在EHCache中,如果设置了overflowToDisk属性,当Cache中的数据超过限制时,EHCache会根据配置的溢出算法(先进先出(FIFO)、最近最少使用算法(LRU)等),选择部分实例,将这些实例的数据写入到磁盘文件中临时存储,已减少内存的负担,当内存中的实例数减少(因为超时或手工移除)或某些实例被使用到时,又可以将这些写入磁盘的数据重新加载到内存中。这个过程包含实例的序列化和反序列化,以及对磁盘文件不同区域的读写管理,这篇文章主要关注于磁盘文件不同区域的读写管理。
需求思考
当Cache系统发现需要溢出某些实例到磁盘时,它需要把实例序列化后,将序列化后的二进制数据写入磁盘,并释放内存中的数据;当用户请求读取已经溢出到磁盘中的实例时,需要读取磁盘中的二进制数据,反序列化成内存实例,返回给用户,由于该实例最近一次被访问,因而根据程序的局部性(或许这里是数据的局部性)原理,Cache会将新读取的实例保存在内存中,并释放是磁盘中占用的空间;如果此时或者在将来的某个时候内存依然或变的非常紧张,Cache系统会根据溢出算法溢出根据算法得到的实例到磁盘,因而这里磁盘的读写是一个动态的、周而复始的行为。在把序列化的实例写入磁盘时,我们需要分配相同大小的磁盘空间,并纪录该实例的key、在磁盘文件中的起始位置、数据大小用于在后来的读回数据并反序列化成内存实例;当一个实例数据被读回内存时,需要释放它在磁盘中占用的内存,从而可以将它原本占用磁盘分配给其他溢出实例。这有点类似内存管理的味道:对一台机器来说,内存大小是有限的,而进程不断的产生、销毁,在启动一个进程时,需要为该进程分配一定的初始空间,并且随着进程的运行,需要不断的为其分配运行期间增长的内存空间;当一个进程销毁时,操作系统需要回收分配给它的空间,以实现循环利用。在操作系统中,内存管理方式有:
1. 固定分区分配,操作系统把内存分成固定大小的相等的或不等的内存分区,每个进程只能分配给这几个固定大小的分区。这是一种最简单的内存管理算法,它需要提前直到一个进程最大会使用的内存大小,并且需要合理分配内存分区的大小,以防止有些进程因为使用内存过多而找不到对应大小的空闲分区而无法载入,虽然此时可能内存还有很多其他比较小的空闲分区,它也要防止内存分区过大,从而在载入过小进程时浪费内存。对这种内存管理方式,只需要一张分区表即可,每个表项纪录了分区号、起始位置、大小、分配状态等。如果表项不多,可以直接用数组表示,实现简单,查找效率影响也不大,如果表项很多,则可以考虑在其上层建立一颗空闲分区红黑树,已提升查找、插入、删除效率。
2. 相对于固定分区分配,自然会存在动态内存分配,已处理不同内存需要不同大小的内存的需求,即操作系统根据不同进程所需的不同内存大小分配内存。可以使用三种数据结构来管理分区:空闲分区表、空闲分区链以及空闲分区红黑树,对于空闲分区表和空闲分区红黑树,每一个节点都纪录了空闲分区号、起始位置、大小等,不同的是分区表组成一个数组,而空闲分区红黑树组成一颗树已提升查找、插入、删除等性能,对空闲分区链,它不象空闲分区表和空闲分区红黑树,使用额外的内存中间存储信息,它直接使用在空闲内存的头和尾存储额外的分区链信息。而对分区分配算法,可以使用:首次适应算法、循环首次适应算法、最佳适应算法、最坏适应算法等。在分配内存时,首先根据一定的算法找到可以装载该进程的空闲分区,然后根据当前分区的大小和进程所需要的内存大小以及最小可存在的内存分区的大小(防止过多的过小的内存碎片产生)选择将当前空闲分区的部分分区划分给该新进程或将当前整个分区分配给新进程,如果只是将当前空闲分区的部分分区划分给新进程,只需调整当前空闲分区项的基本信息即可,否则需要将该空闲进程节点从空闲分区表、链、树中移除。内存回首时,根据不同的算法将该内存区创建出一个空闲分区节点,将它插入到原有空闲分区表、链、树中,在插入前,如果出现相邻的空闲分区表,则需要将所有的相邻空闲分区合并。
3. 伙伴系统。
4. 可重定位分区分配。
