前记
公司内部使用的是MapR版本的Hadoop生态系统,因而从MapR的官网看到了这篇文文章:
An In-Depth Look at the HBase Architecture,原本想翻译全文,然而如果翻译就需要各种咬文嚼字,太麻烦,因而本文大部分使用了自己的语言,并且加入了其他资源的参考理解以及本人自己读源码时对其的理解,属于半翻译、半原创吧。
HBase架构组成
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下:
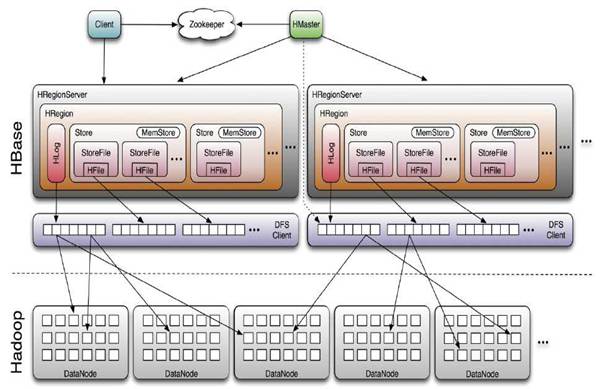
其中
HMaster节点用于:
- 管理HRegionServer,实现其负载均衡。
- 管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上。
- 实现DDL操作(Data Definition
Language,namespace和table的增删改,column
familiy的增删改等)。
- 管理namespace和table的元数据(实际存储在HDFS上)。
- 权限控制(ACL)。
HRegionServer节点用于:
- 存放和管理本地HRegion。
- 读写HDFS,管理Table中的数据。
- Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。
ZooKeeper集群是协调系统,用于:
- 存放整个
HBase集群的元数据以及集群的状态信息。
- 实现HMaster主从节点的failover。
HBase Client通过RPC方式和HMaster、HRegionServer通信;一个HRegionServer可以存放1000个HRegion;底层Table数据存储于HDFS中,而HRegion所处理的数据尽量和数据所在的DataNode在一起,实现数据的本地化;数据本地化并不是总能实现,比如在HRegion移动(如因Split)时,需要等下一次Compact才能继续回到本地化。
本着半翻译的原则,再贴一个《An In-Depth Look At The HBase Architecture》的架构图:
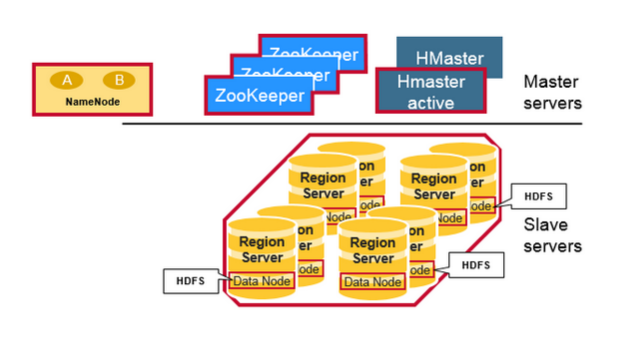
这个架构图比较清晰的表达了HMaster和NameNode都支持多个热备份,使用ZooKeeper来做协调;ZooKeeper并不是云般神秘,它一般由三台机器组成一个集群,内部使用PAXOS算法支持三台Server中的一台宕机,也有使用五台机器的,此时则可以支持同时两台宕机,既少于半数的宕机,然而随着机器的增加,它的性能也会下降;RegionServer和DataNode一般会放在相同的Server上实现数据的本地化。
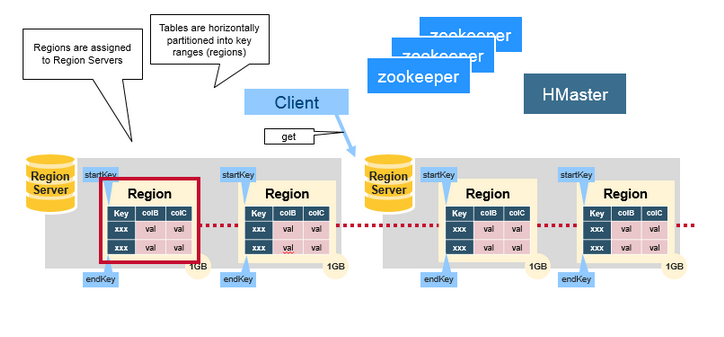
HRegion
HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。每个HRegionServer可以同时管理1000个左右的HRegion(这个数字怎么来的?没有从代码中看到限制,难道是出于经验?超过1000个会引起性能问题?
