|
|
GIS数据建库基本思想(上)
3.
数据规范
这里说的数据规范,指的是可以被系统所正确识别的数据。这依赖于上述数据库建库的第一个过程,即数据库标准的制定和数据规范。这里的主要矛盾在于,因为
GIS
平台的不一致,各个平台对空间数据描述的模型不同,而导致了在一个平台上生成的数据在另一个平台不能正确读出,从而导致转换前后矢量或属性数据的丢失,甚至无法转换的结果。
例如,
AutoCAD
存在拟合曲线
Spline
对象,图形块
Block
对象,区域
Region
对象,代理对象等许多特殊的图形对象,在
GIS
系统中没有相应的图形对象与之相对应。因此要想将这些数据入库,必须先将以上对象转化,使之变成
GIS
可以识别的图形对象。
AutoCAD
的扩展数据由于为
AutoCAD
所特有,因此也必须寻找解决办法
(
例如数据格式转换
)
,使之能被
GIS
所正确读取。
此外还包括数据规范中规定的各个图层之间相互的空间拓扑关系及属性数据等,这些都要求有相应的检测和修正工具予以保证。
4.
数据生产
数据生产过程主要包括准备阶段和数据输入阶段。以下为
AutoCAD
平台下数据的生产过程为例。
准备阶段
此过程包括定义图层名称,配置图层的各种属性(颜色,线性,线宽,图形符号等)。这一过程是数据生产的准备阶段,工作逻辑上非常简单,在认真设置和检查后,产生错误的可能性会很小。
数据生产阶段
包括栅格数据自动矢量化和人工输入两个比较大的方面,有时候全为人工输入。
栅格数据自动矢量化是通过扫描仪器输入栅格数据,然后通过图像识别算法,进行矢量跟踪,从而确定实体的空间位置。在目前的技术发展中,程序的算法往往不能完全识别出所需要的对象并进行正确的矢量化,若栅格数据是经过底图扫描而非遥感影像,可能还会出现扫面不清晰,因此会产成各种各样的问题。常见的错误主要有以下几种:
(1)
房屋等面状闭合物体留有缺口,即不封闭。
(2)
扫描后的线段存在很多重复点的现象。
(3)
扫描后的线段存在自相交的情况。
(4)
在图像边缘上的线段,扫描后出现畸变现象。
(5)
在图像的边缘存在数据丢失的现象。
(6)
由于图像定位不准,导致扫描后图像部分基准点偏移,从而导致相邻的地区存在图形重叠或交叉的现象。
其中基准点偏差的影响尤为显著,严重影响数据建库。一般情况下,我们需要封闭检查,重复点检查,自相交检查,基准点检查和校正等检查工具去发现和排除这些错误。在这些错误中,错误
1
、
2
、
3
、
6
在逻辑上比较简单,相对比较好解决。错误
4
、
5
则比较难于检查和解决。
人工输入是指数据录入人员按照要求用鼠标或绘图议等手工在图纸上进行绘图,并设置和添加各种属性的过程。这一过程十分繁重的,并且工作具有重复性和枯燥性等特点,因此容易造成各种错误,从而影响数据质量。产成的错误的原因主要有两个:
精度问题造成的错误,这种原因往往造成图形拓扑关系错误。例如,应该闭合的面状物体没有闭合,应该端点相连的直线没有连接,不应该重叠的线段存在重叠的部分,不应该交叉的图形存在交叉,面与面之间存在缝隙,面与面之间发生重叠,基准点和控制点定位不准确等等。
人为疏忽造成的原因。例如,有属性的图形物体忘记给属性赋值,导致属性丢失;有属性的图形物体错误赋值,导致属性错误;图幅边框被删除或者移动位置;图幅边界上的图形没有很好的完成接边处理,造成相邻图形不匹配等等。这些错误都经常的会在数据生产过程中发生,如果不加以检测和修正,将直接影响建库的正确性和准确性,应予以注意。
5.
小结
从以上分析可以看出,数据建模、数据规范、数据生产都是
GIS
数据顺利、准确入库的关键,在整个过程中,数据校验起到了非常重要的作用,在实际操作中,需要系统理论知识和经验知识来作为建立
GIS
数据库的架构支撑。根据个人有限的系统工程方面的理论知识,只能对数据校验做出如下概述:
(1)
首先,需要对准备入库的各种源数据进行研究和分析,从中发现数据中存在的明显的错误,并估计潜在的错误。
(2)
根据数据建库标准和数据规范,分析这些错误可能对建库造成的影响,按照严重程度、优先级别、逻辑关系等将错误分类,并制定处解决问题的方案。
(3)
按照制定的解决方案有计划、有步骤的纠正这些错误,使之符合建库的规范。
(4)
这样循环检查几次,尽量消除数据中的错误,一般情况下,总会有少量错误存在。
(5)
当已经很难找出错误时,可以开始进行抽样检测,并小规模进行试验性入库。
(6)
在试验性入库成功后,进行大批量的实际入库。
(7)
入库完毕,对入库成果进行抽样检查,查找不正确的地方,并进行修正。
(8)
GIS
数据入库正式完成,交付使用。
经过上述过程,整个建库工作就已经完成。上文所述,只是个人在
GIS
数据建库方面的一点个人经验和系统知识,在今后的实际工作中仍需不断完善、深入。
原文链接:http://www.gissky.net/blog/blog.asp?name=bluewood
地理信息系统的建设中,数据库的建设极为重要,基础地形库的建设大概要占到整个系统的
60%
甚至更高。因此,若在建库的过程中碰到问题,将导致建库的困难,甚至无法完成建库的工作。要解决建库遇到的各种问题并顺利完成建库,就要对建库的整个过程进行分析,从中找出影响建库的最主要的因素,并认真的分析这些因素产生的根本原因,制定出解决这些问题的解决方案,完成重要的建库工作。
数据库建库主要有三个过程:
First
--
数据库建模。主要是根据具体行业的特点及对其的理解,制定出数据规范,在逻辑上建设数据库。
Second
--
数据校验。主要是检测数据的正确性,保证数据质量。
Third
--
数据入库。主要是将获取的各种数据,例如纸制数据,矢量数据,栅格数据,遥感影像数据等准确的导入到数据库中。
下面对数据库建库的整个过程进行详细分析。
1.
数据建模
数据建模的目的是根据对应用行业的理解,在逻辑和概念上对数据库进行设计,其影响的是数据库建设完毕后的合理性、通用性和可扩展性。建模是否成功将直接影响到系统是否易用、易扩展,甚至是否成功。地理信息数据库建库过程中遇到的各种问题主要是数据问题,对系统成功进行了建模之后,若数据存在问题,将直接影响到数据的入库。
2.
数据入库
在数据入库的过程中,其核心是如何依据所制定的数据规范将各种格式的数据,准确的、快速的导入到数据库中。在这个过程中遇到的问题,其根本就是如何解决不同平台之间数据集成的问题。在《
GIS
开发者》第八期电子杂志中,曾提出共相式地理信息系统,其目的之一也是为了解决数据源的集成问题。在目前,实现地理信息多源数据集成的方式大致有三种,即数据互操作模式,直接数据访问模式和数据格式转换模式。
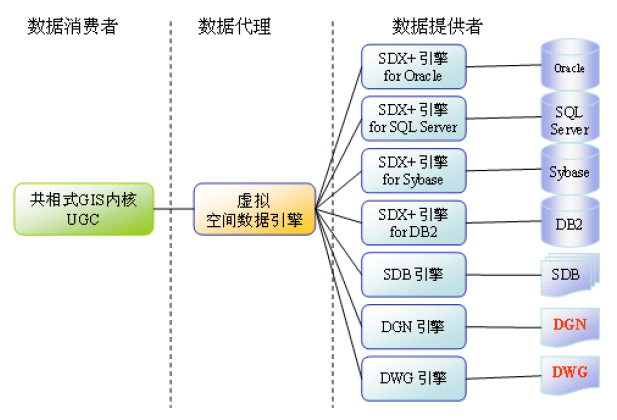
共相式
GIS
支持多种数据格式的技术框架示意图
(
注:该图引用自《
GIS
开发者》第八期电子杂志
)
(1)
数据互操作模式。数据互操作模式是
OpenGIS Consortium
(
OGC
)制定的规范。这种模式和数据入库的思路有所不同。
(2)
直接数据访问模式。直接数据访问模式是指在一个
GIS
软件中,实现对其他软件数据格式的直接访问,用户可以使用单个
GIS
软件存取多种数据格式。以
ArcGIS
为例,它可以打开多种
GIS
平台及其它相关软件的数据。
(3)
数据格式转换模式格式转换模式是传统的
GIS
数据集成方法,也是入库的基本思想。在这种模式下,其他数据格式经专门的数据转换程序进行格式转换后,就可以进行入库了。例如,在
ArcToolBox(
版本
9
以后被整合到
ArcMap
和
ArcCatalog
中
)
里,就有多种数据格式转换的工具。
数据格式转换是目前
GIS
系统集成的主要办法。现在基本上每个主流
GIS
平台都提供了一些数据转换工具,以
ESRI
公司的
ArcGIS
平台提供了
ArcToolBox
工具箱,功能相对完善,基本上支持所有市面上各种主流的
GIS
数据,例如
Autodesk
公司的
DWG
格式文件和
DXF
格式文件,
MapInfo
公司的
MIF
格式,
Intergraph
的
DGN
格式,以及各种栅格图形数据等等,基本上满足了一般数据入库的要求。此外,还有其它许多专门的数据格式转换工具可以使用。由此可以看出,只要提供的源数据是正确的,符合规范的,那么利用上述工具就可以将数据导入到数据库中,从而顺利的完成建库的工作。因此,源数据的准确性和规范性就成为建库成功的十分关键的因素。由此看来,数据校验就成为建库能否顺利进行的关键所在。
数据校验需要完成哪些工作,怎样进行校验与把关才能在建库之初就能预测各种潜在的问题,因此,需要仔细分析导致数据不准确、不规范的原因。一般情况下,需要从数据规范和数据生产过程中考虑。
GIS数据建库基本思想(下)
原文链接:http://www.gissky.net/blog/blog.asp?name=bluewood
文章进行了简单增改,对于本文的争议请看文后的评论。
作者:Flyingis
容器类可以大大提高编程效率和编程能力,在Java2中,所有的容器都由SUN公司的Joshua Bloch进行了重新设计,丰富了容器类库的功能。
Java2容器类类库的用途是“保存对象”,它分为两类:
Collection----一组独立的元素,通常这些元素都服从某种规则。List必须保持元素特定的顺序,而Set不能有重复元素。
Map----一组成对的“键值对”对象,即其元素是成对的对象,最典型的应用就是数据字典,并且还有其它广泛的应用。另外,Map可以返回其所有键组成的Set和其所有值组成的Collection,或其键值对组成的Set,并且还可以像数组一样扩展多维Map,只要让Map中键值对的每个“值”是一个Map即可。
1.迭代器
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
2.List的功能方法
List(interface): 次序是List最重要的特点;它确保维护元素特定的顺序。List为Collection添加了许多方法,使得能够向List中间插入与移除元素(只推荐LinkedList使用)。一个List可以生成ListIterator,使用它可以从两个方向遍历List,也可以从List中间插入和删除元素。
ArrayList: 由数组实现的List。它允许对元素进行快速随机访问,但是向List中间插入与移除元素的速度很慢。ListIterator只应该用来由后向前遍历ArrayList,而不是用来插入和删除元素,因为这比LinkedList开销要大很多。
LinkedList: 对顺序访问进行了优化,向List中间插入与删除得开销不大,随机访问则相对较慢(可用ArrayList代替)。它具有方法addFirst()、addLast()、getFirst()、getLast()、removeFirst()、removeLast(),这些方法(没有在任何接口或基类中定义过)使得LinkedList可以当作堆栈、队列和双向队列使用。
3.Set的功能方法
Set(interface): 存入Set的每个元素必须是唯一的,因为Set不保存重复元素。加入Set的Object必须定义equals()方法以确保对象的唯一性。Set与Collection有完全一样的接口。Set接口不保证维护元素的次序。
HashSet: 为快速查找而设计的Set。存入HashSet的对象必须定义hashCode()。
TreeSet: 保持次序的Set,底层为树结构。使用它可以从Set中提取有序的序列。
LinkedHashSet: 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
HashSet采用散列函数对元素进行排序,这是专门为快速查询而设计的;TreeSet采用红黑树的数据结构进行排序元素;LinkedHashSet内部使用散列以加快查询速度,同时使用链表维护元素的次序,使得看起来元素是以插入的顺序保存的。需要注意的是,生成自己的类时,Set需要维护元素的存储顺序,因此要实现Comparable接口并定义compareTo()方法。
其它相关内容:
Java容器分析--数组
Java容器分析--Map
作者:Flyingis
贴一则消息。
今天在各大网站上都看到这条醒目的新闻:"Java? It's So Nineties"。好像全世界的Java程序员和其他程序员都在讨论这个话题,虽然有时觉得这种话题有点无聊之闲,但关注程度如此之高,赋予了我们关注的意义。也许,从中我们能了解Java今后的大致发展方向。
--------------------------------------
CSDN--缺乏发展空间 Java不及LAMP和.NET?
