c++ difference from java
1. take charge of object management , negotiate ownershiop ,use scoped_ptr,
not to transfer other's ownership
2. use c++ template to express seperation corncern ,such as (static)polymorphy and policy
3. disable copy constructor and assign operator by yourself
4. polymorphy by pointer
5. 使用 template ,macro 取得类似动态语言的能力
6. 偏好无状态的 函数
Myisam is preferred without transaction and little
update(delete)
Big than 4G datafile can user Myisam merge table.
InnoDB with auto_increment primary key is preferred.
Few storage process
Guess: 20m
records max per table , 500G
data max per tablespace , 256 tables per database (may problem)
Use prepared statement and batch
Optimize Your Queries For the Query Cache
// query cache does NOT work
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// query cache works!
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
EXPLAIN Your SELECT Queries
LIMIT 1 When Getting a Unique Row
Index and Use Same Column Types for Joins
Do Not ORDER BY RAND()
Avoid SELECT *
t is a good habit to always specify which
columns you need when you are doing your SELECT’s.
Use ENUM over VARCHAR
Use NOT NULL If You Can
Store IP Addresses as UNSIGNED INT (?)
Fixed-length (Static) Tables are Faster
Vertical Partitioning
Vertical Partitioning is the act of splitting your table
structure in a vertical manner for optimization reasons.
Example
1: You might have a users table that contains
home addresses, that do not get read often. You can choose to split your table
and store the address info on a separate table. This way your main users table
will shrink in size. As you know, smaller tables perform faster.
Example
2: You have a “last_login” field in your
table. It updates every time a user logs in to the website. But every update on
a table causes the query cache for that table to be flushed. You can put that
field into another table to keep updates to your users table to a minimum.
But you also need to make sure you don’t constantly need to
join these 2 tables after the partitioning or you might actually suffer
performance decline.
Split the Big DELETE or INSERT Queries
If you have some kind of maintenance script
that needs to delete large numbers of rows, just use the LIMIT clause to do it
in smaller batches to avoid this congestion.
Smaller Columns Are Faster
Use an Object Relational Mapper
f you do not need the time component, use
DATE instead of DATETIME.
Consider horizontally spitting many-columned tables if
they contain a lot of NULLs or rarely used columns.
Be an SQL programmer who thinks in sets, not procedural
programming paradigms
InnoDB can’t optimize SELECT COUNT(*) queries. Use counter
tables! That’s how to scale InnoDB.
Prefer MM with hive
refer :
http://blog.tuvinh.com/top-20-mysql-best-practices/
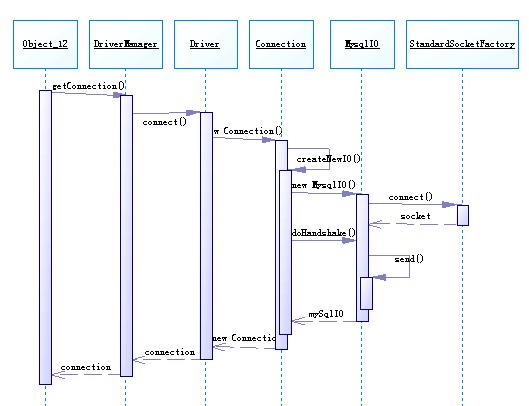
从时序图中可以看到,createNewIO()就是新建了一个com.mysql.jdbc.MysqlIO,利用 com.mysql.jdbc.StandardSocketFactory来创建一个socket。然后就由这个mySqlIO来与MySql服务器进行握手(doHandshake()),这个doHandshake主要用来初始化与Mysql server的连接,负责登陆服务器和处理连接错误。在其中会分析所连接的mysql server的版本,根据不同的版本以及是否使用SSL加密数据都有不同的处理方式,并把要传输给数据库server的数据都放在一个叫做packet的 buffer中,调用send()方法往outputStream中写入要发送的数据。
useServerPreparedStmts置为true的话,mysql驱动可以通过PreparedStatement的子类ServerPreparedStatement来实现真正的PreparedStatement的功能
第一位表示数据包的开始位置,就是数据存放的起始位置,一般都设置为0,就是从第一个位置开始。第二和第三个字节标识了这个数据包的大小,注意的是,这个大小是出去标识的4个字节的大小,对于非最后一个数据包来说,这个大小都是一样的,就是splitSize,也就是maxThreeBytes,它的值是 255 * 255 * 255。
最后一个字节中存放的就是数据包的编号了,从0开始递增。
在标识位设置完毕之后,就可以把255 * 255 * 255大小的数据从我们准备好的待发送数据包中copy出来了,注意,前4位已经是标识位了,所以应该从第五个位置开始copy数据
# packetToSend = compressPacket(headerPacket, HEADER_LENGTH,
# splitSize, HEADER_LENGTH);
LoadBalancingConnectionProxy
package java.lang.reflect 。 proxy .
http://developer.51cto.com/art/200907/137823.htm
http://dev.mysql.com/doc/refman/5.1/en/connector-j-reference-implementation-notes.html
PreparedStatements are implemented by the driver, as MySQL
does not have a prepared statement feature. Because of this,
the driver does not implement
getParameterMetaData() or
getMetaData() as it would require the
driver to have a complete SQL parser in the client.
Starting with version 3.1.0 MySQL Connector/J, server-side
prepared statements and binary-encoded result sets are used
when the server supports them.
但这是不是说PreparedStatement没用呢?不是的,PreparedStatement有其他的好处:
1.代码的可读性和可维护性
2.最重要的一点是极大地提高了安全性,可以防止SQL注入
然后我又看了一些网上其他人的经验,基本和我的判断一致,有两点要特别提请大家注意:
1.并不是说PreparedStatement在所有的DB上都不会提高效率,PreparedStatement需要服务器端的支持,比如在
Oracle上就会有显著效果。上面说的测试都是在MySQL上测试的,我找到了一个MySQL架构师的帖子,比较明确地说明了MySQL不支持
PreparedStatement。
2.即便PreparedStatement不能提高性能,在少数使用时甚至会降低效率,但仍然应该使用PreparedStatement!因为其他好
处实在是太大了!当然,当SQL查询比较复杂时,可能PreparedStatement好处会更大,只是我没有测试,不敢肯定。
3.既然PreparedStatement不能提高效率,那PreparedStatement Pool也就没有必要了。但可以看到每次新建Connection的开销实在很大,因此Connection Pool绝对必要。
download ,annatation and tools 两个项目。
添加相关的 jar.
<taskdef name="hibernatetool" classname="org.hibernate.tool.ant.HibernateToolTask" classpathref="master.classpath" />
<target name="create_table">
<hibernatetool destdir="${script.dir}">
<annotationconfiguration configurationfile="src/hibernate.cfg.xml" />
<hbm2ddl export="false" create="true" delimiter=";" format="true" outputfilename="create-tables.sql" />
</hibernatetool>
</target>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="logi">
<property name="show_sql">true</property>
<mapping class="com.tt.logi.target.Target"/>
</session-factory>
</hibernate-configuration>
import java.io.Serializable;
import javax.persistence.Basic;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Target implements Serializable{
private Long id;
private String name;
@Id
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Basic
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
wget ftp://ftp.jaist.ac.jp/pub/mysql/Downloads/MySQL-5.1/mysql-5.1.41.tar.gz
tar -xzf
./configure --prefix=/usr/local/mysql51m --without-debug --enable-local-infile --enable-assembler --enable-thread-safe-client --with-plugins=all
make
su -
make install
groupadd mysql
useradd -g mysql mysql
bin/mysql_install_db --user=mysql --datadir=/var/lib/mysql51m/data
chown -R mysql /var/lib/mysql51m/
chgrp -R mysql /var/lib/mysql51m/
cp share/mysql/my-innodb-heavy-4G.cnf my.cnf
vi my.cnf
datadir = /var/lib/mysql51m/data
.bin/mysqld_safe --defaults-file=/usr/local/mysql51m/my.cnf &
bin/mysql --defaults-file=my.cnf -uroot
./mysqladmin -u root password ‘humber’
grant all on *.* to root@% identified by 'humber'
default-character-set=utf8
init_connect='SET NAMES utf8'
default-storage-engine = INNODB
jmap -heap 16761
jstat -gcutil 16761
jmap -finalizerinfo 16761
jmap -histo 16761
jstack -l 16761
jinfo 16761
Examine the fatal error log file. Default file name is hs_err_pidpid.log in the working-directory.
