|
|
2009年3月24日
偶然发现了盛大的maiku, 是一个不错的日志和资源整理平台。于是转向了它,地址是 http://note.sdo.com/u/dongwq
欢迎来看看。
• 前者:看见与不看见,但是位置保留。
• 后者处理与位置有关:block, inline, none 分别是有前后换行,不换行,不显示功能但是不保留位置。
• 二者功能差异:保留位置,和位置形式
<script language="javascript">
function toggleVisibility(me)
{
if(me.style.visibility=="hidden")
{
me.style.visibility="visible";
}
else
{
me.style.visibility="hidden";
}
}
</script>
<DIV onclick="toggleVisibility(this)"
style="position:relative">
第一行文本将会触发"hidden"和"visible"属性,注意第二行的变化。
</DIV>
<DIV>因为visibility会保留元素的位置,所以第二行不会移动.</DIV>
<script language="javascript">
function toggleDisplay(me){
if(me.style.display=="block"){
me.style.display="inline";
alert("文本现在是:'inline'.");
}
else{
if(me.style.display=="inline"){
me.style.display="none";
alert("文本现在是:'none'.3秒钟后自动重新显示。");
window.setTimeout("blueText.style.display='block';",
3000,"javascript");
}
else{
me.style.display="block";
alert("文本现在是:'block'.");
}
}
}
</script>
<DIV>在<span id="blueText"
onclick="toggleDisplay(this)"
style="color:blue;position:relative;cursor:hand;">
蓝色</span>文字上点击来查看效果.</DIV>
摘要: 1 . 日志的组成:配置文件,写日志
log.cfg
############################################################
# Default Logging Configuration File
#
# You&nbs... 阅读全文
文章分类:软件开发管理
副标题——名不正言不顺,项目管理难度加倍
你能想象美国总统上任,却没有总统就职仪式吗?
你能想象北京奥林匹克运动会,没有开幕式表演吗??
OK。相信你一定见过这样的场景:
某老板匆匆忙忙地进了屋,忽地来了一嗓子:“大家静静,通知大家一下:以后,某项目就由小张负责了!”
**************************************************
话说楚汉相争。刘邦在萧何的再三举荐下,决定让韩信为大将。
“来人,叫韩信过来,我要封他为大将。”刘邦道。
萧何表示异议:“汉王你一向傲慢没有礼貌,现在拜大将就和喊一个小孩子那么随便,所以韩信才会离开的。汉王要想用人家,必须选一个吉日,吃素,设祭坛,用非常郑重地礼节来拜将才行。”刘邦同意萧何的意见。
结果,尽管韩信是个无名小卒,却顺利的接过了军权,而没有碰到那些元老们的抵抗,成功地导演了一幕幕战争奇迹。
**************************************************
登台拜将,是一件具有深刻管理内涵的故事。它告诉我们这样一个道理:
——内容是重要的,但形式却是不容忽视。
我们不求老板非要在某个公开场合悠扬地宣告:“某项目成立了!!小张从此站起来了!!!”什么吉日,什么斋戒,什么礼仪。。。也就罢了。
但是,不给正式任命书;不在正式场合公布;甚至连一个头衔都舍不得。这绝对是没天理的。
**************************************************
“看,老板不重视这个项目。。。”(相关人员)
“瞧,老板不重视这个家伙。估计这个家伙没有什么后台” (相关人员)
“你负责某项目?我怎么不知道有这么个项目呢?你是哪位啊?” (相关人员)
“老板似乎并不重视/信任我啊” (项目经理)
***************************************************
以上种种,对项目的推动极为不利的。尤其是手下有资深员工、或者项目经理候补者等挑战者的时候,问题将会加倍严重。
大家可能会怀疑:“没有那么严重吧?”
没有不严重,只有更严重!!
这其中蕴含着一个深刻的道理——名不正则言不顺!!
言不顺是什么意思呢?
-你的意见可能被忽视;
-你的命令可能被当作建议;
-你的计划可能被别人忘记;
试想,你如果是项目经理,你的项目将会怎样。。。。。。
*********************************************************
Question: 我没有办法叫老板改变。那么,我该怎么办?
Answer:要写一封邮件!!告诉别人你是谁。
*********************************************************
你的老板犯了错误,可是你不能将错就错!你的老板忽视了“名”的问题(形式问题),你一定要扳回来!!
试想,你的老板不重视,你也不重视,你能指望别人重视吗??
当然,答案就是别人会更不重视!!
那么,这封邮件该怎么写呢??
**************************************************
MailTo: 所有下属
CC: 所有相关领导,所有相关人员,自己
Title: 【A项目】A项目的新项目经理小张向大家问好
Content:
1 开门见山地告诉别人自己的位置(正名)
2 向相关人员致敬,并自然地点出自己的优势(自我介绍)
3 向领导致敬致谢(拉近和领导关系)
4 暗示自己的权利范围(宣布自己的领地)
5 喊两句口号(合作和积极的姿态是必要的)
6 不要忘了签名(进一步加深印象)
//其中,1、2、4是必须要表现出来的
**************************************************
上面这封邮件,基本上完成了告诉别人你是谁的问题,而且完成了你的位置身份暗示。
如果说老板不负责任的任命形式带给你身份位置认同危机,沉重打击了你的威信的话,
通过这份邮件,你已经用身份暗示这个武器,夺回了主动权!!
从这封信以后,由于你的身份位置的明确,
相关人员在潜意识中会认同你的领地所有权,
会对在你的领地上和你发生冲突产生不自然,不合法甚至负罪感,
从而下意识中就会避免和你发生冲突。
反过来讲,你的位置身份的明确,将成为你自信的源泉,
而这种位置感产生的自信将使你的发言充满了正义感,
加上项目经理这个位置所带来的小小的势能。。。
权力这个东西,真好!!
嗯,一个好的开端,不是吗?
1、函数定义和使用
<script>
function sqrt(x) {
return x * x;
}
function other(f) {
var y = f(10);
return y;
}
var farr = new Array();
farr[0] = function(arg) { return arg + arg;};
farr[1] = function(arg) { return arg * arg;};
document.write(farr[0](10) + '<br/>');
document.write(farr[1](10));
document.write(other(sqrt));
</script>
sqrt.count = 0;
sqrt.getcount = function() {
return this.count;
}; // 附加函式
//sqrt();
document.write(sqrt.count, '<br/>');
document.write(sqrt.getcount());
杜拉拉升级记:
关键一点,你的上级要喜欢你。工作中涉及要决策的都要跟上级报告。这是上级的作用。
对于平级的同事是不能用命令,不能要求别人做事的。
事情不能自己承担下来。
感谢小熊同学借我这本书看
说说我的感受:此书没有书评中说的那么好,当然也没有那么坏。大家各取所需就好。与其叫小说,不如说是一种创新形式的职场教材。不要太去在意作者的文笔,而要更多的体会书中各位同学的处事之道。
几句话总结一下:
1、勤奋是王道,其他的都属于EQ范畴了
2、要注意技巧,尤其是沟通技巧,别干了半天,没人知道你的工作量有多少。
3、掂量自己的能力,做好该做的事,不做不该做的事,比如越级汇报。
4、不要说人坏话,能帮助别人时要帮,关键时刻即使没有人帮你说话,但也不会有人说你的坏话。不信的话,去看看圣经怎么说得吧。
5、要有气量,做事要圆通。
6、要有自己的风格,风格没有好坏之分,但是一定要有。
7、告诉我们什么是好工作,这点比较长,见下面的摘抄(感谢“木马|造化弄人”的贡献):
“一、关于什么样的职位算好职位
1.你得找一家好公司
什么是好公司?
1)产品附加值高,生意好,并且从业务线看,具备持续发展的能力和前景;
2)有专业的/聪明能干的/经验丰富的/并且为人现实的管理层,在把握这公司,并且有保护一贯这样用人的制度的公司;
3)有严格的财务制度,对预算、费用和利润等于投入产出有关的内容,敏感并且具有强控制力的公司;
4)崇尚客户导向/市场导向/结果导向/执行力的公司;
5)有专业严谨全面的流程和制度,并且其执行有利于推动业务的良性发展,具有控制性和实操性兼备的特点;
---总结起来,就是一家具有持续赢利能力的牛B公司
2.你的找一个好的方向
什么是好的方向?
永远不要远离核心业务线。你得看明白,在企业中,哪个环节是实现利润最大化的关键环节。有时候是销售环节,有时候是市场策划环节,有时候是研发环节,有时候是生产环节,视乎你所在行业而不同。
最重要的环节,总是 最贵的,最牛的,最得到重视的,也是最有发展前途的部门。它拥有最多的资源和最大的权威--你应该依附在这样的核心业务线上发展,至少能避免被边缘化,而成为关键人才的可能性则更大了。
3.你得跟一个好老板。
好老板的标准很多,关键的是,你要设法跟上一个在公司处于强势地位的老板。他强,你才能跟着上。跟了一个弱势的老板,你的前途就很同意被根着给耽搁了。
二、关于具备谋取好职位的资格
要具备怎么样的资格呢?一般情况下,你得是用人部门眼中的优秀者。
怎么样才算优秀呢?
1.对上级
1)你要知道与他建立一致性,他觉得重要的事情,你就觉得重要,他认为紧急的事情你也认为紧急,你得和他劲往一处使--通常情况下,你得表现和能力好还是不好,主要是你得直接主管说了算的;
2)你的具备从上级那里获得支持和资源的能力--别你干的半死,你的老板还对你爱搭不理的,那你就不具备本条件的能力。
2.对下级
1)要能明确有效的设置正确的工作目标,使其符合SMART原则;
2)要能有效地管理团队内部冲突;
3)要能公平合理地控制分配团队资源;
4) 要有愿望和能力发展指导下属,并恰当授权;
5)恰当的赞扬鼓励认可团队成员;
6)尊重不同想法,分享知识经验和信息,建立信任的氛围。
3.对内、外部客户
1)愿意提供协助和增值服务(不然要你干嘛);
2)善意聆听并了解需求(搞明白人家需要的到底是啥);
3)可靠的提供产品和服务,及时跟进(千万注意及时);
4)了解组织架构并具影响力。及早地建立并维护关键的关系,是这样的关系有利于你达成业绩(专业而明智的选择);
比如你想取得一个内部职位,你的搞明白了,谁是关键的做决定的人物,别傻乎乎不小心给这个人留下坏印象。
比如必要去客人那里拿订单,你找了一个关键的人物A,可是你也别忽略作购买决定环节上的另一个人物B,没准B和A是死敌,本来B会同意给你下订单的,就因为A同意给你单子,B就是不同意给你单子。
4.对本岗任务
1)清楚自己的定位和职责--别搞不清楚自己是谁,什么是自己的活,知道什么该报告,什么要自己独立做决定;
2)结果导向--设立高目标,信守承诺,承担责任,注重质量、速度和期限,争取主动,无需督促;
3)清晰的制定业务计划并有效实施;
4)学习能力--愿意学,坚持学,及时了解行业趋势/竞争状况和技术更新,并学以致用;
5)承受压力的能力--严峻的工作条件下,能坚忍不拔,想办法获取资源、支持和信息,努力以实现甚至超越目标;
6)适应的能力--如适应多项要求并存,优先级变换以及情况不明等工作条件,及时调整自己的行为和风格来适应不同个人及团队的需要(工作重心会变化,老板会换人,客人也会变,别和他们说“我过去如何如何”,多去了解对方的风格) ”。
方与圆:
最少期望的去感谢别人。不要抱着目的去感谢别人,甚至事前感谢也好。感谢只需说一次。
发掘别人不明显的优点加以赞扬。
赞扬行动和品性,而不要扩大到赞扬一个人。赞扬的原因要说明。
和气生财吗?喝杯水。
对陌生人要特别要笑。微笑是影响人气质的一个特别重要的东西。
对生活的真诚,快乐的感情最能够打动人。 男的微笑也很好。
认真的品质:画一个月和十年。
组装的质量差?认真的态度。德国人的认真,指路会指出的很具体的。
只有最认真的人才能做出最好的产品。
自动自发的精神,一定要发挥自己的主观能动性。
当成自己的事来做吧。要主动的来做。
做好产品是人的一种尊严。争强好胜在自己的工作上面。因为这是你的发挥场地。
只办总裁班?成本与质量观念不一样的? 规模经济?质量了的产品成本会降低。
检查的目的是为了改进生活流程。
管制图?
困定的供货商?不是投标。是指定方式做。
永远追求持续不断的完善。
有必要再试一次。
改进自己的产品吧。
也淘汰了自己的竞争者。 一个系列的生产方式是不错的。
到外去演讲,不做化疗?活过了三年?
要有自己的追求。活就要活出自己的价值。无论在何时的年龄,都要有自己的追求。
人生不是直线的,是C型的人生。
人生可以随时开始。
<设计模式:java语言中的应用>摘要、总结 收藏
<设计模式:java语言中的应用>一书已经学完,现做个摘要、总结。
创建模式(Creational Patterns)
Abstract Factory Builder
Factory Method Prototype
Singleton
结构模式(Structural Patterns)
Adapter Bridge
Composite Decorator
Facade Flyweight
Proxy
行为模式(Behavioral Pattern)
Chain of Responsibility Command
Interpreter Iterator
Mediator Memento
Observer State
Strategy Template Method
Visitor
一、创建模式(Creational Patterns)
1.Abstract Factory(抽象工厂)—把相关零件组合成产品
Abstract Factory Pattern 是把各种抽象零件组合成抽象产品。换句话说,处理的重点是在接口(API)而不是零件的具体实现。只利用接口(API)就能把零件组合成产品.
程序示例:
--Main.java 测试用的类
|-factory
| |-------Factory.java 表示抽象工厂的类(产生Link,Tray,Page)
| |-------Itme.java 用来统一处理Link和Tray的类
| |-------Link.java 抽象零件:表示HTML连接的类
| |-------Tray.java 抽象零件:抽取Link和Tray的类
| |-------Page.java 抽象零件:表示HTML网页的类
|
|-listfactory
|-------listFactory.java 表示具体工厂的类(产生ListLink,ListTray,ListPage)
|-------listLink.java 具体零件:表示HTML连接的类
|-------listTray.java 具体零件:抽取Link和Tray的类
|-------listPage.java 具体零件:表示HTML网页的类
步骤:定义抽象零件->用抽象零件定义抽象工厂->定义具体零件(继承实现抽象零件)->定义具体工厂(继承实现抽象工厂,制造实际产品)
2.Factory Method
Factory Method Pattern 在父类规定对象的创建方法,但并没有深入到较具体的类名.所有具体的完整内容都放在子类.根据这个原则,我们可以大致分成产生对象实例的大纲(框架)和实际产生对象实例的类两方面.
程序示例:
--Main.java 测试用的类
|-framework
| |-------Product.java 仅定义抽象方法use的抽象类
| |-------Factory.java 规定createProduct,registerProduct,实现create的抽象类(类似模板方法)
|
|-idcard
|-------IDCard.java 实现方法use的具体类
|-------IDCardFactory.java 实现方法createProduct,registerProduct的类
步骤:定义抽象产品->根据抽象产品定义抽象工厂->定义具体产品(继承实现抽象产品)->定义具体工厂(继承实现抽象工厂,制造实际产品)
3.Singleton(单件)-唯一的对象实例
Singleton Pattern 是针对一个类而言. Singleton类只会产生1个对象实例.Singleton类把singleton定义为static字段(类变量),再以Singleton类的对象实例进行初始化.这个初始化的操作仅在加载Singleton类时进行一次.
Singleton类的构造函数是private的,主要是为了禁止从非Singleton类调用构造函数.即使下面这个表达式不在此类之内,编译时仍然会出现错误.
程序示例:
|--Main.java 测试用的类
|--Singleton.java 只有1个对象实例的类
步骤:定义一个该类类型的static字段,同时实例化->该类的构造方法设为private->定义一个static的getInstance()方法,返回已经实例化的static字段.
4.Builder(生成器)-组合复杂的对象实例
Builder Pattern 是采用循序渐进的方式组合较复杂对象实例的.
程序示例:
|--Main.java 测试用的类
|--Builder.java 规定建立文件时的方法的抽象类
|--Director.java 产生1个文件的类
|--TextBuilder.java 产生plaintext格式(一般文本格式)的类
|--HTMLBuilder.java 产生HTML格式的类
步骤:定义建立文件时的通用方法(Builder.java)->根据通用方法组织建立文件(Director.java)->根据不同需求实现建立文件的通用方法(TextBuilder.java,HTMLBuilder.java)
5.Prototype(原型)-复制建立对象
Prototype Pattern 不是利用类产生对象实例,而是从一个对象实例产生出另一个新对象实例.
程序示例:
|--Main.java 测试用的类
|--MessageBox.java 把字符串框起来use的类.实现use和createClone
|--UnderlinePen.java 把字符串加上下划线的类.实现use和createCone
|--framework
|-------Product.java 已声明抽象方法use和createClone的接口
|-------Manager.java 利用createClone复制对象实例的类
步骤:规定可复制产品的接口(Product.java,继承Cloneable接口)->保存可复制的产品(以Product类型存以哈西表中),并提供复制产品的方法create(调用产品的复制方法,复制工作在具体产品类中执行)(Manager.java)->定义可复制的具体产品(UnderlinePen.java,MessageBox.java,实现复制产品方法)
二、结构模式(Structural Patterns)
1.Adapter(适配器)-换个包装再度利用
Adapter Pattern 把既有的无法直接利用的内容转换成必要的类型后再使用.具有填平"既有内容"和"需要结果"两者间"落差"的功能.
Adapter Pattern 有继承和委托两种形式.
程序示例:
|--Main.java 测试用的类
|--Banner.java 具有原始功能showWithParen,showWithAster的类
|--Print.java 所需新功能printWeak,printStrong的接口或抽象类
|--PrintBanner.java 把原始功能转换成新功能的类
步骤:
(继承)构造具有原始功能的类(Banner.java)->定义具有新功能的接口(Print.java)->转换(PrintBanner.java,继承Banner实现Print接口,即继承旧方法实现新功能)
(委托)构造具有原始功能的类(Banner.java)->定义具有新功能的抽象类(Print.java)->转换(PrintBanner.java,继承具有新功能的Print类.定义委托对象,即原始功能类.构造时传入原始功能实例对象,新功能的实现利用委托对象的原始功能.)
2.Bridge(桥接)-分成功能层次和实现层次
Bridge Pattern 沟通着"功能的类层次"和"实现的类层次"
功能的类层次:给父类增加不同的功能
实现的类层次:给父类以不同的实现
Bridge Pattern 本质上是通过功能类(最上层的功能类)中的一个实现类(最上层的实现类,一般是抽象类)字段来桥接两个类层次的.
程序示例:
|--Main.java 测试用的类
|--Display.java 功能类层次的最上层类
|--CountDisplay.java 功能类层次的新增功能类
|--DisplayImpl.java 实现类层次的最上层类
|--StringDisplayImpl.java 实现类层次的实现类
步骤:定义实现类层次的最上层类(DisplayImpl.java)->定义功能类层次的最上层类(Display.java,使用Adapter Pattern的委托方式把DisplayImpl.java的原始功能转换成Display.java的新功能)->定义功能类层次的新增功能类(CountDisplay.java)->定义实现类层次的实现类(StringDisplayImpl.java)
3.Composite(组成)-对容器和内容一视同仁
有时候把容器和内容当作是同类来处理会比较好下手。容器里面可以是内容,也可以是更小一号的容器;而这个小一号的容器里还可以再放更小一号的容器,可以建立出像这样大套小的结构和递归结构的Pattern就是Composite Pattern
使用Composite Pattern,容器和内容必须有一定的共性.
程序示例:
|--Main.java 测试用的类
|--File.java 表示文件的类
|--Directory.java 表示目录的类
|--Entry.java 对File和Directory一视同仁的抽象类
|--FileTreatmentException.java 欲在文件内新增Entry时所发生的异常类
步骤:定义异常类(FileTreatmentException.java)->定义进入点类,即将容器和内容一视同仁的抽象类(Entry.java,容器和内容都含有共同的方法)->定义容器类和内容类(File.java,Directory.java,继承Entry,实现通用方法)
4.Decorator(装饰)-对装饰和内容一视同仁
先建立一个核心对象,再一层层加上装饰用的功能,就可以完成符合所需的对象.可以看成是多个通用的适配器.
程序示例:
|--Main.java 测试用的类
|--Display.java 打印字符串用的抽象类
|--StringDisplay.java 只有1行的打印字符串用的类
|--Border.java 表示"装饰外框"的抽象类
|--SideBorder.java 只在左右加上装饰外框的类
|--FullBorder.java 在上下左右加上装饰外框的类
步骤:定义核心对象的抽象类(Display.java)->定义核心对象类(StringDisplay.java)->定义装饰类的抽象类(Border.java,继承核心对象的抽象类Display.java,以便装饰和内容一视同仁.装饰类中继承自核心对象抽象类的方法委托给传入的核心对象)->定义其它装饰类(SideBorder.java,FullBorder.java,继承Border.java)
5.Facade(外观)-单一窗口
Facade Pattern 能整理错综复杂的来龙去脉,提供较高级的接口(API).Facade参与者让系统外部看到较简单的接口(API).而且Facade参与者还会兼顾系统内部各类功能和互动关系,以最正确的顺序利用类.
Facade Pattern 把业务逻辑封装起来,只提供一个简单的接口给外部调用.
程序示例:
|--Main.java 测试用的类
|--maildata.txt 邮件列表文件
|--pagemaker
|-------Database.java 从邮件信箱取得用户名称的类
|-------HtmlWriter.java 产生HTML文件的类
|-------PageMaker.java 根据邮件信箱产生用户网页的类
步骤:定义业务逻辑需要的相关类(Database.java,HtmlWriter.java)->定义外部接口类(PageMaker.java)
6.Flyweight(享元)-有相同的部分就共享,采用精简政策
"尽量共享对象实例,不做无谓的new".不是一需要对象实例就马上new,如果可以利用其他现有的对象实例,就让它们共享.这就是Flyweigth Pattern的核心概念.
Flyweight Pattern 实质是把创建的占用内存量大的对象存储起来(一般用hashtable存储),后续使用时,再从hashtable取出.
程序示例:
|--Main.java 测试用的类
|--BigChar.java 表示"大型字符"的类
|--BigCharFactory.java 共享并产生BigChar的对象实例的类
|--BigString.java 表示多个BigChar所产生的"大型文本"的类
步骤:定义占用内存量大,需要共享的类(Display.java)->定义共享实例的类(BigCharFactory.java,共享处理在此进行,将产生的共享对象存储在哈希表中,第二次使用时从表中取出即可,不需要new)->定义共享对象组合使用类(BigString.java)
7.Proxy(代理)-需要再建立
代理就是那个代替本来应该自己动手做事的本人的人.
由于代理纯粹只是代理工作而已,因此能力范围也有限.如果遇到超出代理能力所及的范围,代理就应该去找本人商量才对.
程序示例:
|--Main.java 测试用的类
|--Printer.java 表示命名的打印机的类(本人)
|--Printable.java Printer和PrinterProxy共享的接口
|--PrinterProxy.java 表示命名的打印机的类(代理)
步骤:定义本人和代理都能处理的问题的接口(Printable.java)->建立本人类(Printer.java,实现Printable.java接口)->建立代理类(PrinterProxy.java,定义本人字段,把代理无法处理的问题交给本人)
三、行为模式(Behavioral Pattern)
1.Chain of Responsibility(职责链)-责任转送
先对人产生一个要求,如果这个人有处理的能力就处理掉;如果不能处理的话,就把要求转送给"第二个人".同样的,如果第二个人有处理的能力时就处理掉,不能处理的话,就继续转送给"第三个人",依此类推.这就是Chain of Responsiblility Pattern.
Chain of Responsibility Pattern 的关键在于定义转送字段(next)和定义职责链.
程序示例:
|--Main.java 建立Support的连锁,产生问题的测试用类
|--Trouble.java 表示发生问题的类.内有问题编号.
|--Support.java 解决问题的抽象类.内有转送字段和处理方法.
|--NoSupport.java 解决问题的具体类(永远"不处理")
|--LimitSupport.java 解决问题的具体类(解决小于指定号码的问题)
|--OddSupport.java 解决问题的具体类(解决奇数号码的问题)
|--SpecialSupport.java 解决问题的具体类(解决特殊号码的问题)
步骤:建立问题类(Trouble.java)->建立解决问题的抽象类(Support.java,定义了转送字段next,设置转送字段的方法setNext和处理问题的方法support)->建立解决问题的具体类(NoSupport.java,LimitSupport.java,OddSupport.java,SpecialSupport.java,继承Support.java)->产生处理问题的对象,建立职责链
2.Command(命令)-将命令写成类
用一个"表示命令的类的对象实例"来代表欲执行的操作,而不需采用"调用方法"的类的动态处理.如欲管理相关纪录,只需管理该对象实例的集合即可.而若预先将命令的集合存储起来,还可再执行同一命令;或者是把多个命令结合成一个新命令供再利用.
Command Pattern 重点在于存储/使用命令
程序示例:
--Main.java 测试用的类
|-command
| |-------Command.java 表示"命令"的接口
| |-------MacroCommand.java 表示"结合多个命名的命令"的类
|
|-drawer
|-------DrawCommand.java 表示"点的绘制命令"的类
|-------Drawable.java 表示"绘制对象"的接口
|-------DrawCanvas.java 表示"绘制对象"的类
步骤:建立命令接口(Command.java)->建立命令结合类(MacroCommand.java,将各个命令存储到一个Stack类型的字段)->建立绘制命令类(DrawCommand.java,定义绘制对象字段drawable,实现命令接口)->建立绘制对象接口(Drawable.java)->建立绘制对象类(DrawCanvas.java,实现绘制对象接口,定义命令集合字段history)->测试
3.Interpreter(解释器)-以类来表达语法规则
Interpreter Pattern 是用简单的"迷你语言"来表现程序要解决的问题,以迷你语言写成"迷你程序"而表现具体的问题.迷你程序本身无法独自启动,必须先用java语言另外写一个负责"解释(interpreter)"的程序.解释程序能分析迷你语言,并解释\执行迷你程序.这个解释程序也称为解释器.当应解决的问题发生变化时,要修改迷你程序来对应处理.而不是修改用java语言写成的程序.
迷你语言语法:
<program>::=program<command list>
<command list>::=<command>* end
<command>::=<repeat command>|<primitive command>
<repeat command>::=repeat<number><command list>
<primitive command>::=go|right|left
程序示例:
|--Main.java 测试用的类
|--Node.java 树状剖析中"节点"的类
|--ProgramNode.java 对应<program>的类
|--CommandListNode.java 对应<command list>的类
|--CommandNode.java 对应<command>的类
|--RepeatCommandNode.java 对应<repeat command>的类
|--PrimitiveCommandNode.java 对应<primitive command>的类
|--Context.java 表示语法解析之前后关系的类
|--ParseException.java 语法解析中的例外类
步骤:确定迷你语言的语法->建立语法解析类(Context.java,使用java.util.StringTokenizer类)->建立解析异常类(ParseException.java)->建立语法节点抽象类(Node.java,定义parse解析方法)->建立各语法节点对应的语法类(ProgramNode.java,CommandListNode.java,CommandNode.java,RepeatCommandNode.java,PrimitiveCommand.java,继承语法节点Node.java类)
4.Iterator-迭代器
Iterator Pattern 是指依序遍历并处理多个数字或变量.
程序示例:
|--Main.java 测试用的类
|--Aggregate.java 表示已聚合的类
|--Iterator.java 执行递增\遍历的接口
|--Book.java 表示书籍的类
|--BookShelf.java 表示书架的类
|--BookShelfIterator.java 扫描书架的类
步骤:定义聚合接口(Aggregate.java)->定义遍历接口(Iterator.java)->建立具体的遍历对象类(Book.java)->建立具体的聚合类(BookShelf.java,实现聚合接口)->建立具体的遍历类(BookShelfIterator.java,实现遍历接口)
5.Mediator(中介者)-只要面对一个顾问
每个成员都只对顾问提出报告,也只有顾问会发出指示给各个成员;成员们彼此也不会去探问目前状况如何,或乱发指示给其他成员.
程序示例:
|--Main.java 测试用的类
|--Mediator.java 决定"顾问"接口(API)的接口
|--Colleague.java 决定"成员"接口(API)的接口
|--ColleagueButton.java 实现Colleagues接口.表示按键的类
|--ColleagueTextField.java 实现Colleagues接口.输入文本的类
|--ColleagueCheckbox.java 实现Colleagues接口.表示选择项目(在此为选择按钮)的类
|--LoginFrame.java 实现Mediator接口.表示登录对话框的类
步骤:定义顾问接口(Mediator.java)->定义成员接口(Colleague.java)->建立具体的成员类(ColleagueButton.java,ColleagueTextField.java,ColleagueCheckbox.java,实现成员接口)->建立具体的顾问类(LoginFrame.java,实现顾问接口)
6.Memento(备忘录)-存储状态
Memento Pattern 会把某个时间点的对象实例状态记录存储起来,等到以后再让对象实例复原到当时的状态.
程序示例:
|--Main.java 进行游戏的类.先把Memento的对象实例存储起来,如有必要时再复原Gamer的状态
|--game
|-------Gamer.java 玩游戏的主人翁的类
|-------Memento.java 表示Gamer状态的类.产生Memento的对象实例
步骤:建立需要存储状态的类(Gamer.java)->建立状态类(Memento.java,状态类与需要存储状态的类Gamer.java应具有相同的必要字段)
7.Observer(观察者)-通知状态变化
当被Observer Pattern 列入观察名单的状态发生变化,就会通知观察者.在写一些跟状态变化有关的处理时,Observer Pattern是很好用的工具.
程序示例:
|--Main.java 测试用的类
|--Observer.java 表示观察者的接口
|--NumberGenerator.java 表示产生数值对象的抽象类
|--RandomNumberGenerator.java 产生随机数的类
|--DigitObserver.java 以数字表示数值的类
|--GraphObserver.java 以简易长条图表示数值的类
步骤:定义观察者接口(Observer.java)->建立被观察的类(NumberGenerator.java,RandomNumberGenerator.java,定义观察者结合字段将观察者存储起来)->建立具体的观察者类(DigitObserver.java,GraphObserver.java,实现观察者接口)
8.State(状态)-以类表示状态
以类来表示状态之后,只要切换类就能表现“状态变化”,而且在必须新增其他状态时,也很清楚该编写哪个部分。
程序示例:
|--Main.java 测试用的类
|--State.java 表示金库状态的接口
|--DayState.java 实现State的类。表示白天的状态
|--NightState.java 实现State的类。表示夜间的状态
|--Context.java 管理金库的状态变化,跟保安中心联络的接口
|--SafeFrame.java 实现Context的类。含有按钮、画面显示等的用户接口
步骤:定义状态接口(State.java,将使用State Pattern之前各种行为方法抽象出来)->建立具体的状态类(DayState.java,NightState.java,实现状态接口,状态变化的具体动作在这里执行)->定义管理状态变化的接口(Context.java,规定状态变化及相关的调用方法)->建立状态管理类(SafeFrame.java,实现状态管理接口)
9.Strategy(策略)-把算法整个换掉
在Strategy Pattern之下,可以更换实现算法的部分而且不留痕迹。切换整个算法,简化改为采用其他方法来解决同样的问题。
程序示例:
|--Main.java 测试用的类
|--Hand.java 表示猜拳“手势”的类
|--Strategy.java 表示猜拳“战略”的接口
|--WinningStrategy.java 表示猜赢之后继续出同样招式的战略的类
|--ProbStrategy.java 表示从上一次出的招式,以概率分配方式求出下一个招式机率的类
|--Player.java 表示玩猜拳的游戏者的类
步骤:定义策略接口(Strategy.java)->建立具体的策略类(WinningStrategy.java,ProbStrategy.java,实现策略接口)->建立使用策略的类(Player.java,定义策略字段,以便使用切换策略)->建立其它类(Main.java,Hand.java)
10.Template Method(模板方法)-实际处理交给子类
在父类指定处理大纲、在子类规定具体内容的Design Pattern就称为Template Method Pattern
程序示例:
|--Main.java 测试用的类
|--AbstractDisplay.java 只实现方法display的抽象类
|--CharDisplay.java 实现方法open,print,close的类
|--StringDisplay.java 实现方法open,print,close的类
步骤:定义模板类(AbstractDisplay.java,实现dispaly方法,即制作了模板)->建立具体内容类(CharDisplay.java,StringDisplay.java,继承模板类,实现模板类没有实现的方法)
11.Visitor(访问者)-在结构中穿梭还同时做事
Visitor Pattern 把数据结构和处理两者分开,另外写一个表示在数据结构内穿梭来去的主体“访客”的类,然后把处理交给这个类来进行。如此一来,如果想追加新的处理行为时,只要再建立一个新的“访客”即可。而在数据结构这边,也只要能接受来敲门的“访客”就能完成动作。
在父类指定处理大纲、在子类规定具体内容的Design Pattern就称为Template Method Pattern
程序示例:
|--Main.java 测试用的类
|--Visitor.java 表示访问文件或目录的访客的抽象类
|--Acceptor.java 表示接受Visitor类的对象实例的数据结构的接口
|--ListVisitor.java Visitor类的子类,打印文件和目录信息的类
|--Entry.java File和Directory的父类的抽象类(实现Acceptor接口)
|--File.java 表示文件的类
|--Directory.java 表示目录的类
|--FileTreatmentException.java 发生在对File进行add时的例外类
步骤:定义访问者的抽象类(Visitor.java,定义访问方法)->定义受访者接口(Acceptor.java,定义接受访问的方法)->建立具体的访问者类(ListVisitor.java,继承访问者抽象类,实现访问方法)->建立具体的受访者类(Entry.java,File.java,Directory.java,实现受访者接口)->编写异常类(FileTreatmentException.java)
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/pian_yun/archive/2007/09/14/1784981.aspx
直接在html中使用xml导入数据
<xml id="cdcat" src="cd_catalog.xml"></xml>
<table border="1" datasrc ="#cdcat">
<tr>
<td><span datafld="ARTIST"></span></td>
<td><span datafld="TITLE"></span></td>
<td datafld="price"> </td>
<td><span datafld="year"></span></td>
</tr>
</table>
注意可以引入xml字段的元素有 限:
例如,与DIV元素绑定的代码如下:
d: U) f1 y
注意:并非所有的HTML元素都能与XML数据岛绑定。目前,支持这种DSO绑定机制的元素如下:. H2 V- _% j! E/ {4 i
$ \( \$ l" b+ H( M& Y
A、APPLET、BUTTON、DIV、FRAME、IFRAME、 IMG、INPUT (此处类型是:CHECKBOX、HIDDEN、 LABEL、PASSWORD、RADIO和TEXT)、LABEL、 MARQUEE、SELECT、SPAN、TABLE和 TEXTAREA。
H.264中的NAL技术
NAL技术
1.NAL概述
NAL全称Network Abstract Layer, 即网络抽象层。
在H.264/AVC视频编码标准中,整个系统框架被分为了两个层面:视频编码层面(VCL)和网络抽象层面(NAL)。其中,前者负责有效表示视频数据的内容,而后者则负责格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。
现实中的传输系统是多样化的,其可靠性,服务质量,封装方式等特征各不相同,NAL这一概念的提出提供了一个视频编码器和传输系统的友好接口,使得编码后的视频数据能够有效地在各种不同的网络环境中传输。
2.NAL单元
NAL单元是NAL的基本语法结构,它包含一个字节的头信息和一系列来自VCL的称为原始字节序列载荷(RBSP)的字节流。头信息中包含着一个可否丢弃的指示标记,标识着该NAL单元的丢弃能否引起错误扩散,一般,如果NAL单元中的信息不用于构建参考图像,则认为可以将其丢弃;最后包含的是NAL单元的类型信息,暗示着其内含有效载荷的内容。
送到解码器端的NAL单元必须遵守严格的顺序,如果应用程序接收到的NAL单元处于乱序,则必须提供一种恢复其正确顺序的方法。
3.NAL实现编解码器与传输网络的结合
NAL提供了一个编解码器与传输网络的通用接口,而对于不同的网络环境,具体的实现方案是不同的。对于基于流的传输系统如H.320、MPEG等,需要按照解码顺序组织NAL单元,并为每个NAL单元增加若干比特字节对齐的前缀以形成字节流;对于RTP/UDP/IP系统,则可以直接将编码器输出的NAL单元作为RTP的有效载荷;而对于同时提供多个逻辑信道的传输系统,我们甚至可以根据重要性将不同类型的NAL单元在不同服务质量的信道中传输[2]。
4.结论
为了实现编解码器良好的网络适应性,需要做两方面的工作:第一、在Codec中将NAL这一技术完整而有效的实现;第二、在遵循H.264/AVC NAL规范的前提下设计针对不同网络的最佳传输方案。如果实现了以上两个目标,所实现的就不仅仅是一种视频编解码技术,而是一套适用范围很广的多媒体传输方案,该方案适用于如视频会议,数据存储,电视广播,流媒体,无线通信,远程监控等多种领域。
NALU类型
标识NAL单元中的RBSP数据类型,其中,nal_unit_type为1, 2, 3, 4, 5及12的NAL单元称为VCL的NAL单元,其他类型的NAL单元为非VCL的NAL单元。
0:未规定
1:非IDR图像中不采用数据划分的片段
2:非IDR图像中A类数据划分片段
3:非IDR图像中B类数据划分片段
4:非IDR图像中C类数据划分片段
5:IDR图像的片段
6:补充增强信息 (SEI)
7:序列参数集
8:图像参数集
9:分割符
10:序列结束符
11:流结束符
12:填充数据
13 – 23:保留
24 – 31:未规定
NALU的顺序要求
H.264/AVC标准对送到解码器的NAL单元顺序是有严格要求的,如果NAL单元的顺序是混乱的,必须将其重新依照规范组织后送入解码器,否则解码器不能够正确解码。
1.序列参数集NAL单元必须在传送所有以此参数集为参考的其他NAL单元之前传送,不过允许这些NAL单元中间出现重复的序列参数集NAL单元。所谓重复的详细解释为:序列参数集NAL单元都有其专门的标识,如果两个序列参数集NAL单元的标识相同,就可以认为后一个只不过是前一个的拷贝,而非新的序列参数集。
2.图像参数集NAL单元必须在所有以此参数集为参考的其他NAL单元之先,不过允许这些NAL单元中间出现重复的图像参数集NAL单元,这一点与上述的序列参数集NAL单元是相同的。
3.不同基本编码图像中的片段(slice)单元和数据划分片段(data partition)单元在顺序上不可以相互交叉,即不允许属于某一基本编码图像的一系列片段(slice)单元和数据划分片段(data partition)单元中忽然出现另一个基本编码图像的片段(slice)单元片段和数据划分片段(data partition)单元。
4.参考图像的影响:如果一幅图像以另一幅图像为参考,则属于前者的所有片段(slice)单元和数据划分片段(data partition)单元必须在属于后者的片段和数据划分片段之后,无论是基本编码图像还是冗余编码图像都必须遵守这个规则
5.基本编码图像的所有片段(slice)单元和数据划分片段(data partition)单元必须在属于相应冗余编码图像的片段(slice)单元和数据划分片段(data partition)单元之前。
6.如果数据流中出现了连续的无参考基本编码图像,则图像序号小的在前面。
7.如果arbitrary_slice_order_allowed_flag置为1,一个基本编码图像中的片段(slice)单元和数据划分片段(data partition)单元的顺序是任意的,如果arbitrary_slice_order_allowed_flag置为零,则要按照片段中第一个宏块的位置来确定片段的顺序,若使用数据划分,则A类数据划分片段在B类数据划分片段之前,B类数据划分片段在C类数据划分片段之前,而且对应不同片段的数据划分片段不能相互交叉,也不能与没有数据划分的片段相互交叉。
8.如果存在SEI(补充增强信息) 单元的话,它必须在它所对应的基本编码图像的片段(slice)单元和数据划分片段(data partition)单元之前,并同时必须紧接在上一个基本编码图像的所有片段(slice)单元和数据划分片段(data partition)单元后边。假如SEI属于多个基本编码图像,其顺序仅以第一个基本编码图像为参照。
9.如果存在图像分割符的话,它必须在所有SEI 单元、基本编码图像的所有片段slice)单元和数据划分片段(data partition)单元之前,并且紧接着上一个基本编码图像那些NAL单元。
10.如果存在序列结束符,且序列结束符后还有图像,则该图像必须是IDR(即时解码器刷新)图像。序列结束符的位置应当在属于这个IDR图像的分割符、SEI 单元等数据之前,且紧接着前面那些图像的NAL单元。如果序列结束符后没有图像了,那么它的就在比特流中所有图像数据之后。
11.流结束符在比特流中的最后。
本文来自CSDN博客,转载请标明出处:file:///D:/新建文件夹/桌面/H_264中的NAL技术%20-%20Bolt%20的专栏%20-%20CSDN博客.htm
生成zigzag序,
1、分析关键,在以zigzag序的每一行,以上三角为计算对象分别以i或j的增序排列,因此利用这一点就可以得出结果。
程序中s即为zigzag行号,而变换则以i和j交替。所以程序很简单。
#include<iostream>
#include<iomanip>
using namespace std;
#define M 255
void zigzag(const int N)
{
int squa = N * N;
int a[M][M]={0};
for (int i = 0;i < N; i++)
{
for (int j = 0;j < N;j++)
{
int s = i + j;
if ( s < N)
{
a[i][j] = s * (s+1)/2 + ( (s %2 !=0)?i:j);//注意?:的优先级低于+
}
else
{
int sn = (N-1-i) + (N-1-j);
a[i][j] = squa - sn * (sn+1)/2 - (N - ( (sn%2 != 0)? i:j));
}
}
}
for (int i=0; i < N; i++)
{
for (int j = 0;j < N;j++)
{
cout<<setw(4)<<a[i][j]<<",";
}
cout<<endl<<endl;
}
}
int main()
{
zigzag(5);
cout<<endl;
zigzag(8);
cout<<endl;
return 0;
}
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
void zigzag(int n)
{
int **a =(int**) malloc(n*sizeof(int *)); //分配空间
if(NULL == a)
return ;
int i;
for(i = 0; i < n; i++) {
if((a[i] =(int*) malloc(n * sizeof(int))) == NULL) {
while(--i>=0)
free(a[i]);
free(a);
return;
}
}
bool flag = false; //这个标志位用来判断是从45度角生成还是225度角生成
int count = 0;
for(i=0; i<n; i++) //生成的上半部分的数据
{
if(flag)
{
for(int r = 0; r<=i; r++)
{
a[r][i-r] = count;
count++;
}
flag = false;
}
else
{
for(int r = i; r>=0; r--)
{
a[r][i-r] = count;
count++;
}
flag = true;
}
}
for(i=n-1; i>=0; i--) //生成的是下半部分的数据
{
// cout<<i<<endl;
if(flag)
{
for(int r = 0; r<=i-1; r++)
{
int r1 = n-i+r; //代表当前行
int c1 = 2*n-i-1-r1; //代表当前列
a[r1][c1] = count;
count++;
}
flag = false;
}
else
{
for(int r = i-1; r>=0; r--)
{
cout<<"ddd"<<endl;
int r1 = n-i+r;
int c1 = 2*n-i-1-r1;
// cout<<r1<<","<<c1<<endl;
a[r1][c1] = count;
count++;
}
flag = true;
}
}
for(int r = 0; r<n; r++)
{
for(int c=0; c<n; c++)
cout<<a[r][c]<<",";
cout<<endl;
}
}
int main()
{
int n;
cin>>n;
zigzag(n);
return 0;
}
网上还有一个人写了一个比较巧的算法:
/**
* 得到如下样式的二维数组
* zigzag(jpeg编码里取象素数据的排列顺序)
*
* 0, 1, 5, 6,14,15,27,28,
* 2, 4, 7,13,16,26,29,42,
* 3, 8,12,17,25,30,41,43,
* 9,11,18,24,31,40,44,53,
* 10,19,23,32,39,45,52,54,
* 20,22,33,38,46,51,55,60,
* 21,34,37,47,50,56,59,61,
* 35,36,48,49,57,58,62,63
*/
#include <stdio.h>
int main()
{
int N;
int s, i, j;
int squa;
scanf("%d", &N);
/* 分配空间 */
int **a = malloc(N * sizeof(int *));
if(a == NULL)
return 0;
for(i = 0; i < N; i++) {
if((a[i] = malloc(N * sizeof(int))) == NULL) {
while(--i>=0)
free(a[i]);
free(a);
return 0;
}
}
/* 数组赋值 */
squa = N*N;
for(i = 0; i < N; i++)
for(j = 0; j < N; j++) {
s = i + j;
if(s < N)
a[i][j] = s*(s+1)/2 + (((i+j)%2 == 0)? i : j);
else {
s = (N-1-i) + (N-1-j);
a[i][j] = squa - s*(s+1)/2 - (N - (((i+j)%2 == 0)? i : j));
}
}
/* 打印输出 */
for(i = 0; i < N; i++) {
for(j = 0; j < N; j++)
printf("%-6d", a[i][j]);
printf("\n");
}
return 0;
}
几道面试笔试题
2008-02-26 18:38
一、如何判断一个单链表是有环的?(注意不能用标志位,最多只能用两个额外指针)
struct node { char val; node* next;}
bool check(const node* head) {} //return false : 无环;true: 有环
一种O(n)的办法就是(搞两个指针,一个每次递增一步,一个每次递增两步,如果有环的话两者必然重合,反之亦然):
bool check(const node* head)
{
if(head==NULL)
return false;
node *low=head, *fast=head->next;
while(fast!=NULL && fast->next!=NULL)
{
low=low->next;
fast=fast->next->next;
if(low==fast)
return true;
}
return false;
}
二、删除一个单项链表的最中间的元素,要求时间尽可能短(不能使用两次循环)
struct link
{
int data;
struct link *next;
};
void delMiddle(link *head)
{
if(head == NULL)
return;
else if(head->next == NULL)
{
delete head;
return;
}
else
{
link *low = head;
link *fast = head->next;
while(fast != NULL && fast->next != NULL)
{
fast = fast->next->next;
if(fast == NULL)
break;
low = low->next;
}
link *temp = low->next;
low->next = low->next->next;
delete temp;
}
}
int main()
{
struct link *head,*l;
struct link *s;
head = (link*)malloc(sizeof(link));
head->data=0;
head->next = NULL;
l = head;
for(int i=1; i<9; i++)
{
s = (link*)malloc(sizeof(link));
s->data = i;
s->next = NULL;
l->next= s;
l = l->next;
}
print(head);
delMiddle(head);
print(head);
return 0;
}
三、输入n,求一个n*n矩阵,规定矩阵沿45度线递增(威盛)
/**
* 得到如下样式的二维数组
* zigzag(jpeg编码里取象素数据的排列顺序)
*
* 0, 1, 5, 6,14,15,27,28,
* 2, 4, 7,13,16,26,29,42,
* 3, 8,12,17,25,30,41,43,
* 9,11,18,24,31,40,44,53,
* 10,19,23,32,39,45,52,54,
* 20,22,33,38,46,51,55,60,
* 21,34,37,47,50,56,59,61,
* 35,36,48,49,57,58,62,63
*/
void zigzag(int n)
{
int **a =(int**) malloc(n*sizeof(int *)); //分配空间
if(NULL == a)
return ;
int i;
for(i = 0; i < n; i++) {
if((a[i] =(int*) malloc(n * sizeof(int))) == NULL) {
while(--i>=0)
free(a[i]);
free(a);
return;
}
}
bool flag = false; //这个标志位用来判断是从45度角生成还是225度角生成
int count = 0;
for(i=0; i<n; i++) //生成的上半部分的数据
{
if(flag)
{
for(int r = 0; r<=i; r++)
{
a[r][i-r] = count;
count++;
}
flag = false;
}
else
{
for(int r = i; r>=0; r--)
{
a[r][i-r] = count;
count++;
}
flag = true;
}
}
for(i=n-1; i>=0; i--) //生成的是下半部分的数据
{
// cout<<i<<endl;
if(flag)
{
for(int r = 0; r<=i-1; r++)
{
int r1 = n-i+r; //代表当前行
int c1 = 2*n-i-1-r1; //代表当前列
a[r1][c1] = count;
count++;
}
flag = false;
}
else
{
for(int r = i-1; r>=0; r--)
{
cout<<"ddd"<<endl;
int r1 = n-i+r;
int c1 = 2*n-i-1-r1;
// cout<<r1<<","<<c1<<endl;
a[r1][c1] = count;
count++;
}
flag = true;
}
}
for(int r = 0; r<n; r++)
{
for(int c=0; c<n; c++)
cout<<a[r][c]<<",";
cout<<endl;
}
}
int main()
{
int n;
cin>>n;
zigzag(n);
return 0;
}
网上还有一个人写了一个比较巧的算法:
/**
* 得到如下样式的二维数组
* zigzag(jpeg编码里取象素数据的排列顺序)
*
* 0, 1, 5, 6,14,15,27,28,
* 2, 4, 7,13,16,26,29,42,
* 3, 8,12,17,25,30,41,43,
* 9,11,18,24,31,40,44,53,
* 10,19,23,32,39,45,52,54,
* 20,22,33,38,46,51,55,60,
* 21,34,37,47,50,56,59,61,
* 35,36,48,49,57,58,62,63
*/
#include <stdio.h>
int main()
{
int N;
int s, i, j;
int squa;
scanf("%d", &N);
/* 分配空间 */
int **a = malloc(N * sizeof(int *));
if(a == NULL)
return 0;
for(i = 0; i < N; i++) {
if((a[i] = malloc(N * sizeof(int))) == NULL) {
while(--i>=0)
free(a[i]);
free(a);
return 0;
}
}
/* 数组赋值 */
squa = N*N;
for(i = 0; i < N; i++)
for(j = 0; j < N; j++) {
s = i + j;
if(s < N)
a[i][j] = s*(s+1)/2 + (((i+j)%2 == 0)? i : j);
else {
s = (N-1-i) + (N-1-j);
a[i][j] = squa - s*(s+1)/2 - (N - (((i+j)%2 == 0)? i : j));
}
}
/* 打印输出 */
for(i = 0; i < N; i++) {
for(j = 0; j < N; j++)
printf("%-6d", a[i][j]);
printf("\n");
}
return 0;
}
四、打印1到1000的整数,不能使用流程控制语句(for,while,goto等)也不能使用递归
1.
typedef struct _test{
static int a;
_test(){
printf("%d\n",_test::a);
a++;
}
}Test;
int Test::a = 1;
int main()
{
Test tt[1000];
return 0;
}
2.
#include <stdio.h>
#define B P,P,P,P,P,P,P,P,P,P
#define P L,L,L,L,L,L,L,L,L,L
#define L I,I,I,I,I,I,I,I,I,I,N
#define I printf( "%3d ",i++)
#define N printf( "\n ")
int main()
{
int i = 1;
B;
}
或
#define A(x) x;x;x;x;x;x;x;x;x;x;
int main ()
{
int n = 1;
A(A(A(printf ("%d ", n++))));
return 0;
}
五、struct S {
int i;
int * p;
};
void main()
{
S s;
int * p = &s.i;
p[0] = 4;
p[1] = 3;
s.p = p;
s.p[1] = 1;
s.p[0] = 2;
}
问程序会在哪一行死掉。 (microsoft)
解: S s;
int * p = &s.i; //s.i的地址存储在p里
p[0] = 4; //修改了s.i
p[1] = 3; //修改了s.p
s.p = p; //s.p指向s.i
s.p[1] = 1; //修改s.p本身
s.p[0] = 2; //s.p指向的是0x00000001,尝试向这里写,出错
s.p[0] = 2; 时出错
因为s.p存的是s.i的地址,s.p[1]为s.p,当s.p[1]=1时,s.p此时存放的是1了,而不是地址s.i,故在s.p[0] = 2时出错.
此时相当于s.p=ox00000001;地址ox0000001 = 2;当然就出错了
如果语句s.p[0] =2 先于s.p[1]=1则程序就不会出错.此时语句相当于s.i=2;s.p=1;
六、题目描述:
1. int swap(int *x,int *y)
{
if(x==NULL | | y==NULL)
return -1;
*x += *y;
*y = *x- *y;
*x -= *y;
return 1;
}
请改错,溢出已经考虑,不是错误
2.
void foo(int *x, int *y)
{
*x += *y;
*x += *y;
}
void fun(int *x, int *y)
{
*x += 2 * (*y);
}
问两个函数是否等价,能否互换
解答:第一题的函数是交换。但假如考虑x, y都是指向同一个变量,结果是这个变量的值为0.
第二题的两个函数是有区别的,也考虑x,y是指向同一个变量.这样第一个函数的结果是这个变量的4倍.但第二个函数的结果是变量的3倍.
|
C++ placement new 用法举例zz
2009-12-17 16:16
在处理内存分配的时候,C++程序员会用new操作符(operator new)来分配内存,并用delete操作符(operator delete)来释放内存。这是一个new操作符的例子。
class CTest
{
/* 成员函数和成员数据 */
};
// . . . 代码
// 分配一个对象
CTest * pTest = new Test;
// 分配一个有十个对象的数组 (CTest 要有缺省构造函数(default constuctor))
CTest * p10Tests = new Test[ 10];
虽然这种写法在大多数时候都工作得很好,但还是有些情况下使用new是很烦人的,比如当你想重新分配一个数组或者当你想在预分配的内存上构造一个对象的时候。
比如第一种情况,重新分配一个数组效率是很低的:
// 分配一个有10个对象的数组
CTest * pTests = new Test[ 10];
// . . .
// 假设现在我们需要11个对象
CTest * pNewTests = new Test[ 11];
// . . . 我们必须把原来的对象拷贝到新分配的内存中
for ( int i = 0; i < 10; i++)
pNewTests[ i] = pTests[ i];
delete pTests;
pTests = pNewTests;
如果你想在预分配的内存上创建对象,用缺省的new操作符是行不通的。要解决这个问题,你可以用placement new构造。它允许你构造一个新对象到预分配的内存上:
// buffer 是一个void指针 (void *)
// 用方括号[] 括起来的部分是可选的
[CYourClass * pValue = ] new( buffer) CYourClass[( parameters)];
下面是一些例子:
#include <new>
class CTest
{
public:
CTest()
{}
CTest( int)
{}
/* 代码*/
};
int main(int argc, char* argv[])
{
// 由于这个例子的目的,我们不考虑内存对齐问题
char strBuff[ sizeof( CTest) * 10 + 100];
CTest * pBuffer = ( CTest *)strBuff;
// 缺省构造
CTest * pFirst = new(pBuffer) CTest;
// 缺省构造
CTest * pSecond = new(pBuffer + 1) CTest;
// 带参数的构造;
// 不理会返回的指针
new(pBuffer + 2) CTest( 5);
// 带参数的构造
CTest * pFourth = new( pBuffer + 3) CTest( 10);
// 缺省构造
CTest * pFifth = new(pBuffer + 4) CTest();
// 构造多个元素(缺省构造)
CTest * pMultipleElements = new(pBuffer + 5) CTest[ 5];
return 0;
}
当你有自己的内存缓冲区或者在你实现自己的内存分配策略的时候,placement new会很有用。事实上在STL中广泛使用了placement new来给容器分配内存;每个容器类都有一个模版参数说明了构造/析构对象时所用的分配器(allocator)。
在使用placement new的时候,你要记住以下几点:
- 加上头文件#include <new>
- 你可以用placement new构造一个数组中的元素。
- 要析构一个用placement new分配的对象,你应该手工调用析构函数(并不存在一个“placement delete”)。它的语法如下:
pFirst->~CTest();
pSecond->~CTest();
前段事件,我问过关于placement new的问题,一位仁兄讲了一些道理,他说道:
::栈上的对象(注意,是类对象,char类型就无需了,后面还会提到)保证放在对齐地址上.
但是,个人实验了一下,发现并不是这样
例如:
int main()
{
char c1 = 'A' ;
char c2 = 'B' ;
char c3 = 'C' ;
char c4 = 'D' ;
char c5 = 'E' ;
//-------- 验证这四个地址是否是 4 的倍数 --------------//
if ( ((int)(&c1)) % 4 == 0 )
cout << "c1:Yes" << endl ;
if ( ((int)(&c2)) % 4 == 0 )
cout << "c2:Yes" << endl ;
if ( ((int)(&c3)) % 4 == 0 )
cout << "c3:Yes" << endl ;
if ( ((int)(&c4)) % 4 == 0 )
cout << "c4:Yes" << endl ;
if ( ((int)(&c5)) % 4 == 0 )
cout << "c5:Yes" << endl ;
cout << (int)(&c1) << endl // 输出四个字符所在的地址(输出结果都是 4 的倍数)
<< (int)(&c2) << endl
<< (int)(&c3) << endl
<< (int)(&c4) << endl
<< (int)(&c5) << endl ;
}
-----------------------------
上面的执行结果在VC下运行都是 4 的倍数
--------------
--> 问题1:连栈上分配的空间地址都是 4 的倍数,那就说明系统分配的空间都是 4 的倍数吧???
--> 问题2:如果万一,如果放一个对象的地址不是4的倍数,那么会出现什么情况??可以给简单说一下吗?
--> 问题3:地址对齐的通用性???
-------------
程序1:
Class C1
{
int i ;
char c ;
} ;
cout << sizeof(C1) << endl ;// 输出结果: 8 (是 4 的倍数)
程序2:
class C2
{
char c1 ;
char c2 ;
} ;
cout << sizeof(C2) << endl ;// 输出结果:2 ( 上一个中char类型也给了4个字节,怎么这个地方都给了一个字节??)
--> 问题4:由上面的程序2 引出下面的程序
class C2// sizeof(C2) =2 ,在VC实验下的结果,不是 4
{
char c1 ;
char c2 ;
} ;
//----------用placement new方法建立对象----------------
void *ptr = operator new(100) ;// 分配内存
C2 *POINTER = (C2*)ptr ;// 类型转换
String *str1 = new (POINTER) C2() ;// 建立一C2对象
String *str2 = new (POINTER+1) C2() ;// 再建立一个对象
String *str3 = new (POINTER+2) C2() ;// 再建立一个对象
cout << (int)(str1) << endl// 结果:3608720( 是4的倍数)
<< (int)(str2) << endl // 结果:3608722(不是4的倍数)!!
<< (int)(str3) << endl ;// 结果:3608724(不是4的倍数)!!
|
很实用的word的高级用法总汇2009-04-23 16:26
任意放大/变小 字体
快捷键ctrl+] 放大 字体 ctrl+[ 缩小字体
把文字替换成图片
首先把图片复制到 剪贴板中,然后打开替换对话框,在“查找内容”框中输入将被替换的文字,接着在 “替换为”框中输入“^c”(注意:输入的一定要是半角字符,c要小写),单击替换 即可。说明:“^c”的意思就是指令Word XP以剪贴板中的内容替换“查找内容”框中的内 容。按此原理,“^c”还可替换包括回车符在内的任何可以复制到剪贴板的可视内容,甚至Excel表格。
三招去掉页眉那条横线
1、在页眉中,在“格式”-“边框和底纹”中设置表格和边框为“无”,应用于“段落”
2、同上,只是把边框的颜色设置为白色(其实并没有删的,只是看起来没有了,呵呵)
3、在“样式”栏里把“页眉”换成“正文”就行了——强烈推荐!
会多出--(两个横杠) 这是用户不愿看到的,又要多出一步作删除--
解决方法:替换时在前引号前加上一个空格 问题就解决了
插入日期和时间的快捷键
Alt+Shift+D:当前日期
Alt+Shift+T:当前时间
批量转换全角字符为半角字符
首先全选。然后“格式”→“更改大小写”,在对话框中先选中“半角”,确定即可
Word启动参数简介
单击“开始→运行”命令,然后输入Word所在路径及参数确定即可运行,如“C:\ PROGRAM FILES \MICROSOFT Office \Office 10\ WINWord.EXE /n”,这些常用的参数及功能如下:
/n:启动Word后不创建新的文件。
/a:禁止插件和通用模板自动启动。
/m:禁止自动执行的宏。
/w:启动一个新Word进程,独立与正在运行的Word进程。
/c:启动Word,然后调用Netmeeting。
/q:不显示启动画面。
另外对于常需用到的参数,我们可以在Word的快捷图标上单击鼠标右键,然后在“目标”项的路径后加上该参数即可。
快速打开最后编辑的文档
如果你希望Word在启动时能自动打开你上次编辑的文档,可以用简单的宏命令来完成:
(1)选择“工具”菜单中的“宏”菜单项,单击“录制新宏”命令打开“录制宏”对话框;
(2)在“录制宏”对话框中,在“宏名”输入框中输入“autoexec”,点击“确定”;
(3)从菜单中选择“文件”,点击最近打开文件列表中显示的第一个文件名;并“停止录制”。保存退出。下次再启动Word时,它会自动加载你工作的最后一个文档。
格式刷的使用
1、设定好文本1的格式。
2、将光标放在文本1处。
3、单击格式刷按钮。
4、选定其它文字(文本2),则文本2的格式与文本1 一样。
若在第3步中单击改为双击,则格式刷可无限次使用,直到再次单击格式刷(或按Esc键)为止。
删除网上下载资料的换行符(象这种“↓”)
在查找框内输入半角^l(是英文状态下的小写L不是数字1),在替换框内不输任何内容,单击全部替换,就把大量换行符删掉啦。
选择性删除文件菜单下的最近使用的文件快捷方式。
工具→选项→常规把“列出最近使用文件数改为0”可以全部删除,若要选择性删除,可以按ctrl+Alt+ -三个键,光标变为一个粗减号后,单击文件,再单击要删除的快捷方式就行了。
建立一个矩形选区:
一般的选区建立可用鼠标左键,或用shift键配合pgup、pgdn、home、end、箭头等功能键,当复制一个规则的矩形区域时,可先按住Alt键,然后用鼠标左键来选。我一般用此来删除段首多余的成块的空格。大家试一试*^_^*
将字体快速改为上标或下标的方法:
本人在一次无意间发现了这个方法,选定你要下标的字,然后在英文状态下按住Ctrl,再按一下BASKSPACE旁的+/=的键,就可以了。上标只要在按Ctrl的同时也按住Shift,大家可以试试。
让Word表格快速一分为二
将光标定位在分开的表格某个位置上,按下“Ctrl+Shift+Enter”组合键。这时你就会发现表格中间自动插入一个空行,这样就达到了将一个表格一分为二的目的。
用Word来拆字
首先点击“工具/自定义/命令/分解图片”,按住鼠标左键把它拖放到工具栏任意位置即可;然后点击“插入/图片/艺术字”,例如输入空心字“心”,选择该“心”字剪切,在选择性粘贴中选图片(Windows图元文件),选中该字,点击工具栏中的“分解图片”按钮,这样可以选择“心”中的任意笔画进行一笔一画的拆分了。
快速删除段前段后的任意多个空格
选定这些段段落,单击居中按钮,然后再单击原来的那种对齐方式按钮(如果原来是居中对齐的,先单击其它对齐方式按钮,再单击居中按钮就行了),是不是这些空格全不见了?
只要打开WORD新建一个空文档的时候,出现的不是空的文档,而是我以前打的一份文档
首先:将资源管理器设置为显示所有文件和文件夹;
然后:
C:\Documents and Settings\Administrator\Application Data\Microsoft\Templates文件夹下将所有Normal.doc文件删掉;
然后:OK(XP系统)
快速输入平方的方法
先输入2,然后选重后,按ctrl加shift加+就可以了.
WORD中表格的选择性录入
1.设置好表格,选定表格-视图-工具-窗体-插入下拉型窗体域
2.输入数据,完成
3.点击锁按钮,保护,输入完后再点击进行其它的输入.
标点符号的全角/半的转换用:Ctrl+.
数字字母的全角/半的转换用:Shift+空格
轻松了解工具栏按钮的作用
按下“shift+F1”键,鼠标指针旁多了一个“?”号,想知道哪个按钮
的作用,就用鼠标单击哪个。
要经常在文档中插入自己公司的信息
公司名称
公司住址
联系电话
联系人姓名
QQ号码
可以先选定这些内容,再单击工具→自动更正→在替换框中输入标记名称(如“公司信息”)→添加→确定,以后凡是在文档中要用到这个信息的地方键入“公司信息”(不要引号)这几个字后就自动替换成:
公司名称
公司住址
联系电话
联系人姓名
QQ号码
说明:有些输入法不支持这个功能,键入标记名称后要按一下空格才行。
快速换页的方法
双击某页的右下脚,光标即可定位在那里,然后按回车直到换页。ctrl+回车点插入按纽,分隔符,选中分页符,然后确认就OK了 !!!
表格的简单调整宽度
鼠标放在表格的右边框上带鼠标变成可以调整大小的时候
双击
根据表格内的内容调节表格大小
代替金山词霸
点工具——语言——翻译,在右边出现的搜索框中输入要查的单词,回车就可以翻译了。可以选择英语翻成中文或中文翻成英语。
第一次使用可能要安装。
[Alt]键实现标尺的精确定位
如果你经常使用水平标尺来精确定位标签、页边框、首字缩进及页面对象的位置,那么你点击标尺设置页边框或标签时,您只可以将其设置为1字符或2字符,但不能设为1.5字符!要想设置更为精确的度量单位(例如百分之几字符),在按住[Alt]键的同时,点击并移动标尺或边框,此时标尺将用数字精确显示出当前的位置为百分之几字符位置。
用“记事本”去除格式
网页上COPY下来的东西往往都是有网格的,如果直接粘贴在WORD中会杂乱无章。先粘贴到记事本当中,再粘贴到WORD中,就可以去除网格等格式,再全选选择清除格式,居中再取消居中即可取消所有格式。可以直接在WORD中进行:(菜单)编辑/选择性粘贴……/无格式文本/确定。这样省事多了。
快速将文档转换成图片
先把欲想转换的文档保存退出.如:保存在桌面
然后新建一个文件.把想转换的文档(鼠标左建按住该文档不放)直接施放在页面上
恢复office的默认设置
比如不小心把word设置乱了(如删了菜单栏等等).
查找normal.dot直接删除.
下一次启动word会恢复默认值.
让Word只粘贴网页中的文字而自动去除图形和版式
方法一、选中需要的网页内容并按“Ctrl+C”键复制,打开Word,选择菜单“编辑”→“选择性粘贴”,在出现的对话框中选择“无格式文本”。
方法二、选中需要的网页内容并按“Ctrl+C” 键复制,打开记事本等纯文本编辑工具,按“Ctrl+V”键将内容粘贴到这些文本编辑器中,然后再复制并粘贴到Word中。
ctrl+alt+f可以输入脚注
这个对于经常写论文的朋友应该有点帮助。
将阿拉伯数字转换成中文数字或序号
1、先输入阿拉伯数字(如1234),全选中,单击“插入/数字/数字类型(壹、贰……)/确定”,即变为大写数字(如壹仟贰佰叁拾肆),会计朋友非常适用。
2、其他像一千二百三十四,甲、乙……,子、丑……,罗马数字等的转换,可参考上法。
Word中的常用快捷键吧
“字体”对话框 Ctrl+D
选择框式工具栏中的“字体”框 Ctrl+Shift+F
加粗 Ctrl+B
倾斜 Ctrl+I
下划线Ctrl+U
“上标”效果 Ctrl+Shift+=
“下标”效果 Ctrl+=
“关闭”命令 Ctrl+W
Word快捷键一览表
序号 快捷键CTRL+ 代表意义
1…………Z…………撤消
2…………A…………全选
3…………X…………剪切
4…………C…………复制
5…………V…………粘贴
6…………S…………保存
7…………B…………加粗
8………… Q…………左对齐
9…………E…………据中
10…………R…………右对齐
11…………]…………放大
22…………[…………缩小
12…………N…………新建文档
13…………I…………字体倾斜
14…………W…………退出
15…………P…………打印
16…………U…………下划线
17…………O…………打开
18…………k…………插入超级连接
19…………F…………查找
20…………H…………替换
21…………G…………定位
23…Ctrl+Alt+L……带括号的编号
24…Ctrl+Alt+.________…
25…Alt+数字………区位码输入
26…Ctrl+Alt+Del………关机
27…Ctrl+Alt+Shift+?……¿
28…Ctrl+Alt+Shift+!……¡
29…Alt+Ctrl+E……………?
30…Alt+Ctrl+R……………®
31…Alt+Ctrl+T……………™
32…Alt+Ctrl+Ctrl…………©
33……Ctrl+D……………格式字体
34……Ctrl+Shift+= ………上标
35……Ctrl+=………………下标
36……Ctrl+Shift+>……放大字体
37……Ctrl+Shift+< ……缩小字体
38……Alt+Ctrl+I………打印预览
39……Alt+Ctrl+O………大刚示图
40……Alt+Ctrl+P………普通示图
41……Alt+Ctrl+M………插入批注
42……Alt+菜单上字母………打开该菜单
无级微调
打开“绘图”工具栏-点开下拉菜单-绘图网格...-将水平间距和垂直间距调到最小0.01-确定,这样你就可以无级微调
把work设置成在线打开,但不能修改‘只读’怎搞啊?
文件夹共享为只读
在WORD中输入三个等号然后回车。。。出来的是双横线哦。。。
同样的方法也可以做出波浪线单横线哦!~~~~~ ,
###为中间粗上下细的三线, ***为点线, ~~~为波浪线, ---为单线
输入拼音字母的音调怎么输入
用智能ABC,键入v9,然后自己挑选吧!
页码设置
1、打开页眉/页脚视图,点击插入页码按钮,将页码插入(此时所有的页码是连续编号的) 2、切换到页面视图,在需要从1计数的页面上插入连续分节符(插入--分隔符--分节符--连续) 3、再次换到页眉/页脚视图,点击设置页码格式按钮,将页码编排-起始页码设置为1
把Excel中的表格以图片形式复制到Word中
除了用抓图软件和全屏拷贝法外还有更简单的呢
先选定区域,按住Shift健点击"编辑"会出现"复制图片""粘贴图片",复制了后,在Word中选"粘贴图片"就可像处理图片一样处理Excel表格了!
Ctrl+鼠标滑轮(左右键中间的那个轮子)可以迅速调节显示比例的大小(100%)。向上滑扩大,向下滑缩小。
快速调整页眉横线长度
在word插入页眉后,会自动在此位置添加一条长横线。如果需要调整此线的长度及其水平位置,可以首先激活页眉,选择格式下的段落命令,调整一下左右缩进的字符值,确定可以看到最终效果了!
快速浏览图片
在WORD2003中,如果插入的图片过多,会影响打开和翻滚的速度。其实,我们可以通过改变图片的显示方式改变浏览速度。
工具--选项--视图--图片框
这样,先显示的是图片框,需要看的时候,停留,即可显示!
WORD 中如何输入分数
1、打开word,点击工具菜单栏的“插入”,在下拉菜单中点“域”。
2、在打开的复选框中的类别栏中“选等式公式”,域名中“EQ”。然后点击“选项”,在出现的菜单选项中选“F(,)”,接着点击“添加到域”并“确定”。
3、然后在输入F(,)数字,如要输入23 只需在F(,)输入F(2,3)就能得到2/3
怎样使WORD 文档只有第一页没有页眉,页脚
答:页面设置-页眉和页脚,选首页不同,然后选中首页页眉中的小箭头,格式-边框和底纹,选择无,这个只要在“视图”——“页眉页脚”,其中的页面设置里,不要整个文档,就可以看到一个“同前”的标志,不选,前后的设置情况就不同了
Word中双击鼠标的妙用
在Word的程序窗口中不同位置上双击,可以快速实现一些常用功能,我们归纳如下:
在标题栏或垂直滚动条下端空白区域双击,则窗口在最大化和原来状态之间切换;
将鼠标在标题栏最左边WORD文档标记符号处双击,则直接退出WORD(如果没有保存,会弹出提示保存对话框);
将鼠标移到垂直滚动条的上端成双向拖拉箭头时双击,则快速将文档窗口一分为二;
将鼠标移到两个窗口的分界线处成双向拖拉箭头时双击,则取消对窗口的拆分;
在状态栏上的“修订”上双击,则启动“修订”功能,并打开“审阅”工具栏。再次双击,则关闭该功能,但“审阅”工具栏不会被关闭;
在状态栏上的“改写”上双击,则转换为“改写”形式(再次“双击”,转换为“插入”形式);
如果文档添加了页眉(页脚),将鼠标移到页眉(页脚)处双击,则激活页眉(页脚)进入编辑状态,对其进行编辑;在空白文档处双击,则启动“即点即输”功能;
在标尺前端空白处双击,则启动“页面设置”对话框。
在word编辑中经常要调整字休大小来满足编辑要求
选中要修改的文字,按ctrl+]或ctrl+[来改变字体的大小!
这个方法可以微量改字体大小~
文本框的线条
1. 制作好文档后,通过“视图→页眉页脚”命令,调出“页眉页脚”工具栏,单击其中的“显示→隐藏文档正文文字”按钮,隐藏正文部分的文字内容。
2. 选择“插入”菜单中的“文本框”命令,在页眉的下方插入一个空文本框。
3. 在文本框内加入作为水印的文字、图形等内容,右击图片,选择快捷菜单中的“设置图片格式”命令,在对话框中“图片”选项卡下,通过“图像控制”改变图像的颜色,对比度和亮度,并手动调整图片的大小。
4. 通过“设置文本框格式”命令,把文本框的线条色改为无线条色。
5. 单击“页眉页脚”工具栏的“关闭”按钮,退出“页眉页脚”编辑。
每页添加水印的操作
1. 制作好文档后,通过“视图→页眉页脚”命令,调出“页眉页脚”工具栏,单击其中的“显示→隐藏文档正文文字”按钮,隐藏正文部分的文字内容。
2. 选择“插入”菜单中的“文本框”命令,在页眉的下方插入一个空文本框。
3. 在文本框内加入作为水印的文字、图形等内容,右击图片,选择快捷菜单中的“设置图片格式”命令,在对话框中“图片”选项卡下,通过“图像控制”改变图像的颜色,对比度和亮度,并手动调整图片的大小。
4. 通过“设置文本框格式”命令,把文本框的线条色改为无线条色。
5. 单击“页眉页脚”工具栏的“关闭”按钮,退出“页眉页脚”编辑。
6. 完成上述步骤的操作,水印制作得以完成,这样就为每一页都添加了相同的水印。
让Word页面快速一分为二
将光标定位在想分开的位置上,按下“Ctrl+Shift+Enter”组合键。
使Word中的字体变清晰
Word文档中使用 “仿宋” 字体很淡,可按以下方法使字体更清晰:
右击桌面,点 “属性”,点 “外观”,点 “效果”,选中“使用下列方式使屏幕字体的边缘平滑”选“清晰”,确定。
Word双面打印技巧
我们平时用电脑的时候可能都少不了打印材料,Word是我们平常用的最多的Office软件之一。有时我们要用Word打印许多页的文档,出于格式要求或为了节省纸张,会进行双面打印。
我们一般常用的操作方法是:选择“打印”对话框底部的“打印”下拉列表框中的“打印奇数页”或“打印偶数页”,来实现双面打印。我们设定为先打印奇数页。等奇数页打印结束后,将原先已打印好的纸反过来重新放到打印机上,选择该设置的“打印偶数页”,单击“确定”按钮。这样通过两次打印命令就可以实现双面打印。
我们也可以利用另一种更灵活的双面打印方式:打开“打印”对话框,选中“人工双面打印”,确定后就会出现一个“请将出纸器中已打印好的一面的纸取出并将其放回到送纸器中,然后‘确定’按键,继续打印”的对话框并开始打印奇数页,打完后将原先已打印好的纸反过来重新放到打印机上,然后按下该对话框的“确定”按键,Word就会自动再打印偶数页,这样只用一次打印命令就可以了。
两种方法对比,后者较前者更为方便。
|
字符串拆分的中文处理问题
容健行@2007年7月
转载请注明出处
原文出处:http://www.devdiv.net/home/space.php?uid=125&do=blog&id=365
概述:
拆分一个字符串在程序中使用非常广泛,特别是我们经常跟表格打交道的程序员们。所谓拆分字符串,就是将一个字符串中间以某个(或某些)字符为分隔,拆分成多个字符串。如 std::string s = "abc | ddd | 中国"; 如果以竖线“|”拆分,可以将这个字符串拆分成三个字符串。
当然字符串拆分还包括通过正则表达式来拆分,为了简化问题,我们以单个字符做分隔的拆分,因为这种拆分用得最多。代码使用C++来讲解。
问题:
问题来源于实际,是之前我们组和其他组都有遇上的。先看一个例子,使用"|"拆分以下字符串,看起来怎么数都是分为48列,但我看到好几个版本的字符串拆分函数却报有49列:
"AGZGY1000004|200|刘瓅||20100101||OPRT10|1|0||AAGZ0Y100|0|0|24|0|0|0|0||-1|20030101|0|20991231||AGZGK6172888|200|曾晓翔||20100101||OPRT10|1|0||AAGZ0K617|0|0|24|0|0|0|0||-1|20061215|1|20061215||"
原因分析:
让我们先把以上字符串放到UltraEdit中,并切换到16进制的编辑模式,看看它的编码。
原因是原来的字符串拆分函数只是简单的查找“|”(编码为0x7c),而没有考虑到中文的处理(源代码太多,且有好几个版本,这里略去)。
在boss中,c++程序使用的编码方式几乎全为ansi,而在ansi中,表示中文是用两个字符,且第一个字符是一个大于0x80的字符(字符的第一位为1),第二个字符为任意字符。这里引起一个问题:
当我们要分割字符串时,假如用"|"(0x7c)作为分割符,当分析上面这个字符遇到"瓅"(编码为0xad,0x7c)这个字符时,会把它第二个字符作为了分割符,结果就多出了一列。
解决方案:
问题原因找到了,重新写了一下字符串拆分函数-Split,这里使用的方法是:找到分隔符后,再向前查找字符看一下它前一个字符是否为东亚文字的第一个字符编码(编码大于0x80)。
考虑到以后支持unicode,这里使用了模板。以下可能不是最高效简单的实现,但如果以后遇上这种问题,可以参考一下。
#include "stdafx.h"
#include <stdio.h>
#include <tchar.h>
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <fstream>
// unicode 分割策略
inline
bool __SplitPolicy(
const std::wstring& s,
const std::wstring& splitchar,
std::wstring::size_type& pos)
{
pos = s.find_first_of(splitchar, pos);
return pos != std::string::npos;
}
// ansi 分割策略
inline
bool __SplitPolicy(
const std::string& s,
const std::string& splitchar,
std::string::size_type& pos)
{
pos = s.find_first_of(splitchar, pos);
if (pos != std::string::npos)
{
// 如果前一个字符的第一位为1,且当前字符是在东亚文字的第二个字符,
// 则认为该字符是东亚字的其中一个字符,要跳过,不作为分割符。
std::string::size_type i = 1;
for (; i < pos; ++i)
{
if (!((char)(s[pos - i]) & 0x80)) // 判断第一位是否为1。(0x80的二进制为 10000000)
break;
}
if (!(i % 2)) // 看一下当前字符是否为东亚文字的第二个字符
{
++pos;
__SplitPolicy(s, splitchar, pos);
}
}
return pos != std::string::npos;
}
template<typename char_type> inline
int Split(
const std::basic_string<char_type>& s,
const std::basic_string<char_type>& splitchar,
std::vector<std::basic_string<char_type> >& vec)
{
typedef std::basic_string<char_type> string_t;
typedef typename string_t::size_type size_t;
string_t tmpstr;
size_t pos = 0, prev_pos = 0;
vec.clear();
while (__SplitPolicy(s, splitchar, pos))
{
tmpstr = s.substr(prev_pos, pos - prev_pos);
vec.push_back(tmpstr);
prev_pos = ++pos;
}
size_t len = s.length() - prev_pos;
if (len > 0)
vec.push_back(s.substr(prev_pos, len));
return static_cast<int>(vec.size());
}
// ansi版本测试
void testSplit()
{
std::vector<std::string> vec;
const std::string str = "AGZGY1000004|200|刘瓅瓅||20100101||OPRT10|1|0||AAGZ0Y100|0|0|24|0|0|0|0||-1|20030101|0|20991231||AGZGK6172888|200|曾晓翔||20100101||OPRT10|1|0||AAGZ0K617|0|0|24|0|0|0|0||-1|20061215|1|20061215||a";
const std::string sp = "|";
int count = Split(str, sp, vec);
for (std::vector<std::string>::const_iterator it = vec.begin(); it != vec.end(); ++it)
std::cout << *it << " ";
}
// unicode版本测试
void testSplitW()
{
std::vector<std::wstring> vec;
const std::wstring str = L"AGZGY1000004|200|刘瓅||20100101||OPRT10|1|0||AAGZ0Y100|0|0|24|0|0|0|0||-1|20030101|0|20991231||AGZGK6172888|200|曾晓翔||20100101||OPRT10|1|0||AAGZ0K617|0|0|24|0|0|0|0||-1|20061215|1|20061215||";
const std::wstring sp = L"|";
Split(str, sp, vec);
const char head[3] = {0xff, 0xfe, 0};
const wchar_t line[3] = L" ";
// 控制台输出不了unicode字符,使用输出到文件的方式
std::ofstream fileOut("C:/out.txt");
fileOut.write(head, 2);
for (std::vector<std::wstring>::iterator it = vec.begin(); it != vec.end(); ++it)
{
fileOut.write((const char*)it->c_str(), it->length() * 2);
fileOut.write((const char*)line, 2);
}
}
int main()
{
testSplit();
testSplitW();
}
参考:
1.http://unicode.org/
2.《谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词》
一 引入问题
代码 wchar_t a[3]=L”中国”,编译时出错,出错信息为:数组越界。但wchar_t 是一个宽字节类型,数组a的大小应为6个字节,而两个汉字的的unicode码占4个字节,再加上一个结束符,最多6个字节,所以应该不会越界。难道是编译器出问题了?
二 解决引入问题所需的知识
主要需两方面的知识,第一个为字符尤其是汉字的编码,以及语言和工具的支持情况,第二个是vc/c++中MutiByte Charater Set 和 Wide Character Set有关内存分配的情况.
三 汉字的编码方式及在vc/c++中的处理
1.汉字编码方式的介绍
对英文字符的处理,7位ASCII码字符集中的字符即可满足使用需求,且英文字符在计算机上的输入及输出也非常简单,因此,英文字符的输入、存储、内部处理和输出都可以只用同一个编码(如ASCII码)。
而汉字是一种象形文字,字数极多(现代汉字中仅常用字就有六、七千个,总字数高达5万个以上),且字形复杂,每一个汉字都有"音、形、义"三要素,同音字、异体字也很多,这些都给汉字的的计算机处理带来了很大的困难。要在计算机中处理汉字,必须解决以下几个问题:首先是汉字的输入,即如何把结构复杂的方块汉字输入到计算机中去,这是汉字处理的关键;其次,汉字在计算机内如何表示和存储?如何与西文兼容?最后,如何将汉字的处理结果从计算机内输出?
为此,必须将汉字代码化,即对汉字进行编码。对应于上述汉字处理过程中的输入、内部处理及输出这三个主要环节,每一个汉字的编码都包括输入码、交换码、内部码和字形码。在计算机的汉字信息处理系统中,处理汉字时要进行如下的代码转换:输入码→交换码→内部码→字形码。
(1)输入码: 作用是,利用它和现有的标准西文键盘结合来输入汉字。输入码也称为外码。主要归为四类:
a) 数字编码:数字编码是用等长的数字串为汉字逐一编号,以这个编号作为汉字的输入码。例如,区位码、电报码等都属于数字编码。
b) 拼音码:拼音码是以汉字的读音为基础的输入办法。
c) 字形码:字形码是以汉字的字形结构为基础的输入编码。例如,五笔字型码(王码)。
d) 音形码:音形码是兼顾汉字的读音和字形的输入编码。
(2)交换码:用于汉字外码和内部码的交换。交换码的国家标准代号为GB2312-80。
(3)内部码:内部码是汉字在计算机内的基本表示形式,是计算机对汉字进行识别、存储、处理和传输所用的编码。内部码也是双字节编码,将国标码两个字节的最高位都置为"1",即转换成汉字的内部码。
(4)字形码:字形码是表示汉字字形信息(汉字的结构、形状、笔划等)的编码,用来实现计算机对汉字的输出(显示、打印)。
2.VC中汉字的编码方式
vc/c++正是采用了GB2312内部码作为汉字的编码方式,因此vc/c++中的各种输入输出方法,如cin/wcin,cout/wcout,scanf/wsanf,printf/wprintf...都是基于GB2312的,如果汉字的内码不是这种编码方式,那么利用上述各种方法就不会正确的解析汉字。
仔细观察ASCII字符表,从第161个字符开始,后面的字符并不经常为用户所使用,负值也未使用。GB2312编码方式充分利用这一特性,将161-255(-95~-1)之间的数值空间作为汉字的标识码。既然255-161 = 94不能满足汉字容量的要求,就将每两个字符并在一块(即一个汉字占两个字节),显然,94* 94 =8836基本上已经满足了常用汉字个数的要求。计算机处理字符时,当连续处理到两个大与160(或-95~-1)的字节时,就认为这两个字节存放了一个汉字字符。可以用下面的Demo程序来模拟vc/c++中输出汉字字符的过程。
unsigned char input[50];
cin>>input;
int flag=0;
for(int i =0 ;i < 50 ;i++)
{
if(input[i] > 0xa0 && input[i] != 0)
{
if(flag == 1)
{
cout<<"chinese character"<<endl;
flag = 0;
}
else
{
flag++;
}
}
else if(input[i] == 0)
{
break;
}
else
{
cout<<"english character"<<endl;
}
}
输入:Hello中国 (“中国”对应的GB2312内码为:214 208,185 250)
输出:english character
english character
english character
english character
english character
chinese character
chinese character
vc/c++中的英文字符仍然采用ASCII编码方式。可以设想,其他国家程序员利用vc/c++编写程序输入本国字符时,vc/c++则会采用该国的字符编码方式来处理这些字符。
问题又产生了,韩国的vc/c++程序在中国的vc/c++上运行时,如果没有相应的内码库,则对韩语字符的显示有可能出现乱码。我个人猜测,vc安装程序中应该带有不同国家的内码库,这样一来肯定会占用很大的空间。如果所有的国家使用统一的编码方式,且所有的程序设计语言和开发工具都支持这种编码方式该多好!而现实中,确实已经有这种编码方式了,且许多新的语言也都支持这种编码方式,如Java、C#等,它就是下面的Unicode编码
3.新的内码标准---Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。随着计算机工作能力的增强,Unicode也在面世以来的十多年里得到普及。最新版本的 Unicode 是 2005年3月31日推出的Unicode 4.1.0 。另外,5.0 Beta已于2005年12月12日推出,以供各会员评价。
Unicode 编码系统可分为编码方式和实现方式两个层次。
编码方式:Unicode 的编码方式与 ISO 10646 的通用字符集(Universal Character Set,UCS)概念相对应,目前的用于实用的 Unicode 版本对应于 UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示 216 个字符。基本满足各种语言的使用。实际上目前版本的 Unicode 尚未填充满这16位编码,保留了大量空间作为特殊使用或将来扩展。
实现方式:Unicode 的实现方式不同于编码方式。一个字符的 Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。Unicode 的实现方式称为Unicode转换格式(Unicode Translation Format,简称为 UTF)。如,UTF-8 编码,这是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他 Unicode 字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1进行识别。
Java与C#语言都是采用Unicode编码方式,在这两种语言中定义一个字符,在内存中存放的就是这个字符的两字节Unicode码。如下所示:
char a='我'; => 内存中存放的Unicode码为:25105
4.内码的相互转换
(1)vc中的实现方法
利用Windows系统提供的API:::MultiByteToWideChar和::WideCharToMultiByte
::MultiByteToWideChar:实现当前码到Unicode码的转换;
::WideCharToMultiByte:实现Unicode码到当前码的转换;
(2)Java中的实现方法
String vcString=new String(javaString.getBytes("UTF-8"),"gb2312");
java的编码应该是UTF-8
(3)C#中的实现方法
??
四 vc中的MutiByte Charater Set 和 Wide Character Set
1.MultiByte Charater Set方式
这种方式以按字节为单位存放字符,即如果一个字符码为两字节,则在内存中占两字节,字符码为一字节,就占一字节。例如,字符串“中国abc”的编码为:中(0xd6、0xd0)、国(0xb9、0xfa)、a(0x61)、b(0x62)、c(0x63)、\0(0x00),就存为如下方式:
对应的类型,方法有:
char、scanf、printf、cin、cout …
2.Wide Character Set
这种方式是以两字节为单位存放字符,即如果一个字符码为两字节,则在内存中占四字节,字符码为一字节,就占两字节。例如,字符串“中国abc”就存为如下方式:
对应的类型,方法有:
wchar_t、wscanf、wprintf、wcin、wcout …
造成上面存储方式的根本原因在于,wchar_t类型其实是一个unsigned short 类型。如,存储上面字符串的数组的定义为:wchar_t buffer[8] 等价于unsigned short buffer[8].而所有以字母w开头的方法也都是以unsigned short类型,即两字节为单位来处理字符,因此,存储在wchar_t类型数组中的字符串无法用cout显示,只能用wcout方法来显示。
由于Unicode码也是采用两个字节,因此Wide Character Set方式能够很好的支持Unicode码的存储,但是在vc的环境下要将一个Unicode码存入两字节而不是四字节内存中,必须通过上面的API函数::MultiByteToWideChar。首先,将当前的编码转换为Unicode码,然后,将每个字符的Unicode码放入每一个wchar_t类型的变量中。以下是一个实例代码:
char input[50];
cin>>input;
int size;
size=::MultiByteToWideChar(CP_ACP,0,input,strlen(input)+1,NULL,0);
if(size==0)
return -1;
wchar_t *widebuff=new wchar_t[size];
::MultiByteToWideChar(CP_ACP,0,input,strlen(input)+1,widebuff,size);
输入:中国abc
Debug断点调试:
size==6
数组widebuff[0-size]占12字节,存放了6个字符的Unicode码,码值为:
中(0x4e2d) 国(0x56fd) a(0x0061) b(0x0062) c(0x0063) d(0x0000)
这时,数组的大小size等于输入的字符个数加上一个结束符,符合我们的想象。
五 引入问题的错误分析
(1) 没有理解编译器中的编码方式
虽然vc/c++中汉字的编码占两个字节,但并不是Unicode码,是GB2312码。
(2) 没有理解MutiByte Charater Set 和 Wide Character Set的存储原则;
在vc/c++中,“中国”按char[5]来对待,而wchar_t a[3]实际上是三个unsigned short类型的变量,因此赋值时会越界。
//gameloft 笔试题
/*
1、RGB值转灰度值对32位整数取R,G,B对应的8位并加权合成。
2、求一个字符串中出现频率最高的字符。字符范围并涡有说明,通常应
指ASCII字符集,可是当时考虑复杂了,于是想到了stl的map来做。
结果没有写完。就交了。
*/
#include<iostream>
using namespace std;
#define CHARNUM 256
//计算一个串最出现频率最高的字符
char mostFreq(const char* str)
{
int freq[CHARNUM]= {0};
int firstPos[CHARNUM] = {0};
int pos = 0;
const char* p = str;
while( *p != '\0')
{
if(freq[*p] == 0)
{
firstPos[*p] = pos;
}
freq[*p++]++;
pos++;
}
int maxF = -1;
int ch = '\0';
for(int i = 1;i < 256;i++)
{
if( freq[i] > maxF)
{
ch = i;
maxF = freq[i];
}
if( freq[i] == maxF)
{
if( firstPos[i] < firstPos[ch])
{
ch = i;
}
}
}
cout<<" maxF ="<<maxF<<endl;
return (char)ch;
}
int main()
{
int* a[9][4][5];
int b = a[5] - a[3];
cout<<"b = "<<b<<endl;
int* c[3];
char * str = "aabyebbdfdf 1`5454545$$$#$#$2788kldef";
char ch;
ch = mostFreq( str);
cout<<"ch = " <<ch<<endl;
}
4.给出一个CThing 类的源代码让分析,其中有三个语句要求解释语句作用。
一个填空,分析时有点忙了,应该一个函数一个函数的分析,或许会有清晰思路。
将各个类的名称和功能整理下会理出些思路。
5、给出strcpy的源代码让说明其功能,并指出参数设置上只少一人错误
6、给出一个将整数i转换为8进制的方法,要求对其进行改进。
src:
void count(int i, char* str)
{
map[
sorry, 记忆不清楚了
7、给几个名词让解释placement new,ARM, GCC, android, 还有一人??
8、英文解释题目。第一个还好。第二个说游戏加速的
increment ...update frame , ??这词词认识,放一起读不出来表示什么
意思
摘要: 1
2
3
4#include<cstdio>
5#include<iostream>
6#include<cstdlib>
7#include<typeinfo>&nbs... 阅读全文
摘要: 1
2
3// realize a SingleList class
4/**//*
5实现方法
6add()
7add2Head(dd);
8del
... 阅读全文
/**
* 实现测试:串匹配和词频统计功能
*/
public void largerTextExample()
{
String text = "你好abc,ac,abc,def,ac,okt, ac,dfdfe, ac , what is it 你好啊,bc";
String[] terms = {"你好","ac", "abc", "bc"};
for (int i = 0; i < terms.length; i++)
{
tree.add(terms[i].getBytes(), terms[i]);
System.out.println( terms[i]);
}
tree.prepare();
Set termsThatHit = new HashSet();
Iterator iter = tree.search(text.getBytes());
// 统计词频
Map<String, Integer> freqCount = new HashMap<String, Integer>();
for (; iter.hasNext();)
{
SearchResult result = (SearchResult) iter.next();
Set set = result.getOutputs();
System.out.println(set);
for(Iterator it = set.iterator();it.hasNext();)
{
String str = (String)it.next();
if( freqCount.get(str) == null)
freqCount.put(str, 1);
else
freqCount.put(str, freqCount.get(str)+1);
}
}
for(String key: freqCount.keySet())
{
System.out.println( "key = " + key + ", value "+ freqCount.get(key) );
}
------------结果-------------------------
你好
ac
abc
bc
[你好]
[abc, bc]
[ac]
[abc, bc]
[ac]
[ac]
[ac]
[你好]
[bc]
key = abc, value 2
key = 你好, value 2
key = ac, value 4
key = bc, value 3
从北大的WIBA课程中得知,这本中文名为《知道做到》的书,真正是我所需要的。
书的下载地址:Know and Do
以下是读书时的摘要笔记,书的语言本身已经能说明所讨论的问题了。所以并没有加上去多少自己的话。只是将重点进行了整理。
“在你的工作中,最让你感到失望的事情是什么?”
一个人行为的改变总是先从内心想法的转变开始,然后才逐渐由内而外变化的。
我的关注点一直集中在领导方法和领导行为上,却始终没有考虑过人们的大脑或内心到底在想些什么。
保罗为自己担任董事的一家大型跨国公司准备了一场主题演讲。演讲的题目是“缺失的一环:怎样才能把你从书本、录音带、电视录像或研讨班上学到的知识应用到实际工作中”。这就是《知道做到》创作的开始。
学会三样东西:
1、记笔记
2、24小时内重读笔记,整理学习内容和重点。
3、将学习内容传递给他人。
缺失的一环
1、信息过载
我们首先必须确定自己需要学什么,然后才能更有效率地去学这些东西
每个人,包括你和我的大脑总是在不断地处理一件或两件事,要么是学习新的东西,要么是遗忘。一旦忽视了某件事,我们很快就会将其遗忘。而当学会用间隔性重复来集中思考某件事时,我们就会记住它
2、消极过滤
3、缺少跟进
要想做到这点,关键就在于重复、重复、重复!这就是那缺失的一环.。
重复是克服所有知行差距的3个原因的关键。
重复的力量:这里的重复实际上是指间隔性重复
第五章 应用“少而精”哲学
知行鸿沟的存在,人们没能学以致用的原因
1:信息超载
◆对于那些只接触过一次的信息,我们通常只能记住其中一小部分。
◆我们应该少而精而非多而浅地去学习。
◆要想掌握某件事,我们必须首先选择一些关键点,隔段时间就重复一下,让自己完全沉浸其中,并不断提高自己的知识和技能。关键在于间隔性重复。
◆一旦真正透彻地掌握了自己的工作,人们就会变得更有创造性,甚至能够创造奇迹。
第六章 原因2:消极过滤
“在我们聊天的过程中,我想我明白了两件事。第一,一个对你充满信心的人可以改变你的人生;第二,我们完全可以选择自己去聆听什么。如果我总是在聆听那些否定我的人的话,我可能就会选择接受一个不是那么有挑战性的工作,对自己的期待也会变得非常有限。在爬出‘消极之匣’的过程中,我最最需要的,就是一句鼓励的话。”
第七章 积极聆听
聆听
不要带有任何偏见或先入为主;
带着一种学习的态度,对新的信息感到兴奋;
带着积极的期待;
手里拿支笔,准备做记录;
带着强烈的欲望,不仅要仔细聆听对方的讲话内容,还要努力激发出自己的形象力;
带着一种“我该如何应用这些”的态度。
企业家说:“有趣的是,呈现6次似乎正是间隔性重复秘诀。”
“为什么这么说呢?”
“我发现,当人们第一次接触时,他们会立刻拒绝,因为这个想法跟他们之前的想法有些冲突;第二次接触时,他们会抵制,因为他们仍然无法接受这个想法;第三次接触,他们会部分接受,但在实际应用的时候仍然会有所保留;第四次接触时,他们会完全接受,因为他们感觉这个想法跟自己一直以来的想法完全一致;第五次接触时,他们会将其应用到实际工作中,会部分吸收,将其转化为自己的想法;等到第六次接触时,他们会将其据为己有,完全吸收,并将其传播给其他人。”
通过自己的积极思维所体验到的积极经历越多,你就可以自动跨越这6个步骤,许多创造性的想法几乎会不知不觉地浮现出来。最终你就会像我一样成为一个反向偏执狂(inverted paranoid).
“什么是反向偏执狂?”作家问。
“反向偏执狂就是那些认为世界在合伙照顾自己的人。当一个人总是习惯进行积极思考时,他就容易成为一名反向偏执狂,但这需要一个过程。有时候人们在完成这个过程时需要帮助。”
第八章 使用绿灯思维
人们没能学以致用的原因2:消极过滤
由于在年少时并没有得到无条件的爱和支持,所以我们开始对自己和其他人产生怀疑。
自我怀疑让我们开始对所有的信息进行过滤,无论是从图书、录音带、录像、培训班,还是从谈话中获取的,在过滤的过程中,由于我们会犹豫不决,会封闭自己的观念,让自己带有先入之见,会带着批判的心态,甚至会产生一种恐惧心理,所有这一切都会让我们形成一种消极的思维方式。
消极思维会让我们,只能学到或利用自己接触到的一小部分信息;只能发挥自己的一小部分潜力;过早地拒绝大部分信息;
积极、开放的心态最有利于我们的成长,它会引发我们的创造力和应变力,最大限度地激发我们的灵感。
我们必须设法敞开自己的心胸。每次接触新信息时,我们不要总是琢磨这些信息错在哪里,而是成为绿灯思考者,积极发现其中的正确之处,并告诉自己,“我知道自己读到或听到的信息是有一定价值的,可它究竟在哪儿呢?”
将封闭、消极的心态变成开放而积极的心态并不是偶然事件。一旦下定决心要作出改变,你就需要制定一套清晰的策略,不断加强自己的新思维方式。
第九章 原因3:缺少跟进
作家点点头,“这让我想起了彼得?德鲁克(Peter Drucker)的话,‘没有什么好事是偶然发生的。’”
“一点没错,”菲尔说,“要想改变某个行为,得到自己预期的结果,你需要指导(structure)、支持(support)和问责(accountability)。当这三个要素同时具备时,你便可以制订一份出色的跟进计划。人们没有将知识转化为行动的第三个原因是缺少跟进,而这是所有障碍当中最难克服的,所以我们才需要制订一份周密的计划。”
“为什么说它是最难克服的呢?”作家问。
“这还是有一些历史背景的,”菲尔若有所思地回答,“我是从我父亲那里学到跟进策略的重要性的。他是来自德国的一名大师级木匠。他一再告诉我,除非你能得到名师指点,否则千万不要接受一份工作。”
练习,并不能帮你做到完美。
只有完美的练习才能帮你做到完美。
如何学习及订出计划。
强调积极面,帮人们取得成功
在每一位成功人士的生活中,都有一条贯穿始终的金线。那就是专注的金线,再加上坚持。所有有所成就的人都有一种独特的能力,他们能够像激光一样将自己的能量集中于一点,并在整个实现目标的过程中失重保持焦点集中。
“第一个例子,我们在公司里实行了一套一对一的学习系统,规定所有的管理者每两个星期都要跟自己的直接下属面对面地单独沟通,时间为每次15—30分钟。”
  /** *//** /** *//**
 * 最小堆化,使用递归 * 最小堆化,使用递归
 */ */
 static void minHeapity(int[] a, int i, int size) static void minHeapity(int[] a, int i, int size)
 { {
int left = (i << 1) + 1; // i * 2 + 1,当下标从0正式开始时
int right = (i << 1) + 2;
int t;
if (left < size && a[left] < a[i])
t = left;
else
t = i;
if (right < size && a[right] < a[t])
t = right;
if (t != i)
  { {
a[t] = a[i] + a[t] - (a[i] = a[t]);
minHeapity(a, t, size);
 } }
}
/** *//**
* 最小堆化,不使用递归,并且合并表示
* @param size
*/
static void minHeapityNOCur(int[] a, int i, int size)
{
int p = i;
while(p < size)
{
int q = p * 2 + 1;// q指向最小的孩子结点
if( q >= size) return;
if( q < (size-1) && a[q+1] < a[q])
q = q + 1;// q 指向右
if( a[q] < a[p])
{
a[q] = a[p] + a[q] - ( a[p] = a[q]);
p = q;
}
else break;//已经不用调整了
}
}
static void maxK( int k)
{
int[] maxKs = new int[k];
try
{
Scanner scan = new Scanner(new File("IntNums10K.txt"));
for (int i = 0; i < k; i++)
{
if (scan.hasNextInt())
{
maxKs[i] = scan.nextInt();
}
}
System.out.println("最初K个值"+ Arrays.toString(maxKs));
// builder the heap
int size = maxKs.length;
for (int i = (size - 1) / 2; i >= 0; i--)
minHeapity(maxKs, i, size);
System.out.println( "建堆后"+Arrays.toString(maxKs));
while(scan.hasNextInt())
{
int tmpN = scan.nextInt();
if( tmpN <= maxKs[0])
continue;
maxKs[0] = tmpN;
minHeapity(maxKs, 0, size);
}
System.out.println("得到最大的K个"+ Arrays.toString(maxKs));
} catch (FileNotFoundException e)
{
e.printStackTrace();
}
}
Java作为一门优秀的面向对象的程序设计语言,正在被越来越多的人使用。本文试图列出作者在实际开发中碰到的一些 Java语言的容易被人忽视的细节,希望能给正在学习Java语言的人有所帮助。
1,位移运算越界怎么处理
考察下面的代码输出结果是多少?
int a=5;
System.out.println(a < <33);
按照常理推测,把a左移33位应该将a的所有有效位都移出去了,那剩下的都是零啊,所以输出结果应该是0才对啊,可是执行后发现输出结果是10,为什么呢?因为Java语言对位移运算作了优化处理,Java语言对a < <b转化为a < <(b%32)来处理,所以当要移位的位数b超过32时,实际上移位的位数是b%32的值,那么上面的代码中a < <33相当于a < <1,所以输出结果是10。
2,可以让i!=i吗?
当你看到这个命题的时候一定会以为我疯了,或者Java语言疯了。这看起来是绝对不可能的,一个数怎么可能不等于它自己呢?或许就真的是Java语言疯了,不信看下面的代码输出什么?
double i=0.0/0.0;
if(i==i){
System.out.println("Yes i==i");
}else{
System.out.println("No i!=i");
}
上面的代码输出"No i!=i",为什么会这样呢?关键在0.0/0.0这个值,在IEEE 754浮点算术规则里保留了一个特殊的值用来表示一个不是数字的数量。这个值就是NaN("Not a Number"的缩写),对于所有没有良好定义的浮点计算都将得到这个值,比如:0.0/0.0;其实我们还可以直接使用Double.NaN来得到这个值。在IEEE 754规范里面规定NaN不等于任何值,包括它自己。所以就有了i!=i的代码。
3,怎样的equals才安全?
我们都知道在Java规范里定义了equals方法覆盖的5大原则:reflexive(反身性),symmetric(对称性),transitive(传递性),consistent(一致性),non-null(非空性)。那么考察下面的代码:
public class Student{
private String name;
private int age;
public Student(String name,int age){
this.name=name;
this.age=age;
}
public boolean equals(Object obj){
if(obj instanceof Student){
Student s=(Student)obj;
if(s.name.equals(this.name) && s.age==this.age){
return true;
}
}
return super.equals(obj);
}
}
你认为上面的代码equals方法的覆盖安全吗?表面看起来好像没什么问题,这样写也确实满足了以上的五大原则。但其实这样的覆盖并不很安全,假如Student类还有一个子类CollegeStudent,如果我拿一个Student对象和一个CollegeStudent对象equals,只要这两个对象有相同的name和age,它们就会被认为相等,但实际上它们是两个不同类型的对象啊。问题就出在instanceof这个运算符上,因为这个运算符是向下兼容的,也就是说一个CollegeStudent对象也被认为是一个Student的实例。怎样去解决这个问题呢?那就只有不用instanceof运算符,而使用对象的getClass()方法来判断两个对象是否属于同一种类型,例如,将上面的equals()方法修改为:
public boolean equals(Object obj){
if(obj.getClass()==Student.class){
Student s=(Student)obj;
if(s.name.equals(this.name) && s.age==this.age){
return true;
}
}
return super.equals(obj);
}
这样才能保证obj对象一定是Student的实例,而不会是Student的任何子类的实例。
4,浅复制与深复制
1)浅复制与深复制概念
⑴浅复制(浅克隆)
被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。换言之,浅复制仅仅复制所考虑的对象,而不复制它所引用的对象。
⑵深复制(深克隆)
被复制对象的所有变量都含有与原来的对象相同的值,除去那些引用其他对象的变量。那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。换言之,深复制把要复制的对象所引用的对象都复制了一遍。
2)Java的clone()方法
⑴clone方法将对象复制了一份并返回给调用者。一般而言,clone()方法满足:
①对任何的对象x,都有x.clone() !=x//克隆对象与原对象不是同一个对象
②对任何的对象x,都有x.clone().getClass()= =x.getClass()//克隆对象与原对象的类型一样
③如果对象x的equals()方法定义恰当,那么x.clone().equals(x)应该成立。
⑵Java中对象的克隆
①为了获取对象的一份拷贝,我们可以利用Object类的clone()方法。
②在派生类中覆盖基类的clone()方法,并声明为public。
③在派生类的clone()方法中,调用super.clone()。
④在派生类中实现Cloneable接口。
请看如下代码:
class Student implements Cloneable{
String name;
int age;
Student(String name,int age){
this.name=name;
this.age=age;
}
public Object clone(){
Object obj=null;
try{
obj=(Student)super.clone();
//Object中的clone()识别出你要复制的是哪一个对象。
}
catch(CloneNotSupportedException e){
e.printStackTrace();
}
return obj;
}
}
public static void main(String[] args){
Student s1=new Student("zhangsan",18);
Student s2=(Student)s1.clone();
s2.name="lisi";
s2.age=20;
System.out.println("name="+s1.name+","+"age="+s1.age);//修改学生2
//后,不影响学生1的值。
}
说明:
①为什么我们在派生类中覆盖Object的clone()方法时,一定要调用super.clone()呢?在运行时刻,Object中的clone()识别出你要复制的是哪一个对象,然后为此对象分配空间,并进行对象的复制,将原始对象的内容一一复制到新对象的存储空间中。
②继承自java.lang.Object类的clone()方法是浅复制。以下代码可以证明之。
class Teacher{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
}
class Student implements Cloneable{
String name;
int age;
Teacher t;//学生1和学生2的引用值都是一样的。
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.t=t;
}
public Object clone(){
Student stu=null;
try{
stu=(Student)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
stu.t=(Teacher)t.clone();
return stu;
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.clone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//学生1的老师成为tony,age为40。
}
}
那应该如何实现深层次的克隆,即修改s2的老师不会影响s1的老师?代码改进如下。
class Teacher implements Cloneable{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
public Object clone(){
Object obj=null;
try{
obj=super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
return obj;
}
}
class Student implements Cloneable{
String name;
int age;
Teacher t;
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.t=t;
}
public Object clone(){
Student stu=null;
try{
stu=(Student)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
stu.t=(Teacher)t.clone();
return stu;
}
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.clone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//学生1的老师不改变。
}
3)利用串行化来做深复制
把对象写到流里的过程是串行化(Serilization)过程,Java程序员又非常形象地称为“冷冻”或者“腌咸菜(picking)”过程;而把对象从流中读出来的并行化(Deserialization)过程则叫做“解冻”或者“回鲜(depicking)”过程。应当指出的是,写在流里的是对象的一个拷贝,而原对象仍然存在于JVM里面,因此“腌成咸菜”的只是对象的一个拷贝,Java咸菜还可以回鲜。
在Java语言里深复制一个对象,常常可以先使对象实现Serializable接口,然后把对象(实际上只是对象的一个拷贝)写到一个流里(腌成咸菜),再从流里读出来(把咸菜回鲜),便可以重建对象。
如下为深复制源代码。
public Object deepClone(){
//将对象写到流里
ByteArrayOutoutStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//从流里读出来
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return(oi.readObject());
}
这样做的前提是对象以及对象内部所有引用到的对象都是可串行化的,否则,就需要仔细考察那些不可串行化的对象可否设成transient,从而将之排除在复制过程之外。上例代码改进如下。
class Teacher implements Serializable{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
}
class Student implements Serializable
{
String name;//常量对象。
int age;
Teacher t;//学生1和学生2的引用值都是一样的。
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.p=p;
}
public Object deepClone() throws IOException,
OptionalDataException,ClassNotFoundException
{
//将对象写到流里
ByteArrayOutoutStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//从流里读出来
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return(oi.readObject());
}
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.deepClone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//学生1的老师不改变。
}
佛经里的人生哲理
收藏
快乐使者 @ 2007-12-08 22:36:32
1、人之所以痛苦,在于追求错误的东西。
2、与其说是别人让你痛苦,不如说自己的修养不够。
3、如果你不给自己烦恼,别人也永远不可能给你烦恼。因为你自己的内心,你放不下。
4、好好的管教你自己,不要管别人。
5、不宽恕众生,不原谅众生,是苦了你自己。
6、别说别人可怜,自己更可怜,自己修行又如何?自己又懂得人生多少?
7、学佛是对自己的良心交待,不是做给别人看的。
8、福报不够的人,就会常常听到是非;福报够的人,从来就没听到过是非。
9、修行是点滴的工夫。
10、在顺境中修行,永远不能成佛。
11、你永远要感谢给你逆境的众生。
12、你随时要认命,因为你是人。
13、你永远要宽恕众生,不论他有多坏,甚至他伤害过你,你一定要放下,才能得到真正的快乐。
14、这个世界本来就是痛苦的,没有例外的。
15、当你快乐时,你要想,这快乐不是永恒的。当你痛苦时你要想这痛苦也不是永恒的。
16、认识自己,降伏自己,改变自己,才能改变别人。
17、今日的执著,会造成明日的后悔。
18、你可以拥有爱,但不要执著,因为分离是必然的。
19、不要浪费你的生命在你一定会后悔的地方上。
20、你什么时候放下,什么时候就没有烦恼。
21、内心没有分别心,就是真正的苦行。
22、学佛第一个观念,永远不去看众生的过错。你看众生的过错,你永远污染你自己,你根本不可能修行。
23、你每天若看见众生的过失和是非,你就要赶快去忏悔,这就是修行
24、业障深重的人,一天到晚都在看别人的过失与缺点,真正修行的人,从不会去看别人的过失与缺点。
25、每一种创伤,都是一种成熟。
26、当你知道迷惑时,并不可怜, 当你不知道迷惑时,才是最可怜的。
27、狂妄的人有救,自卑的人没有救。
28、你不要一直不满人家,你应该一直检讨自己才对。不满人家,是苦了你自己。
29、一切恶法,本是虚妄的,你不要太自卑你自己。一切善法,也是虚妄的,你也不要太狂妄你自己。
30、当你烦恼的时候,你就要告诉你自己,这一切都是假的,你烦恼什么?
31、当你未学佛的时候,你看什么都不顺。当你学佛以后,你要看什么都很顺。
32、你要包容那些意见跟你不同的人,这样子日子比较好过。你要是一直想改变他,那样子你会很痛苦。要学学怎样忍受他才是。你要学学怎样包容他才是。
33、承认自己的伟大,就是认同自己的愚疑。
34、修行就是修正自己错误的观念。
35、医生难医命终之人,佛陀难渡无缘的众生。
36、一个人如果不能从内心去原谅别人,那他就永远不会心安理得。
37、心中装满着自己的看法与想法的人,永远听不见别人的心声。
38、毁灭人只要一句话,培植一个人却要千句话,请你多口下留情。
39、当你劝告别人时,若不顾及别人的自尊心,那么再好的言语都没有用的。
40、不要在你的智慧中夹杂着傲慢。不要使你的谦虚心缺乏智慧。
41、根本不必回头去看咒骂你的人是谁?如果有一条疯狗咬你一口,难道你也要趴下去反咬他一口吗?
42、忌妒别人,不会给自己增加任何的好处。忌妒别人,也不可能减少别人的成就。
43、永远不要浪费你的一分一秒,去想任何你不喜欢的人。
44、多少人要离开这个世间时,都会说出同一句话,这世界真是无奈与凄凉啊!
45、恋爱不是慈善事业,不能随便施舍的。感情是没有公式,没有原则,没有道理可循的。可是人们至死都还在执著与追求。
46、请你用慈悲心和温和的态度,把你的不满与委屈说出来,别人就容易接受。
47、创造机会的人是勇者。等待机会的人是愚者。
48、能说不能行,不是真智慧。
49、多用心去倾听别人怎么说,不要急着表达你自己的看法。
50、同样的瓶子,你为什么要装毒药呢?同样的心理,你为什么要充满着烦恼呢?
51、得不到的东西,我们会一直以为他是美好的,那是因为你对他了解太少,没有时间与他相处在一起。当有一天,你深入了解后,你会发现原不是你想像中的那么美好。
52、这个世间只有圆滑,没有圆满的。
53、修行要有耐性,要能甘于淡泊,乐于寂寞。
54、活着一天,就是有福气,就该珍惜。当我哭泣我没有鞋子穿的时候,我发现有人却没有脚。
55、多一分心力去注意别人,就少一分心力反省自己,你懂吗?
56、眼睛不要老是睁得那么大,我且问你,百年以后,那一样是你的。
57、欲知世上刀兵劫,但听屠门夜半声。不要光埋怨自己多病,灾祸横生,多看看横死在你刀下的众生又有多少?
58、憎恨别人对自己是一种很大的损失。
59、每一个人都拥有生命,但并非每个人都懂得生命,乃至于珍惜生命。不了解生命的人,生命对他来说,是一种惩罚。
60、自以为拥有财富的人,其实是被财富所拥有。
61、情执是苦恼的原因,放下情执,你才能得到自在。
62、随缘不是得过且过,因循苟且,而是尽人事听天命。
63、不要太肯定自己的看法,这样子比较少后悔。
64、当你对自己诚实的时候,世界上没有人能够欺骗得了你。
65、用伤害别人的手段来掩饰自己缺点的人,是可耻的。
66、世间的人要对法律负责任。修行的人要对因果负责任。
67、在你贫穷的时候,那你就用身体去布施,譬如说扫地、洒水、搬东西等,这也是一种布施。
68、内心充满忌妒,心中不坦白,言语不正的人,不能算是一位五官端正的人。
69、默默的关怀与祝福别人,那是一种无形的布施。
70、多讲点笑话,以幽默的态度处事,这样子日子会好过一点。
71、与人相处之道,在于无限的容忍。
72、不要刻意去猜测他人的想法,如果你没有智慧与经验的正确判断,通常都会有错误的。
73、要了解一个人,只需要看他的出发点与目的地是否相同,就可以知道他是否真心的。
74、人生的真理,只是藏在平淡无味之中。
75、不洗澡的人,硬擦香水是不会香的。名声与尊贵,是来自于真才实学的。有德自然香。
76、与其你去排斥它已成的事实,你不如去接受它,这个叫做认命。
77、佛菩萨只保佑那些肯帮助自己的人。
78、逆境是成长必经的过程,能勇于接受逆境的人,生命就会日渐的茁壮。
79、你要感谢告诉你缺点的人。
80、能为别人设想的人,永远不寂寞。
81、如果你能像看别人缺点一样,如此准确般的发现自己的缺点,那么你的生命将会不平凡。
82、原谅别人,就是给自己心中留下空间,以便回旋。
83、时间总会过去的,让时间流走你的烦恼吧!
84、你硬要把单纯的事情看得很严重,那样子你会很痛苦。
85、永远扭曲别人善意的人,无药可救。
86、人不是坏的,只是习气罢了,每个人都有习气,只是深浅不同罢了。只要他有向道的心,能原谅的就原谅他,不要把他看做是坏人。
87、说一句谎话,要编造十句谎话来弥补,何苦呢?
88、其实爱美的人,只是与自己谈恋爱罢了。
89、世界上没有一个永远不被毁谤的人,也没有一个永远被赞叹的人。当你话多的时候,别人要批评你,当你话少的时候,别人要批评你,当你沈默的时候,别人还是要批评你。在这个世界上,没有一个不被批评的。
90、夸奖我们,赞叹我们的,这都不是名师。会讲我们,指示我们的,这才是善知识,有了他们我们才会进步。
91、你目前所拥有的都将随着你的死亡而成为他人的,那为何不现在就布施给真正需要的人呢?
92、为了赞美而去修行,有如被践踏的香花美草。
93、白白的过一天,无所事事,就像犯了窃盗罪一样。
94、能够把自己压得低低的,那才是真正的尊贵。
95、广结众缘,就是不要去伤害任何一个人。
96、沈默是毁谤最好的答覆。
97、对人恭敬,就是在庄严你自己。
98、拥有一颗无私的爱心,便拥有了一切。
99、仇恨永远不能化解仇恨,只有慈悲才能化解仇恨,这是永恒的至理。
100、你认命比抱怨还要好,对于不可改变的事实,你除了认命以外,没有更好的办法了。
一个29岁总裁对大学生的16条忠告
上一篇 / 下一篇 2009-02-25 09:44:33 / 个人分类:SAP
一、读大学,究竟读什么?
大学生和非大学生最主要的区别绝对不在于是否掌握了一门专业技能……一个经过独立思考而坚持错误观点的人比一个不假思索而接受正确观点的人更值得肯定……草木可以在校园年复一年地生长,而我们却注定要很快被另外一群人替代……尽管每次网到鱼的不过是一个网眼,但要想捕到鱼,就必须要编织一张网……
二、人生规划:三岔路口的抉择
不走弯路就是捷径…… 仕途,商界,学术。在这人生的三岔路口,你将何去何从……与其跟一百个人去竞争五个职位,不如跟一个人去竞争一个职位……学术精神天然的应当与尘嚣和喧哗保持足够的距离……商场不忌讳任何神话。你也完全可能成为下一个传奇……
三、专业无冷热,学校无高低
没有哪个用人单位会认为你代表了你的学校或者你的专业……既然是概率,就存在不止一种可能性……如果是选择学术,冷门专业比热门专业更容易获得成就……跨专业几乎早已成为一种流行一种时尚……大学之间的实力之争到了考研考场和人才市场原来是那样的微不足道……
四、不可一业不专,不可只专一业
千招会,不如一招熟…… 十个百分之十并不是百分之百,而是零……在这个现实的社会,真正实现个人价值才是最体面最有面子最有尊严的事情……要想知道需要学什么,最好的方式就是留意招聘信息……很多专业因为不具备专长的有效性,所以成为了屠龙之术……为什么不将“买一送一”的促销思维运用到求职应聘的过程中来呢……
五、不逃课的学生不是好学生
什么课都不逃,跟什么课都逃掉没什么两样……读大学,关键是学会思考问题的方法……逃课没有错,但是不要逃错课……英语角绝对不是学英语的地方……为了英语丢了专业,那就舍本逐末了……招聘单位是用人才的地方,而不是培养人才的地方……既要逃课,又要让老师给高分……
六、勤工俭学的辩证法
对于贫困生来说,首先要做的不是挣钱,而是省钱……大部分女生将电脑当成了影碟机,大部分男生将电脑当成了游戏机……在这个处女膜都可以随意伪造的年代,还有什么值得轻易相信……态度决定一切……当学习下降到次要的地位,大学生就只能说是兼职的学生了……
七、做事不如做人,人脉决定成败
学问好不如做事好,做事好不如做人好……会说话,就能减少奋斗三十年……一个人有多少钱并不是指他拥有多少钱的所有权,而是指他拥有多少钱的使用权……一个人赚的钱,12.5%是靠自身的知识,87.5%则来自人脉关系……三十岁以前靠专业赚钱,三十岁以后拿人脉赚钱……你和世界上的任何一个人之间只隔着四个人……
八、互联网:倚天剑与达摩克利斯之剑
花两个小时就写出一篇天衣无缝的优秀毕业论文……在互联网领域创业的技术门槛并不高,关键的是市场眼光和营销能力……轻舞飞扬已经红颜薄命了,而痞子蔡却继续跟别的女孩发生着一次又一次的亲密接触……很多大学生的网友遍布祖国大江南北,可他们却从未主动向周围的人说一声:你好,我们可以聊聊吗……
九、考研:痛苦的安乐死
没有比浪费青春更失败的事情了……研究生扩招的速度是30%,也就意味着硕士学历贬值的速度是30%……同样是付出三年的努力,你可以让E1的值增加1,也可以让E2的值增加2甚至增加3……读完硕士或博士并不等于工作能力更强……面对13.54万的成本,你还会毫不犹豫地投资读研究生吗……努力就会有结果,但不一定是好结果……
十、留学:“海龟”变“海带”
月薪2500元的工作,居然引得三个“海归”硕士争相竞聘……对于某些专业而言,去美国留学和去埃塞俄比亚留学没什么两样……既然全世界的公司都想到中国的市场上来瓜分蛋糕,为什么中国人还要一门心思到国外去留学然后给外国人打工……
十一、非统招:养卑照样处优
她在中国信息产业界创下了几项纪录。她被称为中国的“打工皇后”。而她不过是一名自考大专生……要想把曾经输掉的东西赢回来,就必须把自己比别人少付出的努力补上来……非统招生不但要有一定的实力,而且必须掌握一定的技巧,做到扬长避短出奇制胜……路在脚下。好走,走好……
十二、毕业:十面埋伏的陷阱
母校不把自己当母亲,你又何必把自己当儿女……听辅导班不过是花钱买踏实……人才市场就是一个地雷阵……通过多种方式求职固然没有错,但是千万不要饥不择食……只要用人单位一说要你交钱,你掉头就走便是了……这年头立字尚且不足以为据,更何况一个口头约定……
十三、求职:做人不要太厚道
求职简历必须突出自己的核心竞争力……求职的时候大可不必像严守一那样“有一说一”……一个人说假话并不难,难的是把假话说到底,并且不露一丝破绽……在填写自己的特长时,一定要尽可能详细……一份求职简历只要用一张A4纸做个表格就足够了……面试其实是有规律的,每次面试的时候只要背标准答案就行了……
十四、骑一头能找千里马的驴
美国铁路两条铁轨之间的标准距离是4英尺8.5英寸,为什么呢?因为两匹马臀部之间的宽度是4英尺8.5英寸……垃圾是放错位置的人才……世界上最大的悲剧莫过于有太多的年轻人从来没有发现自己真正想做什么……中小型企业或许能够让你得到更充分的锻炼……从基层做起并不意味着可以从基层的每一个职位做起……要“钱途”,更要前途……
十五、写字楼政治:白领必修课
大公司是做人,小公司是做事……职员能否得到提升,很大程度不在于是否努力,而在于老板对你的赏识程度……公司的事情和秘密永远比你想象的还要复杂和深奥……在适当的时候装糊涂不但是必要的,而且是睿智的……就把你的同事当成一群你可以叫得出名字的陌生人好了……
十六、创业:29岁以前做富翁
瘦死的骆驼比马大……撑死胆大的,饿死胆小的……不再是“大鱼吃小鱼”,而是“快鱼吃慢鱼”……对于趋势的把握是一个创业者最重要的能力……高科技行业留给毕业生的空间已经很小……欲速则不达。在创业以前通过给别人打工而积累经验是非常必要的……市场永远比产品更重要……钱不够花,怎么办?第一,看菜吃饭;第二,借鸡生蛋……
嵌入式编程面试:
笔试题目大概如下:
1:关于指针长度,字符串长度的问题
2:进程间的同步的方式有几种?
3:什么是可重入代码?如何写可重入代码?
4:printf()等可变函数的实现机理
5:volatile 变量的用途?
6:写一个在双链表中插入节点和删除节点的程序。
7:将一个int型a 的第9位置1,将a的第9位置0;
第一关过去还剩下两个人。
然后是IQ测试:
就是网上的一个比较流行的flash测试 结果我的IQ 136,我都把自己下了一跳。
然后是诚信度测试:
也是回答问题,对一个问题翻过来翻过去的问,用好的方式以及不好的方式问你,看你前后的回答是否一致。
好像到这里就剩我一个人了。
同学的blog地址在: http://blog.szu.edu.cn/user/zdl1016
可以有机会自己去学习吧。有模式识别的笔记,还有图像处理和人脸识别的相关内容。
最后是:程序主管出来面试
问题1:
自己简单介绍一下:我就说 06毕业,工作两年了。做CPP。游戏开发。
对公司了解有多少:我没有投你们的简历,然后来的比较匆忙,了解不多。
那人说:我们公司以前只做什么接口转换器的,在赛格有个柜台,后来发展的比较好,招了一批人。然后又发展,就在中银租了一整层。现在工厂在关外梅林。
然后谈了一些技术:
1说使用什么math操作系统。。。
据说嵌入式操作系统中还有一个美国军方的小的七十年代用来控制导弹的嵌入式操作系统。
还说C里面都有自己的一套数据结构,vector等,都要自己实现。(说道这里,搞懂opencv里面的seq挺有用的一定!)
2说用arm7,arm9做平台。
谈待遇,那人说没经验给3000(的确,我没什么嵌入式经验,不过C用的还可以)
这是转载的东亮的笔记,原来他上课看书都会在博客里写笔记,我当时讲了最后一个线性分类器的分类能力。
模式识别理论 chapter 9 Algorithm-independent Machine Learning
 | 浏览数(269) | 评论数(0) | 2008-06-26
本章是同学自己讲述,有些观点可能有些问题.
1: 没有免费的午餐: 对特定问题的先验认识的条件下, 没有最优的分类器.
2: 丑小鸭定理: 对特定问题的先验认识的条件下,没有最优的特征表达.
3: occam' razor: 杀鸡焉用牛刀? 小的剃须刀就可以了,干吗用电锯??? keep it simple,stupid. 简单就是美.
爱因斯坦:描述一个问题,解决一个问题,要尽可能的简单,但不要更简单.
杜达:长期的进化过程, 使我们自身的"模式识别仪器"面临强大的自然选择的压力---要求执行更简单的计算,需要更少的神经元,花费更短的时间,等等,导致我们的分类器趋向简单的方案.
沃伦.巴菲特:盖茨的成功不在于他做了什么,而在于他没做什么.
一个人要专注做一件事情,理想太多了, 变得没有理想了.
总之,我们的分类器要尽可能保持简单,因为,简单的通常是最有效的.这是经验!
4: 回归中的偏差和方差关系
4.1)
偏差小: 准确度高
方差小: 推广性好.
4.2)
曲线拟合的均方误差 = 偏差^2 + 方差. 与两者都有关系
5: 刀切法 和 自助法
由于现实中,获取样本往往是比较困难的,怎么充分的利用好手里的现有的样本???
刀切法: 降低样本中噪声的影响.每次统计模型的参数信息的时候, 去掉一部分样本.
自助法: 把样本分为多个独立的自助集.相当于多次重复里利用手里的样本.
6: bagging & boosting & 基于查询的学习
略去.
7:单个分割平面的能力
也就是说 线性分类面的能力???
一般位置: d维空间的点, 没有d+1个点落在d-1维子空间时,我们称这些点处于一般位置.
eg: d=1,一维空间的点. 如果没有2两个点落在0维子空间(也就是处在同一个点上.)
eg: d=2,2维空间的点. 如果没有3两个点落在1维子空间(也就是处在同一个线上.)
正是由于线性分类器的弱点,
---我们引入了非线性分类器 BP --- 改变分类面的线性关系为非线性
---我们引入了SVM --- 改变样本点的空间位置使之可以使用线性分类器.
一般位置:
| あ隐 |
2009-10-31 15:23 |
一、前言
群P可能对于许多同学来说都是一个恶梦,因为对面试形式的不熟悉,因为紧张而讲话不清,甚至对讨论的题目毫无概念,小弟曾经也有这样的疑惑,不过一个学期走来,成功通过了北电、安永、爱立信、美的、瑞安建业、万科、雀巢、GE医疗等企业的群面,还是积累了一些经验,觉得相对单面来说,群面的技巧性还是相对多一些。个人感觉单面的不确定因素太多,很多时候都要靠面试官的喜好与心情来决定,而群面的评判标准相对多一点,也相对量化一些,所以应对之策会多一些。现在把自己的一点心得体会写出来,希望对仍为群面烦恼的兄弟姐妹以及后来人有所帮助。
二、群面的分类
1、广义的群P
只要面试官或面试者的人数多于1的面试多算群P,从面试者对面试官的角度来说,一般有1对多,多对1以及多对多:
1对多:
这种面试的实质还是单面,能够用的技巧与单面差不多,这里就不献丑了,主要要注意的是尽量照顾各位面试官的感受,在自我介绍与回答问题的时候尽量与所有的面试官都有眼神的交流,但转换不要太频繁,看着一个面试官说一段,下一段的时候看另一个面试官,尽可能表现自然。当然,在思考的时候,不一定始终看着某一个面试官。
多对1:
这种是最猥琐最受面试者鄙视的面试方式,产生根源是招聘企业的HR懒!!为了节省时间,面试官希望在短时间内从人群中挑出表现突出的人。一般的流程是,每个人轮流自我介绍,然后面试官提问。根据面试者人数与面试时长不同,面试官的提问方式有所不同,人多时间少,一般就面试官挑感兴趣的面试者进行提问。相反,人不多时间充足的话,则提出同样的问题,让面试者轮流回答。对于前者,关键就是自我介绍。除了要精心准备自己的自我介绍,学会扬长避短以外,更重要的是准备不同长度的版本,如5秒(可用于回答“请用一个词或一句话来介绍你自己”、“你最大的特点是什么”、“你身边的人是如何评价你的”等单面的问题)、30秒、1分钟、5分钟、10分钟。宗旨就是在指定的时间内尽可能突出自己(当然是优点啦),让面试官记住自己。过了自我介绍以后,后面基本同单面。对于后者,前面所说的自我介绍同样适用,因为这是表现自己的最好时机,但更重要的是后面问题回答。对于这个部分,虽然性质和单面差不多,但难度更大,应为面试官会有所对比。这就要求我们在面试前做好充分的准备,包括简历与开放性问题。对于简历,最好使用STAR法则来回答,而且努力使得自己的例子丰满,自己所做的每一个工作与决定都是经过严密的思考的。对于开放性问题,不仅要根据自己的实际情况来思考,还要想一下大部分的人会怎么回答,自己能够有怎样独到的见解呢。做好准备以后,就是面试时候回答的时机了,一般来说,面试官对不会限定面试者回答的顺序,而是倾向于是否有自愿的人。对于自己比较有把握的问题,或者有独到见解的问题,可以选择主动回答。而对于只能自能其说,毫无特色答案的问题,则一定要主动回答,抢占先机,把自己能想到的都说出来。最后对于毫无想法的问题,先听听别人的观点则是不错的选择,最后做一个有保留的同意性总结是一个折中的做法。当然,这些都没有绝对,即使所有问题你都很有把握,也可以适当收敛,让其他人先答,而不要表现得过于强势。
多对多:
这种面试是上面两种的综合版,但一般人数不会太多,需要注意的地方还是上面那些,前期准备、回答时机与照顾所有面试官。
2、狭义的群P
上面的主要还是与单面比较类似,现在讨论的才是真正的群面,比较常见的有无领导小组讨论、案例分析、角色扮演、辩论等方式,各有各的特点。下文所提到群面均是狭义的群面,以无领导小组讨论为主,其他方式的群面的不同点会另外提。
三、群面的形式
无论是那种方式的群面,其本的布局都差不多,多对多,一位面试官做开场白,包括面试流程与要求等。面试开始后,面试官不再发言,也不会参与到讨论当中,整个过程到结束全部有面试者自己掌握,面试官会分布在面试场地的不同角落观察各面试者的表现并做记录。当然面试过程是有限定时间的,结束的时候面试官会宣布时间到。
有些公司会在面试开始之前让面试者用白纸做个纸牌,上面写上自己的名字,方便面试官辨认。
对于面试者来说,大家都会坐到一起,而不会是并排,因为要方便讨论。而通常公司都会准备好相关的资料与纸笔。面试正式开始后,面试者花一小段时间独自阅读并思考,就最后小组所需要完成的任务思考自己的意见并做适当的记录。然后是各面试者轮流初步发表自己的想法。接着是自由讨论。最后根据具体要求来做总结陈述,一般在向面试官做最后的陈述之前,小组内应该先就总结的内容做一次汇总并达成共识或加以补充(这一步不一定有,北电的角色扮演就是了)。
面试结束后,公司需要回收所有的资料,包括草稿纸,所以一般会禁止面试者在资料上做笔记和记号,这个要注意。而对于草稿纸来说,是不是对面试结果有所影响的话很难说,不过养成一个良好的笔记习惯是没有坏处的,呵呵。
四、指导思想
说了那么多,还没有说什么技巧性的东西,这是为什么呢?其实个人认为,技巧永远都是用于加分的,而讨论的实质与内容才是关键,所以我们应该关注以及思考的重点应该放在讨论的问题上。
一般来说,群面的问题都是非专业的,主要考察面试者的分析能力、逻辑思维能力、创新能力以,解决问题能力以及临场反应等(其他的表达能力、团队合作精神等不在此部分讨论)。所谓的指导思想,其实没有别的,我们高中到大学一直所学的哲学就足够用了。辩证法,两分法、抓住主要矛盾,大局观,世界是不断变化发展的等等,这些都是大家学过并且很容易理解的道理,但是在平常的生活乃至面试里面,我们都难以运用这些道理来帮助我们分析问题。
在我的经历中,其实并不是所有的道理都会完全用到,只要抓住两个:大局观、纵横分析
1、大局观
很多同学在看完材料的时候,一发言就抓住最后要解决的问题不放,单纯地谈自己解决方案。我的做法是,先对材料做一个整体的分析,把几个问题理清:材料基于一个怎样的环境与前提,材料中最大的问题(不一定是需要我们讨论解决的问题,但有可能是所有问题的根源)是什么,问题产生的前因后果以及相互的逻辑关系是什么,我们应该订立一个什么样的标准去看待问题。有了逻辑分析与标准以后,我才会根据自己的分析与标准提出自己的观点。这样做的好处是,可以对问题有一个全局的了解,而不会捡了芝麻丢西瓜,同时也可以向面试官表现自己的各方面能力。
2、纵横分析
材料基本分析好以后,就要在论点或观点上见高下了。在面试的时候,大家的观点难免落于俗套,但还是有办法使得自己的观点尽可能丰满的。
横向分析:
这个是最容易的,尽量多想支持自己观点的例子,可以是从同类型的,也可以从不同类型的,下面举例说明。当然,小弟水平有限,不仅所举的例子与我要说的东西不一定相符,甚至我自己提的观点也是比较弱智,所以仅供参考,大牛们见笑了。
雀巢题:
辩论:选择越多,幸福是越多还是越少?
我方观点:选择越多,幸福越多
从生活出发,衣食住行四个方向找论据,校服、饭堂菜式、住房户型选择、出行交通工具等,都是选择越多越好。发散到平时的娱乐方式,如睡前听的音乐,电视节目的多样性等。结合当前找工,从招聘企业和应聘者出发,都是选择越多越好……
横向分析在辩论赛中非常有用,给以让自己的队友从不同方面来论证观点,从而让所有人都有话可说,有机会表现自己,而且对整个团队的表现都会给人一体的感觉。当时我们的反方所提的分论点并没有明显的逻辑关系,因此每个人起来发言的内容都差不多,重复性就很大了。另外一个好处是,自由辩论的时候,我们很容易主导话题,因为范围广,随便都能找到例子,可以从多点发起攻击。
纵向分析:
这个主要是意识问题,很容易被忽略。很多时候在发表观点的时候,把这个意识用在补充说明的话会给人思维严密的感觉。具体是指自己的观点只适用于局部的时间范围,因为所有东西都是不断发展变化的。
万科题:
小组讨论:成功的定义?在骂声中成名,算不算成功?背景资料:章子怡,胡戈
横向分析:成功的定义可以分成两个方面来讨论(定标准),个人价值与社会价值。
成功对于不同的人有不同的含义,即使是普通的老百姓,只要他对自己的工作、家庭和生活都感到满意,那么他就是成功了
纵向分析:一时与一生相结合,瞬间的辉煌不等于永恒。材料所提到的人物即使是成功,也是暂时的,还不能直接判断这个人的成功是一生的。
对于案例分析case study,其实一般是用在培训而不是招聘中的。而在面试中的案例分析,其实跟无领导小组讨论差别不大,主要是侧重点不同。案例分析会更加关注得出结论的思考过程与理由。
五、角色分工
终于谈到一点技巧性的问题了,首先不得不说的是,很多人都听说过群面一般都有不同的角色,包括时间控制time controller,leader,记录员,总结者等等,有些同学很喜欢在面试前就做好这个分工,指定好各人的角色。对于这种做法,我是比较反对的,首先一点,这些角色从来都不需要告诉面试官,面试官自己会有自己的判断。其次,除了time controller外,其他角色的确定都不利于小组各人的最终表现。首先是leader,这个东西根本不用明说,不然还有可能引起争抢,而最关键的是,在讨论结束前,大家都不知道谁有能力当好LEADER,因此还是通利合作好,只要大家有时间观念,不过分关注细节,注意完成讨论的所有要求,那么没有明确的leader又有什么所谓呢?然后是记录员,其实这个是最不好的,理想的做法是所有人都要做笔记,不仅是自己的观点,还有别人的观点。因为如果你的发言只是从自己的角度出发,将会非常片面。而只有你认真听取并记录了他人的意见的时候,才会有机会去分析别人的观点,从而提出反驳或者改善自己的观点。最后是总结者,通常来说,总结者需要比较清晰的思路,也就是我之前所说的大局观与逻辑思维,能够把众人的观点清晰地串起来,而这个通常都不会有记录员来做,而同样地,在讨论结束前是难以知道哪位最适合做这个总结的。
概括一下各种角色的职责吧:
Time controller:注意安排整个讨论的流程,每个环节需要多长时间,差不多到时的时候提醒所有成员。
Leader:这个职责比较模糊(本来就是无领导小组讨论嘛),一般就是主持整个讨论的进程,提醒成员不要离题、注意发言长度等,当然还有其他素质,后面会再提。
记录员:清楚记录所有人的观点与发言,并整理给总结者。这个需要清晰的笔记能力,尽量减低总结者的阅读困难。一般字不要太难看,各人观点层次分明,按点罗列,并做适当的着重标记。
总结者:把小组讨论的结果向面试官陈述,主要注意的是说话的逻辑性与条理性,最好能够把小组成员思考的过程说明一下。当然,有些陈述的量比较大的话,可以把分论点让给其他成员来扩展。
针对角色扮演这种方式,我就玩过一次,最大的感觉就是要充分融入角色,而且在看完材料后,第一时间和其他角色的成员进行交流。因为通常,一个角色所持有的材料不会有其他角色的内容,所以只有通过充分的交流才能了解到整个讨论的情况以及要实际要解决的问题。
六、技巧与注意事项
以下是小弟总结的一些小技巧,在群面上还是可以适当运用来给自己加分的,当然这个效果很难说,大家斟酌一下咯。
初级版:
1、抢做time controller
每次面试之前把手表或者手机拿在手里,在面试官说完面试流程与要求后,直接把计时的东西拍到桌子上,说上一句“现在是×点×分,我们有×分钟来做……,最后留×分钟做总结,也就是到×点×分,那么我们现在就开始做……吧”。一般来说,就不会有人跟你抢了。当然,抢到了还是要尽职尽责的啊。
2、在强势的人面前争取发言权
这个是很多同学都烦恼,这个讨论下来总是那几个人在说话,自己一句都没插上。主要是靠狠和抓住时机。一般来说,强势的人发言都比较有逻辑性和条理性。因此插嘴时机有二,一是当他解释自己观点的时候,说到一定时间我们就可以插嘴说,“我觉得××说得很有道理,但是由于时间有限,我们还是听一下下一位同学的意见吧”,或者“……(同前),我们还是先讨论下一个问题吧,我觉得……”;二是在对方阐述多个观点的时候用到“第一”、“第二”之类的,在他说完第三个要说第四的时候就插嘴,内容可以同前。
3、面试前相互认识,交换联系方式
虽然说不要提前分工,但提前认识还是有好处的。一是在讨论的时候,赞成或否定他人意见的时候可以加入对方的姓名,而不用只是说“这位同学”,“那位同学”的。二是可以拉上同路的人,在面试结束后有人一起走,并多一些交流的机会。三是可以互通消息,知道自己是否被BS了,而不用受漫长等待的折磨。
4、提反对观点
一般来说,标新立异的风险还是比较大的,但是如果有把握的话,还是可以适当提出反对意见。这个技巧主要是在说话的方式上,“我觉得大家的观点非常棒,但是如果从××角度来考虑的话,我觉得可以……,不知道大家有什么看法呢?”这里还隐含了一个小技巧,就是学会赞美别人,不管什么时候,这招都是很有用的,包括在辩论中。
5、注意材料的限定条件
在看材料的时候,很容易就一些大点直接进行分析,从而忽略了限定条件。如一个公司的沟通出现问题,究竟是个别同事之间,还是上司与下属之间,还是各个部门之间,这些对于我们考虑问题都是很重要的。我们要做的是,在大家都忽略这些的时候,适当提醒一下,但不要强求所有人都接受,只要说了,面试官是会注意到的。
6、发言的逻辑性与条理性
逻辑性主要是弄清楚各点的因果关系,最好能够把自己思考的过程简短说一下。条理性就是要按点来说,学会使用“第一”、“首先”、“最后”等过渡词。这个技巧一般是平时有意养成习惯,面试的时候就会得心应手了。当然要注意的是,分点说明前一定要清楚自己要讲多少点,不要只有“首先”,讲完之后就什么都没有了。
中级版:
1、尽量不要做最后向面试官陈述的人,而是之前在小组内做总结的人。
这样做是因为,最后做陈述的人还是会比较紧张的,即使之前总结的内容有多充分,要完美演出还是有一定难度的。但是怎么向面试官表现自己的总结能力呢?就是这个时候了,当差不多到点的时候,大家的意见都发表得差不多的时候,就可以说“其实大家的观点都非常好,我看时间快要到了,我自己稍稍总结了一下,看看大家有什么补充吧。首先……”。这样做,对于自己的好处是比较明显的,因为即使最后的总结者总结得好,也有你的功劳。但是,稍微有点损人品的是,如果最后的总结者并不够强的时候,很容易受到你思路的影响,从而表现失常。
2、留意并照顾没有或少发言的成员
这个技巧并不总有机会用,只有出现比较紧张,缺乏经验的成员的时候才可以用。在轮流发表观点甚至是自由讨论的时候,我们都要时刻关注比较沉默的成员,当要开始换话题的时候,我们可以说“不如我们先听一下××同学的意见吧”。之前不是说不要抢leader吗,这个动作就会让面试官觉得你有leader的素质了,因为照顾到所有的成员。
3、自由辩论时,没有必要与同一个人做持久的争执
当有人反驳或者质疑自己观点的时候,我们很容易忍不住跟对方争辩,然后两个人就一直站着你一言,我一句地吵,这个很明显就不好啦。其实我们没有必要起来回应他,同队的其他辩手会回应的。这样的好处是,避免把自由辩论变成个别的针锋相对,同时也表现了自己的冷静与团队合作精神。当然,如果队友没有人起来回应的话,还是要靠自己了。
4、做一个协调者
当小组成员出现意见相左的时候,如果人数比较平均,一般到最后还是采取投票比较省时。但如果一面倒的时候,我们可以以大多数人的意见为主,适当考虑另类意见作为补充,并且称赞提意见的同学“有创意”。这样同样是起到让面试官觉得你是一个leader的效果。
高级版:
研发ing……讨教中……
七、结束语
啊,终于搞定了……
一般公司都会采用群面来作为一面,考察的主要是综合素质,不同公司考察的要点以及标准都不会有太大的差异,因此作为应聘者,我们没有必要像单面那样“做好自己”。其实,小组讨论所考察的素质对于每个人来说都很值得去培养,特别是逻辑思维。所以,我们可以适当地把自己往这个方向靠,如果真的是想通过某次群面的话。
以上所有言论都是个人观点,仅供参考,因为最关键的是,从来都没有专业人士出来告诉我上面的东西是否正确有用,可能还有反作用。所以各位看官还是自己思考一下,特别是最后的技巧,要慎用啊……
找工是一个漫长的过程,同时也是一个成长的过程。在一个学期的找工经历当中,感觉自己学到的东西比前3年的还要多,当然不是指专业知识啦。还是那一句,现在什么都说人品,希望这点东西能够帮到有需要的人吧,为自己攒点人品。
最后,祝愿大家都能找到自己喜欢的工作,欢迎大家批评指教! |
|
整理者注:钱老去世以后,许多人问我们:钱老有什么遗言?并希望我们这些身边工作人员写一篇“钱学森在最后的日子”的文稿。我们已告诉大家,钱老去世时很平静安详,他没有什么最后的遗言。因为在钱老去世前的一段日子,他说话已经很困难了。我们可以向大家提供的,是钱老最后一次向我们作的系统谈话的一份整理稿:钱老谈科技创新人才的培养问题。那是于2005年3月29日下午在301医院谈的。后来钱老又多次谈到这个问题,包括在一些中央领导同志看望他时的谈话。那都是断断续续的,没有这一次系统而又全面。今天,我们把这份在保险柜里存放了好几年的谈话整理稿发表出来,也算是对广大读者,对所有敬仰、爱戴钱老的人的一个交代。
今天找你们来,想和你们说说我近来思考的一个问题,即人才培养问题。我想说的不是一般人才的培养问题,而是科技创新人才的培养问题。我认为这是我们国家长远发展的一个大问题。
今天,党和国家都很重视科技创新问题,投了不少钱搞什么“创新工程”、“创新计划”等等,这是必要的。但我觉得更重要的是要具有创新思想的人才。问题在于,中国还没有一所大学能够按照培养科学技术发明创造人才的模式去办学,都是些人云亦云、一般化的,没有自己独特的创新东西,受封建思想的影响,一直是这个样子。我看,这是中国当前的一个很大问题。
最近我读《参考消息》,看到上面讲美国加州理工学院的情况,使我想起我在美国加州理工学院所受的教育。
我是在上个世纪30年代去美国的,开始在麻省理工学院学习。麻省理工学院在当时也算是鼎鼎大名了,但我觉得没什么,一年就把硕士学位拿下了,成绩还拔尖。其实这一年并没学到什么创新的东西,很一般化。后来我转到加州理工学院,一下子就感觉到它和麻省理工学院很不一样,创新的学风弥漫在整个校园,可以说,整个学校的一个精神就是创新。在这里,你必须想别人没有想到的东西,说别人没有说过的话。拔尖的人才很多,我得和他们竞赛,才能跑在前沿。这里的创新还不能是一般的,迈小步可不行,你很快就会被别人超过。你所想的、做的,要比别人高出一大截才行。那里的学术气氛非常浓厚,学术讨论会十分活跃,互相启发,互相促进。我们现在倒好,一些技术和学术讨论会还互相保密,互相封锁,这不是发展科学的学风。你真的有本事,就不怕别人赶上来。我记得在一次学术讨论会上,我的老师冯·卡门讲了一个非常好的学术思想,美国人叫“goodidea”,这在科学工作中是很重要的。有没有创新,首先就取决于你有没有一个“goodidea”。所以马上就有人说:“卡门教授,你把这么好的思想都讲出来了,就不怕别人超过你?”卡门说:“我不怕,等他赶上我这个想法,我又跑到前面老远去了。”所以我到加州理工学院,一下子脑子就开了窍,以前从来没想到的事,这里全讲到了,讲的内容都是科学发展最前沿的东西,让我大开眼界。
我本来是航空系的研究生,我的老师鼓励我学习各种有用的知识。我到物理系去听课,讲的是物理学的前沿,原子、原子核理论、核技术,连原子弹都提到了。生物系有摩根这个大权威,讲遗传学,我们中国的遗传学家谈家桢就是摩根的学生。化学系的课我也去听,化学系主任L·鲍林讲结构化学,也是化学的前沿。他在结构化学上的工作还获得诺贝尔化学奖。以前我们科学院的院长卢嘉锡就在加州理工学院化学系进修过。L·鲍林对于我这个航空系的研究生去听他的课、参加化学系的学术讨论会,一点也不排斥。他比我大十几岁,我们后来成为好朋友。他晚年主张服用大剂量维生素的思想遭到生物医学界的普遍反对,但他仍坚持自己的观点,甚至和整个医学界辩论不止。他自己就每天服用大剂量维生素,活到93岁。加州理工学院就有许多这样的大师、这样的怪人,决不随大流,敢于想别人不敢想的,做别人不敢做的。大家都说好的东西,在他看来很一般,没什么。没有这种精神,怎么会有创新!
加州理工学院给这些学者、教授们,也给年轻的学生、研究生们提供了充分的学术权力和民主氛围。不同的学派、不同的学术观点都可以充分发表。学生们也可以充分发表自己的不同学术见解,可以向权威们挑战。过去我曾讲过我在加州理工学院当研究生时和一些权威辩论的情况,其实这在加州理工学院是很平常的事。那时,我们这些搞应用力学的,就是用数学计算来解决工程上的复杂问题。所以人家又管我们叫应用数学家。可是数学系的那些搞纯粹数学的人偏偏瞧不起我们这些搞工程数学的。两个学派常常在一起辩论。有一次,数学系的权威在学校布告栏里贴出了一个海报,说他在什么时间什么地点讲理论数学,欢迎大家去听讲。我的老师冯·卡门一看,也马上贴出一个海报,说在同一时间他在什么地方讲工程数学,也欢迎大家去听。结果两个讲座都大受欢迎。这就是加州理工学院的学术风气,民主而又活跃。我们这些年轻人在这里学习真是大受教益,大开眼界。今天我们有哪一所大学能做到这样?大家见面都是客客气气,学术讨论活跃不起来。这怎么能够培养创新人才?更不用说大师级人才了。
有趣的是,加州理工学院还鼓励那些理工科学生提高艺术素养。我们火箭小组的头头马林纳就是一边研究火箭,一边学习绘画,他后来还成为西方一位抽象派画家。我的老师冯·卡门听说我懂得绘画、音乐、摄影这些方面的学问,还被美国艺术和科学学会吸收为会员,他很高兴,说你有这些才华很重要,这方面你比我强。因为他小时候没有我那样的良好条件。我父亲钱均夫很懂得现代教育,他一方面让我学理工,走技术强国的路;另一方面又送我去学音乐、绘画这些艺术课。我从小不仅对科学感兴趣,也对艺术有兴趣,读过许多艺术理论方面的书,像普列汉诺夫的《艺术论》,我在上海交通大学念书时就读过了。这些艺术上的修养不仅加深了我对艺术作品中那些诗情画意和人生哲理的深刻理解,也学会了艺术上大跨度的宏观形象思维。我认为,这些东西对启迪一个人在科学上的创新是很重要的。科学上的创新光靠严密的逻辑思维不行,创新的思想往往开始于形象思维,从大跨度的联想中得到启迪,然后再用严密的逻辑加以验证。
像加州理工学院这样的学校,光是为中国就培养出许多著名科学家。钱伟长、谈家桢、郭永怀等等,都是加州理工学院出来的。郭永怀是很了不起的,但他去世得早,很多人不了解他。在加州理工学院,他也是冯·卡门的学生,很优秀。我们在一个办公室工作,常常在一起讨论问题。我发现他聪明极了。你若跟他谈些一般性的问题,他不满意,总要追问一些深刻的概念。他毕业以后到康奈尔大学当教授。因为卡门的另一位高才生西尔斯在康奈尔大学组建航空研究院,他了解郭永怀,邀请他去那里工作。郭永怀回国后开始在力学所担任副所长,我们一起开创中国的力学事业。后来搞核武器的钱三强找我,说搞原子弹、氢弹需要一位搞力学的人参加,解决复杂的力学计算问题,开始他想请我去。我说现在中央已委托我搞导弹,事情很多,我没精力参加核武器的事了。但我可以推荐一个人,郭永怀。郭永怀后来担任九院副院长,专门负责爆炸力学等方面的计算问题。在我国原子弹、氢弹问题上他是立了大功的,可惜在一次出差中因飞机失事牺牲了。那个时候,就是这样一批有创新精神的人把中国的原子弹、氢弹、导弹、卫星搞起来的。
今天我们办学,一定要有加州理工学院的那种科技创新精神,培养会动脑筋、具有非凡创造能力的人才。我回国这么多年,感到中国还没有一所这样的学校,都是些一般的,别人说过的才说,没说过的就不敢说,这样是培养不出顶尖帅才的。我们国家应该解决这个问题。你是不是真正的创新,就看是不是敢于研究别人没有研究过的科学前沿问题,而不是别人已经说过的东西我们知道,没有说过的东西,我们就不知道。所谓优秀学生就是要有创新。没有创新,死记硬背,考试成绩再好也不是优秀学生。
我在加州理工学院接受的就是这样的教育,这是我感受最深的。回国以后,我觉得国家对我很重视,但是社会主义建设需要更多的钱学森,国家才会有大的发展。
我说了这么多,就是想告诉大家,我们要向加州理工学院学习,学习它的科学创新精神。我们中国学生到加州理工学院学习的,回国以后都发挥了很好的作用。所有在那学习过的人都受它创新精神的熏陶,知道不创新不行。我们不能人云亦云,这不是科学精神,科学精神最重要的就是创新。
我今年已90多岁了,想到中国长远发展的事情,忧虑的就是这一点。
(涂元季 顾吉环 李 明整理)
-------------------start of 1
板书:
了解公司
去公司网站对其了解
去搜索引擎中了解对公司的评价
网上搜公司的人员,和他们聊天来了解
去IT公司速查手册查对公司的评价(如深圳软媒)
珠三角求职注意事项:深圳、广州、东莞。。。
简历
把自己的简历以纯文本的形式贴在邮件里,同时以Word文档(低版本)加在附件中。附件千万不能有病毒。
写简历的基本原则:简历是向用人单位推荐你、帮助用人单位了解你的一个工具!它不是公文流程化的表格,不是履历
表。不要什么都写。
要根据应聘职位的职位描述(Job Description)来个性化自己的简历,不要所有的职位都用一个简历,这是大忌,貌似
省事,实则大大降低了成功率。
简历中的项目经历尽量不要写:图书管理系统、网上商店之类的,看的头都疼了,第一反应是反感。不能跟别人雷同!
!!
简历注意事项
控制在两页之内
什么刀枪跟棍棒,都耍得有模有样,什么兵器最喜欢,双截棍柔中带刚。不要C、Java、C#、php、linux都懂!不要就是
一句:精通java就ok了,你用java写过什么?做过什么?有什么认识?
尽量压缩政治面貌、小学中学、大学获奖证书、小学三好学生等用人单位不关心的内容。
项目经历不要写太多,每个项目控制在5行左右,要重点突出项目人数、耗时、功能、系统架构等信息。突出:我在项目
做了什么!我不是打杂的,我不是端茶的。
如果和同学一起去应聘,不要两个人的简历一样
简历注意事项
可以多突出自己的特色,跟别人区隔开。简历上写的一定要经得起拷问(端茶倒水的),没把握的不要乱写,反感。面
试官一般都会按照就简历上写的进行提问:“看到你简历上写的。。。我想问你下你对。。。的看法”。
简历不用弄的太花哨,搞太高档的纸。面试官看的是内容,而不是纸!
人才库=垃圾桶
---------------------end of 1----------------------------------
-------------start of 2--------------
板书:
先介绍自己
禁忌的回答:我都写到简历里边了;我出生在陕北一个小山村,我有三个弟弟,我妈身体不好。。。;
无关的事情不要超过十几秒,因为简单介绍自己的时间最多2分钟。很快的将重点话题转到与工作有关的技能和经验上来
。
首先要把简历中写的总结一下(概述,不要全盘背出来),然后再以口语化的方式谈谈与这个工作、软件开发相关的话
题。
多主动说,不要总等着考官提问,那样会被动,但是也不能抢话说。聊天的效果!!和考官处于平等的地位。
当话说完了的时候要及时说“这就是我的看法。”,千万不能与主考官面面相觑。
说话不用太快,说话要稍微慢于思维,否则说话就不连贯了。
常见面试问题:
1、你的优点是什么,你的缺点是什么?
禁忌回答:我的优点是没有缺点(找抽!)
优点要讲与工作相关的,不要说“我篮球打得好”,不要吹的太厉害;谈优点的时候不能枚举形容词,要举实例。
缺点要是那种可以容忍的或者大家都有的小缺点,比如“当我注意力集中在工作上的时候,容易忽略别人说的话”(某
种程度来讲是优点);“当事情比较多的时候我会忘记一些事项,造成工作疏忽”。谈缺点的时候还要提到自己是怎么
改的“我随身带着笔记本,记下要做的事情,这样容易忘记事情的毛病已经改了很多了”
2、你还有什么问题吗?
不能答“没有了”,这说明你对这个工作根本没放在心上,也不能问太敏感的问题。要让别人感觉你是来做事业的,而
不是来找糊口的饭碗。不要问太多的待遇、补助、伙食、几个老板、公司销售额之类的问题,多关心公司的业务、产品
、发展以及个人进入公司以后的问题等等。问剩下的半年时间我该学些什么?
你为什么要来我们公司?不要回答“你们公司给的钱多”、“我看到了你们的招聘启示”。参考回答“我以前就对**有
了解,**是。。。,所以我一直向往在**工作,也希望能在这个行业中与**共同成长。”
3、你能说一下你的职业发展规划吗?
不要说“2年内成为技术骨干,5年内称为项目经理,8年内自己创业。。。”之类的。参考解答“我有非常强的工作能力
和积极性,而且我相信我一定能够为公司创造越来越多的价值,从而个人的能力也得到提升,由于我工作经验还是有限
的,而且对IT行业的发展也有待于逐步加深了解,所以我希望在初期能够服从公司的工作安排,完成公司交给公司的任
务,相信随着我经验的增长,我会对自己的职业发展规划更加明确,今后无论是做技术专家、业务专家还是管理人员,
我都能够找到适合自己发展的道路,与公司共同成长!”愿意在你这干一辈子。
4、你希望的月薪是多少?
这个问题很难回答,而且不同的面试官也有不同的喜好。不过总的原则是首先不要就月薪问题进行无意义的争论“你们
怎么能才给三千呀,我同学都四千,三千还不够在北京生存的呢,我还有八十岁的老母。。。”,而是说自己的优势、
对公司的价值。“我期望的月薪是四千,不过我知道每个公司都有自己的薪酬体系结构,我也充分尊重公司在考虑我个
人能力的基础上按照公司的规定给予我的报酬”。着眼发展!
1、简单介绍自己时:姓名专业,然后是专业相关的。谈到工作上和以口语话的方式聊一聊。
要主动的和考官聊,要主动的出击不能应对呀。可以互动,这样效果更好,也可以启发自己。聊天的效果最好。不能抢
话,一定要让人把话说完。陈述看法。要有个总结,这就是我的看法。说完了就说完了。一些和人交流的基本功。
说话不要快。快了容易出错。
你的优点是什么?缺点是什么?讲与工作相关的,不是谈别的。这个才是关键点。
你还有什么问题吗?这个工作要放在心上,对企业了解吗?对职业了解吗?不能问敏感的问题。要感觉是做事业的。
在这半年时间要学习些什么?******
你为什么来我们公司???以前就公司有所了解,
对自己的职业规划是不是明确。是不是和公司共同发展。??为公司创造价值,对IT行业的还有待了解,
与公司共同成长。
创业的人不安稳。
板书:
纸上写代码很土吗?
面试时的Code题通常有难度,有些题目就是想看你在遇到困难问题时候的应对能力。不要以答不对而懊恼
一时找不到解决方案的话,也不能看着天花板面无表情的发呆,而是要嘴里描述你的想法和思路。编写代码过程中随时对写的代码进行解释。“我要先创建一个HashMap,然后。。。”。
因为可能是在纸上写代码,所以不要拘泥于细节。
遇到一个小障碍,可以求助主考官,“这个只要使用String类的一个分割字符串的方法就可以,不过我忘了这个方法的名称。。。”。遇到难题就问。
如果一个题只会用最笨的方法解,那么也要写,并且解释“这种方式虽然可以实现,不过效率非常低,我虽然想通过发现其中的规律来优化,不过最终没有发现,如果我在工作中碰到类似的问题,我会寻求他人帮助”
怎么样及时无法完美的写的情况下也能的高分。比如我在中软笔试的时候考xml操作,那时候我只用delphi操作过xml,所以我没有按照题目要求用java写,而是按delphi写的,最后注明。。。企业面试、笔试没有严格的评分标准,不同于高考等考试。
代码要考虑边界条件,这是主考官非常注意的。(得高分的技巧)输入参数的合法性等等。
如果是在纸上Coding的话,代码书写一定要清晰;无论是机试还是“纸试”,都要适当的写注释;
机试由于是在不熟悉的机器中开发,所以不要慌,必要时寻求帮忙
着眼发展,要有平和的就业心态。
在一个公司要沉淀一段时间,不要频繁跳槽
工作中80%的时间是在干无聊的事情,因为你的工作不是创新大赛,老板是要你为他产生效益。
把看似无聊的80%的工作做的Perfect,把20%的时间用来创造!你就是未来的牛人!
注意学习不能停止!!!
xml特殊字符
2008-07-03 14:31
|
转义字符
不合法的XML字符必须被替换为相应的实体。
如果在XML文档中使用类似"<" 的字符, 那么解析器将会出现错误,因为解析器会认为这是一个新元素的开始。所以不应该象下面那样书写代码:
<message>if salary < 1000 then</message>
为了避免出现这种情况,必须将字符"<" 转换成实体,象下面这样:
<message>if salary < 1000 then</message>
下面是五个在XML文档中预定义好的实体:
< < 小于号
> > 大于号
& & 和
' ' 单引号
" " 双引号
实体必须以符号"&"开头,以符号";"结尾。
注意: 只有"<" 字符和"&"字符对于XML来说是严格禁止使用的。剩下的都是合法的,为了减少出错,使用实体是一个好习惯。
CDATA部件
在CDATA内部的所有内容都会被解析器忽略。
如果文本包含了很多的"<"字符和"&"字符——就象程序代码一样,那么最好把他们都放到CDATA部件中。
一个 CDATA 部件以"<![CDATA[" 标记开始,以"]]>"标记结束:
<script>
<![CDATA[
function matchwo(a,b)
{
if (a < b && a < 0) then
{
return 1
}
else
{
return 0
}
}
]]>
</script>
在前面的例子中,所有在CDATA部件之间的文本都会被解析器忽略。
CDATA注意事项:
CDATA部件之间不能再包含CDATA部件(不能嵌套)。如果CDATA部件包含了字符"]]>" 或者"<![CDATA[" ,将很有可能出错哦。
同样要注意在字符串"]]>"之间没有空格或者换行符。
|
MySql数据引擎简介与选择方法
2009-04-18 16:17
一、数据引擎简介
在MySQL 5.1中,MySQL AB引入了新的插件式存储引擎体系结构,允许将存储引擎加载到正在运新的MySQL服务器中。
使用MySQL插件式存储引擎体系结构,允许数据库专 业人员为特定的应用需求选择专门的存储引擎,完全不需要管理任何特殊的应用编码要求。采用MySQL服务器体系结构,由于在存储级别上提供了一致和简单的 应用模型和API,应用程序编程人员和DBA可不再考虑所有的底层实施细节。因此,尽管不同的存储引擎具有不同的能力,应用程序是与之分离的。
MySQL支持数个存储引擎作为对不同表的类型的处理器。MySQL存储引擎包括处理事务安全表的引擎和处理非事务安全表的引擎:
· MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。MyISAM在所有MySQL配置里被支持,它是默认的存储引擎,除非你配置MySQL默认使用另外一个引擎。
· MEMORY存储引擎提供“内存中”表。MERGE存储引擎允许集合将被处理同样的MyISAM表作为一个单独的表。就像MyISAM一样,MEMORY和MERGE存储引擎处理非事务表,这两个引擎也都被默认包含在MySQL中。
注释:MEMORY存储引擎正式地被确定为HEAP引擎。
· InnoDB和BDB存储引擎提供事务安全表。BDB被包含在为支持它的操作系统发布的MySQL-Max二进制分发版里。InnoDB也默认被包括在所有MySQL 5.1二进制分发版里,你可以按照喜好通过配置MySQL来允许或禁止任一引擎。
· EXAMPLE存储引擎是一个“存根”引擎,它不做什么。你可以用这个引擎创建表,但没有数据被存储于其中或从其中检索。这个引擎的目的是服务,在MySQL源代码中的一个例子,它演示说明如何开始编写新存储引擎。同样,它的主要兴趣是对开发者。
· NDB Cluster是被MySQL Cluster用来实现分割到多台计算机上的表的存储引擎。它在MySQL-Max 5.1二进制分发版里提供。这个存储引擎当前只被Linux, Solaris, 和Mac OS X 支持。在未来的MySQL分发版中,我们想要添加其它平台对这个引擎的支持,包括Windows。
· ARCHIVE存储引擎被用来无索引地,非常小地覆盖存储的大量数据。
· CSV存储引擎把数据以逗号分隔的格式存储在文本文件中。
· BLACKHOLE存储引擎接受但不存储数据,并且检索总是返回一个空集。
· FEDERATED存储引擎把数据存在远程数据库中。在MySQL 5.1中,它只和MySQL一起工作,使用MySQL C Client API。在未来的分发版中,我们想要让它使用其它驱动器或客户端连接方法连接到另外的数据源。
插件式存储引擎体系结构提供了标准的管理和支持服务集合,它们对所有的基本存储引擎来说是共同的。存储引擎本身是数据库服务器的组件,负责对在物理服务器层面上维护的基本数据进行实际操作。
这是一种高效的模块化体系结构,它为那些希望专注于特定应用需求的人员提供了巨大的便利和益处,这类特殊应用需求包括数据仓储、事务处理、高可用性情形等,同时还能利用独立于任何存储引擎的一组接口和服务。
应用程序编程人员和DBA通过位于存储引擎之上的连接器API和服务层来处理MySQL数据库。如果 应用程序的变化需要改变底层存储引擎,或需要增加1个或多个额外的存储引擎以支持新的需求,不需要进行大的编码或进程更改就能实现这类要求。MySQL服 务器体系结构提供了一致和易于使用的API,这类API适用于多种存储引擎,通过该方式,该结构将应用程序与存储引擎的底层复杂性隔离开来。
在下图中,以图形方式介绍了MySQL插件式存储引擎体系结构:
二、选择存储引擎
与MySQL一起提供的各种存储引擎在设计时考虑了不同的使用情况。为了更有效地使用插件式存储体系结构,最好了解各种存储引擎的优点和缺点。
在下面的表格中,概要介绍了与MySQL一起提供的存储引擎:

下述存储引擎是最常用的:
· MyISAM:默认的MySQL插件式存储引擎,它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。注意,通过更改STORAGE_ENGINE配置变量,能够方便地更改MySQL服务器的默认存储引擎。
· InnoDB:用于事务处理应用程序,具有众多特性,包括ACID事务支持。
· BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性。
· Memory:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供极快的访问。
· Merge:允许MySQL DBA或开发人员将一系列等同的MyISAM表以逻辑方式组合在一起,并作为1个对象引用它们。对于诸如数据仓储等VLDB环境十分适合。
· Archive:为大量很少引用的历史、归档、或安全审计信息的存储和检索提供了完美的解决方案。
· Federated:能够将多个分离的MySQL服务器链接起来,从多个物理服务器创建一个逻辑数据库。十分适合于分布式环境或数据集市环境。
· Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性。
· Other:其他存储引擎包括CSV(引用由逗号隔开的用作数据库表的文件),Blackhole(用于临时禁止对数据库的应用程序输入),以及Example引擎(可为快速创建定制的插件式存储引擎提供帮助)。
请记住,对于整个服务器或方案,你并不一定要使用相同的存储引擎,你可以为方案中的每个表使用不同的存储引擎,这点很重要。
三、将存储引擎指定给表
可以在创建新表时指定存储引擎,或通过使用ALTER TABLE语句指定存储引擎。
要想在创建表时指定存储引擎,可使用ENGINE参数:
CREATE TABLE engineTest(
id INT
) ENGINE = MyISAM;
也可以使用TYPE选项到CREATE TABLE语句来告诉MySQL你要创建什么类型的表。
CREATE TABLE engineTest(
id INT
) TYPE = MyISAM;
虽然TYPE仍然在MySQL 5.1中被支持,现在ENGINE是首选的术语。
如果你省略掉ENGINE或TYPE选项,默认的存储引擎被使用。一般的默认是MyISAM,但 你可以用--default-storage-engine或--default-table-type服务器启动选项来改变它,或者通过设置 storage_engine或table_type系统变量来改变。
要想更改已有表的存储引擎,可使用ALTER TABLE语句:
ALTER TABLEengineTestENGINE =ARCHIVE;
ALTER TABLE t ENGINE = MYISAM;
ALTER TABLE t TYPE = BDB;
如果你试着使用一个未被编译进MySQL的存储引擎,或者试着用一个被编译进MySQL但没有被 激活的存储引擎,MySQL取而代之地创建一个MyISAM类型的表。当你在支持不同存储引擎的MySQL服务器之间拷贝表的时候,上述的行为是很方便 的。(例如,在一个复制建立中,可能你的主服务器为增加安全而支持事务存储引擎,但从服务器为更快的速度而仅使用非事务存储引擎。)
在不可用的类型被指定时,自动用MyISAM表来替代,这会对MySQL的新用户造成混淆。无论何时一个表被自动改变之时,产生一个警告。
MySQL总是创建一个.frm文件来保持表和列的定义。表的索引和数据可能被存储在一个或多个文件里,这取决于表的类型。服务器在存储引擎级别之上创建.frm文件。单独的存储引擎创建任何需要用来管理表的额外文件。
一个数据库可以包含不同类型的表。
四、存储引擎和事务
下述存储引擎支持事务:
· InnoDB:通过MVCC支持事务,允许COMMIT、ROLLBACK和保存点。
· NDB:通过MVCC支持事务,允许COMMIT和ROLLBACK。
· BDB:支持事务,允许COMMIT和ROLLBACK。
事务安全表(TST) 比起非事务安全表 (NTST)有几大优势:
· 更安全。即使MySQL崩溃或遇到硬件问题,要么自动恢复,要么从备份加事务日志恢复,你可以取回数据。
· 你可以合并许多语句,并用COMMIT语句同时接受它们全部(如果autocommit被禁止掉)。
· 你可以执行ROLLBACK来忽略你的改变(如果autocommit被禁止掉)。
· 如果更新失败,你的所有改变都变回原来。(用非事务安全表,所有发生的改变都是永久的)。
· 事务安全存储引擎可以给那些当前用读得到许多更新的表提供更好的部署。
非事务安全表自身有几个优点,因为没有事务开支,所有优点都能出现:
· 更快
· 需要更少的磁盘空间
· 执行更新需要更少的内存
你可以在同一个语句中合并事务安全和非事务安全表来获得两者最好的情况。尽管如此,在autocommit被禁止掉的事务里,变换到非事务安全表依旧即时提交,并且不会被回滚。
虽然MySQL支持数个事务安全存储引擎,为获得最好结果,你不应该在一个事务那混合不同表类型。如果你混合表类型会发生问题,
五、插入搜索引擎
能够使用存储引擎之前,必须使用INSTALL PLUGIN语句将存储引擎plugin(插件)装载到mysql。例如,要想加载example引擎,首先应加载ha_example.so模块:
INSTALL PLUGINha_exampleSONAME 'ha_example.so';
文件.so必须位于MySQL服务器库目录下(典型情况下是installdir/lib)。
六、拔出存储引擎
要想拔出存储引擎,可使用UNINSTALL PLUGIN语句:
UNINSTALL PLUGINha_example;
如果拔出了正被已有表使用的存储引擎,这些表将成为不可访问的。拔出存储引擎之前,请确保没有任何表使用该存储引擎。
为了安装插件式存储引擎,plugin文件必须位于恰当的MySQL库目录下,而且发出INSTALL PLUGIN语句的用户必须具有SUPER权限。
创建table时可以通过engine关键字指定使用的存储引擎,如果省略则使用系统默认的存储引擎:
CREATE TABLE t (i INT) ENGINE = MYISAM;
查看系统中支持的存储引擎类型:
mysql> show engines;
标准安装程序中只提供部分引擎的支持,如果需要使用其他的存储引擎,需要使用源代码加不同的参数重新编译。其中DEFAULT表明系统的默认存储引擎,可以通过修改配置参数来变更:
default-storage-engine=MyISAM
查看某个存储引擎的具体信息
mysql> show engine InnoDB status\G;
|
如果我们把二叉树看成一个图,父子节点之间的连线看成是双向的,我们姑且定义“距
离”为两个节点之间边的个数。
写一个程序求一棵二叉树中相距最远的两个节点之间的距离。
如图 3-11 所示,粗箭头的边表示最长距离:
图 3-11
树中相距最远的两个节点 A,B
写书评,赢取《编程之美——微软技术面试心得》 www.ieee.org.cn/BCZM.asp
分析与解法
我们先画几个不同形状的二叉树,(如图 3-12 所示),看看能否得到一些启示。
图 3-12
几个例子
从例子中可以看出,相距最远的两个节点,一定是两个叶子节点,或者是一个叶子节点
到它的根节点。(为什么?)
【解法一】
根据相距最远的两个节点一定是叶子节点这个规律,我们可以进一步讨论。
对于任意一个节点,以该节点为根,假设这个根有 K 个孩子节点,那么相距最远的两
个节点 U 和 V 之间的路径与这个根节点的关系有两种情况:
1. 若路径经过根Root,则U和V是属于不同子树的,且它们都是该子树中到根节点最远
的节点,否则跟它们的距离最远相矛盾。这种情况如图3-13所示:
图 3-13
相距最远的节点在左右最长的子树中
写书评,赢取《编程之美——微软技术面试心得》 www.ieee.org.cn/BCZM.asp
2. 如果路径不经过Root,那么它们一定属于根的K个子树之一。并且它们也是该子树中
相距最远的两个顶点。如图3-14中的节点A:
图 3-14
相距最远的节点在某个子树下
因此,问题就可以转化为在子树上的解,从而能够利用动态规划来解决。
设第 K 棵子树中相距最远的两个节点:Uk 和 Vk,其距离定义为 d(Uk, Vk),那么节点
Uk 或 Vk 即为子树 K 到根节点 Rk 距离最长的节点。不失一般性,我们设 Uk 为子树 K 中到根
节点 Rk 距离最长的节点,其到根节点的距离定义为 d(Uk, R)。取 d(Ui, R)(1≤i≤k)中
最大的两个值 max1 和 max2,那么经过根节点 R 的最长路径为 max1+max2+2,所以树 R 中
相距最远的两个点的距离为:max{d(U1, V1), …, d(Uk, Vk),max1+max2+2}。
采用深度优先搜索如图 3-15,只需要遍历所有的节点一次,时间复杂度为 O(|E|)= O
(|V|-1),其中 V 为点的集合,E 为边的集合。
图 3-15
深度遍历示意图
示例代码如下,我们使用二叉树来实现该算法。
代码清单 3-11
// 数据结构定义
写书评,赢取《编程之美——微软技术面试心得》 www.ieee.org.cn/BCZM.asp
struct NODE
{
NODE* pLeft;
NODE* pRight;
int nMaxLeft;
int nMaxRight;
char chValue;
};
int nMaxLen = 0;
// 寻找树中最长的两段距离
void FindMaxLen(NODE* pRoot)
{
// 遍历到叶子节点,返回
if(pRoot == NULL)
{
return;
}
// 如果左子树为空,那么该节点的左边最长距离为0
if(pRoot -> pLeft == NULL)
{
pRoot -> nMaxLeft = 0;
}
// 如果右子树为空,那么该节点的右边最长距离为0
if(pRoot -> pRight == NULL)
{
pRoot -> nMaxRight = 0;
}
// 如果左子树不为空,递归寻找左子树最长距离
if(pRoot -> pLeft != NULL)
{
FindMaxLen(pRoot -> pLeft);
}
// 如果右子树不为空,递归寻找右子树最长距离
if(pRoot -> pRight != NULL)
{
FindMaxLen(pRoot -> pRight);
}
// 计算左子树最长节点距离
if(pRoot -> pLeft != NULL)
{
int nTempMax = 0;
if(pRoot -> pLeft -> nMaxLeft > pRoot -> pLeft -> nMaxRight)
{
nTempMax = pRoot -> pLeft -> nMaxLeft;
}
else
{
nTempMax = pRoot -> pLeft -> nMaxRight;
}
pRoot -> nMaxLeft = nTempMax + 1;
}
// 计算右子树最长节点距离
if(pRoot -> pRight != NULL)
//
//
//
//
//
左孩子
右孩子
左子树中的最长距离
右子树中的最长距离
该节点的值
写书评,赢取《编程之美——微软技术面试心得》 www.ieee.org.cn/BCZM.asp
{
int nTempMax = 0;
if(pRoot -> pRight -> nMaxLeft > pRoot -> pRight -> nMaxRight)
{
nTempMax = pRoot -> pRight -> nMaxLeft;
}
else
{
nTempMax = pRoot -> pRight -> nMaxRight;
}
pRoot -> nMaxRight = nTempMax + 1;
}
// 更新最长距离
if(pRoot -> nMaxLeft + pRoot -> nMaxRight > nMaxLen)
{
nMaxLen = pRoot -> nMaxLeft + pRoot -> nMaxRight;
}
}
扩展问题
在代码中,我们使用了递归的办法来完成问题的求解。那么是否有非递归的算法来解决
这个问题呢?
总结
对于递归问题的分析,笔者有一些小小的体会:
1. 先弄清楚递归的顺序。在递归的实现中,往往需要假设后续的调用已经完成,在此
基础之上,才实现递归的逻辑。在该题中,我们就是假设已经把后面的长度计算出
来了,然后继续考虑后面的逻辑;
2. 分析清楚递归体的逻辑,然后写出来。比如在上面的问题中,递归体的逻辑就是如
何计算两边最长的距离;
3. 考虑清楚递归退出的边界条件。也就说,哪些地方应该写return。
注意到以上 3 点,在面对递归问题的时候,我们将总是有章可循。
-----------------------------------------------------------------------------------
《编程之美》读书笔记:第3.8节“求二叉树中节点的最大距离”扩展问题 收藏
感谢azuryy为大家分享《编程之美》第3.8节扩展问题的答案:用非递归的算法求一颗二叉树中相距最远的两个节点之间的距离。(原博客地址:http://hi.baidu.com/azuryy/blog/item/30ad10ea192424d5d439c96d.html)
#include <stack>
#include <algorithm>
using namespace std;
struct Node
{
bool _visited;
Node* left;
Node* right;
int maxLeft;
int maxRight;
Node()
{
_visited = false;
maxLeft = 0;
maxRight = 0;
left = NULL;
right = NULL;
}
};
int maxLen = 0;
stack<Node*> nodeStack;
void findMaxLen( Node* root )
{
Node* node;
if ( root == NULL )
{
return ;
}
nodeStack.push( root );
while( !nodeStack.empty())
{
node = nodeStack.top();
if ( node->left == NULL && node->right == NULL )
{
nodeStack.pop();
node->_visited = true;
continue;
}
if ( node->left )
{
if ( !node->left->_visited )
{
nodeStack.push( node->left ) ;
}
else
{
node->maxLeft = max( node->left->maxLeft,node->left->maxRight ) + 1;
}
}
if ( ( !node->left || node->left->_visited ) && node->right )
{
if ( !node->right->_visited )
{
nodeStack.push( node->right ) ;
}
else
{
node->maxRight = max( node->right->maxLeft,node->right->maxRight ) + 1;
}
}
if (( !node->left || node->left->_visited ) && ( !node->right || node->right->_visited ))
{
maxLen = max( maxLen, node->maxLeft + node->maxRight );
node->_visited = true;
nodeStack.pop();
}
}
}
Immediate test case 1:
int main()
{
Node *tmp ;
Node* root = new Node();
tmp = new Node();
root->left = tmp ;
tmp = new Node();
root->right = tmp;
tmp = new Node();
root->right->right = tmp;
tmp = new Node();
root->right->right->right = tmp;
tmp = new Node();
root->right->right->right->left = tmp;
findMaxLen( root );
cout << maxLen << endl;
return 0;
}
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/bvbook/archive/2008/07/25/2710209.aspx
JDBC优化策略总结
相比Hibernate、iBatis、DBUtils等,理论上JDBC的性能都超过它们。JDBC提供更底层更精细的数据访问策略,这是Hibernate等框架所不具备的。
在一些高性能的数据操作中,越高级的框架越不适合使用。这里是我在开发中对JDBC使用过程中一些优化经验总结。
1、选择纯Java的JDBC驱动。
2、使用连接池--使用一个“池”来管理JDBC连接,并精心调试池配置的参数,目前可用的数据库连接池很多很多。
如何配置合适的参数呢,需要的是测试,而不是感觉。
3、重用Connection--最大限度使用每个数据库连接,得到了就不要轻易“丢弃”。
有时候在一个过程中,会多次操作数据库,而仅仅需要一个连接就够了,没必用一次就获取一个连接,用完后关闭或者入池。这样会增加“池”管理的成本,千万别以为你用了“池”就可以随便申请和归还连接,都是有代价的。如果是一个庞大循环块中操作数据库,更应该注意此问题!
4、重用Statement--对于一些预定义SQL,设置为静态常量,并尽可能重用预定义SQL产生的PreparedStatement对象。对于多次使用一种模式的SQL,使用预定义SQL可以获取更好的性能。
5、使用批处理SQL。
6、优化结果集ResultSet--查询时候,返回的结果集有不同的类型,优先选择只读结果集、不可滚动的属性。
这里是很容易出现问题的地方:
java.sql.ResultSet
static int CLOSE_CURSORS_AT_COMMIT
该常量指示调用 Connection.commit 方法时应该关闭 ResultSet 对象。
static int CONCUR_READ_ONLY
该常量指示不可以更新的 ResultSet 对象的并发模式。
static int CONCUR_UPDATABLE
该常量指示可以更新的 ResultSet 对象的并发模式。
static int FETCH_FORWARD
该常量指示将按正向(即从第一个到最后一个)处理结果集中的行。
static int FETCH_REVERSE
该常量指示将按反向(即从最后一个到第一个)处理结果集中的行处理。
static int FETCH_UNKNOWN
该常量指示结果集中的行的处理顺序未知。
static int HOLD_CURSORS_OVER_COMMIT
该常量指示调用 Connection.commit 方法时不应关闭 ResultSet 对象。
static int TYPE_FORWARD_ONLY
该常量指示指针只能向前移动的 ResultSet 对象的类型。
static int TYPE_SCROLL_INSENSITIVE
该常量指示可滚动但通常不受其他的更改影响的 ResultSet 对象的类型。
static int TYPE_SCROLL_SENSITIVE
该常量指示可滚动并且通常受其他的更改影响的 ResultSet 对象的类型。
说明下:
结果集分两种类型:只读和可更改,只读的话,更省内存,查询的结果集不能更改。如果结果集在查询后,更改了值又要保存,则使用可更改结果集。
结果集的游标也有两种类型:如果没必要让游标自由滚动,则选择单方向移动的游标类型。
对于是否并发操作:如果不需要考虑线程安全,则选择忽略并发的结果集类型,否则选择并发安全的类型。
另外,还要控制结果的大小,几乎所有的数据库都有查询记录条数控制的策略,可以海量数据进行分批处理,一次一批,这样不至于把系统搞死。
7、事物优化--如果数据库不支持事物,就不要写回滚代码,如果不考虑事物,就不要做事务的控制。
8、安全优化--管理好你的Connection对象,在异常时候能“入池”或者关闭。因此应该将Connection释放的代码写在异常处理的finally块中。
9、异常处理优化--不要轻易吞噬SQLException,对于DAO、Service层次的数据访问,一般在DAO中跑出异常,在Service中处理异常。但DAO中也可以处理异常,并做转义抛出,不要随便抛出RuntimeExeption,因为这是JVM抛出的,不需要你可以去抛出,因为RuntimeException往往会导致系统挂起。
10、代码高层优化--在以上的基础上,优化封装你的数据访问方式,尽可能让代码简洁好维护,如果你还觉得性能不行,那就该从整个系统角度考虑优化了,比如加上缓存服务器,集群、负载均衡、优化数据库服务器等等,以获取更好的系能。
本文出自 “熔 岩” 博客,请务必保留此出处http://lavasoft.blog.51cto.com/62575/225828
java代码优化编程(2)
17、不用new关键词创建类的实例
用new关键词创建类的实例时,构造函数链中的所有构造函数都会被自动调用。但如果一个对象实现了Cloneable接口,我们可以调用它的clone()方法。clone()方法不会调用任何类构造函数。
在使用设计模式(Design Pattern)的场合,如果用Factory模式创建对象,则改用clone()方法创建新的对象实例非常简单。例如,下面是Factory模式的一个典型实现:
public static Credit getNewCredit() {
return new Credit();
}
改进后的代码使用clone()方法,如下所示:
private static Credit BaseCredit = new Credit();
public static Credit getNewCredit() {
return (Credit) BaseCredit.clone();
}
上面的思路对于数组处理同样很有用。
18、乘法和除法
考虑下面的代码:
for (val = 0; val < 100000; val +=5) {
alterX = val * 8; myResult = val * 2;
}
用移位操作替代乘法操作可以极大地提高性能。下面是修改后的代码:
for (val = 0; val < 100000; val += 5) {
alterX = val << 3; myResult = val << 1;
}
修改后的代码不再做乘以8的操作,而是改用等价的左移3位操作,每左移1位相当于乘以2。相应地,右移1位操作相当于除以2。值得一提的是,虽然移位操作速度快,但可能使代码比较难于理解,所以最好加上一些注释。
19、在JSP页面中关闭无用的会话。
一个常见的误解是以为session在有客户端访问时就被创建,然而事实是直到某server端程序调用 HttpServletRequest.getSession(true)这样的语句时才被创建,注意如果JSP没有显示的使用 <%@page session="false"%> 关闭session,则JSP文件在编译成Servlet时将会自动加上这样一条语句HttpSession session = HttpServletRequest.getSession(true);这也是JSP中隐含的 session对象的来历。由于session会消耗内存资源,因此,如果不打算使用session,应该在所有的JSP中关闭它。
对于那些无需跟踪会话状态的页面,关闭自动创建的会话可以节省一些资源。使用如下page指令:<%@ page session="false"%>
20、JDBC与I/O
如果应用程序需要访问一个规模很大的数据集,则应当考虑使用块提取方式。默认情况下,JDBC每次提取32行数据。举例来说,假设我们要遍历一个5000行的记录集,JDBC必须调用数据库157次才能提取到全部数据。如果把块大小改成512,则调用数据库的次数将减少到10次。
[p][/p]21、Servlet与内存使用
许多开发者随意地把大量信息保存到用户会话之中。一些时候,保存在会话中的对象没有及时地被垃圾回收机制回收。从性能上看,典型的症状是用户感到系统周期性地变慢,却又不能把原因归于任何一个具体的组件。如果监视JVM的堆空间,它的表现是内存占用不正常地大起大落。
解决这类内存问题主要有二种办法。第一种办法是,在所有作用范围为会话的Bean中实现HttpSessionBindingListener接口。这样,只要实现valueUnbound()方法,就可以显式地释放Bean使用的资源。 另外一种办法就是尽快地把会话作废。大多数应用服务器都有设置会话作废间隔时间的选项。另外,也可以用编程的方式调用会话的setMaxInactiveInterval()方法,该方法用来设定在作废会话之前,Servlet容器允许的客户请求的最大间隔时间,以秒计。
22、使用缓冲标记
一些应用服务器加入了面向JSP的缓冲标记功能。例如,BEA的WebLogic Server从6.0版本开始支持这个功能,Open Symphony工程也同样支持这个功能。JSP缓冲标记既能够缓冲页面片断,也能够缓冲整个页面。当JSP页面执行时,如果目标片断已经在缓冲之中,则生成该片断的代码就不用再执行。页面级缓冲捕获对指定 URL的请求,并缓冲整个结果页面。对于购物篮、目录以及门户网站的主页来说,这个功能极其有用。对于这类应用,页面级缓冲能够保存页面执行的结果,供后继请求使用。
23、选择合适的引用机制
在典型的JSP应用系统中,页头、页脚部分往往被抽取出来,然后根据需要引入页头、页脚。当前,在JSP页面中引入外部资源的方法主要有两种:include指令,以及include动作。
include 指令:例如<%@ include file="copyright.html" %>。该指令在编译时引入指定的资源。在编译之前,带有 include指令的页面和指定的资源被合并成一个文件。被引用的外部资源在编译时就确定,比运行时才确定资源更高效。
include动作:例如<jsp:include page="copyright.jsp" />。该动作引入指定页面执行后生成的结果。由于它在运行时完成,因此对输出结果的控制更加灵活。但时,只有当被引用的内容频繁地改变时,或者在对主页面的请求没有出现之前,被引用的页面无法确定时,使用include 动作才合算。
24、及时清除不再需要的会话
为了清除不再活动的会话,许多应用服务器都有默认的会话超时时间,一般为30分钟。当应用服务器需要保存更多会话时,如果内存容量不足,操作系统会把部分内存数据转移到磁盘,应用服务器也可能根据“最近最频繁使用 ”(Most Recently Used)算法把部分不活跃的会话转储到磁盘,甚至可能抛出“内存不足”异常。在大规模系统中,串行化会话的代价是很昂贵的。当会话不再需要时,应当及时调用HttpSession.invalidate()方法清除会话。 HttpSession.invalidate()方法通常可以在应用的退出页面调用。
25、不要将数组声明为:public static final 。
26、HashMap的遍历效率讨论
经常遇到对HashMap中的key和value值对的遍历操作,有如下两种方法:Map<String, String[]> paraMap = new HashMap<String, String[]>();
................//第一个循环
Set<String> appFieldDefIds = paraMap.keySet();
for (String appFieldDefId : appFieldDefIds) {
String[] values = paraMap.get(appFieldDefId);
......
}
//第二个循环
for(Entry<String, String[]> entry : paraMap.entrySet()){
String appFieldDefId = entry.getKey();
String[] values = entry.getValue();
.......
}
第一种实现明显的效率不如第二种实现。
分析如下 Set<String> appFieldDefIds = paraMap.keySet(); 是先从HashMap中取得keySet
代码如下:
public Set<K> keySet() {
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
private class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return HashMap.this.removeEntryForKey(o) != null;
}
public void clear() {
HashMap.this.clear();
}
}
其实就是返回一个私有类KeySet, 它是从AbstractSet继承而来,实现了Set接口。
再来看看for/in循环的语法
for(declaration : expression)
statement
在执行阶段被翻译成如下各式
for(Iterator<E> #i = (expression).iterator(); #i.hashNext();){
declaration = #i.next();
statement
}
因此在第一个for语句for (String appFieldDefId : appFieldDefIds) 中调用了HashMap.keySet().iterator() 而这个方法调用了newKeyIterator()
Iterator<K> newKeyIterator() {
return new KeyIterator();
}
private class KeyIterator extends HashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
所以在for中还是调用了
在第二个循环for(Entry<String, String[]> entry : paraMap.entrySet())中使用的Iterator是如下的一个内部类
private class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
此时第一个循环得到key,第二个循环得到HashMap的Entry
效率就是从循环里面体现出来的第二个循环此致可以直接取key和value值
而第一个循环还是得再利用HashMap的get(Object key)来取value值
现在看看HashMap的get(Object key)方法
public V get(Object key) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length); //Entry[] table
Entry<K,V> e = table;
while (true) {
if (e == null)
return null;
if (e.hash == hash && eq(k, e.key))
return e.value;
e = e.next;
}
}
其实就是再次利用Hash值取出相应的Entry做比较得到结果,所以使用第一中循环相当于两次进入HashMap的Entry中
而第二个循环取得Entry的值之后直接取key和value,效率比第一个循环高。其实按照Map的概念来看也应该是用第二个循环好一点,它本来就是key和value的值对,将key和value分开操作在这里不是个好选择。
27、array(数组) 和 ArryList的使用
array([]):最高效;但是其容量固定且无法动态改变;
ArrayList:容量可动态增长;但牺牲效率;
基于效率和类型检验,应尽可能使用array,无法确定数组大小时才使用ArrayList!
ArrayList是Array的复杂版本
ArrayList内部封装了一个Object类型的数组,从一般的意义来说,它和数组没有本质的差别,甚至于ArrayList的许多方法,如Index、IndexOf、Contains、Sort等都是在内部数组的基础上直接调用Array的对应方法。
ArrayList存入对象时,抛弃类型信息,所有对象屏蔽为Object,编译时不检查类型,但是运行时会报错。
注:jdk5中加入了对泛型的支持,已经可以在使用ArrayList时进行类型检查。
从这一点上看来,ArrayList与数组的区别主要就是由于动态增容的效率问题了
28、尽量使用HashMap 和ArrayList ,除非必要,否则不推荐使用HashTable和Vector ,后者由于使用同步机制,而导致了性能的开销。
29、StringBuffer 和StringBuilder的区别:
java.lang.StringBuffer 线程安全的可变字符序列。一个类似于 String 的字符串缓冲区,但不能修改。StringBuilder。与该类相比,通常应该优先使用 java.lang.StringBuilder类,因为它支持所有相同的操作,但由于它不执行同步,所以速度更快。为了获得更好的性能,在构造 StirngBuffer 或 StirngBuilder 时应尽可能指定它的容量。当然,如果你操作的字符串长度不超过 16 个字符就不用了。 相同情况下使用 StirngBuilder 相比使用 StringBuffer 仅能获得 10%-15% 左右的性能提升,但却要冒多线程不安全的风险。而在现实的模块化编程中,负责某一模块的程序员不一定能清晰地判断该模块是否会放入多线程的环境中运行,因此:除非你能确定你的系统的瓶颈是在 StringBuffer 上,并且确定你的模块不会运行在多线程模式下,否则还是用 StringBuffer 吧。
可供程序利用的资源(内存、CPU时间、网络带宽等)是有限的,优化的目的就是让程序用尽可能少的资源完成预定的任务。优化通常包含两方面的内容:减小代码的体积,提高代码的运行效率。本文讨论的主要是如何提高代码的效率。
在 Java程序中,性能问题的大部分原因并不在于Java语言,而是在于程序本身。养成好的代码编写习惯非常重要,比如正确地、巧妙地运用 java.lang.String类和java.util.Vector类,它能够显着地提高程序的性能。下面我们就来具体地分析一下这方面的问题。
1、 尽量指定类的final修饰符 带有final修饰符的类是不可派生的。在Java核心API中,有许多应用final的例子,例如 java.lang.String。为String类指定final防止了人们覆盖length()方法。另外,如果指定一个类为final,则该类所有的方法都是final。Java编译器会寻找机会内联(inline)所有的final方法(这和具体的编译器实现有关)。此举能够使性能平均提高 50% 。
2、 尽量重用对象。特别是String 对象的使用中,出现字符串连接情况时应用StringBuffer 代替。由于系统不仅要花时间生成对象,以后可能还需花时间对这些对象进行垃圾回收和处理。因此,生成过多的对象将会给程序的性能带来很大的影响。
3、 尽量使用局部变量,调用方法时传递的参数以及在调用中创建的临时变量都保存在栈(Stack)中,速度较快。其他变量,如静态变量、实例变量等,都在堆(Heap)中创建,速度较慢。另外,依赖于具体的编译器/JVM,局部变量还可能得到进一步优化。请参见《尽可能使用堆栈变量》。
4、 不要重复初始化变量 默认情况下,调用类的构造函数时, Java会把变量初始化成确定的值:所有的对象被设置成null,整数变量(byte、 short、int、long)设置成0,float和double变量设置成0.0,逻辑值设置成false。当一个类从另一个类派生时,这一点尤其应该注意,因为用new关键词创建一个对象时,构造函数链中的所有构造函数都会被自动调用。
5、 在JAVA + ORACLE 的应用系统开发中,java中内嵌的SQL语句尽量使用大写的形式,以减轻ORACLE解析器的解析负担。
6、 Java 编程过程中,进行数据库连接、I/O流操作时务必小心,在使用完毕后,即使关闭以释放资源。因为对这些大对象的操作会造成系统大的开销,稍有不慎,会导致严重的后果。
7、 由于JVM的有其自身的GC机制,不需要程序开发者的过多考虑,从一定程度上减轻了开发者负担,但同时也遗漏了隐患,过分的创建对象会消耗系统的大量内存,严重时会导致内存泄露,因此,保证过期对象的及时回收具有重要意义。JVM回收垃圾的条件是:对象不在被引用;然而,JVM的GC并非十分的机智,即使对象满足了垃圾回收的条件也不一定会被立即回收。所以,建议我们在对象使用完毕,应手动置成null。
8、 在使用同步机制时,应尽量使用方法同步代替代码块同步。
9、 尽量减少对变量的重复计算
例如:for(int i = 0;i < list.size; i ++) {
…
}
应替换为:
for(int i = 0,int len = list.size();i < len; i ++) {
…
}
10、尽量采用lazy loading 的策略,即在需要的时候才开始创建。
例如: String str = “aaa”;
if(i == 1) {
list.add(str);
}
应替换为:
if(i == 1) {
String str = “aaa”;
list.add(str);
}
11、慎用异常
异常对性能不利。抛出异常首先要创建一个新的对象。Throwable接口的构造函数调用名为fillInStackTrace()的本地(Native)方法,fillInStackTrace()方法检查堆栈,收集调用跟踪信息。只要有异常被抛出,VM就必须调整调用堆栈,因为在处理过程中创建了一个新的对象。 异常只能用于错误处理,不应该用来控制程序流程。
12、不要在循环中使用:
Try {
} catch() {
}
应把其放置在最外层。
13、StringBuffer 的使用:
StringBuffer表示了可变的、可写的字符串。
有三个构造方法 :
StringBuffer (); //默认分配16个字符的空间
StringBuffer (int size); //分配size个字符的空间
StringBuffer (String str); //分配16个字符+str.length()个字符空间
你可以通过StringBuffer的构造函数来设定它的初始化容量,这样可以明显地提升性能。这里提到的构造函数是 StringBuffer(int length),length参数表示当前的StringBuffer能保持的字符数量。你也可以使用 ensureCapacity(int minimumcapacity)方法在StringBuffer对象创建之后设置它的容量。首先我们看看 StringBuffer的缺省行为,然后再找出一条更好的提升性能的途径。
StringBuffer在内部维护一个字符数组,当你使用缺省的构造函数来创建StringBuffer对象的时候,因为没有设置初始化字符长度,StringBuffer的容量被初始化为16个字符,也就是说缺省容量就是16个字符。当StringBuffer达到最大容量的时候,它会将自身容量增加到当前的2倍再加2,也就是(2*旧值+2)。如果你使用缺省值,初始化之后接着往里面追加字符,在你追加到第16个字符的时候它会将容量增加到34(2*16+2),当追加到34个字符的时候就会将容量增加到 70(2*34+2)。无论何事只要StringBuffer到达它的最大容量它就不得不创建一个新的字符数组然后重新将旧字符和新字符都拷贝一遍――这也太昂贵了点。所以总是给StringBuffer设置一个合理的初始化容量值是错不了的,这样会带来立竿见影的性能增益。
StringBuffer初始化过程的调整的作用由此可见一斑。所以,使用一个合适的容量值来初始化StringBuffer永远都是一个最佳的建议。
14、合理的使用Java类 java.util.Vector。
简单地说,一个Vector就是一个java.lang.Object实例的数组。Vector与数组相似,它的元素可以通过整数形式的索引访问。但是,Vector类型的对象在创建之后,对象的大小能够根据元素的增加或者删除而扩展、缩小。请考虑下面这个向Vector加入元素的例子:
Object obj = new Object();
Vector v = new Vector(100000);
for(int I=0;
I<100000; I++) { v.add(0,obj); }
除非有绝对充足的理由要求每次都把新元素插入到Vector的前面,否则上面的代码对性能不利。在默认构造函数中,Vector的初始存储能力是10个元素,如果新元素加入时存储能力不足,则以后存储能力每次加倍。Vector类就象StringBuffer类一样,每次扩展存储能力时,所有现有的元素都要复制到新的存储空间之中。下面的代码片段要比前面的例子快几个数量级:
Object obj = new Object();
Vector v = new Vector(100000);
for(int I=0; I<100000; I++) { v.add(obj); }
同样的规则也适用于Vector类的remove()方法。由于Vector中各个元素之间不能含有“空隙”,删除除最后一个元素之外的任意其他元素都导致被删除元素之后的元素向前移动。也就是说,从Vector删除最后一个元素要比删除第一个元素“开销”低好几倍。
假设要从前面的Vector删除所有元素,我们可以使用这种代码:
for(int I=0; I<100000; I++)
{
v.remove(0);
}
但是,与下面的代码相比,前面的代码要慢几个数量级:
for(int I=0; I<100000; I++)
{
v.remove(v.size()-1);
}
从Vector类型的对象v删除所有元素的最好方法是:
v.removeAllElements();
假设Vector类型的对象v包含字符串“Hello”。考虑下面的代码,它要从这个Vector中删除“Hello”字符串:
String s = "Hello";
int i = v.indexOf(s);
if(I != -1) v.remove(s);
这些代码看起来没什么错误,但它同样对性能不利。在这段代码中,indexOf()方法对v进行顺序搜索寻找字符串“Hello”,remove(s)方法也要进行同样的顺序搜索。改进之后的版本是:
String s = "Hello";
int i = v.indexOf(s);
if(I != -1) v.remove(i);
这个版本中我们直接在remove()方法中给出待删除元素的精确索引位置,从而避免了第二次搜索。一个更好的版本是:
String s = "Hello"; v.remove(s);
最后,我们再来看一个有关Vector类的代码片段:
for(int I=0; I++;I < v.length)
如果v包含100,000个元素,这个代码片段将调用v.size()方法100,000次。虽然size方法是一个简单的方法,但它仍旧需要一次方法调用的开销,至少JVM需要为它配置以及清除堆栈环境。在这里,for循环内部的代码不会以任何方式修改Vector类型对象v的大小,因此上面的代码最好改写成下面这种形式:
int size = v.size(); for(int I=0; I++;I<size)
虽然这是一个简单的改动,但它仍旧赢得了性能。毕竟,每一个CPU周期都是宝贵的。
15、当复制大量数据时,使用System.arraycopy()命令。
16、代码重构:增强代码的可读性。
例如:
public class ShopCart {
private List carts ;
…
public void add (Object item) {
if(carts == null) {
carts = new ArrayList();
}
crts.add(item);
}
public void remove(Object item) {
if(carts. contains(item)) {
carts.remove(item);
}
}
public List getCarts() {
//返回只读列表
return Collections.unmodifiableList(carts);
}
//不推荐这种方式
//this.getCarts().add(item);
}
|
|
精华游戏算法整理 |
 Author: 一滴蔚蓝色 | Author: 一滴蔚蓝色 |  Date: 2007-05-17 | Date: 2007-05-17 |  View: 8311 | View: 8311 |  开发技术 - 程序设计 | 开发技术 - 程序设计 |  Digg: 12 Digg: 12 |
|
游戏算法整理 算法一:A*寻路初探
作者: Patrick Lester
译者:Panic 2005年3月18日
译者序:很久以前就知道了A*算法,但是从未认真读过相关的文章,也没有看过代码,只是脑子里有个模糊的概念。这次决定从头开始,研究一下这个被人推崇备至的简单方法,作为学习人工智能的开始。
这篇文章非常知名,国内应该有不少人翻译过它,我没有查找,觉得翻译本身也是对自身英文水平的锻炼。经过努力,终于完成了文档,也明白的A*算法的原理。毫无疑问,作者用形象的描述,简洁诙谐的语言由浅入深的讲述了这一神奇的算法,相信每个读过的人都会对此有所认识(如果没有,那就是偶的翻译太差了 --b)。
现在是2005年7月19日的版本,应原作者要求,对文中的某些算法细节做了修改。
原文链接:http://www.gamedev.net/reference/articles/article2003.asp
原作者文章链接:http://www.policyalmanac.org/games/aStarTutorial.htm
以下是翻译的正文。
会者不难,A*(念作A星)算法对初学者来说的确有些难度。
这篇文章并不试图对这个话题作权威的陈述。取而代之的是,它只是描述算法的原理,使你可以在进一步的阅读中理解其他相关的资料。
最后,这篇文章没有程序细节。你尽可以用任意的计算机程序语言实现它。如你所愿,我在文章的末尾包含了一个指向例子程序的链接。 压缩包包括C++和Blitz Basic两个语言的版本,如果你只是想看看它的运行效果,里面还包含了可执行文件。
我们正在提高自己。让我们从头开始。。。
序:搜索区域
假设有人想从A点移动到一墙之隔的B点,如下图,绿色的是起点A,红色是终点B,蓝色方块是中间的墙。
[图1]
你首先注意到,搜索区域被我们划分成了方形网格。像这样,简化搜索区域,是寻路的第一步。这一方法把搜索区域简化成了一个二维数组。数组的每一个元素是网格的一个方块,方块被标记为可通过的和不可通过的。路径被描述为从A到B我们经过的方块的集合。一旦路径被找到,我们的人就从一个方格的中心走向另一个,直到到达目的地。
这些中点被称为“节点”。当你阅读其他的寻路资料时,你将经常会看到人们讨论节点。为什么不把他们描述为方格呢?因为有可能你的路径被分割成其他不是方格的结构。他们完全可以是矩形,六角形,或者其他任意形状。节点能够被放置在形状的任意位置-可以在中心,或者沿着边界,或其他什么地方。我们使用这种系统,无论如何,因为它是最简单的。
开始搜索
正如我们处理上图网格的方法,一旦搜索区域被转化为容易处理的节点,下一步就是去引导一次找到最短路径的搜索。在A*寻路算法中,我们通过从点A开始,检查相邻方格的方式,向外扩展直到找到目标。
我们做如下操作开始搜索:
1,从点A开始,并且把它作为待处理点存入一个“开启列表”。开启列表就像一张购物清单。尽管现在列表里只有一个元素,但以后就会多起来。你的路径可能会通过它包含的方格,也可能不会。基本上,这是一个待检查方格的列表。
2,寻找起点周围所有可到达或者可通过的方格,跳过有墙,水,或其他无法通过地形的方格。也把他们加入开启列表。为所有这些方格保存点A作为“父方格”。当我们想描述路径的时候,父方格的资料是十分重要的。后面会解释它的具体用途。
3,从开启列表中删除点A,把它加入到一个“关闭列表”,列表中保存所有不需要再次检查的方格。
在这一点,你应该形成如图的结构。在图中,暗绿色方格是你起始方格的中心。它被用浅蓝色描边,以表示它被加入到关闭列表中了。所有的相邻格现在都在开启列表中,它们被用浅绿色描边。每个方格都有一个灰色指针反指他们的父方格,也就是开始的方格。

