在拥挤的公交车上读完《工作流管理(模型、方法和系统)》,自从搬完家,上班的路途突然变得遥远。
这本书确实是按照它的副标题组织的,分别介绍工作流的建模模型、应用工作流开发的方法以及部分商业的工作流产品。
对petri网的介绍是这本书的重点,如果想对petri网有个大概的了解而又不愿意接触深奥的数学,那么可以一读。本书随后分析了如何对流程模型进行分
析,包括对建模正确性与否的定量分析以及对资源运行效率的定性分析。至于介绍的工作流产品,因为年代久远,可读性不高。应用工作流开发的方法就更是理论
了,不过作为一本2000年的书,里面提到的一些原则还是很有敏捷的意思,例如和客户在一起、迭代开发、交流的重要性等等。
读完这本书,加上先前的范玉顺的书,突然就明白为什么BPEL会如此之流行,原因在于它们都非常强调BPR的概念,即业务流程重组。也就是从一开始,工作
流系统就是瞄准BPR这个目标来的,想利用工作流系统将整个企业的业务流程都管理起来。目标如此远大,整合自然是不能避免,整合包括了对人员的整合,也包
括了对IT系统的集成。如此以来,恍然大悟:BPEL这种强调服务集成的执行语言无怪乎会大红大紫了。至于说国内最普遍的工作流应用:将工作流引擎嵌入应
用系统中,分离流程逻辑与业务逻辑,则自然登不了大雅之堂了。一句话说,就是国内应用工作流的层次太低。或者反过来也可以理解:现在的所谓BPM软件都眼
高手低,不太适合国内的应用。
可是问题依旧存在,即BPEL根本上说是一种执行语言,要业务人员理解简直是强人所难,所以BPMN应运而生。好吧,BPMN有了,自然BPMN到
BPEL的映射就出现了,可惜这终究是一厢情愿,一种是业务建模语言,一种是计算机执行语言,中间的代沟比70、80还宽。就像科比,篮筐在他眼里比大海
还广阔。
此外,BPEL的应用还存在一个天然的障碍,即应用集成从来都不是一件轻松的事情。将接口用web
service包装一下就SOA了?就面向服务了?这鬼话你也信,那可真是你服务,你全家才服务呢。应用集成不轻松,所谓的企业敏捷性:能够根据外部环境
的变化迅速调整服务编排流程那自然是镜中月,水中花了。君不见,无数程序员们在开口大骂:靠,流程又要调整,早吃屎了?!
所以结论有三:
1、国内的嵌入式工作流应用还是什么适用就用什么吧,和XPDL\BPEL都无关;
2、一心要SOA、要BPEL。那别指望它能减少工作量,也别指望流程能够迅速修改;
3、要对企业流程进行敏捷管理,那就考虑文档化,别考虑执行。
posted @
2009-02-19 14:20 ronghao 阅读(1830) |
评论 (7) |
编辑 收藏
大概花了三天的时间读完这本书,书本身也不厚,读起来很快。这本书出版于2001年,所以对它也没有抱有很大的期望,但是还不错,特别是前三章,很有些惊喜。后面关于工作流仿真的描述也很到位。但是关于技术实现,则大都略过了。
总结一下里面个人觉得不错的部分。
第一章很不错,强调为什么需要工作流管理系统。
企业经营环境的变化:过去企业市场竞争主要围绕着如何提高生产率进行,现在则是围绕新产品的竞争而展开。新产品的价格总是高于其价值,通过竞争,价格才逐渐接近价值,产品失去独占期,同时也意味着产品生命周期的结束。与产品生命周期缩短所对应的,是客户定制产品数量的增加。
在这种情况下,传统串行的产品研制会延长产品的上市时间,同时串行过程也是在企业以功能为核心划分组织机构下的必然产物。
敏捷制造提出的背景:用户需求多样化、个性化,所有企业都将处于一种连续改变、不可预见的市场环境中,此时问题的核心在于是否抓住机遇、快速响应市场、开发新产品。敏捷制造的基本思想是,企业能够对持续变化、不可预测的市场需求做出快速反应,强调面向市场的敏捷性。实现敏捷制造的关键是对企业进行敏捷化改造和重组。其中企业组织结构发生重大的变化,传统的企业组织结构是功能部门制,即按照不同的功能和职能设立不同的部门,上下级之间形成一个树型的结构。这种结构的缺点在于:每个单元都由上一级的功能单元进行管理,出现问题时,每一级都会把责任推到上一级,这样会造成部门职责不清。柔性底,一个生产流程往往跨越多个部门,部门之间的协调成本很高,扯皮。需要建立起面向流程的组织机构,按照企业要实现的主要业务流程来配置组织机构,以项目来组织人员,减少内部不必要的沟通协调成本,提高对市场的响应速度。
