2009年5月23日
前两天休眠后机器非正常关机,重新启动后运行eclipse。悲催的发现eclipse
无法启动了。每次双击启动后,确定完workspace后,显示启动画面,没过一会就进入灰色无响应状态。启动画面始终停留在Loading
workbench状态。反复重启,状态依旧。尝试解决。
搜索了一下,应该是非正常关机导致eclipse工作区的文件状态错误导致。在工作区目录中,有一个.metadata目录,里面是工作区及各插件的信息,删除此目录可以解决问题。
为保险起见,将.metadata改名移动到/tmp目录,再重启eclipse,果然可以正常启动eclipse了,但原来工作区的配置和项目信息也都消失,直接显示的是欢迎界面。
如何恢复原来的project配置呢?尝试对比了当前的.metadata和之前备份的那个目录,发现缺少了很多配置文件。试着一点点恢复一些目录,但效
果不理想。因为不知道哪些文件(目录)可以恢复,哪些恢复会带来问题。将备份的整个目录恢复试试?Eclipse又回到了无法启动的状态了。
怎么办?这时想到启动停止时显示的状态:"Loading workbench",看来和这个workbench插件有关。查看原来的.metadata/.plugins目录,在众多文件夹中
com.collabnet.subversion.merge org.eclipse.search
org.eclipse.compare org.eclipse.team.core
org.eclipse.core.resources org.eclipse.team.cvs.core
org.eclipse.core.runtime org.eclipse.team.ui
org.eclipse.debug.core org.eclipse.ui.ide
org.eclipse.debug.ui org.eclipse.ui.intro
org.eclipse.dltk.core org.eclipse.ui.views.log
org.eclipse.dltk.core.index.sql.h2 org.eclipse.ui.workbench
org.eclipse.dltk.ui org.eclipse.ui.workbench.texteditor
org.eclipse.epp.usagedata.recording org.eclipse.wb.discovery.core
org.eclipse.jdt.core org.eclipse.wst.internet.cache
org.eclipse.jdt.ui org.eclipse.wst.jsdt.core
org.eclipse.ltk.core.refactoring org.eclipse.wst.jsdt.ui
org.eclipse.ltk.ui.refactoring org.eclipse.wst.jsdt.web.core
org.eclipse.m2e.core org.eclipse.wst.sse.ui
org.eclipse.m2e.logback.configuration org.eclipse.wst.validation
org.eclipse.mylyn.bugzilla.core org.eclipse.wst.xml.core
org.eclipse.mylyn.tasks.ui org.tigris.subversion.subclipse.core
org.eclipse.php.core org.tigris.subversion.subclipse.graph
org.eclipse.php.ui org.tigris.subversion.subclipse.ui
发现了两个:
org.eclipse.ui.workbench 和
org.eclipse.ui.workbench.texteditor。
不管三七二十一,删了这两个目录,重新启动eclipse。正常启动且原项目信息正确加载。
最近团队遇到一个案例。看似很小的事情,但仔细研究起来,彻底分析,每一个环节都没做好,细节部分糟糕得一塌糊涂,最后导致一件事情的结果:完全失败。
经常有人在聊起公司的时候问我,你现在最担心的事情有哪些? 我当然会重点提到团队。不过在谈及团队的时候,我又最担心在「细节」问题上做不好。
细节就是竞争力,尤其是对小团队来说,小团队更应该注重细节问题。大一点的公司可以追究责任人,靠流程、靠制度,靠各级评审等等一系列的「成本」来提升细节能力。小一点的公司或者团队怎么办? 恐怕只有依赖每个人的能力和责任心了。
细节也是锻炼人的能力的地方,搞清楚每一个细节,将每一个细节涉及到的背景知识和技能掌握好,能力自然也就会得到提升。继而,着手做更大的事情也不
会手忙脚乱。相反,做不好细节和小事的人,如果总嚷着要做「重要」的事情,做更有「挑战」的事情,这样的事情真的到你面前,真的能接住么?
为什么我们在细节上做不好?
对细节问题不够重视 一件事情到了自己这里,头脑中先入为主认为只是一件小事,是一件简单的事情。这样,当然就不会给予足够的重视。小事不一定不重要,小事不一定意味着做起来就简单。
对事情复杂度缺乏认知 不就是给客户写一封电子邮件么? 不就是用 HTML 写一个页面么? 不就是做一则横幅广告么? 那么,这些事情真的简单么? 为什么别人为客户写的邮件打开率更高? 为什么别人写的页面更容易被搜索引擎收录? 为什么别人做的广告转化率更好? 背后涉及到哪些知识? 不想研究一下么? 不能研究一下么?
对细节缺乏耐心 草草了事,应付了事,遇到问题马马虎虎,轻易得放过了很多可以让自己得到成长的机会。「这问题我没想过」「这事情我没遇到过」「设计稿都改过两次了」... 这类借口在任何一个团队都很常见。
缺少责任心 常常觉得自己这里做不好,还有别人会把关呢。担心什么? 可如果所有人都这么想呢? 「文案是产品经理的事情,关我甚么事?」如果你能对文案也有改进意见,谁说以后你就不能做产品经理做的事情呢?
主观上不认可自己的工作 就给我这么一点钱,要我做这么多工作? 问题是我们如果不多做一点工作,不提升一下自己,又怎么能多一点钱呢?
为什么细节上做不好? 不同人不同的角度还会有不同的看法。不过有一点我能肯定,细节不会决定成败,但做不好细节,一定会失败。
做好细节,百事可作。
mac中自带的jdk并不包含源代码,所以在eclipse中无法查看, 需要到apple上去下载,
https://developer.apple.com/downloads/index.action
Documentation and developer runtime of "Java for OS X 2012-005". Contains JavaDoc, tools documentation, and native framework headers.
目前的版本是:Java for OS X 2012-005 Developer Package
下载下来后,直接安装,默认设置就可以了,然后可以建个link,方便选择。
- sudo -s
- cd /System/Library/Frameworks/JavaVM.framework/Home
- ln -s /Library/Java/JavaVirtualMachines/1.6.0_35-b10-428.jdk/Contents/Home/docs.jar
- ln -s /Library/Java/JavaVirtualMachines/1.6.0_35-b10-428.jdk/Contents/Home/src.jar
- 最后跟windows类似,在eclipse中用command + click点击查看一个类的源码。然后选“add source",选中上面的 src.jar 文件即可
虽然android安装完成后会有一套参考手册,其中包括了api,但是如果在开发过程中能查看android的源码(sdk的源码),将对我们学习android有一定的帮助.毕竟,有时候源码比api文档更能说明问题.
我平常学习android用的2.2版本,从网上下载了2.2的源码(从官方git库下载太麻烦,是从网友共享的源码位置下载的).按照网上的说法,我把
解压后的那一堆文档放在了android-sdk-root\platforms\android-8\sources目录下.不过并没有重启
eclipse.而是通过这种方法来做的-----在eclipse中,鼠标放在一个android提供的类上,按下ctrl键,会打开一个新页面,提示
找不到对应的类的class或者源文件,但这个新页面上有个导入源码的按钮,点击之后选择下载好的source位置,确定后就可以了.
顺便说下我下载android源码的位置:
http://tech.cncms.com/UploadFiles/20101025/androidsdk2.2_sources.zip下载源码到maven仓库: http://search.maven.org/#search|gav|1|g%3A%22com.google.android%22%20AND%20a%3A%22android%22
离开淘宝后,自己创业,产品需要推广,考虑到当今流量最大的聚集在微博上,我们也来做做微博运营,我是一个技术人员,运营对于我来说,从0开始,站在巨人的肩膀上学习,稍稍总结了下。
1. 使用工具:微博第三方插件已经提供了很多功能,适合自己的都用起来,这个我觉得最节省我的时间,其他网上提供的软件都可以使用,重要是适合自己,安全第一。
2. 写工具:有很多个性化需求的时候,如果变相的不能实现,人为处理太慢太花时间,我们现在是小创业团队,很多事情都需要自己做,数据增长慢,在有限的资源下,写工具是非常好的方式,作为技术人员就直接动手写,当然也需要看看性价比。
3.微博定位:
找好本微博的主题,内容一般遵循原则:定制+非定制。定制是指针对你的目标群体来选择内容,要让这部分人感兴趣,非定制:是指那种适合任何粉丝的内容。
例如:我的目标群体是女性,我的定制内容就有美容、护肤、服饰搭配、星座、爱情等女性关注的话题,非定制的有笑话、经典语录、旅游等大众类容。根据内容来 建立话题,如#美容护肤# #开心一笑##XX语录#等等,我就为自己建立了10个左右话题,每天的内容按照话题来制作。
4.主要工作流程:(这个图是转的)

5.常用的微博话题(这个图片也是转的)
6. 关注项目:微博和主动@,评论,私信,群,邀请,勋章,策划产品活动,参与微活动
7.微博运营最重要的是:一段时间需要总结挑选合适的方法执行,没有效果的去除。
如:微博发布时间/数量
我(转,不是我)曾在粉丝超过一万之后就开始研究的我的微博改什么时候发布,每天发布多少。我现在粉丝中做了一个投票:你们一般什么时候织微博。最后有200多人参加, 我大概划分了5个时段,9-12点,12-17点 17-19点 19-22点 22-24点 0-3点,做多选择3个答案,结果出来之后就有个大概了。接下来我用一周的时间从9点—24点之间每1小时发布一条信息。总共16条信息,我就分析每条信 息的转发、回复数量,一周之后我就可以摸清粉丝的上网时间规律。然后我选择哪几个时间段重点维护,并在那几个时间段进一步研究发布数量规律,我又分为每1小时,每0.5小时两个因素来研究发布数量。
JMock是帮助创建mock对象的工具,它基于Java开发,在Java测试与开发环境中有不可比拟的优势,更重要的是,它大大简化了虚拟对象的使用。本文中,通过一个简单的测试用例来说明JMock如何帮助我们实现这种孤立测试。
我们在测试某类时,由于它要与其他类发生联系,因此往往在测试此类的代码中也将与之联系的类也一起测试了。这种测试,将使被测试的类直接依赖于其他类,一旦其他类发生改变,被测试类也随之被迫改变。更重要的是,这些其他类可能尚未经过测试,因此必须先测试这些类,才能测试被测试类。这种情况下,测试驱动开发成为空谈。而如果其他类中也引用了被测试类,我们到底先测试哪一个类?因此,在测试中,如果我们能将被测试类孤立起来,使其完全不依赖于其他类的具体实现,这样,我们就能做到测试先行,先测试哪个类,就先实现哪个类,而不管与之联系的类是否已经实现。
虚拟对象(mock object)就是为此需要而诞生的。它通过JDK中的反射机制,在运行时动态地创建虚拟对象。在测试代码中,我们可以验证这些虚拟对象是否被正确地调用了,也可以在明确的情况下,让其返回特定的假想值。而一旦有了这些虚拟对象提供的服务,被测试类就可以将虚拟对象作为其他与之联系的真实对象的替身,从而轻松地搭建起一个很完美的测试环境。
JMock是帮助创建mock对象的工具,它基于Java开发,在Java测试与开发环境中有不可比拟的优势,更重要的是,它大大简化了虚拟对象的使用。
本文中,通过一个简单的测试用例来说明JMock如何帮助我们实现这种孤立测试。有三个主要的类,User,UserDAO,及UserService。本文中,我们只需测试UserService,准备虚拟UserDAO。对于User,由于本身仅是一个过于简单的POJO,可以不用测试。但如果你是一个完美主义者,也可以使用JMock的虚拟它。在这领域,JMock几乎无所不能。
这里我用到的是:(我用的是maven依赖)
<dependency>
<groupId>org.jmock</groupId>
<artifactId>jmock</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.jmock</groupId>
<artifactId>jmock-junit3</artifactId>
<version>2.5.1</version>
</dependency>
在官方的网站上也有的下载。 地址: http://jmock.org/dist/jmock-2.5.1-jars.zip
public class User {
private String name;
public User() {
}
public User(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
UserDAO负责与数据库打交道,通过数据库保存、获取User的信息。尽管我们可以不用知道JMock如何通过JDK 的反射机制来实现孤立测试,但至少应知道,JDK的反射机制要求这些在运行时创建的动态类必须定义接口。在使用JMock的环境中,由于我们要虚拟 UserDAO,意味着UserDAO必须定义接口
public interface UserDAO {
public User getUser(Long id);
}
public interface UserService {
public void setUserDAO(UserDAO userDAO);
public User getUser(Long id);
}
public class UserServiceImpl implements UserService {
private UserDAO userDAO;
public UserServiceImpl() {
}
public void setUserDAO(UserDAO userDAO) {
this.userDAO = userDAO;
}
public User getUser(Long id) {
return userDAO.getUser(id);
}
}
import org.jmock.Expectations;
import org.jmock.integration.junit3.MockObjectTestCase;
public class UserServiceTest extends MockObjectTestCase {
private UserService userService = new UserServiceImpl();
private UserDAO userDAO = null;
public UserServiceTest(String testName) {
super(testName);
}
protected void setUp() throws Exception {
userDAO = mock(UserDAO.class);
userService.setUserDAO(userDAO);
}
public void testGetUser() {
String name = "lsb";
final User fakeUser = new User(name);
checking(new Expectations(){{
oneOf(userDAO).getUser(1L);
will(returnValue(fakeUser));
}});
User user = userService.getUser(1L);
assertNotNull(user);
assertEquals(name, user.getName());
}
protected void tearDown() throws Exception {
}
}
在开发Android和iPhone应用程序时,我们往往需要从服务器不定的向手 机客户端即时推送各种通知消息,iPhone上已经有了比较简单的和完美的推送通知解决方案,可是Android平台上实现起来却相对比较麻烦,最近利用 几天的时间对Android的推送通知服务进行初步的研究。在Android手机平台上,Google提供了C2DM(Cloudto Device Messaging)服务。
Android Cloud to Device Messaging (C2DM)是一个用来帮助开发者从服务器向Android应用程序发送数据的服务。该服务提供了一个简单的、轻量级的机制,允许服务器可以通知移动应用程序直接与服务器进行通信,以便于从服务器获取应用程序更新和用户数据。C2DM服务负责处理诸如消息排队等事务并向运行于目标设备上的应用程序分发这些消息。
使用C2DM框架的要求
1. 需要Android2.2及以上的系统版本
2. 使用C2DM功能的Android设备上需要设置好Google的账户。
3. C2DM需要依赖于Google官方提供的C2DM服务器,由于国内的网络环境,这个服务经常不可用,如果想要很好的使用,我们的App Server必须也在国外,这个恐怕不是每个开发者都能够实现的
要使用C2DM来进行Push操作,基本上要使用以下6个步骤

(1)注册:Android设备把使用C2DM功能的用户账户(比如android.c2dm.demo@gmail.com)和App名称发送给C2DM服务器。
(2)C2DM服务器会返回一个registration_id值给Android设备,设备需要保存这个registration_id值。
(3)Android设备把获得的registration_id和C2DM功能的用户账户(android.c2dm.demo@gmail.com)发送给自己的服务器,不过一般用户账户信息因为和服务器确定好的,所以不必发送。
这样Android设备就完成了C2DM功能的注册过程,接下来就可以接收C2DM服务器Push过来的消息了。
(4)服务器获得数据。这里图中的例子Chrome To Phone,服务器接收到Chrome浏览器发送的数据。数据也可以是服务器本地产生的。这里的服务器是Google AppEngine(很好的一项服务,可惜在国内被屏了),要换成自己的服务器。服务器还要获取注册使用C2DM功能的用户账户(android.c2dm.demo@gmail.com)的ClientLogin权限Auth。
(5)服务器把要发送的数据和registration_id一起,并且头部带上获取的Auth,使用POST的方式发送给C2DM服务器。
(6)C2DM服务器会以Push的方式把数据发送给对应的Android设备,Android设备只要在程序中按之前和服务器商量好的格式从对应的key中获取数据即可。
转自:
地理位置索引支持是MongoDB的一大亮点,这也是全球最流行的LBS服务foursquare 选择MongoDB的原因之一。我们知道,通常的数据库索引结构是B+ Tree,如何将地理位置转化为可建立B+Tree的形式,下文将为你描述。
首先假设我们将需要索引的整个地图分成16×16的方格,如下图(左下角为坐标0,0 右上角为坐标16,16):

单纯的[x,y]的数据是无法建立索引的,所以MongoDB在建立索引的时候,会根据相应字段的坐标计算一个可以用来做索引的hash值,这个值叫做geohash,下面我们以地图上坐标为[4,6]的点(图中红叉位置)为例。
我们第一步将整个地图分成等大小的四块,如下图:

划分成四块后我们可以定义这四块的值,如下(左下为00,左上为01,右下为10,右上为11):
这样[4,6]点的geohash值目前为 00
然后再将四个小块每一块进行切割,如下:
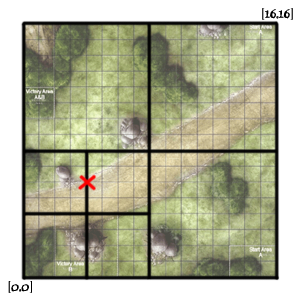
这时[4,6]点位于右上区域,右上的值为11,这样[4,6]点的geohash值变为:0011
继续往下做两次切分:

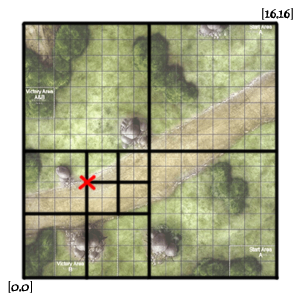
最终得到[4,6]点的geohash值为:00110100
这样我们用这个值来做索引,则地图上点相近的点就可以转化成有相同前缀的geohash值了。
我们可以看到,这个geohash值的精确度是与划分地图的次数成正比的,上例对地图划分了四次。而MongoDB默认是进行26次划分,这个值在建立索引时是可控的。具体建立二维地理位置索引的命令如下:
db.map.ensureIndex({point : "2d"}, {min : 0, max : 16, bits : 4})
其中的bits参数就是划分几次,默认为26次。
摘要: java中的引用分为4种:String Reference, WeakReference, softReference,PhantomReference Strong Reference: 我们平常用的最多的就是强引用了 如:String s = new String("opps");这种形式的引用称为强引用,这种引用有以下几个特点 1.强引用可以直接访问目标对象&...
