|
2009年11月18日
#
作者:NetSeek http://www.linuxtone.org (IT运维专家网|集群架构|性能调优)
欢迎转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明.
首发时间: 2008-11-25 更新时间:2009-1-14
目 录
一、 Nginx 基础知识
二、 Nginx 安装及调试
三、 Nginx Rewrite
四、 Nginx Redirect
五、 Nginx 目录自动加斜线:
六、 Nginx Location
七、 Nginx expires
八、 Nginx 防盗链
九、 Nginx 访问控制
十、 Nginx日志处理
十一、 Nginx Cache
十二、 Nginx负载均衡
十三、 Nginx简单优化
十四、 如何构建高性能的LEMP环境
十五、 Nginx服务监控
十六、 常见问题与错误处理.
十七、 相关资源下载
【前言】:
编写此技术指南在于推广普及NGINX在国内的使用,更方便的帮助大家了解和掌握NGINX的一些使用技巧。本指南很多技巧来自于网络和工作中或网络上朋友们问我的问题.在此对网络上愿意分享的朋友们表示感谢和致意!欢迎大家和我一起丰富本技术指南提出更好的建议!请朋友们关注: http://www.linuxtone.org 技术分享社区! 互想学习共同进步!
一、 Nginx 基础知识
1、简介
Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,它已经在该站点运行超过两年半了。Igor 将源代码以类BSD许可证的形式发布。尽管还是测试版,但是,Nginx 已经因为它的稳定性、丰富的功能集、示例配置文件和低系统资源的消耗而闻名了。
更多的请见官方wiki: http://wiki.codemongers.com/
2、 Nginx的优点
nginx做为HTTP服务器,有以下几项基本特性:
1) 处理静态文件,索引文件以及自动索引;打开文件描述符缓冲.
2) 无缓存的反向代理加速,简单的负载均衡和容错.
3) FastCGI,简单的负载均衡和容错.
4)
模块化的结构。包括gzipping, byte ranges, chunked responses, 以及
SSI-filter等filter。如果由FastCGI或其它代理服务器处理单页中存在的多个SSI,则这项处理可以并行运行,而不需要相互等待。
5) 支持SSL 和 TLS SNI.
Nginx专为性能优化而开发,性能是其最重要的考量, 实现上非常注重效率 。它支持内核Poll模型,能经受高负载的考验, 有报告表明能支持高达 50,000 个并发连接数。
Nginx具有很高的稳定性。其它HTTP服务器,当遇到访问的峰值,或者有人恶意发起慢速连接时,也很可能会导致服务器物理内存耗尽频繁交换,失去响应,只能重启服务器。例如当前apache一旦上到200个以上进程,web响
应速度就明显非常缓慢了。而Nginx采取了分阶段资源分配技术,使得它的CPU与内存占用率非常低。nginx官方表示保持10,000个没有活动的连
接,它只占2.5M内存,所以类似DOS这样的攻击对nginx来说基本上是毫无用处的。就稳定性而言, nginx比lighthttpd更胜一筹。
Nginx支持热部署。它的启动特别容易, 并且几乎可以做到7*24不间断运行,即使运行数个月也不需要重新启动。你还能够在不间断服务的情况下,对软件版本进行进行升级。
Nginx采用master-slave模型, 能够充分利用SMP的优势,且能够减少工作进程在磁盘I/O的阻塞延迟。当采用select()/poll()调用时,还可以限制每个进程的连接数。
Nginx
代码质量非常高,代码很规范, 手法成熟, 模块扩展也很容易。特别值得一提的是强大的Upstream与Filter链。
Upstream为诸如reverse proxy,
与其他服务器通信模块的编写奠定了很好的基础。而Filter链最酷的部分就是各个filter不必等待前一个filter执行完毕。它可以把前一个
filter的输出做为当前filter的输入,这有点像Unix的管线。这意味着,一个模块可以开始压缩从后端服务器发送过来的请求,且可以在模块接收
完后端服务器的整个请求之前把压缩流转向客户端。
Nginx采用了一些os提供的最新特性如对sendfile (Linux 2.2+),accept-filter (FreeBSD 4.1+),TCP_DEFER_ACCEPT (Linux 2.4+) 的支持,从而大大提高了性能
二、 Nginx 安装及调试
1、Pcre 安装
- ./configure
- make && make install
- cd ../
复制代码
2. nginx 编译安装
- ./configure --user=www --group=www --prefix=/usr/local/nginx/ --with-http_stub_status_module --with-openssl=/usr/local/openssl
- make && make install
复制代码
更详细的模块定制与安装请参照官方wiki.
3、Nginx 配置文件测试:
- # /usr/local/nginx/sbin/nginx -t //Debug 配置文件的关键命令需要重点撑握.
- 2008/12/16 09:08:35 [info] 28412#0: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
- 2008/12/16 09:08:35 [info] 28412#0: the configuration file /usr/local/nginx/conf/nginx.conf was tested successfully
复制代码
3、Nginx 启动:
- # /usr/local/nginx/sbin/nginx
复制代码
4、Nginx 配置文件修改重新加载:
- # kill -HUP `cat /usr/local/nginx/logs/nginx.pid
复制代码
`
三、Nginx Rewrite
1. Nginx Rewrite 基本标记(flags)
last - 基本上都用这个Flag。
※相当于Apache里的[L]标记,表示完成rewrite,不再匹配后面的规则
break - 中止Rewirte,不再继续匹配
redirect - 返回临时重定向的HTTP状态302
permanent - 返回永久重定向的HTTP状态301
※原有的url支持正则 重写的url不支持正则
2. 正则表达式匹配,其中:
* ~ 为区分大小写匹配
* ~* 为不区分大小写匹配
* !~和!~* 分别为区分大小写不匹配及不区分大小写不匹配
3. 文件及目录匹配,其中:
* -f和!-f用来判断是否存在文件
* -d和!-d用来判断是否存在目录
* -e和!-e用来判断是否存在文件或目录
* -x和!-x用来判断文件是否可执行
3. Nginx 的一些可用的全局变量,可用做条件判断:
- $args
- $content_length
- $content_type
- $document_root
- $document_uri
- $host
- $http_user_agent
- $http_cookie
- $limit_rate
- $request_body_file
- $request_method
- $remote_addr
- $remote_port
- $remote_user
- $request_filename
- $request_uri
- $query_string
- $scheme
- $server_protocol
- $server_addr
- $server_name
- $server_port
- $uri
复制代码
四、 Nginx Redirect
将所有linuxtone.org与netseek.linuxtone.org域名全部自跳转到http://www.linuxtone.org
- server
- {
- listen 80;
- server_name linuxtone.org netseek.linuxtone.org;
- index index.html index.php;
- root /data/www/wwwroot;
- if ($host !~ "^www.linxtone.org$") {
- rewrite ^(.*) http://www.linuxtone.org$1 redirect;
- }
- ........................
- }
复制代码
五、 Nginx 目录自动加斜线:
- if (-d $request_filename){
- rewrite ^/(.*)([^/])$ http://$host/$1$2/ permanent;
- }
复制代码
六 Nginx Location
1.基本语法:[和上面rewrite正则匹配语法基本一致]
location [=|~|~*|^~] /uri/ { … }
* ~ 为区分大小写匹配
* ~* 为不区分大小写匹配
* !~和!~*分别为区分大小写不匹配及不区分大小写不匹配
示例1:
location = / {
# matches the query / only.
# 只匹配 / 查询。
}
匹配任何查询,因为所有请求都已 / 开头。但是正则表达式规则和长的块规则将被优先和查询匹配
示例2:
location ^~ /images/ {
# matches any query beginning with /images/ and halts searching,
# so regular expressions will not be checked.
# 匹配任何已 /images/ 开头的任何查询并且停止搜索。任何正则表达式将不会被测试。
示例3:
location ~* .(gif|jpg|jpeg)$ {
# matches any request ending in gif, jpg, or jpeg. However, all
# requests to the /images/ directory will be handled by
}
# 匹配任何已 gif、jpg 或 jpeg 结尾的请求。
七、 Nginx expires
1.根据文件类型expires
- # Add expires header for static content
- location ~* .(js|css|jpg|jpeg|gif|png|swf)$ {
- if (-f $request_filename) {
- root /data/www/wwwroot/bbs;
- expires 1d;
- break;
- }
- }
复制代码
2、根据判断某个目录
- # serve static files
- location ~ ^/(images|javascript|js|css|flash|media|static)/ {
- root /data/www/wwwroot/down;
- expires 30d;
- }
复制代码
八、 Nginx 防盗链
1. 针对不同的文件类型
- #Preventing hot linking of images and other file types
- location ~* ^.+.(gif|jpg|png|swf|flv|rar|zip)$ {
- valid_referers none blocked server_names *.linuxtone.org linuxtone.org http://localhost baidu.com;
- if ($invalid_referer) {
- rewrite ^/ ;
- # return 403;
- }
- }
复制代码
2. 针对不同的目录
- location /img/ {
- root /data/www/wwwroot/bbs/img/;
- valid_referers none blocked server_names *.linuxtone.org http://localhost baidu.com;
- if ($invalid_referer) {
- rewrite ^/ ;
- #return 403;
- }
- }
复制代码
3. 同实现防盗链和expires的方法
- #Preventing hot linking of images and other file types
- location ~* ^.+.(gif|jpg|png|swf|flv|rar|zip)$ {
- valid_referers none blocked server_names *.linuxtone.org linuxtone.org http://localhost ;
- if ($invalid_referer) {
- rewrite ^/ ;
- }
- access_log off;
- root /data/www/wwwroot/bbs;
- expires 1d;
- break;
- }
复制代码
九、 Nginx 访问控制
1. Nginx 身份证验证
- #cd /usr/local/nginx/conf
- #mkdir htpasswd
- /usr/local/apache2/bin/htpasswd -c /usr/local/nginx/conf/htpasswd/tongji linuxtone
- #添加用户名为linuxtone
- New password: (此处输入你的密码)
- Re-type new password: (再次输入你的密码)
- Adding password for user
- http://count.linuxtone.org/tongji/data/index.html(目录存在/data/www/wwwroot/tongji/data/目录下)
- 将下段配置放到虚拟主机目录,当访问http://count.linuxtone/tongji/即提示要密验证:
- location ~ ^/(tongji)/ {
- root /data/www/wwwroot/count;
- auth_basic "LT-COUNT-TongJi";
- auth_basic_user_file /usr/local/nginx/conf/htpasswd/tongji;
- }
复制代码
2. Nginx 禁止访问某类型的文件.
如,Nginx下禁止访问*.txt文件,配置方法如下.