-XX:+HeapDumpOnOutOfMemoryError
java -agentlib:hprof=heap=dump,format=b application
$ jmap -dump:format=b,file=snapshot.jmap process-pid
1、在jvm启动时加上:
-agentlib:hprof=heap=sites,file=heap.txt
,然后执行一段时间后执行 kill -3
<pid>,就可以获取jvm的内存镜像。类似的通过-agentlib:hprof=cpu=samples,file=cpu.txt查
看cpu的状况。
http://java.sun.com/javase/6/webnotes/trouble/other/matrix6-Unix.html
Quick Troubleshooting Tips on Solaris OS and Linux for Java SE 6
This "Quick Start Guide" gives you some quick tips for troubleshooting.
The subsections list some typical functions that can help you in
troubleshooting, including one or more ways to get the
information or perform the action.
These tips are organized as follows:
Hung, Deadlocked, or Looping Process
Post-mortem Diagnostics, Memory Leaks
Monitoring
Actions on a Remote Debug Server
Other Functions
Hung, Deadlocked, or Looping Process
- Print thread stack for all Java threads:
- Control-"
- kill -QUIT pid
- jstack pid (or jstack -F pid if jstack pid does not respond)
- Detect deadlocks:
- Request deadlock detection: JConsole tool, Threads tab
- Print information on deadlocked threads: Control-"
- Print list of concurrent locks owned by each thread: -XX:+PrintConcurrentLocks set, then Control-"
- Print lock information for a process: jstack -l pid
- Get a heap histogram for a process:
- Start Java process with -XX:+PrintClassHistogram, then Control-"
- jmap -histo pid (with -F option if pid does not respond)
- Dump Java heap for a process in binary format to file:
- jmap -dump:format=b,file=filename pid (with -F option if pid does not respond)
- Print shared object mappings for a process:
- Print heap summary for a process:
- Print finalization information for a process:
- Attach the command-line debugger to a process:
- jdb -connect sun.jvm.hotspot.jdi.SAPIDAttachingConnector:pid=pid
Post-mortem Diagnostics, Memory Leaks
- Examine the fatal error log file. Default file name is hs_err_pidpid.log in the working-directory.
- Create a heap dump:
- Start the application with HPROF enabled: java -agentlib:hprof=file=file,format=b application; then Control-"
- Start the application with HPROF enabled: java -agentlib:hprof=heap=dump application
- JConsole tool, MBeans tab
- Start VM with -XX:+HeapDumpOnOutOfMemoryError; if OutOfMemoryError is thrown, VM generates a heap dump.
- Browse Java heap dump:
- Dump Java heap from core file in binary format to a file:
- jmap -dump:format=b,file=filename corefile
- Get a heap histogram for a process:
- Start Java process with -XX:+PrintClassHistogram, then Control-"
- jmap -histo pid (with -F option if pid does not respond)
- Get a heap histogram from a core file:
- Print shared object mappings from a core file:
- Print heap summary from a core file:
- Print finalization information from a core file:
- jmap -finalizerinfo corefile
- Print Java configuration information from a core file:
- Print thread trace from a core file:
- Print lock information from a core file:
- Attach the command-line debugger to a core file on the same machine:
- jdb -connect sun.jvm.hotspot.jdi.SACoreAttachingConnector:javaExecutable=path,core=corefile
- Attach the command-line debugger to a core file on a different machine:
- On the machine with the core file: jsadebugd path corefile
and on the machine with the debugger: jdb -connect
sun.jvm.hotspot.jdi.SADebugServerAttachingConnector:debugServerName=machine
- libumem can be used to debug memory leaks.
Monitoring
Note: The vmID argument for the jstat command is the virtual machine identifier.
See the jstat man page for a detailed explanation.
- Print statistics on the class loader:
- Print statistics on the compiler:
- Compiler behavior: jstat -compiler vmID
- Compilation method statistics: jstat -printcompilation vmID
- Print statistics on garbage collection:
- Summary of statistics: jstat -gcutil vmID
- Summary of statistics, with causes: jstat -gccause vmID
- Behavior of the gc heap: jstat -gc vmID
- Capacities of all the generations: jstat -gccapacity vmID
- Behavior of the new generation: jstat -gcnew vmID
- Capacity of the new generation: jstat -gcnewcapacity vmID
- Behavior of the old and permanent generations: jstat -gcold vmID
- Capacity of the old generation: jstat -gcoldcapacity vmID
- Capacity of the permanent generation: jstat -gcpermcapacity vmID
- Monitor objects awaiting finalization:
- JConsole tool, VM Summary tab
- jmap -finalizerinfo pid
- getObjectPendingFinalizationCount method in java.lang.management.MemoryMXBean class
- Monitor memory:
- Heap allocation profiles via HPROF: java -agentlib:hprof=heap=sites
- JConsole tool, Memory tab
- Control-" prints generation information.
- Monitor CPU usage:
- By thread stack: java -agentlib:hprof=cpu=samples application
- By method: java -agentlib:hprof=cpu=times application
- JConsole tool, Overview and VM Summary tabs
- Monitor thread activity:
- JConsole tool, Threads tab
- Monitor class activity:
- JConsole tool, Classes tab
Actions on a Remote Debug Server
First, attach the debug daemon jsadebugd, then execute the command:
- Dump Java heap in binary format to a file: jmap -dump:format=b,file=filename hostID
- Print shared object mappings: jmap hostID
- Print heap summary : jmap -heap hostID
- Print finalization information : jmap -finalizerinfo hostID
- Print lock information : jstack -l hostID
- Print thread trace : jstack hostID
- Print Java configuration information: jinfo hostID
Other Functions
- Interface with the instrumented Java virtual machines:
- Monitor for the creation and termination of instrumented VMs: jstatd daemon
- List the instrumented VMs: jps
- Provide interface between remote monitoring tools and local VMs: jstatd daemon
- Request garbage collection: JConsole tool, Memory tab
- Print Java configuration information from a running process:
- Dynamically set, unset, or change the value of certain Java VM flags for a process:
- Print command-line flags passed to the VM:
- Print Java system properties:
- Pass a Java VM flag to the virtual machine:
- jconsole -Jflag ...
- jhat -Jflag ...
- jmap -Jflag ...
- Print statistics of permanent generation of Java heap, by class loader:
- Report on monitor contention.
- java -agentlib:hprof=monitor=y application
- Evaluate or execute a script in interactive or batch mode:
- Interface dynamically with an MBean, via JConsole tool, MBean tab:
- Show tree structure.
- Set an attribute value.
- Invoke an operation.
- Subscribe to notification.
- Run interactive command-line debugger:
- Launch a new VM for the class: jdb class
- Attach debugger to a running VM: jdb -attach address
http://www.blogjava.net/justinchen/archive/2009/01/08/248738.html
netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,""t",state[key]}'
set nocompatible
set autoindent
set smartindent
set ignorecase
syntax enable
set wrap
set showmatch
set foldmarker={{{,}}}
set tabstop=4
set shiftwidth=4
set ruler
set expandtab
set backspace=eol,start,indent
set whichwrap+=<,>,h,l
set nobackup
setlocal noswapfile
set bufhidden=hide
syntax on
set tags=./tags,~/apsara/tags
set path+=/usr/include/c++/**,~/apsara/include/**
filetype plugin on
filetype indent on
autocmd filetype java,c,cpp setlocal textwidth=100
set pastetoggle=<F7>
nmap <F2> :set nonumber!<CR>
nmap <F8> :TlistToggle<CR>
imap <F11> <C-x><C-p>
map <F12> :!ctags -R --c++-kinds=+p --fields=+iaS --exclude=build --extra=+q .<CR>
map <F6> :w<CR>
imap <F6> <ESC>:w<CR>a
map <F3> /<C-R><C-W><CR>
有 c support 支持,很棒。
-
避免对shared_ptr所管理的对象的直接内存管理操作,以免造成该对象的重释放
shared_ptr并不能对循环引用的对象内存自动管理(这点是其它各种引用计数管理内存方式的通病)。
-
不要构造一个临时的shared_ptr作为函数的参数。
如下列代码则可能导致内存泄漏:
void test()
{
foo(boost::shared_ptr<implementation>(new implementation()),g());
}
正确的用法为:
void test()
{
boost::shared_ptr<implementation> sp (new implementation());
foo(sp,g());
}
-
Employee boss("Morris, Melinda", 83000);
Employee* s = &boss;
This is usually not a good idea. As a rule of thumb, C++ pointers should
only refer to objects allocated wth new.
copy:http://www.diybl.com/course/3_program/c++/cppjs/20090403/163770.html
抄录备忘:
其实没有.h也能很好的工作,但是当你发现一个外部链接的函数或外部变量,需要许多份
声明,因为c++这种语言,在使用函数和变量的时候,必须将他声明,为何要声明?声明之后才
知道他的规格,才能更好的发现不和规格的部分.你别妄想一个编译单元,会自动从另一个
编译单元那里得到什么信息,知道你是如何定义这个函数的.
所以说,只要使用到该函数的单元,就必须写一份声明在那个.cpp里面,这样是不是很麻烦,
而且,如果要修改,就必须一个一个修改.这真让人受不了.
