在Spring MVC中的配置中一般会遇到这两个标签,作为<context:component-scan>的子标签出现。
但在使用时要注意一下几点:
1.在很多配置中一般都会吧Spring-common.xml和Spring-MVC.xml进行分开配置,这种配置就行各施其职一样,显得特别清晰。
在Spring-MVC.xml中只对@Controller进行扫描就可,作为一个控制器,其他的事情不做。
在Spring-common.xml中只对一些事务逻辑的注解扫描。
2.现在给定一个项目包的机构:
com.fq.controlller
com.fq.service
就先给定这两个包机构
(1)在Spring-MVC.xml中有以下配置:
<!-- 扫描@Controller注解 -->
<context:component-scan base-package="com.fq.controller">
<context:include-filter type="annotation"
expression="org.springframework.stereotype.Controller" />
</context:component-scan>
可以看出要把最终的包写上,而不能这样写base-package=”com.fq”。这种写法对于include-filter来讲它都会扫描,而不是仅仅扫描@Controller。哈哈哈,这点需要注意。他一般会导致一个常见的错误,那就是事务不起作用,补救的方法是添加use-default-filters=”false”。
(2)在Spring-common.xml中有如下配置:
<!-- 配置扫描注解,不扫描@Controller注解 -->
<context:component-scan base-package="com.fq">
<context:exclude-filter type="annotation"
expression="org.springframework.stereotype.Controller" />
</context:component-scan>
可以看到,他是要扫描com.fq包下的所有子类,不包含@Controller。对于exculude-filter不存在包不精确后都进行扫描的问题。
posted @
2015-10-29 10:25 kelly 阅读(326) |
评论 (0) |
编辑 收藏
在Eclipse中创建Maven的Web项目时出现错误:An internal error occurred during: “Retrieving archetypes:”. Java heap space,可以通过以下步骤来解决问题。
1. 找到Eclipse的根目录下的eclipse.ini(或myeclipse.ini)文件并打开
2.修改文件中的以下配置
-Dosgi.requiredJavaVersion=1.5(可选)
-Xms512m
-Xmx1024m
这是我的配置,大家可以尝试着修改下,不同的机器配置可能支持的情况不同。
版权声明:本文为博主原创文章,未经博主允许不得转载。
posted @
2015-10-12 15:09 kelly 阅读(5379) |
评论 (0) |
编辑 收藏myeclipse自定义java注释:
Window->Preference->Java->Code Style->Code Template
然后展开Comments节点就是所有需设置注释的元素
-----------------
文件 (Files) 注释标签:
/**
* @Project : ${project_name}
* @Title : ${file_name}
* @Package ${package_name}
* @Description : ${todo}
* @author shenyanghong ahong2011@gmail.com
* @date ${date} ${time}
* @Copyright : ${year} www.1000chi.com Inc. All rights reserved.
* @version V1.0
*/
类 (Types) 注释标签(类的注释):
/**
* @ClassName ${type_name}
* @Description ${todo}
* @author shenyanghong ahong2011@gmail.com
* @date ${date}
* ${tags}
*/
字段 (Fields) 注释标签:
/**
* @Fields ${field} : ${todo}
*/
构造函数标签:
/**
* <p>Title: </p>
* <p>Description: </p>
* ${tags}
*/
方法 (Constructor & Methods) 标签:
/**
* @Title: ${enclosing_method}
* @Description: ${todo}
* @param ${tags} 设定文件
* @return ${return_type} 返回类型
* @throws
*/
覆盖方法 (Overriding Methods) 标签:
/* ( 非 Javadoc)
* <p>Title: ${enclosing_method}</p>
* <p>Description: </p>
* ${tags}
* ${see_to_overridden}
*/
代表方法 (Delegate Methods) 标签:
/**
* ${tags}
* ${see_to_target}
*/
getter 方法标签:
/**
* @return ${bare_field_name}
*/
setter 方法标签:
/**
* @param ${param} 要设置的 ${bare_field_name}
*/
posted @
2015-06-30 10:38 kelly 阅读(290) |
评论 (0) |
编辑 收藏今天将写好的附件服务器的API发给同事
她引入我的jar后, 编译就会报错: 类文件具有错误的版本 50.0,应为 49.0
50.0 对应的是JDK的1.6版本, 而49.0 对应的是JDK的1.5版本
也就是说我的jar的版本高于她所用的版本
由于我们实际部署在1.5之上, 所以我就来修改我的编译环境
首先我先修改了Eclipse的编译环境到1.5, 但是没有效果
转眼一想, 我都是使用Ant来打包发布, 看来Ant是自己编译的
于是我就在网上找到了修改Ant编译版本的方法

最后完成了修改
写个文字记录下, 免得以后忘了= =
PS: 我发现很多人问如何查看class文件是什么版本JDK编译的, 现在我将方法写在下面:
使用UtralEdit打开一个class文件.
根据java虚拟机的规范, java的class文件的前4个字节为magic number(魔数), 0xCAFEBABE(下图的第一行0 - 3列), 标识这个文件是java的class文件
而紧随其后的4个字节, 存储的就是该class文件的主次版本号(下图的第一行的 4 - 7 列), 下图中的31 换算成十进制就是49, 这标识此class文件为JDK1.5编译所得, 若32 就是JDK1.6编译

posted @
2015-03-03 16:08 kelly 阅读(487) |
评论 (0) |
编辑 收藏<mvc:annotation-driven />注解意义
<mvc:annotation-driven /> 是一种简写形式,完全可以手动配置替代这种简写形式,简写形式可以让初学都快速应用默认配置方案。<mvc:annotation-driven /> 会自动注册DefaultAnnotationHandlerMapping与AnnotationMethodHandlerAdapter 两个bean,是spring MVC为@Controllers分发请求所必须的。
并提供了:数据绑定支持,@NumberFormatannotation支持,@DateTimeFormat支持,@Valid支持,读写XML的支持(JAXB),读写JSON的支持(Jackson)。
后面,我们处理响应ajax请求时,就使用到了对json的支持。
后面,对action写JUnit单元测试时,要从spring IOC容器中取DefaultAnnotationHandlerMapping与AnnotationMethodHandlerAdapter 两个bean,来完成测试,取的时候要知道是<mvc:annotation-driven />这一句注册的这两个bean。
posted @
2014-11-16 22:42 kelly 阅读(215) |
评论 (0) |
编辑 收藏1、确保导入了jackson-core-asl-1.9.13.jar和jackson-mapper-asl-1.9.13.jar包
2、在spring的配置文件中加入<mvc:annotation-driven />这句,它提供了读取jason的支持
3、
使用springMVC的@ResponseBody注解
@responsebody表示该方法的返回结果直接写入HTTP response body中
一般在异步获取数据时使用,在使用@RequestMapping后,返回值通常解析为跳转路径,加上@responsebody后返回结果不会被解析为跳转路径,而是直接写入HTTP response body中。比如异步获取json数据,加上@responsebody后,会直接返回json数据。
4、在以上配置都正确的情况下,我的项目还是不能返回json串。报错:The resource identified by this request is only capable of generating responses with characteristics not acceptable according to the request "accept" headers ()。
今天终于在一个外文网站找到答案,是由于spring版本的问题引起的。我之前一直用的是3.0.0的版本。就是因为这个版本的问题。于是果断去官网下载3.2版本的,一切正常运行,成功返回json数据。
posted @
2014-11-16 22:41 kelly 阅读(14199) |
评论 (1) |
编辑 收藏struts和spring整合首先要在Web容器启动的时候自动装配ApplicationContext的配置信息,可想而知应该在web.xml做相应的配置:
[html]
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
classpath:applicationContext.xml
</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
配置了org.springframework.web.context.ContextLoaderListener后我们就不惜要编写代码显示地实例化ApplicationContext对象了。至于为什么要使用监听是因为web.xml 的加载顺序是:context-param -> listener -> filter -> servlet 。如果你是在不想使用监听,或许你可以尝试下继承struts2的org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter重写这个它的init方法在StrutsPrepareAndExecuteFilter过滤器init中实例化ApplicationContext对象加载配置信息,虽然这种方法也可行,但是当拦截每个action都会加载一次配置信息,重新实例化了一个新的web容器,不仅浪费了资源也让spring更加依赖了struts。
1、使用xml方式:
struts2配置
<package name="user" extends="struts-default">
<action name="login" class="userAction">
<result name="success">/success.jsp</result>
<result name="input" type="redirect">/index.jsp</result>
</action>
</package>
spring配置
<bean id="userDao" class="org.han.dao.impl.UserDaoImpl" />
<bean id="biz" class="org.han.service.impl.LoginBizImpl">
<property name="userdao" ref="userDao"/>
</bean>
<bean id="userAction" class="org.han.action.LoginAction" scope="prototype" >
<property name="biz" ref="biz" />
</bean>
注意红色部分,struts2的action class与对应的action bean必须相同,这样才能由spring管理action;
2、struts2使用零配置方式:
当你导入了零配置插件包的时候千万要注意约定大于配置,还是上面的spring配置,只是不需要struts2配置了。
第一种方式:只需要将Action的className对应到spring配置中的bean id就行了
@Action(value = "/login", results = { @Result(name = "success", location = "/success.jsp"),@Result(name="input",location="/index.jsp")},className="userAction")
public String login() throws Exception {
// TODO Auto-generated method stub
User u=biz.login(this.getUser());
if(u!=null){
return SUCCESS;
}
return INPUT;
}
第二种方式:
Action注解不需要className了,将spring配置稍作修改
<bean id="org.han.action.LoginAction" class="org.han.action.LoginAction" scope="prototype" >
<property name="biz" ref="biz" />
</bean>
这样可以是因为当你使用零配置的时候,action的class默认是当前类的全类名,所以和spring整合的时候刚好使用全类名在spring配置中查找以全类名为id的bean。
3、struts2、spring都使用注解方式:
www.2cto.com
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd">
<context:component-scan base-package="org.han.dao.impl,org.han.service.impl,org.han.action"/>
</beans>
<context:component-scan base-package=""/>用此种方式,不需要在配置文件中再配置bean,也不需要再导入上面对应的处理bean。也就是说可以不需要在配置文件中使用<context:annotation-config/>了,因为此种方式会自动导入
[java]
@Namespace("/")
@Component(value="userLogin")
@Scope(value="prototype")
public class LoginAction extends ActionSupport {
public LoginAction() {
super();
// TODO Auto-generated constructor stub
System.out.println("action:"+this.hashCode());
}
@Autowired
private ILoginBiz biz;
private User user;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
@Autowired
public void setBiz(ILoginBiz biz) {
this.biz = biz;
}
@Override
@Action(value = "hello", results = { @Result(name = "success", location = "/success.jsp"),@Result(name="input",location="/index.jsp")})
public String execute() throws Exception {
// TODO Auto-generated method stub
System.out.println("biz:"+this.biz.hashCode());
User u=biz.login(this.getUser());
if(u!=null){
return SUCCESS;
}
return INPUT;
}
}
@Component 有一个可选的入参,用于指定 Bean 的名称。一般情况下,Bean 都是 singleton 的,需要注入 Bean 的地方仅需要通过 byType 策略就可以自动注入了,所以大可不必指定 Bean 的名称。除了提供 @Component 注释外,还定义了几个拥有特殊语义的注释,它们分别是:@Repository、@Service 和 @Controller。在目前的 Spring 版本中,这 3 个注释和 @Component 是等效的,但是从注释类的命名上,很容易看出这 3 个注释分别和持久层、业务层和控制层(Web 层)相对应。虽然目前这 3 个注释和 @Component 相比没有什么新意,但 Spring 将在以后的版本中为它们添加特殊的功能。所以,如果 Web 应用程序采用了经典的三层分层结构的话,最好在持久层、业务层和控制层分别采用 @Repository、@Service 和 @Controller 对分层中的类进行注释,而用 @Component 对那些比较中立的类进行注释。
@Scope用于定义Bean的作用范围。
@Autowired 注释,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。当 Spring 容器启动时,AutowiredAnnotationBeanPostProcessor 将扫描 Spring 容器中所有 Bean,当发现 Bean 中拥有 @Autowired 注释时就找到和其匹配(默认按类型匹配)的 Bean,并注入到对应的地方中去。所以对成员变量使用 @Autowired 后,您大可将它们的 setter 方法删除。
@Qualifier(“name”) 中的 name是 Bean 的名称,所以 @Autowired 和 @Qualifier 结合使用时,自动注入的策略就从 byType 转变成 byName 了。@Autowired 可以对成员变量、方法以及构造函数进行注释,而 @Qualifier 的标注对象是成员变量、方法入参、构造函数入参。
@PostConstruct 和 @PreDestroy:JSR-250 为初始化之后/销毁之前方法的指定定义了两个注释类,这两个注释只能应用于方法上。标注了 @PostConstruct 注释的方法将在类实例化后调用,而标注了 @PreDestroy 的方法将在类销毁之前调用。
通过 <bean> 元素的 init-method/destroy-method 属性进行配置,都只能为 Bean 指定一个初始化 / 销毁的方法。但是使用 @PostConstruct 和 @PreDestroy 注释却可以指定多个初始化 / 销毁方法,那些被标注 @PostConstruct 或@PreDestroy 注释的方法都会在初始化 / 销毁时被执行。
更多的关于注解使用:请看官方文档
4、总结:
1、注释配置不一定在先天上优于 XML 配置。如果 Bean 的依赖关系是固定的,(如 Service 使用了哪几个 DAO 类),这种配置信息不会在部署时发生调整,那么注释配置优于 XML 配置;反之如果这种依赖关系会在部署时发生调整,XML 配置显然又优于注释配置,因为注释是对 Java 源代码的调整,您需要重新改写源代码并重新编译才可以实施调整。
2、如果 Bean 不是自己编写的类(如 JdbcTemplate、SessionFactoryBean 等),注释配置将无法实施,此时 XML 配置是唯一可用的方式。
3、注释配置往往是类级别的,而 XML 配置则可以表现得更加灵活。比如相比于 @Transaction 事务注释,使用 aop/tx 命名空间的事务配置更加灵活和简单。
所以在实现应用中,我们往往需要同时使用注释配置和 XML 配置,对于类级别且不会发生变动的配置可以优先考虑注释配置;而对于那些第三方类以及容易发生调整的配置则应优先考虑使用 XML 配置。Spring 会在具体实施 Bean 创建和 Bean 注入之前将这两种配置方式的元信息融合在一起。
posted @
2014-01-17 21:51 kelly 阅读(331) |
评论 (0) |
编辑 收藏来自:http://hanyexiaoxiao.iteye.com/blog/410123
1. 使用Spring注解来注入属性
1.1. 使用注解以前我们是怎样注入属性的
类的实现:
public class UserManagerImpl implements UserManager {
private UserDao userDao;
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
...
