本文由钉钉技术专家啸台、万泓分享,为了获得更好的阅读效果,本文已对内容进行少修订和重新排版。
1、引言
钉钉后端架构的单元化工作从2018年开始到今年,已经是第五个年头了。五年的时间,钉钉单元化迭代了三个版本,从最初的毛头小子,到达今年已经小有成就。
我们在进行单元化架构建设的过程中,除了网上能找到的屈指可数的文章外,可以直接使用的系统更是乏善可陈,使我们不得不从最基础的系统开始造轮子,极大的影响建设效率。幸运的是,近几年云原生技术的兴起,让我们能复用很多基础设施,进而快速提升我们的单元化建设能力,助力钉钉的发展。
今天想借此文和大家分享我们在钉钉单元化架构实施过程中的心路历程和一些最佳实践。因涉及的技术和业务面太广,本文的分享无法做到面面俱到,主要是想在同路人中形成共鸣,进而能复用一些架构或子系统的设计和实现思路。
学习交流:
(本文同步发布于:http://www.52im.net/thread-4122-1-1.html)
2、系列文章
本文是系列文章的第 10 篇,总目录如下:
3、术语概念
本文内容中使用了一些专有的技术名词,为了方便大家理解,我把关键的几个术语概念的缩写及其含义专门列出来,供大家参考。
主要是以下几个:
- 1)Geo:钉钉专有化部署单位,解决数据合规需求,Geo间数据按需互通,并且互通数据在Geo内部做镜像拷贝,解决两化问题;
- 2)Unit: Geo内部资源物理分区隔离的最小单位,解决Geo内的容灾和容量的问题;
- 3)L0:客户端路由,决定了用户客户端接入钉钉服务器的所属单元,用户长连接所在的逻辑单元,起到连接加速作用。用户接入单元;
- 4)L1:接入层路由,以用户为维度进行调度,即用户操作发生的单元。用户归属单元;
- 5)L2:业务层路由,以业务资源为维度进行调度,大部分的业务资源所在单元应该和用户调度单元一致,但一些业务无法按照用户划分单元,如IM的会话,音视频的会议。 业务归属单元;
- 6)DMB:负责钉钉应用跨单元RPC调用的转发,可以认为是钉钉单元化RPC路由中间件;
- 7)DMR:负责钉钉应用跨单元MQ消息的转发,可以认为是钉钉单元化MQ路由中间件;
- 8)DTIM:钉钉IM系统。
4、单元化架构1.0版:合规驱动下的部署架构
2018年,部分大客户出于法律政策、商业机密数据存储的要求,要求钉钉的数据存储、访问接入、服务部署需要在其信任的区域内。既需要满足其数据存储私有化要求,同时需要满足跨地区网络的rt性能要求。
于是我们结合阿里云机房部署位置、物理距离、用户数据安全等方面出发,钉钉在客户的阿里云机房内建设了一个单元,将通讯录、IM信息等企业数据单独存储在客户机房。

我们通过一条专线,将两个机房逻辑串联到一起,内部通过DMB/DMR系统,实现了请求互通,这就是钉钉单元化架构的1.0版。
1.0版比较简单,纯粹是业务驱动,和支付宝单元化建设的初衷——“容灾驱动”有较大区别。两个站点通过UID分段,将用户划分为中心用户和专有用户。
上图只是一个简化的逻辑结构,内部实现远比上图复杂,但是1.0建设主要是从0到1,和大多数异地多活的系统较相似,这里就只简单的和大家分享一下。
5、单元化架构2.0版:逼出来的容量架构
2020年是一个特殊的年份,由于疫情的原因,带给大家非常多的改变,其中也包括钉钉。
由于在线办公与教育流量的突增,开年第一天上班就给钉钉一个下马威,平峰的流量已经和除夕跨年的持平,但是和除夕不同的是这个流量是持续的,即使节前准备了三倍容量,也抵挡不住流量对系统的冲击。只能借助阿里云的能力,不断的扩容。

但是每天将近30%的流量增幅,单纯的扩容也能难保障服务的连续性,最终也遇到了扩无可扩的场景,张北机房没有机位了,有机器资源但是没有机位让我们有力无处使。我们不得不不断进行系统优化,同时借助限流、降级、双推等措施,勉强抗住了流量的最高峰。
疫情之前,我们一直在做高可用,但是这个高可用主要集中在容灾机制上,比如搭建容灾单元。如同支付宝一样,是因为当时光纤被挖断;又比如银行的两地三中心架构,是担心某一个地域由于天灾或者战争导致数据丢失。疫情的流量给我们上了一课,仅仅关注容灾是不够的,特别是钉钉的DAU从千万走向亿级别之后,更需要在容量上做出提前规划。
正因如此,我们认为“容量架构不是设计出来而是真真切切被逼出来的”,所以容量架构就成为我们单元化核心要素之一。
容量架构是将流量划分到不同单元,每个单元承载各自的流量。容灾架构是单元异常时,能保障核心的能力可用,也可以将流量动态调度到别的单元,实现服务的快速恢复。
因此钉钉单元化进入了2.0时代,专注于容量和容灾的建设。

6、2.0版是基于什么维度进行流量划分的?
