB_BLOCK_BUFFER(
数据缓存区缓存块数量
)
和
DB_BLOCK_SIZE(
数据块大小
)
两者的乘积决定
,
而在
9i
以后
,
直接使用
DB_CACHE_SIZE
指定。
2
、日志缓冲区(
Redo Log Buffer
)
日志缓冲区用于存储数据库的修改信息。当日志缓冲区的日志信息达到一定数量时,由
LGWR
进程将日志写入到日志文件组。
日志缓冲区是一个直接从顶端向底端写入数据的循环缓冲区,当写到最底端时,再返回到缓冲区的起始点循环写入。
日志缓冲区大小由
LOG_BUFFER
参数指定,并可以在运行的过程中中进行动态修改。日志缓冲区对数据库性能的影响较小,当然设置较大的日志缓冲区可以减少日志文件的
I/O
次数,提高数据库性能。
3
、共享池
(Shared Pool)
共享池分为:库缓冲区、数据字典缓冲区、用户全局区
三部分。共享池大小由
SHARED_POOL_SIZE
参数设定。
(1)
库缓冲区:缓存
SQL
语句的分析码、执行计划
(2)
数据字典缓冲区:包含从数据字典中得到的表、列定义和权限
(3)
用户全局区:包含了用户的
session
信息
当一条
SQL
语句提交时,
Oracle
首先从共享池的缓冲区内搜索,查看是否有相同
SQL
被解析并执行,若存在则不必再次解析。
4
、大池
(Large Pool)
大池是数据库管理员能够配置的可选内存空间,可用于不同类型的内存存储。
Oracle
的某些操作可能需要内存中使用大量的缓存,例如:
1
、数据库的备份或恢复操作
2
、执行具有大量排序操作的
SQL
语句
3
、执行并行化的数据库操作
若没有创建大池,这些操作需要的缓存空间都将在共享池或
PGA
中分配,大量的占用会影响到共享池和
PGA
的使用效率。大池的大小通过
LARGE_POOL_SIZE
设定。
注:在共享服务器操作模式下,服务器进程会将
session
信息存储在大池中,而非共享池。
session
结束后大池即释放内存。
5
、
Java
池(
Java Pool
)
Oracle
提供了对
Java
语言的支持,所以提供
Java
池。
Java
池主要用于对
Java
语言提供语法分析区。
Java
池的大小由参数
JAVA_POOL_SIZE
设定。
6
、流池
(Stream Pool)
这是
Oracle Stream
专用的内存池
,Oracle Stream
是数据库中的一个数据共享工具。
该值有
STREAMS_POOL_SIZE
指定大小。若未配置该内存区
,
则当使用到
Stream
功能时
,Oracle
会分配共享池中至多
10%
的空间作为
Stream
内存。
二、程序全局区(
PGA
)
PGA
是包含单独用户或服务器数据和控制文件的内存区域。
PGA
由用户连接到数据库时创建,进行自动分配,且是非共享的,只有服务进程本身才能访问它自己的
PGA
区。
每一个服务进程都有自己的
PGA
区,
PGA
的内容与结构和数据库的操作模式
(
专用
/
共享服务器
)
有关。
PGA
按照oracle官方文档解释,叫做程序全局区(Program Global Area),但也有些资料上说还可以理解为进程全局区(Process Global Area)。这两者没有本质的区别,它首先是一个内存区域,其次,该区域中包含了与某个特定服务器进程相关的数据和控制信息。每个进程都具有自己私有的PGA区,这也就意味着,这块区域只能被其所属的进程进入,而不能被其他进程访问,所以在PGA中不需要latch这样的内存结构来保护其中的信息。笼统的来说,PGA里包含了当前进程所使用的有关操作系统资源的信息(比如打开的文件句柄等)以及一些与当前进程相关的一些私有的状态信息。
每个PGA区都包含两部分:
(1)
固定PGA部分(Fixed PGA):这部分包含一些小的固定尺寸的变量,以及指向变化PGA部分的指针。
(2)
变化PGA部分(Variable PGA):这部分是按照堆(Heap)来进行组织的,所以这部分也叫做PGA堆。可以从X$KSMPP视图中看到有关PGA堆的分布信息。PGA堆中所包含的内存结构包括:
有关一些固定表的永久性内存。
如果session使用的是专用连接方式(dedicated server),则还含有用户全局区(UGA-User Global Area)子堆。如果session使用的是共享连接方式(shared server),则UGA位于SGA中。
调用全局区(CGA-Call Global Area)子堆。
三、用户全局区(
Sort Area
)
UGA是包含与某个特定session相关信息的内存区域,比如session的登录信息以及session私有的SQL区域等。
每个UGA也包含两个部分:
(1) 固定UGA部分(Fixed UGA):这部分包含一些小的固定尺寸的变量,以及指向变化UGA部分的指针。
(2) 变化UGA部分(Variable UGA):这部分也是按照堆来进行组织的,可以从X$KSMUP视图中看到有关UGA堆的分布情况。
UGA堆的分布与OPEN_CURSORS、OPEN_LINKS等参数有关系。所谓的游标(cursor)就是放在这里的。
UGA堆中所包含的内存结构包括:
(1) 私有SQL区域(Private SQL Area):这部分区域包含绑定变量信息以及运行时的内存结构等数据。每一个发出SQL语句的session都有自己的私有SQL区域。
这部分区域又可分成两部分:
(i) 永久内存区域:这里存放了相同SQL语句多次执行时都需要的一些游标信息,比如绑定变量信息、数据类型转换信息等。这部分内存只有在游标被关闭时才会被释放。
(ii) 运行时区域:这里存放了当SQL语句运行时所使用的一些信息。这部分区域的大小尺寸依赖于所要执行的SQL语句的类型(sort或hash-join等)和复杂度以及所要处理的数据行的行数以及行的大小。在处理SQL语句时的第一步就是要创建运行时区域,对于DML(INSERT、UPDATE、DELETE)语句来说,SQL语句执行完毕就释放该区域;而对于查询语句(SELECT)来说,则是在所有数据行都被获取并传递给用户以后被释放,或者该查询被取消以后也会被释放。
(2) Session相关的信息。这部分信息包括:
1.正在使用的包(package)的状态信息。
2.使用alter session这样的命令所启用的跟踪信息、或者所修改的session级别的优化器参数(optimizer_mode)、排序参(sort_area_size等)、修改的NLS参数等。
3.所打开的dblinks。
4.可使用的角色(roles)等。
从上面可以很明显的看出,我们最需要关注的就是私有SQL区域中的运行时区域了。实际上,从9i以后,对这部分区域有了一个新的名称:SQL工作区域(SQL Work Area)。SQL工作区域的大小依赖于所要处理的SQL语句的复杂程度而定。如果SQL语句包含诸如group by、Hash-join等这样的操作,则会需要很大的SQL工作区域。实际上,我们调整PGA也就是调整这块区域。后面还会说到这部分内容。
而UGA所处的位置完全由session连接的方式决定:
如果session是通过共享服务器(shared server)方式连到数据库的,则毫无疑问,UGA必须能够被所有进程访问,所以这个时候UGA是从SGA中进行分配的。进一步说,如果SGA中设置了large pool,则UGA从large pool里进行分配;否则,如果没有设置large pool,则UGA只能从shared pool里进行分配了。
如果session是通过专用服务器(dedicated server)方式连到数据库的,则UGA是从进程的PGA中进行分配的。
==============================================================================================
附一:
SGA
各文件大小解析
(
转载
)
:
SGA中的The fixed area包含了数千个原子变量,以及如latches和指向SGA中其它区域的pointers(指针)等小的数据结构.通过对fixed table内表X$KSMFSV查询(如下)可以获得这些变量的名字,变量类型,大小和在内存中的地址.
