学习JBoss Rules有几天了,因为这方面的中文资料较少,所以这几天都在看官网上的manual。这是一份不错的教程,我把我看的一些重要的东西翻译整理了一下,希望可以对想学习JBoss Rules的同学们提供一点帮助。
在开始这份教程之前,我先简要介绍一下JBoss Rules:
JBoss Rules 的前身是Codehaus的一个开源项目叫Drools。最近被纳入JBoss门下,更名为JBoss Rules,成为了JBoss应用服务器的规则引擎。
Drools是为Java量身定制的基于Charles Forgy的RETE算法的规则引擎的实现。具有了OO接口的RETE,使得商业规则有了更自然的表达。
既然JBoss Rules是一个商业规则引擎,那我们就要先知道到底什么是Rules,即规则。在JBoss Rules中,规则是如何被表示的
Rules
一条规则是对商业知识的编码。一条规则有
attributes
,一个
Left Hand Side
(
LHS
)和一个
Right Hand Side
(
RHS
)。
Drools
允许下列几种
attributes
:
salience
,
agenda-group
,
no-loop
,
auto-focus
,
duration
,
activation-group
。
rule “
<
name
>
”
<
attribute
>
<
value
>
when
<
LHS
>
then
<
RHS
>
end
规则的
LHS
由一个或多个条件(
Conditions
)组成。当所有的条件(
Conditions
)都满足并为真时,
RHS
将被执行。
RHS
被称为结果(
Consequence
)。
LHS
和
RHS
类似于:
if
(
<
LHS
>
) {
<
RHS
>
}
规则可以通过
package
关键字同一个命名空间(
namespace
)相关联;其他的规则引擎可能称此为规则集(
Rule Set
)。一个
package
声明了
imports
,
global
变量,
functions
和
rules
。
package
com.sample
import
java.util.List
import
com.sample.Cheese
global List cheeses
function
void
exampleFunction(Cheese cheese) {
System.out.println( cheese );
}
rule “A Cheesy Rule”
when
cheese : Cheese( type
==
"
stilton
"
)
then
exampleFunction( cheese );
cheeses.add( cheese );
end
对新的数据和被修改的数据进行规则的匹配称为模式匹配(
Pattern Matching
)。进行匹配的引擎称为推理机(
Inference Engine
)。被访问的规则称为
ProductionMemory
,被推理机进行匹配的数据称为
WorkingMemory
。
Agenda
管理被匹配规则的执行。推理机所采用的模式匹配算法有下列几种:
Linear
,
RETE
,
Treat
,
Leaps
。
Drools
采用了
RETE
和
Leaps
的实现。
Drools
的
RETE
实现被称为
ReteOO
,表示
Drools
对
Rete
算法进行了加强和优化的实现。

一条规则的
LHS
由
Conditional Element
和域约束(
Field Constraints
)。下面的例子显示了对一个
Cheese Fact
使用了字面域约束(
Literal Field Constraint
)
rule
"
Cheddar Cheese
"
when
Cheese( type
==
"
cheddar
"
)
then
System.out.println(
"
cheddar
"
);
end
上面的这个例子类似于:
public
void
cheddarCheese(Cheese cheese) {
if
( cheese.getType().equals(
"
cheddar
"
) {
System.out.println(
"
cheddar
"
);
}
}
<!--[if !vml]--> <!--[endif]-->
规则引擎实现了数据同逻辑的完全解耦。规则并不能被直接调用,因为它们不是方法或函数,规则的激发是对
WorkingMemory
中数据变化的响应。结果(
Consequence
,即
RHS
)作为
LHS events
完全匹配的
Listener
。
当
rules
被加入
Productioin Memory
后,
rules
被规则引擎用
RETE
算法分解成一个图:

当
Facts
被
assert
进入
WorkingMemory
中后,规则引擎找到匹配的
ObjectTypeNode
,然后将此
Fact
传播到下一个节点。
ObjectTypeNode
拥有一块内存来保存所有匹配的
facts
。在我们的例子中,下一个节点是一个域约束(
Field Constraint
),
type = = “cheddar”
。如果某个
Cheese
对象的类型不是“
cheddar
”,这个
fact
将不会被传播到网络的下一个节点。如果是“
cheddar
”类型,它将被记录到
AlphaNode
的内存中,并传播到网络的下一个节点。
AlphaNode
是古典
RETE
术语,它是一个单输入
/
单输出的节点。最后通过
AlphaNode
的
fact
被传播到
Terminal Node
。
Terminal Node
是最终节点,到此我们说这条规则被完全匹配,并准备激发。
当一条规则被完全匹配,它并没有立刻被激发(在
RETE
中是这样,但在
Leaps
中它会立刻被激发)。这条规则和与其匹配的
facts
将激活被放入
Agenda
,由
Agenda
来负责安排激发
Activations
(指的是
rule + the matched facts
)。
下面的图很清楚的说明了
Drools
规则引擎的执行过程:
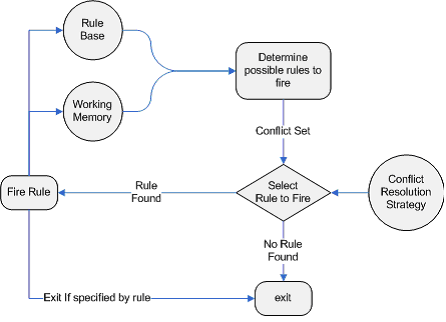
数据被
assert
进
WorkingMemory
后,和
RuleBase
中的
rule
进行匹配(确切的说应该是
rule
的
LHS
),如果匹配成功这条
rule
连同和它匹配的数据(此时就叫做
Activation
)一起被放入
Agenda
,等待
Agenda
来负责安排激发
Activation
(其实就是执行
rule
的
RHS
),上图中的菱形部分就是在
Agenda
中来执行的,
Agenda
就会根据冲突解决策略来安排
Activation
的执行顺序。