BusinessWeek 昨天的一篇文章
"Java? It's So Nineties"
引起了广泛的讨论。其中的主要观点认为,Java在各领域均缺乏发展空间,注定比不上LAMP 和.NET。
文中提到,Sun从前的一位管理人员开了一家 "focused on MySQL and PHP" 公司,宣称“Java是恐龙”;PHP公司主席Marc Andreesen声称,“我们可以看到一种由Java 向PHP转移的现状”;Microsoft's .NET director-John Montgomery说道,“没有人能用Java赚到钱。”
该文作者Steve Hamm 通过列举了大量的统计信息,其中对象主要包括LAMP、.NET、AJAX,等等,试图向读者传达这样一个信号:Java已经走入穷途末路,请广大开发者们赶快迷途知返,悬崖勒马才好。作者甚至以AJAX图书销售量大于Java图书为例。
虽然作者的文章中一些数据和言论的真实性值得商榷,但有一点却是值得我们思考:Java未来的发展方向在哪里?
原文链接:
http://www.businessweek.com/technology/content/dec2005/tc20051213_042973.htm
相关评论:
Is Java losing to LAMP and .NET?
http://www.theserverside.com/news/thread.tss?thread_id=38081
Java? It's So Nineties
http://www.javalobby.org/java/forums/t59582.html
MATRIX--Java被Lamp和.Net赶超?无稽之谈……
BusinessWeek Online 昨天有一篇文章,叫做:"Java? It's So Nineties"。内容是,java虽然异常强大,但是逐渐被Lamp和.Net赶超。
理由是:PHP和AJAX正在变得很受欢迎,特别是AJAX,图书销量正在逐渐赶超Java的图书销量。
另外一个理由是:对于在linux上搭建轻量级的简单的应用的时候,也不需要用到Java。
文章在Tss引起广泛讨论。
实际上,多数开发者都认为,这个结论纯属无稽之谈。并且毫无意义。随便列举几个理由:
1. 企业级开发,Java毫无疑问是完全占据优势的。
2. Dyanimics 和Groovy 是Java 可以较大提升的一个地方,这使得Java更加动态,更适应小型应用。而EJB这些,就更不用说了,LAMP和.Net,基本上是不适用了。
3. PHP很受欢迎,只是证明了PHP在很多简单应用上,开发者上手比较快而已。
4. 最关键的是,PHP和JAVA也不是一个层面比较的东西,如果要比较,那么就是MODE-1的JSP和PHP比较。特别是O/R, AOP, MVC, Patterns, XML config files, Tag libraries 等,在PHP中要实现还是要很长一段时间。
等等了……
毫无意义的比较,本来实在不想post这篇评论,然后在TSS上引起广泛评论,想让大家也给一些意见。总之,大家一致觉得,BusinessWeek 的结论是无稽之谈。
对于BusinessWeek的观点,你的看法又如何?
--------------------------------------------
另外在Matrix上有两则最新的消息,不知道AJAX要火到什么程度,IT这个行业真是说不准:
------------------------------------
MyEclipse 4.1 M2 发布
MyEclipse 4.1 M2 发布了。有很多项值得关注的特性:支持AJAX和Web 2.0,提升了Javascript 编辑器,增加了Javascript 调试器等等..
基于Ajax的Web框架Echo2 2.0发布
NextApp 宣布Echo2 2.0发布了。Echo2是一个基于Mozilla Public License的开源WEB框架。一个可以用于开发基于Web胖客户端应用程序的框架。
-----------------------------------
作者:Flyingis
ClassCastException是JVM在检测到两个类型间转换不兼容时引发的运行时异常。此类错误通常会终止用户请求。在执行任何子系统的应用程序代码时都有可能发生ClassCastException异常。通过转换,可以指示Java编译器将给定类型的变量作为另一种变量来处理。对基础类型和用户定义类型都可以转换。Java语言规范定义了允许的转换,其中大多数可在编译时进行验证。不过,某些转换还需要运行时验证。如果在此运行时验证过程中检测到不兼容,JVM就会引发ClassCastException异常。例如:
Fruit f;
Apple a = (Apple)f;
当出现下列情况时,就会引发ClassCastException异常:
1. Fruit和Apple类不兼容。当应用程序代码尝试将某一对象转换为某一子类时,如果该对象并非该子类的实例,JVM就会抛出ClassCastException异常。
2. Fruit和Apple类兼容,但加载时使用了不同的ClassLoader。这是这种异常发生最常见的原因。在这里,需要了解一下什么是ClassLoader?
ClassLoader
ClassLoader是允许JVM查找和加载类的一种Java类。JVM有内置的ClassLoader。不过,应用程序可以定义自定义的ClassLoader。应用程序定义新的ClassLoader通常出于以下两种原因:
1. 自定义和扩展JVM加载类的方式。例如,增加对新的类库(网络、加密文件等)的支持。
2. 划分JVM名称空间,避免名称冲突。例如,可以利用划分技术同时运行同一应用程序的多个版本(基于空间的划分)。此项技术在应用服务器(如WebLogic Server)内的另一个重要用途是启用应用程序热重新部署,即在不重新启动JVM的情况下启动应用程序的新版本(基于时间的划分)。
ClassLoader按层级方式进行组织。除系统BootClassLoader外,其它ClassLoader都必须有父ClassLoader。
在理解类加载的时候,需要注意以下几点:
1. 永远无法在同一ClassLoader中重新加载类。“热重新部署”需要使用新的ClassLoader。每个类对其ClassLoader的引用都是不可变的:this.getClass().getClassLoader()。
2. 在加载类之前,ClassLoader始终会先询问其父ClassLoader(委托模型)。这意味着将永远无法重写“核心”类。
3. 同级ClassLoader间互不了解。
4. 由不同ClassLoader加载的同一类文件也会被视为不同的类,即便每个字节都完全相同。这是ClassCastException的一个典型原因。
5. 可以使用Thread.setContextClassLoader(a)将ClassLoader连接到线程的上下文。
基于以上的基本原理,可以加深大家对ClassCastException的理解,和在碰到问题时提供一种解决问题的思路。
参考文献:
dev2dev专刊 2005年 第二期 j2sdk-1_5_0-doc
作者:Flyingis
数组是Java语言内置的类型,除此之外,Java有多种保存对象引用的方式。Java类库提供了一套相当完整的容器类,使用这些类的方法可以保存和操纵对象。下面分别进行讨论,在研究Java容器类之前,先了解一下Java数组的基本功能和特性。
1. 数组的基本特性
数组与其它种类的容器(List/Set/Map)之间的区别在于效率、确定的类型和保存基本类型数据的能力。数组是一种高效的存储和随机访问对象引用序列的方式,使用数组可以快速的访问数组中的元素。但是当创建一个数组对象(注意和对象数组的区别)后,数组的大小也就固定了,当数组空间不足的时候就再创建一个新的数组,把旧的数组中所有的引用复制到新的数组中。
Java中的数组和容器都需要进行边界检查,如果越界就会得到一个RuntimeException异常。这点和C++中有所不同,C++中vector的操作符[]不会做边界检查,这在速度上会有一定的提高,Java的数组和容器会因为时刻存在的边界检查带来一些性能上的开销。
Java中通用的容器类不会以具体的类型来处理对象,容器中的对象都是以Object类型处理的,这是Java中所有类的基类。另外,数组可以保存基本类型,而容器不能,它只能保存任意的Java对象。
一般情况下,考虑到效率与类型检查,应该尽可能考虑使用数组。如果要解决一般化的问题,数组可能会受到一些限制,这时可以使用Java提供的容器类。
2. 操作数组的实用功能
在java.util.Arrays类中,有许多static静态方法,提供了操作数组的一些基本功能:
equals()方法----用于比较两个数组是否相等,相等的条件是两个数组的元素个数必须相等,并且对应位置的元素也相等。
fill()方法----用以某个值填充整个数组,这个方法有点笨。
asList()方法----接受任意的数组为参数,将其转变为List容器。
binarySearch()方法----用于在已经排序的数组中查找元素,需要注意的是必须是已经排序过的数组。当Arrays.binarySearch()找到了查找目标时,该方法将返回一个等于或大于0的值,否则将返回一个负值,表示在该数组目前的排序状态下此目标元素所应该插入的位置。负值的计算公式是“-x-1”。x指的是第一个大于查找对象的元素在数组中的位置,如果数组中所有的元素都小于要查找的对象,则x = a.size()。如果数组中包含重复的元素,则无法保证找到的是哪一个元素,如果需要对没有重复元素的数组排序,可以使用TreeSet或者LinkedHashSet。另外,如果使用Comparator排序了某个对象数组,在使用该方法时必须提供同样的Comparator类型的参数。需要注意的是,基本类型数组无法使用Comparator进行排序。
sort()方法----对数组进行升序排序。
在Java标准类库中,另有static方法System.arraycopy()用来复制数组,它针对所有类型做了重载。
3. 数组的排序
在Java1.0和1.1两个版本中,类库缺少基本的算法操作,包括排序的操作,Java2对此进行了改善。在进行排序的操作时,需要根据对象的实际类型执行比较操作,如果为每种不同的类型各自编写一个不同的排序方法,将会使得代码很难被复用。一般的程序设计目标应是“将保持不变的事物与会发改变的事物相分离”。在这里,不变的是通用的排序算法,变化的是各种对象相互比较的方式。
Java有两种方式来实现比较的功能,一种是实现java.lang.Comparable接口,该接口只有一个compareTo()方法,并以一个Object类为参数,如果当前对象小于参数则返回负值,如果相等返回零,如果当前对象大于参数则返回正值。另一种比较方法是采用策略(strategy)设计模式,将会发生变化的代码封装在它自己的类(策略对象)中,再将策略对象交给保持不变的代码中,后者使用此策略实现它的算法。因此,可以为不同的比较方式生成不同的对象,将它们用在同样的排序程序中。在此情况下,通过定义一个实现了Comparator接口的类而创建了一个策略,这个策略类有compare()和equals()两个方法,一般情况下实现compare()方法即可。
使用上述两种方法即可对任意基本类型的数组进行排序,也可以对任意的对象数组进行排序。再提示一遍,基本类型数组无法使用Comparator进行排序。
Java标准类库中的排序算法针对排序的类型进行了优化——针对基本类型设计了“快速排序”,针对对象设计的“稳定归并排序”。一般不用担心其性能。
其它相关内容:
Java容器分析--List和Set
Java容器分析--Map
已经懒得再去数落小日本的罪行了,去年12月侵华日军南京大屠杀遇难同胞纪念馆开通了南京大屠杀史实中文网站,今年又开通了英文网站,让全世界都记住这段历史。
中文网站:
http://www.nj1937.org
英文网站:
http://english.nj1937.org
作者:Flyingis
运行时类型识别(Run-time Type Identification, RTTI)主要有两种方式,一种是我们在编译时和运行时已经知道了所有的类型,另外一种是功能强大的“反射”机制。
要理解RTTI在Java中的工作原理,首先必须知道类型信息在运行时是如何表示的,这项工作是由“Class对象”完成的,它包含了与类有关的信息。类是程序的重要组成部分,每个类都有一个Class对象,每当编写并编译了一个新类就会产生一个Class对象,它被保存在一个同名的.class文件中。在运行时,当我们想生成这个类的对象时,运行这个程序的Java虚拟机(JVM)会确认这个类的Class对象是否已经加载,如果尚未加载,JVM就会根据类名查找.class文件,并将其载入,一旦这个类的Class对象被载入内存,它就被用来创建这个类的所有对象。一般的RTTI形式包括三种:
1. 传统的类型转换。如“(Apple)Fruit”,由RTTI确保类型转换的正确性,如果执行了一个错误的类型转换,就会抛出一个ClassCastException异常。
2. 通过Class对象来获取对象的类型。如
Class c = Class.forName(“Apple”);
Object o = c.newInstance();
3. 通过关键字instanceof或Class.isInstance()方法来确定对象是否属于某个特定类型的实例,准确的说,应该是instanceof / Class.isInstance()可以用来确定对象是否属于某个特定类及其所有基类的实例,这和equals() / ==不一样,它们用来比较两个对象是否属于同一个类的实例,没有考虑继承关系。
反射
如果不知道某个对象的类型,可以通过RTTI来获取,但前提是这个类型在编译时必须已知,这样才能使用RTTI来识别。即在编译时,编译器必须知道所有通过RTTI来处理的类。
使用反射机制可以不受这个限制,它主要应用于两种情况,第一个是“基于构件的编程”,在这种编程方式中,将使用某种基于快速应用开发(RAD)的应用构建工具来构建项目。这是现在最常见的可视化编程方法,通过代表不同组件的图标拖动到图板上来创建程序,然后设置构件的属性值来配置它们。这种配置要求构件都是可实例化的,并且要暴露其部分信息,使得程序员可以读取和设置构件的值。当处理GUI时间的构件时还必须暴露相关方法的细细,以便RAD环境帮助程序员覆盖这些处理事件的方法。在这里,就要用到反射的机制来检查可用的方法并返回方法名。Java通过JavaBeans提供了基于构件的编程架构。
第二种情况,在运行时获取类的信息的另外一个动机,就是希望能够提供在跨网络的远程平台上创建和运行对象的能力。这被成为远程调用(RMI),它允许一个Java程序将对象分步在多台机器上,这种分步能力将帮助开发人员执行一些需要进行大量计算的任务,充分利用计算机资源,提高运行速度。
Class支持反射,java.lang.reflect中包含了Field/Method/Constructor类,每个类都实现了Member接口。这些类型的对象都是由JVM在运行时创建的,用来表示未知类里对应的成员。如可以用Constructor类创建新的对象,用get()和set()方法读取和修改与Field对象关联的字段,用invoke()方法调用与Method对象关联的方法。同时,还可以调用getFields()、getMethods()、getConstructors()等方法来返回表示字段、方法以及构造器的对象数组。这样,未知的对象的类信息在运行时就能被完全确定下来,而在编译时不需要知道任何信息。 另外,RTTI有时能解决效率问题。当程序中使用多态给程序的运行带来负担的时候,可以使用RTTI编写一段代码来提高效率。
Happy Birthday to myself!