由此,需要工作流系统来对企业的流程进行分析和梳理。然后围绕这些流程来进行企业的业务重组和改造。
第二章的亮点在于如何实施工作流系统。
工作流的实施不同于普通的业务处理系统,它首先需要在战略层次上对企业的业务目标进行分析,确定企业的战略目标和组织要求,然后再进入到具体的实施阶段,分为三个阶段:模型建立阶段、模型实例化阶段和模型执行阶段。实施工作流的目的在于提高企业的柔性,能够根据市场的变化不断改进其业务流程。其中作者强调了工作流的两个重要职责:集成和仿真。工作流系统本身是一个完成流程建模和流程管理的软件系统,但是为了在企业的实际业务中得到有效的应用,它必须和企业已有的或购买的其他业务系统实现集成,通过集成来提高整个企业 的应用水平和应用效率。
第三章分析工作流系统的组成以及WFMC定义的五个接口。很清晰。
第四章到第八章描述具体商业产品的大概技术实现、XPDL规范和分布式的工作流,由于现在已经是B/S软件的天下,所以里面的分布式在这里显得理所当然。这部分可以跳过。
第九章讲述作者实现的一个工作流系统CIMFlow。亮点在于分布式工作流机的设计方案。
核心思想是:多个工作流机分配给多个部门,与这个部门相关的流程或流程节点就由这个部门专属的工作流机执行,部门可以各自独立修改这些流程或流程节点。另外为了集中管理,再设置一个主控工作流机,集中管理这些部门工作流机。这样可以提高流程的柔性。很赞的思想,但是实现无疑复杂了。
第十章讲如何在企业流程重组中应用工作流。偶觉得,这本书一旦上升到企业运营的层次讲解工作流,马上就很赞了,O(∩_∩)O~。其中关于流程仿真部分很是好看,颠覆了自己对流程仿真的观点。以前认为是流程仿真是确保流程建模的逻辑正确,属于软件测试的范畴。这里的仿真却是为企业决策提供数据。需要注意的是对资源的定义。资源包括了人、业务系统、运营成本等等,很广义的概念。
最后一章再次强调工作流集成能力的重要意义。不禁让我想起了BPEL。
合上书,我想,这是在讲工作流吗,( ⊙o⊙ )?,咋和我印象中的工作流不一样哩。我想,作者更强调的应该是一种高端的业务流程管理,它既不是现有的工作流、也不是BPM软件,然而又不是BPG,因为它管理的流程是可以马上执行的。只能这么想,作为7年前作者对工作流的理解,期望太多。
如果有电子版,值得一读,如果买纸版,就没有必要了。
posted @
2009-02-09 18:07 ronghao 阅读(2482) |
评论 (3) |
编辑 收藏
在温暖的办公室里写下这些字的时候,外边的天气很好,目光从明亮的窗户扔出去刚好能够触到西直门,所以这应该算是北京的好天气。回想起去年的这个时候,也是坐在办公室里,在上地,不远处的信息环岛,运通105在缓缓挪动。我很喜欢运通105,尽管有很多车可以选择,但是运通的司机总是很生猛,他能够骂骂咧咧地迅速变线超车,也能够抢在绿灯的最后一秒秒穿过路口,上他的车你需要确实坐稳扶好。下雨的时候会去坐车,平时则是骑车,那辆自行车几乎每个月都要修理一次,最近一次是刹车时用力过大结果闸应声而断了。11月换了份工作,坐城铁上班,自行车开始生锈,每天上班时经过车棚,看见布满灰尘的自行车,突然就有一种极不真实的感觉,我认识它吗,为什么它会显得如此之陌生,生活,似乎在一瞬间就完成了转换。
我是一个怀旧的人,经常会沉浸在过去的某种情绪里不能自拔。今年又似乎过得太快,我还没来得及回忆,已悄然流逝。过完年就考虑着要不要换一份工作,公司的效益不好,产品的BUG太多,似乎也看不见前景。然而三月份岳母的生病打断了这一想法,请假回家了一个礼拜,先是手术,然后化验,结果出来,是癌症,然后就是化疗。每月发完工资,我和老婆都会去邮局,给她家里汇钱,然后打电话安慰她的母亲,在电话那头,岳母总是带有愧疚,觉得她拖累了我们。我喜欢她的母亲,和我妈妈一样,都是很朴实的农村人。过年去她家,还没起床,岳母已经把早饭端到床头,糖水煮鸡蛋,一个压着一个,八个,尽管尽了最大的努力,但终究还是没有吃完。