SQL> select ksmfsnam, ksmfstyp, ksmfssiz, ksmfsadr from x$ksmfsv;
这些SGA变量的名字是隐藏的而且几乎完全不需要去知道.但是我们可以通过结合fixed table内表X$KSMMEM获得这些变量的值或者检查它们所指向的数据结构.
SQL>select a.ksmmmval from x$ksmmem a where addr=(select addr from x$ksmfsv where ksmfsnam=
’
kcrfal_
’
);
SGA
中的
fixed area
的每个组成部分的大小是固定的
.
也就是说它们是不依靠于其它的初始化参数的设置来进行调整的
.fixed area
中的所以组成部分的大小相加就是
fixed area
的大小
.
The variable area:
SGA
中的
the variable area
是由
large pool
和
shared pool
组成的
.large pool
的内存大小是动态分配的
,
而
shared pool
的内存大小即包含了动态管理的内存又包含了永久性的
(
已经分配的
)
内存
.
实际上
,
初始化参数
shared_pool_size
的大小设置是指定
shared pool
中动态分配的那部分内存的一个大概的
SIZES
而不是整个
shared pool
的
SIZES
Shared pool
中永久性的内存包含各种数据结构如
:the buffer headers, processes, sessions, transaction arrays, the enqueue resources , locks, the online rollback segment arrays, various arrays for recording statistics.
其中大部分的
SIZE
是依靠初始参数的设置来确定的
.
这些初始参数只能在实例被关闭的状态下才能够进行修改
.
所以这里说的永久性是针对实例打开状态下的生存期而言
.
简单的一个例子
PROCESSES
参数
.
在这个
process arrays
中的
slots
用完之后
,
如果有其它的
process
想再申请一个
process
则会失败
,
因为它们在内存中的大小是在实例启动时预分配的
.
不能动态修改之
.
针对很多永久性的
arrays,
有很多的
X$
表都把这些元素做一个记录而成员结构则作为字段
.V$
视图的数据就是从这些
X$
表获得
.
如
V$PROCESS
是基于
X$KSUPR
内表的
.V$PROCESS
视图不包含
X$KSUPR
的全部字段
.
X$KSUPR也没有覆盖SGA进程结构的所有成员.
The variable area的在SGA中的SIZES就等于LARGE_POOL_SIZE,SHARED_POOL_SIZE和永久性的内存arrays的SIZE三者相加. 永久性的内存arrays的总的SIZE可以通过初始参数的设置来计算得到.然而,你需要知道从参数获得这些array sizes的方程式,每个array元素大小的字节数,还有array头信息的sizes.这些跟Oracle的版本号和OS有关.实际使用中,我们是不必要计算这个永久性的内存arrays的SIZE的.如果想知道,一个方法就是在STARTUP NOMOUNT数据库时记下the variable area.然后减去参数中LARGE_POOL_SIZE和SHARED_POOL_SIZE的大小就可以.
The database block area:
这个区域是数据库块的拷贝.在Oracle 8i中,buffer数由DB_BLOCK_BUFFERS指定.每个buffer的大小由DB_BLOCK_SIZE指定.所以这个区域的大小是两者相乘.在Oracle 9i中,这个区域的大小是DB_CACHE_SIZE指定.这个区不包含它们自己的控制结构,只包含database block copies data.每个buffer的header信息存在于SGA的the variable area中.还有latches信息也放在SGA的the variable area中.在设置DB_BLOCK_BUFFERS时每4个BUFFERS会影响the variable area的1K的SIZE.关于这一点.可以通过测试(针对8i而言).
The log buffer:
这个区域的SIZE是由参数LOG_BUFFER指定的.如果OS支持内存保护,log buffer将会被两个保护页面包围起来以免被一些ORACLE的错误进程损坏log buffer.在SGA中,跟其它的如variable area和database block area相比,log buffer是非常小的.log buffer分成内部的buffer blocks,而这些block各有8个字节的头部信息存在于variable area中.
The instance lock database:
在OPS/RAC配置中,instance locks用来控制由所有instances共享的资源以串行的方式被进入并使用.SGA中的这个区域所维护的是本地实例所要使用的数据库资源,所有实例和进程都会用到的数据库资源,还有所有实例和进程当前需要的或者已经拥有的锁(LOCKS).这三个arrays的SIZE分别由参数LM_RESS,LM_PROCS,LM_LOCKS参数指定.(这三个参数是RAC的参数,在单实例中用SHOW PARAMETER是查看不到的). The instance lock database还包含了message buffers和其它的structure.但是其SIZE是非常小的.
这个区域的SIZE是没办法在实例启动的时候看到的.这是Oracle Internals.可以用ORADEBUG工具查看.SQL>ORADEBUG IPC.至于ORADEBUG工具就不做介绍.用这个工具做操作时需要经过Oracle Support同意.