作者:
Flyingis
Google现在的火热程度都快超过当年Windows 95,在推出Google Talk / Google Map / Google Earth / Gmail / Picasa2 等等重量级服务及软件以后,近日又推出了一项名为Transit Trip Planner(出行路线规划)的新服务,目的是为出行用户找出最便捷的公交路线。
公交线路服务是地理信息的重要应用之一或者是将来全面应用的热点之一,在当今地理信息发展到十字路口,在技术理论理念的突破步履维艰的时候,Google公司的Google Map / Google Earth 和即将在全球普及的Transit Trip Planner服务给地理信息世界注入了一剂强心针,在理想地理信息应用和现阶段的实际应用之间找到了一个平衡点,和Google公司一贯作风一样,以简洁实用高效的特点吸引了无数人的眼光,提供了最简便的应用。
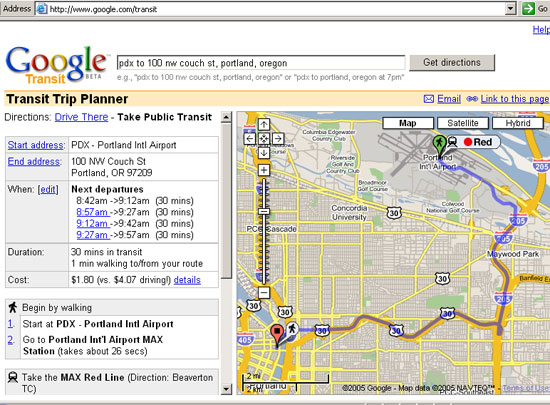
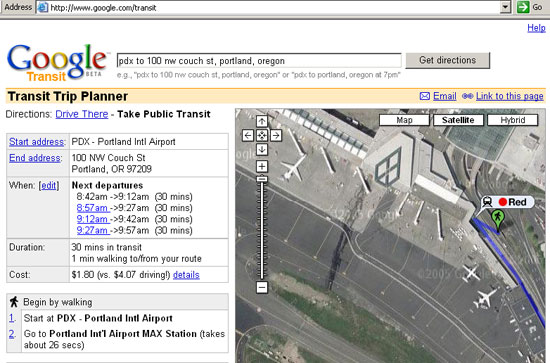

Transit Trip Planner服务需要用户输入他们的首选路线,例如出发地、目的地、出行日期和时间等,然后它会收集所有的公交调度信息,为用户制订出行路线计划。这项服务目前还处于测试阶段,并且还没有和Google本地搜索整合,相信不久就可以和Google Map / Google Earth 一样在全球得到应用,进一步改善用户的地图服务体验,以现有的基础提供最实用的地图影像服务。Google和Sun公司已经建立了良好的合作关系,Google的发展势头将对Java应用的进一步推广产生积极的作用,让我们一起期待Google和Java的发展……
作者:Flyingis
昨天在Matrix上看到一贴子http://www.matrix.org.cn/thread.shtml?topicId=33198&forumId=11,具体的内容我贴过来了:
-------------------------------------------------
朋友刚硕士毕业拿到了Google的Offer!这里gx一下,顺便透露一下Google的情况:
背景:一流大学CS硕士毕业 跨国软件公司实习半年
应征职位:Software Engineer
面试笔试一堆(包括从美国打来的越洋长途提问),最后是面见李开复,加工作餐一顿(他说大约是收50个关门弟子,但个人认为李替google炒作的味道太重)
月薪:16k左右
其它福利:Google的股票40股(现在市值超过400$ 每股)
总的来说,待遇还不是很有竞争力。
不过在国内也是过得去了。
------------------------------------------------
不看作者的评论,我觉得在国内有这种待遇已经很不错了,当然对于一家著名的外资企业,开出这样的工资也很正常,但对于国内大多数软件开发人员来讲,能拿到这份工作却是可望不可及。
这段时间在举行Google中国编程大赛,我第一次听说是在印度举行的,Google通过这种活动不仅可以扩大自己公司在世界上的影响,还可以招募到最优秀的开发人员,并提供优厚的条件。和当今中国大多数公司相反,以Google为代表的公司真正做到了人性化的管理,虽说公司也是为了赚钱,但至少它把员工当成了自己的人,刚成为正式员工就持有公司的股票。好像有点么发牢骚的味道,其实并不想也没必要,因为在各种不同的环境站在不同的角度,都能为现在国内的软件行业的环境、行情说出许多不同的正当理由,也没有争论甚至埋怨中国大多数软件企业和政府职能的必要。如果感兴趣可以看看这篇文章——中国企业对软件人才利用的思考。
这里想说的是,IT人的学习方法与思维方式。像许多年轻人一样,我也曾经对各种开发工具、开发语言产生过浓厚的兴趣,并且现在仍然在持续。在学校有位工作过8年的博士曾对我说,在软件这个行业很刺激,很有挑战力,并且充满活力,最初我们总是有冲劲去学习各种技术,攻克开发语言中的各种难关,使用最流行的框架去实现自己的想法,但是当我们工作一段时间后,会发现自己的青春全花费在了这些框架、语言和工具上面。对于部分人,他们会成为开发高手,他们对于各种开发工具了如指掌,并且看着这些产品更新换代,积累了丰富的经验,加上这几年对项目的理解,他们可以成为项目经理甚至更高。但是对于大多数人,却没有这么幸运,因为公司不需要这么多的项目经理,不需要这么多的架构师,那他们怎么办,这就引出了从前几年开始大家就一直讨论的程序员过了三十怎么办之类的热门话题。
电脑这玩意现在太热,产品的更新换代,技术的不断发展,成本的不断降低,已经将电脑带入的千家万户,从前几年大学校园对计算机科学与技术专业的扩招,到各种软件学院和培训机构的兴起,似乎已经给软件产业提供了充足的后备力量与人力资源。但不幸的是,现在大家在校园中所公认的电脑高手,已经逐渐变成Java语言高手、VC高手、VB高手等等,他们能用Struts+Hibernate+MySQL数据库构建一套教师课程评价系统,能用VB.net+SQLServer设计一套图书信息管理软件等。当然,在校园里能做出这些系统的人今后的确能在软件行中站稳脚跟,占据一席之地,但不是真正的高手,要做核心开发人员都需要付出更多的努力。然而更多的人,甚至达不到他们的水平,却不停的在图书馆看书,凭着自己最初极大的兴趣学习这些开发工具,在中途听过一次讲座,或是经过某些高手的指导后,又改学另外一门被公认最有发展潜力的语言。只要花了时间,等到毕业时,大家的确可以成为一名程序员,工资1000左右,2000不到,每天不停加班,程序写了又改,改了又写。中国需要这些程序员,但不需要这么多这样的程序员,程序员能力水平构成了一座金字塔,底层的人即初级程序员太多了!再看看书店中泛滥的开发相关的书籍,我不禁想说,我们该冷静了!
国外的知名IT企业,它们代表了IT的发展方向,它们需要什么样的软件人才?是精通算法的人员,是精通架构的人员。如果你只会用C语言,但是精通各种常见算法、数据结构,并且能够自己设计优秀的算法,但只是基本了解Java语法结构,Google很有可能会考虑你。如果你精通Java、VB,却对计算机体系结构、编译原理、数据结构知之甚少,我想Google很难被你的“综合能力”所打动。废话了一大堆,在这里才说出我想说的话,作为一个潜资历的懂一点开发的人来说,这样评价似乎欠火候,但我想写下一点自己所想,记录自己这一刻的思维,并欢迎大家讨论、指点,和大家一起共勉!