四月份公司策略发生变化,停止业务平台的开发,以维护为主,同时重新开发工作流,我一直认为单独的工作流产品是有前途的,平台则不然,市场上这类产品已经非常的多,并且都没有什么亮点,如果说解决某一业务类型的问题尚还合适,那么夸大到通用的地步就只能是市场忽悠罢了。至于技术性的平台,我想,在国内,只能是叫好不叫座。再说说工作流,作为很多系统的基础设施,我觉得是越来越普及,同时,也会越来越廉价。
那是快乐的一段时光,功能调研、TDD、制定开发计划,每天都很充实。但是第一个版本迟迟不能发布,终于等到八月,开发被迫终止。原因是人员的流失非常严重,到最后只剩我一人在支撑。作为小公司,如何留住开发人员,这是个很大的问题。其实,我想,有时候不仅仅只是薪水的问题,还有很多因素,例如代码的封闭、人员之间的交流等等。给我印象很深,一次讨论实现时,我坚持了hibernate xml映射的形式,同事想引入注解,我反对,理由是会给团队带来新的技术学习成本,而我们的重点应该是快速实现引擎本身。后来,同事离职,老板找我谈话时提到了这件事情。这让我汗了很长时间。还有很多沟通的方式需要学习。
开始招人,始终找不到合适的人。有人给我的博客留言想面试,是一个四川的小伙子,汶川地震当了一个月志愿者回来没有多久,身上似乎还有沙子、混凝土的味道。一下子就喜欢上他,很勤奋、积极,虽然工作经验不多、也只是大专,但是给人的感觉很向上。有时,真的,觉得工作经验并不是很重要(行业经验除外),但是一定要有精神。离开公司时,我想,这也算是我给公司做出的贡献。
汶川地震时,坐在办公室里,3楼,没有任何感觉,就看到楼下突然聚集了越来越多的人们。QQ同学群发来消息:地震了!哪儿地震了?通州?四川?不,是心里!接下来几天里,看着电视里的不间断报道,眼泪就下来了。我是坚持要对政府批评的那部分人,我认为虽然有进步,但是还不够,一直到今天,政府失职的地方实在是太多。其实,政府一直缺少的就不是赞美,而是批评。我厌恶专家,他们在08年集体华丽地转身,变成砖家。一直在关注冉云飞的博客,每周,他都会有四川掮客周刊,然而,最近,他也被和谐了。
8月份在北京受孕,工作流开发停止,刚好看看书,也从公司的角度思考一下发展。小公司,生存是第一位的,工作流开发需要投入,暂时没有产出,中断可以理解。但是,作为一个技术性公司,如果没有技术那就失去了竞争力,长远的发展是个问题。真是矛盾。中小公司,99%的成败取决于老板。大公司靠财务,小公司靠销售。我觉得公司的销售和市场有些问题:好吧,就算是产品功能不强大,那售前那么少,怎么解释。是客户在没了解你的产品前,就把你的产品给cut了?或者,他们根本就不知道有这么一个产品?你是仅仅提供一个产品,还是提供一整套的解决方案?解决方案仅仅基于自己的产品?有那么多的工作流应用经验,这个能不能以服务的方式提供收益?盈利模式是什么?技术、编码,这些此时都不重要了。
去年的这个时候为自己写下了08年的展望。第一是结婚,10月份的时候实现了。第二个是开发一个基于js的工作流设计器,没有完成,也不打算去做了。第三个是工作上是否有新的挑战,是的,11月终于换了工作,去了自己一直想去的公司,但是要是原公司能够有足够的成本支持工作流的开发,也许现在还在那里,毕竟是自己负责的第一个产品,有很多的想法在里面,并且已经完成了第一个版本目标的80%,有这么个说法,很多产品倒在最后一里路上,我的体会很深。第四是多看看非技术书、善待家人,这点做得还不够,年底和朋友一起翻译了《Spring Recipes》,每天晚上都翻到12点,经常忘记给家里打电话。有次父亲给我打过来,说,吃饭了没。我看看表,11点了,说,都11点了怎么会还没吃饭?父亲用很惊讶的语气说,哦,我还以为你忙得连饭都没空吃呢,原来还是不忙啊。父亲是在怪我没给他打电话呢。