阅读全文
摘要:
一、对ThreadLocal概术
JDK API 写道:
该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始...
阅读全文
摘要: 起因:在写java的时候,经常遇到函数需要返回2个值或者3个值,java必须编写一个Object,来封装,但很多应用场景只是临时使用,构建对象感觉杀鸡用宰牛刀,而其他语言有比较好的实现方法。(当然通过指针引用可以解决一部分问题) 如:一般写法:
Code high...
阅读全文
摘要: java.util.concurrent包分成了三个部分,分别是: ...
阅读全文
不复制内容了,可以看戏如下链接,还是有很多值得看的东东,有空看下。~
http://terryblog.blog.51cto.com/1764499/547777
1.找到你的debug.keystore文件所在的路径:
证书的一般路径为:打开eclipse,选择Windows———>Preference———>Android———>Build,其中Default debug keystore的值便是debug.keystore的路径(windows的一般在 C:\Documents and Settings\当前用户\.android下找到debug.keystore)
2.在命令提示符中执行: keytool -list -keystore debug.keystore (keytool是java一个命令,在%java_home%\bin里可以看到)
需要输入密码:android
然后就会得到MD5的值,进入
http://code.google.com/intl/zh-CN/android/add-ons/google-apis/maps-api-signup.html ,根据MD5值获取MAPS API KEY(前提是你必须有一个google账户)
使input组件的绝对位置覆盖select组件的选择框,当select的状态发生改变的时候,使用this.parentNode.nextSibling.value=this.value把select所选择的值赋给input.
<HTML>
<HEAD>
<META http-equiv='Content-Type' content='text/html; charset=gb2312'>
<TITLE>可输入的下拉框</TITLE>
</HEAD>
<BODY >
<div style="position:relative;">
<span style="margin-left:100px;width:18px;overflow:hidden;">
<select style="width:118px;margin-left:-100px" onchange="this.parentNode.nextSibling.value=this.value">
<option value="
www.taobao.com"> taobao </option>
<option value="
www.baidu.com"> soft </option>
<option value="WEB开发者"> WEB开发者 </option>
</select></span><input name="box" style="width:100px;position:absolute;left:0px;">
</div>
</BODY></HTML>
单例创建模式是一个通用的编程习语。和多线程一起使用时,必需使用某种类型的同步。在努力创建更有效的代码时,Java 程序员们创建了双重检查锁定习语,将其和单例创建模式一起使用,从而限制同步代码量。然而,由于一些不太常见的 Java 内存模型细节的原因,并不能保证这个双重检查锁定习语有效。它偶尔会失败,而不是总失败。此外,它失败的原因并不明显,还包含 Java 内存模型的一些隐秘细节。这些事实将导致代码失败,原因是双重检查锁定难于跟踪。在本文余下的部分里,我们将详细介绍双重检查锁定习语,从而理解它在何处失效。
单例创建习语
要理解双重检查锁定习语是从哪里起源的,就必须理解通用单例创建习语,如清单 1 中的阐释:
清单 1. 单例创建习语
import java.util.*;
class Singleton
{
private static Singleton instance;
private Vector v;
private boolean inUse;
private Singleton()
{
v = new Vector();
v.addElement(new Object());
inUse = true;
}
public static Singleton getInstance()
{
if (instance == null) //1
instance = new Singleton(); //2
return instance; //3
}
}
|
此类的设计确保只创建一个 Singleton 对象。构造函数被声明为 private,getInstance() 方法只创建一个对象。这个实现适合于单线程程序。然而,当引入多线程时,就必须通过同步来保护 getInstance() 方法。如果不保护 getInstance() 方法,则可能返回 Singleton 对象的两个不同的实例。假设两个线程并发调用 getInstance() 方法并且按以下顺序执行调用:
- 线程 1 调用
getInstance() 方法并决定 instance 在 //1 处为 null。
- 线程 1 进入
if 代码块,但在执行 //2 处的代码行时被线程 2 预占。
- 线程 2 调用
getInstance() 方法并在 //1 处决定 instance 为 null。
- 线程 2 进入
if 代码块并创建一个新的 Singleton 对象并在 //2 处将变量 instance 分配给这个新对象。
- 线程 2 在 //3 处返回
Singleton 对象引用。
- 线程 2 被线程 1 预占。
- 线程 1 在它停止的地方启动,并执行 //2 代码行,这导致创建另一个
Singleton 对象。
- 线程 1 在 //3 处返回这个对象。
结果是 getInstance() 方法创建了两个 Singleton 对象,而它本该只创建一个对象。通过同步 getInstance() 方法从而在同一时间只允许一个线程执行代码,这个问题得以改正,如清单 2 所示:
清单 2. 线程安全的 getInstance() 方法
public static synchronized Singleton getInstance()
{
if (instance == null) //1
instance = new Singleton(); //2
return instance; //3
}
|
清单 2 中的代码针对多线程访问 getInstance() 方法运行得很好。然而,当分析这段代码时,您会意识到只有在第一次调用方法时才需要同步。由于只有第一次调用执行了 //2 处的代码,而只有此行代码需要同步,因此就无需对后续调用使用同步。所有其他调用用于决定 instance 是非 null 的,并将其返回。多线程能够安全并发地执行除第一次调用外的所有调用。尽管如此,由于该方法是 synchronized 的,需要为该方法的每一次调用付出同步的代价,即使只有第一次调用需要同步。
为使此方法更为有效,一个被称为双重检查锁定的习语就应运而生了。这个想法是为了避免对除第一次调用外的所有调用都实行同步的昂贵代价。同步的代价在不同的 JVM 间是不同的。在早期,代价相当高。随着更高级的 JVM 的出现,同步的代价降低了,但出入 synchronized 方法或块仍然有性能损失。不考虑 JVM 技术的进步,程序员们绝不想不必要地浪费处理时间。
因为只有清单 2 中的 //2 行需要同步,我们可以只将其包装到一个同步块中,如清单 3 所示:
清单 3. getInstance() 方法
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) {
instance = new Singleton();
}
}
return instance;
}
|
清单 3 中的代码展示了用多线程加以说明的和清单 1 相同的问题。当 instance 为 null 时,两个线程可以并发地进入 if 语句内部。然后,一个线程进入 synchronized 块来初始化 instance,而另一个线程则被阻断。当第一个线程退出 synchronized 块时,等待着的线程进入并创建另一个 Singleton 对象。注意:当第二个线程进入 synchronized 块时,它并没有检查 instance 是否非 null。
双重检查锁定
为处理清单 3 中的问题,我们需要对 instance 进行第二次检查。这就是“双重检查锁定”名称的由来。将双重检查锁定习语应用到清单 3 的结果就是清单 4 。
清单 4. 双重检查锁定示例
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) { //1
if (instance == null) //2
instance = new Singleton(); //3
}
}
return instance;
}
|
双重检查锁定背后的理论是:在 //2 处的第二次检查使(如清单 3 中那样)创建两个不同的 Singleton 对象成为不可能。假设有下列事件序列:
- 线程 1 进入
getInstance() 方法。
- 由于
instance 为 null,线程 1 在 //1 处进入 synchronized 块。
- 线程 1 被线程 2 预占。
- 线程 2 进入
getInstance() 方法。
- 由于
instance 仍旧为 null,线程 2 试图获取 //1 处的锁。然而,由于线程 1 持有该锁,线程 2 在 //1 处阻塞。
- 线程 2 被线程 1 预占。
- 线程 1 执行,由于在 //2 处实例仍旧为
null,线程 1 还创建一个 Singleton 对象并将其引用赋值给 instance。
- 线程 1 退出
synchronized 块并从 getInstance() 方法返回实例。
- 线程 1 被线程 2 预占。
- 线程 2 获取 //1 处的锁并检查
instance 是否为 null。
- 由于
instance 是非 null 的,并没有创建第二个 Singleton 对象,由线程 1 创建的对象被返回。
双重检查锁定背后的理论是完美的。不幸地是,现实完全不同。双重检查锁定的问题是:并不能保证它会在单处理器或多处理器计算机上顺利运行。
双重检查锁定失败的问题并不归咎于 JVM 中的实现 bug,而是归咎于 Java 平台内存模型。内存模型允许所谓的“无序写入”,这也是这些习语失败的一个主要原因。
无序写入
为解释该问题,需要重新考察上述清单 4 中的 //3 行。此行代码创建了一个 Singleton 对象并初始化变量 instance 来引用此对象。这行代码的问题是:在 Singleton 构造函数体执行之前,变量 instance 可能成为非 null 的。
什么?这一说法可能让您始料未及,但事实确实如此。在解释这个现象如何发生前,请先暂时接受这一事实,我们先来考察一下双重检查锁定是如何被破坏的。假设清单 4 中代码执行以下事件序列:
- 线程 1 进入
getInstance() 方法。
- 由于
instance 为 null,线程 1 在 //1 处进入 synchronized 块。
- 线程 1 前进到 //3 处,但在构造函数执行之前,使实例成为非
null。
- 线程 1 被线程 2 预占。
- 线程 2 检查实例是否为
null。因为实例不为 null,线程 2 将 instance 引用返回给一个构造完整但部分初始化了的 Singleton 对象。
- 线程 2 被线程 1 预占。
- 线程 1 通过运行
Singleton 对象的构造函数并将引用返回给它,来完成对该对象的初始化。
此事件序列发生在线程 2 返回一个尚未执行构造函数的对象的时候。
为展示此事件的发生情况,假设为代码行 instance =new Singleton(); 执行了下列伪代码: instance =new Singleton();
mem = allocate(); //Allocate memory for Singleton object.
instance = mem; //Note that instance is now non-null, but
//has not been initialized.
ctorSingleton(instance); //Invoke constructor for Singleton passing
//instance.
|
这段伪代码不仅是可能的,而且是一些 JIT 编译器上真实发生的。执行的顺序是颠倒的,但鉴于当前的内存模型,这也是允许发生的。JIT 编译器的这一行为使双重检查锁定的问题只不过是一次学术实践而已。
为说明这一情况,假设有清单 5 中的代码。它包含一个剥离版的 getInstance() 方法。我已经删除了“双重检查性”以简化我们对生成的汇编代码(清单 6)的回顾。我们只关心 JIT 编译器如何编译 instance=new Singleton(); 代码。此外,我提供了一个简单的构造函数来明确说明汇编代码中该构造函数的运行情况。
清单 5. 用于演示无序写入的单例类
class Singleton
{
private static Singleton instance;
private boolean inUse;
private int val;
private Singleton()
{
inUse = true;
val = 5;
}
public static Singleton getInstance()
{
if (instance == null)
instance = new Singleton();
return instance;
}
}
|
清单 6 包含由 Sun JDK 1.2.1 JIT 编译器为清单 5 中的 getInstance() 方法体生成的汇编代码。
清单 6. 由清单 5 中的代码生成的汇编代码
;asm code generated for getInstance
054D20B0 mov eax,[049388C8] ;load instance ref
054D20B5 test eax,eax ;test for null
054D20B7 jne 054D20D7
054D20B9 mov eax,14C0988h
054D20BE call 503EF8F0 ;allocate memory
054D20C3 mov [049388C8],eax ;store pointer in
;instance ref. instance
;non-null and ctor
;has not run
054D20C8 mov ecx,dword ptr [eax]
054D20CA mov dword ptr [ecx],1 ;inline ctor - inUse=true;
054D20D0 mov dword ptr [ecx+4],5 ;inline ctor - val=5;
054D20D7 mov ebx,dword ptr ds:[49388C8h]
054D20DD jmp 054D20B0
|
注: 为引用下列说明中的汇编代码行,我将引用指令地址的最后两个值,因为它们都以 054D20 开头。例如,B5 代表 test eax,eax。
汇编代码是通过运行一个在无限循环中调用 getInstance() 方法的测试程序来生成的。程序运行时,请运行 Microsoft Visual C++ 调试器并将其附到表示测试程序的 Java 进程中。然后,中断执行并找到表示该无限循环的汇编代码。
B0 和 B5 处的前两行汇编代码将 instance 引用从内存位置 049388C8 加载至 eax 中,并进行 null 检查。这跟清单 5 中的 getInstance() 方法的第一行代码相对应。第一次调用此方法时,instance 为 null,代码执行到 B9。BE 处的代码为 Singleton 对象从堆中分配内存,并将一个指向该块内存的指针存储到 eax 中。下一行代码,C3,获取 eax 中的指针并将其存储回内存位置为 049388C8 的实例引用。结果是,instance 现在为非 null 并引用一个有效的 Singleton 对象。然而,此对象的构造函数尚未运行,这恰是破坏双重检查锁定的情况。然后,在 C8 行处,instance 指针被解除引用并存储到 ecx。CA 和 D0 行表示内联的构造函数,该构造函数将值 true 和 5 存储到 Singleton 对象。如果此代码在执行 C3 行后且在完成该构造函数前被另一个线程中断,则双重检查锁定就会失败。
不是所有的 JIT 编译器都生成如上代码。一些生成了代码,从而只在构造函数执行后使 instance 成为非 null。针对 Java 技术的 IBM SDK 1.3 版和 Sun JDK 1.3 都生成这样的代码。然而,这并不意味着应该在这些实例中使用双重检查锁定。该习语失败还有一些其他原因。此外,您并不总能知道代码会在哪些 JVM 上运行,而 JIT 编译器总是会发生变化,从而生成破坏此习语的代码。
双重检查锁定:获取两个
考虑到当前的双重检查锁定不起作用,我加入了另一个版本的代码,如清单 7 所示,从而防止您刚才看到的无序写入问题。
清单 7. 解决无序写入问题的尝试
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) { //1
Singleton inst = instance; //2
if (inst == null)
{
synchronized(Singleton.class) { //3
inst = new Singleton(); //4
}
instance = inst; //5
}
}
}
return instance;
}
|
看着清单 7 中的代码,您应该意识到事情变得有点荒谬。请记住,创建双重检查锁定是为了避免对简单的三行 getInstance() 方法实现同步。清单 7 中的代码变得难于控制。另外,该代码没有解决问题。仔细检查可获悉原因。
此代码试图避免无序写入问题。它试图通过引入局部变量 inst 和第二个 synchronized 块来解决这一问题。该理论实现如下:
- 线程 1 进入
getInstance() 方法。
- 由于
instance 为 null,线程 1 在 //1 处进入第一个 synchronized 块。
- 局部变量
inst 获取 instance 的值,该值在 //2 处为 null。
- 由于
inst 为 null,线程 1 在 //3 处进入第二个 synchronized 块。
- 线程 1 然后开始执行 //4 处的代码,同时使
inst 为非 null,但在 Singleton 的构造函数执行前。(这就是我们刚才看到的无序写入问题。)
- 线程 1 被线程 2 预占。
- 线程 2 进入
getInstance() 方法。
- 由于
instance 为 null,线程 2 试图在 //1 处进入第一个 synchronized 块。由于线程 1 目前持有此锁,线程 2 被阻断。
- 线程 1 然后完成 //4 处的执行。
- 线程 1 然后将一个构造完整的
Singleton 对象在 //5 处赋值给变量 instance,并退出这两个 synchronized 块。
- 线程 1 返回
instance。
- 然后执行线程 2 并在 //2 处将
instance 赋值给 inst。
- 线程 2 发现
instance 为非 null,将其返回。
这里的关键行是 //5。此行应该确保 instance 只为 null 或引用一个构造完整的 Singleton 对象。该问题发生在理论和实际彼此背道而驰的情况下。
由于当前内存模型的定义,清单 7 中的代码无效。Java 语言规范(Java Language Specification,JLS)要求不能将 synchronized 块中的代码移出来。但是,并没有说不能将 synchronized 块外面的代码移入 synchronized 块中。
JIT 编译器会在这里看到一个优化的机会。此优化会删除 //4 和 //5 处的代码,组合并且生成清单 8 中所示的代码。
清单 8. 从清单 7 中优化来的代码。
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) { //1
Singleton inst = instance; //2
if (inst == null)
{
synchronized(Singleton.class) { //3
//inst = new Singleton(); //4
instance = new Singleton();
}
//instance = inst; //5
}
}
}
return instance;
}
|
如果进行此项优化,您将同样遇到我们之前讨论过的无序写入问题。
用 volatile 声明每一个变量怎么样?
另一个想法是针对变量 inst 以及 instance 使用关键字 volatile。根据 JLS(参见 参考资料),声明成 volatile 的变量被认为是顺序一致的,即,不是重新排序的。但是试图使用 volatile 来修正双重检查锁定的问题,会产生以下两个问题:
- 这里的问题不是有关顺序一致性的,而是代码被移动了,不是重新排序。
- 即使考虑了顺序一致性,大多数的 JVM 也没有正确地实现
volatile。
第二点值得展开讨论。假设有清单 9 中的代码:
清单 9. 使用了 volatile 的顺序一致性
class test
{
private volatile boolean stop = false;
private volatile int num = 0;
public void foo()
{
num = 100; //This can happen second
stop = true; //This can happen first
//...
}
public void bar()
{
if (stop)
num += num; //num can == 0!
}
//...
}
|
根据 JLS,由于 stop 和 num 被声明为 volatile,它们应该顺序一致。这意味着如果 stop 曾经是 true,num 一定曾被设置成 100。尽管如此,因为许多 JVM 没有实现 volatile 的顺序一致性功能,您就不能依赖此行为。因此,如果线程 1 调用 foo 并且线程 2 并发地调用 bar,则线程 1 可能在 num 被设置成为 100 之前将 stop 设置成 true。这将导致线程见到 stop 是 true,而 num 仍被设置成 0。使用 volatile 和 64 位变量的原子数还有另外一些问题,但这已超出了本文的讨论范围。有关此主题的更多信息,请参阅 参考资料。
解决方案
底线就是:无论以何种形式,都不应使用双重检查锁定,因为您不能保证它在任何 JVM 实现上都能顺利运行。JSR-133 是有关内存模型寻址问题的,尽管如此,新的内存模型也不会支持双重检查锁定。因此,您有两种选择:
- 接受如清单 2 中所示的
getInstance() 方法的同步。
- 放弃同步,而使用一个
static 字段。
选择项 2 如清单 10 中所示
清单 10. 使用 static 字段的单例实现
class Singleton
{
private Vector v;
private boolean inUse;
private static Singleton instance = new Singleton();
private Singleton()
{
v = new Vector();
inUse = true;
//...