.h就是为了解决这个问题而诞生,他包含了这些公共的东西.然后所有需要使用该函数的.cpp,只需要
用#include包含进去便可.以后需要修改,也只是修改一份内容.
请注意不要滥用.h,.h里面不要写代码,.h不是.cpp的仓库,什么都塞到里面.
如果在里面写代码,当其他.cpp包含他的时候,就会出现重复定义的情况,
比如将函数func(){printf};放到头文件a.h,里面还有一些a.cpp需要的声明等;
然后你发现b.cpp需要用到a.cpp里面的一个函数,就很高兴的将a.h包含进来.
注意,#include并不是什么申请指令,他就是将指定的文件的内容,原封不动的拷贝
进来.
这时候实际上a.cpp和b.cpp都有一个func()函数的定义.
如果这个函数是内部链接static的话,还好,浪费了一倍空间;
如果是extern,外部链接(这个是默认情况),那么根据在同一个程序内不可出现
同名函数的要求,连接器会毫不留情给你一个连接错误!
http://www.cnblogs.com/shelvenn/archive/2008/02/02/1062446.html
一. Perspective and Metaphor
Platform
Kernel
Framework
二. Philosophy and discipline
Be aware of context
Extreme maintenance
Be pragmatic
Extreme abstract: Program to an interface (abstraction), not an implementation
Extreme separation of concerns
Extreme readability
Testability
No side effect
Do not repeat yourself
三. Principle
DIP ,dependency inversion of control
OCP , open close
LSP , liskov substitute
ISP , interface segregation
SRP , single responsibility
LKP, Lease knowledge principle
四. design pattern
Construction
Behavior
Structure
五. anti-pattern、bad smell
Long method
Diverse change
Repeated code
Talk to stranger
Pre optimize
六. algorithms
nLongN
Divided and conqueror
七. architecture
Hierarchal
Pipes and filter
Micro kernel
Broker
Black Board
Interpreter
八. Distributed & concurrent
What to concurrent
Scalability
Stretch key dimensions to see what breaks
九. languages
Ruby
Erlang
assemble
C
C++
Java
Python
Scala
Be ware of different program paradigms.
十. Performance
Minimize remote calls and other I/O
Speed-up data conversion
release resource as soon as possible
十一. architectures' future
软件设计思想的发展逻辑,大致是提高抽象程度 ,separation of concern 程度。
fn(design )= fn1(abstraction )+ fn2(separation of concern).
由于大规模数据处理时代的来临,下一代设计范式的重点:
1. 将是如何提高distributed(--concurrent) programing 的抽象程度 和 separation of concern 程度。
2. dsl ,按照以上的公式,也确实是一个好的方向。
十二. Reference
<art agile software development>
<prerefactor>
<design patterns>
<beautiful architecture>
<refactor>
<pattern oriented software architecture>
<extreme software development>
<beautiful code>
<patterns for parallel programming>
<java concurrent programming in practice>
<java performance tuning>
<the definite guide to hadoop>
<greenplum>
<DryadLINQ>
<software architecture in practice>
<97 things architecture should known>
http://en.wikipedia.org/wiki/Programming_paradigm
拷贝
mingliu.ttc simsun.ttf SURSONG.TTF tahomabd.ttf tahoma.ttf verdanab.ttf verdanai.ttf verdana.ttf verdanaz.ttf
#mv simsun.ttc /usr/share/fonts/local/simsun.ttf
#cd /usr/share/fonts/local/
sudo mkfontscale
sudo mkfontdir
sudo fc-cache
cp fonts.scale fonts.dir
sudo chmod 755 *
sudo chkfontpath --add /usr/share/fonts/local/
#/etc/init.d/xfs restart
查检是否安装成功
fc-list |grep Sim
NSimSun:style=Regular
SimSun:style=Regular
SimSun\-PUA:style=Regular
experience learned.
1. first think algorithm before concurrent
2. first solve top problem
3. memory can be problem with huge data processing
4. not to use refletion frequently
5. prefering strategy that can optimize both cpu and memory .
technical
1. thread synchronizing is how to queuing
be sure to use "while(!Thread.currentThread.isInterupted())
2. prefer high level synchronizing facility to low level methodology such as await,notify
3. dedicated sorter is much faster
以前听过用友的牛人关于软件设计范型的时代划分,记得不太准确,不过基本上是业界公认的。
大致上是:过程式、面向对象、组件、面向服务。
未来呢?我忘记了,抑或是 dsl ?
我以往也没有自己的认识,不过,最近我有自己的看法
软件设计思想的发展逻辑,大致是提高抽象程度 ,seperation of concern 程度。
fn(design )= fn1(abstraction )+ fn2(seperation of concern).
由于大规模数据处理时代的来临,下一代设计范式的重点:
- 将是如何提高concurrent programing 的抽象程度 和 seperation of concern 程度。
- 至于dsl ,我研究不多,不过,按照以上的公式,也确实是一个好的方向。
对于英文词语的使用,是因为,我想更能表达我的意思,不至于误解。见谅。
欢迎批评指正!
最近看的东西,备忘。
Dryad
DryadLinq
GreenPlum。
技术上看:
Dryad 牛
商业上看,
只有microsoft(Dryad),oracle (?),ibm (?)
其他的cloud data engine 似乎难免被收购宿命,一如bea 。。。。etc .
?google (
Sawzall) ?amazon
?hadoop ,pig
中国:
?友友系统
Saas business
一. chain
customer : operator :application :feature: platform .
二. operator
三. application
office
erp
mall
game
四. feature
search engine
monitor system
security
dynamic language
special db system
special file system
五. platform
virtual computing resource system
cloud file system
cloud db system
cloud os
六. chance
big fish or small fish should find their way to survive.
安装和配置简述
* 英文指南
* 配置tomcat
o 修改 server.xml ,在connector 加 URIEncoding="UTF-8"
o 修改 catalina.sh ,加一行 CATALINA_OPTS="-DHUDSON_HOME=~/apprun/hudsonhome/ -Xms512m -Xmx512m"
+ 其中 HUDSON_HOME 是 hudson 的配置和运行文件所在地
o 修改 tomcat-users.xml
+ <role rolename="admin"/>
+ <user username="hudson" password="hudson" roles="admin"/>
* 把下载的hudson.war 放在 tomcat 的webapps 下,hudson 会自动启动起来,部署就完成了
o 可以访问,比如 http://****:18080/hudson/
* 安装 jdk
* 安装 ant
* 配置hudson
o 配置和管理需要登陆 ,login
o 打开管理页面,比如 http://****:18080/hudson/configure
o 配置安全 ,Enable security ,两个选项:Delegate to servlet container --〉Legacy mode
o 配置 jdk 路径, 比如 /home/**/tools/jdk1.6.0_13/
o 配置 ant 路径, 比如 /home/**/apprun/ant171
o 配置 System Admin E-mail Address ,//写一个很多项目公用的email
o 记得 save
* 新建一个job
o 配置和管理需要登陆 ,login
o new job ,选项 :Build a free-style software project
o 配置 ,比如 :**:18080/hudson/job/icontent/configure
+ 填写svn 路径 ,比如 :http://svn.****
+ Build Triggers,选Poll SCM ,schedule 符合 cron 规则
+ Build ,invoke ant ,填写 ant target
+ Post-build Actions ,选 E-mail Notification , Recipients 填写邮件地址
* 配置linux 的环境变量
o vi .bash_profile
o JAVA_HOME=$HOME/tools/jdk1.6.0_13
o PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HOME/apprun/ant171/bin
o LANG=zh_CN.GB2312 //encoding 与.java 源代码文件的编码一致 ,这样javadoc 不会有警告
o LC_CTYPE=zh_CN.GB2312
easy!
great tool!
1. hibernate 变得不太重要了,jdbc 就很好
2. 数据库不够用了,bdb
3. bdb 不够用了, 自己写b+ tree
4. java 不行了,得用 c++
看来,这个转变是个革命。搞不好得丢饭碗。
从想做一个创业者,到想做一个proferssional 。
<西津渡图解软件项目管理 〉从1年半之前,每当有新的感受,就修订一些。为自己的成长作个备注吧。
code-block with mingw ,setup .
set path=c:\program file\code blocks\mingw\bin;%path%
bjam --toolset=gcc-3.4.5 --prefix=d:\boost\b137345 --build-type=complete install
很久没有来blogjava 了。
一个原因是,关注的内容与blogjava 的东西,重叠的太少了。
不过,我也纳闷,我该去哪里找自己的同好?
blogjava 在云计算,web2.0 ,这些前途领域,没有什么内容。
struts,hibernate,spring, acegi,lucene 这些都是成熟的东西了。
说一下我最近用过的东西:
hadoop,hbase,zookeeper,深入研究了java concurrent.