}
配置文件:
<bean id="userManagerImpl" class="com.kedacom.spring.annotation.service.UserManagerImpl">
<property name="userDao" ref="userDao" />
</bean>
<bean id="userDao" class="com.kedacom.spring.annotation.persistence.UserDaoImpl">
<property name="sessionFactory" ref="mySessionFactory" />
</bean>
1.2. 引入@Autowired注解(不推荐使用,建议使用@Resource)
类的实现(对成员变量进行标注)
public class UserManagerImpl implements UserManager {
@Autowired
private UserDao userDao;
...
}
或者(对方法进行标注)
public class UserManagerImpl implements UserManager {
private UserDao userDao;
@Autowired
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
...
}
配置文件
<bean id="userManagerImpl" class="com.kedacom.spring.annotation.service.UserManagerImpl" />
<bean id="userDao" class="com.kedacom.spring.annotation.persistence.UserDaoImpl">
<property name="sessionFactory" ref="mySessionFactory" />
</bean>
@Autowired可以对成员变量、方法和构造函数进行标注,来完成自动装配的工作。以上两种不同实现方式中,@Autowired的标注位置不同,它们都会在Spring在初始化userManagerImpl这个bean时,自动装配userDao这个属性,区别是:第一种实现中,Spring会直接将UserDao类型的唯一一个bean赋值给userDao这个成员变量;第二种实现中,Spring会调用setUserDao方法来将UserDao类型的唯一一个bean装配到userDao这个属性。
1.3. 让@Autowired工作起来
要使@Autowired能够工作,还需要在配置文件中加入以下代码
<bean class="org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor" />
1.4. @Qualifier
@Autowired是根据类型进行自动装配的。在上面的例子中,如果当Spring上下文中存在不止一个UserDao类型的bean时,就会抛出BeanCreationException异常;如果Spring上下文中不存在UserDao类型的bean,也会抛出BeanCreationException异常。我们可以使用@Qualifier配合@Autowired来解决这些问题。
1. 可能存在多个UserDao实例
@Autowired
public void setUserDao(@Qualifier("userDao") UserDao userDao) {
this.userDao = userDao;
}
这样,Spring会找到id为userDao的bean进行装配。
2. 可能不存在UserDao实例
@Autowired(required = false)
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
1.5. @Resource(JSR-250标准注解,推荐使用它来代替Spring专有的@Autowired注解)
Spring 不但支持自己定义的@Autowired注解,还支持几个由JSR-250规范定义的注解,它们分别是@Resource、@PostConstruct以及@PreDestroy。
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按byName自动注入罢了。@Resource有两个属性是比较重要的,分别是name和type,Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
@Resource装配顺序
- 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
- 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
- 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
- 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配(见2);如果没有匹配,则回退为一个原始类型(UserDao)进行匹配,如果匹配则自动装配;
1.6. @PostConstruct(JSR-250)
在方法上加上注解@PostConstruct,这个方法就会在Bean初始化之后被Spring容器执行(注:Bean初始化包括,实例化Bean,并装配Bean的属性(依赖注入))。
它的一个典型的应用场景是,当你需要往Bean里注入一个其父类中定义的属性,而你又无法复写父类的属性或属性的setter方法时,如:
public class UserDaoImpl extends HibernateDaoSupport implements UserDao {
private SessionFactory mySessionFacotry;
@Resource
public void setMySessionFacotry(SessionFactory sessionFacotry) {
this.mySessionFacotry = sessionFacotry;
}
@PostConstruct
public void injectSessionFactory() {
super.setSessionFactory(mySessionFacotry);
}
...
}
这里通过@PostConstruct,为UserDaoImpl的父类里定义的一个sessionFactory私有属性,注入了我们自己定义的sessionFactory(父类的setSessionFactory方法为final,不可复写),之后我们就可以通过调用super.getSessionFactory()来访问该属性了。
1.7. @PreDestroy(JSR-250)
在方法上加上注解@PreDestroy,这个方法就会在Bean初始化之后被Spring容器执行。由于我们当前还没有需要用到它的场景,这里不不去演示。其用法同@PostConstruct。
1.8. 使用<context:annotation-config />简化配置
Spring2.1添加了一个新的context的Schema命名空间,该命名空间对注释驱动、属性文件引入、加载期织入等功能提供了便捷的配置。我们知道注释本身是不会做任何事情的,它仅提供元数据信息。要使元数据信息真正起作用,必须让负责处理这些元数据的处理器工作起来。
AutowiredAnnotationBeanPostProcessor和CommonAnnotationBeanPostProcessor就是处理这些注释元数据的处理器。但是直接在Spring配置文件中定义这些Bean显得比较笨拙。Spring为我们提供了一种方便的注册这些BeanPostProcessor的方式,这就是<context:annotation-config />:
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<context:annotation-config />
</beans>
<context:annotationconfig />将隐式地向Spring容器注册AutowiredAnnotationBeanPostProcessor、CommonAnnotationBeanPostProcessor、 PersistenceAnnotationBeanPostProcessor以及RequiredAnnotationBeanPostProcessor这4个BeanPostProcessor。
2. 使用Spring注解完成Bean的定义
以上我们介绍了通过@Autowired或@Resource来实现在Bean中自动注入的功能,下面我们将介绍如何注解Bean,从而从XML配置文件中完全移除Bean定义的配置。
2.1. @Component(不推荐使用)、@Repository、@Service、@Controller
只需要在对应的类上加上一个@Component注解,就将该类定义为一个Bean了:
@Component
public class UserDaoImpl extends HibernateDaoSupport implements UserDao {
...
}
使用@Component注解定义的Bean,默认的名称(id)是小写开头的非限定类名。如这里定义的Bean名称就是userDaoImpl。你也可以指定Bean的名称:
@Component("userDao")
@Component是所有受Spring管理组件的通用形式,Spring还提供了更加细化的注解形式:@Repository、@Service、@Controller,它们分别对应存储层Bean,业务层Bean,和展示层Bean。目前版本(2.5)中,这些注解与@Component的语义是一样的,完全通用,在Spring以后的版本中可能会给它们追加更多的语义。所以,我们推荐使用@Repository、@Service、@Controller来替代@Component。
2.2. 使用<context:component-scan />让Bean定义注解工作起来
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<context:component-scan base-package="com.kedacom.ksoa" />
</beans>
这里,所有通过<bean>元素定义Bean的配置内容已经被移除,仅需要添加一行<context:component-scan />配置就解决所有问题了——Spring XML配置文件得到了极致的简化(当然配置元数据还是需要的,只不过以注释形式存在罢了)。<context:component-scan />的base-package属性指定了需要扫描的类包,类包及其递归子包中所有的类都会被处理。
<context:component-scan />还允许定义过滤器将基包下的某些类纳入或排除。Spring支持以下4种类型的过滤方式:
- 过滤器类型 表达式范例 说明
- 注解 org.example.SomeAnnotation 将所有使用SomeAnnotation注解的类过滤出来
- 类名指定 org.example.SomeClass 过滤指定的类
- 正则表达式 com\.kedacom\.spring\.annotation\.web\..* 通过正则表达式过滤一些类
- AspectJ表达式 org.example..*Service+ 通过AspectJ表达式过滤一些类
以正则表达式为例,我列举一个应用实例:
<context:component-scan base-package="com.casheen.spring.annotation">
<context:exclude-filter type="regex" expression="com\.casheen\.spring\.annotation\.web\..*" />
</context:component-scan>
值得注意的是<context:component-scan />配置项不但启用了对类包进行扫描以实施注释驱动Bean定义的功能,同时还启用了注释驱动自动注入的功能(即还隐式地在内部注册了AutowiredAnnotationBeanPostProcessor和CommonAnnotationBeanPostProcessor),因此当使用<context:component-scan />后,就可以将<context:annotation-config />移除了。
2.3. 使用@Scope来定义Bean的作用范围
在使用XML定义Bean时,我们可能还需要通过bean的scope属性来定义一个Bean的作用范围,我们同样可以通过@Scope注解来完成这项工作:
@Scope("session")
@Component()
public class UserSessionBean implements Serializable {
...
}
3. 参考
http://kingtai168.iteye.com/blog/244002
http://www.iteye.com/topic/244153
http://static.springframework.org/spring/docs/2.5.x/reference/beans.html#beans-annotation-config
http://static.springframework.org/spring/docs/2.5.x/reference/beans.html#beans-classpath-scanning
posted @
2014-01-17 12:00 kelly 阅读(295) |
评论 (0) |
编辑 收藏
摘要: Struts2.3+Spring3.2的整合
这两天都是一直在鼓捣Struts2.3如何整合Spring3.2以及dao层到底选用什么以及如何整合。下面就把自己这两天的一些小成果分享出来也以便自己以后在实际项目中快速搭建。
首先是Struts2.3整合Spring3.2
1、新建一个web工程(这个就不说了)
2、添...
阅读全文
posted @
2014-01-16 10:32 kelly 阅读(1998) |
评论 (0) |
编辑 收藏 警告信息如下:
警告: No configuration found for the specified action: '/myNameSpace/login.action' in namespace: ''. Form action defaulting to 'action' attribute's literal value.
struts.xml配置信息(部分)
<package name="packageName" extends="struts-default" namespace="/myNameSpace">
<action name="login" class="com.jato.srvclink.test.login.LoginAction" method="login">
jsp页面配置信息(部分)
<s:form action="/myNameSpace/login.action">
思考:没有在''的namespace中发现指定的action '/myNameSpace/login.action'
答疑:因为配置的struts2标签并未指定namespace属性。所以struts2会默认从根命名空间"/"搜索action串' /myNameSpace/login.action',如果搜索不到将进入默认命名空间''搜索action请求串,在默认命名空间中是肯定找不到我们 定义的action的,所以,struts2抛出一个警告信息。
但是为什么我们没有填写namespace,我们的请求也可以正常访问呢?
我们来看一下解析后的html
查看源码得到的html(部分)
<form id="login" onsubmit="return true;" action="/srvclink/myNameSpace/login.action" method="post">
我们看到form提交的action串是准确的url请求,action串确实是/srvclin(应用根)/myNameSpace(命名空间)/login.action。
命名空间中找不到action定义,并不意味着这个action真的不存在,只是我们的代码有问题而已。还有一点是我们在jsp页面的action请求中 手动的加入了.action后缀。事实上struts2会自动追加.action的,因为我们并没有合法的使用struts2的标签,所以struts2 这里并没有给我们追加.action,解析后的代码中存在的.action,完全是我们手动在jsp页面填写的,有疑问的网友可以不手动添加查看 html。
我们修改我们的程序代码
jsp页面配置信息(部分)修改后加入namespace属性,修改action属性值为/login.action
<s:form action="/login.action" namespace="/myNameSpace">
请求页面后,大家很失望吧?警告依然存在。但是我们看一下警告信息。
警告信息:
警告: No configuration found for the specified action: '/login.action' in namespace: '/myNameSpace'. Form action defaulting to 'action' attribute's literal value.