来回答这个问题:感觉这个1000的数字是从BigTable的论文中来的(5 Implementation节):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))。
HMaster
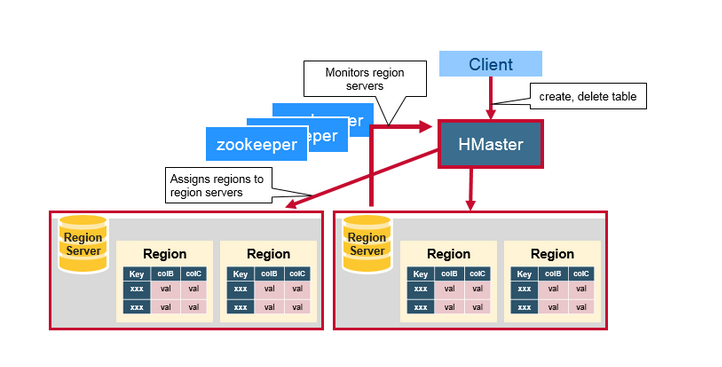
HMaster没有单点故障问题,可以启动多个HMaster,通过ZooKeeper的Master Election机制保证同时只有一个HMaster出于Active状态,其他的HMaster则处于热备份状态。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。前文已经介绍过了HMaster的主要用于HRegion的分配和管理,DDL(Data Definition Language,既Table的新建、删除、修改等)的实现等,既它主要有两方面的职责:
- 协调HRegionServer
- 启动时HRegion的分配,以及负载均衡和修复时HRegion的重新分配。
- 监控集群中所有HRegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态)。
- Admin职能
- 创建、删除、修改Table的定义。
ZooKeeper:协调者
ZooKeeper为HBase集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),并且会在它们宕机时通知给HMaster,从而HMaster可以实现HMaster之间的failover,或对宕机的HRegionServer中的HRegion集合的修复(将它们分配给其他的HRegionServer)。ZooKeeper集群本身使用一致性协议(PAXOS协议)保证每个节点状态的一致性。
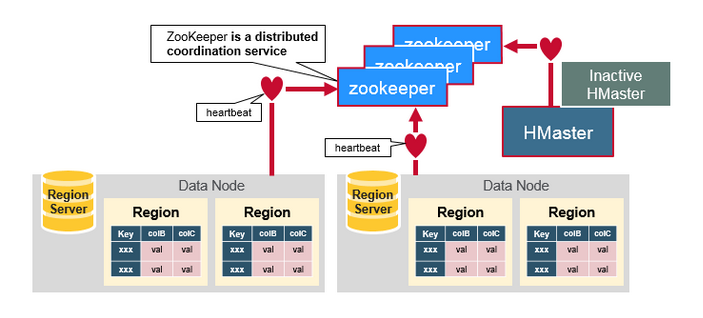
How The Components Work Together
ZooKeeper协调集群所有节点的共享信息,在HMaster和HRegionServer连接到ZooKeeper后创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点实效,则HMaster会收到通知,并做相应的处理。
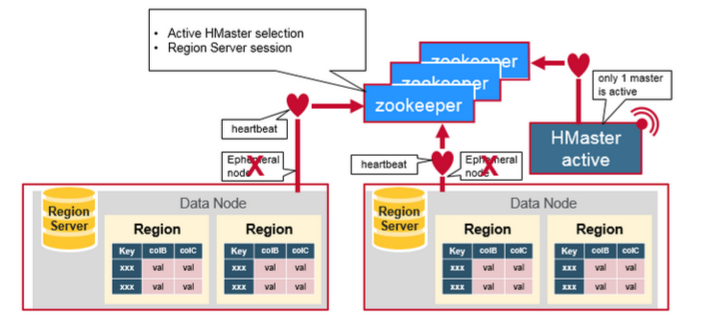
另外,HMaster通过监听ZooKeeper中的Ephemeral节点(默认:/hbase/rs/*)来监控HRegionServer的加入和宕机。在第一个HMaster连接到ZooKeeper时会创建Ephemeral节点(默认:/hbasae/master)来表示Active的HMaster,其后加进来的HMaster则监听该Ephemeral节点,如果当前Active的HMaster宕机,则该节点消失,因而其他HMaster得到通知,而将自身转换成Active的HMaster,在变为Active的HMaster之前,它会创建在/hbase/back-masters/下创建自己的Ephemeral节点。
HBase的第一次读写
在HBase 0.96以前,HBase有两个特殊的Table:-ROOT-和.META.(如