下一步的方向是写一个,distribute document oriented file system.
技术和互联网的发展,绝对是web2.0,云计算,两端厚的架构。blogjava 也该多这方面的内容了。
Conducting and Reviewing the Software Design Model
The design model resides at the core of the software engineering process. It is the place where quality is built into the software (and the place where quality is assessed. For this checklist, the more questions that elicit a negative response, the higher the risk that the analysis model will adequately serve its purpose. . For this checklist, the more questions that elicit a negative response, the higher the risk that the design model will not adequately serve its purpose.
General issues:
o Does the overall design implement all explicit requirements? Has a traceability table been developed?
设计对需求的匹配?
o Does the overall design achieve all implicit requirements?
o Is the design represented in a form that is easily understood by outsiders?
易理解?
o Is design notation standardized? Consistent?
o Does the overall design provide sufficient information for test case design?
可测试。
o Is the design created using recognizable architectural and procedural patterns?
常用的架构 和模式?
o Does the design strive to incorporate reusable components?
重用组件?
o Is the design modular?
模块化
o Has the design defined both procedural and data abstractions that can be reused?
重用的过程 / 数据 抽象?
o Has the design been defined and represented in a stepwise fashion?
逐渐细化的表述?
o Has the resultant software architecture been partitioned for ease of implementation? Maintenance?
可部署性? 可维护性?
o Have the concepts of information hiding and functional independence been followed throughout the design?
封装性?
o Has a Design Specification been developed for the software?
文档?
For data design:
o Have data objected defined in the analysis model been properly translated into required data structured?
数据映射with analysis?
o Do the data structures contain all attributes defined in the analysis model?
数据属性?
o Have any new data structures and/or attributes been defined at design time?
新的数据结构?
o How do any new data structures and/or attributes related to the analysis model and to overall user requirements?
用户需求与数据结构匹配吗?
o Have the simplest data structures required to do the job been chosen?
数据结构简单吗?
o Can the data structures be implemented directly in the programming language of choice?
编程语言适合数据结构?
o How are data communicated between software components?
软件组件之间的数据交换?
o Do explicit data components (e.g., a database) exist? If so, what is their role?
数据库?
For architectural design:
o Has a library of architectural styles been considered prior to the definition of the resultant software architecture?
架构模式?
o Has architectural tradeoff analysis been performed?
架构分析的tradeoff?
o Is the resultant software architecture a recognizable architectural style?
认可的架构风格?
o Has the architecture been exercised against existing usage scenarios?
架构有应用示例吗?
o Has an appropriate mapping been used to translate the analysis model into the architectural model?
分析和架构之间的mapping?
o Can quality characteristics associated with the resultant architecture (e.g., a factored call-and-return architecture) be readily identified from information provided in the design model?
架构的质量特点?
For user interface design:
o Have the results of task analysis been documented?
o Have goals for each user task been identified?
o Has an action sequence been defined for each user task?
o Have various states of the interface been documented?
o Have objects and actions that appear within the context of the interface been defined?
o Have the three "golden rules" (SEPA, 5/e, p. 402) been maintained throughout the GUI design?
o Has flexible interaction been defined as a design criterion throughout the interface?
o Have expert and novice modes of interaction been defined?
o Have technical internals been hidden from the causal user?
o Is the on-screen metaphor (if any) consistent with the overall applications?
o Are icons clear and understandable?
o Is interaction intuitive?
o Is system response time consistent across all tasks?
o Has an integrated help facility been implemented?
o Are all error message displayed by the interface easy to understand? Do they help the user resolve the problem quickly?
o Is color being used effectively?
o Has a prototype for the interface been developed?
o Have user's impressions of the prototype been collected in an organized manner?
For component-level design:
* Have proof of correctness techniques (SEPA, 5/e, Chapter 26) been applied to all algorithms?
算法正确性?
* Has each algorithm been "desk-tested" to uncover errors? Is each algorithm correct?
算法?
* Is the design of the algorithm consistent with the data structured that the component manipulates?
算法?
* Have algorithmic design alternatives been considered? If yes, why was this design chosen?
替代算法考虑了吗?
* Has the complexity of each algorithm been computed?
每个算法的复杂性考虑了吗?
* Have structured programming constructs been used throughout?
结构好吗?
西津渡最近在修改
99街购物搜索引擎,www.99jie.com
根据体会,修订了图解软件项目管理一文。这是今年以来的第三次较大修订。
有需要者请下载。
西津渡图解软件项目管理
下边是目录。
第一章 项目管理的目标
一、 产品,周期,成本的约束。
二、 关键路径管理
三、 可行性分析很重要
四、 人际技巧
五、 谈判技巧
第二章 项目过程
一、 计划阶段
二、 架构阶段和技术攻关
三、 迭代阶段
四、 结束阶段
第三章 分析,形成specification
一、 最重要的是specification 发挥作用
二、 重要的创造性工作
三、 选择适合的表达方式
四、 数据以及数据的key 和约束
五、 测试脚本
六、 Review ,评审
第四章 设计系统UI
一、 一幅图胜过千句话
第五章 设计,code ,build ,test
第六章 部署和重构
第七章 风险
一、 分析风险
二、 技术风险
三、 所有的风险是人的风险,trust and capable
四、 记住50%以上的软件项目以失败告终
五、 所有的风险是管理的风险,遵循一套项目管理哲学
第八章 保持项目的进展
一、 对项目负责,做出决定
二、 让进展可见,持续集成
三、执行,并检查
四、 解决冲突,大家都是兄弟姐妹
五、 能担当者是项目经理
六、 关键路径的变更
第九章 总结经验
第十章 一些效率关键指标
第十一章 项目管理工具
第十二章 参考
第十三章 口诀
http://www.xker.com/edu/dev/104/0652109570034579.html
十二、不要在循环中调用synchronized(同步)方法
方法的同步需要消耗相当大的资料,在一个循环中调用它绝对不是一个好主意。
例子:
import java.util.Vector;
public class SYN {
public synchronized void method (Object o) {
}
private void test () {
for (int i = 0; i < vector.size(); i++) {
method (vector.elementAt(i)); // violation
}
}
private Vector vector = new Vector (5, 5);
}
更正:
不要在循环体中调用同步方法,如果必须同步的话,推荐以下方式:
import java.util.Vector;
public class SYN {
public void method (Object o) {
}
private void test () {
synchronized{//在一个同步块中执行非同步方法
for (int i = 0; i < vector.size(); i++) {
method (vector.elementAt(i));
}
}
}
private Vector vector = new Vector (5, 5);
}
十三、将try/catch块移出循环
把try/catch块放入循环体内,会极大的影响性能,如果编译JIT被关闭或者你所使用的是一个不带JIT的JVM,性能会将下降21%之多!
例子:
import java.io.FileInputStream;
public class TRY {
void method (FileInputStream fis) {
for (int i = 0; i < size; i++) {
try { // violation
_sum += fis.read();
} catch (Exception e) {}
}
}
private int _sum;
}
更正:
将try/catch块移出循环
void method (FileInputStream fis) {
try {
for (int i = 0; i < size; i++) {
_sum += fis.read();
}
} catch (Exception e) {}
}
参考资料:
Peter Haggar: "Practical Java - Programming Language Guide".
Addison Wesley, 2000, pp.81 – 83
十九、不要在循环体中实例化变量
在循环体中实例化临时变量将会增加内存消耗
例子:
import java.util.Vector;
public class LOOP {
void method (Vector v) {
for (int i=0;i < v.size();i++) {
Object o = new Object();
o = v.elementAt(i);
}
}
}
更正:
在循环体外定义变量,并反复使用
import java.util.Vector;
public class LOOP {
void method (Vector v) {
Object o;
for (int i=0;i<v.size();i++) {
o = v.elementAt(i);
}
}
}
二十一、尽可能的使用栈变量
如果一个变量需要经常访问,那么你就需要考虑这个变量的作用域了。static? local?还是实例变量?访问静态变量和实例变量将会比访问局部变量多耗费2-3个时钟周期。
例子:
public class USV {
void getSum (int[] values) {
for (int i=0; i < value.length; i++) {
_sum += value[i]; // violation.
}
}
void getSum2 (int[] values) {
for (int i=0; i < value.length; i++) {
_staticSum += value[i];
}
}
private int _sum;
private static int _staticSum;
}
更正:
如果可能,请使用局部变量作为你经常访问的变量。
你可以按下面的方法来修改getSum()方法:
void getSum (int[] values) {
int sum = _sum; // temporary local variable.
for (int i=0; i < value.length; i++) {
sum += value[i];
}
_sum = sum;
}
参考资料:
Peter Haggar: "Practical Java - Programming Language Guide".