摘要: 一、什么是Java虚拟机
Java虚拟机是一个想象中的机器,在实际的计算机上通过软件模拟来实现。Java虚拟机有自己想象中的硬件,如处理器、堆栈、寄存器等,还具有相应的指令系统。
1. 为什么要使用Java虚拟机
Java语言的一个非常重要的特点就是与平台的无关性。而使用Jav... 阅读全文
作者:Flyingis
在初始化一个类,生成一个实例的时候,newInstance()方法和new关键字除了一个是方法,一个是关键字外,最主要有什么区别?它们的区别在于创建对象的方式不一样,前者是使用类加载机制,后者是创建一个新类。那么为什么会有两种创建对象方式?这主要考虑到软件的可伸缩、可扩展和可重用等软件设计思想。
Java中工厂模式经常使用newInstance()方法来创建对象,因此从为什么要使用工厂模式上可以找到具体答案。 例如:
class c = Class.forName(“Example”);
factory = (ExampleInterface)c.newInstance();
其中ExampleInterface是Example的接口,可以写成如下形式:
String className = "Example";
class c = Class.forName(className);
factory = (ExampleInterface)c.newInstance();
进一步可以写成如下形式:
String className = readfromXMlConfig;//从xml 配置文件中获得字符串
class c = Class.forName(className);
factory = (ExampleInterface)c.newInstance();
上面代码已经不存在Example的类名称,它的优点是,无论Example类怎么变化,上述代码不变,甚至可以更换Example的兄弟类Example2 , Example3 , Example4……,只要他们继承ExampleInterface就可以。
从JVM的角度看,我们使用关键字new创建一个类的时候,这个类可以没有被加载。但是使用newInstance()方法的时候,就必须保证:1、这个类已经加载;2、这个类已经连接了。而完成上面两个步骤的正是Class的静态方法forName()所完成的,这个静态方法调用了启动类加载器,即加载java API的那个加载器。
现在可以看出,newInstance()实际上是把new这个方式分解为两步,即首先调用Class加载方法加载某个类,然后实例化。 这样分步的好处是显而易见的。我们可以在调用class的静态加载方法forName时获得更好的灵活性,提供给了一种降耦的手段。
最后用最简单的描述来区分new关键字和newInstance()方法的区别:
newInstance: 弱类型。低效率。只能调用无参构造。
new: 强类型。相对高效。能调用任何public构造。
有的时候 Vector更好一些;有的时候ArrayList 更好一些;有的时候你一个也不想用。但愿,你不是在期望一个简单明了的答案,因为答案因你在用他们做什么而定。下面是要考虑的四个方面:
API
同步-Synchronization
数据增长-Data growth
使用方法-Usage patterns
让我一个一个来解释吧。
API
在The Java Programming Language (Addison-Wesley, June 2000) 中Ken Arnold, James Gosling, 和 David Holmes 是这样描述Vector的,它是更ArrayList类似的一个东西,所以从API的观点来看,它们俩是很相似的。但是,它们之间还是有些微的差别的。
Synchronization
Vectors是可同步化的,意思就是说,任何操作Vector的内容的方法都是线程安全的,相反的,另一方面,ArrayList是不可同步化的,所以也不是线程安全的。如果你知道了这些的话,你就会发现,Vector的同步会让它在性能发方面有一些小问题。所以,如果你不需要线程安全的话,那么就使用ArrayList吧。为什么要为没有必要的同步付出代价呢?
Data growth
实际上,不管是ArrayList还是Vector,在它们内部都是使用一个Array来保存数据的。编程过程中,在使用它们任何一个的时候,你都需要记住这一点。你在往一个ArrayList或者Vector里插入一个元素的时候,如果内部数组空间不够了,这个对象(译者按:指的是你使用的ArrayList或者Vector)就要扩展它的大小。Vector在默认情况下是产生一个双倍大小,而ArrayList增加50%的大小。只要你合理的使用这些类,你就可以结束你在增加新的元素的时候所付出的性能代价。把对象(译者按:指的是你使用的ArrayList或者Vector)的初始化容量指定为你编程过程中所能用到的最大的容量总是最好的办法。仔细的指定容量,你可以避免以后改变内部Array容量,所要付出的代价。如果你并不知道到底有多少个数据,当是你知道数据的增长率,Vector确实有一点点优势,因为你可以指定增加值(译者按,如果没有猜错的话,作者说的方法应该是setSize(int newSize) Sets the size of this vector.)。
Usage patterns
ArrayList和Vector在从指定位置取得元素,从容器的末尾增加和删除元素都非常的有效,所有的这些操作都能在一个常数级的时间(O(1))内完成。但是从一个其他的位置增加和删除一个元素就显得颇为费时,差不多需要的时间为O(n-i),这里的n代表元素个数,i代表要增加和删除的元素所在的位置。这些操作需花费更多的时间,因为你需要挨个移动i和更高位置的元素。那么,以上这些到底说明了什么呢?
这意味着,如果你取得一个元素,或者从数组末尾增加或删除一个元素的话,随便你使用Vector和ArrayList。如果你想要对数组内容做其他操作的话,那么就为自己好另一个容器吧。比喻说,LinkedList可以在常数级时间(O(1))内为任意一个位置的元素增加和删除。但是,取得一个元素,会稍微慢一点,时间要用O(i) ,这个i是元素的位置。通过ArrayList也是很简单的,因为你可以简单使用一个索引,而不是构造一个iterator 。LinkedList也为每个插入的元素建立一个内部对象。所以,你也必须知道,同时产生了垃圾对象。
最后,Practical Java (Addison-Wesley, Feb. 2000) Peter Haggar 里的“实践41“建议你使用一个普通的原始的数组来代替Vector和ArrayListe,特别是对效率优先的代码来说。通过使用数组(array),你可以避免同步,额外的方法调用,非理想化的大小改变。你付出的只是额外的开发时间。
原文链接:http://www.javaworld.com/javaworld/javaqa/2001-06/03-qa-0622-vector.html
作者:Flyingis
刚刚看到一篇文章《中方落败软件人才争夺战 人才利用率堪忧》,里面谈及了大家经常讨论的话题,中国软件和印度软件的差距。这是一个老生常谈的话题了,经常看到各大媒体网站杂志报道类似的主题文章,对其中的缘由也分析的淋漓尽致,但在实际中始终没有改进,好像国外的高端电子产品到国内销售有一段滞后期,而许多已经被证明是先进的管理经营经验在国内应用难道也要经历一段酝酿的时期吗?下面是这篇文章的链接:
中方落败软件人才争夺战 人才利用率堪忧(一)
中方落败软件人才争夺战 人才利用率堪忧(二)
这让我想到了一件事情。前几年在大学里,大家都认为计算机科学与技术是热门专业,许多优秀的考生都是非计算机不报,都想进入这个金牌领域,抱住这个金饭碗,但实际情况是什么呢,在一般情况下,当大多数人发现一门学科是热门专业的时候,其实这门学科很可能已经开始走下坡路了,或者是说,你现在考进去等到毕业的时候,很有可能不会像现在的毕业生这么风光,不仅单位公司抢着要,并且各个都是高薪高福利,让人羡慕。想想做生意的,当一家理发店在一条街上开始营业,生意火爆,让大家都开始把眼球注意到这条街的商业价值上,然后纷纷开店的时候,你会发现,最佳的赚钱机会已经被抢走了,虽然在初期没有什么影响,但是到了这条街上已经开了许多家理发店的时候,你若还想在这里挖到一桶金,已经不是那么容易了。这些都是我们生活中很简单很平常的事情,但经常被我们忽略。
中国软件公司要像印度一样合理利用人才,对于大多数而言,的确非常困难,因为很多中小型都是在有项目才会招人,而有项目的时候往往又没有合适的或者充足的开发人员可以利用,这样造成了经常加班,开发人员不能专心某领域的研究,工作情绪不稳定的情况。另外,某些中小型公司老板可能总是认为现在每年毕业的软件人才过剩,不用担心找不到人来工作,而临时组成的团队却不能提供最优质的软件与服务,甚至频繁出现不能按期交付安装,一拖再拖的情况。本来想写的更多一些,但说到这里,大家可能会根据自己的实际情况想到更多,所以我回到上面举的几个例子,当中国企业已经认识到和印度软件业差距所在的时候,为什么没有人愿意试着去学习,去培养自己的人才,去完善人才管理,去营造一个良好的人才循环升级培养的氛围呢?特别是有一定实力与经济基础的中型或中大型公司。的确,中国有华为等几家著名的软件公司,但是对于中国偌大一个国家,有着这么多丰富的人才资源的国家来说,这样的公司实在太少太少,为什么这么多公司都不愿做建立合理软件人才培养梯队的先锋呢?就像我前面举出的例子一样,最先放弃急功近利的,按照一种人性化理念去经营的公司,才能获得最大的后期收益,等其它公司看着你眼红,想开始效仿你的时候,你的公司形象已经形成一种强有力的品牌,步入可持续发展的道路。
我还没有做过企业的管理者,市场经济中的意识形态,国内的形势政策以及其它多种因素都会限制着国内软件公司的发展,“不当家不知道柴米油盐贵”。但是,作为一名旁观者,我希望能给中国软件业注入清醒的一针,而我知道仅仅这一针根本不能治愈中国软件业的“病”,仅希望大家特别是管理者都能尽一点微薄之力,慢慢改进。
作者:Flyingis
Action类是用户请求和业务逻辑之间的桥梁。每个Action充当用户的一项业务代理。在RequestProcessor类预处理请求时,在创建了Action的实例后,就调用自身的processActionPerform()方法,该方法再调用Action类的execute()方法。Action的execute()方法调用模型的业务方法,完成用户请求的业务逻辑,然后根据执行结果把请求转发给其他合适的Web组件。在实际的应用中,主要有以下几种比较常见的使用方法:
1.普通的Action应用
<action path="/normalAction"
type="package.OneActionClass">
name="oneForm"
input="page.jsp"
<forward name="success" path="success.jsp"/>
<forward name="failure" path="failure.jsp"/>
</action>
Struts的ActionServlet接收到一个请求,然后根据struts-config.xml的配置定位到相应的mapping(映射);接下来如果form的范围是request或者在定义的范围中找不到这个form,创建一个新的form实例,如果找到则重用;取得form实例以后,调用其reset()方法,然后将表单中的参数放入form,如果validate属性不为false,调用validate()方法;如果validate()返回非空的ActionErrors,将会被转到input属性指定的URI,如果返回空的ActionErrors,那么执行Action的execute()方法,根据返回的ActionForward确定目标URI。即execute()仅当validate()成功以后才执行;input属性指定的是一个URI。
2.有Form的Action应用
<action path="/formAction"
type="org.apache.struts.actions.ForwardAction"
name="oneForm"
input="page.jsp"
parameter="another.jsp"
/>
Struts会在定义的scope搜寻oneForm,如果找到则重用,如果找不到则新建一个实例;取得form实例以后,调用其reset()方法,然后将表单中的参数放入form,如果validate属性不为false,调用validate()方法;如果validate()返回非空的ActionErrors,将会被转到input属性指定的URI,如果返回空的ActionErrors,那么转到parameter属性指定的目标URI。
这种方法使得没有action类可以存放我们的业务逻辑,所以所有需要写入的逻辑都只能写到form的reset()或者validate()方法中。validate()的作用是验证和访问业务层。因为这里的action映射不包括forward,所以不能重定向,只能用默认的那个forward。这种仅有form的action可以用来处理数据获取并forward到另一个JSP来显示。
3.仅有Action的Action应用
<action path="/actionAction"
type="package.OneActionClass">
input="page.jsp"
<forward name="success" path="success.jsp"/>
<forward name="failure" path="failure.jsp"/>
</action>
ActionServlet接收到请求后,取得action类实例,调用execute()方法;然后根据返回的ActionForward在配置中找forward,forward到指定的URI或action。这样就没有form实例被传入execute()方法,于是execute()必须自己从请求中获取参数。Action可以被forward或者重定向。这种action不能处理通过HTML FORM提交的请求,只能处理链接式的请求。
4.仅有JSP的Action应用
<action path="/jspAction"
type="org.apache.struts.actions.ForwardAction"
parameter="another.jsp"
/>
ActionServlet接到请求后调用ForwardAction的execute()方法,execute()根据配置的parameter属性值来forward到那个URI。这种情况下,没有任何form被实例化,比较现实的情形可能是form在request更高级别的范围中定义;或者这个action被用作在应用程序编译好后充当系统参数,只需要更改这个配置文件而不需要重新编译系统。
5.两个Action对应一个Form(和第四种方式部分的Action作用相近)
<action path="/oneAction"
type="package.OneActionClass">
name="oneForm"
input="one.jsp"
<forward name="success" path="/anotherAction.do"/>
</action>
<action path="/anotherAction"
type="package.AnotherActionClass">
name="oneForm"
input="another.jsp"
<forward name="success" path="success.jsp"/>
</action>
这个组合模式可以被用来传递form对象,就每个单独的action来讲,处理上并没有和完整的action有什么实质的区别。需要注意的是在后一个action中同样会调用form的reset()和validate()方法,因此我们必须确保form中的信息不被重写。这种情况分两种方式处理:a) 在request中放入一个指示器表明前一个action有意向后一个action传递form,从而在后一个action可以保留那个form中的值,这一方式只能在使用forward时使用。b) 当使用redirect而不是forward时,可以把指示器放在session或更高的级别,在命令链的最后一环将这个指示器清除。