- location ~* .(txt|doc)$ {
- if (-f $request_filename) {
- root /data/www/wwwroot/linuxtone/test;
- #rewrite …..可以重定向到某个URL
- break;
- }
- }
复制代码
方法2:
- location ~* .(txt|doc)${
- root /data/www/wwwroot/linuxtone/test;
- deny all;
- }
复制代码
实例:
禁止访问某个目录
- location ~ ^/(WEB-INF)/ {
- deny all;
- }
复制代码
3. 使用ngx_http_access_module限制ip访问
- location / {
- deny 192.168.1.1;
- allow 192.168.1.0/24;
- allow 10.1.1.0/16;
- deny all;
- }
复制代码
详细参见wiki: http://wiki.codemongers.com/NginxHttpAccessModule#allow
4. Nginx 下载限制并发和速率
- limit_zone linuxtone $binary_remote_addr 10m;
- server
- {
- listen 80;
- server_name down.linuxotne.org;
- index index.html index.htm index.php;
- root /data/www/wwwroot/down;
- #Zone limit
- location / {
- limit_conn linuxtone 1;
- limit_rate 20k;
- }
- ..........
- }
复制代码
只允许客房端一个线程,每个线程20k.
【注】limit_zone linuxtone $binary_remote_addr 10m; 这个可以定义在主的
5. Nginx 实现Apache一样目录列表
- location / {
- autoindex on;
- }
复制代码
6. 上文件大小限制
主配置文件里加入如下,具体大小根据你自己的业务做调整。
client_max_body_size 10m;
十、 Nginx 日志处理
1.Nginx 日志切割
#contab -e
59 23 * * * /usr/local/sbin/logcron.sh /dev/null 2>&1
[root@count ~]# cat /usr/local/sbin/logcron.sh
- #!/bin/bash
- log_dir="/data/logs"
- time=`date +%Y%m%d`
- /bin/mv ${log_dir}/access_linuxtone.org.log ${log_dir}/access_count.linuxtone.org.$time.log
- kill -USR1 `cat /var/run/nginx.pid`
复制代码
更多的日志分析与处理就关注(同时欢迎你参加讨论):http://bbs.linuxtone.org/forum-8-1.html
2.利用AWSTATS分析NGINX日志
设置好Nginx日志格式,仍后利用awstats进行分析.
请参考: http://bbs.linuxtone.org/thread-56-1-1.html
3. Nginx 如何不记录部分日志
日志太多,每天好几个G,少记录一些,下面的配置写到server{}段中就可以了
location ~ .*.(js|jpg|JPG|jpeg|JPEG|css|bmp|gif|GIF)$
{
access_log off;
}
十一、Nginx Cache服务配置
如果需要将文件缓存到本地,则需要增加如下几个子参数:
- proxy_store on;
- proxy_store_access user:rw group:rw all:rw;
- proxy_temp_path 缓存目录;
复制代码
其中,
proxy_store on用来启用缓存到本地的功能,
proxy_temp_path用来指定缓存在哪个目录下,如:proxy_temp_path html;
在经过上一步配置之后,虽然文件被缓存到了本地磁盘上,但每次请求仍会向远端拉取文件,为了避免去远端拉取文件,必须修改
- proxy_pass:
- if ( !-e $request_filename) {
- proxy_pass http://mysvr;
- }
复制代码
即改成有条件地去执行proxy_pass,这个条件就是当请求的文件在本地的proxy_temp_path指定的目录下不存在时,再向后端拉取。
更多更高级的应用可以研究ncache,详细请参照http://bbs.linuxtone.org 里ncache相关的贴子.
十二、Nginx 负载均衡
1. Nginx 负载均衡基础知识
nginx的upstream目前支持4种方式的分配
1)、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
2)、weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
2)、ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
3)、fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
4)、url_hash(第三方)
2. Nginx 负载均衡实例1
- upstream bbs.linuxtone.org {#定义负载均衡设备的Ip及设备状态
- server 127.0.0.1:9090 down;
- server 127.0.0.1:8080 weight=2;
- server 127.0.0.1:6060;
- server 127.0.0.1:7070 backup;
- }
复制代码
在需要使用负载均衡的server中增加
proxy_pass http://bbs.linuxtone.org/;
每个设备的状态设置为:
a) down 表示单前的server暂时不参与负载
b) weight 默认为1.weight越大,负载的权重就越大。
c) max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误
d) fail_timeout:max_fails次失败后,暂停的时间。
e) backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
nginx支持同时设置多组的负载均衡,用来给不用的server来使用。
client_body_in_file_only 设置为On 可以讲client post过来的数据记录到文件中用来做debug
client_body_temp_path 设置记录文件的目录 可以设置最多3层目录
location 对URL进行匹配.可以进行重定向或者进行新的代理 负载均衡
3. Nginx 负载均衡实例 2
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效,也可以用作提高Squid缓存命中率.
简单的负载均等实例:
#vi nginx.conf //nginx主配置文件核心配置
- ……….
- #loadblance my.linuxtone.org
- upstream my.linuxtone.org {
- ip_hash;
- server 127.0.0.1:8080;
- server 192.168.169.136:8080;
- server 219.101.75.138:8080;
- server 192.168.169.117;
- server 192.168.169.118;
- server 192.168.169.119;
- }
- …………..
- include vhosts/linuxtone_lb.conf;
- ………
- # vi proxy.conf
- proxy_redirect off;
- proxy_set_header Host $host;
- proxy_set_header X-Real-IP $remote_addr;
- proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
- client_max_body_size 50m;
- client_body_buffer_size 256k;
- proxy_connect_timeout 30;
- proxy_send_timeout 30;
- proxy_read_timeout 60;
- proxy_buffer_size 4k;
- proxy_buffers 4 32k;
- proxy_busy_buffers_size 64k;
- proxy_temp_file_write_size 64k;
- proxy_next_upstream error timeout invalid_header http_500 http_503 http_404;
- proxy_max_temp_file_size 128m;
- proxy_store on;
- proxy_store_access user:rw group:rw all:r;
- #nginx cache
- #client_body_temp_path /data/nginx_cache/client_body 1 2;
- proxy_temp_path /data/nginx_cache/proxy_temp 1 2;
复制代码
#vi linuxtone_lb.conf
- server
- {
- listen 80;
- server_name my.linuxtone.org;
- index index.php;
- root /data/www/wwwroot/mylinuxtone;
- if (-f $request_filename) {
- break;
- }
- if (-f $request_filename/index.php) {
- rewrite (.*) $1/index.php break;
- }
- error_page 403 http://my.linuxtone.org/member.php?m=user&a=login;
- location / {
- if ( !-e $request_filename) {
- proxy_pass http://my.linuxtone.org;
- break;
- }
- include /usr/local/nginx/conf/proxy.conf;
- }
- }
复制代码
十三、Nginx简单优化
1. 减小nginx编译后的文件大小 (Reduce file size of nginx)
默认的nginx编译选项里居然是用debug模式(-g)的(debug模式会插入很多跟踪和ASSERT之类),编译以后一个nginx有好几兆。去掉nginx的debug模式编译,编译以后只有几百K
在 auto/cc/gcc,最后几行有:
# debug
注释掉或删掉这几行,重新编译即可。
2. 修改Nginx的header伪装服务器
1) 修改nginx.h
- #vi nginx-0.7.30/src/core/nginx.h
- #define NGINX_VERSION "1.8"
- #define NGINX_VER "LTWS/" NGINX_VERSION
- #define NGINX_VAR "NGINX"
- #define NGX_OLDPID_EXT ".oldbin"
复制代码
2) 修改nginx_http_header_filter_module
#vi nginx-0.7.30/src/http/ngx_http_header_filter_module.c
将如下
- static char ngx_http_server_string[] = "Server: nginx" CRLF;
复制代码
修改为
- static char ngx_http_server_string[] = "Server: LTWS" CRLF;
复制代码
a) 修改nginx_http_header_filter_module
#vi nginx-0.7.30/src/http/ngx_http_special_response.c
将如下:
- static u_char ngx_http_error_full_tail[] =
- "<hr><center>" NGINX_VER "</center>" CRLF
- "</body>" CRLF
- "</html>" CRLF
- ;
复制代码
- static u_char ngx_http_error_tail[] =
- "<hr><center>nginx</center>" CRLF
- "</body>" CRLF
- "</html>" CRLF
- ;
复制代码
修改为:
- static u_char ngx_http_error_full_tail[] =
- "<center> "NGINX_VER" </center>" CRLF
- "<hr><center>http://www.linuxtone.org</center>" CRLF
- "</body>" CRLF
- "</html>" CRLF
- ;
- static u_char ngx_http_error_tail[] =
- "<hr><center>LTWS</center>" CRLF
- "</body>" CRLF
- "</html>" CRLF
- ;
复制代码
修改后重新编译一下环境,
404错误的时候显示效果图(如果没有指定错误页的话):

利用curl命令查看服务器header

3.为特定的CPU指定CPU类型编译优化.