有过很多矛盾,年底前最终还是决定开发一个工作流的开源系统,想法是前公司的老大提出的,基于jbpm,实际我并不是很喜欢jbpm的一些实现,我想自己实现引擎,但是考虑到用户,这无疑是最好的选择。明年的愿望就是:把这个开源的工作流系统做下去,发布出来。
再就是,要锻炼身体,又胖了。
posted @
2008-12-29 17:03 ronghao 阅读(561) |
评论 (0) |
编辑 收藏当面对一个完整的工作流系统时,你可能会被它众多的功能所困惑:流程流转模式、时间服务、组织适配、表单权限等等。但是如果我们转换一种思路,首先从用户使用的角度来进行分析,工作流系统的组成就会变得异常清晰。实际在现实开发中,整个系统也是由用户的业务需求一步步迭代而来。
一、
从用户的角度分析工作流系统的组成
这里的用户分为两类:一类是应用系统开发人员(以后简称开发人员),一类是应用系统的最终用户(以后简称最终用户)。对于最终用户而言,工作流系统往往是不能直接使用的,它需要由IT部门的开发人员嵌入到应用系统中。开发人员才是工作流系统的直接使用者,这造成了问题:工作流系统更多关注于开发人员的需求,例如如何快速开发、如何更好的嵌入业务逻辑等等,而最终用户的需求被或多或少的忽略了。
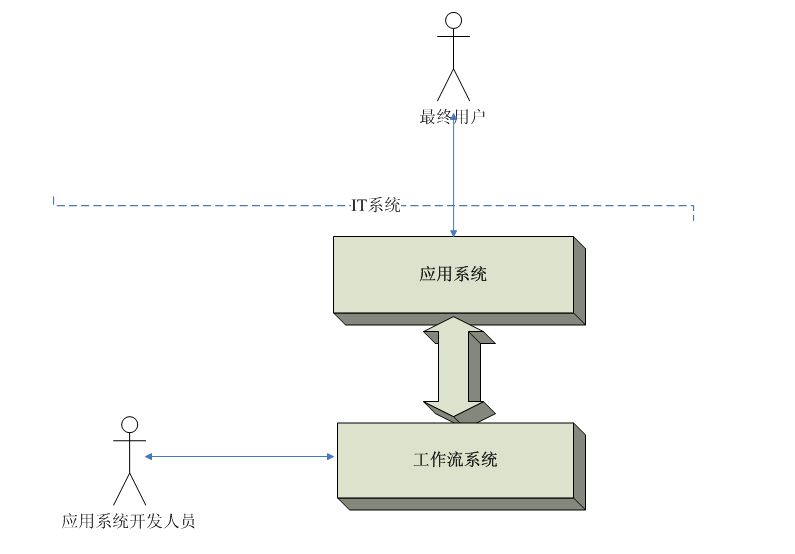
这里从最终用户的角度进行分析。
1、
面向开发人员的流程设计器
最终用户通过流程设计器对业务流程进行描述,实际是一个流程建模的过程。理论上,业务分析师完成这个业务流程建模的过程,并且业务分析师往往被假定为非技术人员。对于业务分析而言,流程建模通常是抽象的,一定程度上是模糊的,建模的目的在于通过图形的形式向其他人解释一个业务的过程,图形只是一种方式,采用它只是它更易于理解和易于沟通,实际类似于DSL。实际上企业的规章制度、文字描述的执行流程都是对业务流程具体的描述方式。
对于工作流而言,这个建模所产生的流程是需要被引擎执行的。这就要求流程中每一个节点的定义都是要有明确含义的,它需要被计算机明确而准确的解释。同时,出于集成业务系统的需要,流程模型定义往往带有很多额外的属性。
所以现实中的流程设计器往往属性配置繁多。导致最终用户在打开设计器后根本无从修改和建模,他需要关注很多与业务无关的配置,无意中的修改往往产生流程无法运行的后果。
2、
工作项列表
即任务列表。工作流系统通过工作项列表进行人工任务的分配。最终用户通过该列表签收、处理每天的工作,工作以工作项的形式展现。对于工作项,用户有着多种业务操作:签收、完成提交、收回、回退等等。对于分配给他人的工作项,也存在着多种业务操作:催办、提醒、时间限定等等。
3、
流程追踪
用户在处理工作项时,对该工作在流程中所处的位置进行查看,了解当前流程的状态和执行情况。一般情况下,流程追踪以图形化的方式展现。用户通过不同的图标和标示来区分流程中各个节点的状态和参与者信息。
4、
流程实例管理
包括流程实例、节点实例、工作项实例的管理。改变状态,包括了挂起、重新启动、终止、跳转等等。主要目的在于对流程人为执行错误进行人工干预以及对流程信息的监控。
二、
系统架构
从用户的角度分析完工作流系统的组成,这里从开发人员的角度分析工作流系统的架构。系统架构里的每一部分是如何与用户使用的部分进行对应,以及每一部分在实现时需要注意的事项。
1、
整体构成
如图,各模块分层组织,位于上层的模块依赖于底层的模块。正如你所看到的,流程定义模型位于整个工作流系统的最低层,因为它是整个工作流系统的基础。
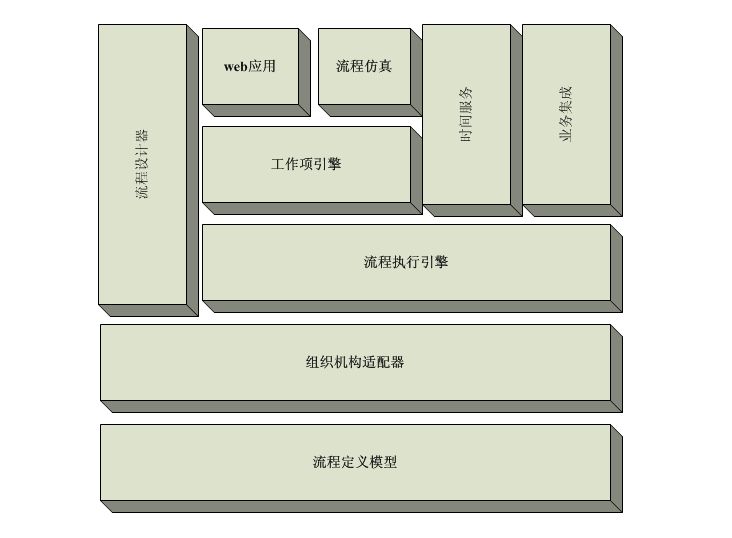
流程定义模型:定义对流程进行描述的所有对象。因为对流程进行描述的本质就是利用这些模型进行建模,所以这些模型对象的实现直接决定着工作流系统对流程的描述能力。
组织结构适配器:工作流系统在与业务系统进行集成时,需要进行组织适配,通过这一过程将业务系统里的组织机构导入到工作流系统里。具体实现时,工作流系统需要建立起自己的组织机构模型(包含在流程定义模型里),要适应多种业务系统,往往需要建立多套模型,根据具体情况进行切换。有多种方式完成这个适配,最简单的方式是利用SQL配置读取数据进行语义转换。
