当前JDK对并发编程的支持
Sun在Java5中引入了concurrent包,它对Java的并发编程提供了强大的支持。首先,它提供了Lock接口,可用了更细粒度的控制锁的区域,它的实现类有ReentrantLock,ReadLock,WriteLock,其中ReadLock和WriteLock共同用于实现ReetrantReadWriteLock(它继承自ReadWriteLock,但是没有实现Lock接口,ReadWriteLock接口也没有继承Lock接口)。而且,它还提供了一些常用并发场景下的类工具:Semaphore、CountDownLatch和CyclicBarrier。它们个字的应用场景:
- Semaphore(信号量)
有n个非线程安全的资源(资源池),这些资源使用一个Semaphore(计数信号量)保护,每个线程在使用这些资源时需要首先获得一个信号量(acquire)表示当前资源池还有可用资源,然后线程从该资源池中获取并移除一个资源,在使用完后,将该资源交回给资源池,并释放已经获得信号量(release)(这里的“移除”、“交回”并不一定需要显示操作,只是一种形象的描述,之所以这么描述是应为这里的各个资源是一样的,因而对一个线程它每次拿到的资源不一定是同一个资源,用于区分Stripe的使用场景),其中Pool是一种典型的应用。
- CountDownLatch(闭锁)
有n个Task,它们执行完成后需要执行另外一个收尾的Task(Aggregated Task),比如在做Report计算中,有n个Report要计算,而在所有Report计算完成后需要生成一个基于所有Report结果的一个总的Report,而这个总的Report需要等到所有Report计算出结果后才能开始,此时就可以定义一个CountDownLatch,其初始值是n,在总的Report计算前调用CountDownLatch的await方法等待其他Report执行完成,而其他Report在完成后都会调用CountDownLatch中的countDown方法。
- CyclicBarrier(关卡)
每个线程执行完成后需要等待,直到n个线程都执行完成后,才能继续执行,在n个线程执行完成之后,而下一次执行开始之前可以添加自定义逻辑(通过构建CyclicBarrier实例时传入一个Runnable实例自定义逻辑),即在每个线程执行完成后调用CyclicBarrier的await方法并等待(即所谓的关卡),当n个线程都完成后,自定义的Runnable实例会自动被执行(如果存在这样的Runnable实例的话),然后所有线程继续下一次执行。这个现实中的例子没有想到比较合适的。。。。
- Exchanger(交换者)
Exchanger是一种特殊的CyclicBarrier,它只有两个线程参与,一个生产者,一个消费者,有两个队列共同参与,生产者和消费者各自有一个队列,其中生产者向它的队列添加数据,而消费者从它包含的队列中拿数据,当生产者中的队列满时调用exchange方法,传入自己原有的队列,期待交换得到消费者中空的队列;而当消费者中的队列满时同样调用exchange方法,传入自己的原有队列,期待获取到生产者中已经填满的队列。这样,生产者和消费者可以和谐的生产消费,并且它们的步骤是一致的(不管哪一方比另一方快都会等待另一方)。
最后,Java5中还提供了一些atomic类以实现简单场景下高效非lock方式的线程安全,以及BlockingQueue、Synchronizer、CompletionService、ConcurrentHashMap等工具类。
在这里需要特别添加对ConcurrentHashMap的描述,因为Guava中的Stripe就是对ConcurrentHashMap实现思想的抽象。在《
Java Core系列之ConcurrentHashMap实现(JDK 1.7)》一文中已经详细讲述了ConcurrentHashMap的实现,我们都知道ConcurrentHashMap的实现是基于Segment的,它内部包含了多个Segment,因而它内部的锁是基于Segment而不是整个Map,从而减小了锁的粒度,提升了性能。而这种分段锁不仅仅在HashMap用到。
Stripe的应用场景
虽然JDK中已经为我们提供了很多用于并发编程的工具类,但是它并没有提供对以下应用场景的支持:有n个资源,我们希望对每个资源的操作都是线程安全的,这里我们不能用Semaphore,因为Semaphore是一个池的概念,它所管理的资源是同质的,比如从数据库的连接池中获取Connection操作的一种实现方式是内部保存一个Semaphore变量,在每次获取Connection时,先调用Semaphore的acquire方法以保证连接池中还有空闲的Connection,如果有,则可以随机的选择一个Connection实例,当Connection实例返回时,该Connection实例必须从空闲列表中移除,从而保证只有一个线程获取到Connection,以保证一次只有一个线程使用一个Connection(在Java中数据库的Connection是线程安全,但是我们在使用时依然会用连接池的方式创建多个Connection而不是在一个应用程序中只用一个Connection是因为有些数据库厂商在实现Connection时,一个Connection内的所有操作都时串行的,而不是并行的,比如MySQL的Connection实现,因而为了提升并行性,采用多个Connection方式)。而这里的需求是对每个资源的操作都是线程安全的,比如对JDK中HashMap的实现采用一个数组链表的结构(参考《
