问题描述
在服务器编程中,通常需要处理多种不同的请求,在正式处理请求之前,需要对请求做一些预处理,如:
- 纪录每个Client的每次访问信息。
- 对Client进行认证和授权检查(Authentication and Authorization)。
- 检查当前Session是否合法。
- 检查Client的IP地址是否可信赖或不可信赖(IP地址白名单、黑名单)。
- 请求数据是否先要解压或解码。
- 是否支持Client请求的类型、Browser版本等。
- 添加性能监控信息。
- 添加调试信息。
- 保证所有异常都被正确捕获到,对未预料到的异常做通用处理,防止给Client看到内部堆栈信息。
在响应返回给客户端之前,有时候也需要做一些预处理再返回:
- 对响应消息编码或压缩。
- 为所有响应添加公共头、尾等消息。
- 进一步Enrich响应消息,如添加公共字段、Session信息、Cookie信息,甚至完全改变响应消息等。
如何实现这样的需求,同时保持可扩展性、可重用性、可配置、移植性?
问题解决
要实现这种需求,最直观的方法就是在每个请求处理过程中添加所有这些逻辑,为了减少代码重复,可以将所有这些检查提取成方法,这样在每个处理方法中调用即可:
public Response service1(Request request) {
validate(request);
request = transform(request);
Response response = process1(request);
return transform(response);
}
此时,如果出现service2方法,依然需要拷贝service1中的实现,然后将process1换成process2即可。这个时候我们发现很多重复代码,继续对它重构,比如提取公共逻辑到基类成模版方法,这种使用继承的方式会引起子类对父类的耦合,如果要让某些模块变的可配置需要有太多的判断逻辑,代码变的臃肿;因而可以更进一步,将所有处理逻辑抽象出一个Processor接口,然后使用Decorate模式(即引用优于继承):
public interface Processor {
Response process(Request request);
}
public class CoreProcessor implements Processor {
public Response process(Request request) {
// do process/calculation
}
}
public class DecoratedProcessor implements Processor {
private final Processor innerProcessor;
public DecoratedProcessor(Processor processor) {
this.innerProcessor = processor;
}
public Response process(Request request) {
request = preProcess(request);
Response response = innerProcessor.process(request);
response = postProcess(response);
return response;
}
protected Request preProcess(Request request) {
return request;
}
protected Response postProcess(Response response) {
return response;
}
}
public void Transformer extends DecoratedProcessor {
public Transformer(Processor processor) {
super(processor);
}
protected Request preProcess(Request request) {
return transformRequest(request);
}
protected Response postProcess(Response response) {
return transformResponse(response);
}
}
此时,如果需要在真正的处理逻辑之前加入其他的预处理逻辑,只需要继承DecoratedProcessor,实现preProcess或postProcess方法,分别在请求处理之前和请求处理之后横向切入一些逻辑,也就是所谓的AOP编程:面向切面的编程,然后只需要根据需求构建这个链条:
Processor processor = new MissingExceptionCatcher(new Debugger(new Transformer(new CoreProcessor());
Response response = processor.process(request);
......
这已经是相对比较好的设计了,每个Processor只需要关注自己的实现逻辑即可,代码变的简洁;并且每个Processor各自独立,可重用性好,测试方便;整条链上能实现的功能只是取决于链的构造,因而只需要有一种方法配置链的构造即可,可配置性也变得灵活;然而很多时候引用是一种静态的依赖,而无法满足动态的需求。要构造这条链,每个前置Processor需要知道其后的Processor,这在某些情况下并不是在起初就知道的。此时,我们需要引入Intercepting Filter模式来实现动态的改变条链。
Intercepting Filter模式
在前文已经构建了一条由引用而成的Processor链,然而这是一条静态链,并且需要一开始就能构造出这条链,为了解决这个限制,我们可以引入一个ProcessorChain来维护这条链,并且这条链可以动态的构建。
有多种方式可以实现并控制这个链:
- 在存储上,可以使用数组来存储所有的Processor,Processor在数组中的位置表示这个Processor在链条中的位置;也可以用链表来存储所有的Processor,此时Processor在这个链表中的位置即是在链中的位置。
- 在抽象上,可以所有的逻辑都封装在Processor中,也可以将核心逻辑使用Processor抽象,而外围逻辑使用Filter抽象。
- 在流程控制上,一般通过在Processor实现方法中直接使用ProcessorChain实例(通过参数掺入)来控制流程,利用方法调用的进栈出栈的特性实现preProcess()和postProcess()处理。
在实际中使用这个模式的有:Servlet的Filter机制、Netty的ChannelPipeline中、Structs2中的Interceptor中都实现了这个模式。
Intercepting Filter模式在Servlet的Filter中的实现(Jetty版本)