BigTable中的设计),其中-ROOT- Table的位置存储在ZooKeeper,它存储了.META. Table的RegionInfo信息,并且它只能存在一个HRegion,而.META. Table则存储了用户Table的RegionInfo信息,它可以被切分成多个HRegion,因而对第一次访问用户Table时,首先从ZooKeeper中读取-ROOT- Table所在HRegionServer;然后从该HRegionServer中根据请求的TableName,RowKey读取.META. Table所在HRegionServer;最后从该HRegionServer中读取.META. Table的内容而获取此次请求需要访问的HRegion所在的位置,然后访问该HRegionSever获取请求的数据,这需要三次请求才能找到用户Table所在的位置,然后第四次请求开始获取真正的数据。当然为了提升性能,客户端会缓存-ROOT- Table位置以及-ROOT-/.META. Table的内容。如下图所示:
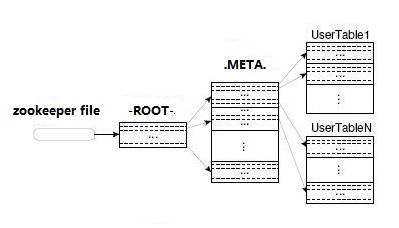
可是即使客户端有缓存,在初始阶段需要三次请求才能直到用户Table真正所在的位置也是性能低下的,而且真的有必要支持那么多的HRegion吗?或许对Google这样的公司来说是需要的,但是对一般的集群来说好像并没有这个必要。在BigTable的论文中说,每行METADATA存储1KB左右数据,中等大小的Tablet(HRegion)在128MB左右,3层位置的Schema设计可以支持2^34个Tablet(HRegion)。即使去掉-ROOT- Table,也还可以支持2^17(131072)个HRegion, 如果每个HRegion还是128MB,那就是16TB,这个貌似不够大,但是现在的HRegion的最大大小都会设置的比较大,比如我们设置了2GB,此时支持的大小则变成了4PB,对一般的集群来说已经够了,因而在HBase 0.96以后去掉了-ROOT- Table,只剩下这个特殊的目录表叫做Meta Table(hbase:meta),它存储了集群中所有用户HRegion的位置信息,而ZooKeeper的节点中(/hbase/meta-region-server)存储的则直接是这个Meta Table的位置,并且这个Meta Table如以前的-ROOT- Table一样是不可split的。这样,客户端在第一次访问用户Table的流程就变成了:
- 从ZooKeeper(/hbase/meta-region-server)中获取hbase:meta的位置(HRegionServer的位置),缓存该位置信息。
- 从HRegionServer中查询用户Table对应请求的RowKey所在的HRegionServer,缓存该位置信息。
- 从查询到HRegionServer中读取Row。
从这个过程中,我们发现客户会缓存这些位置信息,然而第二步它只是缓存当前RowKey对应的HRegion的位置,因而如果下一个要查的RowKey不在同一个HRegion中,则需要继续查询hbase:meta所在的HRegion,然而随着时间的推移,客户端缓存的位置信息越来越多,以至于不需要再次查找hbase:meta Table的信息,除非某个HRegion因为宕机或Split被移动,此时需要重新查询并且更新缓存。
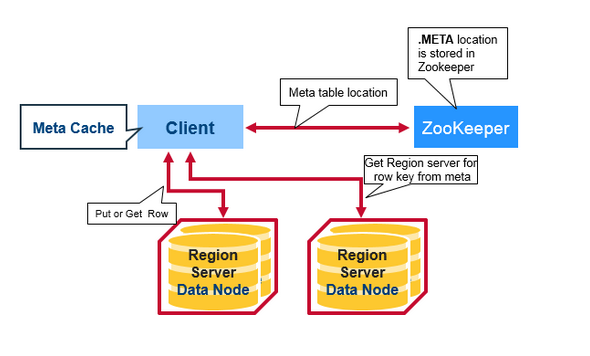
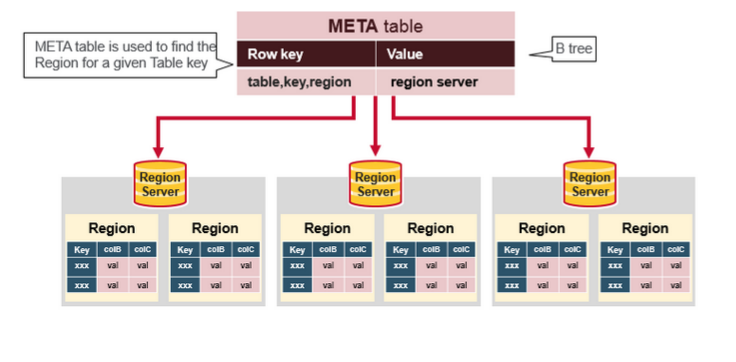
hbase:meta表
hbase:meta表存储了所有用户HRegion的位置信息,它的RowKey是:tableName,regionStartKey,regionId,replicaId等,它只有info列族,这个列族包含三个列,他们分别是:info:regioninfo列是RegionInfo的proto格式:regionId,tableName,startKey,endKey,offline,split,replicaId;info:server格式:HRegionServer对应的server:port;info:serverstartcode格式是HRegionServer的启动时间戳。
