所谓WebMVC即Model2模型是目前Web开发领域的主流模型,Struts/Struts2框架是其典型实现。在概念层面上,这种程序组织模型是怎样建立起来的?与其他Web开发模型(如面向对象模型)具有怎样的联系? 它未来可能的发展方向在哪里? 结合Witrix开发平台的具体实践,基于级列设计理论我们可以看到一条概念发展的脉络。
http://canonical.javaeye.com/blog/33824
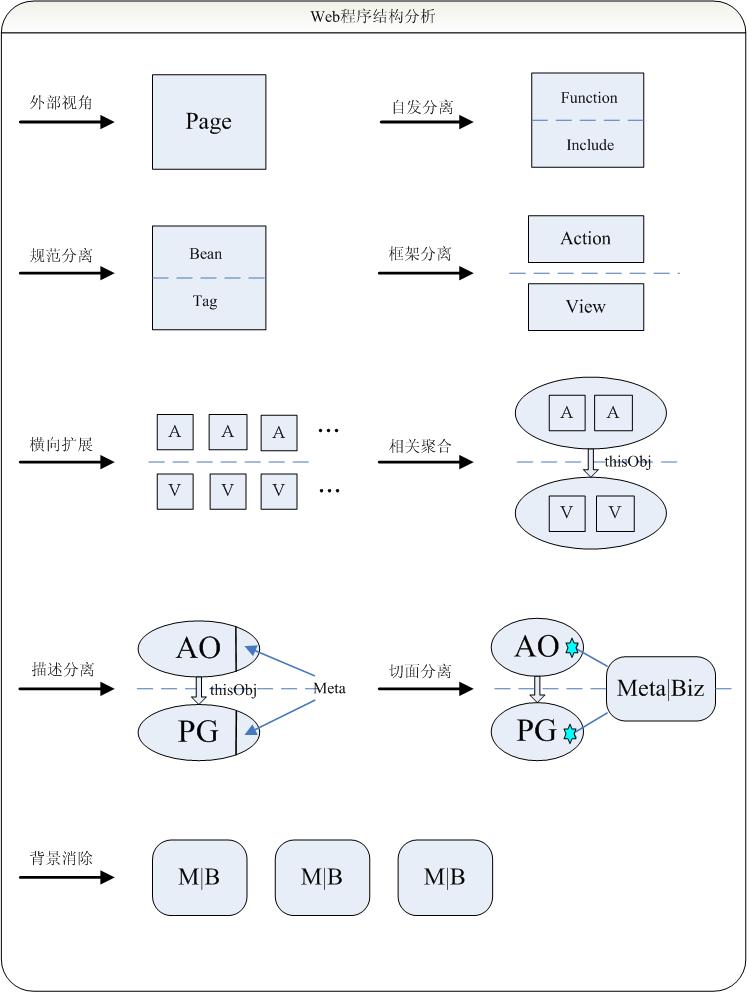
1. 外部视角:原始的servlet规范提供了一个简单的面向IO的程序响应模型。一次前台访问由一个特定的servlet负责响应,它从request中读取输入流,在全局session中保持临时状态,向response中写入输出流。在此基础上,JSP提供的模板概念翻转了程序和输出文本之间的相对地位,简化了文本输出过程。至此,这种整体的程序模型基本上只是规范化了外部系统访问Web服务器的响应模型,并没有对后台程序的具体实现制定明确的约束条件。因此在最粗野的后台实现中,读取参数,业务处理,生成页面等处理步骤是纠缠在一起的,很难理解,也很难重用。每一个后台页面都是一个不可分析的整体。
<%
String paramA = request.getParameter("paramA");
ResultSet rsA = 
%>
result = <%=rsA.getString(0) %>
String paramB = request.getParamter("paramB");
ResultSet rsB =
<%
rsB.close();
rsA.close();
conn.close();
%>
2. 自发分离:在复杂的程序实践中,我们会自发的对业务处理代码和界面代码进行一定程度的分离。因为我们可以直观的感受到这两种代码的稳定性并不匹配。例如不同业务处理过程产生的结果都可以用一个html表格来展现,而同一个业务处理过程产生的结果页面可能经常发生变化。一般我们倾向于将业务代码写在页面上方,而界面代码写在页面下方,并使用一些原始的分解机制,例如include指令。这种分离是随意的,缺乏形式边界的。例如我们无法表达被包含的页面需要哪些参数,也难以避免全局变量名冲突。需要注意的是,分层的一般意义在于各个层面可以独立发展,它的隐含假定是各层面之间的交互是规范化的,只使用确定的数据结构,按照确定的方式进行交互。例如业务层和界面层通过标准的List/Map等数据结构交互,而不是使用具有无限多种样式的特殊的数据结构。(在弱类型语言环境中,实体对象的结构和Map是等价的).