没有在'/myNameSpace'的namespace中发现指定的action '/login.action'
毫无疑问,这里的警告和第一次的警告信息截然不同。我们现在存在命名空间,'/myNameSpace'能够被struts2检索到,并不是开始的''。那问题的关键在哪里呢?
在namespace中没有发现指定的action '/login.action' ???
我们来看一下struts.xml中的配置:
struts.xml配置信息(部分)
<package name="packageName" extends="struts-default" namespace="/myNameSpace">
<action name="login" class="com.jato.srvclink.test.login.LoginAction" method="login">
是的,我们'/myNameSpace'命名空间下,只有action名字为'login'的定义,并没有所谓的'/login.action' 定义,所以struts2的警告并未错。如果大家对这个抱有怀疑,可以修改action的名字'login'为‘/longin.action’
<action name="/login.action" class="com.jato.srvclink.test.login.LoginAction" method="login">
请求页面时你会发现不在报警告信息,原因很简单。因为在命名空间为'myNameSpace'下确实存在命名为'/login.action'的action。
我们再次修改配置文件
jsp页面配置信息(部分)修改后action属性值为longin
<s:form action="login" namespace="/myNameSpace">
请求页面时,我们发现不再有警告信息了。
如果你有足够细心,我想你应该可以彻底的明白为什么struts2会报警了吧?你也应该明白了使用struts2标签action中添加/线后请求反而报错的原因了。
posted @
2014-01-16 10:13 kelly 阅读(285) |
评论 (0) |
编辑 收藏 功能:本实例实现的功能是从输入界面输入用户名和密码,若用户名和密码正确转到成功界面,否则转到失败界面。
实现:
第一步:创建一个Web工程
在MyEclipse,通过菜单File->New->Web Project,在Project Name输入工程名称Strut2Travel,点解确定完成创建一个工程。
简注:MyEclipse属于一个IDE继承开发环境,可以快速的创建Web项目。读者可以手工创建,只需满足项目的文件结构即可。其中WEB-INF文件夹必不可少。
第二步:导入Struts2的核心支持包
commons-fileupload-1.2.1.jar
commons-io-1.3.2.jar
commons-logging-1.0.4.jar
freemarker-2.3.15.jar
ognl-2.7.3.jar
struts2-core-2.1.8.1.jar
xwork-core-2.1.6.jar
简注:Struts2有大量的jar包,支持大量的功能,不同类型的应用可能需要不同的包支持。以上的5个包为Struts2的核心包,使用Struts2必须使用。
第三步:配置struts2转发过滤器
编辑web.xml文件,添加以下内容
<filter>
<filter-name>struts2</filter-name>
<filter-class>
org.apache.struts2.dispatcher.FilterDispatcher
</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
简注:“/*”表示涉及本工程的所有浏览器端的请求都经过struts2过滤器处理。
第四步:创建输入页面login.jsp、结果页面welcome.jsp和error.jsp
login.jsp
<%@ page language="java" import="java.util.*" pageEncoding="GB2312"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head><title>登录界面</title></head>
<body>
<form action="LoginAction.action">
用户名:<input name="username"><br>
密 码:<input type="password" name="userpass"><br>
<input type="submit" value="提 交">
<input type="reset" value="取 消">
</form>
</body>
</html>
welcome.jsp
<%@ page language="java" import="java.util.*" pageEncoding="GB2312"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>欢迎</title>
</head>
<body>
<font color="red" size="10">登录成功!</font>
</body>
</html>
error.jsp
<%@ page language="java" import="java.util.*" pageEncoding="GB2312"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title></title>
</head>
<body>
<font color="red" size="10">用户或密码错误!</font>
</body>
</html>
简注:本实例是最简单的应用,以上为纯JSP文件,Struts2提供大量使用的标签,本书后面的实例会使用到。
第五步:创建Action文件LoginAction和struts2.xml文件
LoginAction.java
package com;
import com.opensymphony.xwork2.ActionSupport;
public class LoginAction extends ActionSupport{
private String username;
private String userpass;
public String execute(){
if("daniel".equals(username)&&"abcde".equals(userpass))
return SUCCESS;
else
return ERROR;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getUserpass() {
return userpass;
}
public void setUserpass(String userpass) {
this.userpass = userpass;
}
}
简注:默认配置情况下执行execute()方法,实际应用中经常更改配置。本书后面将深入讲解。注意本类中的username和userpass必须和网页文件的name属性名一致。
struts.xml
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="struts2demo" extends="struts-default">
<action name="loginAction" class="com.LoginAction">
<result name="success">/welcome.jsp</result>
<result name="error">/error.jsp</result>
</action>
</package>
</struts>
第五步:将程序发布到Tomcat,启动Tomcat即可。
通过本实例读者应该掌握如何配置并编写一个最简单最基本的应用,对于初学读者以了解为主,没必要深究一些问题。
posted @
2014-01-10 11:18 kelly 阅读(313) |
评论 (0) |
编辑 收藏
摘要: 使用注解来配置Action的最大好处就是可以实现零配置,但是事务都是有利有弊的,使用方便,维护起来就没那么方便了。
要使用注解方式,我们必须添加一个额外包:struts2-convention-plugin-2.x.x.jar。
虽说是零配置的,但struts.xml还是少不了的,配置如下:
<?xml version="1.0" enc...
阅读全文
posted @
2014-01-09 16:20 kelly 阅读(234) |
评论 (0) |
编辑 收藏
Struts2教程1:第一个Struts2程序
在本系列教程中我们将学习到Struts2的各种技术。在本教程中使用的工具和程序库的版本如下:
开发工具:MyEclipse6
Web服务器:Tomcat6
Struts版本:Struts2.0.11.1
JDK版本:JDK1.5.0_12
J2EE版本:Java EE5.0
在本系列教程中Web工程的上下文路径都是struts2,如果在Web根目录有一个index.jsp文件,则访问路径如下:
http://localhost:8080/struts2/index.jsp
由于MyEclipse6目前并不支持Struts2,所以我们需要到struts.apache.org去下载Struts2安装包。要想正常使用Struts2,至少需要如下五个包(可能会因为Struts2的版本不同,包名略有差异,但包名的前半部是一样的)。
struts2-core-2.0.11.1.jar
xwork-2.0.4.jar
commons-logging-1.0.4.jar
freemarker-2.3.8.jar
ognl-2.6.11.jar
Struts2虽然在大版本号上是第二个版本,但基本上在配置和使用上已经完全颠覆了Struts1.x的方式(当然,Struts2仍然是基于MVC模式的,也是动作驱动的,可能这是唯一没变的东西)。Struts2实际上是在Webwork基础上构建起来的MVC框架。我们从Struts2的源代码中可以看到,有很多都是直接使用的xwork(Webwork的核心技术)的包。既然从技术上来说Struts2是全新的框架,那么就让我们来学习一下这个新的框架的使用方法。
如果大家使用过Struts1.x,应该对建立基于Struts1.x的Web程序的基本步骤非常清楚。让我们先来回顾一下建立基于Struts1.x的Web程序的基本步骤。
1. 安装Struts。由于Struts的入口点是ActionServlet,所以得在web.xml中配置一下这个Servlet。
2. 编写Action类(一般从org.apache.struts.action.Action类继承)。
3. 编写ActionForm类(一般从org.apache.struts.action.ActionForm类继承),这一步不是必须的,如果要接收客户端提交的数据,需要执行这一步。
4. 在struts-config.xml文件中配置Action和ActionForm。
5. 如果要采集用户录入的数据,一般需要编写若干JSP页面,并通过这些JSP页面中的form将数据提交给Action。
下面我们就按着编写struts1.x程序的这五步和struts2.x程序的编写过程一一对应,看看它们谁更“酷”。下面我们来编写一个基于Struts2的Web程序。这个程序的功能是让用户录入两个整数,并提交给一个Struts Action,并计算这两个数的代数和,如果代码和为非负数,则跳转到positive.jsp页面,否则跳转到negative.jsp页面。
【第1步】 安装Struts2
这一步对于Struts1.x和Struts2都是必须的,只是安装的方法不同。Struts1的入口点是一个Servlet,而Struts2的入口点是一个过滤器(Filter)。因此,Struts2要按过滤器的方式配置。下面是在web.xml中配置Struts2的代码:
<filter>
<filter-name>struts2</filter-name>
<filter-class>
org.apache.struts2.dispatcher.FilterDispatcher
</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
【第2步】 编写Action类
这一步和Struts1.x也必须进行。只是Struts1.x中的动作类必须从Action类中继承,而Struts2.x的动作类需要从com.opensymphony.xwork2.ActionSupport类继承。下面是计算两个整数代码和的Action类,代码如下:
package action;
import com.opensymphony.xwork2.ActionSupport;
public class FirstAction extends ActionSupport
{
private int operand1;
private int operand2;
public String execute() throws Exception
{
if (getSum() >= 0) // 如果代码数和是非负整数,跳到positive.jsp页面
{
return "positive";
}
else // 如果代码数和是负整数,跳到negative.jsp页面
{
return "negative";
}
}
public int getOperand1()
{
return operand1;
}
public void setOperand1(int operand1)
{
System.out.println(operand1);
this.operand1 = operand1;
}
public int getOperand2()
{
return operand2;
}
public void setOperand2(int operand2)
{
System.out.println(operand2);
this.operand2 = operand2;
}
public int getSum()
{
return operand1 + operand2; // 计算两个整数的代码数和
}
}
从上面的代码可以看出,动作类的一个特征就是要覆盖execute方法,只是Struts2的execute方法没有参数了,而Struts1.x的execute方法有四个参数。而且execute方法的返回值也不同的。Struts2只返回一个String,用于表述执行结果(就是一个标志)。上面代码的其他部分将在下面讲解。
【第3步】 编写ActionForm类
在本例中当然需要使用ActionForm了。在Struts1.x中,必须要单独建立一个ActionForm类(或是定义一个动作Form),而在Struts2中ActionForm和Action已经二合一了。从第二步的代码可以看出,后面的部分就是应该写在ActionForm类中的内容。所以在第2步,本例的ActionForm类已经编写完成(就是Action类的后半部分)。
【第4步】 配置Action类
这一步struts1.x和struts2.x都是必须的,只是在struts1.x中的配置文件一般叫struts-config.xml(当然也可以是其他的文件名),而且一般放到WEB-INF目录中。而在struts2.x中的配置文件一般为struts.xml,放到WEB-INF"classes目录中。下面是在struts.xml中配置动作类的代码:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="struts2" namespace="/mystruts"
extends="struts-default">
<action name="sum" class="action.FirstAction">
<result name="positive">/positive.jsp</result>
<result name="negative">/negative.jsp</result>
</action>
</package>
</struts>
在<struts>标签中可以有多个<package>,第一个<package>可以指定一个Servlet访问路径(不包括动作名),如“/mystruts”。extends属性继承一个默认的配置文件“struts-default”,一般都继承于它,大家可以先不去管它。<action>标签中的name属性表示动作名,class表示动作类名。
<result>标签的name实际上就是execute方法返回的字符串,如果返回的是“positive”,就跳转到positive.jsp页面,如果是“negative”,就跳转到negative.jsp页面。在<struts>中可以有多个<package>,在<package>中可以有多个<action>。我们可以用如下的URL来访问这个动作:
http://localhost:8080/struts2/mystruts/sum.action
注:Struts1.x的动作一般都以.do结尾,而Struts2是以.action结尾。
【第5步】 编写用户录入接口(JSP页面)
1. 主界面(sum.jsp)
在Web根目录建立一个sum.jsp,代码如下:
<%@ page language="java" import="java.util.*" pageEncoding="GBK" %>
<%@ taglib prefix="s" uri="/struts-tags"%>
<html>
<head>
<title>输入操作数</title>
</head>
<body>
求代数和
<br/>
<s:form action="mystruts/sum.action" >
<s:textfield name="operand1" label=" 操作数1"/>
<s:textfield name="operand2" label=" 操作数2" />
<s:submit value="代数和" />
</s:form>
</body>
</html>
在sum.jsp中使用了Struts2带的tag。在Struts2中已经将Struts1.x的好几个标签库都统一了,在Struts2中只有一个标签库/struts-tags。这里面包含了所有的Struts2标签。但使用Struts2的标签大家要注意一下。在<s:form>中最好都使用Struts2标签,尽量不要用HTML或普通文本,大家可以将sum.jsp的代码改为如下的形式,看看会出现什么效果:
... ...