流程设计器:供用户使用的可视化图形工具。每种图形都对应着一种流程定义模型。具体的实现有Swing、SWT,但是基于AJAX的WEB设计器无疑会提供更好的可用性。
流程执行引擎:将流程定义模型解释为流程实例模型。利用这些流程实例模型完成流程的调度和执行。在工作流系统里,执行引擎是整个系统的核心。实现时不仅需要考虑各种流程调度的实现,还要考虑执行的效率、缓存、日志等等。
工作项引擎:解析参与者定义模型和工作项定义模型,生成相应的工作项。对用户对工作项的操作作出响应。
WEB应用:工作流系统的WEB展现。包括了工作项列表、流程追踪以及流程实例管理的操作和显示。
流程仿真:对建立好的流程模型进行运行仿真,模拟流程模型的执行过程。目的在于发现流程建模过程中的疏漏,发现由此导致的流程不能运行。
时间服务:提供对整个流程实例执行时间和任务执行时间的控制,根据规则触发相应的时间事件,例如任务超时、任务预警等等。根据规则自动触发启动新的流程实例。
业务集成:提供工作流系统与业务系统的契合方式。典型的实现包括通过注册事件监听器和提供接口抽象类调用业务系统代码、提供API给业务系统调用、工作项驱动业务表单和脚本引擎执行业务逻辑脚本等等。特定于工作项驱动业务表单,为方便开发,绝大多数的工作流厂商都提供了电子表单的实现。
2、
基于事件的流程执行引擎
流程执行引擎的主要职责就是负责流程的调度和执行。
首先需要将流程定义模型解释为流程实例模型,在定义模型和实例模型之间建立起对应关系。一个简单的对应关系如下图所示:
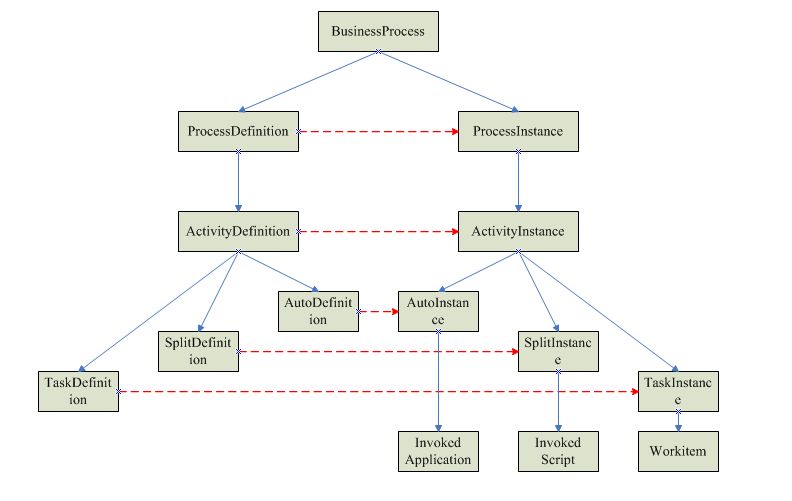
执行引擎将流程定义模型的属性读取到相应的实例模型里,由实例模型完成流程的调度和执行。当然,上图只是一个简单的描述,实际情况要复杂的多,特别是节点定义(ActivityDefinition),根据实际应用,往往存在着多种类型,典型的有开始节点(StartDefinition)、任务节点(TaskDefinition)、自动节点(AutoDefinition)、分裂节点(SplitDefinition)、汇聚节点(JoinDefinition)、结束节点(EndDefinition)等等。这些节点的实例根据类型的不同执行不同的逻辑。其中,分裂节点实例和汇聚节点实例负责流程的调度,它们决定流程的流向,通常情况下,它们会调用一个脚本引擎执行一段脚本来决定流程的流向,同时,也会提供对外暴露的接口,由业务系统实现,接口返回的结果决定流程的流向。任务节点实例和自动节点实例则负责流程的执行,为保证流程执行引擎职责的清晰以及对外围设施的松耦合,它们只是发布相关的事件,通过事件发布/订阅机制来触发具体的逻辑执行。
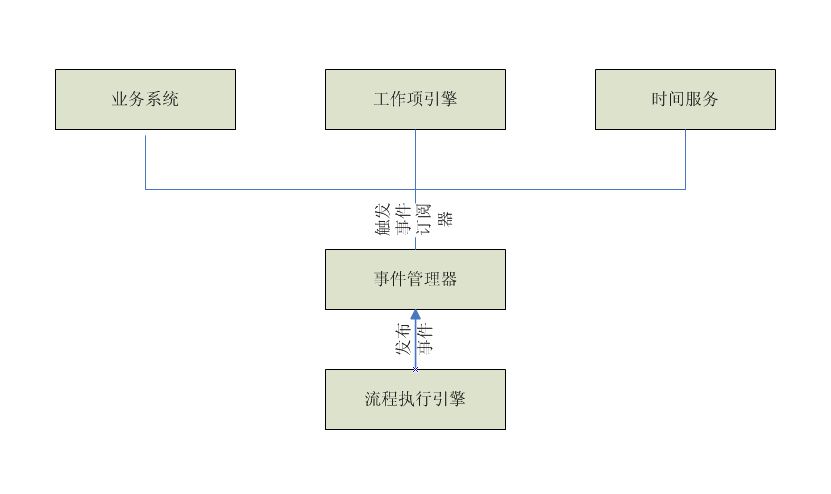
典型的事件有流程启动事件、流程结束事件、进入节点事件、离开节点事件、时间事件等。例如,任务节点实例的进入节点事件将会触发工作项引擎生成工作项(Workitem),并触发时间服务器开始计时。
3、
基于充血模型的工作项引擎
对最终用户而言,大部分的业务操作都集中在对工作项的操作上。常见的包括工作项的提交、收回、委派、追加和退回。这些操作从系统设计的角度不仅涉及到工作项(Workitem)对象内部状态的变化,而且影响到流程执行引擎的调度以及相关的其他工作项对象状态。
工作项引擎的职责包括两部分。第一,监听任务节点实例的进入事件,生成工作项实例。第二,处理上面提到的各种工作项操作。

实现时,工作项生成器根据任务参与者的执行模式典型的分为四种情况:
竞争参与,当有多个参与者参与该任务时,产生竞争,谁先开始这项工作,就由谁负责完成该工作。此时,工作项生成器生成多个工作项实例,在某个工作项完成时会终止其余工作项。
顺序参与,多个参与者按照指定的顺序完成该工作。A完成之后由B完成,B完成之后再交给C完成。此时,工作项生成器生成多个工作项实例,根据顺序依次激活各个工作项。
共同参与,多个参与者同时对工作进行处理。此时,工作项生成器生成多个工作项实例并全部激活。