要实现流量的划分,必然要基于一个维度进行划分,一部分到A单元,一部分到B单元。
钉钉单元化架构也是参考了淘系和支付宝的单元化架构,前两者都是基于UID划分,钉钉单元化的第一个版本其实也是一样的,基于UID做拆分。
但是当我们设计容量架构时,发现基于UID划分无法解决我们的容量问题。
以IM为例:一条消息其实属于聊天双方的,群聊亦是如此。用户能和任意一个人聊天,这样我们根本无法找到一个切入点来划分流量,强行按照UID拆分,必然导致一个用户的消息出现在N个单元,单元的自封闭就无法做了。
也有同学会说:为什么消息不按照每个人存储,这不就能按照UID划分了吗?结论是不行。首先这个消息变成了写扩散,持久化的时候会变成多单元写,其次是成本翻倍,在DTIM这种过亿规模的场景这条路走不通。这里可以多说一点,因为这个观点来之不易,大家都知道,人是有惯性的,既然淘宝、支付宝甚至是微信都是UID划分,为什么钉钉要特立独行?当时我们团队受到了绝大部分钉钉技术团队的挑战,持续长达将近一个月的技术选型的“争吵”,最终还是达成了一致意见。
DTIM主要有3个维度,分别是UID、会话(CID)、消息。其中会话和消息是绑定的,而系统中最大量的是消息,按照第一性原则来看,一定要将消息划分开来,才能做到将容量划分开来的效果。
我们再来看看音视频,是按照房间维度组织流量和数据的,和IM又完全不同。
同样,文档其实更适合按照企业维度来划分。
不同的业务拥有不同的维度,因此我们认为:单元化最重要的找到自身“最大”的业务维度,将这个维护拆分,才能实现单元的横向扩展,我们称之为“业务路由”。
