|
|
CSAPP上的例子,但是书中的源码有问题,修改后的版本:
#include "csapp.h"
#define MAXARGS 128
void eval(char *cmdline);
int parseline(char *buf, char **argv);
int buildin_command(char **argv);
int main()
{
char cmdline[MAXLINE];
while (1)
{
printf("> ");
Fgets(cmdline, MAXLINE, stdin);
if (feof(stdin))
exit(0);
eval(cmdline);
}
}
void eval(char *cmdline)
{
char *argv[MAXARGS];
char buf[MAXLINE];
int bg;
pid_t pid;
strcpy(buf, cmdline);
bg = parseline(buf, argv);
if (argv[0] == NULL)
return;
if (!builtin_command(argv))
{
if ((pid = Fork()) == 0)
{
if (execve(argv[0], argv, environ) < 0)
{
printf("%s: Command not found.\n", argv[0]);
exit(0);
}
}
if (!bg)
{
int status;
if (waitpid(pid, &status, 0) < 0)
unix_error("waitfg: waitpid error");
}
else
printf("%d %s", pid, cmdline);
}
return;
}
int builtin_command(char **argv)
{
if (!strcmp(argv[0], "quit"))
exit(0);
if (!strcmp(argv[0], "&"))
return 1;
return 0;
}
int parseline(char *buf, char **argv)
{
char *delim;
int argc;
int bg;
buf[strlen(buf) - 1] = ' ';
while (*buf && (*buf == ' '))
buf++;
argc = 0;
while ((delim = strchr(buf, ' ')))
{
argv[argc++] = buf;
*delim = '\0';
buf = delim + 1;
while (*buf && (*buf == ' '))
buf++;
}
argv[argc] = NULL;
if (argc == 0)
return 1;
if ((bg = (*argv[argc - 1] == '&')) != 0)
argv[--argc] = NULL;
return bg;
}
摘要: http://www.defmacro.org/ramblings/fp.html还是放在Mathematics类吧
Functional Programming For The Rest of Us
Monday, June 19, 2006
Introduction
Programmers are procrastinators. Get in, get some coffee, ... 阅读全文
1. dup和dup2函数
#include <unistd.h>
int dup(int filedes);
int dup2(int filedes, int filedes2);
// Both return: new file descriptor if OK, -1 on error
dup返回的file descriptor(以下简称fd)为当前可用的最低号码,dup2则指定目的fd,如果该fd已被打开,则首先关闭这个fd。
dup后两个fd指向相同的file table entry,这意味着它们共享同一个的file status flag, read, write, append, offset等。
事实上,dup等价于
fcntl(filedes, F_DUPFD, 0);
dup2和也类似于
close(filedes2);
fcntl(filedes, F_DUPFD, filedes2);
但这不是一个原子操作,而且errno也有一定的不同。
Appending to a File 考虑某个单一进程试图在文件追加写入的操作。由于早期的UNIX系统不支持O_APPEND选项,因此得先用lseek将offset置于文件尾部。 if (lseek(fd, 0L, 2) < 0) err_sys("lseek error"); if (write(fd, buf, 100) != 100) err_sys("write error"); 注意这里的lseek函数的第三个参数2等于SEEK_END常量,但是早期UNIX并没有这个常量名(System V中才引进) 这样的处理在多进程试图在同一文件尾部追加写入时就有可能出现问题。 假设两个独立线程A B要在某个文件尾部追加写入,使用了上述方法,并没有使用O_APPEND开关。 首
先A指向了该文件尾部(假设是offset=1500的地方),接着内核切换到B进程,B也指向了该尾部,然后写入了100字节,此时内核把v-node
中当前文件的大小改为了1600。内核再次切换进程,A继续运行,调用write方法,结果就在offset=1500的地方写入了,覆盖了B进程写入的
内容。 这个问题其实和Java中的多线程差不多,指向文件尾部和写入应该作为一个原子操作执行,就像Java中使用synchronized块保护原子操作。使用O_APPEND选项就是一种解决方法。 另一种解决方法时使用XSI extension中的pread和pwrite函数。 #include <unistd.h> ssize_t pread(int filedes, void *buf, size_t nbytes, off_t offset); // Returns: number of bytes read, 0 if end of file, -1 on error ssize_t pwrite(int filedes, const void *buf, size_t nbytes, off_t offset); // Returns: number of bytes read, 0 if end of file, -1 on error 调用pread与调用lseek后再调用read等价,以下情况除外: 1. pread的两个步骤无法被中断。 2. 文件指针尚未被更新时。 pwrite与lseek+write的差别也相似。 Creating a File
当使用O_CREAT和O_EXCL开关调用open函数时,如果文件已经存在,则open函数返回失败值。如果不使用这两个开关,可以这样写:
if ((fd = open(pathname, O_WRONLY)) < 0) {
if (errno == ENOENT) {
if ((fd = creat(pathname, mode)) < 0)
err_sys("creat error");
} else {
err_sys("open error");
}
}
当open函数执行后creat函数执行前另一个进程创建了同名文件的话,该数据就会被擦除。
