在
软件开发过程中,
数据库的设计是非常重要的。可以说,良好的数据库设计,是对用户需求的理解的精准定位。它不仅能够使得软件开发起来非常便捷,而且还能够使软件系统高效运行,同时,为日后的维护或者更换数据库提供便利。
在最近开发系统的过程中,感觉收获最大的也是关于数据库的操作。最初开发机房收费系统的时候,由于没有经验,而且懂得的知识也非常少,数据库的设计根本谈不上,就是感觉到数据库中缺少某些字段的时候,直接在数据库表中去修改字段。这样就为自己徒增了很多工作量,相关的代码需要一处一处去修改。
开发.NET版机房收费系统的数据库设计明显好多了,由于充分了解了需求,数据库设计当然比上一次好上很多。不过回头去看,数据库的设计还是存在很多的缺陷。表中仍然存在着大量的冗余字段,增删改后也会出现发生一些异常。
在牛腩新闻发布系统中,由于系统非常小,对于数据库的操作也就那两下子,复杂也到不了哪里去。不过尽管如此,感觉牛老师的数据库设计还是非常规范的。类别、评论、新闻分别放在三个表中,完全没有冗余数据。
废话太多了,开始步入正题了。良好的设计能够使程序员的工作事半功倍。
首先,先来看官方解释:
第一范式是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即是实体的某个属性不能有多个值或者不能有重复的属性。
第二范式是指数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖。
第三范式数据库表中不存在非关键字段对任一候选关键字段的传递函数依赖。
简单来说,第一范式是讲数据库表中数据的原子性,数据不可再分,只要是关系型数据库都必须首先满足第一范式。看下图例子:图1中三个字段不可再分,故满足第一范式;图2将专业、年级、班级三个字段放在一个字段里面,就不符合第一范式了。
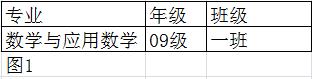

下面再来看机房收费系统中的一个表设计——学生基本数据表。

图A
图A中由于每一个字段都不可再分,故它是满足第一范式的。然而这样的设计就会产生大量的冗余字段。如果一个学生注册两个卡,那么该学生的信息就需要重复两次。
第二范式就解决了上述问题。它强调其属性必须完全依赖主键,实体的属性不能仅仅依赖主关键字的一部分属性。如果存在部分依赖关系,那么这个属性和主关键字相应部分应该分离出来形成一个新的实体,实体与原始体之间是一对多的关系。
像上面例子中,很显然主键是卡号和学号联合做主键,其中姓名、性别、系别、专业、年级、班级都只与学号有关,只依赖学号,而不依赖卡号,这样就不符合第二范式了。
我们的根据第二范式的要求,将其与学生相关的信息分离出来,修改后,我们可得一下两个表:

图B
然而,仅仅满足第二范式的数据库是远远不够的,满足第二范式,仍然可能会出现传递依赖。图B学生表中系别与专业存在传递关系。假如小红和小明的系别都是数信学院,专业都是数学专业,那么这样数据库中系别就重复了两次,增加了冗余字段。
第三范式保证了同一类事物分在一个表中,消除了传递依赖的现象。我们再根据第三范式的设计要求,将其学生表在进行分离,得到下面的表:
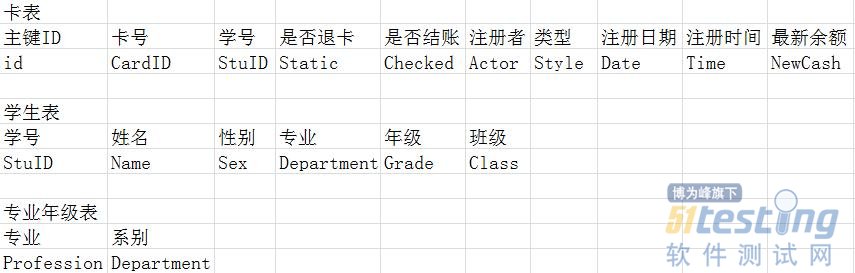
图C
下面给出图C的数据库关系图:
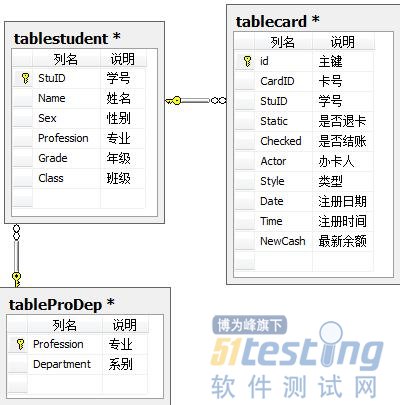
好的数据库设计,是软件开发中非常重要的一步。三范式设计只是一个标准,对于基本表的设计,建议大家尽量按照三范式的要求进行设计;而对于临时表的设计,我们可以适量的增加一些冗余字段,毕竟单一表的查询检索速度比较快,提高了系统性能。