回头来看:我们之前其实是进入了思考误区,以为淘系和支付宝都是UID维度,我们也要这个维度,其实UID正是前者的业务维度,比如订单,也是围绕用户,并不会有交集的情况,会话就是IM的划分维度,因此做单元化之前要先找到属于自己的业务维度。
7、2.0版是如何实现IM消息的全局路由能力的?
7.1概述
UID路由有个最大的好处,就是可以按照UID分段,能实现高效的静态路由,也不用担心多单元之间的一致性问题。但是这种分段路由局限性也比较明显,需要预先分配,单元之间动态调度流量和数据成本极高,而且只能支持这种数值+顺序的场景。
在钉钉的场景中,有会话维度、房间维度、企业维度等等,想简单采用这种预分段机制难以满足业务需求。因此我们需要构建一个业务路由系统(RoutingService),实现消息流量的精确路由。
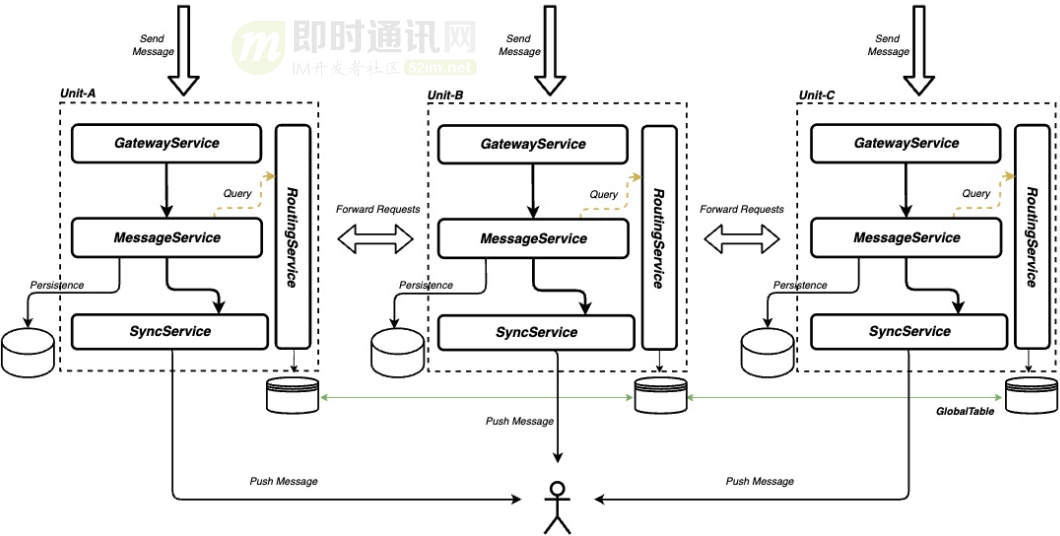
以IM为例:每次消息的发送,在单元化框架层面,会通过消息的会话(CID),查询路由信息,如果是本单元,流量下行并持久化;如果是非本单元,路由到对应的单元中。
下图是三个会话:分别是cid:1001、cid:1002、cid:1003,三个会话隶属不同单元,不管用户从哪个单元发送消息,都会路由到会话所在的单元。比如:用户在Unit B的cid:1001 中发送消息,当消息进入Receiver之后,会先查询此cid:1001所在的单元,发现是Unit A,路由框架将请求转到A单元,消息在A单元持久化并通过A单元的同步协议,将数据推送到客户端。
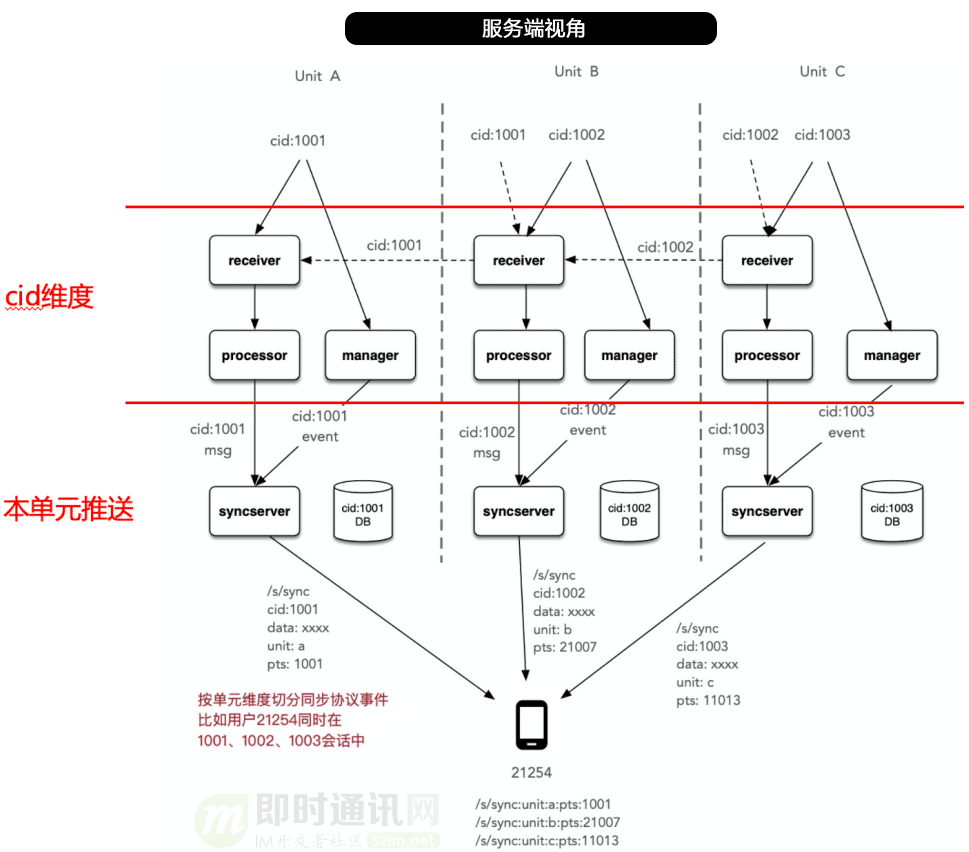