Addison Wesley, 2000, pp.122 – 125
http://www.javafan.net/menu/jczs/200701/20070108185247.html
1). 简单的认为 .append() 效率好于 "+" 是错误的!
2). 不要使用 new 创建 String
3). 注意 .intern() 的使用
4). 在编译期能够确定字符串值的情况下,使用"+"效率最高
5). 避免使用 "+=" 来构造字符串
6). 在声明StringBuffer对象的时候,指定合适的capacity,不要使用默认值(18)
7). 注意以下二者的区别不一样
- String s = "a" + "b";
- String s = "a";
s += "b";
关键点
1. 无论何时只要可能的话使用字符串字面量来常见字符串而不是使用new关键字来创建字符串。
2. 无论何时当你要使用new关键字来创建很多内容重复的字符串的话,请使用String.intern()方法。
3. +操作符会为字符串连接提供最佳的性能――当字符串是在编译期决定的时候。
4. 如果字符串在运行期决定,使用一个合适的初期容量值初始化的StringBuffer会为字符串连接提供最佳的性能。
q16 版.
安装后,把所有的dll 拷贝到system32.
经过一段时间的折腾。一堆东西能避免使用就避免使用。
castor, dwr, acegi, 几乎扔掉。
spring ,hibernate 也只用在适当的场合。
struts2 ,也只用在适当的场合。
一些偷懒的技术,尽量避免。
opensession in view.
一直困扰于 indexSearcher 的重新 new ,query filter 的cache 没了。
重读solr ,发现非常好。也许我应该考虑用 solr 了。
Caching
- Configurable Query Result, Filter, and Document cache instances
- Pluggable Cache implementations
- Cache warming in background
-
When a new searcher is opened, configurable searches are run against it
in order to warm it up to avoid slow first hits. During warming, the
current searcher handles live requests.
- Autowarming in background
- The
most recently accessed items in the caches of the current searcher are
re-populated in the new searcher, enabing high cache hit rates across
index/searcher changes.
- Fast/small filter implementation
- User level caching with autowarming support
9-26
今天,我发现,我可以用不同的方式实现cache ,也许在我的情况下比solr 的方式更好。
在一台 8G ,2 dual core cpu 的2u , struts2+spring+hibernate .
开源软件,用什么样的 proxy, cache, web container 达到最好的性能。
瓶颈在于:
tomcat 只能用到2g ram
经过研究,
xmx 在windows 2003,jdk1.5.06 ,1999M.
所以如果是一台单纯的web container server 就不要搞8G了, 1U 的4G ok.
需要用到那么高的性能场景,只能是两台1U做 banlance.
再次研究
用 session stick ,balance 2 个 tomcat ,应该可以达到较好的性能。
环境 apache + tomcat , ajp 连接。
apr
jvm 优化
nio , connector 优化。
c3p0.
情况下
用jmeter ,tomcat 到 1000 并发没有问题。
发现一个问题: apache 的 250 个 worker 限制。
导致单纯的 tomcat 性能更好。比用ajp.
一个 threadgroup, 3个http sample, 1000 ,5428。
看来,需要编译 apache.
http://www.mchange.com/projects/c3p0/#configuration_properties
spring+hibernate
连接池
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"/>
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/openfire"/>
<property name="user" value="root"/>
<property name="password" value="password"/>
</bean>
</beans>
tomcat jndi:
<Resource auth="Container"
description="DB Connection"
driverClass="com.mysql.jdbc.Driver"
maxPoolSize="4"
minPoolSize="2"
acquireIncrement="1"
name="jdbc/TestDB"
user="test"
password="ready2go"
factory="org.apache.naming.factory.BeanFactory"
type="com.mchange.v2.c3p0.ComboPooledDataSource"
jdbcUrl="jdbc:mysql://localhost:3306/test?autoReconnect=true" />
建议:c3p0.propertyies
c3p0.acquireIncrement=5
c3p0.idleConnectionTestPeriod=1800
c3p0.initialPoolSize=5
c3p0.maxIdleTime=1000
c3p0.maxPoolSize=20
c3p0.maxStatements=100
c3p0.minPoolSize=5
just hibernate:
hibernate.connection.provider_class=org.hibernate.connection.C3P0ConnectionProvider
调优:在我的环境下
maxpoolSize 30, 1822 , 15, 1655 。 可能和测试过程有关。
maxStatement 加上, 3600。严重影响性能。
扩大 xms xmx 512 ,957
tree 结构很常见,当persist 到数据库中。
有些操作,在db 中更好。
1。取得所有的叶子节点。
SELECT Name FROM Projects p
WHERE NOT EXISTS(
SELECT * FROM Projects
WHERE Parent=p.VertexId)
2。multilevel operation ,用数据库的辅助表, 用triger 。
CREATE TABLE ProjectPaths(
VertexId INTEGER,
Depth INTEGER,
Path VARCHAR(300) 。
)
3. 用 hibernate 时,如果 stack over flow,考虑用 stack 代替recursive algrithm
public void traverseDepthFirst( AST ast )
{
// Root AST node cannot be null or
// traversal of its subtree is impossible.
if ( ast == null )
{
throw new IllegalArgumentException(
"node to traverse cannot be null!" );
}
// Map to hold parents of each
// AST node. Unfortunately the AST
// interface does not provide a method
// for finding the parent of a node, so
// we use the Map to save them.
Map parentNodes = new HashMap();
// Start tree traversal with first child
// of the specified root AST node.
AST currentNode = ast.getFirstChild();
// Remember parent of first child.
parentNodes.put( currentNode , ast );
// Iterate through nodes, simulating
// recursive tree traversal, and add them
// to queue in proper order for later
// linear traversal. This "flattens" the
// into a linear list of nodes which can
// be visited non-recursively.
while ( currentNode != null )
{
// Visit the current node.
strategy.visit( currentNode );
// Move down to current node's first child
// if it exists.
AST childNode = currentNode.getFirstChild();
// If the child is not null, make it
// the current node.
if ( childNode != null )
{
// Remember parent of the child.
parentNodes.put( childNode , currentNode );
// Make child the current node.
currentNode = childNode;
continue;
}
while ( currentNode != null )
{
// Move to next sibling if any.
AST siblingNode = currentNode.getNextSibling();
if ( siblingNode != null )
{
// Get current node's parent.
// This is also the parent of the
// sibling node.
AST parentNode = (AST)parentNodes.get( currentNode );
// Remember parent of sibling.
parentNodes.put( siblingNode , parentNode );
// Make sibling the current node.
currentNode = siblingNode;
break;
}
// Move up to parent if no sibling.
// If parent is root node, we're done.
currentNode = (AST)parentNodes.get( currentNode );
if ( currentNode.equals( ast ) )
{
currentNode = null;
}
}
}
参考:
http://wordhoard.northwestern.edu/userman/hibernatechanges.html
《Tansact Sql cookbook.》
一、one-many ,需要一个有序的list. 建议影射方式 :
private List _items;
<bag
name="items"
inverse="true" //尽量使用双向关联
order-by="DATE_TIME"
cascade="all">
<key column="BLOG_ID"/>
<one-to-many class="BlogItem"/>
</bag>
many-to-many ,建议用 set
二、one-to-one 适用
通过主键进行关联
相当于把大表拆分为多个小表
例如把大字段单独拆分出来,以提高数据库操作的性能
三、composite element ,必须依赖的导航关系
<list name="lineItems" table="line_items">
<key column="order_id"/>
<list-index column="line_number"/>
<composite-element class="LineItem">
<property name="quantity"/>
<many-to-one name="product" column="product_id"/>
</composite-element>
</list>
四、 one-one formula , 很复杂,有点不明白
<class name="Person">
<id name="name"/>
<one-to-one name="address"
cascade="all">
<formula>name</formula>
<formula>'HOME'</formula>
</one-to-one>
<one-to-one name="mailingAddress"
cascade="all">
<formula>name</formula>
<formula>'MAILING'</formula>
</one-to-one>
</class>
<class name="Address" batch-size="2"
check="addressType in ('MAILING', 'HOME', 'BUSINESS')">
<composite-id>
<key-many-to-one name="person"
column="personName"/>
<key-property name="type"
column="addressType"/>
</composite-id>
<property name="street" type="text"/>
<property name="state"/>
<property name="zip"/>
</class>
五、继承关系, per subclass table ,no discriminator ,joined-subclass
六、tree
拷贝: http://www.thogau.net/tutorials/tree/tutorial02-01.jsp
package net.thogau.website.model;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang.builder.EqualsBuilder;
import org.apache.commons.lang.builder.HashCodeBuilder;
import org.apache.commons.lang.builder.ToStringBuilder;
import org.apache.commons.lang.builder.ToStringStyle;
/**
* This class implements a persisted tree node.