6.两个Action对应两个form
<action path="/oneAction"
type="package.oneActionClass">
name="oneForm"
input="one.jsp"
<forward name="successful" path="/anotherAction.do" redirect="true"/>
</action>
<action path="/anotherAction"
type="package.AnotherActionClass">"
name="anotherForm"
input="another.jsp"
<forward name="success" path="success.jsp"/>
</action>
这个组合方式跟前一种在流程上没有太大区别,只是我们现在对于两个action分别提供了form,于是代码看上去更加清晰。于是我们可以分别处理WEB应用程序的输入和输出。值得注意的是,后一个action同样会尝试往form中写入那些参数,不过我们可以这样处理:a) 在后一个form中使用另一套属性名;b) 只提供getter而不提供setter。
基本处理过程:
前一个action接收输入、验证、然后将数据写入业务层或持久层,重定向到后一个action,后一个action手动的从业务层/持久层取出数据,写入form(通过其他方式),交给前台JSP显示。这样做的好处是不必保留输入form中的值,因此可以使用redirect而不是forward。这样就降低了两个action之间的耦合度,同时也避免了不必要的重复提交。
注明:文中所提及的“仅有Form”指的是没有继承Struts提供的Action类,而是直接使用了Struts自身提供的Action类;“仅有Action”指的是仅继承了Struts提供的Action类而没有使用Form。
(文章转自CSDN)
Web开发领域的2005年,一方面ASP.NET 2.0、PHP 5.1预期发布,另一方面Perl 6“已经开始看起来像个没有结束的项目了”,此外,Ajax和Ruby On Rails(简称RoR)的火爆让人嫉妒,这些现象的背后正是Web开发的理念悄然发生了变化。
Web标准日渐流行
当Jeffrey Zeldman在2003年出版《Designing With Web Standards》的时候,CSS已经被主流浏览器支持了4年之久。Web标准其实分三方面:结构化标准语言主要包括XHTML和XML,表现标准语言主要包括CSS,行为标准主要包括对象模型(如W3C DOM)、ECMAScript等。他的的主要好处在于缩小了页面大小、布局更加随意、也有利于页面和代码的分离,正是这些好处让微软MSN、网易、阿里巴巴和CSDN等网站在2005年陆续按照Web标准进行了重构。
Ajax:用户体验型的富客户端技术
用过微软Live服务的用户都为网络程序能随意拖动和放置页面栏目、无刷新更新网页数据、渐变的颜色处理感到吃惊,这些“酷”的技术被冠名为Ajax,这项技术最早由Google应用在GoogleMap和GoogleMail中,其实Ajax并不神奇,原理是通过调用XmlHttpRequest实现与服务器的异步通讯,并使用对应平台的XmlDom对返回的Xml消息进行处理,然后再通过DOM对页面中的HTML元素的操作实现丰富的、友好的用户界面。这和当初微软推广的Remote Scripting几乎如出一辙。不过,和当初不同的事,这项技术得到了足够的重视,相关开发包源源不断,成为2005最具亮丽的一道风景线,微软也耐不住寂寞,即将推出Atlas就是用来帮助开发者更容易地构建Ajax站点。Ajax的风行说明用户对于丰富的Web体验的需求日益增长,这种趋势不可逆转。
RoR预示轻型开发框架的流行
RoR是基于Ruby语言的轻型Web开发框架,不仅开发效率高(部署容易)、功能丰富(支持Ajax等流行应用) ,不可思议的是,他的性能比基于Struts和Hibernate的Java应用还高15%-30%。目前,其他语言也已经有类似的框架,如基于Python的Django、PHP的Cake、ASP.NET的Castle等等。Web应用特点是需求变化非常快,Rails提倡的“约定强于配置”的理念正好迎合了这种发展潮流。不过,使用RoR的大型网站还不多见,是否经得起考验,还看2006年。
Web开发的2005年,我们还应当关注的是:
ASP.NET 2.0随NET Framework 2.0发布
每个ASP.NET程序员需要关注的产品。虽然不是一个革命性的升级,很多新特性还是足够让开发者心动。有了2.0,谁还愿意使用1.x?微软的产品总是让人对他产生依赖。
Jdon Framework
这个由国人彭晨阳开发的中小型J2EE应用系统的快速开发框架已经发布了1.3版本,和RoR类似,Jdon框架中, Action的CRUD功能实现是由配置文件实现的,一般情况下无需编码。支持日本的Ruby,不如支持中国的Jdon,你们觉得呢?
作者:Flyingis
在使用Hibernate进行查询的时候大家都会用到Hibernate缓存,其中Session缓存即一块内存空间,存放了相互关联的Java对象,这些位于Session缓存中的对象就是持久化对象,Session根据持久化对象的状态变化来同步更新数据库。这个Session缓存是Hibernate的一级缓存。此外,SessionFactory有一个内置缓存和一个外置缓存,即Hibernate的第二级缓存。而Hibernate正是由于这些缓存的存在,才使得其数据库操作效率提高,就是说,在提供了方便易操作的操作数据库数据的方式的同时保证了工作效率,但是不能因此而免去后顾之忧,需要在设计业务逻辑层的时候考虑使用最优的架构,节省有效的系统资源。在查询方面,Hibernate主要从以下几个方面来优化查询性能:
1.降低访问数据库的频率,减少select语句的数目。实现手段包括:
使用迫切左外连接或迫切内连接检索策略。
对延迟检索或立即检索策略设置批量检索数目。
使用查询缓存。
2.避免多余加载程序不需要访问的数据。实现手段包括:
使用延迟检索策略。
使用集合过滤。
3.避免报表查询数据占用缓存。实现手段为利用投影查询功能,查询出实体的部分属性。
4.减少select语句中的字段,从而降低访问数据库的数据量。实现手段为利用Query的iterate()方法。
在插入和更新数据时,要控制insert和update语句,合理设置映射属性来保证插入更新的性能,例如,当表中包含许多字段时,建议把dynamic-update属性和dynamic-update属性都设为true,这样在insert和update语句中就只包含需要插入或更新的字段,这可以节省数据库执行SQL语句的时间,从而提高应用的运行性能。
还有什么其它的提升性能的方式希望和大家一起讨论。
作者:Flyingis
在关系数据库中的主键可分为自然主键(具有业务含义)和代理主键(不具有业务含义),其中代理主键可以适应不断变化的业务需求,因此更加流行。代理主键通常为整数类型,与此对应,在持久化类中野应该把OID定义为整数类型,Hibernate允许把OID定义为short、int和long类型,以及它们的包装类型。
Hibernate提供了几种内置标识符生成器,每一种标识符生成器都有它的使用范围,应该根据所使用的数据库和Hibernate应用的软件架构来选择合适的标识符生成器。下面是几种常用数据库系统可使用的标识符生成器:
MYSQL: identity increment hilo native
MS SQL Server: identity increment hilo native
Oracle: sequence seqhilo hilo increment native
夸平台开发: native
OID是为持久化层服务的,它不具备业务含义,而域对象位于业务逻辑层,用来描述业务模型。因此,在域对象中强行加入不具备业务含义的OID,可以看作是持久化层对业务逻辑层的一种渗透,但这种渗透是不可避免的,否则Hibernate就无法建立缓存中的对象与数据库中记录的对应关系。
当然,映射中还包括自然主键的映射方案。对于从头设计的关系数据库模型,应该优先考虑使用代理主键。
作者:Flyingis
在网上很多文章和论坛都在讨论Hibernate,初次接触Hibernate,当然需要知道它是什么,可以用来做什么。用简单的语言来描述,可以认为Hibernate是:
它是连接Java应用程序和关系数据库的中间件。
它对JDBC API进行了封装,负责Java对象的持久化。
在分层的软件架构中它位于持久花层,封装了所有数据访问细节,使业务逻辑层可以专注于实现业务逻辑。
它是一种ORM(Object-Relation Mapping)映射工具,能够建立面向对象的域模型和关系数据库模型之间的映射。
在Java应用中使用Hibernate包含以下步骤:
1.创建Hibernate的配置文件。
2.创建持久化类。
3.创建对象-关系映射文件。
4.通过Hibernate API编写访问数据库的代码。
目的,主要是那当前的项目练手,熟悉一下hibernate2和hibernate3的差别,给当前项目一点扩展的空间。
1.首先将hibernate2.jar替换为hibernate3.jar(hibernate-3.0.5)
hibernate-tools.jar也替换成新的(从hibernate-tools-3.0.0.alpha4a找出来的)
2.将所有程序中的net.sf.hibernate替换为org.hibernate.
3.但是有例外
net.sf.hibernate.expression.Expression换为org.hibernate.criterion.Expression
如果用eclipse,用ctrl+shift+o快捷键可以加快速度
4.在使用hql查询时将
createSQLQuery(hql,"c",EZCampaignDTO.class);改为createSQLQuery(hql).addEntity("c",EZCampaignDTO.class);
5.在批量插入时
将原来的int size = ((SessionFactoryImpl)(session.getSessionFactory())).getJdbcBatchSize()
改为int size = ((SessionFactoryImpl)(session.getSessionFactory())).getSettings().getJdbcBatchSize();
6.在计算count时
将原来的int size = ((Integer) session.iterate(hql).next()).intValue();
改为int size = ((Integer) session.createQuery(hql).iterate().next()).intValue();
其中hql="select count(*) from " + DAOVar.contactClass;
7.还有就是把.hbm中的hibernate-mapping-2.0.dtd替换为hibernate-mapping-3.0.dtd
Hibernate Mapping DTD 2.0替换为Hibernate Mapping DTD 3.0
8.hibernate.cfg.xml中
Hibernate Mapping DTD 2.0替换为Hibernate Mapping DTD 3.0
<property name="hibernate.dialect">org.hibernate.dialect.SQLServerDialect</property>
9.hibernate.properties中类似
10.cache-config.xml中
<provider className="net.sf.hibernate.cache.OSCacheProvider"/>替换为
<provider className="org.hibernate.cache.OSCacheProvider"/>
11.classeshibernate.properties中
hibernate.cache.provider_class=org.hibernate.cache.EhCacheProvider
hibernate.dialect=org.hibernate.dialect.SQLServerDialect
12.在自动外部模块部分有一个功能是根据模版自动生成.hbm文件在load,结果出来的.hbm中有问题:
生成的 <composite-id unsaved-value="any" mapped="false">其中mapped="false" 出错。找了半天才发现在网上的hibernate-mapping-3.0.dtd文件有支持mapped="false"这个属性。而本地的hebernate3.0.5中的hibernate-mapping-3.0.dtd文件没有这个属性。晕,hibernate也太不负责了吧。解决办法把hibernate-mapping-3.0.dtd copy到jboss\bin目录下然后,在template文件中<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD//EN" "hibernate-mapping-3.0.dtd">,然后他会在jboss\bin目录下读取该文件。
13.重新测试,还是咣铛,发现子类读父类数据时抛出异常:
"org.hibernate.LazyInitializationException: could not initialize proxy"
延迟抓取出的错,hb3对many-to-one的默认处理是lazy = "proxy",没有搞懂到底怎么回事,把所有many-to-one,one-to-one都加上lazy="false",再测试终于大功告成。
文章原作者Blog: http://blog.csdn.net/chinaewolf/ http://blog.csdn.net/chinaewolf/
作者:Flyingis
在科学和工程技术领域,模型是一个很有用途的概念,它可以用来模拟一个真实的系统。在软件开发领域,模型用来表示真实世界的实体。在软件开发的不同阶段,需要为目标系统创建不同类型的模型。在分析阶段,需要创建概念模型。在设计阶段,需要创建域模型和数据模型。其中,域模型是面向对象的,数据模型是面向关系的,域模型和数据模型之间存在一种对象-关系映射。
概念模型
概念模型清楚地显示了问题域中的实体。不管是技术人员还是非技术人员都能看得懂改面模型,他们可以很容易地提出模型中存在的问题,帮助分析人员及早对模型进行修改。在软件设计域开发周期中,模型的变更需求提出得越晚,所耗费得开发成本就越大。
概念模型描述了每个实体得概念和属性,以及实体之间的关系:一对一、一对多和多对多。在现实生活中都可以找到相应的例子,例如一只母鸡有很多小鸡是一对多关系,一位客户选购了很多商品,而这些商品也可以被许多客户选购,这是多对多关系。
关系数据模型
到目前为止,关系数据库仍然是使用最广泛的数据库,它存储的是关系数据。关系数据模型是在概念模型的基础上建立起来的,用于描述这些关系数据的静态结构,它由以下内容组成:
一个或多个表
表的所有索引
视图
触发器
表与表之间的参照完整性
数据库Schema是对数据模型的实现。对于支持SQL的关系数据库,可以采用SQL DDL语言来创建数据库Schema。SQL DDL 用于生成数据库中的物理实体,例如下面的创建CUSTOMERS表的 SQL DDL:
create table CUSTOMERS {
ID int not null,
NAME varchar(20),
AGE int,
primary key (ID)
};
