The
Strategy Pattern
Overview
This
chapter introduces a new case study, which comes from the area of
e-commerce (electronic commerce over the Internet). It also begins a
solution using the Strategy pattern. I return to this case study in
Chapter 16, “The Analysis Matrix”.
This
chapter
-
Return
to the problem of new requirements and describes approaches to
handling new variations of an existing theme.
-
Explains
which approach is consistent with the Gang of Four’s philosophy
and why.
-
Introduces
the new case study.
-
Describes
the Strategy pattern and shows how it handles a new requirement in
the case study.
-
Describes
the key features of the Strategy pattern.
An
Approach to Handling New Requirements
Many
times in life and many times in software applications, you have to
make choices about the general approach to performing a task or
solving a problem. Most of us have learned that taking the easiest
route in the short run can lead to serious complications in the long
run. For example, none of us would ignore oil changes for our car
beyond a certain point. True, I may not change the oil every 3000
miles, but I also do not wait until 30000 miles before changing the
oil. (If I did so, there would be no need to change the oil any more:
The car would not work!) Or consider the “desktop filing
system”
-the
technique of using the top of the desk as a filing cabinet. It works
well in the short run, but in the long run, as the piles grow, it
becomes tough to find anything. Disaster often comes in the long run
from suboptimal decisions made in the short run.
Unfortunately,
when it comes to software development, many people have not learned
these lessons yet. Many projects are only concerned with handling
immediate, pressing needs, without concern for future maintenance.
There are several reasons projects tend to ignore long-term issues
such as ease of maintenance or ability to change. Common excuses
include the following:
-
We
really can’t figure out how the new requirements are going to
change.
-
If
we try to see how things will change, we’ll stay in analysis
forever.
-
If
we try to write our software so we can add new functionality to it,
we’ll stay in design forever.
-
We
don’t have the budget to do so.
-
The
customer is breathing down my neck to get this implemented right
now. I don’t have time to think.
-
I’ll
get to it later.
There
seem to be only two choices:
-
Overanalyze
or overdesign
- I
like to call this “paralysis by analysis”, or
-
Just
jump in, write the code without concern for long-term issues, and
then get on another project before this short-sightedness causes too
many problems. I like to call this “abandon (by) ship (date)!”
Because
management is under pressure to deliver and not to maintain, maybe
these results are not surprising. But take a (quick!) moment to
reflect. Could there be a third way? Could it be that my basic
assumptions and belief system keep me from being seeing alternatives?
In this case, the belief is that it is more costly to design for
change than to design without worrying about change.
But
this belief is often false. In fact, the opposite is often true:
stepping back to consider how a system might change over time often
results in a better design becoming apparent. And this often takes
less time than the standard, “hurry-up-and-get-it-done-now”
approach. Better quality code is easier to read, test, and modify.
These factors compensate for any additional time it might take to do
it right.
The
following case study is a great illustration of the
“design-with-change-in-mind” approach. Note that I am not trying
to anticipate the exact nature of the change. Instead, I am assuming
that change will happen and I am trying to anticipate where those
changes will occur. This approach is based on the principle described
in the Gang of Four book:
-
“Program
to an interface, not an implementation.”
-
“Favor
project [aggregation] over class inheritance.”
-
“Consider
what should be variable in your design. This approach is the
opposite of focusing on the cause of redesign. Instead of
considering what might force a change to a design, consider what you
want to be able to change without redesign. The focus here is on
encapsulation the concept that varies, a theme of many design
patterns.”
Here
is what I suggest: when faced with modifying code to handle a new
requirement, you should at least consider following these strategies.
If following these strategies will not cost significantly more to
design and implement, then use them. You can expect a long-term
benefit from doing so, with only a modest short-term cost (if any).
I
am not proposing to follow these strategies blindly, however. I can
test the value of an alternative design by examining how well it
conforms to the good principles of object-oriented design. This is
essentially the same approach I use in deriving the Bridge pattern in
Chapter 10, “The Bridge Pattern”. In that chapter, I measure the
quality of alternative designs by seeing which one followed
object-oriented principles the best.
The
International E-Commerce System Case Study: Initial Requirements
In
this new case study, I consider an order-processing system for an
international e-commerce company in the US. This system must be able
to process sales orders in many different countries. In this chapter,
I wan to consider the challenges of changing requirements and ways to
address them. In Chapter 16, I continue the case study, focusing on
the problem of variations.
The
general architecture of this system has a controller object that
handles sales requests. In identifies when a sales order is being
requested and hands the request off to a SalesOrder object to
process the order.