求代数和
<br/>
<s:form action="mystruts/sum.action" >
操作数1:<s:textfield name="operand1" /><br/>
操作数2:<s:textfield name="operand1" /><br/>
<s:submit value="代数和" />
</s:form>
... ...
提示一下,在<s:form>中Struts2使用<table>定位。
2. positive.jsp
<%@ page language="java" import="java.util.*" pageEncoding="GBK"%>
<%@ taglib prefix="s" uri="/struts-tags" %>
<html>
<head>
<title>显示代数和</title>
</head>
<body>
代数和为非负整数<h1><s:property value="sum" /></h1>
</body>
</html>
3. negative.jsp
<%@ page language="java" import="java.util.*" pageEncoding="GBK"%>
<%@ taglib prefix="s" uri="/struts-tags" %>
<html>
<head>
<title>显示代数和</title>
</head>
<body>
代数和为负整数<h1><s:property value="sum" /></h1>
</body>
</html>
这两个jsp页面的实现代码基本一样,只使用了一个<s:property>标签来显示Action类中的sum属性值。<s:property>标签是从request对象中获得了一个对象中得到的sum属性,如我们可以使用如下的代码来代替<s:property value=”sum”/>:
posted @
2014-01-09 11:41 kelly 阅读(263) |
评论 (0) |
编辑 收藏
摘要:
Ibatis+spring整合集成开发
前面的文档学习了ibatis的开发,这节学习ibatis和spring的整合集成开发。
1.需要的开发包包括ibatis开发包和spring常用包
2.创建POJO实体类,Area.java和Define_industry.java
package com.ibatis.samp...
阅读全文
posted @
2014-01-09 11:38 kelly 阅读(342) |
评论 (0) |
编辑 收藏理解ActionContext 、ValueStack 、Stack Context
ActionContext
一次Action调用都会创建一个ActionContext
调用:ActionContext context = ActionContext.getContext()
ValueStack
由OGNL框架实现
可以把它简单的看作一个栈(List) 。
Stack Object:放入stack中的对象,一般是action。
Stack Context(map):stack上下文,它包含一系列对象,包括request/session/attr/application map等。
EL:存取对象的任意属性,调用对象的方法,遍历整个对象结…
ActionContext是Action上下文,可以得到request session application
ValueStack是值栈 存放表单中的值
Stack Context 栈上下文 也是用来存值的
struts2对OGNL上下文的概念又做了进一步扩充,在struts2中,OGNL上下文通常如下所示:
|--request
|
|--application
|
context map---|--OgnlValueStack(root) [ user, action, OgnlUtil, ... ]
|
|--session
|
|--attr
|
|--parameters
在Struts2中,采用标准命名的上下文(Context)来处理OGNL表达式。处理OGNL的顶级对象是一个Map(也叫context map),而OGNL在这个context中就是一个顶级对象(root)。在用法上,顶级对象的属性访问,是不需要任何标记前缀的。而其它非顶级的对象访问,需要使用#标记。
Struts2框架把OGNL Context设置为我们的ActionContext。并且ValueStack作为OGNL的根对象。除value stack之外,Struts2框架还把代表application、session、request这些对象的Map对象也放到ActionContext中去。(这也就是Struts2建议在Action类中不要直接访问Servlet API的原因,他可以通过ActionContext对象来部分代替这些(Servlet API)功能,以方便对Action类进行测试!)
Action的实例,总是放到value stack中。因为Action放在stack中,而stack是root(根对象),所以对Action中的属性的访问就可以省略#标记。但是,要访问ActionContext中其它对象的属性,就必须要带上#标记,以便让OGNL知道,不是从根对象,而是从其它对象中去寻找。
那么访问Action中的属性的代码就可以这样写
<s:property value="postalCode"/>
其它ActionContext中的非根对象属性的访问要像下面这样写:
<s:property value="#session.mySessionPropKey"/> or
<s:property value="#session['mySessionPropKey']"/> or
<s:property value="#request['myRequestPropKey']"/>
对Collection的处理,内容就很简单。
<s:select label="label" name="name" list="{'name1','name2','name3'}" value="%{'name2'}" />
这是处理List。这个代码在页面上建立一个下拉选项,内容是list中的内容,默认值是name2.
处理map
<s:select label="label" name="name" list="#{'foo':'foovalue', 'bar':'barvalue'}" />
需要注意的是,判断一个值是否在collection中。我们要使用in或者not in来处理。
<s:if test="'foo' in {'foo','bar'}">
muhahaha
</s:if>
<s:else>
boo
</s:else>
另外,可以使用通配符来选择collection对象的子集。
?——所有匹配选择逻辑的元素
^——只提取符合选择逻辑的第一个元素
$——只提取符合选择逻辑的最后一个元素
person.relatives.{? #this.gender == 'male'}
?
?
值栈(ValueStack)
Struts2将OGNL上下文设置为Struts2中的ActionContext(内部使用的仍然是OgnlContext),并将值栈设为OGNL的根对象。
我们知道,OGNL上下文中的根对象可以直接访问,不需要使用任何特殊的“标记”,而引用上下文中的其他对象则需要使用“#”来标记。由于值栈是上下文中的根对象,因此可以直接访问。那么对于值栈中的对象该如何访问呢?Struts2提供了一个特殊的OGNLPropertyAccessor,它可以自动查找栈内的所有对象(从栈顶到栈底),直接找到一个具有你所查找的属性的对象。也就是说,对于值栈中的任何对象都可以直接访问,而不需要使用“#”。
假设值栈中有两个对象:student和employee,两个对象都有name属性,student有学号属性number,而employee有薪水属性salary。employee先入栈,student后入栈,位于栈顶,那么对于表达式name,访问的就是student的name属性,因为student对象位于栈顶;表达式salary,访问的就是employee的salary属性。正如你所见,访问值栈中的对象属性或方法,无须指明对象,也不用“#”,就好像值栈中的对象都是OGNL上下文中的根对象一样。这就是Struts2在OGNL基础上做出的改进。
值栈中的Action实例
Struts2框架总是把Action实例放在栈顶。因为Action在值栈中,而值栈又是OGNL中的根,所以引用Action的属性可以省略“#”标记,这也是为什么我们在结果页面中可以直接访问Action的属性的原因。
Struts2中的命名对象
Struts2还提供了一些命名对象,这些对象没有保存在值栈中,而是保存在ActionContext中,因此访问这些对象需要使用“#”标记。这些命名对象都是Map类型。
parameters
用于访问请求参数。如:#parameters['id']或#parameters.id,相当于调用了HttpServletRequest对象的getParameter()方法。
注意,parameters本质上是一个使用HttpServletRequest对象中的请求参数构造的Map对象,一量对象被创建(在调用Action实例之前就已经创建好了),它和HttpServletRequest对象就没有了任何关系。
request
用于访问请求属性。如:#request['user']或#request.user,相当于调用了HttpServletRequest对象的getAttribute()方法。
session
用于访问session属性。如:#session['user']或#session.user,相当于调用了HttpSession对象的getAttribute()方法。
application
用于访问application属性。如:#application['user']或#application.user,相当于调用了ServletContext的getAttribute()方法。
attr
如果PageContext可用,则访问PageContext,否则依次搜索request、session和application对象。
假设你的Action类中有变量String password; 要想获取页面中传过来的password,必须为password设置get 和set 方法。当你的页面进入Action时,ActionContext(Action上下文)通过set方法获取password的值并压入值栈栈顶,同时request也获取到password的值,同时也如堆栈,session等对象的值也被压入堆栈,ActionContext中的值在页面中可以直接用<s:porperty value="password">取值显示,而request中存储的password通过<s:porperty value="#request.password">或者${password}取值。即struts是通过一个值栈来存储所有对象和ActionContext中的值得。ActionContext为栈顶对象,也称跟对象,ActionContext的值可以直接用变量名取,而其他的变量需要用#变量名取值。
posted @
2014-01-09 11:20 kelly 阅读(513) |
评论 (0) |
编辑 收藏- 一、什么是OGNL,有什么特点?
-
- OGNL(Object-Graph Navigation Language),大概可以理解为:对象图形化导航语言。是一种可以方便地操作对象属性的开源表达式语言。OGNL有如下特点:
-
- 1、支持对象方法调用,形式如:objName.methodName();
-
- 2、支持类静态的方法调用和值访问,表达式的格式为@[类全名(包括包路)]@[方法名 | 值名],例如:
-
- @java.lang.String@format('foo %s', 'bar')或@tutorial.MyConstant@APP_NAME;
-
- 3、支持赋值操作和表达式串联,例如:
-
- price=100, discount=0.8, calculatePrice(),这个表达式会返回80;
-
- 4、访问OGNL上下文(OGNL context)和ActionContext;
-
- 5、操作集合对象。
-
-
-
- 二、使用OGNL表达式
-
- OGNL要结合struts标签来使用。由于比较灵活,也容易把人给弄晕,尤其是“%”、“#”、“$”这三个符号的使用。由于$广泛应用于EL中,这里重点写%和#符号的用法。
-
- 1、“#”符号有三种用途:
-
- (1)、访问非根对象(struts中值栈为根对象)如OGNL上下文和Action上下文,#相当于ActionContext.getContext();下表有几个ActionContext中有用的属性:
-
-
-
- 名称
- 作用
- 例子
-
- parameters
- 包含当前HTTP请求参数的Map
- #parameters.id[0]作用相当于request.getParameter("id")
-
- request
- 包含当前HttpServletRequest的属性(attribute)的Map
- #request.userName相当于request.getAttribute("userName")
-
- session
- 包含当前HttpSession的属性(attribute)的Map
- #session.userName相当于session.getAttribute("userName")
-
- application
- 包含当前应用的ServletContext的属性(attribute)的Map
- #application.userName相当于application.getAttribute("userName")
-
-
- 注:attr 用于按request > session > application顺序访问其属性(attribute),#attr.userName相当于按顺序在以上三个范围(scope)内读取userName属性,直到找到为止。用于过滤和投影(projecting)集合,如books.{?#this.price<100};构造Map,如#{'foo1':'bar1', 'foo2':'bar2'}。
-
-
-
- (2)、用于过滤和投影(projecting)集合,如: books.{?#this.price>35}
-
- books.{?#this.price>35}
-
- (3)、构造Map,如: #{'foo1':'bar1', 'foo2':'bar2'}
-
- #{'foo1':'bar1', 'foo2':'bar2'}这种方式常用在给radio或select、checkbox等标签赋值上。如果要在页面中取一个map的值可以这样写:
-
- <s:property value="#myMap['foo1']"/>
-
- <s:property value="#myMap['foo1']"/>
-
- 2、“%”符号的用途是在标签的属性值被理解为字符串类型时,告诉执行环境%{}里的是OGNL表达式。
-
- 这是一开始最让我不能理解的符号,原因是一些相关资源在表述时不太准备,经过一翻痛苦的探索,终于明白了它的用途。实际上就是让被理解为字符串的表达式,被真正当成ognl来执行。很有点类似javascript里面的eval_r()功能,例如 :
-
- var oDiv = eval_r("document.all.div"+index)
-
- var oDiv = eval_r("document.all.div"+index)
-
- 当index变量为1时,语句就会被当作var oDiv = document.all.div1 var oDiv = document.all.div1来执行。%{}就是起这个作用。举例:
-
- <s:set name="myMap" value="#{'key1':'value1','key2':'value2'}"/>
-
- <s:property value="#myMap['key1']"/>
-
- <s:url value="#myMap['key1']" />
-
- <s:set name="myMap" value="#{'key1':'value1','key2':'value2'}"/>
-
- <s:property value="#myMap['key1']"/>
-
- <s:url value="#myMap['key1']"/>
-
- 上面的代码第2行会在页面上输出“value1”,而第3行则会输出"#myMap['key1']"这么一个字符串。 如果将第3行改写成这样:
-
- <s:url value="%{#myMap['key1']}"/>
-
- <s:url value="%{#myMap['key1']}"/>
-
- 则输出为“value1”。
-
-
-
-
-
- 这说明struts2里不同的标签对ognl的表达式的理解是不一样的。如果当有的标签“看不懂”类似“#myMap['key1']”的语句时,就要用%{}来把这括进去,“翻译”一下了。
-
- 3、“$”有两种用途
-
- (1)、在国际化资源文件中,引用OGNL表达式。
-
- (2)、在Struts 2配置文件中,引用OGNL表达式:
-
- <action name="saveUser" class="userAction" method="save">
-
- <result type="redirect">listUser.action?msg=${msg}</result>
-
- </action>
-
- <action name="saveUser" class="userAction" method="save">
-
- <result type="redirect">listUser.action?msg=${msg}</result>
-
- </action>
posted @
2014-01-08 13:58 kelly 阅读(248) |
评论 (0) |
编辑 收藏
摘要: Ibatis介绍与用例
一、介绍
ibatis 是一种“半自动化”的ORM实现。iBATIS是以SQL为中心的持久化层框架。能支持懒加载、关联查询、继承等特性。iBATIS不同于一般的OR映射框架(eg:hibernate)。OR映射框架,将数据库表、字段等映射到类、属性,那是一种元数据(meta-data)映射。iBATIS则是将SQL查询的参数和结果...
