讲起静态代码分析工具,估计大家耳熟能详的都能讲出几个来,像PMD, Checkstyle, Findbug等。没错这些都是我们日常编码代码时用于提升我们代码质量的好工具,本文将从PMD工具实现的规则出发,通过这些规则的定义来学习一下代码优化的技巧,希望通过这些技巧的介绍可以帮助大家在编码过程中提升大家的代码编写质量。同时也算给大家介绍一个比较不错的途径去学习改进代码编写质量的方法。
下面都是从PMD规则中总结的一部分代码优化建议:
1.局部变量只被赋值一次可以声明为final
说明: 使用final标识后,Java在编译的时候会自动把变化替换成常量,这样程序的运行效率就会提升
2.如果传入长度为1的字面意义参数,这调用String.startsWith 可以使用 String.charAt(0) 方法节省运行时间
说明:关于这点比较好理解,String对象本身就是char数组,String.startsWith方法在内部处理比较复杂,又有循环比较操作,所以效率远不及charAt操作。
“Abc”.startsWith(“A”)
//bad
“Abc”.charAt(0)
== ‘A’ //good
3.字符串拼接,使用StringBuffer,而不是直接使用”+”操作符进行拼接
说明: 关于这一点,大家都有认识。因为直接的String对象拼接,会产生新的String的对象进行存储。StringBuffer则会申请一个较大的内存空间(char数组), 针对拼接,如果没有超过char数组大小就直接追加到该数组尾部. 注意StringBuffer默认大小是16个字符,所以建议大家使用时指定创建的数组大小。
4.String 的indexOf方法,如果参数单个字母,则使用char
Abc”.indexOf (“A”) //bad
Abc”.indexOf(‘A’) //good
说明:String indexOf 方法,针对String和char的查找是使用了两个方法,有兴趣的同学可以看一下String的原代码,查找String的方法要比查找char方法复杂,相对耗时
5.建议不要使用无参的StringBuffer构造函数(该初始长度为16个字符)
说明: 大家可能对StringBuffer有一些误解,认为StringBuffer初始的空间比较大,但实际上其默认创建的大小只是16个字符的数组,一旦超过后,需要新申请的数组空间,这个就会有额外的开销。
6.非线程安全的单例实现 NonThreadSafeSingleton
下面代码是单例实现中比较常见的一种

但这段代码引入的一个问题,就是在多线程方式下运行,有可能会出复重新创建对象的问题。解决办法在getFoo方法上加上 synchronized关键字
7.同时需要覆写 hashCode和equals方法
说明:这个也是大家偶尔会忽视的一个问题。hashCode和equlas方法最主要的用途是在基本Hash算法的集合类中,如HashMap,等。
在HashMap实现中,其对一个对方是否相等的判断逻辑如下:
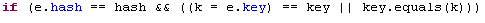
也就是说在HashMap中如果两个对象相等必须是hashCode相等并且equals方法也返回相等。
那如果在一个对象中,只复写了equals,而未复写hashCode方法,就会造成”重复”的对象在HashSet中也会发生。
下面是一个有问题的示例代码:

8.BigDecimal对象初始化时,针对浮点数据值使用String参数(针对精度问题)
说明:例如 new BigDecimal(0.1) 值真正的值可能是 .1000000000000000055511151231257827021181583404541015625
Good Luck!
Yours Matthew!
posted on 2011-04-29 10:54
x.matthew 阅读(2386)
评论(2) 编辑 收藏