<%
List header =
List dataList =
%>
<%@ include file="/show_table.jsp" %>
3. 规范分离:JSP所提供的useBean和tag机制,即所谓的Model1模型,是对程序结构分离的一种规范化。业务代码封装在java类中,一般业务函数与web环境无关,即不使用request和response对象, 允许单元测试。tag机制可以看作是对include指令的增强,是一种代码重用机制。tld描述明确了调用tag时的约束关系。调用tag时需要就地指定调用参数,而include页面所依赖的参数可能是在此前任意地方指定的,是与功能实现分离的。此外tag所使用的参数名是局部对象上的属性名,从而避免了对全局变量的依赖。很遗憾的是,jsp tag所封装的仍然是原始的IO模型,对程序结构缺乏精细的定义,在概念层面上只是对文本片段的再加工,难以支撑复杂的控件结构。早期jsp tag无法利用jsp模板本身来构造,无法构成一个层层递进的概念抽象机制,更是让这种孱弱的重用模型雪上加霜。在其位却无能谋其政,这直接造成了整个j2ee前台界面抽象层的概念缺失,以致很多人认为一种前台模板重用机制是无用的。在Witrix平台中所定义的tpl模板语言,充分利用了xml的结构特点,结合编译期变换技术,成为Witrix平台中进行结构抽象的基本手段。实际上,xml能够有效表达的语义比一般人所想象的要多得多。
<jsp:useBean id="myBiz" class="" />
<% List dataList = myBiz.process(paramA) %>
<ui:Table data="<%= dataList %>" />
4. 框架分离:在Model1模型中,页面中存在着大量的粘结性代码,它们负责解析前台参数,进行类型转换和数据校验,定位特定的业务处理类,设置返回结果,控制页面跳转等。一种自然的想法是定义一个全局的程序框架,它根据集中的配置文件完成所有的粘结性操作。这也就是所谓面向action的WebMVC模型。这一模型实现了服务器端业务层和界面层在实现上的分离,但是对于外部访问者而言,它所暴露的仍然是原始的自动机模型:整个网站是一个庞大的自动机,每次访问都触发一个action,在action中可能更改自动机的状态(作为全局状态容器的session对象或者数据库)。struts作为面向action框架的先驱,它也很自然的成为了先烈。struts中所引入的FormBean, 链接管理等概念已经在实践中被证明是无益的。一些新兴的框架开始回归到通用的Map结构,直接指定跳转页面,或者利用CoC(Convention Over Configuration)缺省映射.