阅读全文
posted @
2014-01-07 15:50 kelly 阅读(435) |
评论 (0) |
编辑 收藏
摘要: 深入Struts2的配置文件
本部分主要介绍struts.xml的常用配置。
1.1. 包配置:
Struts2框架中核心组件就是Action、拦截器等,Struts2框架使用包来管理Action和拦截器等。每个包就是多个Action、多个拦截器、多个拦截器引用的集合。
在struts.xml文件中package元素用于定义包配置,每个pack...
阅读全文
posted @
2014-01-07 15:39 kelly 阅读(198) |
评论 (0) |
编辑 收藏
摘要: 首页要在web.xml中添加相应的struts配置:
<servlet> <servlet-name>action</servlet-name> <servlet-class> org.apache.struts.action.ActionServlet </servle...
阅读全文
posted @
2013-12-27 14:56 kelly 阅读(248) |
评论 (0) |
编辑 收藏
1 编写目的
本文详细介绍了DBCP连接池的各个配置参数的含义,并通过实际例子演示不同的参数设置可能参数的结果。
2 适用对象
项目实施人员
3 参考资料
4 知识文件主要内容4.1连接池知识简介
总所周知建立数据库连接是一个非常耗时耗资源的行为,因此现代的Web中间件,无论是开源的Tomcat、Jboss还是商业的websphere、weblogic都提供了数据库连接池功能,可以毫不夸张的说,数据库连接池性能的好坏,不同厂商对连接池有着不同的实现,本文只介绍拜特公司使用较多的开源web中间件Tomcat中默认的连接池DBCP(DataBase connection pool)的使用。
4.2Tomcat下配置连接池
下面以tomcat5.5.26为例来介绍如何配置连接池
1:需要的jar
在tomcat的安装目录common\lib下有一个naming-factory-dbcp.jar,这个是tomcat修改后的dbcp连接池实现,同时为了能够正常运行,还需要commons-pool.jar。
2:建立context文件
进入到conf\Catalina\localhost新建一个上下文文件,文件的名称既为将来要访问是输入url上下文名称,例如我们建立一个名为btweb的文件内容如下:
<Context debug="0" docBase="D:\v10_workspace\build\WebRoot"
reloadable="false">
<Resource
name="jdbc/btdb1"
type="javax.sql.DataSource"
factory="org.apache.tomcat.dbcp.dbcp.BasicDataSourceFactory"
username="v10"
password="v10"
driverClassName="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@127.0.0.1:1521:cahs"
maxActive="5"
maxIdle="3"
maxWait="5000"
removeAbandoned="true"
removeAbandonedTimeout="60"
testOnBorrow="true"
validationQuery="select count(*) from bt_user"
logAbandoned="true"
/>
</Context>
4.3参数分步介绍
u
数据库连接相关
username="v10"
password="v10"
driverClassName="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@127.0.0.1:1521:cahs"
u
jndi相关
name="jdbc/btdb1"
type="javax.sql.DataSource"
factory="org.apache.tomcat.dbcp.dbcp.BasicDataSourceFactory"
factory默认是org.apache.tomcat.dbcp.dbcp.BasicDataSourceFactory,tomcat也允许采用其他连接实现,不过默认使用dbcp。
u
连接数控制与连接归还策略
maxActive="5"
maxIdle="3"
minIdle=”2”
maxWait="5000"
u
应对网络不稳定的策略
testOnBorrow="true"
validationQuery="select count(*) from bt_user"
u
应对连接泄漏的策略
removeAbandoned="true"
removeAbandonedTimeout="60"
logAbandoned="true"
如下图所示:连接池处于应用程序与数据库之间,一方面应用程序通过它来获取连接,归还连接,另一方面连接又需要从数据里获取连接,归还连接。
步骤1:系统启动
系统启动时,初始化连接池,由于没有任何请求连接池中连接数为0。
maxActive="5"
表示并发情况下最大可从连接池中获取的连接数。如果数据库不是单独,供一个应用使用,通过设置maxActive参数可以避免某个应用无限制的获取连接对其他应用造成影响,如果一个数据库只是用来支持一个应用那么maxActive理论上可以设置成该数据库可以支撑的最大连接数。maxActive只是表示通过连接池可以并发的获取的最大连接数。
从图上我们可以看到连接的获取与释放是双向,当应用程序并发请求连接池时,连接池就需要从数据库获取连接,那么但应用程序使用完连接并将连接归还给连接池时,连接池是否也同时将连接归还给数据库呢?很显然答案是否定的,如果那样的话连接池就变得多此一举,不但不能提高性能,反而会降低性能,那么但应用成归还连接后,连接池如何处理呢?
maxIdle="3"
如果在并发时达到了maxActive=5,那么连接池就必须从数据库中获取5个连接来供应用程序使用,当应用程序关闭连接后,由于maxIdle=3,因此并不是所有的连接都会归还给数据库,将会有3个连接保持在连接池种中,状态为空闲。
minIdle=”2”
最小默认情况下并不生效,它的含义是当连接池中的连接少有minIdle,系统监控线程将启动补充功能,一般情况下我们并不启动补充线程。
问题:如何设置maxActive和maxIdle?
理论上讲maxActive应该设置成应用的最大并发数,这样一来即便是在最大并发的情况下,应用依然能够从连接池中获取连接,但是困难时的是我们很难准确估计到最大并发数,设置成最大并发数是一种最优的服务质量保证,事实上,如果某个用户登录提示系统繁忙,那么在他再次登录时,可能系统资源已经充足,对于拜特资金管理系统我们建议将maxActive设置为系统注册人数的十分之一到二十分之一之间。例如系统的注册人数为1000,那么设置成50-100靠近100的数字,例如85或90。
maxIdle对应的连接,实际上是连接池保持的长连接,这也是连接池发挥优势的部分,理论上讲保持较多的长连接,在应用请求时可以更快的响应,但是过多的连接保持,反而会消耗数据库大量的资源,因此maxIdle也并不是越大越好,同上例我们建议将maxIdle设置成
50-100中靠近50的数字,例如55。这样就能在兼顾最大并发同时,保持较少的数据库连接,而且在绝大多情况,能够为应用程序提供最快的相应速度。
testOnBorrow="true"
validationQuery="select count(*) from bt_user"
我们知道数据库连接从本质上架构在tcp/ip连接之上,一般情况下web服务器与数据库服务器都不在同一台物理机器上,而是通过网络进行连接,那么当建立数据库连接池的机器与数据库服务器自己出现网络异常时,保持在连接池中的连接将失效,不能够在次使用,传统的情况下只能通过重新启动,再次建立连接,通过设置以上两个参数,但应用程序从连接池中获取连接时,会首先进行活动性检测,当获取的连接是活动的时候才会给应用程序使用,如果连接失效,连接将释放该连接。validationQuery是一条测试语句,没有实际意义,现实中,一般用一条最为简单的查询语句充当。
removeAbandoned="true"
removeAbandonedTimeout="60"
logAbandoned="true"
有时粗心的程序编写者在从连接池中获取连接使用后忘记了连接的关闭,这样连池的连接就会逐渐达到maxActive直至连接池无法提供服务。现代连接池一般提供一种“智能”的检查,但设置了removeAbandoned="true"时,当连接池连接数到达(getNumIdle() < 2) and (getNumActive() > getMaxActive() - 3)时便会启动连接回收,那种活动时间超过removeAbandonedTimeout="60"的连接将会被回收,同时如果logAbandoned="true"设置为true,程序在回收连接的同时会打印日志。removeAbandoned是连接池的高级功能,理论上这中配置不应该出现在实际的生产环境,因为有时应用程序执行长事务,可能这种情况下,会被连接池误回收,该种配置一般在程序测试阶段,为了定位连接泄漏的具体代码位置,被开启,生产环境中连接的关闭应该靠程序自己保证。
posted @
2013-12-20 23:01 kelly 阅读(1584) |
评论 (0) |
编辑 收藏一般情况下,URL 中的参数应使用 url 编码规则,即把参数字符串中除了 -_. 之外的所有非字母数字字符都将被替换成百分号(%)后跟两位十六进制数,空格则编码为加号(+)。但是对于带有中文的参数来说,这种编码会使编码后的字符串变得很长。如果希望有短一点的方式对参数编码,可以采用 base64 编码方式对字符串进行编码,但是 base64 编码方式不能处理 JavaScript 中的中文,因为 JavaScript 中的中文都是以 UTF-16 方式保存的。而 base64 只能处理单字节字符,所以不能直接用 base64 对带有中文的 JavaScript 字符串进行编码。但是可以通过 utf.js 这个程序中提供的 utf16to8 来将 UTF-16 编码的中文先转化为 UTF-8 方式,然后再进行 base64 编码。这样编码后的字符串,在传递到服务器端后可以直接通过 base64_decode 解码成 UTF-8 的中文字符串。但是还有个问题需要注意。base64 编码中使用了加号(+),而 + 在 URL 传递时会被当成空格,因此必须要将 base64 编码后的字符串中的加号替换成 %2B 才能当作 URL 参数进行传递。否则在服务器端解码后就会出错。
所以我们需要做的就是:
js中:encodeURI(str).replace(/\+/g,'%2B')
java中:str.replaceAll("\\+","%2B")
posted @
2013-12-17 11:03 kelly 阅读(1585) |
评论 (0) |
编辑 收藏 将mysql数据文件导入到数据库中:
1.在navicat 中创建一个mysql数据库链接,填写端口、用户名、密码
2.创建数据库
3.打开数据库
4.右键选择“运行sql文件”
5.选择sql文件的地址并执行
用navicat将mysql数据库中的数据导出的两种方法:
1.右键,转储sql文件,直接保存文件,不能设置执行选项。
2.右键,数据传输;如果只想导出数据库表结构,不导出数据,可以把“数据传输”-》“高级”-》“记录选项”中的勾去掉,则不会导出记录。
posted @
2013-12-13 15:12 kelly 阅读(325) |
评论 (0) |
编辑 收藏Windows 2008 R2默认是禁止Ping的,但是我们在日常中很多情况都需要用到Ping功能,这时候只需要打开Ping功能即可。
在防火期开启的状态下,怎样才能ping呢?
开始-控制面板-管理工具-服务器管理器,如图
选择配置-高级安全 Windows 防火墙-入站规则:文件和打印机共享(回显请求 - ICMPv4-In)(配置文件为域和公用的这条) 启用该规则即可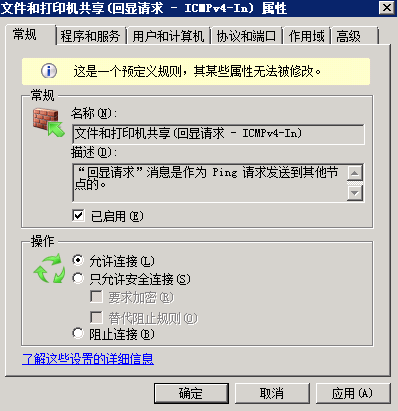 。
。
在本地测试一下:ping ip,已经通了!