从上图可知:每次消息发送,都要查询路由服务,DTIM百万的峰值,对路由必然会带来超大的压力,同时我们能发现,路由数据在多单元实现一致性是一个巨大的挑战。
7.2边缘计算:端到端路由
在DTIM的场景中,会话的路由信息几乎不会变更,只有当我们决定将某些超大的会话或者企业腾挪到新单元时,才会发起路由的变更,因此会话的路由信息几乎可以认为是恒定不变的。那么每次查询路由服务端,效费比太低,是极大的浪费。
既然路由信息几乎不可变,是否将路由信息缓存呢?最常见的是使用一个集中式的Cache系统,缓存Hot的会话,我们也是这么做的,但是这么做还是不够,一旦Cache系统失效,DTIM还是会出现大面积故障,而且这个百万级的请求对Cache也是一个极大的压力。
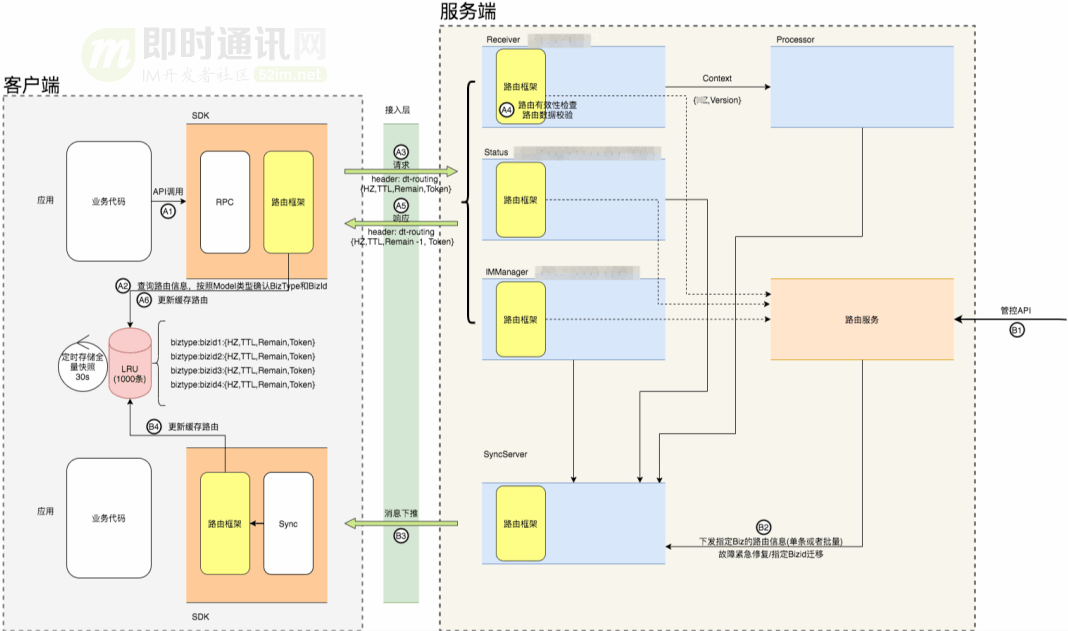
考虑到钉钉有强大的客户端,借用边缘计算的思路,我们将用户的会话数据缓存到客户端。对于客户端来说,也只用缓存用户自身最热的N会话路由数据,消息发送时,通过Header将路由数据携带到服务端,服务端路由SDK只要做合法性和续约即可,这样就将路由流量降低了95%以上。当路由服务出现异常时,还可以继续使用客户端路由,将路由的可用性提升到一个新的高度。
SDK本地会依据上行请求的返回中是否有新的路由信息,进而更新客户端路由。同时可以借助钉钉有主动下推的能力,通过同步协议将新的路由信息主动推送给客户端,使会话迁移做到更平顺。
7.3计算下沉:多单元一致性
对于新会话:比如小明要创建一个群聊,是应该创建在那个单元呢?