HRegionServer详解
HRegionServer一般和DataNode在同一台机器上运行,实现数据的本地性。HRegionServer包含多个HRegion,由WAL(HLog)、BlockCache、MemStore、HFile组成。
- WAL即Write Ahead Log,在早期版本中称为HLog,它是HDFS上的一个文件,如其名字所表示的,所有写操作都会先保证将数据写入这个Log文件后,才会真正更新MemStore,最后写入HFile中。采用这种模式,可以保证HRegionServer宕机后,我们依然可以从该Log文件中读取数据,Replay所有的操作,而不至于数据丢失。这个Log文件会定期Roll出新的文件而删除旧的文件(那些已持久化到HFile中的Log可以删除)。WAL文件存储在/hbase/WALs/${HRegionServer_Name}的目录中(在0.94之前,存储在/hbase/.logs/目录中),一般一个HRegionServer只有一个WAL实例,也就是说一个HRegionServer的所有WAL写都是串行的(就像log4j的日志写也是串行的),这当然会引起性能问题,因而在HBase 1.0之后,通过HBASE-5699实现了多个WAL并行写(MultiWAL),该实现采用HDFS的多个管道写,以单个HRegion为单位。关于WAL可以参考Wikipedia的Write-Ahead Logging。顺便吐槽一句,英文版的维基百科竟然能毫无压力的正常访问了,这是某个GFW的疏忽还是以后的常态?
- BlockCache是一个读缓存,即“引用局部性”原理(也应用于CPU,分空间局部性和时间局部性,空间局部性是指CPU在某一时刻需要某个数据,那么有很大的概率在一下时刻它需要的数据在其附近;时间局部性是指某个数据在被访问过一次后,它有很大的概率在不久的将来会被再次的访问),将数据预读取到内存中,以提升读的性能。HBase中提供两种BlockCache的实现:默认on-heap LruBlockCache和BucketCache(通常是off-heap)。通常BucketCache的性能要差于LruBlockCache,然而由于GC的影响,LruBlockCache的延迟会变的不稳定,而BucketCache由于是自己管理BlockCache,而不需要GC,因而它的延迟通常比较稳定,这也是有些时候需要选用BucketCache的原因。这篇文章BlockCache101对on-heap和off-heap的BlockCache做了详细的比较。
- HRegion是一个Table中的一个Region在一个HRegionServer中的表达。一个Table可以有一个或多个Region,他们可以在一个相同的HRegionServer上,也可以分布在不同的HRegionServer上,一个HRegionServer可以有多个HRegion,他们分别属于不同的Table。HRegion由多个Store(HStore)构成,每个HStore对应了一个Table在这个HRegion中的一个Column Family,即每个Column Family就是一个集中的存储单元,因而最好将具有相近IO特性的Column存储在一个Column Family,以实现高效读取(数据局部性原理,可以提高缓存的命中率)。HStore是HBase中存储的核心,它实现了读写HDFS功能,一个HStore由一个MemStore
和0个或多个StoreFile组成。