Java Core系列之HashMap实现》),如果我们将链表作为一个资源单位(这里的链表资源和上述的数据库连接资源是不一样的,对数据库连接每个线程只需要拿到任意一个Connection实例即可,而这里的链表资源则是不同链表是不一样的,因而对每个操作,我们需要获取特定的链表,然后对链表以线程安全的方式操作,因为这里多个线程会对同一个链表同时操作),那么为了保证对各个单独链表操作的线程安全(如HashMap的put操作,不考虑rehash的情况,有些其他操作需要更大粒度的线程安全,比如contains等),其中一种简单的实现方式是为每条链表关联一个锁,对每条链表的读写操作使用其关联锁即可。然而如果链表很多,就需要使用很多锁,会消耗很多资源,虽然它的锁粒度最小,并发性很高。然而如果各个链表之间没有很高的并发性,我们就可以让多个链表共享一个锁以减少锁的使用量,虽然增大了锁的粒度,但是如果这些链表的并发程度并不是很高,那增大的锁的粒度对并发性并没有很大的影响。
在实际应用中,我们有一个Cache系统,它包含key和payload的键值对(Map),在Cache中Map的实现已经是线程安全了,然而我们不仅仅是向Cache中写数据要保证线程安全,在操作payload时,也需要保证线程安全。因为我们在Cache中的数据量很大,为每个payload配置一个单独的锁显然不现实,也不需要因为它们没有那么高的并发行,因而我们需要一种机制将key分成不同的group,而每个group共享一个锁(这就是ConcurrentHashMap的实现思路)。通过key即可获得一个锁,并且每个相同的key获得的锁实例是相同的(获得相同锁实例的key它们不一定相等,因为这是一对多的关系)。
Stripe的简单实现
根据以上应用场景,Stripe的实现很简单,只需要内部保存一个Lock数组,对每个给定的key,计算其hash值,根据hash值计算其锁对应的数组下标,而该下标下的Lock实例既是和该key关联的Lock实例。这里通过hash值把key和Lock实例关联起来,为了扩展性,在实现时还可以把计算数组下标的逻辑抽象成一个接口,用户可以通过传入自定义该接口的实现类实例加入用户自定义的关联逻辑,默认采用hash值关联方式。
Stripe在Guava中的实现
在Guava中,Stripe以抽象类的形式存在,它定义了通过给定key或index获得相应Lock/Semaphore/ReadWriteLock实例:
public abstract class Striped<L> {
/**
* Returns the stripe that corresponds to the passed key. It is always guaranteed that if
* {@code key1.equals(key2)}, then {@code get(key1) == get(key2)}.
*
* @param key an arbitrary, non-null key
* @return the stripe that the passed key corresponds to
*/ public abstract L get(Object key);
/**
* Returns the stripe at the specified index. Valid indexes are 0, inclusively, to
* {@code size()}, exclusively.
*
* @param index the index of the stripe to return; must be in {@code [0 size())}
size())}
* @return the stripe at the specified index
*/ public abstract L getAt(
int index);
/**
* Returns the index to which the given key is mapped, so that getAt(indexFor(key)) == get(key).
*/ abstract int indexFor(Object key);
/**
* Returns the total number of stripes in this instance.
*/ public abstract int size();
/**
* Returns the stripes that correspond to the passed objects, in ascending (as per
* {@link #getAt(int)}) order. Thus, threads that use the stripes in the order returned
* by this method are guaranteed to not deadlock each other.
*
* <p>It should be noted that using a {@code Striped<L>} with relatively few stripes, and
* {@code bulkGet(keys)} with a relative large number of keys can cause an excessive number
* of shared stripes (much like the birthday paradox, where much fewer than anticipated birthdays
* are needed for a pair of them to match). Please consider carefully the implications of the
* number of stripes, the intended concurrency level, and the typical number of keys used in a
* {@code bulkGet(keys)} operation. See <a href="http://www.mathpages.com/home/kmath199.htm">Balls
* in Bins model</a> for mathematical formulas that can be used to estimate the probability of
* collisions.