The
system looks something like Figure 9-1.
The
functions of SalesOrder include the following:

Figure
9-1 Sales order architecture for an e-commerce system.
Some
of these functions are likely to be implemented with the help of
other objects. For example, SalesOrder would not necessarily
print itself; instead, it serves as a holder for information about
sales orders. A particular SalesOrder object could call a
SalesTicket object that prints the SalesOrder.
Handling
New Requirements
After
writing this application, suppose I receive a new requirement to
change the way I have to handle taxes. For example, now I have to be
able to handle taxes on orders from customers outside the US. At a
minimum, I will need to add new rules for computing these taxes.
What
approaches are available? How can I handle these new rules?
Before
looking at this specific situation, allow me to take a slight detour.
In general, what are ways for handling different implementations of
tasks that are pretty much conceptually the same (such as handling
different tax rules)? The following alternatives jump quickly to my
mind:
-
Copy
and paste
-
Switches
or ifs on a variable specifying the case we have
-
Use
function pointers or delegates (a different one representing each
case)
-
Inheritance
(make a derived class that does it the new way)
-
Delegate
the entire functionality to a new object
The
old standby. I have something that works and need something close.
So, just copy and paste and then make the changes. Of course, this
leads to maintenance headaches because now there are two versions of
the same code that I
- or
somebody else - has
to maintain. I am ignoring the possibility of how to reuse objects.
Certainly the company as a whole ends up with higher maintenance
costs.
A
reasonable approach. But one with serious problems for applications
that need to grow over time. Consider the how coupling and
testability are affected when one variable is used in several
switches. For example, suppose I use the local variable myNation
to identify the country that the customer is in. if the choices are
just the United States and Canada, then using a switch probably works
well. For example, I might have the following switches:
|
//
Handle Tax switch (myNation) {
case
US:
//
US Tax rules here
break;
case
Canada:
//
Canada Tax rules here
break;
}
|
//
Handle Currency switch (myNation) {
case
US:
//
US Currency rules here
break;
case
Canada:
//
Canada Currency rules here
break;
}
|
|
//
Handle Date Format switch (myNation) {
Case
US:
//
use mm/dd/yy format
Break;
case
Canada:
//
use dd/mm/yy format
Break;
}
|
|
But
what happens when there are more variations? For example, suppose I
need to add Germany to the list of countries and also add language as
a result. Now the code looks like this:
|
//
Handle Tax switch (myNation) {
case
US:
//
US Tax rules here
break;
case
Canada:
//
Canada Tax rules here
break;
case
Germany:
//
Germany Tax rules here
Break;
}
|
//
Handle Currency switch (myNation) {
case
US:
//
US Currency rules here
break;
case
Canada:
//
Canada Currency rules here
break;
case
Germany:
//
Germany Currency rules here
Break;
}
|
|
//
Handle Date Format switch (myNation) {
Case
US:
//
use mm/dd/yy format
Break;
case
Canada:
case
Germany:
//
use dd/mm/yy format
Break;
}
|
//
Handle Language switch (myNation) {
case
US:
case
Canada:
//
use English
break;
case
Germany:
//use
German
break;
}
|
This
is still not too bad, but notice how the switches are not quite as
nice as they used to be. There are now fall-throuths. But eventually
I may need to start adding variations within a case. Suddenly, things
get a bad in a hurry. For example, to add French in Quebec, my code
looks like this:
|
//
Handle Language switch (myNation0 {
case
Canada:
if
(inQuebec) {
//
use French
break;
}
case
US:
//
use English
break;
case
Germany:
//
use Germany
break;
}
|
The
flow of the switches themselves becomes confusing. Hard to read. Hard
to decipher. When a new case comes in, the programmer must find every
place it can be involved (often finding all but one of them). I like
to call this “switch creep”.
Function
pointers in C++ and delegates in C# can be used to hide code in a
nice, compact, cohesive function. However, function
pointers/delegates cannot retain state on a per-object basis and
therefore have limited use.
The
new standby. More often than not, inheritance is used incorrectly and
that gives it a bad reputation. There is nothing inherently wrong
with inheritance (sorry for the pun). When used incorrectly, however,
inheritance leads to brittle, rigid designs. The root cause of this
misuse may lie with those who teach object-oriented principles.
When
object-oriented design became mainstream, “reuse” was touted as
being one of its primary advantages. To achieve “reuse”, it was
taught modifications of it in the form of a derived class.