值得注意的是,数据库Schema有两种含义,一种是概念上的Schema,指的是一组DDL语句集,该语句集完整地描述了数据库的结构。还有一种是物理上的Schema,指的是数据库中的一个名字空间,它包含一组表、视图和存储过程等命名对象。物理Schema可以通过标准SQL语句来创建、更新和修改。例如以下SQL语句创建了两个物理Schema:
create schema SCHEMA_A;
create table SCHEMA_A.CUSTOMERS(ID int not null,……);
create schema SCHEMA_B;
create table SCHEMA_B.CUSTOMERS(ID int not null,……);
域模型
域模型由以下内容组成:具有状态和行为的域对象;域对象之间的关系。
域对象
1.实体域对象:代表人、地点、事物或概念。通常,可以把业务领域中的名词,例如客户、订单、商品,当然也包括前面提到过的母鸡,作为实体域对象;
2.过程域对象:代表应用中的业务逻辑或流程。它通常依赖于实体域对象。
3.事件域对象:代表应用中的一些事件,例如异常、警告或超时等。
域对象之间的关系
在域模型中,类之间存在四种关系。
1.关联(Association)
关联指的是类之间的引用关系,这是实体域对象之间最普遍的一种关系。关联可以分为一对一、一对多和多对多关联。
2.依赖(Dependency)
依赖指的是类之间的访问关系。如果类A访问类B的属性或方法,或者说是A负责实例化B,那么可以说类A依赖类B。
3.聚集(Aggregation)
聚集指的是整体与部分之间的关系,在实体域对象之间也很常见。例如,人与手就是聚集关系,在Person类中由一个hands集合,它存放被聚集的Hand对象:
public class Person {
private Set hands = new HashSet();
…………
}
4.一般化(Generalization)
一般化指的是类之间的继承关系。
域对象的持久化概念
当实体域对象在内存中创建后,它们不可能永远存在。最后,他们要么从内存中清除,要么被持久化到数据存储库中。内存无法永久地保存数据,因此必须对实体域对象进行持久化。否则,如果对象没有被持久化,用户在应用运行时创建地订单信息将在应用结束运行后随之消失。
当然,并不是所有地域对象都需要持久化,通常只有实体域对象才需要持久化,另外,有些实体域对象也不需要持久化。
狭义的理解,“持久化”仅仅指把域对象永久保存到数据库中;广义的理解,“持久化”包括和数据库相关的各种操作。
参考书籍:孙卫琴 精通Hibernate Java对象持久化技术详解
就在前一个小时左右的时间博客排行榜上列出的都是前200位博客,现在已经和博客园主页上一样只列出前100位了(我现在恰好是101位)。其实100或200不是最主要的,关键是这里所倡导的原创意识、竞争意识可以促进BlogJava不断完善和发展。这段时间发现BlogJava变化还是挺大的,我在这里定居时间不长,不知道以前怎么样,但这几天我至少看到了首页上加入了“24小时最热随笔”、“最近更新博客”、“最新注册博客”,还有今天排行榜上的变化,这些都让我对这里充满了期待,在这里和大家一起学习,共同发展。
作者:Flyingis
Java不像微软拥有Visual Studio 2005,各个开发组件无缝整合,提供高效的开发与部署环境。开发环境、插件和工具的多样化,给Java开发者带来了一些麻烦,但是却换来了极大的灵活性和选择的空间。Eclipse已经逐渐成为业界首选的开发环境,给Borland等公司带来不少的冲击,使得老牌的Java IDE公司的市场份额逐渐丢失,而在应用服务器、对象关系数据中间件、报表中间件、Web开发框架等领域仍然是热闹非凡,选择众多。
Java Web开发框架主要有Struts/JSF/Tapestry/WebWork/Spring等,它们都非常优秀,有自己的优点与不足,对于我们开发者而言,只选对的,适合项目需求的才是最重要的。这里有一篇文章介绍了JSF和Tapestry之间的相似之处与不同点,可以让我们更好的认识到它们之中哪种框架更适合你。
JSF VS Tapestry 全面比较(一)
JSF VS Tapestry 全面比较(二)
JSF VS Tapestry 全面比较(三)
(文章转自CSDN)
3. 使用XPath语法来查询对象和集合
Commons JXPath是一种让人很吃惊地(非标准的)对XML标准的使用。XPath一段时间以来一直是作为在一个XSL样式表中选择结点或结点集的一种方法。如果你用过XML,你会很熟悉用这样的语法/foo/bar来从foo文档元素中选择bar子元素。
Jakarta Commons JXPath增加了一种有趣的手法:你可以用JXPath来从bean和集合中选择对象,其中如servlet上下文和DOM文档对象。考虑一个包含了Person对象的列表。每一个Person对象有一个属性的类型为Job,每一个Job对象有一个salary(薪水)属性,类型为int。Person对象也有一个coountry属性,它是两个字符的国家代码。使用JXPath,你可以很容易地选出所有国家为美国,薪水超过一百万美元的Person对象。下面是设置一个由JXPath过滤地bean的List的代码:
// Person的构造器设置姓和国家代码
Person person1 = new Person( "Tim", "US" );
Person person2 = new Person( "John", "US" );
Person person3 = new Person( "Al", "US" );
Person person4 = new Person( "Tony", "GB" );
// Job的构造器设工作名称和薪水
person1.setJob( new Job( "Developer", 40000 ) );
person2.setJob( new Job( "Senator", 150000 ) );
person3.setJob( new Job( "Comedian", 3400302 ) );
person4.setJob( new Job( "Minister", 2000000 ) );
Person[] personArr =
new Person[] { person1, person2,
person3, person4 };
List people = Arrays.asList( personArr ); people List包含了四个bean: Tim, John, Al, 和George。Tim是一个挣4万美元的开发者,John是一个挣15万美元的参议员,Al是一个挣340万美元的喜剧演员,Tony是一个挣200万欧元的部长。我们的任务很简单:遍历这个List,打印出每一个挣钱超过100百万美元的美国公民的名字。记住people是一个由Person对象构成的ArrayList,让我们先看一下没有利用JXPath便利的解决方案:
Iterator peopleIter = people.getIterator();
while( peopleIter.hasNext() ) {
Person person = (Person) peopleIter.next();
if( person.getCountry() != null &&
person.getCountry().equals( "US" ) &&
person.getJob() != null &&
person.getJob().getSalary() > 1000000 ) {
print( person.getFirstName() + " "
person.getLastName() );
}
}
}
} 上面的例子是繁重的,并有些容易犯错。为了发现合适的Person对象,你必须首先遍历每一个Person对象并且检查conuntry的属性。如果country属性不为空并且符合要求,那么你就要检查job属性并看一下它是否不为空并且salary属性的值大于100万。上面的例子的代码行数可以被Java 1.5的语法大大减少,但是,哪怕是Java 1.5,你仍旧需要在两层上作两次比较。
如果你想对内存中的一组Person对象也做一些这样的查询呢?如果你的应用想显示所有在英格兰的名叫Tony的人呢?喔,如果你打印出每一个薪水少于2万的工作的名称呢?
如果你将这些对象存储到关系数据库中,你可以用一个SQL查询来解决问题,但你正在处理的是内存中的对象,你可以不必那么奢侈。虽然XPath主要是用在XML上面,但你可以用它来写一个针对对象集合的“查询”,将对象作为元素和,把bean属性作为子元素。是的,这是一种对XPath奇怪的应用,但请先看一下下面的例子如何在people上,一个由Person对象构成的ArrayList,实现这三种查询:
import org.apache.commons.jxpath.JXPathContext;
public List queryCollection(String xpath,
Collection col) {
List results = new ArrayList();
JXPathContext context =
JXPathContext.newContext( col );
Iterator matching =
context.iterate( xpath );
while( matching.hasNext() ) {
results.add( matching.getNext() );
}
return results;
}
String query1 =
".[@country = 'US']/job[@salary > 1000000]/..";
String query2 =
".[@country = 'GB' and @name = 'Tony']";
String query3 =
"./job/name";
List richUsPeople =
queryCollection( query1, people );
List britishTony =
queryCollection( query2, people );
List jobNames =
queryCollection( query3, people );
queryCollection()方法使用了一个XPath表达式,将它应用到一个集合上。XPath表达式被JXPathContext求值, JXPathContext由JXPathContext.newContext()调用创建,并将它传入要执行查询的集合中。凋用context.iterate()来在集合中的每一个元素上应用XPath表达式,返回包含所有符合条件的“节点”(这里是“对象”)的Iterator。上例中执行的第一个查询,query1,执行了和不使用JXPath的例子相同的查询。query2选择所有国家为GB并且名字属性为Tony的Person对象,query3返回了一个String对象的List,包含了所有Job对象的name属性。
当我第一次看到Commons JXPath, 它是一个坏思想的想法触动了我。为什么要把XPath表达式应用到对象上?有点感觉不对。把XPath作为一个bean的集合的查询语言的这种意想不到的用法,在过去几年中已经好多次给我带来了便利。如果你发现你在list中循环来查找符合条件的元素,请考虑一下JXPath。更多的信息,请参考Jakarta Commons Cookbook的第12章,“查找和过滤”,它讨论了Commons JXPath和与Commons Digester配对的Jakarta Lucene。
还有更多
对Jakarta Commons纵深地探索仍然在调试中。在这一系列的下面几部分中,我会介绍一些相关的工具和功能。在Commons Collections中设置操作,在collection中使用Predicate对象,使用Commons Configuration来配置一个应用和使用Commons Betwixt来读写XML。能从Jakarta Commons得到的东西还有很多,不能在几千字中表达,所以我建议你看一下Jakarta Commons Cookbook。许多功能可能会,一眼看上去,有点普通,但Jakarta Commons的能量就蕴藏在这些工具的相互组合和与你的系统的集成当中。
Timothy M. O'Brien是一个专业的独立的开发者,在Chicago地区工作和生活。
资源
·onjava.com:onjava.com
·Matrix-Java开发者社区:http://www.matrix.org.cn/
·APACHE:APACHE.org
(文章转自CSDN)
2.Commons Collections中的算子
算子成为Commons Collections 3.1中的有趣的部分有两个原因:它们没有得到应得的重视并且它们有改变你编程的方式的潜力。算子只是一个奇特的名字,它代表了一个包装了函数的对象—一个“函数对象”。当然,它们不是一回事。如果你曾经使用过C和C++的方法指针,你就会理解算子的威力。
一个算子是一个对象—一个Predicate,一个Closure, 一个Transformer。
Predicates求对象的值并返回一个boolean,Transformer求对象的值并返回新对象,Closure接受对象并执行代码。算子可以被组合成组合算子来模仿循环,逻辑表达式,和控制结构,并且算子也可以被用来过滤和操作集合中的元素。在这么短的篇幅中解释清楚算子是不可能的,所以跳过介绍,我将会通过使用和不使用算子来解决同一问题(解释算子)。在这个例子中,从一个ArrayList中而来的Student对象会被排序到两个List中,如果他们符合某种标准的话。
成绩为A的学生会被加到honorRollStudents(光荣榜)中,得D和F的学生被加到problemStudents (问题学生)list中。学生分开以后,系统将会遍历每个list,给加入到光荣榜中学生一个奖励,并安排与问题学生的家长谈话的时间表。下面的代码不使用算子实现了这个过程:
List allStudents = getAllStudents();
// 创建两个ArrayList来存放荣誉学生和问题学生
List honorRollStudents = new ArrayList();
List problemStudents = new ArrayList();
// 遍历所有学生,将荣誉学生放入一个List,问题学生放入另一个
Iterator allStudentsIter = allStudents.iterator();
while( allStudentsIter.hasNext() ) {
Student s = (Student) allStudentsIter.next();
if( s.getGrade().equals( "A" ) ) {
honorRollStudents.add( s );
} else if( s.getGrade().equals( "B" ) &&
s.getAttendance() == PERFECT) {
honorRollStudents.add( s );
} else if( s.getGrade().equals( "D" ) ||
s.getGrade().equals( "F" ) ) {
problemStudents.add( s );
} else if( s.getStatus() == SUSPENDED ) {
problemStudents.add( s );
}
}
// 对于的有荣誉学生,增加一个奖励并存储到数据库中
Iterator honorRollIter =
honorRollStudents.iterator();
while( honorRollIter.hasNext() ) {
Student s = (Student) honorRollIter.next();
// 给学生记录增加一个奖励
s.addAward( "honor roll", 2005 );
Database.saveStudent( s );
}
// 对所有问题学生,增加一个注释并存储到数据库中