*
* @author <a href="mailto:thogau@thogau.net">thogau</a>
*
* @struts.form include-all="false" extends="BaseForm"
* @hibernate.class table="node"
*/
public class Node extends BaseObject implements Serializable {
// mapped to primary key in node table
protected Long id;
protected String name;
protected Node parent = null;
protected List children = new ArrayList();
/**
* @hibernate.id column="id" generator-class="native" unsaved-value="null"
* @struts.form-field
*/
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
/**
* Returns the node name.
*
* @return String
*
* @hibernate.property column="name" not-null="true" unique="true"
* @struts.form-field
* @struts.validator type="required"
*
*/
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/**
* Returns the node's children.
*
* @return List
*
* @hibernate.list cascade="all-delete-orphan" inverse="true"
* @hibernate.collection-one-to-many class="net.thogau.website.model.Node"
* @hibernate.collection-index column="position"
* @hibernate.collection-key column="parent_id"
* @struts.form-field
*/
public List getChildren() {
return children;
}
public void setChildren(List children) {
this.children = children;
}
/**
* Returns the position of the node in the children list (if it has parent).
* @return int
*
* @hibernate.property column="position"
*/
public int getPosition() {
try{
return parent.getChildren().indexOf(this);
}
catch(NullPointerException e){
// if it has no parent, position makes no sense
return -1;
}
}
public void setPosition(int position) { /* not used */ }
/**
* Returns the node's parent.
*
* @return Node
*
* @hibernate.many-to-one column = "parent_id" class="net.thogau.website.model.Node" cascade = "none"
* @hibernate.column name="parent_id"
*/
public Node getParent() {
return parent;
}
public void setParent(Node n) {
this.parent = n;
}
/**
* @see java.lang.Object#equals(Object)
*/
public boolean equals(Object object) {
if (!(object instanceof Node)) {
return false;
}
Node rhs = (Node) object;
return new EqualsBuilder().append(this.name, rhs.name).append(
this.children, rhs.children).append(this.parent, rhs.parent)
.append(this.id, rhs.id).isEquals();
}
/**
* @see java.lang.Object#hashCode()
*/
public int hashCode() {
return new HashCodeBuilder(1036586079, -537109207).append(this.name)
.append(this.parent.getName()).append(this.id)
.toHashCode();
}
/**
* @see java.lang.Object#toString()
*/
public String toString() {
return new ToStringBuilder(this, ToStringStyle.MULTI_LINE_STYLE)
.append("name", this.name).append("parent", this.parent)
.append("id", this.id).append("position", this.getPosition()).toString();
}
}
好像,equal ,hash 是必须的。
# /**
# * 树形遍历
# * 不用递归,用堆栈.
# * 这里只是做为例子,本人不建议把业务逻辑封装在Entity层.
# */
# public List getVisitResults() {
# List l = new ArrayList();
# Stack s = new Stack();
# s.push(this);
# while (s.empty() == false) {
# Cat c = (Cat) s.pop();
# l.add(c);
# List children = c.getChildren();
# if (children != null) {
# for (int i = 0; i < hildren.size(); i++) {
# Cat cat = (Cat) children.get(i);
# s.push(cat);
# }//end for
# }//end if
# }//end while
# return l;
# }
searcher 新开后,cache 会失效。
所以,重新开 searcher 的频率对于很重的访问量来说,不能太频繁。这样查询肯定有不能同步的问题。
对于不要求同步的场景来说,够了。
继续研究。
在 conf/catalina/localhost/ 建 solr.xml
jndi solr/home :
<Context docBase="D:\sourcecode\apache-solr\dist\solr.war" debug="0" crossContext="true" >
<Environment name="solr/home" type="java.lang.String" value="D:\sourcecode\solr-sample\solr" override="true" />
</Context>
solr/home 的结构
conf
data/index
清净拳。
拳打六根清净,念佛
拳打阴阳分明,悟空
拳打呼吸到肿,得道。
拳打恍恍惚惚,归无。
tomcat6 , jetty6 采用 jsp2.1。
由于 nio 带来的性能提升,tomcat6 不能被忽略。
办法1:
http://www.devzuz.org/blogs/bporter/2006/08/05/1154706744655.html<ww:select list="#{'default' : 'Maven 2.x Repository', 'legacy' : 'Maven 1.x Repository'}" />
改用-------------------------------------------------------------
<ww:select list="#@java.util.HashMap@{'default' : 'Maven 2.x Repository', 'legacy' : 'Maven 1.x Repository'}" />
这样 jsp2.1 el 就不会有问题了。
办法2: 对于旧的程序,不愿意改了,可以向后兼容
http://today.java.net/lpt/a/272#backwards-compatibility必须用 Servlet 2.5 XSD.
<web-app xmlns="http://java.sun.com/xml/ns/javaee" version="2.5" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<jsp-property-group>
<deferred-syntax-allowed-as-literal>
true
</deferred-syntax-allowed-as-literal>
</jsp-property-group>
或者在页面中
<%@page language="java" deferredSyntaxAllowedAsLiteral="true" %>
办法3 :不用 jsp2.1 el
> <jsp-config>
> <jsp-property-group>
> <url-pattern>*.jsp</url-pattern>
> <el-ignored>true</el-ignored>
> </jsp-property-group>
> </jsp-config>
http://www.mail-archive.com/dev@struts.apache.org/msg28920.html
我现在的疑问
在一个页面中采用两个 el 引擎,是否会对性能造成一定影响?
较小。
LoadModule cache_module modules/mod_cache.so
LoadModule disk_cache_module modules/mod_disk_cache.so
LoadModule mem_cache_module modules/mod_mem_cache.so
<IfModule mod_cache.c>
<IfModule mod_mem_cache.c>
CacheEnable mem /images
CacheEnable mem /styles
CacheEnable mem /scripts
MCacheSize 10240
MCacheMaxObjectCount 100
MCacheMinObjectSize 1
MCacheMaxObjectSize 2048
</IfModule>
</IfModule>
LoadModule proxy_http_module modules/mod_proxy_http.so
<VirtualHost *:80>
RewriteLogLevel 3
RewriteLog "f:/temp/logs/lelerewrite.log"
RewriteEngine on
RewriteRule ^(.*)\.html$ http://www.lele.com/ [P]
ProxyPass /images !
ProxyPass /styles !
ProxyPass /scripts !
ProxyPass / http://localhost:8082/
ProxyPassReverse / http://localhost:8082/
ServerName www.lele.com:8082
CustomLog logs/lele_access.log common
DocumentRoot "D:/apachedocroot/www.lele.com/"
<Directory />
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
一 、tomcat 中要配置:<connector ,proxy ,> .否则返回有问题。
二、 mod_proxy_ajp 在 apr 情况下性能应该比 mod_http_proxy 好。
关闭 缺省主机的 log
#customLog logs/access.log common
在 virtualhost 中加
CustomLog logs/lele_access.log common
LoadModule mod_rewrite
在 <virtualHost> 中
RewriteLogLevel 3
RewriteLog "f:/temp/logs/sosorewrite.log"
RewriteEngine on
RewriteRule ^(.*)\.html$ /index.php
一、修改 http.conf
loadmodule mod_proxy
loadmobule mod_proxy_ajp
增加
ProxyRequests Off
<Proxy *>
Order
deny,allow
Allow from all
</Proxy>
<VirtualHost *:80>
ProxyPass /images !
ProxyPass /styles !
ProxyPass /scripts !
ProxyPass / ajp://localhost:8009/
ProxyPassReverse / ajp://localhost:8009/
ServerName www.lele.com:8082
CustomLog logs/lele_access.log common
DocumentRoot "D:/apachedocroot/www.lele.com/"
<Directory />
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
tomcat 不用做修改。
安装 tomcat apr, 性能会比较好。
一、 在 http.conf 末尾加
Listen 80
NameVirtualHost *:80
<VirtualHost *:80>
DocumentRoot "D:/apachedocroot/www.soso.com/"
ServerName www.soso.com
<Directory />
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
<VirtualHost *:80>
DocumentRoot "D:/apachedocroot/static.soso.com/"
ServerName static.soso.com
<Directory />
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
二、修改 hosts 文件
三、 httpd.ext -S 测试配置
只是愈多愈好。
配置 apache2.2.4 ,php 5.2.3.
1. 解压到 c:\php
2. 拷贝 php.ini-dist 到 c:\windows 为 php.ini
** 不能用recommend**
3. 拷贝 php5ts.dll 到 c:\windows\system32
配置:apache ,http.conf
1. LoadModule php5_module "c:/php/php5apache2_2.dll"
** 对应apache2.2 必须用这个**
2. AddType application/x-httpd-php .php
3. if module dir_modle ,
DirectoryIndex index.php ,index.html
配置php.ini ,启动 mysql
extension=php_mysql.dll
extension=php_mysqli.dll
测试
phpinfo.php
<? echo phpinfo(); ?>
ok.
