上周硅谷非常热闹,重大消息频繁出现,其中包括了乔布斯因病休假,苹果的恐怖财报等等。对于我们所关心的移动业界跟互联网来说,Google 换帅是另外一个重量级消息。
Quora 上有一个讨论串,题目是“Larry Page 上任之后,Google 的重点应该是什么?”,讨论相当活跃。我也在这里凑个热闹,谈一谈在我看来,Larry Page 应该如何去改变 Google。

1:关注核心业务,也就是搜索
Google 前段时间在搜索结果上算是饱受攻击,由于与日俱增的垃圾内容,搜索结果的污染状况越发严重。Stack Overflow 的创始人之一 Jeff Atwood 在一篇文章里这样评价 Google 现在的搜索结果:
Google ,这个曾经的必备工具,某种程度上已经失去了它的优势地位。垃圾内容制造者、以点击率为终极目标的内容聚合站点正在走向胜利。
在 这一点上来说,ifanr 感同身受。作为内容提供者,我们是创造价值的人,是在给互联网不断添砖加瓦的一方。而之前在 Google 里搜索我们的原创文章,出现在结果最顶端的却往往是是通过拷贝+粘贴、有时候还不注明出处进行转载的内容聚合站点。它们用毫无成本的方式夺取着应该属于原 作者的访问量。
好在 Google 似乎已经认识到了这一点。之前搜索质量组的 Matt Cutts 表示他 们已经意识到了垃圾内容的增多,以及劣质内容聚合站点引发的不满,并且会很快进行处理。从我今早的实验来看,似乎 Google 已经采取了措施,最近 ifanr 的原创文章都出现在首页头条。从根子上(点击量带来的经济利益)驱逐劣质内容聚合站点,对现代互联网来说,确实是件好事
搜索,是 Google 的立身之本,从上周发布的财报来看,Google 收入的主要增长点仍然是在网站本身的业务。不断改进搜索,添加新的搜索方式,才能保持和增强 Google 在这个领域的领导地位。后院不起火,才有在其他领域发展的资本。
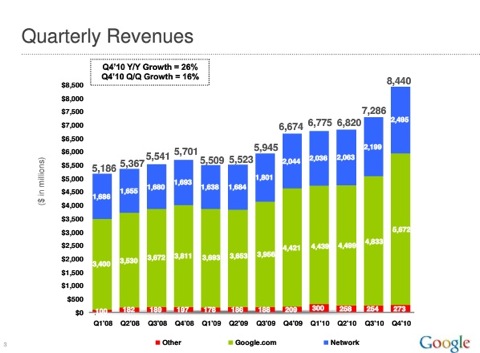
这一条,是 Larry Page 上任以后最需要关注的。未来十年的搜索是什么样子?如何提高内容关联性,改进使用体验?怎么样通过创新,把 Bing 等竞争对手远远甩开,对 Google 来说,至关重要。
2:在社交网络方面另辟蹊径
Google 在社交网络方面的试探,到目前为止都是悲剧,坦率地说,我个人认为Google 已经错过了第一班社交网络的列车。