默认nginx使用的GCC编译参数是-O
需要更加优化可以使用以下两个参数
--with-cc-opt='-O3'
--with-cpu-opt=opteron
使得编译针对特定CPU以及增加GCC的优化.
此方法仅对性能有所改善并不会有很大的性能提升,供朋友们参考.
CPUD类型确定: # cat /proc/cpuinfo | grep "model name"
编译优化参数参考:http://en.gentoo-wiki.com/wiki/Safe_Cflags
4.Tcmalloc优化Nginx 性能
- # wget http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99-alpha.tar.gz
- # tar zxvf libunwind-0.99-alpha.tar.gz
- # cd libunwind-0.99-alpha/
- # CFLAGS=-fPIC ./configure
- # make CFLAGS=-fPIC
- # make CFLAGS=-fPIC install
- # wget http://google-perftools.googlecode.com/files/google-perftools-0.98.tar.gz
- # tar zxvf google-perftools-0.98.tar.gz
- # cd google-perftools-0.98/
- # ./configure
- # make && make install
- # echo "/usr/local/lib" > /etc/ld.so.conf.d/usr_local_lib.conf
- # ldconfig
- # lsof -n | grep tcmalloc
复制代码
编译nginx 加载google_perftools_module:
./configure --with-google_perftools_module
在主配置文件加入nginx.conf 添加:
google_perftools_profiles /path/to/profile;
5.内核参数优化
# vi /etc/sysctl.conf #在末尾增加以下内容:
- net.ipv4.tcp_fin_timeout = 30
- net.ipv4.tcp_keepalive_time = 300
- net.ipv4.tcp_syncookies = 1
- net.ipv4.tcp_tw_reuse = 1
- net.ipv4.tcp_tw_recycle = 1
- net.ipv4.ip_local_port_range = 5000 65000
复制代码
#使配置立即生效
/sbin/sysctl -p
十四、如何构建高性的LEMP
请参见: http://www.linuxtone.org/lemp/lemp.pdf
1、提供完整的配置脚本下载:http://www.linuxtone.org/lemp/scripts.tar.gz
2、提供NGINX常见配置范例含(虚拟主机,防盗链,Rewrite,访问控制,负载均衡
Discuz相关程序静态化及等等),你只要稍稍修改即可线上应用。 3、将原版的xcache替换成EA,并提供相关简单调优脚本及配置文件。
更多的及更新资料请关注: http://www.linuxtone.org
十五、Nginx监控
1、 RRDTOOL+Perl脚本画图监控
先安装好rrdtool ,关于rrdtool本文不作介绍,具体安装请参照linuxtone监控版块.
#cd /usr/local/sbnin
#wget http://blog.kovyrin.net/files/mrtg/rrd_nginx.pl.txt
#mv rrd_nginx.pl.txt rrd_nginx.pl
#chmod a+x rrd_nginx.pl
#vi rrd_nginx.pl //配置脚本文件设置好路径
#!/usr/bin/perl
use RRDs;
use LWP::UserAgent;
# define location of rrdtool databases
my $rrd = '/data/www/wwwroot/nginx/rrd';
# define location of images
my $img = '/data/www/wwwroot/nginx/html';
# define your nginx stats URL
my $URL = "http://219.232.244.13/nginx_status";
…………
【注】根据自己具体的状况修改相应的路径.
#crontab –e //加入如下
* * * * * /usr/local/sbin/rrd_nginx.pl
重启crond后,通过配置nginx虚拟主机指到/data/www/wwwroot/nginx/html目录,通过crond自动执行perl脚本会生成很多图片.
http://xxx/connections-day.png即可看到服务器状态图。
2、 官方Nginx-rrd 监控服务(多虚拟主机)(推荐)
网址:http://www.nginx.eu/nginx-rrd.html
此解决方案其实是基于上述监控方案的一个改进和增强,同样先安装好rrdtool这个画图工具和相应的perl模块再做如下操作:
# yum install perl-HTML*
先建立好生成的库存和图片存放录
- #mkdir -p /data/www/wwwroot/nginx/{rrd,html}
- #cd /usr/local/sbin
- #wget http://www.nginx.eu/nginx-rrd/nginx-rrd-0.1.4.tgz
- #tar zxvf nginx-rrd-0.1.4.tgz
- #cd nginx-rrd-0.1.4
- #cd etc/
- #cp nginx-rrd.conf /etc
- #cd etc/cron.d
- #cp nginx-rrd.cron /etc/cron.d
- #cd /usr/local/src/nginx-rrd-0.1.4/html
- # cp index.php /data/www/wwwroot/nginx/html/
- #cd /usr/local/src/nginx-rrd-0.1.4/usr/sbin
- #cp * /usr/sbin/
复制代码
#vi /etc/nginx-rrd.conf
- #####################################################
- #
- # dir where rrd databases are stored
- RRD_DIR="/data/www/wwwroot/nginx/rrd";
- # dir where png images are presented
- WWW_DIR="/data/www/wwwroot/nginx/html";
- # process nice level
- NICE_LEVEL="-19";
- # bin dir
- BIN_DIR="/usr/sbin";
- # servers to test
- # server_utl;server_name
- SERVERS_URL="http://219.32.205.13/nginx_status;219.32.205.13 http://www.linuxtone.org/nginx_status;www.linuxtone.org""
复制代码
//根据你的具体情况做调整.
SEVERS_URL 格式 http://domain1/nginx_status;domain1 http://domain2/nginx_status;domain2
这种格式监控多虚拟主机连接状态:
重点启crond服务,仍后通过http://219.32.205.13/nginx/html/ 即可访问。配置过程很简单!
3、 CACTI模板监控Nginx
利用Nginx_status状态来画图实现CACTI监控
nginx编译时允许http_stub_status_module
# vi /usr/local/nginx/conf/nginx.conf
- location /nginx_status {
- stub_status on;
- access_log off;
- allow 192.168.1.37;
- deny all;
- }
复制代码
- # kill -HUP `cat /usr/local/nginx/logs/nginx.pid`
- # wget http://forums.cacti.net/download.php?id=12676
- # tar xvfz cacti-nginx.tar.gz
- # cp cacti-nginx/get_nginx_socket_status.pl /data/cacti/scripts/
- # cp cacti-nginx/get_nginx_clients_status.pl /data/cacti/scripts/
- # chmod 755 /data/cacti/scripts/get_nginx*
复制代码
检测插件
- # /data/cacti/scripts/get_nginx_clients_status.pl http://192.168.1.37/nginx_status
复制代码
在cacti管理面板导入
cacti_graph_template_nginx_clients_stat.xml
cacti_graph_template_nginx_sockets_stat.xml
十六、常见问题与错误处理
1、400 bad request错误的原因和解决办法
配置nginx.conf相关设置如下.
client_header_buffer_size 16k;
large_client_header_buffers 4 64k;
根据具体情况调整,一般适当调整值就可以。
2、Nginx 502 Bad Gateway错误
proxy_next_upstream error timeout invalid_header http_500 http_503;
或者尝试设置:
large_client_header_buffers 4 32k;
3、Nginx出现的413 Request Entity Too Large错误
这个错误一般在上传文件的时候会出现,
编辑Nginx主配置文件Nginx.conf,找到http{}段,添加
client_max_body_size 10m; //设置多大根据自己的需求作调整.
如果运行php的话这个大小client_max_body_size要和php.ini中的如下值的最大值一致或者稍大,这样就不会因为提交数据大小不一致出现的错误。
post_max_size = 10M
upload_max_filesize = 2M
4、解决504 Gateway Time-out(nginx)
遇到这个问题是在升级discuz论坛的时候遇到的
一般看来, 这种情况可能是由于nginx默认的fastcgi进程响应的缓冲区太小造成的, 这将导致fastcgi进程被挂起, 如果你的fastcgi服务对这个挂起处理的不好, 那么最后就极有可能导致504 Gateway Time-out
现在的网站, 尤其某些论坛有大量的回复和很多内容的, 一个页面甚至有几百K。
默认的fastcgi进程响应的缓冲区是8K, 我们可以设置大点
在nginx.conf里, 加入: fastcgi_buffers 8 128k
这表示设置fastcgi缓冲区为8×128k
当然如果您在进行某一项即时的操作, 可能需要nginx的超时参数调大点,例如设置成60秒:send_timeout 60;
只是调整了这两个参数, 结果就是没有再显示那个超时, 可以说效果不错, 但是也可能是由于其他的原因, 目前关于nginx的资料不是很多, 很多事情都需要长期的经验累计才有结果, 期待您的发现哈!
5、如何使用Nginx Proxy
朋友一台服务器运行tomcat 为8080端口,IP:192.168.1.2:8080,另一台机器IP:192.168.1.8. 朋友想通过访问http://192.168.1.8即可访问tomcat服务.配置如下:
在192.168.1.8的nginx.conf上配置如下:
- server {
- listen 80;
- server_name java.linuxtone.org
- location / {
- proxy_pass http://192.168.1.2:8080;
- include /usr/local/nginx/conf/proxy.conf;
- }
- }
复制代码
6、如何关闭Nginx的LOG
access_log /dev/null; error_log /dev/null;
十七、相关资源下载
1.nginx配置示例及脚本下载:
# wget http://www.linuxtone.org/lemp/scripts.tar.gz #此脚本范例定期更新.
相关话题 (查看更多,知识库搜索)
其中以下这项挺值得留意的。
Tcmalloc 不单可用于 Mysql 的优化,还能应用于 Nginx
虽说 Nginx 本身的性能跟系统占用已经做到很优秀。
4.Tcmalloc优化Nginx 性能
- # wget http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99-alpha.tar.gz
- # tar zxvf libunwind-0.99-alpha.tar.gz
- # cd libunwind-0.99-alpha/
- # CFLAGS=-fPIC ./configure
- # make CFLAGS=-fPIC
- # make CFLAGS=-fPIC install
- # wget http://google-perftools.googlecode.com/files/google-perftools-0.98.tar.gz
- # tar zxvf google-perftools-0.98.tar.gz
- # cd google-perftools-0.98/
- # ./configure
- # make && make install
- # echo "/usr/local/lib" > /etc/ld.so.conf.d/usr_local_lib.conf
- # ldconfig
- # lsof -n | grep tcmalloc
摘要: tabBar.vim
这个插件实现了类似UltraEdit中的标签页的功能,而且能通过Alt-<n>来切换,
安装:
拷贝文件到[你的gvim的安装目录]"vimfiles"plugin"中即可!