可以用以下的两种方式DUMP SGA:
SQL>ALTER SESSION SET EVENTS 'immediate trace name global_area level 2';
或者
SQL>ORADEBUG DUMP GLOBAL_AREA 2
===================================================================================================
附二、
PGA
管理
(
转载
)
PGA
自动管理概述
在9i之前,我们主要是通过设置sort_area_size、hash_area_size等参数值(通常都叫做*_area_size)来管理PGA的使用,不过严格说来,是对PGA中的UGA中的私有SQL区域进行管理,这块内存区域又有个名称叫做SQL工作区域。但是,这里有个问题,就是这些参数都是针对某个session而言的,也就是说设置的参数值对所有连进来的session都生效。在
数据库
实际运行过程中,总有些session需要的PGA多,而有些session需要的PGA少。如果都设置一个很小的*_area_size,则会使得某些SQL语句运行时由于需要将临时数据交换到磁盘而导致效率低下。而如果都设置一个很大的值,又有可能一方面浪费空间,另一方面,消耗过多内存可能导致
操作系统
其他组件所需要的内存短缺,而引起数据库整体性能下降。所以如何设置*_area_size的值一直都是DBA很头疼的一个问题。
而从9i起所引入的一个新的特性可以有效的解决这个问题,这个特性就是自动PGA管理。DBA可以根据数据库的负载情况估计所有session大概需要消耗的PGA的内存总和,然后把该值设置为初始化参数pga_aggregate_target的值即可。
Oracle
会按照每个session的需要为其分配PGA,同时会尽量维持整个PGA的内存总和不超过该参数所定义的值。这样的话,oracle就能尽量避免整个PGA的内存容量异常增长而影响整个数据库的性能。从而,就有效的解决了设置*_area_size所带来的问题。
不过遗憾的是,9i下的PGA自动管理只对专用连接方式有效,对共享连接方式无效。10g以后对两种连接方式都有效。
启用PGA自动管理是很容易的,只要设置两个初始化参数即可。首先,设置workarea_size_policy参数。该参数为auto(也是缺省值)时,表示启用PGA自动管理;而设置该参数为manual时,则表示禁用PGA自动管理,仍然沿用9i之前的方式,即使用*_area_size对PGA进行管理。其次,就是设置pga_aggregate_target了,该参数可以动态进行调整,范围是从10MB到4096GB
–
1
个字节。
PGA自动管理深入
PGA中对性能影响最大的就是SQL工作区了。通常说来,SQL工作区越大则对于SQL语句的执行的效率就高,从而对于用户的响应时间就越少。理想情况下,SQL工作区应该可以容纳SQL执行过程中所涉及到的所有输入数据和控制信息。当然,这只是理想情况,现实往往总是不能尽如人意,很多情况下SQL工作区是不能容纳执行SQL所需要的内存空间的,从而不得不交换到临时表空间里。为了衡量执行SQL所需要的内存与实际分配给该SQL的SQL工作区之间的契合程度,oracle将所分配的SQL工作区大小分成三种类型:
optimal尺寸:SQL语句能够完全在所分配的SQL工作区内完成所有的操作。这时的性能最佳。
onepass尺寸:SQL语句需要与磁盘上的临时表空间交互一次才能够在所分配的SQL工作区中完成所有的操作。
multipass
尺寸:由于SQL工作区过小,从而导致SQL语句需要与磁盘上的临时表空间交互多次才能完成所有的操作。这个时候的性能将急剧下降。
当系统整体负载不大时,oracle倾向于为每个session的PGA分配optimal尺寸大小的SQL工作区。
而随着负载上升,比如连接的session逐渐增多导致同时执行的SQL语句越来越多时,oracle就会倾向于为每个session的PGA分配onepass尺寸大小的SQL工作区,甚至是multipass尺寸的SQL工作区了。
那么,PGA自动管理机制在内部到底是如何实现的呢?很遗憾,oracle官方并没有给出说明文档。其实这本身也说明了,PGA自动管理的内部算法会随着版本升级而发生变化。不过,知其然而不知其所以然,总是会让诸如我等之类的技术人员感觉如梗在喉。还好,曾经就有一些专门做oracle优化的公司发布的文档中介绍了PGA内部的实现原理,我想这可能是oracle公司透露给这些公司的。这里就做些简单的介绍,不过记住,这里所描述的PGA自动管理的原理并不一定就是将来版本的原理,只能说是截至到9.2的PGA自动管理的原理。
PGA
自动管理是采用名为
“
循环反馈(feedback loop)
”
的算法来实现的。如下图所示。
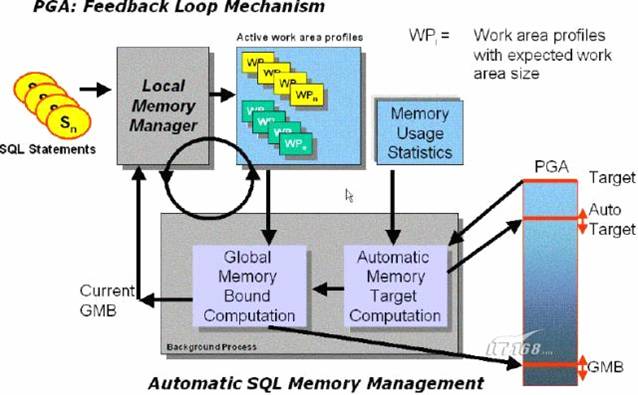
上图中,当开始处理一条SQL时,oracle会使用本地内存管理器(local memory manager)对该SQL语句相关的work area profile进行注册。work area profile是一组元数据,描述了该SQL语句所需要的工作区的所有特征,包括该SQL的类型(sort还是hash-join等)、该SQL语句的并行度、所需要的内存等信息。它是SQL语句操作与内存管理器之间唯一的接口。当SQL语句执行完毕时,其对应的work area profile就会被删除。而在SQL语句执行期间,为了反映SQL语句当前已经消耗的内存以及是否被交换到临时表空间了等状态信息,oracle会不断更新其对应的work area profile。所以说,SQL语句的work area profile是有生命周期的,始终能够体现其对应SQL语句的工作区状态。因此,我们可以说,在任何时间点,所有当前活动的work area profile就能够基本体现当前所有session对PGA内存的需要以及当前正在使用的PGA内存。通过查询视图v$sql_workarea_active,可以显示所有当前活动的work area profile的相关信息。
现在,我们需要引入另外一个后台守护进程(background daemon),叫做全局内存管理器(global memory manager)。这个进程每隔3秒会启动一次。每次启动时,都会根据当前所有活动的work area profile的数量以及其他相关信息计算出这个时候的SQL工作区的
“
内存限度(memory bound)
”
,也就是每个工作区最大尽量不能超过多大(不过,注意,严格说来应该是尽量不超过。实际上这个最大值是可以被超过的,后面会用个实例来说明)。然后立即发布这个
“
内存限度
”
。
最后,本地内存管理器关闭
“
反馈循环
”
,并根据当前的
“
内存限度
”
以及当前work area profile,从而计算出当前SQL工作区应该具有的内存大小,并为进程分配该大小的内存以执行SQL语句,这个内存的大小尺寸就叫做
“
期望尺寸(expect size)
”
,可以从v$sql_workarea_active的expected_size列看到
“
期望尺寸
”
的大小。同时,这个
“
期望尺寸
”
会定时更新,并据此对SQL工作区进行调整。
Oracle内部对这个
“
期望尺寸
”
的大小有如下规则的限制:
“
期望尺寸
”
不能小于最低的内存需求。
“
期望尺寸
”
不能大于optimal尺寸。
如果
“
内存限度
”
介于最低的内存需求和optimal尺寸之间,则使用
“
内存限度
”
作为
“
期望尺寸
”
的大小,但是排序操作除外。因为排序操作算法的限制,对于分配的内存在optimal尺寸和onepass尺寸之间时,排序操作不会随着内存的增加而更快完成,除非能够为排序操作分配optimal尺寸。所以,如果排序操作的
“
内存限度
”
介于onepass尺寸和optimal尺寸之间的话,
“
期望尺寸
”
取onepass尺寸。
如果SQL以并行方式运行,则
“
期望尺寸
”
为上面三个规则算出的值乘以并行度。
非并行模式下,按照通常的说法是
“
期望尺寸
”
不能超过min(5%*pga_aggregate_target,100MB)。但实际上,这是在不修改_pga_max_size和_smm_max_size这两个隐藏参数的前提下,可以简单的这么认为。严格说来,应该是不能超过min(5%*pga_aggregate_target,50%*_pga_max_size,_smm_max_size)。对于并行的情况,就更加复杂,可以简单认为不超过30%*pga_aggregate_target。
下面,我们举例(如下图所示)来说明全局内存管理器是如何计算并应用
“
内存限度
”
的。比如,
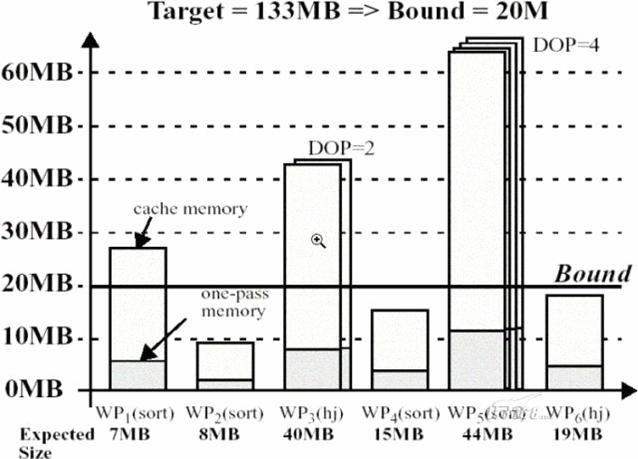
当前系统中有6个活动的work area profile。WP1所需要的onepass内存为7MB,而optimal内存为27MB。WP3是一个并行度为2的hash-join,它需要11MB的onepass内存,以及67MB的optimal的内存。
