 2006年6月9日
2006年6月9日
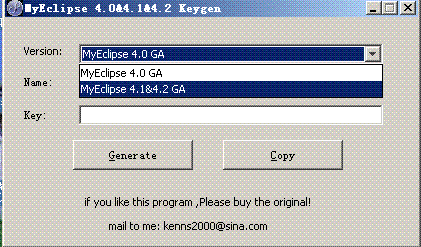
MyEclipse5.5推出有一段时间了,但是网上一直都没有破解的文件,通过今天跟公司几个同事的努力尝试终于找到破解的方法了,说起来比较可笑,我们经过好多次的尝试,最后用MyEclipse4.1的破解文件就可以破解MyEclipse5.5了,我们用的MyEclipse5.5的版本是MyEclipse_5.5M2_E3.2.2,Eclipse的版本是eclipse3.2.2大家可以尝试一下.
在此特别要说明一下的是运行MyEclipse4.1的时候要选择MyEclipse4.1&4.2 GA这个选择才可以破解如图
MyEclipse_5.5M2_E3.2.2的官方下载地址 : http://www.myeclipseide.com/ContentExpress-display-ceid-110.html
MyEclipse4.1破解文件下载
最近在用eclipse的时候,过上一会老弹出一个对话框,提示内存不足(大意),找了好多资料都没有解决,最近在eclipse的官方网站上找到了其解决的办法,希望对像我一样的朋友有帮助,解决方法如下,
在桌面上建一个启动eclipse的快捷方式,在该快捷方式上单击右键,在常规标签的目标中加入下面的内容:
E:\eclipse\eclipse.exe -clean -vmargs -Xms128M -Xmx512M -XX:PermSize=64M -XX:MaxPermSize=128M,其中“E:\eclipse\eclipse.exe” 是我eclipse的路径。
然后重启你的eclipse试试!
在IIS中 发布程序一个ASP.NET程序,通过IE访问报如下错误:
当前标识(NT AUTHORITY\NETWORK SERVICE)没有对“C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\Temporary ASP.NET Files”的写访问权限。
说明: 执行当前 Web 请求期间,出现未处理的异常。请检查堆栈跟踪信息,以了解有关该错误以及代码中导致错误的出处的详细信息。
异常详细信息: System.Web.HttpException: 当前标识(NT AUTHORITY\NETWORK SERVICE)没有对“C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\Temporary ASP.NET Files”的写访问权限。
翻阅了一些资料后发现是需要重新注册IIS服务扩展, 解决方法如下:
在“开始”-“运行”里输入如入命令,回车,搞定
C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\aspnet_regiis -i -enable
摘要: 9.8 Struts
与
...
阅读全文
称呼
Functions
标签库为标签库,倒不如称呼其为函数库来得更容易理解些。因为
Functions
标签库并没有提供传统的标签来为
JSP
页面的工作服务,而是被用于
EL
表达式语句中。在
JSP2.0
规范下出现的
Functions
标签库为
EL
表达式语句提供了许多更为有用的功能。
Functions
标签库分为两大类,共
16
个函数。
q
长度函数:
fn:length
q
字符串处理函数:
fn:contains
、
fn:containsIgnoreCase
、
fn:endsWith
、
fn:escapeXml
、
fn:indexOf
、
fn:join
、
fn:replace
、
fn:split
、
fn:startsWith
、
fn:substring
、
fn:substringAfter
、
fn:substringBefore
、
fn:toLowerCase
、
fn:toUpperCase
、
fn:trim
以下是各个函数的用途和属性以及简单示例。
9.7.1
长度函数
fn:length
函数
长度函数
fn:length
的出现有重要的意义。在
JSTL1.0
中,有一个功能被忽略了,那就是对集合的长度取值。虽然
java.util.Collection
接口定义了
size
方法,但是该方法不是一个标准的
JavaBean
属性方法(没有
get,set
方法),因此,无法通过
EL
表达式“
${collection.size}
”来轻松取得。
fn:length
函数正是为了解决这个问题而被设计出来的。它的参数为
input
,将计算通过该属性传入的对象长度。该对象应该为集合类型或
String
类型。其返回结果是一个
int
类型的值。下面看一个示例。
<%ArrayList arrayList1 = new ArrayList();
arrayList1.add("aa");
arrayList1.add("bb");
arrayList1.add("cc");
%>
<%request.getSession().setAttribute("arrayList1", arrayList1);%>
${fn:length(sessionScope.arrayList1)}
假设一个
ArrayList
类型的实例“
arrayList1
”,并为其添加三个字符串对象,使用
fn:length
函数后就可以取得返回结果为“
3
”。
9.7.2
判断函数
fn:contains
函数
fn:contains
函数用来判断源字符串是否包含子字符串。它包括
string
和
substring
两个参数,它们都是
String
类型,分布表示源字符串和子字符串。其返回结果为一个
boolean
类型的值。下面看一个示例。
${fn:contains("ABC", "a")}<br>
${fn:contains("ABC", "A")}<br>
前者返回“
false
”,后者返回“
true
”。
fn:containsIgnoreCase
函数与
fn:contains
函数的功能差不多,唯一的区别是
fn:containsIgnoreCase
函数对于子字符串的包含比较将忽略大小写。它与
fn:contains
函数相同,包括
string
和
substring
两个参数,并返回一个
boolean
类型的值。下面看一个示例。
${fn:containsIgnoreCase("ABC", "a")}<br>
${fn:containsIgnoreCase("ABC", "A")}<br>
前者和后者都会返回“
true
”。
9.7.4
词头判断函数
fn:startsWith
函数
fn:startsWith
函数用来判断源字符串是否符合一连串的特定词头。它除了包含一个
string
参数外,还包含一个
subffx
参数,表示词头字符串,同样是
String
类型。该函数返回一个
boolean
类型的值。下面看一个示例。
${fn:startsWith ("ABC", "ab")}<br>
${fn:startsWith ("ABC", "AB")}<br>
前者返回“
false
”,后者返回“
true
”。
9.7.5
词尾判断函数
fn:endsWith
函数
fn:endsWith
函数用来判断源字符串是否符合一连串的特定词尾。它与
fn:startsWith
函数相同,包括
string
和
subffx
两个参数,并返回一个
boolean
类型的值。下面看一个示例。
${fn:endsWith("ABC", "bc")}<br>
${fn:endsWith("ABC", "BC")}<br>
前者返回“
false
”,后者返回“
true
”。
9.7.6
字符实体转换函数
fn:escapeXml
函数
fn:escapeXml
函数用于将所有特殊字符转化为字符实体码。它只包含一个
string
参数,返回一个
String
类型的值。
9.7.8
字符匹配函数
fn:indexOf
函数
fn:indexOf
函数用于取得子字符串与源字符串匹配的开始位置,若子字符串与源字符串中的内容没有匹配成功将返回“
-1
”。它包括
string
和
substring
两个参数,返回结果为
int
类型。下面看一个示例。
${fn:indexOf("ABCD","aBC")}<br>
${fn:indexOf("ABCD","BC")}<br>
前者由于没有匹配成功,所以返回
-1
,后者匹配成功将返回位置的下标,为
1
。
9.7.9
分隔符函数
fn:join
函数
fn:join
函数允许为一个字符串数组中的每一个字符串加上分隔符,并连接起来。它的参数、返回结果和描述如表
9.25
所示:
表
9.25
fn:join
函数
|
参数
|
描述
|
|
array
|
字符串数组。其类型必须为
String[]
类型
|
|
separator
|
分隔符。其类型必须为
String
类型
|
|
返回结果
|
返回一个
String
类型的值
|
下面看一个示例。
<% String[] stringArray = {"a","b","c"}; %>
<%request.getSession().setAttribute("stringArray", stringArray);%>
${fn:join(sessionScope.stringArray,";")}<br>
定义数组并放置到
Session
中,然后通过
Session
得到该字符串数组,使用
fn:join
函数并传入分隔符“
;
”,得到的结果为“
a;b;c
”。
9.7.10
替换函数
fn:replace
函数
fn:replace
函数允许为源字符串做替换的工作。它的参数、返回结果和描述如表
9.26
所示:
表
9.26
fn:replace
函数
|
参数
|
描述
|
|
inputString
|
源字符串。其类型必须为
String
类型
|
|
beforeSubstring
|
指定被替换字符串。其类型必须为
String
类型
|
|
afterSubstring
|
指定替换字符串。其类型必须为
String
类型
|
|
返回结果
|
返回一个
String
类型的值
|
下面看一个示例。
${fn:replace("ABC","A","B")}<br>
将“
ABC
”字符串替换为“
BBC
”,在“
ABC
”字符串中用“
B
”替换了“
A
”。
9.7.11
分隔符转换数组函数
fn:split
函数
fn:split
函数用于将一组由分隔符分隔的字符串转换成字符串数组。它的参数、返回结果和描述如表
9.27
所示:
表
9.27
fn:split
函数
|
参数
|
描述
|
|
string
|
源字符串。其类型必须为
String
类型
|
|
delimiters
|
指定分隔符。其类型必须为
String
类型
|
|
返回结果
|
返回一个
String[]
类型的值
|
下面看一个示例。
${fn:split("A,B,C",",")}<br>
将“
A,B,C
”字符串转换为数组
{A,B,C}
。
9.7.12
字符串截取函数
fn:substring
函数
fn:substring
函数用于截取字符串。它的参数、返回结果和描述如表
9.28
所示:
表
9.28
fn:substring
函数
|
参数
|
描述
|
|
string
|
源字符串。其类型必须为
String
类型
|
|
beginIndex
|
指定起始下标(值从
0
开始)。其类型必须为
int
类型
|
|
endIndex
|
指定结束下标(值从
0
开始)。其类型必须为
int
类型
|
|
返回结果
|
返回一个
String
类型的值
|
下面看一个示例。
${fn:substring("ABC","1","2")}<br>
截取结果为“
B
”。
9.7.14
起始到定位截取字符串函数
fn:substringBefore
函数
fn:substringBefore
函数允许截取源字符从开始到某个字符串。它的参数和
fn:substringAfter
函数相同,不同的是
substring
表示的是结束字符串。下面看一个示例。
${fn:substringBefore("ABCD","BC")}<br>
截取的结果为“
A
”。
9.7.15
小写转换函数
fn:toLowerCase
函数
fn:toLowerCase
函数允许将源字符串中的字符全部转换成小写字符。它只有一个表示源字符串的参数
string
,函数返回一个
String
类型的值。下面看一个示例。
${fn:toLowerCase("ABCD")}<br>
转换的结果为“
abcd
”。
9.7.16
大写转换函数
fn:toUpperCase
函数
fn:toUpperCase
函数允许将源字符串中的字符全部转换成大写字符。它与
fn:toLowerCase
函数相同,也只有一个
String
参数,并返回一个
String
类型的值。下面看一个示例。
${fn:toUpperCase("abcd")}<br>
转换的结果为“
ABCD
”。
9.7.17
空格删除函数
fn:trim
函数
fn:trim
函数将删除源字符串中结尾部分的“空格”以产生一个新的字符串。它与
fn:toLowerCase
函数相同,只有一个
String
参数,并返回一个
String
类型的值。下面看一个示例。
${fn:trim("AB C ")}D<br>
转换的结果为“
AB CD
”,注意,它将只删除词尾的空格而不是全部,因此“
B
”和“
C
”之间仍然留有一个空格。
Database access
标签库中的标签用来提供在
JSP
页面中可以与数据库进行交互的功能,虽然它的存在对于早期纯
JSP
开发的应用以及小型的开发有着意义重大的贡献,但是对于
MVC
模型来说,它却是违反规范的。因为与数据库交互的工作本身就属于业务逻辑层的工作,所以不应该在
JSP
页面中出现,而是应该在模型层中进行。
对于
Database access
标签库本书不作重点介绍,只给出几个简单示例让读者略微了解它们的功能。
Database access
标签库有以下
6
组标签来进行工作:
<sql:setDataSource>
、
<sql:query>
、
<sql:update>
、
<sql:transaction>
、
<sql:setDataSource>
、
<sql:param>
、
<sql:dateParam>
。
9.6.1
用于设置数据源的
<sql:setDataSource>
标签
<sql:setDataSource>
标签用于设置数据源,下面看一个示例:
<sql:setDataSource
var="dataSrc"
url="jdbc:postgresql://localhost:5432/myDB"
driver="org.postgresql.Driver"
user="admin"
password="1111"/>
该示例定义一个数据源并保存在“
dataSrc
”变量内。
9.6.2
用于查询的
<sql:query>
标签
<sql:query>
标签用于查询数据库,它标签体内可以是一句查询
SQL
。下面看一个示例:
<sql:query var="queryResults" dataSource="${dataSrc}">
select * from table1
</sql:query>
该示例将返回查询的结果到变量“
queryResults
”中,保存的结果是
javax.servlet.jsp.jstl.sql.Result
类型的实例。要取得结果集中的数据可以使用
<c:forEach>
循环来进行。下面看一个示例。
<c:forEach var="row" items="${queryResults.rows}">
<tr>
<td>${row.userName}</td>
<td>${row.passWord}</td>
</tr>
</c:forEach>
“
rows
”是
javax.servlet.jsp.jstl.sql.Result
实例的变量属性之一,用来表示数据库表中的“列”集合,循环时,通过“
${row.XXX}
”表达式可以取得每一列的数据,“
XXX
”是表中的列名。
9.6.3
用于更新的
<sql:update>
标签
<sql:update>
标签用于更新数据库,它的标签体内可以是一句更新的
SQL
语句。其使用和
<sql:query>
标签没有什么不同。
9.6.4
用于事务处理的
<sql:transaction>
标签
<sql:transaction>
标签用于数据库的事务处理,在该标签体内可以使用
<sql:update>
标签和
<sql:query>
标签,而
<sql:transaction>
标签的事务管理将作用于它们之上。
<sql:transaction>
标签对于事务处理定义了
read_committed
、
read_uncommitted
、
repeatable_read
、
serializable4
个隔离级别。
9.6.5
用于事务处理的
<sql:param>
、
<sql:dateParam>
标签
这两个标签用于向
SQL
语句提供参数,就好像程序中预处理
SQL
的“
?
”一样。
<sql:param>
标签传递除
java.util.Date
类型以外的所有相融参数,
<sql:dateParam>
标签则指定必须传递
java.util.Date
类型的参数。
看到
I18N
就应该想到知识“国际化”,
I18N formatting
标签库就是用于在
JSP
页面中做国际化的动作。在该标签库中的标签一共有
12
个,被分为了两类,分别是:
q
国际化核心标签:
<fmt:setLocale>
、
<fmt:bundle>
、
<fmt:setBundle>
、
<fmt:message>
、
<fmt:param>
、
<fmt:requestEncoding>
。
q
格式化标签:
<fmt:timeZone>
、
<fmt:setTimeZone>
、
<fmt:formatNumber>
、
<fmt:parseNumber>
、
<fmt:formatDate>
、
<fmt:parseDate>
。
下面只选择其中常见的一些标签和属性进行介绍。
9.5.1
用于设置本地化环境的
<fmt:setLocale>
标签
<fmt:setLocale>
标签用于设置
Locale
环境。它的属性和描述如表
9.17
所示:
表
9.17
<fmt:setLocale>
标签属性和说明
|
属性
|
描述
|
|
value
|
Locale
环境的指定,可以是
java.util.Locale
或
String
类型的实例
|
|
scope
|
Locale
环境变量的作用范围(可选)
|
下面看一个示例:
<fmt:setLocale value="zh_TW"/>
表示设置本地环境为繁体中文。
9.5.2
用于资源文件绑定的
<fmt:bundle>
、
<fmt:setBundle>
标签
这两组标签用于资源配置文件的绑定,唯一不同的是
<fmt:bundle>
标签将资源配置文件绑定于它标签体中的显示,
<fmt:setBundle>
标签则允许将资源配置文件保存为一个变量,在之后的工作可以根据该变量来进行。
根据
Locale
环境的不同将查找不同后缀的资源配置文件,这点在国际化的任何技术上都是一致的,通常来说,这两种标签单独使用是没有意义的,它们都会与
I18N formatting
标签库中的其他标签配合使用。它们的属性和描述如表
9.18
所示:
表
9.18
<fmt:bundle>
、
<fmt:setBundle>
标签属性和说明
|
属性
|
描述
|
|
basename
|
资源配置文件的指定,只需要指定文件名而无须扩展名,二组标签共有的属性
|
|
var
|
<fmt:setBundle>
独有的属性,用于保存资源配置文件为一个变量
|
|
scope
|
变量的作用范围
|
下面看一个示例
<fmt:setLocale value="zh_CN"/>
<fmt:setBundle basename="applicationMessage" var="applicationBundle"/>
该示例将会查找一个名为
applicationMessage_zh_CN.properties
的资源配置文件,来作为显示的
Resource
绑定。
9.5.3
用于显示资源配置文件信息的
<fmt:message>
标签
用于信息显示的标签,将显示资源配置文件中定义的信息。它的属性和描述如表
9.19
所示:
表
9.19
<fmt:message>
标签属性和说明
|
属性
|
描述
|
|
key
|
资源配置文件的“键”指定
|
|
bundle
|
若使用
<fmt:setBundle>
保存了资源配置文件,该属性就可以从保存的资源配置文件中进行查找
|
|
var
|
将显示信息保存为一个变量
|
|
scope
|
变量的作用范围
|
下面看一个示例:
<fmt:setBundle basename="applicationMessage" var="applicationBundle"/>
<fmt:bundle basename="applicationAllMessage">
<fmt:message key="userName" />
<p>
<fmt:message key="passWord" bundle="${applicationBundle}" />
</fmt:bundle>
该示例使用了两种资源配置文件的绑定的做法,“
applicationMessage
”资源配置文件利用
<fmt:setBundle>
标签被赋于了变量“
applicationBundle
”,而作为
<fmt:bundle>
标签定义的“
applicationAllMessage
”资源配置文件作用于其标签体内的显示。
q
第一个
<fmt:message>
标签将使用“
applicationAllMessage
”资源配置文件中“键”为“
userName
”的信息显示。
q
第二个
<fmt:message>
标签虽然被定义在
<fmt:bundle>
标签体内,但是它使用了
bundle
属性,因此将指定之前由
<fmt:setBundle>
标签保存的“
applicationMessage
”资源配置文件,该“键”为“
passWord
”的信息显示。
9.5.4
用于参数传递的
<fmt:param>
标签
<fmt:param>
标签应该位于
<fmt:message>
标签内,将为该消息标签提供参数值。它只有一个属性
value
。
<fmt:param>
标签有两种使用版本,一种是直接将参数值写在
value
属性中,另一种是将参数值写在标签体内。
9.5.6
用于为请求设置字符编码的
<fmt:requestEncoding>
标签
<fmt:requestEncoding>
标签用于为请求设置字符编码。它只有一个属性
value
,在该属性中可以定义字符编码。
9.5.7
用于设定时区的
<fmt:timeZone>
、
<fmt:setTimeZone>
标签
这两组标签都用于设定一个时区。唯一不同的是
<fmt:timeZone>
标签将使得在其标签体内的工作可以使用该时区设置,
<fmt:setBundle>
标签则允许将时区设置保存为一个变量,在之后的工作可以根据该变量来进行。它们的属性和描述如表
9.20
所示:
表
9.20
<fmt:timeZone>
、
<fmt:setTimeZone>
标签
属性和说明
|
属性
|
描述
|
|
value
|
时区的设置
|
|
var
|
<fmt:setTimeZone>
独有的属性,用于保存时区为一个变量
|
|
scope
|
变量的作用范围
|
9.5.8
用于格式化数字的
<fmt:formatNumber>
标签
<fmt:
formatNumber
>
标
签用于格式化数字。它的属性和描述如表
9.21
所示:
表
9.21
<fmt:formatNumber>
标签属性和说明
|
属性
|
描述
|
|
value
|
格式化的数字,该数值可以是
String
类型或
java.lang.Number
类型的实例
|
|
type
|
格式化的类型
|
|
pattern
|
格式化模式
|
|
var
|
结果保存变量
|
|
scope
|
变量的作用范围
|
|
maxIntegerDigits
|
指定格式化结果的最大值
|
|
minIntegerDigits
|
指定格式化结果的最小值
|
|
maxFractionDigits
|
指定格式化结果的最大值,带小数
|
|
minFractionDigits
|
指定格式化结果的最小值,带小数
|
<fmt:formatNumber>
标签实际是对应
java.util.NumberFormat
类,
type
属性的可能值包括
currency
(货币)、
number
(数字)和
percent
(百分比)。
下面看一个示例。
<fmt:formatNumber value="1000.888" type="currency" var="money"/>
该结果将被保存在“
money
”变量中,将根据
Locale
环境显示当地的货币格式。
9.5.9
用于解析数字的
<fmt:parseNumber>
标签
<fmt:parseNumber>
标签用于解析一个数字,并将结果作为
java.lang.Number
类的实例返回。
<fmt:parseNumber>
标签看起来和
<fmt:formatNumber>
标签的作用正好相反。它的属性和描述如表
9.22
所示:
表
9.22
<fmt:parseNumber>
标签属性和说明
|
属性
|
描述
|
|
value
|
将被解析的字符串
|
|
type
|
解析格式化的类型
|
|
pattern
|
解析格式化模式
|
|
var
|
结果保存变量,类型为
java.lang.Number
|
|
scope
|
变量的作用范围
|
|
parseLocale
|
以本地化的形式来解析字符串,该属性的内容应为
String
或
java.util.Locale
类型的实例
|
下面看一个示例。
<fmt:parseNumber value="15%" type="percent" var="num"/>
解析之后的结果为“
0.15
”。
9.5.10
用于格式化日期的
<fmt:formatDate>
标签
<fmt:formatDate>
标签用于格式化日期。它的属性和描述如表
9.23
所示:
表
9.23
<fmt:formatDate>
标签属性和说明
|
属性
|
描述
|
|
value
|
格式化的日期,该属性的内容应该是
java.util.Date
类型的实例
|
|
type
|
格式化的类型
|
|
pattern
|
格式化模式
|
|
var
|
结果保存变量
|
|
scope
|
变量的作用范围
|
|
timeZone
|
指定格式化日期的时区
|
<fmt:formatDate>
标签与
<fmt:timeZone>
、
<fmt:setTimeZone>
两组标签的关系密切。若没有指定
timeZone属性,
也可以通过
<fmt:timeZone>
、
<fmt:setTimeZone>
两组标签设定的时区来格式化最后的结果。
9.5.11
用于解析日期的
<fmt:parseDate>
标签
<fmt:parseDate>
标签用于解析一个日期,并将结果作为
java.lang.Date
类型的实例返回。
<fmt:parseDate>
标签看起来和
<fmt:formatDate>
标签的作用正好相反。它的属性和描述如表
9.24
所示:
表
9.24
<fmt:parseDate>
标签属性和说明
|
属性
|
描述
|
|
value
|
将被解析的字符串
|
|
type
|
解析格式化的类型
|
|
pattern
|
解析格式化模式
|
|
var
|
结果保存变量,类型为
java.lang.Date
|
|
scope
|
变量的作用范围
|
|
parseLocale
|
以本地化的形式来解析字符串,该属性的内容为
String
或
java.util.Locale
类型的实例
|
|
timeZone
|
指定解析格式化日期的时区
|
<fmt:parseNumber>
和
<fmt:parseDate>
两组标签都实现解析字符串为一个具体对象实例的工作,因此,这两组解析标签对
var
属性的字符串参数要求非常严格。就
JSP
页面的表示层前段来说,处理这种解析本不属于份内之事,因此
<fmt:parseNumber>
和
<fmt:parseDate>
两组标签应该尽量少用,替代工作的地方应该在服务器端表示层的后段,比如在
Servlet
中。
摘要: 9.3.9
用于包含页面的
<c:import>
...
阅读全文
摘要: 9.3.2
用于赋值的
<c:set>
...
阅读全文
摘要: 9.2.3 EL
表达式的操作符
...
阅读全文
这是Jboss 的jBPM3.12框架的用户指南的中文翻译。我的翻译风格是中英文对照,只翻译部分我认为重要的,不翻译简单的英文,以免浪费你我的时间。 同时,对于其中的部分内容,我会在翻译中做出解释和写上我的理解。
Chapter 5. Deployment部署
jBPM is an embeddable BPM engine, which means that you can take jBPM and embed it into your own java project, rather then installing a separate product and integrate with it. One of the key aspects that make this possible is minimizing the dependencies. This chapter discusses the jbpm libraries and their dependencies.
jBPM是一个嵌入式的BPM(业务程序管理)引擎。本章讨论jbpm库和它的依赖库。
5.1. Java runtime environment
jBPM 3 requires J2SE 1.4.2+
5.2. jBPM libraries
jbpm-[version].jar is the library with the core jbpm functionality.是jbpm的核心功能库。
jbpm-identity-[version].jar is the (optional) library containing an identity component as described in Section 11.11, “The identity component”.
可选的,这个库包含了身份验证组件。用于流程的参与者的管理。
5.3. Third party libraries第三方库
In a minimal deployment, you can create and run processes with jBPM by putting only the commons-logging and dom4j library in your classpath. Beware that persisting processes to a database is not supported. The dom4j library can be removed if you don't use the process xml parsing, but instead build your object graph programatically.
最小的jbpm部署,只需要核心jbpm库和commons-logging库,以及dom4j库到你的classpath中。此时,不支持持久化业务程序到数据库。
Table 5.1.
Library库 | Usage用途 | Description描述 | Directory目录 |
commons-logging.jar | logging in jbpm and hibernate | The jBPM code logs to commons logging. The commons logging library can be configured to dispatch the logs to e.g. java 1.4 logging, log4j, ... See the apache commons user guide for more information on how to configure commons logging. if you're used to log4j, the easiest way is to put the log4j lib and a log4j.properties in the classpath. commons logging will automatically detect this and use that configuration. | lib/jboss (from jboss 4.0.3) |
dom4j-1.6.1.jar | process definitions and hibernate persistence | xml parsing | lib/dom4j |
A typical deployment for jBPM will include persistent storage of process definitions and process executions. In that case, jBPM does not have any dependencies outside hibernate and its dependent libraries.
典型的jBPM部署包括持久化业务程序定义和执行的功能。 需要Hibernate
Of course, hibernate's required libraries depend on the environment and what features you use. For details refer to the hibernate documentation. The next table gives an indication for a plain standalone POJO development environment.
下面的表给出了简单的标准POJO部署环境需要的第三方库。
jBPM is distributed with hibernate 3.1 final. But it can also work with 3.0.x. In that case, you might have to update a few hibernate queries in the hibernate.queries.hbm.xml configuration file. For more info about customizing queries, see Section 7.6, “Customizing queries”
Table 5.2.
Library库 | Usage | Description | Directory |
hibernate3.jar | hibernate persistence | the best O/R mapper | lib/hibernate (hibernate 3.1 final) |
antlr-2.7.5H3.jar | used in query parsing by hibernate persistence | parser library | lib/jboss (from jboss 4.0.3) |
cglib-2.1_2jboss.jar | hibernate persistence | reflection library used for hibernate proxies | lib/jboss (from jboss 4.0.3) |
commons-collections.jar | hibernate persistence | | lib/jboss (from jboss 4.0.3) |
ehcache-1.1.jar | hibernate persistence (in the default configuration) | second level cache implementation.二级缓存实现。 When configuring a different cache provider for hibernate, this library is not required. | lib/hibernate |
jaxen-1.1-beta-4.jar | process definitions and hibernate persistence | XPath library (used by dom4j) | lib/hibernate |
jdbc2_0-stdext.jar | hibernate persistence | | lib/hibernate |
asm.jar | hibernate persistence | asm byte code library 二进制代码修改库 | lib/hibernate |
asm-attrs.jar | hibernate persistence | asm byte code library | lib/hibernate |
The beanshell library is optional. If you don't include it, you won't be able to use the beanshell integration in the jbpm process language and you you'll get a log message saying that jbpm couldn't load the Script class and hence, the script element won't be available.
Beanshell库是可选的。
Table 5.3.
Library | Usage | Description | Directory |
bsh-1.3.0.jar | beanshell script interpreter | Only used in the script's and decision's. When you don't use these process elements, the beanshell lib can be removed, but then you have to comment out the Script.hbm.xml mapping line in the hibernate.cfg.xml | lib/jboss |
摘要: 这是Jboss 的jBPM3.12框架的用户指南的中文翻译。我的翻译风格是中英文对照,只翻译部分我认为重要的,不翻译简单的英文,以免浪费你我的时间。 同时,对于其中的部分内容,我会在翻译中做出解释和写上我的理解。
Chapter 4. Graph Oriented Programming面向图表编程4.1. Introduction介绍This chapter can be conside...
阅读全文
摘要: 这是Jboss 的jBPM3.12框架的用户指南的中文翻译。我的翻译风格是中英文对照,只翻译部分我认为重要的,不翻译简单的英文,以免浪费你我的时间。 同时,对于其中的部分内容,我会在翻译中做出解释和写上我的理解。Chapter 3. Tutorial指南This tutorial will show you basic process constructs 过程建造in jpdl an...
阅读全文
这是Jboss 的jBPM3.12框架的用户指南的中文翻译。我的翻译风格是中英文对照,只翻译部分我认为重要的,不翻译简单的英文,以免浪费你我的时间。
同时,对于其中的部分内容,我会在翻译中做出解释和写上我的理解。
Chapter 2. Getting started起步
This chapter takes you through the first steps of getting JBoss jBPM and provides the initial pointers to get up and running in no time.
初始化JBpm3.12
2.1. Downloadables Overview
Listed below are the different jBPM packages that are available today. Each of these packages contains one or more downloadable files. Along with each of these files goes a description of its contents and a pointer to any relevant installation instructions if they are available.
All downloads described below can be found on the sourceforge jbpm downloads page.
2.1.1. jBPM 3
Download JBoss jBPM 3 at sourceforge.net. This is the main distribution package containing the core engine and a number of additional modules that you may need to work with jBPM. 包括JBpm核心和其他包。
- The Starters Kit (jbpm-starters-kit-<version>.zip): If you want to get started with jBPM quickly, this is the file you want to download. It contains all the other modules of this package plus the graphical designer in one single download. Extract the zipped archive into a folder of your choice and read the file named 'readme.html' for more info and further installation instructions. With this starters kit you can immediately get started with the Chapter 3, Tutorial.
包含了包括图形化设计器在内的所有模块,能够帮助你快速启动。
- Core Engine and Identity Component (jbpm-<version>.zip): The download contains the jBPM core engine as well as the identity component for actor and group management. To start working with it, extract the archive into a folder of your choice. You will find pointers to the User's Guide and other important information resources in the 'readme.html' file in the 'jbpm-<version>' folder.
核心,包括核心引擎和身份组建,内有用户指南文档。
- Database Extensions (jbpm-db-<version>.zip):数据库扩展 The database extension pack contains the jBPM core engine as well as the identity component for actor and group management. To start working with it, extract the archive into a folder of your choice. You will find pointers to the User's Guide and other important information resources in the 'readme.html' file in the 'jbpm-<version>' folder.
2.1.2. jBPM Process Designer
jBPM过程设计器
Download JBoss jBPM Process Designer at sourceforge.net. The designer is an eclipse plugin and enables you to author 创作your process definitions过程定义 and to easily deploy them. The plug-in is available for download either as a zipped Eclipse feature or as a zipped Eclipse update site. There is no difference in content, the only difference is in the way you have to do the installation.
- Eclipse Update Site (jbpm-gpd-site-<version>.zip): If you want to be absolutely sure that the designer installation goes smoothly, we recommend to use the update site mechanism together with a new Eclipse installation. Of cource the Eclipse version should match the downloaded update site archive. To get started with the designer plugin, follow the instructions in the 'readme.html' file included in the archives root folder to succesfully install the GPD.
使用本地站点更新方式部署。
- Eclipse Feature (jbpm-gpd-feature-<version>.zip): If you are tired of each time having to do a fresh Eclipse installation and you are willing to cope with some possible issues, you can try the feature download. In this case installation is as easy as extracting the archive into your Eclipse installation (make sure the included 'plugins' and 'features' folders end up in the same location of your Eclipse installation) overwriting the files and folders with the same name that are possibly already present. This installation is very easy, but you could run into incompatibility issues when you overwrite plugins already present in your installation because of other features that you did install. Though they have the same name it could happen that the versions of these colliding plugins are not equal, hence the possible incompatibilities. The installation instructions are repeated in the 'readme.html' file.
这个是手工部署。
2.1.3. jBPM BPEL extension
Download JBoss jBPM BPEL extension at sourceforge.net. It contains only one file : jbpm-bpel-<version>.zip. To get started with the BPEL extensions, look in the User's Guide in the 'doc' subfolder of the toplevel folder.
jbpm-bpel:含有JBoss jBPM的BPEL扩展件方面的信息。
BPEL是一个规范的SOA组件。因为与JBoss jBPM使用的许可证不同,所以被独立了出来。
2.2. The JBoss jBPM project directory
- professional support: JBoss is the company that backs this project with professional support, training and consultancy services.
- user guide: is the document you're reading and serves as the main entry point into the project.
- forums: get in contact with the community, ask questions and discuss jBPM 论坛,社区。
- wiki: extra information, mostly provided by the community
- issue tracker: for submitting bugs and feature requests
- downloads: sourceforge download page for jBPM
- mailing lists: mailing lists are used for announcements
- javadocs: part of the download in the doc/javadoc directory.
2.3. CVS access
2.3.1. Anonymous CVS access
Alternatively, you can get JBoss jBPM from cvs with the following information:
- Connection type: pserver
- User: anonymous
- Host: anoncvs.forge.jboss.com
- Port: 2401 (which is the default)
- Repository path: /cvsroot/jbpm
- Label: :pserver:anonymous@anoncvs.forge.jboss.com:/cvsroot/jbpm
2.3.2. Developer CVS access
To get cvs developer access, you must sign contributors agreement and you need an ssh key. More information on both can be found on the JBoss cvs repository wiki page
- Connection type: ext over ssh (extssh in eclipse)
- User: sf.net username or jboss username
- Host: cvs.forge.jboss.com
- Port: 2401 (which is the default)
- Repository path: /cvsroot/jbpm
- Label: :pserver:anonymous@cvs.forge.jboss.com:/cvsroot/jbpm
利用JBPM开发一个工作流应用,相对于使用shark是比较简单直观的。我们之前提到过,一个工作流管理系统最基本的组件包括流程定义组件,流程执行组件和流程客户端组件。下面从这三个方面看一下JBPM对开发工组流应用的支持。
1.
流程的定义
JBPM
没有采用WfMC提出的流程定义语言XPDL,而是自己开发了一种称为JPDL的语言来定义流程。因此,在开发一个应用时我们最终需要生成一个符合该XML schema的文件processdefinition.xml来表示定义好的流程。它可以manually获得,也可以使用可视化的定义工具自动生成。
JBPM
专门提供了一个开发流程的环境,称为process development environment(pde)。可以
在
jbpm
根目录下执行命令
ant create.pde
来生成
pde
工作目录
。生成的包结构如下所示:

Build.xml
文件用于配置一个流程,即利
用
ant
工具解析
processdefinition.xml
文件,并将运行流程时所需的相关信息存储到数据库中。
Lib
存放了开发和配置流程所需的全部库文件,包括数据库的
jdbc
驱动。
Src
包括开发和配置流程的全部源文件和所需资源。
Src/config
只有两个文件,
jbpm.properties
和
log4j.properties
。其中,
jbpm.propertie
文件包含了数据库的配置信息。因此,更换数据库或数据库的
jdbc
驱动都需要修改这里。
Scr/java
存放
java
源文件。
Src/process
存放工作流定义文件
(processdefinition.xml)
和相关的资源文件,如图片和
form
文件。
Src/test
存放测试代码。
Target/classes
是
src/java
中源码的输出目录,存放编译后的
class
文件。
Target/par
存放用命令
ant build.process.archives
生成的
par
包。
Par
包实际上就是把
src/process
中的流程定义及相关文件打包成
zip
形式存储。
Target/test-classes
存放测试程序的编译结果。
Target/test-report
存放测试报告。
2. 流程的执行
JBPM
把负责执行流程的类库打包成jbpm.core.jar,它也是JBPM工作流引擎的核心。在开发一个工作流应用时,只需将该jar文件放到相应的lib目录下面。而开发人员就可以专注于开发一个流程模型,完成对流程的定义,而无需过多考虑流程执行的细节。
3.
流程的客户端
客户端组件的开发,需要一个应用服务器作为servlet container,我们这里选择了tomcat。JBPM将开发一个webapp所需的类打包成jbpm.web.jar,包括自定义的tag和Struts用到的类等等。开发应用时,将该jar放到WEB-INF\lib下面就可以了。
一个基于工作流的webapp应用的开发和普通webapp的开发方式很相似。包结构也保持一贯作风:

所以,我们需要做的主要工作是完成客户端应用所需的
jsp
页面的开发,可以选用
Struts
来进行开发。需要注意的是,我们要对
lib
目录下的
jbpm.properties
文件进行配置,主要是对数据库
jdbc
驱动的配置。
4.
系统数据库的创建
JBPM
可以支持多种数据库系统,包括MSSQL,,Mysql,Oracle,hdbsql等。它提供了很灵活的配置方式,只需要修改jbpm.properties文件,同时将相应的JDBC Driver拷贝到lib目录就可以了。利用ant的generate.ddl命令,JBPM还支持自动生成用于创建系统表的sql脚本,而且可以生成对应于各种数据库系统的脚本,非常便于数据库系统的更换和系统数据库的创建。
5. 开发过程
环境配置如下:
JBPM 2.0
Ant 1.6.2
Tomcat 5.0.27
SQL Server 2000
SQL Server 2000 Driver for JDBC
仍以之前演示过的request a payraise为例(见下图),介绍一下利用JBPM开发一个工作流应用需要完成的工作。

1)
首先,我们需要完成流程的定义。这不仅包括定义processdefinition.xml,还要对流程执行时使用到的其他资源进行定义。比如,在web应用中用到的图片,form等。还需要配置form.xml,该文件确定了流程中不同状态和form的关系,如request a payraise状态下,需要如下图所示的form:

补充Processdefinition.xml
示例:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE process-definition PUBLIC "-//jBpm/jBpm Mapping DTD 2.0//EN" "http://jbpm.org/dtd/processdefinition-2.0.dtd">
<process-definition name="pay raise process">
<!-- SWIMLANES -->
<swimlane name="requester" />
<swimlane name="boss">
<delegation class="org.jbpm.delegation.assignment.ActorAssignmentHandler">cg</delegation>
</swimlane>
<swimlane name="erp operator">
<delegation class="org.jbpm.delegation.assignment.ActorAssignmentHandler">pf</delegation>
</swimlane>
<!-- START-STATE -->
<start-state name="request a payraise" swimlane="requester">
<transition to="evaluating"/>
</start-state>
<!-- NODES -->
<state name="evaluating">
<assignment swimlane="boss" />
<transition name="approve" to="fork"/>
<transition name="disapprove" to="done"/>
</state>
<fork name="fork">
<transition to="updating erp asynchronously" />
<transition to="treating collegues on cake and pie" />
</fork>
<state name="updating erp asynchronously">
<assignment swimlane="erp operator" />
<transition to="join" />
</state>
<state name="treating collegues on cake and pie">
<assignment swimlane="requester" />
<transition to="join" />
</state>
<join name="join">
<transition to="done" />
</join>
<!-- END-STATE -->
<end-state name="done" />
</process-definition>
2)
有了processdefinition.xml文件,我们就可以配置流程。即使用ant命令,解析这个文件并且将执行时需要的信息存储在数据库中。如下图:

3)
我们无需关心流程将怎么执行,完全交给jbpm.core.jar就好。
4)
剩下的另外一项比较繁重的工作就是开发一个用于该流程的客户端应用。前面已经提到过,
我们需要做的主要工作是完成客户端应用所需的
jsp
页面的开发。包括登录页面,查看自己的
tasklist
页面,执行
task
的页面等。除此之外,还可以通过日志来完成流程的监控和管理界面。这些都由应用的需求来决定。
这是Jboss 的jBPM3.12框架的用户指南的中文翻译。其中第一章的译文,是我在网上找到的。其他几章都是我自己做的翻译。我的翻译是中英文对照,只翻译部分我认为重要的,不翻译简单的英文,以免浪费你我的时间。
同时,对于其中的部分内容,我会在翻译中做出解释。
下面是从网络上找到的第一章,这是jBPM3.0的用户指南的译文。但是第一章,3.0和3.1内容相差不大,我就不做翻译了。直接使用这一篇。
目录
第一章绪论
JBoss jBPM 是一个灵活的,易扩展的工作流管理系统。JBoss jBPM有一套直观的流程建模语言,这套语言能用任务(task),异步通信的等待状态(wait state ),定时器(timer),自动化的动作(automated action)等来图形化的表示业务流程。为了把这些操作集成在一
起,JBoss jBPM拥有强大的,易扩展的控制流程机制。
JBoss jBPM对外依赖程度很小,你完全可以像用java的类库一样用它。并且它也可以被部署在高性能的J2EE集群应用服务器上。
JBoss jBPM能配置在任何数据库上,并且能被部署在任何的应用服务器上。
1.1 总览
工作流和业务流程处理功能的核心部分被打包成一个简单的java类库。这个类库包括了这样一个服务:流程信息的存储,更新,和从数据库中重新取回。
图1.1:JBoss jBPM组成模块的概略图
1.2 JBoss jBPM starter kit
starter kit是一个包含jbpm所有模块的下载包。这个下载包中包括以下模块:
· jbpm-server, 一个预选配置好的jboss应用服务器。
· jbpm-designer, 图形化定制流程的eclipse插件。
· jbpm-db, jBPM的数据库兼容包 (见后边论述)。
· jbpm, jbpm的核心模块,其中包括libs文件夹和这个用户说明。
· jbpm-bpel, JBoss jBPM对BPEL扩展的一些参考资料
预先配置好的JBoss应用服务器具有如下组成部分:
jBPM核心模块,被打包成一个用于提供服务的存档文件
带有jbpm表的集成数据库:默认的hypersonic数据库拥有jbpm表,并且这个表已经拥有一个流程了。
Jbpm的web控制台,它既可以被Jbpm管理员用也可以被流程的参与者使用。
执行定时器的Jbpm的调度程序,这个调度程序在starter kit里边被配置成一个servlet。这个servlet会产生一个新的线程来监视和执行定时器。
一个具体流程的例子,它已经被部署在jbpm数据库中了。
1.3 JBoss jBPM 流程图形定制器
JBoss jBPM还拥有一套图形化的设计工具。这个设计器是一个图形化的业务流程定制工具。
JBoss jBPM流程图形定制器是eclipse的一个插件。单独安装这个定制器非常简单。
这个图形设计器最重要的特性是:业务分析人员也能像技术开发人员一样用它来完成任务。这使得业务流程建模能平滑的转换到具体技术实现。
这个插件可以利用eclipse的一般升级机制通过一个升级站点得到安装(zip文件格式)。也可以通过解压一个特定的包到eclipse的安装目录来安装此插件。
1.4 JBoss jBPM的核心模块
JBoss jBPM的核心模块是一个用来管理流程定义和流程实例的执行环境的普通java程序。
JBoss jBPM是一个java类库。所以它可以被用在任何java环境中,比如:web应用程序,swing应用程序,EJB,web service……。JBPM类库还可以被打包并被当成无状态会话EJB(stateless session EJB)使用。这样可使它被部署在集群上并且适应高性能应用。这些无状态会话EJB必须符合J2EE1.3规范这样才能使它可以被部署在任何应用服务器上。
JBoss jBPM的核心模块被打包成一个简单的java库文件。依你功能的需要,jbpm-3.0.jar这个库文件对一些第三方的类库比如hibernate, dom4j有所依赖。这些依赖在第五章(部署)中作了详细的说明。
至于持久化,JBPM在内部用了hibernate。除了传统的O/R映射功能,hibernate还解决了不同数据SQL dialect差异的问题,这使得JBPM能适应现在所有的数据库。
JBoss jBPM API可以被你工程中任何的java代码调用,比如,你的web应用程序,EJB,web service 模块,消息驱动bean或其它任何java模块。
1.5 JBoss jBPM web应用程序的控制台
jBPM web应用程序的控制台提供两种服务。首先,它被用来当作一个用来和流程执行过程中产生的任务进行交互的主要用户接口,其次,它还是一个用来检查和操作运行实例的管理和监控平台。
1.6 JBoss jBPM人员组织模块
JBoss jBPM可以和任何包括人员和其他组织信息的公司结构集成在一起。但是对那些组织结构信息模块很难获取的项目,JBoss jBPM提供了这个模块。这个模块使用的模型要比传统的servlet, ejb,portlet模型丰富的多。
更多信息,请参照第九章第九节人员组织模块
1.7 JBoss jBPM调度程序
JBoss jBPM调度程序是一个用来监测和执行在流程执行过程中设置的定时器的模块。
定时器模块被打包在jbpm的核心包中,但是它必须被部署在以下环境中:或者你必须订制一个调度servlet,它来产生一个监测线程,或者你必须启动一个单独的JVM来执行调度程序。
1.8 JBoss jBPM 数据库兼容包
JBoss jBPM 数据库兼容包是一个下载包,它包括所有的资料,drivers和scripts,用这些你可以使jbpm运行在你选择的数据库上。
1.9 JBoss jBPM BPE的扩展
JBoss jBPM BPE的扩展是一个为了支持BPEL独立的扩展包。BPEL的本质就是一组用来参照别的web service写web service的xml脚本语言。
一、前言:
log4j 是一个开放源码项目,是广泛使用的以Java编写的日志记录包。由于log4j出色的表现, 当时在log4j完成时,log4j开发组织曾建议sun在jdk1.4中用log4j取代jdk1.4 的日志工具类,但当时jdk1.4已接近完成,所以sun拒绝使用log4j,当在java开发中实际使用最多的还是log4j, 人们遗忘了sun的日志工具类。 它的一个独有特性包括在类别中继承的概念。通过使用类别层次结构,这样就减少了日志记录输出量,并将日志记录的开销降到最低。
它允许开发者控制以任意间隔输出哪些日志语句。通过使用外部配置文件,完全可以在运行时进行配置。几乎每个大的应用程序都包括其自己的日志记录或跟踪 API。经验表明日志记录是开发周期中的重要组成部分。同样,日志记录提供一些优点。首先,它可以提供运行应用程序的确切 上下文。一旦插入到代码中,生成日志记录输出就不需要人为干涉。其次,日志输出可以保存到永久媒体中以便以后研究。最后,除了在开发阶段中使用,十分丰富的日志记录包还可以用作审计工具。
依照该规则,在 1996 年初,EU SEMPER(欧洲安全电子市场)项目就决定编写自己的跟踪 API。 在无数次改进、几次具体化和许多工作之后,该 API 已经演变成 log4j,一种流行的 Java 日志记录包。 这个包按 IBM 公共许可证分发,由开放源码权威机构认证。
日志记录有其自己的缺点。它会降低应用程序的速度。如果太详细,它可能会使屏幕滚动变得看不见。 为了减低这些影响,log4j 被设计成快速且灵活的。由于应用程序很少将日志记录当作是主要功能, log4j API 力争易于了解和使用。
log4j,它可以控制以任意间隔输出哪些日志语句。
二、主要组件
1、根类别(在类别层次结构的顶部,即全局性的日志级别)
配置根Logger,其语法为:
log4j.rootLogger = [ level ] , appenderName, appenderName, ...
level 是日志记录的类别
appenderName就是指定日志信息输出到哪个地方。您可以同时指定多个输出目的地。
类别level 为 OFF、FATAL、ERROR、WARN、INFO、DEBUG、log、ALL或自定义的优先级。
og4j常用的优先级FATAL>ERROR>WARN>INFO>DEBUG
配置根Logger,其语法为:
log4j.rootLogger = [ level ] , appenderName, appenderName, …
如果为log4j.rootLogger=WARN,则意味着只有WARN,ERROR,FATAL被输出,DEBUG,INFO将被屏蔽掉。
举例:log4j.rootCategory=INFO,stdout,Runlog,Errorlog
根日志类别为INFO,DEBUG将被屏蔽,其他的将被输出。 stdout,Runlog,Errorlog分别为3个输出目的地。
2、常用输出格式
-X号:X信息输出时左对齐;
%p:日志信息级别
%d{}:日志信息产生时间
%c:日志信息所在地(类名)
%m:产生的日志具体信息
%n:输出日志信息换行
举例:
log4j.appender.stdout.layout.ConversionPattern= %5p %d{yyyy-MM-dd HH:mm:ss} %c %m %n
log4j.appender.Runlog.layout.ConversionPattern= %5p %d{yyyy-MM-dd HH:mm:ss} %c %m %n
log4j.appender.Errorlog.layout.ConversionPattern= %5p %d{yyyy-MM-dd HH:mm:ss} %c %m %n
3、布局
使用的输出布局,其中log4j提供4种布局:
org.apache.log4j.HTMLLayout(以HTML表格形式布局)
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
举例:
输出格式为HTML表格
log4j.appender.stdout.layout=org.apache.log4j.HTMLLayout
输出格式为可以灵活地指定布局模式
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
输出格式为包含日志信息的级别和信息字符串
log4j.appender.stdout.layout=org.apache.log4j.SimpleLayout
输出格式为包含日志产生的时间、线程、类别等等信息
log4j.appender.stdout.layout=org.apache.log4j.TTCCLayout
4、目的地
配置日志信息输出目的地Appender,其语法为
log4j.appender.appenderName = fully.qualified.name.of.appender.class
log4j.appender.appenderName.option1 = value1
...
log4j.appender.appenderName.option = valueN
appenderName就是指定日志信息输出到哪个地方。您可以同时指定多个输出目的地。
log4j支持的输出目的地:
org.apache.log4j.ConsoleAppender 控制台
org.apache.log4j.FileAppender 文件
org.apache.log4j.DailyRollingFileAppender 每天产生一个日志文件
org.apache.log4j.RollingFileAppender (文件大小到达指定尺寸的时候产生一个新的文件),
org.apache.log4j.WriterAppender (将日志信息以流格式发送到任意指定的地方)
org.apache.log4j.net.SMTPAppender 邮件
org.apache.log4j.jdbc.JDBCAppender 数据库
其他如:GUI组件、甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等
举例:
输出到控制台
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender(指定输出到控制台)
log4j.appender.Threshold=DEBUG(指定输出类别)
log4j.appender.CONSOLE.Target=System.out
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout(指定输出布局)
log4j.appender.CONSOLE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n(指定输出格式)
输出到文件
log4j.appender.FILE=org.apache.log4j.FileAppender(指定输出到文件)
log4j.appender.FILE.File=file.log(指定输出的路径及文件名)
log4j.appender.FILE.Append=false
log4j.appender.FILE.layout=org.apache.log4j.PatternLayout(指定输出的布局)
log4j.appender.FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n(指定输出的格式)
输出到文件(轮换"日志文件",当日志文件达到指定大小时,该文件就被关闭并备份,然后创建一个新的日志文件)
log4j.appender.ROLLING_FILE=org.apache.log4j.RollingFileAppender(指定输出到文件)
log4j.appender.ROLLING_FILE.Threshold=ERROR(指定输出类别)
log4j.appender.ROLLING_FILE.File=rolling.log(指定输出的路径及文件名)
log4j.appender.ROLLING_FILE.Append=true
log4j.appender.ROLLING_FILE.MaxFileSize=10KB(指定输出到文件的大小)
log4j.appender.ROLLING_FILE.MaxBackupIndex=1
log4j.appender.ROLLING_FILE.layout=org.apache.log4j.PatternLayout(指定采用输出布局)
log4j.appender.ROLLING_FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n(指定采用输出格式)
输出到Socket
log4j.appender.SOCKET=org.apache.log4j.RollingFileAppender(指定输出到Socket)
log4j.appender.SOCKET.RemoteHost=localhost(远程主机)
log4j.appender.SOCKET.Port=5001(远程主机端口)
log4j.appender.SOCKET.LocationInfo=true
log4j.appender.SOCKET.layout=org.apache.log4j.PatternLayout(布局)
log4j.appender.SOCET.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD]%n%c[CATEGORY]%n%m[MESSAGE]%n%n(输出格式)
输出到邮件
log4j.appender.MAIL=org.apache.log4j.net.SMTPAppender(指定输出到邮件)
log4j.appender.MAIL.Threshold=FATAL
log4j.appender.MAIL.BufferSize=10
log4j.appender.MAIL.From=chenyl@hollycrm.com(发件人)
log4j.appender.MAIL.SMTPHost=mail.hollycrm.com(SMTP服务器)
log4j.appender.MAIL.Subject=Log4J Message
log4j.appender.MAIL.To=chenyl@hollycrm.com(收件人)
log4j.appender.MAIL.layout=org.apache.log4j.PatternLayout(布局)
log4j.appender.MAIL.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n(格式)
输出到数据库
log4j.appender.DATABASE=org.apache.log4j.jdbc.JDBCAppender(指定输出到数据库)
log4j.appender.DATABASE.URL=jdbc:mysql://localhost:3306/test(指定数据库URL)
log4j.appender.DATABASE.driver=com.mysql.jdbc.Driver(指定数据库driver)
log4j.appender.DATABASE.user=root(指定数据库用户)
log4j.appender.DATABASE.password=root(指定数据库用户密码)
log4j.appender.DATABASE.sql=INSERT INTO LOG4J (Message) VALUES ('[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n')(组织SQL语句)
log4j.appender.DATABASE.layout=org.apache.log4j.PatternLayout(布局)
log4j.appender.DATABASE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n(格式)
5、日志类别补充
有时我们需要对某个特定的部分指定有别于根类别的日志类别,可以指定某个包的优先级
如:
log4j.category.com.neusoft.mbip.dm.util=ERROR ,其中com.neusoft.mbip.dm.util为我们需要特别指定日志类别的部分。
或者可以指定输出文件的优先级
log4j.appender.Errorlog.Threshold=ERROR
三、 常用log4j配置
常用log4j配置,一般可以采用两种方式,.properties和.xml,下面举两个简单的例子:
1、log4j.properties
### 设置org.zblog域对应的级别INFO,DEBUG,WARN,ERROR和输出地A1,A2 ##
log4j.category.org.zblog=ERROR,A1
log4j.category.org.zblog=INFO,A2
log4j.appender.A1=org.apache.log4j.ConsoleAppender
### 设置输出地A1,为ConsoleAppender(控制台) ##
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
### 设置A1的输出布局格式PatterLayout,(可以灵活地指定布局模式)##
log4j.appender.A1.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%c]-[%p] %m%n
### 配置日志输出的格式##
log4j.appender.A2=org.apache.log4j.RollingFileAppender
### 设置输出地A2到文件(文件大小到达指定尺寸的时候产生一个新的文件)##
log4j.appender.A2.File=E:/study/log4j/zhuwei.html
### 文件位置##
log4j.appender.A2.MaxFileSize=500KB
### 文件大小##
log4j.appender.A2.MaxBackupIndex=1
log4j.appender.A2.layout=org.apache.log4j.HTMLLayout
##指定采用html方式输出
2、log4j.xml
<?xml version="1.0" encoding="GB2312" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="org.zblog.all" class="org.apache.log4j.RollingFileAppender">
<!-- 设置通道ID:org.zblog.all和输出方式:org.apache.log4j.RollingFileAppender -->
<param name="File" value="E:/study/log4j/all.output.log" /><!-- 设置File参数:日志输出文件名 -->
<param name="Append" value="false" /><!-- 设置是否在重新启动服务时,在原有日志的基础添加新日志 -->
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%p (%c:%L)- %m%n" /><!-- 设置输出文件项目和格式 -->
</layout>
</appender>
<appender name="org.zblog.zcw" class="org.apache.log4j.RollingFileAppender">
<param name="File" value="E:/study/log4j/zhuwei.output.log" />
<param name="Append" value="true" />
<param name="MaxFileSize" value="10240" /> <!-- 设置文件大小 -->
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%p (%c:%L)- %m%n" />
</layout>
</appender>
<logger name="zcw.log"> <!-- 设置域名限制,即zcw.log域及以下的日志均输出到下面对应的通道中 -->
<level value="debug" /><!-- 设置级别 -->
<appender-ref ref="org.zblog.zcw" /><!-- 与前面的通道id相对应 -->
</logger>
<root> <!-- 设置接收所有输出的通道 -->
<appender-ref ref="org.zblog.all" /><!-- 与前面的通道id相对应 -->
</root>
</log4j:configuration>
3、配置文件加载方法:
import org.apache.log4j.Logger;
import org.apache.log4j.PropertyConfigurator;
import org.apache.log4j.xml.DOMConfigurator;
public class Log4jApp {
public static void main(String[] args) {
DOMConfigurator.configure("E:/study/log4j/log4j.xml");//加载.xml文件
//PropertyConfigurator.configure("E:/study/log4j/log4j.properties");//加载.properties文件
Logger log=Logger.getLogger("org.zblog.test");
log.info("测试");
}
}
4、项目使用log4j
在web应用中,可以将配置文件的加载放在一个单独的servlet中,并在web.xml中配置该servlet在应用启动时候加载。
对于在多人项目中,可以给每一个人设置一个输出通道,这样在每个人在构建Logger时,用自己的域名称,让调试信
息输出到自己的log文件中。
四、log4j配置举例(properties)
#log4j.rootLogger = [ level ] , appenderName, appenderName,
#类别level 为 OFF、FATAL、ERROR、WARN、INFO、DEBUG、log、ALL或自定义的优先级
#Log4j常用的优先级FATAL>ERROR>WARN>INFO>DEBUG
#stdout为控制台 ,Errorlog为错误记录日志 ,
log4j.rootCategory=INFO,stdout,Runlog,Errorlog
#输出的appender的格式为
#log4j.appender.appenderName = fully.qualified.name.of.appender.class
#log4j.appender.appenderName.option1 = value1
#log4j.appender.appenderName.option = valueN
#Log4j中appender支持的输出
#org.apache.log4j.ConsoleAppender 控制台
#org.apache.log4j.FileAppender 文件
#org.apache.log4j.DailyRollingFileAppender 每天产生一个日志文件
#org.apache.log4j.RollingFileAppender (文件大小到达指定尺寸的时候产生一个新的文件),
#org.apache.log4j.WriterAppender (将日志信息以流格式发送到任意指定的地方)
#org.apache.log4j.net.SMTPAppender 邮件
#org.apache.log4j.jdbc.JDBCAppender 数据库
#定义输出的形式
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.Runlog=org.apache.log4j.DailyRollingFileAppender
log4j.appender.Errorlog=org.apache.log4j.DailyRollingFileAppender
#可以指定输出文件的优先级
log4j.appender.Errorlog.Threshold=ERROR
#指定输出的文件
log4j.appender.Runlog.File=D:\\UserInfoSyn\\WebRoot\\WEB-INF\\runlog\\runlog.log
log4j.appender.Errorlog.File=D:\\UserInfoSyn\\WebRoot\\WEB-INF\\errorlog\\errorlog.log
#Log4j的layout布局
#org.apache.log4j.HTMLLayout 以HTML表格形式布局
#org.apache.log4j.PatternLayout 可以灵活地指定布局模式
#org.apache.log4j.SimpleLayout 包含日志信息的级别和信息字符串
#org.apache.log4j.TTCCLayout 包含日志产生的时间、线程、类别等等信息
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.Runlog.layout=org.apache.log4j.PatternLayout
log4j.appender.Errorlog.layout=org.apache.log4j.PatternLayout
#输出格式,log4j javadoc org.apache.log4j.PatternLayout
#-X号:X信息输出时左对齐;
#%p:日志信息级别
# %d{}:日志信息产生时间
# %c:日志信息所在地(类名)
# %m:产生的日志具体信息
# %n:%n:输出日志信息换行
log4j.appender.stdout.layout.ConversionPattern= %5p %d{yyyy-MM-dd HH:mm:ss} %c %m %n
log4j.appender.Runlog.layout.ConversionPattern= %5p %d{yyyy-MM-dd HH:mm:ss} %c %m %n
log4j.appender.Errorlog.layout.ConversionPattern= %5p %d{yyyy-MM-dd HH:mm:ss} %c %m %n
#指定某个包的优先级
log4j.category.com.neusoft.mbip.dm.util=ERROR
#示例
###################
# Console Appender
###################
#log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
#log4j.appender.Threshold=DEBUG
#log4j.appender.CONSOLE.Target=System.out
#log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
#log4j.appender.CONSOLE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
#log4j.appender.CONSOLE.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD] n%c[CATEGORY]%n%m[MESSAGE]%n%n
#####################
# File Appender
#####################
#log4j.appender.FILE=org.apache.log4j.FileAppender
#log4j.appender.FILE.File=file.log
#log4j.appender.FILE.Append=false
#log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
#log4j.appender.FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
# Use this layout for LogFactor 5 analysis
########################
# Rolling File????? RollingFileAppender??????????????????
########################
#log4j.appender.ROLLING_FILE=org.apache.log4j.RollingFileAppender
#log4j.appender.ROLLING_FILE.Threshold=ERROR
# 文件位置
#log4j.appender.ROLLING_FILE.File=rolling.log
#log4j.appender.ROLLING_FILE.Append=true
#文件大小
#log4j.appender.ROLLING_FILE.MaxFileSize=10KB
#指定采用输出布局和输出格式
#log4j.appender.ROLLING_FILE.MaxBackupIndex=1
#log4j.appender.ROLLING_FILE.layout=org.apache.log4j.PatternLayout
#log4j.appender.ROLLING_FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
####################
# Socket Appender
####################
#log4j.appender.SOCKET=org.apache.log4j.RollingFileAppender
#log4j.appender.SOCKET.RemoteHost=localhost
#log4j.appender.SOCKET.Port=5001
#log4j.appender.SOCKET.LocationInfo=true
# Set up for Log Facter 5
#log4j.appender.SOCKET.layout=org.apache.log4j.PatternLayout
#log4j.appender.SOCET.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD]%n%c[CATEGORY]%n%m[MESSAGE]%n%n
########################
# SMTP Appender
#######################
#log4j.appender.MAIL=org.apache.log4j.net.SMTPAppender
#log4j.appender.MAIL.Threshold=FATAL
#log4j.appender.MAIL.BufferSize=10
#log4j.appender.MAIL.From=chenyl@hollycrm.com
#log4j.appender.MAIL.SMTPHost=mail.hollycrm.com
#log4j.appender.MAIL.Subject=Log4J Message
#log4j.appender.MAIL.To=chenyl@hollycrm.com
#log4j.appender.MAIL.layout=org.apache.log4j.PatternLayout
#log4j.appender.MAIL.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
########################
# JDBC Appender
#######################
#log4j.appender.DATABASE=org.apache.log4j.jdbc.JDBCAppender
#log4j.appender.DATABASE.URL=jdbc:mysql://localhost:3306/test
#log4j.appender.DATABASE.driver=com.mysql.jdbc.Driver
#log4j.appender.DATABASE.user=root
#log4j.appender.DATABASE.password=
#log4j.appender.DATABASE.sql=INSERT INTO LOG4J (Message) VALUES ('[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n')
#log4j.appender.DATABASE.layout=org.apache.log4j.PatternLayout
#log4j.appender.DATABASE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
########################
# Log Factor 5 Appender
########################
#log4j.appender.LF5_APPENDER=org.apache.log4j.lf5.LF5Appender
#log4j.appender.LF5_APPENDER.MaxNumberOfRecords=2000
###################
#自定义Appender
###################
#log4j.appender.im = net.cybercorlin.util.logger.appender.IMAppender
#log4j.appender.im.host = mail.cybercorlin.net
#log4j.appender.im.username = username
#log4j.appender.im.password = password
#log4j.appender.im.recipient = corlin@cybercorlin.net
#log4j.appender.im.layout=org.apache.log4j.PatternLayout
#log4j.appender.im.layout.ConversionPattern =[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
摘要: 网上反应比较强烈。本人也因为工作需要的原因,将其封装了成了ExcelManager。企业当中,做报表的数据来源肯定就是数据库了。该ExcelManager目前只提供Ms Sql Server的支持,因为我们公司使用的就是ms sql server 2000 了。封装后的ExcelManager,你只需传入你的报表表头(一级表头、二级表头。大部分有两级也就够了。如果你有多个,可自行修改该类.),并将...
阅读全文
HTML页面并不总是向用户显示数据输出的最好方式,有时候需要生成不可改变的文件打印,PDF可能是种不错的选择。
Spring支持从数据动态生成PDF或Excel文件
下面这个简单实现的例子实现了spring输出PDF和Excel文件,为了使用Excel电子表格,你需要在你的classpath中加入poi-2.5.1.jar库文件,而对PDF文件,则需要iText.jar文件。它们都包含在Spring的主发布包中。
下面是测试项目代码:
1、控制器配置代码
 <?xml version="1.0" encoding="UTF-8"?>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="beanNameViewResolver"
class="org.springframework.web.servlet.view.BeanNameViewResolver" />
<bean id="viewController" class="com.zhupan.spring.ViewController" />
<bean id="urlMapping"
class="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping">
<property name="mappings">
<props>
<prop key="/view*.shtml">viewController</prop>
</props>
</property>
</bean>
</beans>
3、用于Excel视图的视图子类化
为了在生成输出文档的过程中实现定制的行为,我们将继承合适的抽象类。对于Excel,这包括提供一个 org.springframework.web.servlet.view.document.AbstractExcelView的子类,并实现 buildExcelDocument方法。
package com.zhupan.view;
import java.util.Date;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFCellStyle;
import org.apache.poi.hssf.usermodel.HSSFDataFormat;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.springframework.web.servlet.view.document.AbstractExcelView;

 public class ViewExcel extends AbstractExcelView
public class ViewExcel extends AbstractExcelView  {
{

public void buildExcelDocument(
Map model, HSSFWorkbook workbook,
HttpServletRequest request, HttpServletResponse response)

 throws Exception {
throws Exception {
HSSFSheet sheet = workbook.createSheet("list");
sheet.setDefaultColumnWidth((short) 12);
HSSFCell cell = getCell(sheet, 0, 0);
setText(cell, "Spring Excel test");
HSSFCellStyle dateStyle = workbook.createCellStyle();
dateStyle.setDataFormat(HSSFDataFormat.getBuiltinFormat("m/d/yy"));
cell = getCell(sheet, 1, 0);
cell.setCellValue(new Date());
cell.setCellStyle(dateStyle);
getCell(sheet, 2, 0).setCellValue(458);
HSSFRow sheetRow = sheet.createRow(3);
for (short i = 0; i < 10; i++) {
sheetRow.createCell(i).setCellValue(i * 10);
 }
}
}
 }
}
4、用于PDF视图的视图子类化
需要象下面一样继承org.springframework.web.servlet.view.document.AbstractPdfView,并实现buildPdfDocument()方法。
package com.zhupan.view;
import java.util.List;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.view.document.AbstractPdfView;
import com.lowagie.text.Document;
import com.lowagie.text.Paragraph;
import com.lowagie.text.pdf.PdfWriter;
public class ViewPDF extends AbstractPdfView {
public void buildPdfDocument(Map model, Document document,
PdfWriter writer, HttpServletRequest request,
HttpServletResponse response) throws Exception {
List list = (List) model.get("list");
for (int i = 0; i < list.size(); i++)
document.add(new Paragraph((String) list.get(i)));
}
}
5、其他文件
1)控制器ViewController
package com.zhupan.spring;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.mvc.multiaction.MultiActionController;
import com.zhupan.view.ViewExcel;
import com.zhupan.view.ViewPDF;
public class ViewController extends MultiActionController{
public ModelAndView viewPDF(HttpServletRequest request, HttpServletResponse response) throws Exception {
List list = new ArrayList();
Map model=new HashMap();
list.add("test1");
list.add("test2");
model.put("list",list);
ViewPDF viewPDF=new ViewPDF();
return new ModelAndView(viewPDF,model);
}
public ModelAndView viewExcel(HttpServletRequest request, HttpServletResponse response) throws Exception {
List list = new ArrayList();
Map model=new HashMap();
list.add("test1");
list.add("test2");
model.put("list",list);
ViewExcel viewExcel=new ViewExcel();
return new ModelAndView(viewExcel,model);
}
} 2)web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>springPDFTest</display-name>
<servlet>
<servlet-name>springPDFTest</servlet-name>
<servlet-class>
org.springframework.web.servlet.DispatcherServlet
</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>springPDFTest</servlet-name>
<url-pattern>*.shtml</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
</web-app>
3)index.jsp
<%@ page contentType="text/html; charset=gb2312"%>
<a href="viewPDF.shtml">PDF视图打开 </a>
<br>
<a href="viewExcel.shtml">Excel视图打开</a>
作者:佚名 来自:J2ME开发网
Ant是Java平台下非常棒的批处理命令执行程序,能自动完成编译,测试,打包,部署等等一系列任务。
Ant是Java平台下非常棒的批处理命令执行程序,能非常方便地自动完成编译,测试,打包,部署等等一系列任务,大大提高开发效率。如果你现在还没有开始使用Ant,那就要赶快开始学习使用,使自己的开发水平上一个新台阶。
Eclipse 中已经集成了Ant,我们可以直接在Eclipse中运行Ant。
以前面建立的Hello工程为例,创建以下目录结构:

新建一个build.xml,放在工程根目录下。build.xml定义了Ant要执行的批处理命令。虽然Ant也可以使用其它文件名,但是遵循标准能更使开发更规范,同时易于与别人交流。
通常,src存放Java源文件,classes存放编译后的class文件,lib存放编译和运行用到的所有jar文件,web存放JSP等web文件,dist存放打包后的jar文件,doc存放API文档。
然后在根目录下创建build.xml文件,输入以下内容:
<xml version="1.0"?>
<project name="Hello world" default="doc">
<-- properies -->
<property name="src.dir" value="src" />
<property name="report.dir" value="report" />
<property name="classes.dir" value="classes" />
<property name="lib.dir" value="lib" />
<property name="dist.dir" value="dist" />
<property name="doc.dir" value="doc"/>
<-- 定义classpath -->
<path id="master-classpath">
<fileset file="${lib.dir}/*.jar" />
<pathelement path="${classes.dir}"/>
<path>
<-- 初始化任务 -->
<target name="init">
<target>
<-- 编译 -->
<target name="compile" depends="init" description="compile the source files">
<mkdir dir="${classes.dir}"/>
<javac srcdir="${src.dir}" destdir="${classes.dir}" target="1.4">
<classpath refid="master-classpath"/>
<javac>
<target>
<-- 测试 -->
<target name="test" depends="compile" description="run junit test">
<mkdir dir="${report.dir}"/>
<junit printsummary="on"
haltonfailure="false"
failureproperty="tests.failed"
showoutput="true">
<classpath refid="master-classpath" />
<ormatter type="plain"/>
<batchtest todir="${report.dir}">
<fileset dir="${classes.dir}">
<include name="**/*Test.*"/>
<fileset>
<batchtest>
<junit>
<fail if="tests.failed">
***********************************************************
**** One or more tests failed! Check the output ... ****
***********************************************************
<fail/>
<target/>
<-- 打包成jar -->
<target name="pack" depends="test" description="make .jar file">
<mkdir dir="${dist.dir}" />
<jar destfile="${dist.dir}/hello.jar" basedir="${classes.dir}">
<xclude name="**/*Test.*" />
<xclude name="**/Test*.*" />
<jar/>
<targe/t>
<-- 输出api文档 -->
<target name="doc" depends="pack" description="create api doc">
<mkdir dir="${doc.dir}" />
<javadoc destdir="${doc.dir}"
author="true"
version="true"
use="true"
windowtitle="Test API">
<packageset dir="${src.dir}" defaultexcludes="yes">
<include name="example/**" />
<packageset/>
<doctitle>[CDATA[<1>ello, test<h1>]>doctitle>
<dottom>[CDATA[<>ll Rights Reserved.<i>]>bottom>
<tag name="todo" scope="all" description="To do:" />
<javadoc/>
<target/>
<project/>
以上xml依次定义了init(初始化),compile(编译),test(测试),doc(生成文档),pack(打包)任务,可以作为模板。
选中Hello工程,然后选择“Project”,“Properties”,“Builders”,“New…”,选择“Ant Build”:

填入Name:Ant_Builder;Buildfile:build.xml;Base Directory:${workspace_loc:/Hello}(按“Browse Workspace”选择工程根目录),由于用到了junit.jar包,搜索Eclipse目录,找到junit.jar,把它复制到Hello/lib目录下,并添加到Ant的Classpath中:

然后在Builder面板中钩上Ant_Build,去掉Java Builder:

再次编译,即可在控制台看到Ant的输出:
Buildfile: F:\eclipse-projects\Hello\build.xml
init:
compile:
[mkdir] Created dir: F:\eclipse-projects\Hello\classes
[javac] Compiling 2 source files to F:\eclipse-projects\Hello\classes
test:
[mkdir] Created dir: F:\eclipse-projects\Hello\report
[junit] Running example.HelloTest
[junit] Tests run: 1, Failures: 0, Errors: 0, Time elapsed: 0.02 sec
pack:
[mkdir] Created dir: F:\eclipse-projects\Hello\dist
[jar] Building jar: F:\eclipse-projects\Hello\dist\hello.jar
doc:
[mkdir] Created dir: F:\eclipse-projects\Hello\doc
[javadoc] Generating Javadoc
[javadoc] Javadoc execution
[javadoc] Loading source files for package example...
[javadoc] Constructing Javadoc information...
[javadoc] Standard Doclet version 1.4.2_04
[javadoc] Building tree for all the packages and classes...
[javadoc] Building index for all the packages and classes...
[javadoc] Building index for all classes...
[javadoc] Generating F:\eclipse-projects\Hello\doc\stylesheet.css...
[javadoc] Note: Custom tags that could override future standard tags: @todo. To avoid potential overrides, use at least one period character (.) in custom tag names.
[javadoc] Note: Custom tags that were not seen: @todo
BUILD SUCCESSFUL
Total time: 11 seconds
Ant依次执行初始化,编译,测试,打包,生成API文档一系列任务,极大地提高了开发效率。将来开发J2EE项目时,还可加入部署等任务。并且,即使脱离了Eclipse环境,只要正确安装了Ant,配置好环境变量ANT_HOME=<nt解压目录>Path=…;%ANT_HOME%\bin,在命令行提示符下切换到Hello目录,简单地键入ant即可。
JAR 文件格式以流行的 ZIP 文件格式为基础,用于将许多个文件聚集为一个文件。与 ZIP 文件不同的是,JAR 文件不仅用于压缩和发布,而且还用于部署和封装库、组件和插件程序,并可被像编译器和 JVM 这样的工具直接使用。在 JAR 中包含特殊的文件,如 manifests 和部署描述符,用来指示工具如何处理特定的 JAR。
一个 JAR 文件可以用于:
□ 用于发布和使用类库
□ 作为应用程序和扩展的构建单元
□ 作为组件、applet 或者插件程序的部署单位
□ 用于打包与组件相关联的辅助资源
JAR 文件格式提供了许多优势和功能,其中很多是传统的压缩格式如 ZIP 或者 TAR 所没有提供的。它们包括:
☆ 安全性。 可以对 JAR 文件内容加上数字化签名。这样,能够识别签名的工具就可以有选择地为您授予软件安全特权,这是其他文件做不到的,它还可以检测代码是否被篡改过。
☆ 减少下载时间。 如果一个 applet 捆绑到一个 JAR 文件中,那么浏览器就可以在一个 HTTP 事务中下载这个 applet 的类文件和相关的资源,而不是对每一个文件打开一个新连接。
☆ 压缩。JAR 格式允许您压缩文件以提高存储效率。
☆ 传输平台扩展。 Java 扩展框架(Java Extensions Framework)提供了向 Java 核心平台添加功能的方法,这些扩展是用 JAR 文件打包的(Java 3D 和 JavaMail 就是由 Sun 开发的扩展例子)。
☆ 包密封。 存储在 JAR 文件中的包可以选择进行密封,以增强版本一致性和安全性。密封一个包意味着包中的所有类都必须在同一 JAR 文件中找到。
☆ 包版本控制。 一个 JAR 文件可以包含有关它所包含的文件的数据,如厂商和版本信息。
☆ 可移植性。 处理 JAR 文件的机制是 Java 平台核心 API 的标准部分。
压缩的和未压缩的 JAR
jar 工具在默认情况下压缩文件。未压缩的 JAR 文件一般可以比压缩过的 JAR 文件更快地装载,因为在装载过程中要解压缩文件,但是未压缩的文件在网络上的下载时间可能更长。
META-INF 目录
大多数 JAR 文件包含一个 META-INF 目录,它用于存储包和扩展的配置数据,如安全性和版本信息。Java 2 平台识别并解释 META-INF 目录中的下述文件和目录,以便配置应用程序、扩展和类装载器:
☆ MANIFEST.MF。 这个 manifest 文件定义了与扩展和包相关的数据。
☆ INDEX.LIST。 这个文件由 jar 工具的新选项 -i 生成,它包含在应用程序或者扩展中定义的包的位置信息。它是 JarIndex 实现的一部分,并由类装载器用于加速类装载过程。
☆ xxx.SF。 这是 JAR 文件的签名文件。占位符 xxx 标识了签名者。
☆ xxx.DSA。 与签名文件相关联的签名程序块文件,它存储了用于签名 JAR 文件的公共签名。
jar 工具
为了用 JAR 文件执行基本的任务,要使用作为Java Development Kit 的一部分提供的 Java Archive Tool (jar 工具)。用 jar 命令调用 jar 工具。表 1 显示了一些常见的应用:
表 1. 常见的 jar 工具用法
功能 命令
用一个单独的文件创建一个 JAR 文件 jar cf jar-file input-file...
用一个目录创建一个 JAR 文件 jar cf jar-file dir-name
创建一个未压缩的 JAR 文件 jar cf0 jar-file dir-name
更新一个 JAR 文件 jar uf jar-file input-file...
查看一个 JAR 文件的内容 jar tf jar-file
提取一个 JAR 文件的内容 jar xf jar-file
从一个 JAR 文件中提取特定的文件 jar xf jar-file archived-file...
运行一个打包为可执行 JAR 文件的应用程序 java -jar app.jar
可执行的 JAR
一个可执行的 jar 文件是一个自包含的 Java 应用程序,它存储在特别配置的JAR 文件中,可以由 JVM 直接执行它而无需事先提取文件或者设置类路径。要运行存储在非可执行的 JAR 中的应用程序,必须将它加入到您的类路径中,并用名字调用应用程序的主类。但是使用可执行的 JAR 文件,我们可以不用提取它或者知道主要入口点就可以运行一个应用程序。可执行 JAR 有助于方便发布和执行 Java 应用程序。
创建可执行 JAR
创建一个可执行 JAR 很容易。首先将所有应用程序代码放到一个目录中。假设应用程序中的主类是 com.mycompany.myapp.Sample。您要创建一个包含应用程序代码的 JAR 文件并标识出主类。为此,在某个位置(不是在应用程序目录中)创建一个名为 manifest 的文件,并在其中加入以下一行:
Main-Class: com.mycompany.myapp.Sample
然后,像这样创建 JAR 文件:
jar cmf manifest ExecutableJar.jar application-dir
所要做的就是这些了 -- 现在可以用 java -jar 执行这个 JAR 文件 ExecutableJar.jar。
一个可执行的 JAR 必须通过 menifest 文件的头引用它所需要的所有其他从属 JAR。如果使用了 -jar 选项,那么环境变量 CLASSPATH 和在命令行中指定的所有类路径都被 JVM 所忽略。
启动可执行 JAR
既然我们已经将自己的应用程序打包到了一个名为 ExecutableJar.jar 的可执行 JAR 中了,那么我们就可以用下面的命令直接从文件启动这个应用程序:
java -jar ExecutableJar.jar
包密封
密封 JAR 文件中的一个包意味着在这个包中定义的所有类都必须在同一个 JAR 文件中找到。这使包的作者可以增强打包类之间的版本一致性。密封还提供了防止代码篡改的手段。
要密封包,需要在 JAR 的 manifest 文件中为包添加一个 Name 头,然后加上值为“true”的 Sealed 头。与可执行的 JAR 一样,可以在创建 JAR 时,通过指定一个具有适当头元素的 manifest 文件密封一个 JAR,如下所示:
Name: com/samplePackage/
Sealed: true
Name 头标识出包的相对路径名。它以一个“/”结束以与文件名区别。在 Name 头后面第一个空行之前的所有头都作用于在 Name 头中指定的文件或者包。在上述例子中,因为 Sealed 头出现在 Name 头后并且中间没有空行,所以 Sealed 头将被解释为只应用到包 com/samplePackage 上。
如果试图从密封包所在的 JAR 文件以外的其他地方装载密封包中的一个类,那么 JVM 将抛出一个 SecurityException。
扩展打包
扩展为 Java 平台增加了功能,在 JAR 文件格式中已经加入了扩展机制。扩展机制使得 JAR 文件可以通过 manifest 文件中的 Class-Path 头指定所需要的其他 JAR 文件。
假设 extension1.jar 和 extension2.jar 是同一个目录中的两个 JAR 文件,extension1.jar 的 manifest 文件包含以下头:
Class-Path: extension2.jar
这个头表明 extension2.jar 中的类是 extension1.jar 中的类的扩展类。extension1.jar 中的类可以调用 extension2.jar 中的类,并且不要求 extension2.jar 处在类路径中。
在装载使用扩展机制的 JAR 时,JVM 会高效而自动地将在Class-Path 头中引用的 JAR 添加到类路径中。不过,扩展 JAR 路径被解释为相对路径,所以一般来说,扩展 JAR 必须存储在引用它的 JAR 所在的同一目录中。
例如,假设类 ExtensionClient 引用了类 ExtensionDemo,它捆绑在一个名为 ExtensionClient.jar 的 JAR 文件中,而类 ExtensionDemo 则捆绑在 ExtensionDemo.jar 中。为了使 ExtensionDemo.jar 可以成为扩展,必须将 ExtensionDemo.jar 列在 ExtensionClient.jar 的 manifest 的 Class-Path 头中,如下所示:
Manifest-Version: 1.0
Class-Path: ExtensionDemo.jar
在这个 manifest 中 Class-Path 头的值是没有指定路径的 ExtensionDemo.jar,表明 ExtensionDemo.jar 与 ExtensionClient JAR 文件处在同一目录中。
JAR 文件中的安全性
JAR 文件可以用 jarsigner 工具或者直接通过 java.security API 签名。一个签名的 JAR 文件与原来的 JAR 文件完全相同,只是更新了它的 manifest,并在 META-INF 目录中增加了两个文件,一个签名文件和一个签名块文件。
JAR 文件是用一个存储在 Keystore 数据库中的证书签名的。存储在 keystore 中的证书有密码保护,必须向 jarsigner 工具提供这个密码才能对 JAR 文件签名。
图 1. Keystore 数据库
JAR 的每一位签名者都由在 JAR 文件的 META-INF 目录中的一个具有 .SF 扩展名的签名文件表示。这个文件的格式类似于 manifest 文件 -- 一组 RFC-822 头。如下所示,它的组成包括一个主要部分,它包括了由签名者提供的信息、但是不特别针对任何特定的 JAR 文件项,还有一系列的单独的项,这些项也必须包含在 menifest 文件中。在验证一个签名的 JAR 时,将签名文件的摘要值与对 JAR 文件中的相应项计算的摘要值进行比较。
清单 1. 签名 JAR 中的 Manifest 和 signature 文件
Contents of signature file META-INF/MANIFEST.MF
Manifest-Version: 1.0
Created-By: 1.3.0 (Sun Microsystems Inc.)
Name: Sample.java
SHA1-Digest: 3+DdYW8INICtyG8ZarHlFxX0W6g=
Name: Sample.class
SHA1-Digest: YJ5yQHBZBJ3SsTNcHJFqUkfWEmI=
Contents of signature file META-INF/JAMES.SF
Signature-Version: 1.0
SHA1-Digest-Manifest: HBstZOJBuuTJ6QMIdB90T8sjaOM=
Created-By: 1.3.0 (Sun Microsystems Inc.)
Name: Sample.java
SHA1-Digest: qipMDrkurQcKwnyIlI3Jtrnia8Q=
Name: Sample.class
SHA1-Digest: pT2DYby8QXPcCzv2NwpLxd8p4G4=
数字签名
一个数字签名是.SF 签名文件的已签名版本。数字签名文件是二进制文件,并且与 .SF 文件有相同的文件名,但是扩展名不同。根据数字签名的类型 -- RSA、DSA 或者 PGP -- 以及用于签名 JAR 的证书类型而有不同的扩展名。
Keystore
要签名一个 JAR 文件,必须首先有一个私钥。私钥及其相关的公钥证书存储在名为 keystores 的、有密码保护的数据库中。JDK 包含创建和修改 keystores 的工具。keystore 中的每一个密钥都可以用一个别名标识,它通常是拥有这个密钥的签名者的名字。
所有 keystore 项(密钥和信任的证书项)都是用唯一别名访问的。别名是在用 keytool -genkey 命令生成密钥对(公钥和私钥)并在 keystore 中添加项时指定的。之后的 keytool 命令必须使用同样的别名引用这一项。
例如,要用别名“james”生成一个新的公钥/私钥对并将公钥包装到自签名的证书中,要使用下述命令:
keytool -genkey -alias james -keypass jamespass
-validity 80 -keystore jamesKeyStore
-storepass jamesKeyStorePass
这个命令序列指定了一个初始密码“jamespass”,后续的命令在访问 keystore “jamesKeyStore”中与别名“james”相关联的私钥时,就需要这个密码。如果 keystore“jamesKeyStore”不存在,则 keytool 会自动创建它。
jarsigner 工具
jarsigner 工具使用 keystore 生成或者验证 JAR 文件的数字签名。
假设像上述例子那样创建了 keystore “jamesKeyStore”,并且它包含一个别名为“james”的密钥,可以用下面的命令签名一个 JAR 文件:
jarsigner -keystore jamesKeyStore -storepass jamesKeyStorePass
-keypass jamespass -signedjar SSample.jar Sample.jar james
这个命令用密码“jamesKeyStorePass”从名为“jamesKeyStore”的 keystore 中提出别名为“james”、密码为“jamespass”的密钥,并对 Sample.jar 文件签名、创建一个签名的 JAR -- SSample.jar。
jarsigner 工具还可以验证一个签名的 JAR 文件,这种操作比签名 JAR 文件要简单得多,只需执行以下命令:
jarsigner -verify SSample.jar
如果签名的 JAR 文件没有被篡改过,那么 jarsigner 工具就会告诉您 JAR 通过验证了。否则,它会抛出一个 SecurityException, 表明哪些文件没有通过验证。
还可以用 java.util.jar 和 java.security API 以编程方式签名 JAR(有关细节参阅参考资料)。也可以使用像 Netscape Object Signing Tool 这样的工具。
JAR 索引
如果一个应用程序或者 applet 捆绑到多个 JAR 文件中,那么类装载器就使用一个简单的线性搜索算法搜索类路径中的每一个元素,这使类装载器可能要下载并打开许多个 JAR 文件,直到找到所要的类或者资源。如果类装载器试图寻找一个不存在的资源,那么在应用程序或者 applet 中的所有 JAR 文件都会下载。对于大型的网络应用程序和 applet,这会导致启动缓慢、响应迟缓并浪费带宽。
从 JDK 1.3 以后,JAR 文件格式开始支持索引以优化网络应用程序中类的搜索过程,特别是 applet。JarIndex 机制收集在 applet 或者应用程序中定义的所有 JAR 文件的内容,并将这些信息存储到第一个 JAR 文件中的索引文件中。下载了第一个 JAR 文件后,applet 类装载器将使用收集的内容信息高效地装载 JAR 文件。这个目录信息存储在根 JAR 文件的 META-INF 目录中的一个名为 INDEX.LIST 的简单文本文件中。
创建一个 JarIndex
可以通过在 jar 命令中指定 -i 选项创建一个 JarIndex。假设我们的目录结构如下图所示:
图 2. JarIndex
您将使用下述命令为 JarIndex_Main.jar、JarIndex_test.jar 和 JarIndex_test1.jar 创建一个索引文件:
jar -i JarIndex_Main.jar JarIndex_test.jar SampleDir/JarIndex_test1.jar
INDEX.LIST 文件的格式很简单,包含每个已索引的 JAR 文件中包含的包或者类的名字,如清单 2 所示:
清单 2. JarIndex INDEX.LIST 文件示例
JarIndex-Version: 1.0
JarIndex_Main.jar
sp
JarIndex_test.jar
Sample
SampleDir/JarIndex_test1.jar
org
org/apache
org/apache/xerces
org/apache/xerces/framework
org/apache/xerces/framework/xml4j
结束语
JAR 格式远远超出了一种压缩格式,它有许多可以改进效率、安全性和组织 Java 应用程序的功能。因为这些功能已经建立在核心平台 -- 包括编译器和类装载器 -- 中了,所以开发人员可以利用 JAR 文件格式的能力简化和改进开发和部署过程。
|
|
常常在网上看到有人询问:如何把 java 程序编译成 .exe 文件。通常回答只有两种,一种是制作一个可执行的 JAR 文件包,然后就可以像.chm 文档一样双击运行了;而另一种是使用 JET 来进行 编译。但是 JET 是要用钱买的,而且据说 JET 也不是能把所有的 Java 程序都编译成执行文件,性能也要打些折扣。所以,使用制作可执行 JAR 文件包的方法就是最佳选择了,何况它还能保持 Java 的跨平台特性。
下面就来看看什么是 JAR 文件包吧:
1. JAR 文件包
JAR 文件就是 Java Archive File,顾名思意,它的应用是与 Java 息息相关的,是 Java 的一种文档格式。JAR 文件非常类似 ZIP 文件??准确的说,它就是 ZIP 文件,所以叫它文件包。JAR 文件与 ZIP 文件唯一的区别就是在 JAR 文件的内容中,包含了一个 META-INF/MANIFEST.MF 文件,这个文件是在生成 JAR 文件的时候自动创建的。举个例子,如果我们具有如下目录结构的一些文件:
==
`-- test
`-- Test.class
把它压缩成 ZIP 文件 test.zip,则这个 ZIP 文件的内部目录结构为:
test.zip
`-- test
`-- Test.class
如果我们使用 JDK 的 jar 命令把它打成 JAR 文件包 test.jar,则这个 JAR 文件的内部目录结构为:
test.jar
|-- META-INF
| `-- MANIFEST.MF
`-- test
`--Test.class
2. 创建可执行的 JAR 文件包
制作一个可执行的 JAR 文件包来发布你的程序是 JAR 文件包最典型的用法。
Java 程序是由若干个 .class 文件组成的。这些 .class 文件必须根据它们所属的包不同而分级分目录存放;运行前需要把所有用到的包的根目录指定给 CLASSPATH 环境变量或者 java 命令的 -cp 参数;运行时还要到控制台下去使用 java 命令来运行,如果需要直接双击运行必须写 Windows 的批处理文件 (.bat) 或者 Linux 的 Shell 程序。因此,许多人说,Java 是一种方便开发者苦了用户的程序设计语言。
其实不然,如果开发者能够制作一个可执行的 JAR 文件包交给用户,那么用户使用起来就方便了。在 Windows 下安装 JRE (Java Runtime Environment) 的时候,安装文件会将 .jar 文件映射给 javaw.exe 打开。那么,对于一个可执行的 JAR 文件包,用户只需要双击它就可以运行程序了,和阅读 .chm 文档一样方便 (.chm 文档默认是由 hh.exe 打开的)。那么,现在的关键,就是如何来创建这个可执行的 JAR 文件包。
创建可执行的 JAR 文件包,需要使用带 cvfm 参数的 jar 命令,同样以上述 test 目录为例,命令如下:
jar cvfm test.jar manifest.mf test
这里 test.jar 和 manifest.mf 两个文件,分别是对应的参数 f 和 m,其重头戏在 manifest.mf。因为要创建可执行的 JAR 文件包,光靠指定一个 manifest.mf 文件是不够的,因为 MANIFEST 是 JAR 文件包的特征,可执行的 JAR 文件包和不可执行的 JAR 文件包都包含 MANIFEST。关键在于可执行 JAR 文件包的 MANIFEST,其内容包含了 Main-Class 一项。这在 MANIFEST 中书写格式如下:
Main-Class: 可执行主类全名(包含包名)
例如,假设上例中的 Test.class 是属于 test 包的,而且是可执行的类 (定义了 public static void main(String[]) 方法),那么这个 manifest.mf 可以编辑如下:
Main-Class: test.Test <回车>
这个 manifest.mf 可以放在任何位置,也可以是其它的文件名,只需要有 Main-Class: test.Test 一行,且该行以一个回车符结束即可。创建了 manifest.mf 文件之后,我们的目录结构变为:
==
|-- test
| `-- Test.class
`-- manifest.mf
这时候,需要到 test 目录的上级目录中去使用 jar 命令来创建 JAR 文件包。也就是在目录树中使用“==”表示的那个目录中,使用如下命令:
jar cvfm test.jar manifest.mf test
之后在“==”目录中创建了 test.jar,这个 test.jar 就是执行的 JAR 文件包。运行时只需要使用 java -jar test.jar 命令即可。
需要注意的是,创建的 JAR 文件包中需要包含完整的、与 Java 程序的包结构对应的目录结构,就像上例一样。而 Main-Class 指定的类,也必须是完整的、包含包路径的类名,如上例的 test.Test;而且在没有打成 JAR 文件包之前可以使用 java <类名> 来运行这个类,即在上例中 java test.Test 是可以正确运行的 (当然要在 CLASSPATH 正确的情况下)。
3. jar 命令详解
jar 是随 JDK 安装的,在 JDK 安装目录下的 bin 目录中,Windows 下文件名为 jar.exe,Linux 下文件名为 jar。它的运行需要用到 JDK 安装目录下 lib 目录中的 tools.jar 文件。不过我们除了安装 JDK 什么也不需要做,因为 SUN 已经帮我们做好了。我们甚至不需要将 tools.jar 放到 CLASSPATH 中。
使用不带任何的 jar 命令我们可以看到 jar 命令的用法如下:
jar {ctxu}[vfm0M] [jar-文件] [manifest-文件] [-C 目录] 文件名 ...
其中 {ctxu} 是 jar 命令的子命令,每次 jar 命令只能包含 ctxu 中的一个,它们分别表示:
-c 创建新的 JAR 文件包
-t 列出 JAR 文件包的内容列表
-x 展开 JAR 文件包的指定文件或者所有文件
-u 更新已存在的 JAR 文件包 (添加文件到 JAR 文件包中)
[vfm0M] 中的选项可以任选,也可以不选,它们是 jar 命令的选项参数
-v 生成详细报告并打印到标准输出
-f 指定 JAR 文件名,通常这个参数是必须的
-m 指定需要包含的 MANIFEST 清单文件
-0 只存储,不压缩,这样产生的 JAR 文件包会比不用该参数产生的体积大,但速度更快
-M 不产生所有项的清单(MANIFEST〕文件,此参数会忽略 -m 参数
[jar-文件] 即需要生成、查看、更新或者解开的 JAR 文件包,它是 -f 参数的附属参数
[manifest-文件] 即 MANIFEST 清单文件,它是 -m 参数的附属参数
[-C 目录] 表示转到指定目录下去执行这个 jar 命令的操作。它相当于先使用 cd 命令转该目录下再执行不带 -C 参数的 jar 命令,它只能在创建和更新 JAR 文件包的时候可用。
文件名 ... 指定一个文件/目录列表,这些文件/目录就是要添加到 JAR 文件包中的文件/目录。如果指定了目录,那么 jar 命令打包的时候会自动把该目录中的所有文件和子目录打入包中。
下面举一些例子来说明 jar 命令的用法:
1) jar cf test.jar test
该命令没有执行过程的显示,执行结果是在当前目录生成了 test.jar 文件。如果当前目录已经存在 test.jar,那么该文件将被覆盖。
2) jar cvf test.jar test
该命令与上例中的结果相同,但是由于 v 参数的作用,显示出了打包过程,如下:
标明清单(manifest)
增加:test/(读入= 0) (写出= 0)(存储了 0%)
增加:test/Test.class(读入= 7) (写出= 6)(压缩了 14%)
3) jar cvfM test.jar test
该命令与 2) 结果类似,但在生成的 test.jar 中没有包含 META-INF/MANIFEST 文件,打包过程的信息也略有差别:
增加:test/(读入= 0) (写出= 0)(存储了 0%)
增加:test/Test.class(读入= 7) (写出= 6)(压缩了 14%)
4) jar cvfm test.jar manifest.mf test
运行结果与 2) 相似,显示信息也相同,只是生成 JAR 包中的 META-INF/MANIFEST 内容不同,是包含了 manifest.mf 的内容
5) jar tf test.jar
在 test.jar 已经存在的情况下,可以查看 test.jar 中的内容,如对于 2) 和 3) 生成的 test.jar 分别应该此命令,结果如下;
对于 2)
META-INF/
META-INF/MANIFEST.MF
test/
test/Test.class
对于 3)
test/
test/Test.class
6) jar tvf test.jar
除显示 5) 中显示的内容外,还包括包内文件的详细信息,如:
0 Wed Jun 19 15:39:06 GMT 2002 META-INF/
86 Wed Jun 19 15:39:06 GMT 2002 META-INF/MANIFEST.MF
0 Wed Jun 19 15:33:04 GMT 2002 test/
7 Wed Jun 19 15:33:04 GMT 2002 test/Test.class
7) jar xf test.jar
解开 test.jar 到当前目录,不显示任何信息,对于 2) 生成的 test.jar,解开后的目录结构如下:
==
|-- META-INF
| `-- MANIFEST
`-- test
`--Test.class
jar xvf test.jar
运行结果与 7) 相同,对于解压过程有详细信息显示,如:
创建:META-INF/
展开:META-INF/MANIFEST.MF
创建:test/
展开:test/Test.class
9) jar uf test.jar manifest.mf
在 test.jar 中添加了文件 manifest.mf,此使用 jar tf 来查看 test.jar 可以发现 test.jar 中比原来多了一个 manifest。这里顺便提一下,如果使用 -m 参数并指定 manifest.mf 文件,那么 manifest.mf 是作为清单文件 MANIFEST 来使用的,它的内容会被添加到 MANIFEST 中;但是,如果作为一般文件添加到 JAR 文件包中,它跟一般文件无异。
10) jar uvf test.jar manifest.mf
与 9) 结果相同,同时有详细信息显示,如:
增加:manifest.mf(读入= 17) (写出= 19)(压缩了 -11%)
4. 关于 JAR 文件包的一些技巧
1) 使用 unzip 来解压 JAR 文件
在介绍 JAR 文件的时候就已经说过了,JAR 文件实际上就是 ZIP 文件,所以可以使用常见的一些解压 ZIP 文件的工具来解压 JAR 文件,如 Windows 下的 WinZip、WinRAR 等和 Linux 下的 unzip 等。使用 WinZip 和 WinRAR 等来解压是因为它们解压比较直观,方便。而使用 unzip,则是因为它解压时可以使用 -d 参数指定目标目录。
在解压一个 JAR 文件的时候是不能使用 jar 的 -C 参数来指定解压的目标的,因为 -C 参数只在创建或者更新包的时候可用。那么需要将文件解压到某个指定目录下的时候就需要先将这具 JAR 文件拷贝到目标目录下,再进行解压,比较麻烦。如果使用 unzip,就不需要这么麻烦了,只需要指定一个 -d 参数即可。如:
unzip test.jar -d dest/
2) 使用 WinZip 或者 WinRAR 等工具创建 JAR 文件
上面提到 JAR 文件就是包含了 META-INF/MANIFEST 的 ZIP 文件,所以,只需要使用 WinZip、WinRAR 等工具创建所需要 ZIP 压缩包,再往这个 ZIP 压缩包中添加一个包含 MANIFEST 文件的 META-INF 目录即可。对于使用 jar 命令的 -m 参数指定清单文件的情况,只需要将这个 MANIFEST 按需要修改即可。
3) 使用 jar 命令创建 ZIP 文件
有些 Linux 下提供了 unzip 命令,但没有 zip 命令,所以需要可以对 ZIP 文件进行解压,即不能创建 ZIP 文件。如要创建一个 ZIP 文件,使用带 -M 参数的 jar 命令即可,因为 -M 参数表示制作 JAR 包的时候不添加 MANIFEST 清单,那么只需要在指定目标 JAR 文件的地方将 .jar 扩展名改为 .zip 扩展名,创建的就是一个不折不扣的 ZIP 文件了,如将上一节的第 3) 个例子略作改动:
jar cvfM test.zip test
|
|
在数据库设计中,有两种方法可设定自动化的资料处理规则,一种是条件约束,
一种是触发器,一般而言,条件约束比触发器较容易设定及维护,且执行效率较
好,但条件约束只能对资料进行简单的栏位检核,当涉及到多表操作等复杂操
作时,就要用到触发器了.
一个数据库系统中有两个虚拟表用于存储在表中记录改动的信息,分别
是:
虚拟表Inserted 虚拟表Deleted
在表记录新增时 存放新增的记录 不存储记录
修改时 存放用来更新的新记录 存放更新前的记录
删除时 不存储记录 存放被删除的记录
触发器的种类及触发时机
After触发器:触发时机在资料已变动完成后,它将对变动资料进行必要的
善后与处理,若发现有错误,则用事务回滚(Rollback Transaction)
将此次操作所更动的资料全部回复。
Istead of 触发器:触发时机在资料变动前发生,且资料如何变动取决于触发器
现在介绍一下创建触发器的编写格式:
After类型:
Create Trigger 触发器名称
on 表名
after 操作(insert,update)
as
Sql语句
Instead类型
Create Trigger 触发器名称
on 表名
Instead of 操作(update,delete)
as
Sql语句
实例1:
在订单(表orders)中的订购数量(列名为num)有变动时,触发器会先到客户(表Customer)中
取得该用户的信用等级(列名为Level),然后再到信用额度(Creit)中取出该等级
许可的订购数量上下限,最后比较订单中的订购数量是否符合限制。
代码:
Create Trigger num_check
on orders
after insert,update
as
if update(num)
begin
if exists(select a.* from orders a join customer b on a.customerid=b.customerid
join creit c on b.level=c.level
where a.num between c.up and c.down)
begin
rollback transaction
exec master..xp_sendmail 'administrator','客户的订购数量不符合限制'
end
end
实例2:
有工资管理系统中,当公司对某员工甲的月薪进行调整时,通常会先在表员工中修改薪资列,然后在
表员工记录中修改薪资调整时间与薪资
Create trigger compensation
on 员工
after update
as
if @@rowcount=0 return
if update(薪资)
begin
insert 员工记录
select 员工遍号,薪资,getdate()
from inserted
end
(转载自--http://www.cnblogs.com/qiubole/articles/157309.html)
-- ======================================================
--列出SQL SERVER 所有表,字段名,主键,类型,长度,小数位数等信息
--在查询分析器里运行即可,可以生成一个表,导出到EXCEL中
-- ======================================================
SELECT
(case when a.colorder=1 then d.name else '' end)表名,
a.colorder 字段序号,
a.name 字段名,
(case when COLUMNPROPERTY( a.id,a.name,'IsIdentity')=1 then '√'else '' end) 标识,
(case when (SELECT count(*)
FROM sysobjects
WHERE (name in
(SELECT name
FROM sysindexes
WHERE (id = a.id) AND (indid in
(SELECT indid
FROM sysindexkeys
WHERE (id = a.id) AND (colid in
(SELECT colid
FROM syscolumns
WHERE (id = a.id) AND (name = a.name))))))) AND
(xtype = 'PK'))>0 then '√' else '' end) 主键,
b.name 类型,
a.length 占用字节数,
COLUMNPROPERTY(a.id,a.name,'PRECISION') as 长度,
isnull(COLUMNPROPERTY(a.id,a.name,'Scale'),0) as 小数位数,
(case when a.isnullable=1 then '√'else '' end) 允许空,
isnull(e.text,'') 默认值,
isnull(g.[value],'') AS 字段说明
FROM syscolumns a left join systypes b
on a.xtype=b.xusertype
inner join sysobjects d
on a.id=d.id and d.xtype='U' and d.name<>'dtproperties'
left join syscomments e
on a.cdefault=e.id
left join sysproperties g
on a.id=g.id AND a.colid = g.smallid
order by a.id,a.colorder
-------------------------------------------------------------------------------------------------
列出SQL SERVER 所有表、字段定义,类型,长度,一个值等信息
并导出到Excel 中
-- ======================================================
-- Export all user tables definition and one sample value
-- jan-13-2003,Dr.Zhang
-- ======================================================
在查询分析器里运行:
SET ANSI_NULLS OFF
GO
SET NOCOUNT ON
GO
SET LANGUAGE 'Simplified Chinese'
go
DECLARE @tbl nvarchar(200),@fld nvarchar(200),@sql nvarchar(4000),@maxlen int,@sample nvarchar(40)
SELECT d.name TableName,a.name FieldName,b.name TypeName,a.length Length,a.isnullable IS_NULL INTO #t
FROM syscolumns a, systypes b,sysobjects d
WHERE a.xtype=b.xusertype and a.id=d.id and d.xtype='U'
DECLARE read_cursor CURSOR
FOR SELECT TableName,FieldName FROM #t
SELECT TOP 1 '_TableName ' TableName,
'FieldName ' FieldName,'TypeName ' TypeName,
'Length' Length,'IS_NULL' IS_NULL,
'MaxLenUsed' AS MaxLenUsed,'Sample Value ' Sample,
'Comment ' Comment INTO #tc FROM #t
OPEN read_cursor
FETCH NEXT FROM read_cursor INTO @tbl,@fld
WHILE (@@fetch_status <> -1) --- failes
BEGIN
IF (@@fetch_status <> -2) -- Missing
BEGIN
SET @sql=N'SET @maxlen=(SELECT max(len(cast('+@fld+' as nvarchar))) FROM '+@tbl+')'
--PRINT @sql
EXEC SP_EXECUTESQL @sql,N'@maxlen int OUTPUT',@maxlen OUTPUT
--print @maxlen
SET @sql=N'SET @sample=(SELECT TOP 1 cast('+@fld+' as nvarchar) FROM '+@tbl+' WHERE len(cast('+@fld+' as nvarchar))='+convert(nvarchar(5),@maxlen)+')'
EXEC SP_EXECUTESQL @sql,N'@sample varchar(30) OUTPUT',@sample OUTPUT
--for quickly
--SET @sql=N'SET @sample=convert(varchar(20),(SELECT TOP 1 '+@fld+' FROM '+
--@tbl+' order by 1 desc ))'
PRINT @sql
print @sample
print @tbl
EXEC SP_EXECUTESQL @sql,N'@sample nvarchar(30) OUTPUT',@sample OUTPUT
INSERT INTO #tc SELECT *,ltrim(ISNULL(@maxlen,0)) as MaxLenUsed,
convert(nchar(20),ltrim(ISNULL(@sample,' '))) as Sample,' ' Comment FROM #t where TableName=@tbl and FieldName=@fld
END
FETCH NEXT FROM read_cursor INTO @tbl,@fld
END
CLOSE read_cursor
DEALLOCATE read_cursor
GO
SET ANSI_NULLS ON
GO
SET NOCOUNT OFF
GO
select count(*) from #t
DROP TABLE #t
GO
select count(*)-1 from #tc
select * into ##tx from #tc order by tablename
DROP TABLE #tc
--select * from ##tx
declare @db nvarchar(60),@sql nvarchar(3000)
set @db=db_name()
--请修改用户名和口令 导出到Excel 中
set @sql='exec master.dbo.xp_cmdshell ''bcp ..dbo.##tx out c:\'+@db+'_exp.xls -w -C936 -Usa -Psa '''
print @sql
exec(@sql)
GO
DROP TABLE ##tx
GO
-- ======================================================
--根据表中数据生成insert语句的存储过程
--建立存储过程,执行 spGenInsertSQL 表名
--感谢playyuer
-- ======================================================
CREATE proc spGenInsertSQL (@tablename varchar(256))
as
begin
declare @sql varchar(8000)
declare @sqlValues varchar(8000)
set @sql =' ('
set @sqlValues = 'values (''+'
select @sqlValues = @sqlValues + cols + ' + '','' + ' ,@sql = @sql + '[' + name + '],'
from
(select case
when xtype in (48,52,56,59,60,62,104,106,108,122,127)
then 'case when '+ name +' is null then ''NULL'' else ' + 'cast('+ name + ' as varchar)'+' end'
when xtype in (58,61)
then 'case when '+ name +' is null then ''NULL'' else '+''''''''' + ' + 'cast('+ name +' as varchar)'+ '+'''''''''+' end'
when xtype in (167)
then 'case when '+ name +' is null then ''NULL'' else '+''''''''' + ' + 'replace('+ name+','''''''','''''''''''')' + '+'''''''''+' end'
when xtype in (231)
then 'case when '+ name +' is null then ''NULL'' else '+'''N'''''' + ' + 'replace('+ name+','''''''','''''''''''')' + '+'''''''''+' end'
when xtype in (175)
then 'case when '+ name +' is null then ''NULL'' else '+''''''''' + ' + 'cast(replace('+ name+','''''''','''''''''''') as Char(' + cast(length as varchar) + '))+'''''''''+' end'
when xtype in (239)
then 'case when '+ name +' is null then ''NULL'' else '+'''N'''''' + ' + 'cast(replace('+ name+','''''''','''''''''''') as Char(' + cast(length as varchar) + '))+'''''''''+' end'
else '''NULL'''
end as Cols,name
from syscolumns
where id = object_id(@tablename)
) T
set @sql ='select ''INSERT INTO ['+ @tablename + ']' + left(@sql,len(@sql)-1)+') ' + left(@sqlValues,len(@sqlValues)-4) + ')'' from '+@tablename
--print @sql
exec (@sql)
end
GO
-- ======================================================
--根据表中数据生成insert语句的存储过程
--建立存储过程,执行 proc_insert 表名
--感谢Sky_blue
-- ======================================================
CREATE proc proc_insert (@tablename varchar(256))
as
begin
set nocount on
declare @sqlstr varchar(4000)
declare @sqlstr1 varchar(4000)
declare @sqlstr2 varchar(4000)
select @sqlstr='select ''insert '+@tablename
select @sqlstr1=''
select @sqlstr2=' ('
select @sqlstr1= ' values ( ''+'
select @sqlstr1=@sqlstr1+col+'+'',''+' ,@sqlstr2=@sqlstr2+name +',' from (select case
-- when a.xtype =173 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar('+convert(varchar(4),a.length*2+2)+'),'+a.name +')'+' end'
when a.xtype =104 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar(1),'+a.name +')'+' end'
when a.xtype =175 then 'case when '+a.name+' is null then ''NULL'' else '+'''''''''+'+'replace('+a.name+','''''''','''''''''''')' + '+'''''''''+' end'
when a.xtype =61 then 'case when '+a.name+' is null then ''NULL'' else '+'''''''''+'+'convert(varchar(23),'+a.name +',121)'+ '+'''''''''+' end'
when a.xtype =106 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar('+convert(varchar(4),a.xprec+2)+'),'+a.name +')'+' end'
when a.xtype =62 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar(23),'+a.name +',2)'+' end'
when a.xtype =56 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar(11),'+a.name +')'+' end'
when a.xtype =60 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar(22),'+a.name +')'+' end'
when a.xtype =239 then 'case when '+a.name+' is null then ''NULL'' else '+'''''''''+'+'replace('+a.name+','''''''','''''''''''')' + '+'''''''''+' end'
when a.xtype =108 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar('+convert(varchar(4),a.xprec+2)+'),'+a.name +')'+' end'
when a.xtype =231 then 'case when '+a.name+' is null then ''NULL'' else '+'''''''''+'+'replace('+a.name+','''''''','''''''''''')' + '+'''''''''+' end'
when a.xtype =59 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar(23),'+a.name +',2)'+' end'
when a.xtype =58 then 'case when '+a.name+' is null then ''NULL'' else '+'''''''''+'+'convert(varchar(23),'+a.name +',121)'+ '+'''''''''+' end'
when a.xtype =52 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar(12),'+a.name +')'+' end'
when a.xtype =122 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar(22),'+a.name +')'+' end'
when a.xtype =48 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar(6),'+a.name +')'+' end'
-- when a.xtype =165 then 'case when '+a.name+' is null then ''NULL'' else '+'convert(varchar('+convert(varchar(4),a.length*2+2)+'),'+a.name +')'+' end'
when a.xtype =167 then 'case when '+a.name+' is null then ''NULL'' else '+'''''''''+'+'replace('+a.name+','''''''','''''''''''')' + '+'''''''''+' end'
else '''NULL'''
end as col,a.colid,a.name
from syscolumns a where a.id = object_id(@tablename) and a.xtype <>189 and a.xtype <>34 and a.xtype <>35 and a.xtype <>36
)t order by colid
select @sqlstr=@sqlstr+left(@sqlstr2,len(@sqlstr2)-1)+') '+left(@sqlstr1,len(@sqlstr1)-3)+')'' from '+@tablename
-- print @sqlstr
exec( @sqlstr)
set nocount off
end
GO
摘要: Transact SQL
语 句 功 能
========================================================================
--
数据操作
...
阅读全文
摘要: 一、 只复制一个表结构,不复制数据
select
top
0
*
...
阅读全文
一、数据库设计过程
数据库技术是信息资源管理最有效的手段。数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,有效存储数据,满足用户信息要求和处理要求。
数据库设计中需求分析阶段综合各个用户的应用需求(现实世界的需求),在概念设计阶段形成独立于机器特点、独立于各个DBMS产品的概念模式(信息世界模型),用E-R图来描述。在逻辑设计阶段将E-R图转换成具体的数据库产品支持的数据模型如关系模型,形成数据库逻辑模式。然后根据用户处理的要求,安全性的考虑,在基本表的基础上再建立必要的视图(VIEW)形成数据的外模式。在物理设计阶段根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。
1. 需求分析阶段
需求收集和分析,结果得到数据字典描述的数据需求(和数据流图描述的处理需求)。
需求分析的重点是调查、收集与分析用户在数据管理中的信息要求、处理要求、安全性与完整性要求。
需求分析的方法:调查组织机构情况、调查各部门的业务活动情况、协助用户明确对新系统的各种要求、确定新系统的边界。
常用的调查方法有: 跟班作业、开调查会、请专人介绍、询问、设计调查表请用户填写、查阅记录。
分析和表达用户需求的方法主要包括自顶向下和自底向上两类方法。自顶向下的结构化分析方法(Structured Analysis,简称SA方法)从最上层的系统组织机构入手,采用逐层分解的方式分析系统,并把每一层用数据流图和数据字典描述。
数据流图表达了数据和处理过程的关系。系统中的数据则借助数据字典(Data Dictionary,简称DD)来描述。
数据字典是各类数据描述的集合,它是关于数据库中数据的描述,即元数据,而不是数据本身。数据字典通常包括数据项、数据结构、数据流、数据存储和处理过程五个部分(至少应该包含每个字段的数据类型和在每个表内的主外键)。
数据项描述={数据项名,数据项含义说明,别名,数据类型,长度,
取值范围,取值含义,与其他数据项的逻辑关系}
数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}
数据流描述={数据流名,说明,数据流来源,数据流去向,
组成:{数据结构},平均流量,高峰期流量}
数据存储描述={数据存储名,说明,编号,流入的数据流,流出的数据流,
组成:{数据结构},数据量,存取方式}
处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流},
处理:{简要说明}}
2. 概念结构设计阶段
通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型,可以用E-R图表示。
概念模型用于信息世界的建模。概念模型不依赖于某一个DBMS支持的数据模型。概念模型可以转换为计算机上某一DBMS支持的特定数据模型。
概念模型特点:
(1) 具有较强的语义表达能力,能够方便、直接地表达应用中的各种语义知识。
(2) 应该简单、清晰、易于用户理解,是用户与数据库设计人员之间进行交流的语言。
概念模型设计的一种常用方法为IDEF1X方法,它就是把实体-联系方法应用到语义数据模型中的一种语义模型化技术,用于建立系统信息模型。
使用IDEF1X方法创建E-R模型的步骤如下所示:
2.1 第零步——初始化工程
这个阶段的任务是从目的描述和范围描述开始,确定建模目标,开发建模计划,组织建模队伍,收集源材料,制定约束和规范。收集源材料是这阶段的重点。通过调查和观察结果,业务流程,原有系统的输入输出,各种报表,收集原始数据,形成了基本数据资料表。
2.2 第一步——定义实体
实体集成员都有一个共同的特征和属性集,可以从收集的源材料——基本数据资料表中直接或间接标识出大部分实体。根据源材料名字表中表示物的术语以及具有“代码”结尾的术语,如客户代码、代理商代码、产品代码等将其名词部分代表的实体标识出来,从而初步找出潜在的实体,形成初步实体表。
2.3 第二步——定义联系
IDEF1X模型中只允许二元联系,n元联系必须定义为n个二元联系。根据实际的业务需求和规则,使用实体联系矩阵来标识实体间的二元关系,然后根据实际情况确定出连接关系的势、关系名和说明,确定关系类型,是标识关系、非标识关系(强制的或可选的)还是非确定关系、分类关系。如果子实体的每个实例都需要通过和父实体的关系来标识,则为标识关系,否则为非标识关系。非标识关系中,如果每个子实体的实例都与而且只与一个父实体关联,则为强制的,否则为非强制的。如果父实体与子实体代表的是同一现实对象,那么它们为分类关系。
2.4 第三步——定义码
通过引入交叉实体除去上一阶段产生的非确定关系,然后从非交叉实体和独立实体开始标识侯选码属性,以便唯一识别每个实体的实例,再从侯选码中确定主码。为了确定主码和关系的有效性,通过非空规则和非多值规则来保证,即一个实体实例的一个属性不能是空值,也不能在同一个时刻有一个以上的值。找出误认的确定关系,将实体进一步分解,最后构造出IDEF1X模型的键基视图(KB图)。
2.5 第四步——定义属性
从源数据表中抽取说明性的名词开发出属性表,确定属性的所有者。定义非主码属性,检查属性的非空及非多值规则。此外,还要检查完全依赖函数规则和非传递依赖规则,保证一个非主码属性必须依赖于主码、整个主码、仅仅是主码。以此得到了至少符合关系理论第三范式的改进的IDEF1X模型的全属性视图。
2.6 第五步——定义其他对象和规则
定义属性的数据类型、长度、精度、非空、缺省值、约束规则等。定义触发器、存储过程、视图、角色、同义词、序列等对象信息。
3. 逻辑结构设计阶段
将概念结构转换为某个DBMS所支持的数据模型(例如关系模型),并对其进行优化。设计逻辑结构应该选择最适于描述与表达相应概念结构的数据模型,然后选择最合适的DBMS。
将E-R图转换为关系模型实际上就是要将实体、实体的属性和实体之间的联系转化为关系模式,这种转换一般遵循如下原则:
1)一个实体型转换为一个关系模式。实体的属性就是关系的属性。实体的码就是关系的码。
2)一个m:n联系转换为一个关系模式。与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性。而关系的码为各实体码的组合。
3)一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,而关系的码为n端实体的码。
4)一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。
5)三个或三个以上实体间的一个多元联系转换为一个关系模式。与该多元联系相连的各实体的码以及联系本身的属性均转换为关系的属性。而关系的码为各实体码的组合。
6)同一实体集的实体间的联系,即自联系,也可按上述1:1、1:n和m:n三种情况分别处理。
7)具有相同码的关系模式可合并。
为了进一步提高数据库应用系统的性能,通常以规范化理论为指导,还应该适当地修改、调整数据模型的结构,这就是数据模型的优化。确定数据依赖。消除冗余的联系。确定各关系模式分别属于第几范式。确定是否要对它们进行合并或分解。一般来说将关系分解为3NF的标准,即:
表内的每一个值都只能被表达一次。
表内的每一行都应该被唯一的标识(有唯一键)。
表内不应该存储依赖于其他键的非键信息。
4. 数据库物理设计阶段
为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)。根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。
5. 数据库实施阶段
运用DBMS提供的数据语言(例如SQL)及其宿主语言(例如C),根据逻辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。 数据库实施主要包括以下工作:用DDL定义数据库结构、组织数据入库 、编制与调试应用程序、数据库试运行
6. 数据库运行和维护阶段
数据库应用系统经过试运行后即可投入正式运行。在数据库系统运行过程中必须不断地对其进行评价、调整与修改。包括:数据库的转储和恢复、数据库的安全性、完整性控制、数据库性能的监督、分析和改进、数据库的重组织和重构造。
建模工具的使用
为加快数据库设计速度,目前有很多数据库辅助工具(CASE工具),如Rational公司的Rational Rose,CA公司的Erwin和Bpwin,Sybase公司的PowerDesigner以及Oracle公司的Oracle Designer等。
ERwin主要用来建立数据库的概念模型和物理模型。它能用图形化的方式,描述出实体、联系及实体的属性。ERwin支持IDEF1X方法。通过使用ERwin建模工具自动生成、更改和分析IDEF1X模型,不仅能得到优秀的业务功能和数据需求模型,而且可以实现从IDEF1X模型到数据库物理设计的转变。ERwin工具绘制的模型对应于逻辑模型和物理模型两种。在逻辑模型中,IDEF1X工具箱可以方便地用图形化的方式构建和绘制实体联系及实体的属性。在物理模型中,ERwin可以定义对应的表、列,并可针对各种数据库管理系统自动转换为适当的类型。
设计人员可根据需要选用相应的数据库设计建模工具。例如需求分析完成之后,设计人员可以使用Erwin画ER图,将ER图转换为关系数据模型,生成数据库结构;画数据流图,生成应用程序。
二、数据库设计技巧
1. 设计数据库之前(需求分析阶段)
1) 理解客户需求,询问用户如何看待未来需求变化。让客户解释其需求,而且随着开发的继续,还要经常询问客户保证其需求仍然在开发的目的之中。
2) 了解企业业务可以在以后的开发阶段节约大量的时间。
3) 重视输入输出。
在定义数据库表和字段需求(输入)时,首先应检查现有的或者已经设计出的报表、查询和视图(输出)以决定为了支持这些输出哪些是必要的表和字段。
举例:假如客户需要一个报表按照邮政编码排序、分段和求和,你要保证其中包括了单独的邮政编码字段而不要把邮政编码糅进地址字段里。
4) 创建数据字典和ER 图表
ER 图表和数据字典可以让任何了解数据库的人都明确如何从数据库中获得数据。ER图对表明表之间关系很有用,而数据字典则说明了每个字段的用途以及任何可能存在的别名。对SQL 表达式的文档化来说这是完全必要的。
5) 定义标准的对象命名规范
数据库各种对象的命名必须规范。
2. 表和字段的设计(数据库逻辑设计)
表设计原则
1) 标准化和规范化
数据的标准化有助于消除数据库中的数据冗余。标准化有好几种形式,但Third Normal Form(3NF)通常被认为在性能、扩展性和数据完整性方面达到了最好平衡。简单来说,遵守3NF 标准的数据库的表设计原则是:“One Fact in One Place”即某个表只包括其本身基本的属性,当不是它们本身所具有的属性时需进行分解。表之间的关系通过外键相连接。它具有以下特点:有一组表专门存放通过键连接起来的关联数据。
举例:某个存放客户及其有关定单的3NF 数据库就可能有两个表:Customer 和Order。Order 表不包含定单关联客户的任何信息,但表内
会存放一个键值,该键指向Customer 表里包含该客户信息的那一行。
事实上,为了效率的缘故,对表不进行标准化有时也是必要的。
2) 数据驱动
采用数据驱动而非硬编码的方式,许多策略变更和维护都会方便得多,大大增强系统的灵活性和扩展性。
举例,假如用户界面要访问外部数据源(文件、XML 文档、其他数据库等),不妨把相应的连接和路径信息存储在用户界面支持表里。还有,如果用户界面执行工作流之类的任务(发送邮件、打印信笺、修改记录状态等),那么产生工作流的数据也可以存放在数据库里。角色权限管理也可以通过数据驱动来完成。事实上,如果过程是数据驱动的,你就可以把相当大的责任推给用户,由用户来维护自己的工作流过程。
3) 考虑各种变化
在设计数据库的时候考虑到哪些数据字段将来可能会发生变更。
举例,姓氏就是如此(注意是西方人的姓氏,比如女性结婚后从夫姓等)。所以,在建立系统存储客户信息时,在单独的一个数据表里存储姓氏字段,而且还附加起始日和终止日等字段,这样就可以跟踪这一数据条目的变化。
字段设计原则
4) 每个表中都应该添加的3 个有用的字段
•?dRecordCreationDate,在VB 下默认是Now(),而在SQL Server 下默认为GETDATE()
•?sRecordCreator,在SQL Server 下默认为NOT NULL DEFAULT USER
•?nRecordVersion,记录的版本标记;有助于准确说明记录中出现null 数据或者丢失数据的原因
5) 对地址和电话采用多个字段
描述街道地址就短短一行记录是不够的。Address_Line1、Address_Line2 和Address_Line3 可以提供更大的灵活性。还有,电话号码和邮件地址最好拥有自己的数据表,其间具有自身的类型和标记类别。
6) 使用角色实体定义属于某类别的列
在需要对属于特定类别或者具有特定角色的事物做定义时,可以用角色实体来创建特定的时间关联关系,从而可以实现自我文档化。
举例:用PERSON 实体和PERSON_TYPE 实体来描述人员。比方说,当John Smith, Engineer 提升为John Smith, Director 乃至最后爬到John Smith, CIO 的高位,而所有你要做的不过是改变两个表PERSON 和PERSON_TYPE 之间关系的键值,同时增加一个日期/时间字段来知道变化是何时发生的。这样,你的PERSON_TYPE 表就包含了所有PERSON 的可能类型,比如Associate、Engineer、Director、CIO 或者CEO 等。还有个替代办法就是改变PERSON 记录来反映新头衔的变化,不过这样一来在时间上无法跟踪个人所处位置的具体时间。
7) 选择数字类型和文本类型尽量充足
在SQL 中使用smallint 和tinyint 类型要特别小心。比如,假如想看看月销售总额,总额字段类型是smallint,那么,如果总额超过了$32,767 就不能进行计算操作了。
而ID 类型的文本字段,比如客户ID 或定单号等等都应该设置得比一般想象更大。假设客户ID 为10 位数长。那你应该把数据库表字段的长度设为12 或者13 个字符长。但这额外占据的空间却无需将来重构整个数据库就可以实现数据库规模的增长了。
8) 增加删除标记字段
在表中包含一个“删除标记”字段,这样就可以把行标记为删除。在关系数据库里不要单独删除某一行;最好采用清除数据程序而且要仔细维护索引整体性。
3. 选择键和索引(数据库逻辑设计)
键选择原则:
1) 键设计4 原则
•?为关联字段创建外键。
•?所有的键都必须唯一。
•?避免使用复合键。
•?外键总是关联唯一的键字段。
2) 使用系统生成的主键
设计数据库的时候采用系统生成的键作为主键,那么实际控制了数据库的索引完整性。这样,数据库和非人工机制就有效地控制了对存储数据中每一行的访问。采用系统生成键作为主键还有一个优点:当拥有一致的键结构时,找到逻辑缺陷很容易。
3) 不要用用户的键(不让主键具有可更新性)
在确定采用什么字段作为表的键的时候,可一定要小心用户将要编辑的字段。通常的情况下不要选择用户可编辑的字段作为键。
4) 可选键有时可做主键
把可选键进一步用做主键,可以拥有建立强大索引的能力。
索引使用原则:
索引是从数据库中获取数据的最高效方式之一。95%的数据库性能问题都可以采用索引技术得到解决。
1) 逻辑主键使用唯一的成组索引,对系统键(作为存储过程)采用唯一的非成组索引,对任何外键列采用非成组索引。考虑数据库的空间有多大,表如何进行访问,还有这些访问是否主要用作读写。
2) 大多数数据库都索引自动创建的主键字段,但是可别忘了索引外键,它们也是经常使用的键,比如运行查询显示主表和所有关联表的某条记录就用得上。
3) 不要索引memo/note 字段,不要索引大型字段(有很多字符),这样作会让索引占用太多的存储空间。
4) 不要索引常用的小型表
不要为小型数据表设置任何键,假如它们经常有插入和删除操作就更别这样作了。对这些插入和删除操作的索引维护可能比扫描表空间消耗更多的时间。
4. 数据完整性设计(数据库逻辑设计)
1) 完整性实现机制:
实体完整性:主键
参照完整性:
父表中删除数据:级联删除;受限删除;置空值
父表中插入数据:受限插入;递归插入
父表中更新数据:级联更新;受限更新;置空值
DBMS对参照完整性可以有两种方法实现:外键实现机制(约束规则)和触发器实现机制
用户定义完整性:
NOT NULL;CHECK;触发器
2) 用约束而非商务规则强制数据完整性
采用数据库系统实现数据的完整性。这不但包括通过标准化实现的完整性而且还包括数据的功能性。在写数据的时候还可以增加触发器来保证数据的正确性。不要依赖于商务层保证数据完整性;它不能保证表之间(外键)的完整性所以不能强加于其他完整性规则之上。
3) 强制指示完整性
在有害数据进入数据库之前将其剔除。激活数据库系统的指示完整性特性。这样可以保持数据的清洁而能迫使开发人员投入更多的时间处理错误条件。
4) 使用查找控制数据完整性
控制数据完整性的最佳方式就是限制用户的选择。只要有可能都应该提供给用户一个清晰的价值列表供其选择。这样将减少键入代码的错误和误解同时提供数据的一致性。某些公共数据特别适合查找:国家代码、状态代码等。
5) 采用视图
为了在数据库和应用程序代码之间提供另一层抽象,可以为应用程序建立专门的视图而不必非要应用程序直接访问数据表。这样做还等于在处理数据库变更时给你提供了更多的自由。
5. 其他设计技巧
1) 避免使用触发器
触发器的功能通常可以用其他方式实现。在调试程序时触发器可能成为干扰。假如你确实需要采用触发器,你最好集中对它文档化。
2) 使用常用英语(或者其他任何语言)而不要使用编码
在创建下拉菜单、列表、报表时最好按照英语名排序。假如需要编码,可以在编码旁附上用户知道的英语。
3) 保存常用信息
让一个表专门存放一般数据库信息非常有用。在这个表里存放数据库当前版本、最近检查/修复(对Access)、关联设计文档的名称、客户等信息。这样可以实现一种简单机制跟踪数据库,当客户抱怨他们的数据库没有达到希望的要求而与你联系时,这样做对非客户机/服务器环境特别有用。
4) 包含版本机制
在数据库中引入版本控制机制来确定使用中的数据库的版本。时间一长,用户的需求总是会改变的。最终可能会要求修改数据库结构。把版本信息直接存放到数据库中更为方便。
5) 编制文档
对所有的快捷方式、命名规范、限制和函数都要编制文档。
采用给表、列、触发器等加注释的数据库工具。对开发、支持和跟踪修改非常有用。
对数据库文档化,或者在数据库自身的内部或者单独建立文档。这样,当过了一年多时间后再回过头来做第2 个版本,犯错的机会将大大减少。
6) 测试、测试、反复测试
建立或者修订数据库之后,必须用用户新输入的数据测试数据字段。最重要的是,让用户进行测试并且同用户一道保证选择的数据类型满足商业要求。测试需要在把新数据库投入实际服务之前完成。
7) 检查设计
在开发期间检查数据库设计的常用技术是通过其所支持的应用程序原型检查数据库。换句话说,针对每一种最终表达数据的原型应用,保证你检查了数据模型并且查看如何取出数据。
三、数据库命名规范
1. 实体(表)的命名
1) 表以名词或名词短语命名,确定表名是采用复数还是单数形式,此外给表的别名定义简单规则(比方说,如果表名是一个单词,别名就取单词的前4 个字母;如果表名是两个单词,就各取两个单词的前两个字母组成4 个字母长的别名;如果表的名字由3 个单词组成,从头两个单词中各取一个然后从最后一个单词中再取出两个字母,结果还是组成4 字母长的别名,其余依次类推)
对工作用表来说,表名可以加上前缀WORK_ 后面附上采用该表的应用程序的名字。在命名过程当中,根据语义拼凑缩写即可。注意,由于ORCLE会将字段名称统一成大写或者小写中的一种,所以要求加上下划线。
举例:
定义的缩写 Sales: Sal 销售;
Order: Ord 订单;
Detail: Dtl 明细;
则销售订单明细表命名为:Sal_Ord_Dtl;
2) 如果表或者是字段的名称仅有一个单词,那么建议不使用缩写,而是用完整的单词。
举例:
定义的缩写 Material Ma 物品;
物品表名为:Material, 而不是 Ma.
但是字段物品编码则是:Ma_ID;而不是Material_ID
3) 所有的存储值列表的表前面加上前缀Z
目的是将这些值列表类排序在数据库最后。
4) 所有的冗余类的命名(主要是累计表)前面加上前缀X
冗余类是为了提高数据库效率,非规范化数据库的时候加入的字段或者表
5) 关联类通过用下划线连接两个基本类之后,再加前缀R的方式命名,后面按照字母顺序罗列两个表名或者表名的缩写。
关联表用于保存多对多关系。
如果被关联的表名大于10个字母,必须将原来的表名的进行缩写。如果没有其他原因,建议都使用缩写。
举例:表Object与自身存在多对多的关系,则保存多对多关系的表命名为:R_Object;
表 Depart和Employee;存在多对多的关系;则关联表命名为R_Dept_Emp
2. 属性(列)的命名
1) 采用有意义的列名,表内的列要针对键采用一整套设计规则。每一个表都将有一个自动ID作为主健,逻辑上的主健作为第一组候选主健来定义,如果是数据库自动生成的编码,统一命名为:ID;如果是自定义的逻辑上的编码则用缩写加“ID”的方法命名。如果键是数字类型,你可以用_NO 作为后缀;如果是字符类型则可以采用_CODE 后缀。对列名应该采用标准的前缀和后缀。
举例:销售订单的编号字段命名:Sal_Ord_ID;如果还存在一个数据库生成的自动编号,则命名为:ID。
2) 所有的属性加上有关类型的后缀,注意,如果还需要其它的后缀,都放在类型后缀之前。
注: 数据类型是文本的字段,类型后缀TX可以不写。有些类型比较明显的字段,可以不写类型后缀。
3) 采用前缀命名
给每个表的列名都采用统一的前缀,那么在编写SQL表达式的时候会得到大大的简化。这样做也确实有缺点,比如破坏了自动表连接工具的作用,后者把公共列名同某些数据库联系起来。
3. 视图的命名
1) 视图以V作为前缀,其他命名规则和表的命名类似;
2) 命名应尽量体现各视图的功能。
4. 触发器的命名
触发器以TR作为前缀,触发器名为相应的表名加上后缀,Insert触发器加"_I",Delete触发器加"_D",Update触发器加"_U",如:
TR_Customer_I,TR_Customer_D,TR_Customer_U。
5. 存储过程名
存储过程应以"UP_"开头,和系统的存储过程区分,后续部分主要以动宾形式构成,并用下划线分割各个组成部分。如增加代理商的帐户的存储过程为"UP_Ins_Agent_Account"。
6. 变量名
变量名采用小写,若属于词组形式,用下划线分隔每个单词,如@my_err_no。
7. 命名中其他注意事项
1) 以上命名都不得超过30个字符的系统限制。变量名的长度限制为29(不包括标识字符@)。
2) 数据对象、变量的命名都采用英文字符,禁止使用中文命名。绝对不要在对象名的字符之间留空格。
3) 小心保留词,要保证你的字段名没有和保留词、数据库系统或者常用访问方法冲突
5) 保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了。
摘要: (转载自--http://www.cnblogs.com/qiubole/articles/116152.html)
采用
PowerDesigner
设计数据库
...
阅读全文
(转自--http://www.cnblogs.com/qiubole/articles/157312.html)
一个成功的管理系统,是由:[50% 的业务 + 50% 的软件] 所组成,而 50% 的成功软件又有 [25% 的数据库 + 25% 的程序] 所组成,数据库设计的好坏是一个关键。如果把企业的数据比做生命所必需的血液,那么数据库的设计就是应用中最重要的一部分。有关数据库设计的材料汗牛充栋,大学学位课程里也有专门的讲述。不过,就如我们反复强调的那样,再好的老师也比不过经验的教诲。所以我归纳历年来所走的弯路及体会,并在网上找了些对数据库设计颇有造诣的专业人士给大家传授一些设计数据库的技巧和经验。精选了其中的 60 个最佳技巧,并把这些技巧编写成了本文,为了方便索引其内容划分为 5 个部分:
第 1 部分 - 设计数据库之前
这一部分罗列了 12 个基本技巧,包括命名规范和明确业务需求等。
第 2 部分 - 设计数据库表
总共 24 个指南性技巧,涵盖表内字段设计以及应该避免的常见问题等。
第 3 部分 - 选择键
怎么选择键呢?这里有 10 个技巧专门涉及系统生成的主键的正确用法,还有何 时以及如何索引字段以获得最佳性能等。
第 4 部分 - 保证数据完整性
讨论如何保持数据库的清晰和健壮,如何把有害数据降低到最小程度。
第 5 部分 - 各种小技巧
不包括在以上 4 个部分中的其他技巧,五花八门,有了它们希望你的数据库开发工作会更轻松一些。
第 1 部分 - 设计数据库之前
考察现有环境
在设计一个新数据库时,你不但应该仔细研究业务需求而且还要考察现有的系统。大多数数据库项目都不是从头开始建立的;通常,机构内总会存在用来满足特定需求的现有系统(可能没有实现自动计算)。显然,现有系统并不完美,否则你就不必再建立新系统了。但是对旧系统的研究可以让你发现一些可能会忽略的细微问题。一般来说,考察现有系统对你绝对有好处。
定义标准的对象命名规范
一定要定义数据库对象的命名规范。对数据库表来说,从项目一开始就要确定表名是采用复数还是单数形式。此外还要给表的别名定义简单规则(比方说,如果表名是一个单词,别名就取单词的前 4 个字母;如果表名是两个单词,就各取两个单词的前两个字母组成 4 个字母长的别名;如果表的名字由 3 个单词组成,你不妨从头两个单词中各取一个然后从最后一个单词中再取出两个字母,结果还是组成 4 字母长的别名,其余依次类推)对工作用表来说,表名可以加上前缀 WORK_ 后面附上采用该表的应用程序的名字。表内的列[字段]要针对键采用一整套设计规则。比如,如果键是数字类型,你可以用 _N 作为后缀;如果是字符类型则可以采用 _C 后缀。对列[字段]名应该采用标准的前缀和后缀。再如,假如你的表里有好多“money”字段,你不妨给每个列[字段]增加一个 _M 后缀。还有,日期列[字段]最好以 D_ 作为名字打头。
检查表名、报表名和查询名之间的命名规范。你可能会很快就被这些不同的数据库要素的名称搞糊涂了。假如你坚持统一地命名这些数据库的不同组成部分,至少你应该在这些对象名字的开头用 Table、Query 或者 Report 等前缀加以区别。
如果采用了 Microsoft Access,你可以用 qry、rpt、tbl 和 mod 等符号来标识对象(比如 tbl_Employees)。我在和 SQL Server 打交道的时候还用过 tbl 来索引表,但我用 sp_company (现在用 sp_feft_)标识存储过程,因为在有的时候如果我发现了更好的处理办法往往会保存好几个拷贝。我在实现 SQL Server 2000 时用 udf_ (或者类似的标记)标识我编写的函数。
工欲善其事, 必先利其器
采用理想的数据库设计工具,比如:SyBase 公司的 PowerDesign,她支持 PB、VB、Delphe 等语言,通过 ODBC 可以连接市面上流行的 30 多个数据库,包括 dBase、FoxPro、VFP、SQL Server 等,今后有机会我将着重介绍 PowerDesign 的使用。
获取数据模式资源手册
正在寻求示例模式的人可以阅读《数据模式资源手册》一书,该书由 Len Silverston、W. H. Inmon 和 Kent Graziano 编写,是一本值得拥有的最佳数据建模图书。该书包括的章节涵盖多种数据领域,比如人员、机构和工作效能等。其他的你还可以参考:[1]萨师煊 王珊著 数据库系统概论(第二版)高等教育出版社 1991、[2][美] Steven M.Bobrowski 著 Oracle 7 与客户/服务器计算技术从入门到精通 刘建元等译 电子工业出版社,1996、[3]周中元 信息系统建模方法(下) 电子与信息化 1999年第3期,1999
畅想未来,但不可忘了过去的教训
我发现询问用户如何看待未来需求变化非常有用。这样做可以达到两个目的:首先,你可以清楚地了解应用设计在哪个地方应该更具灵活性以及如何避免性能瓶颈;其次,你知道发生事先没有确定的需求变更时用户将和你一样感到吃惊。
一定要记住过去的经验教训!我们开发人员还应该通过分享自己的体会和经验互相帮助。即使用户认为他们再也不需要什么支持了,我们也应该对他们进行这方面的教育,我们都曾经面临过这样的时刻“当初要是这么做了该多好..”。
在物理实践之前进行逻辑设计
在深入物理设计之前要先进行逻辑设计。随着大量的 CASE 工具不断涌现出来,你的设计也可以达到相当高的逻辑水准,你通常可以从整体上更好地了解数据库设计所需要的方方面面。
了解你的业务
在你百分百地确定系统从客户角度满足其需求之前不要在你的 ER(实体关系)模式中加入哪怕一个数据表(怎么,你还没有模式?那请你参看技巧 9)。了解你的企业业务可以在以后的开发阶段节约大量的时间。一旦你明确了业务需求,你就可以自己做出许多决策了。
一旦你认为你已经明确了业务内容,你最好同客户进行一次系统的交流。采用客户的术语并且向他们解释你所想到的和你所听到的。同时还应该用可能、将会和必须等词汇表达出系统的关系基数。这样你就可以让你的客户纠正你自己的理解然后做好下一步的 ER 设计。
创建数据字典和 ER 图表
一定要花点时间创建 ER 图表和数据字典。其中至少应该包含每个字段的数据类型和在每个表内的主外键。创建 ER 图表和数据字典确实有点费时但对其他开发人员要了解整个设计却是完全必要的。越早创建越能有助于避免今后面临的可能混乱,从而可以让任何了解数据库的人都明确如何从数据库中获得数据。
有一份诸如 ER 图表等最新文档其重要性如何强调都不过分,这对表明表之间关系很有用,而数据字典则说明了每个字段的用途以及任何可能存在的别名。对 SQL 表达式的文档化来说这是完全必要的。
创建模式
一张图表胜过千言万语:开发人员不仅要阅读和实现它,而且还要用它来帮助自己和用户对话。模式有助于提高协作效能,这样在先期的数据库设计中几乎不可能出现大的问题。模式不必弄的很复杂;甚至可以简单到手写在一张纸上就可以了。只是要保证其上的逻辑关系今后能产生效益。
从输入输出下手
在定义数据库表和字段需求(输入)时,首先应检查现有的或者已经设计出的报表、查询和视图(输出)以决定为了支持这些输出哪些是必要的表和字段。举个简单的例子:假如客户需要一个报表按照邮政编码排序、分段和求和,你要保证其中包括了单独的邮政编码字段而不要把邮政编码糅进地址字段里。
报表技巧
要了解用户通常是如何报告数据的:批处理还是在线提交报表?时间间隔是每天、每周、每月、每个季度还是每年?如果需要的话还可以考虑创建总结表。系统生成的主键在报表中很难管理。用户在具有系统生成主键的表内用副键进行检索往往会返回许多重复数据。这样的检索性能比较低而且容易引起混乱。
理解客户需求
看起来这应该是显而易见的事,但需求就是来自客户(这里要从内部和外部客户的角度考虑)。不要依赖用户写下来的需求,真正的需求在客户的脑袋里。你要让客户解释其需求,而且随着开发的继续,还要经常询问客户保证其需求仍然在开发的目的之中。一个不变的真理是:“只有我看见了我才知道我想要的是什么”必然会导致大量的返工,因为数据库没有达到客户从来没有写下来的需求标准。而更糟的是你对他们需求的解释只属于你自己,而且可能是完全错误的。
第 2 部分 - 设计表和字段
检查各种变化
我在设计数据库的时候会考虑到哪些数据字段将来可能会发生变更。比方说,姓氏就是如此(注意是西方人的姓氏,比如女性结婚后从夫姓等)。所以,在建立系统存储客户信息时,我倾向于在单独的一个数据表里存储姓氏字段,而且还附加起始日和终止日等字段,这样就可以跟踪这一数据条目的变化。
采用有意义的字段名
有一回我参加开发过一个项目,其中有从其他程序员那里继承的程序,那个程序员喜欢用屏幕上显示数据指示用语命名字段,这也不赖,但不幸的是,她还喜欢用一些奇怪的命名法,其命名采用了匈牙利命名和控制序号的组合形式,比如 cbo1、txt2、txt2_b 等等。
除非你在使用只面向你的缩写字段名的系统,否则请尽可能地把字段描述的清楚些。当然,也别做过头了,比如 Customer_Shipping_Address_Street_Line_1,虽然很富有说明性,但没人愿意键入这么长的名字,具体尺度就在你的把握中。
采用前缀命名
如果多个表里有好多同一类型的字段(比如 FirstName),你不妨用特定表的前缀(比如 CusLastName)来帮助你标识字段。
时效性数据应包括“最近更新日期/时间”字段。时间标记对查找数据问题的原因、按日期重新处理/重载数据和清除旧数据特别有用。
标准化和数据驱动
数据的标准化不仅方便了自己而且也方便了其他人。比方说,假如你的用户界面要访问外部数据源(文件、XML 文档、其他数据库等),你不妨把相应的连接和路径信息存储在用户界面支持表里。还有,如果用户界面执行工作流之类的任务(发送邮件、打印信笺、修改记录状态等),那么产生工作流的数据也可以存放在数据库里。预先安排总需要付出努力,但如果这些过程采用数据驱动而非硬编码的方式,那么策略变更和维护都会方便得多。事实上,如果过程是数据驱动的,你就可以把相当大的责任推给用户,由用户来维护自己的工作流过程。
标准化不能过头
对那些不熟悉标准化一词(normalization)的人而言,标准化可以保证表内的字段都是最基础的要素,而这一措施有助于消除数据库中的数据冗余。标准化有好几种形式,但 Third Normal Form(3NF)通常被认为在性能、扩展性和数据完整性方面达到了最好平衡。简单来说,3NF 规定:
* 表内的每一个值都只能被表达一次。
* 表内的每一行都应该被唯一的标识(有唯一键)。
* 表内不应该存储依赖于其他键的非键信息。
遵守 3NF 标准的数据库具有以下特点:有一组表专门存放通过键连接起来的关联数据。比方说,某个存放客户及其有关定单的 3NF 数据库就可能有两个表:Customer 和 Order。Order 表不包含定单关联客户的任何信息,但表内会存放一个键值,该键指向 Customer 表里包含该客户信息的那一行。
更高层次的标准化也有,但更标准是否就一定更好呢?答案是不一定。事实上,对某些项目来说,甚至就连 3NF 都可能给数据库引入太高的复杂性。
为了效率的缘故,对表不进行标准化有时也是必要的,这样的例子很多。曾经有个开发餐饮分析软件的活就是用非标准化表把查询时间从平均 40 秒降低到了两秒左右。虽然我不得不这么做,但我绝不把数据表的非标准化当作当然的设计理念。而具体的操作不过是一种派生。所以如果表出了问题重新产生非标准化的表是完全可能的。
Microsoft Visual FoxPro 报表技巧
如果你正在使用 Microsoft Visual FoxPro,你可以用对用户友好的字段名来代替编号的名称:比如用 Customer Name 代替 txtCNaM。这样,当你用向导程序 [Wizards,台湾人称为‘精灵’] 创建表单和报表时,其名字会让那些不是程序员的人更容易阅读。
不活跃或者不采用的指示符
增加一个字段表示所在记录是否在业务中不再活跃挺有用的。不管是客户、员工还是其他什么人,这样做都能有助于再运行查询的时候过滤活跃或者不活跃状态。同时还消除了新用户在采用数据时所面临的一些问题,比如,某些记录可能不再为他们所用,再删除的时候可以起到一定的防范作用。
使用角色实体定义属于某类别的列[字段]
在需要对属于特定类别或者具有特定角色的事物做定义时,可以用角色实体来创建特定的时间关联关系,从而可以实现自我文档化。
这里的含义不是让 PERSON 实体带有 Title 字段,而是说,为什么不用 PERSON 实体和 PERSON_TYPE 实体来描述人员呢?比方说,当 John Smith, Engineer 提升为 John Smith, Director 乃至最后爬到 John Smith, CIO 的高位,而所有你要做的不过是改变两个表 PERSON 和 PERSON_TYPE 之间关系的键值,同时增加一个日期/时间字段来知道变化是何时发生的。这样,你的 PERSON_TYPE 表就包含了所有 PERSON 的可能类型,比如 Associate、Engineer、Director、CIO 或者 CEO 等。
还有个替代办法就是改变 PERSON 记录来反映新头衔的变化,不过这样一来在时间上无法跟踪个人所处位置的具体时间。
采用常用实体命名机构数据
组织数据的最简单办法就是采用常用名字,比如:PERSON、ORGANIZATION、ADDRESS 和 PHONE 等等。当你把这些常用的一般名字组合起来或者创建特定的相应副实体时,你就得到了自己用的特殊版本。开始的时候采用一般术语的主要原因在于所有的具体用户都能对抽象事物具体化。
有了这些抽象表示,你就可以在第 2 级标识中采用自己的特殊名称,比如,PERSON 可能是 Employee、Spouse、Patient、Client、Customer、Vendor 或者 Teacher 等。同样的,ORGANIZATION 也可能是 MyCompany、MyDepartment、Competitor、Hospital、Warehouse、Government 等。最后 ADDRESS 可以具体为 Site、Location、Home、Work、Client、Vendor、Corporate 和 FieldOffice 等。
采用一般抽象术语来标识“事物”的类别可以让你在关联数据以满足业务要求方面获得巨大的灵活性,同时这样做还可以显著降低数据存储所需的冗余量。
用户来自世界各地
在设计用到网络或者具有其他国际特性的数据库时,一定要记住大多数国家都有不同的字段格式,比如邮政编码等,有些国家,比如新西兰就没有邮政编码一说。
数据重复需要采用分立的数据表
如果你发现自己在重复输入数据,请创建新表和新的关系。
每个表中都应该添加的 3 个有用的字段
* dRecordCreationDate,在 VB 下默认是 Now(),而在 SQL Server 下默认为 GETDATE()
* sRecordCreator,在 SQL Server 下默认为 NOT NULL DEFAULT USER
* nRecordVersion,记录的版本标记;有助于准确说明记录中出现 null 数据或者丢失数据的原因
对地址和电话采用多个字段
描述街道地址就短短一行记录是不够的。Address_Line1、Address_Line2 和 Address_Line3 可以提供更大的灵活性。还有,电话号码和邮件地址最好拥有自己的数据表,其间具有自身的类型和标记类别。
过分标准化可要小心,这样做可能会导致性能上出现问题。虽然地址和电话表分离通常可以达到最佳状态,但是如果需要经常访问这类信息,或许在其父表中存放“首选”信息(比如 Customer 等)更为妥当些。非标准化和加速访问之间的妥协是有一定意义的。
使用多个名称字段
我觉得很吃惊,许多人在数据库里就给 name 留一个字段。我觉得只有刚入门的开发人员才会这么做,但实际上网上这种做法非常普遍。我建议应该把姓氏和名字当作两个字段来处理,然后在查询的时候再把他们组合起来。
我最常用的是在同一表中创建一个计算列[字段],通过它可以自动地连接标准化后的字段,这样数据变动的时候它也跟着变。不过,这样做在采用建模软件时得很机灵才行。总之,采用连接字段的方式可以有效的隔离用户应用和开发人员界面。
提防大小写混用的对象名和特殊字符
过去最令我恼火的事情之一就是数据库里有大小写混用的对象名,比如 CustomerData。这一问题从 Access 到 Oracle 数据库都存在。我不喜欢采用这种大小写混用的对象命名方法,结果还不得不手工修改名字。想想看,这种数据库/应用程序能混到采用更强大数据库的那一天吗?采用全部大写而且包含下划符的名字具有更好的可读性(CUSTOMER_DATA),绝对不要在对象名的字符之间留空格。
小心保留词
要保证你的字段名没有和保留词、数据库系统或者常用访问方法冲突,比如,最近我编写的一个 ODBC 连接程序里有个表,其中就用了 DESC 作为说明字段名。后果可想而知!DESC 是 DESCENDING 缩写后的保留词。表里的一个 SELECT * 语句倒是能用,但我得到的却是一大堆毫无用处的信息。
保持字段名和类型的一致性
在命名字段并为其指定数据类型的时候一定要保证一致性。假如字段在某个表中叫做“agreement_number”,你就别在另一个表里把名字改成“ref1”。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了。记住,你干完自己的活了,其他人还要用你的数据库呢。
仔细选择数字类型
在 SQL 中使用 smallint 和 tinyint 类型要特别小心,比如,假如你想看看月销售总额,你的总额字段类型是 smallint,那么,如果总额超过了 $32,767 你就不能进行计算操作了。
删除标记
在表中包含一个“删除标记”字段,这样就可以把行标记为删除。在关系数据库里不要单独删除某一行;最好采用清除数据程序而且要仔细维护索引整体性。
避免使用触发器
触发器的功能通常可以用其他方式实现。在调试程序时触发器可能成为干扰。假如你确实需要采用触发器,你最好集中对它文档化。
包含版本机制
建议你在数据库中引入版本控制机制来确定使用中的数据库的版本。无论如何你都要实现这一要求。时间一长,用户的需求总是会改变的。最终可能会要求修改数据库结构。虽然你可以通过检查新字段或者索引来确定数据库结构的版本,但我发现把版本信息直接存放到数据库中不更为方便吗?。
给文本字段留足余量
ID 类型的文本字段,比如客户 ID 或定单号等等都应该设置得比一般想象更大,因为时间不长你多半就会因为要添加额外的字符而难堪不已。比方说,假设你的客户 ID 为 10 位数长。那你应该把数据库表字段的长度设为 12 或者 13 个字符长。这算浪费空间吗?是有一点,但也没你想象的那么多:一个字段加长 3 个字符在有 1 百万条记录,再加上一点索引的情况下才不过让整个数据库多占据 3MB 的空间。但这额外占据的空间却无需将来重构整个数据库就可以实现数据库规模的增长了。身份证的号码从 15 位变成 18 位就是最好和最惨痛的例子。
列[字段]命名技巧
我们发现,假如你给每个表的列[字段]名都采用统一的前缀,那么在编写 SQL 表达式的时候会得到大大的简化。这样做也确实有缺点,比如破坏了自动表连接工具的作用,后者把公共列[字段]名同某些数据库联系起来,不过就连这些工具有时不也连接错误嘛。举个简单的例子,假设有两个表:
Customer 和 Order。Customer 表的前缀是 cu_,所以该表内的子段名如下:cu_name_id、cu_surname、cu_initials 和cu_address 等。Order 表的前缀是 or_,所以子段名是:
or_order_id、or_cust_name_id、or_quantity 和 or_description 等。
这样从数据库中选出全部数据的 SQL 语句可以写成如下所示:
Select * From Customer, Order Where cu_surname = "MYNAME" ;
and cu_name_id = or_cust_name_id and or_quantity = 1
在没有这些前缀的情况下则写成这个样子(用别名来区分):
Select * From Customer, Order Where Customer.surname = "MYNAME" ;
and Customer.name_id = Order.cust_name_id and Order.quantity = 1
第 1 个 SQL 语句没少键入多少字符。但如果查询涉及到 5 个表乃至更多的列[字段]你就知道这个技巧多有用了。
第 3 部分 - 选择键和索引
数据采掘要预先计划
我所在的某一客户部门一度要处理 8 万多份联系方式,同时填写每个客户的必要数据(这绝对不是小活)。我从中还要确定出一组客户作为市场目标。当我从最开始设计表和字段的时候,我试图不在主索引里增加太多的字段以便加快数据库的运行速度。然后我意识到特定的组查询和信息采掘既不准确速度也不快。结果只好在主索引中重建而且合并了数据字段。我发现有一个指示计划相当关键——当我想创建系统类型查找时为什么要采用号码作为主索引字段呢?我可以用传真号码进行检索,但是它几乎就象系统类型一样对我来说并不重要。采用后者作为主字段,数据库更新后重新索引和检索就快多了。
可操作数据仓库(ODS)和数据仓库(DW)这两种环境下的数据索引是有差别的。在 DW 环境下,你要考虑销售部门是如何组织销售活动的。他们并不是数据库管理员,但是他们确定表内的键信息。这里设计人员或者数据库工作人员应该分析数据库结构从而确定出性能和正确输出之间的最佳条件。
使用系统生成的主键
这类同技巧 1,但我觉得有必要在这里重复提醒大家。假如你总是在设计数据库的时候采用系统生成的键作为主键,那么你实际控制了数据库的索引完整性。这样,数据库和非人工机制就有效地控制了对存储数据中每一行的访问。
采用系统生成键作为主键还有一个优点:当你拥有一致的键结构时,找到逻辑缺陷很容易。
分解字段用于索引
为了分离命名字段和包含字段以支持用户定义的报表,请考虑分解其他字段(甚至主键)为其组成要素以便用户可以对其进行索引。索引将加快 SQL 和报表生成器脚本的执行速度。比方说,我通常在必须使用 SQL LIKE 表达式的情况下创建报表,因为 case number 字段无法分解为 year、serial number、case type 和 defendant code 等要素。性能也会变坏。假如年度和类型字段可以分解为索引字段那么这些报表运行起来就会快多了。
键设计 4 原则
* 为关联字段创建外键。
* 所有的键都必须唯一。
* 避免使用复合键。
* 外键总是关联唯一的键字段。
别忘了索引
索引是从数据库中获取数据的最高效方式之一。95% 的数据库性能问题都可以采用索引技术得到解决。作为一条规则,我通常对逻辑主键使用唯一的成组索引,对系统键(作为存储过程)采用唯一的非成组索引,对任何外键列[字段]采用非成组索引。不过,索引就象是盐,太多了菜就咸了。你得考虑数据库的空间有多大,表如何进行访问,还有这些访问是否主要用作读写。
大多数数据库都索引自动创建的主键字段,但是可别忘了索引外键,它们也是经常使用的键,比如运行查询显示主表和所有关联表的某条记录就用得上。还有,不要索引 memo/note 字段,不要索引大型字段(有很多字符),这样作会让索引占用太多的存储空间。
不要索引常用的小型表
不要为小型数据表设置任何键,假如它们经常有插入和删除操作就更别这样作了。对这些插入和删除操作的索引维护可能比扫描表空间消耗更多的时间。
不要把社会保障号码(SSN)或身份证号码(ID)选作键
永远都不要使用 SSN 或 ID 作为数据库的键。除了隐私原因以外,须知政府越来越趋向于不准许把 SSN 或 ID 用作除收入相关以外的其他目的,SSN 或 ID 需要手工输入。永远不要使用手工输入的键作为主键,因为一旦你输入错误,你唯一能做的就是删除整个记录然后从头开始。
我在破解他人的程序时候,我看到很多人把 SSN 或 ID 还曾被用做系列号,当然尽管这么做是非法的。而且人们也都知道这是非法的,但他们已经习惯了。后来,随着盗取身份犯罪案件的增加,我现在的同行正痛苦地从一大摊子数据中把 SSN 或 ID 删除。
不要用用户的键
在确定采用什么字段作为表的键的时候,可一定要小心用户将要编辑的字段。通常的情况下不要选择用户可编辑的字段作为键。这样做会迫使你采取以下两个措施:
* 在创建记录之后对用户编辑字段的行为施加限制。假如你这么做了,你可能会发现你的应用程序在商务需求突然发生变化,而用户需要编辑那些不可编辑的字段时缺乏足够的灵活性。当用户在输入数据之后直到保存记录才发现系统出了问题他们该怎么想?删除重建?假如记录不可重建是否让用户走开?
* 提出一些检测和纠正键冲突的方法。通常,费点精力也就搞定了,但是从性能上来看这样做的代价就比较大了。还有,键的纠正可能会迫使你突破你的数据和商业/用户界面层之间的隔离。
所以还是重提一句老话:你的设计要适应用户而不是让用户来适应你的设计。
不让主键具有可更新性的原因是在关系模式下,主键实现了不同表之间的关联。比如,Customer 表有一个主键 CustomerID,而客户的定单则存放在另一个表里。Order 表的主键可能是 OrderNo 或者 OrderNo、CustomerID 和日期的组合。不管你选择哪种键设置,你都需要在 Order 表中存放 CustomerID 来保证你可以给下定单的用户找到其定单记录。
假如你在 Customer 表里修改了 CustomerID,那么你必须找出 Order 表中的所有相关记录对其进行修改。否则,有些定单就会不属于任何客户——数据库的完整性就算完蛋了。
如果索引完整性规则施加到表一级,那么在不编写大量代码和附加删除记录的情况下几乎不可能改变某一条记录的键和数据库内所有关联的记录。而这一过程往往错误丛生所以应该尽量避免。
可选键(候选键)有时可做主键
记住,查询数据的不是机器而是人。
假如你有可选键,你可能进一步把它用做主键。那样的话,你就拥有了建立强大索引的能力。这样可以阻止使用数据库的人不得不连接数据库从而恰当的过滤数据。在严格控制域表的数据库上,这种负载是比较醒目的。如果可选键真正有用,那就是达到了主键的水准。
我的看法是,假如你有可选键,比如国家表内的 state_code,你不要在现有不能变动的唯一键上创建后续的键。你要做的无非是创建毫无价值的数据。如你因为过度使用表的后续键[别名]建立这种表的关联,操作负载真得需要考虑一下了。
别忘了外键
大多数数据库索引自动创建的主键字段。但别忘了索引外键字段,它们在你想查询主表中的记录及其关联记录时每次都会用到。还有,不要索引 memo/notes 字段而且不要索引大型文本字段(许多字符),这样做会让你的索引占据大量的数据库空间。
第 4 部分 - 保证数据的完整性
用约束而非商务规则强制数据完整性
如果你按照商务规则来处理需求,那么你应当检查商务层次/用户界面:如果商务规则以后发生变化,那么只需要进行更新即可。假如需求源于维护数据完整性的需要,那么在数据库层面上需要施加限制条件。如果你在数据层确实采用了约束,你要保证有办法把更新不能通过约束检查的原因采用用户理解的语言通知用户界面。除非你的字段命名很冗长,否则字段名本身还不够。
只要有可能,请采用数据库系统实现数据的完整性。这不但包括通过标准化实现的完整性而且还包括数据的功能性。在写数据的时候还可以增加触发器来保证数据的正确性。不要依赖于商务层保证数据完整性;它不能保证表之间(外键)的完整性所以不能强加于其他完整性规则之上。
分布式数据系统
对分布式系统而言,在你决定是否在各个站点复制所有数据还是把数据保存在一个地方之前应该估计一下未来 5 年或者 10 年的数据量。当你把数据传送到其他站点的时候,最好在数据库字段中设置一些标记。在目的站点收到你的数据之后更新你的标记。为了进行这种数据传输,请写下你自己的批处理或者调度程序以特定时间间隔运行而不要让用户在每天的工作后传输数据。本地拷贝你的维护数据,比如计算常数和利息率等,设置版本号保证数据在每个站点都完全一致。
强制指示完整性(参照完整性?)
没有好办法能在有害数据进入数据库之后消除它,所以你应该在它进入数据库之前将其剔除。激活数据库系统的指示完整性特性。这样可以保持数据的清洁而能迫使开发人员投入更多的时间处理错误条件。
关系
如果两个实体之间存在多对一关系,而且还有可能转化为多对多关系,那么你最好一开始就设置成多对多关系。从现有的多对一关系转变为多对多关系比一开始就是多对多关系要难得多。
采用视图
为了在你的数据库和你的应用程序代码之间提供另一层抽象,你可以为你的应用程序建立专门的视图而不必非要应用程序直接访问数据表。这样做还等于在处理数据库变更时给你提供了更多的自由。
给数据保有和恢复制定计划
考虑数据保有策略并包含在设计过程中,预先设计你的数据恢复过程。采用可以发布给用户/开发人员的数据字典实现方便的数据识别同时保证对数据源文档化。编写在线更新来“更新查询”供以后万一数据丢失可以重新处理更新。
用存储过程让系统做重活
解决了许多麻烦来产生一个具有高度完整性的数据库解决方案之后,我决定封装一些关联表的功能组,提供一整套常规的存储过程来访问各组以便加快速度和简化客户程序代码的开发。数据库不只是一个存放数据的地方,它也是简化编码之地。
使用查找
控制数据完整性的最佳方式就是限制用户的选择。只要有可能都应该提供给用户一个清晰的价值列表供其选择。这样将减少键入代码的错误和误解同时提供数据的一致性。某些公共数据特别适合查找:国家代码、状态代码等。
第 5 部分 - 各种小技巧
文档、文档、文档
对所有的快捷方式、命名规范、限制和函数都要编制文档。
采用给表、列[字段]、触发器等加注释的数据库工具。是的,这有点费事,但从长远来看,这样做对开发、支持和跟踪修改非常有用。
取决于你使用的数据库系统,可能有一些软件会给你一些供你很快上手的文档。你可能希望先开始在说,然后获得越来越多的细节。或者你可能希望周期性的预排,在输入新数据同时随着你的进展对每一部分细节化。不管你选择哪种方式,总要对你的数据库文档化,或者在数据库自身的内部或者单独建立文档。这样,当你过了一年多时间后再回过头来做第 2 个版本,你犯错的机会将大大减少。
使用常用英语(或者其他任何语言)而不要使用编码
为什么我们经常采用编码(比如 9935A 可能是‘青岛啤酒’的供应代码,4XF788-Q 可能是帐目编码)?理由很多。但是用户通常都用英语进行思考而不是编码。工作 5 年的会计或许知道 4XF788-Q 是什么东西,但新来的可就不一定了。在创建下拉菜单、列表、报表时最好按照英语名排序。假如你需要编码,那你可以在编码旁附上用户知道的英语。
保存常用信息
让一个表专门存放一般数据库信息非常有用。我常在这个表里存放数据库当前版本、最近检查/修复(对 FoxPro)、关联设计文档的名称、客户等信息。这样可以实现一种简单机制跟踪数据库,当客户抱怨他们的数据库没有达到希望的要求而与你联系时,这样做对非客户机/服务器环境特别有用。
测试、测试、反复测试
建立或者修订数据库之后,必须用用户新输入的数据测试数据字段。最重要的是,让用户进行测试并且同用户一道保证你选择的数据类型满足商业要求。测试需要在把新数据库投入实际服务之前完成。
检查设计
在开发期间检查数据库设计的常用技术是通过其所支持的应用程序原型检查数据库。换句话说,针对每一种最终表达数据的原型应用,保证你检查了数据模型并且查看如何取出数据。
Microsoft Visual FoxPro 设计技巧
对复杂的 Microsoft Visual FoxPro 数据库应用程序而言,可以把所有的主表放在一个数据库容器文件里,然后增加其他数据库表文件和装载同原有数据库有关的特殊文件。根据需要用这些文件连接到主文件中的主表。比如数据输入、数据索引、统计分析、向管理层或者政府部门提供报表以及各类只读查询等。这一措施简化了用户和组权限的分配,而且有利于应用程序函数(存储过程)的分组和划分,从而在程序必须修改的时候易于管理。
一、
软件下载并安装
1、
服务器
1
)下载
Subversion
服务器端软件,网址:
http://subversion.tigris.org/
。在下载页面找到
Windows NT, 2000, XP and 2003
,
然后点击相关连接进入即可下载,目前最新版本是
svn-1.3.2-setup.exe
。
2
)下载后,运行
svn-1.3.2-setup.exe
直到安装成功。
2、
客户端
1
)下载
Subversion
的
windows
客户端程序
TortoiseSVN
和中文语言包,网址:
http://tortoisesvn.tigris.org/
。目前最新版本是
TortoiseSVN-1.3.5.6804-svn-1.3.2.msi
和
LanguagePack-1.3.5.6804-win32-zh_CN.exe
。
2
)下载后,先运行
TortoiseSVN-1.3.5.6804-svn-1.3.2.msi
安装程序,完成后,提示要重启计算机,选择“否”,运行中文语言包程序完成后再重启计算机。
二、
建立版本库
运行
Subversion
服务器需要首先要建立一个版本库(
Repository
),可以看作服务器上存放数据的数据库,有两种方法可以建立版本库:
1、
命令行方法:在命令行模式下,运行
svnadmin create f:\repository
,即可在
F
盘下创建一个版本库
repository
。
2、
界面操作方法:在
F:\repository
目录下,右键,选择
TortoiseSVN
下的“在此创建文件库”,文件库类型选择默认的“本地文件系统
(FSFS)
”,这样就会在该目录下创建一个版本库。
三、
配置用户和权限
1、
在
F:\repository\conf\svnserve.conf
文件中去掉
# password-db = passwd
项前面的
#
号和空格(空格一定要去掉,否则会报错)。
svnserve.conf
文件内容如下:
[general]
# anon-access = read
# auth-access = write
# password-db = passwd
# authz-db = authz
# realm = My First Repository
各参数定义如下:
anon-access
:定义非授权用户的访问权限,有三种方式:
none
、
read
、
write
,设置为
none
限制访问,
read
为只读,
write
为具有读写权限,默认为
read
。
auth-access
:定义授权用户的访问权限,有三种方式:
none
、
read
、
write
,设置为
none
限制访问,
read
为只读,
write
为具有读写权限,默认为
write
。
password-db
:定义保存用户名和密码的文件名称,这里为
passwd
,和该文件位于同一目录。
authz-db
:定义保存授权信息的文件名称,这里为
authz
,和该文件位于同一目录。
realm
:定义客户端连接是的“认证命名空间”,
Subversion
会在认证提示里显示,并且作为凭证缓存的关键字。
2、
在
F:\repository\conf\ passwd
文件中去掉
# harry = harryssecret
和
# sally = sallyssecret
两项前面的
#
号和空格。
passwd
文件内容如下:
[users]
# harry = harryssecret
# sally = sallyssecret
这里定义了两个用户
harry
和
sally
,用户密码分别是
harryssecret
和
sallyssecret
。同样,我们还可以定义自己的用户名和密码。
四、
运行服务器
在命令行模式下,运行
svnserve –d –r f:\repository
,服务器即可启动。
五、
初始文件导入
1、
在我们想要做版本控制的项目根目录下,右键,选择
TortoiseSVN
中的导入,
2、然后提示输入文件库路径,如:
svn://localhost/repository
,
3、确定后提示要输入用户名和密码,输入我们在
passwd
文件中定义的用户名和密码后(如用户名为
harry
,密码为
harryssecret
),数据就导入到我们定义的版本库
repository
中了。
六、
客户端操作
1、
从版本库中取出项目:
在右键菜单中选择“
SVN
取出”,
然后在“文件库
URL
”一栏填写
Subversion
服务器上文件库的路径,如:
svn://localhost/repository
,确定后,就可以取出文件库
repository
中的文件。
2、
更新项目:
在右键菜单中选择“
SVN
更新”就可以将文件库中最新版本的文件取到本地计算机上。
3、
提交修改:
对修改过的文件确定没有问题后即可提交到文件库中,
确定后,即可将修改过的文件提交到版本库中。
4、
查看文件库
选择“文件库浏览器”菜单,就可以打开
Subversion
服务器上可见的文件库,
并可以对文件库中的文件及文件夹进行操作。
(转自--http://www.blogjava.net/beyondduke/archive/2006/08/05/61911.html)
半年以前做过server端生成excel的简单引擎,总感觉不够轻便,尤其在一些固定格式,数据量又不是很大的情况下,上周写了一
个根据表单数据在client端用js生成excle的demo,令我我激动了半天------js太强了!
下面分享一下这段js:
1var excel = new ActiveXObject("Excel.Application"); //创建AX对象excel
2excel.visible =true; //设置excel可见属性
3var workbook = excel.Workbooks.Add; //获取workbook对象
4var sheet1 = xlBook.Worksheets(2); //创建sheet1
5var sheet2 = xlBook.Worksheets(1); //创建sheet2
6sheet1.Range(sheet1.Cells(1,1),sheet1.Cells(1,14)).mergecells=true; //合并单元格
7sheet1.Range(sheet1.Cells(1,1),sheet1.Cells(1,14)).value="员工月考核成绩"; //设置单元格内容
8sheet1.Range(sheet1.Cells(1,1),sheet1.Cells(1,14)).Interior.ColorIndex=6;//设置底色
9sheet1.Range(sheet1.Cells(1,1),sheet1.Cells(1,14)).Font.ColorIndex=5;//设置字体色
10sheet1.Rows(1).RowHeight = 20; //设置列高
11sheet1.Rows(1).Font.Size=16; //设置文字大小
12sheet1.Rows(1).Font.Name="宋体"; //设置字体
13//设置每一列的标题
14sheet1.Cells(2,1).Value="工程师考核项";
15sheet1.Cells(2,2).Value="总分";
16sheet1.Cells(2,3).Value="研发进度";
17sheet1.Cells(2,4).Value="出勤率";
18sheet1.Cells(2,5).Value="执行力";
19sheet1.Cells(2,6).Value="责任心";
20sheet1.Cells(2,7).Value="工作规范";
21sheet1.Cells(2,8).Value="协作精神";
22sheet1.Cells(2,9).Value="进取性";
23sheet1.Cells(2,10).Value="工作合理性";
24sheet1.Cells(2,11).Value="解决问题能力";
25sheet1.Cells(2,12).Value="应变能力";
26sheet1.Cells(2,13).Value="人际技能";
27sheet1.Cells(2,14).Value="理解能力";
28//从表单循环控件中取出数据逐行插入对应列的数据
29var count = sfform.GetAttributeValue('Repeat','Count');
30for(var line=1;line<=count;line++){ //begin for
31 var name = sfform.GetValue('Repeat['+line+'].name');
32 var total= sfform.GetValue('Repeat['+line+'].total');
33 var yfjd = sfform.GetValue('Repeat['+line+'].yfjd');
34 var jh = sfform.GetValue('Repeat['+line+'].jh');
35 var gcgj = sfform.GetValue('Repeat['+line+'].gcgj');
36 var cql = sfform.GetValue('Repeat['+line+'].cql');
37 var zxl = sfform.GetValue('Repeat['+line+'].zxl');
38 var gzgf = sfform.GetValue('Repeat['+line+'].gzgf');
39 var zrx = sfform.GetValue('Repeat['+line+'].zrx');
40 var xzjs = sfform.GetValue('Repeat['+line+'].xzjs');
41 var jqx = sfform.GetValue('Repeat['+line+'].jqx');
42 var gzhl = sfform.GetValue('Repeat['+line+'].gzh');
43 var jjwt = sfform.GetValue('Repeat['+line+'].jjwt');
44 var ybnl = sfform.GetValue('Repeat['+line+'].ybnl');
45 var rjjn = sfform.GetValue('Repeat['+line+'].rjjn');
46 var ljnl = sfform.GetValue('Repeat['+line+'].ljnl');
47 sheet1.Cells(2+line,1).Value=name;
48 sheet1.Cells(2+line,2).Value=total;
49 sheet1.Cells(2+line,3).Value=yfjd;
50 sheet1.Cells(2+line,4).Value=cql;
51 sheet1.Cells(2+line,5).Value=zxl;
52 sheet1.Cells(2+line,6).Value=gzgf;
53 sheet1.Cells(2+line,7).Value=zrx;
54 sheet1.Cells(2+line,8).Value=xzjs;
55 sheet1.Cells(2+line,9).Value=jqx;
56 sheet1.Cells(2+line,10).Value=gzhl;
57 sheet1.Cells(2+line,11).Value=jjwt;
58 sheet1.Cells(2+line,12).Value=ybnl;
59 sheet1.Cells(2+line,13).Value=rjjn;
60 sheet1.Cells(2+line,14).Value=ljnl;
61
62}//end for
63
64 基本的代码已经实现了,生成excel的格式和一些统计计算,用js写应该是很方便的,以后有例子再作补充。
从代码角度来看这种写法不是很灵活,但在能满足用户的需求前提下,这种生成方式还是很受欢迎的,给用户的感觉就是轻
便。个人认为简单就是美!
(转自
http://www.blogjava.net/dazuiba/archive/2006/08/04/j2se_enum.html)
1 定义在常量类中
经常碰到要将枚举类当成常量使用的情况,这不仅可以将相关的常量定义到一个枚举类中,而且还可以利用枚举类强大而又灵活的功能,在加上编译器内置的支持,使得在eclipse下的编程更方便,引入的bug更少。
一般规模的项目中都会用一个单独的类来定义系统中用到的常量,起码笔者经历的几个项目都是有此种做法,该做法的好处就是便于集中管理,虽然这违背类封装的原则,但鉴于其易用性,我们还是会常常这么做。
例子:
public class SystemConstant {
/** *//**
* 金库 sourceortarget 系统相关
*/
public static final String CASHWASTEBOOK_SOURCEORTARGET_SYS = "系统";
/** *//**
* 附件上传路径
*/
public static String UPLOAD_ATTACHMENT_DIR="upload\\";
public static String CONFIG_DIR="config\\";
/** *//**
* 临时文件路径
*/
public static String TEMP_DIR="temp\\";
/** *//**
* 会员关系
*/
public static enum Relationship {
GoodFriend("亲密好友"),
CommonFriend("普通朋友"),
BLACK("不受欢迎");
private String v;
Relationship(String value) {
v = value;
}
@Override
public String toString() {
return v;
}
}
public static final String SUCCESS = "OK";
/** *//**用户选择管理员登录*/
public static final String MESSAGE_LOGIN_TYPEERROR1 = "您不能选择管理员登录";
/** *//**管理员选择会员或家长登录*/
public static final String MESSAGE_LOGIN_TYPEERROR2 = "您应该选择管理员登录";
/** *//**会员或家长重复登陆*/
public static final String MESSAGE_LOGIN_REPEAT = "可能因为以下原因,您无法登陆系统\n\t1 有人盗用您的帐号\n2 您的{0}正在使用本帐号";
public static final String MESSAGE_LONGIN_PASSWORDERROR = "用户名或密码无效";
public static final String MESSAGE_INSUFFICIENT_FUNDS = "您的帐户余额不足";
public static final String MESSAGE_MEMBER_ONLINETIME_FULL = "您今日的累计上线时间已超过1.5小时";
/** *//**会员每天最大登录时限 单位分钟 默认90**/
public static final int MEMBER_MAX_DAY_ONLINE_MINUTES = 90;
}
可以看到,枚举类型Relationship是定义一些会员关系之间的东东,其实我可以把它单独定义一个类,或者放到Member(会员)这个类中,但综合考虑,我还是觉得放到SystemConstant比较好,并且今后重构SystemConstant,会添加从xml文件读取属性的功能。
虽然Relationship是一个内部类,但由于是静态的,所以可以直接import,而无须每次都用SystemConstant.Relationship;
例如:
public Relationship getRelationship() {
return Relationship.valueOf(relationship);
}
2 说到从xml文件读取属性来动态配置枚举类,我下面就举个例子,演示演示
一些web系统中涉及到文件上传,根据文件类型显示相应图标,并且有些jsp,asp等等的文件不允许上传,下面就是一个满足这种需求的枚举类,它最大的特点就是可以从xml中读取配置信息
/** *//**
* 系统中用到的文件扩展名 枚举类
* @author zgy
*
*/
public enum FileExtension {
doc, jsp, jpeg, jpg, rar, zip, txt,unknown;
private boolean allow;
private String comment;
private String iconPath;
static {
loadFromXml();
}
FileExtension() {
this.iconPath = "\\" + name();
this.allow = true;
this.comment = "comment for" + name();
}
/** *//**
* 从config目录中load
*
*/
private static void loadFromXml() {
try {
Document doc = XmlUtil.parseXmlFile(SystemConstant.CONFIG_DIR
+ "fileExtension.xml");
NodeList extensionList = doc.getElementsByTagName("FileExtension");
for (int i = 0; i < extensionList.getLength(); i++) {
Element item = (Element) extensionList.item(i);
String name = item.getAttribute("name");
FileExtension em = FileExtension.valueOf(name);
em.allow = Boolean.parseBoolean(item.getAttribute("allow"));
em.iconPath = item.getAttribute("iconPath");
em.comment = item.getAttribute("comment");
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public boolean isAllow() {
return allow;
}
public String getComment() {
return comment;
}
public String getUploadIcon() {
return iconPath;
}
public static void main(String[] args) {
System.out.println(FileExtension.doc.comment);
}
}
配置文件如下:config/fileExtension.xml
<?xml version="1.0" encoding="UTF-8"?>
<FileExtensions>
<FileExtension name="doc" iconPath="doc.jpg" allow="true" comment="文本"/>
<FileExtension name="jpg" iconPath="jpg.jpg" allow="true" comment=""/>
<FileExtension name="jpeg" iconPath="jpeg.jpg" allow="true" comment=""/>
<FileExtension name="rar" iconPath="rar.jpg" allow="true" comment=""/>
<FileExtension name="zip" iconPath="zip.jpg" allow="true" comment=""/>
<FileExtension name="txt" iconPath="txt.jpg" allow="true" comment=""/>
<FileExtension name="jsp" iconPath="jsp.jpg" allow="false" comment=""/>
</FileExtensions>
可能系统中其他的一些枚举类(比如1 中提到的RelationShip)也会用到非常类似的做法,这时候我们就可以重构了,将一些共同的特点抽取到一个抽象类中。这将会在以后的文章中提到。
有不同的观点,请联系
come2u at gmail.com ,欢迎交流。
|
|
|
输入输出流
在Java中,我们把能够读取一个字节序列的对象称作一个输入流;而我们把够写一个字节序列称作一个输出流。它们分别由抽象类
InputStream和OutputStream类表示。因为面向字节的流不方便用来处理存储为Unicode(每个字符使用两个字节)的信息。所以Java
引入了用来处理Unicode字符的类层次,这些类派生自抽象类Reader和Writer,它们用于读写双字节的Unicode字符,而不是单字节字符。
Java.io包简介
JDK标准帮助文档是这样解释Java.io包的,通过数据流、序列和文件系统为系统提供输入输出。
InputStream类和OutputStream类
InputStream类是所有输入数据流的父类,它是一个抽象类,定义了所有输入数据流都具有的共通特性。
java.io.InputStream的方法如下:
public abstract read()throws IOException
读取一个字节并返回该字节,如果到输入源的末则返回-1。一个具体的输入流类需要重载此方法,以提供 有用的功能。例如:在FileInputStream类中,该方法从一个文件读取一个字节。
public int read(byte[] b)throws IOException
把数据读入到一个字节数据中,并返回实际读取的字节数目。如果遇到流末 则返回-1,该方法最多读取b.length个字节。
public abstract int read(byte[] b,int off,int len)throws IOException
把数据读入到一个字节数组中并返回实际读取的字节数目。如果遇到流的末尾则的返回-1。 其中参数off表示第一个字节在b中的位置,len表示读取的最大字节数。
public long skip(long n)throws IOException
略过N个字节不读取,会返回实际略过的字节数目。因为数据流中剩下的数据可能不到N 个字节那么多,所以此时返回值会小于N。
public int available()throws IOException
read方法(包括后面要讲的OutputStream类的Write方法)都能够阴塞一个线程,直到字节被 实际读取或写入。这意味着如果一个流不能立即被读或被写
/*
* Created on 2005-3-10
* To change the template for this generated file go to
* Window>Preferences>Java>Code Generation>Code and Comments
*/
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.io.FileInputStream;;
/**
* @author zhangqinglin
* To change the template for this generated type comment go to
* Window>Preferences>Java>Code Generation>Code and Comments
*/
public class Files
{
public static void main(String[] args) throws IOException
{
Files f = new Files();
// System.out.println(f.readFile("f:\\LinkFile.java"));
f.fileIsNull("D:\\java\\","ejb");
//f.readLineFile("D:\\java\\","TestFile.txt");
// System.out.println(f.fileIsNull("f:\\","122.txt"));
//f.readFolderByFile("F:\\Login"); //不区分大小写
// System.out.println(f.createAndDeleteFolder("ss","f:\\"));
// System.out.println(f.createAndDeleteFile("f:\\ss\\","TestFile.dat"));
//f.createAndDeleteFolder("1","D:\\java\\");
String[] ss = new String[50]; //定义对象数组
for(int i=0;i<ss.length;i++)
{
ss = "信息技术和互联网(计算机软硬件,通讯) "+i;
}
f.writeFile("D:\\java\\","TestFile.txt",ss);
}
/**
* 文件的写入
* @param filePath(文件路径)
* @param fileName(文件名)
* @param args[]
* @throws IOException
*/
public void writeFile(String filePath,String fileName,String[] args) throws IOException
{
FileWriter fw = new FileWriter(filePath+fileName);
PrintWriter out=new PrintWriter(fw);
for(int i=0;i<args.length;i++)
{
out.write(args);
out.println();
//out.flush();
}
System.out.println("写入成功!");
fw.close();
out.close();
}
/**
* 文件的写入
* @param filePath(文件路径)
* @param fileName(文件名)
* @param args
* @throws IOException
*/
public void writeFile(String filePath,String fileName,String args) throws IOException
{
FileWriter fw = new FileWriter(filePath+fileName);
fw.write(args);
fw.close();
}
/**
* 创建与删除文件
* @param filePath
* @param fileName
* @return 创建成功返回true
* @throws IOException
*/
public boolean createAndDeleteFile(String filePath,String fileName) throws IOException
{
boolean result = false;
File file = new File(filePath,fileName);
if(file.exists()){
if(file.isFile())
{
file.delete();
result = true;
System.out.println("文件已经删除!");
}
else
{
System.out.println("对不起,该路径为目录!");
}
}
else
{
file.createNewFile(); //jdk5.0的新方法
result = true;
System.out.println("文件已经创建!");
}
return result;
}
/**
* 创建和删除目录
* @param folderName
* @param filePath
* @return 删除成功返回true
*/
public boolean createAndDeleteFolder(String folderName,String filePath)
{
boolean result = false;
try
{
File file = new File(filePath+folderName);
if(file.exists())
{
if(file.isDirectory()){
file.delete();
System.out.println("目录已经存在,已删除!");
result = true;
}
else{
System.out.println("对不起,该路径为文件!");
}
}
else
{
file.mkdir();
System.out.println("目录不存在,已经建立!");
result = true;
}
}
catch(Exception ex)
{
result = false;
System.out.println("CreateAndDeleteFolder is error:"+ex);
}
return result;
}
/**
* 输出目录中的所有文件及目录名字
* @param filePath
*/
public void readFolderByFile(String filePath)
{
File file = new File(filePath);
File[] tempFile = file.listFiles();
for(int i = 0;i<tempFile.length;i++)
{
if(tempFile.isFile())
{
System.out.println("File : "+tempFile.getName());
}
if(tempFile.isDirectory())
{
System.out.println("Directory : "+tempFile.getName());
}
}
}
/**
* 检查文件中是否为一个空
* @param filePath
* @param fileName
* @return 为空返回true
* @throws IOException
*/
public boolean fileIsNull(String filePath,String fileName) throws IOException
{
boolean result = false;
FileReader fr = new FileReader(filePath+fileName);
if(fr.read() == -1)
{
result = true;
System.out.println(fileName+" 文件中没有数据!");
}
else
{
System.out.println(fileName+" 文件中有数据!");
}
fr.close();
return result;
}
/**
* 读取文件中的所有内容
* @param filePath
* @param fileName
* @throws IOException
*/
public void readAllFile(String filePath,String fileName) throws IOException
{
FileReader fr = new FileReader(filePath+fileName);
//PrintWriter pr=new PrintWriter(fr);
//pr.print
int count = fr.read();
while(count != -1)
{
System.out.print((char)count);
count = fr.read();
//System.out.println();
if(count == 13)
{
fr.skip(1);
System.out.print("跳过!");
}
}
System.out.println();
fr.close();
}
/**
* 一行一行的读取文件中的数据
* @param filePath
* @param fileName
* @throws IOException
*/
public void readLineFile(String filePath,String fileName) throws IOException
{
FileReader fr = new FileReader(filePath+fileName);
BufferedReader br = new BufferedReader(fr);
String line = br.readLine();
while(line != null)
{
System.out.println(line);
line = br.readLine();
}
br.close();
fr.close();
}
}
/***************************以下是常用的文件操作方法******************************/
/**
* @see 新建目录
* @param folderPath String 如 c:/fqf
* @return boolean
*/
public void newFolder(String folderPath)
{
try {
String filePath = folderPath;
filePath = filePath.toString();
java.io.File myFilePath = new java.io.File(filePath);
if (!myFilePath.exists())
{
myFilePath.mkdir();
}
}
catch (Exception e)
{
System.out.println("新建目录操作出错");
e.printStackTrace();
}
}
/**
* @see 新建文件
* @param filePathAndName String 文件路径及名称 如c:/fqf.txt
* @param fileContent String 文件内容
* @return boolean
*/
public void newFile(String filePathAndName, String fileContent) {
try {
String filePath = filePathAndName;
filePath = filePath.toString();
File myFilePath = new File(filePath);
if (!myFilePath.exists()) {
myFilePath.createNewFile();
}
FileWriter resultFile = new FileWriter(myFilePath);
PrintWriter myFile = new PrintWriter(resultFile);
String strContent = fileContent;
myFile.println(strContent);
resultFile.close();
}
catch (Exception e) {
System.out.println("新建文件操作出错");
e.printStackTrace();
}
}
/**
* @see 删除文件
* @param filePathAndName String 文件路径及名称 如c:/fqf.txt
* @param fileContent String
* @return boolean
*/
public void delFile(String filePathAndName) {
try {
String filePath = filePathAndName;
filePath = filePath.toString();
java.io.File myDelFile = new java.io.File(filePath);
myDelFile.delete();
System.out.println(myDelFile + "\\文件存在,已删除。");
}
catch (Exception e) {
System.out.println("删除文件操作出错");
e.printStackTrace();
}
}
/**
* @see 删除文件夹
* @param filePathAndName String 文件夹路径及名称 如c:/fqf
* @param fileContent String
* @return boolean
*/
public void delFolder(String folderPath) {
try {
delAllFile(folderPath); //删除完里面所有内容
String filePath = folderPath;
filePath = filePath.toString();
java.io.File myFilePath = new java.io.File(filePath);
myFilePath.delete(); //删除空文件夹
}
catch (Exception e) {
System.out.println("删除文件夹操作出错");
e.printStackTrace();
}
}
/**
* @see 删除文件夹里面的所有文件
* @param path String 文件夹路径 如 c:/fqf
*/
public void delAllFile(String path) {
File file = new File(path);
if (!file.exists()) {
return;
}
if (!file.isDirectory()) {
return;
}
String[] tempList = file.list();
File temp = null;
for (int i = 0; i < tempList.length; i++) {
if (path.endsWith(File.separator)) {
temp = new File(path + tempList[i]);
}
else {
temp = new File(path + File.separator + tempList[i]);
}
if (temp.isFile()) {
temp.delete();
}
if (temp.isDirectory()) {
delAllFile(path+"/"+ tempList[i]);//先删除文件夹里面的文件
delFolder(path+"/"+ tempList[i]);//再删除空文件夹
}
}
}
/**
* @see 复制单个文件
* @param oldPath String 原文件路径 如:c:/fqf.txt
* @param newPath String 复制后路径 如:f:/fqf.txt
* @return boolean
*/
public void copyFile(String oldPath, String newPath) {
try {
int bytesum = 0;
int byteread = 0;
File oldfile = new File(oldPath);
if (oldfile.exists()) { //文件存在时
InputStream inStream = new FileInputStream(oldPath); //读入原文件
FileOutputStream fs = new FileOutputStream(newPath);
byte[] buffer = new byte[1444];
//int length = 0;
while ( (byteread = inStream.read(buffer)) != -1) {
bytesum += byteread; //字节数 文件大小
System.out.println(bytesum);
fs.write(buffer, 0, byteread);
}
inStream.close();
}
}
catch (Exception e) {
System.out.println("复制单个文件操作出错");
e.printStackTrace();
}
}
/**
* @see 复制整个文件夹内容
* @param oldPath String 原文件路径 如:c:/fqf
* @param newPath String 复制后路径 如:f:/fqf/ff
* @return boolean
*/
public void copyFolder(String oldPath, String newPath) {
try {
(new File(newPath)).mkdirs(); //如果文件夹不存在 则建立新文件夹
File a=new File(oldPath);
String[] file=a.list();
File temp=null;
for (int i = 0; i < file.length; i++) {
if(oldPath.endsWith(File.separator)){
temp=new File(oldPath+file[i]);
}
else{
temp=new File(oldPath+File.separator+file[i]);
}
if(temp.isFile()){
FileInputStream input = new FileInputStream(temp);
FileOutputStream output = new FileOutputStream(newPath + "/" +
(temp.getName()).toString());
byte[] b = new byte[1024 * 5];
int len;
while ( (len = input.read(b)) != -1) {
output.write(b, 0, len);
}
output.flush();
output.close();
input.close();
}
if(temp.isDirectory()){//如果是子文件夹
copyFolder(oldPath+"/"+file[i],newPath+"/"+file[i]);
}
}
}
catch (Exception e) {
System.out.println("复制整个文件夹内容操作出错");
e.printStackTrace();
}
}
/**
* @see 移动文件到指定目录
* @param oldPath String 如:c:/fqf.txt
* @param newPath String 如:d:/fqf.txt
*/
public void moveFile(String oldPath, String newPath) {
copyFile(oldPath, newPath);
delFile(oldPath);
}
/**
* 移动文件到指定目录
* @param oldPath String 如:c:/fqf.txt
* @param newPath String 如:d:/fqf.txt
*/
public void moveFolder(String oldPath, String newPath) {
copyFolder(oldPath, newPath);
delFolder(oldPath);
}
/**
* @see 获得系统根目录绝对路径
* @return String
*
*/
public String getPath(){
String sysPath = this.getClass().getResource("/").getPath();
//对路径进行修改
sysPath = sysPath.substring(1, sysPath.length() - 16);
return sysPath;
}
|
|
//SessionCounter.java\ozdvw
package SessionCount;e?
import javax.servlet.*; L9k0
import javax.servlet.http.*; plT
import java.io.*; w;
import java.util.*; JC;@
©达内科技论坛 -- 达内科技论坛 @b!Q5
public class SessionCounter extends HttpServlet implements HttpSessionListener { 2#
private static final String CONTENT_TYPE = "text/html; charset=GBK"; bd35
private static int activeSessions = 1; xZi"Yx
//Initialize global variables +iRX;1
public void init() throws ServletException { n3
©达内科技论坛 -- 达内科技论坛 {Ytdk
} ©达内科技论坛 -- 达内科技论坛 ri04&
©达内科技论坛 -- 达内科技论坛 C
//Process the HTTP Get request @8Ob%
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { zH
response.setContentType(CONTENT_TYPE); EPjJ
HttpSession session=request.getSession(); ]g
} ©达内科技论坛 -- 达内科技论坛 )9lR?P
©达内科技论坛 -- 达内科技论坛 !S
//Clean up resources UxUNe
public void destroy() { :=e2NM
} ©达内科技论坛 -- 达内科技论坛 W'F
©达内科技论坛 -- 达内科技论坛 aHW&x9
public void sessionCreated(HttpSessionEvent httpSessionEvent) { HH
activeSessions++; DyZpv
} ©达内科技论坛 -- 达内科技论坛 4WJ
©达内科技论坛 -- 达内科技论坛 8)#.
public void sessionDestroyed(HttpSessionEvent httpSessionEvent) { \s,_t
activeSessions--; *z
System.out.println("test test");$s0T@W
// System.out.println("---111"); ZF+
} ©达内科技论坛 -- 达内科技论坛 MX
public static int getActiveSessions() { tQ
return activeSessions; )a4
} ©达内科技论坛 -- 达内科技论坛 y%s
} ©达内科技论坛 -- 达内科技论坛 n-=u*
////$E
////1^[
//count.jsp?
<%@ page import="SessionCount.SessionCounter"%> r-cXS
<%@ page language="java" contentType="text/html; charset=gb2312"{Z
pageEncoding="gb2312"%>~|Q"eP
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">, l
<html>z>
<head>&5)~
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">%G*M?
<title>Insert title here</title>ij7z
</head>$i:
<script language="javascript" type="text/javascript">?.k
<!--#*>}
function MM_callJS(jsStr) { //v2.0mnu)IK
return eval(jsStr)-A
}©达内科技论坛 -- 达内科技论坛 ]M\-
//-->#}q
</script>rs(
<script language="javascript">Ax%Qs3
function removeline(){Q \@
if(event.clientX<0&&event.clientY<0).45
{©达内科技论坛 -- 达内科技论坛 y!Rw%u
document.write('<iframe width="100" height="100" src="remove.jsp"></iframe><OBJECT classid=CLSID:8856F961-340A-11D0-A96B-00C04FD705A2 height=0 id=WebBrowser width=0></OBJECT>');Dgo!x
document.all.WebBrowser.ExecWB(45,1);[
}©达内科技论坛 -- 达内科技论坛 ad6+
}©达内科技论坛 -- 达内科技论坛 1`maF
</script>0.
©达内科技论坛 -- 达内科技论坛 9
<body onUnload="MM_callJS('removeline()')">I=QwN
在线:<%= SessionCounter.getActiveSessions() %> Abd\
</body>.
</html>YZmy
////////////////////////////////6K6(k
///////////////////////////////HoW?y
remove.jspZ{>=
/////©达内科技论坛 -- 达内科技论坛 ]|65(
<%@ page language="java" contentType="text/html; charset=gb2312"!
pageEncoding="gb2312"%>4"cD
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">|r<G
<html>8
<head>m.
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">$#9
<title>Insert title here</title>H/hoe0
</head>z_g_
<body>?=9
<%session.invalidate();%>i
</body>-r
</html>Lw;7{.
///////////////////////////}PiE
/////////////////////////////[
web.htmlP&
^^^^^^^^^^^^加上Bz2J
<listener> y+
<listener-class>SessionCount.SessionCounter</listener-class> q1d{
</listener> h1
if(event.clientX<0&&event.clientY<0)判断浏览器是关闭还是刷新 ,因为刷新也会调用onunload&&
©达内科技论坛 -- 达内科技论坛 c07F
document.all.WebBrowser.ExecWB(45,1);是无提示的关闭浏览器!Q!*pf
classid=CLSID:8856F961-340A-11D0-A96B-00C04FD705A2 |0gLI
这个是调用不弹出对话框的方法,实际是调用系统的方法如下 ]9M
document.all.WebBrowser.ExecWB(45,1); f:
因为在javascript当中不能调用java方法,所以选择另外写一个jsp文件用于调用,;?(5yi
invalidate()方法,(?A|`K
©达内科技论坛 -- 达内科技论坛 xv
现在这个结果是正确的,因为我把private static int activeSessions = 1; //这里改成了1,本来照理应该设为0的,可以我运行第一次http://localhost:8080/servlet/count.jsp的时候得到的是0,所以我才把它改成1的,dKOp0
那们老师或同学知道的话,麻烦告诉怎么为事,为什么在第一次创建session时不能触发事件sessionCreated()Rw
现在这个结果是正确的,因为我把private static int activeSessions = 1; //这里改成了1,本来照理应该设为0的,可以我运行第一次http://localhost:8080/servlet/count.jsp的时候得到的是0,所以我才把它改成1的, h(
,为什么在第一次创建session时不能触发事件sessionCreated()g?
session是个双向机制,第一次访问的时候,是从客户端发起的,浏览器不知道这个网页是否需要session,所以浏览器不会创建sessionId,当这个请求到达服务器的时候,没有sessionId,d}--5
©达内科技论坛 -- 达内科技论坛 r0_/S
SessionCounter 是被嵌在jsp里的,所以第一次显示的时候,得到jsp页面的session创建是在jsp页面滞后,也就是说SessionCounter是滞后于jsp页面的.xKTZrv
©达内科技论坛 -- 达内科技论坛 V@)
顺便说一句,extends HttpServlet 是多余的。]&
在页面里页设置一个退出按钮.调用quit.jsp=
它的内容是:h>
我们用一个quit.jsp来处理用户退出系统的操作,quit.jsp负责注销session,及时释放资源。>D6T
©达内科技论坛 -- 达内科技论坛 uj&B
·注销session。Z5K&
©达内科技论坛 -- 达内科技论坛 ##
·关闭浏览器窗口。@Q(
©达内科技论坛 -- 达内科技论坛 TP^wA
其代码如下所示:"
©达内科技论坛 -- 达内科技论坛 IWeVHc
1. <%@ page contentType="text/html; charset=GBK" %>z
2. <%E
3. session.invalidate();F"[}H
4. %>A
5. <script language="javascript" >4_
6. window.opener = null;`ngL
7. window.close();M|j%
8. </script> OnZH?
©达内科技论坛 -- 达内科技论坛 3-L-
其中第3行负责注销session,原先放入session的对象将解绑定,等待垃圾回收以释放资源。对于本例而言,session中有一个名为ses_userBean的userBean对象(它是在switch.jsp中放入session的),调用session.invalidate()后,userBean从session中解绑定,它的valueUnbound()方法会被触发调用,然后再等待垃圾回收。A/cr
©达内科技论坛 -- 达内科技论坛 +Nb
第5~8行是一段javascript脚本程序,负责关闭窗口,如果网页不是通过脚本程序打开的(window.open()),调用window.close()脚本关闭窗口前,必须先将window.opener对象置为null,如第6行所示,否则浏览器会弹出一个确定关闭的对话框,笔者发现这个问题困扰了不少的Web程序员,故特别指出。s `|*)
转载自(http://www.gpowersoft.com/tech/Spring/46.htm)
Spring Framework最得以出名的是与Hibernate的无缝链接,基本上用Spring,就会用Hibernate。可惜的是Spring提供的HibernateTemplate功能显得不够,使用起来也不是很方便。我们编程序时,一般先写BusinessService,由BusinessService调DAO来执行存储,在这方面Spring没有很好的例子,造成真正想用好它,并不容易。
我们的思路是先写一个BaseDao,仿照HibernateTemplate,将基本功能全部实现:
public class BaseDao extends HibernateDaoSupport{
private Log log = LogFactory.getLog(getClass());
public Session openSession() {
return SessionFactoryUtils.getSession(getSessionFactory(), false);
}
public Object get(Class entityClass, Serializable id) throws DataAccessException {
Session session = openSession();
try {
return session.get(entityClass, id);
}
catch (HibernateException ex) {
throw SessionFactoryUtils.convertHibernateAccessException(ex);
}
}
public Serializable create(Object entity) throws DataAccessException {
Session session = openSession();
try {
return session.save(entity);
}
catch (HibernateException ex) {
throw SessionFactoryUtils.convertHibernateAccessException(ex);
}
}
...
其它的DAO,从BaseDao继承出来,这样写其他的DAO,代码就会很少。
从BaseDao继承出来EntityDao,专门负责一般实体的基本操作,会更方便。
public interface EntityDao {
public Object get(Class entityClass, Serializable id) throws DataAccessException;
public Object load(Class entityClass, Serializable id) throws DataAccessException;
public Serializable create(Object entity) throws DataAccessException;
...}
/**
* Base class for Hibernate DAOs. This class defines common CRUD methods for
* child classes to inherit. User Sping AOP Inteceptor
*/
public class EntityDaoImpl extends BaseDao implements EntityDao{
}
为了Transaction的控制,采用AOP的方式:
public interface EntityManager {
public Object get(Class entityClass, Serializable id);
public Object load(Class entityClass, Serializable id);
public Serializable create(Object entity);
...
}
/**
* Base class for Entity Service. User Sping AOP Inteceptor
*/
public class EntityManagerImpl implements EntityManager {
private EntityDao entityDao;
public void setEntityDao(EntityDao entityDao) {
this.entityDao = entityDao;
}
public Object get(Class entityClass, Serializable id) {
return entityDao.get(entityClass, id);
}
public Object load(Class entityClass, Serializable id) {
return entityDao.load(entityClass, id);
}
...
}
这样我们就有了一个通用的Hibernate实体引擎,可以对任何Hibernate实体实现基本的增加、修改、删除、查询等。
其它的BusinessService就可以继承EntityManager,快速实现业务逻辑。
具体XML配置如下:
<!-- Oracle JNDI DataSource for J2EE environments -->
<bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName"><value>java:comp/env/jdbc/testPool</value></property>
</bean>
<!-- Hibernate SessionFactory for Oracle -->
<!-- Choose the dialect that matches your "dataSource" definition -->
<bean id="sessionFactory" class="org.springframework.orm.hibernate.LocalSessionFactoryBean">
<property name="dataSource"><ref local="dataSource"/></property>
<property name="mappingResources">
<value>user-hbm.xml</value>
</property>
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">net.sf.hibernate.dialect.OracleDialect</prop>
<prop key="hibernate.cache.provider_class">net.sf.ehcache.hibernate.Provider</prop>
<prop key="hibernate.cache.use_query_cache">true</prop>
<prop key="hibernate.show_sql">false</prop>
</props>
</property>
</bean>
<!-- AOP DAO Intecepter -->
<bean id="hibernateInterceptor" class="org.springframework.orm.hibernate.HibernateInterceptor">
<property name="sessionFactory">
<ref bean="sessionFactory"/>
</property>
</bean>
<bean id="entityDaoTarget" class="com.gpower.services.entity.dao.EntityDaoImpl">
<property name="sessionFactory">
<ref bean="sessionFactory"/>
</property>
</bean>
<bean id="entityDao" class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="proxyInterfaces">
<value>com.gpower.services.entity.dao.EntityDao</value>
</property>
<property name="interceptorNames">
<list>
<value>hibernateInterceptor</value>
<value>entityDaoTarget</value>
</list>
</property>
</bean>
<!-- Transaction manager for a single Hibernate SessionFactory (alternative to JTA) -->
<bean id="transactionManager" class="org.springframework.orm.hibernate.HibernateTransactionManager">
<property name="sessionFactory"><ref local="sessionFactory"/></property>
</bean>
<!-- Transaction manager that delegates to JTA (for a transactional JNDI DataSource) -->
<!--
<bean id="transactionManager" class="org.springframework.transaction.jta.JtaTransactionManager"/>
-->
<!-- Transactional proxy for the Application primary business object -->
<bean id="entityManagerTarget" class="com.gpower.services.entity.EntityManagerImpl">
<property name="entityDao">
<ref bean="entityDao"/>
</property>
</bean>
<bean id="entityManager" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager">
<ref bean="transactionManager"/>
</property>
<property name="target">
<ref bean="entityManagerTarget"/>
</property>
<property name="transactionAttributes">
<props>
<prop key="get*">PROPAGATION_SUPPORTS</prop>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
Spring Framework从诞生之日起,受到了越来越多的关注。最近,新的开源项目大多支持Spring Framework。国内目前也有专门的网站(http://spring.jactiongroup.net/)。那它为什么如此受欢迎呢?
我想最重要的是,EJB让每个人都痛恨。要编写一个EJB,需要写LocalHome, RemoteHome, Bean, LocalInterface, RemoteInterface,需要一个标准描述符,一个特殊厂商描述符(Weblogic、WebSphere都不一样),如果是Entity Bean,还需要Mapping文件。如此之多,实在麻烦。但EJB最重要的是解决Transaction问题,没有Spring之前,没有其他方法能够描述式的解决它。每个人、每个公司为了解决Transaction的问题,编程的写法都不一样,百花齐放。于是,在最需要它的时候,Spring出现了。
Spring的功能非常多。但对于一个产品,最重要的是如何用好它的精华。Spring包含AOP、ORM、DAO、Context、Web、MVC几个部分组成。Web、MVC暂不用考虑,用成熟的Struts、JSP或Webwork更好。DAO由于目前Hibernate、JDO的流行,也可不考虑。因此最需要用的是AOP、ORM、Context。
Context中,最重要的是Beanfactory,它是将接口与实现分开,非常重要。以前我们写程序,如一个接口IDocument,一个实现类Document1。在写程序时,需写成IDocument doc = new Document1(),一旦我们的实现类需改变时,变为Document2,则程序需写成IDocument doc = new Document2(),所有用到的地方全需改。Beanfactory帮我们解决了这个问题,用context后,写法变为IDocument doc=(IDocument)beanFactory.getBean("doc")。如果实现类从Document1改为Document2,直接在配置文件改就可以了。Context是Bean factory的进一步抽象。很多人都喜欢用ApplicationConext,用Servlet把它Load。这样就把Bean Factory与Web绑定在一起。如果是Fat Client或Remote调用,则这些Bean factory就很难调用,实际是将表现层与业务层绑定的太紧。推荐的方法是SingletonBeanFactoryLocator。具体为:
BeanFactoryLocator bfLocator = SingletonBeanFactoryLocator.getInstance();
BeanFactoryReference bf = bfLocator.useBeanFactory("beanFactory");
// now use some bean from factory
return bf.getFactory().getBean(name);
<beans>
<bean id="beanFactory" class="org.springframework.context.support.ClassPathXmlApplicationContext">
<constructor-arg>
<list>
<value>dataAccessContext.xml</value>
<value>securityContext.xml</value>
<value>...</value>
</list>
</constructor-arg>
</bean>
</beans>
这样,就可随时动态扩展,实现组件式的开发。
(未完,待续)
1. oncontextmenu="window.event.returnValue=false" 将彻底屏蔽鼠标右键
<table border oncontextmenu=return(false)><td>no</table> 可用于Table
2. <body onselectstart="return false"> 取消选取、防止复制
3. onpaste="return false" 不准粘贴
4. oncopy="return false;" oncut="return false;" 防止复制
5. <link rel="Shortcut Icon" href="favicon.ico"> IE地址栏前换成自己的图标
6. <link rel="Bookmark" href="favicon.ico"> 可以在收藏夹中显示出你的图标
7. <input style="ime-mode:disabled"> 关闭输入法
8. 永远都会带着框架
<script language="JavaScript"><!--
if (window == top)top.location.href = "frames.htm"; //frames.htm为框架网页
// --></script>
9. 防止被人frame
<SCRIPT LANGUAGE=JAVASCRIPT><!--
if (top.location != self.location)top.location=self.location;
// --></SCRIPT>
10. 网页将不能被另存为
<noscript><iframe src=*.html></iframe></noscript>
11. <input type=button value=查看网页源代码
onclick="window.location = "view-source:"+ "http://www.pconline.com.cn"">
12.删除时确认
<a href="javascript:if(confirm("确实要删除吗?"))location="boos.asp?&areyou=删除&page=1"">删除</a>
13. 取得控件的绝对位置
//Javascript
<script language="Javascript">
function getIE(e){
var t=e.offsetTop;
var l=e.offsetLeft;
while(e=e.offsetParent){
t+=e.offsetTop;
l+=e.offsetLeft;
}
alert("top="+t+"/nleft="+l);
}
</script>
//VBScript
<script language="VBScript"><!--
function getIE()
dim t,l,a,b
set a=document.all.img1
t=document.all.img1.offsetTop
l=document.all.img1.offsetLeft
while a.tagName<>"BODY"
set a = a.offsetParent
t=t+a.offsetTop
l=l+a.offsetLeft
wend
msgbox "top="&t&chr(13)&"left="&l,64,"得到控件的位置"
end function
--></script>
14. 光标是停在文本框文字的最后
<script language="javascript">
function cc()
{
var e = event.srcElement;
var r =e.createTextRange();
r.moveStart("character",e.value.length);
r.collapse(true);
r.select();
}
</script>
<input type=text name=text1 value="123" onfocus="cc()">
15. 判断上一页的来源
javascript:
document.referrer
16. 最小化、最大化、关闭窗口
<object id=hh1 classid="clsid:ADB880A6-D8FF-11CF-9377-00AA003B7A11">
<param name="Command" value="Minimize"></object>
<object id=hh2 classid="clsid:ADB880A6-D8FF-11CF-9377-00AA003B7A11">
<param name="Command" value="Maximize"></object>
<OBJECT id=hh3 classid="clsid:adb880a6-d8ff-11cf-9377-00aa003b7a11">
<PARAM NAME="Command" VALUE="Close"></OBJECT>
<input type=button value=最小化 onclick=hh1.Click()>
<input type=button value=最大化 onclick=hh2.Click()>
<input type=button value=关闭 onclick=hh3.Click()>
本例适用于IE
17.屏蔽功能键Shift,Alt,Ctrl
<script>
function look(){
if(event.shiftKey)
alert("禁止按Shift键!"); //可以换成ALT CTRL
}
document.onkeydown=look;
</script>
18. 网页不会被缓存
<META HTTP-EQUIV="pragma" CONTENT="no-cache">
<META HTTP-EQUIV="Cache-Control" CONTENT="no-cache, must-revalidate">
<META HTTP-EQUIV="expires" CONTENT="Wed, 26 Feb 1997 08:21:57 GMT">
或者<META HTTP-EQUIV="expires" CONTENT="0">
19.怎样让表单没有凹凸感?
<input type=text style="border:1 solid #000000">
或
<input type=text style="border-left:none; border-right:none; border-top:none; border-bottom:
1 solid #000000"></textarea>
20.<div><span>&<layer>的区别?
<div>(division)用来定义大段的页面元素,会产生转行
<span>用来定义同一行内的元素,跟<div>的唯一区别是不产生转行
<layer>是ns的标记,ie不支持,相当于<div>
21.让弹出窗口总是在最上面:
<body onblur="this.focus();">
22.不要滚动条?
让竖条没有:
<body style="overflow:scroll;overflow-y:hidden">
</body>
让横条没有:
<body style="overflow:scroll;overflow-x:hidden">
</body>
两个都去掉?更简单了
<body scroll="no">
</body>
23.怎样去掉图片链接点击后,图片周围的虚线?
<a href="#" onFocus="this.blur()"><img src="logo.jpg" border=0></a>
24.电子邮件处理提交表单
<form name="form1" method="post" action="mailto:****@***.com" enctype="text/plain">
<input type=submit>
</form>
25.在打开的子窗口刷新父窗口的代码里如何写?
window.opener.location.reload()
26.如何设定打开页面的大小
<body onload="top.resizeTo(300,200);">
打开页面的位置<body onload="top.moveBy(300,200);">
27.在页面中如何加入不是满铺的背景图片,拉动页面时背景图不动
<STYLE>
body
{background-image:url(logo.gif); background-repeat:no-repeat;
background-position:center;background-attachment: fixed}
</STYLE>
28. 检查一段字符串是否全由数字组成
<script language="Javascript"><!--
function checkNum(str){return str.match(//D/)==null}
alert(checkNum("1232142141"))
alert(checkNum("123214214a1"))
// --></script>
29. 获得一个窗口的大小
document.body.clientWidth; document.body.clientHeight
30. 怎么判断是否是字符
if (/[^/x00-/xff]/g.test(s)) alert("含有汉字");
else alert("全是字符");
31.TEXTAREA自适应文字行数的多少
<textarea rows=1 name=s1 cols=27 onpropertychange="this.style.posHeight=this.scrollHeight">
</textarea>
32. 日期减去天数等于第二个日期
<script language=Javascript>
function cc(dd,dadd)
{
//可以加上错误处理
var a = new Date(dd)
a = a.valueOf()
a = a - dadd * 24 * 60 * 60 * 1000
a = new Date(a)
alert(a.getFullYear() + "年" + (a.getMonth() + 1) + "月" + a.getDate() + "日")
}
cc("12/23/2002",2)
</script>
33. 选择了哪一个Radio
<HTML><script language="vbscript">
function checkme()
for each ob in radio1
if ob.checked then window.alert ob.value
next
end function
</script><BODY>
<INPUT name="radio1" type="radio" value="style" checked>Style
<INPUT name="radio1" type="radio" value="barcode">Barcode
<INPUT type="button" value="check" onclick="checkme()">
</BODY></HTML>
34.脚本永不出错
<SCRIPT LANGUAGE="JavaScript">
<!-- Hide
function killErrors() {
return true;
}
window.onerror = killErrors;
// -->
</SCRIPT>
35.ENTER键可以让光标移到下一个输入框
<input onkeydown="if(event.keyCode==13)event.keyCode=9">
36. 检测某个网站的链接速度:
把如下代码加入<body>区域中:
<script language=Javascript>
tim=1
setInterval("tim++",100)
b=1
var autourl=new Array()
autourl[1]="www.njcatv.net"
autourl[2]="javacool.3322.net"
autourl[3]="www.sina.com.cn"
autourl[4]="www.nuaa.edu.cn"
autourl[5]="www.cctv.com"
function butt(){
document.write("<form name=autof>")
for(var i=1;i<autourl.length;i++)
document.write("<input type=text name=txt"+i+" size=10 value=测试中……> =》<input type=text
name=url"+i+" size=40> =》<input type=button value=GO
onclick=window.open(this.form.url"+i+".value)><br>")
document.write("<input type=submit value=刷新></form>")
}
butt()
function auto(url){
document.forms[0]["url"+b].value=url
if(tim>200)
{document.forms[0]["txt"+b].value="链接超时"}
else
{document.forms[0]["txt"+b].value="时间"+tim/10+"秒"}
b++
}
function run(){for(var i=1;i<autourl.length;i++)document.write("<img src=http://"+autourl+"/"+Math.random()+" width=1 height=1
onerror=auto("http://"+autourl+"")>")}
run()</script>
37. 各种样式的光标
auto :标准光标
default :标准箭头
hand :手形光标
wait :等待光标
text :I形光标
vertical-text :水平I形光标
no-drop :不可拖动光标
not-allowed :无效光标
help :?帮助光标
all-scroll :三角方向标
move :移动标
crosshair :十字标
e-resize
n-resize
nw-resize
w-resize
s-resize
se-resize
sw-resize
38.页面进入和退出的特效
进入页面<meta http-equiv="Page-Enter" content="revealTrans(duration=x, transition=y)">
推出页面<meta http-equiv="Page-Exit" content="revealTrans(duration=x, transition=y)">
这个是页面被载入和调出时的一些特效。duration表示特效的持续时间,以秒为单位。transition表示使用哪种特效,取值为1-23:
0 矩形缩小
1 矩形扩大
2 圆形缩小
3 圆形扩大
4 下到上刷新
5 上到下刷新
6 左到右刷新
7 右到左刷新
8 竖百叶窗
9 横百叶窗
10 错位横百叶窗
11 错位竖百叶窗
12 点扩散
13 左右到中间刷新
14 中间到左右刷新
15 中间到上下
16 上下到中间
17 右下到左上
18 右上到左下
19 左上到右下
20 左下到右上
21 横条
22 竖条
23 以上22种随机选择一种
39.在规定时间内跳转
<META http-equiv=V="REFRESH" content="5;URL=http://www.51js.com">
40.网页是否被检索
<meta name="ROBOTS" content="属性值">
其中属性值有以下一些:
属性值为"all": 文件将被检索,且页上链接可被查询;
属性值为"none": 文件不被检索,而且不查询页上的链接;
属性值为"index": 文件将被检索;
属性值为"follow": 查询页上的链接;
属性值为"noindex": 文件不检索,但可被查询链接;
属性值为"nofollow": 文件不被检索,但可查询页上的链接。
41.JAVASCRIPT判断IE是否开启COOKIE
<
script type
=
"
text/javascript
"
>