[图2]
接着,我们选择开启列表中的临近方格,大致重复前面的过程,如下。但是,哪个方格是我们要选择的呢?是那个F值最低的。
路径评分
选择路径中经过哪个方格的关键是下面这个等式:
F = G + H
这里:
* G = 从起点A,沿着产生的路径,移动到网格上指定方格的移动耗费。
* H = 从网格上那个方格移动到终点B的预估移动耗费。这经常被称为启发式的,可能会让你有点迷惑。这样叫的原因是因为它只是个猜测。我们没办法事先知道路径的长度,因为路上可能存在各种障碍(墙,水,等等)。虽然本文只提供了一种计算H的方法,但是你可以在网上找到很多其他的方法。
我们的路径是通过反复遍历开启列表并且选择具有最低F值的方格来生成的。文章将对这个过程做更详细的描述。首先,我们更深入的看看如何计算这个方程。
正如上面所说,G表示沿路径从起点到当前点的移动耗费。在这个例子里,我们令水平或者垂直移动的耗费为10,对角线方向耗费为14。我们取这些值是因为沿对角线的距离是沿水平或垂直移动耗费的的根号2(别怕),或者约1.414倍。为了简化,我们用10和14近似。比例基本正确,同时我们避免了求根运算和小数。这不是只因为我们怕麻烦或者不喜欢数学。使用这样的整数对计算机来说也更快捷。你不就就会发现,如果你不使用这些简化方法,寻路会变得很慢。
既然我们在计算沿特定路径通往某个方格的G值,求值的方法就是取它父节点的G值,然后依照它相对父节点是对角线方向或者直角方向(非对角线),分别增加14和10。例子中这个方法的需求会变得更多,因为我们从起点方格以外获取了不止一个方格。
H值可以用不同的方法估算。我们这里使用的方法被称为曼哈顿方法,它计算从当前格到目的格之间水平和垂直的方格的数量总和,忽略对角线方向。然后把结果乘以10。这被成为曼哈顿方法是因为它看起来像计算城市中从一个地方到另外一个地方的街区数,在那里你不能沿对角线方向穿过街区。很重要的一点,我们忽略了一切障碍物。这是对剩余距离的一个估算,而非实际值,这也是这一方法被称为启发式的原因。想知道更多?你可以在这里找到方程和额外的注解。
F的值是G和H的和。第一步搜索的结果可以在下面的图表中看到。F,G和H的评分被写在每个方格里。正如在紧挨起始格右侧的方格所表示的,F被打印在左上角,G在左下角,H则在右下角。
[图3]
现在我们来看看这些方格。写字母的方格里,G = 10。这是因为它只在水平方向偏离起始格一个格距。紧邻起始格的上方,下方和左边的方格的G值都等于10。对角线方向的G值是14。
H值通过求解到红色目标格的曼哈顿距离得到,其中只在水平和垂直方向移动,并且忽略中间的墙。用这种方法,起点右侧紧邻的方格离红色方格有3格距离,H值就是30。这块方格上方的方格有4格距离(记住,只能在水平和垂直方向移动),H值是40。你大致应该知道如何计算其他方格的H值了~。
每个格子的F值,还是简单的由G和H相加得到
继续搜索
为了继续搜索,我们简单的从开启列表中选择F值最低的方格。然后,对选中的方格做如下处理:
4,把它从开启列表中删除,然后添加到关闭列表中。
5,检查所有相邻格子。跳过那些已经在关闭列表中的或者不可通过的(有墙,水的地形,或者其他无法通过的地形),把他们添加进开启列表,如果他们还不在里面的话。把选中的方格作为新的方格的父节点。
6,如果某个相邻格已经在开启列表里了,检查现在的这条路径是否更好。换句话说,检查如果我们用新的路径到达它的话,G值是否会更低一些。如果不是,那就什么都不做。
另一方面,如果新的G值更低,那就把相邻方格的父节点改为目前选中的方格(在上面的图表中,把箭头的方向改为指向这个方格)。最后,重新计算F和G的值。如果这看起来不够清晰,你可以看下面的图示。
好了,让我们看看它是怎么运作的。我们最初的9格方格中,在起点被切换到关闭列表中后,还剩8格留在开启列表中。这里面,F值最低的那个是起始格右侧紧邻的格子,它的F值是40。因此我们选择这一格作为下一个要处理的方格。在紧随的图中,它被用蓝色突出显示。
[图4]
首先,我们把它从开启列表中取出,放入关闭列表(这就是他被蓝色突出显示的原因)。然后我们检查相邻的格子。哦,右侧的格子是墙,所以我们略过。左侧的格子是起始格。它在关闭列表里,所以我们也跳过它。
其他4格已经在开启列表里了,于是我们检查G值来判定,如果通过这一格到达那里,路径是否更好。我们来看选中格子下面的方格。它的G值是14。如果我们从当前格移动到那里,G值就会等于20(到达当前格的G值是10,移动到上面的格子将使得G值增加10)。因为G值20大于14,所以这不是更好的路径。如果你看图,就能理解。与其通过先水平移动一格,再垂直移动一格,还不如直接沿对角线方向移动一格来得简单。
当我们对已经存在于开启列表中的4个临近格重复这一过程的时候,我们发现没有一条路径可以通过使用当前格子得到改善,所以我们不做任何改变。既然我们已经检查过了所有邻近格,那么就可以移动到下一格了。
于是我们检索开启列表,现在里面只有7格了,我们仍然选择其中F值最低的。有趣的是,这次,有两个格子的数值都是54。我们如何选择?这并不麻烦。从速度上考虑,选择最后添加进列表的格子会更快捷。这种导致了寻路过程中,在靠近目标的时候,优先使用新找到的格子的偏好。但这无关紧要。(对相同数值的不同对待,导致不同版本的A*算法找到等长的不同路径。)
那我们就选择起始格右下方的格子,如图。
[图5]
这次,当我们检查相邻格的时候,发现右侧是墙,于是略过。上面一格也被略过。我们也略过了墙下面的格子。为什么呢?因为你不能在不穿越墙角的情况下直接到达那个格子。你的确需要先往下走然后到达那一格,按部就班的走过那个拐角。(注解:穿越拐角的规则是可选的。它取决于你的节点是如何放置的。)
这样一来,就剩下了其他5格。当前格下面的另外两个格子目前不在开启列表中,于是我们添加他们,并且把当前格指定为他们的父节点。其余3格,两个已经在关闭列表中(起始格,和当前格上方的格子,在表格中蓝色高亮显示),于是我们略过它们。最后一格,在当前格的左侧,将被检查通过这条路径,G值是否更低。不必担心,我们已经准备好检查开启列表中的下一格了。
我们重复这个过程,直到目标格被添加进关闭列表(注解),就如在下面的图中所看到的。
[图6]
注意,起始格下方格子的父节点已经和前面不同的。之前它的G值是28,并且指向右上方的格子。现在它的G值是20,指向它上方的格子。这在寻路过程中的某处发生,当应用新路径时,G值经过检查变得低了-于是父节点被重新指定,G和F值被重新计算。尽管这一变化在这个例子中并不重要,在很多场合,这种变化会导致寻路结果的巨大变化。
那么,我们怎么确定这条路径呢?很简单,从红色的目标格开始,按箭头的方向朝父节点移动。这最终会引导你回到起始格,这就是你的路径!看起来应该像图中那样。从起始格A移动到目标格B只是简单的从每个格子(节点)的中点沿路径移动到下一个,直到你到达目标点。就这么简单。
[图7]
A*方法总结
好,现在你已经看完了整个说明,让我们把每一步的操作写在一起:
1,把起始格添加到开启列表。
2,重复如下的工作:
a) 寻找开启列表中F值最低的格子。我们称它为当前格。
b) 把它切换到关闭列表。
c) 对相邻的8格中的每一个?
* 如果它不可通过或者已经在关闭列表中,略过它。反之如下。
* 如果它不在开启列表中,把它添加进去。把当前格作为这一格的父节点。记录这一格的F,G,和H值。
* 如果它已经在开启列表中,用G值为参考检查新的路径是否更好。更低的G值意味着更好的路径。如果是这样,就把这一格的父节点改成当前格,并且重新计算这一格的G和F值。如果你保持你的开启列表按F值排序,改变之后你可能需要重新对开启列表排序。
d) 停止,当你
* 把目标格添加进了关闭列表(注解),这时候路径被找到,或者
* 没有找到目标格,开启列表已经空了。这时候,路径不存在。
3.保存路径。从目标格开始,沿着每一格的父节点移动直到回到起始格。这就是你的路径。
(注解:在这篇文章的较早版本中,建议的做法是当目标格(或节点)被加入到开启列表,而不是关闭列表的时候停止寻路。这么做会更迅速,而且几乎总是能找到最短的路径,但不是绝对的。当从倒数第二个节点到最后一个(目标节点)之间的移动耗费悬殊很大时-例如刚好有一条河穿越两个节点中间,这时候旧的做法和新的做法就会有显著不同。)
题外话
离题一下,见谅,值得一提的是,当你在网上或者相关论坛看到关于A*的不同的探讨,你有时会看到一些被当作A*算法的代码而实际上他们不是。要使用 A*,你必须包含上面讨论的所有元素--特定的开启和关闭列表,用F,G和H作路径评价。有很多其他的寻路算法,但他们并不是A*,A*被认为是他们当中最好的。Bryan Stout在这篇文章后面的参考文档中论述了一部分,包括他们的一些优点和缺点。有时候特定的场合其他算法会更好,但你必须很明确你在作什么。好了,够多的了。回到文章。
实现的注解
现在你已经明白了基本原理,写你的程序的时候还得考虑一些额外的东西。下面这些材料中的一些引用了我用C++和Blitz Basic写的程序,但对其他语言写的代码同样有效。
1.其他单位(避免碰撞):如果你恰好看了我的例子代码,你会发现它完全忽略了其他单位。我的寻路者事实上可以相互穿越。取决于具体的游戏,这也许可以,也许不行。如果你打算考虑其他单位,希望他们能互相绕过,我建议你只考虑静止或那些在计算路径时临近当前单位的单位,把它们当前的位置标志为可通过的。对于临近的运动着的单位,你可以通过惩罚它们各自路径上的节点,来鼓励这些寻路者找到不同的路径(更多的描述见#2).
如果你选择了把其他正在移动并且远离当前寻路单位的那些单位考虑在内,你将需要实现一种方法及时预测在何时何地碰撞可能会发生,以便恰当的避免。否则你极有可能得到一条怪异的路径,单位突然转弯试图避免和一个已经不存在的单位发生碰撞。
当然,你也需要写一些碰撞检测的代码,因为无论计算的时候路径有多完美,它也会因时间而改变。当碰撞发生时,一个单位必须寻找一条新路径,或者,如果另一个单位正在移动并且不是正面碰撞,在继续沿当前路径移动之前,等待那个单位离开。
这些提示大概可以让你开始了。如果你想了解更多,这里有些你可能会觉得有用的链接:
* 自治角色的指导行为:Craig Reynold在指导能力上的工作和寻路有些不同,但是它可以和寻路整合从而形成更完整的移动和碰撞检测系统。
* 电脑游戏中的长短距指导:指导和寻路方面著作的一个有趣的考察。这是一个pdf文件。
* 协同单位移动:一个两部分系列文章的第一篇,内容是关于编队和基于分组的移动,作者是帝国时代(Age of Empires)的设计者Dave Pottinger.
* 实现协同移动:Dave Pottinger文章系列的第二篇。
2. 不同的地形损耗:在这个教程和我附带的程序中,地形只能是二者之-可通过的和不可通过的。但是你可能会需要一些可通过的地形,但是移动耗费更高-沼泽,小山,地牢的楼梯,等等。这些都是可通过但是比平坦的开阔地移动耗费更高的地形。类似的,道路应该比自然地形移动耗费更低。
这个问题很容易解决,只要在计算任何地形的G值的时候增加地形损耗就可以了。简单的给它增加一些额外的损耗就可以了。由于A*算法已经按照寻找最低耗费的路径来设计,所以很容易处理这种情况。在我提供的这个简单的例子里,地形只有可通过和不可通过两种,A*会找到最短,最直接的路径。但是在地形耗费不同的场合,耗费最低的路径也许会包含很长的移动距离-就像沿着路绕过沼泽而不是直接穿过它。
一种需额外考虑的情况是被专家称之为“influence mapping”的东西(暂译为影响映射图)。就像上面描述的不同地形耗费一样,你可以创建一格额外的分数系统,并把它应用到寻路的AI中。假设你有一张有大批寻路者的地图,他们都要通过某个山区。每次电脑生成一条通过那个关口的路径,它就会变得更拥挤。如果你愿意,你可以创建一个影响映射图对有大量屠杀事件的格子施以不利影响。这会让计算机更倾向安全些的路径,并且帮助它避免总是仅仅因为路径短(但可能更危险)而持续把队伍和寻路者送到某一特定路径。
另一个可能得应用是惩罚周围移动单位路径上得节点。A*的一个底限是,当一群单位同时试图寻路到接近的地点,这通常会导致路径交叠。以为一个或者多个单位都试图走相同或者近似的路径到达目的地。对其他单位已经“认领”了的节点增加一些惩罚会有助于你在一定程度上分离路径,降低碰撞的可能性。然而,如果有必要,不要把那些节点看成不可通过的,因为你仍然希望多个单位能够一字纵队通过拥挤的出口。同时,你只能惩罚那些临近单位的路径,而不是所有路径,否则你就会得到奇怪的躲避行为例如单位躲避路径上其他已经不在那里的单位。 还有,你应该只惩罚路径当前节点和随后的节点,而不应处理已经走过并甩在身后的节点。
3. 处理未知区域:你是否玩过这样的PC游戏,电脑总是知道哪条路是正确的,即使它还没有侦察过地图?对于游戏,寻路太好会显得不真实。幸运的是,这是一格可以轻易解决的问题。
答案就是为每个不同的玩家和电脑(每个玩家,而不是每个单位--那样的话会耗费大量的内存)创建一个独立的“knownWalkability”数组,每个数组包含玩家已经探索过的区域,以及被当作可通过区域的其他区域,直到被证实。用这种方法,单位会在路的死端徘徊并且导致错误的选择直到他们在周围找到路。一旦地图被探索了,寻路就像往常那样进行。
4. 平滑路径:尽管A*提供了最短,最低代价的路径,它无法自动提供看起来平滑的路径。看一下我们的例子最终形成的路径(在图7)。最初的一步是起始格的右下方,如果这一步是直接往下的话,路径不是会更平滑一些吗?
有几种方法来解决这个问题。当计算路径的时候可以对改变方向的格子施加不利影响,对G值增加额外的数值。也可以换种方法,你可以在路径计算完之后沿着它跑一遍,找那些用相邻格替换会让路径看起来更平滑的地方。想知道完整的结果,查看Toward More Realistic Pathfinding,一篇(免费,但是需要注册)Marco Pinter发表在Gamasutra.com的文章
5. 非方形搜索区域:在我们的例子里,我们使用简单的2D方形图。你可以不使用这种方式。你可以使用不规则形状的区域。想想冒险棋的游戏,和游戏中那些国家。你可以设计一个像那样的寻路关卡。为此,你可能需要建立一个国家相邻关系的表格,和从一个国家移动到另一个的G值。你也需要估算H值的方法。其他的事情就和例子中完全一样了。当你需要向开启列表中添加新元素的时候,不需使用相邻的格子,取而代之的是从表格中寻找相邻的国家。
类似的,你可以为一张确定的地形图创建路径点系统,路径点一般是路上,或者地牢通道的转折点。作为游戏设计者,你可以预设这些路径点。两个路径点被认为是相邻的如果他们之间的直线上没有障碍的话。在冒险棋的例子里,你可以保存这些相邻信息在某个表格里,当需要在开启列表中添加元素的时候使用它。然后你就可以记录关联的G值(可能使用两点间的直线距离),H值(可以使用到目标点的直线距离),其他都按原先的做就可以了。
Amit Patel 写了其他方法的摘要。另一个在非方形区域搜索RPG地图的例子,查看我的文章Two-Tiered A* Pathfinding。(译者注:译文: A*分层寻路)
6. 一些速度方面的提示:当你开发你自己的A*程序,或者改写我的,你会发现寻路占据了大量的CPU时间,尤其是在大地图上有大量对象在寻路的时候。如果你阅读过网上的其他材料,你会明白,即使是开发了星际争霸或帝国时代的专家,这也无可奈何。如果你觉得寻路太过缓慢,这里有一些建议也许有效:
* 使用更小的地图或者更少的寻路者。
* 不要同时给多个对象寻路。取而代之的是把他们加入一个队列,把寻路过程分散在几个游戏周期中。如果你的游戏以40周期每秒的速度运行,没人能察觉。但是当大量寻路者计算自己路径的时候,他们会发觉游戏速度突然变慢。
* 尽量使用更大的地图网格。这降低了寻路中搜索的总网格数。如果你有志气,你可以设计两个或者更多寻路系统以便使用在不同场合,取决于路径的长度。这也正是专业人士的做法,用大的区域计算长的路径,然后在接近目标的时候切换到使用小格子/区域的精细寻路。如果你对这个观点感兴趣,查阅我的文章Two-Tiered A* Pathfinding。(译者注:译文 :A*分层寻路)
* 使用路径点系统计算长路径,或者预先计算好路径并加入到游戏中。
* 预处理你的地图,表明地图中哪些区域是不可到达的。我把这些区域称作“孤岛”。事实上,他们可以是岛屿或其他被墙壁包围等无法到达的任意区域。A*的下限是,当你告诉它要寻找通往那些区域的路径时,它会搜索整个地图,直到所有可到达的方格/节点都被通过开启列表和关闭列表的计算。这会浪费大量的CPU时间。可以通过预先确定这些区域(比如通过flood-fill或类似的方法)来避免这种情况的发生,用某些种类的数组记录这些信息,在开始寻路前检查它。
* 在一个拥挤的类似迷宫的场合,把不能连通的节点看作死端。这些区域可以在地图编辑器中预先手动指定,或者如果你有雄心壮志,开发一个自动识别这些区域的算法。给定死端的所有节点可以被赋予一个唯一的标志数字。然后你就可以在寻路过程中安全的忽略所有死端,只有当起点或者终点恰好在死端的某个节点的时候才需要考虑它们。
7. 维护开启列表:这是A*寻路算法最重要的组成部分。每次你访问开启列表,你都需要寻找F值最低的方格。有几种不同的方法实现这一点。你可以把路径元素随意保存,当需要寻找F值最低的元素的时候,遍历开启列表。这很简单,但是太慢了,尤其是对长路径来说。这可以通过维护一格排好序的列表来改善,每次寻找F值最低的方格只需要选取列表的首元素。当我自己实现的时候,这种方法是我的首选。
在小地图。这种方法工作的很好,但它并不是最快的解决方案。更苛求速度的A*程序员使用叫做二叉堆的方法,这也是我在代码中使用的方法。凭我的经验,这种方法在大多数场合会快2~3倍,并且在长路经上速度呈几何级数提升(10倍以上速度)。如果你想了解更多关于二叉堆的内容,查阅我的文章,Using Binary Heaps in A* Pathfinding。(译者注:译文:在A*寻路中使用二叉堆)
另一个可能的瓶颈是你在多次寻路之间清除和保存你的数据结构的方法。我个人更倾向把所有东西都存储在数组里面。虽然节点可以以面向对象的风格被动态的产生,记录和保存,我发现创建和删除对象所增加的大量时间,以及多余的管理层次减慢的整个过程的速度。但是,如果你使用数组,你需要在调用之间清理数据。这中情形你想做的最后一件事就是在寻路调用之后花点时间把一切归零,尤其是你的地图很大的时候。
我通过使用一个叫做whichList(x,y)的二维数组避免这种开销,数组的每个元素表明了节点在开启列表还是在关闭列表中。尝试寻路之后,我没有清零这个数组。取而代之的是,我在新的寻路中重置onClosedList和onOpenList的数值,每次寻路两个都+5或者类似其他数值。这种方法,算法可以安全的跳过前面寻路留下的脏数据。我还在数组中储存了诸如F,G和H的值。这样一来,我只需简单的重写任何已经存在的值而无需被清除数组的操作干扰。将数据存储在多维数组中需要更多内存,所以这里需要权衡利弊。最后,你应该使用你最得心应手的方法。
8. Dijkstra的算法:尽管A*被认为是通常最好的寻路算法(看前面的“题外话”),还是有一种另外的算法有它的可取之处-Dijkstra算法。 Dijkstra算法和A*本质是相同的,只有一点不同,就是Dijkstra算法没有启发式(H值总是0)。由于没有启发式,它在各个方向上平均搜索。正如你所预料,由于Dijkstra算法在找到目标前通常会探索更大的区域,所以一般会比A*更慢一些。
那么为什么要使用这种算法呢?因为有时候我们并不知道目标的位置。比如说你有一个资源采集单位,需要获取某种类型的资源若干。它可能知道几个资源区域,但是它想去最近的那个。这种情况,Dijkstra算法就比A*更适合,因为我们不知道哪个更近。用A*,我们唯一的选择是依次对每个目标许路并计算距离,然后选择最近的路径。我们寻找的目标可能会有不计其数的位置,我们只想找其中最近的,而我们并不知道它在哪里,或者不知道哪个是最近的。
进一步的阅读
好,现在你对一些进一步的观点有了初步认识。这时,我建议你研究我的源代码。包里面包含两个版本,一个是用C++写的,另一个用Blitz Basic。顺便说一句,两个版本都注释详尽,容易阅读,这里是链接。
* 例子代码: A* Pathfinder (2D) Version 1.9
如果你既不用C++也不用Blitz Basic,在C++版本里有两个小的可执行文件。Blitz Basic可以在从Blitz Basic网站免费下载的Blitz Basic 3D(不是Blitz Plus)演示版上运行。Ben O'Neill提供一个联机演示可以在这里找到。
你也该看看以下的网页。读了这篇教程后,他们应该变得容易理解多了。
* Amit的 A* 页面:这是由Amit Patel制作,被广泛引用的页面,如果你没有事先读这篇文章,可能会有点难以理解。值得一看。尤其要看Amit关于这个问题的自己的看法。
* Smart Moves:智能寻路:Bryan Stout发表在Gamasutra.com的这篇文章需要注册才能阅读。注册是免费的而且比起这篇文章和网站的其他资源,是非常物有所值的。Bryan用Delphi写的程序帮助我学习A*,也是我的A*代码的灵感之源。它还描述了A*的几种变化。
* 地形分析:这是一格高阶,但是有趣的话题,Dave Pottinge撰写,Ensemble Studios的专家。这家伙参与了帝国时代和君王时代的开发。别指望看懂这里所有的东西,但是这是篇有趣的文章也许会让你产生自己的想法。它包含一些对 mip-mapping,influence mapping以及其他一些高级AI/寻路观点。对"flood filling"的讨论使我有了我自己的“死端”和“孤岛”的代码的灵感,这些包含在我Blitz版本的代码中。
其他一些值得一看的网站:
* aiGuru: Pathfinding
* Game AI Resource: Pathfinding
* GameDev.net: Pathfinding
我同样高度推荐下面这几本书, 里面有很多关于寻路和其他AI话题的文章。 它们也附带了实例代码的CD。这些书我都买了。另外,如果你通过下面的链接购买了它们,我会从Amazon得到几个美分。:)
好了,这就是全部。如果你刚好写一个运用这些观点的程序,我想拜读一下。你可以这样联系我:

现在,好运!
译者参考文献:
在A*寻路中使用二叉堆
A*分层寻
游戏算法整理 算法二:碰撞
1. 碰撞检测和响应
碰撞在游戏中运用的是非常广泛的,运用理论实现的碰撞,再加上一些小技巧,可以让碰撞检测做得非常精确,效率也非常高。从而增加游戏的功能和可玩性。
2D碰撞检测
2D的碰撞检测已经非常稳定,可以在许多著作和论文中查询到。3D的碰撞还没有找到最好的方法,现在使用的大多数方法都是建立在2D基础上的。
碰撞检测
碰撞的检测不仅仅是运用在游戏中,事实上,一开始的时候是运用在模拟和机器人技术上的。这些工业上的碰撞检测要求非常高,而碰撞以后的响应也是需要符合现实生活的,是需要符合人类常规认识的。游戏中的碰撞有些许的不一样,况且,更重要的,我们制作的东西充其量是商业级别,还不需要接触到纷繁复杂的数学公式。
图1
最理想的碰撞,我想莫过于上图,完全按照多边形的外形和运行路径规划一个范围,在这个范围当中寻找会产生阻挡的物体,不管是什么物体,产生阻挡以后,我们运动的物体都必须在那个位置产生一个碰撞的事件。最美好的想法总是在实现上有一些困难,事实上我们可以这么做,但是效率却是非常非常低下的,游戏中,甚至于工业中无法忍受这种速度,所以我们改用其它的方法来实现。