}
public static Singleton getInstance()
{
return instance;
}
}
|
清单 10 的代码没有使用同步,并且确保调用 static getInstance() 方法时才创建 Singleton。如果您的目标是消除同步,则这将是一个很好的选择。
String 不是不变的
鉴于无序写入和引用在构造函数执行前变成非 null 的问题,您可能会考虑 String 类。假设有下列代码:
private String str;
//...
str = new String("hello");
|
String 类应该是不变的。尽管如此,鉴于我们之前讨论的无序写入问题,那会在这里导致问题吗?答案是肯定的。考虑两个线程访问 String str。一个线程能看见 str 引用一个 String 对象,在该对象中构造函数尚未运行。事实上,清单 11 包含展示这种情况发生的代码。注意,这个代码仅在我测试用的旧版 JVM 上会失败。IBM 1.3 和 Sun 1.3 JVM 都会如期生成不变的 String。
清单 11. 可变 String 的例子
class StringCreator extends Thread
{
MutableString ms;
public StringCreator(MutableString muts)
{
ms = muts;
}
public void run()
{
while(true)
ms.str = new String("hello"); //1
}
}
class StringReader extends Thread
{
MutableString ms;
public StringReader(MutableString muts)
{
ms = muts;
}
public void run()
{
while(true)
{
if (!(ms.str.equals("hello"))) //2
{
System.out.println("String is not immutable!");
break;
}
}
}
}
class MutableString
{
public String str; //3
public static void main(String args[])
{
MutableString ms = new MutableString(); //4
new StringCreator(ms).start(); //5
new StringReader(ms).start(); //6
}
}
|
此代码在 //4 处创建一个 MutableString 类,它包含了一个 String 引用,此引用由 //3 处的两个线程共享。在行 //5 和 //6 处,在两个分开的线程上创建了两个对象 StringCreator 和 StringReader。传入一个 MutableString 对象的引用。StringCreator 类进入到一个无限循环中并且使用值“hello”在 //1 处创建 String 对象。StringReader 也进入到一个无限循环中,并且在 //2 处检查当前的 String 对象的值是不是 “hello”。如果不行,StringReader 线程打印出一条消息并停止。如果 String 类是不变的,则从此程序应当看不到任何输出。如果发生了无序写入问题,则使 StringReader 看到 str 引用的惟一方法绝不是值为“hello”的 String 对象。
在旧版的 JVM 如 Sun JDK 1.2.1 上运行此代码会导致无序写入问题。并因此导致一个非不变的 String。
结束语
为避免单例中代价高昂的同步,程序员非常聪明地发明了双重检查锁定习语。不幸的是,鉴于当前的内存模型的原因,该习语尚未得到广泛使用,就明显成为了一种不安全的编程结构。重定义脆弱的内存模型这一领域的工作正在进行中。尽管如此,即使是在新提议的内存模型中,双重检查锁定也是无效的。对此问题最佳的解决方案是接受同步或者使用一个 static field。
薪水族如何“钱滚钱” 教你用2万赚到1000万
工薪族月薪2000元的理财窍门
在有很多的大学生都是在毕业以后选择留在自己上学的城市,一来对城市有了感情,二来也希望能在大的城市有所
发展,而现在很多大城市劳动力过剩,大学生想找到一个自己喜欢又有较高收入的职位已经变得非常难,很多刚毕业的朋友的月收入都可能徘徊在2000元人民币左右,如果您是这样的情况,让我们来核算一下,如何利用手中的有限资金来进行理财。如果您是单身一人,月收入在2000人民币,又没有其他的奖金分红等收入,那年收入就固定在25000元左右。如何来支配这些钱呢?
生活费占收入30%-40%
首先,你要拿出每个月必须支付的生活费。如房租、水电、通讯费、柴米油盐等,这部分约占收入三分之一。它们是你生活中不可或缺的部分,满足你最基本的物质需求。离开了它们,你就会像鱼儿离开了水一样无法生活,所以无论如何,请你先从收入中抽出这部分,不要动用。
储蓄占收入10%-20%
其次,是自己用来储蓄的部分,约占收入的10%-20%。很多人每次也都会在月初存钱,但是到了月底的时候,往往就变成了泡沫,存进去的大部分又取出来了,而且是不知不觉的,好像凭空消失了一样,总是在自己喜欢的衣饰、杂志、CD或朋友聚会上不加以节制。你要自己提醒自己,起码,你的存储能保证你3个月的基本生活。要知道,现在很多公司动辄减薪裁员。如果你一点储蓄都没有,一旦
工作发生了变动,你将会非常被动。
而且这3个月的收入可以成为你的定心丸,工作实在干得不开心了,忍无可忍无需再忍时,你可以潇洒地对老板说声“拜拜”。想想可以不用受你不喜欢的工作和人的气,是多么开心的事啊。所以,无论如何,请为自己留条退路。
活动资金占收入30%~40%
剩下的这部分钱,约占收入的三分之一。可以根据自己当时的生活目标,侧重地花在不同的地方。譬如“五一”、“十一”可以安排
旅游;服装打折时可以购进自己心仪已久的牌子货;还有平时必不可少的购买CD、朋友聚会的开销。这样花起来心里有数,不会一下子把钱都用完。
最关键的是,即使一发薪水就把这部分用完了,也可当是一次教训,可以惩罚自己一个月内什么都不能再干了(就当是收入全部支出了吧),印象会很深刻而且有效。
除去吃、穿、住、行以及其他的消费外,再怎么节省,估计您现在的状况,一年也只有10000元的积蓄,想来这些都是刚毕业的绝大部分学生所面临的实际情况。如何让钱生钱是大家想得最多的事情,然而,毕竟收入有限,很多想法都不容易实现,
建议处于这个阶段的朋友,最重要的是开源,节流只是我们生活工作的一部分,就像大厦的基层一样。而最重要的是怎样财源滚滚、开源有道,为了达到一个新目标,你必须不断进步以求发展,培养自己的实力以求进步,这才是真正的生财之道。可以安心地发展自己的事业,积累自己的经验,充实自己,使自己不断地提高,才会有好的发展,要相信“机会总是给有准备的人”。
当然,既然有了些许积蓄,也不能让它闲置,我们建议把1万元分为5份,分成5个2000元,分别作出适当的投资安排。这样,家庭不会出现用钱危机,并可以获得最大的收益。
(1)用2000元买国债,这是回报率较高而又很保险的一种投资。
(2)用2000元买保险。以往人们的保险意识很淡薄,实际上购买保险也是一种较好的投资方式,而且保险金不在利息税征收之列。尤其是各寿险公司都推出了两全型险种,增加了有关“权益转换”的条款,即一旦银行利率上升,
客户可在保险公司
出售的险种中进行转换,并获得保险公司给予的一定的价格折扣、免予核保等
优惠政策。
(3)用2000元买股票。这是一种风险最大的投资,当然风险与收益是并存的,只要选择得当,会带来理想的投资回报。除股票外,期货、投资债券等都属这一类。不过,参与这类投资,要求有相应的行业知识和较强的风险意识。
(4)用2000元存定期存款,这是一种几乎没有风险的投资方式,也是未来对家庭生活的一种保障。
(5)用2000元存活期存款,这是为了应急之用。如家里临时急需用钱,有一定数量的活期储蓄存款可解燃眉之急,而且存取又很方便。
这种方法是许多人经过多年尝试后总结出的一套成功的理财经验。当然,各个家庭可以根据不同情况,灵活使用。
正确理财三个观念
建立理财观念一:理财是一件正大光明的事,“你不理财,财不理你”。
建立理财观念二:理财要从现在开始,并长期坚持。
建立理财观念三:理财目的是“梳理财富,增值生活”。
理财四个误区
理财观念误区一:我没财可理;
理财观念误区二:我不需要理财;
理财观念误区三:等我有了钱再理财;
理财观念误区四:会理财不如会挣钱。
理财的五大目标
目标一:获得资产增值;
目标二:保证资金安全;
目标三:防御意外事故;
目标四:保证老有所养;
目标五:提供赡养父母及抚养教育子女的基金。
--------------------精彩阅读推荐--------------------
【500强企业的薪水有多高?】
全球500强大企业的薪水实情大揭密
不一定要是自己的offer letter上的数据,凡是能够确认比较准确的公司薪水都可补充。补充的话最好说明职位、本硕区别、多少个月工资、奖金。宝洁:本7200、研8200、博9700,均14个月,另有交通补助,区域补助等,CBD,marketing每几个月涨20%-30%不定。
【工薪族的你跑赢通胀了吗?】
工薪族理财跑赢通胀 开源节流资产合理配备
龙先生家是典型的工薪阶层。龙先生47岁,是某大型企业的技术师,年收入5.5万元,购买了各类基本保险。太太42岁,是某商场的合同工,年收入4万元,购买了基本的社会保险。两人均在单位吃中午饭,搭班车上下班。儿子16岁,尚在读高中。
【怎样才能钱生钱?】
“阶梯存储”应对利率调整 学三招轻松钱生钱
当前,储蓄依然在居民理财的投资组合中占据着重要地位,但在当前的加息周期内,一些人因缺乏科学的储蓄理财规划而损失利息收入。理财专家建议,进入加息周期,为了使储蓄理财能赚取更多的利息收入,储户应在存款期限、存款金额和存款方式上注意以下几点。
【爷们的脸往哪搁!】
女人太会赚钱也是错? 爷们儿的脸往哪搁
女人财大就气粗?别偏激,妻子赚钱自己也是受益者,所以首先心态放平和些,别太执着于传统的思维和他人的看法。会不会赚钱是女人衡量男人的重要标尺。男人没钱,女人觉得没有面子,不愿提及她的男人;有钱男人不怕提及他女人,无论漂亮与否,只要不给他戴绿帽子。
说起精致,最容易想起的词大概是瓷器了,但这个词用到程序员身上,肯定让很多人觉得摸不着头脑,在详述"精致"这个词以前,还是先来看一个"破窗理论",让我们真正的理解"精致"的概念。
最早的"破窗理论",也称"破窗谬论",源自于一位经济学家黑兹利特(也有人说源于法国19世纪经济学家巴斯夏),用来指出"破坏创造财富"的概念,以彻底地否定凯恩斯主义的政府干预政策。但后来美国斯坦福大学心理学家詹巴斗和犯罪学家凯琳也提出了相应的"破窗理论"。
心理学家詹巴斗进行了一项试验,他把两辆一模一样的汽车分别停放在帕罗阿尔托的中产阶级社区和相对杂乱的布朗克斯街区。对停在布朗克斯街区的那一辆,他摘掉了车牌,并且把顶棚打开,结果不到一天就被人偷走了;而停放在帕罗阿尔托的那一辆,停了一个星期也无人问津。后来,詹巴斗用锤子把这辆车的玻璃敲了个大洞,结果仅仅过了几个小时车就不见了。
而犯罪学家凯琳曾注意到一个问题:在她上班的路旁,有一座非常漂亮的大楼,有一天,她注意到楼上有一窗子的玻璃被打破了,那扇破窗与整座大楼的整洁美丽极不调谐,显得格外的刺眼。又过了一段时间,她惊奇地发现:那扇破窗不但没得到及时的维修,反而又增加了几个带烂玻璃的窗子……这一发现使她的心中忽有所悟:如果有人打坏了一个建筑物的窗户玻璃,而这扇窗户又得不到及时维修的话,别人就可能受到某些暗示性的纵容去打烂更多的玻璃。久而久之,这些破窗户就给人造成一种无序的感觉;其结果是:在这种麻木不仁的氛围中,犯罪就会滋生。这就是凯琳著名的"破窗理论"。
后来的"破窗理论",已经突破原有经济学上的概念,有了新的意义:残缺不全的东西更容易遭受到别人的破坏。前面的汽车和窗户都表明了这一点。
其实作为程序员开发软件也是一样,可能有十种好的方法去写一个功能,一个类,但同时可能会有一百种更快捷但不好的方法去做同样的事情,很多程序员会因为各种原因,如时间压力,工作强度,技术水平等一系列问题选择了后者而非前者。同样的事情还发生在维护和修改阶段,当看到别人的代码写的随意,不好时,那么自然就会沿着别人的方向走下去,结果就是产生出更多不好的代码,这是在代码开发中的一个典型"破窗理论"的体现。
承认一点,现实世界是不完美,特别是开发中,因为时间,精力,能力等各种因素,我们始终是要打破一些窗户,但是却要记住两点:
1.一个月前多打破了一扇窗户,结果一个月就会打破10 扇甚至更多的窗户。
2.如果打破了一扇窗户,就要记住,迟早应该将它补上。
因为各方面的原因,一个程序员也许不能做到精致的代码,但是如果一个程序员不想去做精致的代码,那么又何必选择软件开发呢?
最近有Java解压缩的需求,java.util.zip实在不好用,对中文支持也不行。所以选择了强大的TrueZIP,使用时遇到了一个问题,做个记录。
解压缩代码如下:
ArchiveDetector detector = new DefaultArchiveDetector(ArchiveDetector.ALL,
new Object[] { "zip", new CheckedZip32Driver("GBK") } );
File zipFile = new File("zipFile", detector);
File dst = new File("dst");
// 解压缩
zipFile.copyAllTo(dst);
代码十分简洁,注意这个File是
de.schlichtherle.io.File
不是
java.io.File
当处理完业务要删除这个Zip File时,问题出现了:
这个文件删不掉!!!
把自己的代码检查了好久,确认没问题后,开始从TrueZIP下手,发现它有特殊的地方的,是提示过的:
File file = new File(“archive.zip”); // de.schlichtherle.io.File!
Please do not do this instead:
de.schlichtherle.io.File file = new de.schlichtherle.io.File(“archive.zip”);
This is for the following reasons:
1.Accidentally using java.io.File and de.schlichtherle.io.File instances referring to the same path concurrently will result in erroneous behaviour and may even cause loss of data! Please refer to the section “Third Party Access” in the package Javadoc of de.schlichtherle.io for for full details and workarounds.
2.A de.schlichtherle.io.File subclasses java.io.File and thanks to polymorphism can be used everywhere a java.io.File could be used.
原来两个File不能交叉使用,搞清楚原因了,加这么一句代码搞定。
zipFile.deleteAll();
http://www.blogjava.net/Files/lsbwahaha/ANTLR_info.pdf
antlr简介
目前的ANTLR支持的语法层的选项主要包括:
语言选项(Language)、
输出选项(output)、
回溯选项(backtrack)、
记忆选项 (memorize)、
记号词库(tokenVocab)、
重写选项(rewrite)、
超类选项(superClass)、
过滤选项(Filter)、
AST标签类型(ASTLabelType)
K选项
/**
//一些写法
k=2;
backtrack=true;
memoize=true;
*/
1. 语言选项 language
语言选项指定了ANTLR将要产生的代码的目标语言,默认情况下该选项设置为了Java。需要注意的是,ANTLR中的嵌入的动作必须要使用目标语言来写。
grammar T;
options {
language=Java;
}
ANTLR使用了特有的基于字串模板(StringTemplate-based)代码生成器,构建一个新的目标语言显得较为简单,因此我们可以构建多种
语言,诸如Java,C,C++,C#,Python,Objective-C,Ruby等等。语言选项让ANNTLR去模板目录(例如 org/antlr/codegen/templates/Java or org/antlr/codegen/templates/C)下寻找合适的模板,并使用模板来构建语言。该目录下包含大量的模板,我们可以向其中加入其
他的模板以满足我们的需求。
2. 输出选项 output
输出选项控制了ANTLR输出的数据结构,目前支持两种输出:抽象语法树——AST(Abstract Syntax Trees)和字串模板(StringTemplates)——template。当output这个选项被设置后,所有的规则都被输出成了AST或者 template。
grammar T;
options {
output=AST;
}
3. 回溯选项backtrack
当回溯选项打开的时候,在执行一个LL(K)失败的时候,ANTLR会返回至LL(K)开始而尝试其他的规则。
4. 记忆选项 (memorize)
memoize选项打开以后,每条解析方法(Paser Method)开始之前,ANTLR会首先检测以前的尝试结果,并在该方法执行完成之后记录该规则是否执行成功。但是注意,对于单条的规则打开此选项经常比在全局上打开该规则效率更高。
5. 记号词库(tokenVocab)
说白了就是output输出目录中的XX.tokens文件中的定义可以方便的给 大型工程中多个.g中的符号同步更新。
大型的工程中常常利用AST作为中间产物对输入进行多次分析并最终生成代码。对AST的遍历时需要经常使用树语法(tree grammar),而tree grammar中经常需要将符号与其他的文件中的符号进行同步或者更新。tokenVocab实现了这个功能。
例如我们定义了下面的一个语法文件:
grammar P;
options {
output=AST;
}
expr: INT ('+' ^ INT)* ;
INT : '0'..'9' +;
WS : ' ' | '\r' | '\n' ;
利用该文件生成了一个标记:P.token,并生成了语法树(AST)。这时我们需要一个用于遍历该AST的tree grammar,并通过tree grammar 中的tokenVocab选项来向其中更新tokens:
tree grammar Dump;
options {
tokenVocab=P;
ASTLabelType=CommonTree;
}
expr: ^( '+' expr {System.out.print('+' );} expr )
| INT {System.out.print($INT.text);}
;
编译tree grammar的时候ANTLR默认会在当前目录下寻找.token文件,我们可以通过-lib选项来设置用于寻找.token文件的目录,例如:
java org.antlr.Tool -lib . Dump.g
6. 重写选项(rewrite)
通过重写选项可以改变ANTLR对输入的默认处理规则,一般用在输出为template的情况下。将该选项使能之后,ANTLR将一般的输入直接拷贝至输出,而将适于模板重写规则的输入做其他的处理。
7. 超类选项(superClass)
用于指定一个超类。
8. 过滤选项(Filter)
9. AST标签类型(ASTLabelType)
10.