如果在A单元创建了,当会话消息来到B单元,系统怎么能第一时间知道会话已经在被绑定到A单元。
这里一般的方式有两种:
- 1)单元之间的存储系统采用类似DTS的机制进行异步同步,这种机制有秒级延迟;
- 2)在应用层主动同步,比如接入消息队列。
这两种方式由于都是异步的原因,都会出现不一致的问题,如果会话同时被绑定在两个单元,逻辑上会导致用户的历史消息丢失,这个是不能接受的。
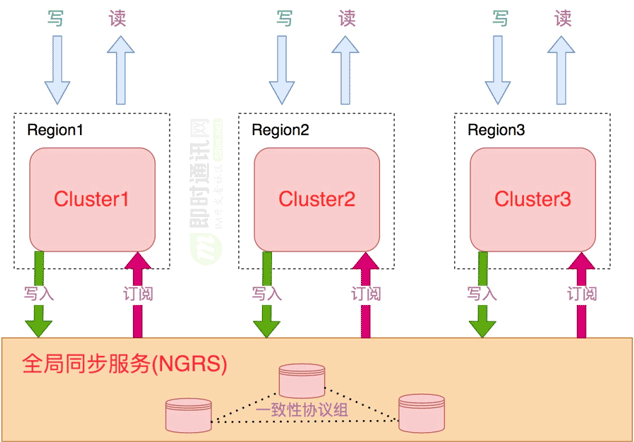
多地域(Region)数据同步其实是通用的技术挑战,我们认为存储系统提供是最好的方式,正如Google的Spanner一样,这样对我们上层才是最友好的方式。
因此我们找到了存储的OTS、Nuwa团队一起共建了GlobalTable。GlobalTable的核心原理还是借助Nuwa的一致性组,组分布在多个地域,采用多数派写入成功即返回的原理,做到20ms以内的一致性写。
8、2.0版的容灾能力
钉钉单元化的容灾能力是深度结合钉钉的业务层场景落地的,和淘系支付宝等有明确的区别。
以DTIM为例,最大的特点是当服务单元异常时,服务侧仍能提供最核心的服务,保障最基本的能力。本质上是由于DTIM是最终一致性系统,可以短暂允许部分环节失败。
可以看一下DTIM发送消息的容灾场景。当某个单元完全不可用的情况下,用户消息发送链路通过降级为local模式,在本地校验非本单元会话数据通过之后直接做消息发送,processor遇到非本单元的会话消息数据可以做单元间投递做数据回放,本地是否落库可选,同步协议推送不必区分是否为本单元会话消息数据直接通过本单元的topic推送给客户端,配合用户无状态快速迁移能力,单元间可以实现真正的分钟级别容灾切换能力。
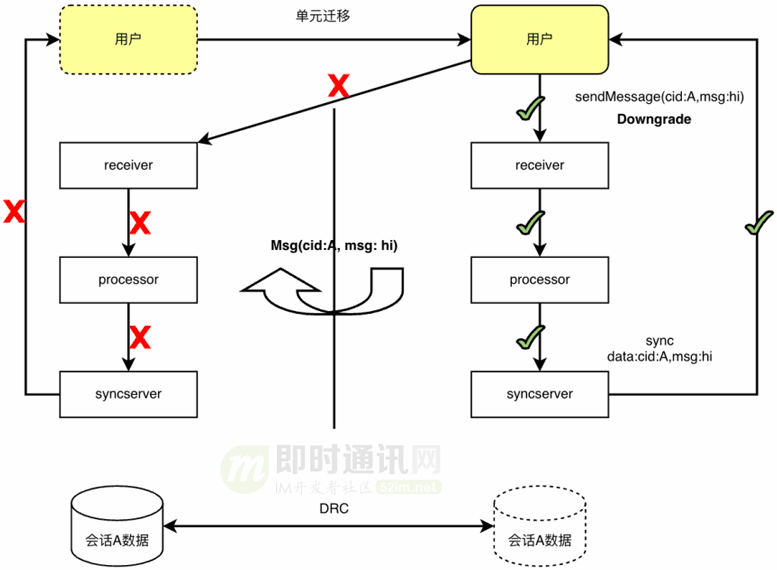
9、2.0版的成果与突破
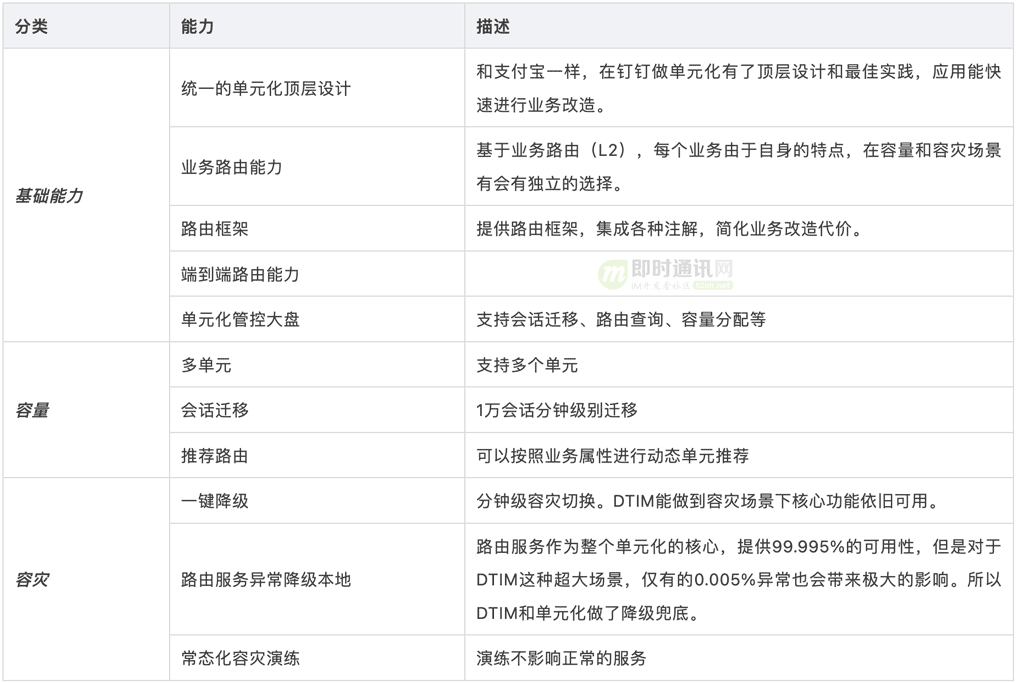
以上是钉钉单元化2.0提供给应用的核心能力,在满足容灾和容量设计需求之后,钉钉单元化给应用带来了更多的能力和想象空间。
比如:
- 1)快速迁移:当某一地域资源不足时,钉钉单元化可以将业务快速的从A单元迁移到B单元;
- 2)常态化切流:比如新建的教育会话,可以放到独立的单元;
- 3)热点治理:当前某一个会话过热,特殊时期可以迁移到独立集群;
- 4)SLA:满足不同的VIP客户需求,基于不同的SLA和售卖价格,将VIP客户放到对应地单元。
核心还是我们拥有单元化能力之后,实现了多单元流量的快速调度,为业务解决了后顾之忧。
10、2.0版在新时代面临的新挑战
10.1鱼和熊掌不可兼得
2022年对钉钉来说是成本之年,成本的压力不光落到了团队,还落到了每个人身上。
正如存储的CAP理论是一样的,我们同时只能满足两个维度,对于流量(性能P)、成本(C)、体验(E)也是一样,在流量不可预知和干预的情况下,选择成本必然导致体验受损,反之选择体验,必然导致成本升高。进入下半年,疫情反复带来流量的反复,为了实现可控的教育成本,只能在高峰期降级部分能力,这又导致体验受损,这段时间的工单量可以窥见一斑。