假设pga_aggregate_target设置为133MB,则可以简单的认为全局内存管理器直接将133除以6,也就是大约20MB作为
“
内存限度
”
的值。于是该
“
内存限度
”
限制了分配给WP1的工作区只能为7MB,也就是onepass的大小,因为WP1是一个排序操作,如果给它分配20MB也不能使它在以optimal的方式完成。而对于20MB的
“
内存限度
”
,WP3可以分到40MB的工作区,因为WP3的并行度为2,所以可以分配20MB×2的大小的工作区。
如何设置新
数据库
的PGA值
我们一旦设置了pga_aggregate_target以后,所有的*_area_size就将被忽略。那么,我们该如何来设置该参数的值呢?这依赖于数据库的用途,如果数据库为OLTP(联机事务处理)应用的,则其应用一般都是小的短的进程,所需要的PGA也相应较少,所以该值该值通常为总共分配给
oracle
实例的20%,另外的80%则给了SGA;如果数据库为OLAP(DSS)(
数据仓库
或决策分析)应用的,则其应用一般都是很大的,运行时间很长的进程,因此需要的PGA就多。所以通常为PGA分配50%的内存。而如果数据库为混合类型的,则情况比较复杂,一般会先分配40%的初始值,而后随着数据库的应用,而不断对PGA进行监控,并进行相应的调整。
比如,对于8GB物理内存的数据库
服务器
来说,按照oracle推荐的,分配给oracle实例的内存为物理内存的80%。那么对于OLTP应用来说,pga_aggregate_target的值大约就是1310MB ((8192 MB× 80%)×20%)。而对于OLAP来说,则该值大约就是3276MB (8192MB×80%)×50%)。
当然,这里所说的都是对于一个新的数据库来说,初始设置的值。这些值并不一定正确,可能设置过大,也可能设置过小。必须随着系统的不断运行,DBA需要不断监控,从而对其进行调整。
PGA
监控及调优
我们已经大致了解了有关PGA的相关理论知识,现在我们可以开始动手实践来验证上面的理论,并
可以开始对PGA的使用进行监控以及调优了。以下测试都是在
windows XP
、oracle 9.2.0.5,以及专用连
接模式下进行的。
准备测试用例
首先,我们先创建一个测试用例。
SQL> create table pga_test as select * from dba_objects;
SQL> select count(*) from pga_test;
COUNT(*)
----------
6243
然后,引入几个监控PGA的脚本。
pga_by_hashvalue.sql
,这是一个监控SQL语句所使用的SQL工作区的脚本:
SELECT
b.sql_text,
a.operation_type,
a.policy,
a.last_memory_used/(1024*1024) as "Used MB" ,
a.estimated_optimal_size/(1024*1024) as "Est Opt MB",
a.estimated_onepass_size/(1024*1024) as "Est OnePass MB",
a.last_execution,
a.last_tempseg_size
FROM v$sql_workarea a,v$sql b
WHERE a.hash_value = b.hash_value
and a.hash_value = &hashvalue
/
pga_by_session.sql
,第二个脚本是pga_by_session.sql,用来监控session所使用的PGA和UGA的大小:
select a.name, b.value
from v$statname a, v$sesstat b
where a.statistic# = b.statistic#
and b.sid = &sid
and a.name like '%ga %'
order by a.name
/
第三个脚本监控进程所使用的PGA的大小,pga_by_process.sql :
SELECT
a.pga_used_mem "PGA Used",
a.pga_alloc_mem "PGA Alloc",
a.pga_max_mem "PGA Max"
FROM v$process a,v$session b
where a.addr = b.paddr
and b.sid= &sid
/
单个session对PGA使用情况的监控
我们分别创建5个session,第一个session(sess#1)执行测试语句;第二个session(sess#2)执行pga_by_hashvalue.sql脚本;第三个session(sess#3)执行pga_by_session.sql脚本;第四个session(sess#4)执行pga_by_process.sql脚本;第五个session(sess#5)设置相关参数。以下按照顺序描述整个测试的过程。
Sess#1:
SQL> select sid from v$mystat where rownum=1;
SID
----------
7
Sess#3
查询当前sid为7的session的PGA和UGA各为多少,可以看到,即使不执行任何的SQL,只要session连接了,就会消耗大约0.23MB的PGA内存:
SQL> @pga_by_session.sql;
NAME
VALUE
------------------------------ ----------
session pga memory
238188
session pga memory max
238188
session uga memory
77008
session uga memory max
77008
Sess#5
,我们将pga_aggregate_target设置为60MB:
SQL> alter system set pga_aggregate_target=60M;
Sess#1
,执行测试语句:
SQL> set autotrace traceonly stat;
SQL> select a.* from pga_test a,pga_test b where rownum<600000 order by 1,2,3,4,5,6,7,8;
Sess#5
,找到sess#1中所执行的SQL语句的hash值:
SQL> select hash_value from v$sql where sql_text='select a.* from pga_test a,pga_test b where rownum<600000 order by 1,2,3,4,5,6,7,8';
HASH_VALUE
----------
2656983355
Sess#2
:
SQL> @d:\pga_by_hashvalue.sql
输入 hashvalue 的值:
2656983355
原值
12:
and a.hash_value = &hashvalue
新值
12:
and a.hash_value = 2656983355
SQL_TEXT
--------------------------------------------------------------------------------
OPERATION_TYPE
POLICY
Used MB
---------------------------------------- -------------------- ----------
Est Opt MB Est OnePass MB LAST_EXECUTION
LAST_TEMPSEG_SIZE
---------- -------------- -------------------- -----------------
select a.* from pga_test a,pga_test b where rownum<600000 order by 1,2,3,4,5,6,7,8
SORT
AUTO
3
66.1376953
2.75390625 2 PASSES
65011712
我们可以看到,该SQL语句所分配的工作区为3MB,这个值就是5%*pga_aggregate_target(60M*0.05)。符合前面说到的
“
期望尺寸
”
为min(5%*pga_aggregate_target,100MB)。
Sess#3:
SQL> @ pga_by_session.sql;
NAME
VALUE
------------------------------ ----------
session pga memory
369796
session pga memory max
4956780
session uga memory
77008
session uga memory max
3677528