K选项
K选项用于限制对LL(K)进行语法分析的次数,从而提高了ANTLR的解析速度。K只能为*或者数字,默认为*。
属性和动作
动作(Actions)实际上是用目标语言写成的、嵌入到规则中的代码(以花括号包裹)。它们通常直接操作输入的标号,但是他们也可以用来调用相应的外部代码。属性,到目前为止我的理解还不多,感觉像是C++中类里面的成员,一会看完应该会更清楚一些。
1. 语法动作(Grammar Actions)
动作(Actions)是指嵌在语法中的、用目标语言写成的代码片段。ANTLR则把这些代码(除了用$或%标记的以外)逐字地插入到生成的识别器中。
动作可以放到规则的外边,也可以嵌入到某条规则当中。当动作位于规则之外时候,这些动作同城定义了一些全局的或者是类的成员(变量或者成员函数);而当其嵌入规则之中时,则用于执行某些特定的命令,这些命令在识别器识别了其预订的字符的时候就会开始执行。例如下面的例子:
parser grammar T;
@header {
package p;
}
@members {
int i;
public TParser(TokenStream input, int foo) {
this(input);
i = foo;
}
}
a[int x] returns [int y]
@init {int z=0;}
@after {System.out.println("after matching rule; before finally");}
: {《action1》} A {《action2 》}
;
catch[RecognitionException re] {
System.err.println("error");
}
finally { 《do-this-no-matter-what 》 }
从中可以看出,前面的两个动作,@head and @members是两个处于规则之外的全局的动作,定义了一些变量和类;而后两个则分别在a这个规则的前后执行(@init在前,@after在后,这个在前面提到过)。
这里针对两种类型详细叙述。
antlr简介
1. 需要有全职的有威信,有能力的产品负责人(PO-Product Owner).
2. PO要和Scrum Team、其他的利益相关者(stakeholder)一起工作
3. 有PO来创建和管理产品backlog.
4. Scrum每日站会必须的3个问题(完成了什么,准备做什么,有什么障碍)。
5. Scrum每日站会要在固定的地方时间不要超过15分钟。
6. 有规律的Sprint长度(不超过30天)
7. 在Sprint计划会议上创建Sprint Backlog和经过详细估算的任务列表。
8. 一定要有Sprint的燃尽图。
9. Team必须的设备及相关的供应要齐全。
10. 使用回顾会议确保过程在不断提升。
11. 有明确的对于“任务完成”的定义。
12. 按照合理的速率给出承诺(根据Sprint的工作量估计)。
13. 团队大小在7 +/- 2,最多不能超过12人
14. 跨职能的团队包括Scrum Master和PO.
15. 自组织的团队 - 团队成员志愿挑选任务。
16. Scrum master要跟踪进度,并且为团队扫清障碍。
17. 确保Team不被外界干扰。
18. Sprint之间不能间断。
19. 合理的节奏 - 根据固定时间段来确定任务量, 不只是一个进度表。
20. 质量是第一,不需要在质量上讨价还价 - 代码缺陷永远位于Backlog的最上层。
javaeye上一篇文章不错,介绍
Linux文件系统简介的,讲解比较基础,遗忘的时候看下不错的,记录一下~!~http://www.javaeye.com/topic/816268
转载于:http://www.infoq.com/cn/articles/skills-for-scrum-agile-teams
敏捷项目的工程独特性
1.
设置开发环境
在传统项目中,团队可以投入充分的时间来设置开发环境;而在敏捷团队里面,他们需要从第一刻时间起就能产出。根据我们的经验,我们认识到缺乏设置开发环境的相关文档是设置环境如此耗时的一个关键原因。第二个关键原因是在设置过程中涉及的手工步骤数。在第0次sprint,我们必须记录每一件开发人员必须做了才能开始编写代码,并集成团队其他人工作的小事。
2.
自动构建
让我们尽早失败!我们领悟到,手工构建可能既脆弱,又特定于某一台机器,而且当时间耗费在手工构建的基础工作上面时,开发和测试的时间就被挤占掉了。除去最小的项目,自动构建过程对于每一个项目都是必不可少的。我们认识到,即使需要抽出时间来创建自动构建的环境,你以后是能把这些时间赚回来的。这也使得我们更易于确保项目有一个人人共有的标准化构建。
3.
持续集成
根据我们过去的经验,我们领悟到,等到最后的几个星期才去把不同团队成员的代码集成到一起是一个灾难。如果你已经拥有了自动构建,接下来的事情就是持续集成。当然,版本控制(或者软件配置管理——另一个更为正式的和令人印象深刻的名字)是自动构建和持续集成环境的前提。我们学到的一个重要教训是,你越快识别出集成的错误,你就能越快地解决这些问题。我们曾经使用过的主要工具包括
CruiseControl、
CruiseControl.Net和
Bamboo。 hadson,基础集成还是不错的。
4.
单元测试
在高度流动的环境中,随着多个开发人员一起工作、需求的变更和优先级的不断变化,确保昨天可以运行的东西今天也能运行,这是至关重要的。此外,我们还要与集成出现的错误为战。一种方法(我们从艰难岁月中学习得来)是使用单元测试,这样代码的更改不会破坏现有的功能。我们也开始在开发编码之前编写单元测试用例。我们曾经使用过的主要工具包括
JUnit(以及其他的xUnit工具如
NUnit、
HttpUnit等)和
MockObjects。
5.
重构
在传统的项目中,通常有一个人保护他们的代码库,直到代码集成阶段。但是在敏捷里面,我们持代码集体所有制的观点——所有的代码属于所有的开发人员,只要开发人员认为有必要,每个人都能不受约束地去改善代码。在一段时间里面,我们的代码库开始出现奇怪的行为——解决办法就是重构(感谢Martin
Fowler在他的同名著作中把重构一词推广开来)。重构的本质归结为修改代码以改善代码的结构和清晰度,但不改变代码的功能。我们学到的一个重要教训是在重构代码之前使用单元测试作为安全网,我们曾经使用过的一些主要工具包括Eclipse、NetBeans、IntelliJ IDEA的和Visual
Studio.NET。
在敏捷团队之中工作所必备的行为特征
由于敏捷团队不同于普通的团队,并且非常倚赖于有效果和有效率的沟通和快速执行,敏捷团队更需要使用软技能。如果我们意识到这一点,并积极鼓励使用这些特征和技能,我们可以使得敏捷团队更有价值和富有成效。
自组织往往倚赖于诸如正反馈、负反馈、深度探索和广度调研之间取得平衡以及多重互动的基本要素。根据我们的经验,团队可能由于许多文化和社会因素无法给予正确的反馈或者回避人与人之间的互动。
根据我个人的经验,这仍然是一个“神话”。我们总是倾向于患有“可预测性综合症”——如果我们做更多的规划,我们将更加功能预测。
团队需要有良好的纪律、有能力承担责任、尽忠尽责以及承担职责和所有权。
团队需要拥有的关键技能之一是有能力寻求帮助,并寻求他人的评价。在某些情形下,我们已经看到了“自我”因素表现为一个主要的障碍。
有些时候,承担责任,尽忠尽责和协作精神是理所当然的,但是根据以往的经验,为了这些能够出现,我们有时需要外部干预。
有些我们常常倾向于忽视的关键技能是积极主动、在激烈的环境中享受工作和易于适应新的形势和框架。
我们的大多数项目都是分布式的,这意味着在客户和服务供应商之间将会共同使用Scrum。在这种情况下,诸如管理多样化团队、时间管理、外交技巧和领导力等技能是非常关键的。
敏捷团队的成功“咒语”
对于任何一个希望成功和高效的敏捷项目,团队需要对向同侪学习(不管资历和专业知识)表现出更大的热情和正确的态度。必须保证一个无畏表达的安全网,这样才会展现出真正的友情,而这反过来会增强团队成员对团队目标的关注,而不是“哪些由我来做”?
结论
根据我个人的经验和观察,对于提高生产率所需的技能,敏捷项目与传统项目有所不同。本文定义了团队提高生产率所需的行为和技术技能。具有这些“delta”
特征的人应该具备了合适的行为和技术技能,这些技能使得他们在敏捷项目中的工作能够富有成效。对于这些技能的总结请见下表。
技能表
|
角色
|
技术技能(在不同的方面)
|
行为技能
|
|
开发人员
|
CRUD操作,开发框架不同层之间的调用
单元测试(工具——NUnit、JUnit)
代码覆盖率的概念和工具
代码审查的概念和工具
持续集成工具
重构的概念
代码味道的概念
Scrum过程
|
沟通
合作
时间管理/计划
思维
冲突管理
处理更改/灵活性
决策
团队合作/团队建设
处理压力
问题解决
领导
外交
|
|
QA
|
“完成”的定义 —> 验收标准
测试管理
自动化/脚本
环境设置
数据库概念
|
与开发人员相同
|
|
Scrum Master
|
Scrum过程
模板和使用
项目管理工具
持续集成工具
设置开发环境
|
开发人员的技能+推动力
|
作者简介
Prasad,拥有10年的IT服务行业经验,他第一次接触敏捷项目是在2005年微软的一个项目;从那时起,他为许多公司如GE、思科、可口可乐等,针对敏捷及其变体提供了解决方案开发、培训、咨询以及指导。目前他正在Symphony
Services的敏捷实验室担任经理。Symphony40%的项目都是关于敏捷或其不同的形式,并且自2004年起就通过敏捷为客户提供商务的关键价值。你可以通过pprabhak@symphonsysv.com与他联系。
查看英文原文:Skills for
Scrum Agile Teams
敏捷最大的特点是:不但快,反应要更快。
最终的目的是:提升效率。
敏捷是一种思想:
沟通:个体交互
简单:快速交付
反馈:客户合作
勇气:响应变化
关键条件还是目标一直的团队
共同愿景
高效沟通
互相信任
严格执行
迅速迭代,越变越美,允许试错
敏捷精华: 小胜+ 反思
想法是:
1.现在列出你认为你能完成的一件事。
比如我认为每天30分钟的话,下一周我能读一本书:书名叫《人人都是产品经理》
2.每天把进度记录到地下
我会把读完的页数写出来,加上一点点感想
看完后,总结下。
任何一个有经验的程序员都知道,软件开发遵循着一些不成文的法则。然而,如果你不遵循这些法则也并不意味着会受到惩罚;相反,有时你还会获得意外的好处。下面的就是软件编程中的21条法则:
- 任何程序一旦部署即显陈旧。
- 修改需求规范来适应程序比反过来做更容易。
- 一个程序如果很有用,那它注定要被改掉。
- 一个程序如果没用,那它一定会有很好的文档。
- 任何程序里都仅仅只有10%的代码会被执行到。
- 软件会一直膨胀到耗尽所有资源为止。
- 任何一个有点价值的程序里都会有至少一个bug。
- 原型完美的程度跟审视的人数成反比,反比值会随着涉及的资金数增大。
- 软件直到被变成产品运行至少6个月后,它最严重的问题才会被发现。
- 无法检测到的错误的形式无限多样,而能被检测到的正好相反,被定义了的十分有限。
- 修复一个错误所需要投入的努力会随着时间成指数级增加。
- 软件的复杂度会一直增加,直到超出维护这个程序的人的承受能力。
- 任何自己的程序,几个月不看,形同其他人写的。
- 任何一个小程序里面都有一个巨大的程序蠢蠢欲出。
- 编码开始的越早,花费的时间越长。
- 一个粗心的项目计划会让你多花3倍的时间去完成;一个细心的项目计划只会让你多花2倍的时间。
- 往大型项目里添加人手会使项目更延迟。
- 一个程序至少会完成90%,但永远完成不了超过95%。
- 如果你想麻烦被自动处理掉,你得到的是自动产生的麻烦。
- 开发一个傻瓜都会使用的软件,只有傻瓜愿意使用它。
- 用户不会真正的知道要在软件里做些什么,除非使用过。
[英文出处]:
21 Laws of Computer Programming
public class CheckQueryParams {
private static interface Validation{
void check(QueryInfo query);
}
private static List<Validation> validations = new ArrayList<Validation>();
static {
validations.add(new Validation() {
public void check(QueryInfo query) {
if(StringUtils.isEmpty(query.getStartKey()) && StringUtils.isEmpty(query.getEndKey()))
throw new RuntimeException("Both keys can not be null or empty at the same time");
}});
}
public static void check(QueryInfo query) {
for(Validation validation : validations) {
validation.check(query);
}
}
}
public class LRUCache<K,V> {
final private int capacity;
final private Map<K,Reference<V>> map;
final private ReentrantLock lock = new ReentrantLock();
final private ReferenceQueue<Reference<V>> queue = new ReferenceQueue<Reference<V>>();
public LRUCache(int capacity) {
this.capacity = capacity;
map = new LinkedHashMap<K,Reference<V>>(capacity,1f,true){
@Override
protected boolean removeEldestEntry(Map.Entry<K,Reference<V>> eldest) {
return this.size() > LRUCache.this.capacity;
}
};
}
public V put(K key,V value) {
lock.lock();
try {
map.put(key, new SoftReference(value,queue));
return value;
}finally {
lock.unlock();
}
}
public V get(K key) {
lock.lock();
try {
queue.poll();
return map.get(key).get();
}finally {
lock.unlock();
}
}
public void remove(K key) {
lock.lock();
try {
map.remove(key);
}finally {
lock.unlock();
}
}
}
1.同步对象的恒定性
对于局部变量和参数来说,java里面的int, float, double, boolean等基本数据类型,都在栈上。这些基本类型是无法同步的;java里面的对象(根对象是Object),全都在堆里,指向对象的reference在栈上。
java中的同步对象,实际上是对于reference所指的“对象地址”进行同步。
需要注意的问题是,千万不要对同步对象重新赋值。举个例子。
class A implements Runnable{
Object lock = new Object();
void run(){
for(...){
synchronized(lock){
// do something
...
lock = new Object();
}
}
}
}
run函数里面的这段同步代码实际上是毫无意义的。因为每一次lock都给重新分配了新的对象的reference,每个线程都在新的reference同步。大家可能觉得奇怪,怎么会举这么一个例子。因为我见过这样的代码,同步对象在其它的函数里被重新赋了新值。这种问题很难查出来。所以,一般应该把同步对象声明为final。 final Object lock = new Object();
使用Singleton Pattern 设计模式来获取同步对象,也是一种很好的选择。
2.如何放置共享数据,粒度,跨类的同步对象
实现线程,有两种方法,一种是继承Thread类,一种是实现Runnable接口。
首先,把需要共享的数据放在一个实现Runnable接口的类里面,然后,把这个类的实例传给多个Thread的构造方法。这样,新创建的多个Thread,都共同拥有一个Runnable实例,共享同一份数据。如果采用继承Thread类的方法,就只好使用static静态成员了。如果共享的数据比较多,就需要大量的static静态成员,令程序数据结构混乱,难以扩展。这种情况应该尽量避免。编写一段多线程代码,处理一个稍微复杂点的问题。两种方法的优劣,一试便知。
线程同步的粒度越小越好,即,线程同步的代码块越小越好。尽量避免用synchronized修饰符来声明方法。尽量使用synchronized(anObject)的方式,如果不想引入新的同步对象,使用synchronized(this)的方式。而且,synchronized代码块越小越好。
对于简单的问题,可以把访问共享资源的同步代码都放在一个类里面。
但是对于复杂的问题,我们需要把问题分为几个部分来处理,需要几个不同的类来处理问题。这时,就需要在不同的类中,共享同步对象。比如,在生产者和消费者之间共享同步对象,在读者和写者之间共享同步对象。
如何在不同的类中,共享同步对象。有几种方法实现,
(1)前面讲过的方法,使用static静态成员,(或者使用Singleton Pattern.)
(2)用参数传递的方法,把同步对象传递给不同的类。
(3)利用字符串常量的“原子性”。
对于第三种方法,这里做一下解释。一般来说,程序代码中的字符串常量经过编译之后,都具有唯一性,即,内存中不会存在两份相同的字符串常量。
(通常情况下,C++,C语言程序编译之后,也具有同样的特性。)
比如,我们有如下代码。
String A = “atom”;
String B = “atom”;
我们有理由认为,A和B指向同一个字符串常量。即,A==B。注意,声明字符串变量的代码,不符合上面的规则。
String C= new String(“atom”);
String D = new String(“atom”);
这里的C和D的声明是字符串变量的声明,所以,C != D。
有了上述的认识,我们就可以使用字符串常量作为同步对象。比如我们在不同的类中,使用synchronized(“myLock”), “myLock”.wait(),“myLock”.notify(), 这样的代码,就能够实现不同类之间的线程同步。本文并不强烈推荐这种用法,只是说明,有这样一种方法存在。本文推荐第二种方法,(2)用参数传递的方法,把同步对象传递给不同的类。
3.线程之间的通知
这里使用“通知”这个词,而不用“通信”这个词,是为了避免词义的扩大化。
线程之间的通知,通过Object对象的wait()和notify() 或notifyAll() 方法实现。
下面用一个例子,来说明其工作原理:
假设有两个线程,A和B。共同拥有一个同步对象,lock。
1.首先,线程A通过synchronized(lock) 获得lock同步对象,然后调用lock.wait()函数,放弃lock同步对象,线程A停止运行,进入等待队列。
2.线程B通过synchronized(lock) 获得线程A放弃的lock同步对象,做完一定的处理,然后调用 lock.notify() 或者lock.notifyAll() 通知等待队列里面的线程A。
3.线程A从等待队列里面出来,进入ready队列,等待调度。
4.线程B继续处理,出了synchronized(lock)块之后,放弃lock同步对象。
5.线程A获得lock同步对象,继续运行。
例子代码如下:
public class SharedResource implements Runnable{
Object lock = new Object();
public void run(){
// 获取当前线程的名称。
String threadName = Thread.currentThread().getName();
if( “A”.equals(threadName)){
synchronized(lock){ //线程A通过synchronized(lock) 获得lock同步对象
try{
System.out.println(“ A gives up lock.”);
lock.wait(); // 调用lock.wait()函数,放弃lock同步对象,
// 线程A停止运行,进入等待队列。
}catch(InterruptedException e){
}
// 线程A重新获得lock同步对象之后,继续运行。
System.out.println(“ A got lock again and continue to run.”);
} // end of synchronized(lock)
}
if( “B”.equals(threadName)){
synchronized(lock){//线程B通过synchronized(lock) 获得线程A放弃的lock同步对象
System.out.println(“B got lock.”);
lock.notify(); //通知等待队列里面的线程A,进入ready队列,等待调度。
//线程B继续处理,出了synchronized(lock)块之后,放弃lock同步对象。
System.out.println(“B gives up lock.”);
} // end of synchronized(lock)
boolean hasLock = Thread.holdsLock(lock); // 检查B是否拥有lock同步对象。
System.out.println(“B has lock ? -- ” +hasLock); // false.
