本文引用了后台技术汇一枚少年郎“大模型应用之:SSE流式响应”的内容,下文有修订和重新排版。
1、引言
文章介绍了SSE(Server-Sent Events)技术在大模型流式响应中的应用,包括其发展历程、ChatGPT流式输出原理、SSE技术特点及与WebSocket的对比,并提供了两种流式响应落地方案。
* 相关阅读:《全民AI时代,大模型客户端和服务端的实时通信到底用什么协议?》、《大模型时代多模型AI网关的架构设计与实现》。
技术交流:
(本文已同步发布于:http://www.52im.net/thread-4856-1-1.html)
2、技术背景
当使用ChatGPT时,模型的回复不是一次性生成整个回答的,而是逐字逐句地生成。
这是因为语言模型需要在每个时间步骤预测下一个最合适的单词或字符。如果等待整个回复生成后再输出到网页,会导致用户长时间等待,极大降低用户体验。相反,逐字蹦出回复可以实现更快的交互响应。
ChatGPT可以在输入消息后迅速开始生成回答的开头,并根据上下文逐渐细化回答。这种渐进式的呈现方式可以提供更流畅的对话体验,同时让用户知道模型正在工作,避免感觉像卡住了或没有响应。
此外,逐字蹦出的回复还有助于用户跟踪模型的思考过程,看到它逐步构建回答的方式。这种可见的生成过程有助于用户理解模型是如何形成回答的,提高对话的透明度和可解释性。
3、SSE的技术演进历程
从实验性到标准化:
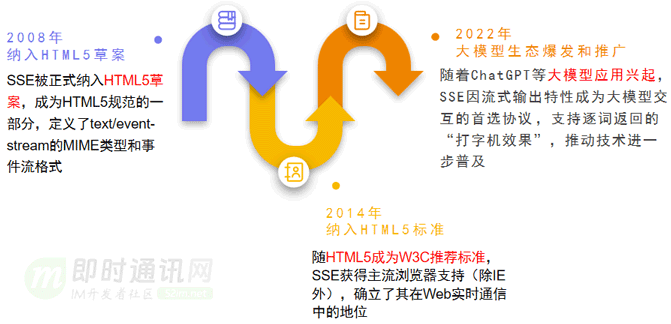
1)前身与痛点(2006年前) 早期Web依赖HTTP的请求-响应模式,实时性需求(如股票行情、IM聊天消息)只能通过轮询或长轮询实现,导致高延迟和资源浪费。Comet技术虽尝试长连接方案,但实现复杂且兼容性差。
2)诞生与早期实践(2006-2008) 2006年,Opera 9浏览器首次引入SSE作为实验性技术,通过DOM事件实现服务器向客户端的单向推送。这一设计基于HTTP协议,避免了WebSocket的双向通信复杂性,初步验证了技术可行性。
3)标准化进程(2008-2014):
- a. 2008年:SSE被正式纳入HTML5草案,成为HTML5规范的一部分,定义了text/event-stream的MIME类型和事件流格式;
- b. 2014年:随HTML5成为W3C推荐标准,SSE获得主流浏览器支持(除IE外),确立了其在Web实时通信中的地位。
4)生态爆发期(2022年后) 随着ChatGPT等大模型应用兴起,SSE因流式输出特性成为大模型交互的首选协议,支持逐词返回的“打字机效果”,推动技术进一步普及。
4、ChatGPT的流式输出技术原理
我们看一下ChatGPT的completion API的completion API。
演示案例:
curl -i -X POST -H 'Content-Type: application/json' -H 'Authorization: Bearer sk-************************************************' [url=https://api.openai.com/v1/chat/completions]https://api.openai.com/v1/chat/completions[/url] -d '{"model":"gpt-3.5-turbo","messages":[{"role": "user", "content": "3+5=?"}],"temperature":0.8,"stream":true}'
结果如下:
HTTP/2 200
date: Fri, 08 Sep 2023 03:39:50 GMT
content-type: text/event-stream
access-control-allow-origin: *
cache-control: no-cache, must-revalidate
openai-organization: metaverse-cloud-pte-ltd-orfbgw
openai-processing-ms: 5
openai-version: 2020-10-01
strict-transport-security: max-age=15724800; includeSubDomains
x-ratelimit-limit-requests: 3500
x-ratelimit-limit-tokens: 90000
x-ratelimit-remaining-requests: 3499
x-ratelimit-remaining-tokens: 89980
x-ratelimit-reset-requests: 17ms
x-ratelimit-reset-tokens: 12ms
x-request-id: 96ff4efafed25a52fbedb6e5c7a3ab09
cf-cache-status: DYNAMIC
server: cloudflare
cf-ray: 80342aa96ae00974-HKG
alt-svc: h3=":443"; ma=86400
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{"role":"assistant","content":""},"finish_reason":null}]}
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{"content":"3"},"finish_reason":null}]}
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{"content":" +"},"finish_reason":null}]}