流量是用户侧触发的,我们无法干预,只能在成本和体验之间寻求平衡。和前面提及的一样,为了减小成本的消耗这就导致我们在扩容和缩容之间疲于奔命,反应不及时甚至有故障的危险,这种机制不可取也不可持续。到底是要流量与成本,还是要流量与体验,给我们技术团队带来了巨大的挑战和矛盾。
10.2商业化路在何方
当前钉钉为支持大客户提供了多种解决方案,专业钉钉、专属存储与打包、专有钉钉。
专属钉钉通过APP专属化以及部分专属功能,比如为一个企业定制一个拥有独立Logo的APP,能满足一般的中大型客户的业务诉求。
对于大型以及超大型客户,我们提供专有钉钉,提供专有化输出,完全隔离的方案,比如浙政钉。
伴随着钉钉的商业化进入深水区,客户对钉钉提出了新的诉求,特别是数据安全与归属、互联互通、完整的能力栈等诉求,当前钉钉输出产品形态都无法同时地满足以上需求。
前几年互联网上出现的几起数据安全事件,数据丢失与泄露,未经客户授权私自访问客户数据,让大多数客户不信任服务提供商,即使服务商的安全能力已经是业界一线能力。其实这个是可以理解的,数据即客户的生命线,数据无法在自身可控范围内,特别是对于很多特殊行业,这是无法接受的,自身性命岂能假手于人。专属钉钉在面临这种客户时,前线售卖同学是无能为力。
那么很多同学肯定会提“如果专属钉钉满足不了需求,我们专有钉钉不是能解决这些问题吗?”,其实单单从诉求来看,专有钉钉场景是切合客户的业务诉求,提供完全独立运行环境、可控的数据安全。但是专有钉钉由于其独特的架构带来高昂的售价以及后期的运维代价,对于超大型的客户来说也难以承担如此高的成本。对于钉钉自身来说,从研发到后续运维,维护一套独立体系也难以在客户侧大面积推广。

11、单元化架构3.0版:混合云架构
11.1概述
钉钉单元化经过四年的发展,在容灾和容量上做出一定的积淀,同时完成了一些核心技术的积累。
当整体架构成熟之后,我们也在思考,单元化能否从技术架构升级为业务架构,比如搭建独立的高可用单元,按照售卖的SLA提供给VIP客户,支持钉钉商业化的发展。
同时我们在云原生逐步发力,将部分核心应用放到云上,经过这一年多的运行,遇到了新的挑战,但更获得云下无法获得的计算弹性能力,云上的弹性对云下是一个降维打击,从一个新的方向解决计算问题。
如上文提到的两个核心挑战,钉钉单元化同样面临这个问题,在持续的发展中找到了一个合适的架构方向。
基本思路是:
- 1)云下作为基本盘,保障核心流量的问题,毕竟云下经过集团多年的打磨,不管是稳定性还是流程的合理性都有保障;
- 2)云上应对高涨异常的流量,比如和疫情正相关的教育流量,既保证了服务的稳定性,又能充分利用云上弹性能力,在提供完整能力的前提下做到一个相对较低的成本。
其次是升级Geo概念:
- 1)将Geo作为一个独立的业务域,实现Geo级别完全独立部署,分布式云模式;
- 2)同时Geo之间按需互通,从研发体系上能做到一套代码。
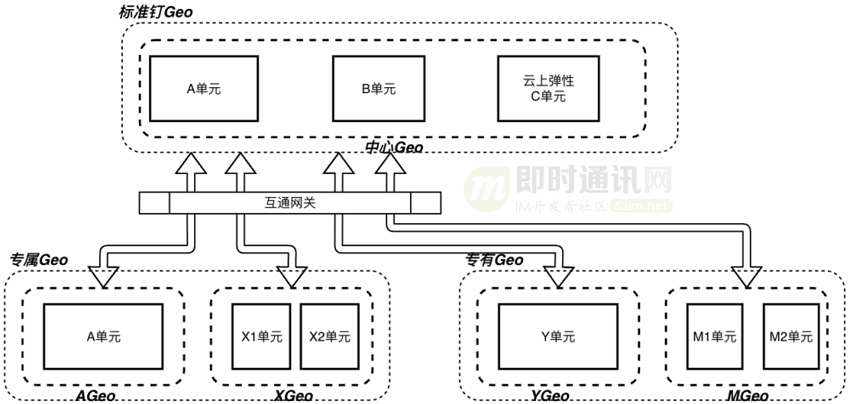
因此,钉钉单元化来到了3.0版本,我们称之为钉钉单元化混合云架构。
混合云主要是从两个维度来看:
- 第一:是云上云下,我们认为云上云下并不是取代的关系,而是相互补充的关系,是一个长期的状态,正如很多大客户随着规模的持续扩张,最终依赖的部分核心能力必然走向自研道理一样,这能做成本的进一步降低,所以架构是一个混合云架构;
- 第二:业务架构上也是混合云架构,通过不同的Geo,将不同的业务逻辑上聚合到一起,构建起一张钉钉的大网,不同Geo按需互通,实现了业务架构的混合。
3.0从系统架构上相对于2.0,最大的区别就是云原生技术的运用和互通网关的建立。
11.2云原生技术 :抵抗系统架构熵增的有效手段
近几年,互联网圈最火的技术莫过于以Docker为代表的云原生技术最为火热,各大云厂商也都在不遗余力的推广云原生技术以及对应的产品。同时钉钉服务过亿DAU的客户,面对各种可靠性、服务连续性、并发、容灾等技术挑战,也都走到了现有技术的边界。
所以我们也在不断吸收新的技术和架构,希望从体系与架构上降低我们的技术复杂度,以抵抗熵增。
我们在2021年底启动了云原生升级战略,升级云原生技术并不是为了技术而升级,而是切实面临巨大的技术挑战。
1)首先我们面临多语言的挑战:
我们以IM为例,IM的核心逻辑都是使用C++构建,但是我们常用的中间件三大件:存储、缓存、异步队列,其中缓存和异步队列在C++客户端上长期建设不足,导致IM长期在使用低版本。
低版本由于长时间缺乏维护,经常会出现异常,比如队列假死、消费不均等,导致我们自己不得不亲自上阵修改SDK的代码,以致最后难以使用到产品的新能力,阻碍IM服务能力的提升。
2)其次是多产品多云的挑战:
我们以阿里云为例,数据库类目下的产品,从类别上就有关系数据库、NoSQL数据库、数仓等等,还有存储也是一样。
对于我们上层业务,其实绝大部分服务都只依赖了底层的CURD,这么多产品,每次对接一个产品都要开发一轮。
配置系统也是一样,弹内有Diamond,云上有Nacos、Mse,K8s有自己的Configmap等,而且这些配置系统不像数据库有标准,而是百花齐放,但是这样却苦了我们使用者。
这些内容不是我们的核心路径,浪费大把时间在各种产品接口的适配上,明显拖累了钉钉的发展。
3)最后就是通用的流量治理挑战:
钉钉很多系统都是最终一致的系统,IM就是典型的最终一致系统,这类系统和强同步系统在架构设计有一个明显的区别,强一致系统如果遇到失败,必须要持续重试直到成功,所以一般编程上都是重试+退避。
但是最终一致系统不是,这类系统允许部分节点失败,不要阻碍其他流程,失败的流量通过一个异步回旋的队列,将数据逐步回放回来即可。这种回旋需要借助异步队列,而且要设计各种消费机制,比如限速、比如丢弃等等,这是一个通用的逻辑,但是每个业务方或多或少都在实现自己的回旋系统,重复的造轮子。又比如各种故障注入,单元化路由流量等等,要想拥有这个能力,团队不得不投入人力研发。
在对付架构复杂度上,我们主要从两个维度来屏蔽复杂度。
首先代码层面我们选择了DDD模式,我们使用DDD分层核心是把对外系统的依赖全部收拢到Infrastructure这一层,全部采用纯虚函数(Interface)对外提供接口。屏蔽底层中间件差异和细节。