貌似有点离题了,作为Cache的溢出数据磁盘文件管理为了简单和效率的考虑,不会也没必要象内存管理一样实现的那么复杂,因而伙伴系统和可重定为分区分配不细讲了,需要进一步了解的可以参考任意一本的操作系统教材。其实Cache的溢出数据磁盘文件管理更类似于内存溢出到磁盘的交换区管理,即操作系统会将暂时不用的进程或数据调换到外存中,已腾出内存供其他需要进程使用,已提升内存使用率。一般进程或内存交换出的数据在交换区中的停留时间比较段,而交换操作又比较频繁,因而交换区中的空间管理主要为了提高进程或数据换入和换出的速度,为此,一般采用的是连续分配方式,较少考虑外存碎片的问题,而对其管理的数据结构和上述的数据结构类似,不再赘述。
EHCache使用AA Tree数据结构来管理磁盘空间
在EHCache中,采用AA Tree数据结构来纪录空闲磁盘块,因而首先了解一下AA Tree的实现(AATreeSet类)。AA Tree出自Arne Andersson在1993年的论文“Balanced Search Trees Made Simple”中提出的对红黑树的改进,因而它是红黑树的变种,但是比红黑树实现要简单。不同于红黑树采用颜色(红色或黑色)来纪录一个节点的状态以调整节点的位置来保持其平衡性,AA Tree采用level值来纪录当前节点的状态以保持它的平衡性,level值相当于红黑树中的黑节点高度。AA Tree的定义如下:
1. AA Tree是红黑树的变种,因而它也是一颗二叉排序树。
2. 每个叶子节点的level是1。
3. 每个左孩子的level是其父节点level值减1。
4. 每个右孩子的level和其父节点的level相等或是其父节点的level减1。
5. 每个右孙子的level一定比其祖父节点的level要小。
6. 每个level大于1的节点有两个孩子。
类似红黑树,AA Tree通过对level值的判断来调整节点位置以保证当前Tree维持以上定义。由于AA Tree采用level来纪录每个节点的状态,并且每个右孩子的level和其父节点的level值相等或是其父节点的level减1,因而一般AA Tree采用如下方式表达(图片来自:http://blog.csdn.net/zhaojinjia/article/details/8121156):
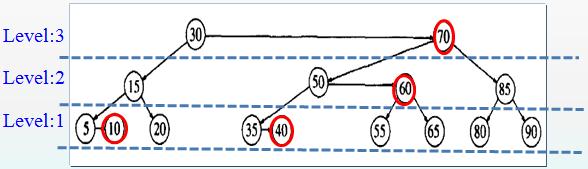
根据以上AA Tree的定义,AA Tree禁止以下两种情况的出现:
1. 禁止出现连续两个水平方向链(horizontal link),所谓horizontal link是指一个结点跟它的右孩子结点的level相同(左孩子结点永远比它的父结点level小1)。这个规定其实相当于RB树中不能出现两个连续的红色结点。即需要满足定义5。
2. 禁止出现向左的水平方向链(left horizontal link),也就是说一个结点最多只能出现一次向右的水平方向链。在AA Tree中水平链相当于红黑树中的红孩子,根据定义3,AA Tree不允许左孩子出现“红节点”,即AA Tree的左孩子的level值总是要比父节点的level值小1。
对不允许的情况如下图所示(图片同样来自:http://blog.csdn.net/zhaojinjia/article/details/8121156):
 AA Tree的节点调整
AA Tree的节点调整
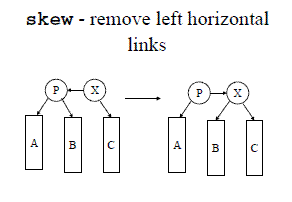
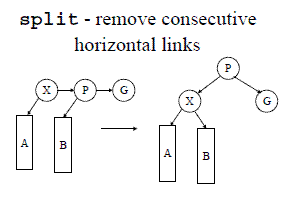
在AA Tree中,只需要当出现以上禁止的两种情况下才需要调整,因而它比红黑树的逻辑要简单的多。同红黑树,AA Tree也通过旋转节点来调整节点以使当前树始终保持AA Tree的特点,然而AA Tree创建了自己的术语:skew和split。skew用于处理出现向左的水平方向链的情况;split用于处理连续两个水平方向链的情况。
skew相当于一个右旋操作:
private static <T> Node<T> skew(Node<T> top) {