图2
最简单的方法如上图,我们寻找物体的中心点,然后用这个中心点来画一个圆,如果是一个3D的物体,那么我们要画的就是一个球体。在检测物体碰撞的时候,我们只要检测两个物体的半径相加是否大于这两个物体圆心的实际距离。
这个算法是最简单的一种,现在还在用,但是不是用来做精确的碰撞检测,而是用来提高效率的模糊碰撞检测查询,到了这个范围以后,再进行更加精密的碰撞检测。一种比较精密的碰撞检测查询就是继续这种画圆的思路,然后把物体细分,对于物体的每个部件继续画圆,然后再继续进行碰撞检测,直到系统规定的,可以容忍的误差范围以后才触发碰撞事件,进行碰撞的一些操作。
有没有更加简单的方法呢?2D游戏中有许多图片都是方方正正的,所以我们不必把碰撞的范围画成一个圆的,而是画成一个方的。这个正方形,或者说是一个四边形和坐标轴是对齐的,所以运用数学上的一些方法,比如距离计算等还是比较方便的。这个检测方法就叫AABBs(Axis-aligned Bounding Boxes)碰撞检测,游戏中已经运用的非常广泛了,因为其速度快,效率高,计算起来非常方便,精确度也是可以忍受的。
做到这一步,许多游戏的需求都已经满足了。但是,总是有人希望近一步优化,而且方法也是非常陈旧的:继续对物体的各个部分进行细分,对每个部件做AABB 的矩形,那这个优化以后的系统就叫做OBB系统。虽然说这个优化以后的系统也不错,但是,许多它可以运用到的地方,别人却不爱使用它,这是后面会继续介绍的地方。
John Carmack不知道看的哪本书,他早在DOOM中已经使用了BSP系统(二分空间分割),再加上一些小技巧,他的碰撞做得就非常好了,再加上他发明的 castray算法,DOOM已经不存在碰撞的问题,解决了这样的关键技术,我想他不再需要在什么地方分心了,只要继续研究渲染引擎就可以了。(Windows游戏编程大师技巧P392~P393介绍)(凸多边形,多边形退化,左手定律)SAT系统非常复杂,是SHT(separating hyperplane theorem,分离超平面理论)的一种特殊情况。这个理论阐述的就是两个不相关的曲面,是否能够被一个超平面所分割开来,所谓分割开来的意思就是一个曲面贴在平面的一边,而另一个曲面贴在平面的另一边。我理解的就是有点像相切的意思。SAT是SHT的特殊情况,所指的就是两个曲面都是一些多边形,而那个超平面也是一个多边形,这个超平面的多边形可以在场景中的多边形列表中找到,而超平面可能就是某个多边形的表面,很巧的就是,这个表面的法线和两个曲面的切面是相对应的。接下来的证明,我想是非常复杂的事情,希望今后能够找到源代码直接运用上去。而我们现在讲究的快速开发,我想AABB就足以满足了。
3D碰撞检测
3D的检测就没有什么很标准的理论了,都建立在2D的基础上,我们可以沿用AABB或者OBB,或者先用球体做粗略的检测,然后用AABB和OBB作精细的检测。BSP技术不流行,但是效率不错。微软提供了D3DIntersect函数让大家使用,方便了许多,但是和通常一样,当物体多了以后就不好用了,明显的就是速度慢许多。
碰撞反应
碰撞以后我们需要做一些反应,比如说产生反冲力让我们反弹出去,或者停下来,或者让阻挡我们的物体飞出去,或者穿墙,碰撞最讨厌的就是穿越,本来就不合逻辑,查阅了那么多资料以后,从来没有看到过需要穿越的碰撞,有摩擦力是另外一回事。首先看看弹性碰撞。弹性碰撞就是我们初中物理中说的动量守恒。物体在碰撞前后的动量守恒,没有任何能量损失。这样的碰撞运用于打砖块的游戏中。引入质量的话,有的物体会是有一定的质量,这些物体通常来说是需要在碰撞以后进行另外一个方向的运动的,另外一些物体是设定为质量无限大的,这些物体通常是碰撞墙壁。
当物体碰到质量非常大的物体,默认为碰到了一个弹性物体,其速度会改变,但是能量不会受到损失。一般在代码上的做法就是在速度向量上加上一个负号。
绝对的弹性碰撞是很少有的,大多数情况下我们运用的还是非弹性碰撞。我们现在玩的大多数游戏都用的是很接近现实的非弹性碰撞,例如Pain-Killer 中的那把吸力枪,它弹出去的子弹吸附到NPC身上时的碰撞响应就是非弹性碰撞;那把残忍的分尸刀把墙打碎的初始算法就是一个非弹性碰撞,其后使用的刚体力学就是先建立在这个算法上的。那么,是的,如果需要非弹性碰撞,我们需要介入摩擦力这个因素,而我们也无法简单使用动量守恒这个公式。
我们可以采取比较简单的方法,假设摩擦系数μ非常大,那么只要物体接触,并且拥有一个加速度,就可以产生一个无穷大的摩擦力,造成物体停止的状态。
基于别人的引擎写出一个让自己满意的碰撞是不容易的,那么如果自己建立一个碰撞系统的话,以下内容是无法缺少的:
– 一个能够容忍的碰撞系统
– 一个从概念上可以接受的物理系统
– 质量
– 速度
– 摩擦系数
– 地心引力
http://www.gamasutra.com/features/20000330/bobic_01.htm
http://www.gamasutra.com/features/20000330/bobic_02.htm
http://www.gamasutra.com/features/20000330/bobic_03.htm
这三篇是高级碰撞检测。
游戏算法整理 算法三:寻路算法新思维
目前常用寻路算法是A*方式,原理是通过不断搜索逼近目的地的路点来获得。
如果通过图像模拟搜索点,可以发现:非启发式的寻路算法实际上是一种穷举法,通过固定顺序依次搜索人物周围的路点,直到找到目的地,搜索点在图像上的表现为一个不断扩大的矩形。如下:
 
很快人们发现如此穷举导致搜索速度过慢,而且不是很符合逻辑,试想:如果要从(0,0)点到达(100,0)点,如果每次向东搜索时能够走通,那么干吗还要搜索其他方向呢?所以,出现了启发式的A*寻路算法,一般通过 已经走过的路程 + 到达目的地的直线距离 代价值作为搜索时的启发条件,每个点建立一个代价值,每次搜索时就从代价低的最先搜索,如下:
 
综上所述,以上的搜索是一种矩阵式的不断逼近终点的搜索做法。优点是比较直观,缺点在于距离越远、搜索时间越长。
现在,我提出一种新的AI寻路方式——矢量寻路算法。
通过观察,我们可以发现,所有的最优路线,如果是一条折线,那么、其每一个拐弯点一定发生在障碍物的突出边角,而不会在还没有碰到障碍物就拐弯的情况:如下图所示:
我们可以发现,所有的红色拐弯点都是在障碍物(可以认为是一个凸多边形)的顶点处,所以,我们搜索路径时,其实只需要搜索这些凸多边形顶点不就可以了吗?如果将各个顶点连接成一条通路就找到了最优路线,而不需要每个点都检索一次,这样就大大减少了搜索次数,不会因为距离的增大而增大搜索时间。
这种思路我尚未将其演变为算法,姑且提出一个伪程序给各位参考:
1.建立各个凸多边形顶点的通路表TAB,表示顶点A到顶点B是否可达,将可达的顶点分组保存下来。如: ( (0,0) (100,0) ),这一步骤在程序刚开始时完成,不要放在搜索过程中空耗时间。
2.开始搜索A点到B点的路线
3.检测A点可以直达凸多边形顶点中的哪一些,挑选出最合适的顶点X1。
4.检测与X1相连(能够接通)的有哪些顶点,挑出最合适的顶点X2。
5.X2是否是终点B?是的话结束,否则转步骤4(X2代入X1)
如此下来,搜索只发生在凸多边形的顶点,节省了大量的搜索时间,而且找到的路线无需再修剪锯齿,保证了路线的最优性。
这种方法搜索理论上可以减少大量搜索点、缺点是需要实现用一段程序得出TAB表,从本质上来说是一种空间换时间的方法,而且搜索时A*能够用的启发条件,在矢量搜索时依然可以使用。
游戏算法整理 算法四:战略游戏中的战争模型算法的初步探讨
《三国志》系列游戏相信大家都有所了解,而其中的(宏观)战斗时关于双方兵力,士气,兵种克制,攻击力,增援以及随战争进行兵力减少等数值的算法是十分值得研究的。或许是由于简单的缘故,我在网上几乎没有找到相关算法的文章。下面给出这个战争的数学模型算法可以保证游戏中战争的游戏性与真实性兼顾,希望可以给有需要这方面开发的人一些启迪。
假设用x(t)和y(t)表示甲乙交战双方在t时刻的兵力,如果是开始时可视为双方士兵人数。
假设每一方的战斗减员率取决于双方兵力和战斗力,用f(x,y)和g(x,y)表示,每一方的增援率是给定函数用u(t)和v(t)表示。
如果双方用正规部队作战(可假设是相同兵种),先分析甲方的战斗减员率f(x,y)。可知甲方士兵公开活动,处于乙方没一个士兵的监视和杀伤范围之内,一但甲方的某个士兵被杀伤,乙方的火力立即集中在其余士兵身上,所以甲方的战斗减员率只与乙方的兵力有关可射为f与y成正比,即f=ay,a表示乙方平均每个士兵对甲方士兵的杀伤率(单位时间的杀伤数),成为乙方的战斗有效系数。类似g= -bx
这个战争模型模型方程1为
x’(t)= -a*y(t)+u(t) x’(t)是x(t)对于t 的导数
y’(t)= -b*x(t)+v(t) y’(t)是y(t)对于t的导数
利用给定的初始兵力,战争持续时间,和增援兵力可以求出双方兵力在战争中的变化函数。
(本文中解法略)
如果考虑由于士气和疾病等引起的非战斗减员率(一般与本放兵力成正比,设甲乙双方分别为h,w)
可得到改进战争模型方程2:
x’(t)= -a*y(t)-h*x(t)+u(t)
y’(t)= -b*x(t)-w*y(t)+v(t)
利用初始条件同样可以得到双方兵力在战争中的变化函数和战争结果。
此外还有不同兵种作战(兵种克制)的数学模型:
模型1中的战斗有效系数a可以进一步分解为a=ry*py*(sry/sx),其中ry是乙方的攻击率(每个士兵单位的攻击次数),py是每次攻击的命中率。(sry/sx)是乙方攻击的有效面积sry与甲方活动范围sx之比。类似甲方的战斗有效系数b=rx*px*(srx/sy),rx和px是甲方的攻击率和命中率,(srx/sy)是甲方攻击的有效面积与乙方活动范围sy之比。由于增加了兵种克制的攻击范围,所以战斗减员率不光与对方兵力有关,而且随着己放兵力增加而增加。因为在一定区域内,士兵越多被杀伤的就越多。
方程
x’(t)= -ry*py*(sry/sx)*x(t)*y(t)-h*x(t)+u(t)
y’(t)= -rx*px*(srx/sy)*x(t)*y(t)-w*y(t)+u(t)
游戏算法整理 算法五:飞行射击游戏中的碰撞检测
在游戏中物体的碰撞是经常发生的,怎样检测物体的碰撞是一个很关键的技术问题。在RPG游戏中,一般都将场景分为许多矩形的单元,碰撞的问题被大大的简化了,只要判断精灵所在的单元是不是有其它的东西就可以了。而在飞行射击游戏(包括象荒野大镖客这样的射击游戏)中,碰撞却是最关键的技术,如果不能很好的解决,会影响玩游戏者的兴趣。因为飞行射击游戏说白了就是碰撞的游戏——躲避敌人的子弹或飞机,同时用自己的子弹去碰撞敌人。
碰撞,这很简单嘛,只要两个物体的中心点距离小于它们的半径之和就可以了。确实,而且我也看到很多人是这样做的,但是,这只适合圆形的物体——圆形的半径处处相等。如果我们要碰撞的物体是两艘威力巨大的太空飞船,它是三角形或矩形或其他的什么形状,就会出现让人尴尬的情景:两艘飞船眼看就要擦肩而过,却出人意料的发生了爆炸;或者敌人的子弹穿透了你的飞船的右弦,你却安然无恙,这不是我们希望发生的。于是,我们需要一种精确的检测方法。
那么,怎样才能达到我们的要求呢?其实我们的前辈们已经总结了许多这方面的经验,如上所述的半径检测法,三维中的标准平台方程法,边界框法等等。大多数游戏程序员都喜欢用边界框法,这也是我采用的方法。边界框是在编程中加进去的不可见的边界。边界框法,顾名思义,就是用边界框来检测物体是否发生了碰撞,如果两个物体的边界框相互干扰,则发生了碰撞。用什么样的边界框要视不同情况而定,用最近似的几何形状。当然,你可以用物体的准确几何形状作边界框,但出于效率的考虑,我不赞成这样做,因为游戏中的物体一般都很复杂,用复杂的边界框将增加大量的计算,尤其是浮点计算,而这正是我们想尽量避免的。但边界框也不能与准确几何形状有太大的出入,否则就象用半径法一样出现奇怪的现象。
在飞行射击游戏中,我们的飞机大多都是三角形的,我们可以用三角形作近似的边界框。现在我们假设飞机是一个正三角形(或等要三角形,我想如果谁把飞机设计成左右不对称的怪物,那他的审美观一定有问题),我的飞机是正着的、向上飞的三角形,敌人的飞机是倒着的、向下飞的三角形,且飞机不会旋转(大部分游戏中都是这样的)。我们可以这样定义飞机:中心点O(Xo,Yo),三个顶点P0(X0,Y0)、P1(X1,Y1)、P2(X2,Y2)。中心点为正三角形的中心点,即中心点到三个顶点的距离相等。接下来的问题是怎样确定两个三角形互相干扰了呢?嗯,现在我们接触到问题的实质了。如果你学过平面解析几何,我相信你可以想出许多方法解决这个问题。判断一个三角形的各个顶点是否在另一个三角形里面,看起来是个不错的方法,你可以这样做,但我却发现一个小问题:一个三角形的顶点没有在另一个三角形的里面,却可能发生了碰撞,因为另一个三角形的顶点在这个三角形的里面,所以要判断两次,这很麻烦。有没有一次判断就可以的方法?我们把三角形放到极坐标平面中,中心点为原点,水平线即X轴为零度角。我们发现三角形成了这个样子:在每个角度我们都可以找到一个距离,用以描述三角形的边。既然我们找到了边到中心点的距离,那就可以用这个距离来检测碰撞。如图一,两个三角形中心点坐标分别为(Xo,Yo)和 (Xo1,Yo1),由这两个点的坐标求出两点的距离及两点连线和X轴的夹角θ,再由θ求出中心点连线与三角形边的交点到中心点的距离,用这个距离与两中心点距离比较,从而判断两三角形是否碰撞。因为三角形左右对称,所以θ取-90~90度区间就可以了。哈,现在问题有趣多了,-90~90度区间正是正切函数的定义域,求出θ之后再找对应的边到中心点的距离就容易多了,利用几何知识,如图二,将三角形的边分为三部分,即图2中红绿蓝三部分,根据θ在那一部分而分别对待。用正弦定理求出边到中心点的距离,即图2中浅绿色线段的长度。但是,如果飞机每次移动都这样判断一次,效率仍然很低。我们可以结合半径法来解决,先用半径法判断是否可能发生碰撞,如果可能发生碰撞,再用上面的方法精确判断是不是真的发生了碰撞,这样基本就可以了。如果飞机旋转了怎么办呢,例如,如图三所示飞机旋转了一个角度α,仔细观察图三会发现,用(θ-α)就可以求出边到中心点的距离,这时你要注意边界情况,即(θ-α)可能大于90度或小于-90度。啰罗嗦嗦说了这么多,不知道大家明白了没有。我编写了一个简单的例程,用于说明我的意图。在例子中假设所有飞机的大小都一样,并且没有旋转。
/////////////////////////////////////////////////////////////////////
//example.cpp
//碰撞检测演示
//作者 李韬
/////////////////////////////////////////////////////////////////////
//限于篇幅,这里只给出了碰撞检测的函数
//define/////////////////////////////////////////////////////////////
#define NUM_VERTICES 3
#define ang_30 -0.5236
#define ang60 1.0472
#define ang120 2.0944
//deftype////////////////////////////////////////////////////////////
struct object
{
float xo, yo;
float radio;
float x_vel, y_vel;
float vertices[NUM_VERTICES][2];
}
//faction/////////////////////////////////////////////////////////////
//根据角度求距离
float AngToDis(struct object obj, float angle)
{
float dis, R;
R = obj.radius;
if (angle <= ang_30)
dis = R / (2 * sin(-angle));
else if (angle >= 0)
dis = R / (2 * sin(angle + ang60));
else dis = R / (2 * sin(ang120 - angle));
return dis;
}
//碰撞检测
int CheckHit(struct object obj1, struct object obj2)
{
float deltaX, deltaY, angle, distance, bumpdis;
deltaX = abs(obj1.xo - obj2.xo);
deltaY = obj1.yo - obj2.yo;
distance = sqrt(deltaX * deltaX + deltaY * deltaY);
if (distance <= obj.radio)
{
angle = atan2(deltaY, deltaX);
bumpdis1 = AngToDis(obj1, angle);
return (distance <= 2 * bumpdis);
}
ruturn 0;
}
//End//////////////////////////////////////////////////////////////
上面程序只是用于演示,并不适合放在游戏中,但你应该明白它的意思,以便写出适合你自己的碰撞检测。游戏中的情况是多种多样的,没有哪种方法能适应所有情况,你一定能根据自己的情况找到最适合自己的方法。
游戏算法整理 算法六:关于SLG中人物可到达范围计算的想法
下面的没有经过实践,因此很可能是错误的,觉得有用的初学朋友读一读吧:)
希望高人指点一二 :)
简介:
在标准的SLG游戏中,当在一个人物处按下鼠标时,会以人物为中心,向四周生成一个菱形的可移动区范围,如下:
0
000
00s00
000
0
这个图形在刚开始学习PASCAL时就应该写过一个画图的程序(是否有人怀念?)。那个图形和SLG的扩展路径一样。
一、如何生成路径:
从人物所在的位置开始,向四周的四个方向扩展,之后的点再进行扩展。即从人物所在的位置从近到远进行扩展(类似广宽优先)。
二、扩展时会遇到的问题:
1、当扩展到一个点时,人物的移动力没有了。
2、当扩展的时候遇到了一个障碍点。
3、当扩展的时候这个结点出了地图。
4、扩展的时候遇到了一个人物正好站在这个点(与2同?)。
5、扩展的点已经被扩展过了。当扩展节点的时候,每个节点都是向四周扩展,因此会产生重复的节点。
当遇到这些问题的时候,我们就不对这些节点处理了。在程序中使用ALLPATH[]数组记录下每一个等扩展的节点,不处理这些问题节点的意思就是不把它们加入到ALLPATH[]数组中。我们如何去扩展一个结点周围的四个结点,使用这个结点的坐标加上一个偏移量就可以了,方向如下:
3
0 2
1
偏移量定义如下:
int offx[4] = { -1, 0, 1, 0 };
int offy[4] = { 0, 1, 0, -1 };
扩展一个节点的相邻的四个节点的坐标为:
for(int i=0; i<4; i )
{
temp.x = temp1.x offx[i];
temp.y = temp1.y offy[i];
}
三、关于地图的结构:
1、地图的二维坐标,用于确定每个图块在地图中的位置。
2、SLG中还要引入一个变量decrease表示人物经过这个图块后他的移动力的减少值。例如,一个人物现在的移动力为CurMP=5,与之相领的图块的decrease=2;这时,如果人物移动到这里,那它的移动力变成CurMP-decrease。
3、Flag域:宽度优先中好像都有这个变量,有了它,每一个点保证只被扩展一次。防止一个点被扩展多次。(一个点只被扩展一次真的能得到正确的结果吗?)
4、一个地图上的图块是否可以通过,我们使用了一个Block代表。1---不可以通过;0---可以通过。
这样,我们可以定义一个简单的地图结构数组了:
#define MAP_MAX_WIDTH 50
#define MAP_MAX_HEIGHT 50
typedef struct tagTILE{
int x,y,decrease,flag,block;
}TILE,*LPTILE;
TILE pMap[MAP_MAX_WIDTH][MAP_MAX_HEIGHT];
以上是顺序数组,是否使用动态的分配更好些?毕竟不能事先知道一个地图的宽、高。
四、关于路径:
SLG游戏中的扩展路径是一片区域(以人物为中心向四周扩展,当然,当人物移动时路径只有一个)。这些扩展的路径必须要存储起来,所有要有一个好的结构。我定义了一个结构,不是很好:
typedef struct tagNODE{
int x,y; //扩展路径中的一个点在地图中的坐标。
int curmp; //人物到了这个点以后的当前的移动力。
}NODE,*LPNODE;
上面的结构是定义扩展路径中的一个点的结构。扩展路径是点的集合,因此用如下的数组进行定义:
NODE AllPath[PATH_MAX_LENGTH];
其中的PATH_MAX_LENGTH代表扩展路径的点的个数,我们不知道这个扩展的路径中包含多少个点,因此定义一个大一点的数字使这个数组不会产生溢出:
#define PATH_MAX_LENGTH 200
上面的这个数组很有用处,以后的扩展就靠它来实现,它应该带有两个变量nodecount 代表当前的数组中有多少个点。当然,数组中的点分成两大部分,一部分是已经扩展的结点,存放在数组的前面;另一部分是等扩展的节点,放在数组的后面为什么会出现已扩展节点和待扩展节点?如下例子:
当前的人物坐标为x,y;移动力为mp。将它存放到AllPath数组中,这时的起始节点为等扩展的节点。这时我们扩展它的四个方向,对于合法的节点(如没有出地图,也没有障碍......),我们将它们存放入AllPath数组中,这时的新加入的节点(起始节点的子节点)就是等扩展结点,而起始节点就成了已扩展节点了。下一次再扩展节点的时候,我们不能再扩展起始节点,因为它是已经扩展的节点了。我们只扩展那几个新加入的节点(待扩展节点),之后的情况以此类推。那么我们如何知道哪些是已经扩展的结点,哪些是等扩展的节点?我们使用另一个变量cutflag,在这个变量所代表的下标以前的结点是已扩展节点,在它及它之后是待扩展结点。
五、下面是基本框架(只扩展一个人物的可达范围):
int nodecount = 0; //AllPath数组中的点的个数(包含待扩展节点和已经扩展的节点
int cutflag = 0; //用于划分已经扩展的节点和待扩展节点
NODE temp; //路径中的一个点(临时)
temp.x = pRole[cur] - >x; //假设有一个关于人物的类,代表当前的人物
temp.y = pRole[cur] - >y;
temp.curmp = pRole[cur] - >MP; //人物的最大MP
AllPath[nodecount] = temp; //起始点入AllPath,此时的起始点为等扩展的节点
while (curflag < nodecount) { //数组中还有待扩展的节点
int n = nodecount; //记录下当前的数组节点的个数。
for (int i = cutflag; i < nodecount; i) { //遍历待扩展节点
for (int j = 0; j < 4; j) { //向待扩展节点的四周各走一步
//取得相邻点的数据
temp.x = AllPath[i].x offx[j];
temp.y = AllPath[i].y offy[j];
temp.curmp = AllPath[i].curmp -
pMap[AllPath[i].x][AllPath[i].y].decrease;
//以下为检测是否为问题点的过程,如果是问题点,不加入AllPath数组,继续处理其它的点
if (pMap[temp.x][temp.y].block) {
continue; //有障碍,处理下一个节点
}
if (temp.curmp < 0) {
continue; //没有移动力了
}
if (temp.x < 0 || temp.x >= MAP_MAX_WIDTH || temp.y < 0 ||
temp.y >= MAP_MAX_HEIGHT) {
continue; //出了地图的范围
}
if (pMap[temp.x][temp.y].flag) {
continue; //已经扩展了的结点
}
//经过了上面几层的检测,没有问题的节点过滤出来,可以加入AllPath
AllPath[nodecount] = temp;
}
pMap[AllPath[i].x][AllPath[i].y].flag = 1; //将已经扩展的节点标记为已扩展节点
}
cutflag = n; //将已扩展节点和待扩展节点的分界线下标值移动到新的分界线
}
for (int i = 0; i < nodecount; i) {
pMap[AllPath[i].x][AllPath[i].y].bFlag = 0; //标记为已扩展节点的标记设回为待扩展节点。
}
游戏算法整理 算法七 无限大地图的实现
这已经不是什么新鲜的东西了,不过现在实在想不到什么好写,而且版面上又异常冷清,我再不说几句就想要倒闭了一样。只好暂且拿这个东西来凑数吧。
无限大的地图,听上去非常吸引人。本来人生活的空间就是十分广阔的,人在这么广阔的空间里活动才有一种自由的感觉。游戏中的虚拟世界由于受到计算机存储空间的限制,要真实地反映这个无限的空间是不可能的。而对这个限制最大的,就是内存的容量了。所以在游戏的空间里,我们一般只能在一个狭小的范围里活动,在一般的RPG中,从一个场景走到另一个场景,即使两个地方是紧紧相连的,也要有一个场景的切换过程,一般的表现就是画面的淡入淡出。
这样的场景切换给人一种不连续的感觉(我不知道可不可以把这种称作“蒙太奇”:o)),从城内走到城外还有情可缘,因为有道城墙嘛,但是两个地方明明没有界限,却偏偏在这一边看不到另外一边,就有点不现实了。当然这并不是毛病,一直以来的RPG都是遵循这个原则,我们(至少是我)已经习惯了这种走路的方式。我在这里说的仅仅是另外一种看起来更自然一点的走路方式,仅此而已。
当然要把整个城市的地图一下子装进内存,现在的确是不现实的,每一次只能放一部分,那么应该怎么放才是我们要讨论的问题。
我们在以前提到Tile方法构造地图时就谈到过Tile的好处之一就是节省内存,这里仍然可以借鉴Tile的思想。我们把整个大地图分成几块,把每一块称作一个区域,在同一时间里,内存中只保存相邻的四块区域。这里每个区域的划分都有一定的要求:每个区域大小应该相等这是一定的了,不然判断当前屏幕在哪个区域中就成了一个非常令人挠头的事;另外每个区域的大小都要大于屏幕的大小,也只有这样才能保证屏幕(就是图中那块半透明的蓝色矩形)在地图上荡来荡去的时候,最多同时只能覆盖四个区域(象左图中所表示的),内存里也只要保存四个区域就足够了;还有一点要注意的,就是地图上的建筑物(也包括树啦,大石头啦什么的)必须在一个区域内,这样也是为了画起来方便,当然墙壁——就是那种连续的围墙可以除外,因为墙壁本来就是一段一段拼起来的。
我们在程序中可以设定4个指针来分别指向这4个区域,当每次主角移动时,就判断当前滚动的屏幕是否移出了这四个区域,如果移出了这四个区域,那么就废弃两个(或三个)已经在目前的四个相邻区域中被滚出去的区域(说得很别扭,各位见谅),读入两个(或三个)新滚进来的区域,并重新组织指针。这里并不涉及内存区域的拷贝。
这样的区域划分方法刚好适合我们以前提到的Tile排列方法,只要每个区域横向Tile的个数是个偶数就行了,这样相邻的两个区域拼接起来刚好严丝合缝,而且每个区域块的结构完全一致,没有那些需要重复保存的Tile(这个我想我不需要再画图说明了,大家自己随便画个草图就看得出来了)。在文件中的保存方法就是按一个个区域分别保存,这样在读取区域数据时就可以直接作为一整块读入,也简化了程序。另外还有个细节就是,我们的整个地图可能不是一个规则的矩形,可能有些地方是无法达到的,如右图所示,背景是黑色的部分代表人物不能达到的地方。那么在整个地图中,这一部分区域(在图中蓝色的3号区域)就可以省略,表现在文件存储上就是实际上不存储这一部分区域,这样可以节省下不少存储空间。对于这种地图可以用一个稀疏矩阵来存储,大家也可以发挥自己的才智用其他对于编程来说更方便的形式来存储地图。
这就是对无限大地图实现的一种方法,欢迎大家提出更好的方法。也希望整个版面能够活跃一点。
|
天是09年1月1日,一个全新的开始,我要珍惜当下每一分一秒!让当下每个呼吸都是崭新的!
新的一年,我希望自已对人生、对生命,能够有一个全新的认识。谢谢陈爷爷前几天送我的那
套《康熙起居注》,最近也越来越认识到,要多读书,读好书的重要性,能够天天在家读书实
在也是一种很大的幸福,我要珍惜!乾隆皇帝十九岁就写下了《读书以明理为先》的文章,说
明读书对明理、对做人的重要性,立身以至诚为本,读书以明理为先!今年还有一个心愿就是
用小楷临摹一遍康熙皇帝抄写的<金刚经>,也终于明白了其实写字这个过程本身也是在训练一
种心境,所以写字是写的一种心境,而不在与字的美丑。一个有着强大心力的人,才可能真正
意义的永无不胜,学佛学道,无论学什么,其实最大的敌人就是自已认为的那颗狂燥不安的心,
黑暗中总有惺惺相惜的敌人!纯静朴素的大道,无时无刻都存在于我们身边,上达于天,下入于
地,化育万物。道法自然,或许真正获得了心灵上的自由,才能达到至人的境界:游于物之所不
得遁而皆存。遵循自然法则因缘和合,才是顺天行事,缘份就像一针一眼,谁也逃不了,如果这
辈子真有一个能把名和利都看的很淡的人,并且愿意和我过一种很简单的生活,我一定要让他成
为这世上第二幸福的人,因为最幸福的人是我!我要跟他一辈子不离不弃,看日出看日落,看北
斗星看流星雨,直到老!09年,让我牵着庄子的手,在轮回的战场中,做个勇敢的战士!
pku3233:Given a n × n matrix A and a positive integer k, find the sum S = A + A2 + A3 + … + Ak.
分析:矩阵相乘O(n^3), 有k次,则复杂度为n^3*k。
使用矩阵技巧,构造:
B= | A A |
| O I |
则B的乘方的结果其右上会是S,其他三个不变。此时化成了矩阵乘方问题,此时可以使用反复平方法,这样复杂度为(2n)^3*logk
反复平方法,迭代版的, 以整数a^m为例:
递归的可以不用变量Z,要简单些,但是要注意了递归的调用顺序和结果的存储。

  /**//*Problem: 1509 User: Uriel /**//*Problem: 1509 User: Uriel
 Memory: 144K Time: 16MS Memory: 144K Time: 16MS
 Language: C Result: Accepted*/ Language: C Result: Accepted*/

#include<stdio.h>
#include<string.h>
int min(int a, int b)
 { {
return a <= b ? a : b;
}
int MinimumRepresentation(char *s, int l)
{
int i = 0, j = 1, k = 0, t;
while (i < l && j < l && k < l)
  { {
t = s[(i + k)%l] - s[(j + k)%l];
if (!t) ++ k;
else
{
if (t > 0) i = i + k + 1;
else j = j + k + 1;
if (i == j) ++j;
k = 0;
 } }
}
return min(i,j);
}
int x,len,i,t;
char str[10010];
int main()
{
scanf("%d",&t);
getchar();
while(t--)
{
memset(str,0x00,sizeof(str));
scanf("%s",str);
len=strlen(str);
x=MinimumRepresentation(str,len);
printf("%d\n",x+1);
}
return 0;
}
//串的同构是,在若干次循环位移后可以变成相同
static boolean isIsomorphism(String s1, String s2)
{
char[] u = (s1+s1).toCharArray();
char[] w = (s2+s2).toCharArray();
int i = 0;
int j = 0;
int len = s1.length();
while(i < u.length && j < w.length)
{
int k = 0;
while((i+k) < u.length && (j+k)<u.length && u[i+k] == w[j+k])k++;//&& k < len
System.out.println(k);
if(k >= len) return true;
if(u[i+k] > w[j+k])i = i+k+1;
else j = j+k+1;
}
return false;
}
在这篇文章里,我们从信息论的角度证明了,基于比较的排序算法需要的比较次数(在最坏情况下)至少为log2(n!),而log(n!)=Θ(nlogn),这给出了比较排序的一个下界。但那里我们讨论的只是最理想的情况。一个事件本身所含的信息量是有大小之分的。看到这篇文章之后,我的思路突然开阔了不少:信息论是非常强大的,它并不只是一个用来分析理论最优决策的工具。从信息论的角度来分析算法效率是一件很有趣的事,它给我们分析排序算法带来了一种新的思路。
假如你手里有一枚硬币。你希望通过抛掷硬币的方法来决定今天晚上干什么,正面上网反面看电影。投掷硬币所产生的结果将给你带来一些“信息”,这些信息的多少就叫做“信息量”。如果这个硬币是“公正”的,正面和反面出现的概率一样,那么投掷硬币后不管结果咋样,你都获得了1 bit的信息量。如果你事先就已经知道这个硬币并不是均匀的,比如出现正面的概率本来就要大得多,这时我们就说事件结果的不确定性比刚才更小。如果投掷出来你发现硬币果然是正面朝上,这时你得到的信息量就相对更小(小于1 bit);反之如果投掷出来居然反面朝上了,那你就得到了一个相对较大的信息量(大于1 bit)。但平均下来,我们得到的信息量是小于1 bit的,因为前者发生的可能性毕竟要大一些。最极端的情况就是,这是一枚被捣了鬼的魔术硬币,你怎么投都是正面。此时,你投了硬币等于没投,反正结果都是正面朝上,你得到的信息量永远为0。
这个理论是很符合生活实际的。昨天晚上我出去吃饭时,坐在我后面的那个人是男的还是女的?这种问题就比较有价值,因为大家都猜不到答案究竟是什么;但要问我昨天跟谁一起出去上自习去了,问题的答案所含的信息量就变小了,因为大家都知道如果我破天荒地跑去自习了的话多半是有MM陪着一起去的。如果有网友问我是男的还是女的,那就更不可思议了,因为我不但多次在这个Blog里提到我一直想找一个合适的MM,还在AboutMe里面发了我的照片。如果某人刚操完一个MM,突然扭过头去问“对了,你是男的还是女的呀”,那这个人绝对是一个不折不扣的大傻B,因为这个问题所能带来的信息量几乎为0。
总之,当每种结果出现的概率都相等,事件的不确定性达到最大,其结果最难预测时,事件的发生将会给我们带来最大的信息量。我们把一个事件的不确定程度叫做“熵”,熵越大表明这个事件的结果越难以预测,同时事件的发生将给我们带来越多的信息。如果在排序算法里每次比较的熵都是最大的,理论上来说这种(基于比较的)排序算法就应当是最优的。但我们一会儿将看到,我们已知的排序算法总是不完美的,每种算法都会或多或少地存在一些价值明显不大的比较。
首先我们来看三种经典的平方复杂度算法。它们的效率并不高,原因就在于算法过程中会出现越来越多概率严重不均的比较。随着冒泡排序的进行,整个序列将变得越来越有序,位置颠倒的泡泡将越来越少;选择排序的每一趟选择中,你都会不断得到越来越大的数,同时在以后的比较中找到更大的数的概率也越来越低;在插入排序中,你总是把新的数与已经排好的数按从大到小的顺序依次进行比较,可以想到新的数一开始就比前面所有的数中最大的那个还大的概率是相当小的。受此启发,我们可以很自然地想到一个插入排序的改进:处理一个新的数时,为何不一开始就与前面处理过的数中的中位数进行比较?这种比较的熵显然更大,能获取的信息量要大得多,明显更有价值一些。这就是插入排序的二分查找改进。
下面我们再来看一看几种O(nlogn)的排序算法。在快速排序算法中,比较的信息熵不会因为排序算法的进行而渐渐减小,这就是快速排序比上面几个排序算法更优秀的根本原因。仔细回顾快速排序算法的过程,我们立即看出,每次比较的两种结果出现的概率完全由这一趟划分过程所选择的基准关键字决定:选择的基准关键字刚好是当前处理的数字集合的中位数,则比较结果的不确定性达到最大;如果选择的基准关键字过大或过小,都会出现比较产生的结果不均等的情况,这使得每次比较平均带来的信息量大大减少。因此,快速排序算法是很看人品的:如果基准选的好,算法完全有可能达到理论上的最优;如果基准选的不好,复杂度很容易退化到O(n^2)。
堆排序所需要的比较次数更多,因为在堆的删除操作中有一种明显不平衡的比较。在删除操作中,我们把根节点用整个堆的最末一个节点来代替,然后不断下沉直到它的儿子都比它大。判断它的两个儿子是否比它大,其信息熵是相当小的,因为这个节点本身就来自堆的底部,除非这个节点已经沉到很底下了,否则儿子比它大的概率是很小的。因此,我们想到了一个堆排序的优化:反正堆建好了以后不需要再插入新元素了,为何不舍弃堆的完全二叉树性质?我们可以直接把根元素改成无穷大,让它沉到底,不用再考虑儿子比它大的问题了,也不再顾及堆的形状。这样的话,堆排序是否就完美了呢?仔细想想你会发现,改进之后的比较操作仍然是不对称的。这种不对称主要来自两个方面:左子树和右子树的节点个数不同,以及被删除的根节点原先是来自左子树还是右子树。比方说,根节点原本就是从右子树提上来的,现在删除了根节点后,左子树的最小值比右子树的最小值更小的概率就偏大一些;此时万一右子树节点本来就比左边少,这样的话这个比较的熵就更小了。
最后看一下归并排序。在有序队列的合并操作中,绝大多数情况下的比较操作都是比较平衡的。左边一半中的最小值和右边一半中的最小值进行比较,结果显然是等概率的。当然,随后将发生其中一边的最小值与另一边的次小值进行比较,这时的比较操作略微有了一些不平衡,并存在较小的可能使得比较操作变得更加不平衡(最小值与第三小的值相比)。有趣的是,比较越是不平衡,重新归于平衡的概率就越大,就好像归并排序中的信息熵会自动调整一样。这就是归并排序比平方复杂度的排序算法效率更高的原因。当然,完全有可能出现这样的情况:右边的数奇小无比,左边的最小值比右边的所有值都大。结果最后右边的队列都处理完了左边还没开始取数,此时合并操作提前结束,所花费的比较次数出人意料地少。从信息熵的角度来看,这种“比较提前结束”的现象是非常自然的:这种情况毕竟是“出人意料”的,事实越出人意料,获得的信息量就越大,因此算法就提前结束了。但这种情况毕竟是相当罕见的,平均情况下每次比较的信息量仍然不足1 bit。
最后,为什么线性排序的算法可以达到O(n)的复杂度?这是因为,线性排序算法并不是基于比较的。一次比较事件(假设没有相等的情况)所能产生的信息量最多1 bit,而一次Hash分类可以获得的信息量远远超过了1 bit,因为它可以一次确定出n种等概率的可能情况。
Matrix67原创,转贴请注明出处~~
传说中效率最高的最大流算法(Dinic)
呵呵,又从DK那偷代码了,好兴奋哈,以下是这个算法的简单介绍,不过我用它去解决HDU的1532 竟然TLE,郁闷.到时候再继续问问DK吧...so 烦躁.
哈哈 终于经过大牛的指点 原来本算法是从0开始标号的......
Dinic是个很神奇的网络流算法。它是一个基于“层次图”的时间效率优先的最大流算法。
层次图是什么东西呢?层次,其实就是从源点走到那个点的最短路径长度。于是乎,我们得到一个定理:从源点开始,在层次图中沿着边不管怎么走,经过的路径一定是终点在剩余图中的最短路。(摘自WC2007王欣上论文)注意,这里是要按照层次走。
那么,MPLA(最短路径增值)的一大堆复杂的证明我就略掉了,有兴趣的请自行参阅WC2007王欣上神牛的论文。
首先我们得知道,Dinic的基本算法步骤是,先算出剩余图,然后用剩余图算层次图,然后在层次图里找增广路。不知道你想到没有,这个层次图找增广路的方法,恰恰就是Ford-Fulkerson类算法的时间耗费最大的地方,就是找一个最短的增广路。所以呢,层次图就相当于是一个已经预处理好的增广路标志图。
如何实现Dinic呢?
首先我们必然要判一下有没有能到达终点的路径(判存在增广路与否),在这个过程中我们顺便就把层次图给算出来了(当然不用算完),然后就沿着层次图一层一层地找增广路;找到一条就进行增广(注意在沿着层次图找增广路的时候使用栈的结构,把路径压进栈);增广完了继续找,找不到退栈,然后继续找有没有与这个结点相连的下一层结点,直到栈空。如果用递归实现,这个东西就很好办了,不过我下面提供的程序是用了模拟栈,当然这样就不存在结点数过多爆栈的问题了……不过写起来也麻烦了一些,对于“继续找”这个过程我专门开了一个数组存当前搜索的指针。
上面拉拉杂杂说了一大堆,实际上在我的理解中,层次图就是一个流从高往低走的过程(这玩意儿有点像预流推进的标号法……我觉得),在一条从高往低的路径中,自然有些地方会有分叉;这就是Dinic模拟栈中退栈的精华。这就把BFS的多次搜索给省略了不说,时间效率比所谓的理论复杂度要高得多。
这里有必要说到一点,网络流的时间复杂度都是很悲观的,一般情况下绝对没有可能到达那个复杂度的。
#include<iostream>
using namespace std;
const long maxn=300;
const long maxm=300000;
const long inf=0x7fffffff;
struct node
{
long v,next;
long val;
}s[maxm*2];
long level[maxn],p[maxn],que[maxn],out[maxn],ind;
void init()
{
ind=0;
memset(p,-1,sizeof(p));
}
inline void insert(long x,long y,long z)
{
s[ind].v=y;
s[ind].val=z;
s[ind].next=p[x];
p[x]=ind++;
s[ind].v=x;
s[ind].val=0;
s[ind].next=p[y];
p[y]=ind++;
}
inline void insert2(long x,long y,long z)
{
s[ind].v=y;
s[ind].val=z;
s[ind].next=p[x];
p[x]=ind++;
s[ind].v=x;
s[ind].val=z;
s[ind].next=p[y];
p[y]=ind++;
}
long max_flow(long n,long source,long sink)
{
long ret=0;
long h=0,r=0;
while(1)
{
long i;
for(i=0;i<n;++i)
level[i]=0;
h=0,r=0;
level[source]=1;
que[0]=source;
while(h<=r)
{
long t=que[h++];
for(i=p[t];i!=-1;i=s[i].next)
{
if(s[i].val&&level[s[i].v]==0)
{
level[s[i].v]=level[t]+1;
que[++r]=s[i].v;
}
}
}
if(level[sink]==0)break;
for(i=0;i<n;++i)out[i]=p[i];
long q=-1;
while(1)
{
if(q<0)
{
long cur=out[source];
for(;cur!=-1;cur=s[cur].next)
{
if(s[cur].val&&out[s[cur].v]!=-1&&level[s[cur].v]==2)
{
break;
}
}
if(cur>=0)
{
que[++q]=cur;
out[source]=s[cur].next;
}
else
{
break;
}
}
long u=s[que[q]].v;
if(u==sink)
{
long dd=inf;
long index=-1;
for(i=0;i<=q;i++)
{
if(dd>s[que[i]].val)
{
dd=s[que[i]].val;
index=i;
}
}
ret+=dd;
//cout<<ret<<endl;
for(i=0;i<=q;i++)
{
s[que[i]].val-=dd;
s[que[i]^1].val+=dd;
}
for(i=0;i<=q;i++)
{
if(s[que[i]].val==0)
{
q=index-1;
break;
}
}
}
else
{
long cur=out[u];
for(;cur!=-1;cur=s[cur].next)
{
if(s[cur].val&&out[s[cur].v]!=-1&&level[u]+1==level[s[cur].v])
{
break;
}
}
if(cur!=-1)
{
que[++q]=cur;
out[u]=s[cur].next;
}
else
{
out[u]=-1;
q--;
}
}
}
}
return ret;
}
long m,n;
int main()
{
while(scanf("%ld %ld",&m,&n)!=EOF)
{
init();
for(int i=0;i<n;i++)
{
long from,to,cost;
scanf("%ld %ld %ld",&from,&to,&cost);
insert(--from,--to,cost);
}
long Start,End;
scanf("%ld %ld",&Start,&End);
printf("%ld\n",max_flow(n,--Start,--End));
}
return 0;
}