- MemStore是一个写缓存(In Memory Sorted Buffer),所有数据的写在完成WAL日志写后,会
写入MemStore中,由MemStore根据一定的算法将数据Flush到地层HDFS文件中(HFile),通常每个HRegion中的每个
Column Family有一个自己的MemStore。
- HFile(StoreFile)
用于存储HBase的数据(Cell/KeyValue)。在HFile中的数据是按RowKey、Column Family、Column排序,对相同的Cell(即这三个值都一样),则按timestamp倒序排列。
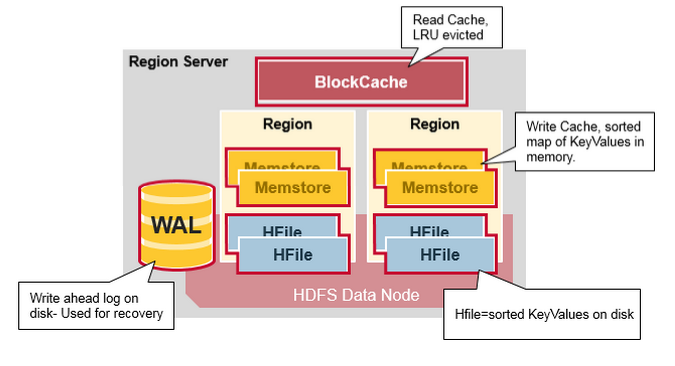
虽然上面这张图展现的是最新的HRegionServer的架构(但是并不是那么的精确),但是我一直比较喜欢看以下这张图,即使它展现的应该是0.94以前的架构。
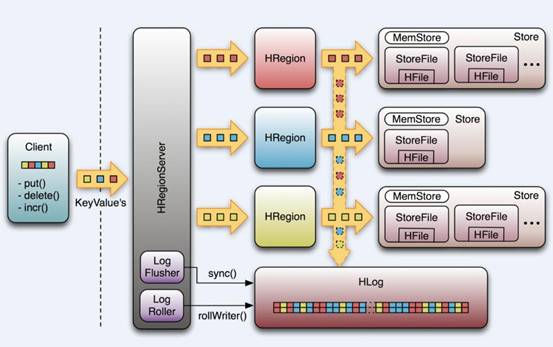
HRegionServer中数据写流程图解
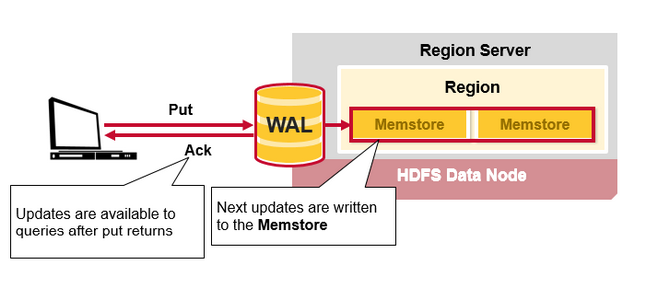
当客户端发起一个Put请求时,首先它从hbase:meta表中查出该Put数据最终需要去的HRegionServer。然后客户端将Put请求发送给相应的HRegionServer,在HRegionServer中它首先会将该Put操作写入WAL日志文件中(Flush到磁盘中)。

写完WAL日志文件后,HRegionServer根据Put中的TableName和RowKey找到对应的HRegion,并根据Column Family找到对应的HStore,并将Put写入到该HStore的MemStore中。此时写成功,并返回通知客户端。
MemStore Flush
MemStore是一个In Memory Sorted Buffer,在每个HStore中都有一个MemStore,即它是一个HRegion的一个Column Family对应一个实例。它的排列顺序以RowKey、Column Family、Column的顺序以及Timestamp的倒序,如下所示:
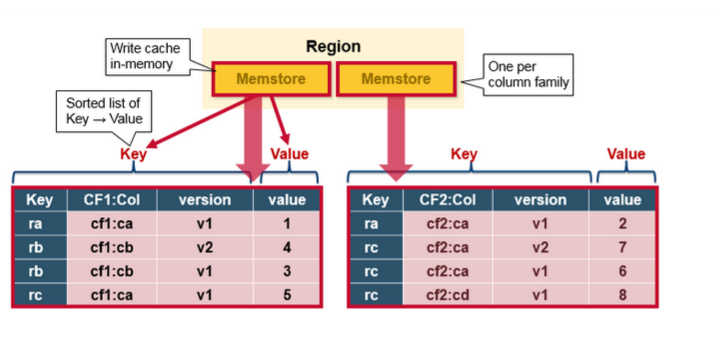
每一次Put/Delete请求都是先写入到MemStore中,当MemStore满后会Flush成一个新的StoreFile(底层实现是HFile),即一个HStore(Column Family)可以有0个或多个StoreFile(HFile)。有以下三种情况可以触发MemStore的Flush动作,
需要注意的是MemStore的最小Flush单元是HRegion而不是单个MemStore。据说这是Column Family有个数限制的其中一个原因,估计是因为太多的Column Family一起Flush会引起性能问题?具体原因有待考证。
- 当一个HRegion中的所有MemStore的大小总和超过了hbase.hregion.memstore.flush.size的大小,默认128MB。此时当前的HRegion中所有的MemStore会Flush到HDFS中。
- 当全局MemStore的大小超过了hbase.regionserver.global.memstore.upperLimit的大小,默认40%的内存使用量。此时当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush顺序是MemStore大小的倒序(一个HRegion中所有MemStore总和作为该HRegion的MemStore的大小还是选取最大的MemStore作为参考?有待考证),直到总体的MemStore使用量低于hbase.regionserver.global.memstore.lowerLimit,默认38%的内存使用量。