}
}
}
public class TestMain{
public static void main(){
Runnable resource = new SharedResource();
Thread A = new Thread(resource,”A”);
A.start();
// 强迫主线程停止运行,以便线程A开始运行。
try {
Thread.sleep(500);
}catch(InterruptedException e){
}
Thread B = new Thread(resource,”B”);
B.start();
}
}
原文地址:
http://coolszy.javaeye.com/blog/588627 作者:
coolszy
1,朋友请你吃饭,不要觉得理所当然,请礼尚往来,否则你的名声会越来越臭。
2,给自己定目标,一年,两年,五年,也许你出生不如别人好,通过努力,往往可以改变70(百分号)的命运。破罐子破摔只能和懦弱做朋友。
3,这是个现实的社会,感情不能当饭吃,贫穷夫妻百事哀。不要相信电影,那只是个供许多陌生人喧嚣情感的场所。
4,好朋友里面,一定要培养出一个知己,不要以为你有多么八面玲珑,到处是朋友,最后真心对你的,只有一个,相信我。
5,不要相信星座命理,那是哄小朋友的,命运在自己手中。难道你想等出栋房子或是车子?
6,不喜欢的人少接触,但别在背后说坏话,说是非之人,必定是是非之人,谨记,祸从口出。
7,少玩游戏,这不是韩国,你打不出房子车子还有女人。
8,学好英语,那些说学英语没用的暂时可以不去管,他们要么年纪大了,要么就是自己早过了CET6准备托福了,在这里哗众取宠。你可以不拿证,但一定要学好。
9,知道自己要干什么,夜深人静,问问自己,将来的打算,并朝着那个方向去实现。
10,偶尔翻翻时尚类的杂志,提高一下自己的品位。
11,尽量少看OOXX,正常的男人即使是单身,也不会成天迷恋OOXX。而每次你SY后都会有大量锌元素流失,此元素与你大脑活动有密切联系。
12,每天早上一杯水,预防胆结石。睡前一小时不要喝水,否则会过早出现眼袋。
13,空闲时间不要全拿去泡BAR,读点文学作品,学习一些经营流程,管理规范,国际时事,法律常识。这能保证你在任何场合都有谈资。
14,大家都年轻,没什么钱,不用太在意谁谁又穿AD ,NIKE ,或者其他。而GF对于PRADA,兰蔻,CD,LV,的热恋,你也不必放在心上,女人天生和美挂上了勾,她们只是宁愿相信你能够为她们买一样昂贵的礼物,以满足她们的虚荣心,然后在同伴面前炫耀一番。实则她们也是热爱生活的,而当你有能力完成时,也会觉得把她包装得漂漂亮亮的很是欣慰。
15,要做一件事,成功之前,没必要告诉其他人。
16,头发,指甲,胡子,打理好。社会是个排斥性的接受体,这个星球所需要的艺术家极其有限,请不要冒这个险,就算你留长头发比较好看,也要尽量给人干净的感觉。
17,不要以为你是个男人,就不需要保养。至少饮食方面不能太随便,多吃番茄,海产品,韭菜,香蕉,都是对男性健康有益处的食物。你要是看不到价值,我可以告诉你。至少你能把看病节约下来的钱给你的女人多买几个DIOR.
18,力求上进的人,不要总想着靠谁谁,人都是自私的,自己才是最靠得住的人。
19,面对失败,不要太计较,天将降大任于斯人也,必先苦其心志,劳其筋骨,饿起体肤……但要学会自责,找到原因,且改掉坏习惯。 二十岁没钱,那很正常;三十岁没钱,那是宿命;四十岁没钱,那是你已经成为女人了。
昨天上网找一个同步工具,windows同步到linux,额,ms不少,但是配置实在是麻烦,而且很多按照步骤做下来 都不能使用,(估计rp问题),最郁闷的事莫过如此,经过一个下午的努力,额,原来真的行的,分享给大家。(估计很多人会觉得啰嗦)
一.介绍 (不想看直接可以跳过)
Rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件。Rsync本来是用以取代rcp的一个工具,它当前由 rsync.samba.org维护。Rsync使用所谓的“Rsync演算法”来使本地和远程两个主机之间的文件达到同步,这个算法只传送两个文件的不同部分,而不是每次都整份传送,因此速度相当快。运行Rsync server的机器也叫backup server,一个Rsync server可同时备份多个client的数据;也可以多个Rsync server备份一个client的数据。
Rsync可以搭配rsh或ssh甚至使用daemon模式。Rsync server会打开一个873的服务通道(port),等待对方Rsync连接。连接时,Rsync server会检查口令是否相符,若通过口令查核,则可以开始进行文件传输。第一次连通完成时,会把整份文件传输一次,下一次就只传送二个文件之间不同的部份。
Rsync支持大多数的类Unix系统,无论是Linux、Solaris还是BSD上都经过了良好的测试。此外,它在windows平台下也有相应的版本,比较知名的有cwRsync和Sync2NAS。
Rsync的基本特点如下:
1.可以镜像保存整个目录树和文件系统;
2.可以很容易做到保持原来文件的权限、时间、软硬链接等;
3.无须特殊权限即可安装;
4.优化的流程,文件传输效率高;
5.可以使用rcp、ssh等方式来传输文件,当然也可以通过直接的socket连接;
6.支持匿名传输。
核心算法介绍:
假定在名为α和β的两台计算机之间同步相似的文件A与B,其中α对文件A拥有访问权,β对文件B拥有访问权。并且假定主机α与β之间的网络带宽很小。那么rsync算法将通过下面的五个步骤来完成:
1.β将文件B分割成一组不重叠的固定大小为S字节的数据块。最后一块可能会比S 小。
2.β对每一个分割好的数据块执行两种校验:一种是32位的滚动弱校验,另一种是128位的MD4强校验。
3.β将这些校验结果发给α。
4.α通过搜索文件A的所有大小为S的数据块(偏移量可以任选,不一定非要是S的倍数),来寻找与文件B的某一块有着相同的弱校验码和强校验码的数据块。这项工作可以借助滚动校验的特性很快完成。
5.α发给β一串指令来生成文件A在β上的备份。这里的每一条指令要么是对文件B经拥有某一个数据块而不须重传的证明,要么是一个数据块,这个数据块肯定是没有与文件B的任何一个数据块匹配上的。
命令:
rsync的命令格式可以为以下六种:
rsync [OPTION]... SRC DEST
rsync [OPTION]... SRC [USER@]HOST:DEST
rsync [OPTION]... [USER@]HOST:SRC DEST
rsync [OPTION]... [USER@]HOST::SRC DEST
rsync [OPTION]... SRC [USER@]HOST::DEST
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
对应于以上六种命令格式,rsync有六种不同的工作模式:
1)拷贝本地文件。当SRC和DES路径信息都不包含有单个冒号":"分隔符时就启动这种工作模式。
2)使用一个远程shell程序(如rsh、ssh)来实现将本地机器的内容拷贝到远程机器。当DST路径地址包含单个冒号":"分隔符时启动该模式。
3)使用一个远程shell程序(如rsh、ssh)来实现将远程机器的内容拷贝到本地机器。当SRC地址路径包含单个冒号":"分隔符时启动该模式。
4)从远程rsync服务器中拷贝文件到本地机。当SRC路径信息包含"::"分隔符时启动该模式。
5)从本地机器拷贝文件到远程rsync服务器中。当DST路径信息包含"::"分隔符时启动该模式。
6)列远程机的文件列表。这类似于rsync传输,不过只要在命令中省略掉本地机信息即可。
二.安装
1.从原始网站下载:[url]http://rsync.samba.org/ftp/rsync/[/url] (http://rsync.samba.org/ftp/rsync/rsync-3.0.7.tar.gz目前是这个版本)
windows版本:
客户端:cwRsync_2.0.10_Installer http://blogimg.chinaunix.net/blog/upfile/070917224721.zip
服务端:cwRsync_Server_2.0.10_Installer http://blogimg.chinaunix.net/blog/upfile/070917224837.zip
对于client 和 server都是windows的,那么可以直接安装如上2个,然后可以通过建 windows的任务,实现定时处理,可以参考:
http://blog.csdn.net/daizhj/archive/2009/11/03/4765280.aspx
2.[root@localhost bin]#./configure
[root@localhost bin]#make
[root@localhost bin]#make install
这里可能会有权限问题,切换到root用户
Rsync配置
/etc/rsyncd.conf (默认是没有的,可以手工创建)
#全局选项
strict modes =yes #是否检查口令文件的权限
port = 873 #默认端口873
log file = /var/log/rsyncd.log #日志记录文件 原文中有的,我没有使用,日志文件
pid file = /usr/local/rsync/rsyncd.pid #运行进程的ID写到哪里 原文中有的,我没有使用,日志文件
#模块选项
[test] # 这里是认证的模块名,在client端需要指定
max connections = 5 #客户端最大连接数,默认0(没限制)
uid = root #指定该模块传输文件时守护进程应该具有的uid
gid = root #指定该模块传输文件时守护进程应该具有的gid
path = /home/admin/testrsync # 需要做备份的目录
ignore errors # 可以忽略一些无关的IO错误
read only = no #no客户端可上传文件,yes只读
write only = no #no客户端可下载文件,yes不能下载
hosts allow = * #充许任何主机连接
hosts deny = 10.5.3.77 #禁止指定的主机连接
auth users = root # 认证的用户名,如果没有这行,则表明是匿名
secrets file = /home/admin/security/rsync.pass # 指定认证口令文件位置
生成rsync密码文件
在server端生成一个密码文件/home/admin/security/rsync.pass
vi rsync.pass
root:hell05a
注意:密码文件的权限,是由rsyncd.conf里的参数
strict modes =yes/no 来决定
Rsync 的启动
rsycn 的启动方式有多种,我们在这里介绍以下几种:
●. 守护进程方式:(我现在只使用这个)
/usr/local/bin/rsync --daemon
验证启动是否成功
ps -aux |grep rsync
root 59120 0.0 0.2 1460 972 ?? Ss 5:20PM 0:00.00 /usr/local/rsync/bin/rsync –daemon
netstat -an |grep 873
tcp4 0 0 *.873 *.* LISTEN
结束进程:kill -9 pid的值
kill -15 进程名
如果是linux之间同步,只需要安装rsync,如果是需要linux与windows之间同步,安装 cwrsync
三.客户端访问:(客户端也需要安装 rsync,如果是windows,安装cwrsync)
实例演示使用:
下载文件:
./rsync -vzrtopg --progress --delete root@xxx.xxx.xxx.xxx::backup /home/admin/getfile
上传文件:
/usr/bin/rsync -vzrtopg --progress /home/admin/getfile root@xxx.xxx.xxx.xxx::backup
Rsync 同步参数说明
-vzrtopg里的v是verbose,z是压缩,r是recursive,topg都是保持文件原有属性如属主、时间的参数。
--progress是指显示出详细的进度情况
--delete是指如果服务器端删除了这一文件,那么客户端也相应把文件删除
root@xxx.xxx.xxx.xxx中的root是指定密码文件中的用户名,xxx为ip地址
backup 是指在rsyncd.conf里定义的模块名
/home/admin/getfile 是指本地要备份目录
可能出现的问题:
@ERROR: auth failed on module backup
rsync error: error starting client-server protocol (code 5) at main.c(1506) [Receiver=3.0.7]
那估计是密码文件没有设置权限哦: chmod 600 /home/admin/security/rsync.pass
应该差不多就可以了。
(2)打开rsync服务
#chkconfig xinetd on
#chkconfig rsync on
(4)启动基于xinetd进程的rsync服务t
#/etc/init.d/xinetd start
3、配置windows的rsync客户端
(1)安装client端的rsync包
(2)打开cmd,执行同步计划:
cd C:\Program Files\cwRsync\bin
下载同步(把服务器上的东东下载当前目录)
rsync -vzrtopg --progress --delete root@xxx.xxx.xxx.xxx::backup ./ff
(此时须输入root用户的密码,就可进行同步了。)
上传同步(把本地东东上传到服务器)
rsync -vzrtopg --progress ./get/ root@xxx.xxx.xxx.xxx::backup
参数说明
-v, --verbose 详细模式输出
-q, --quiet 精简输出模式
-c, --checksum 打开校验开关,强制对文件传输进行校验
-a, --archive 归档模式,表示以递归方式传输文件,并保持所有文件属性,等于-rlptgoD
-r, --recursive 对子目录以递归模式处理
-R, --relative 使用相对路径信息
-b, --backup 创建备份,也就是对于目的已经存在有同样的文件名时,将老的文件重新命名为~filename。可以使用--suffix选项来指定不同的备份文件前缀。
--backup-dir 将备份文件(如~filename)存放在在目录下。
-suffix=SUFFIX 定义备份文件前缀
-u, --update 仅仅进行更新,也就是跳过所有已经存在于DST,并且文件时间晚于要备份的文件。(不覆盖更新的文件)
-l, --links 保留软链结
-L, --copy-links 想对待常规文件一样处理软链结
--copy-unsafe-links 仅仅拷贝指向SRC路径目录树以外的链结
--safe-links 忽略指向SRC路径目录树以外的链结
-H, --hard-links 保留硬链结 -p, --perms 保持文件权限
-o, --owner 保持文件属主信息 -g, --group 保持文件属组信息
-D, --devices 保持设备文件信息 -t, --times 保持文件时间信息
-S, --sparse 对稀疏文件进行特殊处理以节省DST的空间
-n, --dry-run现实哪些文件将被传输
-W, --whole-file 拷贝文件,不进行增量检测
-x, --one-file-system 不要跨越文件系统边界
-B, --block-size=SIZE 检验算法使用的块尺寸,默认是700字节
-e, --rsh=COMMAND 指定使用rsh、ssh方式进行数据同步
--rsync-path=PATH 指定远程服务器上的rsync命令所在路径信息
-C, --cvs-exclude 使用和CVS一样的方法自动忽略文件,用来排除那些不希望传输的文件
--existing 仅仅更新那些已经存在于DST的文件,而不备份那些新创建的文件
--delete 删除那些DST中SRC没有的文件
--delete-excluded 同样删除接收端那些被该选项指定排除的文件
--delete-after 传输结束以后再删除
--ignore-errors 及时出现IO错误也进行删除
--max-delete=NUM 最多删除NUM个文件
--partial 保留那些因故没有完全传输的文件,以是加快随后的再次传输
--force 强制删除目录,即使不为空
--numeric-ids 不将数字的用户和组ID匹配为用户名和组名
--timeout=TIME IP超时时间,单位为秒
-I, --ignore-times 不跳过那些有同样的时间和长度的文件
--size-only 当决定是否要备份文件时,仅仅察看文件大小而不考虑文件时间
--modify-window=NUM 决定文件是否时间相同时使用的时间戳窗口,默认为0
-T --temp-dir=DIR 在DIR中创建临时文件
--compare-dest=DIR 同样比较DIR中的文件来决定是否需要备份
-P 等同于 --partial
--progress 显示备份过程
-z, --compress 对备份的文件在传输时进行压缩处理
--exclude=PATTERN 指定排除不需要传输的文件模式
--include=PATTERN 指定不排除而需要传输的文件模式
--exclude-from=FILE 排除FILE中指定模式的文件
--include-from=FILE 不排除FILE指定模式匹配的文件
--version 打印版本信息
--address 绑定到特定的地址
--config=FILE 指定其他的配置文件,不使用默认的rsyncd.conf文件
--port=PORT 指定其他的rsync服务端口
--blocking-io 对远程shell使用阻塞IO
-stats 给出某些文件的传输状态
--progress 在传输时现实传输过程
--log-format=formAT 指定日志文件格式
--password-file=FILE 从FILE中得到密码
--bwlimit=KBPS 限制I/O带宽,KBytes per second -h, --help 显示帮助信息
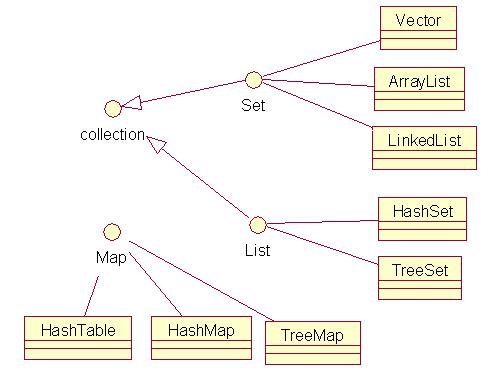
Collection接口 由 Set接口 和 List接口 继承。
Set 被 Vector . ArrayList LinkedList 实现。
List 被 HashSet TreeSet 实现。
Map接口 由 HashTable HashMap TreeMap 实现。
下面看下每个实现类的特征;;;--》(转的。)
1. List (有重复、有序)
Vector基于Array的List,性能也就不可能超越Array,并且Vector是“sychronized”的,这个也是Vector和ArrayList的唯一的区别。
ArrayList:同Vector一样是一个基于Array的,但是不同的是ArrayList不是同步的。所以在性能上要比Vector优越一些,但是当运行到多线程环境中时,可需要自己在管理线程的同步问题。从其命名中可以看出它是一种类似数组的形式进行存储,因此它的随机访问速度极快。
数据增长:当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半
LinkedList:LinkedList不同于前面两种List,它不是基于Array的,所以不受Array性能的限制。它每一个节点(Node)都包含两方面的内容:1.节点本身的数据(data);2.下一个节点的信息(nextNode)。所以当对LinkedList做添加,删除动作的时候就不用像基于Array的List一样,必须进行大量的数据移动。只要更改nextNode的相关信息就可以实现了所以它适合于进行频繁进行插入和删除操作。这就是LinkedList的优势。Iterator只能对容器进行向前遍历,而 ListIterator则继承了Iterator的思想,并提供了对List进行双向遍历的方法。
用在FIFO,用addList()加入元素 removeFirst()删除元素
用在FILO,用addFirst()/removeLast()
ListIterator 提供双向遍历next() previous(),可删除、替换、增加元素
List总结: 1. 所有的List中只能容纳单个不同类型的对象组成的表,而不是Key-Value键值对。例如:[ tom,1,c ]; 2. 所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ]; 3. 所有的List中可以有null元素,例如[ tom,null,1 ]; 4. 基于Array的List(Vector,ArrayList)适合查询,而LinkedList(链表)适合添加,删除操作。
2. Set
HashSet:虽然Set同List都实现了Collection接口,但是他们的实现方式却大不一样。List基本上都是以Array为基础。但是Set则是在HashMap的基础上来实现的,这个就是Set和List的根本区别。HashSet的存储方式是把HashMap中的Key作为Set的对应存储项,这也是为什么在Set中不能像在List中一样有重复的项的根本原因,因为HashMap的key是不能有重复的。HashSet能快速定位一个元素,但是放到HashSet中的对象需要实现hashCode()方法0。
TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外两个实用类Comparable和Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就不需要重复定义相同的排序算法,只要实现Comparator接口即可。TreeSet是SortedSet的子类,它不同于HashSet的根本就是TreeSet是有序的。它是通过SortedMap来实现的。
Set总结: 1. Set实现的基础是Map(HashMap); 2. Set中的元素是不能重复的,如果使用add(Object obj)方法添加已经存在的对象,则会覆盖前面的对象; Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别? Set里的元素是不能重复的,即不能包含两个元素e1、e2(e1.equals(e2))。那么用iterator()方法来区分重复与否。equals()是判读两个Set是否相等。==方法决定引用值(句柄)是否指向同一对象。
3. Map
Map是一种把键对象和值对象进行关联的容器,Map有两种比较常用的实现: HashTable、HashMap和TreeMap。
HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它有一些扩展的方法,比如firstKey(),lastKey()等。
只有HashMap可以让你将空值作为一个表的条目的key或value
HashMap和Hashtable的区别。 HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口。主要区别在于HashMap允许空(null)键(key)或值(value),非同步,由于非线程安全,效率上可能高于Hashtable。 Hashtable不允许空(null)键(key)或值(value),Hashtable的方法是Synchronize的,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。 Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
HashMap:
散列表的通用映射表,无序,可在初始化时设定其大小,自动增长。
只有HashMap可以让你将空值作为一个表的条目的key或value
LinkedHashMap:
扩展HashMap,对返回集合迭代时,维护插入顺序
WeakHashMap:
基于弱引用散列表的映射表,如果不保持映射表外的关键字的引用,则内存回收程序会回收它
TreeMap:
基于平衡树的映射表
内存泄漏几种常见的方式:
1. 无意识的对象保持。 就是接下来的例子。
2. 使用缓存。(很长一段时间仍然留在缓存中)
一旦你把对象引用放到缓存中,它就很容易被遗忘掉,从而使得它不再有用之后很长一段时间内仍然留在缓存中。对于这个问题,有几种可能的解决方案。如果你正好要实现这样的缓存:只要在缓存之外存在对某个项的键的引用,该项就有意义,那么就可以用WeakHashMap代表缓存;当缓存中的项过期之后,它们就会自动被删除。记住只有当所要的缓存项的生命周期是由该键的外部引用而不是由值决定时,WeakHashMap才有用处。
更为常见的情形则是,"缓存项的生命周期是否有意义"并不是很容易确定,随着时间的推移,其中的项会变得越来越没有价值。在这种情况下,缓存应该时不时地清除掉没用的项。这项清除工作可以由一个后台线程(可能是Timer或者ScheduledThreadPoolExecutor)来完成,或者也可以在给缓存添加新条目的时候顺便进行清理。LinkedHashMap类利用它的removeEldestEntry方法可以很容易地实现后一种方案。对于更加复杂的缓存,必须直接使用java.lang.ref。
3. 监听器和其他回调
如果你在实现的是客户端注册回调却没有显式地取消注册的API,除非你采取某些动作,否则它们就会积聚。确保回调立即被当作垃圾回收的最佳方法是只保存它们的弱引用(weak
reference),例如,只将它们保存成WeakHashMap中的键。
对于 1.无意识的对象保持,代码:
1 public class Stack {
2 private Object[] elements;
3 private int size = 0;
4 private static final int DEFAULT_INITIAL_CAPACITY = 16;
5
6 public Stack() {
7 elements = new Object[DEFAULT_INITIAL_CAPACITY];
8 }
9
10 public void push(Object e) {
11 ensureCapacity();
12 elements[size++] = e;
13 }
14
15 public Object pop() {
16 if (size == 0)
17 throw new EmptyStackException();
18 return elements[--size];
19 }
20
21 /**
22 * * Ensure space for at least one more element, roughly* doubling the
23 * capacity each time the array needs to grow.