下载:
http://www.vim.org/scripts/script.php?script_id=1338
C:/Program Files/Vim/_v... 阅读全文
学习:
http://blog.chinaunix.net/u1/59571/showart_2077664.html
个人对上面文章做的 笔记共享出来 和大家分享!

python easy_install moin 或 下载 moin-1.9.0 编译
设置 path 中有 moin.py
#我这 参考
path = $PATH:/Python25/moin-1.9.0/MoinMoin/script
# wikiconfig.py 下面我点下 参数 ,大家看代码 就知道了
vi /Python25/moin-1.9.0/wiki/config/ wikiconfig.py
#instance_dir = '/where/ever/your/instance/is'
instance_dir = wikiconfig_dir+'/../'
# Where your own wiki pages are (make regular backups of this directory):
data_dir = os.path.join(instance_dir, 'data-1', '') # path with trailing /
navi_bar = [
# If you want to show your page_front_page here:
#u'%(page_front_page)s',
u'标题',
u'FindPage',
u'HelpContents',
]
language_default = 'zh'
在修改linux 时不起作用 :
修改/root/tools/moin-1.9.0/MoinMoin/script/server/standalone.py 全局先
运行:
$>moin server standalone --config-dir=/root/wiki/mywiki/config/ --hostname=192.168.102.207 --port=18081
命令是可调参数:
#/root/tools/moin-1.9.0/MoinMoin/script/server/standalone.py
class PluginScript(MoinScript):
def __init__(self, argv, def_values):
MoinScript.__init__(self, argv, def_values)
self.parser.add_option(
"--docs", dest="docs",
help="Set the documents directory. Default: use builtin MoinMoin/web/static/htdocs"
)
self.parser.add_option(
"--user", dest="user",
help="Set the user to change to. UNIX only. Default: Don't change"
)
self.parser.add_option(
"--group", dest="group",
help="Set the group to change to. UNIX only. Default: Don't change"
)
self.parser.add_option(
"--port", dest="port", type="int",
help="Set the port to listen on. Default: 8080"
)
self.parser.add_option(
"--hostname", "--interface", dest="hostname",
help="Set the ip/hostname to listen on. Use \"\" for all interfaces. Default: localhost"
)
self.parser.add_option(
"--start", dest="start", action="store_true",
help="Start server in background."
)
self.parser.add_option(
"--stop", dest="stop", action="store_true",
help="Stop server in background."
)
self.parser.add_option(
"--pidfile", dest="pidfile",
help="Set file to store pid of moin daemon in. Default: moin.pid"
)
self.parser.add_option(
"--debug", dest="debug",
help="Debug mode of server. off: no debugging (default), web: for browser based debugging, external: for using an external debugger."
)
#成功运行 后
2009-12-20 23:31:31,796 WARNING MoinMoin.log:139 using logging configuration read from built-in fallback in MoinMoin.log module!
2009-12-20 23:31:32,515 INFO werkzeug:106 * Running on http://192.168.1.100:8080/
一些简单的语法介绍『其中 HelpOnDrawings 的功能 有“惊艳”的效果!!呵呵,自己搭建个自己的wiki 出来 看吧』
定义:
灰羊群 (无主见的用户群体)
黑羊 ( 对自己需要什么有明确的认识,我们一般称为专家用户。 )
1. 区分 灰(无主见) 黑 羊群
2.
user session 关联 #当 关联关系维护使用 用户的会话ID(用户不同心情,起始在数据中就应该是不同分类的)
user 推荐 # 而推荐出产品 还是 跟 用户唯一编号有关
#在推荐中需要描述 用户的多角度 问题
3.
蛮力推荐( 全数据 ;描述初期清洗后的数据 ) 适合 产品关联
清洗后期的数据(包含用户多维度描述) 适合 用户关联
4.
专家跟随推荐
描述:
用户分类 找到黑绵羊
找到 一群灰绵羊 和 一只黑绵羊的关联关系
让 一群灰绵羊 可以看 黑绵羊 动作
1,负重深蹲,仰卧起坐,慢跑,主要练习心肺功能(腿部锻炼很重要,如果深蹲完了没体力,慢跑可以改成慢走放松)
2,卧推,仰卧飞鸟,站立飞鸟,仰卧起坐,慢跑,主要练习胸部和肩部(飞鸟就是侧举,仰卧的时候用的是胸的力量,站立时用的是肩)
3,引体向上,划船,曲臂,主要练习背部和胳膊,最后加上固定的项目:仰卧起坐和慢跑放松
1的消耗最大,要自己状态最好的时候去
2主要是练习和“推,举”相关的肌群
3是“拉,收”相关的肌群
而且有个原则,就是先练大项目,再练小项目。
深蹲、卧推、引体向上,这3个是最基本的,别的其实都可有可无
另外,适当慢跑也是必要的,是很好的放松和有氧运动,促进代谢。当然,如果有条件可以去户外跑,宁可跑马路,也别在健身房里跑,空气不理想
做动作也是要循序渐进,每次从很轻的重量开始,逐步加大负荷
下面介绍的排序都为:非比较排序法
这里个人认为在某些特定的地方非比较排序的速度非常明显;
比如 : 对待排数据中有顺序分类,使用鸽巢总体分类,然后对不同类别的待排小数据集合采用 插入,快排等排序方式
Counting sort :计数排序
描述:迭代待排序数组出元素x,确定小于此元素[z]个数,然后把x放到它在的最终输出数组[z]上。
特性:与待排值有关;稳定的排序算法;待排序数据要求过于严格,无实际用处;
算法的步骤如下:
1. 找出待排序的数组中最大和最小的元素
2. 统计数组中每个值为i的元素出现的次数,存入数组C的第i项
3. 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
4. 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
Radix sort:基数排序
描述:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零. 然后, 从最低位开始, 依次进行一次排序.这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列.
排序方式:LSD 由右向左排;MSD 由左向右排
特性:非比较排序;待排数据需要统一格式;
假设需排序数列的取值范围从1...k,我们于是建一个K+1元的数组 a[],并赋初值为0,然后便开始排序工作:
算法的步骤如下:
1. 按输入顺序读入数列,如果所读的元素为i(1<=i<=k),我们就将a[i]的值加一,这样直到读完所有的元素。
2. 读出元素并排序:我们遍历整个数组,如果a[i]=j(j>=0),我们就输出j次i(表示元素i在原先数列中出现了j次),这样输出的序列就是已排序的。
3. 由于一般排序算法涉及到元素之间的比较,如果化成比较树可以知道,这样的排序算法复杂度的下限是O(N*lnN),而计数排序没有比较元素,所以所需排序时间就少了,我们可以看到计数排序的复杂度为O(n*k),其中k(k的定义同上)为合并排列所需的时间,是个常数。
4. 此算法适合所需排列的元素取值范围不大的情况下,否则会造成空间的消耗,比如,一共100个元素,其取值范围从1-100000,显然这个时候用基数排序是不合适的。
Bucket sort:桶排序
描述:工作的原理是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。
桶排序以下列程序进行:
1. 设置一个定量的阵列当作空桶子。
2. 寻访序列,并且把项目一个一个放到对应的桶子去。
3. 对每个不是空的桶子进行排序。
4. 从不是空的桶子里把项目再放回原来的序列中。
Pigeonhole sort:鸽巢排序
描述:是一种时间复杂度为O(n)且在不可避免遍历每一个元素并且排序的情况下效率最好的一种排序算法. 但它只有在差值(或者可被映射在差值)很小的范围内的数值排序的情况下实用.
算法的步骤如下:与桶排同
date demo:
实例:
$>date
Mon Dec 7 15:43:39 CST 2009
#格式化输出
$> date +"%Y-%m-%d"
2009-12-07
#时间游走 当前时间 2009-12-07
# year , month , day ,hour , minute,second - ago
#昨天输出
$> date -d "1 day ago" +"%Y-%m-%d"
2009-12-06
#2秒后输出
$> date -d "2 second" +"%Y-%m-%d %H:%M.%S"
2009-12-07 15:50.04
#传说中的 1234567890 秒
$>date -d "1970-01-01 1234567890 seconds" +"%Y-%m-%d %H:%m:%S"
2009-02-13 23:02:30
#其他格式的转换
date -d "$(echo "03/Nov/2009 11:04:28" |perl -ne 'print "$2 $1 $3 $4\n" if /(.*?)"/(.*?)"/(.*?) (.*)/;') " +%Y-%m-%d
2009-11-03
#普通 转格式
$> date -d "2009-12-12" +"%Y/%m/%d %H:%M.%S"
2009/12/12 00:00.00
#apache 格式转换
$>date -d "Dec 5, 2009 12:00:37 AM" +"%Y-%m-%d %H:%M.%S"
2009-12-05 00:00.37
#格式转换 后时间 游走
$>date -d "Dec 5, 2009 12:00:37 AM 2 year ago" +"%Y-%m-%d %H:%M.%S"
2007-12-05 00:00.37
#时间差
#一小时 3600
#一天 86400 秒
$>st=$(date -d "Dec 5, 2009 12:00:37 AM 1 day ago 1 hour ago " +"%s")
$>et=$(date -d "Dec 5, 2009 12:00:37 AM" +"%s")
$>echo "时间差$[($et-$st)/86400]天,$[($et-$st)/3600%24]小时"
时间差1天,1小时
date --help
Usage: date [OPTION] [+FORMAT] [+FORMAT]
or: date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
Display the current time in the given FORMAT, or set the system date.