posted @
2013-12-13 13:54 kelly 阅读(323) |
评论 (0) |
编辑 收藏
改变applicationContext.xml中
<bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<property name="configLocation">
<value>classpath:SqlMapConfig.xml</value>
</property>
<property name="dataSource">
<ref bean="dataSource"/>
</property>
< /bean>
中的
<value>classpath:SqlMapConfig.xml</value>
然后把SqlMapConfig.xml放到src下面
posted @
2013-12-05 13:39 kelly 阅读(508) |
评论 (0) |
编辑 收藏全部删除
如果是删除某个表的所有数据,并且不需要回滚,使用 TRUNCATE 就ok了。关于Trancate 参见这里http://blog.csdn.net/gnolhh168/archive/2011/05/24/6442561.aspx
SQL> truncate table table_name;
条件删除
如果删除数据有条件,如 delete from tablename where col1 = 'lucy';这时除了加索引外, 你可以删除时加NO LOGGING选项,不写日志加快删除速度
引用某人的一句话“几千万条记录的表都不分区,明显有问题嘛。Oracle的技术支持工程师建议,2,000,000条以上记录的表,应该考虑分区,你完全可以按照时间为维度来建表,每个月的数据存放在一个分区表中,以后要删除一个月的数据,直接truncate table即可,不记录日志,速度很快。”
删除大量重复记录
《转》做项目的时候,一位同事导数据的时候,不小心把一个表中的数据全都搞重了,也就是说,这个表里所有的记录都有一条重复的。这个表的数据是千万级的,而且是生产系统。也就是说,不能把所有的记录都删除,而且必须快速的把重复记录删掉。
对此,总结了一下删除重复记录的方法,以及每种方法的优缺点。
为了陈诉方便,假设表名为Tbl,表中有三列col1,col2,col3,其中col1,col2是主键,并且,col1,col2上加了索引。
1、通过创建临时表
可以把数据先导入到一个临时表中,然后删除原表的数据,再把数据导回原表,SQL语句如下:
creat table tbl_tmp (select distinct* from tbl);
truncate table tbl; //清空表记录i
nsert into tbl select * from tbl_tmp;//将临时表中的数据插回来。
这种方法可以实现需求,但是很明显,对于一个千万级记录的表,这种方法很慢,在生产系统中,这会给系统带来很大的开销,不可行。
2、利用rowid
在oracle中,每一条记录都有一个rowid,rowid在整个数据库中是唯一的,rowid确定了每条记录是oracle中的哪一个数据文件、块、行上。在重复的记录中,可能所有列的内容都相同,但rowid不会相同。SQL语句如下:
delete from tbl where rowid in (select a.rowid
from tbl a, tbl b
where a.rowid>b.rowid and a.col1=b.col1 and a.col2 = b.col2)
如果已经知道每条记录只有一条重复的,这个sql语句适用。但是如果每条记录的重复记录有N条,这个N是未知的,就要考虑适用下面这种方法了。
3、利用max或min函数
这里也要使用rowid,与上面不同的是结合max或min函数来实现。SQL语句如下
delete from tbl a
where rowid not in (
select max(b.rowid)
from tbl b
where a.col1=b.col1 and a.col2 = b.col2); //这里max使用min也可以
或者用下面的语句
delete from tbl awhere rowid<(
select max(b.rowid)
from tbl b
where a.col1=b.col1 and a.col2 = b.col2); //这里如果把max换成min的话,前面的where子句中需要把"<"改为">"
跟上面的方法思路基本是一样的,不过使用了group by,减少了显性的比较条件,提高效率。SQL语句如下:
deletefrom tbl where rowid not in (
select max(rowid)
from tbl tgroup by t.col1, t.col2);
delete from tbl where (col1, col2) in (
select col1,col2
from tblgroup bycol1,col2havingcount(*) >1) and rowidnotin(selectnin(rowid)fromtblgroup bycol1, col2havingcount(*) >1) ----???
还有一种方法,对于表中有重复记录的记录比较少的,并且有索引的情况,比较适用。假定col1,col2上有索引,并且tbl表中有重复记录的记录比较少,SQL语句如下4、利用group by,提高效率
posted @
2013-12-02 10:49 kelly 阅读(424) |
评论 (0) |
编辑 收藏
一、 语法:NUMTOYMINTERVAL ( n , 'char_expr' )
char_expr:日期描述,可以是YEAR和MONTH;
作用:可以将数字转换成相应的日期单位时间
比如:NUMTOYMINTERVAL ( 1, 'MONTH' ) 表示一个月,注意:此时跟add_months有点区别,后续有例子会讲到。
NUMTOYMINTERVAL ( 1, 'YEAR' ) 表示一年
对于day、hour、minute、second使用的是numtodsinterval函数,方法和numtoyminterval一样。后面可以跟变量
二、interval后面只能用数字
下面是举例:
SQL> select add_months (to_date('20110228','yyyymmdd'),1) from dual;
ADD_MONTH
---------
31-MAR-11
SQL>
SQL> select add_months(to_date('20110228','yyyymmdd'),-1) from dual;
ADD_MONTH
---------
31-JAN-11
SQL>
SQL>
SQL> select to_date('2007-02-28','yyyy-mm-dd')+numtoyminterval (1,'month') from dual;
TO_DATE('
---------
28-MAR-07
SQL> select to_date('2007-02-28','yyyy-mm-dd')-numtoyminterval (1,'month') from dual;
TO_DATE('
---------
28-JAN-07
此时,注意跟add_months返回结果的区别。
SQL> select to_date('2007-02-28','yyyy-mm-dd')+numtodsinterval(1,'day') from dual;
TO_DATE('
---------
01-MAR-07
SQL>
SQL> select to_date('2007-02-28','yyyy-mm-dd')+interval '+3' hour from dual;
TO_DATE('
---------
28-FEB-07
SQL> select to_date('2007-02-28','yyyy-mm-dd')+interval '+1' month from dual;
TO_DATE('
---------
28-MAR-07
posted @
2013-11-22 10:39 kelly 阅读(696) |
评论 (0) |
编辑 收藏
非整型数,运算由于精度问题,可能会有误差,建议使用BigDecimal类型,具体BigDecimal的详细说明参考jdk开发帮助文档。public class Test {
public static String compare(BigDecimal val1, BigDecimal val2) {
String result = "";
if (val1.compareTo(val2) < 0) {
result = "第二位数大!";
}
if (val1.compareTo(val2) == 0) {
result = "两位数一样大!";
}
if (val1.compareTo(val2) > 0) {
result = "第一位数大!";
}
return result;
}
public static void main(String[] args) {
String a = "200.5"; String b = "1000";
BigDecimal data1 = new BigDecimal(a);
BigDecimal data2 = new BigDecimal(b);
System.out.print(compare(data1, data2));
}
}
posted @
2013-11-07 15:42 kelly 阅读(1042) |
评论 (0) |
编辑 收藏posted @
2013-11-07 13:31 kelly 阅读(2718) |
评论 (0) |
编辑 收藏
分析过程:
运行中输入cmd,、输入sqlplus /nolog,然后用 用sys登陆。
Microsoft Windows [版本 5.2.3790]
(C) 版权所有 1985-2003 Microsoft Corp.
E:\Documents and Settings\Administrator>sqlplus /nolog
SQL*Plus: Release 9.2.0.1.0 - Production on 星期一 4月 8 14:20:05 2
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
SQL> connect sys/sys as sysdba;
已连接。
SQL> shutdown normal
ORA-01109: 数据库未打开
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 135338868 bytes
Fixed Size 453492 bytes
Variable Size 109051904 bytes
Database Buffers 25165824 bytes
Redo Buffers 667648 bytes
数据库装载完毕。
SQL> alter database open;
出现以下错误:
ORA-00600: 内部错误代码,参数: [kcratr1_lostwrt]
出现该错误是因为系统强制关机造成的!
症状为数据库无法打开!
解决这个错误:
SQL> shutdown normal
ORA-01109: 数据库未打开
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 135338868 bytes
Fixed Size 453492 bytes
Variable Size 109051904 bytes
Database Buffers 25165824 bytes
Redo Buffers 667648 bytes
数据库装载完毕。
SQL>recover database;
完成介质恢复
SQL> alter database open;
数据库已更改
SQL>exit;
posted @
2013-04-08 14:53 kelly 阅读(704) |
评论 (0) |
编辑 收藏最近每次启动MyEclipse的时候,都不能自动加载我自己的workspace
通常都要通过File-Switch Workspace来选择一遍才行。
检查了一下问题,发现配置文件X:/MyEclipse6.5/eclipse/configuration/config.ini文件中的osgi.instance.area.default属性被修改为@user.home/workbench
osgi.instance.area.default=@user.home/workbench
等号后面修改为自己的工作空间地址就可以了osgi.instance.area.default=D\:\\Workspaces
posted @
2013-02-20 14:26 kelly 阅读(552) |
评论 (0) |
编辑 收藏linux下JDK1.6和TOMCAT6的安装和配置(root权限,否则要sudo)
准备2个安装包
jdk-6u13-linux-i586.bin
apache-tomcat-6.0.30.tar.gz
1、安装JDK1.6
新建/usr/java文件夹,然后将jdk-6u13-linux-i586.bin拷贝到该文件夹;
进入/usr/java文件夹,使用chmod u+x jdk-6u13-linux-i586.bin 赋予执行权限;
执行./jdk-6u10-linux-i586.bin进行安装,先看一堆说明,然后输入:yes 确定安装,最后按Enter确认,直到出现Done完成安装;
JAVA环境变量一会和TOMCAT一块配置
2、安装TOMCAT6
将apache-tomcat-6.0.30.tar.gz文件放到/usr文件夹下;
然后使用tar -zxvf apache-tomcat-6.0.30.tar.gz进行解压
然后将解压后的文件夹改名为tomcat6,为了配置环境变量方便些
环境变量的配置:
编辑/etc/profile文件(使用SSH下载下来,然后编辑完在上传上去);
在profile文件的最后加入下述内容:
#set java environment
JAVA_HOME=/usr/java/jdk1.6.0_13
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
#set tomcat environment
CATALINA_HOME=/usr/tomcat6
CLASSPATH=$CLASSPATH:$CATALINA_HOME/lib
PATH=$PATH:$CATALINA_HOME/bin
加入后上传覆盖profile文件;
使用source /etc/profile 重新加载环境变量
catalina.sh start (关闭tomcat使用shutdown.sh stop)就可测试了,默认端口为8080
特别提示:如果开启了linux防火墙的话,8080端口要在/et/sysconfig/iptables中配置开通。
虚拟目录挂载连接池只需要在tomcat的conf文件夹下的server.xml中的<Host></Host>中间加入如下配置:
<Context path="/VGOP" reloadable="true" privileged="true" docBase="/root/project/vgoptoeasycode">
<Resource name="jdbc/EasycodeVGOPSystem"
auth="Container"
type="javax.sql.DataSource"
driverClassName="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@192.168.1.200:1521:CMEBP"
username="dev"
password="easycode2008"
maxActive="200"
maxIdle="40"
maxWait="500" />
</Context>
3、设置开机自启动:
修改/etc/rc.d/rc.local
加入:
Export JDK_HOME=/usr/java/jdk1.6.0_13
Export JAVA_HOME=/usr/java/jdk1.6.0_13
/usr/tomcat-6.0.33/bin/startup.sh
posted @
2011-10-17 15:35 kelly 阅读(787) |
评论 (0) |
编辑 收藏修改/etc/rc.d/rc.local
加入:
Export JDK_HOME=/usr/java/jdk1.6.0_13
Export JAVA_HOME=/usr/java/jdk1.6.0_13
/usr/tomcat-6.0.33/bin/startup.sh
posted @
2011-10-17 15:34 kelly 阅读(394) |
评论 (0) |
编辑 收藏1.一般情况下,系统已经默认安装了vsftpd,查看是否安装命令:
#rpm –q vsftpd
如果没有安装,则进行安装:
#Rpm –ivh vsftpd-2.0.5-12.e15.i386.rpm
2.启动vsftpd服务命令
#Service vsftpd start
启动ftp服务。用ie url输入:ftp://192.168.1.165,将可以直接访问,默认路径是/var/ftp/pub
默认情况下ftp配置是允许匿名访问的,但是一般应用中我们需要制定访问用户。
3.配置vsftp ,指定用户访问
新建用户和组:
#groupadd terminal 创建terminal组