In
our tax example, I could attempt to reuse the existing SalesOrder
object. I could treat new tax rules like a new kind of sales order,
only with a different set of taxation rules. For example, for
Canadian sales, I could derive a new class called CanadianSalesOrder
from SalesOrder that would override the tax rules. I show this
solution in Figure 9-2.
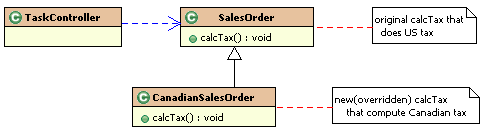
Figure
9-2 Sales order architecture for an e-commerce system.
The
difficulty with this approach is that it works once but not
necessarily twice. For example, when we have to handle Germany or get
other things that are varying (for example, data format, language,
freight rules), the inheritance hierarchy we are building will not
easily handle the variations we have. Repeated specialization such as
this will cause either the code not to be understandable or result in
redundancy. This is a consistent complaint with object-oriented
designs: tall inheritance hierarchies eventually result from
specialization techniques. Unfortunately, these are hard to test, and
have concepts coupled together. No wonder many people say
object-orientation is overrated
- especially
since it all comes from following the common object-orientation
mandate of “reuse”.
How
could I approach this differently? Following the rules I stated
earlier, attempt to “consider what should be variable in your
design”, “encapsulate the concept that varies”, and (most
importantly) “favor object-aggregation over class inheritance.”
Following
this approach, I should do the following:
-
Find
what varies and encapsulate it in a class of its own.
-
Contain
this class in another class.
In
this example, I have already identified that the tax rules are
varying. To encapsulate them would mean creating an abstract class
that defines how to accomplish taxation conceptually, and then
deriving concrete classes for each of the variations. In other words,
I should create a CalcTax object that defines the interface to
accomplish this task. I could then derive the specific versions
needed. Figure 9-3 shows this.
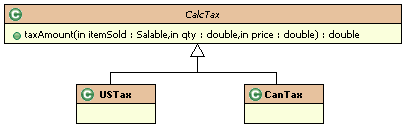
Figure
9-3 Encapsulating tax rules.
Continuing
on, I now use aggregation instead of inheritance. This means, instead
of making different versions of sales orders (using inheritance), I
will contain the variation with aggregation. That is, I will have one
SalesOrder class and have it contain the CalcTax class
to handle the variations. Figure 9-4 shows this.
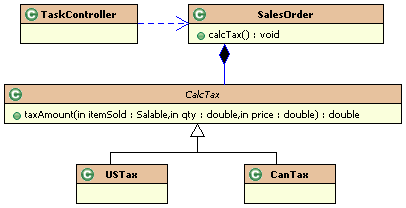
Figure
9-4 Favoring aggregation over inheritance.
Example
9-1 Java Code Fragments: Implementing the Strategy Pattern
public
class
TaskController {
public
void
process () {
//
this code is an emulation of a processing task controller
//
…
//
figure out which country you are in
CalcTax myTax;
myTax
=
getTaxRulesForCountry ();
SalesOrder mySO
=
new
SalesOrder ();
mySO.process ( myTax );
}
private
CalcTax getTaxRulesForCountry () {
//
In real life, get the tax rules based on country you are in.
//
You may have the logic here or you may have it in a configuration file.
//
Here, just return a USTax so this will compile.
return
new
USTax ();
}
}
public
class
SalesOrder {
public
void
process (CalcTax taxToUse) {
long
itemNumber
=
0
;
double
price
=
0
;
//
give the tax object to use
//
…
//
calculate tax
double
tax
=
taxToUse.taxAmount ( itemNumber , price);
}
}
public
abstract
class
CalcTax {
abstract
public
double
taxAmount (
long
itemSold ,
double
price );
}
public
class
CanTex
extends
CalcTax {
public
double
taxAmount (
long
itemSold ,
double
price ) {
//
in real life, figure out tax according to the rules in Canada and return it
//
Here, return 0 so this will compile
return
0.0
;
}
}
public
class
USTax
extends
CalcTax {
public
double
taxAmount (
long
itemSold ,
double
price ) {
//
in real life, figure out tax according to the rules in the US and return it
//
Here, return 0 so this will compile
return
0.0
;
}
}
I
have defined a fairly generic interface for the CalcTax
object. Presumably, I would have a Saleable class that defines
saleable items (and how they are taxed). The SalesOrder object
would give that to the CalcTax object, along with the quantity
and price. This would be all the information the CalcTax
object would need.