-d, --date=STRING display time described by STRING, not `now'
-f, --file=DATEFILE like --date once for each line of DATEFILE
-r, --reference=FILE display the last modification time of FILE
-R, --rfc-2822 output date and time in RFC 2822 format
--rfc-3339=TIMESPEC output date and time in RFC 3339 format.
TIMESPEC=`date', `seconds', or `ns' for
date and time to the indicated precision.
-s, --set=STRING set time described by STRING
-u, --utc, --universal print or set Coordinated Universal Time
--help display this help and exit
--version output version information and exit
工具为 dist/myImg.exe
工具使用:
在 dist 中
myImg.exe Ratio c:/需要等比压缩图片/*.jpg d:/等比后路径 等比款width 等比高height
myImg.exe Watermark c:/水印图片/x.png c:/需要加水印图片/*.jpg d:/添加水印后图片 加水印width处 加水印height处
等比压缩实例:
myImg.exe Ratio
"C:"Documents and Settings"lky"My Documents"My Dropbox"tools"img"src"python"dist"test"img"*.jpg"
"C:"Documents and Settings"lky"My Documents"MyDropbox"tools"img"src"python"dist"test"toimg2"
600 400
结果在 ../dist"test"toimg 目录下 生成 等比图片 testratio_600_400.jpg
水印添加实例:
myImg.exe Watermark
"C:"Documents and Settings"lky"My Documents"My Dropbox"tools"img"src"python"dist"test"img"logo.png"
"C:"Documents and Settings"lky"My Documents"My Dropbox"tools"img"src"python"dist"test"toimg2"*.jpg"
"C:"Documents and Settings"lky"My Documents"My Dropbox"tools"img"src"python"dist"test"toimg3"
100 220
结果在 ../dist"test"toimg3 目录下 生成 等比图片 test_ratio_600_400_watermark_100_220.jpg
安装 python PIL 包
和安装 python py2exe
工具脚本 py
工具编译过程:
python setup.py py2exe
import sys
def imgRatio(imgpath,tpath='.',width=600,height=400):
import Image,os
im = Image.open( imgpath )
im.thumbnail( (width,height) )
imgpath = os.path.split(imgpath)[1]
if not os.path.exists(tpath) : os.makedirs(tpath)
im.save( tpath+'/'+imgpath.split('.')[0]+'_ratio_'+str(width)+'_'+str(height)+'.jpg' )
def imgWatermark(imgwate,imgpath,sw=100,sh=50,tpath='.'):
import Image,os
baseim = Image.open( imgpath )
floatim = Image.open( imgwate )
baseim.paste( floatim, (sw,sh ) )
imgpath = os.path.split(imgpath)[1]
if not os.path.exists(tpath) : os.makedirs(tpath)
baseim.save( tpath+'/'+imgpath.split('.')[0]+'_watermark_'+str(sw)+'_'+str(sh)+'.jpg' )
args = sys.argv
import glob,os
# Ratio /path/*.jpg /tpath width height
if args[1] == 'Ratio' :
for img in glob.glob(args[2]) :
imgRatio(os.path.abspath(img),args[3],int(args[4]),int(args[5]))
# Watermark /path/x.png /path/*.jpg /tpath width height
if args[1] == 'Watermark' :
for img in glob.glob(args[3]) :
imgWatermark(args[2],img,int(args[5]),int(args[6]),args[4])
py2exe
#!/usr/bin/python
# -*- coding: utf-8 -*-
# py2exe file
# 1.install py2exe application
# 2.python setup.py py2exe
from distutils.core import setup
import py2exe
setup(console=['myImg.py'])
# 快排 和 分治 很像 都是 分而治之 ,但他们却是 相反的 方式排序 :
分治 是想拆分完成后,合并以有序的小段进行 排序 ,而快排是直接由原始的“拆分”来 排序 。
#encoding=utf-8
#从 大 到 小
def partition(A,p,r):
tmp=A[p]
while True :
while p+1<r and A[p] > tmp : p+=1
while r-1>p and A[r] <= tmp : r-=1
if A[p]<=A[r]: A[p],A[r]=A[r],A[p]
if r-1<=p : return p
def quickSort(A,p,r):
if p<r:
q=partition(A,p,r)
quickSort(A,p,q)
quickSort(A,q+1,r)
A=[9,61,7,14,-1,7,667,3,6,8]
print A
quickSort(A,0,len(A)-1)
print A
# 结果 [667, 61, 14, 9, 8, 7, 7, 6, 3, -1]
图解:
一次迭代过程描述 (从小到大):
1. 以 A[0] 为切分点 用临时变量 记录 这里是 切分点 = [5]
2. 分别起 2枚指针 [切分起左,右]
3. 分别向中间 靠拢 , 当左指针指向值大于 切分点 停止 左 , 右指针指向值 小于 切分点 停止 右 。
4. 判断 是否是 停止点 上 左值 小于 右值 是:交换两指针值 !
 第一次迭代后 :
第一次迭代后 :
以初始分隔 [5] 就已经切分好了 小于 5 的左 ,大于等于5 的右
转自【http://www.cnblogs.com/coderzh/archive/2008/09/22/1296195.html 】
作者: CoderZh( CoderZh的技术博客 - 博客园)
出处: http://coderzh.cnblogs.com/
# 我这 加了些 个人理解的 说明
#encoding:UTF-8
# [递归] - 单条路 自下往上排序
def heap_adjust(data, s, m):
if 2 * s > m:return
# 声明 预设父节点位置
temp = s - 1
# [左]子节点值 大于 父节点值 : 预设父节点位置 为 左子节点位置
if data[2*s - 1] > data[temp]: temp = 2*s-1
# [右]子节点值 大于 预设父节点 : 预设父节点位置 为 右子节点位置
if 2 * s <= m - 1 and data[2*s] > data[temp]: temp = 2 * s
# 交换值 满足 堆特性 此为 [ 父节点 小于 子节点 ]
if temp <> s - 1:
data[s - 1], data[temp] = data[temp], data[s - 1]
heap_adjust(data, temp + 1, m)
def heap_sort(data):
m = len(data) / 2
# 构建 堆树
# 测试数据 [3,2,1] 数组值为 所以非底层叶节点
for i in range(m , 0, -1):
heap_adjust(data, i, len(data))
# 从堆树中 [出栈] 排序输出
# 测试数据 [5, 4, 3, 2]
data[0], data[-1] = data[-1], data[0]
for n in range(len(data) - 1, 1, -1):
heap_adjust(data, 1, n)
data[0], data[n - 1] = data[n-1], data[0]
data=[2,3,6,3,868,9,8,-1]
heap_sort(data)
print data
# [-1, 2, 3, 3, 6, 8, 9, 868]
转自 【 http://www.cppblog.com/guogangj/ 】
堆存储
 堆 入栈 复杂度为Ο(logn)
堆 入栈 复杂度为Ο(logn)
 堆 出栈 Ο(logn)
堆 出栈 Ο(logn)

http://www.cnpython.org/docs/100/p_19.html
上一回我們談過了圖形介面程式的撰寫,這一次我們要討論圖形 (影像) 本身的處理,而討論的內容將會集中在 Python Imaging Library (PIL) 這一套程式庫上。
PIL
是 Python 下最有名的影像處理套件,由許多不同的模組所組成,並且提供了許多的處理功能,允許我們在簡單的 Python
程式裡進行影像的處理。使用像 PIL 許樣的程式庫套件可以幫助我們把精力集中在影像處理的工作本身,避免迷失在底層的演算法裡面。
由於影像處理牽涉到了大量的數學運算,因此 PIL 中有許多的模組是用 C 語言所寫成的,以提昇處理的效率。不過,在使用的時候,我們當然不必在意這樣的問題,只管放心地用就是了。
PIL 具備 (但不限於) 以下的能力:
- 數
十種圖檔格式的讀寫能力。常見的 JPEG, PNG, BMP, GIF, TIFF 等格式,都在 PIL 的支援之列。另外,PIL
也支援黑白、灰階、自訂調色盤、RGB true color、帶有透明屬性的 RBG true color、CMYK
及其它數種的影像模式。相當齊全。
- 基本的影像資料操作:裁切、平移、旋轉、改變尺寸、調置 (transpose)、剪下與貼上等等。
- 強化圖形:亮度、色調、對比、銳利度。
- 色彩處理。
- PIL 提供十數種濾鏡 (filter)。當然,這個數目遠遠不能與 Photoshop® 或 GIMP® 這樣的專業特效處理軟體相比;但 PIL 提供的這些濾鏡可以用在 Python 程式裡面,提供批次化處理的能力。
- PIL 可以在影像中繪圖製點、線、面、幾何形狀、填滿、文字等等。
接下來,我們開始一步一步地對 Python/PIL 的影像處理程式設計進行討論。
市面上有許多影像處理程式,一般人最常用它們來處理的工作大概就是圖檔格式轉換了;這是影像處理軟體最基本的功能,PIL 當然也要支援。
假設我們有一個 JPG 檔案,名字叫作 sample01.jpg,那麼,以下的程式會把這個檔案載入 Python:
>>> import Image
>>> im = Image.open( "sample01.jpg" )
im 這個物件是由 Image.open() 方法所產生出來的 Image 物件。我們可以用 Image 物件內的屬性來查詢關於此檔案的資訊:
>>> print im.format, im.size, im.mode
JPEG (2288, 1712) RGB
格
式字串放在 format 屬性裡,尺寸放在 size 屬性裡,而 (調色盤) 模式放在 mode
屬性裡。從以上的執行結果,可以看出來我們讀的確實是一個 JPEG 檔案,檔案的尺寸是 2288 像素寬、1712 像素高,調色盤是 RGB
全彩模式。
既然我們已經把圖檔讀入了 Python,要處理它就簡單了。利用 Image 類別的 save() 方法,可以把檔案儲存成 PIL 支援的格式:
>>> im.save( "fileout.png" )
如果圖檔很大,這會花上一點時間。Image.save() 方法會根據欲存檔的副檔名,自動判斷要存圖檔的格式 (剛剛我們用的 open() 函式也會這樣作)。
save() 可以指定存檔格式。在以下的例子裡,我們把存檔格式指定為 JPEG:
>>> im.save( "fileout.png", "JPEG" )
這時候副檔名是無所謂的。
只處理一兩個檔案的時候,使用 Python 直譯器就相當合適。然而若要處理一大群檔案,譬如把一整個目錄的 JPEG 檔轉換為 PNG 檔,那麼寫成一個程式檔會比較方便,例如:
#!/usr/bin/env python
from glob import glob
from os.path import splitext
import Image
jpglist = glob( "python_imaging_pix/*.[jJ][pP][gG]" )
for jpg in jpglist:
im = Image.open(jpg)
png = splitext(jpg)[0]+".png"
im.save(png)
print png
只要在一個放了 *.jpg 或 *.JPG 檔案的目錄裡面執行這個指令稿,它就會把所有的 JPEG 檔轉成 PNG 檔案:
$ ./convertdir.py
file0001.png
file0002.png
.
