概述
捣鼓hdfs、yarn、hbase、zookeeper的代码一年多了,是时候整理一下了。在hadoop (2.5.2)中protobuf是节点之间以及客户端和各个节点通信的基础序列化框架(协议),而基于avro和Writable的序列化框架则是这个协议里的payload,因而这一系列的文章打算从protobuf这个框架开始入手(版本2.5.0)。
从抽象的角度来说,protobuf框架是类实例序列化和远程调用的一种实现。所谓实例序列化简单来说就是将一个类实例转换成字节数组或字节流来表达,这个字节数组或字节流可以通过文件形式保存或者通过网络发送给一个接收方;而另一个程序可以读取文件中的字节或在接收到字节流后反序列化并构造出一个新的和原来相等的实例(这里的相等主要是值);除了protobuf,目前比较流行的序列化反序列化框架有Java自带序列化、反序列化框架(本文默认使用Java,因而忽略C++、Python等语言的相关内容)、JSON格式的序列化反序列化框架、XML格式的序列化反序列化框架以及上文提到的从Hadoop中分支出来的avro框架(关于这些框架的孰优孰略不是本文要讨论的范围,相信关于它们的比较网上也很容易找到)。在protobuf中使用Message/MessageLite来抽象一个可序列化和反序列化的实例,为了提升性能,用户一般需要定义一些.proto文件,并使用protobuf自带的代码生成器(编译器)来生成对具体类的序列化和反序列化代码;并且它使用将每个字段编号的方式来排列字段在序列化后的排列顺序以及处理不同版本的兼容性问题。对于远程调用来说,protobuf并没有多少实现,它用RpcChannel接口来抽象通信层的协议,而使用Service接口来抽象每个具体的可调用接口,RpcChannel需要我们自己实现,而具体的Service可以定义在.proto文件中,由protobuf自带的代码生成器生成。代码生成器同时支持BlockingService和Service(Async)的实现,其中异步方式通过注册RpcCallback来获取返回值。
语法和使用
抽象来说,消息其实是一段段具有特定含义的数据的集合。这些一段段具有特定含义的数据可以是基本类型,如int、string、double等,也可以是几个基本类型聚合而成的另一个消息,即消息中可以内嵌消息。对一个消息字段来说,我们需要定义它的类型、字段名,在protobuf中还需要定义字段规则(field rule)和字段的唯一标识号(tag)。其中字段规则有:required表示该字段必须存在,在调用Builder的build方法时,如果有required的字段还未被设置,会抛出UninitializedMessageException;optional表示该字段是可选的,因而在build()方法中不会对它做检查,在isInitialized()方法中也不会考虑它的设值情况;repeated表示该字段可能存在多个值,在Java版本中采用List来表达(protobuf在这里采用了比较简单的语法,因而我们无法选择集合类型、集合中元素个数的限制等)。字段唯一标识号用于定位一个字段,在XML和JSON中直接使用字段名来维护序列化后和类实例字段之间的映射,而且它们的字段类型(如果存储的话)一般也以字符串的形式保存在序列化后的字节流中,这样做的一个好处是序列化后的消息和消息的定义是相对独立的,并且消息可读性非常好,然而它的坏处也是比较明显的,序列化后的消息字节数会很大,序列化和反序列化的效率也会降低很多,为了解决这个问题,protobuf采用这个字段唯一标识号来定位一个字段,对每个字段在protobuf内部还定义了其类型值,从而在对无法识别的字段编码时可以通过这个类型信息判断使用那种方式解析这个未知字段,字段唯一标识号和类型值一同组成一个int类型的值tag,其中类型值占最低三个bit,字段唯一标识号占剩下29bit,即protobuf最大支持的字段数是2^29-1(536870911,然而19000到19999是系统保留的,因而不可以使用)。因而在每次写入一个字段时都需要先写入这个tag值,而每次读取一个字段时也先读取这个tag值以判断这个字段的标识号以及类型。protobuf使用可变长的整型编码这个tag值,即对1-15的标识号值只需要一个字节(字段类型占用3个bit),16-2047需要两个字节,因而推荐将1-15的标识号值赋值给使用最频繁的字段,并且推荐保留一些空间给将来添加新的使用比较频繁的字段。
关于required字段,如果将一个字段定义为required,在使用它时必须对它进行设值,并且出于兼容性的考虑,以后需要一直保持它的required属性。出于这个原因考虑,在google内部有人提出不要使用required字段,虽然这种提议并不是所有人都赞同。
最后,protobuf还支持optional字段的默认值设置,即在定义一个optional字段时在其后加入一个[…]的修饰,指定默认值(这个默认值应该只支持基本类型和枚举类型,对消息类型貌似没法定义),此时如果该字段没有被赋值,则它返回这个默认值,然而在序列化时这个默认值不会在序列化后的字节流中出现,因而如果.proto文件定义时的默认值发生改变,可能会出现序列化和反序列化出来某个字段值不一样的情况,需要特别注意。对于没有指定默认值的字段,protobuf采用预定义默认值,即string的默认值是空字符串、bool默认值是false、数值类型默认值0、枚举类型默认值是定义的第一个枚举项。
protobuf使用message来抽象序列化、反序列化对象,通常protobuf的用法是在.proto文件中定义需要的message对象,然后使用protobuf提供的protoc将定义的message对象编译成Java/C++/Python对象;在实际项目中引入这些生成的类,对这些message对象赋值,并使用框架提供的方法实现序列化、反序列化。如一个比较简单的SearchRequest例子,其定义如下:
package levin.protobuf;
option java_package = "org.levin.protobuf.generated.simple";