24 */
25 private void ensureCapacity() {
26 if (elements.length == size)
27 elements = Arrays.copyOf(elements, 2 * size + 1);
28 }
29 }
修改方式:
把上面的pop方法修改成如下:
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null;
return result;
}
清空过期引用的另一个好处是,如果它们以后又被错误地解除引用,程序就会立即抛出NullPointerException异常,而不是悄悄地错误运行下去。尽快地检测出程序中的错误总是有益的。
第二条 遇到多个构造器参数时要考虑用构造器
这里考虑的是参数多的情况,如果参数个数比较少,那直接采用一般的构造方法就可以了。
书中介绍了写构造方法的时候几种方式:
1. 重叠构造方法模式:
缺点:有许多参数的时候,客户端代码会很难写,而且较难以阅读。
2. javaBeans模式:
缺点:
在构造过程中JavaBean可能处于不一致的状态,类本身无法判断是否有效性。
类做成不可变的可能。
3. builder模式:
优点:
在build方法生成对象的时候,可以做检查,判断是否符合要求
参数灵活
缺点:
创建对象必须先创建构造器,如果对性能要求非常高的应用少用为妙
具体实现代码:
1.重叠构造方法模式:
public class NutritionFacts {
private final int servingSize;
private final int serviings;
private final int calories;
private final int fat;
private int sodium;
private int carbohydrate;
public NutritionFacts(int servingSize, int serviings){
this(servingSize, serviings, 0);
}
public NutritionFacts(int servingSize, int serviings, int calories){
this(servingSize, serviings, calories, 0);
}
public NutritionFacts(int servingSize, int serviings, int calories, int fat){
this(servingSize, serviings, calories, fat,0);
}
public NutritionFacts(int servingSize, int serviings, int calories, int fat, int sodium){
this(servingSize, serviings, calories, fat, sodium,0);
}
public NutritionFacts(int servingSize, int serviings, int calories, int fat, int sodium, int carbohydrate){
this.servingSize = servingSize;
this.serviings = serviings;
this.calories = calories;
this.fat = fat;
this.sodium = sodium;
this.carbohydrate = carbohydrate;
}
}
2. javaBeans模式 代码:
public class NutritionFacts {
private int servingSize;
private int serviings;
private int calories;
private int fat;
private int sodium;
private int carbohydrate;
public NutritionFacts(){}
public void setServingSize(int servingSize) {
this.servingSize = servingSize;
}
public void setServiings(int serviings) {
this.serviings = serviings;
}
public void setCalories(int calories) {
this.calories = calories;
}
public void setFat(int fat) {
this.fat = fat;
}
public void setSodium(int sodium) {
this.sodium = sodium;
}
public void setCarbohydrate(int carbohydrate) {
this.carbohydrate = carbohydrate;
}
3. builder模式
public class NutritionFacts {
private final int servingSize;
private final int serviings;
private final int calories;
private final int fat;
private final int sodium;
private final int carbohydrate;
public static class Builder {
private final int servingSize;
private final int serviings;
// 可以为空
private int calories = 0;
private int fat = 0;
private int sodium = 0;
private int carbohydrate = 0;
public Builder(int servingSize, int serviings) {
this.servingSize = servingSize;
this.serviings = serviings;
}
public Builder calories(int val){
calories = val;
return this;
}
public Builder fat(int val){
fat = val;
return this;
}
public Builder sodium(int val){
sodium = val;
return this;
}
public Builder carbohydrate(int val){
carbohydrate = val;
return this;
}
public NutritionFacts build(){
return new NutritionFacts(this);
}
}
public NutritionFacts(Builder builder) {
servingSize = builder.servingSize;
serviings = builder.serviings;
calories = builder.calories;
fat = builder.fat;
sodium = builder.sodium;
carbohydrate = builder.carbohydrate;
}
}
这个调用的时候:
NutritionFacts cocaCola = new NutritionFacts.Builder(11,22).calories(1).fat(2).calories(3).build();
在Java中设置变量值的操作,除了long和double类型的变量外都是原子操作,也就是说,对于变量值的简单读写操作没有必要进行同步。
这在JVM 1.2之前,Java的内存模型实现总是从主存读取变量,是不需要进行特别的注意的。而随着JVM的成熟和优化,现在在多线程环境下volatile关键字的使用变得非常重要。
在当前的Java内存模型下,线程可以把变量保存在本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。
要解决这个问题,只需要像在本程序中的这样,把该变量声明为volatile(不稳定的)即可,这就指示JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。一般说来,多任务环境下各任务间共享的标志都应该加volatile修饰。
Volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
Java语言规范中指出:为了获得最佳速度,允许线程保存共享成员变量的私有拷贝,而且只当线程进入或者离开同步代码块时才与共享成员变量的原始值对比。
这样当多个线程同时与某个对象交互时,就必须要注意到要让线程及时的得到共享成员变量的变化。
而volatile关键字就是提示VM:对于这个成员变量不能保存它的私有拷贝,而应直接与共享成员变量交互。
使用建议:在两个或者更多的线程访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量时,不必使用。
由于使用volatile屏蔽掉了VM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。
文章出处:DIY部落(http://www.diybl.com/course/3_program/java/javaxl/20090302/156333.html)
同时查看下IBM中的详细解释:
Java 理论与实践: 正确使用 Volatile 变量
http://www.ibm.com/developerworks/cn/java/j-jtp06197.html
今天在熟悉我们的项目的时候,sql中看到FORCE INDEX,额,都不知道什么东东,有什么特别用处吗? 查了下资料,原来是这样啊,发现一般不搞复杂sql,而且复杂sql DBA也不允许,但优化的sql 还是有必要了解下。(一般来说也不太会使用,总被DBA pk了)
下面部分转:
对于经常使用oracle的朋友可能知道,oracle的hint功能种类很多,对于优化sql语句提供了很多方法。同样,在mysql里,也有类似的hint功能。下面介绍一些常用的。
1。强制索引 FORCE INDEX
SELECT * FROM TABLE1 FORCE INDEX (FIELD1) …
以上的SQL语句只使用建立在FIELD1上的索引,而不使用其它字段上的索引。
2。忽略索引 IGNORE INDEX
SELECT * FROM TABLE1 IGNORE INDEX (FIELD1, FIELD2) …
在上面的SQL语句中,TABLE1表中FIELD1和FIELD2上的索引不被使用。
3。关闭查询缓冲 SQL_NO_CACHE
SELECT SQL_NO_CACHE field1, field2 FROM TABLE1;
有一些SQL语句需要实时地查询数据,或者并不经常使用(可能一天就执行一两次),这样就需要把缓冲关了,不管这条SQL语句是否被执行过,服务器都不会在缓冲区中查找,每次都会执行它。
4。强制查询缓冲 SQL_CACHE
SELECT SQL_CALHE * FROM TABLE1;
如果在my.ini中的query_cache_type设成2,这样只有在使用了SQL_CACHE后,才使用查询缓冲。
5。优先操作 HIGH_PRIORITY
HIGH_PRIORITY可以使用在select和insert操作中,让MYSQL知道,这个操作优先进行。
SELECT HIGH_PRIORITY * FROM TABLE1;
6。滞后操作 LOW_PRIORITY
LOW_PRIORITY可以使用在insert和update操作中,让mysql知道,这个操作滞后。
update LOW_PRIORITY table1 set field1= where field1= …
7。延时插入 INSERT DELAYED
INSERT DELAYED INTO table1 set field1= …
INSERT DELAYED INTO,是客户端提交数据给MySQL,MySQL返回OK状态给客户端。而这是并不是已经将数据插入表,而是存储在内存里面等待排队。当mysql有空余时,再插入。另一个重要的好处是,来自许多客户端的插入被集中在一起,并被编写入一个块。这比执行许多独立的插入要快很多。坏处是,不能返回自动递增的ID,以及系统崩溃时,MySQL还没有来得及插入数据的话,这些数据将会丢失。
8 。强制连接顺序 STRAIGHT_JOIN
SELECT TABLE1.FIELD1, TABLE2.FIELD2 FROM TABLE1 STRAIGHT_JOIN TABLE2 WHERE …
由上面的SQL语句可知,通过STRAIGHT_JOIN强迫MySQL按TABLE1、TABLE2的顺序连接表。如果你认为按自己的顺序比MySQL推荐的顺序进行连接的效率高的话,就可以通过STRAIGHT_JOIN来确定连接顺序。
9。强制使用临时表 SQL_BUFFER_RESULT
SELECT SQL_BUFFER_RESULT * FROM TABLE1 WHERE …
当我们查询的结果集中的数据比较多时,可以通过SQL_BUFFER_RESULT.选项强制将结果集放到临时表中,这样就可以很快地释放MySQL的表锁(这样其它的SQL语句就可以对这些记录进行查询了),并且可以长时间地为客户端提供大记录集。
10。分组使用临时表 SQL_BIG_RESULT和SQL_SMALL_RESULT
SELECT SQL_BUFFER_RESULT FIELD1, COUNT(*) FROM TABLE1 GROUP BY FIELD1;
一般用于分组或DISTINCT关键字,这个选项通知MySQL,如果有必要,就将查询结果放到临时表中,甚至在临时表中进行排序。SQL_SMALL_RESULT比起SQL_BIG_RESULT差不多,很少使用。
其实这篇文章很早看到的,但仔细想想其实没多大意思,有一次维护代码的时候,发现一些看似有意思的写法,就在本博记录下,容易遗忘。
小技巧感觉上很有意思,但并不是很实用,容易理解的配合,方便维护的配置,才是最好的代码。搞点小技巧,不方便维护。
在BeanFactory的配置中,<bean>是我们最常见的配置项,它有两个最常见的属性,即id和name,最近研究了一下,发现这两个属性还挺好玩的,特整理出来和大家一起分享。
1.id属性命名必须满足XML的命名规范,因为id其实是XML中就做了限定的。总结起来就相当于一个Java变量的命名:不能以数字,符号打头,不能有空格,如123,?ad,"ab
"等都是不规范的,Spring在初始化时就会报错,
org.xml.sax.SAXParseException: Attribute value "?ab" of type ID must be a name.
2.name属性则没有这些限定,你可以使用几乎任何的名称,如?ab,123等,但不能带空格,如"a b","
abc",,这时,虽然初始化时不会报错,但在getBean()则会报出诸如以下的错误:
org.springframework.beans.factory.NoSuchBeanDefinitionException: No bean named 'a b' is defined
3.配置文件中不允许出现两个id相同的<bean>,否则在初始化时即会报错,如:
org.xml.sax.SAXParseException: Attribute value "aa" of type ID must be unique within the document.