*
* @param keys arbitrary non-null keys
* @return the stripes corresponding to the objects (one per each object, derived by delegating
* to {@link #get(Object)}; may contain duplicates), in an increasing index order.
*/ public Iterable<L> bulkGet(Iterable<?> keys);
}
可以使用一下几个静态工厂方法创建相应的Striped实例,其中lazyWeakXXX创建的Striped实例中锁以弱引用的方式存在(在什么样的场景中使用呢?):
/**
* Creates a {@code Striped<Lock>} with eagerly initialized, strongly referenced locks.
* Every lock is reentrant.
*
* @param stripes the minimum number of stripes (locks) required
* @return a new {@code Striped<Lock>}
*/
public static Striped<Lock> lock(int stripes);
/**
* Creates a {@code Striped<Lock>} with lazily initialized, weakly referenced locks.
* Every lock is reentrant.
*
* @param stripes the minimum number of stripes (locks) required
* @return a new {@code Striped<Lock>}
*/
public static Striped<Lock> lazyWeakLock(int stripes);
/**
* Creates a {@code Striped<Semaphore>} with eagerly initialized, strongly referenced semaphores,
* with the specified number of permits.
*
* @param stripes the minimum number of stripes (semaphores) required
* @param permits the number of permits in each semaphore
* @return a new {@code Striped<Semaphore>}
*/
public static Striped<Semaphore> semaphore(int stripes, final int permits);
/**
* Creates a {@code Striped<Semaphore>} with lazily initialized, weakly referenced semaphores,
* with the specified number of permits.
*
* @param stripes the minimum number of stripes (semaphores) required
* @param permits the number of permits in each semaphore
* @return a new {@code Striped<Semaphore>}
*/
public static Striped<Semaphore> lazyWeakSemaphore(int stripes, final int permits);
/**
* Creates a {@code Striped<ReadWriteLock>} with eagerly initialized, strongly referenced
* read-write locks. Every lock is reentrant.
*
* @param stripes the minimum number of stripes (locks) required
* @return a new {@code Striped<ReadWriteLock>}
*/
public static Striped<ReadWriteLock> readWriteLock(int stripes);
/**
* Creates a {@code Striped<ReadWriteLock>} with lazily initialized, weakly referenced
* read-write locks. Every lock is reentrant.
*
* @param stripes the minimum number of stripes (locks) required
* @return a new {@code Striped<ReadWriteLock>}
*/
public static Striped<ReadWriteLock> lazyWeakReadWriteLock(int stripes);
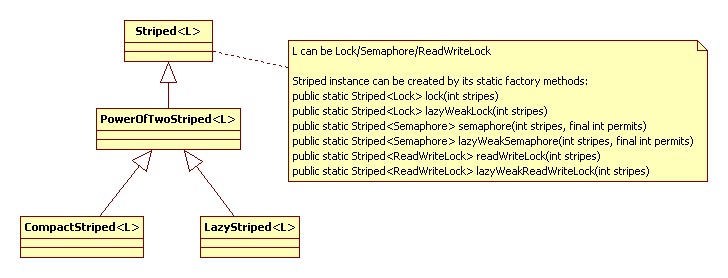
Striped有两个具体实现类,CompactStriped和LazyStriped,他们都继承自PowerOfTwoStriped(用于表达内部保存的stripes值是2的指数值)。PowerOfTwoStriped实现了indexFor()方法,它使用hash值做映射函数:
private abstract static class PowerOfTwoStriped<L> extends Striped<L> {
/** Capacity (power of two) minus one, for fast mod evaluation */
final int mask;
@Override final int indexFor(Object key) {
int hash = smear(key.hashCode());
return hash & mask;
}
}
private static int smear(int hashCode) {
hashCode ^= (hashCode >>> 20) ^ (hashCode >>> 12);
return hashCode ^ (hashCode >>> 7) ^ (hashCode >>> 4);
}
CompactStriped类使用一个数组保存所有的Lock/Semaphore/ReadWriteLock实例,在初始化时就建立所有的锁实例;而LazyStriped类使用一个值为WeakReference的ConcurrentMap做为数据结构,index值为key,Lock/Semaphore/ReadWriteLock的WeakReference为值,所有锁实例在用到时动态创建。在CompactStriped中创建锁实例时对ReentrantLock/Semaphore创建采用PaddedXXX版本,不知道为何要做Pad。
Striped类实现的类图如下:
posted on 2013-12-25 10:03
DLevin 阅读(4327)
评论(3) 编辑 收藏 所属分类:
Guava