- 当前HRegionServer中WAL的大小超过了hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs的数量,当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush使用时间顺序,最早的MemStore先Flush直到WAL的数量少于hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs。这里说这两个相乘的默认大小是2GB,查代码,hbase.regionserver.max.logs默认值是32,而hbase.regionserver.hlog.blocksize是HDFS的默认blocksize,32MB。但不管怎么样,因为这个大小超过限制引起的Flush不是一件好事,可能引起长时间的延迟,因而这篇文章给的建议:“Hint: keep hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs just a bit above hbase.regionserver.global.memstore.lowerLimit * HBASE_HEAPSIZE.”。并且需要注意,这里给的描述是有错的(虽然它是官方的文档)。
在MemStore Flush过程中,还会在尾部追加一些meta数据,其中就包括Flush时最大的WAL sequence值,以告诉HBase这个StoreFile写入的最新数据的序列,那么在Recover时就直到从哪里开始。在HRegion启动时,这个sequence会被读取,并取最大的作为下一次更新时的起始sequence。

HFile格式
HBase的数据以KeyValue(Cell)的形式顺序的存储在HFile中,在MemStore的Flush过程中生成HFile,由于MemStore中存储的Cell遵循相同的排列顺序,因而Flush过程是顺序写,我们直到磁盘的顺序写性能很高,因为不需要不停的移动磁盘指针。
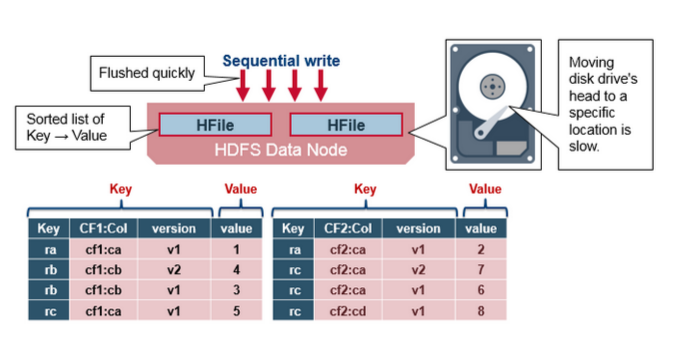
HFile参考BigTable的SSTable和Hadoop的
TFile实现,从HBase开始到现在,HFile经历了三个版本,其中V2在0.92引入,V3在0.98引入。首先我们来看一下V1的格式:
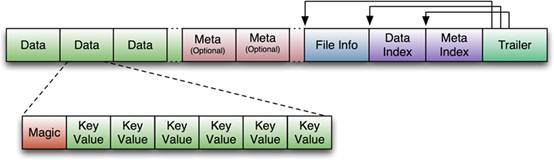
V1的HFile由多个Data Block、Meta Block、FileInfo、Data Index、Meta Index、Trailer组成,其中Data Block是HBase的最小存储单元,在前文中提到的BlockCache就是基于Data Block的缓存的。一个Data Block由一个魔数和一系列的KeyValue(Cell)组成,魔数是一个随机的数字,用于表示这是一个Data Block类型,以快速监测这个Data Block的格式,防止数据的破坏。Data Block的大小可以在创建Column Family时设置(HColumnDescriptor.setBlockSize()),默认值是64KB,大号的Block有利于顺序Scan,小号Block利于随机查询,因而需要权衡。Meta块是可选的,FileInfo是固定长度的块,它纪录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index纪录了每个Data块和Meta块的其实点、未压缩时大小、Key(起始RowKey?)等。Trailer纪录了FileInfo、Data Index、Meta Index块的起始位置,Data Index和Meta Index索引的数量等。其中FileInfo和Trailer是固定长度的。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是
RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time
Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
随着HFile版本迁移,KeyValue(Cell)的格式并未发生太多变化,只是在V3版本,尾部添加了一个可选的Tag数组。
HFileV1版本的在实际使用过程中发现它占用内存多,并且Bloom File和Block Index会变的很大,而引起启动时间变长。其中每个HFile的Bloom Filter可以增长到100MB,这在查询时会引起性能问题,因为每次查询时需要加载并查询Bloom Filter,100MB的Bloom Filer会引起很大的延迟;另一个,Block Index在一个HRegionServer可能会增长到总共6GB,HRegionServer在启动时需要先加载所有这些Block Index,因而增加了启动时间。为了解决这些问题,在0.92版本中引入HFileV2版本:
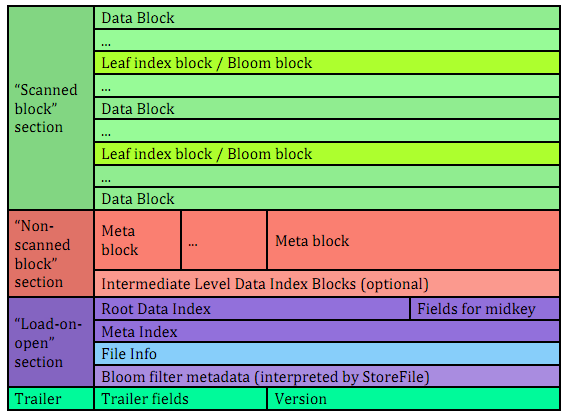
在这个版本中,Block Index和Bloom Filter添加到了Data Block中间,而这种设计同时也减少了写的内存使用量;另外,为了提升启动速度,在这个版本中还引入了延迟读的功能,即在HFile真正被使用时才对其进行解析。
FileV3版本基本和V2版本相比,并没有太大的改变,它在KeyValue(Cell)层面上添加了Tag数组的支持;并在FileInfo结构中添加了和Tag相关的两个字段。关于具体HFile格式演化介绍,可以参考
这里。
对HFileV2格式具体分析,它是一个多层的类B+树索引,采用这种设计,可以实现查找不需要读取整个文件:
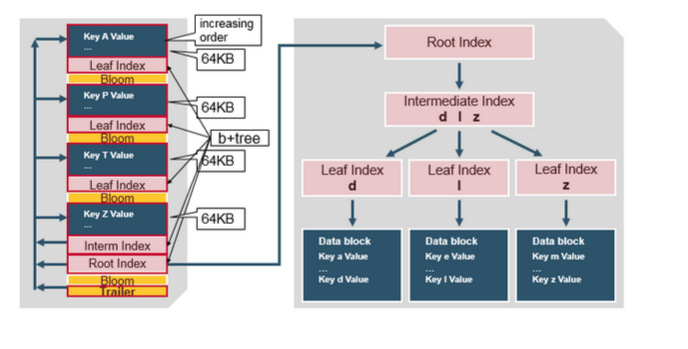
Data Block中的Cell都是升序排列,每个block都有它自己的Leaf-Index,每个Block的最后一个Key被放入Intermediate-Index中,Root-Index指向Intermediate-Index。在HFile的末尾还有Bloom Filter用于快速定位那么没有在某个Data Block中的Row;TimeRange信息用于给那些使用时间查询的参考。在HFile打开时,这些索引信息都被加载并保存在内存中,以增加以后的读取性能。
这篇就先写到这里,未完待续。。。。
参考:
https://www.mapr.com/blog/in-depth-look-hbase-architecture#.VdNSN6Yp3qx
http://jimbojw.com/wiki/index.php?title=Understanding_Hbase_and_BigTable
http://hbase.apache.org/book.html
http://www.searchtb.com/2011/01/understanding-hbase.html
http://research.google.com/archive/bigtable-osdi06.pdf
posted on 2015-08-22 17:44
DLevin 阅读(60868)
评论(0) 编辑 收藏 所属分类:
HBase 、
Architecture