4.但配置文件中允许出现两个name相同的<bean>,在用getBean()返回实例时,后面一个Bean被返回,应该是前面那个<bean>被后面同名的
<bean>覆盖了。有鉴于此,为了避免不经意的同名覆盖的现象,尽量用id属性而不要用name属性。
5.name属性可以用,隔开指定多个名字,如<bean name="b1,b2,b3">,相当于多个别名,这时通过getBean("a1")
getBean("a2") getBean("a3")返回的都是同一个实例(假设是singleton的情况)
6.如果id和name都没有指定,则用类全名作为name,如<bean
class="com.stamen.BeanLifeCycleImpl">,则你可以通过
getBean("com.biao.GroupThreadImpl")返回该实例。
7.如果存在多个id和name都没有指定,且实例类都一样的<bean>,如:
<bean class="com.biao.GroupThreadImpl"/>
<bean class="com.biao.GroupThreadImpl"/>
<bean class="com.biao.GroupThreadImpl"/>
则第一个bean通过getBean("com.biao.GroupThreadImpl")获得,
第二个bean通过getBean("com.biao.GroupThreadImpl#1")获得,
第三个bean通过getBean("com.biao.GroupThreadImpl#2")获得,以此类推。
Cookie是在Web上用于存储客户系统信息的对象。所有的信息都以每行一个Cookie的形式存放在客户端的一个名为cookies.txt的文件里。Cookie在HTTP头标(客户和服务器用来标识自身的分组)中在客户机与服务器之间传输。
Cookie由某个WWW网页在某客户机上进行设置。比如,某个WWW网页已在一个用户的计算机上设置了一个Cookie,其中存储的信息是该用户的身份号(随机赋予该用户的唯一标识),当该用户的浏览器连接该WWW站点时,站点要求浏览器将Cookie送回,他的身份号就通过Cookie 传递给该网页所在的WWW服务器。服务器上的一个CGI程序查找一个服务器端的文件以确定关于他的预设内容。
当某个服务器在客户的计算机上设置Cookie后,请注意如果要让Cookie信息确实写入文件,必须关闭浏览器。在浏览器未关闭之前,任何新的或变化的Cookie都存放在内存中。
二、Cookie的特性
每个Cookie包含有6个元素,常用的有:name、value、expires、domain和secure。这些元素存放了这个Cookie的作用范围及实际的数据。
1.name 这是每一个Cookie必须有的元素,它是该Cookie的名字。name元素是一个不含分号、逗号和空格的字符串。其命名方式与变量命名相同。
2.value value也是每个Cookie必须有的元素,它是该Cookie的值。value元素是实际存放于Cookie中的信息。它是由任何字符构成的字符串。
3.expires expires是一个Cookie的过期时间。没有设置expires元素的Cookie在用户断开连接后过期,但在用户关闭浏览器之前Cookie依然存在。
Cookie有一个过期时间并等于它会从Cookie.txt文件中被删除。在它的位置被用来存放另一个Cookie前,它依然存在着。过期的Cookie只是不被送往要求使用它的服务器。
expire是一个串,它的形式如下:
Wdy, DD-Mon-YY HH:MM:SS GMT
expires元素是可选的。
4.domain domain是设置某个Cookie的Web网页所在的计算机的域名。这样,由一个站点创建的Cookie不会影响到另一个站点上的程序。对于较高层的域名如.com, .edu,或.mil,域名中至少有两个分隔符(.)。而对于较低层的域名如.cn, .uk或.ca,域名中至少有3个分隔符。demain元素自动地被设为网页所在站点的基本域名。比如,你的网页位于http://www.abc.com/~user,则该网页创建的Cookie缺省地对域abc.com有效。如果你希望你的Cookie 只应用于服务器www3.abc.com,那么你必须在设置Cookie的时候指定。
只有拥有域名的站点才能为那个域名设置Cookie
5.path 一个Cookie可以被指定为只针对一个站点的某一层次。如果一个Web站点要区分已注册的和未注册的客户,就可以为已经注册的客户设置Cookie,当注册过的客户访问该站点时,他就可以访问到只对注册客户有效的页面。path是可选项,如果没有指定path,将被缺省地设置为设置Cookie的页面的路径。
6.secure标志 secure是一个布尔值(真或假)。它的缺省值为假。如果它被设为真值, 这个Cookie只被浏览器认为是安全的服务器所记住。
三、关于Cookie的一些限制
一个站点能为一个单独的客户最多设置20个Cookie。如果一个站点有两个服务器(如www.abc.com和www3.abc.com)但没有指定域名,Cookie的域名缺省地是abc.com。如果指定了确切的服务器地址,则每个站点可以设置20个Cookie--而不是总共20个。不仅每个服务器能设置的Cookie数目是有限的,而且每个客户机最多只能存储300个Cookie。如果一个客户机已有300个Cookie,并且一个站点在它上面又设置了一个新Cookie,那么,先前存在的某一个Cookie将被删除。
每个Cookie也有自身的限制。Cookie不得超过4KB(4096bytes),其中包括名字和其他信息。
四、javascript和Cookie
现在大家已经了解有关Cookie的一些基本概念了,让我们更进一步讨论Cookie。可以用javascript来很方便地编写函数用来创建、读取和删除Cookie。下面,我们就介绍这些函数
1.创建Cookie
我们要进行的第一件事就是要创建一个Cookie。下面给出的SctCookie()函数将完成这一功能。
function SetCookit (name, value) {
var argv=SetCookie.arguments;
var argc=SetCookie.arguments.length;
var expires=(argc>2)?argv[2]: null;
var path=(argc>3)? argv[3]: null;
var domain=(argc>4)? argv[4]: null;
var secure=(argc>5)? argv[5]: false;
documents.cookie=name+"="+escape
(value)+
((expires==null)?"":(";expires="
+expires.toGMTString()))+
((path==null)?"":(";path="+path))+
((domain==null)?"":(";domain="+
domain))+
((secure==true)?";secure":"");
}
SetCookie()只要求传递被设置的Cookie的名字和值,但如果必要的话你可以设置其他4 个参数而不必改变这个函数。可选的参数必须用正确的次序使用。如果不想设置某个参数, 必须设置一个空串。比如,如果我们创建的一个Cookie需要指定secure域,但不想设置expires, patb或domain,就可以像这样调用SetCokie(): SetCookie("MyNewCookie","Myvalue" ,"",","tyue);
2.读取Cookie
下面给出的函数GetCookie()用来读取一个Cookie。当一个Cookie的请求被客户机收到时,该客户机查找它的cookies.txt文件以进行匹配。这个函数首先匹配这个Cookie的名字。如果有多个同名的Cookie,它再匹配路径。函数完成匹配后返回这个Cookie的值。如果客户机中没有这个Cookie,或者路径不匹配,该函数返回一个NULL。
function GetCookie(name) {
var arg=name+ "=";
var alen=arg.length;
var clen=documents.cookie.length;
var i=0;
while (i<clen) {
var j=i+alen;
if(documents.cookie.substring(i,j)
==arg)
return getCookieVal(j);
i=documents.cookie.indexOf("",i)+1;
if(i==0)break;
}
return null;
}
函数中使用了getCookieVal()函数,它是GetCookie()函数的补充。getCookieVal()将C ookies.txt文件分解为片断,并从一批Cookie中读出正确的Cookie。该函数的实现如下:
function getCookieVal(offset) {
var endstr=documents.cookie.indexOf
(";",offset);
if(endstr==-1) //没有指定其他元素
endstr=documents.cookie.length;
return unescape(documents.cookie.substring
(offset,endstr));
}
3.删除Cookie
删除一个Cookie很简单,只需将它的过期时间设为NULL。当用户断开连接后,这个Cooki e就过期了(没有过期时间的Cookie将在浏览器关闭时被删除)。下面的函数DeleteCookie() 说明了如何删除一个
Cookie:
function DeleteCookie(name) {
var exp=new Date();
exp.setTime(exp.getTime()-1);
//将exp设为已过期的时间
var cval=GetCookie(name);
documents.cookie=name+"="+cval+";
expires="+exp.toGMTString();
}
网上的解释原因:
Iterator 是工作在一个独立的线程中,并且拥有一个 互斥 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出 java.util.ConcurrentModificationException 异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法 remove() 来删除对象, Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。
廖雪峰 大师 Java源码分析:深入探讨Iterator模式
http://gceclub.sun.com.cn/yuanchuang/week-14/iterator.html
在工作碰到这个问题所有看看:
List list = ...;
for(Iterator iter = list.iterator(); iter.hasNext();) {
Object obj = iter.next();
...
if(***) {
list.remove(obj); //list.add(obj) 其实也是一样的。
}
}
在执行了remove方法之后,再去执行循环,iter.next()的时候,报java.util.ConcurrentModificationException(当然,如果remove的是最后一条,就不会再去执行next()操作了),
下面来看一下源码
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
public interface Collection<E> extends Iterable<E> {
...
Iterator<E> iterator();
boolean add(E o);
boolean remove(Object o);
...
}
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
//AbstractCollection和List都继承了Collection
protected transient int modCount = 0;
private class Itr implements Iterator<E> { //内部类Itr
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification(); //该方法中检测到改变,从而抛出异常
try {
E next = get(cursor);
lastRet = cursor++;
return next;
} catch(IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet == -1)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.remove(lastRet); //执行remove对象的操作
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount; //重新设置了expectedModCount的值,避免了ConcurrentModificationException的产生
} catch(IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount) //当expectedModCount和modCount不相等时,就抛出ConcurrentModificationException
throw new ConcurrentModificationException();
}
}
}
remove(Object o)在ArrayList中实现如下:
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++; //只增加了modCount
....
}
所以,产生ConcurrentModificationException的原因就是:
执行remove(Object o)方法之后,modCount和expectedModCount不相等了。然后当代码执行到next()方法时,判断了checkForComodification(),发现两个数值不等,就抛出了该Exception。
要避免这个Exception,就应该使用remove()方法,但是没有add()方法了,只能另建一个list来处理这个问题了。
第六条 在改写equals的时候请遵守通用规定
有一种“值类”可以不要求改写equals方法,类型安全枚举类型,因为类型安全枚举类型保证每一个值之多只存在一个对象,所有对于这样的类而言,Object的queals方法等同于逻辑意义上的equals方法。
在改写equals方法的时候,要遵循的规范:
1,自反性。对任意的引用值x,x.equals(x)一定是true
2,对称性。对于任意的引用值x和y,当且仅当y.equals(x)返回true时,x.equals(y)也一定返回true.
3,传递性。对于任意的引用值x,y和z,如果x.equals(y)==true and y.equals(z)==true,so x.equals(z)==true.
4,一致性。对于任意的引用值x和y,如果用于equals比较的对象信息没有被修改的话,那么,多次调用x.equals(y)要么一致地返回true,要么一致地返回false.
5,非空性。对于任意的非空引用值x,x.equals(null)一定返回false.
自反性:要求一个对象必须等于其自身。一个例子:你把该类的实例加入到一个集合中,则该集合的contains方法
将果断地告诉你,该集合不包含你刚刚加入的实例.
对称性:
例如:
public final class CaseInsensitiveString{
private String s;
public CaseInsensitiveString(String s){
if(s==null) throw new NullPointerException();
this.s=s;
}
public boolean equals(Object o){
if(o instanceof CaseInsensitiveString)
return s.equalsIgnoreCase(((CaseInsensitiveString)o).s);
if(o instanceof String)
return s.equalsIgnoreCase((String)o);
return false;
}
}
调用:
CaseInsensitiveString cis=new CaseInsensitiveString("Polish");
String s="polish";
正如我们期望的:cis.equals(s)==true but s.equals(cis)==false
这就违反了对称性的原则.为了解决这个问题,只需把企图与String互操作的这段代码从equals方法中去掉旧可以了.这样做之后,你可以重构代码,使他变成一条返回语句:
public boolean equals(Object o){
return o instanceof CaseInsensitiveString && ((CaseInsensitiveString)o).s.equalsIgnoreCase(s);
}
传递性---即如果一个对象等于第二个对象,并且第二个对象又等于第三个对象,则第一个对象一定等于第三个对象。
例如:
public class Point{
private final int x;
private final int y;
public Point(int x,int y){
this.x=x;
this.y=y;
}
public boolean equals(Object o){
if(!(o instanceof Point))
return false;
Point p=(Point)o;
return p.x==x&&p.y==y;
}
}
现在我们来扩展这个类,为一个点增加颜色信息:
public class ColorPoint extends Point{
private Color color;
public ColorPoint(int x,int y,Color color){
super(x,y);
this.color=color;
}
}
分析: equals方法会怎么样呢?如果你完全不提供equals方法,而是直接从Point继承过来,那么在equals座比较的时候颜色信息会被忽略掉。如果你编写一个equals方法,只有当实参是另一个有色点,并且具有同样的位置和颜色的时候,它才返回true:
public boolean equals(Object o){
if(!(o instanceof ColorPoint)) return false;
ColorPoint cp=(ColorPoint)o;
return super.equals(o) && cp.color==color;
}
分析:这个方法的问题在于,我们在比较一个普通点和一个有色点,以及反过来的情形的时候,可能会得到不同的结果。前一种比较忽略了颜色信息,而后一种比较总是返回false,因为实参的类型不正确。例如:
Point p=new Point(1,2);
ColorPoint cp=new ColorPoint(1,2,Color.RED);
然后:p.equals(cp)==true but cp.equals(p)==false
修正:让ColorPoint.equals在进行“混合比较”的时候忽略颜色信息:
public boolean equals(Object o){
if(!(o instanceof Point)) return false;
if(!(o instanceof ColorPoint)) return o.equals(this);
ColorPoint cp=(ColorPoint)o;
return super.equals(o) && cp.color==color;
}
这种方法确实提供了对称性,但是却牺牲了传递性:
ColorPoint p1=new ColorPoint(1,2,Color.RED);
Point p2=new Point(1,2);
ColorPoint p3=new ColorPoint(1,2,Color.BLUE);
此时:p1.equals(p2)==true and p2.equals(p3)==true but p1.equals(p3)==false很显然违反了传递性。前两个比较不考虑颜色信息,而第三个比较考虑了颜色信息。
结论:要想在扩展一个可实例华的类的同时,既要增加新的特征,同时还要保留equals约定,没有一个简单的办法可以做到这一点。根据"复合优于继承",这个问题还是有好的解决办法:我们不让ColorPoint扩展Point,而是在ColorPoint中加入一个私有的Point域,以及一个公有的视图方法,此方法返回一个与该有色 点在同一位置上的普通Point对象:
public class ColorPoint{
private Point point;
private Color color;
public ColorPoint(int x,int y,Color color){
point=new Point(x,y);
this.color=color;
}
public Point asPoint(){
return point;
}
public boolean equals(Object o){
if(!(o instanceof ColorPoint)) return false;
ColorPoint cp=(ColorPoint)o;
return cp.point.equals.(point) && cp.color.equals(color);
}
}
注意,你可以在一个抽象类的子类中增加新的特征,而不会违反equals约定。
一致性:
如果两个对象相等的话,那么它们必须始终保持相等,除非有一个对象被修改了。由于可变对象在不同的时候可以与不同的对象相等,而非可变对象不会这样,这个约定没有严格界定。
非空性:没什么好说的。
1,使用==操作符检查“实参是否为指向对象的一个应用”。如果是的话,则返回true。
2,使用instanceof操作符检查“实参是否为正确的类型”。如果不是的话,则返回false。
3,把实参转换到正确的类型。
4,对于该类中每一个“关键(significant)”域,检查实参中的域与当前对象中对应的域值是否匹配
if (!(this.field == null ? o.field == null : this.equals(o.field)))
//或者写成 if(!(this.field == o.field || (this.field != null && this.field.equals(o.field)))) 对于this.field和o.field通常是相同的对象引用,会更快一些。
return false;
//比较下一个field
//都比较完了
return true;
5.最后还要确认以下事情
5.1)改写equals的同时,总是(必须)要改写hashCode方法(见【第8条】),这是极容易被忽略的,有极为重要的
5.2)不要企图让equals方法过于聪明
5.3)不要使用不可靠的资源。如依赖网络连接
5.4)不要将equals声明中的Object对象替换为其他类型。
public boolean equals(MyClass) 这样的声明并不鲜见,往外使程序员数小时搞不清楚为什么不能正常工作
原因是这里是重载(overload)而并不是改写(override)(或称为覆盖、重写)
相当于给equals又增加了一个实参类型为MyClass的重载,而实参为Object的那个equals并没有被改写,依然还是从Object继承来的最初的那个equals,所总是看不到程序员想要的效果。因为类库或其他人写的代码都是调用实参为Object型的那个equals方法的(别人又如何在事前知晓你今天写的MyClass呢?)
ExtJS可以用来开发RIA也即富客户端的AJAX应用,是一个用javascript写 的,主要用于创建前端用户界面,是一个与后台技术无关的前端ajax框架。因此,可以把ExtJS用在.Net、Java、Php等各种开发语言开发的应 用中。
ExtJs最开始基于YUI技术,由开发人员Jack Slocum开发,通过参考Java Swing等机制来组织可视化组件,无论从UI界面上CSS样式的应用,到数据解析上的异常处理,都可算是一款不可多得的JavaScript客户端技术 的精品。
ExtJS: http://www.spket.com/demos/js.html spket插件(eclipse)
· Start Aptana and navigate the application menu to: Help → Software Updates → Find and Install… → Search for new features to install → New remote site…
· Name: “Spket”, Url: “http://www.spket.com/update/”
· Restart Eclipse
· Watch this Spket IDE Tutorial to see how to easily add Ext code assist (you can point it at the latest /src/ext.jsb to keep code assist up to date with the latest Ext version). The steps are basically:
o Window → Preferences → Spket → JavaScript Profiles → New
o Enter “ExtJS” and click OK
o Select “ExtJS” and click “Add Library”, then choose “ExtJS” from the dropdown
o Select “ExtJS” and click “Add File”, then choose the “ext.jsb” file in your “./ext-2.x/source” directory
o Set the new ExtJS profile as the default by selecting it an clicking the “Default” button on the right-hand side of the “JavaScript Profiles” dialog.
o Restart Eclipse
o Create a new JS file and type: Ext. and you should get the Ext Code completion options.
一个简单的例子:
http://extjs.org.cn/node/83
java程序设计风格:(类的说明介绍)
Java文件注释头
类中开头处插入如下 注释
/******************************************************************
*该类功能及特点的描述(例如:该类是用来.....)
*
*
*该类未被编译测试过。
*
*@see(与该类相关联的类):(AnotherClass.java)
*
*
*
*开发公司或单位:XXX软件有限公司研发中心
*
*版权:本文件版权归属XXX公司研发中心
*
*
*@author(作者):XXX
*
*@since(该文件所支持的JDK版本):Jdk1.3或Jdk1.4
*
*@version(版本):1.0
*
*
*@date(开发日期): 1999-01-29
*
*最后更改日期: 2003-01-02
*
*
*修改人: XXXX
*
*复审人: 张三李四 王五
*
*/
内存管理
伊甸园用来保存新的对象,它就像一个堆栈,新的对象被创建,就像指向该栈的指针在不断的增长一样,当伊甸园区域中的对象满了之后,JVM系统将要做可到达性测试,主要任务是检测有哪些对象由根集合出发是不可到达的,这些对象就可以被JVM回收,并且将所有的活动对象从伊甸园区域拷到TO区域,此时一些对象将发生状态交换,有的对象就从TO区域被转移到From区域,此时From区域就有了对象,这个过程都是JVM控制完成的。
Java 中的析构方法 finalize
对象是使用完了 尽量都赋 为 null
共享静态变量存储空间
不要提前创建对象
........
void f(){
int i;
A a = new A();
//类A的对象a被创建
//在判断语句之中没有
//应用过a对象
.....
if(....){
//类A的对象a仅在此处被应用
a.showMessage();
....
}
.....
}
..........
正确的书写方式为:
void f(){
int i;
.....
if(...){
A a = new A();
//类A的对象a被创建
//应用过a对象
a.showMessage();
}
......
}
JVM内存参数调优
表达式、语句和保留字
非静态方法中可引用静态变量
静态方法不可以引用非静态变量
静态方法中可 创建 非静态变量
调用父类的构造方法必须将其放置子类构造方法的第一行
JAVA核心类与性能优化
线程同步:Vector Hashtable
非线程同步: ArrayList HashMap
字符串累加 尽量使用 StringBuffer +=
方法length() 和 length属性 区别
IO缓存,读写文件优化。
类与接口
内部类(Inner Class)是Java语言中特有的类型,内部类只能被主类以外的其他内部类继承,主类是不能继承其内部类的,因为这样就引起了类循环继承的错误,下面的代码就是错误的。
public class A extends x {
public A(){}
……
Classs x{
…..
}
}
上面的代码将引发类循环继承的错误,这种错误在编译时就会被发现,比较容易发现和排除。
但是下面例子中的内部类的继承方式却是正确的:
class A{
….
public A(){}
……
class X extends Y {
……….