Another
advantage of this approach is that cohesion has improved. Sales tax
is handled in its own class. Another advantage is that as I get new
tax requirements, I just need to derive a new class from CalcTax
that implements them.
Finally,
it becomes easier to shift responsibilities. For example, in the
inheritance-based approach, I had to have the TaskController
decide which type of SalesOrder to use. With the new
structure, I can have either the TaskController do it or the
SalesOrder do it. To have the SalesOrder do it, I would
have some configuration object that would let it know which tax
object to use (probably the same one the TaskController was
using). Figure 9-5 shows this.
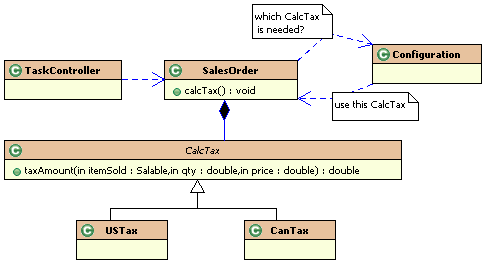
Figure
9-5 the SalesOrder object using Configuration to tell it which
CalcTax to use.
Most
people note that this approach also uses inheritance. This is true.
However, it does it in a way different from just deriving a
CandianSalesOrder from SalesOrder. In the strict
inheritance approach, I am using inheritance within SalesOrder
to handle the variation. In the approach indicated by design
patterns, I am using an object aggregation approach. (That is,
SalesOrder contains a reference to the object that handles the
function that is varying; that is, tax.) From the perspective of the
SalesOrder (the class I am trying to extend), I am favoring
aggregation over inheritance. How the contained class handles its
variation is no concern of the SalesOrder.
One
could ask, “Well, aren’t you just pushing the problem down the
chain?” There are three parts to answering this question. First,
yes I am. But doing so simplifies the bigger, more complicated
program. Second, the original design captured many independent
variables (tax, date format, and so on) in one class hierarchy
(SalesOrder), whereas the new approach captures each of these
variables in its own class hierarchy. This allows them to be
independently extended. Finally, in the new approach, other pieces of
the system can use (or test) these smaller operations independently
of the SalesOrder. The bottom line is, the approach espoused
by patterns will scale, whereas the original use of inheritance will
not.
This
approach allows the business rule to vary independently from the
SalesOrder object that uses it. Note how this woks well for
current variations I have as well as any future ones that might come
along. Essentially, this use of encapsulating an algorithm in an
abstract class (CalcTax) and using one of them at a time
interchangeably is the Strategy pattern.
The
Strategy Pattern
According
to the Gang of Four, the Strategy pattern’s intent is to
Define
a family of algorithms, encapsulate each one, and make them
interchangeable. Strategy lets the algorithm vary independently from
clients that use it.
The
Strategy pattern is based on a few principles:
-
Objects
have responsibilities.
-
Different,
specific implementations of these responsibilities are manifested
through the use of polymorphism.
-
There
is a need to manage several different implementations of what is,
conceptually, the same algorithm.
It
is a good design practice to separate behaviors that occur in the
problem domain from each other
- that
is, to decouple them. This allows me to change the class responsible
for one behavior without adversely affecting another.
Filed
Notes: Using the Strategy Pattern
I
had been using the e-commerce example in my pattern classes when
someone asked, “Are you aware that in the U.K. people over a
certain age don’t get taxed on food?” I wasn’t aware of this,
and the interface for the CalcTax object did not handle this
case. I could handle this in at least one of three ways:
-
Pass
the age of the Customer to the CalcTax object and use
it if needed.
-
Be
more general by passing the Customer object itself and
querying it if needed.
-
Be
more general still by passing a reference to the SalesOrder
object (that is, this) and letting the CalcTax object
query it.
Although
it is true I have to modify the SalesOrder and CalcTax
classes to handle this case, it is clear how to do this. I am not
likely to introduce a problem because of this.
Technically,
this Strategy pattern is about encapsulating algorithms. In practice,
however, I have found that is can be used for encapsulating virtually
any kind of rule. In general, when I am doing analysis and I hear
about applying different business rules at different times, I
consider the possibility of a Strategy pattern handling this
variation for me.
The
Strategy pattern requires that the algorithms (business rules) being
encapsulated now lie outside of the class that is using them (the
Context). This means that the information needed by the
strategies must either be passed to them or obtained in some other
manner.