#mkdir /root/project/ecosystem 创建ftp启用目录
#useradd -g terminal–d /root/project/ecosystem –M terminal 创建ftp访问用户
-g:指定用户所属的群组。
-d:指定用户登入时的启始目录。
-M:不要自动建立用户的登入目录,也就是说在/home下没有自己的目录
接着改变文件夹的属主和权限
为用户terminal创建密码:
#passwd terminal
输入密码和确认密码
#chown terminal.terminal /root/project/ecosystem ----这表示把/root/project/ecosystem的属主定为terminal 用户
#chmod 750 /root/project/ecosystem ----7表示wrx 5表示rx 0表示什么权限都没有
4.主要是修改/etc/vsftpd/vsftpd.conf
把anonymous_enable=YES改成
anonymous_enable=NO 不允许匿名登录
最后加入
Guest_enable=YES 允许虚拟用户访问
Guest_username=terminal 虚拟用户名
Max_clients=150 指明服务器总的客户并发连接数为200
Max_pre_ip=5 指明每个客户机的最大连接数为5
如果需要修改端口的话:把默认端口21改成2121,最后新增一行:
listen_port=2121
5.重启ftp
Service vsftpd restart
posted @
2011-10-17 15:32 kelly 阅读(312) |
评论 (0) |
编辑 收藏posted @
2011-10-17 15:27 kelly 阅读(683) |
评论 (1) |
编辑 收藏Scp命令上传文件:scp file root@192.168.100.2:/root
把file文件传输到192.168.100.2这台服务器的root目录下
如果想从192.168.100.2服务器上把文件file传输到本地机器root目录下命令如下:
scp root@192.168.100.2:/root/file /root
posted @
2011-10-17 14:58 kelly 阅读(411) |
评论 (0) |
编辑 收藏posted @
2011-10-17 14:52 kelly 阅读(399) |
评论 (0) |
编辑 收藏
1:下面第一步当然是确认自己linux系统是否安装VNC
输入命令:rpm -q vnc-server
2、如果没有安装,安装Vnc服务器,一般系统默认都已经安装了VNC服务
vnc-server-4.1.2-9.el5.i386.rpm
rpm -ivh vnc-server-4.1.2-9.el5.i386.rpm
3、 启动VNC,这个是设置一个端口的情况
Vncserver:1
然后相应的输入密码和确认密码
4、编辑/etc/sysconfig/vncservers
vi /etc/sysconfig/vncservers
VNCSERVERS="1:root"
#VNCSERVERARGS[2]="-geometry 1028x768 -nolisten tcp -nohttpd -localhost"
5、编辑 .vnc/xstartup ,使可以看到图形化的界面
vi /root/.vnc/xstartup
#!/bin/sh
# Uncomment the following two lines for normal desktop:
unset SESSION_MANAGERexec
/etc/X11/xinit/xinitrc
[ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup
[ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources
xsetroot -solid grey
vncconfig -iconic &
xterm -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" &
#twm &
#KDE &
gnome-session &
配置完各个用户根目录下的".vnc/xstartup"后,
执行service vncserver restart 重新启动vncserver使配置生效
6、 配置防火墙/etc/sysconfig/iptables
-A RH-Firewall-1-INPUT –m state –state NEW –m tcp –p tcp –dport 5901 –j ACCEPT
执行service iptables restart 重新启动防火墙,使规则生效
7、 启机自动开起vncserver服务,运行以下命令:
chkconfig vncserver on
8、 查看执行状态
chkconfig -- list vncserver
vncserver 0:off 1:off 2:on 3;on 5:on 6:off
如果配置多个端口,如下操作
1、编辑/etc/sysconfig/vncservers
vi /etc/sysconfig/vncservers
VNCSERVERS="1:root 2:kelly"
2、设置VNC用户密码
接下来设置VNC的密码,此步骤不可跳过,否则VNC Server将无法启动,在Linux Shell下执行下列命令:
# su - kelly
# vncpasswd
Password:
Verify:
# su - root
# vncpasswd
Password:
Verify:
service vncserver start //启动vncserver
3、重新配置防火墙规则,
-A RH-Firewall-1-INPUT –m state –state NEW –m tcp –p tcp –dport 5902 –j ACCEPT
执行service iptables restart 重新启动防火墙,使规则生效
4、设置普通用户的图形化界面文件/ home/kelly/.vnc/xstartup
使其看到图形化界面,修改方法同上。
5、重新启动vnc
service vncserver restart
posted @
2011-10-17 14:38 kelly 阅读(771) |
评论 (0) |
编辑 收藏修改两个文件
/etc/sysconfig/network 加一句:HOSTNAME=new-name
/etc/hosts 里面的
ip localhost.localdomain
改成:
ip new-name
posted @
2011-10-17 14:34 kelly 阅读(264) |
评论 (0) |
编辑 收藏
SSH端口修改配置
系统默认是已经开启了SSH服务的。用命令可以看到是否开启
Chkconfig –list sshd
如果需要修改端口的话,则修改/etc/ssh/sshd_config文件
默认端口是22 找到#Port 22一段,这里是标识默认使用22端口,修改为如下:
Port 22
Port 999
然后保存退出
执行/etc/init.d/sshd restart,重新启动SSH服务
这样SSH端口将同时工作与22和999上。
(现在编辑防火墙配置:vi /etc/sysconfig/iptables
启用999端口。
-A RH-Firewall-1-INPUT –m state –state NEW –m tcp –p tcp –dport 999 –j ACCEPT
执行/etc/init.d/iptables restart,重新启动防火墙的访问规则
现在请使用ssh工具连接999端口,来测试是否成功。
如果连接成功了,则再次编辑sshd_config的设置,将里边的Port22删除(dd掉),即可。
之所以先设置成两个端口,测试成功后再关闭一个端口,是为了方式在修改conf的过程中,
万一出现掉线、断网、误操作等未知情况时候,还能通过另外一个端口连接上去调试
以免发生连接不上必须派人去机房,导致问题更加复杂麻烦。
posted @
2011-10-17 14:33 kelly 阅读(1769) |
评论 (0) |
编辑 收藏
项目使用的是UTF-8编码,用get方式提交的时候发现URL中如果有中文,响应页面将得到乱码。然后在tomcat的server.xml中添加了get方式和url访问解决乱码的方式useBodyEncodingForURI="true",
并在响应页面中添加了request.setCharacterEncoding("GB2312");//乱码转换
response.setContentType("text/html;charset=GB2312");
response.setCharacterEncoding("GB2312");但是得到的还是乱码。
后来把项目改成GB2312编码,get方式提交可以得到正常的中文。后来通过百度和googl的编码得到了启发。百度中输入中文搜索,url中显示的是中文。google输入中文进行搜索,url中显示的是带%的编码。说明百度用的是GB2312编码,中文可以正常解析。google用的是UTF-8编码,所以需要对中文进行转码。
下面是我项目中的解决方案:
1、在请求页面中把中文参数进行转码
如:String content="测试短信";
content=URLEncoder.encode(content,"UTF-8");
2、在接收参数的响应页面进行中文参数的解码
如:String message= URLDecoder.decode(request.getParameter,"UTF-8");
经过这次的问题,个人认为还是用GB2312编码比较省事。
posted @
2011-09-30 11:34 kelly 阅读(1561) |
评论 (0) |
编辑 收藏
oracle数据库是重量级的,其管理非常复杂,将其在linux平台上的启动和关闭步骤整理一下。
安装完毕oracle以后,需要创建oracle系统用户,并在/home/oracle下面的.bash_profile添加几个环境变量:ORACLE_SID,ORACLE_BASE,ORACLE_HOME。比如:
export ORACLE_SID=test export ORACLE_BASE=oracle_install_dir export ORACLE_HOME=xxx
启动步骤:注意$代表shell命令提示符,这里的oracle是9.0以上版本。
切换到oracle用户下面:
$ su - oracle
$ sqlplus / nolog
sql> conn / as sysdba
sql> startup (启动数据库,一般不需要加参数,只要设置好环境变量)
sql>shutdown (关闭数据库其参数 :shutdown有四个参数,四个参数的含义如下:
Normal 需要等待所有的用户断开连接
Immediate 等待用户完成当前的语句
Transactional 等待用户完成当前的事务
Abort 不做任何等待,直接关闭数据库
normal需要在所有连接用户断开后才执行关闭数据库任务,所以有的时候看起来好象命令没有运行一样!在执行这个命令后不允许新的连接
immediate在用户执行完正在执行的语句后就断开用户连接,并不允许新用户连接。
transactional 在拥护执行完当前事物后断开连接,并不允许新的用户连接数据库。
abort 执行强行断开连接并直接关闭数据库。
sql> quit (退出sql模式)
启动监听器:
$ su - oracle
然后切换到$oracle_home/bin下面,执行下面命令
$lsnrctl start (启动监听器)
$lsnrctl status (查看监听器启动状态)
$lsnrctl stop(关闭监听器)
经常遇到的问题:
1)权限问题,解决方法,切换到oracle用户;
2)没有关闭监听器 ,解决方法:关闭监听器
3)有oracle实例没有关闭,解决办法:关闭oracle实例
4)环境变量设置不全,解决办法:修改环境变量
posted @
2011-09-26 14:28 kelly 阅读(476) |
评论 (0) |
编辑 收藏
导入 imp username/pwdid@servername file=dataname.dmp
Oracle数据导入导出imp/exp就相当于oracle数据还原与备份。exp命令可以把数据从远程数据库服务器导出到本地的dmp文 件,imp命令可以把dmp文件从本地导入到远处的数据库服务器中。 利用这个功能可以构建两个相同的数据库,一个用来测试,一个用来正式使用。
执行环境:可以在SQLPLUS.EXE或者DOS(命令行)中执行,
DOS中可以执行时由于 在oracle 8i 中 安装目录\ora81\BIN被设置为全局路径,
该目录下有EXP.EXE与IMP.EXE文件被用来执行导入导出。
oracle用java编写,SQLPLUS.EXE、EXP.EXE、IMP.EXE这两个文件有可能是被包装后的类文件。
SQLPLUS.EXE调用EXP.EXE、IMP.EXE所包裹的类,完成导入导出功能。
下面介绍的是导入导出的实例。
数据导出:
1 将数据库TEST完全导出,用户名system 密码manager 导出到D:\daochu.dmp中
exp system/manager@TEST file=d:\daochu.dmp full=y
2 将数据库中system用户与sys用户的表导出
exp system/manager@TEST file=d:\daochu.dmp owner=(system,sys)
3 将数据库中的表inner_notify、notify_staff_relat导出
exp aichannel/aichannel@TESTDB2 file= d:\data\newsmgnt.dmp tables=(inner_notify,notify_staff_relat)
4 将数据库中的表table1中的字段filed1以"00"打头的数据导出
exp system/manager@TEST file=d:\daochu.dmp tables=(table1) query=\" where filed1 like '00%'\"
上面是常用的导出,对于压缩,既用winzip把dmp文件可以很好的压缩。
也可以在上面命令后面 加上 compress=y 来实现。
数据的导入
1 将D:\daochu.dmp 中的数据导入 TEST数据库中。
imp system/manager@TEST file=d:\daochu.dmp
imp aichannel/aichannel@HUST full=y file=file= d:\data\newsmgnt.dmp ignore=y
上面可能有点问题,因为有的表已经存在,然后它就报错,对该表就不进行导入。
在后面加上 ignore=y 就可以了。
2 将d:\daochu.dmp中的表table1 导入
imp system/manager@TEST file=d:\daochu.dmp tables=(table1)
基本上上面的导入导出够用了。不少情况要先是将表彻底删除,然后导入。
注意:
操作者要有足够的权限,权限不够它会提示。
数据库时可以连上的。可以用tnsping TEST 来获得数据库TEST能否连上。
附录一:
给用户增加导入数据权限的操作
第一,启动sql*puls
第二,以system/manager登陆
第三,create user 用户名 IDENTIFIED BY 密码 (如果已经创建过用户,这步可以省略)
第四,GRANT CREATE USER,DROP USER,ALTER USER ,CREATE ANY VIEW ,
DROP ANY VIEW,EXP_FULL_DATABASE,IMP_FULL_DATABASE,
DBA,CONNECT,RESOURCE,CREATE SESSION TO 用户名字
第五, 运行-cmd-进入dmp文件所在的目录,
imp userid=system/manager full=y file=*.dmp
或者 imp userid=system/manager full=y file=filename.dmp
执行示例:
F:\Work\Oracle_Data\backup>imp userid=test/test full=y file=inner_notify.dmp
屏幕显示
Import: Release 8.1.7.0.0 - Production on 星期四 2月 16 16:50:05 2006
(c) Copyright 2000 Oracle Corporation. All rights reserved.
连接到: Oracle8i Enterprise Edition Release 8.1.7.0.0 - Production
With the Partitioning option
JServer Release 8.1.7.0.0 - Production
经由常规路径导出由EXPORT:V08.01.07创建的文件
已经完成ZHS16GBK字符集和ZHS16GBK NCHAR 字符集中的导入
导出服务器使用UTF8 NCHAR 字符集 (可能的ncharset转换)
. 正在将AICHANNEL的对象导入到 AICHANNEL
. . 正在导入表 "INNER_NOTIFY" 4行被导入
准备启用约束条件...
成功终止导入,但出现警告。
附录二:
Oracle 不允许直接改变表的拥有者, 利用Export/Import可以达到这一目的.