if (top.getLeft().getLevel() == top.getLevel() && top.getLevel() != 0) {
Node<T> save = top.getLeft();
top.setLeft(save.getRight());
save.setRight(top);
top = save;
}
return top;
}
split相当于一个左旋操作,并且它还会使父节点的level加1:
private static <T> Node<T> split(Node<T> top) {
if (top.getRight().getRight().getLevel() == top.getLevel() && top.getLevel() != 0) {
Node<T> save = top.getRight();
top.setRight(save.getLeft());
save.setLeft(top);
top = save;
top.incrementLevel();
}
return top;
}
当skew之前已经有一个右孩子的level跟当前结点的level相同,skew 操作之后可能引起两个连续水平方向链,这时需要配合使用split操作。split操作会新的子树的根节点level增加1(原节点的右孩子),当原节点作为其父结点的右孩子而且其父结点跟祖父结点的level相同时,在split操作后会引起两个连续水平方向链,此时需要进一步的split操作,而当原节点作为其父节点的左孩子时,在split操作后会引起向左方向的水平链,此时需要配合使用skew操作;因而AA Tree在做调整时,需要skew和split一起配合操作。
AA Tree节点定义
AA Tree节点定义和红黑树节点定义类似,只是它没有了color字段,而使用level字段替代。在EHCache中采用Node接口表达,在该接口中它还定义了compare()方法以比较两个节点之间的大小关系:
public static interface Node<E> {
public int compareTo(E data);
public void setLeft(Node<E> node);
public void setRight(Node<E> node);
public Node<E> getLeft();
public Node<E> getRight();
public int getLevel();
public void setLevel(int value);
public int decrementLevel();
public int incrementLevel();
public void swapPayload(Node<E> with);
public E getPayload();
}
对该接口的实现也比较简单:
public abstract static class AbstractTreeNode<E> implements Node<E> {
private Node<E> left;
private Node<E> right;
private int level;
.....
}
private static final class TreeNode<E extends Comparable> extends AbstractTreeNode<E> {
private E payload;
public void swapPayload(Node<E> node) {
if (node instanceof TreeNode<?>) {
TreeNode<E> treeNode = (TreeNode<E>) node;
E temp = treeNode.payload;
treeNode.payload = this.payload;
this.payload = temp;
} else {
throw new IllegalArgumentException();
}
}
.....