Iterator problemIter = problemStudents.iterator();
while( problemIter.hasNext() ) {
Student s = (Student) problemIter.next();
// 将学生标记为需特殊注意
s.addNote( "talk to student", 2005 );
s.addNote( "meeting with parents", 2005 );
Database.saveStudent( s );
} 上述例子是非常过程化的;要想知道Student对象发生了什么事必须遍历每一行代码。例子的第一部分是基于成绩和考勤对Student对象进行逻辑判断。
第二部分对Student对象进行操作并存储到数据库中。像上述这个有着50行代码程序也是大多程序所开始的—可管理的过程化的复杂性。但是当需求变化时,问题出现了。一旦判断逻辑改变,你就需要在第一部分中增加更多的逻辑表达式。
举例来说,如果一个有着成绩B和良好出勤记录,但有五次以上的留堂记录的学生被判定为问题学生,那么你的逻辑表达式将会如何处理?或者对于第二部分中,只有在上一年度不是问题学生的学生才能进入光荣榜的话,如何处理?当例外和需求开始改变进而影响到过程代码时,可管理的复杂性就会变成不可维护的面条式的代码。
从上面的例子中回来,考虑一下那段代码到底在做什么。它在一个List遍历每一个对象,检查标准,如果适用该标准,对此对象进行某些操作。上述例子可以进行改进的关键一处在于从代码中将标准与动作解藕开来。下面的两处代码引用以一种非常不同的方法解决了上述的问题。首先,荣誉榜和问题学生的标准被两个Predicate对象模型化了,并且加之于荣誉学生和问题学生上的动作也被两个Closure对象模型化了。这四个对象如下定义:
import org.apache.commons.collections.Closure;
import org.apache.commons.collections.Predicate;
// 匿名的Predicate决定一个学生是否加入荣誉榜
Predicate isHonorRoll = new Predicate() {
public boolean evaluate(Object object) {
Student s = (Student) object;
return( ( s.getGrade().equals( "A" ) ) ||
( s.getGrade().equals( "B" ) &&
s.getAttendance() == PERFECT ) );
}
};
//匿名的Predicate决定一个学生是否是问题学生
Predicate isProblem = new Predicate() {
public boolean evaluate(Object object) {
Student s = (Student) object;
return ( ( s.getGrade().equals( "D" ) ||
s.getGrade().equals( "F" ) ) ||
s.getStatus() == SUSPENDED );
}
};
//匿名的Closure将一个学生加入荣誉榜
Closure addToHonorRoll = new Closure() {
public void execute(Object object) {
Student s = (Student) object;
// 对学生增加一个荣誉记录
s.addAward( "honor roll", 2005 );
Database.saveStudent( s );
}
};
// 匿名的Closure将学生标记为需特殊注意
Closure flagForAttention = new Closure() {
public void execute(Object object) {
Student s = (Student) object;
// 标记学生为需特殊注意
s.addNote( "talk to student", 2005 );
s.addNote( "meeting with parents", 2005 );
Database.saveStudent( s );
}
}; 这四个匿名的Predicate和Closure是从作为一个整体互相分离的。flagForAttention(标记为注意)并不知道什么是确定一个问题学生的标准 。现在需要的是将正确的Predicate和正确的Closure结合起来的方法,这将在下面的例子中展示:
import org.apache.commons.collections.ClosureUtils;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.collections.functors.NOPClosure;
Map predicateMap = new HashMap();
predicateMap.put( isHonorRoll, addToHonorRoll );
predicateMap.put( isProblem, flagForAttention );
predicateMap.put( null, ClosureUtils.nopClosure() );
Closure processStudents =
ClosureUtils.switchClosure( predicateMap );
CollectionUtils.forAllDo( allStudents, processStudents ); 在上面的代码中,predicateMap将Predicate与Closure进行了配对;如果一个学生满足作为键值的Predicate的条件,那么它将把它的值传到作为Map的值的Closure中。通过提供一个NOPClosure值和null键对,我们将把不符合任何Predicate条件的Student对象传给由ClosureUtils调用创建的“不做任何事”或者“无操作”的NOPClosure。
一个SwitchClosure, processStudents,从predicateMap中创建。并且通过使用CollectionUtils.forAllDo()方法,将processStudents Closure应用到allStudents中的每一个Student对象上。这是非常不一样的处理方法;记住,你并没有遍历任何队列。而是通过设置规则和因果关系,以及CollectionUtils和SwitchClosur来完成了这些操作。
当你将使用Predicate的标准与使用Closure的动作将分离开来时,你的代码的过程式处理就少了,而且更容易测试了。isHonorRoll Predicate能够与addToHonorRoll Closure分离开来进行独立的单元测试,它们也可以合起来通过使用Student类的模仿对象进行测试。第二个例子也会演示CollectionUtils.forAllDo(),它将一个Closure应用到了一个Collection的每一个元素中。
你也许注意到了使用算子并没用减少代码行数,实际上,使用算子还增加了代码量。但是,通过算子,你得到了将到了标准与动作的模块性与封装性的好处。如果你的代码题已经接近于几百行,那么请考虑一下更少过程化处理,更多面向对象的解决方案—通过使用算子。
Jakarta Commons Cookbook中的第四章“算子”介绍了Commons Collections中可用的算子,在第五章,“集合”中,向你展示了如何使用算子来操作Java 集合类API。
所有的算子-- Closure, Predicate, 和 Transformer—能够被合并为合并算子来处理任何种类的逻辑问题。switch, while和for结构能够被SwitchClosure, WhileClosure, 和 ForClosure模型化。
复合的逻辑表达式可以被多个Predicate构建,通过使用OrPredicate, AndPredicate, AllPredicate, 和 NonePredicate将它们相互联接。Commons BeanUtils也包含了算子的实现被用来将算子应用到bean的属性中-- BeanPredicate, BeanComparator, 和 BeanPropertyValueChangeClosure。算子是考虑底层的应用架构的不一样的方法,它们可以很好地改造你编码实现的方法。
>>>>下一篇
(文章转自CSDN)
如果你不熟悉Jakarta Commons话,那么很有可能你已经重新发明了好几个轮子。在你编写更多的普通的框架或工具之前,体验一下Commons吧。它将会大大地节约你的时间。太多的人自己写一个,其实是与Commons Lang中的StringUtils重复的StringUtils类,或者,开发者不知道从Commons Collections中重新创建工具,哪怕commons-collections.jar已经在classpath中可用了。
真的,请停一下。看看Commons Collections API,然后再回到你的任务中;我发誓你会发现一些简单有用的东西可以帮你在明年节省一周的时间。如果大家花一点时间看看Jakarta Commons,我们将会得到更少的重复代码—我们将在重用的宗旨下真正做一些有用的事情。
我确实看到这样的情况发生过:一些人研究了一下Commons BeanUtils或者Commons Collections,然后总是有“啊,如果我那时知道这个的话,我就不会写那一万行的代码了”这样的时刻。Jakarta Commons仍有一部分保持相当的神秘;比如,许多人还没有听说过Commons CLI和Commons Configuration,并且大多数人还没有注意到Commons Collections中的functors(算子)包的价值。在这一系列中,我会专门强调一些Jakarta Commons中较少得到重视的工具和功能。
在这一系列的第一部分,我将探索定义在Commons Digester中的XML规则,Commons Collections中的功能,和使用一个有趣的应用,Commons JXPath,来查询一个对象的List。Jakarta Commons包含的功能目的在于帮助你解决低层次的编程问题:遍历集合,解析XML和从List中检出对象。我建议你花一些时间在这些小功能上,学习Jakarta Commons真的会为你节省不少时间。
并不简单地是学习使用Commons Digester来解析XML或者使用CollectionUtils的Predicate来过滤一个集合,而是当你一旦意识到如何将这些功能组合起来使用并且如何将Commons集成到你的项目中去的时候,你才会真正地看到它的好处。如果你这样做地话,你将会把commons-lang.jar, commons-beanutils.jar,和 commons-digester.jar当成JVM本身来看待。
如果你对Jakarta Commons更深的内容感兴趣的话,可以看一下Jakarta Commons Cookbook。这本书给你很多方法来更好的使用Commons,并告诉你如何将Jakarta Commons与其它的小的开源组件集成,如Velocity, FreeMarker, Lucene, 和 Jakarta Slide。这本书,我介绍了一组广泛的工具从Commons Lang中的简单工具到组合了Commons Digester, Commons Collections, 和Jakarta Lucene来搜索威廉.莎士比亚的著作。我希望这一系列和Jakarta Commons Cookbook这本书能够提供给你一些有趣的低层次的编程问题的解决方案。
1. 用于Commons Digester的基于XML的规则集
Commons Digester 1.6提供了将XML转化为对象的最简单的方法。Digester已经由O'Reilly网站上的两篇文章介绍过了:“学习和使用Jakarta Digester”,作者是Philipp K. Janert,和“使用Jakarta Commons, 第二部分”,作者是Vikram Goyal。两篇文章都演示了XML规则集的使用,但如何在XML中定义规则集并没有理解。大多所见到的Digester的使用是程序化地定义规则集,以已编译的形式。你应该避免硬编码的Digester规则,特别是当你可以将映射信息存储在外部文件中或一个类路径资源中时。外部化一个Digester规则可以更好地适应一个演化中的XML文档结构或者说一个演化中的对象模型。
为了演示在XML中定义规则集与硬编码的规则集之间的区别,考虑系统解析XML给一个Person bean,包括在下面定义的属性—id, name和age。
package org.test;
public class Person {
public String id;
public String name;
public int age;
public Person() {}
public String getId() { return id; }
public void setId(String id) {
this.id = id;
}
public String getName() { return name; }
public void setName(String name) {
this.name = name;
}
public int getAge() { return age; }
public void setAge(int age) {
this.age = age;
}
} 确认你的应用需要解析一个包含了多个person元素的XML文件。下面的XML文件,data.xml,包含了两个person元素,你想要把它们解析到Person对象中:
Tom Higgins
25
Barney Smith
75
Susan Shields
53
你希望如果结构和XML文件的内容在未来几个月中变化,你不需要在已编译的Java代码中硬编码XML文件的结构。为了做到这一点,你需要在一个XML文件中定义Digester的规则,并且它可以作为一种资源从类路径中装入。下面的XML文档,person-rules.xml,映射person元素到Person bean:
paramtype="java.lang.Object"/>
上述所做的是指示Digester创建一个新的Person实例,当它遇到一个person元素时,调用add()来将Person对象加入到一个ArrayList中,设置person元素中相匹配的属性,并从下一级元素name和age中设置name和age的属性。
现在你已经看到了Person类,会被解析的文档,和以XML的形式定义的Digester规则。现在你需要创建一个由person-rules.xml定义了规则的Digester的实例。下面的代码创建 了一个Digester,通过将person-rules.xml的URL传递给DigesterLoader
既然person-rules.xml文件是与解析它的类在同一个包内的类路径资源,URL可以通过getClass().getResource()来得到。DigesterLoader然后解析规则并将它加到新创建的Digester上:
import org.apache.commons.digester.Digester;
import org.apache.commons.digester.xmlrules.DigesterLoader;
// 从XML规则集中配置Digester
URL rules = getClass().getResource("./person-rules.xml");
Digester digester =
DigesterLoader.createDigester(rules);
// 将空的List推入到Digester的堆栈
List people = new ArrayList();
digester.push( people );
// 解析XML文档