摘要: 最短路径 之 SPFA算法 (转载)(2009-05-06 20:41:51)
var $tag='spfa,杂谈';
var $tag_code='0c0816ca8a11d99e776ffbef47dd2fd0';
标签:spfa 杂谈
... 阅读全文
#include <stdio.h>
int add(int x,int y) {return x+y;}
int sub(int x,int y) {return x-y;}
int mul(int x,int y) {return x*y;}
int div(int x,int y) {return x/y;}
int (*func[])()={add,sub,mul,div};
int num,curch;
char chtbl[]="+-*/()=";
char corch[]="+-*/()=0123456789";
int getach() {
int i;
while(1) {
curch=getchar();
if(curch==EOF) return -1;
for(i=0;corch[i]&&curch!=corch[i];i++);
if(i<strlen(corch)) break;
}
return curch;
}
int getid() {
int i;
if(curch>='0'&&curch<='9') {
for(num=0;curch>='0'&&curch<='9';getach()) num=10*num+curch-'0';
return -1;
}
else {
for(i=0;chtbl[i];i++) if(chtbl[i]==curch) break;
if(i<=5) getach();
return i;
}
}
int cal() {
int x1,x2,x3,op1,op2,i;
i=getid();
if(i==4) x1=cal(); else x1=num;
op1=getid();
if(op1>=5) return x1;
i=getid();
if(i==4) x2=cal(); else x2=num;
op2=getid();
while(op2<=4) {
i=getid();
if(i==4) x3=cal(); else x3=num;
if((op1/2==0)&&(op2/2==1)) x2=(*func[op2])(x2,x3);
else {
x1=(*func[op1])(x1,x2);
x2=x3;
op1=op2;
}
op2=getid();
}
return (*func[op1])(x1,x2);
}
void main(void) {
int value;
printf("Please input an expression:\n");
getach();
while(curch!='=') {
value=cal();
printf("The result is:%d\n",value);
printf("Please input an expression:\n");
getach();
}
}
(一)简单的函数指针的应用。
//形式1:返回类型(*函数名)(参数表)
char (*pFun)(int);
char glFun(int a){ return;}
void main()
{
pFun = glFun;
(*pFun)(2);
}
第一行定义了一个指针变量pFun。首先我们根据前面提到的“形式1”认识到它是一个指向某种函数的指针,这种函数参数是一个int型,返回值是char类型。只有第一句我们还无法使用这个指针,因为我们还未对它进行赋值。
第二行定义了一个函数glFun()。该函数正好是一个以int为参数返回char的函数。我们要从指针的层次上理解函数——函数的函数名实际上就是一个指针,函数名指向该函数的代码在内存中的首地址。
然后就是可爱的main()函数了,它的第一句您应该看得懂了——它将函数glFun的地址赋值给变量pFun。main()函数的第二句中“*pFun”显然是取pFun所指向地址的内容,当然也就是取出了函数glFun()的内容,然后给定参数为2。
(二)使用typedef更直观更方便。
//形式2:typedef 返回类型(*新类型)(参数表)
typedef char (*PTRFUN)(int);
PTRFUN pFun;
char glFun(int a){ return;}
void main()
{
pFun = glFun;
(*pFun)(2);
}
typedef的功能是定义新的类型。第一句就是定义了一种PTRFUN的类型,并定义这种类型为指向某种函数的指针,这种函数以一个int为参数并返回char类型。后面就可以像使用int,char一样使用PTRFUN了。
第二行的代码便使用这个新类型定义了变量pFun,此时就可以像使用形式1一样使用这个变量了。
(三)在C++类中使用函数指针。
//形式3:typedef 返回类型(类名::*新类型)(参数表)
class CA
{
public:
char lcFun(int a){ return; }
};
CA ca;
typedef char (CA::*PTRFUN)(int);
PTRFUN pFun;
void main()
{
pFun = CA::lcFun;
ca.(*pFun)(2);
}
在这里,指针的定义与使用都加上了“类限制”或“对象”,用来指明指针指向的函数是那个类的这里的类对象也可以是使用new得到的。比如:
CA *pca = new CA;
pca->(*pFun)(2);
delete pca;
而且这个类对象指针可以是类内部成员变量,你甚至可以使用this指针。比如:
类CA有成员变量PTRFUN m_pfun;
void CA::lcFun2()
{
(this->*m_pFun)(2);
}
一句话,使用类成员函数指针必须有“->*”或“.*”的调用。
作者:csumck 更新日期:2004-11-07
来源:CSDN 浏览次数:
系统的可靠度计算公式 收藏
并联:1-(1-p1)(1-p2)
串联:p1p2
p1,p2分别为部件1和部件2的可靠度.
---------------------------------------------------------------------------
eg:
某计算机系统的可靠性结构是如下图所示的双重串并联结构,若所构成系统的每个部件的可靠度为0.9 ,即R=0.9 ,则系统的可靠度为()?
|---(R)————(R)---|
———| |--
|---(R)----(R)---|
类似于串两个电阻,在并两个电阻的图。问怎样计算?
最佳答案
串联的可靠度P1=R1×R1 =0.81
并联起来时可靠度P2=1-(1-P1)×(1-P1)=0.9639
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/zwhfyy/archive/2009/04/02/4042513.aspx
摘要: 背包问题
1.引子
我们人类是一种贪婪的动物,如果给您一个容量一定的背包和一些大小不一的物品,裝到背包里面的物品就归您,遇到这种好事大家一定不会错过,用力塞不一定是最好的办法,用脑子才行,下面就教您如何解决这样的问题,以获得更多的奖品。
2.应用场景
在一个物品向量中找到一个子集满足条件如下 :
1)这个子集加起来的体积大小不能... 阅读全文
在今年的信息学冬令营上,陈启峰提出了一个自己创造的BST数据结构—Size Balanced Tree。这个平衡二叉树被全世界内的许多网站所讨论,大家讨论的主题也只有一个—SBT能够取代Treap吗?本文详细介绍SBT树的性质,以及一些常用的操作,最后证明SBT是一颗高度平衡的二分查找树。
一. 介绍
众所周知,BST能够快速的实现查找等动态操作。但是在某些情况下,比如将一个有序的序列依次插入到BST中,则BST会退化成为一条链,效率非常之低。由此引申出来很多平衡BST,比如AVL树,红黑树,treap树等。这些数据结构都是通过引入其他一些性质来保证BST的高度在最坏的情况下都保持在O(log n)。其中,AVL树和红黑树的很多操作都非常麻烦,因此实际应用不是很多。而treap树加入了一些随机化堆的性质,实际应用效果非常好,实现起来很简单,一直以来受到很多人的青睐。本文介绍一种新的平衡BST树,实现起来也是非常之简单,并且能够支持更多的操作,实际评测效率跟treap也不差上下。
在介绍SBT之前,先介绍一下BST以及在BST上的旋转操作。
1. Binary Search Tree
BST是一种高级的数据结构,它支持很多动态操作,包括查找,求最小值,最大值,前驱,后继,插入和删除,能够用于字典以及优先队列。
BST是一棵二叉树,每个结点最多有2个儿子。每个结点都有个键值,并且键值必须满足下面的条件:
如果x是BST中的一个结点。那么x的键值不小于其左儿子的键值,并且不大于其右儿子的键值。
对于每个结点t,用left[t]和right[t]分别来存放它的两个儿子,ket[t]存放该结点的键值。另外,在SBT中,要增加s[t],用来保存以t为根的子树中结点的个数。
2. 旋转
为了保证BST的平衡(不会退化成为一条链),通常通过旋转操作来改变BST的结构。旋转操作不会影响binary-search-tree的性质!
2.1右旋操作的伪代码
右旋操作必须保证左儿子存在
Right-Rotate(t)
k←left[t]
left[t]←right[k]
right[k]←t
s[k]←s[t]
s[t]←s[left[t]]+s[right[t]]+1
t←k
2.2 左旋操作的伪代码
左旋操作必须保证右儿子存在
Left-Rotate(t)
k←right[t]
right[t]←left[k]
left[k]←t
s[k]←s[t]
s[t]←s[left[t]]+s[right[t]]+1
t←k
二.Size Balanced Tree
Size Balanced Tree(简称SBT)是一种平衡二叉搜索树,它通过子树的大小s[t]来维持平衡性质。它支持很多动态操作,并且都能够在O(log n)的时间内完成。
|
Insert(t,v)
|
将键值为v的结点插入到根为t的树中
|
|
Delete(t,v)
|
在根为t的树中删除键值为v的结点
|
|
Find(t,v)
|
在根为t的树中查找键值为v的结点
|
|
Rank(t,v)
|
返回根为t的树中键值v的排名。也就是树中键值比v小的结点数+1
|
|
Select(t,k)
|
返回根为t的树中排名为k的结点。同时该操作能够实现Get-min,Get-max,因为Get-min等于Select(t,1),Get-max等于Select(t,s[t])
|
|
Pred(t,v)
|
返回根为t的树中比v小的最大的键值
|
|
Succ(t,v)
|
返回根为t的树中比v大的最小的键值
|
SBT树中的每个结点都有left,right,key以及前面提到的size域。SBT能够保持平衡性质是因为其必须满足下面两个条件:
对于SBT中的每个结点t,有性质(a)(b):
(a). s[right[t]]≥s[left[left[t]]],s[right[left[t]]]
(b). s[left[t]]≥s[right[right[t]]],s[left[right[t]]]
即在上图中,有s[A],s[B]≤s[R]&s[C],s[D] ≤s[L]
三. Maintain
假设我们要在BST中插入一个键值为v的结点,一般是用下面这个过程:
Simple-Insert(t,v)
If t=0 then
t←NEW-NODE(v)
Else
s[t]←s[t]+1
If v<key[t] then
Simple-Insert(left[t],v)
Else
Simple-Insert(right[t],v)
执行完操作Simple-Insert后,SBT的性质(a)和(b)就有可能不满足了,这是我们就需要修复(Maintain)SBT。
Maintain(t)用来修复根为t的SBT,使其满足SBT性质。由于性质(a)和(b)是对称的,下面仅讨论对性质(a)的修复。
Case 1:s[left[left[t]]]>s[right[t]]
这种情况下可以执行下面的操作来修复SBT
执行Right-Rotate(T)
有可能旋转后的树仍然不是SBT,需要再次执行Maintain(T)
由于L的右儿子发生了变化,因此需要执行Maintain(L)
Case 2:s[right[left[t]]]>s[right[t]]
这种情况如下图所示:
需要执行一下步骤来修复SBT:
执行Left-Rotate(L)。如下图所示
执行Right-Rotate(T)。如下图所示
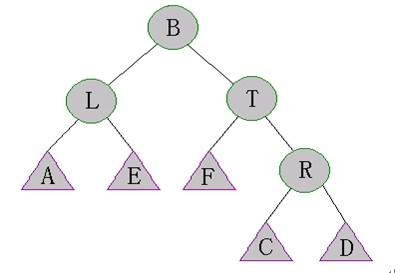
当执行完(1)(2)后,树的结构变得不可预测了。但是幸运的是,在上图中,A,E,F,R子树仍然是SBT。因此我们可以执行Maintain(L)和Maintain(T)来修复B的子树。
Case 3:
这种情况和case 1是对称的
Case 4:
这种情况和case 2是对称的
Maintain操作的伪代码:
在Maintain过程中,用一个变量flag来避免额外的检查。当flag为false时,代表case 1和case 2需要被检查,否则case 3和case 4需要被检查。
Maintain (t,flag)
If flag=false then
If s[left[left[t]]>s[right[t]] then
Right-Rotate(t)
Elseif s[right[left[t]]>s[right[t]] then
Left-Rotate(left[t])
Right-Rotate(t)
Else exit
Elseif s[right[right[t]]>s[left[t]] then
Left-Rotate(t)
Elseif s[left[right[t]]>s[left[t]] then
Right-Rotate(right[t])
Left-Rotate(t)
Else exit
Maintain(left[t],false)
Maintain(right[t],true)
Maintain(t,false)
Maintain(t,true)
四.常用操作
插入操作
SBT和插入操作和BST的基本相同,只是在插入之后需要执行下Maintain操作。
Insert (t,v)
If t=0 then
t←NEW-NODE(v)
Else
s[t] ←s[t]+1
If v<key[t] then
Simple-Insert(left[t],v)
Else
Simple-Insert(right[t],v)
Maintain(t,v≥key[t])
删除操作
如果没有找到要删除的结点,那么就删除最后一个访问的结点并记录。
Delete (t,v)
If s[t]≤2 then
record←key[t]
t←left[t]+right[t]
Exit
s[t] ←s[t]-1
If v=key[t] then
Delete(left[t],v[t]+1)
Key[t] ←record
Maintain(t,true)
Else
If v<key[t] then
Delete(left[t],v)
Else
Delete(right[t],v)
Maintain(t,v<key[t])
另外,由于SBT的平衡性质是靠size域来维护的,而size域本身(子树所含节点个数)对于很多查询算法都特别有用,这样使得查询集合里面的譬如第n小的元素,以及一个元素在集合中的排名等操作都异常简单,并且时间复杂度都稳定在O(log n)。下面仅介绍下上表提到的select(t,k)操作和rank(t,v)操作。
由于SBT的性质(结点t的关键字比其左子树中所有结点的关键字都大,比其左子树中所有的关键字都小),理解下面的算法非常容易。
3.Select操作
Select(t,k)
If k=s[left[t]]+1 then
return key[t]
If k<=s[left[t]] then
return Select(left[t],k)
Else
return Select(right[t],k-1-s[left[t]])
4.Rank操作
Rank(t,v)
If t=0 then
return 1
If v<=key[t] then
return rank(left[t],v)
Else
return s[left[t]]+1+rank(right[t],v)
同样,求前驱结点的操作Pred和后继结点的操作都很容易通过size域来实现。
五.相关证明分析
显然Maintain操作是一个递归过程,可能你会怀疑它是否会结束。下面我们可以证明Maintain操作的平摊时间复杂度为O(1)。
1.关于树的高度的分析
设f[h]表示高度为h的SBT中结点数目的最小值,则有
1 (h=0)
f[h]= 2 (h=1)
f[h-1]+f[h-2]+1 (h>1)
a.证明:
(1) 很明显f[0]=1,f[1]=2。
(2) 首先,对于任意h>1,我们假设t是一颗高度为h的SBT的根结点,则这颗SBT包含一颗高度为h-1的子树。不妨假设t的左子树的高度为h-1,根据f[h]的定义,有
s[left[t] ]≥f[h-1],同样的,左子树中有一颗高度为h-2的子树,换句话说,左子树中含有一颗结点数至少为f[h-2]的子树。由SBT的性质(b),可知s[right[t]] ≥f[h-2]。因此我们有s[t]=s[left[t]]+s[right[t]]+1≥f[h-1]+f[h-2]+1。
另外一方面,我们可以构造一颗高度为h,并且结点数正好为f[h]的SBT,称这样的SBT为tree[t]。可以这样来构造tree[h]:
含有一个结点的SBT (h=0)
tree[h]= 含有2个结点的任意SBT (h=1)
左子树为tree[h-1],右子树为tree[h-2]的SBT (h>1)
由f[h]的定义可知f[h] ≤f[h-1]+f[h-2]+1(h>1)。因此f[h]的上下界都为f[h-1]+f[h-2]+1,因此有f[h]=f[h-1]+f[h-2]+1。
b.最坏情况下的高度
事实上f[h]是一个指数函数,通过f[h]的递推可以计算出通项公式。
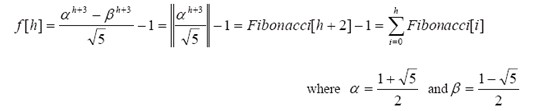
定理:
含有n个结点的SBT在最坏情况下的高度是满足f[h] ≤n的最大的h值。
假设maxh为含有n个结点的SBT的最坏情况下的高度。由上面的定理,有
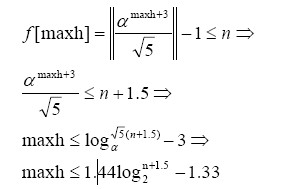
于是很明显SBT的高度为O(logn),是一颗高度平衡的BST!
2.对Maintain操作的分析
通过前面的计算分析我们能够很容易分析出Maintain操作是非常高效的。
首先,有一个非常重要的值来评价一颗BST的好坏:所有结点的平均深度。它是通过所有结点的深度之和SD除以结点个数n计算出来的。一般来说,这个值越小,这颗BST就越好。由于对于一颗BST来说,结点数n是一个常数,因此我们期望SD值越小越好。
现在我们集中来看SBT的SD值,它的重要性在于能够制约Maintain操作的执行时间。回顾先前提到的BST中的旋转操作,有个重要的性质就是:每次执行旋转操作后,SD值总是递减的!
由于SBT树的高度总是O(log n),因此SD值也总是保持在O(log n)。并且SD仅在插入一个结点到SBT后才增加,因此(T是Maintain操作中执行旋转的次数)
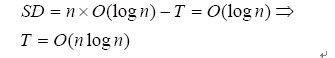
Maintain操作的次数等于T加上不需要旋转操作的Maintain操作的次数。由于后者为O(nlogn)+O(T),因此Maintain的平摊分析时间复杂度为:
对各个操作时间复杂度的分析
现在我们知道了SBT的高度为O(log n),并且 Maintain操作的平摊分析时间复杂度为O(1),因此对于所有的常用操作,时间复杂度都稳定在O(log n)!
摘要: 目前最快的数独求解程序 - 实现了Knuth的Dancing Links+Algorithm X算法
C++语言: 目前最快的数独求解程序 - 实现了Knuth的Dancing Links+Algorithm X算法
//from: http://code.google.com/p/klsudoku/source/checkout
//半瓶墨水修改于 2009 Sept 18
//R... 阅读全文
最大公约数和最小公倍数
语言: C, 标签: 无 2008/07/22发布 5个月前更新 更新记录
作者: 半瓶墨水, 点击5221次, 评论(0), 收藏者(0), , 打分: 登录以后才能打分, 目前平均0.0分,总分0, 共有0个用户参与打分
# 以下描述来自: http://baike.baidu.com/view/47637.htm
#
# 最大公约数(greatest common divisor,简写为gcd;
# 指某几个整数共有公约数中的最大一个
# 例: 在2、4、6中,2就是2,4,6的最大公约数。
#
# 重要性质:
# gcd(a,b)=gcd(b,a) (交换律)
# gcd(-a,b)=gcd(a,b)
# gcd(a,a)=|a|
# gcd(a,0)=|a|
# gcd(a,1)=1
# gcd(a,b)=gcd(b, a mod b)
# gcd(a,b)=gcd(b, a-b)
# 如果有附加的一个自然数m,
# 则: gcd(ma,mb)=m * gcd(a,b) (分配率)
# gcd(a+mb ,b)=gcd(a,b)
# 如果m是a和b的最大公约数,
# 则: gcd(a/m ,b/m)=gcd(a,b)/m
# 在乘法函数中有:
# gcd(ab,m)=gcd(a,m) * gcd(b,m)
# 两个整数的最大公约数主要有两种寻找方法:
# * 两数各分解质因子,然后取出同样有的项乘起来
# * 辗转相除法(扩展版)
# 和最小公倍数(lcm)的关系:
# gcd(a, b) * lcm(a, b) = ab
# a与b有最大公约数,但不一定有最小公倍数。
# 两个整数的最大公因子可用于计算两数的最小公倍数,或分数化简成最简分数。
# 两个整数的最大公因子和最小公倍数中存在分配律:
# * gcd(a, lcm(b, c)) = lcm(gcd(a, b), gcd(a, c))
# * lcm(a, gcd(b, c)) = gcd(lcm(a, b), lcm(a, c))
# 在坐标里,将点(0, 0)和(a, b)连起来,通过整数坐标的点的数目(除了(0, 0)一点之外)就是gcd(a, b)。
#
#
# 以下代码来自: http://bbs.bccn.net/thread-224663-1-1.html
#
int GCD(int a, int b)
{
if(b == 0) return a;
else return GCD(b, a % b);
}
int LCM(int a, int b)
{
return a * b / GCD(a,b);
}
/*以下代码来自:http://en.wikipedia.org/wiki/Binary_GCD_algorithm */
unsigned int gcd(unsigned int u, unsigned int v)
{
int shift;
/* GCD(0,x) := x */
if (u == 0 || v == 0)
return u | v;
/* Let shift := lg K, where K is the greatest power of 2
dividing both u and v. */
for (shift = 0; ((u | v) & 1) == 0; ++shift) {
u >>= 1;
v >>= 1;
}
while ((u & 1) == 0)
u >>= 1;
/* From here on, u is always odd. */
do {
while ((v & 1) == 0) /* Loop X */
v >>= 1;
/* Now u and v are both odd, so diff(u, v) is even.
Let u = min(u, v), v = diff(u, v)/2. */
if (u < v) {
v -= u;
} else {
unsigned int diff = u - v;
u = v;
v = diff;
}
v >>= 1;
} while (v != 0);
return u << shift;
}
摘要:
1package dwq.algo.sort;
2
3import java.util.Arrays;
4
5public class Sorting
6{
7
... 阅读全文
摘要: package com.dwq.algo;
import java.util.ArrayList;
public class LongestIncrementSubarray
{
public static void main(String[] arg... 阅读全文
召集)你能想到的最奇妙的算法题是什么?
http://www.matrix67.com/blog/archives/1850
DLX
http://sqybi.com/works/dlxcn/
OI最后的谢幕·18岁新的开始http://blog.sina.com.cn/s/blog_4a443fd701000bko.html
转]怎样做人
|
1、不要推卸责任,哪怕是别人的责任。无论发生任何事情,首先想到自己是不是做错了。如果自己没错(那是不可能的),那就站在对方的角度上,体验一下对方的感受。(本人将此点放在第一条是提醒自己永远都要带着责任心去做事)
2、要让自己适应环境,而不是让环境来适应你。哪怕这是一个非常痛苦的过程。新到一个地方不要急于融入到其中的哪一个圈子中去,等到了足够的时间和考验,属于你的圈子自然就会接纳你。(本人十几年跳到过的地方多不胜数,这是一条最宝贵的原则)
3、大方一点,不会大方就学大方一点。如果大方让你很心痛,你就装大方一点。(不怕大家笑话,我最大方)
4、低调一点,再低调一点,永远低调一点(要比临时工还要低调一点,可能在别人的眼光中你还不如一个新来的临时工呢,本人还没完全做的到)。
5、嘴甜且不吝惜自己的喝彩声,要会夸人,好的夸奖让人觉得很舒服,但不要过份让人反感。(呵呵,这点我就不太行了,不过还可以)
6、如果你觉得最近工作顺利的不得了,那你就要更加小心了。(顺境思危,本人自信做的还行吧
7、礼貌对待人,打招呼的时候要看着对方的眼睛。永远记着自己就是一个不者不扣的小字辈。(做人起码的原则)
8、言多必失,少说多做,人多的场合少说话。(本人吃的亏太多了,这个原则是用教训换来的)
9、不要把别人的好,当做理所当然,要知道感恩图报。(中国人的优秀传统不要忘记了)
10、手高眼低,要有平常心。(没有什么大不了的,好事呀往坏处想,坏事要往好处想,塞翁失马,祸福难测啊)
11、遵守时间,但不要期待别人同样遵守时间。(对自己永远严格要求不会错)
12、信守诺言,但不要轻易许诺,更不要把别人的对你的承诺记在心里并信以为真。(本人提醒大家就算要承诺也要承诺永远做不到的,呵呵)
13、不要向同事借钱,如果借了那就要准时还;不要借钱给同事,如果不得不借,就当作是送给他的好了。(呵呵,别把金钱看的太重,不过没钱万万不能)
14、如果你带领一个团队,在总结工作时要把错误揽在自己的身上,把功劳都记在下属的头上。当上司和下属同时在场的时候你要记得及时表扬你的下属。(批评人的时候一定要在只有你们两个人的情况下才能进行,保持团队的凝聚力最重要)
15、不要在一个同事面前不要说另外一个同事的坏话,要坚持说人的好话,别担心这好话传不到对方的耳中。如果有人在你面前说其他人的坏话,你要保持正常的微笑,不参与评论。(流言止于己,祸从口出是至理名言)
16、避免与同事公开对立,包括公开提出反对意见,激烈的更不可取。(两虎相争,必有一伤,坚持具备平衡的做人处事能力就会自然化解反对意见)
17、经常帮助别人,但是不要让对方觉得是你理所当然应该做的。(好心有时候不会有好结果,但不能因此而灰心,天长地久见人心,一句话:苦心人,天不误!)
18、说实在话会让你倒足八辈子的霉。(本人吃的亏就是一种财富,这是必须坚持的原则)
19、做事先做人,对事不对人;对事无情,同时对人要有情。(公平、公正、公开)
20、经常检查自己是不是又骄傲了,又自负了,又看不起别人了。(一个人再有天大的本事,如果没有别人的合作和帮助都是白搭)
21、忍耐是人生一辈子要修炼的一门功课,要用一辈子的时间去学。(张家名言:张公百忍,另有“百忍堂”为证)
22、尽量不要和同事发生有什么办公室恋情,如果实在避免不了的话,那就在办公室避免任何形式的接触,包括眼神。(兔子不吃窝边草,烦恼总是从身边开始的)
23、待上以敬,待下以宽。(要会拍上司的马屁,这是和上司沟通的重要途径之一,但千万不要弄脏了手)
24、资历非常重要,不要和老家伙们耍心眼斗法,否则你会死的很难看。(中国的社会传统,不会有错)
|
最长递增子序列的求法 LIS (转)
什么是最长递增子序列呢?
问题描述如下:
设L=<a1,a2,…,an>是n个不同的实数的序列,L的递增子序列是这样一个子序列Lin=<aK1,ak2,…,akm>,其中k1<k2<…<km且aK1<ak2<…<akm。求最大的m值。
对于这个问题有以下几种解决思路:
1、把a1,a2,...,an排序,假设得到a'1,a'2,...,a'n,然后求a的a'的最长公共子串,这样总的时间复杂度为o(nlg(n))+o(n^2)=o(n^2);
2、动态规划的思路:
另设一辅助数组b,定义b[n]表示以a[n]结尾的最长递增子序列的长度,则状态转移方程如下:b[k]=max(max(b[j]|a[j]<a[k],j<k)+1,1);
这个状态转移方程解释如下:在a[k]前面找到满足a[j]<a[k]的最大b[j],然后把a[k]接在它的后面,可得到a[k]的最长递增子序列的长度,或者a[k]前面没有比它小的a[j],那么这时a[k]自成一序列,长度为1.最后整个数列的最长递增子序列即为max(b[k] | 0<=k<=n-1);
实现代码如下:
#include <iostream>
using namespace std;
int main()
{
int i,j,n,a[100],b[100],max;
while(cin>>n)
{
for(i=0;i<n;i++)
cin>>a[i];
b[0]=1;//初始化,以a[0]结尾的最长递增子序列长度为1
for(i=1;i<n;i++)
{
b[i]=1;//b[i]最小值为1
for(j=0;j<i;j++)
if(a[i]>a[j]&&b[j]+1>b[i])
b[i]=b[j]+1;
}
for(max=i=0;i<n;i++)//求出整个数列的最长递增子序列的长度
if(b[i]>max)
max=b[i];
cout<<max<<endl;
}
return 0;
}
显然,这种方法的时间复杂度仍为o(n^2);
3、对第二种思路的改进:
第二种思路在状态转移时的复杂度为o(n),即在找a[k]前面满足a[j]<a[k]的最大b[j]时采用的是顺序查找的方法,复杂度为o(n).
设想如果能把顺序查找改为折半查找,则状态转移时的复杂度为o(lg(n)),这个问题的总的复杂度就可以降到nlg(n).
另定义一数组c,c中元素满足c[b[k]]=a[k],解释一下,即当递增子序列的长度为b[k]时子序列的末尾元素为c[b[k]]=a[k].
先给出这种思路的代码,然后再对其做出解释。
#include <iostream>
using namespace std;
int find(int *a,int len,int n)//若返回值为x,则a[x]>=n>a[x-1]
{
int left=0,right=len,mid=(left+right)/2;
while(left<=right)
{
if(n>a[mid]) left=mid+1;
else if(n<a[mid]) right=mid-1;
else return mid;
mid=(left+right)/2;
}
return left;
}
void fill(int *a,int n)
{
for(int i=0;i<=n;i++)
a[i]=1000;
}
int main()
{
int max,i,j,n,a[100],b[100],c[100];
while(cin>>n)
{
fill(c,n+1);
for(i=0;i<n;i++)
cin>>a[i];
c[0]=-1;// …………………………………………1
c[1]=a[0];// ……………………………………2
b[0]=1;// …………………………………………3
for(i=1;i<n;i++)// ………………………………4
{
j=find(c,n+1,a[i]);// ……………………5
c[j]=a[i];// ………………………………6
b[i]=j;//……………………………………7
}
for(max=i=0;i<n;i++)//………………………………8
if(b[i]>max)
max=b[i];
cout<<max<<endl;
}
return 0;
}
对于这段程序,我们可以用算法导论上的loop invariants来帮助理解.
loop invariant: 1、每次循环结束后c都是单调递增的。(这一性质决定了可以用二分查找)
2、每次循环后,c[i]总是保存长度为i的递增子序列的最末的元素,若长度为i的递增子序
列有多个,刚保存末尾元素最小的那个.(这一性质决定是第3条性质成立的前提)
3、每次循环完后,b[i]总是保存以a[i]结尾的最长递增子序列。
initialization: 1、进入循环之前,c[0]=-1,c[1]=a[0],c的其他元素均为1000,c是单调递增的;
2、进入循环之前,c[1]=a[0],保存了长度为1时的递增序列的最末的元素,且此时长度为1
的递增了序列只有一个,c[1]也是最小的;
3、进入循环之前,b[0]=1,此时以a[0]结尾的最长递增子序列的长度为1.
maintenance: 1、若在第n次循环之前c是单调递增的,则第n次循环时,c的值只在第6行发生变化,而由
c进入循环前单调递增及find函数的性质可知(见find的注释),
此时c[j+1]>c[j]>=a[i]>c[j-1],所以把c[j]的值更新为a[i]后,c[j+1]>c[j]>c[j-1]的性质仍然成
立,即c仍然是单调递增的;
2、循环中,c的值只在第6行发生变化,由c[j]>=a[i]可知,c[j]更新为a[i]后,c[j]的值只会变
小不会变大,因为进入循环前c[j]的值是最小的,则循环中把c[j]更新为更小的a[i],当
然此时c[j]的值仍是最小的;
3、循环中,b[i]的值在第7行发生了变化,因为有loop invariant的性质2,find函数返回值
为j有:c[j-1]<a[i]<=c[j],这说明c[j-1]是小于a[i]的,且以c[j-1]结尾的递增子序列有最大的
长度,即为j-1,把a[i]接在c[j-1]后可得到以a[i]结尾的最长递增子序列,长度为(j-1)+1=j;
termination: 循环完后,i=n-1,b[0],b[1],...,b[n-1]的值均已求出,即以a[0],a[1],...,a[n-1]结尾的最长递
增子序列的长度均已求出,再通过第8行的循环,即求出了整个数组的最长递增子序列。
仔细分析上面的代码可以发现,每次循环结束后,假设已经求出c[1],c[2],c[3],...,c[len]的值,则此时最长递增子序列的长度为len,因此可以把上面的代码更加简化,即可以不需要数组b来辅助存储,第8行的循环也可以省略。
#include <iostream>
using namespace std;
int find(int *a,int len,int n)//修改后的二分查找,若返回值为x,则a[x]>=n
{
int left=0,right=len,mid=(left+right)/2;
while(left<=right)
{
if(n>a[mid]) left=mid+1;
else if(n<a[mid]) right=mid-1;
else return mid;
mid=(left+right)/2;
}
return left;
}
int main()
{
int n,a[100],b[100],c[100],i,j,len;//新开一变量len,用来储存每次循环结束后c中已经求出值的元素的最大下标
while(cin>>n)
{
for(i=0;i<n;i++)
cin>>a[i];
b[0]=1;
c[0]=-1;
c[1]=a[0];
len=1;//此时只有c[1]求出来,最长递增子序列的长度为1.
for(i=1;i<n;i++)
{
j=find(c,len,a[i]);
c[j]=a[i];
if(j>len)//要更新len,另外补充一点:由二分查找可知j只可能比len大1
len=j;//更新len
}
cout<<len<<endl;
}
return 0;
}
|
最长递增部分序列 Longest Ordered Subsequence Extention hoj10027 poj2533
2007-08-21 20:19
求最长递增部分序列是一个比较常见的动态规划题。在导弹拦截等题中都有用到。一般来说就是用经典的O(n^2)的动态规划算法。
算法如下:
设A[i]表示序列中的第i个数,F[i]表示从1到i这一段中以i结尾的最长上升子序列的长度,初始时设F[i] = 0(i = 1, 2, ..., len(A))。则有动态规划方程:F[i] = max{1, F[j] + 1} (j = 1, 2, ..., i - 1, 且A[j] < A[i])。
然而在hoj10027中n的值达到了50000。显而易见经典算法是会超时滴。所以只有另谋出路了。
用一个变量len记录到目前为止所找出来的最长递增序列的长度。另外准备一个数组b[],用这个数组表示长度为j的递增序列中最后一个元素的值。在这里长度为j的递增序列不止一个,我们所要保存是那个最小的。为什么呢?因为最后一个元素越小,那么这个递增序列在往后被延长的机会越大。初始化b[0] = -1;len = 0;从第一个元素a[1]开始 a[i]( 1 <= i <= n)。如果这个元素比len长的序列的最大值大。则把这个元素直接添加到b数组的后面。如果这个元素比b数组的第一个元素还要小则把这个元素赋给b数组的第一个值。否则进行二分查找。当在b数组里面找到一个数比a[i]小,并且他的后面的数大于或等于a[i]则跳出。将a[i]添加到这个数的后面。输出len就可以了。
代码如下:
#include <stdio.h>
#include <string.h>
int main()
{
int a[50001], b[50001];
int i, j, l, r, len, n, mid;
while (scanf("%d", &n) != EOF)
{
for (i = 0; i < n; i++)
scanf("%d", &a[i]);
len = 0;
memset(b, 0, sizeof(int) * 50001);
b[0] = -1;
for (i = 0; i < n; i++)
{
if (a[i] > b[len])
b[++len] = a[i];
else if (a[i] < b[1] )
b[1] = a[i];
else
{
l = 1; r = len;
while (l <= r)
{
mid = (l + r)>>1;
if (a[i] > b[mid] && a[i] <= b[mid + 1])
{
j = mid;
break;
}
if (b[mid] > a[i])
{
r = mid - 1;
}
else
{
j = mid;
l = mid + 1;
}
}
b[j + 1] = a[i];
}
}
printf("%d\n", len);
}
return 0;
|
Java把内存划分成两种:一种是栈内存,一种是堆内存。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。
当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组。
在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。
引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
具体的说:
栈与堆都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
Java的堆是一个运行时数据区,类的(对象从中分配空间。这些对象通过new、newarray、anewarray和multianewarray等 指令建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时 动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本 类型的变量(,int, short, long, byte, float, double, boolean, char)和对象句柄。
栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义:
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找栈中是否有3这个值,如果没找到,就将3存放进来,然后将a指向3。接着处理int b = 3;在创建完b的引用变量后,因为在栈中已经有3这个值,便将b直接指向3。这样,就出现了a与b同时均指向3的情况。这时,如果再令a=4;那么编译器 会重新搜索栈中是否有4值,如果没有,则将4存放进来,并令a指向4;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。要注意这 种数据的共享与两个对象的引用同时指向一个对象的这种共享是不同的,因为这种情况a的修改并不会影响到b, 它是由编译器完成的,它有利于节省空间。而一个对象引用变量修改了这个对象的内部状态,会影响到另一个对象引用变量。
String是一个特殊的包装类数据。可以用:
String str = new String("abc");
String str = "abc";
两种的形式来创建,第一种是用new()来新建对象的,它会在存放于堆中。每调用一次就会创建一个新的对象。
而第二种是先在栈中创建一个对String类的对象引用变量str,然后查找栈中有没有存放"abc",如果没有,则将"abc"存放进栈,并令str指向“abc”,如果已经有“abc” 则直接令str指向“abc”。
比较类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==,下面用例子说明上面的理论。
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true可以看出str1和str2是指向同一个对象的。
String str1 =new String ("abc");
String str2 =new String ("abc");
System.out.println(str1==str2); // false用new的方式是生成不同的对象。每一次生成一个。
因此用第二种方式创建多个“abc”字符串,在内存中其实只存在一个对象而已. 这种写法有利与节省内存空间. 同时它可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String("abc");的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。
另一方面, 要注意: 我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,创建了String类的对象str。担心陷阱!对象可能并没有被创建!而可能只是指向一个先前已经创建的 对象。只有通过new()方法才能保证每次都创建一个新的对象。 由于String类的immutable性质,当String变量需要经常变换其值时,应该考虑使用StringBuffer类,以提高程序效率。
java中内存分配策略及堆和栈的比较
2.1 内存分配策略按照编译原理的观点,程序运行时的内存分配有三种策略,分别是静态的,栈式的,和堆式的.静态存储分配是指在编译时就能确定每个数据目标在运行时刻的存储空间需求,因而在编译时就可以给他们分配固定的内存空间.这种分配策略要求程序代码中不允 许有可变数据结构(比如可变数组)的存在,也不允许有嵌套或者递归的结构出现,因为它们都会导致编译程序无法计算准确的存储空间需求.栈式存储分配也可称为动态存储分配,是由一个类似于堆栈的运行栈来实现的.和静态存储分配相反,在栈式存储方案中,程序对数据区的需求在编译时是完全未知 的,只有到运行的时候才能够知道,但是规定在运行中进入一个程序模块时,必须知道该程序模块所需的数据区大小才能够为其分配内存.和我们在数据结构所熟知 的栈一样,栈式存储分配按照先进后出的原则进行分配。
静态存储分配要求在编译时能知道所有变量的存储要求,栈式存储分配要求在过程的入口处必须知道所有的存储要求,而堆式存储分配则专门负责在编译时或运行时 模块入口处都无法确定存储要求的数据结构的内存分配,比如可变长度串和对象实例.堆由大片的可利用块或空闲块组成,堆中的内存可以按照任意顺序分配和释 放.
2.2 堆和栈的比较
上面的定义从编译原理的教材中总结而来,除静态存储分配之外,都显得很呆板和难以理解,下面撇开静态存储分配,集中比较堆和栈:从堆和栈的功能和作用来通俗的比较,堆主要用来存放对象的,栈主要是用来执行程序的.而这种不同又主要是由于堆和栈的特点决定的:在编程中,例如C/C++中,所有的方法调用都是通过栈来进行的,所有的局部变量,形式参数都是从栈中分配内存空间的。实际上也不是什么分配,只是从栈顶 向上用就行,就好像工厂中的传送带(conveyor belt)一样,Stack Pointer会自动指引你到放东西的位置,你所要做的只是把东西放下来就行.退出函数的时候,修改栈指针就可以把栈中的内容销毁.这样的模式速度最快, 当然要用来运行程序了.需要注意的是,在分配的时候,比如为一个即将要调用的程序模块分配数据区时,应事先知道这个数据区的大小,也就说是虽然分配是在程 序运行时进行的,但是分配的大小多少是确定的,不变的,而这个"大小多少"是在编译时确定的,不是在运行时.堆是应用程序在运行的时候请求操作系统分配给自己内存,由于从操作系统管理的内存分配,所以在分配和销毁时都要占用时间,因此用堆的效率非常低.但是堆的 优点在于,编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间,因此,用堆保存数据时会得到更大的灵活性。事实上,面 向对象的多态性,堆内存分配是必不可少的,因为多态变量所需的存储空间只有在运行时创建了对象之后才能确定.在C++中,要求创建一个对象时,只需用 new命令编制相关的代码即可。执行这些代码时,会在堆里自动进行数据的保存.当然,为达到这种灵活性,必然会付出一定的代价:在堆里分配存储空间时会花 掉更长的时间!这也正是导致我们刚才所说的效率低的原因,看来列宁同志说的好,人的优点往往也是人的缺点,人的缺点往往也是人的优点.
2.3 JVM中的堆和栈JVM是基于堆栈的虚拟机.JVM为每个新创建的线程都分配一个堆栈.也就是说,对于一个Java程序来说,它的运行就是通过对堆栈的操作来完成的。堆栈以帧为单位保存线程的状态。JVM对堆栈只进行两种操作:以帧为单位的压栈和出栈操作。
我们知道,某个线程正在执行的方法称为此线程的当前方法.我们可能不知道,当前方法使用的帧称为当前帧。当线程激活一个Java方法,JVM就会在线程的 Java堆栈里新压入一个帧。这个帧自然成为了当前帧.在此方法执行期间,这个帧将用来保存参数,局部变量,中间计算过程和其他数据.这个帧在这里和编译 原理中的活动纪录的概念是差不多的.从Java的这种分配机制来看,堆栈又可以这样理解:堆栈(Stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有先进后出的特性。
每一个Java应用都唯一对应一个JVM实例,每一个实例唯一对应一个堆。应用程序在运行中所创建的所有类实例或数组都放在这个堆中,并由应用所有的线程 共享.跟C/C++不同,Java中分配堆内存是自动初始化的。Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在堆栈中分配,也 就是说在建立一个对象时从两个地方都分配内存,在堆中分配的内存实际建立这个对象,而在堆栈中分配的内存只是一个指向这个堆对象的指针(引用)而已。
在《编程珠玑》中有详细的讨论。主要出于性能方向改进。
- 二分法很简单吧 ,但要想 一次写对 也不容易吧 ,更何况他的一些扩展应用呢 ,我这里扩展了四种,<P> </P><P>基础知识 还是牢靠的好</P><P> </P>
二分法很简单吧 ,但要想 一次写对 也不容易吧 ,更何况他的一些扩展应用呢 ,我这里扩展了四种,
基础知识 还是牢靠的好
-
-
-
-
-
-
- public class BinarySearch {
-
-
-
-
- public static int b1(int[] array, int v) {
- int left = 0;
- int right = array.length - 1;
- while (left <= right) {
- int middle = (left + right) / 2;
- if (array[middle] == v) return middle;
- if (array[middle] > v)
- right = middle - 1;
- else
- left = middle + 1;
- }
-
- return -1;
-
- }
-
-
-
-
- public static int b2(int[] array, int v) {
- int left = 0;
- int right = array.length - 1;
- while (left < right) {
- int middle = (left + right + 1) / 2;
- if (array[middle] > v)
- right = middle - 1;
- else
- left = middle;
- }
-
- if (array[left] == v)
- return left;
-
- return -1;
-
- }
-
-
-
-
-
- public static int b3(int[] array, int v) {
- int left = 0;
- int right = array.length - 1;
- while (left < right) {
- int middle = (left + right) / 2;
- if (array[middle] < v)
- left = middle + 1;
- else
- right = middle;
- }
-
- if (array[right] == v)
- return right;
-
- return -1;
-
- }
-
-
-
-
-
-
- public static int b4(int[] array, int v, int flag) {
- int left = 0;
- int right = array.length - 1;
- while (left < right) {
- int middle = (left + right) / 2;
- if (array[middle] < v)
- left = middle + 1;
- else
- right = middle;
- }
-
-
- if (array[right] == v)
- return right;
- System.out.println(right - 1 + " -- " + left);
- return -1;
-
- }
-
-
- public static void main(String[] args) {
-
- int[] array = new int[]{1, 2, 3, 4, 10, 16, 16, 16, 16, 16, 16, 18, 110};
-
-
- System.out.println(b1(array, 16));
- System.out.println(b2(array, 16));
- System.out.println(b3(array, 16));
- System.out.println(b4(array, 6, 1));
-
-
- }
- }
/**
* Author: yiminghe
* Date: 2008-10-13
* Time: 23:50:48
* Any problem ,contact yiminghe@fudan.edu.cn.
*/
public class BinarySearch {
//返回中间一个数
//12345666689
// 6 不确定返回哪个6
public static int b1(int[] array, int v) {
int left = 0;
int right = array.length - 1;
while (left <= right) {
int middle = (left + right) / 2;
if (array[middle] == v) return middle;
if (array[middle] > v)
right = middle - 1;
else
left = middle + 1;
}
return -1;
}
//返回重复元素的最后一个数
//123456667
//最后一个6位置返回
public static int b2(int[] array, int v) {
int left = 0;
int right = array.length - 1;
while (left < right) {
int middle = (left + right + 1) / 2;
if (array[middle] > v)
right = middle - 1;
else
left = middle;
}
if (array[left] == v)
return left;
return -1;
}
//返回重复元素的最前一个数
//123456667
//最前一个6位置返回
public static int b3(int[] array, int v) {
int left = 0;
int right = array.length - 1;
while (left < right) {
int middle = (left + right) / 2;
if (array[middle] < v)
left = middle + 1;
else
right = middle;
}
if (array[right] == v)
return right;
return -1;
}
//返回重复元素的最前一个数
//1234566689
//最前一个6位置返回 ,若找不到,显示 比他小的离它最大位置,比它小的离它最小位置
//如 找 7 ,则 输出 最后一个6的位置 和 8 的位置
public static int b4(int[] array, int v, int flag) {
int left = 0;
int right = array.length - 1;
while (left < right) {
int middle = (left + right) / 2;
if (array[middle] < v)
left = middle + 1;
else
right = middle;
}
if (array[right] == v)
return right;
System.out.println(right - 1 + " -- " + left);
return -1;
}
public static void main(String[] args) {
// 0, 1, 2, 3 4 5 6 7
int[] array = new int[]{1, 2, 3, 4, 10, 16, 16, 16, 16, 16, 16, 18, 110};
//array = new int[]{0, 6};
//array = new int[]{6, 7};
System.out.println(b1(array, 16));
System.out.println(b2(array, 16));
System.out.println(b3(array, 16));
System.out.println(b4(array, 6, 1));
}
}
Java AIO初探(异步网络IO)
按照《Unix网络编程》的划分,IO模型可以分为:阻塞IO、非阻塞IO、IO复用、信号驱动IO和异步IO,按照POSIX标准来划分只分为两类:同步IO和异步IO.如何区分呢?首先一个IO操作其实分成了两个步骤:发起IO请求和实际的IO操作,同步IO和异步IO的区别就在于第二个步骤是否阻塞,如果实际的IO读写阻塞请求进程,那么就是同步IO,因此阻塞IO、非阻塞IO、IO服用、信号驱动IO都是同步IO,如果不阻塞,而是操作系统帮你做完IO操作再将结果返回给你,那么就是异步IO.阻塞IO和非阻塞IO的区别在于第一步,发起IO请求是否会被阻塞,如果阻塞直到完成那么就是传统的阻塞IO,如果不阻塞,那么就是非阻塞IO.
Java nio 2.0的主要改进就是引入了异步IO(包括文件和网络),这里主要介绍下异步网络IO API的使用以及框架的设计,以TCP服务端为例。首先看下为了支持AIO引入的新的类和接口:
java.nio.channels.AsynchronousChannel标记一个channel支持异步IO操作。
java.nio.channels.AsynchronousServerSocketChannel ServerSocket的aio版本,创建TCP服务端,绑定地址,监听端口等。
java.nio.channels.AsynchronousSocketChannel面向流的异步socket channel,表示一个连接。
java.nio.channels.AsynchronousChannelGroup异步channel的分组管理,目的是为了资源共享。一个AsynchronousChannelGroup绑定一个线程池,这个线程池执行两个任务:处理IO事件和派发CompletionHandler.AsynchronousServerSocketChannel创建的时候可以传入一个AsynchronousChannelGroup,那么通过AsynchronousServerSocketChannel创建的AsynchronousSocketChannel将同属于一个组,共享资源。
java.nio.channels.CompletionHandler异步IO操作结果的回调接口,用于定义在IO操作完成后所作的回调工作。AIO的API允许两种方式来处理异步操作的结果:返回的Future模式或者注册CompletionHandler,我更推荐用CompletionHandler的方式,这些handler的调用是由AsynchronousChannelGroup的线程池派发的。显然,线程池的大小是性能的关键因素。AsynchronousChannelGroup允许绑定不同的线程池,通过三个静态方法来创建:public static AsynchronousChannelGroup withFixedThreadPool(int nThreads,
ThreadFactory threadFactory)
throws IOException
public static AsynchronousChannelGroup withCachedThreadPool(ExecutorService executor,
int initialSize)
public static AsynchronousChannelGroup withThreadPool(ExecutorService executor)
throws IOException
需要根据具体应用相应调整,从框架角度出发,需要暴露这样的配置选项给用户。
在介绍完了aio引入的TCP的主要接口和类之后,我们来设想下一个aio框架应该怎么设计。参考非阻塞nio框架的设计,一般都是采用Reactor模式,Reacot负责事件的注册、select、事件的派发;相应地,异步IO有个Proactor模式,Proactor负责CompletionHandler的派发,查看一个典型的IO写操作的流程来看两者的区别:
Reactor: send(msg) -> 消息队列是否为空,如果为空 -> 向Reactor注册OP_WRITE,然后返回 -> Reactor select -> 触发Writable,通知用户线程去处理 ->先注销Writable(很多人遇到的cpu 100%的问题就在于没有注销),处理Writeable,如果没有完全写入,继续注册OP_WRITE.注意到,写入的工作还是用户线程在处理。
Proactor: send(msg) -> 消息队列是否为空,如果为空,发起read异步调用,并注册CompletionHandler,然后返回。 -> 操作系统负责将你的消息写入,并返回结果(写入的字节数)给Proactor -> Proactor派发CompletionHandler.可见,写入的工作是操作系统在处理,无需用户线程参与。事实上在aio的API中,AsynchronousChannelGroup就扮演了Proactor的角色。
CompletionHandler有三个方法,分别对应于处理成功、失败、被取消(通过返回的Future)情况下的回调处理:
public interface CompletionHandler {
void completed(V result, A attachment);
void failed(Throwable exc, A attachment);
void cancelled(A attachment);
}
其中的泛型参数V表示IO调用的结果,而A是发起调用时传入的attchment.
在初步介绍完aio引入的类和接口后,我们看看一个典型的tcp服务端是怎么启动的,怎么接受连接并处理读和写,这里引用的代码都是yanf4j 的aio分支中的代码,可以从svn checkout,svn地址: http://yanf4j.googlecode.com/svn/branches/yanf4j-aio
第一步,创建一个AsynchronousServerSocketChannel,创建之前先创建一个AsynchronousChannelGroup,上文提到AsynchronousServerSocketChannel可以绑定一个AsynchronousChannelGroup,那么通过这个AsynchronousServerSocketChannel建立的连接都将同属于一个AsynchronousChannelGroup并共享资源:this.asynchronousChannelGroup = AsynchronousChannelGroup。withCachedThreadPool(Executors.newCachedThreadPool(),this.threadPoolSize);然后初始化一个AsynchronousServerSocketChannel,通过open方法:this.serverSocketChannel = AsynchronousServerSocketChannel。open(this.asynchronousChannelGroup);通过nio 2.0引入的SocketOption类设置一些TCP选项:this.serverSocketChannel。setOption(StandardSocketOption.SO_REUSEADDR,true);this.serverSocketChannel。setOption(StandardSocketOption.SO_RCVBUF,16*1024);
绑定本地地址:
this.serverSocketChannel。bind(new InetSocketAddress("localhost",8080), 100);其中的100用于指定等待连接的队列大小(backlog)。完了吗?还没有,最重要的监听工作还没开始,监听端口是为了等待连接上来以便accept产生一个AsynchronousSocketChannel来表示一个新建立的连接,因此需要发起一个accept调用,调用是异步的,操作系统将在连接建立后,将最后的结果——AsynchronousSocketChannel返回给你:
public void pendingAccept(){
if (this.started this.serverSocketChannel.isOpen()) { this.acceptFuture = this.serverSocketChannel.accept(null,
new AcceptCompletionHandler());
} else {
throw new IllegalStateException("Controller has been closed");
}
注意,重复的accept调用将会抛出PendingAcceptException,后文提到的read和write也是如此。accept方法的第一个参数是你想传给CompletionHandler的attchment,第二个参数就是注册的用于回调的CompletionHandler,最后返回结果Future.你可以对future做处理,这里采用更推荐的方式就是注册一个CompletionHandler.那么accept的CompletionHandler中做些什么工作呢?显然一个赤裸裸的AsynchronousSocketChannel是不够的,我们需要将它封装成session,一个session表示一个连接(mina里就叫IoSession了),里面带了一个缓冲的消息队列以及一些其他资源等。在连接建立后,除非你的服务器只准备接受一个连接,不然你需要在后面继续调用pendingAccept来发起另一个accept请求:
private final class AcceptCompletionHandler implements
CompletionHandler {
@Override
public void cancelled(Object attachment){
logger.warn("Accept operation was canceled");
}
@Override
public void completed(AsynchronousSocketChannel socketChannel,
Object attachment){
try {
logger.debug("Accept connection from " + socketChannel.getRemoteAddress());
configureChannel(socketChannel);
AioSessionConfig sessionConfig = buildSessionConfig(socketChannel);
Session session = new AioTCPSession(sessionConfig,AioTCPController.this.configuration。getSessionReadBufferSize(),AioTCPController.this.sessionTimeout);session.start();
registerSession(session);
} catch(Exception e){
e.printStackTrace();logger.error("Accept error", e);
notifyException(e);
} finally {
pendingAccept();
}
@Override
public void failed(Throwable exc, Object attachment) { logger.error("Accept error", exc);
try {
notifyException(exc);
} finally {
pendingAccept();
}
注意到了吧,我们在failed和completed方法中在最后都调用了pendingAccept来继续发起accept调用,等待新的连接上来。有的同学可能要说了,这样搞是不是递归调用,会不会堆栈溢出?实际上不会,因为发起accept调用的线程与CompletionHandler回调的线程并非同一个,不是一个上下文中,两者之间没有耦合关系。要注意到,CompletionHandler的回调共用的是AsynchronousChannelGroup绑定的线程池,因此千万别在回调方法中调用阻塞或者长时间的操作,例如sleep,回调方法最好能支持超时,防止线程池耗尽。
连接建立后,怎么读和写呢?回忆下在nonblocking nio框架中,连接建立后的第一件事是干什么?注册OP_READ事件等待socket可读。异步IO也同样如此,连接建立后马上发起一个异步read调用,等待socket可读,这个是Session.start方法中所做的事情:
public class AioTCPSession {
protected void start0(){
pendingRead();
}
protected final void pendingRead(){
if (!isClosed() this.asynchronousSocketChannel.isOpen()) { if (!this.readBuffer.hasRemaining()) { this.readBuffer = ByteBufferUtils。increaseBufferCapatity(this.readBuffer);
}
this.readFuture = this.asynchronousSocketChannel.read(this.readBuffer, this, this.readCompletionHandler);
} else {
throw new IllegalStateException(
"Session Or Channel has been closed");
}
}
AsynchronousSocketChannel的read调用与AsynchronousServerSocketChannel的accept调用类似,同样是非阻塞的,返回结果也是一个Future,但是写的结果是整数,表示写入了多少字节,因此read调用返回的是Future,方法的第一个参数是读的缓冲区,操作系统将IO读到数据拷贝到这个缓冲区,第二个参数是传递给CompletionHandler的attchment,第三个参数就是注册的用于回调的CompletionHandler.这里保存了read的结果Future,这是为了在关闭连接的时候能够主动取消调用,accept也是如此。现在可以看看read的CompletionHandler的实现:
public final class ReadCompletionHandler implements
CompletionHandler {
private static final Logger log = LoggerFactory
。getLogger(ReadCompletionHandler.class);
protected final AioTCPController controller;
public ReadCompletionHandler(AioTCPController controller){
this.controller = controller;
}
@Override
public void cancelled(AbstractAioSession session){
log.warn("Session(" + session.getRemoteSocketAddress()
+ ")read operation was canceled");
}
@Override
public void completed(Integer result, AbstractAioSession session) { if (log.isDebugEnabled())
log.debug("Session(" + session.getRemoteSocketAddress()
+ ")read +" + result + " bytes");
if(result 0){
session.updateTimeStamp();session.getReadBuffer()。flip();session.decode();session.getReadBuffer()。compact();
}
} finally {
try {
session.pendingRead();
} catch(IOException e){
session.onException(e);session.close();
}
controller.checkSessionTimeout();
}
@Override
public void failed(Throwable exc, AbstractAioSession session) { log.error("Session read error", exc);session.onException(exc);session.close();
}
}
如果IO读失败,会返回失败产生的异常,这种情况下我们就主动关闭连接,通过session.close()方法,这个方法干了两件事情:关闭channel和取消read调用:if (null != this.readFuture) { this.readFuture.cancel(true);
}
this.asynchronousSocketChannel.close(); 在读成功的情况下,我们还需要判断结果result是否小于0,如果小于0就表示对端关闭了,这种情况下我们也主动关闭连接并返回。如果读到一定字节,也就是result大于0的情况下,我们就尝试从读缓冲区中decode出消息,并派发给业务处理器的回调方法,最终通过pendingRead继续发起read调用等待socket的下一次可读。可见,我们并不需要自己去调用channel来进行IO读,而是操作系统帮你直接读到了缓冲区,然后给你一个结果表示读入了多少字节,你处理这个结果即可。而nonblocking IO框架中,是reactor通知用户线程socket可读了,然后用户线程自己去调用read进行实际读操作。这里还有个需要注意的地方,就是decode出来的消息的派发给业务处理器工作最好交给一个线程池来处理,避免阻塞group绑定的线程池。
IO写的操作与此类似,不过通常写的话我们会在session中关联一个缓冲队列来处理,没有完全写入或者等待写入的消息都存放在队列中,队列为空的情况下发起write调用:
protected void write0(WriteMessage message){
boolean needWrite = false;
synchronized (this.writeQueue) { needWrite = this.writeQueue.isEmpty();this.writeQueue.offer(message);
}
if(needWrite){
pendingWrite(message);
}
protected final void pendingWrite(WriteMessage message){
message = preprocessWriteMessage(message);
if (!isClosed() this.asynchronousSocketChannel.isOpen()) { this.asynchronousSocketChannel.write(message.getWriteBuffer(),this, this.writeCompletionHandler);
} else {
throw new IllegalStateException(
"Session Or Channel has been closed");
}
write调用返回的结果与read一样是一个Future,而write的CompletionHandler处理的核心逻辑大概是这样:
@Override
public void completed(Integer result, AbstractAioSession session) { if (log.isDebugEnabled())
log.debug("Session(" + session.getRemoteSocketAddress()
+ ")writen " + result + " bytes");
WriteMessage writeMessage;
Queue writeQueue = session.getWriteQueue();
synchronized(writeQueue){
writeMessage = writeQueue.peek();if (writeMessage.getWriteBuffer() == null || !writeMessage.getWriteBuffer()。hasRemaining()) { writeQueue.remove();if (writeMessage.getWriteFuture() != null) { writeMessage.getWriteFuture()。setResult(Boolean.TRUE);
}
try {
session.getHandler()。onMessageSent(session,writeMessage.getMessage());
} catch(Exception e){
session.onException(e);
}
writeMessage = writeQueue.peek();
}
if (writeMessage != null) {
try {
session.pendingWrite(writeMessage);
} catch(IOException e){
session.onException(e);session.close();
}
compete方法中的result就是实际写入的字节数,然后我们判断消息的缓冲区是否还有剩余,如果没有就将消息从队列中移除,如果队列中还有消息,那么继续发起write调用。
重复一下,这里引用的代码都是yanf4j aio分支中的源码,感兴趣的朋友可以直接check out出来看看: http://yanf4j.googlecode.com/svn/branches/yanf4j-aio.在引入了aio之后,java对于网络层的支持已经非常完善,该有的都有了,java也已经成为服务器开发的首选语言之一。java的弱项在于对内存的管理上,由于这一切都交给了GC,因此在高性能的网络服务器上还是Cpp的天下。java这种单一堆模型比之erlang的进程内堆模型还是有差距,很难做到高效的垃圾回收和细粒度的内存管理。
这里仅仅是介绍了aio开发的核心流程,对于一个网络框架来说,还需要考虑超时的处理、缓冲buffer的处理、业务层和网络层的切分、可扩展性、性能的可调性以及一定的通用性要求。
Eclipse下的重构:
什么是重构
重构是指在保持程序的全部功能的基础上改变程序结构的过程。重构的类型有很多,如更改类名,改变方法名,或者提取代码到方法中。每一次重构,都要执行一系列的步骤,这些步骤要保证代码和原代码相一致。
重构的理由:为整理,为扩展,为优雅。
在Eclipse下的重构:
重构会关联多个文件,在一次重构时,不可再修改并保存文件,重构无法撤销或重做。
Eclipse中的重构类型
如果你看一下Eclipse的重构菜单,可以看到四部分。第一部分是撤销和重做。其他的三部分包含Eclipse提供的三种类型的重构。
第一种类型的重构改变代码的物理结构,像Rename和Move。第二种是在类层次上改变代码结构,例如Pull Up和Push Down。第三种是改变类内部的代码,像Extract Method和Encapsulate Field。这三部分的重构列表如下。
类型1 物理结构
l Rename
l Move
l Change Method signature
l Convert Anonymous Class to Nested
l Convert Member Type to New File:内部类提出一个单独类。
类型2 类层次结构
l Push Down:将父类中方法或成员移到子类。
l Push Up
l Extract Interface
l Generalize Type (Eclipse 3)
l User Supertype Where Possible
类型3 类内部结构
l Inline
l Extract Method
l Extract Local Variable
l Extract Constant
l Introduce Parameter:引进参数替换local var
l Introduce Factory
l Encapsulate Field
表从Eclipse帮助中提取,列出了各种重构支持的Java资源类型,对应的快捷键。
|
名字
|
可应用的Java元素
|
快捷键
|
|
Undo
|
在一次重构后可执行
|
Alt + Shift + Z
|
|
Redo
|
在一次撤销重构后可执行
|
Alt + Shift + Y
|
|
Rename
|
对方法,成员变量,局部变量,方法参数,对象,类,包,源代码目录,工程可用。
|
Alt + Shift + R
|
|
Move
|
对方法,成员变量,局部变量,方法参数,对象,类,包,源代码目录,工程可用。
|
Alt + Shift + V
|
|
Change Method Signature
|
对方法可用。
|
Alt + Shift + C
|
|
Convert Anonymous Class to Nested
|
对匿名内部类可用。
|
|
|
Move Member Type to New File
|
对嵌套类可用。
|
|
|
Push Down
|
对同一个类中成员变量和方法可用。
|
|
|
Pull Up
|
对同一个类中成员变量和方法,嵌套类可用。
|
|
|
Extract Interface
|
对类可用。
|
|
|
Generalize Type
|
对对象的声明可用。
|
|
|
Use Supertype Where Possible
|
对类可用。
|
|
|
Inline
|
对方法,静态final类,局部变量可用。
|
Alt + Shift + I
|
|
Extract Method
|
对方法中的一段代码可用。
|
Alt + Shift + M
|
|
Extract Local Variable
|
对选中的与局部变量相关的代码可用。
|
Alt + Shift + L
|
|
Extract Constant
|
对静态final类变量,选中的与静态final类变量相关的代码可用。
|
|
|
Introduce Parameter
|
对方法中对成员变量和局部变量的引用可用。
|
|
|
Introduce Factory
|
对构造方法可用。
|
|
|
Convert Local Variable to Field
|
对局部变量可用。
|
Alt + Shift +
|
学习一项知识,必须问自己三个重要问题:1. 它的本质是什么。2. 它的第一原则是什么。3. 它的知识结构是怎样的。