其中Servlet的Filter在Jetty的实现中使用数组存储Filter,Filter末尾可以使用Servlet实例处理真正的业务逻辑,在流程控制上,使用FilterChain的doFilter方法来实现。如FilterChain在Jetty中的实现:
public void doFilter(ServletRequest request, ServletResponse response) throws IOException, ServletException
// pass to next filter
if (_filter < LazyList.size(_chain)) {
FilterHolder holder= (FilterHolder)LazyList.get(_chain, _filter++);
Filter filter= holder.getFilter();
filter.doFilter(request, response, this);
return;
}
// Call servlet
HttpServletRequest srequest = (HttpServletRequest)request;
if (_servletHolder != null) {
_servletHolder.handle(_baseRequest,request, response);
}
}
这里,_chain实际上是一个Filter的ArrayList,由FilterChain调用doFilter()启动调用第一个Filter的doFilter()方法,在实际的Filter实现中,需要手动的调用FilterChain.doFilter()方法来启动下一个Filter的调用,利用方法调用的进栈出栈的特性实现Request的pre-process和Response的post-process处理。如果不调用FilterChain.doFilter()方法,则表示不需要调用之后的Filter,流程从当前Filter返回,在它之前的Filter的FilterChain.doFilter()调用之后的逻辑反向处理直到第一个Filter处理完成而返回。
public class MyFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
// pre-process ServletRequest
chain.doFilter(request, response);
// post-process Servlet Response
}
}
整个Filter链的处理流程如下:

Intercepting Filter模式在Netty3中的实现
Netty3在DefaultChannelPipeline中实现了Intercepting Filter模式,其中ChannelHandler是它的Filter。在Netty3的DefaultChannelPipeline中,使用一个以ChannelHandlerContext为节点的双向链表来存储ChannelHandler,所有的横切面逻辑和实际业务逻辑都用ChannelHandler表达,在控制流程上使用ChannelHandlerContext的sendDownstream()和sendUpstream()方法来控制流程。不同于Servlet的Filter,ChannelHandler有两个子接口:ChannelUpstreamHandler和ChannelDownstreamHandler分别用来请求进入时的处理流程和响应出去时的处理流程。对于Client的请求,从DefaultChannelPipeline的sendUpstream()方法入口:
public void sendDownstream(ChannelEvent e) {
DefaultChannelHandlerContext tail = getActualDownstreamContext(this.tail);
if (tail == null) {
try {
getSink().eventSunk(this, e);
return;
} catch (Throwable t) {
notifyHandlerException(e, t);
return;
}
}
sendDownstream(tail, e);
}
void sendDownstream(DefaultChannelHandlerContext ctx, ChannelEvent e) {
if (e instanceof UpstreamMessageEvent) {
throw new IllegalArgumentException("cannot send an upstream event to downstream");
}
try {
((ChannelDownstreamHandler) ctx.getHandler()).handleDownstream(ctx, e)
} catch (Throwable t) {
e.getFuture().setFailure(t);
notifyHandlerException(e, t);
}
}
如果有响应消息,该消息从DefaultChannelPipeline的sendDownstream()方法为入口:
public void sendUpstream(ChannelEvent e) {
DefaultChannelHandlerContext head = getActualUpstreamContext(this.head);
if (head == null) {
return;
}
sendUpstream(head, e);
}
void sendUpstream(DefaultChannelHandlerContext ctx, ChannelEvent e) {
try {
((ChannelUpstreamHandler) ctx.getHandler()).handleUpstream(ctx, e);
} catch (Throwable t) {
notifyHandlerException(e, t);
}
}
在实际实现ChannelUpstreamHandler或ChannelDownstreamHandler时,调用ChannelHandlerContext中的sendUpstream或sendDownstream方法将控制流程交给下一个ChannelUpstreamHandler或下一个ChannelDownstreamHandler,或调用Channel中的write方法发送响应消息。
public class MyChannelUpstreamHandler implements ChannelUpstreamHandler {
public void handleUpstream(ChannelHandlerContext ctx, ChannelEvent e) throws Exception {
// handle current logic, use Channel to write response if needed.