option java_outer_classname = "SearchRequestProtos";
message SearchRequest {
required string query_string = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3 [
default = 50 ];
}
使用一下命令编译并在test目录下生成org.levin.protobuf.generated.simple.SearchRequestProtos类:
protoc --java_out test SearchRequest.proto
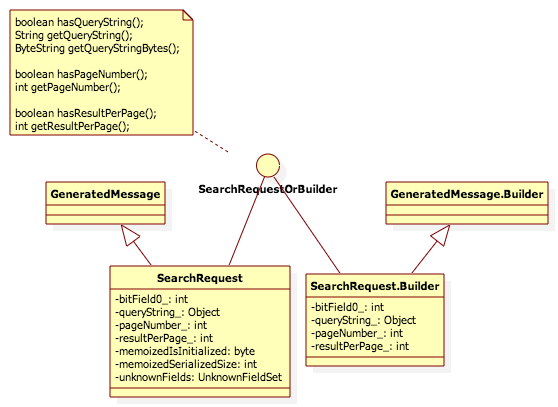
protobuf编译器为每个message对象生成一个<Message>OrBuilder接口,该接口定义了message中所有字段的get方法和has<field>方法(用以判断是否某个字段已经设值);对string类型字段,它还包含了ByteString返回类型的get方法,ByteString是protobuf中对字节数组的一种抽象,它类似String,是一个不可变对象,它有不同的实现,如LiteralByteString只是对字节数组的封装,BoundedByteString则可以从一个字节数组中取处一段作为地层内容,而RopeByteString则采用树状结构来连接一系列的ByteString,以支持大容量并且无需拷贝的字符串。在ByteString中定义了多个方法来实现ByteString和字节数组/字符串互相转换:copyFrom()、copyTo()、toByteArray()、toString()、toStringUtf8()等。在以上的SearchRequst中的接口就是:SearchRequestOrBuilder,它继承自MessageOrBuilder接口,其定义如下:
public interface SearchRequestOrBuilder extends MessageOrBuilder {
boolean hasQueryString();
String getQueryString();
ByteString getQueryStringBytes();
boolean hasPageNumber();
int getPageNumber();
boolean hasResultPerPage();
int getResultPerPage();
}
在生成SearchRequestOrBuilder接口后,protobuf编译器会继续生成定义的Message对象:SearchRequest,这个Message对象也是一个不可变对象(Immutable),它包含bitField<x>_字段,该字段的每一个bit用于表示一个字段是否被已经被设值,因而其个数取决于字段的个数;而后每个Message字段都会有一个对应的字段(其中string类型的字段采用Object表达因为它有可能是String类型或者ByteString类型);之后是两个缓存字段:memoizedIsInitialized和memoizedSerializedSize,用于缓存是否已经初始化以及序列化后的字节数(Message对象是不可变的);最后每个Message对象都包含一个unknownFields字段用于保存无法识别的字段,以及一个静态的default实例,用以保存Message对象初始化状态下的对象实例。编译生成的SearchRequest继承自GeneratedMessage类并实现了SearchRequestOrBuilder接口中的所有方法,它定义了几个静态方法以获取SearchRequest在初始化状态时的实例,获取一个新的Builder实例用于构造SearchRequest实例,以及从字节数组、ByteString、InputStream中解析出SearchRequest实例等。
之后protobuf编译器还会在每个Message对象内部生成一个静态的Builder类,它继承自GeneratedMessage.Builder类,并实现了SearchRequestOrBuilder接口,该Builder类和SearchRequest消息类有类似的字段,并实现了各个字段的set方法以及build()方法用于build消息对象:SearchRequest。另外,它还提供了mergeFrom()方法,可以从字节数组、ByteString、InputStream等解析字节数据。
最后protobuf编译器还会为每一个Message对象生成用于描述该Message对象的字符串,用FileDescriptor.internalBuildGeneratedFileFrom()方法将其解析成一个Descriptor和FileAccessorTable实例。
在这个SearchRequest消息定义的例子中,protobuf编译器生成的类结构如下:
在使用protobuf编译器生成这些类以后,使用起来非常简单,构建SearchRequest只需要使用其静态方法新建Builder实例,设置各个字段的值,然后调用其build()方法即可。
SearchRequest.Builder builder = SearchRequest.newBuilder();
builder.setQueryString("param1=value1¶m2=value2");
builder.setPageNumber(10);
builder.setResultPerPage(100);
SearchRequest request = builder.build();
System.out.println(request);
这段代码的输出结果为:
query_string: "param1=value1¶m2=value2"
page_number: 10
result_per_page: 100
在序列化时,调用可调用MessageLite中的writeTo()方法,反序列化时可调用MessageLite.Builder中的mergeFrom()方法:
ByteArrayOutputStream bytes = new ByteArrayOutputStream();
request.writeTo(bytes);
System.out.println(Arrays.toString(bytes.toByteArray()));
//output: [10, 27, 112, 97, 114, 97, 109, 49, 61, 118, 97, 108, 117, 101, 49, 38, 112, 97, 114, 97, 109, 50, 61, 118, 97, 108, 117, 101, 50, 16, 10, 24, 100]
Sys-tem.out.println(SearchRequest.newBuilder().mergeFrom(request.toByteArray()).build());
//output:
// query_string: "param1=value1¶m2=value2"
// page_number: 10
// result_per_page: 100
代码生成实现细节
在protobuf编译生成的代码中,作为序列化的核心实现比较简单,它只是将每个已经赋值的字段的fieldNumber和值一起写入到CodedOutputStream中:
public void writeTo(CodedOutputStream output) throws ja-va.io.IOException {
getSerializedSize();
if (((bitField0_ & 0x00000001) == 0x00000001)) {
output.writeBytes(1, getQueryStringBytes());
}
if (((bitField0_ & 0x00000002) == 0x00000002)) {
output.writeInt32(2, pageNumber_);
}
if (((bitField0_ & 0x00000004) == 0x00000004)) {
output.writeInt32(3, resultPerPage_);
}
getUnknownFields().writeTo(output);
}
而反序列化的核心代码也基本上是从CodedInputStream读一个tag值,根据从tag值解析出来的fieldNumber值读取对应字段类型的数据并给字段赋值: private SearchRequest(CodedInputStream input, ExtensionRegistryLite extensionRegistry)
throws InvalidProtocolBufferException {
initFields();
UnknownFieldSet.Builder unknownFields = UnknownFieldSet.newBuilder();
boolean done =
false;
while (!done) {
int tag = input.readTag();
switch (tag) {
case 0: { done =
true;
break; }
case 10: {
bitField0_ |= 0x00000001;
queryString_ = input.readBytes();
break;
}
case 16: {
bitField0_ |= 0x00000002;
pageNumber_ = input.readInt32();
break;
}
case 24: {
bitField0_ |= 0x00000004;
resultPerPage_ = input.readInt32();
break;
}
default: {
if (!parseUnknownField(input, unknownFields, extensionRegistry, tag)) {
done =
true;
}
break;
}
}
 this
this.unknownFields = unknownFields.build();
makeExtensionsImmutable();
}
在protobuf消息定义中还支持枚举类型,使用enum作为关键字,并且需要给每个枚举项定义一个唯一的值,从而在序列化时protobuf实际上是将这个唯一的int值以int32可变长编码写入字节流中,从而节省空间,也正是因为这个值采用int32的编码方式,因而不推荐给枚举项赋负数值,因为int32的负数编码要占用10个字节空间。
enum Corpus {
UNIVERSAL = 10;
WEB = 11;
IMAGES = 12;
}
protobuf编译生成的代码中也会生成一个Corpus的枚举类型,它实现ProtobufMessageEnum接口,并包含index和value字段:
public enum Corpus implements ProtocolMessageEnum {
UNIVERSAL(0, 10),
WEB(1, 11),
IMAGES(2, 12);
public final int getNumber() { return value; }
private final int index;
private final int value;
private Corpus(int index, int value) {
this.index = index;
this.value = value;
}
}
而ProtocolMessageEnum的接口定义了获取一个枚举项的值以及其相关的EnumValueDescriptor和EnumDescriptor(Descriptor将在后面小结中详细讲解):
public interface ProtocolMessageEnum extends Internal.EnumLite {
int getNumber();
EnumValueDescriptor getValueDescriptor();