智能决策,存在多个参与者的情况下,工作项生成器能够根据一定的指标(由数据分析,例如人员的处理效率,工作负载等等)和规则来决定该节点的参与者并为其生成相应工作项。这里涉及到算法。
对于工作流系统而言,各种流程实例对象都是充血模型。特定于各种工作项操作的处理,此时的工作项对象亦设计为充血模型,将业务逻辑封装到领域模型里,简化领域模型之间的交互,省去频繁的get/set。由领域模型再委派到具体的处理类里。
Client->(Business Facade)->Domain Model->service->Data Access(DAO)
4、
工作项驱动业务表单的业务集成方式
最终用户对任务的处理,必然由工作项对应着某一业务表单。用户在工作项列表里选择自己需要办理的工作项,由工作项导航到业务表单。
特定于WEB系统,业务表单的导航由url完成。在流程定义模型设计时,将url设置入节点属性,生成工作项时将此url保存在工作项对象属性里。点击工作项详细信息时即打开该url,完成到业务表单的导航。业务表单页面通常需要引入处理工作项逻辑的父页面或者导入定制的js库,这些父页面或js库由工作流产品提供。这样,对于业务表单编写,工作流逻辑是透明的。
posted @
2008-11-07 11:20 ronghao 阅读(2262) |
评论 (0) |
编辑 收藏系统要集群,使用SNA方案。
一、 缓存的处理
缓存要使用统一的缓存服务器,集中式缓存。
原先的实现采用ehcache。
在spring里的配置,以资源缓存为例:
<!-- EhCache Manager -->
<bean id="cacheManager" class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean">
<property name="configLocation">
<value>classpath:ehcache.xml</value>
</property>
</bean>
<bean id="resourceCacheBackend"
class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager"/>
<property name="cacheName" value="resourceCache"/>
</bean>
<bean id="resourceCache"
class="com.framework.extcomponent.security.authentication.services.acegi.cache.EhCacheBasedResourceCache"
autowire="byName">
<property name="cache" ref="resourceCacheBackend"/>
</bean>
cacheManager负责对ehcache进行管理,初始化、启动、停止。
resourceCacheBackend负责实际执行缓存操作,put 、get、remove。
resourceCache实现具有业务语义的业务应用层面的缓存操作,内部调用resourceCacheBackend操作。
现在采用memcached。
关于客户端,采用文初封装的客户端,地址在http://code.google.com/p/memcache-client-forjava/。
使用spring的FactoryBean进行二次封装。同理:
memcachedManager负责对memcached进行管理,初始化、启动、停止。
代码:
/**
* User: ronghao
* Date: 2008-10-14
* Time: 10:36:30
* 管理Memcached 的CacheManager
*/
public class MemcachedCacheManagerFactoryBean implements FactoryBean, InitializingBean, DisposableBean {