先建立import9.par,
然后,使用时命令如下:imp parfile=/filepath/import9.par
例 import9.par 内容如下:
FROMUSER=TGPMS
TOUSER=TGPMS2 (注:把表的拥有者由FROMUSER改为TOUSER,FROMUSER和TOUSER的用户可以不同)
ROWS=Y
INDEXES=Y
GRANTS=Y
CONSTRAINTS=Y
BUFFER=409600
file==/backup/ctgpc_20030623.dmp
log==/backup/import_20030623.log
经验证,属合格产品!
posted @
2011-09-26 14:27 kelly 阅读(431) |
评论 (0) |
编辑 收藏
1、比如修改http://localhost:8080访问的图标,我们可以,修改E:\apache-tomcat-5.5.28\webapps\ROOT下的,ico文件,将该文件替换成想要的图标即可,命名也为favicon.ico,系统会自动找到这个文件。
2、系统部署到TOMCAT,访问时IE栏出现TOMCAT的小猫图标
同样如果部署在webapps下面的也一样处理。
3、或者直接在tomcat安装跟目录下放一个命名为tomcat.ico文件的图标,所有项目将引用这个图标。(我暂时采用的这种方式)
但是,如果直接替换,效果不会显示出来,重启tomcat也不管用,这是由于浏览器缓冲造成的我们把历史记录删除即可。
posted @
2011-06-24 10:46 kelly 阅读(1411) |
评论 (0) |
编辑 收藏
linux安装配置jdk1.5、tomcat5.5、eclipse3.2、Myeclipse
linux安装配置jdk1.5、tomcat5.5、eclipse3.2、Myeclipse5.1详解
包括安装jdk1.5,tomcat5.5,eclipse3.2,Myeclipse5.1到配置搭建成功。
第一步:下载所须要的软件
下载jdk1.5。
下载tomcat5.5。
下载eclipse3.2。
下载Myeclipse5.1
第二步:安装已下载软件
假设你将上诉所要下载的软件全部从光盘拷贝或者通过pc机ftp到linux服务器上传到/home/user/Downloads目录下。
首先要安装jdk1.5
1. 打开终端,运行命令su root 切换到超级用户。
2.cd切换到/home/user/Downloads目录下。运行命令 cp jdk-1_5_0_12-linux-i586.bin /usr/local将jdk复制到/usr/local目录下。
3.cd切换到/usr/local目录下。运行命令 chmod a+x jdk-1_5_0_12-linux-i586.bin给於相应权限。
4.运行命令 ./jdk-1_5_0_12-linux-i586.bin 等待,按提示安装jdk,假设安装在/usr/local目录下。jdk安装完成。
然后安装tomcat5.5
1.cd切换到/home/user/Downloads目录下。运行命令cp apache-tomcat-5.tar.gz /usr/local将其拷贝到/usr/local目录下。
2.cd切换到/usr/local目录下。运行命令tar xvfz apache-tomcat-5.tar.gz将其在/usr/local目录中解压。tomcat5.5安装完成。
安装eclipse3.2
1.cd切换到/home/user/Downloads目录下。运行命令cp eclipse-SDK-3.2.2-linux-gtk.tar.gz /usr/local将其拷贝到/usr/local目录下。
2.cd切换到/usr/local目录下。运行命令tar xvfz eclipse-SDK-3.2.2-linux-gtk.tar.gz 将其解压。eclipse3.2安装完成。
安装Myeclipse5.1
1.cd切换到/home/user/Downloads目录下。运行命令cp MyEclipseEnterprise(Linux)WorkbenchInstaller_5_1_0GA_E3_2_1.bin /usr/local将其拷贝到/usr/local目录下。
2.cd切换到/usr/local目录下。运行命令chmod +x MyEclipseEnterprise(Linux)WorkbenchInstaller_5_1_0GA_E3_2_1.bin ,然后运行$./M*.bin 安装过程中会提示选择Eclipse安装目录,按照你实际的Eclipse安装目录进行选择即可。Myeclipse安装完成。
到此步骤,安装软件已经完成了,但是还不能运行,还要进行配置。
第三步:配置环境变量
首先运行命令 vi /etc/profile 出现profile文件源代码。
按键盘子母“i”进入插入模式。
在profile文件中插入以下代码:
export JAVA_HOME=/usr/local/java
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=.:/usr/local/java/lib:/usr/local/java/jre/lib:$CLASSPATH
export TOMCAT_HOME=/usr/local/tomcat
我得源文件代码是这样:
# /etc/profile
# System wide environment and startup programs, for login setup
# Functions and aliases go in /etc/bashrc
pathmunge () {
if ! echo $PATH | /bin/egrep -q "(^|:)$1($|:)" ; then
if [ "$2" = "after" ] ; then
PATH=$PATH:$1
else
PATH=$1:$PATH
fi
fi
}
# Path manipulation
#if [ `id -u` = 0 ]; then
pathmunge /sbin
pathmunge /usr/sbin
pathmunge /usr/local/sbin
#fi
pathmunge /usr/X11R6/bin after
unset pathmunge
# No core files by default
ulimit -S -c 0 > /dev/null 2>&1
USER="`id -un`"
LOGNAME=$USER
MAIL="/var/spool/mail/$USER"
HOSTNAME=`/bin/hostname`
HISTSIZE=1000
if [ -z "$INPUTRC" -a ! -f "$HOME/.inputrc" ]; then
INPUTRC=/etc/inputrc
fi
export JAVA_HOME=/usr/local/java
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=.:/usr/local/java/lib:/usr/local/java/jre/lib:$CLASSPATH
export TOMCAT_HOME=/usr/local/tomcat
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE INPUTRC
for i in /etc/profile.d/*.sh ; do
if [ -r "$i" ]; then
. $i
fi
done
unset i
export G_BROKEN_FILENAMES=true
黑体字部分是插入代码。
插入完成后按“ESC”健。在按大写的子母“ZZ”。保存退出。
环境变量配置完成后,可以做以下策试。
运行命令java -version,出现jdk版本和相关信息,证明jdk已经OK了。
cd切换到/opt/tomcat/bin目录下,运行命令 ./startup.sh,出现如下信息:
Using CATALINA_BASE: /opt/tomcat
Using CATALINA_HOME: /opt/tomcat
Using CATALINA_TMPDIR: /opt/tomcat/temp
Using JRE_HOME: /usr/java/jre1.5.0_05
证明安装成功。如果以上策试没成功的话,请仔细检查环境变量的配置。
到此步骤为止,已经成功的配置完成了jdk和tomcat。该是配置我们eclipse的时候了。
|
posted @
2011-03-03 17:18 kelly 阅读(6088) |
评论 (4) |
编辑 收藏java处理日期时间 相加减
JAVA处理日期时间常用方法:
1.java.util.Calendar
Calendar 类是一个抽象类,它为特定瞬间与一组诸如 YEAR、MONTH、DAY_OF_MONTH、HOUR 等 日历字段之间的转换提供了一些方法,并为操作日历字段(例如获得下星期的日期)提供了一些方法。瞬间可用毫秒值来表示,它是距历元(即格林威治标准时间 1970 年 1 月 1 日的 00:00:00.000,格里高利历)的偏移量。
例:
Java代码
1. Calendar cal = Calendar.getInstance();//使用默认时区和语言环境获得一个日历。
2. cal.add(Calendar.DAY_OF_MONTH, -1);//取当前日期的前一天.
3.
4. cal.add(Calendar.DAY_OF_MONTH, +1);//取当前日期的后一天.
5.
6. //通过格式化输出日期
7. java.text.SimpleDateFormat format = new java.text.SimpleDateFormat("yyyy-MM-dd");
8.
9. System.out.println("Today is:"+format.format(Calendar.getInstance().getTime()));
10.
11. System.out.println("yesterday is:"+format.format(cal.getTime()));
得到2007-12-25日期:
Java代码
1. Calendar calendar = new GregorianCalendar(2007, 11, 25,0,0,0);
2. Date date = calendar.getTime();
3. System.out.println("2007 Christmas is:"+format.format(date));
java月份是从0-11,月份设置时要减1.
GregorianCalendar构造方法参数依次为:年,月-1,日,时,分,秒.
取日期的部分:
Java代码
1. int year =calendar.get(Calendar.YEAR);
2.
3. int month=calendar.get(Calendar.MONTH)+1;
4.
5. int day =calendar.get(Calendar.DAY_OF_MONTH);
6.
7. int hour =calendar.get(Calendar.HOUR_OF_DAY);
8.
9. int minute =calendar.get(Calendar.MINUTE);
10.
11. int seconds =calendar.get(Calendar.SECOND);
取月份要加1.
判断当前月份的最大天数:
Java代码
1. Calendar cal = Calendar.getInstance();
2. int day=cal.getActualMaximum(Calendar.DAY_OF_MONTH);
3. System.out.println(day);
2.java.util.Date
Java代码
1. java.util.Date today=new java.util.Date();
2. System.out.println("Today is "+formats.format(today));
取当月的第一天:
Java代码
1. java.text.SimpleDateFormat format = new java.text.SimpleDateFormat("yyyy-MM-01");
2. java.util.Date firstDay=new java.util.Date();
3. System.out.println("the month first day is "+formats.format(firstDay));
取当月的最后一天:
Java代码
1.
2. Calendar cal = Calendar.getInstance();
3. int maxDay=cals.getActualMaximum(Calendar.DAY_OF_MONTH);
4. java.text.Format formatter3=new java.text.SimpleDateFormat("yyyy-MM-"+maxDay);
5. System.out.println(formatter3.format(cal.getTime()));
求两个日期之间相隔的天数:
Java代码
1. java.text.SimpleDateFormat format = new java.text.SimpleDateFormat("yyyy-MM-dd");
2. java.util.Date beginDate= format.parse("2007-12-24");
3. java.util.Date endDate= format.parse("2007-12-25");
4. long day=(date.getTime()-mydate.getTime())/(24*60*60*1000);
5. System.out.println("相隔的天数="+day);
一年前的日期:
Java代码
1. java.text.Format formatter=new java.text.SimpleDateFormat("yyyy-MM-dd");
2. java.util.Date todayDate=new java.util.Date();
3. long beforeTime=(todayDate.getTime()/1000)-60*60*24*365;
4. todayDate.setTime(beforeTime*1000);
5. String beforeDate=formatter.format(todayDate);
6. System.out.println(beforeDate);
一年后的日期:
Java代码
1. java.text.Format formatter=new java.text.SimpleDateFormat("yyyy-MM-dd");
2. java.util.Date todayDate=new java.util.Date();
3. long afterTime=(todayDate.getTime()/1000)+60*60*24*365;
4. todayDate.setTime(afterTime*1000);
5. String afterDate=formatter.format(todayDate);
6. System.out.println(afterDate);
求10小时后的时间
Java代码
1. java.util.Calendar Cal=java.util.Calendar.getInstance();
2. Cal.setTime(dateOper);
3. Cal.add(java.util.Calendar.HOUR_OF_DAY,10);
4. System.out.println("date:"+forma.format(Cal.getTime()));
求10小时前的时间
Java代码
1. java.util.Calendar Cal=java.util.Calendar.getInstance();
2. Cal.setTime(dateOper);
3. Cal.add(java.util.Calendar.HOUR_OF_DAY,-10);
4. System.out.println("date:"+forma.format(Cal.getTime()));
3.java.sql.Date
继承自java.util.Date,是操作数据库用的日期类型
Java代码
1. java.sql.Date sqlDate = new java.sql.Date(java.sql.Date.valueOf("2007-12-25").getTime());
日期比较:简单的比较可以以字符串的形式直接比较,也可使用
java.sql.Date.valueOf("2007-03-08").compareTo(java.sql.Date.valueOf("2007-03-18"))方式来比较日期的大小.也可使用java.util.Date.after(java.util.Date)来比较.
相差时间:
long difference=c2.getTimeInMillis()-c1.getTimeInMillis();
相差天数:long day=difference/(3600*24*1000)
相差小时:long hour=difference/(3600*1000)
相差分钟:long minute=difference/(60*1000)
相差秒: long second=difference/1000
补充:
Java代码
1. DateFormat df=new SimpleDateFormat("yyyy-MM-dd EE hh:mm:ss");
2. System.out.println(df.format(new Date()));
3. Date date = new Date();
4. DateFormat shortDate=DateFormat.getDateTimeInstance(DateFormat.SHORT, DateFormat.SHORT);
5. DateFormat mediumDate =DateFormat.getDateTimeInstance(DateFormat.MEDIUM, DateFormat.MEDIUM);
6. DateFormat longDate =DateFormat.getDateTimeInstance(DateFormat.LONG, DateFormat.LONG);
7. DateFormat fullDate =DateFormat.getDateTimeInstance(DateFormat.FULL, DateFormat.FULL);
8.
9. system.out.println(shortDate.format(date));
10. System.out.println(mediumDate.format(date));
11. System.out.println(longDate.format(date));
12. System.out.println(fullDate.format(date));
13.
14. 08-4-15 下午3:24
15. 2008-4-15 15:24:31
16. 2008年4月15日 下午03时24分31秒
17. 2008年4月15日 星期二 下午03时24分31秒CST
18.
19.
20. Calendar c = Calendar.getInstance();
21.
22. c.add(Calendar.MONTH, 1); // 目前時間加1個月
23. System.out.println(df.format(c.getTime()));
24.
25. c.add(Calendar.HOUR, 3); // 目前時間加3小時
26. System.out.println(df.format(c.getTime()));
27.
28. c.add(Calendar.YEAR, -2); // 目前時間減2年
29. System.out.println(df.format(c.getTime()));
30.
31. c.add(Calendar.DAY_OF_WEEK, 7); // 目前的時間加7天
32. System.out.println(df.format(c.getTime()));
posted @
2011-02-21 12:15 kelly 阅读(28880) |
评论 (0) |
编辑 收藏