InputStream input = new FileInputStream( "data.xml" );
digester.parse( input ); 一旦Digester完成对data.xml的解析,三个Person对象将会在ArrayList people中。
与将规则定义在XML不同的方法是使用简便的方法将它们加入到一个Digester实例中。大多数文章和例子都用这种方法,使用addObjectCreate() 和 addBeanPropertySetter()这样的方法来将规则加入中Digester上。下面的代码加入了与定义在person-rules.xml中相同的规则:
digester.addObjectCreate("people/person", Person.class);
digester.addSetNext("people/person", "add", "java.lang.Object");
digester.addBeanPropertySetter("people/person", "name");
digester.addBeanPropertySetter("people/person", "age");
如果你曾经发现自己正在用一个有着2500行代码的类,用SAX来解析一个巨大的XML文档,或者使用DOM或JDOM的完整的一个集合类,你就会理解XML的解析比它应该做的要复杂的多,就大多数情况来说。如果你正在建一个有着严格的速度和内存要求的高效的系统,你会需要SAX解析器的速度。如果你需要DOM级别3的复杂度,你会需要像Apache Xerces的解析器。但如果你只是简单的试图将几个XML文档解析到对象中去的话,看一下Commons Digester, 并把你的规则定义在一个XML文件中。
任何时候你都应该将配置信息从硬编码中移出来。我会建议你在一个XML文件中定义规则并从文件系统或类路径中装入它。这样可以使你的程序更好地适应XML文档以及对象模型的变化。有关在XML文件中定义Digester规则的更多的资料,参看Jakarta Commons Cookbook一书的6.2节,“将XML文档转换为对象”
>>>>下一章
作者:Flyingis
在前面的一篇日志里面,我设计了在数据库表中自动生成ID号的一种算法(点击这里查看),这个算法主要应用于字典表的修改中。字典表的ID号是这样设计的:A01、A05、A28等等,即一位字母+两位数字。由于每个字典表的ID号的第一个字母对于一个字典表来说是固定的,这样做的目的在于在其它表中查看数据的时候可以很容易分辨字典项的ID号是属于哪一个数据字典的,因此这就限制了每个字典表的数据不能超过99条,当数据量大于99条的时候,那个算法就不再适用。
因此这里给出了一个改进的算法(其实只作了一点点改进),可以满足数据在1~999条之间的数据字典,这对于绝大多数应用来说已经是绰绰有余了。下面就给出具体的方法:
/*
* 功能:增加字典信息时,自动生成最小的ID号码
* 参数:String 字典表名称 first 字典ID的首字母,代表唯一的字典
* 返回:String 生成的最小ID号码
*/
public String getId(String table, String first) {
// 所有除去首字母后的ID号码--整型,例如:11
int[] sid;
// 所有原始ID号码,例如:A011
String[] rid;
// 除去首字母后最小的ID号码--字符串
String sid_new = null;
// 程序返回的最小的原始ID号码
String rid_new = null;
// 循环参数
int i = 0;
int k = 0;
con = DatabaseConnection.getConnection("jdbc/wutie";
Statement stm = null;
ResultSet rst = null;
RowSet rowRst = null;
String sql = "SELECT * FROM " + table + " order by id";
try {
if (con.isClosed()) {
throw new IllegalStateException("error.sql.unexpected";
}
stm = con.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);
rst = stm.executeQuery(sql);
while (rst.next()) {
k++;
}
sid = new int[k];
rid = new String[k];
rst = stm.executeQuery(sql);
// 如果不存在结果集,则直接在first字母后面加001,例如first="A",rid_new=A001
if (!rst.first()) {
rid_new = first.concat("001";
return rid_new;
}
// 如果存在结果集,则将表中所有ID号存入数组中,并转换为整型数据
else {
/*
while (rst.next()) {
rid[i] = rst.getString("id";
sid[i] = Integer.parseInt(rid[i].substring(1));
i++;
}
*/
for (rst.previous(); rst.next(); i++) {
rid[i] = rst.getString("id";
sid[i] = Integer.parseInt(rid[i].substring(1));
}
// 如果第一条记录ID号不为fisrt+001,例如A003、A018、A109等,则返回新增数据的ID号为A001
if (sid[0] != 1) {
rid_new = first.concat("001";
return rid_new;
}
// 如果第一条记录ID号为first+001,即A001,则执行下面语句
else {
// 如果总记录数只有一条,例如A001,则返回新增数据为A002
if (i == 1) {
rid_new = first.concat("002";
return rid_new;
}
else {
for (int j = 1; j < k; j++) {
// 如果相邻两条记录ID号的整数位相差1,则保存新增数据ID号整数位是前一位ID号整数位加1
if (sid[j] == sid[j-1] + 1) {
if (sid[j] < 9) {
sid_new = String.valueOf(sid[j] + 1);
rid_new = first.concat("00".concat(sid_new);
}
else if (sid[j]>9 && sid[j]<100){
sid_new = String.valueOf(sid[j] + 1);
rid_new = first.concat("0").concat(sid_new);
}
else {
sid_new = String.valueOf(sid[j] + 1);
rid_new = first.concat(sid_new);
}
}
// 如果相邻两条记录ID号的整数位相差非1,则返回新增数据ID号整数位是前一位ID号整数位加1
if (sid[j] != sid[j-1] + 1) {
if (sid[j-1] < 9) {
sid_new = String.valueOf(sid[j-1] + 1);
rid_new = first.concat("00".concat(sid_new);
return rid_new;
}
else if (sid[j]>9 && sid[j]<100){
sid_new = String.valueOf(sid[j-1] + 1);
rid_new = first.concat("0").concat(sid_new);
}
else {
sid_new = String.valueOf(sid[j-1] + 1);
rid_new = first.concat(sid_new);
return rid_new;
}
}
}
return rid_new;
}
}
}
}
catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException("error.sql.runtime";
}
finally {
try {
stm.close();
con.close();
}
catch (SQLException e1) {
e1.printStackTrace();
throw new RuntimeException("error.sql.runtime";
}
}
}
注意:之所以生成A01而不是A1,是因为在SQLServer2000中根据ID号正确排序的需要,如果按照升序排列,A1后面是A10、A11等,而不是A2。另外,在Hibernate中有多种自动生成ID字段的方法,但是这个项目比较小,我没有使用Hibernate中间件,这里提供的只是生成字典ID字段的一种简单思路,相比原有算法改进了一点,可以适用于字典项不多于1000项的情况,一般情况下,字典项是不可能超过1000项了,在我参与的这个小项目中已经是完全够用了。还有什么更好的方法和思路还请大家多指教!
作者:Flyingis
内部类的功能在于,每个内部类都能独立的继承一个接口的实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。内部类使得多重继承的解决方案变得完整,并且内部类允许继承多个非接口类型(类或抽象类)。
interface Sa {
void today();
void yesterday();
boolean check();
}
public class Sab {
private i = 10;
private Sab_inner implements Sa {
void today() {
return i;
}
void yesterday() {
return --i;
}
Boolean check() {
return i = = 0;
}
}
public Sa getSa() {
return new Sab_inner();
}
}
从上面这段代码可以看出,如果我们只是声明外围类Sab实现接口Sa,那么对于某个特定的Sab对象只能有一个Sa。但是如果使用了内部类,我们就可以通过方法getSa()来获得一个实现Sa接口的序列,这样就增加了应用上的灵活性。 在控制框架,特别是图形用户界面的设计中更能体现内部类的价值,具体的可以参考这方面的资料。
作者:Flyingis
4. 内部类拥有其外围类的所有元素的访问权,当某个外围类的对象创建了一个内部类对象时,此内部类对象必定会保存一个指向那个外围类对象的引用。然后,在访问此外围类的成员时,就是用那个“隐藏”的引用来选择外围类的成员。这与C++嵌套类的设计非常不同,在C++中只是单纯的名字隐藏机制,与外围对象没有联系,也没有隐含的访问权。
另外,一个内部类被嵌套多少层并不重要,它能透明访问所有它所嵌入的外围类的所有成员。
5. 在Java中实现C++的嵌套类功能也是通过嵌套类的机制来实现的,区别是C++中的嵌套类不能访问私有成员,在Java中则可以。
在Java中,使用嵌套类可以使得内部类对象与其外围类对象之间有联系,语法上是将内部类声明为static。而在普通的内部类中是不能有static数据、static字段和嵌套类的。通常,我们可以在一个普通的内部类中,通过一个特殊的this引用链接到其外围类对象,如外围类是Fruit,那么在内部类中应该通过Fruit.this来引用外围类的对象。
6. 内部类的继承比较特殊,我通过一个例子来向大家展示:
class Fruit {
class Inner {}
}
public class Apple extends Fruit.Inner {
Apple(Fruit f) {
f.super(); //为什么要这样使用我也不明白
}
public static void main(String[] args) {
Fruit f = new Fruit();
Apple a = new Apple(f);
}
}
其中为什么要外围类调用super()方法我也不清楚,希望有人指点!
7. 当继承某个外围类的时候,内部类并没有发生任何改变,基类和继承类中的两个内部类是完全独立的实体,各自在自己的命名空间内。如果明确继承某个内部类,则会覆盖原来的内部类。如:
public class A extends Atop {
public Inner extends Atop.Inner {}
}
8. 局部内部类和匿名内部类在功能上基本相似,它们的区别在于,如果我们需要一个已命名的构造器,或者需要重载构造器,就要使用局部内部类,它可以提供多个内部类对象。匿名内部类只能用于实例初始化。
9. 内部类标识符是外围类的名字+$+内部类的名字,如果内部类是匿名的,则会由编译器产生一个数字作为其标识符。
作者:Flyingis
内部类是Java语言一个重要的基本特性,在Java开发的许多领域都会经常用到。内部类的定义说简单一点就是将一个类定义在另外一个类的内部。内部类允许你把一些逻辑相关的类组织在一起,控制内部类代码的可视性,它和类的组合是完全不同的概念。内部类主要有以下比较关键的特性:
1. 普通的非内部类不能被声明为private或protected,否则就失去了创建该类的意义。但是内部类通常可以被声明为private或protected类型,因为这样可以防止他人对该内部类实现的功能进行修改,达到隐藏实现细节的目的。例如:
class Fruit {
private class Weight {
private String i;
private Weight(String j) {
i = j;
}
public String read() {
return i;
}
}
}
class test {
public static void main(String[] args) {
Fruit f = new Fruit();
f.Weight w = f.new Weight(); //不能访问private类,如果Weight为protected类型则可以
}
}
2. 在方法或某控制语句(if/for/while等)的作用域内定义内部类,将只能在该范围内调用内部类的方法和成员变量。
3. 匿名内部类是一种特殊的内部类,如果希望它使用一个在其外部定义的对象,那么编译器会要求其参数引用是final的。
public class Fruit {
public Tea cont(final int j) {
return new Tea() {
private int i = j;
public int read() {
return i;
}
}; //注意这里的分号
}
public static void main(String[] args) {
Fruit f = new Fruit();
Tea t = f.cont;
}
}
而当方法cont(final int j)中的参数j只是被传递到匿名类中的构造器时,可以不用被声明为final类型,如return new Tea(j)。这里提到了匿名内部类的构造器,那么它是怎么被初始化的呢?
public class Fruit {
public Tea cont(int j) {
return new Tea(j) {
System.out.println(j);
};
}
}
还可以这样初始化匿名内部类:
public class Fruit {
public Tea cont(final int j) {
return new Tea(j) {
int i;
// 初始化匿名内部类
{
i = j;
System.out.print(i);
}
};
}
} 方法cont()可以被称为实例初始化方法,使得匿名内部类通过构造器而被初始化,在实际应用中,我们不能重载实例初始化方法,因为匿名内部类只能有一个构造方法。
|