大多数数据库都自带了同步方案,但通常是同步到同一类型的数据库。在一些特定的情况下,我们可能希望把数据从一种数据库,同步到另一种数据库,以便进行数据分析、统计、挖掘等,或是完成实时监控、实时搜索等服务。
本文介绍的就是这样一个方案,把数据从NoSQL数据库ttserver同步到MySQL上。
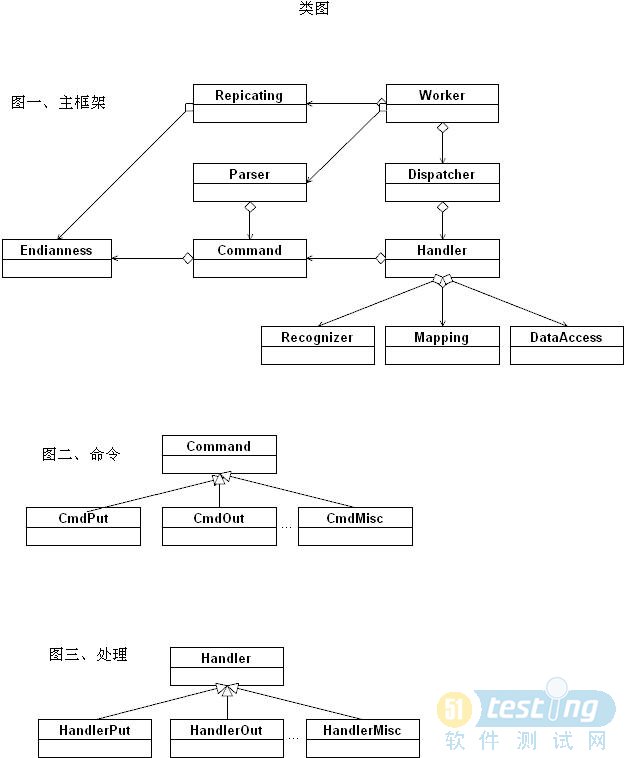
数据的同步过程基本上可以分解成:获取、解析、识别、处理。
获取同步(replicating)过程基本上就是处理高性能网络交互、各层通信协议、基于安全考虑的身份验证等问题的过程。解析(parsing)过程主要处理具体数据结构,由分派器(dispatcher)分派给具体的识别器(recognizer)进行识别。最终由处理器调用数据访问层完成整个过程。基本过程可见下方草图:

以上只是一个简化的草图,实际完成的时候,还有很多细节需要处理,如,
1)快照点的选择,以及生成快照点的方案。不稳定的数据是没用的;
2)协议、数据结构的可配置化。不同的场景下只需要简单配置,就能满足具体业务;
3)对前后端数据服务的抽象。只有抽象化,才能让它成为一个有生命力的方案;
4)高处理能力。异步、非阻塞、多worker、操作合并;
5)考虑对协议升级的兼容方案;
6)可支持前后端数据迁移、数据分片;
7)前后端多实例同时使用;
8)全局同步与增量同步方案同时支持,新同步点支持;
9)各种可能的出错:网络、数据、服务等处理、监控、告警;
10)稳定性、可用性;
11)完备的统计数据。方案做得怎么样,总要有数据才好说话吧:)
顺带把部分初期概念设计图放出来。后来已经有一些演变,但只是少数环节上。在大部分的环节上,基本思路没有太大的变化。
经过一段时间的奋战把方案实现出来,功能验证也比较顺利通过了,实战又将跑得怎么样?具体业务及性能数字未经同意不准备在此公布,但可说侧面说一下。目前,该方案上线应该已经将近一年,除了少数几次前端迁移以外,未停过服。性能方面,一年后,在业务已经有量级发展的情况下,该方案仍能满足需求。
另外,虽然命名为tt2mysql,我从未把该方案当成是数据库之前的同步方案。以前说过会把东西总结出来,一直太懒,翻到了就写一下。