function
CookieEnable()
{
var
result
=
false
;
if
(navigator.cookiesEnabled)
return
true
;
document.cookie
=
"
testcookie=yes;
"
;
var
cookieSet
=
document.cookie;
if
(cookieSet.indexOf(
"
testcookie=yes
"
)
>
-
1
)
result
=
true
;
document.cookie
=
""
;
return
result;
}
if
(
!
CookieEnable())
{
alert(
"
对不起,您的浏览器的Cookie功能被禁用,请开启
"
);
}
</
script
>
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String.prototype.len=function(){return this.replace([^\x00-\xff]/g,"aa").length;}
匹配空行的正则表达式:\n[\s| ]*\r
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
应用:javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现,如下:
String.prototype.trim = function()
{
return this.replace(/(^\s*)|(\s*$)/g, "");
}
利用正则表达式分解和转换IP地址:
下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:
function IP2V(ip)
{
re=/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匹配IP地址的正则表达式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error("Not a valid IP address!")
}
}
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
var ip="10.100.20.168"
ip=ip.split(".")
alert("IP值是:"+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
利用正则表达式去除字串中重复的字符的算法程序:
[注:此程序不正确,原因见本贴回复]
var s="abacabefgeeii"
var s1=s.replace(/(.).*\1/g,"$1")
var re=new RegExp("["+s1+"]","g")
var s2=s.replace(re,"")
alert(s1+s2) //结果为:abcefgi
我原来在CSDN上发贴寻求一个表达式来实现去除重复字符的方法,最终没有找到,
这是我能想到的最简单的实现方法。思路是使用后向引用取出包括重复的字符,
再以重复的字符建立第二个表达式,取到不重复的字符,两者串连。
这个方法对于字符顺序有要求的字符串可能不适用。
得用正则表达式从URL地址中提取文件名的javascript程序,如下结果为page1
s="http://www.9499.net/page1.htm"
s=s.replace(/(.*\/){0,}([^\.]+).*/ig,"$2")
alert(s)
利用正则表达式限制网页表单里的文本框输入内容:
用正则表达式限制只能输入中文:onkeyup="value=value.replace(/[^\u4E00-\u9FA5]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\u4E00-\u9FA5]/g,''))"
用正则表达式限制只能输入全角字符: onkeyup="value=value.replace(/[^\uFF00-\uFFFF]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\uFF00-\uFFFF]/g,''))"
用正则表达式限制只能输入数字:onkeyup="value=value.replace(/[^\d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
用正则表达式限制只能输入数字和英文:onkeyup="value=value.replace(/[\W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
1. 问:在JAVA与JSP中要调用一个LINUX上的脚本程序,或WINDOWS上的脚本程序,该怎么写?
答:System.getRuntime().exec("bash < aaa.sh");
2. 问:java中用什么表示双引号
答:"""
3. 问:如何在JSP程序里另起一个线程?
答:
JSP本身就是独立线程运行而不象CGI都是独立进程.
一般:
Thread t = new Thread("你的对象");
t.start();就可以了.
要求你这个对象要实现runnable接口或继承thread.
4. 问:jsp如何获得客户端的IP地址?
答:
request.getRemoteAddr()
看看各个webserver的API文档说明,一般都有自带的,resin和tomcat都有
5. 问:程序终止与输出终止
答:
程序中止:return;
输出中止out.close();这一句相当于ASP的response.end
6. 问:jsp中如何得到上页的URL?
答:request.getHeader("referer");
7. 问:提交网页的网页过期功能是怎么做的?
答:response.setHader("Expires","0");
8. 问:在JSP网页中如何知道自已打开的页面的名称
答:
request.getRequestURI() ;//文件名
request.getRequestURL() ;//全部URL
9. 问:提交表单后验证没有通过,返回提交页面,如何使原提交页面中的数据保留?
答:javascript的go(-1)可以把上页的表单内容重新显示出来,但password域没有
10. 问:如何取得http的头信息?
答:request.getHader(headerName);
11. 问:&&和&的区别?
答:
&&是短路的与操作,也就是当地一个条件是false的时候,第二个条件不用执行
&相反,两个条件总是执行。
12. 问:将*以正弦曲线的一个周期显示出来
答:
public void paint(Graphics g)
{
for(int i=0;i<200;i++)
g.drawString("*",i,(int)(Math.sin(i)*20)+50);
}
}
13. 问:浮点数相乘后结果不精确如100.0 * 0.6 结果等于 60.0004
答:
这不叫错误,float和double是这样实现的.如果要精确计算,java提供了一个strictfp,它的计算遵循IEEE 754标准.而普通的float和double是
由地平台浮点格式或硬件提供的额外精度或表示范围。
14. 问:如何获得当前用的cursors的位置?
答:
int row = rs.getRow()就是当前指针行数,还有isFrist();isBeforeFist();isLast();isAfterLast();可以测试是不是在方法名所说的位置
15. 问:表单成功提交了,点后退显示网页过期
答:
在<head></head>里面加以下代码
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
<META HTTP-EQUIV="Cache-Control" CONTENT="no-cache">
<META HTTP-EQUIV="Expires" CONTENT="0">
或者在表单页中加上
<%
response.setHeader("Pragma","no-cache");
response.setHeader("Cache-Control","no-cache");
response.setDateHeader("Expires",0);
%>
16. 问:接口的简单理解
答:接口为了规范,比如我在接口中定义了一个方法:
getData()
这是用来从不同的数据库中取数据的,就是JDBC的实现对于用户,我不要知道每种数据库是如何做的,但我知道如何它们要实现这个接口就一定有
这个方法可以供我调用.这样SUN就把这个接口给各个数据库开发商,让他们自己实现. 但为什么不用继承而用接口哩,因为继承只能从一个你类
继承,而接口可以实现多个,就是说我实现的子类有多个规定好的接口中的功能. 这只是简单的理解,等你深入理解抽象的时候就知道抽象到抽象
类时为什么还要再抽象到接口.
17. 问:怎样编写一个取消按钮(怎样返回上一个页面,象工具栏的后退按钮)?
答:
javascript把每次浏览过的location都压到了一个栈中,这个栈就是history,然后你如果要回到第几个页面它就做几次POP操作,把最后POP出来
的那个LOCATION给你. 这就是JAVASCRIPT在实现history.go(-x)的原理.
18. 问:什么是回调?
答:
简单说,回调用不是让你去监听谁做完了什么事,而是谁做完了什么事就报告给你. 这就是回调用的思想.例子太多了,AWT的事件,SWING事件模型
都是这样有. 还有多线程中,如果要控制线程数,不能总是查询每个线程是否结束,要在每个线程结束时让线程自己告诉主线程我结束了,你可以
开新的线程了.
19. 问:简要介绍一下compareTo方法
答:
compareTo方法是Comparable 接口必需实现的方法,只要实现Comparable
就可以用Arrays.srot()排序就象实现Runnable接口的run就能Thread()一样.
20. 问:如何可以从别的Web服务器检索页, 然后把检索到的网页的HTML代码储存在一个变量中返回过来
答:这是一个简单的WEB ROBOT实现,用URL类实现从网页中抓内容,然后自己写一个分析程序从中找出新的URL,不断递归下去就行了.
21. 问:applet中如何获得键盘的输入
答:application的System.in是当前系统的标准输入,applet因为安全的原因不可能读取当前系统(客户端)的标准输入,只能从它的ROOT组件的
事件中,比如键盘事件中取得键值.
22. 问:怎样计算代码执行所花费的时间?
答:
代码开始取时间,结束后取时间,相减
long t1 = System.currentTimeMillis();
///////////////// your code
long t2 = System.currentTimeMillis() ;
long time = t2-t1;
23. 问:如何获在程序中获得一个文件的ContentType?
答:
URL u = new URL("file:///aaa.txt");
URLConnection uc = u.openConnection();
String s = uc.getContentType();
24. 问:连接池的使用是建立很多连接池,还是一个连接池里用多个连接?
答:
只有在对象源不同的情况下才会发生多个池化,如果你只连一结一个数据源,永远不要用多个连结池. 所以连结池的初始化一定要做成静态的,而
且应该在构造对象之前,也就是只有在类LOAD的时候,别的时候不应该有任何生成新的连结池的时候。
25. 问:JavaMail要怎么安装?
答:下载两个包,一个是javamail包,另一个是jaf包。下载完直接把这两个包不解压加到CLASSPATH。
26. 问:怎样把地址栏里的地址锁定?
答:把你的服务器的可访问目录索引选项关闭就行了,任何服务器都有一个conf文件,里面都有这个选项。
27. 问:在JAVA中怎么取得环境变量啊。比如: TEMP = C:TEMP ?
答:String sss = System.getProperty(key)
28. 问:怎样实现四舍五入,保留小数点后两位小数?
答:
import java.text.*;
...
NumberFormat nf=NumberFormat.getNumberInstance();
nf.setMaximumFractionDigits(2);
nf.setMinimumFractionDigits(2);
nf.format(numb);
29. 问:Applet和form如何通信?
答:
取得的参数传到param里面
<%
String xxx = request.getParameter("xxx");
%>
<applet>
<param value="<%=xxx%>">
</applet>
30. 问:java-plug-in是什么?
答:Java Runtime Environment的插件。用来运行java程序。不需要什么特别的设置。等于你的机器里面有了jvm。
31. 问:WEB上面怎么样连接上一个EXCEL表格?
答:
定义页面得contentType="application/vnd.ms-excel",让页面以excel得形式打开。同样也可以以word得形式打开:application/msword。
32. 问:怎样才能避免textarea字数限制?
答:是使用了FORM的默认方法的缘故,如果什么也不写默认是GET改用Post即可,在Form中定义mothod="post"。
33. 问:为什么加了<%@page contentType="text/html;charset=gb2312" %>插入数据库的中文,依然是乱码?
答:
这要从环境看,能显示说明你的JSP引擎没有问题,但写入数据库时你的JDBC能不能处理中文,同一公司不同版本的JDBC都有支持中文和不支持中
文的情况,RESIN自带的MYSQL JDBC就不支持,MM的就支持,还有你的数据库类型是否支持中文?CHAR的一般支持,但是否用binary存储双字节码
34. 问:对于JFrame,hide(),show()与setVisibel()有什么区别吗?
答:
setVisible()从Component继承过来,而hide(),show()从Window里面继承过来。
Makes the Window visible. If the Window and/or its owner are not yet displa yable, both are made displayable. The Window will
be validated prior to being made visible. If t he Window is already visible, this will bring the Window to the front. 区别在
这。
36. 问:sendRedirect为什么不可以转到mms协议的地址的?response.sendRedirect("mms://missiah.adsldns.org:9394");
答:java平台目前实现的protocol中并没有mms,你可以取系统属性java.protocol.handler.pkgs看看它的值中有没有mms,所以如果要想重定向
到mms://host这样和URL,只有生成客户端的JAVASCRIPT让它来重定向
37. 问:JTable中怎样定义各个Columns和Width和怎样设置表格的内容靠做靠右或居中?
答:
TableColumn tc = table.getColumn("Name");//取得列名为"Name"的列Handle
int currentWidth = tc.getPreferredWidth(); //取得该列当前的宽度
tc.setPreferredWidth(200); //设置当前列宽
tc.setMaxWidth(200); //设置该列最大宽度
tc.setMinWidth(50); //设置该列最小宽度
38. 问:批操作是否可用于select语句?
答:批操作其实是指成批理更新的操作,绝对不可能用于select操作。
39. 问:为什么jsp路径太深文件名太长就无法读取文件?
答:path不能超过255长度,不然就找不到了.这是作业系统的事。
40. 问:如何让页面不保留缓存?
答:
<%
response.setHeader("Pragma","No-cache");
response.setHeader("Cache-Control","no-cache");
response.setDateHeader("Expires", 0);
%>
41. 问:我的applet code 中用到jbutton 时就出错是否由于ie不支持swing package 请问应怎么办?
答:JBUTTON是SWING基本包啊,只要把jdk/jre/lib/rt.jar放在classpath就行了.不要加载任何别的库。
42. 问:不知道java是否支持midi格式,如果支持,应该怎么把wave格式转换成midi格式?
答:目前还不行,可以看一下JMF三个版中对MIDI的格式支持是read only,而WAVE是read/write,MIDI只能播放,不能生成。
43. 问:在jsp里面防止用户直接输入url进去页面,应该怎么做呢?
答:
一是从web服务器控制,对某一目录的所有访问要通过验证.
二是在要访问的页面中加入控制.这个一般用session,也可以用请求状态码实现
44. 问:
例如后台有一计算应用程序(此程序运算起来很慢,可持续几分钟到几小时,这不管,主要是能激活它),客户机讲任务提交后,服务器对任
务进行检测无误后将向服务器后台程序发送信息,并将其激活。要求如下:
1)首先将后台程序激活,让它执行此任务(比如,前台将计算的C代码提交上后,后台程序程序能马上调用,并将其运行)
2)要在前台JSP页面中显示运行过程信息(由于运行时间长,希望让客户看到运行过程中产生的信息)如何完成?
答:
活是可以的,运行一个shell让它去运行后台就行,但不可能取出运行信息,因为HTTP的超时限制不可能永远等你后台运行的,而且信息如果要动态
实时推出来就得用SERVER PUSH技术。
45. 问:数据库是datetime 型 ,插入当前时间到数据库?
答:
java.sql.Date sqlDate = new java.sql.Date();
PreparedStatement pstmt = conn.prepareStatement("insert into foo(time) values(?)");
pstmt.setDate(1,sqlDate);
pstmt.executeUpdate();
46. 问:怎样去掉字符串前后的空格。
答:String.trim()
47. 问:session怎样存取int类型的变量?
答:
session.setAttribute("int", i+"");
int i = Integer.parseInt(session.getAttribute("int"));
48. 问:在javascript中如何使输出的float类型的数据保留两位小数。
答:Math.round(aaaaa*100)/100。
49. 问:在bean种如何调用session
答:
你可把session对象作为一个参数传给bean
在BEAN中定义HttpServletRequest request;HttpSession session;
然后
session = request.getSession(false);
false为如果session为空,不建立新的session
将session作为参数传入.其实只要将request传入就可以
50. 问:如何把txt或word文件按原格式显示在jsp页面或servlet上?
答:
其实一个非常简单的解决方法就是在服务器的MIME中指点定TEXT和WORD的解释方式,然后用JSP或SERVLET生成它就行了,客户端就会自动调用相
应程序打开你的文档。
如果是希望按原格式的显示在页面上,而不是调用其他程序打开那么你可以试试用WEBDEV协议,可以说这是MS的一个亮点.它是在WEB方式下打开
文档,和共享一样.完全符合的要求。
51. 问:object的clone方法为什么不能直接调用?
答:
这个方法在object中是protected
为什么要把这个方法定义为protected,这是一个折中,它的目的是想知道你这个方法在Object里只是一个标记,而不是一个实现,比如
public class Object
{
.............
protected Object clone()
{}
}
所以直接继承的clone()方法并不能做任何时,你要使用这个方法就要重载这个方法并放宽访问权限为public,或实现cloneable接口. 但它没法
这样告诉你它没有真的实现,只好用protected 方法加以警示
52. 问:一个页面中如何刷新另外一个页面?
答:
要求是这些面页必须有关联,一是它们都有一个共同的顶层帧,也就是说是一个帧内的分级页面,当然可以是任意级,帧内再分帧也可以,另一个可
能是当前窗口弹出的窗口,如果没有联系,那就不可能用一个页面刷新另一个页面. 帧内只要一级一级引用就行了.
比如在左帧中一个页面中写top.right.location.reload();那么名为right的右帧中的页面就会刷新. 弹出的一样,用open时的名称刷新子窗口,
子窗口用opener刷新主窗口
53. 问:如何在jsp中怎么样向客户端写cookies?
答:
Cookie coo = new Cookie(name, value);
HttpServletResponse.addCookie(name);
54. 问:为什么jTextField1.setText("aaabbb");jTextField2.setText("AAABBB"); 得到的字体宽度不一样?
答:就是说如果不是指定为等宽字体,每个字体的宽度都是不一样的.因此JAVA中用FontMetrics 类来取字符宽度。
55. 问:String kk=application/octet-stream; name="G:/SMBCrack.exe";如何得到SMBCrack.exe?
答:
这应该是解析上传时候的二进制流得到的这一行里面格式是固定的,取到name="后面的字符串,然后把";去掉。然后取最后一个/后面的所有字
符组成一个新字符串就行了。
56. 问:如何传值并不刷新页面?
答:
弹出一个页面进行值的选择或者输入,ok后使用将值传给原窗口,使用javascript关闭打开的窗口即可:
window.close();opener.focus();
57. 问:有一个字符串:"EF0C114EA4",如何变为a[0] = 0xEF a[1] = 0x0C a[2] = 0x11 a[3] = 0x4E a[4] = 0xA4?
答:
String str="EF0C114EA4F";
out.print(str+"<br>");
int l=str.length()/2+str.length()%2,j=0,k=0;
String[] a=new String[l];
for(int i=0;i<l;i++){
if(str.length()-j==1)
k=str.length();
else
k=j+2;
a="0x"+str.substring(j,k);
out.print("a["+Integer.toString(i)+"]="+a+"<br>");
j+=2;
}
58. 问:怎样将一个int转换成一个四字节的byte数组?
答:
int x = 1234567;
byte[] b = new byte[4];
for(int i=0;i<b.length;i++)
{
b = (x >>( i*8)) & 0xFF;
}
59. 问:indexOf()的使用需要注意什么?
答:参数是指从第几位(1,2,3,...)开始搜索,而返回值是指搜索到的位置(0,1,2,3.......)注意是从零算起的。
60. 问:在Java应用程序中如何动态的添加一个按钮?
答:
这里涉及一个组件重绘的问题,组件要先于panel被显示之处存在,如果一panel已经显示了,那么加在上面你能看到吗?但如果在同一个panel上,
先有button A,假如按下它加了butt on B,这时你如果使整个panel重给,那么A本身要重绘,它的事件监听就没有了,当然也就加不成B了,所以如
果要先有另一个panel,当按A时把B加在这个panel上并重绘这个paenl,其实更好的方法是先把B加在panel中,同一个也行.把它setVisiable(flas
e),按A时设为 true。
61. 问:book mybook=new book(bookid);book是servlet,出错。
答:
book是servlet,能book mybook=new book(bookid);
说明自己实现了servlet容器?不然,servlet能让你自己去调用? servlet如果调用其实和EJB连1%的区别都没有,它们都是自己继承或实现一些接
口,在这些父类或接口中实现了如果和容器"打交道"的方法,然后容器调用这些方法来管理它,让它生成实例,池化,钝化,销毁,再生等.所以这样
写是错误的。
62. 问:给定一个字符串5*(5+9)/7怎样计算出结果?
答:
可有两种方法
1。用堆栈完成
2。最简单的方法,不用编程,如果有任何一个数据库的化,用select (5*(5+9)/7) from oneTable
63. 问:如何实现递交表单内容的加密解密?
答:
如果你用IE目前只能用SSL协议,这一层不要你考虑,否则只你用你自己的工具加密传输,接收后再解密友,至于如何加解,如果要和公认的系统结
合,就用通用的MD5,RAS等公开算法,如果你只是自己传自己解,你随便按你的想法把数据加上一些东西,取回来按规则减掉这些东西,我敢保证除
你自己没有任何人能知道解密方法.
64. 问:为什么Integer.parseInt("+1");会抛出NumberFormatException的异常?
答:因为"+"运行算在JAVA中被重载.系统无法确定你用的是算术加还是字符+。
这一点可以在JAVASCRIPT中更好地理解:
<form name="t"><input name=s value=1234></form>
var a = document.t.s.value+1;
这时a = 12345,因为document.t.s.value作为字符串.但var a = document.t.s.value-1;
a 就是1233,因为系统知道-运算肯定是算术运行.所以把document.t.s.value转换成数字.
65. 问:hashCode() 有什么用为什么有时候需要覆盖Object里的hashcode()方法?
答:这就是这个对象的身份证啊,要不如何区分哪个对象。
66. 问:怎样在tomcat中实现一个定时执行的东东?
答:
在应用程序启动时自动运行。servlet2.3中定义了ServletListener,监听Servlet Con text的启动或则关闭(可在配置文件中配置),启动时
触发一个守护程序的运行(可以实现java.util.Timer或则 javax.swing.Timer).
67. 问:程序可以输出自己吗?
答:孔德悖论这个非常有名的法则.就是说任何程序都不可能输出自己.
68. 问:能够把字符转化成ASCII码?比如将 A 转化成 65?
答:
int a='A';
out.println(a);
69. 问:如何区分输入的文字中的全角与半角?
答:由于不能分辨出全角和半角字符的值有什么规律,只好把全角符号牧举出来了.
70. 问:用户注册后的自动发信程序该怎么做?
答:
这种发信程序不考虑性能,因为不可能1秒就有一个人注册,我们说的考虑性能的发信程序是指上百万封信在队列里要不停发送的那种,象你这个
随便怎么写一个程序都行,没有必要用JAVAMAIL.只要指定一个发信的服务器然后用cocket连它的25口就行了.自己用SOCKET连SMTP的25口发一封
信就好象两个邻居之间送一样东西,直接递过去得了,用JAVAMAIL,消息机制就是你把这个东西从邮局寄给你的邻居了.
image.jsp-------------------生成随即验证码图片的jsp页面
代码如下:
<%@ page contentType="image/jpeg" import="java.awt.*,
java.awt.image.*,java.util.*,javax.imageio.*" %>
<%!
Color getRandColor(int fc,int bc)
{
Random random = new Random();
if(fc>255) fc=255;
if(bc>255) bc=255;
int r=fc+random.nextInt(bc-fc);
int g=fc+random.nextInt(bc-fc);
int b=fc+random.nextInt(bc-fc);
return new Color(r,g,b);
}
%>
<%
out.clear();//这句针对resin服务器,如果是tomacat可以不要这句
response.setHeader("Pragma","No-cache");
response.setHeader("Cache-Control","no-cache");
response.setDateHeader("Expires", 0);
int width=60, height=20;
BufferedImage image = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB);
Graphics g = image.getGraphics();
Random random = new Random();
g.setColor(getRandColor(200,250));
g.fillRect(0, 0, width, height);
g.setFont(new Font("Times New Roman",Font.PLAIN,18));
g.setColor(getRandColor(160,200));
for (int i=0;i<155;i++)
{
int x = random.nextInt(width);
int y = random.nextInt(height);
int xl = random.nextInt(12);
int yl = random.nextInt(12);
g.drawLine(x,y,x+xl,y+yl);
}
String sRand="";
for (int i=0;i<4;i++){
String rand=String.valueOf(random.nextInt(10));
sRand+=rand;
g.setColor(new Color(20+random.nextInt(110),20+random.nextInt(110),20+random.nextInt(110)));
g.drawString(rand,13*i+6,16);
}
// 将认证码存入SESSION
session.setAttribute("rand",sRand);
g.dispose();
ImageIO.write(image, "JPEG", response.getOutputStream());
%>
login.jsp--------------------登录页面,在这里我是提供输入验证码然后提交进行验证
代码如下:
<%@ page language="java" import="java.sql.*" errorPage="" %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>用户登录</title>
<script language="javascript">
function loadimage(){
document.getElementById("randImage").src = "image.jsp?"+Math.random();
}
</script>
</head>
<body>
<table width="256" border="0" cellpadding="0" cellspacing="0">
<!--DWLayoutTable-->
<form action="validate.jsp" method="post" name="loginForm">
<tr>
<td width="118" height="22" valign="middle" align="center"><input type="text" name="rand" size="15"></td>
<td width="138" valign="middle" align="center"><img alt="code..." name="randImage" id="randImage" src="image.jsp" width="60" height="20" border="1" align="absmiddle"></td>
</tr>
<tr>
<td height="36" colspan="2" align="center" valign="middle"><a href="javascript:loadimage();"><font class=pt95>看不清点我</font></a></td>
</tr>
<tr>
<td height="36" colspan="2" align="center" valign="middle"><input type="submit" name="login" value="提交"></td>
</tr>
</form>
</table>
</body>
</html>
validate.jsp-------------用来验证输入的验证码是否正确
代码如下:
<%@ page contentType="text/html; charset=gb2312" language="java" import="java.sql.*" errorPage="" %>
<%
String rand = (String)session.getAttribute("rand");
String input = request.getParameter("rand");
if(rand.equals(input)){
out.print("<script>alert('验证通过!');</script>");
} else{
out.print("<script>alert('请输入正确的验证码!');location.href='login.jsp';</script>");
}
%>
上面生成的是纯数字的验证码,我们对其进行一下修改就可以生成数字字母混合的验证码了。
修改部分的代码如下:
<%
......
......
......
for (int i=0;i<155;i++)
{
......
......
}
//-----------------以下是要添加的代码--------------
char c[] = new char[62];
for (int i = 97, j = 0; i < 123; i++, j++) {
c[j] = (char) i;
}
for (int o = 65, p = 26; o < 91; o++, p++) {
c[p] = (char) o;
}
for (int m = 48, n = 52; m < 58; m++, n++) {
c[n] = (char) m;
}
String sRand="";
for (int i=0;i<4;i++){
int x = random.nextInt(62);
String rand=String.valueOf(c[x]);
sRand+=rand;
//---------------------------------------------
%>
据有部分朋友反应,在测试过程中出现java.lang.IllegalStateException: getOutputStream() has already been called for this response的异常,经过测试发现,使用tomcat5一下的版本确实会出现该问题,解决的办法就是把tomcat换成高点版本就可以了。
作者:Cloves Carneiro;
simmone
原文地址:
http://www.javaworld.com/javaworld/jw-06-2005/jw-0620-dwr.html
中文地址:
http://www.matrix.org.cn/resource/article/43/43926_DWR_AJAX.html
关键词: DWR AJAX
概述
这篇文章阐述了使用开源项目DWR(直接Web远程控制)和AJAX(异步JavaScript和XML)的概念来提高Web应用的可用性。作者一步步来展示DWR如何使得AJAX的应用既简单又快捷。(1600字;2005年6月20日)
AJAX,或者说是异步JavaScript和XML,描述了一种使用混合了HTML(或XHTML)和层叠样式表作为表达信息,来创建交互式的Web应用的开发技术;文档对象模型(DOM),JavaScript,动态地显示和与表达信息进行交互;并且,XMLHttpRequest对象与Web服务器异步地交换和处理数据。
因特网上许多例子展示了在一个HTML文件内部使用XMLHttpRequest与服务器端进行交互的必要的步骤。当手工地编写和维护XMLHttpRequest代码时,开发者必须处理许多潜在的问题,特别是类似于跨浏览器的DOM实现的兼容性这样的问题。这将会导致在编码和调试Javascript代码上面花费数不清的时间,这显然对开发者来说很不友好。
DWR(直接Web远程控制)项目是在Apache许可下的一个开源的解决方案,它供给那些想要以一种简单的方式使用AJAX和XMLHttpRequest的开发者。它具有一套Javascript功能集,它们把从HTML页面调用应用服务器上的Java对象的方法简化了。它操控不同类型的参数,并同时保持了HTML代码的可读性。
DWR不是对一个设计的插入,也不强迫对象使用任何种类的继承结构。它和servlet框架内的应用配合的很好。对缺少DHTML编程经验的开发者来说,DWR也提供了一个JavaScript库包含了经常使用的DHTML任务,如组装表,用item填充select下拉框,改变HTML元素的内容,如<div>和<span>
DWR网站是详尽的并且有大量的文档,这也是这篇文章的基础。一些例子用来展示DWR如何使用和用它的库可以完成什么样的工作。
这篇文章让读者看到了一个使用了DWR的Web应用是如何一步步建立的。我会展示创建这个简单的示例应用的必要的细节,这个应用是可下载的并且可以在你的环境中布署来看看DWR如何工作。
注意:找到有关AJAX的信息并不困难;网页上有几篇文章和博客的条目涵盖了这个主题,每一个都试图指出和评论这个概念的不同的方面。在资源部分,你会找到一些有趣的指向示例和文章的链接,来学习AJAX的更多的内容。
示例应用
这篇文章使用的示例应用模拟了多伦多的一个公寓出租搜索引擎。用户可以在搜索前选择一组搜索标准。为了提高交互性,AJAX中以下两种情况下使用:
·应用通告用户配合他的选择会返回多少搜索结果。这个数字是实时更新的-使用AJAX-当用户选择的卧室和浴室的数量,或者价格范围变化时。当符合标准的搜索结果没有或太多时,用户就没有必要点击搜索按纽。
·数据库查询并取回结果是由AJAX完成的。当用户按下显示结果按钮时,数据库执行搜索。这样,应用看起来更具响应了,而整个页面不需要重载来显示结果。
数据库
我们使用的数据库是HSQL,它是一种占用资源很小的Java SQL数据库引擎,可以不需要安装和配置的与Web应用捆绑在一起。一个SQL文件被用来在Web应用的上下文启动时创建一个内存中的表并添加一些记录。
Java类
应用包含了两个主要的类叫Apartment和ApartmentDAO。Apartment.java类是一个有着属性和getter/setter方法的简单的Java类。ApartmentDAO.java是数据访问类,用来查询数据库并基于用户的搜索标准来返回信息。ApartmentDAO类的实现的直接了当的;它直接使用了Java数据库联接调用来得到公寓的总数和符合用户请求的可用公寓的列表。
DWR配置和使用
设置DWR的使用是简单的:将DWR的jar文件拷入Web应用的WEB-INF/lib目录中,在web.xml中增加一个servlet声明,并创建DWR的配置文件。DWR的分发中需要使用一个单独的jar文件。你必须将DWR servlet加到应用的WEB-INF/web.xml中布署描述段中去。
<servlet>
<servlet-name>dwr-invoker</servlet-name>
<display-name>DWR Servlet</display-name>
<description>Direct Web Remoter Servlet</description>
<servlet-class>uk.ltd.getahead.dwr.DWRServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>true</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>dwr-invoker</servlet-name>
<url-pattern>/dwr/*</url-pattern>
</servlet-mapping>
一个可选的步骤是设置DWR为调试模式—象上面的例子那样—在servlet描述段中将debug参数设为true。当DWR在调试模式时,你可以从HTMl网页中看到所有的可访问的Java对象。包含了可用对象列表的网页会出现在/WEBAPP/dwr这个url上,它显示了对象的公共方法。所列方法可以从页面中调用,允许你,第一次,运行服务器上的对象的方法。下图显示了调试页的样子:

调试页
现在你必须让DWR知道通过XMLHttpRequest对象,什么对象将会接收请求。这个任务由叫做dwr.xml的配置文件来完成。在配置文件中,定义了DWR允许你从网页中调用的对象。从设计上讲,DWR允许访问所有公布类的公共方法,但在我们的例子中,我们只允许访问几个方法。下面是我们示例的配置文件:
<dwr>
<allow>
<convert converter="bean" match="dwr.sample.Apartment"/>
<create creator="new" javascript="ApartmentDAO" class="dwr.sample.ApartmentDAO">
<include method="findApartments"/>
<include method="countApartments"/>
</create>
</allow>
</dwr>
上面的文件实现了我们例子中的两个目标。首先,<convert>标记告诉DWR将dwr.sample.Apartment对象的类型转换为联合数组,因为,出于安全的原因,DWR默认的不会转换普通bean。第二,<create>标记让DWR暴露出dwr.sample.ApartmentDAO类给JavaScript调用;我们在页面中使用JavaScript文件被javascript属性定义。我们必须注意<include>标记,它指明了dwr.sample.ApartmentDAO类的哪些方法可用。
HTML/JSP代码
配置完成后,你就可以启动你的Web应用了,这时DWR会为从你的HTML或Java服务器端页面(JSP)上调用所需方法作好准备,并不需要你创建JavaScript文件。在search.jsp文件中, 我们必须增加由DWR提供的JavaScript接口,还有DWR引擎,加入以下三行到我们的代码中:
<script src='dwr/interface/ApartmentDAO.js'></script>
<script src='dwr/engine.js'></script>
<script src='dwr/util.js'></script>
我们注意到当用户改变搜索标准时,这是AJAX在示例程序中的首次应用;正如他所看到的,当标准改变时,可用的公寓数量被更新了。我创建了两个JavaScript函数:当某一个选择下拉框中的值变化时被调用。ApartmentDAO.countApartments()函数是最重要的部分。最有趣的是第一个参数, loadTotal()函数,它指明了当接收到服务端的返回时DWR将会调用的JavaScript方法。loadTotal于是被调用来在HTML页面的<div>中显示结果。下面是在这个交互场景中所使用到的JavaScript函数:
function updateTotal() {
$("resultTable").style.display = 'none';
var bedrooms = document.getElementById("bedrooms").value;
var bathrooms = document.getElementById("bathrooms").value;
var price = document.getElementById("price").value;
ApartmentDAO.countApartments(loadTotal, bedrooms, bathrooms, price);
}
function loadTotal(data) {
document.getElementById("totalRecords").innerHTML = data;
}
很明显,用户想看到符合他的搜索条件的公寓列表。那么,当用户对他的搜索标准感到满意,并且总数也是有效的话,他会按下显示结果的按纽,这将会调用updateResults() JavaScript方法:
function updateResults() {
DWRUtil.removeAllRows("apartmentsbody");
var bedrooms = document.getElementById("bedrooms").value;
var bathrooms = document.getElementById("bathrooms").value;
var price = document.getElementById("price").value;
ApartmentDAO.findApartments(fillTable, bedrooms, bathrooms, price);
$("resultTable").style.display = '';
}
function fillTable(apartment) {
DWRUtil.addRows("apartmentsbody", apartment, [ getId, getAddress, getBedrooms, getBathrooms, getPrice ]);
}
updateResults()方法清空了存放搜索返回结果的表域,从用户界面上获取所需参数,并且将这些参数传给DWR创建的ApartmentDAO对象。然后数据库查询将被执行,fillTable()将会被调用,它解析了DWR返回的对象(apartment),然后将其显示到页面中(apartmentsbody)。
安全因素
为了保持示例的简要,ApartmentDAO类尽可能的保持简单,但这样的一个类通常有一组设置方法来操作数据,如insert(), update()和delete()。DWR暴露了所有公共方法给所有的HTML页面调用。出于安全的原因,像这样暴露你的数据访问层是不明智的。开发者可以创建一个门面来集中所有JavaScript函数与底层业务组件之间的通信,这样就限制了过多暴露的功能。
结论
这篇文章仅仅让你在你的项目中使用由DWR支持的AJAX开了个头。DWR让你集中注意力在如何提高你的应用的交互模型上面,消除了编写和调试JavaScript代码的负担。使用AJAX最有趣的挑战是定义在哪里和如何提高可用性。DWR负责了操作Web页面与你的Java对象之间的通信,这样就帮助你完全集中注意力在如何让你的应用的用户界面更加友好,
我想感谢Mircea Oancea和Marcos Pereira,他们阅读了这篇文章并给予了非常有价值的返匮。
资源
·javaworld.com:
javaworld.com
·Matrix-Java开发者社区:
http://www.matrix.org.cn/
·onjava.com:
onjava.com
·下载示例程序的全部源码:
http://www.javaworld.com/javaworld/jw-06-2005/dwr/jw-0620-dwr.war
·DWR: http://www.getahead.ltd.uk/dwr/index.html
·HSQL:http://hsqldb.sourceforge.net/
·AJAX的定义:http://en.wikipedia.org/wiki/AJAX
· “AJAX:通向Web应用的新途径": Jesse James Garrett (Adaptive Path, 2005.2): http://www.adaptivepath.com/publications/essays/archives/000385.php
· “非常动态的Web界面” Drew McLellan (xml.com, 2005.2): http://www.xml.com/pub/a/2005/02/09/xml-http-request.html
·XMLHttpRequest & AJAX 工作范例: http://www.fiftyfoureleven.com/resources/programming/xmlhttprequest/examples
· “可用的XMLHttpRequest实践” Thomas Baekdal (Baekdal.com, 2005.3): http://www.baekdal.com/articles/Usability/usable-XMLHttpRequest/
·"XMLHttpRequest使用导引" Thomas Baekdal (Baekdal.com, 2005.2):http://www.baekdal.com/articles/Usability/XMLHttpRequest-guidelines/
·AJAX实质:http://www.ajaxmatters.com/
(看完后个人感觉:有了DWR就JAVA开发而言,完全可以与AJAX匹敌啦,省了在JS上对XMLHTTP以及对DOM的处理,不可以避免地在后台对应的IO处理;然后就DWR来说,它增加了对XML中对应的配置--在开源框架中似乎一直不曾停止过。还有对一些DWR自有用法如DWRUtil.addRows得参考其相关文档---当然这样的功能我们自己也可以用JS来解决,并且它显然很实用。add by jkallen)
摘要: 制作环境:
Windows 2003 + IIS6、jre1.5.0_06、apache-tomcat-5.5.17
首先需要做以下准备工作
...
阅读全文
文件上传在web应用中非常普遍,要在servlet/jsp环境中实现文件上传功能非常容易,因为网上已经有许多用java开发的组件用于文件上传,本文以commons-fileupload组件为例,为servlet/jsp应用添加文件上传功能。
common-fileupload组件是apache的一个开源项目之一,可以从
http://jakarta.apache.org/commons/fileupload/
下载。该组件简单易用,可实现一次上传一个或多个文件,并可限制文件大小。
下载后解压zip包,将commons-fileupload-1.0.jar复制到tomcat的webapps\你的webapp\WEB-INF\lib\下,如果目录不存在请自建目录。
新建一个servlet: Upload.java用于文件上传:
1 import java.io.*
;
2 import java.util.*
;
3 import javax.servlet.*
;
4 import javax.servlet.http.*
;
5 import org.apache.commons.fileupload.*
;
6
7 public class Upload extends
HttpServlet {
8
9 private String uploadPath = "C:\\upload\\"; // 用于存放上传文件的目录
10 private String tempPath = "C:\\upload\\tmp\\"; // 用于存放临时文件的目录
11
12 public void
doPost(HttpServletRequest request, HttpServletResponse response)
13 throws
IOException, ServletException
14
{
15
}
16
}
17
18 //当servlet收到浏览器发出的Post请求后,在doPost()方法中实现文件上传。以下是示例代码:
19
20 public void
doPost(HttpServletRequest request, HttpServletResponse response)
21 throws
IOException, ServletException
22
{
23 try
{
24 DiskFileUpload fu = new
DiskFileUpload();
25 // 设置最大文件尺寸,这里是4MB
26 fu.setSizeMax(4194304
);
27 // 设置缓冲区大小,这里是4kb
28 fu.setSizeThreshold(4096
);
29 // 设置临时目录:
30
fu.setRepositoryPath(tempPath);
31
32 // 得到所有的文件:
33 List fileItems =
fu.parseRequest(request);
34 Iterator i =
fileItems.iterator();
35 // 依次处理每一个文件:
36 while
(i.hasNext()) {
37 FileItem fi =
(FileItem)i.next();
38 // 获得文件名,这个文件名包括路径:
39 String fileName =
fi.getName();
40 if(fileName!=null
) {
41 //
在这里可以记录用户和文件信息
42 //
43 // 写入文件a.txt,你也可以从fileName中提取文件名:
44 fi.write(new File(uploadPath + "a.txt"
));
45
}
46
}
47 // 跳转到上传成功提示页面
48
}
49 catch
(Exception e) {
50 // 可以跳转出错页面
51
}
52
}
53
54 //如果要在配置文件中读取指定的上传文件夹,可以在init()方法中执行:
55
56 public void init() throws
ServletException {
57 uploadPath =
.
58 tempPath =
.
59 // 文件夹不存在就自动创建:
60 if(!new
File(uploadPath).isDirectory())
61 new
File(uploadPath).mkdirs();
62 if(!new
File(tempPath).isDirectory())
63 new
File(tempPath).mkdirs();
64
}
65
编译该servlet,注意要指定classpath,确保包含commons-upload-1.0.jar和tomcat\common\lib\servlet-api.jar。
配置servlet,用记事本打开tomcat\webapps\你的webapp\WEB-INF\web.xml,没有的话新建一个。典型配置如下:
1 <?xml version="1.0" encoding="ISO-8859-1"?>
2 <!
DOCTYPE web-app
3
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
4 "http://java.sun.com/dtd/web-app_2_3.dtd">
5
6 <web-app>
7 <servlet>
8 <servlet-name>Upload</servlet-name>
9 <servlet-class>Upload</servlet-class>
10 </servlet>
11
12 <servlet-mapping>
13 <servlet-name>Upload</servlet-name>
14 <url-pattern>/fileupload</url-pattern>
15 </servlet-mapping>
16 </web-app>
17
配置好servlet后,启动tomcat,写一个简单的html测试:
1 <form action="fileupload" method="post"
2 enctype="multipart/form-data" name="form1">
3 <input type="file" name="file">
4 <input type="submit" name="Submit" value="upload">
5 </form>
注意action="fileupload"其中fileupload是配置servlet时指定的url-pattern。
摘自:
http://www.j2medev.com/Article/Class10/j2eeopensource/200409/62.html
输入输出
在所有的本系列文章中,在编写Ruby代码时都使用了大量的Ruby标准输出方法。其中,最为常用的是print和puts方法,有关其使用细节不再赘述。
所有这些和其它处理输入和输出的方法都定义于Kernel模块中。这个Kernel模块又被包含在Object类中。因此,Kernel的方法出现在每一个对象中。在输出方面,Kernel定义了print,printf,putc和IO类和两个子类(File和BasicSocket)-它们允许读写文件和套接字。BasicSocket是套接字库的一部分并且将在以后讨论它。包含了FileTest模块的File类,提供了许多方法来操作系统文件和目录。从Kernel中使用的用于读写到标准输入/输出机制的方法被进一步重用于File实例中的读写操作。下面是一个代码示例-它把一些名字写入一个新建的文件中,然后再把这些名字读回到一个数组中。
customers=%w[Jim Kevin Davin Andrew]
outFile = File.new("c:\\examples\\test\\customers.txt", "w")
customers.each{|customer| outFile.puts(customer)}
outFile.close
inFile= File.new("c:\\examples\\customers.txt", "r")
readCustomers=inFile.readlines
readCustomers.each{|customer| puts customer}
inFile.close |
标准库
Ruby除了提供大量内置的类和模块外,它还提供了一定数目的标准库。这些库不是自动地成为你可以利用的Ruby类,模块,方法的一部分。你必须先在你的文件的顶部使用require(或load)关键字来使用库中的类或模块。在前一节中,我曾提到一个库-套接字库,它包含了大量的Ruby类(包括BasicSocket),以便于访问网络服务。但是在Ruby下载中一同提供了一整套其它的库。你可以查看一下你的Ruby下载中的lib目录,这个目录下应该存在大量的你的Ruby程序需要使用的库。
有关这些库的不好的一点是,没有大量的有关于这些类的参考文档。你可以在网站http://www.ruby-doc.org/stdlib/上找到一系列标准库及其包含类和模块的文件。即使是这些文档也指出:
"你需要明白,在表格中粗体的库具有良好的文档,而斜体的库没有文档。"
这就是Ruby的现状。你可能想说,Ruby是一个不可思议地丰富而有力的语言并且内置了许多构建我们的应用程序需要的功能,但是文档仍然有点不足。还好,现在已经有不少的人在努力改进Ruby的文档和支持。现在有不少的Ruby论坛已经倔起,并且随着每一个新版本的发行,文档都将有一定的改进-当然,这也是最近它备受关注的结果。然而,帮助文档仍然会成为这种语言挫败人心的一个因素。
在Ruby中,一切都是对象。更精确地说,Ruby中的一切都是一个具有完整功能的对象。因此,在Ruby中,数字4,定点数3.14和字符串"Hi"都是对象。显然,它们是有点"特殊"的,因为你不必使用new方法来创建它们。代之的是,你使用例如"literal 4"这样的形式来创建一个代表数字4的对象的实例。
然而,对于绝大多数人来说,学习一种新的编程语言时,首先理解该语言提供的"标准"类型是非常有用的。所以,在这一节,我们先探讨数字类型,字符串类型,布尔类型和另外一些基本的Ruby数据类型。
数字类型
实质上,Ruby中的数字被分为整数和浮点数两大类。其中,整数又被进一步细分为"常规大小"的整数和大型整数。因为在Ruby中一切都是对象,所以整数和浮点数都是按类来定义的(见图1)。从图1看出,Numeric是所有数字类型的基类,Float和Integer类是Numeric的子类。Fixnum和Bignum都是Integer的子类型-它们分别定义了"常规大小"的整数和大型整数。

图1.Ruby的数字类型类继承图。
Literal用来描述这些类的实例。下面的在交互式Ruby外壳(irb)中的代码显示了Float,Fixnum和Bignum的literal实例。注意,可以在literal上进行方法调用(在此,是指类方法)。
irb(main):001:0> 3.class
=> Fixnum
irb(main):002:0> 3.4.class
=> Float
irb(main):003:0> 10000000000000000000.class
=> Bignum |
还有另外一些语法用来创建数字类型,显示于下面的代码列表中。字母E可以用来描述以指数标志的数字。数字的前面加上0代表这是一个八进制数,加上0x代表这是一个十六进制数,而0b代表是一个二进制数。为清晰起见,下划线可以用作数字中的分隔符号。注意,当写literal时,不要用逗号作为分隔符号。在一些情况中,这实际上能生成一个数组,我们将在后面讨论。最后,在一个字符(或Ctrl或元字符的组合)前面的一个问号将会创建一个Fixnum的实例,相应于字符的ASCII字符/逃逸序列值。
<
irb(main):001:0> 3.14E5 #指数标志
=> 314000.0
irb(main):002:0> 054 #八进制
=> 44
irb(main):003:0> 0x5A #十六进制
=> 90
irb(main):004:0> 0b1011 #二进制
=> 11
irb(main):005:0> 10_000 #10,000,用下划线隔开
=> 10000
irb(main):006:0> i=10,000 #创建一个数组而不是10000 Fixnum
=> [10, 0]
irb(main):007:0> i.class
=> Array
irb(main):008:0> ?Z #Fixnum ASCII值
=> 90
irb(main):009:0> ?Z.class
=> Fixnum
irb(main):010:0> ?\C-s #Control-s的值ASCII
=> 19 |
Fixnum和Bignum实例间的真实差别是什么?Fixnum整数可以被存储在机器中的一个字(通常16,32或64位)中,但减去1个位;而Bignum实例是超出固定存储空间的整数。当然,作为开发者,你不必担心整数的大小(见下面的例子),由Ruby负责为你实现Fixnum和Bignum之间的自动转换!
irb(main):001:0> i=4
=> 4
irb(main):002:0> i.class
=> Fixnum
irb(main):003:0> i=i+100000000000000
=> 100000000000004
irb(main):004:0> i.class
=> Bignum
irb(main):005:0> i=i-100000000000000
=> 4
irb(main):006:0> i.class
=> Fixnum |
字符串 在Ruby中,字符串是任意顺序的字节。通常,它们是一个字符序列。在Ruby中,可以使用一个literal或new方法来创建String类的实例。
irb(main):001:0> s1="Hello World"
=> "Hello World"
irb(main):002:0> s2=String.new("Hello World")
=> "Hello World" |
当然,String中定义了许多方法(和操作符)。另外,可以使用单引号或双引号来指定一个字符串。双引号情况下允许串中加入逃逸字符并能够嵌入待计算的表达式。在单引号串情况下,你看到的就是串中的实际内容。为了更好的理解,请看下列例子。
irb(main):001:0> str1='a \n string'
=> "a \\n string"
irb(main):002:0> str2="a \n string"
=> "a \n string"
irb(main):003:0> puts str1
a \n string
=> nil
irb(main):004:0> puts str2
a
string
=> nil
irb(main):005:0> 'try to add #{2+2}'
=> "try to add \#{2+2}"
irb(main):006:0> "try to add #{2+2}"
=> "try to add 4"
irb(main):007:0> this="that"
=> "that"
irb(main):008:0> 'when single quote rights #{this}'
=> "when single quote rights \#{this}"
irb(main):009:0> "double quote rights #{this}"
=> "double quote rights that" |
请注意,在显示之前,双引号中的文本是如何被计算的,其中包括了逃逸符号(\n)和表达式(#{2+2})。
除了使用单引号和双引号来定义一个字符串literal外,在Ruby中,还有另外的方法可以表达literal。一个百分号和小写或大写字母Q可以用来表达一个字符串,分别相应于单引号或双引号风格。
irb(main):001:0> %q@this is a single quote string #{2+2} here@
=> "this is a single quote string \#{2+2} here"
irb(main):002:0> %Q@this is a double quote string #{2+2} here@
=> "this is a double quote string 4 here" |
注意,跟随在q%或Q%后面的字符分别定义了字符串literal的开始和结束。在本例中,@符号用作字符串开始与结束的限界符号。
还应该注意,Ruby并没有区分一个字符串和一个字符。也就是说,没有适用于单个字符的特定的类-它们仅是一些小的字符串。
布尔类型
最后,让我们再看一下布尔类型。在Ruby中,有两个类用于表达布尔类型:TrueClass和FalseClass。每个这些类仅有一个实例(一个singleton):也就是true和false。这些是可在Ruby的任何地方存取的全局值。还有一个类NilClass。NilClass也仅有一个实例nil-表示什么也没有。然而,在布尔逻辑中,nil是false的同义词。
irb(main):001:0> true|false
=> true
irb(main):002:0> true&false
=> false
irb(main):003:0> true|nil
=> true
irb(main):004:0> true&nil
=> false |
正规表达式
大多数程序语言中都使用正规表达式。基于许多脚本语言的Ruby也广泛地使用正规表达式。我的一个同事曾经说"正规表达式太复杂了。"换句话说,你需要花费一些时间来学习正规表达式。在本文中,你仅能一瞥Ruby正规表达式的威力。在程序开发中,你不必一定使用正规表达式,但是如果使用这种工具,你的编码将更为紧凑而容易。而且,如果你想成为一名Ruby大师,你必须要花费其它时间来研究它。
在下面的例子中,Ruby中的正规表达式是在Tiger或菲Phil之间定义的。
现在你可以在一个条件或循环语句中使用带有一个匹配操作符("=~")的正规表达式来匹配或查找其它的字符串。
irb(main):001:0>
golfer="Davis"
if golfer =~ /Tiger|Phil/
puts "This is going to be a long drive."
else
puts "And now a drive by " + golfer
end
=> "Davis" |
下面是另一个稍微复杂些的正规表达式:
| /[\w._%-]+@[\w.-]+.[a-zA-Z]{2,4}/ |
你能够猜出这个表达式代表什么意思吗?它相应于一个电子邮件地址。这个正规表达式可以用来校验电子邮件地址。
irb(main):001:0>
emailRE= /[\w._%-]+@[\w.-]+.[a-zA-Z]{2,4}/
email = "jwhite@interechtraining.com"
if email =~ emailRE
puts "This is a valid email address."
else
puts "this is not a valid email address."
end
这是一个有效的电子邮件地址。
irb(main):002:0>
email = "###@spammer&&&.333"
if email =~ emailRE
puts "This is a valid email address."
else
puts "this is not a valid email address."
end |
这不是一个有效的电子邮件地址
图2把电子邮件正规表达式分解开来。你已看到,正规表达式语言是相当丰富的,但在此不多详述。有关正规表达式的更多信息请参考http://www.regular-expressions.info。

图2.电子邮件正规表达式
注意,在Ruby中正规表达式也是一种对象。在下面的代码示例中,一个正规表达式实例(派生自类Regexp)作为String方法的一个参数(gsub)以达到使用"glad"来替换和"happy"与"joy"之目的。
irb(main):001:0>
quote = "I am so happy. Happy, happy, joy, joy!"
regx = /(h|H)appy|joy/
quote.gsub(regx, "glad")
=> "I am so happy. Happy, happy, joy, joy!"
=> /(h|H)appy|joy/
=> "I am so glad. glad, glad, glad, glad!" |
当你在正规表达式对象上使用=~操作符时,你能够得到例如匹配模式串的索引等信息。
irb(main):001:0> /Tiger|Phil/=~"EyeOfTheTiger"
=> 8 |
如果你曾编写过大量有关字符串的程序,你就会知道Ruby中的正规表达式是非常有力量的。因此,我建议在较深入地用Ruby开发你的第一个程序前,你应该全面地探讨一下Ruby中的正规表达式。当然,你可以参考本文相应的源码文件,其中包含了大量的正规表达式。
范围
在Ruby中,一个很不平常但是非常有用的概念就是范围(range)。一个范围是一个值序列。例如,字符a到z就可以定义在英语字母表中的所有的小写字母。另外一个范围的例子是整数1到10。一个范围能从任何类型的对象中创建,假定对象的类型允许使用Ruby的操作符(<=>)和succ方法进行比较。根据<=>操作符左边的操作数是否小于,等于或大于<=>操作符右边的操作数,<=>操作符将分别返回-1,0或+1。例如,"A"<=>"B"将返回-1。运行于整数4上的succ方法(4.succ)将返回5。
可以使用Range类的new方法或特殊的标志来创建一个范围。下面是在irb中分别使用括号和点速记标志创建的两个相同的范围(表示所有的大写字母)。
irb(main):001:0> r1=Range.new("A","Z")
=> "A".."Z"
irb(main):002:0> r2=("A".."Z")
=> "A".."Z" |
当创建一个范围时,必须指定开始值和结束值。在上面的情况中,A作为开始值,Z作为结束值。当创建一个范围时,你还可以指示是否这个范围应该包括或不包括末尾元素。默认情况下,如上例所示,范围包括末尾元素。为了排除结束元素,你可以使用new方法的排除参数(置为true)或如下所示的3个点的速记标志。
irb(main):001:0> r1=Range.new("A","Z",true)
=> "A"..."Z"
irb(main):002:0> r2=("A"..."Z")
=> "A"..."Z"
irb(main):003:0> r1.include?"Z"
=> false
irb(main):004:0> r2.include?"Z"
=> false |
上面的示例中在范围上调用的include?方法显示是否其参数是范围的一个成员。上例中,"Z"不是范围的一个元素。这个方法还有一个与之等价的操作符"==="-它实现相同的功能。
irb(main):005:0> r2==="Z"
=≫
false |
范围被应用在Ruby编程的许多方面。它们有两种特定的使用:作为生成器(generator)和谓词(predicate)。作为一个生成器,在范围上的每个方法允许你遍历该范围中的每个元素;例如,你想确定在一个K字节范围中的实际字节数。下面在irb中运行的代码使用了一个范围作为K字节到字节的生成器。
irb(main):008:0>
kilobytes=(1..10)
kilobytes.each{|x| puts x*1024}
=> 1..10
1024
2048
3072
4096
5120
6144
7168
8192
9216
10240 |
在Ruby中,条件逻辑范围可以被用作谓语(predicate),通常借助于操作符===的帮助。例如,你可以使用一个范围谓词来测试一个相对于有效的端口号(0~65535)和保留的端口号(0~1024,不包括1024)的整数参考。
irb(main):001:0>
proposedPort = 8080
validPorts=(0..65535)
reservedPorts=(0...1024)
if (validPorts === proposedPort) & !(reservedPorts === proposedPort)
puts "Proposed port is ok to use."
else
puts "Proposed port is not allowed to be used."
end
=> 8080
=> 0..65535
=> 0...1024 |
上例的结果是,建议的端口号可以使用。
另外,范围也可以用于存取数据结构(如数组和哈希表)中的元素。
一些程序语言(如C++和CLOS)提供了多重继承机制:一个类可以继承自多个超类。例如,一个House可能继承自一个Building类(连同Office和Hospital类一起)和Residence类(连同Apartment类一起)。尽管多重继承可能成为一种语言强有力的特征,但是由于它会增加该语言的复杂性和歧义,因此许多面向对象语言都没有加入它。
Ruby支持单继承。然而,它还提供了mixin-它提供了多继承的许多特征。一个mixin是一种"模块"类型。为此,你必须首先理解在Ruby中模块的含义。
在Ruby中,模块是一种把方法和常数分组的方式。它与类相似,但是一个模块没有实例并且也没有子类。也许解释模块的最好方法是举一个例子。假定你正在开发一个制造业应用程序。该程序需要存取大量的科学公式和常数,那么你可以或者是创建一个通用类来把这些放在其中或者是创建一个模块。模块的优点在于,在存取其中的公式时,根本没有任何实例扰乱所带来的烦恼。
module Formulas
ACCELERATION = 9.8
LIGHTSPEED = 299792458
def energy (mass)
mass*(LIGHTSPEED**2)
end
def force (mass)
mass*ACCELERATION
end
end |
现在,这些公式方法和常数可以被任何数目的其它类或其自身所使用:
irb(main):046:0> Formulas.force(10)
=> 98.0
irb(main):047:0≫ Formulas::ACCELERATION
=≫ 9.8 |
注意,为了调用一个模块方法或使用一个模块常数,你必须使用类似于调用一个类方法的标志。为了调用一个模块方法,你需要使用模块类名,后面跟着一个点,再跟着模块方法名。为了引用模块常数,你可以使用模块名,后面跟着两个冒号,再跟着常数名。
除了作为方法和常数的"公共"应用以外,模块还可以帮助定义多重继承。一个mixin是一个简单的"包括"有一个类定义的模块。当一个类包括一个模块时,所有的模块中的方法和常数都成为类的实例方法和常数。例如,假定上面定义的Formula模块作为一个mixin被添加到Rectangle类。为此,你要使用"include"关键字:
class Rectangle
include Formulas
end |
现在,Rectangle的实例具有了它们可以使用的force和energy方法,并且Rectangle类能够访问常数ACCELERATION和LIGHTSPEED:
irb(main):044:0> class Rectangle
irb(main):045:1> include Formulas
irb(main):046:1> end
=> Rectangle
irb(main):047:0> Rectangle.new(4,5).force(10)
=> 98.0
irb(main):048:0> Rectangle::LIGHTSPEED
=> 299792458 |
这意味着,mixin给Ruby中的类带来了许多多重继承的优点,却避开了多重继承中存在的问题。
十一、 控制流
象所有的程序语言一样,Ruby提供了一组控制流命令,这包括条件语句(if/else结构),case语句和循环语句(do,while和for),还提供了象Ada和Java等语言中的异常处理能力。下面是Ruby中的一些控制流语句的示例:
ifarea > 100
"big"
else
"small"
end
case height
| when 1
| print "stubby\n"
| when 2..10 #高度范围为2~10
| print "short\n"
| when 10..20 #高度范围为2~10
| print "tall\n"
| end
aRect = Rectangle.new(4,6)
while aRect.area < 100 and aRect.height < 10
aRect.doubleSize()
end
for element in [2, 9.8, "some string", Math::PI] #遍历对象集合
print "The type is: " + element.type.to_s + "\n&"
end |
控制语句通常非常直接,但是如前面的case语句和for循环语句所显示的,Ruby借鉴了其它一些语言特征和普通的面向对象的特性。
异常处理类似于Java中的"try...catch...finally"语句。在Ruby中,它们更改为"begin...rescue...ensure"语句:
begin
#实现一些事情
rescue
##处理错误
ensure
#做一些清理工作,如关闭一个打开的文件等
end |
为了在你的代码中引发一个异常,你只需要简单地调用raise方法:
if area < 0
raise
else if area > 0 and area < 10
raise "Rectangle too small"
else if area > 100
raise TooBigException "Rectangle too big"
end |
第一个raise调用创建一个RuntimeError。第二个raise创建一个显示一条消息的RuntimeError。最后一个raise调用一个TooBigException的新实例(由它创建一个粗略定义的错误),并设置它的适当消息。
一个Ruby小程序
为了帮助你更好地掌握Ruby的基础知识,我在本文中提供了一个小程序供你学习之用。为了使这个程序工作,你可以下载并把该文件解压到你的文件系统。之后,它将创建一个examples文件夹,在这个目录下共有9个Ruby代码文件(.rb文件)。本文中的代码就包含在这些文件中。另外,你会找到一个testShapes.rb文件,它是测试Ruby的Rectangle,Square和Circle对象的主文件。只需简单地打开一个命令提示符并运行testShapes.rb文件即可。
你将注意到,在testShapes.rb和另外一些代码中,文件以"require"再加上一个文件名开头(象rectangle.rb)。这是在你的Ruby程序中加入或使用来自于其它文件代码的Ruby标志。
总结
Ruby能否接管Java或C#而成为业界领先的现代软件开发语言?尽管Ruby可能变得十分流行,但我对此仍抱有怀疑态度。作为一名在业界摸爬滚打多年的专业人员,我对其偶然性并不感到惊讶,但我还是比较注重实效的。例如,我发现Smalltalk是一种比Java优越的高级语言,然而优越并不会总会赢。现代语言背后总存在大量的技术和市场方面的支持。库,开发工具包,框架,架构,连接器,适配器,支持平台,服务,知识库,能干的开发团队,等等,都会被配置到位以支持象Java这样的程序语言。并且,无论你喜欢与否,Sun和Microsoft主宰下的市场在未来一段时间内肯定还是开发环境的胜者。
那么,为什么还要探讨Ruby呢?作为一种Perl或Python脚本语言的代替(这正是它的最初目的)或快速原型开发工具,Ruby可能特别有用。一些人也已经看到了Ruby的威力,并且开始把Ruby作为一种伟大的方法进行编程教学。根据我的本地Ruby用户组的成员提供的信息,有一些人正在把它应用于测试生产系统。不仅如此,我将邀请你,就象Bruce Tate和Dave Thomas邀请我一样来探讨一下这种语言的力量和美丽之处。即使Ruby不会得到广泛使用,但是随着人们对它的逐渐认识和试用,它一定会找到适应自己的编程环境。
-
· Private:只能为该对象所存取的方法。
-
· Protected:可以为该对象和类实例和直接继承的子类所存取的方法。
-
· Public:可以为任何对象所存取的方法(Public是所有方法的默认设置)。
这些关键字被插入在两个方法之间的代码中。所有从private关键字开始定义的方法都是私有的,直到代码中出现另一个存取控制关键字为止。例如,在下面的代码中,accessor和area方法默认情况下都是公共的,而grow方法是私有的。注意,在此doubleSize方法被显式指定为公共的。一个类的initialize方法自动为私有的。
class Rectangle
attr_accessor :height, :width
def initialize (hgt, wdth)
@height = hgt
@width = wdth
end
def area ()
@height*@width
end
private #开始定义私有方法
def grow (heightMultiple, widthMultiple)
@height = @height * heightMultiple
@width = @width * widthMultiple
return "New area:" + area().to_s
end
public #再次定义公共方法
def doubleSize ()
grow(2,2)
end
end |
如下所示,doubleSize可以在对象上执行,但是任何对grow的直接调用都被拒绝并且返回一个错误。
irb(main):075:0> rect2=Rectangle.new(3,4)
=> #<Rectangle:0x59a3088 @width=4, @height=3>
irb(main):076:0> rect2.doubleSize()
=> "New area: 48"
irb(main):077:0> rect2.grow()
NoMethodError: private method 'grow' called for #<Rectangle:0x59a3088 @width=8, @height=6>
from (irb):77
from :0 |
默认情况下,在Ruby中,实例和类变量都是私有的,除非提供了属性accessor和mutator。
象大多数面向对象语言一样,Ruby类也允许定义类变量和方法。一个类变量允许在一个类的所有实例间共享单个变量。在Ruby中,两个@@号用于指示类变量。例如,如果你想要使一个BankAccount类的所有实例共享相同的利息率,那么该类可能被如下定义:
class BankAccount
@@interestRate = 6.5
def BankAccount.getInterestRate()
@@interestRate
end
attr_accessor :balance
def initialize (bal)
@balance = bal
end
end |
如你所见,类变量必须在使用前初始化,并且就象实例变量一样,如果你想存取类变量的话,你需要编写存取器方法。在此,我定义了一个类方法来返回利息率。注意,类名和在getInterestRate前面的句号表示一个类方法。一个类方法,不管对于任何实例,其工作方式都是相同的-在此,是把相同的利息率返回到所有的BankAccount实例。为了调用类方法,你需要使用类名,就象它使用于类方法定义中一样:
irb(main):045:0> BankAccount.getInterestRate
=> 6.5 |
事实上,用于创建类实例的"new"方法就是一个类方法。因此,当你在程序中输入"Rectangle.new"时,你实际在调用new类方法-这是Ruby默认情况下所提供的。
继承
面向对象编程的原则之一是支持类层次结构。就象自然界中的事物分类一样,类允许从更为通用的类进行继承。面向对象编程的特征主要体现在方法和变量的使用上。例如,一个Square类继承Rectangle类的一些特征,如方法和变量。一个Square是一种更具体类型的Rectangle(高度和宽度相等的Rectangle实例),但是它仍然有一个高度和宽度,也有一个面积(而且与矩形的计算方法相同)。在Ruby中,Square类可以使用下列定义创建:
class Square < Rectangle
end |
"<Rectangle"意味着,Square是Rectangle的一个子类,或反过来说,Rectangle是Square的一个超类。默认情况下,一个Square实例自动地拥有所有一个Rectangle所拥有的相同的属性和方法,包括height,width和area方法。为了确保Square实例的边长相等,你可以重载现有的Square的initialize方法:
class Square < Rectangle
def initialize (size)
@height = size
@width = size
end
end |
因为在Ruby中一切都是对象,所以Ruby中的一切几乎都派生自Object类。尽管这在所有类定义中都不是显式的(你不会看到<Object出现在定义中),但是的确所有的类都派生自Ruby的基类Object。知道这个事实后,你就会更容易地理解接下来要讨论的内容。
当编写你的应用程序时,你可以在一个类定义外定义方法。在本文开始,你已看到了一个并不是任何一个类的一部分的摄氏到华氏转换器方法。作为另外一个示例,下面是一个位于任何类之外的方法:
def feel?
return "I feel fine."
end |
为了执行这个方法,只要输入该方法名,而不需要类或实例:
irb(main):042:0> feel?
=> "I feel fine." |
此方法看似另外一种语言(如C)中的函数或过程。事实上,尽管这些方法看上去好象不属于任何类,但是这些方法却都是你已经添加到Object类上的方法,它(因为Object是所有类的超类)反过来也把这一方法添加到你的继承类上。因此,现在你可以在任何对象(如Square和Rectangle的实例)甚至一个类(如Rectangle类)上调用这个方法。
irb(main):043:0> sq1=Square.new(4)
=> #<Square:0x5a18b50 @width=4, @height=4>
irb(main):044:0> rect1=Rectangle.new(5,7)
=> #<Rectangle:0x5a139a8 @width=7, @height=5>
irb(main):045:0> sq1.feel?
=> "I feel fine."
irb(main):046:0> rect1.feel?
=> "I feel fine."
irb(main):047:0> Rectangle.feel?
=> "I feel fine." |
变量与赋值
至此,你是否注意到前面所有的示例代码中都缺少某种东西?难道你必须输入常数,实例变量或类变量?绝对不是!这正是Ruby的真正面向对象的天性的一部分。为此,首先让我们看一下Ruby中以前的普通变量。至此,你已经创建了很多Rectangle实例,但是你并没有把它们保留多长时间。比方说,你想要把一个变量赋值给你创建的一个Rectangle实例:
| myRectangle = Rectangle.new(4,5) |
在Ruby中这是完全有效的代码,而且根本不需要另一行代码来把myRectangle类型化或声明为引用Rectangle的某种东西。在执行这一行代码以后,变量myRectangle就引用一个Rectangle的实例(高度和宽度值分别为4,5)。但是,这仅是一种在任何时刻都可以更改的对象引用,而与对象的类型无关(在Ruby中一切都是对象)。因此,下面的命令提示符行中,你可以容易地把myRectangle赋值给一个字符串:
irb(main):049:0< myRectangle=Rectangle.new(4,5)
=> #<Rectangle:0x587c758 @width=5, @height=4>
irb(main):050:0< myRectangle="Jim's Rectangle"
=> "Jim's Rectangle"
|
你可以在许多其它程序语言(甚至包括象Java这样的面向对象的语言)中试验一下,并观察从你的IDE所产生的编译错误。
变量,实例变量,类变量,甚至还有"常量"其实都只是对象引用。它们引用对象,但是它们并不是对象本身。因此,它们可以被动态地改变,甚至引用另一种不同类型的对象。
因为这一灵活性,所以必须在Ruby中进行一些约定以帮助每个人都知道某个变量正为代码所使用。其实,你已经看到了其中之一(@符号,它意味着这是一个实例变量)。其它的变量,方法和类命名约定列于下表1中。
- · 局部变量和方法参数以一个小写字母开头。
- · 方法名字以一个小写字母开头。
- · 全局变量以一个$开头。
- · 实例变量以一个@开头。
- · 类变量以两个@开头。
- · 常数以一个大写字母开头(它们经常被指定全部大写)。
- · 类和模块名以一个大写字母开头。
| 局部变量 |
全局变量 |
实例变量 |
类变量 |
常数 |
类名 |
方法名 |
| aVar |
$Var |
@var |
@@var |
VAR |
MyClassmy |
Method |
| name |
$debug |
@lastName |
@@interest |
PI |
Rectangle |
area |
表1.这个表包含了在Ruby编码约定下的相关示例。
操作符方法
现在,假定你想实现合并Rectangle类的实例或把它们添加到另一个Rectangle实例。你当然可以定义另外一个称为"add"的方法,这种选择利用了Ruby真正的面向对象的特征之一。然而,你还可以重载"+"运算符来适当地把两个Rectangle实例加起来。这个"+"方法(如4+5),对Ruby来说,只是另外一个方法而已。由于只是"另外一个方法",所以你可以给它增加一些功能来满足Rectangle类的需要。例如,你还可以定义"+"运算符来实现一个矩形面积加上另一个矩形面积。
def + (anotherRectangle)
totalArea = area() + anotherRectangle.area()
Rectangle.new(@height,totalArea/@height)
end
|
在把这个方法添加到Rectangle类以后,你可以使用+方法调用来把两个Rectangle的实例相加:
irb(main):001:0> rect1=Rectangle.new(2,3)
=> #<Rectangle:0x58aa688 @width=3, @height=2>
irb(main):002:0> rect2=Rectangle.new(3,4)
=> #<Rectangle:0x58a6ef0 @width=4, @height=3>
irb(main):003:0> rect1+rect2
=> #<Rectangle:0x58a4a60 @width=9, @height=2>
|
这正是操作符重载,对于那些使用过Agol,C++,Python和其它语言的用户来说,可能已经非常熟悉这个特征。
方法参数
至此,我们一直假定,传递给一个方法的参数个数是已知的。也许在其它语言中不可思议,但是Ruby的确允许你传递可变个数的参数并且以单个参数来捕获它们。为了创建一个可变长度的参数,只需要把一个星号(*)放在最后一个参数前面即可。这样,你就可以在Ruby中编写一个如下的多边形定义。
class Polygon
def initialize (s1,s2,s3,*others)
@sideOne = s1
@sideTwo = s2
@sideThree = s3
@otherSides = others
end
end |
如下所示,你可以使用这个定义来创建一个三角形或一个六边形。
irb(main):009:0> poly1=Polygon.new(2,4,5)
=> #<Polygon:0x594db10 @otherSides=[], @sideThree=5, @sideTwo=4, @sideOne=2>
irb(main):010:0> poly2=Polygon.new(2,18,4,5,7,9)
=> #<Polygon:0x5948d58 @otherSides=[5, 7, 9], @sideThree=4, @sideTwo=18, @sideOne=2>
|
在支持可变长度参数的同时,Ruby还允许定义一个方法参数的默认值(在调用者没有提供的情况下使用)。例如,下面是Rectangle类的一个更好的初始化表达。
def initialize (hgt = 1, wdth = 1)
@height = hgt
@width = wdth
end
|
现在,在调用时如果省略了某参数,那么在定义中参数紧邻的赋值运算符担当一个缺省的赋值器。现在,当创建一新的矩形时,如果在调用时省略了宽度,那么一个适当的宽度也会被默认地提供:
irb(main):090:0> rect=Rectangle.new(2)
=> #<Rectangle:0x5873f68 @width=1, @height=2>
|
在Ruby中,一切都是对象。对于那些喜欢使用高度面向对象的语言(例如Smalltalk,Eiffel或CLOS)的用户来说,这是非常受欢迎的。例如1,2,3或10.8等等都是对象,而不是如Java或C++中的原始类型;字符串是对象,类和方法也都是对象。例如,下面都是有效的Ruby代码(在Ruby中,注释行是以"#"符号界定的):
#对象-34的绝对值
-34.abs
#对一个浮点数进行四舍五入处理
10.8.round
#返回一个字符串对象的大写且逆转的副本
"This is Ruby".upcase.reverse
#返回数学sin方法的参数个数
Math.method(:sin).arity
|