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{"content":" "},"finish_reason":null}]}
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{"content":"5"},"finish_reason":null}]}
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{"content":" ="},"finish_reason":null}]}
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{"content":" "},"finish_reason":null}]}
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{"content":"8"},"finish_reason":null}]}
data: {"id":"chatcmpl-7wMdSo9fWVTEGzhbuJXEkBBx85boW","object":"chat.completion.chunk","created":1694144390,"model":"gpt-3.5-turbo-0613","choices":[{"index":0,"delta":{},"finish_reason":"stop"}]}
data: [DONE]
小结:服务器返回的响应头为 Content-Type: text/event-stream,数据块以 data: 开头,以 \n\n 分隔,最后以 [DONE] 标记结束。
5、SSE技术原理简述
SSE (Server-Sent Events) 技术是一种用于实现服务器主动推送数据给客户端的通信协议。相比传统的请求-响应模式,SSE 提供了一种持久连接,允许服务器随时向客户端发送事件和数据,实现了实时性的消息传递。
SSE 的工作原理非常简单直观。客户端通过与服务器建立一条持久化的 HTTP 连接,然后服务器使用该连接将数据以事件流(event stream)的形式发送给客户端。这些事件流由多个事件(event)组成,每个事件包含一个标识符、类型和数据字段。客户端通过监听事件流来获取最新的数据,并在接收到事件后进行处理。
SSE 数据交互示意图:
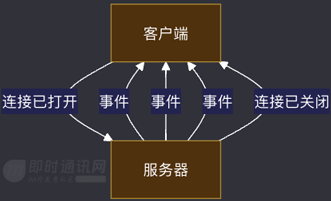
与 WebSocket 技术相比,SSE 使用的是基于 HTTP 的长轮询机制,而不需要建立全双工的网络连接。这使得 SSE 更容易在现有的基础设施上部署,无需特殊的代理或中间件支持。
另外,SSE 能够与现有的 Web 技术(如 AJAX 和 RESTful API)很好地集成,同时也更适合传输较少频繁更新的数据。
SSE 的优点:
- 1)实时性:SSE 允许服务器主动将数据推送给客户端,实现实时更新和通知;
- 2)简单易用:SSE 基于标准的 HTTP 协议,无需额外的库或协议转换;
- 3)可靠性:SSE 使用 HTTP 连接,兼容性好,并能通过处理连接断开和错误情况来确保数据传输的可靠性;
- 4)轻量级:与 WebSocket 相比,SSE 不需要建立全双工连接,减少了通信的开销和服务器负载。
SSE 的弊端:
- 1)单向通信: SSE 是单向通信的,只能由服务器向客户端发送数据,无法实现双向通信;
- 2)兼容性: SSE 不被一些老旧的浏览器支持,而且在某些情况下可能受到浏览器连接数限制;
- 3)无法跨域: SSE 受同源策略的限制,无法直接在跨域情况下使用,需要使用 CORS 等方法解决跨域问题。
综上所述:SSE 技术提供了一种简单、实时的服务器推送数据给客户端的方法,适用于需要实现实时更新和通知的应用场景。它在 Web 开发中具有广泛的应用,可用于构建聊天应用、实时监控系统等,并为开发人员带来便利和灵活性。但在需要双向通信、跨域支持或更复杂的实时应用中,WebSocket 技术可能更为适用。(更多SSE技术资料请阅读《SSE技术详解:一种全新的HTML5服务器推送事件技术》)
6、与WebSocket对比
WebSocket 是 HTML5 引入的 全双工通信协议,允许客户端和服务器之间保持持久连接,实现低延迟的双向通信(详情可阅读《WebSocket从入门到精通,半小时就够!》)。
WebSocket 特点:
- 1)全双工通信:客户端和服务器都可以主动发送数据;
- 2)低延迟:连接建立后,数据交换无需额外的 HTTP 头部,提高通信效率;
- 3)支持二进制数据:可以发送文本(JSON)和二进制数据(Blob、ArrayBuffer);
- 4)需要握手:使用 HTTP 进行 Upgrade: websocket 协商,建立 WebSocket 连接。
适用场景:
- 1)在线聊天应用(如 IM);
- 2)实时游戏(如在线对战);
- 3)股票行情推送;
- 4)直播弹幕。
WebSocket数据交互示意图:
WebSocket 与 SSE 对比总结:
7、流式响应落地示例
1)使用框架接受流式响应:LanghChain的stream接口。
async def _async_stream_with_custom_tokenizer(self, request: Request,
langchain,
prompt:str="",
history_messages: List[Message] = None):
"""
异步非阻塞版,区别 同步阻塞版(_generate_event_stream_with_custom_tokenizer)
"""
total_stream_content = ""