EnumDescriptor getDescriptorForType();
}
在protobuf中还可以定义一个字段为repeated字段,表示该字段时一个集合,在Java版本中使用List表达。对repeated字段,在序列化时对每个值,同时写入tag值和字段值本身:
message SearchResponse {
repeated Result result = 1;
repeated int32 stats = 2;
}
for (int i = 0; i < result_.size(); i++) {
output.writeMessage(1, result_.get(i));
}
for (int i = 0; i < stats_.size(); i++) {
output.writeInt32(2, stats_.get(i));
}
然而这种编码方式对基本类型来说效率太低,因为每项都要同时包含tag值,所以对基本类型,protobuf还只是使用packed来提升编码效率(在反序列化时不管有没有加packed关键字,它都同时支持两种编码方式的读取):
message SearchResponse {
repeated Result result = 1;
repeated int32 stats = 2 [ packed = true ];
}
if (getStatsList().size() > 0) {
output.writeRawVarint32(18);
output.writeRawVarint32(statsMemoizedSerializedSize);
}
for (int i = 0; i < stats_.size(); i++) {
output.writeInt32NoTag(stats_.get(i));
}
在写框架代码时,经常由扩展性的需求,在Java中,只需要简单的定义一个父类或接口即可解决,如果框架本身还负责构建实例本身,可以使用反射或暴露Factory类也可以顺利实现,然而对序列化来说,就很难提供这种动态plugin机制了。然而protobuf还是提出来一个相对可以接受的机制(语法有点怪异,但是至少可以用):在一个message中定义它支持的可扩展字段值的范围,然后用户可以使用extend关键字扩展该message定义:
message Foo {
optional int32 field1 = 1;
extensions 100 to 199;
}
extend Foo {
optional int32 bar = 126;
}
public void writeTo(CodedOutputStream output) throws ja-va.io.IOException {
getSerializedSize();
GeneratedMessage.ExtendableMessage<Foo>.ExtensionWriter extensionWriter = newExtensionWriter();
if (((bitField0_ & 0x00000001) == 0x00000001)) {
output.writeInt32(1, field1_);
}
extensionWriter.writeUntil(200, output);
getUnknownFields().writeTo(output);
}
在反序列化时由于可扩展字段在parseUnknownField()方法中解析,因而没有多少区别,然而在该方法中会使用到ExtensionRegistry实例。另外生成的消息类Foo继承自ExtendableMessage而不是GeneratedMessage,Foo.Builder继承自ExtendableBuilder而不是GeneratedMessage.Builder。最后还会生成GeneratedExtension<Foo, Integer>类型的静态字段bar以及在静态方法registerAllExtensions()将该bar字段注册到ExtensionRegistry实例中以供反序列化时使用: Foo foo = Foo.newBuilder().setField1(10)
.setExtension(ExtensionsProtos.bar, 20)
.build();
System.out.println(foo);
// field1: 10
// [levin.protobuf.bar]: 20
ExtensionRegistry registry = ExtensionRegistry.newInstance();
ExtensionsProtos.registerAllExtensions(registry);
Foo foo2 = Foo.newBuilder()
.mergeFrom(foo.toByteArray(), registry)
.build();
System.out.println(foo2);
// field1: 10
// [levin.protobuf.bar]: 20
在protobuf中默认的optimize_for选项的值是SPEED,然而有些时候我们只需要使用MessageLite的功能即可,不需要Descriptor和反射,这个时候可以指定该值为LITE_RUNTIME。使用该选项,生成的Message类直接继承自GeneratedMessageLite,并且不会生成那些Descriptor信息,此时生成Message类的toString()方法只能打印类实例因为无法通过反射获知类的元数据信息。optimize_for选项的另一个可选值是CODE_SIZE,该选项生成的Message类中不会实现writeTo()方法,它使用AbstractMessage类中实现的writeTo()方法,该方法遍历所有有赋值的字段,使用反射获取字段的值,并写入CodedOutputStream中。
posted on 2015-04-01 09:13
DLevin 阅读(14767)
评论(0) 编辑 收藏 所属分类:
Protobuf