}
calss Y {
……
}
}
什么时候使用继承,什么样的继承是合理的:
1. 现实世界的事物继承关系,可以作为软件系统中类继承关系的依据。
2. 包含关系的类之间不存在继承关系。如:主机,外设 ,电脑。 把主机类和外设类作为电脑类的成员就可以了。
3. 如果在逻辑上类B是类A的一种,并且类的所有属性和行为对类而言都有意义,则允许B继承A的行为和属性(私有属性与行为除外)。
原帖javaeye上的:
http://yongtech.javaeye.com/blog/428671 ,觉得写得挺不错的!不知道您到什么阶段了。。。。hoho
本来我想把这篇文章的名字命名为: <怎样成为一个优秀的Java程序员>的, 但是自己还不够优秀, 而本篇所涉及的都是自己学习和工作中的一些经验, 后来一想, 叫<怎样进阶Java>可能更为合适吧. 能给初学Java的人一个参考, 也就是我本来的心愿. 如果有大牛看到不妥之处, 敬请指正. 我一定会修正的 :).
Java目前是最流行的语言之一, 是很多公司和程序员喜爱的一门程序语言. 而且, Java的入门比C++相对来说要简单一些, 所以有很大一部分程序员都选择Java作为自己的开发语言. 我也是其中之一, 就是因为觉得学C++太难, 当初在学校学了将近一个学期的C++, 啥进步都没有, 哈哈, 天资太差, 所以才选择自学Java(当时学校并没有开设Java的课程), 才走上了程序开发这条路.
Java虽然入门要容易, 然而要精通它, 要成为专家却很难. 主要原因是Java所涉及的技术面比较宽, 人的精力总是有限的. 有些Java方面的技术是必须要要掌握的, 钻研得越深入越好, 比如多线程技术.
1. 基础阶段
基础阶段, 可能需要经历1-2年吧. 这个时段, 应该多写一些基础的小程序(自己动手写的越多越好). 计算机是一门实践性很强的学科, 自己动手的东西, 记忆非常深刻, 效果要胜过读好多书. 当然, 学Java基础的时候, 书籍的选择也非常重要, 好的书籍事半功倍, 能让你打个非常好的基础. 而差的书籍, 很容易将你带入歧途, 多走很多弯路. 书籍不在多, 而在乎读得精(有些书, 你读十遍都不为过). 我记得我学Java的第一本书是<Thinking in Java>的中文版, 网上有很多人都建议不要把这本书作为第一本的入门教程来看, 太难. 我却想在此极力推荐它, 这本书确实是本经典之作. 而且书中确实讲的也是Java中的一些基础技术, 没有什么太难的东西, 只不过比较厚, 学习周期比较长, 所以很多人中途会选择放弃. 其实, 这本书是一本难得的入门教程, 对Java一些基础的东西, 讲得很全, 而且也很清晰, 更重要的是, 这本书能让你养成很多好的编程习惯, 例子也很多. 建议你把大部分的例子自己去实现一遍. 我的亲身经历, 我记得当时认真的看了2遍, 花了大概7个月的时间, 不过真的有很好的效果. 另外一个教程, 就是<Java核心技术>卷一, 卷二的话可以不必要买. 卷一看完, 自己再钻研一下, 就已经能达到卷二的高度了:). 到那时, 你就会觉得看卷二没啥意思, 感觉浪费钱了. 还有一个, 就是张孝祥的Java视频, 看视频有个好处, 就是比看书的记忆要深刻, 还有很多你可以跟着视频的演示同步操作. 张孝祥的Java视频对初学者来说, 确实很有作用. 总结起来: 看这些资料的时候, 一定要多写例子, 写的越多越好!
2. 中级阶段
中级阶段, 是一个更漫长的时期, 能否突破此阶段, 跟个人的努力和天资有着很大的关系. 你不得不承认, 同样一门新技术, 有些人一个月领悟到的东西, 比你一年的都多. 这就是天资, 程序员是一个需要天才的工作. 我想, 很多人听说李一男吧, 此君就是这样的人物, 三个月的时间就能解决好大一帮人几年解决不了的问题, 给华为某部门带来了很多的收益. 哦, 这是题外话了, 与此篇的主题无关, 只是本人偶尔的感慨而已:). 这个阶段, 就需要研究很多专题性的东西了, 比如: IO的实现原理, 多线程和Java的线程模型, 网络编程, swing, RMI, reflect, EJB, JDBC等等很多很多的专题技术, 钻研得越深越好. 为了更好的提高, 研究的更深入, 你需要经常到网络上搜索资料, 这个时候往往一本书起不来很大的作用. 选一个JDK版本吧, 目前建议选用1.6, 多多研究它, 尤其是源代码(尽量! 就是尽自己最大的努力, 虽然研究透是不可能滴). 比如说: util, collection, io, nio, concurrent等等包. 可能有人会反对我说, 不是有API文档吗, 为什么还要研究这么多的源代码? 错了, 有API文档, 你仅仅只是知道怎么用而已, 而认真仔细的研读这些大牛的源码, 你就会深入更高的一个阶层, 自己的编码, 设计都会有很大的提高. 如果有能力和精力, 我建议你把JDK的每一行代码都熟悉一遍, 绝对只有好处, 没有坏处! 而且你会有些意外的收获, 比如, 当你仔细地读完concurrent包的时候(不多, 好像总共是86个类吧), 你就会对Doug Lea佩服得五体投地. 这个时候最忌碰到难题就去寻找帮助, 去网上找答案! 先把自己的脑袋想破吧, 或者等你的老板拿着砍刀冲过来要把你杀了, 再去寻求帮助吧. 对于专题的学习, 英文原版的阅读是非常必要的, 看的越多越好, 多上上IBM的developer, SUN的网站吧, 当然Javaeye也很不错:), 有很多大牛, 呵呵.
这个时候, 你应该建立自己的代码库了, 你应该自己去研究很多有意思的东西了. 从一个200多M的文件中寻找一个字段, 最坏情况(在文件的末尾咯)也只需要1秒左右的时间, 你知道吗? 这个阶段, 有很多很多类似的有趣的东西可以供你去研究, 你需要更多地关注性能, 规范性, 多解决一些疑难问题. 需要学会所有的调试技术, 运用各种性能工具, 还有JDK附带的很多工具, 这些你都要熟练得跟屠夫操刀一样. 也可以看看<Effective Java>, 这本书总结的也不错, 对写高效稳定的Java程序有些帮助. 也可以看看模式方面的东西, 但是我建议模式不要滥用, 非得要用的时候才用, 模式往往会把问题搞复杂:). 总结起来: 这个阶段是一个由点延伸到面的过程, 经过不断的学习, 演变成全面的深入! Java技术中你没什么盲点了, 还能解决很多性能问题和疑难问题, 你就成了一个合格的程序员了! :) [要想成为优秀程序员, 还得对数据库和操作系统很精通.]
3. 高级阶段
高级阶段, 我就不敢妄言了. 呵呵, 我感觉自己也是处于中级阶段吧. 也是根据自己的一些经验, 谈谈自己的理解吧:
这个阶段, 需要研究各种框架, Spring, struts, Junit, Hibernate, iBatis, Jboss, Tomcat, snmp4j等等, 我觉得这个时候, 只要是用Java实现的经典框架, 你都可以去研究. ------在此申明一下, 我的意思不是说会用. 光会用其实是远远不够的, 你可以选择自己喜欢钻研的框架, 去好好研究一下, 兴趣是最好的老师嘛.(2009.07.21)
建议开始的时候, 研究Junit和Struts吧, 小一点, 里面都采用了很多的模式, 呵呵, 可以熟悉一下, 尽量想想人家为什么这么做. 我建议主要的精力可以花在spring和jboss上, 尤其是jboss, 经典中的经典, 设计, 性能, 多线程, 资源管理等等, 你从中可以学到的东西简直是太多了. 而且它还有一本写得很好的参考书, 叫<Jboss管理与开发核心技术>, 英文方面的资料也是非常的多. 在工作中如果有机会参与架构的设计, 业务问题的讨论, 一定想方设法杀进去! 这对自己的设计能力, 以及对设计如何运用在业务上有很大的帮助. 毕竟, 程序都是为了更好地实现用户的业务的. 这个时候, 需要更多看看软件工程和UML方面的资料, 或者自己主持一个项目玩玩, 不一定非得出去拉项目赚钱(能赚钱当然更好), 不管成功或失败, 都是很宝贵的经验, 都能提高很多!
该书介绍了在Java编程中极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。通过对Java平台设计专家所使用的技术的全面描述,揭示了应该做什么,不应该做什么才能产生清晰、健壮和高效的代码。
每天下班花点时间学习下吧,尽量在一个星期内把它看完,总结出来,大多数内容都来自书上,个人觉得该书不错的地方摘出来。
第一条:考虑用静态工厂方法代替构造函数
静态工厂方法(优点):
1.每次调用的时候,不一定要创建一个新的对象,这个可以自由控制。
2.它可以返回一个原返回类型的子类型的对象。
第二条:使用私有构造函数强化singleton属性
第一种:提供共有的静态final域

 public class Elvis
public class Elvis {
{
 public static final Elvis INSTANCE = new Elvis();
public static final Elvis INSTANCE = new Elvis();

 private Elvis(){
private Elvis(){
 }
}
 }
}
第二种:提供一个共有的静态工厂方法
1public class Elvis{
2 private static final Elvis INSTANCE = new Elvis();
3 private Elvis(){
4
5 }
6
7 public static Elvis getInstance(){
8 return INSTANCE;
9 }
10
11}
第一种性能上会稍微好些
第二种提供了灵活性,在不改变API的前提下,允许我们改变想法,把该类做成singleton,或者不做,容易被修改。
注意点:为了使一个singleton类变成克序列花的(Serializable),仅仅在声明中加上implements Serializable是不够的,
为了维护singleton性,必须也要提供一个
private Object readResolve() throws ObjectStreamException{
return INSTANCE;
}
第三条:通过私有构造函数强化不可实例化的能力
只要让这个类包含单个显式的私有构造函数,则它就不可被实例化;
1 public class UtilityClass{
2 private UtilityClass(){
3
4 }
5
6 }
企图通过将一个类做成抽象类来强制该类不可被实例化,这是行不通的。该类可以被子类化,并且该子类也可以被实例化。
更进一步,这样做会误导用户,以为这种类是专门为了继承而设计的。
第四条:避免创建重复的对象
String s = new Sting("silly");//这么恶心的代码就不要写啦。。。
1.静态工厂方法可几乎总是优先于构造方法;Boolean.valueOf(...) > Boolean(...),构造函数每次被调用的时候都会创建一个新的对象,
而静态工厂方法从来不要求这样做。
2.
public class Person {
private final Date birthDate;
public Person(Date date){
this.birthDate = date;
}
//don't do this
public boolean isBabyBoomer(){
Calendar gmtCal = Calendar.getInstance(TimeZone.getTimeZone("GMT"));
gmtCal.set(1946,Calendar.JANUARY,1,0,0,0);
Date boomStart = gmtCal.getTime();
gmtCal.set(1965,Calendar.JANUARY,1,0,0,0);
Date boomEnd = gmtCal.getTime();
return birthDate.compareTo(boomStart) >=0 && birthDate.compareTo(boomEnd) <0;
}
}
isBabyBoomer每次被调用的时候,都会创建一个新的Calendar,一个新的TimeZone和两个新的Date实例。。。
下面的版本避免了这种低效率的动作,代之以一个static 块初始化Calendar对象,而且最体现效率的是,他的生命周期只实例化一次Calendar并且把
80年,90年的出生的值赋值给类静态变量BOOM_START和BOOM_END
class Person {
private final Date birthDate;
public Person(Date birthDate) {
this.birthDate = birthDate;
}
private static final Date BOOM_START;
private static final Date BOOM_END;
static {
Calendar gmtCal = Calendar.getInstance(TimeZone.getTimeZone("GMT"));
gmtCal.set(1980, Calendar.JANUARY, 1, 0, 0, 0);
BOOM_START = gmtCal.getTime();
gmtCal.set(1990, Calendar.JANUARY, 1, 0, 0, 0);
BOOM_END = gmtCal.getTime();
}
public boolean isBabyBoomer() {
return birthDate.compareTo(BOOM_START) >= 0
&& birthDate.compareTo(BOOM_END) < 0;
}
最近在翻《首先,打破一切常规》,书不只翻一遍了,每次都会有一些新的收获.书中经常提到的6个问题越想越觉得有道理,列出跟大家分享:
1.你知道对你工作的要求吗?
第一优先级的问题,如果不知道对你的工作要求,那么你如何衡量你工作的好坏?其他人如何衡量你的工作成果?首当其冲需要考虑的问题.
2.你有做好你当前工作的材料和设备或者资源吗?
当然明确工作要求的时候需要明确你达到你目标的途径,此时需要衡量你能掌控的资源,或者你能够使用到的潜在资源.
3.在工作中你每天都有机会做你最擅长的事情吗?
是否能够发挥自己的潜力,是否是自己的兴趣爱好,是否能做的更好.
4.过去的7天内,你有因你的工作出色而受到表扬吗?
周围同事或者你的主管关注你的个人价值,为什么会受到表扬?是否可以在这件工作上受到一贯的认可.
5.你觉得你的主管或者同事关心你的个人情况吗?
恒定自己在团队中的作用,如果不关心,为什么?你是否了解过其他人的感受?如果关心?关心那点?如何满足期望.
6.工作单位里面有人会鼓励你的发展吗?
职业发展的考虑,企业是否值得呆下去,是否能够共同进步.
定期拿这些问题进行自勉,会有很多收获.包括你的同事,你的主管,你的合作伙伴,甚至会改变你的人生.
问题:
下面一个简单的类:
public class MyTest {
private static String
className = String.class.getName(); //红色部分是下面问题的关键
public static void
main(String[] args){
System.out.println(className);
}
}
经eclipse3.1.1编译后(指定类兼容性版本为1.4),再反编译的结果是:
public class MyTest
{
public MyTest()
{
}
public static void main(String args[])
{
System.out.println(className);
}
private static String className;
static
{
className =
java.lang.String.class.getName();
}
}
而经过sun javac(或者ant, antx)编译后(JDK版本1.4,或者JDK1.5,但是编译结果指定版本为1.4),再反编译的结果是:
public class MyTest
{
public MyTest()
{
}
public static void main(String args[])
{
System.out.println(className);
}
static Class _mthclass$(String x0)
{
return Class.forName(x0);
ClassNotFoundException
x1;
x1;
throw (new
NoClassDefFoundError()).initCause(x1);
}
private static String className;
static
{
className =
(java.lang.String.class).getName();
}
}
也就是说sun javac编译出来的结果里面多了一个_mthclass$方法,这个通常不会有什么问题,不过在使用hot swap技术(例如Antx
eclipse plugin中的快速部署插件利用hot swap来实现类的热替换,或者某些类序列化的地方,这个就成为问题了。
用_mthclass$在google上搜一把,结果不多,比较有价值的是这一篇:http://coding.derkeiler.com/Archive/Java/comp.lang.java.softwaretools/2004-01/0138.html
按照这个说法,这个问题是由于Sun本身没有遵循规范,而eclipse compiler遵循规范导致的,而且eclipse
compiler是没有办法替换的。
尝试将JDK版本换成1.5,sun
javac生成出来的_mthclass$是不见了,不过,这回奇怪的是eclipse的编译结果中多了一个成员变量class$0,
下面是经eclipse3.1.1编译后(指定类兼容性版本为5.0),再反编译的结果:
public
class MyTest
{
public MyTest()
{
}
public static void main(String args[])
{
System.out.println(className);
}
private static String className = java/lang/String.getName();
static Class class$0;
}
而经过sun javac(或者ant, antx)编译后(JDK版本1.5),再反编译的结果是:
public class
MyTest
{
public MyTest()
{
}
public static void main(String args[])
{
System.out.println(className);
}
private static String className = java/lang/String.getName();
}
再在goole上搜了一把,发现了Eclipse3.2有两个比较重要的特征:
1.与javac的兼容性更好。
2.提供了单独的编译器,可以在eclipse外部使用,包括ant中使用。
于是下载eclipse3.2版本,首先验证一下其与sun javac的兼容性如何,
使用JDK1.4版本的时候,还是老样子,sun
javac编译出来的_mthclass$方法在eclipse3.2的编译结果中还是不存在,所以还是不兼容的。
不过使用JDK1.5版本的时候,这会eclipse
3.2的编译结果总算和sun javac一致了。
虽然,用JDK1.5加上eclipse
3.2已经保证了这个类在两种编译器下的兼容性,不过总觉得不踏实:
1.谁知道这两个编译器还有没有其它不兼容的地方呢?
2.版本要求太严格,很多由于各种原因没有使用这些版本的很麻烦。
因此,还是从根本上解决这个问题比较合适:根本上解决最好就是不要使用两种不同的编译器,而使用同一种。
由于eclipse环境下的编译器是不可替换的,所以企图都使用sun
javac的方式不太可行,那么统一使用eclipse自带的编译器如何呢?
刚才提到的eclipse3.2的第二个比较重要的特性就派上用场了。
独立的eclipse编译器(1M大小而已)可以在如下地址下载:http://www.eclipse.org/downloads/download.php?file=/eclipse/downloads/drops/R-3.2-200606291905/ecj.jar
这个独立的编译器在antx下的使用也很简单:(关于该编译器的独立使用或者ant下面的使用可以参看this help section: JDT
Plug-in Developer Guide>Programmer's Guide>JDT Core>Compiling Java
code)
1.将下载下来的编译器放在ANTX_HOME/lib目录下面。
2.在总控项目文件的project.xml增加这么一行即可:<property
name="build.compiler"
value="org.eclipse.jdt.core.JDTCompilerAdapter"/>
这样就保证了通过antx打包的类也是用eclipse的编译器编译出来的,当然就不应该存在类不兼容的情况了。
实际上,eclipse3.1.1版本也已经提供了独立的eclipse编译器,不过当时并没有单独提供独立的包下载,如果希望使用3.1.1版本的eclipse编译器,可以使用org.eclipse.jdt.core_3.1.1.jar以及其中包含的jdtCompilerAdapter.jar。(eclipse3.1.1环境的编译器我没有独立验证过)