可以看到,为了执行测试语句,为该session分配的PGA为4956780个字节,其中UGA为3677528个字节,大约3.5M。
同时可以看出,执行完测试语句以后,
oracle
就把该session的PGA空间回收了(PGA从4956780下降到369796,而UGA从3677528下降到77008),顺带提一下,在8i中分配了PGA以后是不会回收的,也就是说session pga memory始终等于session pga memory max,而9i以后的PGA的分配方式发生了改变,从而能够在分配PGA以后还可以再回收一部分内存。结合上面为SQL语句所分配的3M的工作区,可以知道,UGA中的其他空间占用大约0.5M。而SQL工作区占整个PGA大小大约为64%,从这个方面也可以看出,SQL工作区是PGA中最占空间、也是最重要的部分。
Sess#4
:
SQL> @d:\pga_by_process.sql
输入 sid 的值:
7
原值
7:
and b.sid= &sid
新值
7:
and b.sid= 7
PGA Used
PGA Alloc
PGA Max
---------- ---------- ----------
253932
382664
4969648
可以看到,这几个视图查出来的PGA的大小基本都是一致的。
我们继续测试,从sess#2可以看出,如果要让该SQL语句完全在内存中完成,需要大约67MB的PGA空间。根据5%的原理倒算,可以知道这个时候的pga_aggregate_target应该大于1340MB(67/0.05)。于是,我们设置1500MB,来看看是不是确实进行optimal了。顺便提醒一下,并不是说你的电脑得有超过1500MB的物理内存你才可以设置1500M的pga_aggregate_target,事实上pga_aggregate_target是按需分配的,不象SGA,一旦设置就占着内存,不用也得占着。也就是说是PGA是随着对内存需求的增长而不断增长的。我测试的机器上只有1GB的物理内存,但做测试时完全可以将pga_aggregate_target设置5GB,甚至更高的10GB。
Sess#5
,我们将pga_aggregate_target设置为1500MB:
SQL> alter system set pga_aggregate_target=1500M;
Sess#1
:
SQL> select a.* from pga_test a,pga_test b where rownum<600000 order by 1,2,3,4,5,6,7,8;
Sess#2
:
SQL> @d:\pga_by_hashvalue.sql
输入 hashvalue 的值:
2656983355
原值
12:
and a.hash_value = &hashvalue
新值
12:
and a.hash_value = 2656983355
SQL_TEXT
--------------------------------------------------------------------------------
OPERATION_TYPE
POLICY
Used MB
---------------------------------------- -------------------- ----------
Est Opt MB Est OnePass MB LAST_EXECUTION
LAST_TEMPSEG_SIZE
---------- -------------- -------------------- -----------------
select a.* from pga_test a,pga_test b where rownum<600000 order by 1,2,3,4,5,6,7,8
SORT
AUTO
65.765625
73.9873047
2.90039063 OPTIMAL
我们可以看到,该SQL语句确实完全在内存里完成了(LAST_EXECUTION为
“
OPTIMAL
”
)。同时,实际的
“
期望尺寸
”
始终会小于optimal(65.765625<73.9873047),也符合前面说的第二条规则。
我们继续测试,看看SQL工作区的
“
期望尺寸
”
是否真的不能超过100MB。为此,需要设置5%*
pga_aggregate_target>100MB,因此pga_aggregate_target最少要大于2G,我们设置5GB。
Sess#5,我们将pga_aggregate_target设置为5GB:
SQL> alter system set pga_aggregate_target=5G;
Sess#1
,注意,为了能够占用更多的PGA,这时的SQL语句已经把where条件修改了:
SQL> select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8;
Sess#5
,找到该语句的hash值:
SQL> select hash_value from v$sql where sql_text='select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8';
HASH_VALUE
----------
3008669403
Sess#2
:
SQL> /
输入 hashvalue 的值:
3008669403
原值
12:
and a.hash_value = &hashvalue
新值
12:
and a.hash_value = 3008669403
SQL_TEXT
--------------------------------------------------------------------------------
OPERATION_TYPE
POLICY
Used MB
---------------------------------------- -------------------- ----------
Est Opt MB Est OnePass MB LAST_EXECUTION
LAST_TEMPSEG_SIZE
---------- -------------- -------------------- -----------------
select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8
SORT
AUTO
87.265625
137.232422
3.87109375 1 PASS
127926272
可以看到,optimal尺寸已经超过100MB很多了,但是实际分配的
“
期望尺寸
”
却只有88MB左右。而5G*0.05为250MB,为何该SQL用不了呢?这其实是由两个隐藏参数决定的,分别是_pga_max_size和_smm_max_size。我们来看一下这两个参数的含义和缺省值:
Sess#5:
SQL> select ksppinm, ksppstvl, ksppdesc from x$ksppi x, x$ksppcv y where x.indx = y.indx and ksppinm in ('_pga_max_size','_smm_max_size');
KSPPINM
KSPPSTVL
KSPPDESC
-------------- ---------- -----------------------------------------------
_pga_max_size
209715200
Maximum size of the PGA memory for one process
_smm_max_size
102400
maximum work area size in auto mode (serial)
我们可以看到_pga_max_size缺省值为200M(209715200/1024/1024),而_smm_max_size缺省值为100MB(上面的查询结果中显示的单位是KB)。而每个session的PGA最多只能使用_pga_max_size的一半,也就是100MB。
当你修改参数pga_aggregate_target的值时,Oracle系统会根据pga_aggregate_target和_pga_max_size这两个值来自动修改参数_smm_max_size。具体修改的规则是:
如果_pga_max_size大于5%*pga_aggregate_target,则_smm_max_size为5%*pga_aggregate_target。
如果_pga_max_size小于等于5%*pga_aggregate_target,则_smm_max_size为50%*_pga_max_size。
有些资料上说,可以通过修改_pga_max_size来突破这个100MB的限制。真的是这样吗?我们来测试。Sess#5,修改参数_pga_max_size为600MB:
SQL> show parameter pga
NAME