内核使用三种数据结构表示一个打开的文件,他们之间的关系决定了进程间对于共享文件的作用。 Every process has an entry in the process table. Within each process table entry is a table of open file descriptors, which we can think of as a vector, with one entry per descriptor. Associated with each file descriptor are 1) The file descriptor flags (close-on-exec; refer to Figure 3.6 and Section 3.14) 2) A pointer to a file table entry The kernel maintains a file table for all open files. Each file table entry contains 1) The file status flags for the file, such as read, write, append, sync, and nonblocking 2) The current file offset 3) A pointer to the v-node table entry for the file Each open file (or device) has a v-node structure that contains information about the type of file and pointers to functions that operate on the file. For most files, the v-node also contains the i-node for the file. This information is read from disk when the file is opened, so that all the pertinent information about the file is readily available. For example, the i-node contains the owner of the file, the size of the file, pointers to where the actual data blocks for the file are located on disk, and so on. 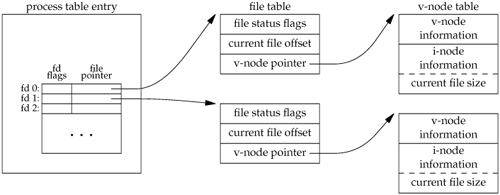 上图为这三种数据结构及其相互联系 其中v-node主要用于提供单个操作系统上的多文件系统支持,Sun把它称为Virtual File System linux中没有v-node,使用了一个generic i-node代替,尽管使用了不同的实现方式,v-node在概念上与generic i-node相同。 下面来讨论两个独立的进程打开同一文件的情况 这种情况下两个进程拥有不同的file table,但其中的两个指针指向了同一个v-node。 知道了这些数据结构的情况以后,我们可以更精确的知道某些操作的结果 1) 每次write操作结束后,当前文件的offset增加,如果这个操作导致当前的offset超出了文件长度,则i-node表中记录的文件大小会被修改为改动后的大小。 2) 使用O_APPEND方式打开文件后,每次调用write函数时,当前文件的offset都会被设置为i-node表中的该文件大小,从而write函数只能在文件尾部追加。 3) lseek 函数只改变在file table中的当前文件offset,并不会产生io操作 注意file descriptor flag和file status flag的作用域差别,前者属于某个单独进程的单独的file descriptor,后者则适用于任意进程中指向给定file table entry的所有descriptor。fcntl函数可以修改这两种flag
1. 貌似和dive into python中的有一定的差异,可能是版本的关系(python 2.2 - 2.5)
minidom.parse("binary.xml")得到的对象是binary.xml的整棵dom树,它的第一个结点包含了DOCTYPE的相关信息,对于它的字节点的firstNode,貌似一般都是空的。
2. unicode 相关
string.encode()
sys.getdefaultencoding()
指定.py文件编码的方法:
在每个文件开头加入编码声明
# -*- coding: UTF-8 -*-
3. python目录的lib/site-packages/sitecustomize.py是一个特殊的脚本,Python会在启动的时候导入它。
4. 搜索元素:
getElementByTagName()
返回的是一个list
5. 元素属性
attributes 是一个xml.dom.minidom.NameNodeMap实例,常用的方法如keys() values(),同时也有__getitem__方法,类似于dictionary
居然要军训两星期后才搬去张江,残念啊。。。
求到了个代理,总算能上外网,却上不了TopCoder
在寝室百无聊赖ing...
算了,还是看会儿书吧
1. 几个常用对象:
os.system 执行命令
sys.stdin sys.stdout
os.path.getsize 获得文件大小
os.path.isdir
os.mkdir
os.listdir
2. walk()函数
很好用的一个函数
os.path.walk(rootdir, f, arg)
rootdir是要访问的目录树的根,f是用户定义的函数,arg是调用f时用的一个参数。
对于每一个"walk"过程中遇到的目录directory,设该目录下的文件列表为filelist,walk函数会调用
f(arg, directory, filelist)
1. 交换x和y的值 [x, y] = [y, x]
2. zip()方法把几个lists的第i个元素合成一个tuple,放在一个新的list中。
zip(seq1 [, seq2 [...]]) -> [(seq1[0], seq2[0] ...), (...)]
函数式编程相关
1. Mapping
map() 方法对序列中的每个元素调用某个函数,返回新生成的结果序列。
有点类似于Ruby的Array.each do | element |
>>> z = map(len, ["abc", "clounds", "rain"])
>>> z
[3, 6, 4]
2. Filtering
过滤掉满足条件的元素,类似与Array.reject do | element |
>>> x = [5,12,-2,13]
>>> y = filter(lambda z: z > 0, x)
>>> y
[5, 12, 13]
3. List Comprehension
来个复杂的例子
>>> y
[[0, 2, 22], [1, 5, 12], [2, 3, 33]]
>>> [a for b in y for a in b[1:]]
[2, 22, 5, 12, 3, 33]
4. Reduction
先看示例
>>> x = reduce(lambda x,y: x+y, range(5))
>>> x
10
执行的顺序是:首先调用函数处理range(5)前两个值,0 + 1 = 1,然后返回的值1作为x,继续与range(5)的第三个值(2,作为y)。
最后的结果是0+1+2+3+4的值
这个常用来代替for循环
|