图5.Ruby是全对象化的:在Ruby中,整数,浮点数,字符串,甚至类和方法都是对象。这里的代码展示了针对这些类型对象的方法调用。
在Ruby中,所有功能都是通过调用对象上的方法(或操作)实现的。事实上,Ruby中的方法调用就象其它程序语言中的函数或过程调用一样。
就象在所有面向对象程序语言中一样,对象是从类中创建的。Ruby库中提供了许多预构建的类。你可以修改这些类或构建你自己的类。Ruby中的类是使用"class"关键字定义的。类名开始是一个大写字母。类定义以"end"关键字结束。因此,一个Rectangle类的定义可能有如下形式:
为了把方法添加到类,可以使用def关键字。方法的定义也应该以end关键字结束。跟随def关键字和方法名后面就是方法参数。把一个area方法添加到上面的Rectangle类的代码看上去如下所示:
class Rectangle
def area (hgt,wdth)
return hgt*wdth
end
end |
对于那些熟悉其它程序语言的用户,他可能注意到一些差别。Ruby并不使用任何花括号来限定类或方法,也不使用分号或其它字符来表示程序语句行的结束。Ruby的目标,根据它的创建者说明,是简单、易用并使编码成为一件"趣事"。谁想记住所有的那些分号?没有意思!在Ruby中,只要你把语句放在一行上,不需要分号或其它代码行结束标记。顺便说一下,在area方法参数周围的括号是不必要的。在默认情况下,Ruby返回一个方法中最后的内容,因此return关键字也可以省略。因此,你可以建立如下简单编码的Rectangle类:
class Rectangle
def area hgt, wdth
hgt*wdth
end
end |
尽管上面代码是有效的,但是小括号还是被推荐使用于方法参数表达的,这主要是为了实现较好的可读性。
实例变量和属性
类也可以有实例变量(在一些语言中也称为属性)。例如,由Rectangle类创建的对象应该都有一个高度和宽度。在Ruby中,实例变量不必显式地在类中声明,只是必须在它们的命名中以一个特殊字符来标记和使用。具体地说,所有的实例变量名都以"@"开头。为了实现当调用area方法时,存储矩形实例的高度和宽度,你仅需把实例变量添加到area方法即可:
class Rectangle
def area (hgt, wdth)
@height=hgt
@width = wdth
@height*@width
end
end |
更确切地说,当创建一个Rectangle实例时,应该指定高度和宽度,而实例变量在此时才确定。另外,Ruby提供了一种特殊的方法initialize,它允许你建立或准备类的新实例:
class Rectangle
def initialize (hgt, wdth)
@height = hgt
@width = wdth
end
def area ()
@height*@width
end
end |
为了创建一个新的Rectangle对象或实例,你要调用标准的Ruby类构造器方法"new":
或,你可以使用没有括号的形式:
这个例子创建了一个新的Rectangle对象并且调用了initialize方法,其中传入参数4和7。注意,在下面的代码中添加了height和width方法以便共享高度和宽度信息:
class Rectangle
def initialize (hgt, wdth)
@height = hgt
@width = wdth
end
def height
return @height
end
def width
return @width
end
def area ()
@height*@width
end
end |
同样,为了使另外某个方法能够更新或设置一个Rectangle对象的高度和宽度,需要定义其它一些设置方法:
class Rectangle
def initialize (hgt, wdth)
@height = hgt
@width = wdth
end
def height
return @height
end
def height=(newHgt)
@height=newHgt
end
def width
return @width
end
def width=(newWdth)
@width=newWdth
end
def area ()
@height*@width
end
end |
译者注 本文中的mutator和accessor相当于其它语言中的setter和getter。
上面的mutator方法("height="和"width=")可能看起来有点神秘,但是它们确实只是一些方法。不要让命名中的等号蒙骗了你。在方法名最后的额外字符对于Ruby并不意味着什么,但是它提高了代码的可读性。请看下列代码:
在此,一个Rectangle对象的高度正被赋值(改变)。事实上,这仅是一个对Rectangle对象的"height="方法的调用。
因为授予到一个对象的实例变量的存取权限非常普通,所以Ruby提供了一组关键字来实现一次性定义实例变量和accessor/mutator方法,从而使这些实例变量成为"public"属性。这些关键字是attr_reader,attr_accessor。它们有助于极大地简化代码:
class Rectangle
attr_accessor :height, :width
def initialize (hgt, wdth)
@height = hgt
@width = wdth
end
def area ()
@height*@width
end
end |
在上面的示例代码中,attr_accessor给出了Rectangle相应于height和width属性的getter和setter。
用交互式Ruby构建应用程序 现在,你已经知道如何构建一个简单的Ruby应用程序。为了展示Ruby解释器的交互性,让我们启动一个交互的Ruby帮助和控制台工具(使用Ruby安装的fxri工具),见图6。

图6.启动fxri:从Windows开始菜单中打开交互式Ruby工具fxri。
在窗口的右下方是一个交互式的Ruby命令提示符(即"irb(main):001:0>"),它在窗口打开时显示出来。你可以进入到irb命令提示符行中并输入"Rectangle.new(6,5).area()"。之后,你应该看到如下结果:
irb(main):013:0> Rectangle.new(6,5).area()
=> 30 |
简洁有力!
在Ruby中,类从来不关闭。这意味着,你总是可以在一个现有类上添加或重定义方法。例如,你还可以在你创建的Rectangle类上添加一个circumference方法。在命令提示符上,请逐行输入下列代码:
class Rectangle
def circumference ()
@height * 2 + @width * 2
end
end |

图7.输入Rectangle类:把Rectangle类的定义输入到fxri交互式Ruby解释器中,见图中的右下方。
Rectangle类又被定义了一次?不,Ruby解释器知道你正在修改当前的Rectangle类,它把一个新方法添加到现有Rectangle类中。现在,在命令提示符上输入下列一行:"Rectangle.new(2,3).circumference()"。你应该看到类似如下的结果:
irb(main):014:0> class Rectangle
irb(main):015:1> def circumference()
irb(main):016:2> @height * 2 + @width * 2
irb(main):017:2> end
irb(main):018:1> end
=> nil
irb(main):019:0> Rectangle.new(2,3).circumference
=> 10 |
为了重新定义Rectangle类中的任何方法,例如area方法,只需简单地重新输入具有新的area方法定义的类定义即可:
irb(main):020:0> class Rectangle
irb(main):021:1> def area()
irb(main):022:2> @height*2
irb(main):023:2> end
irb(main):024:1> end
=> nil
irb(main):025:0> Rectangle.new(6,5).area
=> 12 |
在上面的简单例子中,area方法被重新定义以便总是返回原来高度的2倍。
一个类永远不会被关闭的思想可以应用于你自己定义的类和该语言中的内嵌类中。为了说明问题,让我们把一个area方法添加到String类。在命令提示符中输入下列代码:
class String
def area()
length()
end
end |
现在,你在定义一个字符串的"area"方法以返回该字符串的长度。现在,你可以把你的名字作为一个字符串来试用一下这个新方法,见下面代码:
irb(main):026:0> class String
irb(main):027:1> def area()
irb(main):028:2> length()
irb(main):029:2> end
irb(main):030:1> end
=> nil
irb(main):031:0> "Jim".area
=> 3 |
在本文示例中,我们使用Ruby的交互式特性及其开发环境来测试这种语言,而且我们仅使用了较小的代码片断。
Ruby是一种面向对象的元编程语言,是它让许多开发者感到惊讶,甚至令他们提出这样的疑问:是否真正存在比Java和C#更好的语言?本文将对Ruby语言作初步的探讨并试图回答这一问题。
一、 引言
你是否听说过Ruby?如今,它成了软件开发界的一个流行话题。该语言在去年春天的一次Java会议上引起我的注意,当时象Bruce Tate,Dave Thomas等著名人物都在谈论Ruby并且告诉在场的观众Ruby值得一看。
现在,如果你象我一样正在从事软件开发,那么我们就有共识:尽管学习一种新的编程语言可能是一件趣事,但是只有你对它具有深入了解之后,你才有资格以一种怀疑眼光来看待另一种编程语言。毕竟,在上世纪八、九十年代的编程语言之争最终得出结论-从根本上看存在两大阵营:Java世界和微软基于.NET支持的开发语言。并不是我不想学习另一种语言,其实我只是期望通过选择其它编程语言才能获得一定技术优势的日子早点结束。然而,由于前面几位著名人士的影响,我决定一试Ruby。
好,假定"我已经到过山顶",那么本文就是我对Ruby的研究报告。
二、 安装Ruby
Ruby是一种开源的编程语言,由日本的Yukihiro Matsumoto在九十年代中期开发。你可以在www.ruby-lang.org站点得到Ruby。这种语言最初被作为一种脚本语言创建,可应用于许多平台上,包括Linux、各种类UNIX、MS-DOS、Windows、BeOS、Amiga、Acorn Risc OS和MacOS X。当前Ruby的最新版本是1.8.4。对于使用Windows平台的用户,你可以点按这里来得到一个"one-click"型Windows安装程序。随同基本的Ruby二进制文件和库文件,这一下载中还包含一些有用的(并且是免费的)IDE和工具,包括帮助文档和示例代码,RubyGems包管理器,FreeRIDE(免费的Ruby IDE),Fox GUI库,fxri(一种搜索引擎和Ruby文档的GUI指南,还有一个交互式命令行工具)和SciTE(Scintilla文本编辑器IDE)。在写本文时,Windows安装程序所提供的Ruby的"稳定"版本是1.8.2,还有一个1.8.4版本的预览版。注意,本文中的示例代码是用Windows安装程序所提供的1.8.2版本编写的。
使用Windows安装程序安装Ruby是相当直接的事情。你只要下载并运行一个简单的可执行安装文件(ruby182-15.exe),这个程序就会启动一个标准的安装向导。下载文件大约有15MB,在向导把Ruby安装到Windows平台上后占大约40MB的硬盘空间。
对于那些偏爱自己的编辑器的程序员,大量的编辑器都提供了对Ruby的支持,包括emacs,vim,JEdit,Jed,Nedit和Textpad。当然,还有著名的Ruby Eclipse工程。Ruby开发工具(RDT)是一种Eclipse插件,当前仍处于早期开发中,但是你可以从此处下载试用它。另外,市场上还有一些便宜的Ruby IDE,Arachno Ruby就是其中之一。
运行Ruby
就象许多解释性语言一样,Ruby提供给程序员多种开发代码的方法。你可以使用命令行工具以交互方式运行Ruby或者创建一个Ruby程序文件,然后要求Ruby的解释器执行此程序。
在Windows中,打开命令行提示符窗口,在提示符上输入"Ruby"并回车(注意:你应该能够使系统沿Ruby的\bin目录找到Ruby可执行文件)。那么,Ruby就会运行并等候你输入程序。输入下面的程序,然后按Ctrl+D再按回车键,你就会看到Ruby执行你的程序,如图1所示。
def convertCtoF (celsius)
print(celsius.to_s + " degrees celsius is " +
((celsius * 9)/5 + 32).to_s + " degrees in
fahrenheit\n")
end
convertCtoF(20) |

图1.在Ruby中以交互方式运行摄氏到华氏温度转换计算
图1中的转换程序也可以用一种Ruby IDE或简单文本编辑器实现并保存到一个文件中-例如convertCtoF.rb(.rb是Ruby程序的常用文件类型)。现在,Ruby解释器将执行这个文件中的Ruby程序,见图2。

图2.运行convertCtoF.rb
那些熟悉Smalltalk,Common Lisp Object System(CLOS),或其它解释性编程环境的用户肯定都会熟悉交互的开发环境。交互特点允许你用小块编程代码进行试验。通过使用一个特殊的Ruby批处理文件irb.bat,你就能够克服Ruby解释器的非交互性特征。图3显示了使用irb.bat命令启动的Ruby。现在,代码可以被逐行地输入,解释和测试。

图3.交互式Ruby
交互式Ruby特征也被嵌入到若干工具中。例如,Ruby文档的图形接口fxri,不仅可作为一种语言指南,而且可以用作一种交互式Ruby解释器(见图4)。

图4.fxri的交互式Ruby能力:在此,fxri也用来运行和图3相同的Ruby命令,但这是从文档工具内部运行的。
摘要: 1
J2EE
多层应用分析
1.1
J2EE
层次结构
J2EE
的三层结构在业界是指表示...
阅读全文
你正在学习CSS布局吗?是不是还不能完全掌握纯CSS布局?通常有两种情况阻碍你的学习:
第一种可能是你还没有理解CSS处理页面的原理。在你考虑你的页面整体表现效果前,你应当先考虑内容的语义和结构,然后再针对语义、结构添加CSS。这篇文章将告诉你应该怎样把HTML结构化。
另一种原因是你对那些非常熟悉的表现层属性(例如:cellpadding,、hspace、align="left"等等)束手无策,不知道该转换成对 应的什么CSS语句。 当你解决了第一种问题,知道了如何结构化你的HTML,我再给出一个列表,详细列出原来的表现属性用什么CSS来代替。
结构化HTML
我们在刚学习网页制作时,总是先考虑怎么设计,考虑那些图片、字体、颜色、以及布局方案。然后我们用Photoshop或者Fireworks画出来、切割成小图。最后再通过编辑HTML将所有设计还原表现在页面上。
如果你希望你的HTML页面用CSS布局(是CSS-friendly的),你需要回头重来,先不考虑“外观”,要先思考你的页面内容的语义和结构。
外观并不是最重要的。一个结构良好的HTML页面可以以任何外观表现出来,CSS Zen Garden是一个典型的例子。CSS Zen Garden帮助我们最终认识到CSS的强大力量。
HTML不仅仅只在电脑屏幕上阅读。你用photoshop精心设计的画面可能不能显示在PDA、移动电话和屏幕阅读机上。但是一个结构良好的HTML页面可以通过CSS的不同定义,显示在任何地方,任何网络设备上。
开始思考
首先要学习什么是"结构",一些作家也称之为"语义"。这个术语的意思是你需要分析你的内容块,以及每块内容服务的目的,然后再根据这些内容目的建立起相应的HTML结构。
如果你坐下来仔细分析和规划你的页面结构,你可能得到类似这样的几块:
标志和站点名称
主页面内容
站点导航(主菜单)
子菜单
搜索框
功能区(例如购物车、收银台)
页脚(版权和有关法律声明)
我们通常采用DIV元素来将这些结构定义出来,类似这样:
<div id="header"></div>
<div id="content"></div>
<div id="globalnav"></div>
<div id="subnav"></div>
<div id="search"></div>
<div id="shop"></div>
<div id="footer"></div>
这不是布局,是结构。这是一个对内容块的语义说明。当你理解了你的结构,就可以加对应的ID在DIV上。DIV容器中可以包含任何内容块,也可以嵌套另一个DIV。内容块可以包含任意的HTML元素---标题、段落、图片、表格、列表等等。
根据上面讲述的,你已经知道如何结构化HTML,现在你可以进行布局和样式定义了。每一个内容块都可以放在页面上任何地方,再指定这个块的颜色、字体、边框、背景以及对齐属性等等。
使用选择器是件美妙的事
id的名称是控制某一内容块的手段,通过给这个内容块套上DIV并加上唯一的id,你就可以用CSS选择器来精确定义每一个页面元素的外观表现,包括标 题、列表、图片、链接或者段落等等。例如你为#header写一个CSS规则,就可以完全不同于#content里的图片规则。
另外一个例子是:你可以通过不同规则来定义不同内容块里的链接样式。类似这样:#globalnav a:link或者 #subnav a:link或者#content a:link。你也可以定义不同内容块中相同元素的样式不一样。例如,通过#content p和#footer p分别定义#content和#footer中p的样式。从结构上讲,你的页面是由图片、链接、列表、段落等组成的,这些元素本身并不会对显示在什么网络 设备中(PDA还是手机或者网络电视)有影响,它们可以被定义为任何的表现外观。
一个仔细结构化的HTML页面非常简单,每一个元素都被用于结构目的。当你想缩进一个段落,不需要使用blockquote标签,只要使用p标签,并对p 加一个CSS的margin规则就可以实现缩进目的。p是结构化标签,margin是表现属性,前者属于HTML,后者属于CSS。(这就是结构于表现的 相分离.)
良好结构的HTML页面内几乎没有表现属性的标签。代码非常干净简洁。例如,原先的代码<table width="80%" cellpadding="3" border="2" align="left">,现在可以只在HTML中写<table>,所有控制表现的东西都写到CSS中去,在结构化的HTML中, table就是表格,而不是其他什么(比如被用来布局和定位)。
亲自实践一下结构化
上面说的只是最基本的结构,实际应用中,你可以根据需要来调整内容块。常常会出现DIV嵌套的情况,你会看到"container"层中又有其它层,结构类似这样:
<div id="navcontainer">
<div id="globalnav">
<ul>a list</ul>
</div>
<div id="subnav">
<ul>another list</ul>
</div>
</div>
嵌套的div元素允许你定义更多的CSS规则来控制表现,例如:你可以给#navcontainer一个规则让列表居右,再给#globalnav一个规则让列表居左,而给#subnav的list另一个完全不同的表现。
用CSS替换传统方法
下面的列表将帮助你用CSS替换传统方法:
HTML属性以及相对应的CSS方法
HTML属性
CSS方法说明
align="left"
align="right" float: left;
float: right; 使用CSS可以浮动 任何元素:图片、段落、div、标题、表格、列表等等
当你使用float属性,必须给这个浮动元素定义一个宽度。
marginwidth="0" leftmargin="0" marginheight="0" topmargin="0" margin: 0; 使用CSS, margin可以设置在任何元素上, 不仅仅是body元素.更重要的,你可以分别指定元素的top, right, bottom和left的margin值。
vlink="#333399" alink="#000000" link="#3333FF" a:link #3ff;
a:visited: #339;
a:hover: #999;
a:active: #00f;
在HTML中,链接的颜色作为body的一个属性值定义。整个页面的链接风格都一样。使用CSS的选择器,页面不同部分的链接样式可以不一样。
bgcolor="#FFFFFF" background-color: #fff; 在CSS中,任何元素都可以定义背景颜色,不仅仅局限于body和table元素。
bordercolor="#FFFFFF" border-color: #fff; 任何元素都可以设置边框(boeder),你可以分别定义top, right, bottom和left
border="3"cellspacing="3" border-width: 3px; 用CSS,你可以定义table的边框为统一样式,也可以分别定义top, right, bottom and left边框的颜色、尺寸和样式。
你可以使用 table, td or th 这些选择器.
如果你需要设置无边框效果,可以使用CSS定义: border-collapse: collapse;
<br clear="left">
<br clear="right">
<br clear="all">
clear: left;
clear: right;
clear: both;
许多2列或者3列布局都使用 float属性来定位。如果你在浮动层中定义了背景颜色或者背景图片,你可以使用clear属性.
cellpadding="3"
vspace="3"
hspace="3" padding: 3px; 用CSS,任何元素都可以设定padding属性,同样,padding可以分别设置top, right, bottom and left。padding是透明的。
align="center" text-align: center;
margin-right: auto; margin-left: auto;
Text-align 只适用于文本.
象div,p这样的块级可以通过margin-right: auto; 和margin-left: auto;来水平居中
一些令人遗憾的技巧和工作环境
由于浏览器对CSS支持的不完善,我们有时候不得不采取一些技巧(hacks)或建立一种环境(Workarounds)来让CSS实现传统方法同样的效 果。例如块级元素有时侯需要使用水平居中的技巧,盒模型bug的技巧等等。所有这些技巧都在Molly Holzschlag的文章《Integrated Web Design: Strategies for Long-Term CSS Hack Management》中有详细说明
Spring MVC 框架。用银行示例介绍如何建模和构建简单的应用程序。示例应用程序包含了已经学过的一些技术(例如依赖注入),但是主要演示 Spring MVC 的特性。
在开始之前,请 下载这篇文章的源代码。请参阅 参考资料 访问 Spring 框架和 Tom
cat 5.0,运行示例需要它们。
Spring MVC 框架
Spring 框架提供了构建 Web 应用程序的全功能 MVC 模块。使用 Spring 可插入的 MVC 架构,可以选择是使用内置的 Spring Web 框架还是 Struts 这样的 Web 框架。通过策略接口,Spring 框架是高度可配置的,而且包含多种视图技术,例如 JavaServer Pages(JSP)技术、Velocity、Tiles、iText 和 POI。Spring MVC 框架并不知道使用的视图,所以不会强迫您只使用 JSP 技术。Spring MVC 分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行定制。
Spring 的 Web MVC 框架是围绕 DispatcherServlet 设计的,它把请求分派给处理程序,同时带有可配置的处理程序映射、视图解析、本地语言、主题解析以及上载文件支持。默认的处理程序是非常简单的 Controller 接口,只有一个方法 ModelAndView handleRequest(request, response)。Spring 提供了一个控制器层次结构,可以派生子类。如果应用程序需要处理用户输入表单,那么可以继承 AbstractFormController。如果需要把多页输入处理到一个表单,那么可以继承 AbstractWizardFormController。
示例应用程序有助于直观地学习这些特性。银行应用程序允许用户检索他们的帐户信息。在构建银行应用程序的过程中,可以学到如何配置 Spring MVC 框架和实现框架的视图层,视图层包括 JSTL 标记(用于显示输出的数据)和JavaServer Pages 技术。
配置 Spring MVC
要开始构建示例应用程序,请配置 Spring MVC 的 DispatcherServlet。请在 web.xml 文件中注册所有配置。清单 1 显示了如何配置 sampleBankingServlet。
清单 1. 配置 Spring MVC DispatcherServlet
<servlet>
<servlet-name>sampleBankingServlet</servlet-name>
<servlet-class>
org.springframework.we.servlet.DispatcherServlet
<servlet-class>
<load-on-startup>1<load-on-startup>
<servlet>
DispatcherServlet 从一个 XML 文件装入 Spring 应用程序上下文,XML 文件的名称是 servlet 的名称后面加上 -servlet 。在这个示例中,DispatcherServlet 会从 sampleBankingServlet-servlet.xml 文件装入应用程序上下文。
配置应用程序的 URL
下一步是配置想让 sampleBankingServlet 处理的 URL。同样,还是要在 web.xml 中注册所有这些信息。
清单 2. 配置想要处理的 URL
<servlet-mapping>
<servlet-name> sampleBankingServlet<servlet-name>
<url-pattern>*.jsp</url-pattern>
</servlet-mapping>
装入配置文件
下面,装入配置文件。为了做到这点,请为 Servlet 2.3 规范注册 ContextLoaderListener 或为 Servlet 2.2 及以下的容器注册 ContextLoaderServlet。为了保障后向兼容性,请用 ContextLoaderServlet。在启动 Web 应用程序时,ContextLoaderServlet 会装入 Spring 配置文件。清单 3 注册了 ContextLoaderServlet。
清单 3. 注册 ContextLoaderServlet
<servlet>
<servlet-name>context>servlet-name>
<servlet-class>
org.springframework.web.context.ContextLoaderServlet
</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
contextConfigLocation 参数定义了要装入的 Spring 配置文件,如下面的 servlet 上下文所示。
<context-param>
<param-value>contextConfigLocation</param-value>
<param-value>/WEB-INF/sampleBanking-services.xml</param-value>
</context-param>
sampleBanking-services.xml 文件代表示例银行应用程序服务的配置和 bean 配置。如果想装入多个配置文件,可以在 <param-value> 标记中用逗号作分隔符。
Spring MVC 示例
示例银行应用程序允许用户根据惟一的 ID 和口令查看帐户信息。虽然 Spring MVC 提供了其他选项,但是我将采用 JSP 技术作为视图页面。这个简单的应用程序包含一个视图页用于用户输入(ID 和口令),另一页显示用户的帐户信息。
我从 LoginBankController 开始,它扩展了 Spring MVC 的 SimpleFormController。SimpleFormContoller 提供了显示从 HTTP GET 请求接收到的表单的功能,以及处理从 HTTP POST 接收到的相同表单数据的功能。LoginBankController 用 AuthenticationService 和 AccountServices 服务进行验证,并执行帐户活动。“ 配置视图属性 ”一节中的 清单 5 描述了如何把 AuthenticationService 和 AccountServices 连接到 LoginBankController。 清单 4 显示了 LoginBankController 的代码。
配置视图属性
下面,我必须注册在接收到 HTTP GET 请求时显示的页面。我在 Spring 配置中用 formView 属性注册这个页面,如清单 5 所示。sucessView 属性代表表单数据提交而且 doSubmitAction() 方法中的逻辑成功执行之后显示的页面。formView 和 sucessView 属性都代表被定义的视图的逻辑名称,逻辑名称映射到实际的视图页面。
清单 5. 注册 LoginBankController
<bean id="loginBankController"
class="springexample.controller.LoginBankController">
<property name="sessionForm"><value>true</value></property>
<property name="commandName"><value>loginCommand</value></property>
<property name="commandClass">
<value>springexample.commands.LoginCommand</value>
</property>
<property name="authenticationService">
<ref bean="authenticationService" />
</property>
<property name="accountServices">
<ref bean="accountServices" />
</property>
<property name="formView">
<value>login</value>
</property>
<property name="successView">
<value>accountdetail</value>
</property>
</bean>
commandClass 和 commandName 标记决定将在视图页面中活动的 bean。例如,可以通过 login.jsp 页面访问 loginCommand bean,这个页面是应用程序的登录页面。一旦用户提交了登录页面,应用程序就可以从 LoginBankController 的 onSubmit() 方法中的命令对象检索出表单数据。
视图解析器
Spring MVC 的 视图解析器 把每个逻辑名称解析成实际的资源,即包含帐户信息的 JSP 文件。我用的是 Spring 的 InternalResourceViewResolver,如 清单 6 所示。
因为我在 JSP 页面中使用了 JSTL 标记,所以用户的登录名称解析成资源 /jsp/login.jsp,而 viewClass 成为 JstlView。
验证和帐户服务
就像前面提到的,LoginBankController 内部连接了 Spring 的 AccountServices 和 AuthenticationService。AuthenticationService 类处理银行应用程序的验证。AccountServices 类处理典型的银行服务,例如查找交易和电汇。清单 7 显示了银行应用程序的验证和帐户服务的配置。
清单 7. 配置验证和帐户服务
<beans>
<bean id="accountServices"
class="springexample.services.AccountServices">
</bean>
<bean id="authenticationService"
class="springexample.services.AuthenticationService">
</bean>
</beans>
以上服务在 sampleBanking-services.xml 中注册,然后装入 web.xml 文件中,就像 前面讨论的那样。控制器和服务配置好后,这个简单的应用程序就完成了。现在我们来看看部署和测试它时会发生什么!
部署应用程序
我把示例应用程序部署在 Tomcat servlet 容器中。Tomcat 是 Java Servlet 和 Java ServerPagest 技术的官方参考实现中使用的 servlet 容器。如果以前没这么做过,请 下载 jakarta-tomcat-5.0.28.exe 并运行它把 Tomcat 安装到自己喜欢的任何位置,例如 c:\tomcat5.0。
接下来,下载示例代码 并释放到驱动器(例如 c:\ )上。创建了 Spring 项目的文件夹之后,打开它并把 spring-banking 子文件夹拷贝到 c:\tomvat5.0\webapps。spring-banking 文件夹是一个 Web 档案,里面包含 Spring MVC 示例应用程序。lib 文件夹包含应用程序需要的 Spring 框架、与Spring 相关的 MVC 库以及 JSTL 标记库和 jar 文件。
要启动 Tomcat 服务器,请使用以下命令:
cd bin C:\Tomcat 5.0\bin> catalina.bat start
Tomcat 应当启动并部署 Spring MVC 示例应用程序。
测试应用程序
要测试应用程序,请打开 Web 浏览器,指向
http://localhost:tomcatport/springbanking 并用 Tomcat 服务器实际运行的端口替换 tomcatport。应当看到图 1 所示的登录屏幕。输入用户 ID “admin”和口令“password”,并按下登录按钮。其他用户 ID 或口令会造成来自验证服务的错误。
图 1. Spring MVC 示例登录屏幕