pongba的 知其所以然地学习(以算法学习为例)
中他提出了现有算法类书的讲授者是自顶向下思维,理论和知道点都摆出来,再做个细的推理与低阶的知道做个衔接。但是都没有讲算法的思想是怎么发展而来的,数据思维的过程是怎样的。“如果问题求解是一部侦探小说, 那么算法只是结局而已,而思考过程才是情节。”
那到底什么样的才算是授人以渔的呢?波利亚的《如何解题》绝对算是一本,他的《数学的发现》也值得一看。具体到算法书,那就不是光看text book就足够的了,为了深入理解一个算法的来龙去脉前因后果,从一个算法中领悟尽量深刻的东西,则需要做到三件事情:
寻找该算法的原始出处:TAOCP作为一个资料库是绝对优秀的,基础的算法只要你能想到的,几乎都可以在上面找到原始出处。查到原始出处之后(譬如一篇paper),就可以去网上搜来看了。因为最初的作者往往对一个方案的诞生过程最为了解。比如经典数据结构中的红黑树是出了名的令人费解的结构之一,但它的作者Sedgewick一张PPT,给你讲得通通透透,比算法导论上的讲法强上数倍。
原始的出处其实也未必就都推心置腹地和你讲得那么到位:前面说过,算法设计出来了之后人们几乎是不会去回顾整个的思维过程细节的,只把直指目标的那些东西写出来。结果就又是一篇欧几里德式的文章了。于是你就迷失在一大堆“定义”、“引理”、“定理”之中了。这种文章看上去整个写得井井有条,其实是把发明的过程整个给颠倒过来了,我一直就想,如果作者们能够将整个的思路过程写出来,哪怕文字多上十倍,我也绝对会比看那一堆定义定理要容易理解得多。话说回来,怎么办?可以再去网上找找,牛人讲得未必比经典教材上的差。那倘若实在找不出好的介绍呢,就只能自己揣摩了。揣摩的重要性,是怎么说都不为过的。揣摩的一些指导性的问题有:为什么要这样(为什么这是好的)?为什么不是那样(有其它做法吗?有更好的做法吗?)?这样做是最好的吗?(为什么?能证明吗?)这个做法跟其它的什么做法有本质联系吗?这个跟这个的区别是什么?问题的本质是什么?这个做法的本质又是什么?到底本质上是什么东西导致了这个做法如此..?与这个问题类似的还有其它问题吗?(同样或类似的做法也适用吗?)等等。
不仅学习别人的思路,整理自己的思路也是极其重要的:详见《跟波利亚学解题》的“4. 一个好习惯”和“7. 总结的意义”。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/pongba/archive/2008/07/07/2622713.aspx
什么是你的不可替代性和核心竞争力
By 刘未鹏(pongba) | http://blog.csdn.net/pongba
我虽不是经济学专业,但是翻开任何一本经济学的教材,或者直接翻开 wikipedia 的 economics 条目,都会看到物以稀为贵这条铁律。人才作为资源的一种,也是同样的道理。而稀缺性,换种说法也可以叫做不可替代性。一种资源越是稀缺,不可替代性就越强。再加上如果这种资源是一种具有实实在在使用价值的东西(而不是荷兰的郁金香泡沫),那么其价格就会越高。
问题是,如何构筑你的个人知识体系,使得你的知识技能集尽可能成为不可替代的呢?
CSDN 的孟岩先生前段时间发表了一篇博客“技术路线的选择重要但不具有决定性”,用有说服力的数据阐述了技术路线的选择对于个人知识体系的不可替代性并非一个关键因素,文中也提到了这样一段话:
那么核心竞争力是什么?我观察圈子里很多成功和不成功的技术人,提出一个观点,那就是个人的核心竞争力是是他独特的个性知识经验组合。这个行业里拥挤着上百万聪明人,彼此之间真正的不同在哪里?不在于你学的是什么技术,学得多深,IQ多少,而在于你身上有别人没有的独特的个性、背景、知识和经验的组合。如果这种组合,1,绝无仅有;2,在实践中有价值,3,具有可持续发展性,那你就具备核心竞争力。因此,当设计自己的发展路线时,应当最大限度地加强和发挥自己独特的组合,而不是寻求单项的超越。而构建自己独特组合的方式,主要是通过实践,其次是要有意识地构造。关于这个观点,话题太大,我不打算赘述。
孟岩先生在文中没有对这个问题展开叙述。但我一直也在寻思这个问题,后来在 TopLanguage 上一次讨论的时候,把一些想法整理成形。
长话短说,我相信以下的知识技能组合是具有相当程度的不可替代性的:
专业领域技能:成为一个专业领域的专家,你的专业技能越强,在这个领域的不可替代性就越高。这个自是不用多说的。
跨领域的技能:解决问题的能力,创新思维,判断与决策能力,Critical-Thinking,表达沟通能力,Open Mind 等等。
学习能力:严格来说学习能力也属于跨领域的技能,但由于实在太重要,并且跨任何领域,所以独立出来。如何培养学习能力,到目前为止我所知道的最有效的办法就是持续学习和思考新知识。
性格要素:严格来说这也属于跨领域技能,理由同上。一些我相信很重要的性格要素包括:专注、持之以恒、自省(意识到自己的问题所在的能力,这是改进自身的大前提)、好奇心、自信、谦卑(自信和谦卑是不悖的,前者是相信别人能够做到的自己也能够做到,后者是不要总认为自己确信正确的就一定是正确的,Keep an open mind)等等。
关于如何培养这些方面的能力,呃.. 需要学习的东西太多,对于第2项中列出的一些子项,可以参考我上次列的一些资料(《如何清晰地思考》),我自己也在学习之中。另外我在《一直以来伴随我的一些学习习惯》(一,二,三,四)中也提到了一些相关的方法。
注:
以上将个人的核心竞争力分为4个部分,其中每个部分的罗列并不一定详尽,也有可能我忽略了重要的东西或罗列了不重要的东西,所以欢迎补充和纠正。
以上只是我个人所认为的具有相当程度不可替代性的知识技能集,至于是否有更具不可替代性的“装备”,不妨思考。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/pongba/archive/2009/01/14/3776586.aspx
Eclipse中常用的快捷键(最经典的快捷键,就不用多说了)
Ctrl+D: 删除当前行
Ctrl+Alt+↓ 复制当前行到下一行(复制增加)
Ctrl+Alt+↑ 复制当前行到上一行(复制增加)
Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)
Alt+↑ 当前行和上面一行交互位置(同上)
Alt+← 前一个编辑的页面
Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)
Alt+Enter 显示当前选择资源(工程,or 文件 or文件)的属性
Shift+Enter 在当前行的下一行插入空行(这时鼠标可以在当前行的任一位置,不一定是最后)
Shift+Ctrl+Enter 在当前行插入空行(原理同上条)
Ctrl+Q 定位到最后编辑的地方
Ctrl+L 定位在某行 (对于程序超过100的人就有福音了)
Ctrl+M 最大化当前的Edit或View (再按则反之)
Ctrl+/ 注释当前行,再按则取消注释
Ctrl+O 快速显示 OutLine
Ctrl+T 快速显示当前类的继承结构
Ctrl+W 关闭当前Editer
Ctrl+K 参照选中的Word快速定位到下一个
Ctrl+E 快速显示当前Editer的下拉列表(如果当前页面没有显示的用黑体表示)
Ctrl+/(小键盘) 折叠当前类中的所有代码
Ctrl+×(小键盘) 展开当前类中的所有代码
Ctrl+Space 代码助手完成一些代码的插入(但一般和输入法有冲突,可以修改输入法的热键,也可以暂用Alt+/来代替)
Ctrl+Shift+E 显示管理当前打开的所有的View的管理器(可以选择关闭,激活等操作)
Ctrl+J 正向增量查找(按下Ctrl+J后,你所输入的每个字母编辑器都提供快速匹配定位到某个单词,如果没有,则在stutes line中显示没有找到了,查一个单词时,特别实用,这个功能Idea两年前就有了)
Ctrl+Shift+J 反向增量查找(和上条相同,只不过是从后往前查)
Ctrl+Shift+F4 关闭所有打开的Editer
Ctrl+Shift+X 把当前选中的文本全部变为大写
Ctrl+Shift+Y 把当前选中的文本全部变为小写
Ctrl+Shift+F 格式化当前代码
Ctrl+Shift+P 定位到对于的匹配符(譬如{}) (从前面定位后面时,光标要在匹配符里面,后面到前面,则反之)
下面的快捷键是重构里面常用的,本人就自己喜欢且常用的整理一下(注:一般重构的快捷键都是Alt+Shift开头的了)
Alt+Shift+R 重命名 (是我自己最爱用的一个了,尤其是变量和类的Rename,比手工方法能节省很多劳动力)
Alt+Shift+M 抽取方法 (这是重构里面最常用的方法之一了,尤其是对一大堆泥团代码有用)
Alt+Shift+C 修改函数结构(比较实用,有N个函数调用了这个方法,修改一次搞定)
Alt+Shift+L 抽取本地变量( 可以直接把一些魔法数字和字符串抽取成一个变量,尤其是多处调用的时候)
Alt+Shift+F 把Class中的local变量变为field变量 (比较实用的功能)
Alt+Shift+I 合并变量(可能这样说有点不妥Inline)
Alt+Shift+V 移动函数和变量(不怎么常用)
Alt+Shift+Z 重构的后悔药(Undo)
Ctrl+Shift+U 选择选中的文字后非常类似于UE的列表查询
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/f128690011/archive/2007/06/24/1664354.aspx
1:改变数据库的默认编码配置,在MYSQL的安装目录中,找到my.ini,修改默认编码为:default-character-set=utf8
2:建立数据库时,CREATE DATABASE ms_db CHARACTER SET utf8 COLLATE utf8_general_ci;
3:执行脚本:指定编码格式set names utf8(注意,不是UTF-8
4:如果你采用的是外部接入的方式,在连接中确定请求的编码格式如:jdbc:mysql://localhost:3306 /ms_db?useUnicode=true&characterEncoding=UTF-8(不要出现任何空格,否则出错)
5:set character_set_results=gbk;(解决命令行乱码问题);
--------------------------------------------------------------------------------
问题的关键在于数据导出、导入时要做到所使用的字符集相一致:
1、mysqldump 的 default-character-set变量;
2、mysql 的--default-character-set变量;
3、mysqld的 Db characterset变量。
例如:备份使用latin1字符集则恢复时也要使用该字符集并且数据库的缺省字符集也要是该字符集,即latin1. 换成gbk也应该一样.
乱码的根源在于字符集的不一致:操作系统(Windows为gbk,Linux是UTF-8),数据库(CREATE DATABASE db_name DEFAULT CHARACTER SET gbk 或者CREATE DATABASE db_name DEFAULT CHARACTER SET latin1)使用图形界面是就更要注意其缺省配置。
--------------------------------------------------------------------------------
在这里我把自己知道的东东贴出来,还望大家多多提意见,补充,谢谢~~
show variables like 'character%';查看字符编码
--更改字符集
SET character_set_client = utf-8 ;
SET character_set_connection = utf-8 ;
SET character_set_database = utf-8 ;
SET character_set_results = utf-8 ;
SET character_set_server = utf-8 ;
SET collation_connection = utf8 ;
SET collation_database = utf8 ;
SET collation_server = utf8 ;
MySQL的字符集支持(Character Set Support)有两个方面:字符集(Character set)和排序方式(Collation)。对于字符集的支持细化到四个层次:
服务器(server),数据库(database),数据表(table)和连接(connection)。
1.MySQL默认字符集:MySQL对于字符集的指定可以细化到一个数据库,一张表,一列.传统的程序在创建数据库和数据表时并没有使用那么复杂的配置,它们用的是默认的配置. (1)编译MySQL 时,指定了一个默认的字符集,这个字符集是 latin1;(2)安装MySQL 时,可以在配置文件 (my.ini) 中指定一个默认的的字符集,如果没指定,这个值继承自编译时指定的;(3)启动mysqld 时,可以在命令行参数中指定一个默认的的字符集,如果没指定,这个值继承自配置文件中的配置,此时 character_set_server 被设定为这个默认的字符集;(4)当创建一个新的数据库时,除非明确指定,这个数据库的字符集被缺省设定为character_set_server; (5)当选定了一个数据库时,character_set_database 被设定为这个数据库默认的字符集;(6)在这个数据库里创建一张表时,表默认的字符集被设定为 character_set_database,也就是这个数据库默认的字符集;(7)当在表内设置一栏时,除非明确指定,否则此栏缺省的字符集就是表默认的字符集;如果什么地方都不修改,那么所有的数据库的所有表的所有栏位的都用 latin1 存储,不过我们如果安装 MySQL,一般都会选择多语言支持,也就是说,安装程序会自动在配置文件中把 default_character_set 设置为 UTF-8,这保证了缺省情况下,所有的数据库的所有表的所有栏位的都用 UTF-8 存储。
2.查看默认字符集(默认情况下,mysql的字符集是latin1(ISO_8859_1)通常,查看系统的字符集和排序方式的设定可以通过下面的两条命令:
mysql> SHOW VARIABLES LIKE 'character%';
+--------------------------+---------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | D:"mysql-5.0.37"share"charsets" |
+--------------------------+---------------------------------+
mysql> SHOW VARIABLES LIKE 'collation_%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
+----------------------+-----------------+
3.修改默认字符集
(1) 最简单的修改方法,就是修改mysql的my.ini文件中的字符集键值,
如 default-character-set = utf8
character_set_server = utf8
修改完后,重启mysql的服务,service mysql restart
使用 mysql> SHOW VARIABLES LIKE 'character%';查看,发现数据库编码均已改成utf8
+--------------------------+---------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | D:"mysql-5.0.37"share"charsets" |
+--------------------------+---------------------------------+
(2) 还有一种修改字符集的方法,就是使用mysql的命令
SET character_set_client = utf8 ;
SET character_set_connection = utf8 ;
SET character_set_database = utf8 ;
SET character_set_results = utf8 ;
SET character_set_server = utf8 ;
mysql> SET collation_connection = utf8 ;
mysql> SET collation_database = utf8 ;
mysql> SET collation_server = utf8 ;
一般就算设置了表的默认字符集为utf8并且通过UTF-8编码发送查询,你会发现存入数据库的仍然是乱码。问题就出在这个connection连接层上。解决方法是在发送查询前执行一下下面这句:
SET NAMES 'utf8';
它相当于下面的三句指令:
SET character_set_client = utf8;
SET character_set_results = utf8;
SET character_set_connection = utf8;
不知道什么原因,我在自己机器上把上述三个字符集都设置成utf8后,查询中文结果还是乱码,只有把character_set_results设置成GBK之后才能从命令行正常显示中文.
set character_set_results=GBK;
---------------------------------------------------------------
如果用eclipse :
点击Window-->Preferences,展开General-->WorkSpace,看到左边的Text file encoding没有,默认的设定是简体中文编码(gbk,gb2312这样),而linux下面呢,是UTF-8。
当你新建一个项目,希望使用和WorkSpace不同编码,请右击你的项目,选择Properties,点击Resource,看到Text file encoding了吧,点击Other,选择UTF-8
最后,将my.ini中的两处default 的字符集改为gbk不要使用utf8
JUnit 设计的目的就是有效地抓住编程人员写代码的意图,然后快速检查他们的代码是否与他们的意图相匹配。 JUnit 发展至今,版本不停的翻新,但是所有版本都一致致力于解决一个问题,那就是如何发现编程人员的代码意图,并且如何使得编程人员更加容易地表达他们的代码意图。JUnit 4.4 也是为了如何能够更好的达到这个目的而出现的。
JUnit 4.4 主要提供了以下三个大方面的新特性来更好的抓住编程人员的代码意图:
1)提供了新的断言语法(Assertion syntax)——assertThat 。
*新的断言语法主要提供了assertThat,其操作示例:
// 联合匹配符not和equalTo表示“不等于”
assertThat( something, not( equalTo( "developer" ) ) );
// 联合匹配符not和containsString表示“不包含子字符串”
assertThat( something, not( containsString( "Works" ) ) );
// 联合匹配符anyOf和containsString表示“包含任何一个子字符串”
assertThat(something, anyOf(containsString("developer"), containsString("Works")));
JUnit 4.4 默认提供一些可读的描述性错误信息
String s = "hello world!";
assertThat( s, anyOf( containsString("developer"), containsString("Works") ) );
// 如果出错后,系统会自动抛出以下提示信息:
java.lang.AssertionError:
Expected: (a string containing "developer" or a string containing "Works")
got: "hello world!"
2)提供了假设机制(Assumption)。
提供语句assumeThat, assumeTrue,assumeNotNull 和 assumeNoException。
*assumeThat作用:语法同assertThat,语义当假设成立时执行其后语句。
应用:1、改变条件,可对某些测试用例选择性执行。2、
*使用: assume* 假设语句,必须得 import static org.junit.Assume.*;。 如果引用了第三方 hamcrest 的匹配符库,必须得 import static org.hamcrest.Matchers.*;,如果引用 JUnit 4.4 自带的匹配符库,需要 import static org.hamcrest.CoreMatchers.*;。
3)提供了理论机制(Theory)
Theory机制比较复杂,一般也用不到。
丰田模式,如果我的理解没有错,其最核心最基本的概念是“集体思考”,强调可视性和持续改进。展开来说,比较有趣的几点:
1- 问题是大家共同的,有问题大家一起解决。
2- 在出现问题的现场解决问题而不是在办公桌。
3- 任何人都可以指手画脚,发现质量问题,工人有权直接停掉生产线。
4- 持续发现问题并解决。
5- 建立共识。
6- 对人,尤其是一线工人的尊重。
7- 危机意识。
《谈话的力量》 by Alan Garner
一、 通过问题促进交谈
1. 提出开放式问题而非封闭式
2. 避免问题过于宽泛
3. 一开始的问题要简单、对方易于回答、感兴趣回答,不要过于难
4. 事先做好准备
5. 提问时不要在别人回答之前就包含个人的观点和立场
二、 表达诚实的称赞
1. 鼓励喜欢的行为比惩罚不喜欢的行为更有效
2. 将称赞说得更具体一些
3. 在称赞中加入对方名字,让他觉得是针对他说的而不是敷衍
4. 可以在称赞后加上一个相关问题,帮对方接受称赞
5. 称赞别人时不要有任何索取
6. 切忌一味称赞,否则显得太假
7. 不要用对方称赞自己的话回答对方
8. 适当向第三方称赞另一个人(间接称赞)
9. 积极接受别人对自己的称赞
三、 倾听别人的话语
1. 积极倾听,就是告诉别人你对他发出的信息的理解(“你是说……,是么?”),尤其是不太确定对方意思的时候,以及对方传递重要信息或者感情上的信息时。
四、 利用自由信息
1. 学会利用自由信息(即你没有主动要求也没有预料到的信息)去展开话题
五、 让别人知道你
1. 学会自我透露。通常的交流经历四个阶段:套话、事实、意见、感受,自我透露的程度逐渐提高
2. 自我透露时内容要具体,也可以适当展示自己的缺点和反面
3. 自我透露切忌观点不明确,如不用“我”而说“你”,不用陈述句而用问句,等
六、 开始一段谈话
1. 通过谈论环境、对方、自己来开始一段谈话,通常谈论环境和对方比谈论自己更容易开始
七、 发出可能被接受的邀请
1. 要学会用双重视角,发出对方可能感兴趣的邀请
2. 一开始的邀请要随意一些,从小处着手,不要让对方觉得邀请参加的活动意义太大太重要而不敢随意参加
八、 积极地接受批评
1. 当别人批评自己时,不要急于逃避、反击
2. 当别人批评自己时,首先要询问具体内容,对时间、地点、原因、人物、什么、怎么样提问,搞清楚别人到底为啥批评自己
3. 第二步要同意对方的批评,可以同意对方批评的事实,如果不同意,则要同意对方有表达意见的权利
4. 第三步可以通过自我透露表明自己的立场
九、 拒绝别人的操纵
1. “破唱片”的方法:不管你别人说什么,都可以同意他们的意见或给予他们表达意见的权利,但是自始至终保持一贯的态度,重复同样的话表达拒绝
十、 要求改变
1. 希望别人做出改变时,可以利用如下公式:“我不太满意,你【说明其行为】,(使得)【指出后果】,所以我觉得【描述自己的感受】。
2. 说明其行为的时候,尽量采取客观的态度,说得具体一些,让对方明确领会你的意思,一次只需提一种行为,不要说太多,最好只专注现在发生或刚刚发生不久的行为,不要翻出“陈芝麻烂谷子”的事,不要抱怨对方“总是……”,不要妄加揣测和推断对方的意图
3. 指出后果时,要用积极的态度
4. 描述感受时,要注意用简洁的语言,不要用粗俗的语言
5. 作完以上陈述后要暂停一下,给对方以回想的时间,从而可能提出令人满意的解决方案
6. 如果没有成功,要进行直接要求,要具体要求对方改变某一个做法,一次只提一件事
7. 如果还没有成功,则采用“破唱片”做法,不断重复要求,直到成功
8. 可能对方无法完全按照你的要求去做,这时会进行商谈,商谈过程中要始终牢记你最初的目的——希望某种需要得到满足或者某种权利受到尊重,解决办法可以根据双方反馈进行调整,但一定要满足最初的目的
十一、 通过动作表情达意
1. 注意保持合适的个人空间
2. 表达喜欢的感情可以采用SOFTEN方法:Smile微笑、Open posture开放的姿态(同时和两个人说话时可以上半身对一个人小半身正对另一个人)、Forward lean身体前倾、Touch身体接触、Eye contact眼神交流(对方瞳孔放大表明喜欢你)、Nod点头
十二、 减少社交场合中的紧张心理
1. 紧张的原因是因为有如下几种信念:逃避、恐惧、以偏概全、要求过高。
2. 挑战逃避意识——追问自己有什么证据表明是这件事情让自己紧张;自己对自己叫“停”,从而驱逐头脑中存在的逃避想法
3. 挑战恐惧心理——想想自己头脑中的“可怕”事件发生的可能性有多大(通常会很小);想到最坏的结果,并用感情色彩较弱的词语去描述它(最坏也就是……,顶多只是称得上倒霉……)
4. 挑战以偏概全的习惯——不仅不要对自己“贴标签”也不要对别人“贴标签”,问问自己“贴标签”的证据在哪里,往往发现没有合理的证据;过去发生的事情不代表将来一定发生,失败过并不代表将来不能成功
5. 挑战要求过高的心理——不要要求完美,也不要坚持遵循对自己不利的准则(过去一直以某种方式做事并不意味着必须一直这样做);不要要求别人遵循你自己的准则,别人是你不可控的
十三、 有计划地去努力
1. 设定明确的目标——目标要明确(描述的行为不会与其他行为混淆);要可证实(即使旁观者也可以确定你是否实现了目标);要肯定(“我要……”而不是“我不能/要……”);要可计量;要明白目标的实现完全取决与你自己的行动(不要根据别人的回应来判断是否成功)
2. 划分目标的等级——多个目标需要实现时,分难易,先做最容易的
3. 增加步骤——当一个目标较难时,可以细分为多个步骤,一步一步去实现
4. 预先演练——可以在付诸行动前自己演习
5. 奖励自己——设定目标时同时设定实现目标后对自己的奖励,并切实兑现奖励(奖励要是自己真正想要的),不要吝惜达成目标后对自己的表扬
Learning from "Apprentice"
Tips learned:
1. If you are a leader, do be decisive.
2. Never underestimate the enemy.
3. As a leader, you should be able to manage your team members.
Suggestions from Mr. Trump
1. Deal good with boss.
2. People needed: can handle pressure, creative.
3. Respect from winning.
4. 领导常常需要力排众议。Lead with authority.
5. A leader should be decisive.
6. 有时候做生意靠直觉。Business comes from instinct.
7. Always listen to others, though you may not do as they say.
8. Go big or go home. Think it big.
9. Sell your ideas.
10. Know when to fold.如果一个想法不切实际或效果不理想,即使它是你一手想起来的,也要适时放弃。
11. There is no failure, you can never quit.
12. I don’t need choker.(怯场的人)
13. You should love what you do.
14. A leader should be able to control his underlings.
15. Always focus in the goal.
16. Getting along with people is very important.
17. Be flexible; be able to change.
18. A leader should know how to inspire his/her staff.
19. Good leader knows the strength and weaknesses of his/her employees.
20. Good deal is all about money; money is what proves your success.
21. Members in the best team push each other. You should push your team members to perform their best.
22. Get to the point, don’t waste time.
23. Loyalty is very important.
24. Great business man knows how to balance creativity and feasibility.
25. Always stand up for yourself.
26. A deal is a deal. Once you shake hands with others, never break up the “hand-shake” for no reason.
27. A god is in the details.
28. Never beg when you sell things.
29. You should believe what you sell, or else you will sell nothing.
30. Energy is very crucial.
31. You will not succeed without passion.
作者 陈怀临 | 2009-06-27 07:53 | 类型 专题分析 | 21条用户评论 »
|
【编者注:这是我阅读复旦大学计算机系博士生孙贺的主页和博客时,发现的其讲话稿。阅读之后,对其思想的深邃颇为欣赏。另外我对其文中提到的几个哲学家也都不知道,估计在小孙的眼里,陈首席基本上属于文盲的范畴。有兴趣的读者可参阅:知识分子的故园】
非常感谢复旦大学本科生资助委员会给我提供了这样一个机会,使我很荣幸的来和大家进行交流,提出自己的一些想法。
今天我和大家谈的倒不是我个人的在专业领域的看法,我主要是想和大家谈一谈作为当代的知识分子,应该扮演着一个什么样的角色。为什么要谈这样一个问题呢?因为我们发现今天知识分子的意义和两百年前或者三百年前已经有了明显的不同。比如在十七八世纪,许许多多的知识分子,比如帕斯卡、康德、卢梭,他们把他们的研究和实践结合在一起。我们首先以说帕斯卡为例,我在这里提到的帕斯卡,就是所有学过初等数学,都知道“帕斯卡三角形”的那个帕斯卡。他是一个法国科学家,为了帮助工作繁忙的父亲,他设计了法国的第一台计算器。他利用自己发明的气压计证明了真空的存在。不仅如此,他的《沉思录》被认为是当代人和思想的第一次对话。他还是一个虔诚的天主教徒。
不幸的是,他在三十六岁时疯了,在后面的三十七年里一直住在疯人院里。我们再来看康德。在三十一岁那一年,康德写下了《自然通史与天体理论,或根据牛顿定律研究整个宇宙的结构及其力学起源》的非凡著作。之后,康德还写过《将负数引入哲学的尝试》等论文,从此开始了数学和物理学的研究。众所周知,康德最为重要的著作就是三大批判,即《纯粹理论批判》,《实践理论批判》和《判断力批判》。除此以外,康德还有一系列关于教育学的著作,例如《论教育学》、《系科之争》等。康德的主要著作还包括《使用人类学》。我们很难想象一个终身生活在哥尼斯堡这样一个小镇的单身汉,在他八十岁的生活中没有离开过这个小镇一步。在漫长的八十年的单身寂寞的生活中,他思考了人生中一切的伟大的实践。在他的墓碑上有这样的一句话:“有两样东西,我们越是经常不断地思索他们,他们就越是唤起一种始终新颖和日益增长的赞叹和敬畏充溢我们的心灵,那就是我头顶的星空和我心中的道德律。他们向我印证:上帝在我头顶,也在我心中。”我提及的这些事实意在说明:今天的知识分子和两百年前传统意义上的知识分子在形式上出现了非常显著的差别。关于这一点,五十年前的德国哲学家和精神病学家卡尔•雅思贝斯在《在时代的精神生活》这本书中,就已经一针见血地提出了。
尽管雅氏描绘的是二十世纪三四十年代的欧洲社会,但在今天看来,他的针砭时弊、一针见血的分析同样适用于中国现实社会。一言以蔽之,他所阐述的就是在现代社会我们的知识已经瓦解,人的生活缺乏精神上的向导。文艺分析时期,一个人的学术研究和生命实践始终是结合在一起的。但是在今天,我们并不这样来看代学术研究。雅斯贝斯的分析非常精辟,他说,我们的一种以前从事高尚研究的快乐,被一种从事狭窄技术领域研究的快感所取代。在这样的情况下,一种可怕的情况出现了:我们不再认为学术研究是崇高的。比如今天我问大家,大家儿时的梦想是什么,可能对在场的各位同学而言,你们会说童年时代的纯真的梦想是成为一个科学家,因为在那时的我们内心深处科学家代表了一种崇高。但是在今天,当各位从事学术研究的时候,你们会发现:你们现在所走的学术道路与你们儿时的梦想相差甚远。为什么?我们钻入到一个狭窄的领域,我们在进行研究,但是这种研究并不能给我们带来普遍的幸福。
于是在这一点上一个很关键的问题出现了。我们就要问:这种情况是如何发生的?对于二十年前的中国知识分子而言,他们的存在首先代表了一种人文情怀。但是这种情况在今天已经消失殆尽。今天的中国社会在一定程度上、或者说今天的中国人和全世界的许许多多人,没有两三百年前的人更富有想象力,更能耐得住寂寞。今天的人们听任于娱乐的安排,我们上网,聊天,看电视,然后有各种各样的休闲手段。你如果寂寞的话,你会有一个各种各样的方式去排除寂寞。叔本华说过一句话 “孤独是一种伟大的情感”,但是今天的人已经甚少有一种真正的孤独的感觉。大家有的是什么,是郁闷,对吧?我们有的是郁闷。但是对于今天的人们,更为可怕的是,今天中国的一部分知识分子,居然走上了模特在T字台上所走的猫步。比如说于丹,等等。正是在这一点上,我们看到:今天的知识分子已经与一种作为知识分子本身的使命感相隔绝了。这种使命感是什么?我作为一个知识分子,我要去为国家而奉献、牺牲。天下兴旺,匹夫有责的中国古代人文精神在今天的知识分子中悄然消失了。所以,每当我忆起起俄罗斯文学的时候,俄罗斯知识分子的那种流亡意识总是给予我深刻的印象和泪如泉涌的感动。即一个知识分子,他可以抛弃生命中物质的一切,也要保守某种精神生活。一旦人们承认人的生活不是兽性的,而是文明的,那么他在世界中的生活本质上讲就应该是一种精神生活。
海德格尔曾经说过:人是追求生活意义的生物。如果一个人在他的生活中找不到生命的意义,他宁愿去自杀,哪怕他的身边全是面包。如果我们试图理解这样一句话,一个自然的问题就会被立即提出:即这种生命的意义应该如何去寻找?其实在人类的启蒙时代,就曾经提到过这样的问题。即人类在文明开始之初,他们就已经想到过一个人的生活必须有一种深刻的意义在其中。为什么,我们今天来想一下:如果我们认为,我们出生之前的一切,和我们毫无关系,在我们死亡之后的一切,和我们也没有任何关系。那么我们的生命是不是没有任何意义,我们在世界中的生活就只剩下吃喝玩乐。但是事实并不是如此。所以在东西方文明的早期,人们同时想到了同一个问题:即在终极上,人的生活应该是有意义的。从这一点出发,东西方文明对于这样一个绝对意义,想出了两个不同的途径,即起源于东方、盛行于西方的基督教文明和中国的儒学思想。在西方的基督教世界中,西方人认为:倘若有一个绝对的上帝在我们中间,人生就可以获得形而上学的意义。因为在这刻,人们可以自然地产生一种超验之思。我们可以,把一个人的生活放到一个上帝的维度,因此人就有一个全能的上帝去审视字词。在这时,他就可以约束着我们。与此同时,中国的儒家学派,将人的根本意义,集中到了礼教,伦理这一层面,这是一种脱离了行而上学的思辨。所以黑格尔在他的《哲学演讲录》的第一卷中就曾写过:”中国没有真正的哲学,有的只是伦理学。”可悲的是,今天的中国人,还在信仰着以伦理为基础的东西。我们有没有深刻地思考过,我们这种伦理,它的合理之处在哪里?也许这是我们需要真正思考的问题。今天许多的中国学生,缺少一种独立思考的精神,我在这里,我称其为一种精神,而不是一种能力,因为这本身非常重要,无法通过世俗教育去培养。在中国的儒家学派中,我们说“不孝有三,无后为大”,“父母在,不远游,游必有方”,等等。我们也都知道,为了纪念投汨罗江自尽的现实主义诗人屈原,中国传统中于是又了端午节,并有了吃粽子、赛龙舟的习俗。我们称屈原是一个伟大的现实主义诗人。原因何在?不妨去读屈原的《天问》,他百思不得其解要问的是什么?在我看来,他问核心的是在这样一个以儒教为统治的国家中,王权的合法性在哪里。屈原最早认识到了这一点,对一个人而言,是一种非常痛苦的事实。因为一个人生活在儒家思想中,却不能为以这种思想为生活的合理性提供依据。今天的人们一方面去宣扬儒教,一方面我们去纪念屈原,这不是一个非常可笑的事实吗?我们拿着伦理不放,但我们今天的人们没有真正地去思考,这种伦理的合理性在哪里?
基督教文明从公元五世纪到十五世纪,经历了漫长的一千年中世纪。一千年后,欧洲迎来了文艺复兴。与此同时,近代的基督教社会有了一次又一次的改革。直到十九世纪末尼采“杀死”了上帝。尼采曾经写过《查拉图斯特拉如是说》这本书,有人说这本书的出版把无数人的宗教信仰一劳永逸地消除了。尼采是种非常自信的人。他曾经在一本书的前言中写到:我的书是为这个社会极少数的人写的,但在这极少数的人当中,可能一个都还没有出生。但尼采断言,我的书终将名垂千古,载入史册。晚年的尼采非常寂寞,在日记中他写道,在大街上,我想拥抱随便哪一个人。寂寞之极,一八八九年尼采在都灵大街上抱住了一匹受马夫虐待而发疯的马,尼采疯了。二十世纪的曙光来临之时,尼采安静地离开了这个世界。
尼采杀死上帝后,西方人的生活突然呈现了一种荒诞性。如果没有一个人,没有一种绝对的规则存在的话,人是可以胡作非为的,因为绝对意义消失了。一旦绝对意义消失,那么人在在一个荒诞世界中的生活,其实很容易,吃喝玩乐,仅此而已。但是一个知识分子,如果在一个荒诞的世界中,既要去承担一种荒诞,并且要从荒诞中寻觅意义的话,这就非常困难。此时,存在主义的兴起为二十世纪人的生活的合理性提供准则。我们以最著名的存在主义大师萨特为例:当我们去看他的《他人就是地狱》这本书的时候,我们会发现一篇著名的文章,即《论五月风暴》。在这篇文章中,萨特谈论的是一九六八年全球范围内的学潮运动。萨特这样写道:他们反了,他们要寻找一个他们自己的世界。而这个世界,在我们的年轻时代,也曾经寻找过。但在我们年轻的时代,我们没有去反抗。而今天,他们的反抗和我们年轻时候沉默的事实,证明了在面对同一个制度的时候,他们的伟大和我们的渺小。通过这样的方式人们发现,在一个虚无的世界上,人的活动就是成了人的意义本身。
而在今天的中国社会,一个知识分子如何去创造他自己的意义?今天人们没有,或者说今天的中国人缺乏这样的反思。有人问,中国的知识分子,中国的文学家,为什么没有去拿诺贝尔文学奖。或者有人问,中国的文学家,离诺贝尔奖还有多远。在我看来,这个问题,我可以从这样一个视角给出回答,就是在我们今天中国的作家——或者说从鲁迅开始——所描写的生活,偏重于人的社会生活分析而没有很深刻地剖析人的生存本质。当我们去读马尔克斯的《百年孤独》,我们有一种人的孤寂和幻灭的感觉。甚至有人告诉我,他读过之后有一种自杀的感觉。因为在那里,我们看到了关于人谓之人的深刻反思。而今天的中国作家,中国的知识分子,缺乏这种反思。
为什么这种反思尤其重要?黑格尔曾经说过这样一句话“一个民族总要有一些仰望星空的人,这个民族才有希望。如果这个民族所有人都仰望脚下的事物,那么这个民族是没有希望可言的。”今天中国社会的可怕在于我们太缺乏这样的知识分子。这是一个民族的可悲。如果问今天的中国,有什么可以使我们低下头颅来,我认为,在中国近三百年来,我们没有产生一个可以和西方的知识分子相抗衡的知识分子。我们没有产生萨特这样的人物。没有产生康德,黑格尔,叔本华这样的人物。甚至没有产生加缪和福柯这样的人物。这是一个民族的悲哀。每一个深刻思考过时代精神的知识分子都能意会:夫物质之文明,取诸他国,不数十年而具矣,独至精神上之趣味,非千百年之培养,与一二天才之处,不及此。
让我们去审视德意志民族。德国有一个非常伟大的教育家——洪堡。他按照自己的教育思想,建立了洪堡大学。后来,德国许许多多的大学,都是按照他的模式建立起来的。在我读本科的时候,这种思想,我们全世界仍然是他的受益者,那是什么?那就是关于教育之本质的深刻理解。所有人你来德国学习,学费是全部免掉的。因为教育是一种事业。人并不是仅仅生活在现实生活中,人是一种历史的被造物。置于一切历史之下,教育便有了一种根本的意义,教育的目的是去塑造人。今天的中国之教育,中国的高等教育,把人沦为了一种工具。我们总是评论一所大学的毕业生中,有多少人去国企了,有多少人拿了高薪,当一个高等学府用这个作为一种炫耀的资本的时候,我们便不得不承认:一种恢弘壮丽般教育从根本上堕落了。教育的目的是人,人是目的,不是工具。在洪堡的时代,洪堡几乎是把所有的资源平均地用于教育。所以说德国的大学,他们的好与坏,并没有中国的大学这么悬殊,也没有美国的大学这样悬殊。但是德国,按照洪堡的思想,一个人去接受教育,那么这个教育的钱应该是国家来付。今天的中国人,教育部部长扬言:教育不能产业化;但是从国家到地方,我们实际做地恰恰是教育的产业化。但是现在你去德国留学也是要学费的,全世界已经越来越美国化了。全世界已经一起朝资本看齐的。
这世界仍然有一些非常伟大的人。二十世纪有三个最伟大的知识分子:萨特,福柯和乔母斯基。我不知道在座的各位,有多少人知道这者的名字。有人说,二十世纪的人不知道福柯,就像十九世纪的人不知道马克斯一样。不能说他是文盲,至少不能说他是一个知识分子。我知道我身边很多人都不知道福柯。我去年在西班牙。访问期间,我决定去法国扫福柯的墓。我问了一个在西班牙生活多年的华人,他三岁的时候到了马德里。我告诉他,我想去扫福柯的墓,但不知道福柯的墓在巴黎的什么地方。当然我没有这么直接地问,我先问你知不知道福柯,因为我知道中国的许许多多人都不知道福柯。他跟我说了一句话,他说“我也是读过高中的人”。从这个很小的事情,我们可以看出在欧洲的教育中,仍然没有忽略最核心的精神层面的培养。而这一块,在今天的中国,在我们呼喊素质教育的时候,实际上已经把教育庸俗化。教育的根本目的——人的精神力量的培养——在今天的中国已经被完全忽略了。
我现在指导四个本科生进行研究工作。他们中的每个人都在学术领域崭露头角、甚至取得了令人瞩目的成绩。我时常告诉他们,这还不够。一个学者从专业研究中获得快乐,但是一个思想者应该懂得在学术中生活。思想者这一称谓的定义不是来自他的研究,而应该首先来源他的生活。因为教育的首要目的是培养有思想的人,所以我们经常阅读中西方思想史,试图理解与我们看似久远的西方文明。比如说,福柯有句话:“学校是监狱和医院的混合物”,这句话怎么理解?其实在福柯看来,现在许许多多的人文科学,诸如教育学、心理学、社会学,它们不但不是真理,反而是一种权力、一种杀人的工具。比如说,再让我们回望精神病学,福柯在《疯颠与文明》中探讨了现代精神病的起源。在十六世纪之前,我们并不认为精神病人是疯子。我们甚至把他们作为一种可以预见未来的先知一样看待。疯子可以在大街上游走,并且受到人们的尊敬。这个可能是今天的人们所无法想象的。但是在五个世纪后,在我们所谓更加文明的社会当中,他们为什么就被关进了医院呢?实际上,在一六五六年法国国王下了一条命令,就说建立法国总医院。法国总医院的建立,并不是一个医疗机构。它是一个训诫机构。它要告诉人们:一个人要勤奋的工作,你如果不勤奋工作,就会和大街上的所有流浪汉和所谓的疯子一样,全部都关进了这样一个法国总医院里。当时法国总医院的条件极为恶劣,许许多多的人住在一起,下面就是老鼠乱窜。于是,随着麻风病的消退,精神病人成为了社会唾弃的新对象。但是恰恰在于,今天的人们,我们不能说我们是正常的,从而说你们是非正常的。借福柯之言,现代人需要从他们的角度,去证明精神病人的合法性。但是我们发现,在六百多年的历史进程当中,人们文明的若干关键要素、或者说现代文明,正是通过帕斯卡、梵高、尼采,这些所谓的非理性的人来建立的。但是我们要在他们这些疯子面前,去证明我们的理性是正常的,这不是一个很可笑的事实吗?
现代人的精神,远远没有以前人那样纯洁。现在人在精神层面上已经堕落了。比如说,福柯有一句最为尖锐的话:“只要男人和男人的婚姻一天,现代文明就一天无从谈起。”人们无法理解这样一句话,因为大家听到这句话的时候,大家往往首先想到的不是爱情,而是性。人们认为,两个男人和两个男人在一起,这是很恶心的。人们首先不会去想到,两个男人,只要两个男人他们在精神上在一起,那么这种爱情就是高尚的。而这种爱情曾经在古希腊曾经发生过。在公元五世纪以前也曾经有过。只是在今天,人们越来越强调物质,金钱和欲望的满足。当代社会诸如此类的怪现状还有很多。对于今天的中国的知识分子而言,我们应该有许多深思,当你仔细去想这个时代的时候,你会发现许多反常的现象。如果一代青年人还有一部分人去试图改变这种现象,这个国家就会有希望;如果我们这一代人都试图去迎合世俗,这个国家的精神风貌就会停滞不前。我们的许多知识分子——我们姑且称他们为知识分子——不再把教育作为一种神圣的职业来看待。他们开始炒股,他们开始开公司。他们把学生作为一种免费的劳动力。一种非常神圣的师生关系,一种新货相传的思想之光,在今天堕落得一塌糊涂。他们向国家骗基金,几十万或几百万,然后去做一些不痛不痒的学问。更有甚者,少数知识分子一旦走上领导岗位,便扮演了政客的角色。管你学生好坏、是否才华出众,老子嘴大说得算。在复旦,这是多么大的悲哀。当我忆及国父孙文先生的“天下为公,努力前程”的文字时,我为这些人感到奇耻大辱。
这就我们一个时代的悲哀,也是复旦的悲哀。但许许多多的人没有看到这一点。我希望在复旦,在这样一个很小的优秀本科生当中,在你们思考这些问题的时候,你们要看到这一点。若干年后你们才会试图去改变这一切。
加谬在《西西弗斯神话》的开篇就写道:“真正严肃的哲学问题只有一个,那就是人是否可以自杀。”为什么人他要探讨这样一个问题?刘小枫在《拯救与逍遥》这本书中写道,与其让这个世界以暧昧的方式赢,不如让自己以肯定的方式输。但是在今天,唯独有意义的,是一种生活的创造。是我们可以把生活赋予一种真实的意义。这种真实的意义是通过知识分子的精神活动来体现的。这种精神活动,在一个很低级的层面,正是我们所谓的,一日为师,一生为范。在一个很高级的层面来讲,就是真真正正的知识分子的思想,他的精神能够代代相传。
注定有人会被历史的足迹所记录。比如说贾植芳先生。知识分子不能成为一种政府的附庸。知识分子一词,本来就代表了一个人的精神事实,我们中国的知识分子当中,有贾植芳这样的人,也有类似郭沫若这样的作家。一个人在生活当中,他往往会向某些东西妥协。但是一个人的精神,他的视野,应该是向这个天空的方向去了望。这样一个民族才有希望。
回到具体事情上来,我来谈优秀本科生的专门培养。当我去指导本科生的时候,有一次我和一个本科生聊天。我当时我跟他说,我寝室里有两百本书,你随便看,你看不出我是从事哪一个领域研究的。然后他告诉我,他寝室中也有两百本书。我觉得这样的人才是我欣赏的。首先你是一个有追求的人,其次你是一个在专业领域有所成绩的人。但你一个人仅仅在专业领域有所成绩,你仅仅把发文章当作一种目的的话,那么一个人,他生活的价值就会变得很少。曾经有一个老师对我说,我们总是要把一些东西量化,所以我们博士毕业,发表了多少篇SCI,这种量化就非常重要,因为它很客观。我说,错!这种东西很客观,恰恰是由于我们缺乏了许许多多能够高瞻远瞩的教育者,他认为你是不是具有一种博士的胸怀,博士的研究能力。所以说在今天,我们什么都能量化。一个学生的好坏,我们看GPA;一个国家的发展,我们看GDP;那么一个教授的好坏,我们看发了多少SCI/EI。这到底是现代人的一种文明呢?还是现代人的愚蠢。有个伟大的数学家叫做黎曼。他一生只发表了十八篇论文。还包括手稿。但那十八篇论文确是名垂青史。大家如果对于数学有稍微一些多的了解的话,就是说当代数学有个非常重要的难题——黎曼猜想,就是黎曼提出的。
二十世纪之初,年仅三十八岁的希尔伯特在第二届数学家大会发表了二十世纪人类需要解决的二十三个数学难题。像希尔伯特这样伟大的数学家,他曾经说过这样一句话——请大家注意希尔伯特的用语——他说如果我死后一千年能够复活,那么我问的第一个问题就是黎曼猜想解决了没有。与那个已逝的时代相比,现代人比的不是思想的深邃,比的是一个人在物质上的富有,一个人帅不帅,我们舆论已经为这些所左右。这是一个社会的悲哀,学者和大学的媚俗。但是大学的使命并不是如此。我曾经和我的学生讲过康德的《论教育》。你们很难想象康德这样一个八十岁的单身汉,他的《教育学》会写得如此细腻,初读起来仿佛有一种独特的父爱在身边。康德从婴儿出生开始写起。婴儿出生的时候母亲的乳房中总会流出一些透明的液体,我们翻译成中文叫做初乳。是康德首先发问,这种初乳对于婴儿是不是有益。因为在之前这种初乳都是不要的。但康德首先问这种东西是不是对婴儿有益的。他认为人类总不会做无用功。还有,在婴儿哭的时候,家长总喜欢把婴儿抱起来,摇一摇,这样把孩子不哭了。是康德首先发现:婴儿不哭这一表象的原因是由于成人的行为足以导致婴儿的眩晕,就像我们看儿童坐木马转几圈就晕了一样,这对于他大脑的发展是非常不好的影响。康德从此写起,写到一个人的儿童教育,行为习惯的养成。然后,小学时的认知教育,德育的教育,美育的教育,初中时的体育教育,青春期时的性教育,大学时的哲学教育,科学教育。
除了康德,我们还可以列举其他人。比如亚当斯密,我们最熟悉他的书是《国富论》。但是他还写过一本道德哲学的经典——《道德情操论》。这是一个道德伦理学的经典之作。在今天的中国人,如果能够产生这样的知识分子,就至少代表了一个民族有一种很高贵的气质在里面。如果今天所有的知识分子都在作秀,那么这个民族就没有希望。
最后我要送给大家的是伟大神学家巴特的一句话。他在论述心爱的莫扎特的书中写道
Das Schwere schwebt und das Leichte uwendlich schwer wieget
生活是沉重之轻与轻之沉重
|
方法一:在servlet的init()方法中缓存数据
当应用服务器初始化servlet实例之后,为客户端请求提供服务之前,它会调用这个servlet的init()方法。在一个servlet 的生命周期中,init()方法只会被调用一次。通过在init()方法中缓存一些静态的数据或完成一些只需要执行一次的、耗时的操作,就可大大地提高系统性能。
例如,通过在init()方法中建立一个JDBC连接池是一个最佳例子,假设我们是用jdbc2.0的DataSource接口来取得数据库连接,在通常的情况下,我们需要通过JNDI来取得具体的数据源。我们可以想象在一个具体的应用中,如果每次SQL请求都要执行一次JNDI查询的话,那系统性能将会急剧下降。解决方法是如下代码,它通过缓存DataSource,使得下一次SQL调用时仍然可以继续利用它:
以下是引用片段:
public class ControllerServlet extends HttpServlet{
private javax.sql.DataSource testDS = null;
public void init(ServletConfig config) throws ServletException {
super.init(config);
Context ctx = null;
try{
ctx = new InitialContext();
testDS = (javax.sql.DataSource)ctx.lookup("jdbc/testDS");
}catch(NamingException ne){ne.printStackTrace();}
}catch(Exception e){e.printStackTrace();}
}
public javax.sql.DataSource getTestDS(){
return testDS;
}
...
...
}
方法 2:禁止servlet和JSP 自动重载(auto-reloading)
Servlet/JSP提供了一个实用的技术,即自动重载技术,它为开发人员提供了一个好的开发环境,当你改变servlet和JSP页面后而不必重启应用服务器。然而,这种技术在产品运行阶段对系统的资源是一个极大的损耗,因为它会给JSP引擎的类装载器(classloader)带来极大的负担。因此关闭自动重载功能对系统性能的提升是一个极大的帮助。
方法 3: 不要滥用HttpSession
在很多应用中,我们的程序需要保持客户端的状态,以便页面之间可以相互联系。但不幸的是由于HTTP具有天生无状态性,从而无法保存客户端的状态。因此一般的应用服务器都提供了session来保存客户的状态。在JSP应用服务器中,是通过HttpSession对像来实现session的功能的,但在方便的同时,它也给系统带来了不小的负担。因为每当你获得或更新session时,系统者要对它进行费时的序列化操作。你可以通过对 HttpSession的以下几种处理方式来提升系统的性能。
如果没有必要,就应该关闭JSP页面中对HttpSession的缺省设置。 如果你没有明确指定的话,每个JSP页面都会缺省地创建一个HttpSession。如果你的JSP中不需要使用session的话,那可以通过如下的JSP页面指示符来禁止它:
以下是引用片段:
<%@ page session="false"%>
不要在HttpSession中存放大的数据对像:如果你在HttpSession中存放大的数据对像的话,每当对它进行读写时,应用服务器都将对其进行序列化,从而增加了系统的额外负担。你在HttpSession中存放的数据对像越大,那系统的性能就下降得越快。
当你不需要HttpSession时,尽快地释放它:当你不再需要session时,你可以通过调用 HttpSession.invalidate()方法来释放它。尽量将session的超时时间设得短一点:在JSP应用服务器中,有一个缺省的 session的超时时间。当客户在这个时间之后没有进行任何操作的话,系统会将相关的session自动从内存中释放。超时时间设得越大,系统的性能就会越低,因此最好的方法就是尽量使得它的值保持在一个较低的水平。
方法 4: 将页面输出进行压缩
压缩是解决数据冗余的一个好的方法,特别是在网络带宽不够发达的今天。有的浏览器支持gzip(GNU zip)进行来对HTML文件进行压缩,这种方法可以戏剧性地减少HTML文件的下载时间。因此,如果你将servlet或JSP页面生成的HTML页面进行压缩的话,那用户就会觉得页面浏览速度会非常快。但不幸的是,不是所有的浏览器都支持gzip压缩,但你可以通过在你的程序中检查客户的浏览器是否支持它。下面就是关于这种方法实现的一个代码片段:
以下是引用片段:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
OutputStream out = null;
String encoding = request.getHeader("Accept-Encoding");
if (encoding != null && encoding.indexOf("gzip") != -1){
request.setHeader("Content-Encoding" , "gzip");
out = new GZIPOutputStream(request.getOutputStream());
}
else if (encoding != null && encoding.indexOf("comdivss") != -1){
request.setHeader("Content-Encoding" , "comdivss");
out = new ZIPOutputStream(request.getOutputStream());
}else{
out = request.getOutputStream();
}
...
...
}
方法 5: 使用线程池
应用服务器缺省地为每个不同的客户端请求创建一个线程进行处理,并为它们分派service()方法,当service()方法调用完成后,与之相应的线程也随之撤消。由于创建和撤消线程会耗费一定的系统资源,这种缺省模式降低了系统的性能。但所幸的是我们可以通过创建一个线程池来改变这种状况。
另外,我们还要为这个线程池设置一个最小线程数和一个最大线程数。在应用服务器启动时,它会创建数量等于最小线程数的一个线程池,当客户有请求时,相应地从池从取出一个线程来进行处理,当处理完成后,再将线程重新放入到池中。如果池中的线程不够地话,系统会自动地增加池中线程的数量,但总量不能超过最大线程数。通过使用线程池,当客户端请求急剧增加时,系统的负载就会呈现的平滑的上升曲线,从而提高的系统的可伸缩性。
方法 6: 选择正确的页面包含机制
在JSP中有两种方法可以用来包含另一个页面:
1、使用include指示符
以下是引用片段:
<%@ includee file=”test.jsp” %>
2、使用jsp指示符
以下是引用片段:
<jsp:includee page=”test.jsp” flush=”true”/>
在实际中发现,如果使用第一种方法的话,可以使得系统性能更高。
方法 7:正确地确定javabean的生命周期
JSP的一个强大的地方就是对javabean的支持。通过在JSP页面中使用jsp:useBean标签,可以将javabean直接插入到一个JSP页面中。它的使用方法如下:
以下是引用片段:
<jsp:useBean id="name" scope="page|request|session|application"
class="package.className" type="typeName">
</jsp:useBean>
其中scope属性指出了这个bean的生命周期。缺省的生命周期为page。如果你没有正确地选择bean的生命周期的话,它将影响系统的性能。
举例来说,如果你只想在一次请求中使用某个bean,但你却将这个bean的生命周期设置成了session,那当这次请求结束后,这个 bean将仍然保留在内存中,除非session超时或用户关闭浏览器。这样会耗费一定的内存,并无谓的增加了JVM垃圾收集器的工作量。因此为bean 设置正确的生命周期,并在bean的使命结束后尽快地清理它们,会使用系统性能有一个提高。
其它一些有用的方法
1、在字符串连接操作中尽量不使用“+”操作符:在java编程中,我们常常使用“+”操作符来将几个字符串连接起来,但你或许从来没有想到过它居然会对系统性能造成影响吧?由于字符串是常量,因此JVM会产生一些临时的对像。你使用的“+”越多,生成的临时对像就越多,这样也会给系统性能带来一些影响。解决的方法是用StringBuffer对像来代替“+”操作符。
2、避免使用System.out.println()方法:由于System.out.println()是一种同步调用,即在调用它时,磁盘I/O操作必须等待它的完成,因此我们要尽量避免对它的调用。但我们在调试程序时它又是一个必不可少的方便工具,为了解决这个矛盾,我建议你最好使用 Log4j工具(http://Jakarta.apache.org ),它既可以方便调试,而不会产生System.out.println()这样的方法。
3、ServletOutputStream 与 PrintWriter的权衡:使用PrintWriter可能会带来一些小的开销,因为它将所有的原始输出都转换为字符流来输出,因此如果使用它来作为页面输出的话,系统要负担一个转换过程。而使用ServletOutputStream作为页面输出的话就不存在一个问题,但它是以二进制进行输出的。因此在实际应用中要权衡两者的利弊。
总结
本文的目的是通过对servlet和JSP的一些调优技术来极大地提高你的应用程序的性能,并因此提升整个J2EE应用的性能。通过这些调优技术,你可以发现其实并不是某种技术平台(比如J2EE和.NET之争)决定了你的应用程序的性能,重要是你要对这种平台有一个较为深入的了解,这样你才能从根本上对自己的应用程序做一个优化。
正则表达式规则
|
|
|
String.matches() 这个方法主要是返回是否匹配指定的字符串,如果匹配则为true,否则为false;
如:/**
* 判断字符创是否是一个有效的日期
*
* @param theStr
* @return true 是,false否
*/
public static boolean isDate(String theStr) {
return theStr.matches("\\d{4}\\-\\d{1,2}\\-\\d{1,2}");
}
这个方法的参数为正则表达式,关于正则表达式的用法如下:
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来:(1)检查一个串中是否含有符合某个规则的子串,并且可以得到这个子串;(2)根据匹配规则对字符串进行灵活的替换操作。
正则表达式学习起来其实是很简单的,不多的几个较为抽象的概念也很容易理解。之所以很多人感觉正则表达式比较复杂,一方面是因为大多数的文档没有做到由浅入深地讲解,概念上没有注意先后顺序,给读者的理解带来困难;另一方面,各种引擎自带的文档一般都要介绍它特有的功能,然而这部分特有的功能并不是我们首先要理解的。
文章中的每一个举例,都可以点击进入到测试页面进行测试。闲话少说,开始。
1. 正则表达式规则
1.1 普通字符
字母、数字、汉字、下划线、以及后边章节中没有特殊定义的标点符号,都是"普通字符"。表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。
举例1:表达式 "c",在匹配字符串 "abcde" 时,匹配结果是:成功;匹配到的内容是:"c";匹配到的位置是:开始于2,结束于3。(注:下标从0开始还是从1开始,因当前编程语言的不同而可能不同)
举例2:表达式 "bcd",在匹配字符串 "abcde" 时,匹配结果是:成功;匹配到的内容是:"bcd";匹配到的位置是:开始于1,结束于4。
1.2 简单的转义字符
一些不便书写的字符,采用在前面加 "\" 的方法。这些字符其实我们都已经熟知了。
|
表达式
|
可匹配
|
|
\r, \n
|
代表回车和换行符
|
|
\t
|
制表符
|
|
\\
|
代表 "\" 本身
|
还有其他一些在后边章节中有特殊用处的标点符号,在前面加 "\" 后,就代表该符号本身。比如:^, $ 都有特殊意义,如果要想匹配字符串中 "^" 和 "$" 字符,则表达式就需要写成 "\^" 和 "\$"。
|
表达式
|
可匹配
|
|
\^
|
匹配 ^ 符号本身
|
|
\$
|
匹配 $ 符号本身
|
|
\.
|
匹配小数点(.)本身
|
这些转义字符的匹配方法与 "普通字符" 是类似的。也是匹配与之相同的一个字符。
举例1:表达式 "\$d",在匹配字符串 "abc$de" 时,匹配结果是:成功;匹配到的内容是:"$d";匹配到的位置是:开始于3,结束于5。
1.3 能够与 '多种字符' 匹配的表达式
正则表达式中的一些表示方法,可以匹配 '多种字符' 其中的任意一个字符。比如,表达式 "\d" 可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,不是多个。这就好比玩扑克牌时候,大小王可以代替任意一张牌,但是只能代替一张牌。
|
表达式
|
可匹配
|
|
\d
|
任意一个数字,0~9 中的任意一个
|
|
\w
|
任意一个字母或数字或下划线,也就是 A~Z,a~z,0~9,_ 中任意一个
|
|
\s
|
包括空格、制表符、换页符等空白字符的其中任意一个
|
|
.
|
小数点可以匹配除了换行符(\n)以外的任意一个字符
|
举例1:表达式 "\d\d",在匹配 "abc123" 时,匹配的结果是:成功;匹配到的内容是:"12";匹配到的位置是:开始于3,结束于5。
举例2:表达式 "a.\d",在匹配 "aaa100" 时,匹配的结果是:成功;匹配到的内容是:"aa1";匹配到的位置是:开始于1,结束于4。
1.4 自定义能够匹配 '多种字符' 的表达式
使用方括号 [ ] 包含一系列字符,能够匹配其中任意一个字符。用 [^ ] 包含一系列字符,则能够匹配其中字符之外的任意一个字符。同样的道理,虽然可以匹配其中任意一个,但是只能是一个,不是多个。
|
表达式
|
可匹配
|
|
[ab5@]
|
匹配 "a" 或 "b" 或 "5" 或 "@"
|
|
[^abc]
|
匹配 "a","b","c" 之外的任意一个字符
|
|
[f-k]
|
匹配 "f"~"k" 之间的任意一个字母
|
|
[^A-F0-3]
|
匹配 "A"~"F","0"~"3" 之外的任意一个字符
|
举例1:表达式 "[bcd][bcd]" 匹配 "abc123" 时,匹配的结果是:成功;匹配到的内容是:"bc";匹配到的位置是:开始于1,结束于3。
举例2:表达式 "[^abc]" 匹配 "abc123" 时,匹配的结果是:成功;匹配到的内容是:"1";匹配到的位置是:开始于3,结束于4。
1.5 修饰匹配次数的特殊符号
前面章节中讲到的表达式,无论是只能匹配一种字符的表达式,还是可以匹配多种字符其中任意一个的表达式,都只能匹配一次。如果使用表达式再加上修饰匹配次数的特殊符号,那么不用重复书写表达式就可以重复匹配。
使用方法是:"次数修饰"放在"被修饰的表达式"后边。比如:"[bcd][bcd]" 可以写成 "[bcd]{2}"。
|
表达式
|
作用
|
|
{n}
|
表达式重复n次,比如:"\w{2}" 相当于 "\w\w";"a{5}" 相当于 "aaaaa"
|
|
{m,n}
|
表达式至少重复m次,最多重复n次,比如:"ba{1,3}"可以匹配 "ba"或"baa"或"baaa"
|
|
{m,}
|
表达式至少重复m次,比如:"\w\d{2,}"可以匹配 "a12","_456","M12344"...
|
|
?
|
匹配表达式0次或者1次,相当于 {0,1},比如:"a[cd]?"可以匹配 "a","ac","ad"
|
|
+
|
表达式至少出现1次,相当于 {1,},比如:"a+b"可以匹配 "ab","aab","aaab"...
|
|
*
|
表达式不出现或出现任意次,相当于 {0,},比如:"\^*b"可以匹配 "b","^^^b"...
|
举例1:表达式 "\d+\.?\d*" 在匹配 "It costs $12.5" 时,匹配的结果是:成功;匹配到的内容是:"12.5";匹配到的位置是:开始于10,结束于14。
举例2:表达式 "go{2,8}gle" 在匹配 "Ads by goooooogle" 时,匹配的结果是:成功;匹配到的内容是:"goooooogle";匹配到的位置是:开始于7,结束于17。
1.6 其他一些代表抽象意义的特殊符号
一些符号在表达式中代表抽象的特殊意义:
|
表达式
|
作用
|
|
^
|
与字符串开始的地方匹配,不匹配任何字符
|
|
$
|
与字符串结束的地方匹配,不匹配任何字符
|
|
\b
|
匹配一个单词边界,也就是单词和空格之间的位置,不匹配任何字符
|
进一步的文字说明仍然比较抽象,因此,举例帮助大家理解。
举例1:表达式 "^aaa" 在匹配 "xxx aaa xxx" 时,匹配结果是:失败。因为 "^" 要求与字符串开始的地方匹配,因此,只有当 "aaa" 位于字符串的开头的时候,"^aaa" 才能匹配,比如:"aaa xxx xxx"。
举例2:表达式 "aaa$" 在匹配 "xxx aaa xxx" 时,匹配结果是:失败。因为 "$" 要求与字符串结束的地方匹配,因此,只有当 "aaa" 位于字符串的结尾的时候,"aaa$" 才能匹配,比如:"xxx xxx aaa"。
举例3:表达式 ".\b." 在匹配 "@@@abc" 时,匹配结果是:成功;匹配到的内容是:"@a";匹配到的位置是:开始于2,结束于4。
进一步说明:"\b" 与 "^" 和 "$" 类似,本身不匹配任何字符,但是它要求它在匹配结果中所处位置的左右两边,其中一边是 "\w" 范围,另一边是 非"\w" 的范围。
举例4:表达式 "\bend\b" 在匹配 "weekend,endfor,end" 时,匹配结果是:成功;匹配到的内容是:"end";匹配到的位置是:开始于15,结束于18。
一些符号可以影响表达式内部的子表达式之间的关系:
|
表达式
|
作用
|
|
|
|
左右两边表达式之间 "或" 关系,匹配左边或者右边
|
|
( )
|
(1). 在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰
(2). 取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到
|
举例5:表达式 "Tom|Jack" 在匹配字符串 "I'm Tom, he is Jack" 时,匹配结果是:成功;匹配到的内容是:"Tom";匹配到的位置是:开始于4,结束于7。匹配下一个时,匹配结果是:成功;匹配到的内容是:"Jack";匹配到的位置时:开始于15,结束于19。
举例6:表达式 "(go\s*)+" 在匹配 "Let's go go go!" 时,匹配结果是:成功;匹配到内容是:"go go go";匹配到的位置是:开始于6,结束于14。
举例7:表达式 "¥(\d+\.?\d*)" 在匹配 "$10.9,¥20.5" 时,匹配的结果是:成功;匹配到的内容是:"¥20.5";匹配到的位置是:开始于6,结束于10。单独获取括号范围匹配到的内容是:"20.5"。
2. 正则表达式中的一些高级规则
2.1 匹配次数中的贪婪与非贪婪
在使用修饰匹配次数的特殊符号时,有几种表示方法可以使同一个表达式能够匹配不同的次数,比如:"{m,n}", "{m,}", "?", "*", "+",具体匹配的次数随被匹配的字符串而定。这种重复匹配不定次数的表达式在匹配过程中,总是尽可能多的匹配。比如,针对文本 "dxxxdxxxd",举例如下:
|
表达式
|
匹配结果
|
|
(d)(\w+)
|
"\w+" 将匹配第一个 "d" 之后的所有字符 "xxxdxxxd"
|
|
(d)(\w+)(d)
|
"\w+" 将匹配第一个 "d" 和最后一个 "d" 之间的所有字符 "xxxdxxx"。虽然 "\w+" 也能够匹配上最后一个 "d",但是为了使整个表达式匹配成功,"\w+" 可以 "让出" 它本来能够匹配的最后一个 "d"
|
由此可见,"\w+" 在匹配的时候,总是尽可能多的匹配符合它规则的字符。虽然第二个举例中,它没有匹配最后一个 "d",但那也是为了让整个表达式能够匹配成功。同理,带 "*" 和 "{m,n}" 的表达式都是尽可能地多匹配,带 "?" 的表达式在可匹配可不匹配的时候,也是尽可能的 "要匹配"。这 种匹配原则就叫作 "贪婪" 模式 。
非贪婪模式:
在修饰匹配次数的特殊符号后再加上一个 "?" 号,则可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表达式,尽可能的 "不匹配"。这种匹配原则叫作 "非贪婪" 模式,也叫作 "勉强" 模式。如果少匹配就会导致整个表达式匹配失败的时候,与贪婪模式类似,非贪婪模式会最小限度的再匹配一些,以使整个表达式匹配成功。举例如下,针对文本 "dxxxdxxxd" 举例:
|
表达式
|
匹配结果
|
|
(d)(\w+?)
|
"\w+?" 将尽可能少的匹配第一个 "d" 之后的字符,结果是:"\w+?" 只匹配了一个 "x"
|
|
(d)(\w+?)(d)
|
为了让整个表达式匹配成功,"\w+?" 不得不匹配 "xxx" 才可以让后边的 "d" 匹配,从而使整个表达式匹配成功。因此,结果是:"\w+?" 匹配 "xxx"
|
更多的情况,举例如下:
举例1:表达式 "<td>(.*)</td>" 与字符串 "<td><p>aa</p></td> <td><p>bb</p></td>" 匹配时,匹配的结果是:成功;匹配到的内容是 "<td><p>aa</p></td> <td><p>bb</p></td>" 整个字符串, 表达式中的 "</td>" 将与字符串中最后一个 "</td>" 匹配。
举例2:相比之下,表达式 "<td>(.*?)</td>" 匹配举例1中同样的字符串时,将只得到 "<td><p>aa</p></td>", 再次匹配下一个时,可以得到第二个 "<td><p>bb</p></td>"。
2.2 反向引用 \1, \2...
表达式在匹配时,表达式引擎会将小括号 "( )" 包含的表达式所匹配到的字符串记录下来。在获取匹配结果的时候,小括号包含的表达式所匹配到的字符串可以单独获取。这一点,在前面的举例中,已经多次展示了。在实际应用场合中,当用某种边界来查找,而所要获取的内容又不包含边界时,必须使用小括号来指定所要的范围。比如前面的 "<td>(.*?)</td>"。
其实,"小括号包含的表达式所匹配到的字符串" 不仅是在匹配结束后才可以使用,在匹配过程中也可以使用。表达式后边的部分,可以引用前面 "括号内的子匹配已经匹配到的字符串"。引用方法是 "\" 加上一个数字。"\1" 引用第1对括号内匹配到的字符串,"\2" 引用第2对括号内匹配到的字符串……以此类推,如果一对括号内包含另一对括号,则外层的括号先排序号。换句话说,哪一对的左括号 "(" 在前,那这一对就先排序号。
举例如下:
举例1:表达式 "('|")(.*?)(\1)" 在匹配 " 'Hello', "World" " 时,匹配结果是:成功;匹配到的内容是:" 'Hello' "。再次匹配下一个时,可以匹配到 " "World" "。
举例2:表达式 "(\w)\1{4,}" 在匹配 "aa bbbb abcdefg ccccc 111121111 999999999" 时,匹配结果是:成功;匹配到的内容是 "ccccc"。再次匹配下一个时,将得到 999999999。这个表达式要求 "\w" 范围的字符至少重复5次,注意与 "\w{5,}" 之间的区别。
举例3:表达式 "<(\w+)\s*(\w+(=('|").*?\4)?\s*)*>.*?</\1>" 在匹配 "<td id='td1' style="bgcolor:white"></td>" 时,匹配结果是成功。如果 "<td>" 与 "</td>" 不配对,则会匹配失败;如果改成其他配对,也可以匹配成功。
|
|
在java语言中使用正则表达式
|
|
|
首先让我们构成一个正则表达式。为简单起见,先构成一个正则表达式来识别下面格式的电话号码数字:(nnn)nnn-nnnn。
第一步,创建一个pattern对象来匹配上面的子字符串。一旦程序运行后,如果需要的话,可以让这个对象一般化。匹配上面格式的正则表达可以这样构成: (\d{3})\s\d{3}-\d{4},其中\d单字符类型用来匹配从0到9的任何数字,另外{3}重复符号,是个简便的记号,用来表示有3个连续的数字位,也等效于(\d\d\d)。\s也另外一个比较有用的单字符类型,用来匹配空格,比如Space键,tab键和换行符。
是不是很简单?但是,如果把这个正则表达式的模式用在java程序中,还要做两件事。对java的解释器来说,在反斜线字符(\)前的字符有特殊的含义。在java中,与regex有关的包,并不都能理解和识别反斜线字符(\),尽管可以试试看。但为避免这一点,即为了让反斜线字符(\)在模式对象中被完全地传递,应该用双反斜线字符(\)。此外圆括号在正则表达中两层含义,如果想让它解释为字面上意思(即圆括号),也需要在它前面用双反斜线字符(\)。也就是像下面的一样:
\\(\\d{3}\\)\\s\\d{3}-\\d{4}
现在介绍怎样在java代码中实现刚才所讲的正则表达式。要记住的事,在用正则表达式的包时,在你所定义的类前需要包含该包,也就是这样的一行:
import java.util.regex.*;
下面的一段代码实现的功能是,从一个文本文件逐行读入,并逐行搜索电话号码数字,一旦找到所匹配的,然后输出在控制台。
BufferedReader in;
Pattern pattern = Pattern.compile("\\(\\d{3}\\)\\s\\d{3}-\\d{4}");
in = new BufferedReader(new FileReader("phone"));
String s;
while ((s = in.readLine()) != null)
{
Matcher matcher = pattern.matcher(s);
if (matcher.find())
{
System.out.println(matcher.group());
}
}
in.close();
对那些熟悉用Python或Javascript来实现正则表达式的人来说,这段代码很平常。在Python和Javascript这些语言中,或者其他的语言,这些正则表达式一旦明确地编译过后,你想用到哪里都可以。与Perl的单步匹配相比,看起来多多做了些工作,但这并不很费事。
find()方法,就像你所想象的,用来搜索与正则表达式相匹配的任何目标字符串,group()方法,用来返回包含了所匹配文本的字符串。应注意的是,上面的代码,仅用在每行只能含有一个匹配的电话号码数字字符串时。可以肯定的说,java的正则表达式包能用在一行含有多个匹配目标时的搜索。本文的原意在于举一些简单的例子来激起读者进一步去学习java自带的正则表达式包,所以对此就没有进行深入的探讨。
这相当漂亮吧! 但是很遗憾的是,这仅是个电话号码匹配器。很明显,还有两点可以改进。如果在电话号码的开头,即区位号和本地号码之间可能会有空格。我们也可匹配这些情况,则通过在正则表达式中加入\s?来实现,其中?元字符表示在模式可能有0或1个空格符。
第二点是,在本地号码位的前三位和后四位数字间有可能是空格符,而不是连字号,更有胜者,或根本就没有分隔符,就是7位数字连在一起。对这几种情况,我们可以用(-|)?来解决。这个结构的正则表达式就是转换器,它能匹配上面所说的几种情况。在()能含有管道符|时,它能匹配是否含有空格符或连字符,而尾部的?元字符表示是否根本没有分隔符的情况。
最后,区位号也可能没有包含在圆括号内,对此可以简单地在圆括号后附上?元字符,但这不是一个很好的解决方法。因为它也包含了不配对的圆括号,比如" (555" 或 "555)"。相反,我们可以通过另一种转换器来强迫让电话号码是否带有有圆括号:(\(\d{3}\)|\d{3})。如果我们把上面代码中的正则表达式用这些改进后的来替换的话,上面的代码就成了一个非常有用的电话号码数字匹配器:
Pattern pattern =
Pattern.compile("(\\(\\d{3}\\)|\\d{3})\\s?\\d{3}(-|)?\\d{4}");
可以确定的是,你可以自己试着进一步改进上面的代码。
现在看看第二个例子,它是从Friedl的中改编过来的。其功能是用来检查文本文件中是否有重复的单词,这在印刷排版中会经常遇到,同样也是个语法检查器的问题。
匹配单词,像其他的一样,也可以通过好几种的正则表达式来完成。可能最直接的是\b\w+\b,其优点在于只需用少量的regex元字符。其中\w元字符用来匹配从字母a到u的任何字符。+元字符表示匹配匹配一次或多次字符,\b元字符是用来说明匹配单词的边界,它可以是空格或任何一种不同的标点符号(包括逗号,句号等)。
现在,我们怎样来检查一个给定的单词是否被重复了三次?为完成这个任务,需充分利用正则表达式中的所熟知的向后扫描。如前面提到的,圆括号在正则表达式中有几种不同的用法,一个就是能提供组合类型,组合类型用来保存所匹配的结果或部分匹配的结果(以便后面能用到),即使遇到有相同的模式。在同样的正则表达中,可能(也通常期望)不止有一个组合类型。在第n个组合类型中匹配结果可以通过向后扫描来获取到。向后扫描使得搜索重复的单词非常简单:\b(\w+) \s+\1\b。
圆括号形成了一个组合类型,在这个正则表示中它是第一组合类型(也是仅有的一个)。向后扫描\1,指的是任何被\w+所匹配的单词。我们的正则表达式因此能匹配这样的单词,它有一个或多个空格符,后面还跟有一个与此相同的单词。注意的是,尾部的定位类型(\b)必不可少,它可以防止发生错误。如果我们想匹配"Paris in the the spring",而不是匹配"Java's regex package is the theme of this article"。根据java现在的格式,则上面的正则表达式就是:Pattern pattern =Pattern.compile("\\b(\\w+)\\s+\\1\\b");
最后进一步的修改是让我们的匹配器对大小写敏感。比如,下面的情况:"The the theme of this article is the Java's regex package.",这一点在regex中能非常简单地实现,即通过使用在Pattern类中预定义的静态标志CASE_INSENSITIVE :
Pattern pattern =Pattern.compile("\\b(\\w+)\\s+\\1\\b",
Pattern.CASE_INSENSITIVE);
有关正则表达式的话题是非常丰富,而且复杂的,用Java来实现也非常广泛,则需要对regex包进行的彻底研究,我们在这里所讲的只是冰山一角。即使你对正则表达式比较陌生,使用regex包后会很快发现它强大功能和可伸缩性。如果你是个来自Perl或其他语言王国的老练的正则表达式的黑客,使用过 regex包后,你将会安心地投入到java的世界,而放弃其他的工具,并把java的regex包看成是手边必备的利器。
|
|
摘要: 莫小米文章
地址:http://blog.tianya.cn/blogger/view_blog.asp?BlogName=xiaomi520&idWriter=0&Key=0
几米语录:
米语录 生活永远不是童话
... 阅读全文
**君子耻其言而过其行**
typedef int* pint;
typedef pint* ppint;
void func(ppint &x)
{
x = new int*;
*x= new int(32);
}
//使用方法
int **p=0;
func(p);
cout<<(**p)<<endl;
int *pV;
pV = new int(2); //这里注意与在cpp中与java中语法的差异
cout<<"PV = "<<(*pV)<<endl;
int ival = 1024;
int *pi = &ival;
int* &ptrVal2 = pi;
菩提本无树 (2009-04-04 17:48:59)
佛对我说:你的心上有尘。我用力地擦拭。
佛说:你错了,尘是擦不掉的。我于是将心剥了下来.
佛又说:你又错了,尘本非尘,何来有尘
我想这是从神秀和慧能那两个偈子引申出来。
神秀说:“身是菩提树,心如明镜台,时时勤拂拭,勿使惹尘埃。”
慧能说:“菩提本无树,明镜亦非台,本来无一物,何处惹尘埃。”
的确,要能够参透这两个偈子的确很难,就是正确的理解也不易。
身是菩提树,心如明镜台,时时勤拂拭,勿使惹尘埃
众生的身体就是一棵觉悟的智慧树,
众生的心灵就象一座明亮的台镜。
要时时不断地将它掸拂擦试,
不让它被尘垢污染障蔽了光明的本性。
菩提本无树,明镜亦非台,本来无一物,何处惹尘埃
菩提原本就没有树,
明亮的镜子也并不是台。
本来就是虚无没有一物,
那里会染上什么尘埃?
这首畿子可以看出慧能是个有大智慧的人(后世有人说他是十世比丘转世),他这个畿子很契合禅宗的顿悟的理念。是一种出世的态度,主要意思是,世上本来就是空的,看世间万物无不是一个空字,心本来就是空的话,就无所谓抗拒外面的诱惑,任何事物从心而过,不留痕迹。这是禅宗的一种很高的境界,领略到这层境界的人,就是所谓的开悟了。
禅的境界一花一世界,一叶一如来。这样的境界,是何等的完美。
禅的生活是非常朴实,没有欲望及贪求的,一切的作用都能融入空性。空不是什么都没有,而是使自己生活得更逍遥自在,如鱼得水。做事不要过于认真执着,而是要认真雕刻。
禅是“感情”的生活,禅的感情就是无缘大悲,同体大悲的心量。
禅是启发我们要学会舍得;真正的快乐只有舍得才能得,从舍中构筑一切的有。要辨证的看待拥有和失去,拥有不一定快乐,因为一旦想要拥有烦恼就出现了,因为“有”未必不是一种负担,只有豁达地看待得与失,成与败,拥有一颗无所得的心,你才会快乐。
最快乐的生活,就是善于驭心的生活。境不转心转,如果能够常常调心,就能常生喜悦而少烦恼。
佛法教我们把快乐和痛苦都放下,但是,放下并不是不去追求,而是随缘不变。
当我们能了解到,环境是无法控制、变化无常的,就能获致真正的快乐与内心的安定。
用清静心看世间,世间即清静,用解脱心看世间,心即解脱。
会调心的人就会生活,会生活的人才得大智慧,智慧高的人生活范围大,因为他能包容,能够令人安定,每个人都喜欢跟他在一起。
处理事务要多包容、忍耐,量大福大,量小阻碍多。
尊重别人,就能获得别人的尊重,
不听人我是非,听人我是非即是是非人,不能成大事。
修行就是管自己,自己都管不了,还管得了谁?众生就是我,我就是众生。
认识自己,如果不认识自己的心,就无法安排人生,也许你可以安排你的事业,家庭,希望一切如意,可是你却随时要接受无常的安排。认清自己为认清世界的根本,要研究这世界不如先研究自己。
修行就是要:审查自己的心、规画自己的心、企划自己的心。
身体的健康与心理有关,能够放下,不想烦恼的事,身心就能解脱。
佛法不是在庙里,而是在心里。
浪有高有低,海水依旧是海水,生活有苦有乐,心依旧是心。
其实尘在外,心在内,常拂之,心净无尘;
尘在内,心在外,常剥之,无尘无心;
心中有尘,尘本是心,
何畏心中尘,无尘亦无心?正如慧能所说的仁者心动
佛家追求的是一种超脱
却不是刻意的寻求
主旨在心
世间人,法无定法,然后知非法法也;
天下事,了犹未了,何妨以不了了之
菩提本无树,明镜亦非台。本来无一物,何处惹尘埃?
佛家的学说往往浸透着深奥的人生哲学,从而引得无数人将此作为座右铭,因为一方面这是一种处世方式,另一方面也是人们几千年的经验结晶。在学哲学时,常把佛家学说定义为唯心主义,从这句诗中也可以看出,菩提本无树,就是说,首先没有物质的存在,所以又如何惹尘埃呢?
菩提真的无树吗?记得以前有一部电影,是欧美的,描述的是一个非洲丛林的原始部落,生产力低下,以猎物为生,彼此生活安逸,波澜不惊。但是有一天,有一个人在海滩上拣到了一个易拉罐,把它带到了部落,虽然是一个对于我们来说不值钱的物件,但在那里却是件希罕物,可以说是珍宝。围绕着这一物件,为了得到它,部落里展开了一场争斗,在一场你争我夺的,钩心斗角的争夺后,他们省悟了,最后将易拉罐重新扔入了无际的大海。部落又恢复了昔日的平静。
人是从自然界演变而来,人类的本性就是永远也不满足,这种本性演发了无穷无尽的矛盾,也同时推动者人类社会的前进,在这种前进中,满含着血腥与残酷,在矛盾中,人们会选择一种信仰,目的只是为了逃避现实。
菩提既是树,明镜就是台,这些都是物质,皆是物,你可以闭眼不见,但都是客观存在。本来无一物,只是主观的逃避。
对于现实,我们会采取多种方式,当我们享受着生活的美好时,当我们在阳光下时,是不会去考虑菩提树是否存在的问题的;或当我们在爱河中徜徉,陶醉于其中时,何曾想过明镜?
只有当我们面临着生活的压力,面临着现实的残酷,当我们的爱被背叛,被蹂躏,在施展全身之力皆无果时,便会无奈的寻求心理的安慰。将烦恼抛之脑后,以重新焕发生活的斗志,或者,已丧失了斗志,仅寻求一种解脱。这也就是佛学这种理论赖以存在的基础。
这种理论在今天看来,也许有其积极的作用,那便是引导人们理智对待人生,当有冲突时,回避或退让或是好办法。
然而,人终究是人,一种贪婪,健忘的生物,当生活,现实,爱情等等因素重新回归美好时,便又会看到菩提树,看到明镜台了,便又会去惹尘埃了。
 Tutorial: The H.264 Scalable Video Codec (SVC)收藏 Tutorial: The H.264 Scalable Video Codec (SVC)收藏
Codecs are used to compress video to reduce the bandwidth required to transport streams, or to reduce the storage space required to archive them. The price for this compression is increased computational requirements: The higher the compression ratio, the more computational power is required.
Fixing the tradeoff between bandwidth and computational requirements has the effect of defining both the minimum channel bandwidth required to carry the encoded stream and the minimum specification of the decoding device. In traditional video systems such as broadcast television, the minimum specification of a decoder (in this case a set-top box) is readily defined.
Today, however, video is used in increasingly diverse applications with a correspondingly diverse set of client devices—from computers viewing Internet video to portable digital assistants (PDAs) and even the humble cell phone. The video streams for these devices are necessarily different.
To be made more compatible with a specific viewing device and channel bandwidth, the video stream must be encoded many times with different settings. Each combination of settings must yield a stream that targets the bandwidth of the channel carrying the stream to the consumer as well as the decode capability of the viewing device. If the original uncompressed stream is unavailable, the encoded stream must first be decoded and then re-encoded with the new settings. This quickly becomes prohibitively expensive.
In an ideal scenario, the video would be encoded only once with a high efficiency codec. The resulting stream would, when decoded, yield the full resolution video. Furthermore, in this ideal scenario, if a lower resolution or bandwidth stream was needed to reach further into the network to target a lower performance device, a small portion of the encoded stream would be sent without any additional processing. This smaller stream would be easier to decode and yield lower resolution video. In this way, the encoded video stream could adapt itself to both the bandwidth of the channel it was required to travel through and to the capabilities of the target device. These are exactly the qualities of a scalable video codec.
H.264 SVC
The Scalable Video Codec extension to the H.264 standard (H.264 SVC) is designed to deliver the benefits described in the preceding ideal scenario. It is based on the H.264 Advanced Video Codec standard (H.264 AVC) and heavily leverages the tools and concepts of the original codec. The encoded stream it generates, however, is scalable: temporally, spatially, and in terms of video quality. That is, it can yield decoded video at different frame rates, resolutions, or quality levels.
The SVC extension introduces a notion not present in the original H.264 AVC codec−that of layers within the encoded stream. A base layer encodes the lowest temporal, spatial, and quality representation of the video stream. Enhancement layers encode additional information that, using the base layer as a starting point, can be used to reconstruct higher quality, resolution, or temporal versions of the video during the decode process. By decoding the base layer and only the subsequent enhancement layers required, a decoder can produce a video stream with certain desired characteristics. Figure 1 shows the layered structure of an H.264 SVC stream. During the encode process, care is taken to encode a particular layer using reference only to lower level layers. In this way, the encoded stream can be truncated at any arbitrary point and still remain a valid, decodable stream.