作为新生事物的社交网络,从一开始负载的是用户虚拟交流的需求。
目 前的胜利者里面,Facebook 满足了人们交流的愿望,利用网络,表现了某种程度上真实的人与人关系,而大量互动元素的引入,则是模拟了现实生活的部分人际往来,从根底上来说,没有理念 上的创新,然而它仍然足够伟大,Facebook 把现实生活成功投影到了虚拟世界,是真正意义上的创造者。
另一个赢家是 Twitter,它满足的,是人们表达自己的愿望。通过简短的 140 个字,人与人之间形成了一种奇妙的交流关系,普通人也可以第一时间见证重大事件。可以说,Twitter 与智能手机的结合,创造了一种新媒体。表达自己,记录周边,关注别人,是 Twitter 类社交网络的根本。无论是变种的 foursquare,还是 Quora,从理念上看,都是这样的东西。
Google 之前的尝试呢? Wave 那个体验一塌糊涂的东西不去说它,出生太早了;Buzz 则是无限制版本的 Twitter:Google 试图利用现成的庞大用户群,但没有实质性创新,再加上拙劣的整合方式,这个产品的前景乐观不到哪儿去。
社交网络走到现在,实际上已经到了一个重要的关口,即:虚拟的内容如何与现实社会结合起来,怎样把线上关系与实体经济整合,创造出一个崭新的商业模式。在我看来,这才是第二代社交网络,也即成熟版本的社交网络。这个方向是未来两年的热点,也是 Google 下一步可以突围的角度。
Google 的最大优势是什么?大家应该都非常清楚,其一是庞大的用户群,其二就是信息了。Google 相对于 Twittter、fousquare 等来说,先天就有信息方面的优势。而 Google 在建设社交网络的时候,却完全忽略了这个优势,捆着手脚去从头开始跟已经成熟的对手竞争,怎么可能胜利?
举个最简单的例子,Google Maps 信息丰富,我经常用它来寻找晚餐地点,最大的好处之一就是可以看到多个网站的用户评价,看看截图:
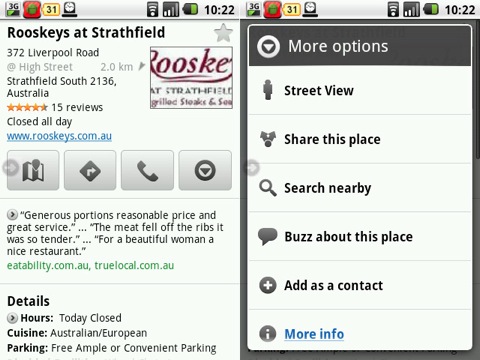
看 到了吧,有 Buzz 选项,然而搞笑的事来了。我可以看到其他网站的评价,可以在 Buzz 上分享这个地点,然后呢?没了。我完全看不到 Buzz 关于这个餐馆的讨论,看不到我分享以后朋友的看法——一点也没有。实体经济方面的内容本身就是 Google 的长项,然而在它的任何产品里面,都没有把这个长处跟自己的社交网络更紧密得结合起来。
放着庞大的现实数据不用,几个产品之间几乎没有交流,捧着金饭碗要饭,这就是 Google 的社交网络。跟现实社会结合的社交网络,将是 Google 在这一领域的最后一个机会。
3:细节,细节,还是细节
有一句老话,细节决定成败,然而 Google 现在的很多做法,却表现了一种对细节的漠视,极大影响了产品的使用体验。还是要以 Android 为例(这玩意简直就是反面教材):
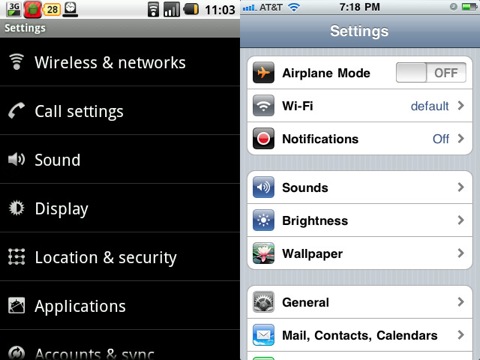
就从简单的设置界面说起。Android 平铺直叙的设置界面,完全没有突出重点(我甚至怀疑这帮人安排顺序的时候是不是拍脑门做出的决定。),跟右边的 iOS 比,孰优孰劣,一目了然。
还有应用市场,每次谈到 Android 的应用市场,我都有爆粗口的冲动。缓慢的速度、时常丢失的已下载应用列表、迟迟没有解决的应用无法下载问题……这是整个产业的核心之一,Google 就准备这么糊弄下去?
Android 不讲究的地方何止这些,工程师文化并不代表着可以不拘小节,Google 的目光,应该多放些在细节上。移动设备,用户体验至关重要。
4: 继续拥抱云,下注新能源产业
在这个卖杂货的、搞 B2C 的、做软件的都在搞云应用平台的当口,互联网界巨头,拥抱云的先驱之一,可能拥有着世界上最好硬件以及网络设施的 Google,当然也拥有自家的 App Engine。
云 计算平台对于中小企业、个人的意义,无论如何赞扬也不会过分,它直接引领了当前的互联网创业潮。低廉的平台成本,按需付费的方式,Amazon EC2 吸引了大量的个人开发者,Google 的 App Engine 当然不错,但我要说,还是不够灵活,如果能提供更多语言支持,就再好不过了。
新能源很好理解,随着碳交易市场的兴起,碳排放量眼看就要变成金融市场上的一个新产品。在这个趋势影响下,每个企业都应该考虑下自己的能源来源,为将来更加严格的排放调控措施做好准备,规避可能的经济风险。

降低所消耗能源的碳排放,对于 Google 这种能源消耗大户来说,是经济跟政治上都很正确的方向,而且同样有大量的利益存在。新能源产业,应该成为 Google 下一步的重点投入方向。
5:提高决策速度与质量,减少内部沟通环节
大 家都知道 Google 著名的 20% 规则:员工可以把 20% 的上班时间放在其他项目上。Google 的员工无疑是优秀的,这些业余时间做出的项目也应该有很多不错的点子,然而,从中孵化的成果却并不多。其中的部分原因,恐怕与 Google 的内部引导以及沟通机制存在很大的关系。由于缺乏引导,员工的项目往往与 Google 本身没什么联系,而因为沟通问题,好的项目不一定能够获得公司的帮助。
Google 的前员工遍布整个互联网业界,大量创新却往往出现在他们离开 Google 以后。应该如何去引发员工的创造力、提高内部效率跟执行力度,Larry Page 需要仔细考虑,以便调整内部架构来适应这个变化迅速的世界。三星这个反应快到根本不像大公司的大公司在全世界攻城掠地,诺基亚反应稍微迟缓一点就束手束 脚,Google,你要快一点,再快一点,才能跟 Facebook 以及数以千计的创业企业进行竞争。
转自:http://www.oschina.net/news/14996/larry-page-google-five-things-todo