摘要: 最近觉得一个网站架构师,应该把高性能问题搞得很好。大致整理一下。今后会在几个方面继续深入。
本文的图形,没有上来。需要看完整的,请下载 :西津渡如何设计软件
高性能是其中的部分内容。目前还不够深思熟虑,请有经验者指正。多谢。
阅读全文
修订了一版图解软件项目管理。
图解软件项目管理加强的部分:
软件项目的商业背景, 项目的平衡术, 关键路径的管理。
这个模式一直没有好好的理解。最近作IM 相关的应用,才明白了。
就是两个人之间要沟通,不是直接,而是通过 mediator.
也就是 ,不是
user1.sendMessage(user2,"some message");
而是
user1.getMediator().sendMessage("user2","some message");
有什么好处呢:
职责分离:mediator 完成自己该承担的职责。
mediator 也可以搞这搞那。
插一段实际代码:
conn.getChatManager().createChat("thewho@stephenli",new MessageListener() {
public void processMessage(Chat chat, Message message) {
if(logger.isDebugEnabled())
logger.debug("Received message: " + message.toXML());
}
}).sendMessage("测试发送!");
下面是junit 一段别人的代码,可以Run:
代码看起来很蠢,不能说明使用mediator 的好处。不过意思就是这样啦!(从C# 拷的)
import junit.framework.TestCase;
public class MediatorTest extends TestCase {
public void testMediator(){
Mediator m = new Mediator();
DataProviderColleague c1 = new DataProviderColleague(m);
DataConsumerColleague c2 = new DataConsumerColleague();
m.IntroduceColleagues(c1,c2);
c1.ChangeData();
}
}
class Mediator
{
private DataProviderColleague dataProvider;
private DataConsumerColleague dataConsumer;
public void IntroduceColleagues(DataProviderColleague c1, DataConsumerColleague c2)
{
dataProvider = c1;
dataConsumer = c2;
}
public void DataChanged()
{
int i = dataProvider.getIMyData();
dataConsumer.NewValue(i);
}
}
class DataConsumerColleague
{
public void NewValue(int i)
{
System.out.println("New value "+ i);
}
}
class DataProviderColleague
{
private Mediator mediator;
private int iMyData=0;
private int MyData ;
public DataProviderColleague(Mediator m)
{
mediator = m;
}
public void ChangeData()
{
iMyData = 403;
// Inform mediator that I have changed the data
if (mediator != null)
mediator.DataChanged();
}
public int getIMyData() {
return iMyData;
}
public void setIMyData(int myData) {
iMyData = myData;
}
}
摘要: 原则: "更多的考虑用对象组合机制,而不是用对象继承机制". 更多的重用。
几种模式的区别:
adapter 意图是把已经有的部件,adapt 过来,到一个需要不同接口的部件。
bridge 的意图是让 abstract. 以及 implementor 可以用在更多的地方。 (费这么大劲,目的就是重用)
proxy 的意图是在proxy 中搞点什么。
下面是在junit 中run 一段别人的代码,演示bridge 模式。
阅读全文
根据我以前的经验,以及最近的struts2 的开发。我感觉的struts2 的性能问题。
找了一篇 讨论 struts2 performance 的文章:
http://www.nabble.com/Struts-2-performance-t4053401.html继续阅读 struts2 的 performance tunning :
http://struts.apache.org/2.x/docs/performance-tuning.html我的判断:
对于heavy user 的website , 不用 struts2? (直接用servlet+jsp /or ??????)
对于few user 的 management 可以用 struts2.
学习 stripes .
stripes download 正是我想要的。
theserverside 关于 stripes 的讨论。
stripes great
摘要:
StAX the odds with Woodstox
刚读了,感觉不错。
Over a decade into XML evolution, however, these parsing technologies are slowly showing their age, requiring bypasses and optimizations to overcome their well-known limitations. StAX, or Streaming API for XML, is the new-age XML parser that offers the best features of the existing models, and at the same time provides high performance and efficient access to the underlyi
阅读全文
我答scjp 比较差,所以感觉自己还不够professional 。做了不少应用,不过作为一个职业人士,基础的东西也应该很好。这两天恶补一下。
swing 也要学习。
1. java performance tuning
2. java5 's new feature ok
3. jdbc performance
最近一直用已有的知识,再规划一下,最近的学习重点
1.rick client 的全面掌握
以前用dwr ,再复习一下 . ok ,prototypes . 07-08-01
2.db procedure
以前基本不会。
3.ejb3
高可靠性transaction
4. StAX, woodstox
学习一下新的xml 处理技术。 ok. 07-08-01
5.REST
新东西,很重要 . ok. 07-08-1
6.english
看来架构师的工作机会还是比较多。
99 街 www.99jie.com ,是一个购物digg 网站。
以后捡周末空余时间,逐渐把功能补全了。
我再次踏入求职者队伍。
领域建模顶级高手。目前做过的项目超过6个。参见我的blog<如何设计软件〉.
spring,hibernate,webwork 顶级高手。目前做过的大小项目超过6个。
lucene 顶级高手。做过的项目超过两个。
垂直搜索顶级高手。两个spider 项目,一个价格更新项目。
软件项目管理顶级高手。参见我的blog<图解软件项目管理〉。
留住客户,促使客户产生购买行为。这就是网站要做的。
白给钱,评测报告,网友推荐,商家的商誉。先行赔付。不满意包换。1折。
我的比较购物网站的理想
1.与 b2c 商店合作拿数据,承诺在5年内佣金只很小的比例,如果销售额不能达到某个值,不拿佣金
2.大规模的铺服务器,吸收最大量的b2c 商家,保证性能
3.对通过我们网站购物的消费者,提供无风险保证,先行赔付
4.管理商家的信誉,对不能达到信誉的商家提高佣金比例
5.为今后的b2c 市场扩展留下广阔的收钱空间
这个商业模式的要点在于
a. 承担中国的b2c 商家的信誉管理责任,这是无价之宝
a.数据主要不靠 spider, 与 EShopping 软件提供商合作,直接用webService 方式拿数据
b. 数据由b2c 商家积极提供,保证质量
c. 订单跟踪直接用 webservice 方式拿,保证及时可靠质量。
pair programming
这个小项目只有我们两个人,通过3天的pair programming ,我把自己的编程习惯,风格,设计理念全部共享给同事。
我们一起思考业务,设计,项目进展非常好。进度提高一倍以上。
多年来,我几乎不肯把自己的经验分享给别人,如今念佛悔改,几乎没有一点保留。
pair programming 的好处在交流,在于知识的共享。
今后做项目也多了一个非常得力的帮手。
我自己考虑,今后我带的所有项目成员,都要经常交叉进行pair programming.充分的交流。
总监,在于权利欲,在于毅力强。
系统分析员,在于综合能力,在于灵活,在于平衡。
架构师,在于执着,在于超然物外。
小的项目,就容不了这么多人,项目经理就够了。
摘要: 读书,编码,架构师之路,每天都在进步。
阅读全文
这个肤浅的东西,该有新的东西替代了。
计划 《ddd 》,《设计模式、算法和架构》,《分布式计算和data sharding>.
半年内作完。
附件:
请下载。
如何设计软件-我的体会.rar
最近把一年多的工作总结了,先有 ‘图解软件项目管理’,又有这一篇。
如何设计软件
-我的体会
李建奇
2007-02-05
我信心不足,勉强为之!
几乎没有普遍适用的原则。设计似乎是一种偶然的事情。所以还称为手艺。
我陈述的主要是自己的经验。
第一章理想的设计
三个判断准则:
l
维护成本低。
l
可以被重用。
l
易于理解。
第二章代码是最好的设计工具
我的做法是,写可以运行的代码,然后生成可以讲解的图形。
好处当然是明显的,避免出现普遍的错误,看起来不错的设计其实不能用。
第三章不管怎样,先让结果出来
Engine can work : can produce the output 。
我的经验:
我总是这么做。比如:
抓取数据:Jobo + htmlParser ,只是把别人的软件连接起来,结果就出来了。
第四章硬核,总有一些东西是可以稳定的
一、
发现领域的硬核,是关键的设计问题。
Firm core: model is steady
我的经验:
Merchandise 的三个要素:name, seller, price. 缺了任何一项就不是一个merchandise 了。
二、
事物之间的关系不外乎1对1,1对多,多对一
为什么不说多对多?
因为我只见
Public
class A {
B b;
Collection <C> l;
}
为什么说多对一?