.
file9999.png
既然 PIL 會從檔名偵測常用的檔案格式,存檔時我們通常都不會指定存檔格式。
然
而,依據檔案格式的不同,save() 方法提供了不同的選項參數。以 JPEG 而言,它可以接受 quality (從 1 到 100
的整數,預設為 75)、optimize (真假值) 及 progression (真假值)。在以下的例子裡,我們以 100 的
quality 來儲存 JPEG 檔案:
>>> im.save( "quality100.jpg", quality=100 )
要訣
PIL 也支援 EPS (Encapsulate PostScript) 格式的寫入。TeX 的使用者可以利用 PIL 來簡單地把圖檔轉成 EPS 以供 TeX compiler 使用。
在了解了基本的圖檔轉換之後,我們來看看如何對影像進行尺寸方面的修改。PIL 對 Image 物件提供了 resize 方法,以執行影像的縮放工作。用我們的 sample01.jpg 檔案來當例子:
>>> im = Image.open( "sample01.jpg" )
>>> print im.size
(2288, 1712)
>>> width = 400
>>> ratio = float(width)/im.size[0]
>>> height = int(im.size[1]*ratio)
>>> nim = im.resize( (width, height), Image.BILINEAR )
>>> print nim.size
(400, 299)
>>> nim.save( "resized.jpg" )
然後我們就會得到比較小的 resized.jpg:
resize()
這個方法會傳回一個新的 Image 物件,所以舊的 Image 不會被更動。resize()
接受兩個參數,第一個用來指定變更後的大小,是一個雙元素
tuple,分別用以指定影像的寬與高;第二個參數可以省略,是用來指定變更時使用的內插法,預設是 Image.NEAREST
(取最近點),這裡我們指定為品質比較好的 Image.BILINEAR。
resize() 可以把影像放大縮小,在使用時一定要傳入寬與高。上面的程式會先限定新影像的寬,再根據舊影像的長寬比例來算出新影像的高應該是多少,最後把尺寸值傳入 resize() 去。由此可知,resize() 是允許我們不等比例縮放的:
>>> width = 400
>>> height = 100
>>> nim2 = im.resize( (width, height), Image.BILINEAR )
>>> nim2.save( "resize2wide.jpg" )
會得到形狀奇怪的縮圖:
我們可以任意改變新影像的尺寸值。
另一個常用的操作是旋轉;rotate() 方法可以用來旋轉影像。它取兩個參數,第一個參數是一個逆時針的度數,第二個參數則也是影像處理時的內插法,可省略:
>>> nim3 = nim.rotate( 45, Image.BILINEAR )
>>> nim3.save( "rotated.jpg" )
rotate() 並不會改變影像的尺寸 (dimension),所以你會看到:
出現了黑邊。如果我們想要連影像尺寸一起變動,得要改用 transpose() 方法:
>>> nim4 = nim.transpose( Image.ROTATE_90 )
>>> nim4.save( "transposed90.jpg" )
結果是:
transpose()
方法接受 Image.FLIP_LEFT_RIGHT, Image.FLIP_TOP_DOWN, ROTATE_90, ROTATE_180,
ROTATE_270 等五種參數;其中後三種的旋轉均為逆時針。rotate() 方法會對像素資料進行內插;而 transpose()
則只是轉置像素資料,所以沒有內插參數可以設定,也不會影響影像的品質。
縮放與旋轉是最常用的兩個操
作,而在其中,縮圖的製作可能是特別常用的;PIL 對縮圖提供了一個方便的 thumbnail() 方法。thumbnail() 會直接修改
Image 物件本身,所以速度能比 resize()
更快,也消耗更少的記憶體。它不接受指定內插法的參數,而且只能縮小影像,不能放大影像;用法是:
>>> im = Image.open( "sample01.jpg" )
>>> im.thumbnail( (400,100) )
>>> im.save( "thumbnail.jpg" )
>>> print im.size
(133, 100)
thumbnail()
在接受尺寸參數的時候,行為與 resize() 不同;resize() 允許我們不等比例進行縮放,但 thumbnail()
只能進行等比例縮小,並且是以長、寬中比較小的那一個值為基準。因此,上面的程式所作出的 thumbnail.jpg 變成了 133*100
的小圖片:
有了這些操作,我們可以很輕易地執行影像管理的任務。
除了可以針對圖形的尺寸作變更之外,PIL 更提供我們變更影像內容的能力。這樣,我們就不只能對影像進行管理,而能更進一步地利用程式來把影像的內容改成我們想要的樣子。
我們從「貼圖」開始:
>>> baseim = Image.open( "resized.jpg" )
>>> floatim = Image.open( "thumbnail.jpg" )
>>> baseim.paste( floatim, (150, 50) )
>>> baseim.save( "pasted.jpg" )
利用 paste() 方法,把之前作的 thumbnail.jpg 貼到 resized.jpg 裡面去:
此種用法的 paste() 方法要求兩個參數,第一是要貼上的 Image,第二是要貼上的位置。第二個參數有三種指定的方式:
- None:不指定位置與尺寸,那麼 pasted() 會假設要貼上的 Image 與被貼上的 Image 的尺寸完全相同。
- (left, upper):雙元素 tuple。pasted() 會把要貼上的 Image 的左上角對齊在指定的位置。
- (left,
upper, right, lower):四元素 tuple。paste()` 除了會把 Image
的左上角對齊外,也會對齊右下角。不過基本上這種寫法和上面那一種一樣,因為 paste()
要求要貼上的影像與這裡指定的尺寸一致,所以不可能出現不同的兩組 right, lower。
除了「貼圖」之外,我們還可以對影像的內容進行裁切:
>>> im = Image.open( "sample01.jpg" )
>>> nim = im.crop( (700, 300, 1500, 1300) )
>>> nim.thumbnail( (400,400) )
>>> nim.save( "croped.jpg" )
(因為裁切之後的圖形還是大了點,所以再縮圖一次) 得到的結果是:
crop() 接受的 box 參數指定要裁切的左、上、右、下四個邊界值,形成一個矩形。
除了剪貼之外,PIL 還可以使用內建的濾鏡 (filter) 作一些特效處理。這些濾鏡都放在 ImageFilter 模組裡面,使用前要先匯入這個模組:
>>> import ImageFilter
我們用個例子,對剛剛裁切的 "No Riding" 禁止牌作 20 次 blur (糊化),來看看 PIL 濾鏡的效果:
>>> im = Image.open( "croped.jpg" )
>>> nim = im
>>> for i in range(20): nim = nim.filter( ImageFilter.BLUR )
...