}
AA Tree的插入操作
同红黑树,作为一颗二叉排序树,AA Tree先以二叉排序树的算法插入一个新节点,然后对插入的节点做skew和split调整,以维持AA Tree的定义,它是一个递归操作,因而可以保证在当前一次调整完成后还需要再调整时,在上一个递归栈中可以继续调整(这里比较使用当前节点和传入数据做比较,因而当direction大于0时表示当前节点要比传入数据大,因而应该插入它的左子树,我刚开始没仔细看,还以为这是一颗倒序树,囧。。。。):
private Node<T> insert(Node<T> top, T data) {
if (top == terminal()) {
mutated = true;
return createNode(data);
} else {
int direction = top.compareTo(data);
if (direction > 0) {
top.setLeft(insert(top.getLeft(), data));
} else if (direction < 0) {
top.setRight(insert(top.getRight(), data));
} else {
return top;
}
top = skew(top);
top = split(top);
return top;
}
}
AA Tree的删除操作AA Tree节点的删除也只需考虑两种情况:
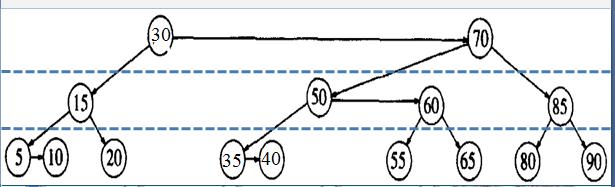
1. 如果删除节点的后继节点不是叶子节点,将后继节点的值赋给当前节点,后继节点右孩子的值赋给后继节点,删除后继节点。
如下图,要删除30,其后继节点是35,删除时,将30和35节点交换,将35和40节点交换,后删除40节点(以下图片都出自:http://blog.csdn.net/zhaojinjia/article/details/8121156):
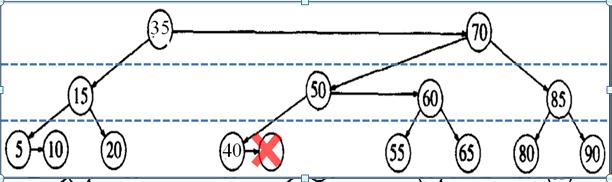
2. 如果删除节点的后继节点是叶子节点,后继节点的值赋给当前节点,并将后继节点的父节点level值减1,如果出现向左的水平链或向右的连续水平链,则做skew和split调整。
如下面两图分别为删除50节点和删除15节点的事例图:

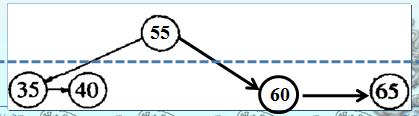
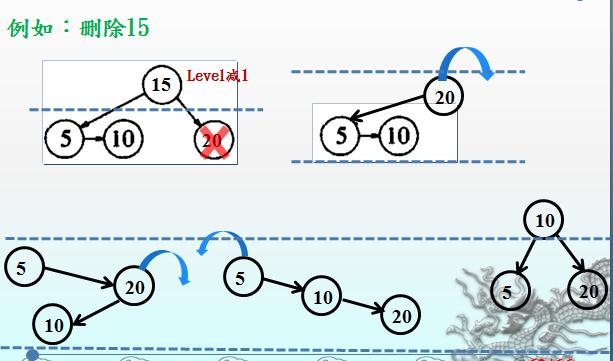
EHCache AATreeSet中删除的代码(这里的比较也是使用当前节点和传入数据比较,因而当direction大于0时,应该向左走,要特别留意):
private Node<T> remove(Node<T> top, T data) {
if (top != terminal()) {
int direction = top.compareTo(data);
heir = top;
if (direction > 0) {
top.setLeft(remove(top.getLeft(), data));
} else {
item = top;
top.setRight(remove(top.getRight(), data));
}
if (top == heir) {
if (item != terminal() && item.compareTo(data) == 0) {
mutated = true;
item.swapPayload(top);
removed = top.getPayload();
top = top.getRight();
}
} else {
if (top.getLeft().getLevel() < top.getLevel() - 1 || top.getRight().getLevel() < top.getLevel() - 1) {
if (top.getRight().getLevel() > top.decrementLevel()) {
top.getRight().setLevel(top.getLevel());
}
top = skew(top);
top.setRight(skew(top.getRight()));
top.getRight().setRight(skew(top.getRight().getRight()));
top = split(top);
top.setRight(split(top.getRight()));
}
}
}
return top;
}
参考文章:
http://blog.csdn.net/zhaojinjia/article/details/8121156
http://www.cnblogs.com/ljsspace/archive/2011/06/16/2082240.html
http://baike.baidu.com/view/10841337.htm
posted on 2013-10-27 19:13
DLevin 阅读(4207)
评论(0) 编辑 收藏 所属分类:
EHCache