第五章模块的主要接口(约定)是稳定的
先把主要接口用简单的方式实现出来,然后让整个系统转起来。
我的经验:
解析模块的主要接口:
Public Object parse(String content , String url){ ……}
第六章功能可扩展
一、
Observer 设计模式:
我的经验:
有一点类似:LogicOrParser ;
我知道的:
我认为 JMX 是使用 Observer 模式。
二、
Chain of Responsibility :
我的经验:
n
StringReplacer : next ().
我知道的:
n
Lucene 的 filterChain
n
Web app 的 ServletFilter.
n
Lucene 的 TokenStream .
三、
Strategy 设计模式
可以增加新的策略。
我的经验。
失败的经验:
PricePattern
有一个地方用
InstanceOf 。
原因是:我不知道Spring 配置Collection 有无可以使用Interface 的!
谁知道?
成功的经验:
UrlPattern:一个基于hibernate 的 inheritance 映射的适用经验:
Public
interface UrlPattern {
Public Boolean isInstance( String
url ) ;
}
第七章模块可插拔
一、
Programming to interface :最重要的设计原则
几乎是所有好的设计的基石!
我的经验:
l
Spring 是我必用的工具。
l
UrlPattern:一个基于hibernate 的 inheritance 映射的适用经验:
Public
interface UrlPattern {
Public Boolean isInstance( String
url ) ;
}
l
HttpReader
当我发现 JoboHttpReader 不能满足的时候,我用HttpClientHttpReader 替换了。
二、
组合优于继承
继承破坏了可替换性。
我的经验:
我好几次把 template method 模式转移到Strategy 或者 command模式。
把 PriceUpdatorManager 迁移到 command 模式。
我现在基本不使用抽象类。
不过也有例外: AbstractHibernateDAO 一直在用。
三、
封装, proxy pattern : managing third party APIs
我的经验:
把lucene 的使用封装起来。
有两个好处:
可替换。
封装好的东西可以方便地用在别的地方。
四、
不要牵涉无关的东西 ISP ,interface segregation
principle ,或者叫 split interface
我的经验:
我有过几次失败的教训,当时的担心,类太多了,类太小了。
后来有些改了,有些没有。
抄录一段话:<prefactoring >
Split a single
interface into multiple interfaces if multiple clients use different portions
of the interface .
第八章分离关注separation
of concerns
我的经验:
Spring 的 transaction 机制
我用SpringAop 和 ehcache 实现 method cache ;
Acegi ,把安全管理分离出来。
第九章性能可扩展
一、
线程池:
基本的提高性能的办法。
我的经验:
blocked Queue :
Semaphore:
二、
分布式运算:
我的经验:
基于RMI 的分布式使用。
第十章结构
一、
减少依赖
我的经验:
似乎没有?!
我知道的:
???在哪里?可能大家都是这么干的!
二、
分层:layering
我的经验:
总是使用的、不变的设计: model, dao, service :
我对Lucene 的封装:一个抽象。
Public
void addDocument( Document doc );
Public Document getDocumentById( Long id
);
第十一章设计思想的变迁
变迁太快,去年的最好的书,一年以后就过时了。
一、
主要的阶段,以及framework 阶段
Structure , 30年
OO , 10年
Pattern ,10 年
framework ,…… 这是我自己定义的。
主要的原因是,很多成熟的framework 的出现,使得我们主要是学习好他们,然后把自己的领域吃透,用好这些
framework 就可以生产出较好的软件。
二、
Jolt 图书大奖
2003
<agile software
development>
2004
<Waltzing with Bears:
Managing Risk on Software Projects>
2005
<headfirst design
pattern>
2006
<prefactoring >
2007
????
第十二章导师
l
我自己的项目经验
l
Eric Gamma < design pattern>
l
Rod Johnson <SpringFramework>
l
Eric freeman <headfirst design pattern>
l
Gavin King <hibernate >
l
Pugh <prefactoring>
l
Robert <agile software development>
摘要: 软件项目管理琢磨了十年,每次总结,总要进步一些,再次总结。2月5日修订了一些内容。
阅读全文
also a dynamic site.session's cache also work for some nearly static page.
since it's need login user's info in page.application's scope isn't fit.
I also use ehcache for hibernate cache.
great solution!
<script language=javaScript> alert("me"); </script>
I don't think follow should be in a java blog.
I think the management thought I have some change.
first I think management can't chease.Just choose those can met your culture.Ond shouldn't think use employee and kick off after.
second ,I think corporation's existence not for profit or some great idea .It's for some people who have similar pursue and ideal to make life. these is most important.
three, If you can't layer it ,you can't manage it.real layer should take clear boardary.
一、两个阵营:
action request based : struts2.0 (mainly webwork2.2's technology)
component based. tapestry4 ,shale1 .
二、趋势:
component based 会稍占优势,不过 action request based 也会占一定地位。
这一点,从05年 javaOne 给与 shale 的肯定。06年duke's choice 给与 tagpestry 的肯定可以看出来。
三、如何选择:
shale1.0 将会于06年 8-12月之间,发正式版,
struts2.0 也将会在 06 年8-12 月,发正式版。
tapestry4 已经是稳定的版本。
当前启动的项目(06年8月):
对于一个有 action based 基础的团队,选 struts2 是可取的。
对于一个全新的团队,选 tapestry 似乎更加符合长期的发展。
shale 还需要一段时间的成熟期。比如1.1 以后,采用会更加稳妥。
四、shale 与 tapestry
shale base on JSF 似乎有一些天时之利。不过tapestry 也可以采取很多的变化。
五、webFrameWork 的今后的发展feature的展望
webFrameWork 经过多年的发展,基本的feature已经达到很高的成熟度。
包括:controller,view template,type converter,validation,ajax, 大的方面已经有很多共识。
重要的方向在于 DSL, 动态语言,meta Programing 方面有一些有益的突破。
xfire+spring 发布service 是容易的。
activeMQ +spring jmsTemplae 也容易。jencks 作为consumer 也容易。
不过 soap over jms ,我没有找到容易的方案。据说 xfire 解决了,可是文档???
mule 下一步解决。等。
server 端,用ThreadExecutor 了。
这两个原则最近有了切肤之痛的感受。
看来坚持面向interface 的开发是必须的了。
问题在
Abstract class 不能复杂,我想这也是template pattern 时候要注意的。
template 要稳定,不确定的东西不能放在template 中,当然简单的东西容易稳定。
否则必然违背 ocp 原则。
由于httpconnection 并不能总是很好的处理 “System.connectionTimeOut" 问题。
htmlParser 会装死。
我想只能加一个monitor thread ,不过没有完成。
html parser 在处理 一些网页的时候,会出现乱码'3f3f' .
问题在于 页面的charset=gb2312 ,而 页面中有gbk 的码 ,比如 'fb9c'.
代码可以验证,
byte[] gbchar = new byte[2];
gbchar[0]=(byte) 0xfb;
gbchar[1]=(byte) 0x9c;
System.out.print(new String(gbchar,"gbk"));
System.out.print(new String(gbchar,"gb2312"));
不过,我并没有解决这个问题。
由于“agile web with rails" 获得了jolt 大奖,我实在无法不关心ruby 了。
基于最近的经验,我的看法:
我不会采用rails 直到ruby 更加成熟,成熟的一些考虑因素。
1. 需要更多的开源工具包
2. killer 级别的IDE
第一个方面:工具支持。
目前还不够丰富,我关心的是
1.cache
仅有 memcache (perl 写的)
2.security 框架
3.xml 处理
4.database connection pool
5. sitemesh 类似的工具
6. urlrewrite
7. rss
8. log
9. webservice
(也许ruby rails已经有,只是我不知道)
在java 环境中,web 项目
我用 spring,hibernate,webwork,dwr ,ehcache ,castor,xfire,acegi ,dbcp(c3p0),log4j,ant,displayTag ,clickstream ,infoma ,etc.
spider 项目
jobo,htmlparser
其他
tm4j 。
我目前觉得java 环境,因为有了很多的工具是高效率的,当然学习的过程也是漫长而艰苦的。
由于所面对的项目不仅仅是 web 开发,能找到解决的问题的java 工具,是非常幸福的,发明轮子是痛苦的。
在 spring+hibernate+webwork+displayTag上,正在考虑用模版工具(freemaker/velocity..etc),生成crud 的代码。(目前主要是拷贝)。如果能够完成,web 开发的效率也是非常高的。
今天,研究scalablity 的问题。
看到国外建议用 perlbal ,不用 apache 的mod_proxy.
今后有时间再搭建环境,可惜 perl 不会,有时间还需要学习一下。
ehcache 有非常棒的设计,我自己感觉就不用oscache 了。
mysql 也支持partion 了。
error 级别,错误,程序不能正常运行
warn, 程序固然可以正常运行,可是不是希望的逻辑
info ,至少应该显示程序的执行逻辑
debug, 显示数据
所以info 对于发现运行时的错误很重要,要有效的撰写。