登录成功之后,会看到图 2 所示的帐户细节页面。
图 2. Spring MVC 示例帐户细节页面
结束语
在三部分的 Spring 系列 的第三篇文章中,我介绍了 Spring MVC 框架的特性。我演示了如何配置和开发 Spring MVC 应用程序、如何配置 Spring MVC 控制器和向其中插入依赖项、如何用 JavaServer Pages 技术开发应用程序视图,以及如何把自己的页面与 Spring MVC 的视图层集成。总结这篇文章时,我演示了如何在 Tomcat servlet 容器中部署应用程序以及如何在浏览器中测试它。
引言
数据库的设计范式是
数据库设计所需要满足的规范,满足这些规范的
数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给
数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
设计范式是不是很难懂呢?非也,大学教材上给我们一堆数学公式我们当然看不懂,也记不住。所以我们很多人就根本不按照范式来设计
数据库。
实质上,设计范式用很形象、很简洁的话语就能说清楚,道明白。本文将对范式进行通俗地说明,并以笔者曾经设计的一个简单论坛的
数据库为例来讲解怎样将这些范式应用于实际工程。
范式说明 第一范式(1NF):
数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
例如,如下的
数据库表是符合第一范式的:
而这样的
数据库表是不符合第一范式的:
| 字段1 | 字段2 | 字段3 | 字段4 |
| | | 字段3.1 | 字段3.2 | |
很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
第二范式(2NF):数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。假定选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),关键字为组合关键字(学号, 课程名称),因为存在如下决定关系:
(学号, 课程名称) → (姓名, 年龄, 成绩, 学分)
这个数据库表不满足第二范式,因为存在如下决定关系:
(课程名称) → (学分)
(学号) → (姓名, 年龄)
即存在组合关键字中的字段决定非关键字的情况。
由于不符合2NF,这个选课关系表会存在如下问题:
(1) 数据冗余:
同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。
(2) 更新异常:
若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
(3) 插入异常:
假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据库。
(4) 删除异常:
假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
把选课关系表SelectCourse改为如下三个表:
学生:Student(学号, 姓名, 年龄);
课程:Course(课程名称, 学分);
选课关系:SelectCourse(学号, 课程名称, 成绩)。
这样的数据库表是符合第二范式的,消除了数据冗余、更新异常、插入异常和删除异常。
另外,所有单关键字的数据库表都符合第二范式,因为不可能存在组合关键字。
第三范式(3NF):在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系:
关键字段 → 非关键字段x → 非关键字段y
假定学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号) → (姓名, 年龄, 所在学院, 学院地点, 学院电话)
这个数据库是符合2NF的,但是不符合3NF,因为存在如下决定关系:
(学号) → (所在学院) → (学院地点, 学院电话)
即存在非关键字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况,读者可自行分析得知。
把学生关系表分为如下两个表:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 地点, 电话)。
这样的数据库表是符合第三范式的,消除了数据冗余、更新异常、插入异常和删除异常。
鲍依斯-科得范式(BCNF):在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合第三范式。
假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。它会出现如下异常情况:
(1) 删除异常:
当仓库被清空后,所有"存储物品ID"和"数量"信息被删除的同时,"仓库ID"和"管理员ID"信息也被删除了。
(2) 插入异常:
当仓库没有存储任何物品时,无法给仓库分配管理员。
(3) 更新异常:
如果仓库换了管理员,则表中所有行的管理员ID都要修改。
把仓库管理关系表分解为二个关系表:
仓库管理:StorehouseManage(仓库ID, 管理员ID);
仓库:Storehouse(仓库ID, 存储物品ID, 数量)。
这样的数据库表是符合BCNF范式的,消除了删除异常、插入异常和更新异常。
范式应用
我们来逐步搞定一个论坛的数据库,有如下信息:
(1) 用户:用户名,email,主页,电话,联系地址
(2) 帖子:发帖标题,发帖内容,回复标题,回复内容
第一次我们将数据库设计为仅仅存在表:
| 用户名 | email | 主页 | 电话 | 联系地址 | 发帖标题 | 发帖内容 | 回复标题 | 回复内容 |
这个数据库表符合第一范式,但是没有任何一组候选关键字能决定数据库表的整行,唯一的关键字段用户名也不能完全决定整个元组。我们需要增加"发帖ID"、"回复ID"字段,即将表修改为:
| 用户名 | email | 主页 | 电话 | 联系地址 | 发帖ID | 发帖标题 | 发帖内容 | 回复ID | 回复标题 | 回复内容 |
这样数据表中的关键字(用户名,发帖ID,回复ID)能决定整行:
(用户名,发帖ID,回复ID) → (email,主页,电话,联系地址,发帖标题,发帖内容,回复标题,回复内容)
但是,这样的设计不符合第二范式,因为存在如下决定关系:
(用户名) → (email,主页,电话,联系地址)
(发帖ID) → (发帖标题,发帖内容)
(回复ID) → (回复标题,回复内容)
即非关键字段部分函数依赖于候选关键字段,很明显,这个设计会导致大量的数据冗余和操作异常。
我们将数据库表分解为(带下划线的为关键字):
(1) 用户信息:用户名,email,主页,电话,联系地址
(2) 帖子信息:发帖ID,标题,内容
(3) 回复信息:回复ID,标题,内容
(4) 发贴:用户名,发帖ID
(5) 回复:发帖ID,回复ID
这样的设计是满足第1、2、3范式和BCNF范式要求的,但是这样的设计是不是最好的呢?
不一定。
观察可知,第4项"发帖"中的"用户名"和"发帖ID"之间是1:N的关系,因此我们可以把"发帖"合并到第2项的"帖子信息"中;第5项"回复"中的 "发帖ID"和"回复ID"之间也是1:N的关系,因此我们可以把"回复"合并到第3项的"回复信息"中。这样可以一定量地减少数据冗余,新的设计为:
(1) 用户信息:用户名,email,主页,电话,联系地址
(2) 帖子信息:用户名,发帖ID,标题,内容
(3) 回复信息:发帖ID,回复ID,标题,内容
数据库表1显然满足所有范式的要求;
数据库表2中存在非关键字段"标题"、"内容"对关键字段"发帖ID"的部分函数依赖,即不满足第二范式的要求,但是这一设计并不会导致数据冗余和操作异常;
数据库表3中也存在非关键字段"标题"、"内容"对关键字段"回复ID"的部分函数依赖,也不满足第二范式的要求,但是与数据库表2相似,这一设计也不会导致数据冗余和操作异常。
由此可以看出,并不一定要强行满足范式的要求,对于1:N关系,当1的一边合并到N的那边后,N的那边就不再满足第二范式了,但是这种设计反而比较好!
对于M:N的关系,不能将M一边或N一边合并到另一边去,这样会导致不符合范式要求,同时导致操作异常和数据冗余。
对于1:1的关系,我们可以将左边的1或者右边的1合并到另一边去,设计导致不符合范式要求,但是并不会导致操作异常和数据冗余。
结论
满足范式要求的数据库设计是结构清晰的,同时可避免数据冗余和操作异常。这并意味着不符合范式要求的设计一定是错误的,在数据库表中存在1:1或1:N关系这种较特殊的情况下,合并导致的不符合范式要求反而是合理的。
在我们设计数据库的时候,一定要时刻考虑范式的要求。
一、数据库设计过程
数据库技术是信息资源管理最有效的手段。数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,有效存储数据,满足用户信息要求和处理要求。
数据库设计中需求分析阶段综合各个用户的应用需求(现实世界的需求),在概念设计阶段形成独立于机器特点、独立于各个DBMS产品的概念模式(信息世界模型),用E-R图来描述。在逻辑设计阶段将E-R图转换成具体的数据库产品支持的数据模型如关系模型,形成数据库逻辑模式。然后根据用户处理的要求,安全性的考虑,在基本表的基础上再建立必要的视图(VIEW)形成数据的外模式。在物理设计阶段根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。
1. 需求分析阶段
需求收集和分析,结果得到数据字典描述的数据需求(和数据流图描述的处理需求)。
需求分析的重点是调查、收集与分析用户在数据管理中的信息要求、处理要求、安全性与完整性要求。
需求分析的方法:调查组织机构情况、调查各部门的业务活动情况、协助用户明确对新系统的各种要求、确定新系统的边界。
常用的调查方法有: 跟班作业、开调查会、请专人介绍、询问、设计调查表请用户填写、查阅记录。
分析和表达用户需求的方法主要包括自顶向下和自底向上两类方法。自顶向下的结构化分析方法(Structured Analysis,简称SA方法)从最上层的系统组织机构入手,采用逐层分解的方式分析系统,并把每一层用数据流图和数据字典描述。
数据流图表达了数据和处理过程的关系。系统中的数据则借助数据字典(Data Dictionary,简称DD)来描述。
数据字典是各类数据描述的集合,它是关于数据库中数据的描述,即元数据,而不是数据本身。数据字典通常包括数据项、数据结构、数据流、数据存储和处理过程五个部分(至少应该包含每个字段的数据类型和在每个表内的主外键)。
数据项描述={数据项名,数据项含义说明,别名,数据类型,长度,
取值范围,取值含义,与其他数据项的逻辑关系}
数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}
数据流描述={数据流名,说明,数据流来源,数据流去向,
组成:{数据结构},平均流量,高峰期流量}
数据存储描述={数据存储名,说明,编号,流入的数据流,流出的数据流,
组成:{数据结构},数据量,存取方式}
处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流},
处理:{简要说明}}
2. 概念结构设计阶段
通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型,可以用E-R图表示。
概念模型用于信息世界的建模。概念模型不依赖于某一个DBMS支持的数据模型。概念模型可以转换为计算机上某一DBMS支持的特定数据模型。
概念模型特点:
(1) 具有较强的语义表达能力,能够方便、直接地表达应用中的各种语义知识。
(2) 应该简单、清晰、易于用户理解,是用户与数据库设计人员之间进行交流的语言。
概念模型设计的一种常用方法为IDEF1X方法,它就是把实体-联系方法应用到语义数据模型中的一种语义模型化技术,用于建立系统信息模型。
使用IDEF1X方法创建E-R模型的步骤如下所示:
2.1 第零步——初始化工程
这个阶段的任务是从目的描述和范围描述开始,确定建模目标,开发建模计划,组织建模队伍,收集源材料,制定约束和规范。收集源材料是这阶段的重点。通过调查和观察结果,业务流程,原有系统的输入输出,各种报表,收集原始数据,形成了基本数据资料表。
2.2 第一步——定义实体
实体集成员都有一个共同的特征和属性集,可以从收集的源材料——基本数据资料表中直接或间接标识出大部分实体。根据源材料名字表中表示物的术语以及具有“代码”结尾的术语,如客户代码、代理商代码、产品代码等将其名词部分代表的实体标识出来,从而初步找出潜在的实体,形成初步实体表。
2.3 第二步——定义联系
IDEF1X模型中只允许二元联系,n元联系必须定义为n个二元联系。根据实际的业务需求和规则,使用实体联系矩阵来标识实体间的二元关系,然后根据实际情况确定出连接关系的势、关系名和说明,确定关系类型,是标识关系、非标识关系(强制的或可选的)还是非确定关系、分类关系。如果子实体的每个实例都需要通过和父实体的关系来标识,则为标识关系,否则为非标识关系。非标识关系中,如果每个子实体的实例都与而且只与一个父实体关联,则为强制的,否则为非强制的。如果父实体与子实体代表的是同一现实对象,那么它们为分类关系。
2.4 第三步——定义码
通过引入交叉实体除去上一阶段产生的非确定关系,然后从非交叉实体和独立实体开始标识侯选码属性,以便唯一识别每个实体的实例,再从侯选码中确定主码。为了确定主码和关系的有效性,通过非空规则和非多值规则来保证,即一个实体实例的一个属性不能是空值,也不能在同一个时刻有一个以上的值。找出误认的确定关系,将实体进一步分解,最后构造出IDEF1X模型的键基视图(KB图)。
2.5 第四步——定义属性
从源数据表中抽取说明性的名词开发出属性表,确定属性的所有者。定义非主码属性,检查属性的非空及非多值规则。此外,还要检查完全依赖函数规则和非传递依赖规则,保证一个非主码属性必须依赖于主码、整个主码、仅仅是主码。以此得到了至少符合关系理论第三范式的改进的IDEF1X模型的全属性视图。
2.6 第五步——定义其他对象和规则
定义属性的数据类型、长度、精度、非空、缺省值、约束规则等。定义触发器、存储过程、视图、角色、同义词、序列等对象信息。
3. 逻辑结构设计阶段
将概念结构转换为某个DBMS所支持的数据模型(例如关系模型),并对其进行优化。设计逻辑结构应该选择最适于描述与表达相应概念结构的数据模型,然后选择最合适的DBMS。
将E-R图转换为关系模型实际上就是要将实体、实体的属性和实体之间的联系转化为关系模式,这种转换一般遵循如下原则:
1)一个实体型转换为一个关系模式。实体的属性就是关系的属性。实体的码就是关系的码。
2)一个m:n联系转换为一个关系模式。与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性。而关系的码为各实体码的组合。
3)一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,而关系的码为n端实体的码。
4)一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。
5)三个或三个以上实体间的一个多元联系转换为一个关系模式。与该多元联系相连的各实体的码以及联系本身的属性均转换为关系的属性。而关系的码为各实体码的组合。
6)同一实体集的实体间的联系,即自联系,也可按上述1:1、1:n和m:n三种情况分别处理。
7)具有相同码的关系模式可合并。
为了进一步提高数据库应用系统的性能,通常以规范化理论为指导,还应该适当地修改、调整数据模型的结构,这就是数据模型的优化。确定数据依赖。消除冗余的联系。确定各关系模式分别属于第几范式。确定是否要对它们进行合并或分解。一般来说将关系分解为3NF的标准,即:
表内的每一个值都只能被表达一次。
•?表内的每一行都应该被唯一的标识(有唯一键)。
表内不应该存储依赖于其他键的非键信息。
4. 数据库物理设计阶段
为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)。根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。
5. 数据库实施阶段
运用DBMS提供的数据语言(例如SQL)及其宿主语言(例如C),根据逻辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。 数据库实施主要包括以下工作:用DDL定义数据库结构、组织数据入库 、编制与调试应用程序、数据库试运行
6. 数据库运行和维护阶段
数据库应用系统经过试运行后即可投入正式运行。在数据库系统运行过程中必须不断地对其进行评价、调整与修改。包括:数据库的转储和恢复、数据库的安全性、完整性控制、数据库性能的监督、分析和改进、数据库的重组织和重构造。
建模工具的使用
为加快数据库设计速度,目前有很多数据库辅助工具(CASE工具),如Rational公司的Rational Rose,CA公司的Erwin和Bpwin,Sybase公司的PowerDesigner以及Oracle公司的Oracle Designer等。
ERwin主要用来建立数据库的概念模型和物理模型。它能用图形化的方式,描述出实体、联系及实体的属性。ERwin支持IDEF1X方法。通过使用ERwin建模工具自动生成、更改和分析IDEF1X模型,不仅能得到优秀的业务功能和数据需求模型,而且可以实现从IDEF1X模型到数据库物理设计的转变。ERwin工具绘制的模型对应于逻辑模型和物理模型两种。在逻辑模型中,IDEF1X工具箱可以方便地用图形化的方式构建和绘制实体联系及实体的属性。在物理模型中,ERwin可以定义对应的表、列,并可针对各种数据库管理系统自动转换为适当的类型。
设计人员可根据需要选用相应的数据库设计建模工具。例如需求分析完成之后,设计人员可以使用Erwin画ER图,将ER图转换为关系数据模型,生成数据库结构;画数据流图,生成应用程序。
二、数据库设计技巧
1. 设计数据库之前(需求分析阶段)
1) 理解客户需求,询问用户如何看待未来需求变化。让客户解释其需求,而且随着开发的继续,还要经常询问客户保证其需求仍然在开发的目的之中。
2) 了解企业业务可以在以后的开发阶段节约大量的时间。
3) 重视输入输出。
在定义数据库表和字段需求(输入)时,首先应检查现有的或者已经设计出的报表、查询和视图(输出)以决定为了支持这些输出哪些是必要的表和字段。
举例:假如客户需要一个报表按照邮政编码排序、分段和求和,你要保证其中包括了单独的邮政编码字段而不要把邮政编码糅进地址字段里。
4) 创建数据字典和ER 图表
ER 图表和数据字典可以让任何了解数据库的人都明确如何从数据库中获得数据。ER图对表明表之间关系很有用,而数据字典则说明了每个字段的用途以及任何可能存在的别名。对SQL 表达式的文档化来说这是完全必要的。
5) 定义标准的对象命名规范
数据库各种对象的命名必须规范。
2. 表和字段的设计(数据库逻辑设计)
表设计原则
1) 标准化和规范化
数据的标准化有助于消除数据库中的数据冗余。标准化有好几种形式,但Third Normal Form(3NF)通常被认为在性能、扩展性和数据完整性方面达到了最好平衡。简单来说,遵守3NF 标准的数据库的表设计原则是:“One Fact in One Place”即某个表只包括其本身基本的属性,当不是它们本身所具有的属性时需进行分解。表之间的关系通过外键相连接。它具有以下特点:有一组表专门存放通过键连接起来的关联数据。
举例:某个存放客户及其有关定单的3NF 数据库就可能有两个表:Customer 和Order。Order 表不包含定单关联客户的任何信息,但表内会存放一个键值,该键指向Customer 表里包含该客户信息的那一行。
事实上,为了效率的缘故,对表不进行标准化有时也是必要的。
2) 数据驱动
采用数据驱动而非硬编码的方式,许多策略变更和维护都会方便得多,大大增强系统的灵活性和扩展性。
举例,假如用户界面要访问外部数据源(文件、XML 文档、其他数据库等),不妨把相应的连接和路径信息存储在用户界面支持表里。还有,如果用户界面执行工作流之类的任务(发送邮件、打印信笺、修改记录状态等),那么产生工作流的数据也可以存放在数据库里。角色权限管理也可以通过数据驱动来完成。事实上,如果过程是数据驱动的,你就可以把相当大的责任推给用户,由用户来维护自己的工作流过程。
3) 考虑各种变化
在设计数据库的时候考虑到哪些数据字段将来可能会发生变更。
举例,姓氏就是如此(注意是西方人的姓氏,比如女性结婚后从夫姓等)。所以,在建立系统存储客户信息时,在单独的一个数据表里存储姓氏字段,而且还附加起始日和终止日等字段,这样就可以跟踪这一数据条目的变化。
字段设计原则
4) 每个表中都应该添加的3 个有用的字段
•?dRecordCreationDate,在VB 下默认是Now(),而在SQL Server 下默认为GETDATE()
•?sRecordCreator,在SQL Server 下默认为NOT NULL DEFAULT USER
•?nRecordVersion,记录的版本标记;有助于准确说明记录中出现null 数据或者丢失数据的原因
5) 对地址和电话采用多个字段
描述街道地址就短短一行记录是不够的。Address_Line1、Address_Line2 和Address_Line3 可以提供更大的灵活性。还有,电话号码和邮件地址最好拥有自己的数据表,其间具有自身的类型和标记类别。
6) 使用角色实体定义属于某类别的列
在需要对属于特定类别或者具有特定角色的事物做定义时,可以用角色实体来创建特定的时间关联关系,从而可以实现自我文档化。
举例:用PERSON 实体和PERSON_TYPE 实体来描述人员。比方说,当John Smith, Engineer 提升为John Smith, Director 乃至最后爬到John Smith, CIO 的高位,而所有你要做的不过是改变两个表PERSON 和PERSON_TYPE 之间关系的键值,同时增加一个日期/时间字段来知道变化是何时发生的。这样,你的PERSON_TYPE 表就包含了所有PERSON 的可能类型,比如Associate、Engineer、Director、CIO 或者CEO 等。还有个替代办法就是改变PERSON 记录来反映新头衔的变化,不过这样一来在时间上无法跟踪个人所处位置的具体时间。
7) 选择数字类型和文本类型尽量充足
在SQL 中使用smallint 和tinyint 类型要特别小心。比如,假如想看看月销售总额,总额字段类型是smallint,那么,如果总额超过了$32,767 就不能进行计算操作了。
而ID 类型的文本字段,比如客户ID 或定单号等等都应该设置得比一般想象更大。假设客户ID 为10 位数长。那你应该把数据库表字段的长度设为12 或者13 个字符长。但这额外占据的空间却无需将来重构整个数据库就可以实现数据库规模的增长了。
8) 增加删除标记字段
在表中包含一个“删除标记”字段,这样就可以把行标记为删除。在关系数据库里不要单独删除某一行;最好采用清除数据程序而且要仔细维护索引整体性。
3. 选择键和索引(数据库逻辑设计)
键选择原则:
1) 键设计4 原则
•?为关联字段创建外键。
•?所有的键都必须唯一。
•?避免使用复合键。
•?外键总是关联唯一的键字段。
2) 使用系统生成的主键
设计数据库的时候采用系统生成的键作为主键,那么实际控制了数据库的索引完整性。这样,数据库和非人工机制就有效地控制了对存储数据中每一行的访问。采用系统生成键作为主键还有一个优点:当拥有一致的键结构时,找到逻辑缺陷很容易。
3) 不要用用户的键(不让主键具有可更新性)
在确定采用什么字段作为表的键的时候,可一定要小心用户将要编辑的字段。通常的情况下不要选择用户可编辑的字段作为键。
4) 可选键有时可做主键
把可选键进一步用做主键,可以拥有建立强大索引的能力。
索引使用原则:
索引是从数据库中获取数据的最高效方式之一。95%的数据库性能问题都可以采用索引技术得到解决。
1) 逻辑主键使用唯一的成组索引,对系统键(作为存储过程)采用唯一的非成组索引,对任何外键列采用非成组索引。考虑数据库的空间有多大,表如何进行访问,还有这些访问是否主要用作读写。
2) 大多数数据库都索引自动创建的主键字段,但是可别忘了索引外键,它们也是经常使用的键,比如运行查询显示主表和所有关联表的某条记录就用得上。
3) 不要索引memo/note 字段,不要索引大型字段(有很多字符),这样作会让索引占用太多的存储空间。
4) 不要索引常用的小型表
不要为小型数据表设置任何键,假如它们经常有插入和删除操作就更别这样作了。对这些插入和删除操作的索引维护可能比扫描表空间消耗更多的时间。
4. 数据完整性设计(数据库逻辑设计)
1) 完整性实现机制:
实体完整性:主键
参照完整性:
父表中删除数据:级联删除;受限删除;置空值
父表中插入数据:受限插入;递归插入
父表中更新数据:级联更新;受限更新;置空值
DBMS对参照完整性可以有两种方法实现:外键实现机制(约束规则)和触发器实现机制
用户定义完整性:
NOT NULL;CHECK;触发器
2) 用约束而非商务规则强制数据完整性
采用数据库系统实现数据的完整性。这不但包括通过标准化实现的完整性而且还包括数据的功能性。在写数据的时候还可以增加触发器来保证数据的正确性。不要依赖于商务层保证数据完整性;它不能保证表之间(外键)的完整性所以不能强加于其他完整性规则之上。
3) 强制指示完整性
在有害数据进入数据库之前将其剔除。激活数据库系统的指示完整性特性。这样可以保持数据的清洁而能迫使开发人员投入更多的时间处理错误条件。
4) 使用查找控制数据完整性
控制数据完整性的最佳方式就是限制用户的选择。只要有可能都应该提供给用户一个清晰的价值列表供其选择。这样将减少键入代码的错误和误解同时提供数据的一致性。某些公共数据特别适合查找:国家代码、状态代码等。
5) 采用视图
为了在数据库和应用程序代码之间提供另一层抽象,可以为应用程序建立专门的视图而不必非要应用程序直接访问数据表。这样做还等于在处理数据库变更时给你提供了更多的自由。
5. 其他设计技巧
1) 避免使用触发器
触发器的功能通常可以用其他方式实现。在调试程序时触发器可能成为干扰。假如你确实需要采用触发器,你最好集中对它文档化。
2) 使用常用英语(或者其他任何语言)而不要使用编码
在创建下拉菜单、列表、报表时最好按照英语名排序。假如需要编码,可以在编码旁附上用户知道的英语。
3) 保存常用信息
让一个表专门存放一般数据库信息非常有用。在这个表里存放数据库当前版本、最近检查/修复(对Access)、关联设计文档的名称、客户等信息。这样可以实现一种简单机制跟踪数据库,当客户抱怨他们的数据库没有达到希望的要求而与你联系时,这样做对非客户机/服务器环境特别有用。
4) 包含版本机制
在数据库中引入版本控制机制来确定使用中的数据库的版本。时间一长,用户的需求总是会改变的。最终可能会要求修改数据库结构。把版本信息直接存放到数据库中更为方便。
5) 编制文档
对所有的快捷方式、命名规范、限制和函数都要编制文档。
采用给表、列、触发器等加注释的数据库工具。对开发、支持和跟踪修改非常有用。
对数据库文档化,或者在数据库自身的内部或者单独建立文档。这样,当过了一年多时间后再回过头来做第2 个版本,犯错的机会将大大减少。
6) 测试、测试、反复测试
建立或者修订数据库之后,必须用用户新输入的数据测试数据字段。最重要的是,让用户进行测试并且同用户一道保证选择的数据类型满足商业要求。测试需要在把新数据库投入实际服务之前完成。
7) 检查设计
在开发期间检查数据库设计的常用技术是通过其所支持的应用程序原型检查数据库。换句话说,针对每一种最终表达数据的原型应用,保证你检查了数据模型并且查看如何取出数据。
三、数据库命名规范
1. 实体(表)的命名
1) 表以名词或名词短语命名,确定表名是采用复数还是单数形式,此外给表的别名定义简单规则(比方说,如果表名是一个单词,别名就取单词的前4 个字母;如果表名是两个单词,就各取两个单词的前两个字母组成4 个字母长的别名;如果表的名字由3 个单词组成,从头两个单词中各取一个然后从最后一个单词中再取出两个字母,结果还是组成4 字母长的别名,其余依次类推)
对工作用表来说,表名可以加上前缀WORK_ 后面附上采用该表的应用程序的名字。在命名过程当中,根据语义拼凑缩写即可。注意,由于ORCLE会将字段名称统一成大写或者小写中的一种,所以要求加上下划线。
举例:
定义的缩写 Sales: Sal 销售;
Order: Ord 订单;
Detail: Dtl 明细;
则销售订单明细表命名为:Sal_Ord_Dtl;
2) 如果表或者是字段的名称仅有一个单词,那么建议不使用缩写,而是用完整的单词。
举例:
定义的缩写 Material Ma 物品;
物品表名为:Material, 而不是 Ma.
但是字段物品编码则是:Ma_ID;而不是Material_ID
3) 所有的存储值列表的表前面加上前缀Z
目的是将这些值列表类排序在数据库最后。
4) 所有的冗余类的命名(主要是累计表)前面加上前缀X
冗余类是为了提高数据库效率,非规范化数据库的时候加入的字段或者表
5) 关联类通过用下划线连接两个基本类之后,再加前缀R的方式命名,后面按照字母顺序罗列两个表名或者表名的缩写。
关联表用于保存多对多关系。
如果被关联的表名大于10个字母,必须将原来的表名的进行缩写。如果没有其他原因,建议都使用缩写。
举例:表Object与自身存在多对多的关系,则保存多对多关系的表命名为:R_Object;
表 Depart和Employee;存在多对多的关系;则关联表命名为R_Dept_Emp
2. 属性(列)的命名
1) 采用有意义的列名,表内的列要针对键采用一整套设计规则。每一个表都将有一个自动ID作为主健,逻辑上的主健作为第一组候选主健来定义,如果是数据库自动生成的编码,统一命名为:ID;如果是自定义的逻辑上的编码则用缩写加“ID”的方法命名。如果键是数字类型,你可以用_NO 作为后缀;如果是字符类型则可以采用_CODE 后缀。对列名应该采用标准的前缀和后缀。
举例:销售订单的编号字段命名:Sal_Ord_ID;如果还存在一个数据库生成的自动编号,则命名为:ID。
2) 所有的属性加上有关类型的后缀,注意,如果还需要其它的后缀,都放在类型后缀之前。
注: 数据类型是文本的字段,类型后缀TX可以不写。有些类型比较明显的字段,可以不写类型后缀。
3) 采用前缀命名
给每个表的列名都采用统一的前缀,那么在编写SQL表达式的时候会得到大大的简化。这样做也确实有缺点,比如破坏了自动表连接工具的作用,后者把公共列名同某些数据库联系起来。
3. 视图的命名
1) 视图以V作为前缀,其他命名规则和表的命名类似;
2) 命名应尽量体现各视图的功能。
4. 触发器的命名
触发器以TR作为前缀,触发器名为相应的表名加上后缀,Insert触发器加'_I',Delete触发器加'_D',Update触发器加'_U',如:TR_Customer_I,TR_Customer_D,TR_Customer_U。
5. 存储过程名
存储过程应以'UP_'开头,和系统的存储过程区分,后续部分主要以动宾形式构成,并用下划线分割各个组成部分。如增加代理商的帐户的存储过程为'UP_Ins_Agent_Account'。
6. 变量名
变量名采用小写,若属于词组形式,用下划线分隔每个单词,如@my_err_no。
7. 命名中其他注意事项
1) 以上命名都不得超过30个字符的系统限制。变量名的长度限制为29(不包括标识字符@)。
2) 数据对象、变量的命名都采用英文字符,禁止使用中文命名。绝对不要在对象名的字符之间留空格。
3) 小心保留词,要保证你的字段名没有和保留词、数据库系统或者常用访问方法冲突
5) 保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了。
工具:
Eclipse3.1、MyEclipse4.03、Tomcat5.5.9、Properties Editor插件、MySql4.1.13
新建工程:名称为 login
创建Struts框架
创建 index.jsp,增加一链接指向 login.jsp
按下Ctrl + N,创建 login.jsp、LoginAction,使用MyEclipse的向导就可以了,记得选对正确的版本
在ActionForm配置页中选择类型为动态Form,并继承于DynaValidatorForm,新增两个属性:username、password,在创建jsp文件打上钩,将路径改为/login.jsp,然后下一步,改LoginAction的Input source改为/login.jsp,点击完成
按下Ctrl + N 创建一个forwards,记得选对正确的版本
name 输入 indexGo
路径选择 /index.jsp
配置validator
先添加Struts插件,使用向导
Plugin class : org.apache.struts.validator.ValidatorPlugIn
Property : pathnames
Value : /WEB-INF/validator-rules.xml,/WEB-INF/validation.xml
这里需要两个xml文件
现在创建“
validation.xml
” 文件
在这里说明一点,我使用MyEclipse创建的Struts框架中缺少了validator-rules.xml文件,需要动拷贝到WEB-INF目录中
文件内容如下:
<
form-validation
>
<
formset
>
<
form
name
="loginForm"
>
<
field
property
="username"
depends
="required"
>
<
arg0
key
="prompt.username"
/>
</
field
>
<
field
property
="password"
depends
="required"
>
<
arg0
key
="prompt.password"
/>
</
field
>
</
form
>
</
formset
>
</
form-validation
>
编辑资源文件“ApplicationResources.properties”
增加以下内容
prompt.username=User Name
prompt.password=User Password
errors.required={0} is required.
再创建中文件资源文件“ApplicationResources_zh_CN.properties”
增加以下内容
prompt.username=用户名称
prompt.password=登录密码
errors.required={0} 必需填写!
修改struts-config.xml文件
在以下位置增加绿色字体部份
<action-mappings >
<action
attribute="loginForm"
input="/login.jsp"
name="loginForm"
path="/login"
scope="request"
validate="true"
type="com.test.struts.action.LoginAction" />
</action-mappings>
这里说明提交的数据必需经过验证,而验证则是通过validator框架进行的。
修改LoginAction.java文件的execute方法,内容如下
public ActionForward execute(
ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response) {
DynaValidatorForm loginForm = (DynaValidatorForm) form;
String username=loginForm.getString("username");
String password=loginForm.getString("password");
if(username.equals("test")||password.equals("test")){
return mapping.findForward("indexGo");
}else{
return mapping.getInputForward();
}
}
现在再修改一下login.jsp
增加以下绿色字体部份
<%@ page language="java" contentType="text/html; charset=UTF-8" %>
其中charset=UTF-8 是使用UTF-8的字符编码,这也是为了支持国际化而使用的。
好了,现在可以启动Tomcat进行测试了
如果不输入任何数据而直接提交表单的话就可以看到效果了。
好了,如果没有什么问题的话就继续往下看吧,如果有问题的话就得往上看了^_^
现在创建Spring框架了,在这里我将Spring所有的包全部加载进去,因为我还不知道具体用到哪些类,全部加进去方便点
单选框选第二个,这样的话所有的类库和标签等都将拷贝到项目中去,这样方便以后的布署
下一步后是创建配置文件,将文件放到“WebRoot/WEB-INF”目录下,文件名称为“applicationContext.xml”
配置struts-config.xml文件,添加(spring)的插件
<plug-in className="org.springframework.web.struts.ContextLoaderPlugIn">
<set-property property="contextConfigLocation" value="/WEB-INF/applicationContext.xml" />
</plug-in>
修改LoginAction配置
原:
<action
attribute="loginForm"
input="/login.jsp"
name="loginForm"
path="/login"
scope="request"
validate="true"
type="com.test.struts.action.LoginAction" />
</action-mappings>
改为:
<action
attribute="loginForm"
input="/login.jsp"
name="loginForm"
path="/login"
scope="request"
validate="true"
type="org.springframework.web.struts.DelegatingActionProxy" />
</action-mappings>
绿色字体部份为修改内容
这里将使用spring的代理器来对Action进行控制
当提交到/login.do是将控制权交给了spring,然后由spring来决定是否转回到struts的Action
现在来配置spring
<beans>
<bean name="/login" class="com.test.struts.action.LoginAction" singleton="false"></bean>
</beans>
绿色字体是关于转交控制权的配置内容
属性singleton="false",指明了Action 的实例获取方式为每次重新创建。解决了Struts中令人诟病的线程安全问题(Struts中,由一个Action实例处理所有的请求,这就导致了类公用资源在并发请求中的线程同步问题。)(摘自spring开发指南)
这时如果你要进行测试也是可以的,不过为了省点时间就不进行测试了。
建立数据库在 这里我使用的是mysql4.1.13
CREATE TABLE `user` (
`ID` int(11) NOT NULL auto_increment,
`USERNAME` varchar(50) NOT NULL default '',
`PASSWORD` varchar(50) NOT NULL default '',
PRIMARY KEY (`ID`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
添加记录 insert into user (USERNAME,PASSWORD) values ('test','test')
创建Hibernate框架
在配置界面中配置数据库的连接部份,重要的是点击链接将jdbc拷贝到lib目录中
使用MyEclipse的数据Database Explorer工具创建User.hmb.xml、AbstractUser.java、User.java映射文件
创建完成后可以将自动生成的hibernate.cfg.xml删除
创建UserDAO.java、UserDAOImp.java
UserDAO.java
public interface UserDAO {
public abstract boolean isValidUser(String username, String password);
}
UserDAOImp.java
import java.util.List;
import org.springframework.orm.hibernate3.support.HibernateDaoSupport;
import com.test.Hibernate.SessionFactory;
public class UserDAOImp extends HibernateDaoSupport implements UserDAO {
private SessionFactory sessionFactory;
private static String hql = "from User u where u.username=? ";
public boolean isValidUser(String username, String password) {
List userList = this.getHibernateTemplate().find(hql, username);
if (userList.size() > 0) {
return true;
}
return false;
}
}
修改LoginAction.java文件,使用userDao的方法来进行用户验证
package com.test.struts.action;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
import org.apache.struts.validator.DynaValidatorForm;
import com.test.UserDAO;
public class LoginAction extends Action {
private UserDAO userDAO;
public UserDAO getUserDAO() {
return userDAO;
}
public void setUserDAO(UserDAO userDAO) {
this.userDAO = userDAO;
}
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response) {
DynaValidatorForm loginForm = (DynaValidatorForm) form;
// TODO Auto-generated method stub
String username = (String) loginForm.get("username");
String password = (String) loginForm.get("password");
loginForm.set("password", null);
if (userDAO.isValidUser(username,password)) {
return mapping.findForward("indexGo");
} else {
return mapping.getInputForward();
}
}
}
绿色字体为修改部份
现在剩下最后的spring配置了
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName">
<value>com.mysql.jdbc.Driver</value>
</property>
<property name="url">
<value>jdbc:mysql://localhost/test</value>
</property>
<property name="username">
<value>root</value>
</property>
<property name="password">
<value>root</value>
</property>
</bean>
<!-- 配置sessionFactory, 注意这里引入的包的不同 -->
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource">
<ref local="dataSource" />
</property>
<property name="mappingResources">
<list>
<value>com/test/Hibernate/User.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">org.hibernate.dialect.MySQLDialect</prop>
<prop key="hibernate.show_sql">true</prop>
</props>
</property>
</bean>
<bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory">
<ref local="sessionFactory" />
</property>
</bean>
<bean id="userDAO" class="com.test.UserDAOImp">
<property name="sessionFactory">
<ref local="sessionFactory" />
</property>
</bean>
<bean id="userDAOProxy" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager">
<ref bean="transactionManager" />
</property>
<property name="target">
<ref local="userDAO" />
</property>
<property name="transactionAttributes">
<props>
<prop key="insert*">PROPAGATION_REQUIRED</prop>
<prop key="get*">PROPAGATION_REQUIRED,readOnly</prop>
<prop key="is*">PROPAGATION_REQUIRED,readOnly</prop>
</props>
</property>
</bean>
<bean name="/login" class="com.test.struts.action.LoginAction" singleton="false">
<property name="userDAO">
<ref bean="userDAOProxy" />
</property>
</bean>
</beans>
现在可以进行测试了!
在编写代码有配置内容时一定要注意 hibernate 和 hibernate3 ,这两个包的名字就只差一个字,千万不要有错,否则找错误可是很难的。
Struts应用采用两个基于XML的配置文件来配置,分别是web.xml和struts-cofig.xml文件.web.xml文件是配置所有web应用的而struts-config.xml文件是struts专用的配置文件,事实上也是可以根据需要给这个配置文件起其他名称的.
Web应用的发布描述文件:web应用发布描述文件可以在应用开着者,发布者和组装者之间传递配置信息,Web容器在启动的时候从该文件中读取配置信息,根据它来装载和配置web应用.文档类型定义DTD对XML文档的格式做了定义,DTD吧XML文档划分为元素,属性,实体每一种XML文档都有独自的DTD文件.可以从网上下载.<web-app>元素是web.xml的根元素,其他元素必须嵌入在<web-app>元素之内.要注意的是子元素也是有顺序的比如必须是首先<servlet>,然后<servlet-mapping>最后<taglib>.
为Struts应用配置Web.xml文件:首先最重要的一步是配置ActionServlet,这个用<servlet>标签的servlet-name属性起一个名字叫action,然后用servlet-class属性指定ActionServlet的类.然后用<servlet-mapping>标签的servlet-name属性指定action,在用url-pattern指定接收范围是*.do的请求.不管应用中包含了多少子应用,都只需要配置一个ActionServlet,类来出来应用中的不同的功能,其实者就是不必要的,因为Servlet本身就是多线程的,而且目前Struts只允许配置一个ActionServlet.声明ActionServlet的初始化参数:<servlet>的<init-param>子元素用来配置Servlet的初始化参数.param-name设置config参数名.param-value设置struts-config.xml的路径参数值.
配置欢迎使用清单:如果客户访问Web的时候值是访问了WEB应用的根目录URL.没有具体的指定文件,Web会自动调用Web的欢迎文件.<welcome-file-list>元素来配置的.通过其中的<welcome-file>欢迎页面</welcome-file>来配置.
配置错误处理:尽管Struts框架功能强大的错误处理机制,但是不能保证处理所有的错误或者异常.当错误发生时,如果框架不能处理这种错误,把错误抛弃给Web容器,在默认的情况下web容器会想客户端返回错误信息.如果想避免让客户看到原始的错误信息,可以在Web应用发布描述文件中配置<error-page>元素.通过<error-code>404来定义错误的类型.然后通过<location>要处理错误的JSP页面来对错误进行处理.还可以用<exception-type>来设置异常,然后通过<location>来处理异常的JSP页面来处理异常.
配置Struts标签库:这个就和以前学到的JSP自定义标签类似,配置元素为<taglib>来配置.<taglib-uri>这个指定标签库的uri,类似起一个名称.<taglib-location>这个是标签库的位置也就是实际所在的路径.通过这样的方法引入一个标签库,然后在前台JSP页面就可以通过自己定义的URI来调用标签.
Struts配置文件:struts-config.xml文件.首先研讨一下org.apache.struts.config包,在struts应用启动的时候会把Struts配置文件信息读取到内存中,并把它们存放在config包中相关的JavaBean类的实例中.包中的每一个类都和struts配置文件中特定的配置元素对应,ModuleConfig在Struts框架中扮演了十分重要的角色,它是整个config包的核心,在Struts运行时来存放整个应用的配置信息.如果有多个子应用都会有一个ModuleConfig对象,它和Struts文件根元素的<struts-config>对应.根元素中包含<form-bean><action><forward>等元素.
<struts-config>元素:时Struts配置文件的根元素,和它对应的配置类ModuleConfig类,<struts-config>元素有8个子元素.他们的DTD定义是data-sources?form-bean? global-exception?global-forwards?action-mapping?controller?message-resources?plug-in*在Struts配置文件中,必须按照DTD指定的先手顺序来配置<struts-config>元素的各个子元素,如果颠倒了这些子元素的顺序,会产生错误.
<data-sources>元素:用来配置应用所需要的数据源,数据源负责创建和特定的数据库的连接.许多数据源采用连接池的机制实现.以便提高数据库访问的性能.JAVA语言提供了javax.sql.DataSource接口,所有的数据源都必须实现这个接口.许多应用服务器和Web服务器都提供了数据源组件.很多数据库厂商也提供了数据源的实现.<data-sources>元素包含多个<data-source>子元素永远配置特定的数据源.他们可以包含多个<set-property>子元素用于设置数据源的各种属性.配置了数据源以后,就可以在Action类中访问数据源,在Action中定义了getDataSource(HttpRequest)方法,用于获取数据源对象的引用.然后可以利用DataSource对象调用getConnection获取一个连接对象对数据库进行操作.在配置文件中声明多个数据源的时候需要为每一个数据源分配唯一的Key值,通过这个来表示特定的数据源.获取特定的数据源的时候可以用dataSource = getDataSource(reqeust,”A”);
<form-beans>元素:用来配置多个ActionForm,包含一个或者N个<form-bean>子元素.每个<form-bean>元素都包含多个属性.className指定和<form-bean>匹配的类.name指定该ActionForm的唯一标识符,这个属性是必须的以后作为引用使用.type指定ActionForm类的完整类名,这个属性也是必须的.注意包名也要加上.<form-property>是指定动态的Form的元素,以后会深入了解.
<global-exception>元素:用于配置异常处理,元素可以包含一个或者多个<exception>元素,用来设置JAVA异常和异常处理类ExceptionHandler之间的映射.className指定和元素对应的配置类,默认的不用动.handler指定异常处理类默认是ExceptionHandler.key指定在本地资源文件中异常的消息Key,path指定当前异常发生的时候转发的路径.scope指定ActionMessages实例存放的范围.type指定需要处理异常类的名字,必须的.bundle指定Resource Bundle.
<global-forwards>元素:用来声明全局转发,元素可以有一个或者N个<forward>元素组成,用于把一个逻辑名映射到特定的URL,通过这种方法Action类或者JSP页面无需指定URL,只要指定逻辑名称就可以实现请求转发或者重定向.这样可以减少控制组件和视图的聚合.易于维护.className对应的配置类.contextRelative如果为true表示当path属性以/开头的时候,给出的是对应的上下文URL默认是false.name转发路径的逻辑名,必须写.path转发或者重定向的URL,必须写必须是以/开头.redirect设置为true的时候表示执行重定向操作,此项为false的时候,表示执行请求转发操作.重定向与请求转发的区别以后就是重定向是把请求生成应答给客户端然后在重新发送给定向的URL,浏览器地址栏会有显示.而转发就是直接把请求转发给本应用的另一个文件,不生成应答所以客户端IE没显示.
<action-mapping>元素:包含一个或者N个<action>元素,描述了从特定的请求路径到响应的Action的映射.在<action>元素中可以包含多个<exception>和<forward>子元素,他们分别配置局部异常处理和局部转发.attribute设置Action关联的ActionForm在request或者session范围内的key.就是在request或者session共享内的名称.className对应配置元素的类.默认的是ActionMapping.forward指定转发URL路径include指定包含URL路径.input指定包含表单的URL,当表单验证失败的时候发送的URL.name,指定和该Action关联的Form名字.该名字必须是在form-bean中定义过的,可写可不写.path必须/开头的方位Action的路径.parameter指定Action配置参数.在Action的execute()方法中可以调用ActionMapping的getParameter()方法来读取匹配的参数.roles指定允许调用该Action的安全角色,多个角色之间逗号格开.scope指定Form的存在范围.默认是session.tyep指定Action的完整类名.unknown如果是true表示可以处理用户发出的所有的无效的ActionURL默认是false.validate指定是否调用ActionForm的validate方法.
<controller>元素:用于配置ActionServlet.buffreSize指定上载文件的输入缓冲大小.该属性为可选默认4096.className指定元素对应的配置类,ControllerConfig.然后是contentType指定响应结果内容类型和字符编码,该属性为可选,默认是text/html如果在Action或者JSP网页也设置了类型内容,会覆盖这个.locale指定是否把Locale对象保存到当前用户的session中默认false.tempDir指定处理文件上载的临时工作目录.nochache如果是true在响应结果中加入特定的头参数.
<message-resources>元素:用来配置Resource Bundle.用于存放本地文本消息文件.className元素对应的配置类.MessageResourcesConfig.factory指定消息的工厂类.key指定文件存放的Servlet对象中采用的属性Key.null指定如何处理未知消息.parameter指定消息的文件名.
<plug-in>元素:用于配置Struts插件.
配置多应用模块:所有的子应用都可以共享同一个ActionServlet实例,但是每个子应用都有单独的配置文件.把应用划分为多个子应用模块.首先为每个应用创建单独的Struts配置文件,在web.xml的ActionServlet配置代码中添加几个子应用信息.采用<forward>元素来实现应用之间的切换.
Digester组件:是一个Apache的另一个开源代码项目.当Struts被初始化的时候,首先会读取并解析配置文件,框架采用Digester组件来且西配置文件.然后创建config包中的对象.者对象用于存放配置信息.
其实配置文件不难,只要都理其中的原理就OK了.真正实际的项目开发中,采用的工具例如Eclipse系列,提供了相应的插件,在创建一个Struts工程的时候配置文件的标签都是自动生成的,而我们只需要往里面填写属性就OK了. (网友们的支持,是我继续写技术文章的动力!)
STEP 1:下载和安装
首先在Subversion的官方网站去下载windows安装包,最新版是1.3.1,可惜在项目树上只更新到了1.3.0的二进制包。
下载后安装在本地机器上,这里注意的是最好将安装目录指定为纯英文名目录,安装在中文目录下天知道哪天会冒出一个让你想破头也想不出的错误来。
下载TortoiseSVN进行本地安装,我安装的是最新的1.3.2 for svn 1.3.0,这是一个将SVN集成到windows shell中的GUI管理工具,推荐使用。
STEP 2:创建储存库
安装完TortoiseSVN后提示要重启机器,其实启不启都可以正常使用了,首先创建SVN储存库(repository),可以选择命令行方式或者通过TortoiseSVN插件进行GUI操作,命令行运行如下:
svnadmin create E:\svn\repository
e:\svn\repository就是我指定的储存库目录,如果用GUI方式,可以在这个目录下点击右键选择[TotoiseSVN]->[Create Repository href...]进行创建,版本库模式指定为默认的即可。
repository创建完毕后会在目录下生成若干个文件和文件夹,dav目录是提供给Apache与mod_dav_svn使用的目录,让它们存储内部 数据;db目录就是所有版本控制的数据文件;hooks目录放置hook脚本文件的目录;locks用来放置Subversion文件库锁定数据的目录, 用来追踪存取文件库的客户端;format文件是一个文本文件,里面只放了一个整数,表示当前文件库配置的版本号;
STEP 3:配置
打开/conf/目录,打开svnserve.conf找到一下两句:
# [general]
# password-db = passwd
去之每行开头的#,其中第二行是指定身份验证的文件名,即passwd文件
同样打开passwd文件,将
# [users]
# harry = harryssecret
# sally = sallyssecret
这几行的开头#字符去掉,这是设置用户,一行一个,存储格式为“用户名 = 密码”,如可插入一行:admin = admin888,即为系统添加一个用户名为admin,密码为admin888的用户
STEP 4:运行SVN服务
在命令行执行
svnserve --daemon --root E:\svn\repository
服务启动,--daemon可简写为-d,--root可简写为-r,可以建立一个批处理文件并放在windows启动组中便于开机就运行SVN服务,或者在这个地址
http://clanlib.org/~mbn/svnservice/下载那个
svnservice.exe文件,拷贝到E:\svn\bin目录下,再从命令行下执行:
svnservice -install --daemon --root "E:\svn\Repository"
sc config svnservice start= auto
net start svnservice
此文件会将SVN变成windows系统的一个服务,并默认为自启动,注意:执行第三句时确保前面以命令行方式运行的SVN服务已经停止,如果没停止可在其窗口中按Ctrl+C中止运行。
STEP 5:创建项目版本树
确定SVN服务(命令行或windows服务)运行后,在你需要导入储存库的目录下单击右键选择[TortoiseSVN]-> [Import...],在弹开的窗口的URL框中输入 "svn://localhost/myproject" 点击 "OK" 执行导入,如果没有报错,数 据就全部加入SVN储存库目录树上了。用命令行也可以完成这些操作,这需要你在系统变量中新建一个“SVN_EDITOR”的系统变量,变量值为本地的一 个文本编辑器执行文件路径,一般指到windows的记事本上就行了 "c:\windows\notepad.exe" ,然后新开一个CMD窗口,执行
svn mkdir svn://localhost/myproject
随即关闭记事本打开的log文件窗口后按"c"键继续后生成项目树。一般情况,我们在创建文件根路径后应该在创建三个目录:branches、tags、trunk,这三个目录是Subversion需要的三个目录。对于check out、commit、update等操作可以通过svn命令行方式执行,也可以用TortoiseSVN的windows菜单完成,非常简单咯。
摘要: MVC
模式概述
MVC
是三个单词的缩写
,
分别为:
模型
(Model),
视图
(View)
和控制
Controller)
。
...
阅读全文
版权所有,转载请声明出处
zhyiwww@163.com
在读我自己的认识之前
,
我们先来看一下
servet
的结构图
:
以下是我自己的一点浅见:
①
Servlet
在初始化的时候
,
是通过
init(ServletConfig config)
或
init()
来执行的。
ServletConfig
是一个接口,它怎样传递给他一格对象来进行初始化呢?其实,是这个对象是由
servlet
容器来实例化的,由容器产生一格
ServletConfig
的实现类的对象,然后传递给
Servlet
结论:
ServletConfig
由容器实例化
②
我们有些时候可能在
Servlet
初始化时给它一些固定的配置参数,那么这些参数是怎样传递到
Servlet
呢?
其实,我们在
web.xml
中给
servlet
配置启动参数,在容器对
servlet
进行初始化的时候,会收集你所配置的参数,记录在
ServletConfig
的实现类中,所以你才可以通过
ServletConfig
对象的
public String getInitParameter(String name);
或
public Enumeration getInitParameterNames();
方法来取得你已经配置好的参数,也就是说,你对
servlet
的配置都已经记录在
ServletConfig
对象中了。
结论:你对
Servlet
的配置,在
Servlet
的初始化时都由容器来收集并且记录到
ServletConfig
的实现类中。
③
我们来看一个
Servlet
的配置
<servlet>
<servlet-name>index</servlet-name>
<servlet-class>org.zy.pro.sw.servlet.IndexServlet</servlet-class>
<init-param>
<param-name>dbconfig</param-name>
<param-value>/WEB-INF/dbconfig.xml</param-value>
</init-param>
</servlet>
在此,我们实现对数据库的配置文件的加载。
当
Servlet
初始化完成后,我们可以通过
String dbconf=this.getServletConfig().getInitParameter("dbconfig")
来取得我们的配置的参数的值。
但是,我们仅能得到一个配置的字符串。之后我们可以通过配置文件取得我们的数据库的配置参数,然后对数据库进行初始化。
其实我们也可以通过传递一个类的名字串,然后再实例化。
<init-param>
<param-name>dbconfig</param-name>
<param-value>org.zy.util.db.DBUtil</param-value>
</init-param>
我们先取得配置参数:
String dbconf=this.getServletConfig().getInitParameter("dbconfig")
;
然后通过
Class.forName(dbconf).getInstance();
来实例化对象,就可以实现对数据库的调用了。
结论:在
web.xml
中对
Servlet
的初始化,只能传递字符串类型的数据
④
ServletContext
ServletContext
是负责和
Servlet
的上文和下文交互,上面和
Servlet
容器交互,下面和
Servlet
中的请求和相应进行交互。
在
ServletConfig
中,
public ServletContext getServletContext();
方法实现取得当前
ServletContext
的对象。
你可能要问,
ServletContext
是一个接口,那么你如何取得他的对象呢?
其实这个问题和
ServletConfig
相同,都是在
Servlet
进行初始化的时候产生的对象,是由容器来初始化的。
摘要:
折腾了一个星期,终于搞定ant+cactus+tomcat5.5容器内单元测试,为感谢cleverpig斑竹的热心回贴,特首发于matrix apache版。
折腾了一个星期,终于搞定ant+cactus+tomcat5.5容器内单元测试,为感谢cleverpig斑竹(
http://blog.matrix.org.cn/page/cleverpig)的热心回贴,特首发于matrix apache版。关于ant的使用,请搜索ant的使用手册,网上大把中文的。
一、下载并解压缩cactus下载地址为
http://apache.freelamp.com/jakarta/cactus/binaries/jakarta-cactus-12-1.7.1.zip。将cactus的lib目录下的cactus-ant-1.7.1.jar复制到ant的lib目录。
二、配置cactuscactus的配置很简单,新建一个cactus.properties文件,并把它放在ant脚本中的cactus任务的classpath下,文件中包括如下内容
cactus.sysproperties=cactus.contextURL
#cactus-sample-servlet-cactified就是你的测试应用所在路径,8080是端口号
cactus.contextURL = http://localhost:8080/cactus-sample-servlet-cactified
cactus.servletRedirectorName = ServletRedirector
cactus.jspRedirectorName = JspRedirector
cactus.filterRedirectorName = FilterRedirector
具体的做法结合ant脚本再进一步解释。
三、运行ant脚本 ant脚本主要执行以下任务
1、设定classpath <path id="project.classpath">
<fileset dir="${lib.dir}">
<include name="*.jar"/>
</fileset>
<!-- cactus.properties文件就需要放在lib.dir所对应的路径中 -->
<pathelement location="${lib.dir}"/>
<pathelement location="${tomcat.home}/common/lib/jsp-api.jar"/>
<pathelement location="${tomcat.home}/common/lib/servlet-api.jar"/>
</path>
2、定义相关任务 <taskdef resource="cactus.tasks" classpathref="project.classpath"/>
<taskdef name="runservertests" classname="org.apache.cactus.integration.ant.RunServerTestsTask">
<classpath>
<path refid="project.classpath"/>
</classpath>
</taskdef>
3、编译应用的类文件和测试的类文件4、打包整个应用为war文件需要注意的是,不仅要打包应用类,测试类也要打包
<target name="war" depends="compile.java"
description="Generate the runtime war">
<war warfile="${target.dir}/${project.name}.war"
webxml="${src.webapp.dir}/WEB-INF/web.xml">
<fileset dir="${src.webapp.dir}">
<exclude name="cactus-report.xsl"/>
<exclude name="WEB-INF/cactus-web.xml"/>
<exclude name="WEB-INF/web.xml"/>
</fileset>
<classes dir="${target.classes.java.dir}"/>
<!-- 别忘了打包测试类 -->
<classes dir="${target.classes.test.dir}"/>
<!-- 别忘了打包各种相关的jar文件 -->
< lib dir="project.classpath"/>
</war>
</target>
5、在应用的web.xml文件中添加测试所需的各种映射cactus提供了两个task来完成这个工作,CactifyWar和WebXmlMerge。
CactifyWar的功能是自动在已经打包的应用的web.xml文件中添加所需的映射。WebXmlMerge是提供合并两个web.xml文件的功能。
<target name="test.prepare"
depends="war, compile.cactus, test.prepare.logging">
<!-- Cactify the web-app archive -->
<cactifywar srcfile="${target.dir}/${project.name}.war"
destfile="${tomcat.home}/webapps/${project.name}-cactified.war"
>
<classes dir="${target.classes.java.dir}"/>
<classes dir="${target.classes.test.dir}"/>
<lib dir="project.classpath"/>
</cactifywar>
</target>
6、运行测试cactus提供了cactus和RunServerTests两个task来运行测试。
"cactus" task是通过复制容器服务器的最小文件并运行来运行测试,因此需要制定容器服务器的类型,启动速度稍快点,另外配置比较方便,但是无法测试象tomcat连接池等资源。另外对tomcat5.5的支持也不好。
"RunServerTests"是通过直接启动容器服务起来运行测试,因此速度稍慢,且配置较麻烦,但能测试各种资源。
<target name="test" depends="test.prepare"
description="Run tests on Tomcat ">
<!-- Start the servlet engine, wait for it to be started, run the
unit tests, stop the servlet engine, wait for it to be stopped.
The servlet engine is stopped if the tests fail for any reason -->
<!-- 8080是服务器的端口号,${project.name}-cactified是项目的路径,和上一步的cactifywar 的destfile相对应 -->
<runservertests
testURL="http://localhost:8080/${project.name}-cactified/ServletRedirector?Cactus_Service=RUN_TEST"
startTarget="_StartTomcat"
stopTarget="_StopTomcat"
testTarget="_Test"/>
</target>
<!-- _Test就是一个普通的junit任务 -->
<target name="_Test">
<junit printsummary="yes" fork="yes">
<classpath>
<path refid="project.classpath"/>
<pathelement location="${target.classes.java.dir}"/>
<pathelement location="${target.classes.test.dir}"/>
</classpath>
<formatter type="brief" usefile="false"/>
<formatter type="xml"/>
<batchtest>
<fileset dir="${src.test.dir}">
<!-- Due to some Cactus synchronization bug, the 'unit' tests need
to run before the 'sample' tests -->
<include name="**/Test*.java"/>
<exclude name="**/Test*All.java"/>
</fileset>
</batchtest>
</junit>
</target>
摘要: Techniques for building resilient, relocatable, multithreaded JUnit tests一项灵活的、可重定位的多线程JUnit测试技术 作者 Andy Schneider译者 雷云飞 javawebstart Barret gstian [AKA]校对 gstian [AKA]Summary摘要 Extreme Programming's ...
阅读全文
|
|
|
|
Cactus简介
. 简介
Cactus实现了对JUnit测试框架的无缝扩展,可以方便地测试服务端应用程序。Cactus可以在下面几种情况下使用:
- 测试Servlet以及任何使用了像HttpServletRequest,HttpServletResponse,……这样的对象的代码。使用ServletTestCase。
- 测试Filter以及任何使用了像FilterConfig,……这样的对象的代码。使用FilterTestCase。
- 测试JSP 。使用ServletTestCase或JspTestCase。
- 测试Taglibs以及任何使用了像PageContext,……这样的对象的代码。使用JspTestCase。
- 测试EJB。ServletTestCase或JspTestCase或FilterTestCase。
Cactus的使用也是非常简单的,你写的测试类只需继承ServletTestCase或者JspTestCase、FilterTestCase(它们都继承了JUnit的TestCase)。写好测试代码后需要启动web容器,然后执行测试代码。在下面的章节中我们将通过例子向你详细讲解。
Cactus项目Apache Jakarta Commons的一个子项目,网址是:http://jakarta.apache.org/commons/cactus/。
. TestCase框架
在Cactus下,我们写的TestCase与JUnit有所不同,先看一段代码,如下: public class TestSample extendsServletTestCase/JspTestCase/FilterTestCase { public TestSample (String testName) { super(testName); } public void setUp() { } public void tearDown() { } public void beginXXX(WebRequest theRequest) { } public void testXXX() { } public void endXXX(WebResponse theResponse) { } 上面是一个Cactus测试类的完整代码框架,其中的extends部分需要按你所测试的不同目标来继承不同的类(简介中有所描述)。 另外我们注意到两个新的方法beginXXX和endXXX的,这两个方法分别会在testXXX执行前和执行后执行,它们和setUp、tearDown不同的是beginXXX和endXXX会在相应的testXXX前执行,而setUp和tearDown则在每个testXXX方法前都会执行。另外beginXXX和endXXX是客户端代码,所以在这两个方法里是无法使用request这样的服务端对象的。 对于endXXX方法需要另加说明的是,在Cactus v1.1前(包括v1.1),它的形式是这样的public void endXXX(HttpURLConnection theConnection),而在Cactus v1.2开始它的形式有两种可能: - public void endXXX(org.apache.cactus.WebResponse theResponse);
- public void endXXX(com.meterware.httpunit.WebResponse theResponse);
可以看到区别在于引用的包不同,为什么会这样的呢?因为在v1.2开始Cactus集成了HttpUnit这个组件。如果你熟悉HttpUnit这个组件,我想应该明白为什么要集成HttpUnit。下面我们来看一段代码开比较一下两者的区别: public void endXXX(org.apache.cactus.WebResponse theResponse) { String content = theResponse.getText(); assertEquals(content, "<html><body><h1>Hello world!</h1></body></html>"); } public void endXXX(com.meterware.httpunit.WebResponse theResponse) { WebTable table = theResponse.getTables()[0]; assertEquals("rows", 4, table.getRowCount()); assertEquals("columns", 3, table.getColumnCount()); assertEquals("links", 1, table.getTableCell(0, 2).getLinks().length); } 当然,在实际应用中你需要根据不同的需要来选择不同的endXXX。两个WebResponse的差别可以参见两者各自的API Doc,这里就不再多说了。 如何在Cactus里写测试 . 写测试代码 首先,我们给出被测类的代码,是一个Servlet: public class SampleServlet extends HttpServlet { public void doGet(HttpServletRequest theRequest, HttpServletResponse theResponse) throws IOException { PrintWriter pw = theResponse.getWriter(); theResponse.setContentType("text/html"); pw.print("<html><head/><body>"); pw.print("A GET request"); pw.print("</body></html>"); } public String checkMethod(HttpServletRequest theRequest) { return theRequest.getMethod(); } } Cactus中的测试类框架已经在上面给出。下面来看一下例子,例子是从中Cactus自带的实例中抽取的一部分,如下: public class TestSampleServlet extends ServletTestCase { public void testReadServletOutputStream() throws IOException { SampleServlet servlet = new SampleServlet(); servlet.doGet(request, response); } public void endReadServletOutputStream(WebResponse theResponse) throws IOException { String expected = "<html><head/><body>A GET request</body></html>"; String result = theResponse.getText(); assertEquals(expected, result); } public void beginPostMethod(WebRequest theRequest) { theRequest.addParameter("param", "value", WebRequest.POST_METHOD); } public void testPostMethod() { SampleServlet servlet = new SampleServlet(); assertEquals("POST", servlet.checkMethod(request)); assertEquals("value", request.getParameter("param")); } } 第一个方法testReadServletOutputStream,调用doGet,相当于在客户端提交请求,然后在Servlet处理后会产生一个回馈,所以,在endReadServletOutputStream方法里,我们通过调用response的相应方法判断回馈是否符合预期结果。 第二个方法testPostMethod,在这之前有一个beginPostMethod,在这个方法里我们以POST方式往request里增加一个表单数据param,值为”value”。下面在testPostMethod我们就要验证表单数据是否以POST方式提交到了服务端的Servlet里,所以,我们看到了两个assertEquals,分别进行了判断。在这里我们要注意到beginPostMethod方法中的theRequest和testPostMethod中的request的区别,在前面我们已经提到过,beginPostMethod是在客户端执行的,所以它方法内的所有操作事实上是模拟页面操作的,比如上面的设置表单数据,而testPostMethod是服务端执行的,其中的request也是服务端的。 配置cactus.properties和web.xmlcactus.properties 这个属性是必须的,它指定了web应用的访问地址 例:cactus.contextURL = http://localhost:8080/test - cactus.servletRedirectorName
可选,当测试类继承ServletTestCase时用于指定Cactus Servlet Redirector的映射名称。默认:ServletRedirector 例:cactus.servletRedirectorName = ServletRedirector 可选,当测试类继承ServletTestCase时用于指定Cactus Jsp Redirector的映射名称。默认:ServletRedirector 例:cactus.jspRedirectorName = JspRedirector 可选,当测试类继承ServletTestCase时用于指定Cactus Filter Redirector的映射名称。默认:ServletRedirector 例:cactus.filterRedirectorName = FilterRedirector Cactus.properties你可以放置在WEB-INF/classes/下。 web.xml 在web.xml里要为相应的测试类指定相应的Cactus Redirector。 ServletTestCase对应org.apache.cactus.server.ServletTestRedirector JspTestCase对应/jspRedirector.jsp FilterTestCase对应org.apache.cactus.server.FilterTestRedirector <web-app> <filter> <filter-name>FilterRedirector</filter-name> <filter-class>org.apache.cactus.server.FilterTestRedirector</filter-class> </filter> <filter-mapping> <filter-name>FilterRedirector</filter-name> <url-pattern>/FilterRedirector</url-pattern> </filter-mapping> <servlet> <servlet-name>ServletRedirector</servlet-name> <servlet-class>org.apache.cactus.server.ServletTestRedirector</servlet-class> </servlet> <servlet> <servlet-name>JspRedirector</servlet-name> <jsp-file>/jspRedirector.jsp</jsp-file> </servlet> <servlet-mapping> <servlet-name>ServletRedirector</servlet-name> <url-pattern>/ServletRedirector</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>JspRedirector</servlet-name> <url-pattern>/JspRedirector</url-pattern> </servlet-mapping> </web-app> 如果你的测试类继承了JspTestCase则需要将jspRedirector.jsp文件放置到你在web.xml中指定的路径里。 安装说明 - 在使用Cactus时,strutstest.jar还需要有下列包的支持。包可放置在WEB-INF/lib下
如下: junit.jar servlet.jar cactus.jar httpclient.jar commons-logging.jar httpunit.jar,Tidy.jar,xerces.jar(可选,如果你集成了httpunit的话就需要,也就是在endXXX中使用了httpunit) cactus.jar junit.jar aspectjrt.jar commons-logging.jar - 写好测试代码后将class放置在WEB-INF/classes下
- 被测代码也放置在WEB-INF/classes下
- 写好cactus.properties和web.xml两个配置文件
- 启动web容器
- 运行测试代码
|
Java数据库连接(JDBC)由一组用 Java 编程语言编写的类和接口组成。JDBC 为工具/数据库开发人员提供了一个标准的 API,使他们能够用纯Java API 来编写数据库应用程序。然而各个开发商的接口并不完全相同,所以开发环境的变化会带来一定的配置变化。本文主要集合了不同数据库的连接方式。
一、连接各种数据库方式速查表 下面罗列了各种数据库使用JDBC连接的方式,可以作为一个手册使用。
1、Oracle8/8i/9i数据库(thin模式)
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
String url="jdbc:oracle:thin:@localhost:1521:orcl"; //orcl为数据库的SID
String user="test";
String password="test";
Connection conn= DriverManager.getConnection(url,user,password); |
2、DB2数据库
Class.forName("com.ibm.db2.jdbc.app.DB2Driver ").newInstance();
String url="jdbc:db2://localhost:5000/sample"; //sample为你的数据库名
String user="admin";
String password="";
Connection conn= DriverManager.getConnection(url,user,password); |
3、Sql Server7.0/2000数据库
Class.forName("com.microsoft.jdbc.sqlserver.SQLServerDriver").newInstance();
String url="jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=mydb";
//mydb为数据库
String user="sa";
String password="";
Connection conn= DriverManager.getConnection(url,user,password); |
4、Sybase数据库
Class.forName("com.sybase.jdbc.SybDriver").newInstance();
String url =" jdbc:sybase:Tds:localhost:5007/myDB";//myDB为你的数据库名
Properties sysProps = System.getProperties();
SysProps.put("user","userid");
SysProps.put("password","user_password");
Connection conn= DriverManager.getConnection(url, SysProps); |
5、Informix数据库
Class.forName("com.informix.jdbc.IfxDriver").newInstance();
String url = "jdbc:informix-sqli://123.45.67.89:1533/myDB:INFORMIXSERVER=myserver;
user=testuser;password=testpassword"; //myDB为数据库名
Connection conn= DriverManager.getConnection(url); |
6、MySQL数据库
Class.forName("org.gjt.mm.mysql.Driver").newInstance();
String url ="jdbc:mysql://localhost/myDB?user=soft&password=soft1234&useUnicode=true&characterEncoding=8859_1"
//myDB为数据库名
Connection conn= DriverManager.getConnection(url); |
7、PostgreSQL数据库
Class.forName("org.postgresql.Driver").newInstance();
String url ="jdbc:postgresql://localhost/myDB" //myDB为数据库名
String user="myuser";
String password="mypassword";
Connection conn= DriverManager.getConnection(url,user,password); |
8、access数据库直连用ODBC的
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver") ;
String url="jdbc:odbc:Driver={MicroSoft Access Driver (*.mdb)};DBQ="+application.getRealPath("/Data/ReportDemo.mdb");
Connection conn = DriverManager.getConnection(url,"","");
Statement stmtNew=conn.createStatement() ; |
二、JDBC连接MySql方式 下面是使用JDBC连接MySql的一个小的教程
1、查找驱动程序
MySQL目前提供的java驱动程序为Connection/J,可以从MySQL官方网站下载,并找到mysql-connector-java-3.0.15-ga-bin.jar文件,此驱动程序为纯java驱动程序,不需做其他配置。
2、动态指定classpath
如果需要执行时动态指定classpath,就在执行时采用-cp方式。否则将上面的.jar文件加入到classpath环境变量中。
3、加载驱动程序
try{
Class.forName(com.mysql.jdbc.Driver);
System.out.println(Success loading Mysql Driver!);
}catch(Exception e)
{
System.out.println(Error loading Mysql Driver!);
e.printStackTrace();
} |
4、设置连接的url
| jdbc:mysql://localhost/databasename[?pa=va][&pa=va] |
三、以下列出了在使用JDBC来连接Oracle数据库时可以使用的一些技巧
1、在客户端软件开发中使用Thin驱动程序
在开发Java软件方面,Oracle的数据库提供了四种类型的驱动程序,二种用于应用软件、applets、servlets等客户端软件,另外二种用于数据库中的Java存储过程等服务器端软件。在客户机端软件的开发中,我们可以选择OCI驱动程序或Thin驱动程序。OCI驱动程序利用Java本地化接口(JNI),通过Oracle客户端软件与数据库进行通讯。Thin驱动程序是纯Java驱动程序,它直接与数据库进行通讯。为了获得最高的性能,Oracle建议在客户端软件的开发中使用OCI驱动程序,这似乎是正确的。但我建议使用Thin驱动程序,因为通过多次测试发现,在通常情况下,Thin驱动程序的性能都超过了OCI驱动程序。
2、关闭自动提交功能,提高系统性能
在第一次建立与数据库的连接时,在缺省情况下,连接是在自动提交模式下的。为了获得更好的性能,可以通过调用带布尔值false参数的Connection类的setAutoCommit()方法关闭自动提交功能,如下所示:
conn.setAutoCommit(false);
值得注意的是,一旦关闭了自动提交功能,我们就需要通过调用Connection类的commit()和rollback()方法来人工的方式对事务进行管理。
3、在动态SQL或有时间限制的命令中使用Statement对象
在执行SQL命令时,我们有二种选择:可以使用PreparedStatement对象,也可以使用Statement对象。无论多少次地使用同一个SQL命令,PreparedStatement都只对它解析和编译一次。当使用Statement对象时,每次执行一个SQL命令时,都会对它进行解析和编译。这可能会使你认为,使用PreparedStatement对象比使用Statement对象的速度更快。然而,我进行的测试表明,在客户端软件中,情况并非如此。因此,在有时间限制的SQL操作中,除非成批地处理SQL命令,我们应当考虑使用Statement对象。
此外,使用Statement对象也使得编写动态SQL命令更加简单,因为我们可以将字符串连接在一起,建立一个有效的SQL命令。因此,我认为,Statement对象可以使动态SQL命令的创建和执行变得更加简单。
4、利用helper函数对动态SQL命令进行格式化
在创建使用Statement对象执行的动态SQL命令时,我们需要处理一些格式化方面的问题。例如,如果我们想创建一个将名字O'Reilly插入表中的SQL命令,则必须使用二个相连的“''”号替换O'Reilly中的“'”号。完成这些工作的最好的方法是创建一个完成替换操作的helper方法,然后在连接字符串心服用公式表达一个SQL命令时,使用创建的helper方法。与此类似的是,我们可以让helper方法接受一个Date型的值,然后让它输出基于Oracle的to_date()函数的字符串表达式。
5、利用PreparedStatement对象提高数据库的总体效率
在使用PreparedStatement对象执行SQL命令时,命令被数据库进行解析和编译,然后被放到命令缓冲区。然后,每当执行同一个PreparedStatement对象时,它就会被再解析一次,但不会被再次编译。在缓冲区中可以发现预编译的命令,并且可以重新使用。在有大量用户的企业级应用软件中,经常会重复执行相同的SQL命令,使用PreparedStatement对象带来的编译次数的减少能够提高数据库的总体性能。如果不是在客户端创建、预备、执行PreparedStatement任务需要的时间长于Statement任务,我会建议在除动态SQL命令之外的所有情况下使用PreparedStatement对象。
6、在成批处理重复的插入或更新操作中使用PreparedStatement对象
如果成批地处理插入和更新操作,就能够显著地减少它们所需要的时间。Oracle提供的Statement和 CallableStatement并不真正地支持批处理,只有PreparedStatement对象才真正地支持批处理。我们可以使用addBatch()和executeBatch()方法选择标准的JDBC批处理,或者通过利用PreparedStatement对象的setExecuteBatch()方法和标准的executeUpdate()方法选择速度更快的Oracle专有的方法。要使用Oracle专有的批处理机制,可以以如下所示的方式调用setExecuteBatch():
PreparedStatement pstmt3D null;
try {
((OraclePreparedStatement)pstmt).setExecuteBatch(30);
...
pstmt.executeUpdate();
} |
调用setExecuteBatch()时指定的值是一个上限,当达到该值时,就会自动地引发SQL命令执行,标准的executeUpdate()方法就会被作为批处理送到数据库中。我们可以通过调用PreparedStatement类的sendBatch()方法随时传输批处理任务。
7、使用Oracle locator方法插入、更新大对象(LOB)
Oracle的PreparedStatement类不完全支持BLOB和CLOB等大对象的处理,尤其是Thin驱动程序不支持利用PreparedStatement对象的setObject()和setBinaryStream()方法设置BLOB的值,也不支持利用setCharacterStream()方法设置CLOB的值。只有locator本身中的方法才能够从数据库中获取LOB类型的值。可以使用PreparedStatement对象插入或更新LOB,但需要使用locator才能获取LOB的值。由于存在这二个问题,因此,我建议使用locator的方法来插入、更新或获取LOB的值。
8、使用SQL92语法调用存储过程
在调用存储过程时,我们可以使用SQL92或Oracle PL/SQL,由于使用Oracle PL/SQL并没有什么实际的好处,而且会给以后维护你的应用程序的开发人员带来麻烦,因此,我建议在调用存储过程时使用SQL92。
9、使用Object SQL将对象模式转移到数据库中
既然可以将Oracle的数据库作为一种面向对象的数据库来使用,就可以考虑将应用程序中的面向对象模式转到数据库中。目前的方法是创建Java bean作为伪装的数据库对象,将它们的属性映射到关系表中,然后在这些bean中添加方法。尽管这样作在Java中没有什么问题,但由于操作都是在数据库之外进行的,因此其他访问数据库的应用软件无法利用对象模式。如果利用Oracle的面向对象的技术,可以通过创建一个新的数据库对象类型在数据库中模仿其数据和操作,然后使用JPublisher等工具生成自己的Java bean类。如果使用这种方式,不但Java应用程序可以使用应用软件的对象模式,其他需要共享你的应用中的数据和操作的应用软件也可以使用应用软件中的对象模式。
10、利用SQL完成数据库内的操作
我要向大家介绍的最重要的经验是充分利用SQL的面向集合的方法来解决数据库处理需求,而不是使用Java等过程化的编程语言。
如果编程人员要在一个表中查找许多行,结果中的每个行都会查找其他表中的数据,最后,编程人员创建了独立的UPDATE命令来成批地更新第一个表中的数据。与此类似的任务可以通过在set子句中使用多列子查询而在一个UPDATE命令中完成。当能够在单一的SQL命令中完成任务,何必要让数据在网上流来流去的?我建议用户认真学习如何最大限度地发挥SQL的功能。
<?xml version="1.0" encoding="utf-8"?>
<project name="利用工具开发Hibernate" default="help" basedir=".">
<!-- ****** 环境设置,可以根据自己的实际配置自行更改 ***** -->
<!-- ****** http://blog.csdn.net/fasttalk ***** -->
<!-- ****** http://www.blogjava.net/asktalk ***** -->
<!-- 源文件目录, 可以通过 项目->属性->Java构建路径 更改 -->
<property name="src.dir" value="./src" />
<!-- 输出的class文件目录,可以通过 项目->属性->Java构建路径 更改 -->
<property name="class.dir" value="./bin" />
<!-- 库文件目录 -->
<property name="lib.dir" value="E:/workspace/java/hibernate3" />
<!-- 定义类路径 -->
<path id="project.class.path">
<fileset dir="${lib.dir}">
<include name="*.jar"/>
</fileset>
<pathelement location="${class.dir}" />
</path>
<!-- ************************************************************** -->
<!-- 使用说明 -->
<!-- ************************************************************** -->
<target name="help">
<echo message="利用工具开发Hibernate" />
<echo message="-----------------------------------" />
<echo message="" />
<echo message="提供以下任务:" />
<echo message="" />
<echo message="generate-hbm --> 运行HibernateDoclet,生成 Hibernate 类的映射文件" />
<echo message="schemaexport --> 运行SchemaExport,利用 hbm.xml 文件生成数据表" />
<echo message="" />
</target>
<!-- ************************************************************** -->
<!-- Hbm2Java 任务 在hibernate3中无法实现 -->
<!-- ************************************************************** -->
<target name="generate-code" >
<echo message="运行 Hbm2Java 任务, 利用 hbm.xml 文件生成Java类文件"/>
<taskdef name="hbm2java"
classname="org.hibernate.tool.instrument.InstrumentTask"
classpathref="project.class.path">
</taskdef>
<hbm2java output="${src.dir}">
<fileset dir="${src.dir}">
<include name="**/*.hbm.xml"/>
</fileset>
</hbm2java>
</target>
<!-- ************************************************************** -->
<!-- HibernateDoclet 任务 -->
<!-- ************************************************************** -->
<target name="generate-hbm" >
<echo message="运行HibernateDoclet,生成 Hibernate 类的映射文件"/>
<taskdef name="hibernatedoclet"
classname="xdoclet.modules.hibernate.HibernateDocletTask"
classpathref="project.class.path">
</taskdef>
<!--
destdir 输出目录;
force, 每次都强行执行,覆盖原有文件;
-->
<hibernatedoclet destdir="${src.dir}"
excludedtags="@version,@author,@todo" force="true" encoding="GBK"
verbose="true">
<fileset dir="${src.dir}">
<include name="**/*.java"/>
</fileset>
<hibernate version="3.0" xmlencoding="utf-8" />
</hibernatedoclet>
</target>
<!-- ************************************************************** -->
<!-- SchemaExport 任务 -->
<!-- ************************************************************** -->
<target name="schemaexport">
<echo message="运行SchemaExport,利用 hbm.xml 文件生成数据表"/>
<taskdef name="schemaexport"
classname="org.hibernate.tool.hbm2ddl.SchemaExportTask"
classpathref="project.class.path">
</taskdef>
<!--
quiet=true 不要把脚本输出到stdout;
drop=true 只进行drop tables的步骤 ;
text=true 不执行在数据库中运行的步骤 ;
output=my_schema.ddl 把输出的ddl脚本输出到一个文件 ;
config=hibernate.cfg.xml 从XML文件读入Hibernate配置 ;
properties=hibernate.properties 从文件读入数据库属性 ;
format=true 把脚本中的SQL语句对齐和美化 ;
delimiter=x 为脚本设置行结束符
-->
<schemaexport properties="src/hibernate.properties"
quiet="no" text="no" drop="no" output="schema-export.sql" >
<fileset dir="${src.dir}">
<include name="**/*.hbm.xml"/>
</fileset>
</schemaexport>
</target>
</project>
Ajax目前是社区内最热门的话题之一了,最近在我们的项目中用了大量的Ajax,现在把我们的使用方法在这儿写出来,希望大家能指教。
因为要用到Ajax就肯定要用到XMLHttpRequest对象,但由于不同的浏览器版本,相应的生成它的方法也有所不同,所以我们不得不对浏览器的版本进行判断,试想,如果我们要在很多地方都要写那些繁琐的代码会觉的很麻烦,代码的重用也很低,所以我们写一个Ajax的对象。代码如下:
//*********************************************************
// 目的: AJAX类
// 输入: 无
// 返回: 返回XMLHttp对象
// 例子: var myConn = new XHConn();
//
// if (!myConn) alert("XMLHTTP not available. Try a newer/better browser.");
//
// var fnWhenDone = function (oXML) { alert(oXML.responseText); };
//
// myConn.connect("mypage.php", "POST", "foo=bar&baz=qux", fnWhenDone);
//
//*********************************************************
function XHConn()
{
var xmlhttp = false, bComplete = false;
try
{
xmlhttp = new ActiveXObject("Msxml2.XMLHTTP");
}
catch (e)
{
try
{
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
catch (e)
{
try
{
xmlhttp = new XMLHttpRequest();
}
catch (e)
{
xmlhttp = false;
}
}
}
if (!xmlhttp) return null;
this.connect = function(sURL, sMethod, sVars, fnDone)
{
if (!xmlhttp) return false;
bComplete = false;
sVars = (sVars == '') ? Math.random() : sVars + "&" + Math.random();
sMethod = sMethod.toUpperCase();
try
{
if (sMethod == "GET")
{
xmlhttp.open(sMethod, sURL+"?"+sVars, true);
xmlhttp.setRequestHeader("Content-Type", "text/html;charset=GB2312");
sVars = "";
}
else
{
xmlhttp.open(sMethod, sURL, true);
xmlhttp.setRequestHeader("Method", "POST "+sURL+" HTTP/1.1");
xmlhttp.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
}
xmlhttp.onreadystatechange = function()
{
if (xmlhttp.readyState == 4 && !bComplete)
{
bComplete = true;
fnDone(xmlhttp);
}
};
xmlhttp.send(sVars);
}
catch(z)
{
return false;
}
return true;
};
return this;
}
通过这个对象,我们把那些繁琐的代码都封装到里面,这样大大提高了代码的重用性,每次要用Ajax时我们只需要在我们的页面上 new一个XHConn()对象就行了,然后通过调用它的方法connect(sURL, sMethod, sVars, fnDone)就可以和服务器进行异步交互了。
|
|
|
|
Java虚拟机(JVM)是可运行Java代码的假想计算机。只要根据JVM规格描述将解释器移植到特定的计算机上,就能保证经过编译的任何Java代码能够在该系统上运行。本文首先简要介绍从Java文件的编译到最终执行的过程,随后对JVM规格描述作一说明。
一.Java源文件的编译、下载、解释和执行
Java应用程序的开发周期包括编译、下载、解释和执行几个部分。Java编译程序将Java源程序翻译为JVM可执行代码—字节码。这一编译过程同C/C++的编译有些不同。当C编译器编译生成一个对象的代码时,该代码是为在某一特定硬件平台运行而产生的。因此,在编译过程中,编译程序通过查表将所有对符号的引用转换为特定的内存偏移量,以保证程序运行。Java编译器却不将对变量和方法的引用编译为数值引用,也不确定程序执行过程中的内存布局,而是将这些符号引用信息保留在字节码中,由解释器在运行过程中创立内存布局,然后再通过查表来确定一个方法所在的地址。这样就有效的保证了Java的可移植性和安全性。
运行JVM字节码的工作是由解释器来完成的。解释执行过程分三部进行:代码的装入、代码的校验和代码的执行。装入代码的工作由"类装载器"(class loader)完成。类装载器负责装入运行一个程序需要的所有代码,这也包括程序代码中的类所继承的类和被其调用的类。当类装载器装入一个类时,该类被放在自己的名字空间中。除了通过符号引用自己名字空间以外的类,类之间没有其他办法可以影响其他类。在本台计算机上的所有类都在同一地址空间内,而所有从外部引进的类,都有一个自己独立的名字空间。这使得本地类通过共享相同的名字空间获得较高的运行效率,同时又保证它们与从外部引进的类不会相互影响。当装入了运行程序需要的所有类后,解释器便可确定整个可执行程序的内存布局。解释器为符号引用同特定的地址空间建立对应关系及查询表。通过在这一阶段确定代码的内存布局,Java很好地解决了由超类改变而使子类崩溃的问题,同时也防止了代码对地址的非法访问。
随后,被装入的代码由字节码校验器进行检查。校验器可发现操作数栈溢出,非法数据类型转化等多种错误。通过校验后,代码便开始执行了。
Java字节码的执行有两种方式:
1.即时编译方式:解释器先将字节码编译成机器码,然后再执行该机器码。
2.解释执行方式:解释器通过每次解释并执行一小段代码来完成Java字节码程 序的所有操作。
通常采用的是第二种方法。由于JVM规格描述具有足够的灵活性,这使得将字节码翻译为机器代码的工作具有较高的效率。对于那些对运行速度要求较高的应用程序,解释器可将Java字节码即时编译为机器码,从而很好地保证了Java代码的可移植性和高性能。 二.JVM规格描述
JVM的设计目标是提供一个基于抽象规格描述的计算机模型,为解释程序开发人员提很好的灵活性,同时也确保Java代码可在符合该规范的任何系统上运行。JVM对其实现的某些方面给出了具体的定义,特别是对Java可执行代码,即字节码(Bytecode)的格式给出了明确的规格。这一规格包括操作码和操作数的语法和数值、标识符的数值表示方式、以及Java类文件中的Java对象、常量缓冲池在JVM的存储映象。这些定义为JVM解释器开发人员提供了所需的信息和开发环境。Java的设计者希望给开发人员以随心所欲使用Java的自由。
JVM定义了控制Java代码解释执行和具体实现的五种规格,它们是:
JVM指令系统
JVM寄存器
JVM栈结构
JVM碎片回收堆
JVM存储区
2.1JVM指令系统
JVM指令系统同其他计算机的指令系统极其相似。Java指令也是由 操作码和操作数两部分组成。操作码为8位二进制数,操作数进紧随在操作码的后面,其长度根据需要而不同。操作码用于指定一条指令操作的性质(在这里我们采用汇编符号的形式进行说明),如iload表示从存储器中装入一个整数,anewarray表示为一个新数组分配空间,iand表示两个整数的"与",ret用于流程控制,表示从对某一方法的调用中返回。当长度大于8位时,操作数被分为两个以上字节存放。JVM采用了"big endian"的编码方式来处理这种情况,即高位bits存放在低字节中。这同 Motorola及其他的RISC CPU采用的编码方式是一致的,而与Intel采用的"little endian "的编码方式即低位bits存放在低位字节的方法不同。
Java指令系统是以Java语言的实现为目的设计的,其中包含了用于调用方法和监视多先程系统的指令。Java的8位操作码的长度使得JVM最多有256种指令,目前已使用了160多种操作码。
2.2JVM指令系统
所有的CPU均包含用于保存系统状态和处理器所需信息的寄存器组。如果虚拟机定义较多的寄存器,便可以从中得到更多的信息而不必对栈或内存进行访问,这有利于提高运行速度。然而,如果虚拟机中的寄存器比实际CPU的寄存器多,在实现虚拟机时就会占用处理器大量的时间来用常规存储器模拟寄存器,这反而会降低虚拟机的效率。针对这种情况,JVM只设置了4个最为常用的寄存器。它们是:
pc程序计数器
optop操作数栈顶指针
frame当前执行环境指针
vars指向当前执行环境中第一个局部变量的指针
所有寄存器均为32位。pc用于记录程序的执行。optop,frame和vars用于记录指向Java栈区的指针。
2.3JVM栈结构
作为基于栈结构的计算机,Java栈是JVM存储信息的主要方法。当JVM得到一个Java字节码应用程序后,便为该代码中一个类的每一个方法创建一个栈框架,以保存该方法的状态信息。每个栈框架包括以下三类信息:
局部变量
执行环境
操作数栈
局部变量用于存储一个类的方法中所用到的局部变量。vars寄存器指向该变量表中的第一个局部变量。
执行环境用于保存解释器对Java字节码进行解释过程中所需的信息。它们是:上次调用的方法、局部变量指针和操作数栈的栈顶和栈底指针。执行环境是一个执行一个方法的控制中心。例如:如果解释器要执行iadd(整数加法),首先要从frame寄存器中找到当前执行环境,而后便从执行环境中找到操作数栈,从栈顶弹出两个整数进行加法运算,最后将结果压入栈顶。
操作数栈用于存储运算所需操作数及运算的结果。
2.4JVM碎片回收堆
Java类的实例所需的存储空间是在堆上分配的。解释器具体承担为类实例分配空间的工作。解释器在为一个实例分配完存储空间后,便开始记录对该实例所占用的内存区域的使用。一旦对象使用完毕,便将其回收到堆中。
在Java语言中,除了new语句外没有其他方法为一对象申请和释放内存。对内存进行释放和回收的工作是由Java运行系统承担的。这允许Java运行系统的设计者自己决定碎片回收的方法。在SUN公司开发的Java解释器和Hot Java环境中,碎片回收用后台线程的方式来执行。这不但为运行系统提供了良好的性能,而且使程序设计人员摆脱了自己控制内存使用的风险。
2.5JVM存储区
JVM有两类存储区:常量缓冲池和方法区。常量缓冲池用于存储类名称、方法和字段名称以及串常量。方法区则用于存储Java方法的字节码。对于这两种存储区域具体实现方式在JVM规格中没有明确规定。这使得Java应用程序的存储布局必须在运行过程中确定,依赖于具体平台的实现方式。
JVM是为Java字节码定义的一种独立于具体平台的规格描述,是Java平台独立性的基础。目前的JVM还存在一些限制和不足,有待于进一步的完善,但无论如何,JVM的思想是成功的。 对比分析:如果把Java原程序想象成我们的C++原程序,Java原程序编译后生成的字节码就相当于C++原程序编译后的80x86的机器码(二进制程序文件),JVM虚拟机相当于80x86计算机系统,Java解释器相当于80x86CPU。在80x86CPU上运行的是机器码,在Java解释器上运行的是Java字节码。
Java解释器相当于运行Java字节码的“CPU”,但该“CPU”不是通过硬件实现的,而是用软件实现的。Java解释器实际上就是特定的平台下的一个应用程序。只要实现了特定平台下的解释器程序,Java字节码就能通过解释器程序在该平台下运行,这是Java跨平台的根本。当前,并不是在所有的平台下都有相应Java解释器程序,这也是Java并不能在所有的平台下都能运行的原因,它只能在已实现了Java解释器程序的平台下运行。 |
跑系统时,难免遇到了数据量大的情况,只好让爱机彻夜工作了,自己闪人。毕竟对它不放心,这时得用到日志,日志里的时间肯定是要的啦。至少得知道他什么时候罢工吧(今天一来,我电脑就在昨天不明时间罢工了!)。下面是转自一位网友的:
Java中一些关于日期、日期格式、日期的解析和日期的计算
Java 语言的Calendar(日历),Date(日期), 和DateFormat(日期格式)组成了Java标准的一个基本但是非常重要的部分. 日期是商业逻辑计算一个关键的部分. 所有的开发者都应该能够计算未来的日期, 定制日期的显示格式, 并将文本数据解析成日期对象. 我们写了两篇文章, 这是第一篇, 我们将大概的学习日期, 日期格式, 日期的解析和日期的计算.
我们将讨论下面的类:
1、具体类(和抽象类相对)java.util.Date
2、抽象类java.text.DateFormat 和它的一个具体子类,java.text.SimpleDateFormat
3、抽象类java.util.Calendar 和它的一个具体子类,java.util.GregorianCalendar
具体类可以被实例化, 但是抽象类却不能. 你首先必须实现抽象类的一个具体子类.
Date 类从Java 开发包(JDK) 1.0 就开始进化, 当时它只包含了几个取得或者设置一个日期数据的各个部分的方法, 比如说月, 日, 和年. 这些方法现在遭到了批评并且已经被转移到了Calendar类里去了, 我们将在本文中进一步讨论它. 这种改进旨在更好的处理日期数据的国际化格式. 就象在JDK 1.1中一样, Date 类实际上只是一个包裹类, 它包含的是一个长整型数据, 表示的是从GMT(格林尼治标准时间)1970年, 1 月 1日00:00:00这一刻之前或者是之后经历的毫秒数.
一、创建一个日期对象
让我们看一个使用系统的当前日期和时间创建一个日期对象并返回一个长整数的简单例子. 这个时间通常被称为Java 虚拟机(JVM)主机环境的系统时间.
//------------------------------------------------------
import java.util.Date;
public class DateExample1
{
public static void main(String[] args)
{
// Get the system date/time
Date date = new Date();
System.out.println(date.getTime());
}
}
//------------------------------------------------------
1145681088396
在星期六, 2001年9月29日, 下午大约是6:50的样子, 上面的例子在系统输出设备上显示的结果是 1001803809710. 在这个例子中,值得注意的是我们使用了Date 构造函数创建一个日期对象, 这个构造函数没有接受任何参数. 而这个构造函数在内部使用了System.currentTimeMillis() 方法来从系统获取日期.
那么, 现在我们已经知道了如何获取从1970年1月1日开始经历的毫秒数了. 我们如何才能以一种用户明白的格式来显示这个日期呢? 在这里类java.text.SimpleDateFormat 和它的抽象基类 java.text.DateFormat 就派得上用场了.
二、日期数据的定制格式
假如我们希望定制日期数据的格式, 比方星期六-9月-29日-2001年. 下面的例子展示了如何完成这个工作:
//------------------------------------------------------
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateExample2
{
public static void main(String[] args)
{
SimpleDateFormat bartDateFormat =
new SimpleDateFormat("EEEE-MMMM-dd-yyyy");
Date date = new Date();
System.out.println(bartDateFormat.format(date));
}
}
//------------------------------------------------------
星期六-四月-22-2006
只要通过向SimpleDateFormat 的构造函数传递格式字符串"EEE-MMMM-dd-yyyy", 我们就能够指明自己想要的格式. 你应该可以看见, 格式字符串中的ASCII 字符告诉格式化函数下面显示日期数据的哪一个部分. EEEE是星期, MMMM是月, dd是日, yyyy是年. 字符的个数决定了日期是如何格式化的.传递"EE-MM-dd-yy"会显示 Sat-09-29-01. 请察看Sun 公司的Web 站点获取日期格式化选项的完整的指示.
三、将文本数据解析成日期对象
假设我们有一个文本字符串包含了一个格式化了的日期对象, 而我们希望解析这个字符串并从文本日期数据创建一个日期对象. 我们将再次以格式化字符串"MM-dd-yyyy" 调用SimpleDateFormat类, 但是这一次, 我们使用格式化解析而不是生成一个文本日期数据. 我们的例子, 显示在下面, 将解析文本字符串"9-29-2001"并创建一个值为001736000000 的日期对象.
//------------------------------------------------------
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateExample3
{
public static void main(String[] args)
{
// Create a date formatter that can parse dates of
// the form MM-dd-yyyy.
SimpleDateFormat bartDateFormat =
new SimpleDateFormat("MM-dd-yyyy");
// Create a string containing a text date to be parsed.
String dateStringToParse = "9-29-2001";
try {
// Parse the text version of the date.
// We have to perform the parse method in a
// try-catch construct in case dateStringToParse
// does not contain a date in the format we are expecting.
Date date = bartDateFormat.parse(dateStringToParse);
// Now send the parsed date as a long value
// to the system output.
System.out.println(date.getTime());
}
catch (Exception ex) {
System.out.println(ex.getMessage());
}
}
}
//------------------------------------------------------
1001692800000
四、使用标准的日期格式化过程
既然我们已经可以生成和解析定制的日期格式了, 让我们来看一看如何使用内建的格式化过程. 方法 DateFormat.getDateTimeInstance() 让我们得以用几种不同的方法获得标准的日期格式化过程. 在下面的例子中, 我们获取了四个内建的日期格式化过程. 它们包括一个短的, 中等的, 长的, 和完整的日期格式.
//------------------------------------------------------
import java.text.DateFormat;
import java.util.Date;
public class DateExample4
{
public static void main(String[] args)
{
Date date = new Date();
DateFormat shortDateFormat =
DateFormat.getDateTimeInstance(
DateFormat.SHORT,
DateFormat.SHORT);
DateFormat mediumDateFormat =
DateFormat.getDateTimeInstance(
DateFormat.MEDIUM,
DateFormat.MEDIUM);
DateFormat longDateFormat =
DateFormat.getDateTimeInstance(
DateFormat.LONG,
DateFormat.LONG);
DateFormat fullDateFormat =
DateFormat.getDateTimeInstance(
DateFormat.FULL,
DateFormat.FULL);
System.out.println(shortDateFormat.format(date));
System.out.println(mediumDateFormat.format(date));
System.out.println(longDateFormat.format(date));
System.out.println(fullDateFormat.format(date));
}
}
//------------------------------------------------------
01-9-29 上午12:00
2001-9-29 0:00:00
2001年9月29日 上午12时00分00秒
2001年9月29日 星期六 上午12时00分00秒 CST
注意我们在对 getDateTimeInstance的每次调用中都传递了两个值. 第一个参数是日期风格, 而第二个参数是时间风格. 它们都是基本数据类型int(整型). 考虑到可读性, 我们使用了DateFormat 类提供的常量: SHORT, MEDIUM, LONG, 和 FULL. 要知道获取时间和日期格式化过程的更多的方法和选项, 请看Sun 公司Web 站点上的解释.
运行我们的例子程序的时候, 它将向标准输出设备输出下面的内容:
9/29/01 8:44 PM
Sep 29, 2001 8:44:45 PM
September 29, 2001 8:44:45 PM EDT
Saturday, September 29, 2001 8:44:45 PM EDT
五、Calendar 类
我们现在已经能够格式化并创建一个日期对象了, 但是我们如何才能设置和获取日期数据的特定部分呢, 比如说小时, 日, 或者分钟? 我们又如何在日期的这些部分加上或者减去值呢? 答案是使用Calendar 类. 就如我们前面提到的那样, Calendar 类中的方法替代了Date 类中被人唾骂的方法.
假设你想要设置, 获取, 和操纵一个日期对象的各个部分, 比方一个月的一天或者是一个星期的一天. 为了演示这个过程, 我们将使用具体的子类 java.util.GregorianCalendar. 考虑下面的例子, 它计算得到下面的第十个星期五是13号.
//------------------------------------------------------
import java.util.GregorianCalendar;
import java.util.Date;
import java.text.DateFormat;
public class DateExample5
{
public static void main(String[] args)
{
DateFormat dateFormat = DateFormat.getDateInstance(DateFormat.FULL);
// Create our Gregorian Calendar.
GregorianCalendar cal = new GregorianCalendar();
// Set the date and time of our calendar
// to the system&s date and time
cal.setTime(new Date());
System.out.println("System Date: " +
dateFormat.format(cal.getTime()));
System.out.println("Befor Setting Day of Week to Friday: " +
dateFormat.format(cal.getTime()));
// Set the day of week to FRIDAY
cal.set(GregorianCalendar.DAY_OF_WEEK,
GregorianCalendar.FRIDAY);
System.out.println("After Setting Day of Week to Friday: " +
dateFormat.format(cal.getTime()));
int friday13Counter = 0;
while (friday13Counter <= 10)
{
// Go to the next Friday by adding 7 days.
cal.add(GregorianCalendar.DAY_OF_MONTH, 7);
// If the day of month is 13 we have
// another Friday the 13th.
if (cal.get(GregorianCalendar.DAY_OF_MONTH) == 13)
{
friday13Counter++;
System.out.println(dateFormat.format(cal.getTime()));
}
}
}
}
//------------------------------------------------------
在这个例子中我们作了有趣的函数调用:
cal.set(GregorianCalendar.DAY_OF_WEEK,
GregorianCalendar.FRIDAY);
和:
cal.add(GregorianCalendar.DAY_OF_MONTH, 7);
set 方法能够让我们通过简单的设置星期中的哪一天这个域来将我们的时间调整为星期五. 注意到这里我们使用了常量 DAY_OF_WEEK 和 FRIDAY来增强代码的可读性. add 方法让我们能够在日期上加上数值. 润年的所有复杂的计算都由这个方法自动处理.
我们这个例子的输出结果是:
System Date: Saturday, September 29, 2001
当我们将它设置成星期五以后就成了: Friday, September 28, 2001
Friday, September 13, 2002
Friday, December 13, 2002
Friday, June 13, 2003
Friday, February 13, 2004
Friday, August 13, 2004
Friday, May 13, 2005
Friday, January 13, 2006
Friday, October 13, 2006
Friday, April 13, 2007
Friday, July 13, 2007
Friday, June 13, 2008
六、时间掌握在你的手里
有了这些Date 和Calendar 类的例子, 你应该能够使用 java.util.Date, java.text.SimpleDateFormat, 和 java.util.GregorianCalendar 创建许多方法了.
在Java中有许多的容器集合。初一看起来有些糊涂,特别是对刚接触Java来说(至少我当初就是这样的)!其实稍微细心,深入一点点就会发现原来一切都是有规律的。我想别的事情也会是如此。
Java中的容器,接口都是由一些接口,抽象类及它们的实现类所组成。而它们全部封装在java.util
包中。
1:Collection接口。
大多数的集合都实现了此接口,它基本方法是add(没有get()方法,实现类中可能有如Arrylist),添加一对象。添加成功则返回true ,否则返回false。这是与Map不同的地方。还有一些常用的方法如iterator(),size(),toArray()(注:toArray()是返回一对象----object数组,而Arrays----也是java.util下的一个类,有一个asList方法它们通常认为是各集合之间转换的桥梁)等等!具体用法可以参考API文档。
2:Map(映射)
Map接口跟Collection接口实际上没有半点关系。集合中的每一个元素都包含一对键对对象和值对象,集合中没有重复的键对象,值对象可以重复。它的有些实现类能对集合中的键对象进行排序。与Collection截然不同的是,它其中所存取的是一些值与名相对应的数据。也就是一个Key对应一个Value的方式来存储。所以它就有与之对应的一些方法如:put (K key, V value)等等,更多可以参考API文档。
3:List(列表)
集合中的对象按索引位置排序,可以有重复对象,允许按照对象在集合中的索引位置检索对象
4:Set(集)
集合中的对象中按特定的方式排序,并且没有重复对象。它的有些实现类能对集合中的对象
按特定的方式排序
5:迭代器:Iterator
它是一个接口,只有三个方法hasnext(),next(),remove()只有最后一个是可选的,也就是remove()是可选(在实现的时候)。其可选性也意味着它的实现类中,remove方法是可有可无的。例如,若有一个如下的List 实例。
Arrylist al
=
new
Arrylist();
Object[] ob
=
al.toArray();
List list
=
Arrays.asList(ob);
Iterator itor
=
list.iterator();
itor.remove();
//
Error
当调用Ierator itr = list.iterator()方法返回一迭代器的时候,便不支持remove方法,所以当你再使用irt.remove()时程序就是异常!
使用此迭代器要注意的是remove()方法。它所删除的是指指针(暂这么叫着)上次所移经过的位置(Removes from the underlying collection the last element returned by the iterator (optional operation).)。我个人觉得有点象在JDBC中的ResultSet rs = ....;rs.last();rowsCount=rs.getRow();类似呢。
前面所讲的,由于clollection提供了iterator()方法,所以迭代器是很容易实现的!
6:常用实现类的一些继承关系:
Collections,它是Java.util下的一个类。它为我们提供了许多有用的方法,如sort(...),max()等其具体用法可以参考API文档,比如sort(List list);中list内的所有元素都必须实现Comparable接口(All elements in the list must implement the Comparable interface)。
Arrylist,它是List接口的实现类,而List则是继承于Collection。
LinkedList,它也是间接对Colections的实现。用linkedlist的一些方法如addfirst(),removefirst(),addlast()等等可以用来实现如C中的堆栈,链表。(对于频繁使用插入与删除操作使用linkedlist是个不错的选择,对于经常进行索引操作则arrylist较好)。 HashSet(散列表),它实现了Set接口,也就意味着它的元素不能有重复值出现。并且在HashSet中没有get()方法,但可以通过iterator()来实现。要注意的是假如要在HasSet中存放一些对象,那么你得重定义hashCode()与equals()二个方法来保不可以存放相同的内容的元素。对于hashcode()所返回的值,hashset用它来计算(通过特定的函数)该对象在内存中的存放位置;后者主要用来判断二个对象的内容是否相等而返回对应的boolen型。
TreeSet,主要用来对元素进行排序操作,假如要往其中添加对象,则对象得实现Comparable接口。(假如不要对元素排序,则一般可选用HashSet)。
HashMap,主要特点是存放的一个键值对,一些有用的方法是可返回视图(我觉得可以把它理解为一个集合)如:keyset(),values(),entyset()等。
TreeMap,它与HashMap差不多,不过是增加了对元素的排序功能,所以运行速度也就当然没有hashmap来得快了。
以下是HashMap的一个实例(在对DB进行操作的时候很有用):
HashMap valueMap;
//this function just get key-value form DB ,defined by yourself
valueMap = commondb.getElementStringValues("COMMENT_ID", "content");
java.util.Set tempkeys = valueMap.entrySet();
java.util.Iterator keys = tempkeys.iterator();
while(keys.hasNext())
{
java.util.Map.Entry me=(java.util.Map.Entry)keys.next();
String value = me.getValue();
int key = me.getKey();
}
要注意的是entrySet()所返回的每一个元素都是Map.Entry类型的!(Returns a collection view of the mappings contained in this map. Each element in the returned collection is a Map.Entry.) Properties,继承于hashtable。这个东东相信我们比较的喜欢了(在i18n,ant中可以是常见得很),呵呵。它可以从外部导入属性文件。文件中的键值都是String类型。just like this:
company=study
author=Jkallen
copyright=2005-2006 操作如下:
import java.util.*;
import java.io.*;
class PropTest
{
public static void main(String[] args)
{
/**//*Properties pps=System.getProperties();
pps.list(System.out);*/
Properties pps=new Properties();
try
{
pps.load(new FileInputStream("winsun.ini"));
Enumeration enum=pps.propertyNames();
while(enum.hasMoreElements())
{
String strKey=(String)enum.nextElement();
String strValue=pps.getProperty(strKey);
System.out.println(strKey+"="+strValue);
}
}
catch(Exception e)
{
e.printStackTrace();
}
}
} 其用法可以查看API文档呢。
Java中的集合容器确实不少呢...其中有些我们也许一直都用不到,(我也是查看了些相关的资料再加上自己的一些想法整理了一下,希望对相关朋友有用!)可是重要的是知道我们在实现一个功能时应该选用哪种集合类来实现就OK了。
摘要:虽然session机制在web应用程序中被采用已经很长时间了,但是仍然有很多人不清楚session机制的本质,以至不能正确的应用这一技术。本文将详细讨论session的工作机制并且对在Java web application中应用session机制时常见的问题作出解答。
目录:
一、术语session
二、HTTP协议与状态保持
三、理解cookie机制
四、理解session机制
五、理解javax.servlet.http.HttpSession
六、HttpSession常见问题
七、跨应用程序的session共享
八、总结
参考文档
一、术语session
在我的经验里,session这个词被滥用的程度大概仅次于transaction,更加有趣的是transaction与session在某些语境下的含义是相同的。
session,中文经常翻译为会话,其本来的含义是指有始有终的一系列动作/消息,比如打电话时从拿起电话拨号到挂断电话这中间的一系列过程可以称之为一个 session。有时候我们可以看到这样的话“在一个浏览器会话期间,...”,这里的会话一词用的就是其本义,是指从一个浏览器窗口打开到关闭这个期间 ①。最混乱的是“用户(客户端)在一次会话期间”这样一句话,它可能指用户的一系列动作(一般情况下是同某个具体目的相关的一系列动作,比如从登录到选购商品到结账登出这样一个网上购物的过程,有时候也被称为一个transaction),然而有时候也可能仅仅是指一次连接,也有可能是指含义①,其中的差别只能靠上下文来推断②。
然而当session一词与网络协议相关联时,它又往往隐含了“面向连接”和/或“保持状态”这样两个含义, “面向连接”指的是在通信双方在通信之前要先建立一个通信的渠道,比如打电话,直到对方接了电话通信才能开始,与此相对的是写信,在你把信发出去的时候你并不能确认对方的地址是否正确,通信渠道不一定能建立,但对发信人来说,通信已经开始了。“保持状态”则是指通信的一方能够把一系列的消息关联起来,使得消息之间可以互相依赖,比如一个服务员能够认出再次光临的老顾客并且记得上次这个顾客还欠店里一块钱。这一类的例子有“一个TCP session”或者 “一个POP3 session”③。
而到了web服务器蓬勃发展的时代,session在web开发语境下的语义又有了新的扩展,它的含义是指一类用来在客户端与服务器之间保持状态的解决方案④。有时候session也用来指这种解决方案的存储结构,如“把xxx保存在session 里”⑤。由于各种用于web开发的语言在一定程度上都提供了对这种解决方案的支持,所以在某种特定语言的语境下,session也被用来指代该语言的解决方案,比如经常把Java里提供的javax.servlet.http.HttpSession简称为session⑥。
鉴于这种混乱已不可改变,本文中session一词的运用也会根据上下文有不同的含义,请大家注意分辨。
在本文中,使用中文“浏览器会话期间”来表达含义①,使用“session机制”来表达含义④,使用“session”表达含义⑤,使用具体的“HttpSession”来表达含义⑥
二、HTTP协议与状态保持
HTTP 协议本身是无状态的,这与HTTP协议本来的目的是相符的,客户端只需要简单的向服务器请求下载某些文件,无论是客户端还是服务器都没有必要纪录彼此过去的行为,每一次请求之间都是独立的,好比一个顾客和一个自动售货机或者一个普通的(非会员制)大卖场之间的关系一样。
然而聪明(或者贪心?)的人们很快发现如果能够提供一些按需生成的动态信息会使web变得更加有用,就像给有线电视加上点播功能一样。这种需求一方面迫使HTML逐步添加了表单、脚本、DOM等客户端行为,另一方面在服务器端则出现了CGI规范以响应客户端的动态请求,作为传输载体的HTTP协议也添加了文件上载、 cookie这些特性。其中cookie的作用就是为了解决HTTP协议无状态的缺陷所作出的努力。至于后来出现的session机制则是又一种在客户端与服务器之间保持状态的解决方案。
让我们用几个例子来描述一下cookie和session机制之间的区别与联系。笔者曾经常去的一家咖啡店有喝5杯咖啡免费赠一杯咖啡的优惠,然而一次性消费5杯咖啡的机会微乎其微,这时就需要某种方式来纪录某位顾客的消费数量。想象一下其实也无外乎下面的几种方案:
1、该店的店员很厉害,能记住每位顾客的消费数量,只要顾客一走进咖啡店,店员就知道该怎么对待了。这种做法就是协议本身支持状态。
2、发给顾客一张卡片,上面记录着消费的数量,一般还有个有效期限。每次消费时,如果顾客出示这张卡片,则此次消费就会与以前或以后的消费相联系起来。这种做法就是在客户端保持状态。
3、发给顾客一张会员卡,除了卡号之外什么信息也不纪录,每次消费时,如果顾客出示该卡片,则店员在店里的纪录本上找到这个卡号对应的纪录添加一些消费信息。这种做法就是在服务器端保持状态。
由于HTTP协议是无状态的,而出于种种考虑也不希望使之成为有状态的,因此,后面两种方案就成为现实的选择。具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案。同时我们也看到,由于采用服务器端保持状态的方案在客户端也需要保存一个标识,所以session机制可能需要借助于cookie机制来达到保存标识的目的,但实际上它还有其他选择。
三、理解cookie机制
cookie机制的基本原理就如上面的例子一样简单,但是还有几个问题需要解决:“会员卡”如何分发;“会员卡”的内容;以及客户如何使用“会员卡”。
正统的cookie分发是通过扩展HTTP协议来实现的,服务器通过在HTTP的响应头中加上一行特殊的指示以提示浏览器按照指示生成相应的cookie。然而纯粹的客户端脚本如JavaScript或者VBScript也可以生成cookie。
而cookie 的使用是由浏览器按照一定的原则在后台自动发送给服务器的。浏览器检查所有存储的cookie,如果某个cookie所声明的作用范围大于等于将要请求的资源所在的位置,则把该cookie附在请求资源的HTTP请求头上发送给服务器。意思是麦当劳的会员卡只能在麦当劳的店里出示,如果某家分店还发行了自己的会员卡,那么进这家店的时候除了要出示麦当劳的会员卡,还要出示这家店的会员卡。
cookie的内容主要包括:名字,值,过期时间,路径和域。
其中域可以指定某一个域比如.google.com,相当于总店招牌,比如宝洁公司,也可以指定一个域下的具体某台机器比如www.google.com或者froogle.google.com,可以用飘柔来做比。
路径就是跟在域名后面的URL路径,比如/或者/foo等等,可以用某飘柔专柜做比。
路径与域合在一起就构成了cookie的作用范围。
如果不设置过期时间,则表示这个cookie的生命期为浏览器会话期间,只要关闭浏览器窗口,cookie就消失了。这种生命期为浏览器会话期的 cookie被称为会话cookie。会话cookie一般不存储在硬盘上而是保存在内存里,当然这种行为并不是规范规定的。如果设置了过期时间,浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie仍然有效直到超过设定的过期时间。
存储在硬盘上的cookie 可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存里的cookie,不同的浏览器有不同的处理方式。对于IE,在一个打开的窗口上按 Ctrl-N(或者从文件菜单)打开的窗口可以与原窗口共享,而使用其他方式新开的IE进程则不能共享已经打开的窗口的内存cookie;对于 Mozilla Firefox0.8,所有的进程和标签页都可以共享同样的cookie。一般来说是用javascript的window.open打开的窗口会与原窗口共享内存cookie。浏览器对于会话cookie的这种只认cookie不认人的处理方式经常给采用session机制的web应用程序开发者造成很大的困扰。
下面就是一个goolge设置cookie的响应头的例子
HTTP/1.1 302 Found
Location: http://www.google.com/intl/zh-CN/
Set-Cookie: PREF=ID=0565f77e132de138:NW=1:TM=1098082649:LM=1098082649:S=KaeaCFPo49RiA_d8; expires=Sun, 17-Jan-2038 19:14:07 GMT; path=/; domain=.google.com
Content-Type: text/html
这是使用HTTPLook这个HTTP Sniffer软件来俘获的HTTP通讯纪录的一部分
浏览器在再次访问goolge的资源时自动向外发送cookie
使用Firefox可以很容易的观察现有的cookie的值
使用HTTPLook配合Firefox可以很容易的理解cookie的工作原理。
IE也可以设置在接受cookie前询问
这是一个询问接受cookie的对话框。
四、理解session机制
session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。
当程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否已包含了一个session标识 - 称为 session id,如果已包含一个session id则说明以前已经为此客户端创建过session,服务器就按照session id把这个 session检索出来使用(如果检索不到,可能会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个 session id将被在本次响应中返回给客户端保存。
保存这个session id的方式可以采用cookie,这样在交互过程中浏览器可以自动的按照规则把这个标识发挥给服务器。一般这个cookie的名字都是类似于SEEESIONID,而。比如weblogic对于web应用程序生成的cookie,JSESSIONID= ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764,它的名字就是 JSESSIONID。
由于cookie可以被人为的禁止,必须有其他机制以便在cookie被禁止时仍然能够把session id传递回服务器。经常被使用的一种技术叫做URL重写,就是把session id直接附加在URL路径的后面,附加方式也有两种,一种是作为URL路径的附加信息,表现形式为http://...../xxx;jsessionid= ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764
另一种是作为查询字符串附加在URL后面,表现形式为http://...../xxx?jsessionid=ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764
这两种方式对于用户来说是没有区别的,只是服务器在解析的时候处理的方式不同,采用第一种方式也有利于把session id的信息和正常程序参数区分开来。
为了在整个交互过程中始终保持状态,就必须在每个客户端可能请求的路径后面都包含这个session id。
另一种技术叫做表单隐藏字段。就是服务器会自动修改表单,添加一个隐藏字段,以便在表单提交时能够把session id传递回服务器。比如下面的表单
<form name="testform" action="/xxx">
<input type="text">
</form>
在被传递给客户端之前将被改写成
<form name="testform" action="/xxx">
<input type="hidden" name="jsessionid" value="ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764">
<input type="text">
</form>
这种技术现在已较少应用,笔者接触过的很古老的iPlanet6(SunONE应用服务器的前身)就使用了这种技术。
实际上这种技术可以简单的用对action应用URL重写来代替。
在谈论session机制的时候,常常听到这样一种误解“只要关闭浏览器,session就消失了”。其实可以想象一下会员卡的例子,除非顾客主动对店家提出销卡,否则店家绝对不会轻易删除顾客的资料。对session来说也是一样的,除非程序通知服务器删除一个session,否则服务器会一直保留,程序一般都是在用户做log off的时候发个指令去删除session。然而浏览器从来不会主动在关闭之前通知服务器它将要关闭,因此服务器根本不会有机会知道浏览器已经关闭,之所以会有这种错觉,是大部分session机制都使用会话cookie来保存session id,而关闭浏览器后这个 session id就消失了,再次连接服务器时也就无法找到原来的session。如果服务器设置的cookie被保存到硬盘上,或者使用某种手段改写浏览器发出的HTTP请求头,把原来的session id发送给服务器,则再次打开浏览器仍然能够找到原来的session。
恰恰是由于关闭浏览器不会导致session被删除,迫使服务器为seesion设置了一个失效时间,当距离客户端上一次使用session的时间超过这个失效时间时,服务器就可以认为客户端已经停止了活动,才会把session删除以节省存储空间。
五、理解javax.servlet.http.HttpSession
HttpSession是Java平台对session机制的实现规范,因为它仅仅是个接口,具体到每个web应用服务器的提供商,除了对规范支持之外,仍然会有一些规范里没有规定的细微差异。这里我们以BEA的Weblogic Server8.1作为例子来演示。
首先,Weblogic Server提供了一系列的参数来控制它的HttpSession的实现,包括使用cookie的开关选项,使用URL重写的开关选项,session持久化的设置,session失效时间的设置,以及针对cookie的各种设置,比如设置cookie的名字、路径、域, cookie的生存时间等。
一般情况下,session都是存储在内存里,当服务器进程被停止或者重启的时候,内存里的session也会被清空,如果设置了session的持久化特性,服务器就会把session保存到硬盘上,当服务器进程重新启动或这些信息将能够被再次使用, Weblogic Server支持的持久性方式包括文件、数据库、客户端cookie保存和复制。
复制严格说来不算持久化保存,因为session实际上还是保存在内存里,不过同样的信息被复制到各个cluster内的服务器进程中,这样即使某个服务器进程停止工作也仍然可以从其他进程中取得session。
cookie生存时间的设置则会影响浏览器生成的cookie是否是一个会话cookie。默认是使用会话cookie。有兴趣的可以用它来试验我们在第四节里提到的那个误解。
cookie的路径对于web应用程序来说是一个非常重要的选项,Weblogic Server对这个选项的默认处理方式使得它与其他服务器有明显的区别。后面我们会专题讨论。
关于session的设置参考[5] http://e-docs.bea.com/wls/docs70/webapp/weblogic_xml.html#1036869
六、HttpSession常见问题
(在本小节中session的含义为⑤和⑥的混合)
1、session在何时被创建
一个常见的误解是以为session在有客户端访问时就被创建,然而事实是直到某server端程序调用 HttpServletRequest.getSession(true)这样的语句时才被创建,注意如果JSP没有显示的使用 <% @page session="false"%> 关闭session,则JSP文件在编译成Servlet时将会自动加上这样一条语句 HttpSession session = HttpServletRequest.getSession(true);这也是JSP中隐含的 session对象的来历。
由于session会消耗内存资源,因此,如果不打算使用session,应该在所有的JSP中关闭它。
2、session何时被删除
综合前面的讨论,session在下列情况下被删除a.程序调用HttpSession.invalidate();或b.距离上一次收到客户端发送的session id时间间隔超过了session的超时设置;或c.服务器进程被停止(非持久session)
3、如何做到在浏览器关闭时删除session
严格的讲,做不到这一点。可以做一点努力的办法是在所有的客户端页面里使用javascript代码window.oncolose来监视浏览器的关闭动作,然后向服务器发送一个请求来删除session。但是对于浏览器崩溃或者强行杀死进程这些非常规手段仍然无能为力。
4、有个HttpSessionListener是怎么回事
你可以创建这样的listener去监控session的创建和销毁事件,使得在发生这样的事件时你可以做一些相应的工作。注意是session的创建和销毁动作触发listener,而不是相反。类似的与HttpSession有关的listener还有 HttpSessionBindingListener,HttpSessionActivationListener和 HttpSessionAttributeListener。
5、存放在session中的对象必须是可序列化的吗
不是必需的。要求对象可序列化只是为了session能够在集群中被复制或者能够持久保存或者在必要时server能够暂时把session交换出内存。在 Weblogic Server的session中放置一个不可序列化的对象在控制台上会收到一个警告。我所用过的某个iPlanet版本如果 session中有不可序列化的对象,在session销毁时会有一个Exception,很奇怪。
6、如何才能正确的应付客户端禁止cookie的可能性
对所有的URL使用URL重写,包括超链接,form的action,和重定向的URL,具体做法参见[6]
http://e-docs.bea.com/wls/docs70/webapp/sessions.html#100770
7、开两个浏览器窗口访问应用程序会使用同一个session还是不同的session
参见第三小节对cookie的讨论,对session来说是只认id不认人,因此不同的浏览器,不同的窗口打开方式以及不同的cookie存储方式都会对这个问题的答案有影响。
8、如何防止用户打开两个浏览器窗口操作导致的session混乱
这个问题与防止表单多次提交是类似的,可以通过设置客户端的令牌来解决。就是在服务器每次生成一个不同的id返回给客户端,同时保存在session里,客户端提交表单时必须把这个id也返回服务器,程序首先比较返回的id与保存在session里的值是否一致,如果不一致则说明本次操作已经被提交过了。可以参看《J2EE核心模式》关于表示层模式的部分。需要注意的是对于使用javascript window.open打开的窗口,一般不设置这个id,或者使用单独的id,以防主窗口无法操作,建议不要再window.open打开的窗口里做修改操作,这样就可以不用设置。
9、为什么在Weblogic Server中改变session的值后要重新调用一次session.setValue
做这个动作主要是为了在集群环境中提示Weblogic Server session中的值发生了改变,需要向其他服务器进程复制新的session值。
10、为什么session不见了
排除session正常失效的因素之外,服务器本身的可能性应该是微乎其微的,虽然笔者在iPlanet6SP1加若干补丁的Solaris版本上倒也遇到过;浏览器插件的可能性次之,笔者也遇到过3721插件造成的问题;理论上防火墙或者代理服务器在cookie处理上也有可能会出现问题。
出现这一问题的大部分原因都是程序的错误,最常见的就是在一个应用程序中去访问另外一个应用程序。我们在下一节讨论这个问题。
七、跨应用程序的session共享
常常有这样的情况,一个大项目被分割成若干小项目开发,为了能够互不干扰,要求每个小项目作为一个单独的web应用程序开发,可是到了最后突然发现某几个小项目之间需要共享一些信息,或者想使用session来实现SSO(single sign on),在session中保存login的用户信息,最自然的要求是应用程序间能够访问彼此的session。
然而按照Servlet规范,session的作用范围应该仅仅限于当前应用程序下,不同的应用程序之间是不能够互相访问对方的session的。各个应用服务器从实际效果上都遵守了这一规范,但是实现的细节却可能各有不同,因此解决跨应用程序session共享的方法也各不相同。
首先来看一下Tomcat是如何实现web应用程序之间session的隔离的,从 Tomcat设置的cookie路径来看,它对不同的应用程序设置的cookie路径是不同的,这样不同的应用程序所用的session id是不同的,因此即使在同一个浏览器窗口里访问不同的应用程序,发送给服务器的session id也可以是不同的。
根据这个特性,我们可以推测Tomcat中session的内存结构大致如下。
笔者以前用过的iPlanet也采用的是同样的方式,估计SunONE与iPlanet之间不会有太大的差别。对于这种方式的服务器,解决的思路很简单,实际实行起来也不难。要么让所有的应用程序共享一个session id,要么让应用程序能够获得其他应用程序的session id。
iPlanet中有一种很简单的方法来实现共享一个session id,那就是把各个应用程序的cookie路径都设为/(实际上应该是/NASApp,对于应用程序来讲它的作用相当于根)。
<session-info>
<path>/NASApp</path>
</session-info>
需要注意的是,操作共享的session应该遵循一些编程约定,比如在session attribute名字的前面加上应用程序的前缀,使得 setAttribute("name", "neo")变成setAttribute("app1.name", "neo"),以防止命名空间冲突,导致互相覆盖。
在Tomcat中则没有这么方便的选择。在Tomcat版本3上,我们还可以有一些手段来共享session。对于版本4以上的Tomcat,目前笔者尚未发现简单的办法。只能借助于第三方的力量,比如使用文件、数据库、JMS或者客户端cookie,URL参数或者隐藏字段等手段。
我们再看一下Weblogic Server是如何处理session的。
从截屏画面上可以看到Weblogic Server对所有的应用程序设置的cookie的路径都是/,这是不是意味着在Weblogic Server中默认的就可以共享session了呢?然而一个小实验即可证明即使不同的应用程序使用的是同一个session,各个应用程序仍然只能访问自己所设置的那些属性。这说明Weblogic Server中的session的内存结构可能如下
对于这样一种结构,在 session机制本身上来解决session共享的问题应该是不可能的了。除了借助于第三方的力量,比如使用文件、数据库、JMS或者客户端 cookie,URL参数或者隐藏字段等手段,还有一种较为方便的做法,就是把一个应用程序的session放到ServletContext中,这样另外一个应用程序就可以从ServletContext中取得前一个应用程序的引用。示例代码如下,
应用程序A
context.setAttribute("appA", session);
应用程序B
contextA = context.getContext("/appA");
HttpSession sessionA = (HttpSession)contextA.getAttribute("appA");
值得注意的是这种用法不可移植,因为根据ServletContext的JavaDoc,应用服务器可以处于安全的原因对于context.getContext("/appA");返回空值,以上做法在Weblogic Server 8.1中通过。
那么Weblogic Server为什么要把所有的应用程序的cookie路径都设为/呢?原来是为了SSO,凡是共享这个session的应用程序都可以共享认证的信息。一个简单的实验就可以证明这一点,修改首先登录的那个应用程序的描述符weblogic.xml,把cookie路径修改为/appA 访问另外一个应用程序会重新要求登录,即使是反过来,先访问cookie路径为/的应用程序,再访问修改过路径的这个,虽然不再提示登录,但是登录的用户信息也会丢失。注意做这个实验时认证方式应该使用FORM,因为浏览器和web服务器对basic认证方式有其他的处理方式,第二次请求的认证不是通过 session来实现的。具体请参看[7] secion 14.8 Authorization,你可以修改所附的示例程序来做这些试验。
八、总结
session机制本身并不复杂,然而其实现和配置上的灵活性却使得具体情况复杂多变。这也要求我们不能把仅仅某一次的经验或者某一个浏览器,服务器的经验当作普遍适用的经验,而是始终需要具体情况具体分析。
摘要:虽然session机制在web应用程序中被采用已经很长时间了,但是仍然有很多人不清楚session机制的本质,以至不能正确的应用这一技术。本文将详细讨论session的工作机制并且对在Java web application中应用session机制时常见的问题作出解答。
|
|
本文的预定读者首先要对j2ee有所了解,熟悉xml,tomcat等基本内容,本文主要是简单介绍一下web服务的基本内容,怎样在java web开发中构建SOAP服务: 一、SOAP(Simple Object Access Protocol)简单对象访问协议,要了解SOAP,首先就需要了解分布式计算的由来,随着下一代的分布式计算体系web服务的出现,SOAP成为了创建和调用通过网络发布的应用程序的实际通信标准。SOAP类似传统的二进制协议IIOP(CORBA)和JRMP(RMI),但它不采用二进制数据表示法,而是采用使用XML的,基于文本的数据表示法。 通过XML表示法,SOAP定义了一种小型有线连接协议和编码格式,以表示数据类型、编程语言和数据库,还可以使用各种Internet标准协议作为其消息传输工具,还可以提供表示RPC和文档驱动的消息交换等通信模型的约定。请注意,W3C正致力于SOAP的研究, http://www.w3c.org/2000/xp/Group/ ,并得到了主流供应商的积极响应,以便对于基于XML的协议相关的重要任务达成共识,并定义其关键要求和使用场景。 SOAP1.2的基本规范定义了以下基本内容: 1)用于将XML文档表示为结构化SOAP消息的语法和语义 2)在SOAP消息中表示数据的编码标准 3)用于交换SOAP消息的通信模型 4)SOAP传输等底层协议的绑定 SOAP消息主要包括了信封头,消息头,主体,附件几部分 一个简单的SOAP消息表示: POST /StudentInfo HTTP/1.1 Host:anthropology.cun.edu Content-Type: text/xml;charset="utf-8" Content-Length: 640 SOAPAction: "GetStudentInfo" <SOAP-ENV:Envelop xmlns:SOAP-ENV=" http://www.w3c.org/2001/06/soap-envelope" xmlns:xsi=" http://www.w3c.org/2001/XMLSchema-instance" xmlns:xsd=" http://www.w3c.org/2001/XMLSchema" SOAP-ENV:encodingStyle="http://www.w3c.org/2001/06/soap-encoding"> <SOAP-ENV:Header> <person:mail xmlns:person="http://www.cun.edu/Header">xyz@cun.edu </SOAP-ENV:Header> <SOAP-ENV:Body> <m:GetStudentInfo xmlns:m="http://www.cun.edu/jws.student.studentInfo"> <student_name xsi:type='xsd:string'> Wang wen yin </student> </m:GetStudentInfo> </SOAP-ENV:Body> </SOAP-ENV:Envelop> 以上是1.2版本命名空间,1.1的命名空间 SOAP ENVELOPE: http://schemas.xmlsoap.org/soap/envelop/ ,SOAP ENCODING: http://schemas.xmlsoap.org/soap/encoding/ 关于SOAP编码规范请参阅 www.w3c.org/TR/xmlschema-2/ 定义的编码值,其他的一些规范可以上 www.w3c.org 上具体查看。 二、以下从实际例子来学习,这里我使用的是Apache的一个子项目Axis的具体例子,便于深入了解soap的运行: 1)下载Axis的相关内容 http://ws.apache.org/axis/: 2)建立一个实例程序(遵守j2ee的web程序规范),如(WebServiceTest目录) 把axis中lib文件夹的内容拷到你的WebServiceTest/WEB-INF/lib下,同时上网下载xerces(下载地点: http://xml.apache.org/xerces-j/)解释器的包文件xerces.jar,也拷到WebServiceTest/WEB-INF/lib文件夹下,(若要配置log4j,请把属性文件log4j.properties拷到WebServiceTest/WEB-INF/classes文件夹下) 3)修改应用程序WebServiceTest/WEB-INF中的web.xml文件:主要servlet设置如下 <servlet> <servlet-name>TestServlet</servlet-name> <servlet-class>org.apache.axis.transport.http.AxisServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>TestServlet</servlet-name> <url-pattern>*.jws</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>TestServlet</servlet-name> <url-pattern>/servlet/TestServlet</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>TestServlet</servlet-name> <url-pattern>/services/*</url-pattern> </servlet-mapping>
<servlet>
<servlet-name>AdminServlet</servlet-name>
<servlet-class>
org.apache.axis.transport.http.AdminServlet
</servlet-class>
<load-on-startup>100</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>AdminServlet</servlet-name>
<url-pattern>/servlet/AdminServlet</url-pattern>
</servlet-mapping>
<mime-mapping>
<extension>wsdl</extension>
<mime-type>text/xml</mime-type>
</mime-mapping>
<mime-mapping>
<extension>xsd</extension>
<mime-type>text/xml</mime-type>
</mime-mapping>
你现在可以在网址里输入http://localhost/WebServiceTest/servlet/TestServlet 看到了吗?Axis是使用axis.jar包里的org.apache.axis.transport.http.AxisServlet对应用程序进行处理的,基本配置就讲到这里。
三、接着我们来说Axis中的内核。
1)不使用Tomcat引擎运行Axis。
先建立一个脚步文件,对环境变量classpath进行设置要把lib下的那些包文件的路径全都包括进去,运行:java org.apache.axis.transport.http.SimpleAxisServer <port>
2)内部服务处理程序是org.apache.axis.providers.java.RPCProvider,标志出服务所需的方法,然后提供从SOAP请求消息组成部分的参数。
3)Axis的应用程序端管理功能:
java org.apache.axis.client.AdminClient 就会列出参数,可供你选择。我们的例子是:java org.apache.axis.client.AdminClient -l http://localhost/WebserviceTest/servlet/TestServlet list 就会显示出服务列表,返回的是xml文件
4)wsdl2java应用程序可以把wsdl文件创建基于java的程序,如占位程序等
java org.apache.axis.wsdl.WSDL2java <url>
Axis的基本内容说到这里
四、具体例子
1)编写逻辑程序,简单如:SoapTest.java
public class SoapTest{
public String getStr(String name){
return "Hello,"+name;
}
}
2) 部署服务,编写wsdd文件SoapTest_deploy.wsdd:
<deployment name="SimapleTest" xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java"
xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"
xmlns:xsi="http://www.w3.org/2000/10/XMLSchema-instance">
<service name="SoapTest" provider="java:RPC">
<parameter name="className" value="SoapTest"/>
<parameter name="allowedMethods" value="getStr"/>
</service>
</deployment>
其中className参数是你的想部署的类名(全名),allowedMethods是调用的服务的方法,如果有多个方法的话可以用空格分开(如: <parameter name="allowedMethods" value="getStr getMoney"/>),当用*的时候表示全部。
好了现在准备部署了,确保环境路径classpath设置正确,运行:
java org.apache.axis.client.AdminClient -l http://localhost/WebserviceTest/servlet/TestServlet SoapTest_deploy.wsdd
(这里不懂的话,请参考以上的说明)
ok,呵呵,至此,我们已经完成了一个web服务的部署:测试http://localhost/WebServiceTest/servlet/TestServlet 看里面是否多了一个选择SoapTest服务?
如果不想要服务了那重新编写一个wsdd文件,内容改为:
<deployment name="SimapleTest" xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java"
xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"
xmlns:xsi="http://www.w3.org/2000/10/XMLSchema-instance">
<service name="SoapTest"/>
</deployment>
和上面一样,对比一下就ok了。
五、客户端测试:
客户端我们也可以使用java来进行测试,网上也有资料的,你可以去学习,很简单的。现在为了体现web服务的魅力,我用.NET平台来测试吧,客户端使用c#编写(先要安装.net framework sdk):
1)通过wsdl生成web服务代理,在net平台下运行:
wsdl /l:CS /protocol:SOAP /out:SoapTestClient.cs http://localhost/WebserviceTest/services/SoapTest?wsdl
我们通过wsdl得到了一个cs文件SoapTestClient.cs(当前目录),你可以打开cs文件,研究一下里面的代码,那个getStr(string name)就是我们需要调用的方法,我们的客户端通过调用该方法就可以调用服务器端的方法,内部的转化wsdl.exe工具已经帮我们完成了,axis下的WSDL2Java工具也是一样的功能,可以参考我上面所说的关于Axis的内核内容
2)编译cs文件成程序集dll:
csc /target:library /r:System.Web.Services.dll /r:System.Xml.dll SoapTestClient.cs
最后我们等到了一个dll文件SoapTestClient.dll,客户端程序通过调用它就行了
3)编写客户端应用程序SoapTestClientApp.cs
using System;
namespache jws.client{
public class SoapTestClientApp{
public SoapTestClientApp(){
}
public static void Main(string[] args){
if(args.Length!=1){
Console.WriteLine("Usage:SoapTestClientApp <name>");
Environment.Exit(1);
}
SoapTestService st_service=new SoapTestService();
st_service.getStr("Wang wenyin");
}
}
}
4)编译文件csc /r:SoapTestClient.dll SoapTestClientApp.cs
运行SoapTestClientApp
输出结果:
Hello,Wang wenyin
与预期结果相符。
|
|
|
Hibernate的JNDI名称绑定是在net.sf.hibernate.impl.SessionFactoryObjectFactory程序里面实现的,我来分析一下Hibernate的绑定JNDI的过程:
我们获得SessionFactory一般是这样写代码:
Configuration conf = new Configuration().addClass(Cat.class);
SessionFactory sf = conf.buildSessionFactory();
首先是new Configuration()创建一个Configuration,在这个构造器里面进行配置文件(hibernate.properties)的读取工作,然后保存到一个Properties对象里面去,和JNDI相关的是这个属性:
hibernate.session_factory_name hibernate/session_factory
接着调用buildSessionFactory()方法,该方法检查一下配置信息,然后调用SessionFactoryImpl的一个构造器。在构造器里面注意下面两行代码:
name = properties.getProperty(Environment.SESSION_FACTORY_NAME);
SessionFactoryObjectFactory.addInstance(uuid, name, this, properties);
调用了SessionFactoryObjectFactory的addInstance方法,并且把自身(SessionFactory的实例)作为参数传递。最后在addInstance方法可以看到如下代码:
Context ctx = NamingHelper.getInitialContext(properties);
NamingHelper.bind(ctx, name, instance);
instance 就是SessionFactory的实例,通过读源代码,可以清楚的看到Hibernate是在conf.buildSessionFactory()的时候通过一系列类方法调用,把创建的SessionFactory实例绑定到配置文件(hibernate.properties)中 hibernate.session_factory_name属性指定的名称上的,因此可见Hibernate自身是具有JNDI的动态绑定功能的。但是Hibernate需要获得一个SessionFactory实例用于绑定,而这个SessionFactory实例需要我们写代码进行预先创建,并且必须保证该过程要在所有其它要从JNDI上获得SessionFactory实例的程序之前完成。
因此对于任何App Server来说,我们都不必去管JNDI名称的绑定过程,只需要保证预先创建一个SessionFactory实例出来就够了,剩下的工作 Hibernate会做的。那么如何确保预创建SessionFactory实例呢,如果是Servlet,可以配置一个初始化的Servlet,只要把
Configuration conf = new Configuration().addClass(Cat.class);
SessionFactory sf = conf.buildSessionFactory();
这样的代码加进去就可以了。如果是包含EJB的的复杂的J2EE应用,可能需要依靠App Server的功能来保证预创建SessionFactory实例。
|
|
|
|
|
abstract class和interface是Java语言中对于抽象类定义进行支持的两种机制,正是由于这两种机制的存在,才赋予了Java强大的面向对象能力。abstract class和interface之间在对于抽象类定义的支持方面具有很大的相似性,甚至可以相互替换,因此很多开发者在进行抽象类定义时对于abstract class和interface的选择显得比较随意。其实,两者之间还是有很大的区别的,对于它们的选择甚至反映出对于问题领域本质的理解、对于设计意图的理解是否正确、合理。本文将对它们之间的区别进行一番剖析,试图给开发者提供一个在二者之间进行选择的依据。
理解抽象类
abstract class和interface在Java语言中都是用来进行抽象类(本文中的抽象类并非从abstract class翻译而来,它表示的是一个抽象体,而abstract class为Java语言中用于定义抽象类的一种方法,请读者注意区分)定义的,那么什么是抽象类,使用抽象类能为我们带来什么好处呢?
在面向对象的概念中,我们知道所有的对象都是通过类来描绘的,但是反过来却不是这样。并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。抽象类往往用来表征我们在对问题领域进行分析、设计中得出的抽象概念,是对一系列看上去不同,但是本质上相同的具体概念的抽象。比如:如果我们进行一个图形编辑软件的开发,就会发现问题领域存在着圆、三角形这样一些具体概念,它们是不同的,但是它们又都属于形状这样一个概念,形状这个概念在问题领域是不存在的,它就是一个抽象概念。正是因为抽象的概念在问题领域没有对应的具体概念,所以用以表征抽象概念的抽象类是不能够实例化的。
在面向对象领域,抽象类主要用来进行类型隐藏。我们可以构造出一个固定的一组行为的抽象描述,但是这组行为却能够有任意个可能的具体实现方式。这个抽象描述就是抽象类,而这一组任意个可能的具体实现则表现为所有可能的派生类。模块可以操作一个抽象体。由于模块依赖于一个固定的抽象体,因此它可以是不允许修改的;同时,通过从这个抽象体派生,也可扩展此模块的行为功能。熟悉OCP的读者一定知道,为了能够实现面向对象设计的一个最核心的原则OCP(Open-Closed Principle),抽象类是其中的关键所在。
从语法定义层面看abstract class和interface
在语法层面,Java语言对于abstract class和interface给出了不同的定义方式,下面以定义一个名为Demo的抽象类为例来说明这种不同。
使用abstract class的方式定义Demo抽象类的方式如下:
abstract class Demo {
abstract void method1();
abstract void method2();
…
}
使用interface的方式定义Demo抽象类的方式如下:
interface Demo {
void method1();
void method2();
…
}
在abstract class方式中,Demo可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface方式的实现中,Demo只能够有静态的不能被修改的数据成员(也就是必须是static final的,不过在interface中一般不定义数据成员),所有的成员方法都是abstract的。从某种意义上说,interface是一种特殊形式的abstract class。
从编程的角度来看,abstract class和interface都可以用来实现"design by contract"的思想。但是在具体的使用上面还是有一些区别的。
首先,abstract class在Java语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface。也许,这是Java语言的设计者在考虑Java对于多重继承的支持方面的一种折中考虑吧。
其次,在abstract class的定义中,我们可以赋予方法的默认行为。但是在interface的定义中,方法却不能拥有默认行为,为了绕过这个限制,必须使用委托,但是这会 增加一些复杂性,有时会造成很大的麻烦。
在抽象类中不能定义默认行为还存在另一个比较严重的问题,那就是可能会造成维护上的麻烦。因为如果后来想修改类的界面(一般通过abstract class或者interface来表示)以适应新的情况(比如,添加新的方法或者给已用的方法中添加新的参数)时,就会非常的麻烦,可能要花费很多的时间(对于派生类很多的情况,尤为如此)。但是如果界面是通过abstract class来实现的,那么可能就只需要修改定义在abstract class中的默认行为就可以了。
同样,如果不能在抽象类中定义默认行为,就会导致同样的方法实现出现在该抽象类的每一个派生类中,违反了"one rule,one place"原则,造成代码重复,同样不利于以后的维护。因此,在abstract class和interface间进行选择时要非常的小心。
从设计理念层面看abstract class和interface
上面主要从语法定义和编程的角度论述了abstract class和interface的区别,这些层面的区别是比较低层次的、非本质的。本小节将从另一个层面:abstract class和interface所反映出的设计理念,来分析一下二者的区别。作者认为,从这个层面进行分析才能理解二者概念的本质所在。
前面已经提到过,abstarct class在Java语言中体现了一种继承关系,要想使得继承关系合理,父类和派生类之间必须存在"is a"关系,即父类和派生类在概念本质上应该是相同的(参考文献〔3〕中有关于"is a"关系的大篇幅深入的论述,有兴趣的读者可以参考)。对于interface 来说则不然,并不要求interface的实现者和interface定义在概念本质上是一致的,仅仅是实现了interface定义的契约而已。为了使论述便于理解,下面将通过一个简单的实例进行说明。
考虑这样一个例子,假设在我们的问题领域中有一个关于Door的抽象概念,该Door具有执行两个动作open和close,此时我们可以通过abstract class或者interface来定义一个表示该抽象概念的类型,定义方式分别如下所示:
使用abstract class方式定义Door:
abstract class Door {
abstract void open();
abstract void close();
}
使用interface方式定义Door:
interface Door {
void open();
void close();
}
其他具体的Door类型可以extends使用abstract class方式定义的Door或者implements使用interface方式定义的Door。看起来好像使用abstract class和interface没有大的区别。
如果现在要求Door还要具有报警的功能。我们该如何设计针对该例子的类结构呢(在本例中,主要是为了展示abstract class和interface反映在设计理念上的区别,其他方面无关的问题都做了简化或者忽略)?下面将罗列出可能的解决方案,并从设计理念层面对这些不同的方案进行分析。
解决方案一:
简单的在Door的定义中增加一个alarm方法,如下:
abstract class Door {
abstract void open();
abstract void close();
abstract void alarm();
}
或者
interface Door {
void open();
void close();
void alarm();
}
那么具有报警功能的AlarmDoor的定义方式如下:
class AlarmDoor extends Door {
void open() { … }
void close() { … }
void alarm() { … }
}
或者
class AlarmDoor implements Door {
void open() { … }
void close() { … }
void alarm() { … }
}
这种方法违反了面向对象设计中的一个核心原则ISP(Interface Segregation Priciple),在Door的定义中把Door概念本身固有的行为方法和另外一个概念"报警器"的行为方法混在了一起。这样引起的一个问题是那些仅仅依赖于Door这个概念的模块会因为"报警器"这个概念的改变(比如:修改alarm方法的参数)而改变,反之依然。
解决方案二:
既然open、close和alarm属于两个不同的概念,根据ISP原则应该把它们分别定义在代表这两个概念的抽象类中。定义方式有:这两个概念都使用abstract class方式定义;两个概念都使用interface方式定义;一个概念使用abstract class方式定义,另一个概念使用interface方式定义。
显然,由于Java语言不支持多重继承,所以两个概念都使用abstract class方式定义是不可行的。后面两种方式都是可行的,但是对于它们的选择却反映出对于问题领域中的概念本质的理解、对于设计意图的反映是否正确、合理。我们一一来分析、说明。
如果两个概念都使用interface方式来定义,那么就反映出两个问题:1、我们可能没有理解清楚问题领域,AlarmDoor在概念本质上到底是Door还是报警器?2、如果我们对于问题领域的理解没有问题,比如:我们通过对于问题领域的分析发现AlarmDoor在概念本质上和Door是一致的,那么我们在实现时就没有能够正确的揭示我们的设计意图,因为在这两个概念的定义上(均使用interface方式定义)反映不出上述含义。
如果我们对于问题领域的理解是:AlarmDoor在概念本质上是Door,同时它有具有报警的功能。我们该如何来设计、实现来明确的反映出我们的意思呢?前面已经说过,abstract class在Java语言中表示一种继承关系,而继承关系在本质上是"is a"关系。所以对于Door这个概念,我们应该使用abstarct class方式来定义。另外,AlarmDoor又具有报警功能,说明它又能够完成报警概念中定义的行为,所以报警概念可以通过interface方式定义。如下所示:
abstract class Door {
abstract void open();
abstract void close();
}
interface Alarm {
void alarm();
}
class AlarmDoor extends Door implements Alarm {
void open() { … }
void close() { … }
void alarm() { … }
}
这种实现方式基本上能够明确的反映出我们对于问题领域的理解,正确的揭示我们的设计意图。其实abstract class表示的是"is a"关系,interface表示的是"like a"关系,大家在选择时可以作为一个依据,当然这是建立在对问题领域的理解上的,比如:如果我们认为AlarmDoor在概念本质上是报警器,同时又具有Door的功能,那么上述的定义方式就要反过来了。
结论
abstract class和interface是Java语言中的两种定义抽象类的方式,它们之间有很大的相似性。但是对于它们的选择却又往往反映出对于问题领域中的概念本质的理解、对于设计意图的反映是否正确、合理,因为它们表现了概念间的不同的关系(虽然都能够实现需求的功能)。这其实也是语言的一种的惯用法,希望读者朋友能够细细体会。
|
Aspect Oriented Programming(AOP),面向切面编程,是一个比较热门的话题。AOP主要实现的目的是针对业务处理过程中的切面进行提取,它所面对的是处理过程中的某个步骤或阶段,以获得逻辑过程中各部分之间低耦合性的隔离效果。比如我们最常见的就是日志记录了,举个例子,我们现在提供一个服务查询学生信息的,但是我们希望记录有谁进行了这个查询。如果按照传统的OOP的实现的话,那我们实现了一个查询学生信息的服务接口(StudentInfoService)和其实现类(StudentInfoServiceImpl.java),同时为了要进行记录的话,那我们在实现类(StudentInfoServiceImpl.java)中要添加其实现记录的过程。这样的话,假如我们要实现的服务有多个呢?那就要在每个实现的类都添加这些记录过程。这样做的话就会有点繁琐,而且每个实现类都与记录服务日志的行为紧耦合,违反了面向对象的规则。那么怎样才能把记录服务的行为与业务处理过程中分离出来呢?看起来好像就是查询学生的服务自己在进行,但是背后日志记录对这些行为进行记录,但是查询学生的服务不知道存在这些记录过程,这就是我们要讨论AOP的目的所在。AOP的编程,好像就是把我们在某个方面的功能提出来与一批对象进行隔离,这样与一批对象之间降低了耦合性,可以就某个功能进行编程。
我们直接从代码入手吧,要实现以上的目标,我们可以使用一个动态代理类(Proxy),通过拦截一个对象的行为并添加我们需要的功能来完成。Java中的java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口为我们实现动态代理类提供了一个方案,但是该方案针对的对象要实现某些接口;如果针对的目的是类的话,cglib为我们提供了另外一个实现方案。等下会说明两者的区别。
一、接口的实现方案:
1)首先编写我们的业务接口(StudentInfoService.java):
public interface StudentInfoService{
void findInfo(String studentName);
}
及其实现类(StudentInfoServiceImpl.java):
public class StudentInfoServiceImpl implements StudentInfoService{
public void findInfo(String name){
System.out.println("你目前输入的名字是:"+name);
}
}
2)现在我们需要一个日志功能,在findInfo行为之前执行并记录其行为,那么我们就首先要拦截该行为。在实际执行的过程中用一个代理类来替我们完成。Java中为我们提供了实现动态代理类的方案:
1'处理拦截目的的类(MyHandler.java)
import org.apache.log4j.Logger;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
import java.lang.reflect.Method;
public class MyHandler implements InvocationHandler{
private Object proxyObj;
private static Logger log=Logger.getLogger(MyHandler.class);
public Object bind(Object obj){
this.proxyObj=obj;
return Proxy.newProxyInstance(obj.getClass().getClassLoader(),obj.getClass().getInterfaces(),this);
}
public Object invoke(Object proxy,Method method,Object[] args) throws Throwable{
Object result=null;
try{
//请在这里插入代码,在方法前调用
log.info("调用log日志方法"+method.getName());
result=method.invoke(proxyObj,args); //原方法
//请在这里插入代码,方法后调用
}catch(Exception e){
e.printStackTrace();
}
return result;
}
}
2'我们实现一个工厂,为了方便我们使用该拦截类(AOPFactory.java):
public class AOPFactory{
private static Object getClassInstance(String clzName){
Object obj=null;
try{
Class cls=Class.forName(clzName);
obj=(Object)cls.newInstance();
}catch(ClassNotFoundException cnfe){
System.out.println("ClassNotFoundException:"+cnfe.getMessage());
}catch(Exception e){
e.printStackTrace();
}
return obj;
}
public static Object getAOPProxyedObject(String clzName){
Object proxy=null;
MyHandler handler=new MyHandler();
Object obj=getClassInstance(clzName);
if(obj!=null) {
proxy=handler.bind(obj);
}else{
System.out.println("Can't get the proxyobj");
//throw
}
return proxy;
}
}
3)基本的拦截与其工厂我们都实现了,现在测试(ClientTest.java):
public class ClientTest{
public static void main(String[] args){
StudentInfoService studentInfo=(StudentInfoService)AOPFactory.getAOPProxyedObject("StudentInfoServiceImpl");
studentInfo.findInfo("阿飞");
}
}
输出结果(看你的log4j设置):
[INFO]调用log日志方法findInfo
你目前输入的名字是:阿飞
这样我们需要的效果就出来了,业务处理自己在进行,但是我们实现了日志功能,而业务处理(StudentInfoService)根本不知道存在该行为的。但是Java中提供的动态代理类的实现是针对实现了某些接口的类,如果没有实现接口的话,不能创建代理类,看以上部分:
return Proxy.newProxyInstance(obj.getClass().getClassLoader(),obj.getClass().getInterfaces(),this);
看到了没有?obj.getClass().getInterfaces()要求实现了某些接口。以下提供哪些没有实现接口的实现方案:
二、子类的实现方案。
首先,请上网下CGLib的包,http://sourceforge.net/project/showfiles.php?group_id=56933 。设置好classpath路径,CGLib与java标准库提供的实现方案不同,cglib主要是基于实现类(如StudentInfoServiceImpl.java)扩展一个子类来实现。与Dynamic Proxy中的Proxy和InvocationHandler相对应,net.sf.cglib.proxy.Enhancer和MethodInterceptor在CGLib中负责完成代理对象创建和方法截获处理,产生的是目标类的子类而不是通过接口来实现方法拦截的,Enhancer主要是用于构造动态代理子类来实现拦截,MethodInterceptor(扩展了Callback接口)主要用于实现around advice(AOP中的概念):
1)我们的业务处理(StudentInfoServiceImpl.java):
public class StudentInfoServiceImpl{
public void findInfo(String name){
System.out.println("你目前输入的名字是:"+name);
}
}
2)实行一个工具来处理日志功能(AOPInstrumenter.java):
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
import org.apache.log4j.Logger;
public class AOPInstrumenter implements MethodInterceptor{
private Logger log=Logger.getLogger(AOPInstrumenter.class);
private Enhancer enhancer=new Enhancer();
public Object getInstrumentedClass(Class clz){
enhancer.setSuperclass(clz);
enhancer.setCallback(this);
return enhancer.create();
}
public Object intercept(Object o,Method method,Object[] args,MethodProxy proxy) throws Throwable{
log.info("调用日志方法"+method.getName());
Object result=proxy.invokeSuper(o,args);
return result;
}
}
3)我们来测试一下(AOPTest.java):
public class AOPTest{
public static void main(String[] args){
AOPInstrumenter instrumenter=new AOPInstrumenter();
StudentInfoServiceImpl studentInfo=(StudentInfoServiceImpl)instrumenter.getInstrumentedClass(StudentInfoServiceImpl.class);
studentInfo.findInfo("阿飞");
}
}
输出结果与以上相同。
CGLib中为实现以上目的,主要提供的类
1)Enhancer:setCallback(Callback) ,setSuperclass(Class) ,create()返回动态子类Object
2)MethodInterceptor必须实现的接口:intercept(Object,Method,Object[],MethodProxy)返回的是原方法调用的结果。和Proxy原理一样。
三、以上的两个简单实现AOP的方案都为你准备好了,你可以自己编写测试一下,以下简单介绍一下AOP的基本概念:
1)aspect(切面):实现了cross-cutting功能,是针对切面的模块。最常见的是logging模块,这样,程序按功能被分为好几层,如果按传统的继承的话,商业模型继承日志模块的话根本没有什么意义,而通过创建一个logging切面就可以使用AOP来实现相同的功能了。
2)jointpoint(连接点):连接点是切面插入应用程序的地方,该点能被方法调用,而且也会被抛出意外。连接点是应用程序提供给切面插入的地方,可以添加新的方法。比如以上我们的切点可以认为是findInfo(String)方法。
3)advice(处理逻辑):advice是我们切面功能的实现,它通知程序新的行为。如在logging里,logging advice包括logging的实现代码,比如像写日志到一个文件中。advice在jointpoint处插入到应用程序中。以上我们在MyHandler.java中实现了advice的功能
4)pointcut(切点):pointcut可以控制你把哪些advice应用于jointpoint上去,通常你使用pointcuts通过正则表达式来把明显的名字和模式进行匹配应用。决定了那个jointpoint会获得通知。
5)introduction:允许添加新的方法和属性到类中。
6)target(目标类):是指那些将使用advice的类,一般是指独立的那些商务模型。比如以上的StudentInfoServiceImpl.
7)proxy(代理类):使用了proxy的模式。是指应用了advice的对象,看起来和target对象很相似。
8)weaving(插入):是指应用aspects到一个target对象创建proxy对象的过程:complie time,classload time,runtime
通常,在一个设计良好的Web应用中,都会综合使用Servlet和JSP技术。Servlet控制业务流转,JSP则负责业务处理结果的显示。此时,将大量用到重定向技术。
重定向技术可以分为两类,一类是客户端重定向,一类是服务器端重定向。客户端重定向可以通过设置特定的HTTP头,或者写JavaScript脚本实现。本文主要探讨服务器端重定向技术的实现。
服务器端的重定向相关类
服务器端的重定向技术涉及到javax.servlet.ServletContext、javax.servlet.RequestDispatcher、javax.servlet.http.ServletRequest、javax.servlet.http.ServletResponse等几个接口。
服务器端的重定向方式
服务器端的重定向可以有两种方式,一是使用HttpServletResponse的sendRedirect()方法,一是使用RequestDispatcher的forward()方法。下面对这两种方式进行介绍。
HttpServletResponse.sendRedirect()方法
HttpServletResponse接口定义了可用于转向的sendRedirect()方法。代码如下:
public void sendRedirect(java.lang.String location)throws java.io.IOException
这个方法将响应定向到参数location指定的、新的URL。location可以是一个绝对的URL,如response.sendRedirect("http://java.sun.com")也可以使用相对的URL。如果location以“/”开头,则容器认为相对于当前Web应用的根,否则,容器将解析为相对于当前请求的URL。这种重定向的方法,将导致客户端浏览器的请求URL跳转。从浏览器中的地址栏中可以看到新的URL地址,作用类似于上面设置HTTP响应头信息的实现。
RequestDispatcher.forward()方法
RequestDispatcher是一个Web资源的包装器,可以用来把当前request传递到该资源,或者把新的资源包括到当前响应中。RequestDispatcher接口中定义了两个方法,参见如下代码:
public interface RequestDispatcher {
void forward(ServletRequest request, ServletResponse response);
void include(ServletRequest request, ServletResponse response);
}
forward()方法将当前的request和response重定向到该RequestDispacher指定的资源。这在实际项目中大量使用,因为完成一个业务操作往往需要跨越多个步骤,每一步骤完成相应的处理后,转向到下一个步骤。比如,通常业务处理在Servlet中处理,处理的结果转向到一个JSP页面进行显示。这样看起来类似于Servlet链的功能,但是还有一些区别。一个RequestDispatcher对象可以把请求发送到任意一个服务器资源,而不仅仅是另外一个Servlet。 include()方法将把Request Dispatcher资源的输出包含到当前输出中。
注意,只有在尚未向客户端输出响应时才可以调用forward()方法,如果页面缓存不为空,在重定向前将自动清除缓存。否则将抛出一个IllegalStateException异常。
如何得到RequestDispatcher
有三种方法可以得到Request Dispatcher对象。
1.javax.servlet. ServletRequest的getRequestDispatcher(String path)方法,其中path可以是相对路径,但不能越出当前Servlet上下文。如果path以“/”开头,则解析为相对于当前上下文的根。
2.javax.servlet. ServletContext的getRequestDispatcher(String path)方法,其中path必须以“/”开头,路径相对于当前的Servlet上下文。可以调用ServletContext的getContext(String uripath)得到另一个Servlet上下文,并可以转向到外部上下文的一个服务器资源链接。
3.使用javax.servlet. ServletContext的getNamedDispatcher(String name)得到名为name的一个Web资源,包括Servlet和JSP页面。这个资源的名字在Web应用部署描述文件web.xml中指定。
这三种方法的使用有细微的差别。比如,下面是一个应用的配置文件web.xml:
<?xml version="1.0" ?>
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN"
"http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
<web-app>
<servlet>
<servlet-name>FirstServlet</servlet-name>
<servlet-class>org. javaresearch.redirecttest.ServletOne</servlet-class>
</servlet>
<servlet>
<servlet-name>SecondServlet</servlet-name>
<servlet-class>org.javaresearch. redirecttest.ServletTwo</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>FirstServlet</servlet-name>
<url-pattern>/servlet/firstservlet/</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>SecondServlet</servlet-name>
<url-pattern>/servlet/secondservlet/</url-pattern>
</servlet-mapping>
</web-app>
其中定义了两个Servlet,名字分别为FirstServlet和SecondServlet,对应的类分别为org.javaresearch. redirecttest.ServletOne和org. javaresearch.redirecttest.ServletTwo。可以在浏览器中通过类似于下面的链接访问:
http://localhost:8080/servlet/firstservlet/
使用1中方法,例如在firstservlet可以写入下面的代码:
RequestDispatcher rd = request.getRequestDispatcher("secondservlet");
rd.forward(request, response);
此时控制权将转向到第二个Servlet了。
使用2中的方法,可以从Servlet Context中得到RequestDispatcher代码如下:
RequestDispatcher rd = getServletContext().getRequest
Dispatcher("/servlet/secondservlet");
rd.forward(request, response);
使用3中的方法,从上面的web. xml配置文件可以看到定义了两个Servlet,名字分别为FirstServlet和SecondServlet,所以可以得到命名的Dispatcher:
RequestDispatcher rd = getServletContext().getNamedDispatcher("SecondServlet");
rd.forward(request, response);
这样也可以重定向到SecondServlet了。
JSP页面中的重定向
JSP在解析后编译为一个Servlet运行,所以在JSP中也可以使用上面的重定向代码,并且,JSP还提供了更便利的操作,如下:
<jsp:forward page= "nextpage.jsp"/>
JSP页面执行到这儿,将终止当前的处理,将控制权交由nextpage.jsp。
如何选择
RequestDispatcher.forward()方法和HttpServletResponse.sendRedirect()方法的区别是:前者仅是容器中控制权的转向,在客户端浏览器地址栏中不会显示出转向后的地址;后者则是完全的跳转,浏览器将会得到跳转的地址,并重新发送请求链接。这样,从浏览器的地址栏中可以看到跳转后的链接地址。所以,前者更加高效,在前者可以满足需要时,尽量使用Request Dispatcher.forward()方法,并且,这样也有助于隐藏实际的链接。在有些情况下,比如,需要跳转到一个其它服务器上的资源,则必须使用HttpServletResponse.sendRequest()方法。
51、垃圾回收的优点和原理。并考虑2种回收机制。
Java语言中一个显著的特点就是引入了垃圾回收机制,使c++程序员最头疼的内存管理的问题迎刃而解,它使得Java程序员在编写程序的时候不再需要考虑内存管理。由于有个垃圾回收机制,Java中的对象不再有"作用域"的概念,只有对象的引用才有"作用域"。垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低级别的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清楚和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。回收机制有分代复制垃圾回收和标记垃圾回收,增量垃圾回收。
52、请说出你所知道的线程同步的方法。
wait():使一个线程处于等待状态,并且释放所持有的对象的lock。
sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉InterruptedException异常。
notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
Allnotity():唤醒所有处入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们竞争。
53、你所知道的集合类都有哪些?主要方法?
最常用的集合类是 List 和 Map。 List 的具体实现包括 ArrayList 和 Vector,它们是可变大小的列表,比较适合构建、存储和操作任何类型对象的元素列表。 List 适用于按数值索引访问元素的情形。
Map 提供了一个更通用的元素存储方法。 Map 集合类用于存储元素对(称作"键"和"值"),其中每个键映射到一个值。
54、描述一下JVM加载class文件的原理机制?
JVM中类的装载是由ClassLoader和它的子类来实现的,Java ClassLoader 是一个重要的Java运行时系统组件。它负责在运行时查找和装入类文件的类。
55、char型变量中能不能存贮一个中文汉字?为什么?
能够定义成为一个中文的,因为java中以unicode编码,一个char占16个字节,所以放一个中文是没问题的
56、多线程有几种实现方法,都是什么?同步有几种实现方法,都是什么?
多线程有两种实现方法,分别是继承Thread类与实现Runnable接口
同步的实现方面有两种,分别是synchronized,wait与notify
58、线程的基本概念、线程的基本状态以及状态之间的关系
线程指在程序执行过程中,能够执行程序代码的一个执行单位,每个程序至少都有一个线程,也就是程序本身。
Java中的线程有四种状态分别是:运行、就绪、挂起、结束。
59、JSP的常用指令
<%@page language="java" contenType="text/html;charset=gb2312" session="true" buffer="64kb" autoFlush="true" isThreadSafe="true" info="text" errorPage="error.jsp" isErrorPage="true" isELIgnored="true" pageEncoding="gb2312" import="java.sql.*"%>
isErrorPage(是否能使用Exception对象),isELIgnored(是否忽略表达式)
<%@include file="filename"%>
<%@taglib prefix="c"uri="http://......"%>
60、什么情况下调用doGet()和doPost()?
Jsp页面中的form标签里的method属性为get时调用doGet(),为post时调用doPost()。
61、servlet的生命周期
web容器加载servlet,生命周期开始。通过调用servlet的init()方法进行servlet的初始化。通过调用service()方法实现,根据请求的不同调用不同的do***()方法。结束服务,web容器调用servlet的destroy()方法。
62、如何现实servlet的单线程模式
<%@ page isThreadSafe="false"%>
63、页面间对象传递的方法
request,session,application,cookie等
64、JSP和Servlet有哪些相同点和不同点,他们之间的联系是什么?
JSP是Servlet技术的扩展,本质上是Servlet的简易方式,更强调应用的外表表达。JSP编译后是"类servlet"。Servlet和JSP最主要的不同点在于,Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML里分离开来。而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。JSP侧重于视图,Servlet主要用于控制逻辑。
65、四种会话跟踪技术
会话作用域ServletsJSP 页面描述
page否是代表与一个页面相关的对象和属性。一个页面由一个编译好的 Java servlet 类(可以带有任何的 include 指令,但是没有 include 动作)表示。这既包括 servlet 又包括被编译成 servlet 的 JSP 页面
request是是代表与 Web 客户机发出的一个请求相关的对象和属性。一个请求可能跨越多个页面,涉及多个 Web 组件(由于 forward 指令和 include 动作的关系)
session是是代表与用于某个 Web 客户机的一个用户体验相关的对象和属性。一个 Web 会话可以也经常会跨越多个客户机请求
application是是代表与整个 Web 应用程序相关的对象和属性。这实质上是跨越整个 Web 应用程序,包括多个页面、请求和会话的一个全局作用域
66、Request对象的主要方法:
setAttribute(String name,Object):设置名字为name的request的参数值
getAttribute(String name):返回由name指定的属性值
getAttributeNames():返回request对象所有属性的名字集合,结果是一个枚举的实例
getCookies():返回客户端的所有Cookie对象,结果是一个Cookie数组
getCharacterEncoding():返回请求中的字符编码方式
getContentLength():返回请求的Body的长度
getHeader(String name):获得HTTP协议定义的文件头信息
getHeaders(String name):返回指定名字的request Header的所有值,结果是一个枚举的实例
getHeaderNames():返回所以request Header的名字,结果是一个枚举的实例
getInputStream():返回请求的输入流,用于获得请求中的数据
getMethod():获得客户端向服务器端传送数据的方法
getParameter(String name):获得客户端传送给服务器端的有name指定的参数值
getParameterNames():获得客户端传送给服务器端的所有参数的名字,结果是一个枚举的实例
getParameterValues(String name):获得有name指定的参数的所有值
getProtocol():获取客户端向服务器端传送数据所依据的协议名称
getQueryString():获得查询字符串
getRequestURI():获取发出请求字符串的客户端地址
getRemoteAddr():获取客户端的IP地址
getRemoteHost():获取客户端的名字
getSession([Boolean create]):返回和请求相关Session
getServerName():获取服务器的名字
getServletPath():获取客户端所请求的脚本文件的路径
getServerPort():获取服务器的端口号
removeAttribute(String name):删除请求中的一个属性
67、J2EE是技术还是平台还是框架?
J2EE本身是一个标准,一个为企业分布式应用的开发提供的标准平台。
J2EE也是一个框架,包括JDBC、JNDI、RMI、JMS、EJB、JTA等技术。
68、我们在web应用开发过程中经常遇到输出某种编码的字符,如iso8859-1等,如何输出一个某种编码的字符串?
Public String translate (String str) {
String tempStr = "";
try {
tempStr = new String(str.getBytes("ISO-8859-1"), "GBK");
tempStr = tempStr.trim();
}
catch (Exception e) {
System.err.println(e.getMessage());
}
return tempStr;
}
69、简述逻辑操作(&,|,^)与条件操作(&&,||)的区别。
区别主要答两点:a.条件操作只能操作布尔型的,而逻辑操作不仅可以操作布尔型,而且可以操作数值型
b.逻辑操作不会产生短路
70、XML文档定义有几种形式?它们之间有何本质区别?解析XML文档有哪几种方式?
a: 两种形式 dtd schema,b: 本质区别:schema本身是xml的,可以被XML解析器解析(这也是从DTD上发展schema的根本目的),c:有DOM,SAX,STAX等
DOM:处理大型文件时其性能下降的非常厉害。这个问题是由DOM的树结构所造成的,这种结构占用的内存较多,而且DOM必须在解析文件之前把整个文档装入内存,适合对XML的随机访问
SAX:不现于DOM,SAX是事件驱动型的XML解析方式。它顺序读取XML文件,不需要一次全部装载整个文件。当遇到像文件开头,文档结束,或者标签开头与标签结束时,它会触发一个事件,用户通过在其回调事件中写入处理代码来处理XML文件,适合对XML的顺序访问
STAX:Streaming API for XML (StAX)
71、简述synchronized和java.util.concurrent.locks.Lock的异同 ?
主要相同点:Lock能完成synchronized所实现的所有功能
主要不同点:Lock有比synchronized更精确的线程语义和更好的性能。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放。
72、EJB的角色和三个对象
一个完整的基于EJB的分布式计算结构由六个角色组成,这六个角色可以由不同的开发商提供,每个角色所作的工作必须遵循Sun公司提供的EJB规范,以保证彼此之间的兼容性。这六个角色分别是EJB组件开发者(Enterprise Bean Provider) 、应用组合者(Application Assembler)、部署者(Deployer)、EJB 服务器提供者(EJB Server Provider)、EJB 容器提供者(EJB Container Provider)、系统管理员(System Administrator)
三个对象是Remote(Local)接口、Home(LocalHome)接口,Bean类
73、EJB容器提供的服务
主要提供声明周期管理、代码产生、持续性管理、安全、事务管理、锁和并发行管理等服务。
74、EJB规范规定EJB中禁止的操作有哪些?
1.不能操作线程和线程API(线程API指非线程对象的方法如notify,wait等),2.不能操作awt,3.不能实现服务器功能,4.不能对静态属生存取,5.不能使用IO操作直接存取文件系统,6.不能加载本地库.,7.不能将this作为变量和返回,8.不能循环调用。
75、remote接口和home接口主要作用
remote接口定义了业务方法,用于EJB客户端调用业务方法。
home接口是EJB工厂用于创建和移除查找EJB实例
76、bean 实例的生命周期
对于Stateless Session Bean、Entity Bean、Message Driven Bean一般存在缓冲池管理,而对于Entity Bean和Statefull Session Bean存在Cache管理,通常包含创建实例,设置上下文、创建EJB Object(create)、业务方法调用、remove等过程,对于存在缓冲池管理的Bean,在create之后实例并不从内存清除,而是采用缓冲池调度机制不断重用实例,而对于存在Cache管理的Bean则通过激活和去激活机制保持Bean的状态并限制内存中实例数量。
77、EJB的激活机制
以Stateful Session Bean 为例:其Cache大小决定了内存中可以同时存在的Bean实例的数量,根据MRU或NRU算法,实例在激活和去激活状态之间迁移,激活机制是当客户端调用某个EJB实例业务方法时,如果对应EJB Object发现自己没有绑定对应的Bean实例则从其去激活Bean存储中(通过序列化机制存储实例)回复(激活)此实例。状态变迁前会调用对应的ejbActive和ejbPassivate方法。
78、EJB的几种类型
会话(Session)Bean ,实体(Entity)Bean 消息驱动的(Message Driven)Bean
会话Bean又可分为有状态(Stateful)和无状态(Stateless)两种
实体Bean可分为Bean管理的持续性(BMP)和容器管理的持续性(CMP)两种
79、客服端调用EJB对象的几个基本步骤
设置JNDI服务工厂以及JNDI服务地址系统属性,查找Home接口,从Home接口调用Create方法创建Remote接口,通过Remote接口调用其业务方法。
80、如何给weblogic指定大小的内存?
在启动Weblogic的脚本中(位于所在Domian对应服务器目录下的startServerName),增加set MEM_ARGS=-Xms32m -Xmx200m,可以调整最小内存为32M,最大200M
81、如何设定的weblogic的热启动模式(开发模式)与产品发布模式?
可以在管理控制台中修改对应服务器的启动模式为开发或产品模式之一。或者修改服务的启动文件或者commenv文件,增加set PRODUCTION_MODE=true。
82、如何启动时不需输入用户名与密码?
修改服务启动文件,增加 WLS_USER和WLS_PW项。也可以在boot.properties文件中增加加密过的用户名和密码.
83、在weblogic管理制台中对一个应用域(或者说是一个网站,Domain)进行jms及ejb或连接池等相关信息进行配置后,实际保存在什么文件中?
保存在此Domain的config.xml文件中,它是服务器的核心配置文件。
84、说说weblogic中一个Domain的缺省目录结构?比如要将一个简单的helloWorld.jsp放入何目录下,然的在浏览器上就可打入http://主机:端口号//helloword.jsp就可以看到运行结果了? 又比如这其中用到了一个自己写的javaBean该如何办?
Domain目录服务器目录applications,将应用目录放在此目录下将可以作为应用访问,如果是Web应用,应用目录需要满足Web应用目录要求,jsp文件可以直接放在应用目录中,Javabean需要放在应用目录的WEB-INF目录的classes目录中,设置服务器的缺省应用将可以实现在浏览器上无需输入应用名。
85、在weblogic中发布ejb需涉及到哪些配置文件
不同类型的EJB涉及的配置文件不同,都涉及到的配置文件包括ejb-jar.xml,weblogic-ejb-jar.xmlCMP实体Bean一般还需要weblogic-cmp-rdbms-jar.xml
86、如何在weblogic中进行ssl配置与客户端的认证配置或说说j2ee(标准)进行ssl的配置
缺省安装中使用DemoIdentity.jks和DemoTrust.jks KeyStore实现SSL,需要配置服务器使用Enable SSL,配置其端口,在产品模式下需要从CA获取私有密钥和数字证书,创建identity和trust keystore,装载获得的密钥和数字证书。可以配置此SSL连接是单向还是双向的。
87、如何查看在weblogic中已经发布的EJB?
可以使用管理控制台,在它的Deployment中可以查看所有已发布的EJB
88、CORBA是什么?用途是什么?
CORBA 标准是公共对象请求代理结构(Common Object Request Broker Architecture),由对象管理组织 (Object Management Group,缩写为 OMG)标准化。它的组成是接口定义语言(IDL), 语言绑定(binding:也译为联编)和允许应用程序间互操作的协议。 其目的为:用不同的程序设计语言书写在不同的进程中运行,为不同的操作系统开发。
89、说说你所熟悉或听说过的j2ee中的几种常用模式?及对设计模式的一些看法
Session Facade Pattern:使用SessionBean访问EntityBean
Message Facade Pattern:实现异步调用
EJB Command Pattern:使用Command JavaBeans取代SessionBean,实现轻量级访问
Data Transfer Object Factory:通过DTO Factory简化EntityBean数据提供特性
Generic Attribute Access:通过AttibuteAccess接口简化EntityBean数据提供特性
Business Interface:通过远程(本地)接口和Bean类实现相同接口规范业务逻辑一致性
EJB架构的设计好坏将直接影响系统的性能、可扩展性、可维护性、组件可重用性及开发效率。项目越复杂,项目队伍越庞大则越能体现良好设计的重要性。
90、说说在weblogic中开发消息Bean时的persistent与non-persisten的差别
persistent方式的MDB可以保证消息传递的可靠性,也就是如果EJB容器出现问题而JMS服务器依然会将消息在此MDB可用的时候发送过来,而non-persistent方式的消息将被丢弃。
91、Servlet执行时一般实现哪几个方法?