The
Strategy pattern simplifies unit testing because each algorithm is in
its own class and can be tested through its interface alone. If the
algorithms are not pulled out, as they are in the Strategy pattern,
any coupling between the context and the strategies makes testing
more difficult. For example, you may have preconditions before you
can instantiate a context object. Or the context may supply some of
what becomes the strategy through a protected date member. Testing is
even further simplified if several different families of algorithms
coexist. (That is, several Strategy patterns are present, which is
typically the case.) This is because by using Strategy patterns the
developer does not need to worry about interactions caused by
coupling with the context. That is, we should be able to test each
algorithm independently and not worry about all the combinations
possible.
In
this sales order example earlier, I had the TaskController pas
the strategy object to the SalesOrder object each time it was
needed. A litter refection would tell me that unless I were reusing
the sales order object for different customers, I would always use
the same strategy object for any one particular SalesOrder
object. A variation of the Strategy pattern I often see is to assign
the strategy object to the context in the Strategy pattern (in this
case, my SalesOrder object) in the context’s constructor.
Then any method that needs to reference it can, without requiring it
be passed in. However, because the context still doesn’t know what
particular type of strategy object it has, the power of the pattern
is still maintained. This can be done if which particular strategy
object is needed is known at the time the context object is
constructed.
I
have sometimes had students complain that the Strategy pattern causes
them to make a number of additional classes. Although I don’t
believe this is a real problem, I have done a few things to minimize
this when I have control of all the strategies. In this situation, if
I am using C++, I might have the abstract strategy header file
contain all the header files for the code for the concrete
strategies. I also have the abstract strategy cpp file contain the
code for the concrete strategies. If I am using Java, I use inner
classes in the abstract strategy class to contain all the concrete
strategies. I do not do this if I do not have control over all the
strategies; that is, if other programmers need to implement their own
algorithms.
Summary
The
Strategy pattern is a way to define a family of algorithms.
Conceptually, all of these algorithms do the same things. They just
have different implementations.
I
showed an example that used a family of tax calculation algorithms.
In an international e-commerce system, there might be different tax
algorithms for different countries. Strategy would enable me to
encapsulate these rules in one abstract class and have a family of
concrete derivations.
By
deriving all the different ways of performing the algorithm from an
abstract class, the main module (SalesOrder in the example
above) does not need to worry about which of many possibilities is
actually in use. This allows for new variations but also creates the
need to manage these variations
- a
challenge I discuss in Chapter 16.
|
The
Strategy Pattern: Key Features
|
|
Intent
|
Enables
you to use different business rules or algorithms depending on the
context in which they occur.
|
|
Problem
|
The
selection of an algorithm that needs to be applied depends on the
client making the request or the data being acted on. If you just
have a rule in place that does not change, you do not need a
Strategy pattern.
|
|
Solution
|
Separates
the selection of algorithm from the implementation of the
algorithm. Allows for the selection to be made based upon context.
|
|
Participants
and collaborators
|
-
Strategy
specifies how the different algorithms are used.
-
ConcreteStrategies
implement these different algorithms.
-
Context
uses a specific ConcreteStrategy with a reference of type
Strategy. Strategy and Context interact to
implement the chosen algorithm. (Sometimes Strategy must
query Context.) The Context forwards requests from
its client to Strategy.
|
|
Consequences
|
-
The
Strategy pattern defines a family of algorithms.
-
Switches
and/or conditionals can be eliminated.
-
You
must invoke all algorithms in the same way. (They must all have
the same interface.) The interaction between the
ConcreteStrategies and the Context may require the
addition of methods that get state to the Context.
|
|
Implementation
|
Have
the class that uses the algorithm (Context) contains an
abstract class (Strategy) that has an abstract method
specifying how to call the algorithm. Each derived class
implements the algorithm as needed.
Note
:
in the prototypical Strategy pattern, the responsibility for
selection the particular implementation to use is done by the
Client object and is given to the Context object of
the Strategy pattern.
|
|
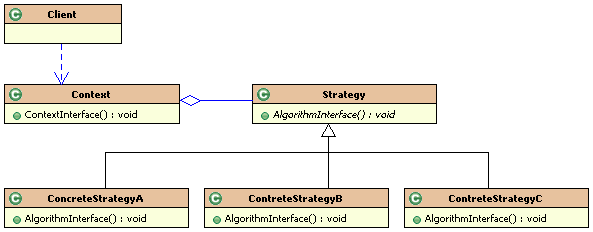
Figure
9-6 Generic structure of the Strategy pattern.
|
posted on 2006-11-05 20:37
xiaosilent 阅读(662)
评论(0) 编辑 收藏 所属分类:
设计模式