public class RegisterAction extends Action {
public ActionForward perform (ActionMapping mapping,
ActionForm form,
HttpServletRequest req,
HttpServletResponse res)
{
RegisterForm rf = (RegisterForm) form;
return mapping.findForward("success");
}
5. 横向延展:分层之后必然导向各个层面的独立发展,我们的视野自然也会扩大到单个页面之外,看到一个层面上更多元素之间的相互作用.在面向对象语言大行其道的今天,继承(inheritance)无疑是多数人首先想到的程序结构组织手段.后台action可以很自然的利用java语言自身的继承机制,配置文件中也可以定义类似的extends或者parent属性.但是对于前台页面一般却很少有适用的抽象手段,于是便有人致力于前台页面的对象语言化:首先将前台页面采用某种对象语言表达,然后再利用对象语言内置的结构抽象机制.放弃界面的可描述性,将其转化为某种活动对象,在我看来是一种错误的方向.而JSF(JavaServerFace)规范却似乎想在这个方向上越走越远.JSF早期设计中存在的一个严重问题是延续了面向对象语言中的状态与行为绑定的组织方式.这造成每次访问后台页面都要重建整个Component Tree, 无法实现页面结构的有效缓存.而Witrix平台中的tpl模板语言编译出的结构是无状态的,可以在多个用户之间重用.
6. 相关聚合:对象化首先意味着相关性的局域化,它并不等价于对象语言化. 当面对一个大的集合的时候,最自然的管理手段便是分组聚合:紧密相关的元素被分配到同一分组,相关性被局域化到组内.例如,针对某个业务对象的增删改查操作可以看作属于同一分组. struts中的一个最佳实践是使用DispatchAction, 它根据一个额外的参数将调用请求映射到Action对象的子函数上.例如/book.do?dispatchMethod=add. 从外部看来,这种访问方式已经超越了原始的servlet响应模型,看起来颇有一些面向对象的样子,但也仅仅局限于样子而已.DispatchAction在struts框架中无疑只是一种权宜之计,它与form, navigation等都是不协调的,而且多个子函数之间并不共享任何状态变量(即不发生内部的相互作用),并不是真正对象化的组织方式.按照结构主义的观点,整体大于部分之和.当一组函数聚集在一起的时候,它们所催生的一个概念便是整体的表征:this指针.Witrix平台中的Jsplet框架是一个面向对象的Web框架,其中同属于一个对象的多个Action响应函数之间可以共享局部的状态变量(thisObj),而不仅仅是通过全局的session对象来发生无差别的全局关联.
http://canonical.javaeye.com/blog/33873 需要注意的是,thisObj不仅仅聚集了后台的业务操作,它同时定义了前后台之间的一个标准状态共享机制,实现了前后台之间的聚合.而前台的add.jsp, view.jsp等页面也因此通过thisObj产生了状态关联,构成页面分组.为了更加明确的支持前台页面分组的概念,Witrix平台提供了其他一些辅助关联手段.例如标准页面中的按钮操作都集中在std.js中的stdPage对象上,因此只需要一条语句stdPage.mixin(DocflowOps);即可为docflow定制多个页面上的众多相关按钮操作.此外Witrix平台中定义了标准的url构建手段,它确保在多个页面间跳转的时候,所有以$字符为前缀的参数将被自动携带.从概念上说这是一种类似于cookie,但却更加灵活,更加面向应用的状态保持机制.