TYPE
VALUE
------------------------------------ ----------- ------------------------------
pga_aggregate_target
big integer 5368709120
SQL> alter system set "_pga_max_size"=600M;
我们将_pga_max_size的值设置为600M,其一半就是300MB,已经超过5%*pga_aggregate_target(即250MB)了。所以这两者的较小值为250M,如果这时我们在sess#1中再次执行测试语句,应该可以使用超过100MB的SQL工作区了。我们来看测试结果。
Sess#1:
SQL> select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8;
Sess#2:
SQL> /
输入 hashvalue 的值:
3008669403
原值
12:
and a.hash_value = &hashvalue
新值
12:
and a.hash_value = 3008669403
SQL_TEXT
--------------------------------------------------------------------------------
OPERATION_TYPE
POLICY
Used MB
---------------------------------------- -------------------- ----------
Est Opt MB Est OnePass MB LAST_EXECUTION
LAST_TEMPSEG_SIZE
---------- -------------- -------------------- -----------------
select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8
SORT
AUTO
87.265625
137.232422
3.87109375 1 PASS
127926272
我们看到,
“
期望尺寸
”
仍然是大约88MB,并没有突破100MB的限制。其中的问题就在于参数
_smm_max_size 上。我们来看这个时候该参数值是多少:
Sess#5:
SQL> select ksppinm, ksppstvl, ksppdesc from x$ksppi x, x$ksppcv y where x.indx = y.indx and ksppinm in ('_pga_max_size','_smm_max_size');
KSPPINM
KSPPSTVL
KSPPDESC
-------------- ---------- -----------------------------------------------
_pga_max_size
629145600
Maximum size of the PGA memory for one process
_smm_max_size
102400
maximum work area size in auto mode (serial)
可以看到参数_smm_max_size的值仍然是100MB。实际上,这也是一个对
“
期望尺寸
”
的限制参数。这里可以看到
“
期望尺寸
”
不能超过100MB。这时,我们只要简单的执行:
Sess#5:
SQL> alter system set pga_aggregate_target=5G;
SQL> select ksppinm, ksppstvl, ksppdesc from x$ksppi x, x$ksppcv y where x.indx = y.indx and ksppinm in ('_pga_max_size','_smm_max_size');
KSPPINM
KSPPSTVL
KSPPDESC
-------------- ---------- -----------------------------------------------
_pga_max_size
629145600
Maximum size of the PGA memory for one process
_smm_max_size
262144
maximum work area size in auto mode (serial)
我们可以看到,只要设置一下pga_aggregate_target,就会按照前面所说的规则重新计算并设置_smm_max_size的值,该参数修改后的值为250MB。这个时候我们重复上面的测试:
Sess#1:
SQL> select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8;
Sess#2:
SQL> /
输入 hashvalue 的值:
3008669403
原值
12:
and a.hash_value = &hashvalue
新值
12:
and a.hash_value = 3008669403
SQL_TEXT
--------------------------------------------------------------------------------
OPERATION_TYPE
POLICY
Used MB
---------------------------------------- -------------------- ----------
Est Opt MB Est OnePass MB LAST_EXECUTION
LAST_TEMPSEG_SIZE
---------- -------------- -------------------- -----------------
select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8
SORT
AUTO
137.195313
154.345703
4.09179688 OPTIMAL
这时,我们看到,
“
期望尺寸
”
为138MB左右,终于超过了100MB。如果我们再次将参数_smm_max_size人为的降低到100MB,则
“
期望尺寸
”
又将不能突破100MB了。我们来看试验。
Sess#5:
SQL> alter system set "_smm_max_size"=102400;
Sess#1:
SQL> select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8;
Sess#2:
SQL> /
输入 hashvalue 的值:
3008669403
原值
12:
and a.hash_value = &hashvalue
新值
12:
and a.hash_value = 3008669403
SQL_TEXT
--------------------------------------------------------------------------------
OPERATION_TYPE
POLICY
Used MB
---------------------------------------- -------------------- ----------
Est Opt MB Est OnePass MB LAST_EXECUTION
LAST_TEMPSEG_SIZE
---------- -------------- -------------------- -----------------
select a.* from pga_test a,pga_test b where rownum<1300000 order by 1,2,3,4,5,6,7,8
SORT
AUTO
87.265625
137.232422
3.87109375 1 PASS
127926272
可以看到,结果正如我们所预料的。由此,得出我们重要的结论,就是在非并行方式下,
“
期望尺寸
”
为min(5%*pga_aggregate_target,50%*_pga_max_size,_smm_max_size),而不是很多资料上所说的不是很严密的min(5%*pga_aggregate_target,50%*_pga_max_size)。
oracle
当然是不推荐我们修改这两个隐藏参数的。
多个并发session对PGA使用情况的监控
现在我们可以来测试多个session并发时PGA的分配情况。测试并发的方式有很多,可以写一个小程序循环创建多个连接,然后执行上面的测试语句,也可以借助一些工具来完成。为了方便起见,我用了一个最简单的方式。就是写一个SQL文本,再写一个bat文件,该bat文件中执行SQL文本。两个文件准备好以后,将bat文件拷贝30份,然后选中这30份一摸一样的bat文件,按回车键后,
windows XP