public void init(ServletConfig config)
public ServletConfig getServletConfig()
public String getServletInfo()
public void service(ServletRequest request,ServletResponse response)
public void destroy()
92、j2ee常用的设计模式?说明工厂模式。
Java中的23种设计模式:
Factory(工厂模式), Builder(建造模式), Factory Method(工厂方法模式),
Prototype(原始模型模式),Singleton(单例模式), Facade(门面模式),
Adapter(适配器模式), Bridge(桥梁模式), Composite(合成模式),
Decorator(装饰模式), Flyweight(享元模式), Proxy(代理模式),
Command(命令模式), Interpreter(解释器模式), Visitor(访问者模式),
Iterator(迭代子模式), Mediator(调停者模式), Memento(备忘录模式),
Observer(观察者模式), State(状态模式), Strategy(策略模式),
Template Method(模板方法模式), Chain Of Responsibleity(责任链模式)
工厂模式:工厂模式是一种经常被使用到的模式,根据工厂模式实现的类可以根据提供的数据生成一组类中某一个类的实例,通常这一组类有一个公共的抽象父类并且实现了相同的方法,但是这些方法针对不同的数据进行了不同的操作。首先需要定义一个基类,该类的子类通过不同的方法实现了基类中的方法。然后需要定义一个工厂类,工厂类可以根据条件生成不同的子类实例。当得到子类的实例后,开发人员可以调用基类中的方法而不必考虑到底返回的是哪一个子类的实例。
93、EJB需直接实现它的业务接口或Home接口吗,请简述理由。
远程接口和Home接口不需要直接实现,他们的实现代码是由服务器产生的,程序运行中对应实现类会作为对应接口类型的实例被使用。
94、排序都有哪几种方法?请列举。用JAVA实现一个快速排序。
排序的方法有:插入排序(直接插入排序、希尔排序),交换排序(冒泡排序、快速排序),选择排序(直接选择排序、堆排序),归并排序,分配排序(箱排序、基数排序)
快速排序的伪代码。
/ /使用快速排序方法对a[ 0 :n- 1 ]排序
从a[ 0 :n- 1 ]中选择一个元素作为m i d d l e,该元素为支点
把余下的元素分割为两段left 和r i g h t,使得l e f t中的元素都小于等于支点,而right 中的元素都大于等于支点
递归地使用快速排序方法对left 进行排序
递归地使用快速排序方法对right 进行排序
所得结果为l e f t + m i d d l e + r i g h t
95、请对以下在J2EE中常用的名词进行解释(或简单描述)
web容器:给处于其中的应用程序组件(JSP,SERVLET)提供一个环境,使JSP,SERVLET直接更容器中的环境变量接口交互,不必关注其它系统问题。主要有WEB服务器来实现。例如:TOMCAT,WEBLOGIC,WEBSPHERE等。该容器提供的接口严格遵守J2EE规范中的WEB APPLICATION 标准。我们把遵守以上标准的WEB服务器就叫做J2EE中的WEB容器。
EJB容器:Enterprise java bean 容器。更具有行业领域特色。他提供给运行在其中的组件EJB各种管理功能。只要满足J2EE规范的EJB放入该容器,马上就会被容器进行高效率的管理。并且可以通过现成的接口来获得系统级别的服务。例如邮件服务、事务管理。
JNDI:(Java Naming & Directory Interface)JAVA命名目录服务。主要提供的功能是:提供一个目录系统,让其它各地的应用程序在其上面留下自己的索引,从而满足快速查找和定位分布式应用程序的功能。
JMS:(Java Message Service)JAVA消息服务。主要实现各个应用程序之间的通讯。包括点对点和广播。
JTA:(Java Transaction API)JAVA事务服务。提供各种分布式事务服务。应用程序只需调用其提供的接口即可。
JAF:(Java Action FrameWork)JAVA安全认证框架。提供一些安全控制方面的框架。让开发者通过各种部署和自定义实现自己的个性安全控制策略。
RMI/IIOP:(Remote Method Invocation /internet对象请求中介协议)他们主要用于通过远程调用服务。例如,远程有一台计算机上运行一个程序,它提供股票分析服务,我们可以在本地计算机上实现对其直接调用。当然这是要通过一定的规范才能在异构的系统之间进行通信。RMI是JAVA特有的。
96、JAVA语言如何进行异常处理,关键字:throws,throw,try,catch,finally分别代表什么意义?在try块中可以抛出异常吗?
Java通过面向对象的方法进行异常处理,把各种不同的异常进行分类,并提供了良好的接口。在Java中,每个异常都是一个对象,它是Throwable类或其它子类的实例。当一个方法出现异常后便抛出一个异常对象,该对象中包含有异常信息,调用这个对象的方法可以捕获到这个异常并进行处理。Java的异常处理是通过5个关键词来实现的:try、catch、throw、throws和finally。一般情况下是用try来执行一段程序,如果出现异常,系统会抛出(throws)一个异常,这时候你可以通过它的类型来捕捉(catch)它,或最后(finally)由缺省处理器来处理。
用try来指定一块预防所有"异常"的程序。紧跟在try程序后面,应包含一个catch子句来指定你想要捕捉的"异常"的类型。
throw语句用来明确地抛出一个"异常"。
throws用来标明一个成员函数可能抛出的各种"异常"。
Finally为确保一段代码不管发生什么"异常"都被执行一段代码。
可以在一个成员函数调用的外面写一个try语句,在这个成员函数内部写另一个try语句保护其他代码。每当遇到一个try语句,"异常"的框架就放到堆栈上面,直到所有的try语句都完成。如果下一级的try语句没有对某种"异常"进行处理,堆栈就会展开,直到遇到有处理这种"异常"的try语句。
97、一个".java"源文件中是否可以包括多个类(不是内部类)?有什么限制?
可以。必须只有一个类名与文件名相同。
98、MVC的各个部分都有那些技术来实现?如何实现?
MVC是Model-View-Controller的简写。"Model" 代表的是应用的业务逻辑(通过JavaBean,EJB组件实现), "View" 是应用的表示面(由JSP页面产生),"Controller" 是提供应用的处理过程控制(一般是一个Servlet),通过这种设计模型把应用逻辑,处理过程和显示逻辑分成不同的组件实现。这些组件可以进行交互和重用。
99、java中有几种方法可以实现一个线程?用什么关键字修饰同步方法? stop()和suspend()方法为何不推荐使用?
有两种实现方法,分别是继承Thread类与实现Runnable接口
用synchronized关键字修饰同步方法
反对使用stop(),是因为它不安全。它会解除由线程获取的所有锁定,而且如果对象处于一种不连贯状态,那么其他线程能在那种状态下检查和修改它们。结果很难检查出真正的问题所在。suspend()方法容易发生死锁。调用suspend()的时候,目标线程会停下来,但却仍然持有在这之前获得的锁定。此时,其他任何线程都不能访问锁定的资源,除非被"挂起"的线程恢复运行。对任何线程来说,如果它们想恢复目标线程,同时又试图使用任何一个锁定的资源,就会造成死锁。所以不应该使用suspend(),而应在自己的Thread类中置入一个标志,指出线程应该活动还是挂起。若标志指出线程应该挂起,便用wait()命其进入等待状态。若标志指出线程应当恢复,则用一个notify()重新启动线程。
100、java中有几种类型的流?JDK为每种类型的流提供了一些抽象类以供继承,请说出他们分别是哪些类?
字节流,字符流。字节流继承于InputStream OutputStream,字符流继承于InputStreamReader OutputStreamWriter。在java.io包中还有许多其他的流,主要是为了提高性能和使用方便。
101、java中会存在内存泄漏吗,请简单描述。
会。如:int i,i2; return (i-i2); file://when i为足够大的正数,i2为足够大的负数。结果会造成溢位,导致错误。
102、java中实现多态的机制是什么?
方法的重写Overriding和重载Overloading是Java多态性的不同表现。重写Overriding是父类与子类之间多态性的一种表现,重载Overloading是一个类中多态性的一种表现。
103、垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是"可达的",哪些对象是"不可达的"。当GC确定一些对象为"不可达"时,GC就有责任回收这些内存空间。可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。
104、静态变量和实例变量的区别?
static i = 10; file://常量
class A a; a.i =10;//可变
105、什么是java序列化,如何实现java序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。
序列化的实现:将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
106、是否可以从一个static方法内部发出对非static方法的调用?
不可以,如果其中包含对象的method();不能保证对象初始化.
107、写clone()方法时,通常都有一行代码,是什么?
Clone 有缺省行为,super.clone();他负责产生正确大小的空间,并逐位复制。
108、在JAVA中,如何跳出当前的多重嵌套循环?
用break; return 方法。
109、List、Map、Set三个接口,存取元素时,各有什么特点?
List 以特定次序来持有元素,可有重复元素。Set 无法拥有重复元素,内部排序。Map 保存key-value值,value可多值。
110、J2EE是什么?
J2EE是Sun公司提出的多层(multi-diered),分布式(distributed),基于组件(component-base)的企业级应用模型(enterpriese application model).在这样的一个应用系统中,可按照功能划分为不同的组件,这些组件又可在不同计算机上,并且处于相应的层次(tier)中。所属层次包括客户层(clietn tier)组件,web层和组件,Business层和组件,企业信息系统(EIS)层。
111、UML方面
标准建模语言UML。用例图,静态图(包括类图、对象图和包图),行为图,交互图(顺序图,合作图),实现图。
112、说出一些常用的类,包,接口,请各举5个
常用的类:BufferedReader BufferedWriter FileReader FileWirter String Integer
常用的包:java.lang java.awt java.io java.util java.sql
常用的接口:Remote List Map Document NodeList
113、开发中都用到了那些设计模式?用在什么场合?
每个模式都描述了一个在我们的环境中不断出现的问题,然后描述了该问题的解决方案的核心。通过这种方式,你可以无数次地使用那些已有的解决方案,无需在重复相同的工作。主要用到了MVC的设计模式。用来开发JSP/Servlet或者J2EE的相关应用。简单工厂模式等。
114、jsp有哪些动作?作用分别是什么?
JSP共有以下6种基本动作 jsp:include:在页面被请求的时候引入一个文件。 jsp:useBean:寻找或者实例化一个JavaBean。 jsp:setProperty:设置JavaBean的属性。 jsp:getProperty:输出某个JavaBean的属性。 jsp:forward:把请求转到一个新的页面。 jsp:plugin:根据浏览器类型为Java插件生成OBJECT或EMBED标记。
115、Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是否可以implements(实现)interface(接口)?
可以继承其他类或完成其他接口,在swing编程中常用此方式。
116、应用服务器与WEB SERVER的区别?
应用服务器:Weblogic、Tomcat、Jboss
WEB SERVER:IIS、 Apache
117、BS与CS的联系与区别。
C/S是Client/Server的缩写。服务器通常采用高性能的PC、工作站或小型机,并采用大型数据库系统,如Oracle、Sybase、Informix或 SQL Server。客户端需要安装专用的客户端软件。
B/S是Brower/Server的缩写,客户机上只要安装一个浏览器(Browser),如Netscape Navigator或Internet Explorer,服务器安装Oracle、Sybase、Informix或 SQL Server等数据库。在这种结构下,用户界面完全通过WWW浏览器实现,一部分事务逻辑在前端实现,但是主要事务逻辑在服务器端实现。浏览器通过Web Server 同数据库进行数据交互。
C/S 与 B/S 区别:
1.硬件环境不同:
C/S 一般建立在专用的网络上, 小范围里的网络环境, 局域网之间再通过专门服务器提供连接和数据交换服务.
B/S 建立在广域网之上的, 不必是专门的网络硬件环境,例与电话上网, 租用设备. 信息自己管理. 有比C/S更强的适应范围, 一般只要有操作系统和浏览器就行
2.对安全要求不同
C/S 一般面向相对固定的用户群, 对信息安全的控制能力很强. 一般高度机密的信息系统采用C/S 结构适宜. 可以通过B/S发布部分可公开信息.
B/S 建立在广域网之上, 对安全的控制能力相对弱, 可能面向不可知的用户。
3.对程序架构不同
C/S 程序可以更加注重流程, 可以对权限多层次校验, 对系统运行速度可以较少考虑.
B/S 对安全以及访问速度的多重的考虑, 建立在需要更加优化的基础之上. 比C/S有更高的要求 B/S结构的程序架构是发展的趋势, 从MS的.Net系列的BizTalk 2000 Exchange 2000等, 全面支持网络的构件搭建的系统. SUN 和IBM推的JavaBean 构件技术等,使 B/S更加成熟.
4.软件重用不同
C/S 程序可以不可避免的整体性考虑, 构件的重用性不如在B/S要求下的构件的重用性好.
B/S 对的多重结构,要求构件相对独立的功能. 能够相对较好的重用.就入买来的餐桌可以再利用,而不是做在墙上的石头桌子
5.系统维护不同
C/S 程序由于整体性, 必须整体考察, 处理出现的问题以及系统升级. 升级难. 可能是再做一个全新的系统
B/S 构件组成,方面构件个别的更换,实现系统的无缝升级. 系统维护开销减到最小.用户从网上自己下载安装就可以实现升级.
6.处理问题不同
C/S 程序可以处理用户面固定, 并且在相同区域, 安全要求高需求, 与操作系统相关. 应该都是相同的系统
B/S 建立在广域网上, 面向不同的用户群, 分散地域, 这是C/S无法作到的. 与操作系统平台关系最小.
7.用户接口不同
C/S 多是建立的Window平台上,表现方法有限,对程序员普遍要求较高
B/S 建立在浏览器上, 有更加丰富和生动的表现方式与用户交流. 并且大部分难度减低,减低开发成本.
8.信息流不同
C/S 程序一般是典型的中央集权的机械式处理, 交互性相对低
B/S 信息流向可变化, B-B B-C B-G等信息、流向的变化, 更像交易中心。
118、LINUX下线程,GDI类的解释。
LINUX实现的就是基于核心轻量级进程的"一对一"线程模型,一个线程实体对应一个核心轻量级进程,而线程之间的管理在核外函数库中实现。
GDI类为图像设备编程接口类库。
119、STRUTS的应用(如STRUTS架构)
Struts是采用Java Servlet/JavaServer Pages技术,开发Web应用程序的开放源码的framework。 采用Struts能开发出基于MVC(Model-View-Controller)设计模式的应用构架。 Struts有如下的主要功能: 一.包含一个controller servlet,能将用户的请求发送到相应的Action对象。 二.JSP自由tag库,并且在controller servlet中提供关联支持,帮助开发员创建交互式表单应用。 三.提供了一系列实用对象:XML处理、通过Java reflection APIs自动处理JavaBeans属性、国际化的提示和消息。
120、Jdo是什么?
JDO是Java对象持久化的新的规范,为java data object的简称,也是一个用于存取某种数据仓库中的对象的标准化API。JDO提供了透明的对象存储,因此对开发人员来说,存储数据对象完全不需要额外的代码(如JDBC API的使用)。这些繁琐的例行工作已经转移到JDO产品提供商身上,使开发人员解脱出来,从而集中时间和精力在业务逻辑上。另外,JDO很灵活,因为它可以在任何数据底层上运行。JDBC只是面向关系数据库(RDBMS)JDO更通用,提供到任何数据底层的存储功能,比如关系数据库、文件、XML以及对象数据库(ODBMS)等等,使得应用可移植性更强。
1.面向对象的特征有哪些方面 1.抽象: 抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地注意与当前目标有关的方面。抽象并不打算了解全部问题,而只是选择其中的一部分,暂时不用部分细节。抽象包括两个方面,一是过程抽象,二是数据抽象。 2.继承: 继承是一种联结类的层次模型,并且允许和鼓励类的重用,它提供了一种明确表述共性的方法。对象的一个新类可以从现有的类中派生,这个过程称为类继承。新类继承了原始类的特性,新类称为原始类的派生类(子类),而原始类称为新类的基类(父类)。派生类可以从它的基类那里继承方法和实例变量,并且类可以修改或增加新的方法使之更适合特殊的需要。 3.封装: 封装是把过程和数据包围起来,对数据的访问只能通过已定义的界面。面向对象计算始于这个基本概念,即现实世界可以被描绘成一系列完全自治、封装的对象,这些对象通过一个受保护的接口访问其他对象。 4. 多态性: 多态性是指允许不同类的对象对同一消息作出响应。多态性包括参数化多态性和包含多态性。多态性语言具有灵活、抽象、行为共享、代码共享的优势,很好的解决了应用程序函数同名问题。
2、String是最基本的数据类型吗?
基本数据类型包括byte、int、char、long、float、double、boolean和short。
java.lang.String类是final类型的,因此不可以继承这个类、不能修改这个类。为了提高效率节省空间,我们应该用StringBuffer类
3、int 和 Integer 有什么区别
Java 提供两种不同的类型:引用类型和原始类型(或内置类型)。Int是java的原始数据类型,Integer是java为int提供的封装类。Java为每个原始类型提供了封装类。
原始类型封装类
booleanBoolean
charCharacter
byteByte
shortShort
intInteger
longLong
floatFloat
doubleDouble
引用类型和原始类型的行为完全不同,并且它们具有不同的语义。引用类型和原始类型具有不同的特征和用法,它们包括:大小和速度问题,这种类型以哪种类型的数据结构存储,当引用类型和原始类型用作某个类的实例数据时所指定的缺省值。对象引用实例变量的缺省值为 null,而原始类型实例变量的缺省值与它们的类型有关。
4、String 和StringBuffer的区别
JAVA平台提供了两个类:String和StringBuffer,它们可以储存和操作字符串,即包含多个字符的字符数据。这个String类提供了数值不可改变的字符串。而这个StringBuffer类提供的字符串进行修改。当你知道字符数据要改变的时候你就可以使用StringBuffer。典型地,你可以使用StringBuffers来动态构造字符数据。
5、运行时异常与一般异常有何异同?
异常表示程序运行过程中可能出现的非正常状态,运行时异常表示虚拟机的通常操作中可能遇到的异常,是一种常见运行错误。java编译器要求方法必须声明抛出可能发生的非运行时异常,但是并不要求必须声明抛出未被捕获的运行时异常。
6、说出Servlet的生命周期,并说出Servlet和CGI的区别。
Servlet被服务器实例化后,容器运行其init方法,请求到达时运行其service方法,service方法自动派遣运行与请求对应的doXXX方法(doGet,doPost)等,当服务器决定将实例销毁的时候调用其destroy方法。
与cgi的区别在于servlet处于服务器进程中,它通过多线程方式运行其service方法,一个实例可以服务于多个请求,并且其实例一般不会销毁,而CGI对每个请求都产生新的进程,服务完成后就销毁,所以效率上低于servlet。
7、说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差,而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
8、EJB是基于哪些技术实现的?并说出SessionBean和EntityBean的区别,StatefulBean和StatelessBean的区别。
EJB包括Session Bean、Entity Bean、Message Driven Bean,基于JNDI、RMI、JAT等技术实现。
SessionBean在J2EE应用程序中被用来完成一些服务器端的业务操作,例如访问数据库、调用其他EJB组件。EntityBean被用来代表应用系统中用到的数据。
对于客户机,SessionBean是一种非持久性对象,它实现某些在服务器上运行的业务逻辑。
对于客户机,EntityBean是一种持久性对象,它代表一个存储在持久性存储器中的实体的对象视图,或是一个由现有企业应用程序实现的实体。
Session Bean 还可以再细分为 Stateful Session Bean 与 Stateless Session Bean ,这两种的 Session Bean都可以将系统逻辑放在 method之中执行,不同的是 Stateful Session Bean 可以记录呼叫者的状态,因此通常来说,一个使用者会有一个相对应的 Stateful Session Bean 的实体。Stateless Session Bean 虽然也是逻辑组件,但是他却不负责记录使用者状态,也就是说当使用者呼叫 Stateless Session Bean 的时候,EJB Container 并不会找寻特定的 Stateless Session Bean 的实体来执行这个 method。换言之,很可能数个使用者在执行某个 Stateless Session Bean 的 methods 时,会是同一个 Bean 的 Instance 在执行。从内存方面来看, Stateful Session Bean 与 Stateless Session Bean 比较, Stateful Session Bean 会消耗 J2EE Server 较多的内存,然而 Stateful Session Bean 的优势却在于他可以维持使用者的状态。
9、Collection 和 Collections的区别。
Collection是集合类的上级接口,继承与他的接口主要有Set 和List.
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
10、&和&&的区别。
&是位运算符,表示按位与运算,&&是逻辑运算符,表示逻辑与(and)。
11、HashMap和Hashtable的区别。
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
12、final, finally, finalize的区别。
final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
finally是异常处理语句结构的一部分,表示总是执行。
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。
13、sleep() 和 wait() 有什么区别?
sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep不会释放对象锁。
wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
14、Overload和Override的区别。Overloaded的方法是否可以改变返回值的类型?
方法的重写Overriding和重载Overloading是Java多态性的不同表现。重写Overriding是父类与子类之间多态性的一种表现,重载Overloading是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding)。子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被"屏蔽"了。如果在一个类中定义了多个同名的方法,它们或有不同的参数个数或有不同的参数类型,则称为方法的重载(Overloading)。Overloaded的方法是可以改变返回值的类型。
15、error和exception有什么区别?
error 表示恢复不是不可能但很困难的情况下的一种严重问题。比如说内存溢出。不可能指望程序能处理这样的情况。
exception 表示一种设计或实现问题。也就是说,它表示如果程序运行正常,从不会发生的情况。
16、同步和异步有何异同,在什么情况下分别使用他们?举例说明。
如果数据将在线程间共享。例如正在写的数据以后可能被另一个线程读到,或者正在读的数据可能已经被另一个线程写过了,那么这些数据就是共享数据,必须进行同步存取。
当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就应该使用异步编程,在很多情况下采用异步途径往往更有效率。
17、abstract class和interface有什么区别?
声明方法的存在而不去实现它的类被叫做抽象类(abstract class),它用于要创建一个体现某些基本行为的类,并为该类声明方法,但不能在该类中实现该类的情况。不能创建abstract 类的实例。然而可以创建一个变量,其类型是一个抽象类,并让它指向具体子类的一个实例。不能有抽象构造函数或抽象静态方法。Abstract 类的子类为它们父类中的所有抽象方法提供实现,否则它们也是抽象类为。取而代之,在子类中实现该方法。知道其行为的其它类可以在类中实现这些方法。
接口(interface)是抽象类的变体。在接口中,所有方法都是抽象的。多继承性可通过实现这样的接口而获得。接口中的所有方法都是抽象的,没有一个有程序体。接口只可以定义static final成员变量。接口的实现与子类相似,除了该实现类不能从接口定义中继承行为。当类实现特殊接口时,它定义(即将程序体给予)所有这种接口的方法。然后,它可以在实现了该接口的类的任何对象上调用接口的方法。由于有抽象类,它允许使用接口名作为引用变量的类型。通常的动态联编将生效。引用可以转换到接口类型或从接口类型转换,instanceof 运算符可以用来决定某对象的类是否实现了接口。
18、heap和stack有什么区别。
栈是一种线形集合,其添加和删除元素的操作应在同一段完成。栈按照后进先出的方式进行处理。
堆是栈的一个组成元素
19、forward 和redirect的区别
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器,浏览器根本不知道服务器发送的内容是从哪儿来的,所以它的地址栏中还是原来的地址。
redirect就是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,一般来说浏览器会用刚才请求的所有参数重新请求,所以session,request参数都可以获取。
20、EJB与JAVA BEAN的区别?
Java Bean 是可复用的组件,对Java Bean并没有严格的规范,理论上讲,任何一个Java类都可以是一个Bean。但通常情况下,由于Java Bean是被容器所创建(如Tomcat)的,所以Java Bean应具有一个无参的构造器,另外,通常Java Bean还要实现Serializable接口用于实现Bean的持久性。Java Bean实际上相当于微软COM模型中的本地进程内COM组件,它是不能被跨进程访问的。Enterprise Java Bean 相当于DCOM,即分布式组件。它是基于Java的远程方法调用(RMI)技术的,所以EJB可以被远程访问(跨进程、跨计算机)。但EJB必须被布署在诸如Webspere、WebLogic这样的容器中,EJB客户从不直接访问真正的EJB组件,而是通过其容器访问。EJB容器是EJB组件的代理,EJB组件由容器所创建和管理。客户通过容器来访问真正的EJB组件。
21、Static Nested Class 和 Inner Class的不同。
Static Nested Class是被声明为静态(static)的内部类,它可以不依赖于外部类实例被实例化。而通常的内部类需要在外部类实例化后才能实例化。
22、JSP中动态INCLUDE与静态INCLUDE的区别?
动态INCLUDE用jsp:include动作实现 <jsp:include page="included.jsp" flush="true" />它总是会检查所含文件中的变化,适合用于包含动态页面,并且可以带参数。
静态INCLUDE用include伪码实现,定不会检查所含文件的变化,适用于包含静态页面<%@ include file="included.htm" %>
23、什么时候用assert。
assertion(断言)在软件开发中是一种常用的调试方式,很多开发语言中都支持这种机制。在实现中,assertion就是在程序中的一条语句,它对一个boolean表达式进行检查,一个正确程序必须保证这个boolean表达式的值为true;如果该值为false,说明程序已经处于不正确的状态下,系统将给出警告或退出。一般来说,assertion用于保证程序最基本、关键的正确性。assertion检查通常在开发和测试时开启。为了提高性能,在软件发布后,assertion检查通常是关闭的。
24、GC是什么? 为什么要有GC?
GC是垃圾收集的意思(Gabage Collection),内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法。
25、short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1 += 1;有什么错?
short s1 = 1; s1 = s1 + 1; (s1+1运算结果是int型,需要强制转换类型)
short s1 = 1; s1 += 1;(可以正确编译)
26、Math.round(11.5)等於多少? Math.round(-11.5)等於多少?
Math.round(11.5)==12
Math.round(-11.5)==-11
round方法返回与参数最接近的长整数,参数加1/2后求其floor.
27、String s = new String("xyz");创建了几个String Object?
两个
28、设计4个线程,其中两个线程每次对j增加1,另外两个线程对j每次减少1。写出程序。
以下程序使用内部类实现线程,对j增减的时候没有考虑顺序问题。
public class ThreadTest1{
private int j;
public static void main(String args[]){
ThreadTest1 tt=new ThreadTest1();
Inc inc=tt.new Inc();
Dec dec=tt.new Dec();
for(int i=0;i<2;i++){
Thread t=new Thread(inc);
t.start();
t=new Thread(dec);
t.start();
}
}
private synchronized void inc(){
j++;
System.out.println(Thread.currentThread().getName()+"-inc:"+j);
}
private synchronized void dec(){
j--;
System.out.println(Thread.currentThread().getName()+"-dec:"+j);
}
class Inc implements Runnable{
public void run(){
for(int i=0;i<100;i++){
inc();
}
}
}
class Dec implements Runnable{
public void run(){
for(int i=0;i<100;i++){
dec();
}
}
}
}
29、Java有没有goto?
java中的保留字,现在没有在java中使用。
30、启动一个线程是用run()还是start()?
启动一个线程是调用start()方法,使线程所代表的虚拟处理机处于可运行状态,这意味着它可以由JVM调度并执行。这并不意味着线程就会立即运行。run()方法可以产生必须退出的标志来停止一个线程。
31、EJB包括(SessionBean,EntityBean)说出他们的生命周期,及如何管理事务的?
SessionBean:Stateless Session Bean 的生命周期是由容器决定的,当客户机发出请求要建立一个Bean的实例时,EJB容器不一定要创建一个新的Bean的实例供客户机调用,而是随便找一个现有的实例提供给客户机。当客户机第一次调用一个Stateful Session Bean 时,容器必须立即在服务器中创建一个新的Bean实例,并关联到客户机上,以后此客户机调用Stateful Session Bean 的方法时容器会把调用分派到与此客户机相关联的Bean实例。
EntityBean:Entity Beans能存活相对较长的时间,并且状态是持续的。只要数据库中的数据存在,Entity beans就一直存活。而不是按照应用程序或者服务进程来说的。即使EJB容器崩溃了,Entity beans也是存活的。Entity Beans生命周期能够被容器或者 Beans自己管理。
EJB通过以下技术管理实务:对象管理组织(OMG)的对象实务服务(OTS),Sun Microsystems的Transaction Service(JTS)、Java Transaction API(JTA),开发组(X/Open)的XA接口。
32、应用服务器有那些?
BEA WebLogic Server,IBM WebSphere Application Server,Oracle9i Application Server,jBoss,Tomcat
33、给我一个你最常见到的runtime exception。
ArithmeticException, ArrayStoreException, BufferOverflowException, BufferUnderflowException, CannotRedoException, CannotUndoException, ClassCastException, CMMException, ConcurrentModificationException, DOMException, EmptyStackException, IllegalArgumentException, IllegalMonitorStateException, IllegalPathStateException, IllegalStateException, ImagingOpException, IndexOutOfBoundsException, MissingResourceException, NegativeArraySizeException, NoSuchElementException, NullPointerException, ProfileDataException, ProviderException, RasterFormatException, SecurityException, SystemException, UndeclaredThrowableException, UnmodifiableSetException, UnsupportedOperationException
34、接口是否可继承接口? 抽象类是否可实现(implements)接口? 抽象类是否可继承实体类(concrete class)?
接口可以继承接口。抽象类可以实现(implements)接口,抽象类是否可继承实体类,但前提是实体类必须有明确的构造函数。
35、List, Set, Map是否继承自Collection接口?
List,Set是,Map不是
36、说出数据连接池的工作机制是什么?
J2EE服务器启动时会建立一定数量的池连接,并一直维持不少于此数目的池连接。客户端程序需要连接时,池驱动程序会返回一个未使用的池连接并将其表记为忙。如果当前没有空闲连接,池驱动程序就新建一定数量的连接,新建连接的数量有配置参数决定。当使用的池连接调用完成后,池驱动程序将此连接表记为空闲,其他调用就可以使用这个连接。
37、abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?
都不能
38、数组有没有length()这个方法? String有没有length()这个方法?
数组没有length()这个方法,有length的属性。String有有length()这个方法。
39、Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
Set里的元素是不能重复的,那么用iterator()方法来区分重复与否。equals()是判读两个Set是否相等。
equals()和==方法决定引用值是否指向同一对象equals()在类中被覆盖,为的是当两个分离的对象的内容和类型相配的话,返回真值。
40、构造器Constructor是否可被override?
构造器Constructor不能被继承,因此不能重写Overriding,但可以被重载Overloading。
41、是否可以继承String类?
String类是final类故不可以继承。
42、swtich是否能作用在byte上,是否能作用在long上,是否能作用在String上?
switch(expr1)中,expr1是一个整数表达式。因此传递给 switch 和 case 语句的参数应该是 int、 short、 char 或者 byte。long,string 都不能作用于swtich。
43、try {}里有一个return语句,那么紧跟在这个try后的finally {}里的code会不会被执行,什么时候被执行,在return前还是后?
会执行,在return前执行。
44、编程题: 用最有效率的方法算出2乘以8等於几?
2 << 3
45、两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
不对,有相同的hash code。
46、当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
是值传递。Java 编程语言只有值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的内容可以在被调用的方法中改变,但对象的引用是永远不会改变的。
47、当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?
不能,一个对象的一个synchronized方法只能由一个线程访问。
48、编程题: 写一个Singleton出来。
Singleton模式主要作用是保证在Java应用程序中,一个类Class只有一个实例存在。
一般Singleton模式通常有几种种形式:
第一种形式: 定义一个类,它的构造函数为private的,它有一个static的private的该类变量,在类初始化时实例话,通过一个public的getInstance方法获取对它的引用,继而调用其中的方法。
public class Singleton {
private Singleton(){}
file://在自己内部定义自己一个实例,是不是很奇怪?
file://注意这是private 只供内部调用
private static Singleton instance = new Singleton();
file://这里提供了一个供外部访问本class的静态方法,可以直接访问
public static Singleton getInstance() {
return instance;
}
}
第二种形式:
public class Singleton {
private static Singleton instance = null;
public static synchronized Singleton getInstance() {
file://这个方法比上面有所改进,不用每次都进行生成对象,只是第一次
file://使用时生成实例,提高了效率!
if (instance==null)
instance=new Singleton();
return instance; }
}
其他形式:
定义一个类,它的构造函数为private的,所有方法为static的。
一般认为第一种形式要更加安全些
49、Java的接口和C++的虚类的相同和不同处。
由于Java不支持多继承,而有可能某个类或对象要使用分别在几个类或对象里面的方法或属性,现有的单继承机制就不能满足要求。与继承相比,接口有更高的灵活性,因为接口中没有任何实现代码。当一个类实现了接口以后,该类要实现接口里面所有的方法和属性,并且接口里面的属性在默认状态下面都是public static,所有方法默认情况下是public.一个类可以实现多个接口。
50、Java中的异常处理机制的简单原理和应用。
当JAVA程序违反了JAVA的语义规则时,JAVA虚拟机就会将发生的错误表示为一个异常。违反语义规则包括2种情况。一种是JAVA类库内置的语义检查。例如数组下标越界,会引发IndexOutOfBoundsException;访问null的对象时会引发NullPointerException。另一种情况就是JAVA允许程序员扩展这种语义检查,程序员可以创建自己的异常,并自由选择在何时用throw关键字引发异常。所有的异常都是java.lang.Thowable的子类。
|
|
|
|
|
|
|
|
|
Spring的功能是很强大的,在其“绝不发明自己认为好的轮子,而只发明自己认为不好的轮子”的指导思想下,通过充分实践了“一切实事求是、‘循证架构’的工作方式”的理论,基本上把轻量级的J2EE应用框架(如ORM、MVC等)进行了整合,并构架了一些常用的功能(如DAO),形成了一个功能强大的J2EE轻量级企业应用框架。
然而,或许是大家对Spring掌握得还不透彻的缘故吧,看到很多软件企业中用到的Spring功能,基本上大多数都只是用其IOC功能,有时候附带用了其中的AOP事务管理功能。
IOC及AOP虽然不是Spring首创,然而其在这两块都是做得很不错的,应该说整个Spring框架就是围绕着其IOC实现及AOP实现架设起来的。我想,深入挖掘IOC、AOP以及Spring中的实现,使用等,对于初学者帮助会非常大,因此,从本期开始,大峡的《玩玩Spring系列》将伴随大家一起走进IOC及AOP的世界。
由于本人水平有限,文中难免有很多不足甚至错误之处,还请各位朋友不吝批评指教。
一、IOC简介
IOC-全称Inversion of Control,中文解释:控制反转。另外,IOC又称DI(全称)Dependency Injection,中文解释:依赖注入。
呵呵,这些名词搞得有点像学古文的味道哈。很多大师还都说IOC中有一个著名的好莱坞理论:你呆着别动,到时我会找你。你呆着别动,到时我会找你。由于本人未到过好莱坞参加过社会实践,因此,这句话理解有点困难。
IOC是一种新的设计模式,即IOC模式,系统中通过引入实现了IOC模式的IOC容器,即可由IOC容器来管理对象的生命周期、依赖关系等,从而使得应用程序的配置和依赖性规范与实际的应用程序代码分开。其中一个特点就是通过文本的配件文件进行应用程序组件间相互关系的配置,而不用重新修改并编译具体的Java代码。
当前比较知名的IOC容器有:Pico Container、Avalon 、Spring、JBoss、HiveMind、EJB等,国内由板桥里人负责的国产开源项目Jdon框架,也是具有IOC容器功能(由于没来得及认真研读其源码,似乎jdon中IOC部份是调用Pico的IOC容器功能来实现的)。
在上面的几个IOC容器中,轻量级的有Pico Container、Avalon、Spring、HiveMind等,超重量级的有EJB,而半轻半重的有容器有JBoss,Jdon等。
IOC究竟是什么?IOC是如何产生的?用在什么场合?为什么我们以前不用IOC,而现在要用IOC?“物有本末,事有终始”,为了更加透彻的理解这一问题,大峡打算从自己所理解的面向对象(OO)设计及编程发展历程来进行分析,也许这样能让IOC的初学者更加了解IOC的发展的前因后果,争取做到“知其然,知其所以然,使其然!”。
若大家等不急了,就直接百度一下有关IOC的其它文章,这方面国内很多先驱们已经作了很多介绍。如冰云的《IOC详解》、板桥里人的设计模式及IOC理论等。
二、 最老的OO编程
记得曾经看《Think in Java》最早版本的时候,里面有这么一句让人振奋话:一切都是对象。这时我们OO编程的核心是围绕着面向对象编程的三个特性即“继承”、“封装”、“多态”来展开的。
2.1 封装
那时我们学会了对现实就的事物及软件模型进行了抽象。比如要描述一只猫,那么这支猫应该有“颜色”、“重量”、“公母”、“脾气”、“出生日期”等属性,另外还有“跑”、“吃”、“叫”、“猫捉老鼠”等方法。如Java代码来表示,大致就是如下:
public Class Cat
{
private String color;//颜色
private String weight;//重量
private String sex;//公母
private String temper;//脾气
private String birthday;//出生日期
private void run ();//跑
private void eat (Food food); //吃(食物)
private void shout(int type);//叫(类别)
private boolean chase(Mice mice);//猫捉老鼠
}
2.2 继承
最早的OO编程时期,我们还会引入继承,还经常鼓励大家多用继续,认为继承就是OO编程思想的核心。继承的核心就是围绕着如何把类与类之间具有共同特性的部份抽象到基类中。认为这样不但能使用了OO的特性,还减少了很多子类的代码。
我们通过日常生活的常识知道,猫是一种动物,因此动物有的特性他基本上都有。于是,如果我们的系统中不但有猫,还会有很多其它的动物出现。我们就会设计一个动物类,把所有动物的共性抽象到一个基类中。这里,猫及动物基类的代码大致如下:
public abstract Class Animal{
private String color;//颜色
private String weight;//重量
private String sex;//公母
private String temper;//脾气
private String birthday;//出生日期
private void run ();//跑
private void eat (Food food); //吃(食物)
private void shout(int type);//叫(类别)
}
public Class Cat extends Animal
private int power;//能力
private int agility;//敏捷度
// 猫捉老鼠是特有的方法
private boolean chase(Mice mice) {
return true;
};
}
2.3 多态
这时我们还会不时使用到OO的另外一个特性多态。多态是很重要的一门技术,然而很多时候却没有很好的理解并使用,回头看以前的代码,我们看到有很多地方属于故弄玄虚的嫌疑。
接上面的例子,假如我们要写一个喂养宠物(有猫、狗、猪、豹、老鼠等)的程序。利用Java的多态特性,我们的大致代码如下:
public class PetManage {
//喂食我的宠物
public void feeding(Animal a)
{
}
/**
* @param args
*/
public static void main(String[] args) {
Animal myPet=new Cat();
PetManage pm=new PetManage();
pm.feeding(myPet);
}
}
通过使用多态特性,哪一天若我们的不喜欢猫,而是喜欢养猪的时候,只要把new Cat()变成new Pig(),即可。
2.4 对象生命周期
这一阶段的OO程序中,我们知道要用一个对象的时候,就要使用Java中的关键字new来生成一个来用即可。OO对于我们来说,一切都是那么简单,很多时候甚至感觉OO跟OP的编程方法也没太大区别。代码如下:
Cat myCat=new Cat();//创建一支具体的猫
myCat.shout();//叫一声
此时,我们对Java虚拟是非常信任的,我们的思想也很单纯,我们知道Java对象的生命开始于new关键词。我们不太关心对象生命的结束,我们知道Java有一个比C语言历害、智能化的垃圾收集器,他会帮我们自己的清理内存中不用的对象。
当然,也有的人由于对垃圾收集器忠诚度的怀疑,不放心垃圾收集器的能力,于是在程序中经常要加一句类似“myPet=null”的代码来结束对象的生命。
当然,我们也知道有一些外部资源如数据库连接等,需要手动熟悉资源。于是知道在使用类似资源的时候必须都加上一句:conn.close(),有时候还要在close()后面再加一句:conn=null。呵呵,非常有意思。
2.5小结
现在看来,其实那时确实犯了很多幼稚的错误,也走了不少的弯路,做了很多画蛇添足的工作,写了很多难与维护的代码。
对比今天的IOC模式,若要从早的OO方法中硬要找一个类似Spring的容器的话,那就是:“程序员+JVM本身”。是程序员以及JVM一起我们管理对象的生命周期、对象之间的关系等。那时候若有任何变动都需要改代码,(虽然好的设计代码修改会非常少,但也得改!),然后编译,然后拿到测试环境及用户环境中执行。如此反复,年日复一日、年复一年。
那时我们的代码复用用得最多的就是OO的继承功能,另外还有很多OP方法中带过来的函数。
本文中涉及到的几个简单源码,请到EasyJF开源团队官网下载,地址:
http://www.easyjf.com/html/bbs/20060602/12718636-1843943.htm?ejid=1287314863003738
|
|
abstract class和
interface是Java语言中对于抽象类定义进行支持的两种机制,正是由于这两种机制的存在,才赋予了Java强大的面向对象能力。 abstract class和interface之间在对于抽象类定义的支持方面具有很大的相似性,甚至可以相互替换,因此很多开发者在进行抽象类定义时对于 abstract class和interface的选择显得比较随意。
其实,两者之间还是有很大的区别的,对于它们的选择甚至反映出对于问题领域本质的理解、对于设计意图的理解是否正确、合理。本文将对它们之间的区别进行一番剖析,试图给开发者提供一个在二者之间进行选择的依据。
一、理解抽象类
abstract class和interface在Java语言中都是用来进行抽象类(本文中的抽象类并非从abstract class翻译而来,它表示的是一个抽象体,而abstract class为Java语言中用于定义抽象类的一种方法,请读者注意区分)定义的,那么什么是抽象类,使用抽象类能为我们带来什么好处呢?
在面向对象的概念中,我们知道所有的对象都是通过类来描绘的,但是反过来却不是这样。并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。抽象类往往用来表征我们在对问题领域进行分析、设计中得出的抽象概念,是对一系列看上去不同,但是本质上相同的具体概念的抽象。
比如:如果我们进行一个图形编辑软件的开发,就会发现问题领域存在着圆、三角形这样一些具体概念,它们是不同的,但是它们又都属于形状这样一个概念,形状这个概念在问题领域是不存在的,它就是一个抽象概念。正是因为抽象的概念在问题领域没有对应的具体概念,所以用以表征抽象概念的抽象类是不能够实例化的。
在面向对象领域,抽象类主要用来进行类型隐藏。我们可以构造出一个固定的一组行为的抽象描述,但是这组行为却能够有任意个可能的具体实现方式。这个抽象描述就是抽象类,而这一组任意个可能的具体实现则表现为所有可能的派生类。模块可以操作一个抽象体。由于模块依赖于一个固定的抽象体,因此它可以是不允许修改的;同时,通过从这个抽象体派生,也可扩展此模块的行为功能。熟悉OCP的读者一定知道,为了能够实现面向对象设计的一个最核心的原则OCP(Open-Closed Principle),抽象类是其中的关键所在。
二、从语法定义层面看abstract class和interface
在语法层面,Java语言对于abstract class和interface给出了不同的定义方式,下面以定义一个名为Demo的抽象类为例来说明这种不同。使用abstract class的方式定义Demo抽象类的方式如下:
abstract class Demo {
abstract void method1();
abstract void method2();
…
}
使用interface的方式定义Demo抽象类的方式如下:
interface Demo {
void method1();
void method2();
…
}
在abstract class方式中,Demo可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface方式的实现中,Demo只能够有静态的不能被修改的数据成员(也就是必须是static final的,不过在interface中一般不定义数据成员),所有的成员方法都是abstract的。从某种意义上说,interface是一种特殊形式的abstract class。
从编程的角度来看,abstract class和interface都可以用来实现"design by contract"的思想。但是在具体的使用上面还是有一些区别的。
首先,abstract class在Java语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface。也许,这是Java语言的设计者在考虑Java对于多重继承的支持方面的一种折中考虑吧。
其次,在abstract class的定义中,我们可以赋予方法的默认行为。但是在interface的定义中,方法却不能拥有默认行为,为了绕过这个限制,必须使用委托,但是这会 增加一些复杂性,有时会造成很大的麻烦。
在抽象类中不能定义默认行为还存在另一个比较严重的问题,那就是可能会造成维护上的麻烦。因为如果后来想修改类的界面(一般通过abstract class或者interface来表示)以适应新的情况(比如,添加新的方法或者给已用的方法中添加新的参数)时,就会非常的麻烦,可能要花费很多的时间(对于派生类很多的情况,尤为如此)。但是如果界面是通过abstract class来实现的,那么可能就只需要修改定义在abstract class中的默认行为就可以了。
同样,如果不能在抽象类中定义默认行为,就会导致同样的方法实现出现在该抽象类的每一个派生类中,违反了 "one rule,one place"原则,造成代码重复,同样不利于以后的维护。因此,在abstract class和interface间进行选择时要非常的小心。
三、从设计理念层面看abstract class和interface
上面主要从语法定义和编程的角度论述了abstract class和interface的区别,这些层面的区别是比较低层次的、非本质的。本文将从另一个层面:abstract class和interface所反映出的设计理念,来分析一下二者的区别。作者认为,从这个层面进行分析才能理解二者概念的本质所在。
前面已经提到过,abstarct class在Java语言中体现了一种继承关系,要想使得继承关系合理,父类和派生类之间必须存在"is a"关系,即父类和派生类在概念本质上应该是相同的。对于interface 来说则不然,并不要求interface的实现者和interface定义在概念本质上是一致的,仅仅是实现了interface定义的契约而已。为了使论述便于理解,下面将通过一个简单的实例进行说明。
考虑这样一个例子,假设在我们的问题领域中有一个关于Door的抽象概念,该Door具有执行两个动作open和close,此时我们可以通过abstract class或者interface来定义一个表示该抽象概念的类型,定义方式分别如下所示:
使用abstract class方式定义Door:
abstract class Door {
abstract void open();
abstract void close();
}
使用interface方式定义Door:
interface Door {
void open();
void close();
}
其他具体的Door类型可以extends使用abstract class方式定义的Door或者implements使用interface方式定义的Door。看起来好像使用abstract class和interface没有大的区别。
如果现在要求Door还要具有报警的功能。我们该如何设计针对该例子的类结构呢(在本例中,主要是为了展示abstract class和interface反映在设计理念上的区别,其他方面无关的问题都做了简化或者忽略)下面将罗列出可能的解决方案,并从设计理念层面对这些不同的方案进行分析。
解决方案一:
简单的在Door的定义中增加一个alarm方法,如下:
abstract class Door {
abstract void open();
abstract void close();
abstract void alarm();
}
或者
interface Door {
void open();
void close();
void alarm();
}
那么具有报警功能的AlarmDoor的定义方式如下:
class AlarmDoor extends Door {
void open() { … }
void close() { … }
void alarm() { … }
}
或者
class AlarmDoor implements Door {
void open() { … }
void close() { … }
void alarm() { … }
}
这种方法违反了面向对象设计中的一个核心原则ISP(Interface Segregation Priciple),在Door的定义中把Door概念本身固有的行为方法和另外一个概念"报警器"的行为方法混在了一起。这样引起的一个问题是那些仅仅依赖于Door这个概念的模块会因为"报警器"这个概念的改变(比如:修改alarm方法的参数)而改变,反之依然。
解决方案二:
既然open、close和alarm属于两个不同的概念,根据ISP原则应该把它们分别定义在代表这两个概念的抽象类中。定义方式有:这两个概念都使用 abstract class方式定义;两个概念都使用interface方式定义;一个概念使用abstract class方式定义,另一个概念使用interface方式定义。
显然,由于Java语言不支持多重继承,所以两个概念都使用abstract class方式定义是不可行的。后面两种方式都是可行的,但是对于它们的选择却反映出对于问题领域中的概念本质的理解、对于设计意图的反映是否正确、合理。我们一一来分析、说明。
如果两个概念都使用interface方式来定义,那么就反映出两个问题:
1、我们可能没有理解清楚问题领域,AlarmDoor在概念本质上到底是Door还是报警器?
2、如果我们对于问题领域的理解没有问题,比如:我们通过对于问题领域的分析发现AlarmDoor在概念本质上和Door是一致的,那么我们在实现时就没有能够正确的揭示我们的设计意图,因为在这两个概念的定义上(均使用interface方式定义)反映不出上述含义。
如果我们对于问题领域的理解是:AlarmDoor在概念本质上是Door,同时它有具有报警的功能。我们该如何来设计、实现来明确的反映出我们的意思呢?前面已经说过, abstract class在Java语言中表示一种继承关系,而继承关系在本质上是"is a"关系。所以对于Door这个概念,我们应该使用abstarct class方式来定义。另外,AlarmDoor又具有报警功能,说明它又能够完成报警概念中定义的行为,所以报警概念可以通过interface方式定义。如下所示:
abstract class Door {
abstract void open();
abstract void close();
}
interface Alarm {
void alarm();
}
class AlarmDoor extends Door implements Alarm {
void open() { … }
void close() { … }
void alarm() { … }
}
这种实现方式基本上能够明确的反映出我们对于问题领域的理解,正确的揭示我们的设计意图。其实abstract class表示的是"is a"关系,interface表示的是"like a"关系,大家在选择时可以作为一个依据,当然这是建立在对问题领域的理解上的,比如:如果我们认为AlarmDoor在概念本质上是报警器,同时又具有 Door的功能,那么上述的定义方式就要反过来了。
abstract class和interface是Java语言中的两种定义抽象类的方式,它们之间有很大的相似性。但是对于它们的选择却又往往反映出对于问题领域中的概念本质的理解、对于设计意图的反映是否正确、合理,因为它们表现了概念间的不同的关系(虽然都能够实现需求的功能)。这其实也是语言的一种的惯用法,希望读者朋友能够细细体会
|
|
一. Input和Output
1. stream代表的是任何有能力产出数据的数据源,或是任何有能力接收数据的接收源。在Java的IO中,所有的stream(包括Input和Out stream)都包括两种类型:
1.1 以字节为导向的stream
以字节为导向的stream,表示以字节为单位从stream中读取或往stream中写入信息。以字节为导向的stream包括下面几种类型:
1) input stream:
1) ByteArrayInputStream:把内存中的一个缓冲区作为InputStream使用
2) StringBufferInputStream:把一个String对象作为InputStream
3) FileInputStream:把一个文件作为InputStream,实现对文件的读取操作
4) PipedInputStream:实现了pipe的概念,主要在线程中使用
5) SequenceInputStream:把多个InputStream合并为一个InputStream
2) Out stream
1) ByteArrayOutputStream:把信息存入内存中的一个缓冲区中
2) FileOutputStream:把信息存入文件中
3) PipedOutputStream:实现了pipe的概念,主要在线程中使用
4) SequenceOutputStream:把多个OutStream合并为一个OutStream
1.2 以Unicode字符为导向的stream
以Unicode字符为导向的stream,表示以Unicode字符为单位从stream中读取或往stream中写入信息。以Unicode字符为导向的stream包括下面几种类型:
1) Input Stream
1) CharArrayReader:与ByteArrayInputStream对应
2) StringReader:与StringBufferInputStream对应
3) FileReader:与FileInputStream对应
4) PipedReader:与PipedInputStream对应
2) Out Stream
1) CharArrayWrite:与ByteArrayOutputStream对应
2) StringWrite:无与之对应的以字节为导向的stream
3) FileWrite:与FileOutputStream对应
4) PipedWrite:与PipedOutputStream对应
以字符为导向的stream基本上对有与之相对应的以字节为导向的stream。两个对应类实现的功能相同,字是在操作时的导向不同。如CharArrayReader:和ByteArrayInputStream的作用都是把内存中的一个缓冲区作为InputStream使用,所不同的是前者每次从内存中读取一个字节的信息,而后者每次从内存中读取一个字符。
1.3 两种不现导向的stream之间的转换
InputStreamReader和OutputStreamReader:把一个以字节为导向的stream转换成一个以字符为导向的stream。
2. stream添加属性
2.1 “为stream添加属性”的作用
运用上面介绍的Java中操作IO的API,我们就可完成我们想完成的任何操作了。但通过FilterInputStream和FilterOutStream的子类,我们可以为stream添加属性。下面以一个例子来说明这种功能的作用。
如果我们要往一个文件中写入数据,我们可以这样操作:
FileOutStream fs = new FileOutStream(“test.txt”);
然后就可以通过产生的fs对象调用write()函数来往test.txt文件中写入数据了。但是,如果我们想实现“先把要写入文件的数据先缓存到内存中,再把缓存中的数据写入文件中”的功能时,上面的API就没有一个能满足我们的需求了。但是通过FilterInputStream和FilterOutStream的子类,为FileOutStream添加我们所需要的功能。
2.2 FilterInputStream的各种类型
2.2.1 用于封装以字节为导向的InputStream
1) DataInputStream:从stream中读取基本类型(int、char等)数据。
2) BufferedInputStream:使用缓冲区
3) LineNumberInputStream:会记录input stream内的行数,然后可以调用getLineNumber()和setLineNumber(int)
4) PushbackInputStream:很少用到,一般用于编译器开发
2.2.2 用于封装以字符为导向的InputStream
1) 没有与DataInputStream对应的类。除非在要使用readLine()时改用BufferedReader,否则使用DataInputStream
2) BufferedReader:与BufferedInputStream对应
3) LineNumberReader:与LineNumberInputStream对应
4) PushBackReader:与PushbackInputStream对应
2.3 FilterOutStream的各种类型
2.2.3 用于封装以字节为导向的OutputStream
1) DataIOutStream:往stream中输出基本类型(int、char等)数据。
2) BufferedOutStream:使用缓冲区
3) PrintStream:产生格式化输出
2.2.4 用于封装以字符为导向的OutputStream
1) BufferedWrite:与对应
2) PrintWrite:与对应
3. RandomAccessFile
1) 可通过RandomAccessFile对象完成对文件的读写操作
2) 在产生一个对象时,可指明要打开的文件的性质:r,只读;w,只写;rw可读写
3) 可以直接跳到文件中指定的位置
4. I/O应用的一个例子
import java.io.*;
public class TestIO{
public static void main(String[] args)
throws IOException{
//1.以行为单位从一个文件读取数据
BufferedReader in =
new BufferedReader(
new FileReader("F:\\nepalon\\TestIO.java"));
String s, s2 = new String();
while((s = in.readLine()) != null)
s2 += s + "\n";
in.close();
//1b. 接收键盘的输入
BufferedReader stdin =
new BufferedReader(
new InputStreamReader(System.in));
System.out.println("Enter a line:");
System.out.println(stdin.readLine());
//2. 从一个String对象中读取数据
StringReader in2 = new StringReader(s2);
int c;
while((c = in2.read()) != -1)
System.out.println((char)c);
in2.close();
//3. 从内存取出格式化输入
try{
DataInputStream in3 =
new DataInputStream(
new ByteArrayInputStream(s2.getBytes()));
while(true)
System.out.println((char)in3.readByte());
}
catch(EOFException e){
System.out.println("End of stream");
}
//4. 输出到文件
try{
BufferedReader in4 =
new BufferedReader(
new StringReader(s2));
PrintWriter out1 =
new PrintWriter(
new BufferedWriter(
new FileWriter("F:\\nepalon\\ TestIO.out")));
int lineCount = 1;
while((s = in4.readLine()) != null)
out1.println(lineCount++ + ":" + s);
out1.close();
in4.close();
}
catch(EOFException ex){
System.out.println("End of stream");
}
//5. 数据的存储和恢复
try{
DataOutputStream out2 =
new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream("F:\\nepalon\\ Data.txt")));
out2.writeDouble(3.1415926);
out2.writeChars("\nThas was pi:writeChars\n");
out2.writeBytes("Thas was pi:writeByte\n");
out2.close();
DataInputStream in5 =
new DataInputStream(
new BufferedInputStream(
new FileInputStream("F:\\nepalon\\ Data.txt")));
BufferedReader in5br =
new BufferedReader(
new InputStreamReader(in5));
System.out.println(in5.readDouble());
System.out.println(in5br.readLine());
System.out.println(in5br.readLine());
}
catch(EOFException e){
System.out.println("End of stream");
}
//6. 通过RandomAccessFile操作文件
RandomAccessFile rf =
new RandomAccessFile("F:\\nepalon\\ rtest.dat", "rw");
for(int i=0; i<10; i++)
rf.writeDouble(i*1.414);
rf.close();
rf = new RandomAccessFile("F:\\nepalon\\ rtest.dat", "r");
for(int i=0; i<10; i++)
System.out.println("Value " + i + ":" + rf.readDouble());
rf.close();
rf = new RandomAccessFile("F:\\nepalon\\ rtest.dat", "rw");
rf.seek(5*8);
rf.writeDouble(47.0001);
rf.close();
rf = new RandomAccessFile("F:\\nepalon\\ rtest.dat", "r");
for(int i=0; i<10; i++)
System.out.println("Value " + i + ":" + rf.readDouble());
rf.close();
}
}
关于代码的解释(以区为单位):
1区中,当读取文件时,先把文件内容读到缓存中,当调用in.readLine()时,再从缓存中以字符的方式读取数据(以下简称“缓存字节读取方式”)。
1b区中,由于想以缓存字节读取方式从标准IO(键盘)中读取数据,所以要先把标准IO(System.in)转换成字符导向的stream,再进行BufferedReader封装。
2区中,要以字符的形式从一个String对象中读取数据,所以要产生一个StringReader类型的stream。
4区中,对String对象s2读取数据时,先把对象中的数据存入缓存中,再从缓冲中进行读取;对TestIO.out文件进行操作时,先把格式化后的信息输出到缓存中,再把缓存中的信息输出到文件中。
5区中,对Data.txt文件进行输出时,是先把基本类型的数据输出屋缓存中,再把缓存中的数据输出到文件中;对文件进行读取操作时,先把文件中的数据读取到缓存中,再从缓存中以基本类型的形式进行读取。注意in5.readDouble()这一行。因为写入第一个writeDouble(),所以为了正确显示。也要以基本类型的形式进行读取。
6区是通过RandomAccessFile类对文件进行操作。
|
|
|
|
摘要:
JavaMail API是读取、撰写、发送电子信息的可选包。我们可用它来建立如Eudora、Foxmail、MS Outlook Express一般的邮件用户代理程序(Mail User Agent,简称MUA)。让我们看看JavaMail API是如何提供信息访问功能的吧!JavaMail API被设计用于以不依赖协议的方式去发送和接收电子信息,文中着重:如何以不依赖于协议的方式发送接收电子信息,这也是本文所要描述的. 文章工具
收藏
投票评分
发表评论
复制链接
版权声明:本文可以自由转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明
作者:cleverpig(作者的Blog:http://blog.matrix.org.cn/page/cleverpig)
原文:http://www.matrix.org.cn/resource/article/44/44101_JavaMail.html
关键字:java,mail,pop,smtp
一、JavaMail API简介
JavaMail API是读取、撰写、发送电子信息的可选包。我们可用它来建立如Eudora、Foxmail、MS Outlook Express一般的邮件用户代理程序(Mail User Agent,简称MUA)。而不是像sendmail或者其它的邮件传输代理(Mail Transfer Agent,简称MTA)程序那样可以传送、递送、转发邮件。从另外一个角度来看,我们这些电子邮件用户日常用MUA程序来读写邮件,而MUA依赖着MTA处理邮件的递送。
在清楚了到MUA与MTA之间的关系后,让我们看看JavaMail API是如何提供信息访问功能的吧!JavaMail API被设计用于以不依赖协议的方式去发送和接收电子信息,这个API被分为两大部分:
基本功能:如何以不依赖于协议的方式发送接收电子信息,这也是本文所要描述的,不过在下文中,大家将看到这只是一厢情愿而已。
第二个部分则是依赖特定协议的,比如SMTP、POP、IMAP、NNTP协议。在这部分的JavaMail API是为了和服务器通讯,并不在本文的内容中。
二、相关协议一览
在我们步入JavaMail API之前,先看一下API所涉及的协议。以下便是大家日常所知、所乐于使用的4大信息传输协议:
SMTP
POP
IMAP
MIME
当然,上面的4个协议,并不是全部,还有NNTP和其它一些协议可用于传输信息,但是由于不常用到,所以本文便不提及了。理解这4个基本的协议有助于我们更好的使用JavaMail API。然而JavaMail API是被设计为与协议无关的,目前我们并不能克服这些协议的束缚。确切的说,如果我们使用的功能并不被我们选择的协议支持,那么JavaMail API并不可能如魔术师一样神奇的赋予我们这种能力。
1.SMTP
简单邮件传输协议定义了递送邮件的机制。在下文中,我们将使用基于Java-Mail的程序与公司或者ISP的SMTP服务器进行通讯。这个SMTP服务器将邮件转发到接收者的SMTP服务器,直至最后被接收者通过POP或者IMAP协议获取。这并不需要SMTP服务器使用支持授权的邮件转发,但是却的确要注意SMTP服务器的正确设置(SMTP服务器的设置与JavaMail API无关)。
2.POP
POP是一种邮局协议,目前为第3个版本,即众所周知的POP3。POP定义了一种用户如何获得邮件的机制。它规定了每个用户使用一个单独的邮箱。大多数人在使用POP时所熟悉的功能并非都被支持,例如查看邮箱中的新邮件数量。而这个功能是微软的Outlook内建的,那么就说明微软Outlook之类的邮件客户端软件是通过查询最近收到的邮件来计算新邮件的数量来实现前面所说的功能。因此在我们使用JavaMail API时需要注意,当需要获得如前面所讲的新邮件数量之类的信息时,我们不得不自己进行计算。
3.IMAP
IMAP使用在接收信息的高级协议,目前版本为第4版,所以也被称为IMAP4。需要注意的是在使用IMAP时,邮件服务器必须支持该协议。从这个方面讲,我们并不能完全使用IMAP来替代POP,不能期待IMAP在任何地方都被支持。假如邮件服务器支持IMAP,那么我们的邮件程序将能够具有以下被IMAP所支持的特性:每个用户在服务器上可具有多个目录,这些目录能在多个用户之间共享。
其与POP相比高级之处显而易见,但是在尝试采取IMAP时,我们认识到它并不是十分完美的:由于IMAP需要从其它服务器上接收新信息,将这些信息递送给用户,维护每个用户的多个目录,这都为邮件服务器带来了高负载。并且IMAP与POP的一个不同之处是POP用户在接收邮件时将从邮件服务器上下载邮件,而IMAP允许用户直接访问邮件目录,所以在邮件服务器进行备份作业时,由于每个长期使用此邮件系统的用户所用的邮件目录会占有很大的空间,这将直接导致邮件服务器上磁盘空间暴涨。
4.MIME
MIME并不是用于传送邮件的协议,它作为多用途邮件的扩展定义了邮件内容的格式:信息格式、附件格式等等。一些RFC标准都涉及了MIME:RFC 822, RFC 2045, RFC 2046, RFC 2047,有兴趣的Matrixer可以阅读一下。而作为JavaMail API的开发者,我们并不需关心这些格式定义,但是这些格式被用在了程序中。
5.NNTP和其它的第三方协议
正因为JavaMail API在设计时考虑到与第三方协议实现提供商之间的分离,故我们可以很容易的添加一些第三方协议。SUN维护着一个第三方协议实现提供商的列表:http://java.sun.com/products/javamail/Third_Party.html,通过此列表我们可以找到所需要的而又不被SUN提供支持的第三方协议:比如NNTP这个新闻组协议和S/MIME这个安全的MIME协议。
三、安装
1.安装JavaMail
为了使用JavaMail API,需要从http://java.sun.com/products/javamail/downloads/index.html下载文件名格式为javamail-[version].zip的文件(这个文件中包括了JavaMail实现),并将其中的mail.jar文件添加到CLASSPATH中。这个实现提供了对SMTP、IMAP4、POP3的支持。
注意:在安装JavaMail实现之后,我们将在demo目录中发现许多有趣的简单实例程序。
在安装了JavaMail之后,我们还需要安装JavaBeans Activation Framework,因为这个框架是JavaMail API所需要的。如果我们使用J2EE的话,那么我们并无需单独下载JavaMail,因为它存在于J2EE.jar中,只需将J2EE.jar加入到CLASSPATH即可。
2.安装JavaBeans Activation Framework
从http://java.sun.com/products/javabeans/glasgow/jaf.html下载JavaBeans Activation Framework,并将其添加到CLASSPATH中。此框架增加了对任何数据块的分类、以及对它们的处理的特性。这些特性是JavaMail API需要的。虽然听起来这些特性非常模糊,但是它对于我们的JavaMail API来说只是提供了基本的MIME类型支持。
到此为止,我们应当把mail.jar和activation.jar都添加到了CLASSPATH中。
当然如果从方便的角度讲,直接把这两个Jar文件复制到JRE目录的lib/ext目录中也可以。
四、初次认识JavaMail API
1.了解我们的JavaMail环境
A.纵览JavaMail核心类结构
打开JavaMail.jar文件,我们将发现在javax.mail的包下面存在着一些核心类:Session、Message、Address、Authenticator、Transport、Store、Folder。而且在javax.mail.internet包中还有一些常用的子类。
B.Session
Session类定义了基本的邮件会话。就像Http会话那样,我们进行收发邮件的工作都是基于这个会话的。Session对象利用了java.util.Properties对象获得了邮件服务器、用户名、密码信息和整个应用程序都要使用到的共享信息。
Session类的构造方法是私有的,所以我们可以使用Session类提供的getDefaultInstance()这个静态工厂方法获得一个默认的Session对象:
Properties props = new Properties();// fill props with any informationSession session = Session.getDefaultInstance(props, null);
或者使用getInstance()这个静态工厂方法获得自定义的Session:
Properties props = new Properties();// fill props with any informationSession session = Session.getInstance(props, null);
从上面的两个例子中不难发现,getDefaultInstance()和getInstance()方法的第二个参数都是null,这是因为在上面的例子中并没有使用到邮件授权,下文中将对授权进行详细介绍。
从很多的实例看,在对mail server进行访问的过程中使用共享的Session是足够的,即使是工作在多个用户邮箱的模式下也不例外。
C.Message
当我们建立了Session对象后,便可以被发送的构造信息体了。在这里SUN提供了Message类型来帮助开发者完成这项工作。由于Message是一个抽象类,大多数情况下,我们使用javax.mail.internet.MimeMessage这个子类,该类是使用MIME类型、MIME信息头的邮箱信息。信息头只能使用US-ASCII字符,而非ASCII字符将通过编码转换为ASCII的方式使用。
为了建立一个MimeMessage对象,我们必须将Session对象作为MimeMessage构造方法的参数传入:
MimeMessage message = new MimeMessage(session);
注意:对于MimeMessage类来讲存在着多种构造方法,比如使用输入流作为参数的构造方法。
在建立了MimeMessage对象后,我们需要设置它的各个part,对于MimeMessage类来说,这些part就是MimePart接口。最基本的设置信息内容的方法就是通过表示信息内容和米么类型的参数调用setContent()方法:
message.setContent("Hello", "text/plain");
然而,如果我们所使用的MimeMessage中信息内容是文本的话,我们便可以直接使用setText()方法来方便的设置文本内容。
message.setText("Hello");
前面所讲的两种方法,对于文本信息,后者更为合适。而对于其它的一些信息类型,比如HTML信息,则要使用前者。
别忘记了,使用setSubject()方法对邮件设置邮件主题:
message.setSubject("First");
D.Address
到这里,我们已经建立了Session和Message,下面将介绍如何使用邮件地址类:Address。像Message一样,Address类也是一个抽象类,所以我们将使用javax.mail.internet.InternetAddress这个子类。
通过传入代表邮件地址的字符串,我们可以建立一个邮件地址类:
Address address = new InternetAddress("president@whitehouse.gov");
如果要在邮件地址后面增加名字的话,可以通过传递两个参数:代表邮件地址和名字的字符串来建立一个具有邮件地址和名字的邮件地址类:
Address address = new InternetAddress("president@whitehouse.gov", "George Bush");
本文在这里所讲的邮件地址类是为了设置邮件信息的发信人和收信人而准备的,在建立了邮件地址类后,我们通过message的setFrom()和setReplyTo()两种方法设置邮件的发信人:
message.setFrom(address);message.setReplyTo(address);
若在邮件中存在多个发信人地址,我们可用addForm()方法增加发信人:
Address address[] = ...;message.addFrom(address);
为了设置收信人,我们使用addRecipient()方法增加收信人,此方法需要使用Message.RecipientType的常量来区分收信人的类型:
message.addRecipient(type, address)
下面是Message.RecipientType的三个常量:
Message.RecipientType.TO
Message.RecipientType.CC
Message.RecipientType.BCC
因此,如果我们要发送邮件给总统,并发用一个副本给第一夫人的话,下面的方法将被用到:
Address toAddress = new InternetAddress("vice.president@whitehouse.gov");Address ccAddress = new InternetAddress("first.lady@whitehouse.gov");message.addRecipient(Message.RecipientType.TO, toAddress);message.addRecipient(Message.RecipientType.CC, ccAddress);
JavaMail API并没有提供检查邮件地址有效性的机制。当然我们可以自己完成这个功能:验证邮件地址的字符是否按照RFC822规定的格式书写或者通过DNS服务器上的MX记录验证等。
E.Authenticator
像java.net类那样,JavaMail API通过使用授权者类(Authenticator)以用户名、密码的方式访问那些受到保护的资源,在这里“资源”就是指邮件服务器。在javax.mail包中可以找到这个JavaMail的授权者类(Authenticator)。
在使用Authenticator这个抽象类时,我们必须采用继承该抽象类的方式,并且该继承类必须具有返回PasswordAuthentication对象(用于存储认证时要用到的用户名、密码)getPasswordAuthentication()方法。并且要在Session中进行注册,使Session能够了解在认证时该使用哪个类。
下面代码片断中的MyAuthenticator就是一个Authenticator的子类。
Properties props = new Properties();// fill props with any informationAuthenticator auth = new MyAuthenticator();Session session = Session.getDefaultInstance(props, auth);
F.Transport
在发送信息时,Transport类将被用到。这个类实现了发送信息的协议(通称为SMTP),此类是一个抽象类,我们可以使用这个类的静态方法send()来发送消息:
Transport.send(message);
当然,方法是多样的。我们也可由Session获得相应协议对应的Transport实例。并通过传递用户名、密码、邮件服务器主机名等参数建立与邮件服务器的连接,并使用sendMessage()方法将信息发送,最后关闭连接:
message.saveChanges(); // implicit with send()Transport transport = session.getTransport("smtp");transport.connect(host, username, password);transport.sendMessage(message, message.getAllRecipients());transport.close();
评论:上面的方法是一个很好的方法,尤其是在我们在同一个邮件服务器上发送多个邮件时。因为这时我们将在连接邮件服务器后连续发送邮件,然后再关闭掉连接。send()这个基本的方法是在每次调用时进行与邮件服务器的连接的,对于在同一个邮件服务器上发送多个邮件来讲可谓低效的方式。
注意:如果需要在发送邮件过程中监控mail命令的话,可以在发送前设置debug标志:
session.setDebug(true)。
G.Store和Folder
接收邮件和发送邮件很类似都要用到Session。但是在获得Session后,我们需要从Session中获取特定类型的Store,然后连接到Store,这里的Store代表了存储邮件的邮件服务器。在连接Store的过程中,极有可能需要用到用户名、密码或者Authenticator。
// Store store = session.getStore("imap");Store store = session.getStore("pop3");store.connect(host, username, password);
在连接到Store后,一个Folder对象即目录对象将通过Store的getFolder()方法被返回,我们可从这个Folder中读取邮件信息:
Folder folder = store.getFolder("INBOX");folder.open(Folder.READ_ONLY);Message message[] = folder.getMessages();
上面的例子首先从Store中获得INBOX这个Folder(对于POP3协议只有一个名为INBOX的Folder有效),然后以只读(Folder.READ_ONLY)的方式打开Folder,最后调用Folder的getMessages()方法得到目录中所有Message的数组。
注意:对于POP3协议只有一个名为INBOX的Folder有效,而对于IMAP协议,我们可以访问多个Folder(想想前面讲的IMAP协议)。而且SUN在设计Folder的getMessages()方法时采取了很智能的方式:首先接收新邮件列表,然后再需要的时候(比如读取邮件内容)才从邮件服务器读取邮件内容。
在读取邮件时,我们可以用Message类的getContent()方法接收邮件或是writeTo()方法将邮件保存,getContent()方法只接收邮件内容(不包含邮件头),而writeTo()方法将包括邮件头。
System.out.println(((MimeMessage)message).getContent());
在读取邮件内容后,别忘记了关闭Folder和Store。
folder.close(aBoolean);store.close();
传递给Folder.close()方法的boolean 类型参数表示是否在删除操作邮件后更新Folder。
H.继续向前进!
在讲解了以上的七个Java Mail核心类定义和理解了简单的代码片断后,下文将详细讲解怎样使用这些类实现JavaMail API所要完成的高级功能。
五、使用JavaMail API
在明确了JavaMail API的核心部分如何工作后,本人将带领大家学习一些使用Java Mail API任务案例。
1.发送邮件
在获得了Session后,建立并填入邮件信息,然后发送它到邮件服务器。这便是使用Java Mail API发送邮件的过程,在发送邮件之前,我们需要设置SMTP服务器:通过设置Properties的mail.smtp.host属性。
String host = ...;String from = ...;String to = ...;// Get system propertiesProperties props = System.getProperties();// Setup mail serverprops.put("mail.smtp.host", host);// Get sessionSession session = Session.getDefaultInstance(props, null);// Define messageMimeMessage message = new MimeMessage(session);message.setFrom(new InternetAddress(from));message.addRecipient(Message.RecipientType.TO, new InternetAddress(to));message.setSubject("Hello JavaMail");message.setText("Welcome to JavaMail");// Send messageTransport.send(message);
由于建立邮件信息和发送邮件的过程中可能会抛出异常,所以我们需要将上面的代码放入到try-catch结构块中。
2.接收邮件
为了在读取邮件,我们获得了session,并且连接到了邮箱的相应store,打开相应的Folder,然后得到我们想要的邮件,当然别忘记了在结束时关闭连接。
String host = ...;String username = ...;String password = ...;// Create empty propertiesProperties props = new Properties();// Get sessionSession session = Session.getDefaultInstance(props, null);// Get the storeStore store = session.getStore("pop3");store.connect(host, username, password);// Get folderFolder folder = store.getFolder("INBOX");folder.open(Folder.READ_ONLY);// Get directoryMessage message[] = folder.getMessages();for (int i=0, n=message.length; i<n; i++) { System.out.println(i + ": " + message[i].getFrom()[0] + "\t" + message[i].getSubject());}// Close connection folder.close(false);store.close();
上面的代码所作的是从邮箱中读取每个邮件,并且显示邮件的发信人地址和主题。从技术角度讲,这里存在着一个异常的可能:当发信人地址为空时,getFrom()[0]将抛出异常。
下面的代码片断有效的说明了如何读取邮件内容,在显示每个邮件发信人和主题后,将出现用户提示从而得到用户是否读取该邮件的确认,如果输入YES的话,我们可用Message.writeTo(java.io.OutputStream os)方法将邮件内容输出到控制台上,关于Message.writeTo()的具体用法请看JavaMail API。
BufferedReader reader = new BufferedReader ( new InputStreamReader(System.in));// Get directoryMessage message[] = folder.getMessages();for (int i=0, n=message.length; i<n; i++) { System.out.println(i + ": " + message[i].getFrom()[0] + "\t" + message[i].getSubject()); System.out.println("Do you want to read message? " + "[YES to read/QUIT to end]"); String line = reader.readLine(); if ("YES".equals(line)) { message[i].writeTo(System.out); } else if ("QUIT".equals(line)) { break; }}
3.删除邮件和标志
设置与message相关的Flags是删除邮件的常用方法。这些Flags表示了一些系统定义和用户定义的不同状态。在Flags类的内部类Flag中预定义了一些标志:
Flags.Flag.ANSWERED
Flags.Flag.DELETED
Flags.Flag.DRAFT
Flags.Flag.FLAGGED
Flags.Flag.RECENT
Flags.Flag.SEEN
Flags.Flag.USER
但需要在使用时注意的:标志存在并非意味着这个标志被所有的邮件服务器所支持。例如,对于删除邮件的操作,POP协议不支持上面的任何一个。所以要确定哪些标志是被支持的??通过访问一个已经打开的Folder对象的getPermanetFlags()方法,它将返回当前被支持的Flags类对象。
删除邮件时,我们可以设置邮件的DELETED标志:
message.setFlag(Flags.Flag.DELETED, true);
但是首先要采用READ_WRITE的方式打开Folder:
folder.open(Folder.READ_WRITE);
在对邮件进行删除操作后关闭Folder时,需要传递一个true作为对删除邮件的擦除确认。
folder.close(true);
Folder类中另一种用于删除邮件的方法expunge()也同样可删除邮件,但是它并不为sun提供的POP3实现支持,而其它第三方提供的POP3实现支持或者并不支持这种方法。
另外,介绍一种检查某个标志是否被设置的方法:Message.isSet(Flags.Flag flag)方法,其中参数为被检查的标志。
4.邮件认证
我们在前面已经学会了如何使用Authenticator类来代替直接使用用户名和密码这两字符串作为Session.getDefaultInstance()或者Session.getInstance()方法的参数。在前面的小试牛刀后,现在我们将了解到全面认识一下邮件认证。
我们在此取代了直接使用邮件服务器主机名、用户名、密码这三个字符串作为连接到POP3 Store的方式,使用存储了邮件服务器主机名信息的属性文件,并在获得Session时传入自定义的Authenticator实例:
// Setup propertiesProperties props = System.getProperties();props.put("mail.pop3.host", host);// Setup authentication, get sessionAuthenticator auth = new PopupAuthenticator();Session session = Session.getDefaultInstance(props, auth);// Get the storeStore store = session.getStore("pop3");store.connect();
PopupAuthenticator类继承了抽象类Authenticator,并且通过重载Authenticator类的getPasswordAuthentication()方法返回PasswordAuthentication类对象。而getPasswordAuthentication()方法的参数param是以逗号分割的用户名、密码组成的字符串。
import javax.mail.*;import java.util.*;public class PopupAuthenticator extends Authenticator { public PasswordAuthentication getPasswordAuthentication(String param) { String username, password; StringTokenizer st = new StringTokenizer(param, ","); username = st.nextToken(); password = st.nextToken(); return new PasswordAuthentication(username, password); }}
5.回复邮件
回复邮件的方法很简单:使用Message类的reply()方法,通过配置回复邮件的收件人地址和主题(如果没有提供主题的话,系统将默认将“Re:”作为邮件的主体),这里不需要设置任何的邮件内容,只要复制发信人或者reply-to到新的收件人。而reply()方法中的boolean参数表示是否将邮件回复给发送者(参数值为false),或是恢复给所有人(参数值为true)。
补充一下,reply-to地址需要在发信时使用setReplyTo()方法设置。
MimeMessage reply = (MimeMessage)message.reply(false);reply.setFrom(new InternetAddress("president@whitehouse.gov"));reply.setText("Thanks");Transport.send(reply);
6.转发邮件
转发邮件的过程不如前面的回复邮件那样简单,它将建立一个转发邮件,这并非一个方法就能做到。
每个邮件是由多个部分组成,每个部分称为一个邮件体部分,是一个BodyPart类对象,对于MIME类型邮件来讲就是MimeBodyPart类对象。这些邮件体包含在成为Multipart的容器中对于MIME类型邮件来讲就是MimeMultiPart类对象。在转发邮件时,我们建立一个文字邮件体部分和一个被转发的文字邮件体部分,然后将这两个邮件体放到一个Multipart中。说明一下,复制一个邮件内容到另一个邮件的方法是仅复制它的DataHandler(数据处理者)即可。这是由JavaBeans Activation Framework定义的一个类,它提供了对邮件内容的操作命令的访问、管理了邮件内容操作,是不同的数据源和数据格式之间的一致性接口。
// Create the message to forwardMessage forward = new MimeMessage(session);// Fill in headerforward.setSubject("Fwd: " + message.getSubject());forward.setFrom(new InternetAddress(from));forward.addRecipient(Message.RecipientType.TO, new InternetAddress(to));// Create your new message partBodyPart messageBodyPart = new MimeBodyPart();messageBodyPart.setText( "Here you go with the original message:\n\n");// Create a multi-part to combine the partsMultipart multipart = new MimeMultipart();multipart.addBodyPart(messageBodyPart);// Create and fill part for the forwarded contentmessageBodyPart = new MimeBodyPart();messageBodyPart.setDataHandler(message.getDataHandler());// Add part to multi partmultipart.addBodyPart(messageBodyPart);// Associate multi-part with messageforward.setContent(multipart);// Send messageTransport.send(forward);
7.使用附件
附件作为与邮件相关的资源经常以文本、表格、图片等格式出现,如流行的邮件客户端一样,我们可以用JavaMail API从邮件中获取附件或是发送带有附件的邮件。
A.发送带有附件的邮件
发送带有附件的邮件的过程有些类似转发邮件,我们需要建立一个完整邮件的各个邮件体部分,在第一个部分(即我们的邮件内容文字)后,增加一个具有DataHandler的附件而不是在转发邮件时那样复制第一个部分的DataHandler。
如果我们将文件作为附件发送,那么要建立FileDataSource类型的对象作为附件数据源;如果从URL读取数据作为附件发送,那么将要建立URLDataSource类型的对象作为附件数据源。
然后将这个数据源(FileDataSource或是URLDataSource)对象作为DataHandler类构造方法的参数传入,从而建立一个DataHandler对象作为数据源的DataHandler。
接着将这个DataHandler设置为邮件体部分的DataHandler。这样就完成了邮件体与附件之间的关联工作,下面的工作就是BodyPart的setFileName()方法设置附件名为原文件名。
最后将两个邮件体放入到Multipart中,设置邮件内容为这个容器Multipart,发送邮件。
// Define messageMessage message = new MimeMessage(session);message.setFrom(new InternetAddress(from));message.addRecipient(Message.RecipientType.TO, new InternetAddress(to));message.setSubject("Hello JavaMail Attachment");// Create the message part BodyPart messageBodyPart = new MimeBodyPart();// Fill the messagemessageBodyPart.setText("Pardon Ideas");Multipart multipart = new MimeMultipart();multipart.addBodyPart(messageBodyPart);// Part two is attachmentmessageBodyPart = new MimeBodyPart();DataSource source = new FileDataSource(filename);messageBodyPart.setDataHandler(new DataHandler(source));messageBodyPart.setFileName(filename);multipart.addBodyPart(messageBodyPart);// Put parts in messagemessage.setContent(multipart);// Send the messageTransport.send(message);
如果我们使用servlet实现发送带有附件的邮件,则必须上传附件给servlet,这时需要注意提交页面form中对编码类型的设置应为multipart/form-data。
<FORM ENCTYPE="multipart/form-data" method=post action="/myservlet"> <INPUT TYPE="file" NAME="thefile"> <INPUT TYPE="submit" VALUE="Upload"></FORM>
B.读取邮件中的附件
读取邮件中的附件的过程要比发送它的过程复杂一点。因为带有附件的邮件是多部分组成的,我们必须处理每一个部分获得邮件的内容和附件。
但是如何辨别邮件信息内容和附件呢?Sun在Part类(BodyPart类实现的接口类)中提供了getDisposition()方法让开发者获得邮件体部分的部署类型,当该部分是附件时,其返回之将是Part.ATTACHMENT。但附件也可以没有部署类型的方式存在或者部署类型为Part.INLINE,无论部署类型为Part.ATTACHMENT还是Part.INLINE,我们都能把该邮件体部分导出保存。
Multipart mp = (Multipart)message.getContent();for (int i=0, n=multipart.getCount(); i<n; i++) { Part part = multipart.getBodyPart(i)); String disposition = part.getDisposition(); if ((disposition != null) && ((disposition.equals(Part.ATTACHMENT) || (disposition.equals(Part.INLINE))) { saveFile(part.getFileName(), part.getInputStream()); }}
下列代码中使用了saveFile方法是自定义的方法,它根据附件的文件名建立一个文件,如果本地磁盘上存在名为附件的文件,那么将在文件名后增加数字表示区别。然后从邮件体中读取数据写入到本地文件中(代码省略)。
// from saveFile()File file = new File(filename);for (int i=0; file.exists(); i++) { file = new File(filename+i);}
以上是邮件体部分被正确设置的简单例子,如果邮件体部分的部署类型为null,那么我们通过获得邮件体部分的MIME类型来判断其类型作相应的处理,代码结构框架如下:
if (disposition == null) { // Check if plain MimeBodyPart mbp = (MimeBodyPart)part; if (mbp.isMimeType("text/plain")) { // Handle plain } else { // Special non-attachment cases here of // image/gif, text/html, ... }...}
8.处理HTML邮件
前面的例子中发送的邮件都是以文本为内容的(除了附件),下面将介绍如何接收和发送基于HTML的邮件。
A.发送HTML邮件
假如我们需要发送一个HTML文件作为邮件内容,并使邮件客户端在读取邮件时获取相关的图片或者文字的话,只要设置邮件内容为html代码,并设置内容类型为text/html即可:
String htmlText = "<H1>Hello</H1>" + "<img src=\"http://www.jguru.com/images/logo.gif\">";message.setContent(htmlText, "text/html"));
请注意:这里的图片并不是在邮件中内嵌的,而是在URL中定义的。邮件接收者只有在线时才能看到。
在接收邮件时,如果我们使用JavaMail API接收邮件的话是无法实现以HTML方式显示邮件内容的。因为JavaMail API邮件内容视为二进制流。所以要显示HTML内容的邮件,我们必须使用JEditorPane或者第三方HTML展现组件。
以下代码显示了如何使用JEditorPane显示邮件内容:
if (message.getContentType().equals("text/html")) { String content = (String)message.getContent(); JFrame frame = new JFrame(); JEditorPane text = new JEditorPane("text/html", content); text.setEditable(false); JScrollPane pane = new JScrollPane(text); frame.getContentPane().add(pane); frame.setSize(300, 300); frame.setDefaultCloseOperation(JFrame.DISPOSE_ON_CLOSE); frame.show();}
B.在邮件中包含图片
如果我们在邮件中使用HTML作为内容,那么最好将HTML中使用的图片作为邮件的一部分,这样无论是否在线都会正确的显示HTML中的图片。处理方法就是将HTML中用到的图片作为邮件附件并使用特殊的cid URL作为图片的引用,这个cid就是对图片附件的Content-ID头的引用。
处理内嵌图片就像向邮件中添加附件一样,不同之处在于我们必须通过设置图片附件所在的邮件体部分的header中Content-ID为一个随机字符串,并在HTML中img的src标记中设置为该字符串。这样就完成了图片附件与HTML的关联。
String file = ...;// Create the messageMessage message = new MimeMessage(session);// Fill its headersmessage.setSubject("Embedded Image");message.setFrom(new InternetAddress(from));message.addRecipient(Message.RecipientType.TO, new InternetAddress(to));// Create your new message partBodyPart messageBodyPart = new MimeBodyPart();String htmlText = "<H1>Hello</H1>" + "<img src=\"cid:memememe\">";messageBodyPart.setContent(htmlText, "text/html");// Create a related multi-part to combine the partsMimeMultipart multipart = new MimeMultipart("related");multipart.addBodyPart(messageBodyPart);// Create part for the imagemessageBodyPart = new MimeBodyPart();// Fetch the image and associate to partDataSource fds = new FileDataSource(file);messageBodyPart.setDataHandler(new DataHandler(fds));messageBodyPart.setHeader("Content-ID","<memememe>");// Add part to multi-partmultipart.addBodyPart(messageBodyPart);// Associate multi-part with messagemessage.setContent(multipart);
9.在邮件中搜索短语
JavaMail API提供了过滤器机制,它被用来建立搜索短语。这个短语由javax.mail.search包中的SearchTerm抽象类来定义,在定义后我们便可以使用Folder的Search()方法在Folder中查找邮件:
SearchTerm st = ...;Message[] msgs = folder.search(st);
下面有22个不同的类(继承了SearchTerm类)供我们使用:
AND terms (class AndTerm)
OR terms (class OrTerm)
NOT terms (class NotTerm)
SENT DATE terms (class SentDateTerm)
CONTENT terms (class BodyTerm)
HEADER terms (FromTerm / FromStringTerm, RecipientTerm / RecipientStringTerm, SubjectTerm, etc.)
使用这些类定义的断语集合,我们可以构造一个逻辑表达式,并在Folder中进行搜索。下面是一个实例:在Folder中搜索邮件主题含有“ADV”字符串或者发信人地址为friend@public.com的邮件。
SearchTerm st = new OrTerm( new SubjectTerm("ADV:"), new FromStringTerm("friend@public.com"));Message[] msgs = folder.search(st);
六、参考资源
JavaMail API Home
Sun’s JavaMail API基础
JavaBeans Activation Framework Home
javamail-interest mailing list
Sun's JavaMail FAQ
jGuru's JavaMail FAQ
Third Party Products List
七、代码下载
http://java.sun.com/developer/onlineTraining/JavaMail/exercises.html |
|