// ctx.getChannel().write(message);
ctx.sendUpstream(e);
}
}
public class MyChannelDownstreamHandler implements ChannelDownstreamHandler {
public void handleDownstream(
ChannelHandlerContext ctx, ChannelEvent e) throws Exception {
// handle current logic
ctx.sendDownstream(e);
}
}
当ChannelHandler向ChannelPipelineContext发送事件时,其内部从当前ChannelPipelineContext
节点出发找到下一个ChannelUpstreamHandler或ChannelDownstreamHandler实例,并向其发送
ChannelEvent,对于Downstream链,如果到达链尾,则将ChannelEvent发送给ChannelSink:
public void sendDownstream(ChannelEvent e) {
DefaultChannelHandlerContext prev = getActualDownstreamContext(this.prev);
if (prev == null) {
try {
getSink().eventSunk(DefaultChannelPipeline.this, e);
} catch (Throwable t) {
notifyHandlerException(e, t);
}
} else {
DefaultChannelPipeline.this.sendDownstream(prev, e);
}
}
public void sendUpstream(ChannelEvent e) {
DefaultChannelHandlerContext next = getActualUpstreamContext(this.next);
if (next != null) {
DefaultChannelPipeline.this.sendUpstream(next, e);
}
}
正是因为这个实现,如果在一个末尾的ChannelUpstreamHandler中先移除自己,在向末尾添加一个新的ChannelUpstreamHandler,它是无效的,因为它的next已经在调用前就固定设置为null了。
在DefaultChannelPipeline的ChannelHandler链条的处理流程为:
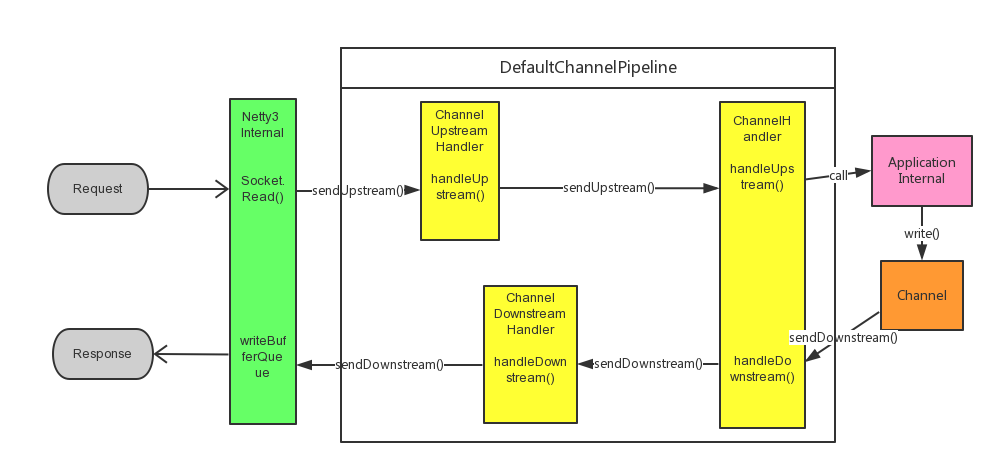
在这个实现中,不像Servlet的Filter实现利用方法调用栈的进出栈来完成pre-process和post-process,而是在进去的链和出来的链各自调用handleUpstream()和handleDownstream()方法,这样会引起调用栈其实是两条链的总和,因而需要注意这条链的总长度。这样做的好处是这条ChannelHandler的链不依赖于方法调用栈,而是在DefaultChannelPipeline内部本身的链,因而在handleUpstream()或handleDownstream()可以随时将执行流程转发给其他线程或线程池,只需要保留ChannelPipelineContext引用,在处理完成后用这个ChannelPipelineContext重新向这条链的后一个节点发送ChannelEvent,然而由于Servlet的Filter依赖于方法的调用栈,因而方法返回意味着所有执行完成,这种限制在异步编程中会引起问题,因而Servlet在3.0后引入了Async的支持。
Intercepting Filter模式的缺点
简单提一下这个模式的缺点:
1. 相对传统的编程模型,这个模式有一定的学习曲线,需要很好的理解该模式后才能灵活的应用它来编程。
2. 需要划分不同的逻辑到不同的Filter中,这有些时候并不是那么容易。
3. 各个Filter之间共享数据将变得困难。在Netty3中可以自定义自己的ChannelEvent来实现自定义消息的传输,或者使用ChannelPipelineContext的Attachment字段来实现消息传输,而Servlet中的Filter则没有提供类似的机制,如果不是可以配置的数据在Config中传递,其他时候的数据共享需要其他机制配合完成。
参考
Core J2EE Pattern - Intercepting Filter
posted on 2015-09-03 22:14
DLevin 阅读(5624)
评论(0) 编辑 收藏 所属分类:
Architecture