将同时执行这30个bat文件,这样就可以模拟出30个session同时连接并同时执行测试语句的环境了。具体这两个文件的具体内容如下:
pga_test.sql:
set autotrace traceonly stat;
select a.* from pga_test a,pga_test b where rownum<600000 order by 1,2,3,4,5,6,7,8;
run.bat
:
@sqlplus -s cost/cost@ora92 @d:\test\pga_test.sql
我们先将pga_aggregate_target设置为60MB。
Sess#5:
SQL> alter system set pga_aggregate_target=60M;
然后同时运行30个bat文件从而启动30个执行相同SQL测试语句的并发session,我执行下面的语句以显示这时正在执行的30个session所消耗的PGA的总内存:
Sess#5:
SQL> select a.name, sum(b.value)/1024/1024 as "MB"
2
from v$statname a, v$sesstat b
3
where a.statistic# = b.statistic#
4
and a.name like '%ga %'
5
and sid in(select sid from v$sql_workarea_active)
6
group by a.name;
NAME
MB
---------------------------------------------------------------- ----------
session pga memory
45.9951134
session pga memory max
95.6863365
session uga memory
19.757431
session uga memory max
72.6992035
我们可以看到,session pga memory max显示出大约96MB的PGA内存,很明显,PGA的总容量已经超出了pga_aggregate_target(60M)的限制的容量。实际上这也就说明,该参数只是说明,oracle会尽量维护整个PGA内存不超过这个值,如果实在没有办法,也还是会突破该参数限制的。
同时,我们可以去查看这个时候该测试SQL语句所分配的工作区变成了多少,同样在Sess#2中:
SQL> @d:\pga_by_hashvalue.sql
输入 hashvalue 的值:
2656983355
原值
12:
and a.hash_value = &hashvalue
新值
12:
and a.hash_value = 2656983355
SQL_TEXT
--------------------------------------------------------------------------------
OPERATION_TYPE
POLICY
Used MB
---------------------------------------- -------------------- ----------
Est Opt MB Est OnePass MB LAST_EXECUTION
LAST_TEMPSEG_SIZE
---------- -------------- -------------------- -----------------
select a.* from pga_test a,pga_test b where rownum<600000 order by 1,2,3,4,5,6,7,8
SORT
AUTO
1.8984375
66.1376953
2.75390625 2 PASSES
65011712
从结果中我们可以看到,该SQL的工作区已经从单个session时的3MB下降到了大约1.9M,我们可以看到,30个session总共至少需要57MB(1.9M*30)的SQL工作区。明显的,60MB的pga_aggregate_target是肯定不能满足需要的。
其他监控并调整PGA的方法
我们监控PGA的视图除了上面介绍到的v$sql_workarea_active、v$sesstat、v$sql_workarea以及v$process以外,还有v$sql_workarea_histogram、v$pgastat以及v$sysstat。
v$sql_workarea_histogram
记录了每个范围的SQL工作区内所执行的optimal、onepass、multipass的次数。如下所示:
SQL> select
2
low_optimal_size/1024 "Low (K)",
3
(high_optimal_size + 1)/1024 "High (K)",
4
optimal_executions "Optimal",
5
onepass_executions "1-Pass",
6
multipasses_executions ">1 Pass"
7
from v$sql_workarea_histogram
8
where total_executions <> 0;
结果类似如下所示,我们可以看到整个系统所需要的PGA的内存大小主要集中在什么范围里面。
Low (K)
High (K)
Optimal
1-Pass
>1 Pass
---------- ---------- ---------- ---------- ----------
8
16
360
0
0
。。。。。。。。。
65536
131072
0
2
0
另外,我们可以将上面的查询语句改写一下,以获得optimal、onepass、multipass执行次数的百分比,很明显,optimal所占的百分比越高越好,如果onepass和multipass占的百分比很高,就不需要增加pga_aggregate_target的值了,或者调整SQL语句以使用更少的PGA区。
SQL> select
2
optimal_count "Optimal",
3
round(optimal_count * 100 / total,2) "Optimal %",
4
onepass_count "OnePass",
5
round(onepass_count * 100 / total,2) "Onepass %",
6
multipass_count "MultiPass",
7
round(multipass_count * 100 / total,2) "Multipass %"
8
from (
9
select
10
sum(total_executions) total,
11
sum(optimal_executions) optimal_count,
12
sum (onepass_executions) onepass_count,
13
sum (multipasses_executions) multipass_count
14
from v$sql_workarea_histogram
15
where total_executions <> 0)
16
/
Optimal
Optimal %
OnePass
Onepass %
MultiPass Multipass %
---------- ---------- ---------- ---------- ---------- -----------
402
99.01
4
0.99
0
0
而v$pgastat则提供了有关PGA使用的整体的概括性的信息。
SQL> select * from v$pgastat;
NAME
VALUE UNIT
---------------------------------------- ---------- ------------
aggregate PGA target parameter
62914560 bytes
aggregate PGA auto target
51360768 bytes
global memory bound
104857600 bytes
total PGA inuse
5846016 bytes
total PGA allocated
8386560 bytes
maximum PGA allocated
66910208 bytes
total freeable PGA memory
0 bytes
PGA memory freed back to OS
0 bytes
total PGA used for auto workareas
0 bytes
maximum PGA used for auto workareas
51167232 bytes
total PGA used for manual workareas
0 bytes
maximum PGA used for manual workareas
0 bytes
over allocation count
0