protected final Log logger = LogFactory.getLog(getClass());
private ICacheManager<IMemcachedCache> cacheManager;
public Object getObject() throws Exception {
return cacheManager;
}
public Class getObjectType() {
return this.cacheManager.getClass();
}
public boolean isSingleton() {
return true;
}
public void afterPropertiesSet() throws Exception {
logger.info("Initializing Memcached CacheManager");
cacheManager = CacheUtil.getCacheManager(IMemcachedCache.class,
MemcachedCacheManager.class.getName());
cacheManager.start();
}
public void destroy() throws Exception {
logger.info("Shutting down Memcached CacheManager");
cacheManager.stop();
}
}
配置:
<bean id="memcachedManager"
class="com.framework.extcomponent.cache.MemcachedCacheManagerFactoryBean"/>
resourceCacheBackend负责实际执行缓存操作,put 、get、remove。
代码:
/**
* User: ronghao
* Date: 2008-10-14
* Time: 10:37:16
* 返回 MemcachedCache
*/
public class MemcachedCacheFactoryBean implements FactoryBean, BeanNameAware, InitializingBean {
protected final Log logger = LogFactory.getLog(getClass());
private ICacheManager<IMemcachedCache> cacheManager;
private String cacheName;
private String beanName;
private IMemcachedCache cache;
public void setCacheManager(ICacheManager<IMemcachedCache> cacheManager) {
this.cacheManager = cacheManager;
}
public void setCacheName(String cacheName) {
this.cacheName = cacheName;
}
public Object getObject() throws Exception {
return cache;
}
public Class getObjectType() {
return this.cache.getClass();
}
public boolean isSingleton() {
return true;
}
public void setBeanName(String name) {
this.beanName=name;
}
public void afterPropertiesSet() throws Exception {
// If no cache name given, use bean name as cache name.