class DaoWebAction extends WebContext{
IEntityDao entityDao;
String metaName;
public Object actQuery(){
thisObj.put("pager",pager);
return success();
}
public Object actExport(){
Pager pager = (Pager)thisObj.get("pager");
return success();
}
}
7. 描述分离:当明确定义了Action所聚集而成的对象结构之后,我们再次回到问题的原点:如何简化程序基元(对象)的构建?继承始终是一种可行的手段,但是它要求信息的组织结构是递进式的,而很多时候我们实际希望的组织方式只是简单的加和。通过明确定义的meta(元数据),从对象中分离出部分描述信息,在实践中被证明是一种有效的手段。同样的后台事件响应对象(ActionObject),同样的前台界面显示代码(PageGroup),配合不同的Meta,可以产生完全不同的行为结果, 表达不同的业务需求。
http://canonical.javaeye.com/blog/114066 从概念上说,这可以看作是一种模板化过程或者是一种复杂的策略模式 ProductWebObject = DaoWebObject<ProductMeta>。当然限于技术实现的原因,在一般框架实现中,meta并不是通过泛型技术引入到Web对象中的。目前常见的开发实践中,经常可以看见类似BaseAction<T>, BaseManager<T>的基类,它们多半仅仅是为了自动实现类型检查。如果结合Annotation技术,则可以超越类型填充,部分达到Meta组合的效果。使用meta的另外一个副作用在于,meta提供了各个层面之间新的信息传递手段,它可以维系多个层面之间的共变(covariant)。例如在使用meta的情况下,后台代码调用requestVars(dsMeta.getUpdatableFields())得到提交参数,前台页面调用forEach dsMeta.getViewableFields()来生成界面. 则新增一个字段的时候,只需要在meta中修改一处,前后台即可实现同步更新,自动维持前后台概念的一致性。有趣的是,前后台在分离之后它们之间的关联变得更加丰富。
8. 切面分离: Meta一般用于引入外部的描述信息,很少直接改变对象的行为结构。AOP(Aspect Oriented Programming)概念的出现为程序结构的组织提供了新的技术手段。AOP可以看作是程序结构空间中定位技术和组装技术的结合,它比继承机制和模板机制更加灵活,也更加强大。
http://canonical.javaeye.com/blog/34941 Witrix平台中通过类似AOP的BizFlow技术实现对DaoWebAction和前台界面的行为扩展,它可以在不扩展DaoWebAction类的情况下,增加/修正/减少web事件响应函数,增加/修正/减少前台界面展现元素。当前台发送的$bizId参数不同的时候,应用到WebObject上的行为切片也不同,从而可以自然的支持同一业务对象具有多个不同应用场景的情况(例如审核和拟制)。在BizFlow中定义了明确的实体化过程,前台提交的集合操作将被分解为针对单个实体的操作。例如前台提交objectEvent=Remove&id=1&id=2,将会调用两次<action id="Remove-default">操作。注意到AOP定位技术首先要求的就是良好的坐标定义, 实体化明确定义了实体操作边界,为实体相关切点的构造奠定了基础。
http://canonical.javaeye.com/blog/33784
9. 背景消除:在Witrix平台中, (DaoWebAction + StdPageGroup + Meta + BizFlow)构成完整的程序模型,因此一般情况下并不需要继承DaoWebAction类,也不需要增加新的前台页面文件,而只需要在BizFlow文件中对修正部分进行描述即可。在某种程度上DaoWebAction+StdPageGroup所提供的CRUD(CreateReadUpdateDelete)模型成为了默认的背景知识。如果背景信息极少泄漏,则我们可以在较高抽象层次上进行工作,而不再理会原始的构造机制。例如在深度集成hibernate的情况下,很少会有必须使用SQL语句的需求。BizFlow是对实体相关的所有业务操作和所有页面展现的集中描述,在考虑到背景知识的情况下,它定义了一个完整的自给自足的程序模型。当我们的建模视角转移到BizFlow模型上时,可以发展出新的程序构造手段。例如BizFlow之间可以定义类似继承机制的extends算子,可以定义实体状态驱动的有限自动机,可以定义不同实体之间的钩稽关系(实体A发生变化的时候自动更新实体B上的相关属性),也可以定义对Workflow的自然嵌入机制。从表面上看,BizFlow似乎回归到了前后台大杂烩的最初场景(甚至更加严重,它同时描述了多个相关页面和多个相关操作),但是在分分合合的模型建立过程中,大量信息被分解到背景模型中,同时发展了各种高级结构抽象机制, 确保了我们注意力的关注点始终是有限的变化部分。而紧致的描述提高了信息密度,简化了程序构造过程。
http://canonical.javaeye.com/blog/126467
<bizflow extends="docflow"> <!-- 引入docflow模型,包括一系列界面修正和后台操作 -->
<biz id="my">
<tpls>
<tpl id="initTpl">
<script src="my_ops.js" ></script>
<script>
stdPage.mixin(MyOps); // 引入多个页面上相关按钮对应的操作
</script>
</tpl>
</tpls>
</biz>
</bizflow>