>>> nim.save( "blured.jpg" )
你應該看不出來它是 "No Riding" 了吧:
使用濾鏡的基本語法是:
newim = im.filter( ImageFilter.FILTERNAME )
其
中 FILTERNAME 是 PIL 中支援的濾鏡名稱,目前有:BLUR, CONTOUR, DETAIL, EDGE_ENHANCE,
EDGE_ENHANCE_MORE, EMBOSS, FIND_EDGES, SMOOTH, SMOOTH_MORE,
SHARPEN,此處就不一一介紹了,但建議你可以自己來把每一個濾鏡都試試看。
利用濾鏡,我們可以對同一類的影像進行相同的特效處理。當然,影像特效需要很精細的調整,在自動化作業中通常只能達到很粗略的效果;但 PIL 既然提供了,我們的自動程序就擁有更多的工具可以使用。
除了對已存在的影像進行編修之外,從零開始建立新影像也是很重要的工作。PIL 中的 ImageDraw 模組提供給我們繪製影像內容的能力。在使用 ImageDraw 之前,要先建立好空白的新影像:
>>> import ImageDraw
>>> im = Image.new( "RGB", (400,300) )
>>> draw = ImageDraw.Draw( im )
最
後建出來的 draw 是一個 ImageDraw 物件會提供各種繪製影像的方法。針對幾何圖形,draw 物件提供 arc()
(弧線)、chord() (弦)、line() (線段)、ellipse() (橢圓)、point() (點)、rectangle()
(矩形) 與 polygon() (多邊形)。不過,我們不準備討論幾何圖形的繪製;相信這些方法的使用對一般人來說應該都很直覺才是。
要訣
你
可以在指令行輸入 pydoc ImageDraw.ImageDraw.<<methodname>> 來查詢上述方法
(<<methodname>>) 的說明,譬如 pydoc ImageDraw.ImageDraw.line。
這裡要介紹的不是幾何圖形,而是文字的繪製。我們要再介紹一個模組:ImageFont,並且以實例來說明如何用 PIL 「寫字」:
>>> import Image, ImageDraw, ImageFont
>>> font = ImageFont.truetype( "
... "/usr/share/fonts/truetype/freefont/FreeMono.ttf", 24 )
>>> im = Image.new( "RGB", (400,300) )
>>> draw = ImageDraw.Draw( im )
>>> draw.text( (20,20), "TEXT", font=font )
>>> im.save( "text.jpg" )
這樣就在一個黑色底圖上用白筆寫了 "TEXT" 四個大字:
接
著一一說明剛剛作的動作。首先我們用 ImageFont 的 truetype() 函式建立了一個 TrueType 字型,大小設定為 16
點。truetype() 函式的第一個參數必須是字型檔的搜尋路徑,第二個參數是字型的點數。然後依序建立影像物件與 draw 物件。寫字的動作用
draw 物件的 text() 方法來完成,它接受兩個參數,分別是文字的左上角點、字串,另外可以用 font 選項來指定所使用的字型
(若不指定,便使用預設字型)。
在 1.1.4 版之前,PIL 是只能使用點陣字型的。現在
PIL 加入了 TrueType 向量字型的支援,對於要「寫字」的人來說實在是一大福音。對點陣字來說,想改變字型的大小得要更換字型才作得到,但
TrueType 就沒有這個限制。如果我們想要寫出兩串不同大小的文字,這樣作就可以了:
>>> largefont = ImageFont.truetype( "
... "/usr/share/fonts/truetype/freefont/FreeMono.ttf", 48 )
>>> smallfont = ImageFont.truetype( "
... "/usr/share/fonts/truetype/freefont/FreeMono.ttf", 24 )
>>> im = Image.new( "RBG", (400,300) )
>>> draw = ImageDraw.Draw( im )
>>> draw.text( (20,20), "SmallTEXT", font=smallfont )
>>> draw.text( (20,120), "LargeTEXT", font=largefont )
>>> im.save( "multitext.jpg" )
結果如:
以上就是在 PIL 裡建立文字圖形的方法。
最後,我們要說明如何改變繪製圖形 (文字) 時的顏色;繪圖時畫筆的顏色是透過 draw 物件的 ink 屬性來改變的:
>>> draw.ink = 0 + 255*256 + 0*256*256
以上會把畫筆設成綠色。ink 值必須要是一個整數,其值由色彩的 RGB 值算出。舉幾個 ink 值的例子:
- 紅色的 ink 值應設為 255(R) + 0(G)*256 + 0(B)*256*256,
- 藍色的 ink 值應設為 0(R) + 0(G)*256 + 255(B)*256*256,
- 靛色的 ink 值應設為 0(R) + 255(G)*256 + 255(B)*256*256
所設定的 ink 會影響所有後續的繪圖動作。
本文介紹了方便好用的 PIL 套件,可以讓我們用 Python 撰寫影像處理的程式。我們對圖檔的格式處理、尺寸處理以及內容的編修都作了討論,最後也說明如何從零開始創作一個影像。
對網頁程式來說,動態產生簡單的影像是特別有用的功能,可以用來補足 HTML 與 CSS 的不足之處。利用 PIL 來執行批次影像處理的工作,更能省去我們許多的操作時間。相信讀者能從其中發現它所提供的生產力。
|
|
| |
|
看第二节 - 递归树方法 :
突发奇想 能否 使用 txt 构造出 递归过程
还是有 上此提到的 递归方法 分治排序
# encoding: utf-8
arr=[]
def printTree():
ac = []
ii = 0
for r in arr :
c,ss,cc = r
sc = [' ' for i in xrange(cc*(c-1))]
for i in xrange(len(sc)) :
if i % cc == 0 : sc[i]="│"
#print "ci %s ii %s = %s "%(ci,ii,ii < ci)
if ii>=c :
sc = "".join(sc)+"├─"+ss+' '
else :
sc = "".join(sc)+"└─"+ss
ii = c
ac.append( sc )
for r in ac[::-1] :
print r
def MERGE(A,p,q,r):
#print "%s:%s - %s:%s" % (p,q+1,q+1,r+1)
if p==q : L = [A[p],10**10]
else : L = A[p:q+1]+[10**10]
if q+1==r : R = [A[r],10**10]
else : R = A[q+1:r+1]+[10*10]
i = j = 0
for k in xrange(p,r+1):
if L[i]<R[j] :
A[k]=L[i]
i+=1
else:
A[k]=R[j]
j+=1
# print "%s:%s = %s \n%s:%s = %s\n\n%s" % ( p,q, L , q+1,r,R, A)
def MERGE_SORT(A,p,r,c=1):
if p<r:
q = (p+r)/2
MERGE_SORT(A,p,q,c+1)
MERGE_SORT(A,q+1,r,c+1)
arr.append( (c,"%s - %s" % ( A[p:q+1],A[q+1:r+1]) , 3 ) )
# Debugging(A,p,q,r, sc )
MERGE(A,p,q,r)
A=[5,2,7,4,1,3,2,6]
MERGE_SORT(A,0,len(A)-1)
print A
printTree()
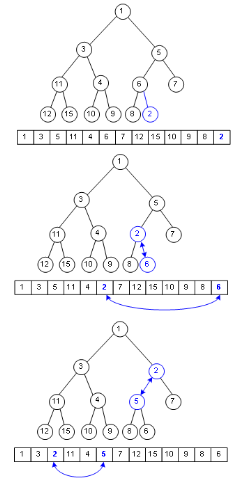
输出 (重下往上看 输出 排序过程 ,我就不多说了 应该很好理解了!!):
[1, 2, 2, 3, 4, 5, 6, 7]
├─[2, 4, 5, 7] - [1, 2, 3, 6]
│ ├─[1, 3] - [2, 6]
│ │ ├─[2] - [6]
│ │ └─[1] - [3]
│ ├─[2, 5] - [4, 7]
│ │ ├─[7] - [4]
│ │ └─[5] - [2]
使用参考: http://boss-wu.com/?p=627
R 语言简介

3.1 渐近号
渐近范围 f(n) = θ(g(n)) ~a=b
渐近上界 f(n) = Ο(g(n)) ~a<=b 0≤f(n)≤cg(n)
渐近下界 f(n) = Ω(g(n)) ~a>=b 0≤cg(n)≤f(n)
非渐近上界 f(n) = o(g(n)) ~a<b 0≤f(n)<cg(n)
=>lim[n<=∞](f(n)/g(n))=0
非渐近下界 f(n) = ω(g(n)) ~a>b 0≤cg(n)<f(n)
=>lim[n<=∞](f(n)/g(n))=0
渐近号使用(目前我能理解到的!):
当渐近符号出现在某个公式中时,我们将其解释为一个不在乎其名称的署名函数。
例:2n^2+3n+1 = 2n^2+θ(n) ,这种用法有助于屏蔽无关紧要的细节,如低阶项。。
∑[1≤k≤n]O(i)
3.2 标准记号和常量函数
单调性 : 单调递增 , 单调递减
# 传说中的广播体操原来是 上下取整啊 ! 呵呵
下取整,上取整 : x-1 < └X┘ <= x <= ┌X┐ < x+1
取模运算 a mod n = a-└a/n┘n
多项式 p(n) = ∑[0≤i≤d] a.i n^i
指数 (a^m)^n = a^(m*n) ; a^m*a^n = a^(m+n)
# 指数中的 特殊符号 e
# e不论对x微分几次,结果都还是e!难怪数学系学生会用e比喻坚定不移的爱情!
# 数学中的爱情符号 e 哈哈!!
e = lim[n≤∞ ](1+1/n)^n
对数
lgn = log_2(n)
lnn=log_e(n)
lg^k(n)=(lgn)^k
lg lg n = lg(lgn)
阶乘 n!
函数迭代
斐波那切
F0 = 0
F1 = 1
..
Fi = Fi-1+Fi-2
数据说明:
knnuu_...txt 文件大小 3.2G 数据格式是
user1 user2 score
..
usern userm score
我这里希望通过清洗得到:
与 user1 关系最近的 top 100 人
由于数据并非需要百分之百准确,我放弃在分隔出的数据
if len(dr)!=3 : continue
开了 7 个线程 也就是 会有 7 个 用户 的 uid 对 top 100 uid 会出现问题
对应 总用户数几十万来说 呵呵 ! 我就用这 完善7个特殊人的列表时间写个 blog 吧
并结合 linux split , awk 等 快速实现的 猥琐 多线程 哈哈!!
怎么修改下 速度提升 5倍,原来的 一小时 到 10多分钟 。。。。。
# split --bytes=500m knnuu_20091123.txt knnuu/
# ls a* | awk '{system( " python uu.py "$0" & " )}'
import bsddb,sys
db = bsddb.hashopen('../id-item-y-09-10-11.db','c')
uid = -1
arr=[]
arrsc=[]
fw = open('tc/'+sys.argv[1]+'uid-uid-sc.txt','w')
ii=0
def insertion_sort(arr,arrsc,uid,sc):
ls = min(100,len(arrsc))
if ls!=0 and sc < arrsc[ls-1] : return
for i in xrange(ls):
if arrsc[i]<=sc :
arrsc.insert(i,sc)
arr.insert(i,uid)
return
elif arrsc[i] > sc : continue
if ls < 99 :
arr.append(uid)
arrsc.append(sc)
#for row in open('knnuu_20091123.txt') :
for row in open(sys.argv[1]):
dr = row.split('\n')[0].split('\t')
if len(dr)!=3 : continue
u1,u2,strsc = dr[0],dr[1],dr[2]
sc = float(strsc)
if uid == -1 : uid = u1
if u1 != uid :
for c in xrange( min(100,len(arrsc)) ):
tu = arr[c]
ts = arrsc[c]
print >>fw,"%s\t%s\t%s" % ( db[u1],db[tu],ts )
print uid
fw.flush()
arr=[u1]
arrsc=[sc]
uid=u1
else :
insertion_sort(arr,arrsc,u2,sc)
ii+=1
#print ii,u1,uid,u2,strsc,len(arr),len(arrsc)
#if ii>10 : break
fw.close()
公式:

#数据 elt 清洗后(txt)
# 一般 user 和 item 分值化
# 比如 用户下载,收藏,试听 某item 等等
user items score
.