bytes processed
142055424 bytes
extra bytes read/written
138369024 bytes
cache hit percentage
50.65 percent
从结果可以看出,第一行表示pga_aggregate_target设置为60M。PGA的一部分被用于无法动态调整的部分,比如UGA中的
“
session
相关的信息
”
等。而PGA内存的剩下部分则是可以动态调整的,由
“
aggregate PGA auto target
”
说明。我们来看第二行的值,就表示可以动态调整的内存数量,该值不能与pga_aggregate_target设置的值差太多。如果该值太小,则
oracle
没有足够的内存空间来动态调整session的内存工作区。其中的global memory bound表示一个工作区的最大尺寸,并且oracle推荐只要该统计值低于1M时,就应该增加pga_aggregate_target的值。另外,9i还提供了两个有用的指标:over allocation count和cache hit percentage。如果在使用SQL工作区过程中,oracle认为pga_aggregate_target过小,则它自己会去多分配需要的内存。则多分配的次数就累加在over allocation count指标里。该值越小越好,最好为0。cache hit percentage则表示完全在内存里完成的操作的字节数与所有完成的操作(包括optimal、onepass、multipass)的字节数的比率。如果所有的操作都是optimal类,则该值为100%。
最后,我们可以查询v$sysstat视图,获得optimal、onepass、multipass执行的总次数:
SQL>
select * from v$sysstat where name like 'workarea executions%';
STATISTIC# NAME
CLASS
VALUE
---------- ---------------------------------------- ---------- ----------
230 workarea executions - optimal
64
360
231 workarea executions - onepass
64
2
232 workarea executions - multipass
64
0
我们可以计算optimal次数占总次数的比率,比如上例中,360/(360+2+0)=99.45%,该比率越大越好,如果发现onepass和multipass较多,则需要增加pga_aggregate_target,或者调整SQL语句以使用更少的PGA区。
那么我们如何找到需要调整以使用更少的PGA的SQL语句呢?我们可以将v$sql_workarea中的记录按照estimated_optimal_size字段由大到小的排序,选出排在前几位的hash值,同时还可以选出last_execution值为
“
n PASSES
”
(这里的n大于或等于2)的hash值,将这些hash值与v$sql关联后找出相应的SQL语句,进行调整,以便使其使用更少的PGA。
PGA
的自动建议特性
那么,如果我们需要调整pga_aggregate_target时,到底我们应该设置多大呢?
oracle
为了帮助我们确定这个参数的值,引入了一个新的视图:v$pga_target_advice。
为了使用该视图,需要将初始化参数statistics_level设置为typical(缺省值)或all。
SQL> select
2
round(pga_target_for_estimate /(1024*1024)) "Target (M)",
3
estd_pga_cache_hit_percentage "Est. Cache Hit %",
4
round(estd_extra_bytes_rw/(1024*1024)) "Est. ReadWrite (M)",
5
estd_overalloc_count "Est. Over-Alloc"
6
from v$pga_target_advice
7
/
Target (M) Est. Cache Hit % Est. ReadWrite (M) Est. Over-Alloc
---------- ---------------- ------------------ ---------------
15
34
264
1
30
34
264
0
45
34
264
0
60
67
66
0
72
67
66
0
84
67
66
0
96
67
66
0
108
67
66
0
120
67
66
0
180
67
66
0
240
67
66
0
360
67
66
0
480
67
66
0
该输出告诉我们
,
按照系统目前的运转情况
,
我们
pga
设置的不同值所带来的不同
效果
。根据该输出,我们找到能使estd_overalloc_count为0的最小pga_aggregate_target的值。从这里可以看出,是30M。注意,随着我们增加pga的尺寸,estd_pga_cache_hit_percentage不断增加,同时estd_extra_bytes_rw(表示onepass、multipass读写的字节数)不断减小。从上面的结果,我们可以知道,将pga_aggregate_target设置为60MB是最合理的,因为即便将其设置为480MB,命中率也不会有所提高。
同时,我们知道v$tempstat里记录了读写临时表空间的数据块数量以及所花费的时间。这样,我们就可以结合v$pga_target_advice和v$tempstat这两个视图。可以得到每一种估计PGA值下的响应时间大致是多少,从而可以换一个角度来显示PGA的建议值:
SQL> SELECT 'PGA Aggregate Target' component,
2
ROUND (pga_target_for_estimate / 1048576) target_size,
3
estd_pga_cache_hit_percentage cache_hit_ratio,
4
ROUND ( ( ( estd_extra_bytes_rw / DECODE ((b.BLOCKSIZE * i.avg_blocks_per_io),0, 1,
5
(b.BLOCKSIZE * i.avg_blocks_per_io)))* i.iotime)/100 ) "response_time(sec)"
6
FROM v$pga_target_advice,
7
(SELECT /*+AVG TIME TO DO AN IO TO TEMP TABLESPACE*/
8
AVG ( (readtim + writetim) /
9
DECODE ((phyrds + phywrts), 0, 1, (phyrds + phywrts)) ) iotime,
10
AVG ( (phyblkrd + phyblkwrt)/
11
DECODE ((phyrds + phywrts), 0, 1, (phyrds + phywrts))) avg_blocks_per_io
12
FROM v$tempstat) i,
13
(SELECT /* temp ts block size */ VALUE BLOCKSIZE
14
FROM v$parameter WHERE NAME = 'db_block_size') b;
COMPONENT
TARGET_SIZE CACHE_HIT_RATIO response_time(sec)
-------------------- ----------- --------------- ------------------
PGA Aggregate Target
15
34
85
PGA Aggregate Target
30
34
85
PGA Aggregate Target
45
34
85
PGA Aggregate Target
60
68
21
PGA Aggregate Target
72
68
21
PGA Aggregate Target
84
68
21
PGA Aggregate Target
96
68
21
PGA Aggregate Target
108
68
21
PGA Aggregate Target
120
68
21
PGA Aggregate Target
180
68
21
PGA Aggregate Target
240
68
21
PGA Aggregate Target
360
68
21
PGA Aggregate Target
480
68
21
注意,每次我们调整了pga_aggregate_target参数以后,都应该在系统运行一、两天以后检查视图:v$sysstat、v$pgastat、v$pga_target_advice,以确定修改的值是否满足系统的需要。
-The End-