(Click to enlarge)
Figure 1. The H.264 SVC Layered Structure.
This layered approach allows the generation of an encoded stream that can be truncated to limit the bandwidth consumed or the decode computational requirements. The truncation process consists simply of extracting the required layers from the encoded video stream with no additional processing on the stream itself. The process can even be performed "in the network". That is, as the video stream transitions from a high bandwidth to a lower bandwidth network (for example, from an Ethernet network to a handheld through a WiFi link), it could be parsed to size the stream for the available bandwidth. In the above example, the stream could be sized for the bandwidth of the wireless link and the decode capabilities of the handheld decoder. Figure 2 shows such an example as a PC forwards a low bandwidth instance of a stream to a mobile device.

Figure 2. Parsing Levels to Reduce Bandwidth and Resolution.
H.264 SVC Under the Hood
To achieve temporal scalability, H.264 SVC links its reference and predicted frames somewhat differently than conventional H.264 AVC encoders. Instead of the traditional Intra-frame (I frame), Bidirectional (B frame) and Predicted (P frame) relationship shown in Figure 3, SVC uses a hierarchical prediction structure.

(Click to enlarge)
Figure 3. Traditional I, P, and B Frame Relationship.
The hierarchical structure defines the temporal layering of the final stream. Figure 4 illustrates a potential hierarchical structure. In this particular example, frames are only predicted from frames that occur earlier in time. This ensures that the structure exhibits not only temporal scalability but also low latency.

(Click to enlarge)
Figure 4. Hierarchical Predicted Frames in SVC.
This scheme has four nested temporal layers: T0 (the base layer), T1, T2, and T3. Frames constituting the T1 and T2 layers are only predicted from frames in the T0 layer. Frames in the T3 layer are only predicted from frames in the T1 or T2 layers.
To play the encoded stream at 3.75 frames per second (fps), only the frames that constitute T0 need be decoded. All other frames can be discarded. To play the stream at 7.5 fps, the layers making up T0 and T1 are decoded. Frames in layers T2 and T3 can be discarded. Similarly, if frames that constitute T0, T1 and T2 are decoded, the resulting stream will play at 15 fps. If all frames are decoded, the full 30 fps stream is recovered.
By contrast, in H.264 AVC (for Baseline Profile where only unidirectional predicted frames are used), all the frames would need to be decoded irrespective of the desired display rate. To transit to a low bandwidth network, the entire stream would need to be decoded, the unwanted frames discarded, and then re-encoded.
Spatial scalability in H.264 SVC follows a similar principle. In this case, lower resolution frames are encoded as the base layer. Decoded and up-sampled base layer frames are used in the prediction of higher-order layers. Additional information required to reconstitute the detail of the original scene is encoded as a self-contained enhancement layer. In some cases, reusing motion information can further increase encoding efficiency.
Simulcast vs. SVC
There is an overhead associated with the scalability inherent in H.264 SVC. As can be seen in Figure 3, the distance between reference and predicted frames can be longer in time (from T0 to T1 for example) than with the conventional frame structure. In scenes with high motion, this can lead to slightly less efficient compression. There is also an overhead associated with the management of the layered structure in the stream.
Overall, an SVC stream containing three layers of temporal scalability and three layers of spatial scalability might be twenty percent larger than an equivalent H.264 AVC stream of full resolution and full frame rate video with no scalability. If scalability is to be emulated with the H.264 AVC codec, multiple encode streams are required, resulting in a dramatically higher bandwidth requirement or expensive decoding and re-encoding throughout the network.
Additional SVC Benefits
Error Resilience:
Error resilience is traditionally achieved by adding additional information to the stream so errors can be detected and corrected. SVC's layered approach means that a higher level of error detection and correction can be performed on the smaller base layer without adding significant overhead. Applying the same degree of error detection and correction to an AVC stream would require that the entire stream be protected, resulting in a much larger stream. If errors are detected in the SVC stream, the resolution and frame rate can be progressively degraded until, if needed, only the highly protected base layer is used. In this way, degradation under noisy conditions is much more graceful than with H.264 AVC.
Storage Management:
Since an SVC stream or file remains decodable even when truncated, SVC can be employed both during transmission and after the file is stored. Parsing files stored to disk and removing enhancement layers allows file size to be reduced without additional processing on the video stream stored within the file. This would not be possible with an AVC file which necessitates an "all or nothing" approach to disk management.
Content Management:
The SVC stream or file inherently contains lower resolution and frame rate streams. These streams can be used to accelerate the application of video analytics or for cataloging algorithms. The temporal scalability also makes the stream easier to search in fast forward or reverse.
An Application Case Study
A typical application for H.264 SVC is a surveillance system. (Stretch offers market-leading solutions in this area; see its web site for details.) Consider the case where an IP camera is sending a video feed to a control room where it is stored, and basic motion detection analytics are run on the stream. The video feed is viewed at the camera's maximum resolution (1280 x 720) on the control room monitors, and is stored in D1 (720 x 480) resolution to conserve disk space. A first-response team also has access to the stream in the field on mobile terminals within the response vehicle. The resolution of those displays is CIF (352 x 240) and the stream is served at 7 fps.
In an implementation using H.264 AVC, the first likely constraint would be that the camera serves multiple streams. In this example, one at 1280x720 resolution and one at 720 x 480 resolution. This places additional cost within the camera, but allows one stream to be directly recorded at the control room while another is decoded and displayed. Without this feature, an expensive decode, resize, and re-encode step would be needed. The D1 stream is also decoded and resized to CIF resolution to feed the video analytics being run on the stream. The CIF resolution video is temporally decimated to achieve 7 frames per second and re-encoded so that it can be made available to the first-response vehicle over a wireless link. Figure 5 shows a potential implementation of the system using H.264 AVC.

Figure 5. H.264 AVC Video Surveillance Application.
Using an H.264 SVC codec, the multi-stream requirement placed on the camera can be relaxed, reducing complexity and network bandwidth between the camera and control room. The full 1280 x 720 stream can now be stored on the network video recorder (NVR) with the knowledge that it can be easily parsed to create a D1 (or CIF) stream to free up disk space after a specified period. A CIF stream can be served directly from the NVR for analytics work, and a second stream at a reduced frame rate can be made available to the first-response vehicle. Figure 6 shows a potential H.264 SVC implementation.

Figure 6. H.264 SVC Video Surveillance Application.
At no point is there a need to operate on the video stream itself—operating on the stored file suffices. The advantages are clear:
- Reduced network bandwidth
- Flexible storage management
- Removal of expensive decode and re-encode stages
- High definition video available on the NVR for archive if needed
Conclusion
Scalable video codecs have been in development for many years. The broadcast industry, strictly controlled by well-established standards, has been slow to adopt this technology. Advances in processor, sensor, and display technology are fuelling an explosion in video adoption. The Internet and IP technologies are seamlessly serving video to an ever more diverse and remote community of display devices. Scalable video codecs such as H.264 SVC satisfy many of the demands of these systems, and they are poised to become a catalyst in wide the spread adoption of video as a communication medium.
About the author
Mark Oliver is the Director of Product Marketing at Stretch. A native of the UK, Oliver gained a degree in Electrical and Electronic Engineering from the University of Leeds. During a ten year tenure with Hewlett Packard, Oliver managed Engineering and Manufacturing functions in HP Divisions both in Europe and the US before heading up Product Marketing and Applications activities at a series of video related startups. Prior to joining Stretch, Oliver managed Marketing for Video and Imaging within the DSP Division of Xilinx.
Related Articles:
摘要: The Scalable Video Coding Amendment of the H.264/AVC Standardfunction StorePage(){d=document;t=d.selection?(d.selection.type!='None'?d.selection.createRange().text:''):(d.getSelection?d.getSelection()... 阅读全文
以下转载于“ Jenny@博客大巴”
第一:看轻自己,重视别人;
曾经有一度,我以为自己相当重要,不仅拼搏着自己的理想,而且承载着别人的未来。我活得很辛苦很紧张,因为生活在他人的世界里。我在意别人的所思所想,我在乎别人的所作所为,周围的微小变化都能够影响到我内心的安宁。我开始焦虑不安,找很多朋友谈话。我知道她们都是对的,我明白她们在说什么,只是我无法说服自己。终于有一天,我顿悟了,所有这一切困惑,是因为我把自己太看重了。
我喜欢看月亮,从新月开始,到上弦月,到圆月,再到下弦月,最后到残月,周而复始,愈发感觉到天地的广袤和自我的渺小。当我真的开始看轻自己的时候,我进入一个全新的世界,周围每个人都能给我惊喜,无论是我崇拜之人,还是我泛泛之交。我发现了他/她们的优点,我理解了他/她们的苦衷,我开始珍惜和重视身边的每个人。我越来越快乐,越来越豁达,学会应该怎样和别人相处,让自己和他人都更舒服一点。
第二:时间是自己的,机会也是自己的;
不知什么时候我开始意识到日月如梭。眼见耳闻着所谓“英雄末路,美人迟暮”的故事在不断上演,唯有唏嘘不已,自我不断警醒。时间面前人人平等,关键在于如何最佳利用,实现最大价值化。人生本原本就没有意义,只是你如何描绘它。
年少无知的时候,我以为应该好好尽情享受青春的感觉,从来没有想到时间只拥有一次,20岁永远不会再来。现在浅薄如我,才发现“书到用时方恨少”。我还有很多书需要看,很多技能需要学习,很多专业知识需要巩固,很多朋友需要关心……不过幸运的是,任何时候都为时不晚,只要随时启程,就有新鲜的发现。机会也永远垂青有准备的人。
第三:平衡就健康。
我向来都知足常乐,极具阿Q精神。 每个人生活都不容易,也都有各自的精彩。活得简单一些,难得糊涂一点,会让自己的内心平和许多。
对于我,工作,家庭,生活,朋友,一个都不能少。我热爱工作,因为我在创造多重价值,个人资本、公司利益和社会责任。多说一句价值观的问题,没有人能给你判定价值几何,只有你自己。你的付出和回报在正常状况下是成正比的,不要过多要求别人,应该更多省视自己,自己做得够好了吗?!家庭是我珍视的,也永远是最安全的避风港,唯有亲人对自己无怨无悔。我向来要求生活品质,不求最贵的,也不求最好的,而是最适合自己的。朋友是我最大的财富,我全心全意地去维护这份感情,谢谢你们给我的一切,甘为树洞,是我莫大的荣幸!
一位心理医生和一位30岁女白领的对话,她想纠正自己最近几个月里总是拖延工作的恶习。
“你喜欢吃蛋糕吗?”“喜欢。” “你喜欢先吃蛋糕,还是蛋糕上的奶油?” “当然是奶油啦!我通常先吃完奶油,然后才吃蛋糕的。”
医生从吃蛋糕的习惯出发,重新讨论她对待工作的态度。正如医生预料的,在上班第一个钟头,她总是把容易和喜欢做的工作先完成,而在剩下6个钟头里,她就尽量规避棘手的差事。
医生建议她从现在开始,在上班第一个钟头,要先去解决那些麻烦的差事,在剩下的时间里,其他工作会变得相对轻松。医生解释其中的道理说:按1天工作7个钟头计算,1个钟头的痛苦与6个钟头的幸福,显然要比1个钟头的幸福,加上6个钟头的痛苦划算。
她完全同意这样的计算方法,而且坚决照此执行,不久就彻底克服了拖延工作的毛病。
这就是推迟满足感,它意味着你不能贪图暂时的安逸,你得重新设置人生快乐与痛苦的次序:首先,面对问题并感受痛苦;然后,解决问题并享受更大的快乐,这是惟一可行的生活方式。
[转载]习惯的力量:35岁之前如何可以做得很成功
习惯的力量是惊人的。习惯能载着你走向成功,也能驮着你滑向失败。如何选择,完全取决于你自己。
1、习惯的力量:35岁以前养成好习惯
你想成功吗?那就及早培养有利于成功的好习惯。
习惯的力量是惊人的,35岁以前养成的习惯决定着你是否成功。
有这样一个寓言故事:
一位没有继承人的富豪死后将自己的一大笔遗产赠送给远房的一位亲戚,这位亲戚是一个常年靠乞讨为生的乞丐。这名接受遗产的乞丐立即身价一变,成了百万富翁。新闻记者便来采访这名幸运的乞丐:“你继承了遗产之后,你想做的第一件事是什么?”乞丐回答说:“我要买一只好一点的碗和一根结实的木棍,这样我以后出去讨饭时方便一些。”
可见,习惯对我们有着绝大的影响,因为它是一贯的,在不知不觉中,经年累月地影响着我们的行为,影响着我们的效率,左右着我们的成败。
一个人一天的行为中,大约只有5%是属于非习惯性的,而剩下的95%的行为都是习惯性的。即便是打破常规的创新,最终可以演变成为习惯性的创新。
根据行为心理学的研究结果:3周以上的重复会形成习惯;3个月以上的重复会形成稳定的习惯,即同一个动作,重复3周就会变成习惯性动作,形成稳定的习惯。
亚里士多德说:“人的行为总是一再重复。因此,卓越不是单一的举动,而是习惯。”
“人的行为总是一再重复。因此,卓越不是单一的举动,而是习惯。”所以,在实现成功的过程中,除了要不断激发自己的成功欲望,要有信心、有热情、有意志、有毅力等之外,还应该搭上习惯这一成功的快车,实现自己的目标。
有个动物学家做了一个实验:他将一群跳蚤放入实验用的大量杯里,上面盖上一片透明的玻璃。跳蚤习性爱跳,于是很多跳蚤都撞上了盖上的玻璃,不断地发叮叮冬冬的声音。过了一阵子,动物学家将玻璃片拿开,发现竟然所有跳蚤依然在跳,只是都已经将跳的高度保持在接近玻璃即止,以避免撞到头。结果竟然没有一只跳蚤能跳出来——依它们的能力不是跳不出来,只是它们已经适应了环境。
后来,那位动物学家就在量杯下放了一个酒精灯并且点燃了火。不到五分钟,量杯烧热了,所有跳蚤自然发挥求生的本能,每只跳蚤再也不管头是否会撞痛(因为它们以为还有玻璃罩),全部都跳出量杯以外。这个试验证明,跳蚤会为了适应环境,不愿改变习性,宁愿降低才能、封闭潜能去适应。
我想,人类之于环境也是如此。人类在适应外界大环境中,又创造出适合于自己的小环境,然后用习惯把自己困在自己所创造的环境中。所以,习惯决定着你的活动空间的大小,也决定着你的成败。养成好习惯对于你的成功非常重要。
心理学巨匠威廉·詹姆士说:“播下一个行动,收获一种习惯;播下一种习惯,收获一种性格;播下一种性格,收获一种命运。”
2、35岁以前成功必备的9大习惯
好习惯会使成功不期而至。
好习惯会使成功不期而至。我认为下面9个好习惯是成功必备的:
(1)积极思维的好习惯
有位秀才第三次进京赶考,住在一个经常住的店里。考试前两天他做了三个梦:第一个梦是梦到自己在墙上种白菜,第二个梦是下雨天,他戴了斗笠还打着伞,第三个梦是梦到跟心爱的表妹脱光了衣服躺在一起,但是背靠着背。临考之际做此梦,似乎有些深意,秀才第二天去找算命的解梦。算命的一听,连拍大腿说:“你还是回家吧。你想想,高墙上种菜不是白费劲吗?戴斗笠打雨伞不是多此一举吗?跟表妹脱光了衣服躺在一张床上,却背靠背,不是没戏吗?”秀才一听,心灰意冷,回店收拾包裹准备回家。
店老板非常奇怪,问:“不是明天才考试吗?今天怎么就打道回府了?”秀才如此这般说了一番,店老板乐了:“唉,我也会解梦的。我倒觉得,你这次一定能考中。你想想,墙上种菜不是高种吗?戴斗笠打伞不是双保险吗?跟你表妹脱光了背靠背躺在床上,不是说明你翻身的时候就要到了吗?”秀才一听,更有道理,于是精神振奋地参加考试,居然中了个探花。
可见,事物本身并不影响人,人们只受到自己对事物看法的影响,人必须改变被动的思维习惯,养成积极的思维习惯。
怎样才算养成了积极思维的习惯呢?当你在实现目标的过程中,面对具体的工作和任务时,你的大脑里去掉了“不可能”三个字,而代之以“我怎样才能”时,可以说你就养成了积极思维的习惯了。
(2)高效工作的好习惯
一个人成功的欲望再强烈,也会被不利于成功的习惯所撕碎,而溶入平庸的日常生活中。所以说,思想决定行为,行为形成习惯,习惯决定性格,性格决定命运。你要想成功,就一定要养成高效率的工作习惯。
确定你的工作习惯是否有效率,是否有利于成功,我觉得可以用这个标准来检验:即在检省自己工作的时候,你是否为未完成工作而感到忧虑,即有焦灼感。如果你应该做的事情而没有做,或做而未做完,并经常为此而感到焦灼,那就证明你需要改变工作习惯,找到并养成一种高效率的工作习惯。
高效工作从办公室开始:
1)了解你每天的精力充沛期。通常人们在早晨9点左右工作效率最高,可以把最困难的工作放到这时来完成。
2)每天集中一、两个小时来处理手头紧急的工作,不接电话、不开会、不受打扰。这样可以事半功倍。
3)立刻回复重要的邮件,将不重要的丢弃。若任它们积累成堆,反而更费时间。
4)做个任务清单,将所有的项目和约定记在效率手册中。手头一定要带着效率手册以帮助自己按计划行事。一个人一天的行为中,大约只有5%是属于非习惯性的,而剩下的95%的行为都是习惯性的。
5)学会高效地利用零碎时间,用来读点东西或是构思一个文件,不要发呆或做白日梦。
6)减少回电话的时间。如果你需要传递的只是一个信息,不妨发个手机短信。
7)对可能打来的电话做到心中有数,这样在你接到所期待的电话后便可迅速找到所需要的各种材料,不必当时乱翻乱找。
8)学习上网高效搜寻的技能,以节省上网查询的时间。把你经常要浏览的网站收集起来以便随时找到。
9)用国际互联网简化商业旅行的安排。多数饭店和航线可以网上查询和预订。
10)只要情况允许就可委派别人分担工作。事必躬亲会使自己疲惫不堪,而且永远也做不完。不妨请同事帮忙,或让助手更努力地投入。
11)做灵活的日程安排,当你需要时便可以忙中偷闲。例如,在中午加班,然后早一小时离开办公室去健身,或是每天工作10个小时,然后用星期五来赴约会、看医生。
12)在离开办公室之前开列次日工作的清单,这样第二天早晨一来便可以全力以赴。
凡事有计划
计划习惯,就等于计划成功。
凡事制定计划有个名叫约翰·戈达德的美国人,当他15岁的时候,就把自己一生要做的事情列了一份清单,被称做“生命清单”。在这份排列有序的清单中,他给自己所要攻克的127个具体目标。比如,探索尼罗河、攀登喜马拉雅山、读完莎士比亚的著作、写一本书等。在44年后,他以超人的毅力和非凡的勇气,在与命运的艰苦抗争中,终于按计划,一步一步地实现了106个目标,成为一名卓有成就的电影制片人、作家和演说家。
中国有句老话:“吃不穷,喝不穷,没有计划就受穷。”尽量按照自己的目标,有计划地做事,这样可以提高工作效率,快速实现目标。
(3)养成锻炼身体的好习惯
增强保健意识
计划习惯,就等于计划成功。如果你想成就一番事业,你就必须有一个健康的身体;要想身体健康,首先要有保健意识。
我认识一个大学教师,身体一直很健康。早些时候,我们经常在一起玩。在谈及各人身体状况时,他说肾部偶尔有轻微不适的感觉。我们曾劝他去医院检查一下,但他自恃身体健康,不以为意。直至后来感觉比较疼痛,其爱人才强迫他去检查。诊断结果是晚期肾癌。虽经手术化疗的等治疗措施,但终未能保住生命,死时才39岁。此前,他曾因学校分房、评职称不如意,心情一直抑郁,他的病和情绪有关,但如果他保健意识强,及早去检查,完全有可以进行预防,消患于未萌。保健意识差,让他付出了生命的代价。
如何落实保健意识呢?一是要有生命第一、健康第一的意识,有了这种意识,你就会善待自己的身体、自己的心理,而不会随意糟踏自己的身体。二是要注意掌握一些相关的知识。三是要使自己有一个对身体应变机制:定期去医院做身体检查;身体觉得有不适的地方,应及早去医院检查;在有条件的情况下,可以请一个保健医生,给自己的健康提出忠告。
有计划地锻炼身体
锻炼身体的重要性已经越来越多地为人们所接受,但我感觉很多人只停留在重视的意识阶段,而缺乏相应的行动。我认为锻炼既要针对特定工作姿势所能引发的相应疾病有目的地进行,以防止和治疗相应的疾病,更要把锻炼当作一种乐趣,养成锻炼的习惯。
因为工作需要,我经常与客户打交道,并因处理突发事情四处奔忙,这在一定程度起到了锻炼身体的作用,同时,我还每周坚持游泳一到两次,以保证有足够的精力去做工作,去享受生活。
身体锻炼,就像努力争取成功一样,贵在坚持。
除上述两点以,注意饮食结构,合理膳食,以及注意养成好的卫生习惯等,都是养成健康习惯的组成部分。
总之,健康是“革命”的本钱,是成功的保证。健康成就自己。
(4)不断学习的好习惯
“万般皆下品,唯有读书高”的年代已经过去了,但是养成读书的好习惯则永远不会过时。
哈利·杜鲁门是美国历史上著名的总统。他没有读过大学,曾经营农场,后来经营一间布店,经历过多次失败,当他最终担任政府职务时,已年过五旬。但他有一个好习惯,就是不断地阅读。多年的阅读,使杜鲁门的知识非常渊博。他一卷一卷地读了《大不列颠百科全书》以及所有查理斯·狄更斯和维克多·雨果的小说。此外,他还读过威廉·莎士比亚的所有戏剧和十四行诗等。
杜鲁门的广泛阅读和由此得到的丰富知识,使他能带领美国顺利度过第二次世界大战的结束时期,并使这个国家很快进入战后繁荣。他懂得读书是成为一流领导人的基础。读书还使他在面对各种有争议的、棘手的问题时,能迅速做出正确的决定。例如,在20世纪50年代他顶住压力把人们敬爱的战争英雄道格拉斯·麦克阿瑟将军解职。
他的信条是:“不是所有的读书人都是一名领袖,然而每一位领袖必须是读书人。”
美国前任总统克林顿说:在19世纪获得一小块土地,就是起家的本钱;而21世纪,人们最指望得到的赠品,再也不是土地,而联邦政府的奖学金。因为他们知道,掌握知识就是掌握了一把开启未来大门的钥匙。”
每一个成功者都是有着良好阅读习惯的人。世界500家大企业的CEO至少每个星期要翻阅大概30份杂志或图书资讯,一个月可以翻阅100多本杂志,一年要翻阅1000本以上。
世界500家大企业的CEO至少每个星期要翻阅大概30份杂志或图书资讯,一个月可以翻阅100多本杂志,一年要翻阅1000本以上。如果你每天读15分钟,你就有可能在一个月之内读完一本书。一年你就至少读过12本书了,10年之后,你会读过总共120本书!想想看,每天只需要抽出15分钟时间,你就可以轻易地读完120本书,它可以帮助你在生活的各方面变得更加富有。如果你每天花双倍的时间,也就是半个小时的话,一年就能读25本书——10年就是250本!
我觉得,每一个想在35岁以前成功的人,每个月至少要读一本书,两本杂志。
(5)谦虚的好习惯
一个人没有理由不谦虚。相对于人类的知识来讲,任何博学者都只能是不及格。
著名科学家法拉第晚年,国家准备授予他爵位,以表彰他在物理、化学方面的杰出贡献,但被他拒绝了。法拉第退休之后,仍然常去实验室做一些杂事。一天,一位年轻人来实验室做实验。他对正在扫地的法拉第说道:“干这活,他们给你的钱一定不少吧?”老人笑笑,说道:“再多一点,我也用得着呀。”“那你叫什么名字?老头?”“迈克尔·法拉第。”老人淡淡地回答道。年轻人惊呼起来:“哦,天哪!您就是伟大的法拉第先生!”“不”,法拉第纠正说,“我是平凡的法拉第。”
谦虚不仅是一种美德,更是是一种人生的智慧,是一种通过贬低自己来保护自己的计谋。
(6)自制的好习惯
任何一个成功者都有着非凡的自制力。
三国时期,蜀相诸葛亮亲自率领蜀国大军北伐曹魏,魏国大将司马懿采取了闭城休战、不予理睬的态度对付诸葛亮。他认为,蜀军远道来袭,后援补给必定不足,只要拖延时日,消耗蜀军的实力,一定能抓住良机,战胜敌人。
诸葛亮深知司马懿沉默战术的利害,几次派兵到城下骂阵,企图激怒魏兵,引诱司马懿出城决战,但司马懿一直按兵不动。诸葛亮于是用激将法,派人给司马懿送来一件女人衣裳,并修书一封说:“仲达不敢出战,跟妇女有什么两样。你若是个知耻的男儿,就出来和蜀军交战,若不然,你就穿上这件女人的衣服。”
“士可杀不可辱。”这封充满侮辱轻视的信,虽然激怒了司马懿,但并没使老谋深算的司马懿改变主意,他强压怒火稳住军心,耐心等待。
相持了数月,诸葛亮不幸病逝军中,蜀军群龙无首,悄悄退兵,司马懿不战而胜。
抑制不住情绪的人,往往伤人又伤己如果司马懿不能忍耐一时之气,出城应战,那么或许历史将会重写。
现代社会,人们面临的诱惑越来越多,如果人们缺乏自制力,那么就会被诱惑牵着鼻子走,偏离成功的轨道。
(7)幽默的好习惯
有人说,男人需要幽默,就像女人需要一个漂亮的脸蛋一样重要。
男人需要幽默,就像女人需要一个漂亮的脸蛋一样重要。美国第16任总统林肯长相丑陋,但他从不忌讳这一点,相反,他常常诙谐地拿自己的长相开玩笑。在竞选总统时,他的对手攻击他两面三刀,搞阴谋诡计。林肯听了指着自己的脸说:“让公众来评判吧。如果我还有另一张脸的话,我会用现在这一张吗?”还有一次,一个反对林肯的议员走到林肯跟前挖苦地问:“听说总统您是一位成功的自我设计者?”“不错,先生。”林肯点点头说,“不过我不明白,一个成功的设计者,怎么会把自己设计成这副模样?”林肯就是这种幽默的方法,多次成功地化解了可能出现的尴尬和难堪场面。
没有幽默的男人不一定就差,但懂得幽默的男人一定是一个优秀的人,懂得幽默的女人更是珍稀动物。
(8)微笑的好习惯
微笑是大度、从容的表现,也是交往的通行证。
举世闻名的希尔顿大酒店,其创建人希尔顿在创业之初,经过多年探索,最终发现了一条简单、易行、不花本钱的经营秘诀——微笑。从此,他要求所有员工:无论饭店本身遭遇到什么困难,希尔顿饭店服务员脸上的微笑永远是属于顾客的阳光。这束“阳光”最终使希尔顿饭店赢得了全世界一致好评。
在欧美发达国家,人们见面都要点头微笑,使人们相互之间感到很温暖。而在中国,如果你在大街上向一个女士微笑,那么你可能被说成“有病”。向西方人学习,让我们致以相互的微笑吧。
从古至今,敬业是所有成功人士最重要的品质之一。
(9)敬业、乐业的好习惯
敬业是对渴望成功的人对待工作的基本要求,一个不敬业的人很难在他所从事的工作中做出成绩。
美国标准石油公司有一个叫阿基勃特的小职员,开始并没有引起人们的特别注意。他的敬业精神特别强,处处注意维护和宣传企业的声誉。在远行住旅馆时总不忘记在自己签名的下方写上“每桶四美元的标准石油”字样,在给亲友写信时,甚至在打收条时也不例外,签名后总不忘记写那几个字。为此,同事们都叫他“每桶四美元”。这事被公司的董事长洛克菲勒知道了,他邀请阿基勃特共进晚餐,并号召公司职员向他学习。后来,阿基勃特成为标准石油公司的第二任董事长。
3、35岁以前成功必须戒除的9大恶习
坏习惯使成功寸步难行。
与建立良好习惯相应的,是克服不良习惯。不破不立,不改掉不良习惯,好习惯是难以建立起来的。
古希腊的佛里几亚国王葛第士以非常奇妙的方法,在战车的轭打了一串结。他预言:谁能打开这个结,就可以征服亚洲。一直到公元前334年还没有一个人能将绳结打开。这时。亚历山大率军入侵小亚细亚,他来到葛第士绳结前,不加考虑便拔剑砍断了它。后来,他果然一举占领了比希腊大50倍的波斯帝国。
一个孩子在山里割草,不小心被毒蛇咬伤了脚。孩子疼痛难忍,而医院在远处的小镇上。孩子毫不犹豫地用镰刀割断受伤的脚趾,然后忍着巨痛艰难地走到医院。虽然缺少了一个脚趾,但这个孩子以短暂的疼痛保住了自己的生命。
改掉坏习惯,就应该有亚历山大的气概,就应有那个小孩的果断和勇敢,彻底改掉坏习惯,让好习惯引领自己走向成功。
以下这9大恶习是你必须戒除的:
1)经常性迟到。你上班或开会经常迟到吗?迟到是造成使老板和同事反感的种子,它传达出的信息:你是一个只考虑自己、缺乏合作精神的人。
2)拖延。虽然你最终完成了工作,但拖后腿使你显得不胜任。为什么会产生延误呢?如果是因为缺少兴趣,你就应该考虑一下你的择业;如果是因为过度追求尽善尽美,这毫无疑问会增多你在工作中的延误。社会心理学专家说:很多爱拖延的人都很害怕冒险和出错,对失败的恐惧使他们无从下手。
3)怨天尤人。这几乎是失败者共同的标签。一个想要成功的人在遇到挫折时,应该冷静地对待自己所面临的问题,分析失败的原因,进而找到解决问题的突破口。
4)一味取悦他人。一个真正称职的员工应该对本职工作内存在的问题向上级说明并提出相应的解决办法,而不应该只是附和上级的决定。对于管理者,应该有严明的奖惩方式,而不应该做“好好先生”,这样做虽然暂时取悦了少数人,却会失去大多数人的支持。
5)传播流言。每个人都可能会被别人评论,也会去评论他人,但如果津津乐道的是关于某人的流言蜚语,这种议论最好停止。世上没有不透风的墙,你今天传播的流言,早晚会被当事人知道,又何必去搬石头砸自己的脚?所以,流言止于智者。
6)对他人求全责备、尖酸刻薄。每个人在工作中都可能有失误。当工作中出现问题时,应该协助去解决,而不应该一味求全责备。特别是在自己无法做到的情况下,让自己的下属或别人去达到这些要求,很容易使人产生反感。长此以往,这种人在公司没有任何威信而言。
7)出尔反尔。已经确定下来的事情,却经常做变更,就会让你的下属或协助员工无从下手。你做出的承诺,如果无法兑现,会在大家面前失去信用。这样的人,难以担当重任。
8)傲慢无礼。这样做并不能显得你高人一头,相反会引起别人的反感。因为,任何人都不会容忍别人瞧不起自己。傲慢无礼的人难以交到好的朋友。人脉就是财脉,年轻时养成这种习惯的人,相信你很难取得成功。
9)随大流。人们可以随大流,但不可以无主见。如果你习惯性地随大流,那你就有可能形成思维定势,没有自己的主见,或者既便有,也不敢表达自己的主见,而没有主见的人是不会成功的。
| jndi全局注册表和enc的基本概念 |
|
通俗的将jndi就是对ejb容器中所有的资源和组件进行管理的花名册,通过该服务,可以很方便的找到希望使用的资源。当组件被部署到服务器上后,该组件就会被自动注册到花名册上,以便用户使用,如果组件被卸载,花名册上的记录就会自动消失。
jndi中注册的所有的资源和组件可以被服务器内外的各种程序请求或者访问,是一种全局性的资源!但是ejb中不同的组件通过全局性的jndi服务器形成依赖关系,则会给系统造成不稳定的因素!因此就引入了enc(ejb组件的企业名称上下文)的概念!通过她来实现不同组件之间的引用关系!!!!
在上一篇文章中写到了通过标注的方式实现方向依赖注入!还以上篇为例:
有接口:HelloWordRemote HelloWordLocal ICal(Remote)
而HelloWordBean实现了分别实现了他们
另外又有了个远程接口:
@Remote
public Interface MyService{
public String helloWord();
public int add(int a,int b);
}
一个类想实现这个接口并且在这个类中引用了...如下:
@Stateless
public class FacedServcie implements MyService{
private HelloWordLocal myserv1;
private ICal ical;
.....
....
}
可以通过配置文件实现反向依赖注入:
<ejb-jar
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/ejb-jar_3_0.xsd"
version="3.0">
<enterprise-beans>
<session>
<ejb-name>FacedServcie</ejb-name>
<ejb-ref>
<ejb-ref-name>abc1</ejb-ref-name>
<ejb-ref-type>Session</ejb-ref-type>
<remote>com.ICal</remote>
<mapped-name>HelloWordBean1/remote</mapped-name>
<injection-target>
<injection-target-class>
xiaoxiao.FacedService
</injection-target-class>
<injection-target-name>
ical
</injection-target-name>
</injection-target>
</ejb-ref>
.........(对于另一个组件的配置)
</session>
</enterprise-beans>
</ejb-jar>
还可以通过检索的方式来实现:
@Stateless
public class FacedServcie implements MyService{
private HelloWordLocal myserv1;
private ICal ical;
public String helloWord(){
try{
InitialContext ctx=new InitalContext();
ical=(ICal)ctx.lookup("java:comp/env/abc1");
//其中java:comp/env是组件局部enc所有记录的根路径而abc1是在配置文件中注册的名字!
}catch(NamingException e){}
if(ical!=null){
return ical.helloWord();
}else{
return "error!";
}
}
....
}
配置文件如下:
<ejb-jar
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/ejb-jar_3_0.xsd"
version="3.0">
<enterprise-beans>
<session>
<ejb-name>FacedServcie</ejb-name>
<ejb-ref>
<ejb-ref-name>abc1</ejb-ref-name>
<ejb-ref-type>Session</ejb-ref-type>
<remote>com.ICal</remote>
<mapped-name>HelloWordBean1/remote</mapped-name>
</ejb-ref>
.........(对于另一个组件的配置)
</session>
</enterprise-beans>
</ejb-jar>
本人建议使用第一种反向依赖注入的方式!
还有其他的一些注入:如持久化单元注入,资源型注入 数据源类型的注入。。。
|
|
|
|
| EJB事务 |
在ejb组件设计中,组件行为有时需要具备事务特征,即使用事务保证组件行为的完整性,使组件要么执行成功,要么回到起点.等价没有执行!
讨论事务时要明确两个概念:
事务范围
算法的可恢复性与事务性:如果事务中的算法动作结果受事务提交或者回滚影响,则该算法具有事务可恢复性,否则就不具备事务可恢复性.
事务在本质上就是一个管理系列算法动作一致性的对象!ejb提供了两种事务类型:声明性和程序性事务
声明性事务:由ejb容器负责事务对象的 生成,管理,销毁;具体算法在事务上的注册,事务的提交和回滚等
主要介绍声明性的事务:
ejb容器为其中的 所有的ejb组件提供了一种默认的事务模式:Requires
在该模式下面,组件中的方法如果在事务环境下被调用(即客户端调用了该组件的方法),则方法中的逻辑会被添加到客户端的事务环境中,和客户端的程序使用相同的事务控制对象.如果不在事务环境中调用(在客户端没有调用该组件中的方法),ejb容器就创建新的事务对象,管理该方法中的所有逻辑.
例如:
ejb组件:
@Statefull
public class personmanager inplements IPersonAdmin{
@PersistenceContext(unitName="mydb")
private EntityManager manager;
@EJB(mappedName="MySession/remote")
private IPersonAdmin mytools;
public List<person> QueryAll(){
....
}
public void createPerson(Person p){
Person pobj=new Person();
pobj.setName("ziaoxioa");
#1 manager.persist(pobj);
#2 mytools.createPerson(p);
#3 manager.persist(null);
}
客户代码:
...
myinf.createPerson(p);
...
默认情况下,ejb读物起会为ejb组件中的所有方法配置一中requires型的事务服务.在这种事务模式下面,如果方法被在事务环境下调用,方法就使用客户端事务对象和事务环境ruguo不在事务环境中被调用,则ejb容器就会创建新的事务对象和环境来负责管理该方法的逻辑完整性!由于上面的#3错误,所以数据库中不会添加任何记录!
ejb容器为ejb组件添加的默认的事务策略能够满足多数情况下的算法要求,特殊情况下,可以通过@TransactionAttribute和<container-transaction>标记修改组件的默认事务策略!如下:
<ejb-jar
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/ejb-jar_3_0.xsd"
version="3.0">
<assembly-descriptor>
<container-transaction>
<method>
<ejb-name>MySession</ejb-name>
<method-name>createPerson</method-name>
</method>
<trans-attribute>RequiresNew</trans-attribute>
</container-transaction>
</assembly-descriptor>
</ejb-jar>
@TransactionAttribute(REQUIRES_NEW)
public void createPerson(Person p){
manager.persist(p);
}
这样MySession中的createPerson方法事务修改成了RequiesNew模式,在这种模式下,ejb容器不论客户端是否具有事务特征,为createPerson创建一个新的事务对象,此时两个createPerson在完全不同的事务对象控制下,所以#2可以提交到数据库中,#1,#3则回滚
声明性事务模式:
| Required |
ejb容器为ejb组件方法提供的默认事务模式,在这种模式下,如果调用程序具备自身的事务对象,则组件方法就和客户程序使用相同的事务对象,否则ejb容器就会创建新的事务对象来管理组件方法逻辑 |
| Supports |
在这种模式下,如果调用程序具备事务特征,则组件方法就会调用调用程序事务对象管理自身逻辑,如果调用程序不包含任何的事务对象,则组件方法也处于无事务管理状态 |
| NotSupported |
这种模式下,组件方法不支持事务,同时也会忽略掉调用程序中的事务对象,组件方法中的逻辑不受客户程序事务的提交或回滚的影响 |
| RequiresNew |
在这种模式下,忽略调用程序具备的事务特征,ejb容器会新创建一个新的事务对象管理组件方法逻辑 |
| Mandatory |
ejb容器不会为该方法创建新的事务管理对象。该组件方法的调用程序必须提供事务对象,处于事务环境中,否则程序将产生异常javax.ejb.EJBTransactionRequiredException
|
| Never |
这种模式下,该方法不会被ejb容器提供事务对象服务,并且调用程序也不能处于事务环境中,否则将产生EJBException异常
|
下面的程序首先清楚组件上的默认事务模式,然后在为方法设定具体事务属性:
<assembly-descriptor>
<container-transaction>
<method>
<ejb-name>MySession</ejb-name>
<method-name>*</method-name>
</method>
<trans-attribute>NotSupported</trans-attribute>
</container-transaction>
<container-transaction>
<method>
<ejb-name>MySession</ejb-name>
<method-name>createPerson</method-name>
</method>
<trans-attribute>Required</trans-attribute>
</container-transaction>
</assembly-descriptor>
声明性事务的控制:
@Stateless
/*10*/public class PersonManager implements IPersonAdmin
/*11*/{
/*12*/ @Resource
/*13*/ private EJBContext ctx;
/*14*/ @PersistenceContext(unitName="mydb")
/*15*/ private EntityManager manager;
/*16*/ @EJB(mappedName="MySession/remote")
/*17*/ private IPersonAdmin mytools;
/*18*/ public List<Person> QueryAll()
/*19*/ {
/*20*/ Query q=manager.createQuery("from Person c");
/*21*/ List results=q.getResultList();
/*22*/ List<Person> result=(List<Person>)results;
/*23*/ return result;
/*24*/ }
/*25*/ public void createPerson(Person p)
/*26*/ {
/*27*/ Person pobj=new Person();
/*28*/ pobj.setName("zhanghao");
/*29*/ pobj.setAge(new Integer(32));
/*30*/ pobj.setSex("male");
/*31*/ manager.persist(pobj);
/*32*/ boolean result=ctx.getRollbackOnly();
/*33*/ if(!result)
/*34*/ {
/*35*/ ctx.setRollbackOnly();
/*36*/ }
/*37*/ }
/*38*/}
该方法使用gejb容器提供的默认的事务模式,事务会在方法结束时自动提交。
getRollbackOnly()返回房前事务的状态,true表示已经回滚,false表示没有回滚。
|
|
|
|
| 视频总结-jndi |
jndi:java命名和目录接口
jndi把object和context(还可以有subcontext)组织成一个jndi树
这样object就可一被绑定到不同的context上面
jndi是一种查找服务,用于查找:
web应用环境变量
EJB和他们的环境变量
通过DataSource的数据库连接池
JMS没有表和连接工厂
其他服务
不要将jndi当做数据库使用
jndi对象存储在内存中
访问jndi对象与网络性能有关
jndi树:
InitialContext是JNDI树所有搜索的起点
对象绑定到jndi树上,java对象是树叶,context是节点
一个绑定把对象与一个逻辑名和一个context关联起来
创建Initial Context
从服务器端对象连接到jndi
//创建一个InitialContext
context ctx=new InitialContext();//链接到当前的jndi树上
从任何一个地方连接到jndi
.创建Environment对象
weblogic.jndi.Enviroment env=new Weblogix.jndi.Enviroment();
填写Enviroment
env.setProviderurl("t3://127.0.0.1:7001");//weblogic server的位置
env.setSecurityPrincipal("system");//安全信息
env.setSecurityCredentiais("password");
//使用Environment对象创建InitialContext
context ctx=env.getInitialContext();
.hashtable的用法....
创建subcontext
创建一个用于绑定对象的subcontext
创建Environment对象
context ctx=env.getInitialContext();//首先获得已经存在的subcontext或者initialcontext
填写Environment
context subcontext=ctx.createSubcontext("newSubcontext");
subcontext.rebind("boundobject",object);
subcontext.close();
ctx.close();
其他链接到jndi的方法:
使用ConstantProperties名和hashtable类:
HashTable env=new HashTable();
env.put(Context.initial_context_factory,"weblogic.jndi.WLInitialContextFactory");
env.put(Context.procider_url,"t3://localhost:7001");
env.put(Context.security_principal,"system");
env.put(Context.crrdentials,"password");
Context ctx=new InitialContext(env);
另一个例子:使用hardcoded名和properties类
Properties env=new Properties();
env.setProperties("java.naming.factory.initial","weblogic.jndi.WLInitialContextFactory");
env.setProperties("java.naming.provider.url","t3://localhost:7001")
env.setProperties("java.naming.security.principal","system");
env.setProperties("java.naming.security.credentials","password");
Context ctx=new InitialContext(env);
jndi.properties
.jndi.properties文件为所有的Initial Contexts设置默认的属性
.jndi.properties文件的搜索顺序
.classpath
.$JAVA_HOME/lib
实例:
java.naming.factoyr.initial=weblogic.jndi.WLInitialContextFactory
java.naming.security.url=t3://localhost:7001
java.naming.security.pricipal=system
java.naming.security.credentials=password
使用默认值:
Context ctx=new InitialContext();
从jndi查找:
.lookup()从jndi树获得对象
.通过lookup()返回的对象必须映射到他们合适的类型
try{
//先获得InitialContext
//Context ic=new Context();
Object obj;
obj=ic.lookup("javax.transation.UserTransaction");
UserTransaction ut=(UserTransaction)obj;
ut.begin();
.....
ic.close();
}catch(NamingEcxeption e){....}
远程绑定对象:
.远程绑定到远程命名服务的对象必须是序列化的
.访问命名服务时,对象是采用复制机制
查找的对象是序列化到客户端的
一个binding实例:
public static Context getInitialContext()throws NamingException{
创建Environment对象
weblogic.jndi.Environment env=new Weblogix.jndi.Environment();
填写Enviroment
env.setProviderurl("t3://127.0.0.1:7001");//weblogic server的位置
env.setSecurityPrincipal("system");//安全信息
env.setSecurityCredentiais("password");
//使用Environment对象创建InitialContext
context ctx=env.getInitialContext();
return ctx;
}
//获得Initial Context
Context ctx=getInitialContext();
//创建名为band的对象
Bank myBank=new Bank();
//把对象绑定到jndi树
ctx.rebind("theBank",myBank);
ctx.close();
|
|
|
|
|