# 结果输出 (bdb)
# user item1:score1,item2:score2,item3:score3.
python<<EOF
import bsddb
db = bsddb.hashopen('user-items.db','c')
for row in open('user-item-sc.txt'):
row=row.split('\n')[0]
dr = row.split(':')
if not db.has_key(dr[0]) : db[dr[0]]=dr[1]+':'+dr[2]
else : db[dr[0]]=db[dr[0]]+';'+dr[1]+':'+dr[2]
db.close()
EOF
# 结果输出 (txt)
# user user score
python<<EOF
import bsddb
from math import *
db = bsddb.hashopen('user-items.db','c')
def ps(u1,u2):
um1={}
for v in db[u1].split(';') :
v=v.split(':')
um1[v[0]]=float(v[1])
um2={}
si=[]
for v in db[u2].split(';') :
v=v.split(':')
um2[v[0]]=float(v[1])
if um1.has_key( v[0] ) : si.append(v[0])
n = len(si)
if n ==0.0 :return None
sum1=sum( [um1[it] for it in si] )
sum2=sum( [um2[it] for it in si] )
sum1Sq=sum([ pow(um1[it],2) for it in si])
sum2Sq=sum([ pow(um2[it],2) for it in si])
pSum = sum( [ um1[it]*um2[it] for it in si ] )
num = pSum - (sum1*sum2/n)
den = sqrt( (sum1Sq-pow(sum1,2)/n )*( sum2Sq-pow(sum2,2)/n ) )
if den==0.0 : return None
return num/den
fc = open('user-user-sc.txt','w')
for i in xrange(1,43381):
for j in xrange(i+1,43381):
sc = ps(str(i),str(j))
if not sc == None: print >>fc, "%s\t%s\t%s" %(i,j,sc)
fc.close()
EOF
# 测试使用
python<<EOF
import bsddb
db = bsddb.hashopen('user-items.db','c')
print db['1']
EOF
25 30604 1.0
print um1['468'],um1['471']
2.0 1.0
(Pdb) print um2['468'],um2['471']
2.0 1.0
如果对大家对 推荐有一些了解,数据能到 用户与用户关系(分值化) ,是能干很多事情了。
比如:
1. 首先得到某用户相近度最高的几位活跃用户,看这几位用户在看什么,听什么 然后推荐出去
扩展:
把初始值 反过来 item user score ,然后统计出 item 和 item 之间的关系 。
当 消费某一产品 ,马上推荐出 其他的相近的产品 (時时推荐)
算法导论,一章二小节 ,分治算法
def MERGE(A,p,q,r):
print "%s:%s - %s:%s" % (p,q+1,q+1,r+1)
if p==q : L = [A[p],10**10]
else : L = A[p:q+1]+[10**10]
if q+1==r : R = [A[r],10**10]
else : R = A[q+1:r+1]+[10*10]
i = j = 0
for k in xrange(p,r+1):
if L[i]<R[j] :
A[k]=L[i]
i+=1
else:
A[k]=R[j]
j+=1
# print "%s:%s = %s \n%s:%s = %s\n\n%s" % ( p,q, L , q+1,r,R, A)
def Debugging(A,p,q,r,c):
print "%s\t%s:%s - %s:%s" % (c,p,q,q+1,r)
def MERGE_SORT(A,p,r,c=1):
if p<r:
q = (p+r)/2
MERGE_SORT(A,p,q,c+1)
MERGE_SORT(A,q+1,r,c+1)
#Debugging(A,p,q,r,c)
MERGE(A,p,q,r)
A=[5,2,7,4,1,3,2,6]
print A
MERGE_SORT(A,0,len(A)-1)
print A
结果输出》》
python 2f.py
[5, 2, 7, 4, 1, 3, 2, 6]
[1, 2, 2, 3, 4, 5, 6, 7]
分享些细节:算法并不难,但确实写了很久,调试让我很郁闷。
直到写了 def Debugging 目测:
python 2f.py
3 0:0 - 1:1
3 2:2 - 3:3
2 0:1 - 2:3
3 4:4 - 5:5
3 6:6 - 7:7
2 4:5 - 6:7
1 0:3 - 4:7
看 每层 对数组的 数组下标取值 :
在 python 中当
arr = [1,2,3,4] 我希望能取出 [2,3] 是 arr[1:3] 是最后一位不计算在内的
最典型的 arr[0,1] == [1]
这是一个很有用的 公式比如:用户消费分值权重 , 产品关联分值权重 等等
公式 
在 http://www.wolframalpha.com 中表示 :
e = (1+1/n) ^n
a*e^(-(x-b)^2/c^2)
a 峰值最大值
b 峰值x轴偏移量
c 弧度跨度
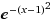 = 1*e^(-(x-1)^2/1^2)
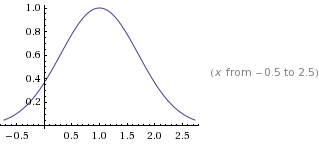
修改 峰值 a = 2
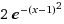
这里 就 不一一展现 b 峰值x轴偏移量 , c 弧度跨度 了 大家可以 去 wolframalpha 自己去尝试
实例1 与时间有关的递减 :
import math
def gaussian(x,peak=1.0,axis=1.0,span=1.0):
return peak*math.e**(-(x-axis)**2/(span)**2 )
跨度 c 参考:
c = 1 : 在2.5 附件急剧衰减
c = 2 : 4
c = 18 :30 # 这个数 衰减统计 一个月 不错
c = 55 :90 # 衰减统计 一个季度 不错
#简单应用
消费1次得峰值4分 浏览1次峰值2分
统计某用户季度得分
数据:在前10天浏览10次,消费1次 ,前11天浏览5次
d10 = gaussian(10,span=55.0)
d11 = gaussian(11,span=55.0)
print d10*10*2+d10*4*1+d11*5*2
#结果 33.0407089687
倒的高斯 - 实例2 :
公式 = 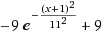
目的 与次数有关的产品分值化
#用户 对 某产品 分值化
# 比如 某用户 用过某产品 n次,我希望 n 无限大是一个 渐进某个值 而不是和 n 无限递增的
#下面的 fun 结果是 1.6 ~ 10 分值直接的区域, 也就是 传说中的 产品感兴趣 “10分制” 简易版
def gs(x,peak=9.0,axis=-2.0,span=11.0):
return "%.4f" % (-1*peak*math.e**(-(x-axis)**2/(span)**2 )+peak+1)
>>> gs(1)
'1.6451'
>>> gs(2)
'2.1148'
>>> gs(3)
'2.6800'
>>> gs(4)
'3.3161'
>>> gs(5)
'3.9970'
>>> gs(6)
'4.6969'
>>> gs(60)
'10.0000'
算法导论 - 算法入门 ,一小节(插入排序,复杂度)
# 插入排序 - 复杂度
def insertion_sort(arr): # 1
for j in xrange( 1,len(arr) ): # n-1
key = arr[j] # n-1
i=j-1 # n-1
while i>=0 and arr[i]> key : # n(n-1)/2
arr[i+1] = arr[i] # n(n-1)/2
i=i-1 # n(n-1)/2
arr[i+1] = key # n-1
print arr # n-1
验证结果 :
>>> arr=[5,2,4,6,1,3]
>>> insertion_sort(arr)
[2, 5, 4, 6, 1, 3]
[2, 4, 5, 6, 1, 3]
[2, 4, 5, 6, 1, 3]
[1, 2, 4, 5, 6, 3]
[1, 2, 3, 4, 5, 6]
验证复杂度:
z = 5(n-1)+1+3n(n-1)/2
我们测试数据 为 n=6
当数据极端情况就是需要全部重新排列
就是 [6,5,4,3,2,1] 要排出 [1,2,3,4,5,6] 这样
>> z = 71
一种比较笨的 验证方法 供大家拍砖 :
def insertion_sort(arr):
ii=0
ii+=1
for j in xrange( 1,len(arr) ):
ii+=1
key = arr[j]
ii+=1
i=j-1
ii+=1
while i>=0 and arr[i]> key :
ii+=1
arr[i+1] = arr[i]
ii+=1
i=i-1
ii+=1
arr[i+1] = key
ii+=1
print arr
ii+=1
print "----",str(ii)
>>> arr=[6,5,4,3,2,1]
>>> insertion_sort(arr)
[5, 6, 4, 3, 2, 1]
[4, 5, 6, 3, 2, 1]
[3, 4, 5, 6, 2, 1]
[2, 3, 4, 5, 6, 1]
[1, 2, 3, 4, 5, 6]
---- 71 #复杂度验证为 71
罗嗦下 n(n-1)/2
极端情况下
i=1 ; j 需要挪动 1次
i=2 ; j 挪动 1+2次
i=3 ; j 挪动 1+2+3次
....
i=n ; j 挪动 1+2....+n
我们又找到 (1+n)+(2+n-1)+(3+n-2).... = (1+n)n/2
我们这 的 i 是从 2 次开始的 也就是说 (n-1)n/2 了
def tn(ii):
ti=0
for i in xrange(ii) :
for j in xrange(i) :
ti+=1
print ti
print tn(2) #1 = 1
print tn(3) #3 = 1+2
print tn(4) #6 = 1+2+3
..
|