async for stream_content in langchain.astream({}):
if await request.is_disconnected():
logger.warning(f"[generate_event_stream] "
f", [trace_id] = {trace_id_context.get()}"
f", gateway connection abort..")
break
if isinstance(stream_content, str):
content = stream_content
total_stream_content += content
elif isinstance(stream_content, AIMessageChunk):
content = stream_content.content
total_stream_content += content
else:
logger.error(f"[generate_event_stream] "
f", [trace_id] = {trace_id_context.get()}"
f", unexpected stream_content type: {type(stream_content)}")
break
# print(f"[custom_tokenizer] langchain stream response: {stream_content}")
# 提取token统计信息
usage = None
if (stream_content.response_metadata is not None
and (stream_content.response_metadata.get('finish_reason') == 'stop'
or stream_content.response_metadata.get('done_reason') == 'stop')):
# hunyuan/azure_openai
# logger.debug(f"=====> finish stream response, signal = {stream_content.response_metadata.get('finish_reason')}")
# logger.debug(f"=====> finish stream response, signal = {stream_content.response_metadata.get('done_reason')}")
if usage is None:
token_usage = TokenTracker(self.model).track_full_token_usage(
input_text=prompt,
output_text=total_stream_content,
context=history_messages
)
usage = self._get_token_usage(self.model, token_usage)
resp = GenerateResponse(code=AiErrorCode.SUCCESS.value["code"],
message=AiErrorCode.SUCCESS.value["message"],
resp=content,
token_usage=usage)
yield resp.to_string()
2)自行拆包整合算法,处理流式响应:使用基础的python库完成网络数据读取。
需要注意的是,缓冲区管理:
- 1)cache_raw_data:存储未处理的二进制数据块,避免因网络分片导致的数据截断;
- 2)buffer:暂存已解码但未完整解析的文本数据(如SSE的 data: 前缀或JSON片段)。
async def _handle_stream_response(self,
resp,
prompt: str = None,
history_messages: List[Message] = None,
model:str=None):
# 全量数据包响应 & 单个数据包响应
total_stream_content = ""
usage = None
buffer = ""
cache_raw_data = b''
cache_raw_data_enable = False
# 分块读取
for stream_response in resp.iter_content(chunk_size=100):
# 解码响应(可能因分块边界截断UTF-8字符)
origin_content = ""
try:
if cache_raw_data_enable:
cache_raw_data += stream_response
# 尝试UTF-8解码
origin_content = cache_raw_data.decode('utf-8')
# 每次成功解码后自动清理缓存
cache_raw_data = b''
else :
# 尝试UTF-8解码
origin_content = stream_response.decode('utf-8')
cache_raw_data_enable = False
except UnicodeDecodeError:
logger.error(f"extract_content, data chunk decode error, trace_id = {trace_id_context.get()}, origin data = {stream_response}")