在架构上采用Sidecar的模式,类似于Dapr的思想,通过标准的GRPC和PB实现应用与中间件解耦。Sidecar中集成了各种中间件、配置系统、灰度系统等,等价实现了应用和中间件的解耦。上文中提到的不管是多语言挑战、多云多产品的挑战、重复造轮子等问题,都能很好的解决。

11.3互通网关 :混合架构的基石
云上云下互通,或者说多个云账户VPC之间的互通,我们常见的有两种方案:
- 1)其一是VPC直接打通,让多个VPC之间形成一个大的局域网,RealServer实现点对点互通;
- 2)其一是中间搭建一个负载均衡器,通过暴露EIP实现互通。
两个方案都有自己的优缺点。
对于方案一:打通的VPC涉及到IP规划,如果前期没有合理规划,后续很难打通;还有这种方案有水桶短板安全问题,一旦一个VPC被攻破,这张网也被攻破;但是对于内部的应用来说架构就比较简单,可以仅仅借助K8s DNS service就能做到服务发现。
对于方案二:最大的缺点就是中间有一个集中式的负载均衡,需要申请独立的LB才可访问;但是这种方案隔离性好。
对于钉钉单元化来说,涉及N个业务方,N * M个应用,对应X个VPC,要想VPC之间打通,几乎没有可能性,而且VPC打通,还面临应用之间的安全性问题。要实现Geo之间互通,环境之间的隔离性是基本要求,与此同时,我们也要考虑到系统的可扩展性,所以我们必须要构建一套独立的流量网关,实现流量加密、寻址、转发等通用能力。
钉钉互通网关是构建在Envoy之上的系统,双向Ingress和Egress,支持GRPC和钉钉自研协议。具备流量管理、传输加密、单元寻址等能力。钉钉单元化借助互通网关的能力,再配合全局流控系统,我们可以在多单元之间实现精确的流量控制和调度。
12、写在最后
伴随着专属集群的持续输出,客户对专属的场景需求会越来越多,需要我们投入更多的人力持续的建设。
比如:
- 1)在架构侧:首先是Sidecar持续强化,支持更多的中间件和环境,提供不同维度的安全能力,满足客户和应用的安全需求;
- 2)在运维侧:我们需要构建多Geo管理能力,完善Geo和单元之间流量快速调度能力,提供自动化的自检系统等;
- 3)在交付侧:如果实现快速交付,比如是否能做到新应用一周完成单元化改造,新Geo一天部署完成。这些挑战都是接下来我们要重点投入的方向。
对于标准钉钉来说,这个是我们的基本盘,一个稳定可靠且低成本的钉钉是我们持之以恒的目标,接下来我们会加大云上流量的占比,充分的借助云上弹性能力,实现可控的成本。
今天我们只是站在钉钉的角度上抛了一个“砖”,希望在异地多活这个领域激起一层浪花,欢迎大家一起讨论。
13、相关资料
[1] 现代IM系统中聊天消息的同步和存储方案探讨
[2] 企业级IM王者——钉钉在后端架构上的过人之处
[3] 深度解密钉钉即时消息服务DTIM的技术设计
[4] 钉钉——基于IM技术的新一代企业OA平台的技术挑战(视频+PPT)
[5] 企业微信的IM架构设计揭秘:消息模型、万人群、已读回执、消息撤回等
[6] IM系统的MQ消息中间件选型:Kafka还是RabbitMQ?
[7] 深度揭密RocketMQ在钉钉IM系统中的应用实践
(本文同步发布于:http://www.52im.net/thread-4122-1-1.html)