if (this.cacheName == null) {
this.cacheName = this.beanName;
}
cache = cacheManager.getCache(cacheName);
}
}
配置:
<bean id="resourceCacheBackend"
class="com.framework.extcomponent.cache.MemcachedCacheFactoryBean">
<property name="cacheManager" ref="memcachedManager"/>
<property name="cacheName" value="memcache"/>
</bean>
resourceCache同上,替换新的实现类MemcachedBasedResourceCache即可。
二、 Session失效的处理
采用memcached作为httpsession的存储,并不直接保存httpsession对象,自定义SessionMap,SessionMap直接继承HashMap,保存SessionMap。
会话胶粘:未失败转发的情况下没必要在memcached保存的SessionMap和httpsession之间复制来复制去,眉来眼去。
利用memcached计数器保存在线人数。
系统权限采用了acegi,在acegi的拦截器链里配置snaFilter
<bean id="filterChainProxy"
class="org.acegisecurity.util.FilterChainProxy">
<property name="filterInvocationDefinitionSource">
<value>
CONVERT_URL_TO_LOWERCASE_BEFORE_COMPARISON
PATTERN_TYPE_APACHE_ANT
/**=snaFilter,httpSessionContextIntegrationFilter,logoutFilter,authenticationProcessingFilter,basicProcessingFilter,securityContextHolderAwareRequestFilter,exceptionTranslationFilter,filterInvocationInterceptor
</value>
</property>
</bean>
注意需要配置在第一个。
snaFilter的职责:
1、 没有HttpSession时,创建HttpSession;
2、 创建Cookie保存HttpSession id;
3、 如果Cookie保存的HttpSession id与当前HttpSession id一致,说明是正常请求;
4、 如果Cookie保存的HttpSession id与当前HttpSession id不一致,说明是失败转发;失败转发的处理:
4.1、根据Cookie保存的HttpSession id从memcached获取SessionMap;
4.2、SessionMap属性复制到当前HttpSession;
4.3、memcached删除SessionMap。
5、 判断当前请求url是否是登出url,是则删除SessionMap,在线人数减1.
代码:
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse,
FilterChain filterChain) throws IOException, ServletException {
final HttpServletRequest hrequest = (HttpServletRequest) servletRequest;
final HttpServletResponse hresponse = (HttpServletResponse) servletResponse;
String uri = hrequest.getRequestURI();
logger.debug("开始SNA拦截-----------------" + uri);
HttpSession httpSession = hrequest.getSession();
String sessionId = httpSession.getId();
//如果是登出,则直接干掉sessionMap
if (uri.equals(logoutUrl)) {
logger.debug("remove sessionmap:" + sessionId);
//在线人数减1
getCache().addOrDecr("userCount",1);
getCache().remove(sessionId);
} else {
String cookiesessionid = getSessionIdFromCookie(hrequest, hresponse);
if (!sessionId.equals(cookiesessionid)) {
createCookie(sessionId, hresponse);
SessionMap sessionMap = getSessionMap(cookiesessionid);
if (sessionMap != null) {
logger.debug("fail over--------sessionid:" + sessionId + "cookiesessionid:" + cookiesessionid);
initialHttpSession(sessionMap, httpSession);
cache.remove(cookiesessionid);
}
}
}
filterChain.doFilter(hrequest, hresponse);
}
利用HttpSessionAttributeListener监听httpsession的属性变化,同步到memecached中的sessionmap。
public void attributeAdded(HttpSessionBindingEvent event) {
HttpSession httpSession = event.getSession();
String attrName = event.getName();
Object attrValue = event.getValue();
String sessionId = httpSession.getId();
logger.debug("attributeAdded sessionId:" + sessionId + "name:" + attrName + ",value:" + attrValue);
SessionMap sessionMap = getSessionMap(sessionId);
if (sessionMap == null){
//在线人数加1
getCache().addOrIncr("userCount",1);
sessionMap = new SessionMap();
}
logger.debug("name:" + attrName + ",value:" + attrValue);
sessionMap.put(attrName, attrValue);
getCache().put(sessionId, sessionMap);
}
public void attributeRemoved(HttpSessionBindingEvent event) {
HttpSession httpSession = event.getSession();
String attrName = event.getName();
String sessionId = httpSession.getId();
logger.debug("attributeRemoved sessionId:" + sessionId + "name:" + attrName);
SessionMap sessionMap = getSessionMap(sessionId);
if (sessionMap != null) {
logger.debug("remove:" + attrName);
sessionMap.remove(attrName);
getCache().put(sessionId, sessionMap);
}
}
public void attributeReplaced(HttpSessionBindingEvent event) {
attributeAdded(event);
}
利用HttpSessionListener,sessionDestroyed事件时根据sessionid删除memcached里的sessionMap(如果存在)。不再担心httpsession的过期问题。
public void sessionDestroyed(HttpSessionEvent event) {
HttpSession httpSession = event.getSession();
String sessionId = httpSession.getId();
logger.debug("session Removed sessionId:" + sessionId);
SessionMap sessionMap = getSessionMap(sessionId);
if (sessionMap != null) {
logger.debug("remove sessionmap:" + sessionId);
//在线人数减1
getCache().addOrDecr("userCount",1);
getCache().remove(sessionId);
}
}
三、 文件保存的处理
和缓存类似,采用集中式的文件服务。对于linux,采用nfs。参考文档http://linux.vbird.org/linux_server/0330nfs.php#What_NFS_perm。关键在于对权限的分配。
应用程序本身不用修改。
posted @
2008-10-28 20:41 ronghao 阅读(2581) |
评论 (3) |
编辑 收藏