# 方案1:容错处理(有乱码字符输出,影响用户体验)
# origin_content = stream_response.decode('utf-8', errors='replace')
# 方案2:解码失败,缓存数据,缓存数据包待处理
logger.debug(f"extract_content, cache_raw_data_enable= {cache_raw_data_enable}, cache_raw_data = {cache_raw_data}")
cache_raw_data += stream_response
cache_raw_data_enable = True
# 跳过后续处理,等待下一块数据
continue
logger.debug(f"extract_content, trace_id = {trace_id_context.get()}, origin data = {origin_content}")
buffer += origin_content
while True:
# SSE协议:定位两个连续换行符,标识事件结束
idx = buffer.find('\n\n')
if idx == -1:
break
event_data = buffer[:idx]
# 移除已处理数据
buffer = buffer[idx + 2:]
# 处理事件数据中的每一行
for line in event_data.split('\n'):
line = line.strip()
if not line.startswith('data:'):
continue
# 移除"data:" or "data: "(这里的data:,后面可能跟1个或0个空格,eg,deepseek是没有空格,而azureopenai又有空格,这里做兼容)
data_str = line
if line.startswith('data: '):
data_str = line[6:]
elif line.startswith('data:'):
data_str = line[5:]
if data_str == '[DONE]':
# 2.1 自定义token计数器
token_usage = TokenTracker(model_name=model).track_full_token_usage(
input_text=prompt,
output_text=total_stream_content,
context=history_messages
)
usage = super()._get_token_usage(model=model, usage=token_usage)
# 2.1 拼接最终结果
res = GenerateResponse(code=AiErrorCode.SUCCESS.value["code"],
message=AiErrorCode.SUCCESS.value["message"],
resp=None,
token_usage=usage)
logger.debug(f"finish stream, trace_id = {trace_id_context.get()}, token data = {usage}")
yield res.to_string()
else:
try:
# 解析JSON数据
data = json.loads(data_str)
# 提取delta中的content
if 'choices' in data:
for choice in data['choices']:
delta = choice.get('delta', {})
content = delta.get('content')
if content is not None:
total_stream_content += content
# 3.8 拼接最终结果
res2 = GenerateResponse(code=AiErrorCode.SUCCESS.value["code"],
message=AiErrorCode.SUCCESS.value["message"],
resp=content,
token_usage=usage)
logger.debug(f"解析一个数据包数据完成, trace_id = {trace_id_context.get()}, origin data = {content}")
yield res2.to_string()
except json.JSONDecodeError:
pass # 忽略无效JSON数据
8、本文小结
实际很多大模型接入的商用场景,并非采用标准化的api-key/base-url的配置化方法,因为出于数据安全因素,大模型服务商并不采用云服务接入方法。如果要进行合作对接,进行类似的API接入和手动的数据拆包是大概率的事情。
9、参考资料
[1] Web端即时通讯技术盘点:短轮询、Comet、Websocket、SSE
[2] SSE技术详解:一种全新的HTML5服务器推送事件技术
[3] 使用WebSocket和SSE技术实现Web端消息推送
[4] 详解Web端通信方式的演进:从Ajax、JSONP 到 SSE、Websocket
[5] 使用WebSocket和SSE技术实现Web端消息推送
[6] 一文读懂前端技术演进:盘点Web前端20年的技术变迁史
[7] WebSocket从入门到精通,半小时就够!
[8] 网页端IM通信技术快速入门:短轮询、长轮询、SSE、WebSocket
[9] 搞懂现代Web端即时通讯技术一文就够:WebSocket、socket.io、SSE
[10] 大模型时代多模型AI网关的架构设计与实现
[11] 全民AI时代,大模型客户端和服务端的实时通信到底用什么协议?
[12] Web端实时通信技术SSE在携程机票业务中的实践应用
(本文已同步发布于:http://www.52im.net/thread-4856-1-1.html)